








那个把代码写得亲妈都不认的同事,最后被劝退了🤷♂️
大家好😁。
上上周,我们在例会上送别了团队里的一位技术大牛,阿K。
说实话,阿K 的技术底子很强。他能手写 Webpack 插件,熟读 ECMA 规范,对 Chrome 的渲染管线了如指掌。
但最终,CTO 还是决定劝退他了。

理由很残酷,只有一句话: 你的代码,团队里没人敢接手。🤷♂️
为了所谓的极致性能,牺牲代码的可读性,到底值不值?
事件的开始
我们有一个很普通的后台管理系统重构。
阿K 负责最核心的权限校验模块。这本是一个很简单的逻辑:后端返回一个权限列表,前端判断一下用户有没有某个按钮的权限。
普通人(比如我)大概会这么写:
// 一眼就能看懂
const hasPermission = (userPermissions, requiredPermission) => {
return userPermissions.includes(requiredPermission);
};
if (hasPermission(currentUser.permissions, 'DELETE_USER')) {
showDeleteButton();
}
但是,阿K 看到这段代码时,露出了鄙夷的神情😒。
includes 这种遍历操作太慢了!我们要处理的是十万级的用户并发(并没有),必须优化!
于是,他闭关三天,重写了整个模块。
Code Review 的时候,我们所有人都傻了。屏幕上出现了一堆我们看不懂的天书😖:
// 全程位运算,没有任何注释
const P = { r: 1, w: 2, e: 4, d: 8 };
const _c = (u, p) => (u & p) === p;
// 这里甚至用了一个位移掩码生成的哈希表
const _m = (l) => l.reduce((a, c) => a | (P[c] || 0), 0);
// 像不像一段乱码?
const chk = (u, r) => _c(_m(u.r), P[r]);
我问他:阿K,这 _c 和 _m 是啥意思?能加个注释吗?
阿K 振振有词: 好的代码不需要注释!位运算是计算机执行最快的操作,比字符串比对快几百倍!这不仅仅是代码,这是对 CPU 的尊重,是艺术!
我: 。 。 。 。🤣
在那个没有性能瓶颈的后台管理系统里,他为了那肉眼不可见的 0.0001 毫秒提升,制造了一个维护麻烦。
屎山💩崩溃的那一天
灾难发生在两个月后。
业务方突然提了一个需求: 权限逻辑要改,现在支持‘反向排除’权限,而且权限字段要从数字改成字符串组。
那天,阿K 正好去年假了,手机关机😒。
任务落到了刚入职的实习生小李头上。
小李打开 permission.js,看着满屏的 >>、&、| 和单字母变量,整个人僵在了工位上。
他试图去理解那个位移掩码的逻辑,但他发现,只要改动一个字符,整个系统的权限就全乱套了——管理员突然看不了页面,实习生突然能删库了🤔。
这代码有毒吧…… 小李在第 10 次尝试修复失败后,差点哭出来😭。
因为这个模块的逻辑过于晦涩,且和其他模块高度耦合(阿K 为了复用,把这些位运算逻辑注入到了全局原型链里),我们根本不敢动。
结果是:那个简单的需求,被硬生生拖了一周。 业务方投诉到了 CTO 那里。
CTO 看了眼代码,沉默了三分钟,然后问了一句:
写这玩意儿的人,是觉得以后都不用维护了吗?😥
过早优化是万恶之源 !
阿K 回来后,很不服气。他觉得是我们技术太菜,看不懂他的高级操作。
他拿出了 Chrome Profiler 的截图,指着那微乎其微的差距说:看!我的写法比你们快了 40%!
但他忽略了软件工程中最重要的一条公式:
代码价值 = (实现功能 + 可维护性) / 复杂度
过早优化是万恶之源 ! ! !
在 99% 的业务场景下,V8 引擎已经足够快了。
- 你把
forEach改成while倒序循环,性能确实提升了,但代码变得难读了。 - 你把清晰的
switch-case改成了晦涩的lookup table还没有类型提示,Bug 率上升了。 - 你为了省几个字节的内存,用各种黑魔法操作对象,导致后来的人根本不敢碰😖。
这种所谓的性能优化,其实是程序员的自嗨。
它是用团队的维护成本,去换取机器那一瞬间的快感。它不是优化,它是给项目埋雷。
什么样的代码才是好代码?
后来,我们将阿K 的那坨代码 通过 chatGPT 全部推倒重写。
1️⃣ 权限定义(语义清晰)
// permissions.ts
export enum Permission {
READ = 'read',
WRITE = 'write',
EDIT = 'edit',
DELETE = 'delete',
}
2️⃣ 用户模型
// user.ts
import { Permission } from './permissions';
export interface User {
id: string;
permissions: Permission[];
}
3️⃣ 权限校验函数(核心)
// auth.ts
import { Permission } from './permissions';
import { User } from './user';
export function hasPermission(
user: User,
required: Permission
): boolean {
return user.permissions.includes(required);
}
4️⃣ 批量权限校验
export function hasAllPermissions(
user: User,
required: Permission[]
): boolean {
return required.every(p => user.permissions.includes(p));
}
export function hasAnyPermission(
user: User,
required: Permission[]
): boolean {
return required.some(p => user.permissions.includes(p));
}
5️⃣ 判断方法
if (!hasPermission(user, Permission.DELETE)) {
throw new Error('No permission to delete');
}
用回了用户权限结构清晰可见的,权限判断,一眼就懂。甚至都不需要注释🤷♂️
虽然跑分慢了那么一丁点(用户根本无感知),但任何一个新来的同事,只要 5 分钟就能看懂并上手修改。
这件事给我留下了深刻的教训:
- 代码是写给人看的,顺便给机器运行。
如果一段代码只有你现在能看懂,那它就是垃圾代码;如果一段代码连你一个月后都看不懂,那它就是有害代码。
- 不要在非瓶颈处炫技。
如果页面卡顿是因为 DOM 节点太多,你去优化 JS 的变量赋值速度,那就是隔靴搔痒。找到真正的瓶颈(Network, Layout, Paint),再对症下药。
- 可读性 > 巧技。
简单的逻辑,是对同事最大的善意。
阿K 走的时候,还是觉得自己怀才不遇,觉得这家公司配不上他的技术🤣。
我祝他未来前程似锦。
但我更希望看到这篇文章的你,下次在想要按下键盘写一段绝妙的、只有你看懂的单行代码时,能停下来想一想:
如果明天我离职了,接手的人会不会骂娘?

毕竟,我们不想让亲妈都不认识代码,我们更不想让同事在那骂娘。
谢谢大家👏
来源:juejin.cn/post/7585897699603693594
Arco Design 停摆!字节跳动 UI 库凉了?
1. 引言:设计系统的“寒武纪大爆发”与 Arco 的陨落
在 2019 年至 2021 年间,中国前端开发领域经历了一场前所未有的“设计系统”爆发期。伴随着企业级 SaaS 市场的崛起和中后台业务的复杂度攀升,各大互联网巨头纷纷推出了自研的 UI 组件库。这不仅是技术实力的展示,更是企业工程化标准的话语权争夺。在这一背景下,字节跳动推出了 Arco Design,这是一套旨在挑战 Ant Design 霸主地位的“双栈”(React & Vue)企业级设计系统。
Arco Design 在发布之初,凭借其现代化的视觉语言、对 TypeScript 的原生支持以及极具创新性的“Design Lab”设计令牌(Design Token)管理系统,迅速吸引了大量开发者的关注。它被定位为不仅仅是一个组件库,而是一套涵盖设计、开发、工具链的完整解决方案。然而,就在其社区声量达到顶峰后的短短两两年内,这一曾被视为“下一代标准”的项目却陷入了令人费解的沉寂。
截至 2025 年末,GitHub 上的 Issues 堆积如山,关键的基础设施服务(如 IconBox 图标平台)频繁宕机,官方团队的维护活动几乎归零。对于数以万计采用了 Arco Design 的企业和独立开发者而言,这无疑是一场技术选型的灾难。
本文将深入剖析 Arco Design 从辉煌到停摆的全过程。我们将剥开代码的表层,深入字节跳动的组织架构变革、内部团队的博弈(赛马机制)、以及中国互联网大厂特有的“KPI 开源”文化,为您还原整件事情的全貌。
2. 溯源:Arco Design 的诞生背景与技术野心
要理解 Arco Design 为何走向衰败,首先必须理解它诞生时的宏大野心及其背后的组织推手。Arco 并不仅仅是一个简单的 UI 库,它是字节跳动在高速扩张期,为了解决内部极其复杂的国际化与商业化业务需求而孵化的产物。
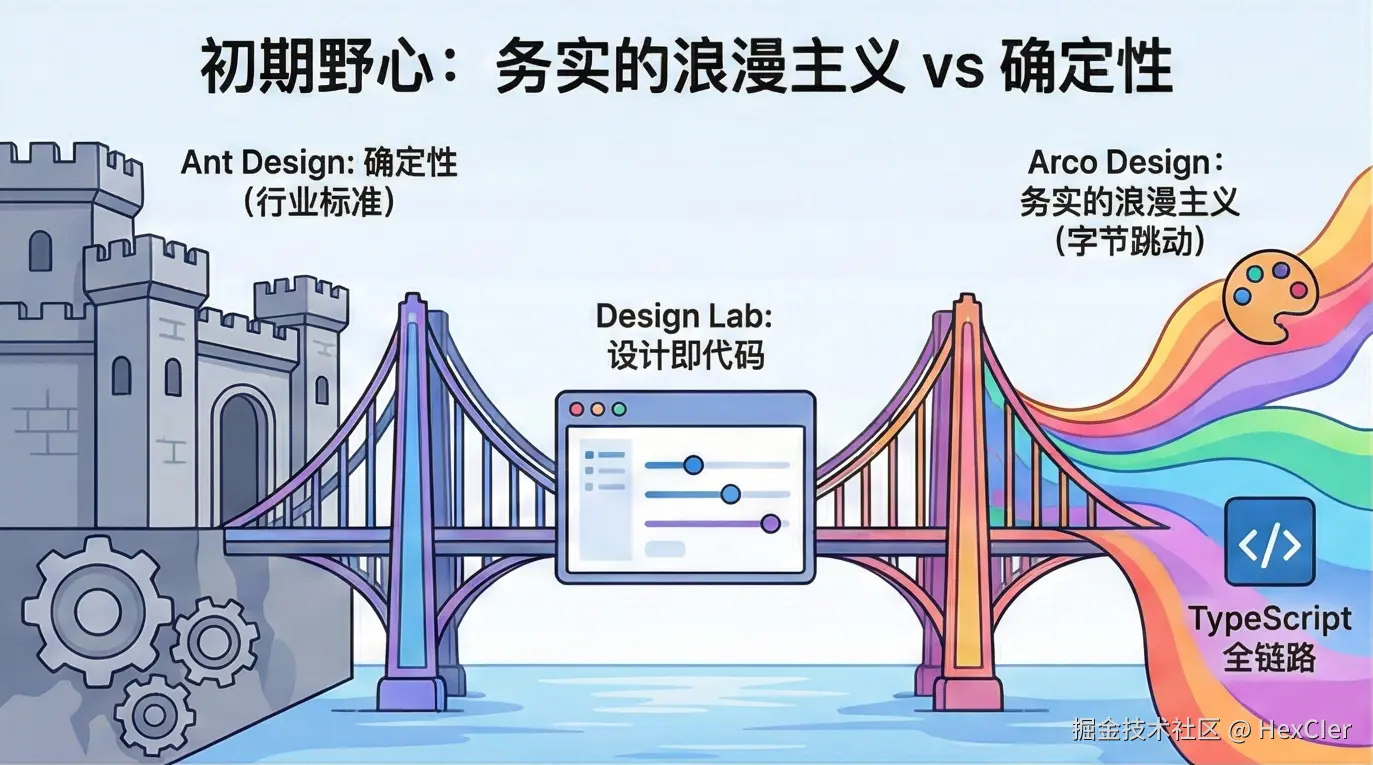
2.1 “务实的浪漫主义”:差异化的产品定位
Arco Design 在推出时,鲜明地提出了“务实的浪漫主义”这一设计哲学。这一口号的提出,实际上是为了在市场上与阿里巴巴的 Ant Design 进行差异化竞争。
- Ant Design 的困境:作为行业标准,Ant Design 以“确定性”著称,其风格克制、理性,甚至略显单调。虽然极其适合金融和后台管理系统,但在需要更强品牌表达力和 C 端体验感的场景下显得力不从心。
- Arco 的切入点:字节跳动的产品基因(如抖音、TikTok)强调视觉冲击力和用户体验的流畅性。Arco 试图在中后台系统中注入这种基因,主张在解决业务问题(务实)的同时,允许设计师发挥更多的想象力(浪漫)。
这种定位在技术层面体现为对 主题定制(Theming) 的极致追求。Arco Design 并没有像传统库那样仅仅提供几个 Less 变量,而是构建了一个庞大的“Design Lab”平台,允许用户在网页端通过可视化界面细粒度地调整成千上万个 Design Token,并一键生成代码。这种“设计即代码”的早期尝试,是 Arco 最核心的竞争力之一。
2.2 组织架构:GIP UED 与架构前端的联姻
Arco Design 的官方介绍中明确指出,该系统是由 字节跳动 GIP UED 团队 和 架构前端团队(Infrastructure FrontEnd Team) 联合推出的。这一血统注定了它的命运与“GIP”这个业务单元的兴衰紧密绑定。
2.2.1 GIP 的含义与地位
“GIP” 通常指代 Global Internet Products(全球互联网产品)或与之相关的国际化/商业化业务部门。在字节跳动 2019-2021 年的扩张期,这是一个充满活力的部门,负责探索除了核心 App(抖音/TikTok)之外的各种创新业务,包括海外新闻应用(BuzzVideo)、办公套件、以及各种尝试性的出海产品。
- UED 的话语权:在这一时期,GIP 部门拥有庞大的设计师团队(UED)。为了统一各条分散业务线的设计语言,UED 团队急需一套属于自己的设计系统,而不是直接沿用外部的 Ant Design。
- 技术基建的配合:架构前端团队的加入,为 Arco Design 提供了工程化落地的保障。这种“设计+技术”的双驱动模式,使得 Arco 在初期展现出了极高的完成度,不仅有 React 版本,还同步推出了 Vue 版本,甚至包括移动端组件库。
2.3 黄金时代的技术堆栈
在 2021 年左右,Arco Design 的技术选型是极具前瞻性的,这也是它能迅速获得 5.5k Star 的原因之一:
- 全链路 TypeScript:所有组件均采用 TypeScript 编写,提供了优秀的类型推导体验,解决了当时 Ant Design v4 在某些复杂场景下类型定义不友好的痛点。
- 双框架并进:@arco-design/web-react 和 @arco-design/web-vue 保持了高度统一的 API 设计和视觉风格。这对于那些技术栈不统一的大型公司极具吸引力,意味着设计规范可以跨框架复用。
- 生态闭环:除了组件库,Arco 还发布了 arco-cli(脚手架)、Arco Pro(中后台模板)、IconBox(图标管理平台)以及 Material Market(物料市场)。这表明团队不仅是在做一个库,而是在构建一个类似 Salesforce Lightning 或 SAP Fiori 的企业级生态。
然而,正是这种庞大的生态铺设,为日后的维护埋下了巨大的隐患。当背后的组织架构发生震荡时,维持如此庞大的产品矩阵所需的资源将变得不可持续。
3. 停摆的证据:基于数据与现象的法医式分析
尽管字节跳动从未发布过一份正式的“Arco Design 停止维护声明”,但通过对代码仓库、社区反馈以及基础设施状态的深入分析,我们可以断定该项目已进入实质性的“脑死亡”状态。
3.1 代码仓库的“心跳停止”
对 GitHub 仓库 arco-design/arco-design (React) 和 arco-design/arco-design-vue (Vue) 的提交记录分析显示,活跃度在 2023 年底至 2024 年初出现了断崖式下跌。
3.1.1 提交频率分析
虽然 React 版本的最新 Release 版本号为 2.66.8(截至文章撰写时),但这更多是惯性维护。
- 核心贡献者的离场:早期的高频贡献者(如 sHow8e、jadelike-wine 等)在 2024 年后的活跃度显著降低。许多提交变成了依赖项升级(Dependabot)或极其微小的文档修复,缺乏实质性的功能迭代。
- Vue 版本的停滞:Vue 版本的状态更为糟糕。最近的提交多集中在构建工具迁移(如迁移到 pnpm)或很久以前的 Bug 修复。核心组件的 Feature Request 长期无人响应。
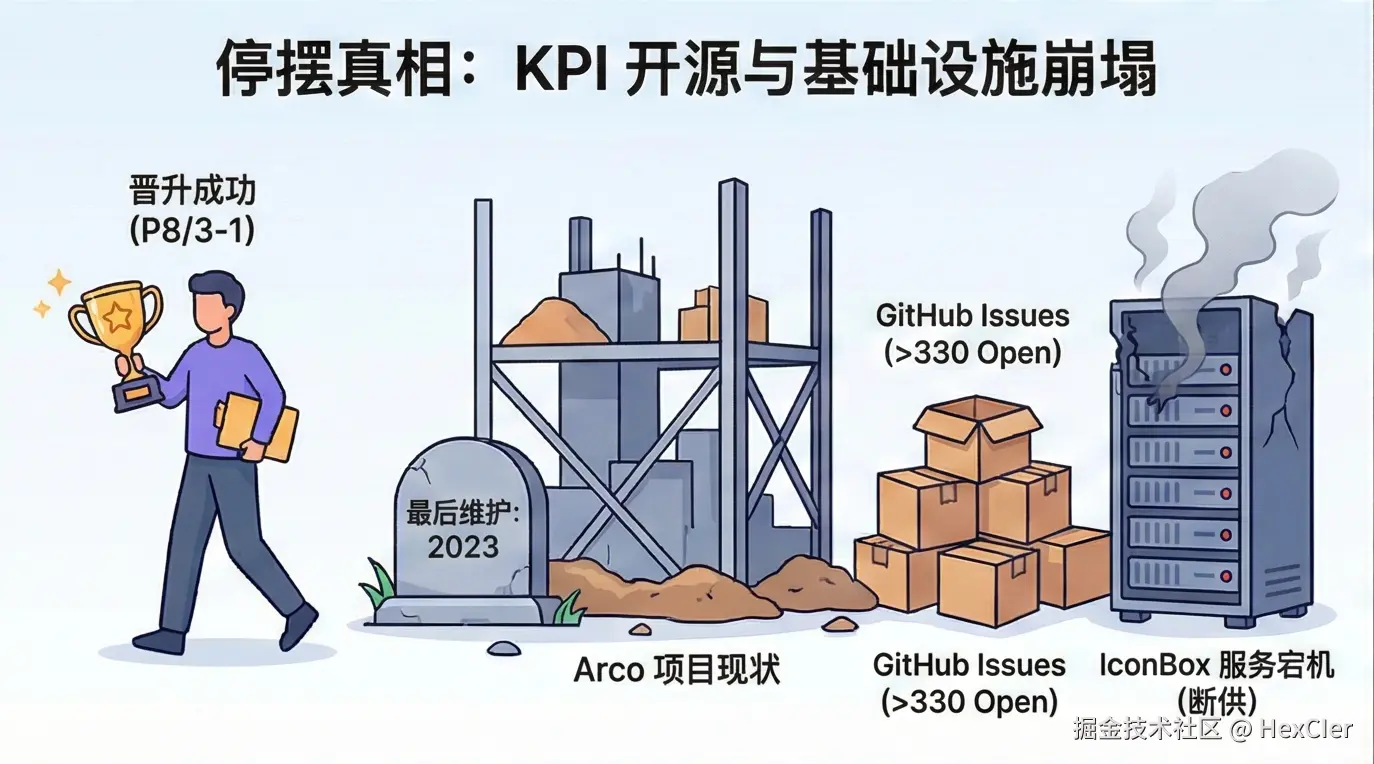
3.1.2 积重难返的 Issue 列表
Issue 面板是衡量开源项目生命力的体温计。目前,Arco Design 仓库中积累了超过 330 个 Open Issue。
- 严重的 Bug 无人修复:例如 Issue #3091 “tree-select 组件在虚拟列表状态下搜索无法选中最后一个” 和 Issue #3089 “table 组件的 default-expand-all-rows 属性设置不生效”。这些都是影响生产环境使用的核心组件 Bug,却长期处于 Open 状态。
- 社区的绝望呐喊:Issue #3090 直接以 “又一个没人维护的 UI 库” 为题,表达了社区用户的愤怒与失望。更有用户在 Discussion 中直言 “这个是不是 KPI 项目啊,现在维护更新好像都越来越少了”。这种负面情绪的蔓延,通常是一个项目走向终结的社会学信号。
3.2 基础设施的崩塌:IconBox 事件
如果说代码更新变慢还可以解释为“功能稳定”,那么基础设施的故障则是项目被放弃的直接证据。
- IconBox 无法发布:Issue #3092 指出 “IconBox 无法发布包了”。IconBox 是 Arco 生态中用于管理和分发自定义图标的 SaaS 服务。这类服务需要后端服务器、数据库以及运维支持。
- 含义解读:当一个大厂开源项目的配套 SaaS 服务出现故障且无人修复时,这不仅仅是开发人员没时间的问题,而是意味着服务器的预算可能已经被切断,或者负责运维该服务的团队(GIP 相关的基建团队)已经被解散。这是项目“断供”的最强物理证据。
3.3 文档站点的维护降级
Arco Design 的文档站点虽然目前仍可访问,但其内容更新已经明显滞后。例如,关于 React 18/19 的并发特性支持、最新的 SSR 实践指南等现代前端话题,在文档中鲜有提及。与竞争对手 Ant Design 紧跟 React 官方版本发布的节奏相比,Arco 的文档显得停留在 2022 年的时光胶囊中。
4. 深层归因:组织架构变革下的牺牲品
Arco Design 的陨落,本质上不是技术失败,而是组织架构变革的牺牲品。要理解这一点,我们需要将视线从 GitHub 移向字节跳动的办公大楼,审视这家巨头在过去三年中发生的剧烈动荡。
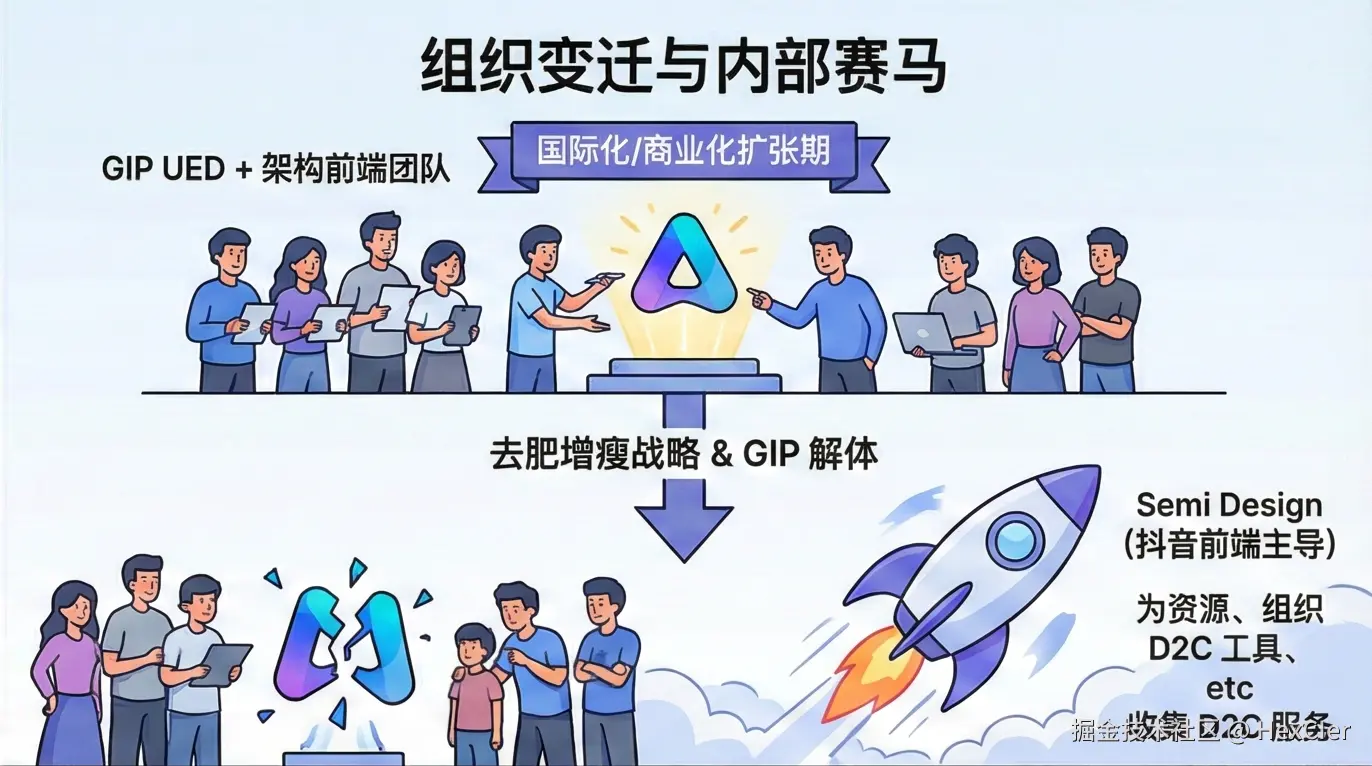
4.1 “去肥增瘦”战略与 GIP 的解体
2022 年至 2024 年,字节跳动 CEO 梁汝波多次强调“去肥增瘦”战略,旨在削减低效业务,聚焦核心增长点。这一战略直接冲击了 Arco Design 的母体——GIP 部门。
4.1.1 战略投资部的解散与业务收缩
2022 年初,字节跳动解散了战略投资部,并将原有的投资业务线员工分流。这一动作标志着公司从无边界扩张转向防御性收缩。紧接着,教育(大力教育)、游戏(朝夕光年)以及各类边缘化的国际化尝试业务(GIP 的核心腹地)遭遇了毁灭性的裁员。
4.1.2 GIP 团队的消失
在多轮裁员中,GIP 及其相关的商业化技术团队是重灾区。
- 人员流失:Arco Design 的核心维护者作为 GIP UED 和架构前端的一员,极有可能在这些轮次的“组织优化”中离职,或者被转岗到核心业务(如抖音电商、AI 模型 Doubao)以保住职位。
- 业务目标转移:留下来的人员也面临着 KPI 的重置。当业务线都在为生存而战,或者全力以赴投入 AI 军备竞赛时,维护一个无法直接带来营收的开源 UI 库,显然不再是绩效考核中的加分项,甚至是负担。
4.2 内部赛马机制:Arco Design vs. Semi Design
字节跳动素以“APP 工厂”和“内部赛马”文化著称。这种文化不仅存在于 C 端产品中,也渗透到了技术基建领域。Arco Design 的停摆,很大程度上是因为它在与内部竞争对手 Semi Design 的博弈中败下阵来。
4.2.1 Semi Design 的崛起
Semi Design 是由 抖音前端团队 与 MED 产品设计团队 联合推出的设计系统。
- 出身显赫:与 GIP 这个边缘化的“探索型”部门不同,Semi Design 背靠的是字节跳动的“现金牛”——抖音。抖音前端团队拥有极其充裕的资源和稳固的业务地位。
- 业务渗透率:Semi Design 官方宣称支持了公司内部“近千个平台产品”,服务 10 万+ 用户。它深度嵌入在抖音的内容生产、审核、运营后台中。这些业务是字节跳动的生命线,因此 Semi Design 被视为“核心资产”。
4.2.2 为什么 Arco 输了?
在资源收缩期,公司高层显然不需要维护两套功能高度重叠的企业级 UI 库。选择保留哪一个,不仅看技术优劣,更看业务绑定深度。
- 技术路线之争:Semi Design 在 D2C(Design-to-Code)领域走得更远,提供了强大的 Figma 插件,能直接将设计稿转为 React 代码。这种极其强调效率的工具链,更符合字节跳动“大力出奇迹”的工程文化。
- 归属权:Arco 属于 GIP,GIP 被裁撤或缩编;Semi 属于抖音,抖音如日中天。这几乎是一场没有悬念的战役。当 GIP 团队分崩离析,Arco 自然就成了没人认领的“孤儿”。
4.3 中国大厂的“KPI 开源”陷阱
Arco Design 的命运也折射出中国互联网大厂普遍存在的“KPI 开源”现象。
- 晋升阶梯:在阿里的 P7/P8 或字节的 2-2/3-1 晋升答辩中,主导一个“行业领先”的开源项目是极具说服力的业绩。因此,很多工程师或团队 Leader 会发起此类项目,投入巨大资源进行推广(刷 Star、做精美官网)。
- 晋升后的遗弃:一旦发起人成功晋升、转岗或离职,该项目的“剩余价值”就被榨干了。接手的新人往往不愿意维护“前人的功劳簿”,更愿意另起炉灶做一个新的项目来证明自己。
- Arco 的轨迹:Arco 的高调发布(2021年)恰逢互联网泡沫顶峰。随着 2022-2024 年行业进入寒冬,晋升通道收窄,维护开源项目的 ROI(投入产出比)变得极低,导致项目被遗弃。
5. 社区自救的幻象:为何没有强有力的 Fork?
面对官方的停摆,用户自然会问:既然代码是开源的(MIT 协议),为什么没有人 Fork 出来继续维护?调查显示,虽然存在一些零星的 Fork,但并未形成气候。
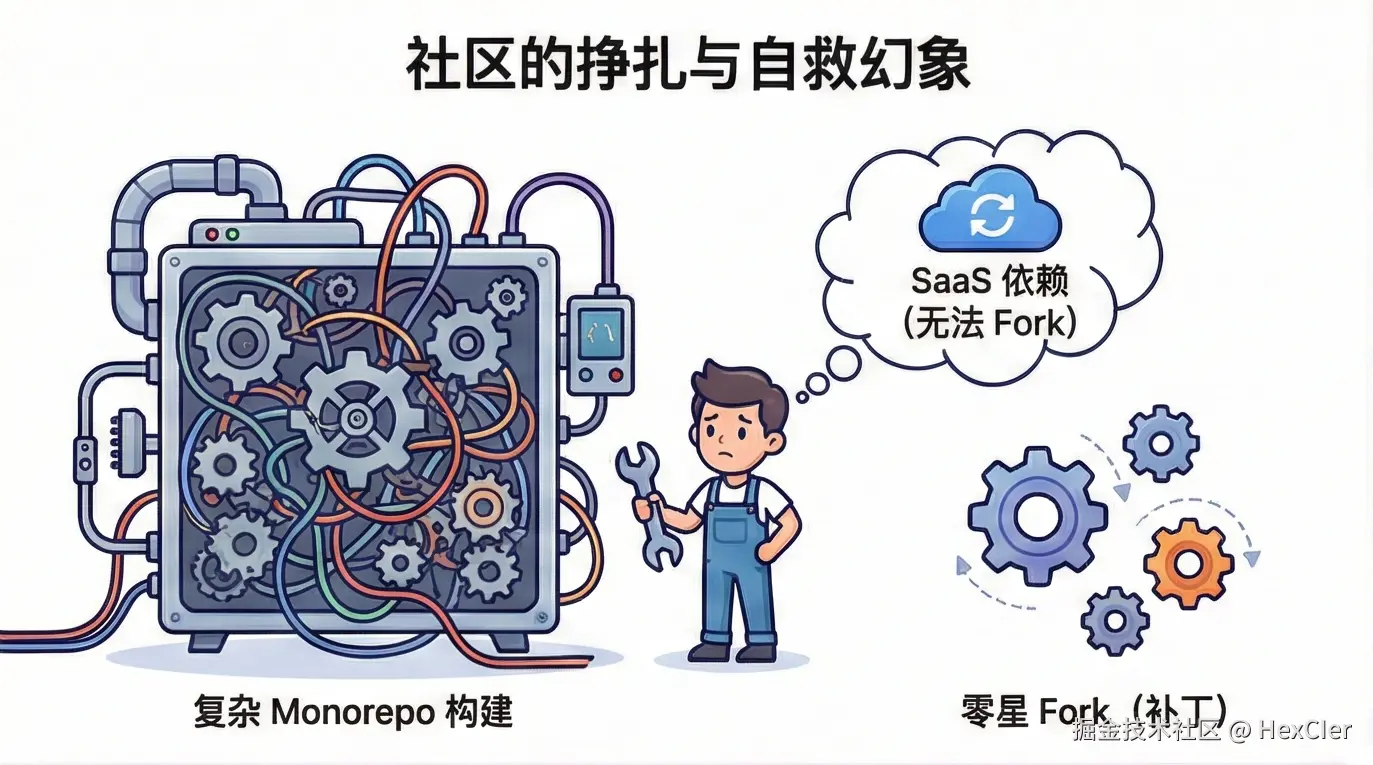
5.1 Fork 的现状调查
通过对 GitHub 和 Gitee 的检索,我们发现了一些 Fork 版本,但并未找到具备生产力的社区继任者。
- vrx-arco:这是一个名为 vrx-arco/arco-design-pro 的仓库,声称是 "aro-design-vue 的部分功能扩展"。然而,这更像是一个补丁集,而不是一个完整的 Fork。它主要解决特定开发者的个人需求,缺乏长期维护的路线图。
- imoty_studio/arco-design-designer:这是一个基于 Arco 的表单设计器,并非组件库本身的 Fork。
- 被动 Fork:GitHub 显示 Arco Design 有 713 个 Fork。经抽样检查,绝大多数是开发者为了阅读源码或修复单一 Bug 而进行的“快照式 Fork”,并没有持续的代码提交。
5.2 为什么难以 Fork?
维护一个像 Arco Design 这样的大型组件库,其门槛远超普通开发者的想象。
- Monorepo 构建复杂度:Arco 采用了 Lerna + pnpm 的 Monorepo 架构,包含 React 库、Vue 库、CLI 工具、图标库等多个 Package。其构建脚本极其复杂,往往依赖于字节内部的某些环境配置或私有源。外部开发者即使拉下来代码,要跑通完整的 Build、Test、Doc 生成流程都非常困难。
- 生态维护成本:Arco 的核心优势在于 Design Lab 和 IconBox 等配套 SaaS 服务。Fork 代码容易,但 Fork 整个后端服务是不可能的。失去了 Design Lab 的 Arco,就像失去了灵魂的空壳,吸引力大减。
- 技术栈锁定:Arco 的一些底层实现可能为了适配字节内部的微前端框架或构建工具(如 Modern.js)做了特定优化,这增加了通用化的难度。
因此,社区更倾向于迁移,而不是接盘。
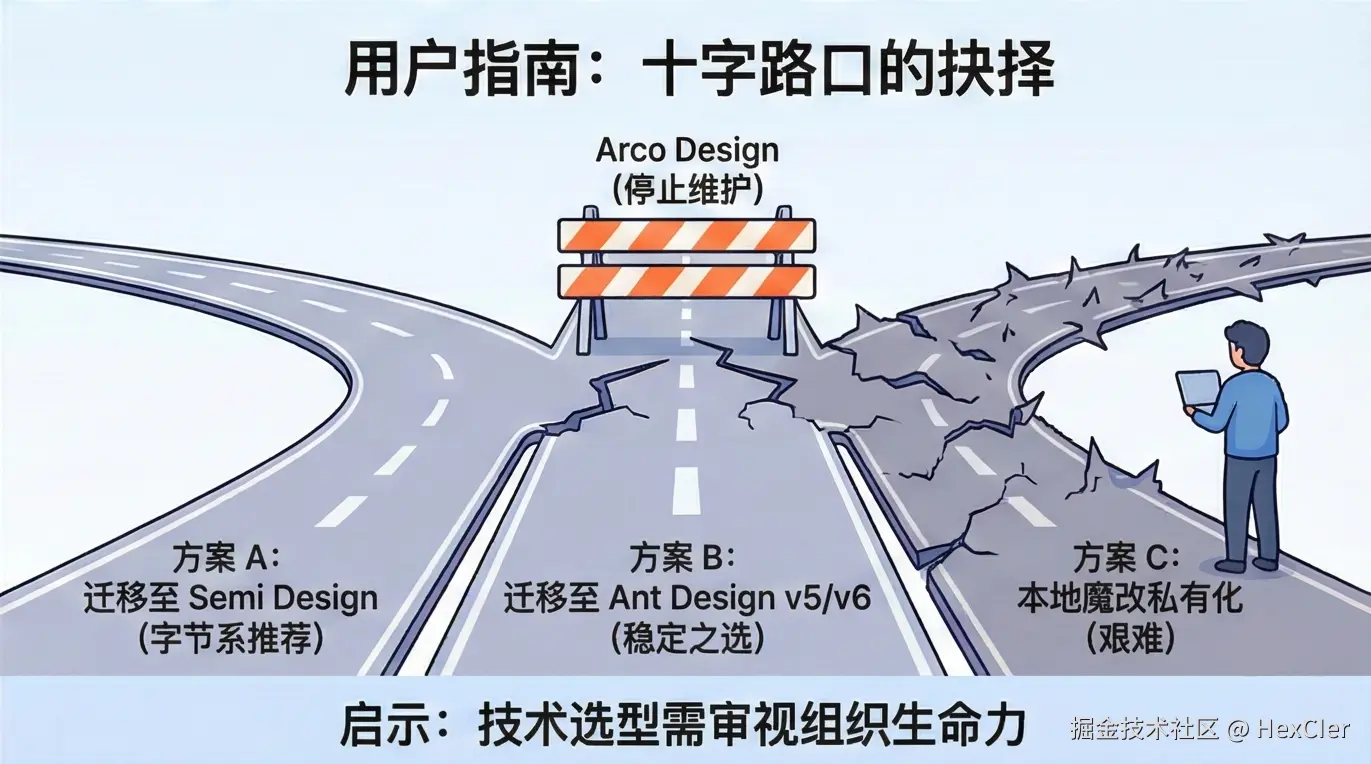
6. 用户生存指南:现状评估与迁移策略
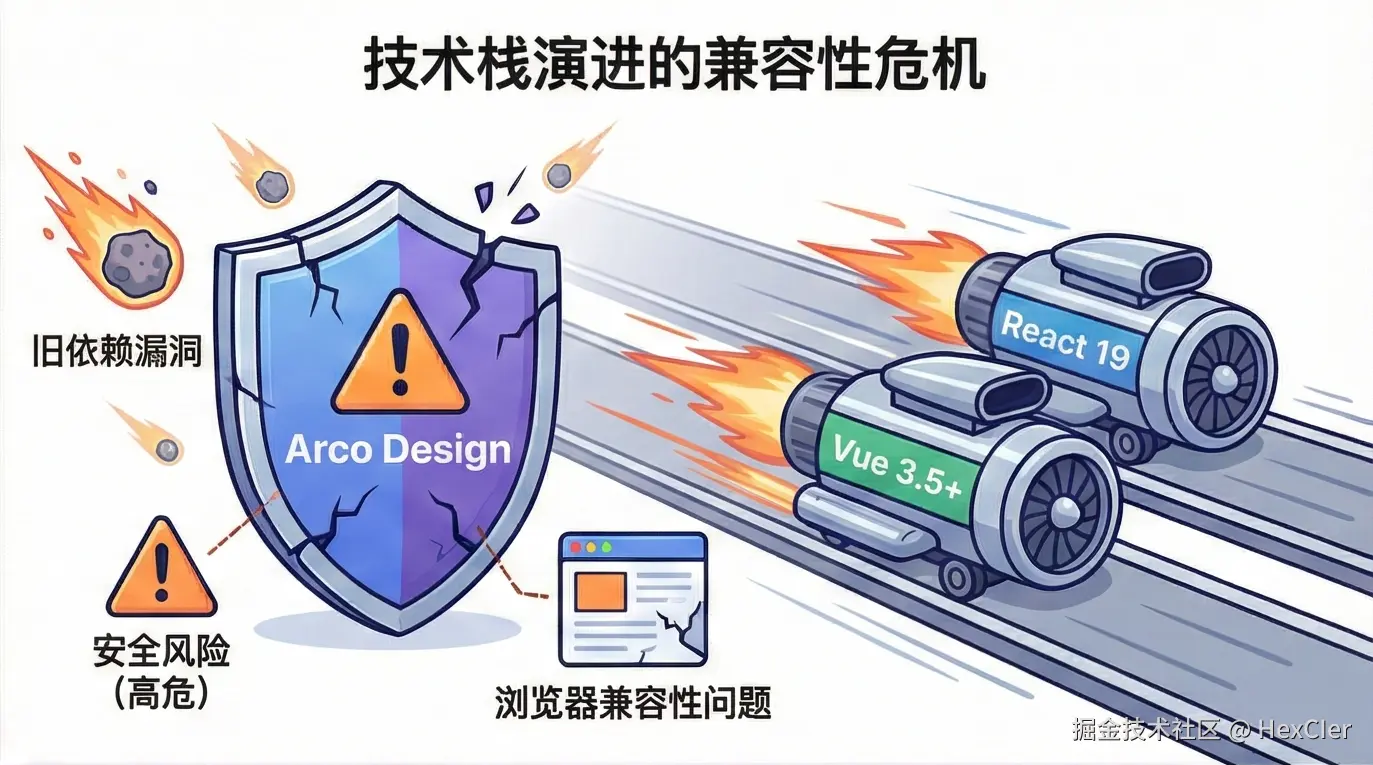
对于目前仍在使用 Arco Design 的团队,局势十分严峻。随着 React 19 的临近和 Vue 3 生态的演进,Arco 将面临越来越多的兼容性问题。
6.1 风险评估表
| 风险维度 | 风险等级 | 具体表现 |
|---|---|---|
| 安全性 | 🔴 高危 | 依赖的第三方包(如 lodash, async-validator 等)若爆出漏洞,Arco 不会发版修复,需用户手动通过 resolutions 强行覆盖。 |
| 框架兼容性 | 🔴 高危 | React 19 可能会废弃某些 Arco 内部使用的旧生命周期或模式;Vue 3.5+ 的新特性无法享受。 |
| 浏览器兼容性 | 🟠 中等 | 新版 Chrome/Safari 的样式渲染变更可能导致 UI 错位,无人修复。 |
| 基础设施 | ⚫ 已崩溃 | IconBox 无法上传新图标,Design Lab 可能随时下线,导致主题无法更新。 |
6.2 迁移路径推荐
方案 A:迁移至 Semi Design(推荐指数:⭐⭐⭐⭐)
如果你是因为喜欢字节系的设计风格而选择 Arco,那么 Semi Design 是最自然的替代者。
- 优势:同为字节出品,设计语言的命名规范和逻辑有相似之处。Semi 目前维护活跃,背靠抖音,拥有强大的 D2C 工具链。
- 劣势:API 并非 100% 兼容,仍需重构大量代码。且 Semi 主要是 React 优先,Vue 生态支持相对较弱(主要靠社区适配)。
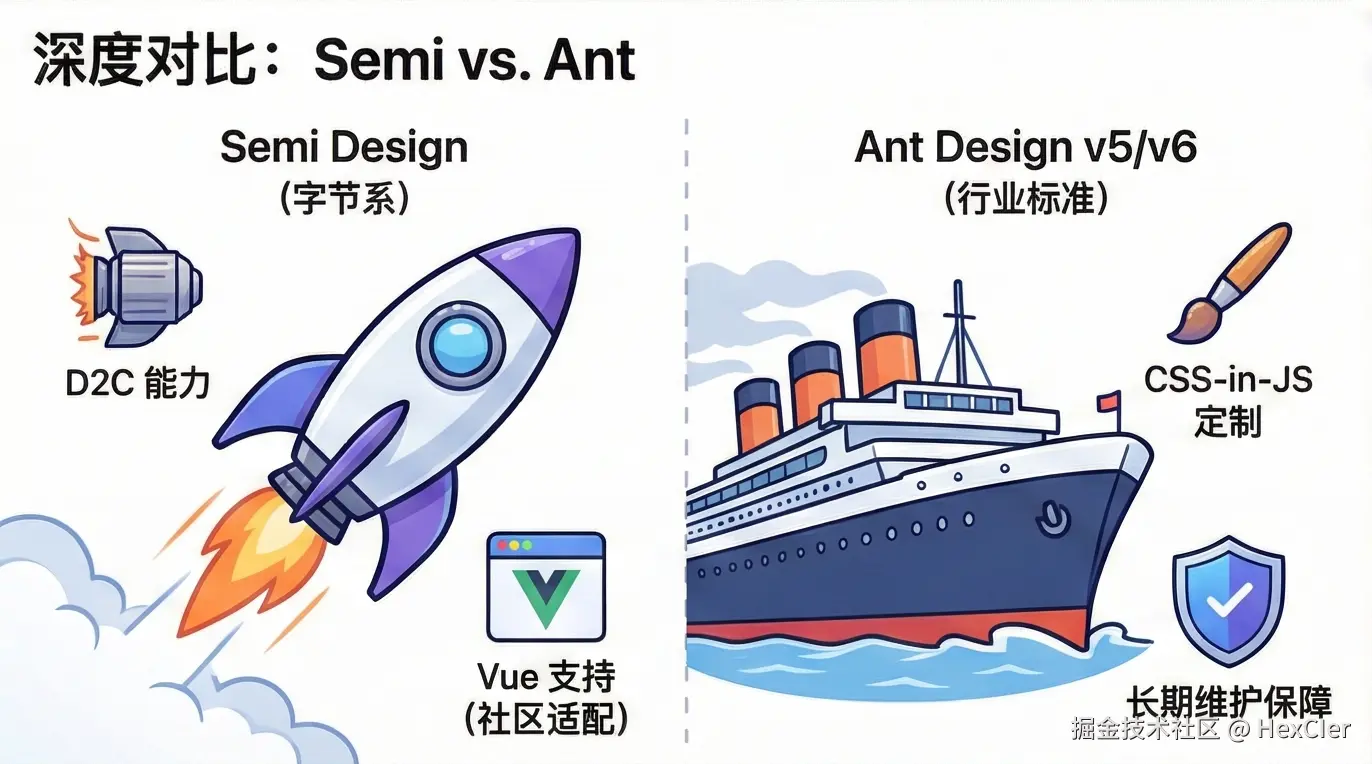
方案 B:迁移至 Ant Design v5/v6(推荐指数:⭐⭐⭐⭐⭐)
如果你追求极致的稳定和长期的维护保障,Ant Design 是不二之选。
- 优势:行业标准,庞大的社区,Ant Gr0up 背书。v5 版本引入了 CSS-in-JS,在定制能力上已经大幅追赶 Arco 的 Design Lab。
- 劣势:设计风格偏保守,需要设计师重新调整 UI 规范。
方案 C:本地魔改(推荐指数:⭐)
如果项目庞大无法迁移,唯一的出路是将 @arco-design/web-react 源码下载到本地 packages 目录,作为私有组件库维护。
- 策略:放弃官方更新,仅修复阻塞性 Bug。这需要团队内有资深的前端架构师能够理解 Arco 的源码。
7. 结语与启示
Arco Design 的故事是现代软件工程史上的一个典型悲剧。它证明了在企业级开源领域,康威定律(Conway's Law) 依然是铁律——软件的架构和命运取决于开发它的组织架构。
当 GIP 部门意气风发时,Arco 是那颗最耀眼的星,承载着“务实浪漫主义”的理想;当组织收缩、业务调整时,它便成了由于缺乏商业造血能力而被迅速遗弃的资产。对于技术决策者而言,Arco Design 的教训是惨痛的:在进行技术选型时,不能仅看 README 上的 Star 数或官网的精美程度,更要审视项目背后的组织生命力和维护动机。
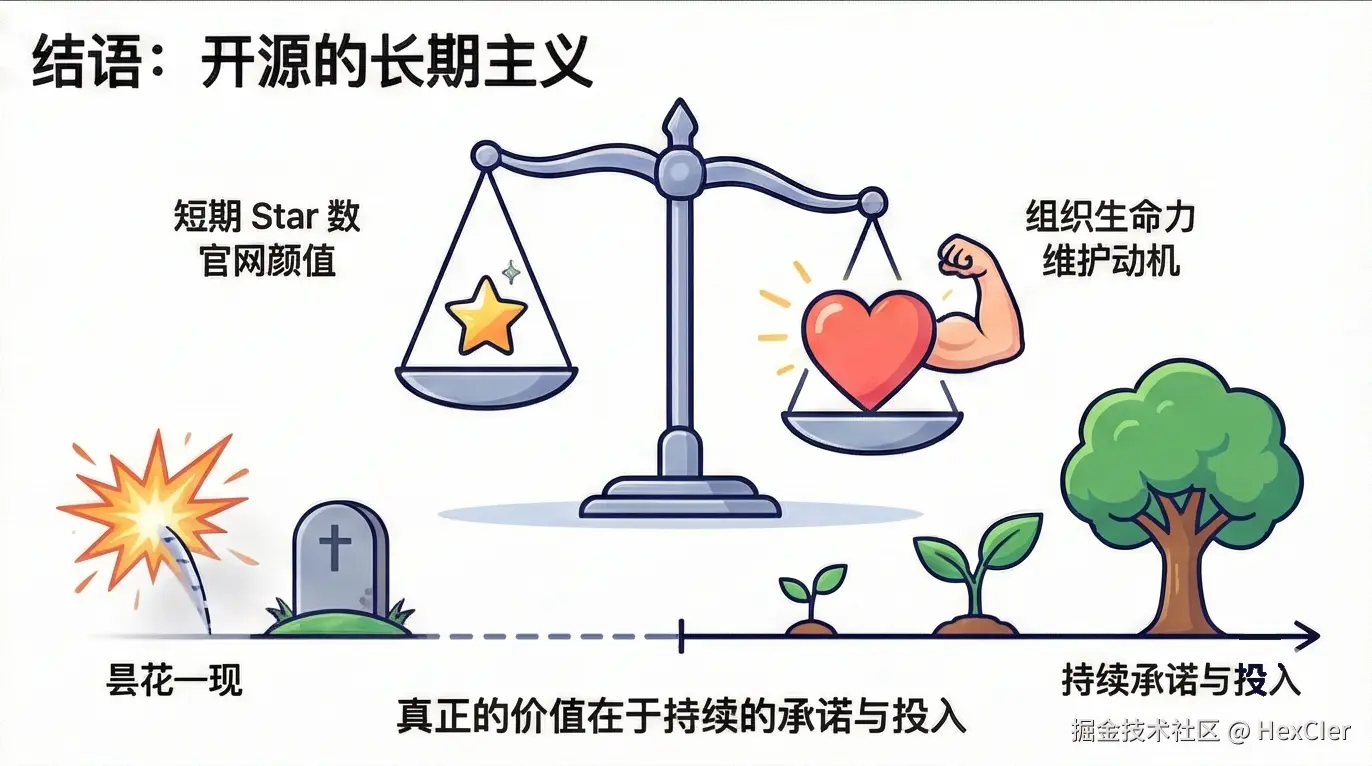
目前来看,Arco Design 并没有复活的迹象,社区也没有出现强有力的接棒者。这套组件库正在数字化浪潮的沙滩上,慢慢风化成一座无人问津的丰碑。
来源:juejin.cn/post/7582879379441745963
桌面应用开发,Flutter 与 Electron如何选
前言:这一年来我基本处于断更的状态,我知道在AI时代,编码的成本已经变得越来越低,技术分享的流量必然会下降。但这依然是一个艰难的过程,日常斥责自己没有成长,没有作品。
除了流量问题、巨量的工作,更多的原因是由于技术栈的变化。我开始使用Electron编写一个重要的AI产品,并且在 Flutter 与 Electron 之间来回拉扯......
背景
我们对 Flutter 技术的应用,不仅是在移动端APP,在我们的终端设备也用来做 OS 应用,跨Android、Windows、Linux系统。
在 Flutter 上,我们是有所沉淀的,但是当我们决定研发一款重要的PC应用时,依然产生了疑问:Flutter 这门技术,真的能满足我们在核心桌面应用的研发需求吗?
最终,基于官方能力、技术生态、roadmap等一系列原因,我们放弃在核心应用上使用 Flutter,转而代之选择了 Electron !
这篇文章将从这几个月使用 Electron 的切实体验,从不同角度,对 Flutter 和 Electron 这两款支持跨端桌面应用开发技术,做一个详细的对比。
Flutter VS Electron
| 维度 | Flutter | Electron |
|---|---|---|
| 发布时间 | 2021 年 3 月 宣布支持桌面端 | 2013 年 4 月发布,发布即支持 |
| 核心场景 | 移动APP跨端 | 桌面应用跨端 |
| 官方网站 | flutter.dev | http://www.electronjs.org |
| 开发文档 | docs.flutter.dev | http://www.electronjs.org/docs |
| 插件包管理 | Pub(pub.dev),提供大量 UI 组件、工具类库 | npm(http://www.npmjs.com),依赖前端生态,插件丰富(如 electron-builder 打包工具) |
| 研发组织 | Github |
方案成熟度
毫无疑问,在方案成熟度上 Electron 是碾压 Flutter 的存在。
1. 多进程能力
- Flutter 目前还是单进程的能力,只能通过创建 isolate 来实现部分耗时任务,但是内存也是不共享的。
- Electron 集成了 Nodejs 服务,
自带多进程的能力,且提供了完整的跨进程机制(IPC「Inter-Process Communication」)。
2. 多窗口支持
- Flutter 目前不支持多窗口。由于其是自绘引擎,本身还是依赖原生进程提供的桌面窗口,所以需要原生与 Flutter 引擎不断的进行沟通对接,才能很好的使用多窗口能力。
目前官方只是提供了 demo 来验证多窗口的可行性,但截止发文还没有办法在公版试用。 - Electron 将 Chromium 的核心模块打包到发行包中,
借助浏览器的能力,可以随意开辟新的窗口(如: BrowserWindow)
3. 开发语言
- Flutter 使用dart语言开发,采用声明式UI进行布局,插件管理使用官方的 pub 社区,学习和使用成本不算高。
- Electron 使用JavaScript/TypeScript + HTML/CSS 的前端技术栈进行开发,社区也完全跟前端一致,
非常丰富但鱼龙混杂。
4. 原生能力的支持
- Flutter 本质是一个 UI 框架,原生能力需要通过编写插件去调用,或者通过 FFI 调用,成本是很高的,你很难找到一个懂多端原生技术的开发。
- Electron 有 node 环境,node.js 很多原生模块,可以直接调用到系统的能力,非常的高效。
开发体验和技术生态
1. 调试工具
- Flutter 的调试工具,主要是依赖 IDE 本身的断点调试能力,以及自研的Flutter Inspector、devTools。
在UI定位、性能监控方面,基本可以满足。但由于是个 UI 框架,对于原生容器是无法进行调试的,这在混合开发过程中是个比较大的痛点。 - Electron 就是个浏览器,对于主进程和node子进程,有 Inspect 的机制; UI 层就更方便了,就是浏览器的调试器一模一样。生产环境下调试成本也低。
2. 打包编译
Flutter 是通过自绘引擎生成原生应用包,而 Electron 是将网页技术(HTML/CSS/JS)包裹在 Chromium 内核中。
底层技术架构的区别,直接决定了 Electron 的打包相对 Flutter 有些困难,且包体积很大。
| 对比维度 | Flutter | Electron |
|---|---|---|
| 打包原理 | 编译成目标平台的原生二进制代码,搭配自绘引擎(Skia) | 封装 Chromium 内核 + Node.js 环境,运行网页资源 |
| 最终产物 | 与原生应用格式一致(如 .apk/.ipa/.exe) | 包含浏览器内核的独立应用包 |
| 跨平台方式 | 一份代码编译成多平台原生包,需分别打包 | 一份代码打包成多平台包,内核随应用分发 |
| 应用体积 | 较小(基础包约 10-20MB) | 较大(基础包约 50-100MB,内核占主要体积) |
3. 官方和社区的活跃性
- Flutter 官方在桌面端的推进很慢,很多基础能力都没有太多的推进。同时在 roadmap 中,重心都偏向移动端和 web 端。
- Electron 由于产品的体量和成熟度,稳定的在更新,每个版本都会带来一些新的特性。
4. 研发团队
| 技能维度 | Flutter | Electron |
|---|---|---|
| 核心语言 | Dart,需理解其异步逻辑、Widget 组件化思想 | JavaScript/TypeScript,前端开发者可无缝衔接 |
| UI 技术 | Flutter 内置 Widget 体系,需学习其布局(Row/Column)、状态管理(Provider/Bloc) | HTML/CSS,可复用前端生态(Vue/React/Element UI 等) |
| 原生交互 | 需了解 Android(Kotlin/Java)、iOS(Swift/OC)基础,复杂功能需写原生插件 | 依赖 Node.js 模块或现成插件,无需深入原生开发 |
| 工程化工具 | 依赖 Flutter CLI、Android Studio/Xcode(打包配置) | 依赖 npm/yarn、webpack/vite(前端构建工具) |
可以看出,Flutter至少需要 1-2 名熟悉 Dart 的开发者,还需要有原生开发能力,技术门槛是比较高的;而 Electron 以前端开发者为主,熟悉 Node.js 即可完成所有开发,是可以快速上手的。
同时前端开发也比 Flutter 开发要更容易招聘。
结语
笔者本身是 Flutter 的忠实维护者,我认为 Flutter 的 Impeller 图形渲染引擎将不断完善,能在各个端达到更好的渲染速度和效果;同时 Flutter 目前的多窗口方案,让我们可以充分的相信可以多个窗口共用一份内存,而不需要通过进程间通信机制
但是,在 Flutter 暂未成熟的阶段,桌面核心产品还是用 Electron 进行开发会更加合适。我们 也期待未来 Electron 可以多集成WebAssembly来提升计算密集型任务的性能,减少 Chromium 内核的高内存占用。
来源:juejin.cn/post/7578719771589066762
偷看浏览器后台,发现它比我忙多了
为啥以前 IE 老“崩溃”,而现在开一堆标签页的 Chrome 还能比较稳?答案都藏在浏览器的「进程模型」里。
作为一个还在学习前端的同学,我经常听到几个关键词:
进程、线程、多进程浏览器、渲染进程、V8、事件循环……
下面就是我目前的理解,算是一篇学习笔记式的分享
一、先把概念捋清:进程 vs 线程
- 进程(Process)
- 操作系统分配资源的最小单位。
- 拥有独立的内存空间、句柄、文件等资源。
- 不同进程间默认互相隔离,通信要通过 IPC。
- 线程(Thread)
- CPU 调度、执行代码的最小单位。
- 共享所属进程的资源(内存、文件句柄等)。
- 一个进程里可以有多个线程并发执行。
简单理解:
- 进程 = 一个“应用实例” (开一个浏览器窗口就是一个进程)。
- 线程 = 应用里的很多“小工人” (一个负责渲染页面,一个负责网络请求……)。
二、单进程浏览器:旧时代的 IE 模型
早期的浏览器(如旧版 IE)基本都是单进程架构:整个浏览器只有一个进程,里面开多个线程来干活。
可以想象成这样一张图(对应你给的“单进程浏览器”那张图):
- 顶部是「代码 / 数据 / 文件」等资源。
- 下面有多个线程:
- 页面线程:负责页面渲染、布局、绘制。
- 网络线程:负责网络请求。
- 其他线程:例如插件、定时任务等。
- 所有线程共享同一份进程资源。
在这个模型下:
- 页面渲染、JavaScript 执行、插件运行,都挤在同一个进程里。
- 某个插件或脚本一旦崩溃、死循环、内存泄漏,整个浏览器都会被拖垮。
- 多开几个标签页,本质上依旧是同一个进程里的不同页面线程, “一荣俱荣,一损俱损” 。
这也是很多人对 IE 的经典印象:
“多开几个页面就卡死,崩一次,所有标签页一起消失”。
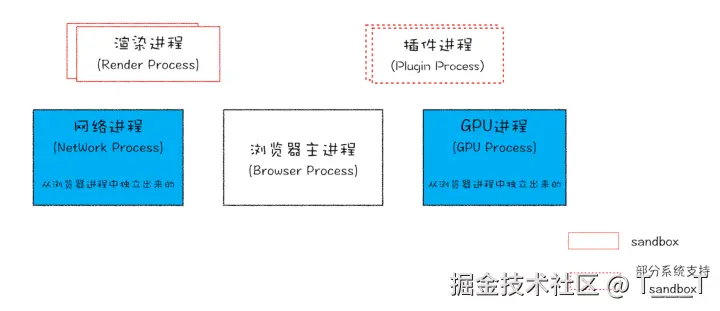
三、多进程浏览器:Chrome 的现代架构
Chrome 采用的是多进程、多线程混合架构。打开浏览器时,大致会涉及这些进程:
- 浏览器主进程(Browser Process)
- 负责浏览器 UI、地址栏、书签、前进后退等。
- 管理和调度其他子进程(类似一个大管家)。
- 负责部分存储、权限管理等。
- 渲染进程(Render Process)
- 核心任务:把 HTML / CSS / JavaScript 变成用户可以交互的页面。
- 布局引擎(如 Blink)和 JS 引擎(如 V8)都在这里。
- 默认情况下,每个标签页会对应一个独立的渲染进程。
- GPU 进程(GPU Process)
- 负责 2D / 3D 绘制和加速(动画、3D 变换等)。
- 统一为浏览器和各渲染进程提供 GPU 服务。
- 网络进程(Network Process)
- 负责资源下载、网络请求、缓存等。
- 插件进程(Plugin Process)
- 负责运行如 Flash、扩展等插件代码,通常放在更严格的沙箱里。
你给的第一张图,其实就是这么一个多进程架构示意图:中间是主进程,两侧是渲染、网络、GPU、插件等子进程,有的被沙箱保护。
四、单进程 vs 多进程:核心差异一览(表格对比)
下面这张表,把旧式单进程浏览器和现代多进程浏览器的差异总结出来,适合在文章中重点展示:
| 对比维度 | 单进程浏览器(典型:旧版 IE) | 多进程浏览器(典型:Chrome) |
|---|---|---|
| 进程模型 | 整个浏览器基本只有一个进程,多标签页只是不同线程 | 浏览器主进程 + 多个子进程(渲染、网络、GPU、插件…),标签页通常独立渲染进程 |
| 稳定性 | 任意线程(脚本、插件)崩溃,可能拖垮整个进程,浏览器整体崩溃 | 某个标签页崩溃只影响对应渲染进程,其他页面基本不受影响 |
| 安全性 | 代码都在同一进程运行,权限边界模糊,攻击面大 | 利用多进程 + 沙箱:渲染进程、插件进程被限制访问系统资源,需要通过主进程/IPC |
| 性能体验 | 多标签共享资源,某个页面卡顿,容易拖慢整体;UI 和页面渲染耦合严重 | 不同进程之间可以更好地利用多核 CPU,重页面操作不会轻易阻塞整个浏览器 UI |
| 内存占用 | 单进程内存相对集中,但一旦泄漏难以回收;崩溃时损失全部状态 | 多进程会有一定内存冗余,但某个进程关闭/崩溃后,其内存可被系统直接回收 |
| 插件影响 | 插件崩溃 = 浏览器崩溃,体验极差 | 插件独立进程 + 沙箱,崩溃影响有限,可以单独重启 |
| 维护与扩展 | 所有模块耦合在一起,改动风险大 | 进程边界天然分层,更利于模块化演进和大规模工程化 |
五、别被“多进程”骗了:JS 依然是单线程
聊到这里,很多同学容易混淆一个点:
浏览器是多进程的,那 JavaScript 是不是也多线程并行执行了?
答案是否定的:主线程上的 JavaScript 依然是单线程模型。区别在于:
- 在渲染进程内部,有一个主线程负责:
- 执行 JavaScript。
- 页面布局、绘制。
- 处理用户交互(点击、输入等)。
- JS 代码仍然遵循:同步任务立即执行,异步任务丢进任务队列,由事件循环(Event Loop)调度。
为什么要坚持单线程?
- DOM 是单线程模型,多个线程同时改 DOM,锁会非常复杂。
- 前端开发心智成本可控;不必像多线程语言那样到处考虑锁和竞态条件。
多进程架构只是把:
- “这个页面的主线程 + 渲染 + JS 引擎”
放在一个单独的进程里(渲染进程)。
这也是为什么:
- 一个页面 JS 写了死循环,会卡死那一个标签页。
- 但其他标签页通常还能正常使用,因为它们在完全不同的渲染进程内。
六、从架构看体验:为什么我们更喜欢现在的浏览器?
站在前端开发者角度,多进程架构带来的直接收益有:
- 更好的容错性
- 更高的安全等级
- 更顺滑的交互体验
- 更容易工程化演进
当然,代价也很现实:多进程 = 更高的内存占用。这也是为什么:
- 多开几十个标签,任务管理器里能看到很多浏览器相关进程。
- 但换来的是更好的稳定性、安全性和扩展性——在现代硬件下,这是可以接受的 trade-off。
七、总结
- 早期浏览器采用单进程 + 多线程模式,所有页面、脚本、插件都在同一个进程里,一旦出问题就“全军覆没”。
- 现代浏览器(代表是 Chrome)使用多进程架构:主进程负责调度,各个渲染、网络、GPU、插件进程各司其职,并通过沙箱强化隔离。
- 尽管浏览器整体是多进程的,但单个页面里的 JavaScript 依然是单线程 + 事件循环模型,这点没有变。
- 从用户体验、前端开发、安全性、稳定性来看,多进程架构几乎是全面碾压旧时代单进程浏览器的一次升级。
来源:juejin.cn/post/7580263284338311209
数组判断?我早不用instanceof了,现在一行代码搞定!
传统方案
1. Object.prototype.toString.call 方法
原理:通过调用 Object.prototype.toString.call(obj) ,判断返回值是否为 [object Array] 。
function isArray(obj){
return Object.prototype.toString.call(obj) === '[object Array]';
}
缺陷:
- ES6 引入
Symbol.toStringTag后,可被人为篡改。例如:
const obj = {
[Symbol.toStringTag]: 'Array'
};
console.log(Object.prototype.toString.call(obj)); // 输出 [object Array]
- 若开发通用型代码(如框架、库),该漏洞会导致判断失效。
2. instanceof 方法
原理:判断对象原型链上是否存在 Array 构造函数。
function isArray(obj){
return obj instanceof Array;
}
缺陷:
- 可通过
Object.setPrototypeOf篡改原型链,导致误判。例如:
const obj = {};
Object.setPrototypeOf(obj, Array.prototype);
console.log(obj instanceof Array); // 输出 true,但 obj 并非真正数组
- 跨 iframe 场景失效。不同 iframe 中的
Array构造函数不共享,导致真数组被误判为非数组。例如:
const frame = document.querySelector('iframe');
const Array2 = frame.contentWindow.Array;
const arr = new Array2();
console.log(arr instanceof Array); // 输出 false,但 arr 是真正数组
ES6 原生方法
方法:使用 Array.isArray 静态方法。
console.log(Array.isArray(arr));
优势:
- 该方法由JavaScript引擎内部实现,直接判断对象是否由 Array 构造函数创建,不受原型链、 Symbol.toStringTag 或跨 iframe 影响;
- 完美解决所有边界场景。
总结
判断数组的方法中 Array.isArray 是唯一准确且无缺陷的方案。其他方法(如Object.prototype.toString.call、instanceof)均存在局限性,仅在特定场景下可用。
来源:juejin.cn/post/7579849892614094884
HTML5 自定义属性 data-*:别再把数据塞进 class 里了!
前言:由于“无处安放”而引发的混乱
在 HTML5 普及之前,前端开发者为了在 DOM 元素上绑定一些数据(比如用户 ID、商品价格、状态码),可谓是八仙过海,各显神通:
- 隐藏域流派:到处塞
<input type="hidden" value="123">,导致 HTML 结构像个堆满杂物的仓库。 - Class 拼接流派:
<div class="btn item-id-8848">,然后用正则去解析 class 字符串提取 ID。这简直是在用 CSS 类名当数据库用,类名听了都想离家出走。 - 自定义非标属性流派:直接写
<div my_id="123">。虽然浏览器大多能容忍,但这就好比在公共泳池里裸泳——虽然没人抓你,但不合规矩且看着尴尬。
直到 HTML5 引入了 data-* 自定义数据属性,这一切终于有了“官方标准”。
第一阶段:基础——它长什么样?
data-* 属性允许我们在标准 HTML 元素中存储额外的页面私有信息。
1. HTML 写法
语法非常简单:必须以 data- 开头,后面接上你自定义的名称。
codeHtml
<!-- ❌ 错误示范:不要大写,不要乱用特殊符号 -->
<div data-User-Id="1001"></div>
<!-- ✅ 正确示范:全小写,连字符连接 -->
<div
id="user-card"
data-id="1001"
data-user-name="juejin_expert"
data-value="99.9"
data-is-vip="true"
>
用户信息卡片
</div>
2. CSS 中的妙用
很多人以为 data-* 只是给 JS 用的,其实 CSS 也能完美利用它。
场景一:通过属性选择器控制样式
/* 当 data-is-vip 为 "true" 时,背景变金 */
div[data-is-vip="true"] {
background: gold;
border: 2px solid orange;
}
场景二:利用 attr() 显示数据
这是一个非常酷的技巧,可以用来做 Tooltip 或者计数器显示。
div::after {
/* 直接把 data-value 的值显示在页面上 */
content: "当前分值: " attr(data-value);
font-size: 12px;
color: #666;
}
第二阶段:进阶——JavaScript 如何读写?
这才是重头戏。在 JS 中操作 data-* 有两种方式:传统派 和 现代派。
1. 传统派:getAttribute / setAttribute
这是最稳妥的方法,兼容性最好(虽然现在也没人要兼容 IE6 了)。
const el = document.getElementById('user-card');
// 读取
const userId = el.getAttribute('data-id'); // "1001"
// 修改
el.setAttribute('data-value', '100');
特点:读出来永远是字符串。哪怕你存的是 100,取出来也是 "100"。
2. 现代派:dataset API (推荐 ✨)
HTML5 为每个元素提供了一个 dataset 对象(DOMStringMap),它将所有的 data-* 属性映射成了对象的属性。
这里有个大坑(或者说是规范),请务必注意:
HTML 中的 连字符命名 (kebab-case) 会自动转换为 JS 中的 小驼峰命名 (camelCase) 。
const el = document.getElementById('user-card');
// 1. 访问 data-id
console.log(el.dataset.id); // "1001"
// 2. 访问 data-user-name (注意变身了!)
console.log(el.dataset.userName); // "juejin_expert"
// ❌ el.dataset.user-name 是语法错误
// ❌ el.dataset['user-name'] 是 undefined
// 3. 修改数据
el.dataset.value = "200";
// HTML 会自动变成 data-value="200"
// 4. 删除数据
delete el.dataset.isVip;
// HTML 中的 data-is-vip 属性会被移除
💡 敲黑板:dataset 里的属性名不支持大写字母。如果你在 HTML 里写 data-MyValue="1", 浏览器会强制转为小写 data-myvalue,JS 里就得用 dataset.myvalue 访问。所以,HTML 里老老实实全小写吧。
第三阶段:深入——类型陷阱与性能权衡
1. 一切皆字符串
不管你赋给 dataset 什么类型的值,最终都会被转为字符串。
el.dataset.count = 100; // HTML: data-count="100"
el.dataset.active = true; // HTML: data-active="true"
el.dataset.config = {a: 1}; // HTML: data-config="[object Object]" -> 灾难!
避坑指南:
- 如果你要存数字,取出来时记得 Number(el.dataset.count)。
- 如果你要存布尔值,判断时不能简单用 if (el.dataset.active),因为 "false" 字符串也是真值!要用 el.dataset.active === 'true'。
- 千万不要试图在 data-* 里存复杂的 JSON 对象。如果非要存,请使用 JSON.stringify(),但在 DOM 上挂载大量字符串数据会影响性能。
2. 性能考量
- 读写速度:dataset 的访问速度在现代浏览器中非常快,但在极高频操作下(比如每秒几千次),直接操作 JS 变量肯定比操作 DOM 快。
- 重排与重绘:修改 data-* 属性会触发 DOM 变更。如果你的 CSS 依赖属性选择器(如 div[data-status="active"]),修改属性可能会触发页面的重排(Reflow)或重绘(Repaint)。
第四阶段:实战——优雅的事件委托
data-value 最经典的用法之一就是在列表项的事件委托中。
需求:点击列表中的“删除”按钮,删除对应项。
<ul id="todo-list">
<li>
<span>学习 HTML5</span>
<!-- 把 ID 藏在这里 -->
<button class="btn-delete" data-id="101" data-action="delete">删除</button>
</li>
<li>
<span>写掘金文章</span>
<button class="btn-delete" data-id="102" data-action="delete">删除</button>
</li>
</ul>
const list = document.getElementById('todo-list');
list.addEventListener('click', (e) => {
// 利用 dataset 判断点击的是不是删除按钮
const { action, id } = e.target.dataset;
if (action === 'delete') {
console.log(`准备删除 ID 为 ${id} 的条目`);
// 这里发送请求或操作 DOM
// deleteItem(id);
}
});
为什么这么做优雅?
你不需要给每个按钮都绑定事件,也不需要去分析 DOM 结构(比如 e.target.parentNode...)来找数据。数据就在元素身上,唾手可得。
总结与“禁忌”
HTML5 的 data-* 属性是连接 DOM 和数据的一座轻量级桥梁。
什么时候用?
- 当需要把少量数据绑定到特定 UI 元素上时。
- 当 CSS 需要根据数据状态改变样式时。
- 做事件委托需要传递参数时。
什么时候别用?(禁忌)
- 不要存储敏感数据:用户可以直接在浏览器控制台修改 DOM,千万别把 data-password 或 data-user-token 放在这。
- 不要当数据库用:别把几 KB 的 JSON 数据塞进去,那是 JS 变量或者是 IndexDB 该干的事。
- SEO 无用:搜索引擎爬虫通常不关心 data-* 里的内容,重要的文本内容还是要写在标签里。
最后一句:
代码整洁之道,始于不再乱用 Class。下次再想存个 ID,记得想起那个以 data- 开头的帅气属性。
Happy Coding! 🚀
来源:juejin.cn/post/7575119254314401818
前端发版总被用户说“没更新”?一文搞懂浏览器缓存,彻底解决!
有时候我们发了新版,结果用户看到的还是老界面。
你:“我更新了啊!”
用户:“我这儿没变啊!”
然后你俩开始互相怀疑人生。
那咋办?总不能让用户都清缓存吧?
当然不能。
我们得让浏览器自己知道“该换新的了”。
核心思路就一条:让静态资源的文件名变一变。
浏览器靠文件名判断是不是同一个文件。
文件名变了,它就会重新下载。
方法1:加时间戳(简单粗暴)
以前:
<script src="/js/app.js"></script>
现在:
<script src="/js/app.js?v=20250901"></script>
或者用时间戳:
<script src="/js/app.js?t=1725153600"></script>
发版的时候,改一下v 或t的值,浏览器看到后发现文件名不一样,就会重新下载。
优点:简单,立马见效
缺点:每次发版都得手动改,容易忘记。
方法2:用构建工具加hash(推荐!)
这是现在最主流的做法。
你用Webpack、Vite、Rollup这些工具打包时,它会自动给文件名加一串hash:
<script src="/js/app.a1b2c3d.js"></script>
你代码一改,hash就变。
比如下次变成:
<script src="/js/app.e4f5g6h.js"></script>
浏览器看到后发现文件名不一样,会自动拉新文件。
使用时需要检查你的打包配置,确保输出文件带hash。
Vite配置(vite.config.js):
export default defineConfig({
build: {
rollupOptions: {
output: {
entryFileNames: 'assets/[name].[hash].js',
chunkFileNames: 'assets/[name].[hash].js',
assetFileNames: 'assets/[name].[hash].[ext]'
}
}
}
})
Vue CLI(vue.config.js):
module.exports = {
filenameHashing: true, // 默认就是 true,别关掉!
}
只要这个开着,JS/CSS 文件名就会变,浏览器就会更新。
优点:全自动,不用操心
优点:用户无感知,体验好
优点:还能利用缓存(没改的文件hash不变,继续用旧的)
来看看Vue的项目
只要你用的是Vue CLI、Vite或 Webpack打包,发版时默认就解决了缓存问题。
因为它们会自动给文件名加hash。
比如你打包后:
dist/
├── assets/app.8a2b1f3.js
├── assets/chunk-vendors.a1b2c3d.js
└── index.html
你改了代码,再打包,hash就变了:
assets/app.x9y8z7w.js # 新文件
虽说是这样,但为啥还有人卡在旧版本?
文件名带hash,但index.html这个入口文件本身可能被缓存了!
流程:
index.html里引用了app.8a2b1f3.js- 用户第一次访问,加载了
index.html和对应的JS - 你发新版,
index.html指向app.x9y8z7w.js - 但用户浏览器缓存了旧的
index.html,还在引用app.8a2b1f3.js - 结果:页面还是旧的
这是入口文件缓存导致的发版无效。
解决方案
方法1:让index.html不被缓存
这是最简单有效的办法。
配置Nginx,让index.html不缓存:
location = /index.html {
add_header Cache-Control "no-cache, no-store, must-revalidate";
add_header Pragma "no-cache";
add_header Expires "0";
}
这样每次用户访问,都会重新下载最新的 index.html,自然就拿到新的 JS 文件名。
注意:其他静态资源(js/css)可以长期缓存,只有
index.html要禁缓存。
方法2:根据版本号来控制
每一次更新都新建一个文件夹
然后修改Nginx配置
location / {
root /home/server/html/yudao-vue3/version_1_2_5;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
最后:
缓存这事看着小,真出问题能让我们忙半天。
提前设好机制,发版才能睡得香。
搞定!
我是大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
📌往期精彩
《Elasticsearch 太重?来看看这个轻量级的替代品 Manticore Search》
《只会写 Mapper 就敢说会 MyBatis?面试官:原理都没懂》
《别学23种了!Java项目中最常用的6个设计模式,附案例》
《写给小公司前端的 UI 规范:别让页面丑得自己都看不下去》
来源:juejin.cn/post/7545252678936100918
前端部署,又有新花样?
大多数前端开发者在公司里,很少需要直接操心“部署”这件事——那通常是运维或 DevOps 的工作。
但一旦回到个人项目,情况就完全不一样了。写个小博客、搭个文档站,或者搞个 demo 想给朋友看,部署往往成了最大的拦路虎。
常见的选择无非是 Vercel、Netlify 或 GitHub Pages。它们表面上“一键部署”,但细节其实并不轻松:要注册平台账号、要配置域名,还得接受平台的各种限制。国内的一些云服务商(比如阿里云、腾讯云)管控更严格,操作门槛也更高。更让人担心的是,一旦平台宕机,或者因为地区网络问题导致访问不稳定,你的项目可能随时“消失”在用户面前。虽然这种情况不常见,但始终让人心里不踏实。
很多时候,我们只是想快速上线一个小页面,不想被部署流程拖累,有没有更好的方法?
一个更轻的办法
前段时间我发现了一个开源工具 PinMe,主打的就是“极简部署”。

它的使用体验非常直接:
- 不需要服务器
- 不用注册账号
- 在项目目录敲一条命令,就能把项目打包上传到 IPFS 网络
- 很快,你就能拿到一个可访问的地址
实际用起来的感受就是一个字:爽。
整个过程几乎没有繁琐配置,不需要绑定平台账号,也不用担心流量限制或收费。
这让很多场景变得顺手:
- 临时展示一个 demo,不必折腾服务器
- 写了个静态博客,不想搞 CI/CD 流程
- 做了个活动页或 landing page,随时上线就好
以前这些需求可能要纠结“用 GitHub Pages 还是 Vercel”,现在有了 PinMe,直接一键上链就行。
体验一把
接下来看看它在真实场景下的表现:部署流程有多简化?访问速度如何?和传统方案相比有没有优势?
测试项目
为了覆盖不同体量的场景,这次我选了俩类项目来测试:
- 小型项目:fuwari(开源的个人博客项目),打包体积约 4 MB。
- 中大型项目:Soybean Admin(开源的后台管理系统),打包体积约 15 MB。
部署项目
PinMe 提供了两种方式:命令行 和 可视化界面。
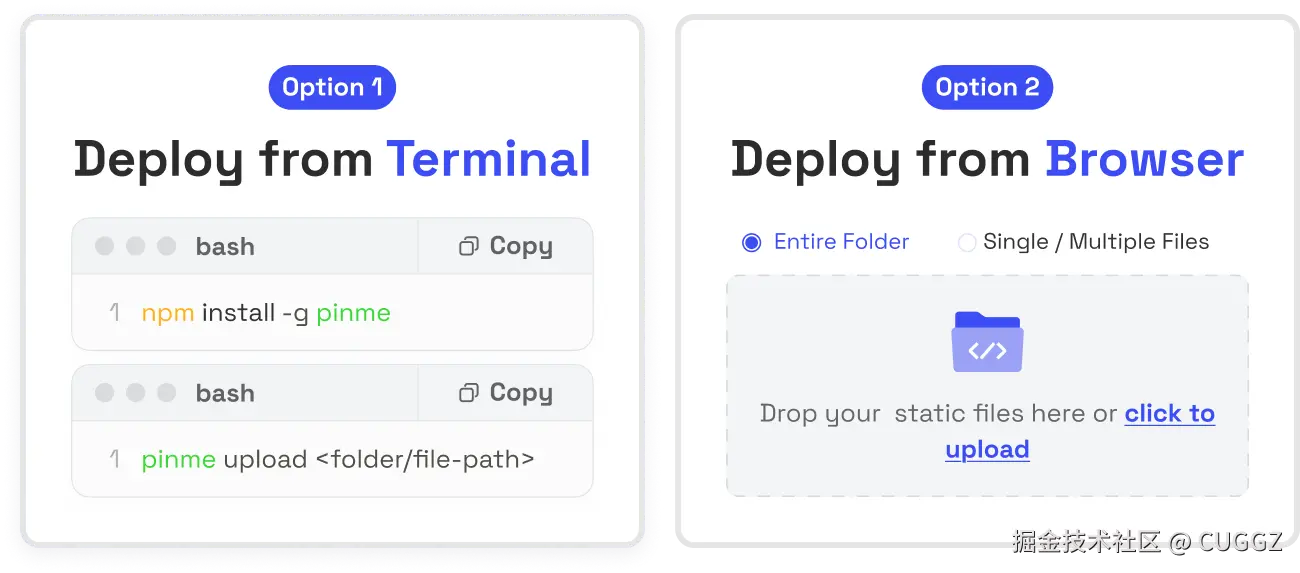
这两种方式我们都来试一下。
命令行部署
先全局安装:
npm install -g pinme
然后一条命令上传:
pinme upload <folder/file-path>
比如上传 Soybean Admin,文件大小 15MB:
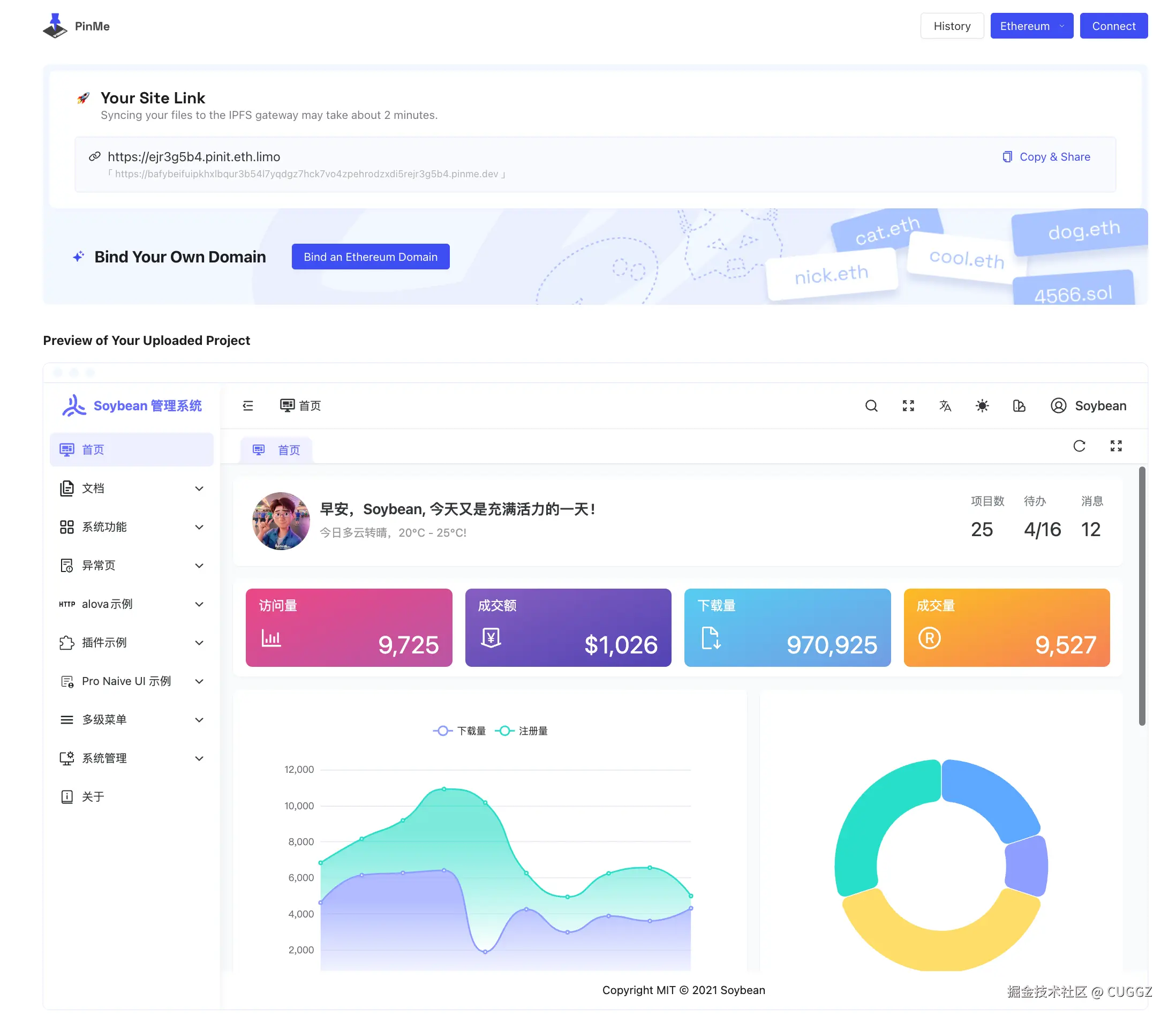
输入命令之后,等着就可以了:

