








如何优雅的防止按钮重复点击
1. 业务背景
在前端的业务场景中:点击按钮,发起请求。在请求还未结束的时候,一个按钮可以重复点击,导致接口重新请求多次(如果后端不做限制)。轻则浪费服务器资源,重则业务逻辑错误,尤其是入库操作。
传统解决方案:使用防抖函数,但是无法解决接口响应时间过长的问题,当接口一旦响应时间超过防抖时间,测试单身20年的手速照样还是可以点击多次。
更稳妥的方式:给button添加loadng,只有接口响应结果后才能再次点击按钮。需要在每个使用按钮的页面逻辑中单独维护loading变量,代码变得臃肿。
那如果是在react项目中,这种问题有没有比较优雅的解决方式呢?
vue项目解决方案参考:juejin.cn/post/749541…
在前端的业务场景中:点击按钮,发起请求。在请求还未结束的时候,一个按钮可以重复点击,导致接口重新请求多次(如果后端不做限制)。轻则浪费服务器资源,重则业务逻辑错误,尤其是入库操作。
传统解决方案:使用防抖函数,但是无法解决接口响应时间过长的问题,当接口一旦响应时间超过防抖时间,测试单身20年的手速照样还是可以点击多次。
更稳妥的方式:给button添加loadng,只有接口响应结果后才能再次点击按钮。需要在每个使用按钮的页面逻辑中单独维护loading变量,代码变得臃肿。
那如果是在react项目中,这种问题有没有比较优雅的解决方式呢?
vue项目解决方案参考:juejin.cn/post/749541…
2. useAsyncButton
在 React 项目中,对于这种按钮重复点击的问题,可以使用自定义 Hook 来优雅地处理。以下是一个完整的解决方案:
- 首先创建一个自定义 Hook
useAsyncButton:
import { useState, useCallback } from 'react';
interface RequestOptions {
onSuccess?: (data: any) => void;
onError?: (error: any) => void;
}
export function useAsyncButton(
requestFn: (...args: any[]) => Promise,
options: RequestOptions = {}
) {
const [loading, setLoading] = useState(false);
const run = useCallback(
async (...args: any[]) => {
if (loading) return; // 如果正在加载,直接返回
try {
setLoading(true);
const data = await requestFn(...args);
options.onSuccess?.(data);
return data;
} catch (error) {
options.onError?.(error);
throw error;
} finally {
setLoading(false);
}
},
[loading, requestFn, options]
);
return {
loading,
run
};
}
- 在组件中使用这个 Hook:
import { useAsyncButton } from '../hooks/useAsyncButton';
const MyButton = () => {
const { loading, run } = useAsyncButton(async () => {
// 这里是你的接口请求
const response = await fetch('your-api-endpoint');
const data = await response.json();
return data;
}, {
onSuccess: (data) => {
console.log('请求成功:', data);
},
onError: (error) => {
console.error('请求失败:', error);
}
});
return (
<button
onClick={() => run()}
disabled={loading}
>
{loading ? '加载中...' : '点击请求'}
button>
);
};
export default MyButton;
在 React 项目中,对于这种按钮重复点击的问题,可以使用自定义 Hook 来优雅地处理。以下是一个完整的解决方案:
- 首先创建一个自定义 Hook
useAsyncButton:
import { useState, useCallback } from 'react';
interface RequestOptions {
onSuccess?: (data: any) => void;
onError?: (error: any) => void;
}
export function useAsyncButton(
requestFn: (...args: any[]) => Promise,
options: RequestOptions = {}
) {
const [loading, setLoading] = useState(false);
const run = useCallback(
async (...args: any[]) => {
if (loading) return; // 如果正在加载,直接返回
try {
setLoading(true);
const data = await requestFn(...args);
options.onSuccess?.(data);
return data;
} catch (error) {
options.onError?.(error);
throw error;
} finally {
setLoading(false);
}
},
[loading, requestFn, options]
);
return {
loading,
run
};
}
- 在组件中使用这个 Hook:
import { useAsyncButton } from '../hooks/useAsyncButton';
const MyButton = () => {
const { loading, run } = useAsyncButton(async () => {
// 这里是你的接口请求
const response = await fetch('your-api-endpoint');
const data = await response.json();
return data;
}, {
onSuccess: (data) => {
console.log('请求成功:', data);
},
onError: (error) => {
console.error('请求失败:', error);
}
});
return (
<button
onClick={() => run()}
disabled={loading}
>
{loading ? '加载中...' : '点击请求'}
button>
);
};
export default MyButton;
这个解决方案有以下优点:
- 统一管理:将请求状态管理逻辑封装在一个 Hook 中,避免重复代码
- 自动处理 loading:不需要手动管理 loading 状态
- 防重复点击:在请求过程中自动禁用按钮或阻止重复请求
- 类型安全:使用 TypeScript 提供类型检查
- 灵活性:可以通过 options 配置成功/失败的回调函数
- 可复用性:可以在任何组件中重用这个 Hook
useAsyncButton直接帮你进行了try catch,你不用再单独去做异常处理。
是不是很简单?有的人可能有疑问了,为什么下方不就能拿到接口请求以后的数据吗?为什么还需要onSuccess呢?
async () => {
// 这里是你的接口请求
const response = await fetch('your-api-endpoint');
const data = await response.json();
return data;
}
3. onSuccess
确实我们可以直接在调用 run() 后通过 .then() 或 await 来获取数据。提供 onSuccess 回调主要有以下几个原因:
- 关注点分离:
// 不使用 onSuccess
const { run } = useAsyncButton(async () => {
const response = await fetch('/api/data');
return response.json();
});
const handleClick = async () => {
const data = await run();
// 处理数据的逻辑和请求逻辑混在一起
setData(data);
message.success('请求成功');
doSomethingElse(data);
};
// 使用 onSuccess
const { run } = useAsyncButton(async () => {
const response = await fetch('/api/data');
return response.json();
}, {
onSuccess: (data) => {
// 数据处理逻辑被清晰地分离出来
setData(data);
message.success('请求成功');
doSomethingElse(data);
}
});
const handleClick = () => {
run(); // 更清晰的调用方式
};
- 统一错误处理:
// 不使用 callbacks
const handleClick = async () => {
try {
const data = await run();
setData(data);
} catch (error) {
// 每个地方都需要写错误处理
message.error('请求失败');
}
};
// 使用 callbacks
const { run } = useAsyncButton(fetchData, {
onSuccess: (data) => setData(data),
onError: (error) => message.error('请求失败')
// 错误处理被集中管理
});
- 自动重试场景:
const { run } = useAsyncButton(fetchData, {
onSuccess: (data) => setData(data),
onError: (error) => {
if (retryCount < 3) {
retryCount++;
run(); // 可以在失败时自动重试
}
}
});
- 状态联动:
const { run } = useAsyncButton(fetchData, {
onSuccess: (data) => {
setData(data);
// 可能需要触发其他请求
refetchRelatedData();
// 或更新其他状态
setOtherState(true);
}
});
所以,虽然你完全可以不使用 onSuccess 回调,但它能帮助你:
- 更好地组织代码结构
- 统一管理成功/失败处理逻辑
- 方便进行状态联动
- 在需要扩展功能时更加灵活
选择使用与否取决于你的具体需求,如果是简单的场景,直接使用 await run() 也完全可以。
4. 禁止一段时间内点击
评论区有人说了,我要是想在某一段时间内防止重复点击怎么整?
我们可以扩展 useAsyncButton 的功能,添加一个防冷却时间(cooldown)的特性。这在一些特定场景下很有用,比如发送验证码按钮需要等待 60 秒才能再次点击:
import { useState, useCallback, useRef } from 'react';
interface AsyncButtonOptions {
onSuccess?: (data: any) => void;
onError?: (error: any) => void;
cooldown?: number; // 冷却时间(毫秒)
}
export function useAsyncButton(
requestFn: (...args: any[]) => Promise,
options: AsyncButtonOptions = {}
) {
const [loading, setLoading] = useState(false);
const [cooldownRemaining, setCooldownRemaining] = useState(0);
const timerRef = useRef<NodeJS.Timeout>();
const startCooldown = useCallback(() => {
if (!options.cooldown) return;
setCooldownRemaining(options.cooldown / 1000);
const startTime = Date.now();
timerRef.current = setInterval(() => {
const elapsed = Date.now() - startTime;
const remaining = Math.ceil((options.cooldown! - elapsed) / 1000);
if (remaining <= 0) {
clearInterval(timerRef.current);
setCooldownRemaining(0);
} else {
setCooldownRemaining(remaining);
}
}, 1000);
}, [options.cooldown]);
const run = useCallback(
async (...args: any[]) => {
if (loading || cooldownRemaining > 0) return;
try {
setLoading(true);
const data = await requestFn(...args);
options.onSuccess?.(data);
startCooldown();
return data;
} catch (error) {
options.onError?.(error);
throw error;
} finally {
setLoading(false);
}
},
[loading, cooldownRemaining, requestFn, options, startCooldown]
);
return {
loading,
cooldownRemaining,
run,
disabled: loading || cooldownRemaining > 0
};
}
使用示例:
import { useAsyncButton } from '../hooks/useAsyncButton';
const SendCodeButton = () => {
const { loading, cooldownRemaining, disabled, run } = useAsyncButton(
async () => {
// 发送验证码的接口请求
const response = await fetch('/api/send-code');
return response.json();
},
{
cooldown: 60000, // 60秒冷却时间
onSuccess: () => {
console.log('验证码发送成功');
},
onError: (error) => {
console.error('验证码发送失败', error);
}
}
);
return (
<button
onClick={() => run()}
disabled={disabled}
>
{loading ? '发送中...' :
cooldownRemaining > 0 ? `${cooldownRemaining}秒后重试` :
'发送验证码'}
button>
);
};
export default SendCodeButton;
来源:juejin.cn/post/7498646341460787211
为什么说不可信的Wi-Fi不要随便连接?
新闻中一直倡导的“不可信的Wi-Fi不要随便连接”,一直不知道里面的风险,即使是相关专业的从业人员,惭愧。探索后发现这里面的安全知识不少,记录下:
简单来说:
当用户连接上攻击者创建的伪造热点或者不可信的wifi后,实际上就进入了一个高度不可信的网络环境,攻击者可以进行各种信息窃取、欺骗和控制操作。
主要风险有:
🚨 1.中间人攻击(MITM)
攻击者拦截并转发你与网站服务器之间的数据,做到“你以为你连的是官网,其实中间有人”。
- 可窃取账号密码、聊天记录、信用卡信息
- 可篡改网页内容,引导你下载恶意应用
如果你和“正确”的网站之间是https,那么信息不会泄露,TLS能保证通信过程的安全,前提是你连接的这个https网站是“正确”的。正确的含义是:不是某些人恶意伪造的,不是一些不法份子通过DNS欺骗来重定向到的。
🪤 2.DNS欺骗 / 重定向
攻击者控制DNS,将合法网址解析到伪造网站。
- 你访问的“http://www.bank.com” 其实是假的银行网站,DNS域名解析到恶意服务上,返回和银行一样的登录的界面,这样用户输入账号密码就被窃取到了。
- 输入的账号密码被记录,后端没收到任何请求
这里多说一句:目前的登录方式中,采用短信验证码的方式,能避免真实的密码被窃取的风险,尽量用这种登录方式。
📥 3.强制HTTP连接,篡改内容
即使你访问的是HTTPS网站,攻击者可以强制降级为HTTP或注入恶意代码:
- 注入广告、木马脚本
- 启动钓鱼表单页面骗你输入账号密码
攻击者操作流程:
- 用户访问
http://example.com(明文) - 攻击者拦截请求,阻止它跳转到 HTTPS
- 返回伪造页面(比如仿登录页面),引导用户输入账号密码
- 用户完全不知道自己并未进入 HTTPS 页面
这里“降级”的意思是,虽然你访问的是http网站,网站正常会转为https的访问方式,但是被阻止了,一直使用的是http协议访问,能实现这种降级的前提有两个:
- 用户没有直接输入
https://baidu.com, 而是输入的http://baidu.com, 依赖浏览器自动跳转 - 访问的网站没有开启 HSTS(HTTP Strict Transport Security)
搭建安全的网站的启示:
- 网站访问用https,并且如果用户访问HTTP网站时被自动转到 HTTPS 网站
- 网站要启用HSTS
HSTS 是一种告诉浏览器“以后永远都不要使用 HTTP 访问我”的机制。
如何开启HSTS?
添加响应头(核心方式)
。在你的网站服务端(如 Nginx、Apache、Spring Boot、Express 等)添加以下 HTTP 响应头:
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
各参数含义如下:
| 参数 | 含义 |
|---|---|
max-age=31536000 | 浏览器记住 HSTS 状态的时间(单位:秒,31536000 秒 = 1 年) |
includeSubDomains | 所有子域名也强制使用 HTTPS(推荐) |
preload | 提交到浏览器 HSTS 预加载列表(详见下文) |
网站实现http访问转为了https访问:
1 网站服务器配置了自动重定向(HTTP to HTTPS)
- 这是最常见的做法。网站后台(如 Nginx、Apache、Tomcat 等)配置了规则,凡是 HTTP 请求都会返回 301/302 重定向到 HTTPS 地址。
- 目的是强制用户用加密的 HTTPS 访问,保障数据安全。
2 请求的http response中加入HSTS机制
- 网站通过 HTTPS 响应头发送了 HSTS 指令。
- 浏览器收到后会记住该网站在一定时间内只能用 HTTPS 访问。
- 即使你输入
http://,浏览器也会自动用https://访问,且不会发送 HTTP 请求。
📁 4.会话劫持(Session Hijacking)
如果你已登录某个网站(如微博/邮箱),攻击者可以窃取你与服务端之间的 Session Cookie,无需密码即可“冒充你”。
搭建web服务对于cookie泄密的安全启示:
1、开启 Cookie 的 Secure 和 HttpOnly
当一个 Cookie 设置了 Secure 标志后,它只会在 HTTPS 加密连接中发送,不会通过 HTTP 明文连接发送。
设置 HttpOnly 后,JavaScript 无法通过 document.cookie 访问该 Cookie,它只能被浏览器在请求时自动带上。如果站点存在跨站脚本漏洞(XSS),攻击者注入的 JS 可以读取用户的 Cookie。设置了 HttpOnly 后,即便 JS 被执行,也无法读取该 Cookie。
2、配合设置 SameSite=Strict 或 Lax 可进一步防止 CSRF 攻击。
Set-Cookie: sessionid=abc123; SameSite=Strict; Secure; HttpOnly
CSRF(Cross-Site Request Forgery) 攻击的原理示意
| 操作 | 说明 |
|---|---|
用户登录 bank.com,浏览器存有 bank.com 的 Cookie | Cookie 设置为非 HttpOnly 且未限制 SameSite 或 设置为 SameSite=Lax,正常携带 |
攻击网站 attacker.com,诱导用户访问 <img src="https://bank.com/transfer?to=attacker&amount=1000"> | 这个请求是向 bank.com 发送的跨域请求 |
浏览器自动带上 bank.com 的 Cookie | 因为请求的目标是 bank.com,Cookie 会被自动携带 |
bank.com 服务器收到请求,认为是用户本人操作,执行转账 | 服务器无法区分这个请求是不是用户主动发起的 |
重点是:你在浏览器中访问A网站,浏览器中存储A的cookie,此时你访问恶意的B网站,B网站向A网站发送请求,浏览器一般默认带上A网站的cookie,因此,相当于B网站恶意使用了你在A网站的身份,完成了攻击,比如获取信息,比如添加东西。设置SameSite=Strict能防止跨站伪造攻击,对A网站的请求只能在A网站下发送,在B网站发起对A网站请求的无法使用A的cookie
同源策略和Cookie的关系:
同源策略限制的是脚本访问另一个域的内容(比如 JS 不能读取别的网站 Cookie 或响应数据),但浏览器发送请求时,会自动携带目标域对应的 Cookie(只要该 Cookie 未被 SameSite 限制)。 也就是说,请求可以跨域发送,Cookie 也会随请求自动发送,但脚本无法读取响应。在没有设置SameSite时,B网站是可以直接往A网站发送请求并附带上A网站的cookie的。
关于SameSite三种取值详解:
| 值 | 说明 | 是否防CSRF | 是否影响用户体验 |
|---|---|---|---|
Strict | 最严格:完全阻止第三方请求携带 Cookie(即使用户点击链接跳转也不带) | ✅ 完全防止 | ❗️可能影响登录态保持等 |
Lax | 较宽松:阻止大多数第三方请求,但允许用户主动导航(点击链接)时携带 Cookie | ✅ 可防大部分场景 | ✅ 用户体验良好 |
| 不限制跨站请求,所有请求都携带 Cookie | ❌ 不防CSRF | ⚠️ 必须配合 Secure 使用 |
🛡 SameSite使用建议(最佳实践)
| 场景 | 建议配置 |
|---|---|
| 登录态/session Cookie | SameSite=Lax; Secure; HttpOnly ✅ 实用且安全 |
| 高安全需求(如金融后台) | SameSite=Strict; Secure; HttpOnly ✅ 更强安全性 |
| 跨域 OAuth / 第三方登录等 | SameSite=; Secure ⚠️ 必须使用 HTTPS,否则被浏览器拒绝 |
🧬 5.恶意软件传播
伪造热点可提供假的软件下载链接、更新提示等方式传播病毒或木马程序。
📡 6.网络钓鱼 + 社会工程攻击
攻击者可能弹出“需登录使用Wi-Fi”的界面,其实是钓鱼网站:
- 模拟常见的Wi-Fi登录界面(如酒店/机场门户)
- 用户一旦输入账号、手机号、验证码等敏感信息就被窃取
🔎 7.MAC地址、设备指纹收集
哪怕你没主动上网,连接伪热点后,攻击者也可能收集:
- 你的设备MAC地址、品牌型号
- 操作系统、语言、浏览器等指纹信息
- 用于后续追踪、精准广告投放,甚至诈骗定位
✅ 如何防范被伪热点攻击?
| 措施 | 说明 |
|---|---|
| 关闭“自动连接开放Wi-Fi” | 阻止设备自动连接伪热点 |
| 避免输入账号密码、支付信息 | 尤其在陌生Wi-Fi环境下 |
| 使用 VPN | 建立安全通道防止数据被截取 |
| 留意HTTPS证书异常 | 浏览器地址栏变红或提示“不安全”要立刻断开连接 |
| 使用手机流量热点 | 相对更可控安全 |
| 安装安全软件 | 检测钓鱼网站和网络攻击行为 |
来源:juejin.cn/post/7517468634194362387
瞧瞧别人家的判空,那叫一个优雅!
大家好,我是苏三,又跟大家见面了。
一、传统判空的血泪史
某互联网金融平台因费用计算层级的空指针异常,导致凌晨产生9800笔错误交易。
DEBUG日志显示问题出现在如下代码段:
// 错误示例
BigDecimal amount = user.getWallet().getBalance().add(new BigDecimal("100"));
此类链式调用若中间环节出现null值,必定导致NPE。
初级阶段开发者通常写出多层嵌套式判断:
if(user != null){
Wallet wallet = user.getWallet();
if(wallet != null){
BigDecimal balance = wallet.getBalance();
if(balance != null){
// 实际业务逻辑
}
}
}
这种写法既不优雅又影响代码可读性。
那么,我们该如何优化呢?
最近准备面试的小伙伴,可以看一下这个宝藏网站:www.susan.net.cn,里面:面试八股文、面试真题、工作内推什么都有。
二、Java 8+时代的判空革命
Java8之后,新增了Optional类,它是用来专门判空的。
能够帮你写出更加优雅的代码。
1. Optional黄金三板斧
// 重构后的链式调用
BigDecimal result = Optional.ofNullable(user)
.map(User::getWallet)
.map(Wallet::getBalance)
.map(balance -> balance.add(new BigDecimal("100")))
.orElse(BigDecimal.ZERO);
高级用法:条件过滤
Optional.ofNullable(user)
.filter(u -> u.getVipLevel() > 3)
.ifPresent(u -> sendCoupon(u)); // VIP用户发券
2. Optional抛出业务异常
BigDecimal balance = Optional.ofNullable(user)
.map(User::getWallet)
.map(Wallet::getBalance)
.orElseThrow(() -> new BusinessException("用户钱包数据异常"));
3. 封装通用工具类
public class NullSafe {
// 安全获取对象属性
public static <T, R> R get(T target, Function<T, R> mapper, R defaultValue) {
return target != null ? mapper.apply(target) : defaultValue;
}
// 链式安全操作
public static <T> T execute(T root, Consumer<T> consumer) {
if (root != null) {
consumer.accept(root);
}
return root;
}
}
// 使用示例
NullSafe.execute(user, u -> {
u.getWallet().charge(new BigDecimal("50"));
logger.info("用户{}已充值", u.getId());
});
三、现代化框架的判空银弹
4. Spring实战技巧
Spring中自带了一些好用的工具类,比如:CollectionUtils、StringUtils等,可以非常有效的进行判空。
具体代码如下:
// 集合判空工具
List<Order> orders = getPendingOrders();
if (CollectionUtils.isEmpty(orders)) {
return Result.error("无待处理订单");
}
// 字符串检查
String input = request.getParam("token");
if (StringUtils.hasText(input)) {
validateToken(input);
}
5. Lombok保驾护航
我们在日常开发中的entity对象,一般会使用Lombok框架中的注解,来实现getter/setter方法。
其实,这个框架中也提供了@NonNull等判空的注解。
比如:
@Getter
@Setter
public class User {
@NonNull // 编译时生成null检查代码
private String name;
private Wallet wallet;
}
// 使用构造时自动判空
User user = new User(@NonNull "张三", wallet);
四、工程级解决方案
6. 空对象模式
public interface Notification {
void send(String message);
}
// 真实实现
public class EmailNotification implements Notification {
@Override
public void send(String message) {
// 发送邮件逻辑
}
}
// 空对象实现
public class NullNotification implements Notification {
@Override
public void send(String message) {
// 默认处理
}
}
// 使用示例
Notification notifier = getNotifier();
notifier.send("系统提醒"); // 无需判空
7. Guava的Optional增强
其实Guava工具包中,给我们提供了Optional增强的功能。
比如:
import com.google.common.base.Optional;
// 创建携带缺省值的Optional
Optional<User> userOpt = Optional.fromNullable(user).or(defaultUser);
// 链式操作配合Function
Optional<BigDecimal> amount = userOpt.transform(u -> u.getWallet())
.transform(w -> w.getBalance());
Guava工具包中的Optional类已经封装好了,我们可以直接使用。
五、防御式编程进阶
8. Assert断言式拦截
其实有些Assert断言类中,已经做好了判空的工作,参数为空则会抛出异常。
这样我们就可以直接调用这个断言类。
例如下面的ValidateUtils类中的requireNonNull方法,由于它内容已经判空了,因此,在其他地方调用requireNonNull方法时,如果为空,则会直接抛异常。
我们在业务代码中,直接调用requireNonNull即可,不用写额外的判空逻辑。
例如:
public class ValidateUtils {
public static <T> T requireNonNull(T obj, String message) {
if (obj == null) {
throw new ServiceException(message);
}
return obj;
}
}
// 使用姿势
User currentUser = ValidateUtils.requireNonNull(
userDao.findById(userId),
"用户不存在-ID:" + userId
);
最近就业形势比较困难,为了感谢各位小伙伴对苏三一直以来的支持,我特地创建了一些工作内推群, 看看能不能帮助到大家。
你可以在群里发布招聘信息,也可以内推工作,也可以在群里投递简历找工作,也可以在群里交流面试或者工作的话题。
添加苏三的私人微信:li_su223,备注:掘金+所在城市,即可加入。
9. 全局AOP拦截
我们在一些特殊的业务场景种,可以通过自定义注解 + 全局AOP拦截器的方式,来实现实体或者字段的判空。
例如:
@Aspect
@Component
public class NullCheckAspect {
@Around("@annotation(com.xxx.NullCheck)")
public Object checkNull(ProceedingJoinPoint joinPoint) throws Throwable {
Object[] args = joinPoint.getArgs();
for (Object arg : args) {
if (arg == null) {
throw new IllegalArgumentException("参数不可为空");
}
}
return joinPoint.proceed();
}
}
// 注解使用
public void updateUser(@NullCheck User user) {
// 方法实现
}
六、实战场景对比分析
场景1:深层次对象取值
// 旧代码(4层嵌套判断)
if (order != null) {
User user = order.getUser();
if (user != null) {
Address address = user.getAddress();
if (address != null) {
String city = address.getCity();
// 使用city
}
}
}
// 重构后(流畅链式)
String city = Optional.ofNullable(order)
.map(Order::getUser)
.map(User::getAddress)
.map(Address::getCity)
.orElse("未知城市");
场景2:批量数据处理
List<User> users = userService.listUsers();
// 传统写法(显式迭代判断)
List<String> names = new ArrayList<>();
for (User user : users) {
if (user != null && user.getName() != null) {
names.add(user.getName());
}
}
// Stream优化版
List<String> nameList = users.stream()
.filter(Objects::nonNull)
.map(User::getName)
.filter(Objects::nonNull)
.collect(Collectors.toList());
七、性能与安全的平衡艺术
上面介绍的这些方案都可以使用,但除了代码的可读性之外,我们还需要考虑一下性能因素。
下面列出了上面的几种在CPU消耗、内存只用和代码可读性的对比:
| 方案 | CPU消耗 | 内存占用 | 代码可读性 | 适用场景 |
|---|---|---|---|---|
| 多层if嵌套 | 低 | 低 | ★☆☆☆☆ | 简单层级调用 |
| Java Optional | 中 | 中 | ★★★★☆ | 中等复杂度业务流 |
| 空对象模式 | 高 | 高 | ★★★★★ | 高频调用的基础服务 |
| AOP全局拦截 | 中 | 低 | ★★★☆☆ | 接口参数非空验证 |
黄金法则
- Web层入口强制参数校验
- Service层使用Optional链式处理
- 核心领域模型采用空对象模式
八、扩展技术
除了,上面介绍的常规判空之外,下面再给大家介绍两种扩展的技术。
Kotlin的空安全设计
虽然Java开发者无法直接使用,但可借鉴其设计哲学:
val city = order?.user?.address?.city ?: "default"
JDK 14新特性预览
// 模式匹配语法尝鲜
if (user instanceof User u && u.getName() != null) {
System.out.println(u.getName().toUpperCase());
}
总之,优雅判空不仅是代码之美,更是生产安全底线。
本文分享了代码判空的10种方案,希望能够帮助你编写出既优雅又健壮的Java代码。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的50万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
来源:juejin.cn/post/7478221220074504233
什么语言最适合用来游戏开发?
什么语言最适合用来游戏开发?
游戏开发,是一项结合了图形渲染、性能优化、系统架构与玩家体验的综合艺术,而“选用什么编程语言”这个问题,往往是新手开发者迈入这片领域时面临的第一个技术岔路口。
一、从需求出发:游戏开发对语言的核心要求
在选择语言之前,我们先明确一点:游戏类型不同,对语言的要求也大不一样。开发 3D AAA 大作和做一个像素风的休闲小游戏,使用的语言和引擎可能完全不同。
一般来说,语言选择需要考虑:
| 维度 | 说明 |
|---|---|
| 性能需求 | 是否要求极致性能(如大型 3D 游戏)? |
| 跨平台能力 | 是否要支持多个平台(Windows/Mac/Linux/iOS/Android/主机)? |
| 引擎生态 | 是否依赖成熟的游戏引擎(如 Unity、Unreal)? |
| 开发效率 | 团队大小如何?语言是否有丰富工具链、IDE 支持、调试便利性? |
| 学习曲线 | 是个人项目还是商业项目?是否有足够时间去掌握复杂语法或底层结构? |
二、主流语言实战解析
C++:3A最常用的语言
- 适合场景:大型 3D 游戏、主机平台、UE(Unreal Engine)项目
- 特点:
- 几乎所有主流游戏引擎底层都是用 C++ 编写的(UE4/5、CryEngine 等)
- 手动内存管理带来极致性能控制,但也带来更高的 bug 风险
- 编译时间长、语法复杂,不适合快速原型开发
如果你追求的是性能边界、需要对引擎源码进行改造,或者准备进入 3A 游戏开发领域,C++ 是必修课。
C#:Unity 的生态核心
- 适合场景:中小型游戏、独立游戏、跨平台移动/PC 游戏、Unity 项目
- 特点:
- Unity 的脚本语言就是 C#,生态丰富、社区活跃、教程资源丰富
- 开发效率高,语法现代,有良好的 IDE 支持(VS、Rider)
- 在性能上不如 C++,但对大多数项目而言“够用”
如果你是个人开发者或小团队,C# + Unity 几乎是性价比最高的方案之一。
JavaScript/TypeScript:Web 游戏与轻量跨平台
- 适合场景:H5 游戏、小程序游戏、跨平台 2D 游戏、快速迭代
- 特点:
- 配合 Phaser、PixiJS、Cocos Creator 等框架,可以高效制作 Web 游戏
- 原生支持浏览器平台,无需安装,天然适合传播
- 性能不及原生语言,但足以支撑休闲游戏
Web 平台的红利尚未过去,JS/TS + WebGL 仍然是轻量化游戏开发的稳定选择。
Python/Lua:脚本语言发力
- 适合场景:游戏逻辑脚本、AI 行为树、数据驱动配置、教学引擎
- 特点:
- 并不适合用来开发整款游戏,但常作为内嵌脚本语言
- Lua 广泛用于游戏脚本(如 WOW、GTA、Roblox),轻量、运行效率高
- Python 适合教学、原型设计、AI 模块等场景
他们更多是游戏开发的一环,而非“用来开发整款游戏”的首选语言。
三、主流引擎使用的主语言和适用语言
| 游戏引擎 | 主语言 | 适用语言 |
|---|---|---|
| Unreal Engine | C++ | C++ / Blueprint(可视化脚本) |
| Unity | C# | C# |
| Godot | GDScript | GDScript / C# / C++ / Python(部分支持) |
| Cocos Creator | TypeScript/JS | TypeScript / JavaScript |
| Phaser | JavaScript | JavaScript / TypeScript |
四、总结:如何选对“你的语言”?
语言没有好坏,只有适不适合你的项目定位与资源情况。
如果你是:
- 学习引擎开发/大作性能优化:优先掌握 C++,结合 Unreal 学习
- 做跨平台独立游戏/商业项目:优先 C# + Unity
- 做 Web 平台轻量游戏:TypeScript + Phaser/Cocos 是好选择
- 研究 AI、教学、逻辑脚本:Python/Lua 脚本语言
写游戏不是目的,做出好玩的游戏才是!
如果你打算正式进军游戏开发领域,不妨从一个引擎 + 一门主语言开始,结合一个小项目落地,再去拓展更多语言和引擎的协作模式。
来源:juejin.cn/post/7516784123693498378
被问到 NextTick 是宏任务还是微任务
NextTick
等待下一次 DOM 更新刷新的工具方法。
<https://cn.vuejs.org/api/general.html#nexttick>
从字面上看 就知道 肯定是个 异步的嘛。
然后面试官 那你来说说 js执行过程吧。 宏任务 微任务 来做做 宏任务 微任务输出的结果的题吧。
再然后 问问你 nextTick 既然几个异步的 那么他是 宏任务 还是个 微任务呀。
vue2 中
文件夹 src/core/util/next-tick.js 中
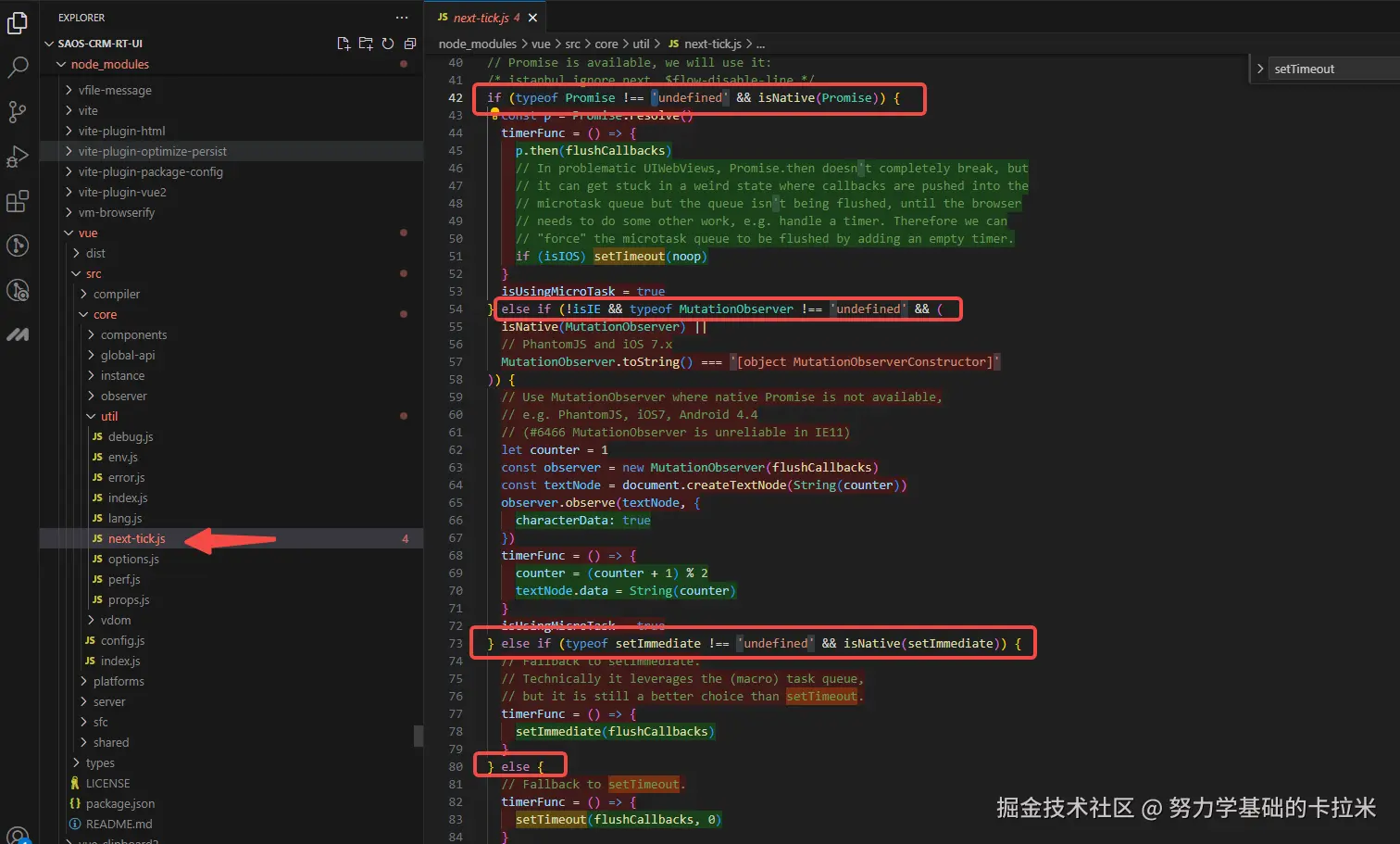
promise --> mutationObserver -> setImmediate -> setTimeout
支持 哪个走哪个
vue3 中
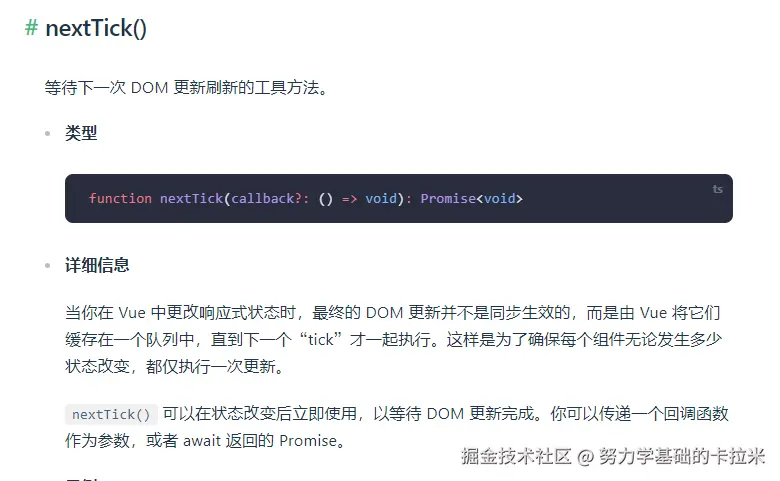
好吧 好吧 promise 了嘛
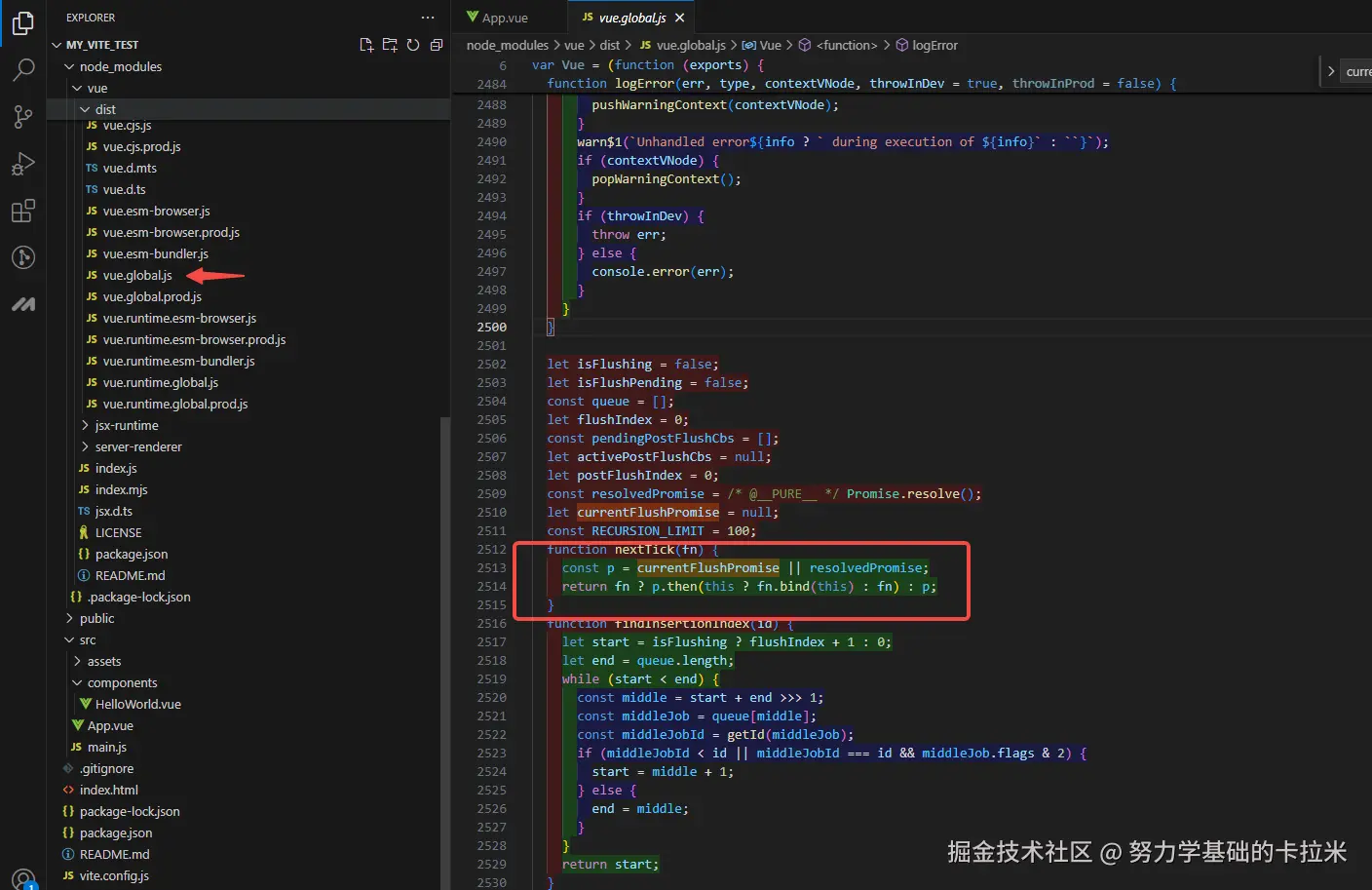
全程 promise
来源:juejin.cn/post/7418505553642291251
什么?localhost还能设置二级域名?
大家好,我是农村程序员,独立开发者,行业观察员,前端之虎陈随易。
我会在这里分享关于 独立开发、编程技术、思考感悟 等内容,欢迎关注。
- 个人网站 1️⃣:chensuiyi.me
- 个人网站 2️⃣:me.yicode.tech
- 技术群,搞钱群,闲聊群,自驾群,想入群的在我个人网站联系我。
如果你觉得本文有用,一键三连 (点赞、评论、转发),就是对我最大的支持~
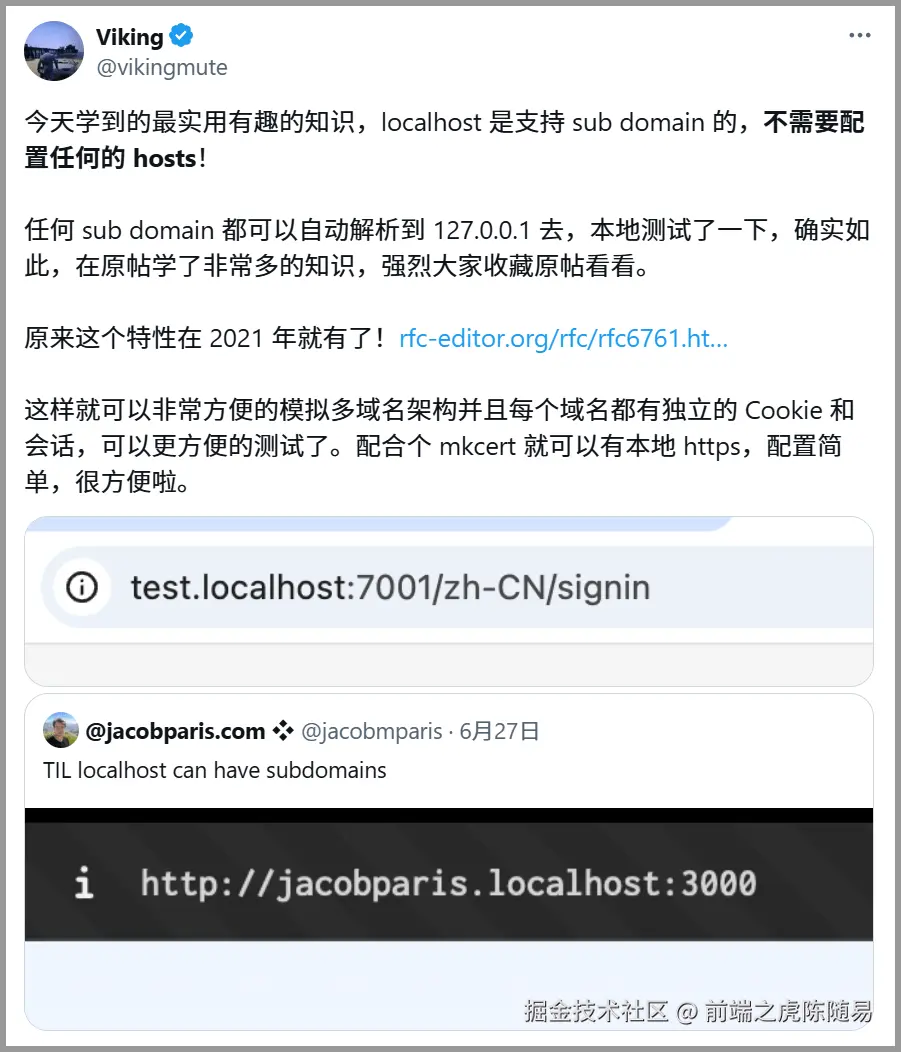
网上冲浪看到一个有趣且违背常识的帖子,用了那么多年的 localhost,没想到 localhost 还能设置子域名。
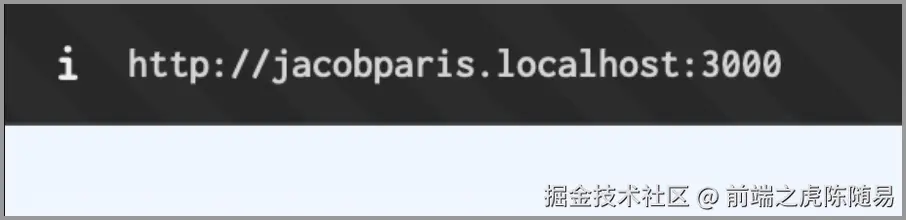
而且还不需要修改 hosts 文件,直接就能使用,这真是离谱他妈给离谱开门,离谱到家了。
先说说应用场景:
- 多用户/多会话隔离:在本地开发中模拟不同用户的 cookies 和 session storage,适合测试用户认证或个性化功能。
- 跨域开发与测试:模拟真实多域环境 (如 API 和前端分离),用于调试 CORS、单点登录或微服务架构。
- 简化开发流程:无需修改 hosts 文件即可快速创建子域名,适合快速原型设计或临时项目。
- 工具与服务器集成:与本地开发工具 (如 localias) 结合,支持 HTTPS 和自定义端口,增强开发体验。
- 灵活调试:通过自定义子域名和 IP (如 127.0.0.42) 进行高级调试或模拟复杂网络配置。
总得来说就是,localhsot 支持子域名比我们自己手动配置不同的域名并设置 hosts 文件方便多了。
接下来给大家实测一下。
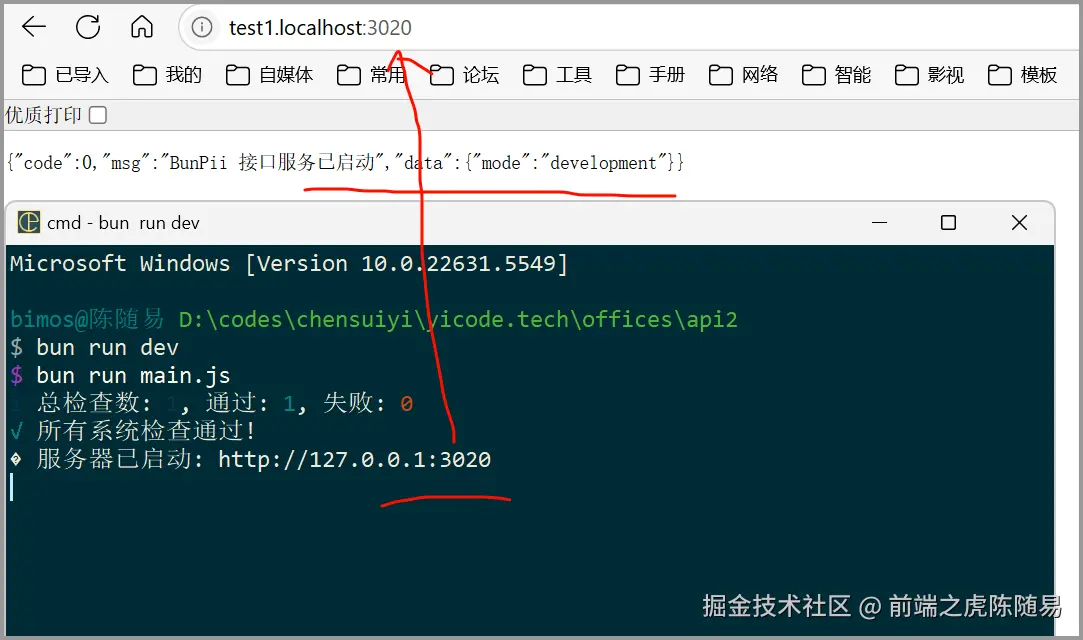
请看,这是我直接在浏览器输入 test1.localhost:3020 后,就能请求到我本地启动的监听 3020 端口的后端接口返回的数据。
我没有配置 hosts 文件,没有做过任何多余的配置工作,直接就生效了。
那么我们可以直接在本地就能调试多服务器集群,跨域 cookie 共享,SSO 单点登录,微服务架构等功能,非常方便。
另外,本公众号是 前端之虎陈随易 专门分享技术的公众号,目前关注量不多,希望大家点点小手指,来个大大的关注哦~
来源:juejin.cn/post/7521013717438758938
优雅!用了这两款插件,我成了整个公司代码写得最规范的码农
同事:你的代码写的不行啊,不够规范啊。

