








transform、translate、transition分别是什么属性,CSS中常用的实现动画方式
transform、translate、transition分别是什么属性,CSS中常用的实现动画方式
在 CSS 中,transform、translate 和 transition 是用于实现元素变换和动画的重要属性。它们各自有不同的作用,通常结合使用可以实现丰富的动画效果。
1. 属性详解
1.1 transform
- 作用:用于对元素进行 2D 或 3D 变换,如旋转、缩放、倾斜、平移等。
- 常用函数:
translate(x, y):平移元素。rotate(angle):旋转元素。scale(x, y):缩放元素。skew(x-angle, y-angle):倾斜元素。matrix(a, b, c, d, e, f):定义 2D 变换矩阵。
- 示例:
.box {
transform: translate(50px, 100px) rotate(45deg) scale(1.5);
}
1.2 translate
- 作用:
translate是transform的一个函数,用于平移元素。 - 语法:
translate(x, y):水平方向移动x,垂直方向移动y。translateX(x):仅水平方向移动。translateY(y):仅垂直方向移动。translateZ(z):在 3D 空间中沿 Z 轴移动。
- 示例:
.box {
transform: translate(50px, 100px);
}
1.3 transition
- 作用:用于定义元素在样式变化时的过渡效果。
- 常用属性:
transition-property:指定需要过渡的属性(如all、opacity、transform等)。transition-duration:指定过渡的持续时间(如1s、500ms)。transition-timing-function:指定过渡的速度曲线(如ease、linear、ease-in-out)。transition-delay:指定过渡的延迟时间(如0.5s)。
- 简写语法:
transition: property duration timing-function delay;
- 示例:
.box {
transition: transform 0.5s ease-in-out, opacity 0.3s linear;
}
2. CSS 中常用的实现动画方式
2.1 使用 transition 实现简单动画
- 适用场景:适用于简单的状态变化动画(如 hover 效果)。
- 示例:
.box {
width: 100px;
height: 100px;
background-color: lightblue;
transition: transform 0.5s ease-in-out;
}
.box:hover {
transform: scale(1.2) rotate(45deg);
}
2.2 使用 @keyframes 和 animation 实现复杂动画
- 适用场景:适用于复杂的多帧动画。
- 步骤:
- 使用
@keyframes定义动画关键帧。 - 使用
animation属性将动画应用到元素上。
- 使用
- 示例:
@keyframes slideIn {
0% {
transform: translateX(-100%);
}
100% {
transform: translateX(0);
}
}
.box {
width: 100px;
height: 100px;
background-color: lightblue;
animation: slideIn 1s ease-in-out;
}
2.3 使用 transform 和 transition 结合实现交互效果
- 适用场景:适用于用户交互触发的动画(如点击、悬停)。
- 示例:
.box {
width: 100px;
height: 100px;
background-color: lightblue;
transition: transform 0.3s ease-in-out;
}
.box:active {
transform: scale(0.9);
}
2.4 使用 will-change 优化动画性能
- 作用:提前告知浏览器元素将会发生的变化,以优化渲染性能。
- 示例:
.box {
will-change: transform;
}
3. 综合示例
示例 1:按钮点击效果
.button {
padding: 10px 20px;
background-color: lightblue;
border: none;
transition: transform 0.2s ease-in-out;
}
.button:active {
transform: scale(0.95);
}
示例 2:卡片翻转动画
.card {
width: 200px;
height: 200px;
position: relative;
perspective: 1000px;
}
.card-inner {
width: 100%;
height: 100%;
transition: transform 0.6s;
transform-style: preserve-3d;
}
.card:hover .card-inner {
transform: rotateY(180deg);
}
.card-front, .card-back {
width: 100%;
height: 100%;
position: absolute;
backface-visibility: hidden;
}
.card-front {
background-color: lightblue;
}
.card-back {
background-color: lightcoral;
transform: rotateY(180deg);
}
示例 3:加载动画
@keyframes spin {
0% {
transform: rotate(0deg);
}
100% {
transform: rotate(360deg);
}
}
.loader {
width: 40px;
height: 40px;
border: 4px solid #f3f3f3;
border-top: 4px solid #3498db;
border-radius: 50%;
animation: spin 1s linear infinite;
}
总结
| 属性/方法 | 作用 | 适用场景 |
|---|---|---|
transform | 对元素进行 2D/3D 变换 | 平移、旋转、缩放、倾斜等 |
translate | transform 的一个函数,用于平移元素 | 移动元素位置 |
transition | 定义元素样式变化的过渡效果 | 简单的状态变化动画 |
@keyframes | 定义动画关键帧 | 复杂的多帧动画 |
animation | 将@keyframes 定义的动画应用到元素上 | 复杂的多帧动画 |
will-change | 优化动画性能 | 性能优化 |
通过灵活运用这些属性和方法,可以实现丰富的动画效果,提升用户体验。
更多vue相关插件及后台管理模板可访问vue admin reference,代码详情请访问github
来源:juejin.cn/post/7480766452653260852
优化Mini React:避免状态未变更时的重复渲染
优化Mini React:避免状态未变更时的重复渲染
在构建Mini React时,我们发现一个常见的性能问题:即使状态值未发生改变,组件也会进行不必要的重复渲染。本文将深入分析问题原因并实现优化方案。
问题现象分析
以下面代码为例:
function Foo() {
console.log('fooo') // 每次点击都会打印
const [bar, setBar] = React.useState('bar')
function handleClick() {
setBar('bar') // 设置相同的值
}
return (
<div>
{bar}
<button onClick={handleClick}>clickbutton>
div>
);
}
当点击按钮时,虽然状态值bar没有实际变化,但每次点击都会触发组件重新渲染(控制台持续输出"fooo")。这在性能敏感场景下会造成资源浪费。
优化原理与实现
React的核心优化策略之一是:当状态值未改变时,跳过渲染流程。我们在useState的setState函数中加入值比较逻辑:
function useState(initial) {
// ... 状态初始化逻辑
const setState = (action) => {
// 计算期望的新状态
const eagerState = typeof action === 'function'
? action(stateHook.state)
: action;
// 关键优化:状态值未改变时提前返回
if (Object.is(eagerState, stateHook.state)) {
return;
}
// 状态更新及重新渲染逻辑
stateHook.state = eagerState;
scheduleUpdate();
};
return [stateHook.state, setState];
}
优化关键点解析
- 提前计算状态值:
- 处理函数式更新:
action(currentState) - 处理直接赋值:
action
- 处理函数式更新:
- 精准状态比较:
- 使用
Object.is()代替===运算符 - 正确处理特殊值:
NaN、+0/-0等边界情况 - 性能考虑:先比较再更新,避免不必要的渲染流程
- 使用
- 渲染流程优化:
- 状态未变更时直接return,阻断后续更新
- 状态变更时才触发重新渲染调度
优化效果验证
优化后,当点击按钮设置相同状态值时:
setBar('bar') // 与当前状态相同
- 控制台不再输出"fooo"
- 组件不会触发重新渲染
- 虚拟DOM不会进行diff比较
- 真实DOM不会更新
实际应用场景
- 表单控件:输入框失去焦点时重置状态
- 多次相同操作:重复点击相同选项
- 防抖/节流:快速触发时的状态保护
- 数据同步:避免接口返回相同数据时的渲染
扩展思考
- 引用类型优化:
setObj({...obj}) // 内容相同但引用不同
需配合immutable.js或immer等库实现深度比较
- 类组件优化: 在setState方法中实现相同的值比较逻辑
- 性能权衡: 简单值比较成本低,复杂对象比较需评估成本
总结
通过实现状态变更的精准判断,我们:
- 减少不必要的渲染流程
- 降低虚拟DOM diff成本
- 避免真实DOM的无效更新
- 提升组件整体性能
在Mini React中实现的这一优化,体现了React框架设计中的核心性能优化思想。理解这一机制有助于我们编写更高效的React应用代码。
优化本质:计算成本 < 渲染成本时,用计算换渲染
来源:juejin.cn/post/7524992966084083766
前端使用CountUp.js制作数字动画效果的教程
在现代网页设计中,动态数字展示能够显著提升用户体验,吸引访客注意力。无论是数据统计、销售数字还是还是评分展示,平滑的数字增长动画都能让信息传递更加生动。CountUp.js 正是一款专门用于创建这种数字动画效果的轻量级 JavaScript 库,本文将详细介绍其使用方法与技巧。
1. 前言
CountUp.js 是一个零依赖的 JavaScript 库,用于创建从一个数字平滑过渡到另一个数字的动画效果。它体积小巧(压缩后仅约 3KB),使用简单,且高度可定制,能够满足各种数字动画需求。
CountUp.js 的特点
- 零依赖,无需引入其他库
- 轻量级,加载迅速
- 高度可配置(动画时长、延迟、小数位数等)
- 支持多种 easing 动画效果
- 支持暂停、恢复、重置等控制
- 兼容所有现代浏览器
2. 快速开始
CountUp.js 有多种引入方式,可根据项目需求选择:
1. 通过 npm 安装
npm install countup.js
然后在项目中导入:
import CountUp from 'countup.js';
2. 直接引入 CDN
<script src="https://cdn.jsdelivr.net/npm/countup.js@2.0.8/dist/countUp.umd.min.js">script>
3. 下载源码
从 GitHub 仓库 下载源码,直接引入本地文件。
2.1. 基本用法
使用 CountUp.js 只需三步:
- 在 HTML 中准备一个用于显示数字的元素
<div id="counter">div>
- 初始化 CountUp 实例
// 获取 DOM 元素
const element = document.getElementById('counter');
// 目标数值
const target = 1000;
// 创建 CountUp 实例
const countUp = new CountUp(element, target);
- 启动动画
// 检查是否初始化成功,然后启动动画
if (!countUp.error) {
countUp.start();
} else {
console.error(countUp.error);
}
3. 配置选项
CountUp.js 提供了丰富的配置选项,让你可以精确控制动画效果:
const options = {
startVal: 0, // 起始值,默认为 0
duration: 2, // 动画时长(秒),默认为 2
decimalPlaces: 0, // 小数位数,默认为 0
useGr0uping: true, // 是否使用千位分隔符,默认为 true
useEasing: true, // 是否使用缓动效果,默认为 true
smartEasingThreshold: 999, // 智能缓动阈值
smartEasingAmount: 300, // 智能缓动数量
separator: ',', // 千位分隔符,默认为 ','
decimal: '.', // 小数点符号,默认为 '.'
prefix: '', // 数字前缀
suffix: '', // 数字后缀
numerals: [] // 数字替换数组,用于本地化
};
// 使用配置创建实例
const countUp = new CountUp(element, target, options);
3.1. 示例:带前缀和后缀的动画
// 显示"$1,234.56"的动画
const options = {
startVal: 0,
duration: 3,
decimalPlaces: 2,
prefix: '$',
suffix: ''
};
const countUp = new CountUp(document.getElementById('price'), 1234.56, options);
countUp.start();
4. 高级控制方法
CountUp.js 提供了多种方法来控制动画过程:
// 开始动画
countUp.start();
// 暂停动画
countUp.pauseResume();
// 重置动画
countUp.reset();
// 更新目标值并重新开始动画
countUp.update(2000);
// 立即完成动画
countUp.finish();
4.1. 示例:带回调函数的动画
// 动画完成后执行回调函数
countUp.start(() => {
console.log('动画完成!');
// 可以在这里执行后续操作
});
5. 实际应用场景
下面是实际应用场景的模拟:
5.1. 数据统计展示
<div class="stats">
<div class="stat-item">
<h3>用户总数h3>
<div class="stat-value" id="users">div>
div>
<div class="stat-item">
<h3>总销售额h3>
<div class="stat-value" id="sales">div>
div>
<div class="stat-item">
<h3>转化率h3>
<div class="stat-value" id="conversion">div>
div>
div>
<script>
// 初始化多个计数器
const usersCounter = new CountUp('users', 12500, { suffix: '+' });
const salesCounter = new CountUp('sales', 458920, { prefix: '$', decimalPlaces: 0 });
const conversionCounter = new CountUp('conversion', 24.5, { suffix: '%', decimalPlaces: 1 });
// 同时启动所有动画
document.addEventListener('DOMContentLoaded', () => {
usersCounter.start();
salesCounter.start();
conversionCounter.start();
});
script>
5.2. 滚动触发动画
结合 Intersection Observer API,实现元素进入视口时触发动画:
<div id="scrollCounter" class="counter">div>
<script>
// 创建计数器实例但不立即启动
const scrollCounter = new CountUp('scrollCounter', 5000);
// 配置交叉观察器
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
// 元素进入视口,启动动画
scrollCounter.start();
// 只观察一次
observer.unobserve(entry.target);
}
});
});
// 观察目标元素
observer.observe(document.getElementById('scrollCounter'));
script>
5.3. 结合按钮控制
<div id="controlledCounter">div>
<button id="startBtn">开始button>
<button id="pauseBtn">暂停button>
<button id="resetBtn">重置button>
<button id="updateBtn">更新到 2000button>
<script>
const counter = new CountUp('controlledCounter', 1000);
// 按钮事件监听
document.getElementById('startBtn').addEventListener('click', () => {
counter.start();
});
document.getElementById('pauseBtn').addEventListener('click', () => {
counter.pauseResume();
});
document.getElementById('resetBtn').addEventListener('click', () => {
counter.reset();
});
document.getElementById('updateBtn').addEventListener('click', () => {
counter.update(2000);
});
script>
6.自定义缓动函数
CountUp.js 允许你自定义缓动函数,创建独特的动画效果:
// 自定义缓动函数
function myEasing(t, b, c, d) {
// t: 当前时间
// b: 起始值
// c: 变化量 (目标值 - 起始值)
// d: 总时长
t /= d;
return c * t * t * t + b;
}
// 使用自定义缓动函数
const options = {
duration: 2,
easingFn: myEasing
};
const countUp = new CountUp(element, target, options);
countUp.start();
7. 常见问题与解决方案
下面是一些常见问题与解决方案:
7.1. 动画不生效
- 检查元素是否正确获取
- 确保目标值大于起始值(如需从大到小动画,可设置 startVal 大于 target)
- 检查控制台是否有错误信息
7.2. 数字格式问题
- 使用 separator 和 decimal 选项配置数字格式
- 对于特殊数字系统,使用 numerals 选项进行替换
7.3. 性能问题
- 避免在同一页面创建过多计数器实例
- 对于非常大的数字,适当增加动画时长
- 考虑使用滚动触发,而非页面加载时同时启动所有动画
8. 总结
CountUp.js 是一个简单而强大的数字动画库,能够为你的网站增添专业感和活力。它的轻量级特性和丰富的配置选项使其适用于各种场景,从简单的数字展示到复杂的数据可视化。
通过本文介绍的基础用法和高级技巧,你可以轻松实现各种数字动画效果,提升用户体验。无论是个人博客、企业官网还是电商平台,CountUp.js 都能成为你前端工具箱中的得力助手。
参考资源
来源:juejin.cn/post/7542403996917989422
uniapp图片上传添加水印/压缩/剪裁
一、前言
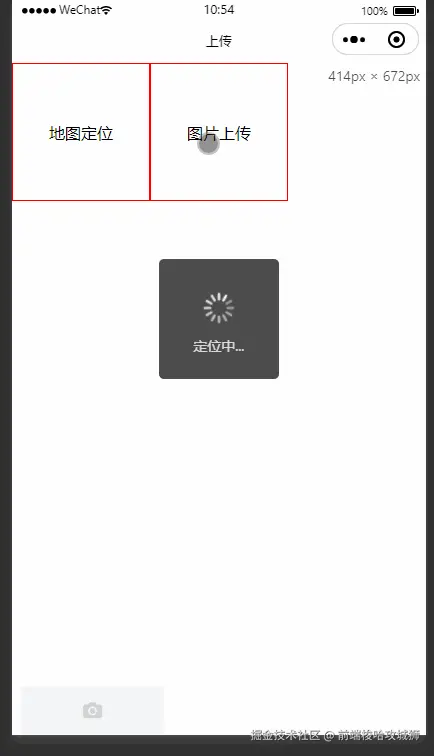
最近遇到一个需求,微信小程序上传图片添加水印的需求,故此有该文章做总结, 功能涵盖定理地位,百度地址解析,图片四角水印,图片压缩,图片压缩并添加水印,图片剪裁,定位授权,保存图片到相册等
二、效果
三、代码实现核心
3.1)添加水印并压缩
核心实现
// 添加水印并压缩
export function addWatermarkAndCompress(options, that, isCompress = false) {
return new Promise((resolve, reject) => {
const {
errLog,
config
} = dealWatermarkConfig(options)
that.watermarkCanvasOption.width = 0
that.watermarkCanvasOption.height = 0
if (!errLog.length) {
const {
canvasId,
imagePath,
watermarkList,
quality = 0.6
} = config
uni.getImageInfo({ // 获取图片信息,以便获取图片的真实宽高信息
src: imagePath,
success: (info) => {
const {
width: oWidth,
height: oHeight,
type,
orientation
} = info; // 获取图片的原始宽高
const fileTypeObj = {
'jpeg': 'jpg',
'jpg': 'jpg',
'png': 'png',
}
const fileType = fileTypeObj[type] || 'png'
let width = oWidth
let height = oHeight
if (isCompress) {
const {
cWidth,
cHeight
} = calcRatioHeightAndWight({
oWidth,
oHeight,
quality,
orientation
})
// 按对折比例缩小
width = cWidth
height = cHeight
}
that.watermarkCanvasOption.width = width
that.watermarkCanvasOption.height = height
that.$nextTick(() => {
// 获取canvas绘图上下文
const ctx = uni.createCanvasContext(canvasId, that);
// 绘制原始图片到canvas上
ctx.drawImage(imagePath, 0, 0, width, height);
// 绘制水印项
const drawWMItem = (ctx, options) => {
const {
fontSize,
color,
text: cText,
position,
margin
} = options
// 添加水印
ctx.setFontSize(fontSize); // 设置字体大小
ctx.setFillStyle(color); // 设置字体颜色为红色
if (isNotEmptyArr(cText)) {
const text = cText.filter(Boolean)
if (position.startsWith('bottom')) {
text.reverse()
}
text.forEach((str, ind) => {
const textMetrics = ctx.measureText(str);
const {
calcX,
calcY
} = calcPosition({
height,
width,
position,
margin,
ind,
fontSize,
textMetrics
})
ctx.fillText(str, calcX, calcY, width);
})
} else {
const textMetrics = ctx.measureText(cText);
const {
calcX,
calcY
} = calcPosition({
height,
width,
position,
margin,
ind: 0,
fontSize,
textMetrics
})
// 在图片底部添加水印文字
ctx.fillText(text, calcX, calcY, width);
}
}
watermarkList.forEach(ele => {
drawWMItem(ctx, ele)
})
// 绘制完成后执行的操作,这里不等待绘制完成就继续执行后续操作,因为我们要导出为图片
ctx.draw(false, () => {
// #ifndef MP-ALIPAY
uni.canvasToTempFilePath({ // 将画布内容导出为图片
canvasId,
x: 0,
y: 0,
width,
height,
fileType,
quality, // 图片的质量,目前仅对 jpg 有效。取值范围为 (0, 1],不在范围内时当作 1.0 处理。
destWidth: width,
destHeight: height,
success: (res) => {
console.log('res.tempFilePath', res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
// #ifdef MP-ALIPAY
ctx.toTempFilePath({ // 将画布内容导出为图片
canvasId,
x: 0,
y: 0,
width: width,
height: height,
destWidth: width,
destHeight: height,
quality,
fileType,
success: (res) => {
console.log('res.tempFilePath', res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
});
})
}
});
} else {
const errStr = errLog.join(';')
showMsg(errStr)
reject(errStr)
}
})
}
3.2)剪切图片
// 剪切图片
export function clipImg(options, that) {
return new Promise((resolve, reject) => {
const {
errLog,
config
} = dealClipImgConfig(options)
that.watermarkCanvasOption.width = 0
that.watermarkCanvasOption.height = 0
if (!errLog.length) {
const {
canvasId,
imagePath,
cWidth,
cHeight,
position
} = config
// 获取图片信息,以便获取图片的真实宽高信息
uni.getImageInfo({
src: imagePath,
success: (info) => {
const {
width,
height
} = info; // 获取图片的原始宽高
// 自定义剪裁范围要在图片内
if (width >= cWidth && height >= cHeight) {
that.watermarkCanvasOption.width = width
that.watermarkCanvasOption.height = height
that.$nextTick(() => {
// 获取canvas绘图上下文
const ctx = uni.createCanvasContext(canvasId, that);
const {
calcSX,
calcSY,
calcEX,
calcEY
} = calcClipPosition({
cWidth,
cHeight,
position,
width,
height
})
// 绘制原始图片到canvas上
ctx.drawImage(imagePath, 0, 0, width, height);
// 绘制完成后执行的操作,这里不等待绘制完成就继续执行后续操作,因为我们要导出为图片
ctx.draw(false, () => {
// #ifndef MP-ALIPAY
uni.canvasToTempFilePath({ // 将画布内容导出为图片
canvasId,
x: calcSX,
y: calcSY,
width: cWidth,
height: cHeight,
destWidth: cWidth,
destHeight: cHeight,
success: (res) => {
console.log('res.tempFilePath',
res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
// #ifdef MP-ALIPAY
ctx.toTempFilePath({ // 将画布内容导出为图片
canvasId,
x: 0,
y: 0,
width: width,
height: height,
destWidth: width,
destHeight: height,
// fileType: 'png',
success: (res) => {
console.log('res.tempFilePath',
res)
resolve(res.tempFilePath)
},
fail() {
reject(false)
}
}, that);
// #endif
});
})
} else {
return imagePath
}
}
})
} else {
const errStr = errLog.join(';')
showMsg(errStr)
reject(errStr)
}
})
}
3.3)canvas画布标签
<!-- 给图片添加的标签 -->
<canvas v-if="watermarkCanvasOption.width > 0 && watermarkCanvasOption.height > 0"
:style="{ width: watermarkCanvasOption.width + 'px', height: watermarkCanvasOption.height + 'px' }"
canvas-id="watermarkCanvas" id="watermarkCanvas" style="position: absolute; top: -10000000rpx;" />
以上代码具体的实现功能不做一一讲解,详细请看下方源码地址
四、源码地址
github: github.com/ArcherNull/…
五、总结
- 图片的操作,例如压缩/剪裁/加水印都是需要借助canvas标签,也就是说需要有canvas实例通过该api实现这些操作
- 当执行 ctx.drawImage(imagePath, 0, 0, width, height) 后,后续的操作的是对内存中的数据,而不是源文件
完结撒花,如果对您有帮助,请一键三连
来源:juejin.cn/post/7513183180092031011
如何将canvas动画导成一个视频?
引言
某一天我突然有个想法,我想用canvas做一个音频可视化的音谱,然后将这个音频导出成视频。
使用canvas实现音频可视化,使用ffmpeg导出视频与音频,看起来方案是可行的,技术也是可行的,说干就干,先写一个demo。
这里我使用vue来搭建项目
- 创建项目
vue create demo
- 安装ffmpeg插件
npm @ffmpeg/ffmpeg @ffmpeg/core
- 组件videoPlayer.vue
这里有个点需要注意:引用@ffmpeg/ffmpeg可能会报错
需要将node_modules中@ffmpeg文件下面的 - ffmpeg-core.js
- ffmpeg-core.wasm
- ffmpeg-core.worker.js
这三个文件复制到public文件下面 - 并且需要在vue。config.js中进行如下配置
const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({
transpileDependencies: true,
devServer:{
headers: {
"Cross-Origin-Opener-Policy": "same-origin",
"Cross-Origin-Embedder-Policy": "require-corp",
}
}
})
准备好这些后,下面是实现代码
<template>
<div class="wrap" v-loading="loading" element-loading-text="正在下载视频。。。">
<div>
<input type="file" @change="handleFileUpload" accept="audio/*" />
<button @click="playAudio">播放</button>
<button @click="pauseAudio">暂停</button>
</div>
<div class="canvas-wrap">
<canvas ref="canvas" id="canvas"></canvas>
</div>
</div>
</template>
<script>
import RainDrop from './rain'
import { createFFmpeg, fetchFile } from '@ffmpeg/ffmpeg';
export default {
name: 'canvasVideo',
data() {
return {
frames: [],
recording: false,
ffmpeg: null,
x: 0,
loading: false,
canvasCtx: null,
audioContext: null,
analyser: null,
bufferLength: null,
dataArray: null,
audioFile: null,
audioElement: null,
audioSource: null,
// 谱频个数
barCount: 64,
// 宽度
barWidth: 10,
marginLeft: 10,
player: false,
rainCount: 200,
rainDrops: [],
pausePng: null,
offscreenCanvas: null
};
},
mounted() {
this.ffmpeg = createFFmpeg({ log: true });
this.initFFmpeg();
},
methods: {
async initFFmpeg() {
await this.ffmpeg.load();
this.initCanvas()
},
startRecording() {
this.recording = true;
this.captureFrames();
},
stopRecording() {
this.recording = false;
this.exportVideo();
},
async captureFrames() {
const canvas = this.canvasCtx.canvas;
const imageData = canvas.toDataURL('image/png');
this.frames.push(imageData);
},
async exportVideo() {
this.loading = true
this.recording = false
const { ffmpeg } = this;
console.log('frames', this.frames)
try {
for (let i = 0; i < this.frames.length; i++) {
const frame = this.frames[i];
const frameData = await fetchFile(frame);
ffmpeg.FS('writeFile', `frame${i}.png`, frameData);
}
// 将音频文件写入 FFmpeg 文件系统
ffmpeg.FS('writeFile', 'audio.mp3', await fetchFile(this.audioFile));
// 使用 FFmpeg 将帧编码为视频
await ffmpeg.run(
'-framerate', '30', // 帧率 可以收费
'-i', 'frame%d.png', // 输入文件名格式
'-i', 'audio.mp3', // 输入音频
'-c:v', 'libx264', // 视频编码器
'-c:a', 'aac', // 音频编码器
'-pix_fmt', 'yuv420p', // 像素格式
'-vsync', 'vfr', // 同步视频和音频
'-shortest', // 使视频长度与音频一致
'output.mp4' // 输出文件名
);
const files = ffmpeg.FS('readdir', '/');
console.log('文件系统中的文件:', files);
const data = ffmpeg.FS('readFile', 'output.mp4');
const url = URL.createObjectURL(new Blob([data.buffer], { type: 'video/mp4' }));
const a = document.createElement('a');
a.href = url;
a.download = 'output.mp4';
a.click();
} catch (e) {
console.log('eeee', e)
}
this.loading = false
},
initCanvas() {
const dom = document.getElementById('canvas');
this.canvasCtx = dom.getContext('2d');
const p = document.querySelector('.canvas-wrap')
console.log('p', p.offsetWidth)
this.canvasCtx.canvas.width = p.offsetWidth;
this.canvasCtx.canvas.height = p.offsetHeight;
console.log('canvasCtx', this.canvasCtx)
this.initAudioContext()
this.createRainDrops()
},
handleFileUpload(event) {
const file = event.target.files[0];
if (file) {
this.audioFile = file
const fileURL = URL.createObjectURL(file);
this.loadAudio(fileURL);
}
},
loadAudio(url) {
this.audioElement = new Audio(url);
this.audioElement.addEventListener('error', (e) => {
console.error('音频加载失败:', e);
});
this.audioSource = this.audioContext.createMediaElementSource(this.audioElement);
this.audioSource.connect(this.analyser);
this.analyser.connect(this.audioContext.destination);
},
playAudio() {
if (this.audioContext.state === 'suspended') {
this.audioContext.resume().then(() => {
console.log('AudioContext 已恢复');
this.audioElement.play();
this.player = true
this.draw();
});
} else {
this.audioElement.play().then(() => {
this.player = true
this.draw();
}).catch((error) => {
console.error('播放失败:', error);
});
}
},
pauseAudio() {
if (this.audioElement) {
this.audioElement.pause();
this.player = false
this.stopRecording()
}
},
initAudioContext() {
this.audioContext = new (window.AudioContext || window.webkitAudioContext)();
this.analyser = this.audioContext.createAnalyser();
this.analyser.fftSize = 256;
this.dataArray = new Uint8Array(this.barCount);
},
bar() {
let barHeight = 20;
const allBarWidth = this.barCount * this.barWidth + this.marginLeft * (this.barCount - 1)
const left = (this.canvasCtx.canvas.width - allBarWidth) / 2
let x = left
for (let i = 0; i < this.barCount; i++) {
barHeight = this.player ? this.dataArray[i] : 0
// console.log('barHeight', barHeight)
// 创建线性渐变
const gradient = this.canvasCtx.createLinearGradient(0, 0, this.canvasCtx.canvas.width, 0); // 从左到右渐变
gradient.addColorStop(0.2, '#fff'); // 起始颜色
gradient.addColorStop(0.5, '#ff5555');
gradient.addColorStop(0.8, '#fff'); // 结束颜色
// 设置阴影属性
this.canvasCtx.shadowColor = i <= 10 ? '#fff' : i > 54 ? '#fff' : '#ff5555';
this.canvasCtx.shadowBlur = 5;
this.canvasCtx.fillStyle = gradient;
this.canvasCtx.fillRect(x, this.canvasCtx.canvas.height - barHeight / 2 - 100, this.barWidth, barHeight / 2);
this.canvasCtx.shadowColor = i <= 10 ? '#fff' : i > 54 ? '#fff' : '#ff5555';
this.canvasCtx.shadowBlur = 5;
this.canvasCtx.beginPath();
this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - barHeight / 2 - 99, 5, 0, Math.PI, true)
// this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - barHeight / 2, 5, 0, Math.PI, false)
this.canvasCtx.closePath();
this.canvasCtx.fill()
this.canvasCtx.shadowColor = i <= 10 ? '#fff' : i > 54 ? '#fff' : '#ff5555';
this.canvasCtx.shadowBlur = 5;
this.canvasCtx.beginPath();
// this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - barHeight / 2 - 100, 5, 0, Math.PI, true)
this.canvasCtx.arc(x + 5, this.canvasCtx.canvas.height - 100, 5, 0, Math.PI, false)
this.canvasCtx.closePath();
this.canvasCtx.fill()
x += this.barWidth + this.marginLeft;
}
},
draw() {
if (this.player) requestAnimationFrame(this.draw);
this.startRecording()
// 获取频谱数据
this.analyser.getByteFrequencyData(this.dataArray);
this.canvasCtx.fillStyle = 'rgb(0, 0, 0)';
this.canvasCtx.fillRect(0, 0, this.canvasCtx.canvas.width, this.canvasCtx.canvas.height); // 清除画布
this.bar()
this.rainDrops.forEach((drop) => {
drop.update();
drop.draw(this.canvasCtx);
});
},
// 创建雨滴对象
createRainDrops() {
for (let i = 0; i < this.rainCount; i++) {
this.rainDrops.push(new RainDrop(this.canvasCtx.canvas.width, this.canvasCtx.canvas.height, this.canvasCtx));
}
},
}
};
</script>
当选择好音频文件点击播放时如下图
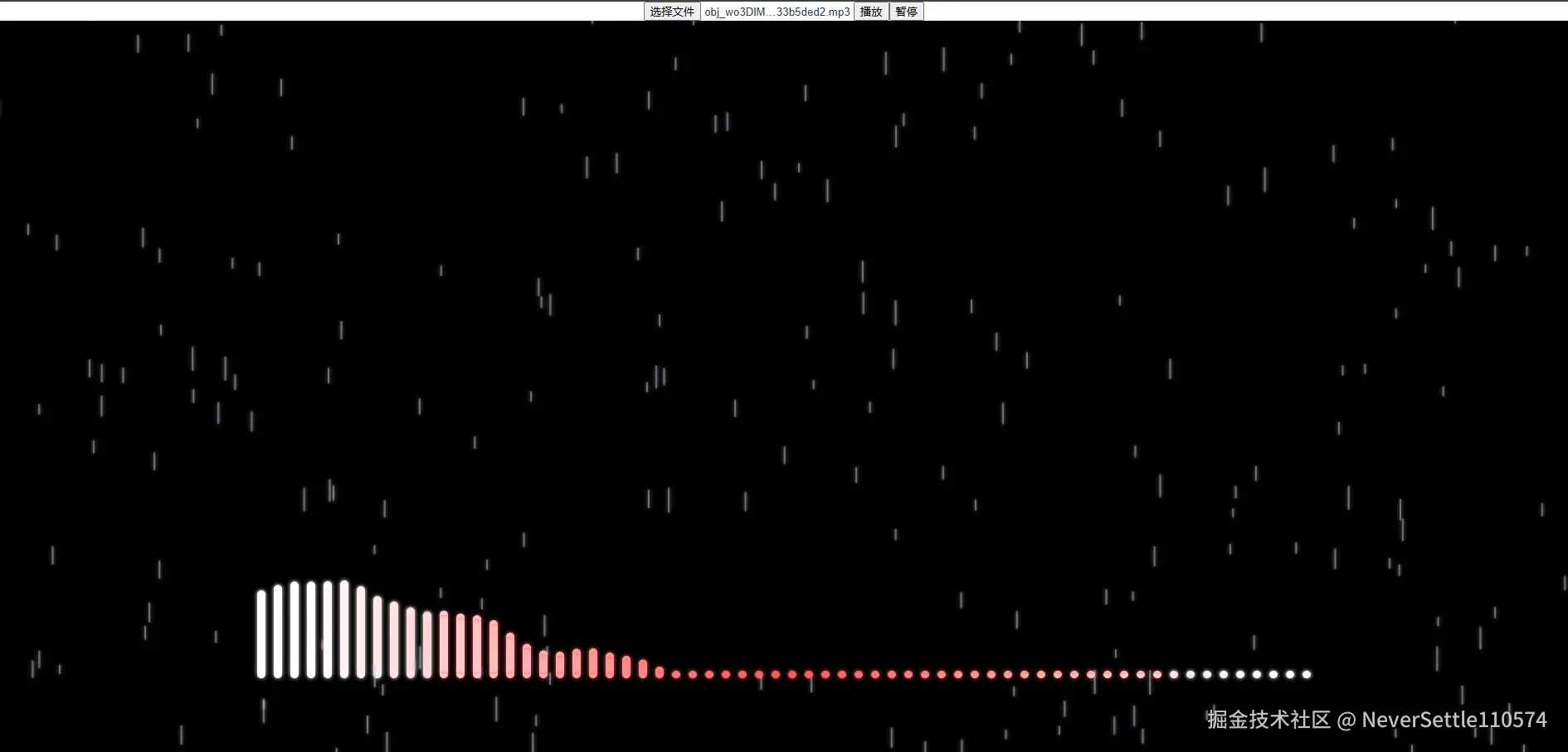
点击暂停则可对已经播放过的音频时长进行视频录制下载
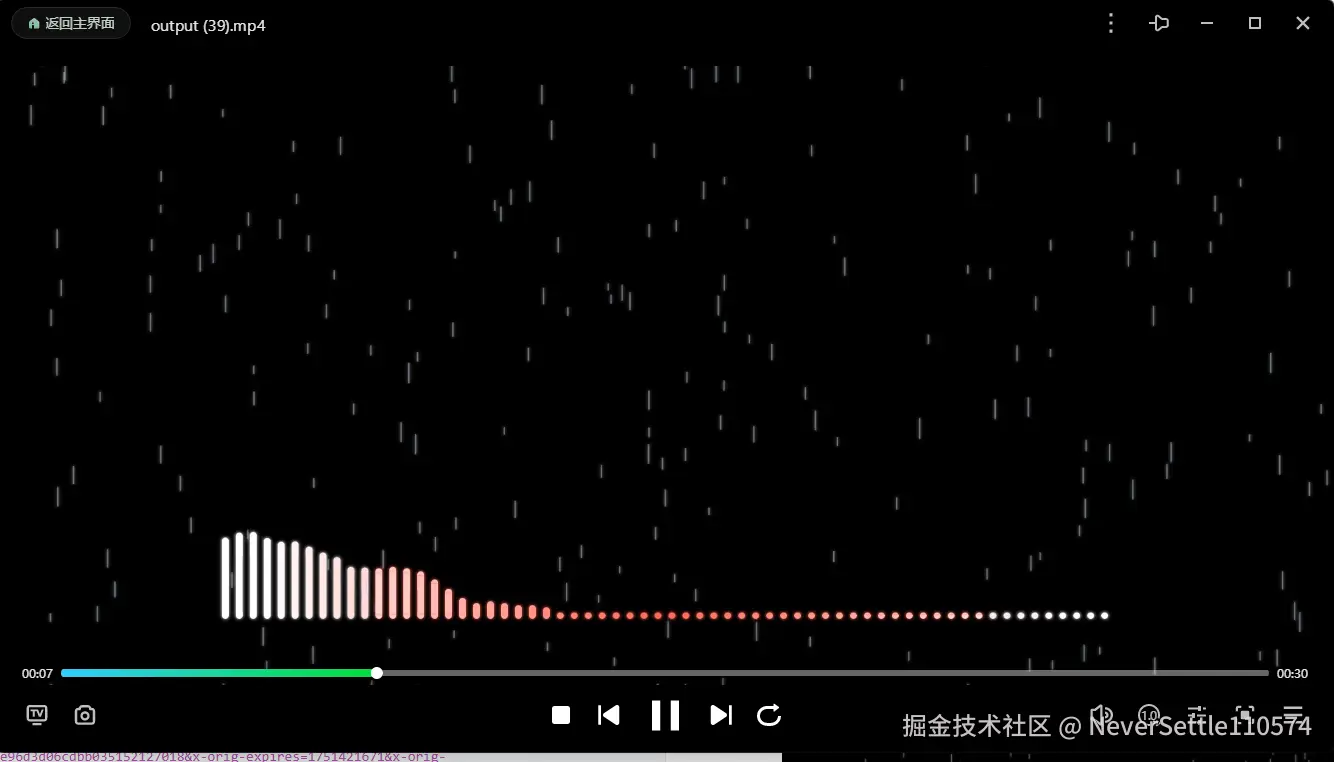
如果有什么其他问题欢迎在评论区交流
来源:juejin.cn/post/7521685642431053863
理解 devDependencies:它们真的不会被打包进生产代码吗?
在前端开发中,很多开发者都有一个常见误解:package.json 中的 devDependencies 是开发时依赖,因此不会被打包到最终的生产环境代码中。这个理解在一定条件下成立,但在真实项目中,打包工具(如 Vite、Webpack 等)并不会根据 devDependencies 或 dependencies 的位置来决定是否将依赖打包到最终的 bundle 中,而是完全俗义于代码中是否引用了这些模块。
本文将通过一个实际例子来说明这个问题,并提出一些实践建议来避免误用。
一、dependencies vs devDependencies 回顾
在 package.json 中,我们通常会看到两个依赖字段:
{
"dependencies": {
"lodash": "^4.17.21"
},
"devDependencies": {
"vite": "^5.0.0"
}
}
dependencies:运行时依赖,通常用于项目在生产环境中运行所需的库。devDependencies:开发时依赖,通常用于构建、测试、打包等过程,比如 Babel、ESLint、Vite 等。
很多人认为把某个库放到 devDependencies 中就意味着它不会被打包进最终代码,但这只是约定俗成,并非构建工具的实际行为。
二、一个实际例子:lodash 被错误地放入 devDependencies
我们以一个使用 Vite 构建的库包为例:
目录结构:
my-lib/
├── src/
│ └── index.ts
├── package.json
├── vite.config.ts
└── tsconfig.json
src/index.ts
import _ from 'lodash';
export function capitalizeName(name: string) {
return _.capitalize(name);
}
错误的 package.json
{
"name": "my-lib",
"version": "1.0.0",
"main": "dist/index.js",
"module": "dist/index.mjs",
"types": "dist/index.d.ts",
"scripts": {
"build": "vite build"
},
"devDependencies": {
"vite": "^5.0.0",
"lodash": "^4.17.21",
"typescript": "^5.4.0"
}
}
注意:lodash 被放到了 devDependencies 中,而不是 dependencies中。
构建后结果:
执行 npm run build 后,你会发现 lodash 的代码被打包进了最终输出的 bundle 中,尽管它被标记为 devDependencies。
dist/
├── index.js ← 包含 lodash 的代码
├── index.mjs
└── index.d.ts
三、为什么会发生这种情况?
构建工具(如 Vite、Webpack)在处理打包时,并不会关心某个依赖是 dependencies 还是 devDependencies。
它只会扫描你的代码:
- 如果你
import了某个模块(如lodash),构建工具会把它包含进 bundle 中,除非你通过external配置显式告诉它不要打包进来。 - 你放在
devDependencies中只是告诉 npm install:这个依赖只在开发阶段需要,npm install --production时不会安装它。
换句话说,打包行为取决于代码,而不是依赖声明。
四、修复方式:将运行时依赖移到 dependencies
为了正确构建一个可以发布的库包,应该:
{
"dependencies": {
"lodash": "^4.17.21"
},
"devDependencies": {
"vite": "^5.0.0",
"typescript": "^5.4.0"
}
}
这样使用你库的开发者才能在安装你的包时自动获取 lodash。
五、如何防止此类问题?
1. 使用 peerDependencies(推荐给库开发者)
如果你希望使用者自带 lodash,而不是你来打包它,可以这样配置:
{
"peerDependencies": {
"lodash": "^4.17.21"
}
}
同时在 Vite 配置中加上:
export default defineConfig({
build: {
lib: {
entry: 'src/index.ts',
name: 'MyLib'
},
rollupOptions: {
external: ['lodash'], // 不打包 lodash
}
}
})
这样打包出来的 bundle 中就不会再包含 lodash 的代码。
2. 使用构建工具的 external 配置
像上面这样将 lodash 标为 external 可以避免误打包。
3. 静态分析工具检测
使用像 depcheck 或 eslint-plugin-import 等工具,可以帮你发现未声明或声明错误的依赖。
六、总结
| 依赖位置 | 作用说明 |
|---|---|
dependencies | 生产环境运行时必须使用的库 |
devDependencies | 开发、构建过程所需的工具库 |
peerDependencies | 你的库需要,但由使用者提供的依赖(库开发推荐) |
构建工具不会参考 package.json 中依赖的位置来决定是否打包,而是基于代码的实际引用。作为库作者,你应该确保:
- 所有运行时依赖都放在
dependencies或peerDependencies; - 构建工具正确配置 external,避免不必要地打包外部依赖;
- 使用工具检查依赖定义的一致性。
来源:juejin.cn/post/7530180739729555491
使用three.js搭建3d隧道监测-2
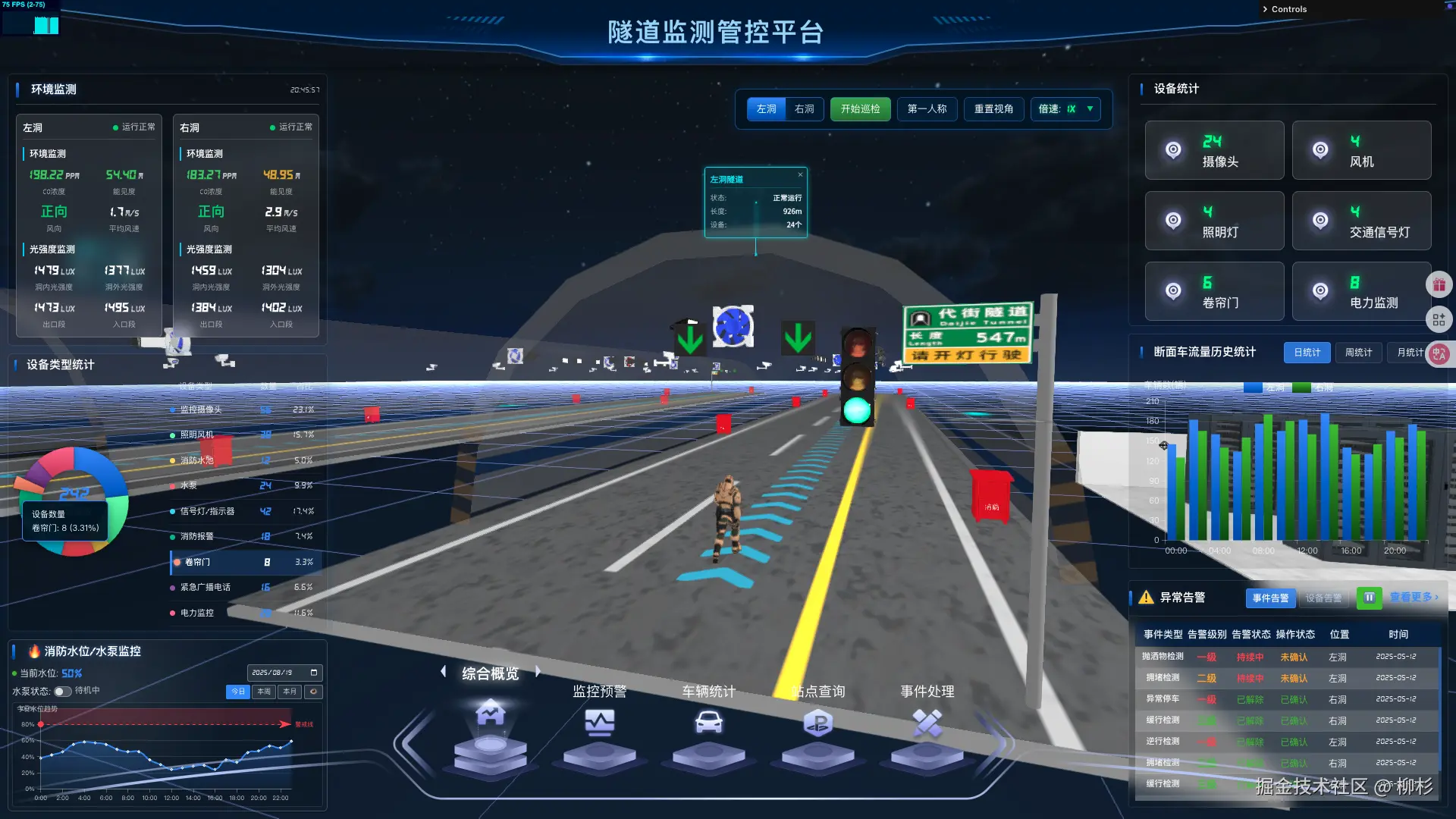
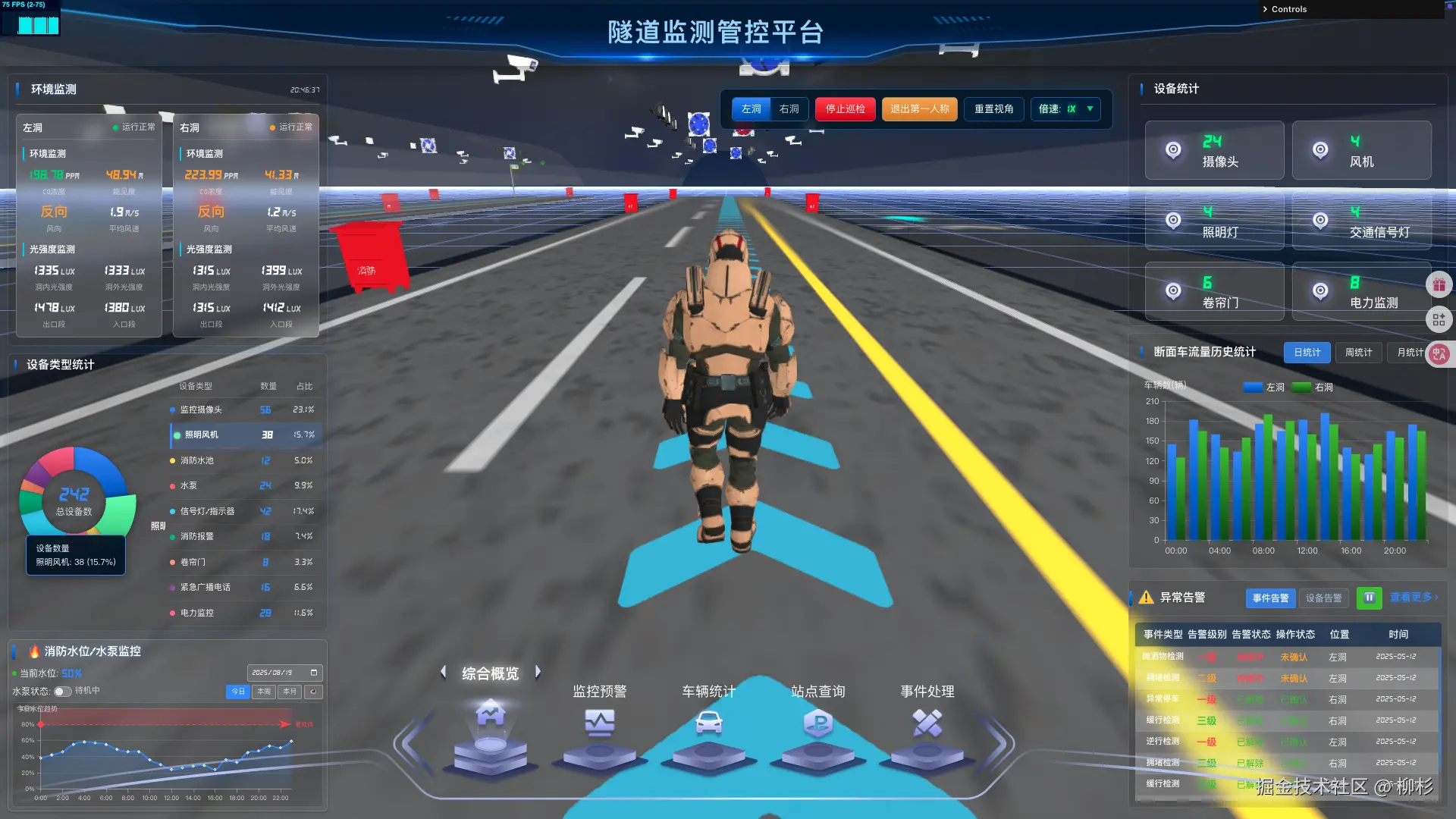
加载基础线条与地面效果


