前言
在Android中记录日志一般是使用Android自带的Log工具,
但是实际项目中,我们经常需要统一控制项目的日志开关或过滤等级,有时还需要将日志写入到文件中。
目前除了自己实现外,基本都是通过第三方的Log日志库比如JakeWharton/timber,orhanobut/logger ,但是有些情况仍然实现起来困难。
比如:
- 多模块或封装SDK的情况,子模块也用到日志框架,如何单独管理子模块的日志开关?
- Java library中没有Android Log类引入日志模块报错,同理使用JUnit做单元测试的时候日志模块报错。
并且替换项目中的Log是痛苦的,因此就需要一个可拓展的日志框架尤为重要。
和大多数流行的Logger框架不同,本文实现的Logger不是对各种数据进行美化输出,本文充分利用Kotlin的拓展函数实现了一个灵活配置的轻量Logger,它具有以下特性:
- 控制模块中的Logger配置
- 输出到文件等多个目标,控制输出线程
- 支持拦截器,实现过滤,格式化
- 支持Jvm使用,支持JUnit
原理和
核心只有3个类
Logger 日志的操作入口:主要保证稳定简单易用,用作门面。
LogPrinter 日志输出目标:配置日志输出。
LogLevel 日志输出等级:(VERBOSE,DEBUG,INFO,WARNING,ERROR,WTF)
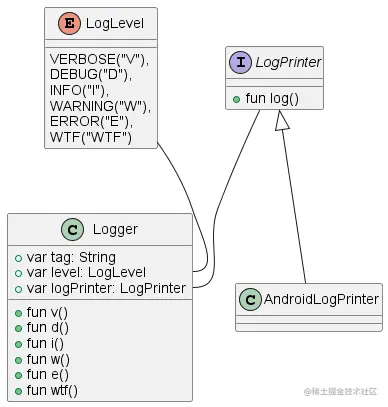
日志记录
通过Logger 可以获取全局实例。
输出日志有许多等级,和android的Log等级是一致的:
Logger.v("Test verbose")
Logger.d("Test debug")
Logger.i("Test info")
Logger.w("Test warning")
Logger.e("Test error")
Logger.wtf("Test wtf")
Logger.v { "Test verbose" }
Logger.d { "Test debug" }
Logger.i { "Test info" }
Logger.w { "Test warning" }
Logger.e { "Test error" }
Logger.wtf { "Test wtf" }
通过Logger["subTag"]可以生成子Logger
默认情况,子Logger的level、logPrinter均继承自父Logger,tag为"$父tag-$subTag"
Logger.tag = "App" //全局Logger的tag设置为“APP”
class XxActivity {
val logger = Logger["XxActivity"] //二级Logger的tag为“APP-XxActivity”
val logger = loggerForClass() //使用当前类名生成二级Logger的tag为“APP-XxActivity”
inner class XxFragment {
val fragmentLogger = logger["XxFragment"]//三级Logger的tag为“APP-XxActivity-XxFragment”
}
}
日志配置
Logger总共只有4个属性:
level 过滤等级(VERBOSE,DEBUG,INFO,WARNING,ERROR,WTF)
tag 日志TAG
logPrinter 日志输出目标,比如Android Logcat,文件,标注输出流,Socket等。
loggerFactory 生产子Logger的工厂,默认情况,子Logger的level、logPrinter均继承自父Logger,tag为"$父tag-$subTag"
如下示例配置了顶级Logger的level和tag,输出目标为AndroidLogcat,同时在子线程把WARNING等级的日志按一定格式输出到文件"warning.log"中,
同时"SubModule"子Logger的输出等级设置为ERROR等级。
Logger.level = LogLevel.VERBOSE
Logger.tag = "AppName"
Logger.logPrinter = AndroidLogPrinter()
.logAlso(FileLogPrinter({ File("warning.log") })
.format { _, _, messageAny, _ -> "【${Thread.currentThread().name}】:$messageAny" }
.logAt(Executors.newSingleThreadExecutor())
.filterLevel(LogLevel.WARNING)
)
Logger.loggerFactory = { subTag ->
Logger("$tag-$it", level, logPrinter).also { child ->
if (child.tag == "SubModule") {
logger.level = LogLevel.ERROR
}
}
}
实现
Logger功能实现:
因为Logger是门面,所以提供便捷的方法来使用,而真正的写入日志代理给LogPrinter
open class Logger(
var tag: String = "LOG",
var level: LogLevel = LogLevel.VERBOSE,
var logPrinter: LogPrinter = createPlatformDefaultLogPrinter(),
) {
fun v(message: Any?) = log(LogLevel.VERBOSE, message, null)
fun log(level: LogLevel, message: Any?, throwable: Throwable? = null) {
if (this.level <= level) {
logPrinter.log(level, tag, message, throwable)
}
}
//省略其他等级...
var loggerFactory: (childTag: String) -> Logger = ::defaultLoggerFactory
/**
* 创建子Logger
* @param subTag 次级tag,一般为模块名
*/
operator fun get(subTag: String): Logger = loggerFactory(subTag)
companion object INSTANCE : Logger(tag = "Logger")
}
enum class LogLevel(val shortName: String) {
VERBOSE("V"),
DEBUG("D"),
INFO("I"),
WARNING("W"),
ERROR("E"),
WTF("WTF")
}
fun interface LogPrinter {
fun log(level: LogLevel, tag: String, messageAny: Any?, throwable: Throwable?)