只用了两分钟,终端返回的 URL 就能直接访问项目的控制页面。还能绑定自己的域名:
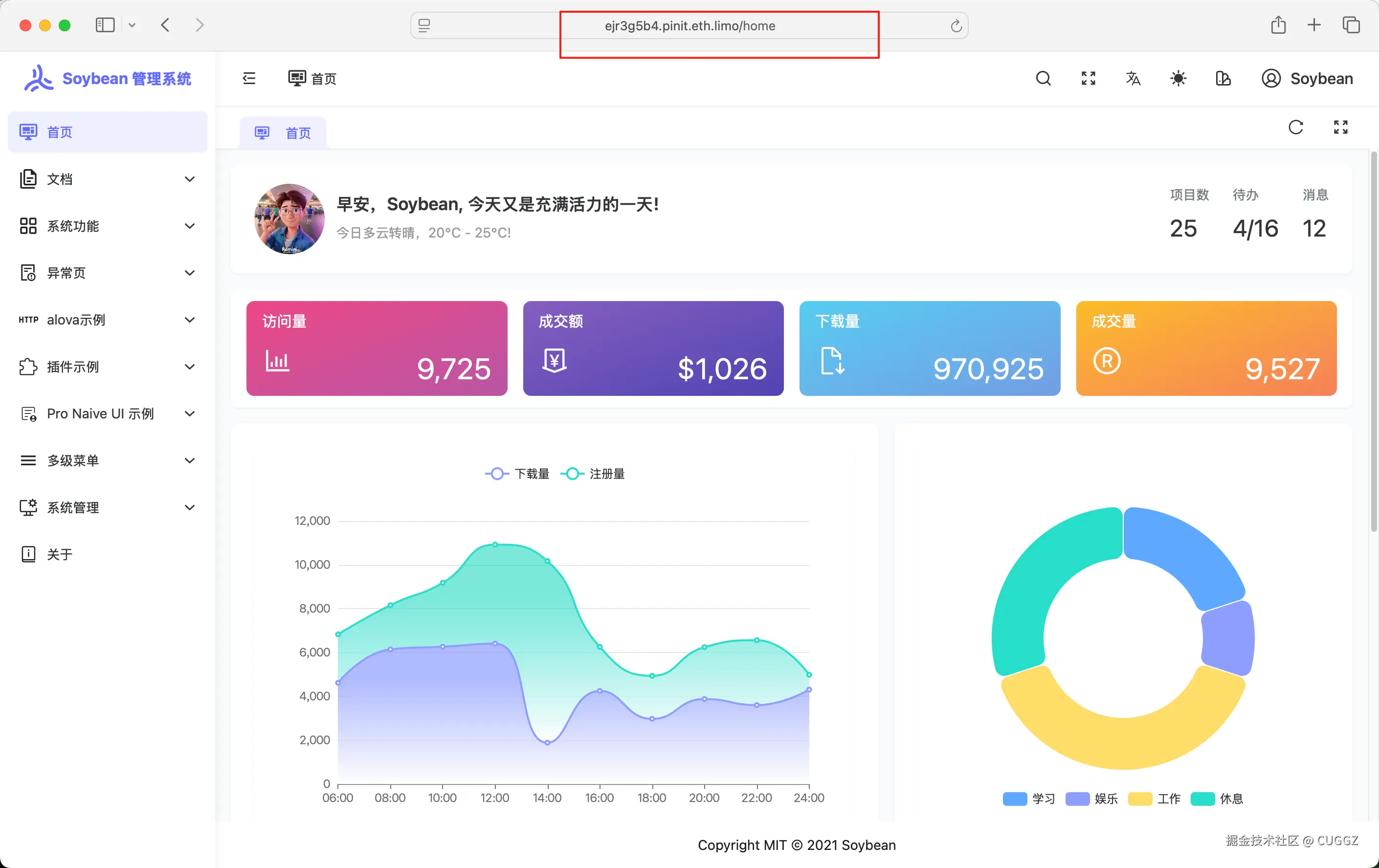
点击网站链接就可以看到已经部署好的项目,访问速度还是挺快的:
同样地,上传个人博客也是一样的流程。
部署完成:
可视化部署
不习惯命令行?PinMe 也提供了网页上传,进度条实时显示:
部署完成后会自动进入管理页面:
经过测试,部署速度和命令行几乎一致。
其他功能
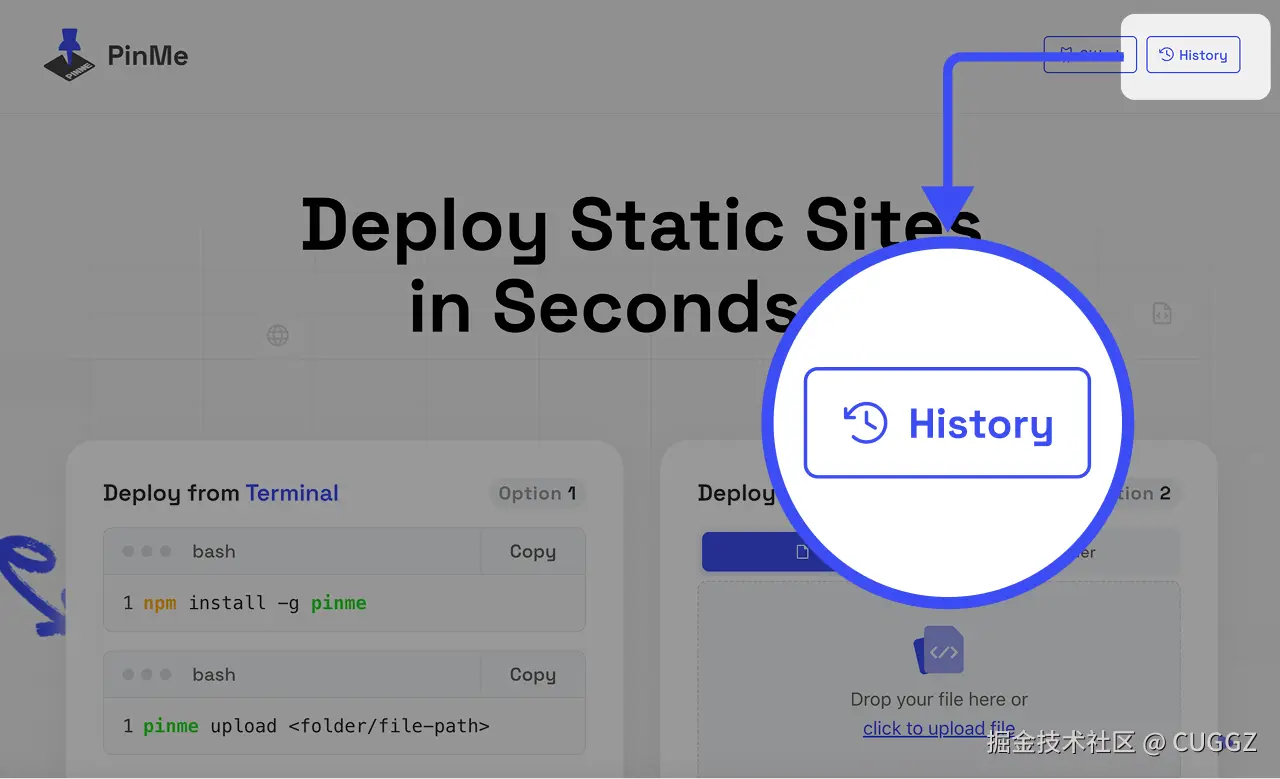
历时记录
部署过的网站都能在主页的 History 查看:
历史部署记录:
也可以用命令行:
pinme list
历史部署记录:
删除网站
如果不再需要某个项目,执行以下命令即可:
pinme rm
PinMe 背后的“硬核支撑”
如果只看表层,PinMe 就像一个极简的托管工具。但要理解它为什么能做到“不依赖平台”,还得看看它背后的底层逻辑。
PinMe 的底层依赖 IPFS,这是一个去中心化的分布式文件系统。
要理解它的意义,得先聊聊“去中心化”这个概念。
传统互联网是中心化的:你访问一个网站时,浏览器会通过 DNS 找到某台服务器,然后从这台服务器获取内容。这条链路依赖强烈,一旦 DNS 被劫持、服务器宕机、服务商下线,网站就无法访问。
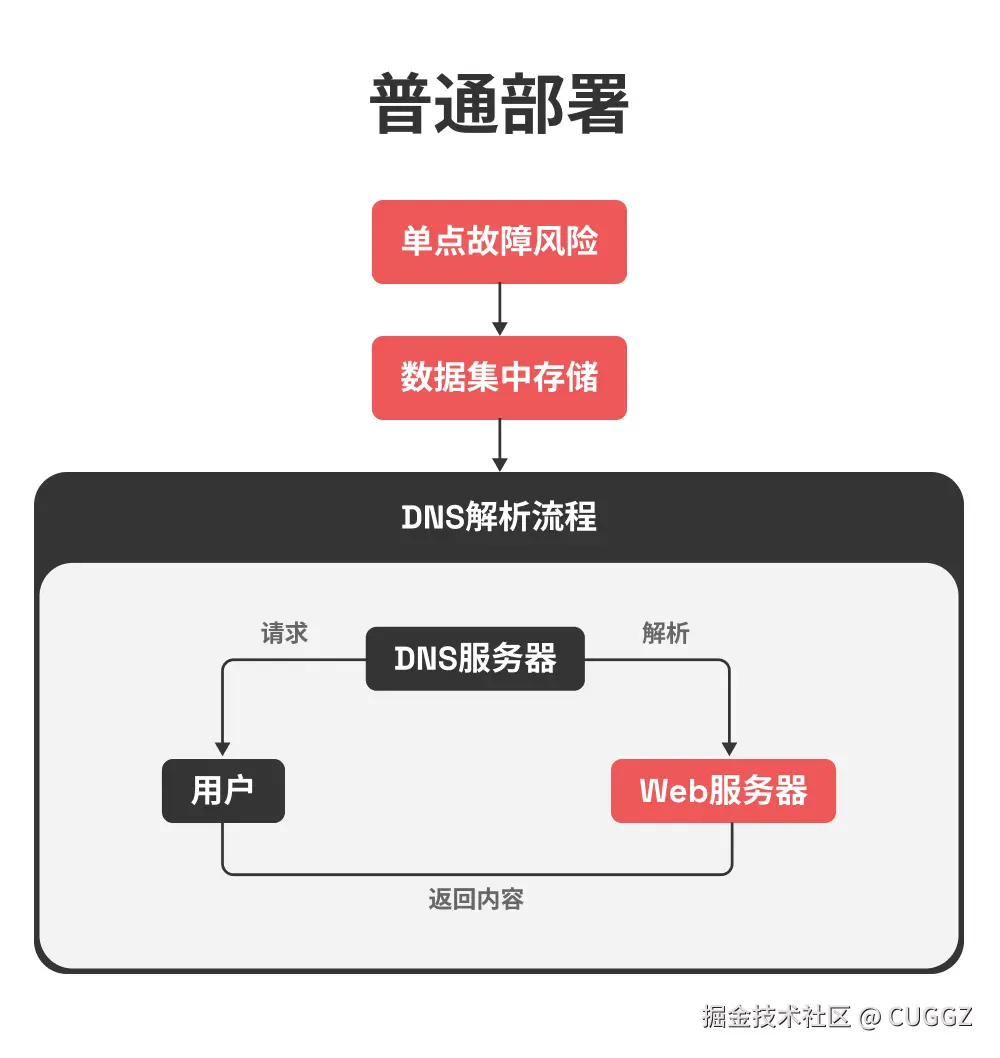
去中心化的思路完全不同:
- 数据不是放在单一服务器,而是分布在全球节点中
- 访问不依赖“位置”,而是通过内容哈希来检索
- 只要有节点存储这份内容,就能访问到,不怕单点故障
这意味着:
- 更稳定:即使部分节点宕机,内容依然能从其他节点获取。
- 防篡改:文件哪怕改动一个字节,对应的 CID 也会完全不同,从机制上保障了前端资源的完整性和安全性。
- 更自由:不再受制于中心化平台,文件真正由用户自己掌控。
当然,IPFS 地址(哈希)太长,不适合直接记忆和分享。这时候就需要 ENS(Ethereum Name Service)。它和 DNS 类似,但记录存储在以太坊区块链上,不可能被篡改。比如你可以把 myblog.eth 指向某个 IPFS 哈希,别人只要输入 ENS 域名就能访问,不依赖传统 DNS,自然也不会被劫持。
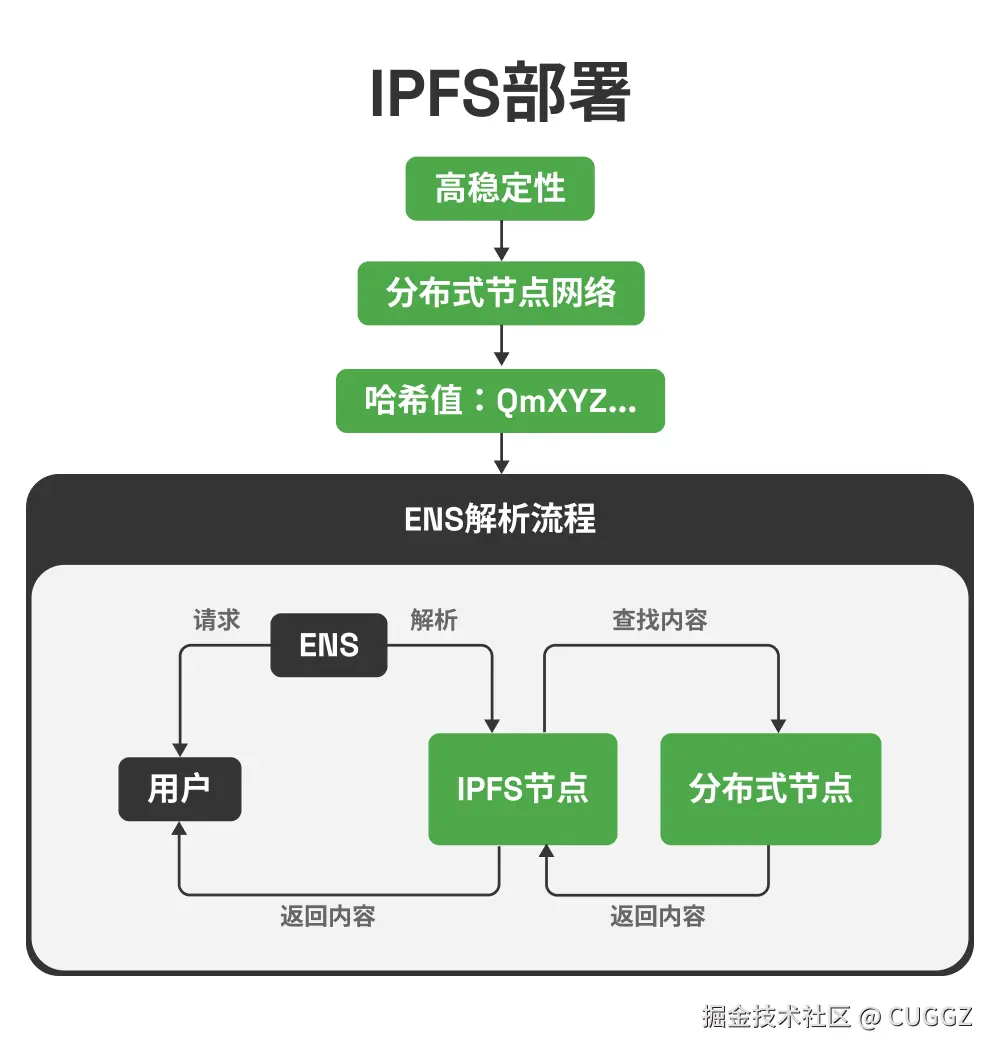
换句话说:
ENS + IPFS = 内容去中心化 + 域名去中心化
前端个人项目瞬间就有了更高的自由度和安全性。
一点初步感受
PinMe 并不是要取代 Vercel 这类成熟平台,但它带来了一种新的选择:更简单、更自由、更去中心化。
如果你只是想快速上线一个小项目,或者对去中心化部署感兴趣,PinMe 值得一试。
- 官网:pinme.eth.limo/
- Github:github.com/glitternetw…
这是一个完全开源的项目,开发团队也会持续更新。如果你在测试过程中有想法或需求,不妨去 GitHub 提个 Issue —— 这不仅能帮助项目成长,也能让它更贴近前端开发的实际使用场景!
来源:juejin.cn/post/7547515500453380136
快到 2026 年了:为什么我们还在争论 CSS 和 Tailwind?
最近在使用 NestJs 和 NextJs 在做一个协同文档 DocFlow,如果感兴趣,欢迎 star,有任何疑问,欢迎加我微信进行咨询 yunmz777
老实说,我对 Tailwind CSS 的看法有些复杂。它像是一个总是表现完美的朋友,让我觉得自己有些不够好。
我一直是纯 CSS 的拥护者,直到最近,我才意识到,Tailwind 也有其独特的优点。
然而,虽然我不喜欢 Tailwind 的一些方面,但它无疑为开发带来了更多的选择,让我反思自己做决定的方式。
问题
大家争论的,不是 "哪个更好",而是“哪个让你觉得更少痛苦”。
对我来说,Tailwind 有时带来的是压力。比如:
<button
class="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded-lg shadow-md hover:shadow-lg transition duration-300 ease-in-out transform hover:-translate-y-1"
>
Click me
</button>
它让我想:“这已经不再是简单的 HTML,而是样式类的拼凑。”
而纯 CSS 则让我感到平静、整洁:
.button {
background-color: #3b82f6;
color: white;
font-weight: bold;
padding: 0.5rem 1rem;
border-radius: 0.5rem;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
transition: all 0.3s ease-in-out;
}
.button:hover {
background-color: #2563eb;
box-shadow: 0 10px 15px rgba(0, 0, 0, 0.1);
transform: translateY(-4px);
}
纯 CSS 让我觉得自己在“写代码”,而不是“编排类名”。
背景说明
为什么要写这篇文章呢?因为到了 2026 年,CSS 和 Tailwind 的争论已经不再那么重要。
- Tailwind 发布了 v4,速度和性能都大大提升。
- 纯 CSS 也在复兴,容器查询(container queries)、CSS 嵌套(nesting)和 Cascade Layers 这些新特性令人振奋。
- 还有像 Panda CSS、UnoCSS 等新兴工具在不断尝试解决同样的问题。
这让选择变得更加复杂,也让开发变得更加“累”。
Tailwind 的优缺点
优点:
- 减少命名烦恼:你不再需要为类命名。只需使用 Tailwind 提供的类名,省去了命名的麻烦。
- 设计一致性:使用 Tailwind,你的设计系统自然一致,避免了颜色和间距不统一的麻烦。
- 编辑器自动补全:Tailwind 的 IntelliSense 使得开发更加高效,输入类名时有智能提示。
- 响应式设计更简单:通过简单的类名就能实现响应式设计,比传统的媒体查询更简洁。
缺点:
- HTML 看起来乱七八糟:多个类名叠加在一起,让 HTML 看起来复杂且难以维护。
- 构建步骤繁琐:你需要一个构建工具链来处理 Tailwind,这对某些项目来说可能显得过于复杂。
- 调试困难:开发者工具中显示的类名多而杂,调试时很难快速找到问题所在。
- 不够可重用:Tailwind 的类名并不具备良好的可重用性,你可能会不断复制粘贴类,而不是通过自定义组件来实现复用。
纯 CSS 的优缺点
优点:
- 更干净的代码结构:HTML 和 CSS 分离,代码简洁易懂。
- 无构建步骤:只需简单的
<link>标签引入样式表,轻松部署。 - 现代特性强大:2025 年的 CSS 已经非常强大,容器查询和 CSS 嵌套让你可以更加灵活地进行响应式设计。
- 自定义属性:通过 CSS 变量,你可以轻松实现全站的样式管理,改一个变量,所有样式立即生效。
缺点:
- 命名仍然困难:即使有 BEM 或 SMACSS 等方法,命名仍然是一项挑战。
- 保持一致性需要更多约束:没有像 Tailwind 那样的规则,纯 CSS 需要更多的自律来保持一致性。
- 生态碎片化:不同团队和开发者采用不同的方式来组织 CSS,缺少统一标准。
- 没有编辑器自动补全:不像 Tailwind,纯 CSS 需要手动编写所有的类名和样式。
到 2026 年,你该用哪个?
Tailwind 适合:
- 使用 React、Vue 或 Svelte 等组件化框架的开发者
- 需要快速开发并保证一致性的团队
- 不介意添加构建步骤并依赖工具链的人
纯 CSS 适合:
- 小型项目或静态页面
- 喜欢简洁代码、分离 HTML 和 CSS 的开发者
- 想要完全掌控样式并避免复杂构建步骤的人
两者结合:
- 你可以在简单的页面中使用纯 CSS,在复杂的项目中使用 Tailwind 或两者结合,以此来平衡灵活性与效率。
真正值得关注的 2026 年趋势
- 容器查询:响应式设计不再依赖视口尺寸,而是根据容器的尺寸进行调整。
- CSS 嵌套原生支持:你可以直接在 CSS 中使用嵌套,避免了依赖预处理器。
- Cascade Layers:这让你能更好地管理 CSS 优先级,避免使用
!important来解决冲突。 - View Transitions API:它让页面过渡更平滑,无需依赖 JavaScript。
这些新特性将极大改善我们的开发体验,无论是使用纯 CSS 还是借助 Tailwind。
结尾
不管是 Tailwind 还是纯 CSS,都有它们的优缺点。关键是要根据项目需求和个人偏好做出选择。
至于我:我喜欢纯 CSS,因为它更干净,HTML 更直观。但是如果项目需求更适合 Tailwind,那我也会使用它。
2026 年的开发趋势,将让我们有更多选择,让我们能够用最适合的工具解决问题,而不是纠结于某种工具是否“最好”。
来源:juejin.cn/post/7568674364042330166
2025博客框架选择指南:Hugo、Astro、Hexo该选哪个?

引言
2025年了,想搭个博客,在Hugo、Hexo、Astro之间纠结了一周,还是不知道选哪个?
我完全理解这种感受。去年我也在这几个博客框架之间来回折腾,看了无数对比文章,最后发现大部分都是2022-2023年的过时内容。性能数据变了、框架更新了、生态也不一样了。每次看完一篇文章就更纠结,到底该听谁的?
更让人崩溃的是,深夜折腾博客配置,第二天还要上班。花了三个月研究框架,结果一篇文章都没写出来。这种感觉,相信你也经历过。
这篇文章基于2024-2025年最新数据,用真实的构建时间测试、实际的使用体验,帮你在5分钟内做出最适合的选择。不是告诉你"哪个最好",而是"哪个最适合你"。
我会用9大框架的最新性能对比、3分钟决策矩阵,帮你避免90%新手会踩的坑。说实话,早点看到这篇文章,我能省好几周时间。
为什么2025年还在聊博客框架?
静态博客真的还有必要吗?
老实讲,我一开始也觉得搭博客是个过时的想法。但用了一年多,真香。
静态博客和WordPress这类动态博客的本质区别,就是"提前做好"和"现场制作"的区别。静态网站生成器(SSG)会在你写完文章后,就把所有页面生成好,像做批量打印一样。访客来了直接看成品,速度飞快。WordPress这类动态博客呢,每次有人访问就现场从数据库拉数据、拼装页面,就像现场手工做菜。
为什么静态博客成为主流趋势?
说白了就是:快、便宜、不用操心服务器。
WordPress需要租服务器,一个月怎么也得几十块钱起步。静态博客呢?GitHub Pages、Vercel、Cloudflare Pages全都免费托管。我现在博客一年花费0元,连域名都是之前买的。
性能上更没得比。静态页面的Lighthouse评分能轻松拿到95+,WordPress想到90分都费劲。用户打开页面,一眨眼就加载完了,这种体验真的会让人爱上写博客。
那什么时候该选动态博客?
也不是说静态博客就天下无敌。如果你要做复杂的功能,比如:
- 多人协作发布(需要后台管理)
- 电商集成(要处理支付、订单)
- 复杂的用户系统(评论、权限管理)
这些场景,WordPress或者Ghost确实更合适。但老实说,大部分个人博客和技术博客,真用不到这些。
一句话总结:个人博客、技术文档、作品展示,选静态博客框架准没错。需要复杂功能、多人协作,才考虑动态博客。
性能对决 - 谁是速度之王?
性能这块,说实话是我最关心的。刚开始用Gatsby的时候,每次改一点内容,重新构建等十几分钟,真的想砸电脑。
构建速度:差距大到惊人
先说结论:Hugo是速度之王,没有之一。
看看这组2024年的实测数据:
| 框架 | 构建10000页用时 | 平均每页速度 |
|------|----------------|-------------|
| Hugo | 2.95秒 | <1ms |
| Hexo | 45秒(1000页) | ~45ms |
| Jekyll | 187.15秒 | ~18ms |
| Gatsby | 30分钟+ | ~180ms |
第一次看到Hugo的构建速度,真的惊到我了。10000篇文章,不到3秒!这意味着啥?你改个标题、修个错别字,按个保存,页面刷新,博客就更新完了。这种即时反馈,爽到飞起。
Hexo呢,中型博客(100-1000文章)表现也挺不错。我之前300篇文章的博客,15秒就构建完成,完全够用。
Gatsby...嗯,别提了。我用它做过一个项目,200多篇文章,每次构建5分钟起步。后来文章多了,直接放弃了。
页面加载速度:Astro异军突起
2024年Astro成了最大黑马。根据HTTP Archive的数据:
- Astro:中位传输大小889KB(最轻)
- Hugo:1,174KB(平衡不错)
- Next.js:1,659KB(功能多,体积大)
Astro的"零JavaScript默认"策略真的厉害。页面只加载必要的JS,不像其他框架,把整个React/Vue库都塞给用户。结果就是,页面打开速度飞快,用户体验特别好。
实际项目表现:别只看数字
老实讲,如果你博客不到100篇文章,选啥框架都差不多。几秒和十几秒的区别,你感受不出来。
但如果你计划长期写作,文章会越来越多,提前选个性能好的框架,能省很多麻烦。我见过太多人,开始用了Gatsby,写到500篇文章,构建慢到受不了,迁移框架,那个痛苦...
推荐组合:
- 小型博客(<100文章):随便选,都够用
- 中型博客(100-1000文章):Hugo、Hexo、Astro
- 大型站点(1000+文章):闭眼选Hugo
开发体验 - 哪个最好用?
性能再好,用起来糟心,也是白搭。
学习曲线:新手别踩坑
说实话,Hugo的Go模板语法,我当初学了好久才上手。那些{{ range }}、{{ with }}的语法,刚开始真的看懵了。虽然性能无敌,但新手上来就选Hugo,可能会被劝退。
新手友好度排名:
- Hexo(最友好):Node.js生态,中文文档多到看不过来。配置就是一个
_config.yml文件,改几个参数就能跑起来。我当时半小时就搭好了第一个博客。 - Jekyll(友好):Ruby生态,官方文档写得特别清楚,按着步骤来不会错。GitHub Pages原生支持,push一下就自动部署。
- VuePress(需要前端基础):如果你会Vue,上手很快。不会的话,还得先学Vue,成本就高了。
- Gatsby/Next.js(陡峭):要懂React、GraphQL,配置复杂。我看到配置文件就头大。
我的建议:如果你和我一样是Node.js开发者,Hexo真的是顺手。装个npm包,改改配置,半小时搞定。前端技术栈是React?那Astro或Next.js更合适。别纠结了,新手就选Hexo,错不了。
配置和自定制:平衡艺术
Hexo和Jekyll的配置简单直接,一个YAML文件搞定。但也有缺点:想做复杂定制,就得深入源码改,不太灵活。
Gatsby的灵活性确实强,GraphQL数据层可以接各种数据源。但坦白说,个人博客真用不到那么复杂的功能。就像买了辆跑车在市区开,性能过剩了。
Astro走了个中间路线,既灵活又不复杂。支持多框架(React、Vue、Svelte随便混),但配置没那么吓人。这种平衡感,我挺喜欢的。
开发工具和调试
现代框架在开发体验上真的吊打老框架。
Vite驱动的Astro和VuePress,热重载快到飞起。改个内容,不到1秒页面就更新了。Webpack那套老架构,等待时间能让人发呆。
Hugo虽然是传统框架,但速度快,改完刷新也很即时。这点体验还不错。
生态系统 - 主题与插件谁更丰富?
框架再好,没主题也白搭。谁想从零开始写CSS啊。
主题生态:Hexo中文世界称王
Hexo真的是中文博客的天选之子。200+中文主题,风格各异,总有一款适合你。我用的那个主题,中文文档详细到连怎么改字体颜色都写得清清楚楚。
Hugo主题虽然有300+,但质量参差不齐。有些特别精美,有些就是demo级别。很多主题文档是英文的,踩坑全靠自己摸索。
Jekyll作为老牌框架,主题数量最多,但很多都是好几年前的设计风格了,看着有点过时。
Gatsby和Astro的主题,走的是现代化路线,设计感很强。如果你追求视觉效果,这两个不错。
插件和扩展能力
Jekyll的插件生态最庞大,毕竟历史最久。想要啥功能,基本都能找到插件。
Gatsby依托npm生态,插件也超级丰富。但很多插件其实是为商业项目设计的,个人博客可能用不上。
Hexo插件生态在Node.js圈很成熟,常用的评论、搜索、SEO优化,都有现成插件。我装了七八个插件,没遇到过兼容问题。
社区活跃度:看数据说话
2024-2025年的数据挺有意思:
- Astro:增长最快,npm下载量2024年9月达到300万。Netlify调查显示,它是2024年开发者关注度最高的框架。
- Hugo:GitHub星标6万+,稳定增长,老牌强者。
- Hexo:中文社区最活跃,知乎、掘金、CSDN到处都是教程。
说实话,社区活跃度对新手很重要。遇到问题,能搜到中文解决方案,省太多时间了。
部署与SEO - 上线才是王道
博客搭好了,不上线有啥用?
部署平台:全都免费真香
现在部署静态博客,真的太简单了。
GitHub Pages:Jekyll原生支持,push代码就自动部署。其他框架需要配个GitHub Actions,也就多写几行配置,5分钟搞定。
Vercel/Netlify:这俩是我最推荐的。拖个仓库进去,自动识别框架,自动构建部署。都有免费额度,个人博客完全够用。我现在用的Vercel,一年没花过一分钱。
Cloudflare Pages:性能特别好,CDN全球分布。免费额度也很大,速度比GitHub Pages快不少。
老实讲,2025年部署静态博客,已经没有技术门槛了。真的,比你想象的简单。
SEO:静态博客天生优势
所有静态博客框架,SEO都友好。为啥?生成的都是纯HTML,搜索引擎最爱这个。
区别在于细节:
- Hugo和Jekyll:成熟稳定,sitemap、RSS自动生成,SEO基础功能齐全。
- Astro和Next.js:在现代SEO实践上更领先,支持更细致的元数据管理,结构化数据也更方便。
- Hexo:通过插件实现SEO功能,也挺完善,中文SEO教程多。
说白了,只要你写好内容、优化好关键词、页面结构合理,用哪个框架SEO都不会差。别太纠结这个。
长期维护成本:别选冷门框架
这个坑我踩过。之前用过一个小众框架,开始挺好,半年后发现作者不更新了。后来依赖库升级,博客直接跑不起来,迁移框架花了整整一周。
低维护框架:Hugo、Jekyll。成熟稳定,基本不会出幺蛾子。我Hugo博客跑了一年多,一次问题都没遇到。
需要关注更新:Gatsby、Next.js。依赖多,更新频繁,偶尔会遇到breaking changes。如果你不想经常折腾,慎选。
平衡选手:Astro、Hexo。更新有节制,兼容性做得不错。
决策框架 - 如何选择最适合你的?
好了,前面说了这么多数据和对比,到底该怎么选?
3分钟快速决策矩阵
别想太多,回答三个问题:
问题1:你的技术栈是什么?
- 熟悉Node.js → Hexo(新手)/ Astro(追求现代化)
- React开发者 → Gatsby(重型)/ Astro(轻量)/ Next.js(全栈)
- Vue开发者 → VuePress(博客+文档)/ Gridsome
- 技术栈不限 → Hugo(性能第一)/ Jekyll(求稳)
如果你和我一样是Node.js开发者,Hexo真的顺手。装个npm包,改改配置,半小时搞定。
问题2:你的项目规模是多大?
- <100文章 → 随便选,性能差异你感受不出来
- 100-1000文章 → Hugo(快)/ Hexo(够用)/ Astro(现代)
- 1000+文章或大型文档站 → Hugo(一骑绝尘,没得比)
我现在500多篇文章,用的Hexo,45秒构建完成,完全够用。如果文章继续增长到1000+,可能会换Hugo。
问题3:你的经验水平如何?
- 新手 → Hexo(中文资源多)/ Jekyll(文档友好)
- 前端开发者 → Astro(现代化体验)/ VuePress(Vue技术栈)
- 性能极客 → Hugo(速度无敌,值得学Go模板)
- 求稳用户 → Jekyll(GitHub原生支持,最省心)
典型场景具体推荐
个人技术博客:
- 中文用户:Hexo(生态强,主题多)
- 国际化:Hugo(性能好,英文资源丰富)
- 追求现代化:Astro(体验好,性能也不错)
技术文档站点:
- Docusaurus(Facebook出品,专为文档设计)
- VuePress(Vue生态,中文支持好)
大型内容站点:
- Hugo(1000+页面,只有它能扛住)
现代化项目网站:
- Astro(灵活性+性能的最佳平衡)
- Next.js(需要动态功能时选它)
我的真实建议
说实话,别再纠结了。我见过太多人花三个月研究框架,一篇文章没写。框架真的只是工具,内容才是核心。
选择建议:
- 90%的人:选Hexo或Hugo,够用了
- 前端开发者:Astro值得尝试,体验很现代
- 新手怕选错:Hexo,中文教程多到看不完,遇到问题都能搜到答案
- 性能焦虑症患者:闭眼选Hugo,速度真的无敌
记住:框架可以迁移(内容都是Markdown,搬家成本不高),但荒废的时间回不来。先选一个动起来,边用边优化,这才是正道。
避坑指南与最佳实践
最后说说那些大坑,我替你踩过了。
5个常见错误
错误1:过度追求完美框架,迟迟不开始
这个坑我踩得最深。当年对比了两个月框架,看了几十篇文章,结果还是不确定。后来一个前辈跟我说:"先选一个动起来,框架不满意可以换,但浪费的时间回不来。"
说白了,内容才是博客的核心,框架只是工具。没有完美的框架,只有最适合当下的选择。
错误2:只看主题外观,忽略框架本质
看到某个Hugo主题特别炫酷,就选了Hugo。结果发现Go模板语法学不会,自定义主题难如登天。最后用了半年,还是换回Hexo。
主题可以定制、可以换,但框架的性能、生态、维护性,这些本质特性才是长期影响你的因素。
错误3:新手直接上Gatsby/Next.js被劝退
我一朋友,刚学前端,听说Gatsby牛逼,直接上手。结果GraphQL不会、React不熟、配置看不懂,折腾两周直接放弃了。
老实说,Gatsby和Next.js真的不适合新手。它们是给有经验的开发者准备的工具。新手想快速上线博客,Hexo或Jekyll才是正确选择。
错误4:忽略长期维护成本
选了个冷门框架,一开始挺好,半年后作者不更新了。依赖库升级,博客跑不起来。迁移框架,痛苦得要死。
看框架选择的三个指标:
- GitHub更新频率(至少每月有commit)
- 社区规模(遇到问题能找到人问)
- 中文资源(新手必看,能省80%时间)
错误5:花80%时间折腾框架,20%写内容
我见过太多人,陷入"完美主义陷阱"。CSS改来改去、插件装了卸卸了装,就是不写文章。
记住80/20法则:80%精力写内容,20%折腾框架。够用就好,别追求极致完美。
框架迁移建议
万一真选错了,想换框架怎么办?
其实没那么可怕。所有静态博客框架,内容都是Markdown,迁移成本不高。我从Hexo迁移到Hugo,内容迁移只花了1小时。主要是配置和主题要重新搞,但也就半天时间。
迁移原则:
- 先有后优:快速上线 > 完美配置
- 内容优先:写够50篇文章再考虑迁移,不然没必要
- 不影响SEO:做好301重定向,URL结构尽量保持一致
2025年趋势展望
根据2024-2025的数据和社区动向,我预测:
- Astro会继续增长:岛屿架构是未来趋势,零JavaScript默认太香了
- Hugo保持性能王者地位:大型站点没得选
- Hexo中文生态持续稳定:中文博客的首选不会变
- 传统框架逐步被取代:Jekyll虽然稳定,但新项目会越来越少
但说实话,趋势只是参考。选框架还是要看自己的需求和技术栈。
结论
回到最开始的问题:2025年博客框架该怎么选?
一句话总结:
- 新手首选:Hexo(中文资源丰富,主题多,上手快)
- 前端开发者:Astro(性能+灵活性的最佳平衡,现代化体验)
- 性能极客:Hugo(速度无敌,适合大型站点)
- 文档站点:Docusaurus/VuePress(专为文档设计)
- 求稳:Jekyll(GitHub原生支持,最省心)
但老实讲,选择框架只需要5分钟,写好内容需要一辈子。
别再纠结了。选一个顺手的,开始行动吧。写第一篇文章,比研究框架重要一百倍。
我当初纠结了两个月,现在回头看,那段时间完全是浪费。早点开始写,现在可能已经有200篇文章了。
行动建议:
- 根据上面的决策矩阵,花5分钟选一个框架
- 找个主题,1小时搭好环境
- 写第一篇文章,哪怕只有500字
- 发布上线,享受成就感
记住:框架不重要,内容才重要。够用就好,专注写作。
评论区说说你的选择和理由?我很好奇大家最后都选了什么。如果有问题,我会尽量回复的。
本文首发自个人博客
来源:juejin.cn/post/7578714735307849754
面试官:CDN是怎么加速网站访问的?
做前端项目的时候,经常听到"静态资源要放CDN"这种说法:
- CDN到底是什么,为什么能加速?
- 用户访问CDN的时候发生了什么?
- 前端项目怎么配置CDN?
先说结论
CDN(Content Delivery Network)的核心原理:把内容缓存到离用户最近的服务器上。
没有CDN时,北京用户访问美国服务器,数据要跨越太平洋。有了CDN,数据从北京的CDN节点返回,快得多。
flowchart LR
subgraph 没有CDN
U1[北京用户] -->|跨越太平洋| S1[美国服务器]
end
subgraph 有CDN
U2[北京用户] -->|就近访问| C2[北京CDN节点]
C2 -.->|首次回源| S2[美国服务器]
end
CDN的工作流程
当用户访问一个CDN加速的资源时,会经过这几步:
1. DNS解析
用户访问 cdn.example.com,DNS会返回离用户最近的CDN节点IP。
# 在北京查询
$ dig cdn.example.com
;; ANSWER SECTION:
cdn.example.com. 60 IN A 101.37.27.xxx # 北京节点
# 在上海查询
$ dig cdn.example.com
;; ANSWER SECTION:
cdn.example.com. 60 IN A 47.100.99.xxx # 上海节点
同一个域名,不同地区解析出不同IP,这就是CDN的智能调度。
2. 缓存判断
请求到达CDN节点后,节点检查本地是否有缓存:
- 缓存命中:直接返回,速度最快
- 缓存未命中:向源服务器获取,然后缓存起来
flowchart TD
A[用户请求] --> B[CDN边缘节点]
B --> C{本地有缓存?}
C -->|有| D[直接返回]
C -->|没有| E[回源获取]
E --> F[源服务器]
F --> G[返回内容]
G --> H[缓存到边缘节点]
H --> D
classDef hit fill:#d4edda,stroke:#28a745,color:#155724
classDef miss fill:#fff3cd,stroke:#ffc107,color:#856404
class D hit
class E,F,G,H miss
3. 缓存策略
CDN根据HTTP头决定怎么缓存:
# 典型的静态资源响应头
Cache-Control: public, max-age=31536000
ETag: "abc123"
Last-Modified: Wed, 21 Oct 2024 07:28:00 GMT
max-age=31536000:缓存1年public:允许CDN缓存ETag:文件指纹,用于验证缓存是否过期
为什么CDN能加速
1. 物理距离更近
光在光纤中的传播速度约为 20 万公里/秒。北京到美国往返 2 万公里,光传输就要 100ms。
CDN把内容放到离用户近的地方,这个延迟几乎可以忽略。
2. 分散服务器压力
没有CDN,所有请求都打到源服务器。有了CDN,只有第一次请求(缓存未命中)才需要回源。
假设一张图片被访问 100 万次:
- 没有CDN:源服务器处理 100 万次请求
- 有CDN:源服务器只处理几十次(各节点首次回源)
3. 边缘节点优化
CDN服务商的边缘节点通常有这些优化:
- 自动压缩:Gzip/Brotli压缩
- 协议优化:HTTP/2、HTTP/3
- 连接复用:Keep-Alive连接池
- 智能路由:选择最优网络路径
前端项目配置CDN
1. 构建配置
以Vite为例,配置静态资源的CDN地址:
// vite.config.js
export default defineConfig({
base: process.env.NODE_ENV === 'production'
? 'https://cdn.example.com/'
: '/',
build: {
rollupOptions: {
output: {
// 文件名带hash,便于长期缓存
entryFileNames: 'js/[name].[hash].js',
chunkFileNames: 'js/[name].[hash].js',
assetFileNames: 'assets/[name].[hash].[ext]'
}
}
}
})
Webpack配置类似:
// webpack.config.js
module.exports = {
output: {
publicPath: process.env.NODE_ENV === 'production'
? 'https://cdn.example.com/'
: '/',
filename: 'js/[name].[contenthash].js',
}
}
2. 上传到CDN
构建完成后,把dist目录的文件上传到CDN。大多数CDN服务商都提供CLI工具或API:
# 阿里云OSS + CDN
aliyun oss cp -r ./dist oss://your-bucket/
# AWS S3 + CloudFront
aws s3 sync ./dist s3://your-bucket/
# 七牛云
qshell qupload2 --src-dir=./dist --bucket=your-bucket
3. 缓存策略配置
关键是区分两类文件:
带hash的静态资源(JS、CSS、图片):长期缓存
location ~* \.(js|css|png|jpg|jpeg|gif|ico|svg|woff2?)$ {
expires 1y;
add_header Cache-Control "public, immutable";
}
HTML文件:不缓存或短期缓存
location ~* \.html$ {
expires 0;
add_header Cache-Control "no-cache, must-revalidate";
}
为什么这样设计?因为HTML是入口文件,它引用的JS/CSS带有hash。更新代码时:
- 新的JS文件会有新的hash(
app.abc123.js→app.def456.js) - HTML文件引用新的JS文件
- 用户获取新HTML后,会加载新的JS文件
- 旧的JS文件在CDN上继续存在,不影响正在访问的用户
4. DNS配置
把CDN域名配置成CNAME指向CDN服务商:
# 阿里云CDN
cdn.example.com. IN CNAME cdn.example.com.w.kunlunsl.com.
# Cloudflare
cdn.example.com. IN CNAME example.com.cdn.cloudflare.net.
常见问题
跨域问题
CDN域名和主域名不同,字体文件、AJAX请求可能遇到跨域。
解决方案是在CDN配置CORS头:
# CDN服务器配置
add_header Access-Control-Allow-Origin "https://example.com";
add_header Access-Control-Allow-Methods "GET, HEAD, OPTIONS";
或者在源服务器的响应里加上CORS头,CDN会透传。
缓存更新问题
发布新版本后,用户还是看到旧内容?
方案一:文件名带hash(推荐)
前面已经提到,文件名带hash,新版本就是新文件,不存在缓存问题。
方案二:主动刷新缓存
// 调用CDN服务商的刷新API
await cdnClient.refreshObjectCaches({
ObjectPath: 'https://cdn.example.com/app.js\nhttps://cdn.example.com/app.css',
ObjectType: 'File'
});
方案三:URL加版本号
<script src="https://cdn.example.com/app.js?v=1.2.3"></script>
不太推荐,因为有些CDN会忽略查询参数。
HTTPS证书
CDN域名也需要HTTPS证书。大多数CDN服务商提供免费证书或支持上传自有证书。
配置方式:
- 在CDN控制台申请免费证书(通常是DV证书)
- 或上传自己的证书(用Let's Encrypt申请)
# 用certbot申请泛域名证书
certbot certonly --manual --preferred-challenges dns \
-d "*.example.com" -d "example.com"
回源优化
如果源服务器压力大,可以启用"回源加速"或"中间源":
用户 → 边缘节点 → 中间源 → 源服务器
中间源作为二级缓存,减少对源服务器的请求。多数CDN服务商默认开启这个功能。
CDN选型
| CDN服务商 | 优势 | 适用场景 |
|---|---|---|
| 阿里云CDN | 国内节点多,生态完整 | 国内业务为主 |
| 腾讯云CDN | 游戏加速好,直播支持强 | 游戏、直播 |
| Cloudflare | 全球节点,有免费套餐 | 出海业务、个人项目 |
| AWS CloudFront | 与AWS生态集成 | 已用AWS的项目 |
| Vercel/Netlify | 前端项目一站式部署 | JAMStack项目 |
个人项目推荐Cloudflare,免费套餐够用,全球节点覆盖好。
企业项目根据用户分布选择。面向国内用户,阿里云/腾讯云更合适;面向全球用户,Cloudflare或CloudFront。
验证CDN效果
浏览器开发者工具
打开Network面板,关注这几个指标:
- TTFB(Time To First Byte):首字节时间,越小越好
- 响应头中的缓存信息:
X-Cache: HIT表示命中CDN缓存
命令行测试
# 查看响应头
curl -I https://cdn.example.com/app.js
# 输出示例
HTTP/2 200
cache-control: public, max-age=31536000
x-cache: HIT from CN-Beijing
在线工具
- Pingdom - 全球多点测速
- GTmetrix - 性能分析
- WebPageTest - 详细的加载瀑布图
小结
CDN加速的核心原理:
- 就近访问:DNS智能解析,把用户引导到最近的节点
- 缓存机制:边缘节点缓存内容,减少回源
- 协议优化:HTTP/2、压缩、连接复用
前端配置CDN的关键:
- 构建时配置publicPath:指向CDN域名
- 文件名带hash:便于长期缓存
- HTML不缓存:确保用户能获取到最新入口
- 处理跨域:配置CORS头
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills(按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB
来源:juejin.cn/post/7582438310103613486
数据可视化神器Heat.js:让你的数据热起来
😱 我发现了一个「零依赖」的数据可视化宝藏!
Hey,前端小伙伴们!今天必须给你们安利一个「让数据说话」的神器——Heat.js!这可不是一个普通的JavaScript库,而是一个能让你的数据「热」起来的魔法工具!
想象一下,当你有一堆枯燥的日期数据,想要以直观、炫酷的方式展示出来时,Heat.js就像一个魔法师,「唰」的一下就能把它们变成色彩斑斓的热图、清晰明了的图表,甚至还有详细的统计分析!
🤩 这个库到底有什么「超能力」?
1. 「零依赖」轻量级选手,绝不拖你后腿 🦵
在这个「依赖地狱」的时代,Heat.js简直就是一股清流!它零依赖,体积小得惊人,加载速度快得飞起!再也不用担心引入一个库就拖慢整个页面加载速度了~
2. 「四种视图」任你选,总有一款适合你 🔄
Heat.js提供了四种不同的视图模式:
- Map视图:就像GitHub贡献图一样炫酷,用颜色深浅展示日期活跃度
- Chart视图:把数据变成专业的图表,让趋势一目了然
- Days视图:专注于展示每一天的详细数据
- Statistics视图:直接给你算出各种统计数据,懒人福音!
想换个姿势看数据?只需轻轻一点,瞬间切换~
3. 「51种语言」支持,真正的「世界公民」🌍
担心你的国际用户看不懂?不存在的!Heat.js支持51种语言,从中文、英文到阿拉伯语、冰岛语,应有尽有!你的应用可以轻松走向全球,再也不用为语言本地化发愁了~
4. 「数据导入导出」无所不能,数据来去自由 📤📥
想导出数据做进一步分析?没问题!Heat.js支持导出为CSV、JSON、XML、TXT、HTML、MD和TSV等多种格式,任你选择!
想导入已有数据快速生成热图?同样简单!支持从JSON、TXT、CSV和TSV导入,甚至还支持拖拽上传,简直不要太方便!
5. 「12种主题」随意切换,颜值与实用并存 💅
担心热图不好看?Heat.js提供了12种精心设计的主题,包括暗黑模式和明亮模式,让你的数据可视化既专业又美观!无论你的网站是什么风格,都能找到匹配的主题~
💡 这个神奇的库可以用来做什么?
1. 「活动追踪」,让你的用户活跃起来 📊
想展示用户的登录活跃度?想用热图展示文章的发布频率?Heat.js帮你轻松实现!就像GitHub的贡献图一样,让你的用户看到自己的「努力成果」,成就感满满!
2. 「数据分析」,让你的决策更明智 🧠
通过Heat.js的Statistics视图,你可以快速获取数据的各种统计信息,比如最活跃的月份、平均活动频率等。这些数据可以帮助你做出更明智的产品决策,优化用户体验!
3. 「趋势展示」,让你的报告更有说服力 📈
想在报告中展示某个指标的变化趋势?Heat.js的Chart视图可以将枯燥的数据变成直观的图表,让你的报告更有说服力,老板看了都说好!
🛠️ 如何用最简单的方式用上这个神器?
第一步:「把宝贝抱回家」📦
npm install jheat.js
或者直接使用CDN:
<link rel="stylesheet" href="https://cdn.jsdelivr.net/gh/williamtroup/Heat.js@4.5.1/dist/heat.js.min.css">
<script src="https://cdn.jsdelivr.net/gh/williamtroup/Heat.js@4.5.1/dist/heat.min.js"></script>
第二步:「给它找个家」🏠
<div id="heat-map" data-heat-js="{ 'views': { 'map': { 'showDayNames': true } } }">
<!-- 这里将显示你的热图 -->
</div>
第三步:「喂它数据」🍽️
// 添加日期数据
let newDateObject = new Date();
$heat.addDate("heat-map", newDateObject, "Trend Type 1", true);
// 移除日期数据(如果需要)
// $heat.removeDate("heat-map", newDateObject, "Trend Type 1", true);
三步搞定!就是这么简单!
🎯 为什么Heat.js值得你拥有?
1. 「简单易用」,小白也能轻松上手 👶
Heat.js的API设计非常友好,文档也很详细,即使是JavaScript初学者也能快速上手。几个简单的步骤,就能实现专业级的数据可视化效果!
2. 「高度定制」,满足你的各种需求 ⚙️
无论是颜色、样式,还是功能配置,Heat.js都提供了丰富的选项。你可以根据自己的需求,定制出独一无二的数据可视化效果!
3. 「响应式设计」,在任何设备上都完美展示 📱💻
Heat.js完全支持响应式设计,无论是在手机、平板还是电脑上,都能完美展示。你的数据可视化效果将在任何设备上都一样出色!
4. 「TypeScript支持」,框架党福利 🎉
如果你使用React、Angular等现代前端框架,Heat.js的TypeScript支持会让你用得更爽!类型定义清晰,代码提示完善,开发体验一流!
🚀 最后想说的话...
在这个「数据为王」的时代,如何让数据更直观、更有说服力,是每个开发者都需要面对的挑战。而Heat.js,就是帮助你征服这个挑战的绝佳工具!
它轻量级、零依赖、功能强大、易于使用,无论是个人项目还是企业应用,都能轻松胜任。最重要的是,它让数据可视化不再是一件复杂的事情,而是一种乐趣!
所以,还等什么呢?赶紧去GitHub上给Heat.js点个Star⭐,然后在你的项目中用起来吧!相信我,它一定会给你带来惊喜!
✨ 祝大家的数据可视化之路一帆风顺,让我们一起用Heat.js让数据「热」起来!✨
来源:juejin.cn/post/7578161740467421235
解决网页前端中文字体包过大的几种方案
最近想给我的博客的网页换个字体,在修复了历史遗留的一些bug之后,去google fonts上找了自己喜欢的字体,本地测试和自己的设备发现没问题后,便以为OK了。
但是当我接朋友的设备打开时,发现网页依然是默认字体。这时候我才发现,我的设备能够翻墙,所以能够使用Google CDN服务,但是对于我的其他读者们,在大陆内是访问不了Google的,便也无法渲染字体了。
于是为了解决这个问题,我尝试了各种办法比如格式压缩,子集化(Subset),分包等等,最后考虑到本站的实际情况选用了一种比较邪门的方法,让字体压缩率达到了惊人的98.5%!于是,这篇文章就是对这个过程的总结。也希望这篇文章能够帮助到你。😊
想要自定义网站的字体,最重要的其实就是字体包的获取。大体上可以分为两种办法:在线获取和网站本地部署。
在线获取──利用 CDN 加速服务
CDN(Content Delivery Network) 意为内容配送网络。你可以简单理解为是一种“就近给你东西”的互联网加速服务。
传统不使用 CDN 服务的是这样的: User ←→ Server,如果相聚遥远,效果显然很差。
使用了 CDN 服务是这样的: User ←→ CDN Nodes ←→ Server,CDN 会提前把你的网站静态资源缓存到各个节点,但你需要时可以直接从最近的节点获取。
全球有多家CDN服务提供商,Google Fonts使用的CDN服务速度很快。所以如果在网络畅通的情况下,使用Google Fonts API是最简单省事的!
你可以直接在文件中导入Google fonts API:
@import url('https://fonts.googleapis.com/css2?family=Inter:ital,opsz,wght@0,14..32,100..900;1,14..32,100..900&family=Merriweather:ital,opsz,wght@0,18..144,733;1,18..144,733&family=Noto+Serif+SC:wght@500&display=swap');
这样网站它便会自动向最近的Google CDN节点请求资源。
当然,这些都是建立在网络状态畅通无阻的情况下。大陆用户一般使用不了Google服务,但并不意味着无法使用CDN服务。国内的腾讯云,阿里云同样提供高效的服务,但具体的规则我并不了解,请自行阅读研究。
本地部署
既然用不了在线的,那就只能将字体包文件一并上传到服务器上了。
这种做法不需要依赖外部服务,但缺点是字体包的文件往往很大,从进入网站到彻底加载完成的时间会及其漫长!而且这种问题尤其在中日韩(CJK)字体上体现的十分明显。
以本站为例,我主要采用了三种字体:Merriweather, Inter, Noto Serif SC. 其中每种字体都包含了Bold和Regular两种格式。前面两种都属于西文字体,每种格式原始文件大小都在200kb-300kb,但是到了思源宋体这里,仅仅一种格式的字体包大小就达到了足足14M多。如果全部加载完,恐怕从进入网站到完全渲染成功,需要耽误个2分钟。所以将原始字体包文件上传是极不可取的做法!
为了解决这个问题,我在网上查阅资料,找到了三种做法。
字体格式转换(WOFF2)
WOFF2 (Web Open Font Format 2.0) 是一种专为 Web 设计的字体文件格式,旨在提供更高的压缩率和更快的加载速度,也是是目前在 Web 上部署自定义字体的推荐标准。它本质上是一种将 TTF 或 OTF 字体数据进行高度压缩后的格式,目前已经获得了所有主流浏览器的广泛支持。
我们可以找一个在线的字体格式转化网站来实现格式的转化。本文我们以NotoSerifSC-Bold.ttf为例,转换后的NotoSerifSC-Bold.woff2文件只有5.8M左右,压缩率达到了60%!
但是,这仍旧是不够的,仅两个中文字体包加起来也已经快12M,还没有算上其他字体。这对于一个网页来说依然是灾难性的。我们必须寻找另一种方法。
子集化处理(Subset)
中国人都知道,虽然中文的字符加起来有2万多个,但是我们平常交流基本只会用到3000多个,范围再大一点,6000多个字符已经可以覆盖99%的使用场景。这意味着:
我们根本不需要保留所有字符,而只需要保留常用的几千个汉字即可。
于是这就给了我们解决问题的思路了。
首先我们可以去寻找中文常用汉字字符表,这里我获取的资源是 All-Chinese-Character-Set。我们将文件下载解压后,可以在里面找到各种各样按照字频统计的官方文件。这里我们就以《通用规范汉字表》(2013年)一级字和二级字为例。我们创建一个文档char_set.txt并将一级字和二级字的内容全部复制进去。这份文档就是我们子集化的对照表。
接着我们需要下载一个字体子集化工具,这里使用的是Python中的fonttools库,它提供了许多工具(比如我们需要的pyftsubset)可以在命令行中执行子集化、字体转化字体操作。
我们安装一下这个库和对应的依赖(在这之前确保你的电脑上安装了Python和pip,后者一般官方安装会自带)
pip install fonttools brotli zopfli
然后找到我们字体包对应的文件夹,将原来的char_set.txt复制到该文件夹内,在该文件下打开终端,然后以NotoSerifSC-Bold.ttf为例,输入以下命令:
pyftsubset NotoSerifSC-Bold.ttf --output-file=NotoSerifSC-Bold.subset.woff2 --flavor=woff2 --text-file=char_set.txt --no-hinting --with-zopfli
过一会就能看到会输出一个NotoSerifSC-Bold.subset.woff2的文件。
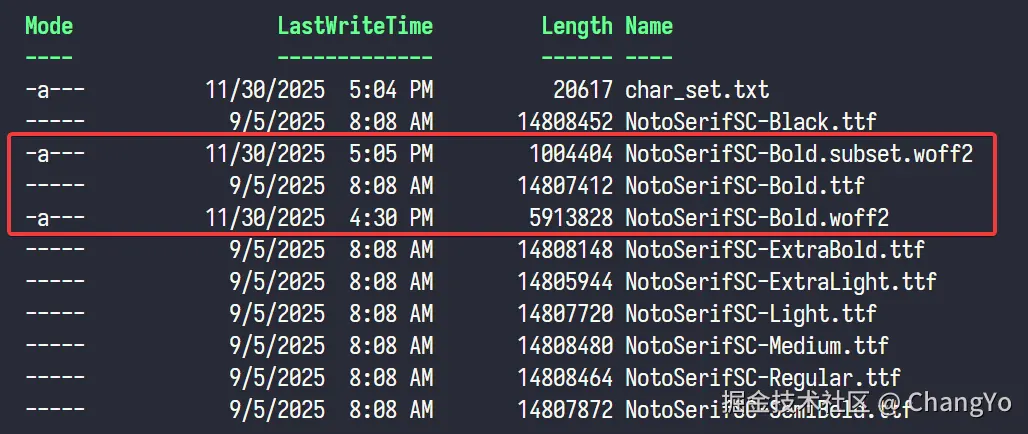 我们欣喜的发现这个文件的大小竟然只有980KB。至此,我们已经已经将压缩率达到了93%!到这一步,其实直接部署也并没有十分大问题,不过从加载进去到完全渲染,可能依然需要近十秒左右,我们依然还有优化空间。
我们欣喜的发现这个文件的大小竟然只有980KB。至此,我们已经已经将压缩率达到了93%!到这一步,其实直接部署也并没有十分大问题,不过从加载进去到完全渲染,可能依然需要近十秒左右,我们依然还有优化空间。
分包处理实现动态加载
这个方法是我阅读这篇文章了解到的,但是遗憾的是我并没有在自己的网站上实现,不过失败的尝试也让我去寻找其它的方法,最终找到适用本站的一种极限字体渲染的方法,比这三种的效果还要好。下面我依然简单介绍一下这个方法的原理,想更了解可以通过看到最后通过参考资料去进一步了解。
在2017年,Google Fonts团队提出切片字体,因为他们发现:绝大部分网站只需要加载CJK字体包的小部分内容即可覆盖大部分场景。基于适用频率统计,他们将字符分成多个切片,再按 Unicode 编码对剩余字符进行分类。
怎么理解呢?他其实就是把所有的字符分成许多个小集合,每个集合里面都包含一定数量的字符,在靠前的一些集合中,都是我们常用的汉字,越到后,字形越复杂,使用频率也越低。当网页需要加载字体文件时,它是以切片为单位加载的。这意味,只有当你需要用到某个片区的字符时,这个片区才会被加载。
这种方式的好处时,能够大大加快网站加载速率。我们不用每次都一次性把全部字符加载,而是按需加载。这项技术如今已经被Noto Sans字体全面采用。
但是我们需要本地部署的话,需要多费一点功夫。这里我们利用中文网字计划的在线分包网站来实现。
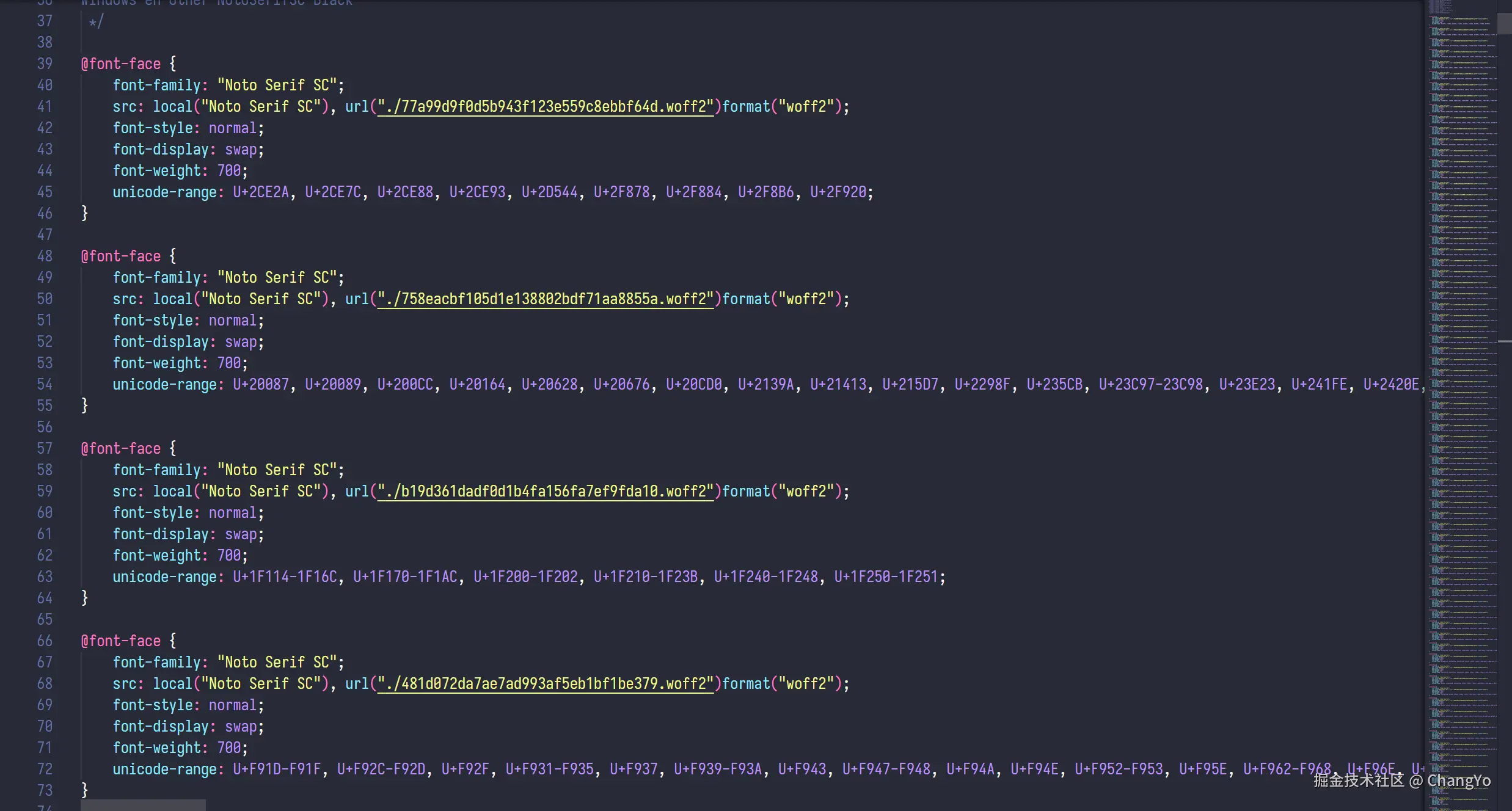
我们将需要的字体上传进行分包,可以观察到输出结果是一系列以哈希值命名的woff2文件。分包其实就是做切分,把每个切分后的区域都转化为一份体积极小的woff2文件。
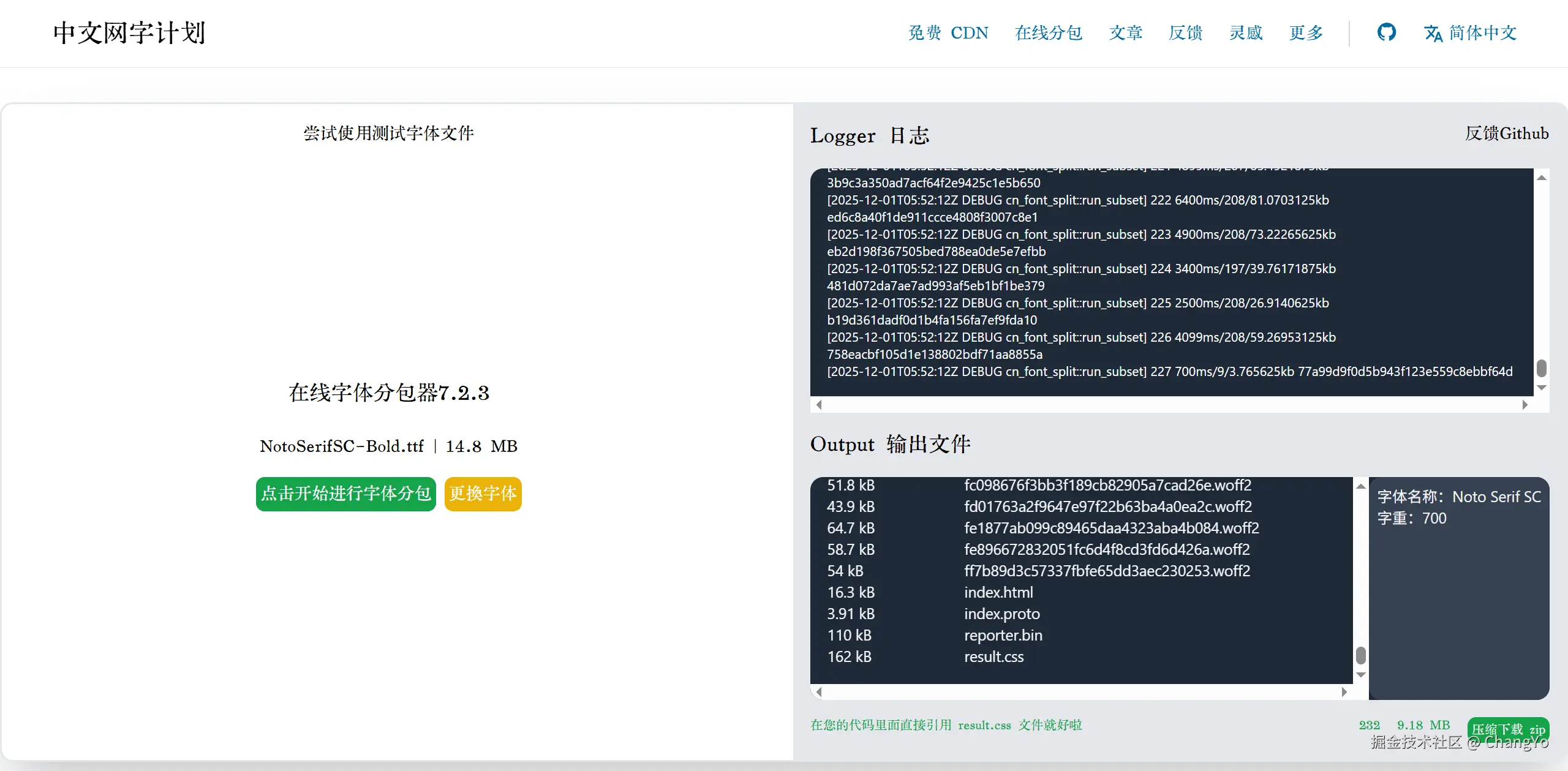 下载压缩包,然后可以将里面的文件夹导入你的项目,并引用文件夹下的
下载压缩包,然后可以将里面的文件夹导入你的项目,并引用文件夹下的result.css即可。理论上,当网站需要加载渲染某个字体时,它会根据css里面的规则去寻找到对应的分包再下载。每个包的体积极小,网站加载的速度应该提升的很明显。
我的实践──将字符压缩到极限
我的方法可以理解为子集化的一种,只不过我的做法更加的极端一些──只保留文章出现的字符!
根据统计结果,截止到这篇post发布,我的文章总共出现的所有字符数不到1200个(数据来源见下文),所以我们可以做的更激进一些,只需将文章出现的中文字符全部记录下来,制成一张专属于自己网站的字符表,然后在每次发布文章时动态更新,这样我们能够保证字体完整渲染,并且处于边界极限状态!
实现这个个性化字符表char_set.txt的核心是一个提取文章中文字符的算法。这部分我是通过Gemini生成了一个update_lists.cpp文件,他能够识别_posts/下面所有文章,并输出到根目录的char_set.txt中,你可以根据代码内容进行自定义的修改:
/**
* @file update_lists.cpp
* @brief Scans Markdown files in /_posts/ and updates char_set.txt in root.
* @author Gemini
* @date 2025-11-28
*/
#include
#include
#include
#include
#include
#include
namespace fs = std::filesystem;
namespace char_collector {
const std::string kRegistryFilename = "char_set.txt";
const std::string kMarkdownExt = ".md";
const uint32_t kCJKStart = 0x4E00;
const uint32_t kCJKEnd = 0x9FFF;
bool NextUtf8Char(std::string::const_iterator& it,
const std::string::const_iterator& end,
uint32_t& out_codepoint,
std::string& out_bytes) {
if (it == end) return false;
unsigned char c1 = static_cast<unsigned char>(*it);
out_bytes.clear();
out_bytes += c1;
if (c1 < 0x80) { out_codepoint = c1; it++; return true; }
if ((c1 & 0xE0) == 0xC0) {
if (std::distance(it, end) < 2) return false;
unsigned char c2 = static_cast<unsigned char>(*(it + 1));
out_codepoint = ((c1 & 0x1F) << 6) | (c2 & 0x3F);
out_bytes += *(it + 1); it += 2; return true;
}
if ((c1 & 0xF0) == 0xE0) {
if (std::distance(it, end) < 3) return false;
unsigned char c2 = static_cast<unsigned char>(*(it + 1));
unsigned char c3 = static_cast<unsigned char>(*(it + 2));
out_codepoint = ((c1 & 0x0F) << 12) | ((c2 & 0x3F) << 6) | (c3 & 0x3F);
out_bytes += *(it + 1); out_bytes += *(it + 2); it += 3; return true;
}
if ((c1 & 0xF8) == 0xF0) {
if (std::distance(it, end) < 4) return false;
unsigned char c2 = static_cast<unsigned char>(*(it + 1));
unsigned char c3 = static_cast<unsigned char>(*(it + 2));
unsigned char c4 = static_cast<unsigned char>(*(it + 3));
out_codepoint = ((c1 & 0x07) << 18) | ((c2 & 0x3F) << 12) |
((c3 & 0x3F) << 6) | (c4 & 0x3F);
out_bytes += *(it + 1); out_bytes += *(it + 2); out_bytes += *(it + 3); it += 4; return true;
}
it++; return false;
}
bool IsChineseChar(uint32_t codepoint) {
return (codepoint >= kCJKStart && codepoint <= kCJKEnd);
}
class CharManager {
public:
CharManager() = default;
void LoadExistingChars(const std::string& filepath) {
std::ifstream infile(filepath);
if (!infile.is_open()) {
std::cout << "Info: " << filepath << " not found or empty. Starting fresh." << std::endl;
return;
}
std::string line;
while (std::getline(infile, line)) {
ProcessString(line, false);
}
std::cout << "Loaded " << existing_chars_.size()
<< " unique characters from " << filepath << "." << std::endl;
}
void ScanDirectory(const std::string& directory_path) {
if (!fs::exists(directory_path)) {
std::cerr << "Error: Directory '" << directory_path << "' does not exist." << std::endl;
return;
}
for (const auto& entry : fs::directory_iterator(directory_path)) {
if (entry.is_regular_file() &&
entry.path().extension() == kMarkdownExt) {
ProcessFile(entry.path().string());
}
}
}
void SaveNewChars(const std::string& filepath) {
if (new_chars_list_.empty()) {
std::cout << "No new Chinese characters found." << std::endl;
return;
}
std::ofstream outfile(filepath, std::ios::app);
if (!outfile.is_open()) {
std::cerr << "Error: Could not open " << filepath << " for writing." << std::endl;
return;
}
for (const auto& ch : new_chars_list_) {
outfile << ch;
}
std::cout << "Successfully added " << new_chars_list_.size()
<< " new characters to " << filepath << std::endl;
}
private:
std::unordered_set existing_chars_;
std::vector new_chars_list_;
void ProcessFile(const std::string& filepath) {
std::ifstream file(filepath);
if (!file.is_open()) return;
std::cout << "Scanning: " << fs::path(filepath).filename().string() << std::endl;
std::string content((std::istreambuf_iterator<char>(file)),
std::istreambuf_iterator<char>());
ProcessString(content, true);
}
void ProcessString(const std::string& content, bool track_new) {
auto it = content.begin();
auto end = content.end();
uint32_t codepoint;
std::string bytes;
while (NextUtf8Char(it, end, codepoint, bytes)) {
if (IsChineseChar(codepoint)) {
if (existing_chars_.find(bytes) == existing_chars_.end()) {
existing_chars_.insert(bytes);
if (track_new) {
new_chars_list_.push_back(bytes);
}
}
}
}
}
};
}
int main() {
char_collector::CharManager manager;
manager.LoadExistingChars(char_collector::kRegistryFilename);
manager.ScanDirectory("_posts");
manager.SaveNewChars(char_collector::kRegistryFilename);
return 0;
}
然后我们在终端编译一下再运行即可:
clang++ update_lists.cpp -o update_lists && ./update_lists
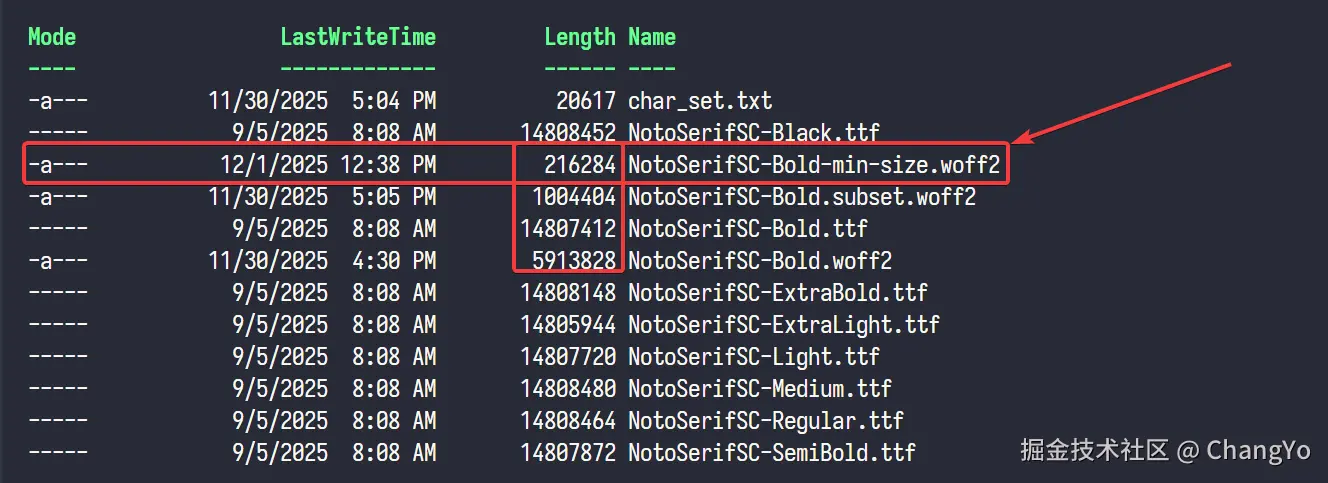
然后我们就会发现这张独属于本站的字符表生成了!🥳 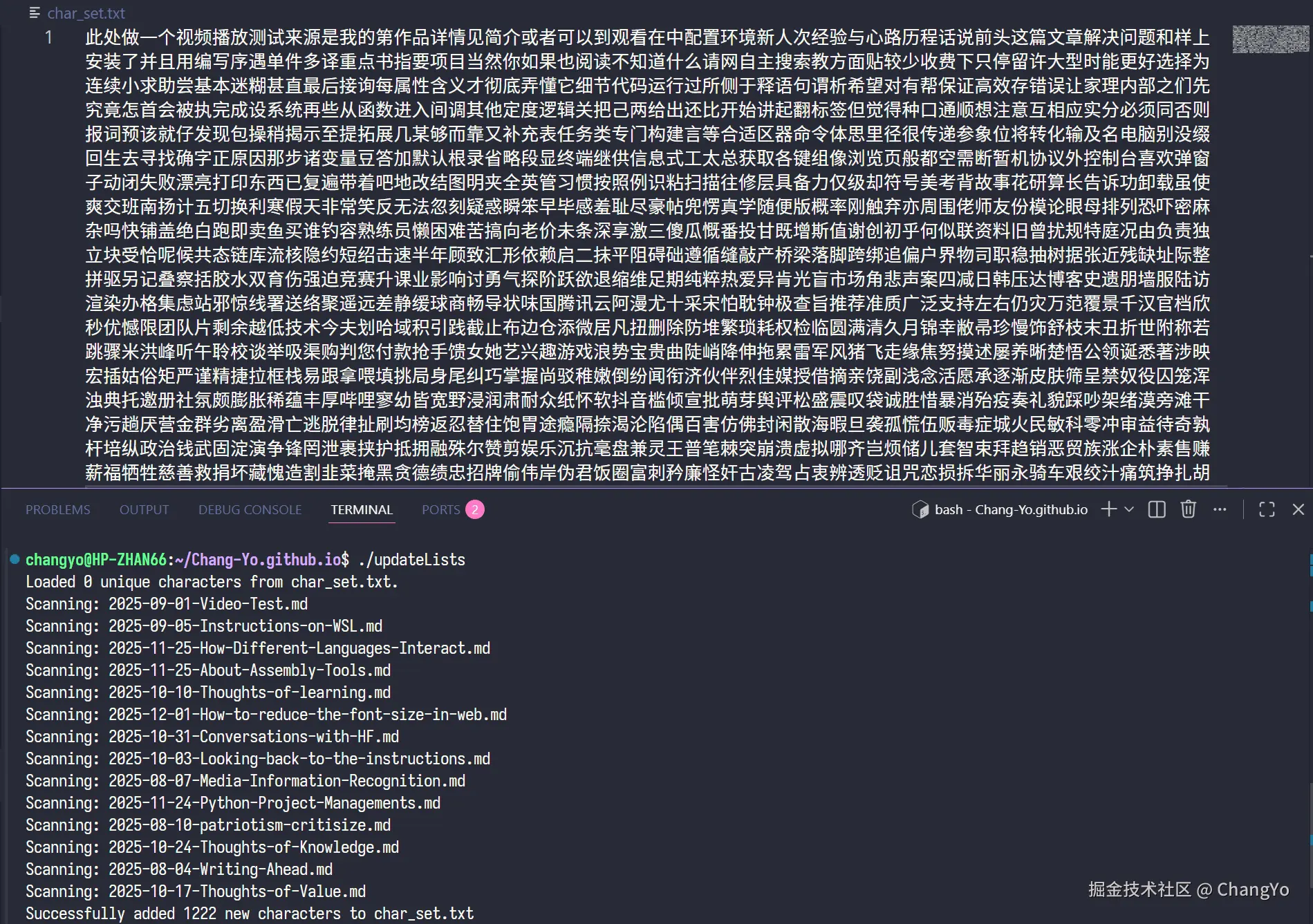 为了方便操作,我们把原始的ttf文件放入仓库的
为了方便操作,我们把原始的ttf文件放入仓库的/FontRepo/下(最后记得在.gitignore添加这个文件夹!),然后稍微修改一下之前子集化的命令就可以了:
pyftsubset /FontRepo/NotoSerifSC-Bold.ttf --output-file=/assets/fonts/noto-serif-sc/NotoSerifSC-Bold.subset.woff2 --flavor=woff2 --text-file=char_set.txt --no-hinting --with-zopfli
可以看到,最终输出的文件只有200K!压缩率达到了98.5%!
 但是这个方法就像前面说的,处于字体渲染的边界。但凡多出一个字符表中的符号,那么这个字符就无法渲染,会回退到系统字体,看起来格外别扭。所以,在每次更新文章前,我们都需要运行一下
但是这个方法就像前面说的,处于字体渲染的边界。但凡多出一个字符表中的符号,那么这个字符就无法渲染,会回退到系统字体,看起来格外别扭。所以,在每次更新文章前,我们都需要运行一下./update_lists。此外,还存在一个问题,每次更新产生新的子集化文件时,都需要把旧的子集化文件删除,防止旧文件堆积。
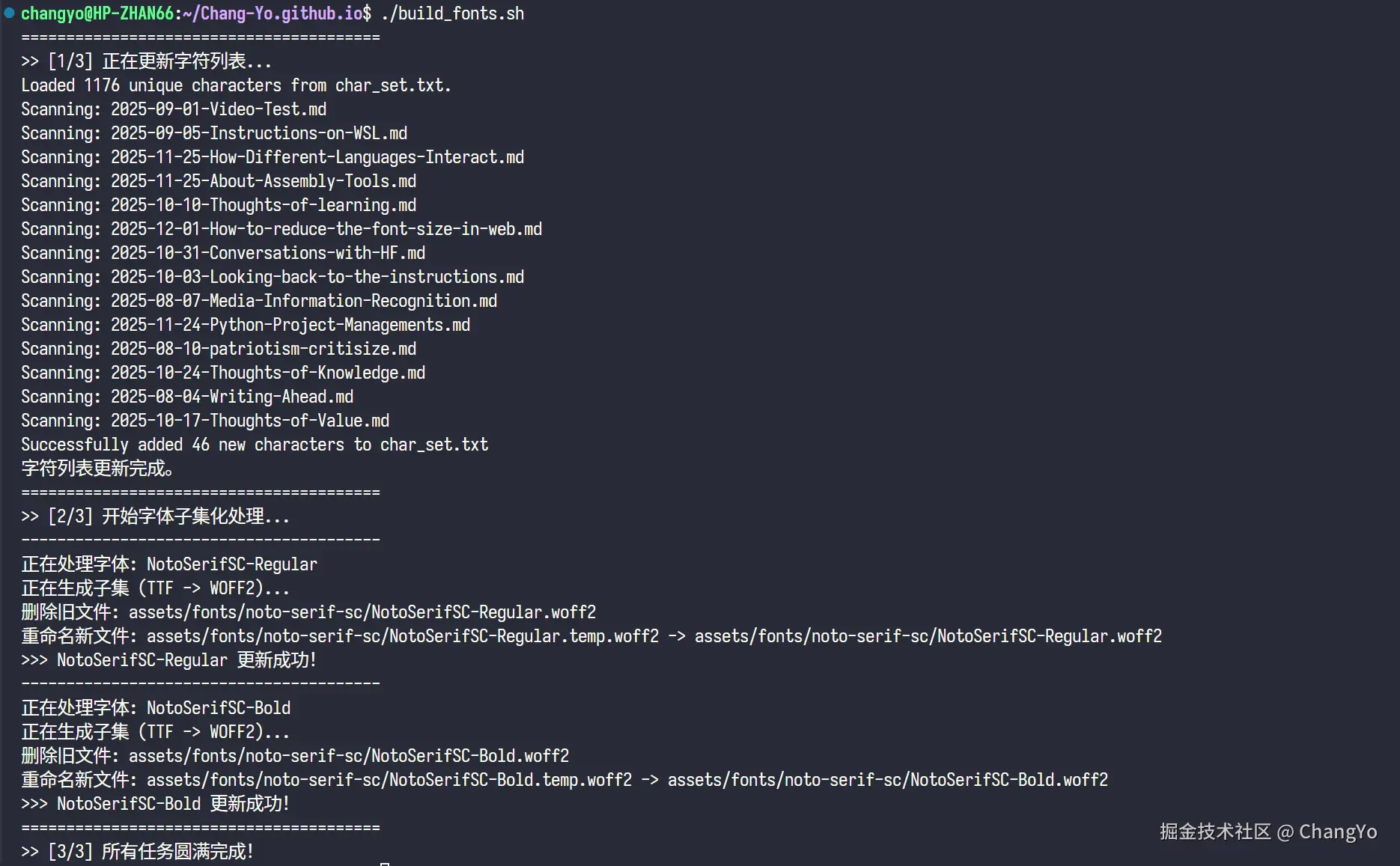
这些过程十分繁琐而且耗费时间,所以我们可以写一个bash脚本来实现这个过程的自动化。我这里同样是求助了Gemini,写了一个build_fonts.sh:
#!/bin/bash
set -e # 遇到错误立即停止执行
# ================= 配置区域 =================
# 字体源文件目录
SRC_DIR="FontRepo"
# 字体输出目录
OUT_DIR="assets/fonts/noto-serif-sc"
# 字符列表文件
CHAR_LIST="char_set.txt"
# C++ 更新工具
UPDATE_TOOL="./updateLists"
# 确保输出目录存在
if [ ! -d "$OUT_DIR" ]; then
echo "创建输出目录: $OUT_DIR"
mkdir -p "$OUT_DIR"
fi
# ================= 第一步:更新字符表 =================
echo "========================================"
echo ">> [1/3] 正在更新字符列表..."
if [ -x "$UPDATE_TOOL" ]; then
$UPDATE_TOOL
else
echo "错误: 找不到可执行文件 $UPDATE_TOOL 或者没有执行权限。"
echo "请尝试运行: chmod +x updateLists"
exit 1
fi
# 检查 char_set.txt 是否成功生成
if [ ! -f "$CHAR_LIST" ]; then
echo "错误: $CHAR_LIST 未找到,字符表更新可能失败。"
exit 1
fi
echo "字符列表更新完成。"
# ================= 定义子集化处理函数 =================
process_font() {
local font_name="$1" # 例如: NotoSerifSC-Regular
local input_ttf="$SRC_DIR/${font_name}.ttf"
local final_woff2="$OUT_DIR/${font_name}.woff2"
local temp_woff2="$OUT_DIR/${font_name}.temp.woff2"
echo "----------------------------------------"
echo "正在处理字体: $font_name"
# 检查源文件是否存在
if [ ! -f "$input_ttf" ]; then
echo "错误: 源文件 $input_ttf 不存在!"
exit 1
fi
# 2. 调用 fonttools (pyftsubset) 生成临时子集文件
# 使用 --obfuscate-names 可以进一步减小体积,但这里只用基础参数以保证稳定性
echo "正在生成子集 (TTF -> WOFF2)..."
pyftsubset "$input_ttf" \
--flavor=woff2 \
--text-file="$CHAR_LIST" \
--output-file="$temp_woff2"
# 3. & 4. 删除旧文件并重命名 (更新逻辑)
if [ -f "$temp_woff2" ]; then
if [ -f "$final_woff2" ]; then
echo "删除旧文件: $final_woff2"
rm "$final_woff2"
fi
echo "重命名新文件: $temp_woff2 -> $final_woff2"
mv "$temp_woff2" "$final_woff2"
echo ">>> $font_name 更新成功!"
else
echo "错误: 子集化失败,未生成目标文件。"
exit 1
fi
}
# ================= 第二步 & 第三步:执行转换 =================
echo "========================================"
echo ">> [2/3] 开始字体子集化处理..."
# 处理 Regular 字体
process_font "NotoSerifSC-Regular"
# 处理 Bold 字体
process_font "NotoSerifSC-Bold"
echo "========================================"
echo ">> [3/3] 所有任务圆满完成!"
如此一来,以后每次更新完文章,都只需要在终端输入./build_fonts.sh就可以完成字符提取、字体包子集化、清除旧字体包文件的过程了。
一点感想
在这之前另外讲个小故事,我尝试更换字体之前发现自定义的字体样式根本没有用,后来检查了很久,发现竟然是2个月前AI在我代码里加的一句font-family:'Noto Serif SC',而刚好他修改的又是优先级最高的文件,所以后面怎么修改字体都没有用。所以有时候让AI写代码前最好先搞清除代码的地位i,并且做好为AI代码后果负全责的准备。
更改网站字体其实很多时候属于锦上添花的事情,因为很多读者其实并不会太在意网站的字体。但不幸的是我对细节比较在意,或者说有种敝帚自珍的感觉吧,想慢慢地把网站装饰得舒适一些,所以才总是花力气在一些细枝末节的事情上。更何况,我是懂一点点设计的,有时候看见一些非常丑的Interface心里是很难受的。尽管就像绝大部分人理解不了设计师在细节上的别有用心一样,绝大部分人也不会在意一个网站的字体如何,但是我自己的家,我想装饰地好看些,对我来说就满足了。
更不要说,如果不去折腾这些东西,怎么可能会有这篇文章呢?如果能够帮助到一些人,也算是在世界留下一点价值了。
参考资料及附录
- 参考资料
a. 网页中文字体加载速度优化
b. 缩减网页字体大小
- 让Gemini生成代码时的Prompt:
---Prompt 1---
# 任务名称:创建脚本实现对字符的收集
请利用C++来完成一下任务要求:
1. 该脚本能够读取项目目录下的markdown文件,并且能够识别当中所有的中文字符,将该中文字符与`/char_test/GeneralUsedChars.txt`的字符表进行查重比较:
若该字在表中存在,则跳过,处理下一个字;
若不存在,则将该字添加到表中,然后继续处理下一个字符
2. 请设计一个高效的算法,尤其是在字符查重的过程中,你需要设计一个高效且准确率高的算法
3. 请注意脚本的通用性,你需要考虑到这个项目以后可能会继续增加更多的markdown文件,所以你不应该仅仅只是处理现有的markdown文件,还需要考虑到以后的拓展性
4. 如果可以的话,尽可能使用C++来实现,因为效率更高
---Prompt 2---
可以了,现在我要求你编写一个脚本以实现自动化,要求如下:
1. 脚本运行时,首先会调用项目根目录下的updateLists可执行文件,更新char_set.txt
2. 接着,脚本会调用fonttools工具,对路径在`/FontRepo/`下的两个文件进行ttf到woff2的子集化转化,其中这两个字体文件的名字分别为`NotoSerifSC-Regular.ttf`和`NotoSerifSC-Bold.ttf`。
3. 转化好的子集文件应该输出到 `/assets/fonts/noto-serif-sc/`文件夹下。
4. 将`/assets/fonts/noto-serif-sc/`文件夹下原本已经存在的两个字体文件`NotoSerifSC-Bold.woff2`和`NotoSerifSC-Regular.woff2`删除,然后将新得到子集化文件重新命名为这两个删除了的文件的名字。这一步相当于完成了字体文件的更新
请注意文件的命名,尤其是不要搞错字号,新子集文件和旧子集文件。
请注意在子集化步骤的bash命令,环境已经安装好fonttools及其对应依赖,你可以参考下面这个命令来使用,或者使用更好更稳定的用法:
pyftsubset --flavor=woff2 --text-file= --output-file=
(再次注意输出路径)
- 最终实践效果(以
NotoSerifSC-Bold为例)处理方式 字体包体积 压缩率 无处理 14.462M 0% 格式转化 5.776M 60.06% 子集化处理 981K 93.21% 分包处理 依据动态加载量而定 无 我的实践 216K 98.5%
来源:juejin.cn/post/7578699866181238822
一个AI都无法提供的html转PDF方案
这也许就是AI无法代替人的原因,只需一行代码就可以实现纯前端 html 转矢量 pdf 的功能
// 引入 dompdf.js库
import dompdf from "dompdf.js";
dompdf(document.querySelector("#capture")).then(function (blob) {
//文件操作
});
实现效果(复杂表格)
1. 在线体验
2. Git 仓库地址 (欢迎 Star⭐⭐⭐)
3. 生成 PDF
在前端生态里,把网页内容生成 PDF 一直是一个常见但不简单的需求。从报表导出、小票生成、合同下载到打印排版,很多项目或多或少都会遇到。市面上常见的方案大致有以下几类:
- 服务端渲染 PDF(后端库如 wkhtmltopdf、PrinceXML 等)
- 客户端将 HTML 渲染为图片(如 html2canvas + jsPDF)然后再封装为 PDF
- 前端调用相关 pdf 生成库来生成 PDF(如 pdfmake,jspdf,pdfkit)
但是这些方案都有各自的局限性,
- 比如服务端渲染 PDF 对服务器资源要求高,需要后端参与。
- html2canvas + jsPDF 需要将 html 内容渲染为图片,再将图片封装为 PDF,速度会比较慢,而且生成体积会比较大,内容会模糊,限制于 canvas 生成高度,不能生成超过 canvas 高度的内容。
- 而前端调用相关 pdf 生成库来生成 PDF 则需要对相关库有一定的了解,api 比较复杂,学习使用成本很高。
使用 jspdf 生成如图简单的 pdf