在我们的隧道监控系统中,地面网格和方向指示器是重要的视觉元素,它们帮助用户理解空间关系和导航方向。
1. 网格地面的创建与优化
javascript
// 初始化场景中的地面
const addGround = () => {
const size = 40000; // 网格大小
const divisions = 100; // 分割数(越高越密集)
// 主网格线颜色(亮蓝色)
const color1 = 0x6E7DB9; // 蓝色
// 次网格线颜色(深蓝色)
const color2 = 0x282C3C; // 深蓝色
const gridHelper = new THREE.GridHelper(size, divisions, color1, color2);
// 调整网格线的透明度和材质
gridHelper.material.opacity = 1;
gridHelper.material.transparent = true;
gridHelper.material.depthWrite = false; // 防止网格阻挡其他物体的渲染
// 设置材质的混合模式以实现发光效果
gridHelper.material.blending = THREE.AdditiveBlending;
gridHelper.material.vertexColors = false;
// 增强线条对比度
gridHelper.material.color.setHex(color1);
gridHelper.material.linewidth = 100;
// 旋转网格,使其位于水平面
gridHelper.rotation.x = Math.PI;
sceneRef.current.add(gridHelper);
};
知识点: Three.js 中的网格地面实现技术
- GridHelper:Three.js 提供的辅助对象,用于创建二维网格,常用于表示地面或参考平面
- 材质优化:通过设置
depthWrite = false避免渲染排序问题,防止网格阻挡其他物体
- 混合模式:
AdditiveBlending混合模式使重叠线条颜色叠加,产生发光效果
- 性能考量:网格分割数(divisions)会影响性能,需要在视觉效果和性能间平衡
- 旋转技巧:通过
rotation.x = Math.PI将默认垂直的网格旋转到水平面
这种科幻风格的网格地面在虚拟现实、数据可视化和游戏中非常常见,能够提供空间参考而不显得过于突兀。
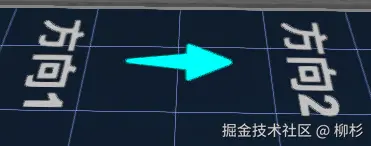
2. 动态方向指示器的实现
javascript
const createPolygonRoadIndicators = (dis) => {
const routeIndicationGeometry = new THREE.PlaneGeometry(3024, 4000); // 创建平面几何体
// 创建文本纹理的辅助函数
const getTextCanvas = (text) => {
const width = 200;
const height = 300;
const canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx.font = "bold 40px Arial"; // 设置字体大小和样式
ctx.fillStyle = '#949292'; // 设置字体颜色
ctx.textAlign = 'center';
ctx.textBaseline = 'middle';
ctx.fillText(text, width / 2, height / 2);
return canvas;
};
// 创建方向1文本平面
const textMap = new THREE.CanvasTexture(getTextCanvas('方向1'));
const textMaterial = new THREE.MeshBasicMaterial({
map: textMap,
transparent: true,
depthTest: false
});
const plane = new THREE.Mesh(routeIndicationGeometry, textMaterial);
plane.castShadow = false;
plane.position.set(1024, 0, 1400);
plane.rotateX(-Math.PI / 2);
// 创建方向2文本平面
const textMap1 = new THREE.CanvasTexture(getTextCanvas('方向2'));
const textMaterial1 = new THREE.MeshBasicMaterial({
map: textMap1,
transparent: true,
depthTest: false
});
const plane1 = new THREE.Mesh(routeIndicationGeometry, textMaterial1);
plane1.castShadow = false;
plane1.position.set(1024, 0, -1400);
plane1.rotateX(-Math.PI / 2);
// 创建箭头指示器
const loader = new THREE.TextureLoader();
const texture = loader.load('/image/arrow1.png', (t) => {
t.wrapS = t.wrapT = THREE.RepeatWrapping;
t.repeat.set(1, 1);
});
const geometryRoute = new THREE.PlaneGeometry(1024, 1200);
const materialRoute = new THREE.MeshStandardMaterial({
map: texture,
transparent: true,
side: THREE.DoubleSide, // 确保可以从两个面看见
});
const plane2 = new THREE.Mesh(geometryRoute, materialRoute);
plane2.receiveShadow = false;
plane2.position.set(1000, 0, 0);
plane2.rotateX(dis==="left"?-Math.PI / 2:Math.PI / 2);
// 将所有元素组合成一个组
const group = new THREE.Gr0up();
group.add(plane2, plane, plane1);
group.scale.set(0.4, 0.4, 0.4);
group.position.set(dis==="left"?500:500-4000, 0, 0);
return group;
};
知识点: Three.js 中的动态文本与指示器实现技术
- Canvas 纹理:使用 HTML Canvas 动态生成文本,然后转换为 Three.js 纹理,这是在 3D 场景中显示文本的高效方法
- CanvasTexture:Three.js 提供的特殊纹理类型,可以直接从 Canvas 元素创建纹理,支持动态更新
- 透明度处理:通过设置
transparent: true和适当的depthTest设置解决透明纹理的渲染问题
- 几何体组织:使用
THREE.Gr0up将多个相关的 3D 对象组织在一起,便于统一变换和管理
- 条件旋转:根据参数
dis动态决定箭头的朝向,实现可配置的方向指示
- 纹理重复:通过
RepeatWrapping和repeat设置可以控制纹理的重复方式,适用于创建连续的纹理效果
这种动态方向指示器在导航系统、虚拟导览和交互式地图中非常有用,可以为用户提供直观的方向引导。
3.地面方向指示器实现
在隧道监控系统中,方向指示是帮助用户理解空间方向和导航的关键元素。我们实现了一套包含文本标签和箭头的地面方向指示系统。
javascript
import * as THREE from "three";
const createPolygonRoadIndicators = (dis) => {
const routeIndicationGeometry = new THREE.PlaneGeometry(3024, 4000); // 创建平面几何体
const getTextCanvas = (text) => {
const width = 200;
const height = 300;
const canvas = document.createElement('canvas');
canvas.width = width;
canvas.height = height;
const ctx = canvas.getContext('2d');
ctx.font = "bold 40px Arial"; // 设置字体大小和样式
ctx.fillStyle = '#949292'; // 设置字体颜色
ctx.textAlign = 'center';
ctx.textBaseline = 'middle';
ctx.fillText(text, width / 2, height / 2);
return canvas;
};
const textMap = new THREE.CanvasTexture(getTextCanvas('方向1'));
const textMaterial = new THREE.MeshBasicMaterial({ map: textMap, transparent: true, depthTest: false }); // 创建材质,depthTest解决黑色块问题
const plane = new THREE.Mesh(routeIndicationGeometry, textMaterial);
plane.castShadow = false; // 不投影阴影"
plane.position.set(1024, 0, 1400);
plane.rotateX(-Math.PI / 2);
const textMap1 = new THREE.CanvasTexture(getTextCanvas('方向2'));
const textMaterial1 = new THREE.MeshBasicMaterial({ map: textMap1, transparent: true, depthTest: false }); // 创建材质,depthTest解决黑色块问题
const plane1 = new THREE.Mesh(routeIndicationGeometry, textMaterial1);
plane1.castShadow = false; // 不投影阴影
plane1.position.set(1024, 0, -1400);
plane1.rotateX(-Math.PI / 2);
const loader = new THREE.TextureLoader();
const texture = loader.load('/image/arrow1.png', (t) => {
t.wrapS = t.wrapT = THREE.RepeatWrapping;
t.repeat.set(1, 1);
});
const geometryRoute = new THREE.PlaneGeometry(1024, 1200);
const materialRoute = new THREE.MeshStandardMaterial({
map: texture,
transparent: true,
side: THREE.DoubleSide, // 确保可以从两个面看见
});
const plane2 = new THREE.Mesh(geometryRoute, materialRoute);
plane2.receiveShadow = false; // 不接收阴影
plane2.position.set(1000, 0, 0);
plane2.rotateX(dis==="left"?-Math.PI / 2:Math.PI / 2);
const group = new THREE.Gr0up();
group.add(plane2, plane, plane1);
group.scale.set(0.4, 0.4, 0.4);
group.position.set(dis==="left"?500:500-4000, 0, 0);
return group;
};
export default createPolygonRoadIndicators;
知识点: Three.js 中的地面方向指示器实现技术
- 平面投影标记:使用
PlaneGeometry创建平面,通过旋转使其平行于地面,形成"地面投影"效果
- 使用
rotateX(-Math.PI / 2)将平面从垂直旋转到水平位置
- 动态文本生成:使用 Canvas API 动态生成文本纹理
getTextCanvas函数创建一个临时 Canvas 并在其上绘制文本
- 使用
CanvasTexture将 Canvas 转换为 Three.js 可用的纹理
- 这种方法比使用 3D 文本几何体更高效,特别是对于频繁变化的文本
- 纹理渲染优化:
transparent: true启用透明度处理,使背景透明
depthTest: false禁用深度测试,解决半透明纹理的渲染问题,防止出现"黑色块"
castShadow: false和receiveShadow: false避免不必要的阴影计算
- 方向性指示:使用箭头纹理创建明确的方向指示
- 通过
TextureLoader加载外部箭头图像
- 根据
dis参数动态调整箭头方向(rotateX(dis==="left"?-Math.PI / 2:Math.PI / 2))
side: THREE.DoubleSide确保从任何角度都能看到箭头
- 组织与缩放:
- 使用
THREE.Gr0up将相关元素(文本标签和箭头)组织在一起
- 通过
group.scale.set(0.4, 0.4, 0.4)统一调整组内所有元素的大小
- 根据方向参数设置整个组的位置,实现左右两侧不同的指示效果
- 纹理重复设置:
RepeatWrapping和repeat.set(1, 1)控制纹理的重复方式
- 这为创建连续的纹理效果提供了基础,虽然本例中设为1(不重复)
这种地面方向指示系统在大型空间(如隧道、机场、展馆)的导航中特别有用,为用户提供直观的方向感,不会干扰主要视觉元素。
隧道指示牌制作
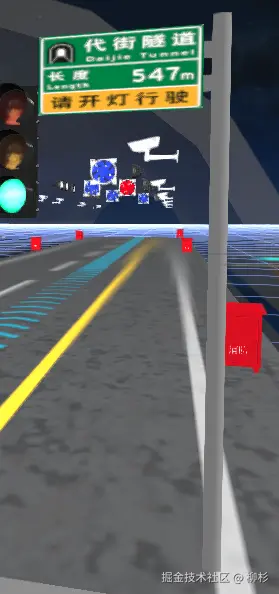
在隧道监控系统中,指示牌是引导用户和提供空间信息的重要元素。我们实现了一种复合结构的隧道指示牌,包含支柱、横梁和信息板。
javascript
import * as THREE from 'three';
import {TextGeometry} from "three/examples/jsm/geometries/TextGeometry";
/**
* 创建石头柱子(竖直 + 横向)
* @returns {THREE.Gr0up} - 返回包含柱子和横梁的组
*/
const createStonePillar = () => {
const pillarGr0up = new THREE.Gr0up();
// 创建六边形的竖直柱子
const pillarGeometry = new THREE.CylinderGeometry(6, 6, 340, 6); // 直径12, 高度340, 六边形柱体
const pillarMaterial = new THREE.MeshStandardMaterial({color: 0x808080}); // 石头颜色
const pillar = new THREE.Mesh(pillarGeometry, pillarMaterial);
pillar.position.set(0, 0, 0);
// 创建第一根横向长方体
const beam1Geometry = new THREE.BoxGeometry(100, 10, 0.1);
const beam1Material = new THREE.MeshStandardMaterial({color: 0x808080});
const beam1 = new THREE.Mesh(beam1Geometry, beam1Material);
beam1.position.set(-50, 150, 0);
// 创建第二根横向长方体
const beam2Geometry = new THREE.BoxGeometry(100, 10, 0.1);
const beam2Material = new THREE.MeshStandardMaterial({color: 0x808080});
const beam2 = new THREE.Mesh(beam2Geometry, beam2Material);
beam2.position.set(-50, 130, 0);
// 将柱子和横梁添加到组
pillarGr0up.add(pillar);
pillarGr0up.add(beam1);
pillarGr0up.add(beam2);
return pillarGr0up;
};
/**
* 创建一个用于绘制文本的 Canvas
* @param {string} text - 要绘制的文本
* @returns {HTMLCanvasElement} - 返回 Canvas 元素
*/
const getTextCanvas = (text) => {
const canvas = document.createElement('canvas');
const context = canvas.getContext('2d');
// 设置 Canvas 尺寸
const fontSize = 32;
canvas.width = 512;
canvas.height = 128;
// 设置背景色
context.fillStyle = '#1E3E9A'; // 蓝底
context.fillRect(0, 0, canvas.width, canvas.height);
// 设置文本样式
context.font = `${fontSize}px Arial`;
context.fillStyle = '#ffffff'; // 白色文本
context.textAlign = 'center';
context.textBaseline = 'middle';
context.fillText(text, canvas.width / 2, canvas.height / 2);
return canvas;
};
/**
* 创建交通指示牌并添加到场景中
* @param {Object} sceneRef - React ref 对象,指向 Three.js 的场景
* @returns {Promise<THREE.Gr0up>} - 返回创建的指示牌组
*/
export default (sceneRef, png, dis) => {
const createSignBoard = async () => {
const signGr0up = new THREE.Gr0up();
const loader = new THREE.TextureLoader();
loader.load(png, texture => {
// 创建一个平面作为标志背景
const signGeometry = new THREE.PlaneGeometry(100, 50); // 宽100,高50
texture.encoding = THREE.sRGBEncoding // 设置纹理的颜色空间
texture.colorSpace = THREE.SRGBColorSpace;
const signMaterial = new THREE.MeshStandardMaterial({
map: texture,
transparent: true,
side: THREE.DoubleSide,
})
const sign = new THREE.Mesh(signGeometry, signMaterial);
sign.position.set(-60, 140, 0.3)
signGr0up.add(sign);
})
// 创建并添加石头柱子
const pillar = createStonePillar();
signGr0up.add(pillar);
if (dis == "left") {
signGr0up.position.set(370, 180, 3750); // 左侧位置
} else {
signGr0up.rotateY(Math.PI); // 旋转180度
signGr0up.position.set(-370 - 2000, 180, 3450 - 7200); // 右侧位置
}
signGr0up.add(pillar);
sceneRef.current.add(signGr0up);
return signGr0up; // 返回整个组
};
// 调用创建指示牌函数
return createSignBoard().then((signGr0up) => {
console.log('交通指示牌创建完成:', signGr0up);
return signGr0up;
});
};
知识点: Three.js 中的复合结构与指示牌实现技术
- 模块化设计:将指示牌分解为柱子、横梁和信息板三个主要组件,便于维护和复用
- 几何体组合:使用简单几何体(圆柱体、长方体、平面)组合构建复杂结构
CylinderGeometry创建六边形柱体作为支撑
BoxGeometry创建横向支撑梁
PlaneGeometry创建平面显示信息
- 空间层次:使用
THREE.Gr0up将相关元素组织在一起,便于整体变换和管理
- 纹理映射:使用
TextureLoader加载外部图像作为指示牌内容
- 设置
colorSpace = THREE.SRGBColorSpace确保颜色正确显示
- 使用
side: THREE.DoubleSide使平面从两面都可见
- 条件定位:根据
dis参数动态决定指示牌的位置和朝向
- 使用
rotateY(Math.PI)旋转180度实现方向反转
- Canvas 动态文本:使用
getTextCanvas函数创建动态文本纹理
- 可以方便地生成不同内容和样式的文本标识
- 异步处理:使用 Promise 处理纹理加载的异步过程,确保资源正确加载
- 返回 Promise 使调用者可以在指示牌创建完成后执行后续操作
这种组合式设计方法允许我们创建高度可定制的指示牌,适用于隧道、道路、建筑内部等多种场景,同时保持代码的可维护性和可扩展性。
多渲染器协同工作机制
在我们的项目中,实现了 WebGL 渲染器、CSS2D 渲染器和 CSS3D 渲染器的协同工作:
const initRenderer = () => {
// WebGL 渲染器
rendererRef.current = new THREE.WebGLRenderer({
antialias: true,
alpha: true,
logarithmicDepthBuffer: true
});
rendererRef.current.setSize(window.innerWidth, window.innerHeight);
rendererRef.current.setPixelRatio(Math.min(window.devicePixelRatio, 2));
rendererRef.current.shadowMap.enabled = true;
rendererRef.current.shadowMap.type = THREE.PCFSoftShadowMap;
rendererRef.current.outputEncoding = THREE.sRGBEncoding;
rendererRef.current.toneMapping = THREE.ACESFilmicToneMapping;
containerRef.current.appendChild(rendererRef.current.domElement);
};
const initCSS2DScene = () => {
// CSS2D 渲染器
css2DRendererRef.current = new CSS2DRenderer();
css2DRendererRef.current.setSize(window.innerWidth, window.innerHeight);
css2DRendererRef.current.domElement.style.position = 'absolute';
css2DRendererRef.current.domElement.style.top = '0';
css2DRendererRef.current.domElement.style.pointerEvents = 'none';
containerRef.current.appendChild(css2DRendererRef.current.domElement);
};
const initCSS3DScene = () => {
// 初始化 CSS3DRenderer
css3DRendererRef.current = new CSS3DRenderer();
css3DRendererRef.current.setSize(sizes.width, sizes.height);
css3DRendererRef.current.domElement.style.position = 'absolute';
css3DRendererRef.current.domElement.style.top = '0px';
css3DRendererRef.current.domElement.style.pointerEvents = 'none'; // 确保CSS3D元素不阻碍鼠标事件
containerRef.current.appendChild(css3DRendererRef.current.domElement);
};
知识点: Three.js 支持多种渲染器同时工作,每种渲染器有不同的优势:
- WebGLRenderer:利用 GPU 加速渲染 3D 内容,性能最佳
- CSS2DRenderer:将 HTML 元素作为 2D 标签渲染在 3D 空间中,适合信息标签
- CSS3DRenderer:将 HTML 元素转换为 3D 对象,支持 3D 变换,适合复杂 UI
多渲染器协同可以充分发挥各自优势,实现复杂的混合现实效果。
后期处理管线设计
项目中实现了基于 EffectComposer 的后期处理管线:
const initPostProcessing = () => {
composerRef.current = new EffectComposer(rendererRef.current);
// 基础渲染通道
const renderPass = new RenderPass(sceneRef.current, cameraRef.current);
composerRef.current.addPass(renderPass);
// 环境光遮蔽通道
const ssaoPass = new SSAOPass(
sceneRef.current,
cameraRef.current,
window.innerWidth,
window.innerHeight
);
ssaoPass.kernelRadius = 16;
ssaoPass.minDistance = 0.005;
ssaoPass.maxDistance = 0.1;
composerRef.current.addPass(ssaoPass);
// 抗锯齿通道
const fxaaPass = new ShaderPass(FXAAShader);
const pixelRatio = rendererRef.current.getPixelRatio();
fxaaPass.material.uniforms['resolution'].value.x = 1 / (window.innerWidth * pixelRatio);
fxaaPass.material.uniforms['resolution'].value.y = 1 / (window.innerHeight * pixelRatio);
composerRef.current.addPass(fxaaPass);
};
知识点: 后期处理(Post-processing)是一种在 3D 场景渲染完成后对图像进行额外处理的技术:
- EffectComposer:Three.js 中的后期处理管理器,可以将多个处理效果组合在一起
- RenderPass:基础渲染通道,将场景渲染到目标缓冲区
- SSAOPass:屏幕空间环境光遮蔽,增强场景深度感和真实感
- FXAAShader:快速近似抗锯齿,提高图像质量
后期处理可以大幅提升画面质量,添加如景深、发光、色彩校正等专业效果。
多层次动画系统
项目实现了一个多层次的动画系统:
// 骨骼动画控制
const getActions = (animations, model) => {
const mixer = new THREE.AnimationMixer(model);
const mixerArray = [];
mixerArray.push(mixer);
const actions = {};
animations.forEach((clip) => {
const action = mixer.clipAction(clip);
actions[clip.name] = action;
});
return {actions, mixerArray};
};
// 动画播放控制
const playActiveAction = (actions, name, startTime = true, loopType = THREE.LoopOnce, clampWhenFinished = true) => {
const action = actions[name];
if (!action) return;
action.reset();
action.clampWhenFinished = clampWhenFinished;
action.setLoop(loopType);
if (startTime) {
action.play();
}
};
知识点: Three.js 提供了多种动画技术:
- AnimationMixer:用于播放和控制模型骨骼动画的核心类,相当于动画播放器
- AnimationClip:包含一组关键帧轨道的动画数据,如"走路"、"跑步"等动作
- AnimationAction:控制单个动画的播放状态,包括播放、暂停、循环设置等
- 动画混合:可以实现多个动画之间的平滑过渡,如从走路切换到跑步
合理使用这些技术可以创建流畅、自然的角色动画和场景变换。
第一人称视角控制算法
项目实现了一种先进的第一人称视角控制算法:
const animate1 = () => {
requestRef1.current = requestAnimationFrame(animate1);
if (isFirstPerson && robotRef.current) {
// 获取机器人的世界坐标
const robotWorldPosition = new THREE.Vector3();
robotRef.current.getWorldPosition(robotWorldPosition);
// 计算摄像机位置偏移
const offset = new THREE.Vector3(0, 140, 20);
// 获取机器人的前方方向向量
const forward = new THREE.Vector3(0, 0, -1).applyQuaternion(robotRef.current.quaternion);
const lookAheadDistance = 150;
// 计算摄像头位置和视线目标
const targetCameraPosition = robotWorldPosition.clone().add(offset);
const lookAtPosition = robotWorldPosition.clone().add(forward.multiplyScalar(lookAheadDistance));
// 使用 TWEEN 实现平滑过渡
cameraTweenRef.current = new TWEEN.Tween(cameraRef.current.position)
.to({
x: targetCameraPosition.x,
y: targetCameraPosition.y,
z: targetCameraPosition.z,
}, 1000)
.easing(TWEEN.Easing.Quadratic.Out)
.onUpdate(() => {
cameraRef.current.lookAt(lookAtPosition);
controlsRef.current.target.set(lookAtPosition.x, lookAtPosition.y, lookAtPosition.z);
})
.start();
}
};
知识点: 第一人称相机控制涉及多个关键技术:
- 世界坐标计算:通过
getWorldPosition()获取对象在世界坐标系中的位置
- 四元数旋转:使用
applyQuaternion()将向量按对象的旋转方向进行变换
- 向量运算:通过向量加法和标量乘法计算相机位置和视线方向
- 平滑过渡:使用 TWEEN.js 实现相机位置的平滑变化,避免生硬的跳变
- lookAt:让相机始终"看着"目标点,实现跟随效果
这种技术常用于第一人称游戏、虚拟导览等应用。
递归资源释放算法
项目实现了一种递归资源释放算法,用于彻底清理 Three.js 资源:
const disposeSceneObjects = (object) => {
if (!object) return;
// 递归清理子对象
while (object.children.length > 0) {
const child = object.children[0];
disposeSceneObjects(child);
object.remove(child);
}
// 清理几何体
if (object.geometry) {
object.geometry.dispose();
}
// 清理材质
if (object.material) {
if (Array.isArray(object.material)) {
object.material.forEach(material => disposeMaterial(material));
} else {
disposeMaterial(object.material);
}
}
// 清理纹理
if (object.texture) {
object.texture.dispose();
}
};
// 清理材质的辅助函数
const disposeMaterial = (material) => {
if (!material) return;
// 清理所有纹理属性
const textureProperties = [
'map', 'normalMap', 'roughnessMap', 'metalnessMap',
'emissiveMap', 'bumpMap', 'displacementMap',
'alphaMap', 'lightMap', 'aoMap', 'envMap'
];
textureProperties.forEach(prop => {
if (material[prop] && material[prop].dispose) {
material[prop].dispose();
}
});
material.dispose();
};
知识点: WebGL 资源管理是 3D 应用开发中的关键挑战:
- JavaScript 垃圾回收的局限性:虽然 JS 有自动垃圾回收,但 WebGL 资源(如纹理、缓冲区)需要手动释放
- 深度优先遍历:通过递归算法遍历整个场景图,确保所有对象都被正确处理
- 资源类型处理:不同类型的资源(几何体、材质、纹理)需要不同的释放方法
- 内存泄漏防护:不正确的资源管理是 WebGL 应用中最常见的内存泄漏原因
合理的资源释放策略对长时间运行的 3D 应用至关重要,可以避免性能下降和浏览器崩溃。
资源预加载与缓存策略
项目实现了资源预加载与缓存策略:
// 资源管理器
const ResourceManager = {
// 资源缓存
cache: new Map(),
// 预加载资源
preload: async (resources) => {
const loader = new GLTFLoader();
// 并行加载所有资源
const loadPromises = resources.map(resource => {
return new Promise((resolve, reject) => {
loader.load(
resource.url,
(gltf) => {
ResourceManager.cache.set(resource.id, {
data: gltf,
lastUsed: Date.now(),
refCount: 0
});
resolve(gltf);
},
undefined,
reject
);
});
});
return Promise.all(loadPromises);
},
// 获取资源
get: (id) => {
const resource = ResourceManager.cache.get(id);
if (resource) {
resource.lastUsed = Date.now();
resource.refCount++;
return resource.data;
}
return null;
},
// 释放资源
release: (id) => {
const resource = ResourceManager.cache.get(id);
if (resource) {
resource.refCount--;
if (resource.refCount <= 0) {
// 可以选择立即释放或稍后由缓存清理机制释放
}
}
}
};
知识点: 3D 应用中的资源管理策略:
- 预加载:提前加载关键资源,减少用户等待时间
- 并行加载:使用 Promise.all 并行加载多个资源,提高加载效率
- 资源缓存:使用 Map 数据结构存储已加载资源,避免重复加载
- 引用计数:跟踪资源的使用情况,只有当引用计数为零时才考虑释放
- 最近使用时间:记录资源最后使用时间,可用于实现 LRU (最近最少使用) 缓存策略
这种资源管理策略可以平衡内存使用和加载性能,适用于资源密集型的 3D 应用。
总结
通过这个隧道监控可视化系统的开发,我们深入实践了 Three.js 的多项高级技术,包括多渲染器协同、后期处理、动画系统、相机控制和资源管理等。这些技术不仅适用于隧道监控,还可以应用于数字孪生、产品可视化、教育培训等多个领域。
希望这次分享对大家了解 Web 3D 开发有所帮助!如有任何问题或改进建议,非常欢迎与我交流讨论。我将在后续分享中带来更多 Three.js 开发的实用技巧和最佳实践。
来源:juejin.cn/post/7540129382540247103
前端如何判断用户设备
在前端开发中,判断用户设备类型是常见需求,可通过浏览器环境检测、设备能力特征分析等方式实现。以下是具体实现思路及代码示例:
一、通过User-Agent检测设备类型
原理:User-Agent是浏览器发送给服务器的标识字符串,包含设备、系统、浏览器等信息。
实现步骤:
- 提取
navigator.userAgent字符串 - 通过正则表达式匹配特征关键词
// 设备检测工具函数
function detectDevice() {
const userAgent = navigator.userAgent.toLowerCase();
const device = {};
// 判断是否为移动设备
const isMobile = /android|webos|iphone|ipad|ipod|blackberry|iemobile|opera mini/i.test(userAgent);
device.isMobile = isMobile;
// 具体设备类型
if (/(iphone|ipad|ipod)/i.test(userAgent)) {
device.type = 'ios';
device.model = /iphone/i.test(userAgent) ? 'iPhone' : 'iPad';
} else if (/android/i.test(userAgent)) {
device.type = 'android';
// 提取Android版本
const androidVersion = userAgent.match(/android (\d+\.\d+)/);
device.version = androidVersion ? androidVersion[1] : '未知';
} else if (/windows phone/i.test(userAgent)) {
device.type = 'windows phone';
} else if (/macint0sh/i.test(userAgent)) {
device.type = 'mac';
} else if (/windows/i.test(userAgent)) {
device.type = 'windows';
} else {
device.type = '其他';
}
// 判断是否为平板(需结合屏幕尺寸进一步确认)
device.isTablet = (/(ipad|android tablet|windows phone 8.1|kindle|nexus 7)/i.test(userAgent)) && !device.isMobile;
// 浏览器类型
if (/chrome/i.test(userAgent)) {
device.browser = 'Chrome';
} else if (/firefox/i.test(userAgent)) {
device.browser = 'Firefox';
} else if (/safari/i.test(userAgent) && !/chrome/i.test(userAgent)) {
device.browser = 'Safari';
} else if (/msie|trident/i.test(userAgent)) {
device.browser = 'IE/Edge';
} else {
device.browser = '未知';
}
return device;
}
// 使用示例
const deviceInfo = detectDevice();
console.log('设备类型:', deviceInfo.type);
console.log('是否为移动设备:', deviceInfo.isMobile);
console.log('浏览器:', deviceInfo.browser);
二、结合屏幕尺寸与触摸事件检测
原理:移动设备通常屏幕较小,且支持触摸操作,而PC设备以鼠标操作为主。
function enhanceDeviceDetection() {
const device = detectDevice(); // 基于User-Agent的检测
// 1. 屏幕尺寸检测(响应式设备类型)
if (window.innerWidth <= 768) {
device.layout = 'mobile'; // 移动端布局
} else if (window.innerWidth <= 1024) {
device.layout = 'tablet'; // 平板布局
} else {
device.layout = 'desktop'; // 桌面端布局
}
// 2. 触摸事件支持检测
device.hasTouch = 'ontouchstart' in window || navigator.maxTouchPoints > 0;
// 3. 指针类型检测(WebKit特有属性,判断鼠标/触摸/笔)
if (navigator.maxTouchPoints === 0) {
device.pointerType = 'mouse';
} else if (navigator.maxTouchPoints > 2) {
device.pointerType = 'pen';
} else {
device.pointerType = 'touch';
}
return device;
}
三、设备能力API检测(更准确的现代方案)
原理:通过浏览器原生API获取设备硬件特性,避免User-Agent被伪造的问题。
async function detectDeviceByAPI() {
const device = {};
// 1. NavigatorDevice API(需HTTPS环境)
if (navigator.device) {
try {
const deviceInfo = await navigator.device.getCapabilities();
device.brand = deviceInfo.brand; // 设备品牌
device.model = deviceInfo.model; // 设备型号
device.vendor = deviceInfo.vendor; // 厂商
} catch (error) {
console.log('NavigatorDevice API获取失败:', error);
}
}
// 2. 屏幕像素密度(区分高清屏)
device.retina = window.devicePixelRatio >= 2;
// 3. 电池状态(移动端常用)
if (navigator.getBattery) {
navigator.getBattery().then(battery => {
device.batteryLevel = battery.level;
device.batteryCharging = battery.charging;
});
}
return device;
}
四、框架/库方案(简化实现)
如果项目中使用框架,可直接使用成熟库:
- react-device-detect(React专用)
- mobile-detect.js(轻量级通用库)
- ua-parser-js(专业User-Agent解析库)
五、注意事项
- User-Agent不可靠:用户可手动修改UA,或某些浏览器(如微信内置浏览器)会伪装UA。
- 结合多种检测方式:建议同时使用User-Agent、屏幕尺寸、触摸事件等多重检测,提高准确性。
- 响应式设计优先:现代开发中更推荐通过CSS媒体查询(
@media)实现响应式布局,而非完全依赖设备检测。 - 性能优化:避免频繁检测设备,可在页面加载时缓存检测结果。
六、面试延伸问题
- 为什么User-Agent检测不可靠?请举例说明。
- 在iOS和Android上,如何区分手机和平板?
- 如果用户强制旋转屏幕(如手机横屏),设备检测结果需要更新吗?如何处理?
通过以上方案,可全面检测用户设备类型、系统、浏览器及硬件特性,为前端适配提供依据。
来源:juejin.cn/post/7515378780371501082
前端获取本地文件目录内容
前端获取本地文件目录内容
一、核心原理说明
由于浏览器的 “沙箱安全机制”,前端 JavaScript 无法直接访问本地文件系统,必须通过用户主动授权(如选择目录操作)才能获取文件目录内容。目前主流实现方案基于两种 API:传统 File API(兼容性优先)和现代 FileSystem Access API(功能优先),以下将详细介绍两种方案的实现流程、代码示例及适用场景。
二、方案一:基于 File API 实现(兼容性首选)
1. 方案概述
通过隐藏的 <input type="file"> 标签(配置 webkitdirectory 和 directory 属性)触发用户选择目录操作,用户选择后通过 files 属性获取目录下所有文件的元数据(如文件名、大小、相对路径等)。该方案兼容几乎所有现代浏览器(包括 Chrome、Firefox、Safari 等),但仅支持 “一次性获取选中目录内容”,无法递归遍历子目录或修改文件。
2. 完整使用示例
2.1 HTML 结构(含 UI 交互区)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>File API 目录访问示例</title>
<!-- 引入 Tailwind 简化样式(也可自定义 CSS) -->
<script src="https://cdn.tailwindcss.com"></script>
<style>
.file-item { display: flex; align-items: center; padding: 8px; border-bottom: 1px solid #eee; }
.file-icon { margin-right: 8px; font-size: 18px; }
.file-info { flex: 1; }
.file-size { color: #666; font-size: 14px; }
</style>
</head>
<body class="p-8 bg-gray-50">
<div class="max-w-4xl mx-auto bg-white p-6 rounded-lg shadow">
<h2 class="text-2xl font-bold mb-4">File API 目录内容获取</h2>
<!-- 触发按钮(隐藏原生 input) -->
<button id="selectDirBtn" class="bg-blue-500 text-white px-4 py-2 rounded hover:bg-blue-600">
选择本地目录
</button>
<input type="file" id="dirInput" webkitdirectory directory style="display: none;">
<!-- 文件列表展示区 -->
<div class="mt-4 border rounded-lg max-h-80 overflow-y-auto">
<div id="fileList" class="p-4 text-center text-gray-500">
请选择目录以查看文件列表
</div>
</div>
</div>
<script>
// 2.2 JavaScript 逻辑实现
const dirInput = document.getElementById('dirInput');
const selectDirBtn = document.getElementById('selectDirBtn');
const fileList = document.getElementById('fileList');
// 1. 点击按钮触发原生 input 选择目录
selectDirBtn.addEventListener('click', () => {
dirInput.click();
});
// 2. 监听目录选择变化,处理文件数据
dirInput.addEventListener('change', (e) => {
const selectedFiles = e.target.files; // 获取选中目录下的所有文件(含子目录文件)
if (selectedFiles.length === 0) {
fileList.innerHTML = '<div class="p-4 text-center text-gray-500">未选择任何文件</div>';
return;
}
// 3. 解析文件数据并渲染到页面
let fileHtml = '';
Array.from(selectedFiles).forEach(file => {
// 判断是否为目录(通过 type 为空且 size 为 0 间接判断)
const isDir = file.type === '' && file.size === 0;
// 获取文件在目录中的相对路径(webkitRelativePath 为非标准属性,但主流浏览器支持)
const relativePath = file.webkitRelativePath || file.name;
// 格式化文件大小(辅助函数)
const fileSize = isDir ? '—' : formatFileSize(file.size);
fileHtml += `
<div class="file-item">
<span class="file-icon ${isDir ? 'text-yellow-500' : 'text-gray-400'}">
${isDir ? '📁' : '📄'}
</span>
<div class="file-info">
<div class="font-medium">${file.name}</div>
<div class="text-xs text-gray-500">${relativePath}</div>
</div>
<div class="file-size text-sm">${fileSize}</div>
</div>
`;
});
fileList.innerHTML = fileHtml;
});
// 辅助函数:格式化文件大小(Bytes → KB/MB/GB)
function formatFileSize(bytes) {
if (bytes === 0) return '0 Bytes';
const k = 1024;
const units = ['Bytes', 'KB', 'MB', 'GB'];
const i = Math.floor(Math.log(bytes) / Math.log(k));
return `${(bytes / Math.pow(k, i)).toFixed(2)} ${units[i]}`;
}
</script>
</body>
</html>
3. 关键特性与限制
- 优势:兼容性强(支持 Chrome 15+、Firefox 4+、Safari 6+),无需额外依赖,实现简单。
- 限制:
- 无法直接识别 “目录” 类型,需通过
type和size间接判断; - 仅能获取选中目录下的 “扁平化文件列表”,无法递归获取子目录结构;
- 无文件读写能力,仅能获取元数据。
三、方案二:基于 FileSystem Access API 实现(功能优先)
1. 方案概述
FileSystem Access API 是 W3C 正在标准化的现代 API(目前主要支持 Chromium 内核浏览器,如 Chrome 86+、Edge 86+),提供 “目录选择、递归遍历、文件读写、持久化权限” 等更强大的能力。通过 window.showDirectoryPicker() 直接请求用户授权,授权后可主动遍历目录结构,支持复杂的文件操作。
2. 完整使用示例
2.1 HTML 结构(含子目录遍历功能)
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>FileSystem Access API 目录访问示例</title>
<script src="https://cdn.tailwindcss.com"></script>
<style>
.dir-tree-item { padding: 4px 0 4px 16px; border-left: 1px solid #eee; }
.dir-header { display: flex; align-items: center; cursor: pointer; padding: 4px 0; }
.dir-icon { margin-right: 8px; }
.file-meta { color: #666; font-size: 14px; margin-left: 8px; }
</style>
</head>
<body class="p-8 bg-gray-50">
<div class="max-w-4xl mx-auto bg-white p-6 rounded-lg shadow">
<h2 class="text-2xl font-bold mb-4">FileSystem Access API 目录遍历</h2>
<!-- 触发目录选择按钮 -->
<button id="openDirBtn" class="bg-green-500 text-white px-4 py-2 rounded hover:bg-green-600">
打开并遍历目录
</button>
<!-- 目录树展示区 -->
<div class="mt-4 border rounded-lg p-4 max-h-80 overflow-y-auto">
<div id="dirTree" class="text-gray-500">
请点击按钮选择目录
</div>
</div>
</div>
<script>
// 2.2 JavaScript 逻辑实现(含递归遍历)
const openDirBtn = document.getElementById('openDirBtn');
const dirTree = document.getElementById('dirTree');
openDirBtn.addEventListener('click', async () => {
try {
// 1. 检查浏览器兼容性
if (!window.showDirectoryPicker) {
alert('您的浏览器不支持该功能,请使用 Chrome 或 Edge 浏览器');
return;
}
// 2. 请求用户选择目录(获取 DirectoryHandle 对象)
const dirHandle = await window.showDirectoryPicker({
mode: 'read', // 权限模式:read(只读)/ readwrite(读写)
startIn: 'documents' // 默认打开目录(可选:documents、downloads 等)
});
// 3. 递归遍历目录结构并渲染
dirTree.innerHTML = '<div class="text-center text-gray-500">正在读取目录...</div>';
const treeHtml = await renderDirectoryTree(dirHandle, 0);
dirTree.innerHTML = treeHtml;
} catch (err) {
// 捕获用户取消选择或权限拒绝错误
if (err.name === 'AbortError') {
dirTree.innerHTML = '<div class="text-center text-gray-500">用户取消选择</div>';
} else {
dirTree.innerHTML = `<div class="text-center text-red-500">错误:${err.message}</div>`;
console.error('目录访问失败:', err);
}
}
});
/**
* 递归渲染目录树
* @param {DirectoryHandle} handle - 目录/文件句柄
* @param {number} depth - 目录深度(用于缩进)
* @returns {string} 目录树 HTML
*/
async function renderDirectoryTree(handle, depth) {
const isDir = handle.kind === 'directory';
const indent = 'margin-left: ' + (depth * 16) + 'px;'; // 按深度缩进
let itemHtml = '';
if (isDir) {
// 处理目录:添加展开/折叠功能
itemHtml += `
<div class="dir-header" style="${indent}" onclick="toggleDir(this)">
<span class="dir-icon text-yellow-500">📁</span>
<span class="font-medium">${handle.name}</span>
<span class="file-meta">(目录)</span>
</div>
<div class="dir-children" style="display: none;">
`;
// 遍历目录下的所有子项(递归)
for await (const childHandle of handle.values()) {
itemHtml += await renderDirectoryTree(childHandle, depth + 1);
}
itemHtml += '</div>'; // 闭合 dir-children
} else {
// 处理文件:获取文件大小等元数据
const file = await handle.getFile();
const fileSize = formatFileSize(file.size);
itemHtml += `
<div style="${indent} display: flex; align-items: center; padding: 4px 0;">
<span class="dir-icon text-gray-400">📄</span>
<span>${handle.name}</span>
<span class="file-meta">${fileSize}</span>
</div>
`;
}
return itemHtml;
}
// 目录展开/折叠切换(全局函数,用于 HTML 内联调用)
function toggleDir(el) {
const children = el.nextElementSibling;
children.style.display = children.style.display === 'none' ? 'block' : 'none';
el.querySelector('.dir-icon').textContent = children.style.display === 'none' ? '📁' : '📂';
}
// 复用文件大小格式化函数(同方案一)
function formatFileSize(bytes) {
if (bytes === 0) return '0 Bytes';
const k = 1024;
const units = ['Bytes', 'KB', 'MB', 'GB'];
const i = Math.floor(Math.log(bytes) / Math.log(k));
return `${(bytes / Math.pow(k, i)).toFixed(2)} ${units[i]}`;
}
</script>
</body>
</html>
3. 关键特性与限制
- 优势:
- 直接识别 “目录 / 文件” 类型(通过
handle.kind); - 支持递归遍历目录结构,可实现 “目录树” 交互;
- 提供文件读写能力(通过
fileHandle.createWritable()); - 可请求持久化权限(
handle.requestPermission()),下次访问无需重新授权。
- 限制:兼容性差,仅支持 Chromium 内核浏览器,Firefox 和 Safari 暂不支持。
四、两种方案对比分析
| 对比维度 | 方案一(File API) | 方案二(FileSystem Access API) |
|---|---|---|
| 浏览器兼容性 | 强(支持所有现代浏览器) | 弱(仅 Chromium 内核浏览器) |
| 目录识别能力 | 间接判断(依赖 type 和 size) | 直接识别(handle.kind) |
| 目录遍历能力 | 仅扁平化列表,无递归支持 | 支持递归遍历,可构建目录树 |
| 文件操作能力 | 仅读取元数据,无读写能力 | 支持文件读写、删除等完整操作 |
| 权限持久化 | 不支持(每次刷新需重新选择) | 支持(可请求持久化权限) |
| 交互体验 | 依赖隐藏 input,体验较基础 | 原生 API 调用,体验更流畅 |
| 适用场景 | 兼容性优先的简单目录查看需求 | 现代浏览器下的复杂文件管理需求 |
五、注意事项与最佳实践
- 安全合规:无论哪种方案,都必须通过 “用户主动操作” 触发授权(如点击按钮),禁止自动触发目录选择,否则浏览器会拦截操作。
- 错误处理:需捕获 “用户取消选择”(AbortError)和 “权限拒绝”(PermissionDeniedError)等错误,避免页面展示异常。
- 兼容性适配:可通过 “特性检测” 实现方案降级,例如:
if (window.showDirectoryPicker) {
// 使用方案二(FileSystem Access API)
} else {
// 使用方案一(File API)
}
- 性能优化:遍历大量文件时(如超过 1000 个文件),建议使用 “分页加载” 或 “虚拟滚动”,避免一次性渲染导致页面卡顿。
- 隐私保护:不建议存储用户本地文件路径等敏感信息,仅在前端临时处理文件数据,避免隐私泄露风险。
来源:juejin.cn/post/7542308569641074724
儿子不收拾玩具,我用AI给他量身定制开发一个APP,这下舒服了
1. 前言
比上班更可怕的是什么?是加班。
比加班更可怕的是什么?是固定加班,也就是 996,大小周。
作为一个荣获 996 福报的牛马,我认为我的际遇已经很可怕了。
没想到还有比这更可怕的,拖着被996折腾过的疲惫身体回家后。我儿子向我展示他一天的劳动成果。

这时候你肯定会说让他收起来不就行了?这时候我应该拿出标志性的礼貌三问:你有对象吗?你有儿子吗?你让你儿子收他就收吗?

不会吧,你儿子收啊。那我和你换个儿子吧。
我对我儿子威逼利诱什么招式都试过了,他每次就3招我就没辙了:
爸爸,我累了你帮我收吧。
爸爸,地上的玩具太多了你和我一起收吧,收着收着这小子就不见了。
爸爸,我要睡觉了,晚安。
每天晚上我都要花时间收拾这个烂摊子,收过十几次后我后知后觉有了个想法。
平时我工作的时候,一个5分钟就能手写完搞定的配置我都要花10分钟写个脚本自动化。
为啥不能让收玩具这件事情自动化呢?我可是个优雅的程序员啊。重复做一个动作在我这应该是严格禁止的才对。
所以我打算做一个自动收玩具的机器。
不是哥们,这我真做不了。在我这自动化是什么意思呢?
不需要自己动手干的就是自动化,把配置做到管理后台,让运营自己去配置算不算自动化?那必须是的呀。
那么,想一种办法让我儿子自己把玩具收起来是不是自动化?那也必须是的呀。
自动化的定义就是不需要自己动手干,管是机器干还是人干,反正不要我来干。

