








Android 在一个APP里打开另一个APP
前言
不知道你们有没有注意过,每次打开一些软件的时候都会有广告引导页,有时候手滑点到了,会有进入手机上的另一个APP,这有没有引起你的注意呢?
运行效果图
# 正文
为了测试这个功能,首先要创建两个项目,然后运行起来都安装在你的手机上,这里为了方便了解,取名就是应用A和应用B,流程就是A应用里面打开B应用。
首先当然是创建项目了
DemoA
DemoB
创建好之后,别的先不管,都在手机上安装一下再说
① 打开另一个APP
接下来在DemoA的MainActivity里面写一个按钮,用于点击之后打开DemoB应用
<Button
android:id="@+id/btn_open_b"
android:text="打开DemoB"
android:textAllCaps="false"
android:layout_width="wrap_content"
android:layout_height="wrap_content"/>
也在DemoB的布局文件改一下显示内容
<TextView
android:textSize="18sp"
android:textColor="#000"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="DemoB" />
运行一下
这样就打开了。那假如我要传递数据到DemoB呢?
② 数据传递
传数据其实就跟平时单个APP内部不同页面传数据类似,也是用Intent
然后在另一个APP里面接收并显示出来。现在先修改一下DemoB的布局,增加一个TextView用来显示接收的内容。
<TextView
android:id="@+id/tv_info"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_marginTop="12dp"
android:textColor="#000"
android:textSize="16sp" />
DemoB的MainActivity里
一旦两个应用程序里面改动了代码你就要在手机上运行一下,否则你改动的代码就不会生效
然后运行一下:
传值的问题就解决了。
③ 打开指定页面
通过包名跳转APP是进入默认的启动页面,你可以打开你的AndroidManifest.xml文件查看
那个Activity下面有这个默认启动就是那个
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
至于要打开指定的页面有两个方法
1.通过包名、类名
首先在DemoB的下面再创建一个TestActivity,简单加一个TextView
因为是要DemoB的TestActivity页面,所以这个activity在AndroidManifest.xml中需要配置
android:exported 属性,布尔类型,是否支持其他应用访问目标 Activity,默认值为 true;android:exported="true"
否则你跳转会报错的,现在运行DemoB,使改动的代码生效
然后修改DemoA里面MainActivity的代码
运行效果
这样就可以了。
2.通过Action
修改DemoB的AndroidManifest.xml
然后运行在手机上,再修改DemoA的MainActivity
运行效果
其实还有一种方式是通过URL打开另一个APP,但是我不推荐这样做,为什么?没有原因...
链接:https://juejin.cn/post/7229498604367904828
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Flutter 3.10 之 Flutter Web 路线已定,可用性进一步提升,快来尝鲜 WasmGC
随着 Flutter 3.10 发布,Flutter Web 也引来了它最具有「里程碑」意义的更新,这里的「里程碑」不是说这次 Flutter Web 有多么重大的更新,而是 Flutter 官方对于 Web 终于有了明确的定位和方向。
提升
首先我们简单聊提升,这不是本篇的重点,只是顺带。
本次提升主要在于两个大点:Element 嵌入支持和 fragment shaders 支持 。
首先是 Element 嵌入,Flutter 3.10 开始,现在可以将 Flutter Web嵌入到网页的任何 HTML 元素中,并带有 flutter.js 引擎和 hostElement 初始化参数。
简单来说就是不需要 iframe 了,如下代码所示,只需要通过 initializeEngine 的 hostElement 参数就可以指定嵌入的元素,灵活度支持得到了提高。
<html>
<head>
<!-- ... -->
<script src="flutter.js" defer></script>
</head>
<body>
<!-- Ensure your flutter target is present on the page... -->
<div id="flutter_host">Loading...</div>
<script>
window.addEventListener("load", function (ev) {
_flutter.loader.loadEntrypoint({
onEntrypointLoaded: async function(engineInitializer) {
let appRunner = await engineInitializer.initializeEngine({
// Pass a reference to "div#flutter_host" into the Flutter engine.
hostElement: document.querySelector("#flutter_host")
});
await appRunner.runApp();
}
});
});
</script>
</body>
</html>
PS :如果你的项目是在 Flutter 2.10 或更早版本中创建的,要先从目录中删除
/web文件 ,然后通过flutter create . --platforms=web重新创建模版。
fragment shaders 部分一般情况下大家可能并不会用到,shaders 就是以 .frag 扩展名出现的 GLSL 文件,在 Flutter 里是在 pubspec.yaml 文件下的 shaders 中声明,现在它支持 Web 了:
flutter:
shaders:
- shaders/myshader.frag
一般运行时会把 frag 文件加载到
FragmentProgram对象中,通过 program 可以获取到对应的shader,然后通过Paint.shader进行使用绘制, 当然 Flutter 里 shaders 文件是存在限制的,比如不支持 UBO 和 SSBO 等。
当然,这里不是讲解 shaders ,而是宣告一下,Flutter Web 支持 shaders 了。
未来
其实未来才是本篇的重点,我们知道 Flutter 在 Web 领域的支持上一直在「妥协」,Flutter Web 在整个 Flutter 体系下一直处于比较特殊的位置,因为它一直存在两种渲染方式:html 和 canvaskit。
简单说 html 就是转化为 JS + Html Element 渲染,而 canvaskit 是采用 Skia + WebAssembly 的方式,而 html 的模式让 Web 在 Flutter 中显得「格格不入」,路径依赖和维护成本也一直是 Flutter Web 的头痛问题。
面对这个困境,官方在年初的 Flutter Forword 大会上提出重新规划 Flutter Web 的未来,而随着 Flutter 3.10 的发布,官方终于对于 Web 的未来有了明确的定位:
“Flutter 是第一个围绕 CanvasKit 和 WebAssembly 等新兴 Web 技术进行架构设计的框架。”
Flutter 团队表示,Flutter Web 的定位不是设计为通用 Web 的框架,类似的 Web 框架现在有很多,比如 Angular 和 React 等在这个领域表现就很出色,而 Flutter 应该是围绕 CanvasKit 和 WebAssembly 等新技术进行架构设计的框架。
所以 Flutter Web 未来的路线会是更多 CanvasKit ,也就是 WebAssembly + Skia ,同时在这个领域 Dart 也在持续深耕:从 Dart 3 开始,对于 Web 的支持将逐步演进为 WebAssembly 的 Dart native 的定位。
什么是 WebAssembly 的 dart native ?一直以来 Flutter 对于 WebAssembly 的支持都是:使用 Wasm 来处理CanvasKit 的 runtime,而 Dart 代码会被编译为 JS,而这对于 Dart 团队来时,其实是一个「妥协」的过渡期。
而随着官方与 WebAssembly 生态系统中的多个团队的深入合作,Dart 已经开始支持直接编译为原生的 wasm 代码,一个叫 WasmGC 的垃圾收集实现被引入标准,该扩展实现目前在基于 Chromium 的浏览器和 Firefox 浏览器中在趋向稳定。
目前在基准测试中,执行速度提高了 3 倍
要将 Dart 和 Flutter 编译成 Wasm,你需要一个支持 WasmGC 的浏览器,目前 Chromium V8 和 Firefox 团队的浏览器都在进行支持,比如 Chromium 下:
通过结构和数组类型为 WebAssembly 增加了对高级语言的有效支持,以 Wasm 为 target 的语言编译器能够与主机 VM 中的垃圾收集器集成。在 Chrome 中启用该功能意味着启用类型化函数引用,它会将函数引用存储在上述结构和数组中。
现在在 Flutter master 分支下就可以提前尝试 wasm 的支持,运行 flutter build web --help 如果出现下图所示场, 说明支持 wasm 编译。
之后执行 flutter build web --wasm 就可以编译一个带有 native dart wasm 的 web 包,命令执行后,会将产物输出到 build/web_wasm 目录下。
之后你可以使用 pub 上的 dhttpd 包在 build/web_wasm目录下执行本地服务,然后在浏览器预览效果。
> cd build/web_wasm
> dhttpd
Server started on port 8080
目前需要版本 112 或更高版本的 Chromium 才能支持,同时需要启动对应的 Chrome 标识位:
enable-experimental-webassembly-stack-switchingenable-webassembly-garbage-collection
当然,目前阶段还存在一些限制,例如:
Dart Wasm 编译器利用了 JavaScript-Promise Integration (JSPI) 特性,Firefox 不支持 JSPI 提议,所以一旦 Dart 从 JSPI 迁移出来,Firefox 应启用适当的标志位才能运行。
另外还需要 JS-interop 支持,因为为了支持 Wasm,Dart 改变了它针对浏览器和 JavaScript 的 API 支持方式, 这种转变是为了防止把 dart:html 或 package:js 编译为 Wasm 的 Dart 代码,大多数特定于平台的包如 url_launcher 会使用这些库。
最后,目前 DevTools 还不支持 flutter run 去运行和调试 Wasm。
最后
很高兴能看到 Flutter 团队最终去定了 Web 的未来路线,这让 Web 的未来更加明朗,当然,正如前面所说的,Flutter 是第一个围绕 CanvasKit 和 WebAssembly 等新兴 Web 技术进行架构设计的框架。
所以 Flutter Web不是为了设计为通用 Web 的框架去 Angular 和 React 等竞争,它是让你在使用 Flutter 的时候,可以将能力很好地释放到 Web 领域,而 CanvasKit 带来的一致性更符合 Flutter Web 的定位,当然,解决加载时长问题会是任重道远的需求。
最后不得不提 WebGPU, WebGPU 作为新一代的 WebGL,可以提供在浏览器绘制 3D 的全新实现,它属于 GPU硬件(显卡)向 Web(浏览器)开放的低级 API,包括图形和计算两方面相关接口。
WebGPU 来自 W3C 制定的标准,与 WebGL 不同,WebGPU 不是基于 OpenGL ,它是一个新的全新标准,发起者是苹果,目前由 W3C GPU 与来自苹果、Mozilla、微软和谷歌一起制定开发,不同于 WebGL (OpenGL ES Web 版本),WebGPU 是基于 Vulkan、Metal 和 Direct3D 12 等,能提供更好的性能和多线程支持。
WebGPU 已经被正式集成到 Chrome 113 中,首个版本可在会支持 Vulkan 的 ChromeOS 设备、 Direct3D 12 的 Windows 设备和 macOS 的 Chrome 113 浏览器,除此之外 Linux、Android 也将在 2023 年内开始陆续发布,同步目前也初步登陆了 Firefox 和 Safari 。
提及 WebGPU 的原因在于:WebGPU + WebAssembly 是否在未来可以让 Web 也支持 Impeller 的可能?。
链接:https://juejin.cn/post/7232164444985622588
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Studio Bot - 让 AI 帮我写 Android 代码
Google I/O 2023
不出所料,今年的 I/O 大会只突出了一个关键词 “AI”。Google 旗下的各类产品都成了其展示 AI 实力的舞台。连面向开发者的产品 Android Studio 也新增了 Studio bot 功能,希望通过 AI 帮助开发者更轻松地写代码:
Studio Bot 使用谷歌编码基础模型 Codey(后者基于最新 PaLM2 大语言模型)帮助开发者生成程序代码,提升生产力。我们还可以向 Studio Bot 询问有关 Android 开发的知识,或者帮助修复当前代码中的错误。Studio Bot 正处于早期阶段,目前只对 US 地区开放,但是支持中文交流!感兴趣的小伙伴可以翻墙体验。
凡涉及到代码自然会让人担心到安全问题,Google 非常重视隐私安全,我们与 Studio Bot 的聊天内容不会被用作其他用途,可以放心使用。
Studio Bot 启动方式
1. 更新 Android Studio
更新到当前最新版的 Android Studio Hedgehog.
2. 打开功能视图
View > Tool Windows > Studio Bot
3. 登录账号
使用 Google 账号登录,点击 Next 就可以开始对话了
Studio Bot 可以做什么?
1. 生成代码
这是非常实用的功能,我们可以让 Studio Bot 帮我们生成所需的代码。而且相对于依靠搜索得到的各种参差不齐的信息,Studio Bot 通过强大的生成式 AI 能力,给出的答案可读性更好,质量更可靠。例如,我需要一段创建 Room 数据库的代码,得到的回答如下:
而且,Studio Bot能够记住对话的上下文,你可以追加相关问题,它可以自己理解你的意图,比如我希望将刚才生成的代码改为 Kotlin 的,如下:
代码变成了 Kotlin 版本,还配了详细的说明
2. 回答问题
回答各种技术问题,比如关于 Android Studio 使用技巧,甚至任何通用的 Android 开发知识。
3. 解读代码
这个功能相当炸裂,你可以选中 IDE 中的任意代码片段,去 Ask Studio Bot 获取代码的解读。
以下是解读的结果,将每一行代码翻译成更能听懂的“人话”。 Studio Bot 是支持中文的,中文回答的效果看起来也不错,对技术词语的翻译很到位,一点不晦涩。
对于很多一眼看不懂的花哨代码,将会非常有用,是大家学习开源项目的利器!
一些常见问题
1. Studio Bot 会将我的代码发送到 Google 服务器吗?
发送给 Studio Bot 的代码需要上传服务器才能获得回答,但是这些代码不会被滥用,如果你担心代码安全可以不提问关于你的代码的问题,IDE 的私有代码绝不会被私自上传服务器
2. 代码会用来训练 Studio Bot 模型吗
Ask Studio Bot 这样的功能不会将你的代码送去训练模型,只是用来获取问题答案
3. Studio Bot 的回答是准确无误的吗?
Studio Bot 目前还是实验性产品,无法保证答案的绝对正确。Bot 在回答后会跟有 “赞” 和 “踩”,通过这些反馈将帮助模型更好地成长,准确度会越来越高。
4. Studio Bot 可以提供关于代码的帮助吗?
当然,如前面介绍的,它可以生成代码,也可以基于你的代码提供一些解读,它主要的场景就是服务写代码这件事情
5. Studio Bot 在回答中如何引用来源?
Studio Bot 应该更多地生成原创内容,而不是复制已有内容。万一 Studio Bot 引用了大篇幅源码,那么它会标记引用来源,引用源可能涉及开源许可证,所以参考回答时也需要遵守许可证的要求。
6. 如何对 Studio Bot 进行反馈?
前面提到了,可以得到回答后,即时给出“赞”或者“踩”的反馈,帮助其成长,服务他人也更好地服务自己。
7. 可以问 Studio Bot 任何问题吗?
Studio Bot 是为了回答各类 Android 开发问题而生的,其他领域的问题它可能无法很好的回答。
8. 与其它大语言模型机器人(如 ChatGPT, GoogleBard 等)有什么不同?
Studio Bot 为 Android Studio 设计,可以与 IDE 很好的集成,提供很多开箱机用的面向编码的功能,这是一般的对话机器人所没有的。
9. 给一些使用建议?
问题尽量简洁清晰,如果 Bot 没有理解你的问题那可以重新组织一下语句,另外对于回答需要有所判断,毕竟这种生成式的答案无法保证绝对正确。
链接:https://juejin.cn/post/7231997803559141413
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android如何设计一个全局可调用的ViewModel对象?
很多时候我们需要维护一个全局可用的ViewModel,因为这样可以维护全局同一份数据源,且方便使用协程绑定App的生命周期。那如何设计全局可用的ViewModel对象?
一、思路
viewModel对象是存储在ViewModelStore中的,那么如果我们创建一个全局使用的ViewModelStore并且在获取viewModel对象的时候从它里面获取就可以了。
viewModel是通过ViewModelProvider的get方法获取的,一般是ViewModelProvider(owner: ViewModelStoreOwner, factory: Factory).get(ViewModel::class.java)。
如何将ViewModelProvider与ViewModelStore关联起来? 纽带就是ViewModelStoreOwner, ViewModelStoreOwner是一个接口,需要实现getViewModelStore()方法,而该方法返回的就是ViewModelStore:
public interface ViewModelStoreOwner {
/**
* Returns owned {@link ViewModelStore}
*
* @return a {@code ViewModelStore}
*/
@NonNull
ViewModelStore getViewModelStore(); //返回一个ViewModelStore
}
让某个类实现这个接口,重写方法返回我们定义的ViewModelStore就可以了。
至于上面ViewModelProvider构造方法的第二个参数Factory是什么呢?
源码中提供了二种Factory,一种是NewInstanceFactory,一种是AndroidViewModelFactory,它们的主要区别是:
NewInstanceFactory创建ViewModel时,会为每个Activity或Fragment创建一个新的ViewModel实例,这会导致ViewModel无法在应用程序的不同部分共享数据。(ComponentActivity源码getDefaultViewModelProviderFactory方法)
AndroidViewModelFactory可以访问应用程序的全局状态,并且ViewModel实例可以在整个应用程序中是共享的。
根据我们的需求,需要用的是AndroidViewModelFactory。
二、具体实现
1、方式一:可以全局添加和获取任意ViewModel
定义Application,Ktx.kt文件
import android.app.Application
lateinit var appContext: Application
fun setApplicationContext(context: Application) {
appContext = context
}
定义全局可用的ViewModelOwner实现类
object ApplicationScopeViewModelProvider : ViewModelStoreOwner {
private val eventViewModelStore: ViewModelStore = ViewModelStore()
override fun getViewModelStore(): ViewModelStore {
return eventViewModelStore
}
private val mApplicationProvider: ViewModelProvider by lazy {
ViewModelProvider(
ApplicationScopeViewModelProvider,
ViewModelProvider.AndroidViewModelFactory.getInstance(appContext)
)
}
fun <T : ViewModel> getApplicationScopeViewModel(modelClass: Class<T>): T {
return mApplicationProvider.get(modelClass)
}
}
定义一个ViewModel通过StateFlow定义发送和订阅事件的方法
class EventViewModel : ViewModel() {
private val mutableStateFlow = MutableStateFlow(0)
fun postEvent(state: Int) {
mutableStateFlow.value = state
}
fun observeEvent(scope: CoroutineScope? = null, method: (Int) -> Unit = { _ -> }) {
val eventScope = scope ?: viewModelScope
eventScope.launch {
mutableStateFlow.collect {
method.invoke(it)
}
}
}
}
定义一个调用的类
object FlowEvent {
//发送事件
fun postEvent(state: Int) {
ApplicationScopeViewModelProvider.getApplicationScopeViewModel(EventViewModel::class.java)
.postEvent(state)
}
//订阅事件
fun observeEvent(scope: CoroutineScope? = null, method: (Int) -> Unit = { _ -> }) {
ApplicationScopeViewModelProvider.getApplicationScopeViewModel(EventViewModel::class.java)
.observeEvent(scope, method)
}
}
测试代码如下:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
//打印协程名称
System.setProperty("kotlinx.coroutines.debug", "on")
FlowEvent.observeEvent {
printMsg("MainActivity observeEvent before :$it")
}
//修改值
FlowEvent.postEvent(1)
FlowEvent.observeEvent {
printMsg("MainActivity observeEvent after :$it")
}
}
}
//日志
内容:MainActivity observeEvent before :0 线程:main @coroutine#1
内容:MainActivity observeEvent before :1 线程:main @coroutine#1
内容:MainActivity observeEvent after :1 线程:main @coroutine#2
2、方式二:更方便在Activity和Fragment中调用
定义Application,让BaseApplication实现ViewModelStoreOwner
//BaseApplication实现ViewModelStoreOwner接口
class BaseApplication : Application(), ViewModelStoreOwner {
private lateinit var mAppViewModelStore: ViewModelStore
private var mFactory: ViewModelProvider.Factory? = null
override fun onCreate() {
super.onCreate()
//设置全局的上下文
setApplicationContext(this)
//创建ViewModelStore
mAppViewModelStore = ViewModelStore()
}
override fun getViewModelStore(): ViewModelStore = mAppViewModelStore
/**
* 获取一个全局的ViewModel
*/
fun getAppViewModelProvider(): ViewModelProvider {
return ViewModelProvider(this, this.getAppFactory())
}
private fun getAppFactory(): ViewModelProvider.Factory {
if (mFactory == null) {
mFactory = ViewModelProvider.AndroidViewModelFactory.getInstance(this)
}
return mFactory as ViewModelProvider.Factory
}
}
Ktx.kt文件也有变化,如下
lateinit var appContext: Application
fun setApplicationContext(context: Application) {
appContext = context
}
//定义扩展方法
inline fun <reified VM : ViewModel> Fragment.getAppViewModel(): VM {
(this.requireActivity().application as? BaseApplication).let {
if (it == null) {
throw NullPointerException("Application does not inherit from BaseApplication")
} else {
return it.getAppViewModelProvider().get(VM::class.java)
}
}
}
//定义扩展方法
inline fun <reified VM : ViewModel> AppCompatActivity.getAppViewModel(): VM {
(this.application as? BaseApplication).let {
if (it == null) {
throw NullPointerException("Application does not inherit from BaseApplication")
} else {
return it.getAppViewModelProvider().get(VM::class.java)
}
}
}
在BaseActivity和BaseFragment中调用上述扩展方法
abstract class BaseActivity: AppCompatActivity() {
//创建ViewModel对象
val eventViewModel: EventViewModel by lazy { getAppViewModel() }
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
}
}abstract class BaseFragment: Fragment() {
//创建ViewModel对象
val eventViewModel: EventViewModel by lazy { getAppViewModel() }
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
}
}
测试代码
class MainActivity : BaseActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
//打印协程名称
System.setProperty("kotlinx.coroutines.debug", "on")
eventViewModel.observeEvent {
printMsg("MainActivity observeEvent :$it")
}
findViewById<AppCompatButton>(R.id.bt).setOnClickListener {
//点击按钮修改值
eventViewModel.postEvent(1)
//跳转到其他Activity
Intent(this, TwoActivity::class.java).also { startActivity(it) }
}
}
}class TwoActivity : BaseActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_two)
eventViewModel.observeEvent {
printMsg("TwoActivity observeEvent :$it")
}
}
}
日志
内容:MainActivity observeEvent :0 线程:main @coroutine#1
内容:MainActivity observeEvent :1 线程:main @coroutine#1
内容:TwoActivity observeEvent :1 线程:main @coroutine#2链接:https://juejin.cn/post/7233686528328286245
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2023年的现代安卓开发
2023年的现代安卓开发
大家好👋🏻, 我想和大家分享一下如何用2023年的最新趋势构建Android应用.
免责声明
这是一篇来自我的观点和专业经验的文章, 考虑到了安卓开发者社区的不同意见, 也不断回顾了谷歌为安卓提供的指南.
我必须明确指出, 有一些非常有趣的工具, 模式和架构, 我可能没有提到, 但这并不意味着它们不能成为开发Android应用程序的其他有趣的选择.
什么是Android?
Android是一个基于Linux内核的开源操作系统, 由谷歌开发.它被广泛用于各种设备, 包括智能手机, 平板电脑, 电视和智能手表.
目前, 安卓是世界上移动设备使用最多的操作系统;根据statcounter的报告, 以过去12个月为样本, 安卓的市场份额为71.96%.
接下来, 我将提到一个工具, 库, 架构, 指南和其他实用工具的清单, 我认为这些工具对在Android上构建现代应用程序非常重要.
Kotlin ❤️
Kotlin是由JetBrains开发的一种编程语言.由谷歌推荐, 谷歌在2017年5月正式宣布了它(见这里的出版物).它是一种现代编程语言, 具有与Java的兼容性, 可以在JVM上运行, 这使得它在Android应用开发中的采用速度非常快.
无论你是否是安卓新手, 你都应该考虑将Kotlin作为你的首选, 不要逆水行舟🏊🏻 😎, 谷歌在2019年谷歌I/O大会上宣布了这一做法.使用Kotlin, 你将能够使用现代语言的所有功能, 包括Coroutines的强大实力和使用为Android生态系统开发的现代库.
官方kotlin文档在这里
Jetpack Compose 😍
Jetpack Compose是Android推荐的用于构建本地UI的现代工具包.它简化并加速了Android上的UI开发.
Jetpack Compose是Android Jetpack库的一部分, 使用Kotlin编程语言来轻松创建本地用户界面.同时, 它还与其他Android Jetpack库(如LiveData和ViewModel)集成, 使其更容易建立反应性和可维护的Android应用程序.
Jetpack Compose的一些主要特点包括:
- 声明式UI.
- 可定制的小工具.
- 易于与现有代码集成.
- 实时预览.
- 改进性能.
资源:
Android Jetpack
Jetpack是一套库, 帮助开发人员遵循最佳实践, 减少模板代码, 并编写在不同的Android版本和设备上一致运行的代码, 以便开发人员可以专注于他们关心的代码.
它的一些最常用的工具是:
Material Design
Material Design是一个由指导方针, 组件和工具组成的适应性系统, 支持用户界面设计的最佳实践.在开源代码的支持下, Material Design简化了设计师和开发人员之间的合作, 并帮助团队快速建立漂亮的产品.
Material Design得到了来自谷歌的设计师和开发人员的支持, 它将使我们有一个指南来为我们的Android, Flutter和Web的UI/UX工作.
目前, Material Design的最后一个版本是3, 你可以看到更多这里.
Clean Architecture
Clean Architecture的概念是由Robert C. Martin提出的.它的基础是通过将软件划分为不同的层来分离责任.
特点:
- 独立于框架.
- 可测试.
- 独立于用户界面.
- 独立于数据库.
- 独立于任何外部代理.
依赖性规则
博文Clean Architecture对依赖性规则做了很好的描述.
使得这个架构发挥作用的首要规则是依赖性规则.这个规则说, 源代码的依赖关系只能指向内部.内圈的任何东西都不能知道外圈的任何东西.特别是, 外圈中声明的东西的名字不能被内圈中的代码所提及.这包括, 函数, 类, 变量或任何其他命名的软件实体.
安卓系统中的Clean Architecture
- 表示层: Activities, Fragments, ViewModels, 其他视图组件.
- 领域层: 用例, 实体, 仓库, 其他的域组件.
- 数据层: 存储库的实现, 映射器, DTO等.
Presentation层的架构模式
架构模式是一种更高层次的策略, 旨在帮助设计一个软件架构, 其特点是在一个可重复使用的框架内为常见的架构问题提供解决方案.架构模式类似于设计模式, 但它们的规模更大, 解决的是更多的全局性问题, 如系统的整体结构, 组件之间的关系以及数据的管理方式.
在Presentation层中, 我们有一些架构模式, 其中我想强调以下几点:
- MVVM
- MVI
我不想逐一解释, 因为在互联网上你可以找到太多的相关信息.
此外, 你还可以看看应用架构指南
依赖注入
依赖注入是一种软件设计模式, 它允许客户端从外部来源获得其依赖, 而不是自己创建.它是一种在对象和其依赖关系之间实现反转控制(IoC)的技术.
模块化
模块化是一种软件设计技术, 它允许你将一个应用程序划分为独立的模块, 每个模块都有自己的功能和责任.
模块化的好处
可重复使用: 通过拥有独立的模块, 它们可以在应用程序的不同部分甚至在其他应用程序中重复使用.
严格的可见性控制: 模块使你能够轻松地控制你向你的代码库的其他部分暴露的内容.
可定制的交付: Google Play的特性交付使用应用程序捆绑的高级功能, 允许你有条件地或按需交付你的应用程序的某些功能.
可扩展性: 通过独立的模块, 功能可以被添加或删除而不影响应用程序的其他部分.
易于维护: 通过将应用程序分为独立的模块, 每个模块都有自己的功能和责任, 更容易理解和维护代码.
易于测试: 通过拥有独立的模块, 它们可以被隔离测试, 这使得检测和修复错误变得容易.
架构的改进: 模块化有助于改善应用程序的架构, 使代码有更好的组织和结构.
改进协作: 通过独立的模块, 开发人员可以同时工作在应用程序的不同部分, 不受干扰.
构建时间: 一些Gradle功能, 如增量构建, 构建缓存或并行构建, 可以利用模块化来提高构建性能.
更多内容请见官方文档.
网络
序列化
在本节中, 我想提及我认为的两个重要工具: Moshi与Retrofit一起广泛使用, 以及Kotlin Serialization, 这是Jetbrain的Kotlin团队的赌注.
Moshi和Kotlin Serialization是Kotlin和Java的两个序列化/反序列化库, 允许你将对象转换成JSON或其他序列化格式, 反之亦然.两者都提供了一个用户友好的界面, 为在移动和桌面应用程序中使用而优化.Moshi主要专注于JSON序列化, 而Kotlin Serialization则支持各种序列化格式, 包括JSON.
图像加载
要从互联网上加载图片, 有几个第三方库可以帮助你处理这个过程.图片加载库为你做了很多繁重的工作;它们既能处理缓存(这样你就不会多次下载图片), 也能处理网络逻辑以下载图片并在屏幕上显示.
Reactivity / Thread Management反应性/线程管理
当我们谈论反应式编程和异步进程时, 我们的第一选择是Kotlin Coroutines;由于suspend函数和Flow, 我们可以满足所有这些需求.然而, 我认为在这一节中值得强调的是RxJava的重要性, 即使在Android应用程序的开发中.对于我们这些已经在Android上工作了几年的人来说, 我们知道RxJava是一个非常强大的工具, 它有非常多的功能来处理数据流.今天我仍然认为RxJava是一个值得考虑的替代方案.
本地存储
在构建移动应用程序时, 很重要的一点是要有在本地持久化数据的能力, 比如一些会话数据或缓存数据等等.根据你的应用程序的需要, 选择合适的存储方式是很重要的.我们可以存储非结构化的数据, 如键值或结构化的数据, 如数据库.请记住, 这一点并没有提到我们可用的所有本地存储类型(如文件存储), 只是提到了允许我们保存数据的工具.
建议:
- S̶h̶a̶r̶e̶d̶P̶r̶e̶f̶e̶r̶e̶n̶c̶e̶s̶
- DataStore
- EncryptedSharedPreferences
测试
R8优化
R8是默认的编译器, 它将你项目的Java字节码转换为在Android平台上运行的DEX格式.它是一个帮助我们混淆和减少应用程序代码的工具, 通过缩短类和其属性的名称, 消除项目内未使用的代码和资源.想了解更多, 请查看Android文档中关于缩减, 混淆和优化你的应用程序.
- 代码缩减
- 资源缩减
- 混淆
- 优化
Play特性交付
Google Play的应用服务模式, 称为动态交付, 使用Android App Bundles为每个用户的设备配置生成和提供优化的APK, 因此用户只下载运行你的应用所需的代码和资源.
自适应布局
随着具有不同外形尺寸的移动设备使用的增长, 我们需要有一些工具, 使我们的Android应用程序能够适应不同类型的屏幕.这就是为什么Android为我们提供了Window Size类, 简单地说, 它是三个大的屏幕格式组, 为我们开发设计标记了关键点.这样我们就避免了考虑许多屏幕设计的复杂性, 将我们的可能性减少到三组, 即: Compat, Medium 和 Expanded..
Windows Size类
我们拥有的另一个重要资源是经典布局, 这是预定义的屏幕设计, 可以用于我们的安卓应用中的大多数场景, 还向我们展示了如何将其适应大屏幕的指南.
其他相关资源
性能
当我们为Android开发应用程序时, 我们必须确保用户体验更好, 不仅是在应用程序的开始, 而且在整个执行过程中.出于这个原因, 重要的是要有一些工具, 使我们能够对可能影响应用程序性能的情况进行预防性分析和持续监测, 因此, 这里有一个工具清单, 可以帮助你达到这个目的:
应用内更新
当你的用户在他们的设备上保持你的应用程序的更新时, 他们可以尝试新的功能, 以及从性能改进和错误修复中获益.虽然有些用户在他们的设备连接到无计量的连接时启用后台更新, 但其他用户可能需要被提醒安装更新.应用内更新是Google Play核心库的一项功能, 提示活跃用户更新你的应用.
应用内更新功能在运行Android 5.0(API级别21)或更高的设备上得到支持.此外, 应用内更新仅支持Android移动设备, Android平板电脑和Chrome OS设备.
应用内评论
Google Play应用内评论API让你可以提示用户提交Play Store的评分和评论, 而不需要离开你的应用或游戏, 这很方便.
一般来说, 应用内评论流程可以在你的应用的整个用户旅程中的任何时候被触发.在流程中, 用户可以使用1至5星系统对你的应用程序进行评分, 并添加一个可选的评论.一旦提交, 评论将被发送到Play Store并最终显示出来.
为了保护用户隐私和避免API被滥用, 您的应用程序应遵循关于何时请求应用内评论和评论提示的设计的严格准则.
- 应用内评论文档
辅助功能
辅助功能是软件设计和建造的一个重要特征, 除了改善他们的用户体验外, 还为有可访问性需求的人提供了使用应用程序的能力.这个概念旨在改善的一些残疾是:有视力问题的人, 色盲, 听力问题, 灵巧问题和认知障碍等等.
考虑的因素:
- 增加文本的可见性(颜色对比, 可调整文本).
- 使用大型, 简单的控件
- 描述每个用户界面元素
安全性
安全性是我们在开发保护设备的完整性, 数据的安全性和用户的信任的应用程序时必须考虑的一个方面, 甚至是最重要的方面, 这就是为什么我在下面列出了一系列的提示, 将帮助你实现这一目的.
- 加密敏感数据和文件: 使用EncryptedSharedPreferences和EncryptedFile.
- 应用基于签名的权限:
- 在你能控制的应用程序之间共享数据时, 使用基于签名的权限.
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.myapp">
<permission android:name="my_custom_permission_name"
android:protectionLevel="signature" />
- 不要将应用程序配置所需的密钥, 令牌或敏感数据直接放在项目库内的文件或类中.使用local.properties代替.
版本目录
Gradle提供了一种集中管理项目依赖关系的标准方式, 称为版本目录;它在7.0版本中试验性地引入, 并在7.4版本中正式发布.
优点是:
- 对于每个目录, Gradle都会生成类型安全的访问器, 这样你就可以在IDE中用自动完成的方式轻松添加依赖关系.
- 每个目录对一个构建的所有项目都是可见的.它是一个集中的地方, 可以声明一个依赖的版本, 并确保对该版本的改变适用于每个子项目.
- 目录可以声明依赖包, 这是通常一起使用的"依赖包组".
- 目录可以将依赖的组和名称与它的实际版本分开, 并使用版本参考来代替, 这样就可以在多个依赖之间共享一个版本声明.
Logger
Logger是一种软件工具, 用于登记有关程序执行的信息;重要事件, 错误调试信息和其他可能对诊断问题或了解程序如何工作有用的信息.记录器可以被配置为将信息写入不同的位置, 如日志文件, 控制台, 数据库, 或通过将信息发送到日志服务器.
Linter
Linter是一种编程工具, 用于分析程序源代码, 以发现代码中的潜在问题或漏洞.这些问题可能是语法问题, 不恰当的代码风格, 缺乏文档, 安全问题等等, 它们会对代码的质量和可维护性产生影响.
链接:https://juejin.cn/post/7229151797415051322
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
短短1个小时,让公司损失近3万
这是一个悲伤的故事,也是教训最深刻的一次。发生在2022年1月份,春节前几周。在聊这个事之前,我想借用美团的一个案例作为切入点。
(我们公司不是美团的这种业务,但也利用了会员发券这种机制,都是在待支付勾选会员产生待使用的券,最后选择使用,这里我就拿美团来讲)
先来看下面这幅图,大家点外卖再熟悉不过的一个页面!
当勾选开通会员时,系统会自动给你发6张优惠券(取消勾选,则6张券消失)
那么问题来了,这6张券是怎样的一种方式存在?
因为这里要考虑到,用户勾选只是勾选,还没有真正的发到用户钱包里,只有用户支付了,才能真正给用户发送,这里面就牵扯到这个临时数据怎么处理更好
我想了想,无非三种
前端自己生成数据,给后端规约传参
后台落noSql,用户在选择券的时候,后台查询优惠券接口会把noSql里的东西也带上
后台存关系型数据库,这里就会牵扯到太多的垃圾数据,因为很多用户可能只是勾选,并不会购买
大的方面应该就这三种,至于细节,那各凭本事,看谁处理的好。
最难的需求
时间拉回到今年1月份,这是春节前最悠哉的时光,年终奖都定好了!
忽然开会说要在待支付界面引入会员机制,周期为一周,快速上线,要先看数据。根据数据节后再做调整。没给开发留一点点评估的时间,还没容得上我们说话,就。。。。
这里简单说下需求吧:
平台会员原来就有,只是没有介入到待支付,原来购买平台会员发两张券,这次到待支付要根据用户不同的属性发送不同的券,张数也不尽相同
作为产品部的技术负责人,在这个周期范围内,首要做的就是看如何快速上线,我和产品商量砍了很多需求,原型设计上的很多细节都包括在内,否则干死都不一定能上线(天下产品都一样,研发不硬,产品必欺。但这次是运营是拿着尚方宝剑给产品下的命令,时间既然是不能变的,那就只能把需求点减到最少)
就这样,技术方案用了最简单的,也是最不安全的,没错,全部交给前端去生成券的数据。金额都是写死的,说白了,就是前端按照ui图出的,后台没有出接口,因为在整体支付流程还有大量工作需要因为平台会员的介入而有大量工作(别说不专业,没办法)。
所以,减免多少钱,是由前端传的(这里可能很多人会笑话我,因为没有一家是前端传金额的,是的,我们做了)
看到这里肯定有人说,虽然不合理,但是应该也不会有大问题啊。
可是问题就是爆发出来了。我们有一种券,叫”全免券“,就可以免掉本次费用。前端因为很多数据写死了,结果这个全免券没有考虑进去。测试当时测试的时候也忽略了,导致线上在某种情况下会走全免券的机制
黑色星期五
我们任何上线的时间都会定到周四晚上,因为周四升级,周五如果有问题,可以处理回退。
清晨睡的正香,电话响了,一看群里,炸锅了。我们的用户端主要是微信小程序,了解的都知道有个审核期,后台服务晚上升级好之后,小程序是早上运维给审核通过的。
结果运营早上看到很多数据,好多用户支付都是0元,对比一看全都购买过平台会员。顿时我就没有了睡意,赶紧通知运维把小程序回退到上一个版本(幸亏后台接口兼容处理得当)
问题就是A类用户在B种情况下,传到后台就是走全免券的逻辑。
顿时“精神抖擞”的我收拾收拾背包去公司了
最后好像运营给出一个数据,3万左右。我私下里也大概算了下。。。。。。
年终奖整个team都削了点,包括我们部分老大,包括测试。主要责任在我,方案是我定的,确实不是最佳选择。
总结教训
这确实是我入行以来最大的bug,作为负责人没有处理好可能出现的问题,从方案到落地,需要慎之又慎。
协调各部门,统筹方案。
也给产品和运营个教训吧。就说到这里吧,希望给大家点经验,祝大家写不出八阿哥
链接:https://juejin.cn/post/7113502041342738439
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
面试题:Android 中 Intent 采用了什么设计模式?
答案是采用了原型模式。
原型模式的好处在于方便地拷贝某个实例的属性进行使用、又不会对原实例造成影响,其逻辑在于对 Cloneable 接口的实现。
话不多说看下 Intent 的关键源码:
// frameworks/base/core/java/android/content/Intent.java
public class Intent implements Parcelable, Cloneable {
...
private static final int COPY_MODE_ALL = 0;
private static final int COPY_MODE_FILTER = 1;
private static final int COPY_MODE_HISTORY = 2;
@Override
public Object clone() {
return new Intent(this);
}
public Intent(Intent o) {
this(o, COPY_MODE_ALL);
}
private Intent(Intent o, @CopyMode int copyMode) {
this.mAction = o.mAction;
this.mData = o.mData;
this.mType = o.mType;
this.mIdentifier = o.mIdentifier;
this.mPackage = o.mPackage;
this.mComponent = o.mComponent;
this.mOriginalIntent = o.mOriginalIntent;
...
if (copyMode != COPY_MODE_FILTER) {
...
if (copyMode != COPY_MODE_HISTORY) {
...
}
}
}
...
}
可以看到 Intent 实现的 clone() 逻辑是直接调用了 new 并传入了自身实例,而非调用 super.clone() 进行拷贝。
默认的拷贝策略是 COPY_MODE_ALL,顾名思义,将完整拷贝源实例的所有属性进行构造。其他的拷贝策略是 COPY_MODE_FILTER 指的是只拷贝跟 Intent-filter 相关的属性,即用来判断启动目标组件的 action、data、type、component、category 等必备信息。无视启动 flag、bundle 等数据。
// frameworks/base/core/java/android/content/Intent.java
public class Intent implements Parcelable, Cloneable {
...
public @NonNull Intent cloneFilter() {
return new Intent(this, COPY_MODE_FILTER);
}
private Intent(Intent o, @CopyMode int copyMode) {
this.mAction = o.mAction;
...
if (copyMode != COPY_MODE_FILTER) {
this.mFlags = o.mFlags;
this.mContentUserHint = o.mContentUserHint;
this.mLaunchToken = o.mLaunchToken;
...
}
}
}
还有中拷贝策略是 COPY_MODE_HISTORY,不需要 bundle 等历史数据,保留 action 等基本信息和启动 flag 等数据。
// frameworks/base/core/java/android/content/Intent.java
public class Intent implements Parcelable, Cloneable {
...
public Intent maybeStripForHistory() {
if (!canStripForHistory()) {
return this;
}
return new Intent(this, COPY_MODE_HISTORY);
}
private Intent(Intent o, @CopyMode int copyMode) {
this.mAction = o.mAction;
...
if (copyMode != COPY_MODE_FILTER) {
...
if (copyMode != COPY_MODE_HISTORY) {
if (o.mExtras != null) {
this.mExtras = new Bundle(o.mExtras);
}
if (o.mClipData != null) {
this.mClipData = new ClipData(o.mClipData);
}
} else {
if (o.mExtras != null && !o.mExtras.isDefinitelyEmpty()) {
this.mExtras = Bundle.STRIPPED;
}
}
}
}
}
总结起来:
| Copy Mode | action 等数据 | flags 等数据 | bundle 等历史 |
|---|---|---|---|
| COPY_MODE_ALL | YES | YES | YES |
| COPY_MODE_FILTER | YES | NO | NO |
| COPY_MODE_HISTORY | YES | YES | NO |
除了 Intent,Android 源码中还有很多地方采用了原型模式。
Bundle也实现了 clone(),提供了 new Bundle(this) 的处理:public final class Bundle extends BaseBundle implements Cloneable, Parcelable {
...
@Override
public Object clone() {
return new Bundle(this);
}
}
组件信息类
ComponentName也在 clone() 中提供了类似的实现:public final class ComponentName implements Parcelable, Cloneable, Comparable<ComponentName> {
...
public ComponentName clone() {
return new ComponentName(mPackage, mClass);
}
}
工具类
IntArray亦是如此:public class IntArray implements Cloneable {
...
@Override
public IntArray clone() {
return new IntArray(mValues.clone(), mSize);
}
}
原型模式也不一定非得实现 Cloneable,提供了类似的实现即可。比如:
Bitmap没有实现该接口但提供了copy(),内部将传递原始 Bitmap 在 native 中的对象指针并伴随目标配置进行新实例的创建:public final class ComponentName implements Parcelable, Cloneable, Comparable<ComponentName> {
...
public Bitmap copy(Config config, boolean isMutable) {
...
noteHardwareBitmapSlowCall();
Bitmap b = nativeCopy(mNativePtr, config.nativeInt, isMutable);
if (b != null) {
b.setPremultiplied(mRequestPremultiplied);
b.mDensity = mDensity;
}
return b;
}
}
链接:https://juejin.cn/post/7204013918958649405
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
落地包体积监控,用Kotlin写一个APK差异分析CLI
引言
当谈到包体积优化时,网上不乏优秀的方案与文章,如 混淆、资源、ReDex、R8、SO 优化等等。
但聊到 包体积监控 时,总是感觉会缺乏落地性,或者总是会下意识认为这可能比较麻烦,需要其他部门连同配合。通常对于有APM基础的团队而言,这倒不算什么,但往往对于小公司而言,到了这一步,可以说就戛然而止😶。
但回到问题本身,这并非难事。或者说,其实很简单 :)
计算差异 、通知 、汇总数据 ,三步即可。
按照最朴素的想法,无论多大的团队,也能至少完成前两步,事实上,也的确如此。
故此,本篇将结合实际需求以及背景,使用 Kotlin 去写一个 APK差异化 对比的基础 CLI 工具,并搭配 CI 完成流水线监控。
本篇并不涉及深度源码等,更多是实操,所以文章风格比较轻松,可放心食用 😁
最终组件地址: Github
写在开始
关于 CLI(command-line interface) ,每个开发同学应该都非常熟悉,可以说基本就是日常操作,比如我们经常在 命令行 里会去敲几个命令,触发几个操作等,常见的 git、gradle 、java 等。
在图形化(GUI)的现在,CLI 往往代表着一种 老派风格 ,有人抵触,觉得繁琐🤨,当然也有同学觉得简单直接。
但总体上的趋势是,越来越多工具趋于图形化。不过两者依然处于一种 互补 ,而非竞争,不同场景也有各自的优势以及差异化。比如在某些场景下,当我们需要去 简化开发流程 时,此时 CLI 就会作为首选项就会映入眼前。
聊聊背景
最近在做 下厨房-懒饭App 的体积优化,优化做完了(后续出文章),那如何做防劣化呢?
因为我们的项目是在 Github 上托管,所以自然而然也有相应的 Action 作为check,所以此时首先最基础想的就是:
- 直接拉上一个版本的
apk作为基准包,然后和本次的包一个diff,并保存结果;
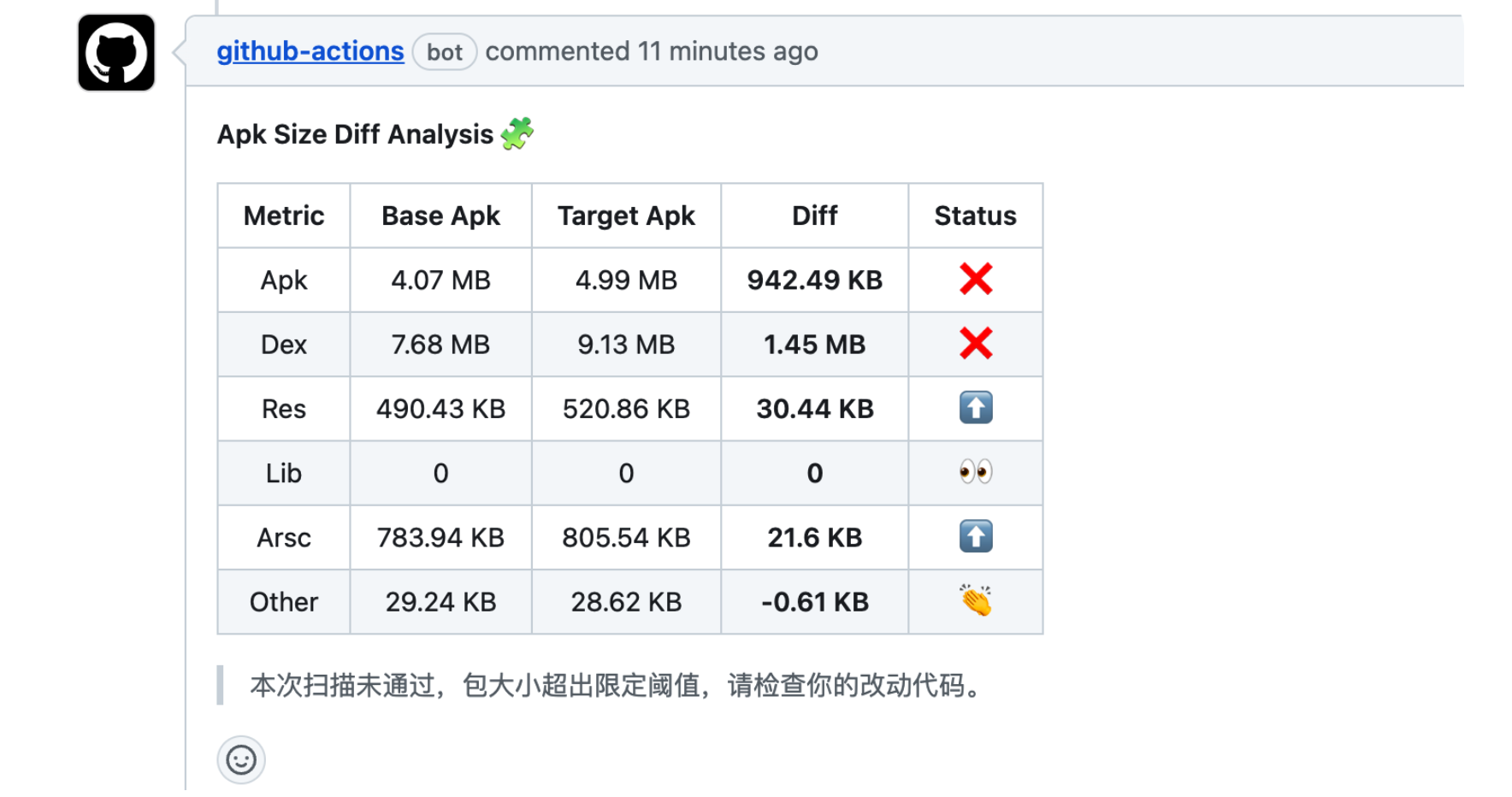
- 如果结果中,某个类别(如
res、dex等)超出指定阈值,则在PR里加一个🤖评论,以及飞书通知一下。
- 至于分版本统计结果等等,这些都是后话了…
先找轮子
思路有了,那关键的工具,diff工具 怎么搞?
作为一个正经的开发仔,所以此时首选肯定是去 Github Action 市场上找现成的(没事就别乱造轮子,你造的又没人家好😅)。
结果发现,还真有,真不戳!
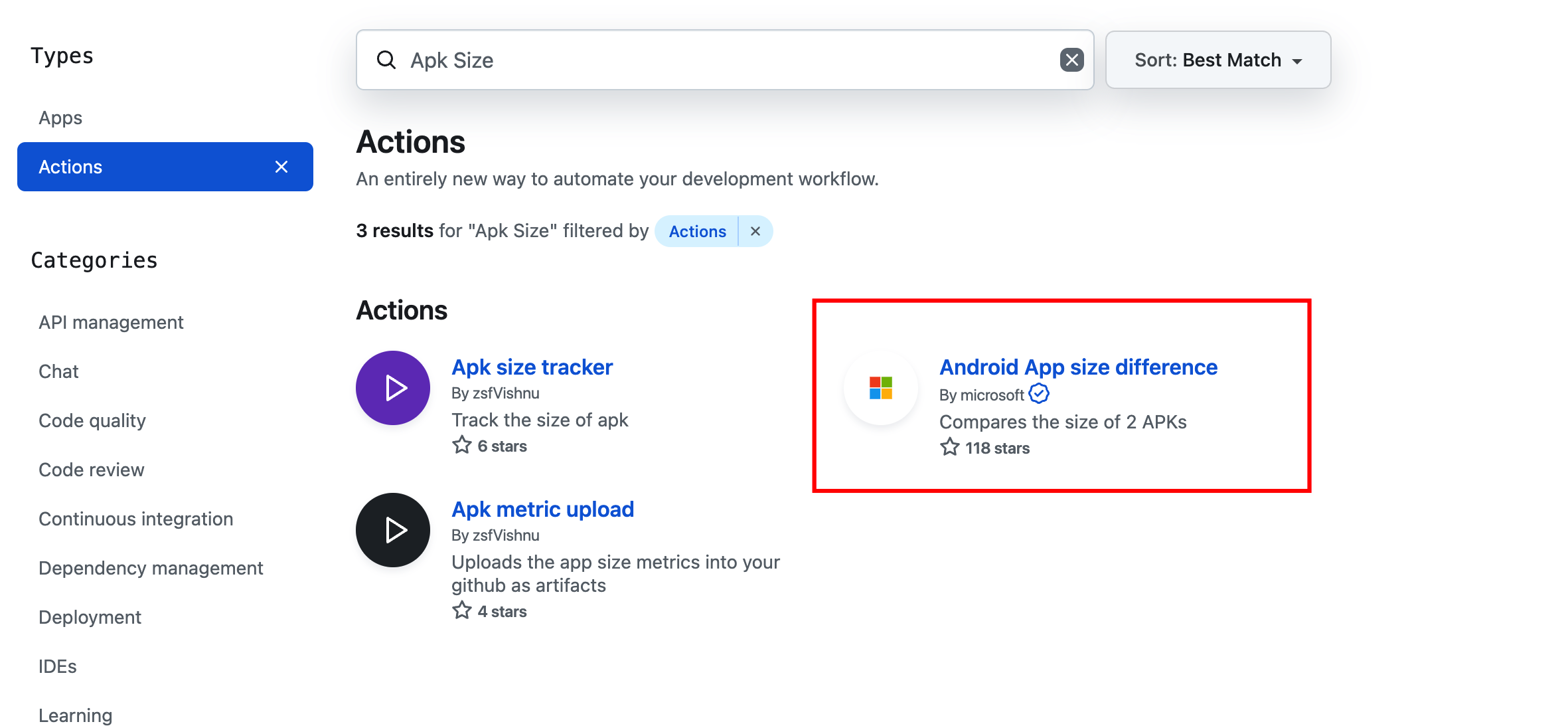
来自微软的开源,那肯定有保障啊!
