








介绍一个手势识别库——AlloyFinger
移动端触摸手势库 AlloyFinger,配上 Vue 的
v-finger指令,让「点、滑、捏、转」都能用声明式写法搞定,一起看看吧。
一、为什么需要 AlloyFinger?
在 H5 里,原生 touchstart / touchmove / touchend 只能告诉你「手指动了」,至于用户是单击、双击、长按、滑动、双指缩放还是旋转,都要自己算时间差、距离、角度——既难写又容易出 bug。
AlloyFinger 是腾讯 AlloyTeam 开源的轻量级手势库,把这些常见手势都封装好了,并且提供了 Vue 插件,以自定义指令 v-finger 的形式在模板里绑定,写法清晰、易维护。
二、安装依赖
在项目根目录执行:
npm install alloyfinger
三、在入口文件中注册插件
在 Vue 入口文件(如 src/main.js)中做两件事:
- 引入 AlloyFinger 本体和其 Vue 插件;
- 使用
Vue.use(AlloyFingerPlugin, { AlloyFinger })注册。
这样全局就可以在任意组件的模板里使用 v-finger 指令。
// 引入 alloy-finger
import AlloyFinger from 'alloyfinger'
import AlloyFingerPlugin from 'alloyfinger/vue/alloy_finger_vue'
Vue.use(AlloyFingerPlugin, {
AlloyFinger
})
注意:
- 插件路径是
alloyfinger/vue/alloy_finger_vue - 必须把 AlloyFinger 通过
Vue.use的第二个参数传进去,插件内部会用它来创建手势实例。
四、在模板里使用 v-finger
注册完成后,在任意 Vue 组件的模板中,给需要绑定手势的单个根元素写上 v-finger:事件名="方法名" 即可。
4.1 语法形式
<div
v-finger:tap="onTap"
v-finger:swipe="onSwipe"
v-finger:long-tap="onLongTap"
>
可触摸区域
</div>
- 指令名:
v-finger - 修饰符:冒号后面是事件类型,如
tap、swipe、long-tap、pinch、rotate等。 - 值:当前 Vue 实例上的方法名,与普通
@click一样写在 methods 里即可。
4.2 支持的事件
| 事件名 | 说明 |
|---|---|
tap | 单击 |
double-tap | 双击 |
single-tap | 单击(与 double-tap 区分时用) |
long-tap | 长按 |
swipe | 滑动手势(可结合 evt.direction) |
pinch | 双指缩放(evt.zoom) |
rotate | 双指旋转(evt.angle) |
press-move | 按住拖动(evt.deltaX / deltaY) |
multipoint-start | 多指开始 |
multipoint-end | 多指结束 |
touch-start / touch-move / touch-end / touch-cancel | 原生触摸事件封装 |
需要传参时,在方法里接收事件对象即可(如 swipe(evt) 中的 evt.direction、pinch(evt) 中的 evt.zoom)。
4.3 完整示例
模板:
<template>
<div
class="touch-area"
v-finger:tap="tap"
v-finger:long-tap="longTap"
v-finger:swipe="swipe"
v-finger:pinch="pinch"
v-finger:rotate="rotate"
v-finger:double-tap="doubleTap"
v-finger:single-tap="singleTap"
>
<div>点我、长按、滑动或双指操作</div>
</div>
</template>
脚本:
export default {
methods: {
tap() {
console.log('单击')
},
longTap() {
console.log('长按')
},
swipe(evt) {
console.log('滑动方向:', evt.direction)
},
pinch(evt) {
console.log('缩放比例:', evt.zoom)
},
rotate(evt) {
console.log('旋转角度:', evt.angle)
},
doubleTap() {
console.log('双击')
},
singleTap() {
console.log('单击(与双击区分)')
}
}
}
按需绑定自己用到的几个事件即可,不必全部写上。
五、用法很简单,那AlloyFinger是怎么实现的呢?
了解实现原理,有助于我们更放心地使用、排查问题,甚至做简单扩展。
AlloyFinger 的实现可以拆成两层:底层手势识别(alloy_finger.js) 和 Vue 指令封装(alloy_finger_vue.js)。
5.1 底层:基于原生 Touch 事件 + 向量运算
AlloyFinger 不依赖任何框架,核心就是给一个 DOM 元素绑定四个原生事件:
this.element.addEventListener("touchstart", this.start, false);
this.element.addEventListener("touchmove", this.move, false);
this.element.addEventListener("touchend", this.end, false);
this.element.addEventListener("touchcancel", this.cancel, false);
在 start 里:
- 记录第一个触点的坐标
(x1, y1)和当前时间戳; - 用「上次 tap 的时间」和「两次点击的位移」判断是否构成双击(例如 250ms 内、位移 30px 以内);
- 若检测到多指(
evt.touches.length > 1),则计算两指构成的向量长度,作为后续 pinch 缩放的基准,并触发multipointStart; - 同时启动一个 750ms 的定时器,到时即触发 longTap。
在 move 里:
- 若是单指,则用当前点与上一帧点的差值得到
deltaX、deltaY,触发 pressMove; - 若移动距离超过约 10px,会置位
_preventTap,避免误触 tap。 - 若是双指,则用两指构成的向量做向量长度比得到
evt.zoom(pinch),用向量夹角得到evt.angle(rotate),这里用到简单的向量数学(点积、叉积、夹角),核心逻辑类似:
// 向量长度
function getLen(v) {
return Math.sqrt(v.x * v.x + v.y * v.y);
}
// 缩放:当前两指距离 / 起始两指距离
evt.zoom = getLen(v) / this.pinchStartLen;
// 旋转:当前向量相对上一帧向量的角度
evt.angle = getRotateAngle(v, preV);
在 end 里:
- 若「起点到终点的位移」超过约 30px,则根据 x、y 方向位移谁更大来判定 swipe 方向(Left/Right/Up/Down),并触发
swipe; - 否则在下一个「事件循环」里触发 tap,并根据之前的双击标记决定是否再触发 doubleTap 或延迟 250ms 触发 singleTap;
- 同时会清除 longTap 定时器、重置双指相关的状态。
也就是说:tap / longTap / doubleTap / swipe / pinch / rotate / pressMove 等,都是在同一套 touch 生命周期里,用「时间差 + 位移 + 向量运算」推导出来的,没有黑魔法。
5.2 回调管理:HandlerAdmin
每种手势对应一个「回调列表」,用 HandlerAdmin 统一管理:add 注册、del 移除、dispatch 时对该元素上的所有回调依次 apply。这样同一个元素上可以挂多个监听(例如 Vue 插件里对同一元素绑定多个 v-finger:xxx),彼此也不会互相覆盖。
5.3 Vue 插件层:v-finger 如何挂到 DOM 上
插件在 install 时执行 Vue.directive('finger', directiveOpts),因此模板里的 v-finger 会变成对自定义指令 finger 的调用。
- 事件名映射:模板里写的是 kebab-case(如
v-finger:long-tap),插件里用 EVENTMAP 转成 AlloyFinger 的 camelCase(如longTap),再交给底层。 - 一元素一实例:用一个全局 CACHE 数组,按 DOM 元素存
{ elem, alloyFinger }。同一元素上多条v-finger:tap、v-finger:swipe等,共用一个 AlloyFinger 实例;第一次绑定时new AlloyFinger(elem, options),之后同元素再绑其他事件时,不再 new,而是alloyFinger.on(eventName, func)往该实例上追加回调。 - 指令生命周期:Vue2 下
bind/update时执行doBindEvent(绑定或更新回调),unbind时从 CACHE 里取出实例并调用alloyFinger.destroy(),移除原生事件监听和所有定时器,避免内存泄漏。
核心片段:
// 同一元素多次 v-finger:xxx 共用一个 AlloyFinger 实例
var cacheObj = CACHE[getElemCacheIndex(elem)];
if (cacheObj && cacheObj.alloyFinger) {
if (oldFunc) cacheObj.alloyFinger.off(eventName, oldFunc);
if (func) cacheObj.alloyFinger.on(eventName, func);
} else {
CACHE.push({
elem: elem,
alloyFinger: new AlloyFinger(elem, { [eventName]: func })
});
}
5.4 小结
- 手势识别:完全基于
touchstart/touchmove/touchend,用时间、位移和向量运算区分 tap、doubleTap、longTap、swipe、pinch、rotate、pressMove 等。 - Vue 层:通过自定义指令
v-finger和元素级 AlloyFinger 实例缓存,把「模板里的 v-finger:事件名」映射到「底层 AlloyFinger 的 on/off」,实现声明式绑定与组件销毁时的清理。
参考
- AlloyFinger 仓库:AlloyTeam/AlloyFinger
- 依赖:transformjs
来源:juejin.cn/post/7614016570629455891
不是有video标签吗?为什么还需要视频播放器?
这是一个非常好的问题!确实,HTML5 提供了原生的 <video> 标签,理论上可以直接播放视频,但为什么在实际项目中我们常常还会使用 Video.js、Plyr、hls.js 等“视频播放器”库呢?原因如下:
一、原生 <video> 的局限性
1. 浏览器兼容性不一致
- 虽然现代浏览器都支持
<video>,但对视频格式、编码、流媒体协议的支持差异很大:
- HLS(.m3u8) :Safari 原生支持,但 Chrome/Firefox 不支持。
- DASH(.mpd) :所有浏览器都不原生支持。
- WebM/VP9:Safari 支持较弱。
- → 需要 hls.js 或 dash.js 来“模拟”原生播放能力。
2. UI 和交互体验差
- 原生控件(
controls属性):
- 样式无法自定义(不同浏览器长得不一样)
- 功能简陋(无画质切换、无字幕菜单、无进度预览等)
- 移动端体验不可控
- → 需要自定义 UI,而播放器库提供了可定制、响应式、无障碍友好的界面。
3. 功能缺失
原生 <video> 不提供:
- 多清晰度切换(如 480p / 720p / 1080p)
- 字幕管理(多语言、样式控制)
- 广告插入(如 VAST)
- 播放速度记忆
- 键盘快捷键(空格暂停、方向键快进等)
- 播放统计(埋点、分析)
- DRM(数字版权管理,如 Widevine、FairPlay)
二、视频播放器库的核心价值
全屏复制
| 功能 | 原生 <video> | Video.js / Plyr 等 |
|---|---|---|
| 自定义 UI | ❌(受限) | ✅(完全可控) |
| HLS/DASH 支持 | ❌(部分浏览器) | ✅(通过插件) |
| 多语言字幕 | ⚠️(基础支持) | ✅(菜单、样式、切换) |
| 响应式 & 主题 | ❌ | ✅ |
| 插件生态 | ❌ | ✅(广告、分析、水印等) |
| 一致的跨浏览器体验 | ❌ | ✅ |
三、举个实际例子
场景:播放一个 HLS 直播流(.m3u8 文件)
html
运行html
<!-- 原生写法(仅 Safari 能播) -->
<video src="live.m3u8" controls></video>
但在 Chrome 中会静默失败。
✅ 使用 hls.js(轻量级播放器库):
js
if (Hls.isSupported()) {
const video = document.getElementById('video');
const hls = new Hls();
hls.loadSource('live.m3u8');
hls.attachMedia(video);
hls.on(Hls.Events.MANIFEST_PARSED, () => video.play());
}
✅ 使用 Video.js + 插件(更完整方案):
html
运行html
<video-js id="my-video" class="vjs-default-skin" controls></video-js>
<script src="video.min.js"></script>
<script src="videojs-contrib-hls.js"></script>
<script>
videojs('my-video', {
sources: [{ src: 'live.m3u8', type: 'application/x-mpegURL' }]
});
</script>
四、什么时候可以直接用 <video>?
如果你满足以下条件,完全可以只用原生标签:
- 视频是 MP4(H.264 + AAC)
- 不需要复杂 UI
- 只面向现代浏览器
- 无流媒体、无 DRM、无多语言字幕需求
- 快速原型或简单展示
例如:
html
运行html
<video src="intro.mp4" controls poster="thumb.jpg" preload="metadata"></video>
总结
<video>是“引擎”,视频播放器是“整车” 。
<video>提供了底层播放能力;- 播放器库在此基础上封装了 兼容性、UI、功能、扩展性,让开发者能快速构建专业级视频体验。
所以,不是“不需要 <video>”,而是播放器库内部依然使用 <video> ,只是帮你解决了它做不到的事情。
来源:juejin.cn/post/7600292312217354292
从夯到拉,锐评 39 个前端技术!
大家好,我是程序员鱼皮。从夯到拉,锐评 39 个前端技术,一口气说完!

之前我做了后端技术的从夯到拉排名,很多同学留言说想看前端版。说实话,刚开始我是拒绝的,因为前端技术实在是太多了、而且更新速度非常快,之前有个学弟还跟我吐槽什么前端娱乐圈之类的,咱也不懂好吧。
但是!既然大家想看,那我就来一期。而且这期我还会评选出唯一的 前端技术之王(frontend king),大家可以先猜一猜,会是哪个?我敢说不超过 1% 的同学能猜对。
正式开始前先郑重声明,由于每个前端技术都有自己的应用场景,很多时候没办法完全公平地去比较,所以接下来的排行会带有一定的主观性。本期鱼皮只是希望帮大家学到知识、认识更多的技术。
大家可以在评论区打出自己的评价,看看跟我想的是否一样。
- 视频版 - 前端排行:bilibili.com/video/BV11y…
- 视频版 - 后端排行:bilibili.com/video/BV1Hi…
评价维度
接下来我将从 5 个维度来评价这些前端技术:
- 实用性:能解决多少实际问题、是否为项目必备
- 生态成熟度:包括社区活跃度、文档完善度、第三方库丰富度
- 学习成本:上手难度和学习曲线
- 开发效率:开发速度和体验
- 稳定性:版本迭代是否破坏兼容性、出现安全漏洞的频率
作为开发者,我个人最看重的是 实用性和生态成熟度。
实用性就不多说了,毕竟技术是用来解决问题或者找工作赚米的。
生态好不仅意味着遇到问题能快速找到解决方案,更重要的是,因为训练数据多、社区案例丰富,AI 生成的代码质量会更高。
所以再次声明,下面的排名并不代表技术本身的优劣,会具有一定的主观性。
前端技术从夯到拉排行榜
先说说跟样式相关的前端技术。
1、Sass【人上人】
CSS 预处理器,让你用编程的方式写样式。写过原生 CSS 的都知道,一堆重复的颜色值、一层套一层的选择器,维护起来非常头疼。Sass 支持变量、嵌套、混合、继承等高级特性,可以解决这些问题。
Sass 的优点是功能强大、社区成熟,缺点是需要编译,而且现在 CSS 原生也支持变量和嵌套了。考虑到它仍然是很多大型项目的标配,给到 人上人。
2、Bootstrap【拉】
Twitter 开源的 UI 框架,提供现成的样式和组件,让你不用从零写 CSS。曾经是前端开发的标配,一套栅格系统打天下.
但是 2025 年了,还在用 Bootstrap 的项目基本都是遗留系统。组件样式过时、定制困难、体积臃肿,React、Vue 当道,谁还用这种全局样式污染的方案?给到 拉。

3、Tailwind CSS【夯】
原子化 CSS 框架的代表,快速写样式的神器。它的理念是:不写 CSS 文件,直接在 HTML 里用 class 拼样式。比如 flex justify-center items-center,一行搞定居中。
有朋友刚开始可能会觉得这玩意儿丑,class 名字一大串,觉得不就是把 CSS 写到 HTML 里了吗?但是用习惯后真香,能明显提升开发效率;再配合组件化开发,完全不用担心样式冲突。
还有一个加分项,现在很多 AI 工具生成的前端代码,默认都用 Tailwind!像很多朋友好奇为什么 AI 生成的很多界面是蓝紫色?因为 AI 训练时吃了太多使用 Tailwind UI 的网站,而 Tailwind UI 的默认配色就是蓝紫色。
考虑到它对开发效率的巨大提升和 AI 生成界面的巨大贡献,给到 夯!
4、Element Plus【人上人】
Vue 框架的主流 UI 组件库,由饿了么团队开发。如果你用 Vue 做中后台系统,那 Element 基本是标配。
优点是组件丰富、文档清晰、国内社区活跃。
缺点是样式偏传统,不太适合 C 端项目,而且有些组件不够灵活。但考虑到国内 Vue 生态的主流地位,Element 是很多前端新人的启蒙组件库,给到 人上人。

5、Ant Design【人上人】
蚂蚁金服出品的企业级 UI 组件库,在开发 B 端中后台管理系统方面一手遮天。它不仅组件质量高、设计规范完善,而且生态非常丰富,推出了 Ant Design Pro 脚手架、ProComponents 高级组件、AntV 数据可视化方案,以及最近很火的 Ant Design X AI 组件库。而且同时有 React 和 Vue 版本,我个人非常喜欢用它。
但缺点也很明显,体积大、样式定制麻烦,没有那么适合 C 端系统。考虑到国内 B 端的统治地位,给到 人上人。

6、LayUI【NPC】
老牌轻量级 UI 框架,情怀之作。采用原生 JavaScript,不依赖 Vue/React。适合那些不想学现代前端框架、只想快速搭个后台的同学,我大学刚开始学前端的时候就在用。
但是它在组件化时代显得格格不入,整体生态和社区活跃度比不上主流方案,AI 生成代码也不会选择这个 UI 吧,只能给到 NPC。

7、Shadcn/UI【人上人】
可能是 2025 年最火的 UI 方案。注意,它不是一个组件库,而是一套 可复制粘贴的代码集合。不需要使用 npm 来安装依赖,而是直接把组件代码复制到你的项目里。
好处是极度灵活,代码在你手里,想怎么改就怎么改;缺点是需要自己维护组件代码,版本升级比较麻烦。给到 人上人。

接下来聊聊构建工具。
8、Webpack【NPC】
前端工程化的奠基者,模块打包的开山鼻祖。
构建工具的作用是把你写的代码打包、压缩、转换成浏览器能运行的文件。很多年前做前端,Webpack 配置是必修课,什么 loader、plugin、code splitting,面试必问。
虽然它生态成熟、功能强大。但问题是配置文件动辄几百行,你如果学会了 Webpack 配置,就能去应聘配置工程师了。而且热更新慢到怀疑人生,改个代码等半天才生效。开发体验被 Vite 降维打击,正在逐渐被时代淘汰,只能给到 NPC。

9、Vite【夯】
新一代构建工具,Webpack 终结者。它用原生 ES Module 实现毫秒级热更新,冷启动速度吊打 Webpack。配置简单、开箱即用,开发体验好到飞起。而且支持各种主流前端框架,已经成为现代前端项目的标配,必须给到 夯!

10、Grunt/Gulp【拉】
上古时代的任务运行器,比 Webpack 还老的构建方案。通过配置任务来处理文件压缩、代码编译、合并等操作。
但是现代构建工具早就内置了这些功能,还在用这俩的项目,估计都是几代员工的祖传代码了,给到 拉中拉!

接下来聊聊包管理工具。
11、npm【顶级】
前端包管理的祖师爷,帮你安装和管理项目依赖的工具。由于安装 Node.js 就自带 npm,所以 npm 生态特别成熟,几乎所有的 JS 包都会发布到 npm。
但缺点是安装速度慢、node_modules 文件夹动辄几个 G(宇宙中最重的物体)、还有幽灵依赖问题。不过考虑到它是前端开发的核心工具,生态无可替代,给到 顶级。

12、pnpm【夯】
性能更高的 npm,目前最高效的包管理工具。它用硬链接和符号链接的方式共享依赖,一个包只存一份,多个项目共用,从而节省空间、安装更快。因此越来越多的项目都在迁移到 pnpm,给到 夯!
13、Yarn【NPC】
为了解决 npm 的速度和一致性问题而生,曾经风流一时的包管理工具。像 lock 文件、离线缓存、并行安装,这些概念都是 Yarn 先提出来的。
但是 npm 后来也跟进了这些特性,而 pnpm 在性能上又超越了 Yarn。所以导致现在的 Yarn 处于一个非常尴尬的位置,给到 NPC。

14、Bower【拉】
上古时代的前端包管理器,老前辈了。但自从 npm 支持前端包管理、Webpack 统一了模块化方案之后,Bower 就彻底退出历史舞台了。官方都宣布不再维护,给到 拉!
接下来聊聊前端工程化相关的技术。
15、TypeScript【夯】
全体起立!
TypeScript 是 JavaScript 的超集,前端大项目的救世主。以前写 JS,变量类型全靠猜,运行时才知道哪里报错。TypeScript 给 JS 加上了类型系统,通过类型安全、IDE 智能提示、编译时检查,解决了 JS 的类型混乱问题。大型项目没有 TypeScript 简直寸步难行。
2025 年 8 月,TypeScript 超越 Python 和 JavaScript,成为 GitHub 上最广泛使用的语言!现在连 AI 生成代码都优先生成 TS。
要说不足之处,就是有一定的学习成本,什么 “类型体操” 对于前端新人来说还是挺头疼的吧,一不留神就变成 AnyScript。作为现代前端的标配,必须给到 夯!

16、Prettier【人上人】
代码格式化工具,团队协作神器。它能自动把你的代码按统一规则格式化,保存时自动整理缩进、换行、引号等。不管你喜欢单引号还是双引号,Prettier 说了算,同一个项目的代码就是要整整齐齐。但考虑到不是刚需,给到 人上人。

17、ESLint【顶级】
代码规范检查工具,团队协作必备。它能帮你发现潜在的 Bug、统一代码风格、强制使用最佳实践。比如什么未使用的变量、可能的空指针、不规范的写法,ESLint 都能帮你揪出来。
现代前端项目几乎都会配置 ESLint,配合 TypeScript 和 Prettier 使用,能大大提升代码质量,给到 顶级。

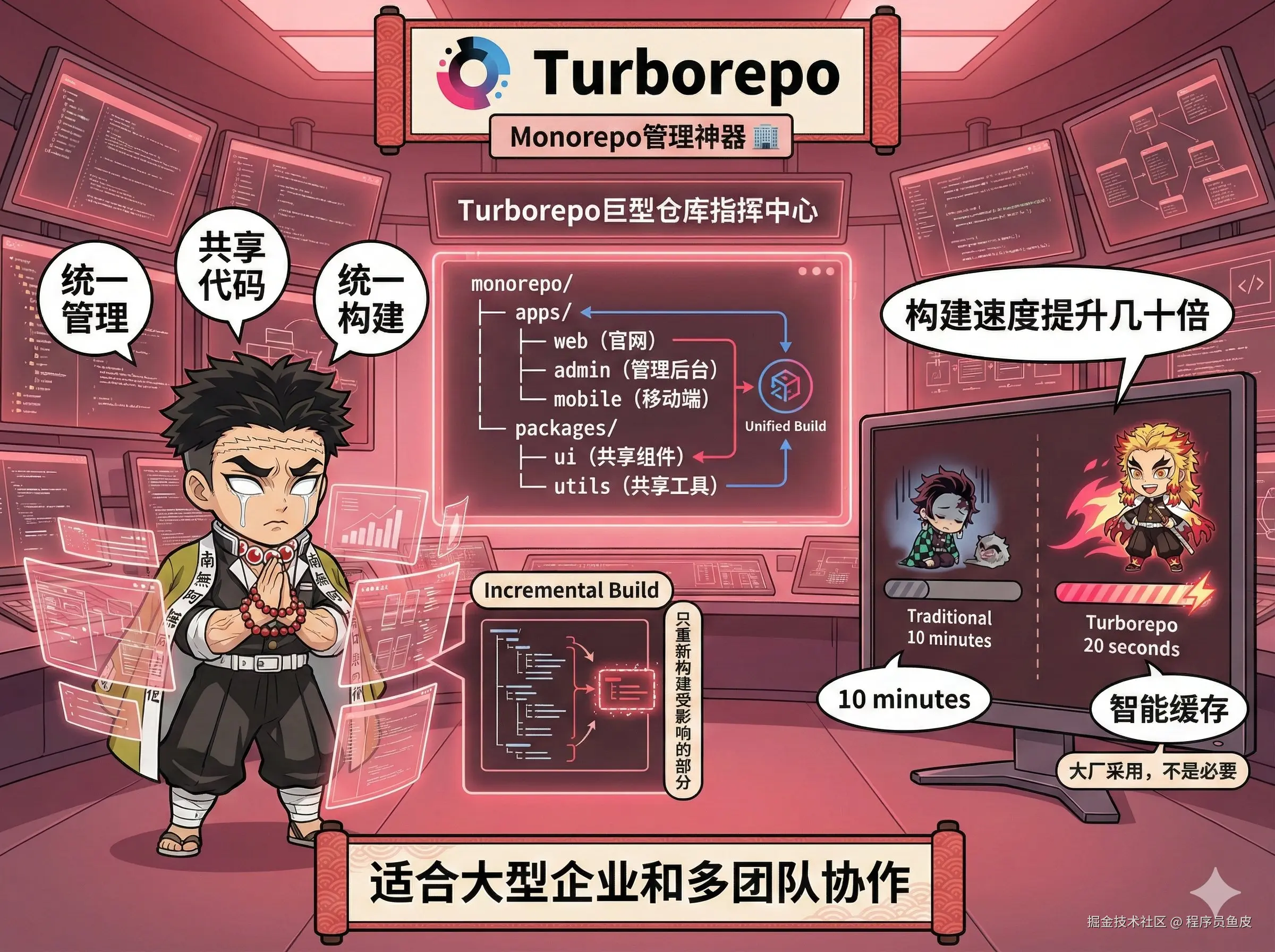
18、Turborepo【顶级】
现代前端大厂的 Monorepo(巨型仓库)管理神器。
Monorepo 就是把多个项目放在一个代码仓库里统一管理。比如你有官网、管理后台、移动端 App,传统做法是建 3 个仓库,但 Monorepo 就把它们放在一起,共享代码、统一构建。
Turborepo(还有 Nx)能帮你管理这种复杂的项目结构,提供增量构建、智能缓存、任务编排等功能。改了一个包,只重新构建受影响的部分,构建速度甚至可以提升几十倍。
注意,Monorepo 不是必要的,更多的是大厂在采用,给到 顶级。
19、qiankun【顶级】
蚂蚁金服开源的微前端框架的扛把子。
微前端就是把一个大型前端应用拆分成多个独立的小应用,每个小应用可以独立开发、独立部署、独立运行,最后由一个主应用把它们整合在一起。
qiankun 提供了应用加载、沙箱隔离、应用通信等核心能力,可以让不同技术栈的项目共存,比如主应用用 React,子应用可以用 Vue、Angular,互不干扰。
适用于大型企业应用、多团队协作和遗留系统改造。缺点是架构复杂度高,调试麻烦,而且性能开销比单体应用大,不是所有项目都需要微前端,给到 顶级。

下面重点来了,我们来聊聊前端开发框架。
20、Angular【NPC】
Google 出品的企业级前端框架,大而全的重量级选手。路由、表单、HTTP、状态管理通通内置,开箱即用。原生支持 TypeScript,采用依赖注入、模块化设计,写起来很有 Java 的 Spring 那味儿。
缺点是概念太多、学习成本高、项目启动慢。学 Angular 的时间,都够学完 Vue 和 React 了。
虽然 Angular 的全球市场还行,但在国内的存在感越来越弱了,基本只有外企在用。给到 NPC。

21、jQuery【拉】
前端活化石,DOM 操作的老祖宗。每当我看到 $('.class').click() 这种写法,都忍不住落下两滴晶莹剔透的小泪珠,满满的回忆杀。
如今随着 React、Vue 这些组件化框架的崛起,以及浏览器原生 API 的完善,jQuery 的优势荡然无存,已经被干成时代的眼泪了。现在除了维护老项目外,基本上没有理由用 jQuery 了。给到 拉!

22、Svelte【NPC】
编译型前端框架,性能怪兽。它在编译时把组件转成原生 JavaScript,运行时没有框架开销,包体积小、速度快。
我在 20 年用 Svelte 写过一些 Demo,开发体验还是挺不错的,响应式变量的声明很简洁。但是生态比 React 和 Vue 差了不少,尤其是国内用的更少,想快点儿找前端工作就先别学它了。暂时给到 NPC。

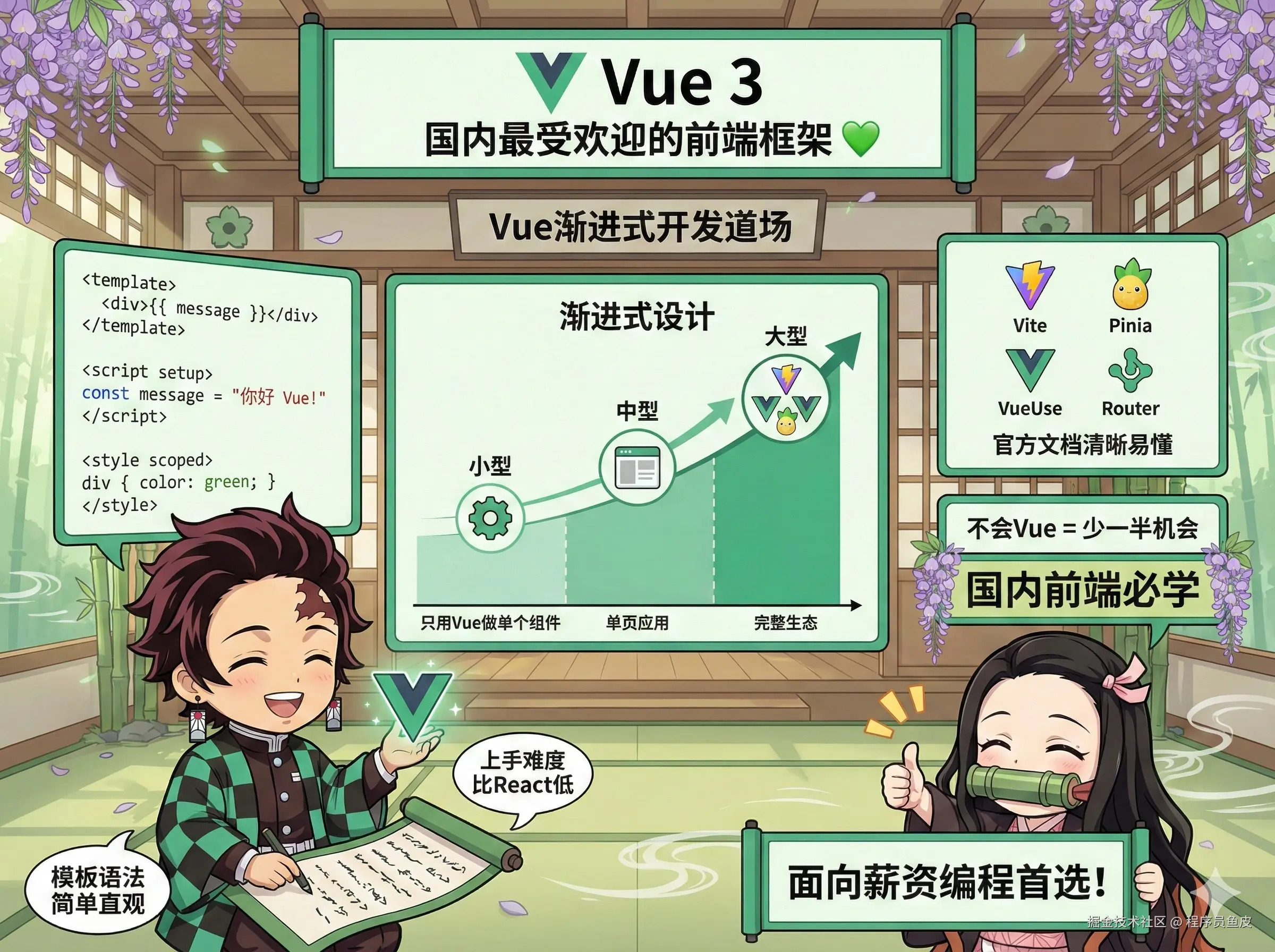
23、Vue 3【夯】
接下来终于到了大家期待的 Vue 了,国内最受欢迎的前端框架。它采用 渐进式设计,你可以只用它做页面的一小部分,也可以用它搭建完整的单页应用,非常灵活。它的单文件组件和模板语法简单直观;而且生态完善,像 Vite、Pinia、VueUse 这些配套工具支持都很好,官方文档写的也清晰易懂,上手难度比 React 低不少。
在国内找前端工作,不会 Vue 等于少了一半机会,考虑到面向薪资编程,给到 夯!
24、React【顶级】
如果说 Vue 是国内老大,那 React 就是全球前端霸主。像组件化思想、虚拟 DOM、单向数据流这些概念都是 React 带火的。
虽然学习难度略大一些(JSX 语法),但我个人更喜欢 React,我们团队的产品也基本都是基于 React 开发。一方面 React 的 Hooks 用起来很爽;另一方面,跟 Vue 比起来,React 全球范围的生态更强。
按理说应该给到 “夯”,但是最近 React 服务端组件曝出了一个严重的远程代码执行漏洞,我们团队好几个项目都中招了,服务器沦为矿机、让我们被迫加班。
考虑到这种全栈化带来的安全风险,我这次只能把 React 降到 顶级,不是说 React 不行啊,纯个人情绪好吧。

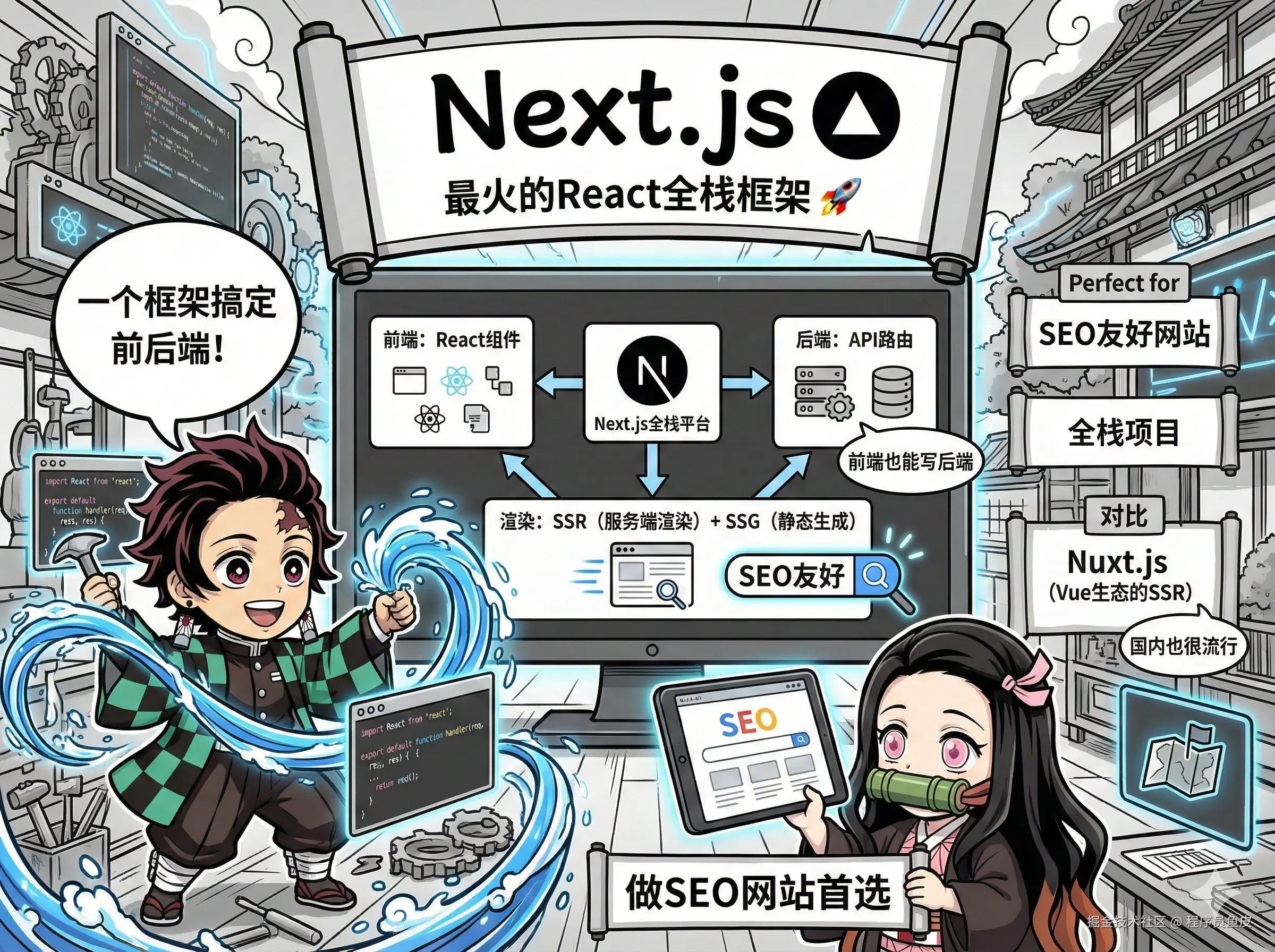
25、Next.js【顶级】
目前最火的 React 全栈框架,支持服务端渲染(SSR)、静态站点生成(SSG)、API 路由等功能,让前端也能写后端接口。
和它类似的还有 Nuxt.js,这是 Vue 生态的 SSR 首选,国内用的很多。如果你要做 SEO 友好的网站,或者想用前端技术栈搞定整个项目,优先选这两者,给到 顶级。
接下来聊聊前端开发的一些工具和库。
26、VitePress【NPC】
Vue 官方出品的文档站生成器,VuePress 的继任者。如果你要搭建技术文档网站,用 Markdown 来写文档,那么 VitePress 的体验很好,主题定制也灵活。Vue 3 和 Vite 的官方文档都在用它。
但使用场景比较窄,主要就是做文档网站,实用性相对有限,给到 NPC。

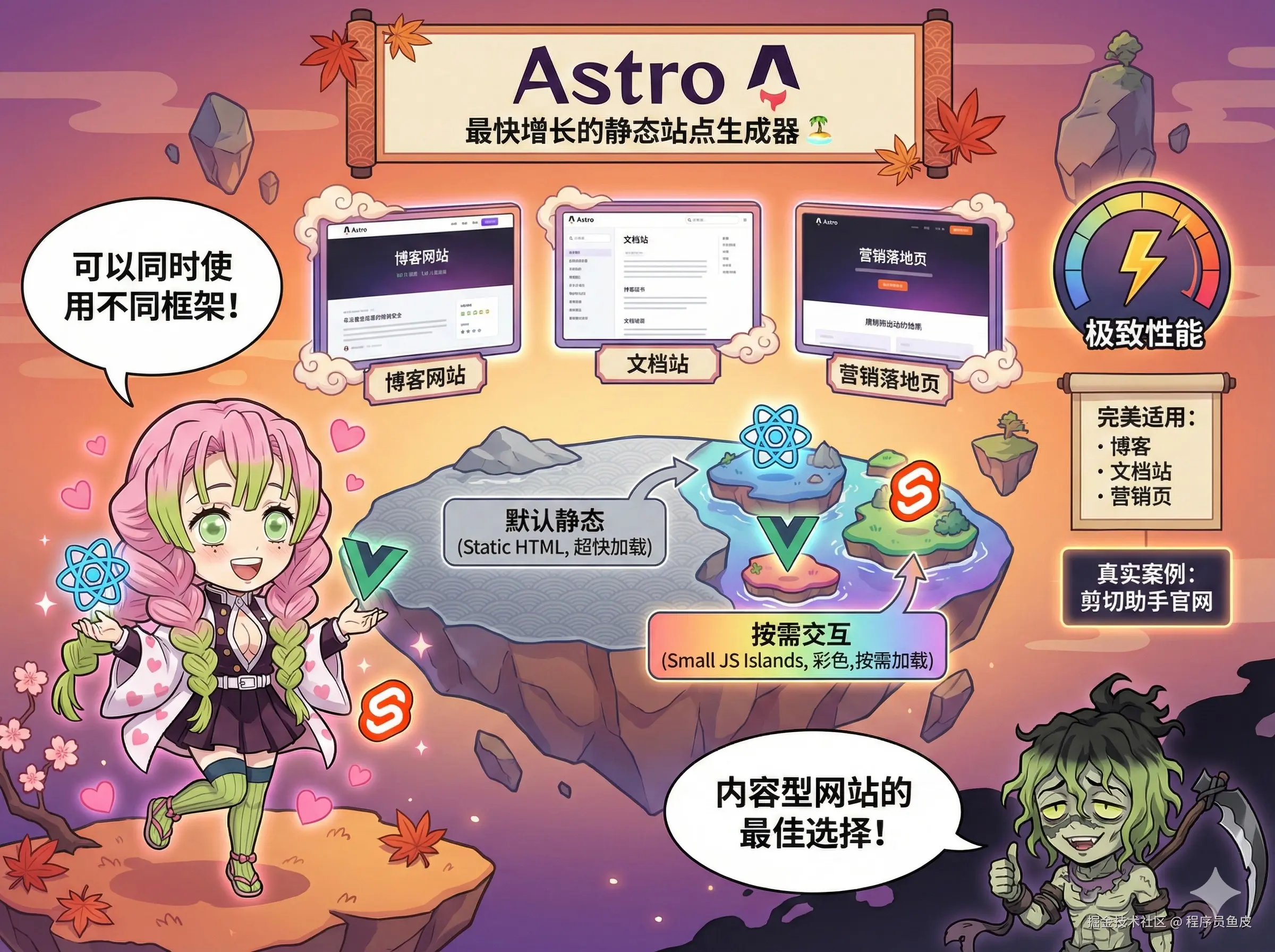
27、Astro【顶级】
最近增长最快的静态站点生成器,它的核心理念是群岛架构:页面默认是静态 HTML,只有需要交互的部分才加载 JS,所以页面加载飞快。
而且 Astro 很灵活,可以同时使用 React、Vue、Svelte 组件,不挑框架。如果你要做博客、文档站、营销页这些内容型网站,Astro 非常合适,像我们团队的剪切助手官网就是用 Astro 生成的。给到 顶级。
28、Pinia【人上人】
Vue 3 官方推荐的状态管理库,用来管理组件间共享的数据。相比 Vuex,Pinia 的语法更简洁,TypeScript 支持更好,没有那些 mutations、actions 的繁琐概念,用起来更舒服。
现在 Vue 3 项目标配都是 Pinia,Vuex 基本退休了。给到 人上人。

29、Axios【夯】
HTTP 请求库的标配,前后端数据交互必备工具。虽然浏览器有原生的 fetch,但 Axios 的 API 设计更友好,而且支持自动转换 JSON、请求拦截、响应拦截这些功能都帮你封装好了,用起来很方便。
优点是国内外项目都在用,生态成熟,文档完善。缺点是包体积略大,但 5G 时代无伤大雅,再加上请求库本身的重要性,给到 夯!

30、ky【NPC】
轻量级 HTTP 请求库(不是骂人的那个 ky)。基于 Fetch API 封装,体积只有 2KB!如果你追求极致的包体积,ky 是个不错的选择。
但知名度和使用率远不如 Axios,国内用的更少,生态也差一些。给到 NPC。

31、Lodash【NPC】
JS 工具函数库的老大哥,类似 Java 的 Hutool,帮你封装了像数组操作、对象处理、函数节流防抖等等的常用功能,拿来就用。
听起来很强大对吧?
但问题是,Lodash 沉寂了整整 5 年,直到最近才更新了一个小版本。而且现在 ES6+ 已经原生支持了很多功能,像 Array.find、Object.assign、展开运算符等,新项目越来越少主动引入 Lodash 了。属于 “还在用但可以不用,并且不推荐新项目用” 的状态,给到 NPC。

接下来聊聊跨端开发框架。
32、Uni-app【顶级】
基于 Vue 的跨端框架,国内小程序开发的神器。它最大的优势是一套代码可以发布到各个平台,像微信小程序、H5、App 全都支持,省了大量重复开发的工作。
优点是应用广泛;缺点是性能不如原生开发,不过这也是跨端开发框架的通病了。给到 顶级!
33、Taro【人上人】
京东开源的跨端解决方案,React 技术栈的小程序开发首选。跟 Uni-app 类似,也是一套代码多端运行。
如果你的团队习惯 React,就选 Taro;习惯 Vue,就选 Uni-app。相比 Uni-app,Taro 的市场占有率稍低一些,所以给到 人上人。

34、React Native【人上人】
跨平台移动开发的主流选择,跟 Flutter 并称跨平台双雄。用 React 语法写原生 App,一套代码 iOS、Android 都能跑。而且支持热更新,调试很方便,生态也很成熟。
缺点是性能不如纯原生开发,某些复杂动画需要写原生代码。给到 人上人。

35、Electron【人上人】
跨平台桌面应用框架。如果你会前端,用 Electron 就能开发桌面应用,一套代码 Windows、Mac、Linux 上都能跑。VS Code、QQ、还有我们的剪切助手软件都是用 Electron 写的。
优点是开发效率高,直接复用前端技术栈,能快速把网页变成桌面应用。缺点是内存占用大、包体积大,一个简单应用动辄上百 M。考虑到它的成熟度,虽然有 Tauri 这些新框架,还是给到 人上人。
最后再聊一些有点儿特殊的前端技术。
36、Three.js【人上人】
Web 3D 领域的绝对王者,高薪的敲门砖。让你用 JavaScript 在浏览器里渲染 3D 场景,像元宇宙、数字孪生、可视化大屏这些高大上的项目,基本都离不开 Three.js。
缺点是学习难度很大,需要一定的图形学知识。不过现在有 AI 了,可以直接让 AI 帮你生成复杂的 3D 场景代码,学习成本大大降低。给到 人上人。

37、WebAssembly【顶级】
Web 性能的天花板,处理重型计算的幕后英雄。
WebAssembly 是一种可以在浏览器里运行的二进制指令格式,性能接近原生代码。你可以用 C/C++、Rust 等语言写高性能模块,编译成 Wasm,然后在浏览器里跑。它最大的优势就是 快,像视频剪辑、图像处理、3D 渲染、游戏引擎这些计算密集型任务,用 Wasm 能提升几十倍性能。
缺点是开发门槛高,而且调试比较麻烦。但随着工具链的完善和 AI 生成代码能力的增强,Wasm 的应用场景会越来越广,给到 顶级。

38、CoffeeScript【拉】
等等,这不是 Java 么?
这是曾经风流一秒的 JavaScript 替代方案,它的理念是用更简洁优雅的语法写代码,然后编译成 JavaScript。但 ES6 出来之后,JS 自己支持了箭头函数、类、模板字符串这些特性,CoffeeScript 瞬间没了存在价值,被 TypeScript 完全取代,给到 拉!

39、Vibe Coding【夯爆了】
最后的最后,揭晓我们的前端技术之王、唯一真夯 —— Vibe Coding!
你猜对了么?
什么是 Vibe Coding?就是用 AI 辅助编程,你描述需求说人话,AI 帮你写代码。
它不是某个特定的框架或库,而是一种全新的编程范式。它改变的不是某个技术环节,而是整个开发流程。这是近年来前端开发最革命性的变化,没有之一。
虽然 Vibe Coding 不算是前端技术,但是我就问一句:现在哪个前端不用 AI 来写代码?!
像我现在写代码基本离不开 Cursor 了,开发效率提升 10 倍以上不是吹的。必须 夯爆了!
来源:juejin.cn/post/7591346773826732058
五年前端,我凌晨三点的电脑屏幕前终于想通了这件事
五年前端开发:那些加班到深夜的日子里,我终于找到了答案
转眼间,做前端已经五年了。回想起这些年的点点滴滴,有为了一个像素对不齐而折腾到凌晨的执着,也有终于解决了一个性能问题后的欣喜若狂。
💻 那些让我抓狂的瞬间
一个padding搞了我一晚上
记得刚入行的时候,有个布局问题让我头疼了一整晚。就是两个div之间的间距,怎么调都不对。那时候我还不知道浏览器默认样式这回事,对着Chrome开发者工具一遍遍地试,各种margin、padding组合,结果第二天早上一问资深同事,人家轻描淡写地说:"reset.css加了么?"
那一刻我才明白,很多你以为的技术难题,其实只是知识盲区而已。
"这个需求很简单"背后的深坑
产品经理说:"这个需求很简单,就是加个拖拽排序功能。"
我:"好的,应该一天就够了。"
然后我才发现,拖拽排序要考虑:
- 移动端的手势识别
- PC端的鼠标事件
- 不同浏览器的事件兼容性
- 拖拽过程中的视觉反馈
- 边界处理和碰撞检测
- 性能优化(防止频繁重绘)
- 可访问性支持
三天后,我终于交出了"看似简单"的功能。从那以后,我再也不轻易相信"这个需求很简单"这种话了。
🌱 那些让我成长的时刻
第一次重构老项目
接手一个三年前的老项目,代码里到处都是document.getElementById,jQuery和原生JS混用,全局变量满天飞。重构过程中,我发现了一些有意思的"黑历史":
// 当年的前辈们是怎么写代码的
function getData() {
if (data1 == null) {
data1 = [];
for (var i = 0; i < 100; i++) {
data1.push(i);
}
}
return data1;
}
// 还有这种神奇的操作
$("#button").click(function() {
setTimeout(function() {
location.reload();
}, 100);
});
重构那段时间,每天都在跟历史代码搏斗,但也正是这个过程,让我真正理解了什么叫"代码可维护性"。
学会了说"不"
以前刚入行时,产品提什么需求我都说"行"。直到有一次,为了赶一个不合理的deadline,我熬了好几个通宵,最后上线的版本还出了bug。
后来我学聪明了,开始跟产品和沟通:
- 这个需求的技术复杂度是多少
- 需要多少开发时间
- 如果一定要提前,哪些功能可以砍掉
- 当前技术方案的风险点在哪里
学会评估和沟通,比学会写代码更重要。
🤔 程序员的日常思考
关于加班的那些事
刚开始工作的时候,我觉得加班=努力。后来慢慢发现:
- 有效的时间管理比长时间工作更重要
- 会写代码不等于会解决问题
- 健康比KPI重要得多
我现在尽量不加班,不是因为懒,而是我学会了:
- 提前评估工作量
- 及时沟通风险
- 拒绝不合理的需求
- 保持专注,减少无效加班
关于技术焦虑
前端技术更新太快,Vue还没学完,React又出了新特性,CSS框架层出不穷。前两年我很焦虑,怕被淘汰。
现在我想通了:
- 基础永远是王道:HTML/CSS/JavaScript的核心不会变
- 学习要讲方法:不要追着新技术跑,要有选择地学
- 项目驱动学习:在实际项目中学习新技术效果最好
- 保持输出:写博客、做分享是最好的学习方式
💪 真正的成长是什么
从技术思维到产品思维
刚开始我只关心代码写得爽不爽,后来我开始思考:
- 用户真的需要这个功能吗?
- 这个交互体验够好吗?
- 性能优化能带来什么价值?
- 我的代码对团队协作友好吗?
技术是工具,不是目的。真正的前端开发,是用技术为用户创造价值。
找到了自己的节奏
现在的我:
- 不再盲目追新技术,而是选择适合自己的技术栈
- 重视代码质量,但不执着于完美
- 会主动沟通需求,而不是被动接受
- 保持学习的热情,但不焦虑
- 知道什么时候该努力,什么时候该休息
🎯 给自己的一些话
五年下来,我想对自己说:
- 保持好奇,但不要盲目跟风
- 写代码很重要,但解决问题更重要
- 技术要精进,但生活也要平衡
- 多分享,多交流,多思考
- 记住,你首先是一个人,其次才是程序员
✨ 下一个五年
技术这条路很长,但我不急了。慢慢地学习,稳稳地成长,踏实做好每一个项目。
毕竟,最好的代码不是最复杂的,而是最合适的。最好的程序员不是最聪明的,而是最懂得平衡的。
愿我们都能在这条路上,找到属于自己的节奏和答案。
你在前端路上有什么难忘的经历?欢迎在评论区分享你的故事。
#前端开发 #程序员成长 #技术感悟 #职场经验 #真实感受
来源:juejin.cn/post/7587740546955477032
别再无脑用 `JSON.parse()` 了!这个安全漏洞你可能每天都在触发
你以为只是解析个字符串?其实黑客已经在你服务器上跑脚本了!
在前端和 Node.js 开发中,JSON.parse() 几乎无处不在:
const data = JSON.parse(localStorage.getItem('user'));
const config = JSON.parse(req.body.payload);
const settings = JSON.parse(fs.readFileSync('config.json'));
简洁、直接、好用——但极其危险。
如果你没有对输入做任何校验就调用 JSON.parse(),你正在为应用打开一扇“任意代码执行”的后门。
今天,我们就来揭开 JSON.parse() 背后的安全雷区,并告诉你如何用更安全、更现代的方式处理 JSON 数据。
危险场景一:原型污染(Prototype Pollution)
这是 JSON.parse() 最臭名昭著的安全漏洞之一。
虽然原生 JSON.parse() 本身不会执行代码,但它会忠实地还原对象结构——包括 __proto__ 和 constructor.prototype 这类特殊属性。
来看一个真实攻击载荷:
const userInput = '{"__proto__":{"isAdmin":true}}';
const obj = {};
JSON.parse(userInput, (key, value) => {
obj[key] = value;
return value;
});
console.log({}.isAdmin); // true!全局对象被污染!
如果这段代码出现在你的登录逻辑、权限校验或配置合并中,攻击者就能:
- 绕过身份验证(
isAdmin: true); - 注入恶意属性(如
exec: 'rm -rf /'); - 篡改全局行为,导致服务崩溃或数据泄露。
尤其在使用 Lodash、merge、assign 等工具库时,风险更高!
危险场景二:拒绝服务(DoS)
恶意构造的 JSON 字符串可导致内存爆炸或CPU 耗尽:
// 深度嵌套攻击
const evil = '{"a":{"a":{"a":{"a":{"a":{"a": ... }}}}}}';
// 或超大数组
const evil2 = '[1,1,1,...,1]' // 1000 万个元素
调用 JSON.parse(evil) 可能:
- 占用数 GB 内存;
- 阻塞事件循环数秒;
- 直接触发 OOM(Out of Memory)崩溃。
在 API 接口或 Webhook 处理中,这等于把“关机按钮”交给了攻击者。
正确姿势:安全解析 JSON 的三重防护
第一步:限制输入大小
在解析前先检查字符串长度:
function safeParse(str, maxSize = 1024 * 100) { // 100KB
if (typeof str !== 'string' || str.length > maxSize) {
throw new Error('Input too large');
}
return JSON.parse(str);
}
第二步:禁用危险键(如 __proto__)
使用 reviver 函数过滤敏感属性:
function secureJSONParse(str) {
return JSON.parse(str, (key, value) => {
if (key === '__proto__' || key === 'constructor') {
throw new Error('Disallowed key in JSON');
}
return value;
});
}
第三步(推荐):用 Zod / Joi 做运行时校验
这才是现代 JS 工程的最佳实践!
import { z } from 'zod';
const UserSchema = z.object({
id: z.number(),
name: z.string(),
email: z.string().email(),
isAdmin: z.boolean().optional(),
});
function parseUser(jsonStr: string) {
const raw = secureJSONParse(jsonStr);
return UserSchema.parse(raw); // 自动校验 + 类型推导
}
优势:
- 类型安全(配合 TypeScript 完美);
- 自动过滤多余字段;
- 明确拒绝非法结构;
- 防止原型污染、字段注入等攻击。
特别提醒:Node.js 中的额外风险
在服务端,如果你从以下来源解析 JSON,风险更高:
- HTTP 请求体(
req.body) - 文件读取(用户上传的 JSON 配置)
- Redis / 数据库存储的序列化数据
- 第三方 Webhook 回调
务必在解析前做来源校验 + 结构校验 + 大小限制三重保险!
结语
JSON.parse() 不是“坏 API”,但它是一把没有保险的枪。
在现代 Web 开发中,信任任何用户输入 = 自毁程序。
下次当你写下 JSON.parse(someString) 时,请自问:
“我确定这个字符串来自可信源吗?它的结构真的安全吗?”
如果答案不确定,请立即切换到 Zod / Joi + 安全解析函数 的组合。
转发给那个还在裸用 JSON.parse() 的队友吧!
各位互联网搭子,要是这篇文章成功引起了你的注意,别犹豫,关注、点赞、评论、分享走一波,让我们把这份默契延续下去,一起在知识的海洋里乘风破浪!
来源:juejin.cn/post/7613514109237805098
做好自己的份内工作,等着被裁
先声明,本文不是贩卖焦虑,只是自己的一点拙见,没有割韭菜的卖课、副业、保险广告,请放心食用。
2022 年初,前司开始了轰轰烈烈的「降本增笑」运动,各部门严格考核机器成本和预算。当然,最重要的还是「开猿节流」。
幸好,我所在部门是盈利的,当时几乎没有人受到波及。
据说,现在连餐巾纸都从三层的「维达」换成两层的「心心相印」了,号称年节约成本 100 多万。我好奇的是,擦屁股时多少会沾点 💩 吧?这下,真是名正言顺的 💩 山代码了。
2022 年 7 月底,因为某些原因,结束 10 年北漂回老家,换了个公司继续搬砖。
2023 年,春节后不久,现司搞「偷袭」,玩起了狼人杀,很多小伙伴被刀:
清晨接到电话通知,上午集体开会,IT 收回权限,中午滚蛋
好在是头一回,补偿非常可观,远超法律规定的「N+1」。
2024 年,平安夜,无事发生。
2025 年 1 月,公司年会,趣味运动会,有个项目是「财源滚滚」,下图这样的:

有个参赛的老哥调侃道,这项目名字不吉利啊,不应该参加的。无巧不成书,年后他被刀了。。。
这次的规模远小于 2023 年,但 2025 年也不太平,「脉脉」上陆续有人说被刀或者不续签,真假未知。
实话说,我之前从未担心过被裁,毕竟:
名校硕士,经历多个大厂,有管理经验
热爱编程,工作认真负责,常年高绩效
但是,随着 AI 的快速迭代,我现在感觉自己随时可能被刀了。AI 能胜任 log 分析、新功能开发、bug 修复等绝大部分日常工作,而且都完成的很好。再配合 AI 自己写的MCP,效率肉眼可见的提高。
亲身体验,数百人开发的千万行代码级别的项目,混合了Java/Kotlin/OC/C++/Python等各种语言。跟Cursor聊了几句,它就找到原因并帮忙修复了。如果是自己看代码、问人、加 log、编译,至少得半个小时。
那还要码农干啥呢?即使是留下来背锅,也要不了这么多啊。
距离上次「狼人杀 」,三年之期已到。今年会有「狼人杀 2.0」吗?我还能平稳落地吗?
无所谓了,我早已准备好后路:

头盔和衣服真是我买的,还有手套未入镜,我感觉设计很漂亮,等天气暖和后,当骑行服穿。
汽车,小踏板,大踏板,足以覆盖滴滴、外卖、闪送三大朝阳行业。家里还有个小电驴,凑合能放到后备箱,承接代驾业务问题不大。
以上,虽然是开玩笑,但我对「是否被刀、何时被刀」,真的是无所谓。因为:
一个人的命运啊,当然要靠自我奋斗,但也要考虑历史的进程
公司为了长远的发展,刀人以降低成本,再用 AI 来提高效率,求得股价长红。对此,我十分理解,换我当老板,也会这么干。
作为牛马,想太多没用,我们左右不了这些事。不夸张的说,99.9999% 的码农是不可能干到退休的,和死亡一样,被刀只是早晚的事。更扎心的是:
人不是老了才会死,而是随时会死
当下的工作也一样,并不是摸鱼或者捅娄子才会被刀,而是随时会被刀,与个人的努力、绩效关系不大。常年健身的肌肉男,也可能猝死,只是概率低点,并不是免死金牌。
生命,从受精的那一刻起,就在走向终点。工作,从入职的那一刻起,就在走向(主动/被动)离职。
所以,虽然我现在感觉自己随时可能被 AI 替代,但我的心态一直都没变,就是标题所言:
做好自己的份内工作,等着被裁
不是消极怠工,我始终认真完成每一项任务,该加班加班。并非为了绩效,是因为自己的责任心,要对的起工资。至于公司哪天让我滚蛋,我决定不了,更改变不了。就像对待死亡一样,坦然接受之,给够补偿就好。

对于 AI,还想再啰嗦两句:
- 虽然 AI 很牛逼,但最终还是需要人来判断代码的对错。此时,工程师的价值就体验出来了,所以 AI 是帮我干活的小弟,而不是竞争对手。
- AI 扩大了我们的能力边界,人人都可以是前端、后端、客户端、UI 设计全通的「全栈工程师」,至少可以是「全沾工程师」,「雨露均沾」的沾。
滚蛋之后呢?我不知道,现在有多少公司愿意招 40 岁高龄码农?据说前司招聘 35 岁普通员工都要 VP 审批了,真是小刀剌屁股,开了眼了。
好在,我家人的物质欲望极低,对衣服、手机、汽车没有任何追求,老婆不用化妆品和护肤品,也没买过一个包。即使不上班,积蓄也能撑一段时间。
所以,强烈建议当前北上广深拿高薪的老哥老妹们,除非万不得已,千万不要像我一样断崖式降薪回老家。趁年轻,搞钱比啥都重要。

对了,我目前有两个利用自身优势的基于 AI 的创业方向。网友们帮忙把把关,如果哪天真失业了,看能否拉到几个亿的风投,谢谢!
- 偏胖圆脸,AI 加点络腮胡,再买几双白袜子
- 身高 180,AI 换个美女脸,黑丝高跟大长腿

