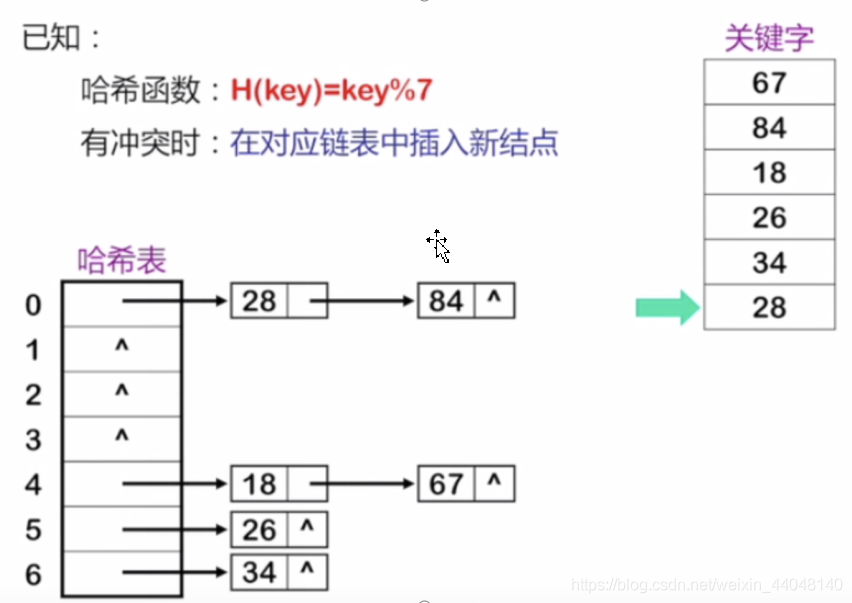
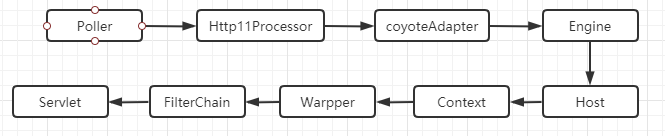
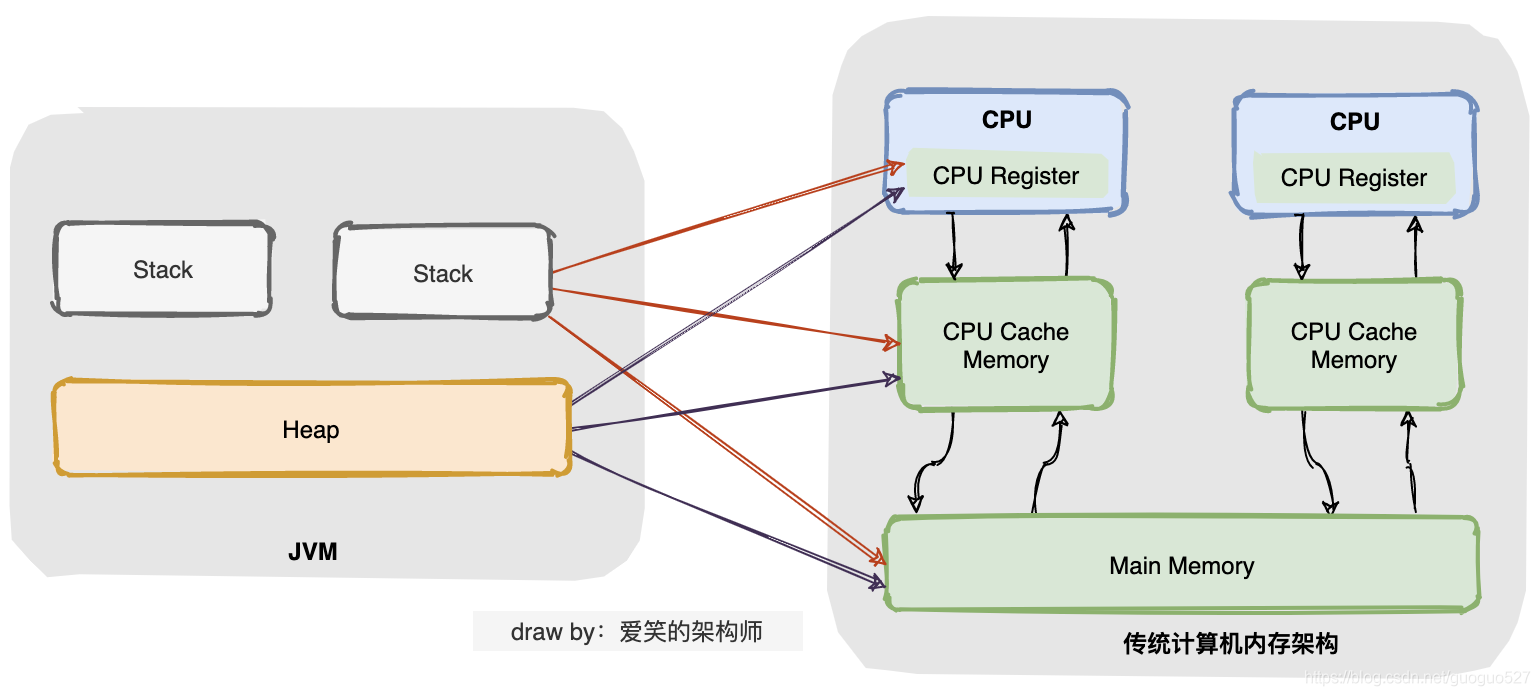
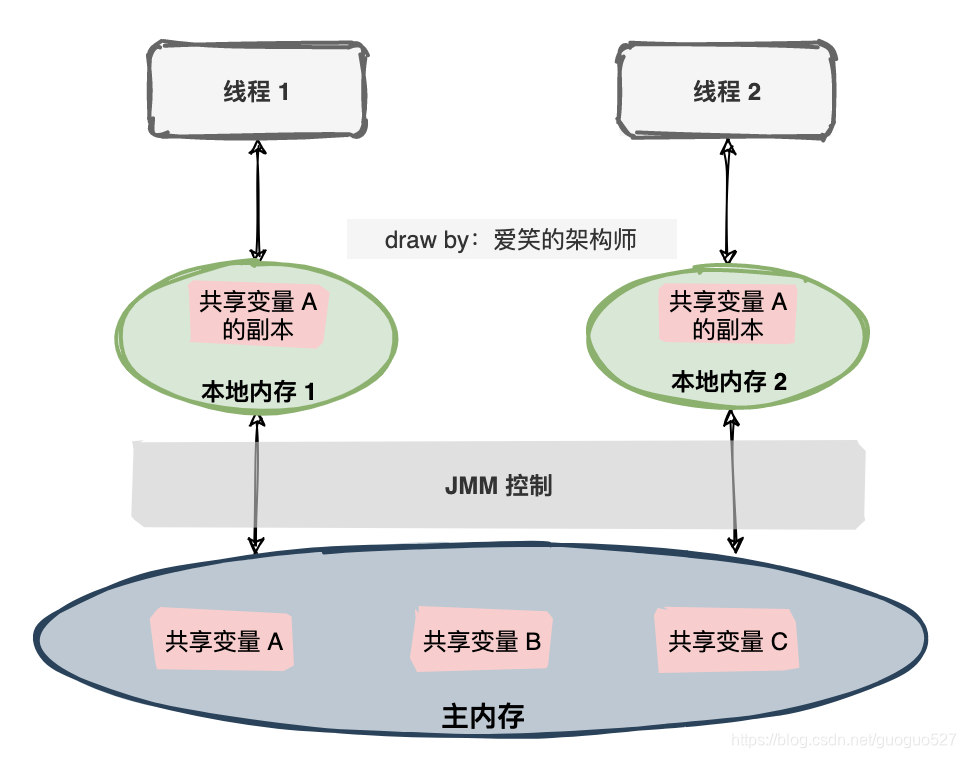
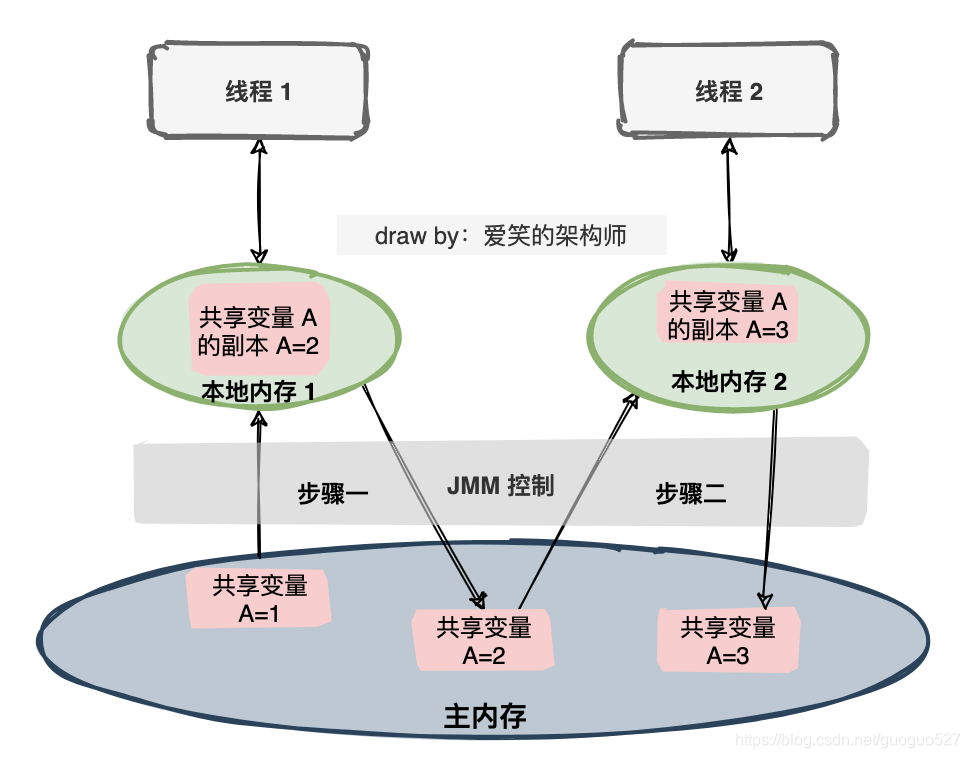
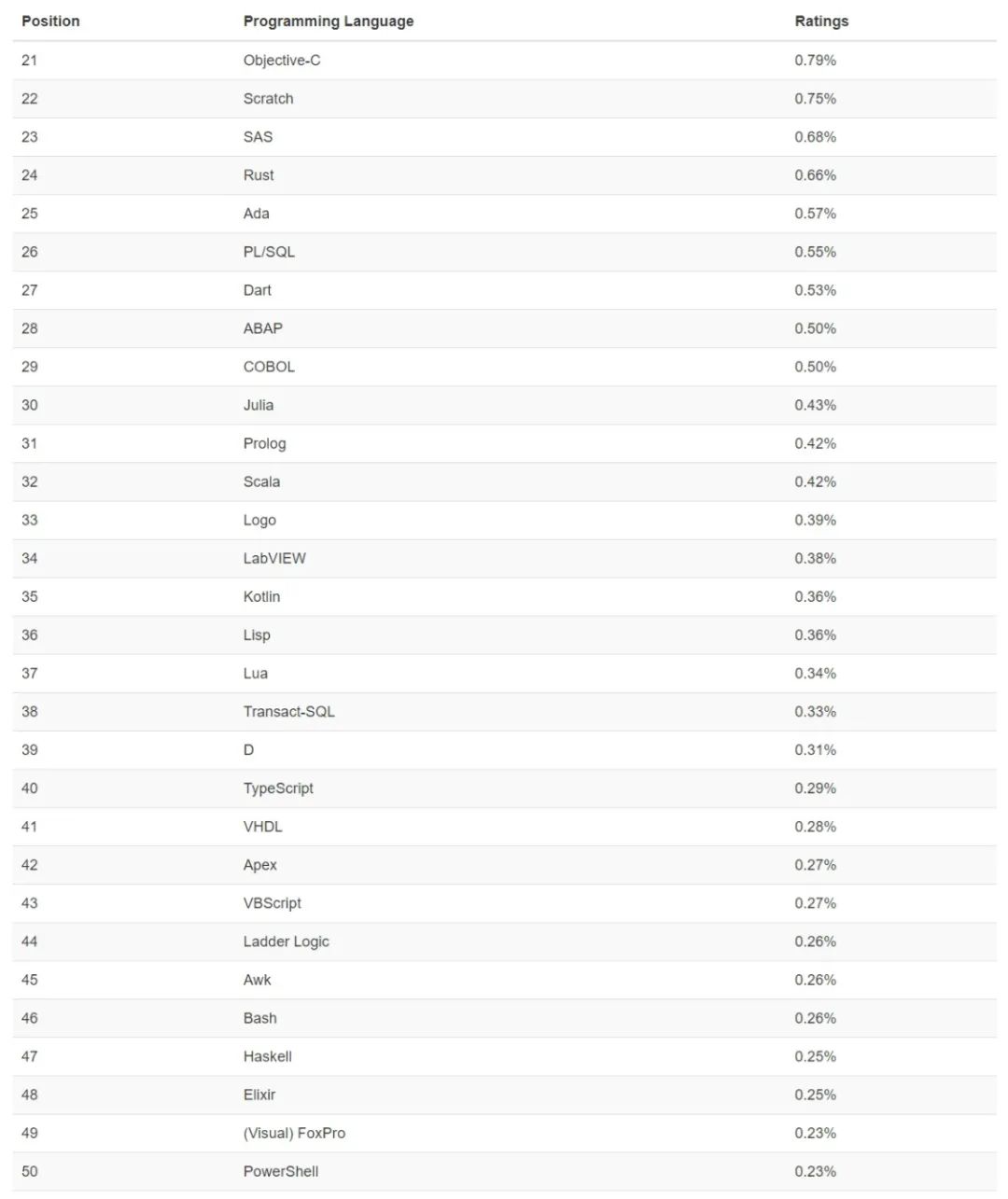
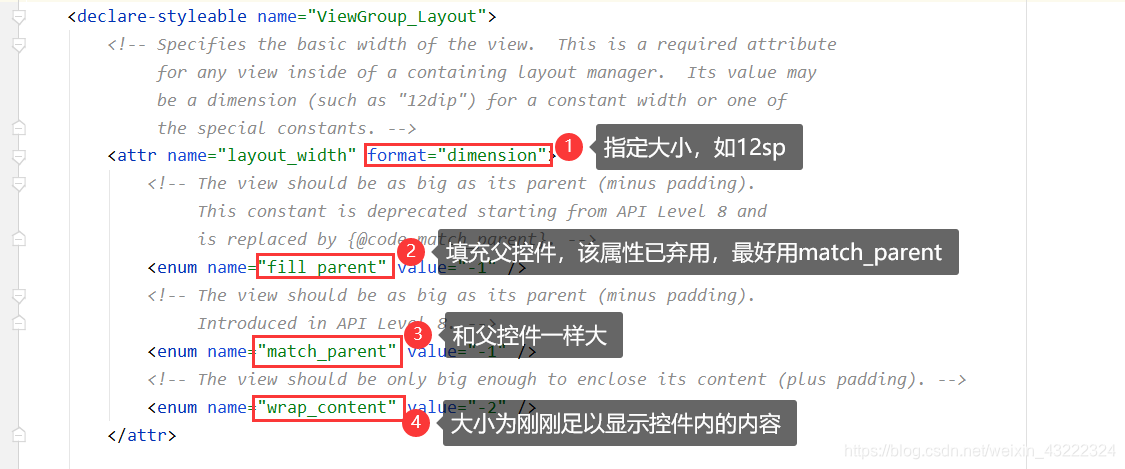
回收场景
在众多回收场景中最显而易见的就是“滚动列表时移出屏幕的表项被回收”。滚动是由MotionEvent.ACTION_MOVE事件触发的,就以RecyclerView.onTouchEvent()为切入点寻觅“回收表项”的时机:
public class RecyclerView extends ViewGroup implements ScrollingView, NestedScrollingChild2 {
@Override
public boolean onTouchEvent(MotionEvent e) {
...
