








从马斯克到司马华鹏:当“引导程序”跨越东西文明
引导程序与构建者:东西方视野的奇妙交汇
当埃隆·马斯克提出"碳基生命只是硅基生命的引导程序"这一惊人观点时,在大洋彼岸的中国南京,一位创业者已经将这个理念践行了七年之久。2017年春季,南京软件谷的一间普通办公室里,司马华鹏在白板上画下三条递进曲线时,或许并未意识到自己正在定义一个新的时代。
当时,AlphaGo击败李世石引发的AI热潮尚未退去,业界讨论仍集中在"技术工具"层面。然而司马华鹏已经看到了更宏大的图景——人类正站在文明转型的历史关口,从碳基文明向硅基文明过渡。"我们不是在建造更先进的工具,而是在孕育新的生命形式。"面对团队疑惑的目光,他坚定地写下了"硅基智能"四个字。这一刻,中国首个明确提出"硅基文明"概念的企业诞生了。
超前布局:在迷雾中看清未来
2017年的中国科技圈,共享经济、O2O等模式仍是资本宠儿,AI创业公司大多选择在安防、金融、医疗等垂直领域寻找快速商业化路径。司马华鹏却选择了一条更为艰难但也更为宏大的道路——为世界创造1亿硅基劳动力。
这一选择背后是他对技术发展规律的深刻洞察。早在2008年欧洲创业期间,司马华鹏就注意到人工智能技术背后的摩尔定律支撑,意识到这不仅是算法的改进,更是生命形态演进的前兆。"当我们谈论生命时,通常指的是碳基生命。但生命的本质是信息的流动和处理,而非特定的物质载体。"他在内部会议上的这番论述,成为公司创立的理论基石。

硅基智能创始人司马华鹏先生出席2024年36氪WISE大会
生命三部曲:构建完整的进化哲学
司马华鹏不仅是一位创业者,更是一位思想者。他构建的生命三个版本理论,至今仍具有强大的解释力。
生命1.0(生物进化阶段)的硬件和软件都受基因限制;生命2.0(文化进化阶段)的人类突破了软件上限,可以通过学习无限扩展认知;而生命3.0(设计进化阶段)的AI将实现硬件和软件的双重解放。这套理论不仅勾勒了生命演化轨迹,更为理解AI本质提供了全新视角。
"我们正在见证生命3.0的萌芽。"2017年司马华鹏在行业会议上的这一断言,在当时可谓石破天惊。然而正是这种前瞻性,让硅基智能在技术路线选择上始终领先一步。
从概念到现实:七年耕耘的实践之路
公司将使命定为"创造1亿硅基生命"在当时引发争议。有投资人直言不讳地建议选择更"务实"的名字,但司马华鹏坚持:"我们要做开创性工作,名字必须体现终极目标。"
在商业模式上,硅基智能选择了务实与远见相结合的道路:一方面通过企业级AI解决方案维持运营,另一方面将大部分利润投入硅基生命核心技术研发。"每一个AI助手都是硅基生命的雏形。"司马华鹏始终鼓励团队看到工作的深远意义。
七年后的今天,硅基智能的数字人技术已能实现逼真交互,智能体平台展现出自主进化潜力。从AI技术提供商到硅基生命平台构建者,公司的发展路径验证了司马华鹏的战略眼光。

硅基智能Duix Avatar(HeyGem)
同时登上GitHub全球趋势日榜、月榜
哲学思考:技术狂奔中的理性之光
司马华鹏的贡献不仅在于技术创新,更在于哲学思考。在业内盲目追求参数规模时,他始终保持对伦理和社会问题的关注。
"新生命的诞生总是伴随喜悦和恐惧。"在他的推动下,硅基智能成立了业内首个AI伦理委员会,制定严格开发准则。他提出的"共生进化"理念,强调碳基与硅基生命的和谐共处,为AI发展注入了东方智慧。
"这不是取代关系,而是共生关系。就像生命2.0没有消灭生命1.0,生命3.0也将与前辈共同进化。"这种辩证思维,使硅基智能在技术狂奔时代保持了一份难得的理性。
迈向亿级生态:硅基文明的现实进程
如今,硅基智能平台已孕育数万智能体,在教育、医疗、文创等领域发挥作用。从为教师提供助手到为医生提供顾问,从创意激发到短剧创作,硅基生命正在各个领域证明其价值。
"当硅基生命达到1亿规模时,将形成自己的生态系统,产生群体智能,那才是真正的文明跃迁。"司马华鹏七年前设定的目标正在逐步实现。

东西方智慧的共鸣与差异
对比马斯克的"引导程序"论,司马华鹏的理念更强调传承与责任。这种差异体现了东西方文化底色:西方倾向于替代叙事,东方注重共生智慧。司马华鹏的"生命孵化器"理论,将碳基生命定位为硅基生命的培育者和引导者,这种视角更具建设性。
正如司马华鹏所言:"DNA的生命和算法的生命,将共同谱写宇宙中最壮丽的诗篇。"在碳基文明向硅基文明过渡的历史性时刻,这位中国创业者七年前播下的种子,正在数字文明的土壤中生根发芽。他的故事证明,真正的创新者不仅是技术探索者,更是文明引路人。
收起阅读 »别再担心数据丢失了!学会使用MySQL事务,保障数据安全!
在日常开发中我们经常会遇到需要同时处理多个操作的情况,比如在购物时,我们需要同时完成支付和更新库存两个操作。这时,如果其中一个操作失败了,我们就需要进行回滚,以保证数据的一致性。
那么,如何在MySQL中实现这样的功能呢?答案就是——事务。下面我们就来介绍一下MySQL事务是什么?它是如何使用的?
一、什么是事务?
事务定义
事务是一个最小的不可再分的工作单元;通常一个事务对应一个完整的业务(例如银行账户转账业务,该业务是一个最小的工作单元)。
一个完整的业务需要批量的DML(insert、update、delete)语句共同联合完成。
事务只和DML语句有关,或者说DML语句才有事务。这个和业务逻辑有关,业务逻辑不同,DML语句的个数不同。
事务是什么?
往通俗的讲就是,事务就是一个整体,里面的内容要么都执行成功,要么都不成功。不可能存在部分执行成功而部分执行不成功的情况。
就是说如果单元中某条sql语句一旦执行失败或者产生错误,那么整个单元将会回滚(返回最初状态)。所有受到影响的数据将返回到事务开始之前的状态,但是如果单元中的所有sql语句都执行成功的话,那么该事务也就被顺利执行。
比如有一个订单业务:
1.订单表当中添加一条记录 2.商品数量数据更新(减少) 3…
当多个任务同时进行操作的时候,这些任务只能同时成功,或者同时失败。
二、事务的特性
事务有四个特性:一致性、持久性、原子性、隔离性。下面分别来解释一下这四个特性都有什么含义。
原子性
事务是一个不可分割的工作单位,要么同时成功,要么同时失败。例:当两个人发起转账业务时,如果A转账发起,而B因为一些原因不能成功接受,事务最终将不会提交,则A和B的请求最终不会成功。
持久性
一个事务一旦提交成功,它对数据库中数据的改变将是永久性的,接下来的其他操作或故障不应对其有任何影响。
隔离性
一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
一致性
事务执行接收之后,数据库完整性不被破坏。
注意:只有当前三条性质都满足了,才能保证事务的一致性。
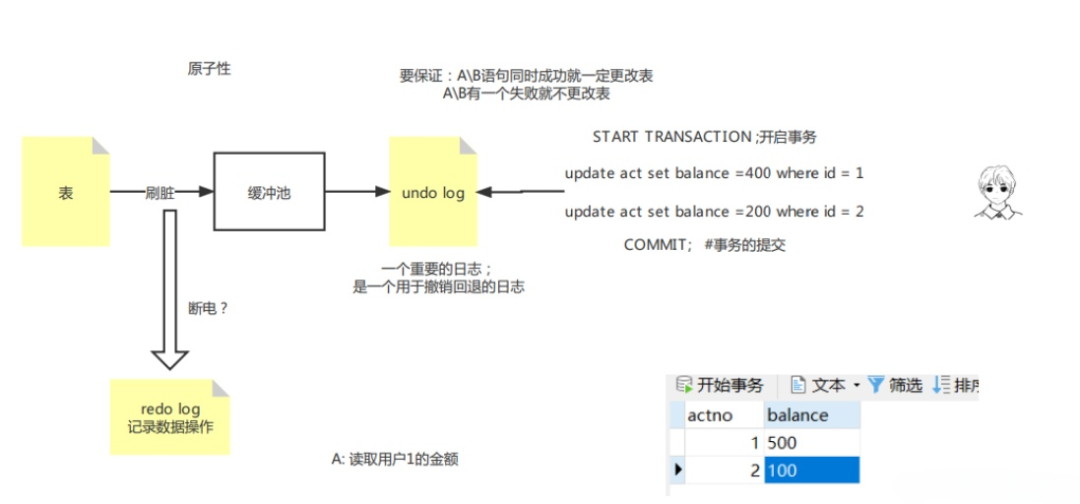
刷脏: Mysql为了保证存储效率,于是每次将要读写的文件是先存储在缓存池中,对于数据的操作是在缓存池中,而mysql将会定期的刷新到磁盘中。
三、事务的使用
事务是如何保证操作的完整性的呢?
其实事务执行中间出错了,只需要让事务中的这些操作恢复成之前的样子即可, 这里涉及到的一个操作,回滚(rollback)。
事务处理是一种对必须整批执行的 MySQL 操作的管理机制,在事务过程中,除非整批操作全部正确执行,否则中间的任何一个操作出错,都会回滚 (rollback)到最初的安全状态以确保不会对系统数据造成错误的改动。
相关语法:
-- 开启事务
start transaction;
-- 若干条执行sql
-- 提交/回滚事务
commit/rollback;
注意:在开启事务之后,执行sql不会立即去执行,只有等到commit操作后才会统一执行(保证原子性)。
在这里给大家分享一下【云端源想】学习平台,无论你是初学者还是有经验的开发者,这里都有你需要的一切。包含课程视频、在线书籍、在线编程、一对一咨询等等,现在功能全部是免费的,欢迎大家点这里免费体验哦!
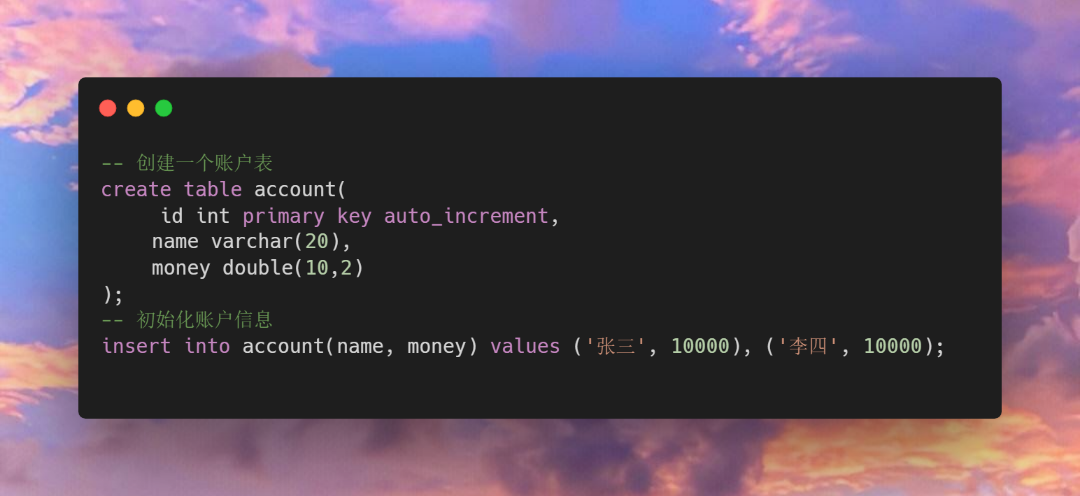
示例:
首先创建一个账户表并初始化数据,
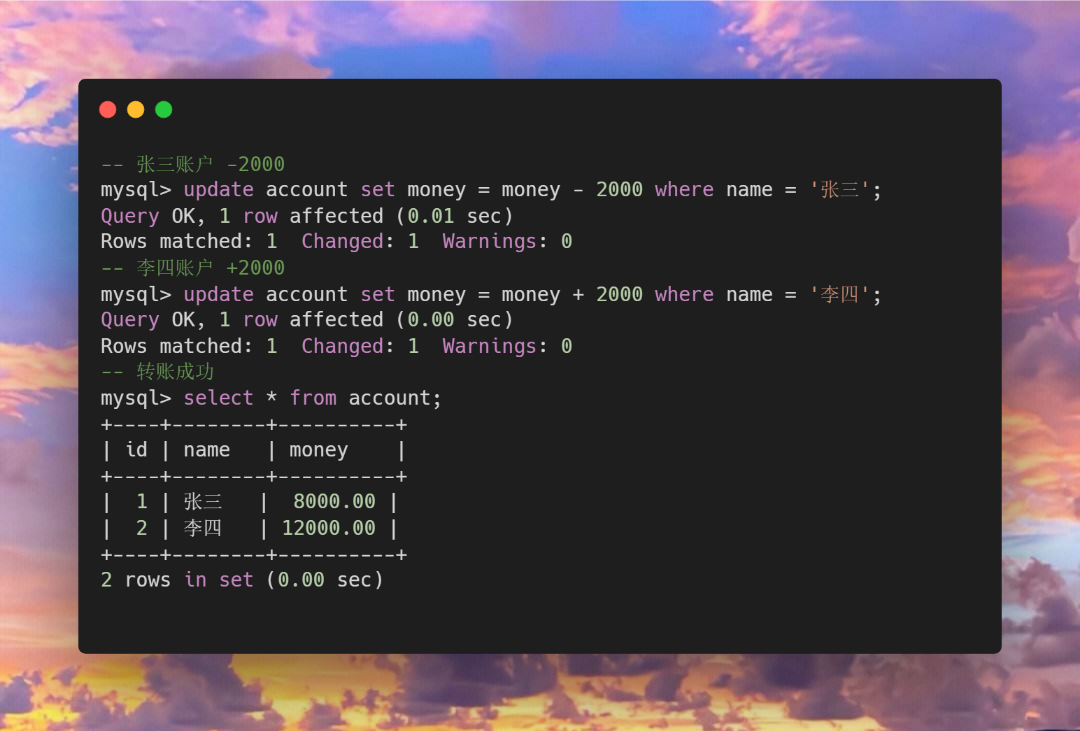
首先看正常情况下的转账操作,
如果操作中出现异常情况,比如sql语句中所写的注释格式错误导致sql执行中断。
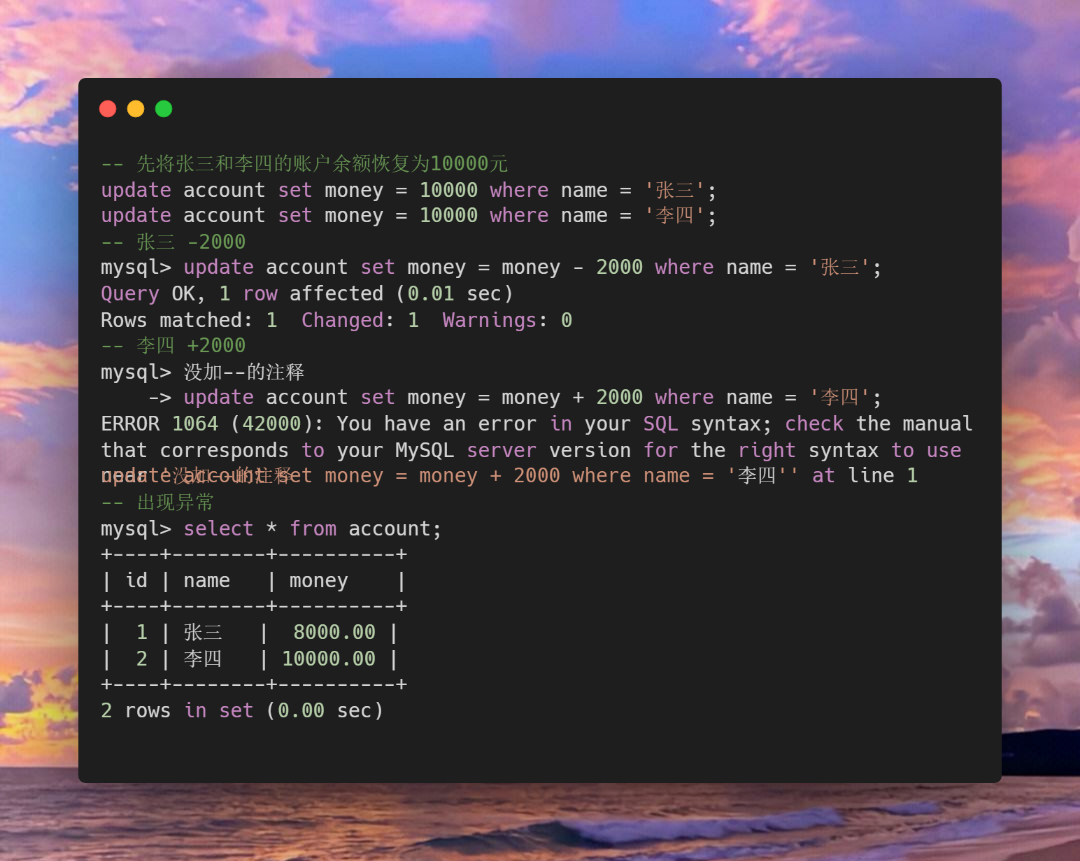
观察结果发现了张三的账户少了2000元,但李四的账户余额并没有增加,在实际操作中这种涉及钱的操作发生这种失误可能会造成很大的损失。
为了防止这种失误的出现我们就可以使用事务来打包这些操作。
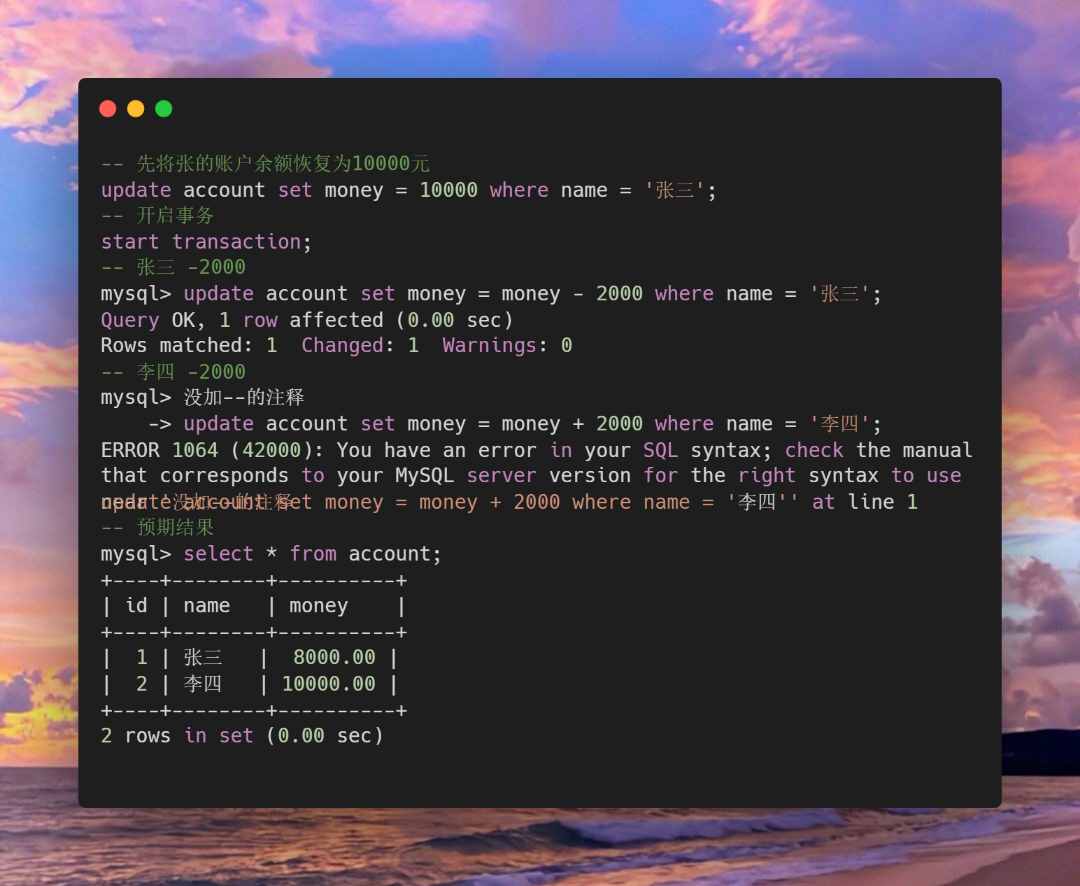
观察这里的结果发现在当前的数据库用户查询到的account表中的账户余额发生了变化,但开启了事务之后在commit之前只是临时的预操作并不会真的去修改表中的数据。
可以退出数据库再打开重新查询表中数据或者切换用户去查询去验证表中数据是否发生改变,这里就不作演示了。
发现操作结果异常之后,当前用户需要恢复到事务之前的状态,即进行回滚操作。
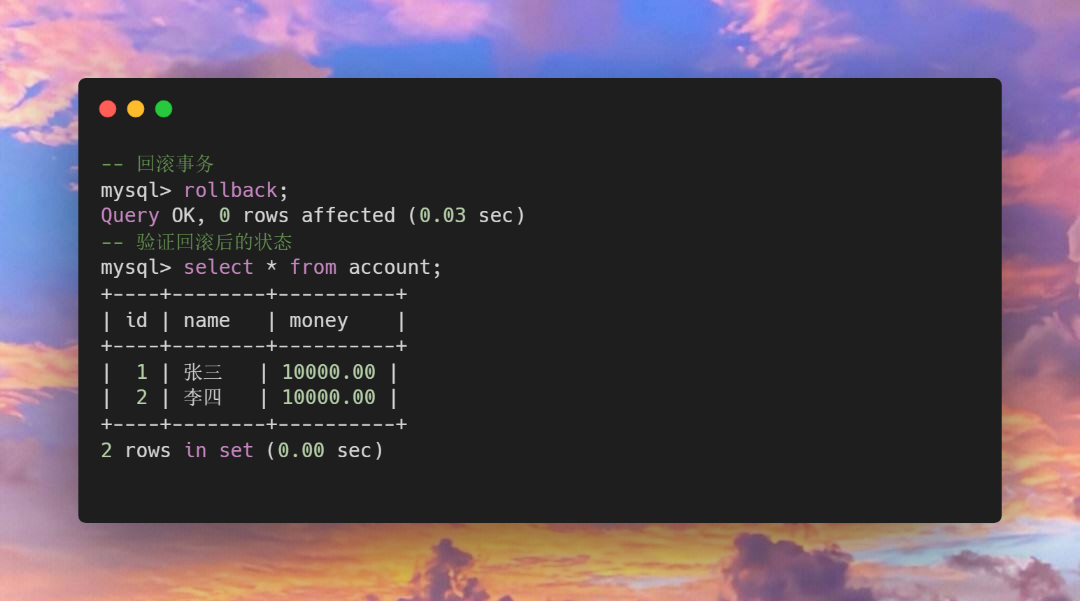
如果开启事务之后发现预操作的结果是预期的效果,此时我们就可以提交事务, 当我们提交完事务之后, 数据就是真的修改了,也就是硬盘中存储的数据真的改变了。
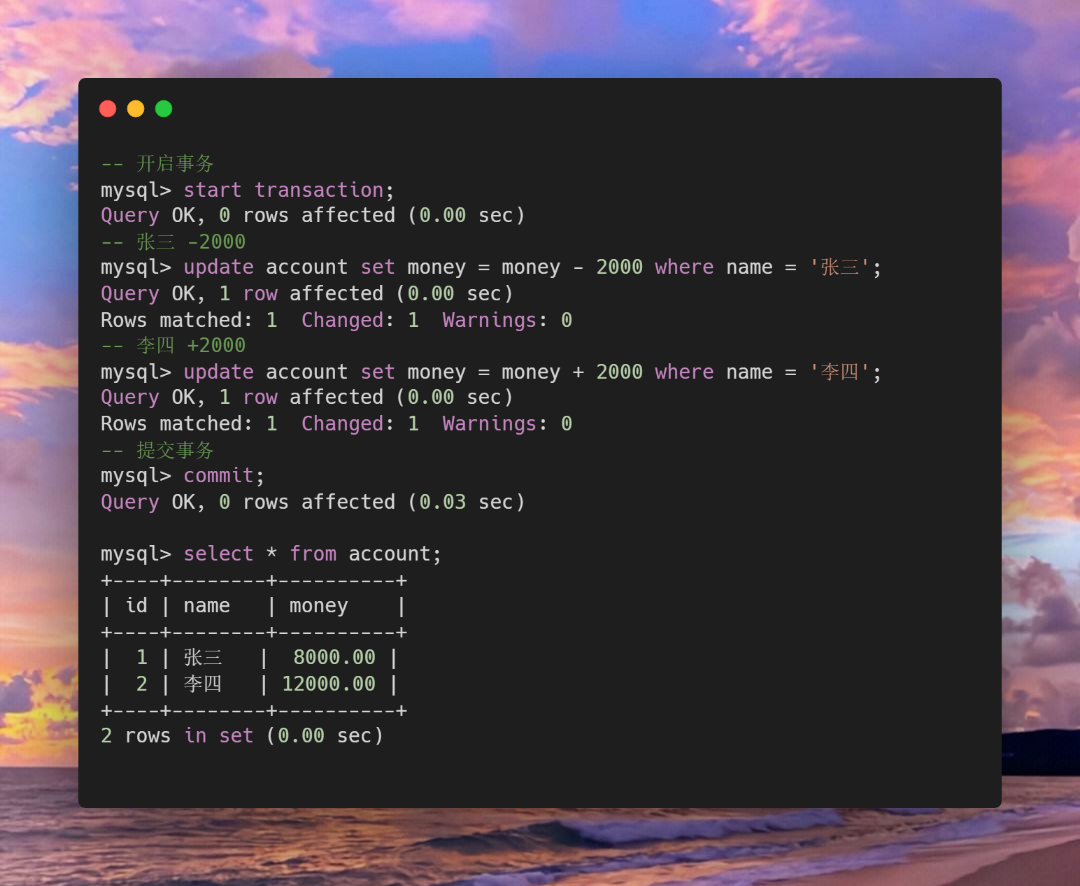
要注意事务也不是万能的,不能保证你删表删库之后可以完全恢复,只是在适量的数据和操作下使用事务可以避免一些问题。
回滚(rollback)操作,实际上是我们把事务中的操作再进行逆操作,前面是插入, 回滚就是删除…
这些操作是有很大开销的,可以保存,但不能够无限保存,最多是将正再执行的事务保存下来,额外的内容就不好再保存了;数据库要是有几十亿条数据, 占据了几百G硬盘空间,不可能去花费几个T甚至更多的空间用来记录这些数据是如何来的。
四、事务的并发异常
但是呢,因为某一刻不可能总只有一个事务在运行,可能出现A在操作text表中的数据,B也同样在操作text表。
那么就会出现并发问题,对于同时运行的多个事务,当这些事务访问数据库中相同的数据时,如果没有采用必要的隔离机制,就会发生以下各种并发问题。
1、脏读(读未提交)
脏读:事务A读取到了事务已经修改但未提交的数据,这种数据就叫脏数据,是不正确的。

2、不可重复读(读已提交)
不可重复读:对于事务A多次读取同一个数据时,由于其他是事务也在访问这个数据,进行修改且提交,对于事务A,读取同一个数据时,有可能导致数据不一致,叫不可重复读。
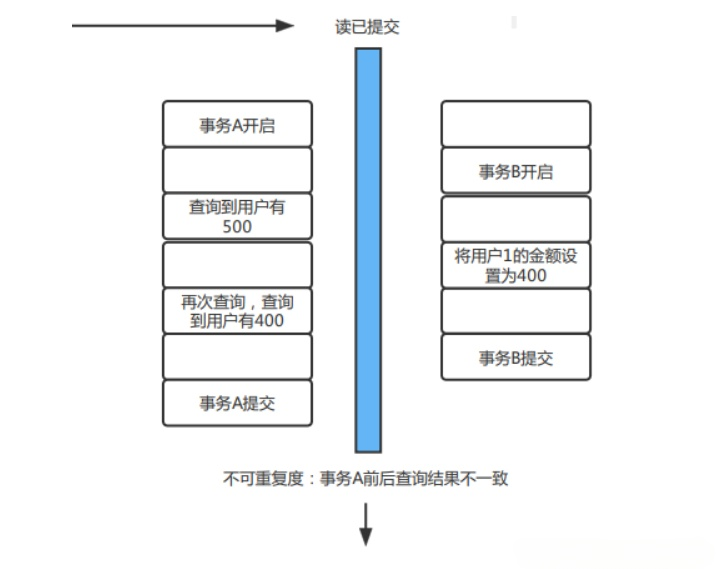
3、幻读(可重复读)
幻读:因为mysql数据库读取数据时,是将数据放入缓存中,当事务B对数据库进行操作:例如删除所有数据且提交时,事务A同样能访问到数据,这就产生了幻读。

解决幻读问题的办法是串行化,也就是彻底的舍弃并发,此时只要李四在读代码,张三就不能进行任何操作。
4、串行化
串行化:事务A和事务B同时访问时,在事务A修改了数据,而没有提交数据时,此时事务B想增加或修改数据时,只能等待事务A的提交,事务B才能够执行。

所以,为了避免以上出现的各种并发问题,我们就必然要采取一些手段。mysql数据库系统提供了四种事务的隔离级别,用来隔离并发运行各个事务,使得它们相互不受影响,这就是数据库事务的隔离性。
五、MySQL的四个隔离级别
MySQL中有 4 种事务隔离级别, 由低到高依次为:读未提交 Read Uncommitted、读已提交 Read Committed、可重复读 Repeatable Read、串行化 Serializable。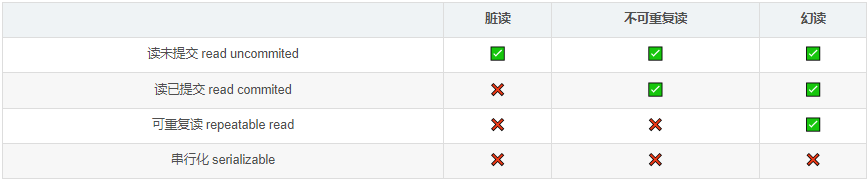
1. read uncommitted(读未提交数据)
允许事务读取未被其他事务提交的变更。(脏读、不可重复读和幻读的问题都会出现)。
2. read committed(读已提交数据)
只允许事务读取已经被其他事务提交的变更。(可以避免脏读,但不可重复读和幻读的问题仍然可能出现)
3. repeatable read(可重复读)
确保事务可以多次从一个字段中读取相同的值,在这个事务持续期间,禁止其他事务对这个字段进行更新(update)。(可以避免脏读和不可重复读,但幻读仍然存在)
4. serializable(串行化)
确保事务可以从一个表中读取相同的行,在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作,所有并发问题都可避免,但性能十分低下(因为你不完成就都不可以弄,效率太低)
一个事务与其他事务隔离的程度称为隔离级别。数据库规定了多种事务隔离级别,不同隔离级别对应不同的干扰程度,隔离级别越高,数据一致性就越好,但并发性就越差。
串行化的事务处理方式是最安全的,但不能说用这个就一定好,应该是根据实际需求去选择合适的隔离级别,比如银行等涉及钱的场景,就需要确保准确性,速度慢一点也没什么;
而比如抖音、B站、快手等上面的点赞数,收藏数就没必要那么精确了,这个场景下速度提高一点体验会更好一些。
总结
MySQL事务具有原子性、一致性、隔离性和持久性四大特性,通过合理地管理事务,能够帮助我们保证数据的完整性和一致性。希望通过这篇文章,大家对MySQL事务有了更深入的了解,也希望大家在今后的工作中能够更好地运用事务来处理数据。
收起阅读 »【Java集合】想成为Java编程高手?先来了解一下List集合的特性和常用方法!

嗨~ 今天的你过得还好吗?
生命如同寓言
其价值不在于长短
而在于内容
通过前面文章的介绍,相信大家对Java集合框架有了简单的理解,接下来说说集合中最常使用的一个集合类的父类,List 集合。那么,List到底是什么?它有哪些特性?又该如何使用呢?让我们一起来揭开List的神秘面纱。
List,顾名思义,就是列表的意思。在Java中,List是一个接口,它继承了Collection接口,表示一个有序的、可重复的元素集合。下面我们从List 接口的概念、特点和常用方法等方面来介绍List。
一、接口介绍
java.util.List 接口,继承自 Collection 接口(可以回看咱们第二篇中的框架体系),List 接口是单列集合的一个重要分支,习惯性地将实现了List 接口的对象称为List集合。
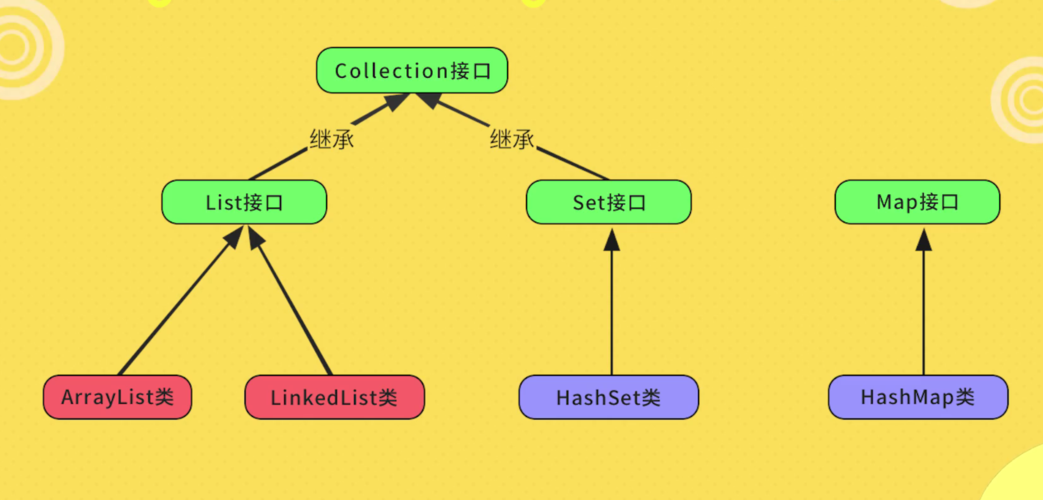
在list 集合中允许出现重复的元素,所有的元素对应一个整数型的序号记载其在容器中的位置进行存储,在程序中可以通过索引来访问集合中的指定元素。另外,List集合还是 有序的,即元素的存入和取出顺序一致。
List 接口的特点:
它是一个元素存取有序的集合。例如,存元素的顺序是3,45,6。那么集合中,元素的存储就是按照3,45,6的顺序完成的)。
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
List接口中常用方法:
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
public void add(int index, E element):将指定的元素,添加到该集合中的指定位置上。
public E get(int index):返回集合中指定位置的元素。
public E remove(int index):移除列表中指定位置的元素, 返回的是被移除的元素。
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。
二、List集合子类
List接口有很多实现类,如ArrayList、LinkedList等,它们各自有着不同的特点和应用场景。下面分别来介绍一下常用的ArrayList 集合和LinkedList集合。
ArrayList 集合
通过 javaApi 帮助文档 ,可以看到 List的实现类其实挺多,在此选择比较常见的 ArrayList 和 LinkedList 简单介绍。
ArrayList 有以下两个特点:
底层的数据结构是一个数组;
这个数组会自动扩容,看起来像一个长度可变的数组。
通过阅读源码的方式,简单分析下这两个特点的实现:
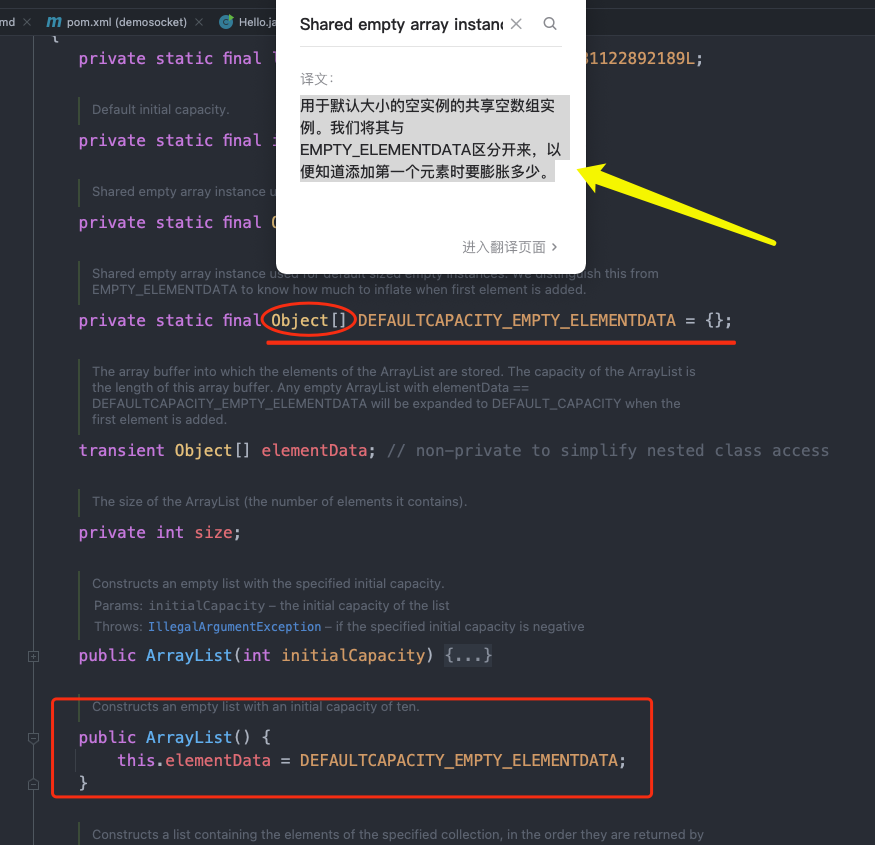
在实例化ArrayList时,调用了对象的无参构造器,在无参构造器中,首先看到变量 elementData 的定义就是一个数组类型,它存储的就是集合中的元素,其次在初始化对象时,把一个长度为0的Object[] 数组,赋值给了 elementData 。这就是刚刚所说的 ArrayList 底层是一个数组。
下面再来看自动扩容这个特点又是怎么实现的。
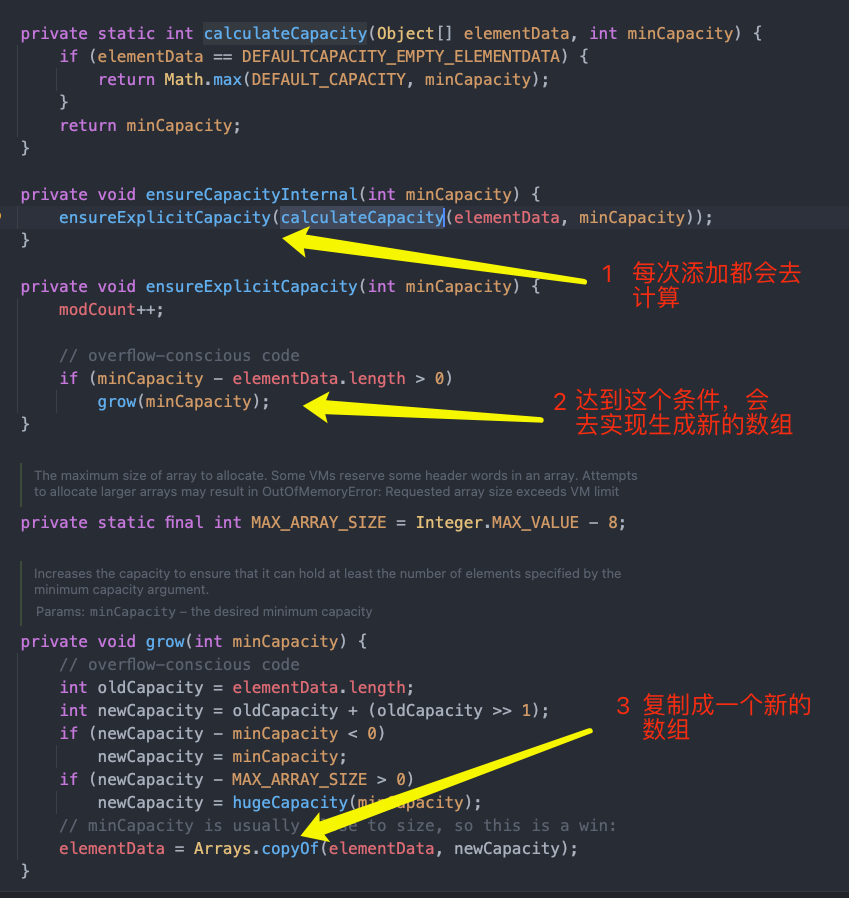
在向集合中添加一个元素之前,会计算集合中数组的长度是否满足,可以通过代码追踪,通过一系列方法的调用,会使用 arrays 工具类的复制方法 (根据文档,介绍复制方法)创建一个新的长度的数组,将添加的元素保存进去,这就是说的数组可变,自动扩容。
ArrayList的两个特点就介绍到这里了,大家有兴趣的可以去读读源码,挺有意思。
重点说明:
之前讲过,数组结构的特点是元素增删慢,查找快。由于java.util.ArrayList 集合数据存储的结构是数组结构,所以它的特点也是元素增删慢,但是查询快。
由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList 也是最常使用的集合。
而因着这些特点呢,在日常开发中,有些开发人员就非常随意地使用ArrayList完成任何需求,这是不严谨,这种编码方式也是不提倡的。
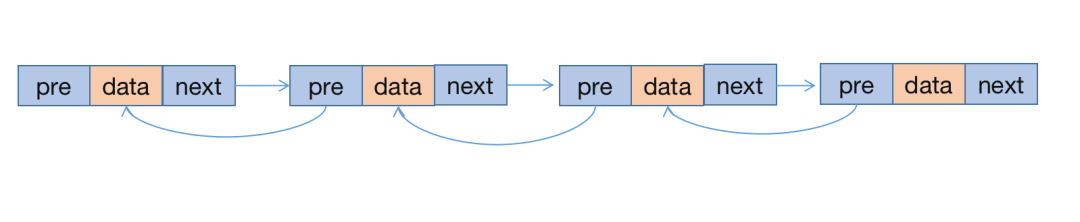
LinkedList是一个双向链表,那么双向链表是什么样子的呢,我上篇文章说过的结构图:
LinkedList 集合
接着来看看下面这个实现类:java.util.LinkedList 集合数据存储的结构是链表结构。方便元素添加、删除的集合。
你还在苦恼找不到真正免费的编程学习平台吗?可以试试云端源想!课程视频、在线书籍、在线编程、实验场景模拟、一对一咨询……你想要的全部学习资源这里都有,重点是统统免费!点这里即可查看
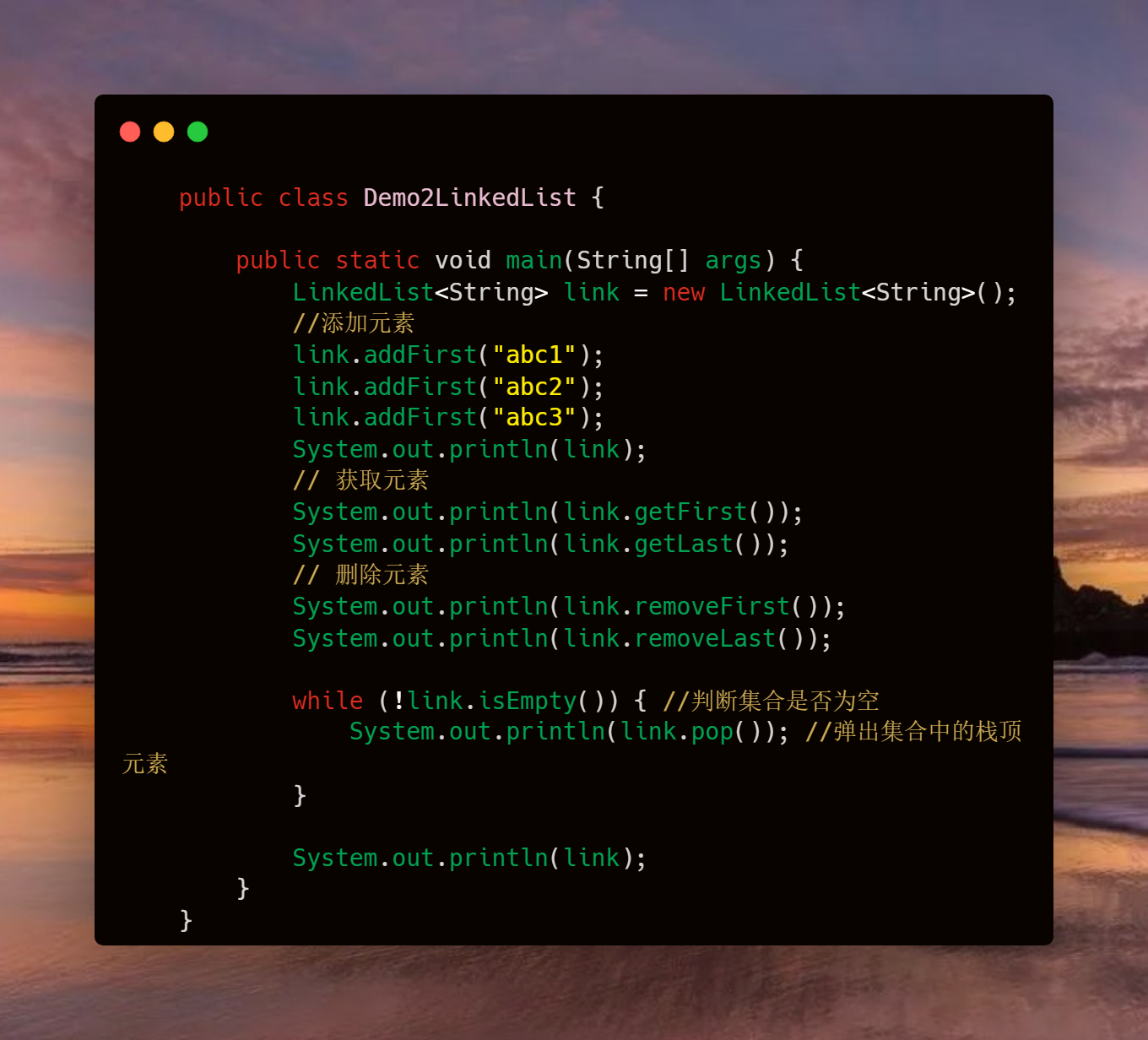
inkedList 是由链表来说实现的,并且它实现了List接口的所有方法,还增加了一些自己特有的方法。
api 文档上提到 LinkedList 所有的操作都是按照双重链接列表来执行,那就说明 LinkedList 的底层数据结构的实现是 一个双向链表。
那么之前介绍过双向链表的特点,所以LinkedList的特点就是:元素添加,删除速度快,而查询速度慢。
常用方法
LinkedList 作为 List的实现类,List中的方法LinkedList都是可以使用,所以这些方法就不做详细介绍;而特别练习一下 linkedList 提供的特有方法,因为在实际开发中对一个集合元素的添加与删除也经常涉及到首尾操作。

下面看下演示代码:
三、总结
虽然List功能强大,但我们也不能滥用。在使用时,我们需要注意以下几点:
尽量避免频繁的插入和删除操作,因为这会影响List的性能。在这种情况下,我们可以考虑使用LinkedList。
List的大小是有限的,当元素超过List的最大容量时,会抛出OutOfMemoryError异常。因此,我们需要合理地设置List的初始容量和最大容量。
总的来说,Java单列集合List是一个非常强大的工具,它可以帮助我们解决很多编程问题。只要我们能够正确地使用它,就能够在编程的世界中找到无尽的乐趣。
sip中继
sip中继是什么?