说干就干,我儿子特别喜欢数字,迷恋加法。那不就盖了帽了。给他安排一个任务APP,收完一件玩具就加分,他肯定特满足特有成就感。
我虽然是一个前端后端运维测试攻城狮,但我的的确确没有开发过APP。除了大学要交 Android 作业抱过同学大腿喵了一眼,从那之后我就下定决定干后端去了。因为艺术细菌不是说本人没有,是本人想有但它对我不感冒啊。
但是别忘了,现在是 AI 的时代。产品的活我不会,AI 来。APP 开发我不会,AI 来。貌似不需要后端,那我只能当当测试了。
2. 正片开始
我调研了一圈,目前有几种方案可以实现:
- 直接刚原生
- 退而求其次,flutter
- 一退再退,直接uniapp 网页糊上
原生做起来体验最好,但是搭个环境真是要了我的老命了,所以弃之。
flutter总体感觉不错,但是要另外学一门语言,想想我就脑壳疼,亦弃之。
uni-app 看起来不咋滴,蛮多人吐槽但也有真正的案例。但我发现它能云打包,不用我在本地配一堆乱七八糟的。下载一个HBuilder 就行了,虽然很多人吐槽这个 IDE,但关我啥事?是 AI 来写代码,又不是我写代码,尽管恶心 AI 去。选它选它
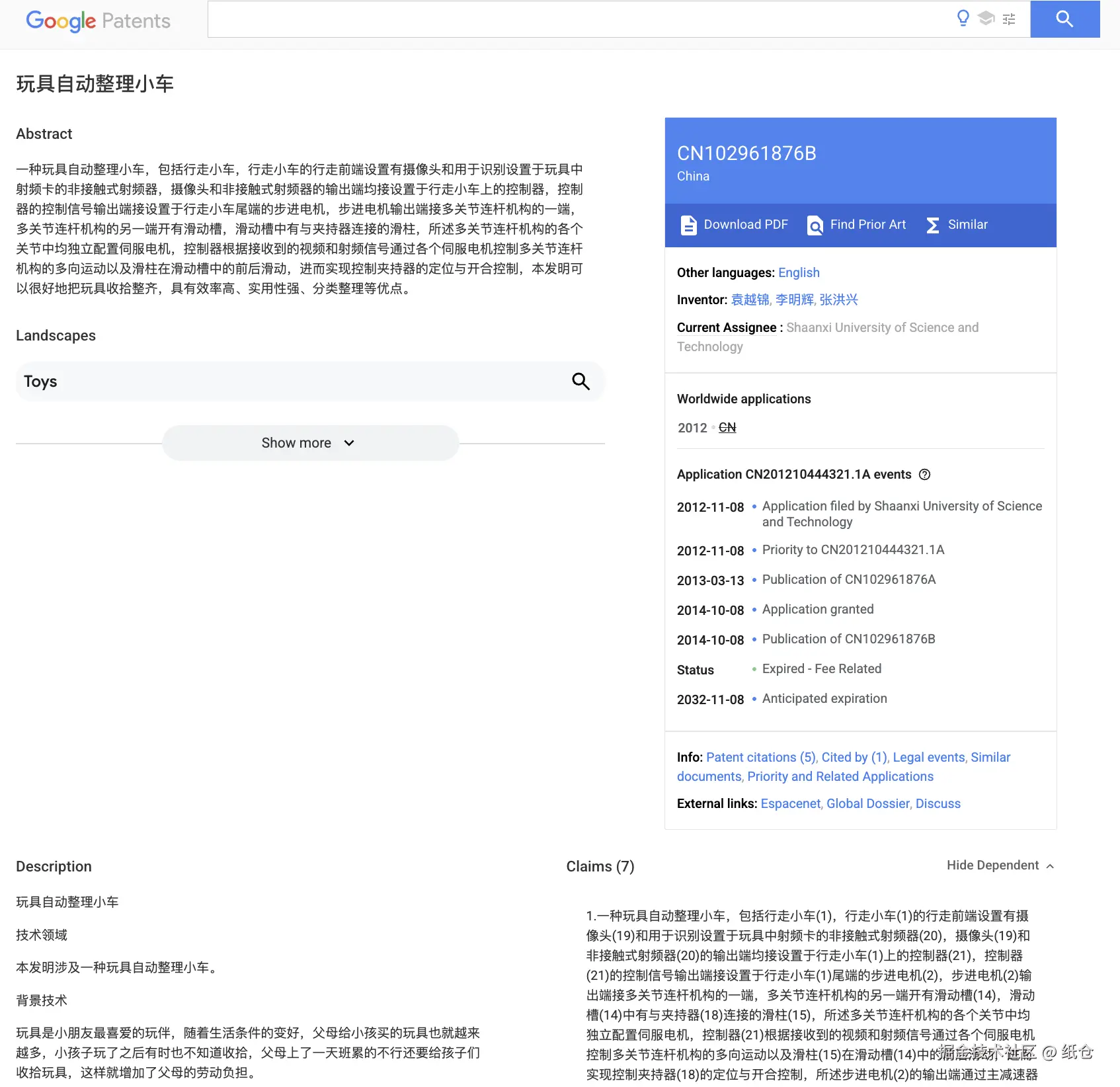
2.1 画原型图
Cursor,Gemini,claude code 我都试了,Gemini的设计感最强,豆包的体验最好。豆包的效果看起来非常的奈斯啊!
2.2 开发
有了原型那就好办了,直接贴图让cursor 或者 claude code 对着实现就行了。
这里要吐槽一下claude code,不能粘贴板直接贴图,只能把图片拖进去,差评。
现在可以粘贴图片了,Mac 可以尝试用ctrl+v(没错,不是command+v)
把所有的原型图贴进去之后,输入这句简单的Prompt,claude code 就会开始干活了。
请根据原型图,使用uniapp 开发一个app
2.3 加需求
第一版完成了他的使命,最近儿子有点腻烦了,收个玩具磨磨蹭蹭的。不行,我得想点法子,加点东西让他保持新鲜感,然后养成习惯,以后就不用我管了,想想就非常的苏胡啊。
所以为了调动他的积极性,更营造一个紧张的氛围,我加入了倒计时功能:
接下来有个新功能。我想为任务增加一个计时完成功能:
1. 完成任务时,不再是简单的点击即可;
2. 完成任务时,应该提供一个开始完成按钮,然后启动倒计时
3. 创建任务时,应该配置预计完成时间
4. 完成任务时,遵循规则:a.如果在预计时间的一半完成可以得到2倍的分数;b.如果超过一半时间完成则得到1.5倍分数;c.如果超时完成则得到1倍分数
直接把需求丢给AI实现去,自己测试测试,没问题就打包。
2.3 测试打包
先浏览器运行看看效果,可以 F12 切换成手机视图看有没有挤压之类的。
测试没问题就直接打包。因为我是尊贵的 Android 用户,所以我只跑了 Android 打包。
我坦白,uni-app部分我基本是看这个老哥的:juejin.cn/post/729631…
2.4 看看效果
来源:juejin.cn/post/7538276577605632046
Vue-Command-Component:让弹窗开发不再繁琐
前言
在Vue项目开发中,弹窗组件的管理一直是一个令人头疼的问题。传统的声明式弹窗开发方式需要管理大量的状态变量、处理复杂的props传递,甚至可能面临多个弹窗嵌套时的状态管理困境。今天给大家介绍一个能够彻底改变这种开发体验的库:Vue-Command-Component。
为什么需要命令式组件?
在传统的Vue开发中,弹窗的使用通常是这样的:
<template>
<el-dialog v-model="visible" title="提示">
<span>这是一段信息</span>
<template #footer>
<span class="dialog-footer">
<el-button @click="visible = false">取消</el-button>
<el-button type="primary" @click="handleConfirm">确认</el-button>
</span>
</template>
</el-dialog>
</template>
<script setup>
const visible = ref(false)
const handleConfirm = () => {
// 处理确认逻辑
visible.value = false
}
</script>
这种方式存在几个明显的问题:
- 需要手动管理弹窗的显示状态
- 组件代码和业务逻辑混杂在一起
- 多个弹窗时代码会变得非常臃肿
- 弹窗之间的嵌套关系处理复杂
Vue-Command-Component 解决方案
使用Vue-Command-Component,上述问题都可以得到优雅的解决。来看看它是如何使用的:
import { useDialog } from "@vue-cmd/element-plus";
const CommandDialog = useDialog()
// 直接调用函数显示弹窗
CommandDialog(<div>这是一段信息</div>)
是的,就是这么简单!一行代码就能唤起一个弹窗,不需要管理状态,不需要写模板,一切都变得如此流畅。
核心特性
1. 极简API设计
无需管理状态,一个函数调用搞定所有事情,符合直觉的开发体验。
2. 完整的类型支持
提供完整的TypeScript类型支持,开发体验一流。
3. 灵活的控制能力
提供了多种控制方式:
destroy:销毁弹窗hide/show:控制弹窗显示/隐藏destroyWithResolve/destroyWithReject:支持Promise风格的控制
4. 强大的扩展性
支持多种UI框架:
- Element Plus
- Naive UI
- Vant
- ...更多框架支持中
5. 原生特性支持
完整支持原生组件的所有特性:
- 属性传递
- 事件处理
- 插槽支持
- Provide/Inject
安装
# 使用 npm
npm install @vue-cmd/core @vue-cmd/element-plus
# 使用 yarn
yarn add @vue-cmd/core @vue-cmd/element-plus
# 使用 pnpm
pnpm add @vue-cmd/core @vue-cmd/element-plus
# 使用 bun
bun add @vue-cmd/core @vue-cmd/element-plus
实战示例
基础用法
import { useDialog } from "@vue-cmd/element-plus";
const CommandDialog = useDialog()
// 基础弹窗
CommandDialog(<Content />)
// 带配置的弹窗
CommandDialog(<Content />, {
attrs: {
title: '标题',
width: '500px'
}
})
嵌套弹窗
import { useDialog } from "@vue-cmd/element-plus";
const CommandDialog = useDialog()
CommandDialog(
<div onClick={() => {
// 在弹窗中打开新的弹窗
CommandDialog(<div>内层弹窗</div>)
}}>
外层弹窗
</div>
)
Promise风格控制
import { useDialog } from "@vue-cmd/element-plus";
import { useConsumer } from "@vue-cmd/core";
const CommandDialog = useDialog()
// 在弹窗组件内部
const FormComponent = defineComponent({
setup() {
const consumer = useConsumer()
const handleSubmit = (data) => {
// 提交数据后关闭弹窗
consumer.destroyWithResolve(data)
}
return () => <Form onSubmit={handleSubmit} />
}
})
// Promise风格的控制
try {
const result = await CommandDialog(<FormComponent />).promise
console.log('表单提交结果:', result)
} catch (error) {
console.log('用户取消或出错:', error)
}
多UI框架支持
// Element Plus
import { useDialog as useElementDialog } from "@vue-cmd/element-plus";
// Naive UI
import { useModal, useDrawer } from "@vue-cmd/naive";
// Vant
import { usePopup } from "@vue-cmd/vant";
const ElementDialog = useElementDialog()
const NaiveModal = useModal()
const VantPopup = usePopup()
// 使用不同的UI框架
ElementDialog(<Content />)
NaiveModal(<Content />)
VantPopup(<Content />)
写在最后
Vue-Command-Component 为Vue开发者带来了一种全新的弹窗开发方式。它不仅简化了开发流程,还提供了更强大的控制能力。如果你的项目中有大量弹窗交互,不妨尝试一下这个库,相信它会为你带来更好的开发体验。
相关链接
来源:juejin.cn/post/7501963430640615436
CSS 黑科技之多重边框:为网页添彩
在前端开发的奇妙世界里,CSS 总是能给我们带来意想不到的惊喜。今天,就让我们一同探索 CSS 的一个有趣特性 —— 多重边框,看看它如何为我们的网页设计增添独特魅力。
什么是多重边框
在传统认知中,一个元素通常只有一层边框。但借助 CSS 的box-shadow属性,我们可以突破这一限制,轻松实现多重边框效果。box-shadow属性原本用于为元素添加阴影,不过通过巧妙设置,它能化身为创造多重边框的利器。
如何实现多重边框
实现多重边框的关键在于对box-shadow属性的灵活运用。下面是一个简单示例:
div {
box-shadow: 0 0 0 5px red, 0 0 0 10px blue;
}
在这段代码中,box-shadow属性接受了两组值,每组值都定义了一个 “边框”。具体来说,0 0 0 5px red表示第一个边框:前两个0分别表示水平和垂直方向的偏移量,这里都为 0,即不偏移;第三个0表示模糊半径为 0,也就是边框清晰锐利;5px表示扩展半径,即边框的宽度;red则是边框的颜色。同理,0 0 0 10px blue定义了第二个边框,宽度为 10px,颜色为蓝色。通过这样的方式,我们就为div元素创建了两层不同颜色和宽度的边框。
多重边框的应用场景
- 突出重要元素:在网页中,有些元素需要特别突出显示,比如导航栏、重要按钮等。使用多重边框可以让这些元素在页面中脱颖而出,吸引用户的注意力。
- 营造层次感:多重边框能够为元素增加层次感,使页面看起来更加丰富和立体。在设计卡片式布局时,这种效果尤为明显,可以让卡片更加生动有趣。
- 创意设计:对于追求独特风格的网页设计,多重边框提供了无限的创意空间。可以通过调整边框的颜色、宽度、模糊度等参数,创造出各种独特的视觉效果,展现出与众不同的设计风格。
注意事项
- 性能问题:虽然多重边框效果很酷,但过多地使用复杂的box-shadow属性可能会影响页面性能,尤其是在移动设备上。因此,在实际应用中需要权衡效果和性能,避免过度使用。
- 兼容性:不同浏览器对box-shadow属性的支持程度略有差异。在使用时,要确保在主流浏览器上进行充分测试,必要时可以添加浏览器前缀来保证兼容性。
CSS 的多重边框特性为前端开发者提供了一种简单而强大的方式来增强网页的视觉效果。通过合理运用这一特性,我们能够打造出更加美观、富有创意的网页界面。希望大家在今后的前端开发中,大胆尝试多重边框,让自己的网页作品更加出彩!
来源:juejin.cn/post/7472233713416110089
JavaScript V8 引擎原理
相关问题
JavaScript事件循环
- 调用栈:这里存放着所有执行中的代码块(函数)。当一个函数被调用时,它被添加到栈中;当返回值被返回时它从栈中被移除。
- 消息队列:当异步事件发生时(如点击事件、文件读取完成等),对应的回调函数会被添加到消息队列中。如果调用栈为空,事件循环将从队列中取出一个事件处理。
- 微任务队列:与消息队列类似,但处理优先级更高。微任务(如Promise的回调)在当前宏任务执行完毕后、下-个宏任务开始前执行。
- 宏任务与微任务:宏任务包括整体的脚本执行、setTimeout、setlnterval等;微任务包括Promise回调.process.nextTick等。事件循环的每个循环称为一个tick,每个tick会先执行所有可执行的微任务,再执行一个宏任务。
- 调用栈:这里存放着所有执行中的代码块(函数)。当一个函数被调用时,它被添加到栈中;当返回值被返回时它从栈中被移除。
- 消息队列:当异步事件发生时(如点击事件、文件读取完成等),对应的回调函数会被添加到消息队列中。如果调用栈为空,事件循环将从队列中取出一个事件处理。
- 微任务队列:与消息队列类似,但处理优先级更高。微任务(如Promise的回调)在当前宏任务执行完毕后、下-个宏任务开始前执行。
- 宏任务与微任务:宏任务包括整体的脚本执行、setTimeout、setlnterval等;微任务包括Promise回调.process.nextTick等。事件循环的每个循环称为一个tick,每个tick会先执行所有可执行的微任务,再执行一个宏任务。
V8引擎中的垃圾回收机制如何工作?
V8引擎使用的垃圾回收策略主要基于“分代收集”(Generational Garbage Collection)的理念:
- 新生代(Young Generation):这部分主要存放生存时间短的小对象。新生代空间较小,使用Scavenge算法进行高效的垃圾回收。Scavenge算法采用复制的方式工作,它将新生代空间分为两半,活动对象存放在一半中,当这一半空间用完时,活动对象会被复制到另一半,非活动对象则被清除。
- 老生代(Old Generation):存放生存时间长或从新生代中晋升的大对象。老生代使用Mark-Sweep(标记-清除)和 Mark-Compact (标记-压缩)算法进行垃圾回收。标记-清除算法在标记阶段标记所有从根节点可达的对象,清除阶段则清除未被标记的对象。标记-压缩算法在清除未标记对象的同时,将存活的对象压缩到内存的一端,减少碎片。
V8引擎使用的垃圾回收策略主要基于“分代收集”(Generational Garbage Collection)的理念:
- 新生代(Young Generation):这部分主要存放生存时间短的小对象。新生代空间较小,使用Scavenge算法进行高效的垃圾回收。Scavenge算法采用复制的方式工作,它将新生代空间分为两半,活动对象存放在一半中,当这一半空间用完时,活动对象会被复制到另一半,非活动对象则被清除。
- 老生代(Old Generation):存放生存时间长或从新生代中晋升的大对象。老生代使用Mark-Sweep(标记-清除)和 Mark-Compact (标记-压缩)算法进行垃圾回收。标记-清除算法在标记阶段标记所有从根节点可达的对象,清除阶段则清除未被标记的对象。标记-压缩算法在清除未标记对象的同时,将存活的对象压缩到内存的一端,减少碎片。
V8 引擎是如何优化其性能的?
V8引擎通过多种方式优化JavaScript的执行性能:
- 即时编译(JIT):V8将JavaScript代码编译成更高效的机器代码而不是传统的解释执行。V8采用了一个独特的两层编译策略,包括基线编译器(lgnition)和优化编译器(TurboFan)。lgnition生成字节码,这是一个相对较慢但内存使用较少的过程。而 TurboFan 则针对热点代码(执行频率高的代码)进行优化,生成更快的机器代码。
- 内联缓存(lnline Caching):V8使用内联缓存技术来减少属性访问的时间。当访问对象属性时,V8会在代码中嵌入缓存信息,记录属性的位置,以便后续的属性访问可以直接使用这些信息,避免再次查找,从而加速属性访问。
- 隐藏类(Hidden Classes):尽管JavaScript是一种动态类型语言,V8引擎通过使用隐藏类来优化对象的存储和访问。每当对象被实例化或修改时,V8会为对象创建或更新隐藏类,这些隐藏类存储了对象属性的布局信息,使得属性访问更加迅速。
V8引擎通过多种方式优化JavaScript的执行性能:
- 即时编译(JIT):V8将JavaScript代码编译成更高效的机器代码而不是传统的解释执行。V8采用了一个独特的两层编译策略,包括基线编译器(lgnition)和优化编译器(TurboFan)。lgnition生成字节码,这是一个相对较慢但内存使用较少的过程。而 TurboFan 则针对热点代码(执行频率高的代码)进行优化,生成更快的机器代码。
- 内联缓存(lnline Caching):V8使用内联缓存技术来减少属性访问的时间。当访问对象属性时,V8会在代码中嵌入缓存信息,记录属性的位置,以便后续的属性访问可以直接使用这些信息,避免再次查找,从而加速属性访问。
- 隐藏类(Hidden Classes):尽管JavaScript是一种动态类型语言,V8引擎通过使用隐藏类来优化对象的存储和访问。每当对象被实例化或修改时,V8会为对象创建或更新隐藏类,这些隐藏类存储了对象属性的布局信息,使得属性访问更加迅速。
引擎基础
冯·诺依曼结构
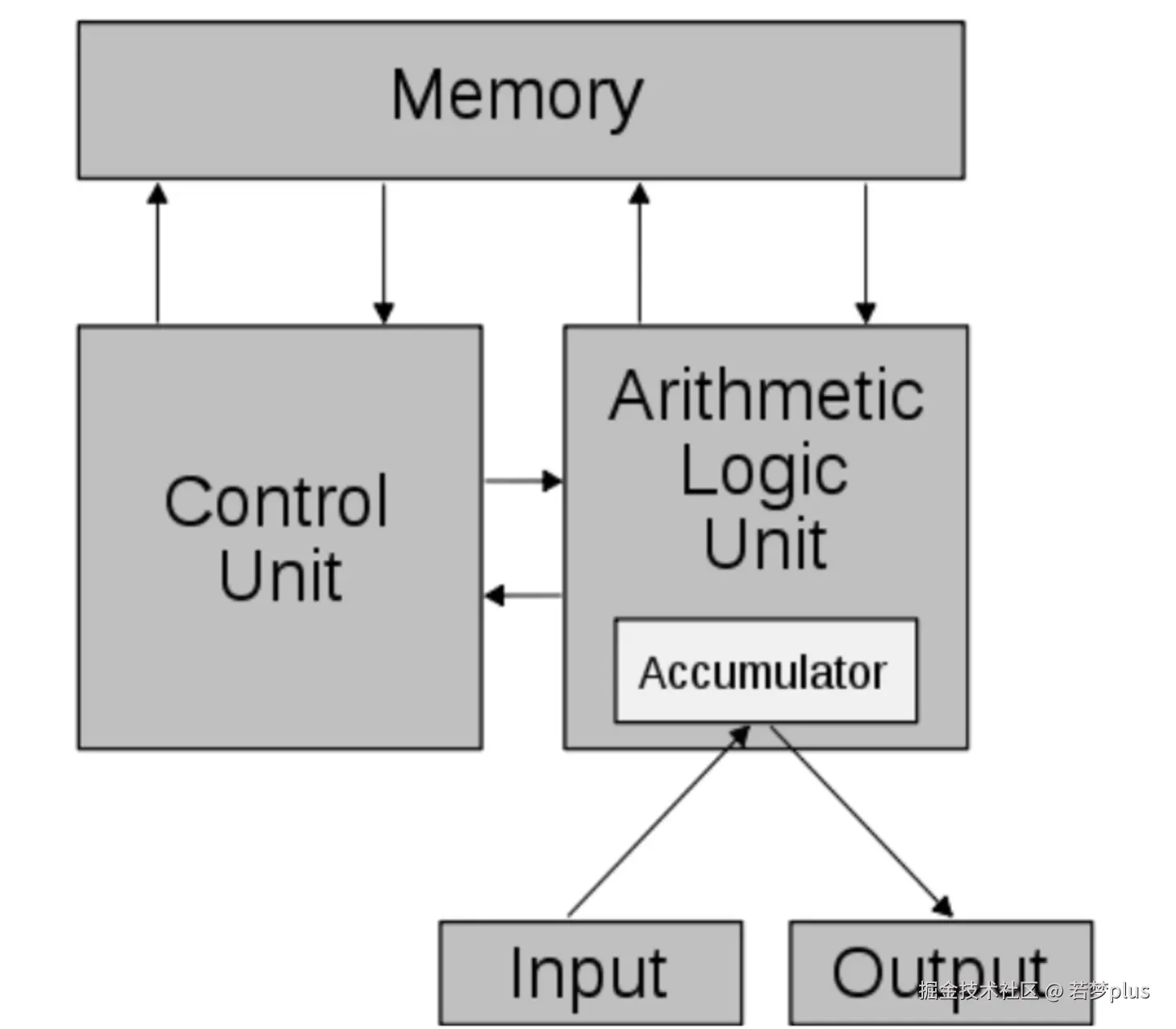
冯·诺依曼结构
解释和编译
Java 编译为 class 文件,然后执行
JavaScript 属于解释型语言,它需要在代码执行时,将代码编译为机器语言。
ast (Abstract Syntax Tree)
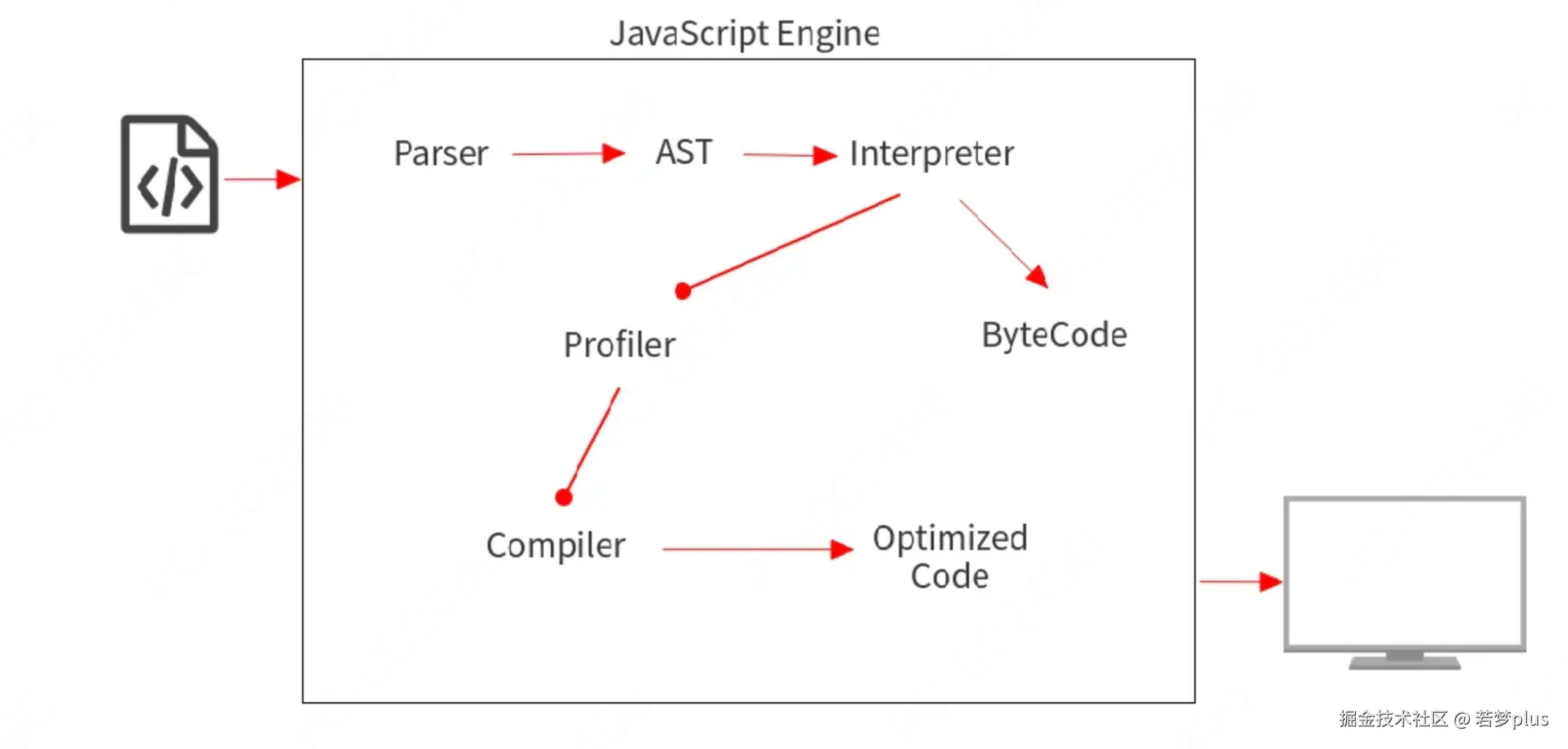
• Interpreter 逐行读取代码并立即执行。
• Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。
Java 编译为 class 文件,然后执行
JavaScript 属于解释型语言,它需要在代码执行时,将代码编译为机器语言。
ast (Abstract Syntax Tree)
• Interpreter 逐行读取代码并立即执行。
• Compiler 读取您的整个代码,进行一些优化,然后生成优化后的代码。
JavaScript引擎
JavaScript 其实有众多引擎,只不过v8 是我们最为熟知的。
- V8 (Google),用 C++编写,开放源代码,由 Google 丹麦开发,是 Google Chrome 的一部分,也用于 Node.js.
- JavascriptCore (Apple),开放源代码,用于 webkit 型浏览器,如 Safari,2008年实现了编译器和字节码解释器,升级为了 SquirreFish。苹果内部代号为“Nitro”的 Javascript 引擎也是基于 JavascriptCore 引擎的。
- Rhino,由Mozilla 基金会管理,开放源代码,完全以Java 编写,用于 HTMLUnit
- SpiderMonkey (Mozilla),第一款 Javascript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
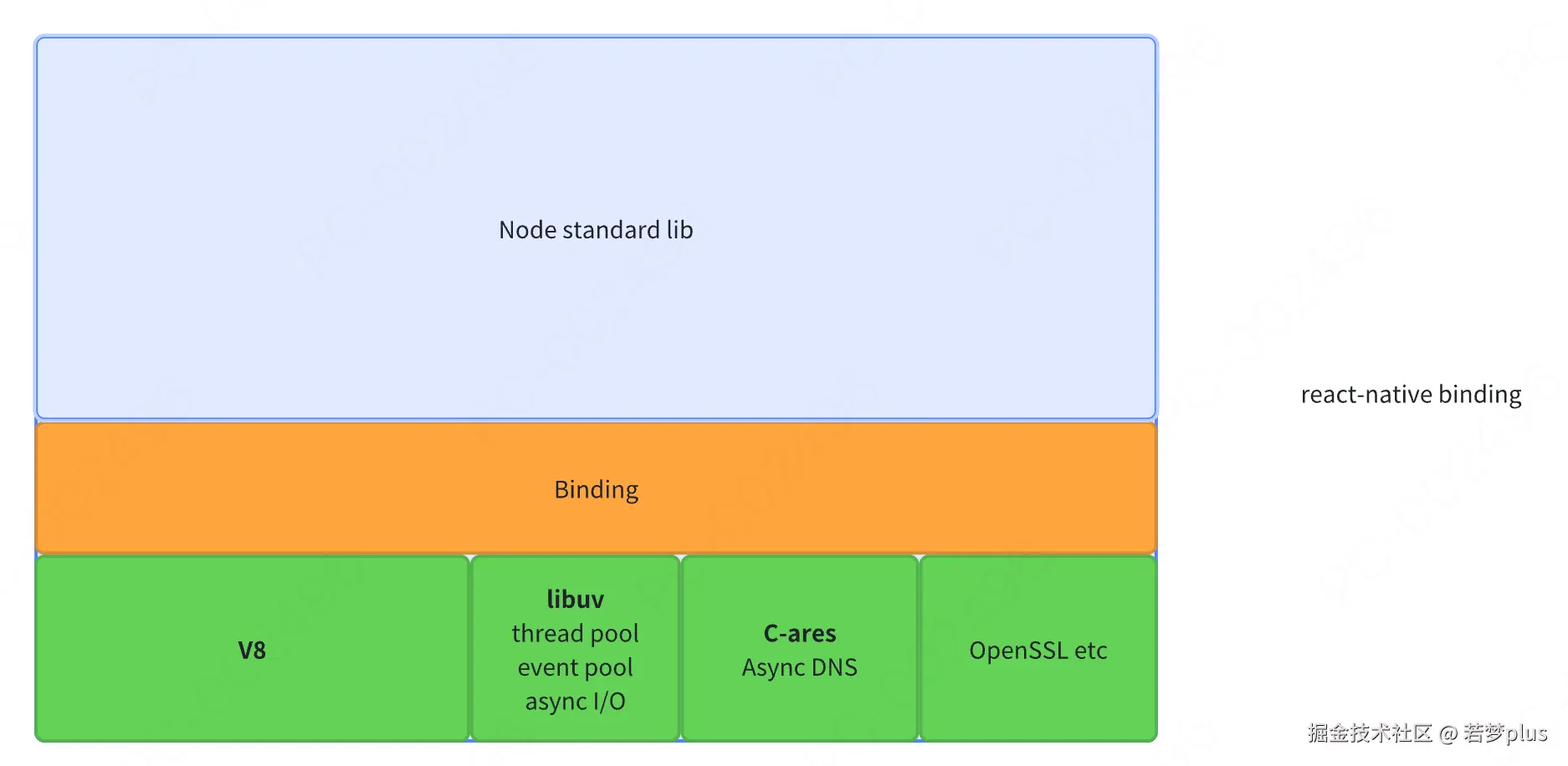
- Nodejs 整个架构
:::info 谷歌的Chrome 使用 V8
Safari 使用 JavaScriptCore,
Firefox 使用 SpiderMonkey。
:::
- V8的处理过程
- 始于从网络中获取 JavaScript 代码。
V8 解析源代码并将其转化为抽象语法树(AST abstract syntax tree)。
- 基于该AST,Ignition 基线解释器可以开始做它的事情,并产生字节码。
- 在这一点上,引擎开始运行代码并收集类型反馈。
- 为了使它运行得更快,字节码可以和反馈数据一起被发送到TurboFan 优化编译器。优化编译器在此基础上做出某些假设,然后产生高度优化的机器代码。
- 如果在某些时候,其中一个假设被证明是不正确的,优化编译器就会取消优化,并回到解释器中。
JavaScript 其实有众多引擎,只不过v8 是我们最为熟知的。
- V8 (Google),用 C++编写,开放源代码,由 Google 丹麦开发,是 Google Chrome 的一部分,也用于 Node.js.
- JavascriptCore (Apple),开放源代码,用于 webkit 型浏览器,如 Safari,2008年实现了编译器和字节码解释器,升级为了 SquirreFish。苹果内部代号为“Nitro”的 Javascript 引擎也是基于 JavascriptCore 引擎的。
- Rhino,由Mozilla 基金会管理,开放源代码,完全以Java 编写,用于 HTMLUnit
- SpiderMonkey (Mozilla),第一款 Javascript 引擎,早期用于 Netscape Navigator,现时用于 Mozilla Firefox。
- Nodejs 整个架构
:::info 谷歌的Chrome 使用 V8
Safari 使用 JavaScriptCore,
Firefox 使用 SpiderMonkey。
:::
- V8的处理过程
- 始于从网络中获取 JavaScript 代码。
V8 解析源代码并将其转化为抽象语法树(AST abstract syntax tree)。
- 基于该AST,Ignition 基线解释器可以开始做它的事情,并产生字节码。
- 在这一点上,引擎开始运行代码并收集类型反馈。
- 为了使它运行得更快,字节码可以和反馈数据一起被发送到TurboFan 优化编译器。优化编译器在此基础上做出某些假设,然后产生高度优化的机器代码。
- 如果在某些时候,其中一个假设被证明是不正确的,优化编译器就会取消优化,并回到解释器中。
垃圾回收算法
垃圾回收,又称为:GC (garbage collection)。
GC 即 Garbage Collection,程序工作过程中会产生很多垃圾,这些垃圾是程序不用的内存或者是之前用过了,以后不会再用的内存空间,而GC 就是负责回收垃圾的,因为他工作在引擎内部,所以对于我们前端来说, GC 过程是相对比较无感的,这一套引擎执行而对我们又相对无感的操作也就是常说的垃圾回收机制了当然也不是所有语言都有 GC,一般的高级语言里面会自带GC,比如 Java、Python、Javascript 等,也有无GC的语言,比如C、C++等,那这种就需要我们程序员手动管理内存了,相对比较麻烦
垃圾回收,又称为:GC (garbage collection)。
GC 即 Garbage Collection,程序工作过程中会产生很多垃圾,这些垃圾是程序不用的内存或者是之前用过了,以后不会再用的内存空间,而GC 就是负责回收垃圾的,因为他工作在引擎内部,所以对于我们前端来说, GC 过程是相对比较无感的,这一套引擎执行而对我们又相对无感的操作也就是常说的垃圾回收机制了当然也不是所有语言都有 GC,一般的高级语言里面会自带GC,比如 Java、Python、Javascript 等,也有无GC的语言,比如C、C++等,那这种就需要我们程序员手动管理内存了,相对比较麻烦
“垃圾”的定义
- “可达性”,有没有被引用,没有被引用的变量,“不可达的变量”
- 变量会在栈中存储,对象在堆中存储
- 我们知道写代码时创建一个基本类型、对象、函数都是需要占用内存的,但是我们并不关注这些,因为这是引擎为我们分配的,我们不需要显式手动的去分配内存,那么 JavaScript 引擎是如何发现并清理垃圾的呢?
- “可达性”,有没有被引用,没有被引用的变量,“不可达的变量”
- 变量会在栈中存储,对象在堆中存储
- 我们知道写代码时创建一个基本类型、对象、函数都是需要占用内存的,但是我们并不关注这些,因为这是引擎为我们分配的,我们不需要显式手动的去分配内存,那么 JavaScript 引擎是如何发现并清理垃圾的呢?
引用计数算法
相信这个算法大家都很熟悉,也经常听说。
它的策略是跟踪记录每个变量值被使用的次数
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1 如果同一个值又被赋给另一个变量,那么引用数加1
- 如果该变量的值被其他的值覆盖了,则引用次数減1
- 当这个值的引用次数变为0的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运
- 行的时候清理掉引用次数为0的值占用的内存
:::info 这个算法最怕的就是循环引用(相互引用),还有比如 JavaScript 中不恰当的闭包写法
:::
相信这个算法大家都很熟悉,也经常听说。
它的策略是跟踪记录每个变量值被使用的次数
- 当声明了一个变量并且将一个引用类型赋值给该变量的时候这个值的引用次数就为 1 如果同一个值又被赋给另一个变量,那么引用数加1
- 如果该变量的值被其他的值覆盖了,则引用次数減1
- 当这个值的引用次数变为0的时候,说明没有变量在使用,这个值没法被访问了,回收空间,垃圾回收器会在运
- 行的时候清理掉引用次数为0的值占用的内存
:::info 这个算法最怕的就是循环引用(相互引用),还有比如 JavaScript 中不恰当的闭包写法
:::
优点
- 引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为0时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
- 而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以
- 引用计数算法的优点我们对比标记清除来看就会清晰很多,首先引用计数在引用值为0时,也就是在变成垃圾的那一刻就会被回收,所以它可以立即回收垃圾
- 而标记清除算法需要每隔一段时间进行一次,那在应用程序(JS脚本)运行过程中线程就必须要暂停去执行一段时间的GC,另外,标记清除算法需要遍历堆里的活动以及非活动对象来清除,而引用计数则只需要在引用时计数就可以
弊端
- 它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
- 它需要一个计数器,而此计数器需要占很大的位置,因为我们也不知道被引用数量的上限,还有就是无法解决循环引用无法回收的问题,这也是最严重的
标记清除(Mark-Sweep)算法
:::info 从根对象进行检测,先标记再清除
:::
- 标记清除(Mark-Sweep),目前在 JavaScript引擎里这种算法是最常用的,到目前为止的大多数浏览器的 Javascript引擎都在采用标记清除算法,各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 Javascript引擎在运行垃圾回收的频率上有所差异。
- 此算法分为标记和清除两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁
- 当变量进入执行环境时,反转某一位(通过一个二进制字符来表示标记),又或者可以维护进入环境变量和离开环境变量这样两个列表,可以自由的把变量从一个列表转移到另一个列表。
- 引擎在执行GC(使用标记清除算法)时,需要从出发点去遍历内存中所有的对象去打标记,而这个出发点有很多, 我们称之为一组根对象,而所谓的根对象,其实在浏览器环境中包括又不止于全局Window对象、文档DOM树
- 整个标记清除算法大致过程就像下面这样:
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0
- 然后从各个根对象开始遍历,把不是垃圾的节点改成1
- 清理所有标记为O的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为O,等待下一轮垃圾回收
:::info 从根对象进行检测,先标记再清除
:::
- 标记清除(Mark-Sweep),目前在 JavaScript引擎里这种算法是最常用的,到目前为止的大多数浏览器的 Javascript引擎都在采用标记清除算法,各大浏览器厂商还对此算法进行了优化加工,且不同浏览器的 Javascript引擎在运行垃圾回收的频率上有所差异。
- 此算法分为标记和清除两个阶段,标记阶段即为所有活动对象做上标记,清除阶段则把没有标记(也就是非活动对象)销毁
- 当变量进入执行环境时,反转某一位(通过一个二进制字符来表示标记),又或者可以维护进入环境变量和离开环境变量这样两个列表,可以自由的把变量从一个列表转移到另一个列表。
- 引擎在执行GC(使用标记清除算法)时,需要从出发点去遍历内存中所有的对象去打标记,而这个出发点有很多, 我们称之为一组根对象,而所谓的根对象,其实在浏览器环境中包括又不止于全局Window对象、文档DOM树
- 整个标记清除算法大致过程就像下面这样:
- 垃圾收集器在运行时会给内存中的所有变量都加上一个标记,假设内存中所有对象都是垃圾,全标记为0
- 然后从各个根对象开始遍历,把不是垃圾的节点改成1
- 清理所有标记为O的垃圾,销毁并回收它们所占用的内存空间
- 最后,把所有内存中对象标记修改为O,等待下一轮垃圾回收
优点
- 标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和 1)就可以为其标记,非常简单
- 标记清除算法的优点只有一个,那就是实现比较简单,打标记也无非打与不打两种情况,这使得一位二进制位(0和 1)就可以为其标记,非常简单
弊端
- 标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题
- 那如何找到合适的块呢?
:::danger 在插入值的时候去解决,最大化使用内存空间,即:通过插入的形式,提升内存空间使用
:::
- 我们可以采取下面三种分配策略
- First-fit,找到大于等于 size 的块立即返回
- Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块
- Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择
- 综上所述,标记清除算法或者说策略就有两个很明显的缺点
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,因为即便是使用 First-fit策略,其操作仍是一个0(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
:::info 归根结底,标记清除算法的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了
:::
- 标记清除算法有一个很大的缺点,就是在清除之后,剩余的对象内存位置是不变的,也会导致空闲内存空间是不连续的,出现了内存碎片(如下图),并且由于剩余空闲内存不是一整块,它是由不同大小内存组成的内存列表,这就牵扯出了内存分配的问题
- 那如何找到合适的块呢?
:::danger 在插入值的时候去解决,最大化使用内存空间,即:通过插入的形式,提升内存空间使用
:::
- 我们可以采取下面三种分配策略
- First-fit,找到大于等于 size 的块立即返回
- Best-fit,遍历整个空闲列表,返回大于等于 size 的最小分块
- Worst-fit,遍历整个空闲列表,找到最大的分块,然后切成两部分,一部分 size 大小,并将该部分返回这三种策略里面 Worst-fit 的空间利用率看起来是最合理,但实际上切分之后会造成更多的小块,形成内存碎片,所以不推荐使用,对于 First-fit 和 Best-fit 来说,考虑到分配的速度和效率 First-fit 是更为明智的选择
- 综上所述,标记清除算法或者说策略就有两个很明显的缺点
- 内存碎片化,空闲内存块是不连续的,容易出现很多空闲内存块,还可能会出现分配所需内存过大的对象时找不到合适的块
- 分配速度慢,因为即便是使用 First-fit策略,其操作仍是一个0(n)的操作,最坏情况是每次都要遍历到最后,同时因为碎片化,大对象的分配效率会更慢
:::info 归根结底,标记清除算法的缺点在于清除之后剩余的对象位置不变而导致的空闲内存不连续,所以只要解决这一点,两个缺点都可以完美解决了
:::
标记整理(Mark-Compact)算法
:::color1 有碎片就整理,整理的过程是有消耗的,所以就会有新生代、老生代
:::
- 而标记整理(Mark-Compact)算法就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存
:::color1 有碎片就整理,整理的过程是有消耗的,所以就会有新生代、老生代
:::
- 而标记整理(Mark-Compact)算法就可以有效地解决,它的标记阶段和标记清除算法没有什么不同,只是标记结束后,标记整理算法会将活着的对象(即不需要清理的对象)向内存的一端移动,最后清理掉边界的内存
Unix/windows/Android/iOS系统中内存碎片空间思想
内存碎片化是所有系统都面临的挑战,不同操作系统和环境中的处理策略各有侧重,但也有其共通之处。以下是不同系统在内存碎片处理上的比较:
内存碎片化是所有系统都面临的挑战,不同操作系统和环境中的处理策略各有侧重,但也有其共通之处。以下是不同系统在内存碎片处理上的比较:
V8引擎中的标记-整理算法
- 标记阶段:识别未使用的对象,标记为垃圾。
- 整理阶段:将存活对象移动到连续区域,释放大块内存空间,减少外部碎片。
- 标记阶段:识别未使用的对象,标记为垃圾。
- 整理阶段:将存活对象移动到连续区域,释放大块内存空间,减少外部碎片。
电脑系统(Unix/Linux vs Windows)
- 内存管理:均使用分页机制,但Linux更倾向于预防碎片,Windows依赖内存压缩。
- 处理策略:Linux通过 slab 分配器优化内存分配,Windows通过内存压缩技术。
- 相同点:分页和交换机制,内存不足时回收内存。
- 不同点:Linux更注重预防,Windows依赖内存压缩,处理方式不同。
- 内存管理:均使用分页机制,但Linux更倾向于预防碎片,Windows依赖内存压缩。
- 处理策略:Linux通过 slab 分配器优化内存分配,Windows通过内存压缩技术。
- 相同点:分页和交换机制,内存不足时回收内存。
- 不同点:Linux更注重预防,Windows依赖内存压缩,处理方式不同。
移动终端(Android vs iOS)
- 内存管理:Android基于Linux,采用内存回收和进程优先级管理;iOS使用更严格的内存管理。
- 处理策略:Android通过Activity生命周期管理内存,iOS通过ARC自动管理。
- 相同点:内存不足时回收内存,依赖垃圾回收机制。
- 不同点:Android更灵活,支持后台进程保活;iOS更严格,强制回收。
- 内存管理:Android基于Linux,采用内存回收和进程优先级管理;iOS使用更严格的内存管理。
- 处理策略:Android通过Activity生命周期管理内存,iOS通过ARC自动管理。
- 相同点:内存不足时回收内存,依赖垃圾回收机制。
- 不同点:Android更灵活,支持后台进程保活;iOS更严格,强制回收。
内存碎片化挑战
- 内部碎片:内存分配导致的未使用空间,需优化分配策略。
- 外部碎片:分散的空闲空间,需整理或置换策略。
- 处理目标:桌面系统注重稳定性,移动设备关注响应和功耗。
- 内部碎片:内存分配导致的未使用空间,需优化分配策略。
- 外部碎片:分散的空闲空间,需整理或置换策略。
- 处理目标:桌面系统注重稳定性,移动设备关注响应和功耗。
工具与分析
- Unix/Linux:使用
top、htop、vmstat等工具。 - Windows:依赖任务管理器和性能监视器。
- 移动设备:Android用Android Profiler,iOS用Instruments。
总结: 不同系统在内存碎片处理上各有特色,但都旨在优化内存使用效率。V8引擎通过标记-整理减少碎片,而操作系统如Unix/Linux和Windows,以及移动系统如Android和iOS则采用不同的内存管理策略,以适应各自的性能和资源需求。
- Unix/Linux:使用
top、htop、vmstat等工具。 - Windows:依赖任务管理器和性能监视器。
- 移动设备:Android用Android Profiler,iOS用Instruments。
总结: 不同系统在内存碎片处理上各有特色,但都旨在优化内存使用效率。V8引擎通过标记-整理减少碎片,而操作系统如Unix/Linux和Windows,以及移动系统如Android和iOS则采用不同的内存管理策略,以适应各自的性能和资源需求。
内存管理
:::info V8的垃圾回收策略主要基于分代式垃圾回收机制,V8中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收
:::
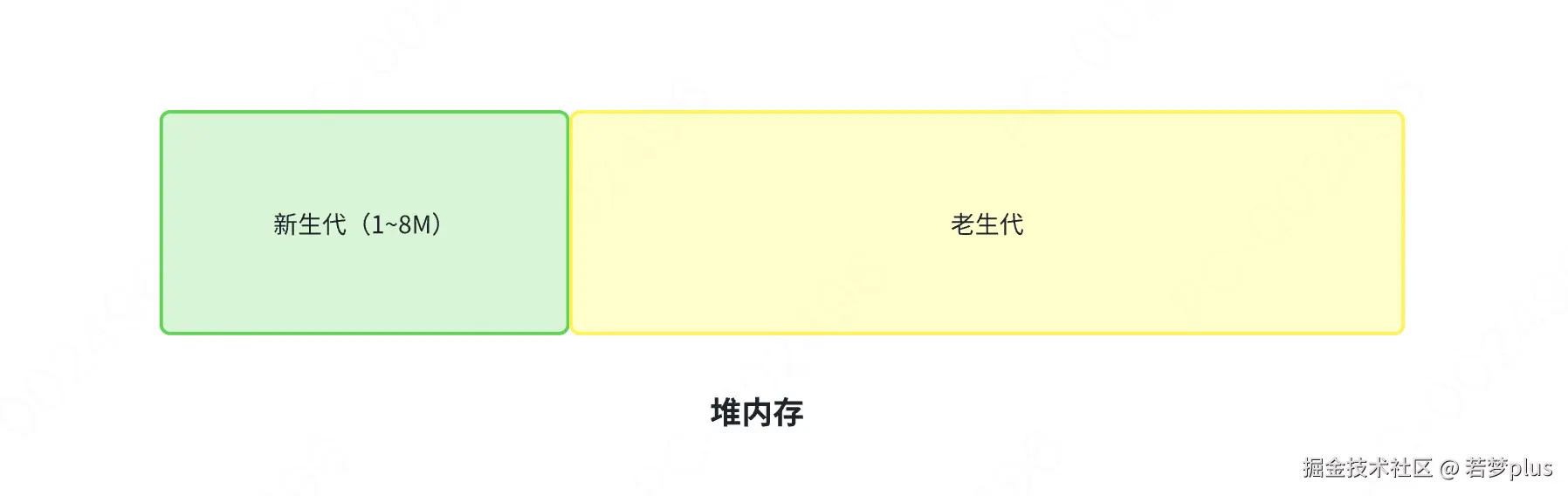
:::info V8的垃圾回收策略主要基于分代式垃圾回收机制,V8中将堆内存分为新生代和老生代两区域,采用不同的垃圾回收器也就是不同的策略管理垃圾回收
:::
新生代
- 当新加入对象时,它们会被存储在使用区。然而,当使用区快要被写满时,垃圾清理操作就需要执行。在开始垃圾回收之前,新生代垃圾回收器会对使用区中的活动对象进行标记。标记完成后,活动对象将会被复制到空闲区并进行排序。然后,垃圾清理阶段开始,即将非活动对象占用的空间清理掉。最后,进行角色互换,将原来的使用区变成空闲区,将原来的空闲区变成使用区。
- 如果一个对象经过多次复制后依然存活,那么它将被认为是生命周期较长的对象,且会被移动到老生代中进行管理。
- 除此之外,还有一种情况,如果复制一个对象到空闲区时,空闲区的空间占用超过了25%,那么这个对象会被直接晋升到老生代空间中。25%比例的设置是为了避免影响后续内存分配,因为当按照 Scavenge 算法回收完成后, 空闲区将翻转成使用区,继续进行对象内存分配。
:::info 一直在开辟空间,达到一定程度,就回晋升到老生代
:::
- 当新加入对象时,它们会被存储在使用区。然而,当使用区快要被写满时,垃圾清理操作就需要执行。在开始垃圾回收之前,新生代垃圾回收器会对使用区中的活动对象进行标记。标记完成后,活动对象将会被复制到空闲区并进行排序。然后,垃圾清理阶段开始,即将非活动对象占用的空间清理掉。最后,进行角色互换,将原来的使用区变成空闲区,将原来的空闲区变成使用区。
- 如果一个对象经过多次复制后依然存活,那么它将被认为是生命周期较长的对象,且会被移动到老生代中进行管理。
- 除此之外,还有一种情况,如果复制一个对象到空闲区时,空闲区的空间占用超过了25%,那么这个对象会被直接晋升到老生代空间中。25%比例的设置是为了避免影响后续内存分配,因为当按照 Scavenge 算法回收完成后, 空闲区将翻转成使用区,继续进行对象内存分配。
:::info 一直在开辟空间,达到一定程度,就回晋升到老生代
:::
老生代
- 不同于新生代,老生代中存储的内容是相对使用频繁并且短时间无需清理回收的内容。这部分我们可以使用标记整理进行处理。
- 从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素就可以判断为非活动对象
- 清除阶段老生代垃圾回收器会直接将非活动对象进行清除。
- 不同于新生代,老生代中存储的内容是相对使用频繁并且短时间无需清理回收的内容。这部分我们可以使用标记整理进行处理。
- 从一组根元素开始,递归遍历这组根元素,遍历过程中能到达的元素称为活动对象,没有到达的元素就可以判断为非活动对象
- 清除阶段老生代垃圾回收器会直接将非活动对象进行清除。
并行回收
:::info 思想类似于 花两个人的钱,让一个人干三个人的活
:::
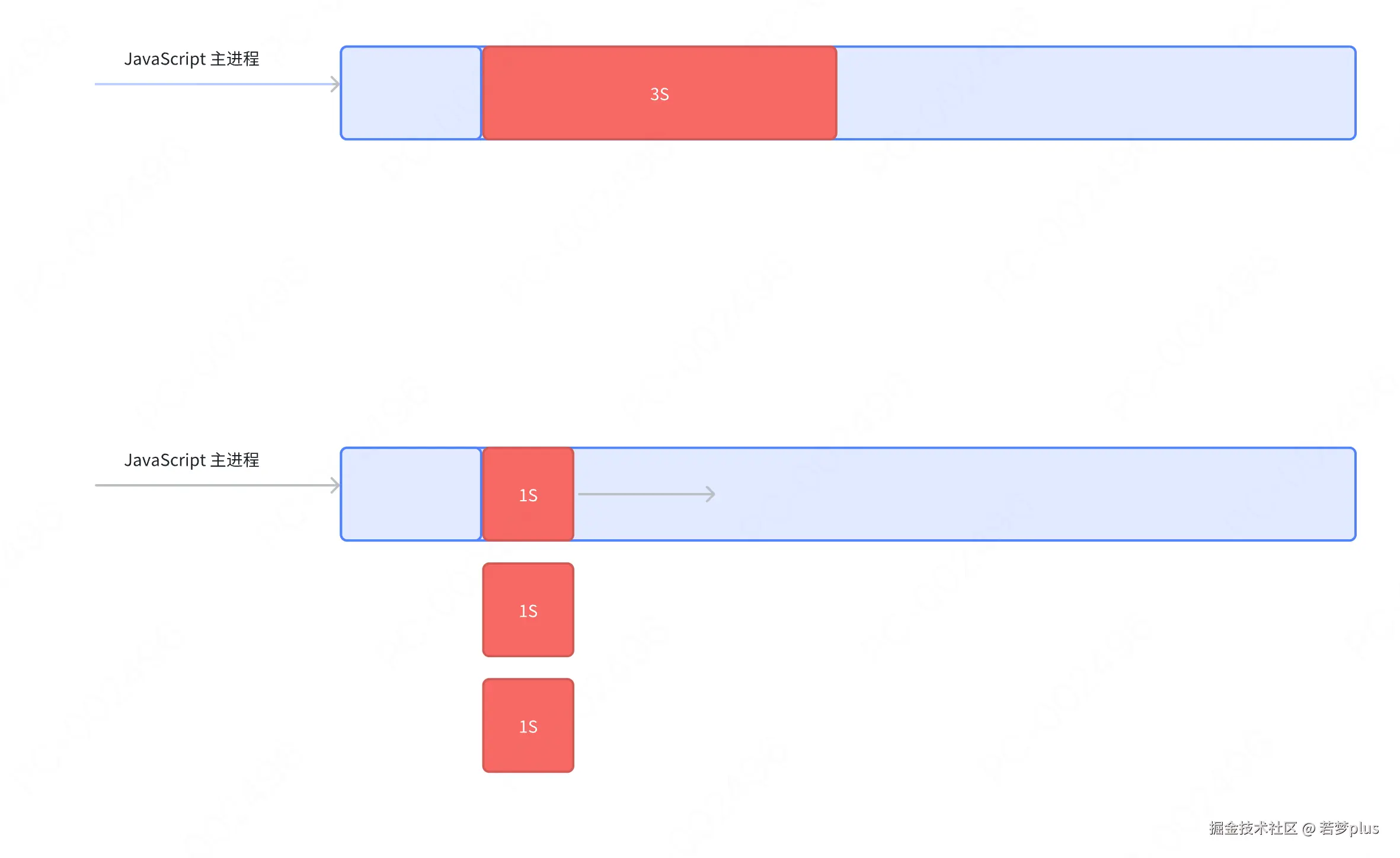
:::info 思想类似于 花两个人的钱,让一个人干三个人的活
:::
全停顿标记
这个概念看字眼好像不好理解,其买如果用前端开发的术语来解释,就是阻塞。
虽然我们的 GC操作被放到了主进程与子进程中去处理,但最终的结果还是主进程被较长时间占用。
在JavaScript的V8引擎中,全停顿标记(Full Stop-the-world Marking)是垃圾回收(GC)过程中的一个重要环节。
这个过程涉及到V8的垃圾回收器暂停JavaScript程序的执行,以便进行垃圾回收的标记阶段。全停顿标记是为了确保在回收内存前正确标记所有活动对象(即正在使用的对象)和非活动对象(即可以清除的对象)。
这个概念看字眼好像不好理解,其买如果用前端开发的术语来解释,就是阻塞。
虽然我们的 GC操作被放到了主进程与子进程中去处理,但最终的结果还是主进程被较长时间占用。
在JavaScript的V8引擎中,全停顿标记(Full Stop-the-world Marking)是垃圾回收(GC)过程中的一个重要环节。
这个过程涉及到V8的垃圾回收器暂停JavaScript程序的执行,以便进行垃圾回收的标记阶段。全停顿标记是为了确保在回收内存前正确标记所有活动对象(即正在使用的对象)和非活动对象(即可以清除的对象)。
全停顿标记的工作原理
1.停止执行:当执行到全停顿标记阶段时,V8引擎会暂停正在执行的JavaScript代码,确保没有任何Javascript代码在运行。这个停顿是必需的,因为在标记活动对象时,对象的引用关系需要保持不变。
2. 标记阶段:在这个阶段,垃圾回收器遍历所有根对象(例如全局变量、活跃的函数的局部变量等),从这些根对象开始,递归地访问所有可达的对象。每访问到一个对象,就将其标记为活动(1)的。
- 恢复执行:标记完成后,V8引擎会恢复JavaScript代码的执行,进入垃圾回收的清除或压缩阶段。
1.停止执行:当执行到全停顿标记阶段时,V8引擎会暂停正在执行的JavaScript代码,确保没有任何Javascript代码在运行。这个停顿是必需的,因为在标记活动对象时,对象的引用关系需要保持不变。
2. 标记阶段:在这个阶段,垃圾回收器遍历所有根对象(例如全局变量、活跃的函数的局部变量等),从这些根对象开始,递归地访问所有可达的对象。每访问到一个对象,就将其标记为活动(1)的。
- 恢复执行:标记完成后,V8引擎会恢复JavaScript代码的执行,进入垃圾回收的清除或压缩阶段。
全停顿的影响及优化
全停顿标记虽然对于确保内存被正确管理是必要的,但它会对应用程序的性能产生影响,特别是在垃圾回收发生时, 应用程序的响应时间和性能会短暂下降。为了缓解这种影响,V8引擎采用了几种策略:
• 增量标记 (Incremental Marking):为了减少每次停顿的时间,V8实现了增量标记,即将标记过程分成多个小部分进行,介于JavaScript执行的间隙中逐步完成标记。
• 并发标记(Concurrent Marking):V8引擎的更高版本中引入了并发标记,允许垃圾回收标记阶段与JavaScript代码的执行同时进行,进一步减少停顿时间。
• 延迟清理(Lazy Sweeping):标记完成后的清理阶段也可以延迟执行,按需进行,以减少单次停顿的时间。
这些优化措施有助于提高应用的响应速度和整体性能,特别是在处理大量数据和复杂操作时,确保用户体验不会因垃圾回收而受到较大影响。
切片标记
- 增量就是将一次 GC标记的过程,分成了很多小步,每执行完一小步就让应用逻辑执行一会儿,这样交替多次后完成一轮 GC 标记
三色标记
我们这里的会,表示的是一个中间状态,为什么会有这个中间状态呢?
• 白色指的是未被标记的对象
• 灰色指自身被标记,成员变量(该对象的引用对象)未被标记 • 黑色指自身和成员变量皆被标记
在V8引擎中使用的三色标记算法是一种用于垃圾回收的有效方法,特别是在进行增量和并发标记时。这个算法通过给对象着色(白色、灰色、黑色)来帮助标记和回收垃圾。
工作原理
- 初始化:
- 白色:初始状态,所有对象都标记为白色,表示这些对象可能是垃圾,如果在标记过程中没有被访问到,最终将被清理。
- 灰色:表示对象已经被标记(访问过),但该对象的引用还没有完全检查完。
- 黑色:表示该对象及其所有引用都已经被完全访问过,并且已经标记。
- 标记过程:
- 垃圾回收开始时,从根集合(如全局变量、活跃的堆栈帧中的局部变量等)出发,将所有根对象标记为灰色。
- 逐一处理灰色对象:将灰色对象标记为黑色,并将其直接引用的所有白色对象转变为灰色。这个过程不断重复,直到没有灰色对象为止。
- 扫描完成:
- 所有从根可达的对象最终都会被标记为黑色。所有仍然为白色的对象被认为是不可达的,因此将被视为垃圾并在清除阶段被回收。
- 初始化:
优点
- 健壮性:三色标记算法非常适合增量和并发的垃圾回收,因为它能够确保即使在应用程序继续执行的情况下也能正确地标记活动对象。
- 防止漏标:通过灰色和黑色的严格区分,算法确保所有可达的对象都会被遍历和标记,防止错误地回收正在使用的对象。
- 效率:虽然在垃圾回收期间会有增加的计算开销,但三色标记算法可以与应用程序的执行并行进行,减少了GC停顿的时间,提高了应用的响应性和性能。
应用
- 在实际应用中,V8和其他现代JavaScript引擎使用这种算法进行内存管理,优化了动态内存的使用,减少了垃圾回收对应用性能的影响。这对于要求高性能和实时响应的Web应用程序尤其重要。
写屏障(增量中修改引用)
- 这一机制用于处理在增量标记进行时修改引用的处理,可自行修改为灰色
在V8引擎中,写屏障(Write Barrier)是垃圾回收(GC)的一个关键机制,尤其是在增量和并发垃圾回收过程中发挥着至关重要的作用。写屏障主要用来维持垃圾回收中的三色不变性,在对象写操作期间动态地更新对象的可达性信息。
作用
- 保持三色不变性,在使用三色标记算法中,写屏障帮助维持所谓的三色不变性。这意味着系统确保如果一个黑色对象(已经被完全扫描的对象)引用了一个白色对象(尚未被扫描的对象,可能是垃圾),那么这个白色对象应当转变为灰色(标记但尚未扫描完毕的对象),从而避免错误的垃圾回收。
- 处理指针更新,当一个对象的指针被更新(例如,一个对象的属性被另一个对象替换),写屏障确保关于这些对象的垃圾回收元数据得到适当的更新。这是确保垃圾回收器正确识别活动对象和非活动对象的必要步骤。
类型
- Pre-Write Barrier(预写屏障),这种类型的写屏障在实际更新内存之前执行。它主要用于某些特定类型的垃圾回收算法,比如分代垃圾回收,以保持老年代和新生代之间的引用正确性。
- Post-Write Barrier(后写屏障),这是最常见的写屏障类型,发生在对象的指针更新之后。在V8中,当黑色对象指向白色对象时,后写屏障会将该白色对象标记为灰色,确保它不会在当前垃圾回收周期中被错误地回收。
实现细节
- 在V8引擎中,写屏障通常由简短的代码片段实现,这些代码片段在修改对象属性或数组元素时自动执行。例如,每当JavaScript代码或内部的V8代码试图写入一个对象的属性时,写屏障代码会检查是否需要更新垃圾回收的元数据。
惰性清理
- 增量标记只是用于标记活动对象和非活动对象,真正的清理释放内存,则V8采用的是惰性清理(Lazy Sweeping)方案。
- 在增量标记完成后,进行清理。当增量标记完成后,假如当前的可用内存足以让我们快速的执行代码,其实我们是没必要立即清理内存的,可以将清理过程稍微延迟一下,让 Javascript 脚本代码先执行,也无需一次性清理完所有非活动对象内存,可以按需逐一进行清理直到所有的非活动对象内存都清理完毕。
并发回收
:::info 本质是切片,然后去插入,做一些动作
:::
- react 中的 Concurrent 吗?
- 我们想想 React演进过程,是不是就会觉得从并行到并发的演进变得很合了呢?
- 并发挥收其实是更进一步的切片,几乎完全不阻塞主进程。
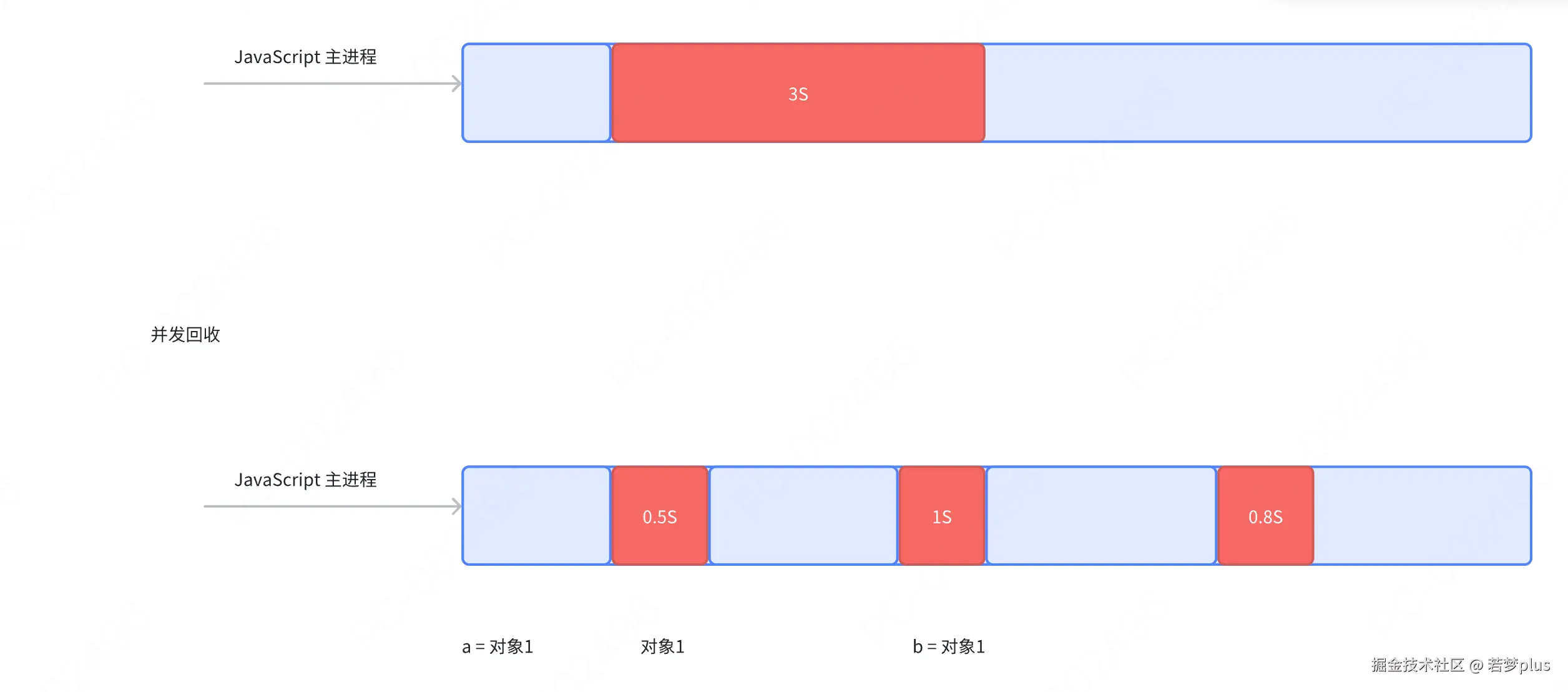
:::success 分代式机制把一些新、小、存活时间短的对象作为新生代,采用一小块内存频率较高的快速清理,而一些大、老、存活时间长的对象作为老生代,使其很少接受检查,新老生代的回收机制及频率是不同的,可以说此机制的出现很大程度提高了垃圾回收机制的效率
:::
怎么理解内存泄露?
怎么解决内存泄露,代码层面如何优化?
- 减少查找
- 减少变量声明
- 使用 Performance + Memory 分析内存与性能
运行机制
- 浏览器主进程
- 协调控制其他子进程(创建、销毁)
- 浏览器界面显示,用户交互,前进、后退、收藏
- 将渲染进程得到的内存中的Bitmap,绘制到用户界面上
- 存储功能等
- 第三方插件进程
- 每种类型的插件对应一个进程,仅当使用该插件时才创建
- GPU进程
- 用于3D绘制等
- 渲染进程,就是我们说的浏览器内核
- 排版引擎 Blink 和 JavaScript 引擎V8 都是运行在该进程中,将HTML、CSS和 JavaScript 转换为用户可以与之交互的网页
- 协调控制其他子进程(创建、销毁)
- 浏览器界面显示,用户交互,前进、后退、收藏
- 将渲染进程得到的内存中的Bitmap,绘制到用户界面上
- 存储功能等
- 每种类型的插件对应一个进程,仅当使用该插件时才创建
- 用于3D绘制等
- 排版引擎 Blink 和 JavaScript 引擎V8 都是运行在该进程中,将HTML、CSS和 JavaScript 转换为用户可以与之交互的网页
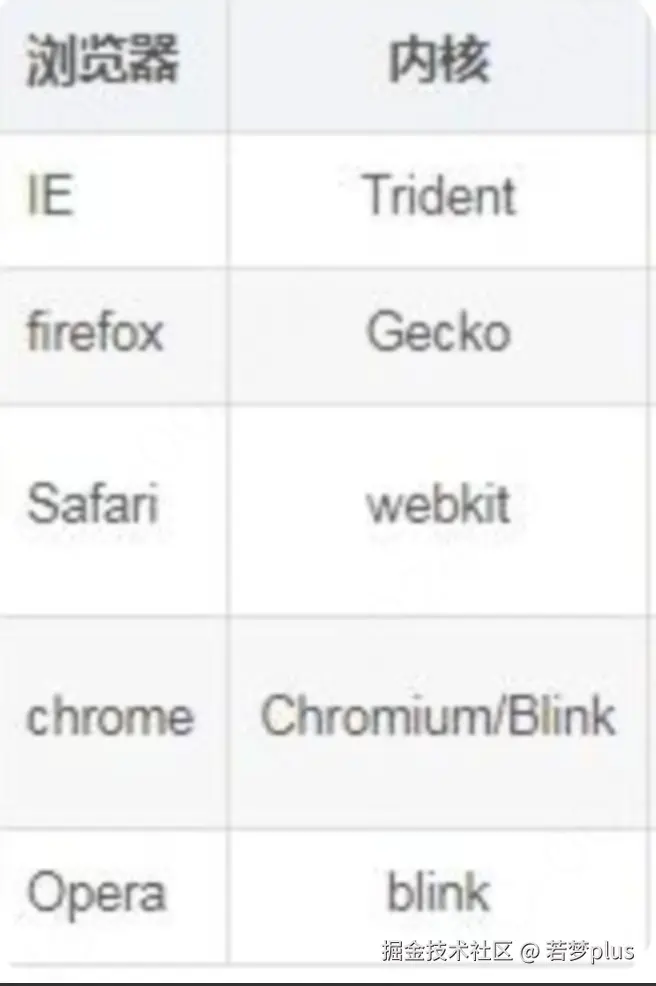
- 负责页面渲染,脚本执行,事件处理等
- 每个tab页一个渲染进程
- 出于安全考虑,渲染进程都是运行在沙箱模式下
- 网络进程
- 负责页面的网络资源加载,之前作为一个模块运行在浏览器主进程里面,最近才独立成为一个单独的进程
浏览器事件循环
:::info 在 Chrome 中,事件循环的执行是由浏览器的渲染引擎(例如 Blink)和V8 引擎配合完成的。V8负责 JavaScript 代码的执行,Blink 负责浏览器的渲染和用户界面的更新
:::
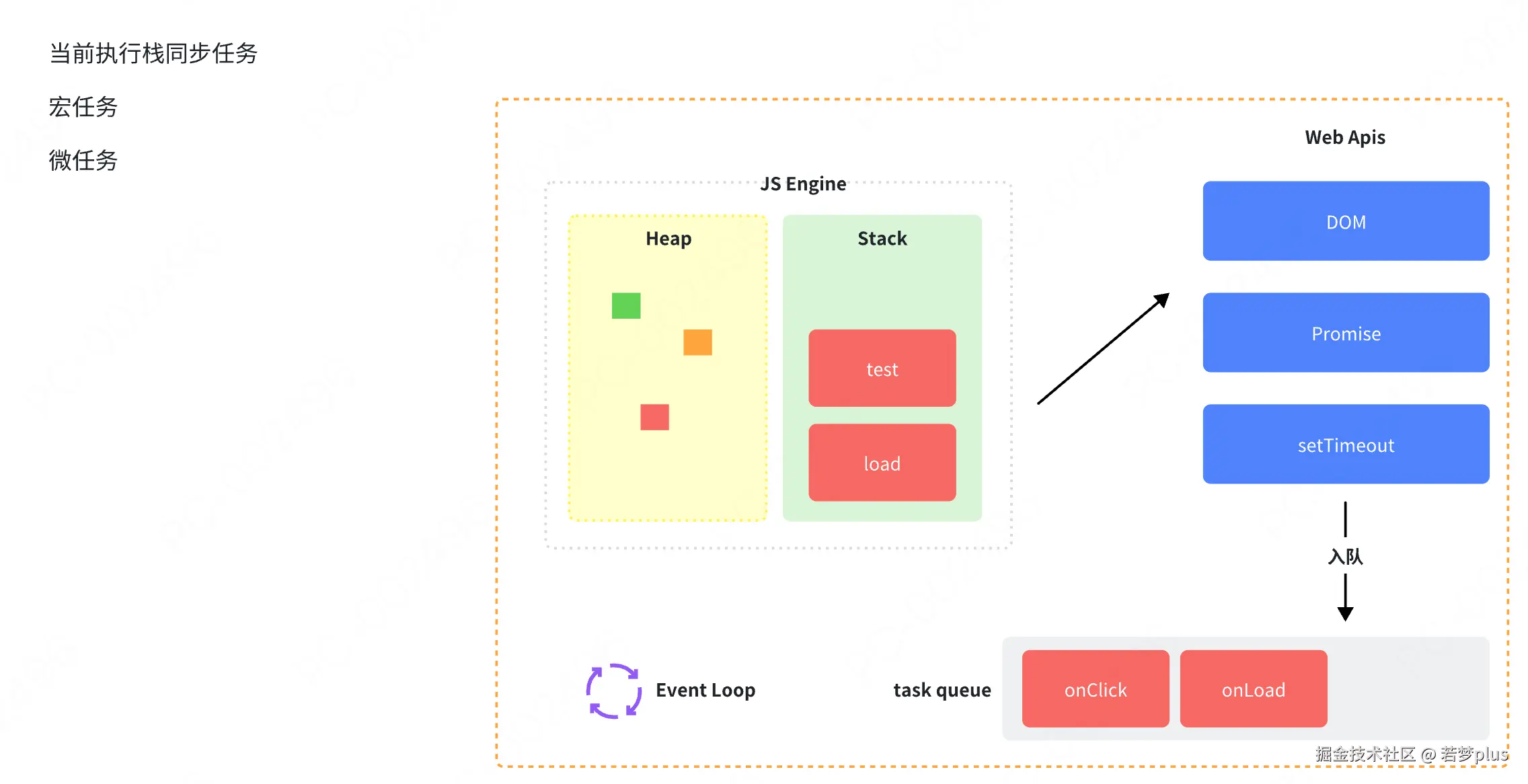
执行任务的顺序
先执行当前执行栈同步任务,再执行(微任务),再执行(宏任务)
宏任务
:::info 在 Chrome的源码中,并未直接出现“宏任务”这一术语,但在 Javascript 运行时引擎(V8)以及事件循环 (Event Loop)相关的实现中,宏任务和微任务的概念是非常重要的。
实际上,“宏任务”这一术语来源于 Javascript 事件循环的抽象,它只是帮助我们理解任务的执行顺序和时机。
:::
可以将每次执行栈执行的代码当做是一个宏任务
- I/O
- setTimeout
- setinterval
- setImmediate
- requestAnimationFrame
微任务
当宏任务执行完,会在渲染前,将执行期间所产生的所有微任务都执行完
- process.nextTick
- MutationObserver
- Promise.then catch finally
完整鏊体流程
- 执行当前执行栈同步任务(栈中没有就从事件队列中获取)
- 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 执行栈同步任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 宏任务执行完毕,开始检查渲染,然后 GUI线程接管渲染
- 渲染完毕后, JS线程继续接管,开始下一个宏任务(从事件队列中获取)
Node事件循环机制
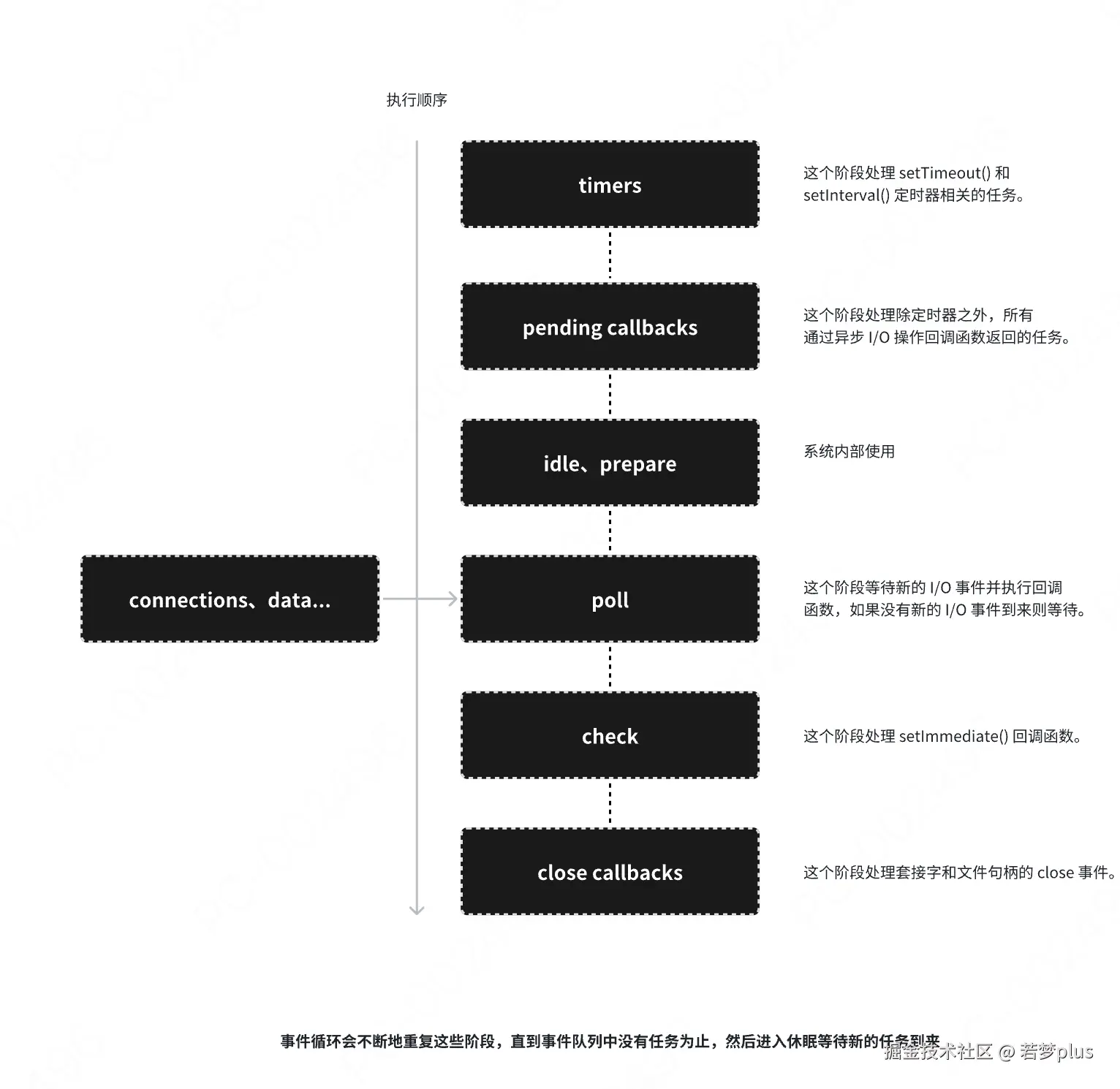
与浏览器事件循环机制的不同
- 在 Node.js 中,为了更高效地管理和调度各种类型的异步任务。这种设计使得 Node.js 能够在单线程环境中有效地处理大量的并发任务。下
- Node.js 的事件循环(Event Loop)是一个处理异步操作的机制,它会按照顺序依次执行不同阶段任务。事件循环机制中分为多个阶段,每个阶段都有自己的任务队列,包括:
- Timers 阶段:
- 处理 setTimeout 和 setInterval 调度的回调函数。
- 如果指定的时间到了,回调函数会被放入这个队列。
- Pending Callbacks 阶段:
- 处理一些1/0操作的回调,比如 TCP 错误类型的回调。
- 这些回调并不完全由开发者控制,而是由操作系统调度的。
- Idle, Prepare 阶段:
- 仅供内部使用的阶段。
- Poll 阶段:
- 获取新的1/0事件,执行1/0回调函数。
- 通常情况下,这个阶段会一直等待,直到有新的!/0 事件到来。
- Check 阶段:
- 处理 :setImmediate 调度的回调函数。
- etImmediate 的回调会在这个阶段执行,比 setTimeout 更早。
- Close Callbacks 阶段:
- 处理一些关闭的回调函数,比如 socket.on('close', ... ) °
- 处理 setTimeout 和 setInterval 调度的回调函数。
- 如果指定的时间到了,回调函数会被放入这个队列。
- 处理一些1/0操作的回调,比如 TCP 错误类型的回调。
- 这些回调并不完全由开发者控制,而是由操作系统调度的。
- 仅供内部使用的阶段。
- 获取新的1/0事件,执行1/0回调函数。
- 通常情况下,这个阶段会一直等待,直到有新的!/0 事件到来。
- 处理 :setImmediate 调度的回调函数。
- etImmediate 的回调会在这个阶段执行,比 setTimeout 更早。
- 处理一些关闭的回调函数,比如 socket.on('close', ... ) °
多个队列的必要性
不同类型的异步任务有不同的优先级和处理方式。使用多个队列可以确保这些任务被正确地调度和执行:
- Timers 和 Poll 阶段的区别:
- setTimeout 和 setInterval 的回调在 Timers 阶段执行,这些回调函数依赖于计时器的到期时间。
- Poll 阶段处理大多数1/0 回调,这是事件循环的主要阶段,处理大部分异步1/O操作。
- mmediate 与 Timeout 的不同:
- setImmediate 的回调函数在 Check 阶段执行,这是在当前事件循环周期结束后立即执行。
- setTimeout 的回调函数则是在 Timers 阶段执行,它可能会延迟到下一个事件循环周期,甚至更久。
- 处理关闭回调:
- Close Callbacks 阶段专门处理如 socket.on('close')这样的回调,以确保在资源释放时执行。
Chrome 任务调度机制
V8与Blink的调度系统密切相关。
:::info Blink 是 Chrome 中的渲染引擎
V8是 Chrome 中的 JavaScript 引擎
:::
Blink 是 Chrome 浏览器中的渲染引擎,负责页面的渲染和绘制任务。V8与 Blink 会协同工作,确保 JavaScript 的执行与页面渲染能够平稳进行。
Blink Scheduler:docs.google.com/document/d/…
接下来我们了解一下 Blink scheduler,一个用于优化 Blink 主线程任务调度的方案,旨在解决现有调度系统中的一些问题。
将任务不断安排到主线程的消息循环中,会导致Blink 主线程阻塞。造成诸多问题:
- 有限的优先级设置-任务按照发布顺序执行,或者可以明确地延迟,但这可能导致一些重要的任务(如输入处理) 被不那么紧急的任务占用优先执行权。
- 缺乏与系统其他部分的协调-比如图形管线虽然已知有输入事件的传递、显示刷新等时序要求,但这些信息无法及时传递给Blink。
- 无法适应不同的使用场景 -某些任务(如垃圾回收)在用户交互时进行非常不合适。
为了解决以上问题,出现了 Blink Scheduler 调度器,它能够更灵活控制任务按照给定优先级执行
- 关键特点
- 调度器的主要功能是决定在特定时刻哪个任务应当执行。
- 调度器提供了更高级的API替代现有的主线程任务调度接口,任务不再是抽象的回调函数,而是更具体、具有明确标签和元数据的对象。例如,输入任务会被明确标记,并附带附加元数据。
- 调度器可以根据系统状态做出更明智的任务决策,而不是依赖给定死的静态优先级。
gitlab.mpi-klsb.mpg.de/eweyulu/qui…
- 性能验证和工具
- 为了验证调度器的效果,文章提到了多项基准测试和性能指标,例如:
- 队列等待时间:衡量任务从发布到执行的延迟。
- 输入事件延迟:衡量输入事件的处理时间。
- 渲染平滑度(jank):衡量渲染的平滑性,避免出现卡顿。
- 页面加载时间:跟踪页面加载时间的变化。
其他资料
- V8:v8.dev/docs/torque
- chromium 中promise:chromium.googlesource.com/v8/v8/+/ref…
- V8定义:chromium.googlesource.com/v8/v8/+/ref…
- Node V8:nodejs.org/en/learn/ge…
- ibuv-in-node-js:http://www.geeksforgeeks.org/libuv-in-no…
- Faster JavaScript calls:v8.dev/blog/adapto…
- blink scheduler:docs.google.com/document/d/…
作者:若梦plus
来源:juejin.cn/post/7493386024878833715
来源:juejin.cn/post/7493386024878833715
我为什么在团队里,强制要求大家用pnpm而不是npm?