case MotionEvent.ACTION_MOVE: {
...
// 内部滚动
if (scrollByInternal(
canScrollHorizontally ? dx : 0,
canScrollVertically ? dy : 0,
vtev)) {
getParent().requestDisallowInterceptTouchEvent(true);
}
...
}
} break;
...
}
}
复制代码
去掉了大量位移赋值逻辑后,一个处理滚动的函数出现在眼前:
public class RecyclerView extends ViewGroup implements ScrollingView, NestedScrollingChild2 {
...
LayoutManager mLayout;// 处理滚动的LayoutManager
...
boolean scrollByInternal(int x, int y, MotionEvent ev) {
...
if (mAdapter != null) {
...
if (x != 0) { // 水平滚动
consumedX = mLayout.scrollHorizontallyBy(x, mRecycler, mState);
unconsumedX = x - consumedX;
}
if (y != 0) { // 垂直滚动
consumedY = mLayout.scrollVerticallyBy(y, mRecycler, mState);
unconsumedY = y - consumedY;
}
...
}
...
}
复制代码
RecyclerView把滚动委托给LayoutManager来处理:
public class LinearLayoutManager extends RecyclerView.LayoutManager implements ItemTouchHelper.ViewDropHandler, RecyclerView.SmoothScroller.ScrollVectorProvider {
@Override
public int scrollVerticallyBy(int dy, RecyclerView.Recycler recycler,
RecyclerView.State state) {
if (mOrientation == HORIZONTAL) {
return 0;
}
return scrollBy(dy, recycler, state);
}
int scrollBy(int dy, RecyclerView.Recycler recycler, RecyclerView.State state) {
...
//更新LayoutState(这个函数对于“回收哪些表项”来说很关键,待会会提到)
updateLayoutState(layoutDirection, absDy, true, state);
//滚动时向列表中填充新的表项
final int consumed = mLayoutState.mScrollingOffset + fill(recycler, mLayoutState, state, false);
...
return scrolled;
}
...
}
复制代码
沿着调用链往下找,发现了一个上一篇中介绍过的函数LinearLayoutManager.fill(),列表滚动的同时会不断的向其中填充表项。
上一遍只关注了其中填充的逻辑,里面还有回收逻辑:
public class LinearLayoutManager extends RecyclerView.LayoutManager {
int fill(RecyclerView.Recycler recycler, LayoutState layoutState, RecyclerView.State state, boolean stopOnFocusable) {
...
int remainingSpace = layoutState.mAvailable + layoutState.mExtra;
LayoutChunkResult layoutChunkResult = mLayoutChunkResult;
//不断循环获取新的表项用于填充,直到没有填充空间
while ((layoutState.mInfinite || remainingSpace > 0) && layoutState.hasMore(state)) {
...
//填充新的表项
layoutChunk(recycler, state, layoutState, layoutChunkResult);
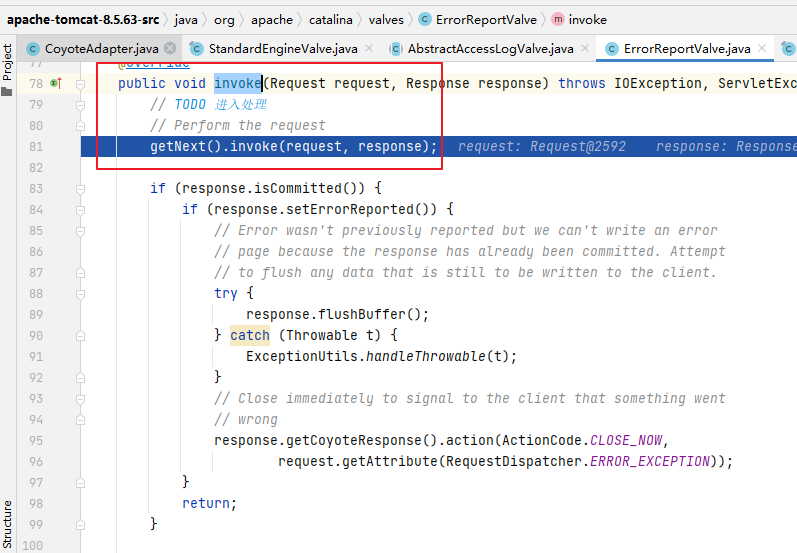
...
if (layoutState.mScrollingOffset != LayoutState.SCROLLING_OFFSET_NaN) {
//在当前滚动偏移量基础上追加因新表项插入增加的像素(这句话对于“回收哪些表项”来说很关键)
layoutState.mScrollingOffset += layoutChunkResult.mConsumed;
...
//回收表项
recycleByLayoutState(recycler, layoutState);
}
...
}
...
return start - layoutState.mAvailable;
}
}
复制代码
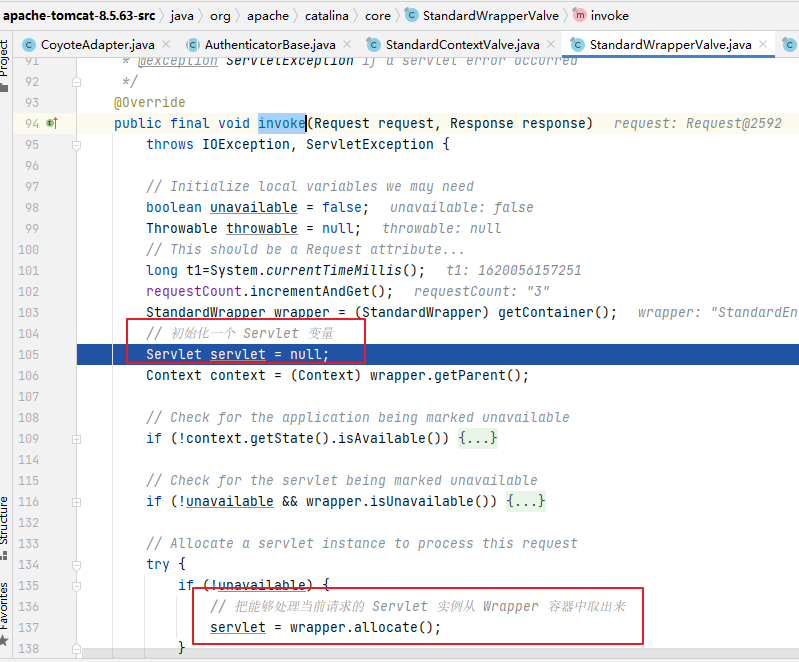
在不断获取新表项用于填充的同时也在回收表项,就好比滚动着的列表,有表项插入的同时也有表项被移出,移步到回收表项的函数:
public class LinearLayoutManager extends RecyclerView.LayoutManager {
...
private void recycleByLayoutState(RecyclerView.Recycler recycler, LayoutState layoutState) {
if (!layoutState.mRecycle || layoutState.mInfinite) {
return;
}
if (layoutState.mLayoutDirection == LayoutState.LAYOUT_START) {
// 从列表头回收
recycleViewsFromEnd(recycler, layoutState.mScrollingOffset);
} else {
// 从列表尾回收
recycleViewsFromStart(recycler, layoutState.mScrollingOffset);
}
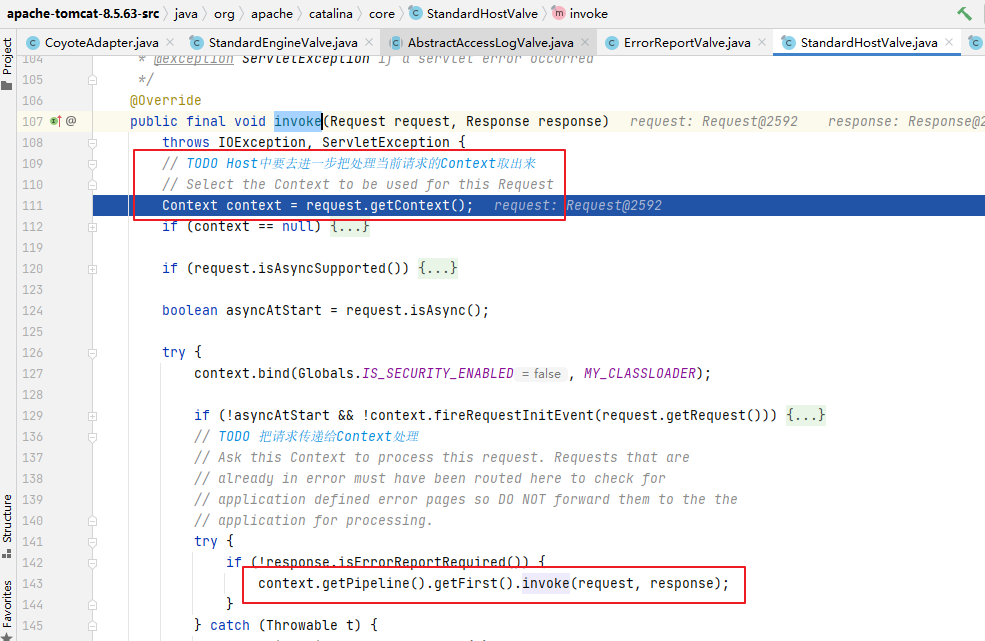
}
...