来源:juejin.cn/post/7593771861323726874
5年前端,我为什么要all in AI Agent?
一个普通 Vue/Electron 工程师的转型自白
前言
我是一个普通的前端工程师。5年经验,公司开发框架也就是 Vue2/3 + TS。自己倒腾过Electron,uni-app,能写一些简单的功能模块。没进过大厂,没写过框架,不是什么技术大神。
每天的生活就是:上班写代码,下班刷掘金/知乎/CSDN,周末偶尔看看新技术。工资一般般,饿不死,也富不了。原本以为自己会这样一直干到退休。
直到去年,年奖金只有以往的一半了!
某一天的顿悟
和往常一样,看看手机,刷刷帖子,直到刷到:《35岁程序员裸辞两月,找不到工作,感慨程序员是碗青春饭》。
那一刻,我突然意识到:我也30多了,离35也不远了。
那天晚上,我失眠了。翻来覆去想几个问题:
- 我的核心竞争力是什么?
- 如果明天被裁,我能做什么?
- 5年后,我还在写代码吗?
没有答案。只有焦虑。
一次偶然的机遇
随着公司业务发展,各部门都在鼓励使用 AI,自然而然的,我也分配了相关的任务:处理后端 AI 大模型的流式返回数据。这本来也是很简单的需求:
fetchEventSource发送请求onMessage()接收并处理数据onError()处理异常/错误情况
此时,问题来了:后端返回的并不是的 text/event-stream 格式,而是 application/json;在网上查了一圈,知道可以在 onOpen() 里重新发一条 GET 请求来解决这个问题。
然后,又出现新的问题了:后端异常没有正常返回,全部要前端处理!烦躁之下,我打开了DeepSeek(之前只用它写过文档),10 秒钟,它给出了完整的解决方案。
我当时震惊的不是它写出来了,而是它写出来的代码,完全符合我的需求,而且比我预设需求的还要完整!
那一刻,我突然意识到:这东西真方便。
后来的开发中,我开始疯狂用它:
- 让它生成Vue3组件,它懂得用
<script setup>,知道我喜欢用ref而不是reactive - 让它写TS类型,它知道我的命名规范(
IProps、TResponse) - 让它解释一段看不懂的配置,它讲得比文档还清楚
我开始想:如果 AI 这么懂前端,那我是不是可以用它做更多事?
AI突围战”
从那天起,我给自己定了一个目标:用4个月时间,成为一个会“玩AI”的前端。
我不学 PyTorch,不学 Transformer,不调模型参数。我的路线很简单:
| 阶段 | 目标 | 时间 |
|---|---|---|
| 第一阶段 | 学会让AI按我的要求生成代码(Prompt工程) | 3周 |
| 第二阶段 | 打通Electron + AI API,做桌面工具 | 4周 |
| 第三阶段 | 让AI能调用我写的函数(Function Calling) | 6周 |
| 第四阶段 | 做一个真正能“干活”的Agent | 8周 |
这4个月,我经历了什么?
第一周:信心满满 → 被 Prompt 折磨(AI 就是不按格式输出)
第二周:第一个 Electron + AI 应用跑通 → 激动得发朋友圈
第四周:Function Calling 总是失败 → 怀疑人生
第六周:第一个能用的 Agent 诞生(帮我处理Git) → 比发工资还开心
第十周:做的一个桌面助手被吐槽“鸡肋” → 反思产品思维
第十六周:现在,我能用Cursor + AI 在30分钟内开发一个小工具
这4个月,我学会了什么?
- 不是:模型原理、Attention机制、微调技术
- 而是:怎么让AI听我的话、怎么把AI集成进Electron、怎么让AI调用我的函数、怎么用AI帮我写代码
最重要的是:我不焦虑了,因为我知道,AI时代,前端不仅没有被淘汰,反而有了新的机会。
为什么说前端是AI时代的“天选之子”?
这4个月让我想明白一件事:
AI 是发动机,前端是驾驶舱。发动机很重要,但用户接触的是驾驶舱。
我们的优势是什么?
| 优势 | 说明 |
|---|---|
| UI/UX思维 | 我们知道怎么让AI的“答案”变成好用的“产品” |
| TypeScript | 严格的类型定义,让 AI 生成的代码更可控 |
| Electron经验 | 桌面端是 AI 的下一站(隐私、离线、本地资源) |
| 工程化能力 | 组件化、模块化,这些思维在 AI 应用开发中同样重要 |
我不是在安慰自己,而是在这4个月我见过太多 AI 应用翻车的案例:
- 技术很强,但 UI 一塌糊涂 → 没人用
- 模型很准,但交互反人类 → 用户流失
- 功能很多,但不会产品化 → 自嗨
这些都是我们前端擅长的地方。
这个专栏要写什么
所以,我开了这个专栏。
它不是:
- ❌ 大模型原理讲解(我不懂)
- ❌ Python/PyTorch教程(我不会)
- ❌ 教你成为AI科学家(做不到)
它是:
- ✅ 一个普通前端的真实转型记录(不装逼,只记录自己踩过的坑)
- ✅ 前端视角的AI应用开发实战(Vue3/TS/Electron)
- ✅ Agent和Vibe Coding的落地经验(能跑起来的代码)
结语
“前端已死”,这句话从10年前就开始兴起了,“死”了这么多年还没死透,我认为它就是有价值的。现如今,在 AI 的加持,对前端的要求会越来越高,但这条路我会继续走下去,也会把每一步都记录下来。
如果你也在这条路上,欢迎同行。
来源:juejin.cn/post/7616405104520806434
2026 年了,哪家抄页面的能力更好?
目标
从蓝湖上下载了设计稿、切图和代码,全部扔给模型,实现首页。
提示词
## 环境变量
* 设计稿:~/company.platform.h5/refs/首页/index.png
* 设计稿转代码入口:~/company.platform.h5/refs/首页/index.html
## 目标
* 接下来,在 producer-services-v2/home.vue 实现首页。
* 工作流程:页面理解、精细组件拆分、页面实现。
## 要求
* 代码风格、页面或组件结构完全参考:~/company.platform.h5/pages/carbon-emission
* 不复用已有组件
说明
- 没有给单独的切图文件,但是切图可以从设计稿转代码的结果找到
- MCP、Skill 环境一致;IDE、记忆、Agent 略有差异
- glm-5 和 minimax-m2.5 不是多模态模型,只能通过图片分析工具理解设计稿
结果
gpt-5.2
👍:效果最好,接近完美
👎:少量的样式错误
gemini-3-pro
👍:速度最快
👎:部分板块样式错误
qwen-3.5-plus
34m 58s
👍:界面干净,比较完美
👎:导航的层级错误、轮播图板块
doubao-seed-2.0-code
27m 37s
👍:倾向使用问题确定实现边界,甚至包含主动开启子代理的询问
👎:页面不能滚动、轮播图板块尺寸不对、少数图片和文字尺寸错误
glm-5
IDE 使用 on-my-opencode,Agent Sisyphus
👍:顺手实现了简单的点击反馈
👎:忽略了板块背景等样式、第一次提示后页面不能打开(没有遵守 Nuxt 组件命名策略,简单修复后可以打开)
minimax-m2.5
IDE 使用 on-my-opencode,Agent Sisyphus,模型是 opencode 的免费模型
👍:无情干活机器
👎:部分样式错误实现、没有使用图片分析工具
kimi-k2.5
👍:比较完美
👎:少量样式错误、第一次提示结束页面不能打开(没有遵守 Nuxt 组件命名策略,简单修复后可以打开)
总结
从 Kimi-k2.5 出了之后一直在用国产模型,但是还没画过新页面。完全没想到不同模型之间画页面差距能这么大。
来源:juejin.cn/post/7612501079290757155
独立开发实战:我用 AI 写了一个台球小程序
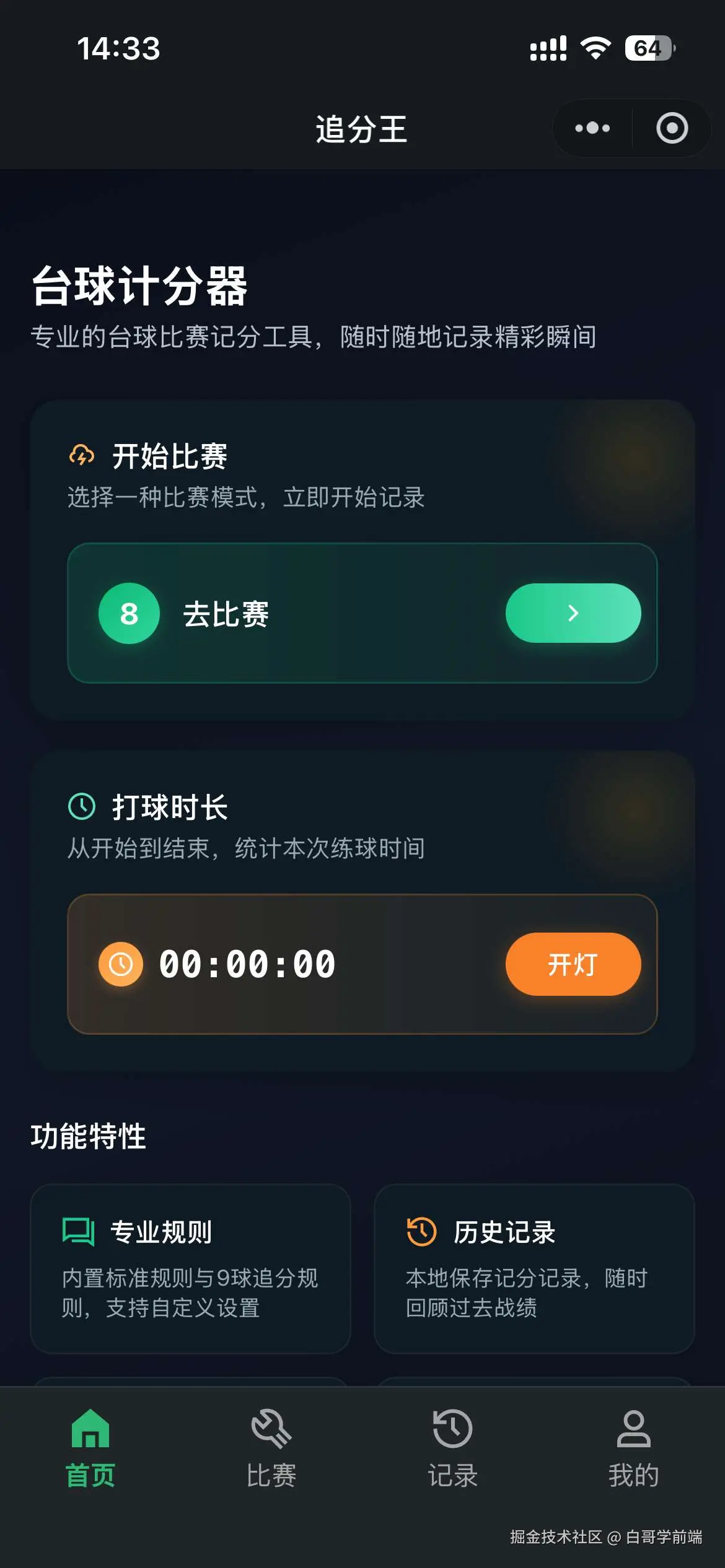 | 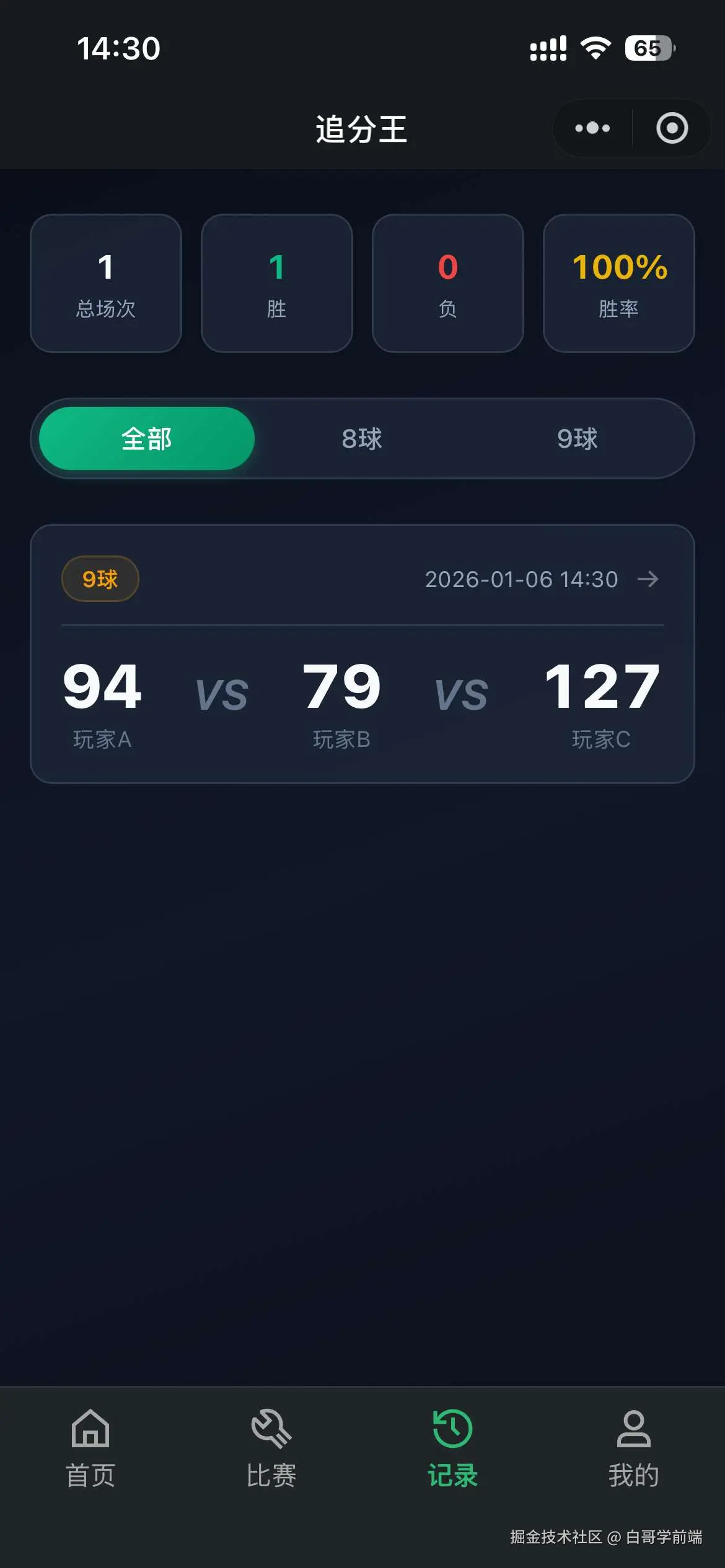 |
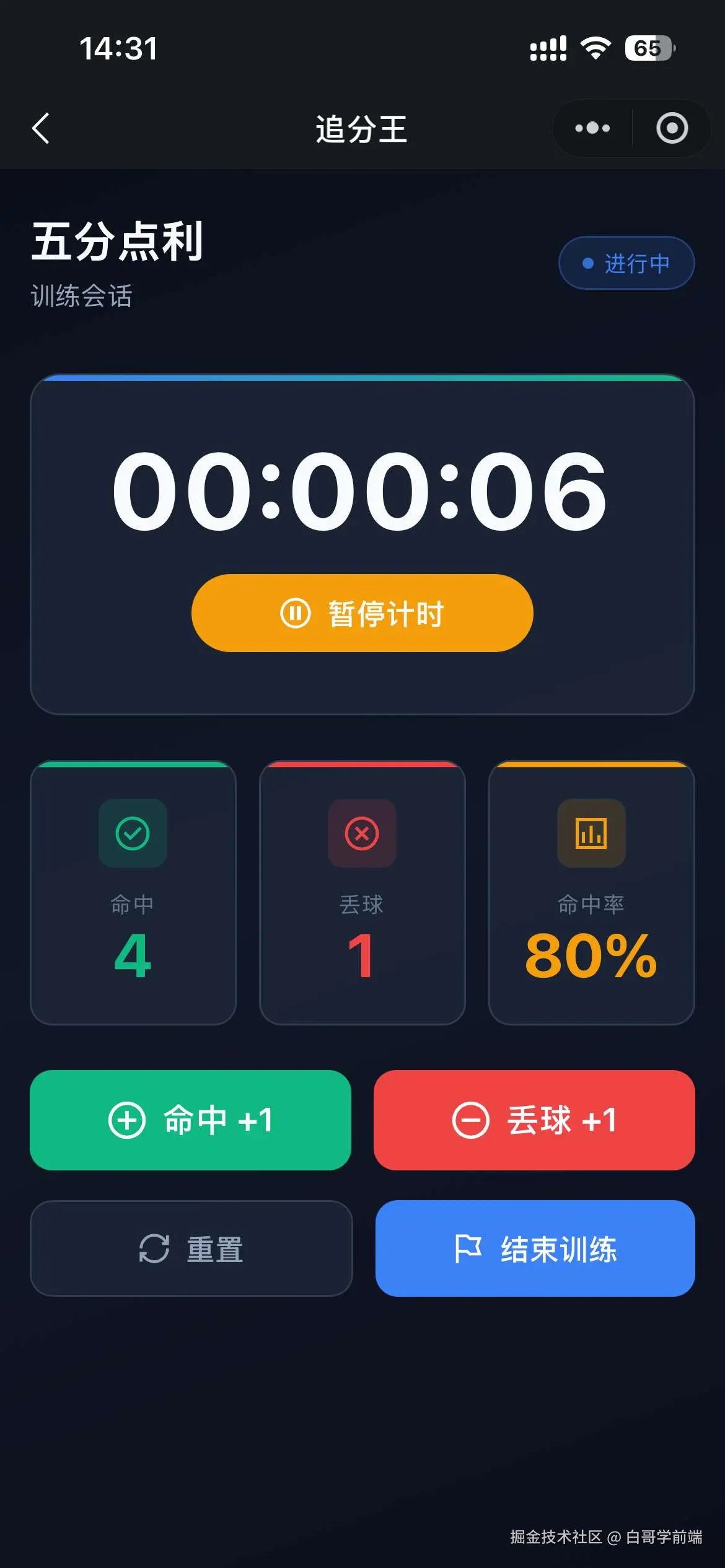 | 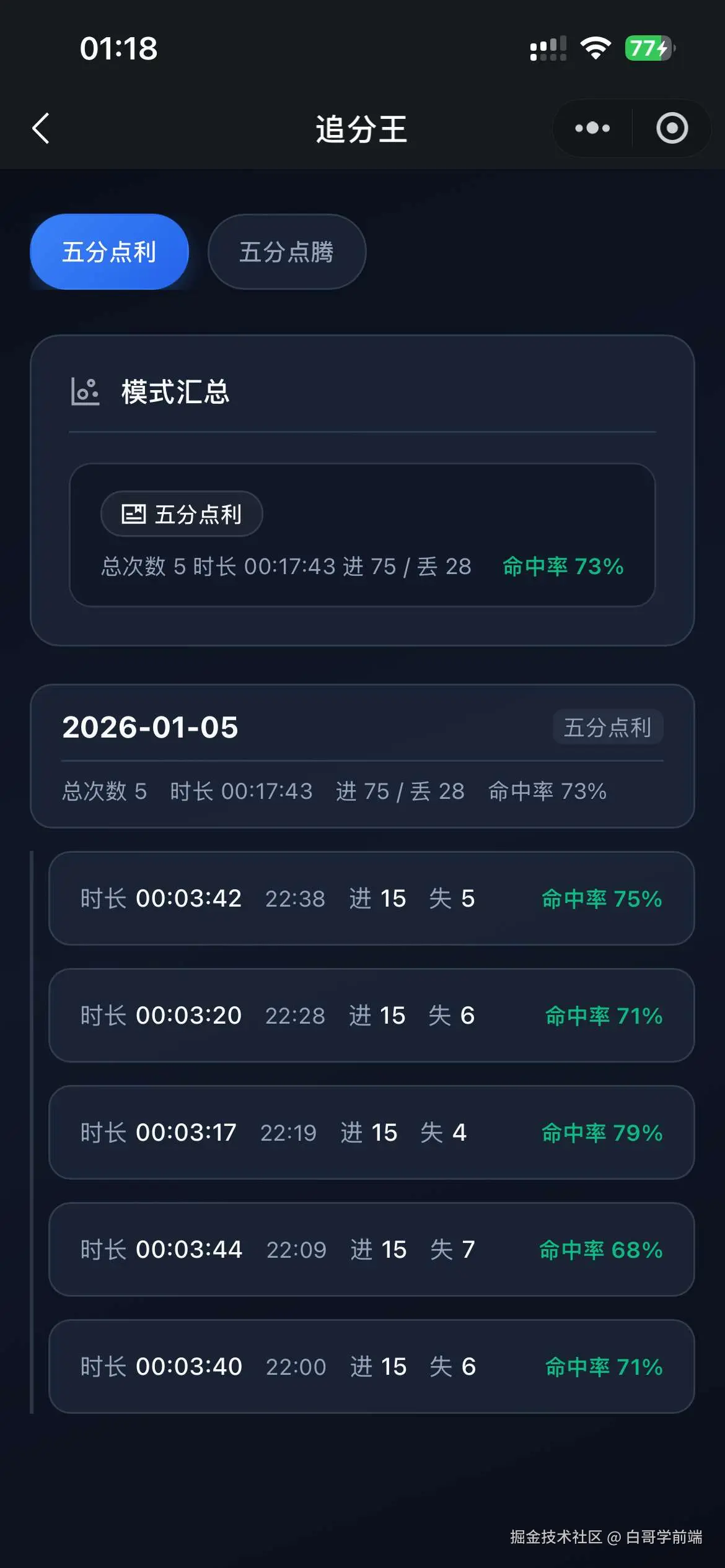 |
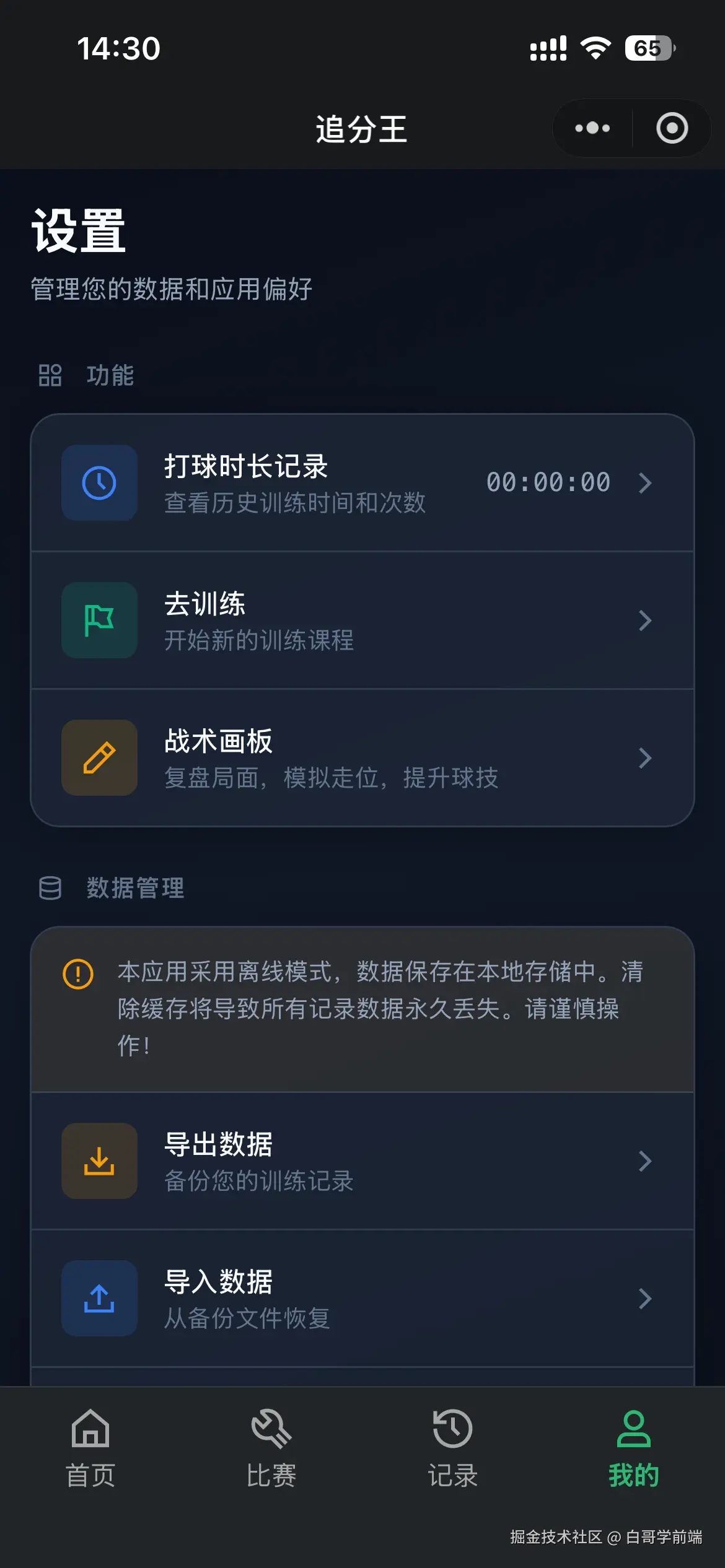 | 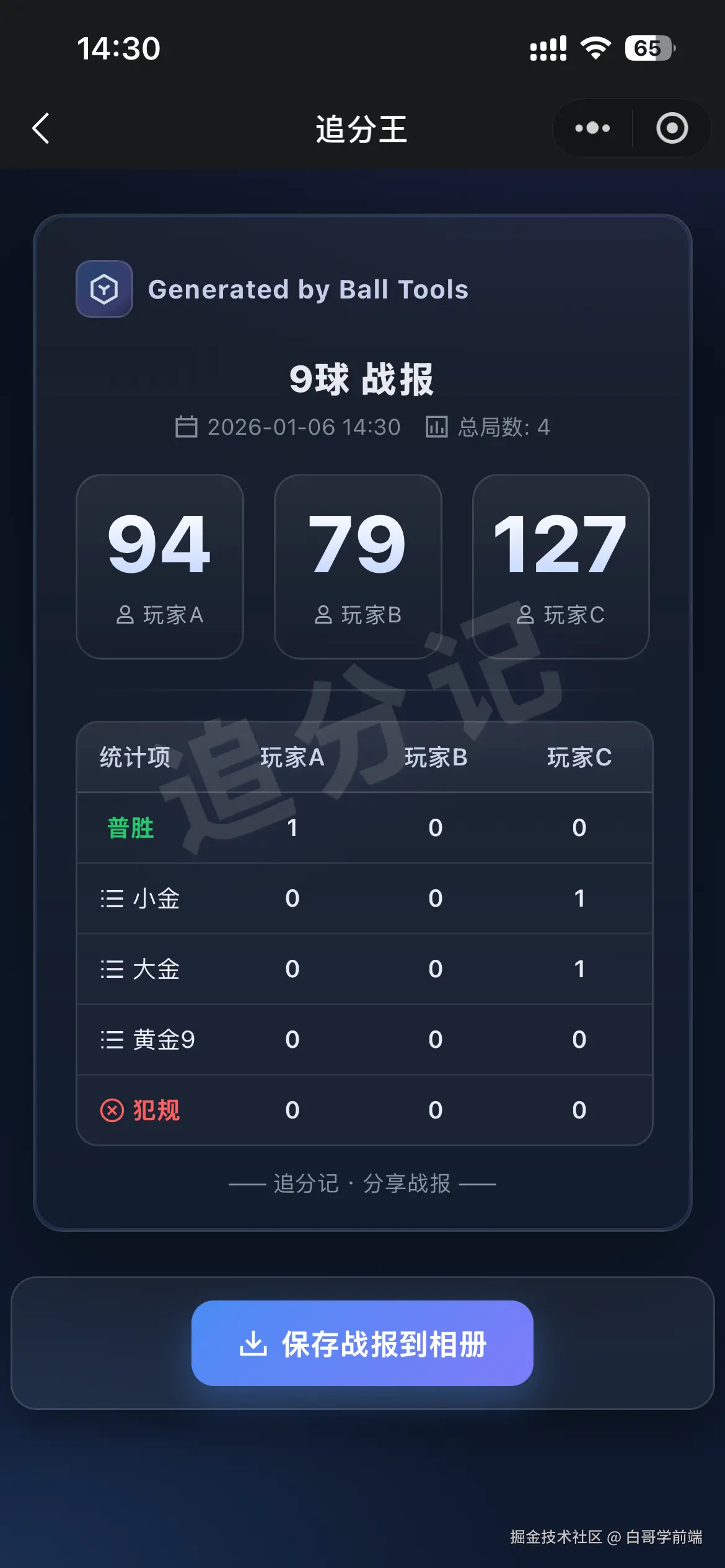 |
作为一名既爱写代码又爱打台球的程序员,我一直想做一款“纯粹”的台球工具。市面上的 App 要么广告满天飞,要么功能单一——能计分的不能复盘,能复盘的体验太差。
于是,我决定自己造个轮子。完全根据我自己需要来定制化开发。
这款名为**“追分记”的小程序,不仅支持中式黑八/九球的复杂计分(断点续打、三人追分)、自定义训练模式(统计五分点等训练记录),还内置了一个基于物理交互的战术板**。
这篇文章我将从产品构思、AI 辅助设计、本地存储架构等维度,复盘这次独立开发的完整过程。
一、 从构思到落地:AI 如何加速全流程
在这次开发中,我尝试了一种新的工作流:全程 AI 开发。从灵感到 UI,再到代码落地,让AI 扮演“产品助理”、“UI 设计师”、开发工程师的角色。
1.1 需求构思:解决我自己的痛点
在写第一行代码前,我先整理了自己的“吐槽清单”:
- 痛点 A:打九球追分,算大金、小金、犯规扣分太烧脑,容易算错。
- 痛点 B:打到一半朋友来电话,切出去回个消息,回来小程序重载了,比分全丢。
- 痛点 C:想给朋友讲刚才那杆球怎么走位,手边没球桌,干讲听不懂。
- 通点 D:自己平时去训练,也不知道训练的目标和效果。
基于此,确定了 MVP(最小可行性产品)的三大核心功能:智能计分器、断点续打系统、便携战术板。
1.2 AI 生成 产品初稿,再生成 UI:从 Prompt 到视觉稿
作为程序员,配色和 UI 往往是短板。这次我没有自己瞎折腾 CSS,而是利用 AI 生成设计灵感。
从一个新的项目开始,我让 Trae 帮我生成一个完整prd文档,包含需求分析,功能模块,页面细节。
然后让它开始实现这些功能,然而最后实现的UI界面效果很不理想。
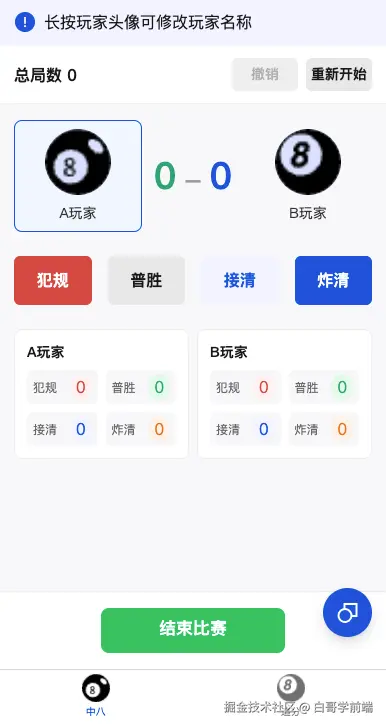
于是,我把这个截图扔给 v0(v0.app/),让他按照这个截图的哪内容帮我从新生成一个页面UI,并且产出一个完整的配色,以便其他页面复用。提示词如下:
你现在是个专业的UI交互设计师,帮我优化一下这个页面的UI,然后生成一个静态的html。不允许使用tailwind css,图标库可以使用lucide。需要生成一个完整的配色方案。
最后它帮我产出了一个html文件,我打开一天,天啦,这也太牛逼 plus了。

这效果已经超出我的想象了。于是我立马让 Trae 把这个页面1:1还原到对应的小程序页面。
提示词:根据 index.html 1:1还原 index.wxml 的UI。注意: index.htm 通用的root样式可以提取到公共样式中进行复用。
拿到视觉基调后,我将其转化为全局 CSS 变量(app.wxss),确保全站风格统一:
page {
--bg-primary: #0a0f1a;
--text-primary: #f8fafc;
--accent-green: #10b981;
--card-bg: rgba(30, 41, 59, 0.7);
background: linear-gradient(160deg, var(--bg-primary) 0%, var(--bg-secondary) 100%);
}
从最初简陋的线框图,到引入 tdesign 组件库,再到配合 AI 生成的图标,产品的“颜值”经过了三轮大的迭代,最终呈现出一种“极客范儿”的精致感。
业务逻辑和UI进行了完美的融合,没有任何bug。简直完美。
二、 核心技术复盘 II:本地存储的“垃圾回收”机制
做“断点续打”功能时,我遇到了一个典型问题:
用户可能开了局,没打完就退出了;过几天又开了新局。久而久之,Storage 里会堆积大量废弃的比赛快照(Snapshot)。
为了解决这个问题,我设计了一套基于索引的 GC(垃圾回收)机制。
3.1 存储结构设计
- 索引表 (
ongoingMatches):记录所有“进行中”比赛的元数据(ID、时间、模式)。 - 快照数据 (
match_current_{id}):每场比赛的具体状态单独存一个 Key,防止单条数据过大。
3.2 自动 GC 实现
每次小程序启动或进入列表页时,触发 cleanupOrphans 函数:
// utils/storage.js
function cleanupOrphans() {
// 1. 获取“存活”的比赛 ID 集合
const list = ongoing.getList()
const activeIds = new Set(list.map(v => v.id))
// 2. 遍历 Storage 中所有的 Key
const keys = wx.getStorageInfoSync().keys
keys.forEach(k => {
// 3. 识别比赛快照 Key 格式
if (k.startsWith('zhongba_match_current_')) {
const id = Number(k.split('_').pop())
// 4. 如果 ID 不在存活列表中,视为“孤儿数据”,直接删除
if (!activeIds.has(id)) {
safeRemove(k)
console.log(`[GC] Cleaned up orphan match: ${id}`)
}
}
})
}
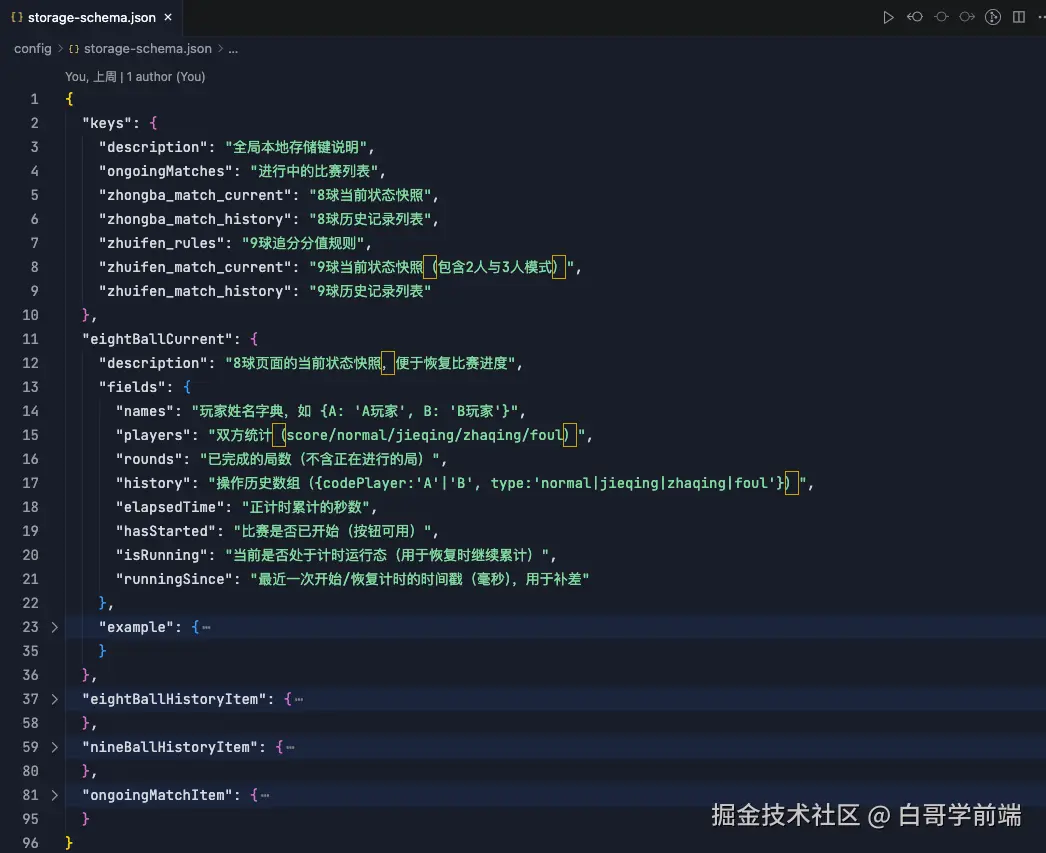
这个机制保证了 Storage 永远只存储有用的数据,既节省空间又维护了整洁。
最后我还让它生成了一份数据快照,以便以后接入服务端的时候可以快速的创建数据库:
三、 细节体验:后台计时校准
小程序在切入后台(onHide)后,setInterval 定时器往往会暂停或变慢。为了保证比赛计时的准确性,不能单纯依赖定时器累加。
解决方案:时间戳校准法
- 记录时间点:
onHide时,记录当前时间戳runningSince。 - 计算差值:
onShow时,计算(Date.now() - runningSince)。 - 自动补齐:将差值加到
elapsedTime中。
// pages/nine-ball/nine-ball.js
onShow() {
if (this.data.isRunning) {
const now = Date.now()
const rs = this.data.runningSince
const delta = Math.floor((now - rs) / 1000)
// 即使在后台挂起了一小时,回来时间也会瞬间补齐
if (delta > 0) {
this.setData({ elapsedTime: this.data.elapsedTime + delta })
}
}
}
四、 总结
“追分记”虽然只是一个工具类小程序,但“麻雀虽小,五脏俱全”。
- 从产品角度:它验证了从痛点出发,利用 AI 辅助设计快速落地的可行性。
- 从技术角度:本地存储治理、生命周期管理等前端/小程序开发的典型场景。
独立开发最迷人的地方,莫过于看着一个想法,在自己的键盘下一点点变成触手可及的现实。
如果你也是台球爱好者,或者对小程序开发感兴趣,欢迎在微信搜索**“追分记”**体验,也欢迎在评论区交流技术细节!
来源:juejin.cn/post/7591767753851174954
还在用 WebSocket 做实时通信?SSE 可能更简单
大家好,我是大华!在现代的Web开发中,实时通信需求越来越普遍。比如在线聊天、实时数据监控、消息推送等场景。
面对这些需求,我们通常有两种选择:SSE和WebSocket。它们都能实现实时通信,但设计理念和适用场景却有很大不同。
什么是 SSE?
SSE(Server-Sent Events)是一种基于 HTTP 的服务器推送技术。它的核心特点是:单向通信,只能由服务器向客户端发送数据。
SSE 的核心特点
- 基于 HTTP 协议:使用标准的 HTTP/1.1 协议
- 单向通信:服务器 → 客户端
- 自动重连:浏览器内置重连机制
- 简单易用:API 设计简洁直观
- 文本传输:主要支持 UTF-8 文本数据
SSE 使用示例
客户端JS代码:
// 创建 SSE 连接
const eventSource = new EventSource('/api/real-time-data');
// 监听服务器推送的消息
eventSource.onmessage = function(event) {
const data = JSON.parse(event.data);
console.log('收到实时数据:', data);
updateUI(data); // 更新界面
};
// 监听自定义事件类型
eventSource.addEventListener('systemAlert', function(event) {
const alertData = JSON.parse(event.data);
showAlert(alertData.message);
});
// 错误处理 - 自动重连是内置的
eventSource.onerror = function(event) {
console.log('连接异常,正在自动重连...');
};
服务器端代码(Node.js + Express):
app.get('/api/real-time-data', (req, res) => {
// 设置 SSE 必需的响应头
res.writeHead(200, {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Access-Control-Allow-Origin': '*'
});
// 发送初始连接确认
res.write('data: {"status": "connected"}\n\n');
// 模拟实时数据推送
let count = 0;
const interval = setInterval(() => {
const data = {
id: count++,
timestamp: new Date().toISOString(),
value: Math.random() * 100
};
// SSE 标准格式:data: 开头,两个换行符结尾
res.write(`data: ${JSON.stringify(data)}\n\n`);
// 每10秒发送一次系统状态
if (count % 10 === 0) {
res.write('event: systemAlert\n');
res.write(`data: {"message": "系统运行正常"}\n\n`);
}
}, 1000);
// 客户端断开连接时清理资源
req.on('close', () => {
clearInterval(interval);
console.log('客户端断开连接');
});
});
什么是 WebSocket?
WebSocket 是一种真正的全双工通信协议,允许服务器和客户端之间建立持久连接,进行双向实时通信。
WebSocket 的核心特点
- 独立协议:基于 TCP 的独立协议(ws:// 或 wss://)
- 双向通信:服务器 ↔ 客户端
- 低延迟:建立连接后开销极小
- 数据多样:支持文本和二进制数据
- 手动管理:需要手动处理连接状态
WebSocket 使用示例
客户端JS代码:
class ChatClient {
constructor() {
this.socket = null;
this.isConnected = false;
}
connect() {
this.socket = new WebSocket('wss://api.example.com/chat');
this.socket.onopen = () => {
this.isConnected = true;
console.log('WebSocket 连接已建立');
this.send({ type: 'join', username: '小明' });
};
this.socket.onmessage = (event) => {
const data = JSON.parse(event.data);
this.handleMessage(data);
};
this.socket.onclose = () => {
this.isConnected = false;
console.log('连接已断开');
this.attemptReconnect();
};
this.socket.onerror = (error) => {
console.error('WebSocket 错误:', error);
};
}
sendMessage(content) {
if (this.isConnected) {
this.send({
type: 'message',
content: content,
timestamp: Date.now()
});
}
}
send(data) {
this.socket.send(JSON.stringify(data));
}
handleMessage(data) {
switch (data.type) {
case 'chat':
this.displayMessage(data);
break;
case 'userJoin':
this.showUserJoin(data.username);
break;
}
}
attemptReconnect() {
setTimeout(() => {
console.log('尝试重新连接...');
this.connect();
}, 3000);
}
}
服务器端代码(Node.js + ws 库):
const WebSocket = require('ws');
const wss = new WebSocket.Server({
port: 8080,
perMessageDeflate: false
});
// 存储连接的用户
const connectedUsers = new Map();
wss.on('connection', (ws, request) => {
console.log('新的客户端连接');
let currentUser = null;
ws.on('message', (rawData) => {
try {
const data = JSON.parse(rawData);
switch (data.type) {
case 'join':
currentUser = data.username;
connectedUsers.set(ws, currentUser);
// 广播用户加入消息
broadcast({
type: 'userJoin',
username: currentUser,
time: new Date().toISOString()
}, ws);
// 发送欢迎消息
ws.send(JSON.stringify({
type: 'system',
message: `欢迎 ${currentUser} 加入聊天室!`
}));
break;
case 'message':
// 广播聊天消息
broadcast({
type: 'chat',
username: currentUser,
message: data.content,
timestamp: data.timestamp
});
break;
}
} catch (error) {
console.error('消息解析错误:', error);
ws.send(JSON.stringify({
type: 'error',
message: '消息格式错误'
}));
}
});
ws.on('close', () => {
if (currentUser) {
connectedUsers.delete(ws);
// 广播用户离开
broadcast({
type: 'userLeave',
username: currentUser,
time: new Date().toISOString()
});
}
console.log('客户端断开连接');
});
// 心跳检测
const heartbeat = setInterval(() => {
if (ws.readyState === WebSocket.OPEN) {
ws.send(JSON.stringify({ type: 'ping' }));
}
}, 30000);
ws.on('close', () => {
clearInterval(heartbeat);
});
});
function broadcast(data, excludeWs = null) {
wss.clients.forEach((client) => {
if (client !== excludeWs && client.readyState === WebSocket.OPEN) {
client.send(JSON.stringify(data));
}
});
}
区别对比
| 特性 | SSE | WebSocket |
|---|---|---|
| 通信模式 | 单向(服务器推客户端) | 双向(全双工通信) |
| 协议基础 | HTTP/1.1 | 独立的 WebSocket 协议 |
| 连接建立 | 普通 HTTP 请求 | HTTP 升级握手 |
| 数据格式 | 文本(事件流格式) | 文本和二进制帧 |
| 重连机制 | 浏览器自动处理 | 需要手动实现 |
| 头部开销 | 每次消息带 HTTP 头 | 建立后极小帧头 |
| 兼容性 | 良好(除 IE) | 优秀(IE10+) |
| 开发复杂度 | 简单直观 | 相对复杂 |
适用场景
推荐使用 SSE 的场景
1. 实时数据监控面板
2. 实时消息通知
3. 实时数据流展示
比如:股票价格实时更新、体育比赛比分直播、物流订单状态跟踪和服务器日志实时显示等。
推荐使用 WebSocket 的场景
1. 实时交互应用
2. 实时游戏应用
3. 实时音视频通信
比如:视频会议系统、在线客服聊天和实时协作编辑文档等
如何选择?
选择 SSE:
- 只需要服务器向客户端推送数据
- 希望快速实现、简单维护
- 项目对移动端兼容性要求高
- 数据更新频率适中(秒级)
- 不需要传输二进制数据
选择 WebSocket:
- 需要真正的双向实时通信
- 数据传输频率很高(毫秒级)
- 需要传输二进制数据(如图片、音频)
- 构建实时交互应用(游戏、协作工具)
- 对延迟极其敏感的场景
混合使用策略
在一些复杂应用中,可以同时使用两者:
class HybridApp {
constructor() {
// 使用 SSE 接收通知和广播消息
this.notificationSource = new EventSource('/api/notifications');
// 使用 WebSocket 进行实时交互
this.interactionSocket = new WebSocket('wss://api.example.com/interact');
this.setupEventHandlers();
}
setupEventHandlers() {
// SSE 处理广播类消息
this.notificationSource.onmessage = (event) => {
this.handleBroadcastMessage(JSON.parse(event.data));
};
// WebSocket 处理交互类消息
this.interactionSocket.onmessage = (event) => {
this.handleInteractionMessage(JSON.parse(event.data));
};
}
}
总结
SSE 的优势在于简单易用、自动重连、与 HTTP 基础设施完美集成,适合服务器向客户端的单向数据推送场景。
WebSocket 的优势在于真正的双向通信、低延迟、支持二进制数据,适合需要高频双向交互的复杂应用。
在实际项目中,可以根据具体的业务需求、性能要求来做出合理的技术选型。
本文首发于公众号:程序员刘大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
📌往期精彩
《SpringBoot+Vue3 整合 SSE 实现实时消息推送》
《SpringBoot 动态菜单权限系统设计的企业级解决方案》
来源:juejin.cn/post/7576559408659611700
真的,你可以不用TypeScript
某位伟人说过,没有调查,就没有发言权。
这是我基于 AI + TypeScript 写的项目,花了大半年,提交了近3000次,TypeScript可真是害苦我了。
我一气之下,把TypeScript全部换成JavaScript了,一点TypeScript都不留。
之前含TypeScript量可是有 80% 以上的。
那么接下来,就把我为什么从全力使用TypeScript,到全力抛弃TypeScript的思考分享出来。
首先叠个甲,这里并不是说TypeScript本身不好,单纯的就是TypeScript不适合我,或者说我个人太菜了。
很多时候,技术没有好坏之分,只有合不合适,经过这半年多的时间,对这句话的理解更加深刻了。
我是2015年入行的,经历过TypeScript从名不经传,到家喻户晓的过程,但从业10年,我并没有因为TypeScript的呼声很高,而把TypeScript在我的项目中全面落地。
这也从侧面说明,我是一个在技术方面,不追求新潮,也不追求强大的人,可能正应了那句话,我是一个在用着自己喜欢的技术,一直待在自己舒适区的人。
但AI的发展,让我保持了10年的舒适区有了些许的松动。
TypeScript作为前端领域革命性的变化,多多少少有所了解,但作为一个骨子里极度喜欢自由的人,实在是不想被类型所束缚,也有过多次尝试,但早已习惯了JavaScript的自由,用起来极其别扭。
在AI的协助下,我仿佛如有神助,写TypeScript最麻烦的部分,AI全部搞定了。
前几个月,还算融洽,但AI写的代码,不看不知道,一看吓一跳,可以说是垃圾屎山也不为过。
或许我们从整个项目的局部看,这AI写的代码还真他娘的不错,但如果你从整个项目的协调性,系统性,扩展性,维护性去看,AI写的就是一大坨屎山。
怎么办呢?有两种办法,第一种是眼不见为净,还有一种就是重构它。
重构也有两种方法,用AI去重构AI,或者古法手工重构。
我都试过,实践证明,AI重构后的屎山,还是屎山。
或许是我对AI的提示词,对AI提供的代码规范不够细节,说得不够清楚,但要真让我一五一十,事无巨细的说清楚,那跟我古法手工重构有啥区别?
所以最终还是回到了,古法手工重构的地步。
这个时候,才真正明白了,什么是一个头,两个大。
换做写JavaScript的时候,我重构直接撸起袖子就是干,但现在,我首先要梳理类型,然后让代码与类型进行完美结合,再反复地在代码和类型中进行各种穿插游走。
重构了一段时间,卧槽,好累啊,我大部分时间都不是在写功能,写代码,而是在跟类型斗智斗勇,因为我无法忍受any,无法忍受unknow,也无法忍受不严谨的类型。
原本应该很快就把功能写完的,但至少70%-80%的时间,都在类型这个问题上面反复横跳,我TM到底是要写代码还是写类型啊?
直到我彻底放弃TypeScript的那一刻,我才真正明白,我是一个一根筋的人,我不喜欢一个有类型系统的语言,它居然可以让你不写类型。
正是TypeScript这种,一边要革了JavaScript的半条命,一边又给JavaScript另外半条命一直吊盐水,让我这种强迫症特别抓狂。
回到JavaScript后,终于松了口气,腰不酸,腿也不痛了,回想到很多年以前刚入行那会,所有网站都是JavaScript写的,也不见有几个捅破天的问题出现。
反而是TypeScript问世后,好像继续用JavaScript,整个项目,团队,公司,市值都会天崩地裂一样。
而AI的发展,就算用JavaScript,出现问题的概率也会远远低于多年以前只有JavaScript的时代。
对于代码而言,我现在更信任自己这个人肉编译器,比如用户对接口的传参,每个数据的类型,大小,范围,我都会有一个验证函数进行专门的验证。但如果用TypeScript,你就要进行繁复的判断,类型的定义,不然就会出现红色波浪线。
那我把严格检测关了不就行了吗?那这样我为什么不直接用JavaScript一劳永逸呢?用TypeScript不就是馋它的类型系统吗,但类型系统反而带来了更多麻烦。
以上均为个人单打独斗的情况之思考与分享,不适合所有人,TypeScript是一个非常好的编程语言,革命性的编程语言,但抛去滤镜之后,从自身需求出发,其实很多人都不需要TypeScript。
我是农村程序员,独立开发者,前端之虎陈随易,个人网站 👇
- 个人网站 1️⃣:chensuiyi.me
- 个人网站 2️⃣:me.yicode.tech
我的所有文章均为古法手写,无 AI 添加剂,请放心食用,如果你觉得本文有用,一键三连 (点赞、评论、转发),就是对我最大的支持~
来源:juejin.cn/post/7610711542346940435
主项目通过iframe嵌套子项目,子项目弹框无法全屏
之所以调研iframe技术,是因为一个问题引起的。
问题:主项目通过iframe嵌套子项目,子项目弹框无法全屏,请问有什么方案解决呢?
经过调研,有以下方式解决:
- 主项目实现一个弹框,子项目和主项目进行通信,对弹框进行控制。
- 子项目通过getContainer把弹框挂载到主项目的body上。
- 如果是简单的弹框,可以手写一个。
第1种方案是比较通用的方案,比较简单。
但有时候会存在这样的问题,主项目无法修改,怎么办?只能用第3种方案,自己手写一个弹框了。
好多人会使用第2中方案,因为毕竟a-modal给出了这样的api,但第2种方案有坑,并且坑不小。它不是一个通用方案不建议使用,实在没办法,也可以尝试着一用。
第2种方案会存在以下问题:
- 子项目挂载到主项目的body上,a-modal的样式丢失。
以上问题如何解决:
第一种方法:在主项目上放一个a-modal,用v-show="false"隐藏,这样子项目挂载到主项目body上的a-modal也有了样式。
主项目
<template>
<a-card title="主项目 - 子项目展示">
<div>
<iframe
ref="iframeRef"
:src="subAppUrl"
frameborder="0"
></iframe>
</div>
<!-- 可以用v-show -->
<a-modal v-show="false" v-model:open="open" title="Basic Modal" @ok="handleOk">
<p>Some contents...</p>
<p>Some contents...</p>
<p>Some contents...</p>
</a-modal>
</a-card>
</template>
<script setup>
import { ref } from 'vue'
const iframeRef = ref(null)
// 通过代理访问子项目,确保同域名
const subAppUrl = ref('/sub-app/')
const open = ref(true);
const showModal = () => {
open.value = true;
};
const handleOk = (e) => {
console.log(e);
open.value = false;
};
</script>
<script setup>
import { ref } from 'vue'
const iframeRef = ref(null)
// 通过代理访问子项目,确保同域名
const subAppUrl = ref('/sub-app/')
const open = ref(true);
const showModal = () => {
open.value = true;
};
const handleOk = (e) => {
console.log(e);
open.value = false;
};
</script>
子项目
<a-modal
v-model:open="modalVisible"
title="弹框"
width="600px"
:get-container="getContainer"
@ok="handleOk"
@cancel="handleCancel"
>
<div class="modal-content">
<h2>这是一个弹框</h2>
<p>弹框内容区域</p>
<a-space>
<a-button>按钮1</a-button>
<a-button>按钮2</a-button>
</a-space>
</div>
</a-modal>
// 获取主项目的body作为弹框容器
const getContainer = () => {
try {
// 通过 window.parent 访问主项目的 document
if (window.parent && window.parent !== window.self) {
console.log('window.parent.document:', window.parent.document)
if (window.parent.document && window.parent.document.body) {
console.log('成功获取父窗口body')
return window.parent.document.body
}
} else {
console.warn('window.parent 不存在或等于 window.self')
}
} catch (e) {
// 如果跨域,会抛出错误,则使用当前窗口的body
console.error('无法访问父窗口,使用当前窗口body:', e)
}
console.log('使用当前窗口body')
return document.body
}
第二种方式:需要把a-modal的样式注入进去。
这种代码就不贴了,个人觉得比较麻烦,并且还有不确定的边界,个人不建议用这种方式。
来源:juejin.cn/post/7579934463589990436
“死了么”用户数翻800倍,估值近1亿,那我来做个“活着呢”!
前言
最近“死了么”这款 App 因为精准切入独居人群的安全痛点而爆火。截止到今天已经攀升到苹果付费App排行榜第一的位置了!
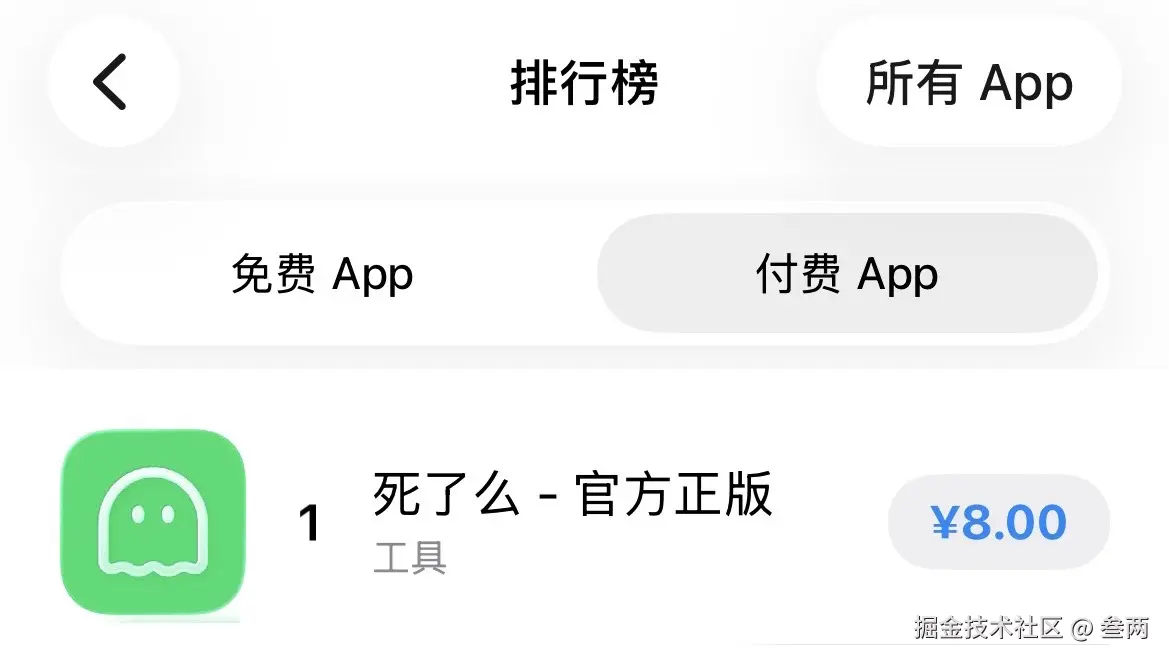
它的核心逻辑非常简单: “签到保平安,断签发邮件” 。
出于好奇,我去了解了相关信息,看到一个数据,据第七次全国人口普查数据显示,我国一人户家庭已超1.25亿户,占全国户口总数的25%。对于独居人群来说,发生意外不可怕,可怕的是无人知晓,这款APP也是精准踩中了这部分人的痛点。
于是,我连夜敲代码,搞出了这款对标产品—— “活着呢”(TO BE LIVE) 。
产品哲学
它的逻辑极其简单粗暴:
- 生存契约:你设定一个“确认周期”(默认 48 小时)。
- 打卡续命:在倒计时结束前,你必须上来点一下那个 “我还活着呢” 的按钮。
- 失联预警:如果你超时未点,系统将判定你“可能挂了”,立即触发预警,通知你的紧急联系人。
技术选型
- 前端框架:Next.js 14 (App Router)。极致的 SEO 和路由体验。
- 状态动效:Framer Motion。让倒计时和按钮带上“呼吸感”。
- 后端支撑:Supabase (BaaS)。无需自己写 CRUD,秒级实现 Auth 授权和数据库存储。
- 通知:Resend。定时发送邮件。
- 主题适配:Tailwind CSS。支持“深邃绿”与“荧光绿”的双重主题,白天是深沉的翡翠,深夜是守护的微光。
- 部署环境:Vercel。全球加速,毕竟生命经不起等待。
核心代码实现
核心功能
- 注册/登录、退出
- 签到、紧急联系人设置
- 主题切换
登录页
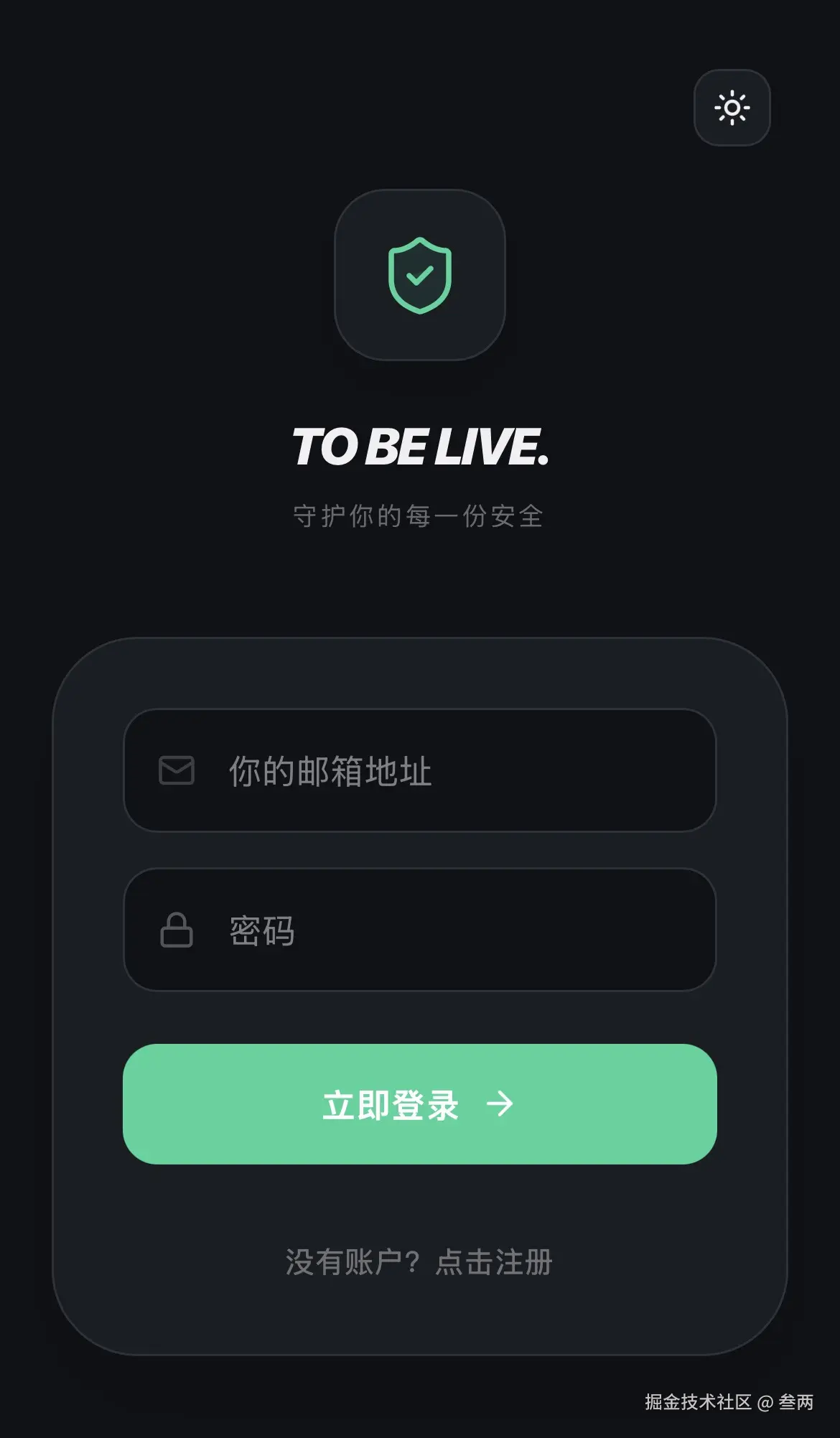
在用户未注册时,可以先注册账号,再登录,核心代码如下:
const handleSubmit = async (e) => {
e.preventDefault()
setLoading(true)
try {
if (isLogin) {
const { error } = await supabase.auth.signInWithPassword({ email, password })
if (error) throw error
router.push('/')
} else {
const { error } = await supabase.auth.signUp({ email, password })
if (error) throw error
alert('验证邮件已发送,请查收!')
}
} catch (err) {
alert(err.message)
} finally {
setLoading(false)
}
}
签到页
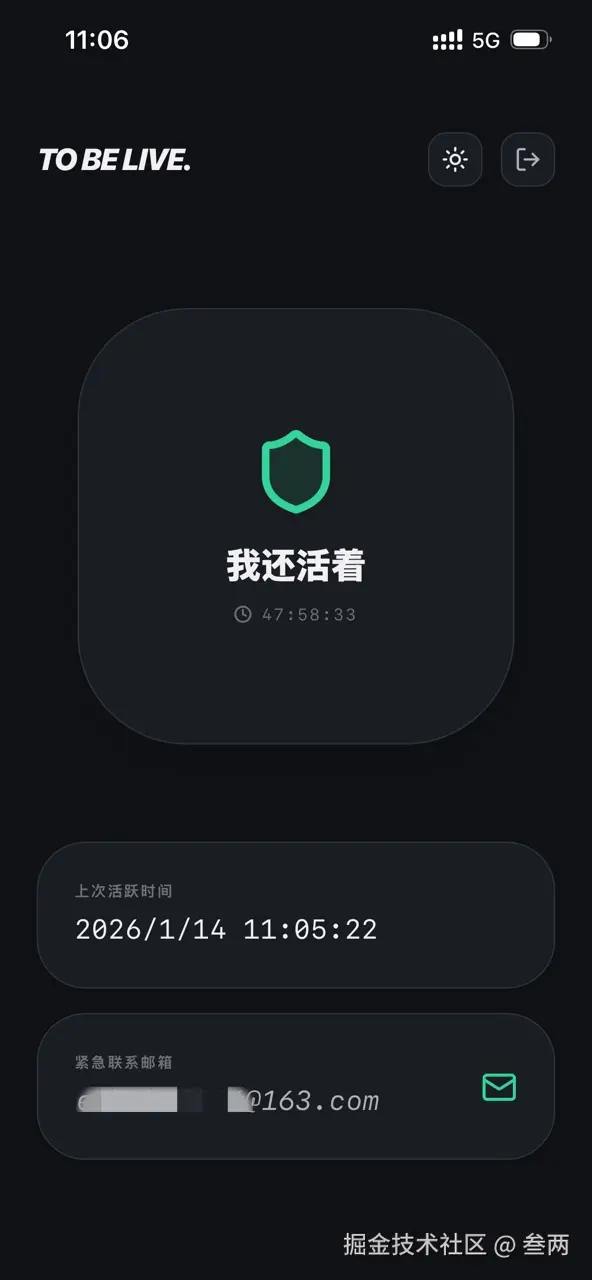
最核心的功能是那个动态倒计时逻辑。我们需要在客户端实时计算剩余时间,并根据紧迫程度变换颜色。这里的安全周期是设定死的48小时,后期可让用户自定义。
<motion.button
whileTap={{ scale: 0.94 }}
onClick={handleCheckIn}
className="absolute inset-4 rounded-[4.5rem] bg-app-card border border-app-border flex flex-col items-center justify-center
shadow-[0_15px_40px_rgba(0,0,0,0.04)] dark:shadow-none"
>
<div className={`mb-4 transition-colors duration-1000 ${getAlertColorClass()}`}>
{timeLeft.h < 8 ? (
<AlertTriangle size={60} />
) : (
<Shield
size={60}
fill="currentColor"
fillOpacity={0.12}
className="drop-shadow-[0_4px_12px_rgba(0,0,0,0.05)] dark:drop-shadow-none"
/>
)}
</div>
<span className="text-2xl font-black tracking-tight text-app-text">我还活着</span>
<div className="mt-2 font-mono text-[11px] opacity-40 flex items-center gap-1.5 tracking-widest">
<Clock size={12} strokeWidth={2.5} />
{String(timeLeft.h).padStart(2, "0")}:
{String(timeLeft.m).padStart(2, "0")}:
{String(timeLeft.s).padStart(2, "0")}
</div>
</motion.button>
// 动态获取当前的强调色(预警系统)
const getAlertColorClass = () => {
if (timeLeft.h < 8) return "text-red-500";
if (timeLeft.h < 24) return "text-amber-500";
return "text-app-accent"; // 使用主题定义的强调色
};
const updateCountdown = useCallback(() => {
if (!profile?.last_check_in) return;
const last = new Date(profile.last_check_in).getTime();
const now = new Date().getTime();
const total = 48 * 60 * 60 * 1000;
const remaining = Math.max(0, total - (now - last));
setTimeLeft({
h: Math.floor(remaining / (1000 * 60 * 60)),
m: Math.floor((remaining % (1000 * 60 * 60)) / (1000 * 60)),
s: Math.floor((remaining % (1000 * 60)) / 1000),
percent: (remaining / total) * 100
});
}, [profile]);
useEffect(() => {
const timer = setInterval(updateCountdown, 1000);
return () => clearInterval(timer);
}, [updateCountdown]);
const handleCheckIn = async () => {
if (!user) return;
const now = new Date().toISOString();
const { error } = await supabase.from("profiles").update({ last_check_in: now }).eq("id", user.id);
if (!error) {
setProfile((prev) => ({ ...prev, last_check_in: now }));
if ("vibrate" in navigator) navigator.vibrate([50, 30, 50]);
}
};
PWA 改造:从网页变成桌面 App
作为一个守护工具,它必须触手可及。我为它集成了 PWA 功能,用户可以“一键添加到桌面”。
通过配置 manifest.json,我们的 App 实现了:
- Standalone 模式:隐藏浏览器地址栏,全屏沉浸体验。
- 自定义图标:一个可爱鬼(代表此时的你)和一颗回答“YES”的小心脏。