集成看看效果:
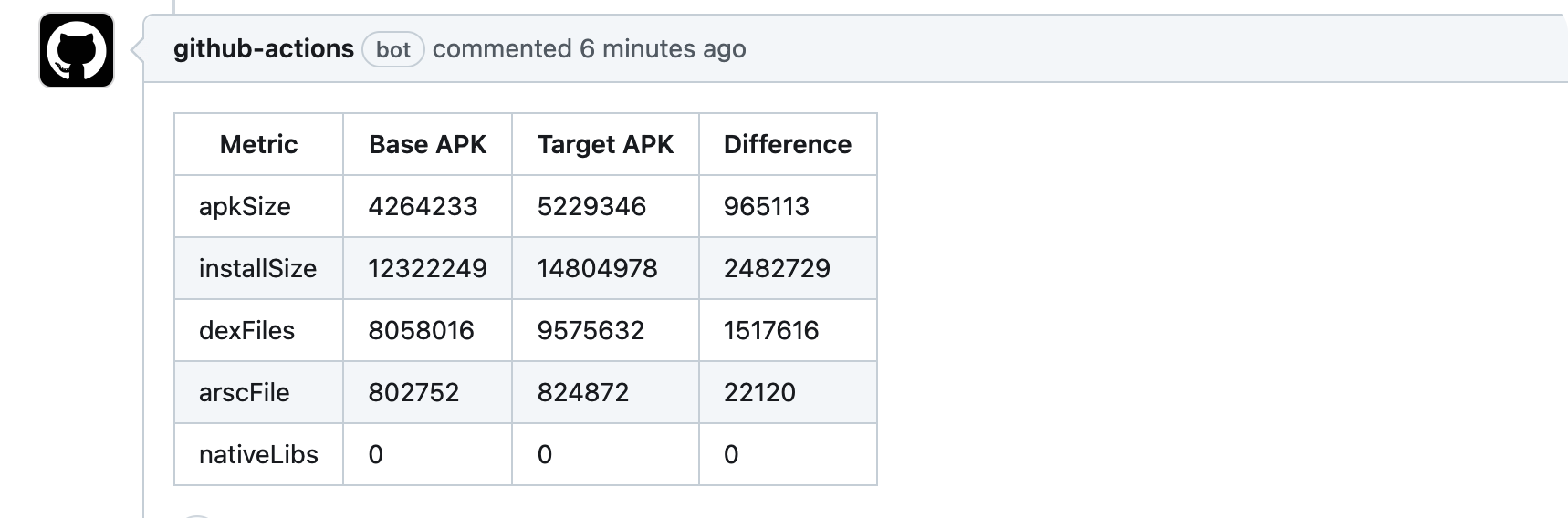
嗯,看着还不错,不过这个输出怎么改呢,官方只有MD格式,而且看着过糙,作为一个稍微有点审美的同学。
那就考虑先 fork 改一下呢,fork 前看了一下仓库:
我是辣鸡🥲,这下触摸到知识盲区了,压根不知道怎么改,无疑大大增加了后续迭代成本,以及看看上一次的版本时间(此处无声胜有声😶)。
那既然没有合适的 Action ,那就自己找一个 jar 工具也行啊,于是又去找了一下现有的jar工具,发现只有腾讯的 matrix-apk-canary 可用,但是这也太顶了吧。虽然功能强大,可是不符合我们现在的需要啊,我还得去手动算两次,然后再拿着json结果去对比,想想就复杂。
回到我们现在,我们完全不需要这么复杂,我们只是需要一个 diff工具 而已。
既然没有合适,那就自己造一个,反正diff逻辑也并不复杂。🤔
万事开头难
Jar怎么写?😅
是的,我也没写过这玩意,但本能觉得很简单。
先去 IDE 直接创建个项目,感觉应该选 JVM ,依赖配置上 Gradle 也更接近 Android 开发者的使用习惯,具体如下:
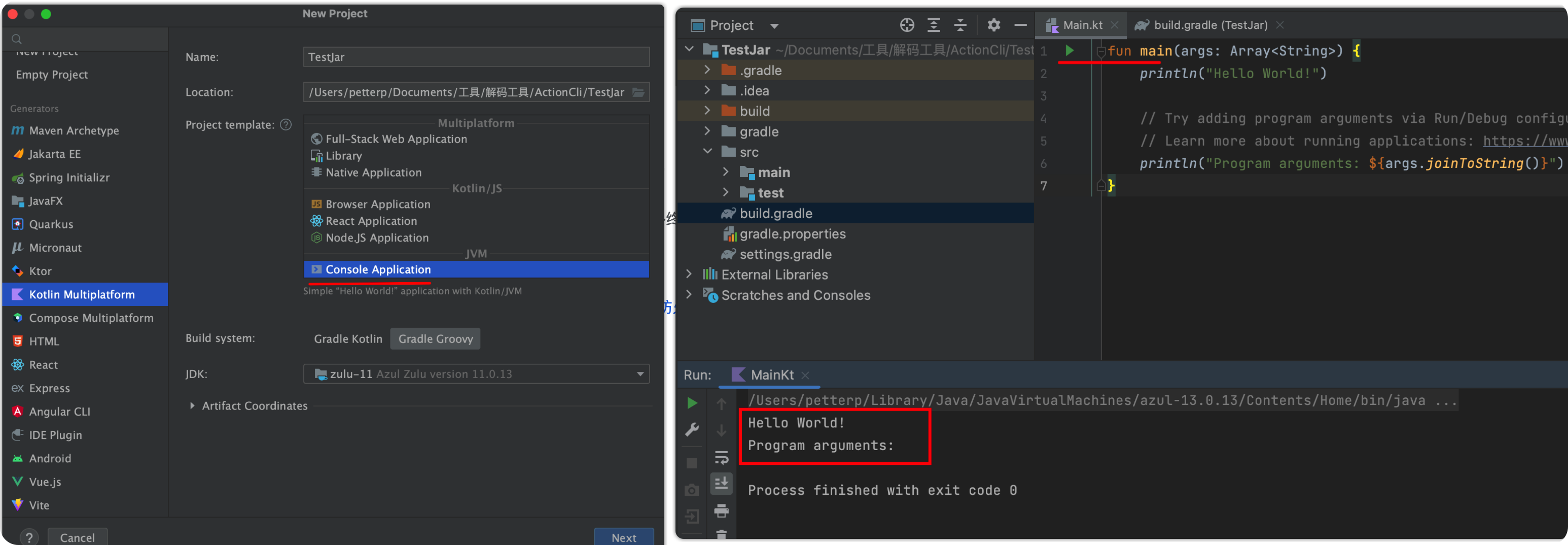
凭着以前用 IDE 学 Kotlin 时的记忆,Jvm 参数应该是在这里进行传递🤔:
输出也没啥问题,正常打印了出来:
Hello World!
Program arguments: Petterp,123
但这不是我要的样子啊,我的 理想状态 下是这种操作:
java -jar xxx.jar -x xxx
不过就算现在能直接这样使用,也不能进行快速开发,首先调试就是个麻烦事。
再回到原点,我甚至不知道怎么在命令行传参呢🥲
说说CLIKT
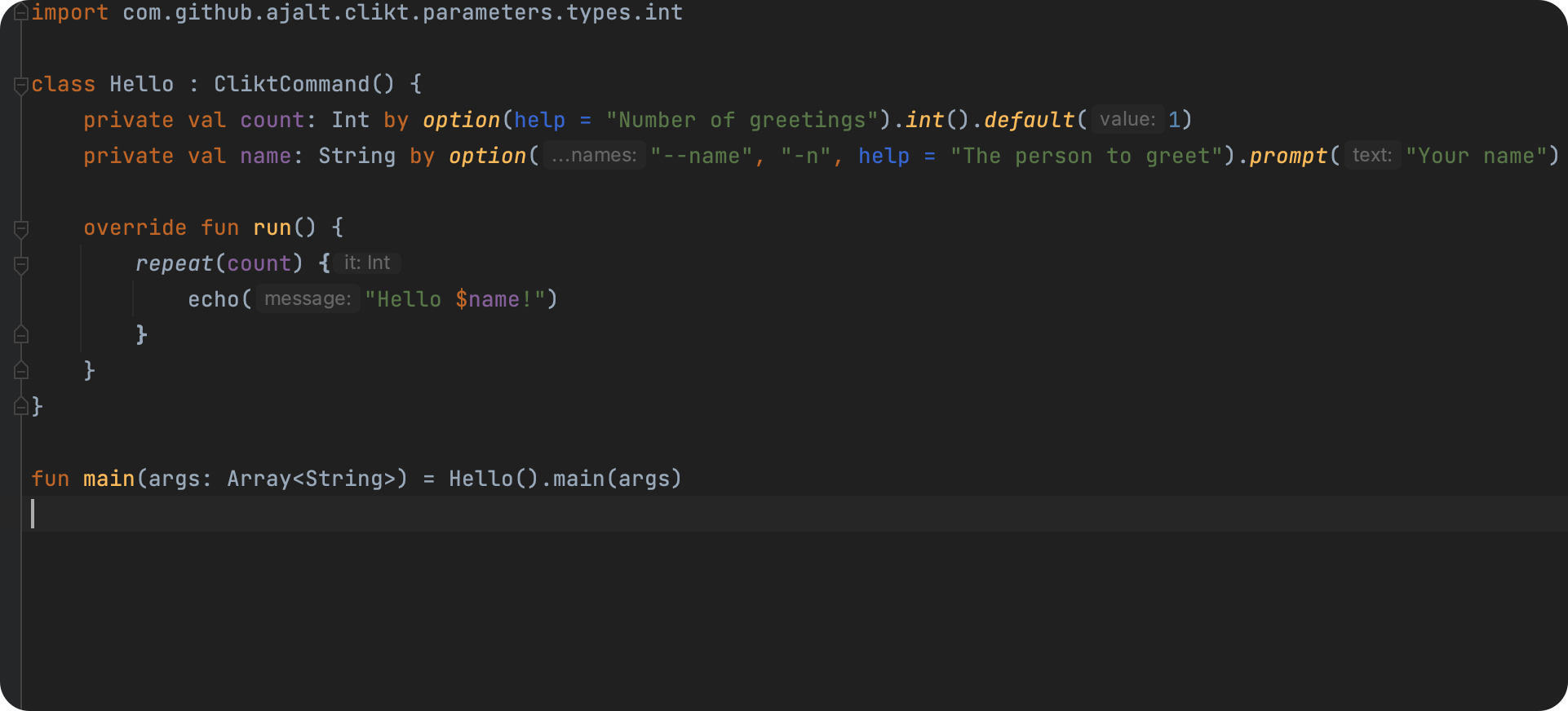
此时就不得不提一个开款库,用 Kotlin 写 CLI 的最强库: CLIKT ,也是无意之间发现的一个框架,可以说是神器不足为过。
简介
Clikt(发音为“clicked”)是一个多平台的 Kotlin 库,可以使编写命令行界面变得简单和直观,它是“Kotlin 的命令行界面”。
该库旨在使编写命令行工具的过程变得轻松,同时支持各种用例,并在需要时允许高级自定义。
Clikt 具有以下特点:
- 命令的任意嵌套;
- 可组合、类型安全的参数值;
- 生成帮助输出和 shell 自动完成脚本;
- 针对 JVM、NodeJS 和本地 Linux、Windows 和 MacOS 的多平台包;
简而言之,Clikt 是一个功能丰富的库,可以帮助开发者快速构建命令行工具,同时具有灵活的自定义和多平台支持。
以上来自官网文档。
依赖方式
因为我们是使用 Gradle 来进行依赖管理,所以直接添加相应的依赖即可:
implementation("com.github.ajalt.clikt:clikt:3.5.2")
同时因为使用的是 Gradle ,所以默认会带有一个 application 插件,因此提供一个 Gradle 任务,来将我们的 jar和脚本 控绑在一起启动(run Main时),从而免除了每次调试都要在命令行 java -jar xxx,非常方便。
示例效果
 |  |
|---|
代码也非常简单,我们定义了两个参数,count 与 name,其中 count 存在默认参数,而 name 没有,故需要我们必须传递,直接运行run方法,然后根据提示键入value即可,就这么简单。👏
在往常的jar命令里,通常都只存在一次性输入的场景。比如必须直接输入全部kay-value,如果输入错误,或者异常,日志或者输出全凭jar包开发者的自觉程度。可以说大多数jar包并不易用,当然这主要的原因是,传统的cli开发的确比较麻烦,并不是所有开发者都能完善好边界。
使用 CLIKT 之后,上面的问题可以说非常低成本解决,我们可以提前配置提示语句,报错语句等等。它可以做到提示使用者接下来该输入什么,也可以做到对输入进行check,甚至如果输入错误或者不符合要求,直接会进行提示,也可以选择继续让用户输入。
上述的示例只是非常简单的一个常见,CLIKT 官网有更多的用法以及高级示例,如果感兴趣,也可以看看。
常见问题
如何打jar包
上面我们实现了 jar包 的编写和本地调试,那该怎么打成 jar包 在命令行运行呢?
因为我们使用了 Gradle 进行依赖配置,那么相应的,也可以使用附带的命令即可,默认有这几个命令可供选择:
jar
直接打成jar包,后续直接在命令行java -jar 的方式驱动。
distTar||distZip
简单来说就是,同时会附带可执行程序
exec的方式,从而免除 java -jar 的硬编码,直接点击执行或者在命令行输入 文件名+附带的参数 即可。不过从打包方式上而言,其最终也需要依附于jar任务。
这里感谢 虾哥(掘金: 究极逮虾户) 解惑,原本以为
exec这种方式会导致传参时的部分默认值无法设置问题。
jar包没有主清单属性
上面打完jar包,在命令行运行时,报错如下:
xxx.jar中没有主清单属性
这是什么鬼,不是已经配置过了吗?直接 run main 方法没有什么问题啊?
application {
mainClassName = 'HelloKt'
}
经过一顿查阅,发现配置需要这样改一下,build.gradle 增加以下配置:
jar {
exclude("**/module-info.class")
from {
configurations.runtimeClasspath.collect {
it.isDirectory() ? it : zipTree(it)
}
}
manifest {
attributes 'Main-Class': "HelloKt"
}
}
原理也很简单,你打出来的 jar 包得配置路径啊。我们调试时走的 application 插件里的 run 。而打 jar 包, jar 命令没配置,导致其并不知道你的配置,所以不难理解为啥找不到主清单属性。
再聊实现思路
要对比 Apk 的差异,最简单的思路莫过于直接解压Apk。因为 Apk 其实是一种 Zip 格式,所以我们只需要遍历解压文件,根据文件后缀以及不同的文件夹分类统计大小即可,比较简单粗暴。
当然如果要做的更精细一点,比如要统计 资源文件差异 、代码增长 、aar变化 等,就要借助其他方式,比如 Android 团队就为我们提供了 apkanalyzer,或者可以通过 META-INF/MANIFEST.MF 文件作为基准进行对比。
业内开源的比较好的有腾讯的
matrix-apk-canary,其设计灵巧,功能也更加强大,具体在实现上,我们也可以借鉴其设计思想。
因为本次我们的需求无需上述那么复杂,只需要在意 apk 、资源 、dex 、lib 等差异,所以直接采用手动解压Apk的方式,手动统计,反而更加直接。
核心代码
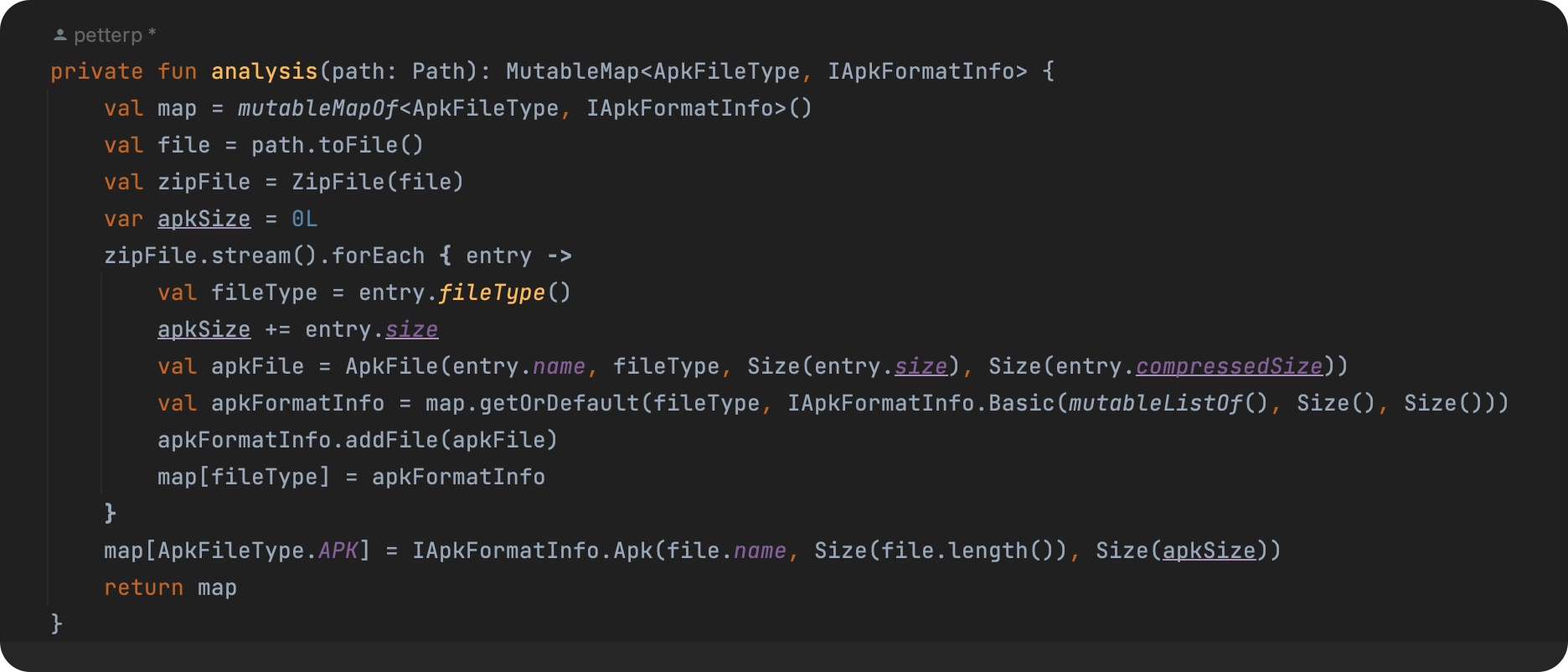
思路如下:
- 解压
apk,开始进行遍历; - 按照自定义的规则进行分类,从而得到apk的实际文件类型映射
Map; - 遍历过程中,同时 分类统计 各类型大小以及子集;
匹配与模型设计
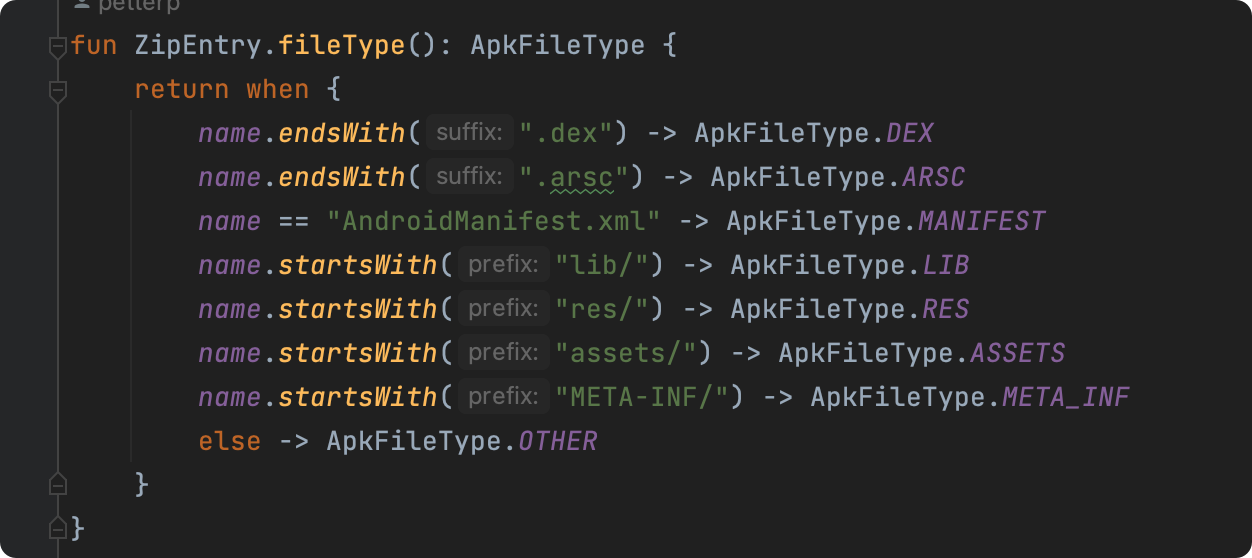 | 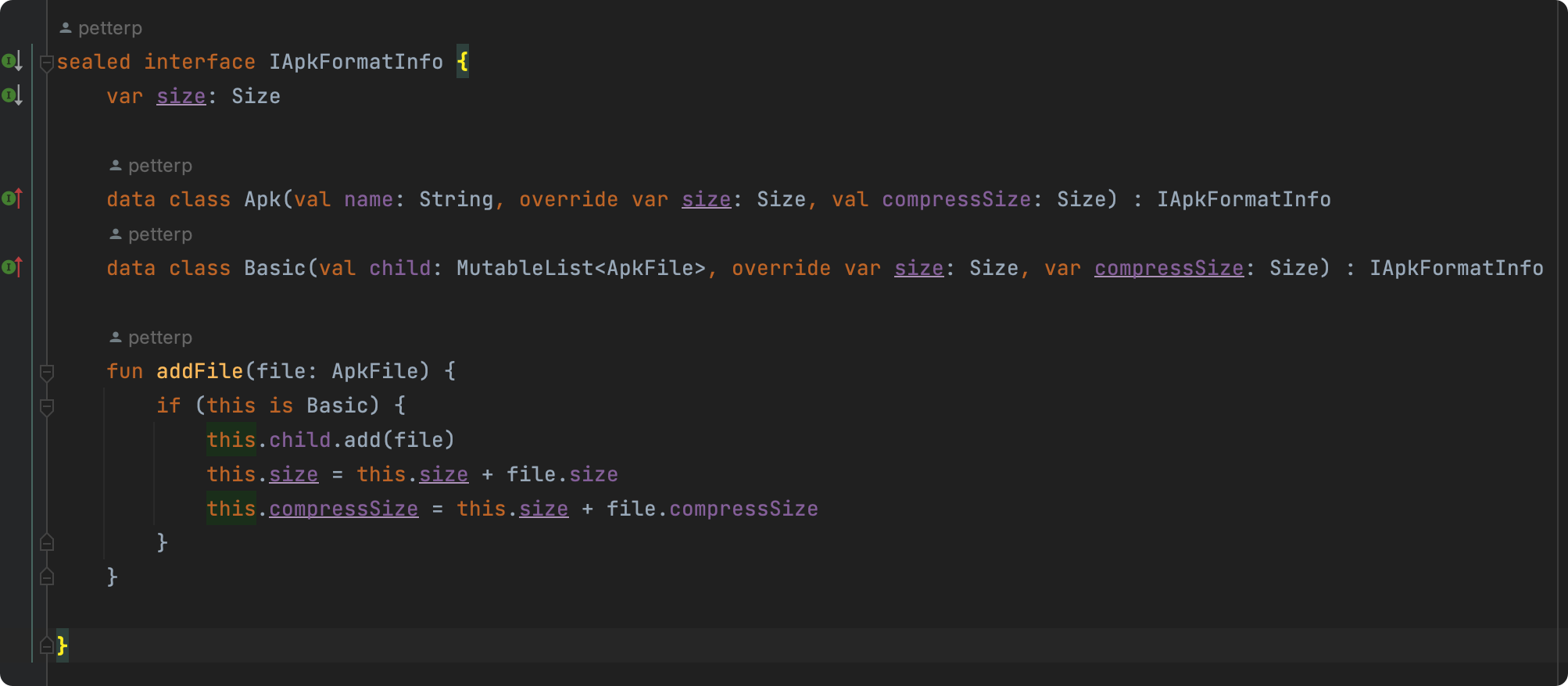 |
|---|---|
| 自定义规则 | 文件Model |
一些小Tips
关于分层的想法
一个合格 CLI 设计,基本应该包含下面的流程:
配置 -> 分析 -> 输出
配置
顾名思义,就是指的是开发者友好,即对用户而言,报错详细,配置灵巧,藏复杂于内部。
比如在阈值的设定上,除了最基本的分类,也要提供统一默认配置,同时要对用户键入的
key-value做基本的 check ,这些借助CLIKT框架能很低成本的实现。
分析
拿到上一步的配置结果后,接下来就要开始进行分析,此时我们要考虑设计上的分层,比如匹配规则如何定义,采用怎样的数据结构比较好,规则是否严谨,甚至如果要替换基础实现思路,改动会不会依然低成本;
输出
输出理论上应该包含多个途径,比如
json、md、命令行等等,不同的用户场景也必然不同。比如应用于CI、或者自定义结果统计等;在具体的设计上,开发者也应该考虑进行分层,比如输出这里只接受数据源,直接按照规则处理即可,而非再次对数据源进行修改。
灵活运用语言技巧
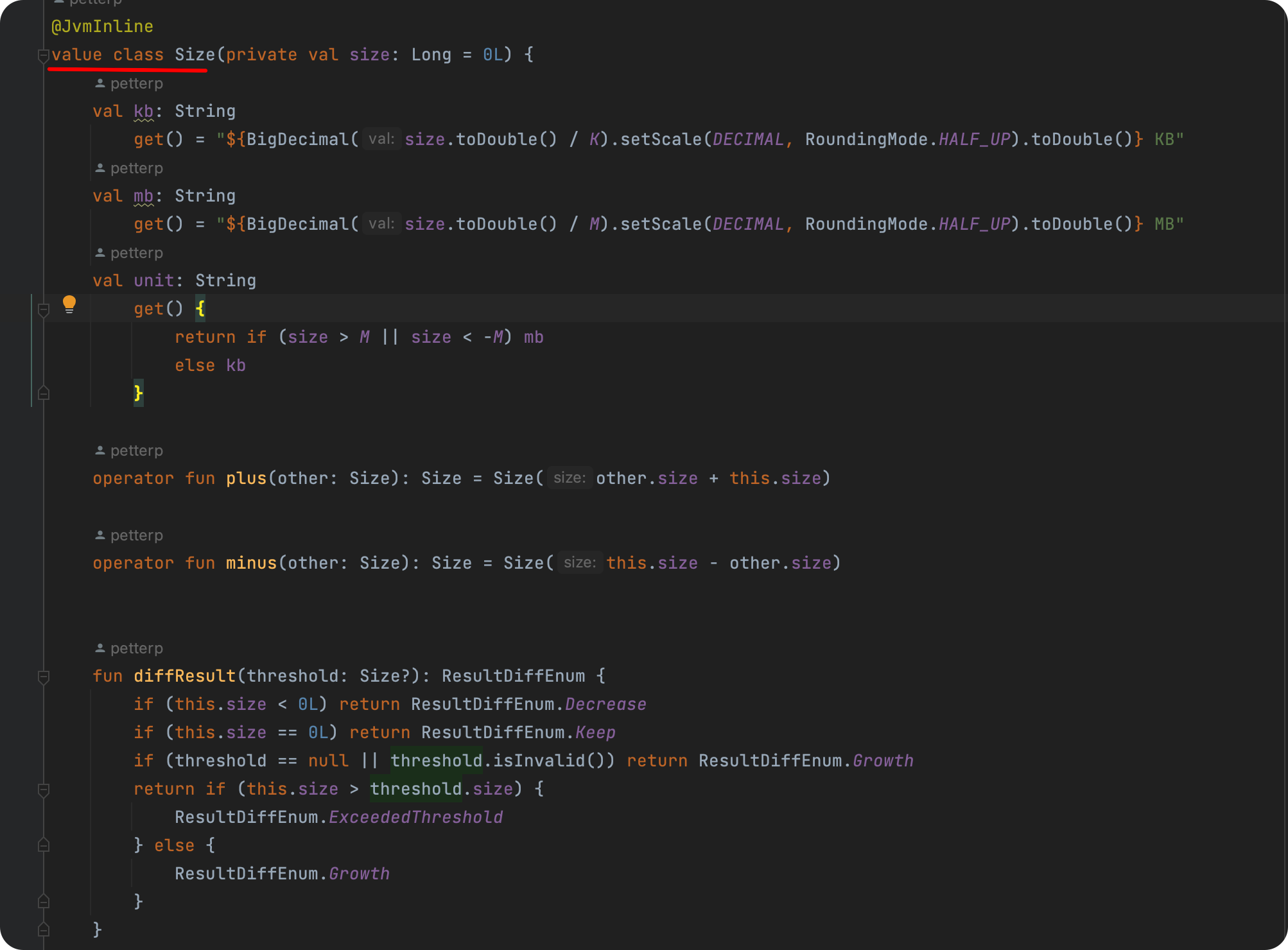
Kotlin 内联类 是一个很棒的特性,无论是性能还是可读性方面,如果我们有某个字段,是使用基本类型作为定义,那么此时就可以考虑将其定义为内联类。
比如我们本篇中的 file大小(size字段),通常我们会使用 Long 类型进行代表,但是 Long 类型用于展示而言,可读性并不好,所以此时使用内联类对其进行包装,并搭配 操作符重载 ,使得开发中的体验度会提高不少。
关于CI方面
关于 CI 方面,首选就是 Github Action,具体 Github 也有专门的教程,上手难度也很低,几分钟足以,对于经常写开源库的作者而言,这个应该也算是基本技巧。相应的,既然我们也是产出了一个 CLI 组件,那么每次 release 时都手动上传jar包,或者版本的定义上,如果每次都手动修改,怎么都显得 不优雅 。
故此,我们可以考虑每次 发布新的release版本 之后,就触发一次 Action,然后打一个 jar 包,并将其上传到我们最新的 release 里。相应的,自动化的版本也可以在这里进行匹配,都比较简单。
这里,以自动化发布jar为例:
name: Cli Release
on:
release:
types: [ published ]
permissions: write-all
jobs:
build_assemble:
runs-on: ubuntu-latest
env:
OUTPUT_DIR: build/libs
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: set up JDK 11
uses: actions/setup-java@v3
with:
java-version: '11'
distribution: 'temurin'
cache: gradle
- uses: burrunan/gradle-cache-action@v1
name: Cache gradle
- name: Grant execute permission for gradlew
run: chmod +x gradlew
- name: Build jar
run: ./gradlew jar
- uses: AButler/upload-release-assets@v2.0
with:
files: build/libs/apk-size-diff-cli.jar
repo-token: ${{ github.token }}
release-tag: ${{ github.event.release.tag_name}}
总体步骤依然非常简单,我们定义这个工作流的触发时机为每次 release 时,然后 拉代码、配置gradle、打jar包、上传到最新release-assets里。
效果如下:
最终效果
最终搭配 Github CI 实现的效果如上,开源地址 apk-size-diff-cli。
使用方式也非常简单,本地使用的话,执行 jar 命令(或者使用 exec 的方式,免除 java -jar) 即可,如下示例所示:
java -jar apk_size_diff_cli.jar -b base.apk -c current.apk -d outpath/result -tss 102400
默认会在指定的输出路径,如 outpath/result 输出一个名为
apk_size_diff.md的文档。
其中 -tss 指的是默认各类别的阈值大小,比如 apk、dex 等如果某一项本次对比上次超过102400,则输出结果里会有相应提示。
如果大家对这个组件比较感兴趣,也不妨点个Star,整体实现较为干净利落,fork更改也非常简单。
结语
本篇到这里就算结束了,总体也并不算什么高深技巧或者深度文章,更多的是站在一个 技术需求 的背景下,由0到1,完成一个 CLI 组件的全流程开发,希望整个过程以及思考会对大家有所帮助。
参考
关于我
我是 Petterp ,一个 Android工程师 ,如果本文对你有所帮助,欢迎 点赞、评论、收藏,你的支持是我持续创作的最大鼓励!
链接:https://juejin.cn/post/7229152434801639482
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android那两个你碰不到但是很重要的类之ViewRootImpl
前言
这两个类就是ActivityThread和ViewRootImpl,之所以说碰不到是因为我们无法通过正常的方式引用这两个类或者其类的对象,调用方法或者直接拿他的属性。但他们其实又无处不在,应用开发中很多时候都和他们息息相关,阅读他们掌握其内部实现对我们理解Android运行机理有醍醐灌顶之疗效,码读百变其义自见,常读常新。本文就尝试从几个我们经常接触的方面先谈谈ViewRootImpl。
1.1 ViewRootImpl哪来的?
首先是ViewRootImpl,位于android.view包下,从它所处的位置大概能猜到,跟View相关。其作用一句话总结,就是连接Window和View的纽带。
这个要从我们最熟悉的Activity开始,我们知道Activity的设置布局View是通过setContentView() 方法这个方法里面也大有文章,我们简单的梳理下。
- Activity setcontentView()内部调用了
getWindow().setContentView(layoutResID);也就是调用了Window的setContentView方法,Android里Window的唯一实现类就是PhoneWindow,PhoneWindow setContentView,初始化DecorView和把我们设置的View作为其子类。 - 目光转移到
ActivityThread没错是我们提及的另外一个主角,先关注他的handleResumeActivity()方法,里面关键的代码如下。
public void handleResumeActivity(){
r.window = r.activity.getWindow();
View decor = r.window.getDecorView();
ViewManager wm = a.getWindowManager();
ViewManager wm = a.getWindowManager();
WindowManager.LayoutParams l = r.window.getAttributes();
wm.addView(decor, l);
}
WindowManager的实现类WindowManageImpl的addView方法里调用了mGlobal.updateViewLayout(view, params);- 最后我们在WindowManagerGlobal的addView方法里找到了
public void addView(){
root = new ViewRootImpl(view.getContext(), display);
view.setLayoutParams(wparams);
mViews.add(view);
mRoots.add(root);
mParams.add(wparams);
}
小结
- 通过梳理这个过程我们知道,setContenview()其实只是在Window的下面挂了一个View链,View链的根就是ViewRootImpl。
- 通过Window把View和Activity联系在一起。
- View链的真正添加操作最终交给了WindowManagerGlobal执行。
- 补充一点:PopupWindow本质就是在当前Window下挂了一个View链,PopupWindow本身没有Window,就如雷锋塔没有雷锋一样;Dialog是有自己的window关于这点可自行查阅源码考证。
2 ViewRootImpl 一个View链渲染的中转站
View的渲染是自顶而下、层层向下发起的,大致经历测量布局和绘制,View链的管理者也就是ViewRootImpl。通过scheduleTraversals()方法发起渲染动作。交给Choreographer安排真正执行的事件。关于Choreographer不熟悉的可以参考我的其他文章。最终执行performTraversals() 方法。
private void performTraversals(){
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
performLayout(lp, mWidth, mHeight);
performDraw();
}
3 不能在子线程操作View?
ViewRoot的RequestLayout中有这样一段代码:
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
scheduleTraversals();
}
}
void checkThread() {
if (mThread != Thread.currentThread()) {
throw new CalledFromWrongThreadException(
"Only the original thread that created a view hierarchy can touch its views.");
}
}
- 我们对View的操作,比如给TextView设置text,最终都会触发ViewRootImpl的
requestLayout()方法,该方法有如上的一个check逻辑。这就是我们常说的不能在子线程中更新View。 - 其实子线程中可以执行View的操作,但是有个前提是:View还未挂载时。 View未挂载时不会触发
requestLayout,只是一个普普通通的java对象。那挂载逻辑在哪?
4 View 挂载
- 在ViewRootImpl的
performTraversals()里有这个代码
private void performTraversals(){
host.dispatchAttachedToWindow(mAttachInfo, 0);//此处的host为ViewGroup
}
- ViewGroup的
dispatchAttachedToWindo()方法会把AttachInfo对象分配每一个View,最终实现我们所谓的挂载。
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
for (int i = 0; i < count; i++) {
final View child = children[i];
child.dispatchAttachedToWindow(info,
combineVisibility(visibility, child.getVisibility()));
}
- 实现挂载的View有任何风吹草动就会把事件传递到大bossViewRootImpl这里了。
通过addView添加进的View也是会收到父View的mAttachInfo这里不展开了。
5 View.post()的Runnable最终在哪执行了?
public boolean post(Runnable action) {
final AttachInfo attachInfo = mAttachInfo;
if (attachInfo != null) {
return attachInfo.mHandler.post(action);
}
getRunQueue().post(action);
return true;
}
- 以上是View post()的代码,可见如果已经实现挂载的View,会直接把post进来的消息交给Hanlder处理,不然就post了HandlerActionQueue里等待后续被处理。
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
..
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);//内部也是调用handler.post()
mRunQueue = null;
}
..
}
- 最终这些Runnable会在View挂载的时候执行,也就是
dispatchAttachedToWindow()方法里执行。
6 为什么View.post 可以获取宽高
这是一个延伸问题,在Activity的
OnCreate()方法中直接获取宽高是获取不到的,我们通常会使用view.post一个Runnable来获取。原因就是ActivityonCreate时通过setContentView只是创建了View而未实现挂载,挂载是在onResume时,未挂载的View没有经历测量过程。
而通过post的方式,通过上一小节知道,未挂载的View上post之后,任务会在挂载之后,通过handler重新post,此时iewRootImpl已经执行了
performTraversals()完成了测量自然就可以得到宽高。
7 还有一点值得注意
ViewRootImpl 不单单是渲染的中转站,还是触摸事件的中转站。
硬件传感器接收到触摸事件经过层层传递分发到应用窗口的第一站就是ViewRootImpl。为什么这么说?因为我有证据~。这是ViewRoot里的代码
public void setView(){
..
mInputEventReceiver = new WindowInputEventReceiver(inputChannel,
Looper.myLooper());
}
- WindowInputEventReceiver是ViewRootImpl的一个内部类,其接收到input事件后,就会进行事件分发。
- 这里给我们的启发是,并不是所有的主线程任务执行都是通过Handler机制, onTouch()事件是底层直接回调过来的,这就和我们之前卡顿监控说的方案里有一项就是对onTouchEvent的监控。
结
- ViewRoot的代码有一万多行,本文分析的只是冰山一角,里面有大量细节直接研究。
- 通过ViewRootImpl相关几个点,简单的做了介绍分析希望对你有帮助。
链接:https://juejin.cn/post/7224518612160151610
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这玩意真的有用吗?对,是的!Kotlin 的 Nothing 详解
视频先行
这是一篇视频形式的分享,如果你方便看,可以直接去看视频:
视频先行
哔哩哔哩
YouTube
下面是视频内容的脚本文案原稿分享。
文案原稿
Kotlin 的 Nothing 类,无法创建出任何实例:
public class Nothing private constructor()
所以所有 Nothing 类型的变量或者函数,都找不到可用的值:
val nothing: Nothing = ???
fun nothing(): Nothing {
...
return ???
}
就这么简单。但——它有啥用啊?
Nothing 的本质
大家好,我是扔物线朱凯。上期讲了 Kotlin 的 Unit,这期讲 Nothing。 Nothing 的源码很简单:
public class Nothing private constructor()
可以看到它本身虽然是 public 的,但它的构造函数是 private 的,这就导致我们没法创建它的实例;而且它不像 Unit 那样是个 object:
public object Unit {
override fun toString() = "kotlin.Unit"
}
而是个普通的 class;并且在源码里 Kotlin 也没有帮我们创建它的实例。
这些条件加起来,结果就是:Nothing 这个类既没有、也不会有任何的实例对象。
基于这样的前提,当我们写出这个函数声明的时候:
fun nothing(): Nothing {
}
我们不可能找到一个合适的值来返回。你必须返回一个值,但却永远找不到合适的返回值。悖论了。
作用一:作为函数「永不返回」的提示
怎么办?
不怎么办。这个悖论,就是 Nothing 存在的意义:它找不到任何可用的值,所以,以它为返回值类型的一定是个不会返回的函数,比如——它可以总是抛异常。 什么意思?就是说,我这么写是可以的:
fun nothing() : Nothing {
throw RuntimeException("Nothing!")
}
这个写法并没有返回任何结果,而是抛异常了,所以是合法的。
可能有的人会觉得有问题:抛异常就可以为所欲为吗?抛异常就可以忽略返回值了吗?——啊对,抛异常就是可以忽略返回值,而且这不是 Nothing 的特性,而是本来就是这样,而且你本来就知道,只是到这里的时候,你可能会忘了。 例如这个写法:
fun getName() : String {
if (nameValue != null) {
return nameValue
} else {
throw NullPointerException("nameValue 不能为空!")
}
}
——其实这个函数可以有更加简洁的写法:
fun getName() = nameValue ?: throw NullPointerException("nameValue 不能为空!")
不过我们为了方便讲解,就不简化了:
fun getName() : String {
if (nameValue != null) {
return nameValue
} else {
throw NullPointerException("nameValue 不能为空!")
}
}
在这个函数里,一个 if 判断,true 就返回,false 就抛异常,这个写法很常见吧?它在 else 的这个分支,是不是就只抛异常而不返回值了?实际上 Java 和 Kotlin 的任何方法或者说函数,在抛异常的时候都是不返回值的——你都抛异常的还返回啥呀返回?是吧?
所以我如果改成这样:
fun getName() : String {
throw NullPointerException("不能为空!")
}
其实也是可以的。只是看起来比较奇怪罢了,会让人觉得「怎么会这么写呢」?但它的写法本身是完全合法的。而且如果我把函数的名字改一下,再加个注释:
/**
当遇到姓名为空的时候,请调用这个函数来抛异常
*/
fun throwOnNameNull() : String {
throw NullPointerException("姓名不能为空!")
}
这就很合理了吧?不干别的,就只是抛异常。这是一种很常用的工具函数的写法,包括 Kotlin 和 Compose 的官方源码里也有这种东西。
那么我们继续来看它的返回值类型:我都不返回了,就没必要还写 String 了吧?那写什么?可以把它改成 Unit:码
/**
当任何变量为空的时候,请统一调用这个函数来抛异常
*/
fun throwOnNameNull() : Unit {
throw NullPointerException("姓名不能为空!")
}
有问题吗?没问题。
不过,Kotlin 又进了一步,提供了一个额外的选项:你还可以把它改成 Nothing:
/**
当任何变量为空的时候,请统一调用这个函数来抛异常
*/
fun throwOnNameNull() : Nothing {
throw NullPointerException("姓名不能为空!")
}
虽然我找不到 Nothing 的实例,但是这个函数本来就是永远抛异常的,找不到实例也没关系。哎,这不就能用了吗?对吧?
不过,能用归能用,这么写有啥意义啊?是吧?价值在哪?——价值就在于,Nothing 这个返回值类型能够给使用它的开发者一个明确的提示:这是个永远不会返回的函数。这种提示本身,就会给开发提供一些方便,它能很好地避免函数的调用者对函数的误解而导致的一些问题。我们从 Java 过来的人可能第一时间不太能感受到这种东西的用处,其实你要真说它作用有多大吧,我觉得不算大,主要是很方便。它是属于「你没有的话也不觉得有什么不好的,但是有了之后就再也不想没有它」的那种小方便。就跟 120Hz 的屏幕刷新率有点像,多少带点毒。
Kotlin 的源码、Compose 的源码里都有不少这样的实践,比如 Compose 的 noLocalProviderFor() 函数:
private fun noLocalProvidedFor(name: String): Nothing {
error("CompositionLocal $name not present")
}
好,这就是 Nothing 的作用之一:作为函数的返回值类型,来明确表达「这是个永不返回的函数」。
其实 Nothing 的「永不返回」除了抛异常之外,还有一种场景,就是无限循环:
fun foreverRepeat(): Nothing {
while (true) {
...
}
}
不过一般很少有人这么去用,大部分都是用在我刚才说的抛异常的场景,这是非常常见的一种用法,你写业务可能用不到,但是基础架构团队给全公司写框架或者对外写 SDK 的话,用到它的概率就非常大了。
作用二:作为泛型对象的临时空白填充
另外 Nothing 除了「没有可用的实例」之外,还有个特性:它是所有类型共同的子类型。这其实是违反了 Kotlin 的「类不允许多重继承」的规定的,但是 Kotlin 强行扩充了规则:Nothing 除外,它不受这个规则的约束。虽然这违反了「类不允许多重继承」,但因为 Nothing 不存在实例对象,所以它的多重继承是不会带来实际的风险的。——我以前还跟人说「Nothing 是所有类型的子类型」这种说法是错误的,惭愧惭愧,是我说错了。
不过,这个特性又有什么作用呢?它就能让你对于任何变量的赋值,都可以在等号右边写一个 Nothing:
val nothing: Nothing = TODO()
var apple: Apple = nothing
这儿其实有个问题:我刚说了 Nothing 不会有任何的实例,对吧?那么这个右边就算能填 Nothing 类型的对象,可是这个对象我用谁啊?
val nothing: Nothing = ???
var apple: Apple = nothing
谁也没法用。
但是我如果不直接用 Nothing,而是把它作为泛型类型的实例化参数:
val emptyList: List<Nothing> = ???
var apples: List<Apple> = emptyList
这就可以写了。一个元素类型为Nothing 的 List,将会导致我无法找到任何的元素实例来填充进去,但是这个 List 本身是可以被创建的:
val emptyList: List<Nothing> = listOf()
var apples: List<Apple> = emptyList
只不过这种写法看起来好像有点废,因为它永远都只能是一个空的 List。但是,如果结合上我们刚说的「Nothing 是所有类型的子类型」这个特性,我们是不是可以把这个空的 List 赋值给任何的 List 变量?
val emptyList: List<Nothing> = listOf()
var apples: List<Apple> = emptyList
var users: List<User> = emptyList
var phones: List<Phone> = emptyList
var images: List<Image> = emptyList
这样,是不是就提供了一个通用的空 List 出来,让这一个对象可以用于所有 List 的初始化?有什么好处?既省事,又省内存,这就是好处。
这种用法不只可以用在 List,Set 和 Map 也都没问题:
val emptySet: Set<Nothing> = setOf()
var apples: Set<Apple> = emptySet
var users: Set<User> = emptySet
var phones: Set<Phone> = emptySet
var images: Set<Image> = emptySetval emptyMap: Map<String, Nothing> = emptyMap()
var apples: Map<String, Apple> = emptyMap
var users: Map<String, User> = emptyMap
var phones: Map<String, Phone> = emptyMap
var images: Map<String, Image> = emptyMap
而且也不限于集合类型,只要是泛型都可以,你自定义的也行:
val emptyProducer: Producer<Nothing> = Producer()
var appleProducer: Producer<Apple> = emptyProducer
var userProducer: Producer<User> = emptyProducer
var phoneProducer: Producer<Phone> = emptyProducer
var imageProducer: Producer<Image> = emptyProducer
它的核心在于,你利用 Nothing 可以创建出一个通用的「空白」对象,它什么实质内容也没有,什么实质工作也做不了,但可以用来作为泛型变量的一个通用的空白占位值。这就是 Nothing 的第二个主要用处:作为泛型变量的通用的、空白的临时填充。多说一句:这种空白的填充一定是临时的才有意义,你如果去观察一下就会发现,这种用法通常都是赋值给 var 属性,而不会赋值给 val:
val emptyProducer: Producer<Nothing> = Producer()
// 没人这么写:
val appleProducer: Producer<Apple> = emptyProducer
val userProducer: Producer<User> = emptyProducer
val phoneProducer: Producer<Phone> = emptyProducer
val imageProducer: Producer<Image> = emptyProducer
因为赋值给 val 那就是永久的「空白」了,永久的空白那不叫空白,叫废柴,这个变量就没意义了。
作用三:语法的完整化
另外,Nothing 的「是所有类型的子类型」这个特点,还帮助了 Kotlin 语法的完整化。在 Kotlin 的下层逻辑里,throw 这个关键字是有返回值的,它的返回值类型就是 Nothing。虽然说由于抛异常这件事已经跳出了程序的正常逻辑,所以 throw 返回不返回值、返回值类型是不是 Nothing 对于它本身都不重要,但它让这种写法成为了合法的:
val nothing: Nothing = throw RuntimeException("抛异常!")
并且因为 Nothing 是所有类型的子类型,所以我们这么写也行:
val nothing: String = throw RuntimeException("抛异常!")
看起来没用是吧?如果我再把它改改,就有用了:
var _name: String? = null
val name: String = _name ?: throw NullPointerException("_name 在运行时不能为空!")
throw 的返回值是 Nothing,我们就可以把它写在等号的右边,在语法层面假装成一个值来使用,但其实目的是在例外情况时抛异常。
Kotlin 里面有个 TODO() 函数对吧:
val someValue: String = TODO()
这种写法不会报错,并不是 IDE 或者编译器做了特殊处理,而是因为 TODO() 的内部是一个 throw:
TODO() 返回的是 Nothing,是 String 的子类,怎么不能写了?完全合法!虽然 throw 不会真正地返回,但这让语法层面变得完全说得通了,这也是 Nothing 的价值所在。
除了 throw 之外,return 也是被规定为返回 Nothing 的一个关键字,所以我也可以这么写:
fun sayMyName(first: String, second: String) {
val name = if (first == "Walter" && second == "White") {
"Heisenberg"
} else {
return // 语法层面的返回值类型为 Nothing,赋值给 name
}
println(name)
}
这段代码也是可以简化的:
fun sayMyName(first: String, second: String) {
if (first == "Walter" && second == "White") println("Heisenberg")
}
不过同样,咱不是为了讲东西么,就不简化了:
fun sayMyName(first: String, second: String) {
val name = if (first == "Walter" && second == "White") {
"Heisenberg"
} else {
return // 语法层面的返回值类型为 Nothing,赋值给 name
}
println(name)
}
虽然直接强行解释为「return 想怎么写就怎么写」也是可以的,但 Kotlin 还是扩充了规则,规定 return 的返回值是 Nothing,让代码从语法层面就能得到解释。
这就是 Nothing 的最后一个作用:语法层面的完整化。
总结
好,Nothing 的定义、定位和用法就是这些。如果没记全,很正常,再看一遍。你看视频花的时间一定没有我研究它花的时间多,所以多看两遍应该不算浪费时间。 下期我会讲一个很多人不关注但很有用的话题:Kotlin 的数值系统,比如 Float 和 Double 怎么选、为什么 0.7 / 5.0 ≠ 0.14 这类的问题。关注我,了解更多 Android 开发相关的知识和技能。我是扔物线,我不和你比高低,我只助你成长。我们下期见!
链接:https://juejin.cn/post/7231816037813321786
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
时隔2年终于开源了基于RecyclerView的阅读器动画方案
Tips:这是一次针对广告业务场景下阅读器动画实现方案的探索。
实现效果
项目地址:github:BookView
- app module:完整的阅读器demo
- gpu_test module:独立的仿真动画demo
手绘一张图,呈现实现原理
如果用文字来阐述原理难免要长篇大论,何况这里涉及到Z轴View堆叠,借此机会展示下我的绘画能力吧🐶(瞎搞)
核心类就4个,它们的职责跟它们的名字很相近。
- BookView 摆放 BookRecyclerView 与PuppetView
- BookRecyclerView 作为底层容器,接受滑动事件,完成页面更换与事件分配
- PaperLayout 作为页面卡片根布局,也就是设置给RecyclerView.Adapter加载的布局
- PuppetView 但本身不处理任何事件,只是展示动画
这东西前后花了得有2周的时间,从0开发了仿真动画,涉及到一些三角函数,相似三角形还专门复习了初中的相关课程。RecycleView,LayoutManager也是那时候深入学习的。
写在最后
当时会下这么多功夫去开发这个阅读器,其真正的原因是我当时还负责阅读器+广告两个业务的产品设计。没错就是跟很多创业团队一样一人肩多职,也正是这份对产品的追求才推着我不断追求更好的产品体验,进而才有了更多的技术积累。直到现在,偶尔在团队人手紧张时我还会负责一些产品设计工作。
很多时候会分不清面前的挑战是挫折还是机遇,但只要沉下心去解决问题,结果就不会都是坏的。
我很喜欢的一句话「铁打的个人能力,流水的公司」用在这里相当合适。
在2年前做阅读器产品时发过一篇文章:LayoutManager实现翻页动画 - 掘金,目的是抛出一个解决方案的同时寻求不同的思路。同时在V2上发过一篇帖子:http://www.v2ex.com/t/694298#re…, 收集到了不同的灵感。
2年前就有人跟我要完整demo,当时我也很想放出来,但出于职业素养维护公司利益没有这样做。可就在前两天有个掘金的同学很真诚的再次跟我询问这个方案,妥妥的点燃了我回馈社区的心呀。现在那个项目垮了,公司也....。那我可没啥负担了,完整的开源出来,希望能帮助一些与他一样碰到阻碍的人,相互成长。我一直也受到了很多社区帮助,包括Google GDE,这算是我的一点回馈吧。
清理好后优先发给了他,晚上看到他给我反馈的视频,还是蛮开心的。
之前我有几次想要好好整理下做个开源,但最终都搁置了。现在想想还是因为那时候纯粹是出于功利心吧。当时想着这东西还是有点门槛的,微信读书做到50fps,我做到40fps+还支持广告,放出来赚点star不是很轻松,可见虚荣对人的激励是很有限的。现在的我也更愿意做一些获取深度快乐的事情。
链接:https://juejin.cn/post/7219288959113330744
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Java、Kotlin不香吗?为什么Flutter要选用Dart作为开发语言?
以上片段改编自成龙大哥经典的洗发水广告,虽然梗本身有点过时了,但却很形象地反映了我对Dart语言态度的转变:从最初的排斥到最后的喜欢。
对于任何想要了解一门新兴技术的开发者来说,语言常常是横亘在学习之路上的第一道障碍,如C/C++之于音视频,Python之于人工智能等,当然也包括Dart之于Flutter。
尤其当你原先从事的是Android开发时,你肯定也曾产生过这样的疑惑:
既然同可以归到移动开发的范畴,也同属于Google旗下的团队,为什么Flutter不能沿用既有的Java或Kotlin语言来进行开发呢?
通过阅读本文,你的疑惑将得到充分的解答,你不仅能够了解到Flutter团队在选用Dart作为开发语言时的考量,还能充分感受到使用Dart语言进行开发的魅力所在。
照例,先奉上思维导图一张,方便复习:
热重载 (Hot Reload)一直以来都是Flutter对外推广的一大卖点,这是因为,相对于现有的基于原生平台的移动开发流程来讲,热重载在开发效率上确实是一个质的飞跃。
简单讲,热重载允许你在无需重启App的情况下,快速地构建页面、添加功能或修复错误。这个功能很大程度上依赖于Dart语言的一个很突出的特性:
同时支持AOT编译与JIT编译
AOT编译与JIT编译
AOT Compilation(Ahead-of-Time Compilation, 提前编译)是指在程序执行之前,将源代码或中间代码(如Java字节码)转换为可执行的机器码的过程。这么做可以提高程序的执行效率,但也需要更长的编译时间。
JIT Compilation(Just-in-Time Compilation, 即时编译)是指在程序执行期间,将源代码或中间代码转换为可执行的机器码的过程。这么做可以提高程序的灵活性和开发效率,但也会带来一些额外的开销,例如会对程序的初始执行造成一定的延迟。
用比较贴近生活的例子来解释二者之间的区别,就是:
AOT编译就像你在上台演讲之前,把原本全是英文的演讲稿提前翻译成中文,并写在纸上,这样当你上台之后,就可以直接照着译文念出来,而不需要再在现场翻译,演讲过程能更为流畅,但就是要在前期花费更多的时间和精力来准备。
JIT编译就像你在上台演讲之前,不需要做过多的准备,等到上台之后,再在现场将演讲稿上的英文逐句翻译成中文,也可以根据实际情况灵活地调整演讲内容,但就是会增加演讲的难度,遇到语法复杂的句子可能也会有更多的停顿。
可以看到,两种编译方式的应用场景不同,各有优劣,而Dart是为数不多的同时支持这两种编译方式的主流编程语言之一。根据当前所处项目阶段的不同,Dart提供了两种不同的构建模式:开发模式与生产模式。
开发模式与发布模式
在开发模式下,会利用 Dart VM 的 JIT 编译器,在运行时将内核文件转换为机器码,以实现热重载等功能,缩短开发周期。
热重载的流程,可以简单概括为以下几步:
扫描改动:当我们保存编辑内容或点击热重载按钮时,主机会扫描自上次编译以来的任何有代码改动的文件。
增量编译:将有代码改动的文件增量编译为内核文件。
推送更新:将内核文件注入到正在运行的 Dart VM。
代码合并:使用新的字段和函数更新类。
Widget重建:应用的状态会被保留,并重建 widget 树,以便快速查看更改效果。
而在发布模式下,则会利用 Dart VM 的 AOT 编译器,在运行前将源代码直接转换为机器码,以实现程序的快速启动和更流畅地运行。
这里的“更流畅地运行”指的是在运行时能够更快地响应用户的操作,提供更流畅的用户体验,而不是单指让程序运行得更“快”。
这是因为Dart代码在被转换为机器码后,是可以直接在硬件上运行的,而不需要在运行时进行解释或编译,因此可以减少运行时的开销,提高程序的执行效率。
此外,经 AOT 编译后的代码,会强制执行健全的 Dart 类型系统,并使用快速对象分配和分代垃圾收集器来更好地管理内存。
因此,根据当前所处项目阶段的不同,采用不同的构建模式,Dart语言可以实现两全其美的效果。
单线程模型
现如今,几乎所有的智能终端设备都支持多核CPU,为使应用在设备上能有更好的表现,我们常常会启动多个共享内存的线程,来并发执行多个任务。
大多数支持并发运行线程的计算机语言,如我们熟知的Java、Objective-C等,都采用了“抢占”的方式在线程之间进行切换,每个线程都被分配了一个时间片以执行任务,一旦超过了分配的时间,操作系统就会中断当前正在执行的线程,将CPU分配给正在等待队列的下一个线程。
但是,如果是在更新线程共享资源(如内存)期间发生的抢占行为,则可能会引致竞态条件的产生。竞态条件会导致严重的错误,轻则数据丢失,重则应用崩溃,且难以被定位和修复。
修复竞争条件的典型做法就是加锁,但锁本身会导致卡顿,甚至引发死锁等更严重的问题。
那Dart语言又是怎么解决这个问题的呢?