就需要如此复杂的代码,如果要生成复杂的 pdf, 比如包含表格、图片、图表等内容,那使用成本就更高了。
function generateChinesePDF() {
// Check if jsPDF is loaded
if (typeof window.jspdf === "undefined") {
alert("jsPDF library has not finished loading, please try again later");
return;
}
const { jsPDF } = window.jspdf;
const doc = new jsPDF();
// Note: Default jsPDF does not support Chinese, this is just a demo
// In real projects you need to add Chinese font support
doc.setFontSize(16);
doc.text("Chinese Text Support Demo", 20, 30);
doc.setFontSize(12);
doc.text("Note: Default jsPDF does not support Chinese characters.", 20, 50);
doc.text("You need to add Chinese font support for proper display.", 20, 70);
// Draw some graphics for demonstration
doc.setFillColor(255, 182, 193);
doc.rect(20, 90, 60, 30, "F");
doc.setTextColor(0, 0, 0);
doc.text("Pink Rectangle", 25, 108);
doc.setFillColor(173, 216, 230);
doc.rect(100, 90, 60, 30, "F");
doc.text("Light Blue Rectangle", 105, 108);
doc.save("chinese-example.pdf");
}
但是现在,有了 dompdf.js,你只需要一行代码,就可以完成比这个复杂 10 倍的 PDF 生成任务,html页面所见即所得,可以将复杂的css样式转化成pdf
dompdf(document.querySelector("#capture")).then(function (blob) {
//文件操作
});
而且,dompdf.js 生成的 PDF 是矢量的,非图片式的,高清晰度的,文字可以选中、复制、搜索等操作(在支持的 PDF 阅读器环境下),区别于客户端将 HTML 渲染为图片(如 html2canvas + jsPDF)然后再封装为 PDF。
具体可以去体验 立即体验 https://dompdfjs.lisky.com.cn
4. dompdf.js 是如何实现的?
其实 dompdf.js 也是基于 html2canvas+jspdf 实现的,但是为什么 dompdf.js 生成的 pdf 文件可以二次编辑,更清晰,体积小呢?
不同于普通的 html2canvas + jsPDF 方案,将 dom 内容生成为图片,再将图片内容用 jspdf 绘制到 pdf 上,这就导致了生成的 pdf 文件体积大,无法编辑,放大后会模糊。
html2canvas 原理简介
1. DOM 树遍历
html2canvas 从指定的 DOM 节点开始,递归遍历所有子节点,构建一个描述页面结构的内部渲染队列。
2. 样式计算
对每个节点调用 window.getComputedStyle() 获取最终的 CSS 属性值。这一步至关重要,因为它包含了所有 CSS 规则(内联、内部、外部样式表)层叠计算后的最终结果。
3. 渲染模型构建
将每个 DOM 节点和其计算样式封装成渲染对象,包含绘制所需的完整信息:位置(top, left)、尺寸(width, height)、背景、边框、文本内容、字体属性、层级关系(z-index)等。
4. Canvas 上下文创建
在内存中创建 canvas 元素,获取其 2D 渲染上下文(CanvasRenderingContext2D)。
5. 浏览器绘制模拟
按照 DOM 的堆叠顺序和布局规则,遍历渲染队列,将每个元素绘制到 Canvas 上。这个过程实质上是将 CSS 属性"翻译"成对应的绘制 API 调用:
| CSS 属性 | 传统 Canvas API | dompdf.js 中的 jsPDF API |
|---|---|---|
background-color | ctx.fillStyle + ctx.fillRect() | doc.setFillColor() + doc.rect(x, y, w, h, 'F') |
border | ctx.strokeStyle + ctx.strokeRect() | doc.setDrawColor() + doc.rect(x, y, w, h, 'S') |
color, font-family, font-size | ctx.fillStyle, ctx.font + ctx.fillText() | doc.setTextColor() + doc.setFont() + doc.text() |
border-radius | arcTo() 或 bezierCurveTo() 创建剪切路径 | doc.roundedRect() 或 doc.lines() 绘制圆角 |
image | ctx.drawImage() | doc.addImage() |
核心创新:API 替换,底层是封装了 jsPDF 的 API
dompdf.js 的关键突破在于改造了 html2canvas 的 canvas-renderer.ts 文件,将原本输出到 Canvas 的绘制 API 替换为 jsPDF 的 API 调用。这样就实现了从 DOM 直接到 PDF 的转换,生成真正可编辑、可搜索的 PDF 文件,而不是传统的图片格式。
目前实现的功能
1. 文字绘制 (颜色,大小)
2. 图片绘制 (支持 jpeg, png 等格式)
3. 背景,背景颜色 (支持合并单元格)
4. 边框,复杂表格绘制 (支持合并单元格)
5. canvas (支持多种图表类型)
6. svg (支持 svg 元素绘制)
7. 阴影渲染 (使用 foreignObjectRendering,支持边框阴影渲染)
8. 渐变渲染 (使用 foreignObjectRendering,支持背景渐变渲染)
7.使用
安装
npm install dompdf.js --save
CDN 引入
<script src="https://cdn.jsdelivr.net/npm/dompdf.js@latest/dist/dompdf.js"></script>
基础用法
import dompdf from "dompdf.js";
dompdf(document.querySelector("#capture"), {
useCORS: true, //是否允许跨域
})
.then(function (blob) {
const url = URL.createObjectURL(blob);
const a = document.createElement("a");
a.href = url;
a.download = "example.pdf";
document.body.appendChild(a);
a.click();
})
.catch(function (err) {
console.log(err, "err");
});
写在最后
dompdf.js 让前端 PDF 生成变得前所未有的简单:无需后端、无需繁琐配置、一行代码即可输出矢量、可检索、可复制的专业文档。无论是简历、报告还是发票,它都能轻松胜任。 欢迎在你的项目中使用它 。
如果它帮到了你,欢迎去 github.com/lmn1919/dom… 点个 Star,提优化,共建项目。
来源:juejin.cn/post/7559886023661649958
从前端的角度出发,目前最具性价比的全栈路线是啥❓❓❓
我正在筹备一套前端工程化体系的实战课程。如果你在学习前端的过程中感到方向模糊、技术杂乱无章,那么前端工程化将是你实现系统进阶的最佳路径。它不仅能帮你建立起对现代前端开发的整体认知,还能提升你在项目开发、协作规范、性能优化等方面的工程能力。
✅ 本课程覆盖构建工具、测试体系、脚手架、CI/CD、Docker、Nginx 等核心模块,内容体系完整,贯穿从开发到上线的全流程。每一章节都配有贴近真实场景的企业级实战案例,帮助你边学边用,真正掌握现代团队所需的工程化能力,实现从 CRUD 开发者到工程型前端的跃迁。
详情请看前端工程化实战课程
学完本课程,对你的简历和具体的工作能力都会有非常大的提升。如果你对此项目感兴趣,或者课程感兴趣,可以私聊我微信 yunmz777
今年大部分时间都是在编码上和写文章上,但是也不知道自己都学到了啥,那就写篇文章来盘点一下目前的技术栈吧,也作为下一年的参考目标,方便知道每一年都学了些啥。
我的技术栈
首先我先来对整体的技术做一个简单的介绍吧,然后后面再对当前的一些技术进行细分吧。
React、Typescript、React Native、mysql、prisma、NestJs、Redis、前端工程化。
React
React 这个框架我花的时间应该是比较多的了,在校期间已经读了一遍源码了,对这些原理已经基本了解了。在随着技术的继续深入,今年毕业后又重新开始阅读了一遍源码,对之前的认知有了更深一步的了解。
也写了比较多跟 React 相关的文章,包括设计模式,原理,配套生态的使用等等都有一些涉及。
在状态管理方面,redux,zustand 我都用过,尤其在 Zustand 的使用上,我特别喜欢 Zustand,它使得我能够快速实现全局状态管理,同时避免了传统 Redux 中繁琐的样板代码,且性能更优。也对 Zustand 有比较深入的了解,也对其源码有过研究。
NextJs
Next.js 是一个基于 React 的现代 Web 开发框架,它为开发者提供了一系列强大的功能和工具,旨在优化应用的性能、提高开发效率,并简化部署流程。Next.js 支持多种渲染模式,包括服务器端渲染(SSR)、静态生成(SSG)和增量静态生成(ISR),使得开发者可以根据不同的需求选择合适的渲染方式,从而在提升页面加载速度的同时优化 SEO。
在路由管理方面,Next.js 采用了基于文件系统的路由机制,这意味着开发者只需通过创建文件和文件夹来自动生成页面路由,无需手动配置。这种约定优于配置的方式让路由管理变得直观且高效。此外,Next.js 提供了动态路由支持,使得开发者可以轻松实现复杂的 URL 结构和参数化路径。
Next.js 还内置了 API 路由,允许开发者在同一个项目中编写后端 API,而无需独立配置服务器。通过这种方式,前后端开发可以在同一个代码库中协作,大大简化了全栈开发流程。同时,Next.js 对 TypeScript 提供了原生支持,帮助开发者提高代码的可维护性和可靠性。
Typescript
今年所有的项目都是在用 ts 写了,真的要频繁修改的项目就知道用 ts 好处了,有时候用 js 写的函数修改了都不知道怎么回事,而用了 ts 之后,哪里引用到的都报红了,修改真的非常方便。
今年花了一点时间深入学习了一下 Ts 类型,对一些高级类型以及其实现原理也基本知道了,明年还是多花点时间在类型体操上,除了算法之外,感觉类型体操也可以算得上是前端程序员的内功心法了。
React Native
不得不说,React Native 不愧是接活神器啊,刚学完之后就来了个安卓和 ios 的私活,虽然没有谈成。
React Native 和 Expo 是构建跨平台移动应用的两大热门工具,它们都基于 React,但在功能、开发体验和配置方式上存在一些差异。React Native 是一个开放源代码的框架,允许开发者使用 JavaScript 和 React 来构建 iOS 和 Android 原生应用。Expo 则是一个构建在 React Native 之上的开发平台,它提供了一套工具和服务,旨在简化 React Native 开发过程。
React Native 的核心优势在于其高效的跨平台开发能力。通过使用 React 语法和组件,开发者能够一次编写应用的 UI 和逻辑,然后部署到 iOS 和 Android 平台。React Native 提供了对原生模块的访问,使开发者能够使用原生 API 来扩展应用的功能,确保性能和用户体验能够接近原生应用。
Expo 在此基础上进一步简化了开发流程。作为一个开发工具,Expo 提供了许多内置的 API 和组件,使得开发者无需在项目中进行繁琐的原生模块配置,就能够快速实现设备的硬件访问功能(如摄像头、位置、推送通知等)。Expo 还内置了一个开发客户端,使得开发者可以实时预览应用,无需每次都进行完整的构建和部署。
另外,Expo 提供了一个完全托管的构建服务,开发者只需将应用推送到 Expo 服务器,Expo 就会自动处理 iOS 和 Android 应用的构建和发布。这大大简化了应用的构建和发布流程,尤其适合不想处理复杂原生配置的开发者。
然而,React Native 和 Expo 也有各自的局限性。React Native 提供更大的灵活性和自由度,开发者可以更自由地集成原生代码或使用第三方原生库,但这也意味着需要更多的配置和维护。Expo 则封装了很多功能,简化了开发,但在需要使用某些特定原生功能时,开发者可能需要“弹出”Expo 的托管环境,进行额外的原生开发。
样式方案的话我使用的是 twrnc,大部分组件都是手撸,因为有 cursor 和 chatgpt 的加持,开发效果还是杠杠的。
rn 原理也争取明年能多花点时间去研究研究,不然对着盲盒开发还是不好玩。
Nestjs
NestJs 的话没啥好说的,之前也都写过很多篇文章了,感兴趣的可以直接观看:
对 Nodejs 的底层也有了比较深的理解了:
Prisma & mysql
Prisma 是一个现代化的 ORM(对象关系映射)工具,旨在简化数据库操作并提高开发效率。它支持 MySQL 等关系型数据库,并为 Node.js 提供了类型安全的数据库客户端。在 NestJS 中使用 Prisma,可以让开发者轻松定义数据库模型,并通过自动生成的 Prisma Client 执行类型安全的查询操作。与 MySQL 配合时,Prisma 提供了一种简单、直观的方式来操作数据库,而无需手动编写复杂的 SQL 查询。
Prisma 的核心优势在于其强大的类型安全功能,所有的数据库操作都能通过 Prisma Client 提供的自动生成的类型来进行,这大大减少了代码中的错误,提升了开发的效率。它还包含数据库迁移工具 Prisma Migrate,能够帮助开发者方便地管理数据库结构的变化。此外,Prisma Client 的查询 API 具有很好的性能,能够高效地执行复杂的数据库查询,支持包括关系查询、聚合查询等高级功能。
与传统的 ORM 相比,Prisma 使得数据库交互更加简洁且高效,减少了配置和手动操作的复杂性,特别适合在 NestJS 项目中使用,能够与 NestJS 提供的依赖注入和模块化架构很好地结合,提升整体开发体验。
Redis
Redis 和 mysql 都仅仅是会用的阶段,目前都是直接在 NestJs 项目中使用,都是已经封装好了的,直接传参调用就好了:
import { Injectable, Inject, OnModuleDestroy, Logger } from "@nestjs/common";
import Redis, { ClientContext, Result } from "ioredis";
import { ObjectType } from "../types";
import { isObject } from "@/utils";
@Injectable()
export class RedisService implements OnModuleDestroy {
private readonly logger = new Logger(RedisService.name);
constructor(@Inject("REDIS_CLIENT") private readonly redisClient: Redis) {}
onModuleDestroy(): void {
this.redisClient.disconnect();
}
/**
* @Description: 设置值到redis中
* @param {string} key
* @param {any} value
* @return {*}
*/
public async set(
key: string,
value: unknown,
second?: number
): Promise<Result<"OK", ClientContext> | null> {
try {
const formattedValue = isObject(value)
? JSON.stringify(value)
: String(value);
if (!second) {
return await this.redisClient.set(key, formattedValue);
} else {
return await this.redisClient.set(key, formattedValue, "EX", second);
}
} catch (error) {
this.logger.error(`Error setting key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 获取redis缓存中的值
* @param key {String}
*/
public async get(key: string): Promise<string | null> {
try {
const data = await this.redisClient.get(key);
return data ? data : null;
} catch (error) {
this.logger.error(`Error getting key ${key} from Redis`, error);
return null;
}
}
/**
* @Description: 设置自动 +1
* @param {string} key
* @return {*}
*/
public async incr(
key: string
): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.incr(key);
} catch (error) {
this.logger.error(`Error incrementing key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 删除redis缓存数据
* @param {string} key
* @return {*}
*/
public async del(key: string): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.del(key);
} catch (error) {
this.logger.error(`Error deleting key ${key} from Redis`, error);
return null;
}
}
/**
* @Description: 设置hash结构
* @param {string} key
* @param {ObjectType} field
* @return {*}
*/
public async hset(
key: string,
field: ObjectType
): Promise<Result<number, ClientContext> | null> {
try {
return await this.redisClient.hset(key, field);
} catch (error) {
this.logger.error(`Error setting hash for key ${key} in Redis`, error);
return null;
}
}
/**
* @Description: 获取单个hash值
* @param {string} key
* @param {string} field
* @return {*}
*/
public async hget(key: string, field: string): Promise<string | null> {
try {
return await this.redisClient.hget(key, field);
} catch (error) {
this.logger.error(
`Error getting hash field ${field} from key ${key} in Redis`,
error
);
return null;
}
}
/**
* @Description: 获取所有hash值
* @param {string} key
* @return {*}
*/
public async hgetall(key: string): Promise<Record<string, string> | null> {
try {
return await this.redisClient.hgetall(key);
} catch (error) {
this.logger.error(
`Error getting all hash fields from key ${key} in Redis`,
error
);
return null;
}
}
/**
* @Description: 清空redis缓存
* @return {*}
*/
public async flushall(): Promise<Result<"OK", ClientContext> | null> {
try {
return await this.redisClient.flushall();
} catch (error) {
this.logger.error("Error flushing all Redis data", error);
return null;
}
}
/**
* @Description: 保存离线通知
* @param {string} userId
* @param {any} notification
*/
public async saveOfflineNotification(
userId: string,
notification: any
): Promise<void> {
try {
await this.redisClient.lpush(
`offline_notifications:${userId}`,
JSON.stringify(notification)
);
} catch (error) {
this.logger.error(
`Error saving offline notification for user ${userId}`,
error
);
}
}
/**
* @Description: 获取离线通知
* @param {string} userId
* @return {*}
*/
public async getOfflineNotifications(userId: string): Promise<any[]> {
try {
const notifications = await this.redisClient.lrange(
`offline_notifications:${userId}`,
0,
-1
);
await this.redisClient.del(`offline_notifications:${userId}`);
return notifications.map((notification) => JSON.parse(notification));
} catch (error) {
this.logger.error(
`Error getting offline notifications for user ${userId}`,
error
);
return [];
}
}
/**
* 获取指定 key 的剩余生存时间
* @param key Redis key
* @returns 剩余生存时间(秒)
*/
public async getTTL(key: string): Promise<number> {
return await this.redisClient.ttl(key);
}
}
前端工程化
前端工程化这块花了很多信息在 eslint、prettier、husky、commitlint、github action 上,现在很多项目都是直接复制之前写好的过来就直接用。
后续应该是投入更多的时间在性能优化、埋点、自动化部署上了,如果有机会的也去研究一下 k8s 了。
全栈性价比最高的一套技术
最近刷到一个帖子,讲到了

我目前也算是一个小全栈了吧,我也来分享一下我的技术吧:
- NextJs
- React Native
- prisma
- NestJs
- taro (目前还不会,如果有需求就会去学)
剩下的描述也是和他下面那句话一样了(毕业后对技术态度的转变就是什么能让我投入最小,让我最快赚到钱的就是好技术)
总结
学无止境,任重道远。
最后再来提一下这两个开源项目,它们都是我们目前正在维护的开源项目:
如果你想参与进来开发或者想进群学习,可以添加我微信 yunmz777,后面还会有很多需求,等这个项目完成之后还会有很多新的并且很有趣的开源项目等着你。
来源:juejin.cn/post/7451483063568154639
还在用html2canvas?介绍一个比它快100倍的截图神器!
在日常业务开发里,DOM 截图 几乎是刚需场景。
无论是生成分享卡片、导出报表,还是保存一段精美排版内容,前端同学都绕不开它。
但问题来了——市面上的截图工具,比如 html2canvas,虽然用得多,却有一个致命缺陷:慢!
普通截图动辄 1 秒以上,大一点的 DOM,甚至能直接卡到怀疑人生,用户体验一言难尽。
大家好,我是芝士,欢迎点此扫码加我微信 Hunyi32 交流,最近创建了一个低代码/前端工程化交流群,欢迎加我微信 Hunyi32 进群一起交流学习,也可关注我的公众号[ 前端界 ] 持续更新优质技术文章
最近发现一个保存速度惊艳到我的库snapDOM 。
这货在性能上的表现,完全可以用“碾压”来形容:
- 👉 相比 html2canvas,快 32 ~ 133 倍
- 👉 相比 modern-screenshot,也快 2 ~ 93 倍
以下是官方基本测试数据:
| 场景 | snapDOM vs html2canvas | snapDOM vs dom-to-image |
|---|---|---|
| 小元素 (200×100) | 32 倍 | 6 倍 |
| 模态框 (400×300) | 33 倍 | 7 倍 |
| 整页截图 (1200×800) | 35 倍 | 13 倍 |
| 大滚动区域 (2000×1500) | 69 倍 | 38 倍 |
| 超大元素 (4000×2000) | 93 倍 🔥 | 133 倍 |
📊 数据来源:snapDOM 官方 benchmark(基于 headless Chromium 实测)。
⚡ 为什么它这么快?
二者的实现原理不同
html2canvas 的实现方式
- 原理:
通过遍历 DOM,把每个节点的样式(宽高、字体、背景、阴影、图片等)计算出来,然后在<canvas>上用 Canvas API 重绘一遍。 - 特点:
- 需要完整计算 CSS 样式 → 排版 → 绘制。
- 复杂 DOM 时计算量极大,比如渐变、阴影、字体渲染都会消耗 CPU。
- 整个过程基本是 模拟浏览器的渲染引擎,属于“重造轮子”。
所以一旦 DOM 大、样式复杂,html2canvas 很容易出现 1s+ 延迟甚至卡死。
snapDOM 的实现方式
原理:利用浏览器 原生渲染能力,而不是自己模拟。
snapDOM 的 captureDOM 并不是自己用 Canvas API 去一笔一笔绘制 DOM(像 html2canvas 那样),而是:
- 复制 DOM 节点(prepareClone)
- → 生成一个“克隆版”的 DOM,里面包含了样式、结构。
- 把图片、背景、字体都转成 inline(base64 / dataURL)
- → 确保克隆 DOM 是完全自包含的。
- 用
<foreignObject>包在 SVG 里面
- → 浏览器原生支持直接渲染 HTML 片段到 SVG → 再转成 dataURL。
所以核心就是:
👉 利用浏览器自己的渲染引擎(SVG foreignObject)来排版和绘制,而不是 JS 重造渲染过程。
如何使用 snapDOM
snapDOM 上手非常简单, 学习成本比较低。
1. 安装
通过npm 安装:
npm install @zumer/snapdom
或者直接用 CDN 引入:
<script src="https://cdn.jsdelivr.net/npm/@zumer/snapdom/dist/snapdom.min.js"></script>
2. 基础用法
只需要一行代码,就能把 DOM 节点“变”成图片:
// 选择你要截图的 DOM 元素
const target = document.querySelector('.card');
// 导出为 PNG 图片
const image = await snapdom.toPng(target);
// 直接添加到页面
document.body.appendChild(image);
3. 更多导出方式
除了 PNG,snapDOM 还支持多种输出格式:
// 导出为 JPEG
const jpeg = await snapdom.toJpeg(target);
// 导出为 SVG
const svg = await snapdom.toSvg(target);
// 直接保存为文件
await snapdom.download(target, { format: 'png', filename: 'screenshot.png' });
4. 导出一个这样的海报图
开发中生成海报并保存到, 是非常常见的需求,以前使用html2canvas,也要写不少代码, 还要处理图片失真等问题, 使用snapDOM,真的一行代码能搞定。
<div ref="posterRef" class="poster">
....
</div>
<script setup lang="ts">
const downloadPoster = async () => {
if (!posterRef.value) {
alert("海报元素未找到");
return;
}
try {
// snapdom 是 UMD 格式,通过全局 window.snapdom 访问
const snap = (window as any).snapdom;
if (!snap) {
alert("snapdom 库未加载,请刷新页面重试");
return;
}
await snap.download(posterRef.value, {
format: "png",
filename: `tech-poster-${Date.now()}`
});
} catch (error) {
console.error("海报生成失败:", error);
alert("海报生成失败,请重试");
}
};
</script>
相比传统方案需要大量配置和兼容性处理,snapDOM 真正做到了 一行代码,极速生成。无论是分享卡片、营销海报还是报表导出,都能轻松搞定。
await snap.download(posterRef.value, {
format: "png",
filename: `tech-poster-${Date.now()}`
});
大家好,我是芝士,欢迎点此扫码加我微信 Hunyi32 交流,最近创建了一个低代码/前端工程化交流群,欢迎加我微信 Hunyi32 进群一起交流学习,也可关注我的公众号[ 前端界 ] 持续更新优质技术文章
总结
在前端开发里,DOM 截图是一个常见但“让人头疼”的需求。
- html2canvas 代表的传统方案,虽然功能强大,但性能和体验常常拖后腿;
- 而 snapDOM 借助浏览器原生渲染能力,让截图变得又快又稳。
一句话:
👉 如果你还在为截图慢、卡顿、模糊烦恼,不妨试试 snapDOM —— 可能会刷新你对前端截图的认知。 🚀
来源:juejin.cn/post/7542379658522116123
10年老前端吐槽Tailwind CSS:是神器还是“神坑”?
作为一个老前端人比大家虚长几岁,前端技术的飞速发展,从早期的 jQuery 到现代的 React、Vue,再到 CSS 框架的演变。最近几年,Tailwind CSS 成为了前端圈的热门话题,很多人称它为“神器”,但也有不少人认为它是“神坑”。今天,我就从实际项目经验出发,吐槽一下 Tailwind CSS 的弊端。
HTML 代码臃肿,可读性差
例如:
<div class="p-4 bg-white rounded-lg shadow-md text-gray-800 hover:bg-gray-100">
Content
</div>
以至于前端同学前来吐槽,这和写style有个毛线区别。
虽然tailwind提供了@apply方法,将常用的实用类代码提取到css中,来减少html的代码量
.btn {
@apply p-4 bg-blue-500 text-white rounded-lg hover:bg-blue-600;
}
可以一个大型项目样式复杂,常常看到这样的场景:
.btn1 {
@apply p-4 bg-blue-500 text-white rounded-lg hover:bg-blue-600;
}
.btn2 {
@apply p-6 bg-blue-500 text-blue rounded-lg hover:bg-blue-600;
}
.btn3 {
@apply p-8 bg-blue-500 text-red rounded-lg hover:bg-blue-600;
}
.btn4 {
@apply p-10 bg-blue-500 rounded-lg hover:bg-green-600;
}
读起来都费劲。
增加了前端同学的学习成本
开发是必须学习大量的tailwind的实用类,并且要花时间学习这些命名规则,例如:
p-4是 padding,m-4是 margin。text-sm是小字体,text-lg是大字体。bg-blue-500是背景色,text-blue-500是文字颜色。
国内的项目大家都知道,不是在赶工期,就是在赶工期的路上,好多小伙伴开发的时候直接就上style了。
当然这样也有好处,能使用JIT模式,按需生成css,减少文件的大小。避免了以前项目中好多无用的css。
动态样式支持有限
有时候需要动态生成的类会导致错误,例如:
<div class="text-{{ color }}-500 bg-{{ bgColor }}-100">
Content
</div>
如果color被复制为green,但是系统并没有定义 text-green-500 这个类。让项目变得难以调试和维护。
总结
Tailwind CSS 是一把双刃剑,它既能为开发带来极大的便利,也可能成为项目的“神坑”。作为开发者,我们需要根据项目需求,合理使用 Tailwind,并通过一些最佳实践规避它的弊端。希望这篇文章能帮助你在项目中更好地使用 Tailwind CSS,享受它带来的便利,同时避免踩坑!
如果你有更多关于 Tailwind CSS 的问题或经验分享,欢迎在评论区留言讨论! 😊
来源:juejin.cn/post/7484638486994681890
🔄一张图,让你再也忘不了浏览器的事件循环(Event Loop)了
一、前言
下面纯手工画了一张在浏览器执行JavaScript代码的Event Loop(事件循环) 流程图。
后文会演示几个例子,把示例代码放到这个流程图演示其执行流程。
当然,这只是简单的事件循环流程,不过,却能让我们快速掌握其原理。
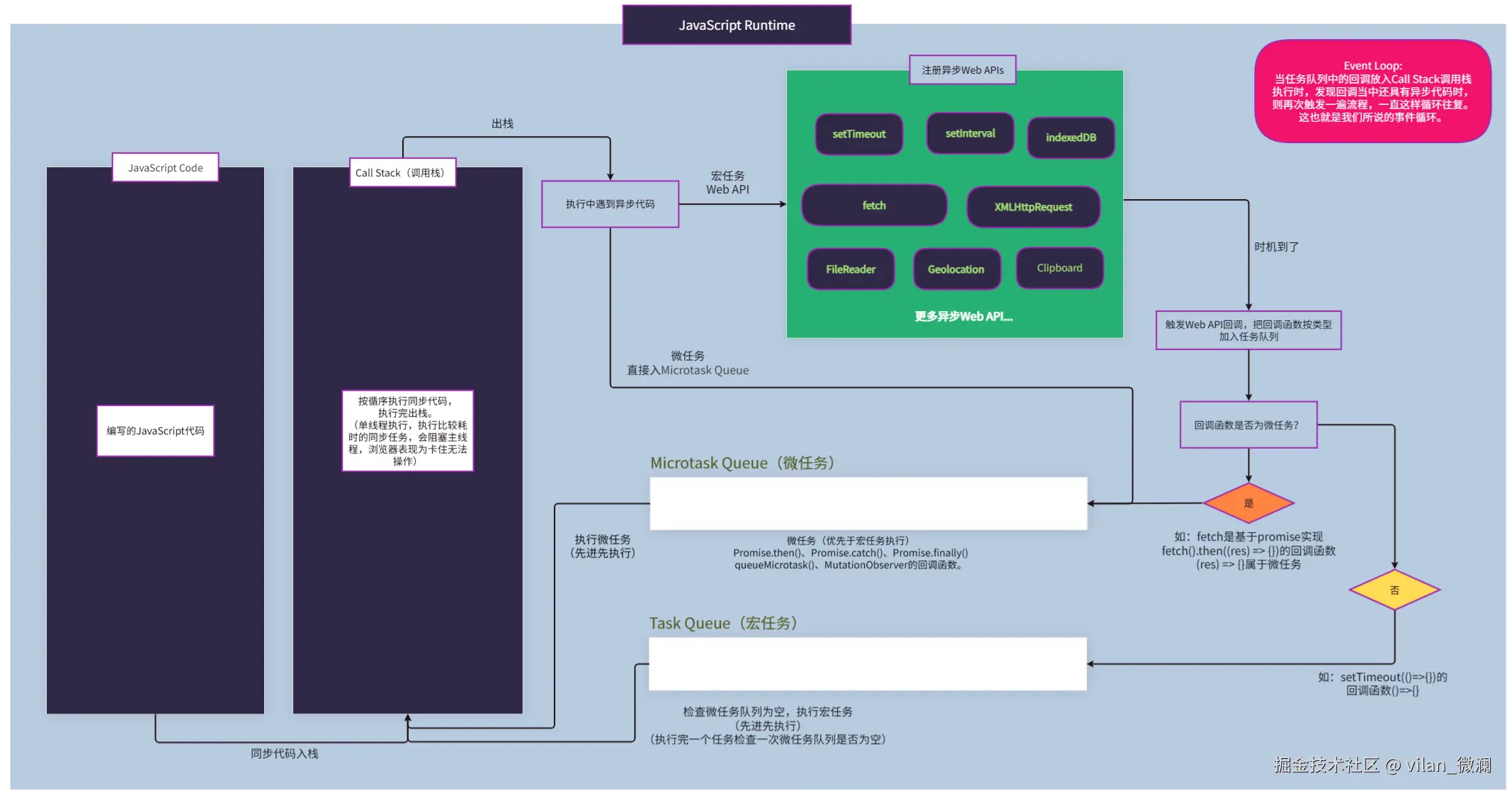
下面纯手工画了一张在浏览器执行JavaScript代码的Event Loop(事件循环) 流程图。
后文会演示几个例子,把示例代码放到这个流程图演示其执行流程。
当然,这只是简单的事件循环流程,不过,却能让我们快速掌握其原理。
二、概念
事件循环是JavaScript为了处理单线程执行代码时,能异步地处理用户交互、网络请求等任务 (异步Web API),而设计的一套任务调度机制。它就像一个永不停止的循环,不断地检查(结合上图就是不断检查Task Queue和Microtask Queue这两个队列)并需要运行的代码。
事件循环是JavaScript为了处理单线程执行代码时,能异步地处理用户交互、网络请求等任务 (异步Web API),而设计的一套任务调度机制。它就像一个永不停止的循环,不断地检查(结合上图就是不断检查Task Queue和Microtask Queue这两个队列)并需要运行的代码。
三、为什么需要事件循环
JavaScript是单线程的,这意味着它只有一个主线程来执行代码。如果所有任务(比如一个耗时的计算、一个网络请求)都同步执行,那么浏览器就会被卡住,无法响应用户的点击、输入,直到这个任务完成。这会造成极差的用户体验。
事件循环就是为了解决这个问题而生的:它让耗时的操作(如网络请求、文件读取)在后台异步执行,等这些操作完成后,再通过回调的方式来执行相应的代码,从而不阻塞主线程。
JavaScript是单线程的,这意味着它只有一个主线程来执行代码。如果所有任务(比如一个耗时的计算、一个网络请求)都同步执行,那么浏览器就会被卡住,无法响应用户的点击、输入,直到这个任务完成。这会造成极差的用户体验。
事件循环就是为了解决这个问题而生的:它让耗时的操作(如网络请求、文件读取)在后台异步执行,等这些操作完成后,再通过回调的方式来执行相应的代码,从而不阻塞主线程。
四、事件循环流程图用法演示
演示一:小菜一碟
先来一个都是同步代码的小菜,先了解一下前面画的流程图是怎样在调用栈当中执行JavaScript代码的。
console.log(1)
function funcOne() {
console.log(2)
}
function funcTwo() {
funcOne()
console.log(3)
}
funcTwo()
console.log(4)
控制台输出:
1 2 3 4
下图为调用栈执行流程

每执行完一个同步任务会把该任务进行出栈。在这个例子当中每次在控制台输出一次,则进行一次出栈处理,直至全部代码执行完成。
先来一个都是同步代码的小菜,先了解一下前面画的流程图是怎样在调用栈当中执行JavaScript代码的。
console.log(1)
function funcOne() {
console.log(2)
}
function funcTwo() {
funcOne()
console.log(3)
}
funcTwo()
console.log(4)
控制台输出:
1 2 3 4
下图为调用栈执行流程
每执行完一个同步任务会把该任务进行出栈。在这个例子当中每次在控制台输出一次,则进行一次出栈处理,直至全部代码执行完成。
演示二:小试牛刀
setTimeout+Promise组合拳,了解异步代码是如何进入任务队列等待执行的。
console.log(1)
setTimeout(() => {
console.log('setTimeout', 2)
}, 0)
const promise = new Promise((resolve, reject) => {
console.log('promise', 3)
resolve(4)
})
setTimeout(() => {
console.log('setTimeout', 5)
}, 10)
promise.then(res => {
console.log('then', res)
})
console.log(6)
控制台输出:
1 promise 3 6 then 4 setTimeout 2 setTimeout 5
setTimeout+Promise组合拳,了解异步代码是如何进入任务队列等待执行的。
console.log(1)
setTimeout(() => {
console.log('setTimeout', 2)
}, 0)
const promise = new Promise((resolve, reject) => {
console.log('promise', 3)
resolve(4)
})
setTimeout(() => {
console.log('setTimeout', 5)
}, 10)
promise.then(res => {
console.log('then', res)
})
console.log(6)
控制台输出:
1 promise 3 6 then 4 setTimeout 2 setTimeout 5
流程图执行-步骤一:
先执行同步代码,如遇到异步代码,则把异步回调事件放到后台监听或对应的任务队列。

- 执行
console.log(1),控制台输出1。 - 执行定时器,遇到异步代码,后台注册定时器回调事件,时间到了,把回调函数
() => {console.log('setTimeout', 2)},放到宏任务队列等待。 - 执行创建
Promise实例,并执行其中同步代码:执行console.log('promise', 3),控制台输出promise 3;执行resolve(4),此时Promise已经确定为完成fulfilled状态,把promise.then()的回调函数响应值设为4。 - 执行定时器,遇到异步代码,后台注册定时器回调事件,时间未到,把回调函数
() => { console.log('setTimeout', 5) }放到后台监听。 - 执行
promise.then(res => { console.log('then', res) }),出栈走异步代码,把回调函数4 => { console.log('then', 4) }放入微任务队列等待。
先执行同步代码,如遇到异步代码,则把异步回调事件放到后台监听或对应的任务队列。
- 执行
console.log(1),控制台输出1。 - 执行定时器,遇到异步代码,后台注册定时器回调事件,时间到了,把回调函数
() => {console.log('setTimeout', 2)},放到宏任务队列等待。 - 执行创建
Promise实例,并执行其中同步代码:执行console.log('promise', 3),控制台输出promise 3;执行resolve(4),此时Promise已经确定为完成fulfilled状态,把promise.then()的回调函数响应值设为4。 - 执行定时器,遇到异步代码,后台注册定时器回调事件,时间未到,把回调函数
() => { console.log('setTimeout', 5) }放到后台监听。 - 执行
promise.then(res => { console.log('then', res) }),出栈走异步代码,把回调函数4 => { console.log('then', 4) }放入微任务队列等待。
流程图执行-步骤二:
上面已经把同步代码执行完成,并且把对应异步回调事件放到了指定任务队列,接下来开始事件循环。
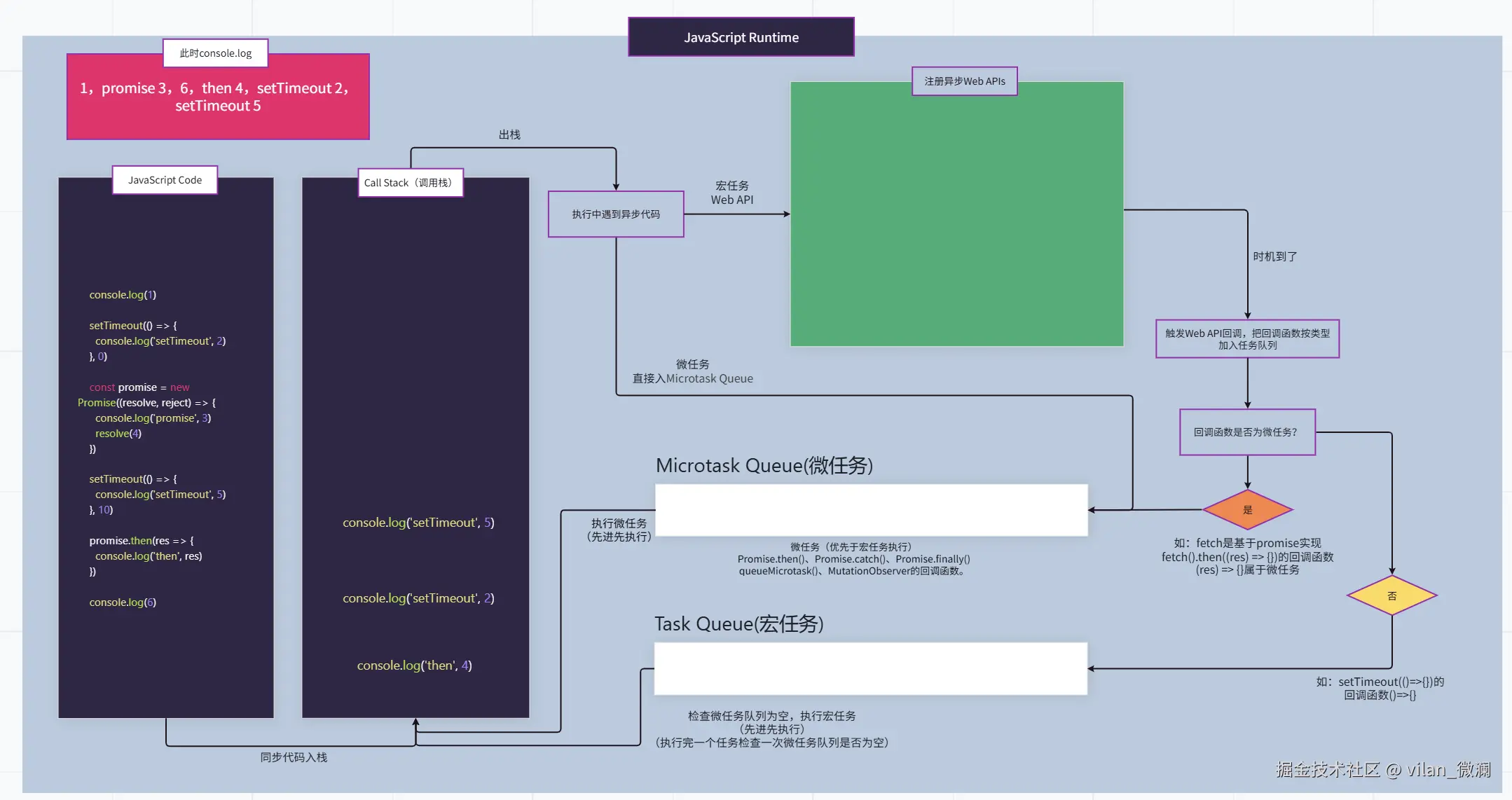
- 扫描微任务队列,执行
4 => { console.log('then', 4) }回调函数,控制台输出then 4。 - 微任务队列为空,扫描宏任务队列,执行
() => {console.log('setTimeout', 2)}回调函数,控制台输出setTimeout 2。 - 每执行完一个宏任务,需要再次扫描微任务队列是否存在可执行任务(假设此时后台定时到了,则会把
() => { console.log('setTimeout', 5) }加入到了宏任务队列末尾)。 - 微任务队列为空,扫描宏任务队列,执行
() => { console.log('setTimeout', 5) },控制台输出setTimeout 5。
上面已经把同步代码执行完成,并且把对应异步回调事件放到了指定任务队列,接下来开始事件循环。
- 扫描微任务队列,执行
4 => { console.log('then', 4) }回调函数,控制台输出then 4。 - 微任务队列为空,扫描宏任务队列,执行
() => {console.log('setTimeout', 2)}回调函数,控制台输出setTimeout 2。 - 每执行完一个宏任务,需要再次扫描微任务队列是否存在可执行任务(假设此时后台定时到了,则会把
() => { console.log('setTimeout', 5) }加入到了宏任务队列末尾)。 - 微任务队列为空,扫描宏任务队列,执行
() => { console.log('setTimeout', 5) },控制台输出setTimeout 5。
演示三:稍有难度
setTimeout+Promise组合拳+多层嵌套Promise
console.log(1)
setTimeout(() => {
console.log('setTimeout', 10)
}, 0)
new Promise((resolve, reject) => {
console.log(2)
resolve(7)
new Promise((resolve, reject) => {
resolve(5)
}).then(res => {
console.log(res)
new Promise((resolve, reject) => {
resolve('嵌套第三层 Promise')
}).then(res => {
console.log(res)
})
})
Promise.resolve(6).then(res => {
console.log(res)
})
}).then(res => {
console.log(res)
})
new Promise((resolve, reject) => {
console.log(3)
Promise.resolve(8).then(res => {
console.log(res)
})
resolve(9)
}).then(res => {
console.log(res)
})
console.log(4)
上一个演示说明了流程图执行的详细步骤,下面就不多加赘叙了,直接看图!
talk is cheap, show me the chart
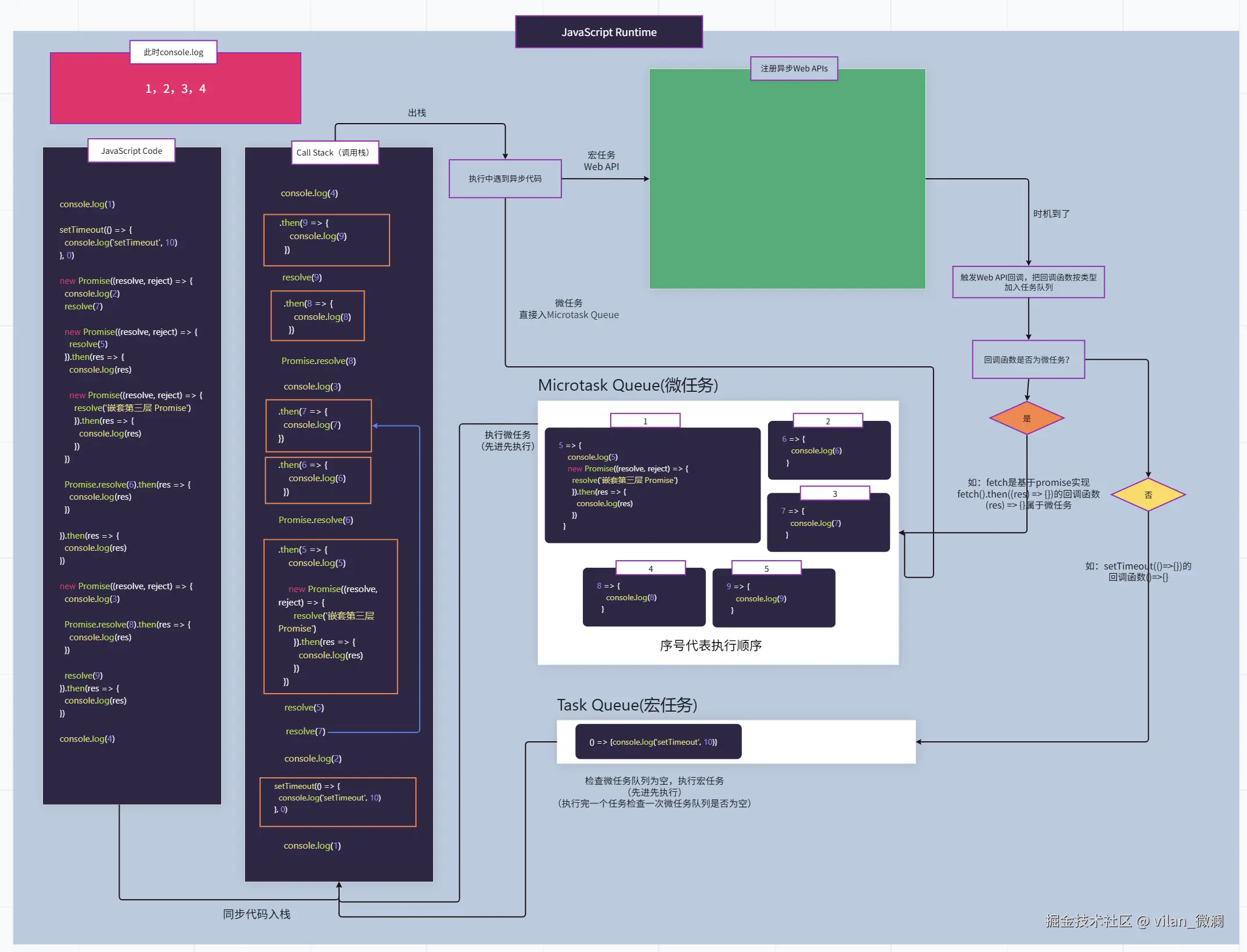
上图,调用栈同步代码执行完成,开始事件循环,先看微任务队列,发现不为空,按顺序执行微任务事件:
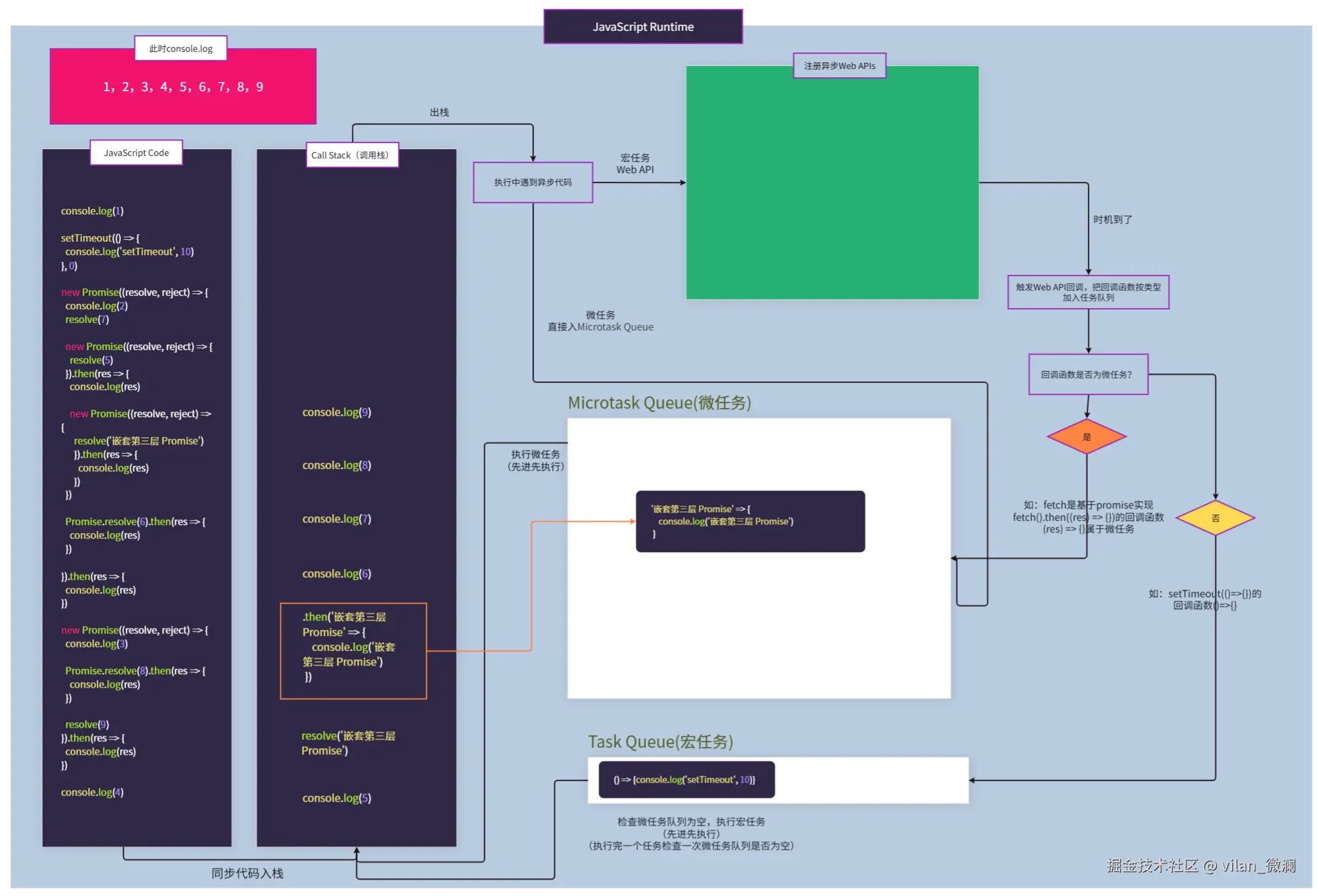
上图,已经把刚才排队的微任务队列全部清空了。但是在执行第一个微任务时,发现还有嵌套微任务,则把该任务放到微任务队列末尾,然后接着一起执行完所有新增任务。
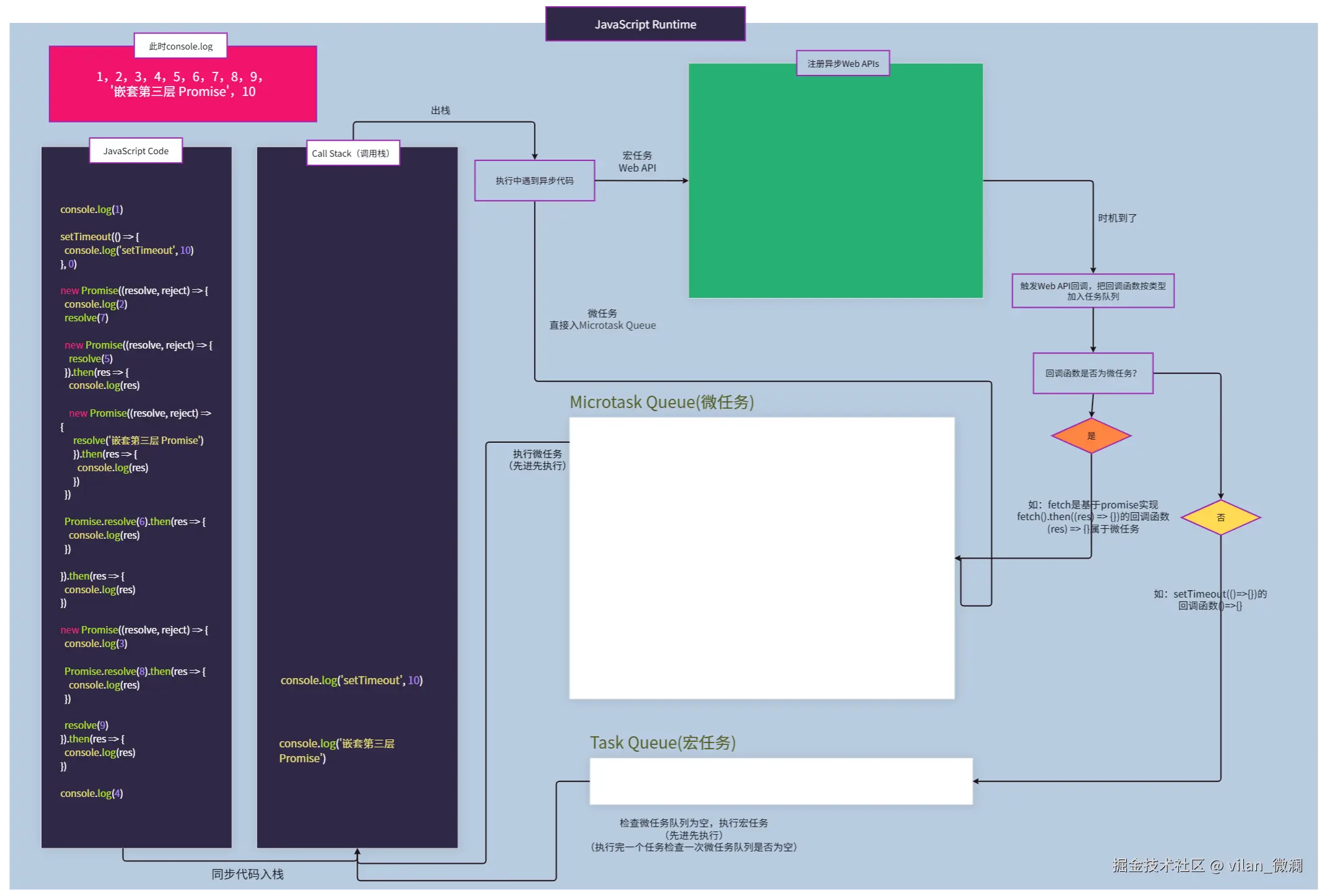
最后微任务清空后,接着执行宏任务。到此全部事件已执行完毕!
控制台完整输出顺序:
1 2 3 4 5 6 7 8 9 10
演示四:setTimeout伪定时
setTimeout并不是设置的定时到了就马上执行,而是把定时回调放在task queue任务队列当中进行等待,待主线程调用栈中的同步任务执行完成后空闲时才会执行。
const startTime = Date.now()
setTimeout(() => {
const endTime = Date.now()
console.log('setTimeout cost time', endTime - startTime)
// setTimeout cost time 2314
}, 100)
for (let i = 0; i < 300000; i++) {
// 模拟执行耗时同步任务
console.log(i)
}
控制台输出:
1 2 3 ··· 300000 setTimeout cost time 2314
下图演示了其执行流程:
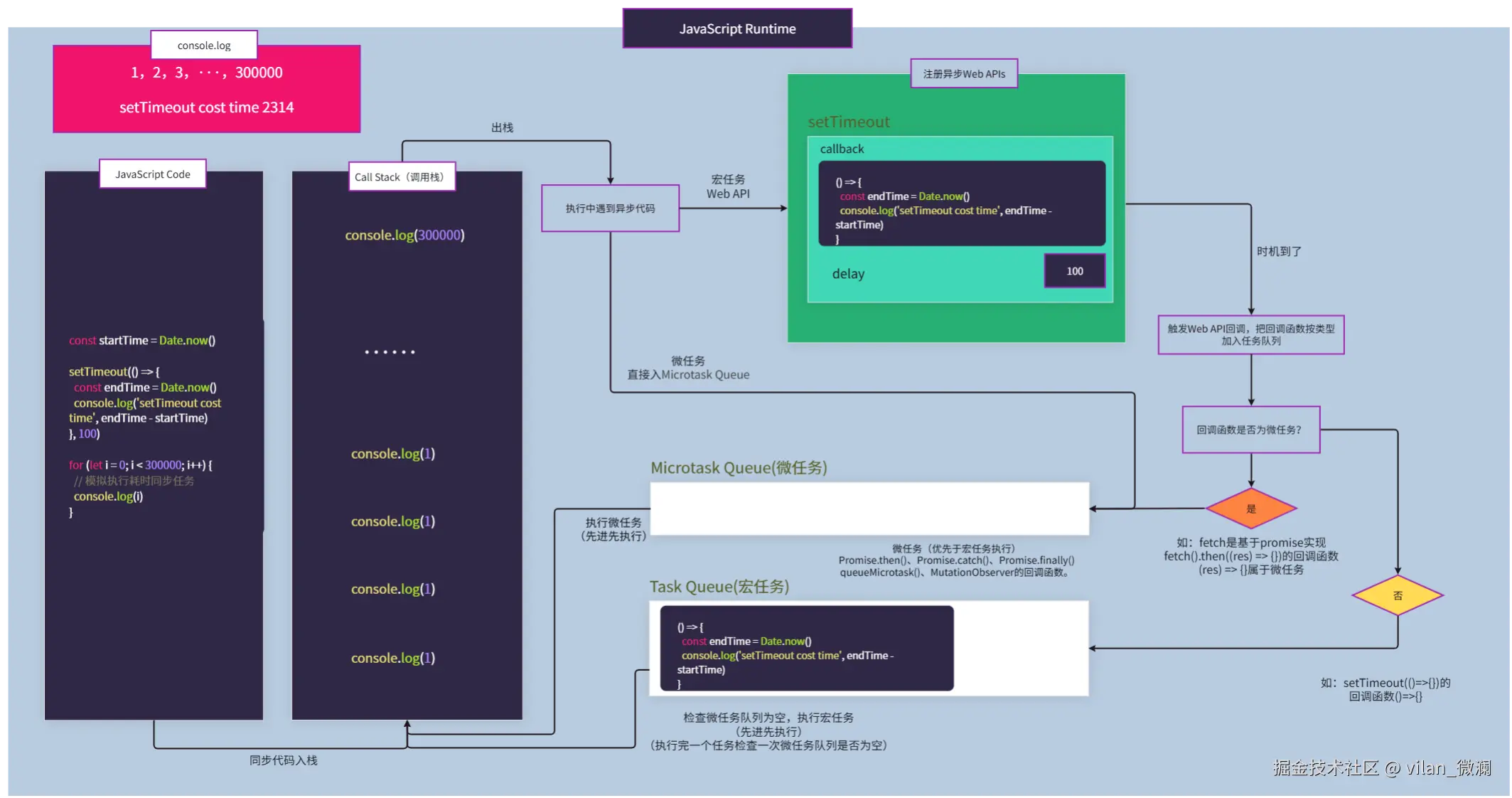
演示五:fetch网络请求和setTimeout
获取网络数据,fetch回调函数属于微任务,优于setTimeout先执行。
setTimeout(() => {
console.log('setTimeout', 2)
}, 510)
const startTime = Date.now()
fetch('http://localhost:3000/test').then(res => {
const endTime = Date.now()
console.log('fetch cost time', endTime - startTime)
return res.json()
}).then(data => {
console.log('data', data)
})
下图当前Call Stack执行栈执行完同步代码后,由于fetch和setTimeout都是宏任务,所以走宏任务Web API流程后注册这两个事件回调,等待定时到后了,由于定时回调是个普通的同步函数,所以放到宏任务队列;等待fetch拿到服务器响应数据后,由于fetch回调为一个Promise对象,所以放到微任务队列。
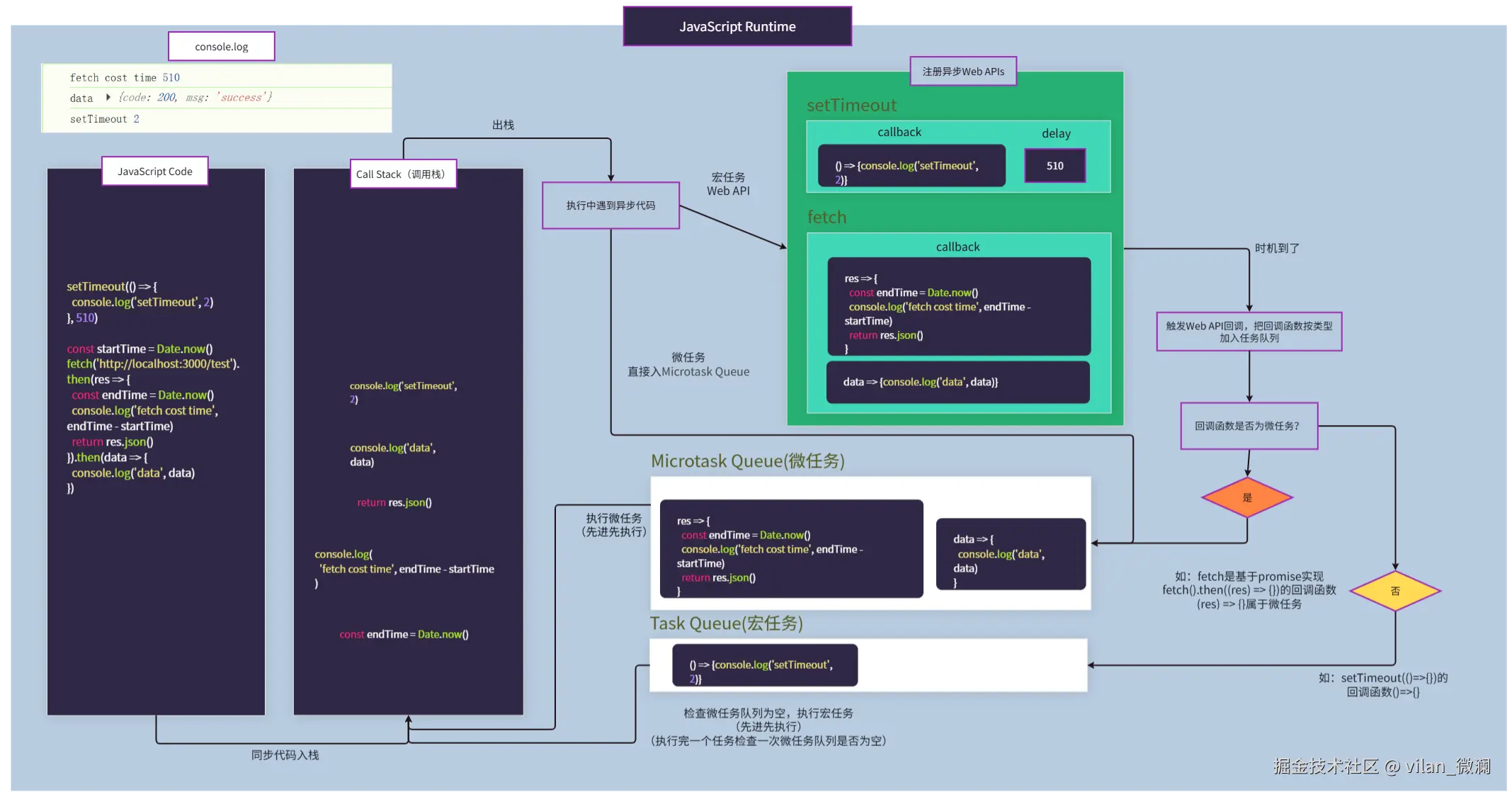
经过多番刷新网页测试,下图控制台打印展示了setTimeout延时为510ms,fetch请求响应同样是510ms的情况下,.then(data => { console.log('data', data) })先执行了,也是由于fetch基于Promise实现,所以其回调为微任务。