/**
* 当向列表尾部滚动时回收滚出屏幕的表项
* @param dt(该参数被用于检测滚出屏幕的表项)
*/
private void recycleViewsFromStart(RecyclerView.Recycler recycler, int scrollingOffset,int noRecycleSpace) {
final int limit = scrollingOffset - noRecycleSpace;
//从头开始遍历 LinearLayoutManager,以找出应该会回收的表项
final int childCount = getChildCount();
for (int i = 0; i < childCount; i++) {
View child = getChildAt(i);
// 如果表项的下边界 > limit 这个阈值
if (mOrientationHelper.getDecoratedEnd(child) > limit
|| mOrientationHelper.getTransformedEndWithDecoration(child) > limit) {
//回收索引为 0 到 i-1 的表项
recycleChildren(recycler, 0, i);
return;
}
}
}
...
}
复制代码
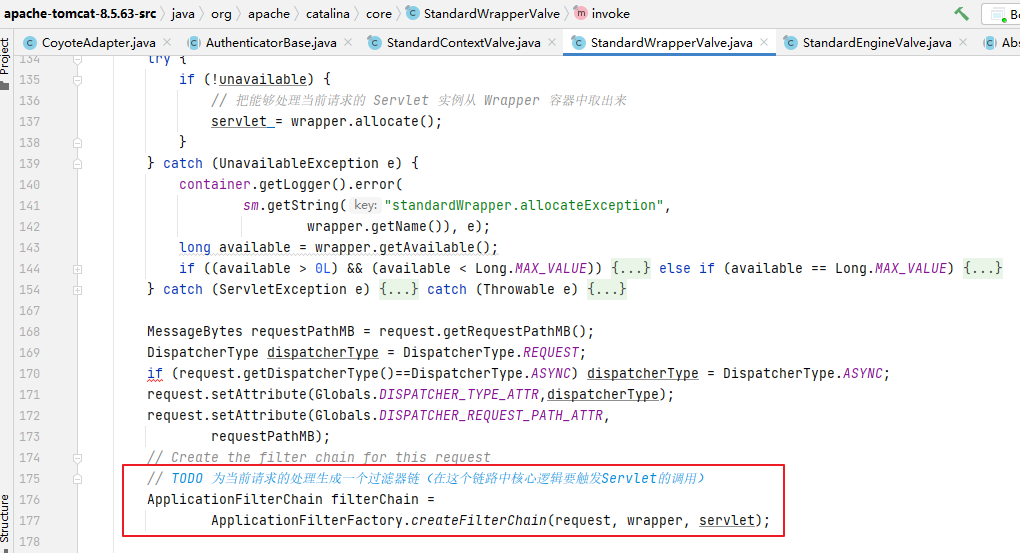
RecyclerView的回收分两个方向:1. 从列表头回收 2.从列表尾回收。
就以“从列表头回收”为研究对象分析下RecyclerView在滚动时到底是怎么判断“哪些表项应该被回收?”。
(“从列表头回收表项”所对应的场景是:手指上滑,列表向下滚动,新的表项逐个插入到列表尾部,列表头部的表项逐个被回收。)
回收哪些表项
要回答这个问题,刚才那段代码中套在recycleChildren(recycler, 0, i)外面的判断逻辑是关键:mOrientationHelper.getDecoratedEnd(child) > limit。
其中的mOrientationHelper.getDecoratedEnd(child)代码如下:
// 屏蔽方向的抽象接口,用于减少关于方向的 if-else
public abstract class OrientationHelper {
// 获取当前表项相对于列表头部的坐标
public abstract int getDecoratedEnd(View view);
// 垂直布局对该接口的实现
public static OrientationHelper createVerticalHelper(RecyclerView.LayoutManager layoutManager) {
return new OrientationHelper(layoutManager) {
@Override
public int getDecoratedEnd(View view) {
final RecyclerView.LayoutParams params = (RecyclerView.LayoutParams)view.getLayoutParams();
return mLayoutManager.getDecoratedBottom(view) + params.bottomMargin;
}
}
复制代码
mOrientationHelper.getDecoratedEnd(child) 表示当前表项的尾部相对于列表头部的坐标,OrientationHelper这层抽象屏蔽了列表的方向,所以这句话在纵向列表中可以翻译成“当前表项的底部相对于列表顶部的纵坐标”。
判断条件mOrientationHelper.getDecoratedEnd(child) > limit中的limit又是什么意思?
在纵向列表中,“表项底部纵坐标 > 某个值”意味着表项位于某条线的下方,即 limit 是列表中隐形的线,所有在这条线上方的表项都应该被回收。
那这条线是如何被计算的?
public class LinearLayoutManager extends RecyclerView.LayoutManager {
private void recycleViewsFromStart(RecyclerView.Recycler recycler, int scrollingOffset,int noRecycleSpace) {
final int limit = scrollingOffset - noRecycleSpace;
...
}
}
复制代码
limit的值由 2 个变量决定,其中noRecycleSpace的值为 0(这是断点告诉我的,详细过程可移步RecyclerView 动画原理 | 换个姿势看源码(pre-layout))
而scrollingOffset的值由外部传入:
public class LinearLayoutManager {
private void recycleByLayoutState(RecyclerView.Recycler recycler, LayoutState layoutState) {
int scrollingOffset = layoutState.mScrollingOffset;
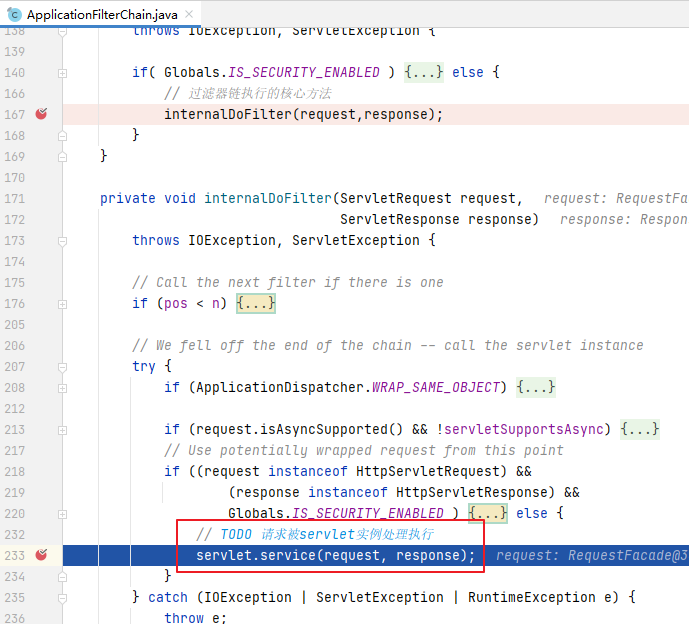
...
recycleViewsFromStart(recycler, scrollingOffset, noRecycleSpace);
}
}
复制代码
问题转换为layoutState.mScrollingOffset的值由什么决定?全局搜索下它被赋值的地方:
public class LinearLayoutManager {
private void updateLayoutState(int layoutDirection, int requiredSpace,boolean canUseExistingSpace, RecyclerView.State state) {
...
int scrollingOffset;
// 获取末尾的表项视图
final View child = getChildClosestToEnd();
// 计算在不往列表里填充新表项的情况下,列表最多可以滚动多少像素
scrollingOffset = mOrientationHelper.getDecoratedEnd(child) - mOrientationHelper.getEndAfterPadding();
...
mLayoutState.mScrollingOffset = scrollingOffset;
}
}
复制代码
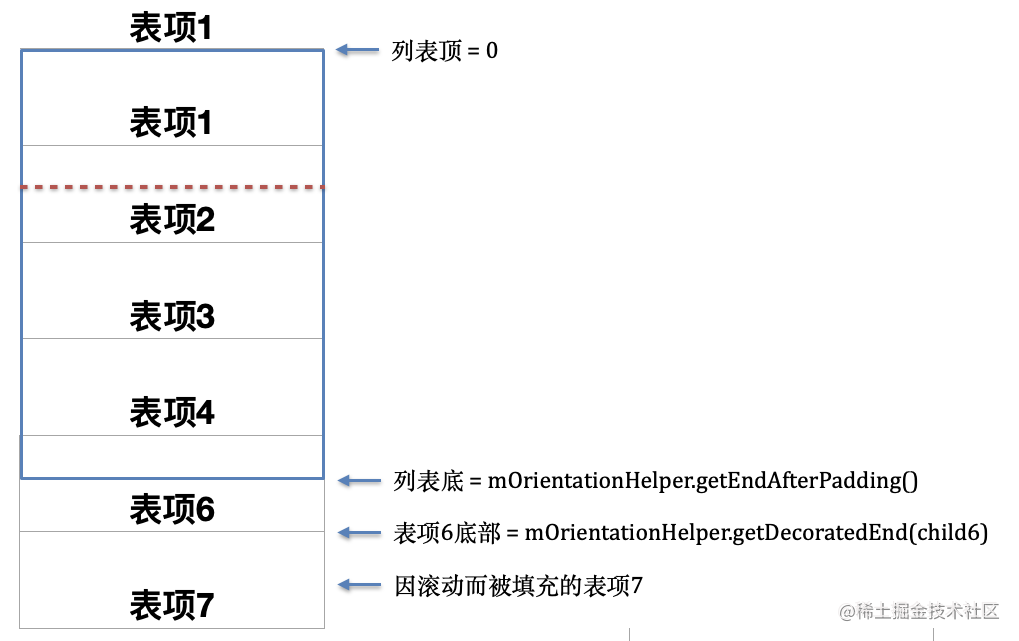
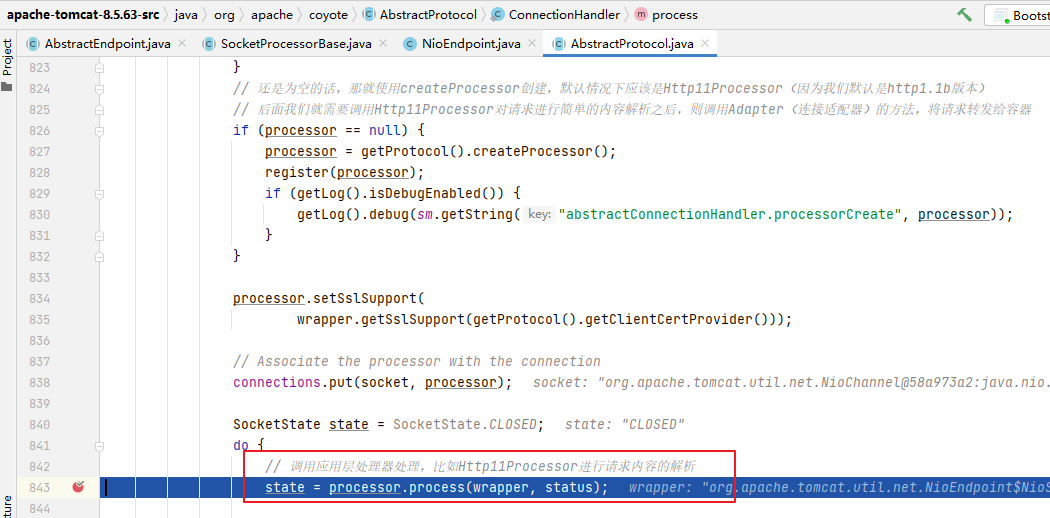
updateLayoutState()方法中先获取了列表末尾表项的视图,并通过mOrientationHelper.getDecoratedEnd(child)计算出该表项底部到列表顶部的距离,然后在减去列表长度。这个差值可以理解为在不往列表里填充新表项的情况下,列表最多可以滚动多少像素。略抽象,图示如下:

图中蓝色边框表示列表,灰色矩形表示表项。
LayoutManager只会加载可见表项,图中表项 6 有一半露出了屏幕,所以它会被加载到列表中,而表项 7 完全不可见,所以不会被加载。这种情况下,如果不继续往列表中填充表项 7,那列表最多滑动的距离就是半个表项 6 的距离,表项在代码中即是mLayoutState.mScrollingOffset的值。
若非常缓慢地滑动列表,并且只滑动“半个表项 6”的距离(即表项 7 没有机会展示)。在这个理想的场景下limit的值 = 半个表项 6 的长度。也就是说limit这根隐形的线应该在如下位置:

回看一下,回收表项的代码:
public class LinearLayoutManager {
private void recycleViewsFromStart(RecyclerView.Recycler recycler, int scrollingOffset,int noRecycleSpace) {
final int limit = scrollingOffset - noRecycleSpace;
//从头开始遍历 LinearLayoutManager,以找出应该会回收的表项
final int childCount = getChildCount();
for (int i = 0; i < childCount; i++) {
View child = getChildAt(i);
// 如果表项的下边界 > limit 这个阈值
if (mOrientationHelper.getDecoratedEnd(child) > limit
|| mOrientationHelper.getTransformedEndWithDecoration(child) > limit) {
//回收索引为 0 到 i-1 的表项
recycleChildren(recycler, 0, i);
return;
}
}
}
}
复制代码
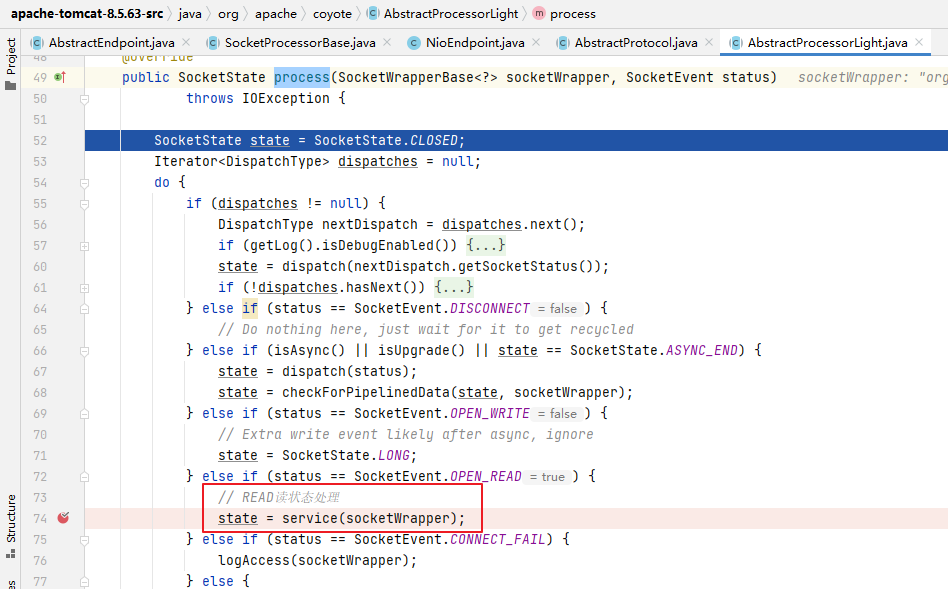
回收逻辑从头开始遍历 LinearLayoutManager,当遍历到表项 1 的时候,发现它的下边界 > limit,所以触发表项回收,回收表项的索引区间为 0 到 0,即没有任何表项被回收。(想想也是,表项 1 还未完整地被移出屏幕)。
若滑动速度和距离更大会发生什么?