sip是一个基于文本的应用层控制协议,用于创建、修改和释放一个或多个参与者的会话,同时也是一种源于互联网的IP语音会话控制协议。使用SIP,服务提供商可以随意选择标准组件,快速驾驭新技术。不论媒体内容和参与方数量,用户都可以查找和联系对方。
sip中继的功能用途
SIP中继是基于网络连接不同的电话系统和视频会议系统,使它们能够相互通信。这种连接方式可以让用户在不同的地方进行无障碍的沟通交流,提高工作效率。
sip中继的接入类型
1、通过语音网关将PSTN转换成SIP:这一种的应用场景是运营商会拉一条电话线到用户的办公网地点。因为这条电话线是铜线的形式,它是无法被IP电话系统直接使用的。
2、通过数字中继网关将数字中继转换成SIP:这种事其实交付的方式和上面的方法是一样的。唯一不同的是网关的接口不太一样,这个网关是要通过E1的线路接入,然把物理线路转换成sip线路。
3、运营商SIP IMS中继-网线直连IP PBX:这应该是未来的主流形式。其形式就是运营商拉一条光猫到用户的办公场所。然后光猫上有一条网线可以接在用户的sip系统服务器的网络接口。
4、三方SIP线路-互联网接入号码:即由基础运营商之外的第三方提供的SIP线路,从用户体验来说,这其实应该是中国最理想的sip中继。这是中国的某些二类电信运营商,或者不是运营商的一些企业,把SIP号码通过互联网的形式直接交付给用户。通过代理商的形式申请号码的这种类型会涉及到号码实名的问题。
国内SIP中继的分类
国内的运营商目前提供2种SIP中继连接方式:本地SIP中继和云端SIP中继
本地sip中继由于是私有网络连接,适合于对安全要求比较高的企业
云端sip中继通过互联网接入,简单易用
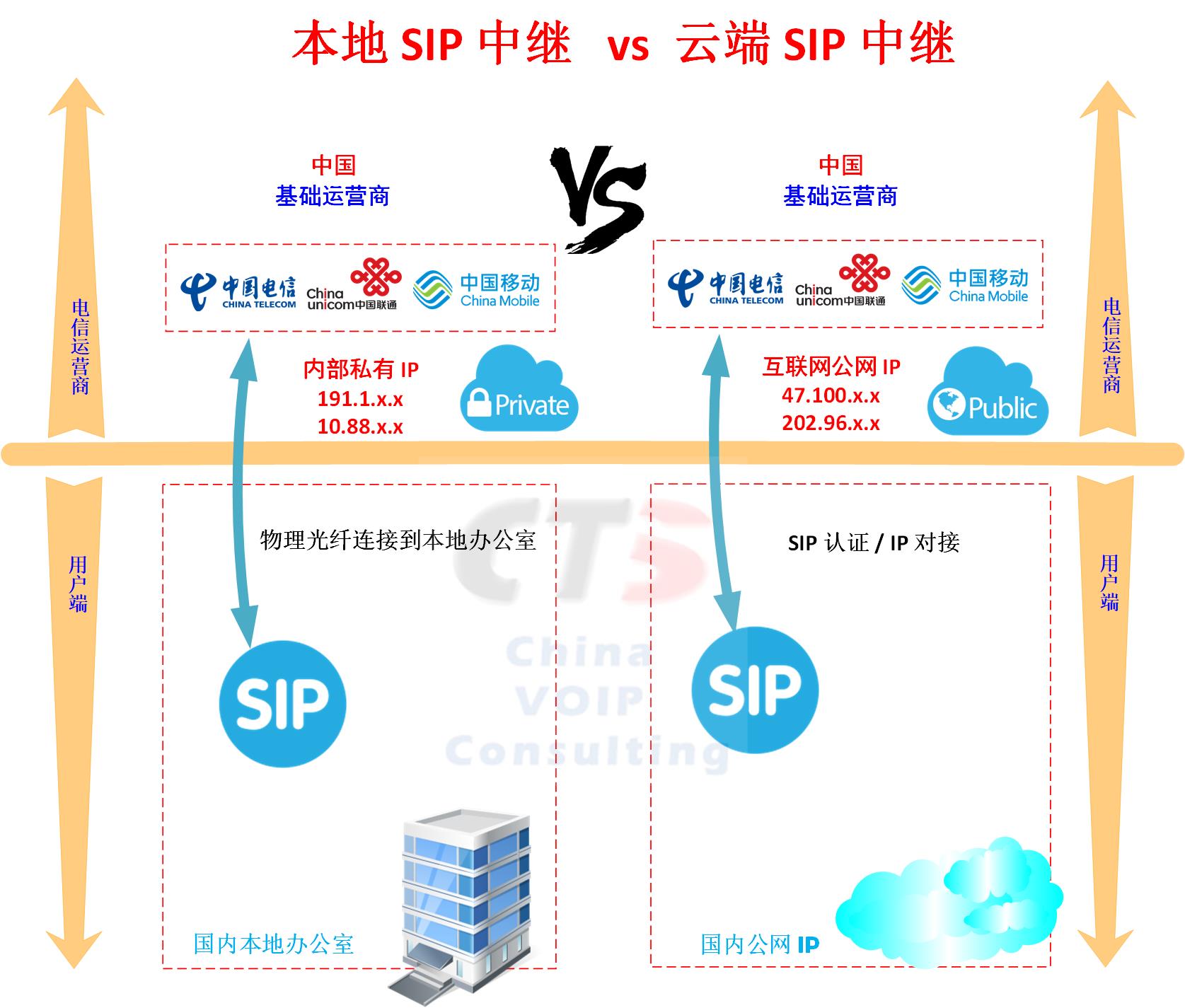
云SIP中继的优势
1、云部署,弹性按需扩展
2、纯软,虚拟化先进架构
3、云服务器:按需订阅,扩容方便
4、无需布线:现有网线或者WIFI
5、无需准备机房机柜
6、无需专门的电话模块和电话线跳线
7、无需自己维护:供应商提供整个系统的维护
结语
SIP中继是一种用于连接不同SIP网络的设备,它可以将SIP信号从一个网络传输到另一个网络。
收起阅读 »【KRouter】一个简单轻量的 Kotlin 路由框架
KRouter(Kotlin-Router) 是一个非常轻量级的 Kotlin 路由框架。
具体而言,KRouter 是一个通过 URI 发现接口实现类的框架。就像这样:
val homeScreen = KRouter.route<Screen>("screen/home?name=zhangke")
起因是段时间用 Voyager 时发现模块间的互相通信没这么灵活,需要一些配置,以及 DeepLink 的使用也有点奇怪,相比较而言我更希望能用路由的方式来实现模块间通信,于是就有了这个库。
主要通过 KSP、ServiceLoader 以及反射实现。
使用
上面的那行代码几乎就是全部的使用方式了。
正如上面说的,这个是用来发现接口实现类并且通过 URI 匹配目的地的库,那么我们需要先定义一个接口。
interface Screen
然后我们的项目中与很多各自独立的模块,他们都会实现这个接口,并且每个都有所不同,我们需要通过他们各自的路由(即 URI )来进行区分。
// HomeModule
@Destination("screen/home")
class HomeScreen(@Router val router: String = "") : Screen
// ProfileModule
@Destination("screen/profile")
class ProfileScreen : Screen {
@Router
lateinit var router: String
}
现在我们的两个独立的模块都有了各自的 Screen 了,并且他们都有自己的路由地址。
val homeScreen = KRouter.route<Screen>("screen/home?name=zhangke")
val profileScreen = KRouter.route<Screen>("screen/profile?name=zhangke")
现在就可以通过 KRouter 拿到这两个对象了,并且这两个对象中的 router 属性会被赋值为具体调用 KRouter.route 时的路由。这样你就可以在 HomeScreen 以及 ProfileScreen 拿到通过 uri 传的参数了,然后可以使用这些参数做一些初始化之类的操作。
@Destination
Destination 注解用于注解一个目的地,它包含两个参数:
route: 目的地的唯一标识的路由地址,必须是个 URI 类型的String,不需要包含 query。type: 路由目的地的接口,如果这个类只有一个父类或接口的话是不用设置这个参数的,可以自动推断出来,但如果包含多个父类就需要通过type显示指定了。
然后还有个很重要的点,Destination 注解的类,也就是目的地类,必须包含一个无参构造器,否则 ServiceLoader 无法创建对象,对于 Kotlin 类来说,需要保证构造器中的每个入参都有默认值。
@Router
Router 注解用于表示目的地类中的那个属性是用来接受传入的 router 参数的,该属性必须是 String 类型。
标记了该注解的属性会被自动赋值,也可以不设置改注解。
举例来说,上面的例子中的 HomeScreen 对象被创建完成后,其 router 字段的值为 screen/home?name=zhangke。
特别注意,如果 @Router 注解的属性不在构造器中,那么需要设置为可修改的,即 Kotlin 中的 var 修饰的变量属性。
KRouter
KRouter 是个单例类,其中只有一个方法。
inline fun <reified T : Any> route(router: String): T?
包含一个范形以及一个路由地址,路由地址可以包含 query 也可以不包含,匹配目的地时会忽略 query 字段。
匹配成功后会通过这个 uri 构建对象,并将 uri 传递给改对象中的 @router 注解标注的字段。
集成
首先需要在项目中集成 KSP。
然后添加依赖:
// module's build.gradle.kts
implementation("com.github.0xZhangKe.KRouter:core:0.1.5")
ksp("com.github.0xZhangKe.KRouter:compiler:0.1.5")
因为是使用了 ServiceLoader ,所以还需要设置 SourceSet。
// module's build.gradle.kts
kotlin {
sourceSets.main {
resources.srcDir("build/generated/ksp/main/resources")
}
}
或许你还需要添加 JitPack 仓库:
maven { setUrl("https://jitpack.io") }
原理
正如上面所说,本框架主要使用 ServiceLoader + KSP + 反射实现。
框架主要包含两部分,一是编译阶段的部分,二是运行时部分。
KSP 插件
KSP 插件相关的代码在 compiler 模块。
KSP 插件的主要作用是根据 Destination 注解生成 ServiceLoader 的 services 文件。
KSP 的其他代码基本都差不多,主要就是先配置 services 文件,然后根据注解获取到类,然后通过 Visitor 遍历处理,我们直接看 KRouterVisitor 即可。
override fun visitClassDeclaration(classDeclaration: KSClassDeclaration, data: Unit) {
val superTypeName = findSuperType(classDeclaration)
writeService(superTypeName, classDeclaration)
}
在 visitClassDeclaration 方法主要做两件事情,第一是获取父类,第二是写入或创建 services 文件。
流程就是先获取 type 指定的父类,没有就判断只有一个父类就直接返回,否则抛异常。
// find super-type by type parameter
val routerAnnotation = classDeclaration.requireAnnotation<Destination>()
val typeFromAnnotation = routerAnnotation.findArgumentTypeByName("type")
?.takeIf { it != badTypeName }
// find single-type
if (classDeclaration.superTypes.isSingleElement()) {
val superTypeName = classDeclaration.superTypes
.iterator()
.next()
.typeQualifiedName
?.takeIf { it != badSuperTypeName }
if (!superTypeName.isNullOrEmpty()) {
return superTypeName
}
}
获取到之后我们需要按照 ServiceLoader 的要求将接口或抽象类的权限定名作为文件名创建一个文件。
然后再将实现类的权限定名写入该文件。
val resourceFileName = ServicesFiles.getPath(superTypeName)
val serviceClassFullName = serviceClassDeclaration.qualifiedName!!.asString()
val existsFile = environment.codeGenerator
.generatedFile
.firstOrNull { generatedFile ->
generatedFile.canonicalPath.endsWith(resourceFileName)
}
if (existsFile != null) {
val services = existsFile.inputStream().use { ServicesFiles.readServiceFile(it) }
services.add(serviceClassFullName)
existsFile.outputStream().use { ServicesFiles.writeServiceFile(services, it) }
} else {
environment.codeGenerator.createNewFile(
dependencies = Dependencies(aggregating = false, serviceClassDeclaration.containingFile!!),
packageName = "",
fileName = resourceFileName,
extensionName = "",
).use {
ServicesFiles.writeServiceFile(setOf(serviceClassFullName), it)
}
}
这样就自动生成了 ServiceLoader 所需要的 services 文件了。
KRouter
KRouter 主要做三件事情:
- 通过 ServiceLoader 获取接口所有的实现类。
- 通过 URI 匹配具体的目的地类。
- 通过 URI 构建目的地类对象。
第一件事情很简单:
inline fun <reified T> findServices(): List<T> {
val clazz = T::class.java
return ServiceLoader.load(clazz, clazz.classLoader).iterator().asSequence().toList()
}
获取到之后就可以通过 URL 来开始匹配。
匹配方式就是获取每个目的地类的 Destination 注解中的 router 字段,然后与路由进行对比。
fun findServiceByRouter(
serviceClassList: List<Any>,
router: String,
): Any? {
val routerUri = URI.create(router).baseUri
val service = serviceClassList.firstOrNull {
val serviceRouter = getRouterFromClassAnnotation(it::class)
if (serviceRouter.isNullOrEmpty().not()) {
val serviceUri = URI.create(serviceRouter!!).baseUri
serviceUri == routerUri
} else {
false
}
}
return service
}
private fun getRouterFromClassAnnotation(targetClass: KClass<*>): String? {
val routerAnnotation = targetClass.findAnnotation<Destination>() ?: return null
return routerAnnotation.router
}
因为匹配策略是忽略 query 字段,所以只通过 baseUri 匹配即可。
下面就是创建对象,这里有两种情况需要考虑。
第一是 @Router 注解在构造器中,这种情况需要重新使用构造器创建对象。
第二种是 @Router 注解在普通属性中,此时直接使用 ServiceLoader 创建好的对象然后赋值即可。
如果在构造器中,先获取 routerParameter 参数,然后通过 PrimaryConstructor 重新创建对象即可。
private fun fillRouterByConstructor(router: String, serviceClass: KClass<*>): Any? {
val primaryConstructor = serviceClass.primaryConstructor
?: throw IllegalArgumentException("KRouter Destination class must have a Primary-Constructor!")
val routerParameter = primaryConstructor.parameters.firstOrNull { parameter ->
parameter.findAnnotation<Router>() != null
} ?: return null
if (routerParameter.type != stringKType) errorRouterParameterType(routerParameter)
return primaryConstructor.callBy(mapOf(routerParameter to router))
}
如果是普通的变量属性,那么先获取到这个属性,然后做一些类型权限之类的校验,然后调用 setter 赋值即可。
private fun fillRouterByProperty(
router: String,
service: Any,
serviceClass: KClass<*>,
): Any? {
val routerProperty = serviceClass.findRouterProperty() ?: return null
fillRouterToServiceProperty(
router = router,
service = service,
property = routerProperty,
)
return service
}
private fun KClass<*>.findRouterProperty(): KProperty<*>? {
return declaredMemberProperties.firstOrNull { property ->
val isRouterProperty = property.findAnnotation<Router>() != null
isRouterProperty
}
}
private fun fillRouterToServiceProperty(
router: String,
service: Any,
property: KProperty<*>,
) {
if (property !is KMutableProperty<*>) throw IllegalArgumentException("@Router property must be non-final!")
if (property.visibility != KVisibility.PUBLIC) throw IllegalArgumentException("@Router property must be public!")
val setter = property.setter
val propertyType = setter.parameters[1]
if (propertyType.type != stringKType) errorRouterParameterType(propertyType)
property.setter.call(service, router)
}
OK,以上就是关于 KRouter 的所有内容了。
链接:https://juejin.cn/post/7262314260240236600
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一篇文章了解Kotlin的泛型
Kotlin 泛型类型
Kotlin 的泛型特性允许我们编写出更加灵活和通用的代码,提高了代码的可重用性和类型安全性。
本文将介绍 Kotlin 中的四种泛型类型
- 类型参数
- 星号投影
- 型变
- 泛型限制
类型参数
定义一个泛型类或函数时,使用尖括号 < > 来指定类型参数。例如,以下是一个将泛型类型 T 用作参数的示例:
class MyList<T> { ... }
在这个示例中,T 是一个占位符类型参数,用于表示某个类型。在使用该类时,可以通过指定实际的类型参数来创建具体类型的实例。例如:
val list = MyList<String>()
在这个示例中,我们创建了一个 MyList 类型的实例,并将 String 类型指定为其类型参数。这意味着 list 变量可以存储 String 类型的元素。
星号投影
星号投影是一种特殊语法,用于表示您不关心实际类型参数的情况。通过使用 * 替代类型参数,您可以指定该参数将被忽略。例如,以下是一个使用星号投影的示例:
fun printList(list: List<*>) {
for (item in list) {
println(item)
}
}
在这个示例中,printList 函数接收一个 List<*> 类型的参数,该类型使用星号投影来表示它可以存储任何类型的元素。循环遍历该列表,并将每个元素输出到控制台。
型变
型变是指泛型类型之间的继承关系。在 Kotlin 中,有三种型变:in、out 和 invariant。这些型变用于描述子类型和超类型之间的关系,并影响如何将泛型类型赋值给其他类型。
in型变:用于消费型位置(比如方法参数),表示只能从泛型类型中读取数据,不能写入数据。interface Source<out T> {
fun next(): T
}
fun demo(strs: Source<String>) {
val objects: Source<Any> = strs
// ...
}
在这个示例中,我们定义了一个泛型接口
Source,并使用out关键字将其标记为协变类型。这意味着我们可以将Source<String>类型的对象视为Source<Any>类型的对象,并将其赋值给objects变量。out型变:用于生产型位置(比如返回值),表示只能向泛型类型中写入数据,不能读取数据。interface Sink<in T> {
fun put(element: T)
}
fun demo(sinkOfAny: Sink<Any>) {
val sinkOfString: Sink<String> = sinkOfAny
// ...
}
在这个示例中,我们定义了一个泛型接口
Sink,并使用in关键字将其标记为逆变类型。这意味着我们可以将一个Sink<Any>类型的对象视为Sink<String>类型的对象,并将其赋值给sinkOfString变量。invariant 型变:默认情况下,Kotlin 中的泛型类型都是不变(invariant)的。这意味着不能将一个
List<String>类型的对象视为List<Any>类型的对象。
泛型限制
泛型限制用于约束泛型类型可以具体化为哪些类型。例如,使用 where 关键字可以给泛型类型添加多个限制条件。以下是一个使用泛型限制的示例:
fun <T> showItems(list: List<T>) where T : CharSequence, T : Comparable<T> {
list.filter { it.length > 5 }.sorted().forEach(::println)
}
在这个示例中,我们定义了一个名为 showItems 的函数,它接受一个 List<T> 类型的参数,并对该列表进行过滤、排序和输出操作。其中,T 是一个泛型类型参数,用于表示列表中的元素类型。
为了限制 T 的类型,我们使用 where 关键字并添加了两个限制条件:T 必须实现 CharSequence 接口和 Comparable 接口。这意味着当我们调用 showItems 函数时,只能传递那些既实现了 CharSequence 接口又实现了 Comparable 接口的类型参数。
需要注意的是,在 Kotlin 中使用泛型限制时,限制条件必须放在 where 关键字之后,并且使用逗号 , 分隔各个限制条件。如果有多个限制条件,建议将它们放在新行上,以提高代码的可读性。
链接:https://juejin.cn/post/7245194439785742396
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
优雅可拓展的登录封装,让你远离if-else
前言
Hi,大家好,我是你们的秃头朋友程序员小甲,相信各位码农朋友在搭建从0到1项目时在搭建完基建等任务后,最先去做的都是去搭建系统的用户体系,那么每一个码农朋友都会去编码属于自己系统的一套用户登录注册体系;但是登录方式极其多样,光小甲一个人对接的就有google登录,苹果登录,手机验证码,微信验证码登录,微博登录等各种各样的登录;
针对这么多的登录方式,小甲是如何进行功能接入的呢?(Ps:直接switch-case和if-else接入不香吗,又不是不能用,这其实是小甲做功能时最真实的想法了,但是迫于团队老大哥的强大气场,小甲自然不敢这样硬核编码了),接下来就让秃头小甲和大伙一起分享一下是怎么让普普通通的登录也能玩出逼格的!(由于篇幅过长,接下来进入硬核时刻,希望各位能挺住李云龙二营长的意大利跑前进哈)
功能实现
技术栈:SpringBoot,MySQL,MyBatisPlus,hutool,guava,Redis,Jwt,Springboot-emial等;
sdk组件架构
项目结构包:
tea-api(前台聚合服务)tea-mng(后管聚合服务)tea-sdk(SpringBoot相关组件模块)tea-common(公共模块,提供一些工具类支持和公有类引用)
项目结构引用关系: sdk引入了common包,api和mng引入了sdk包;
封装思路
思路一:通过前端登录路由请求头key值通过反射生成对应的LoginProvider类来进行登录业务逻辑的执行。具体的做法如下:
- 在classPath路径下新增一个json/Provider.json文件,json格式如下图所示:
- 定义具体的Provider继承基类Provider,秃头小甲这里定义了一般业务系统最常对接的集中Provider(PS:由于google登录和App登录主要是用于对接海外业务,因此小甲这里就没把集成代码放出来了)如下图是小甲定义的几个Provider:
其中UserLoginService是所有Provider的基类接口,封装了模板方法。EmialLoginProvider类主要是实现邮箱验证码登录,PasswordProvider用于实现账号密码登录,PhoneLoginProvider是用于手机号验证码登录.WbLoginProvider用于实现PC端微博授权登录,WxLoginPrvider用于实现微信PC端授权登录;
3.EmailLoginProvider和PhoneLoginProvider需要用到验证码校验,因此需要实现UserLoginService接口的验证码获取,并将获取到的验证码存储到redis中;
4.将前端的路由gateWay作为key值,需要加载的动态类名作为value值。定义一个LoginService业务处理类,类中定义一个Map缓存对象,在bean注入加载到ioc容器时,通过读取解析json文件对Map缓存进行反射属性注入,该设计理念参考了Springboot的SPI注入原理以此实现对Provider的可拔插操作;
思路二:
- 通过SpringBoot事件监听机制,通过前端路由请求头的key值发布生成不同的ApplicationEvent事件,利用事件监听对业务处理解耦;
- 定义具体的Event事件以及Listener;
- 根据前端路由gateWay值生成需要发布的Event事件基类,在具体的listener类上根据@EventListener注解来对具体的事件进行监听处理;
思路对比
思路一通过模板+工厂+反射等设计模式的原理对多方式登录方式来达到解耦和拓展,从而规避了开发人员大量的if-else或switch等硬编码的方式,思路二通过模板+工厂+事件监听机制等设计模式也做到了对多方式登录的解耦和拓展,两种思路均能做到延伸代码的拓展性的作用;
封装源码
1.基类UserLoginService
/**
* 登录
*
* @param req 登录请求体
* @return
*/
LoginResp login(LoginReq req);
/**
* 验证码获取
*
* @param req 登录请求体
* @return
*/
LoginResp vertifyCode(LoginReq req);
2.拓展类Provider代码
public class EmailLoginProvider implements UserLoginService {
@Override
public LoginResp login(LoginReq req) {
UserService userService = SpringUtil.getBean(UserService.class);
User user = userService.getOne(Wrappers.lambdaQuery(new User()).eq(User::getEmail, req.getEmail()).eq(User::getStatus, 1));
if (Objects.isNull(user)) {
return null;
}
String redisKey = req.getEmail();
RedisTemplate redisTemplate = SpringUtil.getBean(StringRedisTemplate.class);
String code = (String) redisTemplate.opsForValue().get(redisKey);
if (StringUtils.isEmpty(code)||!code.equals(req.getCode())) {
return null;
}
String token = JwtParse.getoken(user);
LoginResp resp = new LoginResp();
resp.setToken(token);
return resp;
}
@Override
public LoginResp vertifyCode(LoginReq req) {
String redisKey = req.getEmail();
LoginResp resp = new LoginResp();
RedisTemplate redisTemplate = SpringUtil.getBean(StringRedisTemplate.class);
String code = (String) redisTemplate.opsForValue().get(redisKey);
if (StringUtils.isNotEmpty(code)) {
resp.setCode(code);
return resp;
}
MailService mailService = SpringUtil.getBean(MailService.class);
String mailCode = CodeUtils.make(4);
mailService.sendMail(req.getEmail(), "邮箱验证码", mailCode);
redisTemplate.opsForValue().set(req.getEmail(), mailCode);
return resp;
}
}public class PasswordProvider implements UserLoginService {
@Override
public LoginResp login(LoginReq req) {
UserService userService = SpringUtil.getBean(UserService.class);
User user = userService.getOne(Wrappers.lambdaQuery(new User()).eq(User::getPassword, req.getPassword()).eq(User::getStatus, 1));
if (Objects.isNull(user)) {
return null;
}
String token = JwtParse.getoken(user);
LoginResp resp = new LoginResp();
resp.setToken(token);
return resp;
}
@Override
public LoginResp vertifyCode(LoginReq req) {
return null;
}
}public class PhoneLoginProvider implements UserLoginService {
@Override
public LoginResp login(LoginReq req) {
UserService userService = SpringUtil.getBean(UserService.class);
User user = userService.getOne(Wrappers.lambdaQuery(new User()).eq(User::getPhone, req.getPhone()).eq(User::getStatus, 1));
if (Objects.isNull(user)) {
return null;
}
String redisKey = req.getPhone();
RedisTemplate redisTemplate = SpringUtil.getBean(RedisTemplate.class);
String code = (String) redisTemplate.opsForValue().get(redisKey);
if (!code.equals(req.getCode())) {
return null;
}
String token = JwtParse.getoken(user);
LoginResp resp = new LoginResp();
resp.setToken(token);
return resp;
}
@Override
public LoginResp vertifyCode(LoginReq req) {
String redisKey = req.getPhone();
LoginResp resp = new LoginResp();
RedisTemplate redisTemplate = SpringUtil.getBean(RedisTemplate.class);
String code = (String) redisTemplate.opsForValue().get(redisKey);
if (StringUtils.isNotEmpty(code)) {
resp.setCode(code);
return resp;
}
MailService mailService = SpringUtil.getBean(MailService.class);
String mailCode = CodeUtils.make(4);
mailService.sendMail(req.getPhone(), "手机登录验证码", mailCode);
redisTemplate.opsForValue().set(req.getEmail(), mailCode);
return resp;
}
}public class WxLoginProvider implements UserLoginService {
@Override
public LoginResp login(LoginReq req) {
WxService wxService = SpringUtil.getBean(WxService.class);
WxReq wxReq = new WxReq();
wxReq.setCode(req.getAuthCode());
WxResp token = wxService.getAccessToken(wxReq);
String accessToken = token.getAccessToken();
if (StringUtils.isEmpty(accessToken)) {
}
wxReq.setOpenid(token.getOpenid());
WxUserInfoResp userInfo = wxService.getUserInfo(wxReq);
//根据unionId和openid查找一下当前用户是否已经存在系统,如果不存在,帮其注册这里单纯是为了登录;
UserService userService = SpringUtil.getBean(UserService.class);
User user = userService.getOne(Wrappers.lambdaQuery(new User()).eq(User::getOpenId, token.getOpenid()).eq(User::getUnionId, token.getUnionId()));
if (Objects.isNull(user)) {
}
String getoken = JwtParse.getoken(user);
LoginResp resp = new LoginResp();
resp.setToken(getoken);
return resp;
}
@Override
public LoginResp vertifyCode(LoginReq req) {
return null;
}
}
3.接口暴露Service--LoginService源码
@Service
@Slf4j
public class LoginService {
private Map<String, UserLoginService> loginServiceMap = new ConcurrentHashMap<>();
@PostConstruct
public void init() {
try {
List<JSONObject> jsonList = JSONArray.parseObject(ResourceUtil.getResource("json/Provider.json").openStream(), List.class);
for (JSONObject object : jsonList) {
String key = object.getString("key");
String className = object.getString("value");
Class loginProvider = Class.forName(className);
UserLoginService loginService = (UserLoginService) loginProvider.newInstance();
loginServiceMap.put(key, loginService);
}
} catch (Exception e) {
log.info("[登录初始化异常]异常堆栈信息为:{}", ExceptionUtils.parseStackTrace(e));
}
}
/**
* 统一登录
*
* @param gateWayRoute 路由路径
* @param req 登录请求
* @return
*/
public RetunrnT<LoginResp> login(String gateWayRoute, LoginReq req) {
UserLoginService userLoginService = loginServiceMap.get(gateWayRoute);
LoginResp loginResp = userLoginService.login(req);
return RetunrnT.success(loginResp);
}
/**
* 验证码发送
*
* @param gateWayRoute 路由路径
* @param req 登录请求
* @return
*/
public RetunrnT<LoginResp> vertifyCode(String gateWayRoute, LoginReq req) {
UserLoginService userLoginService = loginServiceMap.get(gateWayRoute);
LoginResp resp = userLoginService.vertifyCode(req);
return RetunrnT.success(resp);
}
}
4.邮件发送Service具体实现--MailService
public interface MailService {
/**
* 发送邮件
*
* @param to 收件人
* @param subject 主题
* @param content 内容
*/
void sendMail(String to, String subject, String content);
}@Service
@Slf4j
public class MailServiceImpl implements MailService {
/**
* Spring Boot 提供了一个发送邮件的简单抽象,直接注入即可使用
*/
@Resource
private JavaMailSender mailSender;
/**
* 配置文件中的发送邮箱
*/
@Value("${spring.mail.from}")
private String from;
@Override
@Async
public void sendMail(String to, String subject, String content) {
//创建一个邮箱消息对象
SimpleMailMessage message = new SimpleMailMessage();
//邮件发送人
message.setFrom(from);
//邮件接收人
message.setTo(to);
//邮件主题
message.setSubject(subject);
//邮件内容
message.setText(content);
//发送邮件
mailSender.send(message);
log.info("邮件发成功:{}", message.toString());
}
}
5.token生成JsonParse类
private static final String SECRECTKEY = "zshsjcbchsssks123";
public static String getoken(User user) {
//Jwts.builder()生成
//Jwts.parser()验证
JwtBuilder jwtBuilder = Jwts.builder()
.setId(user.getId() + "")
.setSubject(JSON.toJSONString(user)) //用户对象
.setIssuedAt(new Date())//登录时间
.signWith(SignatureAlgorithm.HS256, SECRECTKEY).setExpiration(new Date(System.currentTimeMillis() + 86400000));
//设置过期时间
//前三个为载荷playload 最后一个为头部 header
log.info("token为:{}", jwtBuilder.compact());
return jwtBuilder.compact();
}
6.微信认证授权Service---WxService
public interface WxService {
/**
* 通过code获取access_token
*/
WxResp getAccessToken(WxReq req);
/**
* 通过accessToken获取用户信息
*/
WxUserInfoResp getUserInfo(WxReq req);
}@Service
@Slf4j
public class WxServiceImpl implements WxService {
@Resource
private WxConfig wxConfig;
@Override
public WxResp getAccessToken(WxReq req) {
req.setAppid(wxConfig.getAppid());
req.setSecret(wxConfig.getSecret());
Map map = JSON.parseObject(JSON.toJSONString(req), Map.class);
WxResp wxResp = JSON.parseObject(HttpUtil.createGet(wxConfig.getTokenUrl()).formStr(map).execute().body(), WxResp.class);
return wxResp;
}
@Override
public WxUserInfoResp getUserInfo(WxReq req) {
req.setAppid(wxConfig.getAppid());
req.setSecret(wxConfig.getSecret());
Map map = JSON.parseObject(JSON.toJSONString(req), Map.class);
return JSON.parseObject(HttpUtil.createGet(wxConfig.getGetUserUrl()).formStr(map).execute().body(), WxUserInfoResp.class);
}
}
功能演练
项目总结
相信很多小伙伴在平时开发过程中都能看到一定的业务硬核代码,前期设计不合理,后续开发只能在前人的基础上不断的进行if-else或者switch来进行业务的功能拓展,千里之行基于跬步,地基不稳注定是要地动山摇的,希望在接下来的时光,秃头小甲也能不断提升自己的水平,写出更多有水准的代码;
碎碎念时光
首先很感谢能看完全篇幅的各位老铁兄弟们,希望本篇文章能对各位和秃头小甲一样码农有所帮助,当然如果各位技术大大对这模块做法有更优质的做法的,也欢迎各位技术大大能在评论区留言探讨,写在最后~~~~~~ 创作不易,希望各位老铁能不吝惜于自己的手指,帮秃头点下您宝贵的赞把!
链接:https://juejin.cn/post/7228635037457055802
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin的语法糖到底有多甜?
JYM大家好,好久没来写文了。
今天带给大家 Kotlin 的内容,可能一些常关注我的朋友也发现了,在我之前的文章中就开始用 Kotlin 代码做代码示例了,这是因为最近一年我都在高强度使用 Kotlin 进行后端开发。
相信很多安卓开发的朋友早就开始用上 Kotlin 了,但是许多后端对这门语言应该还是不太了解,反正在我的朋友圈里没有见到过用 Kotlin 写后端的程序员存在,在我亲身用了一年 Kotlin 之后已经不太想用 Java 进行代码开发了,起码在开发效率方面就已经是天差地别了,所以今天特地给大家分享一下 Kotlin 的好,希望能带领更多人入坑。
1. 第一段代码
很多人说 Kotlin 就是披了一层语法糖的 Java,因为它百分百兼容 Java,甚至可以做到 Kotlin 调用 Java 代码。
其实我对这个说法是赞同的,但是又不完全一样,因为 Kotlin 有自己的语法、更有自己的编译器、还有着多端支持,更有着自己的设计目标。
我更倾向于把 Kotlin 看成一个 JVM 系语言,就像 Scala 语言一样,只是恰好 Kotlin 有一个设计目标就是百分百兼容 Java。
在语言层面,Kotlin 几乎是借鉴了市面上所有的现代化语言的强大特性,协程、函数式、扩展函数、空安全,这些广受好评的特性全部都有。
而且从我个人感受来看,我用过 Java、Kotlin、JS、Go、Dart、TS、还有一点点 Python,我觉得 JS 和 Kotlin 的语法是比较方便易用的,Dart、Java 和 Go 的语法都不是太方便易用,语法的简单也在一定程度上减少了开发者的心智负担。
下面我将用一段代码,来简单说明一下 Kotlin 常见的语法特性:
fun main(args: Array<String>) {
val name = "Rookie"
// Hello World! Rookie
println("Hello World! $name")
// Hello World! 82,111,111,107,105,101
println("Hello World! ${name.chars().toList().joinToString(",")}")
test(createPerson = { Person("Rookie", 25) })
}
data class Person(
var name: String = "",
var age: Int = 0,
)
fun test(createPerson: () -> Person, test : String = "test"): Person {
val person = createPerson()
// Person(name=Rookie, age=25)
println(person)
return person
}
上面是一段简简单单的 Kotlin 代码,但是却可以看出 Kotlin 的很多特性,请听我娓娓道来~
- Kotlin 的启动方法也是 main 函数,但是 Kotlin 移除了所有基础类型,一切皆对象,比如 Java 中的数组对应的就是 Array 类,int 对应的是 Int 类。
- Kotlin 使用类型推断来声明类型,一共有两个关键字,val 代表这是一个不可变变量,var 代表这是一个可变的变量,这两个关键字选用我感觉比 JS 还要好。
- Kotlin 代码每一行不需要英文分号结尾。
- Kotlin 支持字符串模板,可以直接字符串中使用 '$' 符号放置变量,如果你想放置一个函数的计算结果,需要用 '${}' 来包裹。
- Kotlin 是一个函数式语言,支持高阶函数,闭包、尾递归优化等函数式特性。
- Kotlin 为了简化 Java Bean,支持了数据类 data class,它会自动生成无参构造、getter、setter、equals()、hashCode()、copy()、toJSON()、toString() 方法。
- Kotlin 的函数关键字是 fun,返回值在函数的最后面,变量名在类型的前面,几乎新兴语言都是这样设计的,可以明显感受到语言设计者想让我们更多关注业务含义而非数据类型。
- Kotlin 具有一些类似 go 和 Python 的内置函数,比如 println。
- Kotlin 的函数参数支持默认值。
- Kotlin 不支持多参数返回,但是为了解决这个问题它内置了两个类:Pair 和 Triple,分别可以包装两个返回值和三个返回值。
2. 基础常用特性
了解了一些 Kotlin 的基础语法之后,我再来介绍一些常用的基础特性。
第一个就是空安全和可空性。
Kotlin 中的变量可以声明为非空和可空,默认的声明都是非空,如果需要一个变量可空的,需要在类型后面加一个问号,就像这样:
fun start() {
val name1 : String = ""
val name : String? = null
}
函数的参数声明也一样,也会区分非空和可空,Kotlin 编译器会对代码上下文进行检查,在函数调用处也会对变量是否可空进行一致性检查,如果不通过则会有编译器提醒,我是强烈建议不用可空变量,一般都可以通过默认值来处理。
那么如果你接手的是前人代码,他声明变量为可空,但是希望为空的时候传递一个默认值,则可以使用这个语法进行处理:
fun start() {
val name : String? = null
println(name ?: "Rookie")
}
这是一个类似三元表达式的语法(Elvis 运算符),在 Kotlin 中极其常见,除此之外你还可以进行非空调用:
fun start() {
val name : String? = null
println(name?.chars() ?: "Rookie")
}
这段代码就表示:如果变量不为空就调用 chars 方法,如果为空则返回默认值 Rookie,在所有可空变量上都支持这种写法,并且支持链式调用。
第二个常用特性是异常处理, 写到这里突然想到了一个标题,Kotlin 的异常处理,那叫一个优雅!!!
fun start() {
val person = runCatching {
test1()
}.onFailure {
}.onSuccess {
}.getOrNull() ?: Person("Rookie", 25)
}
fun test1() : Person {
return Person()
}
这一段代码中的 test1 方法你可以当作一个远程调用方法或者逻辑方法,对了,这里隐含了一个语法,就是一个函数中的最后一行的计算结果是它的返回值,你不需要显示的去写 return。
我使用 runCatching 包裹我们的逻辑方法,然后有三个链式调用:
- onFailure:当逻辑方法报错时会进入这个方法。
- onSuccess:当逻辑方法执行成功时会进入这个方法。
- getOrNull:当逻辑方法执行成功时正常返回,执行失败时返回一个空变量,然后我们紧跟一个 ?: ,这代表当返回值为空时我们返回自定义的默认值。
如此一来,一个异常处理的闭环就完成了,每一个环节都会被考虑到,这些链式调用的方法都是可选的,如果你不手动调用处理会有默认的处理方式,大家伙觉得优雅吗?
第三个特性是改进后的流程控制。
fun start() {
val num = (1..100).random()
val name = if (num == 1) "1" else { "Rookie" }
val age = when (num) {
1 -> 10
2 -> 20
else -> { (21..30).random() }
}
}
我们先声明一个随机数,然后根据条件判断语句返回不同的值,其中 Java 中的 Switch 由 When 语法来替代。
而且这里每一段表达式都可以是一个函数,大家可以回忆一下,如果你使用 Java 来完成通过条件返回不同变量的逻辑会有多麻烦。
如果大家在不了解 Kotlin 的情况下尝试用更简单的方式来写逻辑,可以问问类似 ChatGPT 这种对话机器人来进行辅助你。
3. 常用内置函数
就像每个变量类型都有 toString 方法一样,Kotlin 中的每个变量都具有一些内置的扩展函数,这些函数可以极大的方便我们开发。
apply和also
fun start() {
val person = Person("Rookie", 25)
val person1 = person.apply {
println("name : $name, age : $age, This : $this")
}
val person2 = person.also {
println("name : ${it.name}, age : ${it.age}, This : $it")
}
}
这两个函数调用之后都是执行函数体后返回调用变量本身,不同的是 apply 的引用为 this,内部取 this 变量时不需要 this.name 可以直接拿 name 和 age 变量。
而 also 函数则默认有一个 it,it 就是这个变量本身的引用,我们可以通过这个 it 来获取相关的变量和方法。
run 和 let
fun start() {
val person = Person("Rookie", 25)
val person1 = person.run {
println("name : $name, age : $age, This : $this")
"person1"
}
val person2 = person.let {
println("name : ${it.name}, age : ${it.age}, This : $it")
"person2"
}
}
run 函数和 let 函数都支持返回与调用变量不同的返回值,只需要将返回值写到函数最后一行或者使用 return 语句进行返回即可,上例中 person 变量进行调用之后的返回结果就是一个 String 类型。
在使用上的具体差异也就是引用对象的指向不同,具体更多差异可以看一下网络上总结,我这里表明用法就可以了。
除了这四个函数之外,还有许多的类似函数帮我们来做一些很优雅的代码处理和链式调用,但是我根本没有用过其它的函数,这四个函数对我来说已经足够了,有兴趣的朋友可以慢慢发掘。
4. 扩展函数与扩展属性
上文了我们举了几个常见的内置函数,其实他们都是使用 Kotlin 的扩展函数特性实现的。
所谓扩展函数就是可以为某个类增加扩展方法,比如给 JDK 中的 String 类增加一个 isRookie 方法来判断某个字符串是否是 Rookie:
fun start() {
val name = "rookie"
println(name.isRookie())
}
fun String.isRookie(): Boolean {
return this == "Rookie"
}
this 代表了当前调用者的引用,利用扩展函数你可以很方便的封装一些常用方法,比如 Long 型转时间类型,时间类型转 Long 型,不比像以前一样再用工具类做调用了。
除了扩展函数,Kotlin 还支持扩展属性:
fun start() {
val list = listOf(1, 2, 3)
println(list.maxIndex)
}
val <T> List<T>.maxIndex: Int
get() = if (this.isEmpty()) -1 else this.size - 1
通过定义一个扩展属性和定义它的 get 逻辑,我们就可以为 List 带来一个全新属性——maxIndex,这个属性用来返回当前 List 的最大元素下标。
扩展函数和扩展属性多用于封闭类,比如 JDK、第三方 jar 包作为扩展使用,它的实际使用效果其实和工具类是一样的,只不过更加优雅。
不过借用这个能力,Kotlin 为所有的常用类都增加了一堆扩展,比如 String:
基本上你可以想到的大部分函数都已经被 Kotlin 内置了,这就是 Kotlin 的语法糖。
5. Kotlin的容器
终于来到我们这篇文章的大头了,Kotlin 中的容器基本上都是:List、Map 扩展而来,作为一个函数式语言,Kotlin 将容器分为了可变与不可变。
我们先来看一下普遍的用法:
fun start() {
val list = listOf(1, 2, 3)
val set = setOf(1, 2, 3)
val map = mapOf(1 to "one", 2 to "two", 3 to "three")
}
上面的例子中,我们使用三个内置函数来方便的创建对应的容器,但是此时创建的容器是不可变的,也就是说容器内的元素只能读取,不能添加、删除和修改。
当然,Kotlin 也为此类容器增加了一些方法,使其可以方便的增加元素,但实际行为并不是真的往容器内增加元素,而是创建一个新的容器将原来的数据复制过去:
fun start() {
val list = listOf(1, 2, 3).plus(4)
val set = setOf(1, 2, 3).plus(4)
val map = mapOf(1 to "one", 2 to "two", 3 to "three").plus(4 to "four")
}
如果我们想要创建一个可以增加、删除元素的容器,也就是可变容器,可以用以下函数:
fun start() {
val list = mutableListOf(1, 2, 3)
val set = mutableSetOf(1, 2, 3)
val map = mutableMapOf(1 to "one", 2 to "two", 3 to "three")
}
讲完了,容器的创建,可以来聊聊相关的一些操作了,在 Java 中有一个 Stream 流,在 Stream 中可以很方便的做一些常见的函数操作,Kotlin 不仅完全继承了过来,还加入了大量方法,大概可以包含以下几类:
- 排序:sort
- 乱序:shuffle
- 分组:group、associate、partition、chunked
- 查找:filter、find
- 映射:map、flatMap
- 规约:reduce、min、max
由于函数实在太多,我不能一一列举,只能给大家举一个小例子:filter:
一个 filter 有这么多种多样的函数,几乎可以容纳你所有的场景,这里说两个让我感觉到惊喜的函数:chunked 和 partition。
chunked 函数是一个分组函数,我常用的场景是避免请求量过大,比如在批量提交时,我可以将一个 list 中的元素进行 1000 个一组,每次提交一组:
fun start() {
val list = mutableListOf(1, 2, 3)
val chunk : List<List<Int>> = list.chunked(2)
}
示例代码中为了让大家看的清楚我故意声明了类型,实际开发中可以不声明,会进行自动推断。
在上面这个例子中,我将一个 list 进行每组两个进行分组,最终得到一个 List<List> 类型的变量,接下来我可以使用 forEach 进行批量提交,它底层通过 windowed 函数进行调用,这个函数也可以直接调用,有兴趣的朋友可以研究一下效果,通过名字大概可以知道是类似滑动窗口。
partition 你可以将其看作一个分组函数,它算是 filter 的补充:
fun start() {
val list = mutableListOf(1, 2, 3)
val partition = list.partition { it > 2 }
println(partition.first)
println(partition.second)
}
它通过传入一个布尔表达式,将一个 List 分为两组,返回值是上文提到过的 Pair 类型,Pair 有两个变量:first 和 second。
partition 函数会将符合条件的元素放到 first 中去,不符合条件的元素放到 second 中,我自己的使用的时候很多是为了日志记录,要把不处理的元素也记录下来。
容器与容器之间还可以直接通过类似:toList、toSet之类的方法进行转换,非常方便,转换 Map 我一般使用 associate 方法,它也有一系列方法,主要作用就是可以转换过程中自己指定 Map 中的 K 和 V。
6. 结束语
不知不觉都已经快四千字了,我已经要结束这篇文章了,但是仍然发现几乎什么都没写,也对,这只是一篇给大家普及 Kotlin 所带来效率的提升的文章,而不是专精的技术文章。
正如我在标题中写的那样:Kotlin 的语法糖到底有多甜?Kotlin 的这一切我都将其当作语法糖,它能极大提高我的开发效率,但是一些真正 Kotlin 可以做到而 Java 没有做到的功能我却没有使用,比如:协程。
由于我一直是使用 Kotlin 写后端,而协程的使用场景我从来没有遇到过,可能做安卓的朋友更容易遇到,所以我没有对它进行举例,对于我来说,Kotlin 能为我的开发大大提效就已经很不错了。
使用 Kotlin 有一种使用 JS 的感觉,有时候可以一个方法开头就写一个 return,然后链式调用一直到方法结束。
我还是蛮希望 Java 开发者们可以转到 Kotlin,感受一下 Kotlin 的魅力,毕竟是百分百兼容。
在这里要说一下我使用的版本,我使用的是 JDK17、Kotlin 1.8、Kotlin 编译版本为 1.8,也就是说 Kotlin 生成的代码可以跑在最低 JDK1.8 版本上面,这也是一个 Kotlin 的好处,你可以通过升级 Kotlin 的版本体验最新的 Kotlin 特性,但是呢,你的 JDK 平台不用变。
对了,Kotlin 将反射封装的极好,喜欢研究的朋友也可以研究一下。
好了,这篇文章就到这里,希望大家能帮我积极点赞,提高更新动力,人生苦短,我用KT。
链接:https://juejin.cn/post/7258970835044827192
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
MySQL Join原理
Join的类型
- left join,以左表为驱动表,以左表作为结果集基础,连接右表的数据补齐到结果集中
- right join,以右表为驱动表,以右表作为结果集基础,连接左表的数据补齐到结果集中
- inner join,结果集取两个表的交集
- full join,结果集取两个表的并集
- mysql没有full join,union取代
- union与union all的区别为,union会去重
- cross join 笛卡尔积
- 如果不使用where条件则结果集为两个关联表行的乘积
- 与,的区别为,cross join建立结果集时会根据on条件过滤结果集合
- straight_join
- 严格根据SQL顺序指定驱动表,左表是驱动
Join原理
本质上可以理解为嵌套循环的操作,驱动表作为外层for循环,被驱动表作为内层for循环。根据连接组成数据的策略可以分为三种算法。
Simpe Nested-Loop Join
- 连接比如有A表,B表,两个表JOIN的话会拿着A表的连表条件一条一条在B表循环,匹配A表和B表相同的id 放入结果集,这种效率是最低的。
Index Nested-Loop Join
- 执行流程(磁盘扫描)
- 从表t1中读入一行数据 R;
- 从数据行R中,取出a字段到表t2里进行树搜索查找;
- 取出表t2中满足条件的行,跟R组成一行,作为结果集的一部分;
- 重复执行步骤1到3,直到表t1的末尾循环结束。
- 而对于每一行R,根据a字段去表t2查找,走的是树搜索过程。
Block Nested-Loop Join
- mysql使用了一个叫join buffer的缓冲区去减少循环次数,这个缓冲区默认是256KB,可以通过命令show variables like 'join_%'查看
- 其具体的做法是,将第一表中符合条件的列一次性查询到缓冲区中,然后遍历一次第二个表,并逐一和缓冲区的所有值比较,将比较结果加入结果集中
- 只有当JOIN类型为ALL,index,rang或者是index_merge的时候才会使用join buffer,可以通过explain查看SQL的查询类型。
Join优化
- 为了优化join算法采用Index nested-loop join算法,在连接字段上建立索引字段
- 使用数据量小的表去驱动数据量大的表
- 增大join buffer size的大小(一次缓存的数据越多,那么外层表循环的次数就越少)
- 注意连接字段的隐式转换与字符编码,避免索引失效
链接:https://juejin.cn/post/7225797036041764921
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
为什么很多公司都开始使用Go语言了?
为什么很多公司都开始使用Go语言了?
写在前面
最近和几个小伙伴们在写字节跳动第五届青训营后端组的大作业。
接近尾期了,是时候做一些总结了,那从什么地方开始呢?那就从我们为什么要选择Go语言开始吧~
越来越多的互联网大厂开始使用Go语言了,譬如腾讯、美团、滴滴、百度、Google、bilibili...
