
Swift5.0的Runtime机制浅析
导读:你想知道Swift内部对象是如何创建的吗?方法以及函数调用又是如何实现的吗?成员变量的访问以及对象内存布局又是怎样的吗?这些问题都会在这篇文章中得到解答。为了更好的让大家理解这些内部实现,我会将源代码翻译为用C语言表示的伪代码来实现。
Objective-C语言是一门以C语言为基础的面向对象编程语言,其提供的运行时(Runtime)机制使得它也可以被认为是一种动态语言。运行时的特征之一就是对象方法的调用是在程序运行时才被确定和执行的。系统提供的开放接口使得我们可以在程序运行的时候执行方法替换以便实现一些诸如系统监控、对象行为改变、Hook等等的操作处理。然而这种开放性也存在着安全的隐患,我们可以借助Runtime在AOP层面上做一些额外的操作,而这些额外的操作因为无法进行管控, 所以有可能会输出未知的结果。
可能是苹果意识到了这个问题,所以在推出的Swift语言中Runtime的能力得到了限制,甚至可以说是取消了这个能力,这就使得Swift成为了一门静态语言。Swift语言中对象的方法调用机制和OC语言完全不同,Swift语言的对象方法调用基本上是在编译链接时刻就被确定的,可以看做是一种硬编码形式的调用实现。
Swfit中的对象方法调用机制加快了程序的运行速度,同时减少了程序包体积的大小。但是从另外一个层面来看当编译链接优化功能开启时反而又会出现包体积增大的情况。Swift在编译链接期间采用的是空间换时间的优化策略,是以提高运行速度为主要优化考虑点。具体这些我会在后面详细谈到。
通过程序运行时汇编代码分析Swift中的对象方法调用,发现其在Debug模式下和Release模式下的实现差异巨大。其原因是在Release模式下还同时会把编译链接优化选项打开。因此更加确切的说是在编译链接优化选项开启与否的情况下二者的实现差异巨大。
在这之前先介绍一下OC和Swift两种语言对象方法调用的一般实现。
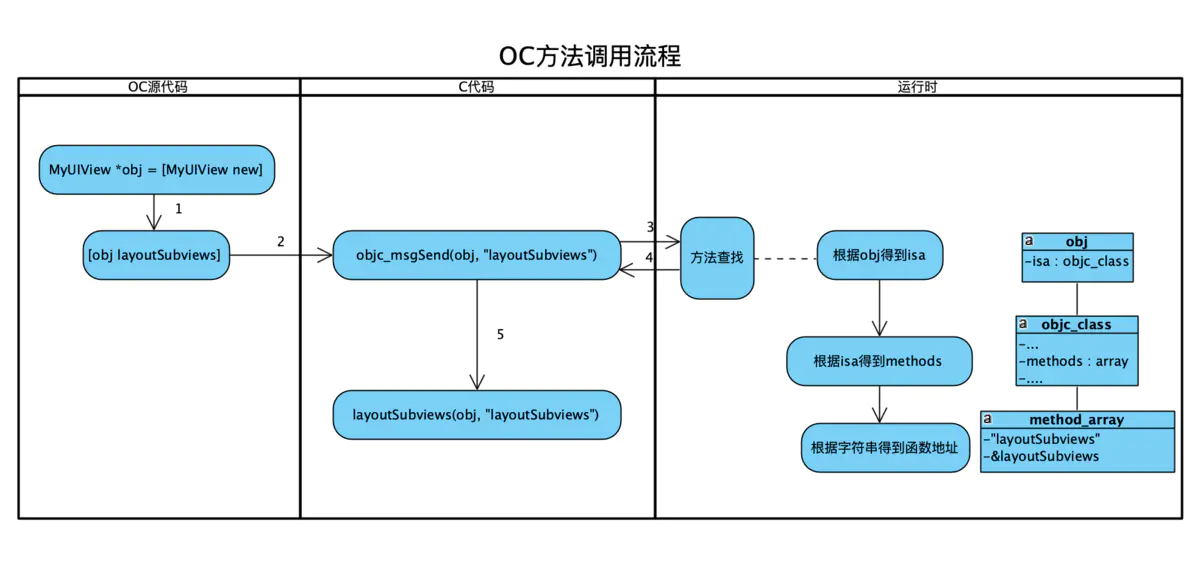
OC类的对象方法调用
对于OC语言来说对象方法调用的实现机制有很多文章都进行了深入的介绍。所有OC类中定义的方法函数的实现都隐藏了两个参数:一个是对象本身,一个是对象方法的名称。每次对象方法调用都会至少传递对象和对象方法名称作为开始的两个参数,方法的调用过程都会通过一个被称为消息发送的C函数objc_msgSend来完成。objc_msgSend函数是OC对象方法调用的总引擎,这个函数内部会根据第一个参数中对象所保存的类结构信息以及第二个参数中的方法名来找到最终要调用的方法函数的地址并执行函数调用。这也是OC语言Runtime的实现机制,同时也是OC语言对多态的支持实现。整个流程就如下表述:
Swift类的对象创建和销毁
在Swift中可以定义两种类:一种是从NSObject或者派生类派生的类,一类是从系统Swift基类SwiftObject派生的类。对于后者来说如果在定义类时没有指定基类则默认会从基类SwiftObject派生。SwiftObject是一个隐藏的基类,不会在源代码中体现。
Swift类对象的内存布局和OC类对象的内存布局相似。二者对象的最开始部分都有一个isa成员变量指向类的描述信息。Swift类的描述信息结构继承自OC类的描述信息,但是并没有完全使用里面定义的属性,对于方法的调用则主要是使用其中扩展了一个所谓的虚函数表的区域,关于这部分会在后续中详细介绍。
Swift类的对象实例都是在堆内存中创建,这和OC语言的对象实例创建方式相似。系统会为类提供一个默认的init构造函数,如果想自定义构造函数则需要重写和重载init函数。一个Swift类的对象实例的构建分为两部分:首先是进行堆内存的分配,然后才是调用init构造函数。在源代码编写中不会像OC语言那样明确的分为alloc和init两个分离的调用步骤,而是直接采用:类名(初始化参数)这种方式来完成对象实例的创建。在编译时系统会为每个类的初始化方法生成一个:模块名.类名.__allocating_init(类名,初始化参数)的函数,这个函数的伪代码实现如下:
//假设定义了一个CA类。
class CA {
init(_ a:Int){}
}//编译生成的对象内存分配创建和初始化函数代码
CA * XXX.CA.__allocating_init(swift_class classCA, int a)
{
CA *obj = swift_allocObject(classCA); //分配内存。
obj->init(a); //调用初始化函数。
}
//编译时还会生成对象的析构和内存销毁函数代码
XXX.CA.__deallocating_deinit(CA *obj)
{
obj->deinit() //调用析构函数
swift_deallocClassInstance(obj); //销毁对象分配的内存。
}其中的swift_class 就是从objc_class派生出来,用于描述类信息的结构体。