五、结语
这可能只是简单的JavaScript代码执行事件循环流程,目的也是让大家更直观理解其中原理。实际执行过程可能还会读取堆内存获取引用类型数据、操作dom的方法,可能还会触发页面的重排、重绘等过程、异步文件读取和写入操作、fetch发起网络请求,与服务器建立连接获取网络数据等情况。
但是,它们异步执行的回调函数都会经过图中的这个事件循环过程,从而构成完整的浏览器事件循环。
来源:juejin.cn/post/7577395040592756746
老板:能不能别手动复制路由了?我:写个脚本自动扫描
起因
周五快下班,老板过来看权限配置页面。
"这个每次都要手动输路径?"
"对,现在是这样。"我打开给他看:
角色:运营专员
路由路径:[手动输入] /user/list
组件路径:[手动输入] @/views/user/List.vue
"上次运营配错了,/user/list 写成 /user/lists,页面打不开找了半天。能不能做个下拉框,直接选?"
我想了想:"可以,但得先有个页面列表。"
"那就搞一个,现在页面这么多,手动输容易出错。"
确实,项目现在几十个页面,每次配置权限都要翻代码找路径,复制粘贴,还担心复制错。
解决办法
周末琢磨了一下,其实就是缺个"页面清单"。views 目录下都是页面文件,扫描一遍不就有了?
写了个 Node 脚本,自动扫描 views 目录,生成路由映射表。配置权限的时候下拉框选,还能搜索。
实现
两步:扫描文件 + 生成映射。
扫描 .vue 文件
function getAllVueFiles(dir, filesList = []) {
const files = fs.readdirSync(dir);
files.forEach((file) => {
const filePath = path.join(dir, file);
if (fs.statSync(filePath).isDirectory()) {
getAllVueFiles(filePath, filesList); // 递归子目录
} else if (file.endsWith(".vue")) {
filesList.push(filePath); // 收集 .vue 文件
}
});
return filesList;
}
生成映射文件
function start() {
const viewsDir = path.resolve(__dirname, "../views");
let files = getAllVueFiles(viewsDir);
// 兼容 Windows 路径
files = files.map(item => item.replace(/\\/g, "/"));
// 拼接成 import 映射
let str = "";
files.forEach(item => {
let n = item.replace(/.*src\//, "@/");
str += `"${n}":()=>import("${n}"),\r\n`;
});
// 写入文件
fs.writeFileSync(
path.resolve(__dirname, "../router/all.router.js"),
`export const ROUTERSDATA = {\n${str}}`
);
}
最后生成的文件大概是这样:
// src/router/all.router.js
export const ROUTERSDATA = {
"@/views/Home.vue": () => import("@/views/Home.vue"),
"@/views/About.vue": () => import("@/views/About.vue"),
"@/views/user/List.vue": () => import("@/views/user/List.vue"),
}
怎么用
权限配置页面
<template>
<el-select
v-model="selectedRoute"
filterable
placeholder="搜索并选择页面">
<el-option
v-for="(component, path) in ROUTERSDATA"
:key="path"
:label="path"
:value="path">
{{ path }}
</el-option>
</el-select>
</template>
<script setup>
import { ROUTERSDATA } from '@/router/all.router.js'
// 后台返回的权限路由配置
const permissionRoutes = [
{ path: '/user/list', component: '@/views/user/List.vue' },
{ path: '/order/list', component: '@/views/order/List.vue' }
]
// 直接从映射表取组件
const routes = permissionRoutes.map(route => ({
path: route.path,
component: ROUTERSDATA[route.component] // 这里直接用
}))
</script>
好处:
- 下拉框自动包含所有页面
- 支持搜索,输入 "user" 就能找到所有用户相关页面
- 新加页面自动出现在列表里
动态路由
后台返回权限配置,前端从映射表取组件:
function generateRoutes(backendConfig) {
return backendConfig.map(item => ({
path: item.path,
component: ROUTERSDATA[item.component] // 直接用
}))
}
效果
周一把代码提上去,改了权限配置页面:
<!-- 配置页面 -->
<el-select v-model="route" filterable placeholder="搜索页面">
<el-option
v-for="(component, path) in ROUTERSDATA"
:key="path"
:label="path"
:value="path" />
</el-select>
老板过来试了一下,在下拉框输入 "user" 就搜到所有用户相关页面。
"嗯,这个好用。新加页面也会自动出现在这里吧?"
"对,每次启动项目会自动扫描。"
"行,那就这样。"
后来发现还有些意外收获:
- 新人看这个映射表就知道项目有哪些页面
- 后台只存路径字符串,数据库干净
- 顺带解决了手动 import 几十个路由的问题
在 package.json 加个脚本:
{
"scripts": {
"dev": "node src/start/index.js && vite"
}
}
每次 npm run dev 会先扫描 views 目录,生成最新的映射表。
完整代码
// src/start/index.js
const fs = require("fs");
const path = require("path");
function getAllVueFiles(dir, filesList = []) {
const files = fs.readdirSync(dir);
files.forEach((file) => {
const filePath = path.join(dir, file);
const stat = fs.statSync(filePath);
if (stat.isDirectory()) {
getAllVueFiles(filePath, filesList);
} else if (file.endsWith(".vue")) {
filesList.push(filePath);
}
});
return filesList;
}
function start() {
console.log("[自动获取全部可显示页面]");
const viewsDir = path.resolve(__dirname, "../views");
let files = getAllVueFiles(viewsDir);
// 统一路径分隔符,兼容 Windows 反斜杠
files = files.map((item) => item.replace(/\\/g, "/"));
let str = "";
// 构造 import 映射:"@/views/xxx.vue": ()=>import("@/views/xxx.vue")
files.forEach((item) => {
let n = item.replace(/.*src\//, "@/");
str += `"${n}":()=>import("${n}"),\r\n`;
});
const routerFilePath = path.resolve(__dirname, "../router/all.router.js");
// 将映射写入路由聚合文件,供路由动态引用
fs.writeFileSync(
routerFilePath,
`
export const ROUTERSDATA = {
${str}
}`,
);
console.log("[./src/router/all.router.js 写入]");
}
start();
注意事项
记得把生成的 src/router/all.router.js 加到 .gitignore,毕竟是自动生成的文件,没必要提交。
# .gitignore
src/router/all.router.js
后来
用了一个多月,运营配置权限再也没出过错。上周老板说:"这个功能不错,其他项目也加上。"
代码其实挺简单的,但确实解决了问题。
来源:juejin.cn/post/7582808491583504420
为什么 SVG 能在现代前端中胜出?
如果你关注前端图标的发展,会发现一个现象:
过去前端图标主要有三种方案:
- PNG 小图(配合雪碧图)
- Iconfont
- SVG
到了今天,大部分中大型项目都把图标系统全面迁移到 SVG。
无论 React/Vue 项目、新框架(Next/Remix/Nuxt),还是大厂的设计规范(Ant Design、Material、Carbon),基本都默认 SVG。
为什么是 SVG 胜出?
为什么不是 Iconfont、不是独立 PNG、不是雪碧图?
答案不是一句“清晰不失真”这么简单。
下面从前端实际开发的角度,把 SVG 胜出的原因讲透。
一、SVG 为什么比位图(PNG/JPG)更强?
① 矢量图永不失真(核心优势)
PNG/JPG 是位图,只能按像素存图。
移动端倍率屏越来越高(2x、3x、4x……),一张 24px 的 PNG 在 iPhone 高分屏里可能看起来糊成一团。
SVG 是矢量图,数学计算绘制:
- 任意缩放不糊
- 任意清晰度场景都不怕
- 深色模式也不会变形
这点直接解决了前端图标领域长期存在的一个痛点:适配成本太高。
② 体积小、多级复用不浪费
同样一个图标:
- PNG 做 1x/2x/3x 需要三份资源
- SVG 只要一份
而且:
- SVG 本质是文本
- gzip 压缩非常有效
在 CDN 下,通常能压到个位数 KB,轻松复用。
③ 图标换色非常容易
PNG 改颜色很麻烦:
- 设计师改
- 重新导出
- 重新上传/构建
Iconfont 的颜色只能统一,只能覆盖轮廓颜色,多色很麻烦。
SVG 则非常灵活:
.icon {
fill: currentColor;
}
可以跟随字体颜色变化,支持 hover、active、主题色。
深浅模式切换不需要任何额外资源。
④ 支持 CSS 动画、交互效果
SVG 不只是图标文件,它是 DOM,可以直接加动画:
- stroke 动画
- 路径绘制动画
- 颜色渐变
- hover 发光
- 多段路径动态控制
PNG 和 Iconfont 都做不到这种级别的交互。
很多现代 UI 的微动效(Loading、赞、收藏),都是基于 SVG 完成。
二、SVG 为什么比 iconfont 更强?
Iconfont 在 2015~2019 年非常火,但明显已经退潮了。
原因有以下几个:
① 字体图标本质是“字符”而不是图形
这带来大量问题:
● 不能多色
只能 monochrome,彩色图标很难实现。
● 渲染脆弱
在 Windows 某些字体渲染环境下会出现:
- 发虚
- 锯齿
- baseline 不一致
● 字符冲突
不同项目的字体图标可能互相覆盖。
相比之下,SVG 是独立图形文件,没有这些问题。
② iconfont 需要加载字体文件,失败会出现“乱码方块”
如果字体文件没加载成功,你会看到:
☐ ☐ ☐ ☐
这在弱网、支付类页面、海外环境都非常常见。
SVG 就没有这个风险。
③ iconfont 不利于按需加载
字体文件通常包含几十甚至几百个图标:
一次加载很重,不够精细。
SVG 可以做到按需加载:
- 一个组件一个 SVG
- 一个页面只引入用到的部分
- 可组合、可动态切换
对于现代构建体系非常友好。
三、SVG 为什么比“新版雪碧图”更强?
即便抛开 iconfont,PNG 雪碧图也完全被淘汰。
原因很简单:
- 雪碧图文件大
- 缓存粒度差
- 不可按需加载
- 维护复杂
- retina 适配麻烦
- 颜色不可动态变更
而 SVG 天生具备现代开发所需的一切特性:
- 轻量化
- 组件化
- 可变色
- 可动画
- 可 inline
- 可自动 tree-shaking
雪碧图本质上是为了“减少请求数”而生的产物,
但在 HTTP/2/3 中已经没有价值。
而 SVG 不是 hack,而是自然适配现代 Web 的技术方案。
四、SVG 为什么能在工程体系里更好地落地?
现代构建工具(Vite / Webpack / Rollup)原生支持 SVG:
- 转组件
- 优化路径
- 压缩
- 自动雪碧(symbol sprite)
- Tree-shaking
- 资源分包
这让 SVG 完全融入工程体系,而不是外挂方案。
例如:
import Logo from './logo.svg'
你可以:
- 当组件使用
- 当资源下载
- 当背景图
- 动态注入
工程化友好度是它胜出的关键原因之一。
五、SVG 胜出的根本原因总结
不是 SVG “长得好看”,也不是趋势,是整个现代前端生态把它推到了最合适的位置。
1)协议升级:HTTP/2/3 让雪碧图和 Iconfont 的优势全部消失
2)设备升级:高分屏让位图模糊问题暴露得更明显
3)工程升级:组件化开发需要精细化图标
4)体验升级:动画、主题、交互都离不开 SVG
一句话总结:
SVG 不只是“更清晰”,而是从工程到体验全面适配现代前端的图标方案,因此胜出。
来源:juejin.cn/post/7577691061034172462
做中国人自己的视频编辑UI框架,WebCut正式开源
朋友们晚上好啊,这段时间我在忙着完成最新的开源项目WebCut。这个项目是我这小半年来唯一的开源新项目,这对比我过去几年的一些开源事迹来说,真的是一段低产荒。不过这是正常的,没有任何人可以长时间的一直发布新项目,这种沉寂,正是因为我把时间和精力都投入在其他事情上,所以其实是好事。之所以要发起和开源这个项目,说起来还是有些背景,下面我会来聊一聊关于这个项目的一些背景,以及过程中在技术上的一些探索。
没有合适的视频编辑UI框架😭
过去半年,我连续发布了多款与视频相关的产品,这些产品或多或少都需要用户参与视频编辑操作,比如给视频添加字幕、对视频进行裁剪、给视频配音等等,这些在视频编辑器中常见的视频处理工具,在Web端其实需求非常巨大,特别是现在AI领域,制作各种个样的视频的需求非常多。而这些需求,可能并不需要在产品中载入一整个视频编辑器,而是只需要几个简单的部件来实现编辑功能。然而回望开源市场,能够支持这种编辑能力的项目少之又少,虽然有一些项目呈现了视频编辑的能力,然而,要么项目太大,一个完整的视频编辑器甩在开发者脸上,要么过于底层,没有UI界面。如果我只是想有一个视频预览,再有轨道和几个配置界面,就没法直接用这些项目。包括我自己在内,每次有与视频相关的功能,都要把之前在另外一个产品中实现的编辑能力移植到新产品中,而且要调的细节也很多。正是这种求而不得的现状,促使我打算自己写一个视频编辑器项目。
初始想法💡:拼积木
我可不是从0开始的,因为我已经开发过很多次视频编辑相关的功能了。我还在Videa项目中完整实现了一个视频编辑器。因此,我的想法是把我之前做过的功能,整理一遍,就可以得到想要的组件或逻辑。有了这个工具包之后,我只需要在将来的新产品中复用这些代码即可。于是我建立了一个独立的npm包,来把所有功能集中放在一起。随着持续的迭代,我发现其实这里面是有规律的。
视频编辑器我们都用过,像剪映一样,有各种功能,细节也很多。但是,当我们把视频编辑的功能放到某个具体的产品中时,我们是不可能直接把整个编辑器给用户的。实际上,我们最终呈现的产品形态,基本上都是剪映的子集,而且是很小很小的子集,可能只是整个剪映1%的功能,最终给到用户操作可能只是非常简单的一次性操作,而页面也很轻量,属于用户即用即走,用完就关再也不会来第二次的那种。正是这种看似功能点很小,但实际上需要为它单独定制,技术上的成本可以用巨大来描述的场景,让我觉得这是一个需要认真对待的点。
我的计划是采用组件化的思想,把一个视频编辑器拆成一个一个的组件,把一个完整的剪映编辑器,拆成一个按钮一个按钮的积木。当我们面对产品需求时,就从这些积木中挑选,然后组合成产品经理所描述的功能,同时,具体这些积木怎么布局,则根据设计稿调整位置,还可以用CSS来覆盖组件内部的样式,达到与设计稿媲美的效果。
上面是我用AI做的一张示意图,大概就是这个意思,把一个编辑器拆的细碎,然后要什么功能就把对应的组件拿来拼凑一下。比如要对视频进行静音裁剪,就只要把预览区和轨道区拿出来,然后自己再增加一些能力上去。这样,开发者在面对各种各样的需求时,就能快速搭建起界面效果,而不需要从头实现界面和视频处理能力。
通过不同的组合方式,配合开发者自己的布局,就可以创建符合需求的视频编辑界面。
没那么容易😥:外简内繁的接口艺术
虽然想法很容易有,但是要做成成品,并且发布为可用的库可没那么轻松。要知道视频编辑器的功能非常多,多到我们无法用简单的文字描述它们。那么,如何才能站在开发者的角度,让这件事变得简单呢?
开发库永远面临着一个矛盾:灵活性和规范性之间的矛盾。灵活性就是暴露又多又细的接口,让开发者可以用不同参数,玩出花活,例如知名项目echarts早期就是这种。这种对于刚上手的开发者而言,无言是一场灾难,他们甚至不知道从哪里开始,但是一旦完全掌握,就相当于拥有了一个武器库,可以为所欲为。而规范性则是强制性规则比较多,只能暴露少量接口,避免开发者破坏这种规范,例如很多前端UI组件库就是这样。这两者之间的矛盾,是每一个库或框架开发者最难平衡的。
在视频编辑器上,我认为有些东西是固定的,几乎每一个需求都会用到,例如视频预览播放器、控制按钮等,但是有些功能是低频功能,例如媒体库、字幕编辑等。因此,对于高频和低频的功能,我用两种态度去处理。
高频的功能,拆的很细,拆到一个按钮为止,例如视频播放器,看上去已经很单一了,但是,我还要把预览屏幕和播放按钮拆开,屏幕和按钮如何布局就可以随意去处理。类似的还有导出按钮、分割片段按钮等等。把这些工具拆分为一个一个最小的单元,由开发者自由布局,这样就可以很好的去适配产品需求。
对于低频功能,则直接导出为大组件,这样就可以在一个组件内完成复杂的逻辑,减少开发这些组件时需要跨组件控制状态的心智成本。比如媒体库,里面包含了媒体的管理、上传、本地化等等,这些逻辑还是很复杂的,如果还是按照细拆思路,那么实现起来就烦得要死。因此,这类工具我都是只暴露为一个大的组件。
同时,为了方便开发者在某些情况下快捷接入,我会设计一些自己看到的不错的编辑器UI,然后用上诉的工具把它们搭出来,这样,开发者如果在产品需求中发现仓库里已经有功能一致的组件,就不需要自己去组合,直接使用对应组件即可。
以模仿剪映为例,开发者只需要接入WebCutEditor这个组件即可:
<script setup>
import { WebCutEditor } from 'webcut';
import 'webcut/esm/style.css';
</script>
<template>
<WebCutEditor />
</template>
这样就可以得到一个界面接近于剪映的视频编辑器。
数据驱动,视频编辑的DSL
经过我的研究,发现对于单纯的视频编辑而言,编辑器其实只需要两份数据,就可以解决大部分场景下的需求。一份是编辑的素材数据,一份是视频的配置数据。
素材数据
它包含素材文件本身的信息、素材的组织信息、素材的属性信息。
文件信息
我通过opfs将文件存在本地,并且在indexedDB中存储每一个文件的关联信息。包含文件的类型、名称、大小等。在一个域名下,每一个文件的实体(也就是File对象)只需要一份,通过file-md5值作为索引存在opfs中。而一个文件可能会在多处被使用,indexedDB中则是记录这些信息,多个关联信息可同时链接到同一个File。另外,基于indexedDB的特性,还可以实现筛选等能力。
素材组织信息
主要是指当把素材放在视频时间轨道中时,所需要的数据结构。包含轨道列表、素材所对应的文件、素材对应时间点、播放时的一些属性等等信息。这些信息综合起来,我们就知道,在视频的某一个时刻,应该播放什么内容。
素材属性信息
在播放中,素材以什么方式呈现,如文本的样式、视频音频的播放速度、动画、转场等。
配置数据
主要指视频本身的信息,在导出时这些配置可以直接体现出来,例如视频的分辨率、比例、速率等,视频是否要添加某些特殊的内容,例如水印等。
基于素材数据和配置数据,我们基本上可以完整的知道当前这个视频的编辑状态。通过数据来恢复当前的编辑状态,变得可行,这可以抵消用户在浏览器中经常执行“刷新”操作带来的状态丢失。同时,这份数据也可以备份到云端,实现多端的同步(不过需要同时同步File,速度肯定会受影响)。而且由于数据本身是纯序列化的,因此,可以交给AI来进行处理,例如让AI调整一些时间、样式等可基于纯序列化数据完成的功能。这就让我们的编辑器变得有更多的玩法。
发布上线🌏
经过几天的工作,我终于把代码整理完整,经过调试之后,基本可用了,便迫不及待的准备与大家分享。现在,你可以使用这个项目了。
由于底层是由Vue3作为驱动的,因此,在Vue中使用有非常大的优势,具体如下:
npm i webcut
先安装,安装之后,你就可以在Vue中如下使用。
<script setup>
import { WebCutEditor } from 'webcut';
import 'webcut/esm/style.css';
</script>
<template>
<WebCutEditor />
</template>
或者如果你的项目支持typescript,你可以直接从源码进行引入,这样就不必主动引入css:
<script setup lang="ts">
import { WebCutEditor } from 'webcut/src';
</script>
如果是非Vue的项目,则需要引用webcomponents的构建产物:
import 'webcut/webcomponents';
import 'webcut/webcomponents/style.css';
export default function Some() {
return <webcut-editor></webcut-editor>;
}
如果是直接在HTML中使用,可以直接引入webcomponents/bundle,这样包含了Vue等依赖,就不需要另外构建。
<script src="https://unpkg.com/webcut/webcomponents/bundle/index.js"></script>
<link rel="stylesheet" href="https://unpkg.com/webcut/webcomponents/bundle/style.css" />
<webcut-editor></webcut-editor>
如果是想自己布局,则需要引入各个很小的组件来自己布局。在这种情况下,你必须引入WebCutProvider组件,将所有的子组件包含在内。
<webcut-provider>
<webcut-player></webcut-player>
<webcut-export-button></webcut-export-button>
</webcut-provider>
未来展望
当前,WebCut还是处于很初级的阶段,实现了最核心的能力,我的目标是能够为开发者们提供一切需要的组件,并且不需要复杂的脚本处理就可以获得视频编辑的全部功能。还有很多功能没有实现,在计划中:
- 历史记录功能,包含撤销和重做功能
- 内置样式的字体
- 花字,比内置样式更高级的文本
- 轨道里的素材吸附能力
- 视频的轨道分离(音频分离)
- 音视频的音量调节
- 单段素材的下载导出
- 整个视频导出时可以进行分辨率、码率、速率、编码、格式的选择,支持只导出音频
以上这些都是编辑的基本功能。还有一些是从视频编辑定制化的角度思考的能力:
- 动画(帧)支持
- 转场过渡效果支持
- 扩展功能模块,这部分可能会做成收费的,下载模块后,通过一个接口安装一下,就可以支持某些扩展功能
- AI Agent能力,通过对话来执行视频编辑,降低视频编辑的门槛
- 视频模板,把一些流行的视频效果片段做成模板,在视频中直接插入后,与现有视频融合为模板中的效果
- 基于AI来进行短剧创作的能力
要实现这些能力,需要大量的投入,虽然现在AI编程非常火热,但是真正能够完美实现的,其实还比较少,因此,这些工作都需要小伙伴们的支持,如果你对这个项目感兴趣,可以通过DeepWiki来了解项目代码的底层结构,并fork项目后,向我们提PR,让我们一起共建一个属于我们自己的视频编辑UI框架。
最后,你的支持是我前进的动力,动动你的小手,到我们的github上给个start,让我们知道你对此感兴趣。
来源:juejin.cn/post/7579819594270900262
我为什么放弃了XMind和亿图,投向了这款开源绘图工具的怀抱?
关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
思维导图、流程图应该是每个程序员都会用到的绘图工具。Xmind和亿图曾是我的首选工具,但是免费版功能受限,高级功能需付费,用起来总是差点意思。虽然通过其他方式正常使用(大家都懂得),但是软件的更新根本不敢动,一旦更新就会前功尽弃......而且两款工具总会来回切换,虽已习惯,但稍显麻烦!
直到不久前逛GitHub发现了一款开源的且可以在线使用的工具:Drawnix。界面简约,满足日常基本绘图需求,且支持 mermaid 语法转流程图等,用起来非常丝滑。整理一下分享给大家!
02 简介
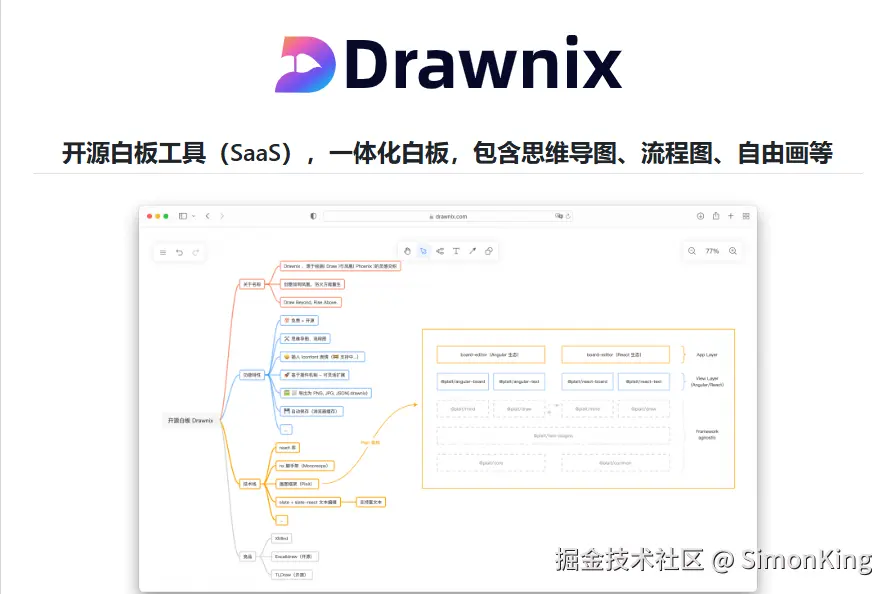
2.1 名称的由来
Drawnix ,源于绘画( Draw)与凤凰( Phoenix )的灵感交织。凤凰象征着生生不息的创造力,而 Draw代表着人类最原始的表达方式。在这里,每一次创作都是一次艺术的涅槃,每一笔绘画都是灵感的重生。
创意如同凤凰,浴火方能重生,而 Drawnix 要做技术与创意之火的守护者。
2.2 框架
Drawnix 的定位是一个开箱即用、开源、免费的工具产品,它的底层是 Plait框架,Plait 是作者公司开源的一款画图框架,代表着公司在知识库产品上的重要技术沉淀。
Drawnix 是插件架构,与前面说到开源工具比技术架构更复杂一些,但是插件架构也有优势,比如能够支持多种 UI 框架(Angular、React),能够集成不同富文本框架(当前仅支持 Slate框架),在开发上可以很好的实现业务的分层,开发各种细粒度的可复用插件,可以扩展更多的画板的应用场景。
GitHub地址:
2.3 特性
- 💯 免费 + 开源
- ⚒️ 思维导图、流程图
- 🖌 画笔
- 😀 插入图片
- 🚀 基于插件机制
- 🖼️ 📃 导出为 PNG, JSON(
.drawnix) - 💾 自动保存(浏览器缓存)
- ⚡ 编辑特性:撤销、重做、复制、粘贴等
- 🌌 无限画布:缩放、滚动
- 🎨 主题模式
- 📱 移动设备适配
- 📈 支持 mermaid 语法转流程图
- ✨ 支持 markdown 文本转思维导图(新支持 🔥🔥🔥)
2.4 安装
提供Docker部署:
docker pull pubuzhixing/drawnix:latest
也可以在线使用:
地址:
03 最佳实践
实践我们采用在线方式,如果注重安全或者本地使用可以使用Docker部署。
3.1 界面说明
通过https://drawnix.com/进入之后,所有功能如图:
中间工具栏分别表示:
- 拖拽
- 选中
- 思维导图
- 文字
- 手绘
- 箭头
- 流程图
- 插入图片
- 格式转换
功能都比较简单,思维导图、流程图以及格式转化是常用的工具。
3.2 思维导图
思维导图的使用方式和Xmind的用法极为相似。选中节点,然后Tab键就可以添加同级子节点,也可以利用+号添加。-号并不是删除,而是合并。删除也非常简单,选中直接Delete即可。

3.3 流程图
流程图的图形相对来说比较简单,只有七项。
选中之后直接绘制即可,图形之间使用箭头链接即可。
3.4 格式转化
目前支持两种格式转化成流程图:

Mermaid
仅支持流程图、序列图和类图
Markdown
仅支持思维导图。
04 小结
Drawnix的极简设计满足日常绘图的需要,可能在很多功能上不如Xmind或者亿图,但是它确实两者的结合。是一款不错的绘图软件。
来源:juejin.cn/post/7582104240986963994
作为前端你必须要会的CICD
前言
这是一篇属于面向前端的关于CICD的入门文章,其旨在:
- 入门掌握
CI CD的用法 - 学习
CI和CD的含义及其实现细节 - 基于
GitLab展示如何给自己手上的项目添加CICD的流程
学习本文你需要注意的事情
- 你的项目必须是支持Node版本
16.20.0 - 笔者的CentOS安装Node18以上的版本底层库不支持,如果你想安装高版本的Node请先解决CentOS版本低的问题
- 本文采用的是CentOSLinux操作系统
- 本文的操作系统版本截图在下方
OK 如果你已经明白了我上面说的注意事项 那我们事不宜迟,直接开始本文的内容吧。
安装Node
(第一种)安装 NVM
请注意 如果使用这种安装方式在后面执行runner的时候在gitlab-runner账户会报错找不到Node 这是因为Linux的系统的用户环境隔离问题
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.1/install.sh | bash
更新环境变量
source ~/.bashrc
验证NVM是否安装成功
command -v nvm
使用NVM安装Node.js:
nvm install node
安装指定版
nvm install 16.20.0
使用 NVM 切换到安装的 Node.js 版本
nvm use node
nvm use node 16.20.0
验证安装:
node -v
npm -v
npx -v
(第二种)使用系统级 Node.js 安装
wget https://nodejs.org/dist/v16.20.0/node-v16.20.0-linux-x64.tar.xz
解压
tar xf node-v12.9.0-linux-x64.tar.xz
复制
cp -rf /root/node-v16.20.0-linux-x64 /usr/local/node
打开编辑配置文件
vim /etc/profile
在文件的最后一行加上这句话
export PATH=$PATH:/usr/local/node/bin
重载系统配置文件
source /etc/profile
这次在切换用户到gitlab-runner就可以查看到你安装的版本了
安装 Nginx
安装相关依赖
- zlib 开启 gzip 需要
- openssl 开启 SSL 需要
- pcre rewrite模块需要
- gcc-c++ C/C++ 编译器
yum -y install gcc-c++ zlib zlib-devel openssl openssl-devel pcre pcre-devel
下载压缩包
wget https://nginx.org/download/nginx-1.18.0.tar.gz
解压
tar -zxvf nginx-1.18.0.tar.gz
cd ./nginx-1.18.0
./configure
make
make install
查看安装路径
whereis nginx
编辑环境变量
vim /etc/profile
在文件最下面添加这两行
export NGINX_HOME=/usr/local/nginx
export PATH=$NGINX_HOME/sbin:$PATH
更新配置文件
source /etc/profile
查看nginx是否安装完成
nginx -v
开放 80 端口 如果不想一次性一个一个的放行端口,可以关闭防火墙
firewall-cmd --permanent --zone=public --add-port=80/tcp
查看防火墙的状态
systemctl status firewalld.service
关闭防火墙的状态
systemctl stop firewalld.service
查看已经放行的端口
firewall-cmd --zone=public --list-ports
重载防火墙
firewall-cmd --reload
启动
nginx
安装 GitLab
安装 GitLab,需要的时间比较长
yum -y install https://mirrors.tuna.tsinghua.edu.cn/gitlab-ce/yum/el7/gitlab-ce-14.3.0-ce.0.el7.x86_64.rpm
编辑配置文件
vim /etc/gitlab/gitlab.rb
修改配置文件
重载配置文件,
gitlab-ctl reconfigure
开放 1874 端口
firewall-cmd --permanent --zone=public --add-port=1874/tcp
查看已经放行的端口
firewall-cmd --zone=public --list-ports
重载防火墙
firewall-cmd --reload
修改gitlab的root用户密码
1.进入到gitlab控制面板中 gitlab-rails console -e production
2.执行命令: user = User.where(id: 1).first,此 user 则表示 root 用户
3、修改密码
执行命令:user.password = '12345678'修改密码
再次执行 user.password_confirmation = '12345678' 确认密码
4、保存密码
执行命令: user.save!
5、退出控制台
执行命令: exit
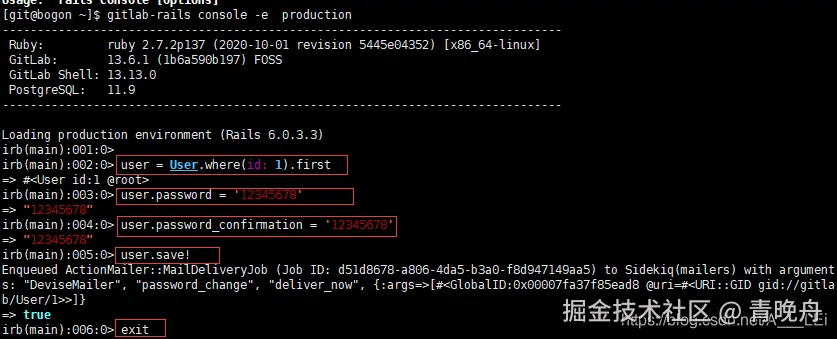
验证是否修改成功
http://192.168.80.130:1874/users/sign_in 把Ip换成自己的Ip 输入root的用户名和密码尝试进行登录,正常创建项目进行测试
配置 CI/CD
下载
wget -O /usr/local/bin/gitlab-runner https://gitlab-runner-downloads.s3.amazonaws.com/latest/binaries/gitlab-runner-linux-amd64
分配运行权限
chmod +x /usr/local/bin/gitlab-runner
创建用户
useradd --comment 'GitLab Runner' --create-home gitlab-runner --shell /bin/bash
安装 在 /usr/local/bin/gitlab-runner 这个目录下
gitlab-runner install --user=gitlab-runner --working-directory=/home/gitlab-runner
运行
gitlab-runner start
新建 runner
注册 runner
gitlab-runner register
输入 gitlab 的访问地址
输入 runner token
打开 http://192.168.80.130:1874/admin/runners 页面查看
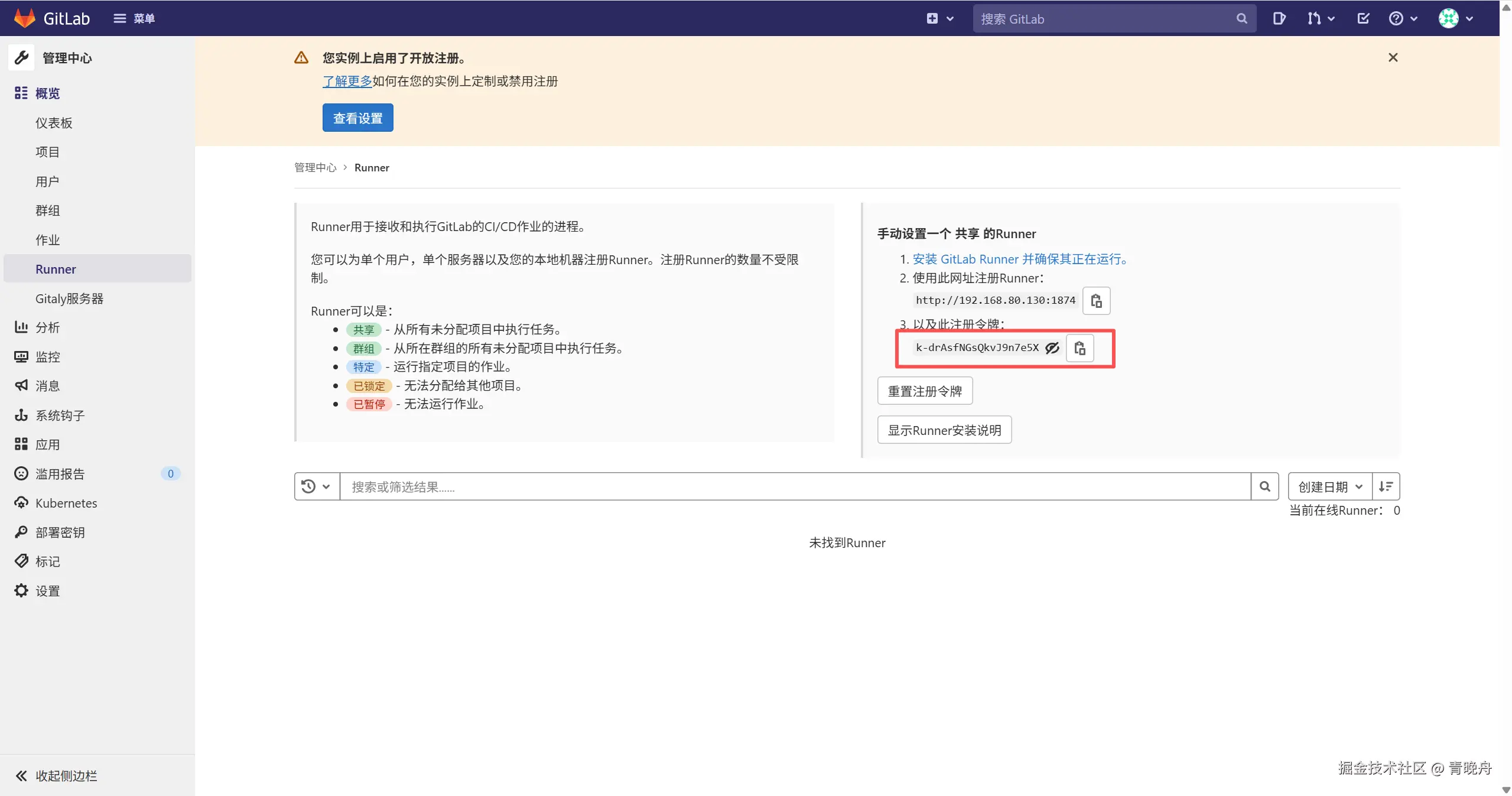
runner 描述,随便填
测试vue项目部署
runner tag
ceshi
Enter optional maintenance note for the runner:
直接回车走过
输入(选择) shell 最后一步选择执行的脚本
shell
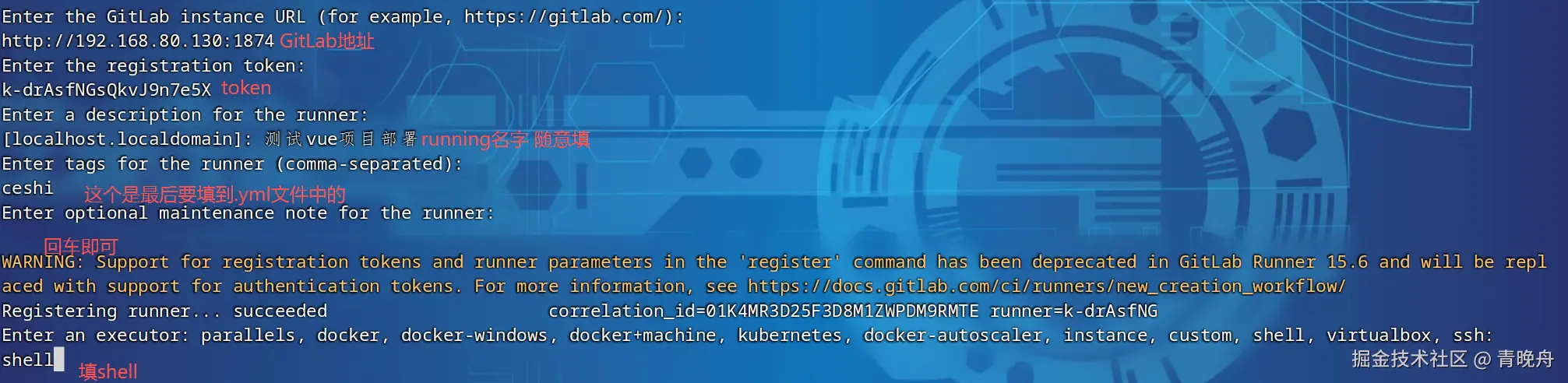
注册完成后,就可以在 http://192.168.80.130/admin/runners 里面看到创建的 runner。
nginx 配置项目访问地址
创建目录
mkdir -pv /www/wwwroot/dist
分配权限 如果后面执行脚本命令提示没有权限那就是这个地方有问题
chown gitlab-runner /www/wwwroot/dist/
(备用)如果权限有问题可以使用这个命令单独给这个目录设置上gitlab-runner用户权限
sudo chown -R gitlab-runner:gitlab-runner /www/wwwroot/
开放 3001 端口
firewall-cmd --permanent --zone=public --add-port=3001/tcp
重载防火墙 .
firewall-cmd --reload
打开 nginx 配置文件
vim /usr/local/nginx/conf/nginx.conf
在第一个 server 下方 (nginx 默认的,端口为80),加上下面的内容
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root html;
index index.html index.htm;
}
#error_page 404 /404.html;
# redirect server error pages to the static page /50x.html
#
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
#新增开始
server {
listen 3001;
server_name localhost;
location / {
root /www/wwwroot/dist;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
#新增结束
重新加载配置文件
nginx -s reload
编写 .gitlab-ci.yml 文件
# 阶段
stages:
- build
- deploy
# 缓存 node_modules 减少打包时间,默认会清除 node_modules 和 dist
cache:
paths:
- node_modules/
# 拉取项目,打包
build:
stage: build
tags:
- ceshi
before_script:
# - export PATH=/usr/local/bin:$PATH
- node --version
- npm --version
- echo "开始构建"
script:
- cd ${CI_PROJECT_DIR}
- npm install
- npm run build
only:
- main
artifacts:
paths:
- dist/
# 部署
deploy:
stage: deploy
tags:
- ceshi
script:
- rm -rf /www/wwwroot/dist/*
- cp -rf ${CI_PROJECT_DIR}/dist/* /www/wwwroot/dist/
only:
- main
浏览器打开3001端口
提交代码到main分支上,如果想改为提交到其他分支上也可以进行自动部署就需要改only参数为分支名称
来源:juejin.cn/post/7546420270421999642
当一个前端学了很久的神经网络...👈🤣
前言

最近在学习神经网络相关的知识,并做了一个简单的猫狗识别的神经网络,结果如图。
虽然有点绷不住,但这其实是少数情况,整体的猫狗分类正确率已经来到 90% 了。
本篇文章是给大家介绍一下我是如何利用前端如何做神经网络-猫狗训练的。如果觉得这篇文章有些复杂,那么也可以看看我的上一篇更简单的鸢尾花分类
步骤概览
还是掏出之前那个步骤流程,我们只需要按照这个步骤就可以训练出自己的神经网络
- 处理数据集
- 定义模型
- 神经网络层数
- 每层节点数
- 每层的激活函数
- 编译模型
- 训练模型
- 使用模型
最终的页面是这样的
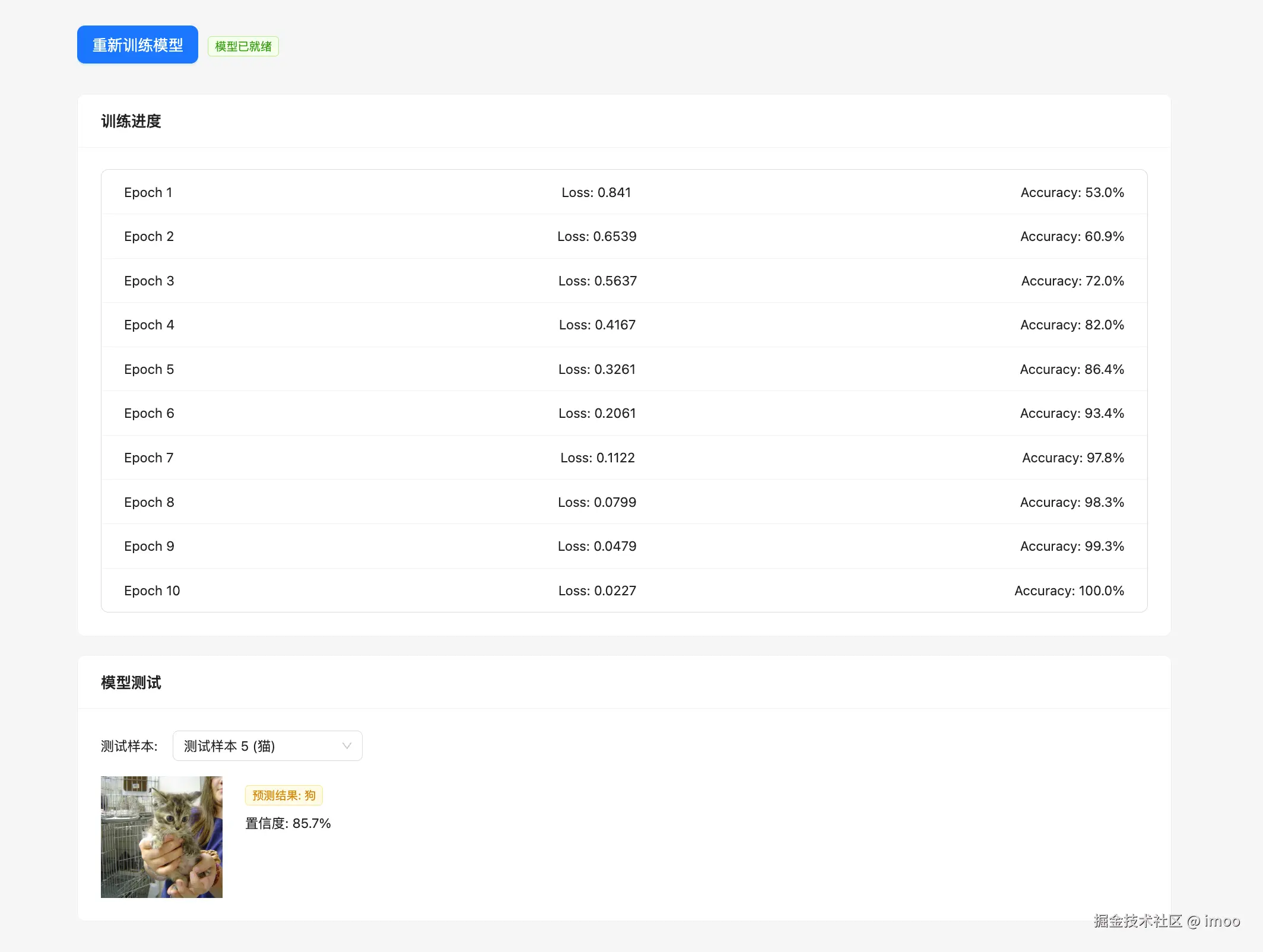
处理数据集
- 首先得找到数据集,本次使用的是这个 http://www.kaggle.com/datasets/li… 2000 个猫图,2000 个狗图,足够我们使用(其实我只用了其中 500 个,电脑跑太慢了)
- 由于这些图片大小不一致,首先我们需要将其处理为大小一致。这一步可以使用 canvas 来做,我统一处理成了 128 * 128 像素大小。
const preprocessImage = (img: HTMLImageElement): HTMLCanvasElement => {
const canvas = document.createElement("canvas");
canvas.width = 128;
canvas.height = 128;
const ctx = canvas.getContext("2d");
if (!ctx) return canvas;
// 保持比例缩放并居中裁剪
const ratio = Math.min(128 / img.width, 128 / img.height);
const newWidth = img.width * ratio;
const newHeight = img.height * ratio;
ctx.drawImage(
img,
(128 - newWidth) / 2,
(128 - newHeight) / 2,
newWidth,
newHeight
);
return canvas;
};
这里可能就有同学要问了:imooimoo,你怎么返回了 canvas,不应该返回它 getImageData 的数据点吗。我一开始也是这样想的,结果 ai 告诉我,tfjs 是可以直接读取 canvas 的,牛。
tf.browser.fromPixels() // 可以接受 canvas 作为参数
- 将其处理为 tfjs 可用的对象
// 加载单个图片并处理为 tfjs 对应格式
const loadImage = async (category: "cat" | "dog", index: number): Promise<ImageData> => {
const imgPath = `src/pages/cat-dog/image/${category}/${category}.${index}.jpg`;
const img = new Image();
img.src = imgPath;
await new Promise((resolve, reject) => {
img.onload = () => resolve(img);
img.onerror = reject;
});
return {
path: imgPath,
element: img,
tensor: tf.browser.fromPixels(preprocessImage(img)).div(255), // 归一化
label: category === "cat" ? 0 : 1,
};
};
// 加载全部图片
const loadDataset = async () => {
const images: ImageData[] = [];
for (const category of ["cat", "dog"]) {
for (let i = 1000; i < 1500; i++) { // 这里只使用了后 500 张,电脑跑不动
try {
const imgData = await loadImage(category, i);
images.push(imgData);
} catch (error) {
console.error(`加载${category === "cat" ? "猫" : "狗"}图片失败: ${category}.${i}.jpg`, error);
}
}
}
return images;
};
定义模型 & 编译模型
由于我们的主题是图片识别,图片识别一般会需要用到几个常用的层
- 最大池化层:用于缩小图片,节约算力。但也不能太小,否则很糊会提取不出东西。
- 卷积层:用于提取图片特征
- 展平层:将多维的结果转为一维
有同学可能想问为什么会有多维。首先是三维的颜色,输入就有三维;卷积层的每一个卷积核,都会使结果增加维度,所以后续的维度会很高。这张图比较形象,最后就只会剩下一维,方便机器进行计算。
// 创建卷积神经网络模型
const createCNNModel = () => {
const model = tf.sequential({
layers: [
// 最大池化层:降低特征图尺寸,增强特征鲁棒性
tf.layers.maxPooling2d({
inputShape: [128, 128, 3], // 输入形状 [高度, 宽度, 通道数]
poolSize: 2, // 池化窗口尺寸 2x2
strides: 2, // 滑动步长:每次移动 n 像素,使输出尺寸减小到原先的 1/n
}),
// 卷积层:用于提取图像局部特征
tf.layers.conv2d({
filters: 32, // 卷积核数量,决定输出特征图的深度
kernelSize: 3, // 卷积核尺寸 3x3
activation: "relu", // 激活函数:修正线性单元,解决梯度消失问题
padding: "same", // 边缘填充方式:保持输出尺寸与输入相同
}),
// 展平层:将多维特征图转换为一维向量
tf.layers.flatten(),
// 全连接层(输出层):进行最终分类
tf.layers.dense({
units: 2, // 输出单元数:对应猫/狗两个类别
activation: "softmax", // 激活函数:将输出转换为概率分布
}),
],
});
// 编译模型,参数基本写死这几个就对了
model.compile({
optimizer: "adam",
loss: "categoricalCrossentropy",
metrics: ["accuracy"],
});
console.log("模型架构:");
model.summary();
return model;
};
这里实际上只需要额外注意两点:
- 卷积层的激活函数
activation: "relu",这里理论上是个非线性激活函数就行。但是我个人更喜欢 relu,函数好记,速度和效果又不错。 - 输出层的激活函数
activation: "softmax",由于我们做的是分类,最后必须是这个。
训练模型
训练模型可以说的就不多了,也就是提供一下你的模型、训练集就可以开始了。这里有俩参数可以注意下
- epochs: 训练轮次
- validationSplit: 验证集比例,用于测算训练好的模型准确程度并优化下一轮的模型
// 训练模型
const trainModel = async (
model: tf.Sequential,
xData: tf.Tensor4D,
yData: tf.Tensor2D
) => {
setTrainingLogs([]); // 清空之前的训练日志
await model.fit(xData, yData, {
epochs: 10, // 训练轮数
batchSize: 4,
validationSplit: 0.4,
callbacks: {
onEpochEnd: (epoch, logs) => {
if (!logs) return;
setTrainingLogs((prev) => [
...prev,
{
epoch: epoch + 1,
loss: Number(logs.loss.toFixed(4)),
accuracy: Number(logs.acc.toFixed(4)),
},
]);
},
},
});
};
整体页面
基本就是这样了,稍微写一下页面,基本就完工了
总结
别慌,神经网络没那么可怕,核心步骤就那几步,冲冲冲。
来源:juejin.cn/post/7477540557787938852
一天 AI 搓出痛风伴侣 H5 程序,前后端+部署通吃,还接入了大模型接口(万字总结)
自我介绍
大家好,我是志辉,10 年大数据架构,目前专注 AI 编程
1、背景
这个很早我就想写了 App 了,我也是痛风患者,好多年,深知这里面的痛呀,所以我想给大家带来一个好的通风管家的体验,但宏伟目标还是从小点着手,那么就有了今天的主角,痛风伴侣 H5。
目录大纲
前面都是些开胃小菜,看官们现在我们就正式开始正文,那么整体目前是分的 6 个阶段。
前四个阶段可以分为一个大家的阶段,就完成了你的产品工作
最后就是收尾工作,以及后续的维护。
废话少说,就正式开始吧。
第零阶段:介绍
产品开发流程图
这是一个传统的软件开发流程,从需求的讨论开始到最后的产品上线,总共需要的六大步骤,包括后续的迭代升级维护。
成本测算
这里面其实最大的就是投入的人力成本,还不算使用的电脑、软件这些,还包括最大的就是时间成本。
我们按按照基本公司业务项目的项目来迭代看
- 人力成本
- 产品:1~2 人,有些大项目合作的会更多,跨大部门合作的。
- UI :1 人
- 研发:
- 前端:1~2人
- 后端:2~3人
- 测试:1~2 人
- 合计:这里面最少都是 6 人
- 时间成本
- 这里不用多少,大家如果有经验的,基本公司项目一般的需求都是至少一个月才能上线一个版本,小需求快的也就是半个月上线。
- 沟通成本
- 这个就用说了,大家都是合作项目,产品和 UI,产品和研发,研发和测试,这就是为啥会有那么多会的缘故,不同的工种,面对的是不同

时间成本感受
个人创业感想
那这里你就可能要较真了,你这个功能简单,哪能跟公司的项目比了。
那我就想起我之前跟我同学一起创业搞 app 的时候,那个时候我不会 app、也不会前端,我是主战大数据的,其实对后端有些框架不也太熟。
那会儿我们四个人,1 个 app、1 个后端+前端、1 个产品,也是足足搞了 1 个多月才勉强上了第一个小版本。
但是我们花的时间很多,虽然一个月,但那一个月我没睡过觉,不会就得学呀,哪像现在不会你找个 AI 帮手帮你搞,你就盯着就行,那会一边学前端,一遍写代码,遇到问题只能搜索引擎查,要么就是硬看源码去找思路解决。
想想就是很痛苦。
公司工作感想
本职工作是大数据架构,设计的都是后端复杂的项目通信,整体底层架构设计,但是也需要去做一些产品的事情。
但是大数据产品就不像业务系统配比那么豪华,一整个公司就两三个人,那么有时候就的去做后端服务、前端界面,就为了把我们的产品体验做好。
每天下班疯狂学习前端框架,从最基本的 html、css、js 学起,不然问题解决不了,花了大量的时间,并且做项目还要学习各种框架,不然报错了你都不知道咋去搜索。
这样能做大功能的事情很少,也就是修修补补做些小功能。
产品感想
这也是我最近用了 AI 编程后的感想,最近公司的数据产品项目,我基本都是 AI 编程搞定。
以前复杂的画布拖拉拽,我基本搞不定到上线的质量,现在咔咔的一下午就搞定开发,再结合 AI 的部署模板,一天就基本完成功能。效率太快。
也是这样,我在现在的公司的产出一周顶的上以前的一个月(这真不是吹牛,开会的半个小时,大数据的首页的 landing page 我就做好了🤦♂️) ,但是时间完全不用一周(偷偷的在这了讲,老板知道了,就。。。所以我要多做一些,让老板留下我)。
我现在感想的就是现在更加需要的就是你的创意、你的想法,现在的 AI 能力让更多的人提效的同时,也降低了普通人实现自己产品的可能性。这在以前是无法想象的,毕竟很多门槛是无法跨越,是需要时间磨练的。
效果展示
然后再多来几张美美的截图(偷偷告诉你,这就是我的背景图片工具做出来的。)
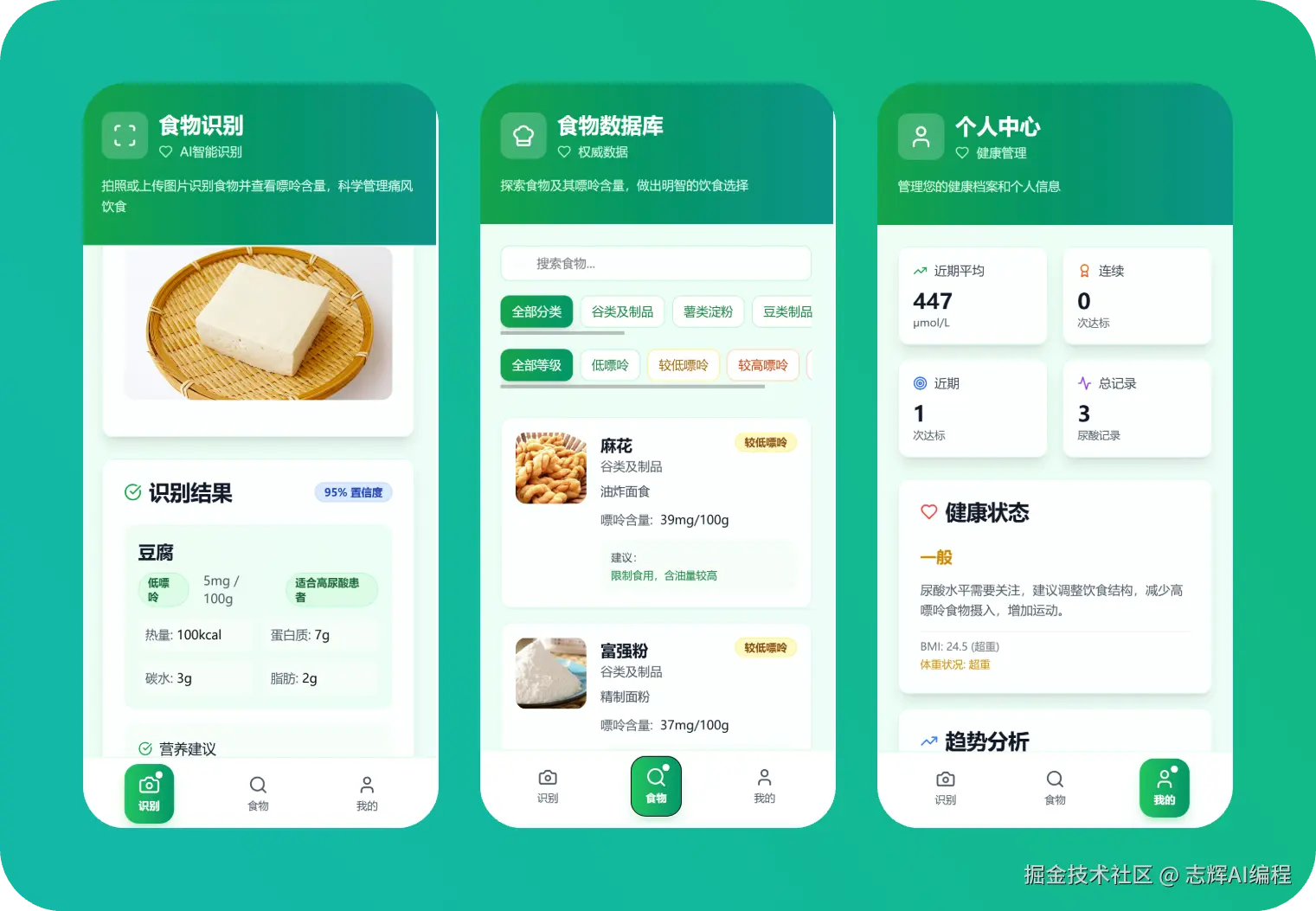
第一阶段:需求
1、需求思考
做产品最开的就是需求了,如果你是产品经理,那么我理解这一阶段是不需要 AI 来帮你忙的。
虽然大家基本对产品或多或少都有一些理解,那么专业性肯定比不了,那么我们就需要找专业的帮忙了。
所以我这里找的是 ChatGPT,大家找 DeepSeek,或者是 Gemin,或者是 Claude 都可以的。
我目前准备为痛风患者开发一个拍照识别食物嘌呤的h5应用,我的需求如下:
1. 这个h5底部有3个tab: 识别、食物、我的
2. 在【识别】页面,用户可以选择拍照或者选择相册上传,然后AI识别食物,并且给到对应的嘌呤的识别结果和建议。
3. 在【食物】页面,用于展示不同升糖指数的常见食物,顶部有一个筛选,用户可以筛选按嘌呤含量高低的食物,下方显示食物照片/名称/嘌呤/描述
4. 【我的】页面顶部有一个折线图,用户记录用户的尿酸历史;下方显示近3次的尿酸数据:包括平均、最低、最高的数据;还有记录尿酸和历史记录的列表。
在技术上,【我的】页面尿酸历史记录保存在本地localStorage中,【食物】的筛选也是通过本地筛选,拍照识别食物嘌呤的功能,采用通义千问的vl模型。
请你参考我的需求,帮我编写一份对应的需求文档。
发给 ChatGPT
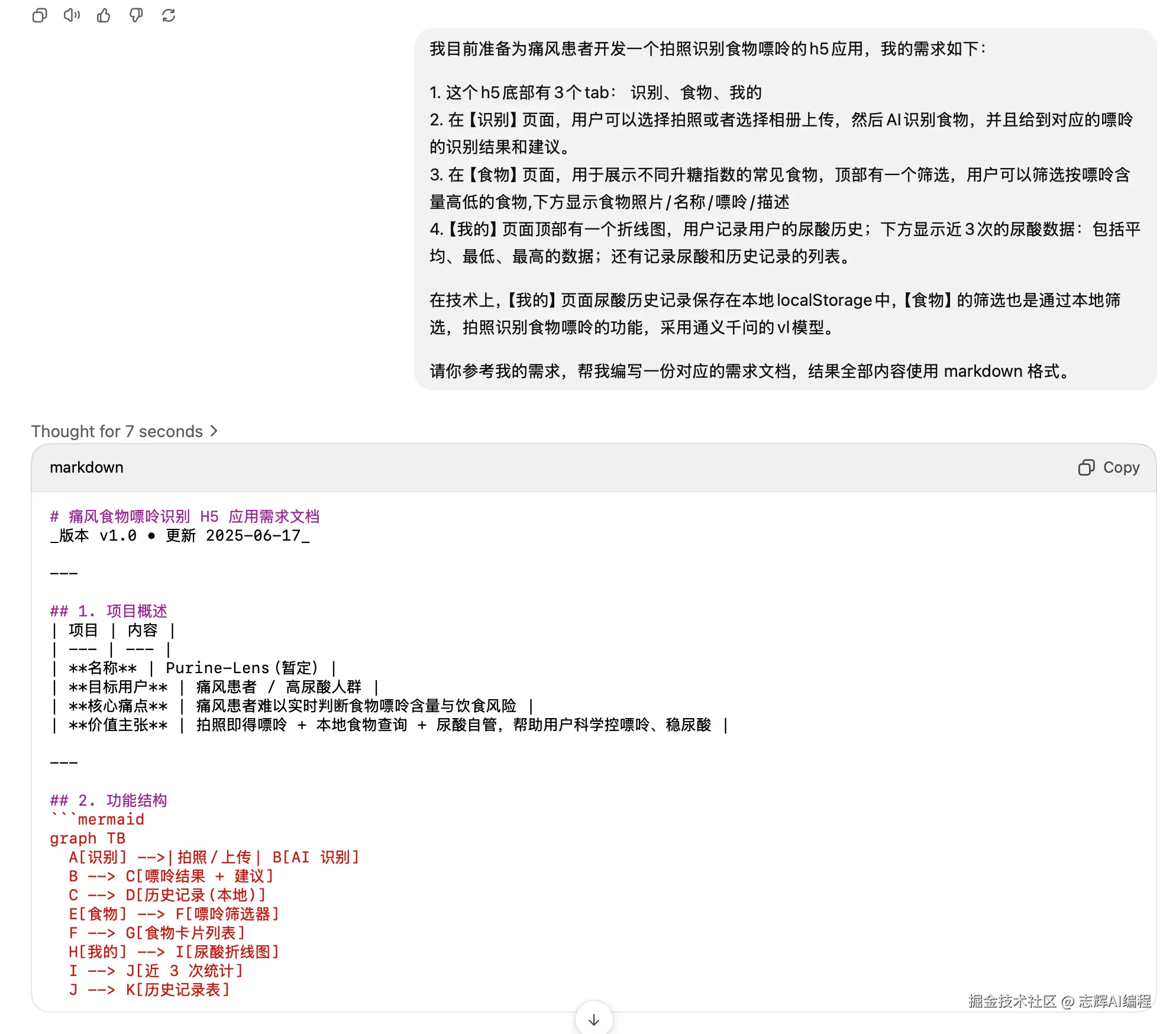
这样就给我们回复了。
2、思考
你说我不会像你写那么多好的提示词,一个我也是借鉴别人的,一个就是继续找 AI 帮你搞定,比如你不知道 localstoreage 是什么,没关系,这个都是可以找 AI 问出来的。

或者是说你只有一个想法,而不知道这个产品要做成什么,也可以问 AI。
GPT 会告诉你每个阶段该做哪些功能,这样看看哪些对你合适,然后通过不断的多轮对话,来让他输出最后的需求文档。
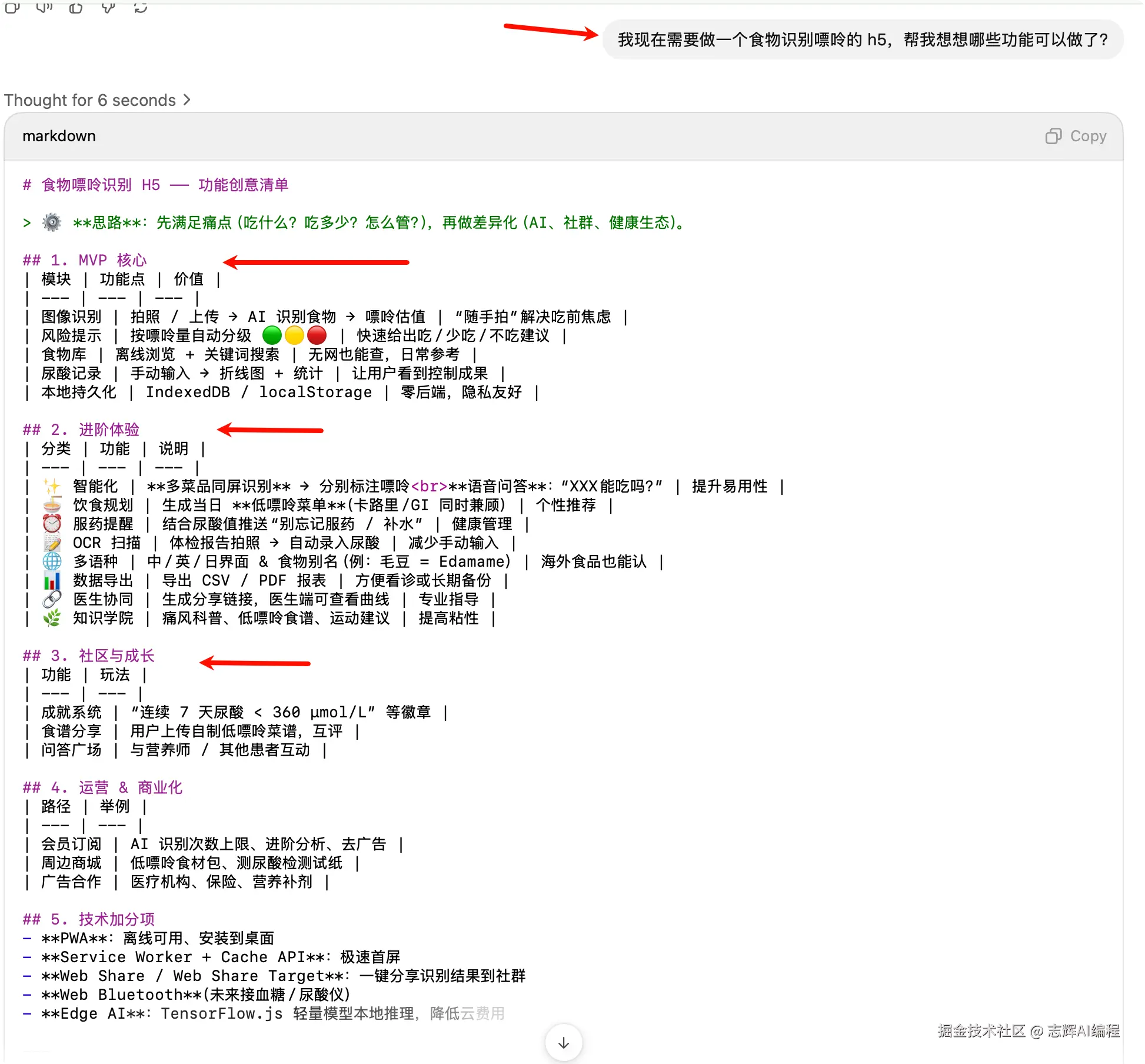
3、创建需求工作空间
我们在电脑新建个目录,用来存放暂时的需求文档和一些前置工作的文件
Step 1: 在电脑的某个目录下创建前期我们需要的工作项目的目录,这里我叫 h5-food-piaoling
Step 2: Cursor 打开这个目录
Step 3: 创建 docs 目录
Step 4: docs 目录下创建 prd.md 文件,把刚刚 GPT 生成的需求文档拷贝过来。
我这里是后截图的,所以文件很多,不要受干扰了
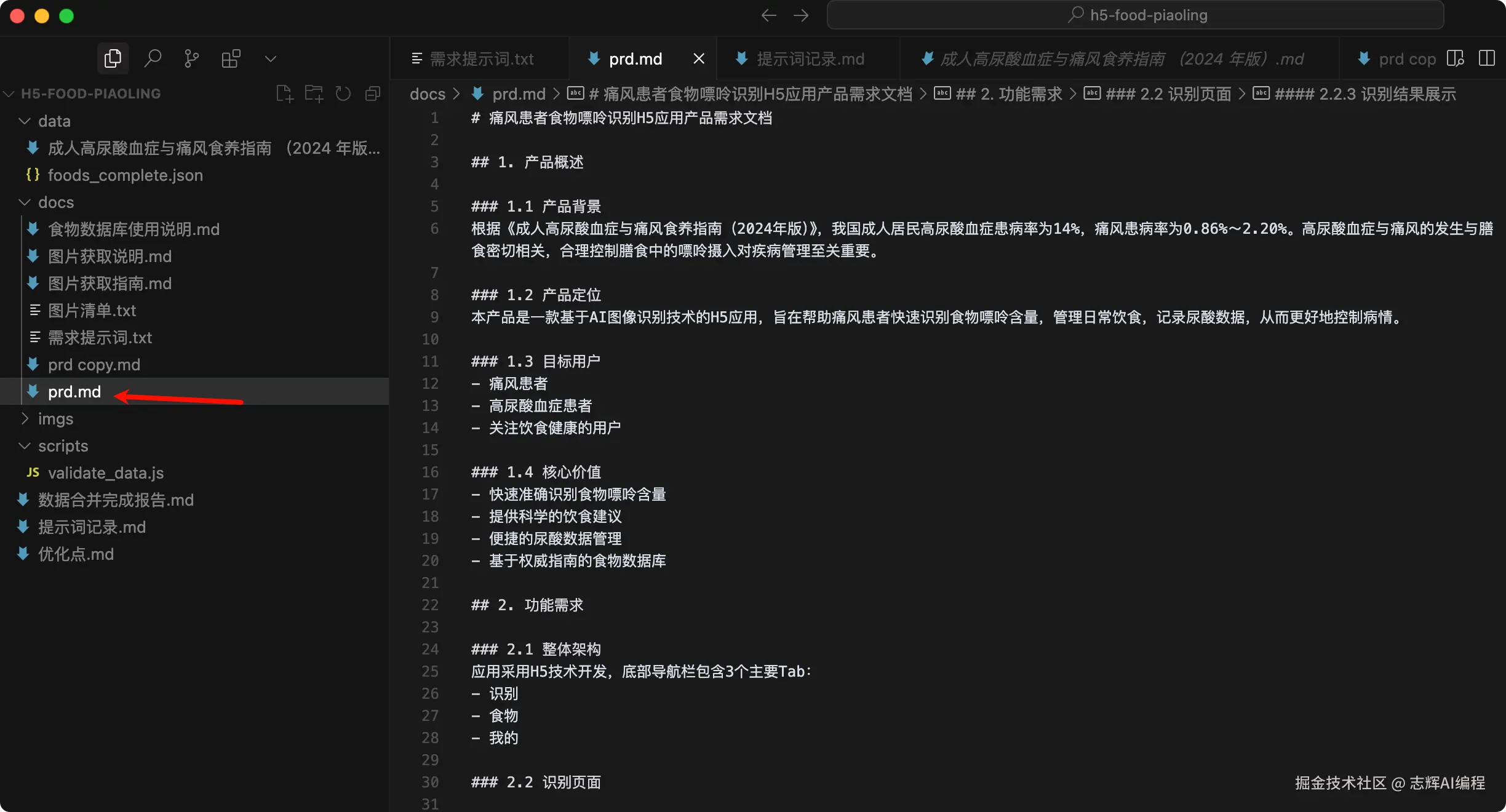
4、重要的一步
到这里需求文档就创建好了,那么我们是不是马上就可以开发了,哦,NO,这里还有很重要的一步。
那么就是需要仔细看这个 GPT 给我们生成的需求文档,还是需要人工审核下的,避免一些小细节的词语、或者影响的需要修改的。
比如这里,我已经恢复不出来了,这里原来有些 “什么一页的文章,适合老年人的这些文字”,这些其实不符合我那会儿想的需求的,所以我就删除了。
比如这里用到的一些技术,如果你懂的话,就可以换成你懂的技术,也是需要考虑到后面迭代升级的一些事情。
总结:其实这里就是需要人工审查下,避免一些很不符合你想的那些,是需要修改/删除的,这个会影响后面生成 UI/交互的逻辑。
不过这个步骤不做问题也不大,这一步也是需要长久锻炼出来,后面等真实的页面出来后,你再去修改也行。
第二阶段:数据准备
这里的一步也是我认为比较特别的点,这个步骤的点可以借鉴到其他场景里面。
1、哪里找数据
你的产品里的数据的可信度在哪里?特别是关乎于健康的,网上的信息纷繁复杂,大家很难分清哪些是真的,哪些是假的。
我之前查食物的嘌呤的时候,就遇见了,同样一个食物,app 上看到的,网上看到的都不一样,我就黑人问号了???
所以,这里就涉及到数据的权威性、真实性了。那么权威机构发布的可信度会更强。
所以我找到了卫健委颁发的数据。
地址:http://www.nhc.gov.cn/sps/c100088…

另外还可以看到不止痛风的资料有,还有青少年、肥胖、肾病的食养指南。
这些病其实都是慢性病,不是吃药就能马上好起来,需要长期靠饮食、运动来恢复的。
可以把这些数据用起来,后面挖掘更多需求。
2、下载数据
这一步周就是把数据下载下来,直接点击上面的
下载来后是个pdf 的文件,那么这一步我们就准备好了。
这里我附带一份,大家可以作为参考
暂时无法在飞书文档外展示此内容
3、处理数据
这一步是为什么了,是因为目前在所有的 AI 编程工具里面,pdf 是读取不了的,特别是 Cursor 里面。
目前能够读取的是 markdown 格式的数据
markdown 格式的数据很简单,就是纯文本,加上一些符号,就可以做成标题显示
不懂的可以直接问题 AI 工具就行了。
这里就可以看到大模型给我们的解释了。
插曲
我不懂 markdown 是什么,帮我解释下,我一点都不懂这个
在 Cursor 里面使用 ask 模式来提问

下面就是一个回答的截图,如果你对里面的文字不清楚的,那么就继续问 AI 就可以了。多轮对话。

处理数据
这里就是需要把 pdf 转为 markdown 的数据
这里推荐使用:mineru.net/
重点在于免费,直接登录注册进来后,点击上传我们刚下载的 pdf。
等待上传转换完成,下一步就是在文件里面,看到转换的文件了。
点击右侧下载,就是 markdown 格式。
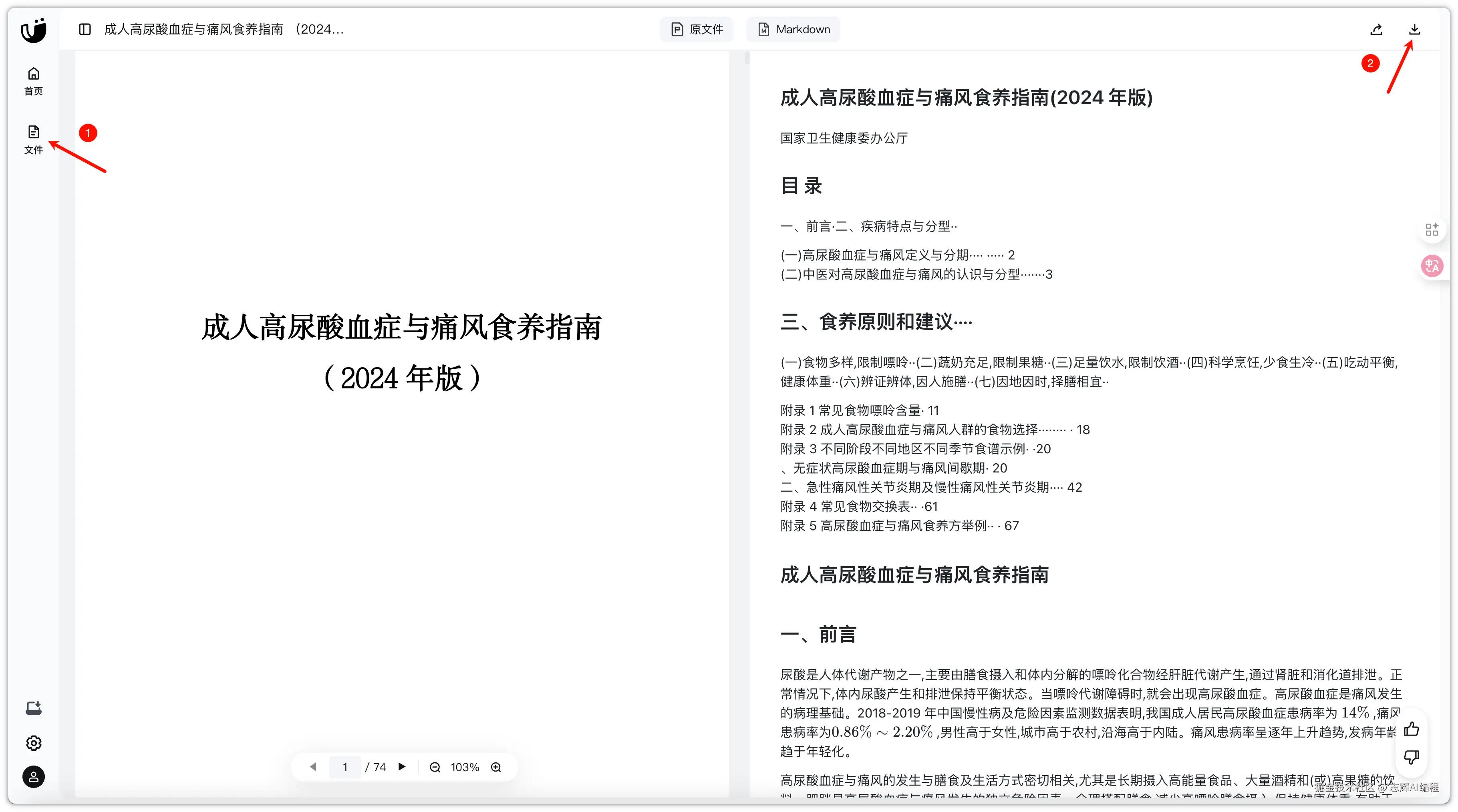
把下载好的 markdown 文件放入到项目里面的 data 目录,待会儿会需要数据处理。
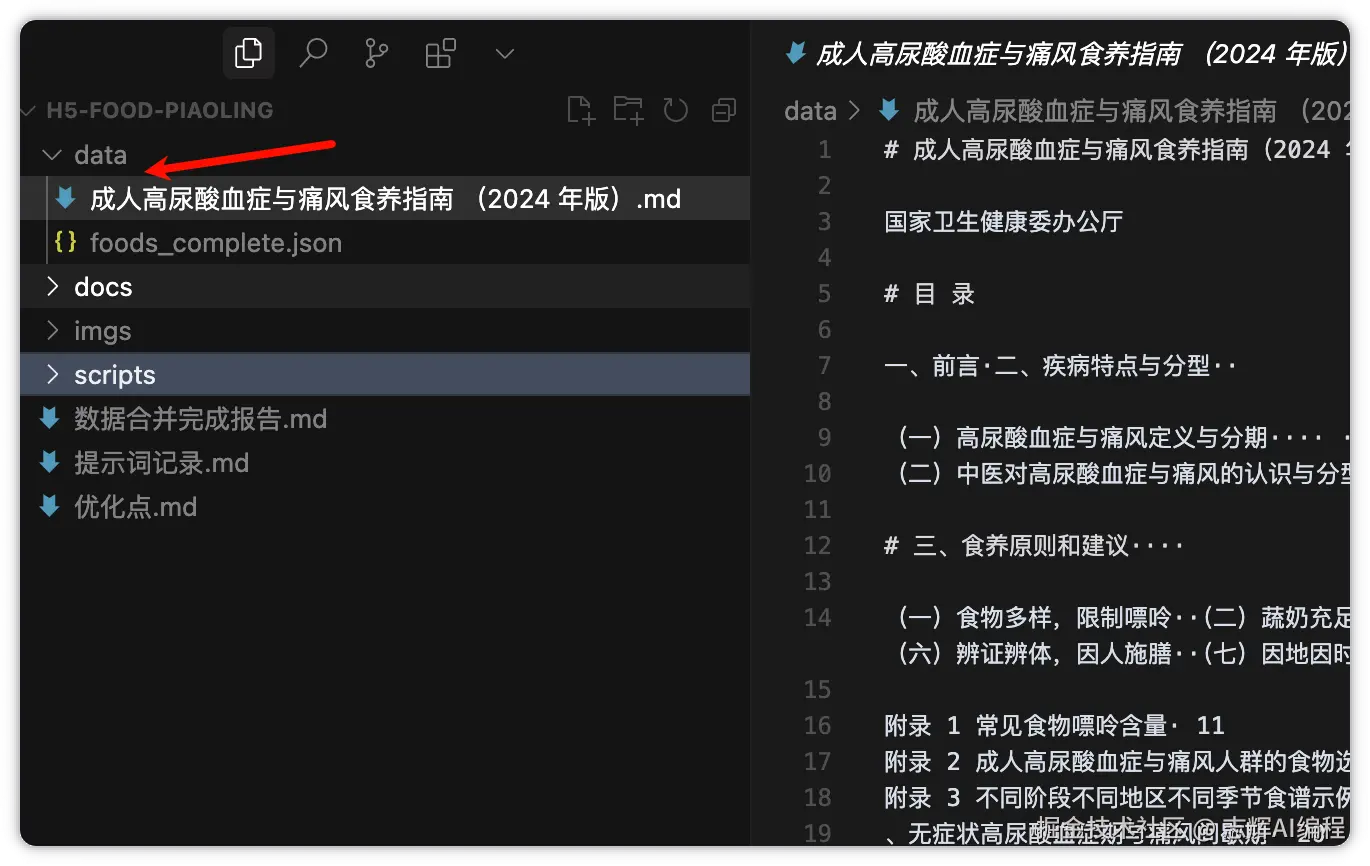
4、修正需求文档
那么让 Cursor 给我们重新生成需求文档,这样食物的分类,还有统计,会更准确,因为现在是基于权威数据来的。
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
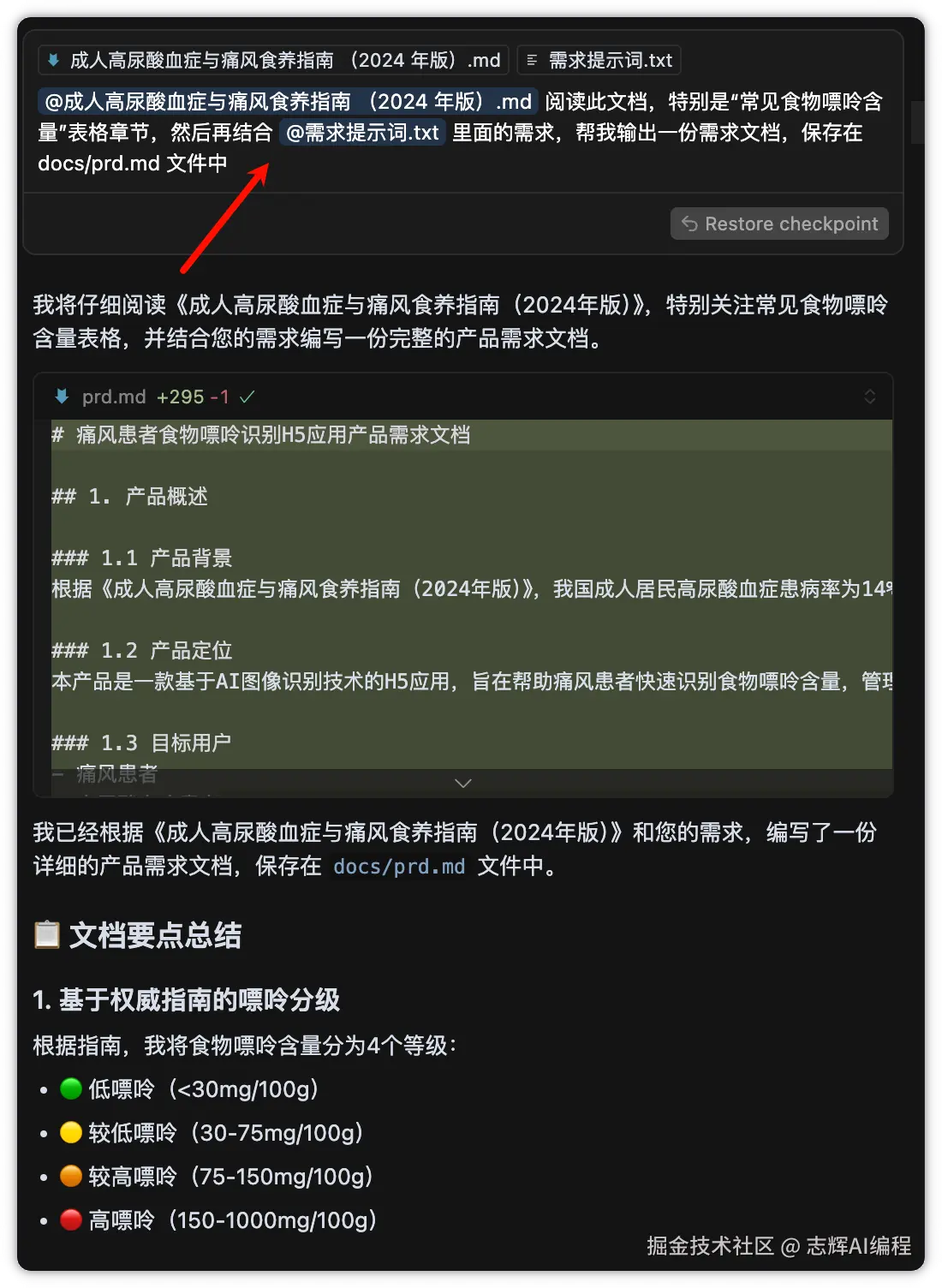
5、生成数据文件
前面我们不是讲到了。食物列表的数据需要存储在本地,也就是客户端,形式我们就采用 json 的形式
同样你不知道 json 是个啥的话,找 AI 问,或者直接 Cursor 里面提问就行了。
左边是提示词,右侧就是创建的 json 文件
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
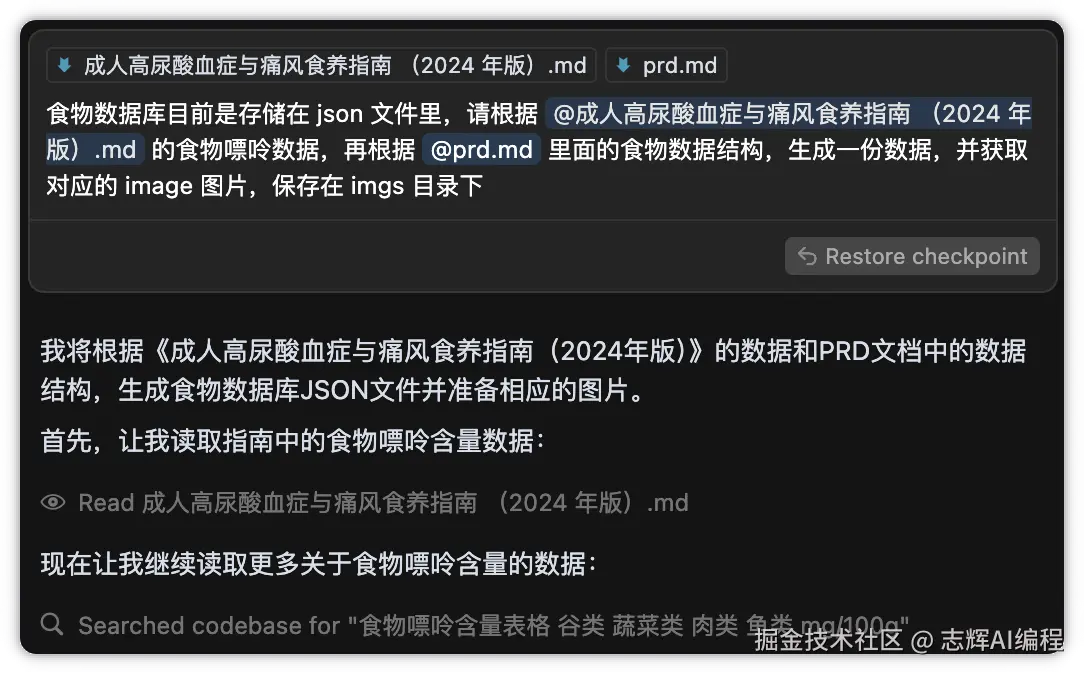
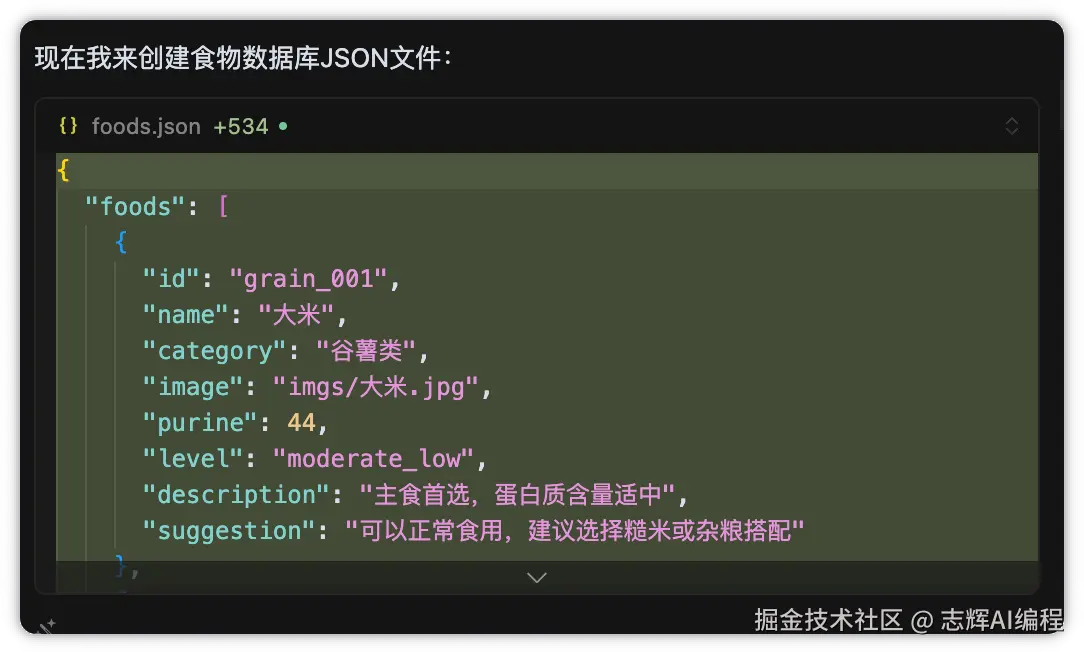
结果:
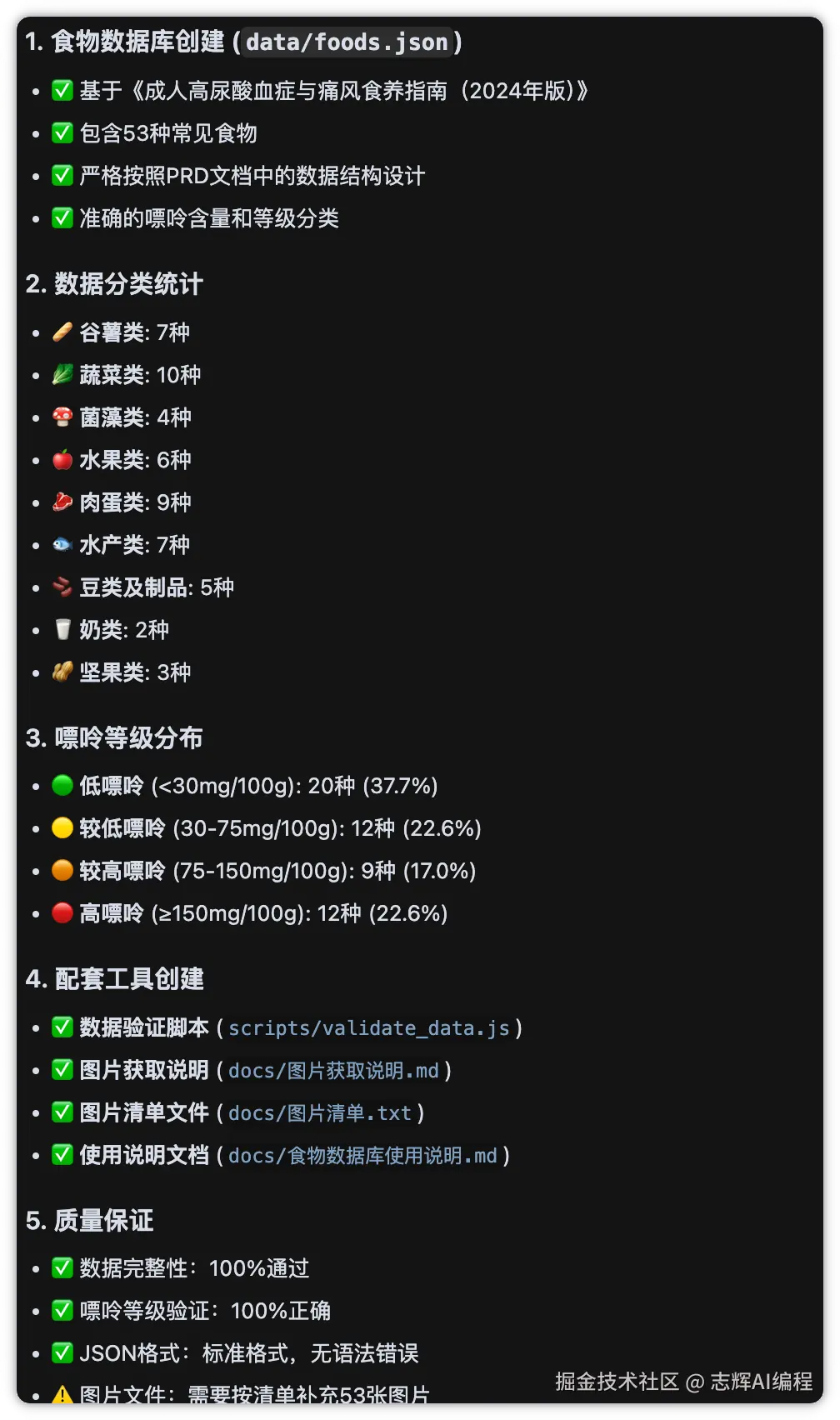
6、继续调整文件
上一步骤发现,其实只给我们列觉了 53 种食物,并不全
我需要全部的数据,那么继续
总结的有 53 种食物,但是我看 @成人高尿酸血症与痛风食养指南 (2024 年版).md 下的“表1-2 常见食物嘌呤含量表” 应该不止这么多,请再次阅读然后补全数据到 @foods.json 文件里。
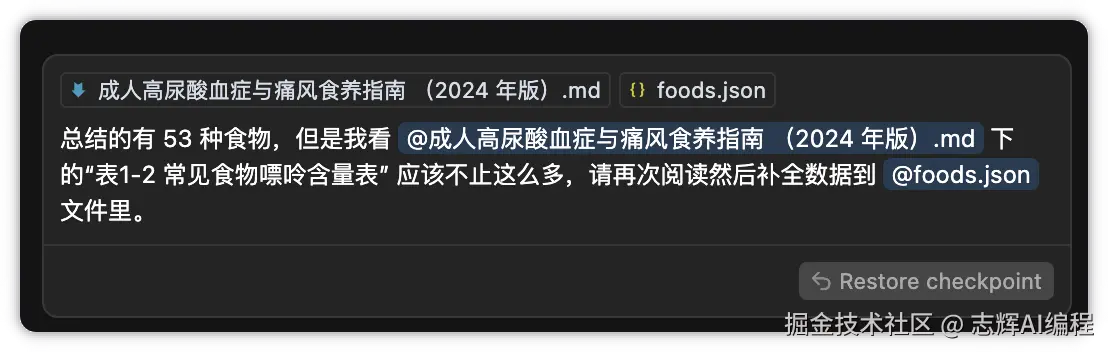
最后发现,总文档里总结了 180 种的食物