}
LogPrinter拓展实现
首先实现对LogPrinter进行拦截,后续的功能都通过拦截器实现。
拦截器
/**
* 拦截器
* logPrinter 被拦截对象
*/
typealias LogPrinterInterceptor = (logPrinter: Logger.LogPrinter, level: Logger.LogLevel, tag: String, messageAny: Any?, throwable: Throwable?) -> Unit
inline fun Logger.LogPrinter.intercept(crossinline interceptor: LogPrinterInterceptor) =
Logger.LogPrinter { level, tag, messageAny, throwable ->
interceptor(this@intercept, level, tag, messageAny, throwable)
}
添加额外的LogPrinter
添加一个额外的LogPrinter,也可看作将2个LogPrinter合并成1个。想要添加多个输出目标时使用。
fun Logger.LogPrinter.logAlso(other: Logger.LogPrinter) =
intercept { logPrinter, level, tag, messageAny, throwable ->
logPrinter.log(level, tag, messageAny, throwable)
other.log(level, tag, messageAny, throwable)
}
设置日志记录线程
控制LogPrinter的输出线程
fun Logger.LogPrinter.logAt(executor: Executor) =
intercept { logPrinter, level, tag, messageAny, throwable ->
executor.execute {
logPrinter.log(level, tag, messageAny, throwable)
}
}
格式化
控制LogPrinter的输出的格式,比如csv格式,Json格式等。
typealias LogFormatter = (level: Logger.LogLevel, tag: String, messageAny: Any?, throwable: Throwable?) -> String
fun Logger.LogPrinter.format(formatter: LogFormatter) =
intercept { logPrinter, level, tag, messageAny, throwable ->
val formattedMessage = formatter(level, tag, messageAny, throwable)
logPrinter.log(level, tag, formattedMessage, throwable)
}
日志过滤
对LogPrinter中输出的日志进行过滤,可以根据tag、message、level、throwable进行组合判断来过滤。
fun Logger.LogPrinter.filter(
predicate: (
level: Logger.LogLevel,
tag: String,
messageAny: Any?,
throwable: Throwable?
) -> Boolean
) =
intercept { logPrinter, level, tag, messageAny, throwable ->
if (predicate(level, tag, messageAny, throwable)) {
logPrinter.log(level, tag, messageAny, throwable)
}
}
Logger拷贝
以Logger为原型拷贝一个新Logger,和生成子Logger不同,它并不是通过loggerFactory生成的,并且tag也是拷贝的。
/**
* 拷贝
*/
fun Logger.copy(
tag: String = this.tag,
level: Logger.LogLevel = this.level,
logPrinter: Logger.LogPrinter = this.logPrinter,
loggerFactory: (childTag: String) -> Logger = ::defaultLoggerFactory,
) = Logger(tag, level, logPrinter).also { it.loggerFactory = loggerFactory }
Json格式化
因为并没有引入任何Android类和Json序列化库,所以没有内置。在此提供Gson示例
方式1,使用LogPrinter拓展
适用于该Logger所有日志都需要转Json的情况
val gson = GsonBuilder().setPrettyPrinting().disableHtmlEscaping().create()
fun Logger.jsonLogger() =
copy(logPrinter = logPrinter.format { _, _, messageAny, _ -> gson.toJson(messageAny) })
//使用
fun testLogJsonLogger() {
val logger = Logger.jsonLogger()
logger.d {
arrayOf("hello", "world")
}
logger.i {
mapOf(
"name" to "tom",
"age" to 19,
)
}
}
方式2,拓展Logger方法
通过拓展Logger方法实现,适用于Logger的部分数据需要输出为Json模式。
inline fun Logger.logJson(level: Logger.LogLevel = Logger.LogLevel.INFO, any: () -> Any) {
log(level, block = { gson.toJson(any()) })
}
//使用
fun testLogJsonExt() {
Logger.logJson {
mapOf(
"name" to "tom",
"age" to 19,
)
}
}
拓展使用
这些拓展方法可以连续调用,就像使用RxJava一样。
Logger.logPrinter = ConsoleLogPrinter()
.format { _, tag, messageAny, _ -> "$tag : $messageAny\n" }
.logAlso(ConsoleLogPrinter()
.format { _, tag, messageAny, _ ->//添加分割线 tag,时间,message转json,同时加上堆栈信息
"""---------------------------\n $tag ${currentTime()} ${Json.toJson(messageAny)} \n${Thread.currentThread().stackTrace.contentToString()}"""
}
.filterLevel(LogLevel.INFO))//仅记录level在INFO及以上的
.logAlso(ConsoleLogPrinter()
.format { _, tag, messageAny, _ -> "$tag :《$messageAny》\n" }
.filter { _, tag, _, _ -> tag.contains("CHILD") })//仅记录tag包含CHILD
混淆
如果通过混淆去除日志信息,可按如下配置。
-assumenosideeffects class me.lwb.logger.Logger {
public *** d(...);
public *** e(...);
public *** i(...);
public *** v(...);
public *** log(...);
public *** w(...);
public *** wtf(...);
}
总结
本文主要使用了Kotlin拓展和高阶函数实现了一个拓展性高的Logger库,通过拓展方法实现线程切换,多输出,格式化等,同时通过配置全局logFactory的方法可以在不修改子模块代码的情况下去控制子模块Logger的level等信息。
该库十分精简,加上拓展和默认实现总代码小于300行,不依赖Android库第三方库,可以在纯Jvm程序中使用,也可在Android程序中使用。