Swift对象的生命周期也和OC对象的生命周期一样是通过引用计数来进行控制的。当对象初次创建时引用计数被设置为1,每次进行对象赋值操作都会调用swift_retain函数来增加引用计数,而每次对象不再被访问时都会调用swift_release函数来减少引用计数。当引用计数变为0后就会调用编译时为每个类生成的析构和销毁函数:模块名.类名.__deallocating_deinit(对象)。这个函数的定义实现在前面有说明。
这就是Swift对象的创建和销毁以及生命周期的管理过程,这些C函数都是在编译链接时插入到代码中并形成机器代码的,整个过程对源代码透明。下面的例子展示了对象创建和销毁的过程。
////////Swift源代码
let obj1:CA = CA(20);
let obj2 = obj1///////C伪代码
CA *obj1 = XXX.CA. __allocating_init(classCA, 20);
CA *obj2 = obj1;
swift_retain(obj1);
swift_release(obj1);
swift_release(obj2);swift_release函数内部会在引用计数为0时调用模块名.类名.__deallocating_deinit(对象)函数进行对象的析构和销毁。这个函数的指针保存在swift类描述信息结构体中,以便swift_release函数内部能够访问得到。
Swift类的对象方法调用
Swift语言中对象的方法调用的实现机制和C++语言中对虚函数调用的机制是非常相似的。(需要注意的是我这里所说的调用实现只是在编译链接优化选项开关在关闭的时候是这样的,在优化开关打开时这个结论并不正确)。
Swift语言中类定义的方法可以分为三种:OC类的派生类并且重写了基类的方法、extension中定义的方法、类中定义的常规方法。针对这三种方法定义和实现,系统采用的处理和调用机制是完全不一样的。
OC类的派生类并且重写了基类的方法
如果在Swift中的使用了OC类,比如还在使用的UIViewController、UIView等等。并且还重写了基类的方法,比如一定会重写UIViewController的viewDidLoad方法。对于这些类的重写的方法定义信息还是会保存在类的Class结构体中,而在调用上还是采用OC语言的Runtime机制来实现,即通过objc_msgSend来调用。而如果在OC派生类中定义了一个新的方法的话则实现和调用机制就不会再采用OC的Runtime机制来完成了,比如说在UIView的派生类中定义了一个新方法foo,那么这个新方法的调用和实现将与OC的Runtime机制没有任何关系了! 它的处理和实现机制会变成我下面要说到的第三种方式。下面的Swift源代码以及C伪代码实现说明了这个情况:
////////Swift源代码
//类定义
class MyUIView:UIView {
open func foo(){} //常规方法
override func layoutSubviews() {} //重写OC方法
}
func main(){
let obj = MyUIView()
obj.layoutSubviews() //调用OC类重写的方法
obj.foo() //调用常规的方法。
}////////C伪代码
//...........................................运行时定义部分
//OC类的方法结构体
struct method_t {
SEL name;
IMP imp;
};
//Swift类描述
struct swift_class {
... //其他的属性,因为这里不关心就不列出了。
struct method_t methods[1];
... //其他的属性,因为这里不关心就不列出了。
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[1];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct MyUIView {
struct swift_class *isa;
}
//类的方法函数的实现
void layoutSubviews(id self, SEL _cmd){}
void foo(){} //Swift类的常规方法中和源代码的参数保持一致。
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
struct swift_class classMyUIView;
classMyUIView.methods[0] = {"layoutSubviews", &layoutSubviews};
classMyUIView.vtable[0] = {&foo};
//...........................................源代码中程序运行的部分
void main(){
MyUIView *obj = MyUIView.__allocating_init(classMyUIView);
obj->isa = &classMyUIView;