最近,我在我们前端团队里推行了一个“强制性”的规定:所有新项目,必须使用pnpm作为包管理工具;所有老项目,必须在两个月内,逐步迁移到pnpm。
这个决定,一开始在团队里是有阻力的。
有同事问:“老大,npm用得好好的,为啥非要换啊?我们都习惯了。”
也有同事说:“yarn不也挺快的吗?再换个pnpm,是不是在瞎折腾?”
我理解大家的疑问。但我之所以要用“强制”这个词,是因为在我看来,在2025年的今天,继续使用npm或yarn,就像是明明有高铁可以坐,你却非要坚持坐绿皮火车一样,不是不行,而是没必要。
这篇文章,我就想把我的理由掰开揉碎了,讲给大家听。
npm和yarn的“原罪”:那个又大又慢的node_modules
在聊pnpm的好处之前,我们得先搞明白,npm和yarn(特指yarn v1)到底有什么问题。
它们最大的问题,都源于一个东西——扁平化的node_modules。
你可能觉得奇怪,“扁平化”不是为了解决npm v2时代的“依赖地狱”问题吗?是的,它解决了老问题,但又带来了新问题:
1. “幽灵依赖”(Phantom Dependencies)
这是我最不能忍受的一个问题。
举个例子:你的项目只安装了A包(npm install A)。但是A包自己依赖了B包。因为是扁平化结构,B包也会被提升到node_modules的根目录。
结果就是,你在你的代码里,明明没有在package.json里声明过B,但你却可以import B from 'B',而且代码还能正常运行!
这就是“幽灵依赖”。它像一个幽灵,让你的项目依赖关系变得混乱不堪。万一有一天,A包升级了,不再依赖B了,你的项目就会在某个意想不到的地方突然崩溃,而你甚至都不知道B是从哪来的。
2. 磁盘空间的巨大浪费
如果你电脑上有10个项目,这10个项目都依赖了lodash,那么在npm/yarn的模式下,你的磁盘上就会实实在在地存着10份一模一样的lodash代码。
对于我们这些天天要开好几个项目的前端来说,电脑的存储空间就这么被日积月累地消耗掉了。
3. 安装速度的瓶颈
虽然npm和yarn都有缓存机制,但在安装依赖时,它们仍然需要做大量的I/O操作,去复制、移动那些文件。当项目越来越大,node_modules动辄上G的时候,那个安装速度,真的让人等到心焦。
pnpm是怎么解决这些问题的?——“符号链接”
好了,现在主角pnpm登场。pnpm的全称是“performant npm”,意为“高性能的npm”。它解决上面所有问题的核心武器,就两个字:链接。
pnpm没有采用扁平化的node_modules结构,而是创建了一个嵌套的、有严格依赖关系的结构。
1. 彻底告别“幽灵依赖”
在pnpm的node_modules里,你只会看到你在package.json里明确声明的那些依赖。
你项目里依赖的A包,它自己所依赖的B包,会被存放在node_modules/.pnpm/这个特殊的目录里,然后通过 符号链接(Symbolic Link) 的方式,链接到A包的node_modules里。
这意味着,在你的项目代码里,你根本访问不到B包。你想import B?对不起,直接报错。这就从结构上保证了,你的项目依赖关系是绝对可靠和纯净的。
2. 磁盘空间的“终极节约”
pnpm会在你的电脑上创建一个“全局内容可寻址存储区”(content-addressable store),通常在用户主目录下的.pnpm-store里。
你电脑上所有项目的所有依赖,都只会在这个全局仓库里,实实在在地只存一份。
当你的项目需要lodash时,pnpm不会去复制一份lodash到你的node_modules里,而是通过 硬链接(Hard Link) 的方式,从全局仓库链接一份过来。硬链接几乎不占用磁盘空间。
这意味着,就算你有100个项目都用了lodash,它在你的硬盘上也只占一份的空间。这个特性,对于磁盘空间紧张的同学来说,简直是福音。
3. 极速的安装体验
因为大部分依赖都是通过“链接”的方式实现的,而不是“复制”,所以pnpm在安装依赖时,大大减少了磁盘I/O操作。
它的安装速度,尤其是在有缓存的情况下,或者在安装一个已经存在于全局仓库里的包时,几乎是“秒级”的。这种“飞一般”的感觉,一旦体验过,就再也回不去了。
为什么我要“强制”?
聊完了技术优势,再回到最初的问题:我为什么要“强制”推行?
因为包管理工具的统一,是前端工程化规范里最基础、也最重要的一环。
如果一个团队里,有人用npm,有人用yarn,有人用pnpm,那就会出现各种各样的问题:
- 不一致的
lock文件:package-lock.json,yarn.lock,pnpm-lock.yaml互相冲突,导致不同成员安装的依赖版本可能不完全一致,引发“在我电脑上是好的”这种经典问题。 - 不一致的依赖结构:用npm的同事,可能会不小心写出依赖“幽灵依赖”的代码,而用pnpm的同事拉下来,代码直接就跑不起来了。
在一个团队里,工具的统一,是为了保证环境的一致性和协作的顺畅。而pnpm,在我看来,就是当前这个时代下,包管理工具的“最优解”。
所以,这个“强制”,不是为了搞独裁,而是为了从根本上提升我们整个团队的开发效率和项目的长期稳定性。
最后的经验
从npm到yarn,再到pnpm,前端的包管理工具一直在进化。
pnpm用一种更先进、更合理的机制,解决了过去遗留下的种种问题。它带来的不仅仅是速度的提升,更是一种对“依赖关系纯净性”和“工程化严谨性”的保障。
我知道,改变一个人的习惯很难。但作为团队的负责人,我有责任去选择一条更高效、更正确的路,然后带领大家一起走下去。
如果你还没用过pnpm,我强烈建议你花十分钟,在你的新项目里试一试🙂。
来源:juejin.cn/post/7530180321619656745
Tauri 2.0 桌面端自动更新方案
前言
最近在研究 Tauri 2.0 如何自动更新,跟着官网教程来了一遍,发现并不顺利,踩了很多坑,不过好在最后终于走通了,今天整理一下供大家参考。
第一步
自动更新利用的是 Tauri 的 Updater 组件,所以这里需要安装一下:
PNPM 执行这个(笔者用的 PNPM):
pnpm tauri add updater
NPM 执行这个:
npm run tauri add updater
接着在 /src-tauri/tauri.conf.json 文件中添加以下配置:
{
"bundle": {
"createUpdaterArtifacts": true
},
"plugins": {
"updater": {
"pubkey": "你的公钥",
"endpoints": ["https://releases.myapp.com/latest.json"]
}
}
}
其中:
createUpdaterArtifacts为是否创建更新包,设置为 true 即可。根据官网介绍,未来发布的 V3 版本将无需设置。pubkey是公钥,用于和私钥匹配(私钥在开发环境配置,并在打包时自动携带)。但此时我们还没有,所以需要生成一下,执行以下命令生成密钥对:
PNPM 执行这个:
pnpm tauri signer generate -w ~/.tauri/myapp.key
NPM 执行这个:
npm run tauri signer generate -- -w ~/.tauri/myapp.key
执行时会要求输入一个密码用来保护密钥,也可以直接按回车跳过,建议还是输入一个:

输入(或跳过)之后,将会继续生成,生成之后进入刚才我们指定的目录
~/.tauri:
打开公钥
myapp.key.pub然后将上面的pubkey替换掉。
私钥的话,打开
myapp.key然后执行以下方法设置到环境变量:
macOS 和 Linux 执行这个(笔者是 macOS):
export TAURI_SIGNING_PRIVATE_KEY="你的私钥"
export TAURI_SIGNING_PRIVATE_KEY_PASSWORD="你刚才输入的密码,没有就不用设置。"
Windows 使用 Powershell 执行这个:
$env:TAURI_SIGNING_PRIVATE_KEY="你的私钥"
$env:TAURI_SIGNING_PRIVATE_KEY_PASSWORD="你刚才输入的密码,没有就不用设置。"
endpoints用于 Tauri 检查更新,是一个数组,所以可以设置多个,将会依次尝试可用的 URL,URL 指向放置在服务器的用于存储版本信息的 JSON 文件(也可以使用 API 的形式,这里不介绍了),格式如下:
{
"version": "1.0.1",
"notes": "更新说明",
"pub_date": "2025-05-21T03:29:28.626Z",
"platforms": {
"darwin-aarch64": {
"signature": "dW50cnVzdGVkIGNvbW1lbnQ6IHNpZ25hdHVyZSBmcm9tIHRhdXJpIHNlY3JldCBrZXkKUlVTU0xJb2k1U3J6ZVFoUWo3R2lMTm5EdzhoNUZTKzdsY0g1NktOOTFNL2RMM0JVVVl4b0k3bFB0MkhyL3pKOHRYZ0x0RVdUYzdyWVJvNDBtRDM0OGtZa2d0RWl0VTBqSndrPQp0cnVzdGVkIGNvbW1lbnQ6IHRpbWVzdGFtcDoxNzQ3Nzk1MTY5CWZpbGU6bXktdGF1cmktYXBwLmFwcC50YXIuZ3oKS1N0UDl5MHRteUd0RHJ6anlSMXBSWmNJUlNKb1pYTDFvK2EvUjArTlBpbXVGN3pnQlA0THhhVUd4S3JrZy9lNHBNbWVSU2VoaCswN25xNEFPcmtUQnc9PQo=",
"url": "macOS 包下载地址"
}
}
}
将此 JSON 文件放置在服务器,然后将上面的
endpoints数组里的地址替换为这个 JSON 的真实地址。
其中:
version是版本号,升级时需要大于当前用户使用的版本。notes是更新说明,可以向用户说明本次更新的内容。pub_date是更新日期,非必填。platform是更新的平台,这里我以 macOS 为例,Windows 同理。signature是每次打包后的签名,所以每次都不一样,macOS 默认在/src-tauri/target/release/bundle/macos/my-tauri-app.app.tar.gz.sig这个位置,将这个文件打开,复制里面的内容替换即可。
第二步
配置好以后,就可以在应用内调用 check 方法进行更新了,比如在用户每次应用启动后。以下是从检查更新到更新完成的全流程的必要代码:
import { check } from '@tauri-apps/plugin-updater'
import { relaunch } from '@tauri-apps/plugin-process'
const fetchVersion = async () => {
const update = await check()
if (update) {
console.log(`found update ${update.version} from ${update.date} with notes ${update.body}`)
let downloaded = 0
let contentLength = 0
// 也可以分开调用 update.download() 和 update.install()
await update.downloadAndInstall(event => {
switch (event.event) {
case 'Started':
contentLength = event.data.contentLength
console.log(`started downloading ${event.data.contentLength} bytes`)
break
case 'Progress':
downloaded += event.data.chunkLength
console.log(`downloaded ${downloaded} from ${contentLength}`)
break
case 'Finished':
console.log('download finished')
break
}
})
console.log('update installed')
// 此处 relaunch 前最好询问用户
await relaunch()
}
}
代码已经很简洁了,相信大家能看懂,但还是简单说一下:
首先调用 check 方法。检查之后,check 方法会返回一个 update 对象,如果检查到有更新,该对象会包含上面的版本更新信息,也包含一个 downloadAndInstall 方法。
执行 downloadAndInstall 方法,该方法执行完之后就代表安装成功了,会在下次启动时更新为新版本。当然也可以立即生效,只需要调用 relaunch 方法重启应用即可,但重启前最好提醒用户。
源码(经测试已经成功实现自动更新)已经上传到 Github:github.com/reallimengz…
来源:juejin.cn/post/7506832196582408226
ESLint + Husky 如何只扫描发生改动的文件?
背景
最近公司对代码质量抓得很严, 出台了一系列组合拳:
- 制定前端编码规范
- 在本地使用git提交代码时进行代码质量检查
- 在CI/CD流水线上, 用sonarQube设置了一个代码质量达标阈值,不达标的话无法构建部署
- 除了运用工具之外,还增加了定期的CodeReview
- 单元测试,线上合并代码时用大模型进行CodeReview也在路上...
今天先说说,在本地使用git提交代码时进行代码质量检查如何实现。现在进入主题
Step1 配置ESLint校验规则
在这一步,踩了一个大坑。现在安装ESLint, 安装的都是ESLint v9.x版本,ESLint v9+的配置文件与之前不太一样了。不管是问大模型,还是上网搜,搜出来的ESLint安装配置方式90%以上都是ESLint V8及以下版本的配置方法。按照那种方式配,会吃很多瘪。
能看懂的,简单一点的报错比如说:
- .eslintignore文件不再被支持,应该在
eslint.config.js或eslint.config.ts配置文件中,使用ignores属性来指定哪些文件或目录需要被忽略。
(node:13688) ESLintIgnoreWarning: The ".eslintignore" file is no longer supported. Switch to using the "ignores" property in "eslint.config.js": https://eslint.org/docs/latest/use/configure/migration-guide#ignoring-files (Usenode --trace-warnings ...to show where the warning was created) Oops! Something went wrong! :( ESLint: 9.25.1), - 改成
ignores又报错,对象字面量只能指定已知属性,并且“ignores”不在类型“ESLintConfig”中,被大模型忽悠了一回。在 ESLint 9.x 中,应该使用ignorePatterns来指定要忽略的文件或文件夹,而不是ignores。 jiti包版本不匹配, 需要升级
Oops! Something went wrong! :( ESLint: 9.25.1 Error: You are using an outdated version of the 'jiti' library. Please update to the latest version of 'jiti' to ensure compatibility and access to the latest features.- 未安装eslint-define-config模块
Oops! Something went wrong! :( ESLint: 9.25.1 Error: Cannot find module 'eslint-define-config'
不太容易看懂的报错比如说 ESLint 没有找到适用于文件 src/main.ts 的配置规则。0:0 warning File ignored because no matching configuration was supplied , 按照大模型的提示,逐一检查了ESLint 配置文件的路径是否正确,确保 root: true 配置生效; TypeScript 和 Vue 插件及解析器配置是否正确; ignorePatterns 是否误忽略了 src 文件夹; 检查 tsconfig.json 中的 include 配置; 手动检查文件是否被 ESLint 正确解析
pnpm eslint --config ./eslint.config.ts src/main.ts
忙活了一圈,未能解决问题。大模型排查技术工具最新版本的故障问题能力偏弱。无奈只能在网上搜,一篇一篇的看与试错。最终验证通过是方案是采用@eslint/config生成eslint v9版本的配置文件。
pnpm create @eslint/config
做7个选择(每个选项的含义一眼就能看懂)之后,就能妥妥地生成eslint配置文件。
Step2 配置Husky
这一步比较简单,虽然Husky最新版本的配置方法与先前的版本不一样了。但新版本的配置比老版本的要简单一些。
✅ 1. 安装Husky v9+版本
pnpm add -D husky
✅ 2. Husky v9+版本初始化
npx husky init
这会自动:
- 创建
.husky/目录 - 在
.husky/下添加pre-commithook 示例 - 在package.json中添加
"prepare": "husky install"脚本
这一步有个小坑,就是如果npx husky init第一次因为某种原因运行失败,第二次再运行,不会生成.husky目录。解决方法也很简单粗暴,卸载husky重新安装。
✅ 3. 在package.json配置检查指令
{
"scripts": {
"lint": "run-s lint:*",
"lint:eslint": "eslint src/**/*.{ts,tsx,vue} --debug --cache",
"lint:prettier": "prettier --check ./",
"lint:style": "stylelint \"src/**/*.{vue,css,less}\" --fix",
},
}
✅ 4. 修改 .husky/pre-commit hook
# 检查指令
pnpm lint
Step3 配置ESLint增量检测
为什么要配置增量检测呢,原因有两点:
- ESLint全量检测执行的很慢,如果不加
--debug参数,很长一段时间,看不到任何输出,会让人误以为卡死了 - 开发业务功能的时间本来就捉襟见肘,对于已有项目,当期要偿还历史技术债务的话,时间不允许。
那么如何做增量检查呢?最质朴的思路就是利用git能监测暂存区代码变更的能力,然后利用ESlint对变更的文件执行代码质量检查。这里有两处要注意一下,一是检查暂存区变更的文件,要过滤掉删除的文件,只检查新增,修改,重命名,复制的文件。另外,当没有匹配类型的文件时,files=$(git diff --cached --name-only --diff-filter=AMRC | grep -E '\.(ts|tsx|vue)$')会抛出一个exit 1的异常,造成改了(ts|tsx|vue)之外的文件不能正常提交,所以要在后面加一个|| true进行兜底。
#!/bin/bash
# set -e
# set -x
trap 'echo "Error at line $LINENO"; exit 1' ERR
# 注意这里加了 || true
files=$(git diff --cached --name-only --diff-filter=AMRC | grep -E '\.(ts|tsx|vue)$' || true)
if [ -z "$files" ]; then
echo "No changed ts/tsx/vue files to check."
exit 0
fi
echo "Running ESLint on the following files:"
echo "$files"
# 用 xargs -r 只有在有输入时才执行
echo "$files" | xargs -r npx eslint
echo "All files passed ESLint."
exit 0
Step4 测试效果
修改 src 下的某个 main.ts 文件,故意触发代码质量问题,然后提交。
- 情形1 通过命令行提交,eslint校验未通过,阻断提交,且是增量校验。
git add . && git commit -m "测试"
- 情形2 通过UI界面提交,成功阻断提交
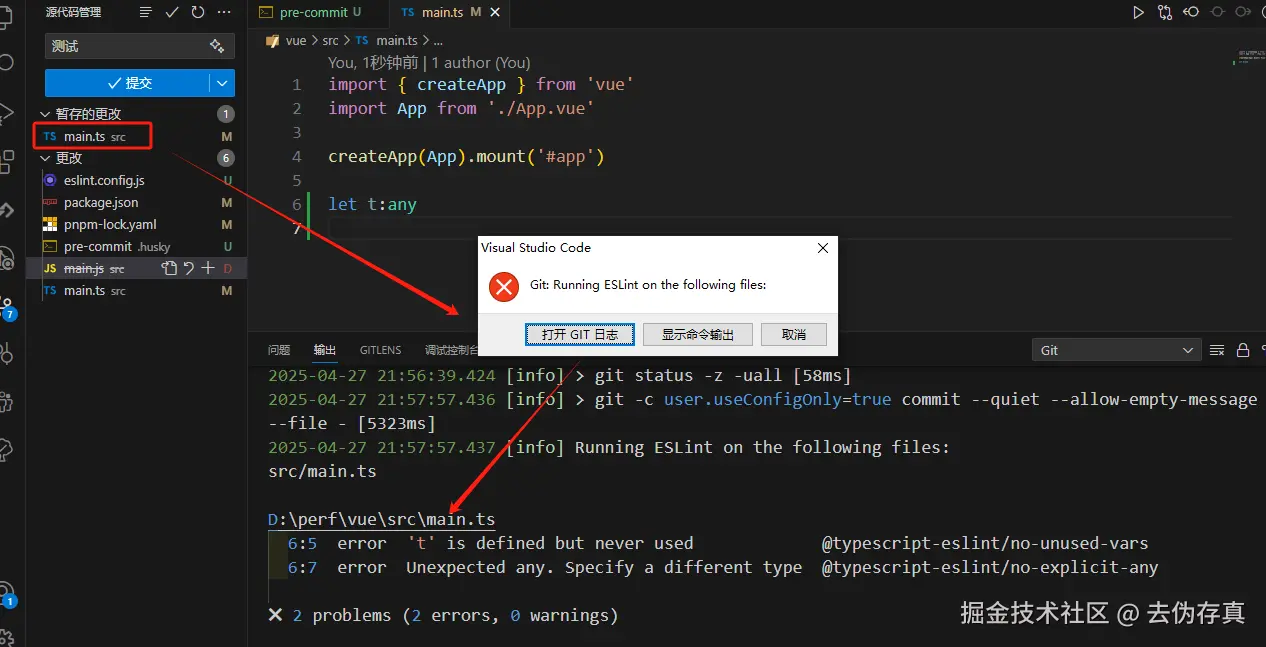
至此大功告成,结果令人满意,如果你的项目也需要实现这样的功能的话,拿走不谢。
后记
业务背景是这样的:gitlab上有个填写公司的仓库,有个提交代码的仓库,现在要将提交代码的仓库的代码变更记录,添加到填写工时的议题评论列表中,只要按照 feat: 跨项目提交测试 #194(#194是填写工时的议题id)这样的格式填写提交语,就能实现在评论列表添加代码变更链接的效果。

在.husky目录下添加prepare-commit-msg文件,内容如下:
#!/bin/sh
. "$(dirname "$0")/_/husky.sh"
# 仅当手动写 commit message 时执行
if [ "$2" = "merge" ] || [ "$2" = "squash" ]; then
exit 0
fi
file="$1"
msg=$(cat "$file")
# 查找是否包含 #数字 格式的 Issue 编号
issue_number=$(echo "$msg" | grep -Eo '#[0-9]+' | head -n1 | sed 's/#//')
if [ -n "$issue_number" ]; then
# 自定义项目路径
project_path="research-and-development/algorithm/项目名"
# 如果已经包含路径,则不重复添加
echo "$msg" | grep -q "$project_path" && exit 0
echo "" >>"$file"
echo "Related to $project_path#$issue_number" >>"$file"
fi
需要注意的是,你使用的gitlab版本必须大于v15,才支持跨项目议题关联功能
来源:juejin.cn/post/7497800812317147170
Three.js-硬要自学系列29之专项学习透明贴图
什么是透明贴图
- 核心作用:像「镂空剪纸」一样控制物体哪些部位透明/不透明
(想象:给树叶模型贴图,透明部分让树叶边缘自然消失而非方形边缘)
- 技术本质:一张 黑白图片(如 PNG 带透明通道),其中:
- 黑色区域 → 模型对应位置 完全透明(消失)
- 白色区域 → 模型 完全不透明(显示)
- 灰色过渡 → 半透明效果(如玻璃边缘)
示例:游戏中的铁丝网、树叶、破碎特效等镂空物体常用此技术
常见问题与解决方案
| 问题现象 | 原因 | 解决方法(代码) |
|---|---|---|
| 贴图完全不透明 | 忘记开 transparent | material.transparent = true |
| 边缘有白边/杂色 | 半透明像素混合错误 | material.alphaTest = 0.5 |
| 模型内部被穿透 | 透明物体渲染顺序错乱 | mesh.renderOrder = 1 |
技巧:透明贴图需搭配 基础颜色贴图(map) 使用,两者共同决定最终外观
实际应用场景
- 游戏植被:草地用方形面片+草丛透明贴图,节省性能
- UI 元素:半透明的警示图标悬浮在 3D 物体上
- 破碎效果:物体裂开时边缘碎片渐变透明
- AR 展示:透明背景中叠加虚拟模型(类似宝可梦 GO)
实践案例一
效果如图

实现思路
通过canvas绘制内容,canvasTexture用来转换为3d纹理
const canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d');
canvas.width = 64;
canvas.height = 64;
ctx.fillStyle = '#404040';
ctx.fillRect(0, 0, 32, 32);
ctx.fillStyle = '#808080';
ctx.fillRect(32, 0, 32, 32);
ctx.fillStyle = '#c0c0c0';
ctx.fillRect(0, 32, 32, 32);
ctx.fillStyle = '#f0f0f0';
ctx.fillRect(32, 32, 32, 32);
const texture = new THREE.CanvasTexture(canvas);
这里画布大小设置为64*64,被均匀分割为4份,并填充不同的颜色
接下来创建一个立方体,为其贴上透明度贴图alphaMap,设置transparent:true这很关键
const geo = new THREE.BoxGeometry(1, 1, 1);
const material = new THREE.MeshBasicMaterial({
color: 'deepskyblue',
alphaMap: texture, // 透明度贴图
transparent: true,
opacity: 1,
side: THREE.DoubleSide
});
如果你尝试将transparent配置改为false, 你将看到如下效果

同样我们尝试修改canvas绘制时候的填充色,来验证黑白镂空情况
ctx.fillStyle = '#000';
ctx.fillRect(0, 0, 32, 32);
ctx.fillStyle = '#000';
ctx.fillRect(32, 0, 32, 32);
ctx.fillStyle = '#000';
ctx.fillRect(0, 32, 32, 32);
ctx.fillStyle = '#fff';
ctx.fillRect(32, 32, 32, 32);

如图所示,黑色消失,白色显示保留
总结本案例需要掌握的API
CanvasTexture
这是Texture的子类,它用于将动态绘制的 2D Canvas 内容(如图表、文字、实时数据)转换为 3D 纹理,使得HTML Canvas元素可以作为纹理映射到3d物体表面
它支持实时更新,默认needsUpdate为true
应用场景
- 动态数据可视化:将实时图表(如温度曲线)映射到 3D 面板。
- 文字标签:在 3D 物体表面显示可变文字(如玩家名称)。
- 程序化纹理:通过算法生成图案(如噪波、分形)。
- 交互式绘制:用户画布涂鸦实时投射到 3D 模型(如自定义 T 恤设计)。
性能优化
- 避免频繁更新:若非必要,减少
needsUpdate=true的调用频率。 - 合理尺寸:Canvas 尺寸建议为 2 的幂(如 256×256, 512×512),兼容纹理映射。
- 复用 Canvas:对静态内容,复用已生成的纹理而非重新创建。
- 替代方案:静态图像用
TextureLoader,视频用VideoTexture,以降低开销。
需要注意
- 跨域限制:若 Canvas 包含外部图片,需设置
crossOrigin="anonymous"。 - 清晰度问题:高缩放比例可能导致模糊,可通过
texture.anisotropy = renderer.capabilities.getMaxAnisotropy()改善。 - 内存管理:不再使用的纹理调用
texture.dispose()释放资源。
实践案例二
效果如图

实现思路
从图上可以看出,立方体每个面上有多个矩形小方块,每个方块都被赋予不同的颜色,创建grid方法来实现生产多个矩形小方块
const drawMethod = {};
drawMethod.grid = (ctx, canvas, opt={} ) => {
opt.w = opt.w || 4;
opt.h = opt.h || 4;
opt.colors = opt.colors || ['#404040', '#808080', '#c0c0c0', '#f0f0f0'];
opt.colorI = opt.colorI || [];
let i = 0;
const len = opt.w * opt.h,
sizeW = canvas.width / opt.w, // 网格宽度
sizeH = canvas.height / opt.h; // 网格高度
while(i<len) {
const x = i % opt.w,
y = Math.floor(i / opt.w);
ctx.fillStyle = typeof opt.colorI[i] === 'number' ? opt.colors[opt.colorI[i]] : opt.colors[i % opt.colors.length];
ctx.fillRect(x * sizeW, y * sizeH, sizeW, sizeH);
i++;
}
}
实现透明贴图
const canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d');
canvas.width = 64;
canvas.height = 64;
const texture = new THREE.CanvasTexture(canvas);
const geo = new THREE.BoxGeometry(1, 1, 1);
const material = new THREE.MeshBasicMaterial({
color: 'deepskyblue',
alphaMap: texture,
transparent: true,
opacity: 1,
side: THREE.DoubleSide
});
这里要注意,canvas上并未绘制任何内容,我们将在loop循环中调用grid方法进行绘制
let frame = 0,
lt = new Date(); // 上一次时间
const maxFrame = 90, // 最大帧数90帧
fps = 20; // 每秒20帧
function loop() {
const now = new Date(), // 当前时间
secs = (now - lt) / 1000, // 时间差
per = frame / maxFrame; // 进度
if (secs > 1 / fps) { // 时间差大于1/20
const colorI = [];
let i = 6 * 6;
while (i--) {
colorI.push(Math.floor(4 * Math.random()))
}
drawMethod.grid(ctx, canvas, {
w: 6,
h: 6,
colorI: colorI
});
texture.needsUpdate = true; // 更新纹理
mesh.rotation.y = Math.PI * 2 * per;
renderer.render(scene, camera);
frame += fps * secs; // 帧数累加
frame %= maxFrame; // 帧数取模,防止帧数溢出
lt = now;
}
// 渲染场景和相机
requestAnimationFrame( loop );
}
你可以看到这里每个面上被绘制了36个小矩形,并通过一下代码,随机填充颜色
while (i--) {
colorI.push(Math.floor(4 * Math.random()))
}
以上就是本章的所有内容,这里并未展示完整案例代码,是希望大家能动手练一练,很多的概念,看似晦涩难懂,实则动手尝试下的话秒懂。
来源:juejin.cn/post/7513158069419048997
从侵入式改造到声明式魔法注释的演进之路
传统方案的痛点:代码入侵
在上一篇文章中,我们通过高阶函数实现了请求缓存功能:
const cachedFetch = memoReq(function fetchData(url) {
return axios.get(url);
}, 3000);
这种方式虽然有效,但存在三个显著问题:
- 结构性破坏:必须将函数声明改为函数表达式
- 可读性下降:业务逻辑与缓存逻辑混杂
- 维护困难:缓存参数与业务代码强耦合
灵感来源:两大技术启示
1. Webpack的魔法注释
Webpack使用魔法注释控制代码分割:
import(/* webpackPrefetch: true */ './module.js');
这种声明式配置给了我们启示:能否用注释来控制缓存行为?
2. 装饰器设计模式
装饰器模式的核心思想是不改变原有对象的情况下动态扩展功能。在TypeScript中:
@memoCache(3000)
async function fetchData() {}
虽然当前项目可能不支持装饰器语法,但我们可以借鉴这种思想!
创新方案:魔法注释 + Vite插件
设计目标
- 零入侵:不改变函数声明方式
- 声明式:通过注释表达缓存意图
- 渐进式:支持逐个文件迁移
使用对比
传统方式:
export const getStockData = memoReq(
function getStockData(symbol) {
return axios.get(`/api/stocks/${symbol}`);
},
5000
);
魔法注释方案:
/* abc-memoCache(5000) */
export function getStockData(symbol) {
return axios.get(`/api/stocks/${symbol}`);
}
而有经验的程序猿会敏锐地发现三个深层问题:
- 结构性破坏:函数被迫改为函数表达式
- 关注点混杂:缓存逻辑侵入业务代码
- 维护陷阱:硬编码参数难以统一管理
技术实现深度解析
核心转换原理
- 编译时处理:通过Vite或者webpack loader插件在代码编译阶段转换
- 正则匹配:实际上是通过正则匹配实现轻量级转换
- 自动导入:智能添加必要的依赖引用
// 转换前
/* abc-memoCache(3000) */
export function fetchData() {}
// 转换后
import { memoCache } from '@/utils/decorators';
export const fetchData = memoCache(function fetchData() {}, 3000);
完整实现代码如下(以vite插件为例)
/**
* 转换代码中的装饰器注释为具体的函数调用,并处理超时配置。
*
* @param {string} code - 待处理的源代码。
* @param {string} [prefix="aa"] - 装饰器的前缀,用于标识特定的装饰器注释。
* @param {string} [utilsPath="@/utils"] - 导入工具函数的路径。
* @returns {string} - 转换后的代码。
*/
export function transformMemoReq(code, prefix = "aa", utilsPath = "@/utils") {
// 检查是否包含魔法注释模式
const magicCommentPattern = new RegExp(`\/\*\s*${prefix}-\w+\s*\([^)]*\)\s*\*\/`);
if (!magicCommentPattern.test(code)) {
return code; // 如果没有找到符合模式的注释,返回原代码
}
let transformedCode = code;
const importsNeeded = new Set(); // 收集需要的导入
// 处理带超时配置的装饰器注释(带超时数字)
const withTimeoutPattern = new RegExp(
`\/\*\s*${prefix}-(\w+)\s*\(\s*(\d*)\s*\)\s*\*\/\s*\nexport\s+function\s+(\w+)\s*\(([^)]*)\)\s*(?::\s*[^{]+)?\s*\{([\s\S]*?)\n\}`,
"g"
);
transformedCode = transformedCode.replace(
withTimeoutPattern,
(match, decoratorName, timeout, functionName, params, body) => {
const timeoutValue = timeout ? parseInt(timeout, 10) : 3000; // 默认超时为3000毫秒
const fileNameSimple = decoratorName.replace(/([A-Z].*$)/, ""); // 获取装饰器文件名
importsNeeded.add({ fileName: fileNameSimple, functionName: decoratorName }); // 添加需要导入的函数
// 提取类型注解(如果存在)
const typeAnnotationMatch = match.match(/)\s*(:\s*[^{]+)/);
const typeAnnotation = typeAnnotationMatch ? typeAnnotationMatch[1] : "";
// 返回转换后的函数定义代码
return `export const ${functionName} = ${decoratorName}(function ${functionName}(${params})${typeAnnotation} {${body}\n}, ${timeoutValue});`;
}
);
// 处理不带超时配置的装饰器注释(无超时数字)
const emptyTimeoutPattern = new RegExp(
`\/\*\s*${prefix}-(\w+)\s*\(\s*\)\s*\*\/\s*\nexport\s+function\s+(\w+)\s*\(([^)]*)\)\s*(?::\s*[^{]+)?\s*\{([\s\S]*?)\n\}`,
"g"
);
transformedCode = transformedCode.replace(emptyTimeoutPattern, (match, decoratorName, functionName, params, body) => {
const fileNameSimple = decoratorName.replace(/([A-Z].*$)/, "");
importsNeeded.add({ fileName: fileNameSimple, functionName: decoratorName });
// 提取类型注解(如果存在)
const typeAnnotationMatch = match.match(/)\s*(:\s*[^{]+)/);
const typeAnnotation = typeAnnotationMatch ? typeAnnotationMatch[1] : "";
// 返回转换后的函数定义代码,默认超时为3000毫秒
return `export const ${functionName} = ${decoratorName}(function ${functionName}(${params})${typeAnnotation} {${body}\n}, 3000);`;
});
// 如果需要导入额外的函数,处理导入语句的插入
if (importsNeeded.size > 0) {
const lines = transformedCode.split("\n");
let insertIndex = 0;
// 检查是否是Vue文件
const isVueFile = transformedCode.includes("<script");
if (isVueFile) {
// Vue文件导入位置逻辑...
for (let i = 0; i < lines.length; i += 1) {
const line = lines[i].trim();
if (line.includes("<script")) {
insertIndex = i + 1;
for (let j = i + 1; j < lines.length; j += 1) {
const scriptLine = lines[j].trim();
if (scriptLine.startsWith("import ") || scriptLine === "") {
insertIndex = j + 1;
} else if (!scriptLine.startsWith("import ")) {
break;
}
}
break;
}
}
} else {
// 普通JS/TS/JSX/TSX文件导入位置逻辑...
for (let i = 0; i < lines.length; i += 1) {
const line = lines[i].trim();
if (line.startsWith("import ") || line === "" || line.startsWith("interface ") || line.startsWith("type ")) {
insertIndex = i + 1;
} else {
break;
}
}
}
// 按文件分组导入
const importsByFile = {};
importsNeeded.forEach(({ fileName, functionName }) => {
if (!importsByFile[fileName]) {
importsByFile[fileName] = [];
}
importsByFile[fileName].push(functionName);
});
// 生成导入语句 - 使用自定义utilsPath
const importStatements = Object.entries(importsByFile).map(([fileName, functions]) => {
const uniqueFunctions = [...new Set(functions)];
return `import { ${uniqueFunctions.join(", ")} } from "${utilsPath}/${fileName}";`;
});
// 插入导入语句
lines.splice(insertIndex, 0, ...importStatements);
transformedCode = lines.join("\n");
}
return transformedCode; // 返回最终转换后的代码
}
/**
* Vite 插件,支持通过魔法注释转换函数装饰器。
*
* @param {Object} [options={}] - 配置选项。
* @param {string} [options.prefix="aa"] - 装饰器的前缀。
* @param {string} [options.utilsPath="@/utils"] - 工具函数的导入路径。
* @returns {Object} - Vite 插件对象。
*/
export function viteMemoDectoratorPlugin(options = {}) {
const { prefix = "aa", utilsPath = "@/utils" } = options;
return {
name: "vite-memo-decorator", // 插件名称
enforce: "pre", // 插件执行时机,设置为"pre"确保在编译前执行
transform(code, id) {
// 支持 .js, .ts, .jsx, .tsx, .vue 文件
if (!/.(js|ts|jsx|tsx|vue)$/.test(id)) {
return null; // 如果文件类型不支持,返回null
}
// 使用动态前缀检查是否需要处理该文件
const magicCommentPattern = new RegExp(`\/\*\s*${prefix}-\w+\s*\([^)]*\)\s*\*\/`);
if (!magicCommentPattern.test(code)) {
return null; // 如果没有找到符合模式的注释,返回null
}
console.log(`🔄 Processing ${prefix}-* magic comments in: ${id}`);
try {
const result = transformMemoReq(code, prefix, utilsPath); // 调用转换函数
if (result !== code) {
console.log(`✅ Transform successful for: ${id}`);
return {
code: result, // 返回转换后的代码
map: null, // 如果需要支持source map,可以在这里添加
};
}
} catch (error) {
console.error(`❌ Transform error in ${id}:`, error.message);
}
return null;
},
};
}
vite使用方式
viteMemoDectoratorPlugin({
prefix: "abc",
}),
结语:成为解决方案的设计者
从闭包到魔法注释的演进:
- 发现问题:识别现有方案的深层缺陷
- 联想类比:从其他领域寻找灵感
- 创新设计:创造性地组合技术要素
- 工程落地:考虑实际约束条件
在这个技术飞速发展的时代,我们牛马面临着知识爆炸,卷到没边的风气,我们只能建立更系统的技术认知体系。只会复制粘贴代码的开发者注定会陷入越忙越累的怪圈,比如最近很火的vue不想使用虚拟dom,其实我们只需要知道为什么,那是不是又多了点知识储备,因为技术迭代的速度永远快于机械记忆的速度。真正的技术能力体现在对知识本质的理解和创造性应用上——就像本文中的缓存方案,从最初的闭包实现到魔法注释优化,每一步实现都源于对多种技术思想的相融。阅读技术博客时,不能满足于解决眼前问题,更要揣摩作者的设计哲学;我们要善用AI等现代工具,但不是简单地向它索要代码,而是通过它拓展思维边界;愿我们都能超越代码搬运工的局限,成为真正的问题解决者和价值创造者。技术之路没有捷径,但有方法;没有终点,但有无尽的风景。加油吧,程序猿朋友们!!!
来源:juejin.cn/post/7536178965851029544
TailwindCSS 与 -webkit-line-clamp 深度解析:现代前端开发的样式革命
引言
在现代前端开发的浪潮中,CSS 的编写方式正在经历一场深刻的变革。传统的 CSS 开发模式虽然功能强大,但往往伴随着样式冲突、维护困难、代码冗余等问题。开发者需要花费大量时间在样式的命名、组织和维护上,而真正用于业务逻辑实现的时间却相对有限。
TailwindCSS 的出现,如同一股清流,为前端开发者带来了全新的开发体验。它不仅仅是一个 CSS 框架,更是一种全新的设计哲学——原子化 CSS 的完美实践。与此同时,在处理文本显示的细节问题上,诸如 -webkit-line-clamp 这样的 CSS 属性,虽然看似简单,却蕴含着深层的浏览器渲染原理。
本文将深入探讨 TailwindCSS 的核心理念、配置方法以及实际应用,同时详细解析 -webkit-line-clamp 的底层工作机制,帮助开发者更好地理解和运用这些现代前端技术。无论你是刚接触前端开发的新手,还是希望提升开发效率的资深开发者,这篇文章都将为你提供有价值的见解和实用的技巧。
TailwindCSS:原子化 CSS 的艺术
什么是原子化 CSS
原子化 CSS(Atomic CSS)是一种 CSS 架构方法,其核心思想是将样式拆分成最小的、不可再分的单元——就像化学中的原子一样。每个 CSS 类只负责一个特定的样式属性,比如 text-center 只负责文本居中,bg-blue-500 只负责设置蓝色背景。
传统的 CSS 开发模式往往采用组件化的方式,为每个 UI 组件编写独立的样式类。例如,一个按钮组件可能会有这样的 CSS:
.button {
padding: 12px 24px;
background-color: #3b82f6;
color: white;
border-radius: 6px;
font-weight: 600;
transition: background-color 0.2s;
}
.button:hover {
background-color: #2563eb;
}
这种方式在小型项目中运行良好,但随着项目规模的增长,会出现以下问题:
- 样式重复:不同组件可能需要相似的样式,导致代码重复
- 命名困难:为每个组件和状态想出合适的类名变得越来越困难
- 维护复杂:修改一个样式可能影响多个组件,需要谨慎处理
- CSS 文件膨胀:随着功能增加,CSS 文件变得越来越大
原子化 CSS 通过将样式拆分成最小单元来解决这些问题。上面的按钮样式在 TailwindCSS 中可以这样表示:
<button class="px-6 py-3 bg-blue-500 text-white rounded-md font-semibold hover:bg-blue-600 transition-colors">
Click me
</button>
每个类名都有明确的职责:
px-6:左右内边距 1.5rem(24px)py-3:上下内边距 0.75rem(12px)bg-blue-500:蓝色背景text-white:白色文字rounded-md:中等圆角font-semibold:半粗体字重hover:bg-blue-600:悬停时的深蓝色背景transition-colors:颜色过渡动画
TailwindCSS 的核心特性
TailwindCSS 作为原子化 CSS 的杰出代表,具有以下核心特性:
1. 几乎不用写 CSS
这是 TailwindCSS 最吸引人的特性之一。在传统开发中,开发者需要在 HTML 和 CSS 文件之间频繁切换,思考类名、编写样式、处理选择器优先级等问题。而使用 TailwindCSS,大部分样式都可以直接在 HTML 中通过预定义的类名来实现。
这种方式带来的好处是显而易见的:
- 开发速度提升:无需在文件间切换,样式即写即见
- 认知负担减轻:不需要思考复杂的类名和样式组织
- 一致性保证:使用统一的设计系统,避免样式不一致
2. AI 代码生成的首选框架
在人工智能辅助编程的时代,TailwindCSS 已经成为 AI 工具生成前端代码时的首选 CSS 框架。这主要有以下几个原因:
- 语义化程度高:TailwindCSS 的类名具有很强的语义性,AI 可以更容易理解和生成
- 标准化程度高:作为业界标准,AI 模型在训练时接触了大量 TailwindCSS 代码
- 组合性强:原子化的特性使得 AI 可以灵活组合不同的样式类
当你使用 ChatGPT、Claude 或其他 AI 工具生成前端代码时,它们几乎总是会使用 TailwindCSS 来处理样式,这已经成为了一种行业默认标准。
3. 丰富的内置类名系统
TailwindCSS 提供了一套完整而系统的类名体系,涵盖了前端开发中几乎所有的样式需求:
- 布局类:
flex、grid、block、inline等 - 间距类:
m-4、p-2、space-x-4等 - 颜色类:
text-red-500、bg-blue-200、border-gray-300等 - 字体类:
text-lg、font-bold、leading-tight等 - 响应式类:
md:text-xl、lg:flex、xl:grid-cols-4等 - 状态类:
hover:bg-gray-100、focus:ring-2、active:scale-95等
这些类名都遵循一致的命名规范,学会了基本规则后,即使遇到没用过的类名也能快速理解其含义。
配置与使用
安装和配置流程
要在项目中使用 TailwindCSS,需要经过以下几个步骤:
1. 安装依赖包
npm install -D tailwindcss @vitejs/plugin-tailwindcss
这里安装了两个包:
tailwindcss:TailwindCSS 的核心包@vitejs/plugin-tailwindcss:Vite 的 TailwindCSS 插件,用于在构建过程中处理 TailwindCSS
2. 生成配置文件
npx tailwindcss init
这个命令会在项目根目录生成一个 tailwind.config.js 文件:
/** @type {import('tailwindcss').Config} */
export default {
content: [
"./index.html",
"./src/**/*.{js,ts,jsx,tsx}",
],
theme: {
extend: {},
},
plugins: [],
}
content 数组指定了 TailwindCSS 应该扫描哪些文件来查找使用的类名,这对于生产环境的样式优化非常重要。
vite.config.js 配置详解
在 Vite 项目中,需要在 vite.config.js 中配置 TailwindCSS 插件:
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import tailwindcss from '@vitejs/plugin-tailwindcss'
export default defineConfig({
plugins: [
react(),
tailwindcss()
],
})
这个配置告诉 Vite 在构建过程中使用 TailwindCSS 插件来处理 CSS 文件。插件会自动:
- 扫描指定的文件查找使用的 TailwindCSS 类名
- 生成对应的 CSS 代码
- 在生产环境中移除未使用的样式(Tree Shaking)
tailwind.css 引入方式
在项目的主 CSS 文件(通常是 src/index.css 或 src/main.css)中引入 TailwindCSS 的基础样式:
@tailwind base;
@tailwind components;
@tailwind utilities;
这三个指令分别引入了:
base:重置样式和基础样式components:组件样式(可以自定义)utilities:工具类样式(TailwindCSS 的核心)
单位系统解析
TailwindCSS 使用了一套独特而直观的单位系统。其中最重要的概念是:1rem = 4 个单位。
这意味着:
w-4=width: 1rem=16px(在默认字体大小下)p-2=padding: 0.5rem=8pxm-8=margin: 2rem=32px
这套系统的设计非常巧妙:
- 易于记忆:4 的倍数关系简单直观
- 设计友好:符合设计师常用的 8px 网格系统
- 响应式友好:基于 rem 单位,能够很好地适应不同的屏幕尺寸
常用的间距对照表:
| 类名 | CSS 值 | 像素值(16px 基准) |
|---|---|---|
p-1 | 0.25rem | 4px |
p-2 | 0.5rem | 8px |
p-3 | 0.75rem | 12px |
p-4 | 1rem | 16px |
p-6 | 1.5rem | 24px |
p-8 | 2rem | 32px |
p-12 | 3rem | 48px |
p-16 | 4rem | 64px |
这套系统不仅适用于内外边距,也适用于宽度、高度、字体大小等其他尺寸相关的属性。
-webkit-line-clamp:文本截断的底层原理
浏览器内核基础知识
在深入了解 -webkit-line-clamp 之前,我们需要先理解浏览器内核的基本概念。浏览器内核(Browser Engine)是浏览器的核心组件,负责解析 HTML、CSS,并将网页内容渲染到屏幕上。不同的浏览器使用不同的内核,这也是为什么某些 CSS 属性需要添加特定前缀的原因。
主要浏览器内核及其前缀:
- WebKit 内核(-webkit-)
- 使用浏览器:Chrome、Safari、新版 Edge、Opera
- 特点:由苹果公司开发,后来被 Google 采用并发展出 Blink 内核
- 市场份额:目前占据主导地位,超过 70% 的市场份额
- Gecko 内核(-moz-)
- 使用浏览器:Firefox
- 特点:由 Mozilla 基金会开发,注重标准化和开放性
- 市场份额:约 3-5% 的市场份额
- Trident/EdgeHTML 内核(-ms-)
- 使用浏览器:旧版 Internet Explorer、旧版 Edge
- 特点:微软开发,现已基本被淘汰
由于 WebKit 内核的广泛使用,许多实验性的 CSS 属性首先在 WebKit 中实现,并使用 -webkit- 前缀。-webkit-line-clamp 就是其中的一个典型例子。
实验性属性的概念
CSS 中的实验性属性(Experimental Properties)是指那些尚未成为正式 W3C 标准,但已经在某些浏览器中实现的功能。这些属性通常具有以下特征:
- 前缀标识:使用浏览器厂商前缀,如
-webkit-、-moz-、-ms-等 - 功能性强:虽然不是标准,但能解决实际开发中的问题
- 兼容性限制:只在特定浏览器中工作
- 可能变化:语法和行为可能在未来版本中发生变化
-webkit-line-clamp 正是这样一个实验性属性。它最初是为了解决移动端 WebKit 浏览器中多行文本截断的需求而设计的,虽然不是 CSS 标准的一部分,但由于其实用性,被广泛采用并逐渐得到其他浏览器的支持。
-webkit-line-clamp 深度解析
属性的工作原理
-webkit-line-clamp 是一个用于限制文本显示行数的 CSS 属性。当文本内容超过指定行数时,多余的内容会被隐藏,并在最后一行的末尾显示省略号(...)。
这个属性的工作原理涉及到浏览器的文本渲染机制:
- 文本流计算:浏览器首先计算文本在容器中的自然流动方式
- 行数统计:根据容器宽度、字体大小、行高等因素计算文本占用的行数
- 截断处理:当行数超过
line-clamp指定的值时,截断多余内容 - 省略号添加:在最后一行的适当位置添加省略号
为什么不能独自生效
这是 -webkit-line-clamp 最容易让开发者困惑的地方。单独使用这个属性是无效的,必须配合其他 CSS 属性才能正常工作。这是因为 -webkit-line-clamp 的设计初衷是作为 Flexbox 布局的一部分来工作的。
具体来说,-webkit-line-clamp 只在以下条件同时满足时才会生效:
- 容器必须是 Flexbox:
display: -webkit-box - 必须设置排列方向:
-webkit-box-orient: vertical - 必须隐藏溢出内容:
overflow: hidden
这种设计反映了早期 WebKit 对 Flexbox 规范的实现方式。在当时,-webkit-box 是 Flexbox 的早期实现,而 -webkit-line-clamp 被设计为在这种布局模式下工作。
必需的配套属性详解
让我们详细分析每个必需的配套属性:
1. display: -webkit-box
display: -webkit-box;
这个属性将元素设置为 WebKit 的旧版 Flexbox 容器。在现代 CSS 中,我们通常使用 display: flex,但 -webkit-line-clamp 需要这个特定的值才能工作。
-webkit-box 是 2009 年 Flexbox 规范的实现,虽然已经过时,但为了兼容 -webkit-line-clamp,我们仍然需要使用它。这个值会:
- 将元素转换为块级容器
- 启用 WebKit 的 Flexbox 布局引擎
- 为
-webkit-line-clamp提供必要的布局上下文
2. -webkit-box-orient: vertical
-webkit-box-orient: vertical;
这个属性设置 Flexbox 容器的主轴方向为垂直。在文本截断的场景中,我们需要垂直方向的布局来正确计算行数。
可选值包括:
horizontal:水平排列(默认值)vertical:垂直排列inline-axis:沿着内联轴排列block-axis:沿着块轴排列
对于文本截断,我们必须使用 vertical,因为:
- 文本行是垂直堆叠的
-webkit-line-clamp需要在垂直方向上计算行数- 只有在垂直布局下,行数限制才有意义
3. overflow: hidden
overflow: hidden;
这个属性隐藏超出容器边界的内容。在文本截断的场景中,它的作用是:
- 隐藏超出指定行数的文本内容
- 确保省略号正确显示在可见区域内
- 防止内容溢出影响页面布局
如果不设置 overflow: hidden,超出行数限制的文本仍然会显示,-webkit-line-clamp 就失去了意义。
完整的文本截断方案
将所有必需的属性组合起来,一个完整的文本截断方案如下:
.text-clamp {
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 2;
overflow: hidden;
}
这个方案会将文本限制在 2 行内,超出的内容会被隐藏并显示省略号。
浏览器兼容性分析
虽然 -webkit-line-clamp 带有 WebKit 前缀,但实际上它的兼容性比想象中要好:
| 浏览器 | 支持版本 | 备注 |
|---|---|---|
| Chrome | 6+ | 完全支持 |
| Safari | 5+ | 完全支持 |
| Firefox | 68+ | 2019年开始支持 |
| Edge | 17+ | 基于 Chromium 的版本支持 |
| IE | 不支持 | 需要 JavaScript 降级方案 |
现代浏览器(除了 IE)都已经支持这个属性,使得它在实际项目中具有很高的可用性。
高级用法和注意事项
1. 响应式行数控制
可以结合媒体查询实现响应式的行数控制:
.responsive-clamp {
display: -webkit-box;
-webkit-box-orient: vertical;
overflow: hidden;
-webkit-line-clamp: 3;
}
@media (max-width: 768px) {
.responsive-clamp {
-webkit-line-clamp: 2;
}
}
2. 与其他 CSS 属性的交互
-webkit-line-clamp 与某些 CSS 属性可能产生冲突:
- white-space: nowrap:会阻止文本换行,使 line-clamp 失效
- height 固定值:可能与 line-clamp 的高度计算冲突
- line-height:会影响行数的计算,需要谨慎设置
3. 性能考虑
使用 -webkit-line-clamp 时需要注意性能影响:
- 浏览器需要重新计算文本布局
- 在大量元素上使用可能影响渲染性能
- 动态改变 line-clamp 值会触发重排(reflow)
实战应用与代码示例
line-clamp 在 TailwindCSS 中的应用
TailwindCSS 内置了对 -webkit-line-clamp 的支持,提供了 line-clamp-{n} 工具类。让我们看看如何在实际项目中使用这些类。
基础使用示例
// 产品卡片组件
function ProductCard({ product }) {
return (
<div className="card max-w-sm">
{/* 产品图片 */}
<div className="relative">
<img
src={product.image}
alt={product.name}
className="w-full h-64 object-cover"
/>
{product.isNew && (
<span className="absolute top-2 left-2 bg-red-500 text-white text-xs font-bold px-2 py-1 rounded">
New
</span>
)}
</div>
{/* 产品信息 */}
<div className="p-6">
{/* 产品标题 - 限制1行 */}
<h3 className="text-lg font-semibold text-gray-900 line-clamp-1 mb-2">
{product.name}
</h3>
{/* 产品描述 - 限制2行 */}
<p className="text-sm text-gray-600 line-clamp-2 mb-4">
{product.description}
</p>
{/* 产品特性 - 限制3行 */}
<div className="text-xs text-gray-500 line-clamp-3 mb-4">
{product.features.join(' • ')}
</div>
{/* 价格和操作 */}
<div className="flex items-center justify-between">
<span className="text-xl font-bold text-gray-900">
${product.price}
</span>
<button className="btn-primary">
Add to Cart
</button>
</div>
</div>
</div>
);
}
在这个示例中,我们使用了不同的 line-clamp 值来处理不同类型的文本内容:
line-clamp-1:产品标题保持在一行内line-clamp-2:产品描述限制在两行内line-clamp-3:产品特性列表限制在三行内
响应式文本截断
TailwindCSS 的响应式前缀可以与 line-clamp 结合使用,实现不同屏幕尺寸下的不同截断行为:
function ArticleCard({ article }) {
return (
<article className="card">
<div className="p-6">
{/* 响应式标题截断 */}
<h2 className="text-xl font-bold text-gray-900 line-clamp-2 md:line-clamp-1 mb-3">
{article.title}
</h2>
{/* 响应式内容截断 */}
<p className="text-gray-600 line-clamp-3 sm:line-clamp-4 lg:line-clamp-2 mb-4">
{article.content}
</p>
{/* 标签列表 - 移动端截断更多 */}
<div className="text-sm text-gray-500 line-clamp-2 md:line-clamp-1">
{article.tags.map(tag => `#${tag}`).join(' ')}
</div>
</div>
</article>
);
}
这个示例展示了如何根据屏幕尺寸调整文本截断行为:
- 移动端:标题显示2行,内容显示3行
- 平板端:标题显示1行,内容显示4行
- 桌面端:标题显示1行,内容显示2行
动态 line-clamp 控制
有时我们需要根据用户交互动态改变文本的截断行为:
import { useState } from 'react';
function ExpandableText({ text, maxLines = 3 }) {
const [isExpanded, setIsExpanded] = useState(false);
return (
<div className="space-y-2">
<p className={`text-gray-700 ${isExpanded ? '' : `line-clamp-${maxLines}`}`}>
{text}
</p>
<button
onClick={() => setIsExpanded(!isExpanded)}
className="text-primary-600 hover:text-primary-700 text-sm font-medium"
>
{isExpanded ? 'Show Less' : 'Show More'}
</button>
</div>
);
}
// 使用示例
function ReviewCard({ review }) {
return (
<div className="card p-6">
<div className="flex items-center mb-4">
<img
src={review.avatar}
alt={review.author}
className="w-10 h-10 rounded-full mr-3"
/>
<div>
<h4 className="font-semibold text-gray-900">{review.author}</h4>
<div className="flex items-center">
{/* 星级评分 */}
{[...Array(5)].map((_, i) => (
<svg
key={i}
className={`w-4 h-4 ${i < review.rating ? 'text-yellow-400' : 'text-gray-300'} fill-current`}
viewBox="0 0 24 24"
>
<path d="M12 2l3.09 6.26L22 9.27l-5 4.87 1.18 6.88L12 17.77l-6.18 3.25L7 14.14 2 9.27l6.91-1.01L12 2z" />
</svg>
))}
</div>
</div>
</div>
{/* 可展开的评论内容 */}
<ExpandableText text={review.content} maxLines={4} />
</div>
);
}
这个示例展示了如何创建一个可展开的文本组件,用户可以点击按钮来显示完整内容或收起到指定行数。
最佳实践与总结
开发建议
在实际项目中使用 TailwindCSS 和 -webkit-line-clamp 时,以下最佳实践将帮助你获得更好的开发体验和项目质量:
TailwindCSS 开发最佳实践
1. 合理组织类名
虽然 TailwindCSS 鼓励在 HTML 中直接使用工具类,但过长的类名列表会影响代码可读性。建议采用以下策略:
// ❌ 避免:过长的类名列表
<div className="flex items-center justify-between p-6 bg-white rounded-lg shadow-sm border border-gray-200 hover:shadow-md transition-shadow duration-200 ease-in-out">
// ✅ 推荐:使用组件抽象
const Card = ({ children, className = "" }) => (
<div className={`card hover:shadow-md transition-shadow ${className}`}>
{children}
</div>
);
// ✅ 推荐:使用 @apply 指令创建组件类
// 在 CSS 中定义
.card {
@apply flex items-center justify-between p-6 bg-white rounded-lg shadow-sm border border-gray-200;
}
2. 建立设计系统
充分利用 TailwindCSS 的配置系统建立项目专属的设计系统:
// tailwind.config.js
module.exports = {
theme: {
extend: {
// 定义项目色彩系统
colors: {
brand: {
primary: '#3B82F6',
secondary: '#10B981',
accent: '#F59E0B',
}
},
// 定义间距系统
spacing: {
'18': '4.5rem',
'88': '22rem',
},
// 定义字体系统
fontSize: {
'xs': ['0.75rem', { lineHeight: '1rem' }],
'sm': ['0.875rem', { lineHeight: '1.25rem' }],
'base': ['1rem', { lineHeight: '1.5rem' }],
'lg': ['1.125rem', { lineHeight: '1.75rem' }],
'xl': ['1.25rem', { lineHeight: '1.75rem' }],
}
}
}
}
3. 性能优化策略
TailwindCSS 的性能优化主要体现在生产环境的样式清理:
// tailwind.config.js
module.exports = {
content: [
// 精确指定扫描路径,避免不必要的文件扫描
"./src/**/*.{js,jsx,ts,tsx}",
"./public/index.html",
// 如果使用了第三方组件库,也要包含其路径
"./node_modules/@my-ui-lib/**/*.{js,jsx}",
],
// 启用 JIT 模式获得更好的性能
mode: 'jit',
}
4. 响应式设计策略
采用移动优先的设计理念,合理使用响应式前缀:
// ✅ 移动优先的响应式设计
<div className="
grid grid-cols-1 gap-4
sm:grid-cols-2 sm:gap-6
md:grid-cols-3 md:gap-8
lg:grid-cols-4
xl:gap-10
">
{/* 内容 */}
</div>
// ✅ 响应式文字大小
<h1 className="text-2xl sm:text-3xl md:text-4xl lg:text-5xl font-bold">
标题
</h1>
line-clamp 使用最佳实践
1. 选择合适的截断行数
不同类型的内容需要不同的截断策略:
| 内容类型 | 推荐行数 | 使用场景 |
|---|---|---|
| 标题 | 1-2行 | 卡片标题、列表项标题 |
| 摘要/描述 | 2-3行 | 产品描述、文章摘要 |
| 详细内容 | 3-5行 | 评论内容、详细说明 |
| 标签列表 | 1-2行 | 标签云、分类列表 |
2. 考虑内容的语义完整性
// ✅ 好的实践:为截断的内容提供完整查看选项
function ProductDescription({ description }) {
const [isExpanded, setIsExpanded] = useState(false);
return (
<div>
<p className={isExpanded ? '' : 'line-clamp-3'}>
{description}
</p>
{description.length > 150 && (
<button
onClick={() => setIsExpanded(!isExpanded)}
className="text-blue-600 text-sm mt-1"
>
{isExpanded ? '收起' : '查看更多'}
</button>
)}
</div>
);
}
3. 处理不同语言的截断
不同语言的文字密度不同,需要相应调整截断行数:
// 根据语言调整截断行数
function MultiLanguageText({ text, language }) {
const getLineClampClass = (lang) => {
switch (lang) {
case 'zh': return 'line-clamp-2'; // 中文字符密度高
case 'en': return 'line-clamp-3'; // 英文需要更多行数
case 'ja': return 'line-clamp-2'; // 日文类似中文
default: return 'line-clamp-3';
}
};
return (
<p className={`text-gray-700 ${getLineClampClass(language)}`}>
{text}
</p>
);
}
性能考虑
TailwindCSS 性能优化
1. 构建时优化
TailwindCSS 在构建时会自动移除未使用的样式,但我们可以进一步优化:
// postcss.config.js
module.exports = {
plugins: [
require('tailwindcss'),
require('autoprefixer'),
// 生产环境启用 CSS 压缩
process.env.NODE_ENV === 'production' && require('cssnano')({
preset: 'default',
}),
].filter(Boolean),
}
2. 运行时性能
避免在运行时动态生成类名,这会影响 TailwindCSS 的优化效果:
// ❌ 避免:动态类名生成
const dynamicClass = `text-${color}-500`; // 可能不会被包含在最终构建中
// ✅ 推荐:使用完整的类名
const colorClasses = {
red: 'text-red-500',
blue: 'text-blue-500',
green: 'text-green-500',
};
const selectedClass = colorClasses[color];
line-clamp 性能影响
1. 重排和重绘
-webkit-line-clamp 的使用会触发浏览器的重排(reflow),在大量元素上使用时需要注意性能:
// ✅ 使用 CSS containment 优化性能
.text-container {
contain: layout style;
-webkit-line-clamp: 2;
display: -webkit-box;
-webkit-box-orient: vertical;
overflow: hidden;
}
2. 虚拟化长列表
在处理大量带有文本截断的列表项时,考虑使用虚拟化技术:
import { FixedSizeList as List } from 'react-window';
function VirtualizedProductList({ products }) {
const Row = ({ index, style }) => (
<div style={style}>
<ProductCard product={products[index]} />
</div>
);
return (
<List
height={600}
itemCount={products.length}
itemSize={200}
>
{Row}
</List>
);
}
总结
TailwindCSS 和 -webkit-line-clamp 代表了现代前端开发中两个重要的技术趋势:工具化的 CSS 开发和细粒度的样式控制。
TailwindCSS 的价值在于:
- 开发效率的显著提升:通过原子化的类名系统,开发者可以快速构建界面而无需编写大量自定义 CSS
- 设计系统的一致性:内置的设计令牌确保了整个项目的视觉一致性
- 维护成本的降低:减少了 CSS 文件的复杂性和样式冲突的可能性
- 团队协作的改善:统一的类名约定降低了团队成员之间的沟通成本
-webkit-line-clamp 的意义在于:
- 用户体验的优化:通过优雅的文本截断保持界面的整洁和一致性
- 响应式设计的支持:在不同屏幕尺寸下提供合适的内容展示
- 性能的考虑:避免了复杂的 JavaScript 文本处理逻辑
- 标准化的推动:虽然是实验性属性,但推动了相关 CSS 标准的发展
在实际项目中,这两个技术的结合使用能够帮助开发者:
- 快速原型开发:在设计阶段快速验证界面效果
- 响应式布局:轻松适配各种设备和屏幕尺寸
- 内容管理:优雅处理动态内容的显示问题
- 性能优化:减少 CSS 体积和运行时计算
随着前端技术的不断发展,我们可以期待看到更多类似的工具和技术出现,它们将继续推动前端开发向着更高效、更标准化的方向发展。对于前端开发者而言,掌握这些现代技术不仅能提升当前的开发效率,更重要的是能够跟上技术发展的步伐,为未来的项目做好准备。
无论你是刚开始学习前端开发的新手,还是希望优化现有项目的资深开发者,TailwindCSS 和 -webkit-line-clamp 都值得你深入学习和实践。它们不仅是技术工具,更代表了现代前端开发的最佳实践和发展方向。
来源:juejin.cn/post/7536092776867840039
React 核心 API 全景实战:从状态管理到性能优化,一网打尽
✨ 为什么写这篇文章?
很多前端朋友在用 React 的时候:
- 只会用
useState做局部状态,结果项目一大就乱套。 - 不了解
useReducer和Context,复杂页面全靠 props 一层层传。 - 性能卡顿后,只知道用
React.memo,但为什么卡? useMemo和useCallback的区别 ?- 明明只是个
Modal,结果被卡在组件层级里动弹不得,不知道可以用Portals。
👉「在什么场景下选用哪个 API」+「如何写出最合理的 React 代码」。
🟢 1. useState:局部状态管理
🌳 场景:表单输入管理
比起枯燥的计数器,这里用表单输入做示例。
import { useState } from 'react';
export default function LoginForm() {
const [username, setUsername] = useState('');
const [password, setPassword] = useState('');
const handleSubmit = e => {
e.preventDefault();
console.log("登录中", username, password);
}
return (
<form onSubmit={handleSubmit}>
<input value={username} onChange={e => setUsername(e.target.value)} placeholder="用户名"/>
<input type="password" value={password} onChange={e => setPassword(e.target.value)} placeholder="密码"/>
<button type="submit">登录</button>
</form>
);
}
🚀 优势
- 简单、直接
- 适用于小型、独立的状态
🟡 2. useEffect:副作用处理
🌍 场景:组件挂载时拉取远程数据
import { useEffect, useState } from 'react';
export default function UserProfile({ userId }) {
const [user, setUser] = useState(null);
useEffect(() => {
fetch(`/api/user/${userId}`)
.then(res => res.json())
.then(data => {
setUser(data);
});
return () => {
// 组件销毁执行此回调
};
}, []);
return user ? <h1>{user.name}</h1> : <p>加载中...</p>;
}
🚀 优势
- 集中管理副作用(请求、订阅、定时器、事件监听)
🔵 3. useRef & useImperativeHandle:DOM、实例方法控制
场景 1:聚焦输入框
import { useRef, useEffect } from 'react';
export default function AutoFocusInput() {
const inputRef = useRef();
useEffect(() => {
inputRef.current.focus();
}, []);
return <input ref={inputRef} placeholder="自动聚焦" />;
}
场景 2:在父组件调用子组件的方法
import { forwardRef, useRef, useImperativeHandle } from 'react';
const FancyInput = forwardRef((props, ref) => {
const inputRef = useRef();
useImperativeHandle(ref, () => ({
focus: () => inputRef.current.focus()
}));
return <input ref={inputRef} />;
});
export default function App() {
const fancyRef = useRef();
return (
<>
<FancyInput ref={fancyRef} />
<button onClick={() => fancyRef.current.focus()}>父组件聚焦子组件</button>
</>
);
}
🧭 4. Context & useContext:解决多层级传值
场景:用户登录信息在多层组件使用
import React, { createContext, useContext } from 'react';
const UserContext = createContext();
/** 设置在 DevTools 中将显示为 User */
UserContext.displayName = 'User'
function Navbar() {
return (
<div>
<UserInfo />
</div>
)
}
function UserInfo() {
const user = useContext(UserContext);
return <span>欢迎,{user.name}</span>;
}
export default function App() {
return (
<UserContext.Provider value={{ name: 'Zheng' }}>
<Navbar />
</UserContext.Provider>
);
}
🚀 优势
- 解决「祖孙组件传值太麻烦」的问题
🔄 5. useReducer:复杂状态管理
import { useReducer } from 'react';
function reducer(state, action) {
switch(action.type){
case 'next':
return { ...state, step: state.step + 1 };
case 'prev':
return { ...state, step: state.step - 1 };
default:
return state;
}
}
export default function Wizard() {
const [state, dispatch] = useReducer(reducer, { step: 1 });
return (
<>
<h1>步骤 {state.step}</h1>
<button onClick={() => dispatch({type: 'prev'})}>上一步</button>
<button onClick={() => dispatch({type: 'next'})}>下一步</button>
</>
);
}
🆔 6. useId:避免 SSR / 并发下 ID 不一致
import { useId } from 'react';
export default function FormItem() {
const id = useId();
return (
<>
<label htmlFor={id}>姓名</label>
<input id={id} type="text" />
</>
);
}
🚀 7. Portals:在根元素渲染 Modal
import { useState } from 'react';
import ReactDOM from 'react-dom';
function Modal({ onClose }) {
return ReactDOM.createPortal(
<div style={{ position: "fixed", top: 100, left: 100, background: "white" }}>
<h1>这是 Modal</h1>
<button onClick={onClose}>关闭</button>
</div>,
document.getElementById('root')
);
}
export default function App() {
const [show, setShow] = useState(false);
return (
<>
<button onClick={() => setShow(true)}>打开 Modal</button>
{show && <Modal onClose={() => setShow(false)} />}
</>
);
}
在上面代码中,我们将要渲染的视图作为createPortal方法的第一个参数,而第二个参数用于指定要渲染到那个DOM元素中。