Dart语言采用了名为Isolate的单线程模型,Isolate模型是以操作系统提供的进程和线程等更为底层的原语进行设计的,所以你会发现它既有进程的特征(如:不共享内存),又有线程的特征(如:可处理异步任务)。
正如Isolate这个单词的原意“隔离”一样,在一个Dart应用中,所有的Dart代码都在Isolate内运行,每个Isolate都会有自己的堆内存,从而确保Isolate之间相互隔离,无法互相访问状态。在需要进行通信的场景里,Isolate会使用消息机制。
因为不共享内存,意味着它根本不允许抢占,因此也就无须担心线程的管理以及后台线程的创建等问题。
在一般场景下,我们甚至完全无需关心Isolate,通常一个Dart应用会在主Isolate下执行完所有代码。
虽然是单线程模型,但这并不意味着我们需要以阻塞UI的方式来运行代码,相反,Dart语言提供了包括 async/await 在内的一系列异步工具,可以帮助我们处理大部分的异步任务。关于 async/await 我们后面会有一篇单独的文章讲到,这里先不展开,只需要知道它跟Kotlin的协程有点像就可以了。
如图所示,Dart代码会在readAsString()方法执行非Dart代码时暂停,并在 readAsString()方法返回值后继续执行。
Isolate内部会运行一个消息循环,按照先进先出的模式处理重绘、点击等事件,可以与Android主线程的Looper相对照。
如图所示,在main()方法执行完毕后,事件队列会依次处理每一个事件。
而如果某个同步执行的操作花费了过长的处理时间,可能会导致应用看起来像是失去了响应。
如图所示,由于某个点击事件的同步处理耗时过长,导致其超过了处理两次重绘事件的期望时间间隔,直观的呈现就是界面卡顿。
因此,当我们需要执行消耗CPU的计算密集型工作时,可以将其转移到另外一个Isolate上以避免阻塞事件循环,这样的Isolate我们称之为后台运行对象。
如图所示,生成的这个Isolate会执行耗时的计算任务,在结束后退出,并把结果返回。
由于这个Isolate持有自己的内存空间,与主Isolate互相隔离,因此即使阻塞也不会对其他Isolate造成影响。
快速对象分配与分代垃圾回收
在Android中,视图 (View)是构成用户界面的基础块,表示用户可以看到并与之交互的内容。在Flutter中,与之大致对应的概念则是Widget。Widget也是通过多个对象的嵌套组合,来形成一个层次结构关系,共同构建成一棵完整的Widget树。
但两者也不能完全等同。首先,Widget并非视图本身,最终的UI树是由一个个称之为Element的节点构成的;其次,Widget也不会直接绘制任何内容,最终的绘制工作是交由RenderObject完成的。Widget只是一个不可变的临时对象,用于描述在当前状态下视图应该呈现的样子。
而所谓的Widget树只是我们描述组件嵌套关系的一种说法,是一种虚拟的结构。但 Element和RenderObject是在运行时实际存在的,如图:
这就好比手机与其规格参数的关系。Widget就像是一台手机的规格参数,是对当前组装成这个手机的真正的硬件配置的描述,当手机的硬件有更新或升级时,重新生成的规格参数也会有所变化。
由于Widget是不可变的,因此,我们无法直接对其更新,而是要通过操作状态来实现。但实际上,当Widget所依赖的状态发生改变时,Flutter框架就会重新创建一棵基于当前最新状态绘制的新的Widget树,对于原先的Widget来说它的生命周期其实已经结束了。
有人可能会对这种抛弃了整棵Widget树并完全重建一棵的做法存有疑问,担心这种行为会导致Flutter频繁创建和销毁大量短暂的Widget对象,给垃圾回收带来了巨大压力,特别对于一些可能由数千个Widget组合而成的复杂页面而言。
实际上这种担心完全没有必要,Dart的快速对象分配与分代垃圾回收足以让它应对这种情况。
快速对象分配
Dart以指针碰撞(Bump Pointer)的形式来完成对象的内存分配。
指针碰撞是指在堆内存中,Dart VM使用一个指针来跟踪下一个可用的内存位置。当需要分配新的内存时,Dart VM会将指针向前移动所需内存大小的距离,从而分配出新的内存空间。
这种方式可以快速地分配内存,而不需要查找可用的内存段,并且使内存增长始终保持线性。
另外,前面我们提到,由于每个Isolate都有自己的堆内存,彼此隔离,无法互相访问状态,因此可以实现无锁的快速分配。
分代垃圾回收
Dart的垃圾回收器是分代的,主要分为新生代(New Generation)与老年代(Old Generation)。
新生代用于分配生命周期较短的临时对象。其所在的内存空间会被分为两半,一个处于活跃状态,另一个处于非活跃状态,并且任何时候都只使用其中的一半。
新的对象会被分配到活跃的那一半,一旦被填满,垃圾回收器就会从根对象开始,查找所有对象的引用状态。
被引用到的对象会被标记为存活状态,并从活跃的一半复制到非活跃的一半。而没有被引用到的对象会被标记为死亡状态,并在随后的垃圾回收事件中被清除。
最后,这两半内存空间会交换活跃状态,非活跃的一半会再次变成活跃的一半,并且继续重复以上过程。
当对象达到一定的生命周期后,它们会被提升为老年代。此时的垃圾回收策略会分为两个阶段:标记与清除。
首先,在标记阶段,会遍历整个对象图,标记仍在使用的对象。
随后,在清除阶段,会扫描整个内存,回收任何没有被标记的对象,然后清除所有标记。
这种形式的垃圾回收发生频率不高,但有时需要暂停Dart Runtime以支持其运行。
为了最小化地降低垃圾回收事件对于应用程序的影响,垃圾回收器为Flutter引擎提供了钩子,当引擎检测到应用程序处于空闲状态并且没有用户交互时会发出通知,使得垃圾回收器可以在不影响性能的情况下执行回收工作。
另外,同样由于每个Isolate都在自己都独立线程内运行,因此每个Isolate的垃圾回收事件不会影响到其他Isolate的性能。
综上可知,Flutter框架所采用的工作流程,很大程度上依赖于其下层的内存分配器和垃圾回收器对于小型的、短生命周期的对象高效的内存分配和回收,缺少这个机制的语言是无法有效运作的。
学习成本低
对于想要转岗Flutter的Android或iOS开发者,Dart语言是很友好的,其语法与Kotlin、Swift等语言都存在一些相似之处。
例如,它们都是面向对象的语言,都支持类、接口、继承、抽象类等概念。绝大多数开发者都拥有面向对象开发的经验,因此可以以极低的学习成本学习Dart语言。
此外,Dart语言也拥有着许多与其他语言相似的优秀的语法特性,可以提高开发人员的生产力,例如:
字符串插值:可以直接在字符串中嵌入变量或表达式,而不需要使用+号相连:
var name = 'Bob'; print('Hello, $name!');
初始化形式参数:可以在构造函数中直接初始化类的属性,而不需要在函数体中赋值:
class Point { num x, y; Point(this.x, this.y); }
函数式编程风格:可以利用高阶函数、匿名函数、箭头函数等特性简化代码的结构和逻辑:
var numbers = [1, 2, 3]; var doubled = numbers.map((n) => n * 2);
Dart团队配合度高
拥有一定工作年限的Android开发者,对于早些年Oracle与Google两家科技公司的Java API版权之争可能还有些许印象。
简单讲就是,Oracle认为Google在Android系统中对Java API的复制使用侵犯了其版权和专利权,这场持续了11年的专利纠纷最终以Google的胜利结束。
相比之下,Dart语言与Flutter之间则没有那么多狗血撕逼的剧情,相反,Flutter与Dart社区展开了密切合作,Dart社区积极投入资源改进Dart语言,以便在Flutter中更易使用。
例如,Flutter在最开始采用Dart语言时,还没有用于生成原生二进制文件的AOT工具链,但在Dart团队为Flutter构建了这些工具后,这个缺失已经不复存在了。
结语
以上,就是我汇总Flutter官网资料及Flutter社区推荐博文的说法之后,总结出的Flutter选用Dart作为开发语言的几大主要原因,希望对于刚入门或想要初步了解Flutter开发的小伙伴们有所帮助。
链接:https://juejin.cn/post/7225629551602565178
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这么好的Android开发辅助工具App不白嫖可惜了
过年期间闲来没事,手撸了一个辅助Android开发调试的工具App,适合Android开发者和测试同学使用。
Github地址下载,
Gitee地址下载(需要登录gitee)
功能概览
对我这样的懒人开发者来说,反复的做同样一件事简直太煎熬了,因此我把我平时开发中需要反复操作的命令和一些繁琐的操作整理成了一个工具。
废话不多说, 先上图了解下工具的大概功能有哪些(内容比截图丰富,欢迎下载体验)
CodeCrafts的核心是一个可拖动的侧边栏的悬浮窗,悬浮窗可以折叠或展开,悬浮窗中包含5大块功能分别对应一个TAB, 这5大块功能分别是应用控制、开发者选项、常用功能,常用系统设置和全局功能
请看视频预览:
高清原图 introduction-floating-bar.gif
功能明细
1. 应用控制
应用控制能力将一些日常开发过程中对应用的一些繁琐的操作或者命令行指令转变为可视化的操作,而且还有自动收集和整理Crash, ANR日志,并且可以自动关联Logcat日志
文字太繁琐, 请直接看视频
高清原图 introduction-application-controls.gif
2. 开发者选项
这里的开发者选项功能是将系统的开发者选项中一些最常用的开关放在悬浮窗中, 随时启用或关闭。
优势是不需要频繁去系统的开发者选项中去找对应开关,一键开闭。
我调研了其他有类似能力的工具App,都是引导用户去开发者选项中去开启或关闭功能。CodeCrafts一键开闭,无需跳转到系统开发者选项页面。
请看视频预览:
3. 最常用功能
没什么好介绍的,略。
4. 常用系统设置页面
这里承载了一些开发过程中经常需要打开的系统设置页面的快捷按钮,没什么好介绍的,略
5. 全局功能
这里的全局是相对于应用控制的,应用控制可以选择你正在开发的任意一款App, 然后应用控制中的所有能力都是对你的这个App的操作。 而全局控制中的功能不针对选中的App,所有App都适用
5.1 实时数据(Realtime data)
实时数据会随着当前页面变化或者系统事件实时变化
(以上图为例介绍, 实时数据的内容不仅仅只有这些)
| 内容 | 含义 | 用途 |
|---|---|---|
| org.chromium.chrome.browser.firstrun.FirstRunActivity | 当前Activity的类名 | 代码定位 |
| launch time: 208ms | 当前Activity的冷启动耗时 | 启动优化 |
| com.android.chrome | 当前Activity所在应用的包名 | 常用信息 |
| Chrome(uid: 10163) | 当前Activity所在应用的名称和UID | 常用信息 |
| pid: 23017 | 当前Activity的进程ID | 常用信息 |
| 192.168.2.56,... | 当前系统的IP地址,可能有多个 | adb connect等 |
| system | 当前应用是系统应用 | |
| allowBackUp | 当前应用有allowBackUp属性 | 告警 |
实时数据未来还会有更多的扩展内容
5.2 不锁定屏幕
不会进入锁屏状态,也不会灭屏,避免开发过程中老是自动锁屏。
和系统开发者选项中的功能类似,区别是无论是否插入USB线都有效,开发者选项中的拔掉USB线后就无效了。
都可以用,具体选择看你的使用场景。
5.3 Latest Crashes
显示缓存中最近发生的Crash的调用堆栈,可能为空也可能不止一个Crash堆栈, 需要自行查看是否是你关注的Crash。
使用说明
CodeCrafts的很多功能依赖Shell权限, 如果发现存在功能不可用的情况,一般都是shell权限获取失败了, 只需要通过在电脑终端输入adb命令"adb tcpip 5555"指令, CodeCrafts就可以自动获取shell权限了。
adb tcpip 5555
- 第一次使用,连接电脑终端发送"adb tcpip 5555" 或
- 手机断电重启,连接电脑终端发送"adb tcpip 5555" 或
- 莫名其妙功能不能用了,连接电脑终端发送"adb tcpip 5555"
新增功能
有不少人反馈对CodeCrafts的实现原理感兴趣,后面新增的功能尽量配上实现原理
- CodeCrafts之断点调试 (1.0.15新增)
建设中
- 文件沙盒, 快速浏览App的文件目录
- 自动化,自动化点击,输入(比如自动跳广告,自动输入账号密码?)
- 组件检查, 快速查看View的类型, id, 颜色等
- ...
后期规划
- 悬浮窗的tab和内容可动态配置
- 应用控制增加应用性能数据
- 提供外部SDK接口,外部应用可接入CodeCrafts进行定制化改造
CodeCrafts持续更新中...
Github地址下载,
Gitee地址下载(需要登录gitee)
链接:https://juejin.cn/post/7194736298521788472
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用 Compose 写 App 可以多快?
休整半年多的我,在今年年后就在思考与尝试我的事业应该怎么走了。其实在去年年终总结中,我已经提及了我的几个方向。
我最开始的方向就是迈入养生行业,虽然我有技术,也有医术,但是没客户,所以我大概需要很长的时间去累积客户,加上现在客户都迷恋让肌肉放松的推拿按摩,以及房租设备之类的开销。还不如找个小公司安心上班来得舒服。可是我又耐不住想折腾的心。
所以我开启了 PlanB,去走中医知识学习领域,虽然现在市面上有一些这类的 app,不过他们都不是真正有中医知识的人主导的,只能说是一堆资源的简单聚合,或者为了卖课而存在。而根本不知道学习中医的痛点是什么,怎样才能真正的提升医术,这就是我的市场了。所以我从零做了一个 app,目前完成了首个版本了。这是真的做一个 app 满足自己的需求。虽然目前功能、数据还很少,但我认为它是有价值的,虽然可能没有钱途。
App 已经在官网villa.qhplus.cn、华为、小米、应用宝、Oppo 的应用市场上架了, 但对于开发而言,并不会懂这个 App 的内容以及结构,毕竟不是为你们而设计的,但是你们可以体验下 Compose 已然是多么的丝滑了。因为这个 app 是全部用 Compose 开发。从立项开始到现在,仅用一个半月左右的时间完成开发,是时候让你们感受下 Compose 开发的速度了。先欣赏下设计稿的数量(辛苦我美丽动人的老婆大人了)。
并且我做的是全栈式的开发,其包括:
- 思考产品形态
- 用
rust写后端服务 - 数据爬取、清洗与整理入库
- 用
vue3写官网、隐私协议等 H5 界面 - 为了上架、登录、push 等要开一个壳公司,跑各种流程(最繁琐、最耗时的工作)
即使是 app 端,也要有各种数据逻辑、上报、存储等逻辑,可想而知,能分配给写 UI 的时间能有多少?
当然,这也归功于在去年修整期间我写的 emo 组件库,极大的加速了业务层的开发。
问:为什么不考虑小程序开发,Flutter 开发,RN 开发?
答:小程序挺好的,但是它却很封闭,我想要实现桌面小组件之类的功能,小程序就完全做到,但对于中医条文,用小组件来让我们每天回忆一条条文,是个我个人很喜欢的功能。
而 RN 的性能太差,而且用它,就要牺牲诸如动画、复杂布局等各种场景。并且往往这些需要与原生交互的场景,就要用力十倍才能解决。
不用 Flutter,首先当然是因为我不会,其次是它和 RN 都是 UI 层面,如果和数据层一起考虑,那就没那么简单了。 而我用 Compose,与整个 Android 生态都是打通的,所以性能又高,开发速度又快。何乐而不为?跨平台?各自写就行了,不再去入整体跨平台的坑了。跨平台的坑不仅是技术抽象应对各自生态不是那么稳定的坑,还有人力资源协调的坑。总会让人心累。
下面我们可以来看看 Compose 和 emo 协同开发带来的一些爽点:
界面管理
用 Compose 加 scheme 路由的方式来处理界面跳转、曝光,就非常简单了, 每一个新界面就是一个 Composable,加上 @ComposeScheme 就完了
@ComposeScheme(
action = SchemeConst.ACTION_THINK_DETAIL,
alternativeHosts = [HolderActivity::class]
)
@SchemeLongArg(name = SchemeConst.ARG_ID)
@SchemeLongArg(name = SchemeConst.ARG_COMMENT_ID)
@Composable
fun ThinkDetailPage(navBackStackEntry: NavBackStackEntry) {
LogicPage(navBackStackEntry = navBackStackEntry) {
// content
}
}
@Composable
fun LogicPage(
navBackStackEntry: NavBackStackEntry,
saveToLatest: Boolean = false,
content: @Composable () -> Unit
) {
content()
LaunchedEffect(navBackStackEntry) {
val scheme = navBackStackEntry.arguments?.getString(SchemeKeys.KEY_ORIGIN)?.let { Uri.decode(it) }
if (scheme != null) {
// 上报 scheme,作为曝光
// 保存 scheme,如果用户退出了,直接重入这个界面。
// 这个在调试中很好用。例如某个界面,需要点5层才能进去,每次编译重启就要点5次才能看到这个界面,那就蛋疼了,所以如果每次把它记录起来,启动就进去,那开发就顺很多了
}
}
}
界面状态
很多界面基本上就是列表,然后就有空界面、错误提示情况,列表,列表可能还有加载更多。在原来 View 体系,就要做各种 View 的显示隐藏操作,写起来贼麻烦。 用 Compose 封装起来就简单了。 看我的封装结果
val logic by vm.thinkFlow.collectAsStateWithLifecycle()
LogicBox(
modifier = Modifier
.fillMaxWidth()
.weight(1f),
logic = { logic },
reload = {
vm.reload()
},
emptyText = "空"
) { list ->
// 列表数据
}
把它往 LogicPage 里面套就完事了,当然这也是数据逻辑层我抽象了强大的 logic 逻辑。借助这个逻辑,可以分分钟完成数据的从网络数据拉取,再到读存 DB,再到界面的渲染,可以快速补充完成空界面、加载出错、加载更多、下拉刷新等功能。
多级评论
看我这个思辨详情页面,假设以旧的 RecyclerView 体系来做这个,想想都痛苦。而我是数据逻辑层加UI一起两三个小时搞定, 毫无 bug。
另外这里还有一个“从通知点击进来滚动到当前评论”的场景,如果是原生或者 RN 来做,最痛苦的事情就是滚动时机了,一般最终会使用 post 万能大法大法,然而总有没滚动的情况发生,然后产品就找过来了。
而 Compose 也就是一小段代码的事了:
if (vm.targetCommentId > 0) {
val targetCommentIndex = remember(vo) {
indexOfTargetCommentId(vo, vm.targetCommentId)
}
if (targetCommentIndex > 0) {
LaunchedEffect(Unit) {
vm.listState.scrollToItem(targetCommentIndex, 0)
}
}
}
嵌套滚动
看看这个一般的嵌套滚动界面
即使有 NestedScroll 或者 CoordinatorLayout,但新手用不懂,高手也容易遗忘某些配置而踩坑。
那么 Compose 需要多少代码呢?
val nestedScrollConnection = remember {
object : NestedScrollConnection {
override fun onPreScroll(available: Offset, source: NestedScrollSource): Offset {
if (available.y < 0 && vm.scrollState.canScrollForward) {
scope.launch {
vm.scrollState.scrollBy(-available.y)
}
return available
}
return super.onPreScroll(available, source)
}
}
}
Column(
modifier = Modifier
.fillMaxSize()
.verticalScroll(vm.scrollState)
.nestedScroll(nestedScrollConnection)
) {
BookInfoBasic(info)
BookInfoPageTabSegment(vm = vm)
HorizontalPager(...)
}
这样就完成整个界面了,其实也是对 nestedScroll 的封装,道理和 View 体系一样,只是用起来更方便了。
ChatGPT
ChatGPT 对于 Compose 而言,很不好,毕竟其训练依赖的是旧版本,所以会有很多错误,所以不能用的,但是它在逻辑层面就很好用了,例如文件上传、下载等,我都是让它写,写完自己校验下,就完工了。为了赶时髦,我当然也在 app 里接入了 ChatGPT,当然,我做了配置,目前对外不开放。
漫长的审核
正如文章开始所说,开发我用了一个多月,但是后面的审核上线则是用了两个月左右,其实说到底还是对规则的不熟悉。在电子版权、安全评估报告等环节都是在处理一份之后才知道必须要另一个,所以化并行为串行了。并且做安全评估,给我的感觉就是我的 app 分分钟有上百万的日活,实际上整个圈子可能不过数万人,但我也得完成相应的功能,例如接入飞书机器人,在飞书群里完成内容审核功能。
所以这两个月,最多的就是认识到了整个市场,在公司注册、记账、上架等各个环节衍生的无数商业行为,很多都是收智商税和信息差赚差价的。所以中国有商业头脑的人还是很多,在各个小环节拉拢豪绅、巧立名目,只要有信息差,我就可以无限拉高价格。因为也铸就了现在创业那高不可攀的围墙。
当然,我已经进到墙内了,如果能够成功,那这个墙就是对我的保护了,毕竟干的又不是 ChatGpt 那种无法轻易复制的产品,所以这堵高墙就可以为我争取更多的成长时间了。
在这两个月,我打造了另一款产品:emo-ai。最主要的功能就是 ChatGpt 的代理,目前维护了一个小用户群体,收到了第一桶小金。
此外,我也了解了下 StableDiffusion,本地搭建了 StableDiffusionWebUi 的环境,了解它的 prompt 玩法、 controlnet、lora 之类的知识。绘图入魔怔~
最后
ChatGPT 的爆火,让人们见识到了 AI 的力量,开发、设计、文案等领域,都快被取代了。中医这个领域,虽然目前完全没有被波及,但我以前曾提过:
**治疗 = 根据【当前的症状/指标】推荐出【相应的药物】
所以医学本质是一个推荐系统,西医强调靶向治疗,中医则是用阴阳五行之类的建立了一个巨大的模型,从这个角度上来讲,中医显然更胜一筹。
但是深度神经网络时代,显然我们可以训练参数规模更大的模型,来完成辨证论治的过程。
但是模型的训练,少不了数据的支撑以及模型的建立。
数据来说,中医有几千年的数据积累,是世界上最大最全的资源,只是需要整合与结构化。
而模型最为重要的是模型的结构是怎样的?损失函数、优化器如何定义?经过长久的学习,我已然有了一些思路,也是我跨领域融合所独有的见解。
但目前数据还不是结构化的,GPU 也不是我能买得起的,所以这条路还很长,也是岐黄小筑想要承载的梦想。
拥有梦想,也要脚踏实地,因为我目前做的事情就比较苦逼了。我要把一本本书籍的拆分出来,存成结构化的数据,并对内容做链接,用技术只能得到模糊的结果,最后还要自己去校对。录入系统的管理后台也还在建设中。
所以, 最后再吹下 Compose, 为我节约了大量的时间。在 View 时代,鉴于喜欢写 UI 和能够写 UI 的人真的偏少,我大概能够一次性取代 6 个业务开发,那在 Compose 的加持下,也许取代 60 个业务开发也不是什么大问题了。
链接:https://juejin.cn/post/7229539262911381563
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android jetpack Compose之约束布局
概述
我们都知道ConstraintLayout在构建嵌套层级复杂的视图界面时可以有效降低视图树的高度,使视图树扁平化,约束布局在测量布局耗时上比传统的相对布局具有更好的性能,并且约束布局可以根据百分比自适应各种尺寸的终端设备。因为约束布局确实很好用,所以,官方也为我们将约束布局迁移到了Compose平台。本文就是介绍约束布局在Compose中的使用。
实例解析
在使用约束布局之前,我们需要先在项目中的app.gradle脚本中添加compose版本的ConstraintLayout依赖
implementation('androidx.constraintlayout:constraintlayout-compose:1.0.1')
引入依赖以后,我们就可以看下如何在Compose中使用约束布局了
1.创建引用
在传统View系统中,我们在布局XML文件中可以给View设置资源的ID,并将资源ID作为索引来声明对应组件的摆放位置。而在Compose的约束布局中,可以主动创建引用并绑定到某个具体组件上,从而实现与资源ID相似的功能,每个组件都可以利用其他组件的引用获取到其他组件的摆放位置信息,从而确定自己摆放位置。
Compose 创建约束布局的方式有两种,分别时createRef()和createRefs(),根据字面意思我们就可以很清楚的知道,createRef(),每次只会创建一个引用,而createRefs()每次可以创建多个引用(最多可以创建16个),创建引用的方式如下:
// 创建单个引用
val text = createRef()
// 创建多个引用
val (button1,button2,text) = createRefs()
2.绑定引用
当我们创建完引用后就可以使用Modifier.constrainAs()修饰符将我们创建的引用绑定到某个具体组件上,可以在contrainAs尾部Lambda内指定组件的约束信息。我们需要注意的是,我们只能在ConstraintLayout尾部的Lambda中使用createRefer,createRefs函数创建引用,并使用Modifier.constrainAs函数来绑定引用,因为ConstrainScope尾部的Lambda的Reciever是一个ConstraintLayoutScope作用域对象。我们可以先看下面一段代码了解下约束布局的引用绑定:
@Composable
fun ConstrainLayoutDemo()
{
ConstraintLayout(modifier = Modifier
.width(300.dp)
.height(100.dp)
.padding(5.dp)
.border(5.dp, color = Color.Red)) {
val portraitImageRef = remember {
createRef()
}
Image(painter = painterResource(id = R.drawable.portrait)
, contentDescription = null,
modifier = Modifier.constrainAs(portraitImageRef){
top.linkTo(parent.top)
bottom.linkTo(parent.bottom)
start.linkTo(parent.start)
})
}
}
运行结果:
上面的代码是实现一个用户卡片的部分代码,从代码中看到我们使用约束的时候需要用到Modifier.constrainsAs(){……}的方式。Modifier.constrainsAs的尾部Lambda是一个ConstrainScope作用域对象,可以在其中获取当前组件的parent,top,bottom,start,end等信息。并使用linkTo指定组件约束。在上面的界面中,我们希望用户的头像可以居左对齐,所以将top拉伸至父组件的顶部,bottom拉伸至父组件的底部,start拉伸至父组件的左边。我们再为卡片添加上用户的昵称和描述,全部代码如下所示:
@Composable
fun ConstrainLayoutDemo()
{
ConstraintLayout(modifier = Modifier
.width(300.dp)
.height(100.dp)
.padding(5.dp)
.border(5.dp, color = Color.Red)) {
val (portraitImageRef,usernameTextRef,descriptionTextRef) = remember {
createRefs()
}
Image(painter = painterResource(id = R.drawable.portrait)
, contentDescription = null,
modifier = Modifier.constrainAs(portraitImageRef){
top.linkTo(parent.top)
bottom.linkTo(parent.bottom)
start.linkTo(parent.start)
})
Text(text = "旅游小美女", fontSize = 16.sp, maxLines = 1,
textAlign = TextAlign.Left,
modifier = Modifier.constrainAs(usernameTextRef){
top.linkTo(portraitImageRef.top)
start.linkTo(portraitImageRef.end,10.dp)
})
Text(text = "个人描述。。。。。。。。", fontSize = 14.sp,
color = Color.Gray,
fontWeight = FontWeight.Light,
modifier = Modifier.constrainAs(descriptionTextRef){
top.linkTo(usernameTextRef.bottom,5.dp)
start.linkTo(portraitImageRef.end,10.dp)
}
)
}
}
运行结果:
在上面的代码中我们也可以在ConstrainScope中指定组件的宽高信息,在ConstrainScope中直接设置width与height的可选值如下所示:
在ConstrainScope中指定组件的宽高信息时,通过在
Modifier.constrainAs(xxxRef){width = Dimension.可选值}来设置,可选值如下:
Dimension.wrapContent: 实际尺寸为根据内容自适应
Dimension.matchParent: 实际尺寸为铺满父组件的尺寸
Dimension,wrapContent: 实际尺寸为根据约束信息拉伸后的尺寸
Dimension.preferredWrapContent: 如果剩余空间大于更具内容自适应的尺寸时,实际尺寸为自适应的尺寸,如果剩余空间小于内容自适应尺寸时,实际尺寸为剩余空间尺寸
Dimension.ratio(String): 根据字符串计算实际尺寸所占比率:如1 :2
Dimension.percent(Float): 根据浮点数计算实际尺寸所占比率
Dimension.value(Dp): 将尺寸设置为固定值
Dimension.perferredValue(Dp): 如果剩余空间大于固定值时,实际尺寸为固定值,如果剩余空间小于固定值时,实际尺寸则为剩余空间尺寸
我们想象下,假如用户的昵称特别长,那么按照我们上面的代码展示则会出现展示不全的问题,所以我们可以通过设置end来指定组件所允许的最大宽度,并将width设置为preferredWrapContent,意思是当用户名很长时,实际的宽度会做自适应调整。我们将上面展示用户名的地方改一下,代码如下:
// 上面的代码只用改这个部分
Text(
text = "旅游小美女美美美美美名字很长长长长长长长长长",
fontSize = 16.sp,
textAlign = TextAlign.Left,
modifier = Modifier.constrainAs(usernameTextRef){
top.linkTo(portraitImageRef.top)
start.linkTo(portraitImageRef.end,10.dp)
end.linkTo(parent.end,10.dp)
width = Dimension.preferredWrapContent
})
运行结果:
辅助布局工具
在传统View的约束布局中有Barrier,GuideLine等辅助布局的工具,在Compose中也继承了这些特性,方便我们完成各种复杂场景的布局需求。
1.Barrier分界线
Barrier顾名思义就是一个屏障,使用它可以隔离UI布局上面的一些相互挤压的影响,举一个例子,比如我们希望两个输入框左对齐摆放,并且距离文本组件中的最长者仍保持着10dp的间隔,当用户名和密码等发生变化时,输入框的位置能够自适应调整。这里使用Barrier特性可以简单的实现这一需求:
@Composable
fun InputFieldLayout(){
ConstraintLayout(
modifier = Modifier
.width(400.dp)
.padding(10.dp)
) {
val (usernameTextRef, passwordTextRef, usernameInputRef, passWordInputRef) = remember { createRefs() }
val barrier = createEndBarrier(usernameTextRef, passwordTextRef)
Text(
text = "用户名",
fontSize = 14.sp,
textAlign = TextAlign.Left,
modifier = Modifier
.constrainAs(usernameTextRef) {
top.linkTo(parent.top)
start.linkTo(parent.start)
}
)
Text(
text = "密码",
fontSize = 14.sp,
modifier = Modifier
.constrainAs(passwordTextRef) {
top.linkTo(usernameTextRef.bottom, 20.dp)
start.linkTo(parent.start)
}
)
OutlinedTextField(
value = "",
onValueChange = {},
modifier = Modifier.constrainAs(usernameInputRef) {
start.linkTo(barrier, 10.dp)
top.linkTo(usernameTextRef.top)
bottom.linkTo(usernameTextRef.bottom)
height = Dimension.fillToConstraints
}
)
OutlinedTextField(
value = "",
onValueChange = {},
modifier = Modifier.constrainAs(passWordInputRef) {
start.linkTo(barrier, 10.dp)
top.linkTo(passwordTextRef.top)
bottom.linkTo(passwordTextRef.bottom)
height = Dimension.fillToConstraints
}
)
}
}
运行结果:
2.Guideline引导线
Barrier分界线需要依赖其他引用,从而确定自身的位置,而使用Guideline不依赖任何引用,例如,我们希望将用户头像摆放在距离屏幕顶部2:8的高度位置,头像以上是用户背景,以下是用户信息,这样的需求就可以使用Guideline实现,代码如下:
@Composable
fun GuidelineDemo(){
ConstraintLayout(modifier = Modifier
.height(300.dp)
.background(color = Color.Gray)) {
val guideline = createGuidelineFromTop(0.2f)
val (userPortraitBackgroundRef,userPortraitImgRef,welcomeRef) = remember {
createRefs()
}
Box(modifier = Modifier
.constrainAs(userPortraitBackgroundRef) {
top.linkTo(parent.top)
bottom.linkTo(guideline)
height = Dimension.fillToConstraints
width = Dimension.matchParent
}
.background(Color(0xFF673AB7)))
Image(painter = painterResource(id = R.drawable.portrait),
contentDescription = null,
modifier = Modifier
.constrainAs(userPortraitImgRef) {
top.linkTo(guideline)
bottom.linkTo(guideline)
start.linkTo(parent.start)
end.linkTo(parent.end)
}
.size(100.dp)
.clip(CircleShape)
.border(width = 2.dp, color = Color(0xFF96659E), shape = CircleShape))
Text(text = "不喝奶茶的小白兔",
color = Color.White,
fontSize = 26.sp,
modifier = Modifier.constrainAs(welcomeRef){
top.linkTo(userPortraitImgRef.bottom,10.dp)
start.linkTo(parent.start)
end.linkTo(parent.end)
})
}
}
运行结果:
在上面的代码中,我们使用createGuidelineFromTop()方法创建了一条从顶部出发的引导线,然后用户背景就可以依赖这条引导线确定宽高了,然后对于头像,我们只需要将top和bottom连接至引导线即可
3.Chain链接约束
ContraintLayout的另一个好用的特性就是Chain链接约束,通过链接约束可以允许多个组件平均分配布局空间,类似于weight修饰符。例如我们要展示一首古诗,用Chain链接约束实现如下:
@Composable
fun showQuotesDemo() {
ConstraintLayout(
modifier = Modifier
.size(400.dp)
.background(Color.Black)
) {
val (quotesFirstLineRef, quotesSecondLineRef, quotesThirdLineRef, quotesForthLineRef) = remember {
createRefs()
}
createVerticalChain(
quotesFirstLineRef, quotesSecondLineRef, quotesThirdLineRef, quotesForthLineRef,
chainStyle = ChainStyle.Spread
)
Text(text = "窗前明月光,",
color = Color.White,
fontSize = 20.sp,
fontWeight = FontWeight.Bold,
modifier = Modifier.constrainAs(quotesFirstLineRef) {
start.linkTo(parent.start)
end.linkTo(parent.end)
})
Text(text = "疑是地上霜。",
color = Color.White,
fontSize = 20.sp,
fontWeight = FontWeight.Bold,
modifier = Modifier.constrainAs(quotesSecondLineRef) {
start.linkTo(parent.start)
end.linkTo(parent.end)
})
Text(text = "举头望明月,",
color = Color.White,
fontSize = 20.sp,
fontWeight = FontWeight.Bold,
modifier = Modifier.constrainAs(quotesThirdLineRef) {
start.linkTo(parent.start)
end.linkTo(parent.end)
})
Text(text = "低头思故乡。",
color = Color.White,
fontSize = 20.sp,
fontWeight = FontWeight.Bold,
modifier = Modifier.constrainAs(quotesForthLineRef) {
start.linkTo(parent.start)
end.linkTo(parent.end)
})
}
}
运行结果:
如上面代码所示,我们要展示四句诗就需要创建四个引用对应四句诗,然后我们就可以创建一条垂直的链接约束将四句诗词连接起来,创建链接约束时末尾参数可以传一个ChainStyle,用来表示我们期望的布局样式,它的取值有三个,效果和意义如下所示:
(1)Spread:链条中的每个元素平分整个父空间
createVerticalChain(
quotesFirstLineRef, quotesSecondLineRef, quotesThirdLineRef, quotesForthLineRef,
chainStyle = ChainStyle.Spread)
运行效果:
(2)SpreadInside:链条中的首尾元素紧贴边界,剩下的每个元素平分整个父空间
createVerticalChain(
quotesFirstLineRef, quotesSecondLineRef, quotesThirdLineRef, quotesForthLineRef,
chainStyle = ChainStyle.SpreadInside)
运行效果:
(3)Packed:链条中的所有元素都聚集到中间,效果如下
createVerticalChain(
quotesFirstLineRef, quotesSecondLineRef, quotesThirdLineRef, quotesForthLineRef,
chainStyle = ChainStyle.Packed)
运行效果:
总结
关于Compose约束布局的内容就是这些了,本文主要是简单的介绍了Compose中约束布局的基本使用,要熟练掌握Compose约束布局,还需要读者多去联系,多使用约束布局写界面,这样就会熟能生巧,在此我只做一个抛砖引玉的活。有任何疑问,欢迎在评论区交流。
链接:https://juejin.cn/post/7226943352414519351
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
安卓组件学习——NavigationView导航视图
前言
日新计划可真头疼,每天更文养成习惯是好,但有时候没思路就很烦,回到正题,本篇回到很久之前的组件学习(安卓UI设计开发——Material Design(BottomSheetDialogFragment篇) - 掘金 (juejin.cn)),这次我们来看看许多APP首页常用的NavigationView——滑动菜单如何使用。
2/22 更正:NavigationView为导航视图,DrawerLayout为抽屉布局,一起组合成滑动菜单(实现侧滑交互体验)
正篇
首先,使用NavigationView前我们先创建一个新项目,我这里为了学习这些组件,命名为MaterialDemo,作为我们学习Materia组件的项目,然后因为要使用Material库的NavigationView,所以我们项目的app目录下的build.gradle文件中的dependencies闭包中添加下面依赖:
implementation 'com.google.android.material:material:1.8.0'
implementation 'de.hdodenhof:circleimageview:3.1.0'
其中第二个依赖是我们导入的开源项目CircleImageView,这可以让我们更容易实现图片圆形化,也就是这个滑动菜单栏上圆形头像的形成。
当然,新建的是Kotlin安卓空Activity项目,我们采用了ViewBinding,所以同时也要在该文件下启用ViewBinding,位置在android闭包中:
buildFeatures {
viewBinding = true
}
sync Gradle(同步 Gradle)完成后,我们再把res/values/theme.xml文件中AppTheme的parent主题换为Theme.MaterialComponents.Light.NoActionBar,用来适配我们的Material库组件:
我们还得事先准备几张图片备用(按钮,头像等),这里我放在了drawable-xxhdpi目录下,当然如果有需要可以到文末我的Github项目中找:
接着,我们在res目录下创建新的名为menu文件夹(和之前文章安卓开发基础——Menu菜单的使用 - 掘金 (juejin.cn)一样):
再在这个文件夹上右击->New->Menu resource file ,创建一个nav_menu.xml文件,添加下面的代码:
<?xml version="1.0" encoding="utf-8"?>
<menu xmlns:android="http://schemas.android.com/apk/res/android">
<group android:checkableBehavior="single">
<item
android:id="@+id/navCall"
android:icon="@drawable/nav_call"
android:title="Call" />
<item
android:id="@+id/navFriends"
android:icon="@drawable/nav_friends"
android:title="Friends" />
<item
android:id="@+id/navLocation"
android:icon="@drawable/nav_location"
android:title="Location" />
<item
android:id="@+id/navMail"
android:icon="@drawable/nav_mail"
android:title="Mail" />
<item
android:id="@+id/navTask"
android:icon="@drawable/nav_task"
android:title="Tasks" />
</group>
</menu>
上面代码中我们加了一个group标签,并把其中的checkableBehavior属性设置为single,这样就能让菜单项变为只可以单选。
然后我们就能预览到这个菜单样式,这就是我们即将用的具体的菜单项:
但NavigationView样式不是这个预览到的,因为有菜单项这样还是不够的,我们还需要准备一个herderLayout用于显示NavigationView的头部布局,这个布局可以按照需求来定制,这里我们就构建了头像、用户名和邮箱地址这三项,这个布局我们直接在layout目录正常创建布局文件就行,我们这里创建一个名为nav_header的XML布局文件:
该文件代码如下:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="180dp"
android:padding="10dp"
android:background="?attr/colorPrimary">
<de.hdodenhof.circleimageview.CircleImageView
android:id="@+id/iconImage"
android:layout_width="70dp"
android:layout_height="70dp"
android:src="@drawable/nav_icon"
android:layout_centerInParent="true" />
<TextView
android:id="@+id/mailText"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:text="tonygreendev@gmail.com"
android:textColor="#FFF"
android:textSize="14sp" />
<TextView
android:id="@+id/userText"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_above="@id/mailText"
android:text="Tony Green"
android:textColor="#FFF"
android:textSize="14sp" />
</RelativeLayout>
我们使用了相对布局(RelativeLayout)作为最外层布局,其中CircleImageView就是之前加依赖提到的开源控件,将我们的图片圆形化,和ImageView用法一样,这里我们用于构建圆形的头像图片,且设为居中,还有两个TextView分别就是我们的用户名和邮箱地址,用相对布局属性定位即可。
这些做完后,我们的准备阶段就完成了,接下来我们开始使用NavigationView控件:
我们先把布局添加NavigationView:
<?xml version="1.0" encoding="utf-8"?>
<androidx.drawerlayout.widget.DrawerLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
android:id="@+id/drawerLayout"
android:layout_width="match_parent"
android:layout_height="match_parent">
<FrameLayout
android:layout_width="match_parent"
android:layout_height="match_parent">
<androidx.appcompat.widget.Toolbar
android:id="@+id/toolbar"
android:layout_width="match_parent"
android:layout_height="?attr/actionBarSize"
android:background="?attr/colorPrimary"
android:theme="@style/ThemeOverlay.AppCompat.Dark.ActionBar"
app:popupTheme="@style/ThemeOverlay.AppCompat.Light" />
</FrameLayout>
<com.google.android.material.navigation.NavigationView
android:id="@+id/navView"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:layout_gravity="start"
app:menu="@menu/nav_menu"
app:headerLayout="@layout/nav_header"/>
</androidx.drawerlayout.widget.DrawerLayout>
Activity中:
package com.example.materialdemo
import androidx.appcompat.app.AppCompatActivity
import android.os.Bundle
import com.example.materialdemo.databinding.ActivityMainBinding
class MainActivity : AppCompatActivity() {
lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding = ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
setSupportActionBar(binding.toolbar)
supportActionBar?.let {
it.setDisplayHomeAsUpEnabled(true)
it.setHomeAsUpIndicator(R.drawable.ic_menu)
}
binding.navView.setCheckedItem(R.id.navCall)
binding.navView.setNavigationItemSelectedListener {
binding.drawerLayout.closeDrawers()
true
}
}
}
最终效果:
这里一开始忘记加我的项目地址了,现在补上:GitHub - ObliviateOnline/MaterialDemo: Material库组件学习
总结
今天学了NavigationView,结果忘记写前面的滑动菜单DrawerLayout和标题栏Toolbar控件了,下一篇就把前面的构建过程给理一遍。
链接:https://juejin.cn/post/7202612506148585529
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android性能启动优化——IO优化进阶
IO优化
1、启动过程不建议出现网络IO。
2、为了只解析启动过程中用到的数据,应选择合适的数据结构,如将ArrayMap改造成支持随机读
写、延时解析的数据存储结构以替代SharePreference。
这里需要注意的是,需要考虑重度用户的使用场景。
补充加油站:Linux IO知识
1、磁盘高速缓存技术
利用内存中的存储空间来暂存从磁盘中读出的一系列盘块中的信息。因此,磁盘高速缓存在逻辑上属于
磁盘,物理上则是驻留在内存中的盘块。
其内存中分为两种形式:
在内存中开辟一个单独的存储空间作为磁速缓存,大小固定。
把未利用的内存空间作为一个缓沖池,供请求分页系统和磁盘I/O时共享。
2、分页
存储器管理的一种技术。
可以使电脑的主存使用存储在辅助存储器中的数据。
操作系统会将辅助存储器(通常是磁盘)中的数据分区成固定大小的区块,称为“页”(pages)。
当不需要时,将分页由主存(通常是内存)移到辅助存储器;当需要时,再将数据取回,加载主存
中。
相对于分段,分页允许存储器存储于不连续的区块以维持文件系统的整齐。
分页是磁盘和内存间传输数据块的最小单位。
3、高速缓存/缓冲器
都是介于高速设备和低速设备之间。
高速缓存存放的是低速设备中某些数据的复制数据,而缓冲器则可同时存储高低速设备之间的数
据。
高速缓存存放的是高速设备经常要访问的数据。
4、linux同步IO:sync、fsync、msync、fdatasync
为什么要使用同步IO?
当数据写入文件时,内核通常先将该数据复制到缓冲区高速缓存或页面缓存中,如果该缓冲区尚未写
满,则不会将其排入输入队列,而是等待其写满或内核需要重用该缓冲区以便存放其他磁盘块数据时,
再将该缓冲排入输出队列,最后等待其到达队首时,才进行实际的IO操作—延迟写。
延迟写减少了磁盘读写次数,但是却降低了文件内容的更新速度,可能会造成文件更新内容的丢失。为
了保证数据一致性,则需使用同步IO。
sync
sync函数只是将所有修改过的块缓冲区排入写队列,然后就返回,它并不等待实际磁盘写操作结束
再返回。
通常称为update的系统守护进程会周期性地(一般每隔30秒)调用sync函数。这就保证了定期冲
洗内核的块缓冲区。
fsync
fsync函数只对文件描述符filedes指定的单一文件起作用,并且等待磁盘IO写结束后再返回。通常
应用于需要确保将修改内容立即写到磁盘的应用如数据库。
文件的数据和metadata通常存放在硬盘的不同地方,因此fsync至少需要两次IO操作。
msync
如果当前硬盘的平均寻道时间是3-15ms,7200RPM硬盘的平均旋转延迟大约为4ms,因此一次IO操作
的耗时大约为10ms。
如果使用内存映射文件的方式进行文件IO(mmap),将文件的page cache直接映射到进程的地址空
间,这时需要使用msync系统调用确保修改的内容完全同步到硬盘之上。
fdatasync
fdatasync函数类似于fsync,但它只影响文件的数据部分。而fsync还会同步更新文件的属性。
仅仅只在必要(如文件尺寸需要立即同步)的情况下才会同步metadata,因此可以减少一次IO操
作。
日志文件都是追加性的,文件尺寸一致在增大,如何利用好fdatasync减少日志文件的同步开销?
创建每个log文件时先写文件的最后一个page,将log文件扩展为10MB大小,这样便可以使用
fdatasync,每写10MB只有一次同步metadata的开销。
2.10 磁盘IO与网络IO
磁盘IO(缓存IO)
标准IO,大多数文件系统默认的IO操作。
数据先从磁盘复制到内核空间的缓冲区,然后再从内核空间中的缓冲区复制到应用程序的缓冲区。
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经有缓存了,那么直接从缓存中返
回;否则,从磁盘中返回,再缓存在操作系统的磁盘中。
写操作:将数据从用户空间复制到内核空间中的缓冲区中,这时对用户来说写操作就已经完成,至
于什么时候写到磁盘中,由操作系统决定,除非显示地调用了sync同步命令。
以上讲解部分Android性能优化中的IO优化部分,除了这些还有启动优化、卡顿优化、UI优化等等技术。了解更多可以前往
传送直达↓↓↓ :link.juejin.cn/?target=htt…
文末
优点
在一定程度上分离了内核空间和用户空间,保护系统本身安全。
可以减少磁盘IO的读写次数,从而提高性能。
缺点
DMA方式可以将数据直接从磁盘读到页缓存中,或者将数据从页缓存中写回到磁盘,而不能在应用程序
地址空间和磁盘之间进行数据传输,这样,数据在传输过程中需要在应用程序地址空间(用户空间)和
缓存(内核空间)中进行多次数据拷贝操作,这带来的CPU以及内存开销是非常大的。
磁盘IO主要的延时(15000RPM硬盘为例)
机械转动延时(平均2ms)+ 寻址延时(2~3ms)+ 块传输延时(0.1ms左右)=> 平均5ms
网络IO主要延时
服务器响应延时 + 带宽限制 + 网络延时 + 跳转路由延时 + 本地接收延时(一般为几十毫秒到几千毫秒, 受环境影响极大)
链接:https://juejin.cn/post/7175501523105873957
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 14 快速适配要点
随着 Google I/O 2023 发布的 Android beta2 ,预计 Android 14 将在2023年第三季度发布,目前看整体需要适配的内容已经趋向稳定,那就根据官方文档简单做个适配要点总结吧。
如何做到最优雅的版本适配?那就是尽可能提高 minitSdkVersion ,说服老板相信低版本用户无价值论,低版本用户更多是羊毛党~
针对 Android 14 或更高版本的应用
这部分主要是影响 targetSdkVersion 34 的情况 ,目前 Google Play 已经开始要求 33 了,相信未来 34 也不远了。
前台服务类型
targetSdkVersion 34 的情况下,必须为应用内的每个前台服务(foreground-services) 指定至少一种前台服务类型。
前台服务类型是在 Android 10 引入的,通过 android:foregroundServiceType 可以指定 <service> 的服务类型,可供选择的前台服务类型有:
cameraconnectedDevicedataSynchealthlocationmediaPlaybackmediaProjectionmicrophonephoneCallremoteMessagingshortServicespecialUsesystemExempted
例如:
<manifest ...>
<uses-permission android:name="android.permission.FOREGROUND_SERVICE" />
<uses-permission android:name="android.permission.FOREGROUND_SERVICE_MEDIA_PLAYBACK" />
<application ...>
<service
android:name=".MyMediaPlaybackService"
android:foregroundServiceType="mediaPlayback"
android:exported="false">
</service>
</application>
</manifest>
如果你 App 中的用例与这些类型中的任何一种都不相关,那么建议还是将服务迁移成 WorkManager 或 jobs 。
更多详细可见:developer.android.com/about/versi…
安全
对 pending/implicit intent 的限制
对于面向 Android 14 的应用,Android 通过以下方式限制应用向内部应用组件发送隐式 intent:
- 隐式 intent 仅传递给导出的组件,应用必须使用明确的 intent 来交付给未导出的组件,或者将组件标记为已导出(exported) 。
- 如果应用创建一个 mutable pending intent ,但 intent 未指定组件或包,系统现在会抛出异常。
这些更改可防止恶意应用拦截只供给用内部组件使用的隐式 intent,例如:
<activity
android:name=".AppActivity"
android:exported="false">
<intent-filter>
<action android:name="com.example.action.APP_ACTION" />
<category android:name="android.intent.category.DEFAULT" />
</intent-filter>
</activity>
如果应用尝试使用隐式 intent 启动该 activity,则会抛出异常:
// Throws an exception when targeting Android 14.
context.startActivity(Intent("com.example.action.APP_ACTION"))
要启动未导出的 Activity,应用应改用显式 Intent:
// This makes the intent explicit.
val explicitIntent =
Intent("com.example.action.APP_ACTION")
explicitIntent.apply {
package = context.packageName
}
context.startActivity(explicitIntent)
运行时注册的广播接收器必须指定导出行为
以 Android 14 为目标,并使用 context-registered receivers (ContextCompat.registerReceiver)应用和服务的需要指定一个标志,以指示接收器是否应导出到设备上的所有其他应用:分别为 RECEIVER_EXPORTED 或 RECEIVER_NOT_EXPORTED。
val filter = IntentFilter(APP_SPECIFIC_BROADCAST)
val listenToBroadcastsFromOtherApps = false
val receiverFlags = if (listenToBroadcastsFromOtherApps) {
ContextCompat.RECEIVER_EXPORTED
} else {
ContextCompat.RECEIVER_NOT_EXPORTED
}
ContextCompat.registerReceiver(context, br, filter, receiverFlags)
仅接收系统广播的接收器例外
如果应用仅通过 Context#registerReceiver 方法为系统广播注册接收器时,那么它可以不在注册接收器时指定标志, 例如 android.intent.action.AIRPLANE_MODE 。
更安全的动态代码加载
如果应用以 Android 14 为目标平台并使用动态代码加载 (DCL),则所有动态加载的文件都必须标记为只读,否则,系统会抛出异常。
我们建议应用尽可能避免动态加载代码,因为这样做会大大增加应用因代码注入或代码篡改而受到危害的风险。
如果必须动态加载代码,请使用以下方法将动态加载的文件(例如 DEX、JAR 或 APK 文件)在文件打开后和写入任何内容之前立即设置为只读:
val jar = File("DYNAMICALLY_LOADED_FILE.jar")
val os = FileOutputStream(jar)
os.use {
// Set the file to read-only first to prevent race conditions
jar.setReadOnly()
// Then write the actual file content
}
val cl = PathClassLoader(jar, parentClassLoader)
处理已存在的动态加载文件
为防止现有动态加载文件抛出异常,我们建议可以尝试在应用中再次动态加载文件之前,删除并重新创建这些文件。
重新创建文件时,请按照前面的指导在写入时将文件标记为只读,或者将现有文件重新标记为只读,但在这种情况下,强烈建议首先验证文件的完整性(例如,通过根据可信值检查文件的签名),以帮助保护应用免受恶意操作。
Zip path traversal
对于针对 Android 14 的应用,Android 通过以下方式防止 Zip 路径遍历漏洞:如果 zip 文件条目名称包含 “..” 或以 “/” 开头,则 ZipFile(String) 和 ZipInputStream.getNextEntry() 会抛出一个 ZipException 。
应用可以通过调用 dalvik.system.ZipPathValidator.clearCallback() 选择退出验证。
从后台启动活动的附加限制
针对 Android 14 的应用,系统进一步限制了应用在后台启动 Activity 的时间:
- 当应用使用
PendingIntent#send()发送PendingIntent以及类似行为时,如果应用想要授予其自己的后台 service 启动权限以启动 pending intent,则该应用现在必须选择加入一个ActivityOptions,具体为带有setPendingIntentBackgroundActivityStartMode(MODE_BACKGROUND_ACTIVITY_START_ALLOWED) - 当一个可见应用使用
bindService()绑定另一个在后台运行的应用的服务时,如果该可见应用想要将其自己的后台 activity 启动权限授予绑定服务,则它现在必须选择加入BIND_ALLOW_ACTIVITY_STARTS标志。
这些更改扩展了现有的一组限制 ,通过防止恶意应用滥用 API 从后台启动破坏性活动来保护用户。
具体可见:developer.android.com/guide/compo…
OpenJDK 17
Android 14 会要求的 OpenJDK 17 的支持,这对一些语法上可以会有一定影响,例如:
- 对正则表达式的更改:现在不允许无效的组引用
- UUID 处理:
java.util.UUID.fromString()方法现在在验证输入参数时会进行更严格的检查 - ProGuard 问题:在某些情况下,如果使用 ProGuard 缩小、混淆和优化应用,添加
java.lang.ClassValue会导致出现问题,问题源于 Kotlin 库,库会根据是否Class.forName("java.lang.ClassValue")返回类来更改运行时行为。
反正适配 OpenJDK 17 就对了,新版 Android Studio Flamingo 也默认内置 OpenJDK 17 了。
针对所有版本的 Android 14 变更
以下行为主要针对在 Android 14 上运行的所有应用,可以看到从 Android 10 开始, Androd Team 针对这些变动越来越强势。
核心功能
默认情况下拒绝计划精确提醒
精确提醒(Exact alarms)用于用户有目的的通知,或用于需要在精确时间发生的操作情况,从 Android 14 开始,该 SCHEDULE_EXACT_ALARM 权限不再预先授予大多数新安装的针对 Android 13 及更高版本的应用,默认情况下该权限会被拒绝。
如果用户通过备份还原操作将应用数据传输到运行Android 14 的设备上,权限仍然会被拒绝。如果现有的应用已经拥有该权限,它将在设备升级到 Android 14 时预先授予。
而现在需要权限 SCHEDULE_EXACT_ALARM 才能通过以下 API 启动确切的提醒,否则将抛出 SecurityException:
注意: 如果确切的 alarms 是使用
OnAlarmListener对象设置的,例如在setExactAPI 中,SCHEDULE_EXACT_ALARM则不需要权限。
现有的权限最佳实践 SCHEDULE_EXACT_ALARM 仍然适用,包括以下内容:
- 在安排确切的提醒之前检查权限
canScheduleExactAlarms()。 - 设置应用以
AlarmManager.ACTION_SCHEDULE_EXACT_ALARM_PERMISSION_STATE_CHANGED监听前台广播并对其做出正确反应 ,系统会在用户授予权限时发送该广播。
详细可见:developer.android.com/about/versi…
Context-registered 广播在缓存应用时排队
在 Android 14 上,当应用处于缓存状态时,系统可能会将上下文注册的广播放入队列中。
这类似于 Android 12(API 级别 31)为异步活页夹事务引入的排队行为,清单声明的广播不会排队,并且应用会从缓存状态中删除以进行广播传输。
当应用离开缓存状态时,例如返回前台,系统会传送任何排队中的广播,某些广播的多个实例可以合并为一个广播。
根据其他因素(例如系统运行状况),应用可能会从缓存状态中删除,并且先前排队的所有广播都会被传送。
应用只能杀死自己的后台进程
从 Android 14 开始,应用调用 killBackgroundProcesses() 时,该 API 只能杀死自己应用的后台进程。
如果传入其他应用的包名,该方法对该应用的后台进程没有影响,Logcat中会出现如下信息:
Invalid packageName: com.example.anotherapp
应用不应该使用 killBackgroundProcesses() API ,或以其他方式尝试影响其他应用的进程生命周期,即使是在较旧的操作系统版本上。
Android 旨在将缓存的应用保留在后台,并在系统需要内存时自动终止它们,如果应用出现不必要地杀死其他应用,它会降低系统性能并增加电池消耗,因为稍后需要完全重启这些应用,比恢复现有的缓存应用占用的资源要多得多。
安全
最低可安装目标 API 级别
从 Android 14 开始,无法安装 targetSdkVersion 低于 23 的应用 ,要求应用必须满足这些最低目标 API 级别,这样可以提高用户的安全性和隐私性。
恶意软件通常以较旧的 API 级别为 target,以绕过较新 Android 版本中引入的安全和隐私保护,例如一些恶意软件应用使用
targetSdkVersion22 的来避免受到 Android 6.0 的运行时权限模型的约束。
Android 14 的这一变化使恶意软件更难避开安全和隐私管理,尝试安装针对较低 API 级别的应用将导致安装失败,并在 Logcat 中显示以下消息:
INSTALL_FAILED_DEPRECATED_SDK_VERSION: App package must target at least SDK version 23, but found 7
在升级到 Android 14 的设备上,任何低于targetSdkVersion23 的应用都将保持安装状态,如果你需要针对较旧 API 级别的应用进行测试,请使用以下 ADB 命令:
adb install --bypass-low-target-sdk-block FILENAME.apk
用户体验
授予对照片和视频的部分访问权限
注意: 如果你的应用已经使用了系统照片选择器(photopicker),那么无需进行任何改动。
在 Android 14 上,当应用请求 Android 13(API 级别 33)中引入的任何 READ_MEDIA_IMAGES或 READ_MEDIA_VIDEO 媒体权限时,用户可以授予对其照片和视频的部分访问权限。
新对话框显示以下权限选项:
- 选择照片和视频: Android 14 中的新功能,用户选择他们想要提供给应用的特定照片和视频。
- 全部允许:用户授予对设备上所有照片和视频的完整库访问权限。
- 不允许:用户拒绝所有访问。
要在应用中出现改逻辑,可以声明新的 READ_MEDIA_VISUAL_USER_SELECTED 权限。
详细可见:developer.android.com/about/versi…
安全的全屏 Intent 通知
在 Android 11(API 级别 30)中,任何应用都可以通过 Notification.Builder.setFullScreenIntent 在手机锁定时发送全屏 intent。
一般可以通过在 AndroidManifest 中声明 USE_FULL_SCREEN_INTENT 权限来在应用安装时自动授予该权限 ,全屏 intent 通知专为需要用户立即关注的极高优先级通知而设计,例如来电或用户配置的闹钟设置。
从 Android 14 开始,允许使用该权限的应用仅限于提供通话和闹钟的应用,Google Play 商店会撤销任何不符合该配置文件的应用的默认权限。
在用户更新到 Android 14 之前,该权限对安装在手机上的应用保持启用状态,用户可以打开和关闭该权限。
开发者可以使用新的API NotificationManager.canUseFullScreenIntent 来检查应用是否具有权限;如果没有,应用可以使用新的 ACTION_MANAGE_APP_USE_FULL_SCREEN_INTENT 来启动跳转到可以授予权限的设置页面。
改变用户体验不可关闭通知的方式
如果你的应用向用户显示不可关闭的前台通知,Android 14 已更改行为以允许用户关闭此类通知。
此次更改适用于通过 Notification.Builder#setOngoing(true) 或者 NotificationCompat.Builder#setOngoing(true) 来设置 Notification.FLAG_ONGOING_EVENT 从而阻止用户关闭前台通知的应用 的行为。
现在 FLAG_ONGOING_EVENT 的行为已经改变,用户实际上可以关闭此类通知。
在以下情况下,该类通知仍然不可关闭:
- 当手机被锁定时
- 如果用户选择清除所有通知操作(这有助于防止意外)
此外,新行为不适用于以下用例中的不可关闭通知:
- 使用
CallStyle与真实通话相关的通知 - 使用
MediaStyle创建的通知 - 设备策略控制器 (DPC) 和企业支持包
辅助功能
非线性字体缩放至 200%
从 Android 14 开始,系统支持高达 200% 的字体缩放,为弱视用户提供符合 Web 内容无障碍指南 (WCAG) 的额外无障碍选项。
如果已经使用缩放像素 (sp) 单位来定义文本大小,那么此次更改可能不会对应用产生重大影响。
链接:https://juejin.cn/post/7231835495557890106
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
DialogFragment 与 BottomSheetDialogFragment
DialogFragment
Android 中 Dialog 并没办法感知生命周期,但 Frg 可以感知,所以将 Diglog 与 Frg 结合后生成 DialogFragment,它提供了可以感知生命周期的 Dialog。另外 DialogFragment 也继承 Fragment,所以也可以当作普通的 Fragment 使用。
由于 DialogFragment 可以感知生命周期,而且还处理了 Dialog 状态的保存与恢复,所以 DialogFragment 应多用。
原理
DialogFragment 中的 Dialog 是在 onGetLayoutInflater 中创建的,该方法会先于 onCreateView() 调用,但后于 onCreate()。
第一个问题:DialogFragment 当作 Dialog 使用时为什么不会显示到 Activity 布局中,而是以 Dialog 形式出现。将 DialogFragment 当作 Dialog 用时需要调用其 show 方法,其内部也是使用了 FragmentTransaction,只不过依赖的 containerViewId 是 0,因此无法添加到某个 View 上,也就不会在 Activity 布局中显示。
// show() 方法节选
FragmentManager manager = ....