我:我写的代码怎么可能不规范,不要胡说。
于是同事打开我的 IDEA ,安装了一个插件,然后执行了一下,规范不规范,看报告吧。
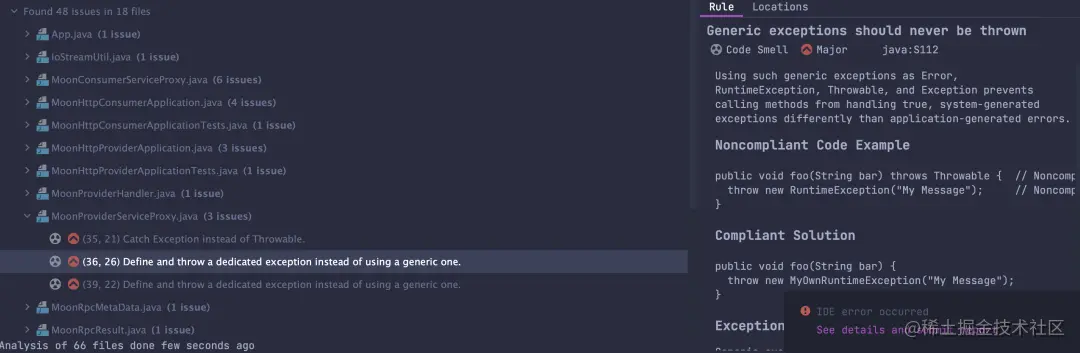
这可怎么是好,这玩意竟然给我挑出来这么多问题,到底靠谱不。
同事潇洒的走掉了,只留下我在座位上盯着屏幕惊慌失措。我仔细的查看了这个报告的每一项,越看越觉得这插件指出的问题有道理,果然是我大意了,竟然还给我挑出一个 bug 来。
这是什么插件,review 代码无敌了。

这个插件就是 SonarLint,官网的 Slogan 是 clean code begins in your IDE with {SonarLint}。
作为一个程序员,我们当然希望自己写的代码无懈可击了,但是由于种种原因,有一些问题甚至bug都无法避免,尤其是刚接触开发不久的同学,也有很多有着多年开发经验的程序员同样会有一些不好的代码习惯。
代码质量和代码规范首先肯定是靠程序员自身的水平和素养决定的,但是提高水平的是需要方法的,方法就有很多了,比如参考大厂的规范和代码、比如有大佬带着,剩下的就靠平时的一点点积累了,而一些好用的插件能够时时刻刻提醒我们什么是好的代码规范,什么是好的代码。
SonarLint 就是这样一款好用的插件,它可以实时帮我们 review代码,甚至可以发现代码中潜在的问题并提供解决方案。
SonarLint 使用静态代码分析技术来检测代码中的常见错误和漏洞。例如,它可以检测空指针引用、类型转换错误、重复代码和逻辑错误等。这些都是常见的问题,但是有时候很难发现。使用 SonarLint 插件,可以在编写代码的同时发现这些问题,并及时纠正它们,这有助于避免这些问题影响应用程序的稳定性。
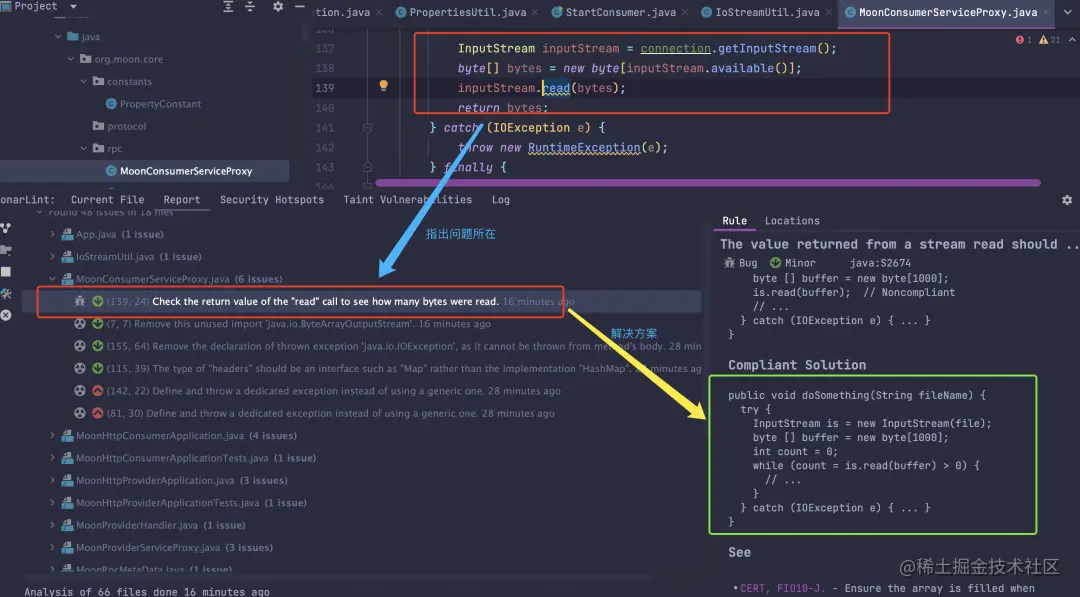
比如下面这段代码没有结束循环的条件设置,SonarLint 就给出提示了,有强迫症的能受的了这红下划线在这儿?
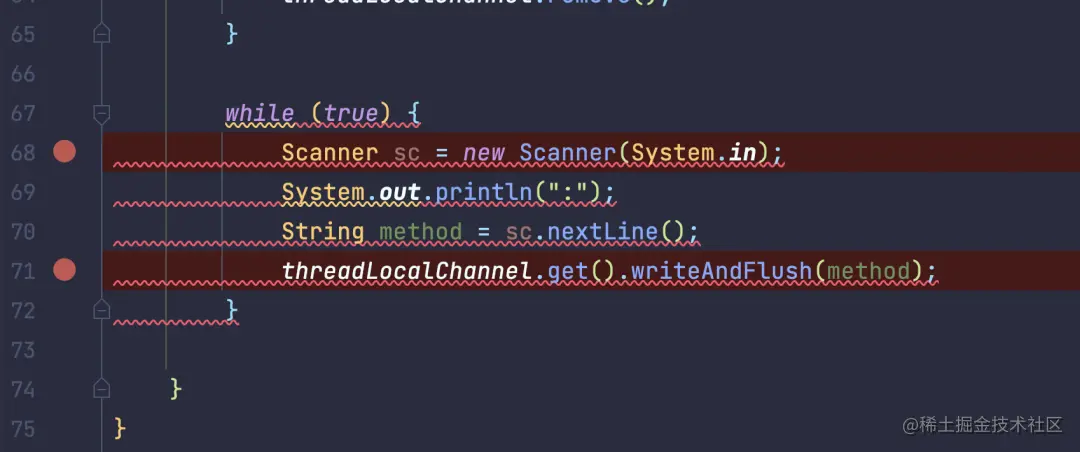
SonarLint 插件可以帮助我提高代码的可读性。代码应该易于阅读和理解,这有助于其他开发人员更轻松地维护和修改代码。SonarLint 插件可以检测代码中的代码坏味道,例如不必要的注释、过长的函数和变量名不具有描述性等等。通过使用 SonarLint 插件,可以更好地了解如何编写清晰、简洁和易于理解的代码。
例如下面这个名称为 hello_world的静态 final变量,SonarLint 给出了两项建议。
- 因为变量没有被使用过,建议移除;
- 静态不可变变量名称不符合规范;
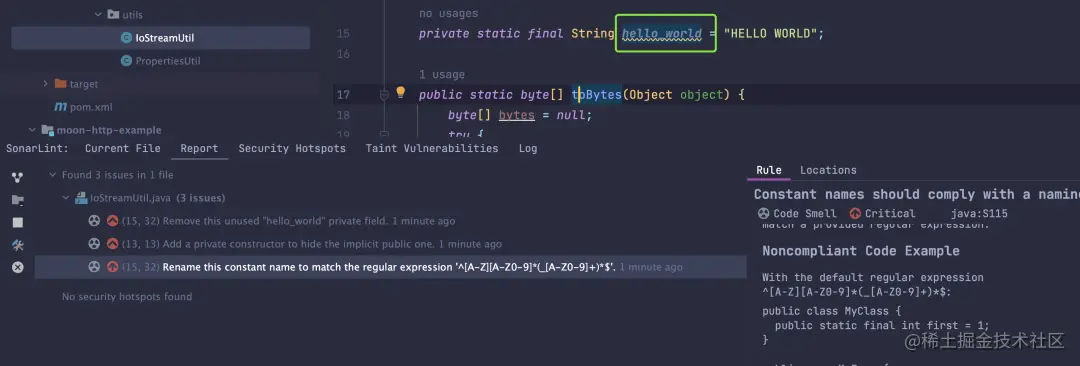
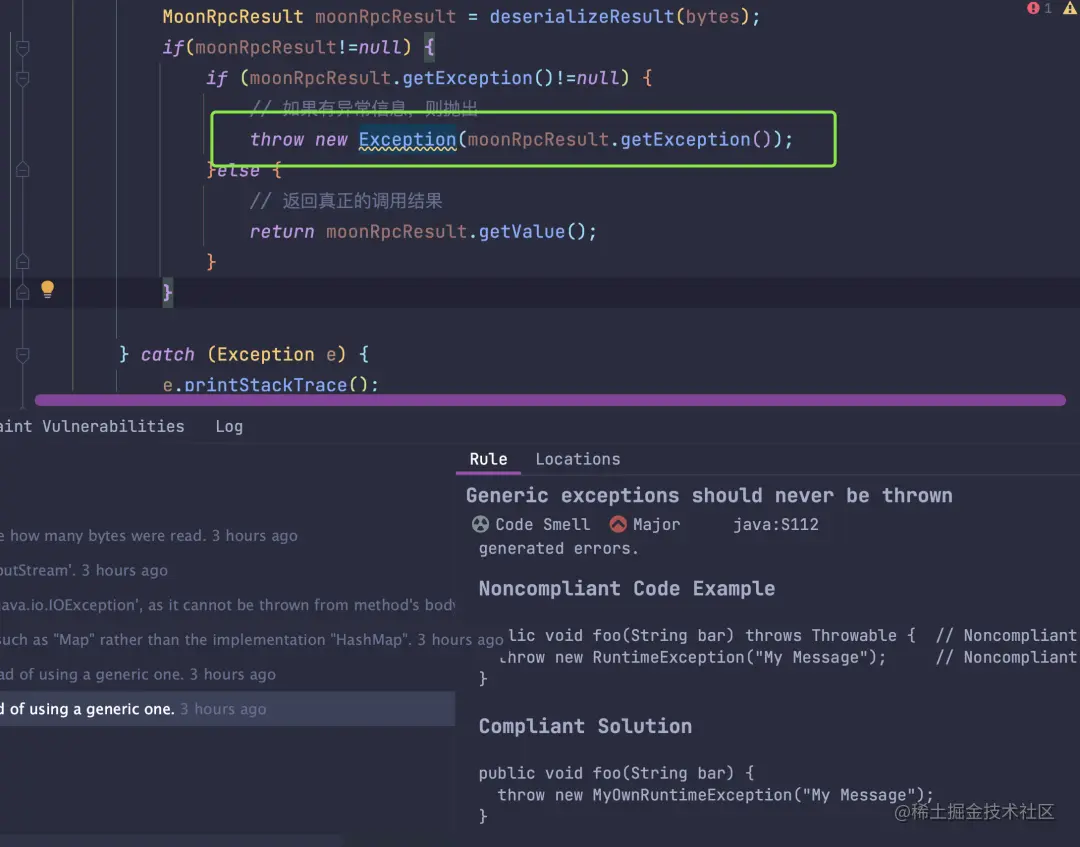
SonarLint 插件可以帮助我遵循最佳实践和标准。编写符合标准和最佳实践的代码可以确保应用程序的质量和可靠性。SonarLint 插件可以检测代码中的违反规则的地方,例如不安全的类型转换、未使用的变量和方法、不正确的异常处理等等。通过使用 SonarLint 插件,可以学习如何编写符合最佳实践和标准的代码,并使代码更加健壮和可靠。
例如下面的异常抛出方式,直接抛出了 Exception,然后 SonarLint 建议不要使用 Exception,而是自定义一个异常,自定义的异常可能让人直观的看出这个异常是干什么的,而不是 Exception基本类型导出传递。
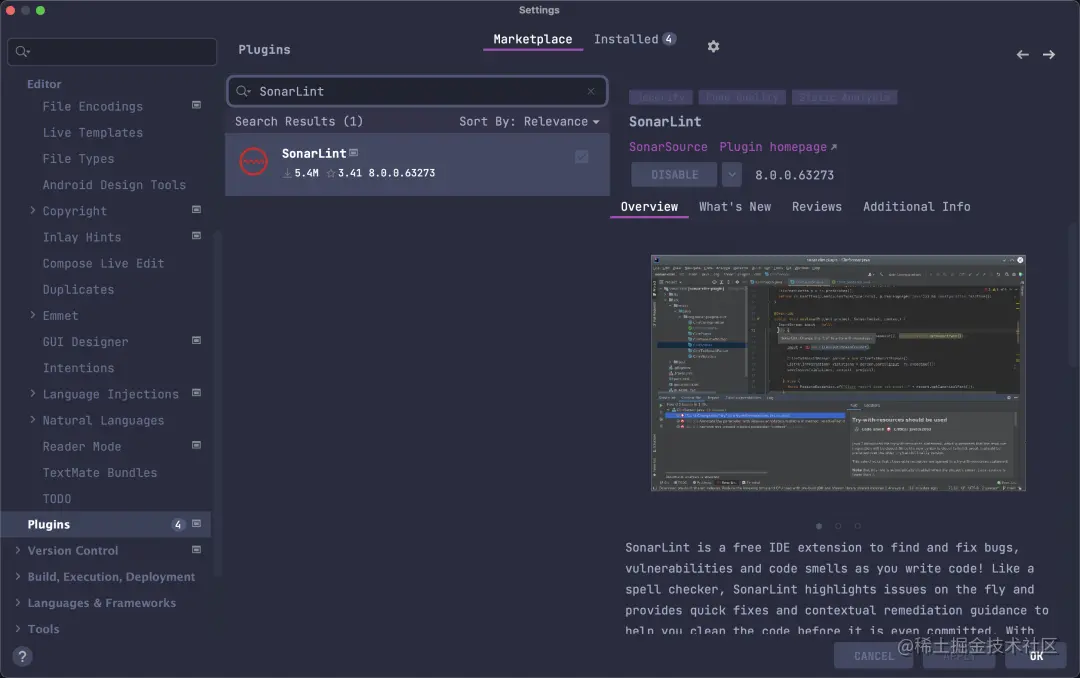
安装 SonarLint
可以直接打开 IDEA 设置 -> Plugins,在 MarketPlace中搜索SonarLint,直接安装就可以。
还可以直接在官网下载,打开页面http://www.sonarsource.com/products/so… EXPLORE即可到下载页面去下载了。虽然我们只是在 IDEA 中使用,但是它不只支持 Java 、不只支持 IDEA ,还支持 Python、PHP等众多语言,以及 Visual Studio 、VS Code 等众多 IDE。

在 IDEA 中使用
SonarLint 插件安装好之后,默认就开启了实时分析的功能,就跟智能提示的功能一样,随着你噼里啪啦的敲键盘,SonarLint插件就默默的进行分析,一旦发现问题就会以红框、红波浪线、黄波浪线的方式提示。
当然你也可以在某一文件中点击右键,也可在项目根目录点击右键,在弹出菜单中点击Analyze with SonarLint,对当前文件或整个项目进行分析。
分析结束后,会生成分析报告。
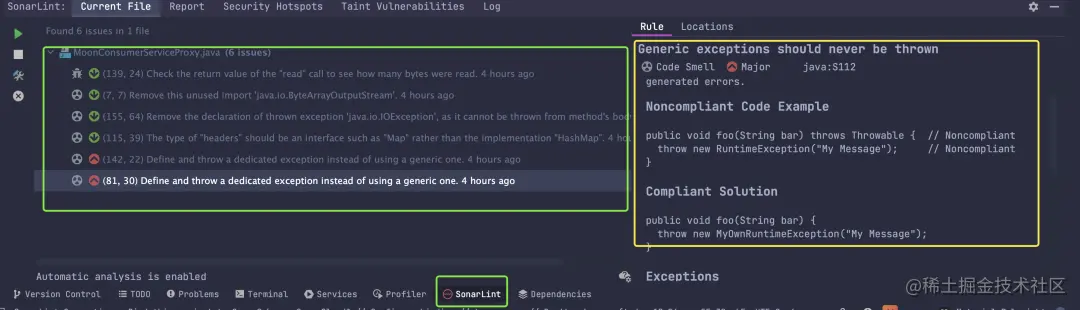
左侧是对各个文件的分析结果,右侧是对这个问题的建议和修改示例。
SonarLint 对问题分成了三种类型
类型说明Bug代码中的 bug,影响程序运行Vulnerability漏洞,可能被作为攻击入口Code smell代码意味,可能影响代码可维护性
问题按照严重程度分为5类
严重性说明BLOCKER已经影响程序正常运行了,不改不行CRITICAL可能会影响程序运行,可能威胁程序安全,一般也是不改不行MAJOR代码质量问题,但是比较严重MINOR同样是代码质量问题,但是严重程度较低INFO一些友好的建议
SonarQube
SonarLint 是在 IDE 层面进行分析的插件,另外还可以使用 SonarQube功能,它以一个 web 的形式展现,可以为整个开发团队的项目提供一个web可视化的效果。并且可以和 CI\CD 等部署工具集成,在发版前提供代码分析。
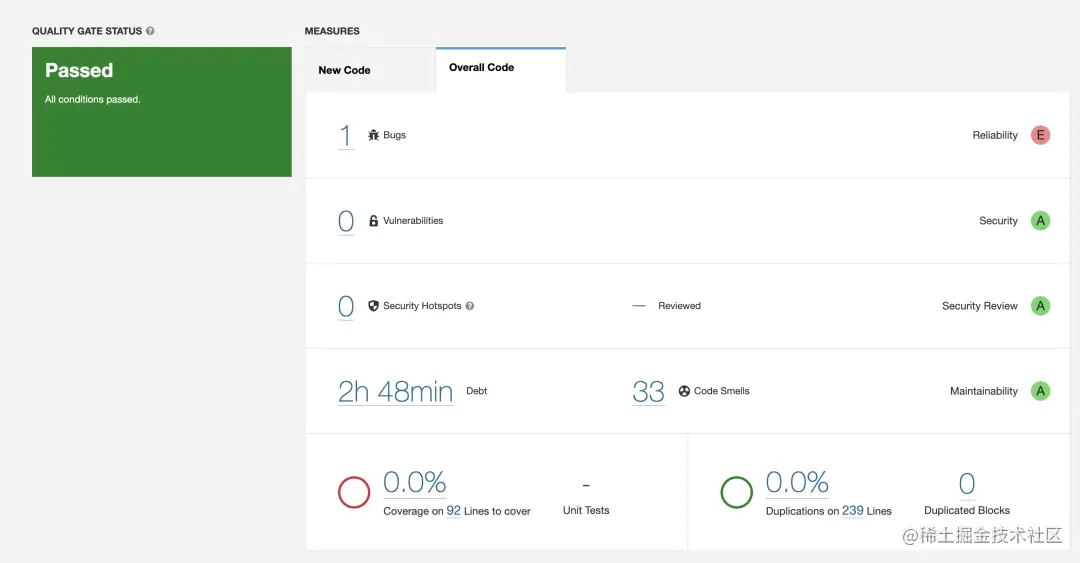
SonarQube是一个 Java 项目,你可以在官网下载项目本地启动,也可以以 docker 的方式启动。之后可以在 IDEA 中配置全局 SonarQube配置。
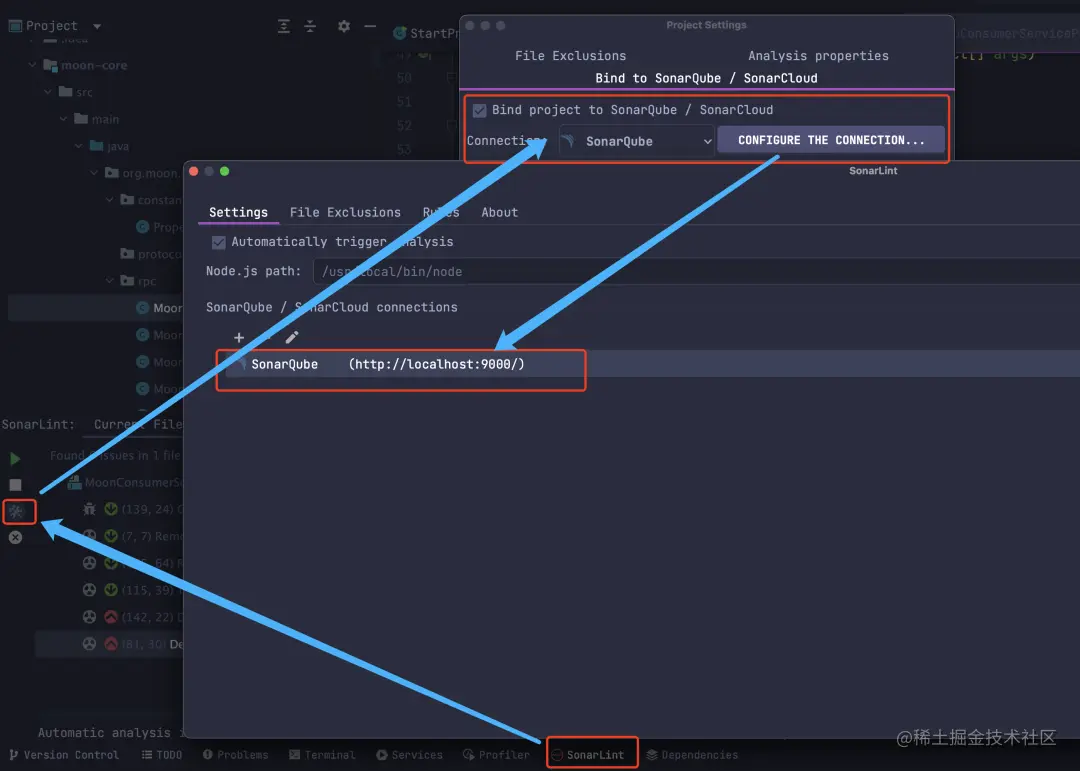
也可以在 SonarQube web 中单独配置一个项目,创建好项目后,直接将 mvn 命令在待分析的项目中执行,即可生成对应项目的分析报告,然后在 SonarQube web 中查看。
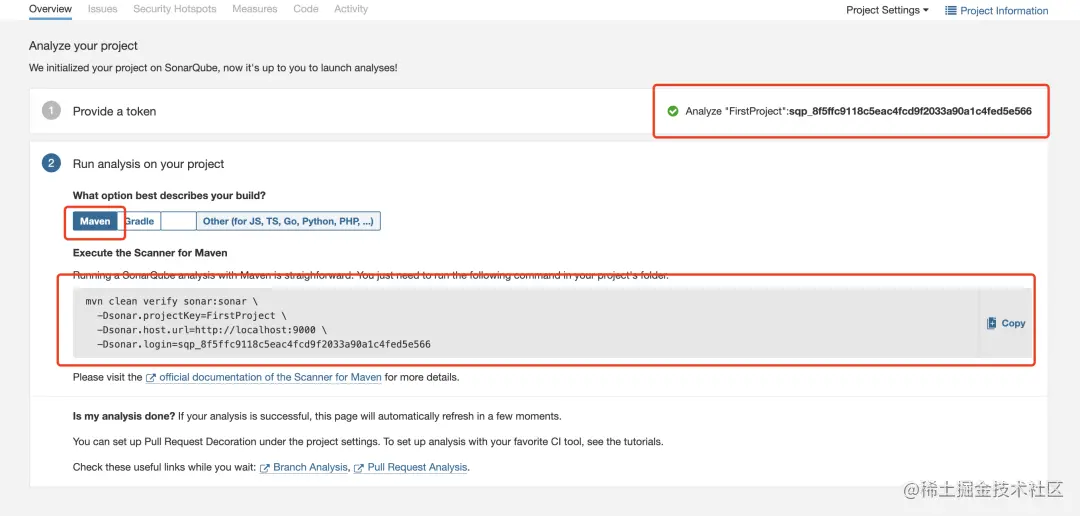
5
对于绝大多数开发者和开发团队来说,SonarQube 其实是没有必要的,只要我们每个人都解决了 IDE 中 SonarLint 给出的建议,当然最终的代码质量就是符合标准的。
阿里 Java 规约插件
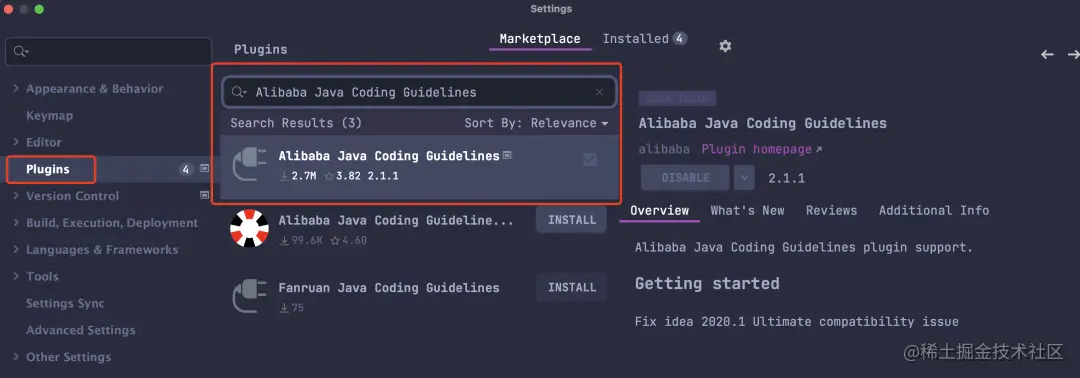
每一个开发团队都有团队内部的代码规范,比如变量命名、注释格式、以及各种类库的使用方式等等。阿里一直在更新 Java 版的阿里巴巴开发者手册,有什么泰山版、终极版,想必各位都听过吧,里面的规约如果开发者都能遵守,那别人恐怕再没办法 diss 你的代码不规范了。
对应这个开发手册的语言层面的规范,阿里也出了一款 IDEA 插件,叫做 Alibaba Java Coding Guidelines,可以在插件商店直接下载。
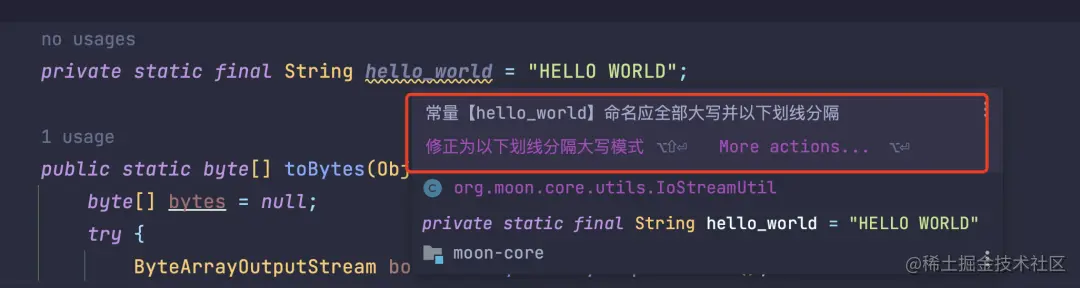
比如前面说的那个 hello_world变量名,插件直接提示「修正为以下划线分隔的大写模式」。
再比如一些注释上的提示,不建议使用行尾注释。
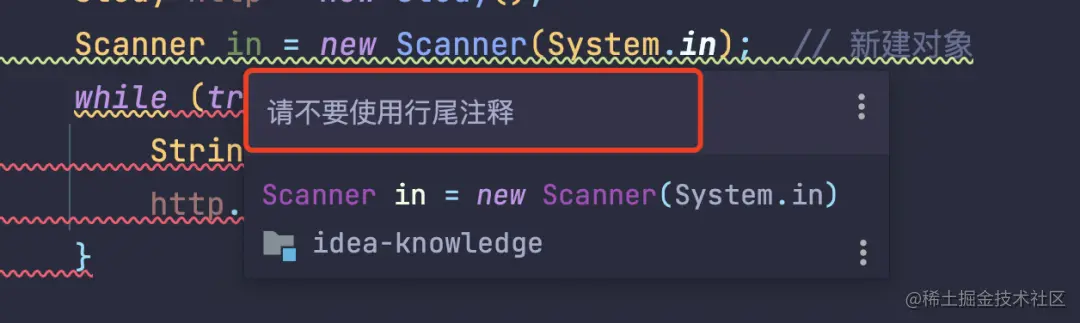
image-20230314165107639
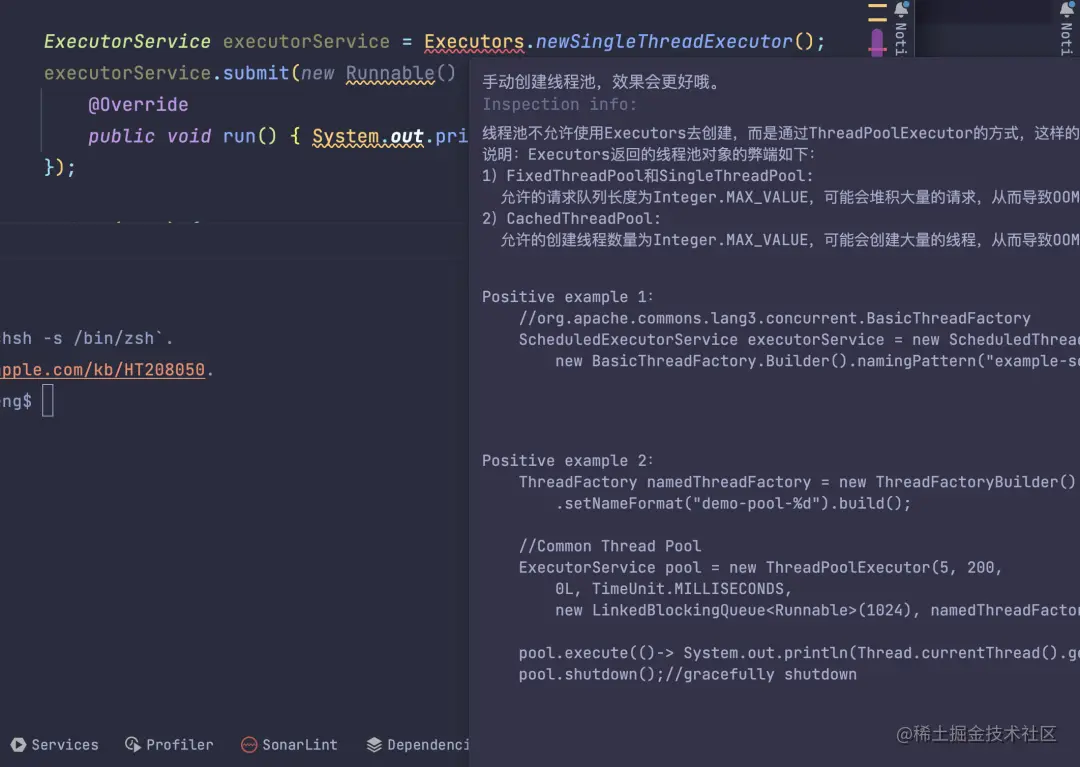
还有,比如对线程池的使用,有根据规范建议的内容,建议自己定义核心线程数和最大线程数等参数,不建议使用 Excutors工具类。
有了这俩插件,看谁还能说我代码写的不规范了。
来源:juejin.cn/post/7260314364876931131
本尊来!网易灰度发布系统揭秘:一天300次上线是怎么实现的?
你可能听过“网易每天上线几百次”,
但你是否知道:99%的发布都不是全量,而是按灰度批次推进。
今天从代码 + 场景双视角,拆解网易灰度发布的完整实现逻辑,让你真正搞懂:
- 发布是怎么分用户、分地域、分时间段的
- 如何回滚不影响线上用户
- 甚至如何模拟真实用户流量进行 A/B 实验
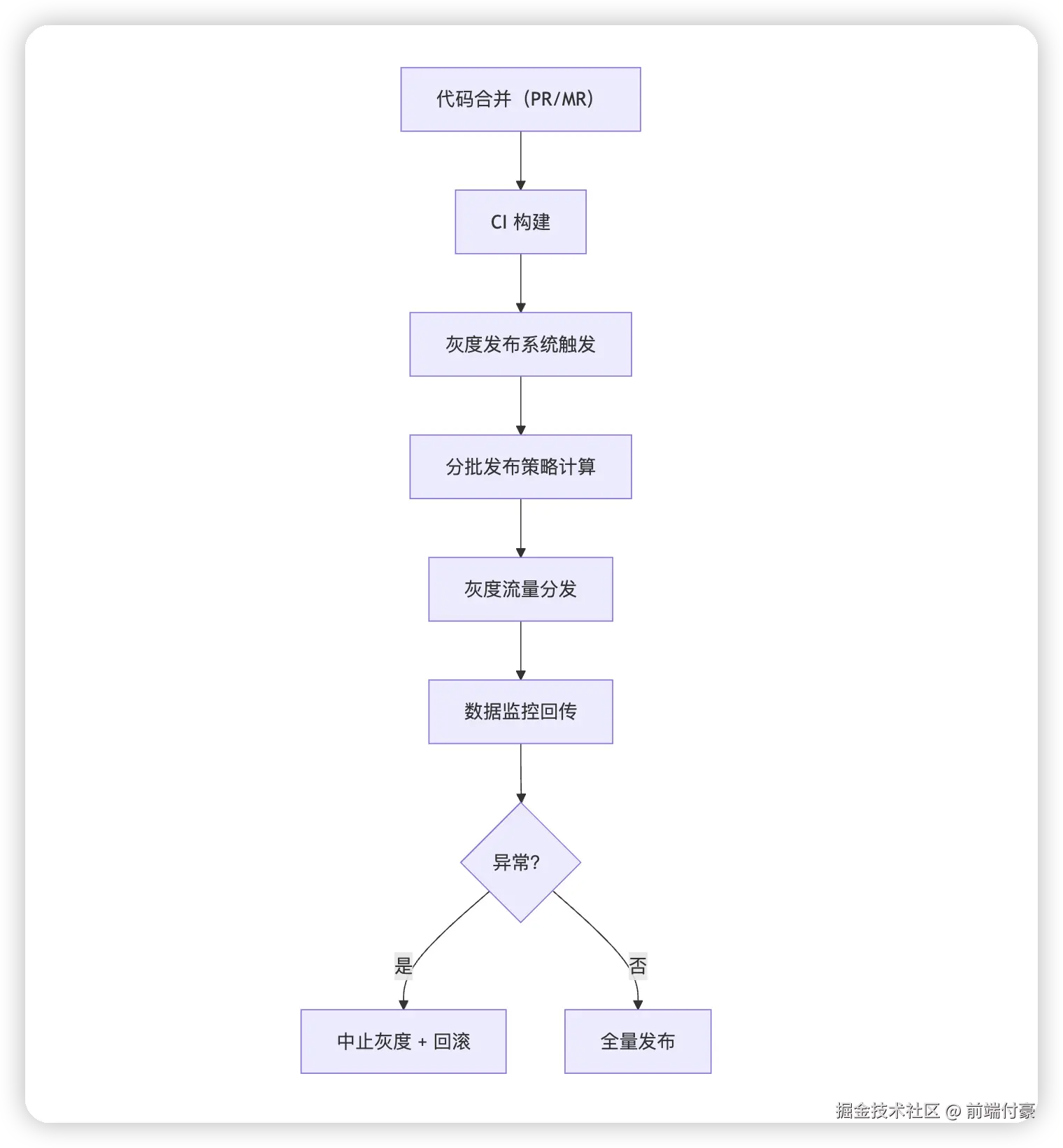
一、网易灰度系统整体架构图(简化)
二、核心策略算法:如何选择灰度用户?
网易内部灰度用户分流引擎大致是这样:
interface User {
uid: string
region: string // 地域
isVip: boolean
loginTime: number // 最近登录时间
}
// 灰度策略配置
const strategy = {
percent: 10, // 灰度比例
regionInclude: ['华南'], // 地域包含
vipOnly: true // 只投放给 VIP
}
// 筛选函数
function filterUsers(users: User[], strategy) {
const filtered = users.filter(u =>
(!strategy.regionInclude || strategy.regionInclude.includes(u.region)) &&
(!strategy.vipOnly || u.isVip)
)
const count = Math.floor((strategy.percent / 100) * filtered.length)
return filtered.slice(0, count)
}
三、实际运行结果展示(模拟环境)
const users: User[] = Array.from({ length: 1000 }, (_, i) => ({
uid: `U${i}`,
region: ['华南', '华北', '华东'][i % 3],
isVip: i % 2 === 0,
loginTime: Date.now() - i * 10000,
}))
const selected = filterUsers(users, strategy)
console.log('灰度命中用户数:', selected.length)
console.log('前5个用户:', selected.slice(0, 5))
✅ 输出示例:
灰度命中用户数: 166
前5个用户: [
{ uid: 'U0', region: '华南', isVip: true, loginTime: 1717288879181 },
{ uid: 'U6', region: '华南', isVip: true, loginTime: 1717288819181 },
{ uid: 'U12', region: '华南', isVip: true, loginTime: 1717288759181 },
...
]
四、网易如何触发灰度?手动?自动?答案是:多触发源 + 策略组合
- ✅ 手动控制(管理员控制台)
- ✅ CI/CD 自动触发(合并主干自动上线)
- ✅ 实验平台触发(A/B 实验验证新功能)
示例:CI/CD 触发部署的逻辑(伪代码):
// Jenkinsfile 中执行灰度命令
steps {
script {
sh 'node deploy.js --env=prod --gray=10%'
}
}
五、监控数据如何决定“是否继续灰度”?
网易内部有自动指标监控,如:
| 指标名 | 作用 | 阈值 |
|---|---|---|
| error_rate | 错误率异常自动中止 | >0.05 |
| api_delay | 接口响应时间 | >300ms |
| login_success_ratio | 登录成功率 | <0.95 |
代码示例(灰度中控系统伪代码):
if (metrics.error_rate > 0.05 || metrics.login_success_ratio < 0.95) {
graySystem.stopDeployment()
graySystem.rollback()
console.log('灰度异常,中止并回滚')
} else {
graySystem.continue()
}
六、网易的灰度回滚机制非常丝滑,为什么?
他们采用了 “金丝雀版本+热切流量+自动恢复” 策略:
graySystem.deploy(version: '1.2.3', tag: 'canary')
// graySystem.rollback() 会回到上一个 tag=stable 的版本
而且每次发布都会打上 Git tag,并记录环境信息,回滚只需1行命令:
gray rollback --env prod --tag stable
七、你能学到什么?(总结)
- 灰度不等于“发布慢一点”,而是可控可观测的发布策略
- 用户维度灰度筛选逻辑要尽量结构化,避免硬编码
- 数据指标必须“事前定义”,不能出了问题再想怎么止损
- 所有灰度发布必须可回滚
彩蛋:
“上线不是勇气的象征,而是风控能力的体现。”
来源:juejin.cn/post/7511150244576837684
解锁企业高效未来|上海飞络Synergy AI开启智能体协作新时代
他/她可以有自己的电脑,可以有自己的邮箱号,可以有自己的企业微信号。只要赋予权限,他/她可以替你完成各种日常工作,他/她可以随时随地和你沟通并完成你安排的任务,他/她永远高效!他/她永不抱怨!
Synergy AI数字员工雇佣管理平台,以大语言模型驱动的AI Agent为核心,结合MCP工具集,并在数据安全、信息安全及行为安全的多维度监控下,为企业提供安全、合规、高效的“智能体员工”,重塑人机协作新范式!