尽管 portal 可以被放置在 DOM 树中的任何地方,但在任何其他方面,其行为和普通的 React 子节点行为一致。由于 portal 仍存在于 React 树, 且与 DOM 树中的位置无关,那么无论其子节点是否是 portal,像 context 这样的功能特性都是不变的。
这包含事件冒泡。一个从 portal 内部触发的事件会一直冒泡至包含 React 树的祖先,即便这些元素并不是 DOM 树中的祖先。
🔍 8. 组件渲染性能优化
🐘 之前类组件时代:shouldComponentUpdate与PureComponent
import { Component } from 'react'
export default class App extends Component {
constructor() {
super();
this.state = {
counter: 1
}
}
render() {
console.log("App 渲染了");
return (
<div>
<h1>App 组件</h1>
<div>{this.state.counter}</div>
<button onClick={() => this.setState({
counter : 1
})}>+1</button>
</div>
)
}
}
在上面的代码中,按钮在点击的时候仍然是设置 counter 的值为1,虽然 counter 的值没有变,整个组件仍然是重新渲染了的,显然,这一次渲染是没有必要的。
当 props 或 state 发生变化时,shouldComponentUpdate 会在渲染执行之前被调用。返回值默认为 true。首次渲染或使用 forceUpdate 方法时不会调用该方法。
下面我们来使用 shouldComponentUpdate 优化上面的示例:
import React from 'react'
/**
* 对两个对象进行一个浅比较,看是否相等
* obj1
* obj2
* 返回布尔值 true 代表两个对象相等, false 代表不相等
*/
function objectEqual(obj1, obj2) {
for (let prop in obj1) {
if (!Object.is(obj1[prop], obj2[prop])) {
// 进入此 if,说明有属性值不相等
// 只要有一个不相等,那么就应该判断两个对象不等
return false
}
}
return true
}
class PureChildCom1 extends React.Component {
constructor(props) {
super(props)
this.state = {
counter: 1,
}
}
// 验证state未发生改变,是否会执行render
onClickHandle = () => {
this.setState({
counter: Math.floor(Math.random() * 3 + 1),
})
}
// shouldComponentUpdate 中返回 false 来跳过整个渲染过程。其包括该组件的 render 调用以及之后的操作。
// 返回true 只要执行了setState都会重新渲染
shouldComponentUpdate(nextProps, nextState) {
if (
objectEqual(this.props, nextProps) &&
objectEqual(this.state, nextState)
) {
return false
}
return true
}
render() {
console.log('render')
return (
<div>
<div>{this.state.counter}</div>
<button onClick={this.onClickHandle}>点击</button>
</div>
)
}
}
export default PureChildCom1
PureComponent内部做浅比较:如果 props/state 相同则跳过渲染。- 不适用于复杂对象(如数组、对象地址未变)。
🥇 React.memo:函数组件记忆化
上面主要是优化类组件的渲染性能,那么如果是函数组件该怎么办呢?
React中为我们提供了memo高阶组件,只要 props 不变,就不重新渲染。
const Child = React.memo(function Child({name}) {
console.log("Child 渲染");
return <div>{name}</div>;
});
🏷 useCallback:缓存函数引用,避免触发子组件更新
import React, { useState, useCallback } from 'react';
function Child({ onClick }) {
console.log("Child 渲染")
return <button onClick={onClick}>点我</button>;
}
const MemoChild = React.memo(Child);
export default function App() {
const [count, setCount] = useState(0);
const handleClick = useCallback(() => {
console.log("点击");
}, []);
return (
<>
<div>{count}</div>
<button onClick={() => setCount(count+1)}>+1</button>
<MemoChild onClick={handleClick} />
</>
);
}
在上面的代码中,我们对Child组件进行了memo缓存,当修改App组件中的count值的时候,不会引起Child组件更新;使用了useCallback对函数进行了缓存,当点击Child组件中的button时也不会引起父组件的更新。
🔢 useMemo:缓存计算
某些时候,组件中某些值需要根据状态进行一个二次计算(类似于 Vue 中的计算属性),由于函数组件一旦重新渲染,就会重新执行整个函数,这就导致之前的二次计算也会重新执行一次。
import React, { useState } from 'react';
function App() {
const [count, setCount] = useState(1);
const [val, setValue] = useState('');
console.log("App render");
// 使用useMemo缓存计算
const getNum = useMemo(() => {
console.log('调用了!!!!!');
return count + 100;
}, [count])
return (
<div>
<h4>总和:{getNum()}</h4>
<div>
<button onClick={() => setCount(count + 1)}>+1</button>
{/* 文本框的输入会导致整个组件重新渲染 */}
<input value={val} onChange={event => setValue(event.target.value)} />
</div>
</div>
);
}
export default App;
在上面的示例中,文本框的输入会导致整个 App 组件重新渲染,但是 count 的值是没有改变的,所以 getNum 这个函数也是没有必要重新执行的。我们使用了 useMemo 来缓存二次计算的值,并设置了依赖项 count,只有在 count 发生改变时,才会重新执行二次计算。
面试题:useMemo 和 useCallback 的区别及使用场景?
useMemo 和 useCallback 接收的参数都是一样,第一个参数为回调,第二个参数为要依赖的数据。
共同作用: 仅仅依赖数据发生变化,才会去更新缓存。
两者区别:
useMemo计算结果是return回来的值, 主要用于缓存计算结果的值。应用场景如:需要进行二次计算的状态useCallback计算结果是函数, 主要用于缓存函数,应用场景如: 需要缓存的函数,因为函数式组件每次任何一个state的变化,整个组件都会被重新刷新,一些函数是没有必要被重新刷新的,此时就应该缓存起来,提高性能,和减少资源浪费。
来源:juejin.cn/post/7525375329105674303
Vue 3 中的 Watch、WatchEffect 和 Computed:深入解析与案例分析
引言
在前端开发中,尤其是使用 Vue.js 进行开发时,我们经常需要监听数据的变化以执行相应的操作。Vue 3 提供了三种主要的方法来实现这一目标:watch、watchEffect 和 computed。虽然它们都能帮助我们监听数据变化,但各自的适用场景和工作原理有所不同。本文将详细探讨这三者的区别,并通过具体的案例进行说明。
一、Computed 属性
1.1 定义与用途
computed 是 Vue 中用于定义计算属性的方法。它允许你基于其他响应式数据创建一个新的响应式数据。这个新数据会根据其依赖的数据自动更新。
生活中的类比:
想象一下你在超市里购买商品,每个商品都有一个价格标签。当你想要知道购物车里所有商品的总价时,你可以手动计算每件商品的价格乘以其数量,然后加起来得到总价。但是如果你使用了一个智能购物车,它能够自动为你计算总价(只要你知道单价和数量),这就是 computed 的作用——它能帮你自动计算并实时更新结果。
1.2 使用示例
import { ref, computed } from 'vue';
const price = ref(10);
const quantity = ref(5);
const totalPrice = computed(() => {
return price.value * quantity.value;
});
console.log(totalPrice.value); // 输出: 50
// 修改其中一个变量
price.value = 15;
console.log(totalPrice.value); // 输出: 75 自动更新
二、Watch 监听器
2.1 定义与用途
watch 允许你监听特定的数据源(如响应式引用或 getter 函数的结果),并在数据发生变化时执行回调函数。它可以监听单个源或多个源。
生活中的类比:
假设你现在正在做菜,你需要监控锅里的水是否沸腾。一旦水开始沸腾,你就知道是时候下饺子了。这里,“水是否沸腾”就是你要监听的数据源,而“下饺子”的动作则是监听到变化后执行的操作。
2.2 使用示例
import { ref, watch } from 'vue';
let waterBoiling = ref(false);
watch(waterBoiling, (newValue, oldValue) => {
if (newValue === true) {
console.log('Water is boiling, time to add the dumplings!');
}
});
waterBoiling.value = true; // 触发监听器
2.3 监听多个来源
有时候我们需要同时监听多个数据源的变化:
watch([sourceA, sourceB], ([newSourceA, newSourceB], [oldSourceA, oldSourceB]) => {
// 处理逻辑
});
三、WatchEffect 响应式效果
3.1 定义与用途
watchEffect 立即运行传入的函数,并响应式地追踪其内部使用的任何 reactive 数据。当这些数据更新时,该函数将再次执行。
生活中的类比:
想象你在厨房里准备晚餐,你需要时刻关注炉子上的火候以及烤箱里的温度。每当任何一个参数发生变化,你都需要相应地调整你的烹饪策略。在这里,watchEffect 就像一个智能助手,它会自动检测这些条件的变化,并即时调整你的行为。
3.2 使用示例
import { ref, watchEffect } from 'vue';
const temperature = ref(180);
const ovenStatus = ref('off');
watchEffect(() => {
console.log(`Oven status is ${ovenStatus.value}, current temperature is ${temperature.value}`);
});
temperature.value = 200; // 自动触发重新执行
ovenStatus.value = 'on'; // 同样会触发重新执行
四、三者之间的对比
| 特性 | Computed | Watch | WatchEffect |
|---|---|---|---|
| 初始执行 | 只有当访问时才会执行 | 立即执行一次 | 立即执行一次 |
| 依赖追踪 | 自动追踪依赖 | 需要明确指定依赖 | 自动追踪依赖 |
| 更新时机 | 当依赖改变时自动更新 | 当指定的值改变时 | 当依赖改变时自动更新 |
| 返回值 | 可以返回值 | 不直接返回值 | 不直接返回值 |
五、面试题
问题 1:请简述 computed 和 watch 的主要区别?
答案:
computed更适合用于需要根据其他状态派生出的新状态,并且这种派生关系是确定性的。watch更适用于监听某个状态的变化,并在变化发生时执行异步操作或昂贵的计算任务。
问题 2:在什么情况下你会选择使用 watchEffect 而不是 watch?
答案:
当你希望立即执行一个副作用并且自动追踪所有被用到的状态作为依赖项时,watchEffect 是更好的选择。它简化了代码结构,因为你不需要显式声明哪些状态是你关心的。
问题 3:如何使用 watch 来监听多个状态的变化?
答案:
可以通过数组的形式传递给 watch,这样就可以同时监听多个状态的变化,并在任一状态发生变化时触发回调函数。
通过以上内容,我们对 watch、watchEffect 和 computed 在 Vue 3 中的应用有了较为全面的理解。理解这些工具的不同之处有助于我们在实际项目中做出更合适的选择。无论是构建简单的用户界面还是处理复杂的业务逻辑,正确运用这些功能都可以显著提高我们的开发效率。
来源:juejin.cn/post/7525375329105035327
手写一个 UML 绘图软件

为何想做一款软件
在日常的开发和学习过程中,我们常常致力于实现各种功能点,解决各种 Bug。然而,我们很少有机会去设计和制作属于自己的产品。有时,我们可能认为市面上已有众多类似产品,自己再做一款似乎没有必要;有时,我们又觉得要做的事情太多,不知从何下手。
最近,我意识到仅仅解决单点问题已没有那么吸引我。相反,如果我自己开发一款产品,它能够被其他人使用,这将是一件有意思的事情。
因此,我决定在新的一年里,根据自己熟悉的领域和过去一年的积累,尝试打造一款自己的 UML 桌面端软件。我想知道,自己是否真的能够创造出一款在日常工作中好用的工具。
目前,这个计划中的产品的许多功能点已经在开发计划中。我已经完成了最基础的技术架构,并实现了核心的绘图功能。接下来,让我们一探究竟,看看这款软件目前支持哪些功能点。
技术方案
Monorepo 项目结构
使用了 Monorepo(单一代码仓库)项目管理模式。
- 这样可以将通用类型和工具方法抽离在 types 包和 utils 包中。
- 像 graph 这样功能独立的模块也可以单独抽离成包发布。
- 通过集中管理依赖,可以更容易地确保所有项目使用相同版本的库,并且相同版本的依赖库可以只安装一次。
项目介绍:
- 其中 draw-client 是 electron 客户端项目,它依赖自定义的 graph 库。
- services 是服务端代码,和 draw-client 同时依赖了,types 和 utils 公共模块。
|-- apps/ # 包含所有应用程序的代码,每个应用程序可以有自己的目录,如draw-client。
|-- draw-client/ # 客户端应用程序的主目录
|-- src
|-- package.json
|-- tsconfig.json
|-- packages/ # 用于存放项目中的多个包或模块,每个包可以独立开发和测试,便于代码复用和维护。
|-- graph/ # 包含与图表绘制相关的逻辑和组件,可能是一个通用的图表库。
|-- src
|-- package.json
|-- tsconfig.json
|-- types/ # 存放TypeScript类型定义文件,为项目提供类型安全。
|-- src
|-- package.json
|-- tsconfig.json
|-- utils/ # 包含工具函数和辅助代码,这些是项目中通用的功能,可以在多个地方复用。
|-- src
|-- package.json
|-- tsconfig.json
|-- services/ # 服务端代码
|-- src
|-- package.json
|-- tsconfig.json
|-- .npmrc
|-- package.json # 项目的配置文件,包含项目的元数据、依赖项、脚本等,是npm和pnpm管理项目的核心。
|-- pnpm-lock.yaml # pnpm的锁定文件,确保所有开发者和构建环境中依赖的版本一致。
|-- pnpm-workspace.yaml # 定义pnpm工作区的结构,允许在同一个仓库中管理多个包的依赖关系。
|-- REDEME.md
|-- tsconfig.base.json
|-- tsconfig.json
|-- tsconfig.tsbuildinfo
技术栈相关
涉及的技术架构图如下:

- draw-client 相关技术栈

- services 相关技术栈

软件操作流程说明
为了深入理解软件开发的流程,我们将通过两个具体的案例来阐述图形的创建、展示以及动态变化的过程。
创建图形流程
在本节中,我们将详细介绍如何使用我们的图形库来创建图形元素。通过序列图可以了解到一个最简单的图形创建的完整流程如下:

撤销操作
在软件开发中,撤销操作是一个常见的需求,它允许用户撤销之前的某些操作,恢复到之前的状态。本节将探讨如何在图形编辑器中实现撤销功能。
当我们想要回退某一个步骤时,流程如下:

规划
目前软件开发还是处于一个初步的阶段,还有很多有趣的功能需要开发。并且软件开发需要大量的时间,我会逐步去开发相关的功能。这不仅是一个技术实现的过程,更是一个不断学习和成长的过程。我计划在以下几个关键领域深入挖掘:
- NestJS服务端:我将深入研究NestJS框架,利用其强大的模块化和依赖注入特性,构建一个高效、可扩展的服务端架构。我希望通过实践,掌握NestJS的高级特性。
- Electron应用开发:利用Electron框架,将Web应用与桌面应用的优势结合起来。
- SVG图形处理:深入SVG的,我将开发相关库,使得用户能够轻松地在应用中绘制和编辑图形。
当然我会也在开发的过程中记录分享到掘金社区,如果有人想要体验和参与的也是非常欢迎!如果对你有帮助感谢点赞关注,可以私信我一起讨论下独立开发相关的话题。
来源:juejin.cn/post/7455151799030317093
React-native中高亮文本实现方案
前言
React-native中高亮文本实现方案,rn中文本高亮并不像h5那样,匹配正则,直接添加标签实现,rn中一般是循环实现了。一般是一段文本,拆分出关键词,然后关键词高亮。
简单实现
const markKeywords = (text, highlight) => {
if (!text || !highlight) return { value: [text], highlight: [] }
for (let index = 0; index < highlight.length; index++) {
const reg = new RegExp(highlight[index], 'g');
text = text.replace(reg, `**${highlight[index]}**`)
}
return {
markKeywordList: text.split('**').filter(item => item),
hightList: highlight.map(item => item)
}
}
上面可以拆分出可以循环的文本,和要高亮的文本。
特殊情况
const title = 'haorooms前端博文章高亮测试一下'
const highLightWords = ['前端博文', '文章高亮']
因为打上星号标记的原因,文章高亮 在被标记成 前端博文 章高亮 后,并不能被 文章高亮 匹配,而且即使能匹配也不能把 前端博文章高亮 拆成 前端博文 、文章高亮,如果能拆成 前端博文章高亮 就好了。
function sort(letter, substr) {
letter = letter.toLocaleUpperCase()
substr = substr.toLocaleUpperCase()
var pos = letter.indexOf(substr)
var positions = []
while(pos > -1) {
positions.push(pos)
pos = letter.indexOf(substr, pos + 1)
}
return positions.map(item => ([item, item + substr.length]))
}
// 高亮词第一次遍历索引
function format (text, hight) {
var arr = []
// hight.push(hight.reduce((prev, curr) => prev+curr), '')
hight.forEach((item, index) => {
arr.push(sort(text, item))
})
return arr.reduce((acc, val) => acc.concat(val), []);
}
// 合并索引区间
var merge = function(intervals) {
const n = intervals.length;
if (n <= 1) {
return intervals;
}
intervals.sort((a, b) => a[0] - b[0]);
let refs = [];
refs.unshift([intervals[0][0], intervals[0][1]]);
for (let i = 1; i < n; i++) {
let ref = refs[0];
if (intervals[i][0] < ref[1]) {
ref[1] = Math.max(ref[1], intervals[i][1]);
} else {
refs.unshift([intervals[i][0], intervals[i][1]]);
}
}
return refs.sort((a,b) => a[0] - b[0]);
}
function getHightLightWord (text, hight) {
var bj = merge(format(text, hight))
const c = text.split('')
var bjindex = 0
try {
bj.forEach((item, index) => {
item.forEach((_item, _index) => {
c.splice(_item + bjindex, 0, '**')
bjindex+=1
})
})
} catch (error) {
}
return c.join('').split('**')
}
export const markKeywords = (text, keyword) => {
if (!text || !keyword || keyword.length === 0 ) {
return { value: [text], keyword: [] }
}
if (Array.isArray(keyword)) {
keyword = keyword.filter(item => item)
}
let obj = { value: [text], keyword };
obj = {
value: getHightLightWord(text, keyword).filter((item) => item),
keyword: keyword.map((item) => item),
};
return obj;
};
述方法中我们先使用了下标匹配的方式,得到一个下标值的映射,然后通过区间合并的方式把连着的词做合并处理,最后再用合并后的下标值映射去打 ** 标记即可。
简单组件封装
function TextHighLight(props) {
const { title = '', highLightWords = [] } = props
const { numberOfLines, ellipsizeMode } = props
const { style } = props
const { markKeywordList, hightList } = markKeywords(title, highLightWords)
return <Text
numberOfLines={numberOfLines}
ellipsizeMode={ellipsizeMode}
style={style}
>
{
markKeywordList ?
markKeywordList.map((item,index) => (
(hightList && hightList.some(i => (i.toLocaleUpperCase().includes(item) || i.toLowerCase().includes(item))))
? <Text key={index} style={{ color: '#FF6300' }}>{item}</Text>
: item
))
: null
}
</Text>
}
来源:juejin.cn/post/7449373647233941541
一个列表页面,初级中级高级前端之间的鸿沟就显出来了
你是不是也写过 20+ 个中后台列表页,却总觉得跳不出 CRUD?你以为你是高级了,其实你只是熟练了。
你可能写过几十个中后台列表页,从最早用 v-model 到后来自定义 hooks,再到封装组件、状态缓存、schema 驱动。
但同样是一个列表页:
- 初级在堆功能;
- 中级在理结构;
- 高级在构建规则。
我们就以这个最常见的中后台场景:搜索 + 分页 + 表格 + 编辑跳转,来看看三个阶段的认知差异到底在哪。
写完 vs 写清楚 vs 写系统
| 等级 | 开发目标 |
|---|---|
| 初级 | 页面能用,接口通,功能不报错 |
| 中级 | 页面结构清晰、组件职责明确、状态复用 |
| 高级 | 页面只是 DSL 映射结果,字段配置驱动生成,具备平台能力 |
搜索区域的处理
| 等级 | 做法 |
|---|---|
| 初级 | el-form + v-model + 手写查询逻辑 |
| 中级 | 封装 SearchForm.vue,支持 props 字段配置 |
| 高级 | 使用字段配置 schema,支持字段渲染、联动、权限控制、字典动态加载 |
初级看起来能用,实则字段散落、表单逻辑零散; 中级可复用,但配置灵活性不足; 高级直接写 schema 字段声明,字段中心统一维护,整个搜索区域自动生成。
表格区域的组织
| 等级 | 做法 |
|---|---|
| 初级 | 表格写死在页面中,columns 手动维护 |
| 中级 | 封装 DataTable 组件,支持 columns + slots |
| 高级 | 表格由字段配置自动渲染,支持国际化、权限、字典映射、格式化 |
高级阶段的表格是“字段中心驱动下的视图映射”,而不是手写 UI 组件。
页面跳转行为
| 等级 | 做法 |
|---|---|
| 初级 | router.push + 返回后状态丢失 |
| 中级 | 缓存搜索条件和分页,支持跳转回填 |
| 高级 | 路由状态与组件状态解耦,编辑行为可抽象为弹窗、滑窗,不依赖跳转 |
体验上,初级只能靠刷新;中级保留了状态;高级压根不跳页,抽象为状态变更。
字段结构理解
| 等级 | 做法 |
|---|---|
| 初级 | 页面写死 status === 1 ? '启用' : '禁用' |
| 中级 | 使用全局字典表:getDictLabel('STATUS', val) |
| 高级 | 字段中心统一配置字段含义、展示方式、权限与控件类型,一份声明全平台复用 |
高级不写字段映射,而是写字段定义。字段即规则,规则即视图。
工程感理解
你以为工程感是“项目结构清晰”,其实高级工程感是:
- 样式有标准;
- 状态有模式;
- 路由有策略;
- 权限有方案;
- 字段有配置中心。
一切都能预期,一切都能对齐。
行为认知:你以为你在“配合”,其实你在“等安排”
你说“接口还没好我就做不了页面”。 你说“等产品图出了我再看组件拆不拆”。
但高级前端早就开始:
- Mock 数据、虚拟字段结构;
- 自定义 useXXX 模块推动业务流转;
- 甚至反推接口结构,引导后端设计。
配合和推进,只有一线之隔。
低水平重复劳动:你写了很多,但没真正沉淀
你遇到过哪些“看似很忙,实则在原地转圈”的开发场景?
有些开发者,写得飞快,需求接得也多,但工作了一两年,回头一看,写过的每一个页面都像复制粘贴出来的拼图。
你看似很忙,实则只是换了一个页面在干一样的事。
最典型的,就是以下这三类“中后台系统里的低水平重复劳动”:
❶ 每页都重复写 table columns 和格式化逻辑
- 每页重复定义
columns; - 状态字段每次都手写
status === 1 ? '启用' : '停用'; - 日期字段每页都在
render中 format; - 操作列、index 列、字典值写满重复逻辑。
📉 问题: 代码冗余,字段维护困难,一改动就全局找引用。
✅ 提升方式:
- 抽象字段结构配置(如 fieldSchema);
- 字段渲染、字典映射、权限统一管理;
- 一份字段配置驱动表格、表单、详情页。
❷ 每个列表页都重复写搜索逻辑和状态变量
- 每页都写
searchForm: {}、search()、reset(); - query 参数、分页、loading 状态变量混杂;
- 页面跳转回来状态丢失,刷新逻辑重复拼接。
📉 问题: 页面逻辑分散、复用性差,体验割裂。
✅ 提升方式:
- 自定义 hook 如
useSmartListPage()统一管理列表页状态; - 统一封装查询、分页、loading、缓存逻辑;
- 形成“搜索+表格+跳转+回填”标准列表模式。
❸ 反复堆砌跳转编辑流程,缺乏行为抽象
- 每次跳转写
this.$router.push({ path, query }); - 返回页面刷新列表,无上下文保留;
- 编辑页都是复制粘贴模板,字段改名。
📉 问题: 编辑与跳转强耦合,逻辑割裂,流程不清。
✅ 提升方式:
- 将“查看 / 编辑 / 创建”抽象为页面模式;
- 支持弹窗、滑窗模式管理,跳转可选;
- 解耦跳转与行为,页面由状态驱动。
真正的成长,不是写得多,而是提取出通用能力、形成规范。
中后台系统里最常见的低水平重复劳动:
- 每次都手写 table columns、格式化字段;
- 搜索表单每页都重新写逻辑、状态绑定;
- 分页、loading、跳转逻辑全靠临时拼;
你遇到过哪些 “看似很忙,实则在原地转圈” 的开发场景?欢迎在评论区说说你的故事。
组件理解:你以为你在写组件,其实你在制造混乱
组件抽象不清、slot 滥用、props 大杂烩、逻辑耦合 UI,写完一个别人不敢接的黑盒。
中级组件关注复用,高级组件关注职责边界和组合方式,具备“可预测性、可替换性、可拓展性”。
页面能力 ≠ 项目交付能力
你能写页面,但你未必能独立交付项目。 缺的可能是:
- 多模块协同能力
- 权限 / 字段 / 配置抽象力
- 异常兜底与流程控制设计
从写完一个页面,到撑起一个系统,中间差的是“体系构建力”。
结语:页面 ≠ 技术,堆功能 ≠ 成长
初级在交付页面,中级在建设结构,高级在定义规则。 真正的高级前端,已经不写“页面”了,而是在定义“页面该怎么写”。
来源:juejin.cn/post/7492086179996090383
你真的了解包管理工具吗?(npm、pnpm、cnpm)
npm (Node Package Manager)
概述
npm是 Node.js 的官方包管理器,也是全球使用最广泛的 JavaScript 包管理工具。它用于管理 JavaScript 项目的依赖包,可以通过命令行来安装、更新、卸载依赖包。
特点
- Node.js 官方默认包管理器。支持全局和本地安装模式
- 通过 package.json 和 package-lock.json 管理依赖版本,可以在 package.json 中定义各种脚本命令
常用命令
npm install [package] # 安装包
npm uninstall [package] # 卸载包
npm update [package] # 更新包
npm init # 初始化项目
npm run [script] # 运行脚本
npm publish # 发布包
依赖管理方式
npm 使用平铺的 node_modules 结构,会导致依赖重复和幽灵依赖问题(phantom dependencies)。这种管理方式导致npm在处理在处理大量依赖时速度会很慢
cnpm (China npm)
特点
- 镜像加速:使用淘宝的 npm 镜像,下载速度更快
- 兼容 npm:命令与 npm 基本一致,学习成本低
- 安装简单:可以通过 npm 直接安装 cnpm
概述
cnpm 是阿里巴巴团队开发的 npm 命令行工具,基于淘宝镜像 registry.npmmirror.com,用于解决国内访问 npm 官方源缓慢的问题。
特点
- 镜像加速:使用淘宝的 npm 镜像,下载速度更快
- 兼容 npm:命令与 npm 基本一致,学习成本低
- 安装简单:可以通过 npm 直接安装 cnpm
本质是和npm一样,只是为了迎合国内的网络环境,更改了依赖包的下载地址,让下载速度更快
pnpm (## Performant npm)
概述
pnpm 是一个新兴的、高性能的包管理工具,最大的特点是使用硬链接(hard link)来复用依赖文件,极大节省磁盘空间和提升安装速度。
特点
- 高效存储:多个项目可以共享同一版本的依赖,节省磁盘空间
- 磁盘空间优化:通过硬链接共享依赖,显著节省了磁盘空间。
- 强制封闭依赖:避免隐式依赖,提高了依赖管理的可靠性。
- 速度更快,兼容性更好:安装速度比 npm 和 yarn 更快,兼容 npm 的工作流和 package.json
依赖管理方式
pnpm (Performant npm) 的依赖管理方式与传统包管理器(npm/yarn)有本质区别,其核心基于内容可寻址存储和符号链接技术。
- 内容可寻址存储 (Content-addressable storage)
pnpm 将所有依赖包存储在全局的 ~/.pnpm-store 目录中(默认位置),存储结构基于包内容的哈希值而非包名称。这意味着: 1. 相同内容的包只会存储一次 2.不同项目可以共享完全相同的依赖版本3.通过哈希值精确验证包完整性
- 符号链接 (Symbolic links) 结构