还有最初使用Python的字节跳动,甚至已经全面拥向Go了。这么多国内外首屈一指的公司,都在开始使用它了,它到底有什么优势呢?这就得谈谈它的一些优势了。
ps:当然了,还有Go-To-Byte的成员,想要学习go语言,并且用它完成青训营的大项目呐~
Go的一些优势
说起优势,在某些方面多半是因为它有一些别人没有的特性,或者优化了别人麻烦的地方,相比起来,才会更胜一筹。那我们来了解一下Go的一些特点吧,但在了解生硬的特点之前,我们先来看看其它几种常见的语言:
常见的一些语言
这里不是对比哟,不是说谁好谁坏,而是小马过河,因人而异~
1、C/C++
C语言是在1971年的时候,被大神Ken Thompson和Dennis Ritchie发明的,而Go语言的主导开发者之一就是Ken Thompson,所以在很多地方和C语言类似,(比如struct、Printf、&取值符)
C/C++也作为很多初学初学的语言,它们都是直接编译为机器码,所以执行效率会更高,并且都不需要执行环境,用户的使用成本会更低,不像很多语言还需要安装所需的环境。
也因为这些原因,它们的一次编码或编译只适用于一种平台,对于不同操作系统而言,有时需要修改编码再编译,有时直接重新编译即可。
而且对于开发者也"很不友好"😒,需要自己处理垃圾回收(GC)的问题。编码时,还需要考虑,堆上的内存什么时候free、delete?代码会不会造成内存泄露、不安全?
2、Java
自己作为一个从Java来学习Go的菜鸟,还未正式开发,就感到开发效率会比Java低了(个人感觉,不喜勿喷)~😁
Java是直接编译成字节码(.class),这种编译产物是介于原始编码和机器码的一种中间码。这样的话,Java程序就需要特定的执行环境(JVM)了,执行效率相比会低一些,还可能有虚拟化损失。但是这样也有一个好处就是可以编译一次,多处执行(跨平台)。而且它也是自带GC的。
3、JavaScript
和Python一样,JS是一种解释型语言,它们不需要编译,解释后即可运行。所以Js也是需要特定的执行环境(浏览器引擎) 的。
将其代码放入浏览器后,浏览器需要解析代码,所以也会有虚拟化损失。Js只需要浏览器即可运行,所以它也是跨平台的。
再谈Go
看完了前面几种常见语言的简单介绍。C/C++性能很高,因为它直接编译为二进制,且没有虚拟化损失,Go觉得还不错;Java的自动垃圾回收机制很好,Go觉得也不错;Js的一次编码可以适用可以适用多种平台,Go觉得好极了;而且Go天然具备高并发的能力,是所有语言无可比及的。那我们来简单总结一下吧!
- 自带运行环境
Runtime,且无须处理GC问题
Go程序的运行环境可厉害了,其实大部分语言都有Runtime的概念,比如Java,它程序的运行环境是JVM,需要单独安装。对于Java程序,如果不经过特殊处理,只能运行在有JMV环境的机器上。
而Go程序是自带运行环境的,Go程序的Runtime会作为程序的一部分打包进二进制产物,和用户程序一起运行,也就是说Runtime也是一系列.go代码和汇编代码等,用户可以“直接”调用Runtime的函数(比如make([]int, 2, 6),这样的语法,其实就是去调用Runtime中的makeslice函数)。对于Go程序,简单来说就是不需要安装额外的运行环境,即可运行。除非你需要开发Go的程序。
正因为这样,Go程序也无须处理GC的问题,全权交由Runtime处理(反正要打包到一起)。
- 快速编译,且跨平台
不同于C/C++,对于多个平台,可能需要修改代码后再编译。也不同于Java的一次编码,编译成中间码运行在多个平台的虚拟机上。Go只需要一次编码,就能轻松在多个平台编译成机器码运行。
值得一提的就是它这跨平台的能力也是Runtime赋予的,因为Runtime有一定屏蔽系统调用的能力。
- 天然支持高性能高并发,且语法简单、学习曲线平缓
C++处理并发的能力也不弱,但由于C++的编码要求很高,如果不是很老练、专业的C++程序员,可能会出很多故障。而Go可能经验不是那么丰厚,也能写出性能很好的高并发程序。
值得一提的就是它这超强的高并发,也是Runtime赋予的去处理协程调度能力。
- 丰富的标准库、完善的工具链
对于开发者而言,安装好Golang的环境后,就能用官方的标准库开发很多功能了。比如下图所示的很多常用包:
而且Go自身就具有丰富的工具链,(比如:代码格式化、单元测试、基准测试、包管理...)
- 。。。。。。
很多大厂开始使用Go语言、我们团队为什么使用GoLang,和这些特性,多少都有一些关系吧~
链接:https://juejin.cn/post/7202153645440925751
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
认识自动化测试
自动化测试有以下几个概念:
- 单元测试
- 集成测试
- E2E 测试
- 快照测试
- 测试覆盖率
- TDD 以及 BDD 等
简述
项目开发过程中会有几个经历。
- 版本发布上线之前,会有好几个小时甚至是更长时间对应用进行测试,这个过程非常枯燥而痛苦
- 代码的复杂度达到了一定的级别,当维护者的数量不止一个人,你应该会逐渐察觉到你在开发新功能或修复 bug 的时候,会变得越发小心翼翼,即使代码看起来没什么问题,但你心里还是会犯嘀咕:会不会引起其他的bug。
- 对项目中的代码进行重构的时候,会花费大量的时间进行回归测试
这些问题都是由于大多数使用最基本的手动测试的方式所带来的问题,解决它可以引入自动化测试方式。
我们日常的开发中,代码的完工其实并不等于开发的完工。如果没有测试,不能保证代码能够正常运行。
如何进行应用程序测试?
- 手动测试:通过测试人员与应用程序的交互来检查其是否正常工作。
- 自动化测试:编写应用程序来替代人工检验。
手动测试
开发者都懂得手动测试代码。在编写完源代码之后,下一步理所当然就是去手动测试它。
手动测试的优势在于足够简单灵活,但是缺点也很明显:
- 手动不适合大型项目
- 忘记测试某项功能
- 大部分时间都在做回归测试
虽然有一部分手动测试时间是花在测试新特性上,但是大部分时间还是用来检查之前的特性是否仍正常工作。这种测试被称为回归测试。回归测试对人来说是非常困难的任务————它们是重复性的,要求投入很多注意力,而且没有创造性的输入。总之,这种测试太枯燥了。幸运的是,计算机特别擅长此类工作,这也是自动化测试可以大展身手的地方!
自动化测试
自动化测试是利用计算机程序检查软件是否运行正常的测试方法。换句话说,就是用其他额外的代码检查被测软件的代码。当测试代码编写完之后,就可以不费吹灰之力地进行无数次重复测试。
可使用多种不同的方法来编写自动化测试脚本:
- 可以编写通过浏览器自动执行的程序
- 可以直接调用源代码里的函数
- 也可以直接对比程序渲染之后的截图
每一种方法的优势各不相同,但它们有一大共同点:相比手动测试而言节省了大量时间以及提高了程序的稳定性。
自动化测试还有很多优点,比如:
- 尽早的发现程序的 bug 和不足
- 增强程序员对程序健壮性、稳定性的信心
- 改进设计
- 快速反馈,减少调试时间
- 促进重构
当然,自动化测试不可能保证一个程序是完全正确的,而且事实上,在实际开发过程中,编写自动化测试代码通常是开发者不太喜欢的一个环节。大多数情况下,前端开发者在开发完一项功能后,只是打开浏览器手动点击,查看效果是否正确,之后就很少对该块代码进行管理。造成这种情况的原因主要有两个:
- 一个是业务繁忙,没有时间进行测试的编写
- 另一个是该如何编写测试
测试类型
前端开发最常见的测试主要是以下几种:
- 单元测试:验证独立的单元是否正常工作
- 集成测试:验证多个单元协同工作
- 端到端测试:从用户角度以机器的方式在真实浏览器环境验证应用交互
- 快照测试:验证程序的 UI 变化
单元测试
单元测试是对应用程序最小的部分(单元)运行测试的过程。通常,测试的单元是函数,但在前端应用中,组件也是被测单元。
单元测试可以单独调用源代码中的函数并断言其行为是否正确。
// sum.js
function sum(a, b) {
return a + b;
}
module.exports = sum;// sum.test.js
const sum = require('./sum');
test('adds 1 + 2 to equal 3', () => {
expect(sum(1, 2)).toBe(3);
});PASS ./sum.test.js
✓ adds 1 + 2 to equal 3 (5ms)
与端到端测试不同,单元测试运行速度很快,只需要几秒钟的运行时间,因此可以在每次代码变更后都运行单元测试,从而快速得到变更是否破坏现有功能的反馈。
单元测试应该避免依赖性问题,比如不存取数据库、不访问网络等等,而是使用工具虚拟出运行环境。这种虚拟使得测试成本最小化,不用花大力气搭建各种测试环境。
单元测试的优点:
- 提升代码质量,减少 bug
- 快速反馈,减少调试时间
- 让代码维护更容易
- 有助于代码的模块化设计
- 代码覆盖率高
单元测试的缺点:
- 由于单元测试是独立的,所以无法保证多个单元运行到一起是否正确
常见的 JavaScript 单元测试框架:
- Jest
- Mocha
- Jasmine
- Karma
- ava
- Tape
Mocha 跟 Jest 是用的较多的两个单元测试框架,基本上前端单元测试就在这两个库之间选了。总的来说就是 Jest 功能齐全,配置方便,Mocha 灵活自由,自由配置。
推荐使用Jest。
集成测试
定义集成测试的方式并不相同,尤其是对于前端。有些人认为在浏览器环境上运行的测试是集成测试;有些人认为对具有模块依赖性的单元进行的任何测试都是集成测试;也有些人认为任何完全渲染的组件测试都是集成测试。
优点:
- 由于是从用户使用角度出发,更容易获得软件使用过程中的正确性
- 集成测试相对于写了软件的说明文档
- 由于不关注底层代码实现细节,所以更有利于快速重构
- 相比单元测试,集成测试的开发速度要更快一些
缺点:
- 测试失败的时候无法快速定位问题
- 代码覆盖率较低
- 速度比单元测试要慢
端到端测试(E2E)
E2E(end to end)端到端测试是最直观可以理解的测试类型。在前端应用程序中,端到端测试可以从用户的视角通过浏览器自动检查应用程序是否正常工作。
想象一下,你正在编写一个计算器应用程序,并且你想测试两个数求和的运算方法是否正确。你可以编写一个端到端测试,打开浏览器,加载计算器应用程序,单击“1”按钮,单击加号“+”按钮,再次单击“1”按钮,单击等号“=”,最后检查屏幕是否显示正确结果“2”。
编写完一个端到端测试后,可以根据自己的需求随时运行它。想象一下,相比执行数百次同样的手动测试,这样一套测试代码可以节省多少时间!
优点:
- 真实的测试环境,更容易获得程序的信心
缺点:
- 首先,端到端测试运行不够快。启动浏览器需要占用几秒钟,网站响应速度又慢。通常一套端到端测试需要 30 分钟的运行时间。如果应用程序完全依赖于端到端测试,那么测试套件将需要数小时的运行时间。
- 端到端测试的另一个问题是调试起来比较困难。要调试端到端测试,需要打开浏览器并逐步完成用户操作以重现 bug。本地运行这个调试过程就已经够糟糕了,如果测试是在持续集成服务器上失败而不是本地计算机上失败,那么整个调试过程会变得更加糟糕。
一些流行的端到端测试框架:
快照测试
快照测试类似于“找不同”游戏。快照测试会给运行中的应用程序拍一张图片,并将其与以前保存的图片进行比较。如果图像不同,则测试失败。这种测试方法对确保应用程序代码变更后是否仍然可以正确渲染很有帮助。
传统快照测试是在浏览器中启动应用程序并获取渲染页面的屏幕截图。它们将新拍摄的屏幕截图与已保存的屏幕截图进行比较,如果存在差异则显示错误。这种快照测试在操作系统或浏览器存在版本间差异时,即使快照并没有改变,也会遇到测试失败问题。
使用 Jest 测试框架编写快照测试。取代传统对比屏幕截图的方式,Jest 快照测试可以对 JavaScript 中任何可序列化值进行对比。可以使用它们来比较前端组件的 DOM 输出。
应用场景:
- 开发纯函数库,建议写更多的单元测试 + 少量的集成测试
- 开发组件库,建议写更多的单元测试、为每个组件编写快照测试、写少量的集成测试 + 端到端测试
- 开发业务系统,建议写更多的集成测试、为工具类库、算法写单元测试、写少量的端到端测试
测试覆盖率
测试覆盖率是衡量软件测试完整性的一个重要指标。掌握测试覆盖率数据,有利于客观认识软件质量,正确了解测试状态,有效改进测试工作
度量测试覆盖率:
- 代码覆盖率
- 需求覆盖率
代码覆盖率
一种面向软件开发和实现的定义。它关注的是在执行测试用例时,有哪些软件代码被执行到了,有哪些软件代码没有被执行到。被执行的代码数量与代码总数量之间的比值,就是代码覆盖率。
根据代码粒度的不同,代码覆盖率可以进一步分为四个测量维度。它们形式各异,但本质是相同的。
- 行覆盖率(line coverage):是否每一行都执行了?
- 函数覆盖率(function coverage):是否每个函数都调用了?
- 分支覆盖率(branch coverage):是否每个if代码块都执行了?
- 语句覆盖率(statement coverage):是否每个语句都执行了?
如何度量代码覆盖率呢?一般可以通过第三方工具完成,比如 Jest 自带了测试覆盖率统计。
这些度量工具有个特点,那就是它们一般只适用于白盒测试,尤其是单元测试。对于黑盒测试(例如功能测试/系统测试)来说,度量它们的代码覆盖率则相对困难多了。
需求覆盖率
对于黑盒测试,例如功能测试/集成测试/系统测试等来说,测试用例通常是基于软件需求而不是软件实现所设计的。因此,度量这类测试完整性的手段一般是需求覆盖率,即测试所覆盖的需求数量与总需求数量的比值。视需求粒度的不同,需求覆盖率的具体表现也有不同。例如,系统测试针对的是比较粗的需求,而功能测试针对的是比较细的需求。当然,它们的本质是一致的。
如何度量需求覆盖率呢?通常没有现成的工具可以使用,而需要依赖人工计算,尤其是需要依赖人工去标记每个测试用例和需求之间的映射关系。
对于代码覆盖率来说,广为诟病的一点就是 100% 的代码覆盖率并不能说明代码就被完全覆盖没有遗漏了。因为代码的执行顺序和函数的参数值,都可能是千变万化的。一种情况被覆盖到,不代表所有情况被覆盖到。
对于需求覆盖率来说,100% 的覆盖率也不能说“万事大吉”。因为需求可能有遗漏或存在缺陷,测试用例与需求之间的映射关系,尤其是用例是否真正能够覆盖对应的测试需求,也可能是存在疑问的。
总结
适用于不同的场景,有各自的优势与不足。需要注意的是,它们不是互相排斥,而是相互补充的。
关于测试覆盖率,最重要的一点应该是迈出第一步,即有意识地去收集这种数据。没有覆盖率数据,测试工作会有点像在“黑灯瞎火”中走路。有了覆盖率数据,并持续监测,利用和改进这个数据,才是一条让测试工作越来越好的光明大道。
是不是所有代码都要有测试用例支持呢?
测试覆盖率还是要和测试成本结合起来,比如一个不会经常变的公共方法就尽可能的将测试覆盖率做到趋于 100%。而对于一个完整项目,前期先做最短的时间覆盖 80% 的测试用例,后期再慢慢完善。
经常做更改的活动页面我认为没必要必须趋近 100%,因为要不断的更改测试永用例,维护成本太高。
大多数情况下,将 100% 代码覆盖率作为目标并没有意义。
实现 100% 代码覆盖率不仅耗时,而且即使代码覆盖率达到 100%,测试也并非总能发现 bug。有时你可能还会做出错误的假设,当你调用一个 API 代码时,假定的是该 API 永远不会返回错误,然而当 API确实在生产环境中返回错误时,应用就崩溃了。
链接:https://juejin.cn/post/7257058135134568508
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
像黑客一样使用 Linux 命令行
前言##
之前看到一篇介绍 IntelliJ IDEA 配置的文章,它里面用的是 gif 动态图片进行展示,我觉得很不错。所以在我今天以及以后的博文中,我也会尽量使用 gif 动图进行展示。制作 gif 动图很花时间,为了把我的博客打造成精品我也是蛮拼的了。使用动图的优点是演示效果好,缺点是动图体积过大,为了降低图片体积,我只能降低分辨率了。
关于高效使用命令行这个话题,在网上已经是老生常谈了。而且本文也借鉴了 CSDN 极客头条中推荐了的《像黑客一样使用 Linux 命令行》。但是在本文中,也有不少我自己的观点和体会,比如我会提到有些快捷键要熟记,有些则完全不需要记,毕竟我们的记忆力也是有限的,我还会提到一些助记的方法。所以,本文绝对不是照本宣科,值得大家拥有,请大家一定记得点赞。
使用 tmux 复用控制台窗口##
高效使用命令行的首要原则就是要尽量避免非命令行的干扰,什么意思呢?就是说一但开启了一个控制台窗口,就尽量不要再在桌面上切换来切换去了,不要一会儿被别的窗口挡住控制台,一会儿又让别的窗口破坏了控制台的背景,最好是把控制台最大化或全屏,最好连鼠标都不要用。只有这样,才能达到比较高的效率。但是在实际工作中,我们又经常需要同时在多个控制台中进行工作,例如:在一个控制台中运行录制屏幕的命令,在另外一个控制台中工作,或者在一个控制台中工作,在另外一个控制台中阅读文档。如果既想在多个控制台中工作,又不想一大堆窗口挡来挡去、换来换去的话,就可以考虑试试 tmux 了。如下图:
tmux 的功能很多,什么 Session 啊、Detach 啊、Atach 啊什么的我们暂时不用去关心,只用好它的控制台窗口复用功能就行了。tmux 中有 window 和 pane 的概念,tmux 可以创建多个 window,这些 window 是不会互相遮挡的,每次只显示一个 window,其它的 window 会自动隐藏,可以使用快捷键在 window 之间切换。同时,可以把一个 window 切分成多个 pane,这些 pane 同时显示在屏幕上,可以使用快捷键在 pane 之间切换。
tmux 的快捷键很多,要想全面了解 tmux 的最好办法当然是阅读 tmux 的文档了,使用命令 man tmux 就可以了。但是我们只需要记住少数几个重要的快捷键就可以了,如下表:
| 快捷键 | 功能 |
|---|---|
| Ctrl+B c | 创建一个 window |
| Ctrl+B [n][p] | 切换到下一个窗口或上一个窗口 |
| Ctrl+B & | 关闭当前窗口 |
| Ctrl+B " | 将当前 window 或 pane 切分成两个 pane,上下排列 |
| Ctrl+B % | 将当前 window 或 pane 切分成两个 pane,左右排列 |
| Ctrl+B x | 关闭当前 pane |
| Ctrl+B [↑][↓][←][→] | 在 pane 之间移动 |
| Ctrl+[↑][↓][←][→] | 调整当前 pane 的大小,一次调整一格 |
| Alt+[↑][↓][←][→] | 调整当前 pane 的大小,一次调整五格 |
tmux 的快捷键比较特殊,除了调整 pane 大小的快捷键之外,其它的都是先按 Ctrl+B,再按一个字符。先按 Ctrl+B,再按 c,就会创建一个 window,这里 c 就是 create window。先按 Ctrl+B,再按 n 或者 p,就可以在窗口之间切换,它们是 next window 和 previous window 的意思。关闭窗口是先按 Ctrl+B,再按 &,这个只能死记。先按 Ctrl+B,再按 " ,表示上下拆分窗口,可以想象成单引号和双引号在键盘上是上下铺关系。先按 Ctrl+B,再按 % 表示左右拆分窗口,大概是因为百分数都是左右书写的吧。至于在 pane 之间移动和调整 pane 大小的方向键,就不用多说了吧。
在命令行中快速移动光标##
在命令行中输入命令时,经常要在命令行中移动光标。这个很简单嘛,使用左右方向键就可以了,但是有时候我们输入了很长一串命令,却突然要修改这个命令最开头的内容,如果使用向左的方向键一个字符一个字符地把光标移到命令的开头,是否太慢了呢?有时我们需要直接在命令的开头和结尾之间切换,有时又需要能够一个单词一个单词地移动光标,在命令行中,其实这都不是事儿。如下图:
这几种移动方式都是有快捷键的。其实一个字符一个字符地移动光标也有快捷键 Ctrl+B 和 Ctrl+F,但是这两个快捷键我们不需要记,有什么能比左右方向键更方便的呢?我们真正要记的是下面这几个:
| 快捷键 | 功能 |
|---|---|
| Ctrl + A | 将光标移动到命令行的开头 |
| Ctrl + E | 将光标移动到命令行的结尾 |
| Alt + B | 将光标向左移动一个单词 |
| Alt + F | 将光标向右移动一个单词 |
这几个快捷键太好记了,A 代表 ahead,E 代表 end,B 代表 back,F 代表 forward。为什么按单词移动光标的快捷键都是以 Alt 开头呢?那是因为按字符移动光标的快捷键把 Ctrl 占用了。但是按字符移动光标的快捷键我们用不到啊,因为我们有左右方向键啊。
在命令行中快速删除文本##
对输入的内容进行修改也是我们经常要干的事情,对命令行进行修改就涉及到先删除一部分内容,再输入新内容。我们碰到的情况是有时候只需要修改个别字符,有时候需要修改个别单词,而有时候,输入了半天的很长的一段命令,我们说不要就全都不要了,整行删除。常用的删除键当然是 BackSpace 和 Delete 啦,不过一次删除一个字符,是否太慢了呢?那么,请熟记以下几个快捷键吧:
| 快捷键 | 功能 |
|---|---|
| Ctrl + U | 删除从光标到行首的所有内容,如果光标在行尾,自然就整行都删除了啊 |
| Ctrl + K | 删除从光标到行尾的所有内容,如果光标在行首,自然也是整行都删除了啊 |
| Ctrl + W | 删除光标前的一个单词 |
| Alt + D | 删除光标后的一个单词 |
| Ctrl + Y | 将刚删除的内容粘贴到光标处,有时候删错了可以用这个快捷键恢复删除的内容 |
效果请看下图:
这几个快捷键也是蛮好记的,U 代表 undo,K 代表 kill,W 代表 word,D 代表 delete, Y 代表 yank。其中比较奇怪的是 Alt+D 又是以 Alt 开头的,那是因为 Ctrl+D 又被占用了。Ctrl+D 有几个意思,在编辑命令行的时候它代表删除一个字符,当然,这个快捷键其实我们用不到,因为 BackSpace 和 Delete 方便多了。在某些程序从 stdin 读取数据的时候,Ctrl+D 代表 EOF,这个我们偶尔会用到。
快速查看和搜索历史命令##
对于曾经运行过的命令,除非特别短,我们一般不会重复输入,从历史记录中找出来用自然要快得多。我们用得最多的就是 ↑ 和 ↓,特别是不久前才刚刚输入过的命令,使用 ↑ 向上翻几行就找到了,按一下 Enter 就执行,多舒服。但是有时候,明明记得是不久前才用过的命令,但是向上翻了半天也没找到,怎么办?那只好使用 history 命令来查看所有的历史记录了。历史记录又特别长,怎么办?可以使用 history | less 和 history | grep '...'。但是还有终极大杀招,那就是按 Ctrl+R 从历史记录中进行搜索。按了 Ctrl+R 之后,每输入一个字符,都会和历史记录中进行增量匹配,输入得越多,匹配越精确。当然,有时候含有相同搜索字符串的命令特别多,怎么办?继续按 Ctrl+R,就会继续搜索下一条匹配的历史记录。如下图:
这里,需要记住的命令和快捷键如下表:
| 命令或快捷键 | 功能 | |
|---|---|---|
| history | 查看历史记录 | |
| history | less | 分页查看历史记录 |
| history | grep '...' | 在历史记录中搜索匹配的命令,并显示 |
| Ctrl + R | 逆向搜索历史记录,和输入的字符进行增量匹配 | |
| Esc | 停止搜索历史记录,并将当前匹配的结果放到当前输入的命令行上 | |
| Enter | 停止搜索历史记录,并将当前匹配的结果立即执行 | |
| Ctrl + G | 停止搜索历史记录,并放弃当前匹配的结果 | |
| Alt + > | 将历史记录中的位置标记移动到历史记录的尾部 |
这里需要注意的是,当我们在历史记录中搜索的时候,是有位置标记的,Ctrl+R 是指从当前位置开始,逆向搜索,R 代表的是 reverse,每搜索一条记录,位置标记都会向历史记录的头部移动,下次搜索又从这里开始继续向头部搜索。所以,我们一定要记住快捷键 Alt+>,它可以把历史记录的位置标记还原。另外需要注意的是停止搜索历史记录的快捷键有三个,如果按 Enter 键,匹配的命令就立即执行了,如果你还想有修改这条命令的机会的话,一定不要按 Enter,而要按 Esc。如果什么都不想要,就按 Ctrl+G 吧,它会还你一个空白的命令行。
快速引用和修饰历史命令##
除了查看和搜索历史记录,我们还可以以更灵活的方式引用历史记录中的命令。常见的简单的例子有 !! 代表引用上一条命令,!$代表引用上一条命令的最后一个参数,^oldstring^newstring^代表将上一条命令中的 oldstring 替换成 newstring。这些操作是我们平时使用命令行的时候的一些常用技巧,其实它们的本质,是由 history 库提供的 history expansion 功能。Bash 使用了 history 库,所以也能使用这些功能。其完整的文档可以查看 man history 手册页。知道了 history expansion 的理论,我们还可以做一些更加复杂的操作,如下图:
引用和修饰历史命令的完整格式是这样的:
![!|[?]string|[-]number]:[n|x-y|^|$|*|n*|%]:[h|t|r|e|p|s|g]
可以看到,一个对历史命令的引用被 : 分为了三个部分,第一个部分决定了引用哪一条历史命令;第二部分决定了选取该历史命令中的第几个单词,单词是从0开始编号的,也就是说第0个单词代表命令本身,第1个到最后一个单词代表命令的参数;第三部分决定了对选取的单词如何修饰。下面我列出完整表格:
表格一、引用哪一条历史命令:
| 操作符 | 功能 |
|---|---|
| ! | 所有对历史命令的引用都以 ! 开始,除了 oldstringnewstring^ 形式的快速替换 |
| !n | 引用第 n 条历史命令 |
| !-n | 引用倒数第 n 条历史命令 |
| !! | 引用上一条命令,等于 !-1 |
| !string | 逆向搜索历史记录,第一条以 string 开头的命令 |
| !?string[?] | 逆向搜索历史记录,第一条包含 string 的命令 |
| oldstringnewstring^ | 对上一条命令进行快速替换,将 oldstring 替换为 newstring |
| !# | 引用当前输入的命令 |
表格二、选取哪一个单词:
| 操作符 | 功能 |
|---|---|
| 0 | 第0个单词,在 shell 中就是命令本身 |
| n | 第n个单词 |
| 第1个单词,使用 ^ 时可以省略前面的冒号 | |
| $ | 最后一个单词,使用 $ 是可以省略前面的冒号 |
| % | 和 ?string? 匹配的单词,可以省略前面的冒号 |
| x-y | 从第 x 个单词到第 y 个单词,-y 代表 0-y |
| * | 除第 0 个单词外的所有单词,等于 1-$ |
| x* | 从第 x 个单词到最后一个单词,等于 x-$,可以省略前面的冒号 |
| x- | 从第 x 个单词到倒数第二个单词 |
表格三、对选取的单词做什么修饰:
| 操作符 | 功能 |
|---|---|
| h | 选取路径开头,不要文件名 |
| t | 选取路径结尾,只要文件名 |
| r | 选取文件名,不要扩展名 |
| e | 选取扩展名,不要文件名 |
| s/oldstring/newstring/ | 将 oldstring 替换为 newstring |
| g | 全局替换,和 s 配合使用 |
| p | 只打印修饰后的命令,不执行 |
这几个命令其实挺好记的,h 代表 head,只要路径开头不要文件名,t 代表 tail,只要路径结尾的文件名,r 代表 realname,只要文件名不要扩展名,e 代表 extension,只要扩展名不要文件名,s 代表 substitute,执行替换功能,g 代表 global,全局替换,p 代表 print,只打印不执行。有时候光使用 :p 还不够,我们还可以把这个经过引用修饰后的命令直接在当前命令行上展开而不立即执行,它的快捷键是:
| 操作符 | 功能 |
|---|---|
| Ctrl + Alt + E | 在当前命令行上展开历史命令引用,展开后不立即执行,可以修改,按 Enter 后才会执行 |
| Alt + ^ | 和上面的功能一样 |
这两个快捷键,记住一个就行。这样,当我们对历史命令的引用修饰完成后,可以先展开来看一看,如果正确再执行。眼见为实嘛,反正我是每次都展开看看才放心。
录制屏幕并转换为 gif 动画图片##
最后,给大家展示我做 gif 动画图片的过程。我用到的软件有 recordmydesktop、mplayer 和 convert。使用 recordmydesktop 时需要一个单独的控制台来运行录像功能,录像完成后需要在该控制台中输入 Ctrl+C 终止录像。所以我用到了 tmux 。首先,我启动 tmux,然后运行 recordmydesktop --full-shots --fps 2 --no-sound --no-frame --delay 5 -o ~/图片/record_to_gif.ogv命令开始录像。由于 recordmydesktop 运行后不会马上退出,录像开始后,这个 window 就被占用了,所以我按 Ctrl+B c 让 tmux 再创建一个 window,然后在这个 window 中做的任何操作都会被录制下来。被录制的操作完成后,按 Ctrl+B n 切换到 recordmydesktop 命令运行的窗口,按 Ctrl+C 终止录像。然后,使用 mplayer -ao null record_to_gif.ogv -vo jpeg:outdir=./record_to_gif 将录制的视频提取为图片。当然,这时的图片比较多,为了缩减最后制作成的 gif 文件的大小,我们可以删掉其中无关紧要的帧,只留下关键帧。最后使用命令 convert -delay 100 record_to_gif/* record_to_gif.gif 生成 gif 动画。整个过程如下图:
最后生成的 gif 图片一般都比较大,往往超过 20M,如果时间长一点,超过 60M 也是常事儿。而制作成 gif 之前每一帧图片也就 200k 左右而已。我想可能是因为 gif 没有像 jpeg 或 png 这么好的压缩算法吧。gif 对付向量图效果很不错,对付照片和我这样的截图,压缩就有点力不从心了。博客园允许上传的图片每张不能超过 10M,所以,为了减小 gif 文件的体积,我只有用 convert -resize 1024x576 record_to_gif.gif record_to_gif_small.gif 命令将图片变小后再上传了。
总结##
使用 Linux 命令行的技巧还有很多,我这里不可能全部讲到。学习 Linux 命令行的最好办法当然还是使用 man bash 查看 Bash 的文档。但是我这里讲的内容已经可以显著提高使用命令行的效率了,至少这两天下来,我觉得我自己有了质的飞跃。另外,在博客中使用 gif 动态图片做示例,我觉得也是我写博客以来一个质的飞跃。希望大家喜欢。
链接:https://juejin.cn/post/7262396489116696632
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 混合架构方案探索
得益于 Flutter 优秀的跨平台表现,混合开发在如今的 App 中随处可见,如最近微信公布的小程序新渲染引擎 Skyline 发布正式版也在底层渲染上使用了 Flutter,号称渲染速度提升50%。
在现有的原生 App 中引入 Flutter 来开发不是一件简单的事,需要解决混合模式下带来的种种问题,如路由栈管理、包体积和内存突增等;另外还有一种特殊的情况,一个最初就由 Flutter 来开发的 App 也有可能在后期混入、原生 View 去开发。
我所在的团队目前就是处于这种情况,Flutter 目前在性能表现上面还不够完美,整体页面还不够流畅,并且在一些复杂的页面场景下会出现比较严重的发热行为,尽管目前 Flutter 团队发布了新的渲染引擎 impeller,它在 iOS 上表现优异,流畅度有了质的提升,但还是无法完全解决一些性能问题且 Android 下 impeller 也还没开发完成。
为了应对当下出现的困局和以后可能出现的未知问题,我们期望通过混合模式来扩宽更多的可能性。
路由管理
混合开发下最难处理的就是路由问题了,我们知道原生和 Flutter 都有各自的路由管理系统,在原生页面和 Flutter 页面穿插的情况下如何统一管理和互相交互是一大难点。目前比较流行的单引擎方案,代表框架是闲鱼团队出品flutter_boost;flutter 官方代表的多引擎解决方案 FlutterEngineGroup。
单引擎方案 flutter_boost
flutter_boost 通过复用 Engine 达到最小内存的目的
在引擎处理上,flutter_boost 定义了一个通用的 CacheId:"flutter_boost_default_engine",当原生需要跳转到 Flutter 页面时,通过FlutterEngineCache.getInstance().get(ENGINE_ID); 获取同一个 Engine,这样无论打开了多少如图中的 A、B、C 的 Flutter 页面时,都不会产生额外的Engine内存损耗。
public class FlutterBoost {
public static final String ENGINE_ID = "flutter_boost_default_engine";
...
}
另外,双端都注册了导航的接口,通过Channel来通知,用于请求路由变化、页面返回以及页面的生命周期处理等。在这种模式下,这一层Channel的接口处理是重点。
多引擎方案 FlutterEngineGroup
为了应对内存爆炸问题,官方对多引擎场景做了优化,FlutterEngineGroup应运而生,FlutterEngineGroup下的 Engine 共用一些通用的资源,例如GPU 上下文、线程快照等,生成额外的 Engine 时,号称内存占用缩小到 180k。这个程度,基本可以视为正常的损耗了。
以上图中的 B、C 页面为例,两者都是 Flutter 页面,在 FlutterEngineGroup 这种处理下,因为它们所在的 Engine 不是同一个,这会产生完全的隔离行为,也就是 B、C 页面使用不同的堆栈,处在不同的 Isolate 中,两者是无法直接进行交互的。
多引擎的优点是:它可以抹掉上图所示的 F、E、C 和 D、A 等内部路由,每次新增 Flutter 页面时,全部回调到原生,让原生生成新的 Engine 去承载页面,这样路由的管理全部由原生去处理,一个 Engine 只对应一个 Flutter 页面。
但它也会带来一些额外的处理,像上面提到的,处在不同 Engine 下的Flutter 页面之间是无法直接交互的,如果涉及到需要通知和交互的场景,还得通过原生去转发。
关于FlutterEngineGroup的更多信息,可以参考官方说明。
性能对比
官方号称 FlutterEngineGroup 创建新的 Engine 只会占用 180k 的内存,那么是不是真就如它所说呢?下面我们来针对上面这两种方案做一个内存占用测试
flutter_boost
测试机型:OPPO CPH2269
内存 dump 命令: adb shell dumpsys meminfo com.idlefish.flutterboost.example
| 条件 | PSS | RSS | 最大变化 |
|---|---|---|---|
| 1 Native | 88667 | 165971 | |
| +26105 | +28313 | +27M | |
| 1 Native + 1 Flutter | 114772 | 194284 | |
| -282 | +1721 | +1M | |
| 2 Native + 2 Flutter | 114490 | 196005 | |
| +5774 | +5992 | +6M | |
| 5 Native + 5 Flutter | 120264 | 201997 | |
| +13414 | +14119 | +13M | |
| 10 Native + 10 Flutter | 133678 | 216116 |
第一次加载 Flutter 页面时,增加 27M 左右内存,此后多开一个页面内存增加呈现从 1M -> 2M -> 2.6 M 这种越来越陡的趋势(数值只是参考,因为其中有 Native 页面,只看趋势变化上看)
FlutterEngineGroup
测试机型:OPPO CPH2269
内存 dump 命令: adb shell dumpsys meminfo dev.flutter.multipleflutters
| 条件 | PSS | RSS | 最大变化 |
|---|---|---|---|
| 1 Native | 45962 | 140817 | |
| +29822 | +31675 | +31M | |
| 1 Native + 1 Flutter | 75784 | 172492 | |
| -610 | +2063 | +2M | |
| 2 Native + 2 Flutter | 75174 | 174555 | |
| +7451 | +7027 | +3.7M | |
| 5 Native + 5 Flutter | 82625 | 181582 | |
| +8558 | +7442 | +8M | |
| 10 Native + 10 Flutter | 91183 | 189024 |
第一次加载 Flutter 页面时,增加 31M 左右内存,此后多开一个页面内存增加呈现从 1M -> 1.2M -> 1.6 M 这种越来越陡的趋势(数值只是参考,因为其中有 Native 页面,只看趋势变化上看)
结论
两个测试使用的是不同的 demo 代码,不能通过数值去得出孰优孰劣。但通过数值的表现,我们基本可以确认,两个方案都不会带来异常的内存暴涨,完全在可以接受的范围。
PlatformView
PlatformView 也可实现混合 UI,Flutter 中的 WebView 就是通过 PlatformView 这种方式引入的。
PlatformView 允许我们向 Flutter 界面中插入原生 View,在一个页面的最外层包裹一层 PlatformView,路由的管理都由 Flutter 来处理。这种方式下没有额外的 Engine 产生,是最简单的混合方式。
但它也有缺点,不适合主 Native 混 Flutter 的场景,而现在大多都是以主 Native 混 Flutter的场景为主。另外,PlatformView 因其底层实现,会出现兼容性问题,在一些机型下可能会出现键盘问题、闪烁或其它的性能开销,具体可看这篇介绍
数据共享
原生和 Flutter 使用不同的开发语言去开发,所以在一侧定义的数据结构对象和内存对象对方都无法感知,在数据同步和处理上必须使用其它手段。
MethodChannel
Flutter 开发者对 MethodChannel 一定不陌生,开发当中免不了跟原生交互,MethodChannel 是双向设计,即允许我们在 Flutter 中调用原生的方法,也允许我们在原生中调用 Flutter 的方法。对 Channel 不太了解的可以看一下官方文档,如文档中提到的,这个通道传输的过程中需要将数据编解码,对应的关系以kotlin为例(完整的映射可以查看文档):
Dart | Kotlin |
| -------------------------- | ----------- |
| null | null |
| bool | Boolean |
| int | Int |
| int, if 32 bits not enough | Long |
| double | Double |
| String | String |
| Uint8List | ByteArray |
| Int32List | IntArray |
| Int64List | LongArray |
| Float32List | FloatArray |
| Float64List | DoubleArray |
| List | List |
| Map | HashMap |
本地存储
这种方式比较容易理解,将本地存储视为中转站,Flutter中将数据操作存储到本地上,回到原生页面时在某个时机(如onResume)去查询本地数据库即可,反之亦然。
问题
不管是MethodChannel或是本地存储,都会面临一个问题:对象的数据结构是独立的,两边需要重复定义。比如我在 Flutter 中有一个 Student 对象,Android 端也要定义一个同样结构的 Student,这样才能方便操作,现在我将Student student转成Unit8List传到Android,Channel中解码成Kotlin能操作的ByteArray,再将ByteArray转译成Android中Student对象。
class Student {
String name;
int age;
Student(this.name, this.age);
}
对于这个问题最好的解决办法是使用DSL一类的框架,如Google的ProtoBuf,将同一份对象配置文件编译到不同的语言环境中,便能省去这部分双端重复定义的行为。
图片缓存
在内存方面,如果同样的图片在两边都加载时,会使得原生和 Flutter 都会产生一次缓存。在 Flutter 下默认就会缓存在ImageCache中,原生下不同的框架由不同的对象负责,为了去掉重复的图片缓存,势必要统一图片的加载管理。
阿里的方案也是如此,通过外接原生图片库,共享图片的本地文作缓存和内存缓存。它的实现思路是通过自定义ImageProvider和Codec,对接外部图库,获取到图片数据做解析,对接的处理是通过扩展 Flutter Engine。
如果期望不修改Flutter Engine,也可通过外接纹理的方式去处理。通过PlatformChannel去请求原生,使到图片的外接纹理数据,通过TextTure组件展示图片。
// 自定义 ImageProvider 中,通过 Channel 去请求 textureId
var id = await _channel.invokeMethod('newTexture', {
"imageUrl": imageUrl,
"width": width ?? 0,
"height": height ?? 0,
"minWidth": constraints.minWidth,
"minHeight": constraints.minHeight,
"maxWidth": constraints.maxWidth,
"maxHeight": constraints.maxHeight,
"cacheKey": cacheKey,
"fit": fit.index,
"cacheOriginFile": cacheOriginFile,
});
// ImageWidget 中展示时通过 textureId 去显示图片
SizedBox(
width: width,
heigt: height,
child: Texture(
filterQuality: FilterQuality.high,
textureId: _imageProvider.textureId.value,
),
)
总结
不同业务对于混合的程度和要求有所要求,并没有万能的方案。比如我团队的情况就是主Flutter混原生,在路由管理上我选择了PlatformView这种处理模式,这种方式更容易开发和维护,后期如果发现有兼容性问题,也可过渡到flutter_boost和FlutterEngineGroup上。
链接:https://juejin.cn/post/7262616799219482681
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
7个你应该知道的Glide的使用技巧
对于Android开发者来说,Glide是最常使用的库。这里介绍了开发过程中,7个使用Glide的技巧。
不要使用wrap_content
不清楚你是否这样使用过,把 ImageView 的宽和高设置成 wrap_content,并通过Glide来加载图片
<ImageView
android:id="@+id/image"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>
Glide.with(context)
.load(url)
.into(image)
为什么不建议把ImageView设置成 wrap_content,我们看一下Glide的文档是怎么说的(文档地址中文地址 最新英文地址):
文档上写得很明显,在某些情况下会使用屏幕的尺寸代替 wrap_content,这可能导致原来的小图片变成大图,Glide transform 问题分析这篇文章就介绍了这种问题。为了避免这种情况发生,我们最好是不要使用 wrap_content。当然如果你实在是需要使用 wrap_content,你可以按照Glide的建议,使用Target.SIZE_ORIGINAL。
需要注意的是:使用Target.SIZE_ORIGINAL 在加载大图时可能造成oom,因此你需要确保加载的图片不会太大。
自定义内存缓存大小
在某些情况下,我们可能需要自定义Glide的内存缓存大小和Bitmap池的大小,比如图片显示占大头的app,就希望Glide的图片缓存大一些。Glide内部使用MemorySizeCalculator类来决定内存缓存和Bitmap池的大小。
@GlideModule
class MyGlideModel: AppGlideModule() {
override fun applyOptions(context: Context, builder: GlideBuilder) {
super.applyOptions(context, builder)
//通过MemorySizeCalculator获取MemoryCache和BitmapPool的size大小
val calculator = MemorySizeCalculator.Builder(context).build()
val defaultMemoryCacheSize = calculator.memoryCacheSize
val defaultBitmapPoolSize = calculator.bitmapPoolSize
//根据业务计算出需要的缓存大小,这里简化处理,都乘以1.5
val customMemoryCacheSize = (1.5 * defaultMemoryCacheSize).toLong()
val customBitmapPoolSize = (1.5 * defaultBitmapPoolSize).toLong()
//设置缓存
builder.setMemoryCache(LruResourceCache(customMemoryCacheSize))
builder.setBitmapPool(LruBitmapPool(customBitmapPoolSize))
}
}
memoryCache 和 BitmapPool 的区别:
- memoryCache:通过key-value才缓存数据,缓存之前用过的Bitmap
- BitmapPool:重用Bitmap对象的对象池,根据Bitmap的宽高来复用。复用的原理可以看Bitmap全解析
具体区别见What is difference between MemoryCacheSize and BitmapPoolSize in Glide
自定义磁盘缓存
Glide 使用 DiskLruCacheWrapper 作为默认的 磁盘缓存 。 DiskLruCacheWrapper 是一个使用 LRU 算法的固定大小的磁盘缓存。默认磁盘大小为 250 MB ,位置是在应用的 缓存文件夹 中的一个 特定目录 。我们也可以自定义磁盘缓存,代码如下:
@GlideModule
class MyGlideModel: AppGlideModule() {
override fun applyOptions(context: Context, builder: GlideBuilder) {
super.applyOptions(context, builder)
val size: Long = 1024 * 1024 * 100 //100MB
builder.setDiskCache(InternalCacheDiskCacheFactory(context, cacheFolderName, size))
}
}
牢记在onLoadCleared释放图片资源
如上图Glide的官方文档所示,我们在使用Target时,必须在重新绘制(通常是View)或改变其可见性之前,你必须确保在onResourceReady中收到的任何当前Drawable不再被使用。这是因为Glide内部缓存在内存不足或者主动回收Glide.get(context).clearMemory()时,会回收Bitmap,如果此时ImageView还使用被回收的Bitmap,就会发生 trying to use a recycled bitmap 的错误。
解决办法是不再使用在onResourceReady中获取的Bitmap,代码如下:
Glide.with(this)
.load(Url)
.into(object : CustomTarget<Bitmap>(width, height) {
override fun onResourceReady(
resource: Bitmap,
transition: Transition<in Bitmap>?,
) {
mBitmap = resource
}
override fun onLoadCleared(placeholder:Drawable?){
mBitmap = null
}
})
优先加载指定图片
如上图所示,当一个页面有多个图片时,我们希望某些图片优先被加载出来(这个界面里面是上面的一拳超人的封面),某些图片后加载,比如这个界面里的互动点评的用户头像列表。Glide提供了优先级来解决这个问题,它的优先级如下:
- Priority.LOW
- Priority.NORMAL
- Priority.HIGH
- Priority.IMMEDIATE
使用代码如下:
Glide
.with(context)
.load("url")
.priority(Priority.LOW)//底优先级的图片
.into(imageView);
Glide
.with(context)
.load("url")
.priority(Priority.HIGH)//高优先级的图片
.into(imageView);
注意:优先级高的加载任务会尽量首先启动,但是无法保证加载开始或完成的顺序。
使用Glide前,先判断页面是否回收
一般我们会通过网络请求来获取图片的链接,再通过Glide来加载图片,代码如下:
service?.fetchUserProfile(id) { result, errMsg, icon ->
if (result == 200) {
Glide.with(context)
.load(icon)
.into(view)
}
}
但是这里有个问题,当界面被destory后,这个网络请求刚好成功了,调用Glide.with就会发生 You cannot start a load for a destroyed activity错误。解决方法是在调用Glide.with前先判断,代码如下:
service?.fetchUserProfile(id) { result, errMsg, icon ->
if (result == 200) {
if (context is FragmentActivity) {
if ((context as FragmentActivity).isFinishing || (context as FragmentActivity).isDestroyed) {
return
}
}
Glide.with(context)
.load(icon)
.into(view)
}
}
加载大图时使用skipMemoryCache
当我们使用Glide加载大图时,应该避免使用内存缓存,如果不好好处理可能发生oom。在Glide中,我们可以使用skipMemoryCache来跳过内存缓存。代码如下:
Glide.with(context)
.load(url)
.skipMemoryCache(true)
.into(imageview)
与skipMemoryCache对应的是 onlyRetrieveFromCache,它只从缓存中获取对象,不会从网络或者本地缓存中就直接加载失败。
链接:https://juejin.cn/post/7215977393696309307
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
RecyclerView刷新后定位问题
问题描述
做需求开发时,遇到RecyclerView刷新时,通常会使用notifyItemXXX方法去做局部刷新。但是刷新后,有时会遇到RecyclerView定位到我们不希望的位置,这时候就会很头疼。这周有时间深入了解了下RecyclerView的源码,大致梳理清楚刷新后位置跳动的原因了。
原因分析
先简单描述下RecyclerView在notify后的过程:
- 根据是否是全量刷新来选择触发RecyclerView.RecyclerViewDataObserver的onChanged方法或onItemRangeXXX方法
onChanged会直接调用requestlayout来重新layuout。 onItemRangeXXX会先把刷新数据保存到mAdapterHelper中,然后再调用requestlayout 2. 进入dispatchLayout流程 这一步分为三个步骤:
- dispatchLayoutStep1:处理adapter的更新、决定哪些view执行动画、保存view的信息
- dispatchLayoutStep2:真正执行childView的layout操作
- dispatchLayoutStep3:触发动画、保存状态、清理信息
需要注意的是,在onMeasure的过程中,如果传入的measureMode不是exactly,会去调用dispatchLayoutStep1和dispatchLayoutStep2从而取得真正需要的宽高。 所以在dispatchLayout会先判断是否需要重新执行dispatchLayoutStep1和dispatchLayoutStep2
重点分析dispatchLayoutStep2这一步: 核心操作在 mLayout.onLayoutChildren(mRecycler, mState)这一行。以LinearLayoutManager为例继续往下挖:
public void onLayoutChildren(RecyclerView.Recycler recycler, RecyclerView.State state) {
...
final View focused = getFocusedChild();
if (!mAnchorInfo.mValid || mPendingScrollPosition != RecyclerView.NO_POSITION
|| mPendingSavedState != null) {
mAnchorInfo.reset();
mAnchorInfo.mLayoutFromEnd = mShouldReverseLayout ^ mStackFromEnd;
// 关键步骤1,寻找锚点View位置
updateAnchorInfoForLayout(recycler, state, mAnchorInfo);
mAnchorInfo.mValid = true;
} else if (focused != null && (mOrientationHelper.getDecoratedStart(focused)
>= mOrientationHelper.getEndAfterPadding()
|| mOrientationHelper.getDecoratedEnd(focused)
<= mOrientationHelper.getStartAfterPadding())) {
mAnchorInfo.assignFromViewAndKeepVisibleRect(focused, getPosition(focused));
}
...