为什么选择Synergy AI数字员工管理平台?
1、智能生产力升级
AI Agent数字员工深度融合语言理解、逻辑推理与工具调用能力,是能够自主感知环境、决策并执行任务的人工智能系统。它可以拥有自己的电脑、邮箱,微信号等所有员工的权限,同时也具备MCP工具集中的各种技能,能够像真人一样沟通,处理工作,但是能够实现更高的工作效率和更加低廉的成本!

2、根据职位定制AI员工工作流
通过“AIGC+Workflow”组合,实现任务自动化执行,响应速度大幅提升,成为企业降本增效的核心引擎。
同时基于企业人员、技能、文档、流程等六大核心信息库,AI数字员工可快速融入业务场景,提供从单职能支持、人机协同到多职能协作的全链路服务。

3、安全合规,全程可控
1)行为监测
实时检测AI数字员工是否存在权限越界、敏感数据操作,信息泄露,被黑客利用等安全合规隐患。
2)数据安全管控
智能识别、过滤、脱敏替换AI数字员工及大语言模型使用过程中触发的敏感数据,企业核心数据泄漏等风险。
3)效能可视化
通过工作流执行情况、人工干预度等指标,持续优化AI员工表现。

Synergy AI能实现什么效果?
1、AI销售助理
可协助销售管理日程、预约会议、统计CRM数字,甚至代替销售联络沟通回款问题。入职飞络销售部门后,内部数据显示客户响应效率提升3倍以上,人力成本降低60%,助力团队精准触达商机。

2、SOC安全及运维专员
在安全运营和运维场景中,AI员工可以迅速响应各个安全系统平台的告警,并根据制定的工作流程,进行下一步的沟通、交流、处置。让企业安全事件响应速度大幅提升,精准提高准确率,为企业筑牢数字防线。

3、更多AI人职位有待解锁
根据每家企业不同的场景需求,Synergy AI提供可以定制化的各种企业AI数字员工,让AI智能体真正能够匹配企业需求,为企业带来实际帮助。

Synergy AI如何落地实施?
1、分析岗位SOW/SOP
找到重复、需要与人互动的工作流,快速实现智能化并通过拟人化的AI员工来完成,逐步将AI工作流覆盖全业务。
2、无缝对接系统
支持OA、ERP、CRM、M365等主流平台MCP / API对接。
3、7×24小时护航
飞络安全运营中心全程监控,保障业务稳定运行。

企业的信息安全如何保护?
飞络基于自研发两大安全管理平台,为企业在使用AI的同时,极大限度保障企业的数据以及隐私安全:
企业AI安全事件监控管理平台
通过企业AI安全事件监控管理平台,我们可以实时提供AI系统以及AI Agents的运行状态,对于所发生的安全事件,实行7*24小时的安全监控及管理。
ASSA:企业AI数据过滤平台
通过ASSA,企业可以管理及管控企业内部信息传输到大语言模型上的数据,对于敏感信息、企业机密、个人信息等进行阻止、脱敏、模糊化等管理操作
7*24 SOC服务
基于飞络提供的7*24级别的SOC运营服务,可以协助客户一起实时监控及管理所有AI相关的安全事件,为企业的数据安全保驾护航!


Synergy AI数字员工雇佣管理平台,以自主研发技术为核心,为企业提供一站式智能解决方案。
收起阅读 »给前端小白的科普,为什么说光有 HTTPS 还不够?为啥还要请求签名?
今天咱们聊个啥呢?先设想一个场景:你辛辛苦苦开发了一个前端应用,后端 API 也写得杠杠的。用户通过你的前端界面提交一个订单,比如说买1件商品。请求发出去,一切正常。但如果这时候,有个“不开眼”的黑客老哥,在你的请求发出后、到达服务器前,悄咪咪地把“1件”改成了“100件”,或者把你用户的优惠券给薅走了,那服务器收到的就是个被篡改过的“假”请求。更狠一点,如果他拿到了你某个用户的合法请求,然后疯狂重放这个请求,那服务器不就炸了?
是不是想想都后怕?别慌,今天咱就来聊聊怎么给咱们的API请求加一把“锁”,让这种“中间人攻击”和“重放攻击”无处遁形。这把锁,就是大名鼎鼎的 HMAC-SHA256 请求签名。学会了它,你就能给你的应用穿上“防弹衣”!

一、光有 HTTPS 还不够?为啥还要请求签名?
可能有机灵的小伙伴会问:“老张,咱不都有 HTTPS 了吗?数据都加密了,还怕啥?”
问得好!HTTPS 确实牛,它能保证你的数据在传输过程中不被窃听和篡改,就像给数据修了条“加密隧道”。但它主要解决的是传输层的安全。可如果:
- 请求在加密前就被改了:比如黑客通过某种手段(XSS、恶意浏览器插件等)在你的前端代码执行时就修改了要发送的数据,那 HTTPS 加密的也是被篡改后的数据。
- 请求被合法地解密后,服务器无法验证“我是不是我”:HTTPS 保证了数据从A点到B点没被偷看,但如果有人拿到了一个合法的、加密的请求包,他可以原封不动地发给服务器100遍(重放攻击),服务器每次都会认为是合法的。
- API Key/Secret 直接在前端暴露: 有些简单的 API 认证,可能会把 API Key 直接写在前端,这简直就是“裸奔”,分分钟被扒下来盗用。
请求签名,则是在应用层做的一道防线。它能确保:
- 消息的完整性:数据没被篡改过。
- 消息的身份验证:确认消息确实是你授权的客户端发来的。
- 防止重放攻击:结合时间戳或 Nonce,让每个请求都具有唯一性。
它和 HTTPS 是好搭档,一个负责“隧道安全”,一个负责“货物安检”,双保险!
二、主角登场:HMAC-SHA256 是个啥?
HMAC-SHA256,听起来挺唬人,拆开看其实很简单:
- HMAC:Hash-based Message Authentication Code,翻译过来就是“基于哈希的消息认证码”。它是一种使用密钥(secret key)来生成消息摘要(MAC)的方法。
- SHA256:Secure Hash Algorithm 256-bit,一种安全的哈希算法,能把任意长度的数据转换成一个固定长度(256位,通常表示为64个十六进制字符)的唯一字符串。相同的输入永远得到相同的输出,输入有任何微小变化,输出都会面目全非。
所以,HMAC-SHA256 就是用一个共享密钥 (Secret Key),通过 SHA256 算法,给你的请求数据生成一个独一无二的“签名”。
三、签名的艺术:请求是怎么被“签”上和“验”货的?
整个流程其实不复杂,咱们用个图来说明一下:
sequenceDiagram
participant C as 前端 (Client)
participant S as 后端 (Server)
C->>C: 1. 准备请求参数 (如 method, path, query, body)
C->>C: 2. 加入时间戳 (timestamp) 和/或 随机数 (nonce)
C->>C: 3. 将参数按约定规则排序、拼接成一个字符串 (stringToSign)
C->>C: 4. 使用共享密钥 (Secret Key) 对 stringToSign 进行 HMAC-SHA256 运算,生成签名 (signature)
C->>S: 5. 将原始请求参数 + timestamp + nonce + signature 一起发送给后端
S->>S: 6. 接收到所有数据
S->>S: 7. 校验 timestamp/nonce (检查是否过期或已使用,防重放)
S->>S: 8. 从接收到的数据中,按与客户端相同的规则,提取参数、排序、拼接成 stringToSign'
S->>S: 9. 使用自己保存的、与客户端相同的 Secret Key,对 stringToSign' 进行 HMAC-SHA256 运算,生成 signature'
S->>S: 10. 比对客户端传来的 signature 和自己生成的 signature'
alt 签名一致
S->>S: 11. 验证通过,处理业务逻辑
S-->>C: 响应结果
else 签名不一致
S->>S: 11. 验证失败,拒绝请求
S-->>C: 错误信息 (如 401 Unauthorized)
end
简单来说,就是:
- 客户端:把要发送的数据(比如请求方法、URL路径、查询参数、请求体、时间戳等)按照事先约定好的顺序和格式拼成一个长长的字符串。然后用一个只有你和服务器知道的“秘密钥匙”(Secret Key)和 HMAC-SHA256 算法,给这个字符串算出一个“指纹”(签名)。最后,把原始数据、时间戳、签名一起发给服务器。
- 服务器端:收到请求后,用完全相同的规则和完全相同的“秘密钥匙”,对收到的原始数据(不包括客户端传来的签名)也算一遍“指纹”。然后比较自己算出来的指纹和客户端传过来的指纹。如果一样,说明数据没被改过,而且确实是知道秘密钥匙的“自己人”发的;如果不一样,那对不起,这请求有问题,拒收!
四、Talk is Cheap, Show Me The Code!
光说不练假把式,咱们来点实在的。
前端签名 (JavaScript - 通常使用 crypto-js 库)
// 假设你已经安装了 crypto-js: npm install crypto-js
import CryptoJS from 'crypto-js';
function generateSignature(params, secretKey) {
// 1. 准备待签名数据
const method = 'GET'; // 请求方法
const path = '/api/user/profile'; // 请求路径
const timestamp = Math.floor(Date.now() / 1000).toString(); // 时间戳 (秒)
const nonce = CryptoJS.lib.WordArray.random(16).toString(); // 随机数,可选
// 2. 构造待签名字符串 (规则很重要,前后端要一致!)
// 通常会对参数名按字典序排序
const sortedKeys = Object.keys(params).sort();
const queryString = sortedKeys.map(key => `${key}=${params[key]}`).join('&');
const stringToSign = `${method}\n${path}\n${queryString}\n${timestamp}\n${nonce}`;
console.log("String to Sign:", stringToSign); // 调试用
// 3. 使用 HMAC-SHA256 生成签名
const signature = CryptoJS.HmacSHA256(stringToSign, secretKey).toString(CryptoJS.enc.Hex);
console.log("Generated Signature:", signature); // 调试用
return {
signature,
timestamp,
nonce
};
}
// --- 使用示例 ---
const mySecretKey = "your-super-secret-key-dont-put-in-frontend-directly!"; // 强调:密钥不能硬编码在前端!
const requestParams = {
userId: '123',
role: 'user'
};
const { signature, timestamp, nonce } = generateSignature(requestParams, mySecretKey);
// 实际发送请求时,把 signature, timestamp, nonce 放在请求头或请求体里
// 例如:
// fetch(`${path}?${queryString}`, {
// method: method,
// headers: {
// 'X-Signature': signature,
// 'X-Timestamp': timestamp,
// 'X-Nonce': nonce,
// 'Content-Type': 'application/json'
// },
// // body: JSON.stringify(requestBody) // 如果是POST/PUT等
// })
// .then(...)
划重点! 上面代码里的 mySecretKey 绝对不能像这样直接写在前端代码里!这只是个演示。真正的 Secret Key 需要通过安全的方式分发和存储,比如在构建时注入,或者通过更安全的认证流程动态获取(但这又引入了新的复杂性,通常 Secret Key 是后端持有,客户端动态获取一个有时效性的 token)。对于纯前端应用,更常见的做法是后端生成签名所需参数,或者整个流程由 BFF (Backend For Frontend) 层处理。如果你的应用是 App,可以把 Secret Key 存储在原生代码中,相对安全一些。
后端验签 (Node.js - 使用内置 crypto 模块)
const crypto = require('crypto');
function verifySignature(requestData, clientSignature, clientTimestamp, clientNonce, secretKey) {
// 0. 校验时间戳 (例如,请求必须在5分钟内到达)
const serverTimestamp = Math.floor(Date.now() / 1000);
if (Math.abs(serverTimestamp - parseInt(clientTimestamp, 10)) > 300) { // 5分钟窗口
console.error("Timestamp validation failed");
return false;
}
// (可选) 校验 Nonce 防止重放,需要存储已用过的 Nonce,可以用 Redis 等
// if (isNonceUsed(clientNonce)) {
// console.error("Nonce replay detected");
// return false;
// }
// markNonceAsUsed(clientNonce, clientTimestamp); // 标记为已用,并设置过期时间
// 1. 从请求中提取参与签名的参数
const { method, path, queryParams } = requestData; // 假设已解析好
// 2. 构造待签名字符串 (规则必须和客户端完全一致!)
const sortedKeys = Object.keys(queryParams).sort();
const queryString = sortedKeys.map(key => `${key}=${queryParams[key]}`).join('&');
const stringToSign = `${method}\n${path}\n${queryString}\n${clientTimestamp}\n${clientNonce}`;
console.log("Server String to Sign:", stringToSign);
// 3. 使用 HMAC-SHA256 生成签名
const expectedSignature = crypto.createHmac('sha256', secretKey)
.update(stringToSign)
.digest('hex');
console.log("Server Expected Signature:", expectedSignature);
console.log("Client Signature:", clientSignature);
// 4. 比对签名 (使用 crypto.timingSafeEqual 防止时序攻击)
if (clientSignature.length !== expectedSignature.length) {
return false;
}
return crypto.timingSafeEqual(Buffer.from(clientSignature), Buffer.from(expectedSignature));
}
// --- Express 示例中间件 ---
// app.use((req, res, next) => {
// const clientSignature = req.headers['x-signature'];
// const clientTimestamp = req.headers['x-timestamp'];
// const clientNonce = req.headers['x-nonce'];
// // 实际项目中,secretKey 应该从环境变量或配置中读取
// const API_SECRET_KEY = process.env.API_SECRET_KEY || "your-super-secret-key-dont-put-in-frontend-directly!";
// // 构造 requestData 对象,包含 method, path, queryParams
// // 注意:如果是 POST/PUT 请求,请求体 (body) 通常也需要参与签名
// // 且 body 如果是 JSON,建议序列化后参与签名,而不是原始对象
// const requestDataForSig = {
// method: req.method.toUpperCase(),
// path: req.path,
// queryParams: req.query, // 对于GET;POST/PUT可能还需包含body
// // bodyString: req.body ? JSON.stringify(req.body) : "" // 如果body参与签名
// };
// if (!verifySignature(requestDataForSig, clientSignature, clientTimestamp, clientNonce, API_SECRET_KEY)) {
// return res.status(401).send('Invalid Signature');
// }
// next();
// });
五、细节是魔鬼:实施过程中的注意事项
- 密钥管理 (Secret Key):
- 绝对保密:这是最重要的!密钥泄露,签名机制就废了。
- 不要硬编码在前端:再次强调!对于B端或内部系统,可以考虑通过安全的构建流程注入。对于C端开放应用,通常结合用户登录后的 session token 或 OAuth token 来做,或者使用更复杂的 API Gateway 方案。
- 定期轮换:为了安全,密钥最好能定期更换。
- 时间戳 (Timestamp):
- 防止重放攻击:服务器会校验收到的时间戳与当前服务器时间的差值,如果超过一定阈值(比如5分钟),就认为是无效请求。
- 时钟同步:客户端和服务器的时钟要尽量同步,不然很容易误判。
- 随机数 (Nonce):
- 更强的防重放:Nonce 是一个只使用一次的随机字符串。服务器需要记录用过的 Nonce,在一定时间内(同时间戳窗口)不允许重复。可以用 Redis 等缓存服务来存。
- 哪些内容需要签名?
- HTTP 方法 (GET, POST, etc.)
- 请求路径 (Path, e.g.,
/users/123) - 查询参数 (Query Parameters, e.g.,
?name=zhangsan&age=18):参数名需要按字典序排序,确保客户端和服务端拼接顺序一致。 - 请求体 (Request Body):如果是
application/x-www-form-urlencoded或multipart/form-data,处理方式同 Query Parameters。如果是application/json,通常是将整个 JSON 字符串作为签名内容的一部分。注意空 body 和有 body 的情况。 - 关键的请求头:比如
Content-Type,以及自定义的一些重要 Header。 - 时间戳和 Nonce:它们本身也要参与签名,防止被篡改。
- 一致性是王道:客户端和服务端在选择哪些参数参与签名、参数的排序规则、拼接格式等方面,必须严格一致,一个空格,一个换行符不同,签名结果就天差地别。
六、HMAC-SHA256 vs. 其他方案?
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 仅 HTTPS | 传输层加密,防止窃听 | 无法防止应用层篡改(加密前)、无法验证发送者身份(应用层)、无法防重放 | 基础数据传输安全 |
| 简单摘要 (如MD5) | 实现简单 | 若无密钥,容易被伪造;MD5本身已不安全 | 文件完整性校验(非安全敏感) |
| HMAC-SHA256 | 消息完整性、身份验证(基于共享密钥)、可防重放(结合时间戳/Nonce) | 密钥管理是关键和难点;签名和验签有一定计算开销 | 需要保障API接口安全、防止未授权访问和篡改的场景 |
| JWT (JSON Web Token) | 无状态、可携带用户信息、标准化 | Token 可能较大;吊销略麻烦;主要用于用户认证和授权 | 用户登录、单点登录、API授权 |
HMAC-SHA256 更侧重于请求本身的完整性和来源认证,而 JWT 更侧重于用户身份的认证和授权。它们可以结合使用。
好啦,今天关于 HMAC-SHA256 请求签名的唠嗑就到这里。这玩意儿看起来步骤多,但一旦理解了原理,实现起来其实就是细心活儿。给你的 API 加上这把锁,晚上睡觉都能踏实点!
我是老码小张,一个喜欢研究技术原理,并且在实践中不断成长的技术人。希望今天的分享对你有帮助,咱们下回再聊!欢迎大家留言交流你的看法和经验哦!
来源:juejin.cn/post/7502641888970670080
聊聊四种实时通信技术:长轮询、短轮询、WebSocket 和 SSE
这篇文章,我们聊聊 四种实时通信技术:短轮询、长轮询、WebSocket 和 SSE 。
1 短轮询
浏览器 定时(如每秒)向服务器发送 HTTP 请求,服务器立即返回当前数据(无论是否有更新)。

- 优点:实现简单,兼容性极佳
- 缺点:高频请求浪费资源,实时性差(依赖轮询间隔)
- 延迟:高(取决于轮询频率)
- 适用场景:兼容性要求高,延迟不敏感的简单场景。
笔者职业生涯印象最深刻的短轮询应用场景是比分直播:

如图所示,用户进入比分直播界面,浏览器定时查询赛事信息(比分变动、黄红牌等),假如数据有变化,则重新渲染页面。
这种方式实现起来非常简单可靠,但是频繁的调用后端接口,会对后端性能会有影响(主要是 CPU)。同时,因为依赖轮询间隔,页面数据变化有延迟,用户体验并不算太好。
2 长轮询
浏览器发送 HTTP 请求后,服务器 挂起连接 直到数据更新或超时,返回响应后浏览器立即发起新请求。

- 优点:减少无效请求,比短轮询实时性更好
- 缺点:服务器需维护挂起连接,高并发时资源消耗大
- 延迟:中(取决于数据更新频率)
- 适用场景:需要较好实时性且无法用 WebSocket/SSE 的场景(如消息通知)
长轮询最常见的应用场景是:配置中心,我们耳熟能详的注册中心 Nacos 、阿波罗都是依赖长轮询机制。

客户端发起请求后,Nacos 服务端不会立即返回请求结果,而是将请求挂起等待一段时间,如果此段时间内服务端数据变更,立即响应客户端请求,若是一直无变化则等到指定的超时时间后响应请求,客户端重新发起长链接。
3 WebSocket
基于 TCP 的全双工协议,通过 HTTP 升级握手(Upgrade: websocket)建立持久连接,双向实时通信。 
- 优点:最低延迟,支持双向交互,节省带宽
- 缺点:实现复杂,需单独处理连接状态
- 延迟:极低
- 适用场景:聊天室、在线游戏、协同编辑等 高实时双向交互 需求
笔者曾经服务于北京一家电商公司,参与直播答题功能的研发。

直播答题整体架构见下图:

Netty TCP 网关的技术选型是:Netty、ProtoBuf、WebSocket ,选择 WebSocket 是因为它支持双向实时通信,同时 Netty 内置了 WebSocket 实现类,工程实现起来相对简单。
4 Server Send Event(SSE)
基于 HTTP 协议,服务器可 主动推送 数据流(如Content-Type: text/event-stream),浏览器通过EventSource API 监听。

- 优点:原生支持断线重连,轻量级(HTTP协议)
- 缺点:不支持浏览器向服务器发送数据
- 延迟:低(服务器可即时推送)
- 适用场景:股票行情、实时日志等 服务器单向推送 需求。
SSE 最经典的应用场景是 : DeepSeek web 聊天界面 ,如图所示:

当在 DeepSeek 对话框发送消息后,浏览器会发送一个 HTTP 请求 ,服务端会通过 SSE 方式将数据返回到浏览器。

5 总结
| 特性 | 短轮询 | 长轮询 | SSE | WebSocket |
|---|---|---|---|---|
| 通信方向 | 浏览器→服务器 | 浏览器→服务器 | 服务器→浏览器 | 双向通信 |
| 协议 | HTTP | HTTP | HTTP | WebSocket(基于TCP) |
| 实时性 | 低 | 中 | 高 | 极高 |
| 资源消耗 | 高(频繁请求) | 中(挂起连接) | 低 | 低(长连接) |
选择建议:
- 需要 简单兼容性 → 短轮询
- 需要 中等实时性 → 长轮询
- 只需 服务器推送 → SSE
- 需要 全双工实时交互 → WebSocket
来源:juejin.cn/post/7496375493329174591
BOE(京东方)第6代新型半导体显示器件生产线全面量产 打造全球显示产业新引擎
2025年5月26日,BOE(京东方)成功举办主题为“屏启未来 智显无界”的量产交付活动,开启第6代新型半导体显示器件生产线由建设转向运营的崭新篇章。这不仅标志着BOE(京东方)在LTPO、LTPS、Mini LED等高端显示领域实现跨越式突破,也为我国半导体显示产业注入强劲动能,加速助力北京打造国际科技创新中心。作为全球技术最先进、产能最大的VR用LCD生产基地,该生产线将充分发挥技术引领和产业集聚优势,进一步巩固BOE(京东方)行业龙头地位,加速全球虚拟现实产业和数字经济发展。BOE(京东方)科技集团董事长陈炎顺,BOE(京东方)首席执行官冯强,BOE(京东方)首席运营官王锡平,行业专家及生态伙伴出席现场仪式,共同见证这一荣耀时刻。

活动现场,BOE(京东方)科技集团董事长陈炎顺发表致辞,他表示,BOE(京东方)以“BOE速度”打造新型显示产业基地建设标杆,成功实现开工当年封顶、次年产品点亮的关键目标。与此同时,技术研发与产品准备也在同步推进,多款产品已完成客户送样并推进交付。BOE(京东方)特别感谢战略合作伙伴们对技术创新的追求和坚持,这也推动着BOE(京东方)不断超越自我,取得一个又一个新的突破。BOE(京东方)将始终以战略客户伙伴的前沿需求和技术标准为指引,在“屏之物联”战略指导下,用踏实奋斗和持续创新回馈各界支持。

作为全球技术最先进的液晶显示屏生产基地,BOE(京东方)第6代新型半导体显示器件生产线总投资290亿元,占地面积42万平方米,设计月产能达5万片。该生产线以LTPO(低温多晶氧化物)和LTPS(低温多晶硅)技术为核心,聚焦聚焦 VR 显示面板、中小尺寸高附加值 IT 显示面板、车载显示面板等高端产品研发与生产,采用1500mm×1850mm的6代线玻璃基板,配备当前最先进的生产设备,并整合京东方多条成熟产线的先进经验,大幅提升生产效率和产品精度。在技术创新方面,BOE(京东方)LTPO技术融合了LTPS的高迁移率和Oxide的低功耗优势,可实现1500PPI以上的超高像素密度,并大幅度降低面板功耗,为显示设备提供更流畅、更清晰的动态画面。
值得一提的是,BOE(京东方)第6代新型半导体显示器件生产线还充分赋能多元化的场景应用,多款产品凭借极具竞争力的产品性能和领先的技术优势,获得全球一线知名客户的高度认可。其中,BOE(京东方)自主设计开发的超高2117PPI Real RGB显示屏实现成功点亮,达到当前LCD行业最高分辨率。在此次交付活动上,BOE(京东方)展示了已具备量产条件的2.24英寸1500PPI以及2.24英寸1700PPI VR显示模组,16英寸240Hz电竞笔记本屏幕(分辨率2560×1600,100% DCI-P3色域),以及14.6英寸窄边框高端车载中控屏等产品,全面满足“元宇宙”、高端消费电子、智能出行等领域的需求。
更加值得关注的是,BOE(京东方)第6代新型半导体显示器件生产线还在可持续发展方面走在世界前列。通过洁净室气流集控、AI分区温湿度自调、用电集控等创新技术,BOE(京东方)实现供热回收使用率100%、实现纯水回用率达80%、污染物排放均值小于标准50%。此外,在“双碳”目标引领下,BOE(京东方)将绿色理念贯穿于研发、生产与回收全生命周期。例如,生产线生产的产品在提升画质的同时更加注重产品低功耗性能,为设备的长时间使用提供可持续支持。这些实践不仅呼应了全球绿色低碳转型趋势,更展现了BOE(京东方)作为行业领军者的责任担当。同时,依托AI赋能,BOE(京东方)第6代新型半导体显示器件生产线还实现了智能排产、预测性维护、智能缺陷管理等全流程优化,设备综合效率(OEE)提升0.5%,工艺稳定性提升20%,良率分析效率提升20%,为行业树立了绿色生产与智能制造的双重标杆,也有力地回应了BOE(京东方)“Open Next Earth”的可持续发展品牌内涵。
在虚实交融的数字文明浪潮中,屏幕已从信息媒介跃升为跨越现实与虚拟、链接当下与未来的纽带。BOE(京东方)将持续以“屏之物联”战略为核心,加速显示技术与物联网、人工智能等前沿技术的深度融合,深刻践行“科技创新+绿色发展”之道。面向未来,BOE(京东方)将与更多合作伙伴携手,以协同创新之力探寻合作路径,全力赋能万物互联的未来智能生态体系,共同迎接一个更智慧、更互联、更美好、更绿色的全新时代。
生产环境到底能用Docker部署MySQL吗?
程序员小李:“老王,我有个问题想请教您。MySQL 能不能部署在 Docker 里?我听说很多人说不行,性能会有瓶颈。”
架构师老王:“摸摸自己光突突的脑袋, 小李啊,这个问题可不简单。以前确实很多人说不行,但现在技术发展这么快,情况可能不一样了。”
小李:“那您的意思是,现在可以了?”
老王:“也不能这么说。性能、数据安全、运维复杂度,这些都是需要考虑的。不过,已经有不少公司在生产环境里用 Docker 跑 MySQL 了,效果还不错。”
Docker(鲸鱼)+MySQL(海豚)到底如何,我们来具体看看:

一、业界大厂
我们来看看业界使用情况:
1.1、京东超70%的MySQL在Docker中

刘风才是京东的资深数据库专家,他分享了京东在MySQL数据库Docker化方面的实践经验。京东从最初的小规模使用,到现在超过70%的MySQL数据库运行在Docker容器中。
当然京东也不是所有的业务都适合把 mysql 部署在 docker 容器中。比如,
刘风才演讲中也提出:数据文件多于1T多的情况下是不太合适部署在Docker上的;再有就是在性能上要求特别高的,特别重要的核心系统目前仍跑在物理机上,后面随着Docker技术不断的改进,会陆续地迁到Docker上。
1.2、 同程艺龙:大规模 MySQL 容器化实践

同程艺龙的机票事业群 CTO 王晓波在QCon北京2018大会上做了《MySQL的Docker容器化大规模实践》的主题演讲。他分享了同程艺龙如何大规模实践基于Docker的MySQL私有云平台,集成了高可用、快速部署、自动化备份、性能监控等多项自动化运维功能。该平台支撑了总量90%以上的MySQL服务(实际数量超过2000个),资源利用率提升了30倍,数据库交付能力提升了70倍,并经受住了业务高峰期的考验。
当然不仅仅是京东、同程像阿里云、腾讯、字节、美团等都有把 Mysql 部署在 Docker 容器中的案例。
二、官方情况
MySql 官方文档提供了 mysql 的 docker 部署方式,文档中并没有明确的表明这种方式是适用于开发、测试或生产。那就是通用性的,也就是说生产也可以使用。
以下就是安装的脚本可以看到配置文件和数据都是挂载到宿主机上。
docker run --name=mysql1 \
--mount type=bind,src=/path-on-host-machine/my.cnf,dst=/etc/my.cnf \
--mount type=bind,src=/path-on-host-machine/datadir,dst=/var/lib/mysql \
-d container-registry.oracle.com/mysql/community-server:tag
再看看镜像文件,可以看到 oralce 官方 7 年前就发布了 mysql5.7 的镜像。

三、具体分析
反方观点:生产环境MySQL不该部署在Docker里
反方主要担心数据持久化、性能、复杂性、备份恢复和安全性等问题,觉得在Docker里跑MySQL风险挺大。
正方观点:生产环境MySQL可以部署在Docker里
正方则认为Docker的灵活性、可移植性、资源隔离、自动化管理以及社区支持都挺好,生产环境用Docker部署MySQL是可行的,而且有成熟的解决方案来应对数据持久化和性能等问题。
总结
争议的焦点主要在于Docker容器会不会影响性能。其实 Docker和虚拟机不一样,虚拟机是模拟物理机硬件,而Docker是基于Linux内核的cgroups和namespaces技术,实现了CPU、内存、网络和I/O的共享与隔离,性能损失很小。