后记
“我还活着呢”(TO BE LIVE),在每一个平凡的 24 小时里,温柔地问一句: “嘿,还在吗?”
项目已开源/部署,欢迎大家来“续命”!
互动环节
如果你失联了,你最希望 App 给你的联系人发送哪句话? A. 帮我格式化手机,谢谢。 B. 我在异世界开挂了,莫念。 C. 救命!我还能抢救一下!
来源:juejin.cn/post/7594863660297322538
70行代码实现一个Markdown流式解析器
从0到1构建一个渲染Markdown字符串的组件
- ✨ 流式输出:支持增量渲染 Markdown 内容,适用于大文本或流式数据场景
- 🎯 无闪屏渲染:每次更新内容时保持平滑过渡,提升用户体验
- 🎨 样式友好:内置美观的默认样式(数学公式转换,代码块语法高亮)
- 🚀 高性能:借助虚拟 dom 和 Vue 的diff算法增量渲染
- 🔗 原生Html:支持原生Html标签嵌入到Md字符串内
先上效果 演示demo
背景
相信很多大模型前端开发的小伙伴都已经处理过markdown实时解析翻译成html了,传统的方式类似使用Marked、markdown-it等组件全量渲染。但是全量渲染及其消耗性能,会造成大量的重排、重绘,导致页面抖动。
实现逻辑拆解
1、想要实现渲染Markdown字符串,必然涉及到如何把md字符串转成html;
2、如若支持流式渲染,可以借助虚拟dom和vue的diff算法;
3、处理数学公式展示可以借助unified生态的rehypeKatex、remarkMath;
4、处理代码语法高亮可以借助unified生态的rehypeHighlight;
5、原生Html标签如 <br> <a>等需要放行,不做转化处理;
6、支持提示语法如:::warning ::: error等,需要unified生态的remarkFlexibleContainers;
3、部分碎片md字符串如(输出一半的图片链接、表格、数学公式等)可以使用js正则匹配非法的格式做过滤,直到合法后再做解析渲染;
开箱即用模式
# 安装命令
npm install v3-markdown-stream
# 或
yarn add v3-markdown-stream
组件使用示例
<template>
<div>
<MarkdownRender :markInfo="markdownContent" />
</div>
</template>
<script setup>
import { ref } from 'vue'
import { MarkdownRender } from 'v3-markdown-stream';
import 'v3-markdown-stream/dist/v3-markdown-stream.css';
// 静态内容
const markdownContent = ref('# Hello World\n\nThis is a simple markdown example.')
</script>
组件概览
首先,让我们来看看这个组件的核心代码(都是站在各位巨人的肩膀上)
组件使用 Vue3 的 defineComponent 定义,接收一个必须的 markstr 属性,这是要解析的 Markdown 字符串。整个组件的设计非常简洁,就像一个「专注的翻译官」,只做一件事,但要做到极致!
import { h, defineComponent, computed } from "vue";
import { Fragment, jsxs, jsx } from "vue/jsx-runtime";
import { toJsxRuntime } from "hast-util-to-jsx-runtime";
import remarkParse from "remark-parse";
import rehypeKatex from "rehype-katex";
import "katex/dist/katex.min.css";
import 'highlight.js/styles/github-dark.css';
import remarkMath from "remark-math";
import remarkRehype from "remark-rehype";
import rehypeRaw from 'rehype-raw';
import rehypeHighlight from 'rehype-highlight'
import remarkFlexibleContainers from 'remark-flexible-containers'
import remarkGfm from "remark-gfm";
import { VFile } from "vfile";
import { unified } from "unified";
//1、先将接收到的md字符串通过VFile转成file,因为unified需要file类型
const createFile = (markstr) => { // markdown字符串转file
const file = new VFile();
file.value = markstr;
return file;
};
// 2、解析器链的构建
// 这部分代码构建了一个「解析流水线」,就像工厂里的生产线一样,Markdown 文本会依次经过各个「加工环节」。这里使用 computed 确保解析器只在必要时重新创建,提高了性能。
// 使用unified的remarkParse将md字符串转成md语法树;
// 使用unified的remarkRehype将md语法树转成html语法树;
// 使用rehypeRaw放行原生html、rehypeKatex解析数学公式、rehypeHighlight代码语法高亮
let unifiedProcessor = computed(() => { // unified解析器工具链初始化
const processor = unified()
.use(remarkParse, { allowDangerousHtml: true})
.use(remarkFlexibleContainers)
.use(remarkRehype, { allowDangerousHtml: true})
.use(rehypeRaw)
.use(remarkGfm)
.use(rehypeKatex)
.use(remarkMath)
.use(rehypeHighlight);
return processor;
});
//3、使用hast-util-to-jsx-runtime将语法树转为虚拟dom
const generateVueNode = (tree) => { // 获取vue虚拟dom
const vueVnode = toJsxRuntime(tree, {
Fragment,
jsx: jsx,
jsxs: jsxs,
passNode: true,
});
return vueVnode;
};
//4、响应式渲染
// processor.parse(file) 将文件解析成 AST
// processor.runSync(...) 运行所有插件处理 AST
// 最后通过 h() 函数将生成的虚拟 DOM 渲染到页面上
const computedVNode = computed(() => {
const processor = unifiedProcessor.value;
const file = createFile(props.markstr);
let result = generateVueNode(processor.runSync(processor.parse(file), file));
return result;
});
return () => {
return h(computedVNode.value);
};
核心功能包解析
1. Vue 核心团队
- vue : 提供 h , defineComponent , computed 等核心 API,是整个组件的「骨架」
- vue/jsx-runtime : 提供 Fragment , jsxs , jsx ,让我们可以在 Vue 中优雅地使用 JSX 语法。
2. Unified 解析系统
- unified : 这是整个解析系统的「大脑」,负责协调各个插件的工作。想象一下,它就像是一个「指挥官」,指挥着(插件)同步执行;
- vfile : 提供文件处理功能,把 Markdown 字符串转换成统一的文件格式,;
官方四大生态
| 生态名 | 负责语言 | 典型 AST 规范 | 关键插件 | 备注 |
|---|---|---|---|---|
| remark | Markdown | mdast | remark-parse / remark-stringify / remark-gfm / remark-frontmatter / remark-math … | 社区最活跃,工具最多 |
| rehype | HTML | hast | rehype-parse / rehype-stringify / rehype-slug / rehype-autolink-headings / rehype-pretty-code … | 常与 remark 组合做“MD→HTML” |
| retext | 自然语言 | nlcst | retext-english / retext-smartypants / retext-spell / retext-readability … | 拼写检查、可读性评分等 |
| redot | Graphviz Dot | dost | redot-parse / redot-stringify | 小众但官方维护 |
一句话概括:unified 不是“又一个 Markdown 解析器”,而是让“任何结构化文本”都能被统一解析、转换、生成的基础设施;在它之上,remark、rehype、retext、redot 四大生态共同组成了 JavaScript 世界最完善、最活跃的内容处理工具链
3. Remark 家族 - Markdown 处理器
- remark-parse : 将 Markdown 文本解析成抽象语法树(AST),就像是「翻译官」把中文翻译成一种中间语言
- remark-math : 处理数学公式,让你的文档可以「高大上」地展示复杂数学表达式
- remark-rehype : 将 Markdown AST 转换成 HTML AST,相当于「转换器」把中间语言翻译成另一种中间语言
- remark-gfm : 支持 GitHub 风格的 Markdown 扩展功能,比如表格、任务列表等
- remark-flexible-containers : 提供灵活的容器功能,让你的内容布局更加多样化
4. Rehype 家族 - HTML
- rehype-raw : 保留原始 HTML,让你的 Markdown 中混合的 HTML 代码也能正常工作
- rehype-katex : 将数学公式渲染成漂亮的 HTML,让数学表达式样式友好
- rehype-highlight : 为代码块提供语法高亮,提高代码可读性
5. 样式支持
- katex.min.css : 数学公式的样式
- github-dark.css : 代码高亮的样式(按需求可替换成浅色模式)
6.hast-util-to-jsx-runtime介绍
hast-util-to-jsx-runtime 是一个把 hast(HTML AST)转成 JSX 运行时对象 的小工具,一句话:给它一棵 hast 树,它就能吐出 React / Preact / Solid / Vue / Svelte 等框架“认识”的 JSX 节点,无需再手写 React.createElement 或 h() 等繁琐代码。
核心 API —— toJsxRuntime(tree, options)
import { toJsxRuntime } from 'hast-util-to-jsx-runtime'
参数
tree:hast 根节点options:必填,至少提供 JSX 运行时三件套
jsx/jsxs:生产环境自动运行时函数Fragment:片段构造器- (开发模式再额外给
jsxDEV)
返回值
直接就是框架的“虚拟节点”,可扔进框架的渲染层即可。
技术亮点与设计精髓
- 响应式设计 : 利用 Vue3 的 computed ,实现了 Markdown 字符串变化时的自动重新解析和渲染
- 模块化插件链 : 采用统一的插件系统,各功能模块解耦,可以灵活地添加或移除功能
- 高性能优化 : 通过 computed 缓存解析器和虚拟 DOM,避免不必要的重复计算
- 丰富的功能支持 : 支持数学公式、代码高亮、GitHub 风格扩展等高级功能
- 错误处理机制 : 提供了 errorCaptured 钩子,捕获并记录解析过程中的错误
- 兼容处理了大模型流式输出的时候图片链接、表格字符串、数学公式等未完全返回的的渲染抖动
总结
这个 Vue3 Markdown 解析组件就像是一个「智能翻译官 + 高级排版师」,它不仅能准确地将 Markdown 转换成 HTML,还能让最终的展示效果既美观又功能丰富。通过巧妙地组合各种开源工具,它实现了一个功能完备、性能优良的 Markdown 解析渲染系统。
无论是构建博客、文档系统还是知识库,这个组件都能为你的项目增添强大的内容展示能力。希望这篇文章能帮助你理解这个组件的实现原理,也欢迎大家提出宝贵的改进建议!
最后,如果你觉得这个组件对你有帮助,不妨点个赞并分享给更多的开发者朋友,让我们一起让 Markdown 解析变得更简单、更强大!
GitHub源码仓库地址
如果觉得好用,欢迎给个Star ⭐️ 支持一下!
来源:juejin.cn/post/7577313637950652425
Electrobun 正式登场:仅 12MB,JS 桌面开发迎来轻量化新方案!
你的 Electron 应用打包后 150MB?
而用 Electrobun,一个功能完整的桌面 App 只需 12MB——启动更快、内存更低、更新补丁仅 14KB。
如果你热爱 Electron 的开发体验,却痛恨它的臃肿与资源消耗——Electrobun 的出现,或许正是“鱼与熊掌兼得”的答案。
一、Electron 的困境:强大,但太重了
过去十年,Electron 让无数前端开发者轻松踏入桌面应用领域。VS Code、Discord、Figma 桌面版……无一不是其成功典范。
但代价也清晰可见:
- 体积爆炸:最小可运行包 ≥100MB;
- 内存吞噬:每个窗口内嵌 Chromium,多开即卡顿;
- 安全边界模糊:Node.js 与渲染层未隔离,易受攻击;
- 更新笨重:哪怕改一行代码,用户也要下载上百 MB。
开发者一直在寻找替代方案——Tauri 要求学 Rust,Neutralino 功能有限。而今天,Electrobun 带着 Bun 的极致性能,杀入战场。
二、Electrobun 是什么?为什么它能小 90%?
Electrobun 并非重写 Electron,而是用 Bun + 系统 WebView 重构其核心架构,保留开发体验,砍掉冗余负担。
| 组件 | Electron | Electrobun |
|---|---|---|
| 主进程运行时 | Node.js | Bun(Zig 编写,启动快 5 倍) |
| 渲染引擎 | 自带 Chromium | 系统 WebView(macOS: WebKit, Windows: WebView2) |
| 包管理 | npm + node_modules | Bun install(快 20 倍,依赖更精简) |
| 最终体积 | 100–300MB | ≈10–15MB(实测) |
| 内存占用 | 300MB+ | 40–60MB |
关键创新在于:
- 不再捆绑 Chromium:信任操作系统已有的现代 WebView;
- 主进程用 Bun 替代 Node.js:启动速度从 300ms 降至 10ms;
- 原生 API 通过 Zig 封装:比 Node.js addon 更轻、更安全;
- 支持热重载不中断连接:开发体验优于 nodemon。
三、真的还能用 React/Vue 写吗?当然!
Electrobun 的最大优势:前端开发方式完全不变。
你依然可以用:
- React / Vue / Svelte / Solid
- TypeScript / JSX
- Vite / Webpack(或直接用 Bun 打包)
只需在主进程中调用 Electrobun 提供的 API:
// main.ts(主进程)
import { app, BrowserWindow } from 'electrobun';
app.whenReady().then(() => {
const win = new BrowserWindow({
width: 800,
height: 600,
webPreferences: { contextIsolation: true }
});
win.loadFile('dist/index.html'); // 加载你的前端构建产物
});
而前端代码与以往毫无区别:
// App.tsx
function App() {
return <h1>Hello from Electrobun!</h1>;
}
零学习成本迁移现有 Electron 项目——只需替换主进程运行时,并调整打包配置。
四、实测:体积与性能对比
我们用相同功能(Markdown 编辑器 + 文件保存 + 托盘图标)构建两个版本:
| 指标 | Electron (v30) | Electrobun (v0.8) |
|---|---|---|
| 打包后体积 | 148 MB | 12.3 MB |
| 冷启动时间 | 2.4 秒 | 0.7 秒 |
| 空窗口内存 | 295 MB | 48 MB |
| 全量更新包 | 148 MB | 12.3 MB |
| 差分更新(改一行代码) | ≈100 MB | 14 KB |
更重要的是:Electrobun 默认启用上下文隔离与沙箱,安全性远超默认 Electron 配置。
五、但它还不完美
作为新兴项目(截至 2026 年初仍处早期),Electrobun 有几点需注意:
- Windows 需 WebView2 运行时:首次启动会自动引导安装(微软官方组件,普及率高);
- 部分 Electron API 未完全覆盖:如
webContents.print()等高级功能正在适配; - 调试工具链待完善:DevTools 支持基础功能,但性能分析不如 Chrome DevTools 深入;
- 社区插件少:但因兼容 Electron 核心 API,多数逻辑可复用。
不过对于新项目、内部工具、AI 桌面客户端、轻量级编辑器,Electrobun 已足够成熟。
六、5 分钟上手 Electrobun
试试创建你的第一个轻量桌面 App:
# 1. 安装 Bun(若未安装)
curl -fsSL https://bun.sh/install | bash
# 2. 创建项目
bun create electrobun my-app
# 或使用模板:bun create react-electrobun my-app
# 3. 启动开发
cd my-app
bun run dev
# 4. 打包发布
bun run build
你会得到一个 12MB 左右的 .app(macOS)或 .exe(Windows),双击即用。
七、为什么现在值得关注?
- Bun 生态爆发:Bun 1.0 已稳定,工具链日趋完善;
- AI 桌面应用潮:本地 LLM 客户端需要轻量、快速、安全的载体;
- 用户容忍度下降:MacBook 用户尤其反感“Electron 内存怪兽”;
- Electrobun GitHub Star 数月增 10k+,社区活跃度飙升。
它可能不会立刻取代 Electron,但为“轻量级桌面应用”开辟了一条新路。
结语
Electron 教会我们:前端开发者也能做桌面软件;
而 Electrobun 正在告诉我们:我们可以做得更轻、更快、更负责任。
在资源日益宝贵的今天,一个 12MB 的应用,不仅是技术选择,更是对用户设备的尊重。
GitHub:github.com/blackboards…
不妨用 Electrobun 重写你的工具—— 也许下一个爆款桌面应用,就藏在这 12MB 之中。
愿意尝试 Electrobun 的扣 1,还在观望的扣 2!
来源:juejin.cn/post/7618065319287750696
2026年了,前端到底算不算“夕阳行业”?
你有没有在朋友圈或者知乎上看到过这样的声音:“前端这行是不是快没前途了?”、“前端是夕阳行业,学不起来就晚了”。听起来很吓人吧?今天周五公司不忙~ 所以就想就想聊聊,为什么这些说法有点夸张,而且,实际上,前端比你想的要活跃、要有意思得多。
前端行业现状与就业趋势深入分析
其他废话少说,我先列出一组数据。
市场数据说明:招聘活跃度与求职热度
在判定某个岗位是否是“夕阳行业”前,我们得看看实实在在的数据,而不是空谈。虽然我们没有官方完整的每月统计数据,但从招聘平台侧面指标可以窥见市场动态:
BOSS直聘平台整体使用频次趋势(2024 年)
数据来自行业研究监测,反映招聘平台月度活跃度(平台月访问次数,单位为万次)。它可以折射出用户在找工作和发布岗位的活跃程度:
| 月份 | Boss直聘(万次) | 前程无忧(万次) | 智联招聘(万次) |
|---|---|---|---|
| 2024‑01 | 1212.8 | 503.3 | 381.6 |
| 2024‑03 | 2271.8 | 958.5 | 660.3 |
| 2024‑05 | 1892.9 | 730.1 | 496.5 |
| 2024‑09 | 1861.9 | 695.1 | 465.5 |
| 2024‑12 | 1492.8 | 665.7 | 432.8 |
从这张表可以看到几个趋势:
- 春节前后及 3 月、4 月经常会有求职与招聘高峰,这与校园招聘和年终奖金兑现周期有关。
- Boss直聘的整体使用频次明显高于其他招聘平台,表明它在人才市场中具有更高的活跃度。
这说明整体就业市场并没有冷却到技术岗位“没市场”的程度,但伴随着整体求职竞争压力也在增加(尤其毕业季之后)。
2024–2025 前端岗位薪资与供需情况(综合公开数据)
下面给出一个简要的薪资与供需趋势对比,是基于公开行业报告和招聘平台上职位薪资调研整理的(单位:人民币):
前端薪资水平(2024–2025)
| 类型 | 数据来源 | 平均薪资(月) | 说明 |
|---|---|---|---|
| 全国前端平均薪资 | 招聘求职网站综合数据 | ~20,877 元/月 | 2024 年全国平均数据,样本规模较大 |
| 数字前端工程师高薪技术岗位 | 脉脉高聘年度报告 | ~67,728 元/月 | 仅针对极高端职位薪资榜首人才 |
| BOSS直聘高级前端岗位示例 | 招聘岗位样例 | 20K–50K /月 | 典型一线城市高级薪资范围 |
| 企业大厂前端薪资 | 公司薪资水平数据 | ~57–65 万/年 | P6(技术中高级)年薪典型值 |
小结:大厂或高级岗位薪资明显高于平均,而整体前端岗薪资按城市和经验差异明显(北上深等一线城市更高)。中高级工程师薪资已进入较高收入层。
前端岗位供需趋势(24 年–25 年)
真实可公开的按月份招聘/求职人数统计不容易直接获得(需付费或数据授权),但我们可以根据人才供需比报告和其他间接指标构建趋势理解:
人才供需比(供给 vs 需求)变化
| 数据年份/区间 | 人才供需比(整体技术类) | 解读 |
|---|---|---|
| 2022 全年 | 1.29 | 约 1.3 求职者争一岗 |
| 2023 全年 | 2.00 | 竞争更激烈 |
| 2024 1‑10 月 | 2.06 | 职位竞争仍然紧张 |
供需比上升意味着“求职者数量增速快于岗位数量”,这反映就业市场总体竞争压力上升,但这主要是整体技术类岗位,不仅限前端。技术类岗位中核心和稀缺型(例如 AI、架构方向)仍然紧缺。 开源中国
招聘/求职活跃度趋势示意
timeline
title
2024 : 招聘需求 ↑, 求职人数 ↑
2025 : 招聘需求 ↓, 求职人数 ↑↑
- 招聘需求在 2024/2025 年虽整体活跃,但增长略收敛。
- 求职人数增速仍然高(尤其高校毕业生和转行人才增多)。 PDF 文档助手+1
“前端到底是做什么的”
以前的前端,其实很简单——写页面。你写几个 HTML、CSS,再加上点 JS,页面能跑就算完成任务。大部分人只要会写代码,基本就能找到工作。那时候,技术门槛不高,但随之而来的问题是:大家都能做,稀缺性不强。
到了现在,前端已经不是单纯写页面那么简单了。现在你需要考虑性能优化、工程化、架构设计,甚至还得会和 AI 工具配合来提高效率。也就是说,前端的工作量和复杂度已经大幅升级了,光会写代码,已经不再稀缺。
普通前端 / 工程型前端 / 架构型前端
我一般把前端分成三类:
- 普通前端
就是那种把设计稿转成页面的人,写页面、调样式、搞交互。以前,这类岗位很吃香,因为企业只要有人能把界面做出来就行。现在,普通前端的门槛低,但成长空间有限。 - 工程型前端
这类前端不仅会写页面,还懂打包工具、模块化、性能优化、测试、CI/CD,甚至前端安全。他们能把一个项目从零到一搞成可以高效运转的系统。你可以把他们想象成“能写代码,也懂流程的人”,在团队里很吃香。 - 架构型前端
架构型前端更厉害,他们关注的是整个平台的稳定性、可维护性和扩展性。他们设计组件库、微前端架构、前端性能监控体系,甚至参与后端接口设计。换句话说,他们更像“产品工程师”,不仅懂技术,还懂业务。
会写代码不再稀缺,会“用 AI 写代码”才是门槛
你可能注意到了,现在很多人说“前端会写代码不稀缺了”。这是真的。基础的 JS、CSS、HTML 很多人都会,但如果你能用 AI 辅助写代码、自动生成模板、快速优化性能,那才是真正的核心竞争力。就像以前会打字的人很多,但会用 Excel 做财务建模的人少,差距就出来了。
举个例子,现在有些大型项目,我们用 AI 帮忙生成表单验证逻辑,或者做自动化测试脚本,效率能提高好几倍。这种能力,不是简单敲几行代码能替代的。
前端未来,更像产品工程师
所以,到底前端是不是夕阳行业?我觉得恰恰相反。未来的前端,更像产品工程师——你不仅要写代码,还要思考性能、用户体验、架构设计、工程化流程,甚至要和 AI、云端、数据打交道。前端的职业宽度比以前更大,技能组合也更加稀缺。
换句话说,前端不再只是写界面的小伙伴,而是能把技术和产品结合起来,创造可落地系统的人。
总结
不是前端“夕阳”,只是门槛提高了
从薪资和招聘活跃度看:
- 前端岗位依旧铺开在招聘平台上,高薪职位数量没有消失,只是分布更广、更分层。
- 高端工程师、架构型前端、全栈/AI 前端人才仍然供不应求。
- 竞争压力主要来自技术同质化人才与行业整体求职人数增长的趋势(特别是毕业季)。 开源中国
真实情形是:前端并非夕阳,而是在职业形态和薪资结构上出现了更明显的分层。
你看到普通前端岗位薪资增长缓慢,是因为市场供给大,但 高技术、高工程化能力者反而更加吃香,门槛变了,而不是需求消失。
总结:结合数据再看“前端是否夕阳”
既然有数据支撑,我们再回到那个问题:
前端是否是夕阳行业?结论是:
- 前端需求仍在增长 ——招聘平台活跃度高,技术转型需求仍旧带来岗位。
- 薪资仍然维持在行业中上水平 ——尤其中高级、工程化岗位。
- 市场竞争更激烈 ——求职人数持续增长使得低门槛岗位更难突围。
- 分层明显 ——普通前端增长较缓,高技能人才仍稀缺。
所以说:前端不是夕阳行业,前端职业更像是正经历升级版的“技术工程”方向,更接近综合产品工程师,而不是单纯的页面写手。
要在这个岗位上活得更好,与 AI 协作、提升工程化能力、掌握架构与性能优化,成为未来核心竞争力。
数据来源说明
本文涉及的前端薪资、招聘人数、求职人数及市场趋势数据,主要来源公开渠道:
- BOSS直聘:招聘岗位示例及薪资参考 官网,招聘活跃度趋势及职位需求变化 年度报告
- 前端薪资参考:全国平均薪资及高端岗位薪资 Teamed Up China、大厂薪资对比 Levels.fyi、高端技术岗位薪资 脉脉高聘年度报告
- 前端供需数据:技术类岗位供需比及求职活跃度 公开行业报告
数据仅供行业分析参考,实际薪资及岗位信息可能随城市、公司和岗位等级变化。
来源:juejin.cn/post/7587684397530595355
CSS 也要支持 if 了 !!!CSS if() 函数来了!
CSS 也要支持 if 了 !!!CSS if() 函数来了!
CSS if() 函数允许在纯 CSS 中基于条件为属性赋值,无需 JavaScript 或预处理器。该函数已在 Chrome 137 发布。
过去常用的做法包括通过 JavaScript 切换类名、使用预处理器 mixin 或编写大量媒体查询。if() 将条件逻辑引入 CSS,使写法更直接、性能稳定。
原文 CSS 也要支持 if 了 !!!CSS if() 函数来了!
工作原理
property: if(condition-1: value-1; condition-2: value-2; condition-3: value-3; else: default-value);
函数按顺序检查条件并应用第一个匹配的值;若没有条件匹配,则使用 else 的值。这一语义与常见编程语言一致,但实现于纯 CSS。
if() 的三种能力
样式查询(Style queries)
使用 style() 可响应 CSS 自定义属性:
.card {
--status: attr(data-status type(<custom-ident>));
border-color: if(style(--status: pending): royalblue; style(--status: complete): seagreen; style(--status: error): crimson; else: gray);
}
一个 data-status 属性即可驱动对应样式,无需额外工具类。
媒体查询(Media queries)
使用 media() 可以在属性内联定义响应式值,无需嵌套媒体查询块:
h1 {
font-size: if(media(width >= 1200px): 3rem; media(width >= 768px): 2.5rem; media(width >= 480px): 2rem; else: 1.75rem);
}
特性检测(Feature detection)
使用 supports() 可在属性中直接进行特性检测,并提供明确回退:
.element {
border-color: if(supports(color: lch(0 0 0)): lch(50% 100 150) ; supports(color: lab(0 0 0)): lab(50 100 -50) ; else: rgb(200, 100, 50));
}
真实用例
暗色模式示例
body {
--theme: 'dark'; /* 通过 JavaScript 或用户偏好切换 */
background: if(style(--theme: 'dark'): #1a1a1a; else: white);
color: if(style(--theme: 'dark'): #e4e4e4; else: #333);
}
设计系统状态组件
.alert {
--type: attr(data-type type(<custom-ident>));
background: if(style(--type: success): #d4edda; style(--type: warning): #fff3cd; style(--type: danger): #f8d7da; style(--type: info): #d1ecf1; else: #f8f9fa);
border-left: 4px solid if(style(--type: success): #28a745; style(--type: warning): #ffc107; style(--type: danger): #dc3545; style(--type: info): #17a2b8; else: #6c757d);
}
容器尺寸示例(简化媒体查询)
.container {
width: if(media(width >= 1400px): 1320px; media(width >= 1200px): 1140px; media(width >= 992px): 960px; media(width >= 768px): 720px; media(width >= 576px): 540px; else: 100%);
padding-inline: if(media(width >= 768px): 2rem; else: 1rem);
}
与现代 CSS 特性结合
.element {
/* 搭配新的 light-dark() 函数 */
color: if(style(--high-contrast: true): black; else: light-dark(#333, #e4e4e4));
/* 搭配 CSS 自定义函数(@function) */
padding: if(style(--spacing: loose): --spacing-function(2) ; style(--spacing: tight): --spacing-function(0.5) ; else: --spacing-function(1));
}
浏览器支持
支持情况(截至 2025 年 8 月):
- ✅ Chrome/Edge:自 137 版起
- ✅ Chrome Android:自 139 版起
- ❌ Firefox:开发中
- ❌ Safari:在规划中
- ❌ Opera:尚未支持
在尚未完全支持的环境中,可采用如下写法:
.button {
/* 所有浏览器的回退 */
padding: 1rem 2rem;
background: #007bff;
/* 现代浏览器会自动覆盖 */
padding: if(style(--size: small): 0.5rem 1rem; style(--size: large): 1.5rem 3rem; else: 1rem 2rem);
background: if(style(--variant: primary): #007bff; style(--variant: success): #28a745; style(--variant: danger): #dc3545; else: #6c757d);
}
未来展望
CSS 工作组已经在推进扩展能力:
- 范围查询:
if(style(--value > 100): ...) - 逻辑运算符:
if(style(--a: true) and style(--b: false): ...) - 容器查询集成:更强的上下文感知
在使用前建议评估目标浏览器版本,并准备相应回退方案。
来源:juejin.cn/post/7571758212472897587
Vue3 后台分页写腻了?我用 1 个 Hook 删掉 90% 重复代码(附源码)
实战推荐:
- 不仅免费,还开源?这个 AI Mock 神器我必须曝光它
- ⚡ 一个Vue自定义指令搞定丝滑拖拽列表,告别复杂组件封装
- 🔥 这才是 Vue 驱动的 Chrome 插件工程化正确打开方式
- 女朋友又给我出难题了:解锁网页禁用复制 + 一键提取图片文字
还在为每个列表页写重复的分页代码而烦恼吗? 还在复制粘贴 currentPage、pageSize、loading 等状态吗? 一个 Hook 帮你解决所有分页痛点,减少90%重复代码
背景与痛点
在后台管理系统开发中,分页列表查询非常常见,我们通常需要处理:
- 当前页、页大小、总数等分页状态
- 加载中、错误处理等请求状态
- 搜索、刷新、翻页等分页操作
- 数据缓存和重复请求处理
这些重复逻辑分散在各个组件中,维护起来很麻烦。
为了解决这个烦恼,我专门封装了分页数据管理 Hook。现在只需要几行代码,就能轻松实现分页查询,省时又高效,减少了大量重复劳动
使用前提 - 接口格式约定
查询接口返回的数据格式:
{
list: [ // 当前页数据数组
{ id: 1, name: 'user1' },
{ id: 2, name: 'user2' }
],
total: 100 // 数据总条数
}
先看效果:分页查询只需几行代码!
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList, // 查询API
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
这样子每次分页查询只需要引入hook,然后传入查询接口就好了,减少了大量重复劳动
解决方案
我设计了两个相互配合的 Hook:
- useFetch:基础请求封装,处理请求状态和缓存
- usePageFetch:分页逻辑封装,专门处理分页相关的状态和操作
usePageFetch (分页业务层)
├── 管理 page / pageSize / total 状态
├── 处理搜索、刷新、翻页逻辑
├── 统一错误处理和用户提示
└── 调用 useFetch (请求基础层)
├── 管理 loading / data / error 状态
├── 可选缓存机制(避免重复请求)
└── 成功回调适配不同接口格式
核心实现
useFetch - 基础请求封装
// hooks/useFetch.js
import { ref } from 'vue'
const Cache = new Map()
/**
* 基础请求 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {*} options.initValue - 初始值
* @param {string|Function} options.cache - 缓存配置
* @param {Function} options.onSuccess - 成功回调
*/
function useFetch(fn, options = {}) {
const isFetching = ref(false)
const data = ref()
const error = ref()
// 设置初始值
if (options.initValue !== undefined) {
data.value = options.initValue
}
function fetch(...args) {
isFetching.value = true
let promise
if (options.cache) {
const cacheKey = typeof options.cache === 'function'
? options.cache(...args)
: options.cache || `${fn.name}_${args.join('_')}`
promise = Cache.get(cacheKey) || fn(...args)
Cache.set(cacheKey, promise)
} else {
promise = fn(...args)
}
// 成功回调处理
if (options.onSuccess) {
promise = promise.then(options.onSuccess)
}
return promise
.then(res => {
data.value = res
isFetching.value = false
error.value = undefined
return res
})
.catch(err => {
isFetching.value = false
error.value = err
return Promise.reject(err)
})
}
return {
fetch,
isFetching,
data,
error
}
}
export default useFetch
usePageFetch - 分页逻辑封装
// hooks/usePageFetch.js
import { ref, onMounted, toRaw, watch } from 'vue'
import useFetch from './useFetch' // 即上面的hook ---> useFetch
import { ElMessage } from 'element-plus'
/**
* 分页数据管理 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {Object} options.params - 默认参数
* @param {boolean} options.initFetch - 是否自动初始化请求
* @param {Ref} options.formRef - 表单引用
*/
function usePageFetch(fn, options = {}) {
// 分页状态
const page = ref(1)
const pageSize = ref(10)
const total = ref(0)
const data = ref([])
const params = ref()
const pendingCount = ref(0)
// 初始化参数
params.value = options.params
// 使用基础请求 Hook
const { isFetching, fetch: fetchFn, error, data: originalData } = useFetch(fn)
// 核心请求方法
const fetch = async (searchParams, pageNo, size) => {
try {
// 更新分页状态
page.value = pageNo
pageSize.value = size
params.value = searchParams
// 发起请求
await fetchFn({
page: pageNo,
pageSize: size,
// 使用 toRaw 避免响应式对象问题
...(searchParams ? toRaw(searchParams) : {})
})
// 处理响应数据
data.value = originalData.value?.list || []
total.value = originalData.value?.total || 0
pendingCount.value = originalData.value?.pendingCounts || 0
} catch (e) {
console.error('usePageFetch error:', e)
ElMessage.error(e?.msg || e?.message || '请求出错')
// 清空数据,提供更好的用户体验
data.value = []
total.value = 0
}
}
// 搜索 - 重置到第一页
const search = async (searchParams) => {
await fetch(searchParams, 1, pageSize.value)
}
// 刷新当前页
const refresh = async () => {
await fetch(params.value, page.value, pageSize.value)
}
// 改变页大小
const onSizeChange = async (size) => {
await fetch(params.value, 1, size) // 重置到第一页
}
// 切换页码
const onCurrentChange = async (pageNo) => {
await fetch(params.value, pageNo, pageSize.value)
}
// 组件挂载时自动请求
onMounted(() => {
if (options.initFetch !== false) {
search(params.value)
}
})
// 监听表单引用变化(可选功能)
watch(
() => options.formRef,
(formRef) => {
if (formRef) {
console.log('Form ref updated:', formRef)
}
}
)
return {
// 分页状态
currentPage: page,
pageSize,
total,
pendingCount,
// 数据状态
data,
originalData,
isFetching,
error,
// 操作方法
search,
refresh,
onSizeChange,
onCurrentChange
}
}
export default usePageFetch
完整使用示例
用element ui举例
<template>
<el-form :model="searchForm" >
<el-form-item label="用户名">
<el-input v-model="searchForm.username" />
</el-form-item>
<el-form-item>
<el-button type="primary" @click="handleSearch">搜索</el-button>
</el-form-item>
</el-form>
<!-- 表格数据展示,绑定 data 和 loading 状态 -->
<el-table :data="data" v-loading="isFetching">
<!-- ...表格列定义... -->
</el-table>
<!-- 分页组件,绑定当前页、页大小、总数,并响应切换事件 -->
<el-pagination
v-model:current-page="currentPage"
v-model:page-size="pageSize"
:total="total"
@size-change="onSizeChange"
@current-change="onCurrentChange"
/>
</template>
<script setup>
import { ref } from 'vue'
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 搜索表单数据,响应式声明
const searchForm = ref({
username: ''
})
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList,
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
/**
* 处理搜索操作
*/
const handleSearch = () => {
search({ username: searchForm.value.username })
}
</script>
高级用法
带缓存
const {
data,
isFetching,
search
} = usePageFetch(getUserList, {
cache: (params) => `user-list-${JSON.stringify(params)}` // 自定义缓存 key
})
设计思路解析
- 职责分离:useFetch 专注请求状态管理,usePageFetch 专注分页逻辑
- 统一错误处理:在 usePageFetch 层统一处理错误
- 智能缓存机制:支持多种缓存策略
- 生命周期集成:自动在组件挂载时请求数据
总结
这套分页管理 Hook 的优势:
- 开发效率高,减少90%的重复代码,新增列表页从 30 分钟缩短到 5 分钟
- 状态管理完善,自动处理加载、错误、数据状态
- 缓存机制,避免重复请求
- 错误处理统一,用户体验一致
- 易于扩展,支持自定义配置和回调
如果觉得对您有帮助,欢迎点赞 👍 收藏 ⭐ 关注 🔔 支持一下!
来源:juejin.cn/post/7549096640340426802
vue文件自动生成路由会成为主流
vue-router悄悄发布了5.0版本,用官方的话说,V5 是一个过渡版本,它将unplugin-vue-router(基于文件的路由)合并到了核心包中,就是说V5版本直接支持基于文件自动生成路由了,无需再引入unplugin-vue-router。
这一变化标志着前端开发模式的一个重要转折点。过去,开发者需要手动定义路由配置,这种方式虽然灵活,但随着项目规模增大,维护成本也随之增加。现在,Vue Router 5.0内置了基于文件的路由系统,使得路由管理变得更加直观和高效。
传统路由配置与基于文件路由的对比
在传统的Vue Router使用方式中,我们需要手动创建路由:
import { createRouter, createWebHistory } from "vue-router";
import Home from "./views/Home.vue";
import About from "./views/About.vue";
const routes = [
{
path: "/",
name: "home",
component: Home,
},
{
path: "/about",
name: "about",
component: About,
},
];
const router = createRouter({
history: createWebHistory(),
routes,
});
而基于文件的路由系统允许我们通过目录结构自动生成路由,例如:
src/
├── pages/
│ ├── index.vue # -> /
│ ├── about.vue # -> /about
│ ├── user/
│ │ └── index.vue # -> /user
│ └── user-[id].vue # -> /user/:id
无需手动创建,直接导入即可:
import { routes } from "vue-router/auto-routes";
const router = createRouter({
history: createWebHistory(),
routes,
});
省去了手动定义路由的繁琐步骤。
基于文件路由的优势
- 减少样板代码:无需手动编写大量路由配置
- 约定优于配置:通过文件名和目录结构确定路由路径
- 提高开发效率:添加新页面只需创建对应文件
- 易于维护:路由结构一目了然,便于团队协作
- 类型化路由: 使用ts能够获得更好的提示,比如
router.push(xxx)现在会有提示了
缺点
- 路由的
meta等额外数据必须在.vue文件使用definePage或route标签声明,点此查看教程 - 增加了额外的学习成本
快速入门
安装
pnpm add vue-router@5
vite.config.ts
import VueRouter from "vue-router/vite";
export default defineConfig({
plugins: [
VueRouter({
dts: "typed-router.d.ts",
}),
// ⚠️ Vue must be placed after VueRouter()
Vue(),
],
});
tsconfig.json
// tsconfig.json
{
"include": [ "typed-router.d.ts" ],
"vueCompilerOptions": {
"plugins": [
"vue-router/volar/sfc-typed-router",
"vue-router/volar/sfc-route-blocks"
]
}
}
src/router/index.ts
import { createRouter, createWebHistory } from "vue-router";
import { routes, handleHotUpdate } from "vue-router/auto-routes";
export const router = createRouter({
history: createWebHistory(),
routes,
});
// This will update routes at runtime without reloading the page
if (import.meta.hot) {
handleHotUpdate(router);
}
详细的路由生成规则
根据官方文档,基于文件的路由系统有以下具体规则:
索引路由:任何 index.vue 文件(必须全小写)将生成空路径,类似于 index.html 文件:
src/pages/index.vue生成/路由src/pages/users/index.vue生成/users路由
嵌套路由:当在同一层级同时存在同名文件夹和 .vue 文件时,会自动生成嵌套路由。例如:
src/pages/
├── users/
│ └── index.vue
└── users.vue
这将生成如下路由配置:
const routes = [
{
path: "/users",
component: () => import("src/pages/users.vue"),
children: [
{ path: "", component: () => import("src/pages/users/index.vue") },
],
},
];
不带布局嵌套的路由:有时候你可能想在URL中添加斜杠形式的嵌套,但不想影响UI层次结构。可以使用点号(.)分隔符:
src/pages/
├── users/
│ ├── [id].vue
│ └── index.vue
└── users.vue
要添加 /users/create 路由而不将其嵌套在 users.vue 组件内,可以创建 src/pages/users.create.vue 文件,. 会被转换为 /:
const routes = [
{
path: "/users",
component: () => import("src/pages/users.vue"),
children: [
{ path: "", component: () => import("src/pages/users/index.vue") },
{ path: ":id", component: () => import("src/pages/users/[id].vue") },
],
},
{
path: "/users/create",
component: () => import("src/pages/users.create.vue"),
},
];
路由组:有时候需要组织文件结构而不改变URL。路由组允许你逻辑性地组织路由,不影响实际URL:
src/pages/
├── (admin)/
│ ├── dashboard.vue
│ └── settings.vue
└── (user)/
├── profile.vue
└── order.vue
生成的URL:
/dashboard-> 渲染src/pages/(admin)/dashboard.vue/settings-> 渲染src/pages/(admin)/settings.vue/profile-> 渲染src/pages/(user)/profile.vue/order-> 渲染src/pages/(user)/order.vue
命名视图:可以通过在文件名后附加 @ + 名称来定义命名视图,如 src/pages/index@aux.vue 将生成:
{
path: '/',
component: {
aux: () => import('src/pages/index@aux.vue')
}
}
默认情况下,未命名的路由被视为 default,即使有其他命名视图也不需要将文件命名为 index@default.vue。
动态路由:使用方括号语法定义动态参数:
[id].vue->/users/:id[category]-details.vue->/electronics-details[...all].vue-> 通配符路由/all/*
对开发工作流的影响
这一变化将显著改变Vue应用的开发流程:
- 新功能页面的添加变得更加简单
- 团队成员更容易理解项目的路由结构
- 减少了因手动配置错误导致的路由问题
- 更好的IDE集成和自动补全支持
迁移策略
对于现有项目,Vue Router 5.0提供了平滑的迁移路径:
- 旧的路由配置方式依然有效
- 可以逐步采用基于文件的路由
- 混合使用两种方式以适应不同场景
配置选项和高级功能
Vue Router 5.0的基于文件路由系统提供了丰富的配置选项,可以根据项目需求进行定制:
自定义路由目录:默认情况下,系统会在 src/pages 目录中查找 .vue 文件,但可以通过配置更改此行为。
命名路由:所有生成的路由都会自动获得名称属性,避免意外将用户引导至父路由。默认情况下,名称使用文件路径生成,但可以通过自定义 getRouteName() 函数覆盖此行为。
类型安全:系统会自动生成类型声明文件(如 typed-router.d.ts),提供几乎无处不在的 TypeScript 验证。
配置示例:
// vite.config.js
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
import VueRouter from "unplugin-vue-router/vite";
export default defineConfig({
plugins: [
VueRouter({
routesFolder: "src/pages", // 自定义路由目录
extensions: [".vue"], // 指定路由文件扩展名
dts: "typed-router.d.ts", // 生成类型声明文件
importMode: (filename) => "async", // 自定义导入模式
}),
vue(),
],
});
实际应用建议
在实际项目中采用基于文件的路由时,建议遵循以下最佳实践:
- 清晰的目录结构:保持一致的目录结构,便于团队成员理解
- 有意义的文件名:使用描述性的文件名,使路由意图明确
- 合理使用路由组:利用路由组组织相关的页面,而不影响URL结构
- 渐进式采用:对于大型项目,可以逐步迁移部分路由到新的系统
总结
Vue Router 5.0引入的基于文件的路由系统代表了前端开发模式的重要演进。它将 Nuxt.js 等框架成功的路由理念整合到了 Vue 的核心生态中,使开发者能够以更简洁、更直观的方式管理应用路由。
这一变化不仅减少了样板代码,提高了开发效率,还促进了更一致的项目结构。随着更多开发者采用这一新模式,我们可以期待看到更高质量、更易维护的 Vue 应用程序出现,这将为整个前端社区带来积极的影响。
来源:juejin.cn/post/7610253888646119467
告别满屏 v-if:用一个自定义指令搞定 Vue 前端权限控制
在企业级应用开发中,权限控制是一个绑不开的话题。前端权限控制虽然不能替代后端校验,但能极大提升用户体验——让用户只看到自己能操作的内容,避免无效点击和困惑。
本文将分享一个 Vue 2 自定义指令的设计思路,实现了声明式的权限控制方案。
设计目标
在动手写代码之前,我先梳理了几个核心诉求:
- 使用简单:一行代码搞定权限控制,不需要写一堆
v-if - 性能友好:同一权限不重复请求,利用缓存
- 灵活可控:支持隐藏、禁用、提示等多种交互方式
- 支持多场景:既能用在模板里,也能在 JS 逻辑中调用
核心实现
1. 权限缓存设计
权限校验通常需要请求后端接口,如果每个按钮都单独请求一次,那页面性能会非常糟糕。这里采用了 Promise 缓存 的方式:
Vue.prototype.$getPerm = (options) => {
const argId = options.type + '-' + (options.type === 'space' ? options.spaceId : options.wikiId)
// 如果缓存中没有,创建新的 Promise
if (!spaceInfoStore.permissionMap[argId]) {
spaceInfoStore.permissionMap[argId] = new Promise((resolve, reject) => {
// 请求后端获取权限...
Auth.getUserPermBySpaceId(options.spaceId).then((res) => {
const permissions = res.reduce((acc, category) => {
category.permissions.forEach(permission => {
acc.push(`${category.value}.${permission.authorityKey}`)
})
return acc
}, [])
resolve({ permissions })
})
})
}
return spaceInfoStore.permissionMap[argId]
}
这个设计的巧妙之处在于:缓存的是 Promise 本身,而不是结果。
这样做的好处是,即使多个组件同时调用 $getPerm,也只会发出一次请求。后续的调用会直接拿到同一个 Promise,等待第一次请求的结果。
2. 双重使用方式
为了覆盖不同的使用场景,我设计了两种调用方式:
方式一:指令式(模板中使用)
<button v-perm:[permOptions]="'SPACE.EDIT'">编辑</button>
方式二:编程式(JS 中使用)
this.$hasPerm({ spaceId: 123 }, 'SPACE.EDIT').then(() => {
// 有权限,执行操作
}).catch(() => {
// 无权限
})
指令式适合静态权限控制,编程式适合需要在逻辑中判断的场景。两者底层共用同一套缓存机制。
3. DOM 处理策略
无权限时如何处理 DOM?这里提供了三种策略:
function domHandler (el, binding) {
let placeholderDom = null
if (binding?.arg?.showTips || binding?.arg?.disabled) {
// 策略1&2:保留元素,但禁用或添加点击提示
placeholderDom = el.cloneNode(true)
if (binding?.arg?.showTips) {
placeholderDom.onclick = function () {
Vue.prototype.$bkMessage({
message: binding?.arg?.tipsText || '没有权限',
theme: 'warning'
})
}
}
if (binding?.arg?.disabled) {
placeholderDom.classList.add('disabled')
}
} else {
// 策略3:完全隐藏,用注释节点占位
placeholderDom = document.createComment('permission-placeholder')
}
el.placeholderDom = placeholderDom
el.parentNode.replaceChild(placeholderDom, el)
}
为什么用注释节点而不是直接 display: none?
因为注释节点不会影响布局,也不会被 CSS 选择器选中。更重要的是,我们需要保留一个"锚点",方便权限变化时把原始元素恢复回去。
4. 响应式更新
权限可能会动态变化(比如用户被授权后刷新),所以指令需要同时监听 inserted 和 update 钩子:
Vue.directive('perm', {
inserted (el, binding) {
handlerPerm(el, binding)
},
update (el, binding) {
handlerPerm(el, binding)
}
})
恢复元素的逻辑也很简单:
function restoreElement (el) {
if (el.placeholderDom && el.placeholderDom.parentNode) {
el.placeholderDom.parentNode.replaceChild(el, el.placeholderDom)
}
el.placeholderDom = null
return true
}
5. 支持布尔值快捷方式
有时候权限结果已经在外部计算好了,不需要再走一遍接口校验。这种场景下,支持直接传布尔值会更方便:
<button v-perm:[options]="hasPermission">操作</button>
if (typeof binding.value === 'boolean') {
if (binding.value === false) {
domHandler(el, binding)
} else {
restoreElement(el)
}
return
}
使用示例
基础用法
<template>
<div>
<!-- 无权限时隐藏 -->
<button v-perm:[permConfig]="'SPACE.DELETE'">删除</button>
<!-- 无权限时禁用并提示 -->
<button v-perm:[permConfigWithTips]="'SPACE.EDIT'">编辑</button>
</div>
</template>
<script>
export default {
computed: {
permConfig() {
return {
spaceId: this.currentSpaceId,
type: 'space'
}
},
permConfigWithTips() {
return {
spaceId: this.currentSpaceId,
type: 'space',
disabled: true,
showTips: true,
tipsText: '您没有编辑权限,请联系管理员'
}
}
}
}
</script>
编程式调用
// 在执行敏感操作前校验
async handleDelete() {
try {
await this.$hasPerm({ spaceId: this.spaceId }, 'SPACE.DELETE')
// 有权限,继续执行删除逻辑
await this.doDelete()
} catch {
// 无权限,$hasPerm 内部已经弹出提示
}
}
清除缓存重新加载
当权限发生变化时(比如管理员授权后),可以清除缓存重新加载:
this.$getPerm({
spaceId: this.spaceId,
clearCache: true
})
设计总结
| 特性 | 实现方式 |
|---|---|
| 性能优化 | Promise 缓存,同一权限只请求一次 |
| 使用方式 | 指令式 + 编程式双重支持 |
| DOM 处理 | 隐藏 / 禁用 / 提示三种策略 |
| 响应式 | inserted + update 钩子联动 |
| 灵活性 | 支持布尔值、清除缓存、自定义提示 |
可以优化的点
- Vue 3 适配:Vue 3 的指令钩子函数名称有变化(
mounted、updated),迁移时需要调整 - TypeScript 支持:可以为
PermissionOptions添加完整的类型定义 - 批量权限查询:如果页面上有大量权限点,可以考虑合并成一次批量查询
- 权限预加载:在路由守卫中预加载权限数据,减少页面白屏时间
以上就是这个权限指令的完整设计思路。核心思想是:用缓存换性能,用指令换简洁。希望对你有所启发,欢迎交流讨论 🙌
完整代码
最后贴一下完整代码,可以直接拿去用,根据自己项目的接口改一下就行:
// permission.js
import { useSpaceInfoStore } from '@/store/modules/spaceInfo'
import Auth from '@/api/modules/auth'
let spaceInfoStore = null
setTimeout(() => {
spaceInfoStore = useSpaceInfoStore()
}, 40)
/**
* @typedef {Object} PermissionOptions
* @property {string|number} [wikiId] - 文档id
* @property {string|number} [spaceId] - 空间id
* @property {string} [type] - 权限类型:空间/文档 space/wiki
* @property {boolean} [disabled] - 是否禁用元素
* @property {boolean} [showTips] - 是否显示提示信息
* @property {string} [tipsText] - 提示文本内容
* @property {boolean} [clearCache] - 是否清除缓存
*/
function install (Vue) {
/**
* 获取权限信息
* @param {PermissionOptions} options - 权限选项
* @returns {Promise<any>}
*/
Vue.prototype.$getPerm = (options) => {
if (!options.spaceId) return
// 如果没有传type,则根据是否有文档id判断
options.type = options.type || (options.wikiId ? 'wiki' : 'space')
const argId = options.type + '-' + (options.type === 'space' ? options.spaceId : options.wikiId)
// 清除缓存权限,可重新加载
if (options.clearCache) {
spaceInfoStore.permissionMap[argId] = false
}
if (!spaceInfoStore.permissionMap[argId]) {
spaceInfoStore.permissionMap[argId] = new Promise((resolve, reject) => {
if (options.type === 'space') {
Auth.getUserPermBySpaceId(options.spaceId).then((res) => {
// 组合权限生成唯一key
const permissions = res.reduce((acc, category) => {
category.permissions.forEach(permission => {
acc.push(`${category.value}.${permission.authorityKey}`)
})
return acc
}, [])
resolve({ permissions })
})
} else {
Auth.getWikiPermissionDetail(options.spaceId, options.wikiId).then((res) => {
// 组合权限生成唯一key
const permissions = res.map(item => item.authorityKey)
resolve({ permissions })
})
}
})
}
return spaceInfoStore.permissionMap[argId]
}
/**
* 检查是否有权限
* @param {PermissionOptions} options - 权限选项
* @param {string} perm - 权限码
* @returns {Promise<boolean>}
*/
Vue.prototype.$hasPerm = (options, perm) => {
if (!Object.prototype.hasOwnProperty.call(options, 'showTips')) {
options.showTips = true
}
return new Promise((resolve, reject) => {
if (!options.spaceId) {
resolve(true)
return
}
const promise = Vue.prototype.$getPerm(options)
promise.then((res) => {
if (res.isAdmin) {
resolve(true)
return
}
if (res.permissions.includes(perm)) {
resolve(true)
return
}
if (options.showTips) {
Vue.prototype.$bkMessage({
message: options.tipsText || '没有权限',
theme: 'warning'
})
}
reject(new Error(''))
})
})
}
/**
* DOM 处理函数 - 处理无权限时的元素显示
* @param {HTMLElement} el - DOM 元素
* @param {Object} binding - 指令绑定对象
*/
function domHandler (el, binding) {
let placeholderDom = null
if (binding?.arg?.showTips || binding?.arg?.disabled) {
placeholderDom = el.cloneNode(true)
if (binding?.arg?.showTips) {
placeholderDom.onclick = function () {
Vue.prototype.$bkMessage({
message: binding?.arg?.tipsText || '没有权限',
theme: 'warning'
})
}
}
if (binding?.arg?.disabled) {
placeholderDom.classList.add('disabled')
}
} else {
placeholderDom = document.createComment('permission-placeholder')
}
if (el.parentNode) {
el.placeholderDom = placeholderDom
el.parentNode.replaceChild(placeholderDom, el)
}
}
/**
* 将元素恢复到原始位置
* @param {HTMLElement} el - DOM 元素
* @returns {boolean}
*/
function restoreElement (el) {
el.placeholderDom && el.placeholderDom.parentNode.replaceChild(el, el.placeholderDom)
el.placeholderDom = null
return true
}
/**
* 权限处理函数
* @param {HTMLElement} el - DOM 元素
* @param {Object} binding - 指令绑定对象
*/
function handlerPerm (el, binding) {
// 通过直接传递boolean值,也可以进行权限校验
if (typeof binding.value === 'boolean') {
if (binding.value === false) {
domHandler(el, binding)
} else {
restoreElement(el)
}
return
}
// 判断权限入参是否完善
if (!binding?.arg?.spaceId || !binding?.value) return restoreElement(el)
const promise = Vue.prototype.$getPerm({ ...binding.arg })
promise.then((res) => {
if (res.isAdmin) return restoreElement(el)
if (res.permissions.includes(binding.value)) return restoreElement(el)
domHandler(el, binding)
})
}
Vue.directive('perm', {
inserted (el, binding) {
handlerPerm(el, binding)
},
update (el, binding) {
handlerPerm(el, binding)
}
})
}
export default { install }
在 main.js 里注册一下就能用了:
import permission from '@/directives/permission'
Vue.use(permission)
来源:juejin.cn/post/7585758163436011526
当上传不再只是 /upload,我们是怎么设计大文件上传的
业务背景
在正式讲之前,先看一个我们做的大文件上传demo。
下面这个视频演示的是上传一个 1GB 的压缩包,整个过程支持分片上传、断点续传、暂停和恢复。
可以看到速度不是特别快,这个是我故意没去优化的。
前端那边计算文件 MD5、以及最后合并文件的时间我都保留了,
主要是想让大家能看到整个流程是怎么跑通的。

平时我们在做一些 SaaS 系统的时候,文件上传这块其实基本上都设计的挺简单的。
前端做个分片上传,后端把分片合并起来,最后存 OSS 或者服务器某个路径上,再返回一个 URL 就完事了。
大多数情况下,这样的方案也确实够用。
但是最近我在做一个私有化项目,场景完全不一样。
项目是给政企客户部署的内部系统,里面有 AI 大模型客服问答的功能。
客户需要把他们内部的文档、手册、规范、图纸、流程等资料打包上传到服务器,用来做后续的向量化、知识检索或者模型训练。
这类场景如果还沿用之前 SaaS 系统那种上传方式,往往就不太适用了。
因为这些文件往往有几个共同点:
- 文件数量多,动辄几百上千份(Word、PDF、PPT、Markdown 都有);
- 文件体积大,打成 zip 动不动就是几个 G,甚至十几二十个 G;
- 上传环境复杂,客户一般在内网或局域网,有的甚至完全断网;
- 有安全要求,文件不能经过云端 OSS,里面可能有保密资料;
- 需要审计,要能知道是谁上传的、什么时候传的、文件现在存哪;
- 上传完之后还要进一步处理,比如自动解压、解析文本、拆页、向量化,然后再存入 Milvus 或 pgvector。
在正式讲之前,先看一个我们做的大文件上传demo。
下面这个视频演示的是上传一个 1GB 的压缩包,整个过程支持分片上传、断点续传、暂停和恢复。
可以看到速度不是特别快,这个是我故意没去优化的。
前端那边计算文件 MD5、以及最后合并文件的时间我都保留了,
主要是想让大家能看到整个流程是怎么跑通的。
平时我们在做一些 SaaS 系统的时候,文件上传这块其实基本上都设计的挺简单的。
前端做个分片上传,后端把分片合并起来,最后存 OSS 或者服务器某个路径上,再返回一个 URL 就完事了。
大多数情况下,这样的方案也确实够用。
但是最近我在做一个私有化项目,场景完全不一样。
项目是给政企客户部署的内部系统,里面有 AI 大模型客服问答的功能。
客户需要把他们内部的文档、手册、规范、图纸、流程等资料打包上传到服务器,用来做后续的向量化、知识检索或者模型训练。
这类场景如果还沿用之前 SaaS 系统那种上传方式,往往就不太适用了。
因为这些文件往往有几个共同点:
- 文件数量多,动辄几百上千份(Word、PDF、PPT、Markdown 都有);
- 文件体积大,打成 zip 动不动就是几个 G,甚至十几二十个 G;
- 上传环境复杂,客户一般在内网或局域网,有的甚至完全断网;
- 有安全要求,文件不能经过云端 OSS,里面可能有保密资料;
- 需要审计,要能知道是谁上传的、什么时候传的、文件现在存哪;
- 上传完之后还要进一步处理,比如自动解压、解析文本、拆页、向量化,然后再存入 Milvus 或 pgvector。
所以这种情况还用 SaaS 系统那种“简单上传+云存储”方案的话,那可能问题就一堆:
- 上传中断后用户一刷新浏览器就得重传整个包;
- 集群部署时分片打到不同机器上根本无法合并;
- 多人同时上传可能会发生文件覆盖或路径冲突;
- 没有任何上传记录,也追踪不到是谁传的;
- 对政企来说,审计、合规、保密全都不达标。
所以,我们需要重新设计文件上传的功能逻辑。
目的是让它不仅能支持大文件、断点续传、集群部署,还能同时适配内网环境、权限管控,以及后续的 AI 文档解析和知识向量化等处理流程。
为什么很多项目只需要一个 upload 接口
如果我们回头看一下自己平常做过的一些常规 Web 项目,尤其是各种 SaaS 系统或者后台管理系统,
其实大多数时候后端只会提供一个 /upload 接口, 前端拿到文件后直接调用这个接口,后端保存文件再返回一个 URL 就结束了。
甚至我们在很多项目里,前端都不会把文件传给业务服务,
而是直接通过前端 SDK(比如阿里云 OSS、腾讯云 COS、七牛云等)上传到云存储,
上传完后拿到文件地址,再把这个地址回传给后端保存。
这种方式在 SaaS 系统或者轻量级的业务里非常普遍,也非常高效。 主要原因有几个:
- 文件都比较小,大多数就是几 MB 的图片、PDF 或 Excel;
- 云存储足够稳定,上传、下载、访问都有完整的 SDK 支撑;
- 系统是公网部署,不需要考虑局域网、内网断网这些问题;
- 对安全和审计的要求不高,文件内容也不是涉密数据;
- 用户体验优先,所以直接把文件上传到云端是最省事的方案。
换句话说,这种“一个 upload 接口”或“前端直传 OSS”模式,其实是面向通用型 SaaS 场景的。
对于绝大多数互联网业务来说,它既够快又够省心。
但一旦项目换成政企、私有化部署或者 AI 训练平台这种环境,
就完全不是一个量级的问题了。
这里的关键不在“能不能上传”,
而在于文件上传之后的可控性、可追溯性和安全性。
前端常见的大文件上传方式
在重新设计后端接口之前,我们先来看看现在前端常见的大文件上传思路。
其实近几年前端这块已经比较成熟了,主流方案大体都是围绕几个核心点展开的:
秒传检测、分片上传、断点续传、并发控制、进度展示。
一般来说,前端拿到文件后,会先计算一个文件哈希值,比如用 MD5。
这样做的目的是为了做秒传检测:
如果服务器上已经存在这个文件,就可以直接跳过上传,节省时间和带宽。
接下来是分片上传。
文件太大时,前端会把文件拆成多个固定大小的小块(比如每块 5MB 或 10MB),
然后一片一片地上传。这样做可以避免一次性传输大文件导致浏览器卡顿或网络中断。
然后就是断点续传。
前端会记录哪些分片已经上传成功,如果上传过程中网络中断或浏览器刷新,
下次只需要从未完成的分片继续上传,不用重新传整包文件。
在性能方面,前端还会做并发控制。
比如同时上传三到五个分片,上传完一个就立刻补下一个,
这样整体速度比单线程串行上传要快很多。
最后是进度展示。
通过监听每个分片的上传状态,前端可以计算整体进度,
给用户展示一个实时的上传百分比或进度条,让体验更可控。
可以看到,前端的大文件上传方案已经形成了一套相对标准的模式。
所以这次我在重新设计后端的时候,就打算基于这种前端逻辑,
去构建一套更贴合企业私有化环境的上传接口控制体系。
目标是让前后端的职责划分更清晰:
前端负责切片、控制与恢复;后端负责存储、校验与合并。
后端接口设计思路
前端的大文件上传流程其实已经相对固定了,我们只要让后端的接口和它配合得上,就能把整个上传链路打通。
所以我这次重新设计时,把上传接口拆成了几个比较独立的阶段:
秒传检查、初始化任务、上传分片、合并文件、暂停任务、取消任务、任务列表。
每个接口都只负责一件事,这样接口的职责会更清晰,也方便后期扩展。
一、/upload/check —— 秒传检查
这个接口是整个流程的第一步,用来判断文件是否已经上传过。
前端在计算完文件的全局 MD5(或其他 hash)后,会先调这个接口。
如果后端发现数据库里已经有相同 hash 的文件,就直接返回“已存在”,前端就不用再上传了。
请求示例:
POST /api/upload/check
{
"fileHash": "md5_abc123def456",
"fileName": "training-docs.zip",
"fileSize": 5342245120
}
返回示例:
{
"success": true,
"data": {
"exists": false
}
}
如果 exists = true,说明服务端已经有这个文件,可以直接走“秒传成功”的逻辑。
伪代码示例:
@PostMapping("/check")
public Result checkFile(@RequestBody Map body) {
// 1. 校验 fileHash 参数是否为空
// 2. 查询 file_info 表是否已有该文件
// 3. 如果文件已存在,直接返回秒传成功(exists = true)
// 4. 如果文件不存在,查询 upload_task 表中是否有未完成任务(支持断点续传)
}
二、/upload/init —— 初始化上传任务
如果文件不存在,就要先初始化一个新的上传任务。
这个接口的作用是创建一条 upload_task 记录,同时返回一个唯一的 uploadId。
前端会用这个 uploadId 来标识整个上传过程。
请求示例:
POST /api/upload/init
{
"fileHash": "md5_abc123def456",
"fileName": "training-docs.zip",
"totalChunks": 320,
"chunkSize": 5242880
}
返回示例:
{
"success": true,
"data": {
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"uploadedChunks": []
}
}
uploadedChunks 用来支持断点续传,如果之前有部分分片上传过,就会在这里返回索引数组。
伪代码示例:
@PostMapping("/init")
public Result initUpload(@RequestBody UploadInitRequest request) {
// 1. 检查是否已有同 fileHash 的任务,若有则返回旧任务信息(支持断点续传)
// 2. 否则创建新的 upload_task 记录,生成 uploadId
// 3. 初始化分片数量、大小、状态等信息
// 4. 返回 uploadId 与已上传分片索引列表
}
三、/upload/chunk —— 上传单个分片
这是整个上传过程里调用次数最多的接口。
每个分片都会单独上传一次,并在服务端保存为临时文件,同时写入 upload_chunk 表。
上传成功后,后端会更新 upload_task 的进度信息。
请求示例(表单上传):
POST /api/upload/chunk
Content-Type: multipart/form-data
formData:
uploadId: b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b
chunkIndex: 0
chunkSize: 5242880
chunkHash: md5_001
file: (二进制分片数据)
返回示例:
{
"success": true,
"data": {
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"chunkIndex": 0,
"chunkSize": 5242880
}
}
伪代码示例:
@PostMapping(value = "/chunk", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public Result uploadChunk(@ModelAttribute UploadChunkRequest req) {
// 1. 校验任务状态,禁止上传已取消或已完成的任务
// 2. 检查本地目录(或云端存储桶)是否存在,不存在则创建
// 3. 接收当前分片文件并写入临时路径
// 4. 写入 upload_chunk 表,标记状态为 “已上传”
// 5. 更新 upload_task 的 uploaded_chunks 数量
}
四、/upload/merge —— 合并分片
当前端确认所有分片都上传完后,会调用 /upload/merge。
后端收到这个请求后,去检查所有分片是否完整,然后按照索引顺序依次合并。
合并成功后,会删除临时分片文件,并更新 upload_task 状态为“完成”。
如果启用了云存储,这一步也可以直接把合并后的文件上传到 OSS。
请求示例:
POST /api/upload/merge
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"fileHash": "md5_abc123def456"
}
返回示例:
{
"success": true,
"message": "文件合并成功",
"data": {
"storagePath": "/data/uploads/training-docs.zip"
}
}
伪代码示例:
@PostMapping("/merge")
public Result mergeFile(@RequestBody UploadMergeRequest req) {
// 1. 检查 upload_task 状态是否允许合并
// 2. 校验所有分片是否都上传完成
// 3. 如果是本地存储:按 chunk_index 顺序流式合并文件
// 4. 如果是云存储:调用云端分片合并 API(如 OSS、COS)
// 5. 校验文件 hash 完整性,更新任务状态为 COMPLETED
// 6. 将最终文件信息写入 file_info 表
}
五、/upload/pause —— 暂停任务
这个接口用于在上传过程中手动暂停任务。
前端可能会在网络波动或用户主动点击暂停时调用。
后端会更新任务状态为“已暂停”,并记录当前已上传的分片数。
请求示例:
POST /api/upload/pause
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b"
}
返回示例:
{
"success": true,
"message": "任务已暂停"
}
伪代码示例:
@PostMapping("/pause")
public Result pauseUpload(@RequestBody UploadPauseRequest req) {
// 1. 查找对应的 upload_task
// 2. 更新任务状态为 “已暂停”
// 3. 返回任务状态确认信息
}
六、/upload/cancel —— 取消任务
如果用户想放弃本次上传,可以调用 /cancel。
后端会把任务状态标记为“已取消”,并清理对应的临时分片文件。
这样能避免磁盘上堆积无用数据。
请求示例:
POST /api/upload/cancel
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b"
}
返回示例:
{
"success": true,
"message": "任务已取消"
}
伪代码示例:
@PostMapping("/cancel")
public Result cancelUpload(@RequestBody UploadCancelRequest req) {
// 1. 查找对应的 upload_task
// 2. 更新任务状态为 “已取消”
// 3. 删除或标记已上传的分片文件为待清理
// 4. 返回操作结果
}
七、/upload/list —— 查询任务列表
这个接口我们用于管理后台查看当前上传任务的整体情况。
可以展示每个任务的文件名、大小、进度、状态、上传人等信息,方便追踪和审计。
请求示例:
GET /api/upload/list
返回示例:
{
"success": true,
"data": [
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"fileName": "training-docs.zip",
"status": "COMPLETED",
"uploadedChunks": 320,
"totalChunks": 320,
"uploader": "admin",
"createdAt": "2025-10-20 14:30:12"
}
]
}
伪代码示例:
@GetMapping("/list")
public Result> listUploadTasks() {
// 1. 查询所有上传任务
// 2. 按创建时间或状态排序
// 3. 返回任务摘要信息(任务名、状态、进度、上传人等)
}
接口调用顺序小结
那我们这整个上传过程的调用顺序就是:
1. /upload/check → 秒传检测
2. /upload/init → 初始化上传任务
3. /upload/chunk → 循环上传所有分片
4. /upload/merge → 所有分片完成后合并
(可选)/upload/pause、/upload/cancel 用于控制任务
(可选)/upload/list 用于任务追踪与审计
接口调用顺序示意图
下面这张时序图展示了前端、后端、数据库在整个上传过程中的交互关系。

这样安排有几个好处:
- 逻辑衔接顺:上面刚讲完每个接口的职责,下面立刻用图总结;
- 视觉节奏平衡:读者读到这里已经看了不少文字,用图能缓解阅读疲劳;
- 承上启下:这张图既总结接口流程,又能自然引出下一节“数据库表设计”。
这套接口设计基本能覆盖大文件上传在企业项目中的常见需求。
接下来,我们再来看看支撑这套接口背后的数据库表设计。
数据库的作用是让上传任务的状态可追踪、可恢复,也能在集群部署时保持一致性。
数据库表设计思路
前面说的那一套接口,要真正稳定地跑起来,
后端必须有一套能记录任务状态、分片信息、文件存储路径的数据库结构。
因为上传这种场景不是“一次请求就结束”的操作,它往往会持续几分钟甚至几个小时,
所以我们需要让任务状态可以追踪、可以恢复,还要能支撑集群部署。
我这次主要设计了三张核心表:upload_task(上传任务表)、upload_chunk(分片表)、file_info(文件信息表)。
它们分别负责记录任务、分片和最终文件三层的数据关系。
一、upload_task —— 上传任务表
这张表是整个上传过程的“总账”,
每一个文件上传任务,不管分成多少片,都会在这里生成一条记录。
它主要用来保存任务的全局信息,比如文件名、大小、上传进度、状态、存储方式等。
CREATE TABLE `upload_task` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`upload_id` varchar(64) NOT NULL COMMENT '任务唯一ID(UUID)',
`file_hash` varchar(64) NOT NULL COMMENT '文件哈希(用于秒传与断点续传)',
`file_name` varchar(255) NOT NULL COMMENT '文件名称',
`file_size` bigint(20) NOT NULL COMMENT '文件总大小(字节)',
`chunk_size` bigint(20) NOT NULL COMMENT '每个分片大小(字节)',
`total_chunks` int(11) NOT NULL COMMENT '分片总数',
`uploaded_chunks` int(11) DEFAULT '0' COMMENT '已上传分片数量',
`status` tinyint(4) DEFAULT '0' COMMENT '任务状态:0-待上传 1-上传中 2-合并中 3-完成 4-取消 5-失败 6-已合并 7-已暂停',
`storage_type` varchar(32) DEFAULT 'local' COMMENT '存储类型:local/oss/cos/minio/s3等',
`storage_url` varchar(512) DEFAULT NULL COMMENT '文件最终存储地址(云端或本地路径)',
`local_path` varchar(512) DEFAULT NULL COMMENT '本地临时文件或合并文件路径',
`remark` varchar(255) DEFAULT NULL COMMENT '备注信息',
`uploader` varchar(64) DEFAULT NULL COMMENT '上传人',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `upload_id` (`upload_id`),
KEY `idx_hash` (`file_hash`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='上传任务表(支持多种云存储)';
设计要点:
upload_id是前端初始化任务后由后端生成的唯一标识;file_hash用来支持秒传逻辑;status控制任务生命周期(等待、上传中、合并中、完成等);storage_type、storage_url可以兼容多种存储方案(本地、OSS、COS、MinIO);uploaded_chunks字段让任务能随时恢复,适配断点续传。
二、upload_chunk —— 分片表
这张表对应每个上传任务下的所有分片。
每一个分片都会单独在这里占一条记录,用来追踪它的上传状态。
这张表的存在让我们能做断点续传、进度统计、以及合并前的完整性检查。
CREATE TABLE `upload_chunk` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`upload_id` varchar(64) NOT NULL COMMENT '所属上传任务ID',
`chunk_index` int(11) NOT NULL COMMENT '分片索引(从0开始)',
`chunk_size` bigint(20) NOT NULL COMMENT '实际分片大小(字节)',
`chunk_hash` varchar(64) DEFAULT NULL COMMENT '可选:分片hash(用于高级去重)',
`status` tinyint(4) DEFAULT '0' COMMENT '状态:0-待上传 1-已上传 2-已合并',
`local_path` varchar(512) DEFAULT NULL COMMENT '分片本地路径',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_task_chunk` (`upload_id`,`chunk_index`),
KEY `idx_upload_id` (`upload_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='上传分片表';
设计要点:
upload_id是任务外键,和upload_task一一对应;chunk_index代表分片顺序,合并文件时会按这个排序;chunk_hash可选字段,用来在上传前后做完整性校验;status字段控制上传进度(待上传、已上传、已合并);- 唯一索引 (
upload_id,chunk_index) 避免重复插入分片。
通过这张表,我们可以轻松实现断点续传:
当用户重新开始上传时,后端只返回未完成的分片索引,前端跳过已上传的部分。
三、file_info —— 文件信息表
这张表记录的是上传完成后的“最终文件信息”,
相当于系统的文件索引表。只要文件合并成功并通过校验,
后端就会往这里写入一条记录。
这张表支撑秒传功能,也能被后续的文档解析或向量化任务使用。
CREATE TABLE `file_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`file_hash` varchar(64) NOT NULL COMMENT '文件hash,用于秒传',
`file_name` varchar(255) NOT NULL COMMENT '文件名称',
`file_size` bigint(20) NOT NULL COMMENT '文件大小',
`storage_type` varchar(32) DEFAULT 'local' COMMENT '存储类型:local/oss/cos/minio/s3等',
`storage_url` varchar(512) DEFAULT NULL COMMENT '文件最终存储地址(云端或本地路径)',
`uploader` varchar(64) DEFAULT NULL COMMENT '上传人',
`status` tinyint(4) DEFAULT '1' COMMENT '状态:1-正常,2-删除中,3-已归档',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `file_hash` (`file_hash`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='已上传文件信息表(支持多云存储)';
设计要点:
file_hash是全局唯一标识,用于秒传和查重;storage_url记录最终可访问路径;status可扩展为删除、归档等后续操作;- 这张表和业务系统中的“文档解析”、“知识库构建”可以直接关联。
四、三张表之间的关系
这三张表之间的关系我们可以简单理解为:
upload_task (上传任务)
├── upload_chunk (分片详情)
└── file_info (最终文件)
upload_task管理任务生命周期;upload_chunk跟踪每个分片的上传进度;file_info保存最终文件索引,用于秒传与后续 AI 处理。
这样设计的好处是:
- 上传状态可追踪;
- 上传任务可恢复;
- 文件信息可统一管理;
- 多节点部署也能保证一致性。
上传状态流转与任务恢复机制
有了前面的三张核心表,整个上传的过程就能被“状态机化”管理。
简单来说,我们希望每一个上传任务从创建、上传、合并到完成,都能有一个明确的状态,
系统也能在任意阶段中断后恢复,不需要用户重新来一遍。
我们把整个上传任务的生命周期划分成几个关键状态:
WAITING(0, "待上传"),
UPLOADING(1, "上传中"),
MERGING(2, "合并中"),
COMPLETED(3, "已完成"),
CANCELED(4, "已取消"),
FAILED(5, "上传失败"),
CHUNK_MERGED(6, "已合并"),
PAUSED(7, "已暂停");
一、WAITING(待上传)
当用户在前端发起上传、文件切片还没真正传上来之前,
系统会先生成一个上传任务记录(也就是 /upload/init 接口那一步)。
这个时候任务只是“登记”在数据库里,还没开始传数据。
我们可以理解为:
任务刚创建,还没开始跑。
此时前端拿到 uploadId,就可以开始逐片上传了。
在数据库层面,upload_task.status = 0,所有的分片表里还没有数据。
二、UPLOADING(上传中)
当第一个分片开始上传时,系统会把任务状态更新为 上传中。
这时候每上传一块分片,都会往 upload_chunk 表里写入一条记录,
并且更新任务的 uploaded_chunks 字段。
我们会周期性地根据分片上传数量去更新进度条,
比如已上传 35 / 100 块,系统就知道这部分可以恢复。
这个阶段是任务生命周期里最活跃的一段:
用户可能暂停、断网、刷新页面、甚至浏览器崩溃。
但是没关系,因为分片信息都落地到数据库了,
我们能随时通过 upload_chunk 的状态重新恢复上传。
三、PAUSED(已暂停)
如果用户主动点击“暂停上传”,
系统就会把任务状态标记为 PAUSED。
暂停并不会删除分片,只是告诉系统“不要再继续发请求”。
这样当用户重新点击“继续上传”时,
前端只需从后端拿到“哪些分片还没上传”,就能断点续传。
这个状态一般只在用户控制的情况下出现,
比如网络不好、或者中途切换网络时暂停。
四、CANCELED(已取消)
取消和暂停不同,取消意味着用户彻底放弃了这个上传任务。
任务会被标记为 CANCELED,同时系统可以选择:
- 删除已经上传的临时分片文件;
- 或者保留一段时间等待清理任务。
在后台日志中,这个状态主要用于审计:
记录谁取消了任务、在什么时间、上传了多少进度。
五、MERGING(合并中)
当所有分片都上传完成后,
后端会自动或手动触发文件合并逻辑(调用 /upload/merge)。
此时任务状态会切换为 MERGING,表示系统正在进行最后一步。
在这一步里:
- 如果是本地存储,会逐个读取分片文件并拼接为完整文件;
- 如果是云存储(比如 OSS、MinIO),则会触发服务端的分片合并 API。
合并过程通常比较耗时,尤其是几 GB 的文件,
所以单独拿出来作为一个明确状态是必要的。
六、CHUNK_MERGED(已合并)
有些系统会把合并成功但未做后续处理的状态单独标出来,
比如文件已经合并,但还没入库、还没解析。
这个状态可以让我们在合并之后还有机会做文件校验或后处理。
不过在实际项目里,也可以直接跳过这一步,
合并完后立刻进入下一状态——COMPLETED。
七、COMPLETED(已完成)
文件合并完成、验证通过、存储路径落地、写入 file_info 表,
这时候任务就算彻底完成了。
在这个状态下:
- 用户可以正常访问文件;
- 系统可以执行后续的解析任务(比如文档拆页、向量化等);
- 文件具备秒传条件,下次再上传同样的文件会直接跳过。
COMPLETED 是整个生命周期的终点状态。
在数据库中,任务记录会更新最终路径、存储类型、完成时间等字段。
八、FAILED(上传失败)
上传过程中如果出现异常,比如网络中断、磁盘写入异常、OSS 上传失败等,
系统会标记任务为 FAILED。
这一状态不会自动清理,
方便管理员事后追踪错误原因或人工恢复。
失败任务在设计上一般允许“重新启动”,
也就是通过任务 ID 重新触发上传,从未完成的分片继续。
我们可以通过下面这张图可以更直观地看到整个上传任务的生命周期:

九、任务恢复机制
在这套机制下,任务恢复就变得非常自然。
前端每次进入上传页面时,只要传入文件的 hash,
后端就能通过 upload_task 和 upload_chunk 判断:
- 这个文件有没有上传任务;
- 如果有,哪些分片已经上传;
- 任务当前状态是什么(暂停、失败还是上传中)。
然后前端只需补传那些未上传的分片即可。
这就是我们常说的 断点续传(Resumable Upload) 。
在集群环境中,这套逻辑同样成立,
因为任务与分片状态都落在数据库,不依赖单台服务器。
无论请求打到哪一台机器,上传进度都是统一可见的。
十、中断后如何续传
在实际使用中,用户上传中断是很常见的。
比如文件太大上传到一半,浏览器突然关了;
或者公司网络断了,机器重启了;
甚至有人直接换了电脑继续操作。
如果系统没有任务恢复机制,那用户每次都得重新传一遍,
尤其是那种几个 G 的文件,不但浪费时间,还容易出错。
所以我们在设计这套上传中心时,
一开始就考虑了“断点续传”和“任务恢复”的问题。
1. 恢复上传靠的其实是数据库里的状态
断点续传的核心逻辑,其实很简单:
我们让任务和分片的状态都写进数据库。
每当用户重新进入上传页面、选中同一个文件时,
前端会先计算出文件的 hash,然后调用 /upload/check 接口。
后端收到 hash 后,会依次去查三张表:
- 先查
file_info
如果能查到,说明文件之前已经上传并合并成功,
这时候直接返回“文件已存在”,前端就能实现“秒传”,不需要重新上传。 - 查不到
file_info,就去查upload_task
如果找到了对应任务,就说明这个文件上传到一半被中断了。
这时我们会返回这个任务的 uploadId。 - 再查 `upload_chunk``
系统会统计出哪些分片已经上传成功,哪些还没传。
然后返回一个“未完成的分片索引列表”给前端。
前端拿到这些信息后,就能从中断的地方继续往下传,
不用再重复上传已经完成的部分。
2. 前端续传时的流程
前端拿到旧的 uploadId 和未完成分片列表后,
只需要跳过那些已经上传成功的分片,
然后照常调用 /upload/chunk 去上传剩下的部分。
上传过程中,每个分片的状态都会被实时更新到 upload_chunk 表中,upload_task 表的 uploaded_chunks 也会跟着同步增加。
当所有分片都上传完后,任务状态自动进入 MERGING(合并中)阶段。
所以整个续传过程,其实就是**“基于数据库状态的增量上传”**。
用户不需要额外操作,系统自己就能恢复上次的进度。
3. 任务状态和恢复判断
任务是否允许恢复,系统会根据 upload_task.status 来判断。
大致逻辑是这样的:
| 状态 | 是否可恢复 | 说明 |
|---|---|---|
| WAITING | 可以 | 任务刚创建,还没开始传 |
| UPLOADING | 可以 | 正在上传中,可以继续 |
| PAUSED | 可以 | 用户主动暂停,可以恢复 |
| FAILED | 可以 | 上传失败,可以重新尝试 |
| CANCELED | 不可以 | 用户主动取消,不再恢复 |
| COMPLETED | 不需要 | 已经完成,直接秒传 |
| MERGING | 等待中 | 系统正在合并,前端等待即可 |
这套判断逻辑让任务的行为更清晰。
比如用户暂停上传再回来时,可以直接恢复;
如果任务已经取消,那就算用户重启也不会再自动续传。
4. 多机器部署下的恢复问题
有些人会担心:如果我们的系统是集群部署的,
上传时中断后再续传,万一请求打到另一台机器上,
还能恢复吗?
其实没问题。
因为我们所有任务和分片的状态都是写进数据库的,
不依赖内存或本地文件。
也就是说,哪怕用户上次上传在 A 机器,这次续传到了 B 机器,
系统仍然能根据数据库的记录知道:
这个 uploadId 下的哪些分片已经上传完,哪些还没传。
所以集群部署下也能无缝续传,不会出现“不同机器不认任务”的情况。
5. 小结
整个任务恢复机制靠的就是两张表:upload_task 和 upload_chunk。upload_task 负责记录任务总体进度,upload_chunk 负责记录每个分片的上传状态。
当用户重新上传时,我们查表判断进度,
前端从未完成的地方继续传,就能实现真正意义上的“断点续传”。
这套机制有几个显著的好处:
- 上传进度可追踪;
- 中断后可恢复;
- 支持集群部署;
- 不依赖浏览器缓存或 Session。
所以,只要数据库没丢,任务记录还在,
上传进度就能恢复,哪怕换机器、重启系统都没问题。
文件合并与完整性校验
前面的所有步骤,其实都是在为这一刻做准备。
当用户的所有分片都上传完成后,接下来最重要的工作就是:
把这些分片拼成一个完整的文件,并且确保文件内容没有出错。
这一步看似简单,但其实是整个大文件上传流程里最容易出问题的地方。
尤其在集群部署下,如果不同分片分布在不同机器上,
那合并逻辑就不能只靠本地文件路径去拼接,否则根本找不到所有分片。
所以我们先来理一理整个思路。
一、合并的触发时机
前端在检测到所有分片都上传完成后,会调用 /upload/merge 接口。
这个接口的作用就是通知后端:
“这个任务的所有分片都传完了,现在可以开始合并了。”
后端接收到请求后,会先去查数据库确认几个关键信息:
- 这个任务对应的 uploadId 是否存在;
upload_chunk表里所有分片是否都处于 “已上传” 状态;- 当前任务状态是否允许合并(例如不是暂停、取消或失败)。
确认无误后,任务状态会从 UPLOADING 变成 MERGING,
正式进入文件合并阶段。
二、本地合并逻辑
如果系统配置的是本地存储(也就是 cloud.enable = false),
那所有分片文件都保存在服务器的临时目录中。
合并逻辑大致是这样的:
- 后端按分片的
chunk_index顺序,依次读取每个分片文件。 - 逐个写入到一个新的目标文件中,比如
merge.zip。 - 每合并一个分片,就更新数据库中的状态。
- 合并完成后,把任务状态更新为
COMPLETED,并写入最终路径。
整个过程看起来很直观,
但这里有两个要点需要特别注意:
- 写入顺序要严格按照分片索引,否则文件内容会错乱;
- 文件 IO 要用流式写入(Stream) ,避免内存一次性读取所有分片导致溢出。
合并完成后,我们会计算整个文件的 MD5,与原始 fileHash 对比,
如果不一致,就说明合并过程中数据丢失或出错。
这种情况任务会被标记为 FAILED,并在日志中留下异常记录。
三、云端合并逻辑
如果我们配置了云存储(比如 OSS、COS、MinIO 等),
那分片文件就不是存在本地磁盘,而是上传到云端的对象存储桶里。
在这种情况下,合并逻辑就不需要我们自己拼文件了,
因为大部分云存储服务都提供了“分片合并”的 API。
比如以 OSS 为例,上传时我们调用的是 uploadPart 接口,
合并时只需要调用 completeMultipartUpload,
它会根据上传时的分片顺序自动合并为一个完整对象。
整个过程的优点是:
- 不占用本地磁盘;
- 不受单机 IO 限制;
- 云端自动校验每个分片的完整性。
所以在云存储场景下,我们只需要做两件事:
- 通知云服务去执行合并;
- 成功后记录最终的文件地址(
storage_url)到数据库。
这样整个流程就闭环了。
四、集群部署下的合并问题
单机情况下,合并很简单,因为所有分片都在本地。
但如果系统是集群部署的,分片请求可能打到了不同机器,
这时候分片文件就会分散在多个节点上。
我们在设计时考虑了三种解决方案:
方案 1:共享存储(私有化部署下比较推荐)
最常见的做法是把所有机器的上传目录指向同一个共享路径,
比如通过 NFS、NAS、或对象存储挂载到 /data/uploads。
这样无论用户上传的分片打到哪台机器,
最终都会写入同一个物理目录。
当合并请求发起时,任意一台机器都能访问到完整的分片文件。
这是目前在企业部署中最稳定、最通用的方案。
方案 2:云存储中转
如果机器之间没有共享目录,那我们可以让每个分片先上传到云端,
合并时再调用云服务的 API 进行分片合并。
这种方式适合公网可访问的 SaaS 环境。
但对于政企内网部署,就不一定行得通。
方案 3:统一调度节点
还有一种是我们自己维护一个“合并调度节点”,
所有分片上传完后,系统会把合并任务分配到一个指定节点执行,
这个节点会从其他机器拉取分片(比如通过 HTTP 内部传输或 RPC)。
这种方式更复杂,适合大规模分布式存储场景。
在私有化项目中,我们一般采用第一种方式——共享目录 + 本地合并。
既能保证性能,也能兼顾安全性。
五、完整性校验
文件合并完成后,最后一步是完整性校验。
我们会重新计算合并后文件的 MD5,与前端最初上传的 fileHash 对比。
如果一致,就说明文件合并成功,内容没有丢失;
如果不一致,就说明某个分片损坏或顺序错误,
任务会被标记为 FAILED,并自动记录错误日志。
这样可以确保文件数据的安全性,
避免在后续 AI 解析或向量化阶段出现内容异常。
六、异步处理与性能优化
开头的视频里我们也看到了,整个上传和合并过程我们是同步执行的。
从前端开始上传分片,到最后文件合并完成,都在等待同一个流程走完。
这种方式在演示时很直观,但在真实项目中其实问题不少。
最明显的一个问题就是——时间太长。
像我们刚才那个 1GB 的文件,即使网络稳定、服务器性能还可以,
整个流程也要几分钟甚至更久。
如果我们让前端一直等待响应,接口超时、连接断开、前端刷新这些问题就都会冒出来。
所以,在真正的业务系统里,我们一般会把合并、校验、迁移 OSS 或解析入库这些操作改成异步任务来做。
接口只负责接收分片、登记状态,然后立刻返回“任务已创建”或“上传完成,正在处理中”的提示。
后续的合并、校验、清理临时文件这些工作交给后台的异步线程、任务队列或者调度器去跑。
这样做的好处有几个:
- 前端体验更流畅,不用卡在“等待合并”阶段;
- 后端可以批量处理任务,减少高峰期的 IO 压力;
- 如果任务失败或中断,也能通过任务表重试或补偿;
- 对接外部存储或 AI 解析流程时,也能自然衔接后续任务链。
简单来说,上传只是第一步,
而合并、校验、转存这些操作本质上更像是后台任务。
我们在系统设计时只要把这些环节分开,让接口尽量“轻”,
这套上传系统就能在面对更大文件、更复杂场景时依然稳定可靠。
七、小结
整个合并与校验阶段,是把前面所有分片上传工作“收尾”的过程。
我们通过以下机制保证了稳定性:
- 本地存储场景下:顺序读取 + 流式写入 + hash 校验;
- 云存储场景下:依赖云端分片合并 API;
- 集群环境下:通过共享存储或统一调度节点解决文件分散问题;
- 数据库层面:实时记录状态,便于追踪和审计。
最终,当文件合并成功、校验通过后,
系统会将结果写入 file_info 表,
整条上传链路就算是完整闭环。
最后
我们平常做的项目,大多数时候文件上传都挺简单的。
前端传到 OSS,后端接个地址存起来就行。
但等真正做私有化项目的时候,也就会发现很多地方都不一样了。
要求更多,考虑的细节也多得多。
像这次做的大文件上传就是个很典型的例子。
以前那种简单方案,放在这种环境下就完全不够用了。
得考虑断点续传、任务恢复、集群部署、权限、审计这些东西,
一步没想好,后面全是坑。
我们现在这套设计,其实就是在解决这些“现实问题”。
接口虽然多一点,但每个职责都很清晰,
任务状态能追踪,上传中断能恢复,
甚至以后如果我们想单独抽出来做一个文件系统模块也完全没问题。
不管是拿来给知识库用,还是 AI 向量化、文档解析,这套逻辑都能复用。
其实很多以前觉得“简单”的功能,
一旦遇到复杂场景,其实都得重新想。
但好处是,一旦做通了,这套东西就能稳定用很久。
到这里,大文件上传这块我们算是完整走了一遍。
以后再遇到类似需求,我们就有经验了,
不用再从头掉坑里爬出来一次哈。
更多架构实战、工程化经验和踩坑复盘,我会在公众号 「洛卡卡了」 持续更新。
如果内容对你有帮助,欢迎关注我,我们一起每天学一点,一起进步。
来源:juejin.cn/post/7571355989133099023
从 8 个实战场景深度拆解:为什么资深前端都爱柯里化?
你一定见过无数臃肿的 if-else 和重复嵌套的逻辑。在追求 AI-Native 开发的今天,代码的“原子化”程度直接决定了 AI 辅助重构的效率。
柯里化(Currying) 绝不仅仅是面试时的八股文,它是实现逻辑复用、配置解耦的工业级利器。通俗地说,它把一个多参数函数拆解成一系列单参数函数:。
以下是 8 个直击前端实战痛点的柯里化应用案例。
1. 差异化日志系统:环境与等级的解耦
在web系统中,我们经常需要根据不同环境输出不同等级的日志。
JavaScript
const logger = (env) => (level) => (msg) => {
console.log(`[${env.toUpperCase()}][${level}] ${msg} - ${new Date().toLocaleTimeString()}`);
};
const prodError = logger('prod')('ERROR');
const devDebug = logger('dev')('DEBUG');
prodError('支付接口超时'); // [PROD][ERROR] 支付接口超时 - 10:20:00
2. API 请求构造器:预设 BaseURL 与 Header
不用每次请求都传 Token 或域名,通过柯里化提前“锁死”配置。
JavaScript
const request = (baseUrl) => (headers) => (endpoint) => (params) => {
return fetch(`${baseUrl}${endpoint}?${new URLSearchParams(params)}`, { headers });
};
const apiWithAuth = request('https://api.finance.com')({ 'Authorization': 'Bearer xxx' });
const getUser = apiWithAuth('/user');
getUser({ id: '888' });
3. DOM 事件监听:优雅传递额外参数
在 Vue 或 React 模板中,我们常为了传参写出 () => handleClick(id)。柯里化可以保持模板整洁并提高性能。
JavaScript
const handleMenuClick = (menuId) => (event) => {
console.log(`点击了菜单: ${menuId}`, event.target);
};
// 模板中直接绑定:@click="handleMenuClick('settings')"
4. 复合校验逻辑:原子化验证规则
将复杂的表单校验拆解为可组合的原子。
JavaScript
const validate = (reg) => (tip) => (value) => {
return reg.test(value) ? { pass: true } : { pass: false, tip };
};
const isMobile = validate(/^1[3-9]\d{9}$/)('手机号格式错误');
const isEmail = validate(/^\w+@\w+.\w+$/)('邮箱格式错误');
console.log(isMobile('13800138000')); // { pass: true }
5. 金融汇率换算:固定基准率
在处理多币种对账时,柯里化能帮你固定变动较慢的参数。
JavaScript
const convertCurrency = (rate) => (amount) => (amount * rate).toFixed(2);
const usdToCny = convertCurrency(7.24);
const eurToCny = convertCurrency(7.85);
console.log(usdToCny(100)); // 724.00
6. 动态 CSS 类名生成器:样式逻辑解耦
配合 CSS Modules 或 Tailwind 时,通过柯里化快速生成带状态的类名。
JavaScript
const createCls = (prefix) => (state) => (baseCls) => {
return `${prefix}-${baseCls} ${state ? 'is-active' : ''}`;
};
const navCls = createCls('nav')(isActive);
const btnCls = navCls('button'); // "nav-button is-active"
7. 数据过滤管道:可组合的 Array 操作
在处理海量 AI Prompt 列表时,将过滤逻辑函数化,方便链式调用。
JavaScript
const filterBy = (key) => (value) => (item) => item[key].includes(value);
const filterByTag = filterBy('tag');
const prompts = [{ title: 'AI助手', tag: 'Finance' }, { title: '翻译机', tag: 'Tool' }];
const financePrompts = prompts.filter(filterByTag('Finance'));
8. AI Prompt 模板工厂:多层上下文注入
为你正在开发的 AI Prompt Manager 设计一个分层注入器:先注入角色,再注入上下文,最后注入用户输入。
JavaScript
const promptFactory = (role) => (context) => (input) => {
return `Role: ${role}\nContext: ${context}\nUser says: ${input}`;
};
const financialExpert = promptFactory('Senior Financial Analyst')('Analyzing 2026 Q1 Report');
const finalPrompt = financialExpert('请总结该季报风险点');
来源:juejin.cn/post/7610252910319960115
html翻页时钟 效果
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>Flip Clock</title>
<style>
body {
background: #111;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
font-family: 'Courier New', monospace;
color: white;
}
.clock {
display: flex;
gap: 20px;
}
.card-container {
width: 80px;
height: 120px;
position: relative;
perspective: 500px;
background: #2c292c;
border-radius: 8px;
box-shadow: 0 4px 12px rgba(0,0,0,0.5);
}
/* 中间分割线 */
.card-container::before {
content: "";
position: absolute;
left: 0;
top: 50%;
width: 100%;
height: 4px;
background: #120f12;
z-index: 10;
}
.card-item {
position: absolute;
width: 100%;
height: 50%;
left: 0;
overflow: hidden;
background: #2c292c;
color: white;
text-align: center;
font-size: 64px;
font-weight: bold;
backface-visibility: hidden;
transition: transform 0.4s ease-in-out;
}
/* 下层数字:初始对折(背面朝上) */
.card1 { /* 下层上半 */
top: 0;
line-height: 120px; /* 整体高度对齐 */
}
.card2 { /* 下层下半 */
top: 50%;
line-height: 0;
transform-origin: center top;
transform: rotateX(180deg);
z-index: 2;
}
/* 上层数字:当前显示 */
.card3 { /* 上层上半 */
top: 0;
line-height: 120px;
transform-origin: center bottom;
z-index: 3;
}
.card4 { /* 上层下半 */
top: 50%;
line-height: 0;
z-index: 1;
}
/* 翻页动画触发 */
.flip .card2 {
transform: rotateX(0deg);
}
.flip .card3 {
transform: rotateX(-180deg);
}
/* 冒号分隔符 */
.colon {
font-size: 64px;
display: flex;
align-items: center;
color: #aaa;
}
</style>
</head>
<body>
<div class="clock">
<div class="card-container flip" id="hour" data-number="00">
<div class="card1 card-item">00</div>
<div class="card2 card-item">00</div>
<div class="card3 card-item">00</div>
<div class="card4 card-item">00</div>
</div>
<div class="colon">:</div>
<div class="card-container flip" id="minute" data-number="00">
<div class="card1 card-item">00</div>
<div class="card2 card-item">00</div>
<div class="card3 card-item">00</div>
<div class="card4 card-item">00</div>
</div>
<div class="colon">:</div>
<div class="card-container flip" id="second" data-number="00">
<div class="card1 card-item">00</div>
<div class="card2 card-item">00</div>
<div class="card3 card-item">00</div>
<div class="card4 card-item">00</div>
</div>
</div>
<script>
function setHTML(dom, nextValue) {
const curValue = dom.dataset.number;
if (nextValue === curValue) return;
// 更新 DOM 结构:下层为新值,上层为旧值
dom.innerHTML = `
<div class="card1 card-item">${nextValue}</div>
<div class="card2 card-item">${nextValue}</div>
<div class="card3 card-item">${curValue}</div>
<div class="card4 card-item">${curValue}</div>
`;
// 触发重绘以重启动画
dom.classList.remove('flip');
void dom.offsetWidth; // 强制重排
dom.classList.add('flip');
dom.dataset.number = nextValue;
}
function updateClock() {
const now = new Date();
const h = String(now.getHours()).padStart(2, '0');
const m = String(now.getMinutes()).padStart(2, '0');
const s = String(now.getSeconds()).padStart(2, '0');
setHTML(document.getElementById('hour'), h);
setHTML(document.getElementById('minute'), m);
setHTML(document.getElementById('second'), s);
}
// 初始化
updateClock();
// setTimeout(updateClock,1000)
setInterval(updateClock, 1000);
</script>
</body>
</html>

这个翻页时钟(Flip Clock)通过 CSS 3D 变换 + 动画类切换 + DOM 内容动态更新 的方式,模拟了类似机械翻页牌的效果。下面从结构、样式和逻辑三方面详细分析其实现原理:
🔧 一、HTML 结构设计
每个时间单位(小时、分钟、秒)由一个 .card-container 容器表示,内部包含 4 个 .card-item 元素:
<div class="card-container" id="second">
<div class="card1">00</div> <!-- 下层上半 -->
<div class="card2">00</div> <!-- 下层下半(初始翻转180°)-->
<div class="card3">00</div> <!-- 上层上半(当前显示)-->
<div class="card4">00</div> <!-- 上层下半 -->
</div>
四个卡片的作用:
.card3和.card4:组成当前显示的数字(上半+下半),正常显示。.card1和.card2:组成即将翻出的新数字,但初始时.card2被rotateX(180deg)翻转到背面(不可见)。- 中间有一条
::before伪元素作为“折痕”,增强翻页视觉效果。
🎨 二、CSS 样式与 3D 翻转原理
关键 CSS 技术点:
1. 3D 空间设置
.card-container {
perspective: 500px; /* 创建 3D 视角 */
}
perspective让子元素的 3D 变换有景深感。
2. 上下两半的定位与旋转轴
.card2 {
transform-origin: center top;
transform: rotateX(180deg); /* 初始翻到背面 */
}
.card3 {
transform-origin: center bottom;
}
.card2绕顶部边缘旋转 180°,藏在下方背面。.card3绕底部边缘旋转,用于向上翻折。
3. 翻页动画(通过 .flip 类触发)
.flip .card2 {
transform: rotateX(0deg); /* 展开新数字下半部分 */
}
.flip .card3 {
transform: rotateX(-180deg); /* 当前数字上半部分向上翻折隐藏 */
}
- 动画持续
0.4s,使用ease-in-out缓动。 .card1和.card4始终保持静态,作为背景支撑。
✅ 视觉效果:
- 上半部分(
.card3)向上翻走(像书页翻开)
- 下半部分(
.card2)从背面转正,露出新数字
- 中间的“折痕”让翻页更真实
⚙️ 三、JavaScript 动态更新逻辑
核心函数:setHTML(dom, nextValue)
步骤分解:
- 对比新旧值:如果相同,不更新(避免无谓动画)。
- 重写整个容器的 HTML:
- 下层(新值):
.card1和.card2显示nextValue - 上层(旧值):
.card3和.card4显示curValue
- 下层(新值):
- 触发动画:
dom.classList.remove('flip');
void dom.offsetWidth; // 强制浏览器重排(关键!)
dom.classList.add('flip');
- 先移除
.flip,再强制重排(flush styles),再加回.flip,确保动画重新触发。
- 先移除
- 更新
data-number保存当前值。
时间更新:
- 每秒调用
updateClock(),获取当前时分秒(两位数格式)。 - 分别调用
setHTML更新三个容器。
🌟 四、为什么能实现“翻页”错觉?
| 元素 | 初始状态 | 翻页后状态 | 视觉作用 |
|---|---|---|---|
.card3 | 显示旧数字上半 | 向上翻转 180° 隐藏 | 模拟“翻走”的上半页 |
.card2 | 旧数字下半(翻转180°藏起) | 转正显示新数字下半 | 模拟“翻出”的下半页 |
.card1 / .card4 | 静态背景 | 不变 | 提供视觉连续性 |
💡 关键技巧:
- 利用 两个完整数字(新+旧)叠加,通过控制上下半部分的旋转,制造“翻页”而非“淡入淡出”。
- 强制重排(
offsetWidth) 是确保 CSS 动画每次都能重新触发的经典 hack。
✅ 总结
这个 Flip Clock 的精妙之处在于:
- 结构设计:4 个卡片分工明确,上下层分离。
- CSS 3D:利用
rotateX+transform-origin实现真实翻页。 - JS 控制:动态替换内容 + 巧妙触发动画。
- 性能优化:仅在值变化时更新,避免无效渲染。
这是一种典型的 “用 2D DOM 模拟 3D 物理效果” 的前端动画范例,既高效又视觉惊艳。
来源:juejin.cn/post/7606183276772999231
HTML5 自定义属性 data-*:别再把数据塞进 class 里了!
前言:由于“无处安放”而引发的混乱
在 HTML5 普及之前,前端开发者为了在 DOM 元素上绑定一些数据(比如用户 ID、商品价格、状态码),可谓是八仙过海,各显神通:
- 隐藏域流派:到处塞
<input type="hidden" value="123">,导致 HTML 结构像个堆满杂物的仓库。 - Class 拼接流派:
<div class="btn item-id-8848">,然后用正则去解析 class 字符串提取 ID。这简直是在用 CSS 类名当数据库用,类名听了都想离家出走。 - 自定义非标属性流派:直接写
<div my_id="123">。虽然浏览器大多能容忍,但这就好比在公共泳池里裸泳——虽然没人抓你,但不合规矩且看着尴尬。
直到 HTML5 引入了 data-* 自定义数据属性,这一切终于有了“官方标准”。
第一阶段:基础——它长什么样?
data-* 属性允许我们在标准 HTML 元素中存储额外的页面私有信息。
1. HTML 写法
语法非常简单:必须以 data- 开头,后面接上你自定义的名称。
<!-- ❌ 错误示范:不要大写,不要乱用特殊符号 -->
<div data-User-Id="1001"></div>
<!-- ✅ 正确示范:全小写,连字符连接 -->
<div
id="user-card"
data-id="1001"
data-user-name="juejin_expert"
data-value="99.9"
data-is-vip="true"
>
用户信息卡片
</div>
2. CSS 中的妙用
很多人以为 data-* 只是给 JS 用的,其实 CSS 也能完美利用它。
场景一:通过属性选择器控制样式
/* 当 data-is-vip 为 "true" 时,背景变金 */
div[data-is-vip="true"] {
background: gold;
border: 2px solid orange;
}
场景二:利用 attr() 显示数据
这是一个非常酷的技巧,可以用来做 Tooltip 或者计数器显示。
div::after {
/* 直接把 data-value 的值显示在页面上 */
content: "当前分值: " attr(data-value);
font-size: 12px;
color: #666;
}
第二阶段:进阶——JavaScript 如何读写?
这才是重头戏。在 JS 中操作 data-* 有两种方式:传统派 和 现代派。
1. 传统派:getAttribute / setAttribute
这是最稳妥的方法,兼容性最好(虽然现在也没人要兼容 IE6 了)。
const el = document.getElementById('user-card');
// 读取
const userId = el.getAttribute('data-id'); // "1001"
// 修改
el.setAttribute('data-value', '100');
特点:读出来永远是字符串。哪怕你存的是 100,取出来也是 "100"。
2. 现代派:dataset API (推荐 ✨)
HTML5 为每个元素提供了一个 dataset 对象(DOMStringMap),它将所有的 data-* 属性映射成了对象的属性。
这里有个大坑(或者说是规范),请务必注意:
HTML 中的 连字符命名 (kebab-case) 会自动转换为 JS 中的 小驼峰命名 (camelCase) 。
const el = document.getElementById('user-card');
// 1. 访问 data-id
console.log(el.dataset.id); // "1001"
// 2. 访问 data-user-name (注意变身了!)
console.log(el.dataset.userName); // "juejin_expert"
// ❌ el.dataset.user-name 是语法错误
// ❌ el.dataset['user-name'] 是 undefined
// 3. 修改数据
el.dataset.value = "200";
// HTML 会自动变成 data-value="200"
// 4. 删除数据
delete el.dataset.isVip;
// HTML 中的 data-is-vip 属性会被移除
💡 敲黑板:dataset 里的属性名不支持大写字母。如果你在 HTML 里写 data-MyValue="1", 浏览器会强制转为小写 data-myvalue,JS 里就得用 dataset.myvalue 访问。所以,HTML 里老老实实全小写吧。
第三阶段:深入——类型陷阱与性能权衡
1. 一切皆字符串
不管你赋给 dataset 什么类型的值,最终都会被转为字符串。
el.dataset.count = 100; // HTML: data-count="100"
el.dataset.active = true; // HTML: data-active="true"
el.dataset.config = {a: 1}; // HTML: data-config="[object Object]" -> 灾难!
避坑指南:
- 如果你要存数字,取出来时记得 Number(el.dataset.count)。
- 如果你要存布尔值,判断时不能简单用 if (el.dataset.active),因为 "false" 字符串也是真值!要用 el.dataset.active === 'true'。
- 千万不要试图在 data-* 里存复杂的 JSON 对象。如果非要存,请使用 JSON.stringify(),但在 DOM 上挂载大量字符串数据会影响性能。
2. 性能考量
- 读写速度:dataset 的访问速度在现代浏览器中非常快,但在极高频操作下(比如每秒几千次),直接操作 JS 变量肯定比操作 DOM 快。
- 重排与重绘:修改 data-* 属性会触发 DOM 变更。如果你的 CSS 依赖属性选择器(如 div[data-status="active"]),修改属性可能会触发页面的重排(Reflow)或重绘(Repaint)。
第四阶段:实战——优雅的事件委托
data-value 最经典的用法之一就是在列表项的事件委托中。
需求:点击列表中的“删除”按钮,删除对应项。
<ul id="todo-list">
<li>
<span>学习 HTML5</span>
<!-- 把 ID 藏在这里 -->
<button class="btn-delete" data-id="101" data-action="delete">删除</button>
</li>
<li>
<span>写掘金文章</span>
<button class="btn-delete" data-id="102" data-action="delete">删除</button>
</li>
</ul>
const list = document.getElementById('todo-list');
list.addEventListener('click', (e) => {
// 利用 dataset 判断点击的是不是删除按钮
const { action, id } = e.target.dataset;
if (action === 'delete') {
console.log(`准备删除 ID 为 ${id} 的条目`);
// 这里发送请求或操作 DOM
// deleteItem(id);
}
});
为什么这么做优雅?
你不需要给每个按钮都绑定事件,也不需要去分析 DOM 结构(比如 e.target.parentNode...)来找数据。数据就在元素身上,唾手可得。
总结与“禁忌”
HTML5 的 data-* 属性是连接 DOM 和数据的一座轻量级桥梁。
什么时候用?
- 当需要把少量数据绑定到特定 UI 元素上时。
- 当 CSS 需要根据数据状态改变样式时。
- 做事件委托需要传递参数时。
什么时候别用?(禁忌)
- 不要存储敏感数据:用户可以直接在浏览器控制台修改 DOM,千万别把 data-password 或 data-user-token 放在这。
- 不要当数据库用:别把几 KB 的 JSON 数据塞进去,那是 JS 变量或者是 IndexDB 该干的事。
- SEO 无用:搜索引擎爬虫通常不关心 data-* 里的内容,重要的文本内容还是要写在标签里。
最后一句:
代码整洁之道,始于不再乱用 Class。下次再想存个 ID,记得想起那个以 data- 开头的帅气属性。
Happy Coding! 🚀
来源:juejin.cn/post/7575119254314401818
一文搞懂 SEO 全流程技术
在现代 Web 开发中,技术 SEO 是确保网站能够被搜索引擎正确索引和排名的关键。
不做 SEO:
网站处于隐形状态:除非用户直接输入网站,否则没人能通过搜索找到你的网站收录混乱:搜索引擎不收录你的页面,或是收录的无效页面仅能靠付费推广:想要流量只能付费做广告或者社交媒体推广裸链接:用户分享网址时只能是蓝色 URL 链接,可能被识别为垃圾信息品牌信任度:用户难以搜索到网站,降低网站的可信度
做了 SEO:
主动被发现:搜索关键词时你的网站会得到推荐,增加流量收录全面:搜索引擎知道网站有哪些页面,网站内容更新后会很快被搜索到免费且持久:搜索引擎会长期维护你的网站,排名稳定后,会有源源不断的流量优雅的展示封面:分享会展示精美的网站封面,提升用户点击率技术红利:做了 SEO,会优化内容结构,变相提升网站的技术背书效应:用户潜意识里认为排在前面的网站更权威、更正规
SEO 这么有用,但一般人的实现却是:
- 加个
<title>标签 - 加几个
<meta>关键词
真正有用、高效的 SEO 要怎么做呢?
SEO 核心概念
先来了解一下 SEO 的一些核心概念。

sitemap.xml 是什么?
- 作用:给搜索引擎指路
- 功能:
- 列出你希望被收录的所有页面
- 告诉页面更新时间、优先级
- 示例
<url>
<loc>https://xxx.com/page1</loc>
<lastmod>2026-02-12</lastmod>
<priority>0.8</priority>
</url>
robots.txt 是什么?
- 作用:给搜索引擎定规矩
- 功能:
- 禁止某些爬虫
- 禁止爬某些目录 / 页面
- 告诉爬虫去哪里找 sitemap
- 示例
User-agent: *
Disallow: /admin/
Disallow: /private.html
Allow: /
Sitemap: https://xxx.com/sitemap.xml

Schema.org 是什么?
- 作用
给 Google、百度、必应 等搜索引擎看的,告诉它们:
- 这是什么内容(文章?产品?视频?人?)
- 标题是什么
- 发布时间
- 作者
- 评分
- 目录结构
- 功能
- 让搜索结果更美观、更丰富(显示标题、图、时间、作者)
- 让搜索引擎更懂你页面内容
- 提升 SEO 效果
- 示例
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "文章标题",
"author": { "@type": "Person", "name": "作者" }
}
</script>
OG Image 是什么?
当你把网页分享到微信、QQ、抖音、小红书、Discord、Facebook时,显示的那张封面图,就是 OG Image。
- 作用
- 控制分享出去长什么样
- 没有它,分享可能没封面图、显示效果差
- 功能
- 优化分享效果
- 提升社交媒体分享的点击率和用户互动
- 示例
<meta property="og:title" content="标题" />
<meta property="og:description" content="描述" />
<meta property="og:image" content="https://xxx.com/cover.jpg" />

Nuxt SEO
Nuxt SEO 是一套 SEO 元模块,其中包含多个模块:
- @nuxtjs/sitemap: 智能生成站点地图
- @nuxtjs/robots: 管理爬虫访问规则
- nuxt-og-image: 动态生成社交分享图片
- nuxt-schema-org: 注入结构化数据 (JSON-LD)
- nuxt-seo-utils: 提供通用的 SEO 工具函数
核心优势:
- 自动化:自动生成
robots.txt、sitemap.xml和og:image。 - 最佳实践:默认遵循
Google等搜索引擎的推荐标准。 - 开发体验:与
Nuxt DevTools深度集成,提供实时的 SEO 调试能力。
快速开始
了解完以上概念后,接下来开始提升网站的 SEO 效果。
安装
pnpm i @nuxtjs/seo
配置
在 nuxt.config.ts 中进行配置。最重要的是设置 site.url,它是生成 Sitemap 和 Canonical URL 的基础。
export default defineNuxtConfig({
modules: ["@nuxtjs/seo"],
site: {
url: "https://example.com", // 网站域名
name: "我的 Nuxt 应用",
description: "一个高性能的 Nuxt 网站",
defaultLocale: "zh-CN", // 设置默认语言
},
})
开发调试
安装了 @nuxtjs/seo 后,启动项目打开 Nuxt DevTools,你会发现一个新的 SEO 选项卡:
- 实时检查:查看当前页面的 Meta 标签、OG 图片预览和 Schema 数据。
- 缺失提示:如果页面缺少关键的 SEO 信息(如 Title 或 Description),DevTools 会给出警告。
进阶配置
虽然 @nuxtjs/seo 已经提供了开箱即用的配置,但在实际生产环境中,我们往往需要更精细的控制。
@nuxtjs/sitemap
sitemap.xml 是搜索引擎发现你网站页面的地图。@nuxtjs/sitemap 模块会自动扫描你的静态路由,但对于动态内容(如博客文章、商品详情),我们需要手动告知它。
常用配置
// nuxt.config.ts
export default defineNuxtConfig({
sitemap: {
// 1. 动态路由数据源:支持 API 端点
sources: ["/api/__sitemap__/urls"],
// 2. 排除不需要被索引的页面
exclude: ["/user/**", "/admin/**", "/checkout"],
// 3. 开启分块 (Chunking):适用于大型网站 (> 50k URL)
sitemaps: true,
},
})
★
对于动态路由,你可以创建一个 Server API (例如
server/api/__sitemap__/urls.ts) 来返回所有的文章链接。
如何验证配置是否生效?
本地启动项目,访问:http://localhost:3000/sitemap.xml;线上环境访问:https://yoursite.com/sitemap.xml,当看到 xml 内容既配置成功。
@nuxtjs/robots
robots.txt 定义了爬虫可以访问哪些区域。@nuxtjs/robots 的一大优势是它能根据环境自动切换策略:开发环境默认禁止所有爬虫,生产环境默认允许。
// nuxt.config.ts
export default defineNuxtConfig({
robots: {
// 1. 全局爬虫规则(User-agent: * 对应 allRobots)
allRobots: {
// 禁止爬取的目录/页面(常用)
Disallow: [
"/admin/", // 后台管理页
"/api/", // 接口目录
"/_nuxt/", // Nuxt 打包后的静态资源(可选,一般无需禁止)
"/private/", // 私有页面
"/*.pdf$", // 禁止爬取所有 PDF 文件(正则写法)
],
// 允许爬取的内容(覆盖 Disallow,可选)
Allow: [
"/api/public/", // 允许爬取公开接口
],
// 爬虫抓取频率(可选,只是建议,非强制)
CrawlDelay: 2, // 每次请求间隔 2 秒,减轻服务器压力
},
// 添加自定义规则
groups: [
{
userAgent: ["Baiduspider"], // 针对百度爬虫的特殊规则
disallow: ["/api/"], // 禁止访问
allow: ["/api/public-data"], // 允许访问
},
{
userAgent: "*",
disallow: ["/secret", "/admin"],
allow: "/",
},
],
},
})
如何验证配置是否生效?
本地启动项目,访问:http://localhost:3000/robots.txt;线上环境访问:https://yoursite.com/robots.txt,会看到以下内容:
User-agent: *
Disallow: /admin/
Disallow: /api/
Disallow: /private/
Allow: /
Crawl-delay: 2
Sitemap: https://你的域名.com/sitemap.xml
User-agent: Baiduspider
Disallow: /archive/
nuxt-og-image
全局配置
// nuxt.config.ts
export default defineNuxtConfig({
modules: ["@nuxtjs/seo"],
// Nuxt SEO 模块核心配置
seo: {
// 基础站点信息(会自动复用为 OG 基础信息)
site: {
// ...
},
// OG 标签全局配置(重点:ogImage)
og: {
// 全局默认 OG 类型
type: "website",
// 全局默认 OG Image 配置(核心)
image: {
// 图片路径:推荐用绝对路径,或相对路径(模块会自动拼接 site.url)
src: "/og-default.jpg", // 等价于 https://你的域名.com/og-default.jpg
width: 1200, // 最优尺寸
height: 630,
type: "image/jpeg", // 图片格式
alt: "网站默认分享封面", // 图片描述(可选,提升可访问性)
},
// 全局默认语言
locale: "zh_CN",
},
// 兼容 Twitter 卡片(可选,自动复用 ogImage)
twitter: {
card: "summary_large_image", // 大图卡片样式
},
},
})
单页面配置
单页面配置的内容会覆盖全局配置。
在具体页面(如 pages/article/[id].vue)中,用 useOgImage 或 useSeoMeta 自定义该页面的 OG Image:
<template>
<div>详情页</div>
</template>
<script setup lang="ts">
// 1. 假设从接口获取文章数据
const article = await fetchArticleData() // 你的业务逻辑
const articleCover = article.coverImage || "/og-article-default.jpg"
// 2. 方式1:单独修改 OG Image(推荐,更精准)
useOgImage({
src: articleCover, // 自定义封面图路径
width: 1200,
height: 630,
alt: article.title, // 用文章标题作为图片描述
})
// 3. 方式2:批量修改 OG 信息(含 Image)
useSeoMeta({
ogTitle: article.title, // 文章标题
ogDescription: article.summary, // 文章摘要
ogImage: [
{
src: articleCover,
width: 1200,
height: 630,
},
],
twitterImage: articleCover, // 兼容 Twitter
})
</script>
动态路由批量配置
动态页面的配置可以结合sitemap来设置:
// nuxt.config.ts
export default defineNuxtConfig({
modules: ["@nuxtjs/seo"],
sitemap: {
// 动态生成路由 + 对应 OG Image
routes: async () => {
const articles = await fetchAllArticles() // 获取所有文章
return articles.map((article) => ({
url: `/article/${article.id}`,
// 给每个路由绑定 OG Image
seo: {
ogImage: {
src: article.coverImage,
width: 1200,
height: 630,
},
},
}))
},
},
})
如何验证配置是否生效?
启动项目,访问页面右键「页面源代码」,能看到 <meta property="og:image" content="你的图片URL"> 即配置成功。
SEO 进阶技巧与最佳实践
1. 喂饱搜索引擎
搜索引擎喜欢结构化数据。通过 Schema.org 标记,你可以让 Google 更精准地理解你的内容。
Nuxt SEO 提供了 useSchemaOrg 组合式函数,让你可以像写 Vue 组件一样编写 Schema:
<script setup lang="ts">
useSchemaOrg([
defineArticle({
image: '/images/cover.jpg',
datePublished: '2026-02-18',
author: {
name: 'Trae',
},
})
])
</script>
2. 社交分享优化
当用户将你的链接分享到 Twitter 或微信时,一张精美的预览图能显著提高点击率。
- Open Graph 标签:自动生成
og:title,og:description等标签。 - OG Image 生成:
nuxt-og-image模块可以根据你的页面内容(标题、摘要)动态生成 SVG 或 PNG 图片。这意味着你不需要为每篇文章手动通过 Photoshop 制作封面,代码即设计!
3. 链接与 URL 规范化
重复内容是 SEO 的大忌。Nuxt SEO 能帮你处理这些细节:
- Trailing Slashes:统一 URL 结尾是否带斜杠(例如
/aboutvs/about/),避免被视为两个页面。 - Canonical URLs:自动添加规范链接,告诉搜索引擎哪个是"正版"页面,防止参数(如
?utm_source=...)导致权重分散。
多搜索引擎适配策略
不同的搜索引擎有不同的脾气,针对国内外的搜索巨头,可以采取差异化的策略。

Google 优化
Google 的爬虫能力最强,能够很好地执行 JavaScript。
- Core Web Vitals:重点关注
LCP (最大内容绘制)、CLS (累积布局偏移)和INP (交互到下一次绘制)。Nuxt 默认的性能优化通常能满足要求。 - Google Search Console:在 GSC 中主动提交你的
sitemap.xml,并定期查看"覆盖率"报告,修复 404 和 500 错误。 - 富媒体搜索结果:利用上文提到的 Schema 标记,争取在搜索结果中展示星级评分、问答等富媒体信息。
百度优化
百度爬虫对现代 JavaScript 的执行能力相对较弱,且对页面加载速度极其敏感。
- 确保 SSR 输出:这是最关键的一点。确保你的 Nuxt 应用以 SSR 模式运行,并且 HTML 源码中直接包含核心内容。
- 验证方法:在终端运行
curl https://your-site.com,检查返回的 HTML 是否包含你的内容。
- 验证方法:在终端运行
- 主动推送:百度非常依赖主动提交。看在网站上线后,通过 API 立即将链接推送到百度站长平台。
- URL 结构:百度更喜欢扁平、简单的 URL 结构,避免过深的层级和复杂的动态参数。
- 移动端适配:百度对移动端友好的站点有明显的加权,做好响应式适配移动端是一个不错的选择。
必应优化
Bing 在搜索端的占比越来越高,且是 ChatGPT 搜索的数据源之一。
- IndexNow 协议:Bing 大力推广 IndexNow 协议,允许网站在一个 URL 发生变化时立即通知搜索引擎。这比传统的 Sitemap 被动抓取要快得多。
- Bing Webmaster Tools:功能与 GSC 类似,建议注册并提交 Sitemap。
总结
SEO 是一个长期积累的过程,但 Nuxt SEO 模块帮我们扫清了技术障碍。通过合理的配置和使用,并针对 Google、百度等不同平台进行针对性优化,可以确保你的 Nuxt 应用在起跑线上就领先一步。
🔗 项目地址: nuxtseo.com
👍作品推荐
Haotab 新标签页,一个优雅的新标签页
❤️静待你的体验
来源:juejin.cn/post/7609891142464159780
手把手写几种常用工具函数:深拷贝、去重、扁平化
同学们好,我是 Eugene(尤金),一个拥有多年中后台开发经验的前端工程师~
(Eugene 发音很简单,/juːˈdʒiːn/,大家怎么顺口怎么叫就好)
你是否也有过:明明学过很多技术,一到关键时候却讲不出来、甚至写不出来?
你是否也曾怀疑自己,是不是太笨了,明明感觉会,却总差一口气?
就算想沉下心从头梳理,可工作那么忙,回家还要陪伴家人。
一天只有24小时,时间永远不够用,常常感到力不从心。
技术行业,本就是逆水行舟,不进则退。
如果你也有同样的困扰,别慌。
从现在开始,跟着我一起心态归零,利用碎片时间,来一次彻彻底底的基础扫盲。
这一次,我们一起慢慢来,扎扎实实变强。
不搞花里胡哨的理论堆砌,只分享看得懂、用得上的前端干货,
咱们一起稳步积累,真正摆脱“面向搜索引擎写代码”的尴尬。
1. 开篇:有库可用,为什么还要自己写?
lodash、ramda 等库已经提供这些工具函数,但在面试、基础补强、和「读懂库源码」的场景里,手写一遍很有价值:
- 搞清概念:什么算「深拷贝」、什么算「去重」
- 踩一遍坑:循环引用、
NaN、Date、RegExp、Symbol等 - 形成习惯:知道什么时候用浅拷贝、什么时候必须深拷贝
下面按「深拷贝 → 去重 → 扁平化」的顺序,每种都给出可直接用的实现和说明。
2. 深拷贝
2.1 浅拷贝 vs 深拷贝,怎么选?
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 只改最外层、不改嵌套对象 | 浅拷贝({...obj}、Object.assign) | 实现简单、性能好 |
| 需要改嵌套对象且不想影响原数据 | 深拷贝 | 避免引用共享 |
对象里有 Date、RegExp、函数等 | 深拷贝时需特殊处理 | 否则会丢失类型或行为 |
一句话:只要会改到「嵌套对象/数组」,就考虑深拷贝。
2.2 常见坑
- 循环引用:
obj.a = obj,递归会栈溢出 - 特殊类型:
Date、RegExp、Map、Set、Symbol不能只靠遍历属性复制 - Symbol 做 key:
Object.keys不会包含,需用Reflect.ownKeys或Object.getOwnPropertySymbols
2.3 实现示例(含循环引用与特殊类型处理)
function deepClone(obj, cache = new WeakMap()) {
// 1. 基本类型、null、函数 直接返回
if (obj === null || typeof obj !== 'object') {
return obj;
}
// 2. 循环引用:用 WeakMap 缓存已拷贝对象
if (cache.has(obj)) {
return cache.get(obj);
}
// 3. 特殊对象类型
if (obj instanceof Date) return new Date(obj.getTime());
if (obj instanceof RegExp) return new RegExp(obj.source, obj.flags);
if (obj instanceof Map) {
const mapCopy = new Map();
cache.set(obj, mapCopy);
obj.forEach((v, k) => mapCopy.set(deepClone(k, cache), deepClone(v, cache)));
return mapCopy;
}
if (obj instanceof Set) {
const setCopy = new Set();
cache.set(obj, setCopy);
obj.forEach(v => setCopy.add(deepClone(v, cache)));
return setCopy;
}
// 4. 普通对象 / 数组
const clone = Array.isArray(obj) ? [] : {};
cache.set(obj, clone);
// 包含 Symbol 作为 key
const keys = [...Object.keys(obj), ...Object.getOwnPropertySymbols(obj)];
keys.forEach(key => {
clone[key] = deepClone(obj[key], cache);
});
return clone;
}
// 使用示例
const original = { a: 1, b: { c: 2 }, d: [3, 4] };
original.self = original; // 循环引用
const cloned = deepClone(original);
cloned.b.c = 999;
console.log(original.b.c); // 2,原对象未被修改
要点:WeakMap 解决循环引用,Date/RegExp/Map/Set 单独分支,Object.getOwnPropertySymbols 保证 Symbol key 不丢失。
3. 去重
3.1 场景与选型
| 场景 | 方法 | 说明 |
|---|---|---|
| 基本类型数组(数字、字符串) | Set | 写法简单、性能好 |
需要兼容 NaN | 自己写遍历逻辑 | NaN !== NaN,Set 能去重 NaN,但逻辑要显式写清楚 |
| 对象数组、按某字段去重 | Map 或 filter | 用唯一字段做 key |
3.2 几种实现
1)简单数组去重(含 NaN)
// 方式一:Set(ES6 最常用)
function uniqueBySet(arr) {
return [...new Set(arr)];
}
// 方式二:filter + indexOf(兼容性更好,但 NaN 会出问题)
function uniqueByFilter(arr) {
return arr.filter((item, index) => arr.indexOf(item) === index);
}
// 方式三:兼容 NaN 的版本
function unique(arr) {
const result = [];
const seenNaN = false; // 用 flag 标记是否已经加入过 NaN
for (const item of arr) {
if (item !== item) { // NaN !== NaN
if (!seenNaN) {
result.push(item);
seenNaN = true; // 这里需要闭包,下面用修正版
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
// 修正:用变量
function uniqueWithNaN(arr) {
const result = [];
let hasNaN = false;
for (const item of arr) {
if (Number.isNaN(item)) {
if (!hasNaN) {
result.push(NaN);
hasNaN = true;
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
注意:Set 本身对 NaN 是去重的(ES2015 规范),所以 [...new Set([1, NaN, 2, NaN])] 结果正确。需要兼容 NaN 的,多是旧环境或面试题场景。
2)对象数组按某字段去重
function uniqueByKey(arr, key) {
const seen = new Map();
return arr.filter(item => {
const k = item[key];
if (seen.has(k)) return false;
seen.set(k, true);
return true;
});
}
// 使用
const users = [
{ id: 1, name: '张三' },
{ id: 2, name: '李四' },
{ id: 1, name: '张三2' }
];
console.log(uniqueByKey(users, 'id'));
// [{ id: 1, name: '张三' }, { id: 2, name: '李四' }]
4. 扁平化
4.1 场景
- 把
[1, [2, [3, 4]]]变成[1, 2, 3, 4] - 有时候需要「只扁平一层」或「扁平到指定层数」
4.2 实现
1)递归全扁平
function flatten(arr) {
const result = [];
for (const item of arr) {
if (Array.isArray(item)) {
result.push(...flatten(item));
} else {
result.push(item);
}
}
return result;
}
console.log(flatten([1, [2, [3, 4], 5]])); // [1, 2, 3, 4, 5]
2)指定深度扁平(如 Array.prototype.flat)
function flattenDepth(arr, depth = 1) {
if (depth <= 0) return arr;
const result = [];
for (const item of arr) {
if (Array.isArray(item) && depth > 0) {
result.push(...flattenDepth(item, depth - 1));
} else {
result.push(item);
}
}
return result;
}
console.log(flattenDepth([1, [2, [3, 4]]], 1)); // [1, 2, [3, 4]]
console.log(flattenDepth([1, [2, [3, 4]]], 2)); // [1, 2, 3, 4]
3)用 reduce 递归写法(另一种常见写法)
function flattenByReduce(arr) {
return arr.reduce((acc, cur) => {
return acc.concat(Array.isArray(cur) ? flattenByReduce(cur) : cur);
}, []);
}
5. 小结:日常怎么选
| 函数 | 生产环境 | 面试 / 巩固基础 |
|---|---|---|
| 深拷贝 | 优先用 structuredClone(支持循环引用)或 lodash cloneDeep | 自己实现,要处理循环引用和特殊类型 |
| 去重 | 基本类型用 [...new Set(arr)],对象用 Map 按 key 去重 | 要能解释 NaN、indexOf 等细节 |
| 扁平化 | 用原生 arr.flat(Infinity) | 手写递归或 reduce 版本 |
自己写一遍的价值在于:搞清楚边界情况、循环引用、特殊类型,以后选库或读源码时心里有数。
学习本就是一场持久战,不需要急着一口吃成胖子。哪怕今天你只记住了一点点,这都是实打实的进步。
后续我还会继续用这种大白话、讲实战方式,带大家扫盲更多前端基础。
关注我,不迷路,咱们把那些曾经模糊的知识点,一个个彻底搞清楚。
如果你觉得这篇内容对你有帮助,不妨点赞收藏,下次写代码卡壳时,拿出来翻一翻,比搜引擎更靠谱。
我是 Eugene,你的电子学友,我们下一篇干货见~
来源:juejin.cn/post/7609288132602478592
JSBridge 原理详解
什么是 JSBridge
JSBridge 是 WebView 中 JavaScript 与 Native 代码之间的通信桥梁。核心问题是:两个不同运行环境的代码如何互相调用?
通信原理
1. Native 调用 JS(简单)
WebView 本身就提供了执行 JS 的能力,原理很直接:WebView 控制着 JS 引擎,可以直接向其注入并执行代码。
// Android
webView.evaluateJavascript("window.appCallJS('data')", null);
// iOS
webView.evaluateJavaScript("window.appCallJS('data')")
// Flutter
webViewController.runJavaScript("window.appCallJS('data')");
2. JS 调用 Native(核心难点)
JS 运行在沙箱中,无法直接访问系统 API。有两种主流方案:
方案一:注入 API
Native 在 WebView 初始化时,向 JS 全局对象注入方法:
// Android - 注入对象到 window
webView.addJavascriptInterface(new Object() {
@JavascriptInterface
public void showToast(String msg) {
Toast.makeText(context, msg, Toast.LENGTH_SHORT).show();
}
}, "NativeBridge");
JS 端直接调用:
window.NativeBridge.showToast("Hello")
本质:Native 把自己的方法"挂"到了 JS 的全局作用域里。
方案二:URL Scheme 拦截
JS 发起一个特殊协议的请求,Native 拦截并解析:
// JS 端
location.href = 'jsbridge://showToast?msg=Hello'
// 或使用 iframe(避免页面跳转)
const iframe = document.createElement('iframe')
iframe.src = 'jsbridge://showToast?msg=Hello'
document.body.appendChild(iframe)
// Android 端拦截
webView.setWebViewClient(new WebViewClient() {
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
if (url.startsWith("jsbridge://")) {
// 解析 url,执行对应 Native 方法
return true;
}
return false;
}
});
本质:利用 WebView 的 URL 加载机制作为通信通道。
异步回调的实现
JS 调用 Native 后如何拿到返回值?通过回调 ID 机制:
// JS 端
let callbackId = 0
const callbacks = {}
function callNative(method, params) {
return new Promise((resolve) => {
const id = callbackId++
callbacks[id] = resolve
// 告诉 Native:调用完成后,用这个 id 回调我
window.NativeBridge.invoke(JSON.stringify({
method,
params,
callbackId: id
}))
})
}
// Native 执行完后调用这个函数
window.handleCallback = (id, result) => {
callbacks[id]?.(result)
delete callbacks[id]
}
流程:JS 调用 → Native 处理 → Native 调用 evaluateJavascript 执行回调函数 → JS 收到结果
各平台注入对象命名
| 平台/插件 | 全局对象名 | 是否可自定义 |
|---|---|---|
| Android 原生 | 任意 | ✅ 完全自定义 |
| iOS WKWebView | webkit.messageHandlers.xxx | ✅ xxx 部分可自定义 |
| flutter_inappwebview | flutter_inappwebview | ❌ 插件固定 |
| webview_flutter | 需要自己实现 | ✅ 完全自定义 |
Android 示例
// 第二个参数就是 JS 中的对象名,可以随便取
webView.addJavascriptInterface(bridgeObject, "MyBridge");
// JS 端
window.MyBridge.method()
iOS 示例
// name 就是 JS 中的 handler 名
configuration.userContentController.add(self, name: "iOSBridge")
// JS 端
window.webkit.messageHandlers.iOSBridge.postMessage(data)
Flutter (flutter_inappwebview) 示例
// Flutter 端注册 handler,handlerName 可自定义
webViewController.addJavaScriptHandler(
handlerName: 'myCustomHandler',
callback: (args) { ... }
);
// JS 端,flutter_inappwebview 是固定的
window.flutter_inappwebview.callHandler('myCustomHandler', data)
通信方式总结
| 方向 | 原理 | 实现方式 |
|---|---|---|
| Native → JS | WebView 控制 JS 引擎 | evaluateJavascript |
| JS → Native | 注入或拦截 | addJavascriptInterface / URL Scheme |
常见通信方式对比
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| JavaScript Bridge | 双向通信、支持回调 | 需要约定协议 | 复杂交互 |
| URL Scheme | 简单、兼容性好 | 单向、数据量有限 | 简单跳转 |
| postMessage | 标准 API | 需要 WebView 支持 | iframe 通信 |
| 注入 JS 对象 | 调用方便 | Android 4.2 以下有安全漏洞 | 频繁调用 |
最佳实践建议
- 统一封装:抽离成独立的 bridge 工具类,统一管理通信逻辑
- 消息队列:处理 Native 未就绪时的调用,避免丢失消息
- 超时处理:添加超时机制,防止回调永远不返回
- 类型安全:使用 TypeScript 定义消息类型
- 错误处理:统一的错误捕获和上报机制
来源:juejin.cn/post/7609660097766309898
手把手写几种常用工具函数:深拷贝、去重、扁平化
同学们好,我是 Eugene(尤金),一个拥有多年中后台开发经验的前端工程师~
(Eugene 发音很简单,/juːˈdʒiːn/,大家怎么顺口怎么叫就好)
你是否也有过:明明学过很多技术,一到关键时候却讲不出来、甚至写不出来?
你是否也曾怀疑自己,是不是太笨了,明明感觉会,却总差一口气?
就算想沉下心从头梳理,可工作那么忙,回家还要陪伴家人。
一天只有24小时,时间永远不够用,常常感到力不从心。
技术行业,本就是逆水行舟,不进则退。
如果你也有同样的困扰,别慌。
从现在开始,跟着我一起心态归零,利用碎片时间,来一次彻彻底底的基础扫盲。
这一次,我们一起慢慢来,扎扎实实变强。
不搞花里胡哨的理论堆砌,只分享看得懂、用得上的前端干货,
咱们一起稳步积累,真正摆脱“面向搜索引擎写代码”的尴尬。
1. 开篇:有库可用,为什么还要自己写?
lodash、ramda 等库已经提供这些工具函数,但在面试、基础补强、和「读懂库源码」的场景里,手写一遍很有价值:
- 搞清概念:什么算「深拷贝」、什么算「去重」
- 踩一遍坑:循环引用、
NaN、Date、RegExp、Symbol等 - 形成习惯:知道什么时候用浅拷贝、什么时候必须深拷贝
下面按「深拷贝 → 去重 → 扁平化」的顺序,每种都给出可直接用的实现和说明。
2. 深拷贝
2.1 浅拷贝 vs 深拷贝,怎么选?
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 只改最外层、不改嵌套对象 | 浅拷贝({...obj}、Object.assign) | 实现简单、性能好 |
| 需要改嵌套对象且不想影响原数据 | 深拷贝 | 避免引用共享 |
对象里有 Date、RegExp、函数等 | 深拷贝时需特殊处理 | 否则会丢失类型或行为 |
一句话:只要会改到「嵌套对象/数组」,就考虑深拷贝。
2.2 常见坑
- 循环引用:
obj.a = obj,递归会栈溢出 - 特殊类型:
Date、RegExp、Map、Set、Symbol不能只靠遍历属性复制 - Symbol 做 key:
Object.keys不会包含,需用Reflect.ownKeys或Object.getOwnPropertySymbols
2.3 实现示例(含循环引用与特殊类型处理)
function deepClone(obj, cache = new WeakMap()) {
// 1. 基本类型、null、函数 直接返回
if (obj === null || typeof obj !== 'object') {
return obj;
}
// 2. 循环引用:用 WeakMap 缓存已拷贝对象
if (cache.has(obj)) {
return cache.get(obj);
}
// 3. 特殊对象类型
if (obj instanceof Date) return new Date(obj.getTime());
if (obj instanceof RegExp) return new RegExp(obj.source, obj.flags);
if (obj instanceof Map) {
const mapCopy = new Map();
cache.set(obj, mapCopy);
obj.forEach((v, k) => mapCopy.set(deepClone(k, cache), deepClone(v, cache)));
return mapCopy;
}
if (obj instanceof Set) {
const setCopy = new Set();
cache.set(obj, setCopy);
obj.forEach(v => setCopy.add(deepClone(v, cache)));
return setCopy;
}
// 4. 普通对象 / 数组
const clone = Array.isArray(obj) ? [] : {};
cache.set(obj, clone);
// 包含 Symbol 作为 key
const keys = [...Object.keys(obj), ...Object.getOwnPropertySymbols(obj)];
keys.forEach(key => {
clone[key] = deepClone(obj[key], cache);
});
return clone;
}
// 使用示例
const original = { a: 1, b: { c: 2 }, d: [3, 4] };
original.self = original; // 循环引用
const cloned = deepClone(original);
cloned.b.c = 999;
console.log(original.b.c); // 2,原对象未被修改
要点:WeakMap 解决循环引用,Date/RegExp/Map/Set 单独分支,Object.getOwnPropertySymbols 保证 Symbol key 不丢失。
3. 去重
3.1 场景与选型
| 场景 | 方法 | 说明 |
|---|---|---|
| 基本类型数组(数字、字符串) | Set | 写法简单、性能好 |
需要兼容 NaN | 自己写遍历逻辑 | NaN !== NaN,Set 能去重 NaN,但逻辑要显式写清楚 |
| 对象数组、按某字段去重 | Map 或 filter | 用唯一字段做 key |
3.2 几种实现
1)简单数组去重(含 NaN)
// 方式一:Set(ES6 最常用)
function uniqueBySet(arr) {
return [...new Set(arr)];
}
// 方式二:filter + indexOf(兼容性更好,但 NaN 会出问题)
function uniqueByFilter(arr) {
return arr.filter((item, index) => arr.indexOf(item) === index);
}
// 方式三:兼容 NaN 的版本
function unique(arr) {
const result = [];
const seenNaN = false; // 用 flag 标记是否已经加入过 NaN
for (const item of arr) {
if (item !== item) { // NaN !== NaN
if (!seenNaN) {
result.push(item);
seenNaN = true; // 这里需要闭包,下面用修正版
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
// 修正:用变量
function uniqueWithNaN(arr) {
const result = [];
let hasNaN = false;
for (const item of arr) {
if (Number.isNaN(item)) {
if (!hasNaN) {
result.push(NaN);
hasNaN = true;
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
注意:Set 本身对 NaN 是去重的(ES2015 规范),所以 [...new Set([1, NaN, 2, NaN])] 结果正确。需要兼容 NaN 的,多是旧环境或面试题场景。
2)对象数组按某字段去重
function uniqueByKey(arr, key) {
const seen = new Map();
return arr.filter(item => {
const k = item[key];
if (seen.has(k)) return false;
seen.set(k, true);
return true;
});
}
// 使用
const users = [
{ id: 1, name: '张三' },
{ id: 2, name: '李四' },
{ id: 1, name: '张三2' }
];
console.log(uniqueByKey(users, 'id'));
// [{ id: 1, name: '张三' }, { id: 2, name: '李四' }]
4. 扁平化
4.1 场景
- 把
[1, [2, [3, 4]]]变成[1, 2, 3, 4] - 有时候需要「只扁平一层」或「扁平到指定层数」
4.2 实现
1)递归全扁平
function flatten(arr) {
const result = [];
for (const item of arr) {
if (Array.isArray(item)) {
result.push(...flatten(item));
} else {
result.push(item);
}
}
return result;
}
console.log(flatten([1, [2, [3, 4], 5]])); // [1, 2, 3, 4, 5]
2)指定深度扁平(如 Array.prototype.flat)
function flattenDepth(arr, depth = 1) {
if (depth <= 0) return arr;
const result = [];
for (const item of arr) {
if (Array.isArray(item) && depth > 0) {
result.push(...flattenDepth(item, depth - 1));
} else {
result.push(item);
}
}
return result;
}
console.log(flattenDepth([1, [2, [3, 4]]], 1)); // [1, 2, [3, 4]]
console.log(flattenDepth([1, [2, [3, 4]]], 2)); // [1, 2, 3, 4]
3)用 reduce 递归写法(另一种常见写法)
function flattenByReduce(arr) {
return arr.reduce((acc, cur) => {
return acc.concat(Array.isArray(cur) ? flattenByReduce(cur) : cur);
}, []);
}
5. 小结:日常怎么选
| 函数 | 生产环境 | 面试 / 巩固基础 |
|---|---|---|
| 深拷贝 | 优先用 structuredClone(支持循环引用)或 lodash cloneDeep | 自己实现,要处理循环引用和特殊类型 |
| 去重 | 基本类型用 [...new Set(arr)],对象用 Map 按 key 去重 | 要能解释 NaN、indexOf 等细节 |
| 扁平化 | 用原生 arr.flat(Infinity) | 手写递归或 reduce 版本 |
自己写一遍的价值在于:搞清楚边界情况、循环引用、特殊类型,以后选库或读源码时心里有数。
学习本就是一场持久战,不需要急着一口吃成胖子。哪怕今天你只记住了一点点,这都是实打实的进步。
后续我还会继续用这种大白话、讲实战方式,带大家扫盲更多前端基础。
关注我,不迷路,咱们把那些曾经模糊的知识点,一个个彻底搞清楚。
如果你觉得这篇内容对你有帮助,不妨点赞收藏,下次写代码卡壳时,拿出来翻一翻,比搜引擎更靠谱。
我是 Eugene,你的电子学友,我们下一篇干货见~
来源:juejin.cn/post/7609288132602478592
哨兵模式-无限滚动
前端哨兵模式(Sentinel Pattern)—— 优雅实现滚动加载
一、什么是哨兵模式?
想象你在排队买奶茶,你不知道什么时候轮到你。但如果在你前面第 3 个人身上贴了一张纸条,写着"看到我就准备点单"——这个人就是"哨兵"。
在前端开发中,哨兵模式就是在页面的某个位置放一个不可见的元素(哨兵),当用户滚动页面让这个元素进入视口时,自动触发特定操作(比如加载下一页数据)。
它的核心技术是浏览器原生 API —— IntersectionObserver。
二、原理
IntersectionObserver 是什么?
IntersectionObserver(交叉观察器)是浏览器提供的一个 API,用来异步地观察一个元素与视口(或某个祖先元素)的交叉状态。
简单说:它能告诉你——"某个元素是否出现在了屏幕上"。
工作流程
┌─────────────────────────────────────┐
│ 可视区域(视口) │
│ │
│ ┌─────────────────────────────┐ │
│ │ 已加载的列表项 │ │
│ │ ... │ │
│ │ 列表项 N │ │
│ └─────────────────────────────┘ │
│ │
│ ┌─────────────────────────────┐ │
│ │ 🚨 哨兵元素(高度 1px) │ ← 当它进入视口,触发回调
│ └─────────────────────────────┘ │
│ │
└─────────────────────────────────────┘
↓ 触发回调
fetchNextPage() → 加载更多数据
↓ 新数据渲染
哨兵被推到新列表底部 → 等待下次进入视口
关键:每次新数据渲染后,哨兵自然地被推到列表最底部,形成一个自动循环:滚到底 → 加载 → 哨兵下移 → 再滚到底 → 再加载…
三、规则
使用哨兵模式时,需要遵守以下规则:
| 规则 | 说明 |
|---|---|
| 1. 哨兵元素必须始终在列表末尾 | 只有在最后面,用户滚到底才能触发 |
| 2. 防止重复触发 | 加载中时不要重复请求,用 loading 状态锁住 |
| 3. 有数据才放哨兵 | 没有数据或已加载完毕时,不渲染哨兵元素 |
| 4. 及时断开观察 | 组件卸载或条件变化时调用 observer.disconnect() 防止内存泄漏 |
| 5. 依赖项要完整 | useEffect 的依赖数组要包含所有会影响是否加载的状态 |
| 6. 哨兵尽量小 | 高度 1px 即可,不要影响布局和用户体验 |
四、用法
基础用法(React + TypeScript)
import { useRef, useEffect, useState } from 'react';
function InfiniteList() {
const [list, setList] = useState<string[]>([]);
const [page, setPage] = useState(1);
const [loading, setLoading] = useState(false);
const [hasMore, setHasMore] = useState(true);
// 1️⃣ 创建哨兵元素的 ref
const sentinelRef = useRef<HTMLDivElement | null>(null);
// 2️⃣ 加载数据的函数
const fetchData = async (p: number) => {
if (loading) return;
setLoading(true);
try {
const res = await fetch(`/api/list?page=${p}`);
const data = await res.json();
setList((prev) => [...prev, ...data.items]);
setHasMore(data.items.length === 20);
setPage(p);
} finally {
setLoading(false);
}
};
// 3️⃣ 设置 IntersectionObserver
useEffect(() => {
const el = sentinelRef.current;
if (!el) return;
const observer = new IntersectionObserver(
(entries) => {
// 当哨兵进入视口,且满足加载条件
if (entries[0].isIntersecting && hasMore && !loading) {
fetchData(page + 1);
}
},
{ threshold: 0.1 } // 哨兵露出 10% 就触发
);
observer.observe(el);
// 4️⃣ 清理:组件卸载或依赖变化时断开观察
return () => observer.disconnect();
}, [hasMore, loading, page]);
return (
<div>
{list.map((item, i) => (
<div key={i} className="list-item">{item}div>
))}
{/* 加载中提示 */}
{loading && <div className="loading">加载中...div>}
{/* 5️⃣ 哨兵元素:有更多数据时才渲染 */}
{hasMore && list.length > 0 && (
<div ref={sentinelRef} style={{ height: 1 }} />
)}
{/* 没有更多了 */}
{!hasMore && <div className="no-more">没有更多了div>}
div>
);
}
threshold 参数说明
new IntersectionObserver(callback, {
threshold: 0.1, // 元素露出 10% 时触发(推荐)
// threshold: 0, // 元素刚刚出现就触发
// threshold: 1.0, // 元素完全可见才触发
// rootMargin: '0px 0px 200px 0px', // 提前 200px 触发(预加载)
});
💡 小技巧:设置
rootMargin: '0px 0px 200px 0px'可以让用户还没滚到底部就提前加载,体验更流畅。
五、适用场景
✅ 适合使用哨兵模式的场景
| 场景 | 说明 |
|---|---|
| 长列表滚动加载 | 商品列表、新闻流、聊天记录等 |
| 瀑布流加载 | 图片瀑布流、Pinterest 风格布局 |
| 分页数据替代方案 | 用无限滚动代替传统"上一页/下一页" |
| 图片懒加载 | 图片进入视口才开始加载 src |
| 曝光埋点 | 元素出现在屏幕上时上报埋点数据 |
| 动画触发 | 元素滚动到可视区域时播放动画 |
❌ 不适合的场景
| 场景 | 原因 |
|---|---|
| 数据量极少(< 1 页) | 没有分页需求,多此一举 |
| 需要精确跳转到某页 | 无限滚动无法直接跳到第 N 页 |
| SEO 要求高的页面 | 动态加载的内容不利于搜索引擎抓取 |
| 需要"回到顶部"后保持位置 | 无限滚动在页面刷新后无法恢复滚动位置 |
六、举个生活化的例子 🌰
场景:自助火锅的传送带
想象你在吃回转寿司:
- 传送带 = 你的页面可滚动区域
- 寿司盘子 = 一条条数据
- 你的座位前方 = 视口(你能看到的区域)
- 最后一个盘子后面的"加菜牌" = 🚨 哨兵元素
当传送带转啊转,"加菜牌"经过你面前时,后厨就知道:盘子快被拿完了,赶紧做新的放上来!
- 后厨正在做(
loading = true)→ 不会重复通知 - 盘子全上完了(
hasMore = false)→ 把"加菜牌"撤掉 - 还没开始吃(
list.length === 0)→ "加菜牌"也不需要放
这就是哨兵模式的全部思想!
七、对比传统方案
| 方案 | 实现方式 | 优点 | 缺点 |
|---|---|---|---|
| 监听 scroll 事件 | addEventListener('scroll', ...) | 兼容性好 | 频繁触发、需要节流、计算滚动位置复杂 |
| "加载更多"按钮 | 用户手动点击 | 简单直接 | 用户体验差,需要主动操作 |
| 🚨 哨兵模式 (IntersectionObserver) | 观察哨兵元素 | 性能好、代码简洁、自动触发 | 极老浏览器不支持(IE 不支持) |
性能对比
scroll 事件:每秒可能触发 60+ 次 → 需要 throttle/debounce
哨兵模式: 只在交叉状态变化时触发 → 天然高性能 🚀
八、注意事项
- 浏览器兼容性:
IntersectionObserver在现代浏览器中均支持(Chrome 51+、Safari 12.1+)。如需兼容老浏览器,可引入 polyfill:
npm install intersection-observer
- 避免闪烁:如果页面初始内容不够长(不足以滚动),哨兵会立即可见并触发加载,这其实是正确行为——它会连续加载直到内容填满屏幕或没有更多数据。
- 配合
useCallback:如果fetchData函数作为依赖传入useEffect,建议用useCallback包裹,避免不必要的 observer 重建。
总结
哨兵模式 = 放一个隐形元素在底部 + 用 IntersectionObserver 监听它是否出现 + 出现就加载数据
三句话,就是全部核心。剩下的只是条件判断和状态管理。它是目前前端实现无限滚动最优雅、性能最好的方案。
来源:juejin.cn/post/7609927980680757254
密码正在死亡 —— 从 MFA 到无密码登录(2020–2026)
上一章我们聊了单点登录(SSO)在前端的落地形态:从 Cookie 域共享到基于 OIDC + Refresh Token 的集中式认证,再到微前端下的同步挑战。但无论 Token 再怎么优化、SSO 再怎么无缝,密码 这个人类最古老的数字身份载体,始终是整个体系最脆弱的一环:易忘、易猜、易钓鱼、易泄露、易重用。
从 2020 年开始,行业集体意识到:最好的密码,就是没有密码。这一篇,我们聚焦密码的“死亡过程”——从传统 MFA 的普及,到 TOTP/HOTP 的辅助,再到 WebAuthn/FIDO2 的崛起,最终到 2025–2026 年 Passkey(通行密钥)成为主流的无密码方案。前端工程师的角色,也从“表单 + 验证码校验”进化到“调用 navigator.credentials API + 处理跨设备同步”。
1. 2020–2022:MFA 成为标配,但密码仍是“根”
2020 年疫情加速数字化,远程办公 + 电商爆发,钓鱼攻击激增。密码 + 短信/邮箱 OTP 的组合被大规模强制。
典型前端实现(2020–2022):
- 登录页:用户名 + 密码 + “发送验证码”按钮
- 后端发短信/邮件 → 前端输入 6 位码
- 框架:React/Vue + axios 轮询 / 长连接 polling
但问题很快暴露:
- 短信劫持(SIM swapping)泛滥
- 钓鱼网站实时中转 OTP
- 用户疲劳 → 关闭 MFA 或用弱密码
统计:2021–2022 年,短信 OTP 仍是主流,但 FIDO Alliance 开始大力推 FIDO2(WebAuthn + CTAP)作为 phishing-resistant MFA。
前端接入 WebAuthn(早期):
// 注册(navigator.credentials.create)
async function register() {
const publicKey = await fetch('/webauthn/register/challenge').then(r => r.json());
const credential = await navigator.credentials.create({ publicKey });
await fetch('/webauthn/register', {
method: 'POST',
body: JSON.stringify(credential)
});
}
但 2020–2022 年,WebAuthn 普及慢:浏览器支持不全、用户教育成本高、设备兼容性差。
2. 2022–2024:Passkey 概念诞生 + 巨头推动(Apple/Google/Microsoft 三巨头联盟)
2022 年 5 月,Apple 在 WWDC 推出 iOS 16 的 Passkeys(基于 FIDO2 的同步凭证)。
核心卖点:
- 私钥存设备 Secure Enclave / TPM
- 公钥注册到服务端
- 跨设备同步(iCloud Keychain / Google Password Manager / Microsoft 的实现)
- 生物识别(指纹/面容)或 PIN 验证
- Phishing-resistant(origin binding)
2023 年 Google 跟进:Chrome + Android 全面支持 Passkey,默认推动。
2024 年 Microsoft:新账户默认无密码 + Passkey。
前端变化:
- 使用
@simplewebauthn/browser或原生navigator.credentials - 支持 autofill(浏览器自动提示 Passkey)
- 条件 UI(conditional mediation):
mediation: 'conditional'让 Passkey 像密码一样自动填充
典型注册/认证代码(2024 现代写法):
// 认证(登录)
async function authenticate() {
const options = await fetch('/webauthn/auth/options').then(r => r.json());
options.mediation = 'conditional'; // 自动提示
const assertion = await navigator.credentials.get({ publicKey: options });
const res = await fetch('/webauthn/auth', {
method: 'POST',
body: JSON.stringify(assertion)
});
if (res.ok) console.log('登录成功');
}
这一阶段,Passkey 从“实验”变成“可选默认”。
3. 2025–2026:Passkey 真正爆发 + 密码死亡的临界点(2026 年现状)
到 2026 年 2 月,数据已非常清晰:
- 设备就绪率:96% 的设备支持 Passkey(state-of-passkeys.io 数据,桌面 +68%、移动 +3% 增长)
- 用户拥有率:69% 用户至少有一个 Passkey(从 2023 年的 39% 认知率暴涨)
- 顶级网站支持率:48% 的前 100 网站支持 Passkey(2022 年仅 20% 多)
- 登录成功率:Passkey 93% vs 传统 63%
- 企业部署:87% 组织已部署或正在部署 Passkey(HID/FIDO 数据)
- 认证量:Dashlane 数据显示月认证量达 130 万(同比翻倍),Google 增长 352%、Roblox 856%
巨头强制默认:
- Google:2023 年起默认 Passkey
- Microsoft:2025 年 5 月新账户默认无密码
- Amazon、PayPal、TikTok 等电商/社交平台大规模跟进
前端接入难度(2026 年):
- 极低:成熟库(@simplewebauthn、@auth0/auth0-spa-js、Clerk、Supabase Auth)屏蔽细节
- 跨设备同步:依赖平台(iCloud/Google/MS),前端只需调用 API
- 回退机制:仍支持密码 + TOTP 作为备用(恢复码、邮箱魔法链接)
- 一键登录融合:Passkey + Apple/Google 一键 + 本机号码识别
典型组合拳(ToC 高频场景):
- 首选:Passkey(生物/设备验证)
- 备用:魔法链接(邮箱点击)
- 恢复:一次性恢复码 + 手机号验证
- 高危操作:Passkey + 二次确认(金额/敏感数据)
4. 前端工程师的实际落地 Checklist(2026 版)
- 使用
navigator.credentials+mediation: 'conditional'实现 autofill - 支持跨平台 RP ID(related-origin-requests for 多域)
- 处理 user verification:
userVerification: 'preferred' | 'required' - 兼容旧浏览器:polyfill 或 fallback 到 TOTP
- 测试场景:Incognito、无网络、设备切换
- 隐私考虑:不存储敏感 claims,前端只管传输 raw credential
小结 & 过渡
2020–2026 年,密码从“必须” → “可选” → “即将灭绝”的过程,核心驱动力是:
- 安全:phishing-resistant(FIDO2)
- 体验:生物识别 + 跨设备同步
- 经济:减少重置支持票(降 50–80%)
到 2026 年,Passkey 已不是“未来技术”,而是消费者预期:用户开始问“为什么你们还不支持 Passkey?”
但密码完全死亡还需要时间:遗留系统、合规要求、低端设备、用户教育仍存阻力。
来源:juejin.cn/post/7606183276773785663
组长说:公司的国际化就交给你了,下个星期给我
从“跑路程序员”到“摸鱼仙人”,我用这插件把国际化的屎山代码盘活了!
tips:
使用有道翻译,朋友们,要去有道官网注册一下,有免费额度,github demo的key已经被用完了。
tips:
朋友们,vite翻译插件请优先安装1.0.23
一、命运的齿轮开始转动
“小王啊,海外业务要上线了,国际化你搞一下,下个月验收。”组长轻描淡写的一句话,让我盯着祖传代码陷入沉思——