FragmentTransaction ft = manager.beginTransaction();
ft.setReorderingAllowed(true);
ft.add(this, tag);
ft.commit();
// FragmentTransaction::add() 方法
public FragmentTransaction add(@NonNull Fragment fragment, @Nullable String tag) {
// 主要第一个参数是 0,这就导致调用 show 方法时不会显示到具体界面
doAddOp(0, fragment, tag, OP_ADD);
return this;
}
// 将 Frg 当作普通 Frg 使用时会调用该方法
public FragmentTransaction add(@IdRes int containerViewId, @NonNull Fragment fragment) {
// 此时 containerViewId 就不是 0,所以 Fragment 中的 view 会显示到界面上
doAddOp(containerViewId, fragment, null, OP_ADD);
return this;
}
通过 show() 方法将当前 Fragment 绑定到了某一个 Activity,当 Frg 感知到生命周期发生变化时就会将 Dialog 显示或隐藏,而且在 onSaveInstanceState 等方法也处理了状态的保存与显示。
// onResume() 回调中会显示 dialog
// onStop() 回调中隐藏 dialog
// onDestroyView() 中会销毁 Dialog
public void onStop() {
super.onStop();
if (mDialog != null) {
mDialog.hide();
}
}
第二个问题:onCreateView() 返回的 View 有什么用。onCreateView() 返回的 View 就是 Dialog 要显示的内容。在 DialogFragment::onAttach() 中会添加一个监听
// mObserver 中通过 requireView() 拿到 onCreateView() 的返回值
// 同时调用 Dialog::setContentView() 将返回值设置成 dialog 显示的内容
// mObserver 节选
if (lifecycleOwner != null && mShowsDialog) {
// 拿到 onCreateView 返回值
View view = requireView();
if (view.getParent() != null) {
throw new IllegalStateException(
"DialogFragment can not be attached to a container view");
}
if (mDialog != null) {
mDialog.setContentView(view);
}
}
// onAttach() 节选
getViewLifecycleOwnerLiveData().observeForever(mObserver);
第三个问题:上面 mObserver 看出如果不重写 onCreateView(),requireView() 应该会报错的,为啥使用时不会出问题。这个主要在 Fragment::performCreateView() 中
mViewLifecycleOwner = new FragmentViewLifecycleOwner(this, getViewModelStore());
// 调用 onCreateView() 默认返回 null
mView = onCreateView(inflater, container, savedInstanceState);
if (mView != null) {
// 只有 mView 不为 null 时才触发 liveData 更新,上面的 mObserver 才会收到通知
// Then inform any Observers of the new LifecycleOwner
mViewLifecycleOwnerLiveData.setValue(mViewLifecycleOwner);
} else {
mViewLifecycleOwner = null;
}
BottomSheetDialogFragment
继承于 DialogFragment,只不过它返回的 Dialog 是 BottomSheetDialog。从上面可以看出 onCreateView() 的返回值最终会传递给 Dialog::setContentView() 中。BottomSheetDialog::setContentView() 会调用 wrapInBottomSheet(),最核心的两句就是:
// 它会初始化一个 View,该 View 就是 Dialog 要显示的 View
ensureContainerAndBehavior();
// view 就是我们传入 setContentView 中的 view
// bottomSheet 就是上面 View 的一个子 View
bottomSheet.addView(view);
// 生成 Dialog 要显示的 View
private FrameLayout ensureContainerAndBehavior() {
if (container == null) {
container =
(FrameLayout) View.inflate(getContext(), R.layout.design_bottom_sheet_dialog, null);
coordinator = (CoordinatorLayout) container.findViewById(R.id.coordinator);
// 查看上面的布局,可以发现 bottomSheet 是 CoordinatorLayout 的子类
// 其 behavior 是 com.google.android.material.bottomsheet.BottomSheetBehavior
bottomSheet = (FrameLayout) container.findViewById(R.id.design_bottom_sheet);
behavior = BottomSheetBehavior.from(bottomSheet);
behavior.addBottomSheetCallback(bottomSheetCallback);
behavior.setHideable(cancelable);
}
return container;
}
总之,BottomSheetDialogFragment 会将 onCreateView() 的返回结果包裹在 CoordinatorLayout 中,从而实现 bottom_sheet 效果。
链接:https://juejin.cn/post/7226287155668549690
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
动手实现Kotlin协程同步切换线程,以及Kotlin协程是如何实现线程切换的
前言
突发奇想想搞一个同步切换线程的Kotlin协程,而不用各种withContext(){},可以减少嵌套且逻辑更清晰,想实现的结果如下图:
分析
实现我们想要的结果,首先需要知道协程为什么可以控制线程的切换以及在挂起函数恢复的时候回到原来设定的线程中
ps:挂起函数比普通函数多出了两个操作:挂起和恢复,具体参考:Kotlin协程在项目中的实际应用_lt的博客-CSDN博客_kotlin协程使用
其实控制线程切换是协程库内内置的一个拦截器类:ContinuationInterceptor
拦截器是一个协程上下文元素(ContinuationInterceptor实现了Element接口 ,Element实现了CoroutineContext接口)
拦截器的作用是将协程体包装一层后,拦截其恢复功能(resumeWith),这样就可以在协程恢复的时候将包装在其内部的协程体在相应的线程中恢复执行(执行resumeWith方法)
比如协程自带的Dispatchers.Main,Dispatchers.IO等都是协程拦截器,下面简单分析下Dispatchers.IO拦截器
我们点进去IO的定义,兜兜转转的找到其实现类LimitingDispatcher,其继承了ExecutorCoroutineDispatcher ,ExecutorCoroutineDispatcher继承了CoroutineDispatcher ,CoroutineDispatcher实现了ContinuationInterceptor接口,也就是其最终实现了协程拦截器的接口
CoroutineDispatcher重写了拦截器的interceptContinuation方法,该方法就是用来包装并拦截的
然后我们在看看DispatchedContinuation的resumeWith方法(也就是如何拦截并将包装的协程体运行在子线程的)
ps:其实走的是resumeCancellableWith方法,因为协程内部做了一个判断,IO的拦截器是继承了DispatchedContinuation的
第一个红框IO那是写死的true,所以只会走第一个流程,而第二个红框你可以简单的理解为将后续任务(下面的代码逻辑)放在这个dispatcher的线程池中运行(就相当于将协程中的代码的线程放到了IO子线程中运行了)
通过上面的分析,其实IO的拦截器可以简单理解为如下代码:
实现
那我们是不是可以将拦截器从协程上下文中移除呢?我试了下并不行,发现是在launch的时候会自动判断,如果没有拦截器则默认附加Dispatchers.Default拦截器用于将操作置于子线程中
ps:可以通过遍历来查看当前协程上下文中都有哪些协程元素(下面是反射的实现,可以使用系统提供的fold来遍历):
/**
* 通过反射遍历协程上下文中的元素
*/
fun CoroutineContext.forEach(action: (CoroutineContext.Element) -> Unit) {
val modeClass = Class.forName("kotlin.coroutines.CombinedContext")
val elementField = modeClass.getDeclaredField("element")
elementField.isAccessible = true
val leftField = modeClass.getDeclaredField("left")
leftField.isAccessible = true
var context: CoroutineContext? = this
while (context?.javaClass == modeClass) {
(elementField.get(context) as? CoroutineContext.Element)?.let(action)
context = leftField.get(context) as? CoroutineContext
}
(context as? CoroutineContext.Element)?.let(action)
}
coroutineContext.forEach {
it.toString().e()
}
pps:协程上下文其实是以链表形式来存储的,CombinedContext就相当于链表的Node节点,其element相当于数据,其left相当于下一个节点,而存储的最后一个节点是未经过CombinedContext包装的协程上下文元素(可能是节省空间);而不管协程上下文,或者CombinedContext的element和left,都是val的,这样上下文都是只读的,避免了并发修改的危险.
那现在看来其实我们只要自己写一个拦截器,然后在运行协程的时候附加上去,线程切换就可以由我们来控制了,那实现起来其实也很简单,代码如下:
/**
* 同步切换线程的协程元素,需要注意所有挂起函数都有可能影响到后面的线程,所以需要注意:最好内部使用不会切换线程的挂起函数(或者你清楚使用的后果)
*/
fun CoroutineScope.launchSyncSwitchThread(block: suspend SyncSwitchThreadCoroutineScope.() -> Unit): Job =
launch(SyncSwitchThreadContinuationInterceptor) { SyncSwitchThreadCoroutineScope(this@launch).block() }
//拦截器
object SyncSwitchThreadContinuationInterceptor : ContinuationInterceptor {
override val key: CoroutineContext.Key<*> = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> = SyncSwitchThreadContinuation(continuation)
//协程体包装类
class SyncSwitchThreadContinuation<T>(private val continuation: Continuation<T>) : Continuation<T> {
override val context: CoroutineContext = continuation.context
//这里我们不进行拦截恢复方法,直接使用恢复者(谁调用了resume)的线程
override fun resumeWith(result: Result<T>): Unit = continuation.resumeWith(result)
}
//协程作用域包装类,用于控制toMain等方法不会被别的地方使用
class SyncSwitchThreadCoroutineScope(coroutineScope: CoroutineScope) : CoroutineScope by coroutineScope {
private suspend inline fun suspendToThread(crossinline threadFunction: (()->Unit) -> Unit) =
suspendCoroutine<Unit> {
threadFunction {
if (it.context.isActive)
it.resume(Unit)
}
}
//切换到主线程,[force]是否强制post到主线程(false:如果当前是主线程则不会post)
suspend fun toMain(force: Boolean = false) {
if (!force && isMainThread) return
suspendToThread(HandlerPool::postEmptyListener)//Handler#post方法
}
//切换到单例子线程
suspend fun toSingle(): Unit = suspendToThread(ThreadPool::submitToSingleThreadPool)//提交到单线程线程池
suspend fun toIO(): Unit = suspendToThread(ThreadPool::submitToCacheThreadPool)//提交到子线程池
suspend fun toCPU(): Unit = suspendToThread(ThreadPool::submitToCPUThreadPool)//提交到CPU密集型子线程池
//或者为了理解起来简单减少封装写成如下方式
suspend fun toCPU(): Unit = suspendCoroutine {
ThreadPool.submitToCacheThreadPool {
if(it.context.isActive)
it.resume(Unit)
}
}
}
}
ps:第一次运行的线程是启动它的线程
pps:这里我们包装了一下协程作用域CoroutineScope,可以防止toMain这些方法用在别的地方造成歧义且无用
然后我们就可以像开头那样使用了
或者通过协程上下文的plus(+)方法来替换掉默认的拦截器:
最后在封装一下:
fun CoroutineScope.launchSyncSwitchThread(block: suspend SyncSwitchThreadCoroutineScope.() -> Unit): Job =
launch(SyncSwitchThreadContinuationInterceptor) { SyncSwitchThreadCoroutineScope(this@launch).block() }
使用方式就和最开始的图一样了
结语
这样就ok了,其实任何事情只要了解原理,就可以很快的想到方案,如果不清楚原理,就会对一些事情一头雾水
ps:其实使用Dispatchers.Unconfined也可以实现相同的效果2333,但是了解原理还是更重要
pps:如果想限制launchSyncSwitchThread的lambda范围内只能使用自己定义的几个挂起函数,只需要给SyncSwitchThreadCoroutineScope类加上@RestrictsSuspension注解即可,这样在SyncSwitchThreadCoroutineScope的作用域内,只能使用他内部定义的挂起函数,可以有效减少别的挂起函数意外切换掉线程的情况
end
链接:https://juejin.cn/post/7122653681714987022
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用Canvas绘制一个数字键盘
Hello啊老铁们,这篇文章还是阐述自定义View相关的内容,用Canvas轻轻松松搞一个数字键盘,本身没什么难度,这种效果实现的方式也是多种多样,这篇只是其中的一种,要说本篇有什么特别之处,可能就是纯绘制,没有用到其它的任何资源,一个类就搞定了,文中不足之处,各位老铁多包含,多指正。
今天的内容大概如下:
1、效果展示
2、快速使用及属性介绍
3、具体代码实现
4、源文件地址及总结
一、效果展示
很常见的数字键盘,背景,颜色,文字大小,点击的事件等等,均已配置好,大家可以看第2项中相关介绍。
静态效果展示:
动态效果展示,录了一个gif,大家可以看下具体的触摸效果。
二、快速使用及属性介绍
鉴于本身就一个类,不值当去打一个远程的Maven,大家用的话可以直接下载,把文件复制到项目里即可,复制到项目中,就可以按照下面的步骤去使用。
引用
1、xml中引用,可以根据需要,设置宽高及相关属性
<KeyboardView
android:id="@+id/key_board_view"
android:layout_width="match_parent"
android:layout_height="wrap_content" />
2、代码直接创建,然后追加到相关视图里即可
val keyboardView=KeyboardView(this)
方法及属性介绍
单个点击的触发监听:
keyboardView.setOnSingleClickListener {
//键盘点击的数字
}
获取最终的字符串点击监听,其实就是把你点击的数字拼接起来,一起输出,特别在密码使用的时候,省的你再自己拼接了,配合number_size属性和setNumberSize方法一起使用,默认是6个长度,可以根据需求,动态设置。
keyboardView.setOnNumClickListener {
//获取最终的点击数字字符串,如:123456,通过number_size属性或setNumberSize方法,设置最长字符
}
其它方法
| 方法 | 参数 | 概述 |
|---|---|---|
| hintLetter | 无参 | 隐藏字母 |
| setBackGroundColor | int类型的颜色值 | 设置整体背景色 |
| setRectBackGroundColor | int类型的颜色值 | 设置数字格子背景色 |
| setTextColor | int类型的颜色值 | 设置文字颜色 |
| setTextSize | Float | 设置数字大小 |
| setNumberSize | int类型 | 设置按下的数字总长度 |
| setRectHeight | Float | 设置数字键盘每格高度 |
| setSpacing | Float | 设置数字键盘每格间隔距离 |
属性介绍
| 属性 | 类型 | 概述 |
|---|---|---|
| background_color | color | 背景颜色 |
| rect_background_color | color | 数字格子背景色 |
| down_background_color | color | 手指按下的背景颜色 |
| text_color | color | 文字颜色 |
| text_size | dimension | 文字大小 |
| letter_text_size | dimension | 字母的文字大小 |
| rect_height | dimension | 数字格子高度 |
| rect_spacing | dimension | 格子间距 |
| is_rect_letter | boolean | 是否显示字母 |
| number_size | integer | 按下的数字总长度字符 |
三、具体代码实现
代码实现上其实也没有什么难的,主要就是用到了自定义View中的onDraw方法,简单的初始化,设置画笔,默认属性就不一一介绍了,直接讲述主要的绘制部分,我的实现思路如下,第一步,绘制方格,按照UI效果图,应该是12个方格,简图如下,需要注意的是,第10个是空的,也就是再绘制的时候,需要进行跳过,最后一个是一个删除的按钮,绘制的时候也需要跳过,直接绘制删除按钮即可。
1、关于方格的绘制
方格的宽度计算很简单,(手机的宽度-方格间距*4)/3即可,绘制方格,直接调用canvas的drawRoundRect方法,单纯的和数字一起绘制,直接遍历12个数即可,记住9的位置跳过,11的位置,绘制删除按钮。
mRectWidth = (width - mSpacing * 4) / 3
mPaint!!.strokeWidth = 10f
for (i in 0..11) {
//设置方格
val rect = RectF()
val iTemp = i / 3
val rectTop = mHeight * iTemp + mSpacing * (iTemp + 1f)
rect.top = rectTop
rect.bottom = rect.top + mHeight
var leftSpacing = (mSpacing * (i % 3f))
leftSpacing += mSpacing
rect.left = mRectWidth!! * (i % 3f) + leftSpacing
rect.right = rect.left + mRectWidth!!
//9的位置是空的,跳过不绘制
if (i == 9) {
continue
}
//11的位置,是删除按钮,直接绘制删除按钮
if (i == 11) {
drawDelete(canvas, rect.right, rect.top)
continue
}
mPaint!!.textSize = mTextSize
mPaint!!.style = Paint.Style.FILL
//按下的索引 和 方格的 索引一致,改变背景颜色
if (mDownPosition == (i + 1)) {
mPaint!!.color = mDownBackGroundColor
} else {
mPaint!!.color = mRectBackGroundColor
}
//绘制方格
canvas!!.drawRoundRect(rect, 10f, 10f, mPaint!!)
}
2、关于数字的绘制
没有字母显示的情况下,数字要绘制到中间的位置,有字母的情况下,数字应该往上偏移,让整体进行居中,通过方格的宽高和自身文字内容的宽高来计算显示的位置。
//绘制数字
mPaint!!.color = mTextColor
var keyWord = "${i + 1}"
//索引等于 10 从新赋值为 0
if (i == 10) {
keyWord = "0"
}
val rectWord = Rect()
mPaint!!.getTextBounds(keyWord, 0, keyWord.length, rectWord)
val wWord = rectWord.width()
val htWord = rectWord.height()
var yWord = rect.bottom - mHeight / 2 + (htWord / 2)
//上移
if (i != 0 && i != 10 && mIsShowLetter) {
yWord -= htWord / 3
}
canvas.drawText(
keyWord,
rect.right - mRectWidth!! / 2 - (wWord / 2),
yWord,
mPaint!!
)
3、关于字母的绘制
因为字母是和数字一起绘制的,所以需要对应的字母则向下偏移,否则不会达到整体居中的效果,具体的绘制如下,和数字的绘制类似,拿到方格的宽高,以及字母的宽高,进行计算横向和纵向位置。
//绘制字母
if ((i in 1..8) && mIsShowLetter) {
mPaint!!.textSize = mLetterTextSize
val s = mWordArray[i - 1]
val rectW = Rect()
mPaint!!.getTextBounds(s, 0, s.length, rectW)
val w = rectW.width()
val h = rectW.height()
canvas.drawText(
s,
rect.right - mRectWidth!! / 2 - (w / 2),
rect.bottom - mHeight / 2 + h * 2,
mPaint!!
)
}
4、关于删除按钮的绘制
删除按钮是纯线条的绘制,没有使用图片资源,不过大家可以使用图片资源,因为图片资源还是比较的靠谱。
/**
* AUTHOR:AbnerMing
* INTRODUCE:绘制删除按键,直接canvas自绘,不使用图片
*/
private fun drawDelete(canvas: Canvas?, right: Float, top: Float) {
val rWidth = 15
val lineWidth = 35
val x = right - mRectWidth!! / 2 - (rWidth + lineWidth) / 4
val y = top + mHeight / 2
val path = Path()
path.moveTo(x - rWidth, y)
path.lineTo(x, y - rWidth)
path.lineTo(x + lineWidth, y - rWidth)
path.lineTo(x + lineWidth, y + rWidth)
path.lineTo(x, y + rWidth)
path.lineTo(x - rWidth, y)
path.close()
mPaint!!.strokeWidth = 2f
mPaint!!.style = Paint.Style.STROKE
mPaint!!.color = mTextColor
canvas!!.drawPath(path, mPaint!!)
//绘制小×号
mPaint!!.style = Paint.Style.FILL
mPaint!!.textSize = 30f
val content = "×"
val rectWord = Rect()
mPaint!!.getTextBounds(content, 0, content.length, rectWord)
val wWord = rectWord.width()
val htWord = rectWord.height()
canvas.drawText(
content,
right - mRectWidth!! / 2 - wWord / 2 + 3,
y + htWord / 3 * 2 + 2,
mPaint!!
)
}
5、按下效果的处理
按下的效果处理,重写onTouchEvent方法,然后在down事件里通过,手指触摸的XY坐标,判断当前触摸的是那个方格,记录下索引,并使用invalidate进行刷新View,在onDraw里进行改变画笔的颜色即可。
根据XY坐标,返回触摸的位置
/**
* AUTHOR:AbnerMing
* INTRODUCE:返回触摸的位置
*/
private fun getTouch(upX: Float, upY: Float): Int {
var position = -2
for (i in 0..11) {
val iTemp = i / 3
val rectTop = mHeight * iTemp + mSpacing * (iTemp + 1f)
val top = rectTop
val bottom = top + mHeight
var leftSpacing = (mSpacing * (i % 3f))
leftSpacing += 10f
val left = mRectWidth!! * (i % 3f) + leftSpacing
val right = left + mRectWidth!!
if (upX > left && upX < right && upY > top && upY < bottom) {
position = i + 1
//位置11默认为 数字 0
if (position == 11) {
position = 0
}
//位置12 数字为 -1 意为删除
if (position == 12) {
position = -1
}
}
}
return position
}
在onDraw里进行改变画笔的颜色。
//按下的索引 和 方格的 索引一致,改变背景颜色
if (mDownPosition == (i + 1)) {
mPaint!!.color = mDownBackGroundColor
} else {
mPaint!!.color = mRectBackGroundColor
}
6、wrap_content处理
在使用当前控件的时候,需要处理wrap_content的属性,否则效果就会和match_parent一样了,具体的处理如下,重写onMeasure方法,获取高度的模式后进行单独的设置。
override fun onMeasure(widthMeasureSpec: Int, heightMeasureSpec: Int) {
super.onMeasure(widthMeasureSpec, heightMeasureSpec)
val heightSpecMode = MeasureSpec.getMode(heightMeasureSpec)
val widthSpecSize = MeasureSpec.getSize(widthMeasureSpec)
if (heightSpecMode == MeasureSpec.AT_MOST) {
//当高度为 wrap_content 时 设置一个合适的高度
setMeasuredDimension(widthSpecSize, (mHeight * 4 + mSpacing * 5 + 10).toInt())
}
}
四、源文件地址及总结
源文件地址:
源文件不是一个项目,是一个单纯的文件,大家直接复制到项目中使用即可,对于26个英文字母键盘绘制,基本上思路是一致的,大家可以在此基础上进行拓展,本文就先到这里吧,整体略有瑕疵,忘包含。
链接:https://juejin.cn/post/7166424996636524557
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 系统启动到App 界面完全展示终于明白(图文版)
之前文章有分析过Activity创建到View的显示过程,属于单应用层面的知识范畴,本篇将结合Android 系统启动部分知识将两者串联分析,以期达到融会贯通的目标。
通过本篇文章,你将了解到:
- Android 系统启动流程概览
- ServiceManager 进程作用
- Zygote 进程创建与fork子进程
- system_server 进程作用
- App 与 system_server 交互
- Activity 与 View的展示
- 全流程图
1. Android 系统启动流程概览
- init 是用户空间的第一个进程,它的父进程是idle进程
- init 进程通过解析init.rc 文件并fork出相应的进程
- zygote是第一个Java 虚拟机进程,通过它孵化出system_server 进程
- system_server 进程启动桌面(Launcher)App
以上为Android 系统上电到桌面启动的简略过程,我们重点关注其中几个进程:
init、servicemanger、zygote、system_server
idle 与 init 关系如下:
查看依赖关系:
init.rc 启动servicemanager、zygote 配置如下:
2. ServiceManager 进程作用
Android 进程间通信运用最广泛的是Binder机制,而ServiceManager进程与Binder息息相关。
DNS 存储着域名和ip的映射关系,类似的ServiceManager存储着Binder客户端和服务端的映射。
App1作为Binder Client端,App2 作为Binder Server端,App2 开放一个接口给App1使用(通常称为服务),此时步骤如下:
- App2 向ServiceManager注册服务,过程为:App2 获取ServiceManager的Binder引用,通过该Binder引用将App2 的Binder对象(实现了接口)添加到Binder驱动,Binder驱动记录对象与生成handle并返回给ServiceManager,ServiceManager记录关键信息(如服务名,handle)。
- App1 向ServcieManager查询服务,过程为: App1 获取ServiceManager的Binder引用,通过该Binder引用发送查询命令给Binder驱动,Binder驱动委托ServiceManager进行查询,ServiceManager根据服务名从自己的缓存链表里查出对应服务,并将该服务的handle写入驱动,进而转为App1的Binder代理。
- App1 拿到App2 的Binder代理后,App1 就可以通过Binder与App2进行IPC通信了,此时ServiceManager已经默默退居幕后,深藏功与名。
由上可知,ServiceManager进程扮演着中介的角色。
3. Zygote 进程创建与fork子进程
Zygote 进程的创建
Zygote 进程大名鼎鼎,Android 上所有的Java 进程都由Zygote孵化,Zygote名字本身也即是受精卵,当然文雅点一般称为孵化器。
Zygote 进程是由init进程fork出来的,进程启动后从入口文件(app_main.cpp)入口函数开始执行:
- 构造AppRuntime对象,并创建Java虚拟机、注册一系列的jni函数(Java和Native层关联起来)
- 从Native层切换到Java层,执行ZygoteInit.java main()函数
- fork system_server进程,预加载进程公共资源(后续fork的子进程可以复用,加快进程执行速度)
- 最后开启LocalSocket,并循环监听来自system_server创建子进程的Socket请求。
通过以上步骤,Zygote 启动完成,并等待创建进程的请求。
初始状态步骤:
- Zygote fork system_server 进程并等待Socket请求
- system_server 进程启动后会请求打开Launcher(桌面),此时通过Socket发送创建请求给Zygote,Zygote 收到请求后负责fork 出Launcher进程并执行它的入口函数
- Launcher 启动后用户就可以看到初始的界面了
用户操作:
桌面显示出来后,此时用户想打开微信,于是点击了桌面上的微信图标,背后的故事如下:
- Launcher App 收到点击请求,会执行startActivity,这个命令会通过Binder传递给system_server进程里的AMS(ActivityManagerService)模块
- AMS 发现对应的微信进程并没有启动,于是通过Socket发送创建微信进程的请求给Zygote
- Zygote 收到Socket请求后,fork 微信进程并执行对应的入口函数,之后就会显示出微信的界面了
用图表示如下:
由上可知,App进程和system_server 进程之间通信方式为Binder,而system_server和Zygote 通信方式为Socket,App进程并不直接请求Zygote做事情,而是通过system_server进行处理,system_server 记录着当前所有App 进程的状态,由它来统一管理各个App的生命周期。
Zygote 进程fork 子进程
Zygote 进程在Java层监听Socket请求,收到请求后层层调用最后切换到Native执行系统调用fork()函数,最后根据fork()返回值区分父子进程,并在子进程里执行入口函数。
4. system_server 进程作用
system_server 为所有App提供服务,可以说是系统的核心进程之一,它主要的功能如下:
可以看出,它创建并启动了许多服务,常见的AMS、PMS、WMS,我们常说系统某某服务返回了啥,往细的说这里的"系统"可以认为是system_server进程。
需要注意的是,这里所说的服务并不是Android四大组件的Service,而是某一类功能。
四大组件的交互也要依靠system_server:
实际调用流程如下:
由上图可知,不管是同一进程内的通信亦或是不同进程间的通信,都需要system_server介入。
App 和 system_server 是属于不同的进程,App进程如何找到system_server呢?
还是要借助ServiceManager进程:
system_server 在启动时候不仅开启了各种服务,同时还将需要暴露的服务注册到ServiceManager里,其它进程想要使用system_server的功能时只需要从SystemManager里查询即可。
5. App 与 system_server 交互
App 想要获取系统的功能,在大部分情况下是绕不过system_server的,接着来看看App如何与system_server进行交互。
前面分析过,App想要获取system_server 服务只需要从ServiceManager里获取即可,调用形式如下:
getSystemService(Context.WINDOW_SERVICE)
那反过来呢?system_server如何主动调用App的服务呢?
既然获取服务的本质是拿到对端的Binder引用,那么也可以反过来,将App的Binder传递给system_server,等到system_server想要调用App时候拿出来用即可,类似回调的功能,如下图:
再细化一下流程:
- App 进程在启动后执行ActivityThread.java里的main()方法,在该方法里调用system_server的接口,并将自己的Binder引用(mAppThread)传递给system_server
- system_server 掌管着Application和四大组件的生命周期,system_server会告诉App进程当前是需要创建Application实例还是调用到Activity某个生命周期阶段(如onCreate/onResume等),此时就是依靠mAppThread回调回来
- 此时的App进程作为Binder Server端,它是在子线程收到system_server进程的消息,因此需要通过post到主线程执行
- 最终Application/Activity 的生命周期函数将会在主线程执行,这也就是为什么四大组件不能执行耗时任务的原因,因为都会切换到主线程执行四大组件的各种重写方法
6. Activity 与 View的展示
通过上面的分析可知现在的流程已经走到App进程本身,Application、Activity 都已经创建完毕了,什么时候会显示View呢?
先看Activity.onCreate()的调用流程:
此流程结束,整个ViewTree都构建好了。
接着需要将ViewTree添加到Window里流程如下:
最后监听屏幕刷新信号,当信号到来之后遍历ViewTree进行Measure、Layout、Draw操作,最终渲染到屏幕上,此时我们的App界面就显示出来了。
7. 全流程图
附源码路径:
init.rc配置文件
ServiceManager入口
Zygote native入口
Zygote java入口
system_server入口
App入口
更多Android 源码查看方式请移步:Android-系统源码查看的几种方式
链接:https://juejin.cn/post/7157001609090695175
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 协程如何与 Java 进行混编?
问题
在 Java 与 Kotlin 混编项目中大概率是会遇到 Kotlin 线程的使用问题。协程的混编相对于其他特性的使用上会相对麻烦而且比较容易踩坑。我们以获取 token 来举例,比如有一个获取 token 的 suspend 函数:
// 常规的 suspend 函数,可以供 Kotlin 使用,Java 无法直接使用
suspend fun getTokenSuspend(): String {
// do something too long
return "Token"
}
想要在 Java 中直接调用则会产出如下错误:
了解 Kotlin 协程机制的同学应该知道 suspend 修饰符在 Kotlin 编译器期会被处理成对应的 Continuation 类,这里不展开讨论。
这个问题也可以使用简单的方式进行解决,那就是使用 runBlocking 进行简单包装一下即可。
使用 runBlocking 解决
一般情况下我们可能会使用以下代码解决上述问题。定义的 Kotlin 协程代码如下:
// 提供给 Java 使用的封装函数,Java 代码可以直接使用
fun getTokenBlocking(): String =runBlocking{// invoke suspend fun
getTokenSuspend()
}
在 Java 层代码的使用方式大致如下:
public void funInJava() {
String token = TokenKt.getTokenBlocking();
}
看上去方案比较简单,但是直接使用 runBlocking 也会存在一些隐患。 runBlocking 会阻塞当前调用者的线程,如果是在主线程进行调用的话,会导致 App 卡顿,严重的会导致 ANR 问题。那有没有比 runBlocking 更合理的解决方案呐?
回答这个问题之前,先梳理下 Java 与 Kotlin 两种语言在处理耗时函数的一般做法。
Java & Kotlin 耗时函数的一般定义
Java
- 靠语义约束。比如定义的函数名中 sync 修饰,表明他可能是一个耗时的函数,更好的还会添加
@WorkerThread注解,让 lint 帮助使用者去做一些检查,确保不会在主线程中去调用一些耗时函数导致页面卡顿。 - 靠语法约束,定义 Callback。将耗时的函数执行放到一个单独的线程中执行,然后将回调的结果通过 Callback 的形式返回。这种方式无论调用者是什么水平,代码质量都不会有问题;
Kotlin
- 靠语义约束,同 Java。
- 添加 suspend 修饰,靠语法约束。内部耗时函数切到子线程中执行。外部调用者使用同步的方式调用耗时函数却不会阻塞主线程(这也是 Kotlin 协程主要宣传的点)。
在 Java 与 Kotlin 混编的项目中,上述情况的复杂度将会上升。
使用 CompletableFuture 解决
在审视一下 runBlocking 的使用问题,这种做法是将 Kotlin 中的语法约束退化到语义约束层面了,有的可能连语义层面的约束都没有,这种情况只能祈求调用者的使用是正确的 -- 在子线程调用,而不是在主线程调用。那应该如何怎么处理,就是采用回调的方式,让语法能够规避的问题就不要采用语义来处理。
suspend fun getToken(): String {
// do something too long
return "Token"
}
fun getTokenFuture(): CompletableFuture<String> {
returnCoroutineScope(Dispatchers.IO).future{getToken()}
}
注意:future 是 org.jetbrains.kotlinx:kotlinx-coroutines-jdk8 包中提供的工具类,基于 CoroutineScope 定义的扩展函数,使用时需要导入依赖包。
Java 中的使用方式如下:
public void funInJava() {
try {
// 通过 Future get() 显示调用 getTokenFuture 函数
TestKt.getTokenFuture().get();
} catch (ExecutionException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
可能会问这里看上去和直接在函数内部使用 runBlocking 没有太大的区别,反而使用上会更麻烦些。的确是这样的,这样的目的是把选择权交给调用者,或者说让调用者显示的知道这不是一个简单的函数,从而提高其在使用 API 时的警惕度,也就是之前提到的从语法层面对 API 进行约束。
退一步说,上述的内容是针对的仅仅是“不得不”这么做的场景,但是对于大部分场景都是可以通过合理的设计来避免出现上述情况:
- 底层定义的 suspend 函数可以在上层的 ViewModel 中的
viewModelScope中调用解决; - 统一对外暴露的 API 是 Java 类的话,新增的 API 提供可以使用 suspend 类型的扩展函数,使用 suspend 类型对外暴露;
- 如果明确知道调用者是 Java 代码,那么请提供 Callback 的 API 定义;
总结
尽量使用合理的设计来尽量规避 Kotlin 协程与 Java 混用的情况,在 API 的定义上语法约束优先与语义约束,语义约束优于没有任何约束。当然在特殊的情况下也可以使用 CompletableFuture API 来封装协程相关 API。
下面对几种常见场景推荐的一些写法:
- 在单元测试中可以直接使用
runBlocking; - 耗时函数可以直接定义为 suspend 函数或者使用 Callback 形式返回;
- 对于 Java 类中调用协程函数的场景应使用显示的声明告知调用者,严格一点的可以判断线程,对于在主线程调用的可以抛出异常或者记录下来统一处理;
链接:https://juejin.cn/post/7130270050572828703
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
通俗易懂 Android 架构组件发展史
前言
谈到 Android 架构,相信谁都能说上两句。从 MVC,MVP,MVVM,再到时下兴起 MVI,架构设计层出不穷。如何为项目选择合适架构,也成常备课题。
由于架构并非空穴来风,每一种设计都有其存在依据。故今天我们一起探寻 “架构演化” 来龙去脉,相信阅读后你会豁然开朗。
文章目录一览
- 前言
- 原生架构
- 原始图形化架构
- 高频痛点 1:Null 安全一致性问题
- 原始工程架构 MVC
- 高频痛点 2:成员变量爆炸
- 高频痛点 3:状态管理一致性问题
- 高频痛点 4:消息分发一致性问题
- 原始图形化架构
- 它山之石
- 矫枉过正 MVP
- 反客为主 Presenter
- 简明易用 三方库
- 拨乱反正 MVVM
- 曲高和寡 DataBinding
- 未卜先知 mBinding
- 矫枉过正 MVP
- 力挽狂澜
- 官方牵头 Jetpack
- 一举多得 ViewModel
- 半路杀出 Kotlin
- 喜闻乐见 ViewBinding
- 官方牵头 Jetpack
- 百花齐放
- 最佳实践 Jetpack MVVM
- 屏蔽回推 UnPeekLiveData
- 消息分发 Dispatcher
- 严格模式 DataBinding
- 另起炉灶 Compose
- 最佳实践 Jetpack MVVM
- 综上
原生架构
原始图形化架构
完整软件服务,通常包含客户端和服务端。
Linux 服务端,开发者通过命令行操作;Android 客户端,面向普通用户,须提供图形化操作。为此,Android 将图形系统设计为,通过客户端 Canvas 绘制图形,并交由 Surface Flinger 渲染。
但正如《过目难忘 Android GUI 关系梳理》所述,复杂图形绘制离不开排版过程,而开发者良莠不齐,如直接暴露 Canvas,易导致开发者误用和产生不可预期错误,
为此 Android 索性基于 “模板方法模式” 设计 View、Drawable 等排版模板,让 UI 开发者可继承标准化模板,配置出诸如 TextView、ImageView、ShapeDrawable 等自定义模板,供业务开发者用。
这样误用 Canvas 问题看似解决,却引入 “高频痛点 1”:View 实例 Null 安全一致性问题。这是 Java 语言项目硬伤,客户端背景下尤明显。
高频痛点 1:Null 安全一致性问题
例如某页面有横竖两布局,竖布局有 TextViewA,横布局无,那么横屏时,findViewbyId 拿到则是 Null 实例,后续 mTextViewA.setText( ) 如未判空处理,即造成 Null 安全问题,
对此不能一味强调 “手动判空”,毕竟一个页面中,控件成员多达十数个,每个控件实例亦遍布数十方法中。疏忽难避免。
那怎办?此时 2008 年,回顾历史,可总结为:“同志们,7 年暗夜已开始,7 年后会有个框架,驾着七彩祥云来救你”。
原始工程架构 MVC
时间来到 2013,以该年问世 Android Studio 为例,
工程结构主要包含 Java 代码和 res 资源。考虑到布局编写预览需求,Android 开发默认基于 XML 声明 Layout,MVC 形态油然而生,
其中 XML 作 View 角色,供 View-Controller 获取实例和控制,
Activity 作 View-Controller 角色,结合 View 和 Model 控制逻辑,
开发者另外封装 DataManager,POJO 等,作 Model 角色,用于数据请求响应,
显而易见,该架构实际仅两层:控制层和数据层,
Activity 越界承担 “领域层” 业务逻辑职责,也因此滋生如下 3 个高频痛点:
高频痛点 2:成员变量爆炸
成员声明,动辄数十行,令人眼花缭乱。接手老项目开发者,最有体会。
高频痛点 3:状态管理一致性问题
View 状态保存和恢复,使用原生 onInstanceStateSave & Restore 机制,开发者容易因 “记得 restore、遗漏 save” 而产生不可预期错误。
高频痛点 4:消息分发一致性问题
由于 Activity 额外承担 “领域层” 职责,乃至消息收发工作也直接在 Activity 内进行,这使消息来源无法保证时效性、一致性,易 “被迫收到” 不可预期推送,滋生千奇百怪问题。
EventBus 等 “缺乏鉴权结构” 框架,皆为该背景下 “消息分发不一致” 帮凶。
“同志们,5 年水深火热已过去,再过 2 年,曙光降临”
好家伙,这是提前拿到剧本。既然如此,这 2 年时间,不如放开手脚,引入它山之石试试(
就逝世)。
它山之石
矫枉过正 MVP
这一版对 “现实状况” 判断有偏差。
MVP 规定 Activity 应充当 View,而 Presenter 独吞 “表现层” 逻辑,通过 “契约接口” 与 View、Model 通信,
这使 Activity 职能被严重剥夺,只剩末端通知 View 状态改变,无法全权自治 “表现逻辑”。
反客为主 Presenter
从 Presenter 角度看,似乎遵循 “依赖倒置原则” 和 “最小知道原则”,但从关系界限层面看,Presenter 属 “空降” 角色,一切都其自作主张、暗箱操作,不仅 “未能实质解决” 原 Activity 面临上述 4 大痛点,反因贪婪夺权引入更多烂事。
这也是为何,开发过 MVP 项目,都知有多别扭。
简明易用 三方库
基于其本质 “依赖倒置原则” 和 “最小知道原则”,更建议将其用于 “局部功能设计”,如 “三方库” 设计,使开发者 无需知道内部逻辑,简单配置即可使用。
我们维护的 “饿了么二级联动列表” 库,即是基于该模式设计,感兴趣可自行查阅。
拨乱反正 MVVM
经历漫长黑夜,Android 开发引来曙光。
2015 年 Google I/O 大会,DataBinding 框架面世。
该框架可用于解决 “高频痛点1:View 实例 Null 安全一致性问题”,并跟随 MVVM 模式步入开发者视野。
曲高和寡 DataBinding
MVVM 是种约定,双向绑定是 MVVM 特征,但非 DataBinding 本质,故长久以来,开发者对 DataBinding 存在误解,认为使用 DataBinding 即须双向绑定、且在 XML 中调试。
事实并非如此。
DataBinding 是通过 “可观察数据 ObservableField” 在编译时与 XML 中对应 View 实例绑定,这使上文所述 “竖布局有 TextViewA 而横布局无” 情况下,有 TextViewA 即被绑定,无即无绑定,于是无论何种情况,都不至于 findViewById 拿到 Null 实例从而诱发 Null 安全问题。
也即,DataBinding 仅负责通知末端 View 状态改变,仅用于规避 Null 安全问题,不参与视图逻辑。而反向绑定是 “迁就” 这一结构的派生设计,非核心本质。
碍于篇幅限制,如这么说无体会,可参见《从被误解到 “真香” Jeptack DataBinding》解析,本文不再累述。
未卜先知 mBinding
除了本质难理解,DataBinding 也有硬伤,由于隔着一层 BindingAdapter,难获取 View 体系坐标等 getter 属性,乃至 “属性动画” 等框架难兼容。
有说 MotionLayout 可破此局,于多数场景轻松完成动画。
但它也非省油灯,不同时支持 Drag & Click,难实现我们 示例项目 “展开面板” 场景。
于是,DataBinding 做出 “违背祖宗” 决定 —— 允许开发者在 Java 代码中拿到 mBinding 乃至 View 实例 … 如此上一节提到的 “改用 ObservableField 的绑定来消除 Null 安全问题” 的努力前功尽弃。
—— 鉴于 App 页面并非总是 “横竖布局皆有”,于是开发者索性通过 “强制竖屏” 扼杀 View 实例 Null 安全隐患,而调用 mBinding 实例仅用于规避 findViewById 样板代码。
至于为何说 mBinding 使用即 “未卜先知”,因为群众智慧多年后即被应验。
力挽狂澜
官方牵头 Jetpack
时间回到 2017,这年 Google I/O 引入一系列 AAC(Android Architecture Components)
一举多得 ViewModel
其中 Jetpack ViewModel,通过支持 View 实例状态 “托管” 和 “保存恢复”,
一举解决 “高频痛点2:成员变量爆炸” 和 “高频痛点 3:状态管理一致性问题”,
Activity 成员变量表,一下简洁许多。Save & Restore 样板代码亦烟消云散。
半路杀出 Kotlin
并且这时期,Kotlin 被扶持为官方语言,背景发生剧变。
Kotlin 直接从语言层面支持 Null 安全,于是 DataBinding 在 Kotlin 项目式微。
喜闻乐见 ViewBinding
千呼万唤,ViewBinding 问世 2019。
如布局中 View 实例隐含 Null 安全隐患,则编译时 ViewBinding 中间代码为其生成 @Nullable 注解,使 Kotlin 开发过程中,Android Studio 自动提醒 “强制使用 Null 安全符”,由此确保 Null 安全一致。
ViewBinding 于 Kotlin 项目可平替 DataBinding,开发者喜闻乐见 mBinding 使用。
百花齐放
最佳实践 Jetpack MVVM
自 2017 年 AAC 问世,部分原生 Jetpack 架构组件至今仍存在设计隐患,
基于 “架构组件本质即解决一致性问题” 理解,我们于 2019 陆续将 “隐患组件” 改造和开源。
屏蔽回推 UnPeekLiveData
LiveData 是效仿响应式编程 BehaviorSubject 的设计,由于
1.Jetpack 架构示例通常只包含 “表现层” 和 “数据层” 两层,缺乏在 “领域层” 分发数据的工具,
2.LiveData Observer 的设计缺乏边界感,
容易让开发者误当做 “一次性事件分发组件” 来使用,造成订阅时 "自动回推脏数据";
容易让开发者误将同一控件实例放在多个 Observer 回调中 造成恢复状态时 “数据不一致” 等问题(具体可参见《MVI 的存在意义》 关于 “响应式编程漏洞” 的描述)
3.DataBinding ObservableField 组件的 Observer 能限定为 "与控件一对一绑定",更适合承担表现层 BehaviorSubject 工作,
4.LiveData 具备生命周期安全等优势,
因此决定将 LiveData 往领域层 PublishSubject 方向改造,去除其 “自动推送最后一次状态” 的能力,使其专职生命周期安全的数据分发。
具体可参见 Github:UnPeek-LiveData 使用。
消息分发 Dispatcher
由于 LiveData 存在的初衷并非是专业的 “一次性事件分发组件”,改造过的 UnPeekLiveData 也只适用于 “低频次数据分发(例如每秒推送 1 次)” 场景,
因而若想满足 “高频次事件分发” 需求(例如每秒推送 5 次以上),请改用或参考专职 “领域层” 数据分发的 Github:MVI-Dispatcher 组件,该组件内部通过消息队列设计,确保不漏掉每一次推送。
Dispatcher 的存在解决了 “高频痛点 4:消息分发一致性问题”,
也即通过在领域层设立 “专职业务处理和结果回推” 的 Dispatcher,来将业务处理过程中产生的 Event 或 State,以串流的方式统一从 output 出口回传,
由此表现层页面可根据消息的性质,采取 “一致性执行” 或 “交由 BehaviorSubject 托管状态”。
对此具体可参见《解决 MVI 架构实战痛点》 解析。
严格模式 DataBinding
此外我们明确约定 Java 下 DataBinding 使用原则,确保 100% Null 安全。如违背原则,便 Debug 模式下警告,方便开发者留意。
具体可参见 Github:KunMinX-MVVM 使用。
另起炉灶 Compose
回到文章开头 Canvas,为实现 View 实例 Null 安全,先是 DataBinding 框架,但它作为一框架,并不体系自洽,与 “属性动画” 等框架难兼容。
于是出现声明式 UI,通过函数式编程 “纯函数原子性” 解决 Null 安全一致。且体系自洽,动画无兼容问题,学习成本也低于 View 体系。
后续如性能全面跟上、120Hz 无压力,建议直接上手 Compose 开发。
注:关于声明式 UI 函数式编程本质,及纯函数原子性为何能实现 Null 安全一致,详见《一通百通 “声明式 UI” 扫盲干货》,本文不作累述。
综上
高频痛点1:Null 安全一致性问题
客户端,图形化,需 Canvas,
为避免接触 Canvas 导致不可预期错误,原生架构提供 View、Drawable 排版模板。
为解决 Java 下 View 实例 Null 安全一致性问题,引入 DataBinding。
但 DataBinding 仅是一框架,难体系自洽,
于是兵分两路,Kotlin + ViewBinding 或 Kotlin + Compose 取代 DataBinding。
高频痛点2:成员变量爆炸
高频痛点3:状态管理一致性问题
引入 Jetpack ViewModel,实现状态托管和保存恢复。
高频痛点4:消息分发一致性问题
引入 Dispatcher 承担 PublishSubject,实现统一的消息推送。
最后,天下无完美架构,唯有高频痛点熟稔于心,不断死磕精进,集思广益,迭代特定场景最优解。
相关资料
Canvas,View,Drawable,排版模板:《过目难忘 Android GUI 关系梳理》
DataBinding,Null 安全一致,ViewBinding:《从被误解到 “真香” Jetpack DataBinding》
Dispatcher,消息分发,State,Event:《解决 MVI 架构实战痛点》
架构组件解决一致性问题:《耳目一新 Jetpack MVVM 精讲》
Compose,纯函数原子性,Null 安全一致:《一通百通 “声明式 UI” 扫盲干货》
版权声明
Copyright © 2019-present KunMinX 原创版权所有。
如需 转载本文,或引用、借鉴 本文 “引言、思路、结论、配图” 进行二次创作发行,须注明链接出处,否则我们保留追责权利。
本文封面 Android 机器人是在 Google 原创及共享成果基础上再创作而成,遵照知识共享署名 3.0 许可所述条款付诸应用。
链接:https://juejin.cn/post/7106042518457810952
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin 协程探索
Kotlin 协程是什么?