计算limit值的方法updateLayoutState()在scrollBy()中被调用:
public class LinearLayoutManager {
int scrollBy(int delta, RecyclerView.Recycler recycler, RecyclerView.State state) {
...
// 将滚动距离的绝对值传入 updateLayoutState()
final int absDelta = Math.abs(delta);
updateLayoutState(layoutDirection, absDelta, true, state);
...
}
private void updateLayoutState(int layoutDirection, int requiredSpace,boolean canUseExistingSpace, RecyclerView.State state) {
...
// 计算在不往列表里填充新表项的情况下,列表最多可以滚动多少像素
scrollingOffset = mOrientationHelper.getDecoratedEnd(child)- mOrientationHelper.getEndAfterPadding();
...
// 将列表因滚动而需要的额外空间存储在 mLayoutState.mAvailable
mLayoutState.mAvailable = requiredSpace;
mLayoutState.mScrollingOffset = scrollingOffset;
...
}
}
复制代码
至此,两个重要的值被分别存储在mLayoutState.mScrollingOffset和mLayoutState.mAvailable,分别是“在不往列表里填充新表项的情况下,列表最多可以滚动多少像素”,及“滚动总像素值”。
srollBy()在调用updateLayoutState()存储了这两个重要的值之后,立马进行了填充表项的操作:
public class LinearLayoutManager {
int scrollBy(int delta, RecyclerView.Recycler recycler, RecyclerView.State state) {
...
final int absDelta = Math.abs(delta);
updateLayoutState(layoutDirection, absDelta, true, state);
final int consumed = mLayoutState.mScrollingOffset + fill(recycler, mLayoutState, state, false);
...
}
}
复制代码
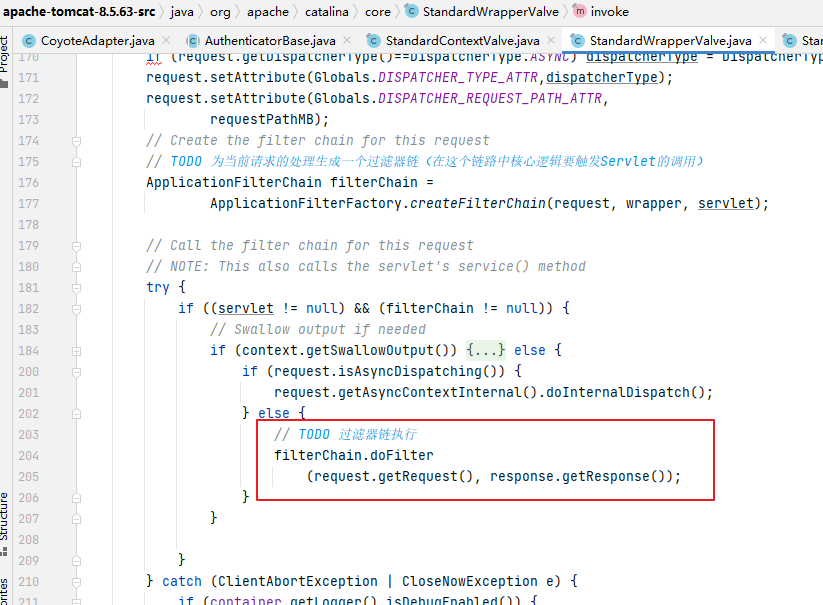
填充表项
其中的fill()即是向列表填充表项的方法:
public class LinearLayoutManager {
// 根据剩余空间填充表项
int fill(RecyclerView.Recycler recycler, LayoutState layoutState,RecyclerView.State state, boolean stopOnFocusable) {
...
// 计算剩余空间 = 可用空间 + 额外空间(=0)
int remainingSpace = layoutState.mAvailable + layoutState.mExtraFillSpace;
// 循环,当剩余空间 > 0 时,继续填充更多表项
while ((layoutState.mInfinite || remainingSpace > 0) && layoutState.hasMore(state)) {
...
// 填充单个表项
layoutChunk(recycler, state, layoutState, layoutChunkResult)
...
// 从剩余空间中扣除新表项占用像素值
layoutState.mAvailable -= layoutChunkResult.mConsumed;
remainingSpace -= layoutChunkResult.mConsumed;
...
}
}
}
复制代码
填充表项是一个while循环,循环结束条件是“列表剩余空间是否 > 0”,每次循环调用layoutChunk()将单个表项填充到列表中:
public class LinearLayoutManager {
// 填充单个表项
void layoutChunk(RecyclerView.Recycler recycler, RecyclerView.State state,LayoutState layoutState, LayoutChunkResult result) {
// 1.获取下一个该被填充的表项视图
View view = layoutState.next(recycler);
// 2.使表项成为 RecyclerView 的子视图
addView(view);
...
// 3.测量表项视图(把 RecyclerView 内边距和表项装饰考虑在内)
measureChildWithMargins(view, 0, 0);
// 获取填充表项视图需要消耗的像素值
result.mConsumed = mOrientationHelper.getDecoratedMeasurement(view);
...
// 4.布局表项
layoutDecoratedWithMargins(view, left, top, right, bottom);
}
}
复制代码
layoutChunk()先从缓存池中获取下一个该被填充表项的视图(关于复用的详细分析可以移步RecyclerView 缓存机制 | 如何复用表项?)。
紧接着调用了addView()使表项视图成为 RecyclerView 的子视图,调用链如下:
public class RecyclerView {
ChildHelper mChildHelper;
public abstract static class LayoutManager {
public void addView(View child) {
addView(child, -1);
}
public void addView(View child, int index) {
addViewInt(child, index, false);
}
private void addViewInt(View child, int index, boolean disappearing) {
...
mChildHelper.attachViewToParent(child, index, child.getLayoutParams(), false);
...
}
}
}
class ChildHelper {
final Callback mCallback;
void attachViewToParent(View child, int index, ViewGroup.LayoutParams layoutParams,boolean hidden) {
...
mCallback.attachViewToParent(child, offset, layoutParams);
}
}
复制代码
调用链从RecyclerView到LayoutManager再到ChildHelper,最后又回到了RecyclerView:
public class RecyclerView {
ChildHelper mChildHelper;
private void initChildrenHelper() {
mChildHelper = new ChildHelper(new ChildHelper.Callback() {
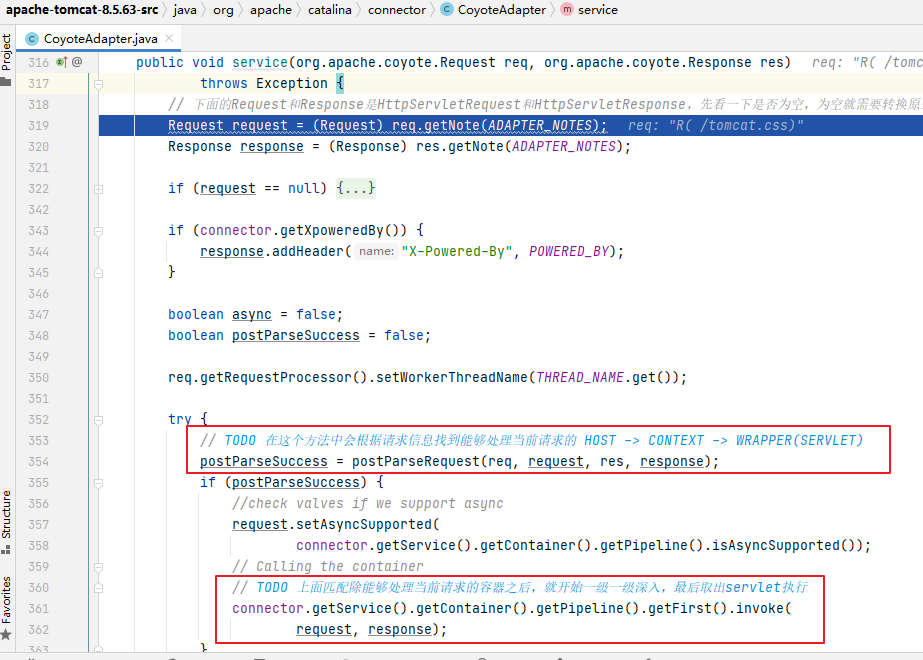
@Override
public void attachViewToParent(View child, int index,ViewGroup.LayoutParams layoutParams) {
...
RecyclerView.this.attachViewToParent(child, index, layoutParams);
}
...
}
}
}
复制代码
addView()的最终落脚点是ViewGroup.attachViewToParent():
public abstract class ViewGroup {
protected void attachViewToParent(View child, int index, LayoutParams params) {
child.mLayoutParams = params;
if (index < 0) {
index = mChildrenCount;
}
// 将子视图添加到数组中
addInArray(child, index);
// 子视图和父亲关联
child.mParent = this;
child.mPrivateFlags = (child.mPrivateFlags & ~PFLAG_DIRTY_MASK
& ~PFLAG_DRAWING_CACHE_VALID)
| PFLAG_DRAWN | PFLAG_INVALIDATED;
this.mPrivateFlags |= PFLAG_INVALIDATED;
if (child.hasFocus()) {
requestChildFocus(child, child.findFocus());
}
dispatchVisibilityAggregated(isAttachedToWindow() && getWindowVisibility() == VISIBLE
&& isShown());
notifySubtreeAccessibilityStateChangedIfNeeded();
}
}
复制代码
attachViewToParent()中包含了“添加子视图”最具标志性的两个动作:1. 将子视图添加到数组中 2. 子视图和父亲关联。
使表项成为 RecyclerView 子视图之后,对其进行了测量:
public class LinearLayoutManager {
// 填充单个表项
void layoutChunk(RecyclerView.Recycler recycler, RecyclerView.State state,LayoutState layoutState, LayoutChunkResult result) {
// 1.获取下一个该被填充的表项视图
View view = layoutState.next(recycler);
// 2.使表项成为 RecyclerView 的子视图
addView(view);
...
// 3.测量表项视图(把 RecyclerView 内边距和表项装饰考虑在内)
measureChildWithMargins(view, 0, 0);
// 获取填充表项视图需要消耗的像素值
result.mConsumed = mOrientationHelper.getDecoratedMeasurement(view);
...
