
全平台开源!面壁智能开源MiniCPM-V 4.6 ,助力开发者快速上手
2026 年 5 月 11 日,面壁智能联合清华大学、OpenBMB 开源社区正式推出新一代端侧多模态大模型 MiniCPM-V 4.6。作为 MiniCPM-V 系列效率与性能平衡的巅峰之作,这款仅 1.3B 参数的模型实现了双重突破:在全球同尺寸模型中全面领跑,同时将端侧运行门槛降至 6G 内存,真正做到“低内存、极速跑”。目前模型已全面开源,并提供覆盖 iOS、Android、HarmonyOS 的测试版本。
性能与效率双突破
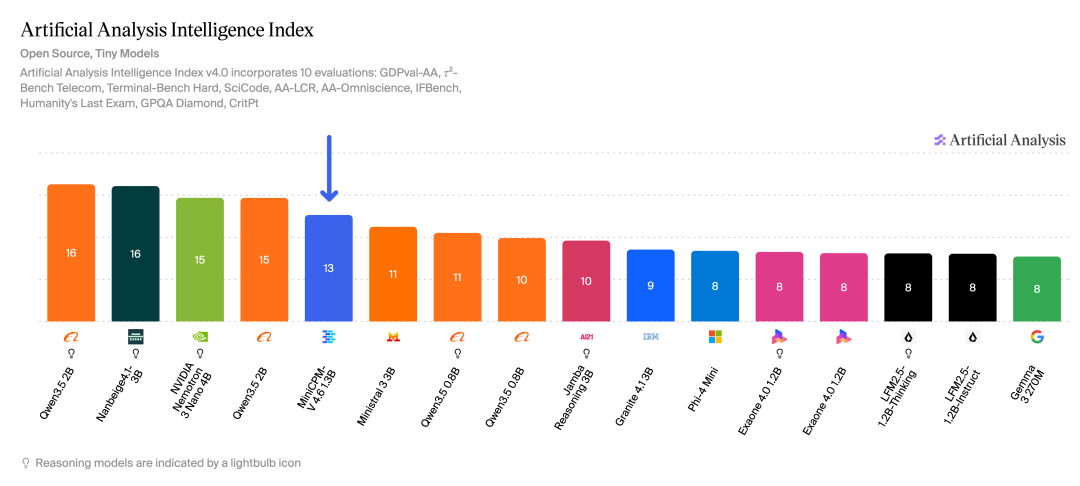
MiniCPM-V 4.6 推出 Instruct 与 Thinking 两个版本。Instruct 版在通用图文理解、STEM 数理推理、文档 OCR、视频时序理解等任务中,全面超越阿里 Qwen3.5-0.8B 与谷歌 Gemma4-E2B-it;Thinking 版在多图像推理和幻觉抑制等高阶任务中同样几乎全面领先。在 Artificial Analysis 榜单中,该模型以 13 分的成绩超越 Mistral 3-3B 等模型,性能逼近 Qwen 3.5-2B,成为 1B 级开源多模态模型的性能标杆。
在效率上,MiniCPM-V 4.6 重新定义了端侧大模型的“智能密度”。基于 vLLM 的推理吞吐量达到 Qwen3.5-0.8B 的 1.5 倍;AA 评测中仅消耗 2.5% 的 token 即实现超越;端侧处理 3136² 高清大图的首响延迟仅 75.7ms,较竞品快 2.2 倍;单卡即可实现 7013 token/s、54.79 张/秒的 1344² 图片处理能力。仅 6G 内存就能流畅运行,显著降低了智能终端部署多模态大模型的门槛。
硬核技术创新,降低多模态落地门槛
MiniCPM-V 4.6 采用面壁智能与清华大学联合研发的 LLaVA-UHD v4 技术,重构 ViT 图像编码,通过高效切片编码与 ViT 浅层压缩模块,将图像编码开销降低 50%,高分辨率浮点运算减少 55.8%。
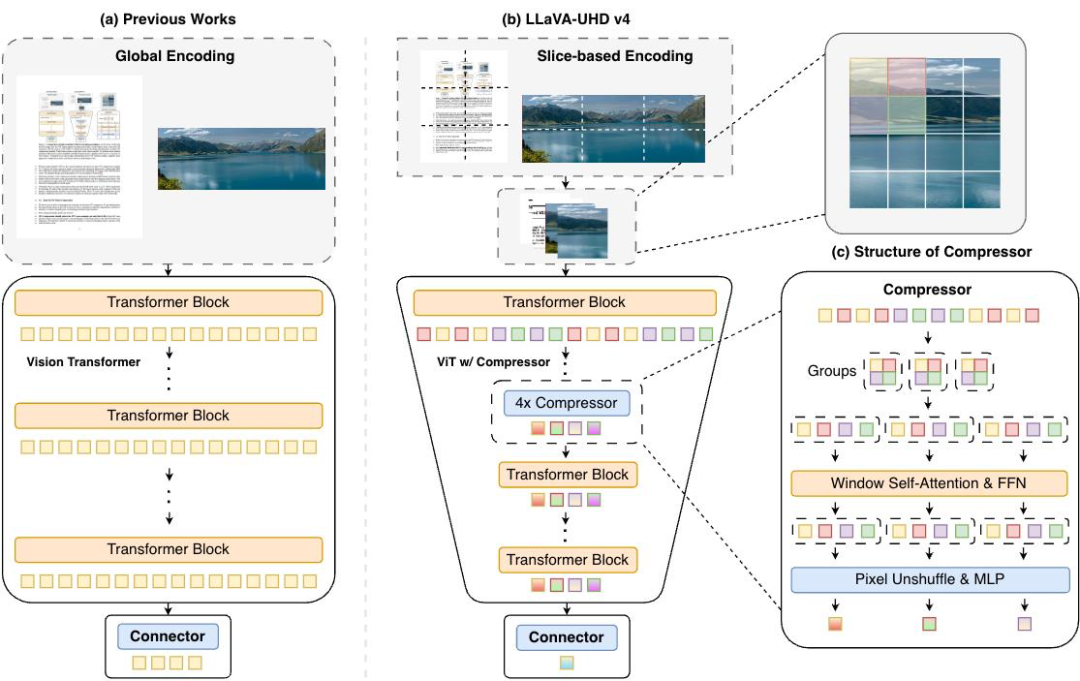
同时,该模型创新地支持 4 倍/16 倍混合 Token 压缩,让模型能够根据任务需求,在“性能优先”与“速度优先”模式间自由切换。值得一提的是,该压缩技术已在产业界得到验证,快手 2025 年发布的推荐大模型 OneRec 便应用了该技术,成功支撑主场景 25% 的流量请求。
全面开源与生态落地
MiniCPM-V 4.6 深度适配 ms-swift、LLaMA-Factory 等微调框架,以及 vLLM、SGLang、llama.cpp、Ollama 等端侧推理框架。开发者仅需一张 RTX 4090 消费级显卡即可完成全量微调,并可通过官方提供的详尽部署指南快速上手。模型已在 GitHub、Hugging Face、ModelScope 等平台开源。
截至目前,MiniCPM-V 系列模型已经在汽车、PC、手机、智能家居、工业检测等多个领域落地,合作伙伴包括联想、吉利、上汽大众、小米、OPPO 等。
此次 MiniCPM-V 4.6 的全面开源,将进一步降低端侧 AI 的应用门槛,吸引更多开发者探索多模态大模型在各类垂直场景的潜力,实现 AI 智能触达每一个终端。