本文只是自己经过研究后,对 Kotlin 协程的理解概括,如有偏差,还请斧正。
简要概括:
协程是 Kotlin 提供的一套线程 API 框架,可以很方便的做线程切换。 而且在不用关心线程调度的情况下,能轻松的做并发编程。也可以说协程就是一种并发设计模式。
下面是使用传统线程和协程执行任务:
Thread{
//执行耗时任务
}.start()
val executors = Executors.newCachedThreadPool()
executors.execute {
//执行耗时任务
}
GlobalScope.launch(Dispatchers.IO) {
//执行耗时任务
}
在实际应用开发中,通常是在主线中去启动子线程执行耗时任务,等耗时任务执行完成,再将结果给主线程,然后刷新UI:
Thread{
//执行耗时任务
runOnMainThread {
//获取耗时任务结果,刷新UI
}
}.start()
val executors = Executors.newCachedThreadPool()
executors.execute {
//执行耗时任务
runOnMainThread {
//获取耗时任务结果,刷新UI
}
}
Observable.unsafeCreate<Unit> {
//执行耗时任务
}.subscribeOn(Schedulers.io()).observeOn(AndroidSchedulers.mainThread()).subscribe {
//获取耗时任务结果,刷新UI
}
GlobalScope.launch(Dispatchers.Main) {
val result = withContext(Dispatchers.IO){
//执行耗时任务
}
//直接拿到耗时任务结果,刷新UI
refreshUI(result)
}
从上面可以看到,使用Java 的 Thread 和 Executors 都需要手动去处理线程切换,这样的代码不仅不优雅,而且有一个重要问题,那就是要去处理与生命周期相关的上下文判断,这导致逻辑变复杂,而且容易出错。
RxJava 是一套优雅的异步处理框架,代码逻辑简化,可读性和可维护性都很高,很好的帮我们处理线程切换操作。这在 Java 语言环境开发下,是如虎添翼,但是在 Kotlin 语言环境中开发,如今的协程就比 RxJava 更方便,或者说更有优势。
下面看一个 Kotlin 中使用协程的例子:
GlobalScope.launch(Dispatchers.Main) {
Log.d("TestCoroutine", "launch start: ${Thread.currentThread()}")
val numbersTo50Sum = withContext(Dispatchers.IO) {
//在子线程中执行 1-50 的自然数和
Log.d("TestCoroutine", "launch:numbersTo50Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo50 = naturalNumbers.takeWhile { it <= 50 }
numbersTo50.sum()
}
val numbers50To100Sum = withContext(Dispatchers.IO) {
//在子线程中执行 51-100 的自然数和
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
val result = numbersTo50Sum + numbers50To100Sum
Log.d("TestCoroutine", "launch end:result=$result ${Thread.currentThread()}")
}
Log.d("TestCoroutine", "Hello World!,${Thread.currentThread()}")
控制台输出结果:
2023-01-02 16:05:45.846 10153-10153/com.wangjiang.example D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-02 16:05:48.058 10153-10153/com.wangjiang.example D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-02 16:05:48.059 10153-10322/com.wangjiang.example D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-02 16:05:49.114 10153-10322/com.wangjiang.example D/TestCoroutine: launch:numbers50To100Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-02 16:05:50.376 10153-10153/com.wangjiang.example D/TestCoroutine: launch end:result=5050 Thread[main,5,main]
在上面的代码中:
launch是一个函数,用于创建协程并将其函数主体的执行分派给相应的调度程序。Dispatchers.MAIN指示此协程应在为 UI 操作预留的主线程上执行。Dispatchers.IO指示此协程应在为 I/O 操作预留的线程上执行。withContext(Dispatchers.IO)将协程的执行操作移至一个 I/O 线程。
从控制台输出结果中,可以看出在计算 1-50 和 51-100 的自然数和的时候,线程是从主线程(Thread[main,5,main])切换到了协程的线程(DefaultDispatcher-worker-1,5,main),这里计算 1-50 和 51-100 都是同一个子线程。
在这里有一个重要的现象,代码从逻辑上看起来是同步的,并且启动协程执行任务的时候,没有阻塞主线程继续执行相关操作,而且在协程中的异步任务执行完成之后,又自动切回了主线程。这就是 Kotlin 协程给开发做并发编程带来的好处。这也是有个概念的来源: Kotlin 协程同步非阻塞。
同步非阻塞”是真的“同步非阻塞” 吗?下面探究一下其中的猫腻,通过 Android Studio ,查看 .class 文件中的上面一段代码:
BuildersKt.launch$default((CoroutineScope)GlobalScope.INSTANCE, (CoroutineContext)Dispatchers.getMain(), (CoroutineStart)null, (Function2)(new Function2((Continuation)null) {
int I$0;
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var10000;
int numbersTo50Sum;
label17: {
Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
Function2 var10001;
CoroutineContext var6;
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch start: " + Thread.currentThread());
var6 = (CoroutineContext)Dispatchers.getIO();
var10001 = (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch:numbersTo50Sum: " + Thread.currentThread());
this.label = 1;
if (DelayKt.delay(1000L, this) == var4) {
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
Sequence naturalNumbers = SequencesKt.generateSequence(Boxing.boxInt(0), (Function1)null.INSTANCE);
Sequence numbersTo50 = SequencesKt.takeWhile(naturalNumbers, (Function1)null.INSTANCE);
return Boxing.boxInt(SequencesKt.sumOfInt(numbersTo50));
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
});
this.label = 1;
var10000 = BuildersKt.withContext(var6, var10001, this);
if (var10000 == var5) {
return var5;
}
break;
case 1:
ResultKt.throwOnFailure($result);
var10000 = $result;
break;
case 2:
numbersTo50Sum = this.I$0;
ResultKt.throwOnFailure($result);
var10000 = $result;
break label17;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
numbersTo50Sum = ((Number)var10000).intValue();
var6 = (CoroutineContext)Dispatchers.getIO();
var10001 = (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch:numbers50To100Sum: " + Thread.currentThread());
this.label = 1;
if (DelayKt.delay(1000L, this) == var4) {
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
Sequence naturalNumbers = SequencesKt.generateSequence(Boxing.boxInt(51), (Function1)null.INSTANCE);
Sequence numbers50To100 = SequencesKt.takeWhile(naturalNumbers, (Function1)null.INSTANCE);
return Boxing.boxInt(SequencesKt.sumOfInt(numbers50To100));
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
});
this.I$0 = numbersTo50Sum;
this.label = 2;
var10000 = BuildersKt.withContext(var6, var10001, this);
if (var10000 == var5) {
return var5;
}
}
int numbers50To100Sum = ((Number)var10000).intValue();
int result = numbersTo50Sum + numbers50To100Sum;
Log.d("TestCoroutine", "launch end:result=" + result + ' ' + Thread.currentThread());
return Unit.INSTANCE;
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
}), 2, (Object)null);
Log.d("TestCoroutine", "Hello World!," + Thread.currentThread());
虽然上面 .class 文件中的代码比较复杂,但是从大体逻辑可以看出,Kotlin 协程也是通过回调接口来实现异步操作的,这也解释了 Kotlin 协程只是让代码逻辑是同步非阻塞,但是实际上并没有,只是 Kotlin 编译器为代码做了很多事情,这也是说 Kotlin 协程其实就是一套线程 API 框架的原因。
再看一个上面例子的变种:
GlobalScope.launch(Dispatchers.Main) {
Log.d("TestCoroutine", "launch start: ${Thread.currentThread()}")
val numbersTo50Sum = async {
withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbersTo50Sum: ${Thread.currentThread()}")
delay(2000)
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo50 = naturalNumbers.takeWhile { it <= 50 }
numbersTo50.sum()
}
}
val numbers50To100Sum = async {
withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(500)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
}
// 计算 1-50 和 51-100 的自然数和是两个并发操作
val result = numbersTo50Sum.await() + numbers50To100Sum.await()
Log.d("TestCoroutine", "launch end:result=$result ${Thread.currentThread()}")
}
Log.d("TestCoroutine", "Hello World!,${Thread.currentThread()}")
控制台输出结果:
2023-01-02 16:32:12.637 13303-13303/com.wangjiang.example D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-02 16:32:13.120 13303-13303/com.wangjiang.example D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-02 16:32:14.852 13303-13444/com.wangjiang.example D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-2,5,main]
2023-01-02 16:32:14.853 13303-13443/com.wangjiang.example D/TestCoroutine: launch:numbers50To100Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-02 16:32:17.462 13303-13303/com.wangjiang.example D/TestCoroutine: launch end:result=5050 Thread[main,5,main]
async 创建了一个协程,它让计算 1-50 和 51-100 的自然数和是两个并发操作。上面控制台输出结果可以看到计算 1-50 的自然数和是在线程 Thread[DefaultDispatcher-worker-2,5,main] 中,而计算 51-100 的自然数和是在另一个线程Thread[DefaultDispatcher-worker-1,5,main]中。
从上面的例子,协程在异步操作,也就是线程切换上:主线程启动子线程执行耗时操作,耗时操作执行完成将结果更新到主线程的过程中,代码逻辑简化,可读性高。
suspend 是什么?
suspend 直译就是:挂起
suspend 是 Kotlin 语言中一个 关键字,用于修饰方法,当修饰方法时,表示这个方法只能被 suspend 修饰的方法调用或者在协程中被调用。
下面看一下将上面代码案例拆分成几个 suspend 方法:
fun getNumbersTo100Sum() {
GlobalScope.launch(Dispatchers.Main) {
Log.d("TestCoroutine", "launch start: ${Thread.currentThread()}")
val result = calcNumbers1To100Sum()
Log.d("TestCoroutine", "launch end:result=$result ${Thread.currentThread()}")
}
Log.d("TestCoroutine", "Hello World!,${Thread.currentThread()}")
}
private suspend fun calcNumbers1To100Sum(): Int {
return calcNumbersTo50Sum() + calcNumbers50To100Sum()
}
private suspend fun calcNumbersTo50Sum(): Int {
return withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbersTo50Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(0) { it + 1 }
val numbersTo50 = naturalNumbers.takeWhile { it <= 50 }
numbersTo50.sum()
}
}
private suspend fun calcNumbers50To100Sum(): Int {
return withContext(Dispatchers.IO) {
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
}
控制台输出结果:
2023-01-03 14:47:57.047 11349-11349/com.wangjiang.example D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-03 14:47:59.311 11349-11349/com.wangjiang.example D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-03 14:47:59.312 11349-11537/com.wangjiang.example D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-3,5,main]
2023-01-03 14:48:00.336 11349-11535/com.wangjiang.example D/TestCoroutine: launch:numbers50To100Sum: Thread[DefaultDispatcher-worker-1,5,main]
2023-01-03 14:48:01.339 11349-11349/com.wangjiang.example D/TestCoroutine: launch end:result=5050 Thread[main,5,main]
suspend 关键字标记方法时,其实是告诉 Kotlin 从协程内调用方法。所以这个“挂起”,并不是说方法或函数被挂起,也不是说线程被挂起。
假设一个非 suspend 修饰的方法调用 suspend 修饰的方法会怎么样呢?
private fun calcNumbersTo100Sum(): Int {
return calcNumbersTo50Sum() + calcNumbers50To100Sum()
}
此时,编译器会提示:
Suspend function 'calcNumbersTo50Sum' should be called only from a coroutine or another suspend function
Suspend function 'calcNumbers50To100' should be called only from a coroutine or another suspend function
下面查看 .class 文件中的上面方法 calcNumbers50To100Sum 代码:
private final Object calcNumbers50To100Sum(Continuation $completion) {
return BuildersKt.withContext((CoroutineContext)Dispatchers.getIO(), (Function2)(new Function2((Continuation)null) {
int label;
@Nullable
public final Object invokeSuspend(@NotNull Object $result) {
Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED();
switch(this.label) {
case 0:
ResultKt.throwOnFailure($result);
Log.d("TestCoroutine", "launch:numbers50To100Sum: " + Thread.currentThread());
this.label = 1;
if (DelayKt.delay(1000L, this) == var4) {
return var4;
}
break;
case 1:
ResultKt.throwOnFailure($result);
break;
default:
throw new IllegalStateException("call to 'resume' before 'invoke' with coroutine");
}
Sequence naturalNumbers = SequencesKt.generateSequence(Boxing.boxInt(51), (Function1)null.INSTANCE);
Sequence numbers50To100 = SequencesKt.takeWhile(naturalNumbers, (Function1)null.INSTANCE);
return Boxing.boxInt(SequencesKt.sumOfInt(numbers50To100));
}
@NotNull
public final Continuation create(@Nullable Object value, @NotNull Continuation completion) {
Intrinsics.checkNotNullParameter(completion, "completion");
Function2 var3 = new <anonymous constructor>(completion);
return var3;
}
public final Object invoke(Object var1, Object var2) {
return ((<undefinedtype>)this.create(var1, (Continuation)var2)).invokeSuspend(Unit.INSTANCE);
}
}), $completion);
}
可以看到 private suspend fun calcNumbers50To100Sum() 经过 Kotlin 编译器编译后变成了private final Object calcNumbers50To100Sum(Continuation $completion), suspend 消失了,方法多了一个参数 Continuation $completion,所以 suspend修饰 Kotlin 的方法或函数,编译器会对此方法做特殊处理。
另外,suspend 修饰的方法,也预示着这个方法是耗时方法,告诉方法调用者要使用协程。当执行 suspend 方法,也预示着要切换线程,此时主线程依然可以继续执行,而协程里面的代码可能被挂起了。
下面再稍为修改 calcNumbers50To100Sum 方法:
private suspend fun calcNumbers50To100Sum(): Int {
Log.d("TestCoroutine", "launch:numbers50To100Sum:start: ${Thread.currentThread()}")
val sum= withContext(Dispatchers.Main) {
Log.d("TestCoroutine", "launch:numbers50To100Sum: ${Thread.currentThread()}")
delay(1000)
val naturalNumbers = generateSequence(51) { it + 1 }
val numbers50To100 = naturalNumbers.takeWhile { it in 51..100 }
numbers50To100.sum()
}
Log.d("TestCoroutine", "launch:numbers50To100Sum:end: ${Thread.currentThread()}")
return sum
}
控制台输出结果:
2023-01-03 15:28:04.349 15131-15131/com.bilibili.studio D/TestCoroutine: Hello World!,Thread[main,5,main]
2023-01-03 15:28:04.803 15131-15131/com.bilibili.studio D/TestCoroutine: launch start: Thread[main,5,main]
2023-01-03 15:28:04.804 15131-15266/com.bilibili.studio D/TestCoroutine: launch:numbersTo50Sum: Thread[DefaultDispatcher-worker-3,5,main]
2023-01-03 15:28:06.695 15131-15131/com.bilibili.studio D/TestCoroutine: launch:numbers50To100Sum:start: Thread[main,5,main]
2023-01-03 15:28:06.696 15131-15131/com.bilibili.studio D/TestCoroutine: launch:numbers50To100Sum: Thread[main,5,main]
2023-01-03 15:28:07.700 15131-15131/com.bilibili.studio D/TestCoroutine: launch:numbers50To100Sum:end: Thread[main,5,main]
2023-01-03 15:28:07.700 15131-15131/com.bilibili.studio D/TestCoroutine: launch end:result=5050 Thread[main,5,main]
主线程不受协程线程的影响。
总结
Kotlin 协程是一套线程 API 框架,在 Kotlin 语言环境下使用它做并发编程比传统 Thread, Executors 和 RxJava 更有优势,代码逻辑上“同步非阻塞“,而且简洁,易阅读和维护。
suspend 是 Kotlin 语言中一个关键字,用于修饰方法,当修饰方法时,该方法只能被 suspend 修饰的方法和协程调用。此时,也预示着该方法是一个耗时方法,告诉调用者需要在协程中使用。
参考文档:
下一篇,将研究 Kotlin Flow。
链接:https://juejin.cn/post/7184628421010391095
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一个特别简单的队列功能
背景
身为一名ui仔,不光要会画ui,也有可能接触一些其他的需求,就比如我做直播的时候,就需要做礼物的队列播放,用户送礼,然后客户收到消息,然后一次播放礼物动画,这个需求很简单,自定义一个view并且里面有一个队列就可以搞定,但是如果要播放不同类型的内容,如果再去改这个ui,耦合度就会越来越大,那么这个view的定义就变了,那就太不酷啦,所以要将队列和ui拆开,所以我们要实现一个队列功能,然后可以接受不同类型的参数,然后依次执行。
如何实现的
一、咱们有两个队列,一个更新ui,一个缓存消息
二、咱们还要定时器,要轮询的检查任务
三、我们还要有队列进入的入口
四、我们也需要有处理队列的地方
五、我们还要有最后处理结果的方案
六、还得需要一个清除的功能,要不怎么回收呢
举一个栗子🌰
假设我们有个需求,收到消息后,弹出一个横幅通知,弹出横幅通知后几秒后消失,但是在这几秒中,会收到多条消息,你需要将这多条消息合并展示,听起来是不是很耳熟,就是说咱们聊天消息,一条消息展示一条内容,多条消息做合并。
现在看实际代码:如下所示
/**
* 堆栈消息帮助类
* */
object QueuePushHelper {
/**
* 通过type修改监听状态
* */
private var type = false
private var queuePushInterface: QueuePushInterface? = null
fun setQueuePushInterface(queuePushInterface: QueuePushInterface) {
this.queuePushInterface = queuePushInterface
}
/**
* 缓存所有消息
*/
private var cacheGiftList: LinkedList<QueuePushBean> =
LinkedList<QueuePushBean>()
/**
* 用于更新界面消息的队列
*/
private var uiMsgList: LinkedList<QueuePushBean> =
LinkedList<QueuePushBean>()
/**
* 定时器
*/
private var msgTimer = Executors.newScheduledThreadPool(2)
private lateinit var futures: ScheduledFuture<*>
/**
* 消息加入队列
*/
@JvmStatic
@Synchronized
fun onMsgReceived(customMsg: QueuePushBean) {
cacheGiftList.offer(customMsg)
}
/**
* 清空队列
* */
fun clearQueue() {
if (cacheGiftList.size > 0) {
cacheGiftList.clear()
}
if (uiMsgList.size > 0) {
uiMsgList.clear()
}
updateStatus(true)
}
/**
* 修改队列状态
* */
fun updateStatus(status: Boolean) {
type = status
}
/**
* 开启定时任务,数据清空
* */
@JvmStatic
fun startReceiveMsg() {
if (cacheGiftList.size > 0) {
cacheGiftList.clear()
}
if (uiMsgList.size > 0) {
uiMsgList.clear()
}
updateStatus(true)
futures = msgTimer.scheduleAtFixedRate(
TimerTask(),
0,
500,
TimeUnit.MILLISECONDS
)
}
/**
* 结束定时任务,数据清空
* ### 退出登录,需要清楚
* */
fun stopReceiveMsg() {
updateStatus(false)
if (cacheGiftList.size > 0) {
cacheGiftList.clear()
}
if (uiMsgList.size > 0) {
uiMsgList.clear()
}
if (::futures.isInitialized) {
futures.cancel(true)
}
msgTimer.shutdown()
}
/**
* 定时任务
* */
class TimerTask : Runnable {
override fun run() {
try {
synchronized(cacheGiftList) {
if (type) {
if (cacheGiftList.isNullOrEmpty()) {
return
}
uiMsgList.clear()
uiMsgList.offer(cacheGiftList.pollLast())
uiMsgList.poll()?.let {
if (cacheGiftList.size > 1) {
it.type = true
}
//poll一个用户信息,且从剩余集合中过滤出第一个不同名字的用户
queuePushInterface?.handleMessage(
it,
cacheGiftList.firstOrNull { its->
it.msg.fromNick !=its.msg.fromNick
}?.msg?.fromNick,
cacheGiftList.size + 1 // 因为poll了一个 所以数量加1
)
}
cacheGiftList.clear()
}
}
} catch (e: Exception) {
Log.d("QueuePushHelper", "run: e $e")
}
}
}
interface QueuePushInterface {
fun handleMessage(item: QueuePushBean, name: String?, msgCount: Int)
}
}
我代码都贴出来了,大家一看就知道 这个也太简单了。就不多解释了,如果还需要解释就留言吧,祝大家事事平安
链接:https://juejin.cn/post/7225198413163479096
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
浅谈 Android 线上帧率统计方案演进
帧率是我们衡量应用流畅度的一个重要基准指标。本文将简单介绍 Android 线上帧率计算方案的演进和业界基于帧率来衡量卡顿的相关指标设计。
帧率计算方案的演进
Choreographer.postFrameCallback
自 Android 4.1 引入 Choreographer 来调度 UI 线程的绘制相关任务之后,我们便有了一个简单衡量 UI 线程绘制效率的方案:通过持续调用 Choreographer 的 postFrameCallback 方法来得到基于 VSync 周期的回调,基于回调的间隔或者方法参数中的当前帧起始时间 frameTimeNanos 来计算帧率( 注意到基于回调间隔计算帧率的情况,由于 postFrameCallback 注册的回调类型是 Animation,早于 Traversal 但晚于 Input,实际回调的起点并不是当前帧的起点 )。
这一方案简单可靠,但关键问题在于 UI 线程通常都不会不间断地执行绘制任务,在不需要执行绘制任务( scheduleTraversals )时,UI 线程原本是不需要请求 VSync 信号的,而持续调用 postFrameCallback 方法的情况,则会连续请求 VSync 信号,使得 UI 线程始终处于比较活跃的状态,同时计算得到的帧率数据实际也会包含不需要绘制时的情况。准确来说,这一方案实际衡量的是 UI 线程的繁忙程度。
Matrix 早期方案
怎么能得到真正的帧率数据呢?腾讯 Matrix 的早期实现上,结合 Looper Printer 和 Choreographer 实现了一个比较巧妙的方案,做到了统计真正的 UI 线程绘制任务的细分耗时。
具体来说,基于 Looper Printer 做到对 UI 线程每个消息执行的监控,同时反射给 Choreographer 的 Input 回调队列头部插入一个任务,用来监听下一帧的起点。队头的 Input 任务被调用时,说明当前所在的消息是处理绘制任务的,则消息执行的终点也就是当前帧的终点。同时,在队头的 Input 任务被调用时,给 Animation 和 Traversal 的回调队列头部也插入任务,如此总共得到了四个时间点,可以将当前帧的耗时细分为 Input,Animation 和 Traversal 三个阶段。在当前处理绘制任务的消息执行完后,重新注册一个 Input 回调队列头部的任务,便可以继续监听下一帧的耗时情况。
这一方案没有使用 postFrameCallback( 不主动请求 VSync 信号 ),避免了前一个方案的问题,但整体方案上偏 hack,可能存在兼容性问题( 实际 Android 高版本上对 Choreographer 的内部回调队列确实有所调整 )。此外,当前方案也会受到上一方案的干扰,如果存在其他业务在持续调用 postFrameCallback,也会使得这里统计到的数据包含非绘制的情况。
JankStats 方案
实际在 Android 7.0 之后,官方已经引入了 FrameMetrics API 来提供帧耗时的详细数据。androidx 的 JankStats 库主要就是基于 FrameMetrics API 来实现的帧耗时数据统计。
在 Android 4.1 - 7.0 之间,JankStats 仍然是基于 Choreographer 来做帧率计算的,但方案和前两者均不同。具体来说,JankStats 通过监听 OnPreDrawListener 来感知绘制任务的发生,此时,通过反射 Choreographer 的 mLastFrameTimeNanos 来获取当前帧的起始时间,再通过往 UI 线程的消息队列头部抛任务的方式来获取当前帧的 UI 线程绘制任务结束时间( 在支持异步消息情况下,将该消息设置为异步消息,尽量保证获取结束时间的任务紧跟在当前任务之后 )。
这一方案简单可靠,而且得到的确实是真正的帧率数据。
在 Android 7.0 及以上版本,JankStats 则直接通过 Window 的新方法 addOnFrameMetricsAvailableListener,注册回调得到每一帧的详细数据 FrameMetrics。
FrameMetrics 的数据统计具体是怎么实现的?简单来说,Android 官方在整个绘制渲染流程上都做了打点来支持 FrameMetrics 的数据统计逻辑,具体包括了
- 基于 Choreographer 记录了 VSync,Input,Animation,Traversal 的起始时间点
- 基于 ViewRootImpl 记录了 Draw 的起始时间点( 结合 Traversal 区分开了 MeasureLayout 和 Draw 两段耗时 )
- 基于 CanvasContext( hwui 中 RenderThread 的渲染流程 )记录了 SyncDisplayList,IssueDrawCommand,SwapBuffer 等时间点,Android 12 上更是进一步支持了 GPU 上的耗时统计
可以看到,FrameMetrics 提供了以往方案难以给到的详细分阶段耗时( 特别注意 FrameMetrics 提供的数据存在系统版本间的差异,具体的数据处理可以参考 JankStats 的内部实现 ),而且在内部实现上,相关数据在绘制渲染流程上默认便会被统计( 即使我们不注册监听 ),基于 FrameMetrics 来做帧率计算在数据采集阶段带来的额外性能开销微乎其微。
帧率相关指标设计
简单的 FPS( 平均帧率 )数据并不能很好的衡量卡顿。在能够准确采集到帧数据之后,怎么基于采集到的数据做进一步处理得到更有实际价值的指标才是更为关键的。
Android Vitals 方案
Android Vitals 本身只定义了两个指标,基于单帧耗时简单区分了卡顿问题的严重程度。将耗时大于 16ms 的帧定义为慢帧,将耗时大于 700ms 的帧定义为冻帧。
JankStats 方案
JankStats 的实现上,则默认将单帧耗时在期望耗时 2 倍以上的情况视为卡顿( 即满帧 60FPS 的情况,将单帧耗时超过 33.3ms 的情况定义为卡顿 )。
Matrix 方案
Matrix 的指标设计则在 Android Vitals 的基础上做了进一步细分,以掉帧数为量化指标( 即满帧 60FPS 的情况,将单帧耗时在 16.6ms 到 33.3ms 间的情况定义为掉一帧 ),将帧耗时细化为 Best / Normal / Middle / High / Frozen 多类情况,其中 Frozen 实际对应的就是 Android Vitals 中的冻帧。
可以看到以上三者都是基于单帧耗时本身而非平均帧率来衡量卡顿。
手淘方案
手淘的方案则给出了更多的指标。
基于帧率数据本身的,细分场景定义了滑动帧率和卡顿帧率。
滑动帧率比较好理解;
卡顿帧率指的是,在出现卡顿帧( 定义为单帧耗时 33.3ms 以上 )之后,持续统计一段时间的帧耗时( 直到达到 99.6ms ( 6 帧 )并且下一帧不是卡顿帧 )来计算帧率,通过单独统计以卡顿帧为起点的细粒度帧率来避免卡顿被平均帧率掩盖的问题。和前面几个方案相比,卡顿帧率的特点在于一定程度上保留了帧数据的时间属性,一定程度上可以区分出离散的卡顿帧和连续的卡顿。
基于单帧耗时的,将冻帧占比( 即大于 700 ms 的帧占总帧数的比例 )作为独立指标;此外还有参考 iOS 定义的 scrollHitchRate,即滑动场景下,预期外耗时( 即每一帧超过期望耗时部分的累加 )的占比。
此外,得益于 FrameMetrics 的详细数据,手淘的方案还实现了简单的自动化归因,即基于 FrameMetrics 的分阶段耗时数据简单判断是哪个阶段导致了当前这一帧的卡顿。
链接:https://juejin.cn/post/7225596319448449083
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
超好用的官方core-ktx库,了解一下(终)~
Handler.postDelayed()简化lambda传入
不知道大家在使用Handler下的postDelayed()方法是不是感觉很不简洁,我们看下这个函数源码:
public final boolean postDelayed(@NonNull Runnable r, long delayMillis) {
return sendMessageDelayed(getPostMessage(r), delayMillis);
}
可以看到Runnable类型的参数r放在第一位,在Kotlin中我们就无法利用其提供的简洁的语法糖,只能这样使用:
private fun test11(handler: Handler) {
handler.postDelayed({
//编写代码逻辑
}, 100)
}
有没有感觉很别扭,估计官方也发现了这个问题,就提供了这样一个扩展方法:
public inline fun Handler.postDelayed(
delayInMillis: Long,
token: Any? = null,
crossinline action: () -> Unit
): Runnable {
val runnable = Runnable { action() }
if (token == null) {
postDelayed(runnable, delayInMillis)
} else {
HandlerCompat.postDelayed(this, runnable, token, delayInMillis)
}
return runnable
}
可以看到将函数类型(相当于上面的Runnable中的代码执行逻辑)放到了方法参数的最后一位,这样利用kotlin的语法糖就可以这样使用:
private fun test11(handler: Handler) {
handler.postDelayed(200) {
}
}
可以看到这个函数类型使用了crossinline修饰,这个是用来加强内联的,因为其另一个Runnable的函数类型中进行了调用,这样我们就无法在这个函数类型action中使用return关键字了(return@标签除外),避免使用return关键字带来返回上的歧义不稳定性。
除此之外,官方core-ktx还提供了类似的扩展方法postAtTime()方法,使用和上面一样!!
Context.getSystemService()泛型实化获取系统服务
看下以往我们怎么获取ClipboardManager:
private fun test11() {
val cm: ClipboardManager = getSystemService(Context.CLIPBOARD_SERVICE) as ClipboardManager
}
看下官方提供的方法:
public inline fun <reified T : Any> Context.getSystemService(): T? =
ContextCompat.getSystemService(this, T::class.java)
借助于内联和泛型实化简化了获取系统服务的代码逻辑:
private fun test11() {
val cm: ClipboardManager? = getSystemService()
}
泛型实化的用处有很多应用场景,大家感兴趣可以参考我另一篇文章:Gson序列化的TypeToken写起来太麻烦?优化它
Context.withStyledAttributes简化操作自定义属性
这个扩展一般只有在自定义View中较常使用,比如读取xml中设置的属性值,先看下我们平常是如何使用的:
private fun test11(
@NonNull context: Context,
@Nullable attrs: AttributeSet,
defStyleAttr: Int
) {
val ta = context.obtainStyledAttributes(
attrs, androidx.cardview.R.styleable.CardView, defStyleAttr,
androidx.cardview.R.style.CardView
)
//获取属性执行对应的操作逻辑
val tmp = ta.getColorStateList(androidx.cardview.R.styleable.CardView_cardBackgroundColor)
ta.recycle()
}
在获取完属性值后,还需要调用recycle()方法回收TypeArray,这个一旦忘记写就不好了,能让程序保证的写法那就尽量避免人为处理,所以官方提供了下面的扩展方法:
public inline fun Context.withStyledAttributes(
@StyleRes resourceId: Int,
attrs: IntArray,
block: TypedArray.() -> Unit
) {
obtainStyledAttributes(resourceId, attrs).apply(block).recycle()
}
使用如下:
private fun test11(
@NonNull context: Context,
@Nullable attrs: AttributeSet,
defStyleAttr: Int
) {
context.withStyledAttributes(
attrs, androidx.cardview.R.styleable.CardView, defStyleAttr,
androidx.cardview.R.style.CardView
) {
val tmp = getColorStateList(androidx.cardview.R.styleable.CardView_cardBackgroundColor)
}
}
上面的写法就保证了recycle()不会漏写,并且带接收者的函数类型block: TypedArray.() -> Unit也能让我们省略this直接调用TypeArray中的公共方法。
SQLiteDatabase.transaction()自动开启事务读写数据库
平常对SQLite进行写操作时为了效率及安全保证需要开启事务,一般我们都会手动进行开启和关闭,还是那句老话,能程序自动保证的事情就尽量避免手动实现,所以一般我们都会封装一个事务开启和关闭的方法,如下:
private fun writeSQL(sql: String) {
SQLiteDatabase.beginTransaction()
//执行sql写入语句
SQLiteDatabase.endTransaction()
}
官方core-ktx也提供了相似的扩展方法:
public inline fun <T> SQLiteDatabase.transaction(
exclusive: Boolean = true,
body: SQLiteDatabase.() -> T
): T {
if (exclusive) {
beginTransaction()
} else {
beginTransactionNonExclusive()
}
try {
val result = body()
setTransactionSuccessful()
return result
} finally {
endTransaction()
}
}
大家可以自行选择使用!
<K : Any, V : Any> lruCache()简化创建LruCache
LruCache一般用作数据缓存,里面使用了LRU算法来优先淘汰那些近期最少使用的数据。在Android开发中,我们可以使用其设计一个Bitmap缓存池,感兴趣的可以参考Glide内存缓存这块的源码,就利用了LruCache实现。
相比较于原有创建LruCache的方式,官方库提供了下面的扩展方法简化其创建流程:
inline fun <K : Any, V : Any> lruCache(
maxSize: Int,
crossinline sizeOf: (key: K, value: V) -> Int = { _, _ -> 1 },
@Suppress("USELESS_CAST")
crossinline create: (key: K) -> V? = { null as V? },
crossinline onEntryRemoved: (evicted: Boolean, key: K, oldValue: V, newValue: V?) -> Unit =
{ _, _, _, _ -> }
): LruCache<K, V> {
return object : LruCache<K, V>(maxSize) {
override fun sizeOf(key: K, value: V) = sizeOf(key, value)
override fun create(key: K) = create(key)
override fun entryRemoved(evicted: Boolean, key: K, oldValue: V, newValue: V?) {
onEntryRemoved(evicted, key, oldValue, newValue)
}
}
}
看下使用:
private fun createLRU() {
lruCache<String, Bitmap>(3072, sizeOf = { _, value ->
value.byteCount
}, onEntryRemoved = { evicted: Boolean, key: String, oldValue: Bitmap, newValue: Bitmap? ->
//缓存对象被移除的回调方法
})
}
可以看到,比之手动创建LruCache要稍微简单些,能稍微节省下使用成本。
bundleOf()快捷写入并创建Bundle对象
bundleOf()方法的参数被vararg声明,代表一个可变的参数类型,参数具体的类型为Pair,这个对象我们之前的文章有讲过,可以借助中缀表达式函数to完成Pair的创建:
private fun test12() {
val bundle = bundleOf("a" to "a", "b" to 10)
}
这种通过传入可变参数实现的Bundle如果大家不太喜欢,还可以考虑自行封装通用扩展函数,在函数类型即lambda中实现更加灵活的Bundle创建及写入:
1.自定义运算符重载方法set实现Bundle写入:
operator fun Bundle.set(key: String, value: Any?) {
when (value) {
null -> putString(key, null)
is Boolean -> putBoolean(key, value)
is Byte -> putByte(key, value)
is Char -> putChar(key, value)
is Double -> putDouble(key, value)
is Float -> putFloat(key, value)
is Int -> putInt(key, value)
is Long -> putLong(key, value)
is Short -> putShort(key, value)
is Serializable -> putSerializable(key, value)
//其实数据类型自定参考bundleOf源码实现
}
}
2.自定义BundleBuild支持向Bundle写入多个值
class BundleBuild(private val bundle: Bundle) {
infix fun String.to(that: Any?) {
bundle[this] = that
}
}
其中to()方法使用了中缀表达式的写法
3.暴漏扩展方法实现在lambda中完成Bundle的写入和创建
private fun bundleOf(block: BundleBuild.() -> Unit): Bundle {
return Bundle().apply {
BundleBuild(this).apply(block)
}
}
然后就可以这样使用:
private fun test12() {
val bundle = bundleOf {
"a" to "haha"
//经过一些逻辑操作获取结果后在写入Bundle
val t1 = 10 * 5
val t2 = ""
t2 to t1
}
}
相比较于官方库提供的bundleOf()提供的创建方式,通过函数类型也就是lambda创建并写入Bundle的方式更加灵活,并内部支持执行操作逻辑获取结果后再进行写入。
总结
关于官方core-ktx的研究基本上已经七七八八了,总共输出了五篇相关文章,对该库了解能够节省我们编写模板代码的时间,提高开发效率,大家如果感觉写的不错,可以点个赞支持下哈,感谢!!
链接:https://juejin.cn/post/7124706297810780191
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
咱不吃亏,也不能过度自卫
我之前写了一篇《吃亏不是福》,主要奉劝大家不要吃亏。这属于保护弱者的一面。
这次我谈谈不吃亏的一种人,他们不吃亏近乎强硬。这类人一点亏都不吃,以至于过度自我保护。
我们公司人事小刘负责考勤统计。发完考勤表之后,有个员工找到他,说出勤少统计了一天。
小刘一听,感觉自己有被指控的风险。
他立刻严厉起来:“每天都来公司,不一定就算全勤。没打卡我是不统计的”。
最后小刘一查,发现是自己统计错了。
小刘反而更加强势了:“这种事情,你应该早点跟我反馈,而且多催着我确认。你自己的事情都不上心,扣个钱啥的只能自己兜着”
这就是明显的不愿意吃亏,即使自己错了,也不愿意让自己置于弱势。
你的反应,决定别人怎么对你。这种连言语的亏都不吃的人,并不会让别人敬畏,反而会让人厌恶,进而影响沟通。
我还有一个同事老王。他是一个职场老人,性格嘻嘻哈哈,业务能力也很强。
以前同事小赵和老王合作的时候,小赵宁愿经两层人传话给老王,也不愿意和他直接沟通。
我当时感觉小赵不善于沟通。
后来,当我和老王合作的时候,才体会到小赵的痛苦。
因为,老王是一个什么亏都不吃的人,谁来找他理论,他就怼谁。
你告诉他有疏漏,他会极力掩盖问题,并且怒怼你愚昧无知。
就算你告诉他,说他家着火了。他首先说没有。你一指那不是烧着的吗?他回复,你懂个屁,你知道我几套房吗?我说的是我另一个家没着火。
有不少人,从不吃亏,无论什么情况,都不会让自己处于弱势。
这类人喜欢大呼小叫,你不小心踩他脚了,他会大喊:践踏我的尊严,和你拼了!
心理学讲,愤怒源于恐惧,因为他想逃避当前不利的局面。
人总会遇到各种不公的待遇,或误会,或委屈。
遇到争议时,最好需要确认一下,排除自己的问题。
如果自己没错,那么比较好的做法就是:“我认为你说得不合理,首先……其次……最后……”。
不盲目服软,也不得理不饶人,全程平心静气,有理有据。这种人绝对人格魅力爆棚,让人敬佩。
最后,有时候过度强硬也是一种策略,可以很好地过滤和震慑一些不重要的事物。
链接:https://juejin.cn/post/7196678344573173816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
抽象类与抽象方法
类到对象是实例化。对象到类是抽象。
抽象类:
1.什么是抽象类?
类和类之间具有共同特征,将这些共同特征提取出来,形成的就是抽象类。
类本身是不存在的,所以抽象类无法创建对象(无法实例化)
2.抽象类属于什么类型?抽象类也属于引用数据类型。
3.抽象类怎么定义?@#^%&^^&^%
语法:
(修饰符列表)abstract class类名{类体}
4.抽象类是无法实例化的,无法创建对象的,所以抽象类是用来被子类继承的。
5.final和abstract不能联合使用,这两个关键字是对立的。
6.抽象类的子类可以是抽象类。
7.抽象类虽然无法实例化,但是抽象类有构造方法,这个构造方法提供子类使用的。
8.抽象类关联到一个概念,抽象方法,什么是抽象方法呢?
抽象方法标识没有实现的方法,没有方法体的方法。例如:
public abstract void dosome();
9.抽象方法的类必须是抽象类,抽象类的方法不一定要是抽象方法。
抽象方法的特点是:特点1:没有方法体,以分号结尾。特点2:前面修饰符列表中有abstract关键字
10.抽象类中不一定有抽象方法,但抽象方法必须出现在抽象类中
11.非抽象方法集成抽象类,必须重写抽象类里的方法,如果是抽象类继承抽象类,那么就不一定要重写父类的方法
public abstract class AbstractTest extends AbstractChildTest{
/**
* 类到对象是实例化。对象到类是抽象
*
*/
public static void main(String[] args) {
}
@Override
void Bird() {
}
}
abstract class AbstractChildTest{
//子类继承抽象类
abstract void Bird();
}链接:https://juejin.cn/post/7144369395916079141
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
检测zip文件完整(进阶:APK文件渠道号)
朋友聊天讨论到一个问题,怎么检测zip的完整性。zip是我们常用的压缩格式,不管是Win/Mac/Linux下都很常用,我们做文件的下载也会经常用到,网络充满不确定性,对于多个小文件(比如配置文件)的下载,我们希望只发起一次连接,因为建立连接是很耗费资源的,即使现在http2.0可以对一条TCP连接进行复用,我们还是希望网络请求的次数越少越好,不管是对于稳定性还是成功失败的逻辑判断,都会有益处。
这个时候我们常用的其实就是把他们压缩成一个zip文件,下载下来之后解压就好了。
但很多时候zip会解压失败,如果我们的zip已经下载下来了,其实不存在没有访问权限的问题了,那原因除了空间不够之外,就是zip格式有问题了,zip文件为空或者只下载了一半。
这个时候就需要检测一下我们下载下来的zip是不是合法有效的zip了。
有这么几种思路:
- 直接解压,抛异常表明zip有问题
- 下载前得到zip文件的length,下载后检测文件大小
- 使用md5或sha1等摘要算法,下载下来后做md5,然后比对合法性
- 检测zip文件结尾的特殊编码格式,检测是否zip合法
这几种做法有利有弊,这里我们只看第4种。
我们讨论之前,可以大致了解一下zip的格式ZIP文件格式分析,我们关注的是End of central directory record,核心目录结束标记,每个zip只会出现一次。
| Offset | Bytes | Description | 译 |
|---|---|---|---|
| 0 | 4 | End of central directory signature = 0x06054b50 | 核心目录结束标记(0x06054b50) |
| 4 | 2 | Number of this disk | 当前磁盘编号 |
| 6 | 2 | number of the disk with the start of the central directory | 核心目录开始位置的磁盘编号 |
| 8 | 2 | total number of entries in the central directory on this disk | 该磁盘上所记录的核心目录数量 |
| 10 | 2 | total number of entries in the central directory | 核心目录结构总数 |
| 12 | 4 | Size of central directory (bytes) | 核心目录的大小 |
| 16 | 4 | offset of start of central directory with respect to the starting disk number | 核心目录开始位置相对于archive开始的位移 |
| 20 | 2 | .ZIP file comment length(n) | 注释长度 |
| 22 | n | .ZIP Comment | 注释内容 |
我们可以看到,0x06054b50所在的位置其实是在zip.length减去22个字节,所以我们只需要seek到需要的位置,然后读4个字节看是否是0x06054b50,就可以确定zip是否完整。
下面是一个判断的代码
//没有zip文件注释时候的目录结束符的偏移量
private static final int RawEndOffset = 22;
//0x06054b50占4个字节
private static final int endOfDirLength = 4;
//目录结束标识0x06054b50 的小端读取方式。
private static final byte[] endOfDir = new byte[]{0x50, 0x4B, 0x05, 0x06};
private boolean isZipFile(File file) throws IOException {
if (file.exists() && file.isFile()) {
if (file.length() <= RawEndOffset + endOfDirLength) {
return false;
}
long fileLength = file.length();
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rw");
//seek到结束标记所在的位置
randomAccessFile.seek(fileLength - RawEndOffset);
byte[] end = new byte[endOfDirLength];
//读取4个字节
randomAccessFile.read(end);
//关掉文件
randomAccessFile.close();
return isEndOfDir(end);
} else {
return false;
}
}
/**
* 是否符合文件夹结束标记
*/
private boolean isEndOfDir(byte[] src) {
if (src.length != endOfDirLength) {
return false;
}
for (int i = 0; i < src.length; i++) {
if (src[i] != endOfDir[i]) {
return false;
}
}
return true;
}
有人可能注意到了,你上面写的结束标识明明是0x06054b50,为什么检测的时候是反着写的。这里就涉及到一个大端小端的问题,录音的时候也能会遇到大小端顺序的问题,反过来读就好了。
涉及到二进制的查看和编辑,我们可以使用010editor这个软件来查看文件的十六进制或者二进制,并且可以手动修改某个位置的二进制。
他的界面大致长这样子,小端显示的,我们可以看到我们要得到的06 05 4b 50,
我们看上面的表格里面最后一个表格里的 .ZIP file comment length(n) 和 .ZIP Comment ,意思是描述长度是两个字节,描述长度是n,表示这个长度是可变的。这个有啥作用呢?
其实就是给了一个可以写额外的描述数据的地方(.ZIP Comment),他的长度由前面的.ZIP file comment length(n)来控制。也就是zip允许你在它的文件结尾后面额外的追加内容,而不会影响前面的数据。描述文件的长度是两个字节,也就是一个short的长度,所以理论上可以寻址2^16^个位置。
举个例子:
修改之前:
修改之后
看上面两个文件,修改之前长度为0,我们把它改成2(注意大小端),我们改成2,然后随便在后面追加两个byte,保存,打开修改之后的zip,发现是可以正常运行的,甚至我们可以在长度是2的基础上追加多个byte,其实还是可以打开的。
所以回到标题内容,其实apk就是zip,我们同样可以在apk的Comment后面追加内容,比如可以当做渠道来源,或者完成这样的需求:h5网页A上下载的需要打开某个ActivityA,h5网页B上下载的需要打开某个ActivityB。
原理还是上面的原理,写入渠道或者配置,读取apk渠道或者配置,做相应统计或者操作。
//magic -> yocn
private static final byte[] MAGIC = new byte[]{0x79, 0x6F, 0x63, 0x6E};
//没有zip文件注释时候的目录结束符的偏移量
private static final int RawEndOffset = 22;
//0x06054b50占4个字节
private static final int endOfDirLength = 4;
//目录结束标识0x06054b50 的小端读取方式。
private static final byte[] endOfDir = new byte[]{0x50, 0x4B, 0x05, 0x06};
//注释长度占两个字节,所以理论上可以支持 2^16 个字节。
private static final int commentLengthBytes = 2;
//注释长度
private static final int commentLength = 8;
private boolean isZipFile(File file) throws IOException {
if (file.exists() && file.isFile()) {
if (file.length() <= RawEndOffset + endOfDirLength) {
return false;
}
long fileLength = file.length();
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r");
//seek到结束标记所在的位置
randomAccessFile.seek(fileLength - RawEndOffset);
byte[] end = new byte[endOfDirLength];
//读取4个字节
randomAccessFile.read(end);
//关掉文件
randomAccessFile.close();
return isEndOfDir(end);
} else {
return false;
}
}
/**
* 是否符合文件夹结束标记
*/
private boolean isEndOfDir(byte[] src) {
if (src.length != endOfDirLength) {
return false;
}
for (int i = 0; i < src.length; i++) {
if (src[i] != endOfDir[i]) {
return false;
}
}
return true;
}
/**
* zip(apk)尾追加渠道信息
*/
private void write2Zip(File file, String channelInfo) throws IOException {
if (isZipFile(file)) {
long fileLength = file.length();
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "rw");
//seek到结束标记所在的位置
randomAccessFile.seek(fileLength - commentLengthBytes);
byte[] lengthBytes = new byte[2];
lengthBytes[0] = commentLength;
lengthBytes[1] = 0;
randomAccessFile.write(lengthBytes);
randomAccessFile.write(getChannel(channelInfo));
randomAccessFile.close();
}
}
/**
* 获取zip(apk)文件结尾
*
* @param file 目标哦文件
*/
private String getZipTail(File file) throws IOException {
long fileLength = file.length();
RandomAccessFile randomAccessFile = new RandomAccessFile(file, "r");
//seek到magic的位置
randomAccessFile.seek(fileLength - MAGIC.length);
byte[] magicBytes = new byte[MAGIC.length];
//读取magic
randomAccessFile.read(magicBytes);
//如果不是magic结尾,返回空
if (!isMagicEnd(magicBytes)) return "";
//seek到读到信息的offest
randomAccessFile.seek(fileLength - commentLength);
byte[] lengthBytes = new byte[commentLength];
//读取渠道
randomAccessFile.read(lengthBytes);
randomAccessFile.close();
char[] lengthChars = new char[commentLength];
for (int i = 0; i < commentLength; i++) {
lengthChars[i] = (char) lengthBytes[i];
}
return String.valueOf(lengthChars);
}
/**
* 是否以魔数结尾
*
* @param end 检测的byte数组
* @return 是否结尾
*/
private boolean isMagicEnd(byte[] end) {
for (int i = 0; i < end.length; i++) {
if (MAGIC[i] != end[i]) {
return false;
}
}
return true;
}
/**
* 生成渠道byte数组
*/
private byte[] getChannel(String s) {
byte[] src = s.getBytes();
byte[] channelBytes = new byte[commentLength];
System.arraycopy(src, 0, channelBytes, 0, commentLength);
return channelBytes;
}
//读取源apk的路径
public static String getSourceApkPath(Context context, String packageName) {
if (TextUtils.isEmpty(packageName))
return null;
try {
ApplicationInfo appInfo = context.getPackageManager().getApplicationInfo(packageName, 0);
return appInfo.sourceDir;
} catch (PackageManager.NameNotFoundException e) {
e.printStackTrace();
}
return null;
}
这里使用了一个魔数的概念,表明是否是写入了我们特定的渠道,只有写了我们特定渠道的基础上才会去读取,防止读到了没有写过的文件。
读取渠道的时候首先获取安装包的绝对路径。Android系统在用户安装app时,会把用户安装的apk拷贝一份到/data/apk/路径下,通过getSourceApkPath 可以获取该apk的绝对路径。如果使用rw可能会有权限问题,所以读取的时候只使用r就可以了。
参考:
ZIP文件格式分析
全民K歌增量升级方案
链接:https://juejin.cn/post/7220985690795933756
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
由浅入深,详解 Lifecycle 生命周期组件的那些事
Hi , 你好 :)
引言
在2022的今天,AndroidX 普遍的情况下,JetPack Lifecycle 也早已经成为了开发中的基础设施,小到 View(扩展库) ,大到 Activity,都隐藏着它的身影,而了解 Lifecycle 也正是理解 JetPack 组件系列库生命感知设计的基础。
本篇定位中级,将从背景到源码实现,从而理解其背后的设计思想。
导航
看完本篇,你将会搞清以下问题:
Lifecycle的前世今生;Lifecycle可以干什么;Lifecycle源码解析;
背景
在开始前,我们先聊聊关于 Lifecycle 的前世今生,从而便于我们更好的理解 Lifecycle 存在的意义。
洪荒之时
在 Lifecycle 之前(不排除现在😂),如果我们要在某个生命周期去执行一些操作时,经常会在Act或者Fragment写很多模版代码,如下两个示例:
- 比如,有一个定时器,我们需要在
Activity关闭时将其关闭,从而避免因此导致的内存问题,所以我们自然会在onDestory()中去stop一下。这些事看起来似乎不麻烦,但如果是一个重复多处使用的代码,细心的开发者会将其单独抽离成为一个 case ,从而通过组合的方式降低我们主类中的逻辑,但不可避免我们依然还要存在好多模版代码,因为每次都需要onStop()清理或者其他操作(除非写到base,但不可接受☹️)。
📌 如果能不需要开发者自己手动,该有多好?
- 在老版本的友盟中,我们经常甚至需要在基类的
Activity中复写onResume()、onPause()等方法,这些事情说麻烦也不麻烦,但总是感觉很不舒服。不过,有经验的开发者肯定会想喷,为什么一个三方库,你就自己不会通过application.registerActivityLifecycleCallbacks监听吗🤌🏼。
📌 注意,Application有监听全局Act生命周期的方法,Act也有这个方法。🤖
盘古开天
在 JetPack 之前,Android 一直秉承着传统的 MVC 架构,即 xml 作为 View, Activity 作为 Control ,Model 层由数据模型或者仓库而定。虽然说官方曾经有一个MVP的示例,但真正用的人并不多。再加上官方一直也没推荐过 Android 的架构指南,这就导致传统的Android开发方式和系统的碎片化一样☹️,五花八门。随着时间的推移,眼看前端的MVVM已愈加成熟,后有Flutter,再加上开发者的需求等背景下,Google于2017年发布了新的开发架构: AAC,全名 Architecture,并且伴随着一系列相关组件,从而帮助开发者提高开发体验,降低错误概率,减少模版代码。
而本篇的主题 Lifecycle 正是其中作为基础设施的存在,在 sdk26 之后,更是被写入了基础库中。
那Lifecycle到底是干什么的呢?
Lifecycle做的事情很简单,其就是用于检测组件(Fragment、Act) 的生命周期,从而不必强依赖于Activity与Fragment,帮助开发者降低模版代码。
常见用法
在官网中,对于 Lifecycle 的生命周期感知的整个流程如下所示:
Api介绍
相关字段
Event
生命周期事件,对应具体的生命周期:
ON_CREATE,ON_START,ON_RESUME,ON_PAUSE,ON_STOP,ON_DESTROY,ON_ANY
State
生命周期状态节点,与 Event 紧密关联,Event 是这些结点的具体边界,换句话说,State 代表了这一时刻的具体状态,其相当于一个范围集,在这个范围里,都是这个状态。而Event代表这一状态集里面触发的具体事件是什么。
INITIALIZED构造函数初始化时,且未收到 `onCreate()` 事件时的状态;
CREATED在 `onCreate()` 调用之后,`onStop()` 调用之前的状态;
STARTED在 `onStart()` 调用之后,`onPause()` 调用之前的状态;
RESUMED
在 `onResume()` 调用时的状态;
`DESTROYED`
`onDestory()` 调用时的状态;
相关接口
LifecycleObserver
基础
Lifecycler实现接口,一般调用不到,可用于自定义的组件,从而避免在Act或者Fragment中的模版代码,例如ViewTreeLifecyleOwner;
LifecycleEventObserver
可以接受所有生命周期变化的接口;
FullLifecycleObserver
用于监听生命周期变化的接口,提供了
onCreate()、onStart()、onPause()、onStop()、onDestory()、onAny();
DefaultLifecycleObserver
FullLifecycleObserver的默认实现版本,相比前者,增加了默认null实现;
举个栗子
如下所示,通过实现 DefaultLifecycleObserver 接口,我们可以在中重写我们想要监听的生命周期方法,从而将业务代码从主类中拆离出来,且更便于复用。最后在相关类中直接使用 lifecycle.addObserver() 方法添加实例即可,这也是google推荐的用法。
上述示例中,我们使用了
viewLifecycle,而不是lifecycle,这里顺便提一下。
见名之意,前者是视图(view)生命周期,后者则是非视图的生命周期,具体区别如下:
viewLifecycle只会在 onCreateView-onDestroyView 之间有效。
lifecycle则是代表 Fragment 的生命周期,在视图未创建时,onCreate(),onDestory()时也会被调用到。
或者你有某个自定义View,想感知Fragment或者Act的生命周期,从而做一些事情,比如Banner组件等,与上面示例类似:
当然你也可以选择依赖:androidx.lifecycle:lifecycle-runtime 扩展库。
从而使用
view.findViewTreeLifecycleOwner()的扩展函数获得一个LifecycleOwner,从而在View内部自行监听生命周期,免除在Activity手动添加观察者的模版代码。
lifecycle.addObserver(view)
源码解析
Lifecycle
在官方的解释里,Lifecycle 是一个类,用于存储有关组件(Act或Fragment)声明周期状态新的类,并允许其他对象观察此类。
直接去看 Lifecycle 的源码,其实现方式如下:
总体设计如上所示,比较简单,就是观察者模式的接口模版:
使用者实现
LifecycleObserver接口(),然后调用 addObserver() 添加到观察者列表,取消观察者时调用 rmeoveObserver() 移除掉即可。在相应的生命周期变动时,遍历观察者列表,然后通知实现了LifecycleObserver的实例,从而调用相应的方法。
因为其是一个抽象类,所以我们调用的一般都是它的具体实现类,也就是 LifecycleRegistry ,目前也是其的唯一实现类。
LifecycleRegistry
Lifecycle 的具体实现者,正如其名所示,主要用于管理当前订阅的 观察者对象 ,所以也承担了 Lifecycle 具体的实现逻辑。因为源码较长,所以我们做了一些删减,只需关注主流程即可,伪代码如下:
public class LifecycleRegistry extends Lifecycle {
// 生命周期观察者map,LifecycleObserver是观察者接口,ObserverWithState具体的状态分发的包装类
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap;
// 当前生命周期状态
private State mState = INITIALIZED;
// 持有生命周期的提供商,Activity或者Fragment的弱引用
private final WeakReference<LifecycleOwner> mLifecycleOwner;
// 当前正在添加的观察者数量,默认为0,超过0则认为多线程调用
private int mAddingObserverCounter = 0;
// 是否正在分发事件
private boolean mHandlingEvent = false;
// 是否有新的事件产生
private boolean mNewEventOccurred = false;
// 存储主类的事件state
private ArrayList<State> mParentStates = new ArrayList<>();
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
// 初始化状态,destory or init
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
// 📌 初始化实际分发状态的包装类
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
// 将观察者添加到具体的map中,如果已经存在了则返回之前的,否则创建新的添加到map中
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
// 如果上一步添加成功了,putIfAbsent会返回null
if (previous != null) {
return;
}
// 如果act或者ff被回收了,直接return
LifecycleOwner lifecycleOwner = mLifecycleOwner.get();
if (lifecycleOwner == null) {
return;
}
// 当前添加的观察者数量!=0||正在处理事件
boolean isReentrance = mAddingObserverCounter != 0 || mHandlingEvent;
// 📌 取得观察者当前的状态
State targetState = calculateTargetState(observer);
mAddingObserverCounter++;
// 📌 如果当前观察者状态小于当前生命周期所在状态&&这个观察者已经被存到了观察者列表中
while ((statefulObserver.mState.compareTo(targetState) < 0
&& mObserverMap.contains(observer))) {
// 保存当前的生命周期状态
pushParentState(statefulObserver.mState);
// 返回当前生命周期状态对应的接下来的事件序列
final Event event = Event.upFrom(statefulObserver.mState);
...