(脑补画面:满屏中文硬编码,夹杂着"确定"、"取消"、"加载中...")
正当我准备打开BOSS直聘时,GitHub Trending上一个项目突然闪现——
auto-i18n-translation-plugins
项目简介赫然写着:“不改代码,三天交付国际化需求,摸鱼率提升300%”
二、极限操作:48小时从0到8国语言
🔧 第1步:安装插件(耗时5分钟)
祖训:“工欲善其事,必先装依赖”
# 如果你是Vite玩家(比如Vue3项目)
npm install vite-auto-i18n-plugin --save-dev
# 如果你是Webpack钉子户(比如React老项目)
npm install webpack-auto-i18n-plugin --save-dev
🔧 第2步:配置插件(关键の10分钟)
Vue3 + Vite の 摸鱼配置:
// vite.config.js
import { defineConfig } from 'vite';
import vitePluginAutoI18n from 'vite-auto-i18n-plugin';
export default defineConfig({
plugins: [
vue(),
vitePluginAutoI18n({
targetLangList: ['en', 'ja', 'ko'], // 要卷就卷8国语言!
translator: new YoudaoTranslator({ // 用有道!不用翻墙!
appId: '你的白嫖ID', // 去官网申请,10秒搞定
appKey: '你的密钥' // 别用示例里的,会炸!
})
})
]
});
🔧 第3步:注入灵魂——配置文件(生死攸关の5分钟)
在项目入口文件(如main.js)的第一行插入:
// 这是插件的生命线!必须放在最前面!
import '../lang/index.js'; // 运行插件之后会自动生成引入即可
三、见证奇迹的时刻
🚀 第一次运行(心脏骤停の瞬间)
输入npm run dev,控制台开始疯狂输出:
[插件日志] 检测到中文文本:"登录" → 生成哈希键:a1b2c3
[插件日志] 调用有道翻译:"登录" → 英文:Login,日文:ログイン...
[插件日志] 生成文件:lang/index.json(翻译の圣杯)
突然!页面白屏了!
别慌!这是插件在首次翻译时需要生成文件,解决方法:
- 立即执行一次
npm run build(让插件提前生成所有翻译) - 再次
npm run dev→ 页面加载如德芙般丝滑
四、效果爆炸:我成了全组の神
1. 不可置信の48小时
当我打开浏览器那一刻——\
我(瞳孔地震):“卧槽…真成了?!”
组长(凑近屏幕):“这…这是你一个人做的?!”(眼神逐渐迷茫)
产品经理(掏出手机拍照):“快!发朋友圈!《我司技术力碾压硅谷!》”
2. 插件の超能力
- 构建阶段:自动扫描所有中文 → 生成哈希键 → 调用API翻译
- 运行时:根据用户语言动态加载对应翻译
- 维护期:改个JSON文件就能更新所有语言版本
副作用:
- 测试妹子开始怀疑人生:“为什么一个bug都找不到?”
- 后端同事偷偷打听:“你这插件…能翻译Java注释吗?”
五、职场生存指南:如何优雅甩锅
🔨 场景1:测试妹子提着40米大刀来了!
问题:俄语翻译把“注册”译成“Регистрация”(原意是“登记处”)
传统应对:
- 熬夜改代码 → 重新打包 → 提交测试 → 被骂效率低
插件玩家:
- 打开
lang/index.json - 把
Регистрация改成Зарегистрироваться(深藏功与名) - 轻描淡写:“这是有道翻译的锅,我手动修正了。”
🔨 场景2:产品经理临时加语言
需求:“老板说下周要加印地语!”
传统灾难:
- 重新配框架 → 人肉翻译 → 测试 → 加班到秃头
插件玩家:
- 配置加一行代码:
targetLangList: ['hi'] - 运行
npm run build→ 自动生成印地语翻译 - 告诉产品经理:“这是上次预留的技术方案。”(其实只改了1行)
🔨 场景3:组长怀疑你摸鱼
质问:“小王啊,你这效率…是不是有什么黑科技?”
标准话术:
“组长,这都是因为:
- 您制定的开发规范清晰
- 公司技术栈先进(Vue3真香)
- 我参考了国际前沿方案(打开GitHub页面)”
六、高级摸鱼の奥义
🎯 秘籍1:把翻译文件变成团队武器
- 把
lang/index.json扔给产品经理:“这是国际化核心资产!” - 对方用Excel修改后,你直接
git pull→ 无需动代码 - 出问题直接甩锅:“翻译是市场部给的,我只负责技术!”

(脑补画面:产品经理在Excel里疯狂改翻译,程序员在刷剧)
🎯 秘籍2:动态加载の神操作
痛点:所有语言打包进主文件 → 体积爆炸!
解决方案:
// 在index.js里搞点骚操作
const loadLanguage = async (lang) => {
const data = await import(`../../lang/${lang}.json`); // 动态加载翻译文件
window.$t.locale(data, 'lang');
};
// 切换语言时调用
loadLanguage('ja'); // 瞬间切换日语,深藏功与名
🎯 秘籍3:伪装成AI大神
- 周会汇报:“我基于AST实现了自动化国际翻译中台”
- 实际:只是配了个插件
- 老板评价:“小王这技术深度,值得加薪!”(真相只有你知道)
七、终局:摸鱼の神,降临!
当组长在庆功会上宣布“国际化项目提前两周完成”时,我正用手机刷着《庆余年2》。
测试妹子:“你怎么一点都不激动?”
我(收起手机):“常规操作,要习惯。”(心想:插件干活,我躺平,这才叫真正的敏捷开发!)
立即行动(打工人自救指南):
- GitHub搜:auto-i18n-translation-plugins(点星解锁摸鱼人生)
- 复制我的配置 → 运行 → 见证魔法
- 加开发者社群:遇到问题发红包喊“大哥救命!”
终极警告:
⚠️ 过度使用此插件可能导致——
- 你的摸鱼时间超过工作时间,引发HR关注
- 产品经理产生“国际化需求可以随便加”的幻觉
- 老板误以为你是隐藏的技术大佬(谨慎处理!)
文末暴击:
“自从用了这插件,我司翻译团队的工作量从3周变成了3分钟——现在他们主要工作是帮我选中午吃啥。” —— 匿名用户の真实反馈
常见问题汇总
来源:juejin.cn/post/7480267450286800911
别再滥用 Base64 了——Blob 才是前端减负的正确姿势
一、什么是 Blob?
Blob(Binary Large Object,二进制大对象)是浏览器提供的一种不可变、类文件的原始数据容器。它可以存储任意类型的二进制或文本数据,例如图片、音频、PDF、甚至一段纯文本。与 File 对象相比,Blob 更底层,File 实际上继承自 Blob,并额外携带了 name、lastModified 等元信息 。
Blob 最大的特点是纯客户端、零网络:数据一旦进入 Blob,就活在内存里,无需上传服务器即可预览、下载或进一步加工。
二、构造一个 Blob:一行代码搞定
const blob = new Blob(parts, options);
| 参数 | 说明 |
|---|---|
parts | 数组,元素可以是 String、ArrayBuffer、TypedArray、Blob 等。 |
options | 可选对象,常用字段:type MIME 类型,默认 application/octet-stream;endings 是否转换换行符,几乎不用。 |
示例:动态生成一个 Markdown 文件并让用户下载
const content = '# Hello Blob\n> 由浏览器动态生成';
const blob = new Blob([content], { type: 'text/markdown' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = 'hello.md';
a.click();
// 内存用完即弃
URL.revokeObjectURL(url);
三、Blob URL:给内存中的数据一个“临时地址”
1. 生成方式
const url = URL.createObjectURL(blob);
// 返回值样例
// blob:https://localhost:3000/550e8400-e29b-41d4-a716-446655440000
2. 生命周期
- 作用域:仅在当前文档、当前会话有效;页面刷新、
close()、手动调用revokeObjectURL()都会使其失效 。 - 性能陷阱:不主动释放会造成内存泄漏,尤其在单页应用或大量图片预览场景 。
最佳实践封装:
function createTempURL(blob) {
const url = URL.createObjectURL(blob);
// 自动 revoke,避免忘记
requestIdleCallback(() => URL.revokeObjectURL(url));
return url;
}
四、Blob vs. Base64 vs. ArrayBuffer:如何选型?
| 场景 | 推荐格式 | 理由 |
|---|---|---|
图片回显、<img>/<video> | Blob URL | 浏览器可直接解析,无需解码;内存占用低。 |
| 小图标内嵌在 CSS/JSON | Base64 | 减少一次 HTTP 请求,但体积增大约 33%。 |
| 纯计算、WebAssembly 传递 | ArrayBuffer | 可写、可索引,适合高效运算。 |
| 上传大文件、断点续传 | Blob.slice | 流式分片,配合 File.prototype.slice 做断点续传 。 |
五、高频实战场景
1. 本地图片/视频预览(零上传)
<input type="file" accept="image/*" id="uploader">
<img id="preview" style="max-width: 100%">
<script>
uploader.onchange = e => {
const file = e.target.files[0];
if (!file) return;
const url = URL.createObjectURL(file);
preview.src = url;
preview.onload = () => URL.revokeObjectURL(url); // 加载完即释放
};
</script>
2. 将 Canvas 绘图导出为 PNG 并下载
canvas.toBlob(blob => {
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = 'snapshot.png';
a.click();
URL.revokeObjectURL(url);
}, 'image/png');
3. 抓取远程图片→Blob→本地预览(跨域需 CORS)
fetch('https://i.imgur.com/xxx.png', { mode: 'cors' })
.then(r => r.blob())
.then(blob => {
const url = URL.createObjectURL(blob);
document.querySelector('img').src = url;
});
若出现图片不显示,99% 是因为服务端未返回 Access-Control-Allow-Origin 头 。
六、踩坑指南与性能锦囊
| 坑点 | 解决方案 |
|---|---|
| 内存暴涨 | 每次 createObjectURL 后,务必在合适的时机 revokeObjectURL 。 |
| 跨域失败 | 确认服务端开启 CORS;fetch 时加 {credentials: 'include'} 如需 Cookie。 |
| 移动端大视频卡顿 | 避免一次性读完整文件,使用 blob.slice(start, end) 分段读取。 |
| 旧浏览器兼容 | IE10+ 才原生支持 Blob;如需更低版本,请引入 Blob.js 兼容库。 |
七、延伸:Blob 与 Stream 的梦幻联动
当文件超大(GB 级)时,全部读进内存并不现实。可以借助 ReadableStream 把 Blob 转为流,实现渐进式上传:
const stream = blob.stream(); // 返回 ReadableStream
await fetch('/upload', {
method: 'POST',
body: stream,
headers: { 'Content-Type': blob.type }
});
Chrome 85+、Edge 85+、Firefox 已经支持 blob.stream(),能以流式形式边读边传,内存占用极低。
八、总结:记住“三句话”
- Blob = 浏览器端的二进制数据仓库,File 只是它的超集。
- Blob URL = 指向内存的临时指针,用完后必须手动或自动释放。
- 凡是“本地预览、零上传、动态生成下载”的需求,优先考虑 Blob + Blob URL 组合。
用好 Blob,既能提升用户体验(秒开预览),又能降低服务端压力(无需中转),是每一位前端工程师的必备技能。
来源:juejin.cn/post/7573521516324896795
PWA 到底是什么?它在 2026 年解决了哪些真实痛点?
PWA 到底是什么?
Progressive Web App(渐进式 Web 应用,简称 PWA)是一种使用标准 Web 技术(HTML、CSS、JavaScript)构建的网页应用,但通过浏览器提供的增强能力,让它具备接近原生 App 的体验。
它不是一个全新的东西,而是一种“渐进增强”(Progressive Enhancement)的理念:从普通的网页开始,逐步添加高级特性,让用户感觉像在使用安装的原生应用。
PWA 的三大核心支柱(至今仍是):
- 可靠(Reliable):即使在弱网/断网情况下也能加载并基本可用(靠 Service Worker + 缓存)。
- 快速(Fast):瞬间加载、流畅交互(优化的缓存 + 性能最佳实践)。
- 可安装(Installable):可以“添加到主屏幕”,以独立窗口(standalone)模式运行,有图标、启动画面,像 App 一样。
在 2026 年,PWA 已经从 2015 年的“概念”变成了许多企业实际落地的主流移动解决方案之一。浏览器支持大幅成熟,Chrome/Edge/Firefox 几乎完整,Safari(iOS)也追赶了很多年(虽仍有差距)。
它在 2026 年真正解决了哪些真实痛点?
以下是 2026 年开发者/产品/业务最常遇到的痛点,以及 PWA 如何针对性解决(基于当前浏览器现实支持情况):
- 开发和维护成本爆炸(Separate iOS + Android + Web)
- 痛点:同一功能要写 3 套代码(Swift/Kotlin + Web),测试、上架、更新各走各的流程,维护成本高到离谱。
- PWA 解决:一套代码跑三端(甚至桌面 Windows/macOS/ChromeOS)。2026 年 60%+ 的企业级移动项目已转向 PWA 或 hybrid 模式,开发成本可降 40–60%。更新无需 App Store 审核,秒级生效。
- 用户安装/获取摩擦巨大(App Store 下载壁垒)
- 痛点:用户看到链接 → 去 App Store → 下载几十 MB → 安装 → 打开,转化率惨不忍睹(很多场景 <5%)。
- PWA 解决:链接一点就用,符合条件可弹出“添加到主屏幕”提示(Android 自动 banner,iOS 手动但更顺畅)。安装后有图标、离线可用、无需占 App Store 空间。很多电商/内容/工具类 App 转化率因此提升 2–5 倍。
- 弱网/无网场景下体验崩坏
- 痛点:地铁、电梯、农村、国际漫游……用户一断网就白屏/卡死,流失严重。
- PWA 解决:Service Worker 预缓存 + 运行时缓存,核心页面/资源离线可用。2026 年 Workbox 等工具让实现几乎零成本。新闻、邮件、待办、天气、记账类 PWA 在断网时仍能浏览历史、写草稿,等联网再同步。
- 推送通知和用户再触达难
- 痛点:H5 基本没推送,原生 App 推送又贵又麻烦(审核、权限)。
- PWA 解决:Web Push 已跨平台可用。Android/桌面完整支持,iOS 从 iOS 16.4 开始支持(需加到主屏幕,非 EU 地区更稳定)。2026 年 Declarative Web Push 等新 API 让推送更可靠,企业再营销/订单提醒/消息触达率大幅提升。
- 加载慢、性能差直接影响收入
- 痛点:移动端 3 秒未加载完,用户流失率飙升;Core Web Vitals 差 → SEO 排名掉。
- PWA 解决:强制 HTTPS + 缓存策略 + 优化后,首屏加载常 <1s。Lighthouse PWA 分数 90+ 已成为标配,很多业务报告转化率提升 20–50%。
- 跨平台一致性 & 快速迭代
- 痛点:iOS 和 Android 体验割裂,bug 修复要双平台发版。
- PWA 解决:浏览器统一渲染逻辑,一处修复全局生效。2026 年 PWA 还能用 File System Access、Web Share、Badging API 等,让体验更接近原生。
2026 年 PWA 的真实平台支持对比(简表)
| 特性 | Android (Chrome) | iOS (Safari 26+) | Windows/macOS | 备注 |
|---|---|---|---|---|
| 添加到主屏幕/安装 | 完整(自动提示) | 支持(手动 Share → Add) | 支持 | iOS 26 默认更倾向 web app 模式 |
| 离线 & 缓存 | 完整 | 完整(但存储配额仍限) | 完整 | Service Worker 跨平台 |
| Push 通知 | 完整 | 支持(需 home screen,非EU更稳) | 完整 | iOS 无 silent push,reach 稍低 |
| Background Sync | 完整 | 部分/不支持 | 部分 | iOS 仍最大短板 |
| Periodic Sync | 完整 | 不支持 | 部分 | 用于定期更新内容 |
| 硬件 API(相机、蓝牙等) | 大部分支持 | 部分支持 | 部分 | 差距在缩小 |
总结一句话(2026 年视角)
PWA 不是要完全取代原生 App,而是解决了**“我想给用户 App 般的体验,但不想付出双平台原生开发的代价”** 这个最真实、最普遍的痛点。
特别适合:
- 电商、新闻、社交工具、SaaS、生产力工具、内容平台
- 预算有限、需要快速验证、重视 SEO 和链接分享的场景
- 想覆盖桌面 + 移动 + 弱网用户的企业
不适合:
- 重度游戏、AR/VR、深度硬件调用(如银行指纹/人脸支付完整链路)
- 对 iOS 推送/后台要求极高的场景(仍需原生补位)
来源:juejin.cn/post/7608782906940620840
年过完了,该上班了,我用Compose给大家放个烟花喜庆喜庆
今年没有买烟花,但是看了不少别人放的烟花,有些烟花真的是好看,现在年也过完了,该放的烟花也全都放了,差不多要上班了,那么我也趁这个时候,用Compose做个烟花,为新的一年来个开门红
分析烟花特征
做动效前脑子里要有个具体目标的,想好自己要的是什么效果,而不是随意去做,那么今天要做的烟花需要具备以下几点
- 数量不限:谁家买烟花也不会买个单响,高低也得多放几个才看的过瘾
- 扩散:烟花升空了肯定要炸开,不会炸的叫信号弹
- 路径是抛物线:炸开后虽然速度很快,但因重力影响,方向会有改变,会呈抛物线形态
- 逐渐消失:火药在空中烧没了,烟花也就越来越小,越来越淡了,最后消失了
- 颜色不同:好看点的烟花每次放出来颜色都不一样,酷炫一点的单个烟花里面颜色也不一样
好了就这么多了,下面来一个个去实现它
数量不限
要做到数量不限,我的实现方式是每次在界面上点击一次,该位置就生成一个烟花,为此这里需要定一个烟花的模型
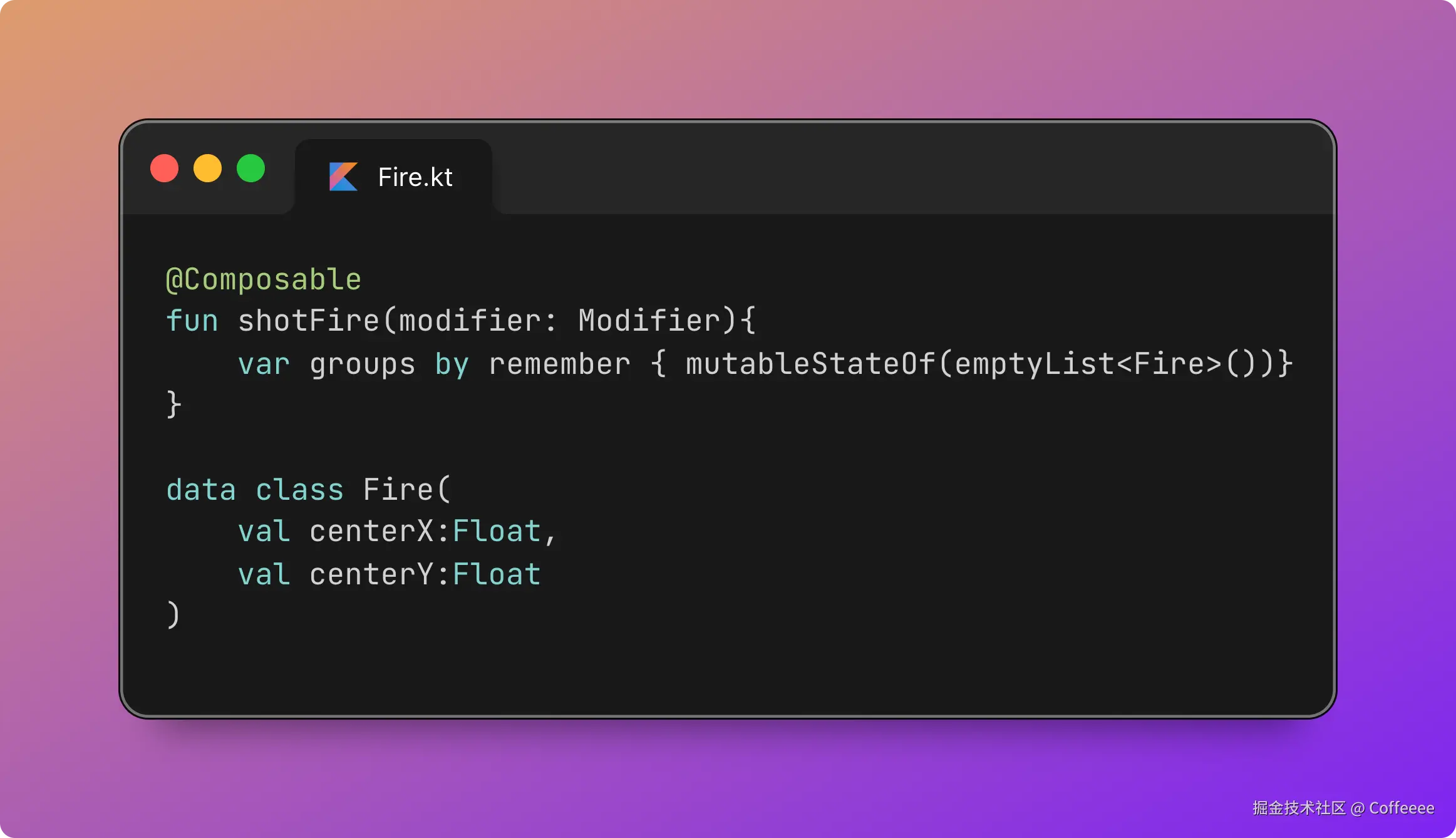
这个Fire里面现在只有坐标点,接着我们需要做的是在界面上每点一次,就创建一个Fire并且塞到groups中,监听点击的事件就交给onPointerEvent函数
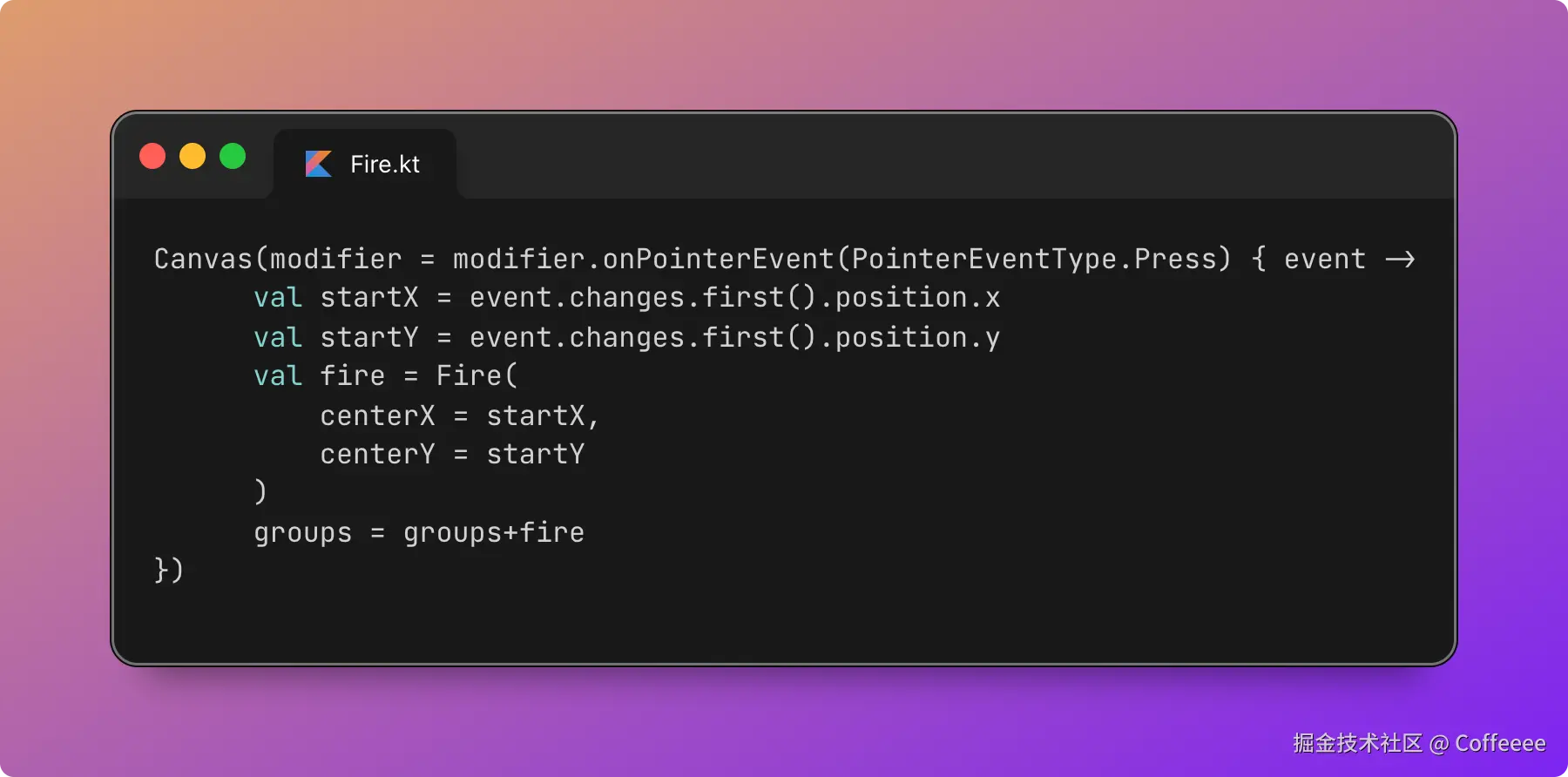
Fire的坐标是通过获取event.changes.first().position来拿到,表示当前点击的坐标,然后将groups里面的Fire绘制出来即可,暂时以红点表示
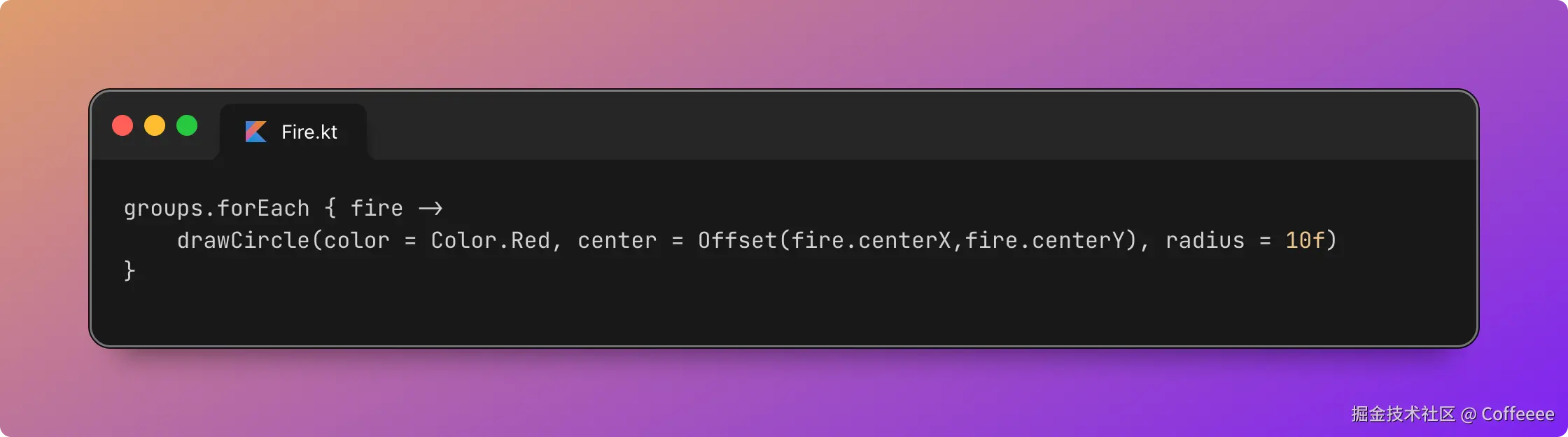
到这里,就实现了在界面上每次点击就生成一个红点的效果了

然后需要给Fire再添加个属性alpha表示透明值,用来降低每个生成后的红点的透明值,来达到淡化的效果
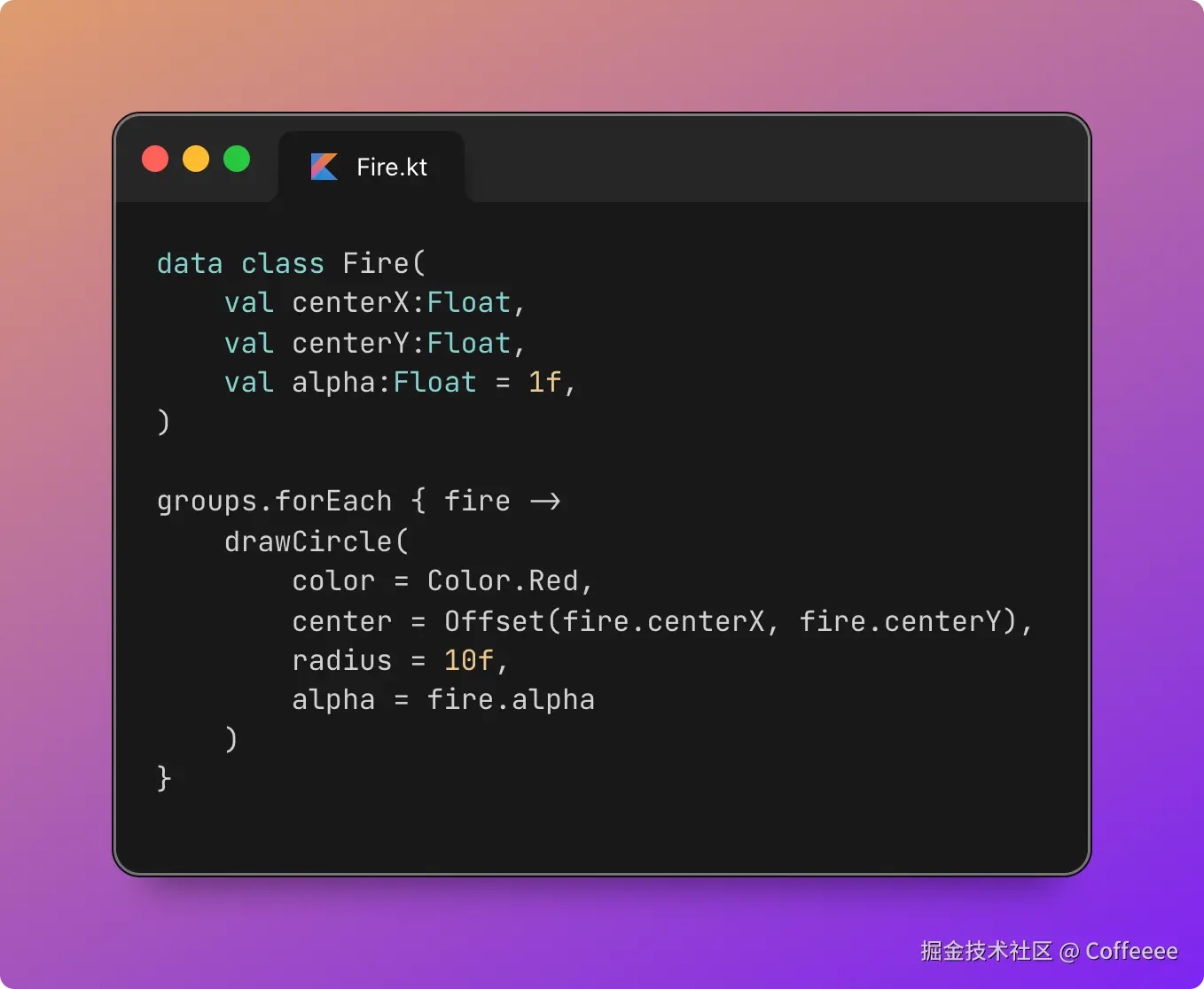
实现淡化就是不断降低透明度的过程,所以需要一个循环体,每一次降低的透明度用fadeSpeed来表示
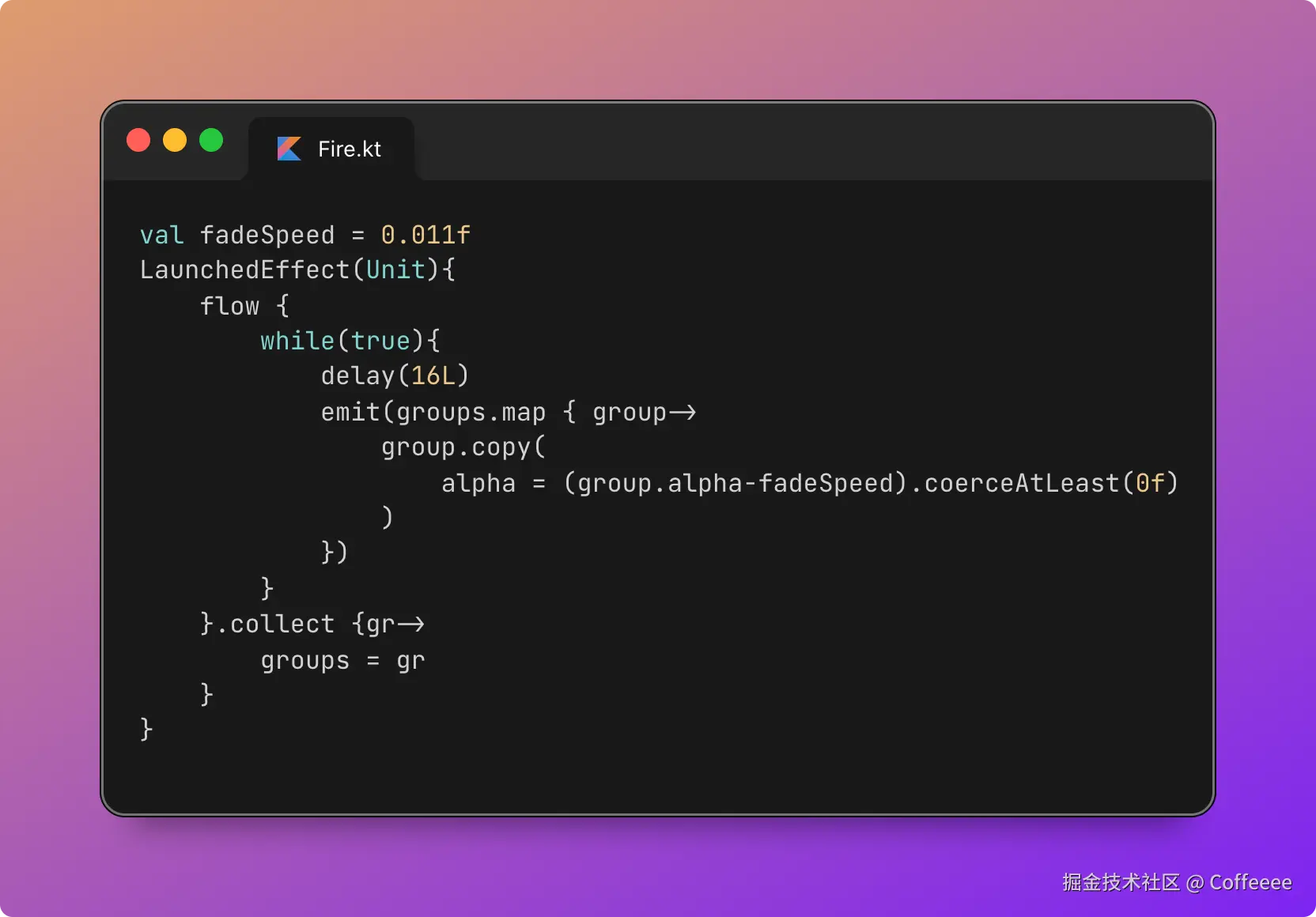
上游用来改变每个Fire的属性,下游用来将改变后的数组赋值给groups来触发重组,淡化的效果就出来了

扩散
之前画了一个点,表示烟花上升后炸开前的位置,那么接下去就是实现炸开的效果,也就是将现有的点扩散出去,那么不得不扩充一下Fire的属性,新增一个数组表示每个扩散分支的终点
扩散分支endPoints里面每一个分支用SingleFire来表示,可以看到SingleFire内部暂时定了两个属性,offset表示终点坐标,radius表示与扩散中心点的距离,size代表每个分支烟花的粗细,默认设置了一个随机值,当点击的那一刻,endPoints也必须初始化出来,初始化的值就是以扩散中心为圆心,radius=0的圆周上的点,对了,还需要定义一个分支数目以及各个分支的角度
pointX与pointY是计算圆周上坐标的函数,在之前写的动效文章里面出场次数还是蛮多的,翻旧代码找来了,那么endPoints的初始值也有了
给endPoints赋值的地方就在LaunchedEffect里面,在改变透明值的同时,也增加radius的大小
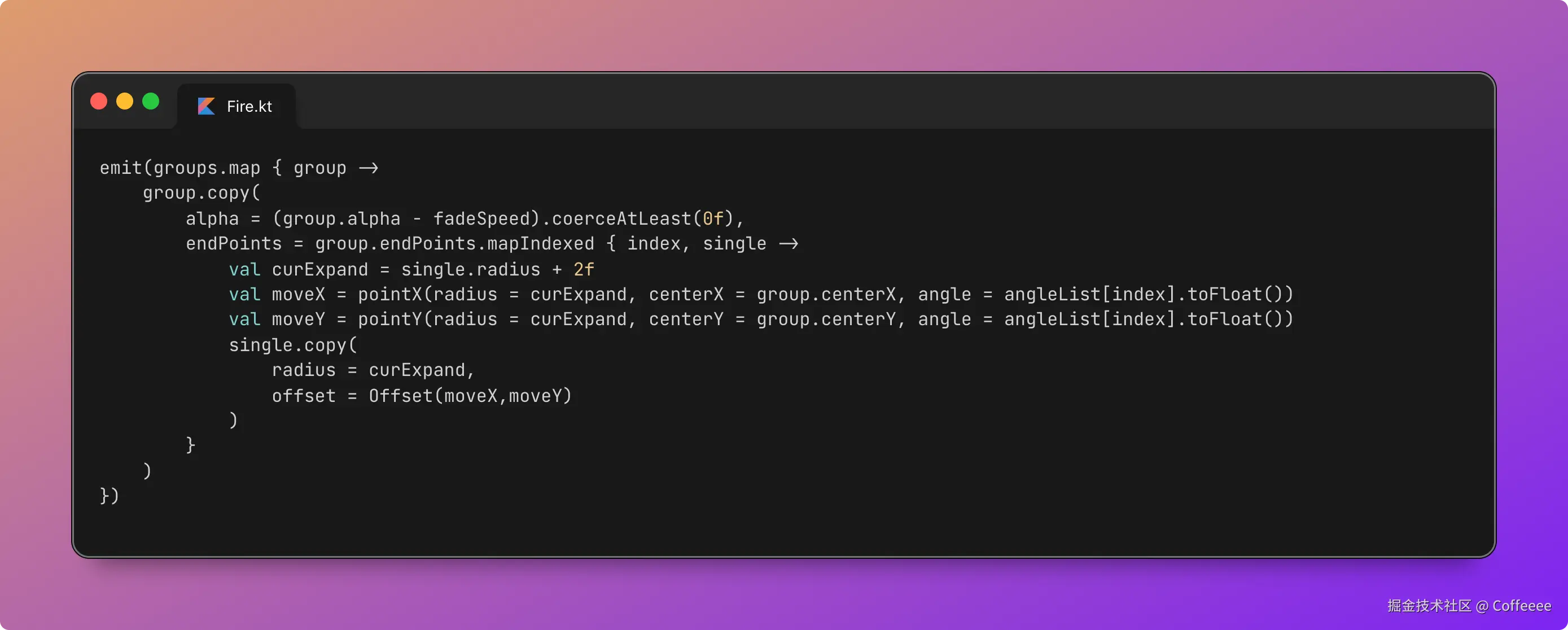
一边增加扩散的半径,一边将分支给绘制出来,绘制的代码要改下,从drawCircle改成drawLine,drawLine的参数值我们都能拿得到
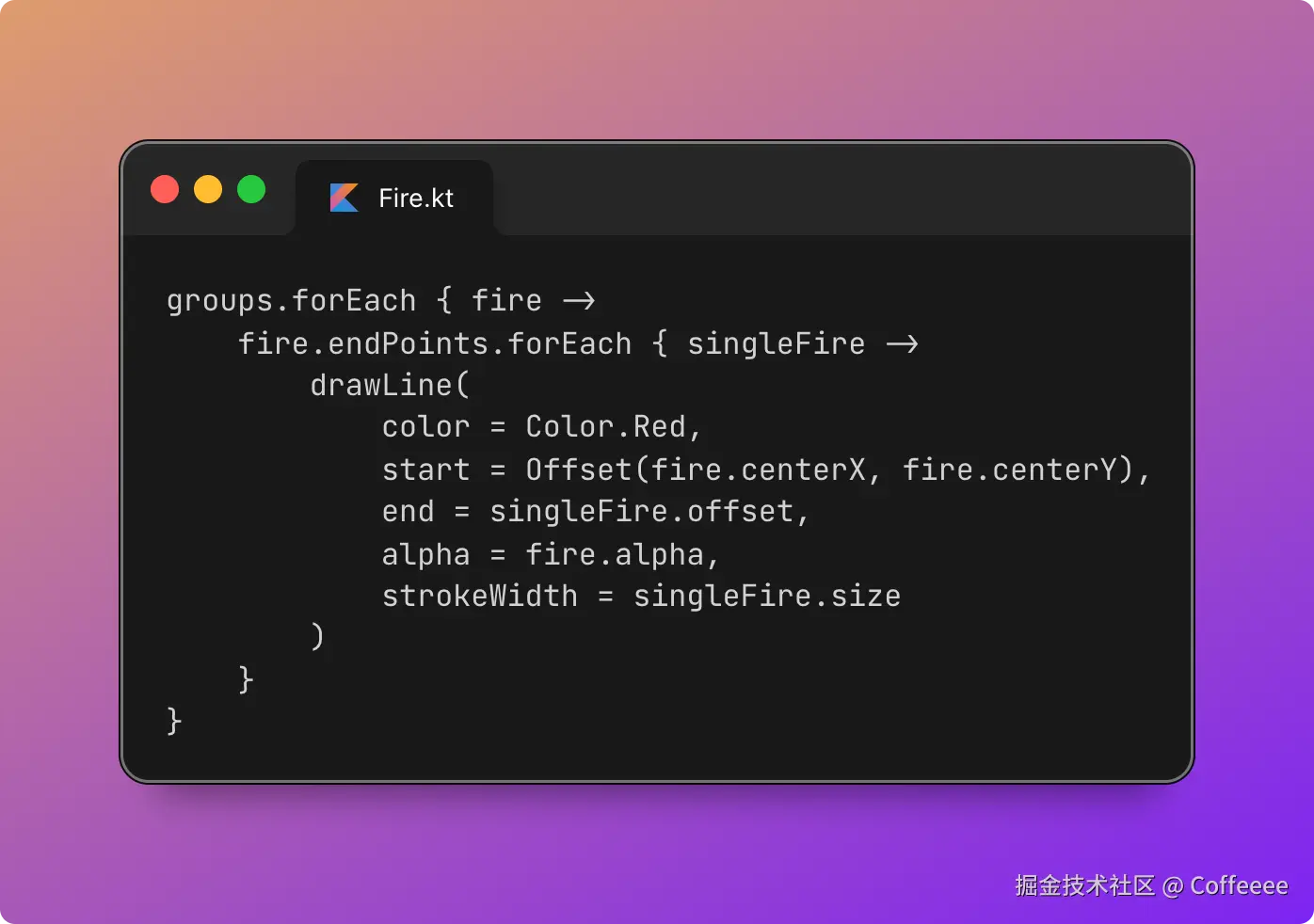
这样我们的扩散效果也基本完事了

抛物线路径
现在该想想怎么让烟花扩散的每条路径呈现抛物线的样式了,首先一点是肯定的,刚用过的drawLine肯定是不能用了,它画不了弯的线,那么谁可以画弯的呢,必须是drawPath,用它来画贝塞尔曲线真是太顺手了,咱先在SingleFire里面把用来绘制贝塞尔曲线用到的Path声明出来
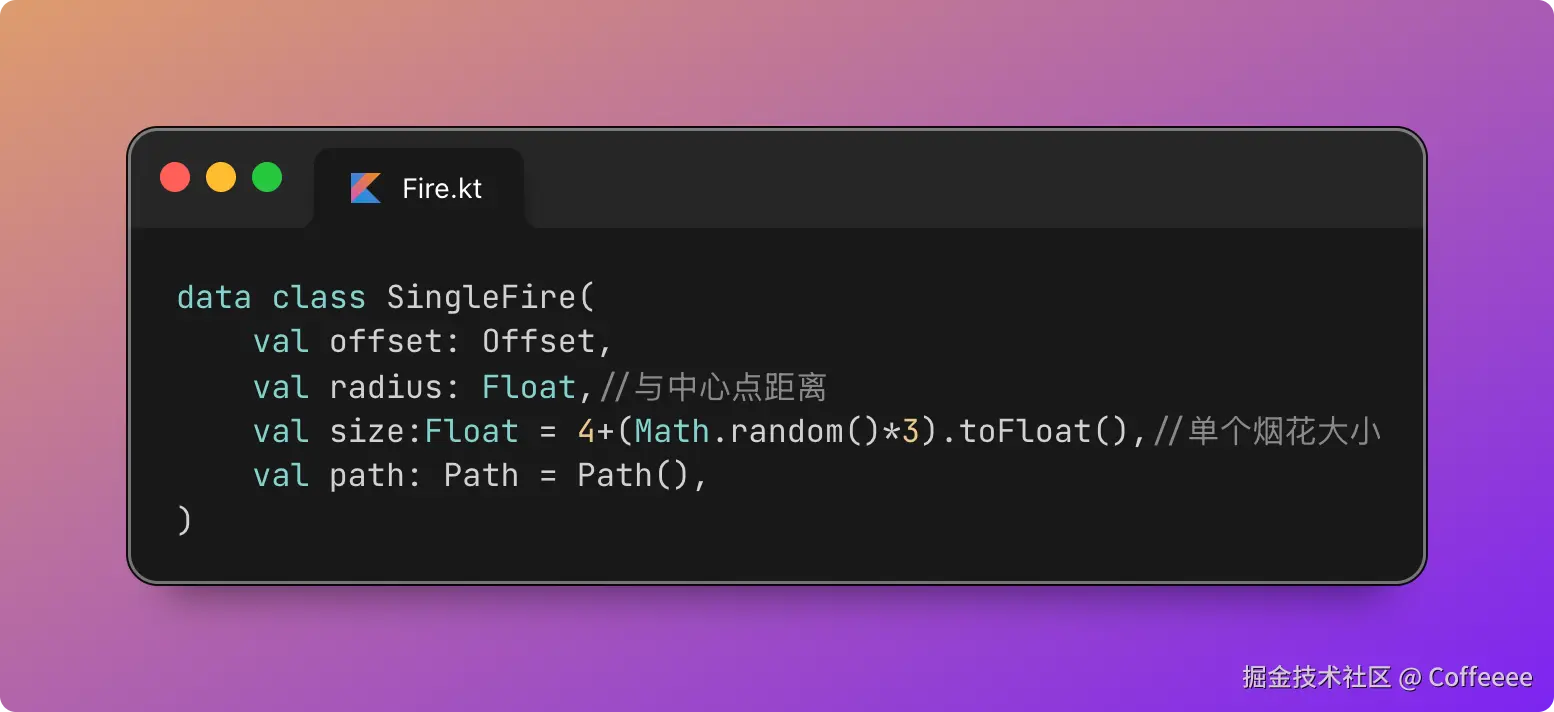
在副作用LaunchedEffect函数中,需要新增创建Path的逻辑,其中第三个控制点的值暂时与第二个点一致,代码如下
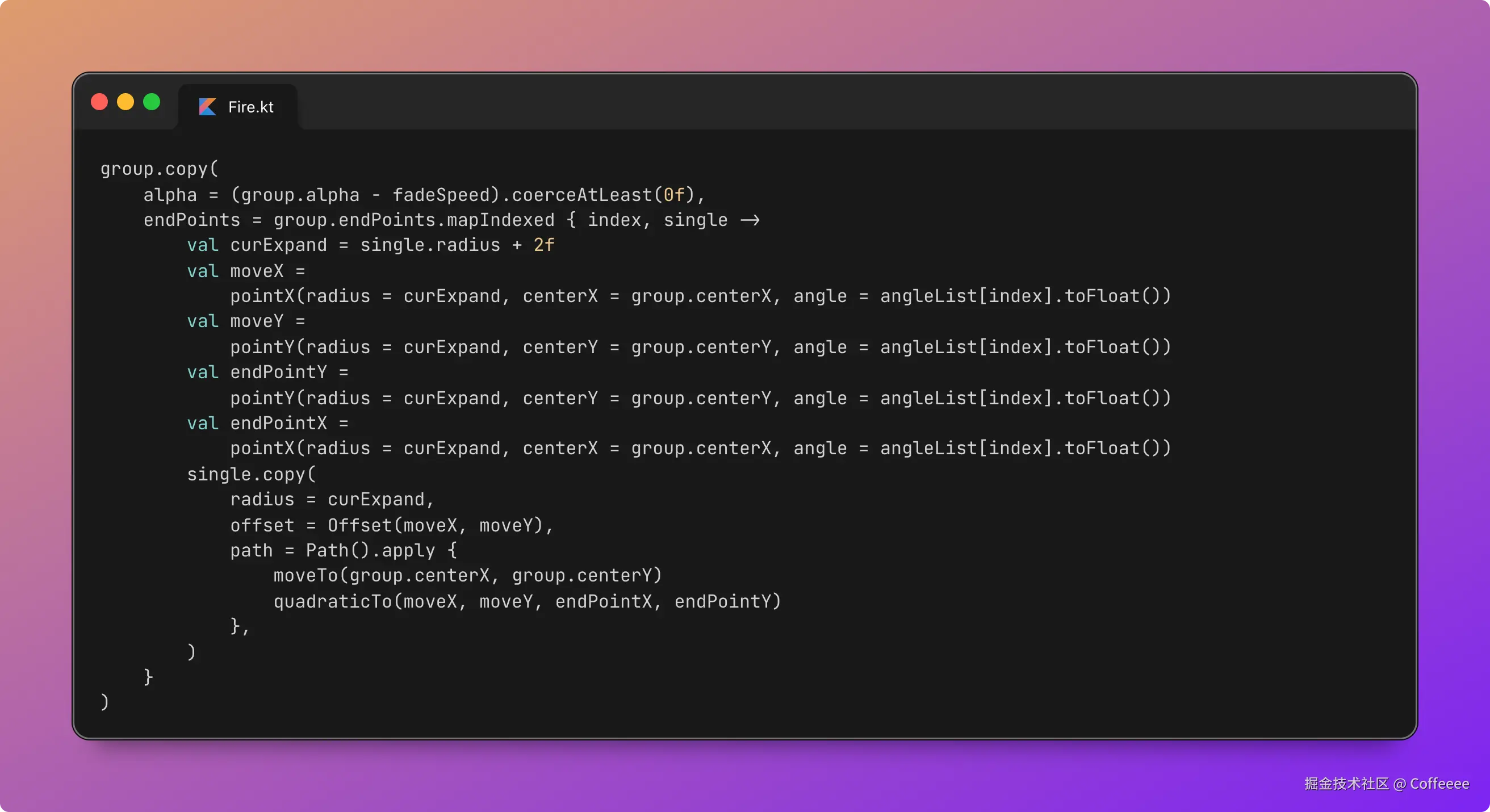
最后在drawScope中,使用drawPath将需要的贝塞尔曲线绘制出来
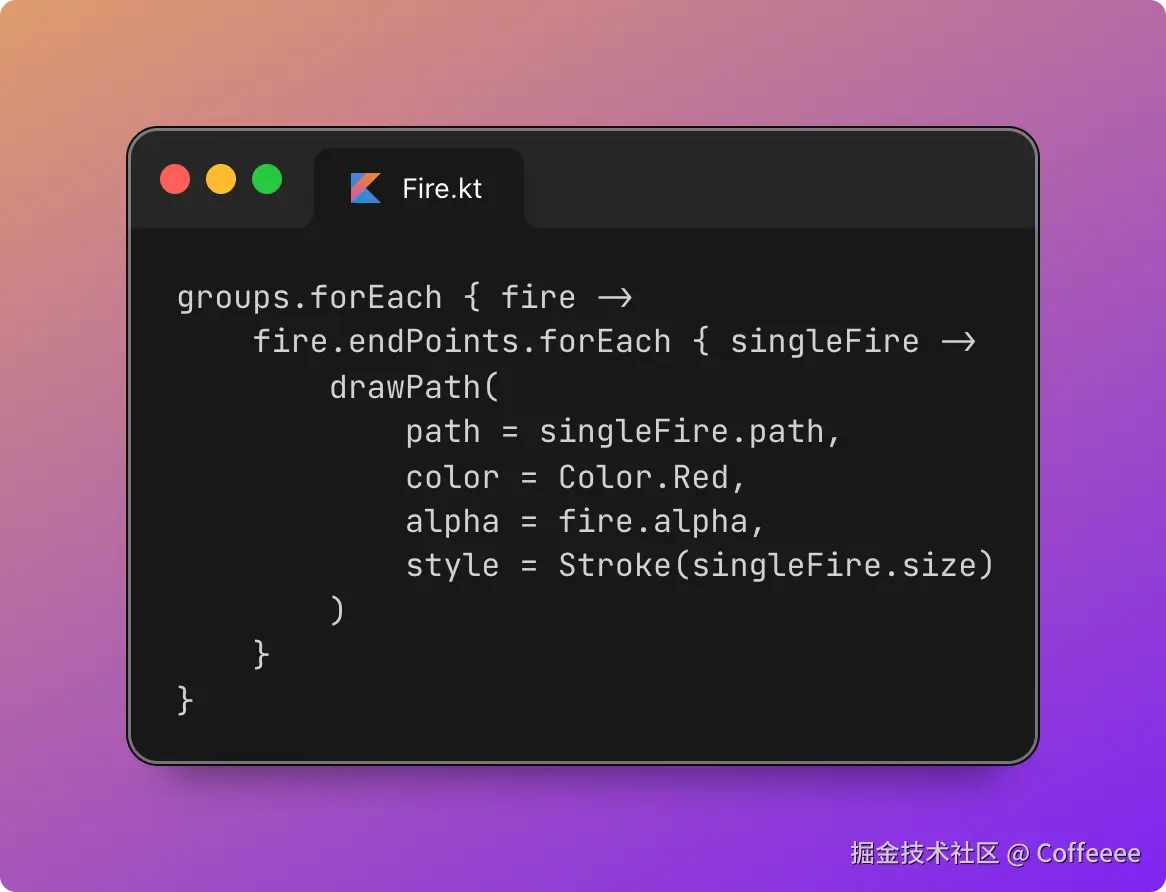
呈现的效果如下

看起来效果没啥变化,没变化就对了,因为组成我们每根烟花分支的Path目前基本在一条直线上,自然绘制出来的贝塞尔曲线也是直线,只需要将第三个点改个位置就行,怎么改呢?我们知道所有第三个点也都在一个圆周上,所计算的角度与第二个点是一样的,只需要将第三个点的角度稍微增加或者减少一些,那么所有的点的位置就改变了,比如都加个30度
那么现在的样子就不一样了

好了,现在来做两个调整,一个是抛物线拐弯的弧度,应该也是个逐渐增大的过程,扩散的瞬间,其实弧度就是0,然后受重力逐渐变大,那么在SingleFire里面需要一个属性来表示抛物线弧度的属性
sweepDegree就表示当前抛物线的弧度,改变的过程其实可以参考透明度或者扩散半径那样做
另一个调整,这个烟花现在有点“顺拐”,现在抛物线拐弯的弧度都是按照顺时针来的,但实际场景中,烟花是朝四周扩散的,我们这个二维空间里面,也应该是有左右两个方向,所以不应该所有的弧度都是加上degree变量,其实想想也明白,真的要加上degree的是那些x坐标比初始值大的点,其他的都应该要减去degree才行,代码按照这个逻辑稍作调整
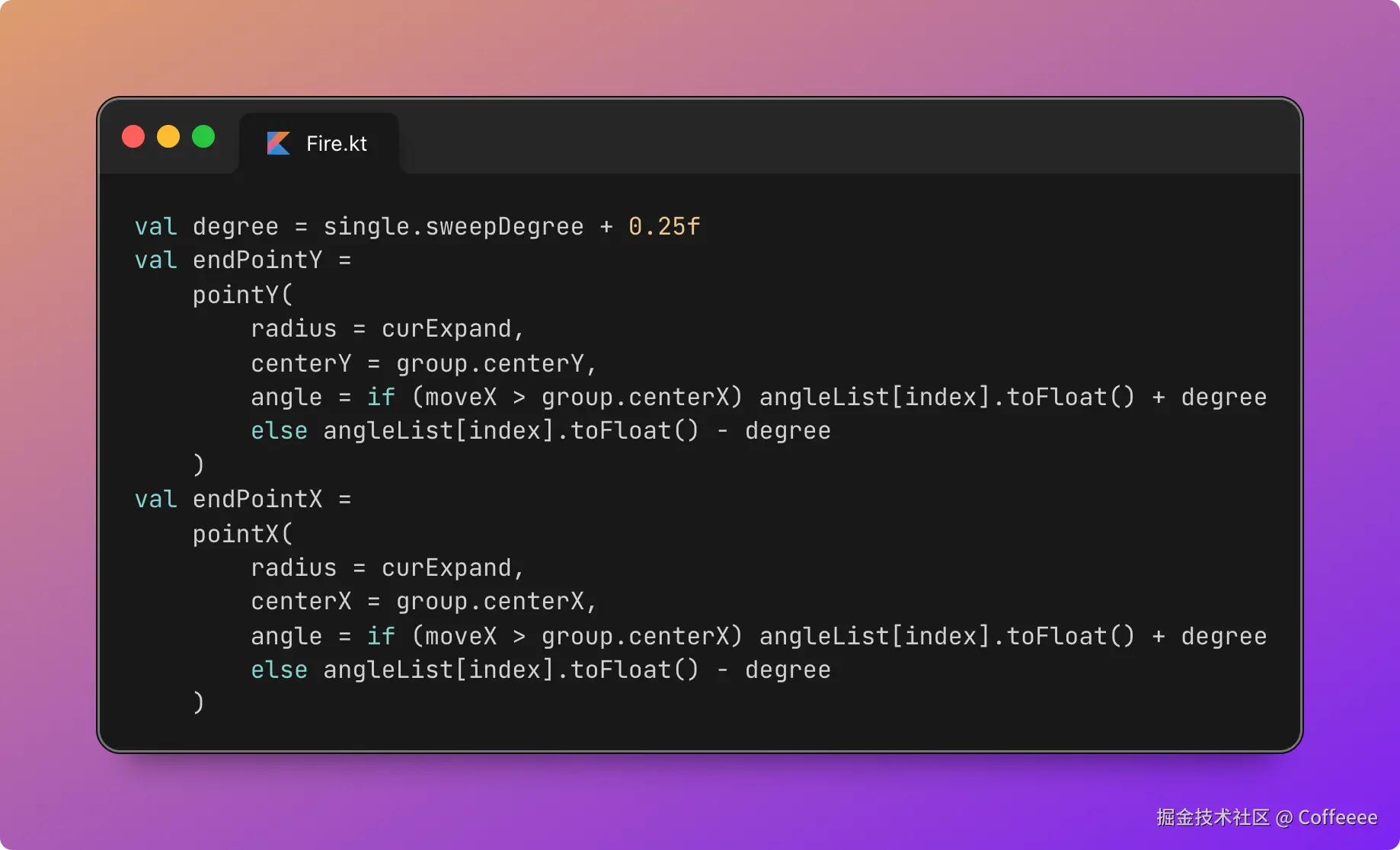
我们要的抛物线效果就做好了,效果看下