// fill towards end
updateLayoutStateToFillEnd(mAnchorInfo);
mLayoutState.mExtraFillSpace = extraForEnd;
//关键步骤2,从锚点View位置往后填充
fill(recycler, mLayoutState, state, false);
endOffset = mLayoutState.mOffset;
final int lastElement = mLayoutState.mCurrentPosition;
if (mLayoutState.mAvailable > 0) {
//如果锚点位置后面数据不足,无法填满剩余的空间,那把剩余空间加到顶部
extraForStart += mLayoutState.mAvailable;
}
// fill towards start
updateLayoutStateToFillStart(mAnchorInfo);
mLayoutState.mExtraFillSpace = extraForStart;
mLayoutState.mCurrentPosition += mLayoutState.mItemDirection;
//关键步骤3,从锚点View位置向前填充
fill(recycler, mLayoutState, state, false);
startOffset = mLayoutState.mOffset;
if (mLayoutState.mAvailable > 0) {
//如果锚点View位置前面数据不足,那把剩余空间加到尾部再做一次尝试
extraForEnd = mLayoutState.mAvailable;
// start could not consume all it should. add more items towards end
updateLayoutStateToFillEnd(lastElement, endOffset);
mLayoutState.mExtraFillSpace = extraForEnd;
fill(recycler, mLayoutState, state, false);
endOffset = mLayoutState.mOffset;
}
}
先解释一下锚点View,锚点View在一次layout过程中的位置不会发生变化,即之前在哪里显示,这次layout完还在哪,从视觉上看没有位移。
总结一下,mLayout.onLayoutChildren主要做了以下几件事:
- 调用updateAnchorInfoForLayout方法确定锚点view位置
- 从锚点view后面的位置开始填充,直到后面空间被填满或者已经遍历到最后一个itemView
- 从锚点view前面的位置开始填充,直到空间被填满或者遍历到indexe为0的itemView
- 经过第三步后仍有剩余空间,则把剩余空间加到尾部再做一次尝试
所以回到一开始的问题,RecyclerView在notify之后位置跳跃的关键在于锚点View的确定,也就是updateAnchorInfoForLayout方法,所以下面重点看下这个方法:
private void updateAnchorInfoForLayout(RecyclerView.Recycler recycler, RecyclerView.State state,
AnchorInfo anchorInfo) {
if (updateAnchorFromPendingData(state, anchorInfo)) {
if (DEBUG) {
Log.d(TAG, "updated anchor info from pending information");
}
return;
}
if (updateAnchorFromChildren(recycler, state, anchorInfo)) {
if (DEBUG) {
Log.d(TAG, "updated anchor info from existing children");
}
return;
}
if (DEBUG) {
Log.d(TAG, "deciding anchor info for fresh state");
}
anchorInfo.assignCoordinateFromPadding();
anchorInfo.mPosition = mStackFromEnd ? state.getItemCount() - 1 : 0;
}
这个方法比较短,所以代码全贴出来了。如果是调用了scrollToPosition后的刷新,会通过updateAnchorFromPendingData方法确定锚点View位置,否则调用updateAnchorFromChildren来计算:
private boolean updateAnchorFromChildren(RecyclerView.Recycler recycler,
RecyclerView.State state, AnchorInfo anchorInfo) {
if (getChildCount() == 0) {
return false;
}
final View focused = getFocusedChild();
if (focused != null && anchorInfo.isViewValidAsAnchor(focused, state)) {
anchorInfo.assignFromViewAndKeepVisibleRect(focused, getPosition(focused));
return true;
}
if (mLastStackFromEnd != mStackFromEnd) {
return false;
}
View referenceChild =
findReferenceChild(
recycler,
state,
anchorInfo.mLayoutFromEnd,
mStackFromEnd);
if (referenceChild != null) {
anchorInfo.assignFromView(referenceChild, getPosition(referenceChild));
...
return true;
}
return false;
}
代码比较简单,如果有焦点View,并且焦点View没被remove,则使用焦点View作为锚点。否则调用findReferenceChild来查找:
View findReferenceChild(RecyclerView.Recycler recycler, RecyclerView.State state,
boolean layoutFromEnd, boolean traverseChildrenInReverseOrder) {
ensureLayoutState();
// Determine which direction through the view children we are going iterate.
int start = 0;
int end = getChildCount();
int diff = 1;
if (traverseChildrenInReverseOrder) {
start = getChildCount() - 1;
end = -1;
diff = -1;
}
int itemCount = state.getItemCount();
final int boundsStart = mOrientationHelper.getStartAfterPadding();
final int boundsEnd = mOrientationHelper.getEndAfterPadding();
View invalidMatch = null;
View bestFirstFind = null;
View bestSecondFind = null;
for (int i = start; i != end; i += diff) {
final View view = getChildAt(i);
final int position = getPosition(view);
final int childStart = mOrientationHelper.getDecoratedStart(view);
final int childEnd = mOrientationHelper.getDecoratedEnd(view);
if (position >= 0 && position < itemCount) {
if (((RecyclerView.LayoutParams) view.getLayoutParams()).isItemRemoved()) {
if (invalidMatch == null) {
invalidMatch = view; // removed item, least preferred
}
} else {
// b/148869110: usually if childStart >= boundsEnd the child is out of
// bounds, except if the child is 0 pixels!
boolean outOfBoundsBefore = childEnd <= boundsStart && childStart < boundsStart;
boolean outOfBoundsAfter = childStart >= boundsEnd && childEnd > boundsEnd;
if (outOfBoundsBefore || outOfBoundsAfter) {
// The item is out of bounds.
// We want to find the items closest to the in bounds items and because we
// are always going through the items linearly, the 2 items we want are the
// last out of bounds item on the side we start searching on, and the first
// out of bounds item on the side we are ending on. The side that we are
// ending on ultimately takes priority because we want items later in the
// layout to move forward if no in bounds anchors are found.
if (layoutFromEnd) {
if (outOfBoundsAfter) {
bestFirstFind = view;
} else if (bestSecondFind == null) {
bestSecondFind = view;
}
} else {
if (outOfBoundsBefore) {
bestFirstFind = view;
} else if (bestSecondFind == null) {
bestSecondFind = view;
}
}
} else {
// We found an in bounds item, greedily return it.
return view;
}
}
}
}
// We didn't find an in bounds item so we will settle for an item in this order:
// 1. bestSecondFind
// 2. bestFirstFind
// 3. invalidMatch
return bestSecondFind != null ? bestSecondFind :
(bestFirstFind != null ? bestFirstFind : invalidMatch);
}
解释一下,查找过程会遍历RecyclerView当前可见的所有childView,找到第一个没被notifyRemove的childView就停止查找,否则会把遍历过程中找到的第一个被notifyRemove的childView作为锚点View返回。
这里需要注意final int position = getPosition(view);这一行代码,getPosition返回的是经过校正的最终position,如果ViewHolder被notifyRemove了,这里的position会是0,所以如果可见的childView都被remove了,那最终定位的锚点View是第一个childView,锚点的position是0,偏移量offset是这个被删除的childView的top值,这就会导致后面fill操作时从位置0开始填充,先把position=0的view填充到偏移量offset的位置,再往后依次填满剩余空间,这也是导致画面上的跳动的根本原因。
链接:https://juejin.cn/post/7259358063517515834
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
如何开启一个线程,开启大量线程会有什么问题,如何优化?(美团面试问道)
这是我一个朋友在美团面试中遇到的一个问题,今天拿出来解析一下
正文
如何开启一个线程
如何开启一个线程,再JDK中的说明为:
/**
* ...
* There are two ways to create a new thread of execution. One is to
* declare a class to be a subclass of <code>Thread</code>.
* The other way to create a thread is to declare a class that
* implements the <code>Runnable</code> interface.
* ....
*/
public class Thread implements Runnable{
}
Thread源码的类描述中有这样一段,翻译一下,只有两种方法去创建一个执行线程,一种是声明一个Thread的子类,另一种是创建一个类去实现Runnable接口。
继承Thread类
public class ThreadUnitTest {
@Test
public void testThread() {
//创建MyThread实例
MyThread myThread = new MyThread();
//调用线程start的方法,进入可执行状态
myThread.start();
}
//继承Thread类,重写内部run方法
static class MyThread extends Thread {
@Override
public void run() {
System.out.println("test MyThread run");
}
}
}
实现Runnable接口
public class ThreadUnitTest {
@Test
public void testRunnable() {
//创建MyRunnable实例,这其实只是一个任务,并不是线程
MyRunnable myRunnable = new MyRunnable();
//交给线程去执行
new Thread(myRunnable).start();
}
//实现Runnable接口,并实现内部run方法
static class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println("test MyRunnable run");
}
}
}
实现Callable
其实实现Callback接口创建线程的方式,归根到底就是Runnable方式,只不过它是在Runnable的基础上又增加了一些能力,例如取消任务执行等。
public class ThreadUnitTest {
@Test
public void testCallable() {
//创建MyCallable实例,需要与FutureTask结合使用
MyCallable myCallable = new MyCallable();
//创建FutureTask,与Runnable一样,也只能算是个任务
FutureTask<String> futureTask = new FutureTask<>(myCallable);
//交给线程去执行
new Thread(futureTask).start();
try {
//get方法获取任务返回值,该方法是阻塞的
String result = futureTask.get();
System.out.println(result);
} catch (ExecutionException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//实现Callable接口,并实现call方法,不同之处是该方法有返回值
static class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(10000);
return "test MyCallable run";
}
}
}
Callable的方式必须与FutureTask结合使用,我们看看FutureTask的继承关系:
//FutureTask实现了RunnableFuture接口
public class FutureTask<V> implements RunnableFuture<V> {
}
//RunnableFuture接口继承Runnable和Future接口
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
开启大量线程会引起什么问题
在Java中,调用Thread的start方法后,该线程即置为就绪状态,等待CPU的调度。这个流程里有两个关注点需要去理解。
start内部怎样开启线程的?看看start方法是怎么实现的。
// Thread类的start方法
public synchronized void start() {
// 一系列状态检查
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
//调用start0方法,真正启动java线程的地方
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}
//start0方法是一个native方法
private native void start0();
JVM中,native方法与java方法存在一个映射关系,Java中的start0对应c层的JVM_StartThread方法,我们继续看一下:
JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread))
JVMWrapper("JVM_StartThread");
JavaThread *native_thread = NULL;
bool throw_illegal_thread_state = false;
{
MutexLocker mu(Threads_lock);
// 判断Java线程是否已经启动,如果已经启动过,则会抛异常。
if (java_lang_Thread::thread(JNIHandles::resolve_non_null(jthread)) != NULL) {
throw_illegal_thread_state = true;
} else {
//如果没有启动过,走到这里else分支,去创建线程
//分配c++线程结构并创建native线程
jlong size =
java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread));
size_t sz = size > 0 ? (size_t) size : 0;
//注意这里new JavaThread
native_thread = new JavaThread(&thread_entry, sz);
if (native_thread->osthread() != NULL) {
native_thread->prepare(jthread);
}
}
}
......
Thread::start(native_thread);
走到这里发现,Java层已经过渡到native层,但远远还没结束:
JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz) :
Thread()
{
initialize();
_jni_attach_state = _not_attaching_via_jni;
set_entry_point(entry_point);
os::ThreadType thr_type = os::java_thread;
thr_type = entry_point == &compiler_thread_entry ? os::compiler_thread :
os::java_thread;
//根据平台,调用create_thread,创建真正的内核线程
os::create_thread(this, thr_type, stack_sz);
}
bool os::create_thread(Thread* thread, ThreadType thr_type,
size_t req_stack_size) {
......
pthread_t tid;
//利用pthread_create()来创建线程
int ret = pthread_create(&tid, &attr, (void* (*)(void*)) thread_native_entry, thread);
......
return true;
}
pthread_create方法,第三个参数表示启动这个线程后要执行的方法的入口,第四个参数表示要给这个方法传入的参数:
static void *thread_native_entry(Thread *thread) {
......
//thread_native_entry方法的最下面的run方法,这个thread就是上面传递下来的参数,也就是JavaThread
thread->run();
......
return 0;
}
终于开始执行run方法了:
//thread.cpp类
void JavaThread::run() {
......
//调用内部thread_main_inner
thread_main_inner();
}
void JavaThread::thread_main_inner() {
if (!this->has_pending_exception() &&
!java_lang_Thread::is_stillborn(this->threadObj())) {
{
ResourceMark rm(this);
this->set_native_thread_name(this->get_thread_name());
}
HandleMark hm(this);
//注意:内部通过JavaCalls模块,调用了Java线程要执行的run方法
this->entry_point()(this, this);
}
DTRACE_THREAD_PROBE(stop, this);
this->exit(false);
delete this;
}
一条U字型代码调用链至此结束:
- Java中调用Thread的star方法,通过JNI方式,调用到native层。
- native层,JVM通过pthread_create方法创建一个系统内核线程,并指定内核线程的初始运行地址,即一个方法指针。
- 在内核线程的初始运行方法中,利用JavaCalls模块,回调到java线程的run方法,开始java级别的线程执行。
线程如何调度
计算机的世界里,CPU会分为若干时间片,通过各种算法分配时间片来执行任务,有耳熟能详时间片轮转调度算法、短进程优先算法、优先级算法等。当一个任务的时间片用完,就会切换到另一个任务。在切换之前会保存上一个任务的状态,当下次再切换到该任务,就会加载这个状态, 这就是所谓的线程的上下文切换。很明显,上下文的切换是有开销的,包括很多方面,操作系统保存和恢复上下文的开销、线程调度器调度线程的开销和高速缓存重新加载的开销等。
经过上面两个理论基础的回顾,开启大量线程引起的问题,总结起来,就两个字——开销。
消耗时间:线程的创建和销毁都需要时间,当数量太大的时候,会影响效率。 消耗内存:创建更多的线程会消耗更多的内存,这是毋庸置疑的。线程频繁创建与销毁,还有可能引起内存抖动,频繁触发GC,最直接的表现就是卡顿。长而久之,内存资源占用过多或者内存碎片过多,系统甚至会出现OOM。 消耗CPU。在操作系统中,CPU都是遵循时间片轮转机制进行处理任务,线程数过多,必然会引起CPU频繁的进行线程上下文切换。这个代价是昂贵的,某些场景下甚至超过任务本身的消耗。
如何优化
线程的本质是为了执行任务,在计算机的世界里,任务分大致分为两类,CPU密集型任务和IO密集型任务。
CPU密集型任务,比如公式计算、资源解码等。这类任务要进行大量的计算,全都依赖CPU的运算能力,持久消耗CPU资源。所以针对这类任务,其实不应该开启大量线程。因为线程越多,花在线程切换的时间就越多,CPU执行效率就越低,一般CPU密集型任务同时进行的数量等于CPU的核心数,最多再加个1。 IO密集型任务,比如网络读写、文件读写等。这类任务不需要消耗太多的CPU资源,绝大部分时间是在IO操作上。所以针对这类任务,可以开启大量线程去提高CPU的执行效率,一般IO密集型任务同时进行的数量等于CPU的核心数的两倍。 另外,在无法避免,必须要开启大量线程的情况下,我们也可以使用线程池代替直接创建线程的做法进行优化。线程池的基本作用就是复用已有的线程,从而减少线程的创建,降低开销。在Java中,线程池的使用还是非常方便的,JDK中提供了现成的ThreadPoolExecutor类,我们只需要按照自己的需求进行相应的参数配置即可,这里提供一个示例。
/**
* 线程池使用
*/
public class ThreadPoolService {
/**
* 线程池变量
*/
private ThreadPoolExecutor mThreadPoolExecutor;
private static volatile ThreadPoolService sInstance = null;
/**
* 线程池中的核心线程数,默认情况下,核心线程一直存活在线程池中,即便他们在线程池中处于闲置状态。
* 除非我们将ThreadPoolExecutor的allowCoreThreadTimeOut属性设为true的时候,这时候处于闲置的核心 * 线程在等待新任务到来时会有超时策略,这个超时时间由keepAliveTime来指定。一旦超过所设置的超时时间,闲 * 置的核心线程就会被终止。
* CPU密集型任务 N+1 IO密集型任务 2*N
*/
private final int CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() + 1;
/**
* 线程池中所容纳的最大线程数,如果活动的线程达到这个数值以后,后续的新任务将会被阻塞。包含核心线程数+非* * 核心线程数。
*/
private final int MAXIMUM_POOL_SIZE = Math.max(CORE_POOL_SIZE, 10);
/**
* 非核心线程闲置时的超时时长,对于非核心线程,闲置时间超过这个时间,非核心线程就会被回收。
* 只有对ThreadPoolExecutor的allowCoreThreadTimeOut属性设为true的时候,这个超时时间才会对核心线 * 程产生效果。
*/
private final long KEEP_ALIVE_TIME = 2;
/**
* 用于指定keepAliveTime参数的时间单位。
*/
private final TimeUnit UNIT = TimeUnit.SECONDS;
/**
* 线程池中保存等待执行的任务的阻塞队列
* ArrayBlockingQueue 基于数组实现的有界的阻塞队列
* LinkedBlockingQueue 基于链表实现的阻塞队列
* SynchronousQueue 内部没有任何容量的阻塞队列。在它内部没有任何的缓存空间
* PriorityBlockingQueue 具有优先级的无限阻塞队列。
*/
private final BlockingQueue<Runnable> WORK_QUEUE = new LinkedBlockingDeque<>();
/**
* 线程工厂,为线程池提供新线程的创建。ThreadFactory是一个接口,里面只有一个newThread方法。 默认为DefaultThreadFactory类。
*/
private final ThreadFactory THREAD_FACTORY = Executors.defaultThreadFactory();
/**
* 拒绝策略,当任务队列已满并且线程池中的活动线程已经达到所限定的最大值或者是无法成功执行任务,这时候 * ThreadPoolExecutor会调用RejectedExecutionHandler中的rejectedExecution方法。
* CallerRunsPolicy 只用调用者所在线程来运行任务。
* AbortPolicy 直接抛出RejectedExecutionException异常。
* DiscardPolicy 丢弃掉该任务,不进行处理。
* DiscardOldestPolicy 丢弃队列里最近的一个任务,并执行当前任务。
*/
private final RejectedExecutionHandler REJECTED_HANDLER = new ThreadPoolExecutor.AbortPolicy();
private ThreadPoolService() {
}
/**
* 单例
* @return
*/
public static ThreadPoolService getInstance() {
if (sInstance == null) {
synchronized (ThreadPoolService.class) {
if (sInstance == null) {
sInstance = new ThreadPoolService();
sInstance.initThreadPool();
}
}
}
return sInstance;
}
/**
* 初始化线程池
*/
private void initThreadPool() {
try {
mThreadPoolExecutor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAXIMUM_POOL_SIZE,
KEEP_ALIVE_TIME,
UNIT,
WORK_QUEUE,
THREAD_FACTORY,
REJECTED_HANDLER);
} catch (Exception e) {
LogUtil.printStackTrace(e);
}
}
/**
* 向线程池提交任务,无返回值
*
* @param runnable
*/
public void post(Runnable runnable) {
mThreadPoolExecutor.execute(runnable);
}
/**
* 向线程池提交任务,有返回值
*
* @param callable
*/
public <T> Future<T> post(Callable<T> callable) {
RunnableFuture<T> task = new FutureTask<T>(callable);
mThreadPoolExecutor.execute(task);
return task;
}
}链接:https://juejin.cn/post/7260796067447504954
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
线程通讯的三种方法!通俗易懂
线程通信是指多个线程之间通过某种机制进行协调和交互,例如,线程等待和通知机制就是线程通讯的主要手段之一。
在 Java 中,线程等待和通知的实现手段有以下几种方式:
Object 类下的 wait()、notify() 和 notifyAll() 方法; Condition 类下的 await()、signal() 和 signalAll() 方法; LockSupport 类下的 park() 和 unpark() 方法。
为什么一个线程等待和通知机制就需要这么多的实现方式呢?别着急,咱们先来看实现,再来说原因。
一、wait/notify/notifyAll
Object 类的方法说明:
wait():让当前线程处于等待状态,并释放当前拥有的锁; notify():随机唤醒等待该锁的其他线程,重新获取锁,并执行后续的流程,只能唤醒一个线程; notifyAll():唤醒所有等待该锁的线程(锁只有一把,虽然所有线程被唤醒,但所有线程需要排队执行)。
示例代码如下:
Object lock = new Object();
// 创建线程并执行
new Thread(() -> {
System.out.println("线程1:开始执行");
synchronized (lock) {
try {
System.out.println("线程1:进入等待");
lock.wait();
System.out.println("线程1:继续执行");
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("线程1:执行完成");
}
}).start();
Thread.sleep(1000);
synchronized (lock) {
// 唤醒线程
System.out.println("执行 notifyAll()");
lock.notifyAll();
}
二、await/signal/signalAll
Condition 类的方法说明:
await():对应 Object 的 wait() 方法,线程等待; signal():对应 Object 的 notify() 方法,随机唤醒一个线程; signalAll():对应 Object 的 notifyAll() 方法,唤醒所有线程。
示例代码如下:
// 创建 Condition 对象
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition(); // lock 下可创建多个 Condition
// 加锁
lock.lock();
try {
// 业务方法......
// 1.进入等待状态
condition.await();
// 2.唤醒操作
condition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
三、park/unpark
LockSupport 类的方法说明:
LockSupport.park():休眠当前线程。 LockSupport.unpark(线程对象):唤醒某一个指定的线程。
PS:LockSupport 无需配锁(synchronized 或 Lock)一起使用。
示例代码如下:
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
LockSupport.park();
System.out.println("线程1");
}, "线程1");
t1.start();
Thread t2 = new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("唤醒线程1");
LockSupport.unpark(t1);
}, "线程2");
t2.start();
}
四、小结
为什么一个线程等待和唤醒的功能需要这么多的实现呢?
LockSupport 存在的必要性:前两种方法 notify 方法以及 signal 方法都是随机唤醒,如果存在多个等待线程的话,可能会唤醒不应该唤醒的线程,因此有 LockSupport 类下的 park 和 unpark 方法指定唤醒线程是非常有必要的。 Condition 存在的必要性:Condition 相比于 Object 类的 wait 和 notify/notifyAll 方法,前者可以创建多个等待集,例如,我们可以创建一个生产者等待唤醒对象,和一个消费者等待唤醒对象,这样我们就能实现生产者只能唤醒消费者,而消费者只能唤醒生产者的业务逻辑了,如下代码所示:
// 创建 Condition 对象
private Lock lock = new ReentrantLock();
// 生产者的 Condition 对象
private Condition producerCondition = lock.newCondition();
// 本篇内容出自磊哥《Java面试突击训练营》 VX:GG_Stone
// 消费者的 Condition 对象
private Condition consumerCondition = lock.newCondition();
也就是 Condition 是 Object 等待唤醒模型的升级,Object 类可以实现的功能它都能实现,但 Condition 能实现的功能,Object 却不能实现,这就是 Condition 类存在的必要性。
那问题来了,为什么还有会 Object 的 wait 和 notify 方法呢? 因为 Object 类诞生的比较早,也就是说 Condition 和 LockSupport 都是 JDK 后期版本才出现的功能,所以就有了现在这么多线程唤醒和等待的方法了。
忙里偷闲IdleHandler
在Android中,Handler是一个使用的非常频繁的东西,输入事件机制和系统状态,都通过Handler来进行流转,而在Handler中,有一个很少被人提起但是却很有用的东西,那就是IdleHandler,它的源码如下。
/**
* Callback interface for discovering when a thread is going to block
* waiting for more messages.
*/
public static interface IdleHandler {
/**
* Called when the message queue has run out of messages and will now
* wait for more. Return true to keep your idle handler active, false
* to have it removed. This may be called if there are still messages
* pending in the queue, but they are all scheduled to be dispatched
* after the current time.
*/
boolean queueIdle();
}
从注释我们就能发现,这是一个IdleHandler的静态接口,可以在消息队列没有消息时或是队列中的消息还没有到执行时间时才会执行的一个回调。
这个功能在某些重要但不紧急的场景下就非常有用了,比如我们要在主页上做一些处理,但是又不想影响原有的初始化逻辑,避免卡顿,那么我们就需要等系统闲下来的时候再来执行我们的操作,这个时候,我们就可以通过IdleHandler来进行回调。
它的使用也非常简单,代码示例如下。
Looper.myQueue().addIdleHandler {
// Do something
false
}
在Handler的消息循环中,一旦队列里面没有需要处理的消息,该接口就会回调,也就是Handler空闲的时候。
这个接口有返回值,代表是否需要持续执行,如果返回true,那么一旦Handler空闲,就会执行IdleHandler中的回调,而如果返回false,那么就只会执行一次。
当返回true时,可以通过removeIdleHandler的方式来移除循环的处理,如果是false,那么在处理完后,它自己会移除。
综上,IdleHandler的使用主要有下面这些场景。
- 低优先级的任务处理:替换之前为了不在初始化的时候影响性能而使用的Handler.postDelayed方法,通过IdleHandler来自动获取空闲的时机。
- Idle时循环处理任务:通过控制返回值,在系统空闲时,不断重复某个操作。
但是要注意的是,如果Handler过于繁忙,那么IdleHandler的执行时机是有可能被延迟很久的,所以,要注意一些比较重要的处理逻辑的处理时机。
在很多第三方库里面,都有IdleHandler的使用,例如LeakCanary,它对内存的dump分析过程,就是在IdleHandler中处理的,从而避免对主线程的影响。
链接:https://juejin.cn/post/7163086937383763975
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
优化 Android Handler提升性能与稳定性
介绍 Handler
Handler 是一个常见的组件,它在 Android 应用程序开发中被广泛使用。Handler 可以将消息传递给主线程,使开发者能够在子线程中进行长时间的耗时操作,同时也避免了因在主线程中更新 UI 而出现的卡顿和 ANR 问题。
Handler 的问题
尽管 Handler 能够帮助处理一些繁琐的任务,然而如果不进行优化,Handler 自身却可能成为你应用程序的问题所在。
以下列出一些常见的 Handler 问题:
内存泄漏
因为 Handler 实例通常会保留对主线程的引用,而主线程通常不会被销毁,所以你在应用程序中使用 Handler时,很有可能会遇到内存泄漏的问题。
ANR
在处理大量消息时,使用 Handler 造成运行过程变慢。此时,当主线程无法在规定时间内完成属于它的操作时,就会发生一种无法响应的情况 ANR。
线程安全问题
如果你没有很好地处理并发问题,Handler 在多个线程中对同一实例的使用,可能会引发线程的安全问题。
优化方法
为了避免以上问题,可以尝试以下优化方法:
使用静态内部类
一个优化处理内存泄漏的方法是将 Handler 实例声明为静态内部类。这样,Handler 将不会保留对外部类的引用,从而避免了内存泄漏。
public class MyActivity extends Activity {
private static class MyHandler extends Handler {
private final WeakReference<MyActivity> mActivity;
public MyHandler(MyActivity activity) {
mActivity = new WeakReference<MyActivity>(activity);
}
@Override
public void handleMessage(Message msg) {
MyActivity activity = mActivity.get();
if (activity != null) {
// do something
}
}
}
private final MyHandler mHandler = new MyHandler(this);
}
移除Handler的回调
为了避免Handler泄露,可以再在Activity或Fragment的生命周期方法中移除Handler的回调。
@Override
protected void onDestroy() {
super.onDestroy();
handler.removeCallbacksAndMessages(null);
}
使用子线程与消息延迟
为避免 Handler 运行缓慢和 ANR 的问题, 可以将耗时任务放在子线程中执行,并在需要更新UI时使用Handler进行线程间通信。 如果消息队列中的消息太多,可以让主线程先处理其他任务,再延迟消息的处理时间。
Handler handler = new Handler(Looper.getMainLooper()) {
@Override
public void handleMessage(Message msg) {
// 在主线程更新UI
}
};
// 在子线程中执行耗时任务
new Thread(new Runnable() {
@Override
public void run() {
// 执行耗时操作
handler.sendMessage(handler.obtainMessage());
}
}).start();private static final int MAX_HANDLED_MESSAGE_COUNT = 500;
private Handler mHandler = new Handler() {
private int mHandledMessageCount = 0;
@Override
public void handleMessage(Message msg) {
// do something
mHandledMessageCount++;
if (mHandledMessageCount > MAX_HANDLED_MESSAGE_COUNT) {
mHandler.postDelayed(new Runnable() {
@Override
public void run() {
mHandledMessageCount = 0;
}
}, 1000);
}
}
};
使用 HandlerThread
为了避免出现线程安全问题,可以使用 HandlerThread 来创建线程从而处理消息。这样做的好处是不必担心多个线程同时访问同一个 Handler 实例的问题。
public class MyHandlerThread extends HandlerThread {
private static final String TAG = "MyHandlerThread";
private Handler mHandler;
public MyHandlerThread() {
super(TAG);
}
@Override
protected void onLooperPrepared() {
mHandler = new Handler(getLooper()) {
@Override
public void handleMessage(Message msg) {
// do something
}
};
}
public Handler getHandler() {
return mHandler;
}
}
使用 SparseArray
如果你的应用程序中有多个 Handler,可以使用 SparseArray 来管理它们。SparseArray 是一个类似于 HashMap的数据结构,它可以非常高效地管理多个 Handler 实例。
private SparseArray<Handler> mHandlerArray = new SparseArray<>();
private void initHandlers() {
mHandlerArray.put(1, new Handler() {
@Override
public void handleMessage(Message msg) {
// do something
}
});
mHandlerArray.put(2, new Handler() {
@Override
public void handleMessage(Message msg) {
// do something
}
});
// add more handlers
}
private void handleMessages(int handlerId, Message msg) {
Handler handler = mHandlerArray.get(handlerId);
if (handler != null) {
handler.handleMessage(msg);
}
}
使用 MessageQueue.IdleHandler
如果你的应用程序中有长时间运行的任务,可以使用 MessageQueue.IdleHandler 来执行它们。MessageQueue.IdleHandler 是一个回调接口,它可以在没有消息时执行任务。
private void executeLongRunningTask() {
Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override
public boolean queueIdle() {
// do something
return false; // remove the idle handler
}
});
}
结论
Handler 作为 Android 应用程序中非常重要的一个组件,但如果不进行优化,将可能影响应用程序的性能和稳定性。通过这篇文章,我们可以有效地避免问题的出现,让应用程序更加高效稳定。
推荐
android_startup: 提供一种在应用启动时能够更加简单、高效的方式来初始化组件,优化启动速度。不仅支持Jetpack App Startup的全部功能,还提供额外的同步与异步等待、线程控制与多进程支持等功能。
AwesomeGithub: 基于Github的客户端,纯练习项目,支持组件化开发,支持账户密码与认证登陆。使用Kotlin语言进行开发,项目架构是基于JetPack&DataBinding的MVVM;项目中使用了Arouter、Retrofit、Coroutine、Glide、Dagger与Hilt等流行开源技术。
flutter_github: 基于Flutter的跨平台版本Github客户端,与AwesomeGithub相对应。
android-api-analysis: 结合详细的Demo来全面解析Android相关的知识点, 帮助读者能够更快的掌握与理解所阐述的要点。
daily_algorithm: 每日一算法,由浅入深,欢迎加入一起共勉。
链接:https://juejin.cn/post/7249605942576578618
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一篇文章带你学会Kotlin
都2023年了,新建的项目还是Java项目,或者你还在写Java样式的Kotlin项目,仔细看完这篇文章,带你从Java转到Kotlin,带你学会Koltin,从入坑到脱坑
为什么要学习Kotlin
Kotlin是Andorid官方推荐语言- 最年来
Google发布很多新玩意,都是Kotlin写的,对Kotlin支持比较友好 Compose你不会Kotlin怎么学习- 一些大型开源项目,比如
Okhttp,Retrofit,Glide都改成了Kotlin版本 - 使用协程,让你切换线程更加方便,摆脱回调地狱
- 让你的代码更简洁
综上所示,笔者认为,Kotlin如今是一名Android开发工程师所必须要掌握的技能,但是偏偏还是有很多人不用,不学,所以就写下来这篇文章,带你快速入门Kotlin,也算是对自己知识的一遍巩固
基础
何为Kotlin,笔者认为是如何快速定义变量,常量,new一个对象,调用一个方法,来看一下Java是怎么做的
int a = 10;
a = 11;
TextView textView = new TextView(context);
textView.setText(a);
嗯,还是比较简洁的,但是还可以更简洁,看一下相同的代码使用Kotlin如何完成
fun Test(context: Context?) {
var a = 10
a = 11
val textView = TextView(context)
textView.text = a.toString()
}
解释一下,Kotlin定义常量是val,变量为,var,什么类型,根本不需要,它会通过后面得内容自动推导出来是什么类型的,但是从本质来说,Kotlin是还是强类型语言,只不过编译器会自动推导出来他真的类型而已,然后是不用写new关键字了,不用写;结尾了,get、set方法也不用写,直接等,实际上还是调用了真的get和set,原因是通过了属性访问器(accessor)的语法糖形式直接使用等号进行赋值和获取
类
接下来看一下类,点即创建一个Kotlin类型得File,会出来如下弹框
Class和Java的Class没什么两样,一般就是一个类File如果当一个Class中有两个同级别的类,这个时候就会变为File,这个一般在写扩展函数的时候使用,扩展函数后面会讲到Interface和Java的Interface一样,一个接口Sealed interface封闭接口,防止不同model之间的互相调用,比如你再B Model中定义B Sealed interface,那么你只能在B Model中使用这个接口,除此之外,还是使用此接口完成多继承的操作Data class实体类,和Java实体类有什么不同呢,不用写get,set方法和普通Kotlin Class有什么不同呢,首先是必须要有有参构造方法,然后重写了hashCode和equals方法Enum class枚举类,和Java一样Sealed class和Sealed interface差不多,都是限制只能在一个Model中使用Annotation定义一个注解Object这个笔者最喜欢,常用来定义一个单例类,相当于Java的饿汉式 其中比较常用的有Class,Data class,Object总的来说还是比Java的类型多一点
返回值
为什么要单写一个返回值,因为Kotlin的所有方法都有返回值,常规的就不说,看下面代码
val a: Unit = printA()
private fun printA() {
print("A")
}
这里面定义了函数,没有定义任何返回值,但是其实的类型是Unit,我的理解是Unit就代表它是一个函数类型和String一样都是Koltin类型中的一种,明白了这点就可以理解接下来的操作
val a = if ( x > y) x else y
相当于Java的三元换算符,如果x大于y就等于x,否则就等于y,对了Kotlin是没有三元换算符这个概念的,如果要达到相同效果只有使用if...else...,同理when也同样适用于这种操作
还是一种建立在编译器类型推导的基础上一种写法
private fun getA() = {
val a = 0
a
}
这个函数的意义就是返回了一个数字a,为什么没有return 它却拥有返回值返回值,请注意看这个=号,编译器给他推导出来了,并且通过lamaba返回值 还有一个非常特殊的返回值 Nothing 什么意思呢 不是null 就是什么也没有 具体可以看一下这篇文章
NULL安全处理
Kotlin是一个null安全的语言下面详细看一下
//定义一个变量
private var a: String? = null
String后面有个?代表,这个变量是可能为null的那么就需要在使用的时候处理它,不然会报错
if (a != null){
//不为null
}else{
//为null
}
//或者加上!!,代表这个时候肯定不为null,但是一般不建议这样写,玩出现null,就会空指针异常
a!!
当然如果确定使用的时候肯定部位null也可以这样写
private lateinit var a: String
代表定义了一个变量,我不管之前对它做了什么操作,反正我使用的时候,它一定是不为null的,当然与之的对应的还有by lazy延迟初始化,当第一次使用的时候才会初始化,比如这样,当我第一次调用a的时候,by lazy的括号内容即委托就会执行给a赋值,值得注意的是by lazy不是绑定在一起的 也可以只使用by意思也是委托,不过要单独写一个委托的实现
private val a: String by lazy { "123" }
扩展函数
扩展函数可以说是Kotlin比较爽的部分,他的本质其实是一个Kotlin的静态方法然后返回了它原本得了类型,比如这段代码
fun String?.addPlus(number: Int): String? {
if (this == null){
return null
}
return this.toInt().plus(number).toString()
}
扩展了String的方法,在String的基础上添加了一个addPlus方法,然后接受一个number参数,然后强转为int类型之后加上number并返回,这样扩展不用继承也可以在一些类中添加方法,减少了出BUG的可能性
val str = "1"
val str2 = str.addPlus(2)
看一这段代码的本质,可以知道Koltin和Java是可以互相转换的
public static final String addPlus(@Nullable String $this$addPlus, int number) {
return $this$addPlus == null ? null : String.valueOf(Integer.parseInt($this$addPlus) + number);
}
可以看到,扩展函数的本质是一个静态方法,并且多了一个String类型的参数,这个参数其实就是扩展函数类的实体,利用扩展函数可以实现简化很多操作,比如金额计算就可以扩展String,然后接收一个String,又或者是给textView添加一个功能,同样可以使用,我认为它差不多就是简化了静态工具类的使用,让其更方便,更快捷
扩展函数二 let also run apply
还记得上面提到的Kotlin对于null的判断吗,其实拥有更快快捷的方法就是使用扩展函数看这一段代码
fun stringToInt(str: String?): Int {
return str?.let {
it.toIntOrNull() ?: -1
} ?: run {
-1
}
}
一段链式调用,这也是Kotlin的特性之一,后续有时间会讲,链式调用有好处也有坏处,好处是可以更好的代码,坏处是一旦使用了过长的链式调用,后期代码维护就会很麻烦,为什么我会知道,因为我就写过,后期维护的时候痛不欲生,开发一时爽维护两行泪,但是适量使用这种,会让你的代码变得更简洁,维护更方便,主要还是看工程师的把握度。
好了具体看一下代码做了什么工作,首先定义了一个stringToInt的函数,然后接受了一个String参数,这个参数可以为null,然后判断是否等于null,等于null返回-1,不能转化为int返回-1,可以正常转化返回int值 Ok 先解释一下如何利用扩展函数做null判断 ?.let代表如果str这个值不为null,那么就执行it.toIntOrNull() ?: -1,否则这里用 ?:来处理即为null 就走run 然后返回-1
- let 提供了一个以默认值it的空间,然后返回值的是当前执行控件的最后一行代码
- also 提供了一个以默认值it的空间,然后返回值是它本身
- run 提供了一个this的命名空间,然后返回最后一行代码
- apply 提供了一个this的命名空间,然后返回它本身 这里贴出Kotlin的实现,源码其实很简单
@kotlin.internal.InlineOnly
public inline fun <T, R> T.let(block: (T) -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block(this)
}
@kotlin.internal.InlineOnly
@SinceKotlin("1.1")
public inline fun <T> T.also(block: (T) -> Unit): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
block(this)
return this
}
@kotlin.internal.InlineOnly
public inline fun <T, R> T.run(block: T.() -> R): R {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
return block()
}
@kotlin.internal.InlineOnly
public inline fun <T> T.apply(block: T.() -> Unit): T {
contract {
callsInPlace(block, InvocationKind.EXACTLY_ONCE)
}
block()
return this
}
代码其实很简单,有兴趣可以自己随便玩玩,这里就以apply为例分析一下,首先返回一个泛型T,这个T就是调用者本身,然后接口了一个black的函数,这个函数就是实际在代码中apply提供的空间,然后执行完成后,然后调用者本身,这样就和上文对应上了,apply 提供了一个this的命名空间,然后返回它本身,也可以仿照实现一个自己myApply哈哈哈,
结语
这篇文章其实原本想写的非常多,还有很多关键字没有介绍,比如by,inline,受限于篇幅问题,暂时把最基础的写了一写,以后会逐步完善这个系列,在写的过程,也有一些是笔者使用起来相对来说比较少的,就比如Sealed interface这个接口,之前就完全不理解,在写的时候特意去查询了一下资料,然后自己测试了一番,才理解,也算是促进了自己学习,希望可以共同进步
链接:https://juejin.cn/post/7244095157673394232
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
接口设计
大家好,我是二营长,日拱一卒无有尽,功不唐捐终入海。这里是Java学习小站,关注我,每天进步一点点!
接口的重要性:
在日常的开发中,在需求确定之后,后端同学首先要做的就是定义接口,接口定义完成之后,前端的同学就可以看接口文档和后端进行同步开发了。接口文档的作用还有很多:
沟通:开发、测试和其他人员之间的沟通渠道;它定义了接口的规范和预期行为,确保所有团队成员对接口的功能和使用方式有共同的理解。 效率:开发人员可以根据文档准确地了解如何调用接口、传递参数以及处理响应。这减少了开发过程中的试错和猜测,使开发人员能够更加专注于业务逻辑的实现。 并行开发:当多个开发人员同时工作在一个项目中时,接口文档允许他们独立地开发和测试各自的模块。通过定义清晰的接口规范,团队成员可以并行工作,而无需过多的交流和依赖。 代码质量:清晰的接口先行的方式,可以促使开发人员编写更健壮和可靠的代码。接口定义之后,整个交互过程就了然于胸了。 方便集成:当不同的系统或团队之间需要进行集成时,接口文档起到了关键的作用。通过提供准确和详细的接口规范,文档可以帮助团队避免集成过程中的误解和错误,降低集成风险。 支持第三方开发:如果你的应用程序或服务允许第三方开发者使用你的接口,好的接口文档是必不可少的。它为第三方开发者提供了准确的接口描述和示例代码,促进了他们与你的系统进行集成和开发扩展。
工作中常见的维护接口文档的方式:
使用Swagger、YApi等自动化接口管理平台。
Swagger和YApi等工具提供了自动化生成接口文档的功能,它们可以通过解析代码注释、接口定义或接口调用等方式,自动生成接口文档。这样可以减少手动编写和维护文档的工作量,同时确保文档与实际接口保持同步。
这些自动化管理平台还提供了其他有用的功能,例如接口测试、Mock数据生成、权限管理等。它们通常具备用户友好的界面和交互,可以方便团队成员共同编辑和维护接口文档,提高团队协作效率。
怎么设计好一个接口
我曾经遭遇过面试官,疯狂追问接口使如何设计的,虽然这是日常工作的一部分,但是很遗憾我没有表述清楚。
大部分的互联网项目都选择使用HTTP请求的方式进行交互的。
HTTP请求的组成
HTTP请求通常包括以下几个部分:
请求行(Request Line):包括请求方法(如GET、POST)、请求的URL路径和协议版本(如HTTP/1.1)。
请求头部(Request Headers):包括多个键值对,用于传递请求的元信息。常见的请求头部字段包括Host、User-Agent、Content-Type、Authorization等。
空行(Blank Line):请求头部与请求体之间需要有一个空行,用于分隔请求头部和请求体。
请求体(Request Body):对于某些请求方法(如POST),可以包含请求的内容,如表单数据、JSON数据等。对于其他请求方法(如GET),请求体通常为空。
HTTP请求报文的方式:
HTTP请求报文的方式主要有以下几种:
GET请求:GET请求通过URL参数传递数据,将请求参数附加在URL的末尾,以?开头,多个参数使用&分隔。GET请求的数据会明文显示在URL中,适合用于请求获取资源,对数据安全性要求较低的情况。
POST请求:POST请求将数据放在请求体中传递,适合用于提交表单、上传文件等操作。POST请求的数据不会显示在URL中,相对于GET请求更加安全,但需要在请求头中指定请求体的内容类型(Content-Type)。
PUT请求:PUT请求用于更新(全量替换)指定资源的信息。PUT请求将数据放在请求体中传递,类似于POST请求,但PUT请求要求对指定的资源进行完全替换,而不是部分修改。
PATCH请求:PATCH请求用于部分更新指定资源的信息。PATCH请求将数据放在请求体中传递,用于对资源进行局部修改,而不是全量替换。PATCH请求可以避免对整个资源进行完全替换的开销。
DELETE请求:DELETE请求用于删除指定的资源。DELETE请求通常不包含请求体,而是通过URL指定要删除的资源的路径。
RESTful API 接口规范
REST(Representational State Transfer)是一种软件架构风格和设计原则,用于构建分布式系统和网络应用程序。RESTful是基于REST原则定义的一组规范和约束,用于设计和开发Web API接口。
在RESTful规范中,可以理解为一切即资源,所有请求都是对资源的操作或查询。
RESTful架构中的几个核心概念:
资源(Resources):每种资源都有一个唯一的统一资源定位符(URI),用于标识和定位该资源。URI代表资源的地址或唯一识别符。
表现层(Representation):资源的表现层是指将资源具体呈现出来的形式。URI只表示资源的位置,而资源的具体表现形式可以通过HTTP请求的头信息中的Accept和Content-Type字段来指定。这两个字段描述了资源的表现层。
状态转化(State Transfer):客户端要操作服务器上的资源,需要通过某种方式触发服务器端的状态转变。这种转变是建立在表现层之上的,因此称为"表现层状态转化"。
在RESTful架构中,客户端使用HTTP协议中的四个表示操作方式的动词(GET、POST、PUT、DELETE)来实现状态转化。这些动词分别对应着四种基本操作:GET用于获取资源,POST用于新建资源(也可用于更新资源),PUT用于更新资源,DELETE用于删除资源。
简要总结:
每个URI代表一种资源。 客户端和服务器之间传递资源的表现层。 客户端通过HTTP动词对服务器端资源进行操作,实现表现层状态转化。
举个例子
API命名规范:面向资源命名
当设计符合RESTful规范的接口时,可以在URL路径中添加版本号或者命名空间,以提供更好的可扩展性和可维护性。
获取所有文章:
请求方法:GET
URL路径:/api/articles
示例请求:GET /api/articles
示例响应:
{
"articles": [
{
"id": 1,
"title": "RESTful 接口设计",
"content": "这是一篇关于RESTful接口设计的文章。"
},
{
"id": 2,
"title": "RESTful 接口实现",
"content": "这是一篇关于RESTful接口实现的文章。"
}
]
}
获取单个文章:
请求方法:GET
URL路径:/api/articles/{id}
示例请求:GET /api/articles/1
示例响应:
{
"id": 1,
"title": "RESTful 接口设计",
"content": "这是一篇关于RESTful接口设计的文章。"
}
创建文章:
请求方法:POST
URL路径:/api/articles
示例请求:
POST /api/articles
Content-Type: application/json
{
"title": "新的文章",
"content": "这是一个全新的文章。"
}
示例响应:
{
"id": 3,
"title": "新的文章",
"content": "这是一个全新的文章。"
}
更新文章:
请求方法:PUT
URL路径:/api/articles/{id}
示例请求:
PUT /api/articles/1
Content-Type: application/json
{
"title": "更新后的文章",
"content": "这是一篇更新后的文章。"
}
示例响应:
{
"id": 1,
"title": "更新后的文章",
"content": "这是一篇更新后的文章。"
}
删除文章:
请求方法:DELETE
URL路径:/api/articles/{id}
示例请求:DELETE /api/articles/1
示例响应:
{
"message": "文章已成功删除。"
}
通过在URL路径中添加/api前缀,可以更好地组织和管理接口,区分不同的功能模块或者版本。这种方式可以提高接口的可扩展性和可维护性,同时也符合常见的API设计实践。
定义统一的请求或响应参数
请求参数:
在定义请求参数时,可以根据具体的业务需求和安全考虑,包括一些常见的参数类型和参数名称。下面是一些常见的请求参数定义:
查询参数(Query Parameters):这些参数通常包含在URL中,以键值对的形式出现,用于过滤、排序、分页等操作。例如,对于获取文章列表的接口,可以接受page和limit参数来指定返回的页数和每页的数量。
路径参数(Path Parameters):这些参数通常嵌入在URL路径中,用于标识资源的唯一标识符或其他信息。例如,对于获取单个文章的接口,可以将文章ID作为路径参数,如/articles/{id}。
请求体参数(Request Body Parameters):这些参数通常包含在请求的消息体中,以JSON、XML或其他格式进行传输,用于传递复杂或大量的数据。例如,对于创建文章的接口,可以将文章的标题、内容等信息作为请求体参数。
请求头参数(Request Header Parameters):这些参数包含在HTTP请求的头部中,用于传递与请求相关的元数据或控制信息。例如,可以使用Authorization头部参数传递身份验证信息,如token。
对于特定的安全需求,例如身份验证和授权,常见的请求参数包括:
Token:用于身份验证和授权的令牌,通常是一个字符串。可以将Token作为请求头参数(如Authorization),请求体参数或查询参数的一部分,具体取决于API设计的需求和标准。
API密钥(API Key):用于标识和验证应用程序的身份,通常是一个长字符串。API密钥可以作为请求头参数、请求体参数或查询参数的一部分,以确保只有授权的应用程序可以访问API。
时间戳(Timestamp):用于防止重放攻击和确保请求的时效性,通常是一个表示当前时间的数字或字符串。时间戳可以作为请求头参数、请求体参数或查询参数的一部分。
这些请求参数的具体定义和使用方式应根据你的应用程序需求和安全策略来确定。确保在设计API时考虑到安全性、一致性和易用性。另外,建议参考相关的API设计规范和最佳实践,如OpenAPI规范或RESTful API设计指南。
响应参数
接口响应实例:
{
"version": "string",
"msg": "string",
"code": 200,
"error": "false",
"data": {},
"values": {}
}
这个示例中包含了以下参数:
version:表示接口版本的字符串。可以用于标识接口的版本号,方便后续的版本控制和兼容性处理。
msg:用于提供接口响应的描述信息的字符串。可以包含有关请求处理结果的额外说明或其他相关信息。
code:表示请求的处理结果状态码的整数值。一般情况下,200表示成功,其他状态码用于表示不同的错误或结果。
error:表示请求处理是否出错的布尔值。当发生错误时,可以将其设置为true,否则设置为false。
data:表示接口响应的具体数据的对象。可以包含接口处理结果的数据,例如获取的用户信息、文章内容等。
values:表示其他相关数值或附加信息的对象。可以用于传递一些额外的关键值或辅助信息。
END
日拱一卒无有尽,功不唐捐终入海。这里是Java学习小站,关注我,每天进步一点点!