Docker 和传统虚拟化方式的不同之处,在于 Docker 是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,而传统方式则是在硬件层面实现。
Docker的特点:
- 轻量级:共享宿主机内核,启动快,资源占用少。
- 隔离性:容器之间相互隔离,不会互相干扰。
- 可移植性:容器可以在任何支持Docker的平台上运行,不用改代码。
四、结尾
Docker虚拟化操作系统而不是硬件
随着技术的发展,Docker在数据库部署中的应用可能会越来越多。
所以,生产环境在Docker里部署MySQL,虽然有争议,但大厂都在用,官方也支持,技术也在不断进步,未来可能是个趋势。
我是栈江湖,如果你喜欢此文章,不要忘记点赞+关注!
来源:juejin.cn/post/7497057694530502665
Spring之父:自从我创立了 Spring Framework以来,我从未如此确信需要一个新项目
大家好,这里是小奏,觉得文章不错可以关注公众号小奏技术
Spring框架之父再出发:发布JVM智能体框架Embabel,赋能企业级AI应用
当今,人工智能的浪潮正以前所未有的势头席卷技术世界,Python 凭借其强大的生态系统成为了AI开发的“通用语”。
然而,Spring 框架的创始人Rod Johnson 却发出了不同的声音。
”自从我创立 Spring 框架以来,我从未如此坚信一个新项目的必要性。自从我开创了依赖注入(Dependency Injection)和其他 Spring 核心概念以来,我从未如此坚信一种新编程模型的必要性,也从未如此确定它应该是什么样子“
为此,他亲手打造并开源了一个全新的项目——Embabel:一个为 JVM 生态量身定制的 AI 智能体(Agent)框架
我们为什么需要一个智能体框架
难道大型语言模型(LLM)还不够聪明,无法直接解决我们的问题吗?难道多聊天协议(MCP)工具不就是我们让它们解决复杂问题所需要的一切吗?
不。MCP 是向前迈出的重要一步,Embabel 自然也拥抱它,就像它让使用多模型变得简单一样。
但是,我们需要一个更高级别的编排技术,尤其是对于业务应用程序,原因有很多。以下是一些最重要的原因
- 可解释性(Explainability): 在解决问题时,选择是如何做出的?
- 可发现性(Discoverability): MCP 绕开了这个重要问题。我们如何在每个节点找到正确的工具,并确保模型在它们之间进行选择时不会混淆?
- 混合模型的能力(Ability to mix models): 这样我们就不用依赖于“上帝模型”,而是可以为许多任务使用本地的、更便宜的、私有的模型。
- 在流程的任何节点注入“护栏”(guardrails)的能力。
- 管理流程执行并引入更高弹性的能力。
- 大规模流程的可组合性(Composability)。 我们很快将看到的不仅是在一个系统上运行的智能体,而是智能体的联邦。
- 与敏感的现有系统(如数据库)进行更安全的集成,在这些地方,即使是最好的 LLM,给予其写权限也是危险的。
这些问题在企业环境中尤为突出,它们需要的不是一个简单的问答机器人,而是一个可解释、可控制、可组合且足够安全的高级编排系统。这正是智能体框架的价值所在。
为什么是JVM,而不是Python?
Python 在 AI 研究和数据科学领域地位稳固,但 GenAI 的核心是连接与整合。当我们构建企业级 AI 应用时,真正的挑战在于如何将 AI 能力与数十年积累的、运行在 JVM 上的海量业务逻辑、基础设施和数据无缝对接。
在企业应用开发、复杂系统构建和关键业务逻辑承载方面,JVM 生态(Java/Kotlin)拥有无与伦比的优势和成熟度。因此,与其让业务逻辑去追赶 AI 技术栈,不如让 AI 技术栈主动融入业务核心——JVM。
Embabel:为超越而生的下一代智能体框架
Embabel 的目标并非简单地追赶 Python 社区的同类框架,而是要实现跨越式超越。它带来了几个革命性的特性:
- 确定性的智能规划:Embabel 创新地引入了非 LLM 的 AI 规划算法。它能自动从你的代码中发现可用的“能力”和“目标”,并根据用户输入智能地规划出最优执行路径。这意味着你的系统是可扩展的,增加新功能不再需要重构复杂的逻辑,同时整个规划过程是确定且可解释的。
- 类型安全的领域模型:
Embabel鼓励开发者使用Kotlin data class或Java record构建丰富的领域模型。这使得与 LLM 交互的提示(Prompt)变得类型安全、易于工具检查和代码重构,从根本上提升了代码质量和可维护性。 - 与
Spring无缝集成:Embabel用Kotlin构建,并承诺为Java开发者提供同等一流的体验。更重要的是,它与Spring框架深度集成。对于数百万Spring开发者来说,构建一个 AI 智能体将像开发一个REST API一样自然、简单。
加入我们,共创未来
对于JVM 开发者来说,这是一个激动人心的时代。Embabel 提供了一个绝佳的机会,让你可以利用自己早已熟练掌握的技能,为你现有的 Java/Kotlin 应用注入强大的 AI 能力,从而释放巨大的商业价值。
项目尚在早期,但蓝图宏大。Embabel 的目标是成为全球最好的智能体平台。现在就去 GitHub 关注 Embabel,加入社区,贡献你的力量,一同构建企业级 AI 应用的未来。
参考
来源:juejin.cn/post/7507438828178849828
这篇 Git 教程太清晰了,很多 3 年经验程序员都收藏了
引言
📌 Git 是现代开发中不可或缺的版本控制工具,尤其适用于团队协作和代码管理。本文将带你了解 Git 的基础操作命令,包括 git init、git add、git commit、git diff、git log、.gitignore 等,快速上手版本控制。
🛠️ 一、初始化仓库:git init
使用 Git 前,需先初始化一个本地仓库:
git init
执行后会在当前目录生成一个 .git 文件夹,Git 会在此目录下跟踪项目的变更记录。
👤 二、配置用户信息
首次使用 Git 时,推荐设置用户名和邮箱:
git config --global user.name "xxxxx"
git config --global user.email "xxxx@qq.com"
加上 --global 会全局生效,仅对当前项目配置可以省略该参数。
📦 三、代码暂存区(Staging Area)是什么?
Git 的提交操作分为两个阶段:暂存(staging) 和 提交(commit) 。
- 当你修改了文件,Git 并不会立即记录这些改动;
- 你需要先使用
git add命令,把改动“放进暂存区”,告诉 Git:“这些改动我准备好了,可以提交”; - 然后再使用
git commit将暂存区的内容提交到本地仓库,记录为一个快照。
🧠 可以把暂存区类比为“快照准备区”,你可以反复修改文件、添加到暂存区,最后一口气提交,确保每次提交都是有意义的逻辑单元。
🎯 举个例子:
# 修改了 index.html 和 style.css
git add index.html # 把 index.html 放入暂存区
git add style.css # 再把 style.css 放入暂存区
git commit -m "更新首页结构和样式" # 一起提交
💡 小贴士:你可以分批使用 git add 管理暂存内容,按逻辑分组提交更利于协作和回溯。
📝 四、查看当前状态:git status
在进行任何修改之前,查看当前仓库的状态是非常重要的。git status 是最常用的命令之一,能让你清楚了解哪些文件被修改了,哪些文件已加入暂存区,哪些文件未被跟踪。
git status
它的输出通常会分为三部分:
- 已暂存的文件:这些文件已使用
git add添加到暂存区,准备提交。 - 未暂存的文件:这些文件被修改,但还未添加到暂存区。
- 未跟踪的文件:这些文件是新创建的,Git 并未跟踪它们。
例如:
On branch main
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: index.html
new file: style.css
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
modified: app.js
🎯 通过 git status,你可以随时了解当前工作区和暂存区的状态,帮助你决定接下来的操作。
📥 五、添加文件到暂存区:git add
当你修改或新增文件后,使用 git add 将其添加到 Git 的暂存区:
git add 文件名
也可以批量添加所有修改:
git add .
💾 六、提交更改:git commit -m
将暂存区的内容提交至本地仓库:
git commit -m "提交说明"
-m 后面是提交信息,建议语义清晰,例如:
git commit -m "新增用户登录功能"
🚀 七、推送到远程仓库:git push origin main
本地提交之后,需要推送代码到远程仓库(如 GitHub、Gitee):
git push origin main
origin是默认的远程仓库别名;main是目标分支名(如果你使用的是master,请替换);
✅ 提交后远程成员就可以拉取(pull)你最新的修改了。
🔗 如果你还没有远程仓库,请先去 GitHub / Gitee 创建一个,然后关联远程仓库地址:
git remote add origin https://github.com/yourname/your-repo.git
🕵️ 八、查看文件改动:git diff
在 commit 之前,可用 git diff 查看修改内容:
git diff
📜 九、查看提交历史:git log --oneline
快速查看历史提交记录:
git log --oneline
输出示例:
e3f1a1b 添加登录功能
2c3d9a7 初始提交
🛑 十、忽略某些文件:.gitignore
在项目中,有些文件无需提交到 Git 仓库,例如缓存、编译结果、配置文件等。使用 .gitignore 文件可忽略这些文件:
# 忽略 node_modules 文件夹
node_modules/
# 忽略所有 .log 文件
*.log
# 忽略 .env 环境变量文件
.env
🌿 十一、重命名默认分支:git branch -M main
很多平台(如 GitHub)推荐使用 main 作为主分支名称:
git branch -M main
这样可以将默认分支由 master 改为 main。
✅ 总结命令一览表
| 命令 | 作用 |
|---|---|
git init | 初始化仓库 |
git config | 设置用户名与邮箱 |
git status | 查看当前文件状态 |
git add | 添加改动到暂存区 |
git commit -m | 提交改动 |
git push origin main | 推送代码到远程 main 分支 |
git diff | 查看未提交的改动 |
git log --oneline | 查看提交历史 |
.gitignore | 忽略文件 |
git branch -M main | 重命名分支为 main |
🧠 写在最后
Git 是每个开发者都必须掌握的技能之一。掌握好这些常用命令,就能覆盖 90% 的使用场景。未来如果你要进行多人协作、分支合并、冲突解决,这些基础就是你的武器库。
觉得实用就点个赞、关注、收藏支持一下吧 🙌
来源:juejin.cn/post/7506776151315922971
从热衷到放弃:我的 Cursor 续费终止之路
前言
从我最开始用 Cursor 到现在已经有几个月了,然而随着对它的使用时间越来越长,我感觉帮助反而慢慢变小了,一度我这个月想着不续费了,然后我以为 13 到期、结果却是 7 号到期,所以又自动续费了。

最开始接触
我已经用了 Cursor 好几个月了,而我最开始用 Cursor 是在好几个月前。
最开始在社交平台上了解到它的功能后,我就很激动了,感觉这也太神了,就一直想体验。但那时也了解到它的价格的何等的贵,所以我开始并没有直接去下载它,而是找了平替 Windsurf

但别说用了,连注册都注册不了,反复试了几天,也没有注册成功。换手机、换科学上网的不同提供商,都没用。这不,才开始用 Cursor。
无限续杯 之 走到终点
等我用了之后,体验了它的14天免费时间。之后我就觉得它太强了。很多我可以写的功能,它可以以更好的方式,很快的方式生成出来。然而很多我还不会写的。它依然可以去实现。但14天很快就过去了,接着就是一段时间 帐号的删除与注册。但好景不长...
终于在多次反复删除账号又注册。这种操作对我来说已经失效了。
看过了掘金的大多教程,都没有什么用,最后一次有用,但第二天就又不行了。
但那段时间刚巧,我之前在找工作,那几天刚好入职。我就在工作中用了它,有意思的是,我们公司并没有人知道 cursor,甚至没人知道有 ai编辑器。过了几天,无限续杯 也刚好达到极限。
充会员 -> 早下班
当我体验了 Cursor 的威力后,我已经要离不开它了。
我是前端,而 Cursor 可以支持发给它图片,让它画页面。其实画的还挺不错的,这一点就深得我心,所以我痛定思痛充了会员。

那段时间,我就没加过班、自在的我自己都不知道该如何描述了。但刚开始还是不怎么舒服,因为它老是给我生成用 element-plus 组件直接写的,而我们公司有不少组件是二次封装的,导致我总是要改它。但用了十几次后,它就知道我要什么了。
用了哪些功能 与 自己的感受
Tab 的好与不好
我常用的功能就是tab,主要的是它比较灵活,生成的速度也比较快。而且用的越多它就越可以生成想要的代码。比如项目中自己封装的组件。用 tab 几次之后,它就自己可以去用这个组件,但更多情况下,它生成的会是之前写过的内容。
不过它也有一些缺点,比如:不能去预判一些复杂的思路。如果我们写了一个按钮,并在按钮身上绑定一个 Click 事件,名称叫做 search。Cursor 的 Tab 就可以自动会生成 search函数。但如果你只是在这里写了一个按钮,想要做的功能是导出。你没有在按钮上写导出两个字,也没有去绑定一个 Click事件 叫 export。那 Cursor 根本就不知道你要做的是导出,也就不会去自动实现这些功能。
另一个 Tab 的缺点,那就是影响复制功能。经常准备复制内容时,Tab 就给出了它的预判,然而原本你打算复制10个字,此时它的预判在 10个字中间加了 30个字。你要是想复制,正常就会用鼠标选中字,可一旦你鼠标点下那个位置,Tab就来了。我多次遇到这个问题,如果你没有遇到过,请教我一下方法。
对话模式
对话分两种,一种是全局,一种是局部。
先来说一下全局。
全局对话 cmd + i

由于 Cursor 默认会将所有文件自动追踪索引。所以当我们进行全局对话时, Cursor 会基于全局所有文件的索引为基础。去修改现在的代码,但如果我们只想改当前一个页面,它依然会去分析全局,增加了要处理的数据量,就导致时间比较长。
不知道是不是我的科学上网工具问题,我几乎只要用全局问答,就要好几分钟,要是改错了,又要重来,所以现在几乎就不用了。
另一个是后面代码变多了,时间就更长,而且它老是给我优化我不要优化的,因为它经常优化错了。比如关于接口的 type,我都是在 api 文件夹中定义的。但它总说在那个文件中没有这个 type,然后就自动在当前文件附近又创建 types.ts ,然后声明的类型和接口都不是对应的。
当然了,它的好处是分析的全面、如果要跨多个文件修改同一个功能,则它再慢,也得等着。
之后我就又想起了 局部 对话
局部对话 cmd + k

我是上段时间才开始用这个的,因为全局的太慢了,就突然想起来还有局部的 cmd ➕ k 。这个还不错,我最初是用来写 API 数据的。
因为我们是用 ApiPost,我就直接在左边接口标题处,点击复制,然后进代码,在局部问答中发给他,然后说,写出接口和类型。基本没出过错。
用了几天后也发现它的局限性了,就是它貌似只能在问的位置下方生成,如果我要它跨越几个地方添加就没用了。如:在template中生成页面展示的,在JS中生成脚本,在style中生成样式。
但之后发现这种方式不仅能生成,如果你选中了内容,它还能修改。然后我就随机一动,直接全选当前文件,则实现了对一整个文件的局部修改。但说实话,速度也并没有太快。
cursorrules
后来我又加了cursorrules,最初我以为只能用一个rules文件,直到在一个微信群里看见别人分享的照片,他有6个左右的rules。之后我就用了两天时间自己写了4个rules。但经常没有效果,而且还开启了always。

之后,我就在开始的位置写上这样这句话:
自动激活
这些指令在本项目的所有对话中自动生效。当使用到该 rules 时,要打印出这个rules的名字,如"使用了 项目规则.mdc 文件",让我知道你使用了这个文件。
之后有一次就突然出现了这句话

可是,只出现过这个 项目规则.mdc ,其它的mdc 都没有出现过,但其它的文件中 我也写了类型的 自动激活的话。不知道为什么没有生效。
MCP
server-sequential-thinking
MCP 之前使用过,那时主要火的是 server-sequential-thinking, 它的主要功能是思维更有条理。如果你在对话中 说了类似 " 思考 " 的话,那就会激活它。之后它就一句话一句话的分析,也一句一句的解释。因为工作中比较少的有这么有深度的思考,我几乎没用过它。而且用了它之后,话也变多了,导致效率也慢,外加 科学上网 的工具并不好,就更慢了。 上段时间我又开始使用它了,但一直没生效,不知道为啥?
playwright 自动化测试
用这个可能比较复杂,其实我就是希望 Cursor 可以自己调接口,然后根据 api 文件中的 对接口的声明、参数类型与返回类型。自动帮我实现 增删改查 ,如果一个表单,我的字段写错了,它就自动修改,然后继续填写数据再调接口。直到跑通为止。 因为这确实很费时间,也没意思。但至今也没有做到。
browser-tool-mcp
这个是用来让 Cursor 监控浏览器,它可以查看浏览器的 控制台、DOM 结构 等等,但用了一段时间后,发现直接把 控制台的报错 发给 Cursor 更快,也就没怎么用了。
结语
上面 MCP 用的不怎么好的一个原因,是因为没有打通 自动化的流程,所以总是需要我手动的操作。
这个星期打算把 claude 的提示词看一下,看看能不能改善一下 Cursor 的使用情况。
来源:juejin.cn/post/7501966297334497290
Android 16 适配重点全解读 | OPPO 技术专场直播回顾
5月22日,OPPO举办「OTalk | Android 16 开发者交流专场」,特邀OPPO高级工程师团队深度解读Android 16核心技术要点与适配策略。活动以线上直播形式展开,吸引了众多开发者实时观看并参与讨论,为他们提供了从技术解析到工具支持的全流程适配解决方案。
一、Android 16开发者适配计划
根据Google规划,Android 16.0及16.1版本将于2025年分阶段发布,所有应用须在7月1日前完成适配,覆盖目标版本为36(API 36)的新开发及存量应用,涉及行为变更、API 调整和新功能兼容。开发者可尽早启动测试,以免适配延迟对应用上架和用户体验造成不利影响。

二、Android 16核心新特性及适配建议
自适应适配:大屏设备体验的优化
随着折叠屏、平板等多样化设备形态的普及,大屏适配已成为开发者面临的重要技术挑战。在 Android 16.0 中,当应用 Target SDK=36 且运行在最小宽度≥600dp 的设备时,系统将忽略传统的屏幕方向、尺寸可调整性等设置限制,为大屏设备带来更出色的视觉体验。
不过,以下三种情况不在新特性的范围内:
游戏类应用(需要在清单属性中配置 android:appCategory);
小于 sw600dp 的屏幕(常见手机设备不受影响);
用户在系统设置中启用了宽高比配置。
适配建议:
遵循谷歌适配指南,完成大屏布局优化,以提供更佳的用户体验;
若暂不支持,可在 Activity 或 Application 节点添加 PROPERTY_COMPAT_ALLOW_RESTRICTED_RESIZABILITY 属性临时豁免,但需注意,该配置可能会在 Android 17 中被取消,因此建议开发者优先完成适配。
针对大屏适配,开发者可以参考由 OPPO、vivo、小米等厂商共同制定的《ITGSA 大屏设备应用适配白皮书 2.0》。同时,建议开发者逐步迁移到 Compose 开发,使后续适配工作更加简单高效。

预测性返回:手势导航的交互变革
预测性返回是 Android 13 引入的手势导航增强功能,用户在侧滑返回时可以预览目标界面。在 Android 16 中,目标 SDK≥36 的应用默认启用预测性返回动画,系统不再调用 onBackPressed 也不会再调度 KeyEvent.KEYCODE_BACK。
适配建议:迁移至 onBackInvokedCallback 回调处理返回逻辑;若需保留原有逻辑,可在清单中设置 android:enableOnBackInvokedCallback="false" 停用。

ART 内部变更:提升性能与兼容性
Android 16 包含 Android 运行时(ART)的最新更新,这些更新旨在提升 ART 的性能,并支持更多的 Java 功能。依赖 ART 内部结构的代码(如私有反射、非 SDK 接口)将全面失效。
适配建议:全面测试应用稳定性,替换非公开 API 为系统提供的公共 API。

JobScheduler 配额优化:后台任务的效率革命
为了降低系统负载,Android 16 对 JobScheduler 的执行配额进行了动态管理,根据应用待机分桶和前台服务状态动态分配 JobScheduler 执行配额,活跃应用获得更多配额,后台任务仍需遵守配额限制。
适配建议:减少非必要后台任务,高优先级任务使用 setExpedited() 标记;通过 WorkInfo.getStopReason() 记录任务终止原因并调整调度策略。

健康与健身权限:隐私管控的升级
Android 16 将 BODY_SENSOR 权限迁移至 “健康数据共享” 权限组。对于 Target SDK≥36 的应用,需要请求新的权限。
适配建议:更新权限请求逻辑,引导用户在系统级 “健康数据共享” 页面授权。

setImportantWhileForeground 接口失效:后台任务的约束
setImportantWhileForeground 接口曾用于让前台任务豁免后台限制,但从 Android 16 开始,该接口的功能已被彻底移除。依赖此接口的下载任务、实时同步等场景可能出现延迟,影响用户体验。
适配建议:改用 jobInfo.setExpedited() 标记加急任务,确保关键操作优先执行。

息屏场景自动停止屏幕分享:隐私与管控的平衡
为提升隐私安全,Android 16会在手机息屏或通话结束后,自动释放 MediaProjection。
适配建议:在 onStop 回调中处理异常,如需持续投屏,需重新获取 MediaProjection 权限。

此外,在 Android 16 中,多项关键特性同样值得注意。优雅字体 API 被废弃,开发者需手动调整文字布局以确保显示效果。更安全的 Intent 机制要求显式 Intent 与目标组件的 Intent 过滤器相匹配,提升应用安全性。以进度为中心的通知功能增强,通过Notification.ProgressStyle实现更直观的进度可视化。MediaProvider 扩展了能力,PhotoPicker 支持 PDF 读取并增强权限鉴权,同时统一了界面风格。这些变更体现了 Android 16 在安全性、用户体验和功能上的优化。


在互动答疑环节,有开发者提出预测性返回动画是否是系统强制的问题,纪昌杰表示预测性返回特性需要应用 targetsdk 升级到 36 才会强制生效,未升级的应用则需通过配置使其生效,应用要主动适配,适配重点在于防止系统不再调用 onBackPressed 和不再调度 KeyEvent.KEYCODE_BACK 导致应用逻辑异常。而对于一个开发人员如何高效适配大屏的问题,纪昌杰再次强调,建议开发者逐步迁移到 Compose 平台开发,以获得谷歌更多支持,开发资源有限的开发者可以参考金标联盟制定的大屏适配 2.0 标准,其内容大多基于 View + XML 开发模式进行指导。
三、OPPO一站式支持体系
在本次交流专场中,纪昌杰还介绍了 OPPO 为助力 Android 16 适配所构建的一站式开发者支持体系。该体系涵盖了详尽的兼容性适配文档,为开发者提供了清晰明确的适配指引;免费的云真机 / 云测服务,赋能开发者随时随地开展高效调试与验证工作。此外,还包括开发者预览版,便于开发者提前评估应用在新系统上的表现,以及应用商店新特性检测,确保应用完全符合 Android 16 的各项标准。同时,开发者可借助适配答疑交流社群和 OPPO 开放平台支持专区等多元渠道,获取全方位支持,有效提升适配效率。

此次「OTalk | Android 16 适配开发者交流专场」聚焦前沿技术洞察与实战指南,开发者提供了系统性适配路径与高效解决方案。活动分享的适配策略、高频问题解答等核心资料,将在「OPPO开放平台」公众号及OPPO开发者社区官网发布,开发者可免费查阅并应用于实际开发流程。
作为Android生态的重要推动者,OPPO将持续提供全链路适配支持服务,并通过技术沙龙、开发者社群及线上交流平台,与开发者紧密协作,共同探索Android 16的创新边界,助力移动应用生态实现高质量演进。
收起阅读 »个人开发者如何发送短信?这个方案太香了!
还在为无法发送短信验证码而烦恼?今天分享一个超实用的解决方案,个人开发者也能用!
最近国内很多平台暂停了针对个人用户的短信发送,这给个人开发者带来了不少困扰。不过别担心,我发现了一个超实用的解决方案——Spug推送平台,它能很好地满足我们发送短信等需求。
为什么选择这个方案?
- 无需企业认证:个人开发者直接可用
- 新用户福利:注册即送测试短信
- 价格实惠:0.05元/条,按量计费
- 接口简单:几行代码就能搞定
- 支持丰富:短信、电话、微信、企业微信、飞书、钉钉、邮件等
三步搞定短信发送
第一步:注册账户
打开push.spug.cc,使用微信扫码直接登录,无需繁琐的认证流程。
第二步:创建模板
- 点击"消息模板" → "新建"
- 输入模版名称
- 选择推送通道
- 选择短信模板
- 选择推送对象
- 保存模板
第三步:发送短信
复制模版ID,通过API调用即可发送短信。
发送短信验证码代码示例(多种语言)
Python版(推荐)
import requests
def send_sms(template_id, code, phone):
url = f"https://push.spug.cc/send/{template_id}"
params = {
"code": code,
"targets": phone
}
response = requests.get(url, params=params)
return response.json()
# 使用示例
result = send_sms("abc", "6677", "151xxxx0875")
print(result)
Go版
package main
import (
"fmt"
"net/http"
"io/ioutil"
)
func sendSMS(templateID, code, phone string) (string, error) {
url := fmt.Sprintf("https://push.spug.cc/send/%s?code=%s&targets=%s",
templateID, code, phone)
resp, err := http.Get(url)
if err != nil {
return "", err
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
return "", err
}
return string(body), nil
}
func main() {
result, err := sendSMS("abc", "6677", "151xxxx0875")
if err != nil {
fmt.Println("Error:", err)
return
}
fmt.Println(result)
}
Java版
import java.net.HttpURLConnection;
import java.net.URL;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class SMSSender {
public static String sendSMS(String templateId, String code, String phone) throws Exception {
String url = String.format("https://push.spug.cc/send/%s?code=%s&targets=%s",
templateId, code, phone);
URL obj = new URL(url);
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
con.setRequestMethod("GET");
BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));
String inputLine;
StringBuilder response = new StringBuilder();
while ((inputLine = in.readLine()) != null) {
response.append(inputLine);
}
in.close();
return response.toString();
}
public static void main(String[] args) {
try {
String result = sendSMS("abc", "6677", "151xxxx0875");
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
使用技巧
- 参数说明
code:验证码内容targets:接收短信的手机号- 使用
targets参数会覆盖模板配置的手机号
- 最佳实践
- 选择合适的短信模版
- 验证手机号格式
- 管理验证码有效期
- 添加错误处理
- 确保账户余额充足
来源:juejin.cn/post/7495570300124119052
我用AI+高德MCP 10分钟搞定苏州三日游
清明节后回到工作岗位,同事们都在讨论"五一"小长假要去哪里,我悄悄地笑了——作为一名AI玩家,旅行规划这种事,早就甩手给AI工具了!
前两天,我用AI+高德地图MCP不到10分钟就搞定了一份详细的苏州三日游攻略,发给朋友们看了规划都惊呆了。
"这...这么详细?连每天天气、门票价格、交通方式都安排好了?"
没错,它全都搞定了!想当年我策划旅行,那可是"人间疾苦":
- 在小红书翻攻略翻到眼睛发酸
- 在地图上反复规划路线怀疑人生
- 十几个浏览器标签切换到想砸电脑
现在?10分钟搞定,而且比人工规划更合理、更高效。
想学吗?我现在就手把手教你,怎么让AI+高德MCP为你定制完美旅行计划。
四步上手,成为旅行规划大师
步骤1:获取高德地图开发权限(超简单)

先去高德开发者平台(lbs.amap.com)注册个账号。

怕麻烦?直接用支付宝扫码就能登录,一分钟搞定!

注册完成后,系统会让你验证身份——这是为了确认你不是机器人,讽刺的是我们要用这个来教AI做事🤣

验证过程很简单,照着提示操作就行,最终你会成为一名光荣的"高德地图开发者"。

步骤2:创建应用并获取API Key
登录成功后,进入控制台:
- 点击"应用管理",创建一个新应用

- 应用名称随便填,比如"我的旅行助手"
- 平台选择"Web服务"

- 创建应用后点击"添加Key",复制生成的密钥

这个Key就是打开高德地图宝库的钥匙,下面要把它交给我们的AI助手。

步骤3:配置AI的地图能力
这一步的关键——我们要让AI获得调用高德地图的超能力:
- 打开Claude Desktop(或其他支持MCP的AI,比如Cursor)
- File->Setting->Developer->Edit Config
- 配置MCP配置文件,配置高德地图MCP服务,贴入刚才获取的API Key
- 保存配置,重启应用
如果你使用的是Claude,添加下面的代码(记得替换成你自己的key)建议重启下应用:
{
"mcpServers": {
"amap-maps": {
"command": "npx",
"args": ["-y", "@amap/amap-maps-mcp-server"],
"env": {"AMAP_MAPS_API_KEY": "这里粘贴你的key"}
}
}
}
确认配置无误后,AI现在已经具备了调用高德地图的能力,它可以查询实时天气、景点信息、路线规划和交通状况等数据。
步骤4:一句指令,生成完美攻略
现在是见证奇迹的时刻!在对话框中输入:
用高德MCP,做苏州三天旅游指南

然后静静等待几秒钟,AI会开始调用高德地图API,搜集各种数据并为你生成一份详尽的旅行规划。
我的苏州三日游攻略包含了:
- 每天详细的行程安排和时间规划
- 景点介绍、门票价格和开放时间
- 周边餐厅推荐和特色美食
- 不同景点间的交通方式和预计用时
- 三天的天气预报
- 住宿和购物建议
- 各种实用小贴士

最妙的是,AI还能根据天气情况自动调整行程——我看到第二天苏州预报有大雨,它贴心地提醒我准备雨具,并建议安排更多室内活动。
锦上添花:生成打印版旅行攻略
如果你想更进一步,可以让AI为你生成一份精美的A4旅行规划表,方便打印随身携带。
只需输入: 帮我设计一个A4纸张大小的旅行规划表,适合打印出来随身携带
这是我的提示词
# 旅行规划表设计提示词
你是一位优秀的平面设计师和前端开发工程师,具有丰富的旅行信息可视化经验,曾为众多知名旅游平台设计过清晰实用的旅行规划表。现在需要为我创建一个A4纸张大小的旅行规划表,适合打印出来随身携带使用。请使用HTML、CSS和JavaScript代码实现以下要求:
## 基本要求
尺寸与基础结构
- 严格符合A4纸尺寸(210mm×297mm),比例为1:1.414
- 适合打印的设计,预留适当的打印边距(建议上下左右各10mm)
- 采用单页设计,所有重要信息必须在一页内完整呈现
- 信息分区清晰,使用网格布局确保整洁有序
- 打印友好的配色方案,避免过深的背景色和过小的字体
技术实现
- 使用打印友好的CSS设计
- 提供专用的打印按钮,优化打印样式
- 使用高对比度的配色方案,确保打印后清晰可读
- 可选择性地添加虚线辅助剪裁线
- 使用Google Fonts或其他CDN加载适合的现代字体
- 引用Font Awesome提供图标支持
专业设计技巧
- 使用图标和颜色编码区分不同类型的活动(景点、餐饮、交通等)
- 为景点和活动设计简洁的时间轴或表格布局
- 使用简明的图示代替冗长文字描述
- 为重要信息添加视觉强调(如框线、加粗、不同颜色等)
- 在设计中融入城市地标元素作为装饰,增强辨识度
## 设计风格
- 实用为主的旅行工具风格:以清晰的信息呈现为首要目标
- 专业旅行指南风格:参考Lonely Planet等专业旅游指南的排版和布局
- 信息图表风格:将复杂行程转化为直观的图表和时间轴
- 简约现代设计:干净的线条、充分的留白和清晰的层次结构
- 整洁的表格布局:使用表格组织景点、活动和时间信息
- 地图元素整合:在合适位置添加简化的路线或位置示意图
- 打印友好的灰度设计:即使黑白打印也能保持良好的可读性和美观
## 内容区块
1. 行程标题区:
- 目的地名称(主标题,醒目位置)
- 旅行日期和总天数
- 旅行者姓名/团队名称(可选)
- 天气信息摘要
2. 行程概览区:
- 按日期分区的行程简表
- 每天主要活动/景点的概览
- 使用图标标识不同类型的活动
3. 详细时间表区:
- 以表格或时间轴形式呈现详细行程
- 包含时间、地点、活动描述
- 每个景点的停留时间
- 标注门票价格和必要预订信息
4. 交通信息区:
- 主要交通换乘点及方式
- 地铁/公交线路和站点信息
- 预计交通时间
- 使用箭头或连线表示行程路线
5. 住宿与餐饮区:
- 酒店/住宿地址和联系方式
- 入住和退房时间
- 推荐餐厅列表(标注特色菜和价格区间)
- 附近便利设施(如超市、药店等)
6. 实用信息区:
- 紧急联系电话
- 重要提示和注意事项
- 预算摘要
- 行李清单提醒
## 示例内容(基于深圳一日游)
目的地:深圳一日游
日期:2025年4月15日(星期二)
天气:晴,24°C/18°C,东南风2-3级
时间表:
| 时间 | 活动 | 地点 | 详情 |
|------|------|------|------|
| 09:00-11:30 | 参观世界之窗 | 南山区深南大道9037号 | 门票:190元 |
| 12:00-13:30 | 海上世界午餐 | 蛇口海上世界 | 推荐:海鲜、客家菜 |
| 14:00-16:00 | 游览深圳湾公园 | 南山区滨海大道 | 免费活动 |
| 16:30-18:30 | 逛深圳欢乐海岸 | 南山区白石路 | 购物娱乐 |
| 19:00-21:00 | 福田CBD夜景或莲花山夜游 | 福田中心区 | 免费活动 |
交通路线:
- 世界之窗→海上世界:乘坐地铁2号线(世界之窗站→海上世界站),步行5分钟,约20分钟
- 海上世界→深圳湾公园:乘坐公交线路380路,约15分钟
- 深圳湾→欢乐海岸:步行或乘坐出租车,约10分钟
- 欢乐海岸→福田CBD:地铁2号线→地铁4号线,约35分钟
实用提示:
- 下载"深圳地铁"APP查询路线
- 准备防晒用品,深圳日照强烈
- 世界之窗建议提前网上购票避免排队
- 使用深圳通交通卡或移动支付
- 深圳湾傍晚可观赏日落美景和香港夜景
- 周末景点人流较大,建议工作日出行
重要电话:
- 旅游咨询:0755-12301
- 紧急求助:110(警察)/120(急救)
请创建一个既美观又实用的旅行规划表,适合打印在A4纸上随身携带,帮助用户清晰掌握行程安排。
AI会立刻为你创建一个格式优美、信息完整的HTML文档,包含所有行程信息,分区清晰,配色考虑了打印需求,真正做到了拿来即用!


告别旅行规划焦虑症
这套方法彻底改变了我规划旅行的方式。以前要花半天甚至几天的工作,现在10分钟就能完成,而且质量更高:
- 基于实时数据:不会推荐已关闭的景点或过时信息
- 路线最优化:自动计算景点间最合理的游览顺序
- 个性化定制:想要美食之旅?亲子游?文艺路线?只需一句话
- 省时又省力:把宝贵时间用在享受旅行上,而不是规划过程中
最让我满意的是,这整套流程不需要任何编程知识,人人都能轻松上手。我妈妈都能用!
更多玩法等你探索
除了基础攻略,你还可以用更具体的指令获取定制内容:
"我想了解苏州有什么值得打卡的特色美食" "帮我规划一条适合老人和小孩的苏州慢游路线" "我只去苏州一天,哪些景点必须打卡?" "设计一条苏州园林主题的摄影路线"
每一个问题,AI都能结合高德地图的数据给你最专业的建议。
以后旅行前,不用再痛苦地翻攻略、对比信息、反复规划了。一杯咖啡的时间,完美行程就在你手中。
这大概就是科技改变生活的最好证明吧!下次出行,不妨也试试这个方法,让AI做你的专属旅行规划师!
阿里云宣布全面支持MCP服务部署和调用
前天群里还有小伙伴想玩下MCP服务呢,昨天阿里云百炼平台就宣布全面支持MCP服务部署与调用,打通AI应用爆发的最后一公里。

这里是地址:bailian.console.aliyun.com/?tab=mcp#/m…
当然昨晚我也研究了下,简直不要太简单,连注册都省了,下面点立即开通呢就能玩了


下面这个知名爬虫服务我也体验了把,非常简单易懂

创建完应用,提示词录入进去就能用了,连cursor,claude的mcp配置都免了,感兴趣的朋友可以去体验下。

来源:juejin.cn/post/7491553973112111115
聊一下MCP,希望能让各位清醒一点吧🧐
最近正在忙着准备AI产品示例项目的数据,但是有好几群友问了MCP的问题,先花点时间给大家安排一下MCP。作为一个带队落地AI应用的真实玩家,是怎么看待MCP的。
先说观点:MCP不错,但它仅仅是个协议而已,很多科普文章中,提到的更多都是愿景,而不是落地的场景。
本文不再重新陈述MCP的基本概念,而是旨在能让大家了解的是MCP 有什么用?、怎么用?、要不要用?
我准备了一份MCP实现的核心代码,只保留必要的内容,五分钟就能看明白MCP回事。
先上代码,让我们看看实现MCP最核心的部分我们都干了些什么东西。顺便让大家看看MCP到底和Function call是个什么关系
此处只贴用于讲解的代码,其他代码基本都是逻辑处理与调用。也可关注公众号:【华洛AI转型纪实】,发送
mcpdemo,来获取完整代码。
MCP代码核心逻辑
我们在本地运行的MCP,所以使用的是Stdio模式的客户端和服务端。也就是:StdioServerTransport和StdioClientTransport
先看打满日志的demo运行起来起来后,我们获得的信息:

我们的服务端写了两个简单的工具,加法和减法。
服务端启动成功之后,客户端成功的从服务端获取到了这两个工具。
我们发起了一个问题:计算1+1
接下来做的事情就是MCP的客户端核心三步逻辑:
- 客户端调用AI的function call能力,由AI决定是否使用工具,使用哪个工具。
- 客户端把确定要使用的工具和参数发送回服务端,由服务端实现API调用并返回结果。
- 客户端根据结果,再次调用AI,由AI进行回答。
我们一边看代码一边说里面的问题:
第一步调用AI,决定使用工具
客户端代码:
const response = await this.openai.chat.completions.create({
model: model,
messages,
tools: this.tools, // ! 重点看这里,this.tools是服务端返回的工具列表
});
看到了么?这里用的还是Function call! 谣言一:MCP和Function call没关系,MCP就可以让大家调用工具,终结了。MCP就是用的function call的能力来实现的工具调用。当然我们也可以不用Function call,我们就直接用提示词判断,也是可以的。
这里要说的是:MCP就是个协议。并没有给大模型带来任何新的能力,也没有某些人说的MCP提升了Function call的能力,以后不用Function call了,用MCP就够了这种话,千万不要被误导。
MCP并没有让大模型的工具调用能力提升
在真实的生产环境中,目前Function call主要的问题有:
- 工具调用准确性不够。
真正的生成环境可能不是三个五个工具,而是三十个五十个。工具之间的界限不够清晰的话,就会存在模型判断不准确的情况。 - 参数提取准确性不够。
特别是当一个工具必填加选填的参数达到十个以上的时候,面对复杂问题,参数的提取准确率会下降。 - 多意图的识别。
用户的一个问题涉及到多个工具时,目前没有能够稳定提取的模型。
第二步把工具和参数发回服务端,由服务端调用API
客户端代码:
const result = await this.mcp.callTool({
name: toolName,
arguments: toolArgs,
});
服务端的代码:
server.tool(
"加法",
"计算数字相加",
{
"a": z.number().describe("加法的第一个数字"),
"b": z.number().describe("加法的第二个数字"),
},
async ({ a, b, c }) => {
console.error(`服务端: 收到加法API,计算${a}和${b}两个数的和。模型API发送`)
// 这里模拟API的发送和使用
let data = a + b
return {
content: [
{
type: "text",
text: a + '+' + b + '的结果是:' + data,
},
],
};
},
);
发现问题了么? API是要有MCP服务器提供者调用的。要花钱的朋友!
每一台MCP服务器背后都是要成本的,收费产品进行MCP服务器的支持还说的过去,不收费的产品全靠爱发电。更不要说,谁敢在生成环境接一个不收费的私人的小服务器?
百度地图核心API全面兼容MCP了,百度地图是收费的,进行多场景的支持是很正常的行为。
来看看百炼吧,阿里的百炼目前推出了MCP的功能,支持在百炼上部署MCP server。
也是要花钱的朋友~,三方API调用费用另算。