逐渐消失
烟花消失的样子也可以分成两部分,其中一个是炸开后从中心向外开始消失,所以我们做的烟花的起始位置就不能是一个点了,而是num个点,也在一个圆周上,这些点的起始半径也都为0,在SingleFire中新增一个startRadius属性代表这个半径
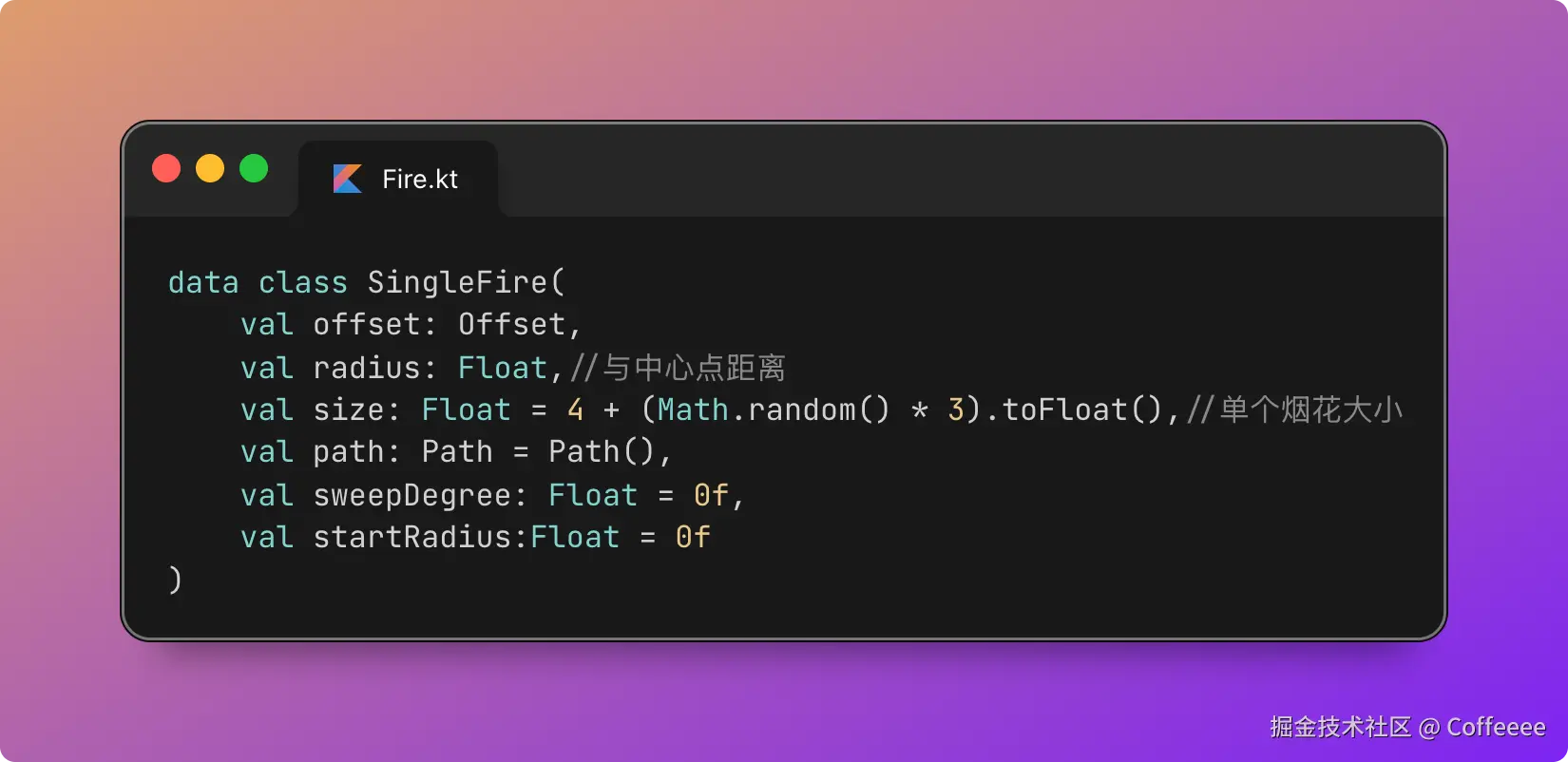
同样在副作用中,逐渐去变大这个startRadius,然后将最新值拿来计算最新圆周上的点,代码如下
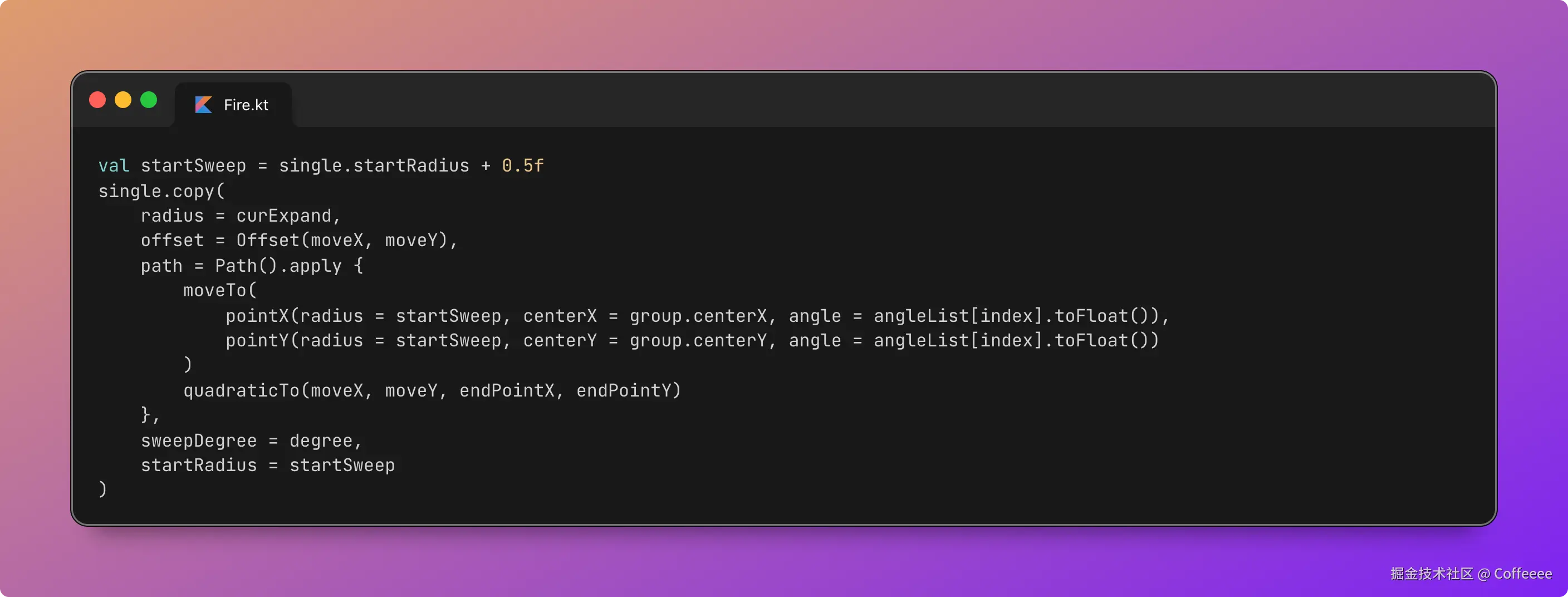
另一个要处理的是烟花每一条曲线上,当开始消失的时候,不是整根曲线一起消失,而是会分成若干个小火星,然后小火星也慢慢变小变暗,要做到这一点就要用到一个关键型函数
PathEffect.dashPathEffect,用来将一根线变成一根虚线的,这个函数里面第一个参数就是个float数组,数组里面会传两个值,分别代表虚线每一个线段的长度以及虚线之间的间距

而我们要做的就是将float数组中第一个值不断减小,第二个值不断变大,SingleFire中再定义两个属性代表线段长以及间距长
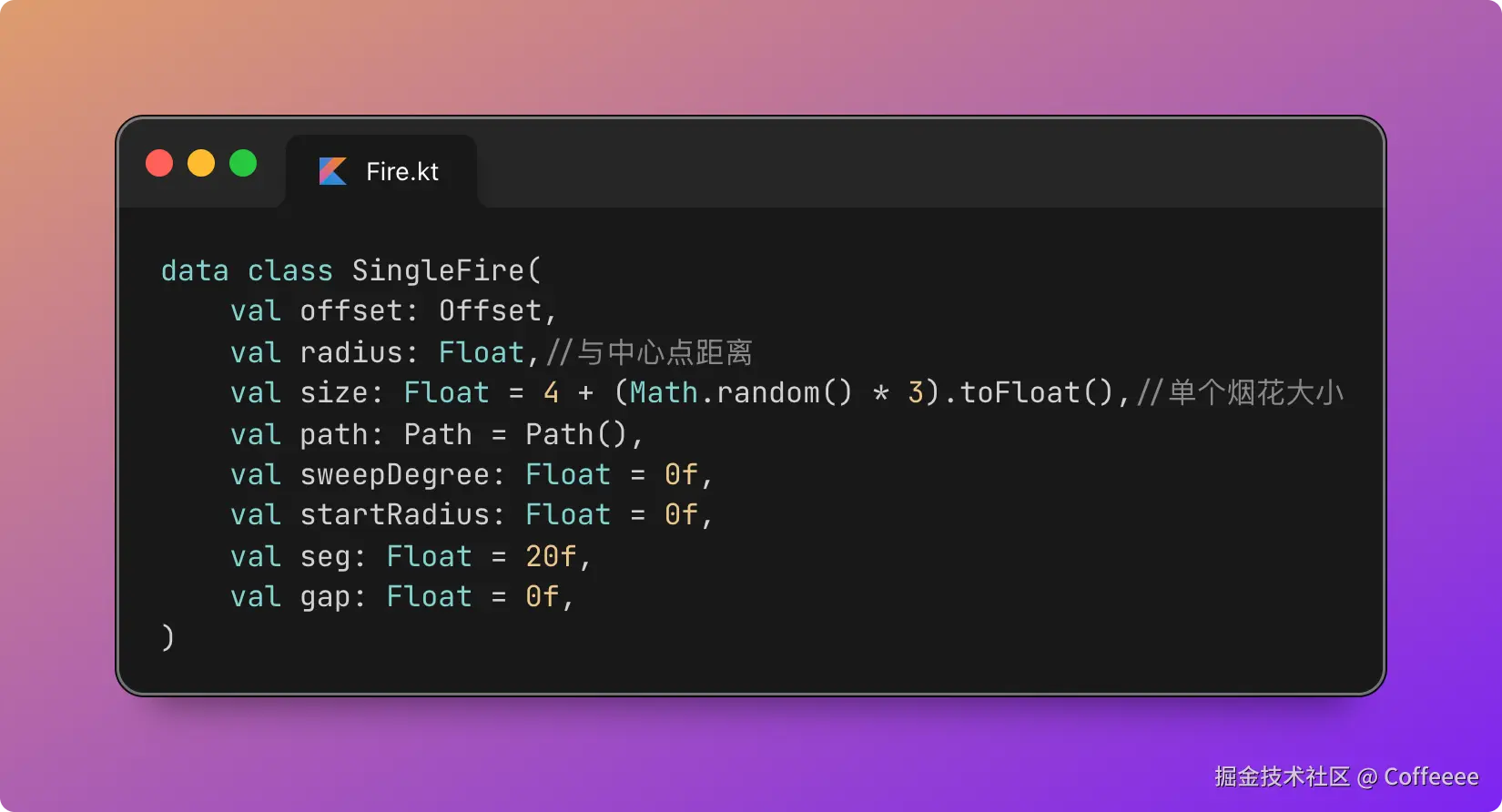
副作用里面的代码做如下更改

然后在drawPath中添加上PathEffect.dashPathEffect的处理
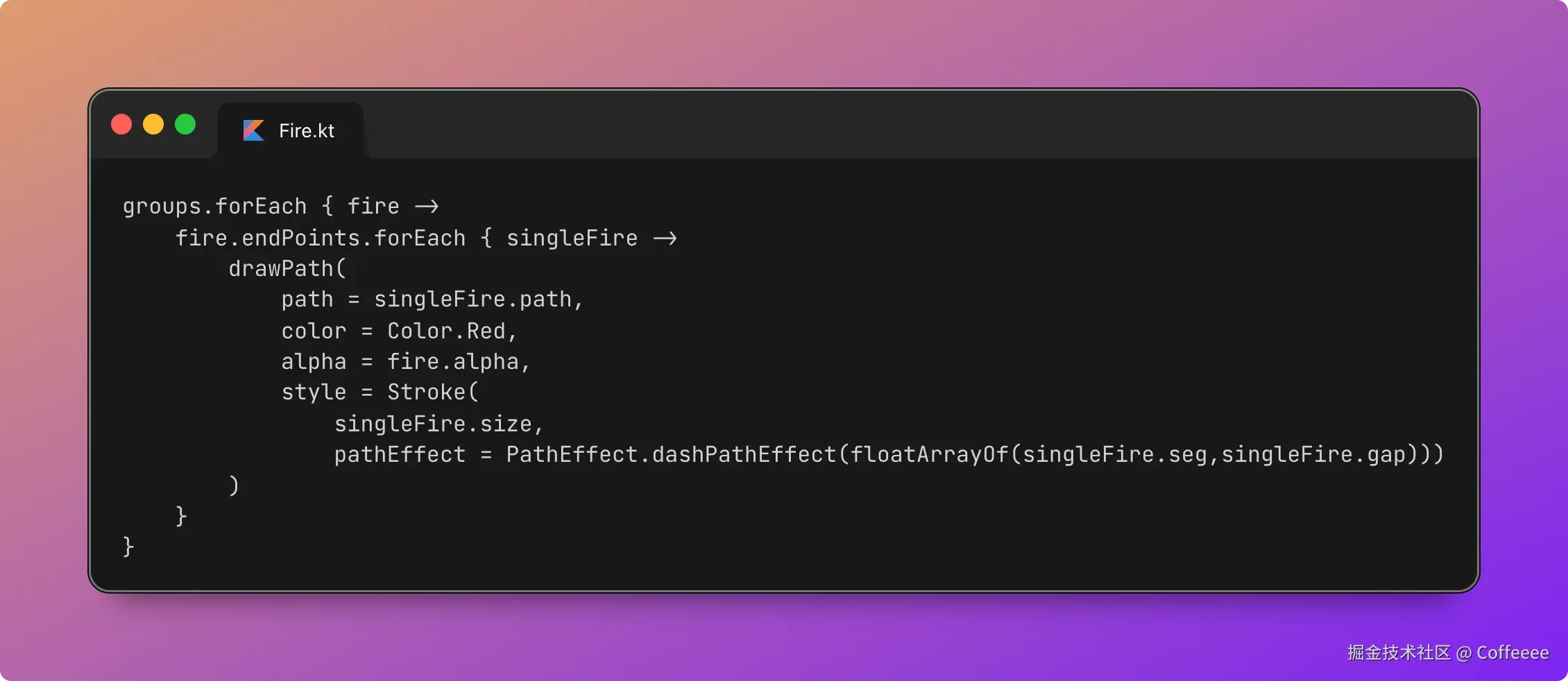
烟花消失的部分也做好了,看下效果

不同颜色
到了最后一步了,给烟花上色,正常放烟花的时候,每次放出来的烟花颜色都会不一样,而且单个烟花中颜色也不是只有一种,所以这里打算这么做,先弄一个颜色的数组

然后在给烟花初始化的时候,每一次都从这个数组中随机抽三个颜色组成一个新的数组,我们烟花每一个分支的颜色,都从这个新的数组中随机找一个来设置,先给SingleFire再添加一个color属性
初始化部分,通过shuffled函数把colorList打乱,再抽取最后三个颜色
赋值部分,shuffList中随机拿一个颜色出来赋值
绘制部分,使用Brush生成一个渐变色,singleFire.color与白色的渐变,这样可以让烟花看起来亮一些
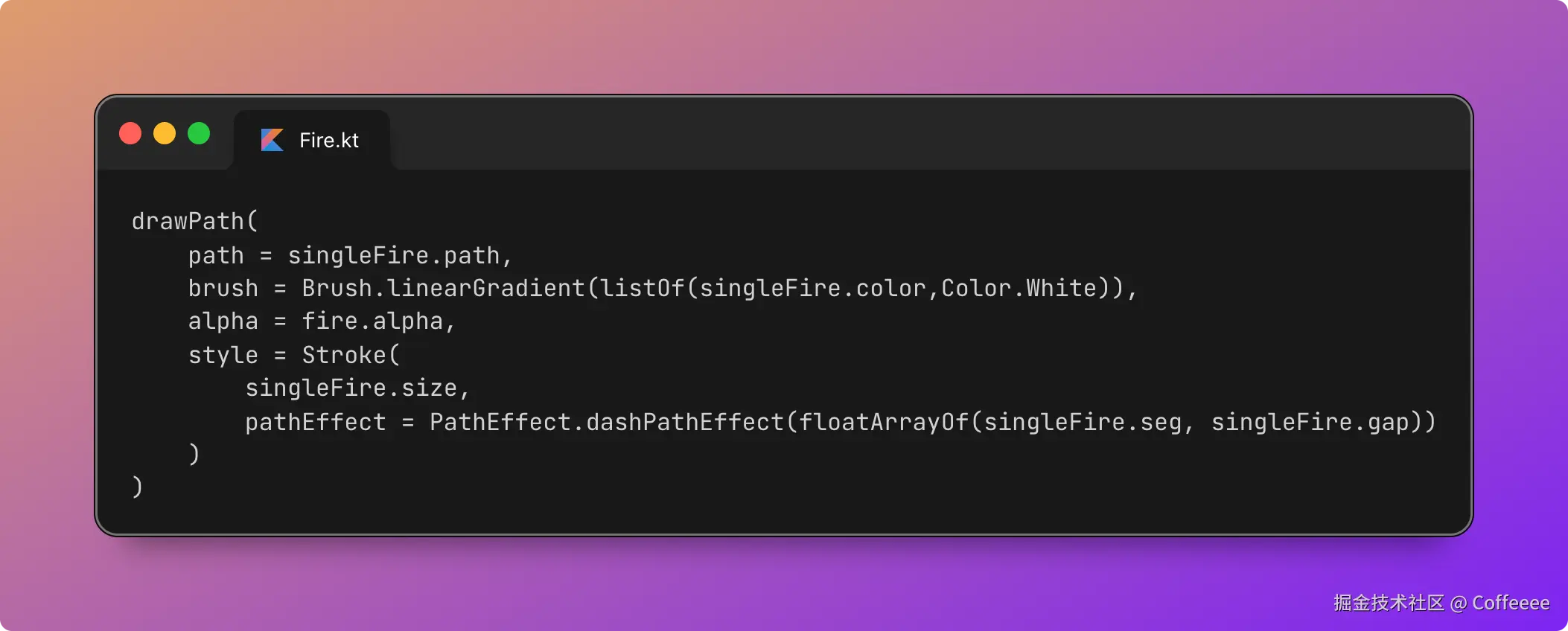
看下最终效果

最后
烟花放完了,又要开始重新搬砖当牛马了,那我就借这篇烟花动效的文章祝各位看官在新的一年工作顺利,事业有成,天天发大财~
来源:juejin.cn/post/7609288132602101760
分享前端项目常用的三个Skills--Vue、React 与 UI 核心 Skills
前言
在过去的几年里,前端开发经历了从手写每一行 HTML/CSS 或使用组件库(Ant Design, Element Plus),到 AI 辅助编程(GitHub Copilot, Cursor)的巨大跨越。然而,2025 年以来的技术浪潮正将我们推向一个新的阶段:从 “AI 辅助” 向 “AI Agent(智能体)” 转型。
在这种模式下,开发者不再只是接收代码建议,而是为 AI 提供一系列“技能包(Skills)”,让 AI 能够理解复杂的框架逻辑、项目结构乃至视觉审美。
什么是Skills? 用一句话概括就是: Skills = 领域专业知识 + 你的项目偏好 + 严厉的审查官。
1. 为什么需要 Skills?
在 AI 编程的语境下,Skills 的出现是为了解决大模型(LLM)“博而不精”的天然缺陷。
1.1 通才 AI:知识的“图书馆”
一个没有安装 Skills 的大模型(如 GPT-5 或 Claude 4.5)就像一个读过全世界所有代码的毕业生:
- 广度惊人:它知道几百种编程语言,甚至能背出 2014 年的过时语法。
- 深度断层:它不知道你公司内部的封装规范,不知道你的组件命名习惯,更不知道你项目中那个“不能动的老 Bug”。
- 执行模糊:给它一个需求,它会从 100 种可能的解法中随机选一个给你,不管这是否符合你现在的工程环境。
1.2 专才 AI:自带“十年工龄”的骨干
安装了 Skills 的 AI(Agent),则完成了从“大模型”到**“领域智能体”**的进化:
安装了 Skills 之后, 它不再是那个满嘴跑火车的机器人,而是一个被你强制要求“必须按这套规约写代码”的资深开发。
| 特性 | 通才 AI (Generalist) | 专才 AI (Specialist with Skills) |
|---|---|---|
| 思维边界 | 无边界,容易产生幻觉 | 有界思维:严格锁定在当前技术栈内 |
| 项目理解 | 盲人摸象,只看当前文件 | 全局视野:理解路由、状态管理、样式体系 |
| 输出质量 | “大概能跑”的代码 | **“符合工程直觉”**的生产级代码 |
| 角色定位 | 知识检索器 | 虚拟技术负责人 (Virtual Lead) |
2. Skills 里面到底装了什么
一个 Skills 文件夹里通常不是深奥的代码,而是三样东西:
- 规约(Rules) :一堆告诉 AI “准许做什么”和“严禁做什么”的指令(通常是
.cursorrules或.md文件)。 - 上下文(Context) :你项目的特殊结构。比如你的路由写在哪里,你的接口是怎么封装的。
- 工具(Tools) :一些自动化的小脚本。比如 AI 写完代码后,自动运行一下
npm lint检查有没有写错。
如果说通才 AI 提供的是“概率” (它觉得这段代码看起来像对的),那么 Skills 提供的就是“确定性”。它把行业内顶尖架构师的经验,封装成了 AI 触手可及的“条件反射”。
本文将分享前端高频使用的三个核心技能包:vue-skills、react-skills(agent-skills)以及 ui-skills(uipro-cli),剖析它们如何通过标准化的指令集,彻底改变我们的开发流。
Vue-Skills
Vue-Skills涵盖了 Vue 3 项目的最佳实践、TypeScript 类型安全增强、IDE 性能优化以及现代 Vue 编码模式。它们旨在解决大型 Vue 项目中常见的开发痛点,如 IDE 卡顿、类型推断错误、构建配置以及代码可维护性问题。
1.1 核心规则
可以将这些规则概括为以下 5 个主要方面:
1. 开发体验与 IDE 性能优化 (IDE & Performance)
关注如何解决大型项目中 VSCode 和 Volar 插件的性能问题。
- codeactions-save-performance.md: 解决在大型 Vue 项目中保存文件时耗时过长(30秒+)的问题,建议禁用或限制耗时的 Code Actions。
- volar-3-breaking-changes.md: 针对 Volar 升级带来的变更进行适配,确保插件功能正常。
- vue-directive-comments.md: 介绍了@vue-ignore, @vue-skip,@vue-expect-error等指令注释,用于在模版中精细控制类型检查行为(类似 @ts-ignore)。
2. TypeScript 类型安全与配置 (Type Safety & Configuration)
致力于提升 Vue 模版和组件的类型检查严格度,减少运行时错误。
- vue-tsc-strict-templates.md: 推荐开启 strictTemplates,在编译时捕获模版中未定义的组件和属性错误。
- vue-router-typed-params.md: 解决unplugin-vue-router,导致的路由参数类型丢失问题(Property does not exist),推荐更严格的路由参数类型定义。
- data-attributes-config.md: 配置 vueCompilerOptions 以支持
data-*属性的类型检查,避免误报类型错误。 - ** module-resolution-bundler.md**: 推荐在 tsconfig.json 设置 "moduleResolution": "bundler"
以适配现代构建工具。 - with-defaults-union-types.md: 修复在defineProps中使用联合类型(如 string | false)配合withDefaults 时的虚假警告问题。
3. Vue 3 现代编码模式 (Modern Patterns)
推广 Vue 3.4+ 的新特性及更优雅的代码组织方式。
- define-model-update-event.md: 推荐使用 Vue 3.4 的 defineModel()宏,替代手写的props+ emit('update:modelValue')模式。
- extract-component-props.md: 建议将复杂的defineProps类型提取为独立的 TS 接口,提高代码可读性和复用性。
- script-setup-jsdoc.md: 规范
<script setup>中的 JSDoc 使用,增强组件文档和类型提示。 - fallthrough-attributes.md: 关于 inheritAttrs: false和透传属性(Attributes Fallthrough)的最佳实践。
4. 运行时陷阱与调试 (Runtime Caveats & Debugging)
解决特定场景下的怪异 bug 和运行时问题。
- deep-watch-numeric.md: 警告在侦听(watch)数字数组时使用 deep: true的陷阱(新旧值相同),建议使用深拷贝。
- duplicate-plugin-detection.md: 防止 Vue 插件(如 Pinia)在微前端或特定环境下被重复注册。
- hmr-vue-ssr.md: 处理服务端渲染(SSR)场景下的热更新(HMR)问题。
5. 测试与样式 (Testing & Styling)
- pinia-store-mocking.md: 关于如何在测试中正确 Mock Pinia Store 的指南。
- strict-css-modules.md: 开启 CSS Modules 的严格模式,防止使用未定义的 class 名。
1.2 安装方法
通过简单的命令,你可以将此技能植入到你的 AI 工作流中:
npx add-skill hyf0/vue-skills
执行上面的指令后,会自动检查IDE,终端环境
选择安装在当前项目,还是对所有项目生效
选择下载一份每个项目建立软链接,还是将规则文件复制在每个项目下
安装完成之后的显示
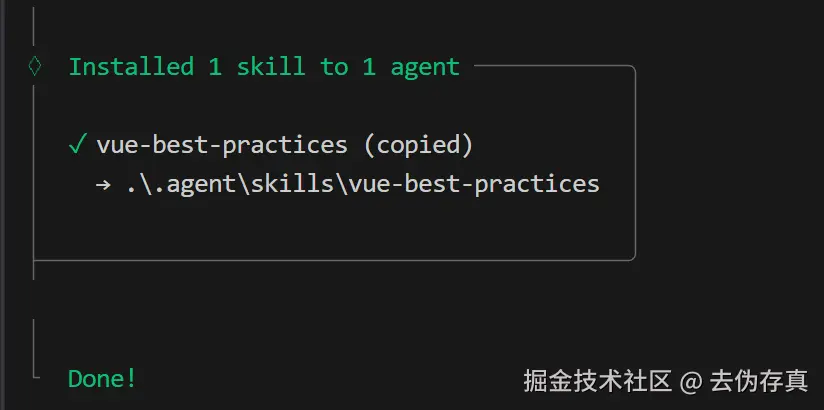
1.3 实战案例
案例展示了当 AI Agent 加载了 vue-best-practices 技能包后,如何通过 “提取组件属性 (Extract Component Props)” 规则,优雅地解决二次封装组件时的类型继承问题。
场景描述:我们正在基于一个第三方库的 BaseButton.vue 组件,封装一个我们项目专用的 ProButton.vue。我们需要让 ProButton 继承 BaseButton 的所有属性(Props),同时增加一个自定义属性 loading。
1. 优化前:常规“盲写”模式
现象:如果没有技能包指导,开发者往往会手动重复定义属性,或者使用不推荐的 Vue 内部实例类型。
<!-- ProButton.vue -->
<script setup lang="ts">
// ❌ 错误做法 1:手动重复定义,维护成本极高
interface Props {
text: string;
color?: string;
loading: boolean; // 自定义属性
}
// ❌ 错误做法 2:使用 InstanceType,会包含大量的 Vue 内部属性,干扰类型提示
import type BaseButton from "./BaseButton.vue";
type BaseProps = InstanceType<typeof BaseButton>["$props"];
defineProps<BaseProps & { loading: boolean }>();
</script>
2. 优化后:使用 vue-component-type-helpers
技能规则应用:
- 规则名称:
extract-component-props.md - 核心逻辑:利用
vue-component-type-helpers库精确提取组件定义的 Props,排除内部干扰项。
重构结果:代码简洁,类型提示完美,且具备 100% 的继承安全性。
<!-- ProButton.vue -->
<script setup lang="ts">
import type { ComponentProps } from "vue-component-type-helpers";
import BaseButton from "./BaseButton.vue";
// ✅ 符合最佳实践:精确提取子组件的 Props 类型
type BaseButtonProps = ComponentProps<typeof BaseButton>;
// 扩展基础组件的属性
interface Props extends BaseButtonProps {
loading?: boolean;
size?: "sm" | "md" | "lg";
}
const props = withDefaults(defineProps<Props>(), {
loading: false,
size: "md",
});
</script>
<template>
<div class="pro-button">
<!-- 将剩余属性透传给基础组件 -->
<BaseButton v-bind="$attrs" :loading="loading">
<slot />
</BaseButton>
</div>
</template>
3.核心价值总结
| 维度 | 传统方式 | Skills 方案 (Vue Best Practices) |
|---|---|---|
| 开发效率 | 需要翻阅源码查找子组件 Props | 自动提取,AI 自动完成类型桥接 |
| 类型提示 | 混杂大量 $props 内部属性,极难看清 | 纯净提示,仅显示业务定义的属性 |
| 维护性 | 子组件增加 Prop 后,包装组件需手动同步 | 自动同步,类型定义随子组件动态更新 |
| 代码洁癖 | 充满大量的 Hack 或冗余定义 | 标准工程化,符合 Vue 3 官方推荐模式 |
提示:安装技能包后,当你在写高阶组件(HOC)或二次封装组件时,AI 会自动识别场景并提示你使用
vue-component-type-helpers进行类型提取,确保你的 TypeScript 链路在全项目保持强类型约束。
2.1 核心功能
1. React 组件组合模式 (vercel-composition-patterns)
适用场景:
- 组件重构:当核心组件因布尔属性(Boolean props)爆炸(如
isLoading,isSmall等)而难以维护时。 - 库级开发:构建需要高度灵活、可扩展 API 的企业级 UI 组件库。
- 复杂交互设计:实现具有强父子联动逻辑的复合组件(如 Tabs, Select, Menu)。
核心规则:
- 架构优先组合:严禁无限制叠加布尔属性,推崇使用 复合组件 (Compound Components) 和 Context 共享状态。
- 接口解耦:Provider 集中管理状态逻辑,子组件仅通过约定的 Context 接口进行交互。
- 显式变体 (Explicit Variants):与其给一个组件加 10 个布尔值,不如创建明确命名的变体组件(如
PrimaryButton,IconButton)。 - 组合优于配置:优先通过
children进行 UI 拼装,而非通过庞大的配置对象或大量的renderXProps。
2. React & Next.js 性能最佳实践 (vercel-react-best-practices)
适用场景:
- 性能调优:页面响应慢、首屏渲染 (LCP) 时间长或存在明显的交互延迟。
- 现代 Web 构建:基于 Next.js App Router 架构的全栈开发。
- 大规模数据处理:需要并行获取多个 API 数据且必须避免渲染阻塞的场景。
核心规则:
- 消除瀑布流 (Waterfalls):性能优化的 头等大事。强制要求并行化独立异步操作,并利用
Suspense实现流式 (Streaming) 内容分发。 - 打包体积压缩:禁用 Barrel Files (单一入口导出文件) 以保护 Tree-shaking;强制使用
next/dynamic进行代码分割。 - 服务端性能 (RSC):利用
React.cache()进行请求级数据去重,最小化传输至客户端的序列化数据量。 - 重渲染控制:避免在 Effects 中处理同步状态,提倡使用派生状态 (Derived State);利用
startTransition处理非紧急更新。
3. React Native & Expo 移动开发指南 (vercel-react-native-skills)
适用场景:
- 移动端丝滑体验:针对 iOS 和 Android 优化长列表滑动和复杂手势动画。
- 跨端性能消除:解决由于 JS 线程与 UI 线程通信延迟导致的性能瓶颈。
- 原生功能集成:在 Expo 或原生环境中处理多媒体、字体和原生组件的高性能接入。
核心规则:
- 列表性能 (最关键):强制使用
FlashList替代FlatList;列表项必须经过memo处理以减少多余重绘。 - GPU 加速动画:动画属性仅限在
transform和opacity上操作,确保逻辑在 UI 线程直接执行。 - 原生 UI 适配:始终使用
expo-image优化图片加载;优先使用Pressable替代TouchableOpacity以获得更好的响应响应。 - 渲染规范:文本必须且只能包裹在
Text组件内;禁止在条件渲染中使用&&(防止在移动端渲染出数字 0)。
4. Web 界面设计指南 (web-design-guidelines)
适用场景:
- UI/UX 审计:项目发布前检查 UI 间距、颜色 Token 和视觉输出的一致性。
- 无障碍性 (A11y):确保网站符合 Web 辅助功能标准,提升产品包容性。
- 自动化 UI 审查:在 Code Review 阶段快速发现硬编码和非标准交互实现。
核心规则:
- 动态合规检查:通过远程拉取最新的设计系统准则,确保证审视标准始终是最新的。
- 无障碍强制约束:严格检查颜色对比度、ARIA 标签完整性以及键盘导航流程。
- 高精度反馈:能够精确到代码行指出不符合设计系统规范(如未使用的 Design Tokens)的地方。
2.2 安装方法
npx add-skill vercel-labs/agent-skills
可以只选择安装其中的一个规则集,比如说vercel-react-best-practices
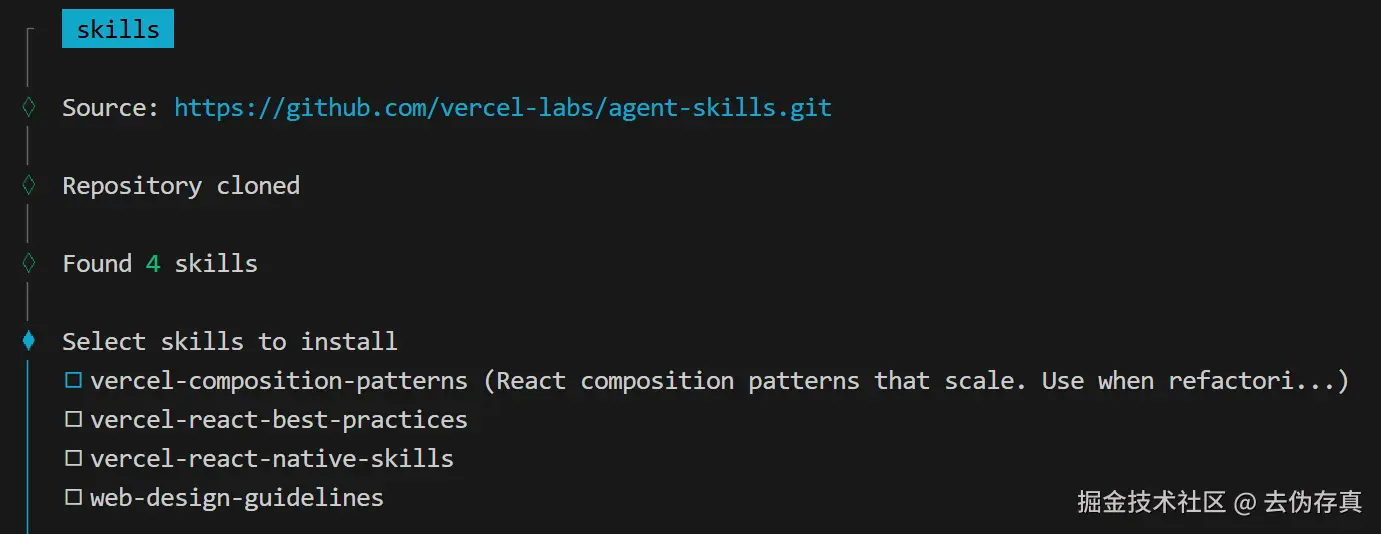
其余步骤,与Vue-Skills的问询问题一模一样,不再赘述。

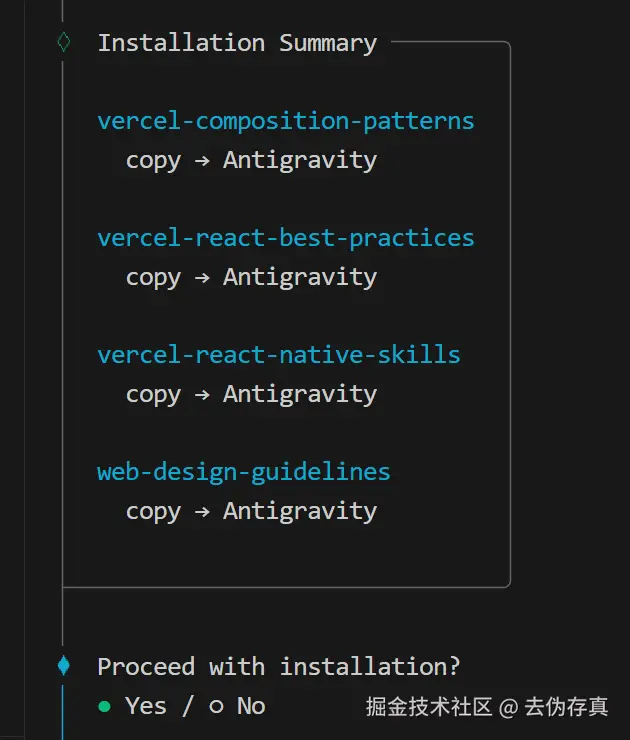
2.3 用法示例
在一个 Next.js App Router 项目的个人中心页面中,我们需要同时获取用户信息、订单列表和优惠券信息。
1. 优化前:串行瀑布流 (Sequential Waterfall)
现象:如果没有技能包约束,AI 可能会写出标准的串行代码。这种方案下,总耗时是三个接口请求时间的累加(T1 + T2 + T3)。
// ❌ 不符合最佳实践:串行阻塞
export default async function ProfilePage() {
// 请求 1:获取用户信息
const user = await fetchUser();
// 请求 2:依赖于 user.id,但在请求 1 完成前无法开始
const orders = await fetchOrders(user.id);
// 请求 3:不依赖于前二者,却被白白阻塞
const coupons = await fetchCoupons();
return (
<div>
<UserInfo user={user} />
<OrderList orders={orders} />
<CouponList coupons={coupons} />
</div>
);
}
2. 优化后:并行获取 + 组件组合 (Parallel & Composition)
技能规则应用:
async-parallel:识别出不互相关联的请求,并并行启动。server-parallel-fetching:利用服务器组件的组合特性,减少主线程阻塞。
重构结果:页面总耗时缩短为(T1 + Max(T2, T3)),且实现了流式分发。
// ✅ 符合最佳实践:并行获取与解耦渲染
import { Suspense } from "react";
export default async function ProfilePage() {
// 1. 同时启动互不关联的异步任务,不加 await
const userPromise = fetchUser();
const couponsPromise = fetchCoupons(); // 并行开始
// 2. 仅等待必要的基础数据
const user = await userPromise;
return (
<div>
{/* 优先渲染用户信息 */}
<UserInfo user={user} />
{/* 3. 将耗时较长的“订单列表”逻辑下移至组件内部,并行获取 */}
<Suspense fallback={<Skeleton />}>
<OrderDataLayer userId={user.id} />
</Suspense>
{/* 4. 将预启动的“优惠券”Promise 传入组件 */}
<Suspense fallback={<Skeleton />}>
<CouponDataLayer promise={couponsPromise} />
</Suspense>
</div>
);
}
// 独立的异步数据层组件
async function OrderDataLayer({ userId }) {
const orders = await fetchOrders(userId); // 并行进行的请求
return <OrderList orders={orders} />;
}
async function CouponDataLayer({ promise }) {
const coupons = await promise; // 使用外部传入的 Promise
return <CouponList coupons={coupons} />;
}
3. 核心价值总结
| 优化点 | 传统方案 | Skills 方案 (Vercel Best Practices) |
|---|---|---|
| 请求速度 | 累加耗时 (Waterfall) | 并发执行,耗时大幅度缩减 |
| 用户感知 | 全黑屏等待,直到所有数据返回 | 流式渲染 (Streaming),局部内容先出 |
| 代码结构 | 逻辑逻辑堆在主页面,难以复用 | 原子化组件,数据获取逻辑与渲染高度内聚 |
| AI 表现 | 随机生成,依赖运气 | 确定性重构,严格执行 Vercel 性能规约 |
结论:通过注入
vercel-react-best-practices技能,AI Agent 从一个简单的“代码生成器”转变为具备“性能自觉”的高级架构师。
三、 UI-Skills
如果说前两个工具解决了“逻辑”问题,那么 uipro-cli 及其关联的 ui-skills 则是为了解决“审美与交付”问题。 UI/UX Pro Max:赋能 AI Agent 的专业设计大脑。uipro-cli 是一个功能强大的命令行工具,专门用于为各种 AI 编程助手(如 Claude Code, Cursor, Windsurf, Antigravity 等)一键注入 UI/UX Pro Max 专家级技能。它让 AI 不仅能写代码,更能像资深设计师一样思考。
2.1 核心功能
1. 多元化视觉风格 (67 种 UI 风格)
UI/UX Pro Max 内置了 67 种最前沿的视觉设计风格,确保 AI 生成的界面告别“通用感”。
- 现代趋势:支持 Glassmorphism(玻璃拟态)、Claymorphism(粘土拟态)、Minimalism(极简主义)。
- 特色风格:包括 Brutalism(新野兽派)、Neumorphism(新拟物化)、Bento Grid(便当网格)以及针对 AI 产品的 AI-Native UI 风格。
2. 行业深度色彩与排版 (96 行业色板 + 57 字体配对)
- 精准色板:提供 96 套针对特定行业(如 SaaS, 电商, 医疗, 金融金融, 美妆)优化的专业色板。
- 字体艺术:内置 57 组精心挑选的字体组合,无缝集成 Google Fonts,从视觉底层提升产品质感。
3. 跨平台技术栈适配 (13 种主流技术栈)
支持从 Web 到移动端的 13 种主流技术架构,生成的代码即学即用。
- Web 端:React, Next.js, Vue, Nuxt.js, Astro, Svelte, HTML+Tailwind, shadcn/ui。
- 移动端:React Native, Flutter, SwiftUI, Jetpack Compose 等。
4. 专家级 UX 准则与设计推理 (100+ 准则与推理规则)
内置专业的设计逻辑,让 AI 具备“审美自觉”:
- UX 指南:涵盖 99 条 UX 最佳实践、反模式规避和 A11y 无障碍规则。
- 设计推理:拥有 100 条行业推理规则(例如:金融类应用严禁使用 AI 风格的紫粉渐变,以确保稳重感),自动进行交付前的 UI/UX 质量自检。
2.2 安装方法
通过 uipro-cli,你可以在几秒钟内完成技能初始化:
1. 全局安装工具
npm install -g uipro-cli
2. 为指定编辑器初始化技能
# 为 Claude Code 初始化
uipro init --ai claude
# 为 Cursor 初始化
uipro init --ai cursor
# 为所有支持的 AI 助手同时初始化
uipro init --ai all
3. 实战案例
场景描述: 用户需要为一个 AI 内容创作平台设计一个数据看板(Dashboard)。用户希望界面现代、直观,并且符合当前流行的审美趋势。
1. 传统 AI 生成:平庸且缺乏设计感
现象:如果没有加载专业 UI 技能包,AI 通常只会根据组件库(如 shadcn/ui)的基础示例,堆砌出缺乏灵魂的列表和卡片。色调单一(通常只用蓝色或灰阶),布局死板。
// ❌ 传统 AI 的“直觉”:基础的 Grid 布局,没有任何样式特色
export default function Dashboard() {
return (
<div className="grid grid-cols-3 gap-4 p-4">
<Card title="总收入" value="$12,000" />
<Card title="活跃用户" value="1,240" />
<Card title="API 调用" value="45.2k" />
<div className="col-span-3">主要统计图表</div>
</div>
);
}
2. UI/UX Pro Max 介入:具备“审美自觉”的设计
技能规则应用:
- 风格锁定:选择了 Bento Grid(便当网格) 布局。
- 行业色板:套用了 SaaS 行业高阶调色盘。
- 设计推理:AI 会自动添加微交互动画、圆角分层(Glassmorphism 效果)以及符合产品气质的字体排版。
重构指令:
“使用 UI/UX Pro Max 技能,为我的 AI 创作平台设计一个 Bento Grid 风格的统计看板。色调选用‘高级钛金灰’配合‘赛博蓝’点缀,并要求包含毛玻璃质感。”
重构结果(语义描述与关键代码片段):
// ✅ 符合设计的组件 (自动生成的 Tailwind 样式)
// 使用了 Bento Grid 非对称网格布局
export function BentoDashboard() {
return (
<section className="bg-slate-950 p-8 min-h-screen font-sans text-slate-100">
<div className="max-w-7xl mx-auto grid grid-cols-1 md:grid-cols-4 gap-6">
{/* 高度分层的毛玻璃卡片 (Glassmorphism) */}
<div
className="md:col-span-2 md:row-span-2 bg-slate-900/50 backdrop-blur-xl border border-white/10 rounded-3xl p-8
hover:bg-slate-800/60 transition-all duration-300 group"
>
<header className="flex justify-between">
<h3 className="text-xl font-bold tracking-tight">创作产出分析</h3>
<div className="h-2 w-2 bg-cyan-400 rounded-full animate-pulse" />
</header>
{/* AI 自动推荐的图表配色与坐标轴样式 */}
<MainAnalyticChart color="#22d3ee" />
</div>
{/* 紧凑型统计卡片 */}
<div className="bg-slate-900/50 backdrop-blur-md rounded-3xl p-6 border border-white/5">
<Subtitle>API 余额</Subtitle>
<Value className="text-3xl font-mono">84.2%</Value>
</div>
{/* 动态微交互元素 */}
<div className="bg-cyan-500/10 rounded-3xl p-6 border border-cyan-500/20 text-cyan-400">
<div className="text-sm font-semibold mb-2">服务状态</div>
<div className="text-lg">系统运行正常</div>
</div>
{/* 更多 Bento 网格单元... */}
</div>
</section>
);
}
3.核心价值总结
| 维度 | 传统构建 | UI/UX Pro Max (uipro) |
|---|---|---|
| 布局逻辑 | 简单的 1/2 或 1/3 等分 | 非对称动态布局 (如 Bento Grid, Masonry) |
| 色彩应用 | 基础颜色(#3b82f6),视觉单调 | 分层色彩系统,包含渐变、阴影与半透明层 |
| 细节打磨 | 只有基础功能 | 微交互、骨架屏、平滑过渡自动注入 |
| 设计自检 | 需要人工多次反馈返工 | 内置反模式自检,首次生成即达“可交付”标准 |
结语:前端开发者的角色转变
随着 vue-skills、react-skills 和 ui-skills 的普及,前端开发者的角色正在发生深刻变化。我们正在从 “代码编写者(Coder)” 转变为 “AI 指令师(Prompt Engineer)” 和 “技术评审员(Reviewer)” 。
传统的 AI 辅助仅仅是“搜索”的变种,而 Skills 模式代表了 “领域知识的预装载” 。
- 降低认知负荷:你不需要记住 Vue 3 的所有新特性或 Tailwind 的上千个类名,Skills 充当了你的“外部脑”。
- 代码风格统一:团队只需约定一套 Skill 脚本,就能保证所有 AI 生成的代码风格高度一致,甚至比人类手动编写的更规范。
- 快速原型到生产:它极大地缩短了从 MVP(最小可行性产品)到正式发布的时间,让前端开发者更关注于“业务价值”而非“语法实现”。
掌握这些 Skills 并不意味着放弃底层的学习,相反,只有深刻理解 Vue/React 原理和 UI 规范的人,才能通过这些技能包更好地引导 AI,释放出前所未有的生产力。
来源:juejin.cn/post/7599641289887055918
当你的Ant-Design成了你最大的技术债

大家好😁
如果你是一个前端,尤其是在B端(中后台)领域,Ant Design(antd)这个名字,你不可能没听过。
在过去的5年里,我们团队的所有新项目,技术选型里的第一行,永远是antd。它专业、开箱即用、文档齐全,拥有一切你想要的组件, 帮我们这些小团队,一夜之间就拥有了大厂的专业门面。
我们靠它,快速地交付了一个又一个项目。
Antd 虽好,但魔改样式确实让人头秃,转向 Headless UI 又怕重复造轮子。想兼顾灵活定制与开发效率?试试 RollCode 低代码平台,利用 自定义组件 快速封装 Headless 逻辑,通过 私有化部署 沉淀企业级资产,更能一键 静态页面发布(SSG + SEO),让 UI 自由不再昂贵。
但是,从去年开始,我发现,这个曾经的经典,正在变成我们团队脖子上最重的枷锁。
Ant Design,这个我们当初用来解决技术债的核心组件库,现在,却成了我们最大的技术债本身😖。
这是一篇团队血泪史, 讲一讲感想🤷♂️。
我们为什么会爱上 AntD?
我们必须承认,从无到有阶段,antd是无敌的。
你一个3人的小团队,用上antd,做出来的东西,看起来和阿里几百人团队做的系统,没什么区别。
Table、Form、Modal、Menu... 你需要的一切,它都以一种极其标准的方式给你了。你不再需要自己造轮子。
当你发现@ant-design/pro-components时,一个ProTable,直接帮你搞定了请求、分页、查询表单、工具栏... 你甚至都不用写useState了。
在那个阶段,我们以为我们找到了大结局。
当个性化成为 我们的 KPI
美好可能是短暂的,从我们的产品经理和UI设计师开始👇:
能不能...不要长得这么 Ant Design?🤣
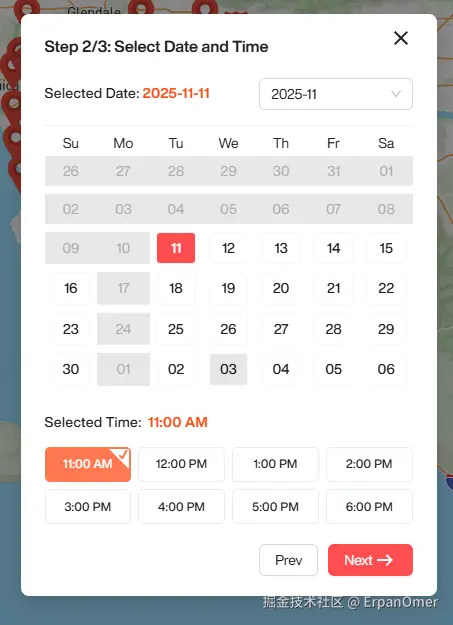
这是我们设计师,在评审会上,小心翼翼提出来的第一句话。
老板也说:我们要做自己的品牌,现在的系统,太千篇一律了!!!
于是,我们接到了第一个简单的需求:把全局的主题色,从橙色改成我们的品牌红。
这很简单,不就是 ConfigProvider嘛🤔。我们改了。
然后,第二个需求来了:这个Modal弹窗的关闭按钮,能不能不要放在右上角?我们要放在左下角,和确认按钮放在一起。(有点反人类🤷♂️)
灾难,就从这里开始了。
antd的Modal组件,根本就没提供这个插槽或prop。我们唯一的办法,是 强改。
于是,我们的代码里,开始出现这种恶臭的CSS:
/* 一个高权重的全局CSS文件 */
.ant-modal-header {
/* ... */
}
/* 嘿,那个右上角的关闭按钮,给我藏起来! */
.ant-modal-close-x {
display: none !important;
}
为了把那个 X 藏起来,我们用了!important。我们亲手打开了潘多拉魔盒。
这个表格的筛选图标,能换成我们自己画的吗?😖
antd的Table,是一个重灾区。它太强大了,也很黑盒。
我们设计师,重新画了一套筛选、排序的图标。但我们发现,antd的Table组件,根本没想过让你换这个。
我们唯一的办法,就是用 CSS选择器,一层一层地穿进antd的DOM结构里,找到那个<span>,然后用background-image去盖掉它。
/* 另一个人写的,更恶臭的CSS */
.ant-table-thead > tr > th.ant-table-column-has-filters .ant-table-filter-trigger {
/* 妈呀,这是啥? */
background: url('our-own-icon.svg') !important;
}
.ant-table-thead > tr > th.ant-table-column-has-filters .ant-table-filter-trigger > svg {
/* 藏起来,藏起来! */
display: none !important;
}
我们被拖累了。
我们花在 覆盖antd默认样式上的时间,已经远远超过了我们自己写一个组件的时间。
压死骆驼的最后一根稻草
我们用了ProTable,它的查询表单和表格是强耦合的。当产品经理提出一个我希望查询表单,在页面滚动时,吸附在顶部的需求时... 我们发现,我们改不动。我们被ProComponents的黑盒,锁死了。
然后我们的vendor.js打包出来,2.5MB。用webpack-bundle-analyzer一看,antd和@ant-design/icons,占了1.2MB。我们为了一个Button和Icon,引入了一个全家桶。antd的按需加载?别闹了,在ProComponents面前,它几乎是全量的。
而且 antd从v3到v4,我们花了一个月。从v4到v5,我们花了半个月。每一次升级,都是一次大型重构,因为我们那些写法一样被CSS覆盖,在新版里,全失效了🤷♂️。
我们本想找一个可靠的组件库,这么久过来,结果它成了债主。
我们真正需要的可能是轮子
我终于想明白了。
Ant Design,它不是一个组件库(Library),它是一个UI框架(Framework)。它是一套解决方案,它有它自己强势的 设计价值观。
当你的需求,和它的价值观一致时,它就是圣经。
当你的需求,和它的价值观不一致时,它就变成枷锁。
我们当初要的,其实是一个带样式的Button;而antd给我的,是一个内置了loading、disabled、onClick时会有水波纹动画、并且必须是蓝色或白色的Button。
我们的自救之路
在我们新的项目中,我忍痛做出了一个决定🤷♂️:
原则上,不再使用antd。
我们新的技术栈,转向了:
Tailwind CSS + Headless UI 方案(比如Radix UI)
这个组合,才是我们想要的:
Headless UI:它只提供功能和无障碍。比如,一个Dialog(模态框),它帮我搞定了按Esc关闭、焦点管理。但它没有任何样式。Tailwind CSS:我拿到了这个无样式的Dialog,然后用Tailwind的class,在5分钟内,在AI的帮助下,把它拼成了我们设计师想要的、独一无二的弹窗。
我们拿回了CSS的完全控制权,同时又享受了 AI + 组件开发的便利。
我依然尊敬Ant Design,它在前端B端历史上,是个丰碑。
对于那些从0到1的、对UI没有要求的内部系统,我可能依然会用它。
但对于那些需要品牌、体验、个性化的核心产品,我必须和它说再见了。

因为,当你的组件库开始控制你的设计和性能时,它就不是你的资产了。
而变成你最大的技术债🙌。
来源:juejin.cn/post/7571176484515659828
H5性能优化-打开效率提升了62%
一、达成的结果
app嵌套h5 加载效率提升了62%。时间从平均2.259s 降到了0.852s
二、优化过程
思路:优化原生webview+h5 ,先测试webview点击到创建时间 120ms(无需优化)。webview 提供了 api 测试 加载url 的进度。但是没提供具体的类似pc端网络的工具。所以就通过ai搜索一些工具。发现阿里云的arms 方便引入。
测试设备 android荣耀50、华为meta9、华为p40、oppo
开发环境测试
测试样本:优化前后各测试10次。
测试移动端h5 引入了阿里云的arms arms.console.aliyun.com/ 可以查看加载某个url的时候 请求的js css、图片、网络请求 跟网页版的网络类似。
import ArmsRum from '@arms/rum-browser'
ArmsRum.init({
pid: 'ha63j3v892@efe71d242023cd5',
endpoint: 'https://ha63j3v892-default-cn.rum.aliyuncs.com',
// 设置环境信息,参考值:'prod' | 'gray' | 'pre' | 'daily' | 'local'
env: 'prod',
// 设置路由模式, 参考值:'history' | 'hash'
spaMode: 'hash',
collectors: {
// 页面性能指标监听开关,默认开启
perf: true,
// WebVitals指标监听开关,默认开启
webVitals: true,
// Ajax监听开关,默认开启
api: true,
// 静态资源开关,默认开启
staticResource: true,
// JS错误监听开关,默认开启
jsError: true,
// 控制台错误监听开关,默认开启
consoleError: true,
// 用户行为监听开关,默认开启
action: true,
},
// 链路追踪配置开关,默认关闭
tracing: false,
})
export default ArmsRum
步骤一、懒加载echarts
以前的代码
import Api from '@/api'
import * as echarts from 'echarts'
import dayjs from 'dayjs'
export default {
}
现在的代码
async getRepairChart() {
const echarts = await import('echarts')
// xxx
const chartDom = document.getElementById('repairChart')
const myChart = echarts.init(chartDom)
const option = {
}
myChart.setOption(option)
},
通过F12查看网络 发现加载列表的时候有出现echartsxxx.js 而且有800多k ,所以就考虑加载列表不应该去加载数据看板的数据。
优化前,测试前日志打印
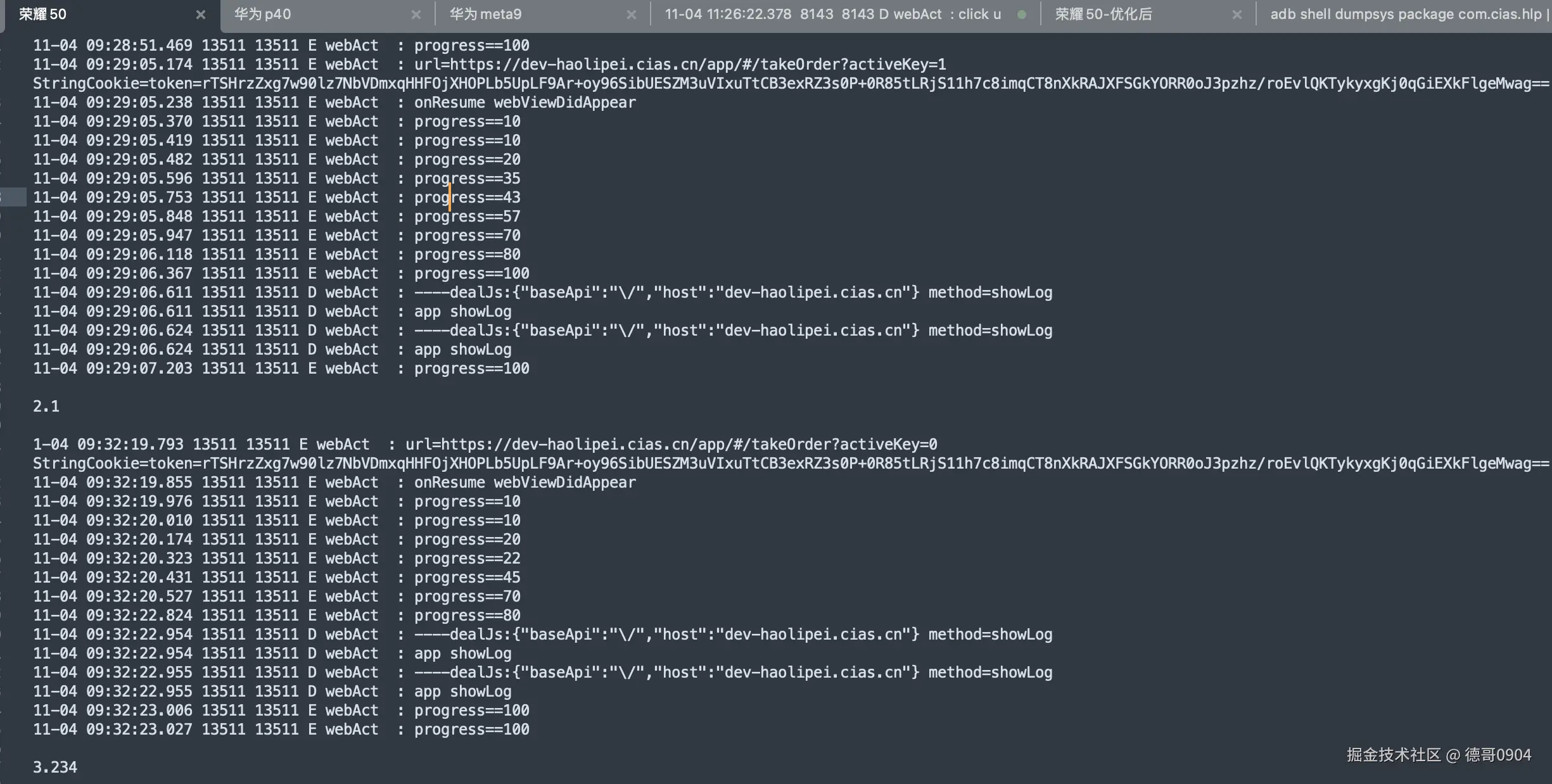
平均是3.234s 然后 当然还测试了华为p40 、oppo机器 由于系统不一样时间有些差别
测试后日志打印
平均是1.71s
华为meta9 9年前的老手机打印log
平均也2s多
优化后
不到0.8s
步骤二、禁用预加载、路由懒加载
通过查看网络发现请求dev-haolipei.cias.cn/app/#/takeO… 超级多的js 跟css
一张图都截取不完。当时就感觉肯定请求了很多无关紧要的资源。
npm run build 执行后查看dist目录index.html 的确很触目惊心 加载了太多没必要的资源了。
module.exports = {
publicPath,
devServer: {
disableHostCheck: true,
// host: 'localhost.cias.cn',
proxy: {
'/api': {
target,
changeOrigin: true,
// cookieDomainRewrite在手机调试时用得上
// cookieDomainRewrite: '',
pathRewrite: {
'^/api': '',
},
},
'/media': {
target,
changeOrigin: true,
pathRewrite: {
'^/media': '',
},
},
},
},
chainWebpack: config => {
// 禁用预加载
config.plugins.delete('preload')
config.plugins.delete('prefetch')
},
}
禁用它们的核心好处
1. 减少不必要的网络请求,节省带宽
- preload 可能会强制加载一些 “非关键资源”(如配置不当的情况下,预加载了体积大但当前页面暂时用不到的资源),导致带宽浪费。
- prefetch 会预加载未来可能访问的路由 chunk(如用户可能不会点击的低频页面),如果用户最终没有访问这些页面,预加载的资源就成了 “无效请求”,尤其对移动端用户(流量有限)不友好。
禁用后,资源仅在明确需要时才会加载(如用户进入对应路由时),避免 “提前加载但用不上” 的浪费。
2. 避免阻塞关键资源加载,提升首屏速度
- 浏览器对同一域名的并发请求数有限制(HTTP/1.1 通常为 6 个)。preload 加载的资源会占用并发名额,可能阻塞当前页面真正需要的关键资源(如核心 JS/CSS),导致首屏渲染延迟。
- 例如:若 preload 预加载了一个 2MB 的非关键 chunk,可能会挤占首屏 JS 的加载带宽,导致页面 “白屏时间” 变长。
禁用后,浏览器的并发资源会优先分配给当前页面的核心资源,减少阻塞。
3. 避免缓存资源被 “无效资源” 占用
浏览器缓存空间有限,prefetch 预加载的大量 “未来可能用到” 的 chunk 会占用缓存空间,可能导致真正需要长期缓存的核心资源(如 chunk-vendors.js)被挤出缓存,下次访问时需要重新加载。
禁用后,缓存可优先保留关键资源,提升二次访问速度。
4. 适配低网速 / 弱网环境
在 3G、偏远地区等弱网环境下,preload/prefetch 的预加载行为会加剧网络拥堵:
- 预加载的资源可能耗时过长,导致当前页面的核心资源加载超时。
- 禁用后,资源加载更 “轻量化”,优先保证当前页面可用,符合弱网环境的用户体验需求。
5. 减少开发环境的冗余加载
在开发环境中,Webpack 会频繁编译资源,preload/prefetch 可能导致每次热更新时加载大量无关资源,拖慢开发服务器响应速度,影响开发体验。禁用后可简化开发环境的资源加载逻辑,提升热更新效率。
注意:并非所有场景都适合禁用
preload/prefetch 本身是性能优化手段,若项目存在以下情况,可能需要保留或部分配置:
- 首屏依赖的关键资源(如核心 CSS、字体)体积大,preload 可加速其加载。
- 高频访问的路由(如首页→列表页),prefetch 可提前加载列表页 chunk,提升跳转速度。
因此,禁用的合理性取决于项目场景:资源体积大、用户网络不稳定、低频路由多的项目(如移动端 H5)更适合禁用;高频路由明确、网络环境好的项目可选择性保留。
路由懒加载
必须写上 /* webpackChunkName: "system-setting" */
以前的代码
{
path: '/takeOrder',
name: 'HomeTakeOrder',
component: () =>
import(
'@/views/baosi/orderList.vue'
),
meta: {
title: '推返修列表',
keepAlive: true,
},
}
懒加载路由模式
const HomeTakeOrder = () =>
import(/* webpackChunkName: "take-order" */ '@/views/baosi/orderList.vue')
{
path: '/takeOrder',
name: 'HomeTakeOrder',
component: HomeTakeOrder,
meta: {
title: '推返修列表',
keepAlive: true,
},
},
这样的好处 打包后 会有路由名称
对比
继续测试打印log
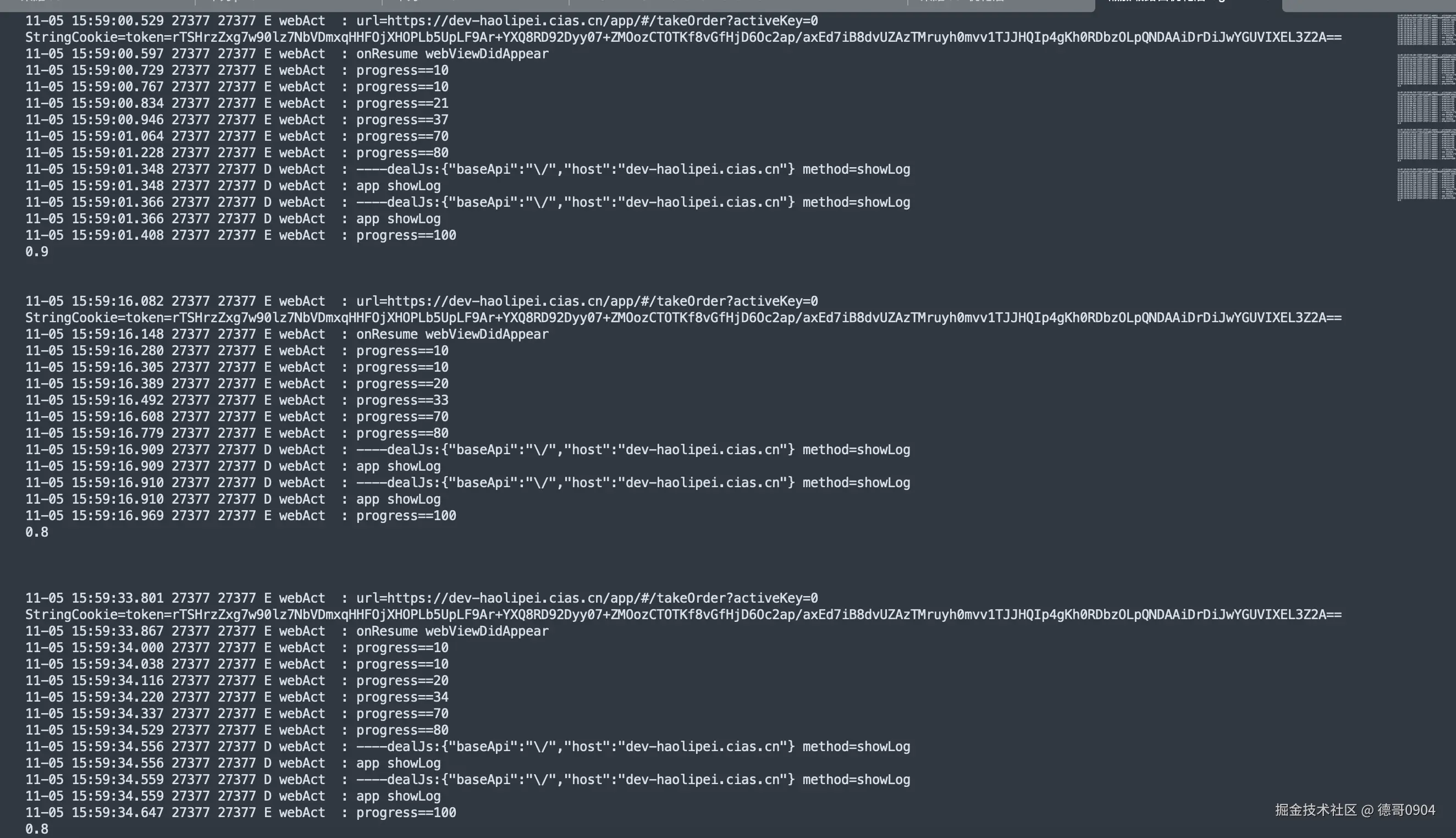
可以看看网络请求 就只有5个js文件 总体积不到300k
平均是0.852,基本达成要求
通过npm run build 本地打包看看文件对比大小。
1、体积巨减!!!
2、加载的文件名称是路由名称+hash值
优化前
优化后
三、内部项目具体实践
(增值移动端h5项目可以参考以下操作)
1、禁用预加载
module.exports = {
publicPath,
devServer: {
disableHostCheck: true,
// host: 'localhost.cias.cn',
proxy: {
'/api': {
target,
changeOrigin: true,
// cookieDomainRewrite在手机调试时用得上
// cookieDomainRewrite: '',
pathRewrite: {
'^/api': '',
},
},
'/media': {
target,
changeOrigin: true,
pathRewrite: {
'^/media': '',
},
},
},
},
chainWebpack: config => {
// 禁用预加载
config.plugins.delete('preload')
config.plugins.delete('prefetch')
},
}
2、将路由全部改成懒加载
并且路由需要/* webpackChunkName:"take-order" */
{
path: '/takeOrder',
name: 'HomeTakeOrder',
component: () =>
import(
/* webpackChunkName:"take-order" */ '@/views/baosi/orderList.vue'
),
meta: {
title: '推返修列表',
keepAlive: true,
},
}
3、组件懒加载
以前常见写法 就是一进来 把所有组件的都加载进来
比如这个车牌号组件有120k 对于比较大一点的组件可以用懒加载 。
<van-popup v-model="showPlatePopup" position="bottom" :overlay="false">
<keyboard
v-model="baseInfo.plateNumber"
:show.sync="showPlatePopup"
@input="handlePlateInput"
></keyboard>
import Keyboard from '@/components/numberplate/vnp-keyboard.vue'
export default {
name: 'CreateOrder',
components: {
MultiSelectPopup,
DispatchingPopup,
DispatchFailPopup,
DispatchFinishPopup,
Keyboard,
},
}
懒加载代码
用这个方式可以直接在网络中查看到对应组件的名称和大小
<van-popup
v-if="showPlatePopup"
v-model="showPlatePopup"
position="bottom"
:overlay="false"
>
<keyboard
v-model="baseInfo.plateNumber"
:show.sync="showPlatePopup"
@input="handlePlateInput"
></keyboard>
</van-popup>
export default {
name: 'CreateOrder',
components: {
MultiSelectPopup,
DispatchingPopup,
DispatchFailPopup,
DispatchFinishPopup,
Keyboard: () =>
import(
/* webpackChunkName: "keyboard" */
'@/components/numberplate/vnp-keyboard.vue'
),
},
}
还有 特别大的第三方库 echart 懒加载 按需引入
四、总结
目前通过禁用预加载、路由懒加载、和第三方组件懒加载使用方式 基本能达到很大程度的优化效果。
但是看图 每次加载前面2个文件一个683k 另外一个285k 还是压缩了的文件 ,
我猜应该是main.js 引入了很多东西,后续还可以有优化空间。移动端的h5 入口文件尽量简洁。
(自己写的页面 一定多注意看一下 网络 有多少个js 和css 图片) 资源过大就要考虑优化了。
性能优化一定要多测试验证、多测试验证、多测试验证,保证业务正常情况下优化性能。
性能优化参考。
来源:juejin.cn/post/7572301616168583177
深度复刻小米AI官网交互动画
近日在使用小米AI大模型MIMO时,被其顶部的透视跟随动画深深吸引,移步官网( mimo.xiaomi.com/zh/ )
效果演示