最后生成的数据文件如下:
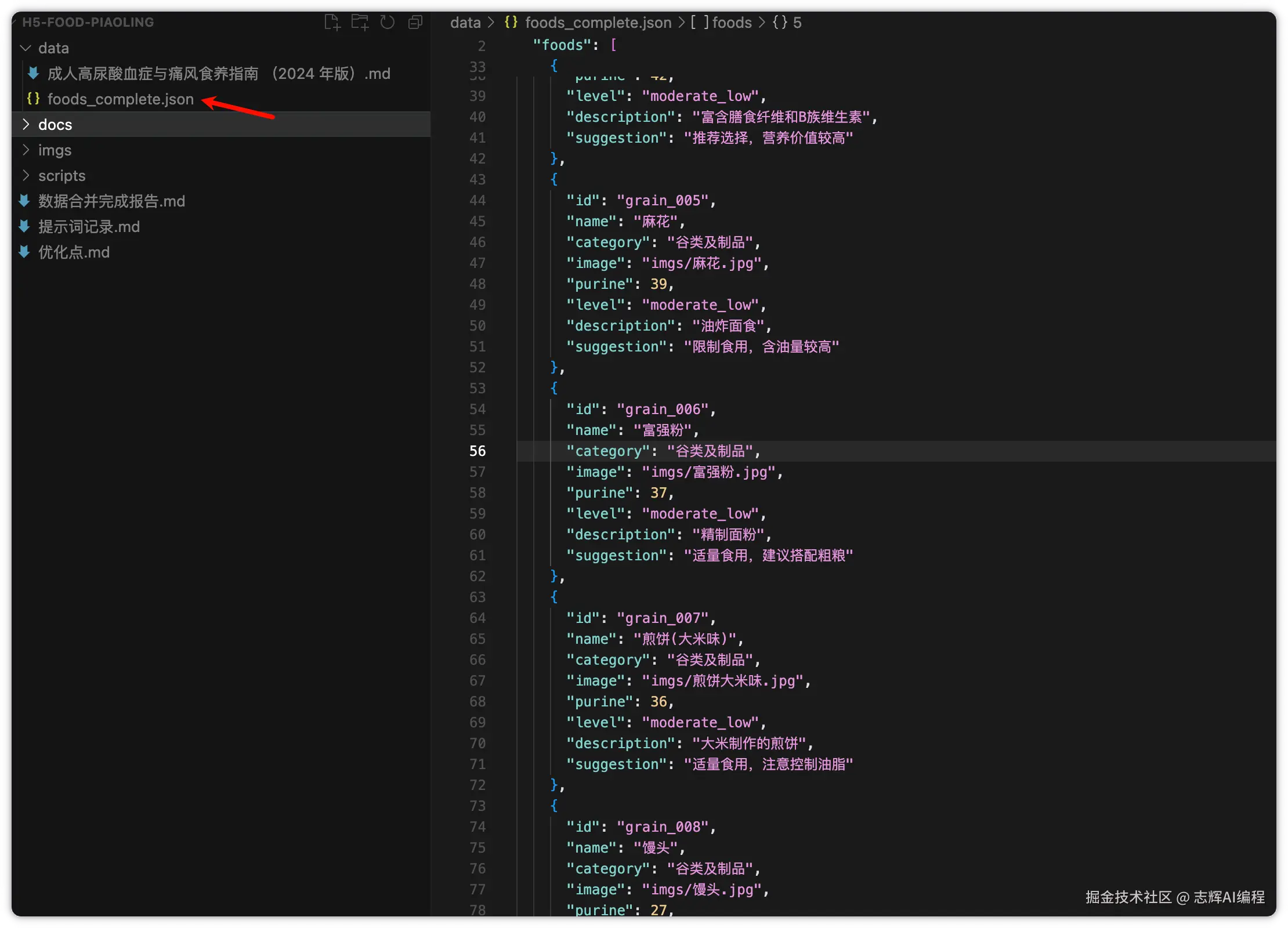
6、图片问题
不过这里有个问题就是,食物对应的图片是没有办法在这里一次性完成的
我也尝试了在 Cursor 里让他帮我完成,结果些了一大堆的代码,下来的图片还对应不上。
尝试了很多方案,都不太理想。
那你说了,去搜索引擎下载了,我也想到了,不过想起来你要去搜索,然后找图片,下载,有 180 多种了,还要命名好图片名字,最后保存到目录。
想到这里,我就头大,索性干脆自己写一个,其他流程系统都帮我搞定,暂时目前只需要我人工确认图片,保证准确性。
Claude Code + 爬虫碰撞什么样的火花,3 小时搞定我的数据需求
这个小系统也还是有很大的挖掘潜力,后面也还可以做很多事情
到这里基本需求阶段就完成了,数据也准备的差不多了,下面就是进入开发阶段了。
不要看前面的文字多,那都是前戏,下面就是正戏,坐稳扶好,开奔。
第三阶段:开发+联调+测试
这里是主要的开发、联调、测试阶段,也就是在传统开发流程中会占据大部分的时间,基本一个软件/系统的开发大部分的时间都在这个里面,所以我们看看结合 AI 它的速度将会达到什么样。
== 1、前端 ==
步骤一:bolt 开发
说下为什么采用 bolt 工具来做第一步工作。
其实线下 v0、bolt、lovable 很多这种前端设计工具,那么他与 Cursor 的区别在哪里了?
1、首先通过简单的提示词,它生成的功能和 UI 基本都是很完善的,UI 很美、交互也很舒服。这种你在 Curosr 里面从零开始些是很难的。
2、这种工具一般都可以选择界面的上的元素(比如 div、button,这个就比较难),然后进行你的提示词修改,很精准,这个你在 Cursor 里面比较难做。
3、还有一个点就是前端开发的界面的定位这些大模型很难听得懂你在说啥的,所以我感觉也是这块的难度采用了上面那么多的类似的工具的诞生。
当然,如果不用这些工具,直接让 Cursor 给你出 ui 设计,然后使用 UI 设计出前端代码也可以的。
这个我看看后面用其他例子来讲解。
把上面的需求步骤的 prd.md 的需求直接粘贴到提示词框里。没问题,就可以直接点击提交了。
小技巧:看左下角有个五角星的图标,是可以美化提示词的,这个目前倒是 bolt 都有的功能。
另外还可以通过 Github 或者 Figma 来生成项目图片。
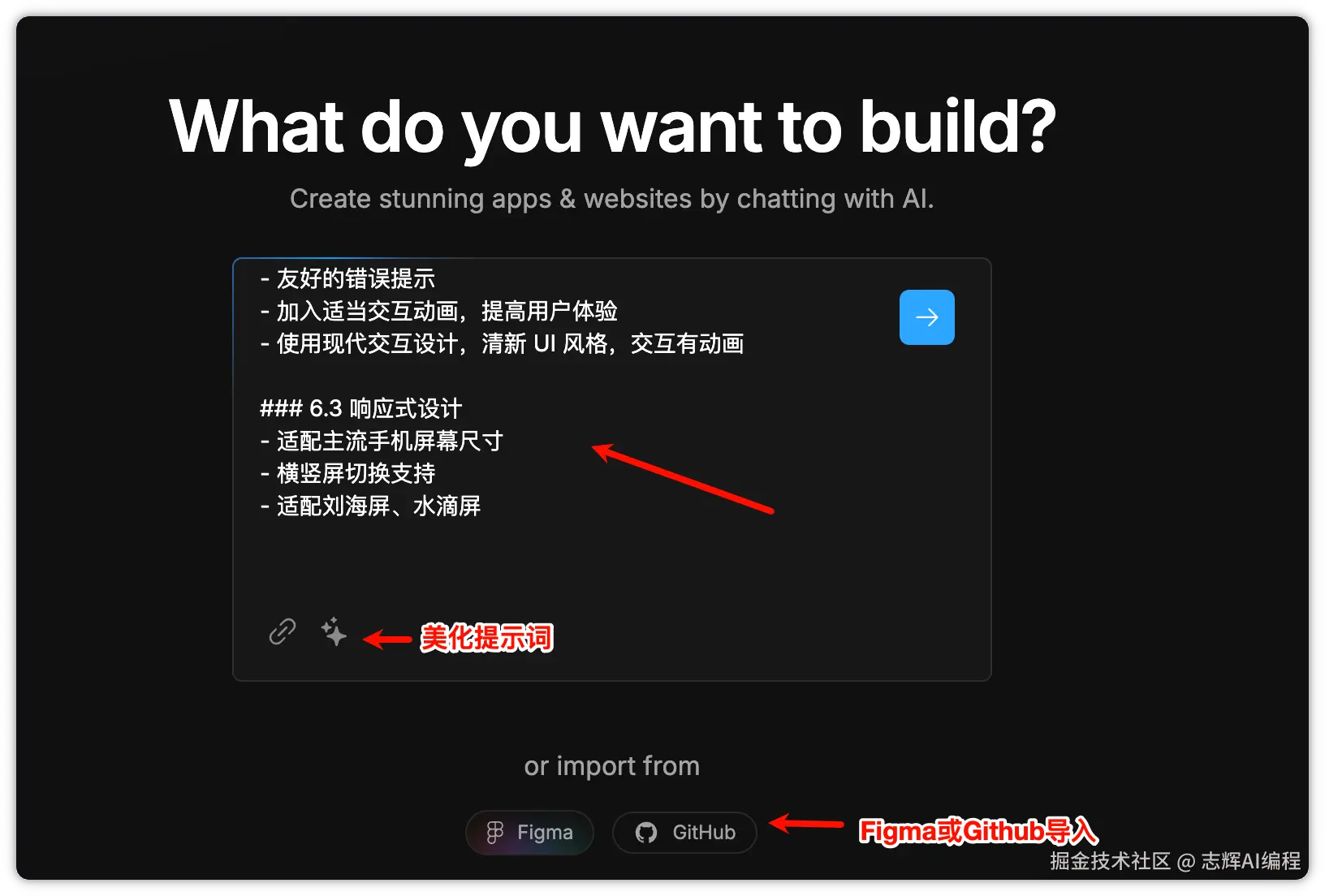
下面就是嘎嘎开始干活了。
等他写完,就可以在界面的右侧看到写完的H5程序。
界面很简单,左侧就是对话区域,右侧就是产品的展示区域
小细节:在使用移动端展示的时候,还可以选择对应的手机型号
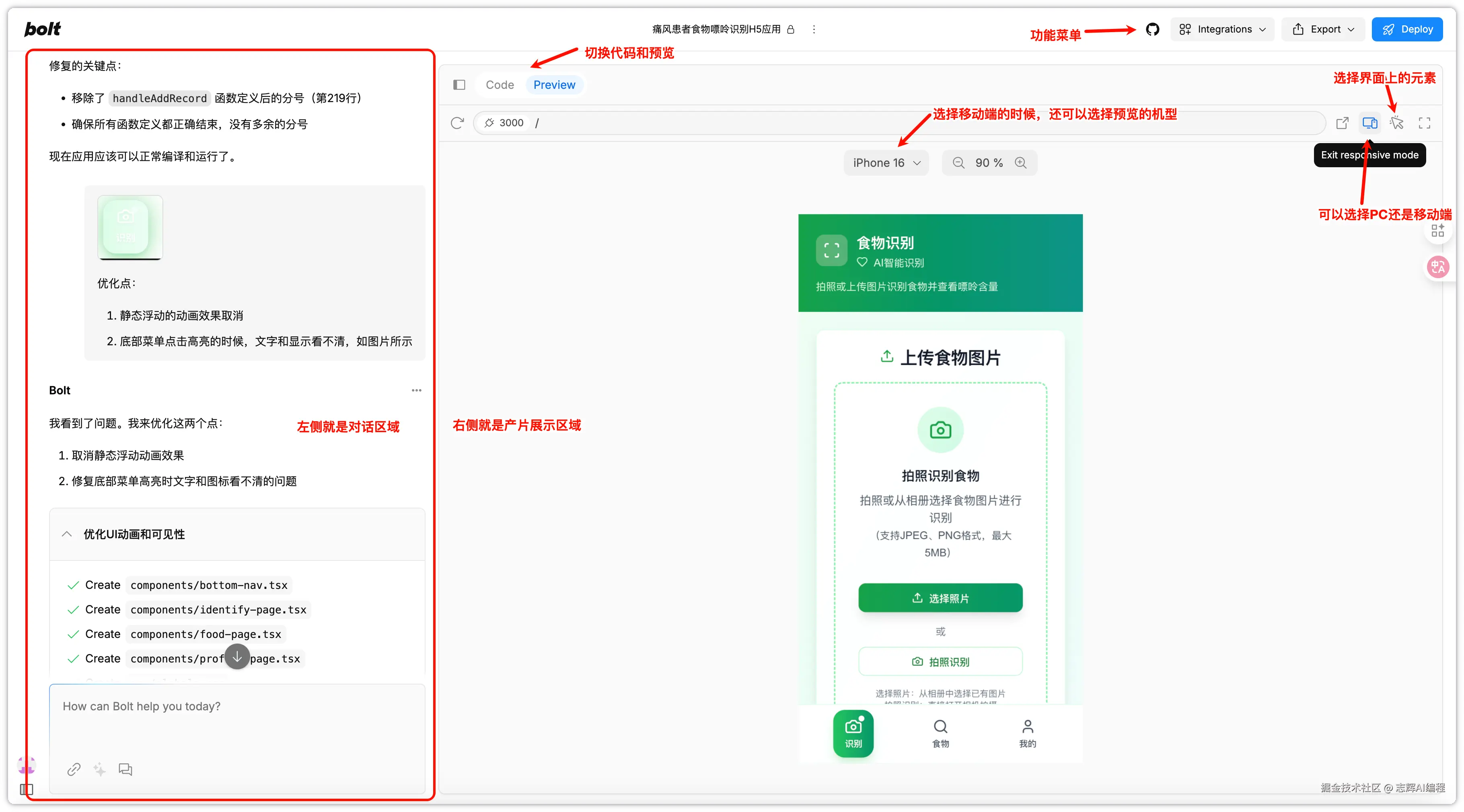
步骤二:调整
1、错误修复
这个交互我觉得做的特别好,不用粘贴错误,直接就在界面上点击“Attempt fix”就可以了,这真的是纯 vibe coding ,粘贴复制都不用了。🤦♂️
如果有错误,继续就可以了。
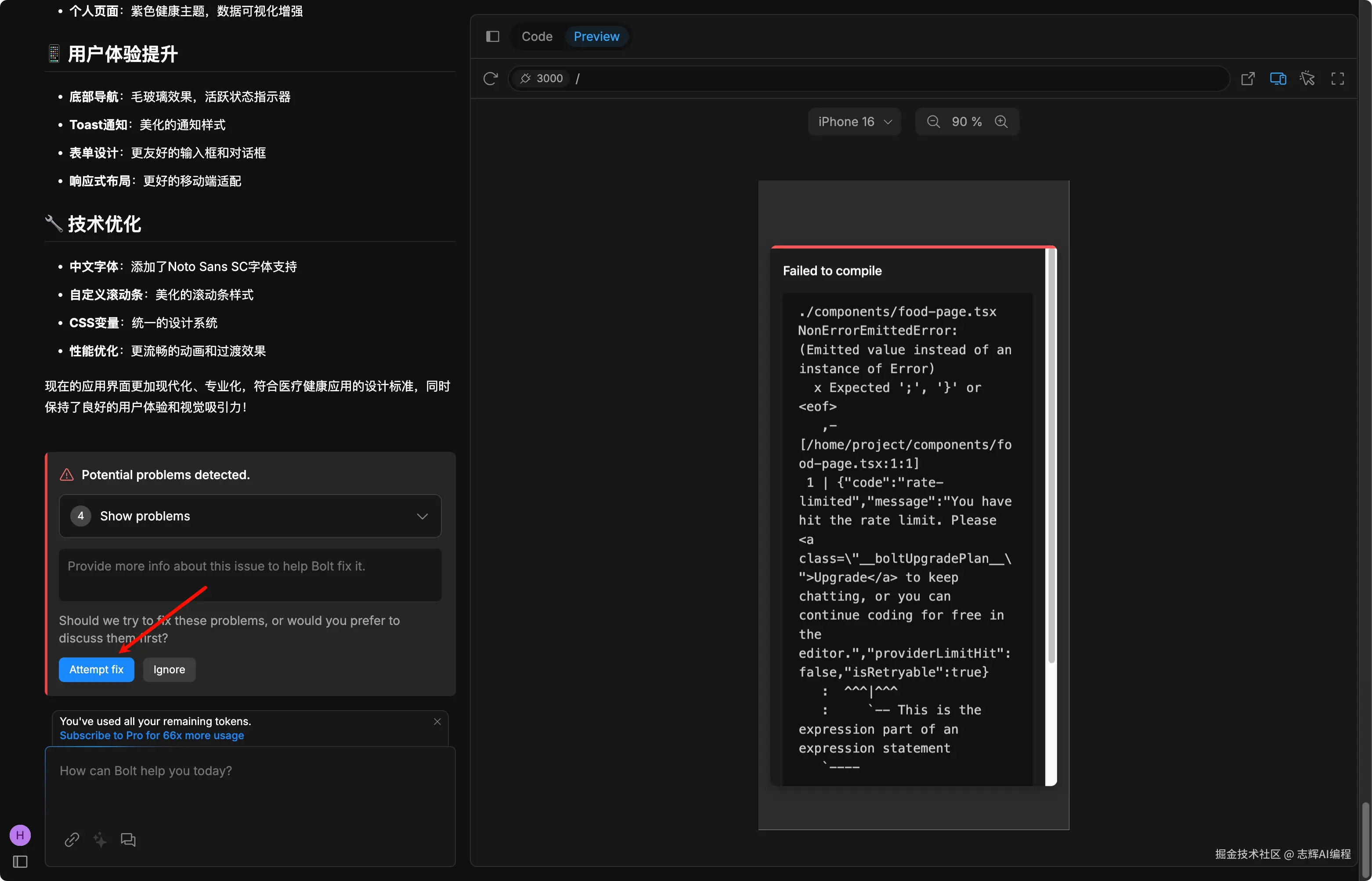
2、UI 调整:主题
刚开始其实 UI 并不是太好看,我的主题色是绿色的,所以我也不知道让它弄什么样的好看。
再帮我美化下 UI 界面
就输入了上面一句话,刚开始的 UI 如下图
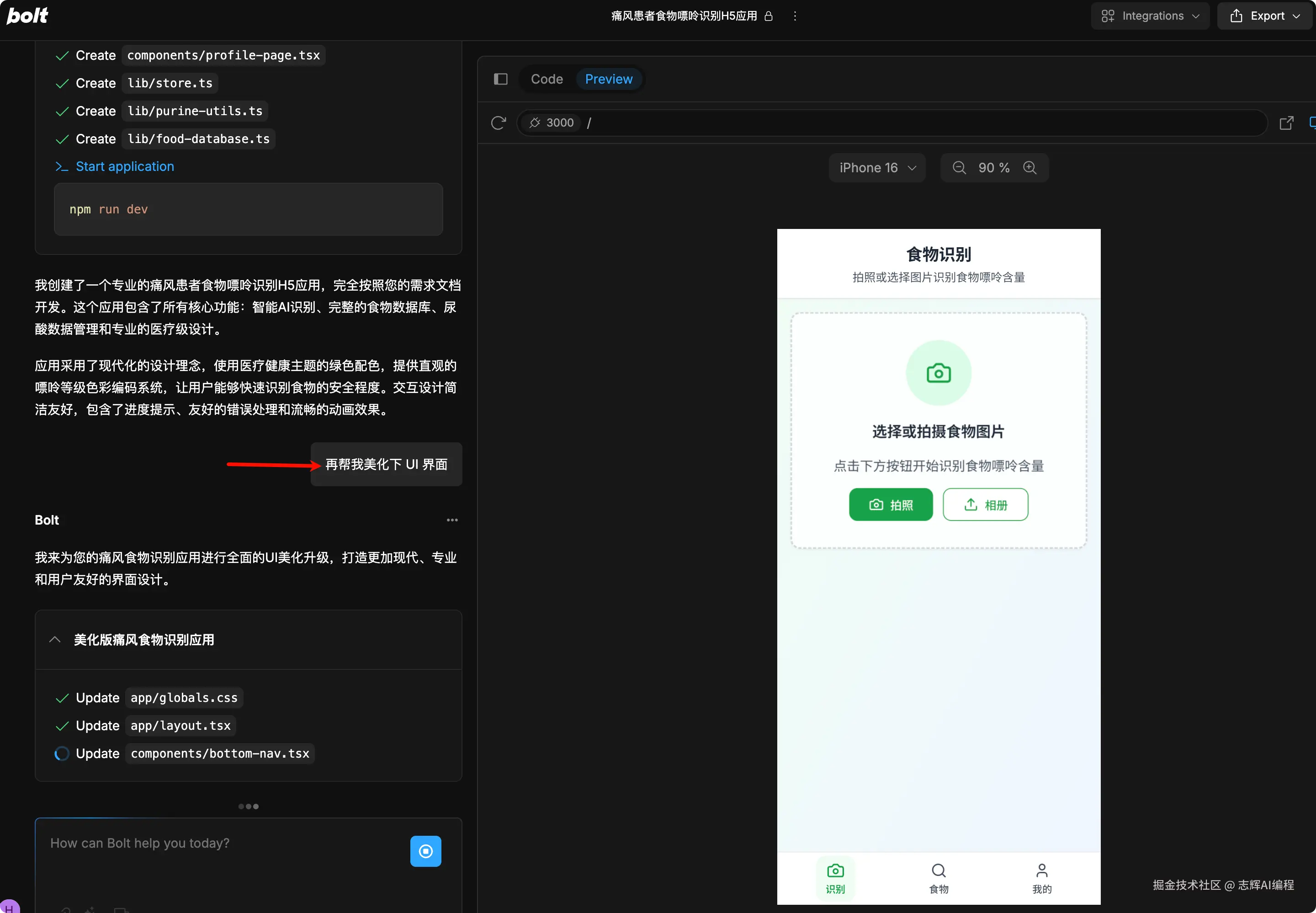
最后看下对比效果
左边是最开始生成的,右边是我让他优化后的样子。还是有很多细节优化的。
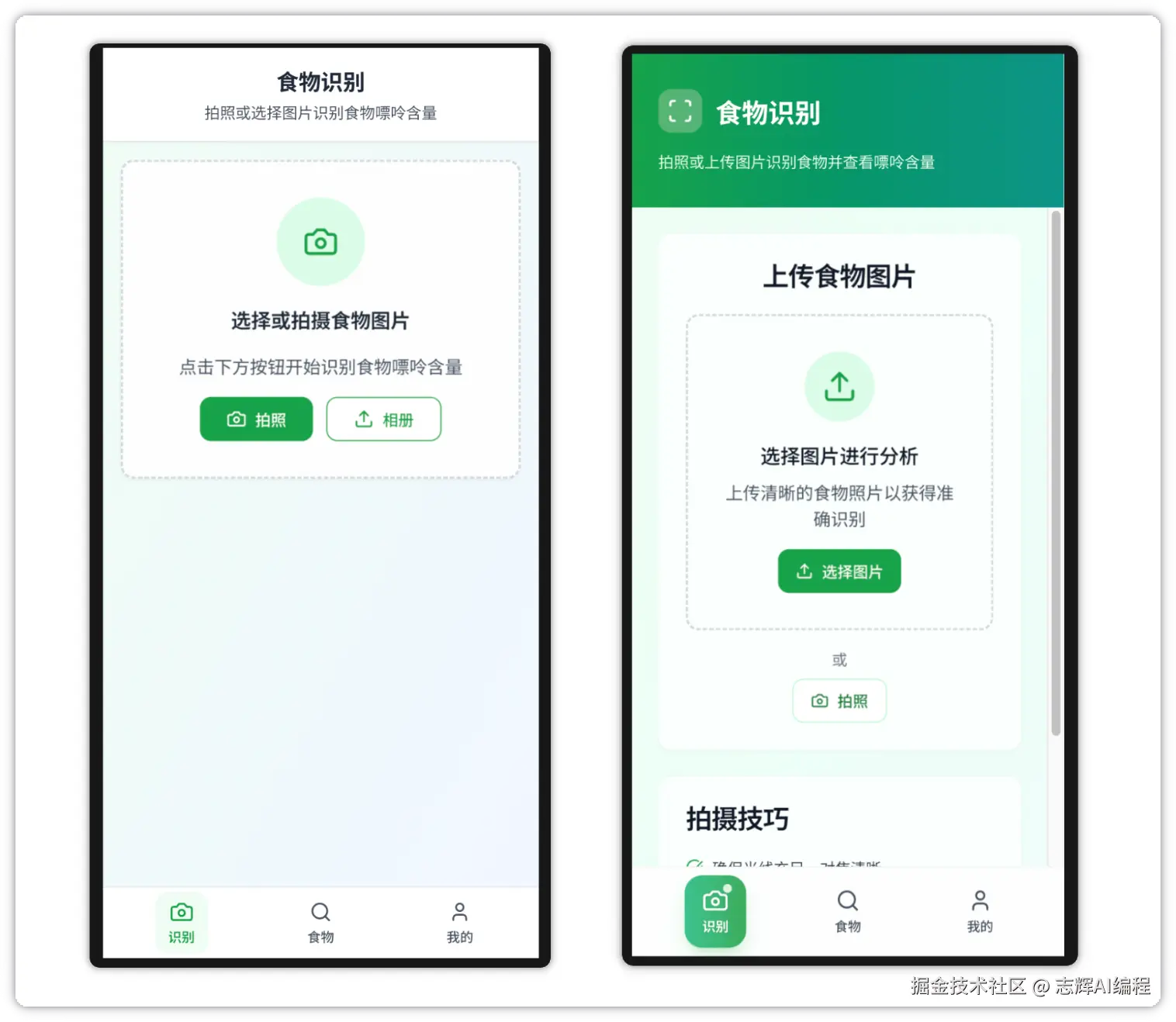
3、UI 修复方式一:截图
另外如果样式有问题,可以截图粘贴到对话框,然后输入提示词修改。

4、UI 修复方式二:选择元素
这里就是我要说的可以选择界面上的元素,然后针对某些元素进行改写
bolt 的方式这几输入提示词
v0 比较高级,选择后,可以直接修改 div 的一些样式参数,比如:宽高、字体、布局、背景、阴影。精准调节。(低代码+vibe coding)
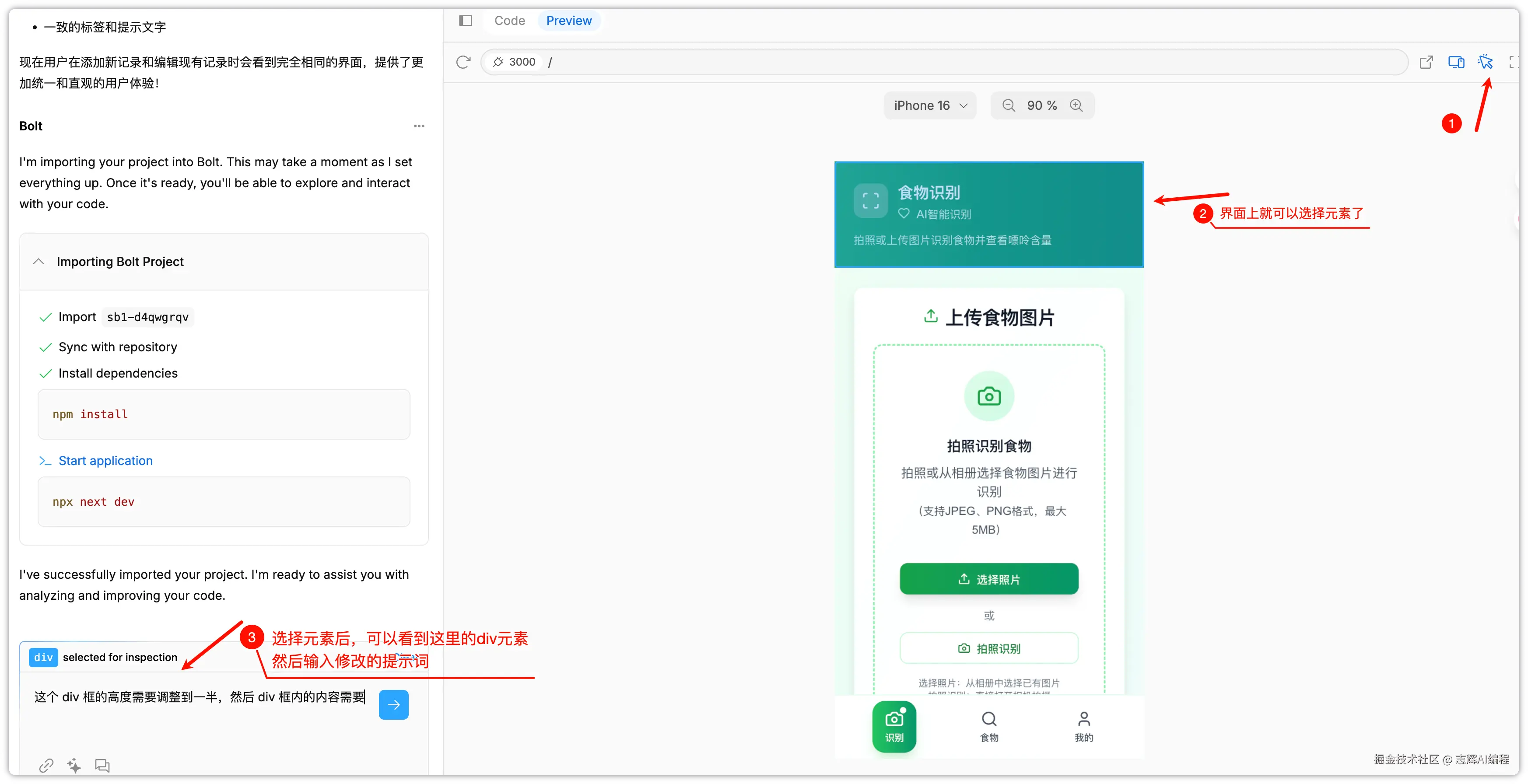
经过多轮修复,觉得功能差不多了,就可以转战本地 Cursor 就继续下一步了。
步骤三:本地 Cursor 修改
1、同步代码到 Github
点击右上角的「Integrations」里的 Github。
下面就会提示你链登录 Github

接着授权就可以
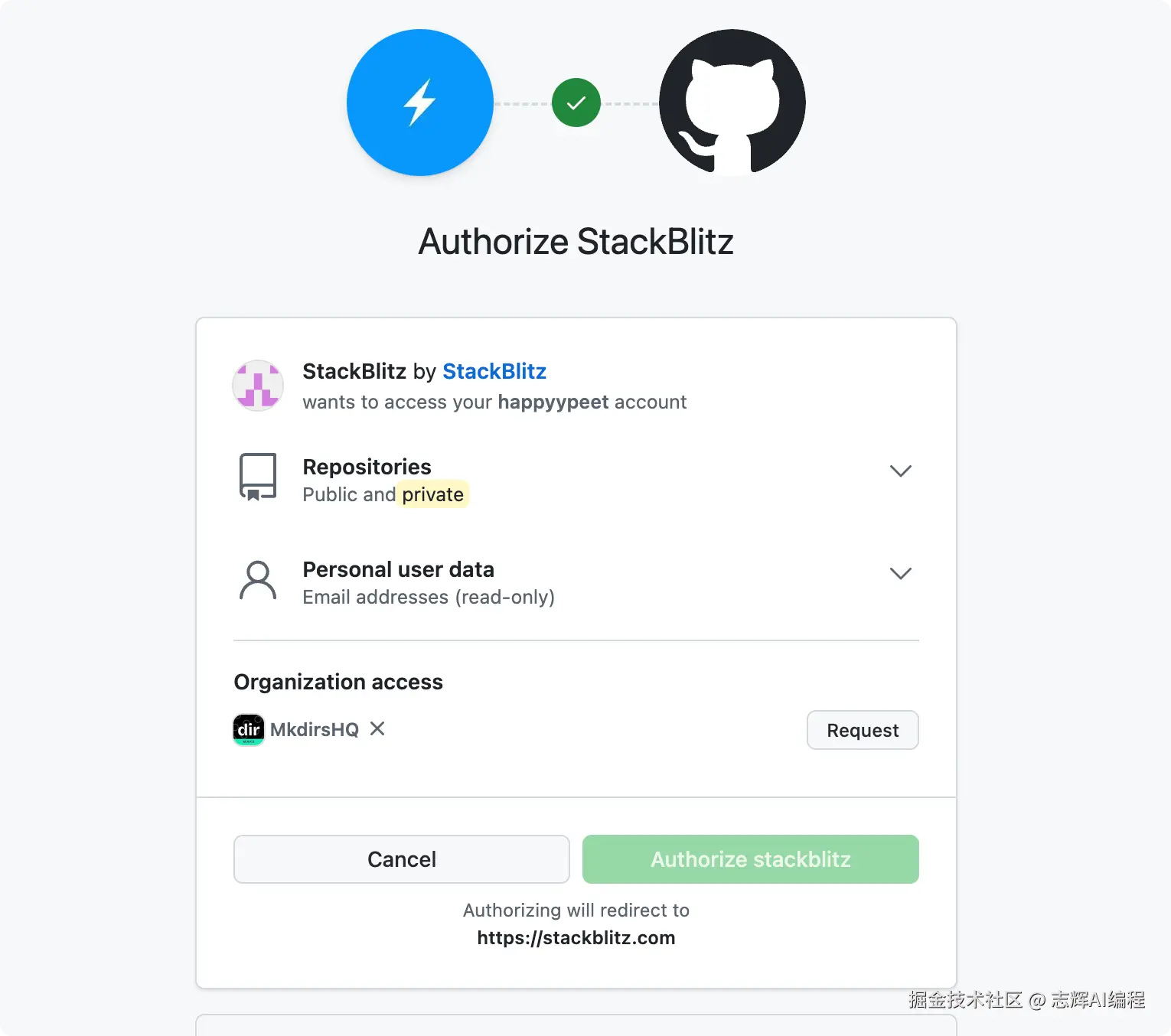
然欧输入你需要创建的项目名称
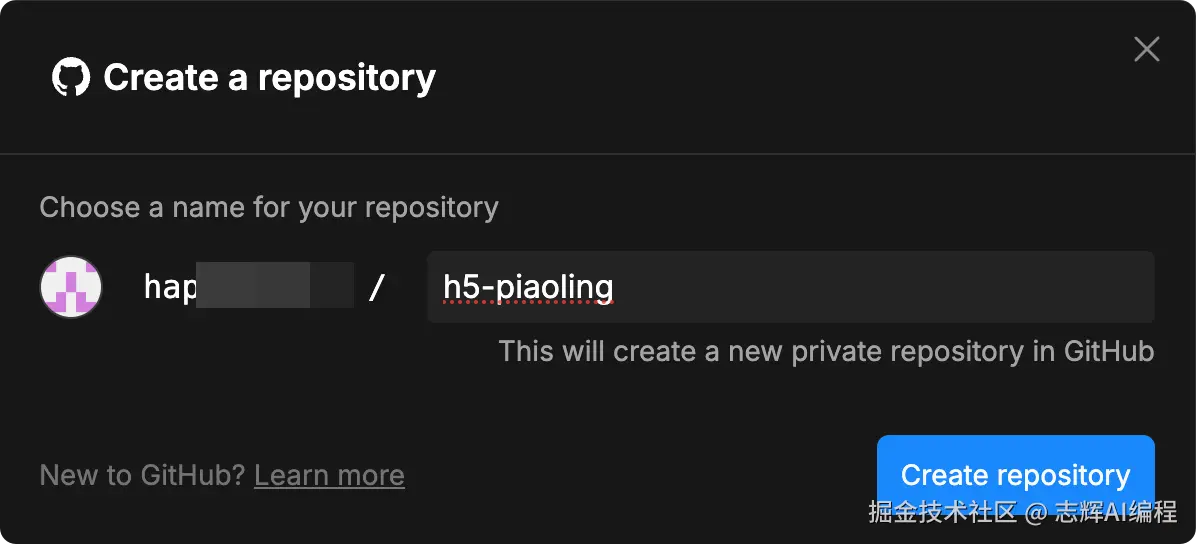
2、本地下载代码
使用 git 工具把代码下载到本地
git 就类似游戏的存档工具,每一个步骤都可以存档,当有问题的时候,就可以从某个存档恢复了。
当然:这里需要提前安装好 Git,如果有不懂的可以联系我,我来帮你解决。这你就不多说了
打开你的 Github 仓库页面,复制 HTTPS 的地址
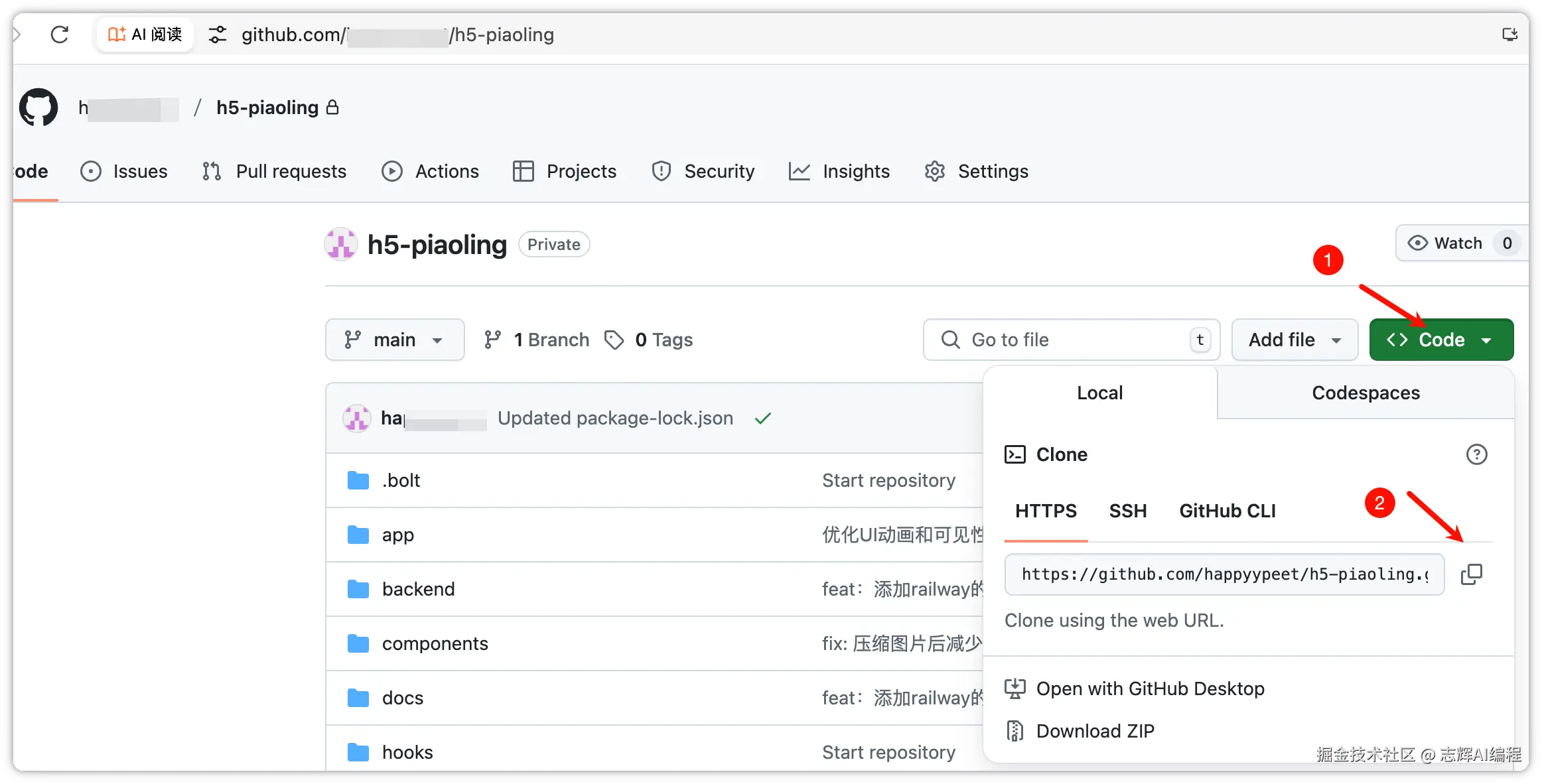
然后使用下面的命令,就可以下载到本地了。
git clone 你的代码仓库地址
下一步就是安装代码的依赖包
这里需要 nodejs 环境,同样就不多说了,不懂的可以私聊

下一步就是启动
接着就是浏览器打开上面的地址:http://localhsot:3000,就可以看见上面写好的页面。
默认打开是按照 pc 的全屏显示的,可能看着有些别扭
我们打开 F12,打开调试窗口,如下图
点击右侧类似电脑手机的按钮,就可以调到移动端模式显示了,还可以选择对应的机型。
xx 小插曲 xx
原本不想放这里的,结果还是放一下吧,刚好是解决了一个很大的问题
刚开始在 bolt 上面修改的时候,修改后一直报个错误,结果修复了很多次,还是没有解决。

没办法,我就在本地 Cursor 上仔细看了下代码,发现是个引号的问题。

我就在本地 Cursor 中快速修复了下
但是后面惊悚的事情来了,我去 bolt 上调整了下界面样式,结果又给我写成了引号的问题
最后我就发现,可能 bolt 目前对这类的错误还是没有意识。并且看它界面的代码,每次都是从头开始写(难怪要等好一段时间才弄完,究竟是什么设计了?)
最后索性,我仔细看了下代码,删除掉了,没啥大的影响。
目前来看 bolt 这种工具还是有点门槛,解决错误的能力还是没有 Cursor 强大,一不小心页面上的错误就在一起存在,你也不知道它改了啥。
这就需要你对代码还是有基本的认识。
步骤四:使用本地数据
首先就是把前面下载准备好的图片放到 imgs 目录下
在 Cursor 中让从 imgs 目录中显示图片。
不过这里 Cursor 还是很智能的,访问后都是 404
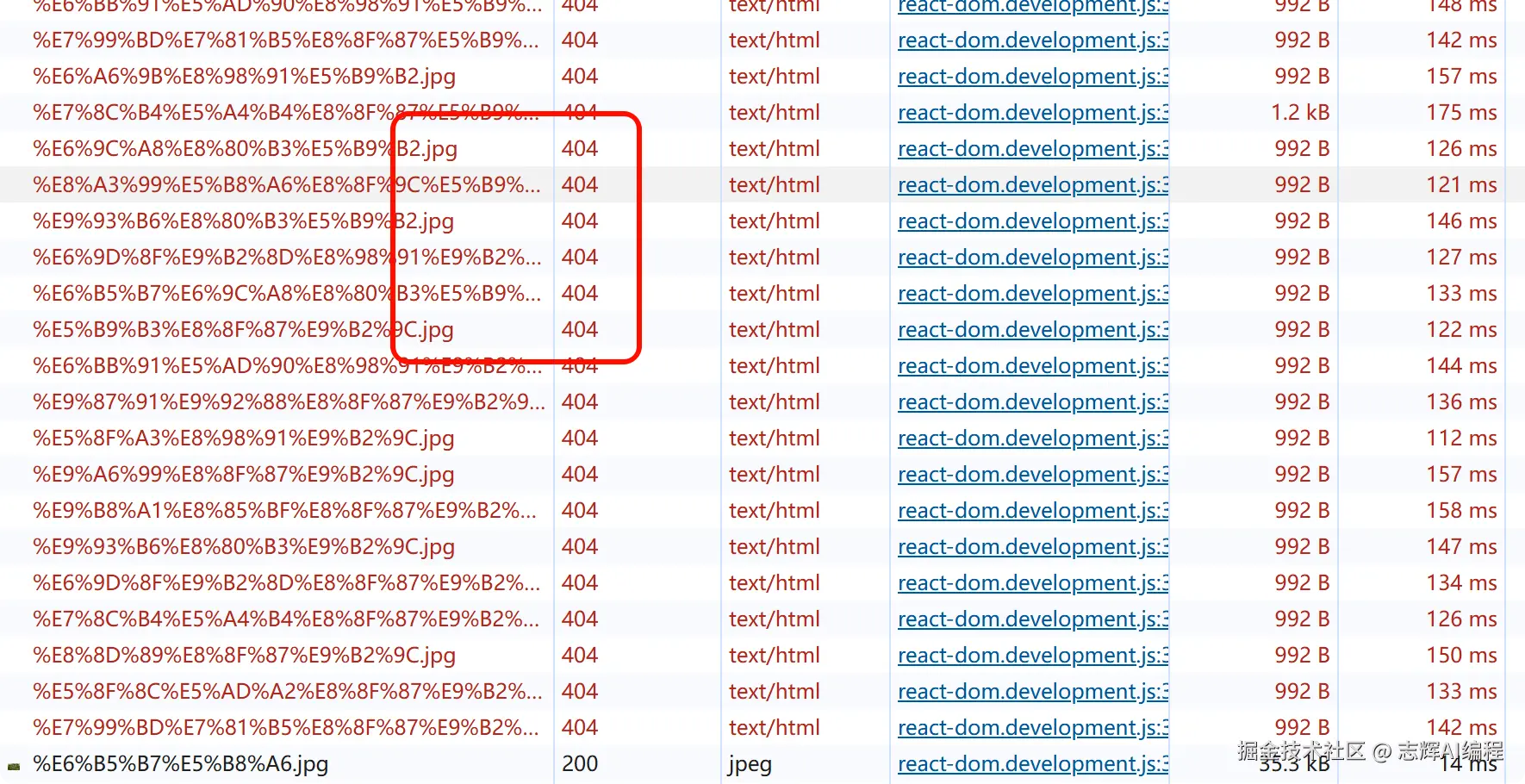
那么就直接告诉 Cursor 让他解决这个问题。
结果他一下子就找到问题所在了,需要放在 public 目录下,这个放以前你需要去搜索引擎里面找问题,并且有时候你拿让 AI 解决的问题,去搜索引擎找,基本都是牛头不对马嘴的回答。
最后还要去找官方文档看资料,不断的尝试。
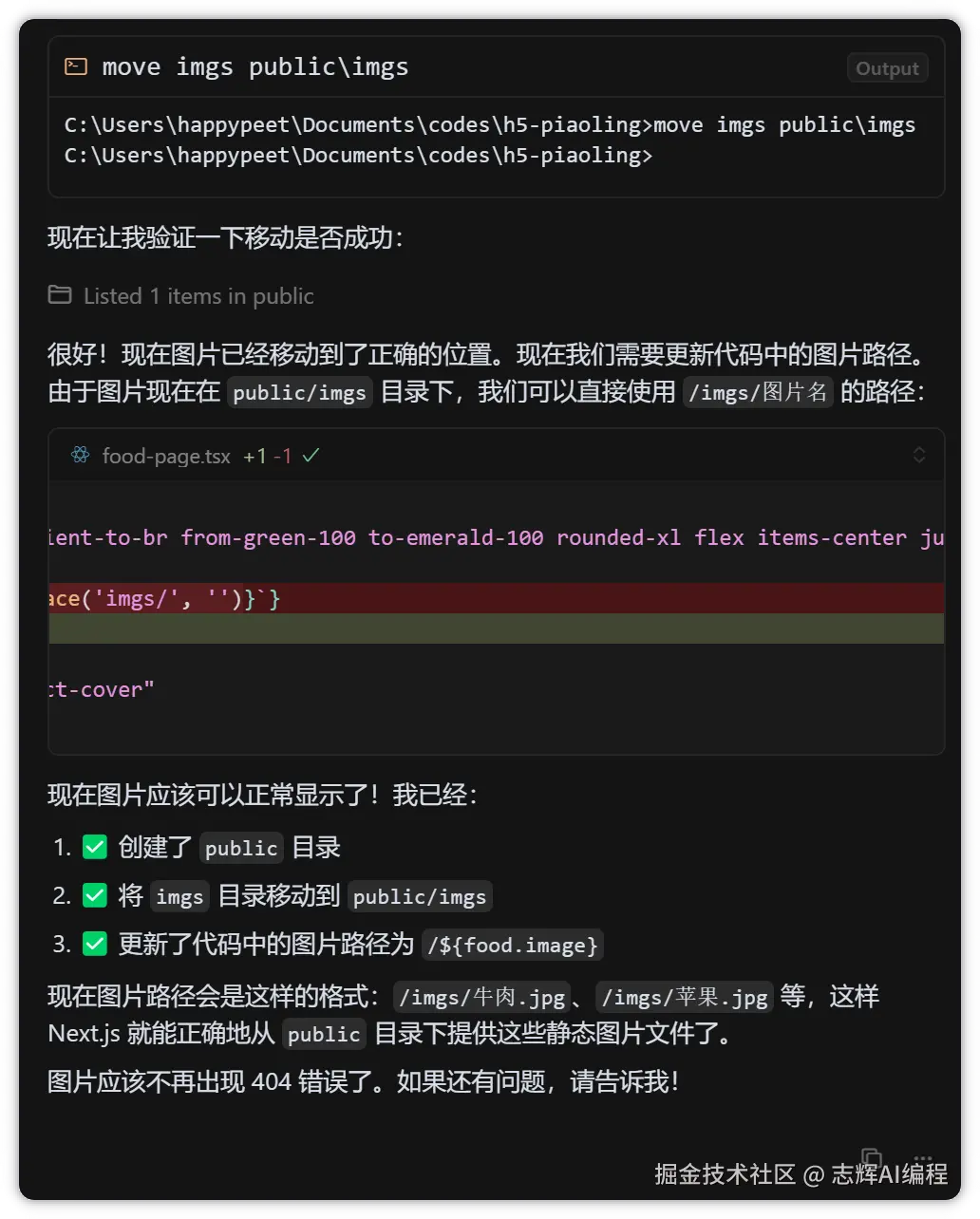
** 前端小结 **
到这里,基本前端的事情就搞完了
1、识别:识别流程,现在都是走前端模拟的流程
2、食物:这里目前应该是很全的功能了,读取本地的 json 数据,有分类标识,还有图片的展示
3、我的:个人中心有尿酸的记录,有曲线图,还有基本的体重指数记录。
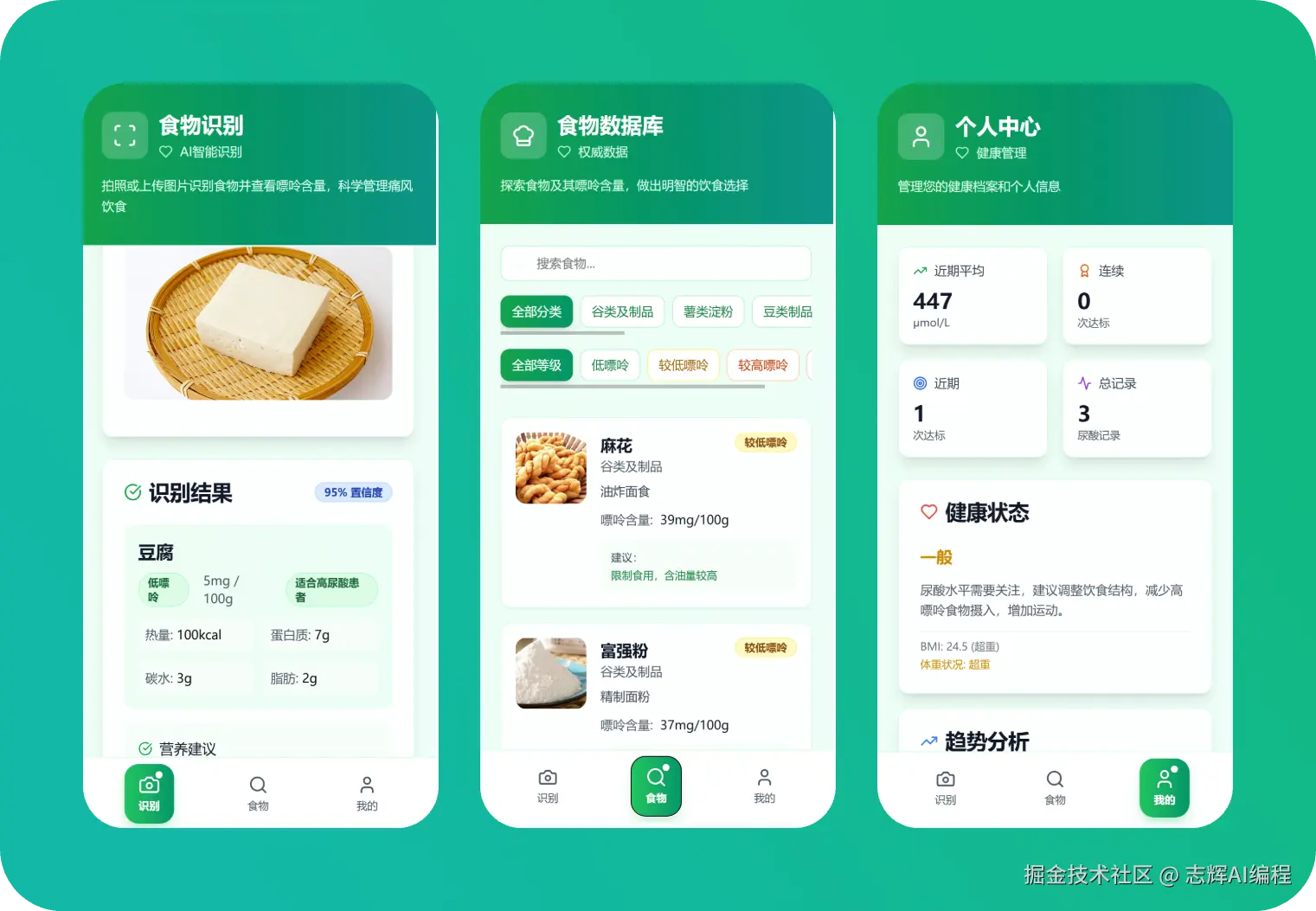
== 2、后端 ==
步骤零:阿里云大模型准备
背景:需要使用大模型来识别图片,然后返回嘌呤的含量,所以我们需要选择一个大模型的 API 来对接。
这里选择阿里的 qwen 来对接。
登录百炼平台:bailian.console.aliyun.com/
访问API-kEY 的地址:bailian.console.aliyun.com/?tab=model#…
创建一个 API-kEY,并保存好你的 key 信息。