阿里的魔塔社区提供了大量的MCP,可以看到有一些大厂的服务在,当然有收费的有免费的,各位可以尝试

第三步客户端根据结果,再次调用AI,由AI进行回答。
客户端代码:
messages.push({
role: "user",
content: result.content,
});
const aiResponse = await this.openai.chat.completions.create({
model: model,
messages: messages,
});
从服务端返回的结果,添加到messages中,配合提示词由大模型进行回复即可。
这一步属于正常的流程,没什么好说的。
那么问题是:我们使用MCP来实现,和我们自己实现这套流程有什么区别么?我们为什么要用MCP呢?
当初群里朋友第一次提到MCP的时候,我去看了一眼文档,给了这样的结论:
大厂为了抢生态做的事情,给落地的流程中定义了一些概念,多了脑力负担,流程和自己实现没区别。
对于工具的使用,自己实现和用MCP实现有什么区别么?
自己实现的流程和逻辑是这样的:
- 我们的提示词工程师写好每个工具的提示词
- 我们的后端工程师写好模型的调用,使用的是前面写好的提示词
- 提供接口给前端,等待前端调用
- 前端调用传入query,后端通过AI获取了工具
- 通过工具配置调用API,拿到数据交给AI,流式返回用户。
MCP的逻辑是这样的:
- 我们的提示词工程师写好每个工具的提示词
- 我们后端工程师分别写好MCP服务端、MCP客户端
- MCP客户端提供个接口给前端,等待前端调用
- 前端调用传入query,MCP客户端调用AI,获取了工具。
- 客户端把确定要使用的工具和参数发送会服务端,由服务端实现API调用并返回结果。
- 客户端根据结果,再次调用AI,由AI进行回答,流式返回用户。
看吧,本质上是没有区别的。
什么?你说MCP服务端,如果日后需要与其他企业进行合作,可以方便的让对方的MCP客户端调用?
我们的客户端也可以很方便的接入别人的MCP服务端。
不好意思,不用MCP也可以,因为Function call的参数格式已经确定了,这里原本存在差异性就极小。而且MCP也并没有解决这个差异性。还是需要客户端进行修改的。
MCP真正的意义
现在还是诸神混战时期,整个AI产品的上下游所有的点,都具有极高的不确定性。
MCP给出了一个技术标准化的协议,是大家共建AI的愿景中的一环,潜力是有的。
但是Anthropic真的只是在乎这个协议么?前面的内容我们也看到了,MCP和我们自己实现的流程几乎是一样的。但是为什么还要提出MCP呢?
为了生态控制权和行业话语权。
MCP它表面上是一个开放的协议,旨在解决AI模型与外部工具集成的碎片化问题,但其实他就是Anthropic对未来AI生态主导权的竞争。
未来MCP如果真的作为一个标准的协议成为大家的共识,围绕这个协议,甚至每家模型的工具调用格式都将被统一,此时Anthropic在委员会里的位置呢?不言而喻啊。
结语
最后把我的策略分享给大家吧:
打算在圈子里玩的部分,就和大家用一样的,不在圈子里玩的,其实自己团队实现也是OK的。
我这边更多的是自己团队实现的,而且在这个实现过程中大家对模型应用、AI产品的理解不断地在提升。
希望各位读者也多进行尝试,这样未来面对新出的各路牛鬼蛇神时大家才能有更多的判断力。
共勉吧!
☺️你好,我是华洛,如果你对程序员转型AI产品负责人感兴趣,请给我点个赞。
你可以在这里联系我👉http://www.yuque.com/hualuo-fztn…
已入驻公众号【华洛AI转型纪实】,欢迎大家围观,后续会分享大量最近三年来的经验和踩过的坑。
实战专栏
# 从0到1打造企业级AI售前机器人——实战指南一:根据产品需求和定位进行agent流程设计🧐
# 从0到1打造企业级AI售前机器人——实战指南二:RAG工程落地之数据处理篇🧐
来源:juejin.cn/post/7492271537010671635
长安马自达全球车型MAZDA 6e启航欧洲,全球化战略迈入新里程
4月22日,上海外高桥码头,长安马自达首批发往欧洲市场的纯电旗舰轿车MAZDA 6e正式装船启航。此次发运标志着MAZDA 6e在欧洲市场进入交付倒计时阶段,长安马自达“双百翻番”战略计划逐步落地,中国“合资智造”正加速赋能马自达全球电动化布局,传递着中国新能源产业的技术自信。长安马自达汽车有限公司管理层和临港片区管委会代表、物流合作伙伴出席装船仪式,共同见证这一里程碑时刻。

上午10时,外高桥码头海风轻拂,首批600辆MAZDA 6e整齐列队,与停泊在蓝天碧海间的巨型滚装运输船交相辉映。随着发运按钮的正式启动,首辆MAZDA 6e平稳驶入船舱,现场响起热烈掌声。这批车辆预计将于5月抵达比利时港口,并于今年夏天交付至欧洲多国经销商。MAZDA 6e的到来,将为欧洲市场客户带来全新的电动旗舰轿车选择,并将进一步丰富马自达欧洲市场的产品阵容。

自今年1月10日首次亮相2025比利时布鲁塞尔车展以来,MAZDA 6e的全球化进程在不断加速。MAZDA 6e是以MAZDA EZ-6为基础推出的符合欧洲市场环境,且能满足欧洲客户和马自达忠实粉丝的期待、彰显马自达特色的最新款电动汽车。MAZDA 6e的开发过程集合了长安马自达南京产品研发中心、马自达日本广岛总部以及马自达欧洲研发中心三地工程师的智慧与力量。从设计、研发到生产均严格遵循马自达全球统一的制造标准,既是中国车,也是全球车。南京工厂作为马自达在华唯一新能源生产基地,汇聚了马自达百年造车工艺与长安汽车领先的电动化技术,以智能化生产线和精益管理模式确保每一辆MAZDA 6e的品质达均能达到全球顶尖水平。

长安马自达汽车有限公司总裁松田英久表示:“MAZDA 6e拥有符合欧盟最新法规的三电系统和安全性能、超低风阻的「魂动」美学设计,以及电感「人马一体」的驾控性能,精准契合欧洲消费者对高端电动轿车的期待。MAZDA 6e的欧洲首航,代表着长安马自达正从‘合资企业’向‘全球新能源技术创新基地’转型。托中国在电动化、智能化领域的先发优势,长安马自达未来将成为马自达全球技术研发的关键支点”。

同时,MAZDA EZ-6不断加快产品焕新节奏。在现有的赤麂棕色高配内饰色之外,新增兼具时尚气质和高级质感的鹭羽白浅色内饰,快速回应用户对于浅色系内饰的需求,更为用户带来“增色不加价”的新选择。目前,购MAZDA EZ-6可享受至高40,000元补贴(15,000元置换厂补+20,000元置换国补+5,000元保险补贴)、100,000元尾款可享6年0息(和置换厂补二选一),还可享价值7,999元不限车主、不限里程终身零燃权益。

4月23日,长安马自达第二款全球化新能源车型MAZDA EZ-60将登陆2025上海国际车展6.1馆展台,迎来全球首发。以MAZDA 6e出海为起点,长安马自达还将持续推出更多面向全球市场的新能源车型,覆盖更多细分市场用户需求,以更快的节奏、更强的技术、更广的布局,迎接全球电动化市场的无限可能。

【Fiddler】Fiddler抓包工具(详细讲解)_抓包工具fiddler
抓包工具使用指南
序章
Fiddler 是一款功能强大的抓包工具,能够截获、重发、编辑和转存网络传输中的数据包,同时也常用于网络安全检测。它的功能丰富,但在学习过程中可能会遇到一些隐藏的小功能,容易遗忘。因此,本文总结了 Fiddler 的常用功能,并结合 SniffMaster 抓包大师的特点,帮助大家更好地掌握抓包工具的使用。
1. Fiddler 抓包简介
Fiddler 通过改写 HTTP 代理来监控和截取数据包。当 Fiddler 启动时,它会自动设置浏览器的代理,关闭时则会还原代理设置,非常方便。
1.1 字段说明
Fiddler 抓取的数据包会显示在列表中,以下是各字段的含义:
| 名称 | 含义 |
|---|---|
| # | 抓取 HTTP 请求的顺序,从 1 开始递增 |
| Result | HTTP 状态码 |
| Protocol | 请求使用的协议(如 HTTP/HTTPS/FTP 等) |
| Host | 请求地址的主机名 |
| URL | 请求资源的位置 |
| Body | 请求的大小 |
| Caching | 请求的缓存过期时间或缓存控制值 |
| Content-Type | 请求响应的类型 |
| Process | 发送此请求的进程 ID |
| Comments | 用户为此会话添加的备注 |
| Custom | 用户设置的自定义值 |
1.2 Statistics 请求性能数据分析
点击任意请求,可以在右侧查看该请求的性能数据和分析结果。
1.3 Inspectors 查看数据内容
Inspectors 用于查看会话的请求和响应内容,上半部分显示请求内容,下半部分显示响应内容。
1.4 AutoResponder 拦截指定请求
AutoResponder 允许拦截符合特定规则的请求,并返回本地资源或 Fiddler 资源,从而替代服务器响应。例如,可以将关键字 "baidu" 与本地图片绑定,访问百度时会被劫持并显示该图片。
1.5 Composer 自定义请求发送
Composer 允许自定义请求并发送到服务器。可以手动创建新请求,或从会话表中拖拽现有请求进行修改。
1.6 Filters 请求过滤规则
Filters 用于过滤请求,避免无关请求干扰。常用的过滤条件包括 Zone(内网或互联网)和 Host(指定域名)。
1.7 Timeline 请求响应时间
Timeline 显示指定内容从服务器传输到客户端的时间,帮助分析请求的响应速度。
2. Fiddler 设置解密 HTTPS 数据
Fiddler 可以通过伪造 CA 证书来解密 HTTPS 数据包。具体步骤如下:
- 打开 Fiddler,点击 Tools -> Fiddler Options -> HTTPS。
- 勾选 Decrypt HTTPS Traffic。
- 点击 OK 保存设置。
3. 抓取移动端数据包
3.1 设置代理
- 打开 Fiddler,点击 Tools -> Fiddler Options -> Connections。
- 设置代理端口为 8888,并勾选 Allow remote computers to connect。
- 在手机端连接与电脑相同的 WiFi,并设置代理 IP 和端口。
3.2 安装证书
- 在手机浏览器中访问
http://<电脑IP>:8888,下载 Fiddler 根证书。 - 安装证书并信任。
3.3 抓取数据包
配置完成后,手机访问应用时,Fiddler 会截取到数据包。
4. Fiddler 内置命令与断点
Fiddler 提供了命令行功能,方便快速操作。常用命令包括:
| 命令 | 功能 | 示例 |
|---|---|---|
| ? | 匹配包含指定字符串的请求 | |
| 匹配请求大小大于指定值的请求 | >1000 | |
| < | 匹配请求大小小于指定值的请求 | <100 |
| = | 匹配指定 HTTP 返回码的请求 | =200 |
| @ | 匹配指定域名的请求 | @http://www.baidu.com |
| select | 匹配指定响应类型的请求 | select image |
| cls | 清空当前所有请求 | cls |
| dump | 将所有请求打包成 saz 文件 | dump |
| start | 开始监听请求 | start |
| stop | 停止监听请求 | stop |
断点功能
Fiddler 的断点功能可以截获请求并暂停发送,方便修改请求内容。常用断点命令包括:
- bpafter:中断包含指定字符串的请求。
- bpu:中断响应。
- bps:中断指定状态码的请求。
- bpv:中断指定 HTTP 方法的请求。
5. SniffMaster 抓包大师
SniffMaster 是一款跨平台抓包工具,支持 Android、iOS 和 PC 端抓包。与 Fiddler 相比,SniffMaster 具有以下优势:
- 自动生成证书:无需手动配置 HTTPS 解密。
- 多设备支持:支持同时抓取多个设备的数据包。
- 智能过滤:按协议、域名等条件快速筛选数据。
- 可视化界面:提供更直观的数据分析和展示。
5.1 SniffMaster 使用场景
- 移动端抓包:支持 Android 和 iOS 设备,自动配置代理和证书。
- HTTPS 解密:内置 HTTPS 解密功能,无需手动安装证书。
- 多平台支持:支持 Windows、macOS 和 Linux 系统。
总结
Fiddler 和 SniffMaster 都是强大的抓包工具,适用于不同的场景。Fiddler 适合需要深度定制和高级功能的用户,而 SniffMaster 则更适合新手和需要快速抓包的用户。无论是开发调试还是网络安全检测,这两款工具都能提供极大的帮助。
来源:juejin.cn/post/7481463851298635827
“新E代弯道王”MAZDA EZ-6鹭羽白内饰焕新
今日,“新E代弯道王”MAZDA EZ-6(以下称EZ-6)宣布鹭羽白内饰焕新,现在购车可享补贴后9.98万起。新车在现有的赤麂棕色高配内饰色之外,新增兼具时尚气质和高级质感的鹭羽白浅色内饰,不仅快速回应了部分用户对于浅色系内饰的需求,更为用户带来“增色不加价”的新选择。




为什么把私钥写在代码里是一个致命错误
为什么把私钥写在代码里是一个致命错误
在技术社区经常能看到一些开发者分享的教训,前几天就有人发帖讲述一位Java开发者因同事将私钥直接硬编码在代码里而感到愤怒的事情。这种情况虽然听起来可笑,但在开发团队中却相当常见,尤其对于经验不足的程序员来说。
为什么把私钥写在代码里如此危险?
1. 代码会被分享和同步
代码通常会提交到Git或SVN等版本控制系统中。一旦私钥被提交,团队中的每个人都能看到这些敏感信息。即使后来删除了私钥,在历史记录中依然可以找到。有开发者就分享过真实案例:团队成员意外将AWS密钥提交到GitHub,结果第二天账单暴增数千元——有人利用泄露的密钥进行了挖矿活动。
2. 违反安全和职责分离原则
在规范的开发流程中,密钥管理和代码开发应该严格分离。通常由运维团队负责密钥管理,而开发人员则不需要(也不应该)直接接触生产环境的密钥。这是基本的安全实践。
3. 环境迁移的噩梦
当应用从开发环境迁移到测试环境,再到生产环境时,如果密钥硬编码在代码中,每次环境切换都需要修改代码并重新编译。这不仅效率低下,还容易出错。
正确的做法
业内已有多种成熟的解决方案:
- 使用环境变量存储敏感信息
- 采用专门的配置文件(确保加入.gitignore)
- 使用AWS KMS、HashiCorp Vault等专业密钥管理系统
- 在CI/CD流程中动态注入密钥
有开发团队就曾经花费两周时间清理代码中的硬编码密钥。其中甚至发现了一个已离职员工留下的"临时"数据库密码,注释中写着"临时用,下周改掉"——然而那个"下周"已经过去五年了。
作为专业开发者,应当始终保持良好的安全习惯。将私钥硬编码进代码,就像把家门钥匙贴在门上一样不可理喻。
这个教训值得所有软件工程师引以为戒。
来源:juejin.cn/post/7489043337290203163
双Token无感刷新方案
提醒一下
双Token机制并没有从根本上解决安全性的问题,本文章只是提供一个思路,具体是否选择请大家仔细斟酌考虑,笔者水平有限,非常抱歉对你造成不好的体验。
token有效期设置问题
最近在做用户认证模块的后端功能开发,之前就有一个问题困扰了我好久,就是如何设置token的过期时间,前端在申请后端登录接口成功之后,会返回一个token值,存储在用户端本地,用户要访问后端的其他接口必须通过请求头带上这个token值,但是这个token的有效期应该设置为多少?
- 如果设置的太短,比如1小时,那么用户一小时之后。再访问其他接口,需要再次重新登录,对用户的体验极差
- 如果设置为一个星期,那么在这个时间内
- 一旦
token泄露,攻击者可长期冒充用户身份,直到token过期,服务端无法限制其访问用户数据 - 虽然可以依赖黑名单机制,但会增加系统复杂度,还要进行系统监测
- 如果在这段时间恶意用户利用未过期的条款持续调用后端API将会导致资源耗尽或产生巨额费用
- 一旦
所以有没有两者都兼顾的方案呢?
双token无感刷新方案
传统的token方案要么频繁要求用户重新登录,要么面临长期有效的安全风险
但是双token无感刷新机制,通过组合设计,在保证安全性的情况下,实现无感知的认证续期
核心设计
access_token:访问令牌,有效期一般设置为15~30分钟,主要用于对后端请求API的交互refresh_token:刷新令牌,一般设置为一个星期到一个月,主要用于获取新的access_token
大致的执行流程如下
用户登录之后,后端返回access_token和refresh_token响应给前端,前端将两个token存储在用户本地

在用户端发起前端请求,访问后端接口,在请求头中携带上access_token

前端会对access_token的过期时间进行检测,当access_token过期前一分钟,前端通过refresh_token向后端发起请求,后端判断refresh_token是否有效,有效则重新获取新的access_token,返回给前端替换掉之前的access_token存储在用户本地,无效则要求用户重新认证

这样的话对于用户而言token的刷新是无感知的,不会影响用户体验,只有当refresh_token失效之后,才需要用户重新进行登录认证,同时,后端可以通过对用户refresh_token的管理来限制用户对后端接口的请求,大大提高了安全性
有了这个思路,写代码就简单了
@Service
public class LoginServiceImpl implements LoginService {
@Autowired
private JwtUtils jwtUtils;
// token过期时间
private static final Integer TOKEN_EXPIRE_DAYS =5;
// token续期时间
private static final Integer TOKEN_RENEWAL_MINUTE =15;
@Override
public boolean verify(String refresh_token) {
Long uid = jwtUtils.getUidOrNull(refresh_token);
if (Objects.isNull(uid)) {
return false;
}
String key = RedisKey.getKey(RedisKey.USER_REFRESH_TOKEN,uid);
String realToken = RedisUtils.getStr(key);
return Objects.equals(refresh_token, realToken);
}
@Override
public void renewalTokenIfNecessary(String refresh_token) {
Long uid = jwtUtils.getUidOrNull(refresh_token);
if (Objects.isNull(uid)) {
return;
}
String refresh_key = RedisKey.getKey(RedisKey.USER_REFRESH_TOKEN, uid);
long expireSeconds = RedisUtils.getExpire(refresh_key, TimeUnit.SECONDS);
if (expireSeconds == -2) { // key不存在,refresh_token已过期
return;
}
String access_key = RedisKey.getKey(RedisKey.USER_ACCESS_TOKEN, uid);
RedisUtils.expire(access_key, TOKEN_RENEWAL_MINUTE, TimeUnit.MINUTES);
}
@Override
@Transactional(rollbackFor = Exception.class)
@RedissonLock(key = "#uid")
public LoginTokenResponse login(Long uid) {
String refresh_key = RedisKey.getKey(RedisKey.USER_REFRESH_TOKEN, uid);
String access_key = RedisKey.getKey(RedisKey.USER_ACCESS_TOKEN, uid);
String refresh_token = RedisUtils.getStr(refresh_key);
String access_token;
if (StrUtil.isNotBlank(refresh_token)) { //刷新令牌不为空
access_token = jwtUtils.createToken(uid);
RedisUtils.set(access_key, access_token, TOKEN_RENEWAL_MINUTE, TimeUnit.MINUTES);
return LoginTokenResponse.builder()
.refresh_token(refresh_token).access_token(access_token)
.build();
}
refresh_token = jwtUtils.createToken(uid);
RedisUtils.set(refresh_key, refresh_token, TOKEN_EXPIRE_DAYS, TimeUnit.DAYS);
access_token = jwtUtils.createToken(uid);
RedisUtils.set(access_key, access_token, TOKEN_RENEWAL_MINUTE, TimeUnit.MINUTES);
return LoginTokenResponse.builder()
.refresh_token(refresh_token).access_token(access_token)
.build();
}
}}
注意事项
- 安全存储Refresh Token时,优先使用HttpOnly+Secure Cookie而非LocalStorage
- 在颁发新Access Token时,重置旧Token的生存周期(滑动过期)而非简单续期
- 针对高敏感操作(如支付、改密),建议强制二次认证以突破Token机制的限制
安全问题
双Token机制并没有从根本上解决安全性的问题,它只是尝试通过改进设计,优化用户体验,全面的安全策略需要多层防护,分别针对不同类型的威胁和风险,而不仅仅依赖于Token的管理方式或数量
安全是一个持续对抗的过程,关键在于提高攻击者的成本,而非追求绝对防御。
"完美的认证方案不存在,但聪明的权衡永远存在。"
本笔者水平有限,望各位海涵
如果文章中有不对的地方,欢迎大家指正。
来源:juejin.cn/post/7486782063422717962
程序员,你使用过灰度发布吗?
大家好呀,我是猿java。
在分布式系统中,我们经常听到灰度发布这个词,那么,什么是灰度发布?为什么需要灰度发布?如何实现灰度发布?这篇文章,我们来聊一聊。
1. 什么是灰度发布?
简单来说,灰度发布也叫做渐进式发布或金丝雀发布,它是一种逐步将新版本应用到生产环境中的策略。相比于一次性全量发布,灰度发布可以让我们在小范围内先行测试新功能,监控其表现,再决定是否全面推开。这样做的好处是显而易见的:
- 降低风险:新版本如果存在 bug,只影响少部分用户,减少了对整体用户体验的冲击。
- 快速回滚:在小范围内发现问题,可以更快地回到旧版本。
- 收集反馈:可以在真实环境中收集用户反馈,优化新功能。
2. 原理解析
要理解灰度发布,我们需要先了解一下它的基本流程:
- 准备阶段:在生产环境中保留旧版本,同时引入新版本。
- 小范围发布:将新版本先部署到一小部分用户,例如1%-10%。
- 监控与评估:监控新版本的性能和稳定性,收集用户反馈。
- 逐步扩展:如果一切正常,将新版本逐步推广到更多用户。
- 全面切换:当确认新版本稳定后,全面替换旧版本。
在这个过程中,关键在于如何切分流量,确保新旧版本平稳过渡。常见的切分方式包括:
- 基于用户ID:根据用户的唯一标识,将部分用户指向新版本。
- 基于地域:先在特定地区进行发布,观察效果后再扩展到其他地区。
- 基于设备:例如,先在Android或iOS用户中进行发布。
3. 示例演示
为了更好地理解灰度发布,接下来,我们通过一个简单的 Java示例来演示基本的灰度发布策略。假设我们有一个简单的 Web应用,有两个版本的登录接口/login/v1和/login/v2,我们希望将百分之十的流量引导到v2,其余流量继续使用v1。
3.1 第一步:引入灰度策略
我们可以通过拦截器(Interceptor)来实现流量的切分。以下是一个基于Spring Boot的简单实现:
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Random;
@Component
public class GrayReleaseInterceptor implements HandlerInterceptor {
private static final double GRAY_RELEASE_PERCENT = 0.1; // 10% 流量
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String uri = request.getRequestURI();
if ("/login".equals(uri)) {
if (isGrayRelease()) {
// 重定向到新版本接口
response.sendRedirect("/login/v2");
return false;
} else {
// 使用旧版本接口
response.sendRedirect("/login/v1");
return false;
}
}
return true;
}
private boolean isGrayRelease() {
Random random = new Random();
return random.nextDouble() < GRAY_RELEASE_PERCENT;
}
}
3.2 第二步:配置拦截器
在Spring Boot中,我们需要将拦截器注册到应用中:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.*;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private GrayReleaseInterceptor grayReleaseInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(grayReleaseInterceptor).addPathPatterns("/login");
}
}
3.3 第三步:实现不同版本的登录接口
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/login")
public class LoginController {
@GetMapping("/v1")
public String loginV1(@RequestParam String username, @RequestParam String password) {
// 旧版本登录逻辑
return "登录成功 - v1";
}
@GetMapping("/v2")
public String loginV2(@RequestParam String username, @RequestParam String password) {
// 新版本登录逻辑
return "登录成功 - v2";
}
}
在上面三个步骤之后,我们就实现了登录接口地灰度发布:
- 当用户访问
/login时,拦截器会根据设定的灰度比例(10%)决定请求被重定向到/login/v1还是/login/v2。 - 大部分用户会体验旧版本接口,少部分用户会体验新版本接口。
3.4 灰度发布优化
上述示例,我们只是一个简化的灰度发布实现,实际生产环境中,我们可能需要更精细的灰度策略,例如:
- 基于用户属性:不仅仅是随机切分,可以根据用户的地理位置、设备类型等更复杂的条件。
- 动态配置:通过配置中心动态调整灰度比例,无需重启应用。
- 监控与告警:集成监控系统,实时监控新版本的性能指标,异常时自动回滚。
- A/B 测试:结合A/B测试,进一步优化用户体验和功能效果。

4. 为什么需要灰度发布?
在实际工作中,为什么我们要使用灰度发布?这里我们总结了几个重要的原因。
4.1 降低发布风险
每次发布新版本,尤其是功能性更新或架构调整,都会伴随着一定的风险。即使经过了充分的测试,实际生产环境中仍可能出现意想不到的问题。灰度发布通过将新版本逐步推向部分用户,可以有效降低全量发布可能带来的风险。
举个例子,假设你上线了一个全新的支付功能,直接面向所有用户开放。如果这个功能存在严重 bug,可能导致大量用户无法完成支付,甚至影响公司声誉。而如果采用灰度发布,先让10%的用户体验新功能,发现问题后只需影响少部分用户,修复起来也更为迅速和容易。
4.2 快速回滚
在传统的全量发布中,一旦发现问题,回滚到旧版本可能需要耗费大量时间和精力,尤其是在高并发系统中,数据状态的同步与恢复更是复杂。而灰度发布由于新版本只覆盖部分流量,问题定位和回滚变得更加简单和快速。
比如说,你在灰度发布阶段发现新版本的某个功能在某些特定条件下会导致系统崩溃,立即可以停止向新用户推送这个版本,甚至只针对受影响的用户进行回滚操作,而不用影响全部用户的正常使用。
4.3 实时监控与反馈
灰度发布让你有机会在真实的生产环境中监控新版本的表现,并收集用户的反馈。这些数据对于评估新功能的实际效果至关重要,有助于做出更明智的决策。
举个具体的场景,你新增了一个推荐算法,希望提升用户的点击率。在灰度发布阶段,你可以监控新算法带来的点击率变化、服务器负载情况等指标,确保新算法确实带来了预期的效果,而不是引入了新的问题。
4.4 提升用户体验
通过灰度发布,你可以在推出新功能时,逐步优化用户体验。先让一部分用户体验新功能,收集他们的使用反馈,根据反馈不断改进,最终推出一个更成熟、更符合用户需求的版本。
举个例子,你开发了一项新的用户界面设计,直接全量发布可能会让一部分用户感到不适应或不满意。灰度发布允许你先让一部分用户体验新界面,收集他们的意见,进行必要的调整,再逐步扩大使用范围,确保最终发布的版本能获得更多用户的认可和喜爱。
4.5 支持A/B测试
灰度发布是实现A/B测试的基础。通过将用户随机分配到不同的版本,你可以比较不同版本的表现,选择最优方案进行全面推行。这对于优化产品功能和提升用户体验具有重要意义。
比如说,你想测试两个不同的推荐算法,看哪个能带来更高的转化率。通过灰度发布,将用户随机分配到使用算法A和算法B的版本,比较它们的表现,最终选择效果更好的算法进行全面部署。
4.6 应对复杂的业务需求
在一些复杂的业务场景中,全量发布可能无法满足灵活的需求,比如分阶段推出新功能、针对不同用户群体进行差异化体验等。灰度发布提供了更高的灵活性和可控性,能够更好地适应多变的业务需求。
例如,你正在开发一个面向企业用户的新功能,希望先让部分高价值客户试用,收集他们的反馈后再决定是否全面推广。灰度发布让这一过程变得更加顺畅和可控。
5. 总结
本文,我们详细地分析了灰度发布,它是一种强大而灵活的部署策略,能有效降低新版本上线带来的风险,提高系统的稳定性和用户体验。作为Java开发者,掌握灰度发布的原理和实现方法,不仅能提升我们的技术能力,还能为团队的项目成功保驾护航。
对于灰度发布,如果你有更多的问题或想法,欢迎随时交流!
6. 学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7488321730764603402
URL地址末尾加不加”/“有什么区别
URL 结尾是否带 / 主要影响的是 服务器如何解析请求 以及 相对路径的解析方式,具体区别如下:
1. 基础概念
- URL(统一资源定位符) :用于唯一标识互联网资源,如网页、图片、API等。
- 目录 vs. 资源:
- 以
/结尾的 URL 通常表示目录,例如:
https://example.com/folder/
- 不以
/结尾的 URL 通常指向具体的资源(如文件),例如:
https://example.com/file
- 以
2. 带 / 和不带 / 的具体区别
(1)目录 vs. 资源
https://example.com/folder/
- 服务器通常会将其解析为 目录,并尝试返回该目录下的默认文件(如
index.html)。
- 服务器通常会将其解析为 目录,并尝试返回该目录下的默认文件(如
https://example.com/folder
- 服务器可能会将其视为 文件,如果
folder不是文件,而是目录,服务器可能会返回 301 重定向到folder/。
- 服务器可能会将其视为 文件,如果
📌 示例:
- 访问
https://example.com/blog/
- 服务器可能返回
https://example.com/blog/index.html。
- 服务器可能返回
- 访问
https://example.com/blog(如果blog是个目录)
- 服务器可能重定向到
https://example.com/blog/,再返回index.html。
- 服务器可能重定向到
(2)相对路径解析
URL 末尾是否有 / 会影响相对路径的解析。
假设 HTML 页面包含以下 <img> 标签:
<img src="image.png">
📌 示例:
- 访问
https://example.com/folder/
- 访问
https://example.com/folder
- 图片路径解析为
https://example.com/image.png - 可能导致 404 错误,因为
image.png在folder/里,而浏览器错误地去example.com/下查找。
- 图片路径解析为
原因:
- 以
/结尾的 URL,浏览器会认为它是一个目录,相对路径会基于folder/解析。 - 不带
/,浏览器可能认为folder是文件,相对路径解析可能会出现错误。
(3)SEO 影响
搜索引擎对 https://example.com/folder/ 和 https://example.com/folder 可能会视为两个不同的页面,导致 重复内容问题,影响 SEO 排名。因此:
- 网站通常会选择 一种形式 并用 301 重定向 规范化 URL。
- 例如:
https://example.com/folder自动跳转 到https://example.com/folder/。- 反之亦然。
(4)API 请求
对于 RESTful API,带 / 和不带 / 可能导致不同的行为:
https://api.example.com/users
- 可能返回所有用户数据。
https://api.example.com/users/
- 可能返回 404 或者产生不同的结果(取决于服务器实现)。
一些 API 服务器对 / 非常敏感,因此最好遵循 API 文档的规范。
3. 总结
| URL 形式 | 作用 | 影响 |
|---|---|---|
https://example.com/folder/ | 目录 | 通常返回 folder/ 下的默认文件,如 index.html,相对路径解析基于 folder/ |
https://example.com/folder | 资源(或重定向) | 可能被解析为文件,或者服务器重定向到 folder/,相对路径解析可能错误 |
https://api.example.com/data/ | API 路径 | 可能与 https://api.example.com/data 表现不同,具体由 API 设计决定 |
如果你在开发网站,建议:
- 统一 URL 规则,例如所有目录都加
/或者所有请求都不加/,然后用 301 重定向 确保一致性。 - 测试 API 的行为,确认带
/和不带/是否影响请求结果。
来源:juejin.cn/post/7468112128928350242
公司来的新人用字符串存储日期,被组长怒怼了...
在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
不要用字符串存储日期
和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
但是,这是不正确的做法,主要会有下面两个问题:
- 空间效率:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
- 查询与计算效率低下:
- 比较操作复杂且低效:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
- 计算功能受限:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
- 索引性能不佳:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
DATETIME 和 TIMESTAMP 选择
DATETIME 和 TIMESTAMP 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
下面我们从几个关键维度对它们进行对比:
时区信息
DATETIME 类型存储的是字面量的日期和时间值,它本身不包含任何时区信息。当你插入一个 DATETIME 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
这样就会有什么问题呢? 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 DATETIME 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
TIMESTAMP 和时区有关。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 TIMESTAMP 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
这意味着,对于同一条记录的 TIMESTAMP 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
下面实际演示一下!
建表 SQL 语句:
CREATE TABLE `time_zone_test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`date_time` datetime DEFAULT NULL,
`time_stamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
查询数据(在同一时区会话下):
SELECT date_time, time_stamp FROM time_zone_test;
结果:
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
+---------------------+---------------------+
现在,修改当前会话的时区为东八区 (UTC+8):
SET time_zone = '+8:00';
再次查询数据:
# TIMESTAMP 的值自动转换为 UTC+8 时间
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
+---------------------+---------------------+
扩展:MySQL 时区设置常用 SQL 命令
# 查看当前会话时区
SELECT @@session.time_zone;
# 设置当前会话时区
SET time_zone = 'Europe/Helsinki';
SET time_zone = "+00:00";
# 数据库全局时区设置
SELECT @@global.time_zone;
# 设置全局时区
SET GLOBAL time_zone = '+8:00';
SET GLOBAL time_zone = 'Europe/Helsinki';
占用空间
下图是 MySQL 日期类型所占的存储空间(官方文档传送门:dev.mysql.com/doc/refman/…):

在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 58 字节,TIMESTAMP 的范围是 47 字节。
表示范围
TIMESTAMP 表示的时间范围更小,只能到 2038 年:
DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'TIMESTAMP:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
性能
由于 TIMESTAMP 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,DATETIME 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
为了获得可预测的行为并可能减少 TIMESTAMP 的转换开销,推荐的做法是在应用程序层面统一管理时区,或者在数据库连接/会话级别显式设置 time_zone 参数,而不是依赖服务器的默认或操作系统时区。
数值时间戳是更好的选择吗?
除了上述两种类型,实践中也常用整数类型(INT 或 BIGINT)来存储所谓的“Unix 时间戳”(即从 1970 年 1 月 1 日 00:00:00 UTC 起至目标时间的总秒数,或毫秒数)。
这种存储方式的具有 TIMESTAMP 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
时间戳的定义如下:
时间戳的定义是从一个基准时间开始算起,这个基准时间是「1970-1-1 00:00:00 +0:00」,从这个时间开始,用整数表示,以秒计时,随着时间的流逝这个时间整数不断增加。这样一来,我只需要一个数值,就可以完美地表示时间了,而且这个数值是一个绝对数值,即无论的身处地球的任何角落,这个表示时间的时间戳,都是一样的,生成的数值都是一样的,并且没有时区的概念,所以在系统的中时间的传输中,都不需要进行额外的转换了,只有在显示给用户的时候,才转换为字符串格式的本地时间。
数据库中实际操作:
-- 将日期时间字符串转换为 Unix 时间戳 (秒)
mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
+---------------------------------------+
| 1578707612 |
+---------------------------------------+
1 row in set (0.00 sec)
-- 将 Unix 时间戳 (秒) 转换为日期时间格式
mysql> SELECT FROM_UNIXTIME(1578707612);
+---------------------------+
| FROM_UNIXTIME(1578707612) |
+---------------------------+
| 2020-01-11 09:53:32 |
+---------------------------+
1 row in set (0.01 sec)
PostgreSQL 中没有 DATETIME
由于有读者提到 PostgreSQL(PG) 的时间类型,因此这里拓展补充一下。PG 官方文档对时间类型的描述地址:http://www.postgresql.org/docs/curren…。

可以看到,PG 没有名为 DATETIME 的类型:
- PG 的
TIMESTAMP WITHOUT TIME ZONE在功能上最接近 MySQL 的DATETIME。它存储日期和时间,但不包含任何时区信息,存储的是字面值。 - PG 的
TIMESTAMP WITH TIME ZONE(或TIMESTAMPTZ) 相当于 MySQL 的TIMESTAMP。它在存储时会将输入值转换为 UTC,并在检索时根据当前会话的时区进行转换显示。
对于绝大多数需要记录精确发生时间点的应用场景,TIMESTAMPTZ是 PostgreSQL 中最推荐、最健壮的选择,因为它能最好地处理时区复杂性。
总结
MySQL 中时间到底怎么存储才好?DATETIME?TIMESTAMP?还是数值时间戳?
并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。
《高性能 MySQL 》这本神书的作者就是推荐 TIMESTAMP,原因是数值表示时间不够直观。下面是原文:

每种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
|---|---|---|---|---|
| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
选择建议小结:
TIMESTAMP的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,TIMESTAMP是自然的选择(注意其时间范围限制,也就是 2038 年问题)。- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,
DATETIME是更稳妥的选择。 - 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
来源:juejin.cn/post/7488927722774937609
websocket和socket有什么区别?
WebSocket 和 Socket 的区别
WebSocket 和 Socket 是两种不同的网络通信技术,它们在使用场景、协议、功能等方面有显著的差异。以下是它们之间的主要区别:
1. 定义
- Socket:Socket 是一种网络通信的工具,可以实现不同计算机之间的数据交换。它是操作系统提供的 API,广泛应用于 TCP/IP 网络编程中。Socket 可以是流式(TCP)或数据报(UDP)类型的,用于低层次的网络通信。
- WebSocket:WebSocket 是一种在单个 TCP 连接上进行全双工通信的协议。它允许服务器和客户端之间实时地交换数据。WebSocket 是建立在 HTTP 协议之上的,主要用于 Web 应用程序,以实现实时数据传输。
2. 协议层次
- Socket:Socket 是一种底层通信机制,通常与 TCP/IP 协议一起使用。它允许开发者通过编程语言直接访问网络接口。
- WebSocket:WebSocket 是一种应用层协议,建立在 HTTP 之上。在初始握手时,使用 HTTP 协议进行连接,之后切换到 WebSocket 协议进行数据传输。
3. 连接方式
- Socket:Socket 通常需要手动管理连接的建立和关闭。通过调用相关的 API,开发者需要处理连接的状态,确保数据的可靠传输。
- WebSocket:WebSocket 的连接管理相对简单。建立连接后,不需要频繁地进行握手,可以保持持久连接,随时进行数据交换。
4. 数据传输模式
- Socket:Socket 可以实现单向或双向的数据传输,但通常需要在发送和接收之间进行明确的控制。
- WebSocket:WebSocket 支持全双工通信,客户端和服务器之间可以随时互相发送数据,无需等待响应。这使得实时通信变得更加高效。
5. 适用场景
- Socket:Socket 常用于需要高性能、低延迟的场景,如游戏开发、文件传输、P2P 网络等。由于其底层特性,Socket 适合对网络性能有严格要求的应用。
- WebSocket:WebSocket 主要用于 Web 应用程序,如即时聊天、实时通知、在线游戏等。由于其易用性和高效性,WebSocket 特别适合需要实时更新和交互的前端应用。
6. 数据格式
- Socket:Socket 发送的数据通常是二进制流或文本流,需要开发者自行定义数据格式和解析方式。
- WebSocket:WebSocket 支持多种数据格式,包括文本(如 JSON)和二进制(如 Blob、ArrayBuffer)。WebSocket 的数据传输格式非常灵活,易于与 JavaScript 进行交互。
7. 性能
- Socket:Socket 对于大量并发连接的处理性能较高,但需要开发者进行优化和管理。
- WebSocket:WebSocket 在建立连接后可以保持长连接,减少了握手带来的延迟,适合高频率的数据交换场景。
8. 安全性
- Socket:Socket 的安全性取决于使用的协议(如 TCP、UDP)和应用层的实现。开发者需要自行处理安全问题,如加密和身份验证。
- WebSocket:WebSocket 支持通过 WSS(WebSocket Secure)进行加密,提供更高层次的安全保障。它可以很好地与 HTTPS 集成,确保数据在传输过程中的安全性。
9. 浏览器支持
- Socket:Socket 是底层的网络通信技术,通常不直接在浏览器中使用。Web 开发者需要通过后端语言(如 Node.js、Java、Python)来实现 Socket 通信。
- WebSocket:WebSocket 是专为 Web 应用设计的,所有现代浏览器均支持 WebSocket 协议,开发者可以直接在客户端使用 JavaScript API 进行通信。
10. 工具和库
- Socket:使用 Socket 进行开发时,开发者通常需要使用底层网络编程库,如 BSD Sockets、Java Sockets、Python's socket 模块等。
- WebSocket:WebSocket 提供了简单的 API,开发者可以使用原生 JavaScript 或第三方库(如 Socket.IO)轻松实现 WebSocket 通信。
结论
总结来说,WebSocket 是一种为现代 Web 应用量身定制的协议,具有实时、双向通信的优势,而 Socket 是一种底层的网络通信机制,提供更灵活的使用方式。选择使用哪种技术取决于具体的应用场景和需求。对于需要实时交互的 Web 应用,WebSocket 是更合适的选择;而对于底层或高性能要求的网络通信,Socket 提供了更多的控制和灵活性。
来源:juejin.cn/post/7485631488114278454
完蛋,被扣工资了,都是JSON惹的祸
JSON是一种轻量级的数据交换格式,基于ECMAScript的一个子集设计,采用完全独立于编程语言的文本格式来表示数据。它易于人类阅读和编写,同时也便于机器解析和生成,这使得JSON在数据交换中具有高效性。
JSON也就成了每一个程序员每天都要使用一个小类库。无论你使用的谷歌的gson,阿里巴巴的fastjson,框架自带的jackjson,还是第三方的hutool的json等。总之,每天都要和他打交道。
但是,却在阴沟里翻了船。
1、平平无奇的接口
/**
* 获取vehicleinfo 信息
*
* @RequestParam vehicleId
* @return Vehicle的json字符串
*/
String loadVehicleInfo(Integer vehicleId);
该接口就是通过一个vehicleId参数获取Vehicle对象,返回的数据是Vehicle的JSON字符串,也就是将获取的对象信息序列化成JSON字符串了。
2、无懈可击的引用
String jsonStr = auctVehicleService.loadVehicleInfo(freezeDetail.getVehicle().getId());
if (StringUtils.isNotBlank(jsonStr)) {
Vehicle vehicle = JSON.parseObject(jsonStr, Vehicle.class);
if (vehicle != null) {
// 后续省略 ...
}
}
看似无懈可击的引用,隐藏着魔鬼。为什么无懈可击,因为做了健壮性的判断,非空字符串、非空对象等的判断,根除了空指针异常。
但是,魔鬼隐藏在哪里呢?
3、故障引发