// 分发事件
statefulObserver.dispatchEvent(lifecycleOwner, event);
// 移除当前的生命周期状态
popParentState();
// 再次获得当前的状态,以便继续执行
targetState = calculateTargetState(observer);
}
// 处理一遍事件,保证事件同步
if (!isReentrance) {
sync();
}
// 回归默认值
mAddingObserverCounter--;
}
...
static class ObserverWithState {
State mState;
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
// 初始化事件观察者
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
mState = initialState;
}
void dispatchEvent(LifecycleOwner owner, Event event) {
State newState = event.getTargetState();
mState = min(mState, newState);
mLifecycleObserver.onStateChanged(owner, event);
mState = newState;
}
}
...
}
我们重点关注的是 addObserver() 即订阅生命周期变更时的逻辑,具体如下:
- 先初始化当前观察者的状态,默认两种,即
DESTROYED(销毁) 或者INITIALIZED(无效),分别对应onDestory()和onCreate()之前; - 初始化 状态观察者(ObserverWithState) ,内部使用
Lifecycling.lifecycleEventObserver()将我们传递进来的 生命周期观察者(LifecycleObser) 包装为一个 生命周期[事件]观察者LifecycleEventObserver,从而在状态变更时触发事件通知; - 将第二步生成的状态观察者添加到缓存map中,如果之前已经存在,则停止接下来的操作,否则继续初始化;
- 调用
calculateTargetState()获得当前真正的状态。 - 开始事件轮训,如果 当前观察者的状态小于此时真正的状态 && 观察者已经被添加到了缓存列表 中,则获得当前观察者下一个状态,并触发相应的事件通知
dispatchEvent(),然后继续轮训。直到不满足判断条件;
需要注意的是, 关于状态的判断,这里使用了compareTo() ,从而判断当前状态枚举是否小于指定状态。
Activity中的实现
Tips:
写过权限检测库的小伙伴,应该很熟悉,为了避免在 Activity 中手动实现 onActivityRequest() ,从而实现以回调的方式获得权限结果,我们往往会使用一个透明的 Fragment ,从而将模版方法拆离到单独类中,而这种实现方式正是组合的思想。
而 Lifecycle 在 Activity 中的实现正是上述的方式。
如下所示,当我们在 Activity 中调用 lifecycle 对象时,内部实际上是调用了 ComponentActivity.mLifecycleRegistry,具体逻辑如下:
不难发现,在我们的 Activity 初始化时,相应的 LifecycleRegistry 已经被初始化。
在上面我们说过,为了避免对基类的入侵,我们一般会用组合的方式,所以这里的 ReportFragment 正是 Lifecycle 在 Activity 中具体的逻辑承载方,具体逻辑如下:
ReportFragment.injectIfNeededIn
内部会对sdk进行判断,对应着两套流程,对于 sdk>=29 的,通过注册 Activity.registerActivityLifecycleCallbacks() 事件实现监听,对于 sdk<29 的,重写 Fragment 相应的生命周期方法完成。
ReportFragment 具体逻辑如下:
Fragment中的实现
直接去 Fragment.lifecycle 中看一下即可,伪代码如下:
总结如下:lifecycle 实例会在 Fragment 构造函数 中进行初始化,而 mViewLifecycleOwner 会在 performCreateView() 执行时初始化,然后在相应的 performXxx 生命周期执行时,调用相应的 lifecycle.handleLifecycleEvent() 从而完成事件的通知。
总结
Lifecycle 作为 JetPack 的基石,而理解其是我们贯穿相应生命周期的关键所在。
关于生命周期的通知,Lifecycle 并没有采用直接通知的方式,而是采用了 Event(事件) + State(状态) 的设计方式。
- 对于外部生命周期订阅者而言,只需要关注事件
Event的调用;
- 而对于
Lifecycle而言,其内部只关注State,并将生命周期划分为了多个阶段,每个状态又代表了一个事件集,从而对于外部调用者而言,无需拘泥于当前具体的状态是什么。
在具体的实现底层上面:
- 在
Activity中,采用组合的方式而非继承,在 Activity.onCreate() 触发时,初始化了一个透明Fragment,从而将逻辑存于其中。对于sdk>=29的版本,因为Activity本身有监听生命周期的方法,从而直接注册监听器,并在相应的会调用触发生命周期事件更新;对于sdk<29的版本,因为需要兼容旧版本,所以重写了Fragment相应的生命周期方法,从而实现手动触发更新我们的生命周期观察者。
- 在
Fragment中,会在Fragment构造函数中初始化相应的Lifecycle,并重写相应的生命周期方法,从而触发事件通知,实现生命周期观察者的更新。
每当我们调用 addObserver() 添加新的观察者时:
内部都会对我们的观察者进行包装,并将其包装为一个具体的事件观察者
LifecycleEventObserver,以及生成当前的观察者对应的状态实例(内部持有LifecycleEventObserver),并将其保存到 缓存map 中。接着会去对比当前的 观察者的状态 和 lifecycle此时实际状态 ,如果 当前观察者状态<lifecycle对应的状态 ,则触发相应Event的通知,并 更新此观察者对应的状态 ,不断轮训,直到当前观察者状态 >=lifecycle对应状态。
参阅
关于我
我是 Petterp ,一个 Android工程师 ,如果本文对你有所帮助,欢迎点赞支持,你的支持是我持续创作的最大鼓励!
链接:https://juejin.cn/post/7168868230977552421
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
关于 Android App 架构,你可能会被问到的 20 个问题
LiveData 是否已经被弃用?
没有被弃用。在可以预见的未来也没有废弃的计划。
LiveData 可以使用简单的方式获取一个易于观察、状态安全的对象。虽然其缺少一些丰富的操作符,但是对于一些简单的 UI 业务场景已经足够。
Flow 有 LiveData 相同的功能,其包含大量丰富的操作符,可以简单的完成复杂的业务逻辑处理。相应的会增加一定的使用门槛,如果不需要 Flow 的 全部功能,继续使用 LiveData 即可。
更多内容:Migrating from LiveData to Kotlin’s Flow
什么是业务逻辑?为什么将业务逻辑移动到 Data Layer ?
业务逻辑是给 App 带来价值的东西,是一系列决定 App 如何运行的规则集。比如,如果你有一个显示新闻文章的 App,你点击书签按钮,从书签文章到持久的交互,这就是业务逻辑。
将业务逻辑移动到 Data Layer 的主要原因是提供单一信源,App 的不同页面和不同逻辑使用到这部分数据将从同一个地方进行获取,方便统一管理;其次是分离职责,将不同的处理逻辑(控制UI的与操作数据)分散在不同的层级中,可以减少各自交互的复杂度。
如何在 ViewModel 中获取系统资源(字符串、颜色等)?
访问资源只应该放在 UI 层,如 View 或者是 Compose。 可以在 ViewModel 中提供资源 ID,但是不应该直接在 ViewModel 中直接访问资源。除了单一职责之外,就是可以响应手机配置的变化:
- 切换语言的时候,会变成对应的语种字符串;
- 切换亮暗模式的时候,对应的颜色会随之变化;
另外就是 Context 的上下文与 ViewModel 的生命周期不一致,可能会导致内存泄漏。
如何让 Service 与 Compose/ViewModel 进行交互?
他们不应该直接进行交互或者说是互相引用。
应该采用单一信源的方式定义一个 Repository,在 Service/ViewModel 中调用 Repository 中的方法来更改状态,UI(Views/Compose) 层通过数据流的方式监听数据变化。
可以确定的是,在 ViewModel 中应尽可能少的依赖 Android 系统组件,如 Service、Activity 等。
未来平稳过度到 KMM/KMP 的最佳实践有哪些?
通常最佳实践会随着时间的推移而建立起来的。对于未来如果 KMM/KMP ,并不需要做过多的事情,遵循架构指南即可。比如:将数据的操作放在 Data Layer,在此层尽量少的调用系统 API。但是目前并需要定义跨端的接口定义,因为 KMM/KMP 还是比较新的技术,在他被大规模使用之前还有不少变数。
ViewModel 被建议当做 State Holders 之后,其在 MVVM 中的职责?
ViewModel 在 MVVM 中就是一个状态持有者。在不同的语义场景下可能有不同的含义。如果是整个页面中的 View(不论是 Activity 还是 Compose 中的目的地),其对应的是 AAC 中的 ViewModel 类。如果是普通的自定义 View 或是 Compose 中的一个可组合函数,那么 View 的状态持有者定义成一个普通的类就可以。这里可以类比下 RecycleView 中的 ViewHolder 设计。
所以这是根据 UI 的范围所决定的,整个页面对应的就是 ViewModel,局部页面对应的就是普通的类。
ViewModel 可以当做是一种特殊的状态管理器,他可以持有普通的 State Holders。
架构指南中的层级对模块化开发有什么建议么?
官方正在研究模块化的架构指南,希望今年能够完成。
应该在 DataSource/Repostory/UseCase 中使用 Flow 么?
可以,但是应该在合适的地方使用 Flow。如果是提供一个一次性的数据(比如从云端接口返回的一个数据),使用 suspend 函数是比较合适的。如果是从 Room 或者是其他类似的数据源中提供可以变化的数据流时,应该使用 Flow。
在 Repository 中会合并多个数据源的数据,这些数据可能会会随时间的变化而变化,因此需要使用 Flow。
什么时候应该使用 UseCase ?
UseCase 主要是为了解决以下两个问题:
- 封装复杂的业务逻辑,避免出现大型的
ViewModel类; - 封装多
ViewModel通用的业务逻辑,避免代码重复;
满足上述两个条件的任何一个都可以使用 UseCase。除此之外,使用 UseCase 之后可以 ViewModel 就不必依赖 Repository,而是在构造函数中直接使用 UseCase,这样在构造函数中就可以知道 ViewModel 中做了哪些事情。
在 Repository 中传递多个 Suspend 函数是反模式的么?
并不是,如果只是进行一次性的操作应该使用 suspend 函数。否则的话应该使用 Flow。
ViewModel 中如何处理页面跳转?
这部分内容在 UI Layer 中有提到,我们把他称之为 UI Event 之类的东西。不管是 UI 事件还是构建 UI 的数据都应该放在 UiState 中,一旦 UI 层监听到对应的事件,进行响应的跳转即可。
具体取决于采用何种方式建模,比如你可以把他定义为一个 Boolean 值,在 ViewModel 中更新对应的 UiState,UI 层就可以根据对应的事件跳转到对应的页面中了。
以用户登录为例,用户登录成功之后需要进入到主页面。这其实是一种状态的变化,从未登录变成了已登录,所以只要改变 UiState UI 层就可以处理他。你可能会说这是不是太复杂了?
对一些人来说这可能是一个顿悟时刻,不会把命令视为事件。ViewModel 中的事件整体上来看就是 App 的状态数据,这样 ViewModel 并不是告诉 UI 层应该做什么,而是 UI 层根据 App 的状态去做一些事情,这是思维方式上的转变。
如果根据用户配置定义导航视图?
和上一个问题基本类似,通过设置不同的 UiState 来控制导航到不同的视图。
WorkManager/Service 在架构中的什么位置?
WorkManager/Service 应该作为入口类来调用 Repository 中的 API。这样可以使我们的业务逻辑与 Android 系统的 API 中解放出来,因为 Android 系统 API 的行为逻辑一般是我们不可控的。当然还有另外的好处,比如更容易测试、以及后续有可能迁移到 KMM 。
当然,WorkManager 有其 API 自身的优势,其内部逻辑与节省电量 、WIFI 链接等 Android 平台的优势,可以根据设备自身的状态进行一次性或者周期性的任务。当然,如果是正常的耗时操作(如网络请求)使用简单的协程即可。
为什么有时在 Repository 中使用 IoDispatcher 访问数据库,有时不用?
Room 数据库目前已支持 suspend 函数,其默认会将任务放到后台线程中执行,当然也可以对其进行自定义的配置。当你调用 Room 的一个 suspend 函数的时候,你并不需要关心线程的问题,把这个问题交给 Room 处理即可。这样 Room 的所有操作都会放到 Room 控制的线程中执行,以尽可能的减少因访问同一个文件而导致的互相争夺资源的问题。
不管由于什么原因你无法使用/提供 suspend 函数,Room 不支持将其移动到另一个线程中。这种情况下可以使用 IO 线程或者 IoDispatcher 。通常情况下还是建议使用 suspend 函数或是 Flow。
另外,每个 DataSource 中都建议处理自己的线程问题,所以在 Repository 中并不需要关心 IO 线程的问题。
当我们处理内存敏感数据时,将复杂数据从一个屏幕传输到另一个屏幕的建议方法是什么?
最原始的处理方式可能是使用 Activity 当做两个 Fragment 的中介,在 Activity 中实现 Fragment 中定义接口,当 Fragment 被关联到 Activity 之后就可以调用 Fragment 中相关的逻辑了。当然这种方式已经一去不复返了。
现在可以使用 ViewModel 调用 UseCase 或者是 Repository 来更新数据,另外的 ViewModel 会使用 Flow 的方式接收到数据的变化,然后根据变化做出相应的处理即可。
在 Compose 中应该使用 MVVM 还是 MVI ?
两者没有本质的区别,都是采用单向数据流的方式。MVI 的特点是将 UI 事件封装成枚举方式,统一在一个函数中处理事件。
随着项目的扩展,我应该将 Domain Layer 或者 Data Layer移动到单独的模块吗?
这取决于你是否想进行模块化,但是两者的差异并不大,这里并没有一个明确的答案。 随着项目的扩展建议把 Data Layer 放到单独的 module 中,如果有 Domain Layer 的话,也是建议把他放在单独的模块中。
[!info] 注: 如果是在多仓库的模块架构以及同一数据层可能有不同 UI 实现的场景下建议采用上述方式,如果没有类似需求的话,个人建议通过 Feature (特性)划分模块,这样可以减少不必要的编译耗时,同样的功能也想多内聚。 当然,如果有对外提供 SDK 需求的,也应将 Data Layer 定义在单独的模块中。
将错误从其他层返回到表示层的最佳方法是什么?
指导文档 中的建议的方式是使用协程的异常处理机制将错误传递到展示层(UI Layer)。
对于使用协程或者是 Flow 的方式,建议使用协程的异常处理机制,当然 Folw 中也可以使用 catch 操作符;对于使用 suspend 函数的地方可以使用 try/catch 块。
另外一种 Data Layer 和上层交互的方式就是使用 Kotlin 自带的 Result<T> 类,此类中除了包含正常的数据 T 之外,还包含错误信息。除此之外提供很多好用的 API ,建议使用。
新的架构方式是否适用与非移动端的领域?如平板、Auto 等
在上述的领域上,仍然建议使用 UI Layer、Domain Layer、Data Layer 这种架构方式。这种架构方式主要是用到了关注点分离以及数据驱动的方式,而这两种设计原则对非移动端的应用也是适用的。
多 Activity 还是单 Activity + 多 Fragment ?
Activity 有其自身的一些特定及职责,在以下场景中应该使用 Activity:
- 当前页面需要支持 PIP(画中画)功能时;
- 当 App 有多个入口可以启动时,如在其他 App 中拉起当前 App 中的一个二级页面,这个页面就需要使用 Activity;
简而言之,就是需要在 manifest 文件中 exported 需要被设置为 true 的逻辑都需要使用 Activity 来实现。
除此之外的一些逻辑,通常是 App 内部的一些页面导航,这个时候应该使用 Fragment 来实现。当然,现在我们还有另外一个新的选择,那就是使用 Compose 。
总结
这篇文章中的内容根据 Arch - MAD Skills 中的问答部分,结合自己的理解整理而得,会包含个人观点,更多详细内容可以观看原文。
链接:https://juejin.cn/post/7106518672981622797
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
封装Kotlin协程请求,这一篇就够了
协程(coroutines)的封装
在默认的Kotlin协程环境中,我们需要自定义协程的作用域CoroutineScope,还有负责维护协程的调度等等,有没有方法可以让协程的使用者屏蔽对底层协程的认识,简单就能使用呢?这里带来了一个封装思路。(这里没有考虑生命周期相关的封装,如果需要实际落地可以在deferred里面封装),这里有个背景,比如在java kotlin混合开发的时候,如果java同学不会kotlin,就需要更上一层的抽象了
封装前例子
假如我们有个一个suspend函数
suspend fun getTest():String{
delay(5000)
return "11"
}
我们要实现的封装是:
1.执行suspend函数,并且使用者对底层无感知,无需了解协程就可以使用,这就要求我们屏蔽CoroutineScope细节
2.自动类型转换,比如返回String我们就应该可以在成功的回调中自动转型为String
3.成功的回调,失败的回调等
4.要不,来个DSL风格
//
async{
// 请求
getTest()
}.await(onSuccess = {
//成功时回调,并且具有返回的类型
Log.i("print",it)
},onError = {
},onComplete = {
})
可以看到,编译时就已经将it变为我们想要的类型了!
我们最终想要实现上面这种方式
封装开始
思路:我们自动对请求进行线程切换,使用Dispatchers即可,还有就是我们需要有监听的回调和DSL写法,所以就可以考虑用协程的async方式发起一个请求,返回值是Deferred类型,我们就可以使用扩展函数实现.await的形式!如果熟悉flutter的同学看的话,是不是很像我们的dio请求方式呢!下面是代码,可以根据更细节的需求进行补充噢:
fun <T> async(loader:suspend () ->T): Deferred<T> {
val deferred = CoroutineScope(Dispatchers.IO).async {
loader.invoke()
}
return deferred
}
fun <T> Deferred<T>.await(onSuccess:(T)->Unit,onError:(e:Exception)->Unit,onComplete:(()->Unit)?=null){
CoroutineScope(Dispatchers.Main).launch {
try{
val result = this@await.await()
onSuccess(result)
}catch (e:Exception){
onError(e)
}
finally {
onComplete?.invoke()
}
}
}
总结
是不是非常好玩呢!我们实现了一个dio风格的请求,对于开发者来说,只需定义suspend修饰的函数,就可以无缝使用我们的请求框架!
链接:https://juejin.cn/post/7100856445905666079
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我尝试以最简单的方式帮你梳理 Lifecycle
前言
我们都知道 Activity 与 Fragment 都是有生命周期的,例如:onCreate()、onStop() 这些回调方法就代表着其生命周期状态。我们开发者所做的一些操作都应该合理的控制在生命周期内,比如:当我们在某个 Activity 中注册了广播接收器,那么在其 onDestory() 前要记得注销掉,避免出现内存泄漏。
生命周期的存在,帮助我们更加方便地管理这些任务。但是,在日常开发中光凭 Activity 与 Fragment 可不够,我们通常还会使用一些组件来帮助我们实现需求,而这些组件就不像 Activity 与 Fragment 一样可以很方便地感知到生命周期了。
假设当前有这么一个需求:
开发一个简易的视频播放器组件以供项目使用,要求在进入页面后注册播放器并加载资源,一旦播放器所处的页面不可见或者不位于前台时就暂停播放,等到页面可见或者又恢复到前台时再继续播放,最后在页面销毁时则注销掉播放器。
试想一下:如果现在让你来实现该需求?你会怎么去实现呢?
实现这样的需求,我们的播放器组件就需要获取到所处页面的生命周期状态,在 onCreate() 中进行注册,onResume() 开始播放,onStop() 暂停播放,onDestroy() 注销播放器。
最简单的方法:提供方法,暴露给使用方,供其自己调用控制。
class VideoPlayerComponent(private val context: Context) {
/**
* 注册,加载资源
*/
fun register() {
loadResource(context)
}
/**
* 注销,释放资源
*/
fun unRegister() {
releaseResource()
}
/**
* 开始播放当前视频资源
*/
fun startPlay() {
startPlayVideo()
}
/**
* 暂停播放
*/
fun stopPlay() {
stopPlayVideo()
}
}
然后,我们的使用方MainActivity自己,主动在其相对应的生命周期状态进行控制调用相对应的方法。
class MainActivity : AppCompatActivity() {
private lateinit var videoPlayerComponent: VideoPlayerComponent
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
videoPlayerComponent = VideoPlayerComponent(this)
videoPlayerComponent.register(this)
}
override fun onResume() {
super.onResume()
videoPlayerComponent.startPlay()
}
override fun onPause() {
super.onPause()
videoPlayerComponent.stopPlay()
}
override fun onDestroy() {
videoPlayerComponent.unRegister()
super.onDestroy()
}
}
虽然实现了需求,但显然这不是最优雅的实现方式。一旦使用方忘记在 onDestroy() 进行注销播放器,就容易造成内存泄漏,而忘记注销显然是一件很容易发生的事情😂 。
回想初衷,之所以将方法暴露给使用方来调用,就是因为我们的组件自身无法感知到使用者的生命周期。所以,一旦我们的组件自身可以感知到使用者的生命周期状态的话,我们就不需要将这些方法暴露出去了。
那么问题来了,组件如何才能感知到生命周期呢?
答:Lifecycle !
直接上案例,借助 Lifecycle 我们改进一下我们的播放器组件👇
class VideoPlayerComponent(private val context: Context) : DefaultLifecycleObserver {
override fun onCreate(owner: LifecycleOwner) {
super.onCreate(owner)
register(context)
}
override fun onResume(owner: LifecycleOwner) {
super.onResume(owner)
startPlay()
}
override fun onPause(owner: LifecycleOwner) {
super.onPause(owner)
stopPlay()
}
override fun onDestroy(owner: LifecycleOwner) {
super.onDestroy(owner)
unRegister()
}
/**
* 注册,加载资源
*/
private fun register(context: Context) {
loadResource(context)
}
/**
* 注销,释放资源
*/
private fun unRegister() {
releaseResource()
}
/**
* 开始播放当前视频资源
*/
private fun startPlay() {
startPlayVideo()
}
/**
* 暂停播放
*/
private fun stopPlay() {
stopPlayVideo()
}
}
改进完成后,我们的调用方MainActivity只需要一行代码即可。
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
lifecycle.addObserver(VideoPlayerComponent(this))
}
}
这样是不是就优雅多了。
那这 Lifecycle 又是怎么感知到生命周期的呢?让我们这就带着问题,出发探一探它的实现方式与源码!
如果让你来做,你会怎么做
在查看源码前,让我们试着思考一下,如果让你来实现 Jetpack Lifecycle 这样的功能,你会怎么做呢?该从何入手呢?
我们的目的是不通过回调方法即可获取到生命周期,这其实就是解耦,实现解耦的一种很好方法就是利用观察者模式。
利用观察者模式,我们就可以这么设计👇
被观察者对象就是生命周期,而观察者对象则是需要知晓生命周期的对象,例如:我们的三方组件。
接着我们就具体探探源码,看一看Google是如何实现的吧。
Google 实现方式
Lifecycle
一个代表着Android生命周期的抽象类,也就是我们的抽象被观察者对象。
public abstract class Lifecycle {
public abstract void addObserver(@NonNull LifecycleObserver observer);
public abstract void removeObserver(@NonNull LifecycleObserver observer);
public enum Event {
ON_CREATE,
ON_START,
ON_RESUME,
ON_PAUSE,
ON_STOP,
ON_DESTROY,
ON_ANY;
}
public enum State {
DESTROYED,
INITIALIZED,
CREATED,
STARTED,
RESUMED;
}
}
内包含 State 与 Event 分别者代表生命周期的状态与事件,同时定义了抽象方法 addObserver(LifecycleObserver) 与removeObserver(LifecycleObserver) 方法用于添加与删除生命周期观察者。
Event 很好理解,就像是 Activity | Fragment 的 onCreate()、onDestroy()等回调方法,它代表着生命周期的事件。
那这 State 又是什么呢?何为状态?他们之间又是什么关系呢?
Event 与 State 之间的关系
关于 Event 与 State 之间的关系,Google官方给出了这么一张两者关系图👇
乍一看,可能第一感觉不是那么直观,我整理了一下👇
INITIALIZED:在ON_CREATE事件触发前。CREATED:在ON_CREATE事件触发后以及ON_START事件触发前;或者在ON_STOP事件触发后以及ON_DESTROY事件触发前。STARTED:在ON_START事件触发后以及ON_RESUME事件触发前;或者在ON_PAUSE事件触发后以及ON_STOP事件触发前。RESUMED:在ON_RESUME事件触发后以及ON_PAUSE事件触发前。DESTROYED:在ON_DESTROY事件触发之后。
Event 代表生命周期发生变化那个瞬间点,而 State 则表示生命周期的一个阶段。这两者结合的好处就是让我们可以更加直观的感受生命周期,从而可以根据当前所处的生命周期状态来做出更加合理操作行为。
例如,在LiveData的生命周期绑定观察者源码中,就会判断当前观察者对象的生命周期状态,如果当前是DESTROYED状态,则直接移除当前观察者对象。同时,根据观察者对象当前的生命周期状态是否 >= STARTED来判断当前观察者对象是否是活跃的。
class LifecycleBoundObserver extends ObserverWrapper implements LifecycleEventObserver {
......
@Override
boolean shouldBeActive() {
//根据观察者对象当前的生命周期状态是否 >= STARTED 来判断当前观察者对象是否是活跃的。
return mOwner.getLifecycle().getCurrentState().isAtLeast(STARTED);
}
@Override
public void onStateChanged(@NonNull LifecycleOwner source,
@NonNull Lifecycle.Event event) {
//根据当前观察者对象的生命周期状态,如果是DESTROYED,直接移除当前观察者
Lifecycle.State currentState = mOwner.getLifecycle().getCurrentState();
if (currentState == DESTROYED) {
removeObserver(mObserver);
return;
}
......
}
......
}
其实 Event 与 State 这两者之间的联系,在我们生活中也是处处可见,例如:自动洗车。
想必现在你对 Event 与 State 之间的关系有了更好的理解了吧。
LifecycleObserver
生命周期观察者,也就是我们的抽象观察者对象。
public interface LifecycleObserver {
}
所以,我们想成为观察生命周期的观察者的话,就需要具体实现该接口,也就是成为具体观察者对象。
换句话说,就是如果你想成为观察者对象来观察生命周期的话,那就必须实现 LifecycleObserver 接口。
例如Google官方提供的 DefaultLifecycleObserver、 LifecycleEventObserver 。
LifecycleOwner
正如其名字一样,生命周期的持有者,所以像我们的 Activity | Fragment 都是生命周期的持有者。
大白话很好理解,但代码应该如何实现呢?
抽象概念 + 具体实现
抽象概念:定义 LifecycleOwner 接口。
public interface LifecycleOwner {
@NonNull
Lifecycle getLifecycle();
}
具体实现:Fragment 实现 LifecycleOwner 接口。
public class Fragment implements ComponentCallbacks, OnCreateContextMenuListener, LifecycleOwner,
ViewModelStoreOwner, HasDefaultViewModelProviderFactory, SavedStateRegistryOwner,
ActivityResultCaller {
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
......
}
具体实现:Activity 实现 LifecycleOwner 接口。
public class ComponentActivity extends androidx.core.app.ComponentActivity implements
ContextAware,
LifecycleOwner,
ViewModelStoreOwner,
HasDefaultViewModelProviderFactory,
SavedStateRegistryOwner,
OnBackPressedDispatcherOwner,
ActivityResultRegistryOwner,
ActivityResultCaller {
@NonNull
@Override
public Lifecycle getLifecycle() {
return mLifecycleRegistry;
}
......
}
这样,Activity | Fragment 就都是生命周期持有者了。
疑问?在上方 Activity | Fragment 的类中,getLifecycle() 方法中都是返回 mLifecycleRegistry,那这个 mLifecycleRegistry 又是什么玩意呢?
LifecycleRegistry
是
Lifecycle的一个具体实现类。
LifecycleRegistry 负责管理生命周期观察者对象,并将最新的生命周期事件与状态及时通知给对应的生命周期观察者对象。
添加与删除观察者对象的具体实现方法。
//用户保存生命周期观察者对象
private FastSafeIterableMap<LifecycleObserver, ObserverWithState> mObserverMap = new FastSafeIterableMap<>();
@Override
public void addObserver(@NonNull LifecycleObserver observer) {
enforceMainThreadIfNeeded("addObserver");
State initialState = mState == DESTROYED ? DESTROYED : INITIALIZED;
//将生命周期观察者对象包装成带生命周期状态的观察者对象
ObserverWithState statefulObserver = new ObserverWithState(observer, initialState);
ObserverWithState previous = mObserverMap.putIfAbsent(observer, statefulObserver);
... 省略代码 ...
}
@Override
public void removeObserver(@NonNull LifecycleObserver observer) {
mObserverMap.remove(observer);
}
可以从上述代码中发现,LifecycleRegistry 还对生命周期观察者对象进行了包装,使其带有生命周期状态。
static class ObserverWithState {
//生命周期状态
State mState;
//生命周期观察者对象
LifecycleEventObserver mLifecycleObserver;
ObserverWithState(LifecycleObserver observer, State initialState) {
//这里确保observer为LifecycleEventObserver类型
mLifecycleObserver = Lifecycling.lifecycleEventObserver(observer);
//并初始化了状态
mState = initialState;
}
//分发事件
void dispatchEvent(LifecycleOwner owner, Event event) {
//根据 Event 得出当前最新的 State 状态
State newState = event.getTargetState();
mState = min(mState, newState);
//触发观察者对象的 onStateChanged() 方法
mLifecycleObserver.onStateChanged(owner, event);
//更新状态
mState = newState;
}
}
将最新的生命周期事件通知给对应的观察者对象。
public void handleLifecycleEvent(@NonNull Lifecycle.Event event) {
... 省略代码 ...
ObserverWithState observer = mObserverMap.entrySet().getValue();
observer.dispatchEvent(lifecycleOwner, event);
... 省略代码 ...
mLifecycleObserver.onStateChanged(owner, event);
}
那 handleLifecycleEvent() 方法在什么时候被调用呢?
相信看到下方这个代码,你就明白了。
public class FragmentActivity extends ComponentActivity {
......
final LifecycleRegistry mFragmentLifecycleRegistry = new LifecycleRegistry(this);
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_CREATE);
}
@Override
protected void onDestroy() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_DESTROY);
}
@Override
protected void onPause() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_PAUSE);
}
@Override
protected void onStop() {
mFragmentLifecycleRegistry.handleLifecycleEvent(Lifecycle.Event.ON_STOP);
}
......
}
在 Activity | Fragment 的 onCreate()、onStart()、onPause()等生命周期方法中,调用LifecycleRegistry 的 handleLifecycleEvent() 方法,从而将生命周期事件通知给观察者对象。
总结
Lifecycle 通过观察者设计模式,将生命周期感知对象与生命周期提供者充分解耦,不再需要通过回调方法来感知生命周期的状态,使代码变得更加的精简。
虽然不通过 Lifecycle,我们的组件也是可以获取到生命周期的,但是 Lifecycle 的意义就是提供了统一的调用接口,让我们的组件可以更加方便的感知到生命周期,方便广达开发者。而且,Google以此推出了更多的生命周期感知型组件,例如:ViewModel、LiveData。正是这些组件,让我们的开发变得越来越简单。
链接:https://juejin.cn/post/7176901382702628924
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我就问Zygote进程,你到底都干了啥
前言
OK,这是Android系统启动的第二篇文章。第二篇我们讲解一个我们一直都在用,但是却很少提起的进程---Zygote。
提到Zygote可能了解一些的小伙伴会说,它是分裂进程用的。没错它最大的作用的确是分裂进程,但是它除了分裂进程外还做了什么呢。
还是老规矩,让我们抱着几个问题来看文章。最后在结尾,再对问题进行思考回复。
- 你能大概描述一遍Zygote的启动流程吗
- 我们为什么可以执行java代码,和zygote有什么关系
- Zygote到底都做了哪些事情
另外,我最近也看了一些写底层的文章。要么就是言简意赅到只知道Zygote的作用,但是完全不知道如何实现的,就像是背作文一样。要么是全篇都是代码,又臭又长,让人完全没有看下去的动力。
不过作为一个读者,太长的我可能完全不想看,太短的又真的完全就是被课文一点都不明白原理。
因此,本篇文章,仍旧会引入一些代码,方便大家通过代码方便记忆。但是又会将代码进行精简,以免给大家造成过度疲劳。我们的目的都是希望用最少的时间,能掌握更多的知识。
读源码时:不要过于纠结细节,不要过于纠结细节,不要过于纠结细节!重要的事情说三遍!!!
OK,让我们进入正题瞅瞅Zygote到底是个什么东西。
1.C++还是Java
选这个当标题当然是有原因的。我们知道的是Android系统启动的时候,运行的是Linux内核,执行的是C++代码。这是一个很有趣的事情。
因为我们在写App的时候,AndroidStudio默认给我们创建的都是Activity.java,而选择的语言,要么是Java要么就是Kotlin。
启动时候运行的是C++代码,应用层却可以使用Java代码,这到底是为什么呢?其实这就是Zygote的功劳之一。
2.Native层
Init进程创建Zygote时,会调用app_main.cpp的main() 方法。此时它依旧运行的是C++代码。我们通过下面的代码,来看下它到底做了什么。
这里它做的最关键的一件事就是启动AndroidRuntime(Android运行时)。另外这里需要注意的是 start方法 中的 "com.android.internal.os.ZygoteInit" 这个类似于全类名。他到底是做什么的?别着急,大概2分钟后,你可能就会得到答案。
Zygote的新手村:app_main.cpp
int main(int argc, char* const argv[])
{
// 创建Android运行时对象
AppRuntime runtime(argv[0], computeArgBlockSize(argc, argv));
// 代码省略...
// 调用AppRuntime.start方法,
// 而AppRuntime是AndroidRuntime的子类,并且没有重写start方法
// 因此调用的是AndroidRuntime的start方法
runtime.start("com.android.internal.os.ZygoteInit", args, zygote);
}
精简后的代码告诉我们,这里一共就做了两件事,第一件创建AppRuntime,第二件调用start方法。
不过,AppRuntime是AndroidRuntime的子类,他没有重写start方法,因此这里调用的是 AndroidRuntime的start() 方法。
奇迹的诞生地:AndroidRuntime:
这里我依旧只保留关键代码,源码关键注释也进行了保留。由下方代码看出这里做了三件改变命运的事情。
- startVM -- 启动Java虚拟机
- startReg -- 注册JNI
- 通过JNI调用Java方法,执行com.android.internal.os.ZygoteInit 的 main 方法
/*
* Start the Android runtime.
*/
void AndroidRuntime::start(const char* className, const Vector<String8>& options, bool zygote)
{
/* start the virtual machine */
JNIEnv* env;
if (startVm(&mJavaVM, &env, zygote, primary_zygote) != 0) {
return;
}
/*
* Register android functions.
*/
if (startReg(env) < 0) {
ALOGE("Unable to register all android natives\n");
return;
}
/*
* Start VM. This thread becomes the main thread of the VM, and will
* not return until the VM exits.
*/
jmethodID startMeth = env->GetStaticMethodID(startClass, "main","([Ljava/lang/String;)V");
env->CallStaticVoidMethod(startClass, startMeth, strArray);
}
有了JVM,注册了JNI,我们就可以执行Java代码了。
这里我个人建议不要过于纠结细节,比如JVM是如何创建的,JNI是如何注册的。如果感兴趣的童鞋,可以下载源码,到app_main.cpp里进行查看。这里就不进行赘述了。否则代码量太大,适得其反。
3.Java层
命运的十字路口:ZygoteInit.java:
之所以说是命运的十字路口,因为Zygote会在这里创建SystemServer,但是二者却走向了截然不同的道路。
从这里就开始执行Java代码了,当然这些Java代码是运行在JVM中的。
让我们通过代码来看一下,到底都做了些什么。
class ZygoteInit{
/**
* This is the entry point for a Zygote process. It creates the Zygote server, loads resources,
* and handles other tasks related to preparing the process for forking into applications.
* This process is started with a nice value of -20 (highest priority).
*/
// 上面是源码中的注释,小伙伴们可以自行翻译一下。
// 创建了ZygoteServer,加载资源,并且介绍了这个进程的优先级是最高的-20.
public static void main(String argv[]) {
ZygoteServer zygoteServer = null;
// 1. 预加载资源,常用的:resource,class,library等在此处进行加载
preload(bootTimingsTraceLog);
// 2. 创建ZygoteServer,实际是一个Socket用来进行跨进程间通信用的。
zygoteServer = new ZygoteServer(isPrimaryZygote);
// 3. fork出SystemServer进程,这个进程会创建AMS,ATMS,WMS,电池服务等一切只有你想不到没有它做不到的服务
forkSystemServer(abiList, zygoteSocketName, zygoteServer);
// 4.里面是一个while(true)循环,等待接收AMS创建进程的消息,类似于handler中的Looper.loop()
zygoteServer.runSelectLoop(abiList);
}
}
上面代码里的注释基本说明了ZygoteInit都干了啥。下面会再稍微总结下:
- 创建了ZygoteServer:这是一个Socket相关的服务,目的是进行跨进程通信。
- 预加载preload:预加载相关的资源。
- 创建SystemServer进程:通过forkSystemServer分裂出了两个进程,一个Zygote进程,一个SystemServer进程。而且由于是分裂的,所以新分裂出来的进程也拥有虚拟机,也能调用JNI,也拥有预加载的资源,也会执行后续的代码。
- 执行runSelectLoop():内部是一个while(true)循环,等待AMS创建新的进程的消息。(想想Looper.loop())
4. 戛然而止
没错就是这么突然,Zygote的故事到这就结束了。至于它是如何创建SystemServer,如何去创建App那就是后面的故事了。所以你还记得我的问题嘛?我替你总结一下Zygote到底做了什么:
- 创建虚拟机
- 注册JNI
- 回调Java方法ZygoteInit.java 的main方法,从这儿开始运行Java代码
- 创建ZygoteServer,内部包含Socket用于跨进程通信
- 预加载class,resource,library等相关资源
- fork 出了 SystemServer进程。他俩除了返回的pid不同,剩下一模一样。通过返回值不同来决定剩下的代码如何运行。这个留待后续进行讲解。
- 进入while(true)循环等待,等待AMS创建进程的消息(类似于Looper.loop())
5. 多说一句
这个系列才刚刚进行到第二章,我尽量让文章不是特别长的情况下,既有代码整理思路,又有总结方便记忆。代码是源码中摘抄的,省略了很大一部分,只能保证执行顺序。有兴趣的小伙伴可以下载源码进行查看。
其实最近我看了很多文章和视频,最后却选择写文章来对知识进行总结。归根结底就是因为一句话,好记性不如烂笔头。要是真的想快速记住,真的需要亲自查看一下源码。翻源码的同时,也是在不知不觉中锻炼你阅读源码的能力。 万一以后让你学习一个新的库,你也知道大概该怎么看。
都已经到这儿了,就稍微厚个脸皮,希望各位看官,能够点个赞,加个关注。毕竟一篇文章可能就要耗费几个小时的时间,上一篇文章就几个赞,感谢这几个小伙伴,让我有继续写下去的动力。 真心感谢你们。
另外,文章中有哪里出错,请及时指出。毕竟各位才是真正的大佬。希望各位Androider,可以一起取暖,度过这个互联网寒冬!加油各位!!!
6. Zygote功能图
链接:https://juejin.cn/post/7172878330323173384
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
模块化时,如何进行模块拆分?
本文内容根据 Android 开发者大会内容整理而得,详见:By Layer or Feature? Why Not Both?! Guide to Android App Modularization
问题
- 随着项目的逐步增多,项目中的类文件如何存放、组织逐步变成一个问题;
- 在模块化的过程中,如何拆分代码或者拆分代码仓库需要一个指导原则;
衡量模块化好坏的标准
衡量模块化好坏主要有三个层面:耦合程度、内聚程度以及模块的颗粒度。耦合是衡量模块相互依赖的程度,内聚衡量单个模块的元素在功能上的相关性,颗粒度是指代码模块化的程度。好的模块应做到以下几点:
- 低耦合:模块不应该了解其他模块的内部工作原理。 这意味着模块应该尽可能地相互独立,以便对一个模块的更改对其他模块的影响为零或最小。
- 高内聚:意味着模块应该仅包含相关性的代码。在一个示例电子书应用程序,将书籍和支付的代码混合在同一个模块中可能是不合适的,因为它们是两个不同的功能领域。
适中颗粒度:代码量与模块数量有恰当的比例,模块太多会产生一定的开销,模块太少达不到复用的效果。
按照层级(Layer)划分
层级是指 Android 官方架构指南中的三层架构,分别为 UI Layer、Domain Layer 和 Data Layer :
在小型项目中按照 Layer 进行分层是可以满足需求的,随着项目的增大,需要将更多功能拆分到更多的模块中,否则就会出现高耦合和低内聚的情况。
按照特性(Feature)划分
若是按照特性划分,每个模块中会包含相似/相同逻辑(如 Reviews),从而导致代码冗余。
模块间的依赖逻辑耦合严重,不利于独立开发。
同时使用分层和特性划分
可以同时结合分层与特性划分的优势,扬长避短。首先按照特性拆分,在拆分后的这个小的逻辑单元中再按照层级来分,这也是壳工程的一个基本思路。
链接:https://juejin.cn/post/7160360502885875742
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin协程:协程上下文与上下文元素
一.EmptyCoroutineContext
EmptyCoroutineContext代表空上下文,由于自身为空,因此get方法的返回值是空的,fold方法直接返回传入的初始值,plus方法也是直接返回传入的context,minusKey方法返回自身,代码如下:
public object EmptyCoroutineContext : CoroutineContext, Serializable {
private const val serialVersionUID: Long = 0
private fun readResolve(): Any = EmptyCoroutineContext
public override fun <E : Element> get(key: Key<E>): E? = null
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = initial
public override fun plus(context: CoroutineContext): CoroutineContext = context
public override fun minusKey(key: Key<*>): CoroutineContext = this
public override fun hashCode(): Int = 0
public override fun toString(): String = "EmptyCoroutineContext"
}
二.CombinedContext
CombinedContext是组合上下文,是存储Element的重要的数据结构。内部存储的组织结构如下图所示:
可以看出CombinedContext是一种左偏(从左向右计算)的列表,这么设计的目的是为了让CoroutineContext中的plus方法工作起来更加自然。
由于采用这种数据结构,CombinedContext类中的很多方法都是通过循环实现的,代码如下:
internal class CombinedContext(
// 数据结构左边可能为一个Element对象或者还是一个CombinedContext对象
private val left: CoroutineContext,
// 数据结构右边只能为一个Element对象
private val element: Element
) : CoroutineContext, Serializable {
override fun <E : Element> get(key: Key<E>): E? {
var cur = this
while (true) {
// 进行get操作,如果当前CombinedContext对象中存在,则返回
cur.element[key]?.let { return it }
// 获取左边的上下文对象
val next = cur.left
// 如果是CombinedContext对象
if (next is CombinedContext) {
// 赋值,继续循环
cur = next
} else { // 如果不是CombinedContext对象
// 进行get操作,返回
return next[key]
}
}
}
// 数据结构左右分开操作,从左到右进行fold运算
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)
public override fun minusKey(key: Key<*>): CoroutineContext {
// 如果右边是指定的Element对象,则返回左边
element[key]?.let { return left }
// 调用左边的minusKey方法
val newLeft = left.minusKey(key)
return when {
// 这种情况,说明左边部分已经是去掉指定的Element对象的,右边也是如此,因此返回当前对象,不需要在进行包裹
newLeft === left -> this
// 这种情况,说明左边部分包含指定的Element对象,因此返回只右边
newLeft === EmptyCoroutineContext -> element
// 这种情况,返回的左边部分是新的,因此需要和右边部分一起包裹后,再返回
else -> CombinedContext(newLeft, element)
}
}
private fun size(): Int {
var cur = this
//左右各一个
var size = 2
while (true) {
cur = cur.left as? CombinedContext ?: return size
size++
}
}
// 通过get方法实现
private fun contains(element: Element): Boolean =
get(element.key) == element
private fun containsAll(context: CombinedContext): Boolean {
var cur = context
// 循环展开每一个CombinedContext对象,每个CombinedContext对象中的Element对象都要包含
while (true) {
if (!contains(cur.element)) return false
val next = cur.left
if (next is CombinedContext) {
cur = next
} else {
return contains(next as Element)
}
}
}
...
}
三.Key与Element
Key接口与Element接口定义在CoroutineContext接口中,代码如下:
public interface Key<E : Element>
public interface Element : CoroutineContext {
// 一个Key对应着一个Element对象
public val key: Key<*>
// 相等则强制转换并返回,否则则返回空
public override operator fun <E : Element> get(key: Key<E>): E? =
@Suppress("UNCHECKED_CAST")
if (this.key == key) this as E else null
// 自身与初始值进行fold操作
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
// 如果要去除的是当前的Element对象,则返回空的上下文,否则返回自身
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
}
四.CoroutineContext
CoroutineContext接口定义了协程上下文的基本行为以及Key和Element接口。同时,重载了"+"操作,相关代码如下:
public interface CoroutineContext {
public operator fun <E : Element> get(key: Key<E>): E?
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
public operator fun plus(context: CoroutineContext): CoroutineContext =
// 如果要与空上下文相加,则直接但会当前对象,
if (context === EmptyCoroutineContext) this else
// 当前Element作为初始值
context.fold(this) { acc, element ->
// acc:已经加完的CoroutineContext对象
// element:当前要加的CoroutineContext对象
// 获取从acc中去掉element后的上下文removed,这步是为了确保添加重复的Element时,移动到最右侧
val removed = acc.minusKey(element.key)
// 去除掉element后为空上下文(说明acc中只有一个Element对象),则返回element
if (removed === EmptyCoroutineContext) element else {
// ContinuationInterceptor代表拦截器,也是一个Element对象
// 下面的操作是为了把拦截器移动到上下文的最右端,为了方便快速获取
// 从removed中获取拦截器
val interceptor = removed[ContinuationInterceptor]
// 若上下文中没有拦截器,则进行累加(包裹成CombinedContext对象),返回
if (interceptor == null) CombinedContext(removed, element) else {
// 若上下文中有拦截器
// 获取上下文中移除到掉拦截器后的上下文left
val left = removed.minusKey(ContinuationInterceptor)
// 若移除到掉拦截器后的上下文为空上下文,说明上下文left中只有一个拦截器,
// 则进行累加(包裹成CombinedContext对象),返回
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
// 否则,现对当前要加的element和left进行累加,然后在和拦截器进行累加
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
public fun minusKey(key: Key<*>): CoroutineContext
... // (Key和Element接口)
}
1.plus方法图解
假设我们有一个上下文顺序为A、B、C,现在要按顺序加上D、C、A。
1)初始值A、B、C
2)加上D
3)加上C
4)加上A
2.为什么要将ContinuationInterceptor放到协程上下文的最右端?
在协程中有大量的场景需要获取ContinuationInterceptor。根据之前分析的CombinedContext的minusKey方法,ContinuationInterceptor放在上下文的最右端,可以直接获取,不需要经过多次的循环。
五.AbstractCoroutineContextKey与AbstractCoroutineContextElement
AbstractCoroutineContextElement实现了Element接口,将Key对象作为构造方法必要的参数。
public abstract class AbstractCoroutineContextElement(public override val key: Key<*>) : Element
AbstractCoroutineContextKey用于实现Element的多态。什么是Element的多态呢?假设类A实现了Element接口,Key为A。类B继承自类A,Key为B。这时将类B的对象添加到上下文中,通过指定不同的Key(A或B),可以得到不同类型对象。具体代码如下:
// baseKey为衍生类的基类的Key
// safeCast用于对基类进行转换
// B为基类,E为衍生类
public abstract class AbstractCoroutineContextKey<B : Element, E : B>(
baseKey: Key<B>,
private val safeCast: (element: Element) -> E?
) : Key<E> {
// 顶置Key,如果baseKey是AbstractCoroutineContextKey,则获取baseKey的顶置Key
private val topmostKey: Key<*> = if (baseKey is AbstractCoroutineContextKey<*, *>) baseKey.topmostKey else baseKey
// 用于类型转换
internal fun tryCast(element: Element): E? = safeCast(element)
// 用于判断当前key是否是指定key的子key
// 逻辑为与当前key相同,或者与当前key的顶置key相同
internal fun isSubKey(key: Key<*>): Boolean = key === this || topmostKey === key
}
1.getPolymorphicElement方法与minusPolymorphicKey方法
如果衍生类使用了AbstractCoroutineContextKey,那么基类在实现Element接口中的get方法时,就需要通过getPolymorphicElement方法,实现minusKey方法时,就需要通过minusPolymorphicKey方法,代码如下:
public fun <E : Element> Element.getPolymorphicElement(key: Key<E>): E? {
// 如果key是AbstractCoroutineContextKey
if (key is AbstractCoroutineContextKey<*, *>) {
// 如果key是当前key的子key,则基类强制转换成衍生类,并返回
@Suppress("UNCHECKED_CAST")
return if (key.isSubKey(this.key)) key.tryCast(this) as? E else null
}
// 如果key不是AbstractCoroutineContextKey
// 如果key相等,则强制转换,并返回
@Suppress("UNCHECKED_CAST")
return if (this.key === key) this as E else null
}public fun Element.minusPolymorphicKey(key: Key<*>): CoroutineContext {
// 如果key是AbstractCoroutineContextKey
if (key is AbstractCoroutineContextKey<*, *>) {
// 如果key是当前key的子key,基类强制转换后不为空,说明当前Element需要去掉,因此返回空上下文,否则返回自身
return if (key.isSubKey(this.key) && key.tryCast(this) != null) EmptyCoroutineContext else this
}
// 如果key不是AbstractCoroutineContextKey
// 如果key相等,说明当前Element需要去掉,因此返回空上下文,否则返回自身
return if (this.key === key) EmptyCoroutineContext else this
}链接:https://juejin.cn/post/7126161787392622623
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose 中嵌套原生 View 原理
Compose 是用于构建原生 Android UI 的现代工具包,他只需要在 xml 布局中添加 ComposeView,或是通过 setContent 扩展函数,即可将 Compose 组件绘制界面中。
Compose 天然就支持被原生 View 嵌套,但也支持嵌套原生 View,Compose 是通过自己的一套重组算法来构建界面,测量和布局已经脱离了原生 View 体系。既然脱离了这套体系,那 Compose 是如何完美支持嵌套原生 View 的呢?脱离了原生 View 布局体系的 Compose,是如何对原生 View 进行测量和布局的呢?
带着疑问我们从示例 demo 开始,然后再翻阅源码.
一、示例
Compose 通过 AndroidView 组件来嵌套原生 View,示例如下:
TimeAssistantTheme {
Surface {
Column {
// Text 为 Compose 组件
Text(text = "hello world")
// AndroidView 为 Compose 组件
AndroidView(factory = {context->
// 原生 ImageView
ImageView(context).apply {
setImageResource(R.mipmap.ic_launcher)
}
})
}
}
}
Compose 完美展现原生 View 效果,接下来,我们需要对 AndroidView 一探究竟。
二、源码分析
1、分析 AndroidView
AndroidView 通过 factory 闭包来拿到我们的 ImageView,我们在探索 AndroidView 源码的时候,只需要观察这个 factory 究竟被谁使用了:
@Composable
fun <T : View> AndroidView(
factory: (Context) -> T,
modifier: Modifier = Modifier,
update: (T) -> Unit = NoOpUpdate
) {
...
ComposeNode<LayoutNode, UiApplier>(
factory = {
//1、创建 ViewFactoryHolder
...
val viewFactoryHolder = ViewFactoryHolder<T>(context, parentReference)
// 2、factory 被赋值给了 ViewFactoryHolder
viewFactoryHolder.factory = factory
...
// 3、从 ViewFactoryHolder 拿到 LayoutNode
viewFactoryHolder.layoutNode
},
...
)
- 创建了个 ViewFactoryHolder
- 将包裹原生 View 的 factory 函数赋值给 ViewFactoryHolder
- 从 ViewFactoryHolder 中拿到 LayoutNode 给 ComposeNode,后面会讲解该操作
大家可能对 ComposeNode 有点陌生,如果你阅读过 Compose 中组件源码的话,例如 Text,在你一直跟踪下去的时候会发现,他们都有一个共同点,那就是都会走到 ComposeNode,并且,ComposeNode 函数中会拿到 factory 的返回值 LayoutNode 来创建一个 Node 节点来参与 Compose 的绘制。也即Compose 在排版和布局的时候,操控的就是 LayoutNode,并且这个 LayoutNode 能拿到 Compose 执行中的一些回调,例如 measure 和 layout 来改变自身的位置和状态。
小结:在 AndroidView 这个函数中我们发现,原生 View 是通过外部包裹一层 Compose 组件参与到 Compose 布局中的
2、分析 ViewFactoryHolder
我们来看下,原生 View 的 factory 函数,在赋值给 ViewFactoryHolder 做了些什么:
@OptIn(ExperimentalComposeUiApi::class)
internal class ViewFactoryHolder<T : View>(
context: Context,
parentContext: CompositionContext? = null
) : AndroidViewHolder(context, parentContext), ViewRootForInspector {
internal var typedView: T? = null
override val viewRoot: View? get() = parent as? View
var factory: ((Context) -> T)? = null
...
set(value) {
// 1、将 factory 复制给幕后字段
field = value
// 2、factory 不为空
->if (value != null) {
// 3、invoke factory 函数,拿到原生 View 本身
typedView = value(context)
// 4、将原生 View 复制给 view
view = typedView
}
}
...
}
在赋值发生时,会触发 ViewFactoryHolder 中 factory 的 set(value),value 就是嵌套原生 view 的 factory 函数
- 将 factory 函数赋值给幕后字段,也即
ViewFactoryHolder.factory = factory - 判断 factory 是否为空,我们提供了原生 ImageView 组件,这里为 true
- 执行 factory 函数,也即拿到我们的 ImageView 组件,赋值给全局变量的 typedView
- 并且也赋值给了 view
我们需要找到原生 ImageView 被谁持有,目前来看的话,typedView 被复制到了全局,没有被其他变量持有,被复赋值的 view 并不在 ViewFactoryHolder 中,那么,我们需要去 ViewFactoryHolder 的父类 AndroidViewHolder 看看了
3、分析 AndroidViewHolder
跟进 view 字段:
@OptIn(ExperimentalComposeUiApi::class)
\internal abstract class AndroidViewHolder(
context: Context,
parentContext: CompositionContext?
// 1、AndroidViewHolder 是一个继承自 ViewGroup 的原生组件
) : ViewGroup(context) {
...
/**
* The view hosted by this holder.
*/
-> var view: View? = null
internal set(value) {
if (value !== field) {
// 2、将 view 赋值给幕后字段
field = value
// 3、移除所有子 View
removeAllViews()
// 4、原生 view 不为空
-> if (value != null) {
// 5、将原生 view 添加到当前的 ViewGroup
addView(value)
// 6、触发更新
runUpdate()
}
}
}
...