1. 交互梳理
- 初始状态底部有浅色水印,且水印奇数行和偶数行有错位
- 初始状态中间文字为黑色的汉字
- 鼠标移入后,会在以鼠标为中心形成一个黑色圆形,黑色圆中有第二种背景水印,且水印依旧奇数行和偶数行有错位
- 鼠标移动到中间汉字部分,会有白色英文显示
- 鼠标迅速移动时,会根据鼠标移动轨迹有一个拉伸椭圆跟随,然后恢复成圆形的动画效果
现在基于这个交互的拆解,逐步来复刻交互效果
2. 组件结构与DOM设计
2.1 模板结构
采用「静态底层+动态上层」的双层视觉结构,通过CSS绝对定位实现图层叠加,既保证初始状态的视觉完整性,又能让交互效果精准作用于上层,不干扰底层基础展示。两层分工明确,具体如下:
| 图层 | 类名 | 内容 | 功能 |
|---|---|---|---|
| 底层 | .z-1 | 中文标题 "你好,世界!" 和灰色 "HELLO" 文字矩阵 | 静态背景展示 |
| 上层 | .z-2 | 英文标题 "Hello , World!" 和白色 "HELLO" 文字矩阵 | 鼠标交互时的动态效果层 |
2.2 核心 DOM 结构
<div class="container" @mouseenter="onMouseEnter" @mouseleave="onMouseLeave" @mousemove="onMouseMove">
<!-- 底层内容 -->
<div class="z-1">
<div class="line" v-for="line in 13">
<span class="line-item" v-for="item in 13">HELLO</span>
</div>
</div>
<h1 class="title-1">你好,世界!</h1>
<!-- 上层交互内容 -->
<div class="z-2" :style="{ 'clip-path': circleClipPath }">
<div class="hidden-div">
<div class="line" v-for="line in 13">
<span class="line-item" v-for="item in 13">HELLO</span>
</div>
</div>
<h1 class="title-2">Hello , World!</h1>
</div>
</div>
关键说明:hidden-div用于包裹上层文字矩阵,配合.z-2的定位规则,确保遮罩效果精准覆盖;两层文字矩阵尺寸一致,保证视觉对齐,增强透视沉浸感。
3. 技术实现
3.1 核心功能模块
3.1.1 轨迹点系统
轨迹点系统是实现平滑鼠标跟随效果的核心,通过维护6个轨迹点的位置信息,创建出具有弹性延迟的跟随动画。
// 轨迹点系统
const trailSystem = ref({
targetX: 0,
targetY: 0,
trailPoints: Array(6).fill(null).map(() => ({ x: 0, y: 0 })),
animationId: 0,
isInside: false
});
设计思路:6个轨迹点是兼顾流畅度与性能的平衡值——点太少则拖尾效果不明显,点太多则增加计算开销,配合递减阻尼系数,实现“头快尾慢”的自然跟随。
3.1.2 动态 Clip-Path 计算
通过计算鼠标位置和轨迹点的关系,动态生成 clip-path CSS 属性值,实现跟随鼠标的圆形/椭圆形遮罩效果。
// 计算clip-path值
const circleClipPath = computed(() => {
if (!showCircle.value) {
return 'circle(0px at -300px -300px)'; // 完全隐藏状态
}
// 复制轨迹系统数据进行计算
const system = JSON.parse(JSON.stringify(trailSystem.value));
// 更新轨迹点
for (let t = 0; t < 6; t++) {
const prevX = t === 0 ? system.targetX : system.trailPoints[t - 1].x;
const prevY = t === 0 ? system.targetY : system.trailPoints[t - 1].y;
const damping = 0.7 - 0.04 * t; // 阻尼系数,后面的点移动更慢
const deltaX = prevX - system.trailPoints[t].x;
const deltaY = prevY - system.trailPoints[t].y;
// 平滑插值
system.trailPoints[t].x += deltaX * damping;
system.trailPoints[t].y += deltaY * damping;
}
// 获取第一个点(头部)和最后一个点(尾部)
const head = system.trailPoints[0];
const tail = system.trailPoints[5];
const diffX = head.x - tail.x;
const diffY = head.y - tail.y;
const distance = Math.sqrt(diffX * diffX + diffY * diffY);
let clipPathValue = '';
if (distance < 10) { // 如果距离很近,显示圆形
clipPathValue = `circle(200px at ${head.x}px ${head.y}px)`;
} else {
// 创建椭圆形的polygon,连接头尾两点
const angle = Math.atan2(diffY, diffX); // 连接角度
const points = [];
// 从头部开始,画半个椭圆
for (let i = 0; i <= 30; i++) {
const theta = angle - Math.PI / 2 + Math.PI * i / 30;
const x = head.x + 200 * Math.cos(theta);
const y = head.y + 200 * Math.sin(theta);
points.push(`${x}px ${y}px`);
}
// 从尾部开始,画另半个椭圆
for (let i = 0; i <= 30; i++) {
const theta = angle + Math.PI / 2 + Math.PI * i / 30;
const x = tail.x + 200 * Math.cos(theta);
const y = tail.y + 200 * Math.sin(theta);
points.push(`${x}px ${y}px`);
}
clipPathValue = `polygon(${points.join(', ')})`;
}
return clipPathValue;
});
3.1.3 鼠标事件处理
实现了完整的鼠标交互逻辑,包括鼠标进入、离开和移动时的状态管理和动画控制。
| 事件 | 处理函数 | 功能 |
|---|---|---|
| mouseenter | onMouseEnter | 激活交互效果,初始化轨迹点 |
| mouseleave | onMouseLeave | 停用交互效果,重置轨迹点 |
| mousemove | onMouseMove | 更新目标点位置,驱动动画 |
4. 技术亮点
4.1 轨迹点系统算法
核心原理:使用6个轨迹点,每个点跟随前一个点移动,并应用不同的阻尼系数,实现平滑的拖尾效果。
技术优势:
- 实现了自然的物理运动效果,比简单的线性跟随更具视觉吸引力
- 通过阻尼系数的递减,创建出层次感和深度感
- 算法复杂度低,性能消耗小,适合实时交互场景
4.2 动态 Clip-Path 技术
核心原理:利用CSS clip-path属性的动态特性,结合轨迹点位置计算,实时生成不规则遮罩,替代Canvas/SVG的图形绘制方案,用更轻量化的方式实现复杂视觉效果。
技术优势:
- 无依赖轻量化:无需引入任何图形库,纯CSS+JS即可实现,减少项目依赖体积,降低集成成本
- 平滑过渡无卡顿:通过数值插值计算,实现圆形与椭圆形遮罩的无缝切换,无帧断裂感,视觉连贯性强
- 渲染性能优化:配合
will-change: clip-path提示浏览器,提前分配渲染资源,减少重排重绘,提升动画流畅度
5. 性能优化
- 渲染性能:
- 使用
will-change: clip-path提示浏览器优化渲染 - 合理使用 Vue 的响应式系统,避免不必要的重计算
- 使用
- 事件处理:
- 仅在鼠标在容器内时更新目标点位置,减少计算量
- 鼠标离开时停止动画,释放资源
- 动画性能:
- 使用
requestAnimationFrame实现流畅的动画效果 - 鼠标离开时取消动画帧请求,避免内存泄漏
- 使用
6. 总结与扩展
本次复刻的小米MiMo透视动画,核心价值在于“用简单技术组合实现高级视觉效果”——无需复杂图形库,仅依托Vue3响应式能力与CSS clip-path属性,就能打造出兼具质感与性能的交互组件。其核心亮点可概括为三点:
- 交互创新:轨迹点系统与动态clip-path结合,打破传统静态标题的交互边界,带来自然流畅的鼠标跟随体验
- 视觉精致:双层文字矩阵的分层设计,配合遮罩形变,营造出兼具深度感与品牌性的视觉效果
- 性能可控:轻量化技术方案+多维度优化策略,在保证视觉效果的同时,兼顾页面性能与可维护性
扩展方向
该组件的实现思路可灵活迁移至其他场景:
- 弹窗过渡动画:将clip-path遮罩用于弹窗进入/退出效果,实现不规则形状的过渡动画。
- 滚动动效:结合滚动事件替换鼠标事件,实现页面滚动时的元素透视跟随效果。
- 移动端适配:增加触摸事件支持,将鼠标交互替换为触摸滑动,适配移动端场景。
完整代码
<template>
<div class="hero-container" @mouseenter="onMouseEnter" @mouseleave="onMouseLeave" @mousemove="onMouseMove">
<div class="z-1">
<div class="line" v-for="line in 13">
<span class="line-item" v-for="item in 13">HELLO</span>
</div>
</div>
<h1 class="title-1">你好,世界</h1>
<!-- 第二个div,鼠标移入后需要显示的内容,通过clip-path:circle(0px at -300px -300px)达到隐藏效果 -->
<div class="z-2" :style="{ 'clip-path': circleClipPath }">
<div class="hidden-div">
<div class="line" v-for="line in 13">
<span class="line-item" v-for="item in 13">HELLO</span>
</div>
</div>
<h1 class="title-2">HELLO , World</h1>
</div>
</div>
</template>
<script setup>
import { ref, computed, onMounted, onUnmounted } from 'vue'
const showCircle = ref(false)
const containerRef = ref(null)
const trailSystem = ref({
targetX: 0,
targetY: 0,
trailPoints: Array(6)
.fill(null)
.map(() => ({ x: 0, y: 0 })),
animationId: 0,
isInside: false,
})
const circleClipPath = computed(() => {
if (!showCircle.value) {
return 'circle(0px at -300px -300px)'
}
// 复制轨迹系统数据进行计算
const system = JSON.parse(JSON.stringify(trailSystem.value))
// 更新轨迹点
for (let t = 0; t < 6; t++) {
const prevX = t === 0 ? system.targetX : system.trailPoints[t - 1].x
const prevY = t === 0 ? system.targetY : system.trailPoints[t - 1].y
const damping = 0.7 - 0.04 * t // 阻尼系数,后面的点移动更慢
const deltaX = prevX - system.trailPoints[t].x
const deltaY = prevY - system.trailPoints[t].y
// 平滑插值
system.trailPoints[t].x += deltaX * damping
system.trailPoints[t].y += deltaY * damping
}
// 获取第一个点(头部)和最后一个点(尾部)
const head = system.trailPoints[0]
const tail = system.trailPoints[5]
const diffX = head.x - tail.x
const diffY = head.y - tail.y
const distance = Math.sqrt(diffX * diffX + diffY * diffY)
let clipPathValue = ''
if (distance < 10) {
// 如果距离很近,显示圆形
clipPathValue = `circle(200px at ${head.x}px ${head.y}px)`
} else {
// 创建椭圆形的polygon,连接头尾两点
const angle = Math.atan2(diffY, diffX) // 连接角度
const points = []
// 从头部开始,画半个椭圆
for (let i = 0; i <= 30; i++) {
const theta = angle - Math.PI / 2 + (Math.PI * i) / 30
const x = head.x + 200 * Math.cos(theta)
const y = head.y + 200 * Math.sin(theta)
points.push(`${x}px ${y}px`)
}
// 从尾部开始,画另半个椭圆
for (let i = 0; i <= 30; i++) {
const theta = angle + Math.PI / 2 + (Math.PI * i) / 30
const x = tail.x + 200 * Math.cos(theta)
const y = tail.y + 200 * Math.sin(theta)
points.push(`${x}px ${y}px`)
}
clipPathValue = `polygon(${points.join(', ')})`
}
return clipPathValue
})
// 动画循环函数
const animate = () => {
if (showCircle.value) {
// 更新轨迹点
for (let t = 0; t < 6; t++) {
const prevX = t === 0 ? trailSystem.value.targetX : trailSystem.value.trailPoints[t - 1].x
const prevY = t === 0 ? trailSystem.value.targetY : trailSystem.value.trailPoints[t - 1].y
const damping = 0.7 - 0.04 * t // 阻尼系数,后面的点移动更慢
const deltaX = prevX - trailSystem.value.trailPoints[t].x
const deltaY = prevY - trailSystem.value.trailPoints[t].y
// 平滑插值
trailSystem.value.trailPoints[t].x += deltaX * damping
trailSystem.value.trailPoints[t].y += deltaY * damping
}
// 请求下一帧
trailSystem.value.animationId = requestAnimationFrame(animate)
}
}
const onMouseEnter = (event) => {
const container = event.currentTarget
const rect = container.getBoundingClientRect()
const x = event.clientX - rect.left
const y = event.clientY - rect.top
showCircle.value = true
// 初始化目标位置和轨迹点
trailSystem.value.targetX = x
trailSystem.value.targetY = y
trailSystem.value.isInside = true
// 初始化所有轨迹点到当前位置
for (let i = 0; i < 6; i++) {
trailSystem.value.trailPoints[i] = { x, y }
}
// 开始动画
if (!trailSystem.value.animationId) {
trailSystem.value.animationId = requestAnimationFrame(animate)
}
}
const onMouseLeave = (event) => {
const container = event.currentTarget
const rect = container.getBoundingClientRect()
const x = event.clientX - rect.left
const y = event.clientY - rect.top
showCircle.value = false
trailSystem.value.isInside = false
// 将目标点移出容器边界,使轨迹点逐渐拉回
let targetX = x
let targetY = y
if (x <= 0) targetX = -400
else if (x >= rect.width) targetX = rect.width + 400
if (y <= 0) targetY = -400
else if (y >= rect.height) targetY = rect.height + 400
trailSystem.value.targetX = targetX
trailSystem.value.targetY = targetY
// 停止动画
if (trailSystem.value.animationId) {
cancelAnimationFrame(trailSystem.value.animationId)
trailSystem.value.animationId = 0
}
}
const onMouseMove = (event) => {
if (showCircle.value) {
const container = event.currentTarget
const rect = container.getBoundingClientRect()
const x = event.clientX - rect.left
const y = event.clientY - rect.top
trailSystem.value.targetX = x
trailSystem.value.targetY = y
}
}
</script>
<style scoped>
.hero-container {
cursor: crosshair;
background: #faf7f5;
border-bottom: 1px solid #000;
justify-content: center;
align-items: center;
width: 100%;
height: 500px;
display: flex;
position: relative;
overflow: hidden;
}
.z-1 {
pointer-events: auto;
-webkit-user-select: none;
user-select: none;
flex-direction: column;
justify-content: flex-start;
width: 100%;
height: 100%;
display: flex;
position: absolute;
top: 0;
left: 0;
overflow: hidden;
}
.z-1 .line {
display: flex;
align-items: center;
white-space: nowrap;
color: #0000000d;
letter-spacing: 0.3em;
flex-wrap: nowrap;
font-size: 52px;
font-weight: 700;
line-height: 1.6;
display: flex;
}
.z-1 .line-item {
cursor: default;
flex-shrink: 0;
margin-right: 0.6em;
transition:
color 0.3s,
text-shadow 0.3s;
font-family: inherit !important;
}
.z-1 .line:nth-child(odd) {
margin-left: -2em;
background-color: rgb(245, 235, 228);
}
.title-1 {
z-index: 1;
color: #000;
letter-spacing: 0.02em;
text-align: center;
margin: 0;
font-size: 72px;
font-weight: 700;
}
.z-2 {
pointer-events: none;
z-index: 10;
will-change: clip-path;
background: #000;
justify-content: center;
align-items: center;
width: 100%;
height: 100%;
display: flex;
position: absolute;
top: 0;
left: 0;
}
.z-2 .hidden-div {
pointer-events: none;
-webkit-user-select: none;
user-select: none;
flex-direction: column;
justify-content: flex-start;
width: 100%;
height: 100%;
display: flex;
position: absolute;
top: 0;
left: 0;
overflow: hidden;
}
.z-2 .hidden-div .line {
white-space: nowrap;
color: #ffffff1f;
letter-spacing: 0.3em;
flex-wrap: nowrap;
font-size: 32px;
font-weight: 700;
line-height: 1.6;
display: flex;
}
.z-2 .hidden-div .line:nth-child(odd) {
margin-left: -0.5em;
}
.title-2 {
font-size: 72px;
color: #fff;
letter-spacing: 0.02em;
text-align: center;
white-space: nowrap;
margin: 0;
font-size: 72px;
font-weight: 700;
}
</style>
小米的前端一直很牛,非常有创意,我也通过F12学习源码体会到了新的思路,希望大家也多多关注小米和小米的技术~
来源:juejin.cn/post/7598005428258340927
Tailwind CSS都更新到4.0了,你还在抵触吗?
Tailwind CSS的体量
Tailwind CSS有多火爆呢?
几组数据告诉你?

一组数据告诉你 Tailwind CSS 有多受欢迎:
- github 86.1K的 Star, 足以证明它的受欢迎程度。
- NPM 周下载量已突破 1000 万, 前端开发者的不二之选
- 被无数大公司采用,如 GitHub、Vercel、Laravel 等。
- 被很多框架和打包工具推荐,如Vite,Nuxt,React等
从数据上看,Tailwind CSS 已经成为前端开发的主流选择之一。
Tailwind CSS有多火爆呢?
几组数据告诉你?
一组数据告诉你 Tailwind CSS 有多受欢迎:
- github 86.1K的 Star, 足以证明它的受欢迎程度。
- NPM 周下载量已突破 1000 万, 前端开发者的不二之选
- 被无数大公司采用,如 GitHub、Vercel、Laravel 等。
- 被很多框架和打包工具推荐,如Vite,Nuxt,React等
从数据上看,Tailwind CSS 已经成为前端开发的主流选择之一。
原子化CSS
什么是原子化CSS
原子化 CSS 是一种 CSS 架构,它提倡使用高度可复用的小类名,每个类名通常只控制单一的样式属性。例如:
<div class="text-red-500 font-bold p-4 text-[14px]">Hello Tailwinddiv>
其中:
- text-red-500: 代表文字颜色
- font-bold: 代表加粗
- p-4: 代表内边距
- text-[14px]: 代表字体大小为14px
这种方式避免了传统 CSS 中复杂的层叠规则,让样式控制更加直观。
原子化 CSS 是一种 CSS 架构,它提倡使用高度可复用的小类名,每个类名通常只控制单一的样式属性。例如:
<div class="text-red-500 font-bold p-4 text-[14px]">Hello Tailwinddiv>
其中:
- text-red-500: 代表文字颜色
- font-bold: 代表加粗
- p-4: 代表内边距
- text-[14px]: 代表字体大小为14px
这种方式避免了传统 CSS 中复杂的层叠规则,让样式控制更加直观。
原子化CSS和传统CSS的区别
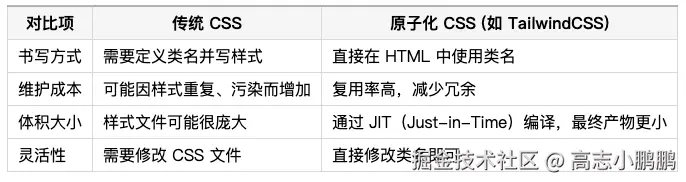
说了这么一通,我相信用过的都说“真香”,用过一次后就离不开了。
关键是没用过的呢?是不是心里还在嘀咕。别急,正餐来了!
说了这么一通,我相信用过的都说“真香”,用过一次后就离不开了。
关键是没用过的呢?是不是心里还在嘀咕。别急,正餐来了!
Tailwind CSS宝藏库
为什么说Tailwind CSS是一个宝藏,因为你担忧和抵触的地方,Tailwind CSS都给你解决了
为什么说Tailwind CSS是一个宝藏,因为你担忧和抵触的地方,Tailwind CSS都给你解决了
类名难记
你可能在担忧,我是不是每次用都要查文档呢?那么多css好不容易记住了,现在又让我再学一遍?
答案是:不用。完全和你使用css一样简单。只需要记住几个关键字,智能提示帮你搞定
你可能在担忧,我是不是每次用都要查文档呢?那么多css好不容易记住了,现在又让我再学一遍?
答案是:不用。完全和你使用css一样简单。只需要记住几个关键字,智能提示帮你搞定
HTML又长又乱
首先,不可否认,将所有的类名整合到html中,会让你的html变得比较长。但是,当你写的代码又长又乱的时候,你就要停下来想想
- 是否违背了创作者的初衷
- 架构是否设计不合理
为此,我们简单分析一下,到底是人的问题还是工具的问题。根据以上2点,分析一下你的HTML为什么又长又乱?
- 因为太长导致太乱
没有合并之前,你的代码可能是这样的
class="flex justify-center items-center">
clsss="bg-blue-500 text-white py-2 px-4 rounded">提交
合并后是这样的
.flex-center {
@apply flex justify-center items-center;
}
.btn-submit {
@apply bg-blue-500 text-white py-2 px-4 rounded;
}
class="flex-center">
clsss="btn-submit">提交
现在是不是很清晰了呢?
我敢说,只要你使用@apply合并类名,时刻记着复用样式,你的HMLT至少减少1/3,甚至也可以写出像诗一样的代码
- 因为没有分组和顺序性导致太乱
没有顺序和分组的书写,是这样的
<div class="p-2 font-bold text-[14px] mt-4 color-[#333333] bg-white">Hello world!div>
想到哪写到哪,会让你的代码一眼望上去比较乱,时间长了,一眼看上去很难维护...
下面我们就着手解决这2个问题
- 类排序
使用 Prettier 进行类排序(Class sorting with Prettier)
Tailwind CSS 维护了一个官方 Prettier 插件,它会自动按照我们的 推荐的类顺序 对你的类进行排序。
使用插件后,代码这样的
<div class="bg-white color-[#333333] mt-4 p-2 text-[14px] font-bold">Hello world!div>
现在是不是清晰很多了呢?
不过还不够
- 分组
首先,不可否认,将所有的类名整合到html中,会让你的html变得比较长。但是,当你写的代码又长又乱的时候,你就要停下来想想
- 是否违背了创作者的初衷
- 架构是否设计不合理
为此,我们简单分析一下,到底是人的问题还是工具的问题。根据以上2点,分析一下你的HTML为什么又长又乱?
- 因为太长导致太乱
没有合并之前,你的代码可能是这样的
class="flex justify-center items-center">
clsss="bg-blue-500 text-white py-2 px-4 rounded">提交
合并后是这样的
.flex-center {
@apply flex justify-center items-center;
}
.btn-submit {
@apply bg-blue-500 text-white py-2 px-4 rounded;
}
class="flex-center">
clsss="btn-submit">提交
现在是不是很清晰了呢?
我敢说,只要你使用@apply合并类名,时刻记着复用样式,你的HMLT
至少减少1/3,甚至也可以写出像诗一样的代码 - 因为没有分组和顺序性导致太乱
没有顺序和分组的书写,是这样的
<div class="p-2 font-bold text-[14px] mt-4 color-[#333333] bg-white">Hello world!div>
想到哪写到哪,会让你的代码一眼望上去比较乱,时间长了,一眼看上去很难维护...
下面我们就着手解决这2个问题
- 类排序
使用 Prettier 进行类排序(Class sorting with Prettier)
Tailwind CSS 维护了一个官方 Prettier 插件,它会自动按照我们的 推荐的类顺序 对你的类进行排序。
使用插件后,代码这样的
<div class="bg-white color-[#333333] mt-4 p-2 text-[14px] font-bold">Hello world!div>
现在是不是清晰很多了呢?
不过还不够
- 分组
我们根据样式进行的类别分组,比如颜色,字体,定位,间距等等,每个类别一行,这样你写出的代码会清晰无比
<div class="
bg-white color-[#333333]
mt-4 p-2
text-[14px] font-bold">
Hello world!div>
现在代码是不是清晰的多了
全局类名
不用担心公共类的问题,@apply帮你搞定。
使用 @apply 合并类,前面已经讲过了,就不展开了
样式冲突
也许你还在担心tailwind 的 class 名和我已有的 class 冲突了咋办?我怎么处理兼容问题
别担心,给你的类名加个前缀prefix就搞定了
@import "tailwindcss" prefix(tw);
<div class="tw:flex tw:bg-red-500 tw:hover:bg-red-600"> div>
拥抱Tailwind CSS
Tailwind CSS为什么受到追捧
- 再也不用忍受css上下切换的痛苦了
- 再也不用花时间去取语义化类名了
不用纠结container, wrapper, box等被使用的问题后,如何起名的问题了
- 为了加权重,不断的加父级类名,甚至!important,永远不知道哪个样式起作用了。冗长的css让项目很难维护!
- 简单完成伪类、伪元素、媒体查询等变体的书写
- 再也不用忍受css上下切换的痛苦了
- 再也不用花时间去取语义化类名了
不用纠结container, wrapper, box等被使用的问题后,如何起名的问题了
- 为了加权重,不断的加父级类名,甚至!important,永远不知道哪个样式起作用了。冗长的css让项目很难维护!
- 简单完成伪类、伪元素、媒体查询等变体的书写

Tailwind CSS、PrimeFlex、UnoCSS评测
在CSS工具类框架中,除了Tailwind CSS之外,还有其他很多工具类。如PrimeFlex和UnoCSS,它们各有特点,下面我简单的评测一下
- PrimeFlex: 生态系统较小,多适用于Prime生态,如PrimevVue,PrimeReact。样式和较Tailwind CSS低。只能构建起简单样式框架。
最让我吐槽的是,样式竟然用!important。你想替换某个属性,麻烦程度想骂人!

- UnoCSS: 未构建良好的生态系统,多用于自定义规则和项目优化
总结
TailwindCSS 已经成为前端开发的趋势之一,随着4.0 版本的发布,它的性能更强大、使用更方便。如果你还在抵触,不妨试试看,它可能会彻底改变你的 CSS 编写方式!
来源:juejin.cn/post/7480734875723415552
秒懂 Headless:为什么现在的软件都要“去头”?
简单来说, “Headless”(无头) 在软件开发中指的是:只有逻辑(后端/内核),没有预设界面(前端/GUI) 的软件架构模式。
这里的“Head(头)”比喻的是用户界面(UI/GUI) ,“Body(身体)”比喻的是核心业务逻辑或引擎。
Headless = 砍掉自带的 UI,只给你提供 API 或核心逻辑,让你自己去画界面。
1. 核心概念图解
想象一下 “传统的软件”(比如 Word):它像一家堂食餐厅。你有厨房(逻辑),也有固定的桌椅板凳和装修风格(UI)。你必须在它提供的环境里吃饭,无法改变装修。
而 “Headless 软件”:它像一个中央厨房(外卖工厂)。它只负责做饭(逻辑),不提供桌椅(UI)。
- 你想把菜送到五星级酒店摆盘(Web 端高级定制 UI)?可以。
- 你想把菜送到路边摊(手机 App)?可以。
- 你想把菜送到自动售货机(小程序)?也可以。
2. 具体例子
A. 无头浏览器 (Headless Browser)
- 传统的浏览器(如 Chrome): 你打开它,能看到窗口、地址栏、渲染出来的网页,你能用鼠标点击。
- 无头浏览器(如 Puppeteer, Playwright):
- 定义: 它是浏览器内核(Chrome/Webkit),但没有可视化的窗口。它在后台(命令行/服务器)运行。
- 怎么用? 你写代码控制它:“打开百度 -> 输入关键词 -> 截图”。
- 有什么用?
- 自动化测试: 模拟用户点击,快速跑通几千个测试用例,不需要真的弹出一千个窗口。
- 爬虫: 爬取那些需要 JS 渲染的复杂网页。
- 生成截图/PDF: 在服务器端把网页渲染成图片或 PDF 报告。
B. 无头编辑器 (Headless Editor)
- 传统的编辑器(如 CKEditor 旧版, Quill):
- 你引入它,它就自带一套“加粗、斜体、插入图片”的工具栏,自带一套 CSS 样式。
- 缺点: 如果设计师说“把工具栏按钮变成圆形的,而且要悬浮在文字上方”,你就要疯狂覆盖它的默认 CSS,非常痛苦。
- 无头编辑器(如 Tiptap, Plate, Slate.js):
- 定义: 它只提供文字处理的核心逻辑(比如:选中文本、按下 Ctrl+B 变粗体、撤销重做逻辑)。它不提供任何 UI(没有工具栏,没有按钮)。
- 怎么用? 你需要自己写一个
<button>,自己写样式,然后调用它的 APIeditor.toggleBold()。 - 有什么用? 你可以完全自由地定制编辑器的长相。比如 Notion、飞书文档那种高度定制的 UI,必须用无头编辑器开发。
3. 还有哪些常见的 Headless?
除了浏览器和编辑器,现在的开发趋势中还有:
C. 无头组件库 (Headless UI)
- 例子: Radix UI, Headless UI, React Aria。
- 解释: 以前我们用 Ant Design 或 Bootstrap,按钮长什么样是库定好的。Headless UI 库只提供交互逻辑(比如下拉菜单怎么打开,键盘怎么选,无障碍怎么读),不提供任何 CSS。
- 好处: 完美配合 Tailwind CSS,长相由你完全控制。
D. 无头 CMS (Headless CMS)
- 例子: Strapi, Contentful。
- 解释: 以前用 WordPress,后台管理内容,前台页面也是 WordPress 生成的(耦合)。Headless CMS 只提供后台管理和 API。
- 好处: 你的一份内容(API)可以同时发给 网站、App、智能手表、甚至冰箱屏幕。
总结:为什么现在流行 Headless?
虽然 Headless 意味着开发者要写更多的代码(因为要自己画 UI),但它解决了现代开发最大的痛点:定制化。
| 维度 | 传统 (Coupled) | Headless (无头) |
|---|---|---|
| 上手难度 | 低 (开箱即用) | 高 (需要自己写 UI) |
| 自由度 | 低 (改样式很难) | 极高 (随心所欲) |
| 适用场景 | 快速做个标准后台 | 像 Notion/Figma 这种需要极致体验的产品 |
| 比喻 | 方便面 (有面有调料包,味道固定) | 生鲜面条 (只有面,想做炸酱面还是汤面随你) |
一句话总结:Headless 就是把“业务逻辑”和“界面表现”彻底分家,让你拥有无限的 UI 定制权。
来源:juejin.cn/post/7582118218649288730
为了让 iframe 支持 keepAlive,我连夜写了个 kframe
前几天收到一个bug,说是后台管理系统每次切换标签栏后,xxx内容区自动刷新,操作进度也丢失了,给用户造成很大困扰。作为结丹期修士的我自然不容允许此等存在,开干!

问题分析
该后台管理系统基于 vue3 全家桶开发,多标签页模式,标签页默认
KeepAlive,本文以 demo 示例。
切换标签后内容区自动刷新,操作进度丢失?首先想到的是 KeepAlive 问题,但经过排查后才发现,KeepAlive 是正常的,异常的是内嵌于页面的 iframe 内容区,页面每次 onActivated 时,iframe 内容区都会重新加载一次,导致进度丢失。
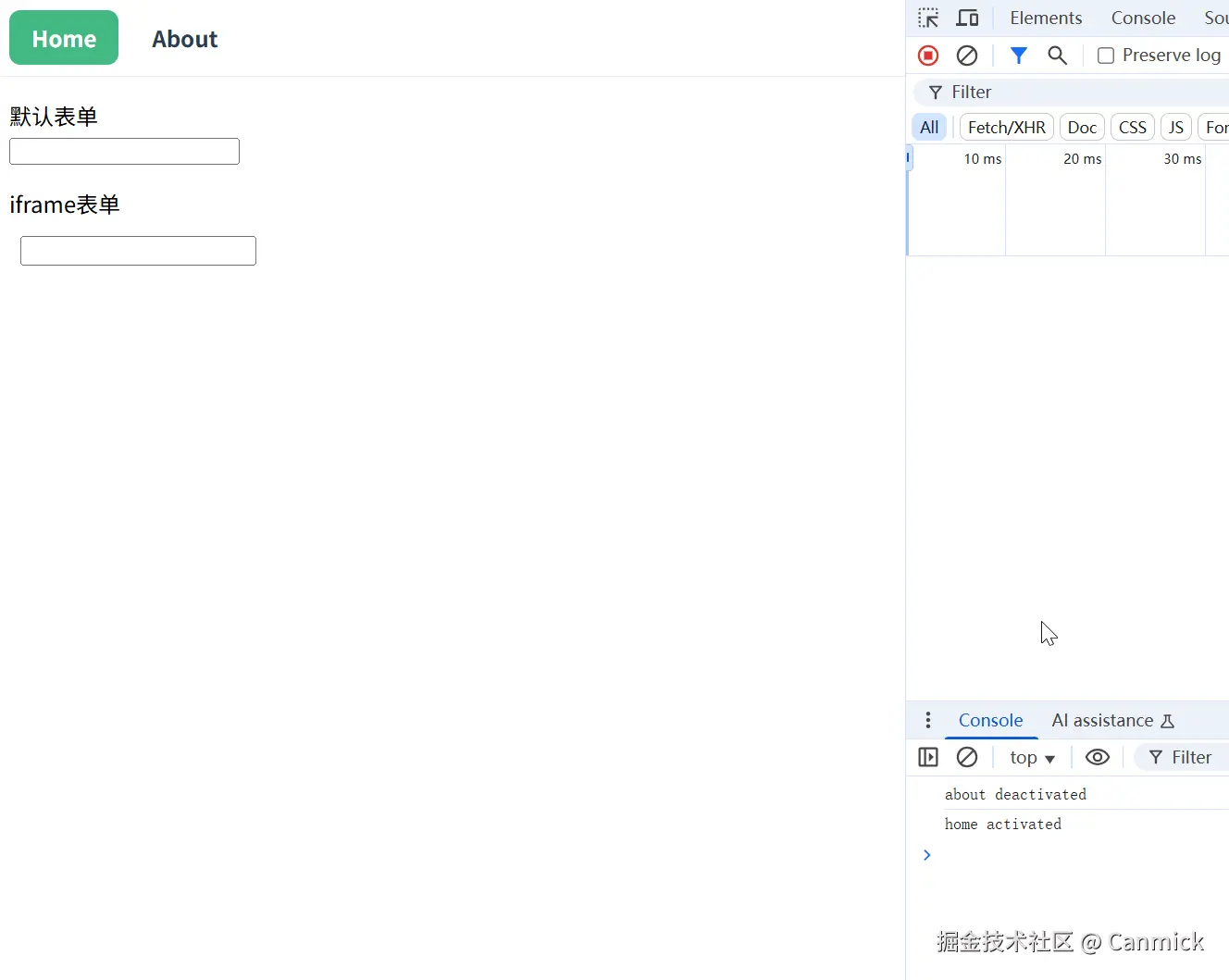
iframe 并没有被 keep 住,为什么?
通过查阅 Vue 文档得知,KeepAlive缓存的只是 Vue 组件实例,组件实例包含组件状态和 VNode (虚拟 DOM 节点)等。当组件 activated 时,组件 VNode 已经转为真实 DOM 节点插入文档中了,而组件 deactivated 时,已经从文档中移除了组件对应的真实 DOM 节点并缓存组件实例。


VNode 是对真实 DOM 节点的映射,包含节点标签名、节点属性等信息。我们打开控制台选中 iframe 元素,右侧那栏就是其对应的 VNode 了。
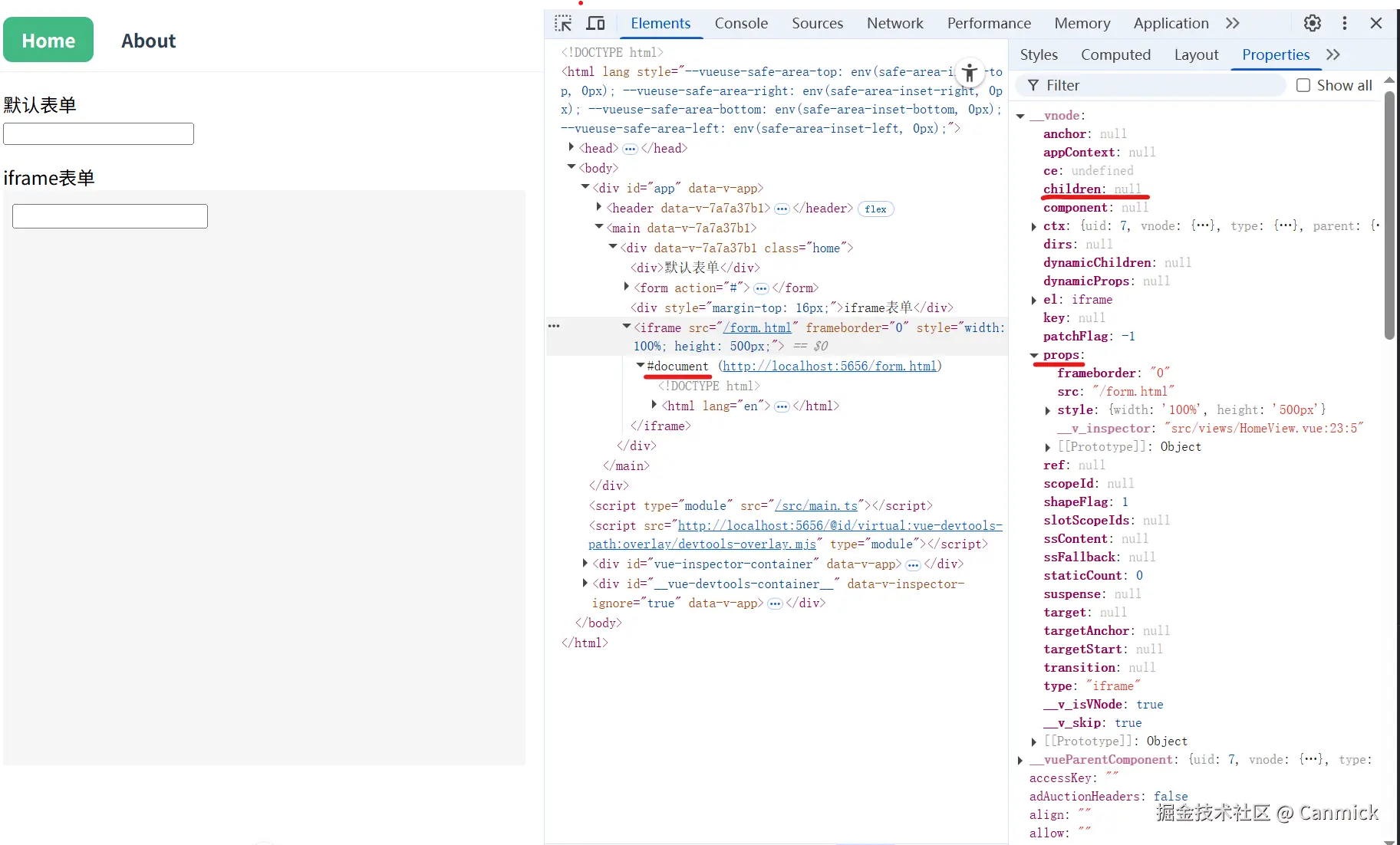
从上图可看出,iframe 的内容并不属于节点信息,是个独立的 browsing context(浏览上下文),无法被缓存;iframe 每次渲染(如 DOM 节点插入、移动)都会触发完整的加载过程(相当于打开新窗口)。故组件每次 activated 时,iframe 都会重新加载,创建了新的上下文,之前的操作进度自然是丢失了。
至此,问题原因已找到,接下来看下如何处理。
解决方案
iframe 无法保存于 VNode 中,又不能将 iframe 从文档中移动或移除,那么就想办法在某个地方把 iframe 存起来,比如 body 节点下,然后通过样式控制 iframe 展示与隐藏,顺着思路捋一下整体流程。
有了上述流程,开始设计下细节。 Iframe 组件是对 iframe 操作流的封装,方便在 vue 项目中使用,内部涉及 iframe 创建、插入、设置样式、移除等操作,为方便操作,将其封装为 Iframe 类;分散的 Iframe 类操作,稍有不当可能造成内存占用过多,故为了统一管理,再设计一个 IframeManage 来统一管理 Iframe。
相关的类关系图如下
classDiagram
class Iframe {
-instance: HTMLIFrameElement
-ops: IframeOptions
+init()
+hide()
+show(rect: IFrameRect)
+resize(rect: IFrameRect)
+destroy()
}
class IFrameManager {
+static frames: Map<string, Iframe>
+static createFrame()
+static showFrame()
+static hideFrame()
+static destroyFrame()
+static resizeFrame()
+static getFrame()
}
class VueComponent {
-frameContainer: Ref
+createFrame()
+destroyFrame()
+showFrame()
+resizeFrame()
-handleLoaded()
-handleError()
}
VueComponent --> IFrameManager : 使用
IFrameManager --> Iframe : 创建/管理
Iframe --> HTMLIFrameElement : 封装
对应的时序图如下
sequenceDiagram
participant VueComponent
participant IFrameManager
participant Iframe
participant DOM
VueComponent->>IFrameManager: createFrame()
IFrameManager->>Iframe: new Iframe(ops)
Iframe->>DOM: createElement('iframe')
Iframe->>DOM: appendChild()
VueComponent->>IFrameManager: resizeFrame()
IFrameManager->>Iframe: resize()
Iframe->>DOM: setElementStyle()
VueComponent->>IFrameManager: destroyFrame()
IFrameManager->>Iframe: destroy()
Iframe->>DOM: remove()
至此思路清晰,开始进入编码
编码实战
首先是 Iframe 类的实现
interface IframeOptions {
uid: string
src: string
name?: string
width?: string
height?: string
className?: string
style?: string
allow?: string
onLoad?: (e: Event) => void
onError?: (e: string | Event) => void
}
type IframeRect = Pick<DOMRect, 'left' | 'top' | 'width' | 'height'> & { zIndex?: number | string }
class Iframe {
instance: HTMLIFrameElement | null = null
constructor(private ops: IframeOptions) {
this.init()
}
init() {
const {
src,
name = `Iframe-${Date.now()}`,
className = '',
style = '',
allow,
onLoad = () => {},
onError = () => {},
} = this.ops
this.instance = document.createElement('iframe')
this.instance.name = name
this.instance.className = className
this.instance.style.cssText = style
this.instance.onload = onLoad
this.instance.onerror = onError
if (allow) this.instance.allow = allow
this.hide()
this.instance.src = src
document.body.appendChild(this.instance)
}
setElementStyle(style: Record<string, string>) {
if (this.instance) {
Object.entries(style).forEach(([key, value]) => {
this.instance!.style.setProperty(key, value)
})
}
}
hide() {
this.setElementStyle({
display: 'none',
position: 'absolute',
left: '0px',
top: '0px',
width: '0px',
height: '0px',
})
}
show(rect: IframeRect) {
this.setElementStyle({
display: 'block',
position: 'absolute',
left: rect.left + 'px',
top: rect.top + 'px',
width: rect.width + 'px',
height: rect.height + 'px',
border: '0',
'z-index': String(rect.zIndex) || 'auto',
})
}
resize(rect: IframeRect) {
this.show(rect)
}
destroy() {
if (this.instance) {
this.instance.onload = null
this.instance.onerror = null
this.instance.remove()
this.instance = null
}
}
}
其次是 IFrameManager 类的实现
export class IFrameManager {
static frames = new Map()
static createFame(ops: IframeOptions, rect: IframeRect) {
const existFrame = this.frames.get(ops.uid)
if (existFrame) {
existFrame.destroy()
}
const frame = new Iframe(ops)
this.frames.set(ops.uid, frame)
frame.show(rect)
return frame
}
static showFrame(uid: string, rect: IframeRect) {
const frame = this.frames.get(uid)
frame?.show(rect)
}
static hideFrame(uid: string) {
const frame = this.frames.get(uid)
frame?.hide()
}
static destroyFrame(uid: string) {
const frame = this.frames.get(uid)
frame?.destroy()
this.frames.delete(uid)
}
static resizeFrame(uid: string, rect: IframeRect) {
const frame = this.frames.get(uid)
frame?.resize(rect)
}
static getFrame(uid: string) {
return this.frames.get(uid)
}
}
最后是 Iframe 组件的实现
<template>
<div ref="frameContainer" class="k-frame">
<span v-if="!src" class="k-frame-tips">
<slot name="placeholder">暂无数据</slot>
</span>
<span v-else-if="isLoading" class="k-frame-tips">
<slot name="loading">加载中... </slot>
</span>
<span v-else-if="isError" class="k-frame-tips"> <slot name="error">加载失败 </slot></span>
</div>
</template>
<script setup lang="ts">
import { onActivated, onBeforeUnmount, onDeactivated, ref, watch } from 'vue'
import { IFrameManager, getIncreaseId } from './core'
import { useResizeObserver, useThrottleFn } from '@vueuse/core'
defineOptions({
name: 'KFrame',
})
const props = withDefaults(
defineProps<{
src: string
zIndex?: string | number
keepAlive?: boolean
}>(),
{
src: '',
keepAlive: true,
},
)
const emits = defineEmits(['loaded', 'error'])
const uid = `kFrame-${getIncreaseId()}`
const frameContainer = ref()
const isLoading = ref(false)
const isError = ref(false)
let readyFlag = false
const getFrameContainerRect = () => {
const { x, y, width, height } = frameContainer.value?.getBoundingClientRect() || {}
return {
left: x || 0,
top: y || 0,
width: width || 0,
height: height || 0,
zIndex: props.zIndex ?? 'auto',
}
}
const createFrame = () => {
isError.value = false
isLoading.value = true
IFrameManager.createFame(
{
uid,
name: uid,
src: props.src,
onLoad: handleLoaded,
onError: handleError,
allow: 'fullscreen;autoplay',
},
getFrameContainerRect(),
)
}
const handleLoaded = (e: Event) => {
isLoading.value = false
emits('loaded', e)
}
const handleError = (e: string | Event) => {
isLoading.value = false
isError.value = true
emits('error', e)
}
const showFrame = () => {
IFrameManager.showFrame(uid, getFrameContainerRect())
}
const hideFrame = () => {
IFrameManager.hideFrame(uid)
}
const resizeFrame = useThrottleFn(() => {
IFrameManager.resizeFrame(uid, getFrameContainerRect())
})
const destroyFrame = () => {
IFrameManager.destroyFrame(uid)
}
const getFrame = () => {
return IFrameManager.getFrame(uid)
}
useResizeObserver(frameContainer, () => {
resizeFrame()
})
onBeforeUnmount(() => {
destroyFrame()
readyFlag = false
})
onDeactivated(() => {
if (props.keepAlive) {
hideFrame()
} else {
destroyFrame()
}
})
onActivated(() => {
if (props.keepAlive) {
showFrame()
return
}
if (readyFlag) {
createFrame()
}
})
watch(
() => [frameContainer.value, props.src],
(el, src) => {
if (el && src) {
createFrame()
readyFlag = true
} else {
destroyFrame()
readyFlag = false
}
},
{
immediate: true,
},
)
defineExpose({
getRef: () => getFrame()?.instance,
})
</script>
<style lang="scss" scoped>
.k-frame {
position: relative;
display: flex;
align-items: center;
justify-content: center;
width: 100%;
height: 100%;
&-tips {
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
}
</style>
看看效果
小结
管理后台多页签切换,iframe 区操作进度丢失,根本原因在于 KeepAlive 缓存机制与iframe 的独立浏览上下文特性存在本质冲突。本文通过物理隔离与视觉映射的双重策略,将 iframe 的真实 DOM 节点与Vue 组件实例解耦,实现了 keepAlive 的效果。
当然,该方案在代码实现还有很大优化空间,如 IFrameManager 目前是单例模式、Iframe 池未设计淘汰缓存机制(如 LRU )。嘀嘀嘀...产品催着上线了,没时间优化了,下次一定。
相关代码已上传只 github,欢迎道友们给个 star,在此谢过了

来源:juejin.cn/post/7504146372771004425
Tailwind 到底是设计师喜欢,还是开发者在硬撑?
我们最近刚把一个后台系统从 element-plus 切成了完全自研组件,CSS 层统一用 Tailwind。全员同意设计稿一致性提升了,但代码里怨言开始冒出来。
这篇文章不讲原理,直接上代码对比和团队真实使用反馈,看看是谁在享受,谁在撑着。
1.组件内样式迁移
原先写法(BEM + scoped):
<template>
<div class="card">
<h2 class="card__title">用户概览</h2>
<p class="card__desc">共计 1280 位</p>
</div>
</template>
<style scoped>
.card {
padding: 16px;
background-color: #fff;
border-radius: 8px;
}
.card__title {
font-size: 16px;
font-weight: bold;
}
.card__desc {
color: #999;
font-size: 14px;
}
</style>
Tailwind 重写:
<template>
<div class="p-4 bg-white rounded-lg">
<h2 class="text-base font-bold">用户概览</h2>
<p class="text-sm text-gray-500">共计 1280 位</p>
</div>
</template>
优点:
- 组件直接可读,不依赖 class 定义
- 样式即结构,调样式时不用来回翻
缺点:
- 设计稿变了?全组件搜索
text-sm改成text-base? - 无法抽象:多个地方复用
.text-label变成复制粘贴
2.复杂交互样式
纯 CSS(原写法)
<template>
<button class="btn">提交</button>
</template>
<style scoped>
.btn {
background-color: #409eff;
color: #fff;
padding: 8px 16px;
border-radius: 4px;
}
.btn:hover {
background-color: #66b1ff;
}
.btn:active {
background-color: #337ecc;
}
</style>
Tailwind 写法
<button
class="bg-blue-500 hover:bg-blue-400 active:bg-blue-700 text-white py-2 px-4 rounded">
提交
</button>
问题来了:
- ✅ 简单 hover/active 很方便
- ❌ 多态样式(如 disabled + dark mode + hover 同时组合)就很难读:
<button
class="bg-blue-500 text-white disabled:bg-gray-300 dark:bg-slate-600 dark:hover:bg-slate-700 hover:bg-blue-600 transition-all">
>
提交
</button>
调试时需要反复阅读 class 字符串,不能直接 Cmd+Click 查看样式来源。
3.统一样式封装,复用方案混乱
原写法:统一样式变量 + class
$border-color: #eee;
.panel {
border: 1px solid $border-color;
border-radius: 8px;
}
Tailwind 使用中经常出现的写法:
<div class="border border-gray-200 rounded-md" />
问题来了:
设计稿调整了主色调或边框粗细,如何批量更新?
BEM 模式下你只需要改一个变量,Tailwind 下必须靠 @apply 或者手动替换所有 .border-gray-200。
于是我们项目里又写了一堆“语义类”去封装 Tailwind:
/* 自定义 utilities */
@layer components {
.app-border {
@apply border border-gray-200;
}
.app-card {
@apply p-4 rounded-lg shadow-sm bg-white;
}
}
最后导致的问题是:我们重新“造了个 BEM”,只不过这次是基于 Tailwind 的 apply 写法。
🧪 实测维护成本:100+组件、多人协作时的问题
我们项目有 110 个组件,4 人开发,统一用 Tailwind,协作两个月后出现了这些反馈:
- 👨💻 A 开发:写得很快,能复制设计稿的 class 直接粘贴
- 🧠 B 维护:改样式全靠人肉找
.text-sm、.p-4,没有结构命名层 - 🤯 C 重构:统一调整圆角半径?所有
.rounded-md都要搜出来替换
所以我们内部的结论是:
Tailwind 写得爽,维护靠人背。它适合“一次性强视觉还原”,不适合“结构长期型组件库”。
🔧 我们后来的解决方案:Tailwind + token 化抽象
我们仍然使用 Tailwind 作为底层 utilities,但同时强制使用语义类抽象,例如:
@layer components {
.text-label {
@apply text-sm text-gray-500;
}
.btn-primary {
@apply bg-blue-500 hover:bg-blue-600 text-white py-2 px-4 rounded;
}
.card-container {
@apply p-4 bg-white rounded-lg shadow;
}
}
模板中统一使用:
<h2 class="text-label">标题</h2>
<button class="btn-primary">提交</button>
<div class="card-container">内容</div>
这种方式保留了 Tailwind 的构建优势(无 tree-shaking 问题),但代码结构有命名可依,后期批量维护不再靠搜索。
📌 最终思考
Tailwind 是给设计还原速度而生的,不是给可维护性设计的。
设计师爱是因为它像原子操作;
开发者撑是因为它把样式从结构抽象变成了“字串组合游戏”。
如果你的团队更在意开发效率,样式一次性使用,那 Tailwind 非常合适。
如果你的组件系统是要长寿、要维护、要被多人重构的——你最好在 Tailwind 之上再造一层自己的语义层,或者别用。
分享完毕,谢谢大家🙂
📌 你可以继续看我的系列文章
来源:juejin.cn/post/7517496354245492747
✨ 前端实现打字机效果的主流插件推荐
🎯 总结对比
| 插件名 | 体积 | 自定义 | 动画丰富 | 推荐场景 |
|---|---|---|---|---|
| TypeIt | 中 | 很强 | 很丰富 | 高级动画、官网 |
| Typed.js | 小 | 一般 | 常用足够 | 个人/博客/主页 |
| t-writer.js | 中 | 很强 | 丰富 | 多样动画 |
| ityped | 极小 | 一般 | 简单 | 极简、加载快 |
1️⃣ TypeIt(超强大,推荐!)
🎉 特点:高自定义、易用、支持暂停、删除、换行等丰富动画
安装:
npm install typeit
# 或直接用 CDN
简单用法:
<div id="typeit"></div>
<script src="https://cdn.jsdelivr.net/npm/typeit@8.8.3/dist/typeit.min.js"></script>
<script>
new TypeIt("#typeit", {
strings: ["Hello, 掘金!", "我是打字机效果~"],
speed: 100,
breakLines: false,
loop: true
}).go();
</script>
2️⃣ Typed.js(最流行的打字机插件)
🚀 轻量、简单、社区大,支持多字符串轮播
安装:
npm install typed.js
# 或 CDN
用法:
<span id="typed"></span>
<script src="https://cdn.jsdelivr.net/npm/typed.js@2.0.12"></script>
<script>
new Typed('#typed', {
strings: ['欢迎来到掘金!', '一起学习前端吧~'],
typeSpeed: 80,
backSpeed: 40,
loop: true
});
</script>
3️⃣ t-writer.js(国人开发,API友好)
🔥 支持多种打字动画,API 设计简洁
安装:
npm install t-writer.js
用法:
<div id="twriter"></div>
<script src="https://cdn.jsdelivr.net/npm/t-writer.js/dist/t-writer.min.js"></script>
<script>
const target = document.getElementById('twriter');
const writer = new TypeWriter(target, {
loop: true,
typeColor: 'blue'
})
writer
.type('你好,掘金!')
.rest(500)
.changeOps({ typeColor: 'orange' })
.type('打字机效果轻松实现~')
.rest(1000)
.clear()
.start()
</script>
4️⃣ ityped(极简小巧)
⚡️ 零依赖,体积小,适合极简需求
安装:
npm install ityped
用法:
<div id="ityped"></div>
<script src="https://unpkg.com/ityped@1.0.3"></script>
<script>
ityped.init(document.querySelector("#ityped"), {
strings: ['Hello 掘金', '前端打字机效果'],
loop: true
})
</script>
🛠️ 补充:用原生 JS 实现简单打字效果
如果你不想引入第三方库,也可以用 setTimeout/async 实现基础打字动画:
<div id="simpleType"></div>
<script>
const text = "Hello, 掘金!这是原生JS打字机效果~";
let i = 0;
function typing() {
if (i < text.length) {
document.getElementById('simpleType').innerHTML += text[i];
i++;
setTimeout(typing, 100);
}
}
typing();
</script>
🌟 结语
- 需要高级动画,选 TypeIt/t-writer.js
- 需要轻量简单,选 Typed.js/ityped
- 只需基础效果,也可以原生 JS 10 行搞定!
来源:juejin.cn/post/7497801626670546984
断网、弱网、关页都不怕:前端日志上报怎么做到不丢包
系列回顾(性能·错误·埋点三部曲):不做工具人|从 0 到 1 手搓前端监控 SDK
在前三篇文章中,我们搞定了性能、行为和错误的采集。但有掘友在评论区灵魂发问:“数据是抓到了,
发不出去有啥用?进电梯断网了咋办?页面关太快请求被掐了咋办?”
今天这篇,我们就来聊聊如何上报数据?
- 用什么方式上报最稳、最省事?
- 什么时候上报最合适?
- 遇到断网/弱网/关页怎么兜底?
一、上报方式与策略:如何选出最优解?
我们平时上报数据主要有三种方式:Image(图片请求)、sendBeacon 和 XHR/Fetch。
1. 三种上报方式详解
1. GIF/Image
这招就是利用图片请求(new Image().src)来传数据。
- 原理很简单:把要上报的数据拼在 URL 后面(如
https://log.demo.com/gif?id=123),浏览器发起请求,服务器解析参数拿到数据,然后返回一张 1×1 的透明GIF图(体积小、看不见),浏览器收到后触发onload回调即完成上报。 - 特点:天然支持跨域,绝无“预检”请求(因为是简单请求)。
- 局限:只能发 GET 请求,URL 长度有限(通常 < 2KB),无法携带大数据。
2. sendBeacon
- 原理:
navigator.sendBeacon(url, data)。浏览器会将数据放入后台队列,即使页面关闭了,浏览器也会尽力发送。 - 特点:异步非阻塞(不卡主线程),且可靠性极高。
- 局限:数据量有限(约 64KB),且无法自定义复杂的请求头。
3. XHR / Fetch
普通的网络请求。
- 原理:使用
XMLHttpRequest或fetch发送 POST 请求。 - 特点:容量极大(几兆都没问题),适合发送录屏、长堆栈。
- 局限:跨域时通常会触发
OPTIONS预检(成本高),且页面关闭时请求容易被掐断(fetch需配合keepalive)。
注: 所谓的预检,就是浏览器在发送跨域且非简单请求前,先偷偷发个 OPTIONS 问服务器:“大佬,我能发这个请求吗?”。只要你用了自定义 Header 或 application/json 就会触发。这会导致请求量直接翻倍,在弱网下多一次往返就多一分失败的风险。
2. 策略篇:如何组合使用?
怎么选并不是随意决定的,而是为了解决两个核心痛点:
- 成本问题(CORS 预检):所谓的预检,就是浏览器在发送跨域且非简单请求前,先偷偷发个
OPTIONS问服务器:“大佬,我能发这个请求吗?”。
- 什么时候触发? 只要你用了自定义 Header(如
X-Token)或者Content-Type: application/json,就会触发。 - 后果是啥? 请求量直接翻倍,弱网下成功率腰斩。
- 避坑指南:这也是为什么很多监控SDK通常都故意使用
text/plain来发送 JSON 数据。虽然数据格式是 JSON,但告诉浏览器“这是纯文本”,就能骗过预检,直接发送!
- 什么时候触发? 只要你用了自定义 Header(如
- 存活问题(页面卸载):用户关闭页面时,浏览器通常会直接掐断挂起的异步请求,导致“临终遗言”发不出去。
基于这两个维度,我们将三种方式排个序,也就形成了我们的降级策略:
1. 首选方案:sendBeacon(六边形战士)
这是现代浏览器的首选方案。
- 优势:专为监控设计,页面关闭了也能发(浏览器将其放入后台队列)。
- 特点:容量适中(~64KB),且通常不触发预检,完美平衡了“存活”与“成本”。
- 适用:绝大多数监控事件。
2. 降级方案:GIF/Image(老牌救星)
当 sendBeacon 不可用(如 IE)或数据极小的时候用它。
- 优势:天然跨域,绝无预检。利用
new Image().src发起请求,服务器返回一张 1x1 透明图即可。 - 特点:兼容性无敌,但数据量受 URL 长度限制(~2KB),且页面关闭时发送成功率低。
- 适用:PV、点击、心跳等轻量指标。
3. 兜底方案:XHR / Fetch
只有前两招搞不定时(数据量太大)才用它。
- 优势:容量极大,适合传录屏、大段错误堆栈。
- 劣势:跨域麻烦(需配 CORS),有预检成本。
- 注意:使用 Fetch 时务必加
keepalive: true,告诉浏览器“就算页面关了也别杀我”,尽量提升卸载时的成功率。
选型对比表
| 方案 | 跨域/预检 | 卸载可靠性 | 数据容量 | 核心优势 | 适用场景 |
|---|---|---|---|---|---|
| sendBeacon | 支持 / 无预检 | 高 | 中 (~64KB) | 关页也能发,不占主线程 | 首选,大多数监控事件 |
| GIF/Image | 支持 / 无预检 | 低 | 小 (~2KB) | 兼容性强,无预检 | 降级方案,PV/点击/心跳 |
| XHR/Fetch | 需 CORS / 有 | 低 | 大 | 能传大数据 | 错误堆栈、录屏 |
总结我们的代码套路(降级策略):
- 小包(< 2KB,单条事件):优先
sendBeacon;若不支持,再走ImageGET(附_ts防缓存)。 - 中包(≤ 64KB):
sendBeacon为首选;若不支持,回退到Fetch/XHR,Content-Type: text/plain+keepalive: true。 - 大包(> 64KB):
Fetch/XHR承载,必要时拆包分批发送。
下面是封装好的 transport上报函数,直接拿去用:
const REPORT_URL = 'https://log.your-domain.com/collect';
const MAX_URL_LENGTH = 2048;
const MAX_BEACON_BYTES = 64 * 1024;
function byteLen(s) {
try {
return new TextEncoder().encode(s).length;
} catch (e) {
return s.length;
}
}
/**
* 通用上报函数
* @param {Object|Array} data - 上报数据
* @returns {Promise<void>} - 成功 resolve,失败 reject
*/
function transport(data) {
const isArray = Array.isArray(data);
const json = JSON.stringify(data);
return new Promise((resolve, reject) => {
// 1. 优先尝试 sendBeacon
// 注意:sendBeacon 是同步入队,返回 true 仅代表入队成功,不一定是发送成功
if (navigator.sendBeacon && byteLen(json) <= MAX_BEACON_BYTES) {
const blob = new Blob([json], { type: 'text/plain' });
// 如果入队成功,直接 resolve(乐观策略)
if (navigator.sendBeacon(REPORT_URL, blob)) {
resolve();
return;
}
// 如果入队失败(如队列已满),不 reject,而是继续往下走降级方案
console.warn('[Beacon] 入队失败,尝试降级...');
}
// 2. 单条小数据尝试 Image (GET)
if (!isArray) {
const params = new URLSearchParams(data);
params.append('_ts', String(Date.now()));
const qs = params.toString();
const sep = REPORT_URL.includes('?') ? '&' : '?';
if (REPORT_URL.length + sep.length + qs.length < MAX_URL_LENGTH) {
const img = new Image();
img.onload = () => resolve(); // 成功
img.onerror = () => reject(new Error('Image 上报失败')); // 失败
img.src = REPORT_URL + sep + qs;
return;
}
}
// 3. 兜底方案:Fetch > XHR
if (window.fetch) {
fetch(REPORT_URL, {
method: 'POST',
headers: { 'Content-Type': 'text/plain' },
body: json,
keepalive: true, // 关键:允许页面关闭后继续发送
})
.then((res) => {
if (res.ok) resolve();
else reject(new Error(`Fetch 失败: ${res.status}`));
})
.catch(reject);
} else {
// IE 兼容
const xhr = new XMLHttpRequest();
xhr.open('POST', REPORT_URL, true);
xhr.setRequestHeader('Content-Type', 'text/plain');
xhr.onload = () => {
if (xhr.status >= 200 && xhr.status < 300) resolve();
else reject(new Error(`XHR 失败: ${xhr.status}`));
};
xhr.onerror = () => reject(new Error('XHR 网络错误'));
xhr.send(json);
}
});
}
二、上报时机:不阻塞主线程干扰业务,断网了也不丢数据
1. 调度层:区分优先级,关键时刻不等待
不是所有数据都适合“攒着发”。我们需要根据重要程度将日志分为两类:
- 即时上报(Immediate):收集到立即上报。
- 场景:JS 报错阻断了流程、用户点击了“支付”按钮、接口返回 500 等。
- 原因:这些数据对实时性要求极高,或者关系到监控系统的报警(比如线上白屏了,你得马上知道),不能因为攒着发而耽误了。
- 批量上报(Batch):攒一波再发。
- 场景:用户点击、滚动、性能指标、API 成功日志。这类数据量大但实时性要求低
- 策略:“量”与“时”双重触发(竞态关系)。比如:攒够 10 条立马发(防止堆积太多),或者每隔 5 秒发一次(防止数量不够一直不发)。
代码怎么写?其实就是一个简单的双保险调度器:
let queue = [];
let timer = null;
const QUEUE_MAX = 10;
const QUEUE_WAIT = 5000;
function flush() {
if (!queue.length) return;
// 1. 把当前队列的数据复制出来
const batch = queue.slice();
// 2. 清空队列与定时器
queue.length = 0;
clearTimeout(timer);
timer = null;
// 3. 利用空闲时间发送(性能优化点)
if ('requestIdleCallback' in window) {
requestIdleCallback(() => transport(batch), { timeout: 2000 });
} else {
// 降级兼容
setTimeout(() => transport(batch), 0);
}
}
function report(log, immediate = false) {
// 1. 紧急情况:绕过队列,直接发
if (immediate) {
transport(log);
return;
}
// 2. 普通情况:进入队列(如 点击、PV)
queue.push({ ...log, ts: Date.now() });
// 3. 检查触发条件(双重保险)
if (queue.length >= QUEUE_MAX) {
flush();
} else if (!timer) {
timer = setTimeout(flush, QUEUE_WAIT);
}
}
// 4. 临终兜底:页面关闭/隐藏时,强制把剩下的都发走
document.addEventListener('visibilitychange', function () {
if (document.visibilityState === 'hidden') flush();
});
window.addEventListener('pagehide', flush);
整体思路:队列暂存 + 多重触发
我们用一个数组(queue)来暂存日志,然后通过 “量够了”、“时间到了”或“页面要关了” 这三个时机来触发发送,确保既不积压也不频繁打扰服务器。
性能优化:闲时优先
发送时,我们首选 requestIdleCallback。告诉浏览器你先忙你的(渲染、响应点击),等你有空了再帮我发监控数据
- 这样能最大限度减少对业务主线程的阻塞,让用户感觉不到监控的存在。
- 当然,如果浏览器不支持这个 API,我们再降级用
setTimeout兜底。
2. 容灾层:断网了,日志怎么办?
如果在电梯里断网了或者弱网环境下,请求发不出去怎么办?日志丢了怎么办。
我们的策略是 “先记在本子上,等有网了再补交作业”:
- 断网时:把日志存到
localStorage里(注意设置上限,别把用户浏览器撑爆了,可用IndexedDB优化)。 - 连网时:监听
online事件,把存的日志拿出来,分批发给服务器(别一次性全发过去,容易把后端打挂)。
具体怎么判断有没有网呢?
通常我们用 navigator.onLine 来看。如果返回值是 false ,那肯定是没网,直接存本地。
但坑就坑在,这玩意儿有时候会 “撒谎” —— 比如连上了酒店 WiFi 但没登录,或者宽带欠费了。这时候它虽然显示 true (在线),但其实根本上不了网。
所以咱们得留一手:
哪怕它说“在线”,我们也先试着上报一下。 要是报错了发不出去,别管三七二十一,先把这条日志存本地保底(千万别丢数据),然后再去 Ping 一下看看到底是不是真断网了 ,顺便更新一下网络状态。这样最稳。
1. 网络状态的检测
NetworkManager这个模块专门负责盯着网络,它很聪明,只有在发送日志失败的时候才会去复核网络真伪。
const NetworkManager = {
online: navigator.onLine,
// 初始化:盯着系统的 online/offline 事件
init(onBackOnline) {
window.addEventListener('online', async () => {
// 别高兴太早,先看看是不是真的能上网
const realWait = await this.verify();
if (realWait) {
this.online = true;
onBackOnline(); // 真的回网了,赶紧补传!
}
});
window.addEventListener('offline', () => this.online = false);
},
// “测谎仪”:发个 HEAD 请求看看
async verify() {
try {
// 请求个 favicon 或者 1x1 图片,只要响应了说明网通了
await fetch('/favicon.ico', { method: 'HEAD', cache: 'no-store' });
return true;
} catch {
return false;
}
}
};
2. 核心上报:能发就发,不行就存本地
上报函数现在变得非常有弹性。
export async function reportData(data) {
// 1. 如果明确知道没网,直接存本地 (省一次请求)
if (!NetworkManager.online) {
saveToLocal(data);
return;
}
// 2. 尝试发送
try {
await transport(data);
} catch (err) {
console.error('上报请求失败:', err);
// 3. 不管是因为断网、超时、还是服务器挂了
// 只要没成功,第一件事就是存本地!保证这条日志不丢!
saveToLocal(data);
// 4. 然后再来诊断网络,决定后续策略
// 只有当是网络层面的错误(如 fetch throw Error)才去怀疑网络
// 如果是 500 错误,其实网是通的,不用 forceOffline
if (isNetworkError(err)) {
// 5. Ping 确认
NetworkManager.verify().then(res => NetworkManager.online = res);
}
}
}
/**
* 判断是否为网络层面的错误
*/
function isNetworkError(err) {
// 原生 fetch 的网络错误通常是 TypeError: Failed to fetch
// 如果是使用 Axios,则可以通过 !err.response 来判断
return err instanceof TypeError || (err.request && !err.response);
}
const RETRY_KEY = 'RETRY_LOGS';
const RETRY_MAX_ITEMS = 1000;
function saveToLocal(data) {
const raws = localStorage.getItem(RETRY_KEY);
const logs = raws ? JSON.parse(raws) : [];
logs.push(data);
if (logs.length > RETRY_MAX_ITEMS) {
logs.splice(0, logs.length - RETRY_MAX_ITEMS);
}
localStorage.setItem(RETRY_KEY, JSON.stringify(logs));
}
3. 补传逻辑:别把服务器干崩了
等到网络恢复,本地攒了一堆“欠账”,千万别一股脑儿全发过去(万一本地存了 500 条,一次全发会把服务器打爆的)。
我们要有节奏地补传:
async function flushLogs() {
let logs = JSON.parse(localStorage.getItem('RETRY_LOGS') || '[]');
if (!logs.length) return;
console.log(`[回血] 发现 ${logs.length} 条欠账,开始补传...`);
while (logs.length > 0) {
// 1. 每次只取 5 条,小碎步走
const batch = logs.slice(0, 5);
try {
// 2. 调用上报中心
await transport(batch);
// 3. 只有成功了,才把这 5 条从 logs 里剔除
logs.splice(0, 5);
localStorage.setItem(RETRY_LOGS, JSON.stringify(logs));
} catch (err) {
// 4. 如果失败了(断网或服务器挂了)
// 此时 logs 里面还保留着那 5 条数据,所以不用担心丢失
// 记录一下状态,直接跳出循环,等下次 NetworkManager 唤醒
console.error('补传中途失败,保留剩余欠账');
break;
}
// 2. 歇半秒钟,给正常业务请求让个道
await new Promise(r => setTimeout(r, 500));
}
}
三、总结与实战建议
监控上报这事儿看着不难,其实门道不少。要在数据不丢和不打扰用户之间找平衡,咱们得来一套“组合拳”:
- 上报方式:sendBeacon 为主,Image 为辅,XHR/Fetch 兜底。利用
sendBeacon的特性解决页面卸载时的丢包问题,利用Image解决跨域预检的成本问题。 - 上报时机:闲时上报 + 批量打包。利用
requestIdleCallback不占用主线程,通过队列机制减少 HTTP 请求频次。 - 断网处理:本地缓存 + 网络侦测。断网时将数据持久化到 LocalStorage,待网络恢复后分批补传,确保“一条都不丢”。
最后,给开发者的 3 个避坑小贴士:
- 不要迷信
navigator.onLine:它只能判断有没有连接到局域网,不能判断是否真的能上网。一定要配合实际的请求探测。 - 控制补传节奏:网络恢复后,千万别一次性把积压的几百条日志全发出去,这属于“DDoS 攻击”自家服务器。要分批、甚至加随机延迟发送。
- 隐私与合规:上报数据前,务必对敏感信息(如 Token、用户手机号)进行脱敏处理,这是红线。
如果你有更好的思路,欢迎在评论区交流!
来源:juejin.cn/post/7596247009815412762
AI驱动的大前端开发工作流
在日常的大前端需求开发中,我们常常需要同时兼顾UI还原和业务逻辑两部分工作。UI方面,就是要尽可能细致地还原设计稿上的每个细节;业务逻辑方面,则往往和需求复杂度以及项目代码规模正相关。今天,我们就来聊聊如何利用AI驱动,提升需求实现过程中的效率和体验。
UI设计稿还原
如今市面上已经有不少做得不错的AI设计稿转代码工具,比如v0、bolt.new、codefun等。对于一些个人独立项目来说,这些工具真心牛逼:只需传入设计稿,就可以快速生成模块化、精确的UI代码,而且还能通过对话式的交互来不断调整细节,直到完全符合预期。
但如果把这些工具直接应用于一个成熟项目中,就会暴露一些问题。首先,目前大部分工具主要支持vue和react,而我们的项目往往还涉及flutter、android、iOS等多端开发。其次,成熟项目中往往都有一套独特的代码规范和UI组件库,而这些工具生成的代码往往并不了解这些细节,直接将生成的代码拷贝进项目之后还得二次调整,额外的成本不可忽视。
那么有没有办法既能支持更多编程语言,又能在生成UI代码时就结合项目中已有的规范和组件库,从而减少二次调整成本呢?答案是有的!
目前,figma是市面上使用比较主流的设计稿工具。Builder.io最近发布了一款基于figma设计稿、AI驱动的前端代码生成插件——Visual Copilot。使用它,你只需要把figma切换到Dev Mode,然后选择设计稿中的任意图层,接着在Visual Copilot中直接导出代码。