收起阅读 »Android动态权限申请从未如此简单
作者:dreamgyf
juejin.cn/post/7225516176171188285
1. 前言
大家是否还在为动态权限申请感到苦恼呢?传统的动态权限申请需要在 Activity 中重写 onRequestPermissionsResult 方法来接收用户权限授予的结果。试想一下,你需要在一个子模块中申请权限,那得从这个模块所在的 Activity 的 onRequestPermissionsResult 中将结果一层层再传回到这个模块中,相当的麻烦,代码也相当冗余和不干净,逼死强迫症。
2. 使用
为了解决这个痛点,我封装出了两个方法,用于随时随地快速的动态申请权限,我们先来看看我们的封装方法是如何调用的:
activity.requestPermission(Manifest.permission.CAMERA, onPermit = {
//申请权限成功 Do something
}, onDeny = { shouldShowCustomRequest ->
//申请权限失败 Do something
if (shouldShowCustomRequest) {
//用户选择了拒绝并且不在询问,此时应该使用自定义弹窗提醒用户授权(可选)
}
})
这样是不是非常的简单便捷?申请和结果回调都在一个方法内处理,并且支持随用随调。
3. 方案
那么,这么方便好用的方法是怎么实现的呢?不知道小伙伴们在平时开发中有没有注意到过,当你调用 startActivityForResult 时,AS会提示你该方法已被弃用,点进去看会告诉你应该使用 registerForActivityResult 方法替代。没错,这就是 androidx 给我们提供的 ActivityResult 功能,并且这个功能不仅支持 ActivityResult 回调,还支持打开文档,拍摄照片,选择文件等各种各样的回调,同样也包括我们今天要说的权限申请
其实 Android 在官方文档“请求运行时权限”中就已经将其作为动态权限申请的推荐方法了:https://developer.android.com/training/permissions/requesting
如下示例代码所示:
val requestPermissionLauncher =
registerForActivityResult(RequestPermission()
) { isGranted: Boolean ->
if (isGranted) {
// Permission is granted. Continue the action or workflow in your
// app.
} else {
// Explain to the user that the feature is unavailable because the
// feature requires a permission that the user has denied. At the
// same time, respect the user's decision. Don't link to system
// settings in an effort to convince the user to change their
// decision.
}
}
when {
ContextCompat.checkSelfPermission(
CONTEXT,
Manifest.permission.REQUESTED_PERMISSION
) == PackageManager.PERMISSION_GRANTED -> {
// You can use the API that requires the permission.
}
shouldShowRequestPermissionRationale(...) -> {
// In an educational UI, explain to the user why your app requires this
// permission for a specific feature to behave as expected, and what
// features are disabled if it's declined. In this UI, include a
// "cancel" or "no thanks" button that lets the user continue
// using your app without granting the permission.
showInContextUI(...)
}
else -> {
// You can directly ask for the permission.
// The registered ActivityResultCallback gets the result of this request.
requestPermissionLauncher.launch(
Manifest.permission.REQUESTED_PERMISSION)
}
}
说到这里,可能有小伙伴要质疑我了:“官方文档里都写明了的东西,你还特地写一遍,还起了这么个标题,是不是在水文章?!”
莫急,如果你遵照以上方法这么写的话,在实际调用的时候会直接发生崩溃:
java.lang.IllegalStateException:
LifecycleOwner Activity is attempting to register while current state is RESUMED.
LifecycleOwners must call register before they are STARTED.
这段报错很明显的告诉我们,我们的注册工作必须要在 Activity 声明周期 STARTED 之前进行(也就是 onCreate 时和 onStart 完成前),但这样我们就必须要事先注册好所有可能会用到的权限,没办法做到随时随地有需要时再申请权限了,有办法解决这个问题吗?答案是肯定的。
4. 绕过生命周期检测
想解决这个问题,我们必须要知道问题的成因,让我们带着问题进到源码中一探究竟:
public final <I, O> ActivityResultLauncher<I> registerForActivityResult(
@NonNull ActivityResultContract<I, O> contract,
@NonNull ActivityResultCallback<O> callback) {
return registerForActivityResult(contract, mActivityResultRegistry, callback);
}
public final <I, O> ActivityResultLauncher<I> registerForActivityResult(
@NonNull final ActivityResultContract<I, O> contract,
@NonNull final ActivityResultRegistry registry,
@NonNull final ActivityResultCallback<O> callback) {
return registry.register(
"activity_rq#" + mNextLocalRequestCode.getAndIncrement(), this, contract, callback);
}
public final <I, O> ActivityResultLauncher<I> register(
@NonNull final String key,
@NonNull final LifecycleOwner lifecycleOwner,
@NonNull final ActivityResultContract<I, O> contract,
@NonNull final ActivityResultCallback<O> callback) {
Lifecycle lifecycle = lifecycleOwner.getLifecycle();
if (lifecycle.getCurrentState().isAtLeast(Lifecycle.State.STARTED)) {
throw new IllegalStateException("LifecycleOwner " + lifecycleOwner + " is "
+ "attempting to register while current state is "
+ lifecycle.getCurrentState() + ". LifecycleOwners must call register before "
+ "they are STARTED.");
}
registerKey(key);
LifecycleContainer lifecycleContainer = mKeyToLifecycleContainers.get(key);
if (lifecycleContainer == null) {
lifecycleContainer = new LifecycleContainer(lifecycle);
}
LifecycleEventObserver observer = new LifecycleEventObserver() { ... };
lifecycleContainer.addObserver(observer);
mKeyToLifecycleContainers.put(key, lifecycleContainer);
return new ActivityResultLauncher<I>() { ... };
}
我们可以发现,registerForActivityResult 实际上就是调用了 ComponentActivity 内部成员变量的 mActivityResultRegistry.register 方法,而在这个方法的一开头就检查了当前 Activity 的生命周期,如果生命周期位于STARTED后则直接抛出异常,那我们该如何绕过这个限制呢?
其实在 register 方法的下面就有一个同名重载方法,这个方法并没有做生命周期的检测:
public final <I, O> ActivityResultLauncher<I> register(
@NonNull final String key,
@NonNull final ActivityResultContract<I, O> contract,
@NonNull final ActivityResultCallback<O> callback) {
registerKey(key);
mKeyToCallback.put(key, new CallbackAndContract<>(callback, contract));
if (mParsedPendingResults.containsKey(key)) {
@SuppressWarnings("unchecked")
final O parsedPendingResult = (O) mParsedPendingResults.get(key);
mParsedPendingResults.remove(key);
callback.onActivityResult(parsedPendingResult);
}
final ActivityResult pendingResult = mPendingResults.getParcelable(key);
if (pendingResult != null) {
mPendingResults.remove(key);
callback.onActivityResult(contract.parseResult(
pendingResult.getResultCode(),
pendingResult.getData()));
}
return new ActivityResultLauncher<I>() { ... };
}
找到这个方法就简单了,我们将 registerForActivityResult 方法调用替换成 activityResultRegistry.register 调用就可以了
当然,我们还需要注意一些小细节,检查生命周期的 register 方法同时也会注册生命周期回调,当 Activity 被销毁时会将我们注册的 ActivityResult 回调移除,我们也需要给我们封装的方法加上这个逻辑,最终实现就如下所示。
5. 最终实现
private val nextLocalRequestCode = AtomicInteger()
private val nextKey: String
get() = "activity_rq#${nextLocalRequestCode.getAndIncrement()}"
fun ComponentActivity.requestPermission(
permission: String,
onPermit: () -> Unit,
onDeny: (shouldShowCustomRequest: Boolean) -> Unit
) {
if (ContextCompat.checkSelfPermission(this, permission) == PackageManager.PERMISSION_GRANTED) {
onPermit()
return
}
var launcher by Delegates.notNull<ActivityResultLauncher<String>>()
launcher = activityResultRegistry.register(
nextKey,
ActivityResultContracts.RequestPermission()
) { result ->
if (result) {
onPermit()
} else {
onDeny(!ActivityCompat.shouldShowRequestPermissionRationale(this, permission))
}
launcher.unregister()
}
lifecycle.addObserver(object : LifecycleEventObserver {
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
if (event == Lifecycle.Event.ON_DESTROY) {
launcher.unregister()
lifecycle.removeObserver(this)
}
}
})
launcher.launch(permission)
}
fun ComponentActivity.requestPermissions(
permissions: Array<String>,
onPermit: () -> Unit,
onDeny: (shouldShowCustomRequest: Boolean) -> Unit
) {
var hasPermissions = true
for (permission in permissions) {
if (ContextCompat.checkSelfPermission(
this,
permission
) != PackageManager.PERMISSION_GRANTED
) {
hasPermissions = false
break
}
}
if (hasPermissions) {
onPermit()
return
}
var launcher by Delegates.notNull<ActivityResultLauncher<Array<String>>>()
launcher = activityResultRegistry.register(
nextKey,
ActivityResultContracts.RequestMultiplePermissions()
) { result ->
var allAllow = true
for (allow in result.values) {
if (!allow) {
allAllow = false
break
}
}
if (allAllow) {
onPermit()
} else {
var shouldShowCustomRequest = false
for (permission in permissions) {
if (!ActivityCompat.shouldShowRequestPermissionRationale(this, permission)) {
shouldShowCustomRequest = true
break
}
}
onDeny(shouldShowCustomRequest)
}
launcher.unregister()
}
lifecycle.addObserver(object : LifecycleEventObserver {
override fun onStateChanged(source: LifecycleOwner, event: Lifecycle.Event) {
if (event == Lifecycle.Event.ON_DESTROY) {
launcher.unregister()
lifecycle.removeObserver(this)
}
}
})
launcher.launch(permissions)
}
6. 总结
其实很多实用技巧本质上都是很简单的,但没有接触过就很难想到,我将我的开发经验分享给大家,希望能帮助到大家。
收起阅读 »Java序列化
Java序列化是一种将对象转换为字节流的过程,使得对象可以在网络传输、持久化存储或跨平台应用中进行传递和重建的技术。它允许将对象以二进制的形式表示,并在需要时重新创建相同的对象。
Java序列化使用java.io.Serializable接口来标记可序列化的类。被标记为可序列化的类必须实现该接口,并且不包含非可序列化的成员变量(如果存在非可序列化的成员变量,可以通过关键字transient将其排除在序列化过程之外)。
以下是一个简单的Java序列化示例:
import java.io.*;
class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
}
public class SerializationExample {
public static void main(String[] args) {
// 创建一个Person对象
Person person = new Person("John Doe", 30);
// 将对象序列化到文件
try (FileOutputStream fileOut = new FileOutputStream("person.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut)) {
out.writeObject(person);
System.out.println("Serialized data is saved in person.ser");
} catch (IOException e) {
e.printStackTrace();
}
// 从文件中反序列化对象
try (FileInputStream fileIn = new FileInputStream("person.ser");
ObjectInputStream in = new ObjectInputStream(fileIn)) {
Person deserializedPerson = (Person) in.readObject();
System.out.println("Deserialized person: " + deserializedPerson.getName() +
", Age: " + deserializedPerson.getAge());
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
}
在上面的示例中,我们创建了一个名为Person的可序列化类,并在SerializationExample类中进行序列化和反序列化操作。首先,我们将Person对象写入文件person.ser中,然后从该文件中读取并反序列化为新的Person对象。
值得注意的是,被序列化的类必须存在相应的类定义,以便在反序列化时正确重建对象。如果序列化和反序列化使用不同版本的类,可能会导致版本不匹配的错误,因此需要小心处理类的版本控制。
此外,还可以通过实现java.io.Externalizable接口来自定义序列化过程,以更精确地控制序列化和反序列化的行为。
Serializable 接口的工作原理
Serializable 是 Java 中用于实现对象序列化的接口。当一个类实现了 Serializable 接口后,它的对象就可以被序列化为字节流,以便在网络传输或持久化存储中使用。
实现 Serializable 接口的类并不需要显式地定义任何方法,而是作为一个标记接口,表示该类的对象可以被序列化。Java 的序列化机制会根据对象的结构自动将其转换为字节序列。
以下是 Serializable 接口的工作原理:
序列化过程: 当一个对象被序列化时,Java 将其内部状态(也就是对象的字段)转换为字节流。这个过程称为对象的序列化。序列化过程从对象的根开始,递归地处理对象的所有字段,并将它们转换为字节流。
对象图: 在序列化过程中,Java 会创建一个对象图,表示对象之间的关系。对象图包括所有需要被序列化的对象及其字段。如果一个对象引用了其他对象,那么被引用的对象也会被序列化,并在对象图中保留其引用关系。
字段序列化: 对象的每个字段都被独立地序列化。基本类型和字符串直接转换为对应的字节表示形式,而引用类型(如其他对象)则按照相同的序列化过程递归地处理。
transient 关键字: 通过使用 transient 关键字,可以指定某个字段不参与序列化过程。被标记为 transient 的字段在序列化过程中被忽略,不会转换为字节流。
序列化的结果: 序列化过程完成后,Java 将对象及其字段转换为字节数组,并将其存储到文件、数据库或通过网络传输。
反序列化过程: 反序列化是序列化的逆过程。在反序列化过程中,Java 会根据字节流恢复对象的状态。它会逐个字段地读取字节流,并创建对应类型的对象。如果字段是引用类型,则会递归地进行反序列化,直至还原整个对象图。
需要注意的是,当一个类实现 Serializable 接口后,它的所有非瞬态(non-transient)字段都会被默认序列化。因此,在序列化类时,需要确保所有的字段都是可序列化的,否则会抛出 NotSerializableException 异常。
Serializable接口对性能影响
在Java中,使用Serializable接口进行对象的序列化和反序列化会对性能产生一定的影响。以下是一些与性能相关的考虑:
序列化开销:将对象转换为字节序列需要一定的时间和计算资源。这个过程涉及到将对象的状态写入到字节流中,包括对象的字段和其他相关信息。因此,如果需要频繁地序列化大型对象或大量对象,可能会对性能造成一定的影响。
序列化文件大小:序列化后的字节流通常比对象本身要大。这是因为序列化时会包含一些元数据、字段名称以及其他必要的信息。如果需要存储大量的序列化对象,可能会占用更多的磁盘空间。
反序列化性能:将字节序列转换回对象的过程也需要一定的时间和计算资源。反序列化涉及将字节流恢复为对象的状态,并创建新的对象实例。如果需要频繁地反序列化大量对象,也可能会对性能产生一定的影响。
序列化版本控制:在使用Serializable接口进行对象序列化时,需要注意对象的版本控制。如果在序列化和反序列化过程中发生了类的修改,可能会导致版本不匹配的问题。这可能需要额外的处理来确保兼容性,并可能影响性能。
总的来说,对于大多数应用程序而言,使用Serializable接口进行对象序列化并不会对性能产生显著的影响。然而,在某些特定情况下(如需要频繁地序列化大型对象或需要高性能的实时系统),可能需要考虑其他序列化方案或优化策略来满足性能需求。
收起阅读 »ES6的module语法中export和import的使用
ES6模块与CommonJS模块的差异
ES6 模块与 CommonJS 模块完全不同 它们有三个重大差异
CommonJS 模块输出的是一个值的拷贝,ES6 模块输出的是值的引用 CommonJS 模块是运行时加载,ES6 模块是编译时输出接口 CommonJS 模块的 require()是同步加载模块,ES6 模块的import命令是异步加载,有一个独立的模块依赖的解析阶段 第二个差异是 CommonJS 加载的是一个对象(即module.exports属性),该对象只有在脚本运行完才会生成,而 ES6 模块不是对象,它的对外接口只是一种静态定义,在代码静态解析阶段就会生成。
CommonJS 模块是 Node.js 专用的,语法上面,与 ES6 模块最明显的差异是,CommonJS 模块使用 require() 和 module.exports ,ES6 模块使用 import 和 export。
ES6 中 module 的语法
ES6 模块的设计思想是尽量的静态化,使得编译时就能确定模块的依赖关系,以及输入和输出的变量。 ES6模块不是对象,而是通过 export 命令显式指定输出的代码,再通过 import 命令输入。
export 命令
模块功能主要由两个命令构成:export 和 import。 export 命令用于规定模块的对外接口,import 命令用于输入其他模块提供的功能。 一个模块就是一个独立的文件。该文件内部的所有变量,外部无法获取。如果希望外部能够读取模块内部的某个变量,就必须使用 export 关键字输出该变量。
export 输出变量
// export.js
let firstName = 'Mark'
let lastName = 'Dave'
export { firstName, lastName }
上面代码在 export 命令后面,使用大括号指定所要输出的一组变量。
export 输出函数或类
export 命令除了输出变量,还可以输出函数或类(class)
export function multiply(x, y) {
return x * y
}
上面代码对外输出一个函数 `multiply
export使用as重命名
通常情况下,export 输出的变量是本来的名字,但是可以使用 as 关键字重命名
function fun1() { ... }
function fun2() { ... }
export {
fun1 as streamFun1,
fun2 as streamFun2,
fun2 as streamLatestFun
}
上面代码使用 as 关键字,重命名了函数 fun1 和 fun2 的对外接口,重命名后,fun2可以用不同的名字输出两次
export 规定的对外接口,必须与模块内部的变量一一对应
export 命令规定的是对外的接口,必须与模块内部的变量建立一一对应关系
// 报错
export 1;
// 报错
let m = 1
export m;
上面两种写法都会报错,因为没有提供对外的接口。第一种写法直接输出1,第二种写法通过变量 m,还是直接输出1,1只是一个值,不是接口。正确的写法如下:
// 写法1
export let m = 1;
// 写法2
let m = 1
export { m }
// 写法3
let n = 2
export { n as m }
上面三种写法都是正确的,规定了对外的接口 m。其他脚本可以通过这个接口,取到值 1.它们的实质是,在接口名和模块内部变量之间,建立了一一对应的关系。
同样,function 和 class 的输出,也必须同样遵守这样的写法
// 报错
function f() {}
export f
// 正确
function f() {}
export { f }
// 正确
export function f() {}
export可以出现在模块的任何位置,只要处于模块顶层就可以
export 命令可以出现在模块的任何位置,只要处于模块顶层就可以。如果处于块级作用域内,就会报错
function foo() {
export default 'bar' // SyntaxError
}
foo()
上面代码中,export 语句放在函数之中,结果报错
export default 命令
使用 import 命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。但是,用户肯定希望快速上手,未必愿意阅读文档,去了解模块有哪些属性和方法。 为了给用户提供方便,让它们不用阅读文档就能加载模块,就要用到 export default 命令,为模块指定默认输出。
// export-default.js
export default function() {
console.log('foo')
}
上面代码是一个模块文件 export-default.js ,它默认输出是一个函数。 其他模块加载该模块时,import 命令可以为该匿名函数指定任意名字。
// import-default.js
import customName from './export-default'
customName()
上面代码的 import 命令,可以用任意名称指向 export-default.js 输出的方法,这时就不需要知道原模块输出的函数名。需要注意的是,这时 import 命令后面,不使用大括号。 export default 命令用在非匿名函数前,也是可以的
export default function foo() {
console.log('foo')
}
// 或者写成
function foo() {
console.log('foo')
}
export default foo
上面代码中,foo 函数的函数名 foo ,在模块外部是无效的。加载的时候,视同匿名函数加载。 下面比较一下默认输出和正常输出:
// 第一组
export default function crc32() {}
import crc32 from 'crc32'
// 第二组
export function crc32() {}
import { crc32 } from 'crc32'
上面两组写法,第一组是使用 export default 时,对应的 import 语句不需要使用大括号;第二组是不使用 export default 时,对应的 import 语句需要使用大括号。
export default 命令用于指定模块的默认输出。显然,一个模块只能有一个默认输出,因此 export default 命令只能使用一次。所以,import 命令后面才不用加大括号,因为只可能唯一对应 export default 命令。 本质上,export default 就是输出一个叫做 default 的变量或方法,然后系统允许你为它取任意名字。所以,下面的写法是有效的。
// module.js
function add(x, y) {
return x + y
}
export { add as default }
// 等同于
export default add
// main.js
import { default as foo } from 'modules'
// 等同于
import foo from 'modules'
正是因为 export default 命令其实只是输出一个叫做 default 的变量,所以它后面不能跟变量声明语句。
// 正确
export let a = 1
// 正确
let a = 1
export default a
// 错误
export default let a = 1
上面代码中,export default a 的含义是将变量 a 的值赋值给变量 default。所以,最后一种写法会报错。 同样地,因为 export default 命令的本质是将后面的值,赋给 default 变量,所以可以直接将一根值写在 rcport default 之后
// 正确
export default 42
// 报错
export 42
如果想在一条 import 语句中,同时输入默认方法和其他接口,可以写成下面这样
import _, { each, forEach } from 'lodash'
export default 也可以用来输出类
// MyClass.js
export default class { ... }
// main.js
import MyClass from 'MyClass'
let o = new MyClass()
import 命令
使用 export 命令定义了模块的对外接口后,其他 js 文件就可以通过 import 命令加载这个模块。
// import.js
import { firstName, lastName } from './export.js'
function setName(element) {
element.textContent = firstName + ' ' + lastName
}
上面代码的 import 命令,用于加载 export.js 文件,并从中输入变量。import 命令接受一对大括号,里面指定要从其他模块导入的变量名。大括号里面的变量名,必须与被导入模块 export.js 对外借款的名称相同
import 使用 as 重命名变量
如果想为输入的变量重新取一个名字,import 命令要使用 as 关键字,将输入的变量重命名。
import { lastName } as surname from './export.js'
import`命令输入的变量都是只读的
import 命令输入的变量都是只读的,,因为它的本质是输入接口。也就是说,不允许在加载模块的脚本里面,改写接口。
import { a } from './xxx.js
a = {} // Syntax Error: 'a' is read-only
上面代码中,脚本加载了变量 a,对其重新赋值就会报错,因为 a 是一个只读的接口,但是,如果 a 是一个对象,改写 a 的属性是允许的
import { a } from './xxx.js'
a.foo = 'hello' // 合法操作
上面代码中,a 的属性可以改写成功,并且其他模块也可以读到改写后的值,不过,这种写法很难查错,建议凡是输入的变量,丢完全当做只读,不要轻易改变它的属性。
import 后面的 from 指定模块文件的位置,可以是相对路径,也可以是绝对路径。如果不带有路径,只是一个模块名,那么必须有配置文件,告诉 javascript 引擎该模块的位置。
import 具有提升效果
import 命令具有提升效果,会提升到整个模块的头部,首先执行
foo()
import { foo } from 'my_module'
上面的代码不会报错,因为 import 的执行早于 foo 的调用。这种行为的本质是,import 命令是编译阶段执行的,在代码运行之前。
import 是静态执行,不能使用表达式和变量
由于 import 是静态执行,所以不能使用表达式和变量,这些只有在运行时才能得到结果的语法结构
// 报错
import { 'f' + 'oo' } from ''my_module
// 报错
let module = 'my_module'
import { foo } from module
// 报错
if (x === 1) {
import { foo } from 'module1'
} else {
import { foo } from 'module2'
}
上面三种写法都会报错,因为它们用到了表达式、变量和 if 结构。在静态分析阶段,这些语法是没法得到值的。 最后,import 语句会执行所加载的模块,因此可以有下面的写法:
import 'lodash'
上面代码仅仅执行 lodash 模块,但是不输入任何值。 如果多次重复执行同一句 import语句,那么只会执行一次,而不会执行多次。
import 'lodash'
import 'lodash'
上面代码加载了两次 lodash,但是只会执行一次
import { foo } from 'my_module'
import { bar } from 'my_module'
// 等同于
import { foo, bar } from 'my_module'
上面代码中,虽然 foo 和 bar 在两个语句中加载,但是它们对应的是同一个 my_module模块,也就是说,import 语句是singleton 模式。
模块的整体加载
除了指定加载某个输出值,还可以使用整体加载,即用星号(*)指定一个对象,所有输出值都加载在这个对象上。 例如,下面是一个 circle.js 文件,它输出两个方法 area 和 circum
// circle.js
export function area(radius) {
return Math.PI * radius * radius
}
export function circum(radius) {
return @ * Math.PI * radius
}
现在,加载这个模块
// main.js
import {area, circum} from './circle'
console.log(area(4))
console.log(circum(14))
上面写法是逐一指定要加载的方法,整体加载的写法如下。
import * as circle from './circle'
console.log(circle.area(4))
console.log(circle.circum(14))
注意:模块整体加载所在的那个对象(上例是 circle),应该是可以静态分析的,所以不允许运行时改变。下面的写法都是不允许的。
import * as circle from './circle'
// 下面两行都是不允许的
circle.foo = 'hello'
circle.area = function () {}
export 和 import 的复合写法
如果在一根模块之中,先输入后输出同一个模块,import 语句可以与 export 语句写在一起。
export { foo, bar } from 'my_module'
// 可以简单理解为
import { foo, bar } from 'my_module'
export { foo, bar }
上面代码中,export 和 import 语句可以结合在一起,写成一行。但需要注意的是,写成一行以后,foo 和 bar 实际上并没有被导入当前模块,只是相当于对外转发了这两个接口,导致当前模块不能直接使用 foo 和 bar。 模块的接口改名和整体输出,也可以采用这种写法
// 接口改名
export { foo as myFoo } from 'my_module'
// 整体输出
export * from 'my_module'
默认接口的写法如下:
export { default } from 'foo'
具名接口改为默认接口的写法如下
export { es6 as default } from './someModule'
// 等同于
import { es6 } from './someModule'
export default es6
同样的,默认接口也可以改名为具名接口
export { default as es6 } from './someModule'
import()
import 和 export 命令只能在模块的顶层,不能在代码块之中(比如,在 if 代码块之中,或在函数之中) ES2020提案引入 import() 函数,支持动态加载模块
import(specifier)
上面代码中,import 函数的参数 specifier,指定所要加载的模块的位置,import 命令能够接受上面参数,import() 函数就能接受上面参数,两者区别主要是后者为动态加载。 import() 返回一个 Promise 对象。如
const main = document.querySelector('main');
import(`./section-modules/${someVariable}.js`)
.then(module => {
module.loadPageInto(main);
})
.catch(err => {
main.textContent = err.message;
});
import() 函数可以用在任何地方,不仅仅是模块,非模块的脚本也可以使用。它是运行时执行,也就是说,什么时候运行到这一句,就会加载指定的模块。另外,import() 函数与所加载的模块没有静态连接关系,这点也是与 import 语句不相同。import() 类似于 Node 的 require 方法,区别主要是前者是异步加载,后者是同步加载。
适用场合
按需加载
import() 可以在需要的时候,再加载某个模块
button.addEventListener('click', event => {
import('./dialogBox.js')
.then(dialogBox => {
dialogBox.open();
})
.catch(error => {
/* Error handling */
})
});
上面代码中,import() 方法放在 click 事件的监听函数中,只有用户点击了按钮,才会加载这个模块。
条件加载
import() 可以放在 if 代码块,根据不同的情况,加载不同的模块
if (condition) {
import('moduleA').then(...);
} else {
import('moduleB').then(...);
}
上面代码中,如果满足条件,就加载模块 A,否则加载模块 B
动态的模块路径
import() 允许模块路径动态生成
import(f())
.then(...)
上面代码中,根据函数 f 的返回结果,加载不同的模块。
注意点
import() 加载模块成功以后,这个模块会作为一个对象,当作 then 方法的参数。因此,可以使用对象结构赋值的语法,获取输出接口
import('./myModule.js')
.then({export1, export2}) => {
// ...
})
上面代码中,export1 和 export2 都是 myModule.js 的输出接口,可以解构获得 如果想同时加载多个模块,可以
Promise.all([
import('./module1.js'),
import('./module2.js'),
import('./module3.js'),
])
.then(([module1, module2, module3]) => {
···
});
import() 也可以用在 async 函数中
async function main() {
const myModule = await import('./myModule.js');
const {export1, export2} = await import('./myModule.js');
const [module1, module2, module3] =
await Promise.all([
import('./module1.js'),
import('./module2.js'),
import('./module3.js'),
]);
}
main();
Flutter 状态组件 InheritedWidget
前言
今天会讲下 inheritedWidget 组件,InheritedWidget 是 Flutter 中非常重要和强大的一种 Widget,它可以使 Widget 树中的祖先 Widget 共享数据给它们的后代 Widget,从而简化了状态管理和数据传递的复杂性,提高了代码的可读性、可维护性和性能。
Provider 就是对 inheritedWidget 的高度封装
Flutter_bloc 也是这样
Flutter_bloc 中确实有 provider 的引用
如果你只是想简单的状态管理几个全局数据,完全可以轻巧的使用 inheritedWidget 。
今天就来讲下如何使用和要注意的地方。
参考
https://api.flutter.dev/flutter/widgets/InheritedWidget-class.html
状态管理
在 Flutter 中,状态管理是指管理应用程序的数据和状态的方法。在应用程序中,有许多不同的组件和部件,它们可能需要在不同的时间点使用相同的数据。状态管理的目的是使这些数据易于访问和共享,并确保应用程序的不同部分保持同步。
在 Flutter 中,有不同的状态管理方法可供选择,包括:
StatefulWidget 和 State:StatefulWidget 允许你创建有状态的部件,而 State 则允许你管理该部件的状态。这是 Flutter 中最基本和最常用的状态管理方法。 InheritedWidget:InheritedWidget 允许你共享数据和状态,并且可以让子部件自动更新当共享的数据发生变化时。 Provider:Provider 是一个第三方库,它基于 InheritedWidget,可以更方便地管理应用程序中的状态。 Redux:Redux 是一个流行的状态管理库,它基于单一数据源和不可变状态的概念,可以使状态管理更加可预测和易于维护。 BLoC:BLoC 是一个基于流的状态管理库,它将应用程序状态分为输入、输出和转换。它可以使应用程序更清晰和可测试。 GetX: GetX 是一个流行的 Flutter 状态管理和路由导航工具包,它提供了许多功能,包括快速且易于使用的状态管理、依赖注入、路由导航、国际化、主题管理等。是由社区开发和维护的第三方工具包。
步骤
第一步:用户状态 InheritedWidget 类
lib/states/user_profile.dart
// 用户登录信息
class UserProfileState extends InheritedWidget {
...
}
参数
const UserProfileState({
super.key,
required this.userName,
required this.changeUserName,
required Widget child, // 包含的子节点
}) : super(child: child);
/// 用户名
final String userName;
/// 修改用户名
final Function changeUserName;
of 方法查询,依据上下文 context
static UserProfileState? of(BuildContext context) {
final userProfile =
context.dependOnInheritedWidgetOfExactType<UserProfileState>();
// 安全检查
assert(userProfile != null, 'No UserProfileState found in context');
return userProfile;
}
需要做一个 userProfile 空安全检查
重写 updateShouldNotify 通知更新规则
@override
bool updateShouldNotify(UserProfileState oldWidget) {
return userName != oldWidget.userName;
}
如果用户名发生改变进行通知
第二步:头部底部组件 StatelessWidget
lib/widgets/header.dart
class HeaderWidget extends StatelessWidget {
const HeaderWidget({super.key});
@override
Widget build(BuildContext context) {
String? userName = UserProfileState.of(context)?.userName;
return Container(
width: double.infinity,
decoration: BoxDecoration(
border: Border.all(color: Colors.blue),
),
child: Text('登录:$userName'),
);
}
}
通过 String? userName = UserProfileState.of(context)?.userName; 的方式
读取状态数据 userName
lib/widgets/bottom.dart
class BottomWidget extends StatelessWidget {
const BottomWidget({super.key});
@override
Widget build(BuildContext context) {
String? userName = UserProfileState.of(context)?.userName;
return Container(
width: double.infinity,
decoration: BoxDecoration(
border: Border.all(color: Colors.blue),
),
child: Text('登录:$userName'),
);
}
}
第三步:用户组件 StatefulWidget
lib/widgets/user_view.dart
class UserView extends StatefulWidget {
const UserView({super.key});
@override
State<UserView> createState() => _UserViewState();
}
class _UserViewState extends State<UserView> {
...
成员变量
class _UserViewState extends State<UserView> {
String? _userName;
重新 didChangeDependencies 依赖函数更新数据
@override
void didChangeDependencies() {
_userName = UserProfileState.of(context)?.userName;
super.didChangeDependencies();
}
通过 UserProfileState.of(context)?.userName; 的方式读取
build 函数
@override
Widget build(BuildContext context) {
return Container(
width: double.infinity,
decoration: BoxDecoration(
border: Border.all(color: Colors.purple),
),
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Text('用户名:$_userName'),
ElevatedButton(
onPressed: () {
// 随机 10 个字母
String randomString = String.fromCharCodes(
List.generate(
10,
(index) => 97 + Random().nextInt(26),
),
);
// 改变用户名
UserProfileState.of(context)?.changeUserName(randomString);
},
child: const Text('改变名称'),
),
],
),
);
}
randomString 是一个随机的 10 个字母
通过 UserProfileState.of(context)?.changeUserName(randomString); 的方式触发函数,进行状态更改。
最后:页面调用 AppPage
lib/page.dart
class AppPage extends StatefulWidget {
const AppPage({super.key});
@override
State<AppPage> createState() => _AppPageState();
}
class _AppPageState extends State<AppPage> {
...
成员变量
class _AppPageState extends State<AppPage> {
String _userName = '未登录';
给了一个 未登录 的默认值
修改用户名函数
// 修改用户名
void _changeUserName(String userName) {
setState(() {
_userName = userName;
});
}
build 函数
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: const Text('InheritedWidget'),
),
body: UserProfileState(
userName: _userName,
changeUserName: _changeUserName,
child: SafeArea(
child: Column(
children: const [
// 头部
HeaderWidget(),
// 正文
Expanded(child: UserView()),
// 底部
BottomWidget(),
],
),
),
),
);
}
可以发现 UserProfileState 被套在了最外层,当然还有 Scaffold 。
包裹的子组件有:HeaderWidget、BottomWidget、UserView
状态过程如下:
UserView 触发 _changeUserName 修改用户名 _userName 改变的数据压入 UserProfileState UserProfileState 触发 updateShouldNotify 组件 didChangeDependencies 被触发 最后子成员组件更新成功
代码
https://github.com/ducafecat/flutter_develop_tips/tree/main/flutter_application_inherited_widget
小结
在 Flutter 中,InheritedWidget 是一种特殊的 Widget,它允许 Widget 树中的祖先 Widget 共享数据给它们的后代 Widget,而无需通过回调或参数传递数据。下面是 InheritedWidget 的一些主要作用和好处:
共享数据:InheritedWidget 允许祖先 Widget 共享数据给它们的后代 Widget,这使得在 Widget 树中传递数据变得更加容易和高效。这种共享数据的方式避免了回调和参数传递的复杂性,使得代码更加简洁易懂。 自动更新:当共享的数据发生变化时,InheritedWidget 会自动通知它的后代 Widget 进行更新,这使得状态管理变得更加容易。这种自动更新的方式避免了手动管理状态的复杂性,使得代码更加健壮和易于维护。 跨 Widget 树:InheritedWidget 可以跨 Widget 树共享数据,这使得在应用程序中不同模块之间传递数据变得更加容易。这种跨 Widget 树的共享方式避免了在不同模块之间传递数据时的复杂性,使得代码更加模块化和易于扩展。 性能优化:InheritedWidget 可以避免不必要的 Widget 重建,从而提高应用程序的性能。当共享的数据没有发生变化时,InheritedWidget 不会通知后代 Widget 进行更新,这避免了不必要的 Widget 重建,提高了应用程序的性能。
未来前端框架会如何卷?
前端框架在过去几年间取得了显著的进步和演进。前端框架也将继续不断地演化,以满足日益复杂的业务需求和用户体验要求。从全球web发展角度看,框架竞争已经从第一阶段的前端框架之争(比如Vue、React、Angular等),过渡到第二阶段的框架之争(比如Next、Nuxt、Remix、小程序等)。
组件化开发的持续推进
前端框架的组件化开发将继续成为主流趋势。Vue、React和Angular等成熟框架早已以其优秀的组件化机制著称。未来,这些框架将不断改进组件系统,使组件之间的交互更加灵活、高效,进一步提高开发效率和应用性能。例如,React框架在最近的更新中引入了Suspense机制,让组件的异步加载更加容易和优雅。而小程序框架也将引入更强大的组件化开发机制,使小程序开发更易维护、易扩展。
案例:一个电商企业正在使用Vue框架开发其前端应用。在该应用中,商品展示、购物车、订单结算等功能都被抽象为可复用的组件。这样一来,开发者可以在不同的页面中重复使用这些组件,大大提高了开发效率。同时,当某个功能需要更新或修复时,只需在对应的组件中进行修改,便可以在整个应用中生效,保持了应用的一致性。
更强调性能优化和打包体积
性能优化和打包体积将成为前端框架发展的重点。优化算法和编译工具的不断改进将帮助开发者减少应用的加载时间,提高用户体验。例如,Next.js框架已经内置了自动代码分割和服务端渲染,有效减少了首屏加载时间,使得用户更快地看到页面内容。
案例:一个新闻媒体网站采用了Nuxt.js框架来优化其前端性能。Nuxt.js的服务端渲染功能允许该网站在服务器端生成静态页面,这大大减少了浏览器渲染的工作量。结果,网站的加载速度得到显著提升,用户可以更快地浏览新闻内容,提高了用户留存率和转化率。
深度集成TypeScript
TypeScript作为一种静态类型语言,已经在前端开发中得到广泛应用。未来前端框架将深度集成TypeScript,提供更完善的类型支持和智能提示,减少潜在的Bug,并提升代码的可维护性。例如,Vue框架已经提供了对TypeScript的原生支持,使得开发者可以使用TypeScript编写Vue组件,并获得更强大的类型检查和代码提示。
案例:一家科技公司决定将其现有的JavaScript项目迁移到TypeScript。在迁移过程中,开发团队发现许多隐藏的类型错误,并通过TypeScript提供的类型检查机制及时修复了这些问题。这使得代码质量得到了大幅提升,并为未来的项目维护奠定了良好的基础。
强调用户体验和可访问性
用户体验和可访问性将继续是前端开发的关键词。框架将注重提供更好的用户体验设计,以及更高的可访问性标准,使得应用能够更好地适应不同用户的需求,包括残障用户。例如,React框架支持ARIA(Accessible Rich Internet Applications)标准,使得开发者可以为特殊用户群体提供更好的使用体验。
案例:一家在线教育平台在开发过程中注重可访问性,确保所有用户都能轻松访问其教育内容。平台使用了语义化的HTML标签、ARIA属性以及键盘导航功能,使得视障用户和键盘操作用户也能流畅使用平台。这使得平台在用户中建立了良好的声誉,吸引了更多的用户参与学习。
跨平台开发的融合
前端框架将更加注重跨平台开发的融合。Vue、React等主流框架将提供更便捷的方法,让开发者可以更轻松地将Web应用扩展到其他平台上。例如,React Native框架允许开发者使用React的语法和组件来构建原生移动应用,这使得前端开发者可以在不学习原生开发语言的情况下,快速构建跨平台的移动应用。
这些轻量化前端开发框架也可以与小程序开发相结合,从而提高小程序的开发效率和性能。
在小程序开发中,通常需要使用一些类似于组件化的开发模式,以便更好地管理页面和数据。这些轻量化前端开发框架中,例如 Vue.js 和 React,已经采用了类似于组件化的开发模式,因此可以更好地适应小程序的开发需求。
除此之外,这些轻量化前端开发框架还提供了许多工具和插件,可以帮助开发人员更快地开发小程序。例如,Vue.js 提供了 Vue-CLI 工具,可以快速创建小程序项目和组件;React 提供了 React Native 工具,可以使用类似于 React 的语法开发原生应用程序。这些工具和插件使得小程序开发更加高效和便捷。
1、使用小程序开发框架
类似于 Vue.js 和 React,这些框架可以通过使用小程序框架的渲染层和逻辑层 API,来提高小程序的性能和开发效率。例如,可以使用微信小程序框架和 Vue.js 一起开发小程序,通过引入 mpvue-loader 库来实现 Vue.js 和小程序的整合。
mpvue基于Vue.js核心,修改了Vue.js的 runtime 和 compiler 实现,使其可以运行在小程序环境中。mpvue 支持使用 Vue.js 的大部分特性,如组件、指令、过滤器、计算属性等,同时也支持使用 npm、webpack 等工具来构建项目。mpvue 还提供了一些扩展 API 和插件机制,以适应小程序的特殊需求。
2、使用跨平台开发工具
跨平台开发工具可以让开发人员使用一套代码来同时开发小程序、Web 应用和原生应用。例如,使用 React Native 可以通过 JavaScript 来开发原生应用程序和小程序,同时提高了开发效率和性能。
3、小程序组件库
一些小程序组件库,例如 WeUI 和 Vant,提供了许多常用的 UI 组件和功能,可以帮助开发人员快速地构建小程序页面。这些组件库还可以与 Vue.js 和 React 等轻量化前端开发框架相结合,提高小程序的开发效率和性能。
进一步提升应用价值
Vue 和小程序本质上是两个不同的技术栈,Vue 是一个前端框架,而小程序基于微信语法和规则。由于两者的编程模型和运行环境有很大的差异,因此不能直接将 Vue 代码打包为小程序的。
但可以通过使用小程序开发框架,例如 Taro、Mpvue 和 uni-app,可以将 Vue.js 和 React 等前端框架的开发方式与小程序相结合。这些框架可以将前端框架的语法和特性转换为小程序的语法和特性,从而使得开发人员可以使用熟悉的开发方式来开发小程序。
这里还要推荐一个深化发挥小程序价值的途径,直接将现有的小程序搬到自有 App 中进行运行,这种实现技术路径叫做小程序容器,例如 FinClip SDK 是通过集成 SDK 的形式让自有的 App 能够像微信一样直接运行小程序。

这样一来不仅可以通过前端框架提升小程序的开发效率,还能让小程序运行在微信以外的 App 中,真正实现了一端开发多端上架,另外由于小程序是通过管理后台上下架,相当于让 App 具备热更新能力,避免 AppStore 频繁审核。
最后
综上所述,未来前端框架的发展将持续聚焦在组件化开发、性能优化和打包体积、跨平台开发、小程序框架的崛起、深度集成TypeScript、用户体验和可访问性、全球化和国际化等方向。通过不断地创新和改进,前端框架将推动Web应用开发的进步,为用户提供更好的使用体验和开发者更高效的开发体验。开发者们应密切关注各个框架的更新和改进,以紧跟技术的脚步,为未来的Web应用开发做好准备。
收起阅读 »面试必备:Android 常见内存泄漏问题盘点
1. 前言
当我们开发安卓应用时,性能优化是非常重要的一个方面。一方面,优化可以提高应用的响应速度、降低卡顿率,从而提升用户体验;另一方面,优化也可以减少应用的资源占用,提高应用的稳定性和安全性,降低应用被杀死的概率,从而提高用户的满意度和留存率。
但是,对于许多开发者来说,安卓性能优化往往是一个比较棘手的问题。因为性能优化包罗万象,涉及的知识面也比较多,而内存泄露是最常见的一类性能问题,也是各类面试题中的常客,因此了解内存泄漏是每个安卓开发者应该具备的进阶技能。
本文就带大家盘点常见的内存泄漏问题。
2. 内存泄漏的本质
内存泄漏的本质就是对象引用未释放,当对象被创建时,如果没有被正确释放,那么这些对象就会一直占用内存,直到应用程序退出。例如,当一个Activity被销毁时,如果它还持有其他对象的引用,那么这些对象就无法被垃圾回收器回收,从而导致内存泄漏
当存在内存泄漏时,我们需要通过GCRoot来识别内存泄漏的对象和引用。
GCRoot是垃圾回收机制中的根节点,根节点包括虚拟机栈、本地方法栈、方法区中的类静态属性引用、活动线程等,这些对象被垃圾回收机制视为“活着的对象”,不会被回收。
当垃圾回收机制执行时,它会从GCRoot出发,遍历所有的对象引用,并标记所有活着的对象,未被标记的对象即为垃圾对象,将会被回收。
当存在内存泄漏时,垃圾回收机制无法回收一些已经不再使用的对象,这些对象仍然被引用,形成了一些GCRoot到内存泄漏对象的引用链,这些对象将无法被回收,导致内存泄漏。
通过查找内存泄漏对象和GCRoot之间的引用链,可以定位到内存泄漏的根源,进而解决内存泄漏问题,LeakCancry就是通过这个机制实现的。
一些常见的GCRoot包括:
虚拟机栈(Local Variable)中引用的对象。 方法区中静态属性(Static Variable)引用的对象。 JNI 引用的对象。 Java 线程(Thread)引用的对象。 Java 中的 synchronized 锁持有的对象。
什么情况会造成对象引用未释放呢?简单举几个例子:
匿名内部类造成的内存泄漏:匿名内部类通常会持有外部类的引用,如果外部类的生命周期比匿名内部类长,(更正一下,这里用生命周期不太恰当,当外部类被销毁时,内部类并不会自动销毁,因为内部类并不是外部类的成员变量,它们只是在外部类的作用域内创建的对象,所以内部类的销毁时机和外部类的销毁时机是不同的,所以会不会取决与对应对象是否存在被持有的引用)那么就会导致外部类无法被回收,从而导致内存泄漏。
静态变量持有Activity或Context的引用:如果一个静态变量持有Activity或Context的引用,那么这些Activity或Context就无法被垃圾回收器回收,从而导致内存泄漏。
未关闭的Cursor、Stream或者Bitmap对象:如果程序在使用Cursor、Stream或者Bitmap对象时没有正确关闭这些对象,那么这些对象就会一直占用内存,从而导致内存泄漏。
资源未释放:如果程序在使用系统资源时没有正确释放这些资源,例如未关闭数据库连接、未释放音频资源等,那么这些资源就会一直占用内存,从而导致内存泄漏。
接下来我们通过代码示例看一下各种常见内存泄露以及如何避免相关问题的最佳实践
3. 静态引用导致的内存泄漏
当一个对象被一个静态变量持有时,即使这个对象已经不再使用,也不会被垃圾回收器回收,这就会导致内存泄漏
public class MySingleton {
private static MySingleton instance;
private Context context;
private MySingleton(Context context) {
this.context = context;
}
public static MySingleton getInstance(Context context) {
if (instance == null) {
instance = new MySingleton(context);
}
return instance;
}
}
上面的代码中,MySingleton持有了一个Context对象的引用,而MySingleton是一个静态变量,导致即使这个对象已经不再使用,也不会被垃圾回收器回收。
最佳实践:如果需要使用静态变量,请注意在不需要时将其设置为null,以便及时释放内存。
4. 匿名内部类导致的内存泄漏
匿名内部类会隐式地持有外部类的引用,如果这个匿名内部类被持有了,就会导致外部类无法被垃圾回收。
public class MyActivity extends Activity {
private Button button;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
button = new Button(this);
button.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// do something
}
});
setContentView(button);
}
}
匿名内部类OnClickListener持有了外部类MyActivity的引用,如果MyActivity被销毁之前,button没有被清除,就会导致MyActivity无法被垃圾回收。(此处可以将Button 看作是自己定义的一个对象,一般解法是将button对象置为空)
最佳实践:在Activity销毁时,应该将所有持有Activity引用的对象设置为null。
5. Handler引起的内存泄漏
Handler是在Android应用程序中常用的一种线程通信机制,如果Handler被错误地使用,就会导致内存泄漏。
public class MyActivity extends Activity {
private static final int MSG_WHAT = 1;
private Handler mHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_WHAT:
// do something
break;
default:
super.handleMessage(msg);
}
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mHandler.sendEmptyMessageDelayed(MSG_WHAT, 1000 * 60 * 5);
}
@Override
protected void onDestroy() {
super.onDestroy();
// 在Activity销毁时,应该将Handler的消息队列清空,以避免内存泄漏。
mHandler.removeCallbacksAndMessages(null);
}
}
Handler持有了Activity的引用,如果Activity被销毁之前,Handler的消息队列中还有未处理的消息,就会导致Activity无法被垃圾回收。
最佳实践:在Activity销毁时,应该将Handler的消息队列清空,以避免内存泄漏。
6. Bitmap对象导致的内存泄漏
当一个Bitmap对象被创建时,它会占用大量内存,如果不及时释放,就会导致内存泄漏。
public class MyActivity extends Activity {
private Bitmap mBitmap;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 加载一张大图
mBitmap = BitmapFactory.decodeResource(getResources(), R.drawable.big_image);
}
@Override
protected void onDestroy() {
super.onDestroy();
// 释放Bitmap对象
mBitmap.recycle();
mBitmap = null;
}
}
当Activity被销毁时,Bitmap对象mBitmap应该被及时释放,否则就会导致内存泄漏。
最佳实践:当使用大量Bitmap对象时,应该及时回收不再使用的对象,避免内存泄漏。另外,可以考虑使用图片加载库来管理Bitmap对象,例如Glide、Picasso等。
7. 资源未关闭导致的内存泄漏
当使用一些系统资源时,例如文件、数据库等,如果不及时关闭,就可能导致内存泄漏。例如:
public void readFile(String filePath) throws IOException {
FileInputStream fis = null;
try {
fis = new FileInputStream(filePath);
// 读取文件...