// 4.布局表项
layoutDecoratedWithMargins(view, left, top, right, bottom);
}
}
复制代码
测量之后,有了视图的尺寸,就可以知道填充该表项会消耗掉多少像素值,将该数值存储在LayoutChunkResult.mConsumed中。
有了尺寸后,就可以布局表项了,即确定表项上下左右四个点相对于 RecyclerView 的位置:
public class RecyclerView {
public abstract static class LayoutManager {
public void layoutDecoratedWithMargins(@NonNull View child, int left, int top, int right,
int bottom) {
final LayoutParams lp = (LayoutParams) child.getLayoutParams();
final Rect insets = lp.mDecorInsets;
// 为表项定位
child.layout(left + insets.left + lp.leftMargin, top + insets.top + lp.topMargin,
right - insets.right - lp.rightMargin,
bottom - insets.bottom - lp.bottomMargin);
}
}
}
复制代码
调用控件的layout()方法即是为控件定位,关于定位子控件的详细介绍可以移步Android自定义控件 | View绘制原理(画在哪?)。
填充完一个表项后,会从remainingSpace中扣除它所占用的空间(这样 while 循环才能结束)
public class LinearLayoutManager {
// 根据剩余空间填充表项
int fill(RecyclerView.Recycler recycler, LayoutState layoutState,RecyclerView.State state, boolean stopOnFocusable) {
...
// 计算剩余空间 = 可用空间 + 额外空间(=0)
int remainingSpace = layoutState.mAvailable + layoutState.mExtraFillSpace;
// 循环,当剩余空间 > 0 时,继续填充更多表项
while ((layoutState.mInfinite || remainingSpace > 0) && layoutState.hasMore(state)) {
...
// 填充单个表项
layoutChunk(recycler, state, layoutState, layoutChunkResult)
...
// 从剩余空间中扣除新表项占用像素值
layoutState.mAvailable -= layoutChunkResult.mConsumed;
remainingSpace -= layoutChunkResult.mConsumed;
...
// 在 limit 上追加新表项所占像素值
layoutState.mScrollingOffset += layoutChunkResult.mConsumed;
...
// 根据当前状态回收表项
recycleByLayoutState(recycler, layoutState);
}
}
}
}
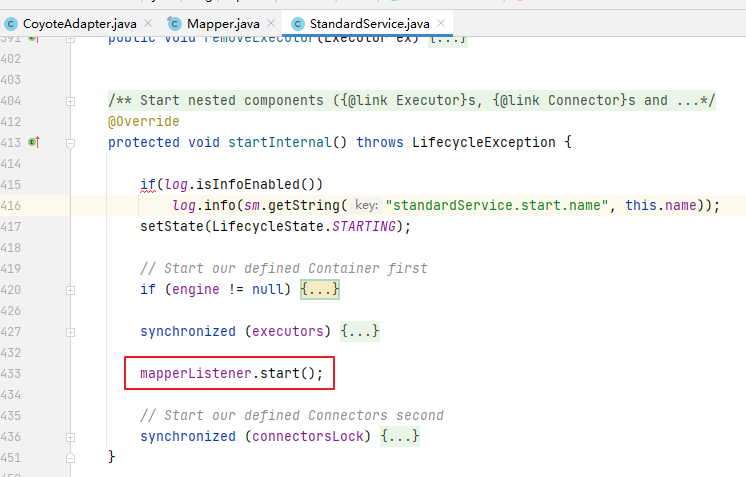
复制代码
layoutState.mScrollingOffset会追加新表项所占用的像素值,即它的值在不断增大(limit 隐形线在不断下移)。
在一次while循环的最后,会根据当前limit 隐形线的位置回收表项:
public class LinearLayoutManager {
private void recycleByLayoutState(RecyclerView.Recycler recycler, LayoutState layoutState) {
...
ecycleViewsFromStart(recycler, scrollingOffset, noRecycleSpace);
}
}
private void recycleViewsFromStart(RecyclerView.Recycler recycler, int scrollingOffset,int noRecycleSpace) {
final int limit = scrollingOffset - noRecycleSpace;
final int childCount = getChildCount();
// 从头遍历表项
for (int i = 0; i < childCount; i++) {
View child = getChildAt(i);