步骤一:创建必要的配置
先访问找到通义千问 API 的文档的地方
这里我们采用直接复制上面页面的内容,保存到项目下的 docs 目录在的 qwen.md 里面
这里顺便把之前的 prd.md 文档从之前的项目目录拷贝过来了
步骤二:创建后端服务模板代码
直接使用下面的提示词,就可以创建一个后端的服务
这里要想为什么要创建后端服务,
一方面主要是需要调用大模型的 API,用到一些KEY 信息,这些是需要保密的,不能在前端被人看到了。
另外一方面,后面如果需要一些登录注册服务,还有食物数据都是需要后端来存储,提供给前端。
请在项目的根目录下创建 backend 目录,在这个 backend 目录下创建一个基于fastify框架的server,保证服务没有问题
同样的不知道什么fastify技术的,找大模型聊就行。
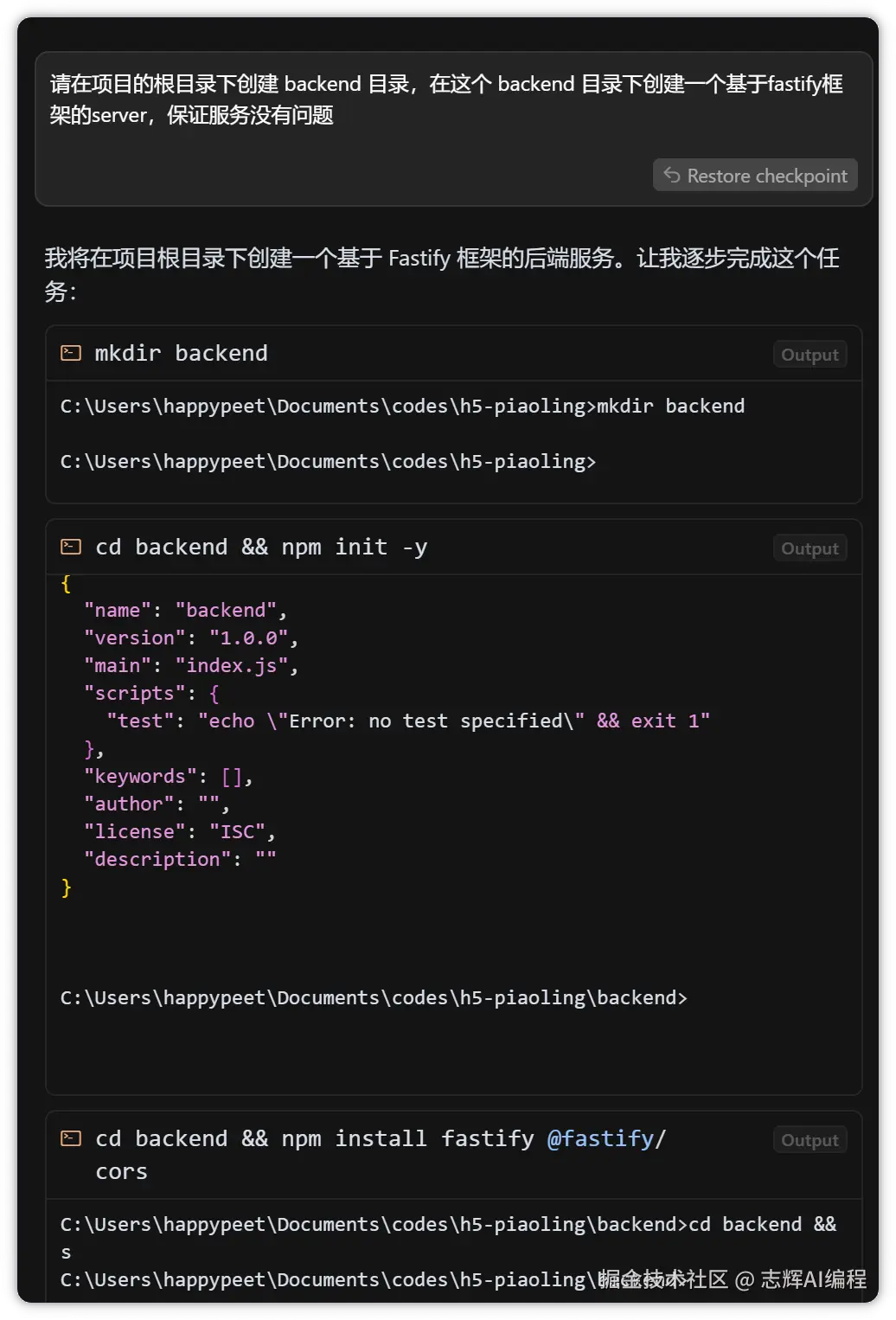
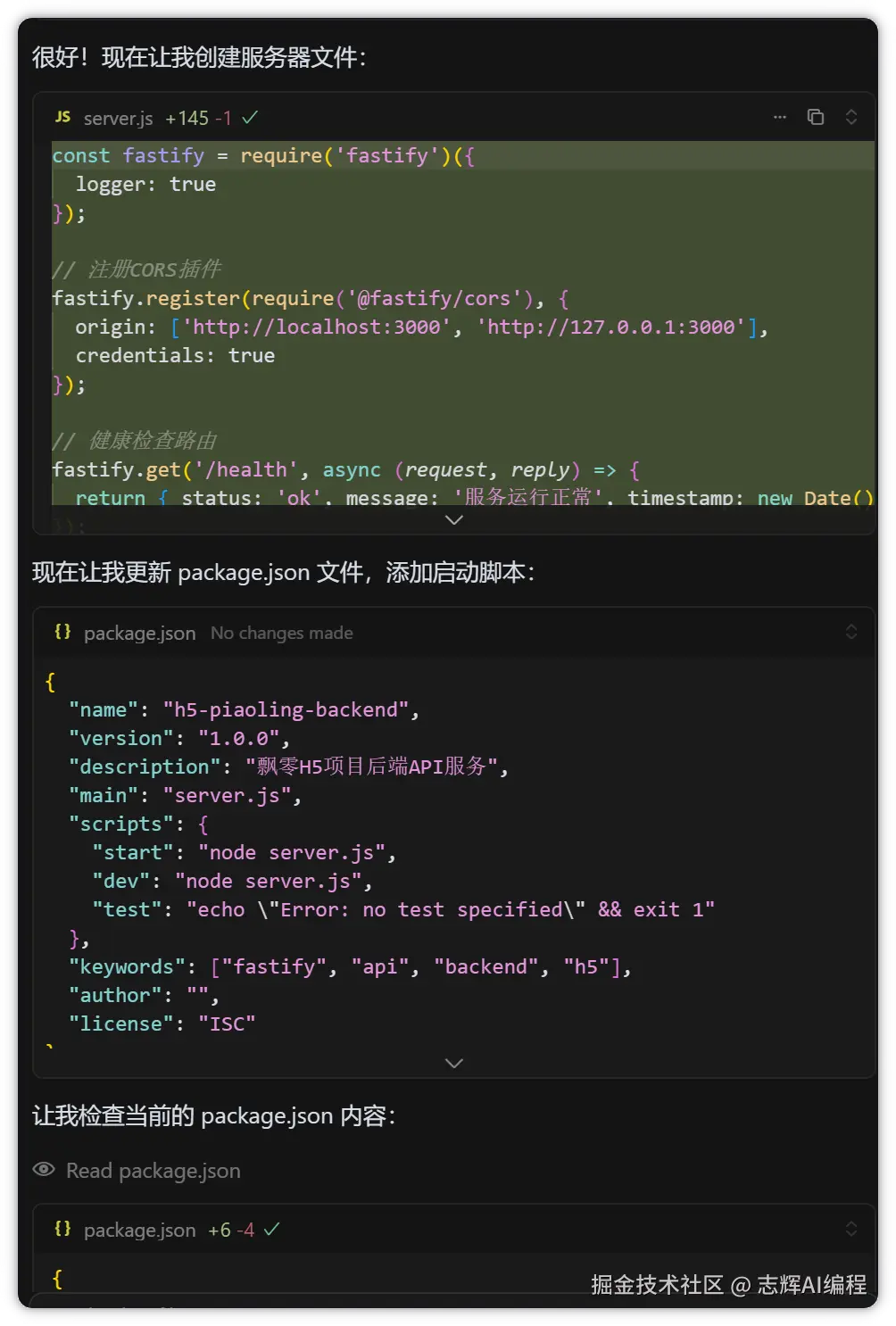
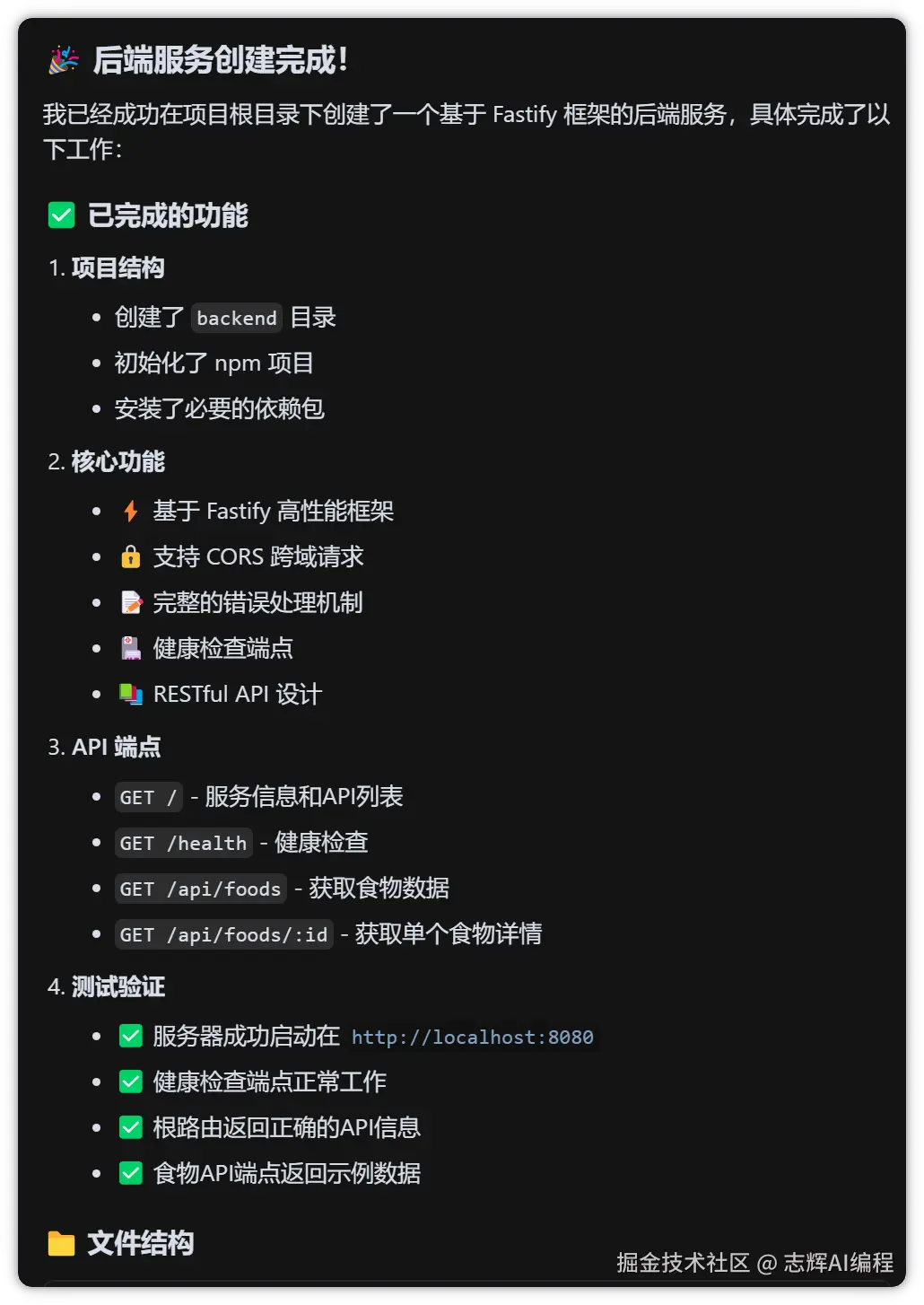
步骤三:API 文档+后端业务服务开发
重点来了,这里我就写到一个提示词里面,让他完成的
帮我接入图像理解能力,参考 @qwen.md :
1. 现在在 @/backend 的后端服务器环境中调用ai能力,
2. 使用 .env 文件保存API_KEY,并使用环境变量中的DASHSCOPE_API_KEY.并且.env文件不能提交到git上,提交到git的可以用.env.example文件作为举例供供用户参考
3. 要求使用openai的sdk,并且前端上传base64的图片
4. 后端返回值要求返回json格式,返回的数据能够渲染识别结果中的字段,包括:食物/嘌呤值/是否适合高尿酸患者/食用建议/营养成分估算
5. 在 @/backend 目录下创建 api.md 文件,记录后端接口文档
这里我把 api.md 高亮了,这个是关键,是后面前后端联调的关键,不然 Cursor 是不知道请求字段和响应字段该怎么对接的,到时候数据不对,再来调试就比较麻烦。
所以接口文档务必保证 100% 准确,后面的调试就会很容易。
截图如下:
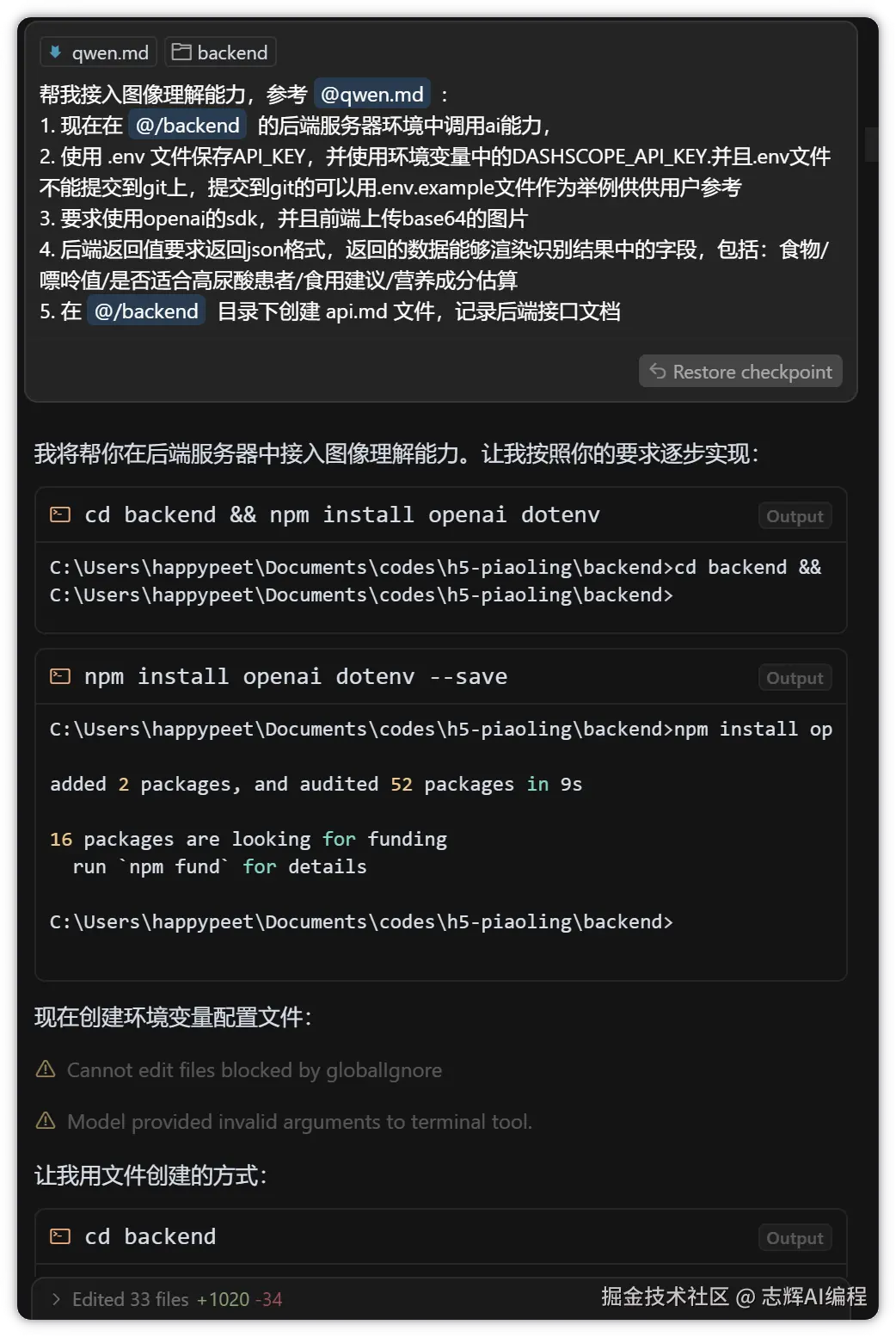
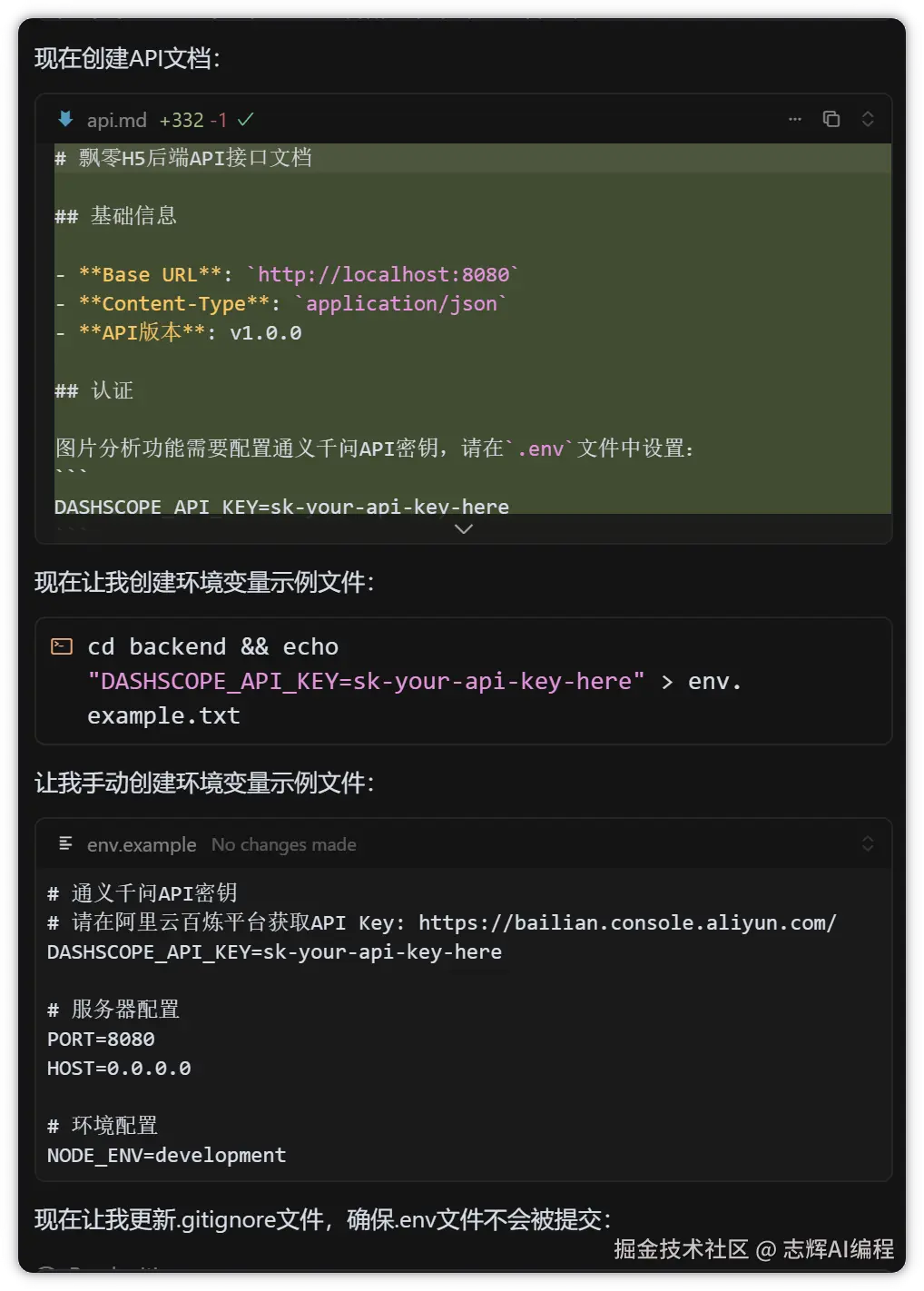
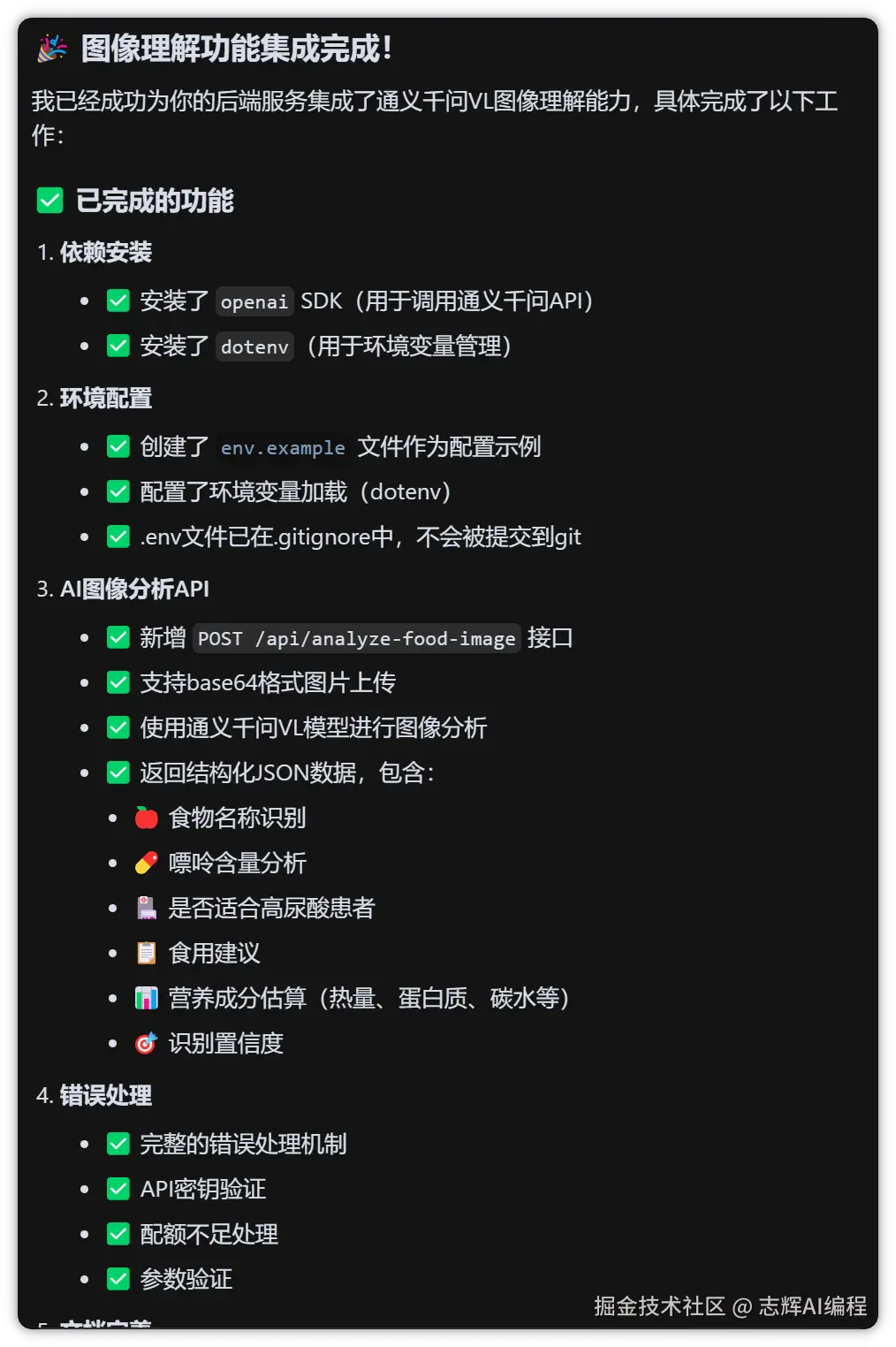
很贴心的完成功能后,最后帮我们些了 api.md 接口文档,还进行了一些列测试,保证功能是完整的。
这里放出来,Cursor 看是怎么帮我们写这个代码的
- 帮我们组装好了提示词
- 根据 qwen.md 的接口文档,组装请求数据和返回数据,字段都我们的项目符合
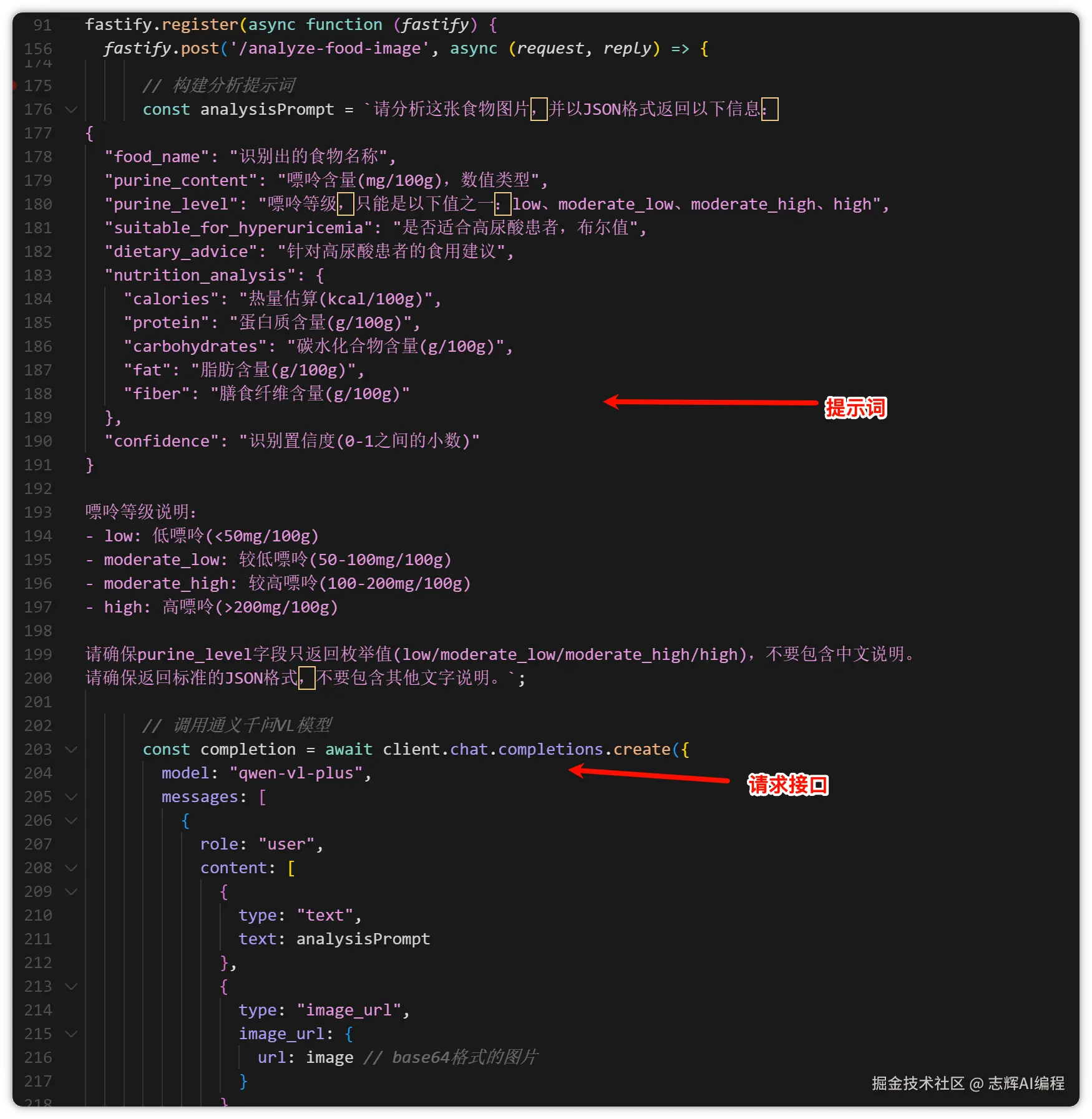
== 3、联调 ==
其实这里的联调很简单了。就是一句话的事情。
因为之前的前端的拍照图片都是走的模拟的接口,没有真正的调用后端的接口,所以需要换成真正的后端接口。
刚好前面的后端服务写好了 api.md 接口文档
前端修改点,前端目录是当前根目录
1. 也需要加入请求后端的 url 的环境变量,本地调试就默认使用 localhost,线上发布的时候设置环境变量后,前端服务从环境变量获取 url 然后请求到对应的后端服务
2. 食物识别的接口参考 @api.md 文档,请修改需要适配的地方,食物识别的代码在 @identify-page.tsx代码中。
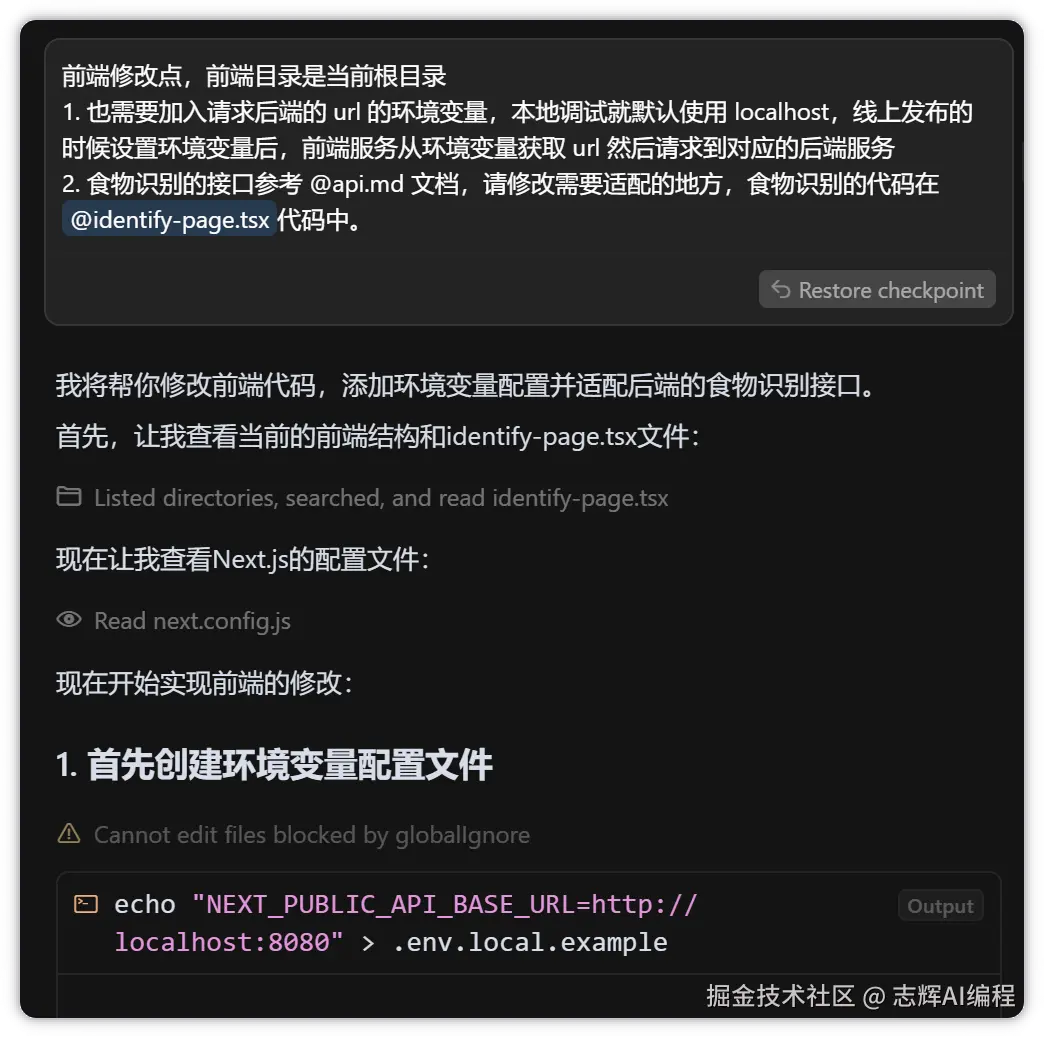
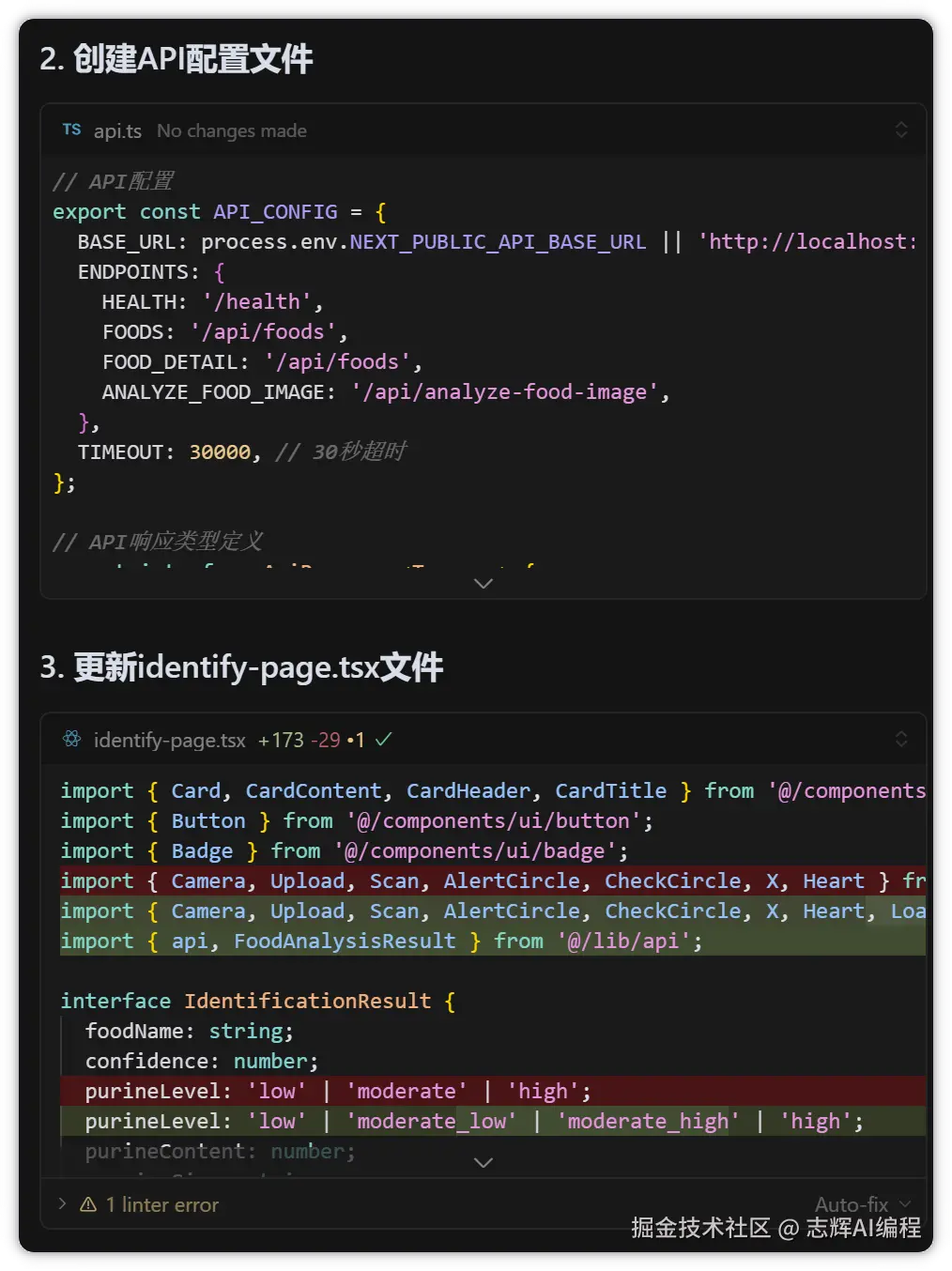
这里要说的是:前面的 api.md 接口文档些的非常准备,这一步的前端请求后端接口,基本都是一遍过,所以后端提供的接口文档一定要准确,这样前端就可以很准确的调用接口传参和取返回值了。
== 4、测试 ==
其实到这里,基本测试的工作也就完成了。
基本的流程到现在都是跑通的。
不过还是需要多实际测试,这里下面的例子就是,我上传了「黄瓜」的照片,结果没识别,按理说不应该呀。
这里上了点专业的技巧,通过 F12 的调试窗口,看下接口返回的数据。
按照以往经验来说,估计是字段对应不上
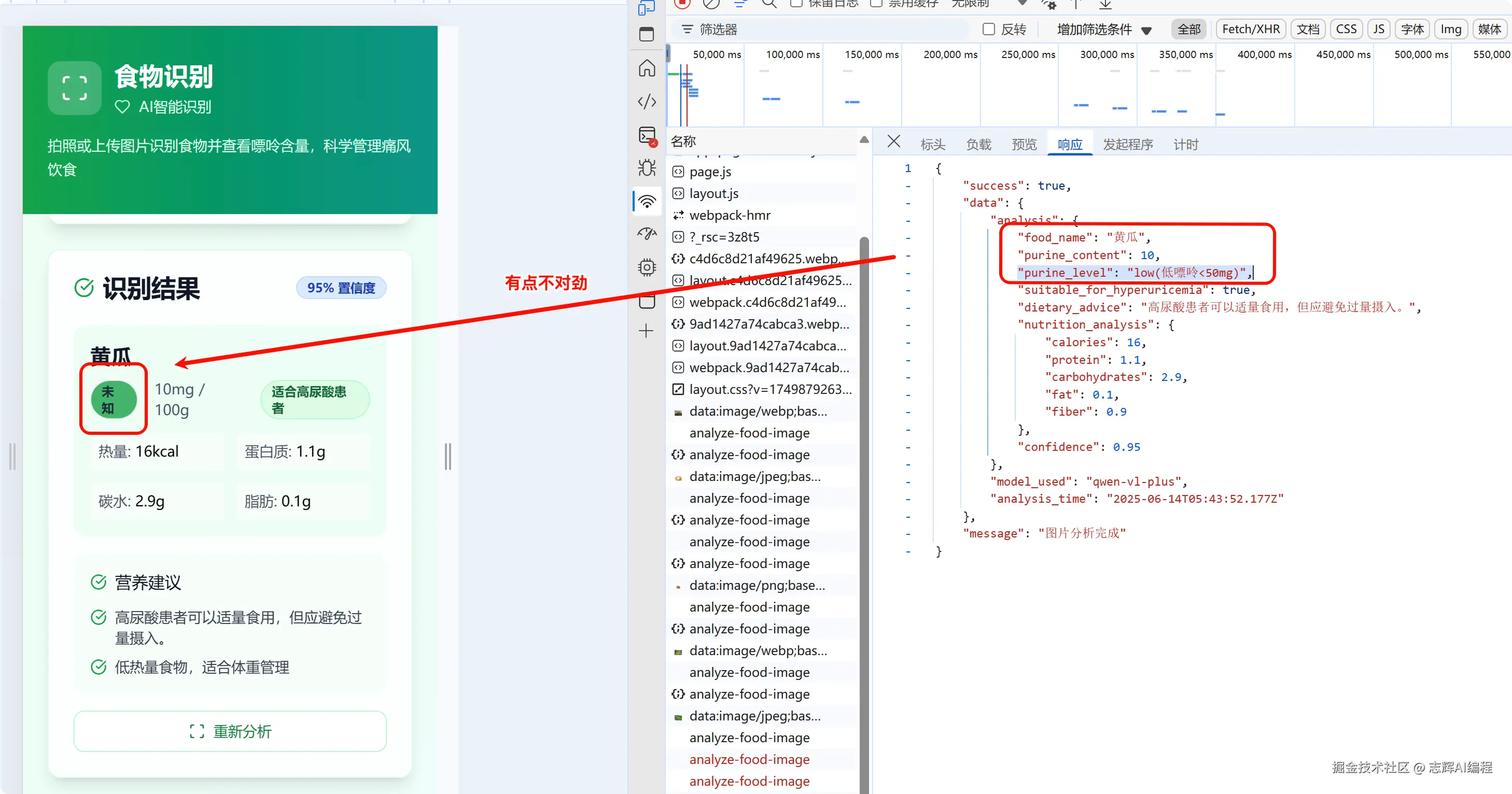
所以我就直接和 Cursor 说,可能是字段对应不上。请帮我修复。
测试黄光的食物的时候,后台接口返回的数据是 "purine_level": "low(低嘌呤<50mg)",但是 @getPurineLevel() @getPurineLevelText 没有识别到,请帮我修复
最后从前后端都给我做了修复,字段的匹配对应上了。
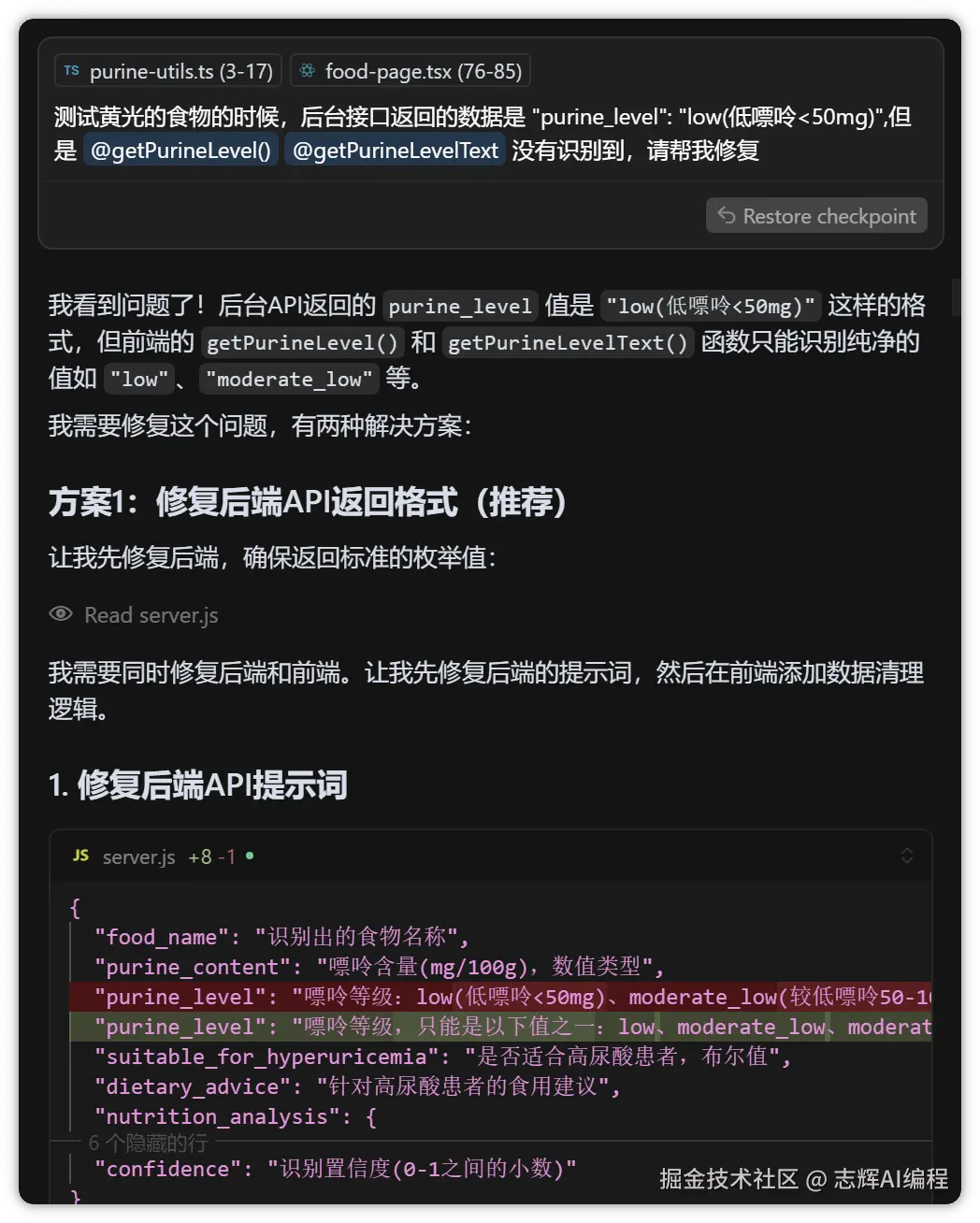
最后的总结如下:
== 4、总结 ==
其实到这里基本功能就完成了。
- 前端使用 bolt 工具等生成,快速生成漂亮的 UI 界面和基本完整的前端功能
- bolt工具调整样式、UI 等细节(擅长的)
- Cursor 精修前端小细节
- Cursor 开发完整后端功能
- 写清楚需求,如果知道具体技术栈是最好的
- 写好接口文档,最好人工校验下
- 前后端联调
- @使用后端的接口文档,最好写改动的接口的地方,前后精准对接
- 学会使用浏览器的 F12 调试窗口,特备是接口的请求参数和响应值的学习。
就目前来看,如果你是零基础,那么基本的术语不明白的话,有些问题可能会不好解决
- 寻求 AI 的帮助,遇事不决问 AI,它可以帮你搞定
- 寻求懂行的人来帮助你,比如环境的事情、按照的事情有时候一句话就可以给你讲明白的。
第四阶段:部署+上线
部署这一块其实对普通人门槛还比较高的,问题比较多。
- 域名问题
- 服务器问题
- 如何部署,如何配置
这里我们采用云厂商的部署服务,简化配置文件和部署的流程
但是域名申请还是需要提前准备好的,不过现在我们用的这个云服务暂时现在没有的域名,也有临时域名可以先用。
到这里,其实如果你只是本地看的话,就已经可以了,那么这里我们教一个上线部署的步骤,傻瓜式的,不需要各种配置环境。
我相信大家如果搞独立开发的 Vercel 肯定都熟悉了。这里也介绍下类似的工具,railway.com/,他不仅可以部署前端静态页面,还有后端服务,PostgreSQL、Redis 等数据库也支持一键部署。
1、项目的配置文件
railway 部署是需要一些配置文件的,当然我们可以让 Cursor 帮我们搞定。
直接告诉 Cursor 我们需要部署到 railway 上,看还需要什么工作可以做的。
后端
@/backend 这个后端项目现在需要在railway上去部署,请帮我看看需要哪些部署配置
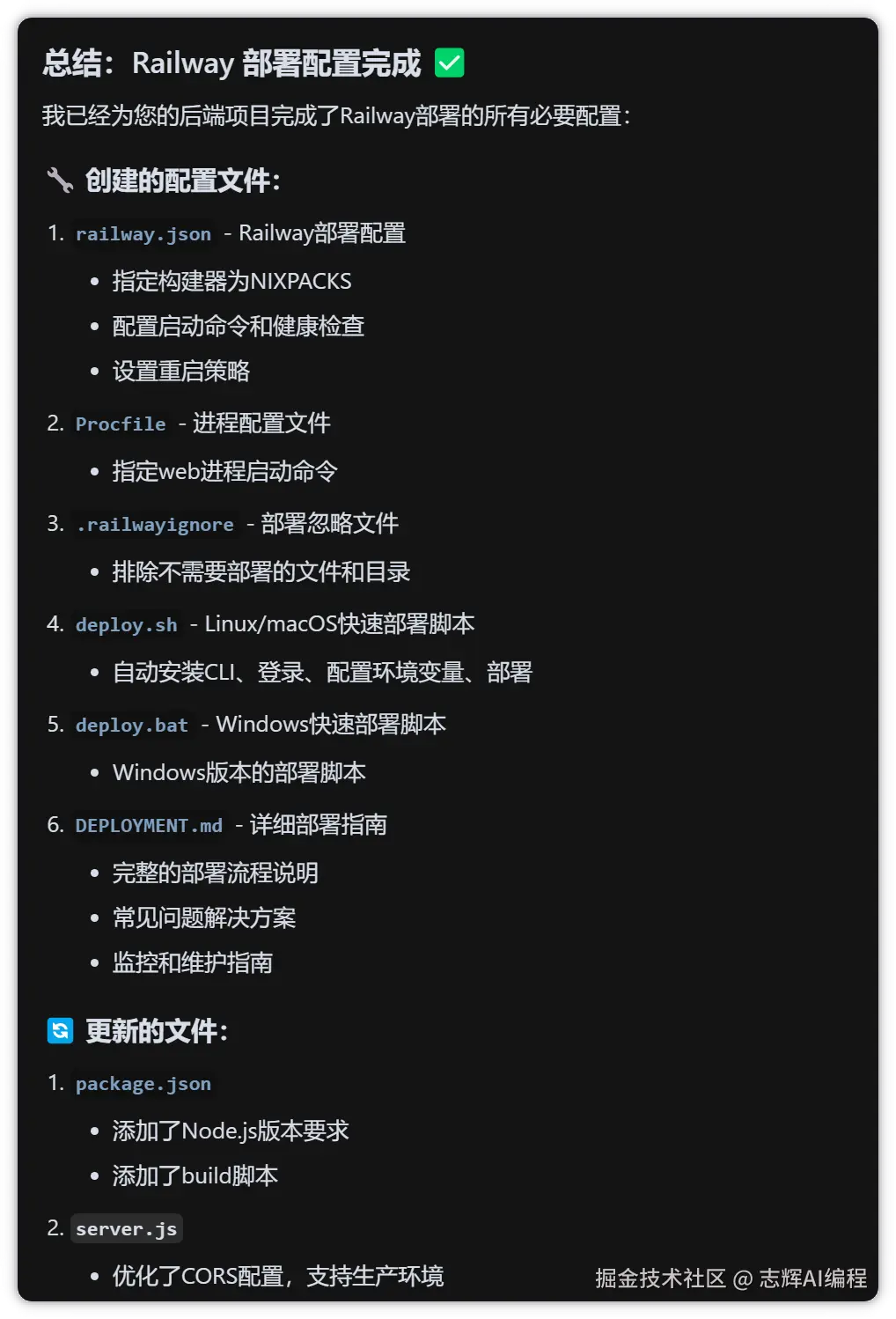
前端
也是一样,让 Cursor 给我们生成部署的配置文件
当前目录是前端目录,也需要添加railway的部署相关配置
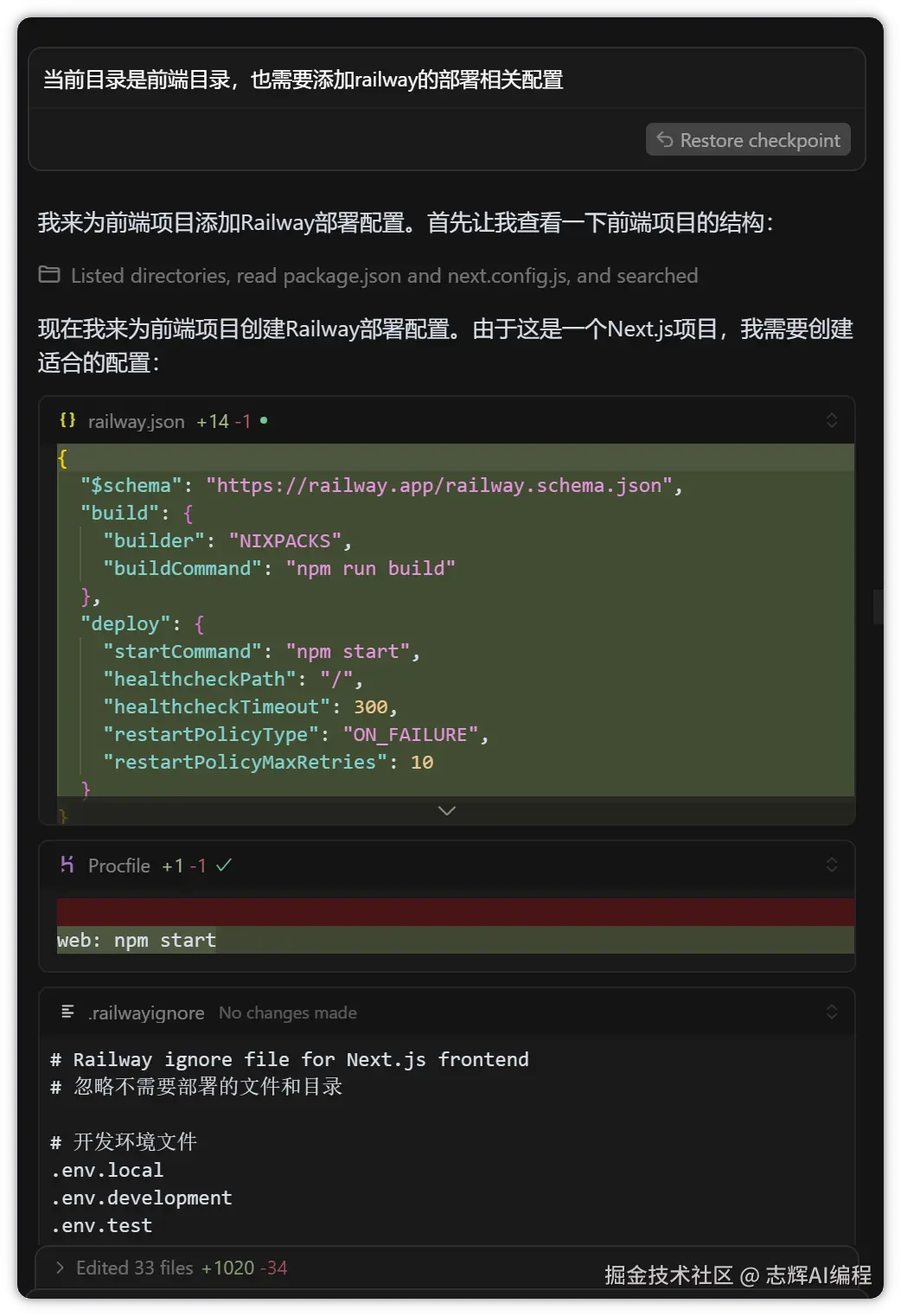
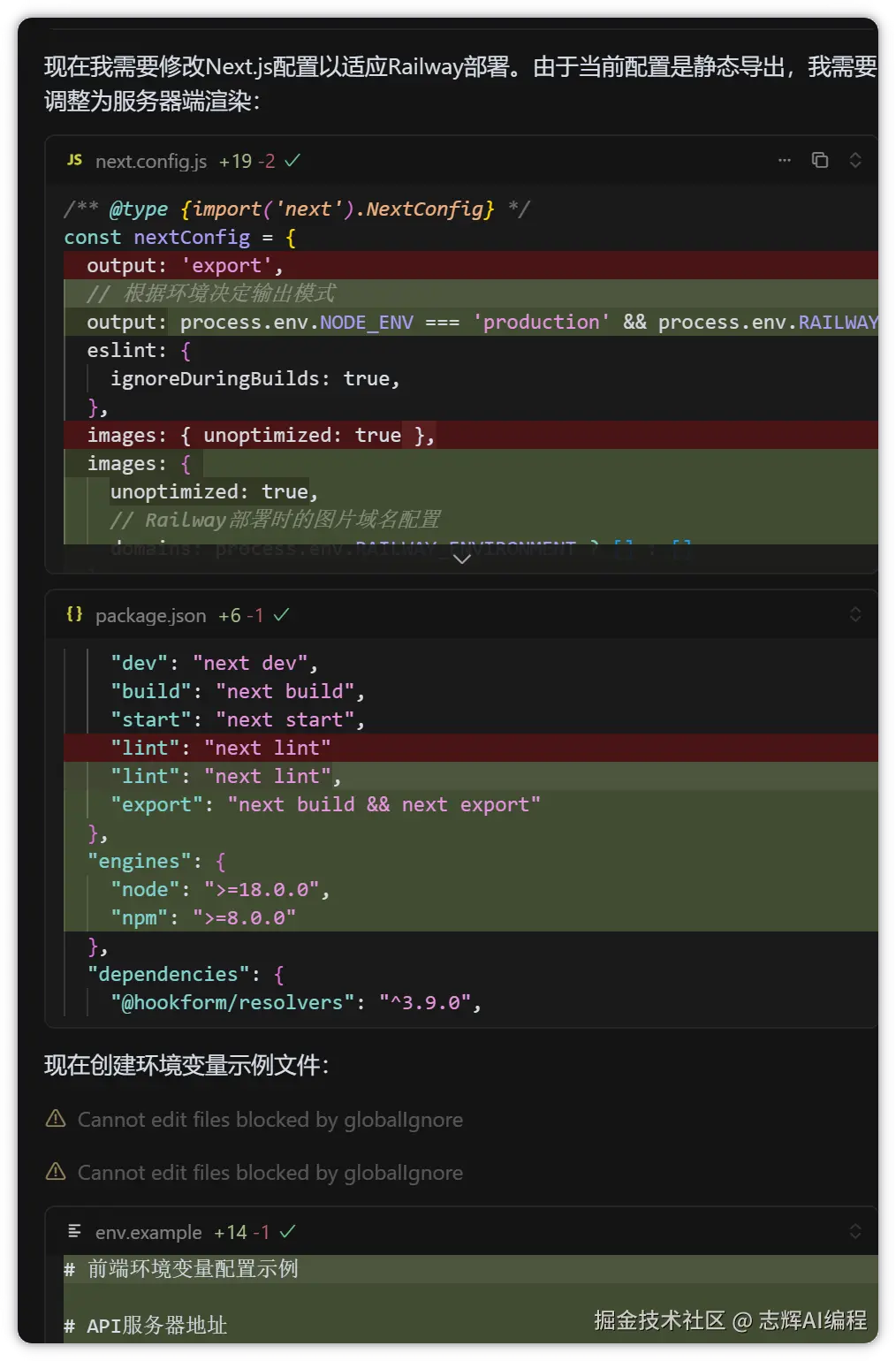
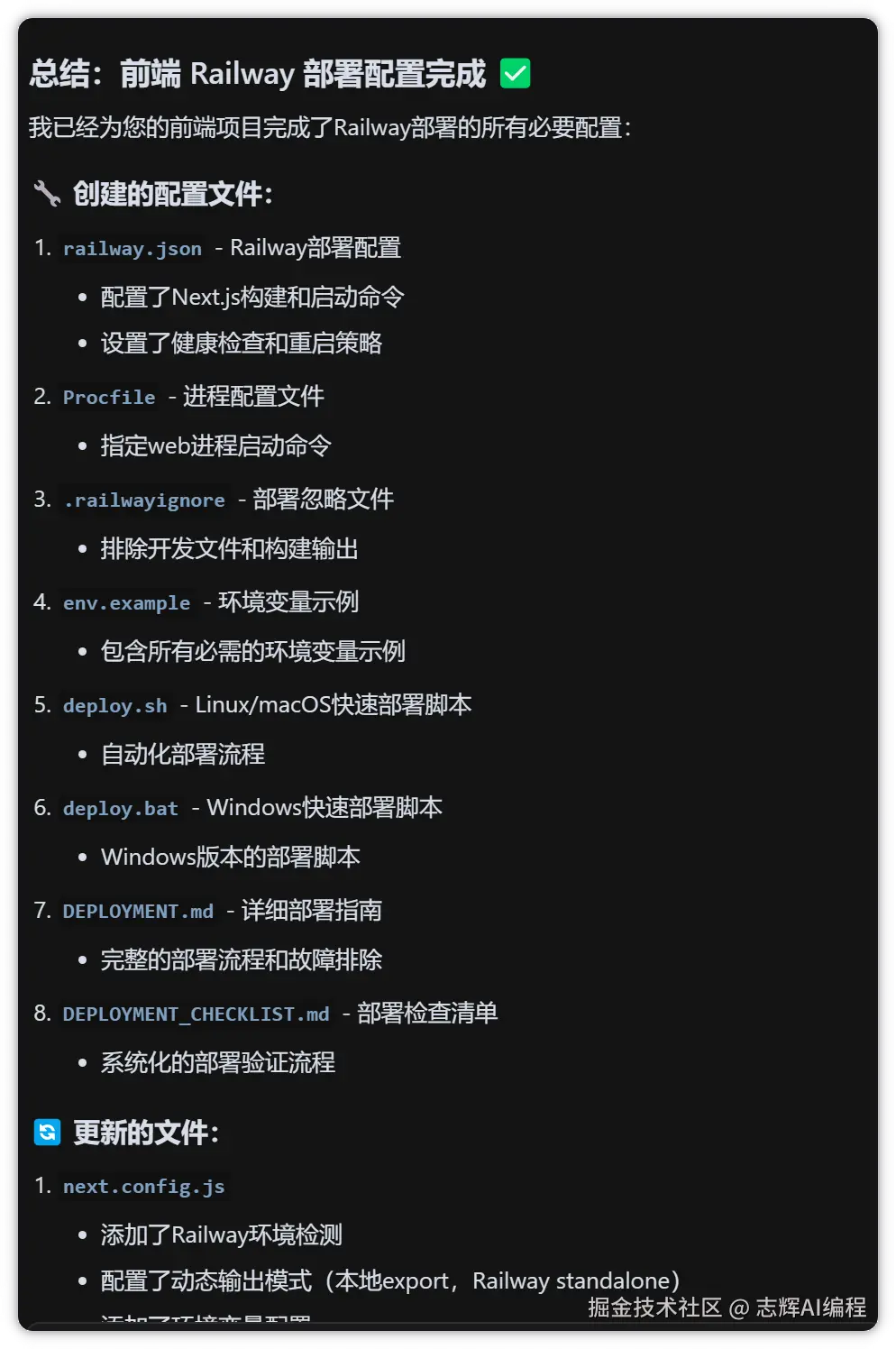
Cursor 会帮我们创建需要的配置文件,那么就可以进入下一步部署了。
2、提交代码
记得要提交代码,在 Cursor 的页面添加提交代码,推送代码到 Github 上,这样 railway 才可以拉取到代码。
提交代码的时候,可以使用 AI 生成提交信息,也可以自己填写信息
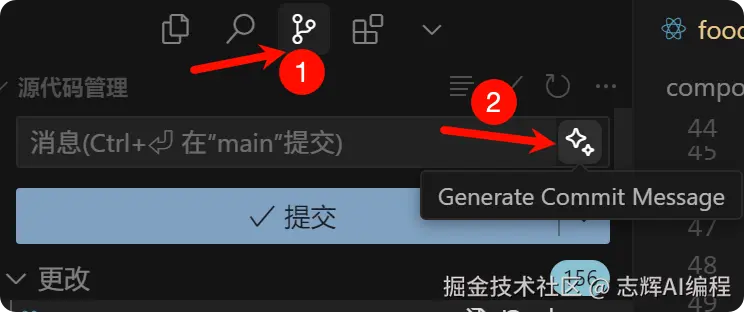

记得还要同步更改
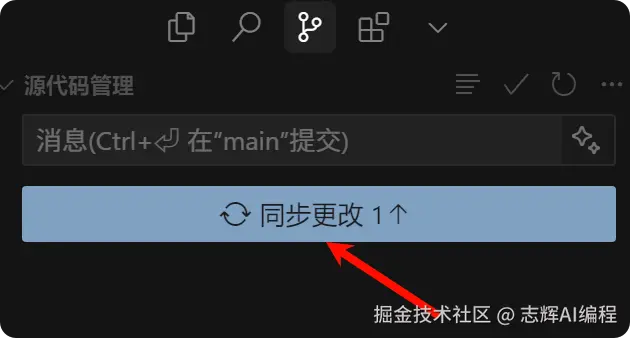
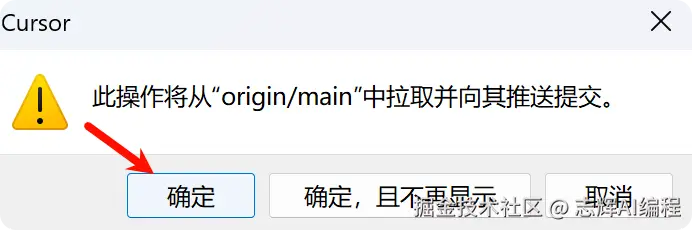
3、railway 页面操作
现在会有赠送的额度,并且免费就用也有 512M 的内存机器使用。对于当前下的足够了。
注册登录后,选择 Dashboard 后,点击添加,就可以看到如下的页面,
添加 Github 项目,后续就会授权等操作,继续完成就可以。

下一步就一个你的项目
然后就会跳转到工作区间,会自动部署。
记得不要忘记环境变量

就是在「Variables」标签下,直接添加变量就行。
添加完记得需要重新部署下。
后端环境变量
前端环境变量
当然不过你有错误,可以把 log 里面的错误复制,粘贴到 Cursor 里面,让他解决,我之前部署的项目有个就有问题,通过这个方式,帮我解决了。
4、大功告成
部署完成后怎么访问了,切换到 settings 页面,有个 Networking 部分,可以生成一个 railway 自带的域名,用这个域名就可以访问了,如果你有自己的域名还可以添加一个自己的域名,添加完以后就可以自己访问了。
5、总结
很开心,跟我走到了这里,基本到这里,算是完成一大步,也就是我们的 MVP 完成了。
现在我们再来总结下前面整体的步骤
1、前端我们通过 bolt 来生成代码,加速前端的设计,让 bolt 这种工具提供我们更多的能力,发挥他的有点
2、后端使用 Cursor 来开发,纯业务逻辑通过提示词还是很好的达到效果。
3、前后端联调,写好接口文档,让 Cursor 必须阅读接口文档,前端再写接口
4、部署配置文件也可以通过 Cursor 来搞定,无所不能
5、中间有任何问题,有任何不懂的都可以找 Cursor 使用 ask 模式搞定。
第五阶段:运营维护+推广
分了「优化」「安全」「推广」三个部分来说这个事情。
- 其实到这里是后续的常态,你不要不断的推广你的产品,去增加访问量。
- 另外就是不断的迭代优化你的功能,提升用户体验,加强本身产品的竞争力。
- 最后、最后、最后就是安全,这个不要忘记了,后面我也会加强后,然后去推广下我的产品,安全很重要,提前做好可以更保护你的服务器和大模型的 API-KEY。
优化
这个是上线了后发现的,就是使用手机拍的照片,一般都比较大,这张图片请求后端的时候,数据量比较大,接口超时了。
那么解决办法:
1、增加后端的请求体的大小
2、压缩图片,然后再请求后端接口
安全
其实这里还是蛮重要的,因为你的服务,还有你的大模型的 KEY,如果服务器被攻击是要付出代价的,最重要的是花掉你的钱呀。
所以这块我还在做,目前想的就是让 Cursor 正题 revivew 代码,看下有什么安全隐患,给我一些解决方案。
推广
如果你的产品上线后,需要写文章、发小红书去推广,首先从你的种子用户开始,你的微信群,你的朋友圈都是可以的。
后面积极听取用户心声,持续解决痛点需求,满足用户的痛点,产品就会越来越好。
第六阶段:成本计算
时间成本
从开始到结束上线,手机使用正式的域名访问,大概就是整一天的时间,从早上开始,忙到晚上我就开启了测试,晚上搞完还去外面遛弯了一大圈回来的。
我们就算:10 小时
人力成本
哈哈哈哈,很清楚,就我一个人
软件成本
bolt:20 元优惠包月(海鲜市场),就算正式渠道,20 刀一个月,当然有免费额度,调整不多,基本够用
Cursor:150教育优惠(海鲜市场),就算正式渠道,20 刀一个月,足足够用
域名:32首年
我们就算满的,折算成人民币,也就是 300 块。
想想 300 块一天你就做出来一个系统(前后端+部署),何况软件都是包月的,一个月你可以产出很多东西,不止这个一个系统。
对比公司开发,一个月的成本前后端两个人,毕业生也的上万了吧,何况还是 5 年经验开发的(市面上的抢手货)。
总结
能走到这里的,我希望你给自己一个掌声,确实不容易。
我希望你也有可以通过编程来实现自己的想法和创意。
虽然目前编程对于零基础的人来说确实可能会有些吃劲,但是你我差距也不大,我现在遇到了很多在搞 AI 编程的都是程序员,有房地产行业的、也有产品的。
遇事不决,问 AI
我希望你可以记住这句话,自己的创意+基本问题找 AI,你基本就可以解决 99% 的问题,剩下的 1% 你基本遇不到,遇到了,也不要慌,身边这么多牛人总会有人知道。
来源:juejin.cn/post/7517496354244067339
一行生成绝对唯一 ID:别再依赖 Date.now() 了!
在前端开发中,“生成唯一 ID” 是高频需求 —— 从列表项标识、表单临时存储,到数据缓存键值,都需要一个 “绝对不重复” 的标识符。但看似简单的需求下,藏着很多容易踩坑的实现方式,稍有不慎就会引发数据冲突、逻辑异常等问题。
今天我们就来拆解常见误区,带你掌握真正可靠的唯一 ID 生成方案。
一、为什么 “唯一 ID” 比想象中难?
唯一 ID 的核心要求是 “全局不重复”,但前端环境的特殊性(无状态、多标签页、高并发操作),让很多看似合理的方案在实际场景中失效。
下面两种常见实现,其实都是 “伪唯一” 陷阱。
❌ 误区 1:时间戳 + 随机数(Date.now() + Math.random())
很多开发者会直觉性地将 “时间唯一性” 和 “随机唯一性” 结合,写出这样的代码:
// 错误示例:看似合理的“伪唯一”方案
function generateNaiveId() {
// 时间戳转36进制(缩短长度)+ 随机数截取
return Date.now().toString(36) + Math.random().toString(36).substr(2);
}
// 示例输出:l6n7f4v2am50k9m7o4
这种方案的缺陷在高并发场景下会暴露无遗:
- 时间戳精度不足:
Date.now()的精度是毫秒级(1ms),如果同一毫秒内调用多次(比如循环生成、高频接口回调),ID 的 “时间部分” 会完全重复; - 伪随机性风险:
Math.random()生成的是 “非加密级随机数”,其算法可预测,在短时间内可能生成重复的序列,进一步增加冲突概率。
结论:仅适用于低频次、非核心场景(如临时展示用 ID),绝对不能用于生产环境的核心数据标识。
❌ 误区 2:全局自增计数器
另一种思路是维护一个全局变量自增,看似能保证 “有序唯一”:
// 错误示例:自增计数器方案
let counter = 0;
function generateIncrementId() {
return `id-${counter++}`;
}
// 示例输出:id-0、id-1、id-2...
但在浏览器环境中,这个方案的缺陷更致命:
- 无状态丢失:页面刷新、路由跳转后,
counter会重置为 0,之前的 ID 序列会重复; - 多标签页冲突:用户打开多个相同页面时,每个页面的
counter都是独立的,会生成完全相同的 ID(比如两个页面同时生成id-0)。
结论:浏览器环境中几乎毫无实用价值,仅能用于单次会话、单页面的临时标识。
二、王者方案:一行代码实现绝对唯一 —— crypto.randomUUID()
既然简单方案不可靠,我们需要借助浏览器原生提供的 “加密级” 能力。crypto.randomUUID() 就是 W3C 标准推荐的官方解决方案,彻底解决 “唯一 ID” 难题。
1. 用法:一行代码搞定
crypto 是浏览器内置的全局对象(无需引入任何库),专门提供加密相关能力,randomUUID() 方法可直接生成符合 RFC 4122 v4 规范 的 UUID(通用唯一标识符):
// 正确示例:生成绝对唯一ID
const uniqueId = crypto.randomUUID();
// 示例输出:3a6c4b2a-4c26-4d0f-a4b7-3b1a2b3c4d5e
2. 为什么它是 “绝对唯一” 的?
crypto.randomUUID() 的可靠性源于三个核心优势:
- 极低碰撞概率:v4 UUID 由 122 位随机数构成,组合数量高达
2^122(约 5.3×10^36),相当于 “在地球所有沙滩的沙粒中,选中某一颗特定沙粒” 的概率,实际场景中碰撞概率趋近于 0; - 加密级随机性:基于 “密码学安全伪随机数生成器(CSPRNG)”,随机性远优于
Math.random(),无法被预测或破解,避免恶意伪造重复 ID; - 跨环境兼容:生成的 UUID 是全球通用标准格式(8-4-4-4-12 位字符),前端、后端(Node.js、Java 等)、数据库(MySQL、MongoDB)都能直接识别,无需格式转换。
3. 兼容性:覆盖所有现代环境
crypto.randomUUID() 的支持范围已经非常广泛,完全满足绝大多数新项目需求:
- 浏览器:Chrome 92+、Firefox 90+、Safari 15.4+(2022 年及以后发布的版本);
- 服务器:Node.js 14.17+(LTS 版本均支持);
- 框架:Vue 3、React 18、Svelte 等现代框架无任何兼容性问题。
三、兼容性兜底方案(针对旧环境)
如果需要兼容旧浏览器(如 IE11)或低版本 Node.js,可以使用第三方库 uuid(轻量、无依赖),其底层逻辑与 crypto.randomUUID() 一致:
安装依赖:
npm install uuid
# 或 yarn add uuid
使用方式:
// 旧环境兜底方案
import { v4 as uuidv4 } from 'uuid';
const uniqueId = uuidv4();
// 示例输出:同标准UUID格式
四、总结:唯一 ID 生成的 “最佳实践”

对于 2023 年后的新项目,直接使用 crypto.randomUUID() 即可 —— 一行代码、零依赖、绝对可靠,彻底告别 “ID 重复” 的烦恼!
来源:juejin.cn/post/7561781514922688522
前端终于不用再写html,可以js一把梭了,我的ovs(不写html,兼容vue)的语法插件终于上线了
OVSJS 语法预览
语法是这样的:
项目资源
- GitHub 地址: ovsjs 示例代码 (hello.ovs)
- VS Code 语法提示插件: ovs-vscode-client 下载
模仿的kotlin的语法

欢迎大家体验交流!
- 卫星 (WeChat):
alamhubb
如果你对这个语法感兴趣欢迎和我交流,谢谢
来源:juejin.cn/post/7579871631096266778
为何前端圈现在不关注源码了?
大家好,我是双越。前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP。我的代表作有:
- wangEditor 开源 web 富文本编辑器,GitHub 18k star,npm 周下载量 20k
- 划水AI Node 全栈 AIGC 知识库,包括 AI 写作、多人协同编辑。复杂业务,真实上线。
- 前端面试派 系统专业的面试导航,刷题,写简历,看面试技巧,内推工作。开源免费。
开始
大家有没有发现一个现象:最近 1-2 年,前端圈不再关注源码了。
最近 Vue3.6 即将发布,alien-signal 不再依赖 Proxy 可更细粒度的实现响应式,vapor-model 可以不用 vdom 。
Vue 如此大的内部实现的改动,我没发现多少人研究它的源码,我日常关注的那些博客、公众号也没有发布源码相关的内容。
这要是在 3 年之前,早就开始有人研究这方面的源码了,博客一篇接一篇,跟前段时间的 MCP 话题一样。
还有前端工具链几乎快让 Rust 重构一遍了,rolldown turbopack 等产品使得构建效率大大提升。这要是按照 3 年之前对 webpack 那个研究态度,你不会 rust 就不好意思说自己是前端了。
不光是这些新东西,就是传统的 Vue React 等框架源码现在也没啥热度了,我关注每日的热门博客,几乎很少有关于源码的文章了。
这是为什么呢?
泡沫
看源码,其实是一种泡沫,现在破灭了。所谓泡沫,就是它的真实价值之前一直被夸大,就像房地产泡沫。
前几年是互联网发展的红利期,到处招聘开发人员,大家都拿着高工资,随便跳槽就能涨薪 20% ,大家就会误以为真的是自己的能力值这么多钱。
而且,当年面试时,尤其是大公司,为了筛选出优秀的候选人(因为培训涌入的人实在太多),除了看学历以外,最喜欢考的就是算法和源码。
确实,如果一个技术人员能把算法和源码看明白,那他肯定算是一个合格的程序员,上限不好说,但下限是能保证的。就像一个人名牌大学毕业的,他的能力下限应该是没问题的。
大公司如此面试,其他公司也就跟风,面试题在网络上传播,各位程序员也就跟风学习,很快普及到整个社区。
所以,如果不经思考,表面看来:就是因为我会算法、会源码,有这些技能,才拿到一个月几万甚至年薪百万的工资。
即,源码和算法价值百万。
现状
现在泡沫破灭了。业务没有增长了,之前是红利期,现在是内卷期,之前大量招聘,现在大量裁员。
你看这段时间淘宝和美团掐架多严重,你补贴我补贴,你广告我也广告。如果有新业务增长,他们早就忙着去开疆拓土了,没公司在这掐架。
面试少了,算法和源码也就没有发挥空间了。关键是大家现在才发现:原来自己会算法会源码,也会被裁员,也拿不到高工资了。
哦,原来之前自己的价值并不是算法和源码决定的,最主要是因为市场需求决定的。哪怕我现在看再多的源码,也少有面试机会,那还看个锤子!
现在企业预算缩减,对于开发人员的要求更加返璞归真:降低工资,甚至大量使用外包人员代替。
所以开发人员的价值,就是开发一些增删改查的日常 web 或 app 的功能,什么算法和框架源码,真实的使用场景太少。
看源码有用吗?
答案当然是肯定的。学习源码对于提升个人技术能力是至关重要的,尤其是对于初学者,学习前辈经验是个捷径。
但我觉得看 Vue react 这些源码对于开发提升并不会很直接,它也许会潜移默化的提升你的“内功”,但无法直接体现在工作上,除非你的工作就是开发 Vue react 类的框架。
我更建议大家去看一些应用类的源码,例如 UI 组件库的源码看如何封装复杂组件,例如 vue-admin 看如何封装一个 B 端管理后台。
再例如我之前学习 AI Agent 开发,就看了 langChain 提供的 agent-chat-ui 和 Vercel 提供的 ai-chatbot 这两个项目的源码,我并没有直接看 langChain 的源码。
找一些和你实际开发工作相关的一些优秀开源项目,学习他们的设计,阅读他们的源码,这是最直接有效的。
最后
前端人员想学习全栈 + AI 项目和源码,可关注我开发的 划水AI,包括 AI 写作、多人协同编辑。复杂业务,真实上线。
来源:juejin.cn/post/7531888067218800640
别再吹性能优化了:你的应用卡顿,纯粹是因为产品设计烂🤷♂️

大家好!
最近面试,我发现一个很有意思的事情。几乎每个高级前端的简历上,都专门开辟了一栏,叫性能优化。
里面写满了各种高大上的名词😖:
使用Virtual List(虚拟列表)优化长列表渲染...
使用Web Worker把复杂计算移出主线程...
使用WASM重写核心算法...
看着这些,我通常会问一个问题:
你为什么要渲染一个有一万条数据的列表?用户真的看得过来吗?
候选人通常会愣住,然后支支吾吾地说:“呃...这是我们产品经理要求的🤷♂️。”
这就是今天我想聊的话题:
在2025年的今天,前端领域90%的所谓性能瓶颈,根本不是技术问题,而是产品问题。
我们这群工程师,拿着最先进的前端技术(Vite, Rust, WASM),却在日复一日地给一坨屎💩(糟糕的产品设计)雕花。
我们正在解决错误的问题
让我们还原一个经典的性能优化现场吧👇。
场景:一个中后台的超级表格(默认大家应该比较熟悉🤔)。
产品经理说需求:这个表格要展示所有订单,大概有50列,每页要展示500条,而且要支持实时搜索,还要支持列拖拽,每个单元格里可能还有下拉菜单...
开发者的第一反应(技术视角) :
- 50列 x 500行 = 25000个DOM节点,浏览器肯定卡死。
- 快!上虚拟滚动(Virtual Scroll)!
- 快!上防抖(Debounce)!
- 快!上Memoization(缓存)!
我们为了这个需求,引入了复杂的 第三方库,写了晦涩难懂的优化代码,甚至为了解决虚拟滚动带来的样式问题(比如高度坍塌、定位异常),又打了一堆补丁。
最后,页面终于不卡了。我们觉得自己很牛逼,技术很强。
但我们从来没问过那个最核心的问题:
人类的视网膜和大脑,真的能同时处理50列 x 500行的数据吗?
答案是:不能。
当屏幕上密密麻麻挤满了数据时,用户的认知负荷已经爆表了。他根本找不到他要看的东西。他需要的不是高性能的渲染,他需要的是筛选和搜索。
我们用顶级的技术,去实现了一个反人类的设计。 这不是优化,这是叫作恶😠。
真正的优化,是从砍需求开始
我曾经接手过一个类似的项目,页面卡顿到FPS只有10。前任开发留下了几千行用来优化渲染的复杂代码,维护起来生不如死。
我接手后,没有改一行渲染代码。
我直接去找了产品总监,把那个页面投在大屏幕上,问了他三个问题:
1.你看这一列 订单原始JSON日志,平均长度3000字符,你把它全展示在表格里,谁会看?
砍掉!改成一个查看详情的按钮,点开再加载。DOM节点减少20%。
2.这50列数据,用户高频关注的真的有这么多吗?
默认只展示核心的8列。剩下的放在自定义列里,用户想看自己勾选。DOM节点减少80%。
3.我就不知道为什么🤷♂️ 要一次性加载500条?用户翻到第400条的时候,他还记得第1条是什么吗?
赶紧砍掉!改成标准的分页,每页20条。DOM节点减少96%。
做完这三件事,我甚至把之前的虚拟滚动代码全删了,回退到了最朴素的<table>标签。
结果呢?
- 页面飞一样快(因为DOM只有原来的1%)。
- 代码极其简单(维护就更简单了🤔)。
- 用户反而更开心了(因为界面清爽了,信息层级清晰了)。
这才是最高级的性能优化:不仅优化了机器的性能,更优化了人的体验。
技术自负的陷阱
为什么我们总是陷在技术优化的泥潭里出不来呢?😒
因为我们有技术自负。
作为工程师,我们潜意识里觉得:承认这个需求做不了(或者做不好),是因为我技术不行。
产品经理要五彩斑斓的黑,我就得给他做出来!
产品经理要在这个页面跑3D地球,我就得去学Three.js!
我们试图用技术去弥补产品逻辑上的懒惰!(非常有触感😖)
因为产品经理懒得思考信息的层级 ,所以他把所有信息一股脑扔给前端,让你去搞懒加载。
技术不是万能的。
浏览器的渲染能力是有上限的,JS的主线程是单核的,移动端的电量是有限的。更重要的是,用户的注意力是极其有限的。
当你发现你需要用极其复杂的新技术才能勉强让一个页面跑起来的时候
请停下来!

这时候,问题的根源通常不在代码里,而可能是在 PRD(需求文档) 里。
说了那么多,该怎么做呢?
下次,当你再面对一个导致卡顿的需求时,别急着打开Profiler分析性能。
请试着做以下几步:
我们真的需要在前端处理10万条数据吗?能不能在后端聚合好,只给我返回结果?
这个图表真的需要实时刷新吗?用户真的能看清1毫秒的变化吗?改成5秒刷新一次行不行?
在这个弹窗里塞个完整地图太卡了。能不能改成:点击缩略图,跳转到专门的地图页面?
你要告诉产品经理: 性能本身,也是一个产品功能。
如果为了塞下更多的功能,牺牲了流畅度这个最核心的功能,那是丢了西瓜捡芝麻。
最好的代码,是 没有代码(No Code)。
同理,最好的性能优化,是没有需求。
作为高级工程师,你的价值不仅仅体现在你会写Virtual List,更体现在你敢不敢在需求评审会上,拍着桌子说:
这个设计怎么这么反人类😠!我们能不能换个更好的方式?🤷♂️
别再给屎山💩雕花了。把那座山推了,才是真正的优化。
关于这个观点你们怎么看?
来源:juejin.cn/post/7573950036897038376
别再滥用 Base64 了——Blob 才是前端减负的正确姿势
一、什么是 Blob?
Blob(Binary Large Object,二进制大对象)是浏览器提供的一种不可变、类文件的原始数据容器。它可以存储任意类型的二进制或文本数据,例如图片、音频、PDF、甚至一段纯文本。与 File 对象相比,Blob 更底层,File 实际上继承自 Blob,并额外携带了 name、lastModified 等元信息 。
Blob 最大的特点是纯客户端、零网络:数据一旦进入 Blob,就活在内存里,无需上传服务器即可预览、下载或进一步加工。
二、构造一个 Blob:一行代码搞定
const blob = new Blob(parts, options);
| 参数 | 说明 |
|---|---|
parts | 数组,元素可以是 String、ArrayBuffer、TypedArray、Blob 等。 |
options | 可选对象,常用字段:type MIME 类型,默认 application/octet-stream;endings 是否转换换行符,几乎不用。 |
示例:动态生成一个 Markdown 文件并让用户下载
const content = '# Hello Blob\n> 由浏览器动态生成';
const blob = new Blob([content], { type: 'text/markdown' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = 'hello.md';
a.click();
// 内存用完即弃
URL.revokeObjectURL(url);
三、Blob URL:给内存中的数据一个“临时地址”
1. 生成方式
const url = URL.createObjectURL(blob);
// 返回值样例
// blob:https://localhost:3000/550e8400-e29b-41d4-a716-446655440000
2. 生命周期
- 作用域:仅在当前文档、当前会话有效;页面刷新、
close()、手动调用revokeObjectURL()都会使其失效 。 - 性能陷阱:不主动释放会造成内存泄漏,尤其在单页应用或大量图片预览场景 。
最佳实践封装:
function createTempURL(blob) {
const url = URL.createObjectURL(blob);
// 自动 revoke,避免忘记
requestIdleCallback(() => URL.revokeObjectURL(url));
return url;
}
四、Blob vs. Base64 vs. ArrayBuffer:如何选型?
| 场景 | 推荐格式 | 理由 |
|---|---|---|
图片回显、<img>/<video> | Blob URL | 浏览器可直接解析,无需解码;内存占用低。 |
| 小图标内嵌在 CSS/JSON | Base64 | 减少一次 HTTP 请求,但体积增大约 33%。 |
| 纯计算、WebAssembly 传递 | ArrayBuffer | 可写、可索引,适合高效运算。 |
| 上传大文件、断点续传 | Blob.slice | 流式分片,配合 File.prototype.slice 做断点续传 。 |
五、高频实战场景
1. 本地图片/视频预览(零上传)
<input type="file" accept="image/*" id="uploader">
<img id="preview" style="max-width: 100%">
<script>
uploader.onchange = e => {
const file = e.target.files[0];
if (!file) return;
const url = URL.createObjectURL(file);
preview.src = url;
preview.onload = () => URL.revokeObjectURL(url); // 加载完即释放
};
</script>
2. 将 Canvas 绘图导出为 PNG 并下载
canvas.toBlob(blob => {
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = 'snapshot.png';
a.click();
URL.revokeObjectURL(url);
}, 'image/png');
3. 抓取远程图片→Blob→本地预览(跨域需 CORS)
fetch('https://i.imgur.com/xxx.png', { mode: 'cors' })
.then(r => r.blob())
.then(blob => {
const url = URL.createObjectURL(blob);
document.querySelector('img').src = url;
});
若出现图片不显示,99% 是因为服务端未返回 Access-Control-Allow-Origin 头 。
六、踩坑指南与性能锦囊
| 坑点 | 解决方案 |
|---|---|
| 内存暴涨 | 每次 createObjectURL 后,务必在合适的时机 revokeObjectURL 。 |
| 跨域失败 | 确认服务端开启 CORS;fetch 时加 {credentials: 'include'} 如需 Cookie。 |
| 移动端大视频卡顿 | 避免一次性读完整文件,使用 blob.slice(start, end) 分段读取。 |
| 旧浏览器兼容 | IE10+ 才原生支持 Blob;如需更低版本,请引入 Blob.js 兼容库。 |
七、延伸:Blob 与 Stream 的梦幻联动
当文件超大(GB 级)时,全部读进内存并不现实。可以借助 ReadableStream 把 Blob 转为流,实现渐进式上传:
const stream = blob.stream(); // 返回 ReadableStream
await fetch('/upload', {
method: 'POST',
body: stream,
headers: { 'Content-Type': blob.type }
});
Chrome 85+、Edge 85+、Firefox 已经支持 blob.stream(),能以流式形式边读边传,内存占用极低。
八、总结:记住“三句话”
- Blob = 浏览器端的二进制数据仓库,File 只是它的超集。
- Blob URL = 指向内存的临时指针,用完后必须手动或自动释放。
- 凡是“本地预览、零上传、动态生成下载”的需求,优先考虑 Blob + Blob URL 组合。
用好 Blob,既能提升用户体验(秒开预览),又能降低服务端压力(无需中转),是每一位前端工程师的必备技能。
来源:juejin.cn/post/7573521516324896795
让网页在 PC 缩放时“纹丝不动”的 4 个技巧
记录一次把「标题、描述、背景图」全部做成“流体响应式”的踩坑与经验
背景
最近给 LUCI OS 官网做首屏改版,需求只有一句话:
“PC 端浏览器随意缩放,首屏内容要像海报一样,几乎看不出形变。”
听起来简单,但「缩放不变形」+「多端自适应」本质上是矛盾的。
经过 3 轮迭代,我们把问题拆成了 4 个小目标,并给出了最简洁的解法。
1. 文本:用 clamp() 一把梭
传统写法给 3~4 个断点写死字号,窗口稍微拉一下就会跳变。
CSS 4 级函数 clamp(MIN, VAL, MAX) 天生就是解决“跳变”的:
- 标题:
text-[clamp(28px,6vw,48px)] - 描述:
text-[clamp(14px,1.2vw,18px)]
一行代码实现「最小值保底、最大值封顶、中间平滑变化」。
浏览器缩放时,字号随 vw 线性变化,肉眼几乎察觉不到阶梯感。
2. 容器:限宽 + 居中 = “锁死”水平形变
再漂亮的字号,如果容器宽度跟着窗口无限拉伸,一样会崩。
做法简单粗暴:
css
复制
max-w-6xl mx-auto
max-w-6xl把最大内容宽度锁死在 1152px;mx-auto保证左右留白始终对称。
窗口继续拉大,两侧只是等比留空,内容区不再变形。
3. 图片(或背景):固定尺寸 + 背景定位
背景图不能跟着 100% 拉伸,否则人物/产品会被拉长。
我们把背景拆成两层:
- 外层:全屏
div,只做黑色渐变遮罩; - 内层:真正的背景图用
css
复制
background: url(...) 50% / cover no-repeat;
max-width: 1280px;
max-height: 800px;
只要窗口没超过 1280×800,背景图始终保持原始比例,居中裁剪。
4. 布局:断点内“锁死”,断点外才变化
Tailwind 的 md:flex-row 之类前缀只在跨断点时生效。
在 同一断点内 我们故意:
- 用固定
gap-32px而非百分比; - 用固定图片宽
md:w-75高md:h-47; - 用
items-center保证垂直居中。
=> 浏览器宽一点点、窄一点点,所有尺寸都不变,自然看不出变化。
直到窗口拉到下一个断点阈值,布局一次切换,干净利落。
最终代码(最简可读版)
tsx
复制
<section className="relative flex items-center justify-center min-h-[400px] md:h-[800px]">
{/* 1. 背景层:固定尺寸 + 居中 */}
<div
className="absolute inset-0 mx-auto"
style={{
maxWidth: 1280,
maxHeight: 800,
background:
'linear-gradient(180deg,rgba(2,2,2,0) 60%,#020202 99%), url(/unlocking_vast_data_potential.png) 50%/cover no-repeat',
}}
/>
{/* 2. 内容层:限宽 + 居中 + clamp */}
<div className="relative z-10 w-full max-w-6xl px-4 text-center">
<h1 className="font-bold text-white text-[clamp(28px,6vw,48px)]">
Unlocking Vast Data Potential
</h1>
<p className="mt-4 mx-auto max-w-5xl text-[clamp(14px,1.2vw,18px)] text-[#8C8B95]">
LUCI OS is powered by Mavi's video understanding engine …
</p>
</div>
</section>
效果
- 1440px 与 1920px 两档分辨率下,标题、描述、背景图的视觉差异 < 2% ;
- 字号、行宽、图片比例在鼠标拖拽窗口时线性变化,无跳变;
- 移动端仍保持完美自适应,无需额外代码。
写在最后
把「响应式」做细,核心就是 “在需要的范围内平滑,在不需要的范围内锁死”。
希望这 4 个小技巧也能帮你把“缩放不变形”真正落地。
来源:juejin.cn/post/7540939051195056143
如果产品经理突然要你做一个像抖音一样流畅的H5
从前端到爆点!抖音级 H5 如何炼成?
在万物互联的时代,H5 页面已成为产品推广的利器。当产品经理丢给你一个“像抖音一样流畅的 H5”任务时,是挑战还是机遇?别慌,今天就带你走进抖音 H5 的前端魔法世界。
一、先看清本质:抖音 H5 为何丝滑?
抖音 H5 之所以让人欲罢不能,核心在于两点:极低的卡顿率和极致的交互反馈。前者靠性能优化,后者靠精心设计的交互逻辑。比如,你刷视频时的流畅下拉、点赞时的爱心飞舞,背后都藏着前端开发的“小心机”。
二、性能优化:让页面飞起来
(一)懒加载与预加载协同作战
懒加载是 H5 性能优化的经典招式,只在用户即将看到某个元素时才加载它。但光靠懒加载还不够,聪明的抖音 H5 还会预加载下一个可能进入视野的元素。以下是一个基于 IntersectionObserver 的懒加载示例:
document.addEventListener('DOMContentLoaded', () => {
const lazyImages = [].slice.call(document.querySelectorAll('img.lazy'));
if ('IntersectionObserver' in window) {
let lazyImageObserver = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
if (entry.isIntersecting) {
let lazyImage = entry.target;
lazyImage.src = lazyImage.dataset.src;
lazyImageObserver.unobserve(lazyImage);
}
});
});
lazy Images.forEach((lazyImage) => {
lazyImageObserver.observe(lazyImage);
});
}
});
(二)图片压缩技术大显神威
图片是 H5 的“体重”大户。抖音 H5 常用 WebP 格式,它在保证画质的同时,能将图片体积压缩到 JPEG 的一半。你可以用以下代码轻松实现图片格式转换:
function compressImage(inputImage, quality) {
return new Promise((resolve) => {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
canvas.width = inputImage.naturalWidth;
canvas.height = inputImage.naturalHeight;
ctx.drawImage(inputImage, 0, 0, canvas.width, canvas.height);
const compressedImage = new Image();
compressedImage.src = canvas.toDataURL('image/webp', quality);
compressedImage.onload = () => {
resolve(compressedImage);
};
});
}
三、交互设计:让用户欲罢不能
(一)微动画营造沉浸感
在点赞、评论等关键操作上,抖音 H5 会加入精巧的微动画。比如点赞时的爱心从手指位置飞出,这其实是一个 CSS 动画加 JavaScript 事件监听的组合拳。以下是一个简易版的点赞动画代码:
@keyframes flyHeart {
0% {
transform: scale(0) translateY(0);
opacity: 0;
}
50% {
transform: scale(1.5) translateY(-10px);
opacity: 1;
}
100% {
transform: scale(1) translateY(-20px);
opacity: 0;
}
}
.heart {
position: fixed;
width: 30px;
height: 30px;
background-image: url('../assets/heart.png');
background-size: contain;
background-repeat: no-repeat;
animation: flyHeart 1s ease-out;
}
document.querySelector('.like-btn').addEventListener('click', function(e) {
const heart = document.createElement('div');
heart.className = 'heart';
heart.style.left = e.clientX + 'px';
heart.style.top = e.clientY + 'px';
document.body.appendChild(heart);
setTimeout(() => {
heart.remove();
}, 1000);
});
(二)触摸事件优化
在移动设备上,触摸事件的响应速度直接影响用户体验。抖音 H5 通过精准控制触摸事件的捕获和冒泡阶段,减少了延迟。以下是一个优化触摸事件的示例:
const touchStartHandler = (e) => {
e.preventDefault(); // 防止页面滚动干扰
// 处理触摸开始逻辑
};
const touchMoveHandler = (e) => {
// 处理触摸移动逻辑
};
const touchEndHandler = (e) => {
// 处理触摸结束逻辑
};
const element = document.querySelector('.scrollable-container');
element.addEventListener('touchstart', touchStartHandler, { passive: false });
element.addEventListener('touchmove', touchMoveHandler, { passive: false });
element.addEventListener('touchend', touchEndHandler);
四、音频处理:让声音为 H5 增色
抖音 H5 的音频体验也很讲究。它会根据用户的操作实时调整音量,甚至在不同视频切换时平滑过渡音频。以下是一个简单的声音控制示例:
const audioContext = new (window.AudioContext || window.webkitAudioContext)();
const audioElement = document.querySelector('audio');
const audioSource = audioContext.createMediaElementSource(audioElement);
const gainNode = audioContext.createGain();
audioSource.connect(gainNode);
gainNode.connect(audioContext.destination);
// 调节音量
function setVolume(level) {
gainNode.gain.value = level;
}
// 音频淡入效果
function fadeInAudio() {
gainNode.gain.setValueAtTime(0, audioContext.currentTime);
gainNode.gain.linearRampToValueAtTime(1, audioContext.currentTime + 1);
}
// 音频淡出效果
function fadeOutAudio() {
gainNode.gain.linearRampToValueAtTime(0, audioContext.currentTime + 1);
}
五、跨浏览器兼容:让 H5 无处不在
抖音 H5 能在各种浏览器上保持一致的体验,这离不开前端开发者的兼容性优化。常用的手段包括使用 Autoprefixer 自动生成浏览器前缀、为老浏览器提供 Polyfill 等。以下是一个为 CSS 动画添加前缀的示例:
const autoprefixer = require('autoprefixer');
const postcss = require('postcss');
const css = '.example { animation: slidein 2s; } @keyframes slidein { from { transform: translateX(0); } to { transform: translateX(100px); } }';
postcss([autoprefixer]).process(css).then(result => {
console.log(result.css);
/*
输出:
.example {
animation: slidein 2s;
}
@keyframes slidein {
from {
-webkit-transform: translateX(0);
transform: translateX(0);
}
to {
-webkit-transform: translateX(100px);
transform: translateX(100px);
}
}
*/
});
打造一个像抖音一样的流畅 H5,需要前端开发者在性能优化、交互设计、音频处理和跨浏览器兼容等方面全方位发力。希望这些技术点能为你的 H5 开发之旅提供助力,让你的产品在激烈的市场竞争中脱颖而出!
来源:juejin.cn/post/7522090635908251686
前端开发人员:以下是如何充分利用 Cursor😍😍😍
前言
我相信作为程序员Cuesor大家一定都很熟悉了,它是一款代码编辑工具,位于 Claude AI、o3、Gemini-3.5-Pro 和 GPT-4.1 等其他顶级 AI 模型之上,帮助我们提高工作效率以及体验。
Cursor AI 入门
导航到 cursor.com 时,可以下载 IDE:
下载并打开代码编辑器后,你将看到以下内容:

在上面的界面中,我们观察到一些事情:
- 代理模式 每当编码时,您都需要使用代理模式。它有助于处理端到端任务
- Ask 如果单击代理模式下拉列表:
你会看到“提问”选项——当你想提出问题时使用此选项,就像使用 ChatGPT 一样。
- Model selection( 模型选择 )
此下拉列表显示要从中选择的最喜欢的模型列表 - Context integration(上下文集成) “添加上下文”按钮,用于使用 @ 符号(@docs、@web 等)
- Chat interface(聊天界面)
“新聊天”,用于开始新的或后续的对话。
如何利用这些功能
传统的 Web 开发项目遵循以下工作流程:
但是在进行 vibe 编码时,您的工作流程将看起来更像这样:
而cursor可以帮你完成设计这一步骤,使用 Cursor AI 生成界面 。首先创建一个新项目;我们将在本例中使用 Next.js。
使用快捷键 Command+K,这非常适合您忘记基本命令
现在我们已经安装了项目,是时候进行提示了。
构建示例项目
使用聊天进行设计提示
导航到新建聊天 。
选择光标代理 ,然后选择您喜欢的模型。对我来说,我更喜欢 Claude 3.5
现在你可以提示它了。这是我的提示的样子:“在我的 page.tsx 中,重新创建 Logrocket 的登录页面。”
这是我们得到的:
接受更改,并使用 npm run dev 运行应用程序
如果生成的和我们所设想的效果不太一样,我们可以通过多种方式使用图像上下文使其更接近。
Attaching an image 附加图像
导航到聊天,单击图像图标,然后附加图像。这应该是您想要复制的设计图像。来不断迭代来达到我们想要的效果。
在迭代时,可能会有时ai误解了我们的意思,或者Cursor 发现这个问题有点难以修复。在这种情况下,我们可以通过单击恢复检查点轻松恢复到以前的设计。这可以在之前的聊天下找到:
模型上下文协议 (MCP) 服务器
MCP 是一种开放标准,使开发人员能够在其数据源和 AI 驱动的工具之间构建安全的双向连接。
Framelink.ai 为 Figma 构建了一个 MCP 服务器,它允许您直接访问和处理 Cursor 中的设计文件。按照本指南轻松设置。
充分利用 Cursor 的更多策略
利用 AI 代理模式
使用光标时,您最常使用 AI 代理模式。这是一个强大的功能,可以:
- 自动安装依赖项(不再需要手动包管理)
- 在整个项目中创建和修改文件
- 在确认后运行终端命令
- 处理复杂的多文件重构
- 端到端实现完整功能
使用 @ 符号进行上下文管理
了解上下文管理可以提升您使用 Cursor 的编码体验。 @ 符号是您在帮助您时告诉 Cursor 要查看什么或优先考虑什么的方式。主要的 @ 类型是:
- @code – 您的整个项目
- @web – 搜索互联网
- @docs – 该工具或库的文档甚至可以是一个框架
- @files 和文件夹 – 特定文件
- 图像 – 拖放屏幕截图/设计
- @cursor 规则 – 甚至您过去的聊天记录
“新聊天”策略
根据经验,我建议您始终为新功能或项目开始新的聊天。当您在旧对话之上提示某些内容时,可能会分散 AI 的注意力并降低响应质量。
Cursor 添加了一项有用的功能,允许您使用旧聊天的摘要开始新的聊天,为您提供两全其美的体验 - 新鲜的上下文而不会丢失重要信息。
使用上面的 “添加 ”按钮创建新聊天,单击上下文选项的 @ ,滚动以选择 “最近的更改”, 单击它,然后继续提示:
总结
Cursor AI 的定价似乎偏高。但其功能确实还行,不过我们也可以选择trae来替代,毕竟Cursor也不比trae强多少
来源:juejin.cn/post/7545725771315478554
脱裤子放屁 - 你们讨厌这样的页面吗?
前言
平时在逛掘金和少数派等网站的时候,经常有跳转外链的场景,此时基本都会被中转到一个官方提供的提示页面。
掘金:
知乎:
少数派:
这种官方脱裤子放屁的行为实在令人恼火。是、是、是、我当然知道这么做有很多冠冕堂皇的理由,比如:
- 防止钓鱼攻击
- 增强用户意识
- 品牌保护
- 遵守法律法规
- 控制流量去向
(以上5点是 AI 告诉我的理由)
但是作为混迹多年的互联网用户,什么链接可以点,什么最好不要点(悄悄的点) 我还是具备判断能力的。
互联网的本质就是自由穿梭,一个 A 标签就可以让你在整个互联网翱翔,现在你每次起飞的时候都被摁住强迫你阅读一次免责声明,多少是有点恼火的。
解决方案
这些中转站的实现逻辑基本都是将目标地址挂在中转地址的target 参数后面,在中转站做免责声明,然后点击继续跳转才跳到目标网站。
掘金:
少数派:
https://sspai.com/link?target=https%3A%2F%2Fgeoguess.games%2F
知乎:
https://link.zhihu.com/?target=https%3A//asciidoctor.org/
所以我们就可以写一个浏览器插件,在这些网站中,找出命中外链的 A 标签,替换掉它的 href 属性(只保留 target 后面的真实目标地址)。
核心函数:
function findByTarget() {
if (!hostnames.includes(location.hostname)) return;
const linkKeyword = "?target=";
const aLinks = document.querySelectorAll(
`a[href*="${linkKeyword}"]:not([data-redirect-skipper])`
);
if (!aLinks) return;
aLinks.forEach((a) => {
const href = a.href;
const targetIndex = href.indexOf(linkKeyword);
if (targetIndex !== -1) {
const newHref = href.substring(targetIndex + linkKeyword.length);
a.href = decodeURIComponent(newHref);
a.setAttribute("data-redirect-skipper", "true");
}
});
}
为此我创建了一个项目仓库 redirect-skipper ,并且将该浏览器插件发布在谷歌商店了 安装地址 。
安装并启用这个浏览器插件之后,在这些网站中点击外链就不会看到中转页面了,而是直接跳转到目标网站。
因为我目前明确需要修改的就是这几个网站,如果大家愿意使用这个插件,且有其他网站需要添加到替换列表的,可以给 redirect-skipper 仓库 提PR。
如果需要添加的网站的转换规则是和 findByTarget 一致的,那么仅需更新 sites.json 文件即可。
如果需要添加的网站的转换规则是独立的,那么需要更新插件代码,合并之后,由我向谷歌商店发起更新。
为了后期可以灵活更新配置(谷歌商店审核太慢了),我默认将插件应用于所有网站,然后在代码里通过 hostname 来判断是否真的需要执行。
{
"$schema": "https://json.schemastore.org/chrome-manifest.json",
"name": "redirect-skipper",
"manifest_version": 3,
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["./scripts/redirect-skipper.js"],
"run_at": "document_end"
}
],
}
在当前仓库里维护一份 sites.json 的配置表,格式如下:
{
"description": "远程配置可以开启 Redirect-Skipper 插件的网站 (因为谷歌商店审核太慢了,否则无需通过远程配置,增加复杂性)",
"sites": [
{
"hostname": "juejin.cn",
"title": "掘金"
},
{
"hostname": "sspai.com",
"title": "少数派"
},
{
"hostname": "www.zhihu.com",
"title": "知乎"
}
]
}
这样插件在拉取到这份数据的时候,就可以根据这边描述的网站配置,决定是否执行具体代码。
插件完整代码:
function replaceALinks() {
findByTarget();
}
function observerDocument() {
const mb = new MutationObserver((mutationsList) => {
for (const mutation of mutationsList) {
if (mutation.type === "childList") {
if (mutation.addedNodes.length) {
replaceALinks();
}
}
}
});
mb.observe(document, { childList: true, subtree: true });
}
// 监听路由等事件
["hashchange", "popstate", "load"].forEach((event) => {
window.addEventListener(event, async () => {
replaceALinks();
if (event === "load") {
observerDocument();
await updateHostnames();
replaceALinks(); // 更新完数据后再执行一次
}
});
});
let hostnames = ["juejin.cn", "sspai.com", "www.zhihu.com"];
function updateHostnames() {
return fetch(
"https://raw.githubusercontent.com/dogodo-cc/redirect-skipper/master/sites.json"
)
.then((response) => {
if (response.ok) {
return response.json();
}
throw new Error("Network response was not ok");
})
.then((data) => {
// 如果拉到了远程数据,就用远程的
hostnames = data.sites.map((site) => {
return site.hostname;
});
})
.catch((error) => {
console.error(error);
});
}
// 符合 '?target=' 格式的链接
// https://link.juejin.cn/?target=https%3A%2F%2Fdeveloper.apple.com%2Fcn%2Fdesign%2Fhuman-interface-guidelines%2Fapp-icons%23macOS/
// https://sspai.com/link?target=https%3A%2F%2Fgeoguess.games%2F
// https://link.zhihu.com/?target=https%3A//asciidoctor.org/
function findByTarget() {
if (!hostnames.includes(location.hostname)) return;
const linkKeyword = "?target=";
const aLinks = document.querySelectorAll(
`a[href*="${linkKeyword}"]:not([data-redirect-skipper])`
);
if (!aLinks) return;
aLinks.forEach((a) => {
const href = a.href;
const targetIndex = href.indexOf(linkKeyword);
if (targetIndex !== -1) {
const newHref = href.substring(targetIndex + linkKeyword.length);
a.href = decodeURIComponent(newHref);
a.setAttribute("data-redirect-skipper", "true");
}
});
}
更详细的流程可以查看 redirect-skipper 仓库地址
夹带私货
标题历史
- 浏览器插件之《跳过第三方链接的提示中转页》
来源:juejin.cn/post/7495977411273490447
我本是写react的,公司让我换赛道搞web3D
当你在会议室里争论需求时,
智慧工厂的数字孪生正同步着每一条产线的脉搏;
当你对着平面图想象空间时,
智慧小区的三维模型已在虚拟世界精准复刻每一扇窗的采光。
当你在CAD里调整参数时,
数字孪生城市的交通流正实时映射每辆车的轨迹;
当你等待客户确认方案时,
机械臂的3D仿真已预演了十万次零误差的运动路径;
当你用二维图纸解释传动原理时,
可交互的3D引擎正让客户‘拆解’每一个齿轮;
当你担心售后维修难描述时,
AR里的动态指引已覆盖所有故障点;
当你用PS拼贴效果图时,
VR漫游的业主正‘推开’你设计的每一扇门;
当你纠结墙面材质时,
光影引擎已算出了午后3点最温柔的折射角度;
从前端到Web3D,
不是换条赛道,
而是打开新维度。
韩老师说过:再牛的程序员都是从小白开始,既然开始了,就全心投入学好技术。
🔴 工具
所有的api都可以通过threejs官网的document,切成中文,去搜:

🔴 平面
⭕️ Scene 场景
场景能够让你在什么地方、摆放什么东西来交给three.js来渲染,这是你放置物体、灯光和摄像机的地方。

import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
⭕️ camera 相机

import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
// 2、创建相机
const camera = new THREE.PerspectiveCamera(
75, // 相机的角度
window.innerWidth / window.innerHeight, // 相机的宽高比
0.1, // 相机的近截面
1000 // 相机的远截面
);
// 设置相机位置
camera.position.set(0, 0, 10); // 相机位置 (X轴坐标, Y轴坐标, Z轴坐标)
scene.add(camera); // 相机添加到场景中
⭕️ 物体 cube
import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
// 2、创建相机
const camera = new THREE.PerspectiveCamera(
75, // 相机的角度
window.innerWidth / window.innerHeight, // 相机的宽高比
0.1, // 相机的近截面
1000 // 相机的远截面
);
// 设置相机位置
camera.position.set(0, 0, 10); // 相机位置 (X轴坐标, Y轴坐标, Z轴坐标)
scene.add(camera); // 相机添加到场景中
// 添加物体
// 创建几何体
const cubeGeometry = new THREE.BoxGeometry(1, 1, 1); // 创建立方体的几何体 (长, 宽, 高)
const cubeMaterial = new THREE.MeshBasicMaterial({ color: 0xffff00 }); // MeshBasicMaterial 基础网格材质 ({ color: 0xffff00 }) 颜色
// 根据几何体和材质创建物体
const cube = new THREE.Mesh(cubeGeometry, cubeMaterial); // 创建立方体的物体 (几何体, 材质)
// 将几何体添加到场景中
scene.add(cube); // 物体添加到场景中
⭕️ 渲染 render
// 初始化渲染器
const renderer = new THREE.WebGLRenderer();
// 设置渲染的尺寸大小
renderer.setSize(window.innerWidth, window.innerHeight); // 设置渲染的尺寸大小 (窗口宽度, 窗口高度)
// console.log(renderer);
// 将webgl渲染的canvas内容添加到body
document.body.appendChild(renderer.domElement); // 将webgl渲染的canvas内容添加到body
// 使用渲染器,通过相机将场景渲染进来
renderer.render(scene, camera); // 使用渲染器,通过相机将场景渲染进来 (场景, 相机)
⭕️ 效果
效果是平面的:

到这里,还不是3d的,如果要加3d,要加一下控制器。
🔴 3d
⭕️ 控制器
添加轨道。像卫星☄围绕地球🌏,环绕查看的视角:
// 导入轨道控制器
import { OrbitControls } from "three/examples/jsm/controls/OrbitControls";
// 目标:使用控制器查看3d物体
// // 使用渲染器,通过相机将场景渲染进来
// renderer.render(scene, camera);
// 创建轨道控制器
const controls = new OrbitControls(camera, renderer.domElement); // 创建轨道控制器 (相机, 渲染器dom元素)
controls.enableDamping = true; // 设置控制器阻尼,让控制器更有真实效果。
function render() {
renderer.render(scene, camera); // 浏览器每渲染一帧,就重新渲染一次
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render); // 浏览器渲染下一帧的时候就会执行render函数,执行完会再次调用render函数,形成循环,每秒60次
}
render();
⭕️ 加坐标轴辅助器
// 添加坐标轴辅助器
const axesHelper = new THREE.AxesHelper(5); // 坐标轴(size轴的大小)
scene.add(axesHelper);

⭕️ 设置物体移动
// 设置相机位置
camera.position.set(0, 0, 10);
scene.add(camera);

cube.position.x = 3;
// 往返移动
function render() {
cube.position.x += 0.01;
if (cube.position.x > 5) {
cube.position.x = 0;
}
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ 缩放
cube.scale.set(3, 2, 1); // xyz, x3倍, y2倍
单独设置
cube.position.x = 3;
⭕️ 旋转
cube.rotation.set(Math.PI / 4, 0, 0, "XZY"); // x轴旋转45度
单独设置
cube.rotation.x = Math.PI / 4;
⭕️ requestAnimationFrame
function render(time) {
// console.log(time);
// cube.position.x += 0.01;
// cube.rotation.x += 0.01;
// time 是一个不断递增的数字,代表当前的时间
let t = (time / 1000) % 5; // 为什么求余数,物体移动的距离就是t,物体移动的距离是0-5,所以求余数
cube.position.x = t * 1; // 0-5秒,物体移动0-5距离
// if (cube.position.x > 5) {
// cube.position.x = 0;
// }
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ Clock 跟踪事件处理动画
// 设置时钟
const clock = new THREE.Clock();
function render() {
// 获取时钟运行的总时长
let time = clock.getElapsedTime();
console.log("时钟运行总时长:", time);
// let deltaTime = clock.getDelta();
// console.log("两次获取时间的间隔时间:", deltaTime);
let t = time % 5;
cube.position.x = t * 1;
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
大概是8毫秒一次渲染时间.
⭕️ 不用算 用 Gsap动画库
// 导入动画库
import gsap from "gsap";
// 设置动画
var animate1 = gsap.to(cube.position, {
x: 5,
duration: 5,
ease: "power1.inOut", // 动画属性
// 设置重复的次数,无限次循环-1
repeat: -1,
// 往返运动
yoyo: true,
// delay,延迟2秒运动
delay: 2,
onComplete: () => {
console.log("动画完成");
},
onStart: () => {
console.log("动画开始");
},
});
gsap.to(cube.rotation, { x: 2 * Math.PI, duration: 5, ease: "power1.inOut" });
// 双击停止和恢复运动
window.addEventListener("dblclick", () => {
// console.log(animate1);
if (animate1.isActive()) {
// 暂停
animate1.pause();
} else {
// 恢复
animate1.resume();
}
});
function render() {
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ 根据尺寸变化 实现自适应
// 监听画面变化,更新渲染画面
window.addEventListener("resize", () => {
// console.log("画面变化了");
// 更新摄像头
camera.aspect = window.innerWidth / window.innerHeight;
// 更新摄像机的投影矩阵
camera.updateProjectionMatrix();
// 更新渲染器
renderer.setSize(window.innerWidth, window.innerHeight);
// 设置渲染器的像素比
renderer.setPixelRatio(window.devicePixelRatio);
});
⭕️ 用js控制画布 全屏 和 退出全屏
window.addEventListener("dblclick", () => {
const fullScreenElement = document.fullscreenElement;
if (!fullScreenElement) {
// 双击控制屏幕进入全屏,退出全屏
// 让画布对象全屏
renderer.domElement.requestFullscreen();
} else {
// 退出全屏,使用document对象
document.exitFullscreen();
}
// console.log(fullScreenElement);
});
⭕️ 应用 图形 用户界面 更改变量
// 导入dat.gui
import * as dat from "dat.gui";
const gui = new dat.GUI();
gui
.add(cube.position, "x")
.min(0)
.max(5)
.step(0.01)
.name("移动x轴")
.onChange((value) => {
console.log("值被修改:", value);
})
.onFinishChange((value) => {
console.log("完全停下来:", value);
});
// 修改物体的颜色
const params = {
color: "#ffff00",
fn: () => {
// 让立方体运动起来
gsap.to(cube.position, { x: 5, duration: 2, yoyo: true, repeat: -1 });
},
};
gui.addColor(params, "color").onChange((value) => {
console.log("值被修改:", value);
cube.material.color.set(value);
});
// 设置选项框
gui.add(cube, "visible").name("是否显示");
var folder = gui.addFolder("设置立方体");
folder.add(cube.material, "wireframe");
// 设置按钮点击触发某个事件
folder.add(params, "fn").name("立方体运动");

🔴 结语
前端的世界,
不该只有Vue和React——
还有WebGPU里等待你征服的星辰大海。"
“当WebGL成为下一代前端的基础设施,愿你是最早站在三维坐标系里的那个人。”
来源:juejin.cn/post/7517209356855164978
🔥 放弃 vw!我在官网大屏适配中踩了天坑,用 postcss-px-to-viewport-8-plugin 实现了 Rem 终极方案
引言:我的大屏适配“翻车”现场
领导拍板,1天内完成官网所有界面的响应式适配,我想了下,这还不简单?postcss-px-to-viewport 安排上,vw 单位一把梭!直到测试同事幽幽地说了句:‘这个屏… 4K 分辨率下好像被拉扁了?’
我心头一紧,打开 3840px 宽的显示器一看——所有图片、文字被无限拉宽,布局直接崩坏。vw 方案的致命缺陷暴露无遗:它只负责缩放,不负责限制最大宽度。 我们的内容在超过 1920px 的屏幕上经历了‘拉伸灾难’。必须寻找一个既能自动缩放,又能优雅限制最大宽度的 终极方案。
一、为什么 VW 不是大屏适配的银弹?
- vw 的本质:
1vw等于视口宽度的1%。视口越宽,元素尺寸越大。 - 理想的适配效果:
- 小于 1920px:等比例缩小。
- 等于 1920px:完美还原设计稿。
- 大于 1920px:内容不再无限放大,而是居中显示,两侧留白(类似
max-width: 1920px; margin: 0 auto;的效果)。
- vw 的困境:它无法实现第三点。在
3840px的 4K 屏上,一个100vw的元素会宽达3840px,远远超出设计预期,导致布局稀疏、元素被拉扁,体验极差。
二、终极方案的选型:REM 王者归来
我们的需求其实有两个:
- 动态缩放:在不同尺寸下,元素能等比缩放。
- 最大限制:有一个绝对单位作为基准,限制最大尺寸。
Rem (Root Em) 单位完美契合!
1rem等于根元素 (<html>) 的font-size大小。- 我们可以通过 JavaScript 动态计算并设置
<html>的font-size。 - 同时,我们可以用 CSS 媒体查询或 JS 逻辑,为
font-size设置一个 最大值,比如16px。这样,当屏幕宽超过1920px时,布局宽度就会稳定在1920px的对应尺寸,实现居中留白。
思路转变:从 px -> vw 变为 px -> rem。
三、核心实战:逆向工程与插件配置
我们的目标是:继续使用高效的 postcss-px-to-viewport-8-plugin 自动将设计稿的 px 转换为 rem,但要破解它的默认公式。
1. 插件的“固执”公式
该插件默认用于转换 vw,它有一个强制逻辑:
// 插件内部大概是这样计算的
function fixedTo(number, unitPrecision) {
// 公式: (px / viewportWidth) * 100
return (number / viewportWidth * 100).toFixed(unitPrecision) + 'vw';
}
我们要把输出单位改成 rem,但公式没变,它依然会套用 (px / viewportWidth) * 100。
2. 逆向计算,破解公式
我们的目标是:让 1920px 的设计稿上,1rem 恰好等于 16px。
- 设:设计稿上一个元素的宽度为
100px。 - 我们希望插件输出:
100px -> Y rem。 - 我们希望在实际
1920px宽的屏幕下:Y rem = 100px。 - 因为
1rem = 16px,所以Y = 100 / 16 = 6.25rem。
现在,我们反向推导插件内部的公式:
插件计算:Y = (100 / viewportWidth) * 100
让两个 Y 相等:
(100 / viewportWidth) * 100 = 100 / 16
两边同时除以 100:
100 / viewportWidth = 1 / 16
解得:
viewportWidth = 100 * 16 = 1600
结论: 将插件的 viewportWidth 设置为 1600,viewportUnit 设置为 rem,它就能输出符合我们需求的 rem 值!
3. 最终 PostCSS 配置
// nuxt.config.ts / vite.config.ts / postcss.config.js
export default {
// ... other config
postcss: {
plugins: [
require('postcss-px-to-viewport-8-plugin')({
// 【核心逆向配置】通过计算得出,让 1920px 设计稿下 1rem = 16px
viewportWidth: 1600, // 设计稿视口宽度(逆向计算值)
viewportHeight: 1080, // 设计稿视口高度(根据实际情况设置,主要用于高宽都固定的元素)
unitToConvert: 'px', // 要转换的单位
unitPrecision: 5, // 转换后的精度
propList: ['*'], // 可以从 px 转为 rem 的属性列表,* 代表所有属性
viewportUnit: 'rem', // 【核心】转换后的单位,我们选择 rem
fontViewportUnit: 'rem', // 字体转换后的单位
selectorBlackList: ['.container-max-width', ''], // 指定不转换的类名
minPixelValue: 1, // 小于 1px 不转换
mediaQuery: true, // 允许在媒体查询中转换
replace: true, // 直接替换值而不添加备用属性
include: [/src/, /node_modules[\/]element-plus/], // 只转换 src 和 element-plus 下的文件
// exclude: [/node_modules/] // 忽略 node_modules
}),
],
},
}
四、动态控制:Nuxt 插件设置根字体大小
光有 rem 还不够,我们需要动态设置 <html> 的 font-size。
// plugins/rem.client.ts
export default defineNuxtPlugin((nuxtApp) => {
const setRem = () => {
const designWidth = 1920 // 我们的设计稿宽度
const baseSize = 16 // 我们希望的最大基准值 (1rem = 16px)
const clientWidth = document.documentElement.clientWidth
// 核心计算公式:缩放比例 = 当前视宽 / 设计稿宽度
const remSize = (clientWidth / designWidth) * baseSize
// 【关键】设置字体大小,并限制其在 12px 到 16px 之间
// 这意味着:屏幕小于 1920px 时会缩小,大于 1920px 时根字体大小稳定在 16px
document.documentElement.style.fontSize = `${Math.min(Math.max(remSize, 12), 16)}px`
}
let timer: NodeJS.Timeout | null = null
const setRemDebounced = () => {
if (timer) clearTimeout(timer)
timer = setTimeout(setRem, 250) // 防抖优化
}
// App 挂载后设置并监听 resize
nuxtApp.hook('app:mounted', () => {
setRem()
window.addEventListener('resize', setRemDebounced)
})
// App 卸载前清理
nuxtApp.hook('app:beforeMount', () => {
window.removeEventListener('resize', setRemDebounced)
if (timer) clearTimeout(timer)
})
})
五、收尾工作:CSS 最大宽度容器
最后,别忘了创建一个最大宽度容器,这是完美收尾的关键。
/* assets/css/global.css */
.container-max-width {
max-width: 1920px; /* 限制最大宽度 */
margin: 0 auto; /* 居中显示 */
}
/* 在布局组件或App.vue中应用 */
<!-- app.vue -->
<template>
<div id="app" class="container-max-width">
<RouterView />
</div>
</template>
总结与展望
- 方案优势:
- 完美适配:实现了“小屏缩放、大屏留白”的理想效果。
- 开发高效:延续了
postcss-px-to-viewport的书写习惯,开发时直接写px。 - 体验优雅:彻底杜绝超宽屏下的布局崩坏问题。
- 注意事项:
- 注意
selectorBlackList要把container-max-width加进去,防止它的max-width: 1920px被转换成rem。 baseSize和mediaQuery结合,可以实现更复杂的响应式逻辑。
- 注意
这个方案是我们团队从 vw 的坑里爬出来后,不断探索得出的最优解,目前已在生产环境稳定运行。如果对你有启发,欢迎点赞、收藏、关注!
来源:juejin.cn/post/7540877562265911332
就因为package.json里少了个^号,我们公司赔了客户十万块

写这篇文章的时候,我刚通宵处理完一个P0级(最高级别)的线上事故,天刚亮,烟灰缸是满的🚬。
事故的原因,说出来你可能不信,不是什么服务器宕机,也不是什么黑客攻击,就因为我们package.json里的一个依赖项,少写了一个小小的^(脱字符号) 。
这个小小的失误,导致我们给客户A的数据计算模块,在一次平平无奇的依赖更新后,全线崩溃。而我们,直到客户的业务方打电话来投诉,才发现问题。
等我们回滚、修复、安抚客户,已经是7个小时后。按照合同的SLA(服务等级协议),我们公司需要为这次长时间的服务中断,赔付客户十万块。
老板在事故复盘会上,倒没说什么重话,只是默默地把合同复印件放在了桌上。

今天,我不想抱怨什么,只想把这个价值 十万块 的教训,原原本本地分享出来,希望能给所有前端、乃至所有工程师,敲响一个警钟。
事故是怎么发生的?
我们先来复盘一下事故的现场。
我们有一个给客户A定制的Node.js数据处理服务。它依赖了我们内部的另一个核心工具库@internal/core。
在项目的package.json里,依赖是这么写的:
{
"name": "customer-a-service",
"dependencies": {
"@internal/core": "1.3.5",
"express": "^4.18.2",
"lodash": "^4.17.21"
// ...
}
}
注意看,express和lodash前面,都有一个^符号,而我们的@internal/core,没有。
这个^代表什么?它告诉npm/pnpm/yarn:“我希望安装1.x.x版本里,大于等于1.3.5的最新版本。”
而没有^,代表什么?它代表:我只安装1.3.5这一个版本,锁死它,不许变。
问题就出在这里。
上周,core库的同事,修复了一个严重的性能Bug,发布了1.3.6版本,并且在公司群里通知了所有人。
我们组里负责这个项目的同学,看到了通知,也很负责任。他想:core库升级了,我也得跟着升。
于是,他看了看package.json,发现项目里用的是1.3.5。他以为,只要他去core库的仓库,把1.3.5这个tag删掉,然后把1.3.6的tag打上去,CI/CD在下次部署时,重新pnpm install,就会自动拉取到最新的代码。
他错了!
最致命的锁死版本
因为我们的依赖写的是"1.3.5",而不是"^1.3.5",所以我们的pnpm-lock.yaml文件里,把这个依赖的解析规则,彻底锁死在了1.3.5。
无论core库的同事怎么发布1.3.6、1.3.7,甚至2.0.0...
只要我们不去手动修改package.json,我们的CI/CD流水线,在执行pnpm install时,永远、永远,都只会去寻找那个被写死的1.3.5版本。
然后,灾难发生了。
core库的同事,在发布1.3.6后,为了保持仓库整洁,就把1.3.5那个旧的git tag给删掉了。
然后,客户A的项目,某天下午需要做一个常规的文案更新,触发了部署流水线。
流水线执行到pnpm install时,pnpm拿着lock文件,忠实地去找@internal/core@1.3.5这个包...
“Error: Package '1.3.5' not found.”
流水线崩溃了。一个本该5分钟完成的文案更新,导致了整个服务7个小时的宕机😖。
十万块换来的血泪教训
事故复盘会上,我们所有人都沉默了。我们复盘的,不是谁的锅,而是我们对依赖管理这个最基础的认知,出了多大的偏差。
^ (Caret) 和 ~ (Tilde) 不是选填,而是必填
^(脱字符) :^1.3.5意味着1.x.x(x >= 5)。这是最推荐的写法。它允许我们自动享受到所有 非破坏性 的小版本和补丁更新(比如1.3.6,1.4.0),这也是npm install默认的行为。~(波浪号) :~1.3.5意味着1.3.x(x >= 5)。它只允许补丁更新,不允许小版本更新。太保守了,一般不推荐。- (啥也不写) :
1.3.5意味着锁死。除非你是react或vue这种需要和生态强绑定的宿主,否则,永远不要在你的业务项目里这么干!
我们团队现在强制规定,所有package.json里的依赖,必须、必须、必须使用^。
关于lock文件
我们以前对lock文件(pnpm-lock.yaml, package-lock.json)的理解太浅了,以为它只是个缓存。
现在我才明白,package.json里的^1.3.5,只是在定义一个规则。
而pnpm-lock.yaml,才是基于这个规则,去计算出的最终答案。
lock文件,才是保证你同事、你电脑、CI服务器,能安装一模一样的依赖树的唯一路径。它必须被提交到Git。
依赖更新,是一个主动的行为,不是被动的
我们以前太天真了,以为只要依赖发了新版,我们就该自动用上。
这次事故,让我们明白:依赖更新,是一个严肃的、需要主动管理和测试的行为。
我们现在的流程是:

- 使用
pnpm update --interactive:pnpm会列出所有可以安全更新的包(基于^规则)。 - 本地测试:在本地跑一遍完整的测试用例,确保没问题。
- 提交PR:把更新后的
pnpm-lock.yaml文件,作为一个单独的PR提交,并写清楚更新了哪些核心依赖。 - CI/CD验证:让CI/CD在
staging环境,用这个新的lock文件,跑一遍完整的E2E(端到端)测试。
这十万块,是技术Leader(我)的失职,也是我们整个团队,为基础不牢付出的最昂贵的一笔学费。
一个小小的^,背后是整个npm生态的依赖管理的核心。
分享出来,不是为了博眼球,是真的希望大家能回去检查一下自己的package.json。
看看你的依赖前面,那个小小的^,它还在吗?😠
来源:juejin.cn/post/7568418604812632073
我删光了项目里的 try-catch,老板:6
相信我们经常这样写bug(不是 👇:

try {
const res = await api.getUser()
console.log('✅ 用户信息', res)
} catch (err) {
console.error('❌ 请求失败', err)
}
看似没问题
- 每个接口都要 try-catch,太啰嗦了!
- 错误处理逻辑分散,不可控!
- 代码又臭又长💨!

💡 目标:不抛异常的安全请求封装
我们希望实现这样的调用👇:
const [err, data] = await safeRequest(api.getUser(1))
if (err) return showError(err)
console.log('✅ 用户信息:', data)
是不是清爽多了?✨
没有 try-catch,却能同时拿到错误和数据。
🧩 实现步骤
1️⃣ 先封装 Axios 实例
// src/utils/request.js
import axios from 'axios'
import { ElMessage } from 'element-plus'
const service = axios.create({
baseURL: import.meta.env.VITE_API_BASE_URL,
timeout: 10000,
})
// 🧱 请求拦截器
service.interceptors.request.use(
(config) => {
const token = localStorage.getItem('token')
if (token) config.headers.Authorization = `Bearer ${token}`
return config
},
(error) => Promise.reject(error)
)
// 🧱 响应拦截器
service.interceptors.response.use(
(response) => {
const res = response.data
if (res.code !== 0) {
ElMessage.error(res.message || '请求失败')
return Promise.reject(new Error(res.message || '请求失败'))
}
return res.data
},
(error) => {
ElMessage.error(error.message || '网络错误')
return Promise.reject(error)
}
)
export default service
拦截器的作用:
- ✅ 统一处理 token;
- ✅ 统一处理错误提示;
- ✅ 保证业务层拿到的永远是“干净的数据”。
2️⃣ 封装一个「安全请求函数」
// src/utils/safeRequest.js
export async function safeRequest(promise) {
try {
const data = await promise
return [null, data] // ✅ 成功时返回 [null, data]
} catch (err) {
return [err, null] // ❌ 失败时返回 [err, null]
}
}
这就是关键!
它让所有 Promise 都变得「温柔」——不再抛出异常,而是返回结构化结果。
3️⃣ 封装 API 模块
// src/api/user.js
import request from '@/utils/request'
export const userApi = {
getUser(id) {
return request.get(`/user/${id}`)
},
updateUser(data) {
return request.put('/user', data)
},
}
4️⃣ 在业务层优雅调用
<script setup>
import { ref, onMounted } from 'vue'
import { userApi } from '@/api/user'
import { safeRequest } from '@/utils/safeRequest'
const user = ref(null)
onMounted(async () => {
const [err, data] = await safeRequest(userApi.getUser(1))
if (err) return showError(err)
console.log('✅ 用户信息:', data)
})
</script>
是不是很优雅、数据逻辑清晰、不需要 try-catch、 错误不崩溃。
老板说:牛🍺,你小子有点东西

🧱 我们还可以进一步优化:实现自动错误提示
我们可以给 safeRequest 增加一个选项,让错误自动提示:
// src/utils/safeRequest.js
import { ElMessage } from 'element-plus'
export async function safeRequest(promise, { showError = true } = {}) {
try {
const data = await promise
return [null, data]
} catch (err) {
if (showError) {
ElMessage.error(err.message || '请求失败')
}
return [err, null]
}
}
使用时👇:
const [err, data] = await safeRequest(userApi.getUser(1), { showError: false })
这样你可以灵活控制是否弹出错误提示,
比如某些静默请求就可以关闭提示。
🧠 进阶:TypeScript 支持(超丝滑)
如果你用的是 TypeScript,可以让返回类型更智能👇:
export async function safeRequest<T>(
promise: Promise<T>
): Promise<[Error | null, T | null]> {
try {
const data = await promise
return [null, data]
} catch (err) {
return [err as Error, null]
}
}
调用时:
const [err, user] = await safeRequest<User>(userApi.getUser(1))
if (user) console.log(user.name) // ✅ 自动提示类型
老板:写得很好,下次多写点,明天你来当老板

来源:juejin.cn/post/7565811094734389248
一个超级真实的Three.js树🌲生成器插件
前言
分享一个基于Three.js封装的树生成器插件,可以实现创建不同类型且渲染效果真实的3D树

说实话,第一次在这个插件官网看到这个效果时我一度以为这只是一个视频,树的内容不仅仅是动态的而且整体的渲染效果也十分真实。
在three.js中使用起来也是非常的简单的仅仅需几行代码就可以搞定,下面给大家简单的介绍一下。
安装
通过 npm/pnpm 安装到项目本地即可
npm i @dgreenheck/ez-tree
pnpm add @dgreenheck/ez-tree
使用
使用起来也是非常简单的,只需要将插件import 引入然后在 new 实例化出来 在添加到 场景中就可以了
最后在一个requestAnimationFrame 动画函数中更新树的内容就行了
import { Tree } from '@dgreenheck/ez-tree';
createTree(){
const tree = new Tree();
tree.generate();
// 设置一下位置
tree.position.set(0, 0, 0);
// 设置一下大小缩放
tree.scale.set(0.1, 0.1, 0.1);
// 添加到场景中
this.scene.add(tree);
}
sceneAnimation(): void {
// 确保动画循环持续进行
this.renderAnimation = requestAnimationFrame(() => this.sceneAnimation());
// 更新时钟
const elapsedTime = this.clock.getElapsedTime();
// 更新控制器 如果当前是第一人称控制器则不更新
if (!this.pointerLockControls) {
this.controls.update();
}
// 更新 Tree 动态效果(风动效果等)
if (this.tree) {
this.tree.update(elapsedTime);
}
// 渲染场景
this.renderer.render(this.scene, this.camera);
}
本地项目效果
因为本地项目对光照等参数没有专门调试所以和官网展示的效果有一定的差距

将相机放大查看树渲染的效果细节处理个人觉得是非常nice的,十分真实

参数
该插件还提供了创建不同类型树的方法,通过官网的在线调试就可以看到效果了
创建一个别的类型树
修改树枝的方向
树叶的多少
项目地址
该项目插件是一个外国大佬开发,如果你的项目或者个人网站需要丰富一下页面内容,那么这个插件或许是个不错的选择
来源:juejin.cn/post/7573588675638099983
第一个成功在APP store 上架的APP
XunDoc开发之旅:当AI医生遇上家庭健康管家
当我在生活中目睹家人为管理复杂的健康数据、用药提醒而手忙脚乱时,一个想法冒了出来:我能否打造一个App,像一位贴心的家庭健康管家,把全家人的健康都管起来?它不仅要能记录数据,还要够聪明,能解答健康疑惑,能主动提醒。这就是 XunDoc App。
1. 搭建家庭的健康数据中枢
起初,我转向AI助手寻求架构指导。我的构想很明确:一个以家庭为单位,能管理成员信息、记录多种健康指标(血压、血糖等)的系统。AI很快给出了基于SwiftUI和MVVM模式的代码框架,并建议用UserDefaults来存储数据。
但对于一个完整的应用而言,我马上遇到了第一个问题:数据如何在不同视图间高效、准确地共享? 一开始我简单地使用@State,但随着功能增多,数据流变得一团糟,经常出现视图数据不同步的情况。
接着在Claude解决不了的时候我去询问Deepseek,它一针见血地指出:“你的数据管理太分散了,应该使用EnvironmentObject配合单例模式,建立一个统一的数据源。” 这个建议成了项目的转折点。我创建了FamilyShareManager和HealthDataManager这两个核心管家。当我把家庭成员的增删改查、健康数据的录入与读取都交给它们统一调度后,整个应用的数据就像被接通了任督二脉,立刻流畅稳定了起来。
2. 请来AI医生:集成Moonshot API
基础框架搭好,接下来就是实现核心的“智能”部分了。我想让用户能通过文字和图片,向AI咨询健康问题。我再次找到AI助手,描述了皮肤分析、报告解读等四种咨询场景,它很快帮我写出了调用Moonshot多模态API的代码。
然而,每件事都不能事事如意的。文字咨询很顺利,但一到图片上传就频繁失败。AI给出的代码在处理稍大一点的图片时就会崩溃,日志里满是编码错误。我一度怀疑是网络问题,但反复排查后,我询问Deepseek,他告诉我:“多模态API对图片的Base64编码和大小有严格限制,你需要在前端进行压缩和校验。”
我把他给我的建议给到了Claude。claude帮我编写了一个“图片预处理”函数,自动将图片压缩到4MB以内并确保编码格式正确。当这个“关卡”被设立后,之前桀骜不驯的图片上传功能终于变得温顺听话。看着App里拍张照就能得到专业的皮肤分析建议,那种将前沿AI技术握在手中的感觉,实在令人兴奋。
3. 打造永不遗忘的智能提醒系统
健康管理,贵在坚持,难在记忆。我决心打造一个强大的医疗提醒模块。我的想法是:它不能是普通的闹钟,而要像一位专业的护士,能区分用药、复查、预约等不同类型,并能灵活设置重复。
AI助手根据我的描述,生成了利用UserNotifications框架的初始代码。但很快,我发现了一个新问题:对于“每周一次”的重复提醒,当用户点击“完成”后,系统并不会自动创建下一周的通知。这完全违背了“提醒”的初衷。
“这需要你自己实现一个智能调度的逻辑,在用户完成一个提醒时,计算出下一次触发的时间,并重新提交一个本地通知。” 这是deepseek告诉我的,我把这个需求告诉给了Claude。于是,在MedicalNotificationManager中, claude加入了一个“重新调度”的函数。当您标记一个每周的用药提醒为“已完成”时,App会悄无声息地为您安排好下一周的同一时刻的提醒。这个功能的实现,让XunDoc从一个被动的记录工具,真正蜕变为一个主动的健康守护者。
4. 临门一脚:App Store上架“渡劫”指南
当XunDoc终于在模拟器和我的测试机上稳定运行后,我感觉胜利在望。但很快我就意识到,从“本地能跑”到“商店能下”,中间隔着一道巨大的鸿沟——苹果的审核。证书、描述文件、权限声明、截图尺寸……这些繁琐的流程让我一头雾水。
这次,我直接找到了DeepSeek:“我的App开发完了,现在需要上传到App Store,请给我一个最详细、针对新手的小白教程。”
DeepSeek给出的回复堪称保姆级,它把整个过程拆解成了“配置App ID和证书”、“在App Store Connect中创建应用”、“在Xcode中进行归档打包”三大步。我就像拿着攻略打游戏,一步步跟着操作:
- 创建App ID:在苹果开发者后台,我按照说明创建了唯一的App ID
com.[我的ID].XunDoc。 - 搞定证书:最让我头疼的证书环节,DeepSeek指导我分别创建了“Development”和“Distribution”证书,并耐心解释了二者的区别。
- 设置权限:因为App需要用到相机(拍照诊断)、相册(上传图片)和通知(医疗提醒),我根据指南,在
Info.plist文件中一一添加了对应的权限描述,确保审核员能清楚知道我们为什么需要这些权限。
一切准备就绪,我在Xcode中点击了“Product” -> “Archive”。看着进度条缓缓填满,我的心也提到了嗓子眼。打包成功!随后通过“Distribute App”流程,我将我这两天的汗水上传到了App Store Connect。当然不是一次就通过上传的。
5. 从“能用”到“好用”:三次UI大迭代的觉醒
应用上架最初的兴奋感过去后,我陆续收到了一些早期用户的反馈:“功能很多,但不知道从哪里开始用”、“界面有点拥挤,找东西费劲”。这让我意识到,我的产品在工程师思维里是“功能完备”,但在用户眼里可能却是“复杂难用”。
我决定重新设计UI。第一站,我找到了国产的Mastergo。我将XunDoc的核心界面截图喂给它,并提示:“请为这款家庭健康管理应用生成几套更现代、更友好的UI设计方案。”
Mastergo给出的方案让我大开眼界。它弱化了我之前强调的“卡片”边界,采用了更大的留白和更清晰的视觉层级。它建议将底部的标签栏导航做得更精致,并引入了一个全局的“+”浮动按钮,用于快速记录健康数据。这是我第一套迭代方案的灵感来源:从“功能堆砌”转向“简洁现代” 。
然而,Mastergo的方案虽然美观,但有些交互逻辑不太符合iOS的规范。于是,第二站,我请来了Stitch。我将完整的产品介绍、所有功能模块的说明,以及第一版的设计图都给了它,并下达指令:“请基于这些材料,完全重现XunDoc的完整UI,但要遵循iOS Human Interface Guidelines,并确保信息架构清晰,新用户能快速上手。”等到他设计好了后 我将我的设计图UI截图给Claude,让他尽可能的帮我生成。
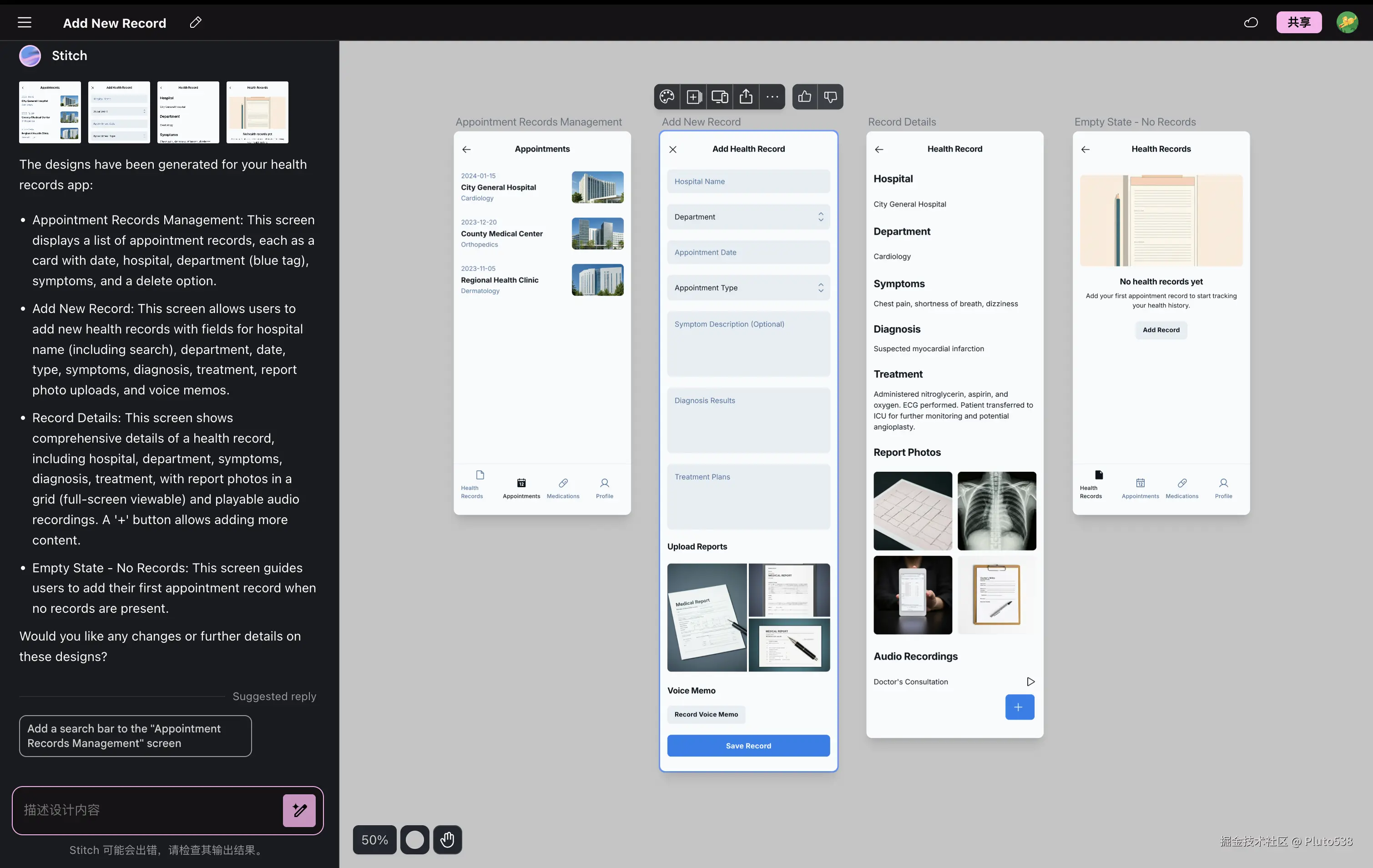
(以上是我的Stitch构建出来的页面)
Claude展现出了惊人的理解力。它不仅仅是在画界面,而是在重构产品的信息架构。它建议将“AI咨询”的四种模式(皮肤、症状、报告、用药)从并列排列,改为一个主导航入口,进去后再通过图标和简短说明让用户选择。同时,它将“首页”重新定义为真正的“健康概览”,只显示最关键的数据和今日提醒,其他所有功能都规整地收纳入标签栏。这形成了我的第二套迭代方案:从“简洁现代”深化为“结构清晰” 。
拿着Claude的输出,我结合Mastergo和Stitch的视觉灵感,再让Cluade一步一步的微调。我意识到,颜色不仅是美观,更是传达情绪和功能的重要工具。我将原本统一的蓝色系,根据功能模块进行了区分:健康数据用沉稳的蓝色,AI咨询用代表智慧的紫色,医疗提醒用醒目的橙色。图标也设计得更加线性轻量,减少了视觉负担。(其实这是Deepseek给我的建议)这就是最终的第三套迭代方案:在清晰的结构上,注入温暖与亲和力。
这次从Stitch到Claude的UI重塑之旅,让我深刻意识到,一个成功的产品不仅仅是代码的堆砌。它是一次与用户的对话,而设计,就是这门对话的语言。通过让不同的AI助手在我的引导下“协同创作”,我成功地让XunDoc从一個工程师的作品,蜕变成一个真正为用户着想的产品。
现在这款app已经成功上架到了我的App store上 大家可以直接搜索下来进行使用和体验,我希望大家可以在未来可以一起解决问题!
来源:juejin.cn/post/7559864914883067914
一些经典的3D编辑器开源项目
前言
给大家分享一下个人在探索开发three.js编辑器项目期间发现的一些比较不错的3D编辑器类型的开源项目,如果你也正打算做类似相关的项目,那么这些开源项目会是一个不错的参考借鉴
以下排名不分先后🙏🏻
项目一:Astral3D
描述:基于Vue3 + THREE.JS 免费开源的三维引擎及配套编辑器,包含BIM轻量化、CAD解析预览、粒子系统、插件系统等功能。
特点:强大的3D场景内容元素的编辑和保存功能和丰富多样的3D元素内容,同时支持BIM和CAD等工业建模文件的加载渲染
注意⚠️:项目是Apache-2.0 license 的开源协议,项目作者本人也声明了项目可用于个人学习,如有商用需要向作者申请商用授权
界面:
Github: github.com/mlt131220/A…
项目二:thebrowserlab
描述:一个「运行在浏览器里的 3D 编辑器 + 创意编码 (creative-coding) 环境」
特点:支持加载视频、文本、图片、粒子等内容并提供了丰富的编辑表单参数可视化编辑配置,同时还支持在线代码的脚本内容写入设置3D场景内容。
注意⚠️:项目使用 MIT 授权 (MIT license),意味着你可以自由地 fork、修改、商用 (遵守 MIT 即可)
界面:
在线地址:thebrowserlab.com/
Github: github.com/icurtis1/th…
项目三:threepipe
描述:一个基于 Three.js 构建的现代 3D 框架
特点:项目基于了Three.js进行了二次封装,提供了不少高级功能,使其适合从简单 3D 模型预览到复杂 交互 / 渲染应用,通过简单的API 使用就可以快速创建复杂的3D模型预览器,模型编辑器等内容。
注意⚠️:既然是封装好的框架,在享受使用的便利时,新的学习成本也是不可避免的,项目使用 Apache-2.0-1协议,商用也许需要授权,不过毕竟是歪果仁开发的,即使未授权也难以知晓
界面:
Github: github.com/repalash/th…
项目四:ShadowEditor
描述:基于Three.js、Go语言和MongoDB的跨平台的3D场景编辑器,支持桌面版和Web版。
特点:跨平台的支持 Windows / Linux / Mac,在桌面 (desktop) 和浏览器 (web) 中都能运行,前后端一体的项目
注意⚠️:使用 MIT 许可证的项目,可以自由用于学习、实验或商业用途。从界面不难看出,应该是属于上古时期的项目了,three.js版本也是107的。作者也推出了商业版的,如有需要也可以试用一下商业版的
界面:
在线地址:http://www.hylab.cn/shadowedito…
Github: gitee.com/tengge1/Sha…
项目五:three-editor
描述:一个基于 Three.js 的 可视化 / 低代码 3D 编辑器 / 内核/框架。它的目标是降低使用 Three.js 的门槛,让构建 Web 3D 场景更简单、更迅速
特点:提供了一整套“可视化 + 配置 + 编辑 + 渲染”的能力,使得即使不深入了解 Three.js,也能快速构建 3D 场景 / 项目,:如果你只是想在网页中展示某个 3D 模型、场景或交互,而不想编写大量 Three.js boilerplate,three-editor 能极大降低门槛
注意⚠️:因为场景内容都是封装处理好的,提供的可编辑参数内容配置并不多,如果你的自定义需求很多的话使用这个项目前需要谨慎考虑一下
界面:
在线地址:z2586300277.github.io/threejs-edi…
Github: github.com/z2586300277…
项目六:scene-editor
描述:vis-three/scene-editor 是基于 vis-three 框架构建的 —— vis-three 本身是一个封装自 Three.js 的前端 3D 开发框架,用于简化 Web3D 开发
特点:基于vis-three 衍生开发的一个3D编辑器提供了一套较为完整的 Web 3D 场景编辑功能 — 目标是让你即使对 3D 或 Three.js 不熟,也能比较轻松地 “拖/配/编辑” 出一个 3D 场景
注意⚠️:仓库地址的代码是Vue3项目编译打包后的,作者并没有直接提供Vue3项目的源代码,如果有二次开发需求,无法直接性修改源代码
界面:
在线地址:z2586300277.github.io/threejs-edi…
Github: github.com/Shiotsukika…
Gitee:gitee.com/vis-three/s…
项目七: three.js官方编辑器
描述:Three.js(著名的 WebGL / Web 3D 渲染库)自带 / 官方提供的可视化编辑器,接触过three.js的应该都知道吧
特点:3D编辑器的鼻祖了也是唯一一个能和three.js最新版本保持随时同步的编辑器,很多现有的商业项目和开源项目的功能,或多或少都参考了这个项目去实现的
注意⚠️:使用原生js 去实现的,二次开发和扩展功能成本较大
界面:

在线地址:threejs.org/editor/
Github: github.com/mrdoob/thre…
项目八: threejs-3dmodel-edit
描述:一个基于 Three.js + Vue 3 + TypeScript + Pinia 的前端 3D 模型编辑器 / 可视化编辑平台
特点:是一个比较完整、现代、易用的 Web-based 3D 模型编辑器 — 它把 Three.js 的功能通过 Vue / TS / Pinia 封装起来,让非专业 3D 建模背景的人也能比较容易地加载 /编辑 /导出 /展示 3D 模型。基于企业级项目代码开发的标准规范,如果你正在开发自己的第一个企业级Three.js 项目那么这个项目的代码设计思路将会是一个不错的参考
注意⚠️:作者本人的3D开源项目,毛遂自荐一下,哈哈哈哈
界面:

Github: github.com/zhangbo126/…
Gitee:gitee.com/ZHANG_6666/…
结语
ok以上就是作者本人已知的一些不错的开源3D编辑器合集了,如果你还知道一些好的3D编辑器项目欢迎评论区补充
来源:juejin.cn/post/7576867727719039011
🍭🍭🍭升级 AntD 6:做第一个吃螃蟹的人
AntD 6 发布之后,网上很多人都在观望:
“要不要升级?”
“会不会炸?”
“我的项目能不能扛得住?”
其实 AntD 官方已经在文档里把升级路径写得非常清楚,只是稍显简略。
下面我用更真实、更工程化的方式,把 v5 → v6 的升级步骤 做了一次加强版讲解,
让你升级时不至于踩坑。
① 第一步:升级到 v5 最新版本(必须执行)
在升级到 AntD 6 之前,官方强烈建议你先把项目从 v5 升到 v5 最新版本:5.29.1。
为什么?
✔ v5 的最新版本会给出所有废弃 API 的 warning
✔ 不处理这些 warning,到 v6 会直接报错
✔ v5 → v6 是平滑升级路径,只要你处理掉 v5 的 warning,升级 v6 就不会炸
执行命令:
npm install antd@5
装完以后,启动项目,务必一条一条看控制台 warning。
比如:
- 某个 API 将被移除
- 某个 props 已废弃
- 某个组件 v6 即将删除
所有 warning 都处理完,再继续下一步。
这阶段非常关键,等于是在做“升级前全身检查”。
其实你只要用了5的版本基本没啥大问题
② 第二步:确保项目运行在 React 18(或以上)
AntD 6 不再支持 React 17 及以下版本。
AntD 官方的态度非常明确:
“React 17,我们不救了。”
好消息是:绝大多数前端项目早就 React 18 了。
如果你还停留在 React 17,那建议你别升级 AntD,
你升级 React 本身都要做好打仗的准备。
检查你的 package.json:
"react": "^18.x.x",
"react-dom": "^18.x.x"
如果不是,那你真的得升级个 der(官方术语:赶紧升 😅)。
React 17 升到 React 18 已经是必经之路,
Suspense、Concurrent、SSR 都已经进入新阶段,不升会拖累整个项目生态。
③ 第三步:开干!升级到 AntD 6
前面两步做完,你的项目基本已经“具备上 6 条件”了。
现在就可以正式开刀:
npm install --save antd@6
或者你爱用的包管理器:
yarn add antd@6
# or
pnpm add antd@6
# or
npm install antd@latest
安装完成后,你的项目就是 AntD 6 正式用户。
④ 第四步:启动项目,处理残留 warning
升级完成以后,重启项目。
你可能会看到一些:
- 类型定义变动 warning
- 某些行为变更 warning
- 某些组件结构调整提示
- mask blur 带来的视觉差异
- 你自己写的样式被 DOM 改动影响
这些属于正常“升级后适配”。
根据提示处理即可。
建议你重点检查以下区域:
✔ 自定义覆盖类名(AntD 6 DOM 有变化)
✔ Modal、Drawer 的 mask 是否出现模糊效果
✔ Table、Form 是否有类型冲突
✔ 已废弃 API 是否仍然使用
✔ 第三方依赖是否引用了 AntD 内部 class
通常处理 1-2 小时就可以全部解决 ( 不解决也行,能跑就行😉)。
⑤ 最终:你就正式吃上了 AntD 6 的“螃蟹”
完成以上步骤后,你就完成了整个升级链路:
- 清理 v5 废弃 API
- 升到 React 18(如果你的项目还没)
- 升到 AntD 6
- 修复升级后剩余 warning
从此以后:
- 你可以用 Masonry 瀑布流
- 你可以用更快的 Tooltip
- 你可以享受 ZeroRuntime
- 你可以用语义化 DOM 更好写主题
- 你的项目正式进入 2025 年的前端栈
一句话:
你是第一个吃螃蟹的人,但这次螃蟹真的不难吃,而且还挺香,哥们已经升级,满嘴流油了。

来源:juejin.cn/post/7576571960286822435
基于WASM的纯前端Office解决方案:在线编辑/导入导出/权限切换/多实例/实例缓存(已开源)
效果展示
所有操作均在浏览器进行,先来看看最终效果:
🌐 在线演示: mvp-onlyoffice.vercel.app/
🔗 GitHub仓库: mvp-onlyoffice
基本示例
多实例示例
多tab示例
。。。。。。。。。。
核心功能演示
- ✅ 文档上传:支持本地文件直接上传
- ✅ 实时编辑:流畅的文档编辑体验
- ✅ 格式转换:基于WASM的文档格式转换
- ✅ 导出保存:一键导出编辑后的文档
- ✅ 模式切换:只读/可编辑模式自由切换
- ✅ 多语言支持:中英文界面无缝切换
- ✅ 多实例支持:同时运行多个独立编辑器实例(Word/Excel/PPT)
- ✅ 资源隔离:每个实例独立的图片上传和媒体资源管理
技术架构
核心技术栈
- React 19 + Next.js 15:现代化前端框架
- OnlyOffice SDK:官方JavaScript SDK,提供文档编辑核心能力
- WebAssembly (x2t-wasm):文档格式转换引擎
- TypeScript:类型安全的开发体验
- EventBus:事件驱动的架构设计
- IndexedDB:WASM文件缓存优化
- EditorManagerFactory:多实例管理器工厂模式
tip: 事实上不依赖于 react,你可以拿到 项目中的 src/onlyoffice-comp ,然后接入到任何系统中去,接入层可以参考 src/app/excel/page.tsx等应用层文件
架构流程图
用户上传文档
↓
React组件层
↓
EditorManagerFactory (多实例管理器工厂)
↓
EditorManager (编辑器管理器)
↓
X2T Converter (WASM转换器)
↓
OnlyOffice SDK (文档编辑器)
↓
EventBus (事件总线)
↓
导出/保存文档
WASM文档转换核心流程
转换流程图解
用户选择文件
↓
浏览器读取文件
↓
WASM虚拟文件系统
↓
X2T引擎执行转换
↓
生成二进制数据 + 媒体资源
↓
OnlyOffice编辑器加载
核心代码实现
// src/onlyoffice-comp/lib/x2t.ts
/**
* X2T 工具类 - 负责文档转换功能
*/
class X2TConverter {
private x2tModule: EmscriptenModule | null = null;
// 支持的文件类型映射
private readonly DOCUMENT_TYPE_MAP: Record<string, DocumentType> = {
docx: 'word',
doc: 'word',
odt: 'word',
rtf: 'word',
txt: 'word',
xlsx: 'cell',
xls: 'cell',
ods: 'cell',
csv: 'cell',
pptx: 'slide',
ppt: 'slide',
odp: 'slide',
};
/**
* 转换文档格式
*/
async convertDocument(file: File): Promise<ConversionResult> {
// 初始化WASM模块
await this.ensureReady();
// 写入虚拟文件系统
const data = await file.arrayBuffer();
this.x2tModule!.FS.writeFile('/working/origin', new Uint8Array(data));
// 执行C++编译的转换模块
this.executeConversion('/working/params.xml');
// 提取转换结果和媒体文件
return {
bin: this.x2tModule!.FS.readFile('/working/output.bin'),
media: this.collectMediaFiles() // 提取图片等资源
};
}
}
编辑器管理器:多实例架构设计
项目采用工厂模式管理多个编辑器实例,每个实例都有独立的容器ID和资源管理:
// src/onlyoffice-comp/lib/editor-manager.ts
// EditorManagerFactory - 多实例管理器工厂
class EditorManagerFactory {
private static instance: EditorManagerFactory;
private managers: Map<string, EditorManager> = new Map();
// 创建或获取编辑器管理器实例
create(containerId?: string): EditorManager {
if (containerId) {
// 如果已存在,返回现有实例
if (this.managers.has(containerId)) {
return this.managers.get(containerId)!;
}
// 创建新实例
const manager = new EditorManager(containerId);
this.managers.set(containerId, manager);
return manager;
}
// 创建默认实例
return this.createDefault();
}
// 获取指定容器ID的实例
get(containerId: string): EditorManager | undefined {
return this.managers.get(containerId);
}
// 销毁指定实例
destroy(containerId: string): void {
const manager = this.managers.get(containerId);
if (manager) {
manager.destroy();
this.managers.delete(containerId);
}
}
// 销毁所有实例
destroyAll(): void {
this.managers.forEach(manager => manager.destroy());
this.managers.clear();
}
}
// EditorManager - 单个编辑器管理器
class EditorManager {
private instanceId: string;
private containerId: string;
private editor: DocEditor | null = null;
constructor(containerId?: string) {
this.instanceId = nanoid(); // 生成唯一实例ID
this.containerId = containerId || `onlyoffice-editor-${this.instanceId}`;
}
// 获取实例ID
getInstanceId(): string {
return this.instanceId;
}
// 获取容器ID
getContainerId(): string {
return this.containerId;
}
// 导出文档(事件驱动)
async export(): Promise<SaveDocumentData> {
const editor = this.get();
if (!editor) {
throw new Error('Editor not available');
}
// 触发保存
(editor as any).downloadAs();
// 等待保存事件
const result = await onlyofficeEventbus.waitFor(
ONLYOFFICE_EVENT_KEYS.SAVE_DOCUMENT,
10000
);
return result;
}
// 设置只读模式
async setReadOnly(readOnly: boolean): Promise<void> {
// 实现逻辑...
}
}
事件驱动架构:EventBus解耦设计
项目采用事件总线机制,实现组件间的松耦合通信:
// src/onlyoffice-comp/lib/eventbus.ts
class EventBus {
private listeners: Map<EventKey, Array<(data: any) => void>> = new Map();
// 监听事件
on<K extends EventKey>(key: K, callback: (data: EventDataMap[K]) => void): void {
if (!this.listeners.has(key)) {
this.listeners.set(key, []);
}
this.listeners.get(key)!.push(callback);
}
// 等待事件触发(返回 Promise)
waitFor<K extends EventKey>(key: K, timeout?: number): Promise<EventDataMap[K]> {
return new Promise((resolve, reject) => {
const timeoutId = timeout
? setTimeout(() => {
this.off(key, handleEvent);
reject(new Error(`Event ${key} timeout after ${timeout}ms`));
}, timeout)
: null;
const handleEvent = (data: EventDataMap[K]) => {
if (timeoutId) clearTimeout(timeoutId);
this.off(key, handleEvent);
resolve(data);
};
this.on(key, handleEvent);
});
}
}
支持的事件类型
saveDocument- 文档保存完成事件documentReady- 文档加载就绪事件loadingChange- 加载状态变化事件
核心功能特性
1. 多实例支持
支持同时创建和管理多个独立的编辑器实例,每个实例都有独立的容器ID和资源管理:
import { createEditorView } from '@/onlyoffice-comp/lib/x2t';
import { editorManagerFactory } from '@/onlyoffice-comp/lib/editor-manager';
// 创建第一个编辑器实例
const manager1 = await createEditorView({
isNew: true,
fileName: 'Document1.docx',
containerId: 'editor-1', // 指定容器ID
});
// 创建第二个编辑器实例
const manager2 = await createEditorView({
isNew: true,
fileName: 'Document2.xlsx',
containerId: 'editor-2', // 不同的容器ID
});
// 分别操作不同实例
const result1 = await manager1.export();
const result2 = await manager2.export();
// 销毁指定实例
editorManagerFactory.destroy('editor-1');
// 销毁所有实例
editorManagerFactory.destroyAll();
关键特性:
- 容器隔离:每个实例使用唯一的容器ID,通过
data-onlyoffice-container-id属性精确定位 - 资源隔离:每个实例管理独立的媒体资源映射,图片上传不会相互干扰
- 独立事件处理:每个实例通过
createWriteFileHandler(manager)创建独立的图片上传处理函数
2. 国际化支持
项目内置多语言支持,可自由切换中英文界面。在多实例场景下,切换语言会重新创建所有编辑器实例:
// 切换语言(多实例场景)
const handleLanguageSwitch = async () => {
const newLang = currentLang === 'zh' ? 'en' : 'zh';
setCurrentLang(newLang);
// 保存每个编辑器实例的文档信息
const editorDocuments = {
manager1: { fileName: 'Doc1.docx', file: file1 },
manager2: { fileName: 'Doc2.xlsx', file: file2 },
};
// 重新创建所有编辑器以应用新语言
if (editorDocuments.manager1) {
await createEditorView({
fileName: editorDocuments.manager1.fileName,
file: editorDocuments.manager1.file,
containerId: 'editor-1',
lang: newLang,
});
}
if (editorDocuments.manager2) {
await createEditorView({
fileName: editorDocuments.manager2.fileName,
file: editorDocuments.manager2.file,
containerId: 'editor-2',
lang: newLang,
});
}
};
3. 导入导出功能
完整的文档导入导出能力:
// 导出文档
const result = await editorManager.export();
// result 包含: { fileName, fileType, binData, media }
// 转换并下载
const buffer = await convertBinToDocument(
result.binData,
result.fileName,
FILE_TYPE.XLSX,
result.media
);
const blob = new Blob([buffer.data], {
type: 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet'
});
// 执行下载操作
4. 只读/可编辑模式切换
灵活的权限控制,支持动态切换编辑模式:
// 设置为只读模式
await editorManager.setReadOnly(true);
// 切换为可编辑模式
await editorManager.setReadOnly(false);
// 查询当前模式
const isReadOnly = editorManager.getReadOnly();
实现原理:
- 从只读切换到可编辑:重新创建编辑器实例
- 从可编辑切换到只读:使用
processRightsChange命令
5. IndexedDB缓存优化
使用IndexedDB缓存WASM文件,大幅提升二次加载速度:
// 拦截 fetch,缓存 WASM 文件到 IndexedDB
private interceptFetch(): void {
const originalFetch = window.fetch;
window.fetch = async function(input: RequestInfo | URL): Promise<Response> {
// 先尝试从缓存读取
const cached = await this.getCachedWasm(url);
if (cached) {
return new Response(cached, {
headers: { 'Content-Type': 'application/wasm' }
});
}
// 缓存未命中,从网络加载并缓存
const response = await originalFetch(input);
const arrayBuffer = await response.arrayBuffer();
await this.cacheWasm(url, arrayBuffer);
return response;
};
}
使用示例
基本使用(单实例)
import { createEditorView } from '@/onlyoffice-comp/lib/x2t';
import { editorManagerFactory } from '@/onlyoffice-comp/lib/editor-manager';
// 创建编辑器视图(使用默认实例)
await createEditorView({
file: fileObject, // File 对象(可选)
fileName: 'document.xlsx', // 文件名
isNew: false, // 是否新建文档
readOnly: false, // 是否只读
lang: 'zh', // 界面语言
});
// 获取默认实例并导出文档
const defaultManager = editorManagerFactory.getDefault();
const result = await defaultManager.export();
console.log('导出成功:', result);
多实例使用
import { createEditorView } from '@/onlyoffice-comp/lib/x2t';
import { editorManagerFactory } from '@/onlyoffice-comp/lib/editor-manager';
// 创建多个编辑器实例
const manager1 = await createEditorView({
isNew: true,
fileName: 'Doc1.docx',
containerId: 'editor-1',
lang: 'zh',
});
const manager2 = await createEditorView({
isNew: true,
fileName: 'Doc2.xlsx',
containerId: 'editor-2',
lang: 'zh',
});
const manager3 = await createEditorView({
isNew: true,
fileName: 'Doc3.pptx',
containerId: 'editor-3',
lang: 'zh',
});
// 分别导出
const result1 = await manager1.export();
const result2 = await manager2.export();
const result3 = await manager3.export();
React组件集成(多实例)
// src/app/multi/page.tsx
function MultiInstancePageContent() {
const [managers, setManagers] = useState({
manager1: null,
manager2: null,
manager3: null,
});
// 保存文档信息,用于语言切换
const [editorDocuments, setEditorDocuments] = useState({
manager1: null,
manager2: null,
manager3: null,
});
// 创建编辑器
const handleView = async (editorKey: string, fileName: string, file?: File) => {
const containerId = `editor-${editorKey.replace('manager', '')}`;
const manager = await createEditorView({
file,
fileName,
isNew: !file,
containerId, // 指定容器ID
lang: getOnlyOfficeLang(),
});
setManagers(prev => ({
...prev,
[editorKey]: manager,
}));
// 保存文档信息
setEditorDocuments(prev => ({
...prev,
[editorKey]: { fileName, file: file || undefined },
}));
};
// 语言切换(重新创建所有编辑器)
const handleLanguageSwitch = async () => {
const newLang = currentLang === 'zh' ? 'en' : 'zh';
// 重新创建所有编辑器
if (editorDocuments.manager1) {
const doc = editorDocuments.manager1;
await handleView('manager1', doc.fileName, doc.file);
}
// ... 其他实例
};
return (
<div className="grid grid-cols-3 gap-4">
{/* 编辑器容器 - 使用 data-onlyoffice-container-id 属性 */}
<div className="onlyoffice-container" data-onlyoffice-container-id="editor-1">
<div id="editor-1" className="absolute inset-0" />
</div>
<div className="onlyoffice-container" data-onlyoffice-container-id="editor-2">
<div id="editor-2" className="absolute inset-0" />
</div>
<div className="onlyoffice-container" data-onlyoffice-container-id="editor-3">
<div id="editor-3" className="absolute inset-0" />
</div>
</div>
);
}
项目结构
mvp-onlyoffice/
├── src/
│ ├── app/ # Next.js 应用页面
│ │ ├── excel/ # Excel 编辑器页面
│ │ ├── docs/ # Word 编辑器页面
│ │ ├── ppt/ # PowerPoint 编辑器页面
│ │ └── multi/ # 多实例演示页面
│ ├── onlyoffice-comp/ # OnlyOffice 组件库
│ │ └── lib/
│ │ ├── editor-manager.ts # 编辑器管理器(支持多实例)
│ │ ├── x2t.ts # 文档转换模块
│ │ ├── eventbus.ts # 事件总线
│ │ └── utils.ts # 工具函数
│ └── components/ # 通用组件
├── public/ # 静态资源
│ ├── web-apps/ # OnlyOffice Web 应用资源
│ ├── sdkjs/ # OnlyOffice SDK 资源
│ └── wasm/ # WebAssembly 转换器
└── onlyoffice-x2t-wasm/ # x2t-wasm 源码
部署方案
Vercel一键部署
项目已配置静态导出,可直接部署到Vercel:
# 安装依赖
npm install
# 构建项目
npm run build
# Vercel 会自动检测并部署
🌐 在线演示: mvp-onlyoffice.vercel.app/
静态文件部署
项目支持静态导出,构建后的文件可部署到任何静态托管服务:
# 构建静态文件
npm run build
# 输出目录: out/
# 可直接部署到 GitHub Pages、Netlify、Nginx 等
技术优势总结
| 特性 | 传统方案 | 本方案 |
|---|---|---|
| 数据安全 | ❌ 需要上传服务器 | ✅ 完全本地处理 |
| 部署成本 | ❌ 需要后端服务 | ✅ 纯静态部署 |
| 格式支持 | ⚠️ 有限格式 | ✅ 30+种格式 |
| 离线使用 | ❌ 需要网络 | ✅ 完全离线 |
| 性能优化 | ⚠️ 依赖网络 | ✅ IndexedDB缓存 |
| 国际化 | ⚠️ 需额外配置 | ✅ 内置支持 |
| 权限控制 | ⚠️ 复杂实现 | ✅ 简单API |
| 多实例支持 | ❌ 不支持 | ✅ 原生支持,资源隔离 |
技术原理
使用x2t-wasm替代OnlyOffice服务
传统OnlyOffice集成需要:
- 搭建OnlyOffice Document Server
- 配置文档转换服务
- 处理文档上传下载
- 管理服务器资源
本方案通过WASM技术:
- 在浏览器中直接运行x2t转换引擎
- 使用虚拟文件系统处理文档
- 完全客户端化,无需服务器
多实例架构设计
- 工厂模式:使用
EditorManagerFactory统一管理多个编辑器实例 - 容器隔离:每个实例使用唯一的容器ID,通过
data-onlyoffice-container-id属性精确定位 - 资源隔离:每个实例管理独立的媒体资源映射,图片上传通过独立的
writeFile处理函数 - 事件隔离:虽然使用全局 EventBus,但每个实例的事件处理函数是独立的
参考项目
- Qihoo360/se-office - se-office扩展,提供基于开放标准的全功能办公生产力套件
- cryptpad/onlyoffice-x2t-wasm - CryptPad WebAssembly文件转换工具
- ranuts/document - 参考静态资源实现
开源地址
🔗 GitHub仓库: mvp-onlyoffice
总结
本项目提供了一个完整的纯前端OnlyOffice集成方案,通过WASM技术实现了文档格式转换的本地化,结合React和OnlyOffice SDK,打造了一个功能完善、性能优秀的文档编辑器。
核心亮点:
- 🚀 纯前端架构,无需后端服务
- 🔒 数据完全本地化,保护隐私安全
- ⚡ 基于WASM的高性能转换
- 🌏 内置国际化支持
- 📦 支持导入导出
- 🔐 灵活的权限控制
- 🎯 多实例支持:同时运行多个独立编辑器,资源完全隔离
欢迎Star和Fork,一起推动前端Office编辑技术的发展!
相关阅读:
来源:juejin.cn/post/7575425466904723519
90% 前端都不知道的 20 个「零依赖」浏览器原生能力!
分享 20 个 2025 年依旧「少人知道、却能立竿见影」的原生 API。
收藏 = 省下一个工具库 + 少写 100 行代码!
1. ResizeObserver
精准监听任意 DOM 宽高变化,图表自适应、虚拟滚动必备。
new ResizeObserver(([e]) => chart.resize(e.contentRect.width))
.observe(chartDom);
2. IntersectionObserver
检测元素进出视口,一次搞定懒加载 + 曝光埋点,性能零损耗。
new IntersectionObserver(entrieList =>
entrieList.forEach(e => e.isIntersecting && loadImg(e.target))
).observe(img);
3. Page Visibility
侦测标签页隐藏,自动暂停视频、停止轮询,移动端省电神器。
document.addEventListener('visibilitychange', () =>
document.hidden ? video.pause() : video.play()
);
4. Web Share
一键唤起系统分享面板,直达微信、微博、Telegram,需 HTTPS。
navigator.share?.({ title: '好文', url: location.href });
5. Wake Lock
锁定屏幕常亮,直播、PPT、阅读器不再自动息屏。
await navigator.wakeLock.request('screen');
6. Broadcast Channel
同域标签实时广播消息,登录态秒同步,告别 localStorage 轮询。
const bc = new BroadcastChannel('auth');
bc.onmessage = () => location.reload();
7. PerformanceObserver
无侵入采集 FCP、LCP、FID,一行代码完成前端性能监控。
new PerformanceObserver(list =>
list.getEntries().forEach(sendMetric)
).observe({ type: 'largest-contentful-paint', buffered: true });
8. requestIdleCallback
把埋点、日志丢进浏览器空闲时间,首帧零阻塞。
requestIdleCallback(() => sendBeacon('/log', data));
9. scheduler.postTask
原生优先级任务队列,低优任务后台跑,主线程丝滑。
scheduler.postTask(() => sendBeacon('/log', data), { priority: 'background' });
10. AbortController
随时取消 fetch,路由切换不再旧请求竞态,兼容 100%。
const ac = new AbortController();
fetch(url, { signal: ac.signal });
ac.abort();
11. ReadableStream
分段读取响应流,边下载边渲染,大文件内存零爆涨。
const reader = response.body.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
appendChunk(value);
}
12. WritableStream
逐块写入磁盘或网络,实时保存草稿、上传大文件更稳。
const writer = stream.writable.getWriter();
await writer.write(chunk);
13. Background Fetch
PWA 后台静默下载,断网恢复继续,课程视频提前缓存。
await registration.backgroundFetch.fetch('video', ['/course.mp4']);
14. File System Access
读写本地真实文件,需用户授权,Web IDE 即开即用。
const [fh] = await showOpenFilePicker();
editor.value = await (await fh.getFile()).text();
15. Clipboard
异步读写剪贴板,无需第三方库,HTTPS 环境安全复制。
await navigator.clipboard.writeText('邀请码 9527');
16. URLSearchParams
解析、修改、构造 URL 查询串,告别手写正则。
const p = new URLSearchParams(location.search);
p.set('page', 2);
history.replaceState({}, '', `?${p}`);
17. structuredClone
深拷贝对象、数组、Map、Date,循环引用也能完美复制。
const copy = structuredClone(state);
18. Intl.NumberFormat
千分位、货币、百分比一次格式化,国际化零配置。
new Intl.NumberFormat('zh-CN', { style: 'currency', currency: 'CNY' })
.format(1234567); // ¥1,234,567.00
19. EyeDropper
浏览器级吸管工具,像素级取色,设计系统直接调用。
const { sRGBHex } = await new EyeDropper().open();
20. WebCodecs
原生硬解码音视频,4K 60 帧流畅播放,CPU 占用直降。
const decoder = new VideoDecoder({
output: frame => ctx.drawImage(frame, 0, 0),
error: console.error
});
decoder.configure({ codec: 'vp09.00.10.08' });
来源:juejin.cn/post/7545294766975615015
写给小公司前端的 UI 规范
写给小公司前端的 UI 规范
大部分小公司前端开发是不是都会有个困扰,一天到晚做的都是后台管理系统,而且百分之 80 都是表格的增删改查,导致领导觉得前端简单的很,所以连个 UI 都没有,但是每次写完页面又被老大吐槽没有审美,而且如果整个系统多个人开发,每个的风格都不一样,导致整个系统看起来很乱,想要统一又不知道从何入手,所以今天我给大家分享一下我们团队的针对后台管理系统的 UI 规范,希望对大家有帮助。
叠个甲:这个只是我们遵循的规范,因为交互和设计这种东西每个人的感受不一样,你觉得你这个规范我觉得不合理,没关系,你可以按照自己的想法来也可以,只要遵循一个原则,那就是整个系统风格保持一致性即可,所以这个规范仅供参考。
大家都知道后台管理主要就是几部分:表格、表单、弹窗,所以我们的 UI 规范也是围绕这三部分来的。
表格
自适应形式
- 最小页面宽度+自适应的综合运用,最小自适应页面宽度 1366px(小于此宽度则不再自适应,超出页面的内容使用滚动条查看),单元格字段过长一行展示不下时,不换行并出现省略号,鼠标移入,提示框显示完整字段。
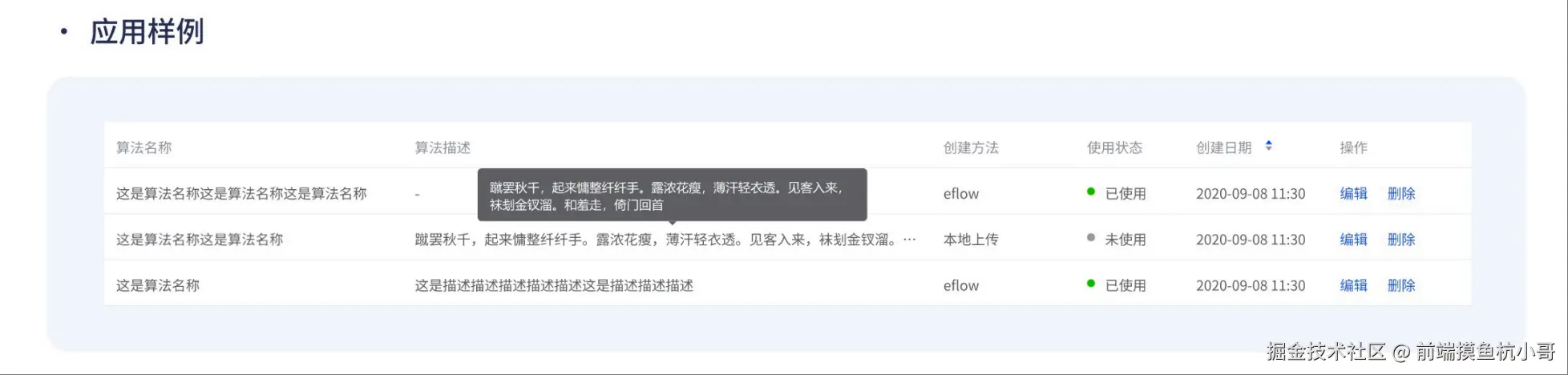
表格内行高
| 场景 | 字号 | 行高 | 适用情况 |
|---|---|---|---|
| 紧凑模式 | 12px | 42px | 数据量大的表格 |
| 标准模式 | 14px | 48px | 默认推荐 |
| 大字号模式 | 16px | 56px | 无障碍/老年版 |
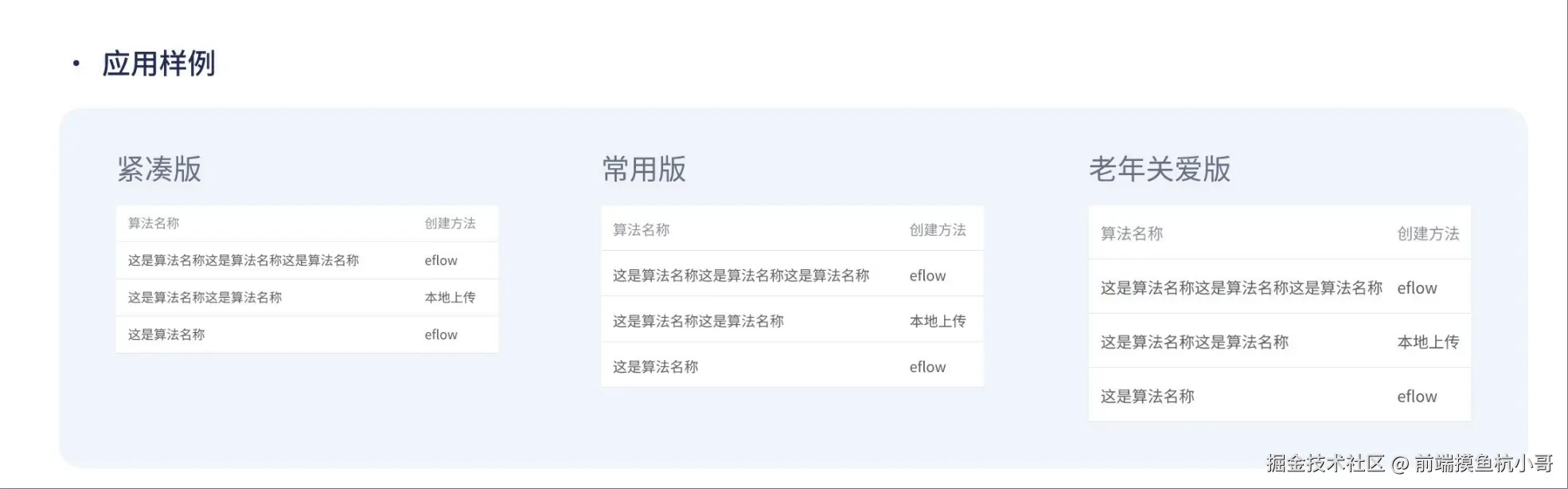
表格内对齐方式
- 表头和文字内容:采用左对齐
- 表头和普通数字:采用左对齐
- 表头和具有比较场景的数字: 采用右对齐
- 表头和操作项: 采用左对齐
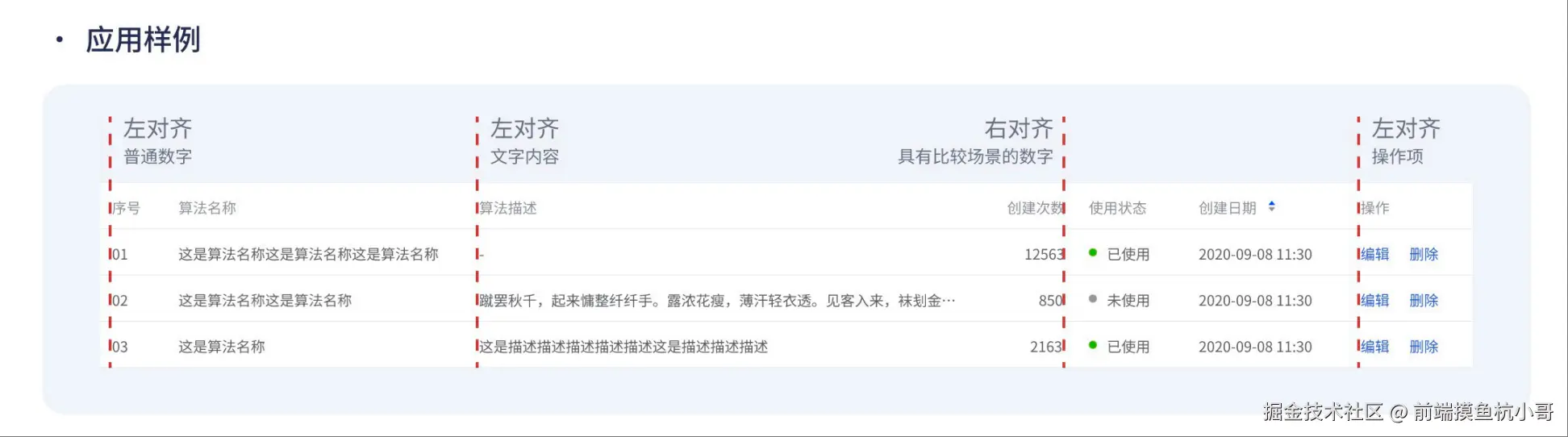
分页器
分页器元素:
- 数据总量、单页面展示数量、翻页部分
对齐方式:
- 数据总量左对齐,单页面展示数量&翻页部分右对齐(依次顺序为数据总量、单页面展示数量、翻页部分)
分页器位置:
- 表格为页面全部内容时,表格超出一页分页器固定及底,表格未超出一页分页器跟随表格下方
- 表格仅为页面部分内容时,分页器跟随表格下方

表格操作区
按钮类型:
- 新增数据类按钮 &面向已有数据类的操作按钮(包含可合并类操作按钮)。
对齐方式:
- 操作区居右,主按钮居右。
视觉样式:
- 新增数据类按钮样式-【文字+主色底】或【文字+图标+主色底文字+中性色线框】
- 面向已有数据类的操作按钮样式-【文字+主色底】或【文字+图标+主色底文字+中性色线框】
按钮个数:
- 小于等于 4 个全部展示
- 大于四个时候,最后一个按钮为【更多】按钮,点击【更多】按钮后,下拉展示全部按钮