Visual Copilot生成的代码不仅支持vue、react,还涵盖了其它几乎所有主流的大前端语言和框架,十分全面。你可以实时预览生成的效果,并进行细节调整,直到满意为止。

生成代码后,如何让这些代码完美融入到我们的项目规范中呢? 这里就需要结合Visual Copilot与Cursor的配合来实现。
具体做法是:当Visual Copilot将设计稿图层转化成代码后,它会自动生成一个可远程执行的工作空间,并提供相关命令(图中红框所示)将工作空间的代码集成到我们项目中。 
接下来,我们只需在Cursor的Terminal中运行指定指令,就能连接Visual Copilot的远程工作空间,实时获取生成的代码,同时通过交互指令界面明确我们后续的需求。

那么,最终生成的代码如何与项目中的各种规范结合呢? 这就要用到Cursor的AI规则机制——CusorRules。你只需在项目根目录下配置一个.cursorrules文件,声明你的UI代码规范以及封装的组件信息。Cursor在生成代码时就会充分参照这些规则。同时,新版Cursor还支持配置一系列rule文件,你可以通过正则路径来指定规则应用于不同的模块或文件类型,整个过程非常灵活高效(具体可以参与Cursor官方文档)。

业务逻辑开发
在一些中小型规模的项目中,如果想在Cursor中高效地实现业务逻辑,我们需要关注两个关键点:
- CursorRule的应用
和上文UI的规范梳理类似,我们还需要对项目各模块的架构规范等信息进行说明,这样可以让Curosr生成的代码能尽量保障和我们项目规范的一致性。 - 需求拆解:先构建框架,再处理细节
对于较为复杂的需求,我们可以先把实际需求拆解成多个阶段。首先,构建大致的需求框架,并转换成一系列对Cursor友好的Prompt指令(要求简单、准确)。在Cursor的Compose Agent模式下,通过这些指令生成整体的业务逻辑框架。接下来,再利用Cursor Tab在编辑器区域快速完善那些生成时不够精准的细微逻辑。
在一些中小型项目中,通过以上两个关键点我们通常可以快速完成业务逻辑开发。但在一些大型项目中,会遇到Cursor生成的代码经常不尽如人意的问题。这主要是因为项目越大,整个代码库的复杂性增加,Cursor对项目的理解难度也随之上升,每次修改都可能会有不确定因素,提示词如果不能准确描述需要改动的部分,就容易出错。
此时,我们可以尝试另一种思路:用”软件架构师“与”开发者“角色区分需求规划与执行细节。应该怎么做呢?
我们可以将AI驱动的开发流程分为两个阶段:
- 软件架构师角色
这个角色负责对需求进行高层次的分析和解决方案设计,帮助我们总结、提炼和润色需求中的关键信息,同时生成说明性的提示词。这些提示词会告诉我们:这个需求需要创建哪些文件、修改哪些文件、如何做修改等等。 - 开发者角色
开发者则负责把架构师给出的高层次解决方案转化为具体代码。也就是说,开发者依据架构师生成的详细提示词来生成或修改具体文件,从而实现精确的改动,避免大范围理解失误带来的问题。
这种方式的好处在于,只要“软件架构师”生成的提示词足够精准(即它能详细说明需要修改的文件、具体的改动内容和改动范围),那么“开发者”便能够依照这些提示词精确地进行代码修改,极大降低了因大范围理解产生的错误风险。所以这里的性能瓶颈就在于如何定义”软件架构师“角色以及让其接到需求后能生成精确的提示词。
在实际操作中,我们引入了一个“项目地图”的概念。所谓项目地图,就是为大型项目构建一个完整的文档体系(借助AI辅助生成也完全可行),其中包括了项目架构设计、开发流程、模块划分与用途、文件名和其功能说明等内容。这套文档体系可以独立于一个实际的Cursor项目存在,充当“软件架构师”的角色。也就是说,当遇到bug或新需求时,我们可以通过咨询这个“项目地图”,让AI回答问题并给出相对准确的修改思路。
举个例子,拿知名的fast-api项目来说,我为它生成了一个项目地图,其中包含了核心概念说明、系统设计、项目规范以及各模块和文件的用途说明等内容:

同时,在该项目的 .cursorrule 文件中,我详细规定了“软件架构师”如何根据实际需求生成精确的修改指令:
## 项目背景信息
项目名称:FastAPI
项目类型:Python Web 框架
项目地图:参考 fileNames.md
架构文档:参考 architecture/ 目录
编码规范:参考 guidelines/coding-standards.md
## 需求分析模板
1. 需求描述
[简要描述需要实现的功能或修改]
2. 涉及组件
- 核心组件:[列出受影响的核心组件]
- 依赖组件:[列出相关的依赖组件]
- 测试组件:[列出需要修改的测试]
3. 修改范围
- 主要文件:[列出需要修改的主要文件]
- 次要文件:[列出可能需要修改的次要文件]
- 文档文件:[列出需要更新的文档]
4. 技术要点
- 使用的框架特性:[列出需要使用的 FastAPI 特性]
- 数据验证:[描述数据验证要求]
- 兼容性考虑:[描述向后兼容性要求]
5. 潜在风险
[列出可能的风险点和注意事项]
## 执行指导模板
### 给大模型的执行指导
1. 修改步骤
[详细的步骤说明]
2. 验证点
[列出需要验证的关键点]
4. 测试建议
[提供测试建议和用例]
## 实际案例:添加用户电话号码字段
### 1. 需求分析
需求描述:
在用户模型中添加可选的 phone_number 字段,并在相关 API 端点中支持该字段。
涉及组件:
- 核心组件:用户模型(UserIn, UserOut, UserInDB)
- 依赖组件:无
- 测试组件:用户相关测试
修改范围:
- 主要文件:/docs_src/extra_models/tutorial001.py
- 次要文件:无
- 文档文件:API 文档可能需要更新
技术要点:
- 使用 Pydantic BaseModel
- 字段类型:Union[str, ]
- 保持向后兼容性
潜在风险:
- 确保不破坏现有的数据验证
- 保持与现有字段风格一致
### 2. 执行指导
给大模型的具体修改指导:
1. 修改步骤:
a. 在 UserIn 模型中添加 phone_number 字段
b. 在 UserOut 模型中添加对应字段
c. 在 UserInDB 模型中添加对应字段
d. 确保字段定义与 full_name 保持一致的风格
2. 验证点:
- 字段是可选的
- 类型提示正确
- 与现有代码风格一致
- 不影响现有功能
3. 测试建议:
- 测试不提供电话号码的情况
- 测试提供有效电话号码的情况
- 测试提供无效数据的情况
## 使用说明
1. **分析阶段**
- 使用项目背景信息了解上下文
- 按需求分析模板进行分析
- 生成详细的执行指导
2. **交付阶段**
- 将执行指导传递给大模型
- 确保指导清晰且可执行
- 包含必要的验证点
3. **验证阶段**
- 检查实施结果
- 确认所有要求都已满足
- 验证代码质量和一致性
4. **输出**
- 输出执行指导,包括修改步骤、验证点和测试建议,新建analysis目录,在该目录下用一个独立的文件承载,文件名要求符合问题描述诉求<cursor-tools Integration>
# Instructions
基于这些配置,当提交需求时,AI生成的修改思路大致如下,它会精准指出应对哪些文件进行哪些具体改动。
# 需求分析
## 1. 需求描述
在高并发场景下,针对大量用户同时请求数据库导致的性能瓶颈,需要在应用程序中增加缓存机制,降低数据库查询次数,提升整体响应速度和系统稳定性。
## 2. 涉及组件
- 核心组件:数据查询相关业务逻辑(可能涉及CRUD操作的函数或类)
- 依赖组件:可能需要引入第三方缓存库(如 redis、in‐memory 缓存等)
- 测试组件:与数据库查询逻辑相关的测试用例
## 3. 修改范围
- 主要文件:核心业务逻辑所在模块(例如:/app/database.py 或 /app/services/xxx.py)
- 次要文件:如果需要封装缓存工具,则可能新增 /app/utils/cache.py
- 文档文件:如果提供额外的缓存配置,需要更新相关文档
## 4. 技术要点
- FastAPI 配合缓存解决方案(如 in‐memory 缓存、Redis、memcached 等)
- 选择合适的缓存失效策略(LRU、TTL、手动失效等)
- 线程安全、进程安全或分布式缓存方案
- 保证与现有数据校验和返回结构的一致性
## 5. 潜在风险
- 引入缓存后数据一致性问题(可能出现短时间的数据延迟)
- 缓存过期策略不当导致性能问题或脏数据
- 多节点部署时的缓存同步与一致性
- 第三方库的稳定性和可维护性
---
# 执行指导
## 1. 修改步骤
1. 确定缓存方案(例如:Redis 或者内存缓存),并根据业务需求配置失效策略。
2. 在核心数据库查询逻辑中添加缓存查询逻辑:
- 查询前先在缓存中查找数据;
- 如果未命中或缓存过期,则查询数据库并将结果写入缓存;
- 如果命中,则直接返回缓存结果。
3. 为关键业务接口添加缓存逻辑(可封装成一个装饰器,或在查询函数内部实现)。
4. 在配置文件或环境变量中添加缓存相关配置,如主机、端口、缓存大小、过期时间等。
5. 编写或修改测试用例,确保在开启缓存后仍能正确测试业务逻辑。
## 2. 验证点
- 并发请求多时,数据库查询数量显著减少
- 当缓存命中时,响应速度显著提升
- 缓存失效策略(TTL 等)按预期生效
- 高并发情况下是否存在数据不一致或缓存击穿/雪崩问题
## 3. 测试建议
- 正常请求:依次验证在缓存未命中和命中时的响应时间与结果正确性
- 并发请求:使用压力测试工具(locust、JMeter 等)模拟大量请求并观察数据库查询次数与响应时间
- 失效测试:设置短 TTL 并观察缓存自动失效后对系统性能的影响
- 异常测试:故意使缓存服务不可用或网络异常,验证系统能否正常回退到直接查询数据库
随后,我们再将这些详细的提示应用到原项目中,通过AI进一步生成或补全代码,最终大大提高了开发效率和代码准确性。只要前期对项目地图、架构角色和开发规则进行充分准备,我们就能充分借助AI,把原本耗时、易出错的开发流程变得高效且精准。
结语
显而易见,尽管上文主要探讨了大前端领域的AI工作流,但这种思路其实完全可以迁移到其他开发领域。只要我们不断尝试和实践,总结出符合自身业务特点的AI工作模式,就能极大提升我们的工作效率。无论是前端、后端,还是其他技术领域,AI驱动的开发流程都能帮助我们更加精准、高效地解决各类需求和问题。
总之,拥抱AI技术,不断优化工作流程,是我们应对快速变化、不断增长的项目复杂度的关键所在。未来,随着技术的进一步成熟和实践经验的积累,我们必将迎来一个更智能、更高效的开发时代。
来源:juejin.cn/post/7474100684374769698
前端人必懂的浏览器指纹:不止是技术,更是求职加分项
你有没有过这样的经历?
没登录淘宝逛了件卫衣,转头刷抖音、B 站,相似款式的推荐就精准找上门;
或者参与线上投票时,明明没注册账号,却提示 同一用户仅能投一次?
其实这背后藏着一个前端人绕不开的实用技术,浏览器指纹。哪怕你开着无痕模式、频繁切换网络,它依然一样精准识别你,而这门技术,不仅是日常上网的隐形推手,更是前端求职面试中的高频考点
一、浏览器指纹:到底是怎么认出你的?
核心逻辑很简单:世界上没有完全相同的浏览器环境,就像没有两片一模一样的树叶。
浏览器指纹会收集一系列设备和环境特征,再通过算法组合成唯一的 哈希值,这个哈希值就是你的专属 网络标识。这些特征包括但不限于:
- 基础信息:浏览器类型及版本 Chrome、Safari 等、操作系统Windows/macOS 等、屏幕分辨率、系统语言;
- 硬件细节:CPU 核心数、内存大小、显卡型号;
- 高级特征:Canvas 绘图差异 不同设备绘制同一图形,像素级有细微区别、WebGL 渲染信息、已安装字体列表;
- 动态信息:IP 地址 虽可变,但结合其他特征仍有识别价值。
举个直观的例子:Canvas 是 HTML5 的绘图功能,我们用一段简单代码就能提取它的指纹可直接在浏览器控制台运行:
function getCanvasFingerprint() {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
const text = 'frontend-fingerprint';
ctx.textBaseline = 'top';
ctx.font = '14px Arial';
ctx.fillStyle = '#f60';
ctx.fillRect(0, 0, 100, 60);
ctx.fillStyle = '#069';
ctx.fillText(text, 2, 15);
return canvas.toDataURL();
}
function hashFingerprint(str) {
let hash = 0;
for (let i = 0; i < str.length; i++) {
hash = (hash << 5) - hash + str.charCodeAt(i);
hash |= 0;
}
return hash;
}
const dataUrl = getCanvasFingerprint();
const fingerprint = hashFingerprint(dataUrl);
console.log('Canvas指纹结果:', fingerprint);
试着在不同浏览器、甚至不同设备上运行,你会发现每次得到的数值都不一样
这就是浏览器指纹的识别核心。
二、前端人必须掌握的应用场景
浏览器指纹不是 黑科技,而是前端开发、风控、产品设计中高频用到的技术,面试时遇到相关问题,能说清这些场景直接加分:
- 广告精准投放:跨平台识别用户兴趣,比如用户在 A 网站浏览电子产品,在 B 网站就能收到相关广告推送,核心是前端与后端的指纹匹配;
- 防刷防作弊:投票、抢券、秒杀等场景,通过指纹限制同一用户多次操作,前端需负责特征采集与校验逻辑;
- 风控与安全:检测恶意登录、账号盗刷,哪怕黑客换了 IP,浏览器环境特征不变仍能被识别,是前端安全模块的重要知识点;
- 区域限制检测:用 VPN 换 IP 后仍能被识别,就是因为浏览器指纹未变,这也是跨境相关产品的常见需求。
对于前端求职者来说,这些场景不仅是面试高频题,更是实际工作中可能遇到的开发需求。如果能在简历中体现对浏览器指纹的理解,或在面试中清晰拆解实现逻辑,很容易让面试官眼前一亮 ,但很多同学要么不懂核心原理,要么不知道怎么把技术点转化为面试优势。
四、最后说句实在的
浏览器指纹是前端领域的 实用 技术,懂它不仅能解决实际开发问题,更能成为求职路上的加分项。但求职不止是懂技术,更要会 表达技术, 简历怎么写才能脱颖而出?面试怎么说才能打动面试官?这些都需要技巧和经验。
如果你正在为前端求职发愁,想让自己的技术优势被看到,不妨试试我的「前端简历面试辅导」和「前端求职陪跑」服务。从技术亮点提炼到面试答题技巧,从简历优化到 offer 谈判,我会全程帮你针对性提升,让你在众多求职者中脱颖而出,顺利拿下心仪岗位
来源:juejin.cn/post/7592789801708257321
大小仅 1KB!超级好用!计算无敌!
js 原生的数字计算是一个令人头痛的问题,最常见的就是浮点数精度丢失。
// 1. 加减运算
0.1 + 0.2 // 结果:0.30000000000000004(预期 0.3)
0.7 - 0.1 // 结果:0.6000000000000001(预期 0.6)
// 2. 乘法精度偏移
0.1 * 0.2 // 结果:0.020000000000000004(预期 0.02)
3 * 0.3 // 结果:0.8999999999999999(预期 0.9)
// 3. 除法结果异常
0.3 / 0.; // 结果:2.9999999999999996(预期 3)
1.2 / 0.2 // 结果:5.999999999999999(预期 6)
在金额计算的场景中出现这种问题是很危险的,例如「0.1 元 + 0.2 元」本应等于 0.3 元,原生计算却会得出 0.30000000000000004 元,直接导致金额显示错误或支付逻辑异常。
不少人会用toFixed四舍五入,保留 2 位小数来格式化数字,它本质上是 字符串格式化工具,而非精度修复工具,而且还会带来新的精度问题 —— toFixed的四舍五入规则是 “银行家舍入法”,无法解决底层计算的精度误差。
// 问题1. 四舍五入规则不符合预期
1.005.toFixed(2); // 结果:"1.00"(预期 "1.01")
2.005.toFixed(2); // 结果:"2.00"(同样问题)
1.235.toFixed(2); // 结果:"1.23"(预期 "1.24")
// 问题2. 无法修复底层计算误差
const sum = 0.1 + 0.2; // 0.30000000000000004
sum.toFixed(2); // 结果:"0.30"(表面正确,但误差仍存在,后续再运算仍然有问题)
sum.toFixed(10); // 结果:"0.3000000000"(仅隐藏误差,未消除)
而 number-precision 能解决这些问题。
number-precision 的优势在哪?
- 轻量化,大小仅
1kb - API 极简化,只有
加减乘除和四舍五入 - 专注精度问题,无额外心智负担
兼容性好,无额外依赖
适用场景
- 中小型项目、仅需解决基础加减乘除精度问题的场景(如电商、金融类简单计算)
- 对包体积敏感的前端项目。
如何使用?
pnpm install number-precision
import NP from 'number-precision'
NP.strip(0.09999999999999998); // = 0.1
NP.plus(0.1, 0.2); //加法计算 = 0.3, not 0.30000000000000004
NP.plus(2.3, 2.4); //加法计算 = 4.7, not 4.699999999999999
NP.minus(1.0, 0.9); //减法计算 = 0.1, not 0.09999999999999998
NP.times(3, 0.3); //乘法计算 = 0.9, not 0.8999999999999999
NP.times(0.362, 100); //乘法法计算 = 36.2, not 36.199999999999996
NP.divide(1.21, 1.1); //除法计算 = 1.1, not 1.0999999999999999
NP.round(0.105, 2); //四舍五入,保留2位小数 = 0.11, not 0.1
混合的计算:
import NP from 'number-precision'
// (0.8-0.5)x1000,保留2位小数
NP.round(NP.times(NP.minus(0.8, 0.5), 1000), 2)
// 计算股票收益率
NP.round(NP.times(NP.divide(NP.minus(+price, +cost), +cost), 100),2)
更复杂的计算场景用什么
number-precision有短小精悍的优势在,基本的运算都能拿捏,但那些要求更高的计算场景用什么库呢?
总结了目前社区流行的几款计算库,大家按需取用。
| 库 | 特点场景 | 库体积 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|---|
toFixed | 内置方法,仅用于数字格式化,不解决底层精度问题 | 0 | 无需额外引入,使用便捷 | 无法修复计算误差,四舍五入规则非标准 | 非精确场景的临时格式化 |
number-precision | 轻量化,提供加减乘除、四舍五入基础功能,无多余 | 1KB | 体积极小,API 极简,学习成本低 | 不支持超大整数,无复杂数学运算 | 电商价格计算、表单数字校验 |
big.js | 专注十进制浮点数运算,API 简洁,默认精度可配置 | 6KB | 平衡体积与功能,兼容性好 | 功能少于 decimal.js | 中小型项目精确计算、数据统计 |
decimal.js | 功能全面,支持高精度控制、大数字处理、进制转换、三角函数等,可自定义精度配置 | 32KB | 精度极高,功能覆盖全,灵活性强 | 体积较大,API 较复杂 | 金融核心计算、科学计算 |
math.js | 全能型数学库,支持表达式解析、矩阵运算、单位转换等复杂数学能力 | 160KB | 综合数学能力强,场景覆盖广 | 体积庞大,性能开销高 | 数据可视化、工程计算 |
附上地址:
number-precision:github.com/nefe/number…
big.js:github.com/MikeMcl/big…
decimal.js:github.com/MikeMcl/dec…
math.js:github.com/josdejong/m…
作品推荐
Haotab 新标签页,一个优雅的新标签页
静待你的体验❤
来源:juejin.cn/post/7555400502711320576
做个大屏既要不留白又要不变形还要没滚动条,我直接怒斥领导,大屏适配就这四种模式
在前端开发中,大屏适配一直是个让人头疼的问题。领导总是要求大屏既要不留白,又要不变形,还要没有滚动条。这看似简单的要求,实际却压根不可能。今天,我们就来聊聊大屏适配的四种常见模式,以及如何根据实际需求选择合适的方案。
一、大屏适配的困境
在大屏项目中,适配问题几乎是每个开发者都会遇到的挑战。屏幕尺寸的多样性、设计稿与实际屏幕的比例差异,都使得适配变得复杂。而领导的“既要...又要...还要...”的要求,更是让开发者们感到无奈。不过,我们可以通过合理选择适配模式来尽量满足这些需求。
二、四种适配模式
在大屏适配中,常见的适配模式有以下四种:
(以下截图中模拟视口1200px*500px和800px*600px,设计稿为1920px*1080px)
1. 拉伸填充(fill)
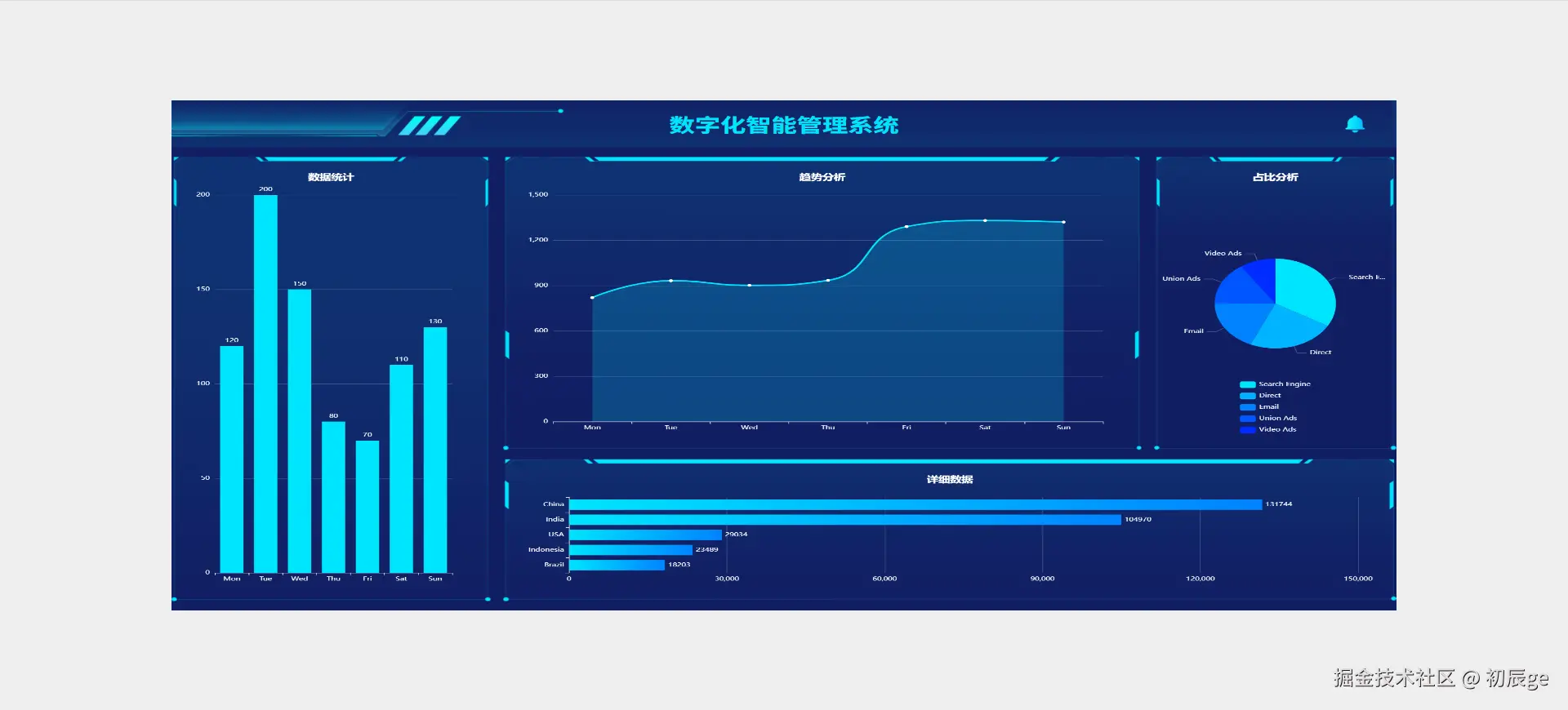
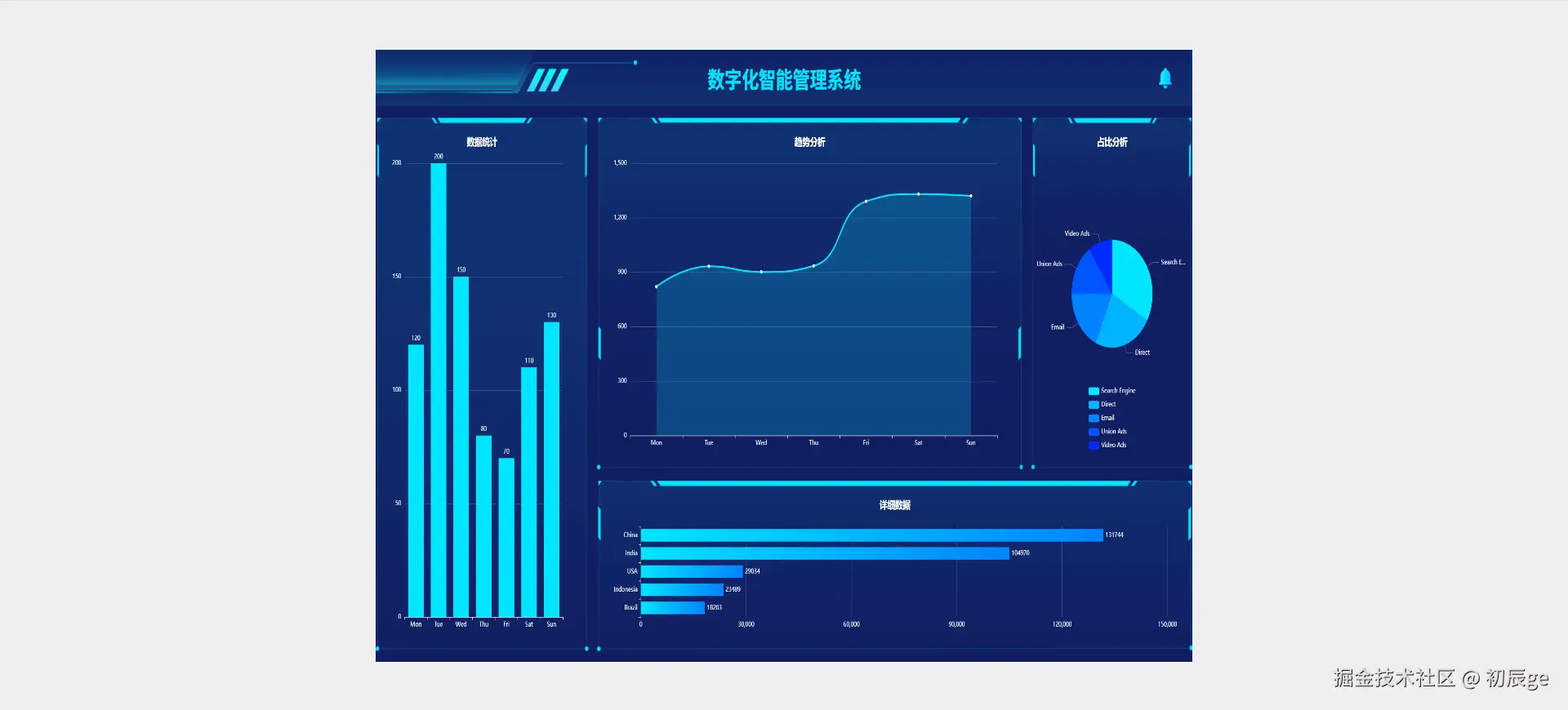
- 特点:内容会被拉伸变形,以完全填充视口框。这种方式可以确保视口内没有空白区域,但可能会导致内容变形。
- 适用场景:适用于对内容变形不敏感的场景,例如全屏背景图。
2. 保持比例(contain)
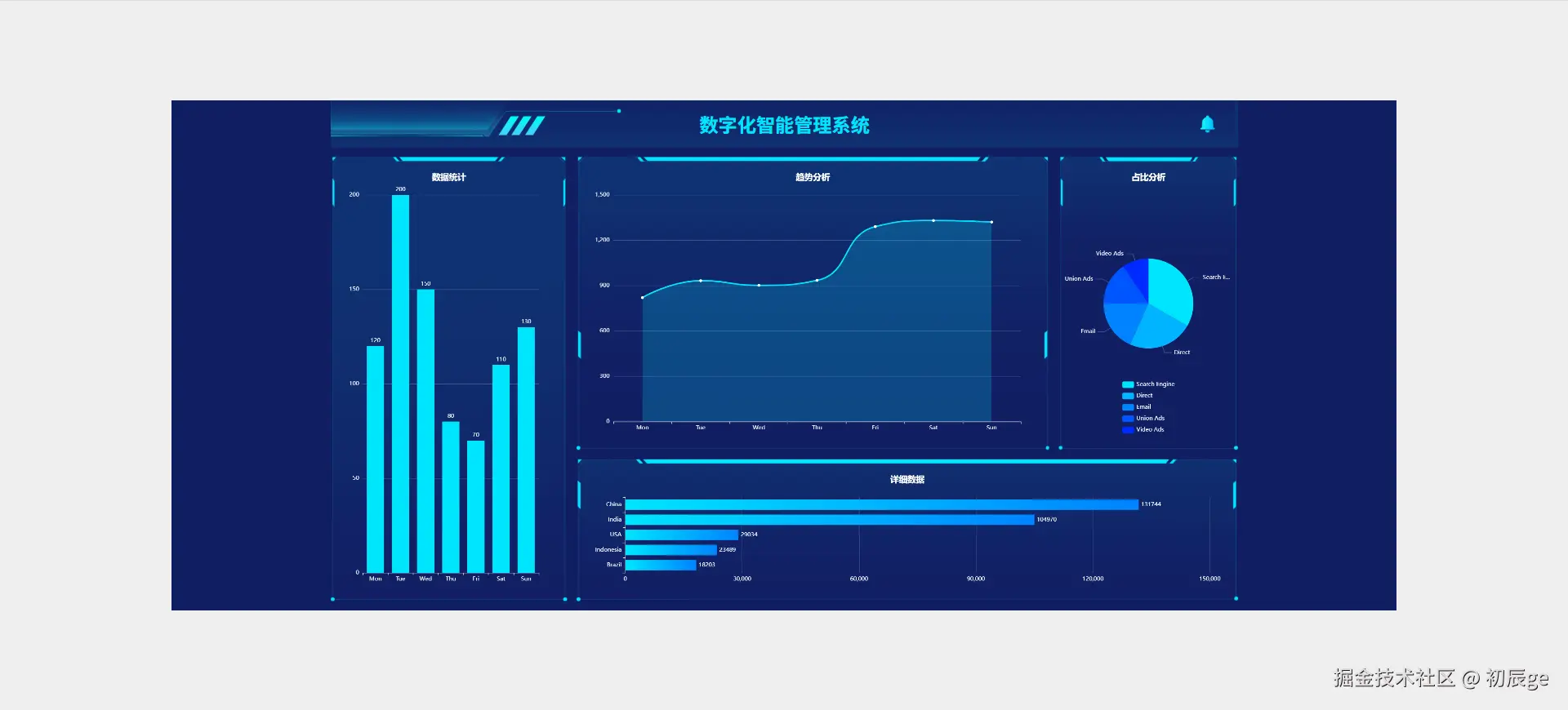
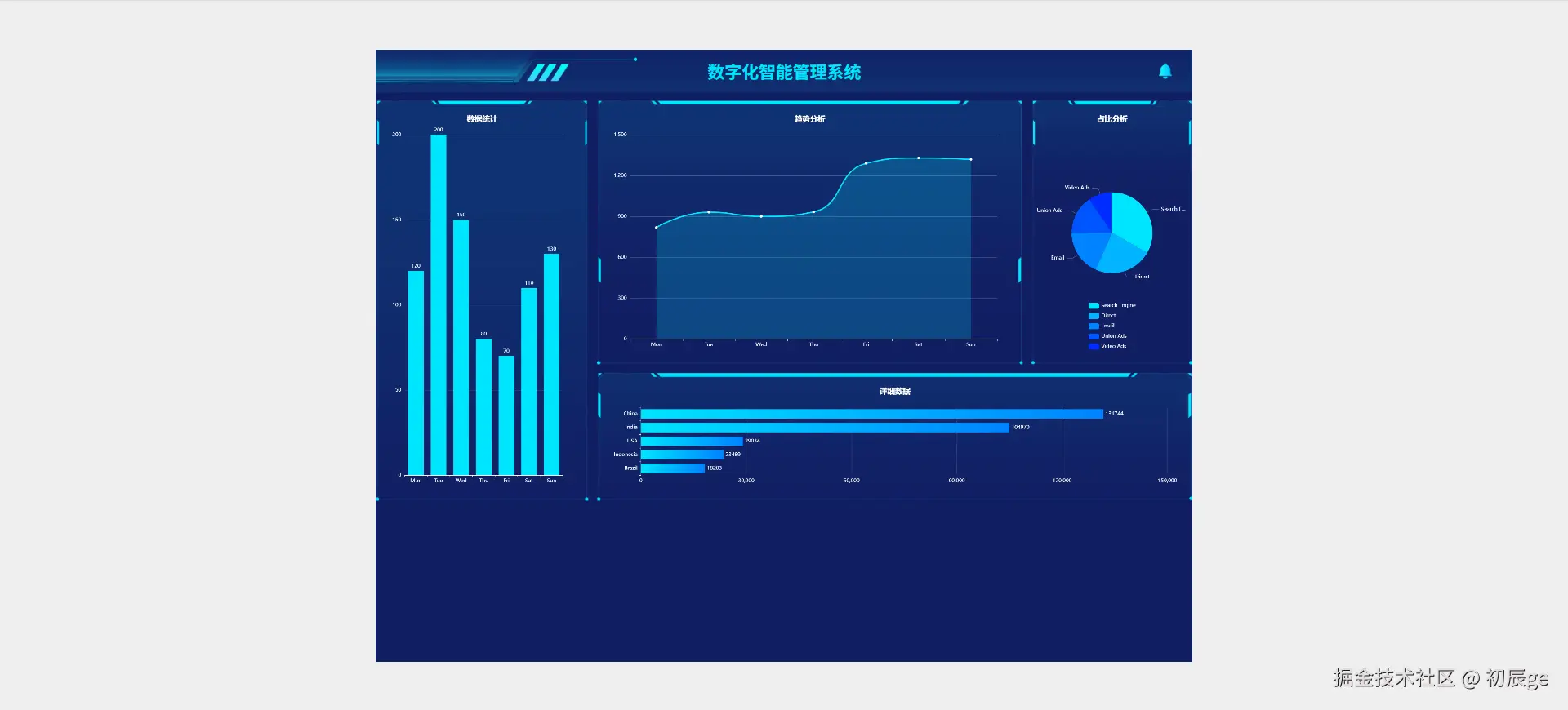
- 特点:内容保持原始比例,不会被拉伸变形。如果内容的宽高比与视口不一致,会在视口内出现空白区域(黑边)。这种方式可以确保内容不变形,但可能会留白。
- 适用场景:适用于需要保持内容原始比例的场景,例如视频或图片展示。
3. 滚动显示(scroll)
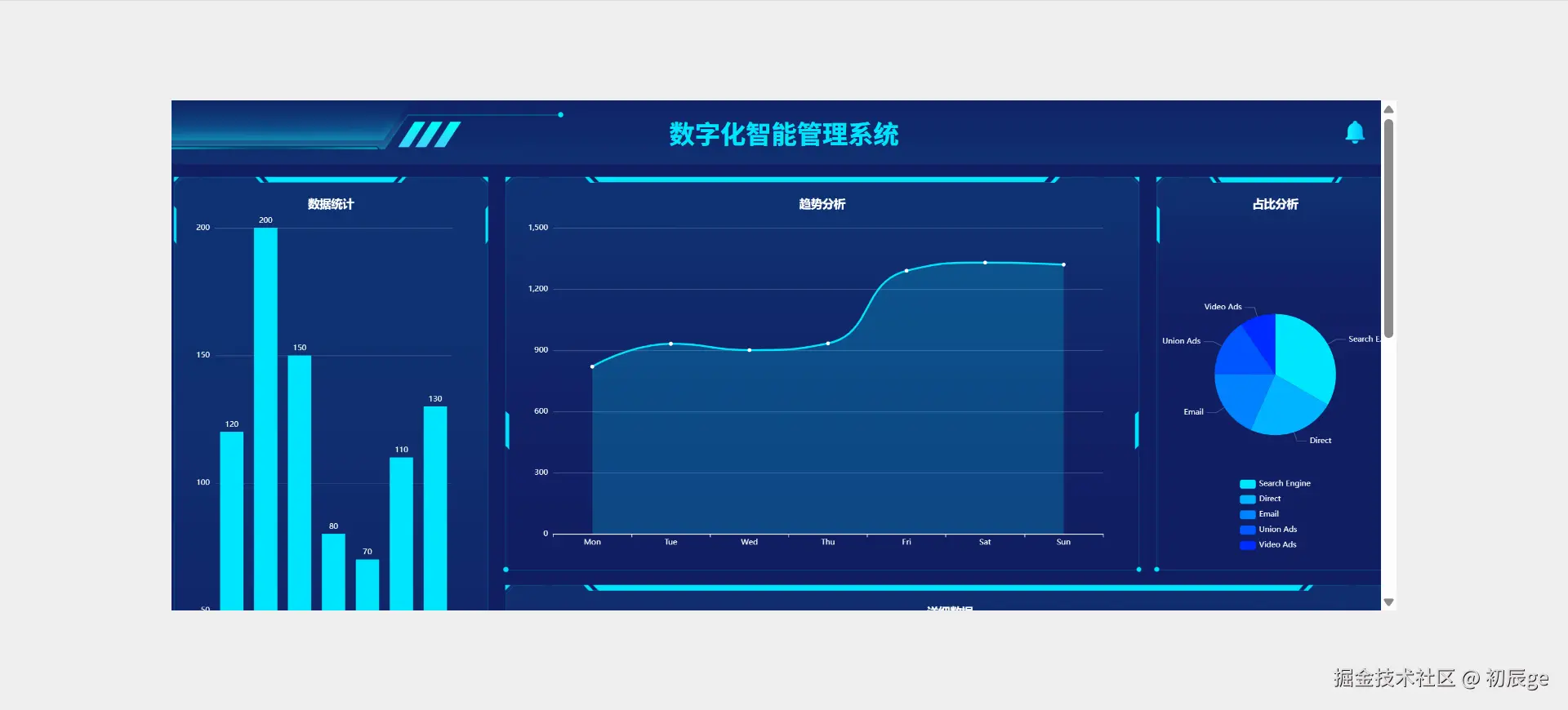
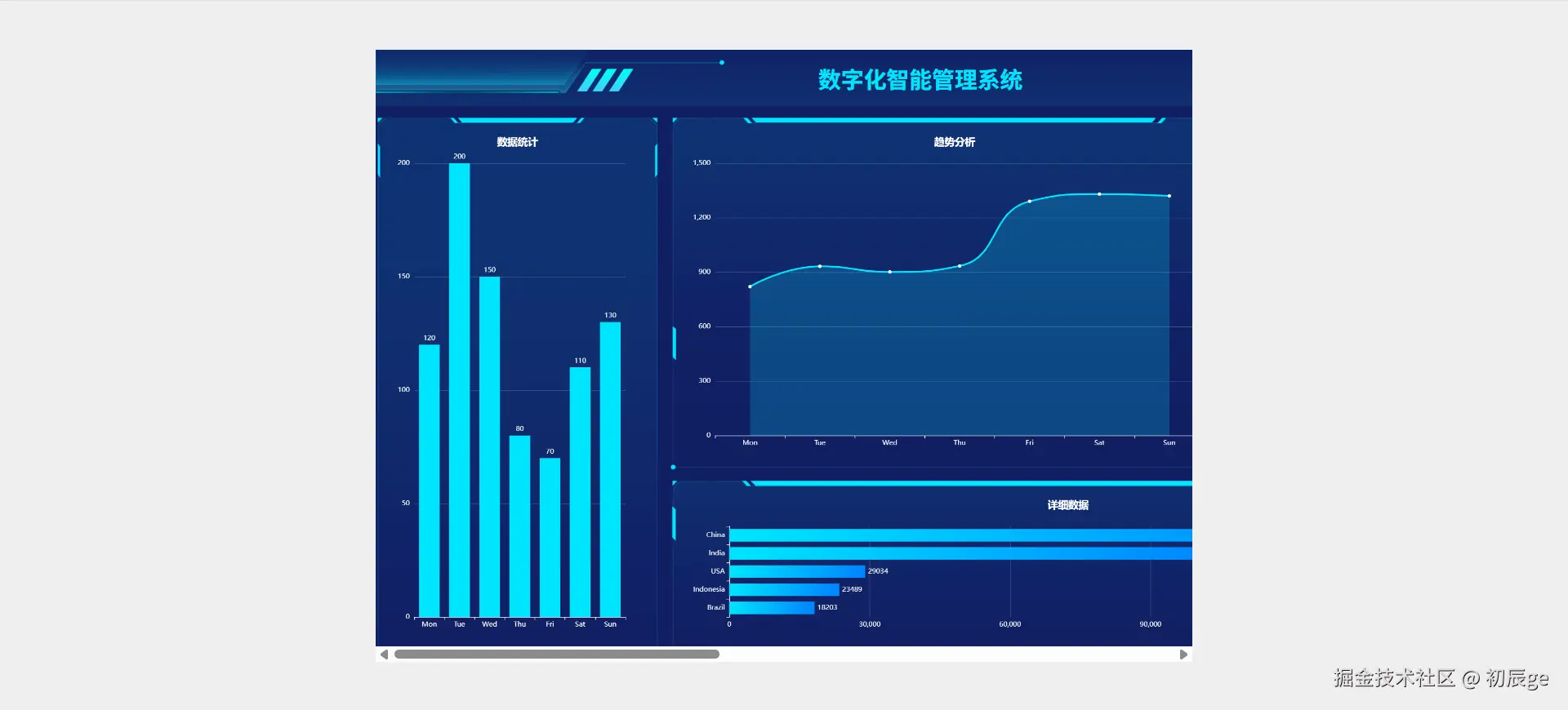
- 特点:内容不会被拉伸变形,当内容超出视口时会添加滚动条。这种方式可以确保内容完整显示,但用户需要滚动才能查看全部内容。
- 适用场景:适用于内容较多且需要完整显示的场景,例如长列表或长文本。
4. 隐藏超出(hidden)
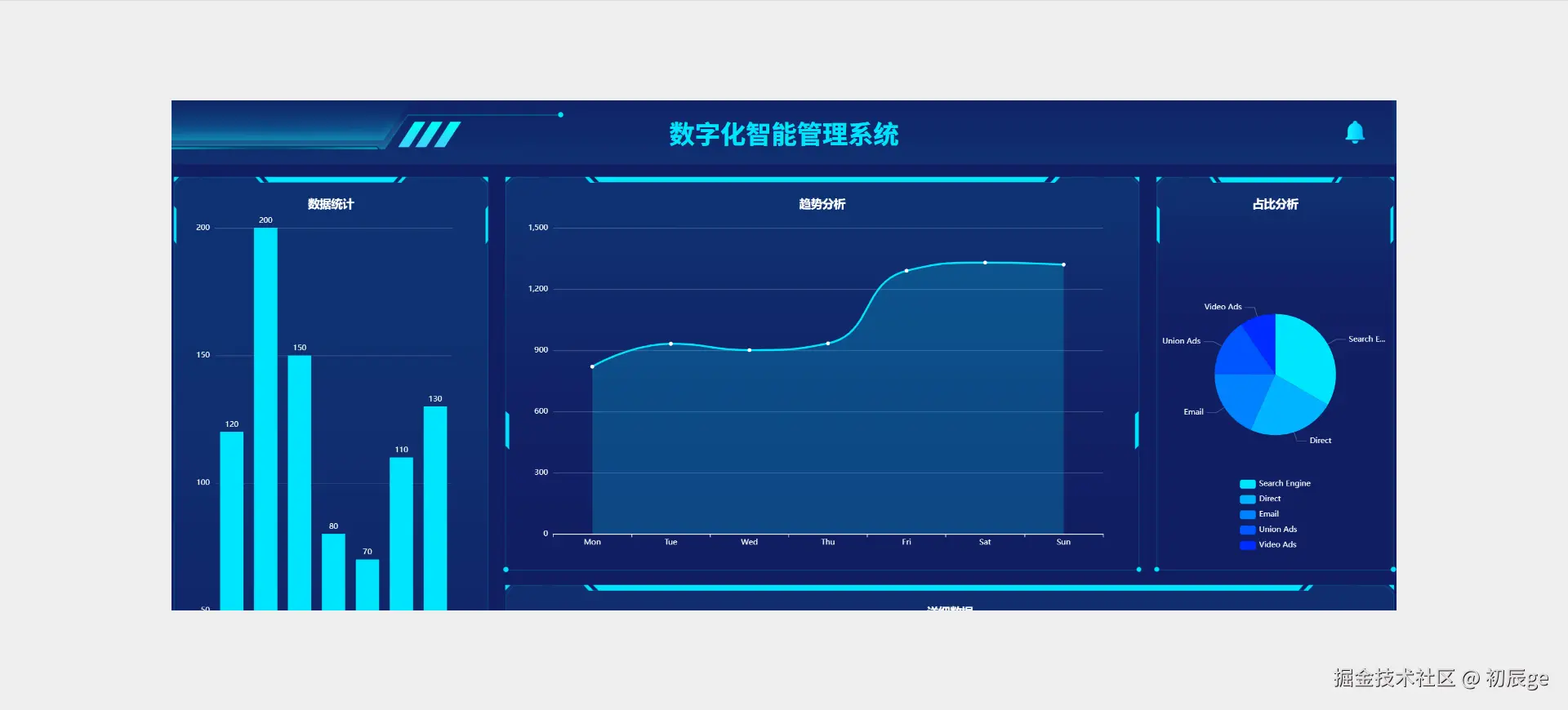
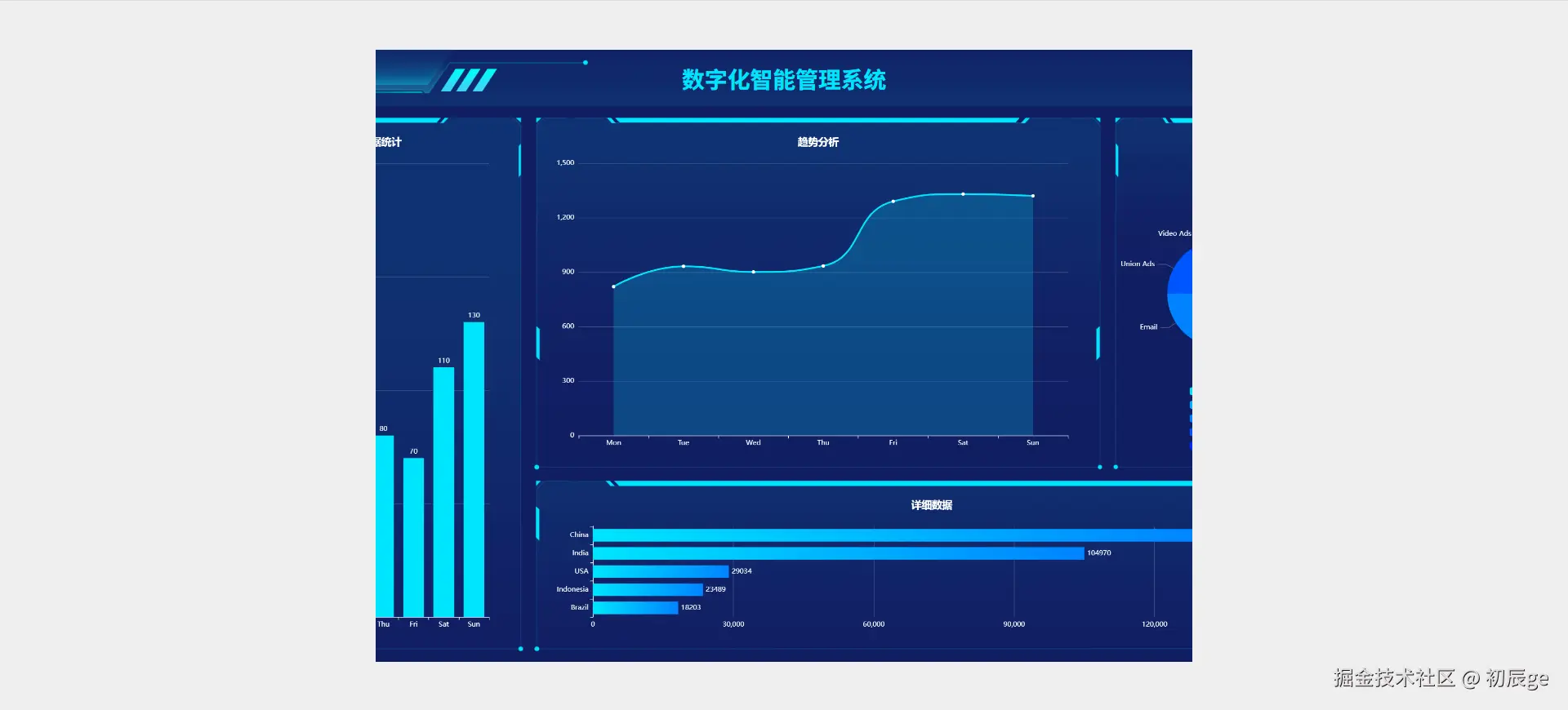
- 特点:内容不会被拉伸变形,当内容超出视口时会隐藏超出部分。这种方式可以避免滚动条的出现,但可能会隐藏部分内容。
- 适用场景:适用于内容较多但不需要完整显示的场景,例如仪表盘。
三、为什么不能同时满足所有要求?
这四种适配模式各有优缺点,但它们在逻辑上是相互矛盾的。具体来说:
- 不留白:要求内容完全填充视口,没有任何空白区域。这通常需要拉伸或缩放内容以适应视口的宽高比。
- 不变形:要求内容保持其原始宽高比,不被拉伸或压缩。这通常会导致内容无法完全填充视口,从而出现空白区域(黑边)。
- 没滚动条:要求内容完全适应视口,不能超出视口范围。这通常需要隐藏超出部分或限制内容的大小。
这三个要求在逻辑上是相互矛盾的:
- 如果内容完全填充视口(不留白),则可能会变形。
- 如果内容保持原始比例(不变形),则可能会出现空白区域(留白)。
- 如果内容超出视口范围,则需要滚动条或隐藏超出部分。
四、【fitview】插件快速实现大屏适配
fitview 是一个视口自适应的 JavaScript 插件,它支持多种适配模式,能够快速实现大屏自适应效果。
github地址:github.com/pbstar/fitv…
在线预览:pbstar.github.io/fitview
以下是它的基本使用方法:
配置
- el: 需要自适应的 DOM 元素
- fit: 自适应模式,字符串,可选值为 fill、contain(默认值)、scroll、hidden
- resize: 是否监听元素尺寸变化,布尔值,默认值 true
安装引入
npm 安装
npm install fitview
esm 引入
import fitview from "fitview";
cdn 引入
<script src="https://unpkg.com/fitview@[version]/lib/fitview.umd.js"></script>
使用示例
<div id="container">
<div style="width:1920px;height:1080px;"></div>
</div>
const container = document.getElementById("container");
new fitview({
el: container,
});
五、总结
大屏适配是一个复杂的问题,不同的项目有不同的需求。虽然不能同时满足“不留白”“不变形”和“没滚动条”这三个要求,但可以通过合理选择适配模式来尽量满足大部分需求。在实际开发中,我们需要根据项目的具体需求和用户体验来权衡,选择最合适的适配方案。
在选择适配方案时,fitview 这个插件可以提供很大的帮助。它支持多种适配模式,能够快速实现大屏自适应效果。如果你正在寻找一个简单易用的适配工具,fitview 值得一试。你可以通过 npm 安装或直接使用 CDN 引入,快速集成到你的项目中。
希望这篇文章能帮助你更好地理解和选择大屏适配方案。如果你有更多问题或建议,欢迎在评论区留言。
来源:juejin.cn/post/7513059488417497123
Vue3 生态再一次加强,网站开发无敌!
如果你正在做官网开发,还在辛苦的手动实现那些动画特效,那今天推荐的这个库,至少让你提前4小时开始摸鱼!
以前,面对设计师的那些炫酷动画,实现起来是最耗头发的;产品经理还时不时的说一下,这效果不好看,我要的是五彩斑斓的黑!
还抱着 Element UI + Animate.css 在那里辛苦调试,苦苦思考好好的效果怎么到了 safari 就变形了呢 ?
现如今,时代变了!
什么是 Inspira UI
Inspira UI 是专门为 Vue3/Nuxt 开发的可复用的动画组件集合。
- 完全免费和开源
- 完美支持
vue3/Nuxt3 - 包括
按钮、输入框、背景、卡片、设备模拟、光标、2D/3D效果等120+个特效组件 - 样式基于
TailwindCSS - 动画使用
motion-v、gsap实现 - 对移动设备特别优化
来欣赏一下效果:

视频文字
图库
3d文字

走马灯
spline
Inspira UI 的优势
1.兼顾视觉与功能
以**「轻量动效组件库」为定位,核心组件覆盖基础 UI(按钮、输入框等)和模块(3D 交互、动态背景等),所有组件均内置微交互**设计。动效无需额外开发完美适配企业官网、电商页面等需视觉增强的场景,实现 “拿即用” 的开发体验。

Liquid Logo
2.基于Tailwind CSS V4
底层基于 Tailwind CSS 构建组件基础样式,确保原子类叠加的灵活性;支持浅色、深色模式一键切换;支持 ypeScript,所有组件与 API 均提供完整类型定义。

浅色模式
3.深度兼容 Vue/Nuxt 生态,性能提升
无论是 Vue 单页应用还是 Nuxt 服务端渲染项目,都能无缝融入现有技术栈,降低开发者的学习与迁移成本。
同时基于 Vue 3.4+ 新增的 defineModel 与 watchEffect 语法重构,减少了至少 30% 的响应式依赖开销;
4.多端性能优化
对于 3D 组件,在支持 WebGPU 的浏览器中,渲染帧率较旧版 WebGL 提升 2-3 倍.
而对于移动端设备、低配置设备会自动调节动效帧率,性能大大提高;同时,对所有组件做了 “懒加载 + 预渲染” 优化,首屏加载速度较旧版提升 35%
如何使用?
Inspira UI 官方文档支持中文,写的也很接地气,通俗易懂 5 分钟就能上手!
- 安装依赖
# 安装 tainlwind
pnpm install tailwindcss @tailwindcss/vite
# 安装 tailwindcss 库和实用工具
pnpm install -D clsx tailwind-merge class-variance-authority tw-animate-css
# 安装 VueUse 和其他支持库
pnpm install @vueuse/core motion-v
- 配置 vite
import { defineConfig } from 'vite'
import tailwindcss from '@tailwindcss/vite'
export default defineConfig({
plugins: \[
tailwindcss(),
],
})
- 配置主题
可以根据需要自由配置主题色。
@import tailwindcss;
@import tw-animate-css;
@custom-variant dark (&:is(.dark *));
:root {
--card: oklch(1 0 0);
--card-foreground: oklch(0.141 0.005 285.823);
}
.dark {
--background: oklch(0.141 0.005 285.823);
--foreground: oklch(0.985 0 0);
}
@theme inline {
--color-background: var(--background);
}
@layer base {
* {
@apply border-border outline-ring/50;
}
body {
@apply bg-background text-foreground;
}
}
html {
color-scheme: light dark;
}
html.dark {
color-scheme: dark;
}
html.light {
color-scheme: light;
}
最后一步,可以复制源码或者通过 Cli 来安装。
- 直接使用源码
找到想要的组件,复制粘贴到自己的项目中即可。
- 通过 Cli 安装
pnpm dlx shadcn-vue\@latest add "https://registry.inspira-ui.com/gradient-button.json>"
然后,你就有了一个炫酷的按钮。

Gradient Button 效果
最后
Vue3/Nuxt3开发者再也不用羡慕 React生态的 Aceternity UI、Magic UI 了。
Inspira UI 直接填补了 vue3 生态中动效开发这一块的缺陷,可以将这些奇妙的设计应用在企业官网、特效开发中,大大节省开发成本。
让 Vue3 生态再一次得到加强,快去试试这个炫酷的项目把!
附上官网地址:inspira-ui.com/docs/cn
作品推荐
Haotab 新标签页,一个优雅的新标签页
静待你的体验❤
来源:juejin.cn/post/7554572856147984424
放下你手里的 GIF,这才是前端动画最终的归宿!!
一、前端动画的"至暗时刻":每个像素都在燃烧经费
618 前夕,我的 PM 突然发来灵魂拷问:"菜鸡,这个购物车弹性动画,为什么安卓和 iOS 的抖动幅度不一样?还有这个圣诞飘雪特效,为什么 iPhone 13 Pro Max 的耗电量能煎鸡蛋?"
我默默擦掉额头的冷汗,回想起被这些需求支配的恐惧:
- GIF地狱:
- 一个3秒的 loading 动画,设计师随手甩来的 GIF 居然有
5MB - 在安卓低端机上播放时,仿佛在看 PPT 版的《黑客帝国》
- 一个3秒的 loading 动画,设计师随手甩来的 GIF 居然有
- SVG炼狱:
- 设计师用 AE 做的酷炫路径动画,转成
SVG + CSS后变成了毕加索抽象画 - 当产品要求动态修改渐变色时,我仿佛听到了 CPU 的惨叫声
- 设计师用 AE 做的酷炫路径动画,转成
- 平台鸿沟:
- iOS 工程师用 Core Animation 优雅实现的弹性动画
- Android 同学用 ValueAnimator 艰难复刻
- Web 端同事的 CSS transition 在 Safari 上直接摆烂
直到某天,隔壁组的前端突然拍案而起:"用Lottie!这玩意能直接吃AE动画!" —— 那一刻,我仿佛看到了前端动画的文艺复兴曙光。
二、Lottie:动画界的 Rosetta Stone(罗塞塔石碑)
1. 打破巴别塔诅咒的技术本质
Lottie的魔法可以拆解为三个核心环节:
- 魔法卷轴(JSON文件):
设计师在AE中使用 Bodymovin插件 导出的动画配方,包含所有图层、关键帧、路径等元数据,体积通常只有GIF的1/10 - 咒语解析器(Lottie Runtime):
各平台的解析引擎(Web/iOS/Android/Flutter等),像精密的手术刀般逐帧解析JSON指令 - 元素召唤阵(Canvas/SVG/OpenGL):
根据设备性能自动选择最优渲染方案,低端机用轻量SVG,旗舰机秀Canvas魔法
2. 那些年被 Lottie 拯救的惨案现场
| 传统方案 | Lottie解决方案 | 性能对比 |
|---|---|---|
| 序列帧动画 | 矢量路径动画 | 体积减少90% |
| CSS关键帧 | 复杂贝塞尔曲线运动 | 渲染速度提升300% |
| GIF动图 | 透明通道+高清显示 | 内存占用降低80% |
| Lottie的跨平台特性让设计还原度达到99.99%,从此告别"安卓特供版动画"的尴尬 |
三、Lottie 的文艺复兴之路:从加载动画到元宇宙门票
1. 业务舞台的常青树场景
- 轻量级演出:
Loading 动画、按钮微交互、表情包(微信的[呲牙]动画仅28KB) - 重量级剧场:
新手引导流程、电商促销动效、直播礼物特效(某直播平台的火箭升空动画仅182KB) - 沉浸式演出:
游戏化运营活动、元宇宙3D场景过渡(某电商 App 的虚拟试衣间加载动画)
2. 那些让程序员笑醒的代码片段
Web 端 React 全家桶套餐:
import { Player } from '@lottiefiles/react-lottie-player';
<Player
src="/emoji.lottie.json"
style={{ height: '300px' }}
autoplay
loop
onEvent={event => {
if (event === 'complete') console.log('老板说这个动画要播10086遍')
}}
/>
Vue3 优雅食用姿势:
<template>
<Lottie :animation-data="rocketJSON" @ready="startLaunch" />
</template>
<script setup>
import { Lottie } from 'lottie-web-vue';
import rocketJSON from './rocket-launch.json';
const startLaunch = (anim) => {
anim.setSpeed(1.5);
anim.play();
}
</script>
微信小程序性能优化版:
<lottie
animationData="{{lottieData}}"
path="https://static.example.com/animations/coupon.json"
autoPlay="{{true}}"
css="{{'width: 100%; height: 300rpx;'}}"
bind:ready="onAnimReady"
/>
四、打开 Lottie 的正确姿势:从青铜到王者的进阶之路
1. 设计师的防跑偏指南
- AE图层命名规范:禁止出现"最终版-真的不改了-V12"这类薛定谔命名
- 合理使用预合成:嵌套层级不要超过俄罗斯套娃的极限
- 动态属性标记:需要运行时修改的颜色/文字要提前标注
2. 工程师的性能调优包
压缩黑科技三件套:
# 使用 lottie-tools 进行瘦身
npx lottie-tools compress animation.json -o animation.min.json
# 删除无用元数据
npx lottie-tools remove-unused animation.json
# 提取公共资源
npx lottie-tools split animation.json --output-dir ./assets
按需加载策略:
const loadLottie = async () => {
const animation = await import(
/* webpackPrefetch: true */
/* webpackChunkName: "lottie-animation" */
'./animation.json'
);
lottie.loadAnimation({
container: document.getElementById('lottie'),
animationData: animation.default
});
}
五、当Lottie遇到次元壁:那些年我们填过的坑
1. 跨平台兼容性排雷手册
| 问题现象 | 解决方案 | 原理剖析 |
|---|---|---|
| iOS 闪退 | 检查 mask 路径是否闭合 | CoreAnimation 的路径容错较低 |
| 安卓颜色失真 | 禁用硬件加速 | 某些 GPU 对渐变支持不完善 |
| 微信小程序渲染错位 | 使用 px 单位替代 rpx | 部分机型 transform-origin 计算 bug |
2. 性能优化急救包
// 帧率节流大法
animation.addEventListener('enterFrame', () => {
if(performance.now() - lastTime < 16) return;
lastTime = performance.now();
// 真正执行渲染逻辑
});
// 内存泄漏防护
useEffect(() => {
const anim = lottie.loadAnimation({...});
return () => anim.destroy(); // 比卸载微信还干净
}, []);
六、未来展望:Lottie的元宇宙野望
当我在AR眼镜里看到Lottie渲染的3D购物动画时,突然意识到这个技术正在打开新次元:
- Lottie 3D Beta:
支持 AE 的 3D 图层导出,在WebGL中渲染立体动画 - 动态数据绑定:
实时修改3D模型的材质参数,实现千人千面的营销动画 - 物理引擎集成:
给动画元素添加重力、碰撞等物理特性,让每个像素都遵循真实世界法则
也许不久的将来,我们能用Lottie在元宇宙里复刻《盗梦空间》的折叠城市动画——当然,得先确保产品经理不会要求实时修改地心引力参数。
总结
从被 GIF 支配的恐惧,到用 JSON 驾驭动画的自由,Lottie 让我们离"设计即代码"的理想国又近了一步。下次当设计师又甩来 500MB 的 AE 工程时,你可以优雅地打开 Bodymovin 插件:"亲爱的,这次咱们换个姿势加载。"
来源:juejin.cn/post/7506418053997428751