//OC类重写的方法layoutSubviews调用还是用objc_msgSend来实现
objc_msgSend(obj, @selector(layoutSubviews);
//Swift方法调用时对象参数被放到x20寄存器中
asm("mov x20, obj");
//Swift的方法foo调用采用间接调用实现
obj->isa->vtable[0]();
}extension中定义的方法
如果是在Swift类的extension中定义的方法(重写OC基类的方法除外)。那么针对这个方法的调用总是会在编译时就决定,也就是说在调用这类对象方法时,方法调用指令中的函数地址将会以硬编码的形式存在。在extension中定义的方法无法在运行时做任何的替换和改变!而且方法函数的符号信息都不会保存到类的描述信息中去。这也就解释了在Swift中派生类无法重写一个基类中extension定义的方法的原因了。因为extension中的方法调用是硬编码完成,无法支持多态!下面的Swift源代码以及C伪代码实现说明了这个情况:
////////Swift源代码
//类定义
class CA {
open func foo(){}
}
//类的extension定义
extension CA {
open func extfoo(){}
}
func main() {
let obj = CA()
obj.foo()
obj.extfoo()
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了。
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[1];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct CA {
struct swift_class *isa;
}
//类的方法函数的实现定义
void foo(){}
//类的extension的方法函数实现定义
void extfoo(){}
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
//extension中定义的函数不会保存到虚函数表中。
struct swift_class classCA;
classCA.vtable[0] = {&foo};
//...........................................源代码中程序运行的部分
void main(){
CA *obj = CA.__allocating_init(classCA)
obj->isa = &classCA;
asm("mov x20, obj");
//Swift中常规方法foo调用采用间接调用实现
obj->isa->vtable[0]();
//Swift中extension方法extfoo调用直接硬编码调用,而不是间接调用实现
extfoo();
}需要注意的是extension中是可以重写OC基类的方法,但是不能重写Swift类中的定义的方法。具体原因根据上面的解释就非常清楚了。
类中定义的常规方法
如果是在Swift中定义的常规方法,方法的调用机制和C++中的虚函数的调用机制是非常相似的。Swift为每个类都建立了一个被称之为虚表的数组结构,这个数组会保存着类中所有定义的常规成员方法函数的地址。每个Swift类对象实例的内存布局中的第一个数据成员和OC对象相似,保存有一个类似isa的数据成员。isa中保存着Swift类的描述信息。对于Swift类的类描述结构苹果并未公开(也许有我并不知道),类的虚函数表保存在类描述结构的第0x50个字节的偏移处,每个虚表条目中保存着一个常规方法的函数地址指针。每一个对象方法调用的源代码在编译时就会转化为从虚表中取对应偏移位置的函数地址来实现间接的函数调用。下面是对于常规方法的调用Swift语言源代码和C语言伪代码实现:
////////Swift源代码
//基类定义
class CA {
open func foo1(_ a:Int){}
open func foo1(_ a:Int, _ b:Int){}
open func foo2(){}
}
//扩展
extension CA{
open func extfoo(){}
}
//派生类定义
class CB:CA{
open func foo3(){}
override open func foo1(_ a:Int){}
}
func testfunc(_ obj:CA){
obj.foo1(10)
}
func main() {
let objA = A()
objA.foo1(10)
objA.foo1(10,20)
objA.foo2()
objA.extfoo()
let objB = B()
objB.foo1(10)
objB.foo1(10,20)
objB.foo2()
objB.foo3()
objB.extfoo()
testfunc(objA)