// 当某表项底部位于 limit 隐形线之后时,回收它以上的所有表项
if (mOrientationHelper.getDecoratedStart(child) > limit || mOrientationHelper.getTransformedStartWithDecoration(child) > limit) {
recycleChildren(recycler, 0, i);
return;
}
}
}
}
复制代码
每向列表尾部填充一个表项,limit隐形线的位置就往下移动表项占用的像素值,这样列表头部也就有更多的表项符合被回收的条件。
关于回收细节的分析,可以移步RecyclerView 缓存机制 | 回收到哪去?。
预计的滑动距离被传入scrollBy(),scrollBy()把即将滑入屏幕的表项填充到列表中,同时把即将移出屏幕的表项回收到缓存池,最后它会比较预计滑动值和计算滑动值的大小,取其中的较小者返回:
public class LinearLayoutManager {
// 第一个参数是预计的滑动距离
int scrollBy(int delta, RecyclerView.Recycler recycler, RecyclerView.State state) {
...
final int absDelta = Math.abs(delta);
updateLayoutState(layoutDirection, absDelta, true, state);
// 经过计算的滚动值
final int consumed = mLayoutState.mScrollingOffset + fill(recycler, mLayoutState, state, false);
// 最终返回的滚动值
final int scrolled = absDelta > consumed ? layoutDirection * consumed : delta;
...
return scrolled;
}
}
复制代码
沿着scrollBy()调用链网上寻找:
public class LinearLayoutManager {
@Override
public int scrollVerticallyBy(int dy, RecyclerView.Recycler recycler,
RecyclerView.State state) {
if (mOrientation == HORIZONTAL) {
return 0;
}
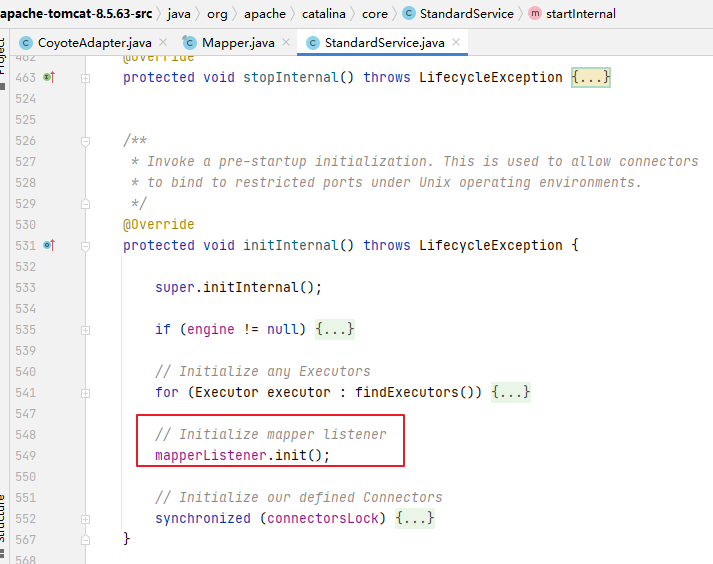
return scrollBy(dy, recycler, state);
}
}
public class RecyclerView {
void scrollStep(int dx, int dy, @Nullable int[] consumed) {
...
if (dy != 0) {
consumedY = mLayout.scrollVerticallyBy(dy, mRecycler, mState);
}
...
}
boolean scrollByInternal(int x, int y, MotionEvent ev) {
...
scrollStep(x, y, mReusableIntPair);
...
dispatchNestedScroll(consumedX, consumedY, unconsumedX, unconsumedY, mScrollOffset,TYPE_TOUCH, mReusableIntPair);
...
}
}
复制代码
只有当执行了dispatchNestedScroll()才会真正触发列表的滚动,也就说 RecyclerView 在列表滚动发生之前就预先计算好了,哪些表项会移入屏幕,哪些表项会移出屏幕,并分别将它们填充到列表或回到到缓存池。而做这两件事的依据即是limit隐形线,最后用一张图来概括下这条线的意义:
limit的值表示这一次滚动的总距离。(图中是一种理想情况,即当滚动结束后新插入表项 7 的底部正好和列表底部重叠)
limit隐形线可以理解为:隐形线当前所在位置,在滚动完成后会和列表顶部重合










































 选择一个空应用
选择一个空应用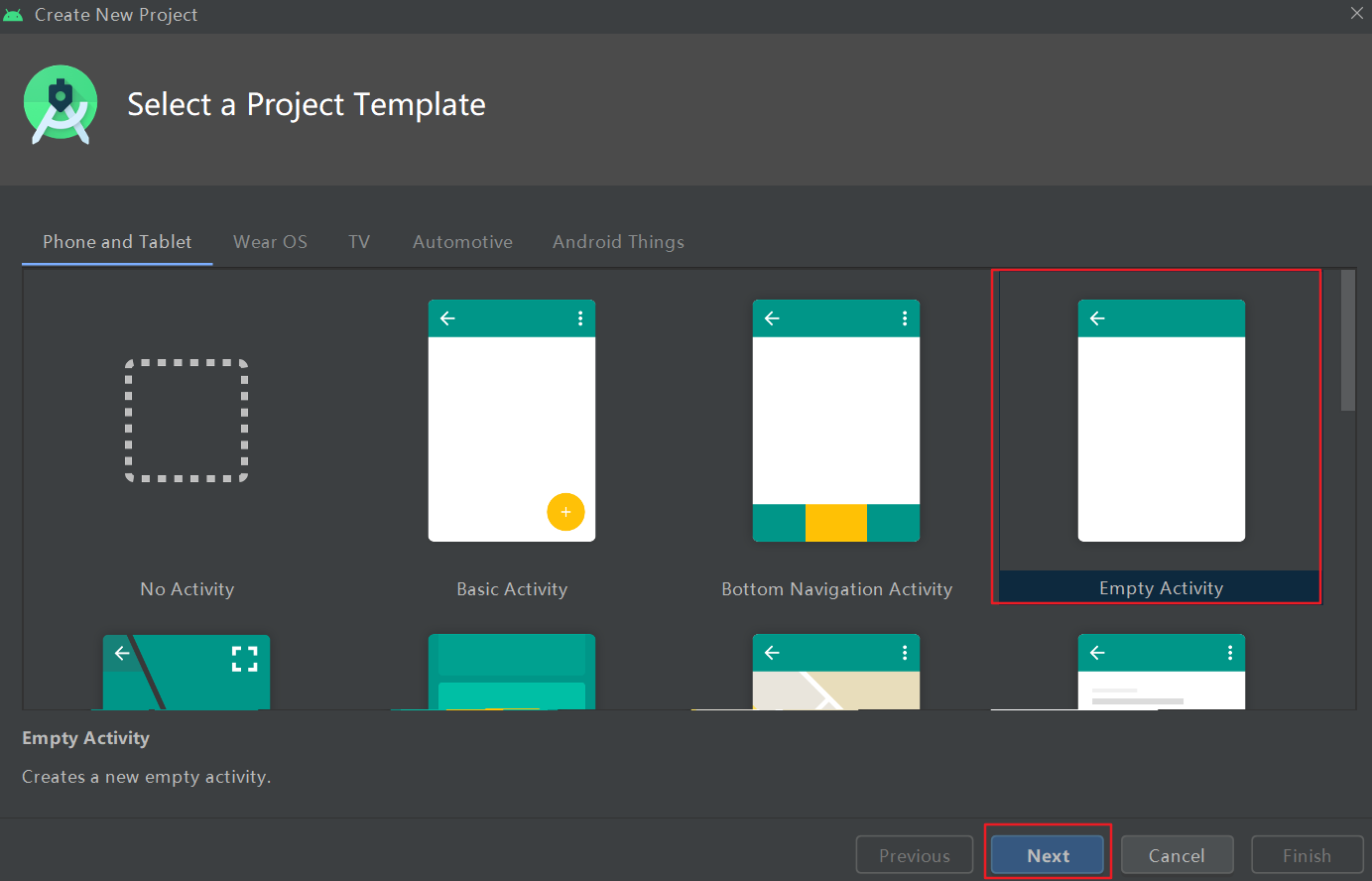 按照图片的配置方法,设置好工程名和路径
按照图片的配置方法,设置好工程名和路径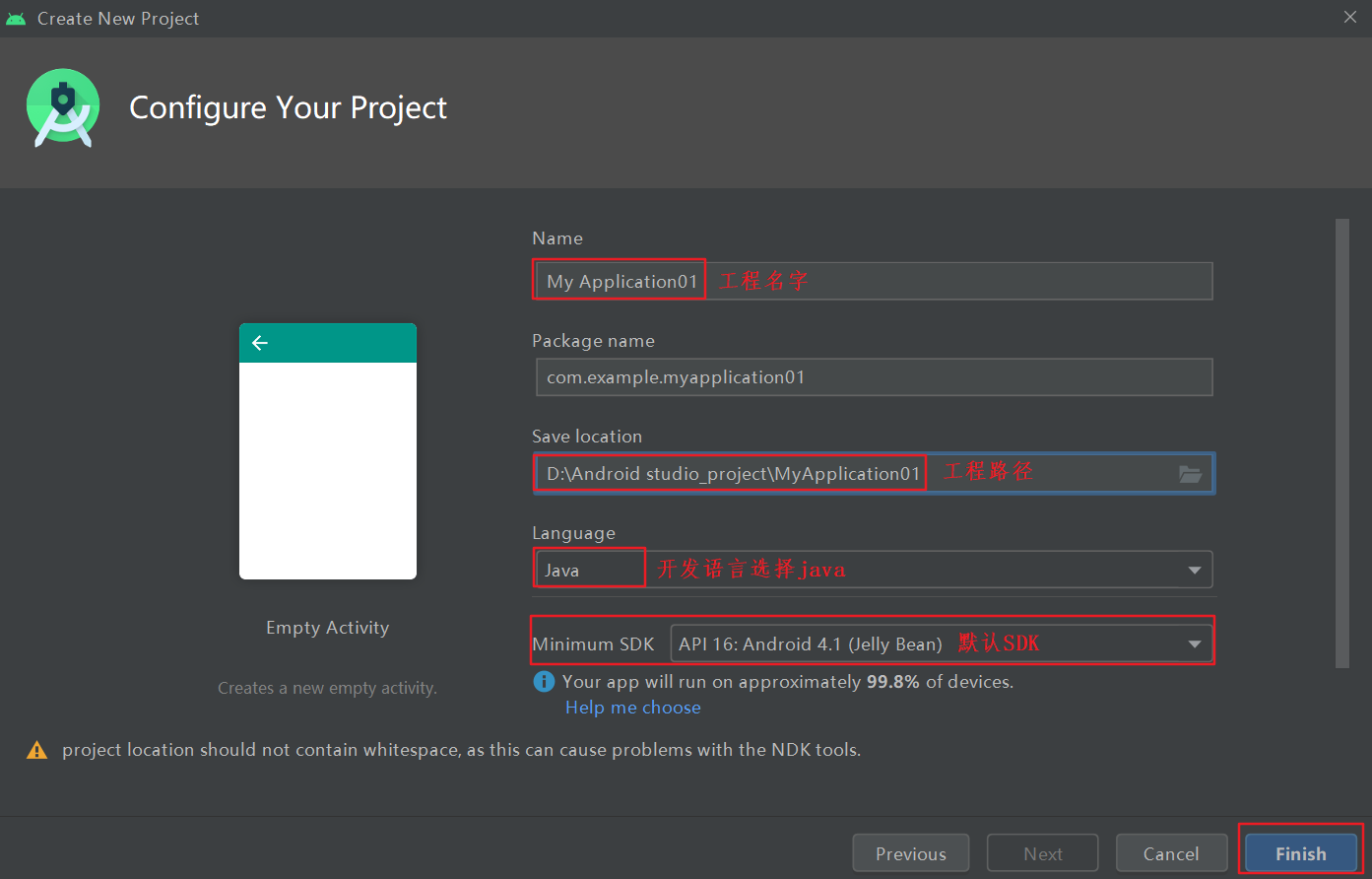
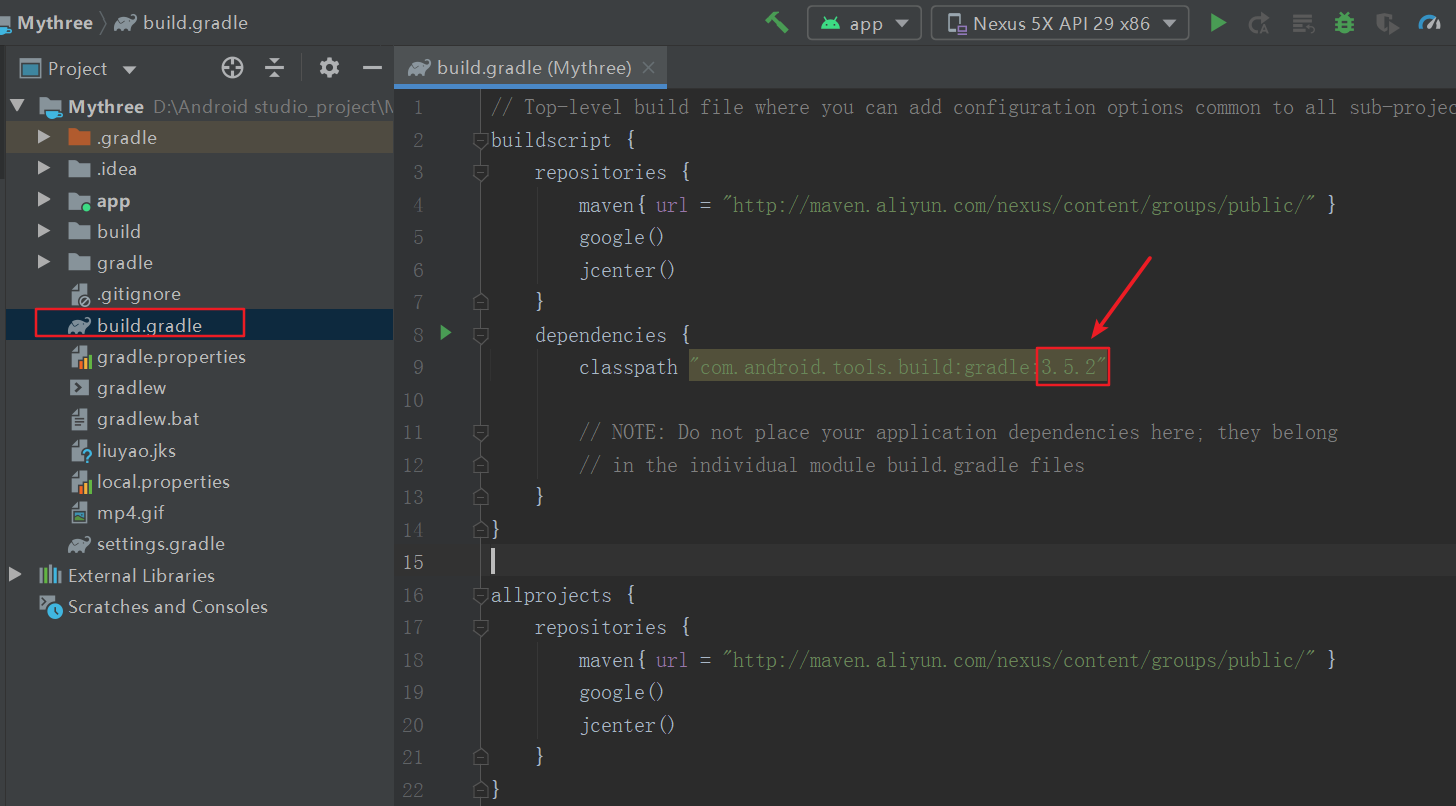
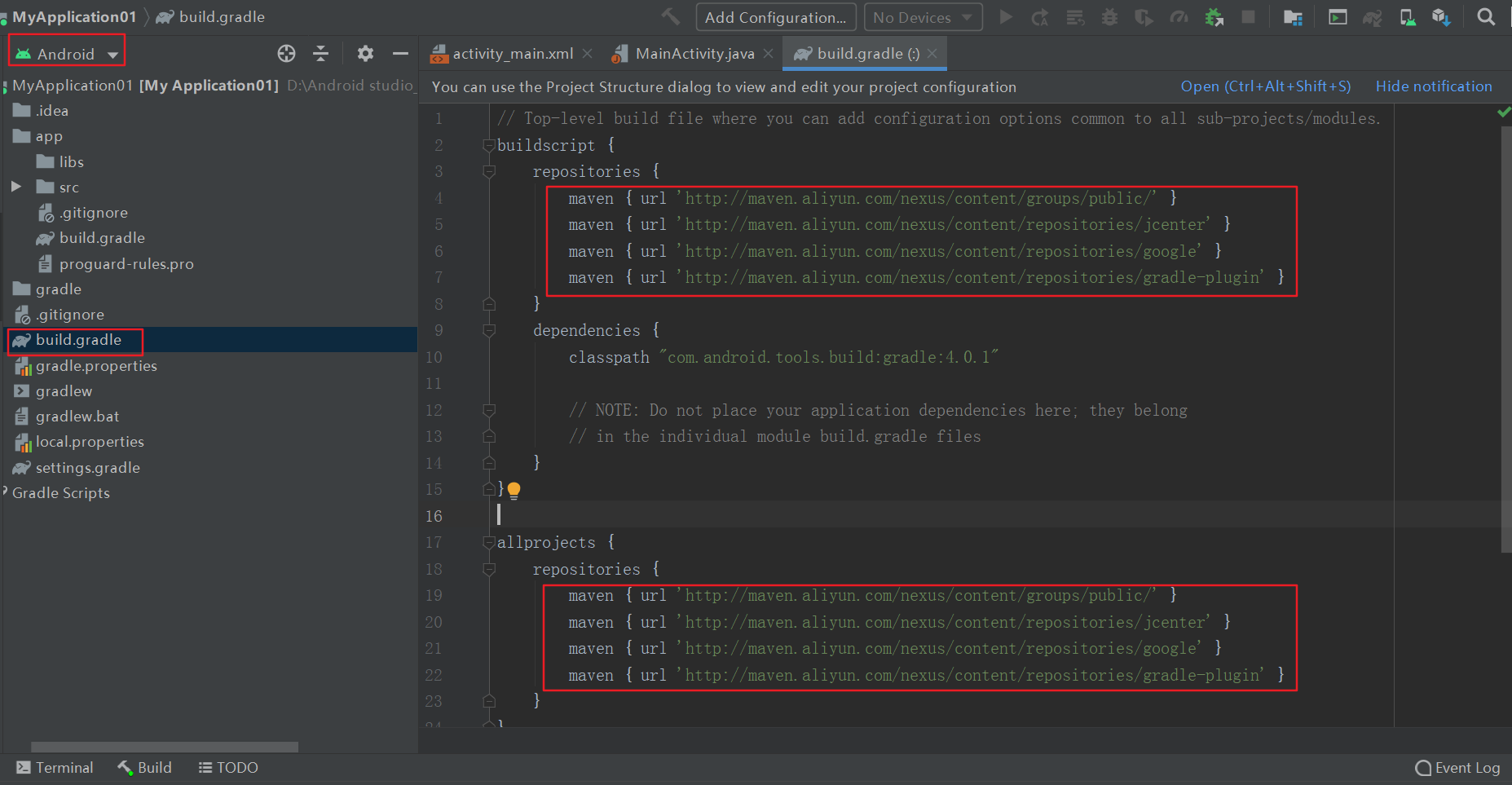 第一处代码
第一处代码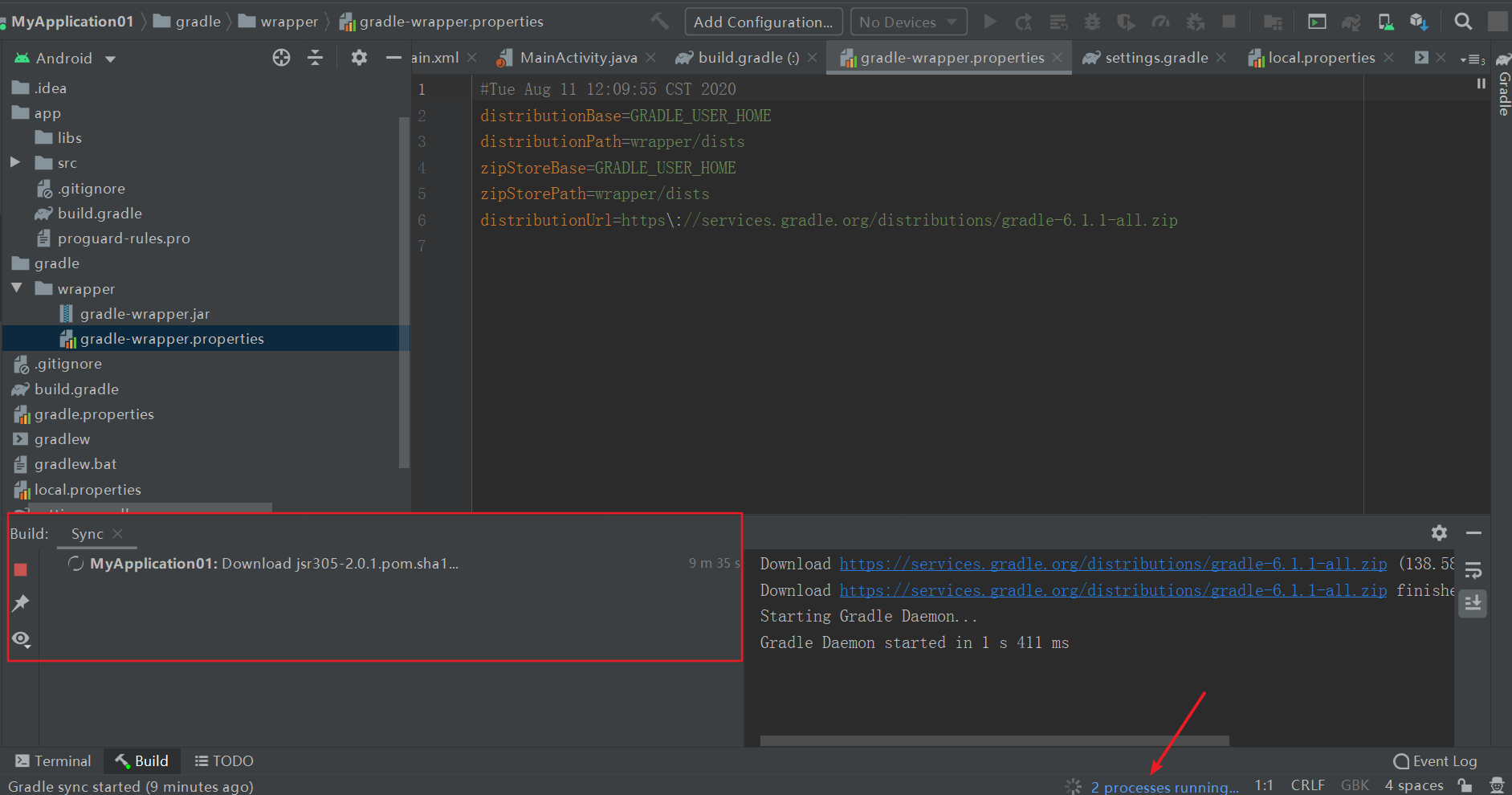 这样编译起来就会快很多,建议这样修改,不然很可能下载失败导致编译不成功!