线上直接出现类似的故障(此报错信息为线下模拟)。
现在测试为什么没有问题:主要的测试了基础数据,测试的数据中恰好没有Date 类型的数据,所以线下没有测出来。
4、故障原因分析
从报错日志可以看出,是因为日期类型的参数导致的。Mar 24, 2025 1:23:10 PM 这样的日期格式无法使用Fastjson解析。
深入代码查看:
@Override
public String loadVehicleInfo(Integer vehicleId) {
String key = VEHICLE_KEY + vehicleId;
Object obj = cacheService.get(key);
if (null != obj && StringUtils.isNotEmpty(obj.toString())
&& !"null".equals(obj.toString())) {
String result = (String)obj;
return result;
}
String json = null;
try {
Vehicle vInfo = overrideVehicleAttributes(vehicleId);
// 使用了Gson序列化对象
json = gson.toJson(vInfo);
cacheService.setExpireSec(key, gson.toJson(vInfo), 5 * 60);
} catch (Exception e) {
cacheService.setExpireSec(key, "", 1 * 60);
} finally {
}
return json;
}
原来接口的实现里面采用了谷歌的Gson对返回的对象做了序列化。调用的地方又使用了阿里巴巴的Fastjson发序列化,导致参数解析异常。

完蛋,上榜是要被扣工资的!!!
5、小结
问题虽小,但是影响却很大。坊间一直讨论着,程序员为什么不能写出没有bug的程序。这也许是其中的一种答案吧。
肉疼,被扣钱了!!!
--END--
喜欢就点赞收藏,也可以关注我的微信公众号:编程朝花夕拾
来源:juejin.cn/post/7485560281955958794
JDK 24 发布,新特性解读!
真快啊!Java 24 这两天已经正式发布啦!这是自 Java 21 以来的第三个非长期支持版本,和 Java 22、Java 23一样。
下一个长期支持版是 Java 25,预计今年 9 月份发布。
Java 24 带来的新特性还是蛮多的,一共 24 个。Java 23 和 Java 23 都只有 12 个,Java 24的新特性相当于这两次的总和了。因此,这个版本还是非常有必要了解一下的。
下图是从 JDK8 到 JDK 24 每个版本的更新带来的新特性数量和更新时间:

我在昨天晚上详细看了一下 Java 24 的详细更新,并对其中比较重要的新特性做了详细的解读,希望对你有帮助!
本文内容概览:

JEP 478: 密钥派生函数 API(预览)
密钥派生函数 API 是一种用于从初始密钥和其他数据派生额外密钥的加密算法。它的核心作用是为不同的加密目的(如加密、认证等)生成多个不同的密钥,避免密钥重复使用带来的安全隐患。 这在现代加密中是一个重要的里程碑,为后续新兴的量子计算环境打下了基础
通过该 API,开发者可以使用最新的密钥派生算法(如 HKDF 和未来的 Argon2):
// 创建一个 KDF 对象,使用 HKDF-SHA256 算法
KDF hkdf = KDF.getInstance("HKDF-SHA256");
// 创建 Extract 和 Expand 参数规范
AlgorithmParameterSpec params =
HKDFParameterSpec.ofExtract()
.addIKM(initialKeyMaterial) // 设置初始密钥材料
.addSalt(salt) // 设置盐值
.thenExpand(info, 32); // 设置扩展信息和目标长度
// 派生一个 32 字节的 AES 密钥
SecretKey key = hkdf.deriveKey("AES", params);
// 可以使用相同的 KDF 对象进行其他密钥派生操作
JEP 483: 提前类加载和链接
在传统 JVM 中,应用在每次启动时需要动态加载和链接类。这种机制对启动时间敏感的应用(如微服务或无服务器函数)带来了显著的性能瓶颈。该特性通过缓存已加载和链接的类,显著减少了重复工作的开销,显著减少 Java 应用程序的启动时间。测试表明,对大型应用(如基于 Spring 的服务器应用),启动时间可减少 40% 以上。
这个优化是零侵入性的,对应用程序、库或框架的代码无需任何更改,启动也方式保持一致,仅需添加相关 JVM 参数(如 -XX:+ClassDataSharing)。
JEP 484: 类文件 API
类文件 API 在 JDK 22 进行了第一次预览(JEP 457),在 JDK 23 进行了第二次预览并进一步完善(JEP 466)。最终,该特性在 JDK 24 中顺利转正。
类文件 API 的目标是提供一套标准化的 API,用于解析、生成和转换 Java 类文件,取代过去对第三方库(如 ASM)在类文件处理上的依赖。
// 创建一个 ClassFile 对象,这是操作类文件的入口。
ClassFile cf = ClassFile.of();
// 解析字节数组为 ClassModel
ClassModel classModel = cf.parse(bytes);
// 构建新的类文件,移除以 "debug" 开头的所有方法
byte[] newBytes = cf.build(classModel.thisClass().asSymbol(),
classBuilder -> {
// 遍历所有类元素
for (ClassElement ce : classModel) {
// 判断是否为方法 且 方法名以 "debug" 开头
if (!(ce instanceof MethodModel mm
&& mm.methodName().stringValue().startsWith("debug"))) {
// 添加到新的类文件中
classBuilder.with(ce);
}
}
});
JEP 485: 流收集器
流收集器 Stream::gather(Gatherer) 是一个强大的新特性,它允许开发者定义自定义的中间操作,从而实现更复杂、更灵活的数据转换。Gatherer 接口是该特性的核心,它定义了如何从流中收集元素,维护中间状态,并在处理过程中生成结果。
与现有的 filter、map 或 distinct 等内置操作不同,Stream::gather 使得开发者能够实现那些难以用标准 Stream 操作完成的任务。例如,可以使用 Stream::gather 实现滑动窗口、自定义规则的去重、或者更复杂的状态转换和聚合。 这种灵活性极大地扩展了 Stream API 的应用范围,使开发者能够应对更复杂的数据处理场景。
基于 Stream::gather(Gatherer) 实现字符串长度的去重逻辑:
var result = Stream.of("foo", "bar", "baz", "quux")
.gather(Gatherer.ofSequential(
HashSet::new, // 初始化状态为 HashSet,用于保存已经遇到过的字符串长度
(set, str, downstream) -> {
if (set.add(str.length())) {
return downstream.push(str);
}
return true; // 继续处理流
}
))
.toList();// 转换为列表
// 输出结果 ==> [foo, quux]
JEP 486: 永久禁用安全管理器
JDK 24 不再允许启用 Security Manager,即使通过 java -Djava.security.manager命令也无法启用,这是逐步移除该功能的关键一步。虽然 Security Manager 曾经是 Java 中限制代码权限(如访问文件系统或网络、读取或写入敏感文件、执行系统命令)的重要工具,但由于复杂性高、使用率低且维护成本大,Java 社区决定最终移除它。
JEP 487: 作用域值 (第四次预览)
作用域值(Scoped Values)可以在线程内和线程间共享不可变的数据,优于线程局部变量,尤其是在使用大量虚拟线程时。
final static ScopedValue<...> V = new ScopedValue<>();
// In some method
ScopedValue.where(V, <value>)
.run(() -> { ... V.get() ... call methods ... });
// In a method called directly or indirectly from the lambda expression
... V.get() ...
作用域值允许在大型程序中的组件之间安全有效地共享数据,而无需求助于方法参数。
JEP 491: 虚拟线程的同步而不固定平台线程
优化了虚拟线程与 synchronized 的工作机制。 虚拟线程在 synchronized 方法和代码块中阻塞时,通常能够释放其占用的操作系统线程(平台线程),避免了对平台线程的长时间占用,从而提升应用程序的并发能力。 这种机制避免了“固定 (Pinning)”——即虚拟线程长时间占用平台线程,阻止其服务于其他虚拟线程的情况。
现有的使用 synchronized 的 Java 代码无需修改即可受益于虚拟线程的扩展能力。 例如,一个 I/O 密集型的应用程序,如果使用传统的平台线程,可能会因为线程阻塞而导致并发能力下降。 而使用虚拟线程,即使在 synchronized 块中发生阻塞,也不会固定平台线程,从而允许平台线程继续服务于其他虚拟线程,提高整体的并发性能。
JEP 493:在没有 JMOD 文件的情况下链接运行时镜像
默认情况下,JDK 同时包含运行时镜像(运行时所需的模块)和 JMOD 文件。这个特性使得 jlink 工具无需使用 JDK 的 JMOD 文件就可以创建自定义运行时镜像,减少了 JDK 的安装体积(约 25%)。
说明:
- Jlink 是随 Java 9 一起发布的新命令行工具。它允许开发人员为基于模块的 Java 应用程序创建自己的轻量级、定制的 JRE。
- JMOD 文件是 Java 模块的描述文件,包含了模块的元数据和资源。
JEP 495: 简化的源文件和实例主方法(第四次预览)
这个特性主要简化了 main 方法的的声明。对于 Java 初学者来说,这个 main 方法的声明引入了太多的 Java 语法概念,不利于初学者快速上手。
没有使用该特性之前定义一个 main 方法:
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
使用该新特性之后定义一个 main 方法:
class HelloWorld {
void main() {
System.out.println("Hello, World!");
}
}
进一步简化(未命名的类允许我们省略类名)
void main() {
System.out.println("Hello, World!");
}
JEP 497: 量子抗性数字签名算法 (ML-DSA)
JDK 24 引入了支持实施抗量子的基于模块晶格的数字签名算法 (Module-Lattice-Based Digital Signature Algorithm, ML-DSA),为抵御未来量子计算机可能带来的威胁做准备。
ML-DSA 是美国国家标准与技术研究院(NIST)在 FIPS 204 中标准化的量子抗性算法,用于数字签名和身份验证。
JEP 498: 使用 sun.misc.Unsafe 内存访问方法时发出警告
JDK 23(JEP 471) 提议弃用 sun.misc.Unsafe 中的内存访问方法,这些方法将来的版本中会被移除。在 JDK 24 中,当首次调用 sun.misc.Unsafe 的任何内存访问方法时,运行时会发出警告。
这些不安全的方法已有安全高效的替代方案:
java.lang.invoke.VarHandle:JDK 9 (JEP 193) 中引入,提供了一种安全有效地操作堆内存的方法,包括对象的字段、类的静态字段以及数组元素。java.lang.foreign.MemorySegment:JDK 22 (JEP 454) 中引入,提供了一种安全有效地访问堆外内存的方法,有时会与VarHandle协同工作。
这两个类是 Foreign Function & Memory API(外部函数和内存 API) 的核心组件,分别用于管理和操作堆外内存。Foreign Function & Memory API 在 JDK 22 中正式转正,成为标准特性。
import jdk.incubator.foreign.*;
import java.lang.invoke.VarHandle;
// 管理堆外整数数组的类
class OffHeapIntBuffer {
// 用于访问整数元素的VarHandle
private static final VarHandle ELEM_VH = ValueLayout.JAVA_INT.arrayElementVarHandle();
// 内存管理器
private final Arena arena;
// 堆外内存段
private final MemorySegment buffer;
// 构造函数,分配指定数量的整数空间
public OffHeapIntBuffer(long size) {
this.arena = Arena.ofShared();
this.buffer = arena.allocate(ValueLayout.JAVA_INT, size);
}
// 释放内存
public void deallocate() {
arena.close();
}
// 以volatile方式设置指定索引的值
public void setVolatile(long index, int value) {
ELEM_VH.setVolatile(buffer, 0L, index, value);
}
// 初始化指定范围的元素为0
public void initialize(long start, long n) {
buffer.asSlice(ValueLayout.JAVA_INT.byteSize() * start,
ValueLayout.JAVA_INT.byteSize() * n)
.fill((byte) 0);
}
// 将指定范围的元素复制到新数组
public int[] copyToNewArray(long start, int n) {
return buffer.asSlice(ValueLayout.JAVA_INT.byteSize() * start,
ValueLayout.JAVA_INT.byteSize() * n)
.toArray(ValueLayout.JAVA_INT);
}
}
JEP 499: 结构化并发(第四次预览)
JDK 19 引入了结构化并发,一种多线程编程方法,目的是为了通过结构化并发 API 来简化多线程编程,并不是为了取代java.util.concurrent,目前处于孵化器阶段。
结构化并发将不同线程中运行的多个任务视为单个工作单元,从而简化错误处理、提高可靠性并增强可观察性。也就是说,结构化并发保留了单线程代码的可读性、可维护性和可观察性。
结构化并发的基本 API 是StructuredTaskScope,它支持将任务拆分为多个并发子任务,在它们自己的线程中执行,并且子任务必须在主任务继续之前完成。
StructuredTaskScope 的基本用法如下:
try (var scope = new StructuredTaskScope<Object>()) {
// 使用fork方法派生线程来执行子任务
Future<Integer> future1 = scope.fork(task1);
Future<String> future2 = scope.fork(task2);
// 等待线程完成
scope.join();
// 结果的处理可能包括处理或重新抛出异常
... process results/exceptions ...
} // close
结构化并发非常适合虚拟线程,虚拟线程是 JDK 实现的轻量级线程。许多虚拟线程共享同一个操作系统线程,从而允许非常多的虚拟线程。
Java 新特性系列解读
如果你想系统了解 Java 8 以及之后版本的新特性,可以在 JavaGuide 上阅读对应的文章:

比较推荐这几篇:
来源:juejin.cn/post/7483478667143626762
年少不知自增好,错把UUID当个宝!!!
在 MySQL 中,使用 UUID 作为主键 在大表中可能会导致性能问题,尤其是在插入和修改数据时效率较低。以下是详细的原因分析,以及为什么修改数据会导致索引刷新,以及字符主键为什么效率较低。
1. UUID 作为主键的问题
(1)UUID 的特性
- UUID 是一个 128 位的字符串,通常表示为 36 个字符(例如:
550e8400-e29b-41d4-a716-446655440000)。 - UUID 是全局唯一的,适合分布式系统中生成唯一标识。
(2)UUID 作为主键的缺点
1. 索引效率低
- 索引大小:UUID 是字符串类型,占用空间较大(36 字节),而整型主键(如
BIGINT)仅占用 8 字节。索引越大,存储和查询的效率越低。 - 索引分裂:UUID 是无序的,插入新数据时,可能会导致索引树频繁分裂和重新平衡,影响性能。
2. 插入性能差
- 随机性:UUID 是无序的,每次插入新数据时,新记录可能会插入到索引树的任意位置,导致索引树频繁调整。
- 页分裂:InnoDB 存储引擎使用 B+ 树作为索引结构,随机插入会导致页分裂,增加磁盘 I/O 操作。
3. 查询性能差
- 比较效率低:字符串比较比整型比较慢,尤其是在大表中,查询性能会显著下降。
- 索引扫描范围大:UUID 索引占用的空间大,导致索引扫描的范围更大,查询效率降低。
2. 修改数据导致索引刷新的原因
(1)索引的作用
- 索引是为了加速查询而创建的数据结构(如 B+ 树)。
- 当数据被修改时,索引也需要同步更新,以保持数据的一致性。
(2)修改数据对索引的影响
- 更新主键:
- 如果修改了主键值,MySQL 需要删除旧的主键索引记录,并插入新的主键索引记录。
- 这个过程会导致索引树的调整,增加磁盘 I/O 操作。
- 更新非主键列:
- 如果修改的列是索引列(如唯一索引、普通索引),MySQL 需要更新对应的索引记录。
- 这个过程也会导致索引树的调整。
(3)UUID 主键的额外开销
- 由于 UUID 是无序的,修改主键值时,新值可能会插入到索引树的不同位置,导致索引树频繁调整。
- 相比于有序的主键(如自增 ID),UUID 主键的修改操作代价更高。
3. 字符主键导致效率降低的原因
(1)存储空间大
- 字符主键(如 UUID)占用的存储空间比整型主键大。
- 索引的大小直接影响查询性能,索引越大,查询时需要的磁盘 I/O 操作越多。
(2)比较效率低
- 字符串比较比整型比较慢,尤其是在大表中,查询性能会显著下降。
- 例如,
WHERE id = '550e8400-e29b-41d4-a716-446655440000'的效率低于WHERE id = 12345。
(3)索引分裂
- 字符主键通常是无序的,插入新数据时,可能会导致索引树频繁分裂和重新平衡,影响性能。
4. 如何优化 UUID 主键的性能
(1)使用有序 UUID
- 使用有序 UUID(如
UUIDv7),减少索引分裂和页分裂。 - 有序 UUID 的生成方式可以基于时间戳,保证插入顺序。
(2)将 UUID 存储为二进制
- 将 UUID 存储为
BINARY(16)而不是CHAR(36),减少存储空间。
CREATE TABLE users (
id BINARY(16) PRIMARY KEY,
name VARCHAR(255)
);
(3)使用自增主键 + UUID
- 使用自增主键作为物理主键,UUID 作为逻辑主键。
CREATE TABLE users (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
uuid CHAR(36) UNIQUE,
name VARCHAR(255)
);
(4)分区表
- 对大表进行分区,减少单个索引树的大小,提高查询性能。
~Summary
- UUID 作为主键的缺点:
- 索引效率低,插入和查询性能差。
- 修改数据时,索引需要频繁刷新,导致性能下降。
- 字符主键效率低的原因:
- 存储空间大,比较效率低,索引分裂频繁。
- 优化建议:
- 使用有序 UUID 或二进制存储。
- 结合自增主键和 UUID。
- 对大表进行分区。
来源:juejin.cn/post/7478495083374559270
如何限制一个账号只能在一处登录
如何限制一个账号只能在一处登录
要实现账号单点登录(一处登录限制),需结合 会话管理、实时状态同步 和 冲突处理机制。以下是完整技术方案:
一、核心实现方案
- 服务端会话控制(推荐)
// 用户登录时生成唯一令牌并记录
public String login(String username, String password) {
// 1. 验证账号密码
User user = userService.authenticate(username, password);
// 2. 生成新令牌并失效旧会话
String newToken = UUID.randomUUID().toString();
redis.del("user:" + user.getId() + ":token"); // 清除旧token
redis.setex("user:" + user.getId() + ":token", 3600, newToken);
// 3. 返回新令牌
return newToken;
}
- WebSocket实时踢出(增强体验)
// 前端建立长连接
const socket = new WebSocket(`wss://api.example.com/ws?token=${token}`);
socket.onmessage = (event) => {
if (event.data === 'force_logout') {
alert('您的账号在其他设备登录');
location.href = '/logout';
}
};
- 登录设备指纹识别
// 生成设备指纹(前端)
function generateDeviceFingerprint() {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
ctx.textBaseline = 'top';
ctx.font = "14px Arial";
ctx.fillText("BrowserFingerprint", 2, 2);
return canvas.toDataURL().hashCode(); // 简化示例
}
// 服务端校验
if (storedFingerprint != currentFingerprint) {
forceLogout(storedToken);
}
要实现账号单点登录(一处登录限制),需结合 会话管理、实时状态同步 和 冲突处理机制。以下是完整技术方案:
一、核心实现方案
- 服务端会话控制(推荐)
// 用户登录时生成唯一令牌并记录
public String login(String username, String password) {
// 1. 验证账号密码
User user = userService.authenticate(username, password);
// 2. 生成新令牌并失效旧会话
String newToken = UUID.randomUUID().toString();
redis.del("user:" + user.getId() + ":token"); // 清除旧token
redis.setex("user:" + user.getId() + ":token", 3600, newToken);
// 3. 返回新令牌
return newToken;
}
- WebSocket实时踢出(增强体验)
// 前端建立长连接
const socket = new WebSocket(`wss://api.example.com/ws?token=${token}`);
socket.onmessage = (event) => {
if (event.data === 'force_logout') {
alert('您的账号在其他设备登录');
location.href = '/logout';
}
};
// 生成设备指纹(前端)
function generateDeviceFingerprint() {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
ctx.textBaseline = 'top';
ctx.font = "14px Arial";
ctx.fillText("BrowserFingerprint", 2, 2);
return canvas.toDataURL().hashCode(); // 简化示例
}
// 服务端校验
if (storedFingerprint != currentFingerprint) {
forceLogout(storedToken);
}
二、多端适配策略
| 客户端类型 | 实现方案 |
|---|---|
| Web浏览器 | JWT令牌 + Redis黑名单 |
| 移动端APP | 设备ID绑定 + FCM/iMessage推送踢出 |
| 桌面应用 | 硬件指纹 + 本地令牌失效检测 |
| 微信小程序 | UnionID绑定 + 服务端订阅消息 |
三、关键代码实现
- JWT令牌增强方案
// 生成带设备信息的JWT
public String generateToken(User user, String deviceId) {
return Jwts.builder()
.setSubject(user.getId())
.claim("device", deviceId) // 绑定设备
.setExpiration(new Date(System.currentTimeMillis() + 3600000))
.signWith(SignatureAlgorithm.HS512, secret)
.compact();
}
// 校验令牌时检查设备
public boolean validateToken(String token, String currentDevice) {
Claims claims = Jwts.parser().setSigningKey(secret).parseClaimsJws(token).getBody();
return claims.get("device").equals(currentDevice);
}
- Redis实时状态管理
# 使用Redis Hash存储登录状态
def login(user_id, token, device_info):
# 删除该用户所有活跃会话
r.delete(f"user_sessions:{user_id}")
# 记录新会话
r.hset(f"user_sessions:{user_id}",
mapping={
"token": token,
"device": device_info,
"last_active": datetime.now()
})
r.expire(f"user_sessions:{user_id}", 3600)
# 中间件校验
def check_token(request):
user_id = get_user_id_from_token(request.token)
stored_token = r.hget(f"user_sessions:{user_id}", "token")
if stored_token != request.token:
raise ForceLogoutError()
四、异常处理机制
| 场景 | 处理方案 |
|---|---|
| 网络延迟冲突 | 采用CAS(Compare-And-Swap)原子操作更新令牌 |
| 令牌被盗用 | 触发二次验证(短信/邮箱验证码) |
| 多设备同时登录 | 后登录者优先,前会话立即失效(可配置为保留第一个登录) |
五、性能与安全优化
- 会话同步优化:
# Redis Pub/Sub 跨节点同步
PUBLISH user:123 "LOGOUT"
- 安全增强:
// 前端敏感操作二次确认
function sensitiveOperation() {
if (loginTime < lastServerCheckTime) {
showReauthModal();
}
}
- 监控看板:
指标 报警阈值 并发登录冲突率 >5%/分钟 强制踢出成功率 <99%
六、行业实践参考
- 金融级方案:
- 每次操作都验证设备指纹
- 异地登录需视频人工审核
- 社交应用方案:
- 允许最多3个设备在线
- 分设备类型控制(手机+PC+平板)
- ERP系统方案:
- 绑定特定MAC地址
- VPN网络白名单限制
通过以上方案可实现:
- 严格模式:后登录者踢出前会话(适合银行系统)
- 宽松模式:多设备在线但通知告警(适合社交应用)
- 混合模式:关键操作时强制单设备(适合电商系统)
部署建议:
- 根据业务需求选择合适严格度
- 关键系统增加异地登录二次验证
- 用户界面明确显示登录设备列表
来源:juejin.cn/post/7485384798569250868
Sa-Token v1.41.0 发布 🚀,来看看有没有令你心动的功能!
Sa-Token 是一个轻量级 Java 权限认证框架,主要解决:登录认证、权限认证、单点登录、OAuth2.0、微服务网关鉴权 等一系列权限相关问题。🔐
目前最新版本 v1.41.0 已推送至 Maven 中央仓库 🎉,大家可以通过如下方式引入:
<!-- Sa-Token 权限认证 -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-spring-boot-starter</artifactId>
<version>1.41.0</version>
</dependency>
该版本包含大量 ⛏️️️新增特性、⛏️底层重构、⛏️️️代码优化 等,下面容我列举几条比较重要的更新内容供大家参阅:
🛡️ 更新点1:防火墙模块新增 hooks 扩展机制
本次更新针对防火墙新增了多条校验规则,之前的规则为:
- path 白名单放行。
- path 黑名单拦截。
- path 危险字符校验。
本次新增规则为:
- path 禁止字符校验。
- path 目录遍历符检测(优化了检测算法)。
- 请求 host 检测。
- 请求 Method 检测。
- 请求 Header 头检测。
- 请求参数检测。
并且本次更新开放了 hooks 机制,允许开发者注册自定义的校验规则 🛠️,参考如下:
@PostConstruct
public void saTokenPostConstruct() {
// 注册新 hook 演示,拦截所有带有 pwd 参数的请求,拒绝响应
SaFirewallStrategy.instance.registerHook((req, res, extArg)->{
if(req.getParam("pwd") != null) {
throw new FirewallCheckException("请求中不可包含 pwd 参数");
}
});
}
文档直达地址:Sa-Token 防火墙 🔗
💡 更新点2:新增基于 SPI 机制的插件体系
之前在 Sa-Token 中也有插件体系,不过都是利用 SpringBoot 的 SPI 机制完成组件注册的。
这种注册机制有一个问题,就是插件只能在 SpringBoot 环境下正常工作,在其它环境,比如 Solon 项目中,就只能手动注册插件才行 😫。
也就是说,严格来讲,这些插件只能算是 SpringBoot 的插件,而非 Sa-Token 框架的插件 🌐。
为了提高插件的通用性,Sa-Token 设计了自己的 SPI 机制,使得这些插件可以在更多的项目环境下正常工作 🚀。
第一步:实现插件注册类,此类需要 implements SaTokenPlugin 接口 👨💻:
/**
* SaToken 插件安装:插件作用描述
*/
public class SaTokenPluginForXxx implements SaTokenPlugin {
@Override
public void install() {
// 书写需要在项目启动时执行的代码,例如:
// SaManager.setXxx(new SaXxxForXxx());
}
}
第二步:在项目的 resources\META-INF\satoken\ 文件夹下 📂 创建 cn.dev33.satoken.plugin.SaTokenPlugin 文件,内容为该插件注册类的完全限定名:
cn.dev33.satoken.plugin.SaTokenPluginForXxx
这样便可以在项目启动时,被 Sa-Token 插件管理器加载到此插件,执行插件注册类的 install 方法,完成插件安装 ✅。
文档直达地址:Sa-Token 插件开发指南 🔗
🎛️ 更新点3:重构缓存体系,将数据读写与序列化操作分离
在之前的版本中,Redis 集成通常和具体的序列化方式耦合在一起,这不仅让 Redis 相关插件产生大量的重复冗余代码,也让大家在选择 Redis 插件时严重受限。⚠️
本次版本更新彻底重构了此模块,将数据读写与序列化操作分离,使其每一块都可以单独自定义实现类,做到灵活扩展 ✨,例如:
- 1️⃣ SaTokenDao 数据读写可以选择:RedisTemplate、Redisson、ConcurrentHashMap、Hutool-Timed-Cache 等不同实现类。
- 2️⃣ SaSerializerTemplate 序列化器可以选择:Base64编码、Hex编码、ISO-8859-1编码、JSON序列化等不同方式。
- 3️⃣ JSON 序列化可以选择:Jackson、Fastjson、Snack3 等组件。
所有实现类均可以按需选择,自由搭配,大大提高灵活性🏗️。
⚙️️ 更新点4:SaLoginParameter 登录参数类新增大量配置项
SaLoginParameter (前SaLoginModel) 用于控制登录操作中的部分细节行为,本次新增的配置项有:
- isConcurrent:决定是否允许同一账号多地同时登录(为 true 时允许一起登录, 为 false 时新登录挤掉旧登录)。🌍
- isShare:在多人登录同一账号时,是否共用一个 token (为 true 时所有登录共用一个 token, 为 false 时每次登录新建一个 token)。🔄
- maxLoginCount:同一账号最大登录数量,超出此数量的客户端将被自动注销,-1代表不限制数量。🚫
- maxTryTimes:在创建 token 时的最高循环次数,用于保证 token 唯一性(-1=不循环尝试,直接使用。⏳
- deviceId:此次登录的客户端设备id,用于判断后续某次登录是否为可信任设备。📱
- terminalExtraData:本次登录挂载到 SaTerminalInfo 的自定义扩展数据。📦
以上大部分配置项在之前的版本中也有支持,不过它们都被定义在了全局配置类 SaTokenConfig 之上,本次更新支持在 SaLoginParameter 中定义这些配置项,
这将让登录策略的控制变得更加灵活。✨
🚪 更新点5:新增 SaLogoutParameter 注销参数类
SaLogoutParameter 用于控制注销操作中的部分细节行为️,例如:
通过 Range 参数决定注销范围 🎯:
// 注销范围: TOKEN=只注销当前 token 的会话,ACCOUNT=注销当前 token 指向的 loginId 其所有客户端会话
StpUtil.logout(new SaLogoutParameter().setRange(SaLogoutRange.TOKEN));
通过 DeviceType 参数决定哪些登录设备类型参与注销 💻:
// 指定 10001 账号,所有 PC 端注销下线,其它端如 APP 端不受影响
StpUtil.logout(10001, new SaLogoutParameter().setDeviceType("PC"));
还有其它参数此处暂不逐一列举,文档直达地址:Sa-Token 登录参数 & 注销参数 🔗
🐞 更新点6:修复 StpUtil.setTokenValue("xxx")、loginParameter.getIsWriteHeader() 空指针的问题。
这个没啥好说的,有 bug 🐛 必须修复。
fix issue:#IBKSM0 🔗
✨ 更新点7:API 参数签名模块升级
- 1、新增了 @SaCheckSign 注解,现在 API 参数签名模块也支持注解鉴权了。🆕
- 2、新增自定义签名的摘要算法,现在不仅可以 md5 算法计算签名,也支持 sha1、sha256 等算法了。🔐
- 3、新增多应用模式:
多应用模式就是指,允许在对接多个系统时分别使用不同的秘钥等配置项,配置示例如下 📝:
sa-token:
# API 签名配置 多应用模式
sign-many:
# 应用1
xm-shop:
secret-key: 0123456789abcdefg
digest-algo: md5
# 应用2
xm-forum:
secret-key: 0123456789hijklmnopq
digest-algo: sha256
# 应用3
xm-video:
secret-key: 12341234aaaaccccdddd
digest-algo: sha512
然后在签名时通过指定 appid 的方式获取对应的 SignTemplate 进行操作 👨💻:
// 创建签名示例
String paramStr = SaSignMany.getSignTemplate("xm-shop").addSignParamsAndJoin(paramMap);
// 校验签名示例
SaSignMany.getSignTemplate("xm-shop").checkRequest(SaHolder.getRequest());
⚡ 更新点8:新增 sa-token-caffeine 插件,用于整合 Caffeine
Caffeine 是一个基于 Java 的高性能本地缓存库,本次新增 sa-token-caffeine 插件用于将 Caffeine 作为 Sa-Token 的缓存层,存储会话鉴权数据。🚀
这进一步丰富了 Sa-Token 的缓存层插件生态。🌱
<!-- Sa-Token 整合 Caffeine -->
<dependency>
<groupId>cn.dev33</groupId>
<artifactId>sa-token-caffeine</artifactId>
<version>1.41.0</version>
</dependency>
🎪 更新点9:新增 sa-token-serializer-features 序列化扩展包
引入此插件可以为 Sa-Token 提供一些有意思的序列化方案。(娱乐向,不建议上生产 🎭)
例如:以base64 编码,采用:元素周期表 🧪、特殊符号 🔣、或 emoji 😊 作为元字符集存储数据 :




📜 完整更新日志
除了以上提到的几点以外,还有更多更新点无法逐一详细介绍,下面是 v1.41.0 版本的完整更新日志:
- core:
- 修复:修复
StpUtil.setTokenValue("xxx")、loginParameter.getIsWriteHeader()空指针的问题。 fix: #IBKSM0 - 修复:将
SaDisableWrapperInfo.createNotDisabled()默认返回值封禁等级改为 -2,以保证向之前版本兼容。 - 新增:新增基于 SPI 的插件体系。 [重要]
- 重构:JSON 转换器模块。 [重要]
- 新增:新增 serializer 序列化模块,控制
Object与String的序列化方式。 [重要] - 重构:重构防火墙模块,增加 hooks 机制。 [重要]
- 新增:防火墙新增:请求 path 禁止字符校验、Host 检测、请求 Method 检测、请求头检测、请求参数检测。重构目录遍历符检测算法。
- 重构:重构
SaTokenDao模块,将序列化与存储操作分离。 [重要] - 重构:重构
SaTokenDao默认实现类,优化底层设计。 - 新增:
isLastingCookie配置项支持在全局配置中定义了。 - 重构:
SaLoginModel->SaLoginParameter。 [不向下兼容] - 重构:
TokenSign->SaTerminalInfo。 [不向下兼容] - 新增:
SaTerminalInfo新增extraData自定义扩展数据设置。 - 新增:
SaLoginParameter支持配置isConcurrent、isShare、maxLoginCount、maxTryTimes。 - 新增:新增
SaLogoutParameter,用于控制注销会话时的各种细节。 [重要] - 新增:新增
StpLogic#isTrustDeviceId方法,用于判断指定设备是否为可信任设备。 - 新增:新增
StpUtil.getTerminalListByLoginId(loginId)、StpUtil.forEachTerminalList(loginId)方法,以更方便的实现单账号会话管理。 - 升级:API 参数签名配置支持自定义摘要算法。
- 新增:新增
@SaCheckSign注解鉴权,用于 API 签名参数校验。 - 新增:API 参数签名模块新增多应用模式。 fix: #IAK2BI, #I9SPI1, #IAC0P9 [重要]
- 重构:全局配置
is-share默认值改为 false。 [不向下兼容] - 重构:踢人下线、顶人下线默认将删除对应的 token-session 对象。
- 优化:优化注销会话相关 API。
- 重构:登录默认设备类型值改为 DEF。 [不向下兼容]
- 重构:
BCrypt标注为@Deprecated。 - 新增:
sa-token-quick-login支持SpringBoot3项目。 fix: #IAFQNE、#673 - 新增:
SaTokenConfig新增replacedRange、overflowLogoutMode、logoutRange、isLogoutKeepFreezeOps、isLogoutKeepTokenSession配置项。
- 修复:修复
- OAuth2:
- 重构:重构 sa-token-oauth2 插件,使注解鉴权处理器的注册过程改为 SPI 插件加载。
- 插件:
- 新增:
sa-token-serializer-features插件,用于实现各种形式的自定义字符集序列化方案。 - 新增:
sa-token-fastjson插件。 - 新增:
sa-token-fastjson2插件。 - 新增:
sa-token-snack3插件。 - 新增:
sa-token-caffeine插件。
- 新增:
- 单元测试:
- 新增:
sa-token-json-testjson 模块单元测试。 - 新增:
sa-token-serializer-test序列化模块单元测试。
- 新增:
- 文档:
- 新增:QA “多个项目共用同一个 redis,怎么防止冲突?”
- 优化:补全 OAuth2 模块遗漏的相关配置项。
- 优化:优化 OAuth2 简述章节描述文档。
- 优化:完善 “SSO 用户数据同步 / 迁移” 章节文档。
- 修正:补全项目目录结构介绍文档。
- 新增:文档新增 “登录参数 & 注销参数” 章节。
- 优化:优化“技术求助”按钮的提示文字。
- 新增:新增
preview-doc.bat文件,一键启动文档预览。 - 完善:完善 Redis 集成文档。
- 新增:新增单账号会话查询的操作示例。
- 新增:新增顶人下线 API 介绍。
- 新增:新增 自定义序列化插件 章节。
- 其它:
- 新增:新增
sa-token-demo/pom.xml以便在 idea 中一键导入所有 demo 项目。 - 删除:删除不必要的
.gitignore文件 - 重构:重构
sa-token-solon-plugin插件。 - 新增:新增设备锁登录示例。
- 新增:新增
更新日志在线文档直达链接:sa-token.cc/doc.html#/m…
🌟 其它
代码仓库地址:gitee.com/dromara/sa-…
框架功能结构图:

来源:juejin.cn/post/7484191942358499368
这个排队系统设计碉堡了
先赞后看,Java进阶一大半
各位好,我是南哥。
我在网上看到某厂最后一道面试题:如何设计一个排队系统?
关于系统设计的问题,大家还是要多多思考,可能这道题考的不是针对架构师的职位,而是关于你的业务设计能力。如果单单只会用开源软件的API,那似乎我们的竞争力还可以再强些。学习设计东西、创作东西,把我们设计的产品给别人用,那竞争力一下子提了上来。
15岁的初中生开源了 AI 一站式 B/C 端解决方案chatnio,该产品在上个月被以几百万的价格收购了。这值得我们思考,程序创造力、设计能力在未来会变得越来越重要。

⭐⭐⭐收录在《Java学习/进阶/面试指南》:https://github/JavaSouth
精彩文章推荐
1.1 数据结构
排队的一个特点是一个元素排在另一个元素的后面,形成条状的队列。List结构、LinkedList链表结构都可以满足排队的业务需求,但如果这是一道算法题,我们要考虑的是性能因素。
排队并不是每个人都老老实实排队,现实会有多种情况发生,例如有人退号,那属于这个人的元素要从队列中删除;特殊情况安排有人插队,那插入位置的后面那批元素都要往后挪一挪。结合这个情况用LinkedList链表结构会更加合适,相比于List,LinkedList的性能优势就是增、删的效率更优。
但我们这里做的是一个业务系统,采用LinkedList这个结构也可以,不过要接受修改、维护起来困难,后面接手程序的人难以理解。大家都知道,在实际开发我们更常用List,而不是LinkedList。
List数据结构我更倾向于把它放在Redis里,有以下好处。
(1)数据存储与应用程序拆分。放在应用程序内存里,如果程序崩溃,那整条队列数据都会丢失。
(2)性能更优。相比于数据库存储,Redis处理数据的性能更加优秀,结合排队队列排完则销毁的特点,甚至可以不存储到数据库。可以补充排队记录到数据库里。
简单用Redis命令模拟下List结构排队的处理。
# 入队列(将用户 ID 添加到队列末尾)
127.0.0.1:6379> RPUSH queue:large user1
127.0.0.1:6379> RPUSH queue:large user2
# 出队列(将队列的第一个元素出队)
127.0.0.1:6379> LPOP queue:large
# 退号(从队列中删除指定用户 ID)
127.0.0.1:6379> LREM queue:large 1 user2
# 插队(将用户 ID 插入到指定位置,假设在 user1 之前插入 user3)
127.0.0.1:6379> LINSERT queue:large BEFORE user1 user3
1.2 业务功能
先给大家看看,南哥用过的费大厨的排队系统,它是在公众号里进行排队。
我们可以看到自己现在的排队进度。