举例解释就是
场景假设:你有 100 个项目,每个项目都用到了相同的
lodash库
1. npm:每个项目都自己带一本书
- npm 的方式:
- 每个项目都有一本完整的
lodash,即使内容一模一样。
- 结果:你的硬盘上存了 100 本相同的书(100 份
lodash副本),占用大量空间。
- 更新问题:如果
lodash发布新版本,哪怕只改了一行代码,npm 也会重新下载整本书,而不是只更新变化的部分。
2. pnpm:所有项目共享同一本书
- pnpm 的方式:
- 统一存储:所有版本的
lodash都存放在一个中央仓库(类似“云端书库”)。
- 按需链接:每个项目只是“链接”到这本书,而不是复制一份。
- 版本更新优化:如果
lodash新版本只改了一个文件,pnpm 只存储这个变化的文件,而不是整个新版本。
来源:juejin.cn/post/7518212477650927666
p5.js 圆弧的用法
点赞 + 关注 + 收藏 = 学会了
在 p5.js 中,arc() 函数用于绘制圆弧,它是创建各种圆形图形和动画的基础。圆弧本质上是椭圆的一部分,由中心点、宽度、高度、起始角度和结束角度等参数定义。通过灵活运用 arc() 函数可以轻松创建饼图、仪表盘、时钟等常见 UI 组件,以及各种创意图形效果。
arc() 的基础语法
基础语法
arc() 函数的完整语法如下:
arc(x, y, w, h, start, stop, [mode], [detail])
核心参数解释:
- x, y:圆弧所在椭圆的中心点坐标
- w, h:椭圆的宽度和高度,如果两者相等,则绘制的是圆形的一部分
- start, stop:圆弧的起始角度和结束角度,默认以弧度(radians)为单位
可选参数:
- mode:定义圆弧的填充样式,可选值为
OPEN(开放式半圆)、CHORD(封闭式半圆)或PIE(闭合饼图) - detail:仅在 WebGL 模式下使用,指定组成圆弧周长的顶点数量,默认值为 25
角度单位与转换
在 p5.js 中,角度可以使用弧度或角度两种单位表示:
- 默认单位是弧度:0 弧度指向正右方(3 点钟方向),正角度按顺时针方向增加
- 使用角度单位:可以通过
angleMode(DEGREES)函数将角度单位设置为角度
两种单位之间的转换关系:
- 360 度 = 2π 弧度
- 180 度 = π 弧度
- 90 度 = π/2 弧度
p5.js 提供了两个辅助函数用于单位转换:
radians(degrees):将角度转换为弧度degrees(radians):将弧度转换为角度
举个例子(基础示例)
举个例子讲解一下如何使用 arc() 函数绘制不同角度的圆弧。
function setup() {
createCanvas(400, 400);
angleMode(DEGREES); // 使用角度单位
}
function draw() {
background(220);
// 绘制不同角度的圆弧
arc(100, 100, 100, 100, 0, 90); // 90度圆弧
arc(250, 100, 100, 100, 0, 180); // 180度圆弧
arc(100, 250, 100, 100, 0, 270); // 270度圆弧
arc(250, 250, 100, 100, 0, 360); // 360度圆弧(整圆)
}
这段代码会在画布上绘制四个不同角度的圆弧,从 90 度到 360 度不等。注意,当角度为 360 度时,实际上绘制的是一个完整的圆形。
三种圆弧模式:OPEN、CHORD 与 PIE
arc() 函数的第七个参数mode决定了圆弧的填充方式,有三种可选值:
- OPEN(默认值):仅绘制圆弧本身,不填充任何区域
- CHORD:绘制圆弧并连接两端点形成闭合的半圆形区域
- PIE:绘制圆弧并连接两端点与中心点形成闭合的扇形区域
这三种模式不需要手动定义,p5.js 已经在全局范围内定义好了这些常量。
举个例子:
function setup() {
createCanvas(400, 200);
angleMode(DEGREES);
}
function draw() {
background(220);
// 绘制不同模式的圆弧
arc(100, 100, 100, 100, 0, 270, OPEN);
arc(220, 100, 100, 100, 0, 270, CHORD);
arc(340, 100, 100, 100, 0, 270, PIE);
}
这段代码会在画布上绘制三个 270 度的圆弧,分别展示 OPEN、CHORD 和 PIE 三种模式的效果。可以明显看到,OPEN 模式只绘制弧线,CHORD 模式连接两端点形成闭合区域,而 PIE 模式则从两端点连接到中心点形成扇形。
如何选择合适的模式
选择圆弧模式时,应考虑以下因素:
- 视觉效果需求:需要纯弧线效果时选择
OPEN,需要闭合区域时选择CHORD或PIE - 应用场景:饼图通常使用
PIE模式,仪表盘可能使用CHORD模式,而简单装饰线条可能使用OPEN模式 - 填充与描边需求:不同模式对填充和描边的处理方式不同,需要根据设计需求选择
值得注意的是,arc() 函数绘制的默认是填充的扇形区域。如果想要获取纯圆弧(没有填充区域),可以使用 noFill() 函数拒绝 arc() 函数的填充。
做几个小demo玩玩
简易数字时钟
在这个示例中,我将使用 arc() 函数创建一个简单的数字时钟,显示当前的小时、分钟和秒数。
let hours, minutes, seconds;
function setup() {
createCanvas(400, 400);
angleMode(DEGREES); // 使用角度单位
}
function draw() {
background(220);
// 获取当前时间
let now = new Date();
hours = now.getHours();
minutes = now.getMinutes();
seconds = now.getSeconds();
// 绘制时钟边框
stroke(0);
strokeWeight(2);
noFill();
arc(width/2, height/2, 300, 300, 0, 360);
// 绘制小时刻度
strokeWeight(2);
for (let i = 0; i < 12; i++) {
let angle = 90 - i * 30;
let x1 = width/2 + 140 * cos(radians(angle));
let y1 = height/2 + 140 * sin(radians(angle));
let x2 = width/2 + 160 * cos(radians(angle));
let y2 = height/2 + 160 * sin(radians(angle));
line(x1, y1, x2, y2);
}
// 绘制分钟刻度
strokeWeight(1);
for (let i = 0; i < 60; i++) {
let angle = 90 - i * 6;
let x1 = width/2 + 150 * cos(radians(angle));
let y1 = height/2 + 150 * sin(radians(angle));
let x2 = width/2 + 160 * cos(radians(angle));
let y2 = height/2 + 160 * sin(radians(angle));
line(x1, y1, x2, y2);
}
// 绘制小时指针
let hourAngle = 90 - (hours % 12) * 30 - minutes * 0.5;
let hourLength = 80;
let hx = width/2 + hourLength * cos(radians(hourAngle));
let hy = height/2 + hourLength * sin(radians(hourAngle));
line(width/2, height/2, hx, hy);
// 绘制分钟指针
let minuteAngle = 90 - minutes * 6;
let minuteLength = 120;
let mx = width/2 + minuteLength * cos(radians(minuteAngle));
let my = height/2 + minuteLength * sin(radians(minuteAngle));
line(width/2, height/2, mx, my);
// 绘制秒针
stroke(255, 0, 0);
let secondAngle = 90 - seconds * 6;
let secondLength = 140;
let sx = width/2 + secondLength * cos(radians(secondAngle));
let sy = height/2 + secondLength * sin(radians(secondAngle));
line(width/2, height/2, sx, sy);
// 显示当前时间文本
noStroke();
fill(0);
textSize(24);
text(hours + ":" + nf(minutes, 2, 0) + ":" + nf(seconds, 2, 0), 50, 50);
}
关键点解析:
- 获取当前时间:使用Date()对象获取当前的小时、分钟和秒数
- 角度计算:根据时间值计算指针的旋转角度,注意将角度转换为 p5.js 使用的坐标系(0 度指向正上方)
- 刻度绘制:使用循环绘制小时和分钟刻度,每个小时刻度间隔 30 度,每个分钟刻度间隔 6 度
- 指针绘制:根据计算的角度和长度绘制小时、分钟和秒针,注意秒针使用红色以区分
- 时间文本显示:使用text()函数在画布左上角显示当前时间
饼图
在这个示例中,我将创建一个简单的饼图,展示不同类别数据的比例。
let data = [30, 10, 45, 35, 60, 38, 75, 67]; // 示例数据
let total = 0;
let lastAngle = 0;
function setup() {
createCanvas(720, 400);
angleMode(DEGREES); // 使用角度单位
noStroke(); // 不绘制边框
total = data.reduce((a, b) => a + b, 0); // 计算数据总和
}
function draw() {
background(100);
pieChart(300, data); // 调用饼图绘制函数
}
function pieChart(diameter, data) {
lastAngle = 0; // 重置起始角度
for (let i = 0; i < data.length; i++) {
// 设置圆弧的灰度值,map函数将数据映射到0-255的灰度范围
let gray = map(i, 0, data.length, 0, 255);
fill(gray);
// 计算当前数据点的角度范围
let startAngle = lastAngle;
let endAngle = lastAngle + (data[i] / total) * 360;
// 绘制圆弧
arc(
width / 2,
height / 2,
diameter,
diameter,
startAngle,
endAngle,
PIE // 使用PIE模式创建扇形
);
lastAngle = endAngle; // 更新起始角度为下一个数据点做准备
}
}
关键点解析:
- 数据准备:定义示例数据数组data,并计算数据总和total
- 颜色设置:使用map()函数将数据索引映射到 0-255 的灰度范围,实现渐变效果
- 角度计算:根据每个数据点的值与总和的比例计算对应的角度范围
- 圆弧绘制:使用PIE模式绘制每个数据点对应的扇形,形成完整的饼图
这个饼图示例可以通过添加标签、交互效果或动态数据更新来进一步增强功能。
描边效果
在 p5.js 中,我们可以通过以下函数定制圆弧的描边效果:
- stroke(color):设置描边颜色
- strokeWeight(weight):设置描边宽度
- strokeCap(cap):设置描边端点样式(可选值:BUTT, ROUND, SQUARE)
- strokeJoin(join):设置描边转角样式(可选值:MITER, ROUND, BEVEL)
以下示例展示了如何定制圆弧的描边效果:
function setup() {
createCanvas(400, 200);
angleMode(DEGREES);
}
function draw() {
background(220);
// 示例1:粗红色描边
stroke(255, 0, 0);
strokeWeight(10);
arc(100, 100, 100, 100, 0, 270);
// 示例2:带圆角端点的描边
stroke(0, 255, 0);
strokeWeight(10);
strokeCap(ROUND);
arc(220, 100, 100, 100, 0, 270);
// 示例3:带阴影效果的描边
stroke(0, 0, 255);
strokeWeight(15);
strokeCap(SQUARE);
arc(340, 100, 100, 100, 0, 270);
// 恢复默认设置
noStroke();
}
关键点解析:
- 颜色设置:使用stroke()函数设置不同颜色的描边
- 宽度设置:使用strokeWeight()函数调整描边粗细
- 端点样式:使用strokeCap()函数设置描边端点的样式(圆角效果特别适合圆弧)
- 阴影效果:通过增加描边宽度并偏移绘制位置可以创建简单的阴影效果
填充效果
在 p5.js 中,我们可以通过以下函数定制圆弧的填充效果:
- fill(color):设置填充颜色
- noFill():禁用填充效果
- colorMode(mode):设置颜色模式(RGB、HSB 等)
- alpha():设置颜色透明度
以下示例展示了如何定制圆弧的填充效果:
function setup() {
createCanvas(400, 200);
angleMode(DEGREES);
colorMode(HSB, 360, 100, 100); // 使用HSB颜色模式
}
function draw() {
background(220);
// 示例1:单色填充
fill(120, 100, 100); // 绿色
arc(100, 100, 100, 100, 0, 270);
// 示例2:渐变填充
noFill();
stroke(0, 0, 100);
strokeWeight(10);
for (let i = 0; i < 360; i += 10) {
fill(i, 100, 100);
arc(220, 100, 100, 100, i, i+10);
}
// 示例3:透明填充
fill(240, 100, 100, 50); // 半透明蓝色
arc(340, 100, 100, 100, 0, 270);
// 恢复默认设置
noFill();
stroke();
}
关键点解析:
- 颜色模式:使用colorMode()函数切换到 HSB 模式,方便创建渐变效果
- 单色填充:直接使用fill()函数设置单一填充颜色
- 渐变填充:通过循环绘制多个小角度的圆弧,每个使用不同的色相值实现渐变效果
- 透明度设置:在fill()函数中添加第四个参数(0-100)设置透明度
旋转圆弧
在 p5.js 中创建圆弧动画非常简单,主要通过以下方法实现:
- **draw()**函数:每秒自动执行约 60 次,用于更新动画帧
- 变量控制:使用变量控制圆弧的参数(如位置、大小、角度等)
- frameRate(fps):设置动画帧率(可选)
- millis():获取当前时间(毫秒),用于精确控制动画时间
圆弧动画效果示例:
let angle = 0;
function setup() {
createCanvas(400, 400);
angleMode(DEGREES);
}
function draw() {
background(220);
// 绘制旋转的红色圆弧
stroke(255, 0, 0);
strokeWeight(10);
arc(width/2, height/2, 300, 300, angle, angle + 90);
// 更新角度值,实现旋转效果
angle += 2; // 调整这个值可以改变旋转速度
// 恢复默认设置
noStroke();
}
关键点解析:
- 角度变量:使用
angle变量控制圆弧的起始角度 - 角度更新:在每次
draw()调用时增加angle值,实现旋转效果 - 速度控制:通过调整每次增加的角度值(这里是 2 度)控制旋转速度
弧度与角度的转换技巧
在 p5.js 中,arc()函数默认使用弧度作为角度单位,但我们通常更习惯使用角度。以下是一些转换技巧:
- 角度转弧度:使用
radians(degrees)函数将角度转换为弧度 - 弧度转角度:使用
degrees(radians)函数将弧度转换为角度 - 设置角度单位:使用
angleMode(DEGREES)函数将全局角度单位设置为角度,这样arc()函数就可以直接使用角度值 - 常见角度值:记住一些常用角度的弧度值,如 90 度 = PI/2,180 度 = PI,270 度 = 3PI/2,360 度 = 2PI
圆弧绘制的常见问题与解决方案
在使用 arc() 函数时,可能会遇到以下问题:
- arc () 函数中的 bug:当
start_angle == end_angle时,可能会出现意外绘制效果。例如,当start_angle == end_angle == -PI/2时会绘制一个半圆,这不符合预期。解决方案是避免start_angle和end_angle相等。 - 起始角度的位置:在 p5.js 中,0 弧度(或 0 度,如果使用
angleMode(DEGREES))指向正右方(3 点钟方向),而不是数学上的正上方。这可能导致方向与预期不符。 - 描边宽度的影响:较宽的描边会使圆弧看起来比实际大。这是因为描边会向路径的两侧扩展。如果需要精确控制大小,可以考虑将arc()的尺寸适当减小,或者使用
shapeMode()函数调整坐标系。 - 浮点精度问题:在进行角度计算时,尤其是涉及到除法和循环时,可能会遇到浮点精度问题。建议使用
nf()函数(如nf(value, 2, 0))来格式化显示的数值,避免显示过多的小数位。
以上就是本文的全部内容啦,如果想了解更多 p5.js 的玩法可以关注 《P5.js中文教程》
点赞 + 关注 + 收藏 = 学会了
来源:juejin.cn/post/7529753277770022921
🎨 CSS 写到手抽筋?Stylus 说:‘让我来!’
前言
还在手动重复写 margin: 0; padding: 0;?还在为兼容性疯狂加 -webkit- 前缀?大厂前端早已不用原始 CSS 硬刚了!Stylus 作为一款现代化 CSS 预处理器,让你写样式像写 JavaScript 一样爽快。
还在手动重复写 margin: 0; padding: 0;?还在为兼容性疯狂加 -webkit- 前缀?大厂前端早已不用原始 CSS 硬刚了!Stylus 作为一款现代化 CSS 预处理器,让你写样式像写 JavaScript 一样爽快。
Stylus:高效的CSS预处理器
基本特性
Stylus是一种CSS预处理器,提供了许多CSS不具备的高级功能:
// 定义变量
$background_color = rgba(255, 255, 255, 0.95)
.wrapper
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
Stylus是一种CSS预处理器,提供了许多CSS不具备的高级功能:
// 定义变量
$background_color = rgba(255, 255, 255, 0.95)
.wrapper
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
优势与使用场景
- 变量支持:避免重复值,便于主题切换
- 嵌套规则:更清晰的DOM结构表示
- 混合(Mixins) :复用样式块
- 函数与运算:动态计算样式值
- 简洁语法:可选的花括号、分号和冒号
- 变量支持:避免重复值,便于主题切换
- 嵌套规则:更清晰的DOM结构表示
- 混合(Mixins) :复用样式块
- 函数与运算:动态计算样式值
- 简洁语法:可选的花括号、分号和冒号
编译与使用
安装Stylus后,可以通过命令行编译.styl文件:
npm install -g stylus
stylus -w common.styl -o common.css
- 第一个语句是用来安装
stylus的直接运行就好 - 第二个语句是你编译
common.styl文件时使用的,也就是你写CSS代码时使用的,因为浏览器并不能直接编译.styl文件,所以你要先将.styl文件编译成.css文件,也就是用上面给的那个命令,注意要自己切换成自己的.styl文件名,后面的css名可以随便取一个自己想要的
安装Stylus后,可以通过命令行编译.styl文件:
npm install -g stylus
stylus -w common.styl -o common.css
- 第一个语句是用来安装
stylus的直接运行就好 - 第二个语句是你编译
common.styl文件时使用的,也就是你写CSS代码时使用的,因为浏览器并不能直接编译.styl文件,所以你要先将.styl文件编译成.css文件,也就是用上面给的那个命令,注意要自己切换成自己的.styl文件名,后面的css名可以随便取一个自己想要的
插件的使用
我们要想使用stylus,除了要全局安装之外还要下载一下下面的这个插件。
我们要先进入插件市场,然后搜索stylus,点击我选择的那个插件点击安装即可
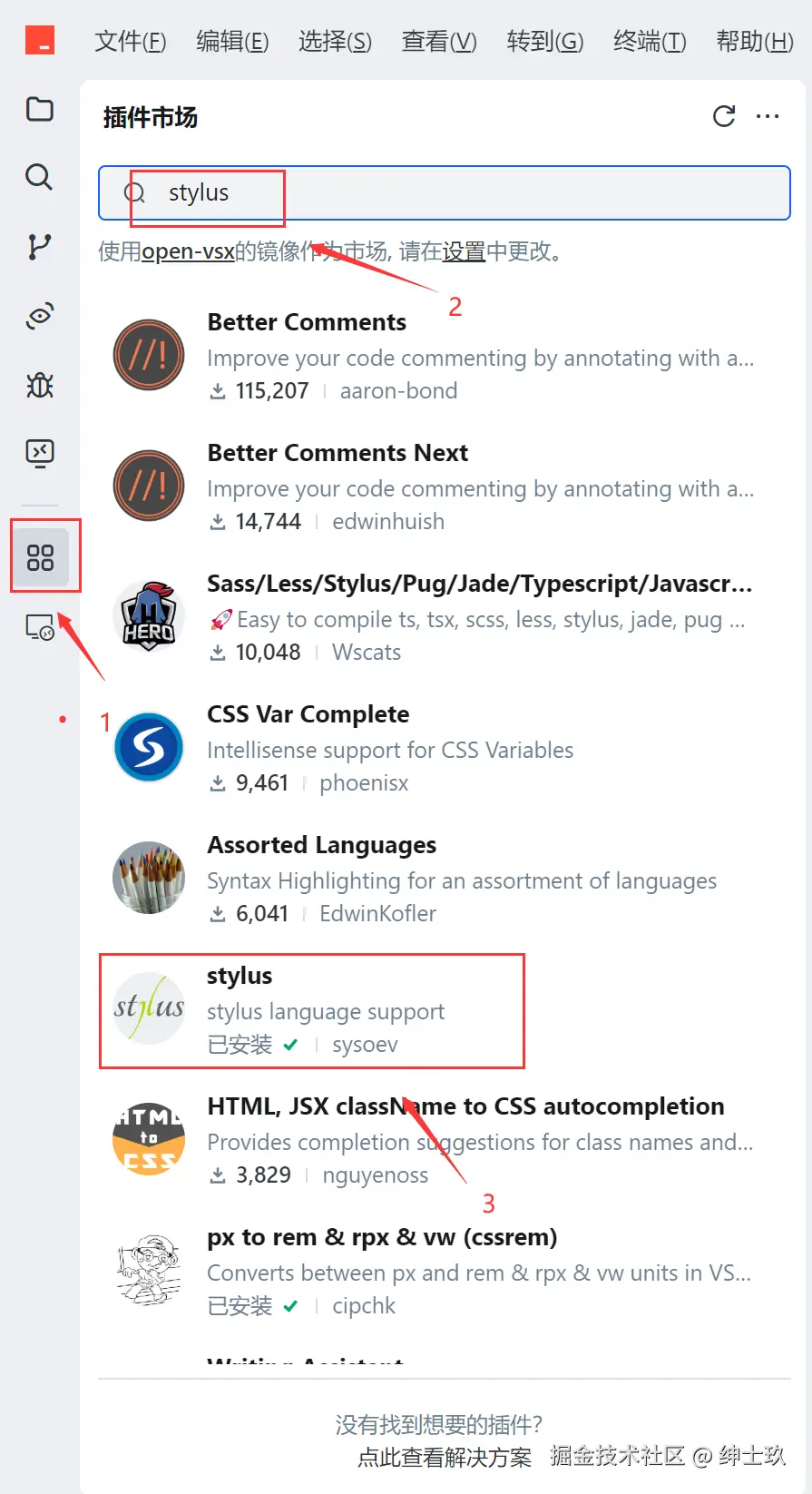
我们要想使用stylus,除了要全局安装之外还要下载一下下面的这个插件。
我们要先进入插件市场,然后搜索stylus,点击我选择的那个插件点击安装即可
案例实战
先看效果,再上代码,最后在分析考点易错点
先看效果,再上代码,最后在分析考点易错点
效果
下面是我们实现的一个简单的效果界面图
下面是我们实现的一个简单的效果界面图
代码
$background_color = rgba(255, 255, 255, 0.95)
html
box-sizing border-box
min-height 100vh
display flex
flex-direction column
justify-content center
align-items center
text-align center
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
*
box-sizing border-box
.wrapper
padding 20px
min-width 350px
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
h2
text-align center
margin 0
font-weight 200
body
color pink
.plates
margin 0
padding 0
text-align left
list-style: none
li
border-bottom 1px solid rgba(0, 0, 0, 0.2)
padding 10px 0px
display flex
label
flex 1
cursor pointer
input
display none
.add-items
margin-top 20px
input
padding 10px
outline 0
border 1px solid rgba(0, 0, 0, 0.1)
我们可以看到.styl文件不用去写:和{}了,而且可以直接层叠样式
当我们运行stylus -w common.styl -o common.css命令时,它会实时的将common.styl文件编译成common.css,你可以根据自己的需求来编写,让我们看看它帮我写好的common.css文件吧
html {
box-sizing: border-box;
min-height: 100vh;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
text-align: center;
background: url("http://wes.io/hx9M/oh-la-la.jpg") center no-repeat;
background-size: cover;
}
* {
box-sizing: border-box;
}
.wrapper {
padding: 20px;
min-width: 350px;
background: rgba(255,255,255,0.95);
box-shadow: 0 0 0 10px rgba(0,0,0,0.1);
}
.wrapper h2 {
text-align: center;
margin: 0;
font-weight: 200;
}
body {
color: #ffc0cb;
}
.plates {
margin: 0;
padding: 0;
text-align: left;
list-style: none;
}
.plates li {
border-bottom: 1px solid rgba(0,0,0,0.2);
padding: 10px 0px;
display: flex;
}
.plates label {
flex: 1;
cursor: pointer;
}
.plates input {
display: none;
}
.add-items {
margin-top: 20px;
}
.add-items input {
padding: 10px;
outline: 0;
border: 1px solid rgba(0,0,0,0.1);
}
// 获取DOM元素
// 获取添加项目的表单元素
const addItems = document.querySelector('.add-items');
// 获取显示项目列表的元素
const itemsList = document.querySelector('.plates');
// 从本地存储获取项目数据,如果没有则初始化为空数组
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
// 添加新项目函数
function addItem(e) {
// 阻止表单默认提交行为
e.preventDefault();
// 获取输入框中的文本值
const text = this.querySelector('[name=item]').value;
// 创建新项目对象
const item = {
text, // 项目文本
done: false // 完成状态初始为false
};
// 将新项目添加到数组中
items.push(item);
// 更新列表显示
populateList(items, itemsList);
// 将更新后的数组保存到本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重置表单
this.reset();
}
// 渲染项目列表函数
function populateList(plates = [], platesList) {
// 使用map方法将数组转换为HTML字符串
platesList.innerHTML = plates.map((plate, i) => {
return `
${i} id="item${i}" ${plate.done ? 'checked' : ''}>
`;
}).join(''); // 将数组转换为字符串
}
// 切换项目完成状态函数
function toggleDone(e) {
// 如果点击的不是input元素则直接返回
if (!e.target.matches('input')) return;
// 获取被点击元素的data-index属性值
const el = e.target;
const index = el.dataset.index;
// 切换项目的完成状态
items[index].done = !items[index].done;
// 更新本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重新渲染列表
populateList(items, itemsList);
}
// 添加事件监听器
// 表单提交事件 - 添加新项目
addItems.addEventListener('submit', addItem);
// 列表点击事件 - 切换项目完成状态
itemsList.addEventListener('click', toggleDone);
// 初始化加载 - 页面加载时渲染已有项目
populateList(items, itemsList);
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
<title>Documenttitle>
<link rel="stylesheet" href="./common.css">
head>
<body>
<div class="wrapper">
<h2>Local TAPASh2>
<p>请添加您的TAPASp>
<ul class="plates">
<li>Loading Tapas ...li>
ul>
<form action="" class="add-items">
<input
type="text"
placeholder="Item Name"
required -- 让输入框变成必须填写 -->
name="item"
>
<input type="submit" value="+ Add Item">
form>
div>
<script src="./common.js">
script>
body>
html>
$background_color = rgba(255, 255, 255, 0.95)
html
box-sizing border-box
min-height 100vh
display flex
flex-direction column
justify-content center
align-items center
text-align center
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
*
box-sizing border-box
.wrapper
padding 20px
min-width 350px
background $background_color
box-shadow 0 0 0 10px rgba(0, 0, 0, 0.1)
h2
text-align center
margin 0
font-weight 200
body
color pink
.plates
margin 0
padding 0
text-align left
list-style: none
li
border-bottom 1px solid rgba(0, 0, 0, 0.2)
padding 10px 0px
display flex
label
flex 1
cursor pointer
input
display none
.add-items
margin-top 20px
input
padding 10px
outline 0
border 1px solid rgba(0, 0, 0, 0.1)
我们可以看到.styl文件不用去写:和{}了,而且可以直接层叠样式
当我们运行stylus -w common.styl -o common.css命令时,它会实时的将common.styl文件编译成common.css,你可以根据自己的需求来编写,让我们看看它帮我写好的common.css文件吧
html {
box-sizing: border-box;
min-height: 100vh;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
text-align: center;
background: url("http://wes.io/hx9M/oh-la-la.jpg") center no-repeat;
background-size: cover;
}
* {
box-sizing: border-box;
}
.wrapper {
padding: 20px;
min-width: 350px;
background: rgba(255,255,255,0.95);
box-shadow: 0 0 0 10px rgba(0,0,0,0.1);
}
.wrapper h2 {
text-align: center;
margin: 0;
font-weight: 200;
}
body {
color: #ffc0cb;
}
.plates {
margin: 0;
padding: 0;
text-align: left;
list-style: none;
}
.plates li {
border-bottom: 1px solid rgba(0,0,0,0.2);
padding: 10px 0px;
display: flex;
}
.plates label {
flex: 1;
cursor: pointer;
}
.plates input {
display: none;
}
.add-items {
margin-top: 20px;
}
.add-items input {
padding: 10px;
outline: 0;
border: 1px solid rgba(0,0,0,0.1);
}
// 获取DOM元素
// 获取添加项目的表单元素
const addItems = document.querySelector('.add-items');
// 获取显示项目列表的元素
const itemsList = document.querySelector('.plates');
// 从本地存储获取项目数据,如果没有则初始化为空数组
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
// 添加新项目函数
function addItem(e) {
// 阻止表单默认提交行为
e.preventDefault();
// 获取输入框中的文本值
const text = this.querySelector('[name=item]').value;
// 创建新项目对象
const item = {
text, // 项目文本
done: false // 完成状态初始为false
};
// 将新项目添加到数组中
items.push(item);
// 更新列表显示
populateList(items, itemsList);
// 将更新后的数组保存到本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重置表单
this.reset();
}
// 渲染项目列表函数
function populateList(plates = [], platesList) {
// 使用map方法将数组转换为HTML字符串
platesList.innerHTML = plates.map((plate, i) => {
return `
${i} id="item${i}" ${plate.done ? 'checked' : ''}>
`;
}).join(''); // 将数组转换为字符串
}
// 切换项目完成状态函数
function toggleDone(e) {
// 如果点击的不是input元素则直接返回
if (!e.target.matches('input')) return;
// 获取被点击元素的data-index属性值
const el = e.target;
const index = el.dataset.index;
// 切换项目的完成状态
items[index].done = !items[index].done;
// 更新本地存储
localStorage.setItem('tapasItems', JSON.stringify(items));
// 重新渲染列表
populateList(items, itemsList);
}
// 添加事件监听器
// 表单提交事件 - 添加新项目
addItems.addEventListener('submit', addItem);
// 列表点击事件 - 切换项目完成状态
itemsList.addEventListener('click', toggleDone);
// 初始化加载 - 页面加载时渲染已有项目
populateList(items, itemsList);
html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
<title>Documenttitle>
<link rel="stylesheet" href="./common.css">
head>
<body>
<div class="wrapper">
<h2>Local TAPASh2>
<p>请添加您的TAPASp>
<ul class="plates">
<li>Loading Tapas ...li>
ul>
<form action="" class="add-items">
<input
type="text"
placeholder="Item Name"
required -- 让输入框变成必须填写 -->
name="item"
>
<input type="submit" value="+ Add Item">
form>
div>
<script src="./common.js">
script>
body>
html>
分析考点易错点
1. Stylus 变量 $background_color
考点:
- Stylus 中变量的定义和使用
- RGBA 颜色值的表示方法
答案:
$background_color = rgba(255, 255, 255, 0.95) 定义了一个半透明白色背景变量- 在 Stylus 中,变量名可以包含
$ 符号,但不是必须的 - 可以直接在样式中引用变量,如
background $background_color
易错点:
- 忘记变量名前加
$(虽然 Stylus 允许不加,但加了更清晰) - RGBA 值写错格式,如漏掉 alpha 通道或使用错误范围值
- 变量作用域问题(Stylus 变量有作用域概念)
考点:
- Stylus 中变量的定义和使用
- RGBA 颜色值的表示方法
答案:
$background_color = rgba(255, 255, 255, 0.95)定义了一个半透明白色背景变量- 在 Stylus 中,变量名可以包含
$符号,但不是必须的 - 可以直接在样式中引用变量,如
background $background_color
易错点:
- 忘记变量名前加
$(虽然 Stylus 允许不加,但加了更清晰) - RGBA 值写错格式,如漏掉 alpha 通道或使用错误范围值
- 变量作用域问题(Stylus 变量有作用域概念)
2. 背景图片设置
考点:
- CSS 背景属性的简写方式
background-size: cover 的作用- 多背景属性的正确顺序
答案:
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
等价于 CSS:
background-image: url('http://wes.io/hx9M/oh-la-la.jpg');
background-position: center;
background-repeat: no-repeat;
background-size: cover;
易错点:
- 混淆
cover 和 contain 的区别:cover:完全覆盖容器,可能裁剪图片contain:完整显示图片,可能留白
- 背景图片 URL 未加引号导致错误
- 多个背景属性顺序错误(简写时有特定顺序要求)
- 忘记设置
no-repeat 导致图片平铺
考点:
- CSS 背景属性的简写方式
background-size: cover的作用- 多背景属性的正确顺序
答案:
background url('http://wes.io/hx9M/oh-la-la.jpg') center no-repeat
background-size cover
等价于 CSS:
background-image: url('http://wes.io/hx9M/oh-la-la.jpg');
background-position: center;
background-repeat: no-repeat;
background-size: cover;
易错点:
- 混淆
cover和contain的区别:cover:完全覆盖容器,可能裁剪图片contain:完整显示图片,可能留白
- 背景图片 URL 未加引号导致错误
- 多个背景属性顺序错误(简写时有特定顺序要求)
- 忘记设置
no-repeat导致图片平铺
3. localStorage 使用
考点:
- localStorage 的 API 使用
- JSON 序列化与反序列化
- 数据持久化策略
答案:
// 存储数据
localStorage.setItem('tapasItems', JSON.stringify(items));
// 读取数据
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
易错点:
- 忘记使用
JSON.stringify 直接存储对象,导致存储为 [object Object] - 读取时忘记使用
JSON.parse,导致得到的是字符串而非对象 - 未处理
getItem 返回 null 的情况(代码中使用 || [] 做了默认值处理) - 存储大量数据超出 localStorage 容量限制(通常 5MB)
- 不考虑隐私模式下 localStorage 可能不可用的情况
考点:
- localStorage 的 API 使用
- JSON 序列化与反序列化
- 数据持久化策略
答案:
// 存储数据
localStorage.setItem('tapasItems', JSON.stringify(items));
// 读取数据
let items = JSON.parse(localStorage.getItem('tapasItems')) || [];
易错点:
- 忘记使用
JSON.stringify直接存储对象,导致存储为[object Object] - 读取时忘记使用
JSON.parse,导致得到的是字符串而非对象 - 未处理
getItem返回 null 的情况(代码中使用|| []做了默认值处理) - 存储大量数据超出 localStorage 容量限制(通常 5MB)
- 不考虑隐私模式下 localStorage 可能不可用的情况
4. Viewport Meta 标签
考点:
- 响应式设计基础
- 移动端视口控制
- 各属性的含义
答案:
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
各属性含义:
width=device-width:视口宽度等于设备宽度initial-scale=1:初始缩放比例为1user-scalable=no:禁止用户缩放viewport-fit=cover:覆盖整个屏幕(针对刘海屏设备)
易错点:
- 拼写错误如
user-scalable 写成 user-scalabe - 错误理解
initial-scale 的作用 - 在需要用户缩放功能的场景错误地设置
user-scalable=no - 忽略
viewport-fit=cover 导致刘海屏设备显示问题 - 多个属性间缺少逗号分隔(viewport 内容是用逗号分隔的)
考点:
- 响应式设计基础
- 移动端视口控制
- 各属性的含义
答案:
<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no, viewport-fit=cover">
各属性含义:
width=device-width:视口宽度等于设备宽度initial-scale=1:初始缩放比例为1user-scalable=no:禁止用户缩放viewport-fit=cover:覆盖整个屏幕(针对刘海屏设备)
易错点:
- 拼写错误如
user-scalable写成user-scalabe - 错误理解
initial-scale的作用 - 在需要用户缩放功能的场景错误地设置
user-scalable=no - 忽略
viewport-fit=cover导致刘海屏设备显示问题 - 多个属性间缺少逗号分隔(viewport 内容是用逗号分隔的)
小知识
最后再讲一个我也是刚刚才了解到的小知识,毕竟我还是小白嘛🚀🚀
- 首先打开自己的手机开启热点,然后用自己的电脑连接手机上的热点
- 在电脑上按住
Win+R键,输入cmd,进入终端
 3. 在终端中输入
3. 在终端中输入ipconfig的命令,找到一个名为IPv4的地址,复制一下
- 然后运行
html文件,要用Open with Live Serve运行项目
最后再讲一个我也是刚刚才了解到的小知识,毕竟我还是小白嘛🚀🚀
- 首先打开自己的手机开启热点,然后用自己的电脑连接手机上的热点
- 在电脑上按住
Win+R键,输入cmd,进入终端
3. 在终端中输入ipconfig的命令,找到一个名为IPv4的地址,复制一下
- 然后运行
html文件,要用Open with Live Serve运行项目
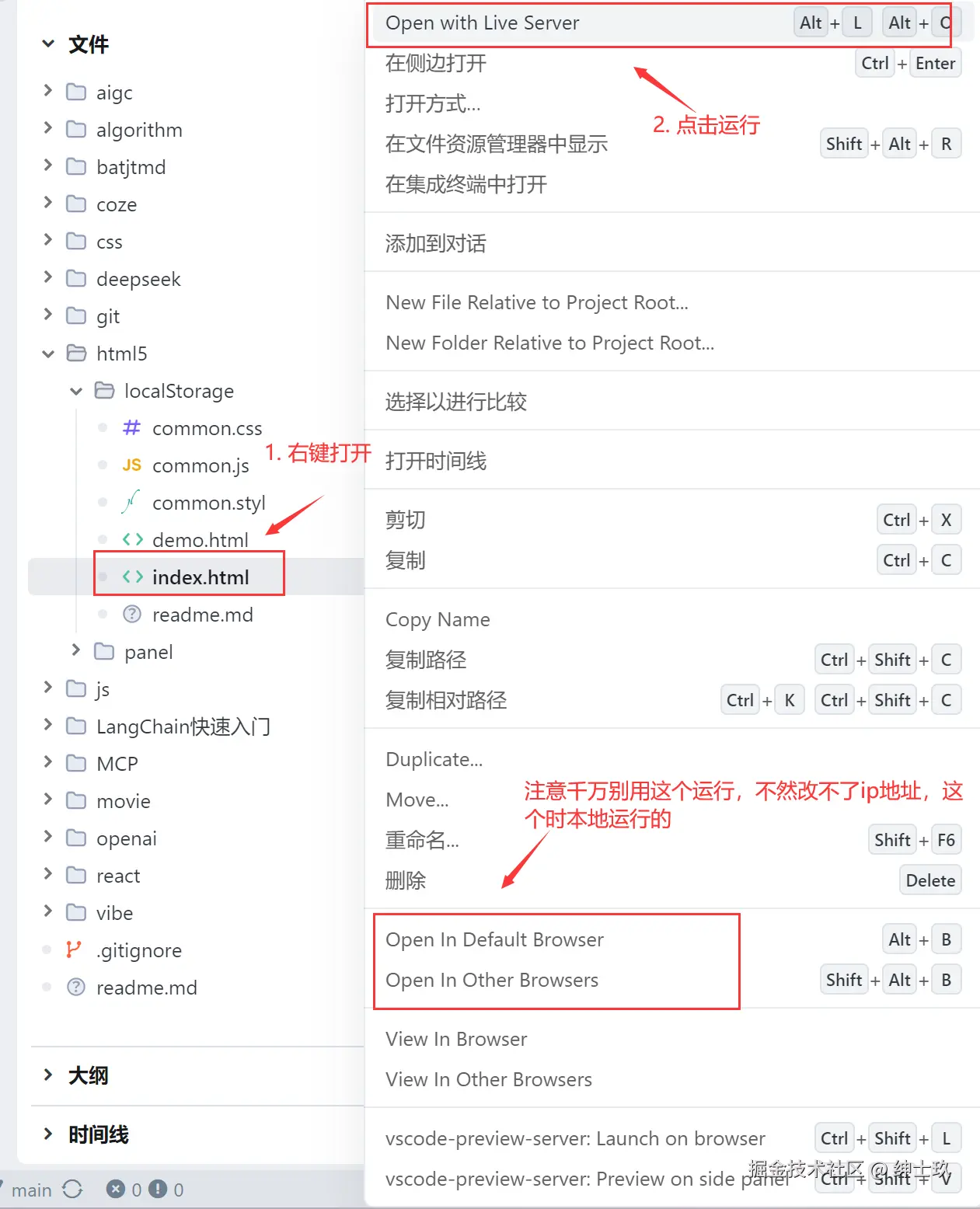
- 将你之前复制的
IPv4的地址更改到下面的位置,也就是在我图片的127.0.0.1的位置上填写上你自己之前复制的地址
- 之后可以先运行一下,运行成功的话,将这整个链接复制发给你的手机,然后你手机点击这个链接就可以登录上这个网页了。
- 如果出现了一些
BUG,有可能是防火墙的问题,或者你没有IPv4的地址,那就在终端的那个页面复制一个你显示了的地址就可以了,如果是其它问题自行上网搜索吧,小白的我也解决不了🚀🚀
来源:juejin.cn/post/7516797727066406966
浏览器缓存方案
一、浏览器缓存的核心作用与分类
作用:减少网络请求,提升页面加载速度,降低服务器压力。
分类:
- 强缓存:浏览器直接从本地缓存获取资源,不发请求到服务器;
- 协商缓存:发送请求到服务器验证缓存是否有效,有效则返回304状态码,浏览器使用本地缓存。
二、强缓存实现方案(Cache-Control/Expires)
1. Cache-Control(HTTP/1.1,推荐)
- 核心指令:
Cache-Control: max-age=31536000 // 缓存1年(单位:秒)
Cache-Control: no-cache // 强制协商缓存
Cache-Control: no-store // 禁止缓存
Cache-Control: public/private // 缓存可见范围
- 示例配置(Nginx):
location ~* \.(js|css|png|jpg|jpeg|gif|svg)$ {
expires 1y; // 等价于Cache-Control: max-age=31536000
add_header Cache-Control "public";
}
2. Expires(HTTP/1.0,兼容性好)
- 格式:
Expires: Thu, 01 Jan 2024 00:00:00 GMT // 绝对过期时间
- 与Cache-Control的优先级:
- 若同时存在,
Cache-Control优先级更高(因Expires依赖服务器时间)。
- 若同时存在,
三、协商缓存实现方案(Last-Modified/ETag)
1. ETag(推荐,更精准)
- 原理:服务器为资源生成唯一标识(如文件哈希值),浏览器请求时通过
If--Match发送标识,服务器对比后返回304(未修改)或200(修改)。 - 示例流程:
- 首次请求:服务器返回资源+
ETag: "abc123"; - 再次请求:浏览器发送
If--Match: "abc123"; - 服务器对比标识,未修改则返回304,否则返回新资源。
- 首次请求:服务器返回资源+
2. Last-Modified/If-Modified-Since
- 原理:服务器返回资源最后修改时间(
Last-Modified),浏览器下次请求时通过If-Modified-Since发送时间,服务器对比后判断是否更新。 - 缺点:
- 精度有限(仅精确到秒);
- 无法检测文件内容未变但修改时间变更的情况(如编辑器自动保存)。
四、缓存策略对比表
| 策略 | 强缓存 | 协商缓存 |
|---|---|---|
| 核心字段 | Cache-Control/Expires | ETag/Last-Modified |
| 是否发请求 | 否(直接读本地) | 是(验证缓存有效性) |
| 服务器压力 | 低 | 中(需验证请求) |
| 更新及时性 | 差(需等max-age过期) | 好(每次请求验证) |
五、各类资源的缓存策略
1. 静态资源(JS/CSS/图片)
- 策略:
- 强缓存(
max-age=31536000)+ 版本号(如app.v1.0.0.js); - 版本更新时修改文件名,强制浏览器加载新资源。
- 强缓存(
- Nginx配置:
location ~* \.(js|css|png|jpg|jpeg|gif|svg|woff|woff2|ttf|eot)$ {
expires 1y;
add_header Cache-Control "public, max-age=31536000";
add_header ETag on; // 开启ETag协商缓存
}
2. HTML页面
- 策略:
- 不缓存或短缓存(
max-age=0)+ 协商缓存(ETag); - 因HTML常包含动态内容,避免强缓存导致页面不更新。
- 不缓存或短缓存(
- 配置:
location / {
expires 0;
add_header Cache-Control "no-cache, no-store, must-revalidate";
add_header Pragma "no-cache";
}
3. 动态接口(API)
- 策略:
- 禁止缓存(
Cache-Control: no-cache); - 或根据业务需求设置短缓存(如5分钟)。
- 禁止缓存(
六、问题
1. 问:强缓存和协商缓存的执行顺序?
- 答:
- 浏览器先检查强缓存(
Cache-Control/Expires),有效则直接使用本地缓存; - 强缓存失效后,发送请求到服务器验证协商缓存(
ETag/Last-Modified),有效则返回304; - 协商缓存失效后,服务器返回新资源(200 OK)。
- 浏览器先检查强缓存(
2. 问:如何强制浏览器更新缓存?
- 答:
- 前端:修改资源URL(如加版本号
?v=2.0); - 后端:
- 发送
Cache-Control: no-cache强制协商缓存; - 更改
ETag或Last-Modified值,使协商缓存失效。
- 发送
- 前端:修改资源URL(如加版本号
3. 问:ETag和Last-Modified的优缺点?
- 答:
- ETag:
✅ 优点:精准检测资源变化(基于内容哈希);
❌ 缺点:计算哈希有性能开销,资源量大时影响服务器效率。 - Last-Modified:
✅ 优点:实现简单,服务器压力小;
❌ 缺点:精度低,无法检测内容未变但修改时间变更的情况。
- ETag:
4. 问:如何处理缓存导致的登录状态失效?
- 答:
- 在响应头中添加
Cache-Control: private(仅客户端可缓存); - 或对包含登录状态的资源设置
Cache-Control: no-cache,强制每次请求验证; - 前端路由跳转时,通过
window.location.reload(true)强制刷新(跳过强缓存)。
- 在响应头中添加
七、缓存调试与优化工具
- Chrome DevTools:
- Network面板:查看请求的缓存状态(
from disk cache/from memory cache/304 Not Modified); - 禁用缓存:勾选
Disable cache可临时关闭缓存,方便开发调试。
- Network面板:查看请求的缓存状态(
- Lighthouse:
- 审计缓存策略是否合理,给出优化建议(如“可缓存的资源未设置缓存”)。
- 服务器日志:
- 分析
304请求比例,评估缓存命中率(理想情况下静态资源命中率应>80%)。
- 分析
来源:juejin.cn/post/7522093523966197812
前端文件下载全攻略:从单文件到批量下载,哪种方法最优?
小张是一名刚入职的前端开发工程师,某天,他的领导给他布置了一个看似简单的任务:
让用户能够通过文件链接下载多个文件
小张信心满满,觉得这不过是个小问题。然而,当他真正动手时,才发现这个需求并不简单。不同的下载方式各有优缺点,甚至有些方法会带来意想不到的问题,他决定一一尝试,探索最优解。
方案一:window.open——简单粗暴,但会打开新标签页
小张首先想到的是 window.open(url),它可以让浏览器直接打开下载链接。
window.open('https://example.com/file.pdf');
优点:
- 代码简单,直接调用即可。
- 适用于单个文件的下载。
缺点:
- 每次下载都会打开一个新的浏览器标签页,影响用户体验。
- 部分浏览器可能会拦截
window.open,导致下载失败。
方案二:window.location.href 简单有效,但不能同时下载多个文件
小张发现,window.location.href 也可以实现下载,且不会打开新标签页。
window.location.href = 'https://example.com/file.pdf';
优点:
- 适用于单文件下载。
- 不会像
window.open那样打开新页面。
缺点:
- 无法循环下载多个文件。如果连续多次赋值
window.location.href,后一个请求会覆盖前一个,导致只能下载最后一个文件。
方案三:iframe 支持多文件下载,但无法监听完成状态
为了让多个文件能够顺利下载,小张尝试用 iframe。
function downloadFile(url) {
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.src = url;
document.body.appendChild(iframe);
setTimeout(() => {
document.body.removeChild(iframe);
}, 5000); // 延迟移除 iframe,防止影响下载
}
优点:
- 适用于多文件下载。
缺点:
iframe无法监听文件下载是否完成。- 需要在合适的时机移除
iframe,否则可能会影响页面性能。
方案四:fetch + blob——最优雅的下载方式
小张最终发现,fetch 可以获取文件数据,再通过 Blob 处理并使用 a 标签下载。
async function downloadFile(url, fileName) {
const response = await fetch(url);
if (!response.ok) throw new Error('Download failed');
const blob = await response.blob();
const blobUrl = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = blobUrl;
a.download = fileName;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(blobUrl);
}
function download(fileList){
for(const file of fileList) {
await downloadFile(file.url,file.name)
}
}
优点:
- 不会打开新标签页。
- 可以同时下载多个文件。
- 适用于现代浏览器,兼容性较好。
缺点:
- 需要处理异步
fetch请求。 - 服务器必须支持跨域资源共享(CORS),否则
fetch请求会失败。 - 多次文件下载会导致多个浏览器下载图标:每次调用
a.click()时,浏览器都会显示一个下载图标,影响用户体验。
方案五:jsZip 打包多个文件为 ZIP 下载——避免多次下载图标
为了进一步优化方案四,避免浏览器每次下载时显示多个下载图标,小张决定使用 jsZip 插件将多个文件打包成一个 ZIP 文件下载。
import JSZip from 'jszip';
async function downloadFilesAsZip(files) {
const zip = new JSZip();
// 循环遍历多个文件,获取每个文件的数据
for (const file of files) {
const response = await fetch(file.url);
if (!response.ok) throw new Error(`Failed to fetch ${file.name}`);
const blob = await response.blob();
zip.file(file.name, blob); // 将文件添加到 ZIP 包中
}
// 生成 ZIP 文件并触发下载
zip.generateAsync({ type: "blob" })
.then(function(content) {
const a = document.createElement('a');
const blobUrl = URL.createObjectURL(content);
a.href = blobUrl;
// 给压缩包设置下载文件名
a.download = 'files.zip';
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
// 释放 URL 对象
URL.revokeObjectURL(blobUrl);
});
}
优点:
- 提升用户体验:用户下载一个压缩包后,只需解压就可以获取所有文件,避免了多次点击和等待的麻烦。
- 适用于多文件下载:非常适合需要批量下载的场景。
缺点:
- 浏览器对大文件的支持:如果要下载的文件非常大,或者文件总大小很大,可能会导致内存消耗过高,甚至在浏览器中崩溃。
- 下载速度受限于压缩处理:打包文件为 ZIP 需要时间,尤其是文件较多时,会稍微影响压缩的速度,只适用于文件不是很大且数量不是很多的时候
结语:小张的最终选择
经过一番探索,小张最终选择了 jsZip 打包文件的方案,因为它不仅解决了多个文件下载时图标显示的问题,还提高了用户体验,让下载更加流畅,没有哪个方案比另外一个方案好,只有最适合的方案,根据实际的场景能满足需求最优解就是最好的。
来源:juejin.cn/post/7488172786692685835
赋能大模型:ant-design系列组件的文档知识库搭建
引言
在当今组件化开发时代,知识库建设已成为提升开发效率的重要环节。然而传统爬虫方式在获取结构化组件文档时往往面临诸多挑战。为此,开发了 antd-doc-gen 工具,用来快速生成 antd 系列组件库的文档,将其作为大模型补充的知识库,生成的文档可以非常方便的导入到 像 ima,cursor,Obsidian 等支持知识库的工具。本文将解析其技术实现与设计理念。
npm 地址:http://www.npmjs.com/package/ant…
github 仓库:github.com/xuanxuan321…
一、核心功能概览
antd-doc-gen 作为专业的命令行工具,具备以下核心能力:
- 多库支持:原生支持 Ant Design 主库、Mobile、Mini、Web3 及 X 系列组件库
- 智能文档解析:自动识别组件文档结构,合并主文档与示例代码
- 格式标准化:生成统一格式的 Markdown 文档,并创建索引目录
- 远程协作:支持从 GitHub 仓库直接下载代码并处理
二、使用指南
快速安装
npm install -g antd-doc-gen
典型用例
生成 antd 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design
生成 antd-mobile 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design-mobile
生成 antd-mini 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design-mini
生成 antd-x 文档
antd-doc-gen -d -r https://github.com/ant-design/x
生成 antd-web3 文档
antd-doc-gen -d -r https://github.com/ant-design/ant-design-web3
三、技术实现解析
智能文档处理流程
工具通过五层处理流程实现文档自动化生成:
- 命令行解析:使用 commander 库处理参数,支持多路径输入
- 代码下载:基于 simple-git 实现多协议下载(HTTPS/SSH),含分支容错机制
- 文档定位:针对不同仓库类型采用差异化路径策略(如 antd 使用 components/*/index.zh-CN.md)
- 内容整合:通过正则表达式提取示例代码,自动补全扩展名(.tsx → .ts)
- 输出生成:按组件名称生成 Markdown 文件,并创建字母序索引
其他:
● 智能路径处理:支持跨平台路径分隔符自动转换,兼容绝对/相对路径
● 文档格式统一:保留原始结构,将示例代码以 Markdown 代码块嵌入
● 容错机制:提供分支/协议降级策略,支持无示例文档的直接复制
技术栈与扩展性
核心技术栈
● Node.js 生态:fs/path 模块实现文件操作,readline 处理用户交互
● 第三方库:commander(命令行)、simple-git(Git 操作)、ora(加载动画)
扩展能力
工具支持通过代码修改实现:
- 新组件库类型适配
- 自定义文档输出格式
- 新增文档处理逻辑
适用场景
需要 antd 系列组件库文档作为知识库的场景
局限性与优化方向
当前版本依赖特定文档结构(需包含 index.md 及 code 标签),未来计划:
● 增强非标准文档的兼容性
● 支持更多文档格式输出
● 集成文档预览功能
结语
antd-doc-gen 通过自动化文档处理流程,显著提升了组件库文档的维护效率。文档可以直接导入像 ima,cursor,Obsidian 等知识库工具,进一步提升大模型的能力
来源:juejin.cn/post/7479814468601085986
JavaScript 数据扁平化方法大全
前言
数据扁平化是指将多维数组转换为一维数组的过程。由于嵌套数据结构增加了访问和操作数据的复杂度,所以·我们可以将嵌套数据变成一维的数据结构,下面就是我搜集到的一些方法,希望可以给你带来帮助!!
1. 使用 Array.prototype.flat()(推荐)
ES2019 引入的专门方法:
const nestedArr = [1, [2, [3, [4]], 5]];
// 默认只扁平化一层
const flattened1 = nestedArr.flat();
console.log(flattened1); // [1, 2, [3, [4]], 5]
// 指定深度为2
const flattened2 = nestedArr.flat(2);
console.log(flattened2); // [1, 2, 3, [4], 5]
// 完全扁平化
const fullyFlattened = nestedArr.flat(Infinity);
console.log(fullyFlattened); // [1, 2, 3, 4, 5]
解析:
flat(depth)方法创建一个新数组,所有子数组元素递归地连接到指定深度- 参数
depth指定要提取嵌套数组的结构深度,可选的参数,默认为1 - 使用
Infinity可展开任意深度的嵌套数组,Infinity是一个特殊的数值,表示无穷大。
2. 使用 reduce() 和 concat() 递归
function flatten(arr) {
// 使用 reduce 方法遍历数组元素
return arr.reduce((acc, val) => {
// 如果当前元素是数组,则递归调用 flatten 继续展开,并拼接到累积数组 acc
if (Array.isArray(val)) {
return acc.concat(flatten(val));
}
// 如果当前元素不是数组,直接拼接到累积数组 acc
else {
return acc.concat(val);
}
}, []); // 初始累积值是一个空数组 []
}
// 测试用例
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // 输出: [1, 2, 3, 4, 5]
解析:
- 递归处理嵌套数组
- 遇到子数组时,递归调用
flatten(val)继续展开,直到所有层级都被展开为单层。
- 遇到子数组时,递归调用
reduce方法的作用
- 遍历数组,通过
acc(累积值)逐步拼接结果,初始值设为[](空数组)。
- 遍历数组,通过
Array.isArray(val)检查
- 判断当前元素是否为数组,决定是否需要递归展开。
concat拼接结果
- 将非数组元素或递归展开后的子数组拼接到累积数组
acc中。
- 将非数组元素或递归展开后的子数组拼接到累积数组
3. 使用 concat() 和扩展运算符递归
function flatten(arr) {
// 使用扩展运算符 (...) 展开数组的第一层,并合并成一个新数组
const flattened = [].concat(...arr);
// 检查当前展开后的数组中是否仍然包含嵌套数组
// 如果存在嵌套数组,则递归调用 flatten 继续展开
// 如果所有元素都是非数组类型,则直接返回展开后的数组
return flattened.some(item => Array.isArray(item))
? flatten(flattened)
: flattened;
}
// 测试用例
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // 输出: [1, 2, 3, 4, 5]
解析:
[].concat(...arr)展开一层数组
- 使用扩展运算符
...展开arr的最外层,并通过concat合并成一个新数组。 - 例如:
[].concat(...[1, [2, [3]]])→[1, 2, [3]](仅展开一层)。
- 使用扩展运算符
flattened.some(Array.isArray)检查嵌套
- 使用 Array.prototype.some() 检查当前数组是否仍然包含子数组。
- 如果存在,则递归调用
flatten继续展开。
- 递归终止条件
- 当
flattened不再包含任何子数组时,递归结束,返回最终结果。
- 当
4. 使用 toString() 方法(仅适用于数字数组)
const nestedArr = [1, [2, [3, [4]], 5]];
const flattened = nestedArr.toString().split(',').map(Number);
console.log(flattened); // [1, 2, 3, 4, 5]
解析:
toString()的隐式转换
- JavaScript 的
Array.prototype.toString()会自动展开嵌套数组,并用逗号连接所有元素。 - 例如:
[1, [2, [3]]].toString()→"1,2,3"。
- JavaScript 的
split(',')分割字符串
- 将字符串按逗号拆分成字符串数组,但所有元素会是字符串类型(如
"2")。
- 将字符串按逗号拆分成字符串数组,但所有元素会是字符串类型(如
map(Number)类型转换
- 通过
Number构造函数将字符串元素转换为数字类型。 - 注意:如果原数组包含非数字(如
['a', [2]]),结果会变成[NaN, 2]。
- 通过
优缺点:
- 优点:代码极其简洁,适合纯数字的嵌套数组。
- 缺点:
- 仅适用于数字数组(其他类型会被强制转换,如
true→1,null→0)。 - 无法保留原数据类型(如字符串
'3'会被转成数字3)。
- 仅适用于数字数组(其他类型会被强制转换,如
适用场景:
- 快速展开纯数字的嵌套数组,且不关心中间过程的性能损耗(
toString和split会有临时字符串操作)。
5. 使用 JSON.stringify() 和正则表达式
function flatten(arr) {
// 1. 使用 JSON.stringify 将数组转换为字符串表示
// 例如:[1, [2, [3]], 'a'] → "[1,[2,[3]],\"a\"]"
const jsonString = JSON.stringify(arr);
// 2. 使用正则表达式移除所有的 '[' 和 ']' 字符
// 例如:"[1,[2,[3]],\"a\"]" → "1,2,3,\"a\""
const withoutBrackets = jsonString.replace(/[\[\]]/g, '');
// 3. 按逗号分割字符串,生成字符串数组
// 例如:"1,2,3,\"a\"" → ["1", "2", "3", "\"a\""]
const stringItems = withoutBrackets.split(',');
// 4. 尝试将每个字符串解析回原始数据类型
// - 数字会变成 Number 类型(如 "1" → 1)
// - 字符串会保留(如 "\"a\"" → "a")
// - 其他 JSON 可解析类型也会被正确处理
return stringItems.map(item => {
try {
// 尝试 JSON.parse 解析(处理字符串、数字等)
return JSON.parse(item);
} catch (e) {
// 如果解析失败(如空字符串或非法 JSON),返回原始字符串
return item;
}
});
}
// 测试用例
const nestedArr = [1, [2, [3, [4]], 5, 'a', { b: 6 }];
console.log(flatten(nestedArr));
// 输出: [1, 2, 3, 4, 5, "a", { b: 6 }]
解析:
JSON.stringify的作用
- 将整个数组(包括嵌套结构)转换为 JSON 字符串,保留所有数据类型信息。
- 正则替换
/[[]]/g
- 移除所有方括号字符
[和],只保留逗号分隔的值。
- 移除所有方括号字符
split(',')分割字符串
- 生成一个字符串数组,但每个元素可能仍是被 JSON 字符串化的(如
""a"")。
- 生成一个字符串数组,但每个元素可能仍是被 JSON 字符串化的(如
- JSON.parse() 尝试恢复数据类型
- 通过
JSON.parse将字符串转换回原始类型(数字、字符串、对象等)。 - 使用
try-catch处理不合法的 JSON 字符串(如空字符串或格式错误的情况)。
- 通过
优缺点:
- 优点:
- 支持任意数据类型(数字、字符串、对象等)。
- 能正确处理嵌套对象(如
{ b: 6 })。
- 缺点:
- 性能较低(涉及 JSON 序列化、正则替换、解析等操作)。
- 如果原始数组包含特殊字符串(如
"[1]") ,可能会被错误解析。
适用场景:
- 需要处理混合数据类型(非纯数字)的嵌套数组。
- 对性能要求不高,但需要代码简洁的场景。
6. 使用堆栈的非递归实现
function flatten(arr) {
// 创建栈并初始化(使用扩展运算符浅拷贝原数组)
const stack = [...arr];
const result = [];
// 循环处理栈中的元素
while (stack.length) {
// 从栈顶取出一个元素
const next = stack.pop();
if (Array.isArray(next)) {
// 如果是数组,展开后压回栈中(保持顺序)
stack.push(...next);
} else {
// 非数组元素,添加到结果数组前端(保持原顺序)
result.unshift(next);
}
}
return result;
}
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // [1, 2, 3, 4, 5]
解析:
- 栈结构初始化
- 使用扩展运算符
[...arr]创建原数组的浅拷贝作为初始栈 - 避免直接修改原数组
- 使用扩展运算符
- 栈处理循环
- 使用
while循环处理栈直到为空 - 每次从栈顶
pop()一个元素进行处理
- 使用
- 元素类型判断
- 使用
Array.isArray()检查元素是否为数组 - 如果是数组则展开后重新压入栈
- 非数组元素则添加到结果数组
- 使用
- 顺序保持
- 使用
unshift()将元素添加到结果数组前端,当然这样比较费性能,可以改用push()+reverse()替代unshift() - 确保最终结果的顺序与原数组一致
- 使用
优缺点
- 优点:
- 支持任意数据类型(不限于数字)
- 可以处理深层嵌套结构(无递归深度限制)
- 相比递归实现,不易导致栈溢出
- 缺点:
- 使用 unshift() 导致时间复杂度较高(O(n²))
- 需要额外空间存储栈结构
- 相比原生
flat()方法性能稍差 - 无法控制扁平化深度(总是完全扁平化)
适用场景
- 需要处理混合数据类型的深层嵌套数组
- 需要避免递归导致的栈溢出风险
7. 使用 Array.prototype.some() 和扩展运算符
function flatten(arr) {
// 循环检测数组中是否还包含数组元素
while (arr.some(item => Array.isArray(item))) {
// 使用扩展运算符展开当前层级的所有数组
// 并通过concat合并为一层
arr = [].concat(...arr);
}
return arr;
}
const nestedArr = [1, [2, [3, [4]], 5]];
console.log(flatten(nestedArr)); // [1, 2, 3, 4, 5]
解析:
- 循环条件检测
- 使用
arr.some()方法检测数组中是否还存在数组元素 Array.isArray(item)判断每个元素是否为数组
- 使用
- 层级展开
- 使用扩展运算符
...arr展开当前层级的数组 - 通过
[].concat()将展开的元素合并为新数组
- 使用扩展运算符
- 迭代处理
- 每次循环处理一层嵌套
- 重复直到没有数组元素存在
性能比较
对于大多数现代应用:
- 优先使用
flat(Infinity)(最简洁且性能良好) - 对于深度嵌套的大数组,考虑非递归的堆栈实现
- 递归方法在小数据集上表现良好且代码简洁
- 避免
toString()方法除非确定只有数字数据
总结
JavaScript 提供了多种扁平化数组的方法,从简单的内置 flat() 方法到各种手动实现的递归、迭代方案。选择哪种方法取决于:
- 运行环境是否支持 ES2019+
- 数据结构的复杂程度
- 对性能的要求
- 代码可读性需求
在大多数现代应用中,flat(Infinity) 是最佳选择,因为它简洁、高效且语义明确。
来源:juejin.cn/post/7522371045652578356
5 个理由告诉你为什么有了 JS 还要需要 TypeScript
在前端开发圈,JavaScript(简称JS)几乎无处不在。但你有没有发现,越来越多的大型项目和团队都在用 TypeScript(简称TS)?明明 JS 已经这么强大,为什么还要多此一举用 TS 呢?今天就用通俗易懂的语言,结合具体例子,带你彻底搞懂这个问题!🌟
1. JS的弱类型让大型项目“踩坑”不断
JavaScript 是一种弱类型语言,也就是说,变量的类型可以随时变化。虽然这让 JS 写起来很灵活,但在大型项目中却容易埋下隐患。
举个例子:
// JS 代码
function sum(a, b) {
return a + b;
}
console.log(sum(1, 2)); // 输出 3
console.log(sum('1', 2)); // 输出 '12',字符串拼接
console.log(sum(true, [])); // 输出 'true',奇怪的结果
在 JS 里,sum 函数参数类型完全不受限制,传什么都行。小项目还好,项目一大,团队一多,类型混乱就会导致各种难以发现的bug,甚至上线后才暴雷,影响开发效率和用户体验。
2. TS的类型检查让错误“消灭在摇篮里”
TypeScript 是 JS 的超集,在 JS 的基础上增加了类型系统。这意味着你可以在写代码时就发现类型错误,而不是等到运行时才发现。
同样的例子,用 TS 改写:
// TS 代码
function sum(a: number, b: number): number {
return a + b;
}
sum(1, 2); // 正常
sum('1', 2); // ❌ 报错:参数类型不匹配
TS 会在你写代码时就提示错误,防止类型不一致带来的 bug。这样,开发效率和代码质量都大大提升!
3. TS的类型推断让开发更智能
你可能担心,TS 要写很多类型声明,会不会很麻烦?其实不用担心,TS 有类型推断功能,能根据你的代码自动判断类型。
例子:
let age = 18; // TS 自动推断 age 是 number 类型
age = '二十'; // ❌ 报错:不能把 string 赋值给 number
你只需要在关键地方声明类型,其他地方 TS 会帮你自动推断,大大减少了重复劳动。
4. TS让团队协作更高效
在多人协作的大型项目中,TS 的类型系统就像一份“契约”,让每个人都能清楚知道每个函数、对象、变量的类型,极大减少沟通成本和踩坑概率。
例子:
// 定义一个工具函数
function formatUser(user: { name: string; age: number }) {
return `${user.name} (${user.age})`;
}
// 调用时,TS 会自动检查参数类型
formatUser({ name: '小明', age: 20 }); // 正常
formatUser({ name: '小红', age: '二十' }); // ❌ 报错
有了类型约束,团队成员只要看类型定义就能明白怎么用,不用再靠口头说明或文档补充,协作效率大大提升。
5. TS支持现代开发工具,体验更丝滑
TS 的类型信息可以被编辑器和IDE(如 VSCode)利用,带来更智能的自动补全、跳转、重构、查找引用等功能,让开发体验飞升!
例子:
- 输入对象名时,编辑器会自动提示有哪些属性;
- 修改类型定义,相关代码会自动高亮出错,方便全局重构;
- 查找函数引用时,TS 能精确定位所有用到的地方。
这些功能在 JS 里是做不到的,TS 让开发更高效、更安全、更快乐! 😄
TS的常见类型一览表
| 类型 | 说明 | 示例 |
|---|---|---|
| any | 任意类型 | let a: any |
| unknown | 未知类型 | let b: unknown |
| never | 永不存在的类型 | function error(): never { throw new Error() } |
| string | 字符串 | let s: string |
| number | 数字 | let n: number |
| boolean | 布尔 | let b: boolean |
| null | 空 | let n: null |
| undefined | 未定义 | let u: undefined |
| symbol | 符号 | let s: symbol |
| bigint | 大整数 | let b: bigint |
| object | 狭义对象类型 | let o: object |
| Object | 广义对象类型 | let O: Object |
小贴士:
any虽然灵活,但会失去类型检查,不推荐使用;unknown更安全,推荐用来接收不确定类型的数据。
TS的安装与使用
TypeScript 的安装和使用也非常简单:
npm install -g typescript
npm install -g ts-node
typescript用于编译.ts文件, 在当前目录生成一个同名的.js文件;ts-node可以直接运行 TS 文件,开发更方便。
总结
有了 JS,为什么还要用 TS?
归根结底,TS 让代码更安全、开发更高效、协作更顺畅、体验更丝滑。尤其是在大型项目和团队协作中,TS 的优势会越来越明显。
5个理由再回顾:
- JS 弱类型,容易埋坑,TS 静态类型,提前发现错误;
- TS 类型检查,bug 消灭在摇篮里;
- TS 类型推断,开发更智能;
- TS 类型约束,团队协作更高效;
- TS 支持现代开发工具,体验更丝滑。
如果你还没用过 TypeScript,不妨试试,相信你会爱上它!💙
来源:juejin.cn/post/7525660078722154511
你不会使用css函数 clamp()?那你太low了😀

我们做前端的,为了让网站在不同设备上都好看,天天都在和“响应式”打交道。其中最常见的一个场景,就是处理字体大小。
通常,我们是这么做的:
/* 手机上是16px */
h1 {
font-size: 16px;
}
/* 平板上大一点 */
@media (min-width: 768px) {
h1 {
font-size: 24px;
}
}
/* 电脑上再大一点 */
@media (min-width: 1200px) {
h1 {
font-size: 32px;
}
}
这套代码能用,但它有一个问题:字体大小的变化,是“跳跃式”的,像在走楼梯。 当你的屏幕宽度从767px变成768px时,字体会“Duang”地一下突然变大。这种体验,不够平滑。
今天,我想聊一个能让我们告别大部分这种繁琐媒体查询的CSS函数:clamp()。它能让我们的元素尺寸,像在走一个平滑的斜坡一样,实现真正的 “流体式”缩放。
clamp() 到底是个啥?
clamp() 的中文意思是“夹子”或“钳子”,非常形象。它的作用就是把一个值的范围,“夹”在一个最大值和一个最小值之间。
它的语法极其简单:

width: clamp(最小值, 理想值, 最大值);
你可以把它理解成,你在设定一个规则:
最小值(MIN) :这是“下限”。不管怎么样,这个值都不能比它更小了。最大值(MAX) :这是“上限”。不管怎么样,这个值都不能比它更大了。理想值(IDEAL) :这是“首选值”。它通常是一个根据视口变化的相对单位,比如vw。浏览器会先尝试使用这个值。
它的工作逻辑是:
- 如果“理想值”小于“最小值”,那就取“最小值”。
- 如果“理想值”大于“最大值”,那就取“最大值”。
- 如果“理想值”在两者之间,那就取“理想值”。
使用场景:流体字号(Fluid Typography)
这是clamp()最经典,也是最强大的用途。我们来改造一下文章开头的那个例子。
以前(媒体查询版):
h1 { font-size: 16px; }
@media (min-width: 768px) { h1 { font-size: 24px; } }
@media (min-width: 1200px) { h1 { font-size: 32px; } }
现在(clamp()版):
h1 {
/* 最小值是16px,
理想值是视口宽度的4%,
最大值是32px。
*/
font-size: clamp(16px, 4vw, 32px);
}
看,一行代码,代替了原来的一堆媒体查询。
现在你拖动浏览器窗口,会发现标题的大小是在平滑地、线性地变化,而不是“阶梯式”地跳变。它在小屏幕上不会小于16px,在大屏幕上不会大于32px,而在中间的尺寸,它会根据4vw这个值自动调整。
使用场景:动态间距(Dynamic Spacing)
clamp() 不仅仅能用在font-size上,任何需要长度值的地方,比如margin, padding, gap,它都能大显身手。
我们可以用它来创建一个“呼吸感”更强的布局。
.grid-container {
display: grid;
/* 网格间距最小15px,最大40px,中间根据视口宽度5%来缩放 */
gap: clamp(15px, 5vw, 40px);
}
.section {
/* section的上下内边距,最小20px,最大100px */
padding-top: clamp(20px, 10vh, 100px);
padding-bottom: clamp(20px, 10vh, 100px);
}
这样做的好处是,你的布局在任何尺寸的屏幕上,都能保持一个和谐的、自适应的间距,不再需要为不同断点去写多套padding和gap的值。
结合 calc() 实现更精准的控制
有时候,我们不希望缩放是纯线性的vw,而是希望它有一个“基础值”,然后再根据vw去微调。这时候,clamp()可以和calc()结合使用。
h1 {
/* 理想值不再是单纯的3vw,
而是 1rem + 3vw。
这意味着它有一个1rem的基础大小,然后再叠加上与视口相关的部分。
*/
font-size: clamp(1.5rem, calc(1rem + 3vw), 3rem);
}
这个calc(1rem + 3vw)的公式,是一个非常流行和实用的流体排版计算方法。它能让你对字体大小的缩放速率有更精细的控制,是一个非常值得收藏的技巧。
兼容性如何呢?
你可能会担心浏览器的兼容性。
好消息是,在2025年的今天,clamp()已经在所有主流现代浏览器(Chrome, Firefox, Safari, Edge)中获得了良好支持。除非你的项目需要兼容非常古老的浏览器,否则完全可以放心在生产环境中使用。