这样编译起来就会快很多,建议这样修改,不然很可能下载失败导致编译不成功!
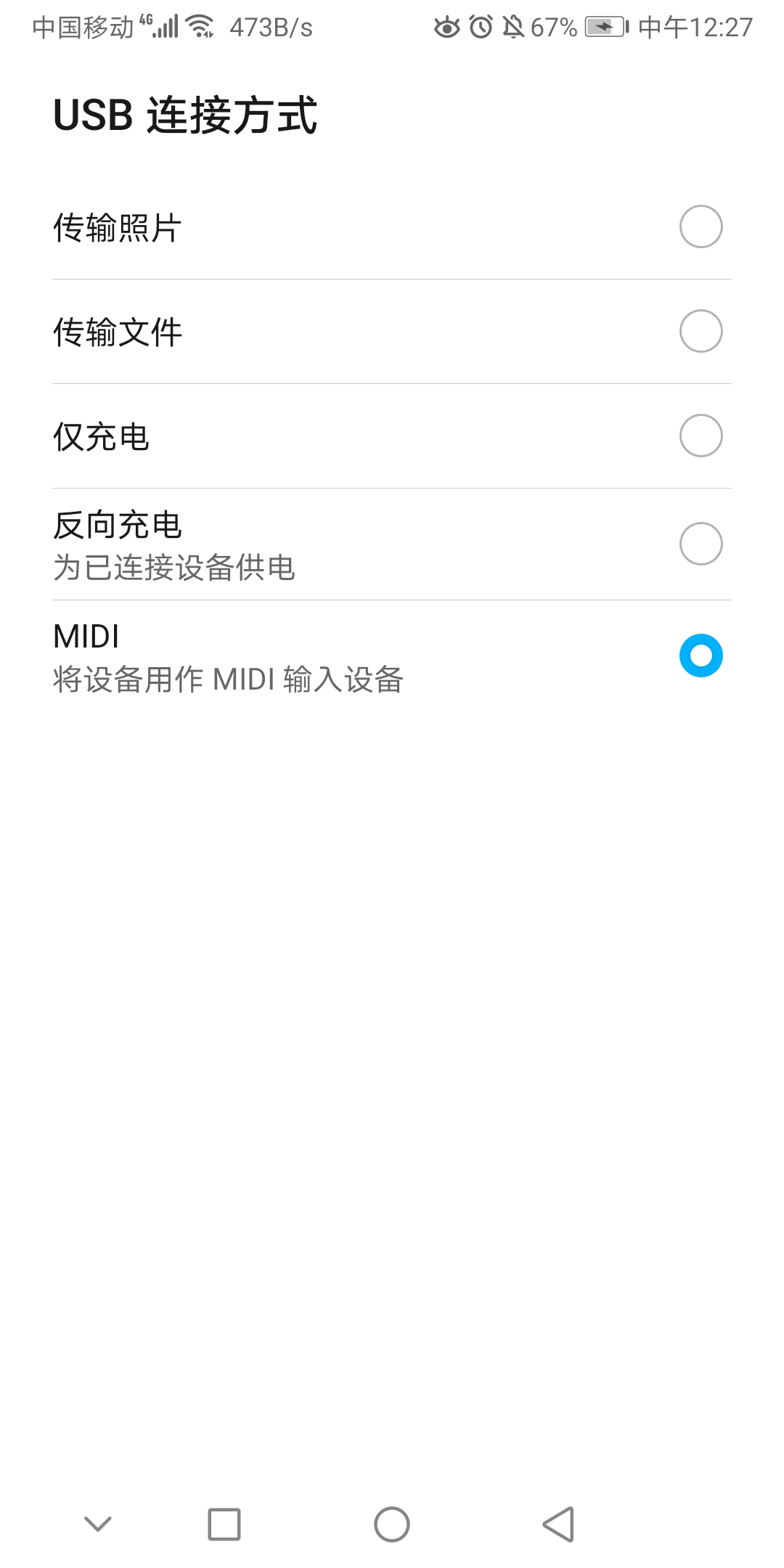 设备作为MIDI设备
设备作为MIDI设备 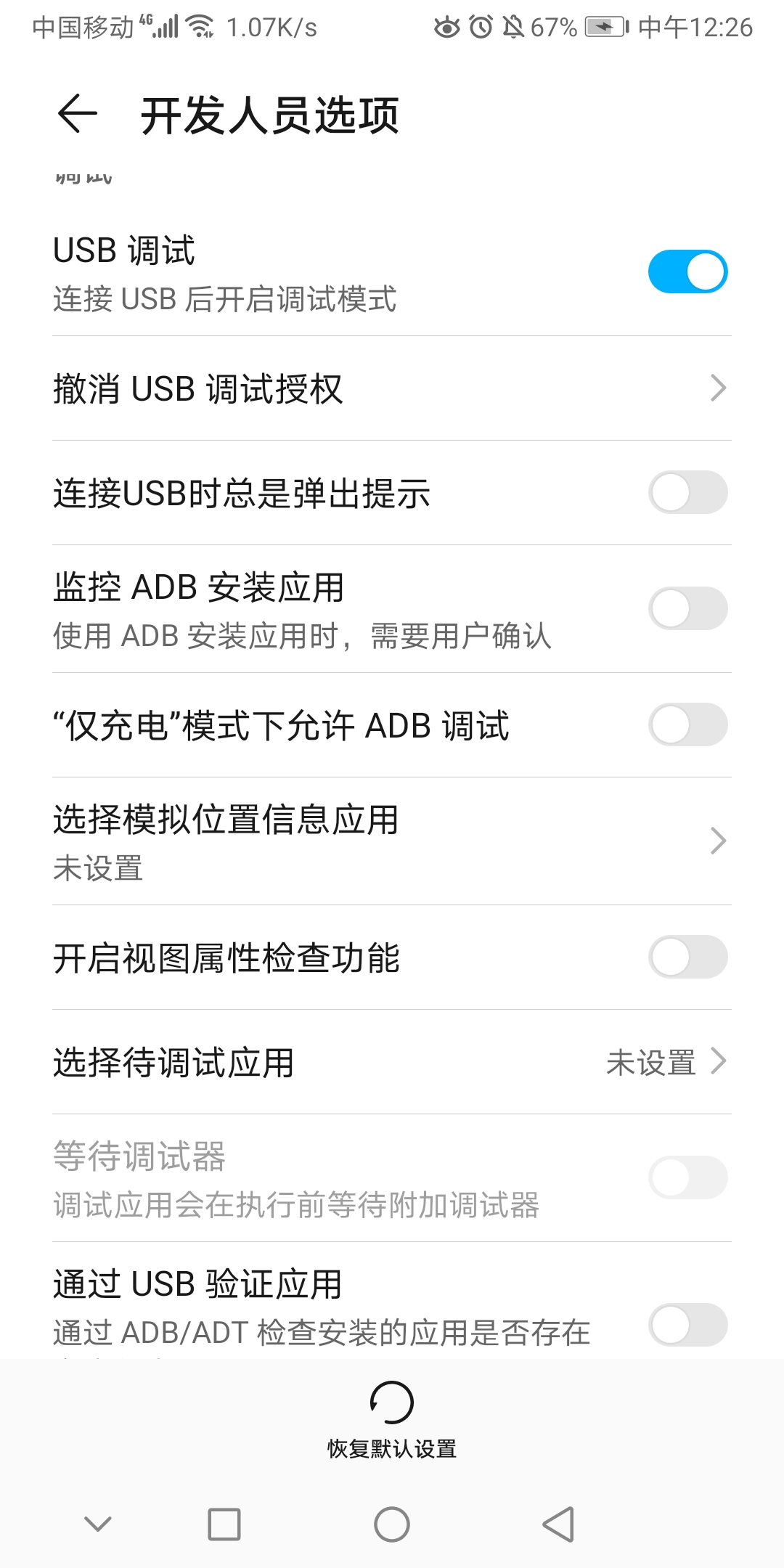 开启USB调试
开启USB调试 

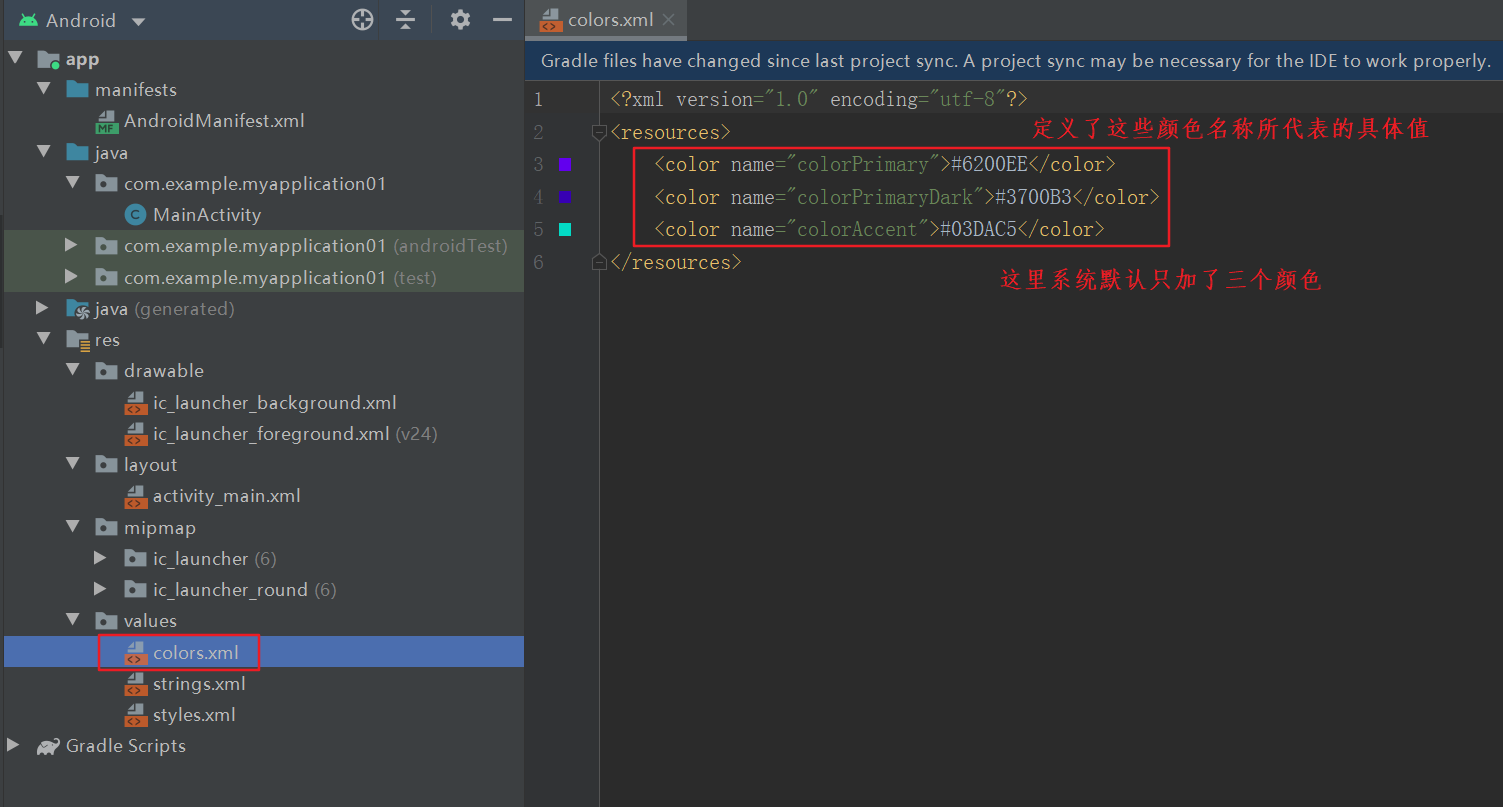