testfunc(objB)
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[0];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//基类定义
struct CA {
struct swift_class *isa;
};
//派生类定义
struct CB {
struct swift_class *isa;
};
//基类CA的方法函数的实现,这里对所有方法名都进行修饰命名
void _$s3XXX2CAC4foo1yySiF(int a){} //CA类中的foo1
void _$s3XXX2CAC4foo1yySi_SitF(int a, int b){} //CA类中的两个参数的foo1
void _$s3XXX2CAC4foo2yyF(){} //CA类中的foo2
void _$s3XXX2CAC6extfooyyF(){} //CA类中的extfoo函数
//派生类CB的方法函数的实现。
void _$s3XXX2CBC4foo1yySiF(int a){} //CB类中的foo1,重写了基类的方法,但是名字不一样了。
void _$s3XXX2CBC4foo3yyF(){} //CB类中的foo3
//构造基类的描述信息以及虚函数表
struct swift_class classCA;
classCA.vtable[3] = {&_$s3XXX2CAC4foo1yySiF, &_$s3XXX2CAC4foo1yySi_SitF, &_$s3XXX2CAC4foo2yyF};
//构造派生类的描述信息以及虚函数表,注意这里虚函数表会将基类的函数也添加进来而且排列在前面。
struct swift_class classCB;
classCB.vtable[4] = {&_$s3XXX2CBC4foo1yySiF, &_$s3XXX2CAC4foo1yySi_SitF, &_$s3XXX2CAC4foo2yyF, &_$s3XXX2CBC4foo3yyF};
void testfunc(A *obj){
obj->isa->vtable[0](10); //间接调用实现多态的能力。
}
//...........................................源代码中程序运行的部分
void main(){
CA *objA = CA.__allocating_init(classCA);
objA->isa = &classCA;
asm("mov x20, objA")
objA->isa->vtable[0](10);
objA->isa->vtable[1](10,20);
objA->isa->vtable[2]();
_$s3XXX2CAC6extfooyyF()
CB *objB = CB.__allocating_init(classCB);
objB->isa = &classCB;
asm("mov x20, objB");
objB->isa->vtable[0](10);
objB->isa->vtable[1](10,20);
objB->isa->vtable[2]();
objB->isa->vtable[3]();
_$s3XXX2CAC6extfooyyF();
testfunc(objA);
testfunc(objB);
}从上面的代码中可以看出一些特点:
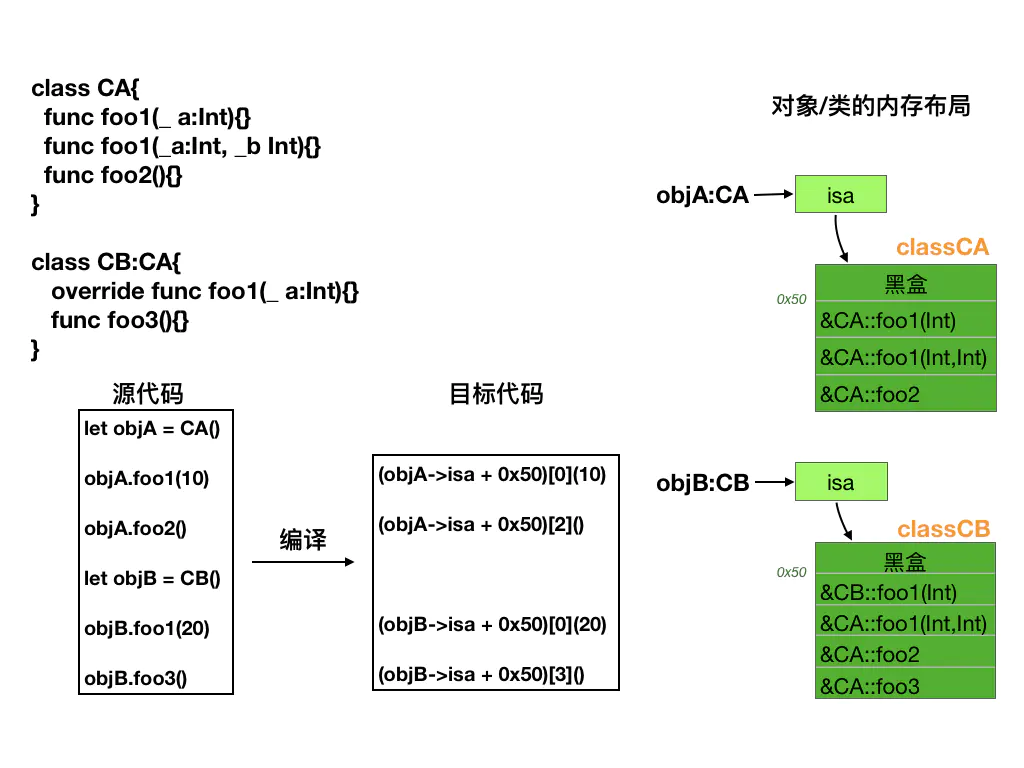
1、Swift类的常规方法中不会再有两个隐藏的参数了,而是和字面定义保持一致。那么问题就来了,方法调用时对象如何被引用和传递呢?在其他语言中一般情况下对象总是会作为方法的第一个参数,在编译阶段生成的机器码中,将对象存放在x0这个寄存器中(本文以arm64体系结构为例)。而Swift则不同,对象不再作为第一个参数来进行传递了,而是在编译阶段生成的机器码中,将对象存放在x20这个寄存器中(本文以arm64体系结构为例)。这样设计的一个目的使得代码更加安全。
2、每一个方法调用都是通过读取方法在虚表中的索引获取到了方法函数的真实地址,然后再执行间接调用。在这个过程虚表索引的值是在编译时就确定了,因此不再需要通过方法名来在运行时动态的去查找真实的地址来实现函数调用了。虽然索引的位置在编译时确定的,但是基类和派生类虚表中相同索引处的函数的地址确可以不一致,当派生类重写了父类的某个方法时,因为会分别生成两个类的虚表,在相同索引位置保存不同的函数地址来实现多态的能力。
3、每个方法函数名字都和源代码中不一样了,原因在于在编译链接是系统对所有的方法名称进行了重命名处理,这个处理称为命名修饰。之所以这样做是为了解决方法重载和运算符重载的问题。因为源代码中重载的方法函数名称都一样只是参数和返回类型不一样,因此无法简单的通过名字进行区分,而只能对名字进行修饰重命名。另外一个原因是Swift还提供了命名空间的概念,也就是使得可以支持不同模块之间是可以存在相同名称的方法或者函数。因为整个重命名中是会带上模块名称的。下面就是Swift中对类的对象方法的重命名修饰规则:
_$s<模块名长度><模块名><类名长度><类名>C<方法名长度><方法名>yy<参数类型1>_<参数类型2>_<参数类型N>F
就比如上面的CA类中的foo1两个同名函数在编译链接时刻就会被分别重命名为:
//这里面的XXX就是你工程模块的名称。
void _$s3XXX2CAC4foo1yySiF(int a){} //CA类中的foo1
void _$s3XXX2CAC4foo1yySi_SitF(int a, int b){} //CA类中的两个参数的foo1下面这张图就清晰的描述了Swift类的对象方法调用以及类描述信息。
Swift类中成员变量的访问
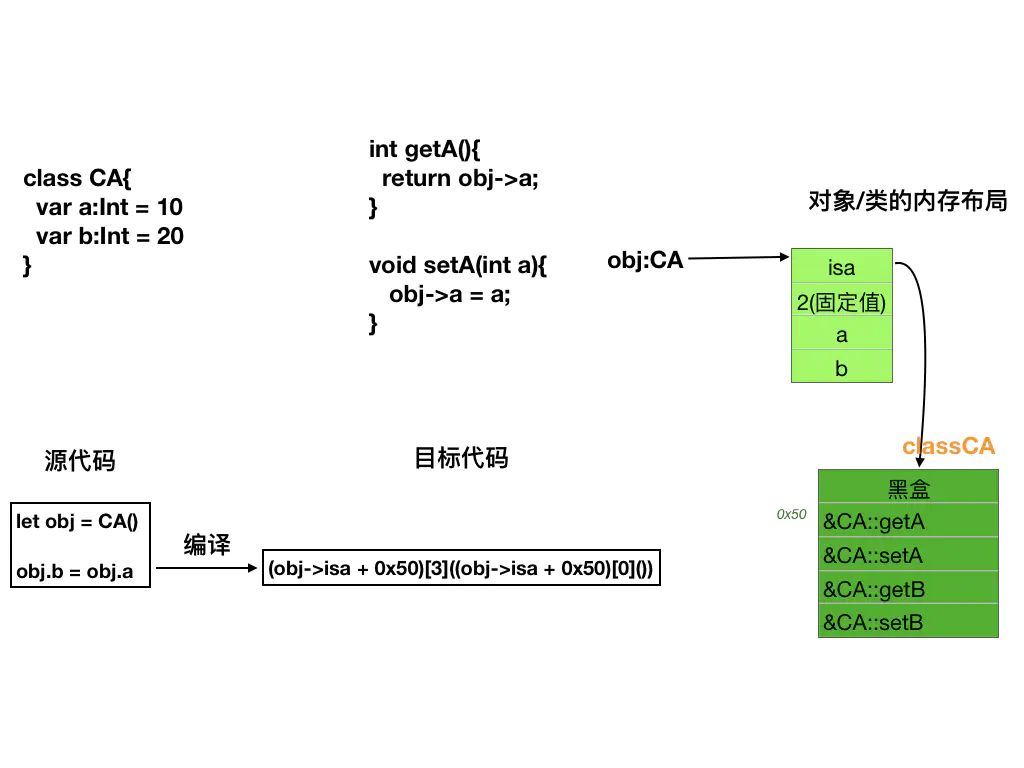
虽然说OC类和Swift类的对象内存布局非常相似,每个对象实例的开始部分都是一个isa数据成员指向类的描述信息,而类中定义的属性或者变量则一般会根据定义的顺序依次排列在isa的后面。OC类还会为所有成员变量,生成一张变量表信息,变量表的每个条目记录着每个成员变量在对象内存中的偏移量。这样在访问对象的属性时会通过偏移表中的偏移量来读取偏移信息,然后再根据偏移量来读取或设置对象的成员变量数据。在每个OC类的get和set两个属性方法的实现中,对于属性在类中的偏移量值的获取都是通过硬编码来完成,也就是说是在编译链接时刻决定的。
对于Swift来说,对成员变量的访问得到更加的简化。系统会对每个成员变量生成get/set两个函数来实现成员变量的访问。系统不会再为类的成员变量生成变量偏移信息表,因此对于成员变量的访问就是直接在编译链接时确定成员变量在对象的偏移位置,这个偏移位置是硬编码来确定的。下面展示Swift源代码和C伪代码对数据成员访问的实现:
////////Swift源代码
class CA
{
var a:Int = 10
var b:Int = 20
}
void main()
{
let obj = CA()
obj.b = obj.a
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[4];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//CA类的结构体定义也是CA类对象在内存中的布局。
struct CA
{
struct swift_class *isa;
long reserve; //这里的值目前总是2
int a;
int b;
};
//类CA的方法函数的实现。
int getA(){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
return obj->a;
}
void setA(int a){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
obj->a = a;
}
int getB(){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
return obj->b;
}
void setB(int b){
struct CA *obj = x20; //取x20寄存器的值,也就是对象的值。
obj->b = b;
}
struct swift_class classCA;
classCA.vtable[4] = {&getA,&setA,&getB, &setB};
//...........................................源代码中程序运行的部分
void main(){
CA *obj = CA.__allocating_init(classCA);
obj->isa = &classCA;
obj->reserve = 2;
obj->a = 10;
obj->b = 20;
asm("mov x20, obj");
obj->isa->vtable[3](obj->isa->vtable[0]()); // obj.b = obj.a的实现
}从上面的代码可以看出,Swift类会为每个定义的成员变量都生成一对get/set方法并保存到虚函数表中。所有对对象成员变量的方法的代码都会转化为通过虚函数表来执行get/set相对应的方法。 下面是Swift类中成员变量的实现和内存结构布局图:
结构体中的方法
在Swift结构体中也可以定义方法,因为结构体的内存结构中并没有地方保存结构体的信息(不存在isa数据成员),因此结构体中的方法是不支持多态的,同时结构体中的所有方法调用都是在编译时硬编码来实现的。这也解释了为什么结构体不支持派生,以及结构体中的方法不支持override关键字的原因。
类的方法以及全局函数