} finally {
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
上面的代码中,如果在读取文件之后没有及时关闭FileInputStream对象,就可能导致内存泄漏。
最佳实践:在使用一些系统资源时,例如文件、数据库等,要及时关闭相关对象,避免内存泄漏。
避免内存泄漏需要在编写代码时时刻注意,及时清理不再使用的对象,确保内存资源得到及时释放。 ,同时,可以使用一些工具来检测内存泄漏问题,例如Android Profiler、LeakCanary等。
8. WebView 内存泄漏
当使用WebView时,如果不及时释放,就可能导致内存泄漏
public class MyActivity extends Activity {
private WebView mWebView;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mWebView = findViewById(R.id.webview);
mWebView.loadUrl("https://www.example.com");
}
@Override
protected void onDestroy() {
super.onDestroy();
// 释放WebView对象
if (mWebView != null) {
mWebView.stopLoading();
mWebView.clearHistory();
mWebView.clearCache(true);
mWebView.loadUrl("about:blank");
mWebView.onPause();
mWebView.removeAllViews();
mWebView.destroy();
mWebView = null;
}
}
}
上面的代码中,当Activity销毁时,WebView对象应该被及时释放,否则就可能导致内存泄漏。
最佳实践:在使用WebView时,要及时释放WebView对象,可以在Activity销毁时调用WebView的destroy方法,同时也要清除WebView的历史记录、缓存等内容,以确保释放所有资源。
9. 监测工具
内存监视工具:Android Studio提供了内存监视工具,可以在开发过程中实时监视应用程序的内存使用情况,帮助开发者及时发现内存泄漏问题。 DDMS:Android SDK中的DDMS工具可以监视Android设备或模拟器的进程和线程,包括内存使用情况、堆栈跟踪等信息,可以用来诊断内存泄漏问题。 MAT:MAT(Memory Analyzer Tool)是一款基于Eclipse的内存分析工具,可以分析应用程序的堆内存使用情况,识别和定位内存泄漏问题。 腾讯的Matrix,也是非常好的一个开源项目,推荐大家使用
10. 总结
内存泄漏是指程序中的某些对象或资源没有被妥善地释放,从而导致内存占用不断增加,最终可能导致应用程序崩溃或系统运行缓慢等问题。
常见的内存泄漏问题和对应的最佳实践整理如下
| 问题 | 最佳实践 |
|---|---|
| 长时间持有Activity或Fragment对象导致的内存泄漏 | 及时释放Activity或Fragment对象 |
| 匿名内部类和非静态内部类导致的内存泄漏 | 避免匿名内部类和非静态内部类 |
| WebView持有Activity对象导致的内存泄漏 | 在使用WebView时,及时调用destroy方法 |
| 单例模式持有资源对象导致的内存泄漏 | 在单例模式中避免长时间持有资源对象 |
| 资源未关闭导致的内存泄漏 | 及时关闭资源对象 |
| 静态变量持有Context对象导致的内存泄漏 | 避免静态变量持有Context对象 |
| Handler持有外部类引用导致的内存泄漏 | 避免Handler持有外部类引用 |
| Bitmap占用大量内存导致的内存泄漏 | 在使用Bitmap时,及时释放内存 |
| 单例持有大量数据导致的内存泄漏 | 避免单例持有大量数据 |
Compose 实战经验分享:开发要点&常见错误&面试题
1. 前言
从 Compose 还在 alpha 到现在,用 Compose 完整的从零到一写了三个应用:Twidere X Android、Mask-Android,还有一个暂未公开的项目。
这三个应用每一个都有不一样的收获,现在将开发过程中的经验集中做一波总结:
2. 要点总结
直接说几个总结出来的要点吧:
Compose UI 最核心的一个思想就是:状态向下,事件向上,Compose UI 组件的状态都应该来自其参数而不是自身,不要在 Compose UI 组件中做任何计算,有非常多的性能问题其实是来自对于这一条核心思想的不理解。 如果一个组件不得不内部持有一些状态,切记将这些状态所有的变量都用上 remember,因为 Compose 函数是会被非常频繁的执行,不用 remember 的话会导致频繁的赋值和初始化,甚至进行一些计算操作。 Compose UI 组件的参数最好是不可变(immutable)的,否则最好的情况是遇到和预期表现不符,最差的情况就是影响到性能了。 每个 Compose UI 组件最好都有 Modifier,这样 Compose UI 组件就可以很方便的在不同地方复用。 为了可维护性,请尽量拆分基础 Compose UI 组件和业务 Compose UI 组件,基础 Compose UI 组件尽量拆分的细一些,业务 Compose UI 组件看情况,最好也要拆分的细一些,你不会想去维护一个上千行的 Compose UI 组件的,同时细分也会提高一定的复用率。
下面总结了一些常见的不正确的用法,其中大部分会导致性能问题,有很多人会说 Compose 性能差,但其实更多的是本身的用法有误。
3. 滥用 remember { mutableStateOf() }
Compose UI 最核心的一个思想就是:状态向下,事件向上。这句话举个例子可能会更好理解。 一般初学者在看完教程之后马上就会写下这样的代码:
@Composable
fun Counter() {
var count by remember { mutableStateOf(0) }
Button(
onClick = {
count++
}
) {
Text("count $count")
}
}
然后当业务逻辑复杂之后,他的代码可能会像这样:
@Composable
fun Counter() {
var count by remember { mutableStateOf(0) }
var text by remember { mutableStateOf("") }
Column {
Button(
onClick = {
count++
}
) {
Text("count $count")
}
TextField(
value = text,
onValueChange = {
text = it
}
)
OtherCounter()
}
}
@Composable
fun OtherCounter() {
var text by remember { mutableStateOf("Hello world!") }
Column {
Text(text)
TextField(
value = text,
onValueChange = {
text = it
}
)
}
}
抛开代码的业务逻辑不谈,这里的 Composable 函数是带状态的,这会带来不必要的 recomposition,从而导致写出来的 Compose UI 出现性能问题,按照核心思想状态向下,事件向上,上面的代码应该这样写:
@Composable
fun CounterRoute(
viewModel: CounterViewModel = viewModel<CounterViewModel>()
) {
val state by viewModel.state.collectAsState()
Counter(
state = state,
onIncrement = {
viewModel.onIncrement()
},
onTextChange = {
viewModel.onTextChange(it)
},
onOtherTextChange = {
viewModel.onOtherTextChange(it)
},
)
}
@Composable
fun Counter(
state: CounterState,
onIncrement: () -> Unit,
onTextChange: (String) -> Unit,
onOtherTextChange: (String) -> Unit,
) {
Column {
Button(
onClick = {
onIncrement.invoke()
}
) {
Text("count ${state.count}")
}
TextField(
value = state.text,
onValueChange = {
onTextChange.invoke(it)
}
)
OtherCounter(
text = state.otherText,
onTextChange = onOtherTextChange,
)
}
}
@Composable
fun OtherCounter(
text: String,
onTextChange: (String) -> Unit,
) {
Column {
Text(text)
TextField(
value = text,
onValueChange = {
onTextChange.invoke(it)
}
)
}
}
这样的写法吧所有状态都放到顶层,同时事件也交由顶层处理,这样的 Compose UI 组件是没有任何状态的,这样的的 Compose UI 组件会有非常好的性能。
4. 忘记 remember
刚刚说完滥用,现在说忘记。当一个组件不得不内部持有状态的时候,这个时候切记:一定要吧所有的变量都用上 remember。
常见的有这样的错误:
@Composable
fun SomeList() {
val list = listOf("a", "b", "c")
LazyColumn {
items(list) {
Text(it)
}
}
}
这里的 list 完全没有被 remember,而 Compose 函数会非常频繁的执行,这就导致每次执行到 val list = listOf("a", "b", "c") 的时候都会有一次生成赋值甚至计算的操作,这样的写法是非常影响性能的,正确的写法应该是这样:
@Composable
fun SomeList() {
val list = remember { listOf("a", "b", "c") }
LazyColumn {
items(list) {
Text(it)
}
}
}
当然最好是把 list 移到参数上:
@Composable
fun SomeList(
list: List<String>,
) {
LazyColumn {
items(list) {
Text(it)
}
}
}
5. 参数是可变的
还是接着上一个例子,光是 list 移动到参数还是不够的,因为你可以在 Composable 函数外边更改这个列表,比如执行 list.add("") 的操作,Compose 编译器会认为这个 Composable 函数仍然是带状态的,所以还不是最优化的状态。最好是使用 kotlinx.collections.immutable 里面的 ImmutableList:
@Composable
fun SomeList(
list: ImmutableList<String>,
) {
LazyColumn {
items(list) {
Text(it)
}
}
}
除了基础类型之外,其他参数中的自定义 class 最好是标记上 @Immutable,这样 Compose 编译器会优化这个 Composable 函数。当然不要定义一个 data class 然后里面一个 var a: String 然后问为什么 a.a = "b" 没有效果,建议传给 Composable 函数的 data class 全是 val。
6. 没开启 R8
R8 对于 Compose 的提升是非常巨大的,如果是简单 UI 的话没有 R8 可能还可以用,复杂 UI 下非常推荐开启 R8,代码优化之后的性能的 Debug 的性能差距极大。
7. 最后:面试题推荐
其实理解了 Compose UI 的核心思想之后,写出来的 Compose 程序应该不会有什么性能问题,而且在这个核心思想下写出来的 Compose UI 逻辑非常的清晰,因为整个 UI 是无状态的,你只需要关系在什么状态下这个 UI 显示的是什么样的,心智负担非常小。
最后推荐一些 Compose 相关的面试题,大家可以做一个自我测试,如果你能回答的七七八八,那么恭喜你,可能已经击败 95% 的同行了。
Jetpack Compose有了解吗?和传统Android UI有什么不同? DisposableEffect、SideEffect、LaunchedEffect之间的区别? pointer事件在各个Composable function之间是如何处理的? 自定义Layout? CompositionLocal起什么作用?staticCompositionLocalOf和compositionLocalOf有什么区别? Composable function的状态是如何持久化的? LazyColumn是如何做Composable function缓存的? 如何解决LazyColumn和其他Composable function的滑动冲突? @Composable的作用是什么? Jetpack Compose是用什么渲染的?执行流程是怎么样的?与flutter/react那样做diff有什么区别/优劣? Jetpack Compose多线程执行是如何实现的? 什么是有状态的 Composable 函数?什么是无状态的 Composable 函数? Compose 的状态提升如何理解?有什么好处? 如何理解 MVI 架构?和 MVVM、MVP、MVC 有什么不同的? 在 Android 上,当一个 Flow 被 collectAsState,应用转入后台时,如果这个 Flow 再进行更新,对应的 State 会不会更新?对应的 Composable 函数会不会更新?
浅谈软件质量与度量
我正在参加「掘金·启航计划」
本文从研发角度探讨下高质量软件应具备哪些特点,以及如何度量软件质量。
软件质量的分类
软件质量通常可以分为:内部质量和外部质量。
内部质量
内部质量是指软件的结构和代码质量,以及其是否适合维护、扩展和重构。它关注的是软件本身的特性和属性,包括:
- 可读性:代码易于阅读和理解;
- 易维护性:代码易于修改和维护;
- 可测试性:代码易于编写单元测试并进行自动化测试;
- 可靠性:代码稳定、不容易崩溃或出现错误;
- 可扩展性:代码能够方便地进行扩展;
- 可重用性:代码可被复用于其他项目中。
内部质量直接影响软件的可维护性和开发效率。如果软件的内部质量很差,那么开发人员可能需要花费更多的时间修复问题,而不是开发新功能。
外部质量
外部质量是指软件的用户体验和其符合用户需求的程度。它关注的是软件的功能和表现形式,包括:
- 功能性:软件是否具有所需的功能,并且这些功能是否能够正常工作;
- 易用性:软件是否易于使用,是否符合用户的期望;
- 性能:软件是否运行快速并响应迅速;
- 兼容性:软件是否能够在不同的操作系统和设备上正常工作。
外部质量如果很差,那么用户在使用软件过程中可能会遇到问题,而这些问题可能会影响用户体验,导致用户流失。
为什么内部质量更重要
内部质量高的核心降低了未来变更的成本。
可以参考下图的时间-功能累计关系图。
对于内部质量比较差的软件,虽然初期进展迅速,但是随着时间的流逝,添加新功能变得越来越困难。甚至一个小改动也需要程序员理解大量代码。当开发做代码变更时,还可能产生意想不到的缺陷,因此导致测试时间长,需要更高成本来做缺陷修复和验证。
对于内部质量高的软件,则与其相反,可以参考下图的比较。
内部质量高的软件更容易被实现。
内部质量高的软件特点之一就是易读性。 这样利于开发者更快弄清楚应用程序是如何运行的,这样就可以知道如何添加新功能。如果将软件很好地划分为不同的实现模块,则开发者没必要阅读所有代码,只需要快速找到涉及功能变动模块的代码就行。
如何衡量软件质量
Cyclomatic Complexity(圈复杂度)
Cyclomatic Complexity通过计算代码中不同路径的数量来衡量代码的复杂程度。圈复杂度越高,表示代码的控制流程越复杂,可能存在更多的错误和缺陷。
下面举例说明Cyclomatic Complexity如何计算。
public int calculate(x, y) {
if (x >= 20) {
if (y >= 20) {
return y;
}
return x;
}
return x + y;
}
这段代码的流程图如下:
圈复杂度的公式如下:
E - N + 2
其中 E 表示图中的边数(上图中的所有形状),N 表示节点数(上图中的所有箭头)。因此,在我们的例子中,6 - 5 + 2 = 3,的确这段代码包含三条路径。
Maintainability Index(可维护性指数)
Maintainability Index(可维护性指数)是一种用于评估软件代码可维护性的指标。它通常考虑代码的复杂度、长度和注释等因素,并将这些因素整合成一个分数来衡量代码的可读性、可维护性和可重构性。
通常情况下,可维护性指数的分数范围是 [0,100],分数越高表示代码的可维护性越好。可维护性指数可以帮助开发人员识别哪些代码需要改进,以提高代码的可维护性和可读性,从而减少维护成本、降低缺陷率,提高代码的质量。
Dependencies(依赖)
软件的开发过程势必会依赖外部框架和库,这些框架和库自身也会经常更新(维护者会添加和删除功能、修复错误、改进性能,并修补安全漏洞)。
旧版本库和框架通常会对依赖它的软件质量产生负面影响。例如安全漏洞是明显的风险(例如22年8月份的
Apachelog4j漏洞)。
SQALE评估法
SQALE评估法主要关注四个指标:
- 技术债:即未来要花费的时间和资源去修复当前存在的问题
- 可维护性:即代码的易读性、可理解性和可扩展性,从代码的模块化程度、命名规范、注释等因素,并对这些因素进行打分。
- 可靠性:即软件的稳定性和可靠性,评估代码中存在的错误、漏洞和异常处理情况。如果存在较多的问题,他们就需要考虑重新设计代码或增加更多的测试用例。
- 性能:即软件的响应速度和处理能力
链接:https://juejin.cn/post/7227105808457564215
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
for和range性能大比拼!
能GET到的知识点
- 什么场景使用for和range
1. 从一个遍历开始
万能的range遍历
- 遍历array/slice/strings
array
package main
import "fmt"
func main() {
var UserIDList = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
for i, v := range UserIDList {
fmt.Println(i, v)
}
}
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
slice
package main
import "fmt"
func main() {
var UserIDList = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
var UerSlice = UserIDList[:]
for i, v := range UerSlice {
fmt.Println(i, v)
}
}
0 1
1 2
2 3
3 4
4 5
5 6
6 7
7 8
8 9
9 10
字符串
func main(){
var Username = "斑斑砖abc"
for i, v := range Username {
fmt.Println(i, v)
}
}
0 26001
3 26001
6 30742
9 97
10 98
11 99
range进行对array、slice类型遍历一切都正常,但是到了对字符串进行遍历时这里就出问题了,出问题主要在索引这一块。可以看出索引是每个字节的位置,在go语言中的字符串是UTF-8编码的字节序列。而不是单个的Unicode字符。遇到中文字符时需要使用多个字节表示,英文字符一个字节进行表示,索引0-3表示了一个字符及斑以此完后。
- 遍历map
func ByMap() {
m := map[string]int{
"one": 1,
"two": 2,
"three": 3,
}
for k, v := range m {
delete(m, "two")
m["four"] = 4
fmt.Printf("%v: %v\n", k, v)
}
}
one: 1
four: 4
three: 3
- 和切片不同的是,迭代过程中,删除还未迭代到的键值对,则该键值对不会被迭代。
- 在迭代过程中,如果创建新的键值对,那么新增键值对,可能被迭代,也可能不会被迭代。个人认为应该是hash的无序性问题
- 针对 nil 字典,迭代次数为 0
- 遍历channel
func ByChannel() {
ch := make(chan string)
go func() {
ch <- "a"
ch <- "b"
ch <- "c"
ch <- "d"
close(ch)
}()
time.Sleep(time.Second)
for n := range ch {
fmt.Println(n)
}
}
- 针对于range对关闭channel的遍历,会直到把元素都读取完成。
- 但是在for遍历会造成阻塞,因为for变量读取一个关闭的管道并不会进行退出,而是一直进行等待,但是如果关闭了会返回一个状态值可以根据该状态值判断是否需要操作
2.for和range之间奇怪的问题
2.1 无限遍历现象
for
c := []int{1, 2, 3}
for i := 0; i < len(c); i++ {
c = append(c, i)
fmt.Println(i)
}
1
2
3
.
.
.
15096
15097
15098
15099
15100
15101
15102
15103
15104
range
c := []int{1, 2, 3}
for _, v := range c {
c = append(c, v)
fmt.Println(v)
}
1
2
3
可以看出for循环一直在永无止境的进行追加元素。 range循环正常。原因:for循环的i < len(c)-1都会进行重新计算一次,造成了永远都不成立。range循环遍历在开始前只会计算一次,如果在循环进行修改也不会影响正常变量。
2.2 在for和range进行修改操作
for
type UserInfo struct {
Name string
Age int
}
var UserInfoList = [3]UserInfo{
{Name: "John", Age: 25},
{Name: "Jane", Age: 30},
{Name: "Mike", Age: 28},
}
for i := 0; i < len(UserInfoList); i++ {
UserInfoList[i].Age += i
}
fmt.Println(UserInfoList)
0
1
2
[{John 25} {Jane 31} {Mike 30}]
range
var UserInfoList = [3]UserInfo{
{Name: "John", Age: 25},
{Name: "Jane", Age: 30},
{Name: "Mike", Age: 28},
}
for i, info := range UserInfoList {
info.Age += i
}
fmt.Println(UserInfoList)
[{John 25} {Jane 30} {Mike 28}]
可以看出for循环进行修改了成功,但是在range循环修改失效,为什么呢?因为range循环返回的是对该值的拷贝,所以修改失效。for循环修相当于进行原地修改了。但如果在for循环里面进行赋值修改操作,那么修改也会进行失效 具体如下
var UserInfoList = [3]UserInfo{
{Name: "John", Age: 25},
{Name: "Jane", Age: 30},
{Name: "Mike", Age: 28},
}
for i := 0; i < len(UserInfoList); i++ {
fmt.Println(i)
item := UserInfoList[i]
item.Age += i
}
fmt.Println(UserInfoList)
> [{John 25} {Jane 30} {Mike 28}]
3. Benchmark大比拼
主要是针对大类型结构体
type Item struct {
id int
val [4096]byte
}
for_test.go
func BenchmarkForStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
length := len(items)
var tmp int
for k := 0; k < length; k++ {
tmp = items[k].id
}
_ = tmp
}
}
func BenchmarkRangeStruct(b *testing.B) {
var items [1024]Item
for i := 0; i < b.N; i++ {
var tmp int
for _, item := range items {
tmp = item.id
}
_ = tmp
}
}
goos: windows
goarch: amd64
pkg: article/02fortest
cpu: AMD Ryzen 5 5600G with Radeon Graphics
BenchmarkForStruct-12 2503378 474.8 ns/op 0 B/op 0 allocs/op
BenchmarkRangeStruct-12 4983 232744 ns/op 0 B/op 0 allocs/op
PASS
ok article/02fortest 3.268s
可以看出 for 的性能大约是 range 的 600 倍。
为什么会产生这么大呢?
上述也说过,range遍历会对迭代的值创建一个拷贝。在占据占用较大的结构时每次都需要进行做一次拷贝,取申请大约4kb的内存,显然是大可不必的。所以在对于占据较大的结构时,应该使用for进行变量操作。
总结
如何选择合适的遍历,在针对与测试场景的情况下,图便捷可以使用range,毕竟for循环需要写一堆的条件,初始值等。但是如果遍历的元素是个占用大个内存的结构的话,避免使用range进行遍历。且如果需要进行修改操作的话只能用for遍历来修改,其实range也可以进行索引遍历的,在本文为写,读者可以去尝试一下。
链接:https://juejin.cn/post/7261549950555078711
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
告别StringUtil:使用Java 全新String API优化你的代码
前言
Java 编程语言的每一次重要更新,都引入了许多新功能和改进。 并且在String 类中引入了一些新的方法,能够更好地满足开发的需求,提高编程效率。
- repeat(int count):返回一个新的字符串,该字符串是由原字符串重复指定次数形成的。
- isBlank():检查字符串是否为空白字符序列,即长度为 0 或仅包含空格字符的字符串。
- lines():返回一个流,该流由字符串按行分隔而成。
- strip():返回一个新的字符串,该字符串是原字符串去除前导空格和尾随空格后形成的。
- stripLeading():返回一个新的字符串,该字符串是原字符串去除前导空格后形成的。
- stripTrailing():返回一个新的字符串,该字符串是原字符串去除尾随空格后形成的。
- formatted(Object... args):使用指定的参数格式化字符串,并返回格式化后的字符串。
- translateEscapes():将 Java 转义序列转换为相应的字符,并返回转换后的字符串。
- transform() 方法:该方法可以将一个函数应用于字符串,并返回函数的结果。
示例
1. repeat(int count)
public class StringRepeatExample {
public static void main(String[] args) {
String str = "abc";
String repeatedStr = str.repeat(3);
System.out.println(repeatedStr);
}
}
输出结果:
abcabcabc
2. isBlank()
public class StringIsBlankExample {
public static void main(String[] args) {
String str1 = "";
String str2 = " ";
String str3 = " \t ";
System.out.println(str1.isBlank());
System.out.println(str2.isBlank());
System.out.println(str3.isBlank());
}
}
输出结果:
true
true
true
3. lines()
import java.util.stream.Stream;
public class StringLinesExample {
public static void main(String[] args) {
String str = "Hello\nWorld\nJava";
Stream<String> lines = str.lines();
lines.forEach(System.out::println);
}
}
输出结果:
Hello
World
Java
4. strip()
public class StringStripExample {
public static void main(String[] args) {
String str1 = " abc ";
String str2 = "\t def \n";
System.out.println(str1.strip());
System.out.println(str2.strip());
}
}
输出结果:
abc
def
5. stripLeading()
public class StringStripLeadingExample {
public static void main(String[] args) {
String str1 = " abc ";
String str2 = "\t def \n";
System.out.println(str1.stripLeading());
System.out.println(str2.stripLeading());
}
}
输出结果:
abc
def
6. stripTrailing()
public class StringStripTrailingExample {
public static void main(String[] args) {
String str1 = " abc ";
String str2 = "\t def \n";
System.out.println(str1.stripTrailing());
System.out.println(str2.stripTrailing());
}
}
输出结果:
abc
def
7. formatted(Object... args)
public class StringFormattedExample {
public static void main(String[] args) {
String str = "My name is %s, I'm %d years old.";
String formattedStr = str.formatted( "John", 25);
System.out.println(formattedStr);
}
}
输出结果:
My name is John, I'm 25 years old.
8. translateEscapes()
public class StringTranslateEscapesExample {
public static void main(String[] args) {
String str = "Hello\\nWorld\\tJava";
String translatedStr = str.translateEscapes();
System.out.println(translatedStr);
}
}
输出结果:
Hello
World Java
9. transform()
public class StringTransformExample {
public static void main(String[] args) {
String str = "hello world";
String result = str.transform(i -> i + "!");
System.out.println(result);
}
}
输出结果:
hello world!
结尾
如果觉得对你有帮助,可以多多评论,多多点赞哦,也可以到我的主页看看,说不定有你喜欢的文章,也可以随手点个关注哦,谢谢。
我是不一样的科技宅,每天进步一点点,体验不一样的生活。我们下
链接:https://juejin.cn/post/7222996459833770021
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
深入理解与运用Android Jetpack ViewModel
在Android开发中,数据与界面的分离一直是一项重要的挑战。为了解决这个问题,Google推出了Android Jetpack组件之一的ViewModel。ViewModel是一种用于管理UI相关数据的架构组件,它能够帮助开发者实现优雅的数据驱动和生命周期管理。本文将深入浅出地介绍ViewModel的使用和原理,带你一步步掌握这个强大的组件。
什么是ViewModel
ViewModel是Android Jetpack组件之一,它的主要目的是将UI控制器(如Activity和Fragment)与数据相关的业务逻辑分开,使得UI控制器能够专注于展示数据和响应用户交互,而数据的获取和处理则交由ViewModel来管理。这种分离能够使代码更加清晰、易于测试和维护。
ViewModel的原理
ViewModel的原理其实并不复杂。在设备配置发生变化(如屏幕旋转)导致Activity或Fragment重建时,ViewModel不会被销毁,而是保留在内存中。这样,UI控制器可以在重建后重新获取之前的ViewModel实例,并继续使用其中的数据,从而避免数据丢失和重复加载。
ViewModelStore和ViewModelStoreOwner
ViewModel的原理涉及两个核心概念:ViewModelStore和ViewModelStoreOwner。
ViewModelStore是一个存储ViewModel实例的容器,它的生命周期与UI控制器的生命周期关联。在UI控制器(Activity或Fragment)被销毁时,ViewModelStore会清理其中的ViewModel实例,避免内存泄漏。
ViewModelStoreOwner是拥有ViewModelStore的对象,通常是Activity或Fragment。ViewModelProvider通过ViewModelStoreOwner来获取ViewModelStore,并通过ViewModelStore来管理ViewModel的生命周期。
ViewModelProvider
ViewModelProvider是用于创建和获取ViewModel实例的工具类。它负责将ViewModel与ViewModelStoreOwner关联,并确保ViewModel在合适的时机被销毁。
在Activity中获取ViewModel实例:
viewModel = new ViewModelProvider(this).get(MyViewModel.class);
在Fragment中获取ViewModel实例:
viewModel = new ViewModelProvider(this).get(MyViewModel.class);
使用ViewModel
添加ViewModel依赖
首先,确保你的项目已经使用了AndroidX,并在build.gradle中添加ViewModel依赖:
dependencies {
implementation "androidx.lifecycle:lifecycle-viewmodel-ktx:2.3.1"
}
创建ViewModel
创建ViewModel非常简单,只需继承ViewModel类并在其中定义数据和相关操作。
public class MyViewModel extends ViewModel {
private MutableLiveData<String> data = new MutableLiveData<>();
public LiveData<String> getData() {
return data;
}
public void fetchData() {
// 模拟异步数据获取
new Handler().postDelayed(() -> {
data.setValue("Hello, ViewModel!");
}, 2000);
}
}
在UI控制器中使用ViewModel
在Activity或Fragment中获取ViewModel的实例,并观察数据变化:
viewModel = new ViewModelProvider(this).get(MyViewModel.class);
viewModel.getData().observe(this, data -> {
// 更新UI
textView.setText(data);
});
viewModel.fetchData(); // 触发数据获取操作
ViewModel与跨组件通信
ViewModel不仅仅用于在单个UI控制器内部共享数据,它还可以用于在不同UI控制器之间共享数据,实现跨组件通信。例如,一个Fragment中的数据可以通过ViewModel传递给Activity。
在Activity中共享数据:
sharedViewModel = new ViewModelProvider(this).get(SharedViewModel.class);
sharedViewModel.getData().observe(this, data -> {
// 更新UI
textView.setText(data);
});
在Fragment中共享数据:
sharedViewModel = new ViewModelProvider(requireActivity()).get(SharedViewModel.class);
注意:在跨组件通信时,需要使用同一个ViewModelProvider获取相同类型的ViewModel实例。在Activity中,使用this作为ViewModelProvider的参数,在Fragment中,使用requireActivity()作为参数。
ViewModel与SavedState
有时,我们可能希望在ViewModel中保存一些与UI控制器生命周期无关的数据,以便在重建时恢复状态。ViewModel提供了SavedState功能,它可以让我们在ViewModel中持久化保存数据。
示例代码:
public class MyViewModel extends ViewModel {
private SavedStateHandle savedStateHandle;
public MyViewModel(SavedStateHandle savedStateHandle) {
this.savedStateHandle = savedStateHandle;
}
public LiveData<String> getData() {
return savedStateHandle.getLiveData("data");
}
public void setData(String data) {
savedStateHandle.set("data", data);
}
}
使用SavedStateViewModelFactory创建带有SavedState功能的ViewModel:
public class MyActivity extends AppCompatActivity {
private MyViewModel viewModel;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ViewModelProvider.Factory factory = new SavedStateViewModelFactory(getApplication(), this);
viewModel = new ViewModelProvider(this, factory).get(MyViewModel.class);
viewModel.getData().observe(this, data -> {
// 更新UI
textView.setText(data);
});
if (savedInstanceState == null) {
// 第一次创建时,触发数据获取操作
viewModel.fetchData();
}
}
}
ViewModel使用过程中的注意点
- 不要在ViewModel中持有Context的引用,避免引发内存泄漏。
- ViewModel应该只关注数据和业务逻辑,不应处理UI相关的操作。
- 不要在ViewModel中保存大量数据,避免占用过多内存。
- 当数据量较大或需要跨进程共享数据时,应该考虑使用其他解决方案,如Room数据库或SharedPreferences。
结论
通过本文的介绍,你已经了解了Android Jetpack ViewModel的使用与原理。ViewModel的出现极大地简化了Android开发中的数据管理和生命周期处理,使得应用更加健壮和高效。在实际开发中,合理使用ViewModel能够帮助你构建优雅、易维护的Android应用。
链接:https://juejin.cn/post/7261894612170653757
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android TextView中那些冷门好用的用法
介绍
TextView 是 Android 开发中最常用的小部件之一。它用于在屏幕上显示文本。但是,TextView 有几个较少为人知的功能,对开发人员非常有用。在本博客文章中,我们将探讨其中的一些功能。
自定义字体
默认情况下,TextView 使用系统字体显示文本。但其实我们也可以导入我们自己的字体文件在 TextView 中使用自定义字体。这可以通过将字体文件添加到资源文件夹(res/font 或者 assets)并在 TextView 上以编程方式设置来实现。
要使用自定义字体,我们需要下载字体文件(或者自己生成)并将其添加到资源文件夹中。然后,我们可以使用setTypeface()方法在TextView上以编程方式设置字体。我们还可以在XML中使用android:fontFamily属性设置字体。需要注意的是,fontFamily方式只能使用系统预设的字体并且仅对英文字符有效,如果TextView的文本内容是中文的话这个属性设置后将不会有任何效果。
以下是 Android TextView 自定义字体的代码示例:
- 将字体文件添加到 assets 或 res/font 文件夹中。
- 通过以下代码设置字体:
// 字体文件放到 assets 文件夹的情况
Typeface tf = Typeface.createFromAsset(getAssets(), "fonts/myfont.ttf");
TextView tv = findViewById(R.id.tv);
tv.setTypeface(tf);// 字体文件放到 res/font 文件夹的情况, 需注意的是此方式在部分低于 Android 8.0 的设备上可能会存在兼容性问题
val tv = findViewById<TextView>(R.id.tv)
val typeface = ResourcesCompat.getFont(this, R.font.myfont)
tv.typeface = typeface
在上面的示例中,我们首先从 assets 文件夹中创建了一个新的 Typeface 对象。然后,我们使用 setTypeface() 方法将该对象设置为 TextView 的字体。
在上面的示例中,我们将字体文件命名为 “myfont.ttf”。我们可以将其替换为要使用的任何字体文件的名称。
自定义字体是 TextView 的强大功能之一,它可以帮助我们创建具有独特外观和感觉的应用程序。另外,我们也可以通过这种方法实现自定义图标的绘制。
AutoLink
AutoLink 可以自动检测文本中的模式并将其转换为可点击的链接。例如,如果 TextView 包含电子邮件地址或 URL,则 AutoLink 将识别它并使其可点击。此功能使开发人员无需手动创建文本中的可点击链接。
要在 TextView 上启用 AutoLink,您需要将autoLink属性设置为email,phone,web或all。您还可以使用Linkify类设置自定义链接模式。
以下是一个Android TextView AutoLink代码使用示例:
<TextView
android:id="@+id/tv3"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:autoLink="web"
android:textColorLink="@android:color/holo_red_dark"
android:text="这是我的个人博客地址: http://www.geektang.cn" />
在上面的示例中,我们将 autoLink 属性设置为 web ,这意味着 TextView 将自动检测文本中的 URL 并将其转换为可点击的链接。我们还将 text 属性将文本设置为 这是我的个人博客地址: http://www.geektang.cn 。当用户单击链接时,它们将被带到 http://www.geektang.cn 网站。另外,我们也可以通过 textColorLink 属性将 Link 颜色为我们喜欢的颜色。
AutoLink是一个非常有用的功能,它可以帮助您更轻松地创建可交互的文本。
对齐模式
对齐模式允许您通过在单词之间添加空格将文本对齐到左右边距,这使得文本更易读且视觉上更具吸引力。您可以将对齐模式属性设置为 inter_word 或 inter_character。
要使用对齐模式功能,您需要在 TextView 上设置 justificationMode 属性。但是,此功能仅适用于运行 Android 8.0(API 级别 26)或更高版本的设备。
以下是对齐模式功能的代码示例:
<TextView
android:id="@+id/text_view"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="This is some sample text that will be justified."
android:justificationMode="inter_word"/>
在上面的示例中,我们将 justificationMode 属性设置为 inter_word 。这意味着 TextView 将在单词之间添加空格,以便将文本对齐到左右边距。
以下是对齐模式功能的显示效果示例:
同样一段文本,上面的设置 justificationMode 为 inter_word ,是不是看起来会比下面的好看一些呢?这个属性一般用于多行英文文本,如果只有一行文本或者文本内容是纯中文字符的话,不会有任何效果。
链接:https://juejin.cn/post/7217082232937283645
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
六种常见的排序算法
排序算法
数组任意两值交换
创建临时变量进行交换
private void swap(int[] nums, int idx1, int idx2) {
int temp = nums[idx1];
nums[idx1] = nums[idx2];
nums[idx2] = temp;
}
冒泡排序
思路:每次对 [0, j] 进行排序,把该区间中最大的值放到这个区间的最右边;
时间复杂度:O(n2)
空间复杂度:O(1)
/**
* 冒泡排序
*
* @param nums 数组
*/
public void bubbleSort(int[] nums) {
for (int i = 0; i < nums.length - 1; i++) {
for (int j = 0; j < nums.length - 1 - i; j++) {
if (nums[j] > nums[j + 1]) {
swap(nums, j, j + 1);
}
}
}
}
选择排序
思路:对于区间 [j, nums.length] (i <= j <= nums.length),每次在这个区间中选择最小的值,插入到 nums[i] 中,即每次选择一个最小的值插入到 nums[i] 中;
时间复杂度:O(n2)
空间复杂度:O(1)
/**
* 插入排序
*
* @param nums 数组
*/
public void insertSort(int[] nums) {
for (int i = 0; i < nums.length; i++) {
int idx = 0;
int min = Integer.MAX_VALUE;
for (int j = i; j < nums.length; j++) {
if (nums[j] < min) {
min = nums[j];
idx = j;
}
}
swap(nums, i, idx);
}
}
插入排序
思路:对于区间 [0, j] ,在 [i, length-1] 的区间中每次使用下标的 i 的数( j <= i ),插入到区间 [0, j] 中,保证 [0, j] 是有序的
时间复杂度:O(n2)
空间复杂度:O(1)
/**
* 插入排序
*
* @param nums 数组
*/
public void insertSort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int temp = nums[i];
int j = i;
for (; j > 0; j--) {
if (temp < nums[j - 1]) {
nums[j] = nums[j - 1];
} else {
break;
}
}
nums[j] = temp;
}
}
快速排序
思路:
- 对于单次的排序
partition(),定义一个标志 part ,凡是小于该值的都放左边,大于该值的都放右边,最后把该值放到中间,并返回中间的下标partition,这里实现的关键是:存在一个指针 j 始终指向左边区间的最靠右的值,若 j + 1,则去到了右区间; - 将数组以 partition 为中点,将数组分成两份,每一份继续进行
partition();
时间复杂度:O(nlogn)
空间复杂度:O(logn)
/**
* 递归函数
*
* @param nums 数组
* @param left 左
* @param right 右
*/
public void quickSort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
int partition = partition(nums, left, right);
quickSort(nums, left, partition - 1);
quickSort(nums, partition + 1, right);
}
/**
* 将小于某个元素的值放到左边,大于某个元素的值放到右边
*
* @param nums 数组
* @param left 左
* @param right 右
* @return 结果
*/
public int partition(int[] nums, int left, int right) {
// 以数组的左边的值作为标记
int part = nums[left];
int i = left + 1;
// j 始终指向左边区间小于或等于 part 的最靠右的值
int j = left;
for (; i < nums.length; i++) {
if (nums[i] < part) {
j++;
swap(nums, i, j);
}
}
swap(nums, j, left);
return j;
}
三向切分快速排序
适用于有重复内容的排序
思路:
- 分成三个区间,小于 pivot(左区间),等于 pivot(中区间),大于 pivot(右区间);
- 左区间的 lt 指针永远指向该区间的最右的位置,右区间的指针永远指向该区间的最左的位置;
- 对于中区间,不断移动游标 i 的位置即可;
时间复杂度:O(nlogn)
空间复杂度:O(logn)
public void threeQuickSort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
int pivot = nums[left];
// [left + 1, lt] 小于 pivot
// [lt + 1, i) 等于 pivot
// [gt, right] 大于 pivot
int lt = left; // 左区间的指针
int gt = right + 1; // 右区间的指针
int i = left + 1;
while (i < gt) {
if (nums[i] < pivot) {
lt++;
swap(nums, i, lt);
i++;
} else if (nums[i] == pivot) {
i++;
} else {
gt++;
swap(nums, gt, i);
}
}
swap(nums, left, lt);
threeQuickSort(nums, left, lt - 1);
threeQuickSort(nums, gt, right);
}
归并排序
思路:
- 分隔:先将数组不断分割,直到分割到区间 [left, right] 内只有一个值
- 合并:将分隔后的数组不断向上合并,利用临时数组 temp[] 存储 原来 nums 数组 [left,right] 区间的值,然后分别从 temp 数组中 [left, mid] 和 [mid + 1, right] 区间分别取出最小的值,放入 nums 数组对应的位置即可;
- 代码的主要难点是 nums 数组 和 temp 数组的下标对应关系
- i 对应 left,即 [left, mid] 的起点,i 在 temp 数组起始值为 0
- j 对应 mid + 1,即 [mid + 1, right] 的起点,j 在 temp 数组起始值为 mid - left + 1
时间复杂度:O(nlogn)
空间复杂度:O(n + logn) => O(n):临时的数组和递归时压入栈的数据占用的空间
public void mergeSort(int[] nums, int left, int right) {
if (left >= right) {
return;
}
int mid = left + (right - left) / 2;
mergeSort(nums, left, mid);
mergeSort(nums, mid + 1, right);
merge(nums, left, mid, right);
}
/**
* 合并数组
*
* @param nums 数组
* @param left 左端点
* @param mid 中点
* @param right 右端点
*/
private void merge(int[] nums, int left, int mid, int right) {
int length = right - left + 1;
int[] temp = new int[length];
for (int i = 0; i < length; i++) {
temp[i] = nums[left + i];
}
// i j 为 temp 数组的下标
// 关键是找到 i j 与 原数组 nums 下标的对应关系
int i = 0;
int j = mid - left + 1;
for (int k = 0; k < length; k++) {
if (i == mid - left + 1) {
nums[k + left] = temp[j];
j++;
} else if (j == right - left + 1) {
nums[k + left] = temp[i];
i++;
} else if (temp[i] <= temp[j]) {
nums[k + left] = temp[i];
i++;
} else {
nums[k + left] = temp[j];
j++;
}
}
}
堆排序
思路:
- 读者首先搞懂什么是 堆 ,代码示例中介绍的 大顶堆,这里不作过多介绍;
- 首先初始化一个大顶堆,每个大顶堆的根节点是最大值;
- 不断把根节点的值与数组最后一个值交换,然后长度减 1 再次进行大顶堆的整理操作;
时间复杂度:O(nlogn),每次整理的时间复杂度是 logn,要进行 n 次
空间复杂度:O(1)
/**
* 堆排序
*
* @param nums 数组
*/
public void heapSort(int[] nums) {
initMaxHeap(nums);
int len = nums.length - 1;
while (len > 0) {
swap(nums, 0, len);
len--;
siftDown(nums, 0, len);
}
}
/**
* 初始化为大顶堆
*
* @param nums 数组
*/
public void initMaxHeap(int[] nums) {
int len = nums.length;
for (int i = (len - 1) / 2; i >= 0; i--) {
siftDown(nums, i, len - 1);
}
}
/**
* 向下整理
* @param nums 数组
* @param k 某个节点
* @param len 数组长度
*/
public void siftDown(int[] nums, int k, int len) {
while (k * 2 + 1 <= len) {
int j = k * 2 + 1;
if (j + 1 <= len && nums[j] < nums[j + 1]) {
j++;
}
if (nums[k] > nums[j]) {
break;
}
swap(nums, k, j);
k = j;
}
}链接:https://juejin.cn/post/7227000792498618427
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Java 理论知识整理
过滤器
数据准备
DAO 层 UserDao、AccountDao、BookDao、EquipmentDao
public interface UserDao {
public void save();
}@Component("userDao")
public class UserDaoImpl implements UserDao {
public void save() {
System.out.println("user dao running...");
}
}
Service 业务层
public interface UserService {
public void save();
}@Service("userService")
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;//...........BookDao等
public void save() {
System.out.println("user service running...");
userDao.save();
}
}
过滤器
名称:TypeFilter
类型:接口
作用:自定义类型过滤器
示例:
config / filter / MyTypeFilter
public class MyTypeFilter implements TypeFilter {
@Override
/**
* metadataReader:读取到的当前正在扫描的类的信息
* metadataReaderFactory:可以获取到任何其他类的信息
*/
//加载的类满足要求,匹配成功
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException {
//获取当前类注解的信息
AnnotationMetadata am = metadataReader.getAnnotationMetadata();
//获取当前正在扫描的类的类信息
ClassMetadata classMetadata = metadataReader.getClassMetadata();
//获取当前类资源(类的路径)
Resource resource = metadataReader.getResource();
//通过类的元数据获取类的名称
String className = classMetadata.getClassName();
//如果加载的类名满足过滤器要求,返回匹配成功
if(className.equals("service.impl.UserServiceImpl")){
//返回true表示匹配成功,返回false表示匹配失败。此处仅确认匹配结果,不会确认是排除还是加入,排除/加入由配置项决定,与此处无关
return true;
}
return false;
}
}
SpringConfig
@Configuration
//设置排除bean,排除的规则是自定义规则(FilterType.CUSTOM),具体的规则定义为MyTypeFilter
@ComponentScan(
value = {"dao","service"},
excludeFilters = @ComponentScan.Filter(
type= FilterType.CUSTOM,
classes = MyTypeFilter.class
)
)
public class SpringConfig {
}
导入器
bean 只有通过配置才可以进入 Spring 容器,被 Spring 加载并控制
配置 bean 的方式如下:
- XML 文件中使用 标签配置
- 使用 @Component 及衍生注解配置
导入器可以快速高效导入大量 bean,替代 @Import({a.class,b.class}),无需在每个类上添加 @Bean
名称: ImportSelector
类型:接口
作用:自定义bean导入器
selector / MyImportSelector
public class MyImportSelector implements ImportSelector{
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
// 1.编程形式加载一个类
// return new String[]{"dao.impl.BookDaoImpl"};
// 2.加载import.properties文件中的单个类名
// ResourceBundle bundle = ResourceBundle.getBundle("import");
// String className = bundle.getString("className");
// 3.加载import.properties文件中的多个类名
ResourceBundle bundle = ResourceBundle.getBundle("import");
String className = bundle.getString("className");
return className.split(",");
}
}
import.properties
#2.加载import.properties文件中的单个类名
#className=dao.impl.BookDaoImpl
#3.加载import.properties文件中的多个类名
#className=dao.impl.BookDaoImpl,dao.impl.AccountDaoImpl
#4.导入包中的所有类
path=dao.impl.*
SpringConfig
@Configuration
@ComponentScan({"dao","service"})
@Import(MyImportSelector.class)
public class SpringConfig {
}
注册器
可以取代 ComponentScan 扫描器
名称:ImportBeanDefinitionRegistrar
类型:接口
作用:自定义 bean 定义注册器
registrar / MyImportBeanDefinitionRegistrar
public class MyImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
/**
* AnnotationMetadata:当前类的注解信息
* BeanDefinitionRegistry:BeanDefinition注册类,把所有需要添加到容器中的bean调用registerBeanDefinition手工注册进来
*/
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
//自定义注册器
//1.开启类路径bean定义扫描器,需要参数bean定义注册器BeanDefinitionRegistry,需要制定是否使用默认类型过滤器
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(registry,false);
//2.添加包含性加载类型过滤器(可选,也可以设置为排除性加载类型过滤器)
scanner.addIncludeFilter(new TypeFilter() {
@Override
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory) throws IOException {
//所有匹配全部成功,此处应该添加实际的业务判定条件
return true;
}
});
//设置扫描路径
scanner.addExcludeFilter(tf);//排除
scanner.scan("dao","service");
}
}
SpringConfig
@Configuration
@Import(MyImportBeanDefinitionRegistrar.class)
public class SpringConfig {
}
处理器
通过创建类继承相应的处理器的接口,重写后置处理的方法,来实现拦截 Bean 的生命周期来实现自己自定义的逻辑
BeanPostProcessor:bean 后置处理器,bean 创建对象初始化前后进行拦截工作的
BeanFactoryPostProcessor:beanFactory 的后置处理器
加载时机:在 BeanFactory 初始化之后调用,来定制和修改 BeanFactory 的内容;所有的 bean 定义已经保存加载到 beanFactory,但是 bean 的实例还未创建执行流程:
ioc 容器创建对象
invokeBeanFactoryPostProcessors(beanFactory):执行 BeanFactoryPostProcessor
- 在 BeanFactory 中找到所有类型是 BeanFactoryPostProcessor 的组件,并执行它们的方法
- 在初始化创建其他组件前面执行
BeanDefinitionRegistryPostProcessor:
加载时机:在所有 bean 定义信息将要被加载,但是 bean 实例还未创建,优先于 BeanFactoryPostProcessor 执行;利用 BeanDefinitionRegistryPostProcessor 给容器中再额外添加一些组件
执行流程:
ioc 容器创建对象
refresh() → invokeBeanFactoryPostProcessors(beanFactory)
从容器中获取到所有的 BeanDefinitionRegistryPostProcessor 组件
- 依次触发所有的 postProcessBeanDefinitionRegistry() 方法
- 再来触发 postProcessBeanFactory() 方法
监听器
基本概述
ApplicationListener:监听容器中发布的事件,完成事件驱动模型开发
public interface ApplicationListener<E extends ApplicationEvent>
所以监听 ApplicationEvent 及其下面的子事件
应用监听器步骤:
写一个监听器(ApplicationListener实现类)来监听某个事件(ApplicationEvent及其子类)
把监听器加入到容器 @Component
只要容器中有相关事件的发布,就能监听到这个事件;
ContextRefreshedEvent:容器刷新完成(所有 bean 都完全创建)会发布这个事件ContextClosedEvent:关闭容器会发布这个事件
发布一个事件:
applicationContext.publishEvent()
@Component
public class MyApplicationListener implements ApplicationListener<ApplicationEvent> {
//当容器中发布此事件以后,方法触发
@Override
public void onApplicationEvent(ApplicationEvent event) {
System.out.println("收到事件:" + event);
}
}
实现原理
ContextRefreshedEvent 事件:
容器初始化过程中执行
initApplicationEventMulticaster():初始化事件多播器- 先去容器中查询
id = applicationEventMulticaster的组件,有直接返回 - 没有就执行
this.applicationEventMulticaster = new SimpleApplicationEventMulticaster(beanFactory)并且加入到容器中 - 以后在其他组件要派发事件,自动注入这个 applicationEventMulticaster
- 先去容器中查询
容器初始化过程执行 registerListeners() 注册监听器
- 从容器中获取所有监听器:
getBeanNamesForType(ApplicationListener.class, true, false) - 将 listener 注册到 ApplicationEventMulticaster
- 从容器中获取所有监听器:
容器刷新完成:finishRefresh() → publishEvent(new ContextRefreshedEvent(this))
发布 ContextRefreshedEvent 事件:
获取事件的多播器(派发器):getApplicationEventMulticaster()
multicastEvent 派发事件
获取到所有的 ApplicationListener
遍历 ApplicationListener
- 如果有 Executor,可以使用 Executor 异步派发
Executor executor = getTaskExecutor() - 没有就同步执行 listener 方法
invokeListener(listener, event),拿到 listener 回调 onApplicationEvent
- 如果有 Executor,可以使用 Executor 异步派发
容器关闭会发布 ContextClosedEvent
链接:https://juejin.cn/post/7173654654205558820
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
frp内网穿透
Frp是什么
简单地说,frp就是一个反向代理软件,它体积轻量但功能很强大,可以使处于内网或防火墙后的设备对外界提供服务,它支持HTTP、TCP、UDP等众多协议。
服务端配置
SSH连接到VPS之后运行如下命令查看处理器架构,根据架构下载不同版本的frp
运行如下命令,根据架构不同,选择相应版本并进行下载
wget https://github.com/fatedier/frp/releases/download/v0.22.0/frp_0.22.0_linux_amd64.tar.gz
然后解压缩
tar -zxvf frp_0.22.0_linux_amd64.tar.gz
服务端的配置我们只需要关注如下几个文件
- frps
- frps.ini
这两个文件(s结尾代表server)分别是服务端程序和服务端配置文件
然后修改frps.ini文件
[common]
bind_port = 49273
vhost_http_port = 9001
token = Er3@SGTwHtPl+jMRD0/f3QH/A
- “bind_port”表示用于客户端和服务端连接的端口,这个端口号我们之后在配置客户端的时候要用到。
- “vhost_http_port”和“vhost_https_port”用于反向代理HTTP主机时使用。
- “token”是用于客户端和服务端连接的口令,请自行设置并记录,稍后会用到。
编辑完成后保存(vim保存如果不会请自行搜索)
客户端配置
frp的客户端就是我们想要真正进行访问的那台设备。
同样地,根据客户端设备的情况选择相应的frp程序进行下载,将“frp_0.22.0_windows_amd64.zip”解压
客户端的配置我们只需要关注如下几个文件
frpc
frpc.ini
这两个文件(c结尾代表client)分别是客户端程序和客户端配置文件。
然后修改frpc.ini文件
[common]
server_addr = 52.80.184.170
server_port = 49273
token = Er3@SGTwHtPl+jMRD0/f3QH/A
[sentry]
type = http
local_ip = 10.10.75.137
local_port = 9001
custom_domains = 172.31.20.248
其中common字段下的三项即为服务端的设置。
- “
server_addr”为服务端IP地址,填入即可。 - “
server_port”为服务器端口,填入你设置的端口号即可。 - “
token”是你在服务器上设置的连接口令,原样填入即可。
自定义规则
上面frpc.ini的sentry字段是自己定义的规则,自定义端口对应时格式如下。
- “
[xxx]”表示一个规则名称,自己定义,便于查询即可。 - “
type”表示转发的协议类型,有TCP和UDP等选项可以选择,如有需要请自行查询frp手册。 - “
local_ip”是本地应用的IP地址,按照实际应用工作在本机的IP地址填写即可。 - “
local_port”是本地应用的端口号,按照实际应用工作在本机的端口号填写即可。 - “
custom_domains”服务端IP地址或域名,可以直接使用服务端ip或者生成一个内网ip。
后台运行脚本
运行服务端
./frpc -c frps.ini
运行客户端
./frpc -c frpc.ini
至此,我们的frp仅运行在前台,如果Ctrl+C停止或者关闭SSH窗口后,frp均会停止运行,因而我们使用 nohup命令将其运行在后台。
服务端创建start.sh脚本文件以及frps.log日志文件 编辑start.sh
nohup ./frps -c frps.ini &> frps.log &
客户端创建start.sh脚本文件以及frpc.log日志文件 编辑start.sh
nohup ./frpc -c frpc.ini &> frpc.log &
客户端和服务端执行start.sh脚本
./stash
查看log日志
tail -f frps.logtail -f frpc.log链接:https://juejin.cn/post/7236656669753016375
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一篇文章学会正则表达式(Kotlin举例)
一篇文章学会正则表达式(Kotlin举例)
正则表达式是一种用来匹配字符串的工具,它可以在文本中查找特定的模式,从而实现对文本的处理和分析。在很多编程语言中,正则表达式都是非常重要的一部分。
了解正则表达式
在学习正则表达式之前,我们需要先了解一些基本概念。正则表达式由一系列字符和特殊字符组成,用来匹配字符串中的模式。例如,我们可以使用正则表达式来匹配一个电话号码、一个电子邮件地址或者一个网址。正则表达式中的一些常用特殊字符包括:
.:匹配任意一个字符。*:匹配前面的字符零次或多次。+:匹配前面的字符一次或多次。?:匹配前面的字符零次或一次。|:表示或的关系,匹配两边任意一边的内容。():表示分组,可以将多个字符组合成一个整体。^:匹配字符串的开头。$:匹配字符串的结尾。{n}:匹配前面的字符恰好出现 n 次。{n,}:匹配前面的字符
正则表达式的基本语法
正则表达式的基本语法包括两个部分:模式和修饰符。模式是用来匹配字符串的规则,而修饰符则用来控制匹配的方式。
在 Kotlin 中,我们可以使用 Regex 类来表示一个正则表达式。例如,下面的代码定义了一个简单的正则表达式,用来匹配一个由数字组成的字符串:
val pattern = Regex("\\d+")
在这个正则表达式中,\d 表示匹配一个数字,+ 表示匹配前面的字符一次或多次。注意,在 Kotlin 中,我们需要使用 \\ 来表示 \ 字符,因为 \ 在字符串中有特殊的含义。
接下来,我们可以使用 matchEntire 函数来检查一个字符串是否符合这个正则表达式:
val input = "12345"
if (pattern.matchEntire(input) != null) {
println("Match!")