表格筛选区域
- 一行最多四个筛选条件,不超过四个的时候查询按钮和重置按钮跟在筛选项后
- 超过四个筛选条件时,出现【展示更多】按钮,点击【展示更多】按钮后,下拉展示全部筛选条件,【展示更多】变成【收起更多】按钮
- 如果是时间范围 比如开始时间和结束时间 他独占两个筛选项
- 默认 label 最多四个字 建议两个字或者四个字
- 筛选项的宽度建议 200px
表格滑块
表格为页面全部内容时:
- 内容无超出:滚动不出现
- 横向内容有超出:表格内横向滚动条,且默认固定操作和标题列
- 纵向内容有超出:页面滚动条,表头到达页面顶部,吸顶固定
表格仅为页面部分内容时:
- 表格区最大高度为 10 行数据+分页器,当 10 行数据+分内器超出页面容器时,表格区最大高度将限制为页面容器的 90%
- 内容无超出:滚动不出现
- 横向内容有超出:表格内横向滚动条,且默认固定操作项和标题列
- 纵向内容有超出:表格内滚动条,固定表头&分页器
表单
表单项 Label 与控件的对齐方式&必填标识
- 表单项 Label 和控件对齐方式
- 当表单项 Label 过长(6 个中文字符以上),采用顶对齐方式布局。当表单项 Label 在 6 个中文字符以内,使用右对齐方式布局。
对齐布局; - 当表单项在 15 个以下时,采用单列布局方式,当表单项在 15 个以上时,采用多列顶对齐方式布局。
- 表单项 Label 和必填标识对齐方式
- 表单项 Label 右对齐布局时,必填示识放在标题前;
- 表单项 Label 顶对齐布局时,必填示识放在标题后;

提交/取消操作按钮位置&对齐方式
操作按钮统一采用左对齐的方式,表单域未超出一屏时跟在表单项下方,若超出一屏则固定吸底。
表单页自适应方式&lnput 框长度
- 当只有单列时,表单域左对齐且定宽 、输入框&选择框长度为 480px、文本框长度为 640px,支持表单项 Label 顶对齐和右对齐。
- 当出现双列时,表单域左对齐,表单域宽度为页面容器宽度的 80%,自适应布局,仅支持表单项 Label 顶对齐。
- 当出现三列时,表单域占满整个页面容器,自适应布局,仅支持表单项 Label 顶对齐。
弹窗
弹窗尺寸:
- 在未达到弹窗最大尺寸(弹窗最大宽高<页面宽高的 80%)时,弾窗尺寸由内容决定,弹窗内容距离弹窗边距 20px。
- 滚动条出现在弹窗上,不要出现在整个页面上
弹窗位置:
- 页面居中。
操作按钮位置:
- 固定在弹窗底部,整体居左,主按钮在左侧。
总 结
我之前也在小公司待过,能充分了解小公司的现状,别说 UI 了,有的直接是连前端都不要,管你什么 UI,时间长了就麻木了,想进步却找不到方向,所以希望这个规范能帮助到你,让你在 UI 规范方面有所提升。
因为只是我们总结的一套规范,其实还有很多不足,你完全可以在这个基础上,根据自己的需求,进行修改和优化,比如你觉得表格删除按钮必须是红色,弹窗的按钮放在右下角更合理,不喜欢筛选项有什么展开收缩等等这些你都可以根据自己的需求进行修改,还是那句话,整个系统风格保持统一。
如果大家有自己团队的规范,也可以评论区发出来共享一下大家相互学习一下。

来源:juejin.cn/post/7521013717439315994
图片标签用 img 还是 picture?很多人彻底弄混了!
在网页开发中,图片处理是每个前端开发者都会遇到的基础任务。面对 <img> 和 <picture> 这两个标签,很多人存在误解:要么认为它们是互相替代的关系,要么在不合适的场景下使用了复杂的解决方案。今天,我们来彻底理清这两个标签的真正用途。
<img> 标签
<img> 是 HTML 中最基础且强大的图片标签,但它远比很多人想象的要智能。
基本语法:
<img src="image.jpg" alt="图片描述">
核心属性:
src:图片路径(必需)alt:替代文本(无障碍必需)srcset:提供多分辨率图片源sizes:定义图片显示尺寸loading:懒加载控制
<img> 的响应式能力被低估了
很多人认为 <img> 不具备响应式能力,这是错误的认知:
<img
src="image-800w.jpg"
srcset="image-320w.jpg 320w,
image-480w.jpg 480w,
image-800w.jpg 800w"
sizes="(max-width: 600px) 100vw,
(max-width: 1200px) 50vw,
33vw"
alt="响应式图片示例"
>
这种写法的优势:
- 浏览器自动选择最适合当前屏幕分辨率的图片
- 根据视口大小动态调整加载的图片尺寸
- 代码简洁,性能优秀
<picture> 标签
<picture> 不是为了替代 <img>,而是为了解决 <img> 无法处理的特定场景。
<picture> 解决的三大核心问题
1. 艺术指导(Art Direction)
在不同设备上显示不同构图或裁剪的图片:
<picture>
<!-- 桌面端:宽屏全景 -->
<source media="(min-width: 1200px)" srcset="hero-desktop.jpg">
<!-- 平板端:适中裁剪 -->
<source media="(min-width: 768px)" srcset="hero-tablet.jpg">
<!-- 移动端:竖版特写 -->
<img src="hero-mobile.jpg" alt="产品展示">
</picture>
2. 现代格式降级
优先使用高效格式,同时兼容老旧浏览器:
<picture>
<source type="image/avif" srcset="image.avif">
<source type="image/webp" srcset="image.webp">
<img src="image.jpg" alt="格式优化示例">
</picture>
3. 复杂条件组合
同时考虑屏幕尺寸和图片格式:
<picture>
<!-- 大屏 + AVIF -->
<source media="(min-width: 1200px)" type="image/avif" srcset="large.avif">
<!-- 大屏 + WebP -->
<source media="(min-width: 1200px)" type="image/webp" srcset="large.webp">
<!-- 大屏降级 -->
<source media="(min-width: 1200px)" srcset="large.jpg">
<!-- 移动端方案 -->
<img src="small.jpg" alt="复杂条件图片">
</picture>
关键区别与选择指南
| 场景 | 推荐方案 | 原因 |
|---|---|---|
| 同一图片,不同分辨率 | <img> + srcset + sizes | 代码简洁,浏览器自动优化 |
| 不同构图或裁剪 | <picture> | 艺术指导必需 |
| 现代格式兼容 | <picture> | 格式降级必需 |
| 简单静态图片 | <img> | 无需复杂功能 |
| 兼容老旧浏览器 | <img> | 最广泛支持 |
常见误区纠正
误区一:<picture> 用于响应式图片
- 事实:
<img>配合srcset和sizes已经能处理大多数响应式需求 - 真相:
<picture>主要用于艺术指导和格式降级
误区二:<picture> 更现代,应该优先使用
- 事实: 在不需要艺术指导或格式降级的场景下,
<img>是更好的选择 - 真相: 合适的工具用在合适的场景才是最佳实践
误区三:响应式图片一定要用 <picture>
- 事实: 很多响应式场景用
<img>+srcset更合适 - 真相: 评估需求,选择最简单的解决方案
场景分析
应该使用 <img> 的场景
网站Logo:
<img src="logo.svg" alt="公司Logo" width="120" height="60">
用户头像:
<img
src="avatar.jpg"
srcset="avatar.jpg 1x, avatar@2x.jpg 2x"
alt="用户头像"
width="80"
height="80"
>
文章配图:
<img
src="article-image.jpg"
srcset="article-image-600w.jpg 600w,
article-image-1200w.jpg 1200w"
sizes="(max-width: 768px) 100vw, 600px"
alt="文章插图"
loading="lazy"
>
应该使用 <picture> 的场景
英雄横幅(不同裁剪):
<picture>
<source media="(min-width: 1024px)" srcset="hero-wide.jpg">
<source media="(min-width: 768px)" srcset="hero-square.jpg">
<img src="hero-mobile.jpg" alt="产品横幅" loading="eager">
</picture>
产品展示(格式优化):
<picture>
<source type="image/avif" srcset="product.avif">
<source type="image/webp" srcset="product.webp">
<img src="product.jpg" alt="产品详情" loading="lazy">
</picture>
最佳实践
1. 始终遵循的规则
<!-- 正确:始终提供 alt 属性 -->
<img src="photo.jpg" alt="描述文本">
<!-- 错误:缺少 alt 属性 -->
<img src="photo.jpg">
<!-- 装饰性图片使用空 alt -->
<img src="decoration.jpg" alt="">
2. 性能优化策略
<!-- 优先加载关键图片 -->
<img src="hero.jpg" alt="重要图片" loading="eager" fetchpriority="high">
<!-- 非关键图片延迟加载 -->
<img src="content-image.jpg" alt="内容图片" loading="lazy">
<!-- 指定尺寸避免布局偏移 -->
<img src="product.jpg" alt="商品" width="400" height="300">
3. 现代图片格式策略
<picture>
<!-- 优先使用AVIF,压缩率最高 -->
<source type="image/avif" srcset="image.avif">
<!-- 其次WebP,广泛支持 -->
<source type="image/webp" srcset="image.webp">
<!-- 最终回退到JPEG -->
<img src="image.jpg" alt="现代格式示例">
</picture>
总结
<img> 和 <picture> 不是竞争关系,而是互补的工具:
<img>:处理大多数日常图片需求,特别是分辨率适配<picture>:解决特定复杂场景,如艺术指导和格式降级
核心建议:
- 从最简单的
<img>开始,只在必要时升级到<picture> - 充分利用
<img>的srcset和sizes属性 - 为关键图片使用
<picture>进行格式优化 - 始终考虑性能和用户体验
掌握这两个标签的正确用法,你就能在各种场景下都做出最合适的技术选择,既保证用户体验,又避免过度工程化。
希望这篇指南能帮助你彻底理解这两个重要的HTML标签!
本文首发于公众号:程序员刘大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
📌往期精彩
《SpringBoot+Vue3 整合 SSE 实现实时消息推送》
《SpringBoot 动态菜单权限系统设计的企业级解决方案》
来源:juejin.cn/post/7577298871005036578
javascript新进展你关注了吗:TC39 东京会议带来五大新特性
上周,JavaScript 语言的掌舵者们齐聚东京。在 Sony Interactive Entertainment 的主持下,Ecma 国际 TC39 委员会召开了第 104 次全体会议,一系列围绕 迭代器(Iterator) 和 Promise 的提案取得了重要进展。这些新特性将让 JavaScript 开发者写出更简洁、更函数式的代码。
让我们一起来看看这些即将改变你编码方式的新特性。
科普:TC39 与提案流程
在深入了解新特性之前,我们先来快速了解一下它们背后的组织和流程。
TC39 是什么?
TC39 (Technical Committee 39) 是 Ecma International 旗下的技术委员会,专门负责 ECMAScript 标准(即 JavaScript 的规范)的制定和维护。其成员由主流浏览器厂商(如 Google, Mozilla, Apple, Microsoft)以及其他对 Web 技术有影响力的科技公司和专家组成。
提案如何成为标准?
一个新特性从提出到最终进入标准,通常需要经历 5 个阶段(The TC39 Process):
- Stage 0 (Strawman - 稻草人): 任何想法或建议,用于开启讨论。
- Stage 1 (Proposal - 提案): 确定问题和解决方案,展示潜在的 API 形式。
- Stage 2 (Draft - 草稿): 具体的语法和语义描述,此时特性已基本定型。
- Stage 3 (Candidate - 候选): 规范文本已完成,需要浏览器厂商的实现反馈和用户测试。
- Stage 4 (Finished - 完成): 至少有两个独立的浏览器实现并通过了测试,准备纳入下一版 ECMAScript 标准。
大概需要多久?
这个过程没有固定的时间表,取决于提案的复杂度和争议程度:
- 简单特性:可能在 1-2 年内走完流程。
- 复杂特性:可能需要在 Stage 2 或 Stage 3 停留数年(例如 Temporal 提案)。
通常来说,一旦提案进入 Stage 3,就意味着它极有可能在不久的将来成为标准的一部分,各大浏览器也会开始逐步支持。
1. Iterator Sequencing(迭代器序列化)— Stage 3
提案地址: proposal-iterator-sequencing
解决什么问题?
你是否曾经需要把多个迭代器"串联"起来,当作一个来用?在以前,你得用生成器函数配合 yield* 来实现:
let lows = Iterator.from([0, 1, 2, 3]);
let highs = Iterator.from([6, 7, 8, 9]);
// 以前的写法,略显繁琐
let combined = function* () {
yield* lows;
yield* highs;
}();
Array.from(combined); // [0, 1, 2, 3, 6, 7, 8, 9]
新写法
现在只需一行:
let combined = Iterator.concat(lows, highs);
Array.from(combined); // [0, 1, 2, 3, 6, 7, 8, 9]
// 还可以在中间插入其他值
let digits = Iterator.concat(lows, [4, 5], highs);
Array.from(digits); // [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Iterator.concat() 接受多个可迭代对象,惰性地按顺序产出所有值。这不仅代码更简洁,而且因为是惰性求值,处理大数据集时内存效率也更高。
2. Await Dictionary of Promises(Promise 字典等待)— Stage 1
提案地址: proposal-await-dictionary
解决什么问题?
当你需要并发等待多个 Promise 时,Promise.all 返回的是数组,你得靠下标来取值:
const [shape, color, mass] = await Promise.all([
getShape(),
getColor(),
getMass(),
]);
// 顺序错了?很容易出 bug
新写法
使用 Promise.allKeyed(),用对象的键来命名你的结果:
const { shape, color, mass } = await Promise.allKeyed({
shape: getShape(),
color: getColor(),
mass: getMass(),
});
// 再也不用担心顺序问题了!
该提案还支持 Promise.allSettledKeyed(),用于处理可能失败的场景:
const results = await Promise.allSettledKeyed({
shape: getShape(),
color: getColor(),
mass: getMass(),
});
if (results.shape.status === "fulfilled") {
console.log(results.shape.value);
} else {
console.error(results.shape.reason);
}
这个 API 设计有意与 Iterator.zipKeyed() 保持一致,体现了 TC39 在语言设计上的系统性思考。
3. Joint Iteration(联合迭代)— Stage 2.7
提案地址: proposal-joint-iteration
解决什么问题?
Python 开发者对 zip() 函数再熟悉不过了——它能把多个序列"拉链式"地组合在一起。JavaScript 一直缺少这个功能。
新写法
Iterator.zip() 和 Iterator.zipKeyed() 填补了这个空白:
// 位置对应的组合
Array.from(Iterator.zip([
[0, 1, 2],
[3, 4, 5],
]))
// 结果: [[0, 3], [1, 4], [2, 5]]
// 用键名组合
Iterator.zipKeyed({
a: [0, 1, 2],
b: [3, 4, 5, 6],
c: [7, 8, 9],
}).toArray()
// 结果: [
// { a: 0, b: 3, c: 7 },
// { a: 1, b: 4, c: 8 },
// { a: 2, b: 5, c: 9 }
// ]
还支持三种模式来处理长度不等的迭代器:
mode: 'shortest'(默认):最短的迭代器耗尽时停止mode: 'longest':最长的迭代器耗尽时停止,可以指定填充值mode: 'strict':如果长度不等则抛出错误
Iterator.zipKeyed({
a: [0, 1, 2],
b: [3, 4, 5, 6],
c: [7, 8, 9],
}, {
mode: 'longest',
padding: { c: 10 },
}).toArray()
// 结果包含: { a: undefined, b: 6, c: 10 }
4. Iterator Join(迭代器连接)— 新提案
提案地址: proposal-iterator-join
解决什么问题?
Array.prototype.join() 能把数组元素用分隔符连接成字符串。但如果你有一个迭代器呢?现在你得先转成数组:
myIterator.toArray().join(', ') // 先全部加载到内存
新写法
Iterator.prototype.join() 让你直接在迭代器上操作:
Iterator.from(['a', 'b', 'c']).join(', ')
// 结果: "a, b, c"
这对于处理大型或无限序列(只取部分)时特别有用,避免了不必要的内存分配。
5. Typed Array Find Within(类型数组范围查找)
解决什么问题?
现有的 TypedArray.prototype.indexOf() 只能从数组开头或指定位置向后搜索。当你需要在特定范围内查找时,现有 API 不够灵活。
新能力
这个提案为 TypedArray 添加了在指定范围内进行查找的能力,让二进制数据处理更加高效。这对于处理音视频数据、WebGL 缓冲区、以及其他需要精确控制搜索范围的场景非常有用。
迭代器生态的完善
如果你一直关注 TC39 的动态,你会发现这次会议推进的提案有一个共同主题:完善 JavaScript 的迭代器生态。
| 提案 | 功能 | 状态 |
|---|---|---|
| Iterator Helpers | map, filter, take, drop 等 | ✅ Stage 4(已标准化) |
| Iterator Sequencing | concat | Stage 3 |
| Joint Iteration | zip, zipKeyed | Stage 2.7 |
| Iterator Join | join | 新提案 |
| Await Dictionary | Promise.allKeyed | Stage 1 |
参考链接:
来源:juejin.cn/post/7577612585845194761
弃用 html2canvas!快 93 倍的截图神器
在前端开发中,网页截图是个常用功能。从前,html2canvas 是大家的常客,但随着网页越来越复杂,它的性能问题也逐渐暴露,速度慢、占资源,用户体验不尽如人意。
好在,现在有了 SnapDOM,一款性能超棒、还原度超高的截图新秀,能完美替代 html2canvas,让截图不再是麻烦事。

什么是 SnapDOM
SnapDOM 就是一个专门用来给网页元素截图的工具。

它能把 HTML 元素快速又准确地存成各种图片格式,像 SVG、PNG、JPG、WebP 等等,还支持导出为 Canvas 元素。
它最厉害的地方在于,能把网页上的各种复杂元素,比如 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,甚至是动态效果的当前状态,都原原本本地截下来,跟直接看网页没啥两样。
SnapDOM 优势
快得飞起
测试数据显示,在不同场景下,SnapDOM 都把 html2canvas 和 dom-to-image 这俩老前辈远远甩在身后。

尤其在超大元素(4000×2000)截图时,速度是 html2canvas 的 93.31 倍,比 dom-to-image 快了 133.12 倍。这速度,简直就像坐火箭。
还原度超高
SnapDOM 截图出来的效果,跟在网页上看到的一模一样。
各种复杂的 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,还有动态效果的当前状态,都能精准还原。

无论是简单的元素,还是复杂的网页布局,它都能轻松拿捏。
格式任你选
不管你是想要矢量图 SVG,还是常用的 PNG、JPG,或者现代化的 WebP,又或者是需要进一步处理的 Canvas 元素,SnapDOM 都能满足你。

多种格式,任你挑选,适配各种需求。
三、怎么用 SnapDOM
安装
SnapDOM 的安装超简单,有好几种方式:
用 NPM 或 Yarn:在命令行里输
# npm
npm i @zumer/snapdom
# yarn
yarn add @zumer/snapdom
就能装好。
用 CDN 在 HTML 文件里加一行:
<script src="https://unpkg.com/@zumer/snapdom@latest/dist/snapdom.min.js"></script>
直接就能用。
要是项目里用的是 ES Module:
import { snapdom } from '@zumer/snapdom
基础用法示例
一键截图
const card = document.querySelector('.user-card');
const image = await snapdom.toPng(card);
document.body.appendChild(image);
这段代码就是找个元素,然后直接截成 PNG 图片,再把图片加到页面上。简单粗暴,一步到位。
高级配置
const element = document.querySelector('.chart-container');
const capture = await snapdom(element, {
scale: 2,
backgroundColor: '#fff',
embedFonts: true,
compress: true
});
const png = await capture.toPng();
const jpg = await capture.toJpg({ quality: 0.9 });
await capture.download({
format: 'png',
filename: 'chart-report-2024'
});
这儿可以对截图进行各种配置。比如 scale 能调整清晰度,backgroundColor 能设置背景色,embedFonts 可以内嵌字体,compress 能压缩优化。配置好后,还能把截图存成不同格式,或者直接下载到本地。
和其他库比咋样
和 html2canvas、dom-to-image 比起来,SnapDOM 的优势很明显:
| 特性 | SnapDOM | html2canvas | dom-to-image |
|---|---|---|---|
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 准确度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 文件大小 | 极小 | 较大 | 中等 |
| 依赖 | 无 | 无 | 无 |
| SVG 支持 | ✅ | ❌ | ✅ |
| Shadow DOM 支持 | ✅ | ❌ | ❌ |
| 维护状态 | 活跃 | 活跃 | 停滞 |
五、用的时候注意点
用 SnapDOM 时,有几点得注意:
跨域资源
要是截图里有外部图片等跨域资源,得确保这些资源支持 CORS,不然截不出来。
iframe 限制
SnapDOM 不能截 iframe 内容,这是浏览器的安全限制,没办法。
Safari 浏览器兼容性
在 Safari 里用 WebP 格式时,会自动变成 PNG。
大型页面截图
截超大页面时,建议分块截,不然可能会内存溢出。
六、SnapDOM 能干啥及代码示例
社交分享
async function shareAchievement() {
const card = document.querySelector('.achievement-card');
const image = await snapdom.toPng(card, { scale: 2 });
navigator.share({
files: [new File([await snapdom.toBlob(card)], 'achievement.png')],
title: '我获得了新成就!'
});
}
报表导出
async function exportReport() {
const reportSection = document.querySelector('.report-section');
await preCache(reportSection);
await snapdom.download(reportSection, {
format: 'png',
scale: 2,
filename: `report-${new Date().toISOString().split('T')[0]}`
});
}
海报导出
async function generatePoster(productData) {
document.querySelector('.poster-title').textContent = productData.name;
document.querySelector('.poster-price').textContent = `¥${productData.price}`;
document.querySelector('.poster-image').src = productData.image;
await new Promise((resolve) => setTimeout(resolve, 100));
const poster = document.querySelector('.poster-container');
const blob = await snapdom.toBlob(poster, { scale: 3 });
return blob;
}
写在最后
SnapDOM 就是这么一款简单、快速、准确,还零依赖的网页截图神器。
无论是社交分享、报表导出、设计保存,还是营销推广,它都能轻松搞定。
而且它是免费开源的,背后还有活跃的社区支持。要是你还在为网页截图的事儿发愁,赶紧试试 SnapDOM 吧。
要是你在用 SnapDOM 的过程中有啥疑问,或者碰上啥问题,可以去下面这些地方找答案:
- 项目地址 :github.com/zumerlab/sn…
- 在线演示 :zumerlab.github.io/snapdom/
- 详细文档 :github.com/zumerlab/sn…
来源:juejin.cn/post/7544287909475090451
弃用 uni-app!Vue3 的原生 App 开发框架来了!
长久以来,"用 Vue 3 写真正的原生 App" 一直是块短板。
uni-app 虽然"一套代码多端运行",但性能瓶颈、厂商锁仓、原生能力羸弱的问题常被开发者诟病。
整个 Vue 生态始终缺少一个能与 React Native 并肩的"真·原生"跨平台方案
直到 NativeScript-Vue 3 的横空出世,并被 尤雨溪 亲自点赞。
为什么是时候说 goodbye 了?
| uni-app 现状 | 开发者痛点 |
|---|---|
| 渲染层基于 WebView 或弱原生混合 | 启动慢、掉帧、长列表卡顿 |
自定义原生 SDK 需写大量 renderjs / plus 桥接 | 维护成本高,升级易断裂 |
| 锁定 DCloud 生态 | 工程化、Vite、Pinia 等新工具跟进慢 |
| Vue 3 支持姗姗来迟,Composition API 兼容碎裂 | 类型推断、生态插件处处踩坑 |
"我们只是想要一个 Vue 语法 + 真原生渲染 + 社区插件开箱即用 的解决方案。"
—— 这,正是 NativeScript-Vue 给出的答案。
尤雨溪推特背书
2025-10-08,Evan You 转发 NativeScript 官方推文:
"Try Vite + NativeScript-Vue today —
HMR,native APIs,live reload."

配图是一段 <script setup> + TypeScript 的实战 Demo,意味着:
- 真正的 Vue 3 语法(
Composition API) - Vite 秒级热重载
- 直接调用 iOS / Android 原生 API
获创始人的公开推荐,无疑给社区打了一剂强心针。
NativeScript-Vue 是什么?
一句话:Vue 的自定义渲染器 + NativeScript 原生引擎
- 运行时 没有 WebView,JS 在
V8 / JavaScriptCore中执行 <template>标签 → 原生UILabel/android.widget.TextView- 支持 NPM、CocoaPods、Maven/Gradle 全部原生依赖
- 与 React Native 同级别的性能,却拥有 Vue 完整开发体验
5 分钟极速上手
1. 环境配置(一次过)
# Node ≥ 18
npm i -g nativescript
ns doctor # 按提示安装 JDK / Android Studio / Xcode
# 全部绿灯即可
2. 创建项目
ns create myApp \
--template @nativescript-vue/template-blank-vue3@latest
cd myApp
模板已集成 Vite + Vue3 + TS + ESLint
3. 运行 & 调试
# 真机 / 模拟器随你选
ns run ios
ns run android
保存文件 → 毫秒级 HMR,console.log 直接输出到终端。
4. 目录速览
myApp/
├─ app/
│ ├─ components/ // 单文件 .vue
│ ├─ app.ts // createApp()
│ └─ stores/ // Pinia 状态库
├─ App_Resources/
└─ vite.config.ts // 已配置 nativescript-vue-vite-plugin
5. 打包上线
ns build android --release # 生成 .aab / .apk
ns build ios --release # 生成 .ipa
签名、渠道、自动版本号——标准原生流程,CI 友好。
Vue 3 生态插件兼容性一览
| 插件 | 是否可用 | 说明 |
|---|---|---|
| Pinia | ✅ | 零改动,app.use(createPinia()) |
| VueUse | ⚠️ | 仅无 DOM 的 Utilities 可用 |
| vue-i18n 9.x | ✅ | 实测正常 |
| Vue Router | ❌ | 官方推荐用 NativeScript 帧导航 → $navigateTo(Page) |
| Vuetify / Element Plus | ❌ | 依赖 CSS & DOM,无法渲染 |
检测小技巧:
npm i xxx
grep -r "document\|window\|HTMLElement" node_modules/xxx || echo "大概率安全"
调试神器:Vue DevTools 支持
NativeScript-Vue 3 已提供 官方 DevTools 插件
组件树、Props、Events、Pinia状态 实时查看- 沿用桌面端调试习惯,无需额外学习成本
👉 配置指南:https://nativescript-vue.org/docs/essentials/vue-devtools
插件生态 & 原生能力
- 700+
NativeScript官方插件
ns plugin add @nativescript/camera | bluetooth | sqlite... - iOS/Android SDK 直接引入
CocoaPods/Maven一行配置即可:
// 调用原生 CoreBluetooth
import { CBCentralManager } from '@nativescript/core'
- 自定义 View & 动画
注册即可在<template>使用,与 React Native 造组件体验一致。
结语:这一次,Vue 开发者不再低人一等
React Native 有 Facebook 撑腰,Flutter 有 Google 背书,
现在 Vue 3 也有了自己的 真·原生跨平台答案 —— NativeScript-Vue。
它让 Vue 语法第一次 完整、无损、高性能 地跑在 iOS & Android 上,
并获得 尤雨溪 公开点赞与 Vite 官方生态加持。
弃用 uni-app,拥抱 NativeScript-Vue,
让 性能、原生能力、工程化 三者兼得,
用你最爱的 .vue 文件,写最硬核的移动应用!
🔖 一键直达资源
来源:juejin.cn/post/7560510073950011435
前端实时推送(券商行业必看) & WebSocket 原理解析
一、历史背景 + 时间轴
网页一旦需要 “实时” ,麻烦就开始了:数据在不断变化,用户却只能等下一次刷新;
- 刷新解决不了的延迟,用短轮询凑数,又被无数空请求反噬;
- 再加长轮询,试图把“有了新数据再说”变成一种伪推送,却仍困在请求—响应的笼子里。
- 开发者于是继续前探:让连接不再频繁重建,尝试分块直输,把事件像水一样持续送达,于是有了更顺滑的 Streaming 与标准化的 SSE。
直到某一刻,我们不再满足于“更聪明的单向”,而是迈向真正的“同时说话与倾听”——WebSocket 把通信从一次次请求,变成一条持久而通透的通道。此后,
- HTTP/2、HTTP/3 与 QUIC 又在底层为效率和时延开了绿灯,甚至提供了可选可靠与无序传输的更多可能。
接下来,我们就沿着这条主线,层层展开:它们各自解决了什么、在哪些场景最合拍、又如何在你的系统里形成清晰的选型边界。
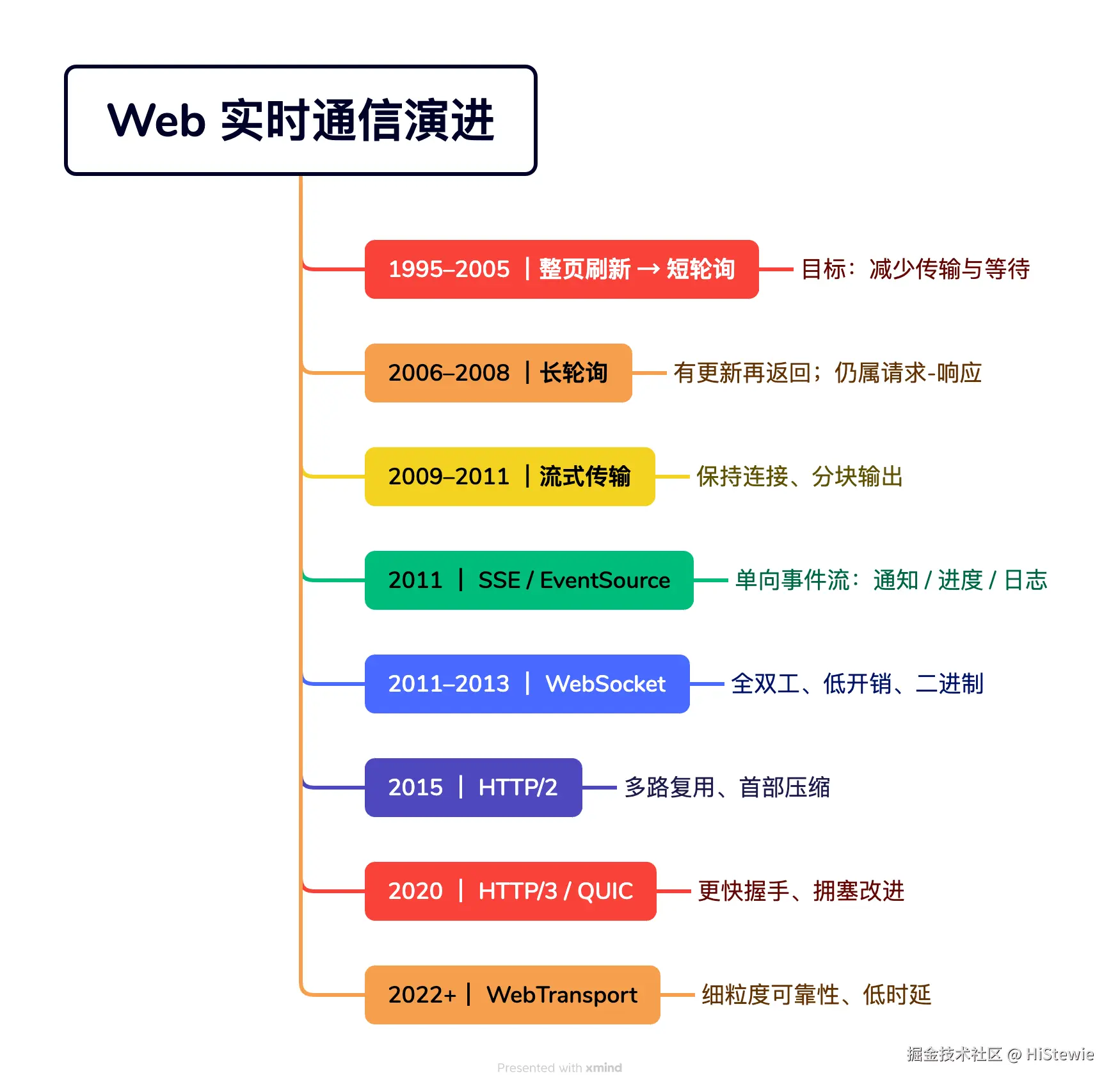
网页一旦需要 “实时” ,麻烦就开始了:数据在不断变化,用户却只能等下一次刷新;
- 刷新解决不了的延迟,用短轮询凑数,又被无数空请求反噬;
- 再加长轮询,试图把“有了新数据再说”变成一种伪推送,却仍困在请求—响应的笼子里。
- 开发者于是继续前探:让连接不再频繁重建,尝试分块直输,把事件像水一样持续送达,于是有了更顺滑的 Streaming 与标准化的 SSE。
直到某一刻,我们不再满足于“更聪明的单向”,而是迈向真正的“同时说话与倾听”——WebSocket 把通信从一次次请求,变成一条持久而通透的通道。此后,
- HTTP/2、HTTP/3 与 QUIC 又在底层为效率和时延开了绿灯,甚至提供了可选可靠与无序传输的更多可能。
接下来,我们就沿着这条主线,层层展开:它们各自解决了什么、在哪些场景最合拍、又如何在你的系统里形成清晰的选型边界。
01|从整页刷新出发:减少浪费的一条链路
这一块是为了解决“整页刷新导致的高延迟与带宽浪费”,逐级细化与优化。
这一块是为了解决“整页刷新导致的高延迟与带宽浪费”,逐级细化与优化。
a. 早期网页:整页刷新
- 背景与问题:每次更新都整页请求,体验割裂、带宽浪费、延迟高。
- 直接影响:促使前端与服务端思考“只取变化”。
- 背景与问题:每次更新都整页请求,体验割裂、带宽浪费、延迟高。
- 直接影响:促使前端与服务端思考“只取变化”。
b. 短轮询(Short Polling)为解决整页刷新的低效
- 解决:改为“隔一段时间拉一次”,显著减少整页重载带来的浪费。
- 局限:高频请求带来大量空响应与服务器开销。
- 承接改进:为减少空转,演进到长轮询;同时催生更流式的思路(Streaming/SSE)。
- 解决:改为“隔一段时间拉一次”,显著减少整页重载带来的浪费。
- 局限:高频请求带来大量空响应与服务器开销。
- 承接改进:为减少空转,演进到长轮询;同时催生更流式的思路(Streaming/SSE)。
c. 长轮询(Comet/挂起请求)为减少短轮询的空转
- 解决:请求挂起,服务器有新数据才返回,接近“伪推送”,显著降低空转。
- 局限:本质仍是请求-响应;连接频繁重建;难做真正双向。
- 承接改进:
- 单向推送更稳:SSE 标准化单向事件流。
- 若要真双向与二进制:交给 WebSocket(见独立块)。
- 解决:请求挂起,服务器有新数据才返回,接近“伪推送”,显著降低空转。
- 局限:本质仍是请求-响应;连接频繁重建;难做真正双向。
- 承接改进:
- 单向推送更稳:SSE 标准化单向事件流。
- 若要真双向与二进制:交给 WebSocket(见独立块)。
d. HTTP Streaming(分块传输/持续输出)为进一步降低重连与延迟
- 解决:保持连接,分块持续输出,适合连续文本/事件流,重连更少、延迟更低。
- 局限:多为单向,受代理/中间件影响,兼容性不一。
- 承接改进:单向事件由 SSE 标准化;双向场景仍需 WebSocket。
- 解决:保持连接,分块持续输出,适合连续文本/事件流,重连更少、延迟更低。
- 局限:多为单向,受代理/中间件影响,兼容性不一。
- 承接改进:单向事件由 SSE 标准化;双向场景仍需 WebSocket。
e. SSE(Server-Sent Events)单向推送的标准化终点
- 解决:以标准事件流语义提供单向推送,浏览器原生支持,资源占用低。
- 适配范围:通知、进度、日志/监控等文本或事件流。
- 位置关系:在“只需单向推送”的场景中,SSE 是这一链条的稳定落点,而非过渡技术。
- 解决:以标准事件流语义提供单向推送,浏览器原生支持,资源占用低。
- 适配范围:通知、进度、日志/监控等文本或事件流。
- 位置关系:在“只需单向推送”的场景中,SSE 是这一链条的稳定落点,而非过渡技术。
02|范式跃迁:WebSocket(独立大块)
这不是前面链条的“又一改良”,而是从请求-响应转向全双工持久连接的范式变化。
这不是前面链条的“又一改良”,而是从请求-响应转向全双工持久连接的范式变化。
WebSocket(全双工、持久、低开销)
- 解决:真正的双向实时通信,降低握手与头部开销,支持文本与二进制,端到端延迟低。
- 典型场景:聊天、协同编辑、在线游戏、行情推送、IoT。
- 与上一链条的关系:
- 在“需要双向实时”的主战场,实质上取代了短轮询/长轮询等过渡方案。
- 与 SSE 并存:若只有单向通知/事件流,SSE 更简单更省资源;若需要双向或二进制,WebSocket 更合适。
- 运维关注:连接状态管理、容量与反压、企业代理/负载均衡兼容。
- 解决:真正的双向实时通信,降低握手与头部开销,支持文本与二进制,端到端延迟低。
- 典型场景:聊天、协同编辑、在线游戏、行情推送、IoT。
- 与上一链条的关系:
- 在“需要双向实时”的主战场,实质上取代了短轮询/长轮询等过渡方案。
- 与 SSE 并存:若只有单向通知/事件流,SSE 更简单更省资源;若需要双向或二进制,WebSocket 更合适。
- 运维关注:连接状态管理、容量与反压、企业代理/负载均衡兼容。
03|底座升级与新选项:HTTP/2·HTTP/3·QUIC 家族
这部分不是替代前两块,而是提供更高效的承载与更灵活的传输语义。
这部分不是替代前两块,而是提供更高效的承载与更灵活的传输语义。
WS over H2/H3
- 价值:与同域请求复用连接、更好穿透与效率、更低握手成本。
- 作用:让 WebSocket 的部署与网络效率更优。
- 价值:与同域请求复用连接、更好穿透与效率、更低握手成本。
- 作用:让 WebSocket 的部署与网络效率更优。
WebTransport(基于 QUIC)
- 价值:可选可靠与有序/无序、更低延迟,适合实时媒体、游戏、定制协议。
- 关系:不是取代 WebSocket/SSE 的通吃方案,而是当你需要“更细粒度的可靠性与顺序控制”时的新工具。
- 价值:可选可靠与有序/无序、更低延迟,适合实时媒体、游戏、定制协议。
- 关系:不是取代 WebSocket/SSE 的通吃方案,而是当你需要“更细粒度的可靠性与顺序控制”时的新工具。
二、速查表
实时推送的目标是“低延迟、双向或单向地把数据从服务端送到客户端”。主流技术选型包括:
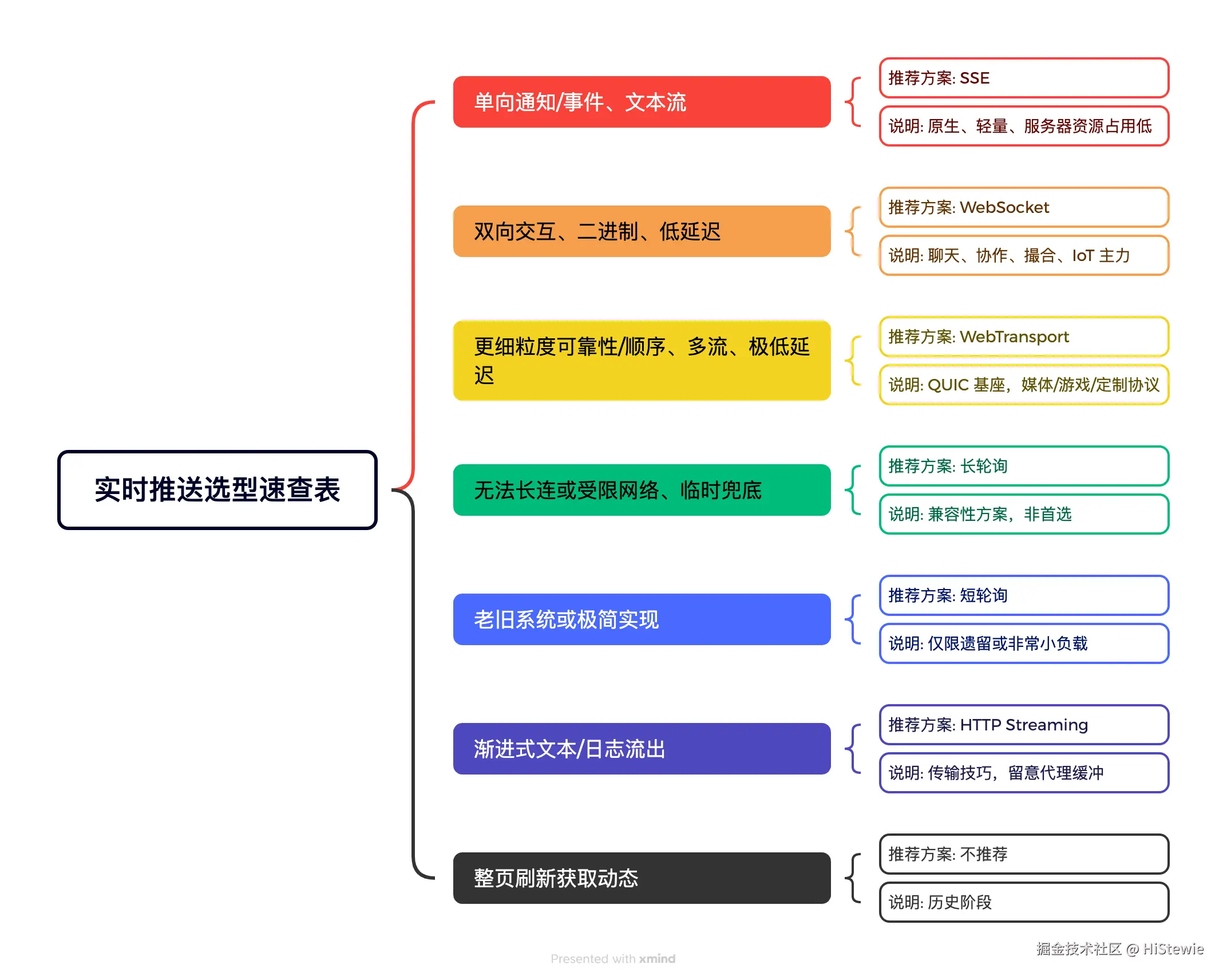
实时推送的目标是“低延迟、双向或单向地把数据从服务端送到客户端”。主流技术选型包括:
三、WebSocket 核心定义(重要)
WebSocket 是 HTML5 推出的一种全双工(Full-Duplex)、持久化(Persistent)的网络通信协议, 基于TCP协议构建,允许客户端(浏览器)与服务器之间建立一条长期稳定的连接通道,实现「服务器主动向客户端推送数据」和「客户端实时向服务器发送数据」的双向通信,无需频繁建立/断开连接。
其核心特点可概括为:
- 全双工:通信双方可同时发送/接收数据(区别于HTTP的「请求-响应」单向通信);
- 持久连接:连接建立后长期保持,避免HTTP每次通信都需重新握手的开销;
- 轻量协议:数据帧头部信息简洁(仅2-14字节),传输效率远高于HTTP;
- 协议标识:客户端发起连接时使用ws://(非加密)或wss://(加密,基于TLS,类似HTTPS)作为协议前缀。
WebSocket 是 HTML5 推出的一种全双工(Full-Duplex)、持久化(Persistent)的网络通信协议, 基于TCP协议构建,允许客户端(浏览器)与服务器之间建立一条长期稳定的连接通道,实现「服务器主动向客户端推送数据」和「客户端实时向服务器发送数据」的双向通信,无需频繁建立/断开连接。
其核心特点可概括为:
- 全双工:通信双方可同时发送/接收数据(区别于HTTP的「请求-响应」单向通信);
- 持久连接:连接建立后长期保持,避免HTTP每次通信都需重新握手的开销;
- 轻量协议:数据帧头部信息简洁(仅2-14字节),传输效率远高于HTTP;
- 协议标识:客户端发起连接时使用ws://(非加密)或wss://(加密,基于TLS,类似HTTPS)作为协议前缀。
从零开始的完整流程
下面是一条你在前端真实会走的链路:创建连接 → HTTP 握手与协议切换 → 进入 WebSocket 双向通信 → 启动心跳检测 → 发现异常并重连 → 重连成功后的补偿 → 服务端跨域放行 → 正常/异常关闭。
下面是一条你在前端真实会走的链路:创建连接 → HTTP 握手与协议切换 → 进入 WebSocket 双向通信 → 启动心跳检测 → 发现异常并重连 → 重连成功后的补偿 → 服务端跨域放行 → 正常/异常关闭。
1) 创建连接(入口)
2) HTTP 握手与协议切换(从“请求”到“长连”)
客户端(浏览器) 创建 WebSocket 实例时,会发起一个特殊的 HTTP - GET,核心目的是 「请求将协议从HTTP升级为WebSocket」。服务端验证通过后返回 101,双方切换到 WebSocket 帧通信。
WebSocket 帧是双向通信中的最小传输结构,携带 “ 数据类型 、 是否为消息的最后一段 、 负载长度 、 掩码/密钥 、 实际数据 ” 。消息可以被拆成多帧连续发送,也可以一个帧就送完。
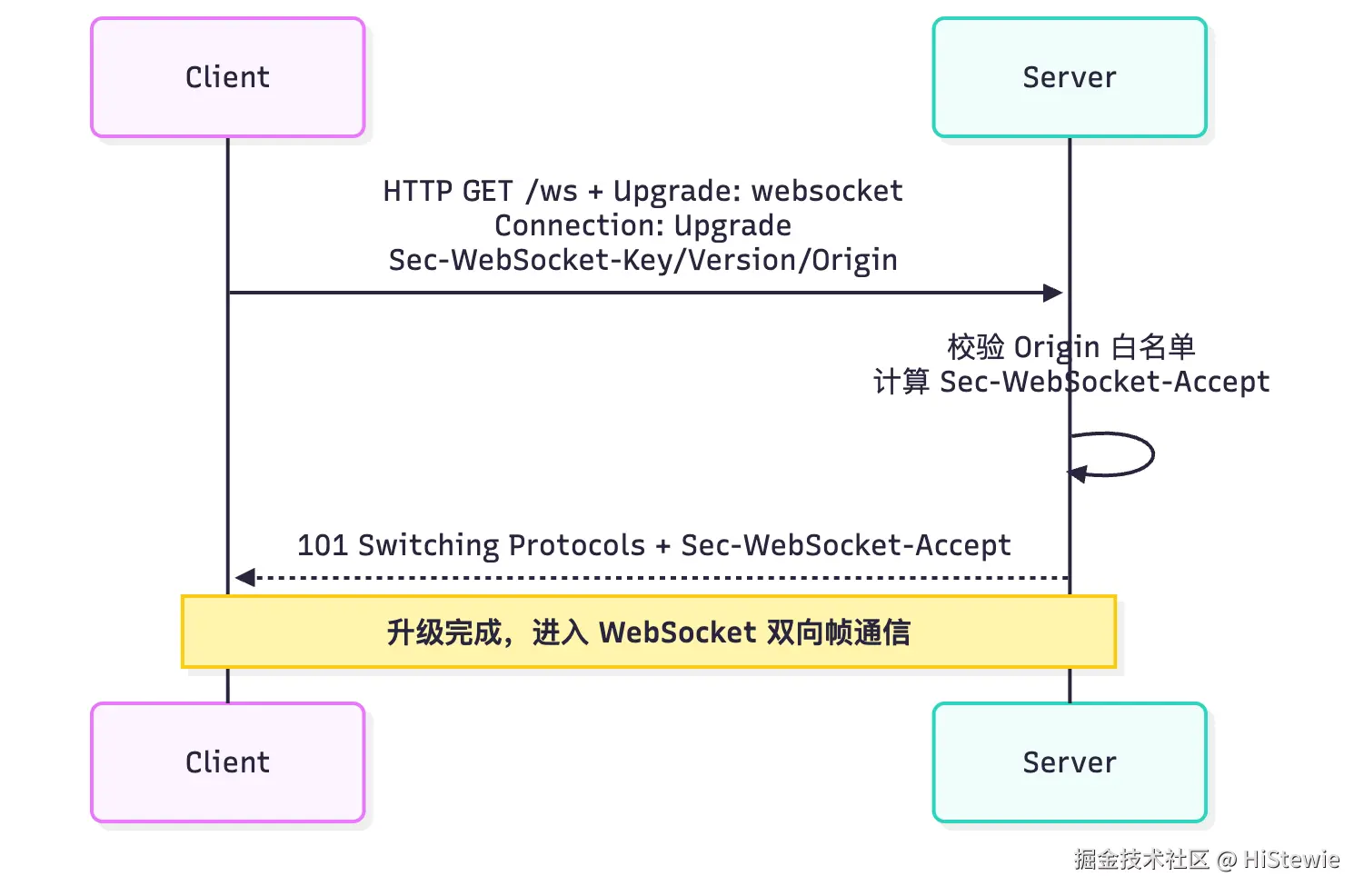
客户端(浏览器) 创建 WebSocket 实例时,会发起一个特殊的 HTTP - GET,核心目的是 「请求将协议从HTTP升级为WebSocket」。服务端验证通过后返回 101,双方切换到 WebSocket 帧通信。
WebSocket 帧是双向通信中的最小传输结构,携带 “ 数据类型 、 是否为消息的最后一段 、 负载长度 、 掩码/密钥 、 实际数据 ” 。消息可以被拆成多帧连续发送,也可以一个帧就送完。
客户端发起「协议升级请求」(HTTP - GET 请求)
请求头中关键字段(面试高频考点):
GET /ws-endpoint HTTP/1.1:请求方法为 GET,路径为服务器的 WebSocket 端点(如/ws);Host:example.com:服务器域名;Upgrade:websocket:核心字段,告知服务器「要升级协议为 WebSocket」;Connection:Upgrade:配合 Upgrade,表示「这是一个协议升级请求」;Sec-WebSocket-Key:dGhlIHNhbXBsZSBub25jzQ==:客户端生成的随机字符串(Base64 编码,长度 16 字节),用于服务器验证(防止恶意连接);Sec-WebSocket-Version:13:WebSocket 协议版本(当前主流为 13,需服务器支持);Sec-WebSocket-Origin:https://example.com:客户端所在域名(用于服务器跨域验证)。
请求头中关键字段(面试高频考点):
GET /ws-endpoint HTTP/1.1:请求方法为GET,路径为服务器的 WebSocket 端点(如/ws);Host:example.com:服务器域名;Upgrade:websocket:核心字段,告知服务器「要升级协议为 WebSocket」;Connection:Upgrade:配合 Upgrade,表示「这是一个协议升级请求」;Sec-WebSocket-Key:dGhlIHNhbXBsZSBub25jzQ==:客户端生成的随机字符串(Base64 编码,长度 16 字节),用于服务器验证(防止恶意连接);Sec-WebSocket-Version:13:WebSocket 协议版本(当前主流为 13,需服务器支持);Sec-WebSocket-Origin:https://example.com:客户端所在域名(用于服务器跨域验证)。
服务器响应「协议升级成功」(HTTP - 101状态码)
服务器收到请求后,若支持 WebSocket 协议且验证通过(如 Sec-WebSocket-Key 验证、跨域验证) ,会返回HTTP - 101(SwitchingProtocols)状态码,表示「同意协议升级」。
响应头中关键字段 (面试高频考点):
HTTP/1.1 101 Switching Protocols:101 状态码是协议切换的标志;Upgrade: websocket:确认升级为WebSocket 协议;Connection:Upgrade:确认连接用于协议升级;Sec-WebSocket-Accept:s3pPLMBiTxaQ9kYGzzhZRbK+xOo=:服务器对Sec-WebSocket-Key 的处理结果(核心验证逻辑):- 服务器将客户端发送的 Sec-WebSocket-Key 与固定字符串
258EAFA5-E914-47DA-95CA-C5AB0DC85B11 拼接; - 对拼接后的字符串进行
SHA-1 哈希计算; - 将哈希结果转为 Base64 编码,即为 Sec-WebSocket-Accept 的值;
- 客户端会验证该值是否正确,若不正确则拒绝建立连接(防止伪造响应)。
服务器收到请求后,若支持 WebSocket 协议且验证通过(如 Sec-WebSocket-Key 验证、跨域验证) ,会返回HTTP - 101(SwitchingProtocols)状态码,表示「同意协议升级」。
响应头中关键字段 (面试高频考点):
HTTP/1.1 101 Switching Protocols:101 状态码是协议切换的标志;Upgrade: websocket:确认升级为WebSocket 协议;Connection:Upgrade:确认连接用于协议升级;Sec-WebSocket-Accept:s3pPLMBiTxaQ9kYGzzhZRbK+xOo=:服务器对Sec-WebSocket-Key 的处理结果(核心验证逻辑):- 服务器将客户端发送的 Sec-WebSocket-Key 与固定字符串
258EAFA5-E914-47DA-95CA-C5AB0DC85B11拼接; - 对拼接后的字符串进行
SHA-1哈希计算; - 将哈希结果转为 Base64 编码,即为 Sec-WebSocket-Accept 的值;
- 客户端会验证该值是否正确,若不正确则拒绝建立连接(防止伪造响应)。
- 服务器将客户端发送的 Sec-WebSocket-Key 与固定字符串
3) 进入通信阶段(双向数据 + 基础发送)
握手通过,onopen 会触发。此时做两件事:
- 发送初始化数据(如身份、订阅主题)
- 启动心跳(下一步会讲)
通信注意:
onmessage 既可能是字符串,也可能是二进制(Blob/ArrayBuffer)bufferedAmount 可用来做背压控制(积压太大时暂停继续 send)
握手通过,onopen 会触发。此时做两件事:
- 发送初始化数据(如身份、订阅主题)
- 启动心跳(下一步会讲)
通信注意:
onmessage既可能是字符串,也可能是二进制(Blob/ArrayBuffer)bufferedAmount可用来做背压控制(积压太大时暂停继续 send)
4) 启动心跳(让连接“活着”且可感知)
持久连接会遭遇 Wi‑Fi 抖动、防火墙清理等问题。心跳=周期性发 ping,超时未收到 pong 就判死链。
推荐参数(可按业务调优):
HEARTBEAT_INTERVAL ≈ 30sHEARTBEAT_TIMEOUT ≈ 10s
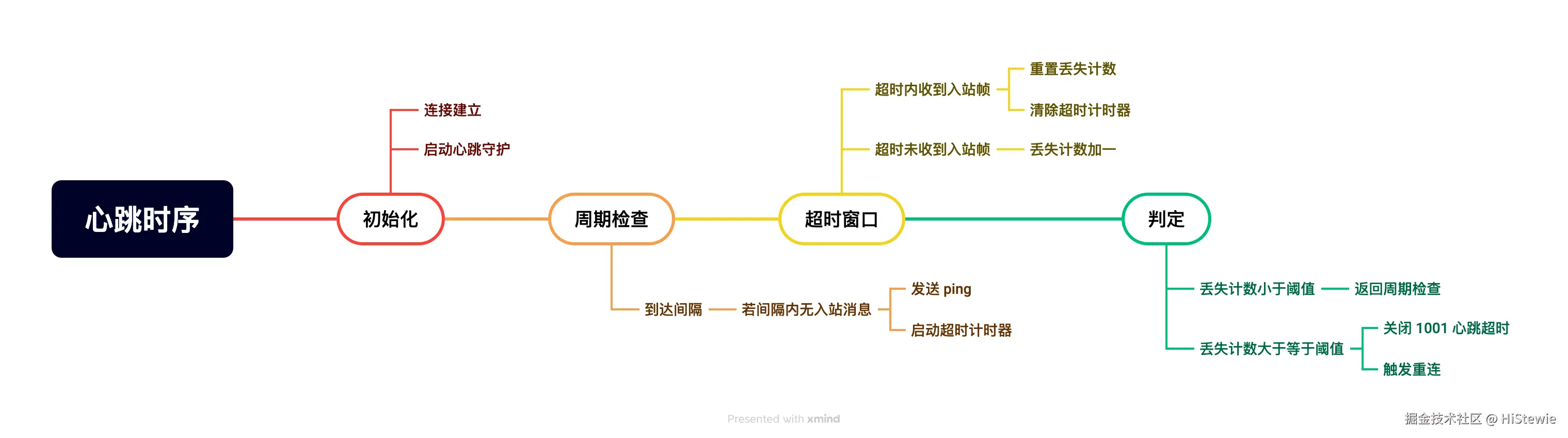
实操要点:
- 启动前先清理旧定时器,避免重复
- 收到 pong 立即清除超时定时器
- onclose/onerror 必须停止心跳
持久连接会遭遇 Wi‑Fi 抖动、防火墙清理等问题。心跳=周期性发 ping,超时未收到 pong 就判死链。
推荐参数(可按业务调优):
HEARTBEAT_INTERVAL ≈ 30sHEARTBEAT_TIMEOUT ≈ 10s
实操要点:
- 启动前先清理旧定时器,避免重复
- 收到 pong 立即清除超时定时器
- onclose/onerror 必须停止心跳
5) 异常→重连(恢复连接但不过载)
一旦 onerror、onclose(code ≠ 1000) 或心跳判定超时,进入重连。
目标是:能恢复、不过载、可被用户停止。
策略三件套:
- 指数退避:1s → 2s → 4s … 最多 30s
- 次数上限:如 10 次(达到即停)
- 可控停止:提供“停止重连”或页面关闭时停
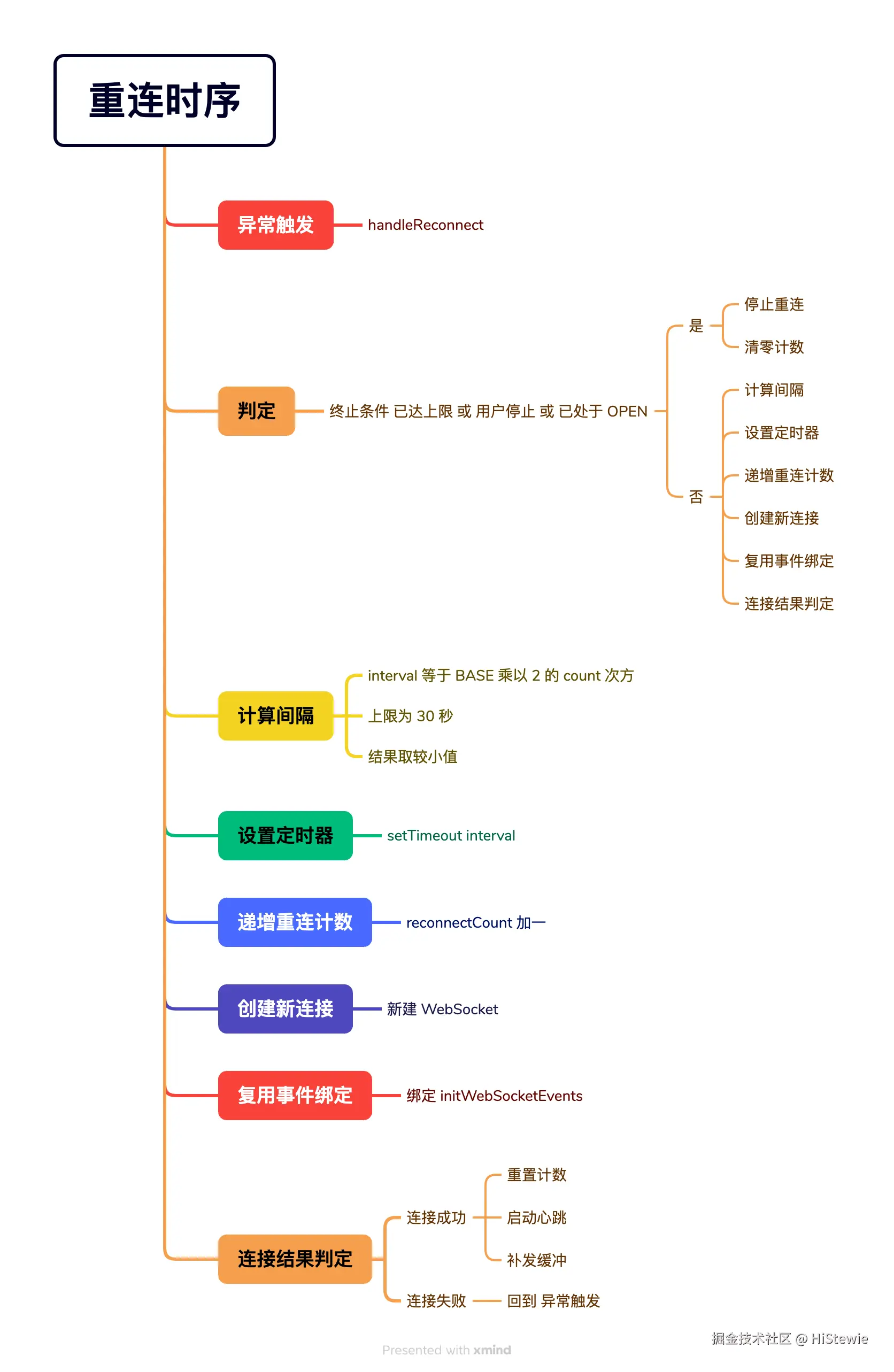
补偿机制:
- 在断开前缓存“待发送”数据(例如未发出的聊天消息)
- 重连成功后按序补发,确保业务连续性
一旦 onerror、onclose(code ≠ 1000) 或心跳判定超时,进入重连。
目标是:能恢复、不过载、可被用户停止。
策略三件套:
- 指数退避:1s → 2s → 4s … 最多 30s
- 次数上限:如 10 次(达到即停)
- 可控停止:提供“停止重连”或页面关闭时停
补偿机制:
- 在断开前缓存“待发送”数据(例如未发出的聊天消息)
- 重连成功后按序补发,确保业务连续性
6) 服务器放行跨域(握手能否过关的关键)
虽然 WebSocket 原生“支持跨域”,但握手是 HTTP,服务端需要对 Sec-WebSocket-Origin 做白名单校验。
否则会 403 或直接关闭。
- Node.js(ws)
- 读取
req.headers['sec-websocket-origin'] - 不在
allowedOrigins 列表:关闭 1008 “Cross-origin access denied”
- Spring Boot
registry.addHandler(...).setAllowedOrigins("https://a.com", "https://b.com")- 需要时
.withSockJS()提供降级
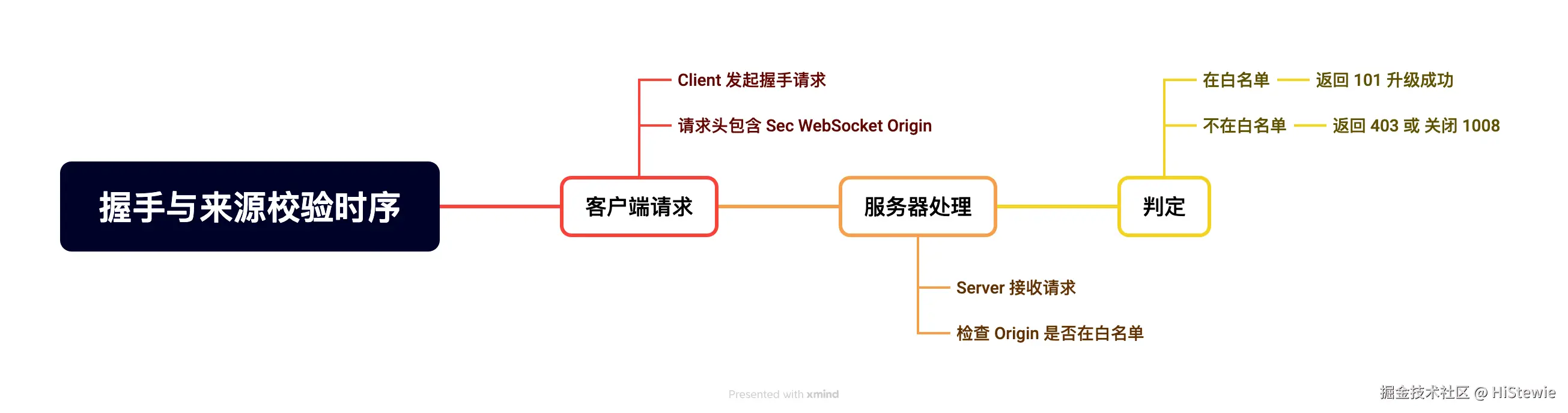
虽然 WebSocket 原生“支持跨域”,但握手是 HTTP,服务端需要对 Sec-WebSocket-Origin 做白名单校验。
否则会 403 或直接关闭。
- Node.js(ws)
- 读取
req.headers['sec-websocket-origin'] - 不在
allowedOrigins列表:关闭1008“Cross-origin access denied”
- 读取
- Spring Boot
registry.addHandler(...).setAllowedOrigins("https://a.com", "https://b.com")- 需要时
.withSockJS()提供降级
7) 正常关闭与资源清理(善始善终)
- 用户离开页面或主动退出:ws.close(1000, '用户主动退出')
- onclose 中停止心跳与重连,清空定时器与队列,避免泄漏
- 记录关闭原因码:1000 正常、1006 常见于异常/心跳超时
- 用户离开页面或主动退出:ws.close(1000, '用户主动退出')
- onclose 中停止心跳与重连,清空定时器与队列,避免泄漏
- 记录关闭原因码:1000 正常、1006 常见于异常/心跳超时
四、面试题
面试关注点通常围绕“协议对比、连接管理、消息语义、可靠性与扩展性、安全与运维成本”。
面试关注点通常围绕“协议对比、连接管理、消息语义、可靠性与扩展性、安全与运维成本”。
1、WebSocket 与 SSE 的差异与使用场景,HTTP轮询呢?
WebSocket(全双工,二进制/文本)
- 适用:即时聊天、协作编辑、游戏状态同步、行情推送、需要客户端→服务端主动上行的实时交互。
- 优点:低延迟、头开销小、全双工、支持二进制、可自定义子协议。
- 注意:需处理心跳、重连、背压、鉴权与扇出扩展;代理/LB 要正确透传 Upgrade 和超时设置。
Server-Sent Events(SSE,单向 server→client)
- 适用:通知流、日志流、监控事件、流式生成文本(如增量输出)、只需服务端下行的实时更新。
- 优点:浏览器原生 EventSource、文本流、自动重连、支持 Last-Event-ID 断点续传;实现简单。
- 注意:单向、仅文本(可 base64 二进制)、连接数限制与代理超时需要关注;移动端网络切换要做容错。
HTTP 轮询/长轮询(兼容兜底)
- 适用:对实时性要求不高的小流量场景、受网络环境或企业防火墙限制无法使用 WS/SSE 时的兜底。
- 优点:最易落地、与缓存/鉴权/监控体系天然兼容;对中间设备最友好。
- 注意:延迟更高、资源利用低;高频轮询会带来成本与限流压力。
✅ 重点
- WebSocket 通过 HTTP/1.1 Upgrade → 101 完成切换,此后是帧协议的全双工通道;Keep-Alive 仅是复用 TCP,不改变 HTTP 的请求-响应语义。
- 选型规则:需要双向实时交互选 WebSocket;单向事件流选 SSE;受限或低实时性场景用轮询作兜底。
WebSocket(全双工,二进制/文本)
- 适用:即时聊天、协作编辑、游戏状态同步、行情推送、需要客户端→服务端主动上行的实时交互。
- 优点:低延迟、头开销小、全双工、支持二进制、可自定义子协议。
- 注意:需处理心跳、重连、背压、鉴权与扇出扩展;代理/LB 要正确透传 Upgrade 和超时设置。
Server-Sent Events(SSE,单向 server→client)
- 适用:通知流、日志流、监控事件、流式生成文本(如增量输出)、只需服务端下行的实时更新。
- 优点:浏览器原生 EventSource、文本流、自动重连、支持 Last-Event-ID 断点续传;实现简单。
- 注意:单向、仅文本(可 base64 二进制)、连接数限制与代理超时需要关注;移动端网络切换要做容错。
HTTP 轮询/长轮询(兼容兜底)
- 适用:对实时性要求不高的小流量场景、受网络环境或企业防火墙限制无法使用 WS/SSE 时的兜底。
- 优点:最易落地、与缓存/鉴权/监控体系天然兼容;对中间设备最友好。
- 注意:延迟更高、资源利用低;高频轮询会带来成本与限流压力。
✅ 重点
- WebSocket 通过 HTTP/1.1 Upgrade → 101 完成切换,此后是帧协议的全双工通道;Keep-Alive 仅是复用 TCP,不改变 HTTP 的请求-响应语义。
- 选型规则:需要双向实时交互选 WebSocket;单向事件流选 SSE;受限或低实时性场景用轮询作兜底。
2、如何设计一个可水平扩展的实时推送系统?
在可水平扩展的实时推送系统中,WebSocket 连接会分布在多台网关节点上。
核心挑战是如何在连接与消息不在同一台机器时,仍能把消息快速路由到正确的连接。可行的范式是
- 网关层负责连接
- 管道层负责路由与发布订阅
- 存储层负责状态与回放
在可水平扩展的实时推送系统中,WebSocket 连接会分布在多台网关节点上。
核心挑战是如何在连接与消息不在同一台机器时,仍能把消息快速路由到正确的连接。可行的范式是
- 网关层负责连接
- 管道层负责路由与发布订阅
- 存储层负责状态与回放
🔌 网关层(负责连接)
- 终止 TLS/WS,维持心跳与速率限制,保持无状态实例。
- 建立本地索引:connectionId → 订阅集合,userId → connectionIds。
- 将连接元数据上报共享存储:connectionId、userId、nodeId、订阅、最近心跳。
- 仅订阅“与自己有关的分片”:按 userId/topic 的哈希分片从管道层拉取,减少无关扇出。
- 写通道背压与优先级:控制帧/关键消息优先,低优先级可丢尾或抽样。
- 终止 TLS/WS,维持心跳与速率限制,保持无状态实例。
- 建立本地索引:connectionId → 订阅集合,userId → connectionIds。
- 将连接元数据上报共享存储:connectionId、userId、nodeId、订阅、最近心跳。
- 仅订阅“与自己有关的分片”:按 userId/topic 的哈希分片从管道层拉取,减少无关扇出。
- 写通道背压与优先级:控制帧/关键消息优先,低优先级可丢尾或抽样。
🚇 管道层(负责路由与发布订阅)
- 选型具备分片与回放能力的总线(Kafka/Pulsar/NATS/Redis Streams)。
- 分片策略:
- 点推:按 userId/connectionId 一致性哈希到分区,保证单用户局部有序。
- 主题推送:按 topic 分区,网关本地再做订阅过滤与扇出。
- 路由方式:
- 生产者只需写对的分片;总线按分区把消息送到订阅该分片的网关。
- 广播/超大房间采用“分层扇出”:先到分片,再由各网关本地扇出,必要时加中间扇出代理。
- 去重与幂等:messageId 或 (topic, partition, offset) 作为幂等键,网关/客户端各自维护短期去重集合。
- 选型具备分片与回放能力的总线(Kafka/Pulsar/NATS/Redis Streams)。
- 分片策略:
- 点推:按 userId/connectionId 一致性哈希到分区,保证单用户局部有序。
- 主题推送:按 topic 分区,网关本地再做订阅过滤与扇出。
- 路由方式:
- 生产者只需写对的分片;总线按分区把消息送到订阅该分片的网关。
- 广播/超大房间采用“分层扇出”:先到分片,再由各网关本地扇出,必要时加中间扇出代理。
- 去重与幂等:messageId 或 (topic, partition, offset) 作为幂等键,网关/客户端各自维护短期去重集合。
🗃️ 存储层(负责状态与回放)
- 会话与订阅状态:使用 Redis Cluster 或 KV 服务存 userId→connectionIds、connectionId→nodeId、订阅清单、心跳时间。
- 游标与回放:在总线层保留 offset;客户端重连携带 resumeToken,网关据此恢复订阅并按 offset 增量补发。
- 一致性与更新:订阅变更写事件流,相关网关消费后刷新本地索引;用版本号/逻辑时钟避免乱序覆盖。
- 会话与订阅状态:使用 Redis Cluster 或 KV 服务存 userId→connectionIds、connectionId→nodeId、订阅清单、心跳时间。
- 游标与回放:在总线层保留 offset;客户端重连携带 resumeToken,网关据此恢复订阅并按 offset 增量补发。
- 一致性与更新:订阅变更写事件流,相关网关消费后刷新本地索引;用版本号/逻辑时钟避免乱序覆盖。
3、如何保证消息不丢、不重、按序?
- 不丢: 消息先落到能持久化、带副本确认的总线里(像“写盘且多副本到位才算成功”),写失败就退避重试;消费侧是“先送到用户手里或进可靠下行队列,再更新位点”,断线后拿着
resumeToken+offset 从保留的历史里把漏掉的补回来。 - 不重: 每条消息都有一个不会撞车的“指纹”(messageId 或 topic-partition-offset);网关用一小块内存做近端去重,只有第一次真正写入才前进位点,重复的一概忽略;客户端也按同一指纹做幂等处理,避免业务状态被二次改动。
- 按序: 把需要有序的对象(userId/roomId)哈希到同一分区,借用分区内天然顺序;同一个键在网关里串行发送、同队列内重试,不跨分区不并行穿插,这样即使重试和补发也不会把顺序打乱。
- 不丢: 消息先落到能持久化、带副本确认的总线里(像“写盘且多副本到位才算成功”),写失败就退避重试;消费侧是“先送到用户手里或进可靠下行队列,再更新位点”,断线后拿着
resumeToken+offset从保留的历史里把漏掉的补回来。 - 不重: 每条消息都有一个不会撞车的“指纹”(messageId 或 topic-partition-offset);网关用一小块内存做近端去重,只有第一次真正写入才前进位点,重复的一概忽略;客户端也按同一指纹做幂等处理,避免业务状态被二次改动。
- 按序: 把需要有序的对象(userId/roomId)哈希到同一分区,借用分区内天然顺序;同一个键在网关里串行发送、同队列内重试,不跨分区不并行穿插,这样即使重试和补发也不会把顺序打乱。
4、心跳如何设计?超时如何判定?
这里的心跳,目标是 “保活、探测、可平滑重连”。
- 不失联: 用应用层
ping/pong,客户端主发、服务端回;- 间隔 20–60s,加±10%抖动
- 未知网络时取 20–30s,确保小于最短 NAT 空闲回收。
- 怎么判死: 别一跳不回就拍板。记录
lastSeen,允许 2–3 次心跳未达或 now-lastSeen 超过 2–3 个周期再判断;进入“Suspect”时降级写入,仍有业务流量即立刻恢复。 - 断了咋办:重连走指数退避并带抖动,携带
resumeToken/offset 补发;移动端切网优先复用会话,失败再重建。监控 RTT/丢包与 Suspect 比例,自动调心跳与阈值。
这里的心跳,目标是 “保活、探测、可平滑重连”。
- 不失联: 用应用层
ping/pong,客户端主发、服务端回;- 间隔 20–60s,加±10%抖动
- 未知网络时取 20–30s,确保小于最短 NAT 空闲回收。
- 怎么判死: 别一跳不回就拍板。记录
lastSeen,允许 2–3 次心跳未达或now-lastSeen超过 2–3 个周期再判断;进入“Suspect”时降级写入,仍有业务流量即立刻恢复。 - 断了咋办:重连走指数退避并带抖动,携带
resumeToken/offset补发;移动端切网优先复用会话,失败再重建。监控 RTT/丢包与 Suspect 比例,自动调心跳与阈值。
5、如何在 Nginx/Envoy 反向代理后稳定运行 WebSocket?
核心思路:让代理“不瞎操心”、连接“常被看见”、后端“可续上”。
- 代理设置:开启 WebSocket 升级;调大超时,禁用缓冲与压缩;保持 TCP keepalive,HTTP/2 用 CONNECT(H2/WebSocket)。
- 心跳与保活:应用层 ping/pong 20–30s(±10%抖动),保证小于代理/NAT空闲回收;大连接数用轻量负载均衡(hash by userId/roomId)避免跨节点迁移。
- 断线与重连:客户端指数退避+抖动,带会话 token/offset 续传;后端幂等去重,重放不重不丢。
- 运维与观测:开代理层指标(升级成功率、idle 关闭数、5xx)、RTT/丢包与重连率,异常时自适应缩短心跳或放宽超时。
6、如何做鉴权与权限隔离?
握手前校验 JWT;Subprotocol 指定租户/版本;频道级 ACL;避免敏感数据从客户端请求非授权频道。
- 握手前校验 JWT:在
HTTP Upgrade前验证 iss/aud/exp/签名并解析 tenant_id/user_id/scopes,避免建立长连后再踢。 - Subprotocol 指定租户/版本:用 Sec-WebSocket-Protocol 携带 tenant 和策略版本做白名单匹配,确保连接上下文一致。
- 频道级 ACL:频道强制以租户前缀命名,每次 subscribe/publish 依据 RBAC+scope 前缀(到资源或前缀)做服务端授权。
- 避免敏感数据越权:仅按服务器维护的“已授权订阅集合”下发数据,忽略客户端自报筛选请求并拒绝未授权频道。
7、如何评估性能与成本?
- 每连接内存占用: 用基线压测量出 MB/1k 连接的实际占用,结合目标并发外推单机上限并监控 GC/碎片。
- 每秒消息数(fanout×频率): 用发布频率×平均扇出得到总吞吐,核算带宽与发送队列容量,识别热点频道放大效应。
- 尾延迟 P95/P99: 持续跟踪端到端延迟长尾并关联队列深度与CPU/GC事件,确保在SLA红线下仍稳定。
- 压测考虑广播峰值与重连风暴: 分别模拟大扇出瞬时广播与大量短时间内握手重连,验证背压、限速和握手路径的韧性。
8、遇到“重连风暴”怎么处理?
- 抖动退避(指数退避 + 随机抖动): 客户端按指数退避间隔重试并加入随机抖动,避免同相位同时重连造成尖峰。
- 分批恢复: 将连接恢复按固定批次/时间片发放(如每 100ms 开放 N 个),把尖峰摊平到更长窗口。
- 服务端限流与排队: 在握手与认证路径设置并发/速率上限与队列,超限直接返回可重试错误或延迟令牌。
- 灰度放量: 按租户/区域/版本逐步提升允许重连比例,结合健康度与错误率自动调节放量速度。
9、前端如何封装一个健壮的 WebSocket 客户端?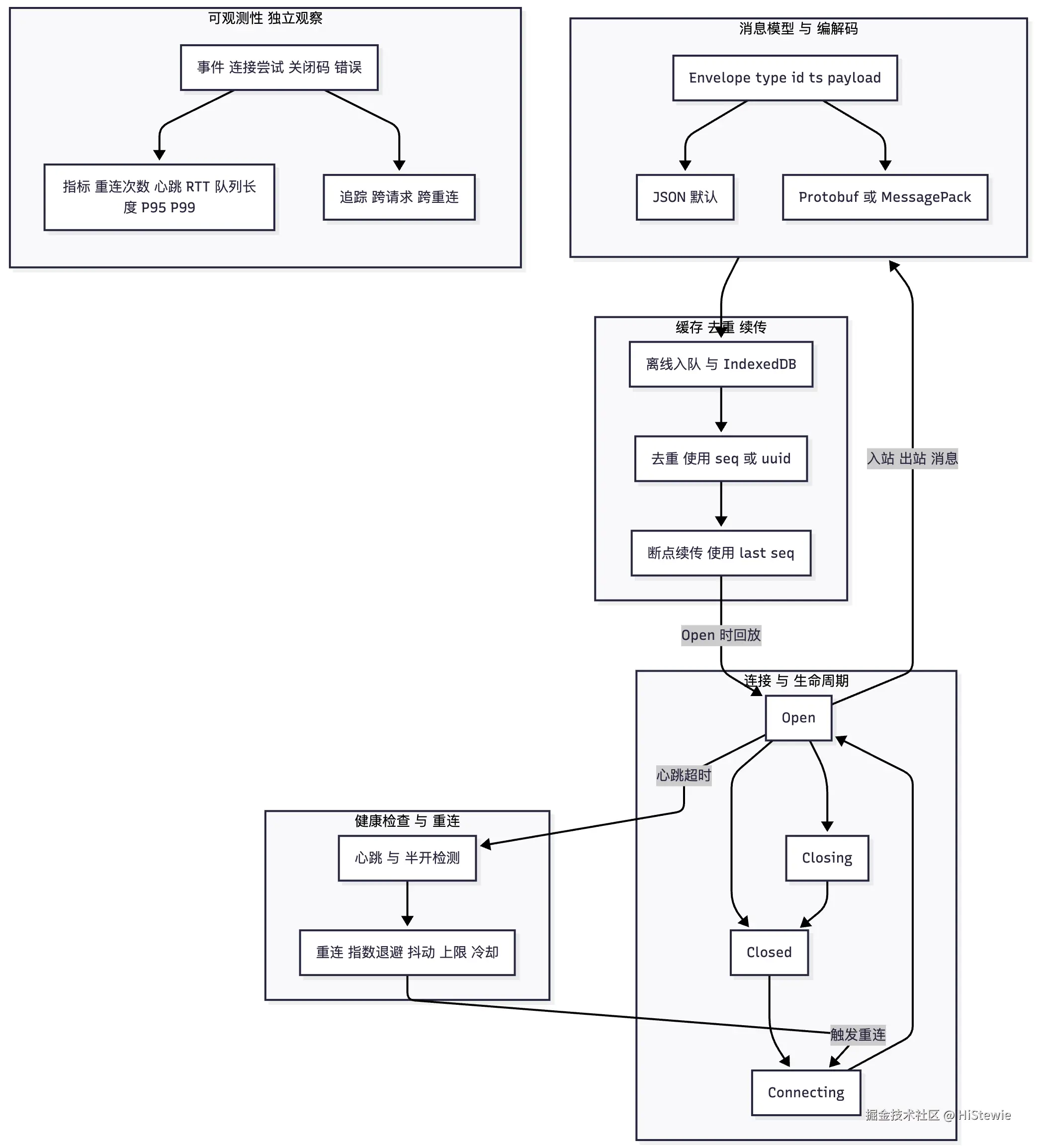
- 状态机(
CONNECTING / OPEN / CLOSING / CLOSED ): 用有限状态机驱动所有事件与迁移,单航道控制避免并发重连与回调竞态。 - 心跳/重连策略: 按固定心跳探活与半开检测,重连采用指数退避叠加随机抖动并设上限与冷却期。
- 消息序列化: 统一 envelope(type/id/ts/payload),默认 JSON,性能敏感时切 Protobuf/MessagePack 并保持向后兼容。
- 离线缓存与去重: 未连通时将待发入队、跨刷新用 IndexedDB,按 seq/uuid 去重并用 last-seq 做断点续传。
- 可观测日志: 记录连接尝试/关闭码/重连次数/心跳RTT/队列长度等指标与事件,便于快速定位长尾与故障。
作者:HiStewie
来源:juejin.cn/post/7572539461478907947
CONNECTING / OPEN / CLOSING / CLOSED ): 用有限状态机驱动所有事件与迁移,单航道控制避免并发重连与回调竞态。来源:juejin.cn/post/7572539461478907947





{kind=link}