}
- 需要注意的是,AndroidViewHolder 是一个继承自 ViewGroup 的原生组件
- 将原生 view 赋值给幕后字段,也即 view 的实体是 ImageView
- 移除所有的子 View,看来,AndroidViewHolder 只支持添加一个原生 View
- 判断原生 view 是否为空,我们提供了 ImageView ,所以该判断为 true
- 将原生 view 添加到当前的 ViewGroup,也即我们的 ImageView 被添加到了 AndroidViewHolder 中
- runUpdate 会触发 Compose 的一系列更新,我们先暂时不管他
小结:我们提供的原生 View,最终会被 addView 到 ViewFactoryHolder 中,只是 addView 这个操作是发生在他的父类 AndroidViewHolder 中的,然后将原生 ImageView 赋值到全局变量 view 中
现在,我们还有一些疑问,原生 view 虽然被 addView 到 ViewFactoryHolder 中了,那 ViewFactoryHolder 这个 ViewGroup 是如何被添加到界面上的呢?ViewFactoryHolder 是如何测量和布局的呢?我们需要回到 AndroidView 的函数中,找到 AndroidView 中的 viewFactoryHolder.layoutNode 进行源码跟进
4、分析 ViewFactoryHolder.layoutNode
layoutNode 字段也在 ViewFactoryHolder 的父类 AndroidViewHolder 中:
val layoutNode: LayoutNode = run {
// 1、一句注释直接讲透
// Prepare layout node that proxies measure and layout passes to the View.
-> val layoutNode = LayoutNode()
...
// 2、注册 attach 回调
layoutNode.onAttach = { owner ->
// 2.1 重点: 将当前 ViewGroup 添加到 AndroidComposeView 中
(owner as? AndroidComposeView)?.addAndroidView(this, layoutNode)
if (viewRemovedOnDetach != null) view = viewRemovedOnDetach
}
// 3、注册 detach 回调
layoutNode.onDetach = { owner ->
// 3.1 重点: 将当前 ViewGroup 从 AndroidComposeView 中移除
(owner as? AndroidComposeView)?.removeAndroidView(this)
viewRemovedOnDetach = view
view = null
}
// 4、注册 measurePolicy 绘制策略回调
layoutNode.measurePolicy = object : MeasurePolicy {
override fun MeasureScope.measure(
measurables: List<Measurable>,
constraints: Constraints
): MeasureResult {
...
// 4.1、layoutNode 的测量,触发 AndroidViewHolder 的测量
measure(
obtainMeasureSpec(constraints.minWidth, constraints.maxWidth,layoutParams!!.width),
obtainMeasureSpec(constraints.minHeight,constraints.maxHeight,layoutParams!!.height)
)
// 4.1、layoutNode 的布局,触发 AndroidViewHolder 的布局
-> return layout(measuredWidth, measuredHeight) {
layoutAccordingTo(layoutNode)
}
}
...
}
// 5、返回 layoutNode
layoutNode
}
这段代码有点多,但却是最精华的核心部分:
- 注释直接道破,这个 LayoutNode 会代理原生 View 的 measure、layout,将测量和布局结果反应到 AndroidViewHolder 这个 ViewGroup 中
- 注册 LayoutNode 的 attach 回调,这个 attach 可以理解成 LayoutNode 被贴到了 Compose 布局中触发的回调,和原生 View 被添加到布局中,触发 onViewAttachedToWindow 类似
- 将当前 AndroidViewHolder 添加到 AndroidComposeView 中
- 注册 LayoutNode 的 detach 回调,这个 detach 可以理解成 LayoutNode 从 Compose 布局中被移除触发的回调,和原生 View 从布局中移除,触发 onViewDetachedFromWindow 类似
- 将当前 ViewGroup 从 AndroidComposeView 中移除
- 注册 LayoutNode 的绘制策略回调,在 LayoutNode 被贴到 Compose 中,Compose 在重组控件的时候,会触发 LayoutNode 的绘制策略
- 触发 ViewGroup 的 measure 测量
- 触发 ViewGroup 的 layout 布局
- 返回 LayoutNode
在 2.1 的 attach 步骤中发现,我们的 ImageView 经过 AndroidViewHolder 的包裹,被 addAndroidView 到了 AndroidComposeView 中,这里我们又有个疑问,owner 转换成的 AndroidComposeView 是从哪来的?addAndroidView 做了哪些事情?
这里先小结下:
AndroidViewHolder 中的 layoutNode 是一个不可见的 Compose 代理节点,他将 Compose 中触发的回调结果应用到 ViewGroup 中,以此来控制 ViewGroup 的绘制与布局
5、分析 AndroidComposeView.addAndroidView
internal class AndroidComposeView(context: Context) :
ViewGroup(context), Owner, ViewRootForTest, PositionCalculator, DefaultLifecycleObserver {
...
internal .val androidViewsHandler: AndroidViewsHandler
get() {
if (_androidViewsHandler == null) {
_androidViewsHandler = AndroidViewsHandler(context)
// 1、将 AndroidViewsHandler addView 到 AndroidComposeView 中
addView(_androidViewsHandler)
}
return _androidViewsHandler!!
}
// Called to inform the owner that a new Android View was attached to the hierarchy.
-> fun addAndroidView(view: AndroidViewHolder, layoutNode: LayoutNode) {
androidViewsHandler.holderToLayoutNode[view] = layoutNode
// 2、AndroidViewHolder 被添加到 AndroidViewsHandler 中
androidViewsHandler.addView(view)
androidViewsHandler.layoutNodeToHolder[layoutNode] = view
...
}
}
- 将 AndroidViewsHandler 添加到 AndroidComposeView 中
- 将 AndroidViewHolder 添加到 AndroidViewsHandler 中
现在 addView 的逻辑已经走到了 AndroidComposeView,我们现在还需要知晓 AndroidComposeView 从何而来
这次,我们需要先从 ComposeView 开始分析:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContent {
AndroidWidget()
}
}
在 Activity 的 onCreate 方法中,我们通过 setContent 将 ComposeView 应用到界面上,我们需要跟踪这个 setContent 拓展函数一探究竟:
public fun ComponentActivity.setContent(
parent: CompositionContext? = null,
content: @Composable () -> Unit
) {
...
if (existingComposeView != null) with(existingComposeView) {
...
// 1、设置 compose 布局
setContent(content)
} else ComposeView(this).apply {
...
// 1、设置 compose 布局
setContent(content)
...
// 2、调用 Activity 的 setContentView 方法,布局为 ComposeView
setContentView(this, DefaultActivityContentLayoutParams)
}
}
- 调用 ComposeView 内部的 setContent 方法,将 compose 布局设置进去
- 调用 Activity 的 setContentView 方法,布局为 ComposeView,这也是 Activity 中没有找到设置 setContentView 的原因,因为拓展函数已经做了这个操作
我们需要跟踪下 ComposeView 的 setContent 方法:
-> fun setContent(content: @Composable () -> Unit)
-> fun createComposition()
-> fun ensureCompositionCreated()
-> internal fun ViewGroup.setContent(
parent: CompositionContext,
content: @Composable () -> Unit
): Composition {
GlobalSnapshotManager.ensureStarted()
val composeView =
// 1、获取 ComposeView 的子 View 是否为 AndroidComposeView
-> if (childCount > 0) {
getChildAt(0) as? AndroidComposeView
} else {
removeAllViews(); null
// 2、如果为空,则创建个 AndroidComposeView,并调用 addView 将 AndroidComposeView 添加进 ComposeView
} ?: AndroidComposeView(context).also { addView(it.view, DefaultLayoutParams) }
return doSetContent(composeView, parent, content)
}
-> private fun doSetContent(
owner: AndroidComposeView,
parent: CompositionContext,
content: @Composable () -> Unit
): Composition {
...
val wrapped = owner.view.getTag(R.id.wrapped_composition_tag)
as? WrappedComposition
// 3、将 AndroidComposeView 设置到 WrappedComposition 中,并返回 Composition
?: WrappedComposition(owner, original).also {
owner.view.setTag(R.id.wrapped_composition_tag, it)
}
wrapped.setContent(content)
return wrapped
}
- 获取 ComposeView 的子 View 是否为 AndroidComposeView
- 如果获取为空,则创建个 AndroidComposeView,并调用 addView 将 AndroidComposeView 添加进 ComposeView
- 将 AndroidComposeView 设置到 WrappedComposition 中,并返回 Composition,这也就是为什么在 LayoutNode 中,能拿到 owner ,并且为 AndroidComposeView 的原因
三、总结
至此,我们分析完了原生 View 是如何添加进 Compose 中的,我们可以画个图来简单总结下:
- 橙色:在 Compose 中嵌套 AndroidView 才会有,如果没有使用,则没有橙色层级
- 黄色: 嵌套的原生 View,此处演示的为示例的 ImageView
- 绿色:Compose 的控件,也即 LayoutNode
然后我们遍历打印一下 view 树,以此来确认我们的跟踪的是否正确
System.out: viewGroup --> android.widget.FrameLayout{47cc49 V.E...... ........ 0,95-1080,2400 #1020002 android:id/content}
System.out: viewGroup --> androidx.compose.ui.platform.ComposeView{134250 V.E...... ........ 0,0-232,257}
System.out: viewGroup --> androidx.compose.ui.platform.AndroidComposeView{8e162e1 VFED..... ........ 0,0-232,257}
System.out: viewGroup --> androidx.compose.ui.platform.AndroidViewsHandler{fbb7614 V.E...... ......ID 0,0-232,257}
System.out: viewGroup --> androidx.compose.ui.viewinterop.ViewFactoryHolder{4b0e4aa V.E...... ......I. 0,59-198,257}
System.out: view --> android.widget.ImageView{8438ebd V.ED..... ........ 0,0-198,198}
现在,我们可以来回答开头说的问题了:
- Compose 是通过 addView 的方式,将原生 View 添加到 AndroidComposeView 中的,他依然使用的是原生布局体系
- 嵌套原生 View 的测量与布局,是通过创建个代理 LayoutNode ,然后添加到 Compose 中参与组合,并将每次重组返回的测量信息设置到原生 View 上,以此来改变原生 View 的位置与大小
链接:https://juejin.cn/post/7100162348069879839
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android推送实践总结
前提条件
这篇文章主要讲集成阿里的EMAS推送过程中的一些坑和接入流程,主要是对接入过程的一个总结(毕竟浪费了我3天时间)。
- 开通了EMAS服务并创建了应用(创建方式)
- 创建了各厂商的应用(国内的厂商必须有,要不然离线状态收不到通知,三星除外(貌似也不算国内厂商-O-))
接入SDK
接入方式官方文档上已写好步骤,这里就不重复赘述了,这里只做个总结。
- 工程的setting.gradle中添加阿里云仓库,代码如下:
pluginManagement {
repositories {
...
maven { url "https://maven.aliyun.com/nexus/content/repositories/releases/" }
}
}
dependencyResolutionManagement {
// repositoriesMode.set(RepositoriesMode.FAIL_ON_PROJECT_REPOS)
repositoriesMode.set(RepositoriesMode.PREFER_SETTINGS)
repositories {
...
maven { url "https://maven.aliyun.com/nexus/content/repositories/releases/" }
maven {url 'https://developer.huawei.com/repo/'}//接入华为推送时需要
}
}
- 工程的build.gradle中添加gradle依赖
buildscript {
dependencies {
...
classpath 'com.aliyun.ams:emas-services:1.0.4'//可以在阿里云仓库查找最新的版本:https://developer.aliyun.com/mvn/search
}
}
在项目app的build.gradle下面添加插件和依赖,并在同级目录下添加配置文件
aliyun-emas-services.json
所有依赖版本均可在阿里云仓库找到最新版本:developer.aliyun.com/mvn/search
plugins {
...
id 'com.aliyun.ams.emas-services'
}
android {
defaultConfig {
...
ndk {
abiFilters 'armeabi', 'armeabi-v7a', 'arm64-v8a', 'x86_64'//你支持的cpu架构
}
}
dependencies {
implementation 'com.alipay.sdk:alipaysdk-android:15.8.12'//阿里云基础依赖
implementation 'com.aliyun.ams:alicloud-android-push:3.8.4.1'//推送依赖
implementation 'com.aliyun.ams:alicloud-android-third-push:3.8.4'//辅助推送依赖使用厂商推送时需要,提高到达率
implementation 'com.aliyun.ams:alicloud-android-third-push-xiaomi:3.8.4'
implementation 'com.aliyun.ams:alicloud-android-third-push-huawei:3.8.4'
implementation 'com.aliyun.ams:alicloud-android-third-push-vivo:3.8.4'
implementation 'com.aliyun.ams:alicloud-android-third-push-oppo:3.8.4'
}
aliyun-emas-services.json中配置信息修改
aliyun-emas-services.json中包含多种服务,对应有status来控制是否启用,1为启用0为不启用,推送服务对应为cps_service,如果只用推送可以只开启这个服务具体可看文档
{
"config": {
"emas.appKey":"*******",
"emas.appSecret":"*******",
"emas.packageName":"*******",
"hotfix.idSecret":"*******",
"hotfix.rsaSecret":"*******",
"httpdns.accountId":"*******",
"httpdns.secretKey":"*******",
"appmonitor.tlog.rsaSecret":"*******",
"appmonitor.rsaSecret":"*******"
},
"services": {
"hotfix_service":{//移动热修复
"status":0,
"version":"3.3.8"
},
"ha-adapter_service":{//性能分析/远程日志基础库
"status":0,
"version":"1.1.5.4-open"
},
"feedback_service":{//移动用户反馈
"status":0,
"version":"3.4.2"
},
"tlog_service":{//远程日志
"status":0,
"version":"1.1.4.5-open"
},
"httpdns_service":{//HTTPDNS
"status":0,
"version":"2.3.0-intl"
},
"apm_service":{//性能分析
"status":0,
"version":"1.1.1.0-open"
},
"man_service":{
"status":1,
"version":"1.2.7"
},
"cps_service":{//移动推送
"status":1,
"version":"3.8.4.1"
}
},
"use_maven":true,//true表示使用远程依赖,false表示使用本地libs依赖
"proguard_keeplist":"********"
}
- 项目app的AndroidManifest.xml文件中配置appkey
...
<uses-permission android:name="android.permission.INTERNET" /> <!-- 网络访问 -->
<uses-permission android:name="android.permission.ACCESS_WIFI_STATE" /> <!-- 检查Wi-Fi网络状态 -->
<uses-permission android:name="android.permission.GET_TASKS" /> <!-- 推送使用,运行状态 -->
<uses-permission android:name="android.permission.REORDER_TASKS" /> <!-- 推送使用,运行状态 -->
<application
android:allowBackup="false"
tools:replace="android:allowBackup">
<meta-data
android:name="com.alibaba.app.appkey"
android:value="阿里云的APPKEY" />
<meta-data
android:name="com.alibaba.app.appsecret"
android:value="阿里云的appsecret" />
<meta-data
android:name="com.huawei.hms.client.appid"
android:value="appid=华为的appid" />
<meta-data
android:name="com.vivo.push.api_key"
android:value="vivo的apikey" />
<meta-data
android:name="com.vivo.push.app_id"
android:value="vivo的appid" />
<receiver
android:name=".push.PushReceiver"//接收通知的广播继成自MessageReceiver,当app为在线状态或走阿里云通道时调用
android:exported="false">
<intent-filter>
<action android:name="com.alibaba.push2.action.NOTIFICATION_OPENED" />
</intent-filter>
<intent-filter>
<action android:name="com.alibaba.push2.action.NOTIFICATION_REMOVED" />
</intent-filter>
<intent-filter>
<action android:name="com.alibaba.sdk.android.push.RECEIVE" />
</intent-filter>
</receiver>
<activity
android:name=".push.PushPopupActivity"//辅助推送Activity继成自AndroidPopupActivity,当走厂商渠道,通知被点击时调用到onSysNoticeOpened()方法中
android:exported="true"
android:label="@string/title_activity_third_push_notice"
android:launchMode="singleInstance"
android:screenOrientation="portrait" >
<!-- scheme 配置开始 vivo通道需要添加 -->
<intent-filter>
<action android:name="android.intent.action.VIEW" />
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE" />
<data
android:host="${applicationId}"
android:path="/thirdpush"
android:scheme="agoo" />
</intent-filter>
<!-- scheme 配置结束 -->
</activity>
初始化SDK
在Application的onCreate()方法中初始化
open class BaseApp : Application() {
override fun onCreate() {
super.onCreate()
PushServiceFactory.init(this)
initNotificationChannel(this)
MiPushRegister.register(this, "小米的appid", "小米的appkey")
HuaWeiRegister.register(this)
VivoRegister.register(this)
OppoRegister.register(this,"oppo的appkey","oppo的appSecret")
val pushService = PushServiceFactory.getCloudPushService()
if (ProjectSwitch.isDebug) {
pushService.setLogLevel(CloudPushService.LOG_DEBUG) //仅适用于Debug包,正式包不需要此行
}
pushService.setNotificationShowInGroup(true)
pushService.register(this, object : CommonCallback {
override fun onSuccess(response: String?) {
}
override fun onFailed(errorCode: String, errorMessage: String) {
}
})
}
private fun initNotificationChannel(context: Context) {
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
val mNotificationManager: NotificationManager? =
context.getSystemService(Context.NOTIFICATION_SERVICE) as NotificationManager?
// 通知渠道的id,后台推送选择渠道时对应的id。
val id = "1"
// 用户可以看到的通知渠道的名字。
val name: CharSequence = "通知渠道的名字"
// 用户可以看到的通知渠道的描述。
val description = "渠道的描述"
val importance: Int = NotificationManager.IMPORTANCE_HIGH
val mChannel = NotificationChannel(id, name, importance)
// 配置通知渠道的属性。
mChannel.setDescription(description)
// 设置通知出现时的闪灯(如果Android设备支持的话)。
mChannel.enableLights(true)
mChannel.setLightColor(Color.RED)
// 设置通知出现时的震动(如果Android设备支持的话)。
mChannel.enableVibration(true)
mChannel.setVibrationPattern(longArrayOf(100, 200, 300, 400, 500, 400, 300, 200, 400))
// 最后在notificationmanager中创建该通知渠道。
mNotificationManager?.createNotificationChannel(mChannel)
}
}
}
各厂商集成步骤
查看官方辅助通道集成文档help.aliyun.com/document_de…
问题处理
完成上面一堆后本以为可以大功告成了吗,no~no~no~,怎么可能这么简单,接下来就是踩坑之旅了。
- Android13对通知做了权限控制,需要显示请求通知权限:developer.android.google.cn/about/versi…
- 各厂商对通知做了限制处理,导致必须申请对应渠道才能正常使用通知:
- 小米推送创建通知类别具体见文档:文档中心 (mi.com)
- 华为默认一天可以推送两条,如需要更多则需要申请自分类权益:消息分类标准(huawei.com)
- vivo默认一天两条,如需更多则需要申请消息分类:vivo开放平台
- oppo默认一天两条,如需更多需要申请消息分类:OPPO 开放平台
链接:https://juejin.cn/post/7220698356775272505
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Bundle源码解析
Bundle源码解析
做一个调用系统分享json的时候遇到一个问题,在用Bundle传递String太大的时候会报错,所以可以计算String的大小,size小的时候传String,size大的时候可以把String存文件然后分享文件。但是问题来了,这个大小的边界在哪儿呢?到底传多大的数据才会报错呢?
我们先看一个报错的错误栈:
Caused by: android.os.TransactionTooLargeException: data parcel size 1049076 bytes
at android.os.BinderProxy.transactNative(Native Method)
at android.os.BinderProxy.transact(Binder.java:1129)
at android.app.IActivityManager$Stub$Proxy.startActivity(IActivityManager.java:3754)
at android.app.Instrumentation.execStartActivity(Instrumentation.java:1671)
at android.app.Activity.startActivityForResult(Activity.java:4586)
at android.app.Activity.startActivityForResult(Activity.java:4544)
at android.app.Activity.startActivity(Activity.java:4905)
at android.app.Activity.startActivity(Activity.java:4873)
跟着各种startActivity追溯上去,BinderProxy#transact方法里面调用transactNative方法,这是个native方法,我们去往androidxref网站查看。追查到/frameworks/base/core/jni/android_util_Binder.cpp里面android_os_BinderProxy_transact方法,最后调用signalExceptionForError(env, obj, err, true /*canThrowRemoteException*/, data->dataSize());方法771行,看到:
发现把parcelSize限制在了200K的大小,当大于200K的时候就会报错。
那到底Bundle扮演了什么角色呢?我们从一个最简单的场景看起:
使用方法
//putExtra
public static void startActivity(Context context) {
Intent intent = new Intent(context, TestActivity.class);
intent.putExtra("KEY", 1);
context.startActivity(intent);
}
//使用getStringExtra获取
String msg = getIntent().getStringExtra(KEY);
几乎是最简单的StartActivity场景,我们分步来看这几句代码都做了什么:
数据的写入 - Intent#putExtra
Intent#putExtra实际上是调用了Bundle#putExtra:
//Intent.java
public @NonNull Intent putExtra(String name, int value) {
if (mExtras == null) {
mExtras = new Bundle();
}
mExtras.putInt(name, value);
return this;
}
//BaseBundle.java
BaseBundle() {
this((ClassLoader) null, 0);
}
BaseBundle(@Nullable ClassLoader loader, int capacity) {
mMap = capacity > 0 ? new ArrayMap<String, Object>(capacity) : new ArrayMap<String, Object>();
//初始化了一个叫mMap的空ArrayMap,同时初始化了一个mClassLoader,用来实例化Bundle里面的对象。
mClassLoader = loader == null ? getClass().getClassLoader() : loader;
}
public void putInt(@Nullable String key, int value) {
unparcel();
mMap.put(key, value);
}
mMap是用来存储我们需要传递的Kay-Value的,在putInt的方法里面调了一个unparcel()方法,然后往mMap里面put了一个value,看起来很简单,其实我们可以看到在所有的putXXX方法里面都是先调用了一个unparcel()再执行了put方法,其实我们可以从名字和逻辑猜出来这个方法是做什么的,其实就是在put之前如果已经有了序列化的数据,需要先反序列化填到eMap里面,再尝试去添加新的数据。
带着这个猜测我们来看unparcel()方法
//BaseBundle.java
void unparcel() {
synchronized (this) {
final Parcel source = mParcelledData;
if (source != null) {//parcelledData不为空的时候会走initializeFromParcelLocked。mParcelledData什么时候赋值呢?在后面初始化的时候能看到。
initializeFromParcelLocked(source, /*recycleParcel=*/ true, mParcelledByNative);
} else {
...
}
}
}
//把data从NativeData中读取出来,save到mMap中。
private void initializeFromParcelLocked(@NonNull Parcel parcelledData, boolean recycleParcel, boolean parcelledByNative) {
...
final int count = parcelledData.readInt();//拿到count,也就是size,是write的时候第一个写入的。
if (count < 0) {
return;
}
ArrayMap<String, Object> map = mMap;
if (map == null) {
map = new ArrayMap<>(count);//根据拿到的count初始化map
} else {
map.erase();
map.ensureCapacity(count);
}
try {
if (parcelledByNative) {
parcelledData.readArrayMapSafelyInternal(map, count, mClassLoader);
} else {
parcelledData.readArrayMapInternal(map, count, mClassLoader);
}
} catch (BadParcelableException e) {
...
} finally {
mMap = map;
if (recycleParcel) {
recycleParcel(parcelledData);
}
mParcelledData = null;
mParcelledByNative = false;
}
}
//Parcel.java
void readArrayMapSafelyInternal(@NonNull ArrayMap outVal, int N, @Nullable ClassLoader loader) {
while (N > 0) {
String key = readString();
Object value = readValue(loader);
outVal.put(key, value);
N--;
}
}
public final Object rea(@Nullable ClassLoader loader) {
int type = readInt();
switch (type) {
...
case VAL_INTEGER:
return readInt();
...
}
public final int readInt() {
return nativeReadInt(mNativePtr);
}
private static native int nativeReadInt(long nativePtr);
调用到native方法里面,我们可以到androidxref网站查看相关源码,下面的代码基于Android 9.0
// /frameworks/base/core/jni/android_os_Parcel.cpp
788 {"nativeReadInt", "(J)I", (void*)android_os_Parcel_readInt},
// /frameworks/base/core/jni/android_os_Parcel.cpp
static jint android_os_Parcel_readInt(jlong nativePtr)
402{
403 Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
404 if (parcel != NULL) {
405 return parcel->readInt32();
406 }
407 return 0;
408}
// /frameworks/native/libs/binder/Parcel.cpp
int32_t Parcel::readInt32() const
1822{
1823 return readAligned<int32_t>();
1824}
// /frameworks/native/libs/binder/Parcel.cpp
template<class T>
T Parcel::readAligned() const {
1606 T result;
1607 if (readAligned(&result) != NO_ERROR) {
1608 result = 0;
1609 }
1610
1611 return result;
1612}
/frameworks/base/core/jni/android_os_Parcel#android_os_Parcel_readInt(jlong nativePtr)
- frameworks/native/libs/binder/Parcel#Parcel::readInt32()
// /frameworks/native/libs/binder/Parcel.cpp
template<class T>
status_t Parcel::readAligned(T *pArg) const {
1583 COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
1584
1585 if ((mDataPos+sizeof(T)) <= mDataSize) {//越界检查
1586 if (mObjectsSize > 0) {
1587 status_t err = validateReadData(mDataPos + sizeof(T));//检测是否可以读取到这么多数据
1588 if(err != NO_ERROR) {
1590 mDataPos += sizeof(T);
1591 return err;
1592 }
1593 }
1594
1595 const void* data = mData+mDataPos;//指针偏移,指向期待的数据地址。
1596 mDataPos += sizeof(T);//数据偏移量增加。
1597 *pArg = *reinterpret_cast<const T*>(data);//指针强转赋值,读取到对应的数据
1598 return NO_ERROR;
1599 } else {
1600 return NOT_ENOUGH_DATA;
1601 }
1602}
最终都是调用到Parcel的方法,根据count循环的读取KEY/VALUE,先读key,再根据value的类型读value,我们可以看到最终都是调用了nativeReadXxx方法去读取对应的值。
Parcel的读取大致是首先我们init的时候会拿到一个native给我们的地址值nativePtr,java拿到这个地址值用一个long存储起来,long是64位的,所以用来存储32/64位的机器的地址就都够用了,相当于java调用native去申请了一块内存,并且java可以随时随地的访问到这块内存地址,再根据偏移量就可以拿到这块内存上存储的内容。
我们知道为了方便读取之类的原因,Native里面都是要做内存对齐的,所以Parcel的存储都是最少为4个字节,So,存储一个byte和一个int都会占用4个字节。
所有的存储和读取都是在native层面进行的,只需要得到偏移量就能够访问,毫无疑问这种处理是高效的。
但是问题就是我们无法得知下一个是Int还是Long,所以需要严格保证顺序,序列化和反序列化要保证顺序。
关于Parcel推荐看(关于Parcel),深入浅出。
所以,Intent#putExtra其实就是调用了bundle#putExtra,先检查是否有unparcel的数据,有就先读取出来,一个流程图如下:
上面是写一个数据的代码,我们知道Intent实现了Parcelable接口,所以Parcelable的写入接口方法就是writeToParcel方法,最终调用了BaseBundle的writeToParcelInner.
//Intent.java
public void writeToParcel(Parcel out, int flags) {
...
out.writeBundle(mExtras);
}
//Parcel.java
public final void writeBundle(@Nullable Bundle val) {
if (val == null) {
writeInt(-1);
return;
}
val.writeToParcel(this, 0);
}
public void writeToParcel(Parcel parcel, int flags) {
...
super.writeToParcelInner(parcel, flags);
...
}
//BaseBundle.java
void writeToParcelInner(Parcel parcel, int flags) {
// 如果parcal自己set了一个ReadWriteHelper,先调用unparcel,mMap赋值,mParcelledData为null
if (parcel.hasReadWriteHelper()) {
unparcel();
}
final ArrayMap<String, Object> map;
synchronized (this) {
if (mParcelledData != null) {
if (mParcelledData == NoImagePreloadHolder.EMPTY_PARCEL) {
parcel.writeInt(0);
} else {
int length = mParcelledData.dataSize();
parcel.writeInt(length);
parcel.writeInt(mParcelledByNative ? BUNDLE_MAGIC_NATIVE : BUNDLE_MAGIC);
parcel.appendFrom(mParcelledData, 0, length);
}
return;
}
map = mMap;
}
// 如果map为空,直接写入length = 0
if (map == null || map.size() <= 0) {
parcel.writeInt(0);
return;
}
int lengthPos = parcel.dataPosition();//先记录开始的位置
parcel.writeInt(-1); // dummy, will hold length 写入-1占length的位置
parcel.writeInt(BUNDLE_MAGIC); //写入MAGIC CODE
int startPos = parcel.dataPosition();
parcel.writeArrayMapInternal(map);
int endPos = parcel.dataPosition();
// 表示游标回到之前记录的开始位置
parcel.setDataPosition(lengthPos);
int length = endPos - startPos;
parcel.writeInt(length); //写入length
parcel.setDataPosition(endPos); //aprcel回到结束位置。
}
Parcel的写入是按照顺序先写入data的length,再写入一个MAGIC,然后写入真正的data。当然,读取的时候也是按照这个顺序来读取的。mParcelledData是存储的Parcel格式的Bundle的,如果mParcelledData不为空,那么mMap一定是空的。如果data被unparcel出来了,那么mMap有数据mParcelledData为空。
所以,写入的时候发现mParcelledData不为空,直接把mParcelledData写入parcel就好了,否则调用writeXXX把mMap写入parcel。
parcel的dataPosition()表示当前在写的位置,类似写文件吧,seek到不同的位置开始写对应位置的数据。默认获取到的dataPosition()是在数据的最后的位置。
写入的时候有个小Trick,这里写入的时候先记录一个开始的位置lengthPos,先写一个-1代表length,再写MAGIC CODE,然后开始写数据并且记录开始结束位置startPos和endPos,得到数据的length之后再seek到-1的位置用length把-1覆盖掉再seek到结束位置。
写入逻辑结束。
数据读取 - getIntent().getStringExtra
数据读取,直接调用到了Bundle的getString方法,除了调用了unparcel,上面我们看了unparcel的代码,作用就是给mMap赋值,反序列化之后就是直接从mMap中取数据了。
//Intent.java
public @Nullable String getStringExtra(String name) {
return mExtras == null ? null : mExtras.getString(name);
}
//BaseBundle.java
public String getString(@Nullable String key) {
unparcel();
final Object o = mMap.get(key);
try {
return (String) o;
} catch (ClassCastException e) {
typeWarning(key, o, "String", e);
return null;
}
}
void unparcel() {
synchronized (this) {
final Parcel source = mParcelledData;//这里我们看下上面没看到的条件,mParcelledData什么时候赋值呢?
if (source != null) {
initializeFromParcelLocked(source, /*recycleParcel=*/ true, mParcelledByNative);
} else {
...
}
}
}
那mMap是什么时候赋值的呢?我们知道Bundle是实现了Parcelable接口的,需要实现序列化和反序列化方法,我们在Intent里能找到CREATOR方法:
//Intent.java
public static final @android.annotation.NonNull Parcelable.Creator<Intent> CREATOR
= new Parcelable.Creator<Intent>() {
public Intent createFromParcel(Parcel in) {
return new Intent(in);
}
public Intent[] newArray(int size) {
return new Intent[size];
}
};
反序列化的调用顺序,代码逻辑很简单,都略过,只看调用逻辑:
Intent#Intent(Parcel in)
- Intent#readFromParcel(Parcel in)
- Parcel#readBundle()
- Parcel#readBundle(ClassLoader loader)
- Bundle#Bundle(Parcel parcelledData, int length)
- BaseBundle#BaseBundle(Parcel parcelledData, int length)
- BaseBundle#readFromParcelInner(Parcel parcel, int length)
//调用到readFromParcelInner方法,看一下这个方法做了什么。
//BaseBundle.java
void readFromParcelInner(Parcel parcel) {
int length = parcel.readInt();//先读了一个length
readFromParcelInner(parcel, length);
}
//BaseBundle.java
private void readFromParcelInner(Parcel parcel, int length) {
...
final int magic = parcel.readInt();
final boolean isJavaBundle = magic == BUNDLE_MAGIC;
final boolean isNativeBundle = magic == BUNDLE_MAGIC_NATIVE;
if (!isJavaBundle && !isNativeBundle) {
throw new IllegalStateException("Bad magic number for Bundle: 0x" + Integer.toHexString(magic));
}
if (parcel.hasReadWriteHelper()) {
synchronized (this) {
initializeFromParcelLocked(parcel, /*recycleParcel=*/ false, isNativeBundle);
}
return;
}
// Advance within this Parcel
int offset = parcel.dataPosition();
parcel.setDataPosition(MathUtils.addOrThrow(offset, length));
Parcel p = Parcel.obtain();
p.setDataPosition(0);
p.appendFrom(parcel, offset, length);
p.adoptClassCookies(parcel);
p.setDataPosition(0);
mParcelledData = p;
mParcelledByNative = isNativeBundle;
}
So,结合我们上面看过的源码,Bundle实际数据的存储有两种形式,一种是作为Parcel存储在mParcelledData里面,一种是作为K-V存储在mMap里面。区别是parcel.hasReadWriteHelper(),有没有给Parcel设置ReadWriteHelper。
- 如果设置了,实际逻辑是调用了
initializeFromParcelLocked,跟上面我们看过的unparcel方法调用的一致,把数据unparcel出来放到mMap中。 - 如果没设置,obtain一个可用的Parcel,把数据从传过来的
parcel中放进去,赋值给mParcelledData。
后面如果有putXXX操作的时候再通过unparcel方法反序列化到mMap中使用。
总结:
- Bundle里面最多能传递200K的数据。
- 调用
putExtra的时候K-V数据需要放到mMap中
- 如果Bundle是新new出来的,初始化一个mMap,
K-V直接放到mMap中。 - 如果Bundle之前就存在,
readFromParcelInner方法中反序列化,结束后数据有两种方式存储,一种是K-V结构存储在mMap中,一种是以parcel结构存储在mParcelledData中。如果还需要putExtra,如果mMap中有值,直接put到mMap中,否则调用unparcel将mParcelledData反序列化到mMap中再put到mMap中。
- 如果Bundle是新new出来的,初始化一个mMap,
- Bundle的存和读都是调用的Parcel的
WriteXXX/ReadXXX方法,都会调用到nativeWriteXXX/nativeReadXXX,native中也有一个Parcel与java中的对应。类似于DexClassLoader中DexFile的处理,也是java持有一个native申请的地址指针,读写的时候都是用这个指针去操作。
链接:https://juejin.cn/post/7222833868503253051
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
10 个有用的 Kotlin flow 操作符
Kotlin 拥有函数式编程的能力,运用得当,可以简化代码,层次清晰,利于阅读,用过都说好。
然而操作符数量众多,根据使用场景选择合适的操作符是一个很大的难题,网上搜索了许久只是学习了一个操作符,还要再去验证它,实在浪费时间,开发效率低下。
一种方式是转至命令式开发,将过程按步骤实现,即可完成需求;另一种方式便是一次学习多个操作符,在下次选择操作符时,增加更多选择。
本篇文章当然关注的是后者,列举一些比较常用 Kotlin 操作符,为提高效率助力,文中有图有代码有讲解,文末有参考资料和一个交互式学习的网站。
让我们开始吧。
1. reduce
reduce 操作符可以将所有数据累加(加减乘除)得到一个结果
listOf(1, 2, 3).reduce { a, b ->
a + b
}
输出:6
如果 flow 中没有数据,将抛出异常。如不希望抛异常,可使用 reduceOrNull 方法。
reduce 操作符不能变换数据类型。比如,Int 集合的结果不能转换成 String 结果。
2. fold
fold 和 reduce 很类似,但是 fold 可以变换数据类型
有时候,我们不需要一个结果值,而是需要继续操 flow,可使用 runningFold 。
flowOf(1, 2, 3).runningFold("a") { a, b ->
a + b
}.collect {
println(it)
}
输出:
a
a1
a12
a123
同样的,reduce 也有类似的方法 runningReduce
flowOf(1, 2, 3).runningReduce { a, b ->
a + b
}.collect {
println(it)
}
输出:
1
3
6
3. debounce
debounce 需要传递一个毫秒值参数,功能是:只有达到指定时间后才发出数据,最后一个数据一定会发出。
例如,定义 1000 毫秒,也就是 1 秒,被观察者发出数据,1秒后,观察者收到数据,如果 1 秒内多次发出数据,则重置计算时间。
flow {
emit(1)
delay(590)
emit(2)
delay(590)
emit(3)
delay(1010)
emit(4)
delay(1010)
}.debounce(
1000
).collect {
println(it)
}
输出结果:
3
4
rebounce 的应用场景是限流功能
4. sample
sample 和 debounce 很像,功能是:在规定时间内,只发送一个数据
flow {
repeat(4) {
emit(it)
delay(50)
}
}.sample(100).collect {
println(it)
}
输出结果:
1
3
sample 的应用场景是截流功能
debounce 和 sample 的限流和截流功能已有网友实现,点击这里
5. flatmapMerge
简单的说就是获得两个 flow 的乘积或全排列,合并并且平铺,发出一个 flow。
描述的仍然不好理解,一看代码便能理解了
flowOf(1, 3).flatMapMerge {
flowOf("$it a", "$it b")
}.collect {
println(it)
}
输出结果:
1 a
1 b
3 a
3 b
flatmapMerge 还有一个特性,在下一个操作符里提及。
6. flatmapConcat
先看代码。
flowOf(1, 3).flatMapConcat {
flowOf("a", "b", "c")
}.collect {
println(it)
}
功能和 flatmapMerge 一致,不同的是 flatmapMerge 可以设置并发量,可以理解为 flatmapMerge 是线程安全的,而 flatmapConcat 不是线程安全的。
本质上,在 flatmapMerge 的并发参数设置为 1 时,和 flatmapConcat 基本一致,而并发参数大于 1 时,采用 channel 的方式发出数据,具体内容请参阅源码。
7. buffer
介绍 buffer 的时候,先要看这样一段代码。
flowOf("A", "B", "C", "D")
.onEach {
println("1 $it")
}
.collect { println("2 $it") }
输出结果:
1 A
2 A
1 B
2 B
1 C
2 C
1 D
2 D
注意输出的内容。
加上 buffer 的代码。
flowOf("A", "B", "C", "D")
.onEach {
println("1 $it")
}
.buffer()
.collect { println("2 $it") }
输出结果:
1 A
1 B
1 C
1 D
2 A
2 B
2 C
2 D
输出内容有所不同,buffer 操作符可以改变收发顺序,像有一个容器作为缓冲似的,在容器满了或结束时,下游开始接到数据,onEach 添加延迟,效果更明显。
8. combine
合并两个 flow,长的一方会持续接受到短的一方的最后一个数据,直到结束
flowOf(1, 3).combine(
flowOf("a", "b", "c")
) { a, b -> b + a }
.collect {
println(it)
}
输出结果:
a1
b3
c3
9. zip
也是合并两个 flow,结果长度与短的 flow 一致,很像木桶原理。
flowOf(1, 3).zip(
flowOf("a", "b", "c")
) { a, b -> b + a }
.collect {
println(it)
}
输出结果:
a1
b3
10. distinctUntilChanged
就像方法名写的那样,和前一个数据不同,才能收到,和前一个数据想通,会被过滤掉。
flowOf(1, 1, 2, 2, 3, 1).distinctUntilChanged().collect {
println(it)
}
输出结果:
1
2
3
1
最后
以上就是今天要介绍的操作符,希望对大家有所帮助。
参考文章:Android — 9 Useful Kotlin Flow Operators You Need to Know
Kotlin 交互式操作符网站:交互式操作符网站
链接:https://juejin.cn/post/7135013334059122719
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
使用 Kotlin Compose Desktop 实现了一个简易的"手机助手"
一. adbd-connector
adbd-connector 是一个实现 adb server 和 adb daemon 之间的通信协议的库,使用 Kotlin 编写。支持 PC 端直接连接 Android 设备操作 adb 相关的指令。
github 地址:github.com/fengzhizi71…
二. 背景
在下图中的 adb client 和 adb server 都共存在 PC 中,PC 上安装过 adb 程序就会有。adb dameon (简称adbd)是存在于 Android 手机中的一个进程/服务。
当我们启动命令行输入 adb 命令时,实际上使用的是 adb client,它会跟 PC 本地的 adb server 进行通信(当然,有一个前提先要使用 adb-start 启动 adb server 才能调用 adb 命令)。
然后 adb server 会跟 Android 手机进行通信(手机通过 usb 口连上电脑)。最终,我们会看到 adb client 返回命令执行的结果。
一次命令的执行包含了 1-6 个步骤。其实,还要算上 adb server 内部的通信和 adb dameon 内部的通信。一次命令的执行,路径会很长。
所以,一次完整的 adb 通信会涉及如下的概念:
- adb client:运行在 PC 上,通过在命令行执行 adb,就启动了 adb client 程序
- adb server:运行于 PC 的后台进程,用于管理 adb client 和 daemon 之间的通信
- adb daemon(adbd):运行在模拟器或 Android 设备上的后台服务。当 Android 系统启动时,由 init 程序启动 adbd。如果 adbd 挂了,则 adbd 会由 init 重新启动。
- DDMS:DDMS 将 IDE 和手机设备之间建立起了一座桥梁,可以很方面的查看到目标机器上的信息。
- JDWP:即 java debug wire protocol,Java 调试线协议,是一个为 Java 调试而设计的通讯交互协议,它定义了调试器和被调试程序之间传递的信息的格式。
在 adb server 和 adbd 之间有一个 TCP 的传输协议,它定义在 Android 源码的 system/core/adb/protocol.txt 文件中。只要是能通过 adb 命令连接的手机,都会遵循这个协议,无论是 Android 或是鸿蒙系统。
因此,基于这个协议实现了一个 TCP 的客户端(adbd-connector)就可以跟手机的 adbd 服务/进程进行通信,从而实现 adb 的所有指令。
另外,我还使用 Kotlin Compose Desktop 在这个协议上做了一层 UI,实现了一个可以在 PC 上使用的简易"手机助手",且支持 Mac、Linux、Windows 等系统。
在手机连接前,先要打开手机的开发者模式。在连接过程中,手机会弹出信任框,提示是否允许 usb 调试。需要点击信任,才能完成后续的连接。
还要打开手机的 5555 端口(使用 adb 命令:adb tcpip 5555),以及获取手机连接当前 wifi 的局域网 ip 地址。有了局域网的 ip 地址和端口,才可以通过 adbd-connector 跟 adbd 进行连接。
三. adbd-connector 使用
3.1 手机的连接效果:
连上手机,获取手机的基础信息
3.2 执行 adb shell 命令的效果:
执行 adb shell 相关的命令(输入时省略 adb shell,直接输入后面的命令)
3.3 install app
目前还处在疫情期间,所以就在应用宝上找了一个跟生活相关的 App,最主要是这个 App 体积小
安装 App 时分成2步:
1.使用 push 命令将 apk 推送到手机的目录 /data/local/tmp/ 下
- 使用 adb shell pm install 命令安装 apk
3.4 uninstall app
adb shell pm uninstall 包名
四. 总结
这款工具 github.com/fengzhizi71… 是一个 PoC(Proof of Concept)的产物,参考了很多开源项目,特别是 github.com/sunshinex/a…
它能够实现绝大多数的 adb 命令。后续这个项目的部分代码可能会用于公司的项目。所以,这个仓库不一定会持续更新了。而且,这款工具使用起来也很繁琐,需要打开手机的 5555 端口以及输入手机局域网 ip 的地址。因此在实际业务中,还有很多东西需要改造以适合自身的业务。
链接:https://juejin.cn/post/7113546507709579295
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Dart 3.0 语法新特性 | Records 记录类型 (元组)
1. 记录类型的声明与访问
通过 () 将若干个对象组合在一块,作为一个新的聚合类型。定义时可以直接当放入对象,也可以进行命名传入:
var record = ('first', a: 2, b: true, 'last');
print(record.runtimeType);
--->[打印输出]---
(String, String, {int a, bool b})
上面的 record 对象由四个数据构成,通过 runtimeType 可以查看到其运行时类型,类型为各个非命名数据类型 + 各命名类型。
非命名类型数据可以通过
$index进行访问:
print(record.$1);
print(record.$2);
--->[打印输出]---
first
last
命名类型数据可以通过
名称进行访问:
print(record.a);
print(record.b);
--->[打印输出]---
2
true
注意: 一个记录对象的数据不允许被修改:
2. 记录类型声明对象
一个 Records 本质上也是一种类型,可以用该类型来声明对象,比如现在通过 (double,double,double) 的记录类型表示三个坐标,如下定义 p0 和 p1 对象:
void main() {
(double x, double y, double z) p0 = (1, 2, 3);
(double x, double y, double z) p1 = (1, 2, 6);
}
既然可以实例化为对象,那么自然也可以将其作为参数类型传入函数中,如下 distance 方法传入两个三维点,计算距离:
double distance(
(double x, double y, double z) p0,
(double x, double y, double z) p1,
) {
num result = pow(p0.$1 - p1.$1, 2) + pow(p0.$2 - p1.$2, 2) + pow(p0.$3 - p1.$3, 2);
return sqrt(result);
}
但记录类型一旦显示声明,写起来比较繁琐;和函数类型类似,也可以通过 typedef 来定义类型的别名。如下所示,定义 Point3D 作为别名,功能是等价的,但书写和可读性会更好一些:
typedef Point3D = (double, double, double);
void main() {
Point3D p0 = (1, 2, 3);
Point3D p1 = (1, 2, 6);
print(distance(p0, p1));
}
double distance(Point3D p0, Point3D p1) {
num result = pow(p0.$1 - p1.$1, 2) + pow(p0.$2 - p1.$2, 2) + pow(p0.$3 - p1.$3, 2);
return sqrt(result);
}
同理,记录类型也可以作为返回值,这样可以解决一个函数返回多值的问题。如下 addTask 方法可以计算 1 ~ count 的累加值,返回计算结果和耗时毫秒数:
({int result, int cost}) addTask2(int count) {
int start = DateTime.now().millisecondsSinceEpoch;
int sum = 0;
for (int i = 0; i < count; i++) {
sum += i;
}
int end = DateTime.now().millisecondsSinceEpoch;
return (
result: sum,
cost: end - start,
);
}
3. 记录类型对象的等值
记录类型会根据字段的结构自动定义 hashCode 和 == 方法。 所以两个记录对象相等,就是其中的各个数值相等。但是通过 identical 可以看出 p0 和 p1 仍是两个对象,内存地址不同:
(double, double, double) p0 = (1, 2, 3);
(double, double, double) p1 = (1, 2, 3);
print(p0 == p1);
print(identical(p0, p1));
--->[打印输出]---
true
false
如下所示,第二个数据是 List<double> 类型,两个 [2] 是两个不同的对象,所以 p2,p3 不相等:
(double, List<double>, double) p2 = (1, [2], 3);
(double, List<double>, double) p3 = (1, [2], 3);
print(p2==p3);
--->[打印输出]---
false
下面测试中, 列表使用同一对象,则 p2,p3 相等:
List<double> li = [2];
(double, List<double>, double) p2 = (1, li, 3);
(double, List<double>, double) p3 = (1, li, 3);
print(p2==p3);
--->[打印输出]---
true
4. 记录类型的价值
对于编程语言来说,Dart 的记录类型也不是什么新的东西,就是其他语言中的元组。如下所示,可以创建一个 TaskResult 类来维护数据作为返回值。但如果只是返回一些临时的数据,为此新建一个类来维护数据就会显得比较繁琐,还要定义构造函数。
class TaskResult{
final int result;
final int cost;
TaskResult(this.result, this.cost);
}
TaskResult addTask(int count) {
int start = DateTime.now().millisecondsSinceEpoch;
int sum = 0;
for (int i = 0; i < count; i++) {
sum += i;
}
int end = DateTime.now().millisecondsSinceEpoch;
return TaskResult(sum, end - start);
}
除此之外,一个函数返回多个数据也可以使用 Map 对象:
Map<String,dynamic> addTask(int count) {
int start = DateTime.now().millisecondsSinceEpoch;
int sum = 0;
for (int i = 0; i < count; i++) {
sum += i;
}
int end = DateTime.now().millisecondsSinceEpoch;
return {
'result' : sum,
'cost': end - start
};
}
但这种方式的弊端也很明显,返回和使用时都需要固定的字符串作为 key。如果 key 写错了,代码在运行前也不会有任何错误,这样很容易出现风险。多人协作时,而且如果函数的书写者和调用者不是一个人,那该使用什么键得到什么值就很难分辨。
Map<String,dynamic> task = addTask2(100000000);
print(task['result']);
print(task['cost']);
所以,相比于新建 class 或通过 Map 来维护多个数据,使用记录类型更加方便快捷和精确。但话说回来,如果属性数据量过多,使用记录类型看起来会非常麻烦,也不能定义成员方法来操作、修改内部数据。所以它有自己的特点使用场景,比如临时聚合多个数据来方便使用。
链接:https://juejin.cn/post/7233067863500849209
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
内向性格的开发同学,没有合适的工作方法是不行的
一、背景
做软件开发同学的从性格上来说有两类人:外向的、内向的。
外向的人在工作中擅长交流,内向的人在工作中善于总结,两种的人都是开发团队需要的。
外向的人在工作中善于活跃团队内的气氛,逐渐走向技术管理路线,带领团队走的更远,控制开发目标与路线;内向的人更擅长观察,容易成为团队的定心骨,逐渐走向技术专家路线,肯研究肯花时间提高自己。
那么,在这个过程中,内向人前期的成长尤为重要,合适的工作方法和习惯也会提高在团队中的地位,而不是单纯的低头干活,本文分享下自己的经验,不一定对希望对大家有参考。
不同的性格的人,具有不同的工作方式和方法,和生活习惯,对于软件开发这个职场环境来说,内向性格不是劣势,很多人外表看着外向,其实潜意识也有很多内向性格的特征。
内向也是人的宝贵的一面,有时也是能力优势的一部分(如善于深度思考等),如果让自己掌握外向同学的行动方式,逐渐的做出改变,会更好。
二、现状
刚毕业不久进入到职场中工作的毕业生,如果性格是外向的,那么他其实问题并不大,很多的时候,可以快速调整自己,并被其他人看到自己的工作成果,而内向性格的毕业生,如果在职场中没有主动去做某些工作和承担哪些职责,或对自己目前的工作状况没有及时调整和改变,就会造成成长缓慢,有的人会出现明明自己每天努力学习,却还是工作中那个让同时感觉能力最差的,导致经常没有分配到核心的开发工作,长此以往,消极的各种状态就出现了。
比如内向性格的毕业生在初入职场中经常会出现如下症状:
1、明知项目组的工作环境和方式存在一些不健康的因素,自己不太愿意去参与或评论
2、对开发整体流程和环节不清楚,及需求的判断有问题,需求频繁改动,代码写了被删除,自己却不敢说,或说了一次被骂以后沉默了
3、项目组缺失技术经理等全流程人员,需求自己理解和功能设计,自己却没有及时吧自己的想法与他人沟通 ,外包团队更明显
4、身边缺乏可以聊天的mentor、同事,自己感觉开发能力无法提升,却一直憋在心里,产生怀疑
5、不知道工作中如何问同事问题,才愿意帮忙解答,持续很长时间未获得同事的信任
6、有时过于逞强,不想让别人觉得自己不行,不会拒绝,实际工作量与评估有差别,导致自己延误工期。
以上的这些问题,可能不止内向性格的人会有,很多外向的人可能也会有,只是在内向性格的人身上更明显而已,如果内向性格的毕业生,明知道自己有这种情况,却不思考解决办法和改变,长时间后自我开始产生怀疑。 职场中,沟通、反馈、改变是很重要的,但是沟通不一定就是说话,反馈不一定是面对面,而改变是一直要持续去做的。
之前看过一点得到的沟通训练营的视频教程,感觉里面有些技巧是值得大家去学习的,不仅仅是开发类型的同学。
三、经验分享
下面我分享下,我的一些经验,可能不太对,但是希望可以帮助到看到这篇文章,深有同感的你。
问题1:内向性格的毕业生,说的话,或者请求别人的东西,别人听不懂怎么办?