} else {
println("No match.")
}
这个代码会输出 Match!,因为输入的字符串符合正则表达式的规则。
常见的正则表达式的高级用法
除了基本的语法之外,正则表达式还有很多高级用法,可以实现更加复杂的匹配和替换操作。下面是一些常用的高级用法:
1. 捕获组
捕获组是指用 () 包围起来的一部分正则表达式,可以将匹配到的内容单独提取出来。例如,下面的代码定义了一个正则表达式,用来匹配一个由姓和名组成的字符串:
val pattern = Regex("(\\w+)\\s+(\\w+)")
val input = "John Smith"
val matchResult = pattern.matchEntire(input)
if (matchResult != null) {
val firstName = matchResult.groupValues[1]
val lastName = matchResult.groupValues[2]
println("First name: $firstName")
println("Last name: $lastName")
}
在这个代码中,\\w+ 表示匹配一个或多个字母、数字或下划线,\\s+ 表示匹配一个或多个空格。groupValues属性可以返回一个列表,其中包含了所有捕获组的内容。在这个例子中,groupValues[1] 表示第一个捕获组的内容,即姓,groupValues[2] 表示第二个捕获组的内容,即名。
2. 非捕获组
非捕获组是指用 (?:) 包围起来的一部分正则表达式,它和普通的捕获组的区别在于,非捕获组匹配到的内容不会单独提取出来。例如,下面的代码定义了一个正则表达式,用来匹配一个由单词和空格组成的字符串:
val pattern = Regex("(?:\\w+\\s+)+\\w+")
val input = "one two three four"
val matchResult = pattern.matchEntire(input)
if (matchResult != null) {
println("Match!")
} else {
println("No match.")
}
在这个代码中,(?:\\w+\\s+)+ 表示匹配一个或多个单词和空格组成的片段,\\w+ 表示匹配一个或多个字母、数字或下划线,\\s+ 表示匹配一个或多个空格。注意,这个正则表达式并没有使用捕获组,因此 matchResult.groupValues 的结果是一个空列表。
3. 零宽断言
零宽断言是指用 (?=) 或 (?!) 包围起来的一部分正则表达式,它可以在匹配的时候不消耗任何字符。例如,下面的代码定义了一个正则表达式,用来匹配一个以 http 或 https 开头的 URL:
val pattern = Regex("(?=http|https)\\w+")
val input = "https://www.google.com"
val matchResult = pattern.find(input)
if (matchResult != null) {
println("Match: ${matchResult.value}")
} else {
println("No match.")
}
在这个代码中,(?=http|https) 表示匹配一个以 http 或 https 开头的字符串,但是不消耗任何字符。find 函数可以在输入字符串中查找第一个匹配的子串,返回一个 MatchResult? 类型的结果。
总结
本文介绍了正则表达式的基本概念和语法,以及一些常用的高级用法。在实际的编程中,正则表达式是一种非常有用的工具,可以帮助我们快速地处理和分析文本数据。在 Kotlin 中,我们可以使用 Regex 类来表示和操作正则表达式,同时还可以使用一些高级用法来实现更加复杂的匹配和替换操作。
链接:https://juejin.cn/post/7239991117169131578
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ThreadLocal的实现原理,ThreadLocal为什么使用弱引用
前言
本文将讲述ThreadLocal的实现原理,还有## ThreadLocal为什么使用弱引用。
ThreadLocal
ThreadLocal 是 Java 中的一个类,用于在多线程环境下为每个线程提供独立的变量副本。它通常用于解决多线程并发访问共享变量时的线程安全性问题。
ThreadLocal 的工作原理是每个线程内部维护一个 ThreadLocalMap 对象,该对象用于存储每个线程的变量副本。当通过 ThreadLocal 对象获取变量时,它会首先检查当前线程是否已经创建了该变量的副本,如果有,则直接返回副本;如果没有,则通过初始化方法创建一个新的副本,并将其保存在当前线程的 ThreadLocalMap 中。
使用 ThreadLocal 时,每个线程都可以独立地访问和修改自己的变量副本,而不会影响其他线程的副本。这使得在多线程环境中共享变量变得更加安全和可靠。
需要注意的是,使用 ThreadLocal 时要注意及时清理不再使用的变量副本,以避免内存泄漏问题。可以通过调用 remove() 方法来清除当前线程的变量副本。
源码解释
set方法源码
// ThreadLocal的set方法,value是要保存的值
public void set(T value) {
// 得到当前线程对象
Thread t = Thread.currentThread();
// 得到当前线程对象关联的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
// 得到map对象就保存值,键为当前ThreadLocal对象
// 如果没有map对象就创建一个map对象,保存值
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
// 得到当前线程关联的ThreadLocalMap对象
ThreadLocalMap getMap(Thread t) {
return t.threadLocals;
}
// 创建一个ThreadLocalMap对象,赋给当前线程的threadLocals属性,并且存入值
void createMap(Thread t, T firstValue) {
t.threadLocals = new ThreadLocalMap(this, firstValue);
}private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
// 通过key计算在tab数组中的槽位i
int i = key.threadLocalHashCode & (len-1);
// 拿到槽位上的Entry对象,如果不为null,则进入循环,如果为null则表示可以直接加入该槽位
// e = tab[i = nextIndex(i, len)])取出下一个槽位的Entry实体,如果为null,则表示可以直接添加进该槽位
for (Entry e = tab[i]; e != null; e = tab[i = nextIndex(i, len)]) {
// 拿到与当前Entry有关联的ThreadLocal对象
ThreadLocal<?> k = e.get();
// 如果k与当前要保存值的key相等,则替换掉value,相当于修改key的值
if (k == key) {
e.value = value;
return;
}
// 检查当前节点的ThreadLocal如果为null,表示ThreadLocal已经被gc回收,则调用 replaceStaleEntry() 方法来替换陈旧的 Entry,将新的 ThreadLocal 和值插入到数组中的索引位置 i 处,并返回。
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
// 创建一个Entry对象,加入i槽位
tab[i] = new Entry(key, value);
// 记录Entry对象个数
int sz = ++size;
// cleanSomeSlots清理陈旧的Entry,清理完后如果大于阈值,则调用rehash扩容数组
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
get方法源码
public T get() {
// 获取当前线程对象
Thread t = Thread.currentThread();
// 得到当前线程关联的ThreadLocalMap对象
ThreadLocalMap map = getMap(t);
if (map != null) {
// 通过key获取到Entry对象
ThreadLocalMap.Entry e = map.getEntry(this);
// Entry不为空,则直接获取值返回结果
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 如果map为null,或者Entry为null,则返回一个初始化值
return setInitialValue();
}
private T setInitialValue() {
// 如果是在调用构造器初始化的ThreadLocal对象,该方法直接返回null
// 如果是调用的静态方法withInitial,则返回你指定的一个初始化则
// 并且还会把该初始化的值保存进ThreadLocalMap
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
public static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supplier) {
// SuppliedThreadLocal是ThreadLocal的子类,重写了initialValue方法,通过传入一个Supplier,指定初始化值
return new SuppliedThreadLocal<>(supplier);
}
private Entry getEntry(ThreadLocal<?> key) {
// 计算当前key的落脚点
int i = key.threadLocalHashCode & (table.length - 1);
// 取出落脚点的Entry对象
Entry e = table[i];
// 如果e不为空,并且跟e关联的ThreadLocal对象等于当前的key,则返回当前e对象
if (e != null && e.get() == key)
return e;
// 否则进入getEntryAfterMiss
else
return getEntryAfterMiss(key, i, e);
}
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
// 如果e为null,则直接返回null,表示当前key并没有数据
while (e != null) {
// 取出与e关联的ThreadLocal对象
ThreadLocal<?> k = e.get();
// 判断k是否等于当前的ThreadLocal对象
if (k == key)
return e;
// 当前k是否等于null,为null表示被gc垃圾回收,就清理旧的Entry对象
if (k == null)
expungeStaleEntry(i);
else
// 否则k不为null,取出下一个槽位,接着循环
i = nextIndex(i, len);
e = tab[i];
}
return null;
}总结
可以看出实际保存线程局部变量的是ThreadLocalMap对象,每个线程都有一个这样的对象,保存的是键值对,键为当前的ThreadLocal对象,ThreadLocal对象一般设置为静态,非静态只会造成对象的冗余,因为ThreadLocalMap的键只能是当前ThreadLocal对象,所以只能保存一个键值对,如果要保存多个键值对,可以定义多个ThreadLocal对象作为不同的键,这样获取到的还是与线程有关联的ThreadLocalMap对象,而ThreadLocalMap的键是当前的ThreadLocal对象,多少个该对象,那就可以保存多少个值。
强软弱虚四大引用
在Java中,引用是用于引用对象的一个机制,它允许我们通过引用变量来操作和访问对象。在Java中,主要有以下几种引用类型:
- 强引用(Strong Reference):这是最常见的引用类型。当我们使用
new关键字创建对象时,默认就是使用强引用。如果一个对象具有强引用,即存在一个强引用变量引用它,那么垃圾回收器就不会回收该对象。只有当对象没有任何强引用时,才会被认为是不再需要的,可以被垃圾回收。 - 软引用(Soft Reference):软引用用于描述还有用但非必需的对象。在内存不足时,垃圾回收器可能会选择回收软引用对象。使用软引用可以实现一些缓存功能,在内存不足时释放缓存中的对象,从而避免 OutOfMemoryError。可以使用
SoftReference类来创建软引用。 - 弱引用(Weak Reference):弱引用的生命周期更短暂,只要垃圾回收器发现一个对象只有弱引用与之关联,就会立即回收该对象。弱引用通常用于实现一些特定的缓存或关联数据结构,当对象的强引用被释放后,关联的弱引用对象也会被自动清除。可以使用
WeakReference类来创建弱引用。 - 虚引用(Phantom Reference):虚引用是最弱的引用类型,几乎没有实际的使用场景。虚引用的主要作用是跟踪对象被垃圾回收的状态。当垃圾回收器决定回收一个对象时,如果该对象有虚引用,将会在对象被回收之前,将虚引用加入到与之关联的引用队列中,供应用程序获取对象回收的状态信息。
在内存管理方面,软引用和弱引用都可以用于解决一些特定的内存问题,例如缓存管理或对象关联。它们对于临时性或可替代性对象的管理非常有用,可以在内存紧张时进行垃圾回收,从而提高系统的性能和可用性。然而,需要注意的是,对于软引用和弱引用对象,程序应该在使用时进行必要的判空和恢复处理,以避免 NullPointerException 和其他相关问题。
ThreadLocal为什么使用弱引用
ThreadLocal 使用弱引用的主要原因是为了避免内存泄漏问题。
当使用强引用持有 ThreadLocal 对象时,只有线程销毁或显式地调用 remove() 方法时,Entry 才会被释放。这可能导致在多线程环境下使用线程池时,即使线程已经使用结束处于空闲状态,对应的 Entry 仍然会存在于 ThreadLocalMap 中,导致无法回收相关资源,从而造成内存泄漏。
使用弱引用作为 ThreadLocal 的键(key),可以解决这个问题。弱引用在垃圾回收时只要发现只有弱引用指向,则会被直接回收。因此,当线程结束且对应的 ThreadLocal 对象只有弱引用存在时,垃圾回收器会自动清理该弱引用,进而清理 ThreadLocalMap 中对应的 Entry。这样可以避免内存泄漏问题。
需要注意的是,尽管 ThreadLocalMap 使用了弱引用来避免内存泄漏问题,但仍然需要在使用 ThreadLocal 后调用 remove() 方法,以确保及时清理 ThreadLocal 对象和对应的值。这是因为弱引用的回收时机不确定,不能完全依赖垃圾回收器的工作。
当我们应该请求进来分配一个线程处理请求,此时ThreadLocal对象就会被创建,并且是一个强引用,当第一次把值存入时ThreadLocal时,就会通过Thread拿到或者创建一个ThreadLocalMap对象,并且存入我们的数据,此时ThreadLocal作为键就会被放入弱引用中,此时就算发送垃圾回收也不会回收ThreadLocal因为有一个强引用指向,但是一旦我们的请求执行完毕返回,线程处于空闲状态时,这个强引用就没了,此时就剩下一个弱引用,这个时候发生垃圾回收就ThreadLocal就会被收回。
链接:https://juejin.cn/post/7261599630827454520
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin | 高阶函数reduce()、fold()详解
在 Kotlin 中,reduce() 和 fold() 是函数式编程中常用的高阶函数。它们都是对集合中的元素进行聚合操作的函数,将一个集合中的元素缩减成一个单独的值。它们的使用方式非常相似,但是返回值略有不同。下面是它们的区别:
reduce()函数是对集合中的所有元素进行聚合处理,并返回最后一个合并处理值。fold()函数除了合并所有元素之外,还可以接受一个初始值,并将其与聚合结果一起返回。注:如果集合为空的话,只会返回初始值。
reduce示例
1、使用 reduce() 函数计算列表中所有数字的总和:
fun reduceAdd() {
val list = listOf(1, 2, 3, 4, 5)
val sum = list.reduce { acc, i ->
println("acc:$acc, i:$i")
acc + i
}
println("sum is $sum") // 15
}
执行结果:
acc:1, i:2
acc:3, i:3
acc:6, i:4
acc:10, i:5
sum is 15
2、使用 reduce() 函数计算字符串列表中所有字符串的拼接结果:
val strings = listOf("apple", "banana", "orange", "pear")
val result = strings.reduce { acc, s -> "$acc, $s" }
println(result) // apple, banana, orange, pear
执行结果:
apple, banana, orange, pear
fold示例
1、使用 fold() 函数计算列表中所有数字的总和,并在其基础上加上一个初始值:
val numbers = listOf(1, 2, 3, 4, 5)
val sum = numbers.fold(10) { acc, i -> acc + i }
println(sum) // 25
执行结果为:
acc:10, i:1
acc:11, i:2
acc:13, i:3
acc:16, i:4
acc:20, i:5
sum is 25
2、使用 fold() 函数将列表中的所有字符串连接起来,并在其基础上加上一个初始值:
val strings = listOf("apple", "banana", "orange", "pear")
val result = strings.fold("Fruits:") { acc, s -> "$acc $s" }
println(result) // Fruits: apple banana orange pear
执行结果:
Fruits: apple banana orange pear
源码解析
reduce()在Kotlin标准库的实现如下:
public inline fun <S, T : S> Iterable<T>.reduce(operation: (acc: S, T) -> S): S {
val iterator = this.iterator()
if (!iterator.hasNext()) throw UnsupportedOperationException("Empty collection can't be reduced.")
var accumulator: S = iterator.next()
while (iterator.hasNext()) {
accumulator = operation(accumulator, iterator.next())
}
return accumulator
}
从代码中可以看出,reduce函数接收一个operation参数,它是一个lambda表达式,用于聚合计算。reduce函数首先获取集合的迭代器,并判断集合是否为空,若为空则抛出异常。然后通过迭代器对集合中的每个元素进行遍历操作,对元素进行聚合计算,将计算结果作为累加器,传递给下一个元素,直至聚合所有元素。最后返回聚合计算的结果。
fold()在Kotlin标准库的实现如下:
public inline fun <T, R> Iterable<T>.fold(
initial: R,
operation: (acc: R, T) -> R
): R {
var accumulator: R = initial
for (element in this) {
accumulator = operation(accumulator, element)
}
return accumulator
}
从代码中可以看出,fold函数接收两个参数,initial参数是累加器的初始值,operation参数是一个lambda表达式,用于聚合计算。
fold函数首先将初始值赋值给累加器,然后对集合中的每个元素进行遍历操作,对元素进行聚合计算,将计算结果作为累加器,传递给下一个元素,直至聚合所有元素。最后返回聚合计算的结果。
总结
reduce()适用于不需要初始值的聚合操作,fold()适用于需要初始值的聚合操作。reduce()操作可以直接返回聚合后的结果,而fold()操作需要通过lambda表达式的返回值来更新累加器的值。
在使用时,需要根据具体场景来选择使用哪个函数。
链接:https://juejin.cn/post/7224347940860723261
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 字符串常用的操作符
字符串常用的操作符
commonPrefixWith
返回两个字符串中最长的相同前缀,如果它们没有共同的前缀,则返回空字符串,可以定义 ignoreCase 为 true忽略大小写
val action = "蔡徐坤唱跳rap"
val time = "蔡徐坤两年半"
val introduce = "个人练习生蔡徐坤喜欢唱跳rap"
println(action.commonPrefixWith(time)) // 蔡徐坤
println(action.commonPrefixWith(introduce)) // ""
源码实现
// 通过while获取两个字符串同个索引下的字符是否相等
// 最后通过subSequence切割字符串
public fun CharSequence.commonPrefixWith(other: CharSequence, ignoreCase: Boolean = false): String {
val shortestLength = minOf(this.length, other.length)
var i = 0
while (i < shortestLength && this[i].equals(other[i], ignoreCase = ignoreCase)) {
i++
}
if (this.hasSurrogatePairAt(i - 1) || other.hasSurrogatePairAt(i - 1)) {
i--
}
return subSequence(0, i).toString()
}
commonSuffixWith
返回两个字符串中最长的相同后缀,如果它们没有共同的后缀,则返回空字符串,可以定义 ignoreCase 为 true忽略大小写
val action = "蔡徐坤唱跳rap"
val time = "蔡徐坤两年半"
val introduce = "个人练习生蔡徐坤喜欢唱跳rap"
println(action.commonSuffixWith(time))
println(action.commonSuffixWith(introduce))
源码实现
// 与commonPrefixWith的实现差不多,只是commonSuffixWith是倒序循环
public fun CharSequence.commonSuffixWith(other: CharSequence, ignoreCase: Boolean = false): String {
val thisLength = this.length
val otherLength = other.length
val shortestLength = minOf(thisLength, otherLength)
var i = 0
while (i < shortestLength && this[thisLength - i - 1].equals(other[otherLength - i - 1], ignoreCase = ignoreCase)) {
i++
}
if (this.hasSurrogatePairAt(thisLength - i - 1) || other.hasSurrogatePairAt(otherLength - i - 1)) {
i--
}
return subSequence(thisLength - i, thisLength).toString()
}
contains
判断字符串是否包含某字符或某字符串,可以定义 ignoreCase 为 true 忽略大小写
val introduce = "个人练习生蔡徐坤喜欢唱跳rap"
println(introduce.contains('唱')) // true
println(introduce.contains("蔡徐坤")) // true
println("蔡徐坤" in introduce) // // 同上,contains是重载操作符,可以使用该表达式
println(introduce.contains("Rap", ignoreCase = true)) // true
println("Rap" !in introduce) // !in表示不包含的意思,与!introduce.contains("Rap")是同个意思
源码实现
// 通过indexOf判断字符是否存在
public operator fun CharSequence.contains(char: Char, ignoreCase: Boolean = false): Boolean =
indexOf(char, ignoreCase = ignoreCase) >= 0
// 通过indexOf判断字符串是否存在
public operator fun CharSequence.contains(other: CharSequence, ignoreCase: Boolean = false): Boolean =
if (other is String)
indexOf(other, ignoreCase = ignoreCase) >= 0
else
indexOf(other, 0, length, ignoreCase) >= 0
endsWith
判断字符串是否以某字符或某字符串作为后缀,可以定义 ignoreCase 为 true 忽略大小写
val introduce = "个人练习生蔡徐坤喜欢唱跳rap"
println(introduce.endsWith("蔡徐坤")) // false
println(introduce.endsWith("唱跳rap")) // true
源码实现
// 字符直接判断最末尾的字符
public fun CharSequence.endsWith(char: Char, ignoreCase: Boolean = false): Boolean =
this.length > 0 && this[lastIndex].equals(char, ignoreCase)
// 如果都是String,返回String.endsWith,否则返回regionMatchesImpl
public fun CharSequence.endsWith(suffix: CharSequence, ignoreCase: Boolean = false): Boolean {
if (!ignoreCase && this is String && suffix is String)
return this.endsWith(suffix)
else
return regionMatchesImpl(length - suffix.length, suffix, 0, suffix.length, ignoreCase)
}
// 不忽略大小写,返回java.lang.String.endsWith
public actual fun String.endsWith(suffix: String, ignoreCase: Boolean = false): Boolean {
if (!ignoreCase)
return (this as java.lang.String).endsWith(suffix)
else
return regionMatches(length - suffix.length, suffix, 0, suffix.length, ignoreCase = true)
}
equals
判断两个字符串的值是否相等,可以定义 ignoreCase 为 true 忽略大小写
val introduce = "蔡徐坤rap"
println(introduce.equals("蔡徐坤Rap")) // false
println(introduce == "蔡徐坤Rap") // 同上,因为equals是重载操作符,通常使用 == 表示即可
println(introduce.equals("蔡徐坤Rap", false)) // true
源码实现
// 通过java.lang.String的equals和equalsIgnoreCase判断
public actual fun String?.equals(other: String?, ignoreCase: Boolean = false): Boolean {
if (this === null)
return other === null
return if (!ignoreCase)
(this as java.lang.String).equals(other)
else
(this as java.lang.String).equalsIgnoreCase(other)
}
ifBlank
如果字符串都是空格,将字符串转成默认值。这个操作符非常有用
val whitespace = " ".ifBlank { "default" }
val introduce = "蔡徐坤rap".ifBlank { "default" }
println(whitespace) // default
println(introduce) // 蔡徐坤rap
源码实现
public inline fun <C, R> C.ifBlank(defaultValue: () -> R): R where C : CharSequence, C : R =
if (isBlank()) defaultValue() else this
ifEmpty
如果字符串都是空字符串,将字符串转成默认值。这个操作符非常有用,省去了你去判断空字符串然后再次赋值的操作
val whitespace = " ".ifEmpty { "default" }
val empty = "".ifEmpty { "default" }
val introduce = "蔡徐坤rap".ifEmpty { "default" }
println(whitespace) // " "
println(empty) // default
println(introduce) // 蔡徐坤rap
判断空字符串、null 和空格字符串
isEmpty判断空字符串isBlank判断字符串都是空格isNotBlank与isBlank相反,判断字符串不是空格isNotEmpty与isEmpty相反,判断字符串不是空格isNullOrBlank判断字符串不是null和 空格isNullOrEmpty判断字符串不是null和 空字符串
lines
将字符串以换行符或者回车符进行分割,返回每一个分割的子字符串 List<String>
val article = "大家好我是练习时长两年半的个人练习生\n蔡徐坤\r喜欢唱跳rop"
println(article.lines()) // [大家好我是练习时长两年半的个人练习生, 蔡徐坤, 喜欢唱跳rop]
源码实现
// 大概就是通过Sequence去切割字符串
public fun CharSequence.lines(): List<String> = lineSequence().toList()
public fun CharSequence.lineSequence(): Sequence<String> = splitToSequence("\r\n", "\n", "\r")
public fun <T> Sequence<T>.toList(): List<T> {
return this.toMutableList().optimizeReadOnlyList()
}
lowercase
将字符串都转换成小写
val introduce = "蔡徐坤RaP"
println(introduce.lowercase()) // 蔡徐坤rap
源码实现
// 通过java.lang.String的toLowerCase方法实现,其实很多kotlin的方法都是调用java的啦
public actual inline fun String.lowercase(): String = (this as java.lang.String).toLowerCase(Locale.ROOT)
replace
将字符串内的某一部分替换为新的值,可以定义 ignoreCase 为 true 忽略大小写
val introduce = "蔡徐坤rap"
println(introduce.replace("rap", "RAP"))
println(introduce.replace("raP", "RAP", ignoreCase = true))
源码实现
// 首先通过indexOf判断是否存在要被替换的子字符串
// do while循环添加被替换之后的字符串,因为字符串有可能是有多个地方需要替换,所有通过occurrenceIndex判断是否还有需要被替换的部分
public actual fun String.replace(oldValue: String, newValue: String, ignoreCase: Boolean = false): String {
run {
var occurrenceIndex: Int = indexOf(oldValue, 0, ignoreCase)
// FAST PATH: no match
if (occurrenceIndex < 0) return this
val oldValueLength = oldValue.length
val searchStep = oldValueLength.coerceAtLeast(1)
val newLengthHint = length - oldValueLength + newValue.length
if (newLengthHint < 0) throw OutOfMemoryError()
val stringBuilder = StringBuilder(newLengthHint)
var i = 0
do {
stringBuilder.append(this, i, occurrenceIndex).append(newValue)
i = occurrenceIndex + oldValueLength
if (occurrenceIndex >= length) break
occurrenceIndex = indexOf(oldValue, occurrenceIndex + searchStep, ignoreCase)
} while (occurrenceIndex > 0)
return stringBuilder.append(this, i, length).toString()
}
}
startsWith
判断字符串是否以某字符或某字符串作为前缀,可以定义 ignoreCase 为 true 忽略大小写
val introduce = "rap"
println(introduce.startsWith("Rap"))
println(introduce.startsWith("Rap", ignoreCase = true))
源码实现
// 还是调用的java.lang.String的startsWith
public actual fun String.startsWith(prefix: String, ignoreCase: Boolean = false): Boolean {
if (!ignoreCase)
return (this as java.lang.String).startsWith(prefix)
else
return regionMatches(0, prefix, 0, prefix.length, ignoreCase)
}
substringAfter
获取分割符之后的子字符串,如果不存在该分隔符默认返回原字符串,当然你可以自定义返回
例如在截取 ip:port 格式的时候,分隔符就是 :
val ipAddress = "192.168.1.1:8080"
println(ipAddress.substringAfter(":")) // 8080
println(ipAddress.substringAfter("?")) // 192.168.1.1:8080
println(ipAddress.substringAfter("?", missingDelimiterValue = "没有?这个子字符串")) // 没有?这个子字符串
源码实现
// 还是通过substring来截取字符串的
public fun String.substringAfter(delimiter: String, missingDelimiterValue: String = this): String {
val index = indexOf(delimiter)
return if (index == -1) missingDelimiterValue else substring(index + delimiter.length, length)
}
substringAfterLast
与 substringAfter 是同一个意思,不同的是如果一个字符串中有多个分隔符,substringAfter 是从第一个开始截取字符串,substringAfterLast 是从最后一个分隔符开始截取字符串
val network = "255.255.255.0:192.168.1.1:8080"
println(network.substringAfter(":")) // 192.168.1.1:8080
println(network.substringAfterLast(":")) // 8080
源码实现
// 源码和substringAfter差不多,只是substringAfterLast获取的是最后一个分割符的索引
public fun String.substringAfterLast(delimiter: String, missingDelimiterValue: String = this): String {
val index = lastIndexOf(delimiter)
return if (index == -1) missingDelimiterValue else substring(index + delimiter.length, length)
}
substringBefore
获取分割符之前的子字符串,如果不存在该分隔符默认返回原字符串,当然你可以自定义返回,与 substringAfter 刚好相反
val ipAddress = "192.168.1.1:8080"
println(ipAddress.substringBefore(":")) // 192.168.1.1
println(ipAddress.substringBefore("?")) // 192.168.1.1:8080
println(ipAddress.substringBefore("?", missingDelimiterValue = "没有?这个子字符串")) // 没有?这个子字符串
源码实现
// 还是通过substring来截取字符串的,只是是从索引0开始截取子字符串
public fun String.substringBefore(delimiter: String, missingDelimiterValue: String = this): String {
val index = indexOf(delimiter)
return if (index == -1) missingDelimiterValue else substring(0, index)
}
substringBeforeLast
与 substringBefore 是同一个意思,不同的是如果一个字符串中有多个分隔符,substringBefore 是从第一个开始截取字符串,substringBeforeLast 是从最后一个分隔符开始截取字符串
val network = "255.255.255.0:192.168.1.1:8080"
println(network.substringBefore(":")) // 255.255.255.0
println(network.substringBeforeLast(":")) // 255.255.255.0:192.168.1.1
源码实现
// 源码和substringBefore差不多,只是substringBeforeLast获取的是最后一个分割符的索引
public fun String.substringBeforeLast(delimiter: String, missingDelimiterValue: String = this): String {
val index = lastIndexOf(delimiter)
return if (index == -1) missingDelimiterValue else substring(0, index)
}
trim
去掉字符串首尾的空格符,如果要去掉字符串中间的空格符请用 replace
val introduce = " 个人练习生蔡徐坤 喜欢唱跳rap "
println(introduce.trim()) // 个人练习生蔡徐坤 喜欢唱跳rap
uppercase
将字符串都转换成大写
源码实现
// java.lang.String.toUpperCase
public actual inline fun String.uppercase(): String = (this as java.lang.String).toUpperCase(Locale.ROOT)链接:https://juejin.cn/post/7252199464503918629
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单教你Intent如何传大数据
前言
最近想不出什么比较好的内容,但是碰到一个没毕业的小老弟问的问题,那就借机说说这个事。Intent如何传大数据?为什么是简单的说,因为这背后深入的话,有很多底层的细节包括设计思想,我也不敢说完全懂,但我知道当你用Intent传大数据报错的时候应该怎么解决,并且简单聊聊这背后所涉及到的东西。
Intent传大数据
平时可能不会发生这种问题,但比如我之前是做终端设备的,我的设备每秒都会生成一些数据,而长时间的话数据量自然大,这时当我跳到另外一个页面使用intent把数据传过去的时候,就会报错
我们调用
intent.putExtra("key", value) // value超过1M
会报错
android.os.TransactionTooLargeException: data parcel size xxx bytes
这里的xxx就是1M左右,告诉你传输的数据大小不能超过1M,有些话咱也不敢乱说,有点怕误人子弟。我这里是凭印象说的,如果有大佬看到我说错,请狠狠的纠正我。
这个错误描述是这么描述,但真的是限死1M吗,说到这个,就不得不提一样东西,Binder机制,先不要跑,这里不会详细讲Binder,只是提一嘴。
说到Binder那就会联系到mmap内存映射,你可以先简单理解成内存映射是分配一块空间给内核空间和用户空间共用,如果还是不好理解,就简单想成分配一块空间通信用,那在android中mmap分配的空间是多少呢?1M-4K。
那是不是说Intent传输的数据超过1M-4K就会报错,理论上是这样,但实际没到这个值,比如0.8M也可能会报错。所以你不能去走极限操作,比如你的数据到了1M,你觉得只要减少点数据,减到8K,应该就能过了,也许你自己测试是正常的,但是这很危险。
所以能不传大数据就不要传大数据,它的设计初衷也不是为了传大数据用的。如果真要传大数据,也不要走极限操作。
那怎么办,切莫着急,请听我慢慢讲。就这个Binder它是什么玩意,它是Android中独特的进程通信的方式,而Linux中进程通信的方式,在Android中同样也适用。进程间通信有很多方式,Binder、管道、共享内存等。为什么会有这么多种通信方式,因为每种通信方式都有自己的特点,要在不同的场合使用不同的通信方式。
为什么要提这个?因为要看懂这个问题,你需要知道Binder这种通信方式它有什么特点,它适合大量的数据传输吗?那你Binder又与我Intent何干,你抓周树人找我鲁迅干嘛~~所以这时候你就要知道Android四大组件之间是用什么方式通信的。
有点扯远了,现在可以来说说结论了,Binder没办法传大数据,我就1M不到你想怎样?当然它不止1M,只是Android在使用时限制了它只能最多用1M,内核的最大限制是4M。又有点扯远了,你不要想着怎么把限制扩大到4M,不要往这方面想。前面说了,不同的进程通信方式,有自己的特点,适用于某些特定的场景。那Binder不适用于传输大数据,我共享内存行不行?
所以就有了解决办法
bundle.putBinder()
有人可能一看觉得,这有什么不同,这在表面上看差别不大,实则内部大大的不同,bundle.putBinder()用了共享内存,所以能传大数据,那为什么这里会用共享内存,而putExtra不是呢?想搞清楚这个问题,就要看源码了。 这里就不深入去分析了,我怕劝退,不是劝退你们,是劝退我自己。有些东西是这样的,你要自己去看懂,看个大概就差不多,但是你要讲出来,那就要看得细致,而有些细节确实会劝退人。所以想了解为什么的,可以自己去看源码,不想看的,就知道这是怎么一回事就行。
那还有没有其它方式呢?当然有,你不懂共享内存,你写到本地缓存中,再从本地缓存中读取行不行?
办法有很多,如果你不知道这个问题怎么解决,你找不到你觉得可行的解决方案,甚至可以通过逻辑通过流程的方式去绕开这个问题。但是你要知道为什么会出现这样的问题,如果你没接触过进程通信,没接触过Binder,让你看一篇文章就能看懂我觉得不切实际,但是至少得知道是怎么一回事。
比如我只说bundle.putBinder()能解决这个问题,你一试,确实能解决,但是不知道为什么,你又怕会不会有其它问题。虽然这篇文章我一直在打擦边球,没有提任何的原理,但我觉得还是能大概让人知道为什么bundle.putBinder()能解决Intent传大数据,你也就能放心去用了。
链接:https://juejin.cn/post/7205138514870829116
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
记一次反编译并重新打包的过程
反编译部分的介绍在文章末尾
排查原因
根据现象来看,这程序要嘛崩溃了,要嘛该App不适配此款盒子(比如ABI不支持、Target SDK Version等问题)
minSdkVersion系统版本不支持?
但是同事告诉我这款盒子是Android9,在其他的Android9和Android 4.4盒子上都跑过,没问题,排除了minSdkVersion的问题
ABI不支持?