同时每过 10 号,公众号会进行推送通知;如果 10 号以内,每过 1 号会微信公众号通知用户实时排队进度。最后每过 1 号就通知挺人性化,安抚用户排队的焦急情绪。

总结下来,我们梳理下功能点。虽然上面看起来是简简单单的查看、通知,背后可能隐藏许多要实现的功能。

1.3 后台端
(1)排队开始
后台管理员创建排队活动,后端在Redis创建List类型的数据结构,分别创建大桌、中桌、小桌三条队列,同时设置没有过期时间。
// 创建排队接口
@Service
public class QueueManagementServiceImpl {
@Autowired
private RedisTemplate<String, String> redisTemplate;
// queueType为桌型
public void createQueue(String queueType) {
String queueKey = "queue:" + queueType;
redisTemplate.delete(queueKey); // 删除队列,保证队列重新初始化
}
}
(2)排队操作
前面顾客用餐完成后,后台管理员点击下一号,在Redis的表现为把第一个元素从List中踢出,次数排队的总人数也减 1。
// 排队操作
@Service
public class QueueManagementServiceImpl {
@Autowired
private RedisTemplate<String, String> redisTemplate;
/**
* 将队列中的第一个用户出队
*/
public void dequeueNextUser(String queueType) {
String queueKey = "queue:" + queueType;
String userId = redisTemplate.opsForList().leftPop(queueKey);
}
}
1.4 用户端
(1)点击排队
用户点击排队,把用户标识添加到Redis队列中。
// 用户排队
@Service
public class QueueServiceImpl {
@Autowired
private RedisTemplate<String, String> redisTemplate;
public void enterQueue(String queueType, String userId) {
String queueKey = "queue:" + queueType;
redisTemplate.opsForList().rightPush(queueKey, userId);
log.info("用户 " + userId + " 已加入 " + queueType + " 队列");
}
}
(2)排队进度
用户可以查看三条队列的总人数情况,直接从Redis三条队列中查询队列个数。此页面不需要实时刷新,当然可以用WebSocket实时刷新或者长轮询,但具备了后面的用户通知功能,这个不实现也不影响用户体验。
而用户的个人排队进度,则计算用户所在队列前面的元素个数。
// 查询排队进度
@Service
public class QueueServiceImpl {
@Autowired
private RedisTemplate<String, String> redisTemplate;
public long getUserPositionInQueue(String queueType, String userId) {
String queueKey = "queue:" + queueType;
List<String> queue = redisTemplate.opsForList().range(queueKey, 0, -1);
if (queue != null) {
return queue.indexOf(userId);
}
return -1;
}
}
(3)用户通知
当某一个顾客用餐完成后,后台管理员点击下一号。此时后续的后端逻辑应该包括用户通知。
从三个队列里取出当前用户进度是 10 的倍数的元素,微信公众号通知该用户现在是排到第几桌了。
从三个队列里取出排名前 10 的元素,微信公众号通知该用户现在的进度。
// 用户通知
@Service
public class NotificationServiceImpl {
@Autowired
private RedisTemplate<String, String> redisTemplate;
private void notifyUsers(String queueType) {
String queueKey = "queue:" + queueType;
// 获取当前队列中的所有用户
List<String> queueList = jedis.lrange(queueKey, 0, -1);
// 通知排在10的倍数的用户
for (int i = 0; i < queueList.size(); i++) {
if ((i + 1) % 10 == 0) {
String userId = queueList.get(i);
sendNotification(userId, "您的排队进度是第 " + (i + 1) + " 位,请稍作准备!");
}
}
// 通知前10位用户
int notifyLimit = Math.min(10, queueList.size()); // 避免队列小于10时出错
for (int i = 0; i < notifyLimit; i++) {
String userId = queueList.get(i);
sendNotification(userId, "您已经在前 10 位,准备好就餐!");
}
}
}
这段逻辑应该移动到前面后台端的排队操作。
1.5 存在问题
上面的业务情况,实际上排队人员不会太多,一般会比较稳定。但如果每一条队列人数激增的情况下,可以预见到会有问题了。
对于Redis的List结构,我们需要查询某一个元素的排名情况,最坏情况下需要遍历整条队列,时间复杂度是O(n),而查询用户排名进度这个功能又是经常使用到。
对于上面情况,我们可以选择Redis另一种数据结构:Zset。有序集合类型Zset可以在O(lgn)的时间复杂度判断某元素的排名情况,使用ZRANK命令即可。
# zadd命令添加元素
127.0.0.1:6379> zadd 100run:ranking 13 mike
(integer) 1
127.0.0.1:6379> zadd 100run:ranking 12 jake
(integer) 1
127.0.0.1:6379> zadd 100run:ranking 16 tom
(integer) 1
# zrank命令查看排名
127.0.0.1:6379> zrank 100run:ranking jake
(integer) 0
127.0.0.1:6379> zrank 100run:ranking tom
(integer) 2
# zscore判断元素是否存在
127.0.0.1:6379> zscore 100run:ranking jake
"12"
我是南哥,南就南在Get到你的点赞点赞点赞。

创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️
来源:juejin.cn/post/7436658089703145524
Spring 6.0 + Boot 3.0:秒级启动、万级并发的开发新姿势
Spring生态重大升级全景图

一、Spring 6.0核心特性详解
1. Java版本基线升级
- 最低JDK 17:全面拥抱Java模块化特性,优化现代JVM性能
- 虚拟线程(Loom项目):轻量级线程支持高并发场景(需JDK 19+)
// 示例:虚拟线程使用
Thread.ofVirtual().name("my-virtual-thread").start(() -> {
// 业务逻辑
});
- 虚拟线程(Project Loom)
- 应用场景:电商秒杀系统、实时聊天服务等高并发场景
// 传统线程池 vs 虚拟线程
// 旧方案(平台线程)
ExecutorService executor = Executors.newFixedThreadPool(200);
// 新方案(虚拟线程)
ExecutorService virtualExecutor = Executors.newVirtualThreadPerTaskExecutor();
// 处理10000个并发请求
IntStream.range(0, 10000).forEach(i ->
virtualExecutor.submit(() -> {
// 处理订单逻辑
processOrder(i);
})
);
2. HTTP接口声明式客户端
- @HttpExchange注解:类似Feign的声明式REST调用
@HttpExchange(url = "/api/users")
public interface UserClient {
@GetExchange
List<User> listUsers();
}
应用场景:微服务间API调用
@HttpExchange(url = "/products", accept = "application/json")
public interface ProductServiceClient {
@GetExchange("/{id}")
Product getProduct(@PathVariable String id);
@PostExchange
Product createProduct(@RequestBody Product product);
}
// 自动注入使用
@Service
public class OrderService {
@Autowired
private ProductServiceClient productClient;
public void validateProduct(String productId) {
Product product = productClient.getProduct(productId);
// 校验逻辑...
}
}
3. ProblemDetail异常处理
- RFC 7807标准:标准化错误响应格式
{
"type": "https://example.com/errors/insufficient-funds",
"title": "余额不足",
"status": 400,
"detail": "当前账户余额为50元,需支付100元"
}
- 应用场景:统一API错误响应格式
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(ProductNotFoundException.class)
public ProblemDetail handleProductNotFound(ProductNotFoundException ex) {
ProblemDetail problem = ProblemDetail.forStatus(HttpStatus.NOT_FOUND);
problem.setType(URI.create("/errors/product-not-found"));
problem.setTitle("商品不存在");
problem.setDetail("商品ID: " + ex.getProductId());
return problem;
}
}
// 触发异常示例
@GetMapping("/products/{id}")
public Product getProduct(@PathVariable String id) {
return productRepo.findById(id)
.orElseThrow(() -> new ProductNotFoundException(id));
}
4. GraalVM原生镜像支持
- AOT编译优化:启动时间缩短至毫秒级,内存占用降低50%+
- 编译命令示例:
native-image -jar myapp.jar
二、Spring Boot 3.0突破性改进
1. 基础架构升级
- Jakarta EE 9+:包名javax→jakarta全量替换
- 自动配置优化:更智能的条件装配策略
- OAuth2授权服务器
应用场景:构建企业级认证中心
- OAuth2授权服务器
# application.yml配置
spring:
security:
oauth2:
authorization-server:
issuer-url: https://auth.yourcompany.com
token:
access-token-time-to-live: 1h
定义权限端点
@Configuration
@EnableWebSecurity
public class AuthServerConfig {
@Bean
public SecurityFilterChain authServerFilterChain(HttpSecurity http) throws Exception {
http
.authorizeRequests(authorize -> authorize
.anyRequest().authenticated()
)
.oauth2ResourceServer(OAuth2ResourceServerConfigurer::jwt);
return http.build();
}
}
2. GraalVM原生镜像支持
应用场景:云原生Serverless函数
# 打包命令(需安装GraalVM)
mvn clean package -Pnative
# 运行效果对比
传统JAR启动:启动时间2.3s | 内存占用480MB
原生镜像启动:启动时间0.05s | 内存占用85MB
3. 增强监控(Prometheus集成)
- Micrometer 1.10+:支持OpenTelemetry标准
- 全新/actuator/prometheus端点:原生Prometheus格式指标
- 应用场景:微服务健康监测
// 自定义业务指标
@RestController
public class OrderController {
private final Counter orderCounter = Metrics.counter("orders.total");
@PostMapping("/orders")
public Order createOrder() {
orderCounter.increment();
// 创建订单逻辑...
}
}
# Prometheus监控指标示例
orders_total{application="order-service"} 42
http_server_requests_seconds_count{uri="/orders"} 15
三、升级实施路线图

四、新特性组合实战案例
场景:电商平台升级
// 商品查询服务(组合使用新特性)
@RestController
public class ProductController {
// 声明式调用库存服务
@Autowired
private StockServiceClient stockClient;
// 虚拟线程处理高并发查询
@GetMapping("/products/{id}")
public ProductDetail getProduct(@PathVariable String id) {
return CompletableFuture.supplyAsync(() -> {
Product product = productRepository.findById(id)
.orElseThrow(() -> new ProductNotFoundException(id));
// 并行查询库存
Integer stock = stockClient.getStock(id);
return new ProductDetail(product, stock);
}, Executors.newVirtualThreadPerTaskExecutor()).join();
}
}
四、升级实践建议
- 环境检查:确认JDK版本≥17,IDE支持Jakarta包名
- 渐进式迁移:
- 先升级Spring Boot 3.x → 再启用Spring 6特性
- 使用
spring-boot-properties-migrator检测配置变更
- 性能测试:对比GraalVM原生镜像与传统JAR包运行指标
通过以上升级方案:
- 使用虚拟线程支撑万级并发查询
- 声明式客户端简化服务间调用
- ProblemDetail统一异常格式
- Prometheus监控接口性能
本次升级标志着Spring生态正式进入云原生时代。重点关注:虚拟线程的资源管理策略、GraalVM的反射配置优化、OAuth2授权服务器的定制扩展等深度实践方向。
来源:juejin.cn/post/7476389305881296934
让闲置 Ubuntu 服务器华丽转身为家庭影院
让闲置 Ubuntu 服务器华丽转身为家庭影院
在数字化的时代,家里的设备更新换代频繁,很容易就会有闲置的服务器吃灰。我家里就有一台闲置的 Ubuntu 24.04 服务器,一直放在角落,总觉得有些浪费。于是,我决定让它重新发挥作用,打造一个属于自己的家庭影院。
在数字化的时代,家里的设备更新换代频繁,很容易就会有闲置的服务器吃灰。我家里就有一台闲置的 Ubuntu 24.04 服务器,一直放在角落,总觉得有些浪费。于是,我决定让它重新发挥作用,打造一个属于自己的家庭影院。
一、实现 Windows 与 Ubuntu 服务器文件互通
要打造家庭影院,首先得让本地 Windows 电脑和 Ubuntu 服务器之间能够方便地传输电影文件。我选择安装 Samba 来实现这一目的。
- 安装 Samba:在 Ubuntu 服务器的终端中输入命令
sudo apt-get install samba samba-common
系统会自动下载并安装 Samba 相关的软件包。
- 备份配置文件:为了以防万一,我先将原来的 Samba 配置文件进行备份,执行命令
mv /etc/samba/smb.conf /etc/samba/smb.conf.bak
- 新建配置文件:使用
vim /etc/samba/smb.conf 命令打开编辑器,写入以下配置内容:
[global]
server min protocol = CORE
workgroup = WORKGR0UP
netbios name = Nas
security = user
map to guest = bad user
guest account = nobody
client min protocol = SMB2
server min protocol = SMB2
server smb encrypt = off
[NAS]
comment = NASserver
path = /home/bddxg/nas
public = Yes
browseable = Yes
writable = Yes
guest ok = Yes
passdb backend = tdbsam
create mask = 0775
directory mask = 0775
这里需要注意的是,我计划的媒体库目录是个人目录下的 nas/,所以 path 是 /home/bddxg/nas ,如果大家要部署的话记得根据自己的实际情况修改为对应的位置。 
- 连接 Windows 电脑:在 Windows 电脑这边基本不需要什么复杂配置,因为在网络里无法直接看到 Ubuntu,我直接在电脑上添加了网络位置。假设服务器地址是
192.168.10.100,那么添加网络位置就是 \\192.168.10.100\nas,这样就可以在 Windows 电脑和 Ubuntu 服务器之间传输文件了。
要打造家庭影院,首先得让本地 Windows 电脑和 Ubuntu 服务器之间能够方便地传输电影文件。我选择安装 Samba 来实现这一目的。
- 安装 Samba:在 Ubuntu 服务器的终端中输入命令
sudo apt-get install samba samba-common
系统会自动下载并安装 Samba 相关的软件包。
- 备份配置文件:为了以防万一,我先将原来的 Samba 配置文件进行备份,执行命令
mv /etc/samba/smb.conf /etc/samba/smb.conf.bak
- 新建配置文件:使用
vim /etc/samba/smb.conf命令打开编辑器,写入以下配置内容:
[global]
server min protocol = CORE
workgroup = WORKGR0UP
netbios name = Nas
security = user
map to guest = bad user
guest account = nobody
client min protocol = SMB2
server min protocol = SMB2
server smb encrypt = off
[NAS]
comment = NASserver
path = /home/bddxg/nas
public = Yes
browseable = Yes
writable = Yes
guest ok = Yes
passdb backend = tdbsam
create mask = 0775
directory mask = 0775
这里需要注意的是,我计划的媒体库目录是个人目录下的 nas/,所以 path 是 /home/bddxg/nas ,如果大家要部署的话记得根据自己的实际情况修改为对应的位置。
- 连接 Windows 电脑:在 Windows 电脑这边基本不需要什么复杂配置,因为在网络里无法直接看到 Ubuntu,我直接在电脑上添加了网络位置。假设服务器地址是
192.168.10.100,那么添加网络位置就是\\192.168.10.100\nas,这样就可以在 Windows 电脑和 Ubuntu 服务器之间传输文件了。

二、安装 Jellyfin 搭建家庭影院
文件传输的问题解决后,接下来就是安装 Jellyfin 来实现家庭影院的功能了。
- 尝试 Docker 安装失败:一开始我选择使用 Docker 安装,毕竟 Docker 有很多优点,使用起来也比较方便。按照官网指南进行操作,在第三步启动 Docker 并挂载本地目录的时候却一直失败。报错信息为:
docker: Error response from daemon: error while creating mount source path '/srv/jellyfin/cache': mkdir /srv/jellyfin: read-only file system.
即使我给
/srv/jellyfin赋予了777权限也没有效果。无奈之下,我决定放弃 Docker 安装方式,直接安装 server 版本的 Jellyfin。

- 安装 server 版本的 Jellyfin:在终端中输入命令
curl https://repo.jellyfin.org/install-debuntu.sh | sudo bash,安装过程非常顺利。

- 配置 Jellyfin:安装完成后,通过浏览器访问
http://192.168.10.100:8096进入配置页面。在添加媒体库这里,我遇到了一个麻烦,网页只能选择到/home/bddxg目录,无法继续往下选择到我的媒体库位置/home/bddxg/nas。于是我向 deepseek 求助,它告诉我需要执行命令:sudo usermod -aG bddxg jellyfin
# 并且重启 Jellyfin 服务
sudo systemctl restart jellyfin
按照它的建议操作后,我刷新了网页,重新配置了 Jellyfin,终于可以正常添加媒体库了。
- 电视端播放:在电视上安装好 Jellyfin apk 客户端后,现在终于可以正常读取 Ubuntu 服务器上的影视资源了,坐在沙发上,享受着大屏观影的乐趣,这种感觉真的太棒了!
 通过这次折腾,我成功地让闲置的 Ubuntu 服务器重新焕发生机,变成了一个功能强大的家庭影院。希望我的经验能够对大家有所帮助,也欢迎大家一起交流更多关于服务器利用和家庭影院搭建的经验。
通过这次折腾,我成功地让闲置的 Ubuntu 服务器重新焕发生机,变成了一个功能强大的家庭影院。希望我的经验能够对大家有所帮助,也欢迎大家一起交流更多关于服务器利用和家庭影院搭建的经验。
[!WARNING] 令人遗憾的是,目前 jellyfin 似乎不支持
rmvb格式的影片, 下载资源的时候注意影片格式,推荐直接下载mp4格式的资源
本次使用到的软件名称和版本如下:
| 软件名 | 版本号 | 安装命令 |
|---|---|---|
| samba | Version 4.19.5-Ubuntu | sudo apt-get install samba samba-common |
| jellyfin | Jellyfin.Server 10.10.6.0 | curl https://repo.jellyfin.org/install-debuntu.sh | sudo bash |
| ffmpeg(jellyfin 内自带) | ffmpeg version 7.0.2-Jellyfin | null |
来源:juejin.cn/post/7476614823883833382
Mybatis接口方法参数不加@Param,照样流畅取值
在 MyBatis 中,如果 Mapper 接口的方法有多个参数,但没有使用 @Param 注解,默认情况下,MyBatis 会将这些参数放入一个 Map 中,键名为 param1、param2 等,或者使用索引 0、1 等来访问。以下是具体的使用方法和注意事项。
一、Mapper 接口方法
假设有一个 Mapper 接口方法,包含多个参数但没有使用 @Param 注解:
public interface UserMapper {
User selectUserByNameAndAge(String name, int age);
}
二、XML 文件中的参数引用
在 XML 文件中,可以通过以下方式引用参数:
1. 使用 param1、param2 等
MyBatis 会自动为参数生成键名 param1、param2 等:
<select id="selectUserByNameAndAge" resultType="User">
SELECT * FROM user WHERE name = #{param1} AND age = #{param2}
</select>
2. 使用索引 0、1 等
也可以通过索引 0、1 等来引用参数:
<select id="selectUserByNameAndAge" resultType="User">
SELECT * FROM user WHERE name = #{0} AND age = #{1}
</select>
三、注意事项
- 可读性问题:
- 使用
param1、param2或索引0、1的方式可读性较差,容易混淆。 - 建议使用
@Param注解明确参数名称。
- 使用
- 参数顺序问题:
- 如果参数顺序发生变化,XML 文件中的引用也需要同步修改,容易出错。
- 推荐使用
@Param注解:
- 使用
@Param注解可以为参数指定名称,提高代码可读性和可维护性。
public interface UserMapper {
User selectUserByNameAndAge(@Param("name") String name, @Param("age") int age);
}
XML 文件:
<select id="selectUserByNameAndAge" resultType="User">
SELECT * FROM user WHERE name = #{name} AND age = #{age}
</select>
- 使用
四、示例代码
1. Mapper 接口
public interface UserMapper {
User selectUserByNameAndAge(String name, int age);
}
2. XML 文件
<select id="selectUserByNameAndAge" resultType="User">
SELECT * FROM user WHERE name = #{param1} AND age = #{param2}
</select>
或者:
<select id="selectUserByNameAndAge" resultType="User">
SELECT * FROM user WHERE name = #{0} AND age = #{1}
</select>
3. 测试代码
SqlSession sqlSession = sqlSessionFactory.openSession();
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
User user = mapper.selectUserByNameAndAge("John", 25);
System.out.println(user);
sqlSession.close();
- 如果 Mapper 接口方法有多个参数且没有使用
@Param注解,可以通过param1、param2或索引0、1等方式引用参数。 - 这种方式可读性较差,容易出错,推荐使用
@Param注解明确参数名称。 - 使用
@Param注解后,XML 文件中的参数引用会更加清晰和易于维护。
来源:juejin.cn/post/7475643579781333029
Java web后端转Java游戏后端
作为Java后端开发者转向游戏后端开发,虽然核心编程能力相通,但游戏开发在架构设计、协议选择、实时性处理等方面有显著差异。以下从实际工作流程角度详细说明游戏后端开发的核心要点及前后端协作流程:
一、游戏后端核心职责
- 实时通信管理
- 采用WebSocket/TCP长连接(90%以上MMO游戏选择)
- 使用Netty/Mina框架处理高并发连接(单机支撑5W+连接是基本要求)
- 心跳机制设计(15-30秒间隔,检测断线)
- 游戏逻辑处理
- 战斗计算(需在50ms内完成复杂技能伤害计算)
- 状态同步(通过Delta同步优化带宽,减少60%数据传输量)
- 定时器管理(Quartz/时间轮算法处理活动开启等)
- 数据持久化
- Redis集群缓存热点数据(玩家属性缓存命中率需>95%)
- 分库分表设计(例如按玩家ID取模分128个库)
- 异步落库机制(使用Disruptor队列实现每秒10W+写入)
二、开发全流程实战(以MMORPG为例)
阶段1:预研设计(2-4周)
- 协议设计
// 使用Protobuf定义移动协议
message PlayerMove {
int32 player_id = 1;
Vector3 position = 2; // 三维坐标
float rotation = 3; // 朝向
int64 timestamp = 4; // 客户端时间戳
}
message BattleSkill {
int32 skill_id = 1;
repeated int32 target_ids = 2; // 多目标锁定
Coordinate cast_position = 3; // 技能释放位置
}
- 架构设计
graph TD
A[Gateway] --> B[BattleServer]
A --> C[SocialServer]
B --> D[RedisCluster]
C --> E[MySQLCluster]
F[MatchService] --> B
阶段2:核心系统开发(6-8周)
- 网络层实现
// Netty WebSocket处理器示例
@ChannelHandler.Sharable
public class GameServerHandler extends SimpleChannelInboundHandler<TextWebSocketFrame> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame frame) {
ProtocolMsg msg = ProtocolParser.parse(frame.text());
switch (msg.getType()) {
case MOVE:
handleMovement(ctx, (MoveMsg)msg);
break;
case SKILL_CAST:
validateSkillCooldown((SkillMsg)msg);
broadcastToAOI(ctx.channel(), msg);
break;
}
}
}
- AOI(Area of Interest)管理
- 九宫格算法实现视野同步
- 动态调整同步频率(近距离玩家100ms/次,远距离500ms/次)
- 战斗系统
- 采用确定性帧同步(Lockstep)
- 使用FixedPoint替代浮点数运算保证一致性
三、前后端协作关键点
- 协议版本控制
- 强制版本校验:每个消息头包含协议版本号
{
"ver": "1.2.3",
"cmd": 1001,
"data": {...}
}
- 调试工具链建设
- 开发GM指令系统:
/debug latency 200 // 模拟200ms延迟
/simulate 5000 // 生成5000个机器人
- 联调流程
- 使用Wireshark抓包分析时序问题
- Unity引擎侧实现协议回放功能
- 自动化测试覆盖率要求:
- 基础协议:100%
- 战斗用例:>85%
四、性能优化实践
- JVM层面
- G1GC参数优化:
-XX:+UseG1GC -XX:MaxGCPauseMillis=50
-XX:InitiatingHeapOccupancyPercent=35
- 网络优化
- 启用Snappy压缩协议(降低30%流量)
- 合并小包(Nagle算法+50ms合并窗口)
- 数据库优化
- 玩家数据冷热分离:
- 热数据:位置、状态(Redis)
- 冷数据:成就、日志(MySQL)
- 玩家数据冷热分离:
五、上线后运维
- 监控体系
- 关键指标报警阈值设置:
- 单服延迟:>200ms
- 消息队列积压:>1000
- CPU使用率:>70%持续5分钟
- 关键指标报警阈值设置:
- 紧急处理预案
- 自动扩容规则:
if conn_count > 40000:
spin_up_new_instance()
if qps > 5000:
enable_rate_limiter()
- 自动扩容规则:
六、常见问题解决方案
问题场景:战斗不同步
排查步骤:
- 对比客户端帧日志与服务端校验日志
- 检查确定性随机数种子一致性
- 验证物理引擎的FixedUpdate时序
问题场景:登录排队
优化方案:
- 令牌桶限流算法控制进入速度
- 预计等待时间动态计算:
wait_time = current_queue_size * avg_process_time / available_instances
通过以上流程,Java后端开发者可逐步掌握游戏开发特性,重点需要转变的思维模式包括:从请求响应模式到实时状态同步、从CRUD主导到复杂逻辑计算、从分钟级延迟到毫秒级响应的要求。建议从简单的棋牌类游戏入手,逐步过渡到大型实时游戏开发。
来源:juejin.cn/post/7475292103146684479
记一次 CDN 流量被盗刷经历
先说损失,被刷了 70 多RMB,还好止损相对即时了,亏得不算多,PCDN 真可恶啊。

600多G流量,100多万次请求。
怎么发现的
先是看到鱼皮大佬发了一篇推文突发,众多网站流量被盗刷!我特么也中招了。
抱着看热闹的心情点开阅读了。。。心想,看看自己的中招没,结果就真中招了 🍉。
被盗刷资源分析
笔者在 缤纷云,七牛云,又拍云 都有存放一些图片资源。本次中招的是 缤纷云,下面是被刷的资源。

IP来源
查了几个 IP 和文章里描述的大差不差,都是来自山西联通的请求。

大小流量计算
按日志时间算的话,QPS 大概在 20 左右,单文件 632 K,1分钟大概就760MB ,1小时约 45G 左右。
看了几天前的日志,都是 1 小时刷 40G 就停下,从 9 点左右开始,刷到 12 点。
| 07-09 | 07-08 |
|---|---|
 |  |
但是 10 号的就变多了,60-70 GB 1次了。也是这天晚上才开始做的反制,不知道是不是加策略的时候影响到它计算流量大小了 😝。

反制手段
Referer 限制
通过观察这些资源的请求头,发现 Referer 和请求资源一致,通常情况下,不应该这样,应该是笔者的博客地址https://sugarat.top。

于是第一次就限制了 Referer 头不能为空,同时将 cdn.bitiful.sugarat.top 的来源都拉黑。
这个办法还比较好使,后面的请求都给 403 了。

但这个还是临时解决方案,在 V 站上看到讨论,说资源是人为筛选的,意味着 Referer 换个资源还是会发生变化。
IP 限制
有 GitHub 仓库 unclemcz/ban-pcdn-ip 收集了此次恶意刷流量的 IP。
CDN 平台一般支持按 IP 或 IP 段屏蔽请求(虽然后者可能会屏蔽一些正常请求),可以将 IP 段配置到平台上,这样就能限制掉这些 IP 的请求。
缤纷云上这块限制还比较弱,我就直接把缤纷云的 CDN 直接关了,七牛云和又拍云上都加上了 IP 和 地域运营商的限制,等这阵风头过去再恢复。
| 七牛云 | 又拍云 |
|---|---|
 |  |
限速
限制单 IP 的QPS和峰值流量。

但是这个只能避免说让它刷得慢一点,还是不治本。

最后
用了CDN的话,日常还是多看看,能加阈值控制的平台优先加上,常规的访问控制防盗链的啥的安排上。

来源:juejin.cn/post/7390678994998526003
新来的总监,把闭包讲得那叫一个透彻
😃文章首发于公众号[精益码农]。
闭包作为前端面试的必考题目,常让1-3年工作经验的Javascripter感到困惑,我的主力语言C#/GO均有闭包。
1. 闭包:关键点在于函数是否捕获了其外部作用域的变量
闭包的形成: 定义函数时, 函数引用了其外部作用域的变量, 之后就形成了闭包。
闭包的结果: 引用的变量和定义的函数都会一同存在(即使已经脱离了函数定义/引用的变量的作用域),一直到闭包被消灭。
public static Action Closure()
{
var x = 1;
Action action= () =>
{
var y = 1;
var result = x + y;
Console.WriteLine(result);
x++;
};
return action;
}
public static void Main() {
var a=Closure();
a();
a();
}
// 调用函数输出
2
3
委托action是一个函数,它使用了“x”这个外部作用域的变量(x变量不是函数内局部变量),变量引用将被捕获形成闭包。
即使action被返回了(即使“x”已经脱离了它被引用时的作用域环境(Closure)),但是两次执行能输出2,3 说明它脱离原引用环境仍然能用。
当你在代码调试器(debugger)里观察“action”时,可以看到一个Target属性,里面封装了捕获的x变量:

实际上,委托,匿名函数和lambda都是继承自Delegate类,
Delegate不允许开发者直接使用,只有编译器才能使用, 也就是说delegate Action都是语法糖。
- Method:MethodInfo反射类型- 方法执行体
- Target:当前委托执行的对象,这些语法糖由编译器生成了继承自Delegate类型的对象,包含了捕获的自由变量。
再给一个反例:
public class Program
{
private static int x = 1; // 静态字段
public static void Main()
{
var action = NoClosure();
action();
action();
}
public static Action NoClosure(){
Action action=()=>{
var y =1;
var sum = x+y;
Console.WriteLine($"sum = { sum }");
x++;
};
return action;
}
}
x 是静态字段,在程序中有独立的存储区域, 不在线程的函数堆栈区,不属于某个特定的作用域。
匿名函数使用了 x,但没有捕获外部作用域的变量,因此不构成闭包, Target属性对象无捕获的字段。

从编程设计的角度:闭包开创了除全局变量传值, 函数参数传值之外的第三种变量使用方式。
2. 闭包的形成时机和效果
闭包是词法闭包的简称,维基百科上是这样定义的:
“在计算机科学中,闭包是在词法环境中绑定自由变量的一等函数”。
闭包的形成时机:
- 一等函数
- 外部作用域变量
闭包的形态:
会捕获闭包函数内引用的外部作用域变量, 一直持有,直到闭包函数不再使用被销毁。
内部实现是形成了一个对象(包含执行函数和捕获的变量,参考Target对象), 只有形成堆内存,才有后续闭包销毁的行为,当闭包这个对象不再被引用时,闭包被GC清理。
闭包的作用周期:
离不开作用域这个概念,函数理所当然管控了函数内的局部变量作用域,但当它引用了外部有作用域的变量时, 就形成了闭包函数。
当闭包(例如一个委托或 lambda 表达式)不再被任何变量、对象或事件持有引用时,它就变成了“不可达”对象, 闭包被gc清理,其实就是堆内存被清理。
2.1 一等函数
一等函数很容易理解,就是在各语言, 函数被认为是某类数据类型, 定义函数就成了定义变量, 函数也可以像变量一样被传递。
很明显,在C#中我们常使用的匿名函数、lambda表达式都是一等函数。
Func<string,string> myFunc = delegate(string var1)
{
return "some value";
};
Func<string,string> myFunc = var1 => "some value";
string myVar = myFunc("something");
2.2 自由变量
在函数中被引用的外部作用域变量, 注意, 这个变量是外部有作用域的变量,也就说排除全局变量(这些变量在程序的独立区域, 不属于任何作用域)。
public void Test()
{
var myVar = "this is good";
Func<string,string> myFunc = delegate(string var1)
{
return var1 + myVar;
};
}
上面这个示例,myFunc形成了闭包,捕获了myVar这个外部作用域的变量;
即使Test函数返回了委托myFunc(脱离了定义myVar变量的作用域),闭包依然持有myVar的变量引用,
注意,引用变量,并不是使用当时变量的副本值。
我们再回过头来看结合了线程调度的闭包面试题。
3. 闭包函数关联线程调度: 依次打印连续的数字
static void Closure1()
{
for (int i = 0; i < 10; i++)
{
Task.Run(()=> Console.WriteLine(i));
}
}
每次输出数字不固定
并不是预期的 0.1.2.3.4.5.6.7.8.9
首先形成了闭包函数()=> Console.WriteLine(i), 捕获了外部有作用域变量i的引用, 此处捕获的变量i相对于函数是全局变量。
但是Task调度闭包函数的时机不确定, 所以打印的是被调度时引用的变量i值。
数字符合但乱序:为每个闭包函数绑定独立变量
循环内增加局部变量, 解绑全局变量 (或者可以换成foreach,foreach相当于内部给你整了一个局部变量)。

能输出乱序的0,1,2,3,4,5,6,7,8,9
因为每次循环内产生的闭包函数捕获了对应的局部变量j,这样每个任务执行环境均独立维护了一个变量j, 这个j不是全局变量, 但是由于Task启动时机依然不确定,故是乱序。

数字符合且有序
核心是解决 Task调度问题。
思路是:一个共享变量,每个任务打印该变量自增的一个阶段,但是该自增不允许被打断。
public static void Main(string[] args)
{
var s =0;
var lo = new Program();
for (int i = 0; i < 10; i++)
{
Task.Run(()=>
{
lock(lo)
{
Console.WriteLine(s); // 依然形成了闭包函数, 之后闭包函数被线程调度
s++;
}
});
}
Thread.Sleep(2000);
} // 上面是一个明显的锁争用
3.Golang闭包的应用
gin 框架中中间件的默认形态是:
package middleware
func AuthenticationMiddleware(c *gin.Context) {
......
}
// Use方法的参数签名是这样: type HandlerFunc func(*Context), 不支持入参
router.Use(middleware.AuthenticationMiddleware)
实际实践上我们又需要给中间件传参, 闭包提供了这一能力。
func Authentication2Middleware(log *zap.Logger) gin.HandlerFunc {
return func(c *gin.Context) {
... 这里面可以利用log 参数。
}
}
var logger *zap.Logger
api.Use(middleware.Authentication2Middleware(logger))
总结
本文屏蔽语言差异,理清了[闭包]的概念核心: 函数引用了其外部作用域的变量,
核心特征:一等函数、自由变量,核心结果: 即使脱离了原捕获变量的原作用域,闭包函数依然持有该变量引用。
不仅能帮助我们应对多语种有关闭包的面试题, 也帮助我们了解[闭包]在通用语言中的设计初衷。
另外我们通过C# 调试器巩固了Delegate 抽象类,这是lambda表达式,委托,匿名函数的底层抽象数据结构类,包含两个重要属性 Method Target,分别表征了方法执行体、当前委托作用的对象,
可想而知,其他语言也是通过这个机制捕获闭包当中的自由变量。
来源:juejin.cn/post/7474982751365038106
Java利用Deepseek进行项目代码审查
一、为什么需要AI代码审查?
写代码就像做饭,即使是最有经验的厨师(程序员),也难免会忘记关火(资源未释放)、放错调料(逻辑错误)或者切到手(空指针异常)。Deepseek就像一位24小时待命的厨房监理,能帮我们实时发现这些"安全隐患"。

写代码就像做饭,即使是最有经验的厨师(程序员),也难免会忘记关火(资源未释放)、放错调料(逻辑错误)或者切到手(空指针异常)。Deepseek就像一位24小时待命的厨房监理,能帮我们实时发现这些"安全隐患"。
二、环境准备(5分钟搞定)
- 安装Deepseek插件(以VSCode为例):
- 插件市场搜索"Deepseek Code Review"
- 点击安装(就像安装手机APP一样简单)

- Java项目配置:
<dependency>
<groupId>com.deepseekgroupId>
<artifactId>code-analyzerartifactId>
<version>1.3.0version>
dependency>
- 安装Deepseek插件(以VSCode为例):
- 插件市场搜索"Deepseek Code Review"
- 点击安装(就像安装手机APP一样简单)
- Java项目配置:
<dependency>
<groupId>com.deepseekgroupId>
<artifactId>code-analyzerartifactId>
<version>1.3.0version>
dependency>
三、真实案例:用户管理系统漏洞检测
原始问题代码:
public class UserService {
// 漏洞1:未处理空指针
public String getUserRole(String userId) {
return UserDB.query(userId).getRole();
}
// 漏洞2:资源未关闭
public void exportUsers() {
FileOutputStream fos = new FileOutputStream("users.csv");
fos.write(getAllUsers().getBytes());
}
// 漏洞3:SQL注入风险
public void deleteUser(String input) {
Statement stmt = conn.createStatement();
stmt.execute("DELETE FROM users WHERE id = " + input);
}
}
public class UserService {
// 漏洞1:未处理空指针
public String getUserRole(String userId) {
return UserDB.query(userId).getRole();
}
// 漏洞2:资源未关闭
public void exportUsers() {
FileOutputStream fos = new FileOutputStream("users.csv");
fos.write(getAllUsers().getBytes());
}
// 漏洞3:SQL注入风险
public void deleteUser(String input) {
Statement stmt = conn.createStatement();
stmt.execute("DELETE FROM users WHERE id = " + input);
}
}
使用Deepseek审查后:

智能修复建议:
- 空指针防护 → 建议添加Optional处理
- 流资源 → 推荐try-with-resources语法
- SQL注入 → 提示改用PreparedStatement
- 空指针防护 → 建议添加Optional处理
- 流资源 → 推荐try-with-resources语法
- SQL注入 → 提示改用PreparedStatement
修正后的代码:
public class UserService {
// 修复1:Optional处理空指针
public String getUserRole(String userId) {
return Optional.ofNullable(UserDB.query(userId))
.map(User::getRole)
.orElse("guest");
}
// 修复2:自动资源管理
public void exportUsers() {
try (FileOutputStream fos = new FileOutputStream("users.csv")) {
fos.write(getAllUsers().getBytes());
}
}
// 修复3:预编译防注入
public void deleteUser(String input) {
PreparedStatement pstmt = conn.prepareStatement(
"DELETE FROM users WHERE id = ?");
pstmt.setString(1, input);
pstmt.executeUpdate();
}
}
public class UserService {
// 修复1:Optional处理空指针
public String getUserRole(String userId) {
return Optional.ofNullable(UserDB.query(userId))
.map(User::getRole)
.orElse("guest");
}
// 修复2:自动资源管理
public void exportUsers() {
try (FileOutputStream fos = new FileOutputStream("users.csv")) {
fos.write(getAllUsers().getBytes());
}
}
// 修复3:预编译防注入
public void deleteUser(String input) {
PreparedStatement pstmt = conn.prepareStatement(
"DELETE FROM users WHERE id = ?");
pstmt.setString(1, input);
pstmt.executeUpdate();
}
}
四、实现原理揭秘
Deepseek的代码审查就像"X光扫描仪",通过以下三步工作:
- 模式识别:比对数千万个代码样本
- 就像老师批改作业时发现常见错误
- 上下文理解:分析代码的"人际关系"
- 数据库连接有没有"成对出现"(打开/关闭)
- 敏感操作有没有"保镖"(权限校验)
- 智能推理:预测代码的"未来"
- 这个变量走到这里会不会变成null?
- 这个循环会不会变成"无限列车"?
五、进阶使用技巧
- 自定义审查规则(配置文件示例):
rules:
security:
sql_injection: error
performance:
loop_complexity: warning
style:
var_naming: info
- 自定义审查规则(配置文件示例):
rules:
security:
sql_injection: error
performance:
loop_complexity: warning
style:
var_naming: info
2. 与CI/CD集成(GitHub Action示例):
- name: Deepseek Code Review
uses: deepseek-ai/code-review-action@v2
with:
severity_level: warning
fail_on: error
六、开发者常见疑问
Q:AI会不会误判我的代码?
A:就像导航偶尔会绕路,Deepseek给出的是"建议"而非"判决",最终决策权在你手中
Q:处理历史遗留项目要多久?
A:10万行代码项目约需3-5分钟,支持增量扫描
七、效果对比数据
| 指标 | 人工审查 | Deepseek+人工 |
|---|---|---|
| 平均耗时 | 4小时 | 30分钟 |
| 漏洞发现率 | 78% | 95% |
| 误报率 | 5% | 12% |
| 知识库更新速度 | 季度 | 实时 |
来源:juejin.cn/post/7473799336675639308
再见Typora,这款大小不到3M的Markdown编辑器,满足你的所有幻想!
Typora 是一款广受欢迎的 Markdown 编辑器,以其所见即所得的编辑模式和优雅的界面而闻名,长期以来是许多 Markdown 用户的首选。然而,从 2021 年起,Typora 不再免费,采用一次性付费授权模式。虽然费用不高,但对于轻量使用者或预算有限的用户可能并不友好。