这里先记住一件事情,在职场中,开发者要学会给不懂技术的人员,讲明白事情,要逐渐学会用生活中的事情去类比。
这个真的很重要,当你给不懂技术人讲的多以后,很多人可能都会来请教你关于某件事的理解,这个通常我们和系统的售前、需求人员、产品人员用的比较多,得学会用生活中的例子或故事去告诉他,XX能做,XX不能做的原因是什么。要坚持去练习。
对于请教一些人技术问题时,不管是同事也好还是网友也好,要明确自己给他的这个消息,别人是否会听懂,马上给出解决办法,还是别人看到这个问题以后,还要和我交流1小时才能知道是啥意思,这个也是很多有经验的人,不愿因帮助低级程序员的原因,这里分享下请教问题的描述模板:
我遇到了一个问题或场景:【问题描述】,我想要实现【X功能】,但是出现了【Y现象】,我经过以下尝试:【思路细节】,但是不能解决,报错如下:【报错信息或截图】,或者我使用【关键词】百度,但是找不到答案,请问我该怎么解决或分析。
而很多时候有经验的人,也会发现你百度的搜索词不对,这个时候,他根据你的阐述可能会告诉你怎么输入比较靠谱的搜索词来解决办法。
问题2:评估工作计划有时过于逞强,不想让别人觉得自己不行,不会拒绝
这个真的想说,工作前期真的别逞强,没做过就是没做过,不行就是不行,别找啥接口,但是别直接和负责人说这个东西我不会(这个是很不好的,不能说不会,这是明显不相干的意思),比较合适的说法是:这个东西或概念我暂时不太清楚,没接触过过,需要一会儿或下来后我需要去研究下,然后咱们在沟通或者确定一下。
而很多内向性格的毕业生,缺少了这种意识,同时安排某项工作任务时,缺少对任务的分解能力和排期能力和工作后排期后的To do List梳理能力,以至于自己5天完成的任务,口头说2天就搞定了。
其实这种,前期mentor该给你做个示范分解的操作,或者自己主动问下,如何分解项目的需求和任务。
而真正开发的时候,每天可能都感觉这里需要加上XXX功能,那里需要加上YYY功能,但是不知道是否需要做,这里我的建议是,把他加入到自己To do List中,然后找个时间和同事去沟通下这个想法,长此以往,同事的心里,你就是一个有想法的人,虽然不善言辞。
主要就是这里,我们要体现自己的一个工作的对待方式,而不是一直被动接受,不拒绝,不反馈。
问题3:明显知道产品经理、项目经理等等人员对需求的认识不足,自己闷着不反馈和说话
很多时候,任务的返工和需求的变更,有一部分是这个原因的,在经验尚少的情况下,自己未能说出自己对这个需求的认识和怀疑,就去搞了,最后大家都不是特别的好,尤其是在产品需求设计初期,包括需求提出者也是理解不够的,这里可能有很多内容其实是你可以提供的服务,也有一些是产品在犹豫使用哪种方式实现的功能,在与你讨论后,觉得你说的又道理,而决定复用你已经有的系统。
很多出入职场的同学,觉得没成长也有这方面的一点原因,自己开发的功能,缺少自己设计思想和认知的影子,如果能在当前系统中体现出了自己的想法,时间久了多少成就感会有点提升的。
要学会做自己负责的模块/功能的主人,把他们当做自己的孩子一样,主键养成主人翁的意识
问题4:项目组,当前啥都没有,文档、测试,自己也和别人一样不做改变
这个也是目前很多公司的现状,但是不代表别人不干,你就不干,这个时候,谁主动,谁就能表现一把,同时,这也是被动让同事主动问你或咨询你的机会。
比如没有协同的东西,那你能不能自己先装个Confluence Wiki或飞书云文档工具,自己先用起来,然后某个时机在同事眼前展示下,自己基于这个软件形成的技术思考、技术经验、技术记录等等等。
比如没有自动发布或代码质量的东西,那你能不能自己先搞个jenkins、sonarqube、checkstyle、findbug,让自己每次写完的代码,自己先搞下,然后某个时机告诉同事这个东西必须这么写怎怎么样。
是不是有人又说了,工作没时间搞这些东西,你是不是又在扯皮呢,我只能说起码比你空闲时间自己偷偷学习公司短期内用不上的技术或长时间用不上的东西好吧,至少我能非常快速的获得1个同事的信任、2个同事的信任,从而获得团队的信任与核心工作的委派。
大部分人的想用的技术都是和公司的技术栈不搭边的,至少先把脚下的路走出来。
四、总结
其实最近几年,发现好像很多人被卷字冲昏了头脑,每天都在想着高大尚的技术点和八股文,导致短期的这个工作没干好,还说没成长,以至于某些情况下还被认为是工作和团队中那个能力最差的,即使做了很多的努力。我想说的是,某段时间点或时期内,至少要把当前工作做好在谈论吧,这个在一些内向性格的人身上会表现的明显一些。
IT行业,很多优秀的人也是内向性格的,掌握了合适方法,会让他们成为内向性格顶端的那批优秀的人群。
说道性格吧,即使是内向型的,可能针对十二星座还是衍生出不同的人生和结果,每个星座的也是有区别的。而在这里面最突出的我觉得是天蝎座的人群。
身为天蝎座的我,经常会想到那些和我一个星座的大佬们:
搜狐创始人张朝阳、腾讯创始人马化腾、百度创始人李彦宏、雅虎创始人杨致远、微软创始人比尔.盖茨、联想集团CEO杨元庆、推特CEO杰克.多尔西、新浪董事长曹国伟。
他们的成长也一直在激励着我。
这些经验对正在阅读文章的你有用吗,欢迎一起交流,让我们一起交流您遇到的问题。
这篇文章是去年写的,今天增加了点内容,掘金上同步更新了一下,希望可以被更多的人看到。
如果这篇文章说道你心里了,可以点赞、分享、评论、收藏、转发哦。
链接:https://juejin.cn/post/7232625387296096312
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android gradle迁移至kts
背景
在kotlin语言已经渗透至各领域的环境下,比如服务端,android,跨平台Kmm,native for kotlin,几乎所有的领域都可以用kotlin去编写了,当然还有不成熟的地方,但是JB的目标是很一致的!我们最常用的gradle构建工具,也支持kotlin好久了,但是由于编译速度或者转换成本的原因,真正实现kts转换的项目很少。在笔者的mac m1 中使用最新版的AS去编译build.gradle.kts,速度已经是和用groovy写的gradle脚本不相上下了,所以就准备写了这篇文章,希望做一个记录与分享。
| groovy | kotlin |
|---|---|
| 好处:构建速度较快,运用广泛,动态灵活 | 好处:编译时完成所有,语法简洁,android项目中可用一套语言开发构建脚本与app编写 |
| 坏处:语法糖的作用下,很难理解gradle运行的全貌,作用单一,维护成本较高 | 坏处:编译略慢于groovy,学习资料较少 |
虽然主流的gradle脚本编写依旧是groovy,但是android开发者官网也在推荐迁移到kotlin
编译前准备
这里推荐看看这篇文章,里面也涵盖了很多干货,
全局替换‘’为“”
在kotlin中,表示一个字符串用“”,不同于groovy的‘ ’,所以我们需要全局替换。可以通过快捷方式command/control+shift+R 全局替换,选中匹配正则表达式并设定file mask 为 *.gradle:
正则表达式
'(.*?[^\\])'
作用范围为
"$1"
全局替换方法调用
在groovy中,方法是可以隐藏(),举个例子
apply plugin: "com.android.application"
这里实际上是调用apply方法,然后命名参数是plugin,内容围为"com.android.application",然而在kotlin语法中,我们需要以()或者invoke的方式才能调用一个方法,所以我们要给所有的groovy函数调用添加()
正则表达式
(\w+) (([^=\{\s]+)(.*))
作用范围为
$1($2)
很遗憾的是,这个对于多行来说还是存在不足的,所以我们全局替换后还需要手动去修正部分内容即可,这里我们只要记得一个原则即可,想要调用一个kotlin函数,把参数包裹在()内即可,比如调用一个task函数,那么参数即为
task(sourcesJar(type: Jar) {
from(android.sourceSets.main.java.srcDirs)
classifier = "sources"
})
gradle kt化
接下来我们只需要把build.gradle 更改为文件名称为build.gradle.kts 即可,由于我们修改文件为了build.gradle.kts,所以当前就以kts脚本进行编译,所以很多的参数都是处于找不到状态的,即使sync也会报错,所以我们需要把报错的地方先注释掉,然后再进行sync操作,如果成功的话,AS就会帮我们进行一次编译,此时就可以有代码提示了。
开始前准备
以kotlin的方式编译,此时函数就处于可点击查看状态,区别于groovy,因为groovy是动态类型语言,所以很多做了很多语法糖,但是也给我们在debug阶段带来了很多困难,比如没有提示等等,因为groovy只需要保证在运行时找到函数即可,而kotlin却不一样,所以很多动态生成的函数就无法在编译时直接使用了,比如
对于这种动态函数,kotlin for gradle 其实也给我们内置了很多参数来对应着groovy的动态函数,下面我们来从以下方面去实践吧,tip:以下是gradle脚本编写常用
ext
我们在groovy脚本中,可以定义额外的变量在ext{}中,那么这个在kotlin中可以使用吗?嘿嘿,能用我就不会提到对吧!对的,不可以,因为ext也是一个动态函数,我们kotlin可没法用呀!那怎么办!别怕,kts中给我们定义了一个类似的变量,即extra,我们可以通过by extra去定义,然后就可以自由用我们的myNewProperty变量啦!
val myNewProperty by extra("initial value")
但是,如果我们在其他的gradle.kts脚本中用myNewProperty这个变量,那么也会找不到,因为myNewProperty这个的作用域其实只在当前文件中,确切来说是我们的build.gradle 最后会被编译生成一个Build_Init的类,这个类里面的东西能用的前提是,被先编译过!如果当前编译中的module引用了未被编译的module的变量,这当然不可行啦!当然,还是有对策的,我们可以在BuildScr这个module中定义自定义的函数,因为BuildScr这个module被定义在第一个先执行的module,所以我们后面的module就可以引用到这个“第一个module”的变量的方式去引用自定义的变量!
task
- 新建task
groovy版本
task clean(type: Delete) {
delete rootProject.buildDir
}
比如clean就是一个我们自定义的task,转换为kotlin后其实也很简单,task是一个函数名,Delete是task的类型,clean是自定义名称
task<Delete>("clean",{
delete(rootProject.buildDir)
})
当然,我们的task类型可能在编写的由于泛型推断,隐藏了具体的类型,这个时候我们可以通过
./gradlew help --task task名
去查看相应的类型
- 已有task修改
对于有些是已经在gradle编译时存在的函数任务,比如
groovy版本
wrapper{
gradleVersion = "7.1.1"
distributionType = Wrapper.DistributionType.BIN
}
这个我们kotlin版本的build.gradle能不能识别呢?其实是不可以的,因为编译器也不知道从哪里去找wrapper的定义,因为这个函数在groovy中隐藏了作用域,其实它存在于TaskContainerScope这个作用域中,所以对于所有的的task,其实都是执行在这里面的,我们可以通过tasks去找到
tasks {
named<Wrapper>("wrapper") {
gradleVersion = "7.1.1"
distributionType = Wrapper.DistributionType.BIN
}
}
这种方式,去找到一个我们想要的task,并配置其内容
- 生命周期函数
我们可以通过函数调用的方式去配置相应的生命周期函数,比如doLast
tasks.create("greeting") {
doLast { println("Hello, World!") }
}
再比如dependOn
task<Jar>("javadocJar", {
dependsOn(tasks.findByName("javadoc"))
})
动态函数
sourceSets就是一个典型的动态函数,为什么这么说,因为很多plugin都有自己的设置,比如Groovy的sourceSets,再比如Android的SourceSets,它其实是一个接口,正在实现其实是在plugin中。如果我们需要自定义配置一些东西,比如配置jniLibs的libs目录,直接迁移到kts就会出现main找不到的情况,这里是因为main不是一个内置的函数,但是存在相应的成员,这个时候我们可以通过by getting方式去获取,只要我们的变量在作用域内是存在的(编译阶段会添加),就可以获取到。如果我们想要生成其他成员,也可以通过by creating{}方式去生成一个没有的成员
sourceSets{
val main by getting{
jniLibs.srcDirs("src/main/libs")
jni.srcDirs()
}
}
也可以通过getByName方式去获取
sourceSets.getByName("main")
plugins
在比较旧的版本中,我们AS默认创建引入一个plugin的方式是
apply plugin: 'com.android.application'
其实这也是依赖了groovy的动态编译机制,这里针对的是,比如android{}作用域,如果我们转换成了build.gradle.kts,我们会惊讶的发现,android{}这个作用域居然爆红找不到了!这个时候我们需要改写成
plugins {
id("com.android.application")
}
就能够找到了,那么这背后的原理是什么呢?我们有必要去探究一下gradle的内部实现。
说了这么多的应用层写法,了解我的小伙伴肯定知道,原理解析肯定是放在最后啦!但是gradle是一个庞大的工程,单单靠着干唠是写不完的,所以我选出了最重要的一个例子,即plugins的解析,希望能够抛砖引玉,一起学习下去吧!
Plugins解析
我们可以通过在gradle文件中设置断点,然后debug运行gradle调试来学习gradle,最终在编译时,我们会走到DefaultScriptPluginFactory中进行相应的任务生成,我们来看看
DefaultScriptPluginFactory
final ScriptTarget initialPassScriptTarget = initialPassTarget(target);
ScriptCompiler compiler = scriptCompilerFactory.createCompiler(scriptSource);
// 第一个阶段Pass 1, extract plugin requests and plugin repositories and execute buildscript {}, ignoring (i.e. not even compiling) anything else
CompileOperation<?> initialOperation = compileOperationFactory.getPluginsBlockCompileOperation(initialPassScriptTarget);
Class<? extends BasicScript> scriptType = initialPassScriptTarget.getScriptClass();
ScriptRunner<? extends BasicScript, ?> initialRunner = compiler.compile(scriptType, initialOperation, baseScope, Actions.doNothing());
initialRunner.run(target, services);
PluginRequests initialPluginRequests = getInitialPluginRequests(initialRunner);
PluginRequests mergedPluginRequests = autoAppliedPluginHandler.mergeWithAutoAppliedPlugins(initialPluginRequests, target);
PluginManagerInternal pluginManager = topLevelScript ? initialPassScriptTarget.getPluginManager() : null;
pluginRequestApplicator.applyPlugins(mergedPluginRequests, scriptHandler, pluginManager, targetScope);
// 第二个阶段Pass 2, compile everything except buildscript {}, pluginManagement{}, and plugin requests, then run
final ScriptTarget scriptTarget = secondPassTarget(target);
scriptType = scriptTarget.getScriptClass();
CompileOperation<BuildScriptData> operation = compileOperationFactory.getScriptCompileOperation(scriptSource, scriptTarget);
final ScriptRunner<? extends BasicScript, BuildScriptData> runner = compiler.compile(scriptType, operation, targetScope, ClosureCreationInterceptingVerifier.INSTANCE);
if (scriptTarget.getSupportsMethodInheritance() && runner.getHasMethods()) {
scriptTarget.attachScript(runner.getScript());
}
if (!runner.getRunDoesSomething()) {
return;
}
Runnable buildScriptRunner = () -> runner.run(target, services);
boolean hasImperativeStatements = runner.getData().getHasImperativeStatements();
scriptTarget.addConfiguration(buildScriptRunner, !hasImperativeStatements);
}
可以看到,源码中特别注释了,编译时的两个阶段,我们可以看到,所有的script(指函数调用),都是分别经过了阶段1和阶段2之后才真正生效的。
那么为什么android作用域在apply plugin的方式不行,plugins方式却可以呢?其实就是两个运行阶段不一致的问题。groovy可以在运行时动态找到android 这个函数,即使两者都在阶段2运行,因为groovy语法本身的特性,即使android这个函数没有定义我们也可以引用,也是在运行时阶段报错。而kotlin不一样,kotlin需要在编译的时候需要找到我们要引用的函数,即android,所以同一个阶段即plugin都没有生效(需要执行完阶段才生效),我们当然也找不到android函数,那为什么plugins又可以呢?其实很容易想到,因为plugins是在第一阶段中执行并生效的,而android引用在第二个阶段,我们接着看源码
重点关注一下compileOperationFactory.getPluginsBlockCompileOperation方法,这个方法的实现类是DefaultCompileOperationFactory,在这里我们可以看到里面定义了两个阶段
public class DefaultCompileOperationFactory implements CompileOperationFactory {
private static final StringInterner INTERNER = new StringInterner();
private static final String CLASSPATH_COMPILE_STAGE = "CLASSPATH";
private static final String BODY_COMPILE_STAGE = "BODY";
private final BuildScriptDataSerializer buildScriptDataSerializer = new BuildScriptDataSerializer();
private final DocumentationRegistry documentationRegistry;
public DefaultCompileOperationFactory(DocumentationRegistry documentationRegistry) {
this.documentationRegistry = documentationRegistry;
}
public CompileOperation<?> getPluginsBlockCompileOperation(ScriptTarget initialPassScriptTarget) {
InitialPassStatementTransformer initialPassStatementTransformer = new InitialPassStatementTransformer(initialPassScriptTarget, documentationRegistry);
SubsetScriptTransformer initialTransformer = new SubsetScriptTransformer(initialPassStatementTransformer);
String id = INTERNER.intern("cp_" + initialPassScriptTarget.getId());
return new NoDataCompileOperation(id, CLASSPATH_COMPILE_STAGE, initialTransformer);
}
public CompileOperation<BuildScriptData> getScriptCompileOperation(ScriptSource scriptSource, ScriptTarget scriptTarget) {
BuildScriptTransformer buildScriptTransformer = new BuildScriptTransformer(scriptSource, scriptTarget);
String operationId = scriptTarget.getId();
return new FactoryBackedCompileOperation<>(operationId, BODY_COMPILE_STAGE, buildScriptTransformer, buildScriptTransformer, buildScriptDataSerializer);
}
}
getPluginsBlockCompileOperation中创建了一个InitialPassStatementTransformer类对象,我们关注transform方法的内容,即如果找到了plugins,我们就进行接下来的transform操作transformPluginsBlock,这就验证了,plugins的确在第一个阶段即classpath阶段运行
@Override
public Statement transform(SourceUnit sourceUnit, Statement statement) {
...
if (scriptBlock.getName().equals(PLUGINS)) {
return transformPluginsBlock(scriptBlock, sourceUnit, statement);
}
...
总结
文章列出来了几个关键的迁移了,相信大部分的问题都可以解决了,的确在迁移到kotlin之后,还是存在一定的迁移成本的,大部分就只能生啃官网介绍,希望看完都有收获吧!
链接:https://juejin.cn/post/7116333902435893261
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android的线程和线程池
从用途上来说Android的线程主要分为主线程和子线程两类,主线程主要处理和界面相关的工作,子线程主要处理耗时操作。除Thread之外,Android中还有其他扮演线程的角色如AsyncTask、IntentService、HandleThread,其中AsyncTask的底层用到了线程池,IntentService和HandleThread的底层直接使用了线程。
AsyncTask内部封装了线程池和Handler主要是为了方便开发者在在线程中更新UI;HandlerThread是一个具有消息循环的线程,它的内部可以使用Handler;IntentService是一个服务,系统对其进行了封装使其可以更方便的执行后台任务,IntentService内部采用HandleThread来执行任务,当任务执行完毕后IntentService会自动退出。IntentService是一个服务但是它不容易被系统杀死因此它可以尽量的保证任务的执行。
1.主线程和子线程
主线程是指进程所拥有的的线程,在Java中默认情况下一个进程只能有一个线程,这个线程就是主线程。主线程主要处理界面交互的相关逻辑,因为界面随时都有可能更新因此在主线程不能做耗时操作,否则界面就会出现卡顿的现象。主线程之外的线程都是子线程,也叫做工作线程。
Android沿用了Java的线程模型,也有主线程和子线程之分,主线程主要工作是运行四大组件及处理他们和用户的交互,子线程的主要工作就是处理耗时任务,例如网络请求,I/O操作等。Android3.0开始系统要求网络访问必须在子线程中进行否则就会报错,NetWorkOnMainThreadException
2.Android中的线程形态
2.1 AsyncTask
AsyncTask是一个轻量级的异步任务类,它可以在线程池中执行异步任务然后把执行进度和执行结果传递给主线程并在主线程更新UI。从实现上来说AsyncTask封装了Thread和Handler,通过AsyncTask可以很方便的执行后台任务以及主线程中访问UI,但是AsyncTask不适合处理耗时任务,耗时任务还是要交给线程池执行。
AsyncTask的四个核心类如下:
- onPreExecute():主要用于做一些准备工作,在主线程中执行异步任务执行之前
- doInBackground(Params ... params):在线程池执行,此方法用于执行异步任务,params表示输入的参数,在此方法中可以通过publishProgress方法来更新任务进度,publishProgress会调用onProgressUpdate
- onProgressUpdate(Progress .. value):在主线程执行,当任务执行进度发生改变时会调用这个方法
- onPostExecute(Result result):在主线程执行,异步任务之后执行这个方法,result参数是返回值,即doInBackground的返回值。
2.2 AsyncTask的工作原理
2.3 HandleThread
HandleThread继承自Thread,它是一种可以使用Handler的Thread,它的实现在run方法中调用Looper.prepare()来创建消息队列然后通过Looper.loop()来开启消息循环,这样在实际使用中就可以在HandleThread中创建Handler了。
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
HandleThread和Thread的区别是什么?
- Thread的run方法中主要是用来执行一个耗时任务;
- HandleThread在内部创建了一个消息队列需要通过Handler的消息方式来通知HandleThread执行一个具体的任务,HandlerThread的run方法是一个无限循环因此在不使用是调用quit或者quitSafely方法终止线程的执行。HandleTread的具体使用场景是IntentService。
2.4 IntentService
IntentService继承自Service并且是一个抽象的类因此使用它时就必须创建它的子类,IntentService可用于执行后台耗时的任务,当任务执行完毕后就会自动停止。IntentService是一个服务因此它的优先级要比线程高并且不容易被系统杀死,因此可以利用这个特点执行一些高优先级的后台任务,它的实现主要是HandlerThread和Handler,这点可以从onCreate方法中了解。
//IntentService#onCreate
@Override
public void onCreate() {
// TODO: It would be nice to have an option to hold a partial wakelock
// during processing, and to have a static startService(Context, Intent)
// method that would launch the service & hand off a wakelock.
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}
当IntentService第一次被启动时回调用onCreate方法,在onCreate方法中会创建HandlerThread,然后使用它的Looper创建一个Handler对象ServiceHandler,这样通过mServiceHandler把消息发送到HandlerThread中执行。每次启动IntentService都会调用onStartCommand,IntentService在onStartCommand中会处理每个后台任务的Intent。
//IntentService#onStartCommand
@Override
public int onStartCommand(@Nullable Intent intent, int flags, int startId) {
onStart(intent, startId);
return mRedelivery ? START_REDELIVER_INTENT : START_NOT_STICKY;
}
//IntentService#onStart
@Override
public void onStart(@Nullable Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}
onStartCommand是如何处理外界的Intent的?
在onStartCommand方法中进入了onStart方法,在这个方法中IntentService通过mserviceHandler发送了一条消息,然后这个消息会在HandlerThread中被处理。mServiceHandler接收到消息后会把intent传递给onHandlerIntent(),这个intent跟启动IntentService时的startService中的intent是一样的,因此可以通过这个intent解析出启动IntentService传递的参数是什么然后通过这些参数就可以区分具体的后台任务,这样onHandleIntent就可以对不同的后台任务做处理了。当onHandleIntent方法执行结束后IntentService就会通过stopSelf(int startId)方法来尝试停止服务,这里不用stopSelf()的原因是因为这个方法被调用之后会立即停止服务但是这个时候可能还有其他消息未处理完毕,而采用stopSelf(int startId)方法则会等待所有消息都处理完毕后才会终止服务。调用stopSelf(int startId)终止服务时会根据startId判断最近启动的服务的startId是否相等,相等则立即终止服务否则不终止服务。
每执行一个后台任务就会启动一次intentService,而IntentService内部则通过消息的方式向HandlerThread请求执行任务,Handler中的Looper是顺序处理消息的,这就意味着IntentService也是顺序执行后台任务的,当有多个后台任务同时存在时这些后台任务会按照外界发起的顺序排队执行。
3.Android中的线程池
线程池的优点:
- 线程池中的线程可重复使用,避免因为线程的创建和销毁带来的性能开销;
- 能有效控制线程池中的最大并发数避免大量的线程之间因互相抢占系统资源导致的阻塞现象;
- 能够对线程进行简单的管理并提供定时执行以及指定间隔循环执行等功能。
Android的线程池的概念来自于Java中的Executor,Executor是一个接口,真正的线程的实现是ThreadPoolExecutor,它提供了一些列参数来配置线程池,通过不同的参数可以创建不同的线程池。
3.1 ThreadPoolExecutor
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
ThreadPoolExecutor是线程池的真正实现,它的构造函数中提供了一系列参数,先看一下每个参数的含义:
- corePoolSize:线程池的核心线程数,默认情况下核心线程会在线程池中一直存活即使他们处于闲置状态。如果将ThreadPoolExecutor的allowCoreThreadTimeOut置为true那么闲置的核心线程在等待新的任务到来时会有超时策略,超时时间由keepAliveTime指定,当等待时间超过keepAliveTime设置的时间后核心线程就会被终止。
- maxinumPoolSize:线程池中所能容纳的最大线程数,当活动线程达到做大数量时后续的新任务就会被阻塞。
- keepAliveTime:非核心线程闲置时的超时时长,超过这个时长非核心线程就会被回收。
- unit:用于指定超时时间的单位,常用单位有毫秒、秒、分钟等。
- workQueue:线程池中的任务队列,通过线程池中的execute方法提交的Runnable对象会存储在这个参数中。
- threadFactory:线程工厂,为线程池提供创建新的线程的功能。
- handler:这个参数不常用,当线程池无法执行新的任务时,这可能是由于任务队列已满或者无法成功执行任务,这个时候ThreadPoolExecutor会调用handler的rejectExecution方法来通知调用者。
ThreadPoolExecutor执行任务时大致遵循如下规则:
- 如果线程池中的线程数量没有达到核心线程的数量那么会直接启动一个核心线程来执行任务;
- 如果线程池中线程数量已经达到或者超过核心线程的数量那么会把后续的任务插入到队列中等待执行;
- 如果任务队列也无法插入那么在基本可以确定是队列已满这时如果线程池中的线程数量没有达到最大值就会立刻创建非核心线程来执行任务;
- 如果非核心线程的创建已经达到或者超过线程池的最大数量那么就拒绝执行此任务,同时ThreadPoolExecutor会通过RejectedExecutionHandler抛出异常rejectedExecution。
3.2线程池的分类
- FixedThreadPool:它是一种数量固定的线程池,当线程处于空闲状态时也不会被回收,除非线程池被关闭。当所有的线程都处于活动状态时,新任务都会处于等待状态,直到有空闲线程出来。FixedThreadPool只有核心线程并且不会被回收因此它可以更加快速的响应外界的请求。
- CacheThreadPool:它是一种线程数量不定的线程池且只有非核心线程,线程的最大数量是Integer.MAX_VALUE,当线程池中的线程都处于活动状态时如果有新的任务进来就会创建一个新的线程去执行任务,同时它还有超时机制,当一个线程闲置超过60秒时就会被回收。
- ScheduleThreadPool:它是一种拥有固定数量的核心线程和不固定数量的非核心线程的线程池,当非核心线程闲置时会立即被回收。
- SignleThreadExecutor:它是一种只有一个核心线程的线程池,所有任务都在同一个线程中按顺序执行。
链接:https://juejin.cn/post/7178847227598045241
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我从 Android 官方 App 中学到了什么?
最近 Android 官方开源了一个新的 App: Now in Android ,这个 App 主要展示了其他 App 可能没有的一些最佳实践、架构设计、以及完整的线上 App (后面会发布到 Google Play 商店中)解决方案,其次是帮助开发者及时了解到自己感兴趣的 Android 开发领域。现在已经在 GitHub 中开源。
通过这篇文章你可以了解到 Now in Android 的应用架构:分层、关键类以及他们之间的交互。
目标&要求
App 的架构目标有以下几点:
- 尽可能遵循 官方架构指南 。
- 易于开发人员理解,没有什么太实验性的特性。
- 支持多个开发人员在同一个代码库上工作。
- 在开发人员的机器上和使用持续集成 (CI) 促进本地和仪器测试。
- 最小化构建时间。
架构概述
App 目前包括 Data layer 和 UI layer ,Domain layer 正在开发中。
该架构遵循单向数据流的响应式编程方式。Data Layer 位于底层,主要包括:
UI Layer需对Data Layer的变化做出反应。- 事件应向下流动。
- 数据/状态应向上流动。
数据流是采用 Kotlin Flows 来实现的。
示例:在 For you 页面展示新闻信息
App 首次运行的时候,会尝试从云端加载新闻列表(选择 staging 或 release 构建变体时,debug 构建将使用本地数据)。加载后,这些内容会根据用户选择的兴趣显示给用户。
下图详细展示了事件以及数据是流转的。
下面是每一步的详细过程。 Code 列中的内容是对应的代码,可以下载项目后在 Android Studio 查看。
| 步骤 | 描述 | Code |
|---|---|---|
| 1 | App 启动的时候,WorkManager 的同步任务会把所有的 Repository 添加到任务队列中。 | SyncInitializer.create |
| 2 | 初始状态会设置为 Loading,这样会在 UI 页面上展示一个旋转的动画。 | ForYouFeedState.Loading |
| 3 | WorkManager 开始执行 OfflineFirstNewsRepository 中的同步任务,开始同步远程的数据源。 | SyncWorker.doWork |
| 4 | OfflineFirstNewsRepository 开始调用 RetrofitNiaNetwork 开始使用 Retrofit 进行真正的网络请求。 | OfflineFirstNewsRepository.syncWith |
| 5 | RetrofitNiaNetwork 调用云端接口。 | RetrofitNiaNetwork.getNewsResources |
| 6 | RetrofitNiaNetwork 接收到远程服务器返回的数据。 | RetrofitNiaNetwork.getNewsResources |
| 7 | OfflineFirstNewsRepository 通过 NewsResourceDao 将远程数据更新(增删改查)到本地的 Room 数据库中。 | OfflineFirstNewsRepository.syncWith |
| 8 | 当 NewsResourceDao 中的数据发生变化的时候,其会被更新到新闻的数据流(Flow)中。 | NewsResourceDao.getNewsResourcesStream |
| 9 | OfflineFirstNewsRepository 扮演数据流中的 中间操作符, 将 PopulatedNewsResource (数据层内部数据库的一个实体类) 转换成公开的 NewsResource 实体类供其他层使用。 | OfflineFirstNewsRepository.getNewsResourcesStream |
| 10 | 当 ForYouViewModel 接收到 Success 成功, ForYouScreen 会使用新的 State 来渲染页面。页面将会展示最新的新闻内容。 | ForYouFeedState.Success |
Data Layer
数据层包含 App 数据以及业务逻辑,会优先提供本地离线数据,它是 App 中所有数据的唯一信源。
每个 Repository 中都有自己的实体类(model/entity)。如,TopicsRepository 包含 Topic 实体类, NewsRepository 包含 NewsResource 实体类。
Repository 是其他层的公共的 API,提供了访问 App 数据的唯一途径。Repository 通常提供一种或多种数据读取和写入的方法。
读取数据
数据通过数据流提供。这意味着 Repository 的调用者都必须准备好对数据的变化做出响应。数据不会作为快照(例如 getModel )提供,因为无法确保它在使用时仍然有效。
Repository 以本地存储数据作为单一信源,因此从实例读取时不会出现错误。但是,当尝试将本地存储中的数据与云端数据进行合并时,可能会发生错误。有关错误的更多信息,请查看下面的数据同步部分。
示例:读取作者信息
可以用过订阅 AuthorsRepository::getAuthorsStream 发出的流来获得 List<Authors> 信息。每当作者列表更改时(例如,添加新作者时),更新后的 List<Author> 的内容都会发送到数据流中。如下:
class OfflineFirstTopicsRepository @Inject constructor(
private val topicDao: TopicDao,
private val network: NiANetwork,
private val niaPreferences: NiaPreferences,
) : TopicsRepository {
// 监听 Room 数据的变化,当数据发生变化的时候,调用者就会收到对应的数据
override fun getTopicsStream(): Flow<List<Topic>> = topicDao.getTopicEntitiesStream().map {
it.map(TopicEntity::asExternalModel)
}
// ...
}
写入数据
为了写入数据,Repository 库提供了 suspend 函数。由调用者来确保它们在合适的 scope 中被执行。
示例: 关注 Topic
调用 TopicsRepository.setFollowedTopicId 将用户想要关注的 topic id 传入即可。
在 OfflineFirstTopicsRepository 中定义:
interface TopicsRepository : Syncable {
suspend fun setFollowedTopicIds(followedTopicIds: Set<String>)
}
在 ForYouViewModel 中定义:
class ForYouViewModel @Inject constructor(
private val topicsRepository: TopicsRepository,
// ...
) : ViewModel() {
// ...
fun saveFollowedInterests() {
// ...
viewModelScope.launch {
topicsRepository.setFollowedTopicIds(inProgressTopicSelection)
// ...
}
}
}
数据源(Data Sources)
Repository 可能依赖于一个或多个 DataSource。例如,OfflineFirstTopicsRepository 依赖以下数据源:
| 名称 | 使用 | 目的 |
|---|---|---|
| TopicsDao | Room/SQLite | 持久化和 Topics 相关的关系型数据。 |
| NiaPreferences | Proto DataStore | 持久化和用户相关的非结构化偏好数据,主要是用户感兴趣的 Topics 内容。这里使用的是 .proto 文件。 |
| NiANetwork | Retrofit | 云端以 JSON 形式提供对应的 Topics 数据。 |
数据同步
Repository 的职责之一就是整合本地数据与云端数据。一旦从云端返回数据就会立即将其写入本地数据中。更新后的数据将会从本地数据(Room)中发送到相关的数据流中,调用者便可以监听到对应的变化。
这种方法可确保应用程序的读取和写入关注点是分开的,不会相互干扰。
在数据同步过程中出现错误的情况下,应采用对应的回退策略。App 中是经由 SyncWorker 代理给 WorkManager 的。 SyncWorker 是 Synchronizer 的实现类。
可以通过 OfflineFirstNewsRepository.syncWith 来查看数据同步的示例,如下:
class OfflineFirstNewsRepository @Inject constructor(
private val newsResourceDao: NewsResourceDao,
private val episodeDao: EpisodeDao,
private val authorDao: AuthorDao,
private val topicDao: TopicDao,
private val network: NiANetwork,
) : NewsRepository {
override suspend fun syncWith(synchronizer: Synchronizer) =
synchronizer.changeListSync(
versionReader = ChangeListVersions::newsResourceVersion,
changeListFetcher = { currentVersion ->
network.getNewsResourceChangeList(after = currentVersion)
},
versionUpdater = { latestVersion ->
copy(newsResourceVersion = latestVersion)
},
modelDeleter = newsResourceDao::deleteNewsResources,
modelUpdater = { changedIds ->
val networkNewsResources = network.getNewsResources(ids = changedIds)
topicDao.insertOrIgnoreTopics(
topicEntities = networkNewsResources
.map(NetworkNewsResource::topicEntityShells)
.flatten()
.distinctBy(TopicEntity::id)
)
// ...
}
)
}
UI Layer
UI Layer 包含:
- Jetpack Compose 中的 UI 元素。
- Android ViewMode 。
ViewModel 从 Repository 接收数据流并将其转换为 UI State。UI 元素根据 UI State 进行渲染,并为用户提供了与 App 交互的方式。这些交互作为事件(UI Event)传递到对应的 ViewModel 中。
构建 UI State
UI State 一般是通过接口和 data class 来组装的密封类。State 对象只能通过数据流的转换发出。这种方法可确保:
UI State始终代表底层应用程序数据 - App 中的单一信源。- UI 元素处理所有可能的
UI State。
示例:For You 页面的新闻列表
For You 页面的新闻列表数据源是 ForYouFeedState ,他是一个 sealed interface 类,包含 Loading 和 Success 两种状态:
Loading表示数据正在加载。Success表示数据加载成功。Success 状态包含新闻资源列表。
sealed interface ForYouFeedState {
object Loading : ForYouFeedState
data class Success(val feed: List<SaveableNewsResource>) : ForYouFeedState
}
ForYouScreen 中会处理 feedState 的这两种状态,如下:
private fun LazyListScope.Feed(
feedState: ForYouFeedState,
//...
) {
when (feedState) {
ForYouFeedState.Loading -> {
// show loading
}
is ForYouFeedState.Success -> {
// show feed
}
}
}
将数据流转换为 UI State
ViewModel 从一个或者多个 Repository 中接收数据流当做冷流 。将他们一起 组合 成单一的 UI State。然后使用 stateIn 将冷流转换成热流。转换的状态流使 UI 元素可以读取到数据流中最后的状态。
示例: 展示已关注的话题及作者
InterestsViewModel 暴露 StateFlow<FollowingUiState> 类型的 uiState 。通过组合 4 个数据流来创建热流:
- 作者列表
- 已关注的作者 ID 列表
- Topics 列表
- 已关注 Topics 列表的 IDs
将 Author 转换为 FollowableAuthor,FollowableAuthor 是对 Author 的包装类, 添加了当前用户是否已经关注了作者。对 Topic 也做了相同转换。 如下:
val uiState: StateFlow<InterestsUiState> = combine(
authorsRepository.getAuthorsStream(),
authorsRepository.getFollowedAuthorIdsStream(),
topicsRepository.getTopicsStream(),
topicsRepository.getFollowedTopicIdsStream(),
) { availableAuthors, followedAuthorIdsState, availableTopics, followedTopicIdsState ->
InterestsUiState.Interests(
// 将 Author 转换为 FollowableAuthor,FollowableAuthor 是对 Author 的包装类,
// 添加了当前用户是否已经关注了作者
authors = availableAuthors
.map { author ->
FollowableAuthor(
author = author,
isFollowed = author.id in followedAuthorIdsState
)
}
.sortedBy { it.author.name },
// 将 Topic 转换为 FollowableTopic,同 Author
topics = availableTopics
.map { topic ->
FollowableTopic(
topic = topic,
isFollowed = topic.id in followedTopicIdsState
)
}
.sortedBy { it.topic.name }
)
}
.stateIn(
scope = viewModelScope,
started = SharingStarted.WhileSubscribed(5_000),
initialValue = InterestsUiState.Loading
)
两个新的列表创建了新的 FollowingUiState.Interests UiState 暴露给 UI 层。
处理用户交互
用户对 UI 元素的操作通过常规的函数调用传递给 ViewModel ,这些方法作为 lambda 表达式传递给 UI 元素。
示例:关注话题
InterestsScreen 通过 followTopic lambda 表达式传递事件,然后会调用到 InterestsViewModel.followTopic 函数。当用户点击关注话题的时候,函数将会被调用。然后 ViewModel 就会通过通知 TopicsRepository 处理对应的用户操作。
如下在 InterestsRoute 中关联 InterestsScreen 与 InterestsViewModel :
@Composable
fun InterestsRoute(
modifier: Modifier = Modifier,
navigateToAuthor: (String) -> Unit,
navigateToTopic: (String) -> Unit,
viewModel: InterestsViewModel = hiltViewModel()
) {
val uiState by viewModel.uiState.collectAsState()
val tabState by viewModel.tabState.collectAsState()
InterestsScreen(
uiState = uiState,
tabState = tabState,
followTopic = viewModel::followTopic,
// ...
)
}
@Composable
fun InterestsScreen(
uiState: InterestsUiState,
tabState: InterestsTabState,
followTopic: (String, Boolean) -> Unit,
// ...
) {
//...
}
扩展阅读
本文主要是根据 Now in Android 中的 Architecture Learning Journey 整理而得,感兴趣的可以进一步阅读原文。除此之外,还可以进一步学习 Android 官方相关的资料:
关于架构指南部分,我之前也整理了部分对应的解读部分,大家可以移步查看
链接:https://juejin.cn/post/7099245635269820453
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
聊一聊Kotlin协程"低级"api
聊一聊kotlin协程“低级”api
Kotlin协程已经出来很久了,相信大家都有不同程度的用上了,由于最近处理的需求有遇到协程相关,因此今天来聊一Kotlin协程的“低级”api,首先低级api并不是它真的很“低级”,而是kotlin协程库中的基础api,我们一般开发用的,其实都是通过低级api进行封装的高级函数,本章会通过低级api的组合,实现一个自定义的async await 函数(下文也会介绍kotlin 高级api的async await),涉及的低级api有startCoroutine ,ContinuationInterceptor 等
startCoroutine
我们知道,一个suspend关键字修饰的函数,只能在协程体中执行,伴随着suspend 关键字,kotlin coroutine common库(平台无关)也提供出来一个api,用于直接通过suspend 修饰的函数直接启动一个协程,它就是startCoroutine@SinceKotlin("1.3")
@Suppress("UNCHECKED_CAST")
public fun <R, T> (suspend R.() -> T).startCoroutine(
作为Receiver
receiver: R,
当前协程结束时的回调
completion: Continuation<T>
) {
createCoroutineUnintercepted(receiver, completion).intercepted().resume(Unit)
}
可以看到,它的Receiver是(suspend R.() -> T),即是一个suspend修饰的函数,那么这个有什么作用呢?我们知道,在普通函数中无法调起suspend函数(因为普通函数没有隐含的Continuation对象,这里我们不在这章讲,可以参考kotlin协程的资料)
但是普通函数是可以调起一个以suspend函数作为Receiver的函数(本质也是一个普通函数)
其中startCoroutine就是其中一个,本质就是我们直接从外部提供了一个Continuation,同时调用了resume方法,去进入到了协程的世界
startCoroutine实现
createCoroutineUnintercepted(completion).intercepted().resume(Unit)
这个原理我们就不细讲下去原理,之前也有写过相关的文章。通过这种调用,我们其实就可以实现在普通的函数环境,开启一个协程环境(即带有了Continuation),进而调用其他的suspend函数。
ContinuationInterceptor
我们都知道拦截器的概念,那么kotlin协程也有,就是ContinuationInterceptor,它提供以AOP的方式,让外部在resume(协程恢复)前后进行自定义的拦截操作,比如高级api中的Diapatcher就是。当然什么是resume协程恢复呢,可能读者有点懵,我们还是以上图中出现的mySuspendFunc举例子mySuspendFunc是一个suspned函数
::mySuspendFunc.startCoroutine(object : Continuation<Unit> {
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: Result<Unit>) {
}
})
它其实等价于val continuation = ::mySuspendFunc.createCoroutine(object :Continuation<Unit>{
override val context: CoroutineContext
get() = EmptyCoroutineContext
override fun resumeWith(result: Result<Unit>) {
Log.e("hello","当前协程执行完成的回调")
}
})
continuation.resume(Unit)
startCoroutine方法就相当于创建了一个Continuation对象,并调用了resume。创建Continuation可通过createCoroutine方法,返回一个Continuation,如果我们不调用resume方法,那么它其实什么也不会执行,只有调用了resume等执行方法之后,才会执行到后续的协程体(这个也是协程内部实现,感兴趣可以看看之前文章)
而我们的拦截器,就相当于在continuation.resume前后,可以添加自己的逻辑。我们可以通过继承ContinuationInterceptor,实现自己的拦截器逻辑,其中需要复写的方法是interceptContinuation方法,用于返回一个自己定义的Continuation对象,而我们可以在这个Continuation的resumeWith方法里面(当调用了resume之后,会执行到resumeWith方法),进行前后打印/其他自定义操作(比如切换线程)
class ClassInterceptor() :ContinuationInterceptor {override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>):Continuation<T> by continuation{
override fun resumeWith(result: Result<T>) {
Log.e("hello","MyContinuation start ${result.getOrThrow()}")
continuation.resumeWith(result)
Log.e("hello","MyContinuation end ")
}
}
其中的key是ContinuationInterceptor,协程内部会在每次协程恢复的时候,通过coroutineContext取出key为ContinuationInterceptor的拦截器,进行拦截调用,当然这也是kotlin协程内部实现,这里简单提一下。
实战
kotlin协程api中的 async await
我们来看一下kotlin Coroutine 的高级api async await用法
CoroutineScope(Dispatchers.Main).launch {
val block = async(Dispatchers.IO) {
// 阻塞的事项
}
// 处理其他主线程的事务
// 此时必须需要async的结果时,则可通过await()进行获取
val result = block.await()
}
我们可以通过async方法,在其他线程中处理其他阻塞事务,当主线程必须要用async的结果的时候,就可以通过await等待,这里如果结果返回了,则直接获取值,否则就等待async执行完成。这是Coroutine提供给我们的高级api,能够将任务简单分层而不需要过多的回调处理。
通过startCoroutine与ContinuationInterceptor实现自定义的 async await
我们可以参考其他语言的async,或者Dart的异步方法调用,都有类似这种方式进行线程调用
async {
val result = await {
suspend 函数
}
消费result
}
await在async作用域里面,同时获取到result后再进行消费,async可以直接在普通函数调用,而不需要在协程体内,下面我们来实现一下这个做法。
首先我们想要限定await函数只能在async的作用域才能使用,那么首先我们就要定义出来一个Receiver,我们可以在Receiver里面定义出自己想要暴露的方法
interface AsyncScope {
fun myFunc(){
}
}
fun async(
context: CoroutineContext = EmptyCoroutineContext,
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
注意这个类,resumeWith 只会跟startCoroutine的这个协程绑定关系,跟await的协程没有关系
class AsyncStub(override val context: CoroutineContext = EmptyCoroutineContext) :
Continuation<Unit>, AsyncScope {
override fun resumeWith(result: Result<Unit>) {
// 这个是干嘛的 == > 完成的回调
Log.e("hello","AsyncStub resumeWith ${Thread.currentThread().id} ${result.getOrThrow()}")
}
}
上面我们定义出来一个async函数,同时定义出来了一个AsyncStub的类,它有两个用处,第一个是为了充当Receiver,用于规范后续的await函数只能在这个Receiver作用域中调用,第二个作用是startCoroutine函数必须要传入一个参数completion,是为了收到当前协程结束的回调resumeWith中可以得到当前协程体结束回调的信息
await方法里面
suspend fun<T> AsyncScope.await(block:() -> T) = suspendCoroutine<T> {
// 自定义的Receiver函数
myFunc()
Thread{
切换线程执行await中的方法
it.resumeWith(Result.success(block()))
}.start()
}
在await中,其实是一个扩展函数,我们可以调用任何在AsyncScope中定义的方法,同时这里我们模拟了一下线程切换的操作(Dispatcher的实现,这里不采用Dispatcher就是想让大家知道其实Dispatcher.IO也是这样实现的),在子线程中调用it.resumeWith(Result.success(block())),用于返回所需要的信息
通过上面定的方法,我们可以实现
async {
val result = await {
suspend 函数
}
消费result
}
这种调用方式,但是这里引来了一个问题,因为我们在await函数中实际将操作切换到了子线程,我们想要将消费result的动作切换至主线程怎么办呢?又或者是加入我们希望获取结果前做一些调整怎么办呢?别急,我们这里预留了一个CoroutineContext函数,我们可以在外部传入一个CoroutineContext
public interface ContinuationInterceptor : CoroutineContext.Element
而CoroutineContext.Element又是继承于CoroutineContext
CoroutineContext.Element:CoroutineContext
而我们的拦截器,正是CoroutineContext的子类,我们把上文的ClassInterceptor修改一下
class ClassInterceptor() : ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>) :
Continuation<T> by continuation {
private val handler = Handler(Looper.getMainLooper())
override fun resumeWith(result: Result<T>) {
Log.e("hello", "MyContinuation start ${result.getOrThrow()}")
handler.post {
continuation.resumeWith(Result.success(自定义内容))
}
Log.e("hello", "MyContinuation end ")
}
}
同时把async默认参数CoroutineContext实现一下即可
fun async(
context: CoroutineContext = ClassInterceptor(),
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
此后我们就可以直接通过,完美实现了一个类js协程的调用,同时具备了自动切换线程的能力
async {
val result = await {
test()
}
Log.e("hello", "result is $result ${Looper.myLooper() == Looper.getMainLooper()}")
}
结果
E start
E MyContinuation start kotlin.Unit
E MyContinuation end
E end
E 执行阻塞函数 test 1923
E MyContinuation start 自定义内容数值
E MyContinuation end
E result is 自定义内容的数值 true
E AsyncStub resumeWith 2 kotlin.Unit
最后,这里需要注意的是,为什么拦截器回调了两次,因为我们async的时候开启了一个协程,同时await的时候也开启了一个,因此是两个。AsyncStub只回调了一次,是因为AsyncStub被当作complete参数传入了async开启的协程block.startCoroutine,因此只是async中的协程结束才会被回调。
本章代码
class ClassInterceptor() : ContinuationInterceptor {
override val key = ContinuationInterceptor
override fun <T> interceptContinuation(continuation: Continuation<T>): Continuation<T> =
MyContinuation(continuation)
}
class MyContinuation<T>(private val continuation: Continuation<T>) :
Continuation<T> by continuation {
private val handler = Handler(Looper.getMainLooper())
override fun resumeWith(result: Result<T>) {
Log.e("hello", "MyContinuation start ${result.getOrThrow()}")
handler.post {
continuation.resumeWith(Result.success(6 as T))
}
Log.e("hello", "MyContinuation end ")
}
}interface AsyncScope {
fun myFunc(){
}
}
fun async(
context: CoroutineContext = ClassInterceptor(),
block: suspend AsyncScope.() -> Unit
) {
// 这个有两个作用 1.充当receiver 2.completion,接收回调
val completion = AsyncStub(context)
block.startCoroutine(completion, completion)
}
class AsyncStub(override val context: CoroutineContext = EmptyCoroutineContext) :
Continuation<Unit>, AsyncScope {
override fun resumeWith(result: Result<Unit>) {
// 这个是干嘛的 == > 完成的回调
Log.e("hello","AsyncStub resumeWith ${Thread.currentThread().id} ${result.getOrThrow()}")
}
}
suspend fun<T> AsyncScope.await(block:() -> T) = suspendCoroutine<T> {
myFunc()
Thread{
it.resumeWith(Result.success(block()))
}.start()
}模拟阻塞
fun test(): Int {
Thread.sleep(5000)
Log.e("hello", "执行阻塞函数 test ${Thread.currentThread().id}")
return 5
}async {
val result = await {
test()
}
Log.e("hello", "result is $result ${Looper.myLooper() == Looper.getMainLooper()}")
}
最后
我们通过协程的低级api,实现了一个与官方库不同版本的async await,同时也希望通过对低级api的设计,也能对Coroutine官方库的高级api的实现有一定的了解。
链接:https://juejin.cn/post/7172813333148958728
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Kotlin | 理解泛型使用
泛型类 & 泛型方法
泛型,指的是具体的类型泛化,多用在集合中(如List、Map),编码时使用符号代替,在使用时再确定具体类型。
泛型通常用于类和方法中,称为泛型类、泛型方法,使用示例:
/**
* 泛型类
*/
abstract class BaseBook<T> {
private var books: ArrayList<T> = ArrayList()
/**
* 泛型方法
*/
fun <E : T> add(item: E) {
books.add(item)
println("list:$books, size:${books.size}")
}
}
/**
* 子类继承BaseBook并传入泛型参数MathBook
*/
class BookImpl : BaseBook<MathBook>()
fun main() {
BookImpl().apply {
add(MathBook("数学"))
}
}
执行main()方法,输出:
list:[MathBook(math=数学)], size: 1
Java泛型通配符
? extends E 定义上界
Java中的泛型是不型变的,举个例子:Integer是Object的子类,但是List<Integer>并不是List<Object>的子类,因为List是不型变的。如:
如果想让List<Integer>成为List<Object>的子类,可以通过上界操作符 ? extends E 来操作。
? extends E 表示此方法接受 E 或者 E 的 一些子类型对象的集合,而不只是 E 自身。extends操作符可以限定上界通配符类型,使得通配符类型是协变的。注意,经过协变之后,数据是可读不可写的。示例:
//继承关系Child -> Parent
class Parent{
protected String name = "Parent";
}
class Child extends Parent {
protected String name = "Child";
}
定义实体类,继承关系:Child -> Parent
class CList<E> {
//通过<? extends E>来定义上界
public void addAll(List<? extends E> list) {
//...
}
}
/**
* <? extends E>来定义上界,可以保证协变性
*/
public void GExtends() {
//1、Child是Parent的子类
Parent parent = new Child();
//2、协变,泛型参数是Parent
CList<Parent> objs = new CList<>();
List<Child> strs = new ArrayList<>(); //声明字符串List
strs.add(new Child());
objs.addAll(strs); //addAll()方法中的入参必须为List<? extends E>,从而保证了List<Child>是List<Parent>的子类。
}
addAll()方法中的入参必须为List<? extends E>,从而保证了List<Child>是List<Parent>的子类。如果addAll()中的入参改为List<E>,则编译器会直接报错,因为List<Child>并不是List<Parent>的子类,如下:
? super E 定义下界
? super E 可以看作一个E或者E的父类的“未知类型”,这里的父类包括直接和间接父类。super定义泛型的下界,使得通配符类型是逆变的。经过逆变之后,数据是可写不可读的,如: List<? super Child> 是 List<Parent> 的一个超类。示例:
class CList<E> {
//通过<? super E>来定义下界
public void popAll(List<? super E> dest) {
//...
}
/**
* 逆变性
*/
public void GSuper(){
CList<Child> objs = new CList<>();
List<Parent> parents = new ArrayList<>(); //声明字符串List
parents.add(new Parent());
objs.popAll(parents); //逆变
}
可以看到popAll()的入参必须声明为List<? super E>,如果改为List<E>,编译器会直接报错:
Kotlin泛型
和 Java 一样,Kolin 泛型本身也是不能型变的。
- 使用关键字
out来支持协变,等同于Java中的上界通配符? extends T。 - 使用关键字
in来支持逆变,等同于Java中的下界通配符? super T。
声明处型变
协变< out T>
interface GenericsP<T> {
fun get(): T //读取并返回T,可以认为只能读取T的对象是生产者
}
如上声明了GenericsP< T>接口,如果其内部只能读取并返回T,可以认为GenericsP实例对象为生产者(返回T)。
open class Book(val name: String)
data class EnglishBook(val english: String) : Book(english)
data class MathBook(val math: String) : Book(math)
已知EnglishBook、MathBook为Book的子类,但是如果将Book、EnglishBook当成泛型放入GenericsP,他们之间的关系还成立吗?即:
可以看到编译器直接报错,因为虽然EnglishBook是Book的子类,但是GenericsP<EnglishBook>并不是GenericsP<Book>的子类,如果想让这个关系也成立,Kotlin提供了out修饰符,out修饰符能够确保:
1、T只能用于函数返回中,不能用于参数输入中;
2、GenericsP< EnglishBook>可以安全的作为GenericsP< Book>的子类
示例如下:
interface GenericsP<out T> {
fun get(): T //读取并返回T,可以认为只能读取T的对象是生产者
// fun put(item: T) //错误,不允许在输入参数中使用
}
经过如上的改动后,可以看到GenericsP<EnglishBook>可以正确赋值给GenericsP<Book>了:
逆变< in T>
interface GenericsC<T> {
fun put(item: T) //写入T,可以认为只能写入T的对象是消费者
}
如上声明了GenericsC<T>接口,如果其内部只能写入T,可以认为GenericsC实例对象为消费者(消费T)。为了保证T只能出现在参数输入位置,而不能出现在函数返回位置上,Kotlin可以使用in进行控制:
interface GenericsC<in T> {
fun put(item: T) //写入T,可以认为只能写入T的对象是消费者
//fun get(): T //错误,不允许在返回中使用
}
继续编写如下函数:
/**
* 称为GenericsC在Book上是逆变的。
* 跟系统源码中的Comparable类似
*/
private fun consume(to: GenericsC<Book>) {
//GenericsC<Book>实例赋值给了GenericsC<EnglishBook>
val target: GenericsC<EnglishBook> = to
target.put(EnglishBook("英语"))
}
可以看到GenericsC中的泛型参数声明为in后,GenericsC<Book>实例可以直接赋值给了GenericsC<EnglishBook>,称为GenericsC在Book上是逆变的。在系统源码中我们经常使用的一个例子就是Comparable:
//Comparable.kt
public interface Comparable<in T> {
public operator fun compareTo(other: T): Int
}
使用处型变(类型投影)
上一节中in、out都是写在类的声明处,从而控制泛型参数的使用场景,但是如果泛型参数既可能出现在函数入参中,又可能出现在函数返回中,典型的类就是Array:
class Array<T>(val size: Int) {
fun get(index: Int): T { …… }
fun set(index: Int, value: T) { …… }
}
这时候就不能在声明处做任何协变/逆变的操作了,如下函数中使用Array:
fun copy(from: Array<Any>, to: Array<Any>) {
if (from.size != to.size) return
for (i in from.indices)
to[i] = from[i]
}
调用方:
val strs: Array<String> = arrayOf("1", "2")
val any = Array<Any>(2) {}
copy(strs, any) //编译器报错 strs其类型为 Array<String> 但此处期望 Array<Any>
错误原因就是因为Array<String>并不是Array<Any>的子类,即不是协变的,这里是为了保证数据的安全性。如果可以保证Array< String>传入copy()函数之后不能被写入,那么就保证了安全性,既然我们在声明Array时不能限制泛型参数,那么完全可以在使用处进行限制,如下:
fun copy(from: Array<out Any>, to: Array<Any>) {
if (from.size != to.size) return
for (i in from.indices)
to[i] = from[i]
}
可以看到对from添加了out限制,这种被称为使用处型变。即不允许from进行写入操作,那么就可以保证了from的安全性,再进行上面的调用时,copy(strs, any)就可以正确的执行了。
星投影< *>
当不使用协变、逆变时,某些场景下可以使用<*>来实现泛型,如:
- 对于
GenericsP<out T: Book>,GenericsP< *>相当于GenericsP<out Book>,当T未知时,可以安全的从GenericsP<*>中读取Book值; - 对于
GenericsC<in T>,GenericsC<*>相当于GenericsC<in Nothing>,当T未知时,没有安全方式写入GenericsC<*>; - 对于
Generics<T: Book>,T为有上界Book的不型变参数,当Generics<*>读取时等价于Generics<out Book>;写入时等价于Generics<in Nothing>。
泛型擦除
泛型参数会在编译期间存在,在运行期间会被擦除,例如:Generics<EnglishBook> 与 Generics<MathBook> 的实例都会被擦除为 Generics<*>。运行时期检测一个泛型类型的实例无法通过is关键字进行判断,另外运行期间具体的泛型类型判断也无法判断,如: books as List<Book>,只会对非泛型部分进行检测,形如:books as List<*>。
如果想具体化泛型参数,可以通过inline + reified的方式:
/**
* inline + reified 使得类型参数被实化 reified:实体化的
* 注:带reified类型参数的内联函数,Java是无法直接调用的
*/
inline fun <reified T> isAny(value: Any): Boolean {
return value is T
}
参考
【1】https://www.kotlincn.net/docs/reference/generics.html
【2】https://mp.weixin.qq.com/s/vSwx7fgROJcrQwEOW7Ws8A
【3】https://juejin.cn/post/7042606952311947278
链接:https://juejin.cn/post/7221777883161821245
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