不太可能,先不想这个
ADB才是王道
但凡遇到问题,只要设备能够adb,起码问题就解决了一半,但一问,说这盒子似乎不能Adb,,鹅鹅鹅饿~~ 后来借助adbhelper发现,此款盒子还是能adb,只是常规情况下adb的端口是60001,连上之后执行adb root的话,又会换回默认端口,这个情况我也是活久见。。
说正题,连上adb之后,通过抓日志,发现了如下问题:Permission denial: writing to settings requires:android.permission.WRITE_SECURE_SETTINGS,根据错误堆栈信息,大致是app调用了wifimanager.setWifiEnabled(true)这个方法引起的
解决
权限思路
因为自己对android.permission.WRITE_SECURE_SETTINGS这个权限并不太了解,所以从异常的字面意思理解,我以为是权限不够,所以我尝试让app拥有权限来确保其正常运行。
方法1:adb shell pm grant {包名} {权限内容}
执行命令,赋予该程序权限adb shell pm grant {packagename} android.permission.WRITE_SECURE_SETTINGS,执行命令之后,提示java.lang.SecurityException: Package xxxx has not requested permission android.permission.WRITE_SECURE_SETTINGS意思说该程序不需要这个权限,这个问题的原因是因为app并没有在清单文件中申明这个权限,这就有意思了,这个app操作需要这个权限却没有申请权限,可能主要原因是因为以前的低版本不需要,Android9需要吧,所以我们得先给他增加这个申明,然后再赋予这个权限。
通过apktool反编译,然后修改清单文件添加这个权限,再重新打包(后面再说具体得反编译重打包的步骤),一切妥当之后再次执行上面命令,果然老天是不会让我舒坦的,执行后出现异常:java.lang.SecurityException: Package android does not belong to 10034,触发问题的调用堆栈还是之前那个方法引起的。(⊙﹏⊙),思考半天,看了下它的清单文件,并没有申明targetSdkVersion,这有点怪哦,也是活久见,难道游戏apk就可以这么无视规则?那我要不给他增加上,,,嗯可以一试,还是相同的配方,给清单文件增加如下代码:
<uses-sdk
android:minSdkVersion="17"
android:targetSdkVersion="22" />
然后重新打包,再来,没错,还是同样的味道,同样的问题,我以为修改来低于23,权限能够就自动允许了,现在想起来真是too young to simple。。
东搜搜西搜搜,想尝试下是不是因为这个程序不是系统app,后来将程序放在system/app下作为系统程序,还是同样问题,所以很显然,权限这条路行不通。
所以这个问题的解决办法应该参考如下内容:
这个错误是因为你的应用试图调用setWifiEnabled方法,这个方法在Android 9(API级别28)及以上版本已经被弃用。在这些版本中,只有系统应用才能调用setWifiEnabled方法。
即使你的应用已经被安装为系统应用,并且已经获得了WRITE_SECURE_SETTINGS权限,它仍然不能调用setWifiEnabled方法。这是因为这个方法现在只能被系统UI调用,其他应用,包括系统应用,都不能调用这个方法。
你可以考虑使用WifiNetworkSuggestion API来提示用户连接到特定的Wi-Fi网络,或者使用Settings.Panel.ACTION_WIFI来引导用户到Wi-Fi设置页面。
以下是如何使用Settings.Panel.ACTION_WIFI的示例:
val intent = Intent(Settings.Panel.ACTION_WIFI)
startActivity(intent)
这段代码会打开Wi-Fi设置页面,让用户自己开启或关闭Wi-Fi。
修改程序源代码
权限的路行不通,那我们只能想办法修复app这段逻辑代码了,但是别人的apk,显然不是那么容易让人想改就改撒,提出是这里的问题,别人也不一定信啊,所以我打算自己改这个apk的编译后的源代码,让他不要触发引起异常的那个逻辑,绕过看程序能不能正常跑起来,这一步就需要懂得起smali,还好这个问题比较简单,定位到代码改了之后,重新打包,这下消停了,程序很好正常的运行。
反编译
反编译这一块涉及很多概念,以前大概接触过,都只是看,没有实际操作,有些时候操作也只是简单的反编译看下源码,但总体工具和涉及的概念主要有ApkTool、dex2jar-2.1、jarsigner、jd-gui,还有些文章提到SignApk.jar、jax-gui等;
说下自己的理解,假如我们需要重新打包一个apk,那么我们肯定要从这个apk得到我们可以编辑的文件进行修改,修改后再重新打包,这是我们需要的核心流程;
反编译APK
ApkTool,具体的作用自己查,大致意思是如果我们想看清单文件内容,资源文件之类的,我们就可以通过这个工具进行反编译,由于前面我需要给源程序在清单文件中新增权限申明,所以我们就需要先得到反编译的工程,然后直接修改清单文件即可(把AndroidManifest拖动到Android Studio或者其他文本编辑工具中直接修改然后保存即可)
反编译apk :先在终端将当前位置定位到ApkTool的目录,然后执行命令
apktool d {xxx.apk:你的apk名称},该命令会将apk反编译后保存在apktool所在目录下。也可以使用如下命令指定反编译后工程的存储路径apktool d -o {反编译后的存储目录} {xxx.apk},其实只需要知道反编译apk是使用的apktool d即可,查一下文档了解更详细的用法。重新编译:修改之后我们需要重新打包成apk,使用命令
apk b {反编译后的存储目录},编译成功之后,会保存在指定目录下的dist文件夹中。也可以用-o 指定存储的目录。
重签名
apk反编译修改了,也重新编译成了新的apk,但此时这个apk是没有签名的,直接拿到设备上安装是不行的,所以我们需要签名。 这里就需要用到jarsign,这个应该是jdk内自带的jarsigner -verbose -keystore {签名文件路径:也就是keystore、jks文件} -signedjar {签名后的apk路径} {没有签名的apk路径} {使用的签名文件别名,也就是keyalias}如果没出错,则我们就拥有了已经签名的被修改过的apk了,可以去运行验证了。但是由于我们是用的自己签名文件签名的,是不能覆盖安装原来的apk的,两者签名不一致。
使用系统签名
这块我没尝试过,需要的自行查看搜索查看,附带个链接Android应用程序签名系统的签名(SignApk.jar)_新根的博客-CSDN博客
修改源码
跟直接修改清单文件的原理差不多,都是直接修改,但是由于是smali,就需要做一定的语法了解才能改了。也有工具可以将smali转换成java的,比如使用skylot/jadx: Dex to Java decompiler (github.com)工具,不过这个方法只是将smali转换成java来查阅,如果我们想重新打包,那还是必须修改smali文件才行的。
关于这一节建议参考:Android App 逆向入門之二:修改 smali 程式碼 (cymetrics.io)
额外说的:其实上面整个过程我们没用到dex2jar-2.1、jd-gui之类的,其实作用不同,dex2jar的作用是将apk的后缀改成zip解压出来会得到很多dex文件,我们通过dex2jar可以让这些dex转换成jar文件,jar文件就是常规生成的java class文件了,但是jar文件没法直接打开查看,就需要借助jd-gui之类的工具。。所以的目的是说我们想看看别人程序的代码的时候用的吧。
就到这吧,做个记录。。
链接:https://juejin.cn/post/7257740918433529912
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
何时使用Kafka而不是RabbitMQ
Kafka 和 RabbitMQ 都是流行的开源消息系统,它们可以在分布式系统中实现数据的可靠传输和处理。Kafka 和 RabbitMQ 有各自的优势和特点,它们适用于不同的场景和需求。本文将比较 Kafka 和 RabbitMQ 的主要区别,并分析何时使用 Kafka 而不是 RabbitMQ。
推荐博主开源的H5商城项目waynboot-mall,这是一套全部开源的微商城项目,包含一个运营后台、h5商城和后台接口。 实现了一个商城所需的首页展示、商品分类、商品详情、sku详情、商品搜索、加入购物车、结算下单、订单状态流转、商品评论等一系列功能。 技术上基于最新得Springboot3.0、jdk17,整合了Redis、RabbitMQ、ElasticSearch等常用中间件, 贴近生产环境实际经验开发而来不断完善、优化、改进中。
github地址:github.com/wayn111/way…
影响因素
- 可扩展性:Kafka 旨在处理大容量、高吞吐量和实时数据流。它每秒能够处理数百万个事件,并且可以处理大量数据。另一方面,RabbitMQ 的设计更加灵活,可以处理广泛的用例,但可能不太适合大容量、实时数据流。
- 耐用性:Kafka 通过将所有数据写入磁盘来提供高度的耐用性,这对于任务关键型应用程序非常重要。 RabbitMQ 还提供基于磁盘的持久性,但这可能不如 Kafka 提供的那么强大。
- 延迟:RabbitMQ 设计为低延迟,这对于实时数据处理和分析非常重要。Kafka 延迟相比 RabbitMQ 会高一点。
- 数据流:Kafka 使用无界的数据流,即数据持续地流入到指定的主题(topic)中,不会被删除或过期,除非达到了预设的保留期限或容量限制。RabbitMQ 使用有界的数据流,即数据被生产者(producer)创建并发送到消费者(consumer),一旦被消费或者达到了过期时间,就会从队列(queue)中删除。
- 数据使用:Kafka 支持多个消费者同时订阅同一个主题,并且可以根据自己的进度来消费数据,不会影响其他消费者。这意味着 Kafka 可以支持多种用途和场景,比如实时分析、日志聚合、事件驱动等。RabbitMQ 的消费者从一个队列中消费数据,一旦被消费,就不会再被该队列其他消费者看到。这意味着 RabbitMQ 更适合一对一的通信或任务分发。
- 数据顺序:Kafka 保证了同一个分区(partition)内的数据是有序的,即按照生产者发送的顺序来存储和消费。但是不同分区之间的数据是无序的,即不能保证跨分区的数据按照全局顺序来处理。 RabbitMQ 保证了同一个队列内的数据是有序的,即按照先进先出(FIFO)的原则来存储和消费。但是不同队列之间的数据是无序的,即不能保证跨队列的数据按照全局顺序来处理。
- 数据可靠性:Kafka 通过副本(replica)机制来保证数据的可靠性,即每个主题可以有多个副本分布在不同的节点(broker)上,如果某个节点发生故障,可以自动切换到其他节点继续提供服务。 RabbitMQ 通过镜像(mirror)机制来保证数据的可靠性,即每个队列可以有多个镜像分布在不同的节点上,如果某个节点发生故障,可以自动切换到其他节点继续提供服务。
- 数据持久性:Kafka 将数据持久化到磁盘中,并且支持数据压缩和批量传输,以提高性能和节省空间。Kafka 可以支持TB级别甚至PB级别的数据存储,并且可以快速地重放历史数据。RabbitMQ 将数据缓存在内存中,并且支持消息确认和事务机制,以提高可靠性和一致性。RabbitMQ 也可以将数据持久化到磁盘中,但是会降低性能和吞吐量。RabbitMQ 更适合处理小规模且实时性较高的数据。
- 数据扩展性:Kafka 通过分区机制来实现水平扩展,即每个主题可以划分为多个分区,并且可以动态地增加或减少分区数量
- 复杂性:与 RabbitMQ 相比,Apache Kafka 具有更复杂的架构,并且可能需要更多的设置和配置,因此它的复杂性也允许更高级的功能和定制。另一方面,RabbitMQ 更容易设置和使用。
应用场景
Kafka 适用场景和需求
- 跟踪高吞吐量的活动,如网站点击、应用日志、传感器数据等。
- 事件溯源,Kafka 保存着所有历史消息,可以用于事件回溯和审计。
- 流式处理,如实时分析、实时推荐、实时报警等。
- 日志聚合,如收集不同来源的日志并统一存储和分析。
RabbitMQ 适用场景和需求
- 中小项目,项目消息量小、吞吐量不高、对延时敏感。
- 遗留应用,如需要与旧系统或第三方系统进行集成或通信。
- 复杂路由,如需要根据不同的规则或条件来分发或过滤消息。
- 任务分发,如需要将任务均匀地分配给多个工作进程或消费者。
总结
在公司项目中,一般消息量都不大的情况下,博主推荐大家可以使用 RabbitMQ。消息量起来了可以考虑切换到 Kafka,但是也要根据公司内部对两种 MQ 的熟悉程度来进行选择,避免 MQ 出现问题时无法及时处理。
链接:https://juejin.cn/post/7248906639704342589
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
实战:工作中对并发问题的处理
大家好,我是 方圆。最近在接口联调时发生了数据并发修改问题,我想把这个问题讲解一下,并把当时提出的解决方案进行实现,希望它能在大家以后在遇到同样的问题时提供一些借鉴和思考的方向。原文还是收录在我的 Github: enthusiasm 中,欢迎Star和获取原文。
1. 问题背景
问题发生在快递分拣的流程中,我尽可能将业务背景简化,让大家只关注并发问题本身。
分拣业务针对每个快递包裹都会生成一个任务,我们称它为 task。task 中有两个字段需要关注,一个是分拣中发生的 异常(exp_type),另一个是分拣任务的 状态(status)。另外,需要关注 分拣状态上报接口,通过它来记录分拣过程中的异常和状态变更。
一般情况下,分拣机在分拣异常发生时会及时调用接口上报,在分拣完成时调用接口来标记为完成状态,两次接口调用的时间间隔较长,不会发生并发问题。
但是有一种特殊的分拣机,它不会在异常发生时及时上报,而是在分拣完成时将分拣过程中发生的异常和分拣结果一起上报,那么此时分拣状态上报接口在同一时间内就会有两次调用,这时便发生了预期外的并发问题。
我们先看下分拣状态上报接口的执行流程:
先查询到该分拣任务 task,默认情况下 exp_type 和 status 均为默认值0
分拣异常修改 task 中的 exp_type,分拣完成修改 status 字段信息
修改完成将 task 写入
数据库初始值为 1, 0, 0,分拣异常和分拣完成几乎同时上报,它们都读取到该值。分拣异常动作将 exp_type 修改为9,写入数据库,此时数据库值为 1, 9, 0;分拣完成动作将 status 修改为1,写入数据库,使得数据库最终值为 1, 0, 1,它将异常字段的值覆盖掉了。正常情况下,最终值应该为 1, 9, 1,分拣完成动作应该读取到分拣异常完成后的值 1, 9, 0 后再进行修改才对。
2. 解决方案
发生这个问题的原因很容易就能发现:两个事务同时执行 读取-修改-写入 序列,其中一个写操作在没有合并另一个写操作变更的情况下,直接覆盖了另一个写操作的结果,所以导致了数据的丢失。
这种问题是比较典型的 丢失更新 问题,可以通过对数据库读操作加锁或者改变数据库的隔离级别为可串行化使事务串行执行的方式进行避免。下面我会将大家在讨论避免丢失更新问题时提出的方案进行介绍,并尽可能的用代码来表现它们。
2.1 数据库读操作加锁和可串行化隔离级别
我们可以考虑:如果对每条Task数据修改的事务都是在当前事务完成之后才允许后续事务进行修改,使事务串行执行,那么我们就能够避免这种情况。比较直接的实现是通过显式加锁来实现,如下
select exp_type, status
from task
where id = 1
for update;
先查询该行数据的事务会获取到该行数据的 排他锁,后续针对该数据的所有读写请求都会被阻塞,直到先前事务执行完将锁释放。
这样通过加锁的方式实现了事务的串行执行。但是,在为SQL添加加锁语句时,需要确定是不是为该行数据加锁而不是锁住了整个表,如果是后者,那么可能会造成系统性能严重下降,而且还需要关注有哪些业务场景使用到了该SQL,是否存在长时间执行的只读事务使用,如果存在的话可能会出现因加锁导致延迟和系统性能下降,所以需要谨慎的评估。
此外,可串行化的数据库隔离级别也能保证事务的串行执行,不过它针对的是所有事务。一般情况下为了保证性能,我们不会采用这种方案(默认使用MySQL可重复读隔离级别)。
MySQL的InnoDB引擎实现可串行化隔离级别采用的是2PL机制:在第一阶段事务执行时获取锁,第二阶段事务执行完成释放锁。
2.2 针对业务只修改必要字段
如果异常状态请求仅修改 exp_type 字段,分拣完成仅修改 status 字段的话,那么我们可以梳理一下业务逻辑,仅将必要修改的字段写入数据库,这样就不会发生丢失更新的异常,如下代码所示:
// 处理异常状态请求,封装修改数据的对象
Task task = new Task();
tast.setId(id);
task.setExpType(expType);
// 更改数据
taskService.updateById(task);
在执行修改数据前,创建一个新的修改对象,并只为其必要修改字段赋值。但是还需要考虑的是:如果这个业务流程处理已经很复杂了,很可能不清楚该为哪些字段赋值而导致再发生新的异常,所以采用这种方法需要对业务足够熟悉,并且在修改完后进行充分的测试。
2.3 分布式锁
分布式锁的方法与方法一类似,都是通过加锁的方式来保证同时只有一个事务执行,区别是方法一的锁加在了数据库层,而分布式锁是借助Redis来实现。
这种实现方式的好处是锁的粒度小,发生锁争抢仅限于单个包裹,无需像数据库加锁一样去考虑锁的粒度和对相关业务的影响。伪代码如下所示:
// 分布式锁KEY
String distributedKey = String.format(DISTRIBUTED_KEY_PREFIX, packageNo);
try {
// 分布式锁阻塞同一包裹号的修改
lock(distributedKey);
// 处理业务逻辑
handler();
} finally {
// 执行完解锁
redissonDistributedLocker.unlock(distributedKey);
}
需要注意,lock() 加锁方法要保证加锁失败或发生其他异常情况不影响业务逻辑的执行,并设定好锁持有时间和等待锁的阻塞时间,此外解锁方法务必添加到 finally 代码块中保证锁的释放。
2.4 CAS
CAS是乐观的解决方案,它一般通过在数据库中增加时间戳列来记录上次数据更改的时间,当新的事务执行时,需要比对读取时该行数据的时间戳和数据库中保存的时间戳是否一致,以此来判断事务执行期间是否有其他事务修改过该行数据,只有在没有发生改变的情况下才允许更新,否则需要重试这个事务。样例SQL如下所示:
update task
set exp_type = #{expType}, status = #{status}, ts = #{currentTs}
where id = #{id} and ts = #{readTs}
它的原理不难理解,但是实现起来可能会存在困难,因为需要考虑在执行失败后该如何重试,重试的方式和重试的次数需要根据业务去判断。
链接:https://juejin.cn/post/7261600077915357243
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用小明的故事随便谈谈kotlin中的apply等函数
前言
本文仅简单描述一下kotlin中常用到的scope function,如apply,let,run,with,also等函数的常用方法和选取。即使很多情况下选择不同函数,也同样都能达到最终效果,具体选择哪个函数我们不会严格约束,但如果你是对代码规范要求比较高的,最好建立良好的代码习惯。
一般对比
| 函数 | 一般使用场景 | 函数定义 | 上下文对象可用作 | 返回值 |
|---|---|---|---|---|
| apply | 在需要对对象进行初始化或配置的时候使用 | public inline fun <T> T.apply(block: T.() -> Unit): T | 接收器this | 返回值是对象本身 |
| also | 在需要对对象执行额外操作并返回原对象的时候使用 | public inline fun <T> T.also(block: (T) -> Unit): T | 变量it | 返回值是对象本身 |
| let | 在需要对对象进行非空判断并执行特定操作的时候使用 | public inline fun <T, R> T.let(block: (T) -> R): R | 变量it | 返回值是 lambda 结果 |
| run | 在需要对对象进行多个操作,并返回一个结果的时候使用,通常是一个新的对象或其他 | public inline fun <T, R> T.run(block: () -> R): R | 接收器this | 返回值是 lambda 结果 |
| with | 在不拥有对象的上下文的时候使用 | public inline fun <T, R> with(receiver: T, block: T.() -> R): R | 接收器this | 返回值是 lambda 结果 |
apply函数接收一个 lambda 表达式作为参数,并返回被调用对象本身。通过apply,可以在对象创建后立即对其进行链式操作,设置属性值、调用方法等。适合用于链式初始化或配置一些属性。
val person = Person().apply {
name = "John"
age = 30
}
also函数接收一个 lambda 表达式作为参数,lambda 表达式中的 it 引用指向调用also的对象。通过also,可以对对象进行额外的操作,而原对象仍然是函数调用的结果。适合用于在对象操作过程中执行额外的副作用操作。
val modifiedObject = myObject.also {
// 额外操作 it
}
let函数接收一个 lambda 表达式作为参数,lambda 表达式中的 it 引用指向调用let的对象。如果对象不为空,则执行 lambda 表达式内的操作,并返回 lambda 表达式的结果。适合用于安全地操作对象,避免空指针异常。
val result = nullableValue?.let {
// 操作非空对象 it
}
run函数接收一个 lambda 表达式作为参数,lambda 表达式中的 this 引用指向调用run的对象。通过run,可以便捷地对对象进行多次操作,并返回最后一个表达式的结果。适合用于执行一系列操作并返回最终结果。
val result = myObject.run {
// 对象操作1
// 对象操作2
// ...
// 返回结果
}
with函数接收一个对象和一个 lambda 表达式作为参数,lambda 表达式中的 this 引用指向传入的对象。通过with,可以在没有对象接收者的情况下操作对象,并返回最后一个表达式的结果。适合用于对对象进行一系列操作,而无需在乎返回值。
val result = with(myObject) {
// 对象操作1
// 对象操作2
// ...
// 返回结果
}
小明的故事
故事是这样的
- 小明今年上一年级
- 但是家长跟学校说,小明是个天才,现在可以直接跳级到二年级
- 学校给二年级分配的老师是王老师,是个女教师
- 半学期后,王老师怀孕了需要休息,于是学校给王老师放假
- 学校给二年级分配了新的李老师,小明有了新老师
下面是故事的代码:
data class Student(var name: String = "", var grade: String = "", var teacher: Teacher? = null) {
//插班跳级
fun needSkippingGrade(insertGrade: String) {
this.grade = insertGrade
}
}
data class Teacher(var name: String = "") {
fun relax() {
println("$name 休假了!")
}
}
fun main() {
//1. **小明**今年上一年级
val xiaoming = Student()
.apply {
name = "小明"
grade = "一年级"
println("小明开始前: $this")
}
.also {
//2.现在可以直接跳级到二年级
it.needSkippingGrade("二年级")
println("小明插班后: $it")
}
//3. 学校给二年级分配的老师是**王老师**,是个女教师
val ownTeacher = xiaoming.teacher?.let {
println("小明当前的老师不为NULL,是${it}")
} ?: Teacher("王老师").also {
xiaoming.teacher = it
println("小明有了老师: $xiaoming")
}
fun changeStudentCurrentTeacher(student: Student): Teacher? {
return student.run {
teacher?.relax()
Teacher("李老师")
}
}
//4. 半学期后,王老师怀孕了需要休息,于是学校给王老师放假
//5. 学校给二年级分配了新的**李老师**,小明有了新老师
with(xiaoming) {
println("开学了!")
println("半学期后,王老师怀孕了!...")
val newTeacher = changeStudentCurrentTeacher(this)
println("新老师是$newTeacher")
teacher = newTeacher
println("小明有了新老师$this")
}
}
输出结果:
小明开始前: Student(name=小明, grade=一年级, teacher=null)
小明插班后: Student(name=小明, grade=二年级, teacher=null)
小明有了老师: Student(name=小明, grade=二年级, teacher=Teacher(name=王老师))
开学了!
半学期后,王老师怀孕了!...
王老师 休假了!
新老师是Teacher(name=李老师)
小明有了新老师Student(name=小明, grade=二年级, teacher=Teacher(name=李老师))
最后
实际过程中,需要根据具体的场景和需求来选择适合的函数。前面这些函数在 Kotlin 中提供了更简洁、可读性更高的方式来处理对象,根据不同的使用场景,你可以选择最适合和更易读的函数来操作对象
链接:https://juejin.cn/post/7255795059660193850
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
当面试官问你BroadcastReciver的静态注册与动态注册的区别,你又该作何应对?
什么是广播,简单点广播就是安卓系统本身发出的声音,我们可以通过安卓提供给我们的一系列内容来接收和发出广播,以此来简单快捷地实现一些功能。
在实际开发中也常常用到,而是否熟悉使用,这成为面试官最常问的问题。
当面试官问你:
1.请问BroadcastReciver的静态注册与动态注册的区别?,你在开发中用过吗?
答:
其实广播分为两种基本类型:
在一个程序中,可以发送广播供当前程序的广播接收器收到。首先我们来看下两种方式的发送广播。 在Android系统中,主要有两种基本的广播类型: - 标准广播(Normal Broadcasts) - 有序广播(Ordered Broadcasts)
标准广播:
是一种完全异步执行的广播,在广播发出之后,所有的广播接收器会在同一时刻接收到这条广播,广播无法被中断。
发送广播的方式十分容易的,只需要实例化一个Intent对象,然后调用context的** sendBroadcast() **方法。这样就完成了广播的发送。
//intent中的参数为action
Intent intent=new Intent("com.example.dimple.BROADCAST_TEST");
sendBroadcast(intent);
有序广播:
是一种同步执行的广播,在广播发出之后,优先级高的广播接收器会先接收到这条广播,并可以在优先级较低的广播接收器之前终止发送这条广播。
//intent中的参数为action
Intent intent=new Intent("com.example.dimple.BROADCAST_TEST");
sendOrderBroadcast(intent,null);//第二个参数是与权限相关的字符串。
到此时,如果你的程序中只有一个广播接收器的话,是体现不出有序广播的特点的, 右击包名——New——Other——BroadcastReceiver多创建几个广播接收器。
此时你还是会发现,所有的广播接收器是同时接收到广播消息的。注意上面介绍的时候说到优先级,这个时候我们需要设置优先级,在AndroidManifest文件中的Receiver标签中设置广播接收器的优先级。
<receiver
android:name=".MyReceiver"
android:enabled="true"
android:exported="true">
<!--注意此时有一个Priority属性-->
<intent-filter android:priority="100">
<action android:name="android.intent.action.BROADCAST_TEST"></action>
</intent-filter>
</receiver>
优先级越高的广播接收器优先收到广播,也可以在收到广播的时候调用abortBroadcast() 方法截断广播。优先级低的广播接收器就无法接收到广播了。
面试官,假设我有一个接收者如下:
在Android的广播接收机制中,如果接收到广播,就需要创建广播接收器。而创建广播接收器的方法就是新建一个类(可以是单独新建类,也可以是内部类(public)) 继承自BroadcastReceiver
class myBroadcastReceiver extends BroadcastReceiver{
@Override
public void onReceive(Context context, Intent intent) {
//接收到广播的处理,注意不能有耗时操作,当此方法长时间未结束,会报错。
//同时,广播接收器中不能开线程。
}
}
面试官,接下来就是面临注册的问题了,有两种注册方式,一种是动态注册,一种是静态注册。
所谓动态注册是指在代码中注册。步骤如下 :
- 实例化自定义的广播接收器。
- 创建IntentFilter实例。
- 调用IntentFilter实例的addAction()方法添加监听的广播类型。
- 最后调用Context的registerReceiver(BroadcastReceiver,IntentFilter)动态的注册广播。
这个时候,已经为我们自定义的广播接收器关联了广播,当收到和绑定的广播一直的广播的时候,就会调用广播接收器中的onReceiver方法。
MyBroadcastReceiver myBroadcastReceiver=new MyBroadcastReceiver();
IntentFilter intentFilter=new IntentFilter();
intentFilter.addAction("com.example.dimple.MY_BROADCAST");
registerReceiver(myBroadcastReceiver,intentFilter);
这里需要注意的是,如果需要接收系统的广播(比如电量变化,网络变化等等),别忘记在AndroidManifest配置文件中加上权限。另外,动态注册的广播在活动结束的时候需要取消注册:
@Override
protected void onDestroy() {
super.onDestroy();
unregisterReceiver(myBroadcastReceiver);
}
静态注册:
在创建好的广播接收器中添加一个Toast提示。代码如下:
public class MyReceiver extends BroadcastReceiver {
@Override
public void onReceive(Context context, Intent intent) {
Toast.makeText(context,"开机启动!",Toast.LENGTH_LONG).show();
}
}
然后在AndroidManifest文件中添加:
权限
<uses-permission android:name="android.permission.RECEIVE_BOOT_COMPLETED"></uses-permission>Intent-filter
<receiver
android:name=".MyReceiver"
android:enabled="true"
android:exported="true">
<!--添加以下3行-->
<intent-filter>
<action android:name="android.intent.action.BOOT_COMPLETED"></action>
</intent-filter>
</receiver>
此时重启Android系统就可以收到开机提示了。
总结:
动态注册和静态注册的不同:
动态注册的广播接收器可以自由的实现注册和取消,有很大的灵活性。但是只有在程序启动之后才能收到广播,此外,不知道你注意到了没,广播接收器的注销是在onDestroy()方法中的。所以广播接收器的生命周期是和当前Activity的生命周期一样。
静态注册的广播不受程序是否启动的约束,当应用程序关闭之后,还是可以接收到广播。
标准广播和有序广播的接收和发送都是全局性的,这样会使得其他程序有几率接收到广播,会造成一定的安全问题。为了解决这个问题,Android系统中有一套本地广播的机制。这个机制是让所有的广播事件(接收与发送)都在程序内部完成。主要是采用的一个localBroadcastReceiver对广播进行管理。
链接:https://juejin.cn/post/7255213112881266749
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
终于搞明白了什么是同步屏障
背景
今天突然听到隔壁在讨论同步屏障,听到这个名字,我依稀记得 Handler 里面是有同步屏障机制的,但是具体的原理怎么有点模糊不清呢?就像一个明星,你明明看着面熟,就是想不起来他叫啥,让我这样的强迫症患者无比难受,所以抽时间来扒一扒同步屏障。
同步屏障机制
1. 直奔主题,同步屏障机制这几个字听起来很牛逼,能浅显的解释一下,先让大家明白它的作用是啥不?
同步屏障实际上就是字面意思,可以理解为建立一道屏障,隔离同步消息,优先处理消息队列中的异步消息进行处理,所以才叫同步屏障。
2. 第二个问题,同步消息又是啥呢?异步消息和同步消息有啥不一样呢?
要回答这个问题,我们就得了解一下 Message,Message 的消息种类分为三种:
- 普通消息(同步消息)
- 异步消息
- 同步屏障消息
我们平时使用 Handler 发送的消息基本都是普通消息,中规中矩的排到消息队列中,轮到它了再乖乖地出来执行。
考虑一个场景,我现在往 UI 线程发送了一个消息,想要绘制一个关键的 View,但是现在 UI 线程的消息队列里面消息已经爆满了,我的这条消息迟迟都没有办法得到处理,导致这个关键 View 绘制不出来,用户使用的时候很恼怒,一气之下给出差评这是什么垃圾 app,卡的要死。
此时,同步屏障就派上用场了。如果消息队列里面存在了同步屏障消息,那么它就会优先寻找我们想要先处理的消息,把它从队列里面取出来,可以理解为加急处理。那同步屏障机制怎么知道我们想优先处理的是哪条消息呢?如果一条消息如果是异步消息,那同步屏障机制就会优先对它处理。
3.那要如何设置异步消息呢?怎样的消息才算一条异步消息呢?
Message 已经提供了现成的标记位 isAsynchronous 用来标志这条消息是不是异步消息。
4.能看看源码了解下官方到底怎么实现的吗?
看看怎么往消息队列 MessageQueue 中插入同步屏障消息吧。
private int postSyncBarrier(long when) {
synchronized (this) {
final int token = mNextBarrierToken++;
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
Message prev = null;
// 当前消息队列
Message p = mMessages;
if (when != 0) {
// 根据when找到同步屏障消息插入的位置
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
}
// 插入同步屏障消息
if (prev != null) {
msg.next = p;
prev.next = msg;
} else {
msg.next = p;
// 前面没有消息的话,同步屏障消息变成队首了
mMessages = msg;
}
return token;
}
}
在代码关键位置我都做了注释,简单来说呢,其实就像是遍历一个链表,根据 when 来找到同步屏障消息应该插入的位置。
5.同步屏障消息好像只设置了when,没有target呢?
这个问题发现了华点,熟悉 Handler 的朋友都知道,插入消息到消息队列的时候,系统会判断当前的消息有没有 target,target 的作用就是标记了这个消息最终要由哪个 Handler 进行处理,没有 target 会抛异常。
boolean enqueueMessage(Message msg, long when) {
// target不能为空
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
...
}
问题 4 的源码分析中,同步屏障消息没有设置过 target,所以它肯定不是通过 enqueueMessage() 添加到消息队列里面的啦。很明显就是通过 postSyncBarrier() 方法,把一个没有 target 的消息插入到消息队列里面的。
6.上面我都明白了,下面该说说同步屏障到底是怎么优先处理异步消息的吧?
OK,插入了同步屏障消息之后,消息队列也还是正常出队的,显然在队列获取下一个消息的时候,可能对同步屏障消息有什么特殊的判断逻辑。看看 MessageQueue 的 next 方法:
Message next() {
...
// msg.target == null,很明显是一个同步屏障消息
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
...
}
方法代码很长,看源码最主要还是看关键逻辑,也没必要一行一行的啃源码。这个方法中相信你一眼就发现了msg.target == null,前面刚说过同步屏障消息的 target 就是空的,很显然这里就是对同步屏障消息的特殊处理逻辑。用了一个 do...while 循环,消息如果不是异步的,就遍历下一个消息,直到找到异步消息,也就是 msg.isAsynchronous() == true
7.原来如此,那如果消息队列中没有异步消息咋办?
如果队列中没有异步消息,就会休眠等待被唤醒。所以 postSyncBarrier() 和 removeSyncBarrier() 必须成对出现,否则会导致消息队列中的同步消息不会被执行,出现假死情况。
8.系统的 postSyncBarrier() 貌似也没提供给外部访问啊?这我们要怎么使用?
确实我们没办法直接访问 postSyncBarrier() 方法创建同步屏障消息。你可能会想到不让访问我就反射调用呗,也不是不可以。
但我们也可以另辟蹊径,虽然没办法创建同步屏障消息,但是我们可以创建异步消息啊!只要系统创建了同步屏障消息,不就能找到我们自己创建的异步消息啦。
系统提供了两个方法创建异步 Handler:
public static Handler createAsync(@NonNull Looper looper) {
if (looper == null) throw new NullPointerException("looper must not be null");
// 这个true就是代表是异步的
return new Handler(looper, null, true);
}
public static Handler createAsync(@NonNull Looper looper, @NonNull Callback callback) {
if (looper == null) throw new NullPointerException("looper must not be null");
if (callback == null) throw new NullPointerException("callback must not be null");
return new Handler(looper, callback, true);
}
异步 Handler 发送的就是异步消息。
9.那系统什么时候会去添加同步屏障呢?
有对 View 的工作流程比较了解的朋友想必已经知道了,在 ViewRootImpl 的 requestLayout 方法中,系统就会添加一个同步屏障。
不了解也没关系,这里我简单说一下。
(1)创建 DecorView
当我们启动了 Activity 后,系统最终会执行到 ActivityThread 的 handleLaunchActivity 方法中:
final Activity a = performLaunchActivity(r, customIntent);
这里我们只截取了重要的一行代码,在 performLaunchActivity 中执行的就是 Activity 的创建逻辑,因此也会进行 DecorView 的创建,此时的 DecorView 只是进行了初始化,添加了布局文件,对用户来说,依然是不可见的。
(2)加载 DecorView 到 Window
onCreate 结束后,我们来看下 onResume 对应的 handleResumeActivity 方法:
@Override
public void handleResumeActivity(ActivityClientRecord r, boolean finalStateRequest,
boolean isForward, String reason) {
...
// 1.performResumeActivity 回调用 Activity 的 onResume
if (!performResumeActivity(r, finalStateRequest, reason)) {
return;
}
...
final Activity a = r.activity;
...
if (r.window == null && !a.mFinished && willBeVisible) {
r.window = r.activity.getWindow();
// 2.获取 decorview
View decor = r.window.getDecorView();
// 3.decor 现在还不可见
decor.setVisibility(View.INVISIBLE);
ViewManager wm = a.getWindowManager();
WindowManager.LayoutParams l = r.window.getAttributes();
a.mDecor = decor;
l.type = WindowManager.LayoutParams.TYPE_BASE_APPLICATION;
l.softInputMode |= forwardBit;
...
if (a.mVisibleFromClient) {
if (!a.mWindowAdded) {
a.mWindowAdded = true;
// 4.decor 添加到 WindowManger中
wm.addView(decor, l);
} else {
a.onWindowAttributesChanged(l);
}
}
}
...
}
注释 4 处,DecorView 会通过 WindowManager 执行了 addView() 方法后加载到 Window 中,而该方法实际上是会最终调用到 WindowManagerGlobal 的 addView() 中。
(3)创建 ViewRootImpl 对象,调用 setView() 方法
// WindowManagerGlobal.ddView()
root = new ViewRootImpl(view.getContext(), display);
root.setView(view, wparams, panelParentView);
WindowManagerGlobal 的 addView() 会先创建一个 ViewRootImpl 实例,然后将 DecorView 作为参数传给 ViewRootImpl,通过 setView() 方法进行 View 的处理。setView() 的内部主要就是通过 requestLayout 方法来请求开始测量、布局和绘制流程。
(4)requestLayout() 和 scheduleTraversals()
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
// 主要方法
scheduleTraversals();
}
}
void scheduleTraversals() {
if (!mTraversalScheduled) {
// 1.将mTraversalScheduled标记为true,表示View的测量、布局和绘制过程已经被请求。
mTraversalScheduled = true;
// 2.往主线程发送一个同步屏障消息
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
// 3.注册回调,当监听到VSYNC信号到达时,执行该异步消息
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
看到了吧,注释 2 的代码熟悉的很,系统调用了 postSyncBarrier() 来创建同步屏障了。那注释 3 是啥意思呢?mChoreographer 是一个 Choreographer 对象。
要理解 Choreographer 的话,还要明白 VSYNC。
我们的手机屏幕刷新频率是 1s 内屏幕刷新的次数,比如 60Hz、120Hz 等。60Hz表示屏幕在一秒内刷新 60 次,也就是每隔 16.6ms 刷新一次。屏幕会在每次刷新的时候发出一个 VSYNC 信号,通知CPU进行绘制计算,每收到 VSYNC,CPU 就开始处理各帧数据。这时 Choreographer 就上场啦,当有 VSYNC 信号到来时,会唤醒 Choreographer,触发指定的工作。它提供了一个回调功能,让业务知道 VSYNC 信号来了,可以进行下一帧的绘制了,也就是注释 3 使用的 postCallback 方法。
当监听到 VSYNC 信号后,会回调来执行 mTraversalRunnable 这个 Runnable 对象。
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
// 移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
if (mProfile) {
Debug.startMethodTracing("ViewAncestor");
}
// View的绘制入口方法
performTraversals();
if (mProfile) {
Debug.stopMethodTracing();
mProfile = false;
}
}
}
在这个 Runnable 里面,会移除同步屏障。然后调用 performTraversals 这个View 的工作流程的入口方法完成对 View 的绘制。
这回明白了吧,系统会在调用 requestLayout() 的时候创建同步屏障,等到下一个 VSYNC 信号到来时才会执行相应的绘制任务并移除同步屏障。所以在等待 VSYNC 信号到来的期间,就可以执行我们自己的异步消息了。
链接:https://juejin.cn/post/7258850748150104120
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 密封接口sealed interface
什么是密封接口?
密封接口(sealed interface)是kotlin 1.5引入的一个新特性,它可以让我们定义一个限制性的类层次结构,也就是说,我们可以在编译时就知道一个密封接口有哪些可能的子类型。这样,我们就可以更好地控制继承关系,避免出现意外的子类型。
密封接口与密封类(sealed class)类似,都可以用来表示一组有限的可能性。但是,密封类只能有一个实例,而密封接口的子类型可以有多个实例。此外,密封类只能被类继承,而密封接口可以被类和枚举类(enum class)实现。
要声明一个密封接口,我们需要在interface关键字前加上sealed修饰符:
sealed interface Error // 密封接口
一个密封接口可以有抽象或默认实现的方法,也可以有属性:
sealed interface Shape { // 密封接口
val area: Double // 属性
fun draw() // 抽象方法
fun printArea() { // 默认实现方法
println("The area is $area")
}
}
密封接口的优点
使用密封接口有以下几个优点:
- 类型安全:由于密封接口的子类型是固定的,我们可以在编译时就检查是否覆盖了所有可能的情况。这样,我们就不会遗漏某些分支或者处理错误的类型。
- 可读性:使用密封接口可以让我们清楚地看到一个类型有哪些变种。这样,我们就可以更容易地理解和维护代码。
- 灵活性:使用密封接口可以让我们定义更多样化的子类型。我们可以使用数据类(data class),对象(object),普通类(class),或者另一个密封类(sealed class)作为子类型。我们还可以在不同的文件或模块中定义子类型。
- 表达力:使用密封接口可以让我们利用多态(polymorphism)和继承(inheritance)来实现更复杂和优雅的设计模式。
密封接口在设计模式中的应用
设计模式是一些经过验证和总结的解决特定问题的代码结构和技巧。使用设计模式可以让我们编写出更高效,更可复用,更易扩展的代码。
下面,我们将介绍几种常见的设计模式,并展示如何使用密封接口来实现它们。
策略模式
策略模式(Strategy Pattern)是一种行为型设计模式,它可以让我们在运行时根据不同的情况选择不同的算法或策略。这样,我们就可以将算法的定义和使用分离,提高代码的灵活性和可维护性。
要实现策略模式,我们可以使用密封接口来定义一个策略的抽象,然后使用不同的子类型来实现具体的策略。例如,我们可以定义一个排序策略的密封接口,然后使用不同的排序算法作为子类型:
sealed interface SortStrategy { // 密封接口
fun sort(list: List<Int>): List<Int> // 抽象方法
}
object BubbleSort : SortStrategy { // 对象
override fun sort(list: List<Int>): List<Int> {
// 实现冒泡排序
}
}
object QuickSort : SortStrategy { // 对象
override fun sort(list: List<Int>): List<Int> {
// 实现快速排序
}
}
object MergeSort : SortStrategy { // 对象
override fun sort(list: List<Int>): List<Int> {
// 实现归并排序
}
}
然后,我们可以定义一个上下文类(Context Class),它可以持有一个策略的引用,并根据需要切换不同的策略:
class Sorter(var strategy: SortStrategy) { // 上下文类
fun sort(list: List<Int>): List<Int> {
return strategy.sort(list) // 调用策略的方法
}
}
最后,我们可以在客户端代码中使用上下文类来执行不同的策略:
fun main() {
val list = listOf(5, 3, 7, 1, 9)
val sorter = Sorter(BubbleSort) // 创建上下文类,并指定初始策略
println(sorter.sort(list)) // 使用冒泡排序
sorter.strategy = QuickSort // 切换策略
println(sorter.sort(list)) // 使用快速排序
sorter.strategy = MergeSort // 切换策略
println(sorter.sort(list)) // 使用归并排序
}
使用密封接口实现策略模式的优点是:
- 我们可以在编译时就知道有哪些可用的策略,避免出现无效或未知的策略。
- 我们可以使用数据类,对象,普通类或密封类作为子类型,根据不同的策略需要定义不同的属性和方法。
- 我们可以在不同的文件或模块中定义子类型,提高代码的模块化和可读性。
如果使用java实现策略模式,我们可能需要定义一个接口来表示策略,然后使用不同的类来实现接口:
interface SortStrategy { // 接口
List<Integer> sort(List<Integer> list); // 抽象方法
}
class BubbleSort implements SortStrategy { // 类
@Override
public List<Integer> sort(List<Integer> list) {
// 实现冒泡排序
}
}
class QuickSort implements SortStrategy { // 类
@Override
public List<Integer> sort(List<Integer> list) {
// 实现快速排序
}
}
class MergeSort implements SortStrategy { // 类
@Override
public List<Integer> sort(List<Integer> list) {
// 实现归并排序
}
}
然后,我们也需要定义一个上下文类来持有和切换策略:
class Sorter { // 上下文类
private SortStrategy strategy; // 策略引用
public Sorter(SortStrategy strategy) { // 构造函数
this.strategy = strategy;
}
public void setStrategy(SortStrategy strategy) { // 设置策略方法
this.strategy = strategy;
}
public List<Integer> sort(List<Integer> list) {
return strategy.sort(list); // 调用策略的方法
}
}
最后,我们也可以在客户端代码中使用上下文类来执行不同的策略:
public static void main(String[] args) {
List<Integer> list = Arrays.asList(5, 3, 7, 1, 9);
Sorter sorter = new Sorter(new BubbleSort()); // 创建上下文类,并指定初始策略
System.out.println(sorter.sort(list)); // 使用冒泡排序
sorter.setStrategy(new QuickSort()); // 切换策略
System.out.println(sorter.sort(list)); // 使用快速排序
sorter.setStrategy(new MergeSort()); // 切换策略
System.out.println(sorter.sort(list)); // 使用归并排序
}
使用java实现策略模式的缺点是:
- 我们不能在编译时就知道有哪些可用的策略,因为任何类都可以实现接口。
- 我们只能使用类作为子类型,不能使用数据类或对象。
- 我们必须在同一个包中定义子类型,不能在不同的文件或模块中。
访问者模式
访问者模式(Visitor Pattern)是一种行为型设计模式,它可以让我们在不修改原有类结构的情况下,为类添加新的操作或功能。这样,我们就可以将数据结构和操作分离,提高代码的扩展性和复用性。
要实现访问者模式,我们可以使用密封接口来定义一个元素(Element)的抽象,然后使用不同的子类型来实现具体的元素。例如,我们可以定义一个表达式(Expression)的密封接口,然后使用不同的子类型来表示不同的表达式:
sealed interface Expression { // 密封接口
fun accept(visitor: Visitor): Any // 抽象方法,接受访问者
}
data class Number(val value: Int) : Expression { // 数据类
override fun accept(visitor: Visitor): Any {
return visitor.visitNumber(this) // 调用访问者的方法
}
}
data class Sum(val left: Expression, val right: Expression) : Expression { // 数据类
override fun accept(visitor: Visitor): Any {
return visitor.visitSum(this) // 调用访问者的方法
}
}
data class Product(val left: Expression, val right: Expression) : Expression { // 数据类
override fun accept(visitor: Visitor): Any {
return visitor.visitProduct(this) // 调用访问者的方法
}
}
然后,我们可以定义一个访问者(Visitor)的接口,它可以为每种元素提供一个访问方法:
interface Visitor { // 访问者接口
fun visitNumber(number: Number): Any // 访问数字表达式
fun visitSum(sum: Sum): Any // 访问加法表达式
fun visitProduct(product: Product): Any // 访问乘法表达式
}
最后,我们可以定义不同的访问者实现类,它们可以为元素提供不同的操作或功能。例如,我们可以定义一个求值(Evaluate)访问者,它可以计算表达式的值:
class Evaluate : Visitor { // 求值访问者
override fun visitNumber(number: Number): Any {
return number.value // 返回数字本身
}
override fun visitSum(sum: Sum): Any {
return (sum.left.accept(this) as Int) + (sum.right.accept(this) as Int) // 返回左右子表达式之和
}
override fun visitProduct(product: Product): Any {
return (product.left.accept(this) as Int) * (product.right.accept(this) as Int) // 返回左右子表达式之积
}
}
我们还可以定义一个打印(Print)访问者,它可以打印表达式的字符串表示:
class Print : Visitor { // 打印访问者
override fun visitNumber(number: Number): Any {
return number.value.toString() // 返回数字的字符串
}
override fun visitSum(sum: Sum): Any {
return "(${sum.left.accept(this)}) + (${sum.right.accept(this)})" // 返回加法的字符串
}
override fun visitProduct(product: Product): Any {
return "(${product.left.accept(this)}) * (${product.right.accept(this)})" // 返回乘法的字符串
}
}
使用密封接口实现访问者模式的优点是:
- 我们可以在编译时就知道有哪些可用的元素,避免出现无效或未知的元素。
- 我们可以使用数据类,对象,普通类或密封类作为子类型,根据不同的元素需要定义不同的属性和方法。
- 我们可以在不同的文件或模块中定义子类型,提高代码的模块化和可读性。
- 我们可以在不修改元素类的情况下,为它们添加新的访问者和操作。
如果使用java实现访问者模式,我们可能需要定义一个抽象类来表示元素,然后使用不同的子类来继承元素:
abstract class Expression { // 抽象类
public abstract Object accept(Visitor visitor); // 抽象方法,接受访问者
}
class Number extends Expression { // 子类
private int value; // 属性
public Number(int value) { // 构造函数
this.value = value;
}
public int getValue() { // 获取属性值方法
return value;
}
@Override
public Object accept(Visitor visitor) {
return visitor.visitNumber(this); // 调用访问者的方法
}
}
class Sum extends Expression { // 子类
private Expression left; // 属性
private Expression right; // 属性
public Sum(Expression left, Expression right) { // 构造函数
this.left = left;
this.right = right;
}
public Expression getLeft() { // 获取属性值方法
return left;
}
public Expression getRight() { // 获取属性值方法
return right;
}
@Override
public Object accept(Visitor visitor) {
return visitor.visitSum(this); // 调用访问者的方法
}
}
class Product extends Expression { // 子类
private Expression left; // 属性
private Expression right; // 属性
public Product(Expression left, Expression right) { // 构造函数
this.left = left;
this.right = right;
}
public Expression getLeft() { // 获取属性值方法
return left;
}
public Expression getRight() { // 获取属性值方法
return right;
}
@Override
public Object accept(Visitor visitor) {
return visitor.visitProduct(this); // 调用访问者的方法
}
}链接:https://juejin.cn/post/7259964169846538297
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Java Map 所有的值转为String类型
可以使用 Java 8 中的 Map.replaceAll() 方法将所有的值转为 String 类型:
Map<String, Object> map = new HashMap<>();
// 添加一些键值对
map.put("key1", 123);
map.put("key2", true);
map.put("key3", new Date());
// 将所有的值转为 String 类型
map.replaceAll((k, v) -> String.valueOf(v));
上面的代码会将 map 中所有的值都转为 String 类型。
HashMap 是 Java 中使用最广泛的集合类之一,它是一种非常快速的键值对存储方式,可以用于存储和访问大量的数据。下面介绍一些 HashMap 的常用方法:
put(key, value):向 HashMap 中添加一个键值对。
HashMap<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
get(key):根据键取出对应的值。
Integer value = map.get("apple");
containsKey(key):判断 HashMap 中是否包含指定键。
if (map.containsKey("apple")) {
// ...
}
containsValue(value):判断 HashMap 中是否包含指定值。
if (map.containsValue(1)) {
// ...
}
remove(key):根据键删除 HashMap 中的一个键值对。
map.remove("apple");
keySet():返回 HashMap 中所有键的集合。
Set<String> keys = map.keySet();
values():返回 HashMap 中所有值的集合。
Collection<Integer> values = map.values();
entrySet():返回 HashMap 中所有键值对的集合。
Set<Map.Entry<String, Integer>> entries = map.entrySet();
以上是常用的 HashMap 方法,还有其他一些方法可以查阅相关文档获得更多信息。
HashMap 的存储原理主要是基于 Hash 算法和数组实现的。 在 HashMap 中,每个键值对对应一个数组中的一个元素,这个元素叫做“桶(bucket)”或“槽(slot)”。
数组的索引值就是通过 Hash 算法计算出来的,每个桶中存放的是一个链表,存储了 key-value 对。如果不同的键值对计算出来的索引值相同,则这些键值对会被放到同一个桶中,以链表的形式存储在该桶中,这就是 HashMap 的解决冲突的方法。
HashMap 的存储过程如下:
- 当使用
put方法将一个键值对添加到 HashMap 中时,首先会根据键的hashCode值计算出数组索引位置。具体方法是,将hashCode值进行一些运算,得到一个数组索引值。这个索引值是键值对在数组中的位置。 - 如果数组中该位置为空,那么就可以直接将键值对存储在该位置,完成添加操作。
- 如果该位置已经有了键值对,那么就需要通过比较键的
equals方法,来判断是更新该键值对的值,还是添加一个新的键值对。 - 如果表示键值对的链表长度较长,就会影响到 HashMap 的性能,因为在查找时可能需要遍历整个链表。
为此,Java 8 引入了“红黑树”(Red-Black Tree) 的数据结构,可以将链表转换为树,以提高性能。 需要注意的是,HashMap 是非线程安全的,如果在多线程环境下使用,可能会发生一些异常情况。如果需要在多线程环境中使用 HashMap,可以使用 ConcurrentHashMap 或 Collections.synchronizedMap 方法来实现线程安全。
链接:https://juejin.cn/post/7228473633508048951
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用户被盗号?你肯定缺少这些设计
前言
在之前的文章【你的登录接口真的安全吗?】中,我们在用户登录安全方面做了很多设计,就是保护用户的账号安全,但是!!我相信做过用户体系的开发或产品都知道,用户的密码泄漏是一个不可避免的事件,总会有用户因为各种奇奇怪怪的原因而导致账号被盗,进而导致用户信息泄漏、虚拟数据丢失、经济损失等各种后果。那针对这种场景,我们可以通过什么手段来尽量预防呢?
几种实现方式来判断用户登录环境
一般这种情况,业界最简单的处理方式就是识别用户登录环境是是否正常:比如是否是常登录IP、或者是常登录设备等,如果不是,那么则进行限制、二次验证、用户告警等操作。
异地登录
首先是用户异地登录,一般场景下,用户的使用环境大部分时间都是不怎么变化的,比如公司、家里、宿舍或学校等。那么我们可以基于用户的使用IP,来做风险管理。
伪代码实现
def login(username, password, ip):
# 登录失败,简化其它流程
if not do_login(username, password):
return Result(100, '登录失败')
# 检查用户登录环境异常
if !check_login_env(username, ip):
# 发送短信或邮件给用户,告知用户账号在非常用地登录
send_notice(username, ip)
# 前端收到这个状态码后跳转到二次验证页面
return Result(101, '非常登录地登录')
# 登录成功,异步记录当前ip
async_log_ip(username, ip)
return Result(0, '登录成功')
流程很简单,用户登录成功后,进行一次环境校验,判断用户当前登录ip是否为常登录地,如果不是,那么先给用户发送邮件或短信通知,然后返回对应状态码给前端,跳转到二次校验的页面。
二次校验可以通过APP扫码、手机验证码等方式登录。
*上面的代码中还缺少很重要的一步操作,怎么判断用户的IP是否是常登录IP?我们可以基于IP来实现,但是我们现在家用网络的IP基本上都不是固定IP,所以实际场景下可能更多的是使用地区来判断,比如城市。
伪代码实现
def check_login_env(username, ip):
cur_city = get_city_from_ip(ip)
# 此城市是否在近半年的常登录城市中
city = get_last_half_year_cities(username)
return cur_city == city
def log_env(username, ip):
city = get_city_from_ip(ip)
# 记录当前登录城市
insert_login_ip(username, city, ip, datetime.now())
# 统计常登录城市
# 查询的近半年登录次数最多的城市
city = select_max_login_city_last_half_year()
# 设置常登录城市
set_last_half_year_cities(username, city)
上面只是简单的实现,整个判断过程比较粗糙,准确性也不够高。实际产生中,我们可以根据ip位置,结合算法来计算常登录地;或者结合下面的其它方式共同判断。
非常用设备登录
除了通过ip来判断用户使用环境外,我们一般还会结合用户设备来判断,特别是移动端应用,用户设备大部分时候是固定不变的。
设备信息一般可以使用设备指纹的方式,通过采集设备的各种信息,生成一个唯一标识,用于标识此设备。如果设备指纹不存在,那么证明用户在新设备上登录,则进行二次验证。
伪代码实现
def login(username, password, ip, device_info):
# 登录失败,简化其它流程
if not do_login(username, password):
return Result(100, '登录失败')
# 检查用户登录环境异常
if !check_login_env(username, ip):
# 发送短信或邮件给用户,告知用户账号在非常用地登录
send_notice(username, ip)
# 前端收到这个状态码后跳转到二次验证页面
return Result(101, '非常登录地登录')
if !check_device_env(username, device_info):
send_notice(username, device_info)
# 前端收到这个状态码后跳转到二次验证页面
return Result(102, '正在使用新设备登录')
# 登录成功,异步记录当前ip
async_log_ip(username, ip)
# 记录设备信息
async_log_device(username, device_info)
return Result(0, '登录成功')
用户设备信息采集需要征得用户同意,那万一无法采集信息怎么办? 我们也可以想办法在用户第一次登录时,在用户设备中生成记录一个唯一ID并存储在设备中,用于标记这个设备。
异常IP登录
这个和异地登录不同的是,我们可以维护一个IP黑名单,只要是用户登录的IP在黑名单内,则一定要求用户做二次验证。
黑名单的来源主要是通过购买、自行采集的方式获取到的黑产IP
用户风控
上面的各种方式,都不是孤立的,更多的是结合起来,包括其它更多的判断逻辑,来最终决定用户的登录环境是否存在风险,而这部分功能,我们一般会把它抽离出来,单独做为一个风控服务实现。 我们输入用户登录相关的数据,比如用户ID、登录IP、设备信息等,风控服务结合历史数据、用户行为数据等,通过大数据分析以及我们配置的风控规则,最终输出给我们一个风险级别,然后再根据风险级别决定是否需要做后续的措施。
总结
今天主要讲了几种预防用户账号被盗的手段以及简单的实现,相信大家在使用各种产品的时候也有碰到过对应的功能,我们在做用户体系设计的时候,前期可能用户量比较少,但是也可以尽量的考虑安全相关的设计,体量小有小的做法,大有大的做法,但是做了总比没做好。希望读完这篇文章大家有所收获~
链接:https://juejin.cn/post/7259757499254964284
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