Swift类中定义的类方法和全局函数一样,因为不存在对象作为参数,因此在调用此类函数时也不会存在将对象保存到x20寄存器中这么一说。同时源代码中定义的函数的参数在编译时也不会插入附加的参数。Swift语言会对所有符号进行重命名修饰,类方法和全局函数也不例外。这也就使得全局函数和类方法也支持名称相同但是参数不同的函数定义。简单的说就是类方法和全局函数就像C语言的普通函数一样被实现和定义,所有对类方法和全局函数的调用都是在编译链接时刻硬编码为函数地址调用来处理的。
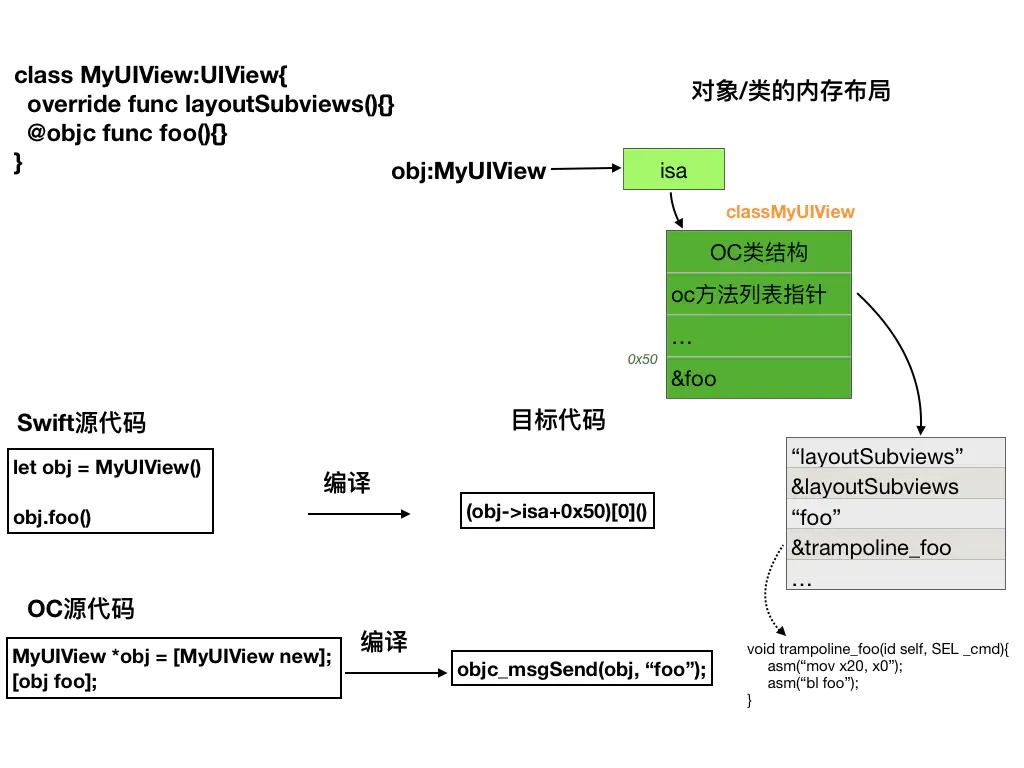
OC调用Swift类中的方法
如果应用程序是通过OC和Swift两种语言混合开发完成的。那就一定会存在着OC语言代码调用Swift语言代码以及相反调用的情况。对于Swift语言调用OC的代码的处理方法是系统会为工程建立一个桥声明头文件:项目工程名-Bridging-Header.h,所有Swift需要调用的OC语言方法都需要在这个头文件中声明。而对于OC语言调用Swift语言来说,则有一定的限制。因为Swift和OC的函数调用ABI规则不相同,OC语言只能创建Swift中从NSObject类中派生类对象,而方法调用则只能调用原NSObject类以及派生类中的所有方法以及被声明为@objc关键字的Swift对象方法。如果需要在OC语言中调用Swift语言定义的类和方法,则需要在OC语言文件中添加:#import "项目名-Swift.h"。当某个Swift方法被声明为@objc关键字时,在编译时刻会生成两个函数,一个是本体函数供Swift内部调用,另外一个是跳板函数(trampoline)是供OC语言进行调用的。这个跳板函数信息会记录在OC类的运行时类结构中,跳板函数的实现会对参数的传递规则进行转换:把x0寄存器的值赋值给x20寄存器,然后把其他参数依次转化为Swift的函数参数传递规则要求,最后再执行本地函数调用。整个过程的实现如下:
////////Swift源代码
//Swift类定义
class MyUIView:UIView {
@objc
open func foo(){}
}
func main() {
let obj = MyUIView()
obj.foo()
}
//////// OC源代码
#import "工程-Swift.h"
void main() {
MyUIView *obj = [MyUIView new];
[obj foo];
}////////C伪代码
//...........................................运行时定义部分
//OC类的方法结构体
struct method_t {
SEL name;
IMP imp;
};
//Swift类描述
struct swift_class {
... //其他的属性,因为这里不关心就不列出了。
struct method_t methods[1];
... //其他的属性,因为这里不关心就不列出了。
//虚函数表刚好在结构体的第0x50的偏移位置。
IMP vtable[1];
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct MyUIView {
struct swift_class *isa;
}
//类的方法函数的实现
//本体函数foo的实现
void foo(){}
//跳板函数的实现
void trampoline_foo(id self, SEL _cmd){
asm("mov x20, x0");
self->isa->vtable[0](); //这里调用本体函数foo
}
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
struct swift_class classMyUIView;
classMyUIView.methods[0] = {"foo", &trampoline_foo};
classMyUIView.vtable[0] = {&foo};
//...........................................源代码中程序运行的部分
//Swift代码部分
void main()
{
MyUIView *obj = MyUIView.__allocating_init(classMyUIView);
obj->isa = &classMyUIView;
asm("mov x20, obj");
//Swift方法foo的调用采用间接调用实现。
obj->isa->vtable[0]();
}
//OC代码部分
void main()
{
MyUIView *obj = objc_msgSend(objc_msgSend(classMyUIView, "alloc"), "init");
obj->isa = &classMyUIView;
//OC语言对foo的调用还是用objc_msgSend来执行调用。
//因为objc_msgSend最终会找到methods中的方法结构并调用trampoline_foo
//而trampoline_foo内部则直接调用foo来实现真实的调用。
objc_msgSend(obj, @selector(foo));