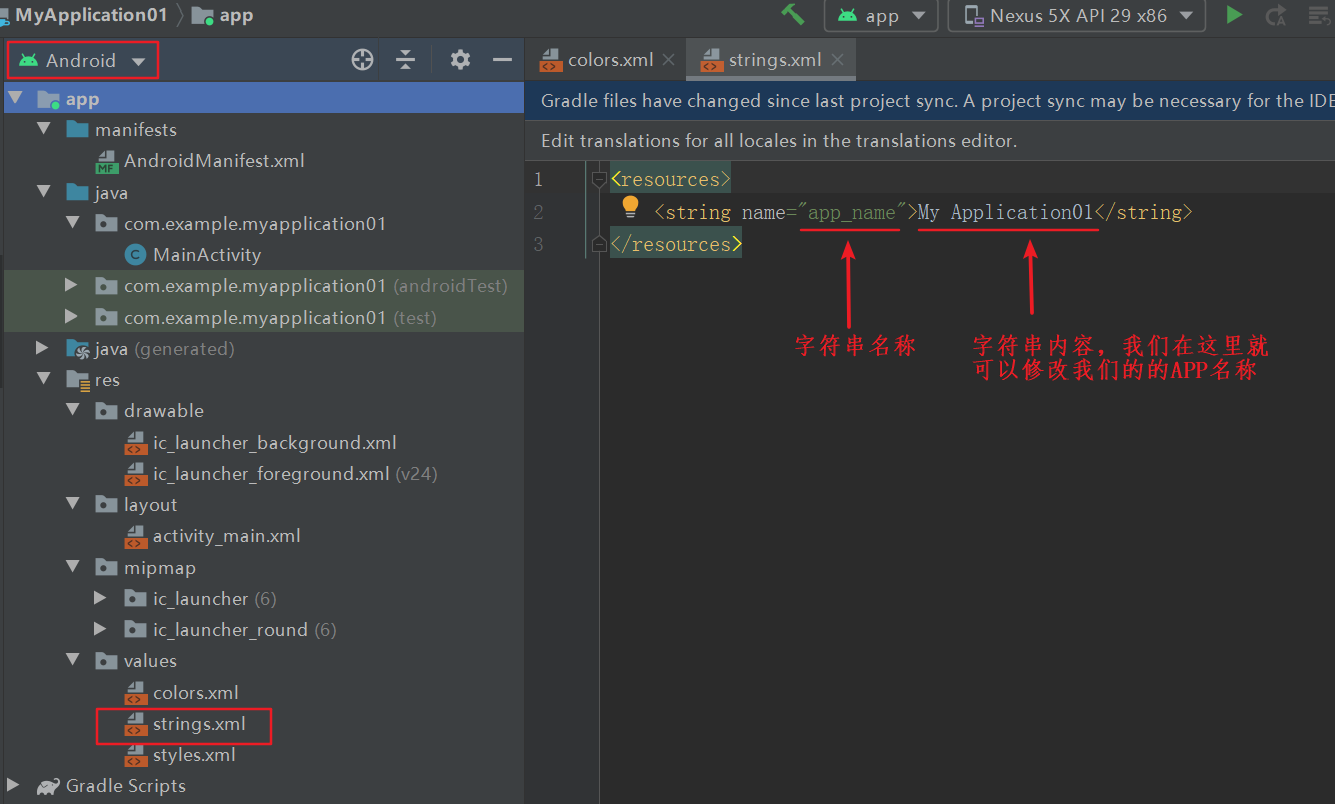
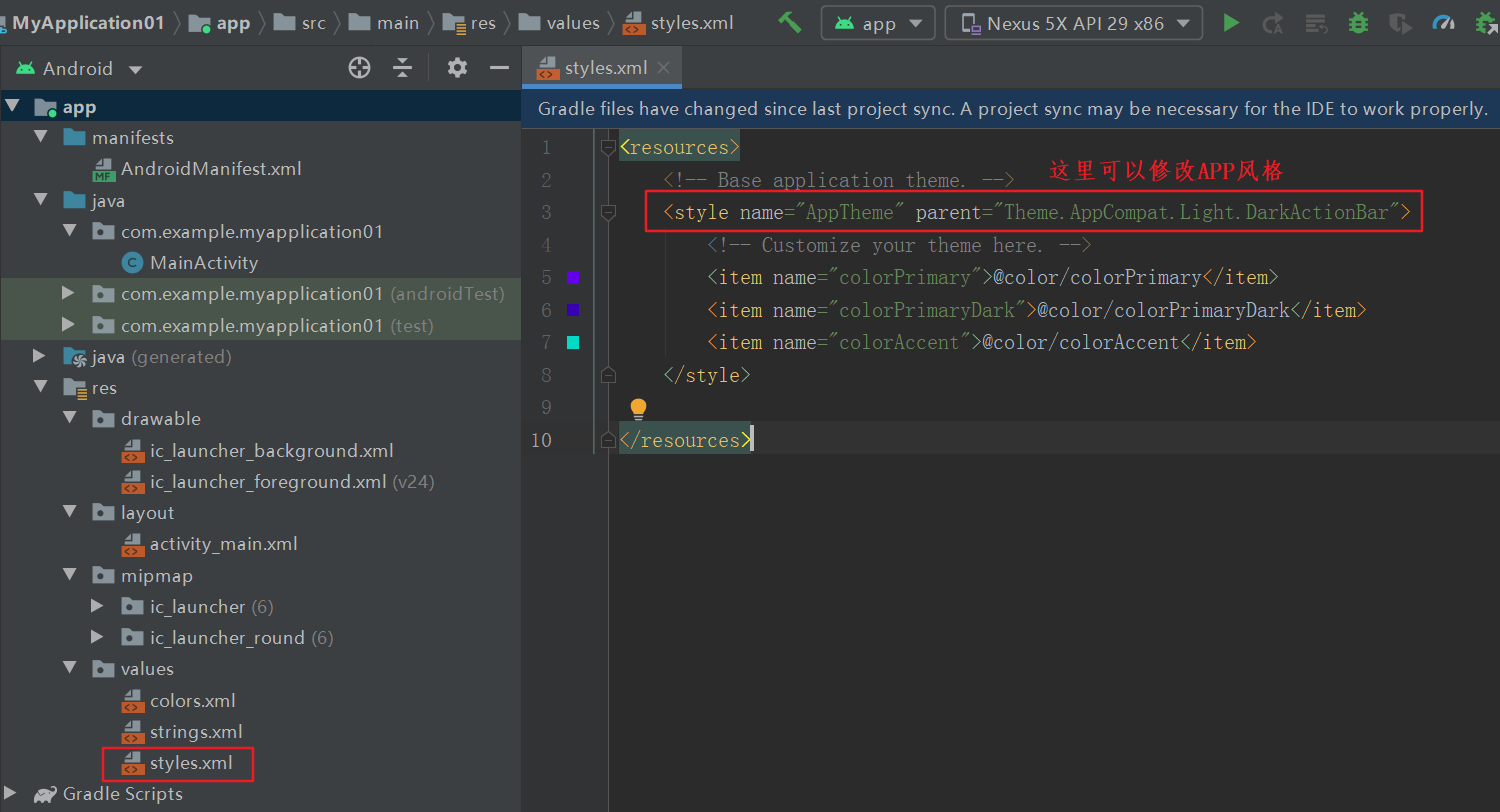 ***
***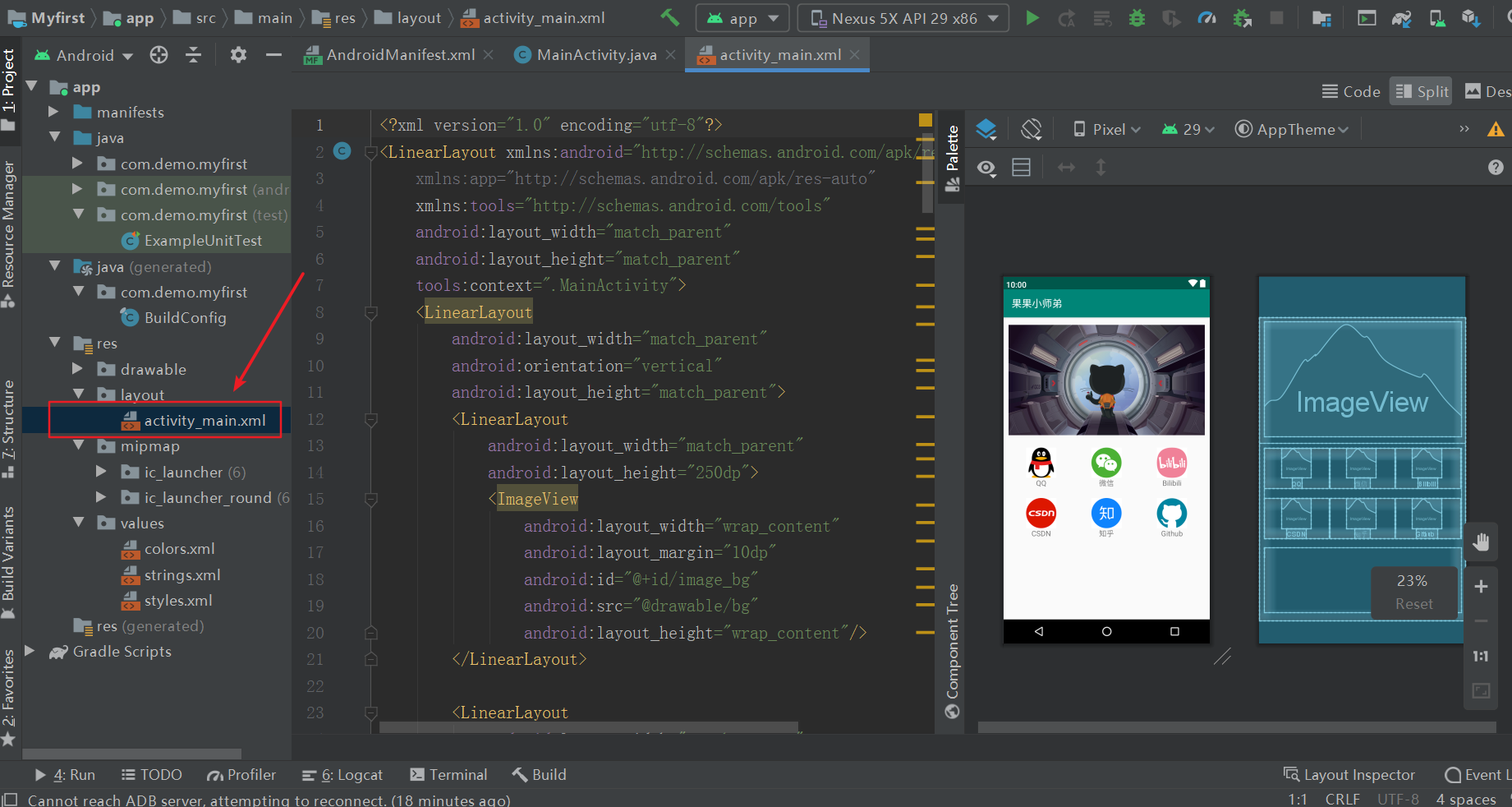 在这里我们可以修改点击图片所转换的网址,大家打开源码就知道如何修改了,这里就不在赘述!
在这里我们可以修改点击图片所转换的网址,大家打开源码就知道如何修改了,这里就不在赘述! 在
在