下次,当你又准备写一堆媒体查询来控制字号或间距时,不妨先停下来,问问自己:
“这个场景,是不是用clamp()一行代码就能搞定?”
希望你试试看😀。
参考:
来源:juejin.cn/post/7527576206695776302
掌握 requestFullscreen:网页全屏功能的实用指南与技巧
想让网页上的图片、视频或者整个界面铺满用户屏幕?浏览器的 requestFullscreen api 是开发者实现这个功能的关键。
它比你想象的要强大,但也藏着一些需要注意的细节。本文将详细介绍如何正确使用它,并分享一些提升用户体验的实用技巧。
一、 开始使用 requestFullscreen:基础与常见问题
直接调用 element.requestFullscreen() 是最简单的方法,但有几个关键点容易出错:
并非所有元素都能直接全屏:
、 等媒体元素通常可以直接全屏。
浏览器兼容性问题:
老版本浏览器(特别是 Safari)需要使用带前缀的方法 webkitRequestFullscreen。安全起见,最好检测并调用正确的方法。
必须在用户操作中触发:
浏览器出于安全考虑,要求全屏请求必须在用户点击、触摸等交互事件(如 click、touchstart)的处理函数里直接调用。不能放在 setTimeout 或者异步回调里直接调用,否则会被浏览器阻止。
二、 控制全屏时的样式
全屏状态下,你可以使用特殊的 css 选择器为全屏元素或其内部的元素定制样式:
/* 为处于全屏状态的 <video> 元素设置黑色背景 */
video:fullscreen {
background-color: #000;
}
/* 当某个具有 id="controls" 的元素在全屏模式下时,默认半透明,鼠标移上去变清晰 */
#controls:fullscreen {
opacity: 0.3;
transition: opacity 0.3s ease;
}
#controls:fullscreen:hover {
opacity: 1;
}
:-webkit-full-screen (WebKit 前缀) : 针对老版本 WebKit 内核浏览器(如旧 Safari)
:fullscreen (标准) : 现代浏览器支持的标准写法。优先使用这个。
三、 实用的进阶技巧
在多个元素间切换全屏:
创建一个管理器能方便地在不同元素(如图库中的图片)之间切换全屏状态,并记住当前全屏的是哪个元素。
const fullscreenManager = {
currentElement: null, // 记录当前全屏的元素
async toggle(element) {
// 如果点击的元素已经是全屏元素,则退出全屏
if (document.fullscreenElement && this.currentElement === element) {
try {
awaitdocument.exitFullscreen();
this.currentElement = null;
} catch (error) {
console.error('退出全屏失败:', error);
}
} else {
// 否则,尝试让新元素进入全屏
try {
await element.requestFullscreen();
this.currentElement = element; // 更新当前元素
} catch (error) {
console.error('进入全屏失败:', error);
// 可以在这里提供一个后备方案,比如模拟全屏的CSS类
element.classList.add('simulated-fullscreen');
}
}
}
};
// 给图库中所有图片绑定点击事件
document.querySelectorAll('.gallery-img').forEach(img => {
img.addEventListener('click', () => fullscreenManager.toggle(img));
});
在全屏模式下处理键盘事件:
全屏时,你可能想添加自定义快捷键(如切换滤镜、截图)。
functionhandleFullscreenHotkeys(event) {
// 保留 Escape 键退出全屏的功能
if (event.key === 'Escape') return;
// 自定义快捷键
if (event.key === 'f') toggleFilter(); // 按 F 切换滤镜
if (event.ctrlKey && event.key === 'p') enterPictureInPicture(); // Ctrl+P 画中画
if (event.shiftKey && event.key === 's') captureScreenshot(); // Shift+S 截图
// 阻止这些键的默认行为(比如防止F键触发浏览器查找)
event.preventDefault();
}
// 监听全屏状态变化
document.addEventListener('fullscreenchange', () => {
if (document.fullscreenElement) {
// 进入全屏,添加自定义键盘监听
document.addEventListener('keydown', handleFullscreenHotkeys);
} else {
// 退出全屏,移除自定义键盘监听
document.removeEventListener('keydown', handleFullscreenHotkeys);
}
});
记住用户的全屏状态:
如果用户刷新页面,可以尝试自动恢复他们之前全屏查看的元素。
// 页面加载完成后检查是否需要恢复全屏
window.addEventListener('domContentLoaded', () => {
const elementId = localStorage.getItem('fullscreenElementId');
if (elementId) {
const element = document.getElementById(elementId);
if (element) {
setTimeout(() => element.requestFullscreen().catch(console.error), 100); // 稍延迟确保元素就绪
}
}
});
// 监听全屏变化,保存当前全屏元素的ID
document.addEventListener('fullscreenchange', () => {
if (document.fullscreenElement) {
localStorage.setItem('fullscreenElementId', document.fullscreenElement.id);
} else {
localStorage.removeItem('fullscreenElementId');
}
});
处理嵌套全屏(沙盒内全屏):
在已经全屏的容器内的 中再次触发全屏是可能的(需要 allow="fullscreen" 属性)。
<divid="main-container">
<iframeid="nested-content"src="inner.html"allow="fullscreen"></iframe>
</div>
<script>
const mainContainer = document.getElementById('main-container');
const iframe = document.getElementById('nested-content');
// 主容器全屏后,可以尝试触发iframe内部元素的全屏(需内部配合)
mainContainer.addEventListener('fullscreenchange', () => {
if (document.fullscreenElement === mainContainer) {
// 假设iframe内部有一个id为'innerVideo'的视频元素
// 注意:这需要在iframe加载完成后,且iframe内容同源或允许跨域操作
const innerDoc = iframe.contentDocument || iframe.contentWindow.document;
const innerVideo = innerDoc.getElementById('innerVideo');
if (innerVideo) {
setTimeout(() => innerVideo.requestFullscreen().catch(console.error), 500);
}
}
});
</script>
四、 实际应用场景
媒体展示: 图片画廊、视频播放器(隐藏浏览器UI获得更好沉浸感 { navigationUI: 'hide' })。
数据密集型应用: 全屏表格、图表或数据看板,提供更大的工作空间。
游戏与交互: WebGL 游戏、交互式动画、全景图查看器(结合陀螺仪 API),全屏能提升性能和体验。
演示模式: 在线文档、幻灯片展示。
专注模式: 写作工具、代码编辑器。
安全措施: 在全屏内容上添加低透明度水印(使用 ::before / ::after 伪元素),增加录屏难度。
五、 开发者需要注意的问题与解决建议
| 问题描述 | 解决方案 |
|---|---|
| iOS Safari 全屏视频行为 | 为 添加 playsinline 属性防止自动横屏。提供手动旋转按钮。 |
| 全屏导致滚动位置丢失 | 进入全屏前记录 scrollTop,退出后恢复。或使用 scroll-snap 等布局技术。 |
| 全屏触发页面重排/抖动 | 提前给目标元素设置 width: 100%; height: 100%; 或固定尺寸。 |
| 全屏时难以打开开发者工具 | 在开发环境,避免拦截 F12 或右键菜单快捷键。使用 console 调试。 |
| 全屏元素内 iframe 权限 | 为 添加 allow="fullscreen" 属性。 |
| 检测用户手动全屏 (F11) | 比较 window.outerHeight 和 screen.height 有一定参考价值,但非绝对可靠。通常建议引导用户使用应用内的全屏按钮。 |
六、 兼容性处理封装(推荐使用)
下面是一个更健壮的工具函数,处理了不同浏览器的前缀问题:
/**
* 全屏工具类 (简化版,展示核心功能)
*/
const FullscreenHelper = {
/**
* 请求元素进入全屏模式
* @param {HTMLElement} [element=document.documentElement] 要全屏的元素,默认是整个页面
* @returns {Promise<boolean>} 是否成功进入全屏
*/
async enter(element = document.documentElement) {
const reqMethods = [
'requestFullscreen', // 标准
'webkitRequestFullscreen', // Safari, Old Chrome/Edge
'mozRequestFullScreen', // Firefox
'msRequestFullscreen'// Old IE/Edge
];
for (const method of reqMethods) {
if (element[method]) {
try {
// 可以传递选项,例如隐藏导航UI: { navigationUI: 'hide' }
await element[method]({ navigationUI: 'hide' });
returntrue; // 成功进入全屏
} catch (error) {
console.warn(`${method} 失败:`, error);
// 继续尝试下一个方法
}
}
}
returnfalse; // 所有方法都失败
},
/**
* 退出全屏模式
* @returns {Promise<boolean>} 是否成功退出全屏
*/
async exit() {
const exitMethods = [
'exitFullscreen', // 标准
'webkitExitFullscreen', // Safari, Old Chrome/Edge
'mozCancelFullScreen', // Firefox
'msExitFullscreen'// Old IE/Edge
];
for (const method of exitMethods) {
if (document[method]) {
try {
awaitdocument[method]();
returntrue; // 成功退出全屏
} catch (error) {
console.warn(`${method} 失败:`, error);
}
}
}
returnfalse; // 所有方法都失败或不在全屏状态
},
/**
* 检查当前是否有元素处于全屏状态
* @returns {boolean} 是否在全屏状态
*/
isFullscreen() {
return !!(
document.fullscreenElement || // 标准
document.webkitFullscreenElement || // Safari, Old Chrome/Edge
document.mozFullScreenElement || // Firefox
document.msFullscreenElement // Old IE/Edge
);
},
/**
* 添加全屏状态变化监听器
* @param {Function} callback 状态变化时触发的回调函数
*/
onChange(callback) {
const events = [
'fullscreenchange', // 标准
'webkitfullscreenchange', // Safari, Old Chrome/Edge
'mozfullscreenchange', // Firefox
'MSFullscreenChange'// Old IE/Edge
];
// 为每种可能的事件添加监听,确保兼容性
events.forEach(eventName => {
document.addEventListener(eventName, callback);
});
}
};
// 使用示例
const myButton = document.getElementById('fullscreen-btn');
const myVideo = document.getElementById('my-video');
myButton.addEventListener('click', async () => {
if (FullscreenHelper.isFullscreen()) {
await FullscreenHelper.exit();
} else {
await FullscreenHelper.enter(myVideo); // 让视频全屏
}
});
// 监听全屏变化
FullscreenHelper.onChange(() => {
console.log('全屏状态变了:', FullscreenHelper.isFullscreen() ? '进入全屏' : '退出全屏');
});
总结
requestFullscreen API 是实现网页元素全屏展示的核心工具。理解其基础用法、兼容性处理、样式控制和状态管理是第一步。
通过掌握切换控制、键盘事件处理、状态持久化和嵌套全屏等进阶技巧,以及规避常见的陷阱,你可以为用户创建更流畅、功能更丰富的全屏体验。
上面的 FullscreenHelper 工具类封装了兼容性细节,推荐在实际项目中使用。现在就去尝试在你的网页中应用这些技巧吧!
来源:juejin.cn/post/7527612394044850227
40岁老前端2025年上半年都学了什么?
前端学习记录第5波,每半年一次。对前四次学习内容感兴趣的可以去我的掘金专栏“每周学习记录”进行了解。
第1周 12.30-1.5
本周学习了一个新的CSS媒体查询prefers-reduced-transparency,如果用户在系统层面选择了降低或不使用半透明,这个媒体查询就能够匹配,此特性与用户体验密切相关的。

更多内容参见我撰写的这篇文章:一个新的CSS媒体查询prefers-reduced-transparency —— http://www.zhangxinxu.com/wordpress/?…
第2周 1.6-1.12
这周新学习了一个名为Broadcast Channel的API,可以实现一种全新的广播式的跨页面通信。
过去的postMessage通信适合点对点,但是广播式的就比较麻烦。
而使用BroadcastChannel就会简单很多。
这里有个演示页面:http://www.zhangxinxu.com/study/20250…
左侧点击按钮发送消息,右侧两个内嵌的iframe页面就能接收到。

此API的兼容性还是很不错的:

更多内容可以参阅此文:“Broadcast Channel API简介,可实现Web页面广播通信” —— http://www.zhangxinxu.com/wordpress/?…
第3周 1.13-1.19
这周学习的是SVG半圆弧语法,因为有个需求是实现下图所示的图形效果,其中几段圆弧的长度占比每个人是不一样的,因此,需要手写SVG路径。

圆弧的SVG指令是A,语法如下:
M x1 y1 A rx ry x-axis-rotation large-arc-flag sweep-flag x2 y2
看起来很复杂,其实深究下来还好:

详见这篇文章:“如何手搓SVG半圆弧,手把手教程” - http://www.zhangxinxu.com/wordpress/?…
第4周-第5周 1.20-2.2
春节假期,学什么学,high起来。
第6周 2.3-2.9
本周学习Array数组新增的with等方法,这些方法在数组处理的同时均不会改变原数组内容,这在Vue、React等开发场景中颇为受用。
例如,在过去,想要不改变原数组改变数组项,需要先复制一下数组:

现在有了with方法,一步到位:

类似的方法还有toReversed()、toSorted()和toSpliced()。
更新内容参见这篇文章:“JS Array数组新的with方法,你知道作用吗?” - http://www.zhangxinxu.com/wordpress/?…
第7周 2.10-2.16
本周学习了两个前端新特性,一个JS的,一个是CSS的。
1. Set新增方法
JS Set新支持了intersection, union, difference等方法,可以实现类似交集,合集,差集的数据处理,也支持isDisjointFrom()是否相交,isSubsetOf()是否被包含,isSupersetOf()是否包含的判断。
详见此文:“JS Set新支持了intersection, union, difference等方法” - http://www.zhangxinxu.com/wordpress/?…

2. font-size-adjust属性
CSS font-size-adjust属性,可以基于当前字形的高宽自动调整字号大小,以便各种字体的字形表现一致,其解决的是一个比较细节的应用场景。
例如,16px的苹方和楷体,虽然字号设置一致,但最终的图形表现楷体的字形大小明显小了一圈:

此时,我们可以使用font-size-adjust进行微调,使细节完美。
p { font-size-adjust: 0.545;}
此时的中英文排版效果就会是这样:

更新细节知识参见我的这篇文章:“不要搞混了,不是text而是CSS font-size-adjust属性” - http://www.zhangxinxu.com/wordpress/?…
第8周 2.17-2.23
本周学习的是HTML permission元素和Permissions API。
这两个都是与Web浏览器的权限申请相关的。
在Web开发的时候,我们会经常用到权限申请,比方说摄像头,访问相册,是否允许通知,又或者地理位置信息等。

但是,如果用户不小心点击了“拒绝”,那么用户就永远没法使用这个权限,这其实是有问题的,于是就有了元素,权限按钮直接暴露在网页中,直接让用户点击就好了。

但是,根据我后来的测试,Chrome浏览器放弃了对元素的支持,因此,此特性大家无需关注。
那Permissions API又是干嘛用的呢?
在过去,不同类型的权限申请会使用各自专门的API去进行,这就会导致开始使用的学习和使用成本比较高。
既然都是权限申请,且系统出现的提示UI都近似,何必来个大统一呢?在这种背景下,Permissions API被提出来了。
所有的权限申请全都使用一个统一的API名称入口,使用的方法是Permissions.query()。

完整的介绍可以参见我撰写的这篇文章:“HTML permission元素和Permissions API简介” - http://www.zhangxinxu.com/wordpress/?…
第9周 2.24-3.2
CSS offset-path属性其实在8年前就介绍过了,参见:“使用CSS offset-path让元素沿着不规则路径运动” - http://www.zhangxinxu.com/wordpress/?…
不过那个时候的offset-path属性只支持不规则路径,也就是path()函数,很多CSS关键字,还有基本形状是不支持的。
终于,盼星星盼月亮。
从Safari 18开始,CSS offset-path属性所有现代浏览器全面支持了。

因此,很多各类炫酷的路径动画效果就能轻松实现了。例如下图的蚂蚁转圈圈动画:

详见我撰写的此文:“终于等到了,CSS offset-path全浏览器全支持” - http://www.zhangxinxu.com/wordpress/?…
第10周 3.3-3.9
CSS @supports规则新增两个特性判断,分别是font-tech()和font-format()函数。
1. font-tech()
font-tech()函数可以检查浏览器是否支持用于布局和渲染的指定字体技术。
例如,下面这段CSS代码可以判断浏览器是否支持COLRv1字体(一种彩色字体技术)技术。
@supports font-tech(color-COLRv1) {}
2. font-format()
font-format()这个比较好理解,是检测浏览器是否支持指定的字体格式的。
@supports font-format(woff2) { /* 浏览器支持woff2字体 */ }
不过这两个特性都不实用。
font-tech()对于中文场景就是鸡肋特性,因为中文字体是不会使用这类技术的,成本太高。
font-format()函数的问题在于出现得太晚了。例如woff2字体的检测,这个所有现代浏览器都已经支持了,还有检测的必要吗,没了,没有意义了。
不过基于衍生的特性还是有应用场景的,具体参见此文:“CSS supports规则又新增font-tech,font-format判断” - http://www.zhangxinxu.com/wordpress/?…
第11周 3.10-3.16
本周学习了一种更好的文字隐藏的方法,那就是使用::first-line伪元素,CSS世界这本书有介绍。
::first-line伪元素可以在不改变元素color上下文的情况下变色。
可以让按钮隐藏文字的时候,里面的图标依然保持和原本的文字颜色一致。

详见这篇文章:“一种更好的文字隐藏的方法-::first-line伪元素” - http://www.zhangxinxu.com/wordpress/?…
第12周 3.17-3.23
本周学习了下attachInternals方法,这个方法很有意思,给任意自定义元素使用,可以让普通元素也有原生表单控件元素一样的特性。
比如浏览器自带的验证提示:

比如说提交的时候的FormData或者查询字符串:

有兴趣的同学可以访问“研究下attachInternals方法,可让普通元素有表单特性”这篇文章继续了解 - http://www.zhangxinxu.com/wordpress/?…
第13周 3.24-3.30
本周学习了一个新支持的HTML属性,名为blocking 属性。
它主要用于控制资源加载时对渲染的阻塞行为。
blocking 属性允许开发者对资源加载的优先级和时机进行精细控制,从而影响页面的渲染流程。浏览器在解析 HTML 文档时,会根据 blocking 属性的值来决定是否等待资源加载完成后再继续渲染页面,这对于优化页面性能和提升用户体验至关重要。
blocking 属性目前支持的HTML元素包括
使用示意:

更多内容参见我撰写的这篇文章:“光速了解script style link元素新增的blocking属性” - http://www.zhangxinxu.com/wordpress/?…
第14周 3.31-4.6
本周学习了JS EditContext API。
EditContext API 是 Microsoft Edge 浏览器提供的一个 Web API,它允许开发者在网页中处理文本输入事件,以便在原生输入事件(如 keydown、keypress 和 input)之外,实现更高级的文本编辑功能。

详见我撰写的这篇文章:“JS EditContext API 简介” - http://www.zhangxinxu.com/wordpress/?…
第15周 4.7-4.13
本周学习一个DOM新特性,名为caretPositionFromPoint API。
caretPositionFromPoint可以基于当前的光标位置,返回光标所对应元素的位置信息,在之前,此特性使用的是非标准的caretRangeFromPoint方法实现的。
和elementsFromPoint()方法的区别在于,前者返回节点及其偏移、尺寸等信息,而后者返回元素。
比方说有一段
元素文字描述信息,点击这段描述的某个文字,caretPositionFromPoint()方法可以返回精确的文本节点以及点击位置的字符偏移值,而elementsFromPoint()方法只能返回当前
元素。
不过此方法的应用场景比较小众,例如点击分词断句这种,大家了解下即可。

详见我撰写的这篇文章:“DOM新特性之caretPositionFromPoint API” - http://www.zhangxinxu.com/wordpress/?…
第16周 4.14-4.20
本周学习的是getHTML(), setHTMLUnsafe()和parseHTMLUnsafe()这三个方法,有点类似于可读写的innerHTML属性,区别在于setHTMLUnsafe()似乎对Shadow DOM元素的设置更加友好。
parseHTMLUnsafe则是个document全局方法,用来解析HTML字符串的。
这几个方法几乎是同一时间支持的,如下截图所示:

具体参见我写的这篇文章:介绍两个DOM新方法setHTMLUnsafe和getHTML - http://www.zhangxinxu.com/wordpress/?…
第17周 4.21-4.27
光速了解HTML shadowrootmode属性的作用。
shadowRoot的mode是个只读属性,可以指定其模式——打开或关闭。
这定义了影子根的内部功能是否可以从JavaScript访问。
当影子根的模式为“关闭”时,影子根的实现内部无法从JavaScript访问且不可更改,就像元素的实现内部不能从JavaScript访问或不可更改一样。
属性值是使用传递给Element.attachShadow()的对象的options.mode属性设置的,或者在声明性创建影子根时使用
来源:juejin.cn/post/7524548909530005540
async/await 必须使用 try/catch 吗?
前言
在 JavaScript 开发者的日常中,这样的对话时常发生:
- 👨💻 新人:"为什么页面突然白屏了?"
- 👨🔧 老人:"异步请求没做错误处理吧?"
async/await 看似优雅的语法糖背后,隐藏着一个关键问题:错误处理策略的抉择。
在 JavaScript 中使用 async/await 时,很多人会问:“必须使用 try/catch 吗?”
其实答案并非绝对,而是取决于你如何设计错误处理策略和代码风格。
接下来,我们将探讨 async/await 的错误处理机制、使用 try/catch 的优势,以及其他可选的错误处理方法。
async/await 的基本原理
异步代码的进化史
// 回调地狱时代
fetchData(url1, (data1) => {
process(data1, (result1) => {
fetchData(url2, (data2) => {
// 更多嵌套...
})
})
})
// Promise 时代
fetchData(url1)
.then(process)
.then(() => fetchData(url2))
.catch(handleError)
// async/await 时代
async function workflow() {
const data1 = await fetchData(url1)
const result = await process(data1)
return await fetchData(url2)
}
async/await 是基于 Promise 的语法糖,它使异步代码看起来更像同步代码,从而更易读、易写。一个 async 函数总是返回一个 Promise,你可以在该函数内部使用 await 来等待异步操作完成。
如果在异步操作中出现错误(例如网络请求失败),该错误会使 Promise 进入 rejected 状态。
async function fetchData() {
const response = await fetch("https://api.example.com/data");
const data = await response.json();
return data;
}
使用 try/catch 捕获错误
打个比喻,就好比铁路信号系统
想象 async 函数是一列高速行驶的列车:
- await 是轨道切换器:控制代码执行流向
- 未捕获的错误如同脱轨事故:会沿着铁路网(调用栈)逆向传播
- try/catch 是智能防护系统:
- 自动触发紧急制动(错误捕获)
- 启动备用轨道(错误恢复逻辑)
- 向调度中心发送警报(错误日志)
为了优雅地捕获 async/await 中出现的错误,通常我们会使用 try/catch 语句。这种方式可以在同一个代码块中捕获抛出的错误,使得错误处理逻辑更集中、直观。
- 代码逻辑集中,错误处理与业务逻辑紧密结合。
- 可以捕获多个 await 操作中抛出的错误。
- 适合需要在出错时进行统一处理或恢复操作的场景。
async function fetchData() {
try {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const data = await response.json();
return data;
} catch (error) {
console.error("Error fetching data:", error);
// 根据需要,可以在此处处理错误,或者重新抛出以便上层捕获
throw error;
}
}
不使用 try/catch 的替代方案
虽然 try/catch 是最直观的错误处理方式,但你也可以不在 async 函数内部使用它,而是在调用该 async 函数时捕获错误。
在 Promise 链末尾添加 .catch()
async function fetchData() {
const response = await fetch("https://api.example.com/data");
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
return response.json();
}
// 调用处使用 Promise.catch 捕获错误
fetchData()
.then(data => {
console.log("Data:", data);
})
.catch(error => {
console.error("Error fetching data:", error);
});
这种方式将错误处理逻辑移至函数调用方,适用于以下场景:
- 当多个调用者希望以不同方式处理错误时。
- 希望让 async 函数保持简洁,将错误处理交给全局统一的错误处理器(例如在 React 应用中可以使用 Error Boundary)。
将 await 与 catch 结合
async function fetchData() {
const response = await fetch('https://api.example.com/data').catch(error => {
console.error('Request failed:', error);
return null; // 返回兜底值
});
if (!response) return;
// 继续处理 response...
}
全局错误监听(慎用,适合兜底)
// 浏览器端全局监听
window.addEventListener('unhandledrejection', event => {
event.preventDefault();
sendErrorLog({
type: 'UNHANDLED_REJECTION',
error: event.reason,
stack: event.reason.stack
});
showErrorToast('系统异常,请联系管理员');
});
// Node.js 进程管理
process.on('unhandledRejection', (reason, promise) => {
logger.fatal('未处理的 Promise 拒绝:', reason);
process.exitCode = 1;
});
错误处理策略矩阵
决策树分析
graph TD
A[需要立即处理错误?] -->|是| B[使用 try/catch]
A -->|否| C{错误类型}
C -->|可恢复错误| D[Promise.catch]
C -->|致命错误| E[全局监听]
C -->|批量操作| F[Promise.allSettled]
错误处理体系
- 基础层:80% 的异步操作使用 try/catch + 类型检查
- 中间层:15% 的通用错误使用全局拦截 + 日志上报
- 战略层:5% 的关键操作实现自动恢复机制
小结
我的观点是:不强制要求,但强烈推荐
- 不强制:如果不需要处理错误,可以不使用
try/catch,但未捕获的 Promise 拒绝(unhandled rejection)会导致程序崩溃(在 Node.js 或现代浏览器中)。 - 推荐:90% 的场景下需要捕获错误,因此
try/catch是最直接的错误处理方式。
所有我个人观点:使用 async/await 尽量使用 try/catch。好的错误处理不是消灭错误,而是让系统具备优雅降级的能力。
你的代码应该像优秀的飞行员——在遇到气流时,仍能保持平稳飞行。大家如有不同意见,还请评论区讨论,说出自己的见解。
来源:juejin.cn/post/7482013975077928995
表妹问:前端好玩吗?我说好玩,但表妹接下来的回复看哭了我
表妹问:前端好玩吗?我说好玩,但表妹接下来的回复看哭了我。
是的,回复如下:
这红海血途上,新兵举着 "大前端" 旌旗冲锋,老兵拖着node_modules残躯撤退。资本织机永不停歇,框架版本更迭如暴君换季,留下满地deprecated警告如秋后落叶。
其一、夹缝中的苦力
世人都道前端易,不过调接口、改颜色,仿佛稚童搭积木。却不知那屏幕上寸寸像素之间,皆是血泪。产品拍案,需求朝夕三变,昨日之红蓝按钮,今晨便成黑白圆角。UI稿纸翻飞如雪,设计师手持“用户体验”四字大旗,将五更赶工的代码尽数碾碎。后端端坐高台,接口文档空悬如镜花水月,待到交付时辰,方抛来残缺数据。此时节,前端便成了那补天的女娲,于混沌中捏造虚拟对象,用JSON.parse('{"data": undefined}')这等荒诞戏法,将虚无粉饰成真实。
看这段代码何等悲凉:
// 后端曰:此接口返data字段,必不为空
fetch('api/data').then(res => {
const { data } = res;
render(data[0].children[3].value || '默认值'); // 层层掘墓,方见白骨
});
此乃前端日常——在数据废墟里刨食,用||与?.铸成铁锹,掘出三分体面。
其二、技术的枷锁
JavaScript本是脚本小儿,如今却要扛鼎江山。君不见React、Vue、Angular三座大山压顶,每年必有新神像立起。昨日方学得Redux真经,今朝GraphQL又成显学。更有Electron、ReactNative、Flutter诸般法器,教人左手写桌面应用,右手调移动端手势。所谓“大前端”,实乃资本画饼之术,人前跨端写,人后页面仔——既要马儿跑,又要马儿不吃草;以切图之名,许一份低劣薪水,行三五岗位之事。
且看这跨平台代码何等荒诞:
// 一套代码统治三界(iOS/Android/Web)
<View>
{Platform.OS === 'web' ?
<div onClick={handleWebClick} /> :
<TouchableOpacity onPress={handleNativePress} />
}
View>
此类缝合怪代码,恰似给长衫打补丁,既失体统,又损性能。待到内存泄漏、渲染卡顿时,众人皆指前端曰:"此子学艺不精!"
何人怜悯前端 node18 react19 逐人老,后端写着 java8 看着 java22 笑。
其三、尊严的消亡
领导提拔,必先问尔可懂SpringBoot、MySQL分库分表?纵使前端用WebGL绘出三维宇宙,用WebAssembly重写操作系统,在会议室里仍是“做界面的”。工资单上数字最是直白——同司后端新人起薪万数,前端老将苦熬三年方摸得此数。更可笑者,产品经理醉酒时吐真言:"你们不就是改改CSS么?"
再看这可视化代码何等心酸:
// 用Canvas画十万级数据点
ctx.beginPath();
dataPoints.forEach((point, i) => {
if (i % 100 === 0) ctx.stroke(); // 分段渲染防卡死
ctx.lineTo(point.x, point.y);
});
此等精密计算,在他人眼中不过"动画效果",与美工修图无异。待浏览器崩溃,众人皆曰:"定是前端代码劣质!"
技术大会,后端高谈微服务、分布式,高并发,满座掌声如雷,实则系统使用量百十来人也是远矣;前端言及 CSS 栅格、浏览器渲染,众人瞌睡连天。领导抚掌笑曰:“后端者,国之重器;前端者,雕虫小技。” 晋升名单,后端之名列如长蛇,前端者埋没于墙角尘埃。纵使将那界面写出花来,终是 “切图仔” 定终身。
其四、维护者的悲歌
JavaScript本无类型,如野马脱缰。若非经验老道之一,常写出这等代码:
function handleData(data) {
if (data && typeof data === 'object') { // 万能判断
return data.map(item => ({
...item,
newProp: item.id * Math.random() // 魔改数据
}));
}
return []; // 默认返回空阵,埋下百处报错
}
此类代码如瘟疫蔓延,领导却言“这些功能实习生也能写!”,却不顾三月后连作者亦不敢相认,只得下任前端难上加难。
而后端有Type大法,编译检查护体,有Swagger契约,有Docker容器,纵使代码如乱麻,只需扩内存、增实例,便可遮掩性能疮疤。
其五、末路者的自白
诸君且看这招聘启事:"需精通Vue3+TS+Webpack,熟悉React/Node.js,有Electron/小程序经验,掌握Three.js/WebGL者重点考虑。" 薪资却标着"6-8K"。更有机智者发明"全栈"之名,实欲以一人之躯,承三头六臂之劳。
再看这面试题何等荒谬:
// 手写Promise实现A+规范
class MyPromise {
// 三千行后,方知自己仍是蝼蚁
}
此等屠龙之术,入职后唯调API用。恰似逼庖丁解牛,却令其日日杀鸡。
或以使用组件库之经验薪资招之,又以写不好组件库之责裁出。
尾声:铁屋中的叩问
前端者,数字化时代的纺织工也。资本织机日夜轰鸣,框架如梭穿行不息。程序员眼底血丝如网。所谓"全栈工程师",实为包身工雅称;所谓"技术革新",不过剥削新法。
若仍有少年热血未冷,欲投身此业,且听我一言:君有凌云志,何不学Rust/C++,做那操作系统、数据库等真·屠龙技?莫要困在这CSS牢笼中,为圆角像素折腰,为虚无需求焚膏。前端之路,已是红海血途,望后来者三思,三思!
来源:juejin.cn/post/7475351155297402891
😝我怎么让设计师不再嫌弃 Antd,后台系统也能高端大气上档次
前言
如果一个团队计划开发一个面向 B 端的管理后台系统,既希望具备高效开发能力,又想要拥有好看的 UI,避免千篇一律的“土味”风格,而你作为前端主程参与开发,会怎么做?
本文将分享我在这一方向上的思考与实践。虽然目前所在公司的 B 端系统已经迭代许多内容,短期内没有设计师人力支持我推行这套方法,但我依然希望能将这套思路分享给有类似困扰的朋友。如果未来我有机会从零带队启动新项目,我依旧会沿用这一套方案。
当前的问题:前端与设计如何协作?
在开发 B 端系统时,大多数国内团队都会选用如 Umi、Ant Design、ProComponents、Semi Design 等成熟的 B 端技术栈和 UI 库。
这些库大大提升了开发效率,尤其是 Antd 提供的 Table、Form 等组件,功能丰富,使用便捷,非常值得肯定。
但问题也随之而来:因为太多后台项目使用 Antd,导致整体 UI 风格高度同质化,设计师逐渐产生审美疲劳。在尝试打破这种风格束缚时,设计师往往会自由发挥,或者采用非 Antd 的组件库来设计 Figma 稿。
这导致前端不得不花大量时间去覆写样式,以适配非标准组件,工作量激增,最终形成恶性循环:设计觉得前端“不还原设计”,前端觉得设计“在刁难人”,项目开发节奏也被 UI 卡住。
如何解决?
其实 Antd 本身提供了非常强的定制能力。借助 ConfigProvider 全局配置 和 主题编辑器,我们可以通过修改 CSS Token 来全局调整组件样式,做到“深度魔改”。
这在前端层面可以很好地解决样式定制的问题,但设计师要怎么参与?
答案是:使用的 Antd Figma 文件(这份是 figma 社区大佬维护的算是比较新的版本 5.20)。这个 Figma 文件已经全面绑定了 Antd 的 Design Token,设计师可以直接在 Figma 中打开,点击右侧的 Variables 面板,通过修改颜色、圆角、阴影等变量来完成 UI 风格定制。
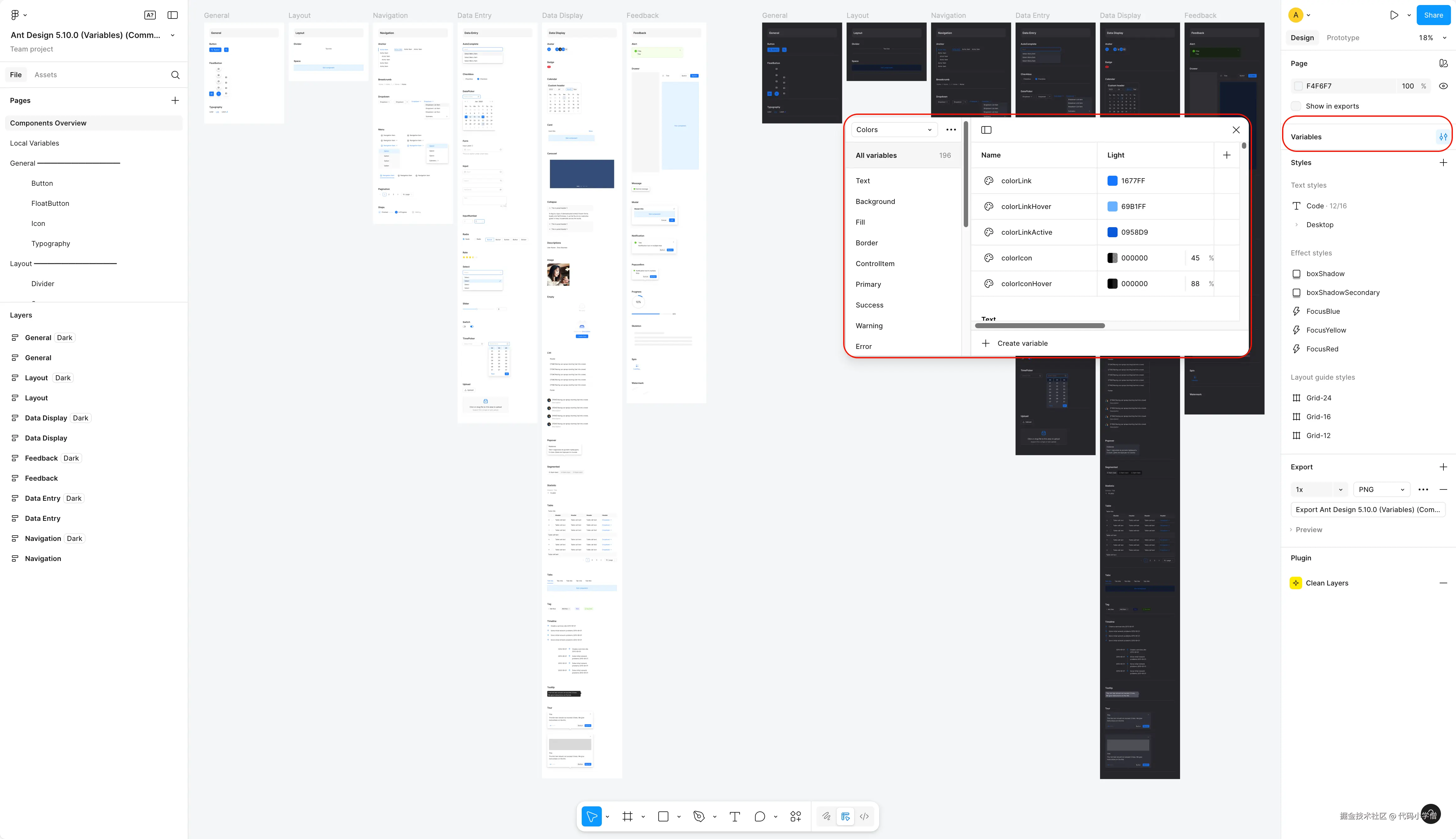
由于每个组件都与 Design Token 强关联,设计师的修改可以精确反映到各个 UI 组件上,实现灵活定制。同时,也应记录这些变量的修改项,前端就可以据此配置对应的 JSON 文件,通过 ConfigProvider 注入到项目中,从而实现样式一致的组件系统。
最后,设计师可将修改后的组件库加入 Figma 的 Asset Libraries 中,供未来在设计稿中重复复用。这就等于团队共同维护了一套定制的 UI 体系。

结语
通过上述方法,前端与设计师可以真正做到“同源协作”:基于同一套设计变量开发和设计,避免不必要的重复劳动与沟通摩擦,释放更多精力专注在业务开发本身上。
来源:juejin.cn/post/7507982656686145562
折腾我2周的分页打印和下载pdf

1.背景
一开始接到任务需要打印html,之前用到了vue-print-nb-jeecg来处理Vue2一个打印的问题,现在是遇到需求要在Vue3项目里面去打印十几页的打印和下载为pdf,难点和坑就在于我用的库vue3-print-nb来做分页打印预览,下载pdf后面介绍
2.预览打印实现
<div id="printMe" style="background:red;">
<p>葫芦娃,葫芦娃</p>
<p>一根藤上七朵花 </p>
<p>小小树藤是我家 啦啦啦啦 </p>
<p>叮当当咚咚当当 浇不大</p>
<p> 叮当当咚咚当当 是我家</p>
<p> 啦啦啦啦</p>
<p>...</p>
</div>
<button v-print="'#printMe'">Print local range</button>
因为官方提供的方案都是DOM加载完成后然后直接打印,但是我的需求是需要点击打印的时候根据id渲染不同的组件然后渲染DOM,后面仔细看官方文档,有个beforeOpenCallback方法在打印预览之前有个钩子,但是这个钩子没办法确定我接口加载完毕,所以我的思路就是用户先点击我写的点击按钮事件,等异步渲染完毕之后,我再同步触发真正的打印预览按钮,这样就变相解决了我的需求。
坑
- 没办法处理接口异步渲染数据展示DOM进行打印操作
- 在布局相对定位的时候在谷歌浏览器会发现有布局整体变小的问题(后续用zoom处理的)
3.掉头发之下载pdf
下载pdf这种需求才是我每次去理发店不敢让tony把我头发打薄的原因,我看了很多技术文章,结合个人业务情况,采取的方案是html2canvas把html转成canvas然后转成图片然后通过jsPDF截取图片分页最后下载到本地。本人秉承着不生产水,只做大自然的搬运工的匠人精神,迅速而又果断的从社区来到社区去,然后找到了适配当前业务的逻辑代码(实践出真知)。
import html2canvas from 'html2canvas'
import jsPDF, { RGBAData } from 'jspdf'
/** a4纸的尺寸[595.28,841.89], 单位毫米 */
const [PAGE_WIDTH, PAGE_HEIGHT] = [595.28, 841.89]
const PAPER_CONFIG = {
/** 竖向 */
portrait: {
height: PAGE_HEIGHT,
width: PAGE_WIDTH,
contentWidth: 560
},
/** 横向 */
landscape: {
height: PAGE_WIDTH,
width: PAGE_HEIGHT,
contentWidth: 800
}
}
// 将元素转化为canvas元素
// 通过 放大 提高清晰度
// width为内容宽度
async function toCanvas(element: HTMLElement, width: number) {
if (!element) return { width, height: 0 }
// canvas元素
const canvas = await html2canvas(element, {
// allowTaint: true, // 允许渲染跨域图片
scale: window.devicePixelRatio * 2, // 增加清晰度
useCORS: true // 允许跨域
})
// 获取canvas转化后的宽高
const { width: canvasWidth, height: canvasHeight } = canvas
// html页面生成的canvas在pdf中的高度
const height = (width / canvasWidth) * canvasHeight
// 转化成图片Data
const canvasData = canvas.toDataURL('image/jpeg', 1.0)
return { width, height, data: canvasData }
}
/**
* 生成pdf(A4多页pdf截断问题, 包括页眉、页脚 和 上下左右留空的护理)
* @param param0
* @returns
*/
export async function outputPDF({
/** pdf内容的dom元素 */
element,
/** 页脚dom元素 */
footer,
/** 页眉dom元素 */
header,
/** pdf文件名 */
filename,
/** a4值的方向: portrait or landscape */
orientation = 'portrait' as 'portrait' | 'landscape'
}) {
if (!(element instanceof HTMLElement)) {
return
}
if (!['portrait', 'landscape'].includes(orientation)) {
return Promise.reject(
new Error(`Invalid Parameters: the parameter {orientation} is assigned wrong value, you can only assign it with {portrait} or {landscape}`)
)
}
const [A4_WIDTH, A4_HEIGHT] = [PAPER_CONFIG[orientation].width, PAPER_CONFIG[orientation].height]
/** 一页pdf的内容宽度, 左右预设留白 */
const { contentWidth } = PAPER_CONFIG[orientation]
// eslint-disable-next-line new-cap
const pdf = new jsPDF({
unit: 'pt',
format: 'a4',
orientation
})
// 一页的高度, 转换宽度为一页元素的宽度
const { width, height, data } = await toCanvas(element, contentWidth)
// 添加
function addImage(
_x: number,
_y: number,
pdfInstance: jsPDF,
base_data: string | HTMLImageElement | HTMLCanvasElement | Uint8Array | RGBAData,
_width: number,
_height: number
) {
pdfInstance.addImage(base_data, 'JPEG', _x, _y, _width, _height)
}
// 增加空白遮挡
function addBlank(x: number, y: number, _width: number, _height: number) {
pdf.setFillColor(255, 255, 255)
pdf.rect(x, y, Math.ceil(_width), Math.ceil(_height), 'F')
}
// 页脚元素 经过转换后在PDF页面的高度
const { height: tFooterHeight, data: headerData } = footer ? await toCanvas(footer, contentWidth) : { height: 0, data: undefined }
// 页眉元素 经过转换后在PDF的高度
const { height: tHeaderHeight, data: footerData } = header ? await toCanvas(header, contentWidth) : { height: 0, data: undefined }
// 添加页脚
async function addHeader(headerElement: HTMLElement) {
headerData && pdf.addImage(headerData, 'JPEG', 0, 0, contentWidth, tHeaderHeight)
}
// 添加页眉
async function addFooter(pageNum: number, now: number, footerElement: HTMLElement) {
if (footerData) {
pdf.addImage(footerData, 'JPEG', 0, A4_HEIGHT - tFooterHeight, contentWidth, tFooterHeight)
}
}
// 距离PDF左边的距离,/ 2 表示居中
const baseX = (A4_WIDTH - contentWidth) / 2 // 预留空间给左边
// 距离PDF 页眉和页脚的间距, 留白留空
const baseY = 15
// 除去页头、页眉、还有内容与两者之间的间距后 每页内容的实际高度
const originalPageHeight = A4_HEIGHT - tFooterHeight - tHeaderHeight - 2 * baseY
// 元素在网页页面的宽度
const elementWidth = element.offsetWidth
// PDF内容宽度 和 在HTML中宽度 的比, 用于将 元素在网页的高度 转化为 PDF内容内的高度, 将 元素距离网页顶部的高度 转化为 距离Canvas顶部的高度
const rate = contentWidth / elementWidth
// 每一页的分页坐标, PDF高度, 初始值为根元素距离顶部的距离
const pages = [rate * getElementTop(element)]
// 获取该元素到页面顶部的高度(注意滑动scroll会影响高度)
function getElementTop(contentElement) {
if (contentElement.getBoundingClientRect) {
const rect = contentElement.getBoundingClientRect() || {}
const topDistance = rect.top
return topDistance
}
}
// 遍历正常的元素节点
function traversingNodes(nodes) {
for (const element of nodes) {
const one = element
/** */
/** 注意: 可以根据业务需求,判断其他场景的分页,本代码只判断表格的分页场景 */
/** */
// table的每一行元素也是深度终点
const isTableRow = one.classList && one.classList.contains('ant4-table-row')
// 对需要处理分页的元素,计算是否跨界,若跨界,则直接将顶部位置作为分页位置,进行分页,且子元素不需要再进行判断
const { offsetHeight } = one
// 计算出最终高度
const offsetTop = getElementTop(one)
// dom转换后距离顶部的高度
// 转换成canvas高度
const top = rate * offsetTop
const rateOffsetHeight = rate * offsetHeight
// 对于深度终点元素进行处理
if (isTableRow) {
// dom高度转换成生成pdf的实际高度
// 代码不考虑dom定位、边距、边框等因素,需在dom里自行考虑,如将box-sizing设置为border-box
updateTablePos(rateOffsetHeight, top)
}
// 对于普通元素,则判断是否高度超过分页值,并且深入
else {
// 执行位置更新操作
updateNormalElPos(top)
// 遍历子节点
traversingNodes(one.childNodes)
}
updatePos()
}
}
// 普通元素更新位置的方法
// 普通元素只需要考虑到是否到达了分页点,即当前距离顶部高度 - 上一个分页点的高度 大于 正常一页的高度,则需要载入分页点
function updateNormalElPos(top) {
if (top - (pages.length > 0 ? pages[pages.length - 1] : 0) >= originalPageHeight) {
pages.push((pages.length > 0 ? pages[pages.length - 1] : 0) + originalPageHeight)
}
}
// 可能跨页元素位置更新的方法
// 需要考虑分页元素,则需要考虑两种情况
// 1. 普通达顶情况,如上
// 2. 当前距离顶部高度加上元素自身高度 大于 整页高度,则需要载入一个分页点
function updateTablePos(eHeight: number, top: number) {
// 如果高度已经超过当前页,则证明可以分页了
if (top - (pages.length > 0 ? pages[pages.length - 1] : 0) >= originalPageHeight) {
pages.push((pages.length > 0 ? pages[pages.length - 1] : 0) + originalPageHeight)
}
// 若 距离当前页顶部的高度 加上元素自身的高度 大于 一页内容的高度, 则证明元素跨页,将当前高度作为分页位置
else if (
top + eHeight - (pages.length > 0 ? pages[pages.length - 1] : 0) > originalPageHeight &&
top !== (pages.length > 0 ? pages[pages.length - 1] : 0)
) {
pages.push(top)
}
}
// 深度遍历节点的方法
traversingNodes(element.childNodes)
function updatePos() {
while (pages[pages.length - 1] + originalPageHeight < height) {
pages.push(pages[pages.length - 1] + originalPageHeight)
}
}
// 对pages进行一个值的修正,因为pages生成是根据根元素来的,根元素并不是我们实际要打印的元素,而是element,
// 所以要把它修正,让其值是以真实的打印元素顶部节点为准
const newPages = pages.map(item => item - pages[0])
// 根据分页位置 开始分页
for (let i = 0; i < newPages.length; ++i) {
// 根据分页位置新增图片
addImage(baseX, baseY + tHeaderHeight - newPages[i], pdf, data!, width, height)
// 将 内容 与 页眉之间留空留白的部分进行遮白处理
addBlank(0, tHeaderHeight, A4_WIDTH, baseY)
// 将 内容 与 页脚之间留空留白的部分进行遮白处理
addBlank(0, A4_HEIGHT - baseY - tFooterHeight, A4_WIDTH, baseY)
// 对于除最后一页外,对 内容 的多余部分进行遮白处理
if (i < newPages.length - 1) {
// 获取当前页面需要的内容部分高度
const imageHeight = newPages[i + 1] - newPages[i]
// 对多余的内容部分进行遮白
addBlank(0, baseY + imageHeight + tHeaderHeight, A4_WIDTH, A4_HEIGHT - imageHeight)
}
// 添加页眉
if (header) {
await addHeader(header)
}
// 添加页脚
if (footer) {
await addFooter(newPages.length, i + 1, footer)
}
// 若不是最后一页,则分页
if (i !== newPages.length - 1) {
// 增加分页
pdf.addPage()
}
}
return pdf.save(filename)
}
4.分页的小姿势
如果有需求把打印预览的时候的页眉页脚默认取消不展示,然后自定义页面的边距可以这么设置样式
@page {
size: auto A4 landscape;
margin: 3mm;
}
@media print {
body,
html {
height: initial;
padding: 0px;
margin: 0px;
}
}
5.关于页眉页脚
由于业务是属于比较自定义化的展示,所以我封装成组件,然后根据返回的数据进行渲染到每个界面,然后利用绝对定位放在相同的位置,最后一点小优化就是,公共化提取界面的样式,然后整合为pub.scss然后引入到界面里面,这样即使产品有一定的样式调整,我也可以在公共样式里面去配置和修改,大大的减少本人的工作量。在日常的开发中也是这样,不要去抱怨需求的变动频繁,而是力争在写组件的过程中考虑到组件的健壮性和灵活度,给自己的工作减负,到点下班。
参考文章
来源:juejin.cn/post/7397319113796780042
如果产品经理突然要你做一个像抖音一样流畅的H5
从前端到爆点!抖音级 H5 如何炼成?
在万物互联的时代,H5 页面已成为产品推广的利器。当产品经理丢给你一个“像抖音一样流畅的 H5”任务时,是挑战还是机遇?别慌,今天就带你走进抖音 H5 的前端魔法世界。
一、先看清本质:抖音 H5 为何丝滑?
抖音 H5 之所以让人欲罢不能,核心在于两点:极低的卡顿率和极致的交互反馈。前者靠性能优化,后者靠精心设计的交互逻辑。比如,你刷视频时的流畅下拉、点赞时的爱心飞舞,背后都藏着前端开发的“小心机”。
二、性能优化:让页面飞起来
(一)懒加载与预加载协同作战
懒加载是 H5 性能优化的经典招式,只在用户即将看到某个元素时才加载它。但光靠懒加载还不够,聪明的抖音 H5 还会预加载下一个可能进入视野的元素。以下是一个基于 IntersectionObserver 的懒加载示例:
document.addEventListener('DOMContentLoaded', () => {
const lazyImages = [].slice.call(document.querySelectorAll('img.lazy'));
if ('IntersectionObserver' in window) {
let lazyImageObserver = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
if (entry.isIntersecting) {
let lazyImage = entry.target;
lazyImage.src = lazyImage.dataset.src;
lazyImageObserver.unobserve(lazyImage);
}
});
});
lazy Images.forEach((lazyImage) => {
lazyImageObserver.observe(lazyImage);
});
}
});
(二)图片压缩技术大显神威
图片是 H5 的“体重”大户。抖音 H5 常用 WebP 格式,它在保证画质的同时,能将图片体积压缩到 JPEG 的一半。你可以用以下代码轻松实现图片格式转换:
function compressImage(inputImage, quality) {
return new Promise((resolve) => {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
canvas.width = inputImage.naturalWidth;
canvas.height = inputImage.naturalHeight;
ctx.drawImage(inputImage, 0, 0, canvas.width, canvas.height);
const compressedImage = new Image();
compressedImage.src = canvas.toDataURL('image/webp', quality);
compressedImage.onload = () => {
resolve(compressedImage);
};
});
}
三、交互设计:让用户欲罢不能
(一)微动画营造沉浸感
在点赞、评论等关键操作上,抖音 H5 会加入精巧的微动画。比如点赞时的爱心从手指位置飞出,这其实是一个 CSS 动画加 JavaScript 事件监听的组合拳。以下是一个简易版的点赞动画代码:
@keyframes flyHeart {
0% {
transform: scale(0) translateY(0);
opacity: 0;
}
50% {
transform: scale(1.5) translateY(-10px);
opacity: 1;
}
100% {
transform: scale(1) translateY(-20px);
opacity: 0;
}
}
.heart {
position: fixed;
width: 30px;
height: 30px;
background-image: url('../assets/heart.png');
background-size: contain;
background-repeat: no-repeat;
animation: flyHeart 1s ease-out;
}
document.querySelector('.like-btn').addEventListener('click', function(e) {
const heart = document.createElement('div');
heart.className = 'heart';
heart.style.left = e.clientX + 'px';
heart.style.top = e.clientY + 'px';
document.body.appendChild(heart);
setTimeout(() => {
heart.remove();
}, 1000);
});
(二)触摸事件优化
在移动设备上,触摸事件的响应速度直接影响用户体验。抖音 H5 通过精准控制触摸事件的捕获和冒泡阶段,减少了延迟。以下是一个优化触摸事件的示例:
const touchStartHandler = (e) => {
e.preventDefault(); // 防止页面滚动干扰
// 处理触摸开始逻辑
};
const touchMoveHandler = (e) => {
// 处理触摸移动逻辑
};
const touchEndHandler = (e) => {
// 处理触摸结束逻辑
};
const element = document.querySelector('.scrollable-container');
element.addEventListener('touchstart', touchStartHandler, { passive: false });
element.addEventListener('touchmove', touchMoveHandler, { passive: false });
element.addEventListener('touchend', touchEndHandler);
四、音频处理:让声音为 H5 增色
抖音 H5 的音频体验也很讲究。它会根据用户的操作实时调整音量,甚至在不同视频切换时平滑过渡音频。以下是一个简单的声音控制示例:
const audioContext = new (window.AudioContext || window.webkitAudioContext)();
const audioElement = document.querySelector('audio');
const audioSource = audioContext.createMediaElementSource(audioElement);
const gainNode = audioContext.createGain();
audioSource.connect(gainNode);
gainNode.connect(audioContext.destination);
// 调节音量
function setVolume(level) {
gainNode.gain.value = level;
}
// 音频淡入效果
function fadeInAudio() {
gainNode.gain.setValueAtTime(0, audioContext.currentTime);
gainNode.gain.linearRampToValueAtTime(1, audioContext.currentTime + 1);
}
// 音频淡出效果
function fadeOutAudio() {
gainNode.gain.linearRampToValueAtTime(0, audioContext.currentTime + 1);
}
五、跨浏览器兼容:让 H5 无处不在
抖音 H5 能在各种浏览器上保持一致的体验,这离不开前端开发者的兼容性优化。常用的手段包括使用 Autoprefixer 自动生成浏览器前缀、为老浏览器提供 Polyfill 等。以下是一个为 CSS 动画添加前缀的示例:
const autoprefixer = require('autoprefixer');
const postcss = require('postcss');
const css = '.example { animation: slidein 2s; } @keyframes slidein { from { transform: translateX(0); } to { transform: translateX(100px); } }';
postcss([autoprefixer]).process(css).then(result => {
console.log(result.css);
/*
输出:
.example {
animation: slidein 2s;
}
@keyframes slidein {
from {
-webkit-transform: translateX(0);
transform: translateX(0);
}
to {
-webkit-transform: translateX(100px);
transform: translateX(100px);
}
}
*/
});
打造一个像抖音一样的流畅 H5,需要前端开发者在性能优化、交互设计、音频处理和跨浏览器兼容等方面全方位发力。希望这些技术点能为你的 H5 开发之旅提供助力,让你的产品在激烈的市场竞争中脱颖而出!
来源:juejin.cn/post/7522090635908251686
做个大屏既要不留白又要不变形还要没滚动条,我直接怒斥领导,大屏适配就这四种模式
在前端开发中,大屏适配一直是个让人头疼的问题。领导总是要求大屏既要不留白,又要不变形,还要没有滚动条。这看似简单的要求,实际却压根不可能。今天,我们就来聊聊大屏适配的四种常见模式,以及如何根据实际需求选择合适的方案。
一、大屏适配的困境
在大屏项目中,适配问题几乎是每个开发者都会遇到的挑战。屏幕尺寸的多样性、设计稿与实际屏幕的比例差异,都使得适配变得复杂。而领导的“既要...又要...还要...”的要求,更是让开发者们感到无奈。不过,我们可以通过合理选择适配模式来尽量满足这些需求。
二、四种适配模式
在大屏适配中,常见的适配模式有以下四种:
(以下截图中模拟视口1200px*500px和800px*600px,设计稿为1920px*1080px)
1. 拉伸填充(fill)


- 特点:内容会被拉伸变形,以完全填充视口框。这种方式可以确保视口内没有空白区域,但可能会导致内容变形。
- 适用场景:适用于对内容变形不敏感的场景,例如全屏背景图。
2. 保持比例(contain)


- 特点:内容保持原始比例,不会被拉伸变形。如果内容的宽高比与视口不一致,会在视口内出现空白区域(黑边)。这种方式可以确保内容不变形,但可能会留白。
- 适用场景:适用于需要保持内容原始比例的场景,例如视频或图片展示。
3. 滚动显示(scroll)


- 特点:内容不会被拉伸变形,当内容超出视口时会添加滚动条。这种方式可以确保内容完整显示,但用户需要滚动才能查看全部内容。
- 适用场景:适用于内容较多且需要完整显示的场景,例如长列表或长文本。
4. 隐藏超出(hidden)