}下面的图形展示了Swift中带@objc关键字的方法实现,以及OC语言调用Swift对象方法的实现:
Swift类方法的运行时替换实现的可行性
从上面的介绍中我们已经了解到了Swift类的常规方法定义和调用实现的机制,同样了解到Swift对象实例的开头部分也有和OC类似的isa数据,用来指向类的信息结构。一个令人高兴的事情就是Swift类的结构定义部分是存放在可读写的数据段中,这似乎给了我们一个提示是说可以在运行时通过修改一个Swift类的虚函数表的内容来达到运行时对象行为改变的能力。要实现这种机制有三个难点需要解决:
1、一个是Swift对内存和指针的操作进行了极大的封装,同时Swift中也不再支持简单直接的对内存进行操作的机制了。这样就使得我们很难像OC那样直接修改类结构的内存信息来进行运行时的更新处理,因为Swift不再公开运行时的相关接口了。虽然可以将方法函数名称赋值给某个变量,但是这个变量的值并非是类方法函数的真实地址,而是一个包装函数的地址。
2、第二个就是Swift中的类方法调用和参数传递的ABI规则和其他语言不一致。在OC类的对象方法中,对象是作为方法函数的第一个参数传递的。在机器指令层面以arm64体系结构为例,对象是保存在x0寄存器作为参数进行传递。而在Swift的对象方法中这个规则变为对象不再作为第一个参数传递了,而是统一改为通过寄存器x20来进行传递。需要明确的是这个规则不会针对普通的Swift函数。因此当我们想将一个普通的函数来替换类定义的对象方法实现时就几乎变得不太可能了,除非借助一些OC到Swift的桥的技术和跳板技术来实现这个功能也许能够成功。
当然我们也可以通过为类定义一个extension方法,然后将这个extension方法函数的指针来替换掉虚函数表中类的某个原始方法的函数指针地址,这样能够解决对象作为参数传递的寄存器的问题。但是这里仍然需要面临两个问题:一是如何获取得到extension中的方法函数的地址,二是在替换完成后如何能在合适的时机调用原始的方法。
3、第三是Swift语言将不再支持内嵌汇编代码了,所以我们很难在Swift中通过汇编来写一些跳板程序了。
因为Swift具有比较强的静态语言的特性,外加上函数调用的规则特点使得我们很难在运行时进行对象方法行为的改变。还有一个非常大的因素是当编译链接优化开关打开时,上述的对象方法调用规则还将进一步被打破,这样就导致我们在运行时进行对象方法行为的替换变得几乎不可能或者不可行。
编译链接优化开启后的Swift方法定义和调用
一个不幸的事实是,当我们开启了编译链接的优化选项后,Swift的对象方法的调用机制做了非常大的改进。最主要的就是进一步弱化了通过虚函数表来进行间接方法调用的实现,而是大量的改用了一些内联的方式来处理方法函数调用。同时对多态的支持也采用了一些别的策略。具体用了如下一些策略:
1、大量的将函数实现换成了内联函数模式,也就是对于大部分类中定义的源代码比较少的方法函数都统一换成内联。这样对象方法的调用将不再通过虚函数表来间接调用,而是简单粗暴的将函数的调用改为直接将内联函数生成的机器码进行拷贝处理。这样的一个好处就是由于没有函数调用的跳转指令,而是直接执行方法中定义的指令,从而极大的加速了程序的运行速度。另外一个就是使得整个程序更加安全,因为此时函数的实现逻辑已经散布到各处了,除非恶意修改者改动了所有的指令,否则都只会影响局部程序的运行。内联的一个的缺点就是使得整个程序的体积会增大很多。比如下面的类代码在优化模式下的Swift语言源代码和C语言伪代码实现:
////////Swift源代码
//类定义
class CA {
open func foo(_ a:Int, _ b:Int) ->Int {
return a + b
}
func main() {
let obj = CA()
let a = obj.foo(10,20)
let b = obj.foo(a, 40)
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述。
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//这里也没有虚表的信息。
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct CA {
struct swift_class *isa;
};
//这里没有方法实现,因为短方法被内联了。
struct swift_class classCA;
//...........................................源代码中程序运行的部分
void main() {
CA *obj = CA.__allocating_init(classCA);
obj->isa = &classCA;
int a = 10 + 20; //代码被内联优化
int b = a + 40; //代码被内联优化
}2、就是对多态的支持,也可能不是通过虚函数来处理了,而是通过类型判断采用条件语句来实现方法的调用。就比如下面Swift语言源代码和C语言伪代码:
////////Swift源代码
//基类
class CA{
@inline(never)
open func foo(){}
}
//派生类
class CB:CA{
@inline(never)
override open func foo(){}
}
//全局函数接收对象作为参数
@inline(never)
func testfunc(_ obj:CA){
obj.foo()
}
func main() {
//对象的创建以及方法调用
let objA = CA()
let objB = CB()
testfunc(objA)
testfunc(objB)
}////////C伪代码
//...........................................运行时定义部分
//Swift类描述
struct swift_class {
... //其他的属性,因为这里不关心就不列出了
//这里也没有虚表的信息。
};
//...........................................源代码中类的定义和方法的定义和实现部分
//类定义
struct CA {
struct swift_class *isa;
};
struct CB {
struct swift_class *isa;
};
//Swift类的方法的实现
//基类CA的foo方法实现
void fooForA(){}
//派生类CB的foo方法实现
void fooForB(){}
//全局函数方法的实现
void testfunc(CA *obj)
{
//这里并不是通过虚表来进行间接调用而实现多态,而是直接硬编码通过类型判断来进行函数调用从而实现多态的能力。
asm("mov x20, obj");
if (obj->isa == &classCA)
fooForA();
else if (obj->isa == &classCB)
fooForB();
}
//类的描述信息构建,这些都是在编译代码时就明确了并且保存在数据段中。
struct swift_class classCA;
struct swift_class classCB;
//...........................................源代码中程序运行的部分
void main() {
//对象实例创建以及方法调用的代码。
CA *objA = CA.__allocating_init(classCA);
objA->isa = &classCA;
CB *objB = CB.__allocating_init(classCB);
objB->isa = &classCB;
testfunc(objA);
testfunc(objB);
}也许你会觉得这不是一个最优的解决方案,而且如果当再次出现一个派生类时,还会继续增加条件分支的判断。 这是一个多么低级的优化啊!但是为什么还是要这么做呢?个人觉得还是性能和包大小的问题。对于性能来说如果我们通过间接调用的形式可能需要增加更多的指令以及进行间接的寻址处理和指令跳转,而如果采用简单的类型判断则只需要更少的指令就可以解决多态调用的问题了,这样性能就会得到提升。至于第二个包大小的问题这里有必要重点说一下。
编译链接优化的一个非常重要的能力就是减少程序的体积,其中一个点即是链接时如果发现某个一个函数没有被任何地方调用或者引用,链接器就会把这个函数的实现代码整体删除掉。这也是符合逻辑以及正确的优化方式。回过头来Swift函数调用的虚函数表方式,因为根据虚函数表的定义需要把一个类的所有方法函数地址都存放到类的虚函数表中,而不管类中的函数是否有被调用或者使用。而通过虚函数表的形式间接调用时是无法在编译链接时明确哪个函数是否会被调用的,所以当采用虚函数表时就不得不把类中的所有方法的实现都链接到可执行程序中去,这样就有可能无形中增加了程序的体积。而前面提供的当编译链接优化打开后,系统尽可能的对对象的方法调用改为内联,同时对多态的支持改为根据类型来进行条件判断处理,这样就可以减少对虚函数表的使用,一者加快了程序运行速度,二者删除了程序中那些永远不会调用的代码从而减少程序包的体积。但是这种减少包体积的行为又因为内联的引入也许反而增加了程序包的体积。而这二者之间的平衡对于链接优化器是如何决策的我们就不得而知了。
综上所述,在编译器优化模式下虚函数调用的间接模式改变为直接模式了,所以我们几乎很难在运行时通过修改虚表来实现方法调用的替换。而且Swift本身又不再支持运行时从方法名到方法实现地址的映射处理,所有的机制都是在编译时静态决定了。正是因为Swift语言的特性,使得原本在OC中可以做的很多事情在Swift中都难以实现,尤其是一些公司的无痕埋点日志系统的建设,APM的建设,以及各种监控系统的建设,以及模拟系统的建设都将失效,或者说需要寻找另外一些途径去做这些事情。对于这些来说,您准备好了吗?
链接:https://www.jianshu.com/p/158574ab8809