- 特点:内容不会被拉伸变形,当内容超出视口时会隐藏超出部分。这种方式可以避免滚动条的出现,但可能会隐藏部分内容。
- 适用场景:适用于内容较多但不需要完整显示的场景,例如仪表盘。
三、为什么不能同时满足所有要求?
这四种适配模式各有优缺点,但它们在逻辑上是相互矛盾的。具体来说:
- 不留白:要求内容完全填充视口,没有任何空白区域。这通常需要拉伸或缩放内容以适应视口的宽高比。
- 不变形:要求内容保持其原始宽高比,不被拉伸或压缩。这通常会导致内容无法完全填充视口,从而出现空白区域(黑边)。
- 没滚动条:要求内容完全适应视口,不能超出视口范围。这通常需要隐藏超出部分或限制内容的大小。
这三个要求在逻辑上是相互矛盾的:
- 如果内容完全填充视口(不留白),则可能会变形。
- 如果内容保持原始比例(不变形),则可能会出现空白区域(留白)。
- 如果内容超出视口范围,则需要滚动条或隐藏超出部分。
四、【fitview】插件快速实现大屏适配
fitview 是一个视口自适应的 JavaScript 插件,它支持多种适配模式,能够快速实现大屏自适应效果。
github地址:github.com/pbstar/fitv…
在线预览:pbstar.github.io/fitview
以下是它的基本使用方法:
配置
- el: 需要自适应的 DOM 元素
- fit: 自适应模式,字符串,可选值为 fill、contain(默认值)、scroll、hidden
- resize: 是否监听元素尺寸变化,布尔值,默认值 true
安装引入
npm 安装
npm install fitview
esm 引入
import fitview from "fitview";
cdn 引入
<script src="https://unpkg.com/fitview@[version]/lib/fitview.umd.js"></script>
使用示例
<div id="container">
<div style="width:1920px;height:1080px;"></div>
</div>
const container = document.getElementById("container");
new fitview({
el: container,
});
五、总结
大屏适配是一个复杂的问题,不同的项目有不同的需求。虽然不能同时满足“不留白”“不变形”和“没滚动条”这三个要求,但可以通过合理选择适配模式来尽量满足大部分需求。在实际开发中,我们需要根据项目的具体需求和用户体验来权衡,选择最合适的适配方案。
在选择适配方案时,fitview 这个插件可以提供很大的帮助。它支持多种适配模式,能够快速实现大屏自适应效果。如果你正在寻找一个简单易用的适配工具,fitview 值得一试。你可以通过 npm 安装或直接使用 CDN 引入,快速集成到你的项目中。
希望这篇文章能帮助你更好地理解和选择大屏适配方案。如果你有更多问题或建议,欢迎在评论区留言。
来源:juejin.cn/post/7513059488417497123
弃用 html2canvas!快 93 倍的截图神器!
作者:前端开发爱好者
原文:mp.weixin.qq.com/s/t0s5dCOrs…
在前端开发中,网页截图是个常用功能。从前,html2canvas 是大家的常客,但随着网页越来越复杂,它的性能问题也逐渐暴露,速度慢、占资源,用户体验不尽如人意。
好在,现在有了 SnapDOM,一款性能超棒、还原度超高的截图新秀,能完美替代 html2canvas,让截图不再是麻烦事。

什么是 SnapDOM
SnapDOM 就是一个专门用来给网页元素截图的工具。

它能把 HTML 元素快速又准确地存成各种图片格式,像 SVG、PNG、JPG、WebP 等等,还支持导出为 Canvas 元素。

它最厉害的地方在于,能把网页上的各种复杂元素,比如 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,甚至是动态效果的当前状态,都原原本本地截下来,跟直接看网页没啥两样。
SnapDOM 优势
快得飞起
测试数据显示,在不同场景下,SnapDOM 都把 html2canvas 和 dom-to-image 这俩老前辈远远甩在身后。

尤其在超大元素(4000×2000)截图时,速度是 html2canvas 的 93.31 倍,比 dom-to-image 快了 133.12 倍。这速度,简直就像坐火箭。
还原度超高
SnapDOM 截图出来的效果,跟在网页上看到的一模一样。
各种复杂的 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,还有动态效果的当前状态,都能精准还原。

无论是简单的元素,还是复杂的网页布局,它都能轻松拿捏。
格式任你选
不管你是想要矢量图 SVG,还是常用的 PNG、JPG,或者现代化的 WebP,又或者是需要进一步处理的 Canvas 元素,SnapDOM 都能满足你。

多种格式,任你挑选,适配各种需求。
怎么用 SnapDOM
安装
SnapDOM 的安装超简单,有好几种方式:
用 NPM 或 Yarn:在命令行里输
# npm
npm i @zumer/snapdom
# yarn
yarn add @zumer/snapdom
就能装好。
用 CDN 在 HTML 文件里加一行:
<script src="https://unpkg.com/@zumer/snapdom@latest/dist/snapdom.min.js"></script>
直接就能用。
要是项目里用的是 ES Module:
import { snapdom } from '@zumer/snapdom
基础用法示例
一键截图
const card = document.querySelector('.user-card');
const image = await snapdom.toPng(card);
document.body.appendChild(image);
这段代码就是找个元素,然后直接截成 PNG 图片,再把图片加到页面上。简单粗暴,一步到位。
高级配置
const element = document.querySelector('.chart-container');
const capture = await snapdom(element, {
scale: 2,
backgroundColor: '#fff',
embedFonts: true,
compress: true
});
const png = await capture.toPng();
const jpg = await capture.toJpg({ quality: 0.9 });
await capture.download({
format: 'png',
filename: 'chart-report-2024'
});
这儿可以对截图进行各种配置。比如 scale 能调整清晰度,backgroundColor 能设置背景色,embedFonts 可以内嵌字体,compress 能压缩优化。配置好后,还能把截图存成不同格式,或者直接下载到本地。
和其他库比咋样
和 html2canvas、dom-to-image 比起来,SnapDOM 的优势很明显:
| 特性 | SnapDOM | html2canvas | dom-to-image |
|---|---|---|---|
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 准确度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 文件大小 | 极小 | 较大 | 中等 |
| 依赖 | 无 | 无 | 无 |
| SVG 支持 | ✅ | ❌ | ✅ |
| Shadow DOM 支持 | ✅ | ❌ | ❌ |
| 维护状态 | 活跃 | 活跃 | 停滞 |
用的时候注意点
用 SnapDOM 时,有几点得注意:
跨域资源
要是截图里有外部图片等跨域资源,得确保这些资源支持 CORS,不然截不出来。
iframe 限制
SnapDOM 不能截 iframe 内容,这是浏览器的安全限制,没办法。
Safari 浏览器兼容性
在 Safari 里用 WebP 格式时,会自动变成 PNG。
大型页面截图
截超大页面时,建议分块截,不然可能会内存溢出。
SnapDOM 能干啥及代码示例
社交分享
async function shareAchievement() {
const card = document.querySelector('.achievement-card');
const image = await snapdom.toPng(card, { scale: 2 });
navigator.share({
files: [new File([await snapdom.toBlob(card)], 'achievement.png')],
title: '我获得了新成就!'
});
}
报表导出
async function exportReport() {
const reportSection = document.querySelector('.report-section');
await preCache(reportSection);
await snapdom.download(reportSection, {
format: 'png',
scale: 2,
filename: `report-${new Date().toISOString().split('T')[0]}`
});
}
海报导出
async function generatePoster(productData) {
document.querySelector('.poster-title').textContent = productData.name;
document.querySelector('.poster-price').textContent = `¥${productData.price}`;
document.querySelector('.poster-image').src = productData.image;
await new Promise((resolve) => setTimeout(resolve, 100));
const poster = document.querySelector('.poster-container');
const blob = await snapdom.toBlob(poster, { scale: 3 });
return blob;
}
写在最后
SnapDOM 就是这么一款简单、快速、准确,还零依赖的网页截图神器。
无论是社交分享、报表导出、设计保存,还是营销推广,它都能轻松搞定。
而且它是免费开源的,背后还有活跃的社区支持。要是你还在为网页截图的事儿发愁,赶紧试试 SnapDOM 吧。
要是你在用 SnapDOM 的过程中有啥疑问,或者碰上啥问题,可以去下面这些地方找答案:
- 项目地址 :github.com/zumerlab/sn…
- 在线演示 :zumerlab.github.io/snapdom/
- 详细文档 :github.com/zumerlab/sn…
来源:juejin.cn/post/7524740743165722634
别再用 100vh 了!移动端视口高度的终极解决方案
作为一名前端开发者,我们一定都遇到过这样的需求:实现一个占满整个屏幕的欢迎页、弹窗蒙层或者一个 fixed 定位的底部菜单。
直觉告诉我们,这很简单,给它一个 height: 100vh 就行了。
.fullscreen-element {
height: 100vh;
width: 100%;
color: #000;
display: flex;
justify-content: center;
align-items: center;
font-size: 10em;
background-color: #fff;
}
在PC端预览,完美!然而,当你在手机上打开时,可能会看到下面这个令人抓狂的场景:

明明是 100vh,为什么会超出屏幕高度?这个烦人的滚动条到底从何而来?
如果你也曾为此抓耳挠腮,那么恭喜你,这篇文章就是你的“终极答案”。今天,我将带你彻底搞懂 100vh 在移动端的“坑”,并为你介绍当下最完美的解决方案。
1. 问题根源:移动端动态变化的“视口”
要理解问题的本质,我们首先要明白 vh (Viewport Height) 单位的定义:1vh 等于视口高度的 1%。
在PC端,浏览器窗口大小是相对固定的,所以 100vh 就是浏览器窗口的可见高度,这没有问题。
但在移动端,情况变得复杂了。为了在有限的屏幕空间里提供更好的浏览体验,手机浏览器(尤其是Safari和Chrome)的地址栏和底部工具栏是动态变化的。
- 初始状态:当你刚进入页面时,地址栏和工具栏是完全显示的。
- 滚动时:当你向下滚动页面,这些UI元素会自动收缩,甚至隐藏,以腾出更多空间展示网页内容。
关键点来了:大多数移动端浏览器将 100vh 定义为“最大视口高度”,也就是当地址栏和工具栏完全收起时的高度。
这就导致了:
在页面初始加载、地址栏还未收起时,
100vh的实际计算高度 > 屏幕当前可见区域的高度。
于是,那个恼人的滚动条就出现了。

2. “过去式”的解决方案:JavaScript 动态计算
在很长一段时间里,前端开发者们只能求助于 JavaScript 来解决这个问题。思路很简单:通过 window.innerHeight 获取当前可见视口的高度,然后用它来动态设置元素的 height。
JavaScript
function setRealVH() {
const vh = window.innerHeight * 0.01;
document.documentElement.style.setProperty('--vh', `${vh}px`);
}
// 初始加载时设置
window.addEventListener('load', setRealVH);
// 窗口大小改变或旋转屏幕时重新设置
window.addEventListener('resize', setRealVH);
然后在 CSS 中这样使用:
CSS
.fullscreen-element {
height: calc(var(--vh, 1vh) * 100);
}
这个方案的缺点显而易见:
- 性能开销:监听
resize事件过于频繁,可能会引发性能问题。 - 逻辑耦合:纯粹的样式问题却需要JS来解决,不够优雅。
- 时机问题:执行时机需要精确控制,否则可能出现闪烁。
虽然能解决问题,但这绝不是我们想要的“终极方案”。
3. “现在时”的终极解决方案:CSS动态视口单位
谢天谢地,CSS 工作组听到了我们的呼声!为了解决这个老大难问题,CSS Values and Units Module Level 4 引入了一套全新的动态视口单位。
它们就是我们今天的“主角”:
svh(Small Viewport Height): 最小视口高度。对应于地址栏和工具栏完全展开时的可见高度。lvh(Large Viewport Height): 最大视口高度。对应于地址栏和工具栏完全收起时的高度(这其实就等同于旧的100vh)。dvh(Dynamic Viewport Height): 动态视口高度。这是最智能、最实用的单位!它的值会随着浏览器UI元素(地址栏)的出现和消失而动态改变。
所以,我们的终极解决方案就是:
CSS
.fullscreen-element {
height: 100svh; /* 如果你希望高度固定,且永远不被遮挡 */
/* 或者,也是我最推荐的 */
height: 100dvh; /* 如果你希望元素能动态地撑满整个可见区域 */
}
使用 100dvh,当地址栏收起时,元素高度会平滑地增加以填满屏幕;当地址栏滑出时,元素高度又会平滑地减小。整个过程如丝般顺滑,没有任何滚动条,完美!
浏览器兼容性
你可能会担心兼容性问题。好消息是,从2023年开始,所有主流现代浏览器(Safari, Chrome, Edge, Firefox)都已经支持了这些新的视口单位。


(数据截至2025年6月,兼容性已非常好)
可以看到,兼容性已经非常理想。除非你需要支持非常古老的浏览器版本,否则完全可以放心地在生产环境中使用。
告别 100vh 的时代
让我们来快速回顾一下:
- 问题:在移动端,
100vh通常被解析为“最大视口高度”,导致在浏览器UI未收起时内容溢出。 - 旧方案:使用 JavaScript 的
window.innerHeight动态计算,但有性能和维护问题。 - 终极方案:使用CSS新的动态视口单位,尤其是
100dvh,它能根据浏览器UI的变化自动调整高度,完美解决问题。
当需要实现移动端全屏布局时,请大胆地告别 100vh,拥抱 100dvh!
来源:juejin.cn/post/7520548278338322483
为什么响应性语法糖最终被废弃了?尤雨溪也曾经试图让你不用写 .value
你将永远需要在 Vue3 中写
.value
前言
相信有不少新手在初次接触 Vue3 的组合式 API 时都会产生一个疑问:”为什么一定要写 .value ?",一些 Vue3 老玩家也认为到处写 .value 十分不优雅。
那么有没有办法能不用写 .value 呢?有的兄弟,至少曾经有的,那就是响应性语法糖,可惜在 Vue 3.4 之后已经被移除了。
响应性语法糖是如何实现免去 .value 的?这一特性为何最终被废弃了呢?
响应性语法糖
Vue 的响应性语法糖是一个编译时的转换步骤,让我们可以像这样书写代码:
<script setup>
let count = $ref(0)
console.log(count)
function increment() {
count++
}
</script>
<template>
<button @click="increment">{{ count }}</button>
</template>
这里的 $ref() 方法是一个编译时的宏命令:它不是一个真实的、在运行时会调用的方法,而是用作 Vue 编译器的标记。使用 $ref() 声明的响应式变量可以直接读取与修改,无需 .value。
上面例子中 <script> 部分的代码会被编译成下面这样,在代码中自动加上 .value:
import { ref } from 'vue'
let count = ref(0)
console.log(count.value)
function increment() {
count.value++
}
每一个会返回 ref 的响应式 API 都有一个相对应的、以 $ 为前缀的宏函数。包括以下这些 API:
ref->$refcomputed->$computedshallowRef->$shallowRefcustomRef->$customReftoRef->$toRef
通过 $() 解构
当一个组合式函数返回包含数个 ref 的对象,我们希望解构得到这些 ref,并且在后续使用它们时也不用写 .value 时,可以使用 $() 这个宏:
import { useMouse } from '@vueuse/core'
const { x, y } = $(useMouse())
// x,y 和用 $ref 声明的响应式变量一样,不用写 .value
console.log(x, y)
通过 $$() 防止响应性丢失
假设有一个期望接收一个 ref 对象为参数的函数:
function trackChange(x: Ref<number>) {
watch(x, (x) => {
console.log('x 改变了!')
})
}
let count = $ref(0)
trackChange(count) // 无效!
上面的例子不会正常工作,因为代码被编译成了这样子:
let count = ref(0)
trackChange(count.value)
trackChange 函数期望接收的参数是一个 ref 类型值,而我们传入的 count.value 实际是一个 number 类型。
对于一个使用 $ref() 声明的响应式变量,当我们希望获取到它的原始 ref 值时,可以使用 $$()。
我们将上述例子改写为:
let count = $ref(0)
- trackChange(count)
+ trackChange($$(count))
此时代码可以正常工作,不会再丢失响应性了。
看到这里,聪明的你可能已经意识到了问题:使用响应性语法糖的初衷是为了免去到处写
.value的麻烦,结果现在新引入了$ref()、$()、$(),各自还有不同的使用场景,不是更麻烦了吗?
废弃原因
最终,在收集了大量来自社区的反馈后,经过 Vue 核心团队全员投票,决定移除这一特性。在 Vue 3.3 版本中使用会报 warning,从 3.4 版本开始正式移除。
尤雨溪本人也在 github 上发表了决定将响应性语法糖移除的根本原因,链接:github.com/vuejs/rfcs/…
原文是英语,担心有小伙伴可能看不懂,在这里简单翻译一下:
响应性语法糖的初衷是提供一些简练的语法提升开发体验。我们将它作为实验特性发布并在真实场景的使用中获得反馈。尽管它有一些好处,但我们还是发现了下列问题:
- 没有
.value使得难以辨认响应式变量的读取和设置。这个问题在 SFC 中可能不那么明显,但是在大型项目中会造成心智负担的明显增大,尤其是在 SFC 外也使用此语法时。
- 因为第一条,一些开发者倾向于只在 SFC 中使用响应性语法糖,这就造成了代码的不一致性以及在不同心智模型间切换的成本。这是一个进退两难的窘境:只在 SFC 中使用会造成不一致性,而在 SFC 之外使用则会降低可维护性。
- 既然总有外部函数会使用原始 ref,那么在响应性语法糖与原始 ref 之间的转换是不可避免的。这就产生了另一个需要学习的东西以及额外的认知负担,并且我们发现这会比纯粹的组合式 API 更让初学者感到困惑。
最重要的是,响应性语法糖会带来代码风格分裂的潜在危险。尽管这一功能是自愿使用的,一些使用者还是强烈反对该提议,因为他们不想维护用了语法糖和没用两种风格的代码。这确实值得担心因为使用响应性语法糖需要的心智模型违背了 JavaScript 的基本语义(对变量赋值会触发响应式副作用)。
在考虑了所有因素之后,我们认为将它发布为一个稳定功能带来的问题会大于收益。
结语
在 Vue3 发布之初,Vue 核心团队就考虑到了 ref 需要到处使用 .value 的繁琐,推出了响应性语法糖试图解决这一问题。
响应性语法糖提供了一系列编译器宏,让开发者在书写代码时不必使用 .value,而是在编译阶段由编译器自动加上。
最终,出于代码风格一致性和可维护性上的考量,这一特性最终在 Vue 3.4 版本被正式废弃。
来源:juejin.cn/post/7523231174620102671
纯前端用 TensorFlow.js 实现智能图像处理应用(一)
随着人工智能技术的不断发展,图像处理应用已经在医疗影像分析、自动驾驶、视频监控等领域得到广泛应用。TensorFlow.js 是 Google 开源的机器学习库 TensorFlow 的 JavaScript 版本,能够让开发者在浏览器中运行机器学习模型,在前端应用中轻松实现图像分类、物体检测和姿态估计等功能。本文将介绍如何使用 TensorFlow.js 在纯前端环境中实现这三项任务,并帮助你构建一个智能图像处理应用。
什么是 TensorFlow.js?
TensorFlow.js 是一个能够让开发者在前端直接运行机器学习模型的 JavaScript 库。它允许你无需将数据发送到服务器,便可以在浏览器中运行模型进行推理,这不仅减少了延迟,还可以更好地保护用户的隐私数据。通过 TensorFlow.js,前端开发者能够轻松实现图像分类、物体检测和姿态估计等功能。
TensorFlow.js 的应用非常广泛,尤其是在一些实时交互和隐私敏感的场景下,例如 医疗影像分析、自动驾驶 和 智能监控。在这些领域,前端模型推理能够提升响应速度,并且避免将用户的数据上传到服务器,从而保护用户的隐私。
要开始使用 TensorFlow.js,你需要安装相关的模型库。以下是你需要安装的 npm 包:
npm install @tensorflow/tfjs
npm install @tensorflow-models/mobilenet
npm install @tensorflow-models/coco-ssd
npm install @tensorflow-models/posenet
加载预训练模型
在 TensorFlow.js 中,加载预训练模型非常简单。首先,确保 TensorFlow.js 已经准备好,然后加载所需的模型进行推理。
// 导入
import * as tf from '@tensorflow/tfjs'
// 加载
tf.ready(); // 确保 TensorFlow.js 准备好
用户上传图片
为了使用这些模型进行推理,我们需要让用户上传一张图片。以下是一个处理图片上传的代码示例:
const handleImageUpload = async (event) => {
const file = event.target.files[0]
if (file) {
const reader = new FileReader()
reader.onload = async (e) => {
imageSrc.value = e.target.result
await runModels(e.target.result)
}
reader.readAsDataURL(file)
}
}
图像分类:识别图片中的物体
图像分类是计算机视觉中的基本任务,目的是将输入图像归类到某个类别中。例如,我们可以用图像分类模型识别图像中的“猫”还是“狗”。


使用预训练模型进行图像分类
TensorFlow.js 提供了多个预训练模型,MobileNet 是其中一个常用的图像分类模型。它是一个轻量级的卷积神经网络,适合用来进行图像分类。接下来,我们通过 MobileNet 实现一个图像分类功能:
const mobilenetModel = await mobilenet.load()
const predictions = await mobilenetModel.classify(image)
classification.value = `分类结果: ${predictions[0].className}, 信心度: ${predictions[0].probability.toFixed(3)}`
这段代码实现了图像分类。我们加载 MobileNet 模型,并对用户上传的图像进行推理,最后返回图像的分类结果。
物体检测:找出图像中的所有物体
物体检测不仅仅是识别图像中的物体是什么,还需要标出它们的位置,通常用矩形框来框住物体。Coco-SSD 是一个强大的物体检测模型,能够在图像中检测出多个物体并标出它们的位置。
使用 Coco-SSD 进行物体检测
const cocoModel = await cocoSsd.load();
const detectionResults = await cocoModel.detect(image);
objects.value = detectionResults.map((prediction) => ({
class: prediction.class,
bbox: prediction.bbox,
}));
通过 Coco-SSD 模型,我们可以检测图像中的多个物体,并标出它们的位置。
绘制物体的边界框
为了更直观地展示检测结果,我们可以在图像上绘制出物体的边界框:
// 绘制物体检测边界框
const drawObjects = (detectionResults, image) => {
nextTick(() => {
const ctx = objectCanvas.value.getContext('2d')
const imageWidth = image.width
const imageHeight = image.height
objectCanvas.value.width = imageWidth
objectCanvas.value.height = imageHeight
ctx.clearRect(0, 0, objectCanvas.value.width, objectCanvas.value.height)
ctx.drawImage(image, 0, 0, objectCanvas.value.width, objectCanvas.value.height)
// 绘制边界框
detectionResults.forEach((prediction) => {
const [x, y, width, height] = prediction.bbox
ctx.beginPath()
ctx.rect(x, y, width, height)
ctx.lineWidth = 2
ctx.strokeStyle = 'green'
ctx.stroke()
// 添加标签
ctx.font = '16px Arial'
ctx.fillStyle = 'green'
ctx.fillText(prediction.class, x + 5, y + 20)
})
})
}
这段代码通过绘制边界框来标出检测到的物体位置,同时在边界框旁边显示物体类别。
姿态估计:识别人体的关键点
姿态估计主要是识别人类的身体部位,例如头部、手臂、腿部等。通过这些关键点,我们可以了解一个人当前的姿势。TensorFlow.js 提供了 PoseNet 模型来进行姿态估计。

使用 PoseNet 进行姿态估计
// 加载 PoseNet 模型
const posenetModel = await posenet.load()
const poseResult = await posenetModel.estimateSinglePose(image, {
flipHorizontal: false
})
// 人体关键点
pose.value = poseResult.keypoints.map((point) => `${point.part}: (${point.position.x.toFixed(2)}, ${point.position.y.toFixed(2)})`)
PoseNet 模型会估计图像中人物的关键点,并返回每个关键点的位置。
绘制姿态估计骨架图
const drawPose = (keypoints, image) => {
nextTick(() => {
const ctx = canvas.value.getContext('2d')
const imageWidth = image.width
const imageHeight = image.height
canvas.value.width = imageWidth
canvas.value.height = imageHeight
ctx.clearRect(0, 0, canvas.value.width, canvas.value.height)
// 绘制图像
ctx.drawImage(image, 0, 0, canvas.value.width, canvas.value.height)
const scaleX = canvas.value.width / image.width
const scaleY = canvas.value.height / image.height
// 绘制关键点并标记名称
keypoints.forEach((point) => {
const { x, y } = point.position
const scaledX = x * scaleX
const scaledY = y * scaleY
ctx.beginPath()
ctx.arc(scaledX, scaledY, 5, 0, 2 * Math.PI)
ctx.fillStyle = 'red'
ctx.fill()
// 标记点的名称
ctx.font = '12px Arial'
ctx.fillStyle = 'blue'
ctx.fillText(point.part, scaledX + 8, scaledY)
})
// 连接骨架
const poseConnections = [
['leftShoulder', 'rightShoulder'],
['leftShoulder', 'leftElbow'],
['leftElbow', 'leftWrist'],
['rightShoulder', 'rightElbow'],
['rightElbow', 'rightWrist'],
['leftHip', 'rightHip'],
['leftShoulder', 'leftHip'],
['rightShoulder', 'rightHip'],
['leftHip', 'leftKnee'],
['leftKnee', 'leftAnkle'],
['rightHip', 'rightKnee'],
['rightKnee', 'rightAnkle'],
['leftEye', 'rightEye'],
['leftEar', 'leftShoulder'],
['rightEar', 'rightShoulder']
]
poseConnections.forEach(([partA, partB]) => {
const keypointA = keypoints.find((point) => point.part === partA)
const keypointB = keypoints.find((point) => point.part === partB)
if (keypointA && keypointB && keypointA.score > 0.5 && keypointB.score > 0.5) {
const scaledX1 = keypointA.position.x * scaleX
const scaledY1 = keypointA.position.y * scaleY
const scaledX2 = keypointB.position.x * scaleX
const scaledY2 = keypointB.position.y * scaleY
ctx.beginPath()
ctx.moveTo(scaledX1, scaledY1)
ctx.lineTo(scaledX2, scaledY2)
ctx.lineWidth = 2
ctx.strokeStyle = 'blue'
ctx.stroke()
}
})
})
}
这段代码通过 PoseNet 返回的人体关键点信息,绘制人体姿态的骨架图,帮助用户理解图像中的人物姿势。

总结
通过 TensorFlow.js,我们可以轻松地将图像分类、物体检测和姿态估计等功能集成到前端应用中,无需依赖后端计算,提升了应用的响应速度并保护了用户隐私。在本文中,我们介绍了如何使用 MobileNet、Coco-SSD 和 PoseNet 等预训练模型,在前端实现智能图像处理应用。无论是开发图像识别应用还是增强现实应用,TensorFlow.js 都是一个强大的工具,值得前端开发者深入学习和使用。
来源:juejin.cn/post/7437392938441687049
网易微前端架构实战:如何管理100+子应用而不崩
你知道网易有多少个前端项目吗?
超过 1000 个代码仓库、200+子应用、每天发布300次。
如果没有一套微前端治理系统,项目早炸了。
今天就来带你拆解网易微前端架构的核心——基座 + 动态加载 + 权限隔离 + 独立发布。
一、网易为什么早早就用上了微前端?
因为早年起就有大量频道、游戏门户、社区运营、CMS后台等:
- 功能多样、团队独立
- 迭代频繁、部署不可等待
- 技术栈各异:Vue2、Vue3、React、甚至还有 jQuery...
👇于是他们选择了模块化能力最强的方案:微前端架构(Micro Frontends)
二、整体架构图(网易实战版)

三、主子应用通信怎么做?(网易方案)
网易没有用 qiankun,而是基于内部封装的微前端 SDK,核心原理类似。
// 主应用提供通信桥
window.__MICRO_APP_EVENT_BUS__ = new EventTarget()
// 子应用监听事件
window.__MICRO_APP_EVENT_BUS__.addEventListener('global-refresh', () => {
window.location.reload()
})
// 主应用触发事件
window.__MICRO_APP_EVENT_BUS__.dispatchEvent(new Event('global-refresh'))
👉这种方式:
- 不侵入框架(Vue/React 通吃)
- 不耦合代码,只用浏览器原生事件系统
四、部署与权限如何统一管理?
网易配套了一整套“发布平台 + 权限系统”,做到:
| 功能 | 说明 |
|---|---|
| 独立部署 | 每个子应用都有独立 Jenkins/流水线 |
| 权限接入 | 每个子应用上线必须绑定角色权限模块 |
| 域名配置 | 主应用统一路由配置,动态注入 iframe 或模块 |
| 沙箱运行 | 子应用运行在 iframe + ShadowDOM + CSP 下,完全隔离 |
五、实战代码:子应用注册和加载
// 主应用注册子应用(JSON 配置化)
const microAppList = [ { name: 'content-manage', entry: 'https://cdn.xxx.com/apps/content-manage/index.html', activeRule: '/content' }, { name: 'user-center', entry: 'https://cdn.xxx.com/apps/user-center/index.html', activeRule: '/user' }]
// 动态加载示例(简化版)
function loadMicroApp(appConfig) {
const iframe = document.createElement('iframe')
iframe.src = appConfig.entry
iframe.style = 'width:100%;height:100%;border:none'
document.getElementById('micro-container').appendChild(iframe)
}
六、网易踩过的3个坑(干货!)
| 坑 | 解决方案 |
|---|---|
| 子应用样式污染 | 每个子应用编译时加 prefixCls,搭配 ShadowDOM 隔离 |
| 子应用登录状态不一致 | 所有项目统一通过 Cookie + SSO 网关授权 |
| 子应用发布顺序冲突 | 发布系统支持灰度 + 停发自动依赖检查 |
七、总结:你能从中学到什么?
- 不要迷信 qiankun,自己也能搞微前端(原理简单)
- 微前端不仅是技术,更是权限、部署、治理一整套体系
- 想要稳定运行,必须有主子应用契约 + 灰度发布 + 统一通信策略
尾声:
“你看到的稳定,其实是他们踩了无数坑后的优雅。”
来源:juejin.cn/post/7510653719672094739
写了个脚本,发现CSDN的前端居然如此不严谨
引言
最近在折腾油猴脚本开发,顺手搞了一个可以拦截任意网页接口的小工具,并修改了CSDN的博客数据接口,成功的将文章总数和展现量进行了修改。
如果你不了解什是油猴,参考这篇文章:juejin.cn/book/751468…
然后我突然灵光一闪:
既然能拦截接口、篡改数据,那我为什么不顺便测试一下 CSDN 博客在极端数据下的表现呢?
毕竟我们平时开发的时候,测试同学各种花式挑刺,什么 null、undefined、999999、-1、空数组……
每次都能把页面测出一堆边角 bug。
今天,轮到我来当一回“灵魂测试”了!
用我的脚本,造几个极限场景,看看 CSDN 的前端到底稳不稳!
实现原理
其实原理并不复杂,核心就一句话:
借助油猴的脚本注入能力 + ajax-hook 对接口请求进行拦截和修改。
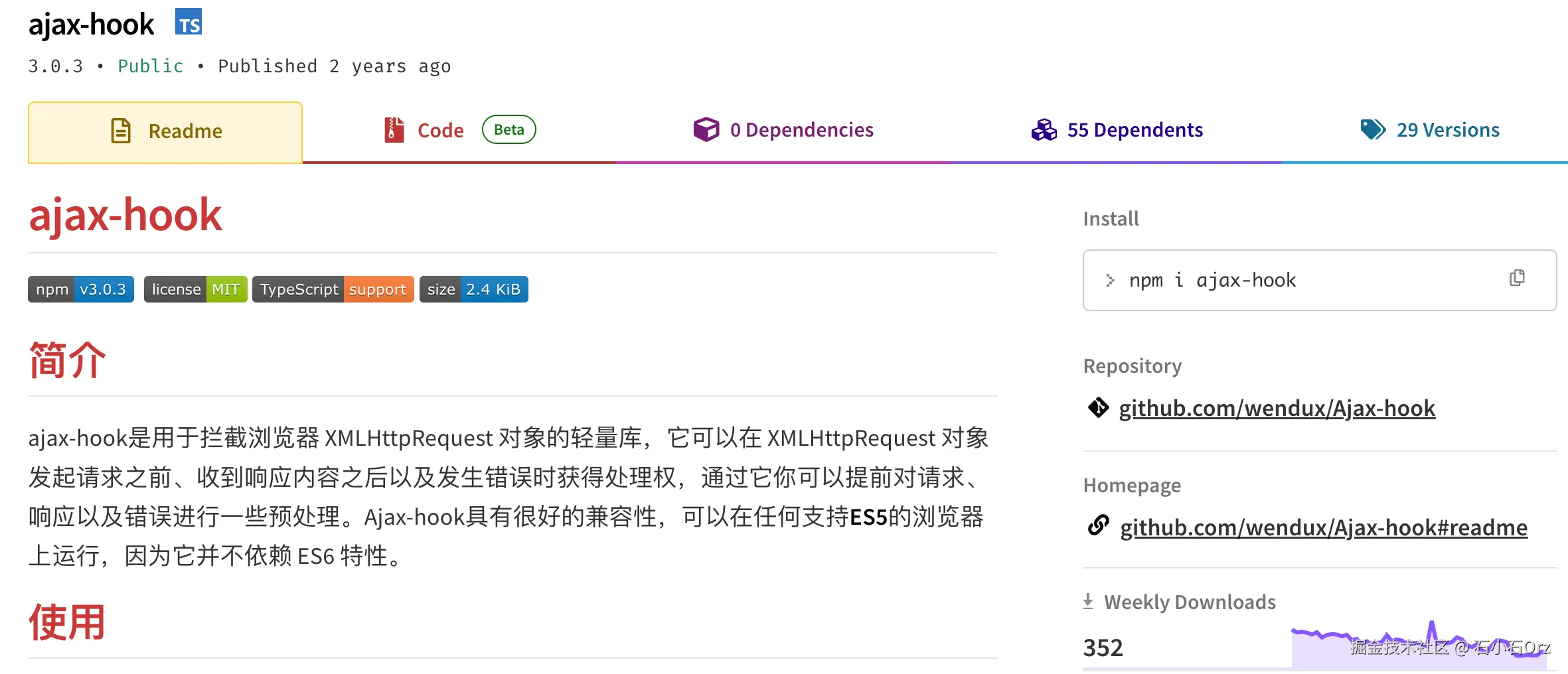
我们知道,大部分网页的数据接口都是通过 XMLHttpRequest 或 fetch 发起的,而 ajax-hook 就是一个开源的轻量工具,它能帮我们劫持原生的 XMLHttpRequest,在请求发出前、响应返回后进行自定义处理。
配合油猴脚本的注入机制,我们就可以实现在浏览器端伪造任意接口数据,用来调试前端样式、模拟数据异常、测试权限控制逻辑等等。
ajax-hook 快速上手
我们用的是 CDN 方式直接引入,简单暴力:
<script src="https://unpkg.com/ajax-hook@3.0.3/dist/ajaxhook.min.js"></script>
引入后,页面上会多出一个全局对象 ah,我们只需要调用 ah.proxy(),就可以注册一套钩子:
ah.proxy({
onRequest: (config, handler) => {
// 请求发出前
handler.next(config);
},
onError: (err, handler) => {
// 请求出错时
handler.next(err);
},
onResponse: (response, handler) => {
// 请求成功响应后
console.log("响应内容:", response.response);
handler.next(response);
}
});
拦截实现
我们以 CSDN 博客后台为例,先找到博客数据接口
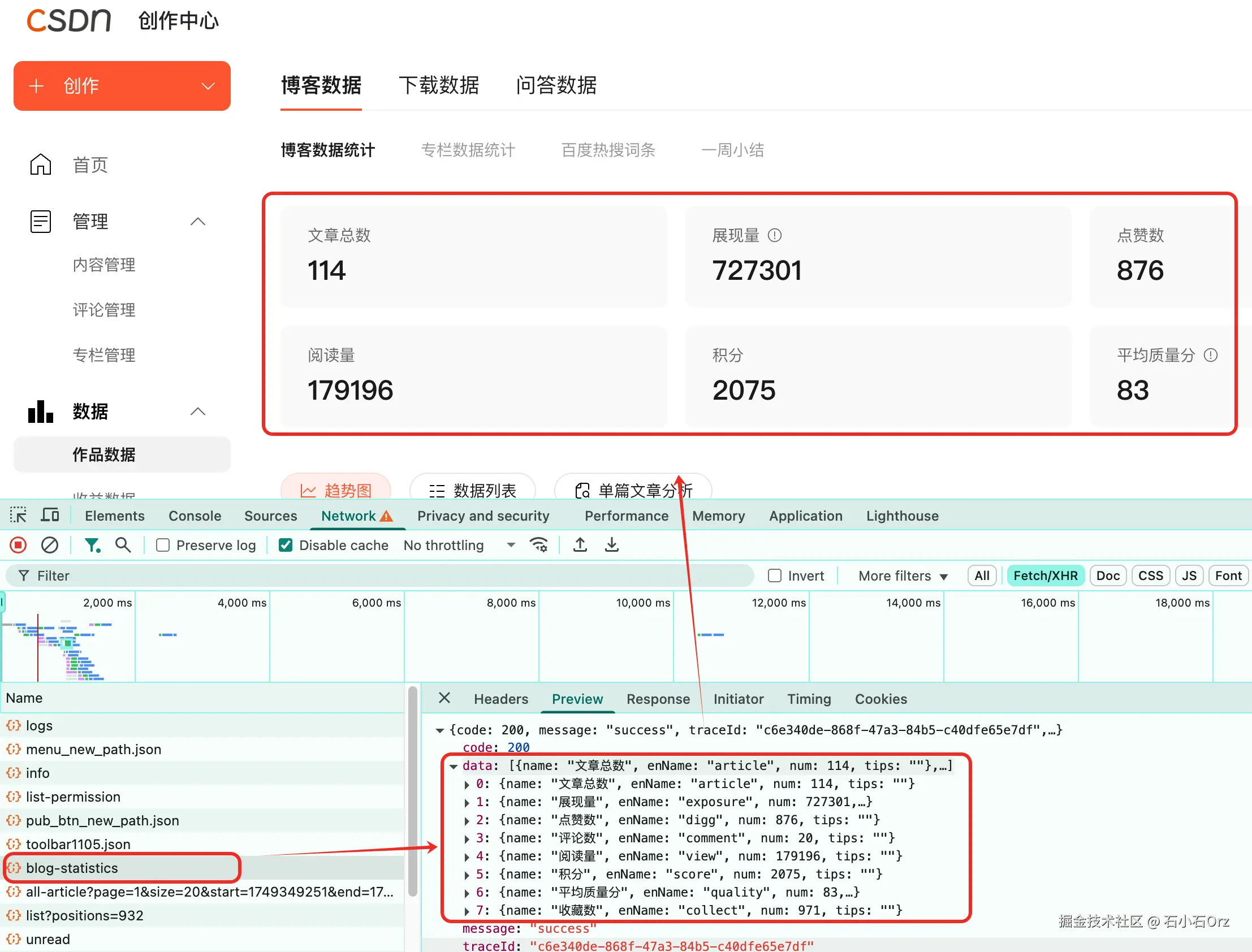
地址长这样:bizapi.csdn.net/blog/phoeni…
我们在 onResponse 钩子中,加入 URL 判断,专门拦截这个接口:
onResponse: (response, handler) => {
if (response.config.url.includes("https://bizapi.csdn.net/blog/phoenix/console/v1/data/blog-statistics")) {
const hookResponse = JSON.parse(response.response);
console.log("拦截到的数据:", hookResponse);
handler.next(response);
} else {
handler.next(response);
}
}
就这样,接口拦截器初步搭建完成!
使用油猴将脚本运行在网页
接下来我们用油猴把这段脚本注入到 CSDN 博客后台页面。
// ==UserScript==
// @name CSDN博客数据接口拦截
// @namespace http://tampermonkey.net/
// @version 0.0.1
// @description 拦截接口数据,验证极端情况下的样式展示
// @author 石小石Orz
// @match https://mpbeta.csdn.net/*
// @require https://unpkg.com/ajax-hook@3.0.3/dist/ajaxhook.min.js
// @run-at document-start
// @grant none
// ==/UserScript==
(function() {
'use strict';
ah.proxy({
onRequest: (config, handler) => {
handler.next(config);
},
onError: (err, handler) => {
handler.next(err);
},
onResponse: (response, handler) => {
console.log("接口响应列表:", response);
// 这里写拦截逻辑
handler.next(response);
}
});
})();
为了测试前端的容错能力,我们可以伪造一些极端数据返回:
- 文章总数设为
null - 展现量设为
0 - 点赞数设为一个异常大的值
onResponse: (response, handler) => {
if (response.config.url.includes("https://bizapi.csdn.net/blog/phoenix/console/v1/data/blog-statistics")) {
const hookResponse = JSON.parse(response.response);
// 伪造数据
hookResponse.data[0].num = null; // 文章总数
hookResponse.data[1].num = 0; // 展现量
hookResponse.data[2].num = 99999999999999999; // 点赞数
console.log("修改后的数据:", hookResponse);
response.response = JSON.stringify(hookResponse);
}
handler.next(response);
}
结果验证
修改成功后刷新页面,可以观察到如下问题:
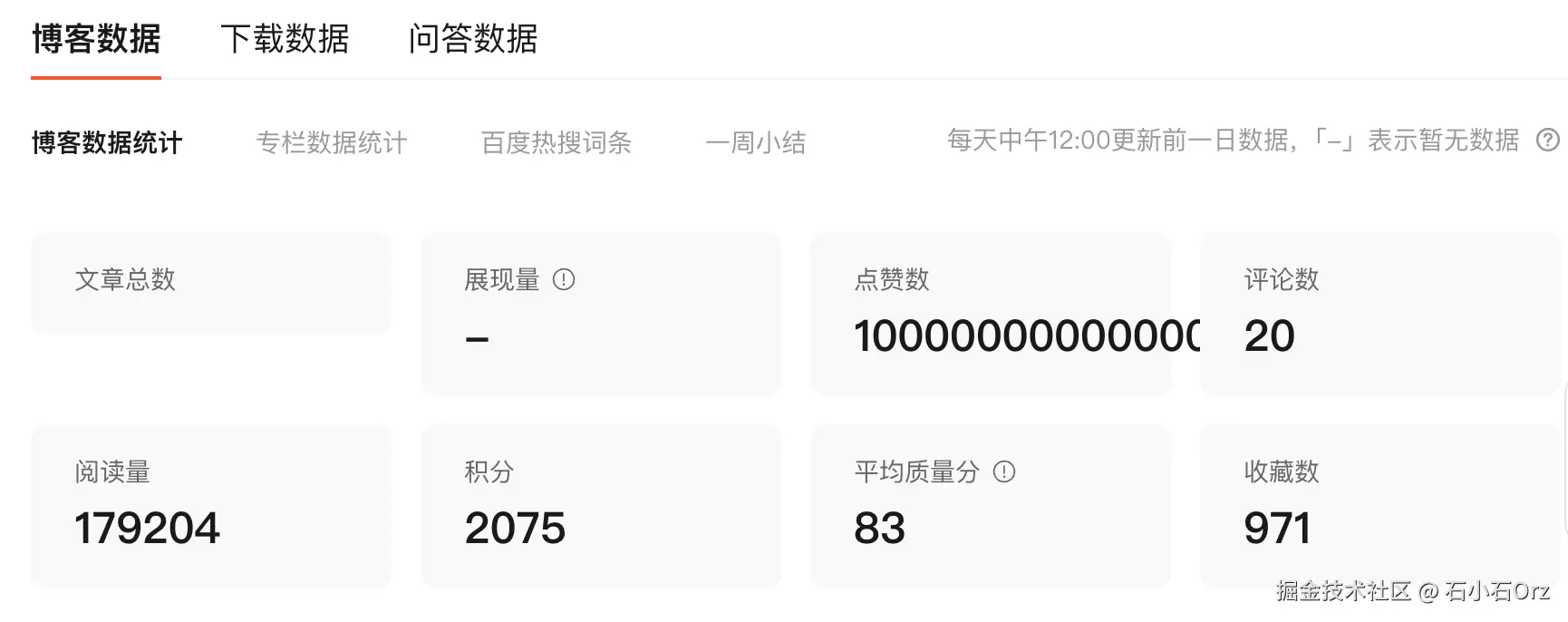
- 文章总数为
null时,布局异常,显然缺乏空值判断。 - 点赞数为超大值 时,页面直接渲染出
100000000000000000,不仅视觉上溢出容器,连排版都崩了,前端没有做任何兼容处理。
CSDN的前端还是偷懒了呀,一点也不严谨!差评!
总结
通过这篇文章的示例,我们前端应该引以为戒,永远不要相信后端同学返回的数据,一定要做好容错处理!
通过本文,相信大家也明白了油猴脚本不仅是玩具,它在前端开发中其实是个非常实用的辅助工具!
如果你对油猴脚本的开发感兴趣,不妨看看我写的这篇教程 《油猴脚本实战指南》
从小脚本写起,说不定哪天你也能靠一个脚本搞出点惊喜来!
来源:juejin.cn/post/7519005878566748186
用 iframe 实现前端批量下载的优雅方案 —— 从原理到实战
传统的下载方式如window.open()或标签点击存在诸多痛点:
- 批量下载时浏览器会疯狂弹窗
- HTTPS页面下载HTTP资源被拦截
今天分享的前端iframe批量下载方案,可以有效解决以上问题。
一、传统批量下载方案的局限性
传统的批量下载方式通常是循环创建 a 标签并触发点击事件:
urls.forEach(url => {
const link = document.createElement('a');
link.href = url;
link.download = 'filename';
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
});
这种方式存在以下问题:
- 浏览器会限制连续的自动点击行为
- 用户体验不佳,会弹出多个下载对话框
二、iframe 批量下载解析
更优雅的解决方案是使用 iframe 技术,通过动态创建和移除 iframe 元素来触发下载:
downloadFileBatch(url) {
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.style.height = '0';
iframe.src = this.urlProtocolDelete(url);
document.body.appendChild(iframe);
setTimeout(() => {
iframe.remove();
}, 5000);
}
urlProtocolDelete(url: string = '') {
if (!url) {
return;
}
return url.replace('http://', '//').replace('https://', '//');
}
这种方案的优势在于:
- 不依赖用户交互,可自动触发下载
- 隐藏 iframe 不会影响页面布局,每个iframe独立运行,互不干扰
- 主线程保持流畅
三、核心代码实现解析
让我们详细分析一下这段代码的工作原理:
- 动态创建 iframe 元素:
const iframe = document.createElement('iframe');
iframe.style.display = 'none';
iframe.style.height = '0';
通过创建一个不可见的 iframe 元素,我们可以在不影响用户界面的情况下触发下载请求。
- 协议处理函数:
urlProtocolDelete(url: string = '') {
return url.replace('http://', '//').replace('https://', '//');
}
这个函数将 URL 中的协议部分替换为//,这样可以确保在 HTTPS 页面中请求 HTTP 资源时不会出现混合内容警告。
- 触发下载并清理 DOM:
iframe.src = this.urlProtocolDelete(url);
document.body.appendChild(iframe);
setTimeout(() => {
iframe.remove();
}, 5000);
将 iframe 添加到 DOM 中会触发浏览器对 src 的请求,从而开始下载文件。设置 5 秒的超时时间后移除 iframe,既保证了下载有足够的时间完成,又避免了 DOM 中积累过多无用元素。
四、批量下载的实现与优化
对于多个文件的批量下载,可以通过循环调用 downloadFileBatch 方法:
result.forEach(item => {
this.downloadFileBatch(item.url);
});
五、踩坑+注意点
在实现批量下载 XML 文件功能时,你可能会遇到这种情况:明明请求的 URL 地址无误,服务器也返回了正确的数据,但文件却没有被下载到本地,而是直接在浏览器中打开预览了。这是因为 XML 作为一种可读的文本格式,浏览器默认会将其视为可直接展示的内容,而非需要下载保存的文件。
解决方案:
通过在下载链接中添加response-content-disposition=attachment参数,可以强制浏览器将 XML 文件作为附件下载,而非直接预览。这个参数会覆盖浏览器的默认行为,明确告诉浏览器 "这是一个需要下载保存的文件"。
addDownloadDisposition(url: string, filename: string): string {
try {
const urlObj = new URL(url);
// 添加 response-content-disposition 参数
const disposition = `attachment;filename=${encodeURIComponent(filename)}`;
urlObj.searchParams.set('response-content-disposition', disposition);
return urlObj.toString();
} catch (error) {
console.error('URL处理失败:', error);
return url;
}
}
六、大量文件并发控制
有待补充
来源:juejin.cn/post/7524627104580534306
前端高手才知道的秘密:Blob 居然这么强大!
🔍 一、什么是 Blob?
Blob(Binary Large Object)是 HTML5 提供的一个用于表示不可变的、原始二进制数据块的对象。
✨ 特点:
- 不可变性:一旦创建,内容不能修改。
- 可封装任意类型的数据:字符串、ArrayBuffer、TypedArray 等。
- 支持 MIME 类型描述,方便浏览器识别用途。
💡 示例:
const blob = new Blob(['Hello World'], { type: 'text/plain' });
🧠 二、Base64 编码的前世今生
虽然名字听起来像是某种“64进制”,但实际上它是一种编码方式,不是数学意义上的“进制”。
📜 起源背景:
Base64 最早起源于电子邮件协议 MIME(Multipurpose Internet Mail Extensions),因为早期的电子邮件系统只能传输 ASCII 文本,不能直接传输二进制数据(如附件)。于是人们发明了 Base64 编码方法,把二进制数据转换成文本形式,从而安全地在网络上传输。
🧩 使用场景:
| 场景 | 说明 |
|---|---|
| 图片嵌入到 HTML/CSS 中 | Data URI 方式减少请求 |
| JSON 数据中传输二进制信息 | 如头像、加密数据等 |
| WebSocket 发送二进制消息 | 避免使用 ArrayBuffer |
| 二维码生成 | 将图像转为 Base64 存储 |
⚠️ 注意:Base64 并非压缩算法,它会将数据体积增加约 33%。
🔁 三、从 Base64 到 Blob 的全过程
1. Base64 字符串解码:atob()
JavaScript 提供了一个内置函数 atob(),可以将 Base64 字符串解码为原始的二进制字符串(ASCII 表示)。
const base64Data = 'SGVsbG8gd29ybGQh'; // "Hello world!"
const binaryString = atob(base64Data);
⚠️ 返回的是 ASCII 字符串,不是真正的字节数组。
2. 构建 Uint8Array(字节序列)
为了构造 Blob,我们需要一个真正的字节数组。我们可以用 charCodeAt() 将每个字符转为对应的 ASCII 数值(即 0~255 的整数)。
const byteArray = new Uint8Array(binaryString.length);
for (let i = 0; i < binaryString.length; i++) {
byteArray[i] = binaryString.charCodeAt(i);
}
现在,byteArray 是一个代表原始图片二进制数据的数组。
3. 创建 Blob 对象
有了字节数组,就可以创建 Blob 对象了:
const blob = new Blob([byteArray], { type: 'image/png' });
这个 Blob 对象就代表了一张 PNG 图片的二进制内容。
4. 使用 URL.createObjectURL() 显示图片
为了让浏览器能够加载这个 Blob 对象,我们需要生成一个临时的 URL 地址:
const imageUrl = URL.createObjectURL(blob);
document.getElementById('blobImage').src = imageUrl;
这样,你就可以在网页中看到这张图片啦!
🛠️ 四、Blob 的核心功能与应用场景
| 功能 | 说明 |
|---|---|
| 分片上传 | .slice(start, end) 方法可用于大文件切片上传 |
| 本地预览 | Canvas.toBlob() 导出图像,配合 URL.createObjectURL 预览 |
| 文件下载 | 使用 a 标签 + createObjectURL 实现无刷新下载 |
| 缓存资源 | Service Worker 中缓存 Blob 数据提升性能 |
| 处理用户上传 | 结合 FileReader 和 File API 操作用户文件 |
🧪 五、Blob 的高级玩法
1. 文件切片上传(分片上传)
const chunkSize = 1024 * 1024; // 1MB
const firstChunk = blob.slice(0, chunkSize);
2. Blob 转换为其他格式
FileReader.readAsText(blob)→ 文本FileReader.readAsDataURL(blob)→ Base64FileReader.readAsArrayBuffer(blob)→ Array Buffer
3. Blob 下载为文件
const a = document.createElement('a');
a.href = URL.createObjectURL(blob);
a.download = 'example.png';
a.click();
🧩 六、相关知识点汇总
| 技术点 | 作用 |
|---|---|
| Base64 | 将二进制数据编码为文本,便于传输 |
| atob() | 解码 Base64 字符串,还原为二进制字符串 |
| charCodeAt() | 获取字符的 ASCII 值(0~255) |
| Uint8Array | 构建字节数组,表示原始二进制数据 |
| Blob | 封装二进制数据,作为文件对象使用 |
| URL.createObjectURL() | 生成临时地址,让浏览器加载 Blob 数据 |
🧾 七、完整代码回顾
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Blob 实战</title>
</head>
<body>
<img src="" id="blobImage" width="100" height="100" alt="Blob Image" />
<script>
const base64Data = 'UklGRiAHAABXRUJQVlA4IBQHAACwHACdASpQAFAAPok0lEelIyIhMziOYKARCWwAuzNaQpfW+apU37ZufB5rAHqW2z3mF/aX9o/ev9LP+j9KrqSOfp9mf+6WmE1P1yFc3gTlw8B8d/TebelHaI3mplPrZ+Aa0l5qDGv5N8Tt9vYhz3IH37wqm2al+FdcFQhDnObv2+WfpwIZ+K6eBPxKL2RP6hiC/K1ZynnvVYth9y+ozyf88Obh4TRYcv3nkkr43girwwJ54Gd0iKBPZFnZS+gd1vKqlfnPT5wAwzxJiSk+pkbtcOVP+QFb2uDqUhuhNiHJ8xPt6VfGBfUbTsUzYuKgAP4L9wrkT8KU4sqIHwM+ZeKDBpGq58k0aDirXeGc1Odhvfx+cpQaeas97zVTr2pOk5bZkI1lkF9jnc0j2+Ojm/H+uPmIhS7/BlxuYfgnUCMKVZJGf+iPM44vA0EwvXye0YkUUK...';
const binaryString = atob(base64Data); // Base64 解码
const byteArray = new Uint8Array(binaryString.length); // 创建 Uint8Array
for (let i = 0; i < binaryString.length; i++) {
byteArray[i] = binaryString.charCodeAt(i); // 填充字节数据
}
const blob = new Blob([byteArray], { type: 'image/png' }); // 创建 Blob
const imageUrl = URL.createObjectURL(blob); // 生成 URL
document.getElementById('blobImage').src = imageUrl; // 显示图片
</script>
</body>
</html>
📚 八、扩展阅读建议
🧩 九、结语
Blob 是连接 JavaScript 世界与真实二进制世界的桥梁,是每一个想要突破瓶颈的前端开发者必须掌握的核心技能之一。
掌握了 Blob,你就拥有了操作二进制数据的能力,这在现代 Web 开发中是非常关键的一环。
下次当你看到一张图片在网页中加载出来,或者一个文件被顺利下载时,不妨想想:这一切的背后,都有 Blob 的身影。
来源:juejin.cn/post/7523065182429904915
🫴为什么看大厂的源码,看不到undefined,看到的是void 0
void 0 是 JavaScript 中的一个表达式,它的作用是 返回 undefined。
解释:
void运算符:
- 它会执行后面的表达式(比如
void 0),但不管表达式的结果是什么,void始终返回undefined。 - 例如:
console.log(void 0); // undefined
console.log(void (1 + 1)); // undefined
console.log(void "hello"); // undefined
- 它会执行后面的表达式(比如
- 为什么用
void 0代替undefined?
- 在早期的 JavaScript 中,
undefined并不是一个保留字,它可以被重新赋值(比如undefined = 123),这会导致代码出错。 void 0是确保获取undefined的安全方式,因为void总是返回undefined,且不能被覆盖。- 现代 JavaScript(ES5+)已经修复了这个问题,
undefined现在是只读的,但void 0仍然在一些旧代码或压缩工具中出现。
- 在早期的 JavaScript 中,
常见用途:
- 防止默认行为(比如
<a>标签的href="javascript:void(0)"):
<a href="javascript:void(0);" onclick="alert('Clicked!')">
点击不会跳转
</a>
这样点击链接时不会跳转页面,但仍然可以执行 JavaScript。
- 在函数中返回
undefined:
function doSomething() {
return void someOperation(); // 明确返回 undefined
}
为什么用void 0
源码涉及到 undefined 表达都会被编译成 void 0
//源码
const a: number = 6
a === undefined
//编译后
"use strict";
var a = 6;
a === void 0;
也就是void 0 === undefined。void 运算符通常只能用于获取 undefined 的原始值,一般用void(0),等同于void 0,也可以使用全局变量 undefined 替代。
为什么不直接写 undefined
undefined 是 js 原始类型值之一,也是全局对象window的属性,在一部分低级浏览器(IE7-IE8)中or局部作用域可以被修改。
undefined在js中,全局属性是允许被覆盖的。
//undefined是window的全局属性
console.log(window.hasOwnProperty('undefined'))
console.log(window.undefined)
//旧版IE
var undefined = '666'
console.log(undefined)//666 直接覆盖改写undefined
window.undefined在局部作用域中是可以被修改的 在ES5开始,undefined就已经被设定为仅可读的,但是在局部作用域内,undefined依然是可变的。
①某些情况下用undefined判断存在风险,因undefined有被修改的可能性,但是void 0返回值一定是undefined
②兼容性上void 0 基本所有的浏览器都支持
③ void 0比undefined字符所占空间少。
拓展
void(0) 表达式会返回 undefined 值,它一般用于防止页面的刷新,以消除不需要的副作用。
常见用法是在 <a> 标签上设置 href="javascript:void(0);",即当单击该链接时,此表达式将会阻止浏览器去加载新页面或刷新当前页面的行为。
<!-- 点击下面的链接,不会重新加载页面,且可以得到弹框消息 -->
<a href="javascript:void(0);" onclick="alert('干的漂亮!')">
点我呀
</a>
总结:
void 0 是一种确保得到 undefined 的可靠方式,虽然在现代 JavaScript 中直接用 undefined 也没问题,但在一些特殊场景(如代码压缩、兼容旧代码)仍然有用。
来源:juejin.cn/post/7511618693714427914