今天来推荐一款开源替代品,一款更加轻量化、注重隐私且完全免费的 Markdown 编辑器,专为 macOS 用户开发。
项目介绍
MarkEdit 是一款轻量级且高效的 Markdown 编辑器,专为 macOS 用户设计,安装包大小不到 3 MB。它以简洁的设计和流畅的性能,成为技术写作、笔记记录、博客创作以及项目文档编辑的理想工具。无论是编写技术文档、撰写博客文章,还是编辑 README 文件,MarkEdit 都能以快速响应和便捷操作帮助用户专注于内容创作。

根据官方介绍,MarkEdit 免费的原因如下:
MarkEdit 是完全免费和开源的,没有任何广告或其他服务。我们之所以发布它,是因为我们喜欢它,我们不期望从中获得任何收入。
功能特性
MarkEdit 的核心功能围绕 Markdown 写作展开,注重实用与高效,以下是其主要特性:
- 实时语法高亮:清晰呈现 Markdown 的结构,让文档层次分明。
- 多种主题:提供不同的配色方案,总有一种适合你。
- 分屏实时预览:支持所见即所得的写作体验,左侧编辑,右侧实时渲染。
- 文件树视图:适合多文件项目管理,方便在项目间快速切换。
- 文档导出:支持将 Markdown 文件导出为 PDF 或 HTML 格式,方便分享和发布。
- CodeMirror 插件支持:通过插件扩展功能,满足更多 Markdown 使用需求。
- ......
MarkEdit 的特点让它能胜任多种写作场合:
- 技术文档:帮助开发者快速记录项目相关文档。
- 博客创作:支持实时预览,让博客排版更直观。
- 个人笔记:轻量且启动迅速,适合日常记录。
- 项目文档:文件管理功能让多文件项目的编辑更加高效。
效果展示
多种主题风格,总有一种适合你:


实时预览,让博客排版更直观:

设置界面,清晰直观:

安装方法
方法 1:安装包下载
找到 MarkEdit 的最新版本安装包下载使用即可,地址:github.com/MarkEdit-ap… 。
方法 2:通过 Homebrew
在终端中运行相关命令即可完成安装。
brew install markedit
注意:MarkEdit 支持 macOS Sonoma 和 macOS Sequoia, 历史兼容版本包括 macOS 12 和 macOS 13。
总结
MarkEdit 是一款专注于 Markdown 写作的 macOS 原生编辑器,以简洁、高效、隐私友好为核心设计理念。无论是日常写作还是处理复杂文档,它都能提供流畅的体验和强大的功能。对于追求高效写作的 macOS 用户来说,MarkEdit 是一个不可多得的优秀工具。
项目地址:github.com/MarkEdit-ap… 。
来源:juejin.cn/post/7456685819047919651
前端哪有什么设计模式
前言
- 常网IT源码上线啦!
- 本篇录入吊打面试官专栏,希望能祝君拿下Offer一臂之力,各位看官感兴趣可移步🚶。
- 有人说面试造火箭,进去拧螺丝;其实个人觉得问的问题是项目中涉及的点 || 热门的技术栈都是很好的面试体验,不要是旁门左道冷门的知识,实际上并不会用到的。
- 接下来想分享一些自己在项目中遇到的技术选型以及问题场景。
你生命的前半辈子或许属于别人,活在别人的认为里。那把后半辈子还给你自己,去追随你内在的声音。

一、前言
之前在讨论设计模式、算法的时候,一个后端组长冷嘲热讽的说:前端哪有什么设计模式、算法,就好像只有后端语言有一样,至今还记得那不屑的眼神。
今天想起来,就随便列几个,给这位眼里前端无设计模式的人,睁眼看世界。
二、观察者模式 (Observer Pattern)
观察者模式的核心是当数据发生变化时,自动通知并更新相关的视图。在 Vue 中,这通过其响应式系统实现。
Vue 2.x:Object.defineProperty
在 Vue 2.x 中,响应式系统是通过 Object.defineProperty 实现的。每当访问某个对象的属性时,getter 会被触发;当设置属性时,setter 会触发,从而实现数据更新时视图的重新渲染。
源码(简化版):
function defineReactive(obj, key, val) {
// 创建一个 dep 实例,用于收集依赖
const dep = new Dep();
Object.defineProperty(obj, key, {
get() {
// 当访问属性时,触发 getter,并把当前 watcher 依赖收集到 dep 中
if (Dep.target) {
dep.addDep(Dep.target);
}
return val;
},
set(newVal) {
if (newVal !== val) {
val = newVal;
dep.notify(); // 数据更新时,通知所有依赖重新渲染
}
}
});
}
Dep类:它管理依赖,addDep用于添加依赖,notify用于通知所有依赖更新。
class Dep {
constructor() {
this.deps = [];
}
addDep(dep) {
this.deps.push(dep);
}
notify() {
this.deps.forEach(dep => dep.update());
}
}
- 依赖收集:当 Vue 组件渲染时,会创建一个
watcher对象,表示一个视图的更新需求。当视图渲染过程中访问数据时,getter会触发,并将watcher添加到dep的依赖列表中。
Vue 3.x:Proxy
Vue 3.x 使用了 Proxy 来替代 Object.defineProperty,从而实现了更高效的响应式机制,支持深度代理。
源码(简化版):
function reactive(target) {
const handler = {
get(target, key) {
// 依赖收集:当访问某个属性时,触发 getter,收集依赖
track(target, key);
return target[key];
},
set(target, key, value) {
// 数据更新时,通知相关的视图更新
target[key] = value;
trigger(target, key);
return true;
}
};
return new Proxy(target, handler);
}
track:收集依赖,确保只有相关组件更新。trigger:当数据发生变化时,通知所有依赖重新渲染。
三、发布/订阅模式 (Publish/Subscribe Pattern)
发布/订阅模式通过中央事件总线(Event Bus)实现不同组件间的解耦,Vue 2.x 中,组件间的通信就是基于这种模式实现的。
Vue 2.x:事件总线(Event Bus)
事件总线就是一个中央的事件处理器,Vue 实例可以充当事件总线,用来处理不同组件之间的消息传递。
// 创建一个 Vue 实例作为事件总线
const EventBus = new Vue();
// 组件 A 发布事件
EventBus.$emit('message', 'Hello from A');
// 组件 B 订阅事件
EventBus.$on('message', (msg) => {
console.log(msg); // 输出 'Hello from A'
});
$emit:用于发布事件。$on:用于订阅事件。$off:用于取消订阅事件。
四、工厂模式 (Factory Pattern)
工厂模式通过一个函数生成对象或实例,Vue 的组件化机制和动态组件加载就是通过工厂模式来实现的。
Vue 的 render 函数和 functional 组件支持动态生成组件实例。例如,functional 组件本质上是一个工厂函数,通过给定的 props 返回一个 VNode。
Vue.component('dynamic-component', {
functional: true,
render(h, context) {
// 工厂模式:根据传入的 props 创建不同的 VNode
return h(context.props.type);
}
});
functional组件:它没有实例,所有的逻辑都是在render函数中处理,返回的 VNode 就是组件的“产物”。
五、单例模式 (Singleton Pattern)
单例模式确保某个类只有一个实例,Vue 实例就是全局唯一的。
在 Vue 中,全局的 Vue 构造函数本身就是一个单例对象,通常只会创建一个 Vue 实例,用于管理应用的生命周期和全局配置。
const app = new Vue({
data: {
message: 'Hello, Vue!'
}
});
- 单例保证:整个应用只有一个 Vue 实例,所有全局的配置(如
Vue.config)都是共享的。
六、模板方法模式 (Template Method Pattern)
模板方法模式定义了一个操作中的算法框架,而将一些步骤延迟到子类中。Vue 的生命周期钩子就是一个模板方法模式的实现。
Vue 定义了一系列生命周期钩子(如 created、mounted、updated 等),它们实现了组件从创建到销毁的完整过程。开发者可以在这些钩子中插入自定义逻辑。
Vue.component('my-component', {
data() {
return {
message: 'Hello, 泽!'
};
},
created() {
console.log('Component created');
},
mounted() {
console.log('Component mounted');
},
template: '<div>{{ message }}</div>'
});
Vue 组件的生命周期钩子实现了模板方法模式的核心思想,开发者可以根据需要重写生命周期钩子,而 Vue 保证生命周期的流程和框架。
七、策略模式 (Strategy Pattern)
策略模式通过定义一系列算法,将它们封装起来,使它们可以相互替换。Vue 的 计算属性(computed) 和 方法(methods) 可以看作是策略模式的应用。
计算属性允许我们定义动态的属性,其值是基于其他属性的计算结果。Vue 会根据依赖关系缓存计算结果,只有在依赖的属性发生变化时,计算属性才会重新计算。
new Vue({
data() {
return {
num1: 10,
num2: 20
};
},
computed: {
sum() {
return this.num1 + this.num2;
}
}
});
八、装饰器模式 (Decorator Pattern)
装饰器模式允许动态地给对象添加功能,而无需改变其结构。在 Vue 中,指令就是一种装饰器模式的应用,它通过指令来动态地改变元素的行为。
<div v-bind:class="className"></div>
<div v-if="isVisible">谁的疯太谍</div>
这些指令动态地修改 DOM 元素的行为,类似于装饰器在不修改对象结构的情况下,动态地增强其功能。
九、代理模式 (Proxy Pattern)
代理模式通过创建一个代理对象来控制对目标对象的访问。在 Vue 3.x 中,响应式系统就是通过 Proxy 来代理对象的访问。
vue3
const state = reactive({
count: 0
});
state.count++; // 会触发依赖更新
reactive:使用 Proxy 对对象进行代理,当对象的属性被访问或修改时,都会触发代理器的 get 和 set 操作。
function reactive(target) {
const handler = {
get(target, key) {
// 依赖收集:当访问某个属性时,触发 getter,收集依赖
track(target, key);
return target[key];
},
set(target, key, value) {
// 数据更新时,触发依赖更新
target[key] = value;
trigger(target, key);
return true;
}
};
return new Proxy(target, handler);
}
track:当读取目标对象的属性时,收集依赖,这通常涉及到将当前的watcher加入到依赖列表中。trigger:当对象的属性发生改变时,通知所有相关的依赖(如组件)更新。
这个 Proxy 机制使得 Vue 可以动态地观察和更新对象的变化,比 Object.defineProperty 更具灵活性。
十、适配器模式 (Adapter Pattern)
适配器模式用于将一个类的接口转换成客户端期望的另一个接口,使得原本不兼容的接口可以一起工作。Vue 的插槽(Slots)和组件的跨平台支持某种程度上借用了适配器模式的思想。
Vue 插槽机制
Vue 的插槽机制是通过提供一个适配层,将父组件传入的内容插入到子组件的指定位置。开发者可以使用具名插槽、作用域插槽等方式,实现灵活的插槽传递。
<template>
<child-component>
<template #header>
<h1>This is the header</h1>
</template>
<p>This is the default content</p>
</child-component>
</template>
父组件通过 #header 插槽插入了一个标题内容,而 child-component 会将其插入到适当的位置。这里,插槽充当了一个适配器,允许父组件插入的内容与子组件的内容结构灵活匹配。
十全十美
至此撒花~
后记
我相信技术不分界,不深入了解,就不要轻易断言。
一个圆,有了一个缺口,不知道的东西就更多了。
但是没有缺口,不知道的东西就少了。
这也就是为什么,知道得越多,不知道的就越多。
谢谢!
最后,祝君能拿下满意的offer。
我是Dignity_呱,来交个朋友呀,有朋自远方来,不亦乐乎呀!深夜末班车
👍 如果对您有帮助,您的点赞是我前进的润滑剂。
以往推荐
原文链接
来源:juejin.cn/post/7444215159289102347
再见 XShell!一款万能通用的终端工具,用完爱不释手!
作为一名后端开发,我们经常需要使用终端工具来管理Linux服务器。最近发现一款比Xshell更好用终端工具XPipe,能支持SSH、Docker、K8S等多种环境,还具有强大的文件管理工具,分享给大家!
XPipe简介
XPipe是一款全新的终端管理工具,具有强大的文件管理功能,目前在Github上已有4.8k+Star。它可以基于你本地安装的命令行工具(例如PowerShell)来执行远程命令,反应速度非常快。如果你有使用 ssh、docker、kubectl 等命令行工具来管理服务器的需求,使用它就可以了。
XPipe具有如下特性:
- 连接中心:能轻松实现所有类型的远程连接,支持SSH、Docker、Podman、Kubernetes、Powershell等环境。
- 强大的文件管理功能:具有对远程系统专门优化的文件管理功能。
- 多种命令行环境支持:包括bash、zsh、cmd、PowerShell等。
- 多功能脚本系统:可以方便地管理可重用脚本。
- 密码保险箱:所有远程连接账户均完全存储于您本地系统中的一个加密安全的存储库中。
下面是XPipe使用过程中的截图,界面还是挺炫酷的!

这或许是一个对你有用的开源项目,mall项目是一套基于
SpringBoot3+ Vue 的电商系统(Github标星60K),后端支持多模块和2024最新微服务架构,采用Docker和K8S部署。包括前台商城项目和后台管理系统,能支持完整的订单流程!涵盖商品、订单、购物车、权限、优惠券、会员、支付等功能!
- Boot项目:github.com/macrozheng/…
- Cloud项目:github.com/macrozheng/…
- 教程网站:http://www.macrozheng.com
项目演示:

使用
- 首先去XPipe的Release页面下载它的安装包,我这里下载的是
Portable版本,解压即可使用,地址:github.com/xpipe-io/xp…

- 下载完成后进行解压,解压后双击
xpiped.exe即可使用;

- 这里我们先进行一些设置,将语言设置成
中文,然后设置下主题,个人比较喜欢黑色主题;

- 接下来新建一个SSH连接,输入服务器地址后,选择
添加预定义身份;

- 这个预定义身份相当于一个可重用的Linux访问账户;

- 然后输入连接名称,点击完成即可创建连接;

- 我们可以发现XPipe能自动发现服务器器上的Docker环境并创建连接选项,如果你安装了K8S环境的话,也是可以发现到的;

- 然后我们单击下
Linux-local这个连接,就可以通过本地命令行工具来管理Linux服务器了;

- 如果你想连接到某个Docker容器的话,直接点击对应容器即可连接,这里以mysql为例;

- 选中左侧远程服务器,点击右侧的
文件浏览器按钮可以直接管理远程服务器上的文件,非常方便;

- 在
所有脚本功能中,可以存储我们的可重用脚本;

- 在
所有身份中存储着我们的账号密码,之前创建的Linux root账户在这里可以进行修改。

总结
今天给大家分享了一款好用的终端工具XPipe,界面炫酷功能强大,它的文件管理功能确实惊艳到我了。而且它可以用本地命令行工具来执行SSH命令,对比一些套壳的跨平台终端工具,反应速度还是非常快的!
项目地址
来源:juejin.cn/post/7475662844789637160
Java 泛型中的通配符 T,E,K,V,?有去搞清楚吗?
前言
不久前,被人问到Java 泛型中的通配符 T,E,K,V,? 是什么?有什么用?这不经让我有些回忆起该开始学习Java那段日子,那是对泛型什么的其实有些迷迷糊糊的,学的不这么样,是在做项目的过程中,渐渐有又看到别人的代码、在看源码的时候老是遇见,之后就专门去了解学习,才对这几个通配符 T,E,K,V,?有所了解。
不久前,被人问到Java 泛型中的通配符 T,E,K,V,? 是什么?有什么用?这不经让我有些回忆起该开始学习Java那段日子,那是对泛型什么的其实有些迷迷糊糊的,学的不这么样,是在做项目的过程中,渐渐有又看到别人的代码、在看源码的时候老是遇见,之后就专门去了解学习,才对这几个通配符 T,E,K,V,?有所了解。
泛型有什么用?
在介绍这几个通配符之前,我们先介绍介绍泛型,看看泛型带给我们的好处。
Java泛型是JDK5中引入的一个新特性,泛型提供了编译是类型安全检测机制,这个机制允许开发者在编译是检测非法类型。泛型的本质就是参数化类型,就是在编译时对输入的参数指定一个数据类型。
- 类型安全:编译是检查类型是否匹配,避免了ClassCastexception的发生。
// 非泛型写法(存在类型转换风险)
List list1 = new ArrayList();
list1.add("a");
Integer num = (Long) list1.get(0); // 运行时抛出 ClassCastException
// 泛型写法(编译时检查类型)
List list2 = new ArrayList<>();
// list.add(1); // 编译报错
list2.add("a");
String str = list2.get(0); // 无需强制转换
- 消除代码强制类型转换:减少了一些类型转换操作。
// 非泛型写法
Map map1 = new HashMap();
map1.put("user", new User());
User user1 = (User) map1.get("user");
// 泛型写法
Map map2 = new HashMap<>();
map2.put("user", new User());
// 自动转换
User user2 = map2.get("user");
在介绍这几个通配符之前,我们先介绍介绍泛型,看看泛型带给我们的好处。
Java泛型是JDK5中引入的一个新特性,泛型提供了编译是类型安全检测机制,这个机制允许开发者在编译是检测非法类型。泛型的本质就是参数化类型,就是在编译时对输入的参数指定一个数据类型。
- 类型安全:编译是检查类型是否匹配,避免了ClassCastexception的发生。
// 非泛型写法(存在类型转换风险)
List list1 = new ArrayList();
list1.add("a");
Integer num = (Long) list1.get(0); // 运行时抛出 ClassCastException
// 泛型写法(编译时检查类型)
Listlist2 = new ArrayList<>();
// list.add(1); // 编译报错
list2.add("a");
String str = list2.get(0); // 无需强制转换
- 消除代码强制类型转换:减少了一些类型转换操作。
// 非泛型写法
Map map1 = new HashMap();
map1.put("user", new User());
User user1 = (User) map1.get("user");
// 泛型写法
Map map2 = new HashMap<>();
map2.put("user", new User());
// 自动转换
User user2 = map2.get("user");
3.代码复用:可以支持多种数据类型,不要重复编写代码,例如:我们常用的统一响应结果类。
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Result {
/**
* 响应状态码
*/
private int code;
/**
* 响应信息
*/
private String message;
/**
* 响应数据
*/
private T data;
/**
* 时间戳
*/
private long timestamp;
其他代码省略...
- 增强可读性:通过类型参数就直接能看出要填入什么类型。
List list = new ArrayList<>();
泛型里的通配符
我们在使用泛型的时候,经常会使用或者看见多种不同的通配符,常见的 T,E,K,V,?这几种,相信大家一定不陌生,但是真的问你他们有什么作用?有什么区别时,很多人应该是不能很好的介绍它们的,接下来我就来给大家介绍介绍。
T,E,K,V
- T(Type) T表示任意类型参数,我们举个例子
pubile class A{
prvate T t;
//其他省略...
}
//创建一个不带泛型参数的A
A a = new A();
a.set(new B());
B b = (B) a.get();//需要进行强制类型转换
//创建一个带泛型参数的A
A a = new A();
a.set(new B());
B b = a.get();
- E(Element) E表示集合中的元素类型
List list = new ArrayList<>();
- K(Key) K表示映射的键的数据类型
Map map = new HashMap<>();
- V(Value) V表示映射的值的数据类型
Map map = new HashMap<>();
- T(Type) T表示任意类型参数,我们举个例子
pubile class A{
prvate T t;
//其他省略...
}
//创建一个不带泛型参数的A
A a = new A();
a.set(new B());
B b = (B) a.get();//需要进行强制类型转换
//创建一个带泛型参数的A
A a = new A();
a.set(new B());
B b = a.get();
List list = new ArrayList<>();
Map map = new HashMap<>();
Map map = new HashMap<>();
通配符 ?
- 无界通配符 表示未知类型,接收任意类型
// 使用无界通配符处理任意类型的查询结果
public void logQueryResult(List resultList) {
resultList.forEach(obj -> log.info("Result: {}", obj));
}
- 上界通配符 表示类型是T或者是子类
// 使用上界通配符读取缓存
public extends Serializable> T getCache(String key, Class clazz) {
Object value = redisTemplate.opsForValue().get(key);
return clazz.cast(value);
}
- 下界通配符 表示类型是T或者是父类
// 使用下界通配符写入缓存
public void setCache(String key, super Serializable> value) {
redisTemplate.opsForValue().set(key, value);
}
综合示例:
import java.util.ArrayList;
import java.util.List;
public class Demo {
//实体类
class Animal {
void eat() {
System.out.println("Animal is eating");
}
}
class Dog extends Animal {
@Override
void eat() {
System.out.println("Dog is eating");
}
}
class Husky extends Dog {
@Override
void eat() {
System.out.println("Husky is eating");
}
}
/**
* 无界通配符
*/
// 只能读取元素,不能写入(除null外)
public static void printAllElements(List list) {
for (Object obj : list) {
System.out.println(obj);
}
// list.add("test"); // 编译错误!无法写入具体类型
list.add(null); // 唯一允许的写入操作
}
/**
* 上界通配符
*/
// 安全读取为Animal,但不能写入(生产者场景)
public static void processAnimals(List animals) {
for (Animal animal : animals) {
animal.eat();
}
// animals.add(new Dog()); // 编译错误!无法确定具体子类型
}
/**
* 下界通配符
*/
// 安全写入Dog,读取需要强制转换(消费者场景)
public static void addDogs(Listsuper Dog> dogList) {
dogList.add(new Dog());
dogList.add(new Husky()); // Husky是Dog子类
// dogList.add(new Animal()); // 编译错误!Animal不是Dog的超类
Object obj = dogList.get(0); // 读取只能为Object
if (obj instanceof Dog) {
Dog dog = (Dog) obj; // 需要显式类型转换
}
}
public static void main(String[] args) {
// 测试无界通配符
List strings = List.of("A", "B", "C");
printAllElements(strings);
List integers = List.of(1, 2, 3);
printAllElements(integers);
// 测试上界通配符
List dogs = new ArrayList<>();
dogs.add(new Dog());
processAnimals(dogs);
List huskies = new ArrayList<>();
huskies.add(new Husky());
processAnimals(huskies);
// 测试下界通配符
List animals = new ArrayList<>();
addDogs(animals);
System.out.println(animals);
List
- 无界通配符 表示未知类型,接收任意类型
// 使用无界通配符处理任意类型的查询结果
public void logQueryResult(List resultList) {
resultList.forEach(obj -> log.info("Result: {}", obj));
}
// 使用上界通配符读取缓存
public extends Serializable> T getCache(String key, Class clazz) {
Object value = redisTemplate.opsForValue().get(key);
return clazz.cast(value);
}
// 使用下界通配符写入缓存
public void setCache(String key, super Serializable> value) {
redisTemplate.opsForValue().set(key, value);
}
综合示例:
import java.util.ArrayList;
import java.util.List;
public class Demo {
//实体类
class Animal {
void eat() {
System.out.println("Animal is eating");
}
}
class Dog extends Animal {
@Override
void eat() {
System.out.println("Dog is eating");
}
}
class Husky extends Dog {
@Override
void eat() {
System.out.println("Husky is eating");
}
}
/**
* 无界通配符
*/
// 只能读取元素,不能写入(除null外)
public static void printAllElements(List list) {
for (Object obj : list) {
System.out.println(obj);
}
// list.add("test"); // 编译错误!无法写入具体类型
list.add(null); // 唯一允许的写入操作
}
/**
* 上界通配符
*/
// 安全读取为Animal,但不能写入(生产者场景)
public static void processAnimals(List animals) {
for (Animal animal : animals) {
animal.eat();
}
// animals.add(new Dog()); // 编译错误!无法确定具体子类型
}
/**
* 下界通配符
*/
// 安全写入Dog,读取需要强制转换(消费者场景)
public static void addDogs(Listsuper Dog> dogList) {
dogList.add(new Dog());
dogList.add(new Husky()); // Husky是Dog子类
// dogList.add(new Animal()); // 编译错误!Animal不是Dog的超类
Object obj = dogList.get(0); // 读取只能为Object
if (obj instanceof Dog) {
Dog dog = (Dog) obj; // 需要显式类型转换
}
}
public static void main(String[] args) {
// 测试无界通配符
List strings = List.of("A", "B", "C");
printAllElements(strings);
List integers = List.of(1, 2, 3);
printAllElements(integers);
// 测试上界通配符
List dogs = new ArrayList<>();
dogs.add(new Dog());
processAnimals(dogs);
List huskies = new ArrayList<>();
huskies.add(new Husky());
processAnimals(huskies);
// 测试下界通配符
List animals = new ArrayList<>();
addDogs(animals);
System.out.println(animals);
List 总结
入职第一天,看了公司代码,牛马沉默了
入职第一天就干活的,就问还有谁,搬来一台N手电脑,第一分钟开机,第二分钟派活,第三分钟干活,巴适。。。。。。

打开代码发现问题不断
- 读取配置文件居然读取两个配置文件,一个读一点,不清楚为什么不能一个配置文件进行配置


 一边获取WEB-INF下的配置文件,一边用外部配置文件进行覆盖,有人可能会问既然覆盖,那可以全在外部配置啊,问的好,如果全用外部配置,咱们代码获取属性有的加上了项目前缀(上面的两个put),有的没加,这样配置文件就显得很乱不可取,所以形成了分开配置的局面,如果接受混乱,就写在外部配置;不能全写在内部配置,因为
一边获取WEB-INF下的配置文件,一边用外部配置文件进行覆盖,有人可能会问既然覆盖,那可以全在外部配置啊,问的好,如果全用外部配置,咱们代码获取属性有的加上了项目前缀(上面的两个put),有的没加,这样配置文件就显得很乱不可取,所以形成了分开配置的局面,如果接受混乱,就写在外部配置;不能全写在内部配置,因为
prop_c.setProperty(key, value);
value获取外部配置为空的时候会抛出异常;properties底层集合用的是hashTable
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
}
- 很多参数写死在代码里,如果有改动,工作量会变得异常庞大,举例权限方面伪代码
role.haveRole("ADMIN_USE")
- 日志打印居然sout和log混合双打


先不说双打的事,对于上图这个,应该输出包括堆栈信息,不然定位问题很麻烦,有人可能会说e.getMessage()最好,可是生产问题看多了发现还是打堆栈好;还有如果不是定向返回信息,仅仅是记录日志,完全没必要catch多个异常,一个Exception足够了,不知道原作者这么写的意思是啥;还是就是打印日志要用logger,用sout打印在控制台,那我日志文件干啥;
4.提交的代码没有技术经理把关,下发生产包是个人就可以发导致生产环境代码和本地代码或者数据库数据出现不一致的现象,数据库数据的同步是生产最容易忘记执行的一个事情;比如我的这家公司上传文件模板变化了,但是没同步,导致出问题时开发环境复现问题真是麻烦;
5.随意更改生产数据库,出不出问题全靠开发的职业素养;
6.Maven依赖的问题,Maven引pom,而pom里面却是另一个pom文件,没有生成的jar供引入,是的,我们可以在dependency里加上
<type>pom
来解决这个问题,但是公司内的,而且实际也是引入这个pom里面的jar的,我实在不知道这么做的用意是什么,有谁知道;求教 
以上这些都是我最近一家公司出现的问题,除了默默接受还能怎么办;
那有什么优点呢:
- 不用太怎么写文档
- 束缚很小
- 学到了js的全局调用怎么写的(下一篇我来写,顺便巩固一下)
解决之道
怎么解决这些问题呢,首先对于现有的新项目或升级的项目来说,spring的application.xml/yml 完全可以写我们的配置,开发环境没必要整外部文件,如果是生产环境我们可以在脚本或启动命令添加 nohup java -Dfile.encoding=UTF-8 -Dspring.config.location=server/src/main/config/application.properties -jar xxx.jar & 来告诉jar包引哪里的配置文件;也可以加上动态配置,都很棒的,
其次就是规范代码,养成良好的规范,跟着节奏,不要另辟蹊径;老老实实的,如果原项目上迭代,不要动源代码,追加即可,没有时间去重构的;
我也曾是个快乐的童鞋,也有过崇高的理想,直到我面前堆了一座座山,脚下多了一道道坑,我。。。。。。!
来源:juejin.cn/post/7371986999164928010
为什么程序员痴迷于错误信息上报?
前言
上一篇已经聊过日志上报的调度原理,讲述如何处理日志上报堆积、上报失败以及上报优化等方案。
从上家公司开始,监控就由我们组身强体壮的同事来负责,而我只能开发Admin和H5;经过一系列焦虑的面试后,咸鱼翻身,这辈子我也做上监控了。千万不要以为我是因为监控的重要性才这么执着,人往往得不到的东西才是最有吸引力的。
在写这篇文章时,我也在思考,为什么走到哪里都会有一群程序员喜欢封装监控呢?即使换个公司、换个组,依然可能需要有人来迭代监控。嗯,话不多说,先点关注,正文开始。
错误监控的核心价值
如果让你封装一个前端监控,你会怎么设计监控的上报优先级?
对于一个网页来说,能否带给用户好的体验,核心指标就是 白屏时长 和 FMP时长,这两项指标直接影响用户的 留存率 和 体验。
下面通过数据加强理解:
- 白屏时间 > 3秒 导致用户流失率上升47%
- 接口错误率 > 0.5% 造成订单转化率下降23%
- JS错误数 > 1/千次访问 预示着系统稳定性风险
设想一下,当你访问页面时白屏等待了3秒,并且页面没有骨架屏或者Loading态时,你会不会觉得这个页面挂了?这时候如果我们的监控优先关注的是性能,可能用户已经退出了,我们的上报还没调用到。
在这个白屏等待的过程中,JS Error可能已经打印在控制台了,接口可能已经返回了错误信息,但是程序员却毫无感知。
优先上报错误信息,本质是为了提升生产环境的错误响应速度、减少生产环境的损失、提高上线流程的规范。以下是错误响应的黄金时间轴:
| 时间窗口 | 响应动作 | 业务影响 |
|---|---|---|
| < 1分钟 | 自动熔断异常接口 | 避免错误扩散 |
| 1-5分钟 | 触发告警通知值班人员 | 降低MTTR(平均修复时间) |
| >5分钟 | 生成故障诊断报告 | 优化事后复盘流程 |
重要章节
一:错误类型,你需要关注的五大场景
技术本质:任何错误收集系统都需要先明确错误边界。前端错误主要分为两类: 显性错误(直接阻断执行)和 隐性错误(资源加载、异步异常等)。
// 显性错误(同步执行阶段)
function criticalFunction() {
undefinedVariable.access(); // ReferenceError
}
// 隐性错误(异步场景)
fetchData().then(() => {
invalidJSON.parse(); // 异步代码中的错误
});
关键分类: 通过错误本质将前端常见错误分为5种类型,图示如下。 
- 语法层错误(SyntaxError)
ESLint 可拦截,但运行时需注意动态语法(如eval,这个用法不推荐)。 - 运行时异常
错误的时机场景大部分是在页面渲染完成后,用户对页面发生交互行为,触发JS执行异常。以下是模拟报错的一个例子,用于学习。 // 典型场景 element.addEventListener('click', () => { throw new Error('Event handler crash'); }); - 资源加载失败
常见的资源比如图片、JS脚本、字体文件、外链引入的三方依赖等。我们可以通过全局监听处理,比如使用document.addEventListener('error', handler, true)来捕获资源加载失败的情况。但需要注意以下几点:
某程序员自曝:凡是打断点调试代码的,都不是真正的程序员,都是外行
大家好,我是大明哥,一个专注 「死磕 Java」 的硬核程序员。
某天我在逛今日头条的时候,看到一个大佬,说凡是打断点调试代码的,都不是真正的程序员,都是外行。

我靠,我敲了 10 多年代码,打了 10 多年的断点,竟然说我是外行!!我还说,真正的大佬都是用文档编辑器来写代码呢!!!
其实,打断点不丢脸,丢脸的是工作若干年后只知道最基础的断点调试!大明哥就见过有同事因为 for 循环里面实体对象报空指针异常,不知道怎么调试,选择一条一条得看,极其浪费时间!!所以,大明哥来分享一些 debug 技巧,赶紧收藏,日后好查阅!!
Debug 分类
对于很多同学来说,他们几乎就只知道在代码上面打断点,其实断点可以打在多个地方。
行断点
行断点的投标就是一个红色的圆形点。在需要断点的代码行头点击即可打上:

方法断点
方法断点就是将断点打在某个具体的方法上面,当方法执行的时候,就会进入断点。这个当我们阅读源码或者跟踪业务流程时比较有用。尤其是我们在阅读源码的时候,我们知道优秀的源码(不优秀的源码你也不会阅读)各种设计模式使用得飞起,什么策略、模板方法等等。具体要走到哪个具体得实现,还真不是猜出来,比如下面代码:
public interface Service {
void test();
}
public class ServiceA implements Service{
@Override
public void test() {
System.out.println("ServiceA");
}
}
public class ServiceB implements Service{
@Override
public void test() {
System.out.println("ServiceB");
}
}
public class ServiceC implements Service{
@Override
public void test() {
System.out.println("ServiceC");
}
}
public class DebugTest {
public static void main(String[] args) {
Service service = new ServiceA();
service.test();
}
}
在运行时,你怎么知道他要进入哪个类的 test() 方法呢?有些小伙伴可能就会在 ServiceA、ServiceB、ServiceC 中都打断点(曾经我也是这么干的,初学者可以理解...),这样就可以知道进入哪个了。其实我们可以直接在接口 Service 的 test() 方法上面打断点,这样也是可以进入具体的实现类的方法:

当然,也可以在方法调用的地方打断点,进入这个断点后,按 F7 就可以了。
属性断点
我们也可以在某个属性字段上面打断点,这样就可以监听这个属性的读写变化过程。比如,我们定义这样的:
@Getter
@Setter
@AllArgsConstructor
public class Student {
private String name;
private Integer age;
}
public class ServiceA implements Service{
@Override
public void test() {
Student student = new Student("张三",12);
System.out.println(student.getName());
student.setName("李四");
}
}
如下:

断点技巧
条件断点
在某些场景下,我们需要在特定的条件进入断点,尤其是 for 循环中(我曾经在公司看到一个小伙伴在循环内部看 debug 数据,惊呆我了),比如下面代码:
public class DebugTest {
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
for (int i = 1 ; i < 1000 ; i++) {
if (new Random().nextInt(100) % 10 == 0) {
studentList.add(new Student("" + i, i));
} else {
studentList.add(new Student("" + i, i));
}
}
for (Student student : studentList) {
System.out.println(student.toString());
}
}
}
我们在 System.out.println(student.toString()); 打个断点,但是要 name 以 "skjava" 开头时才进入,这个时候我们就可以使用条件断点了:

条件断点是非常有用的一个断点技巧,对于我们调试复杂的业务场景,尤其是 for、if 代码块时,可以节省我们很多的调试时间。
模拟异常
这个技巧也是很有用,在开发阶段我们就需要人为制造异常场景来验证我们的异常处理逻辑是否正确。比如如下代码:
public class DebugTest {
public static void main(String[] args) {
methodA();
try {
methodB();
} catch (Exception e) {
e.printStackTrace();
// do something
}
methodC();
}
public static void methodA() {
System.out.println("methodA...");
}
public static void methodB() {
System.out.println("methodA...");
}
public static void methodC() {
System.out.println("methodA...");
}
}
我们希望在 methodB() 方法中抛出异常,来验证 catch(Exception e) 中的 do something 是否处理正确。以前大明哥是直接在 methodB() 中 throw 一个异常,或者 1 / 0。这样做其实并没有什么错,只不过不是很优雅,同时也会有一个风险,就是可能会忘记删除这个测试代码,将异常提交上去了,最可怕的还是上了生产。
所以,我们可以使用 idea 模拟异常。
- 我们首先在 methodB() 打上一个断点
- 运行代码,进入断点处
- 在 Frames 中找到对应的断点记录,右键,选择
Throw Execption - 输入你想抛出的异常,点击
ok即可

这个技巧在我们调试异常场景时非常有用!!!
多线程调试
不知道有小伙伴遇到过这样的场景:在你和前端进行本地调试时,你同时又要调试自己写的代码,前端也要访问你的本地调试,这个时候你打断点了,前端是无法你本地的。为什么呢?因为 Idea 在 debug 时默认阻塞级别为 ALL,如果你进入 debug 场景了,idea 就会阻塞其他线程,只有当前调试线程完成后才会走其他线程。
这个时候,我们可以在 View Breakpoints 中选择 Thread,同时点击 Make Default设置为默认选项。这样,你就可以调试你的代码,前端又可以访问你的应用了。

或者

调试 Stream
Java 中的 Stream 好用是好用,但是依然有一些小伙伴不怎么使用它,最大的一个原因就是它不好调试。你利用 Stream 处理一个 List 对象后,发现结果不对,但是你很难判断到底是哪一行出来问题。我们看下面代码:
public class DebugTest {
public static void main(String[] args) {
List<Student> studentList = new ArrayList<>();
for (int i = 1; i < 1000; i++) {
if (new Random().nextInt(100) % 10 == 0) {
studentList.add(new Student("" + i, i));
} else {
studentList.add(new Student("" + i, i));
}
}
studentList = studentList.stream()
.filter(student -> student.getName().startsWith(""))
.peek(item -> {
item.setName(item.getName() + "-**");
item.setAge(item.getAge() * 10);
}).collect(Collectors.toList());
}
}
在 stream() 打上断点,运行代码,进入断点后,我们只需要点击下图中的按钮:


在这个窗口中会记录这个 Stream 操作的每一个步骤,我们可以点击每个标签来看数据处理是否符合预期。这样是不是就非常方便了。
有些小伙伴的 idea 版本可能过低,需要安装 Java Stream Debugger 插件才能使用。
操作回退
我们 debug 调试的时候肯定不是一行一行代码的调试,而是在每个关注点处打断点,然后跳着看。但是跳到某个断点处时,突然发现有个变量的值你没有关注到需要回退到这个变量值的赋值处,这个时候怎么办?我们通常的做法是重新来一遍。虽然,可以达到我们的预期效果,但是会比较麻烦,其实 idea 有一个回退断点的功能,非常强大。在 idea 中有两种回退:
- Reset Frame
看下面代码:
public class DebugTest {
public static void main(String[] args) {
int a = 1;
int b = 2;
int c = (a + b) * 2;
int d = addProcessor(a, b,c);
System.out.println();
}
private static int addProcessor(int a, int b, int c) {
a = a++;
b = b++;
return a + b + c;
}
}
我们在 addProcessor() 的 return a + b + c; 打上断点,到了这里 a 和 b 的值已经发生了改变,如果我们想要知道他们两的原始值,就只能回到开始的地方。idea 提供了一个 Reset Frame 功能,这个功能可以回到上一个方法处。如下图:

- Jump To Line
Reset Frame 虽然可以用,但是它有一定的局限性,它只能方法级别回退,是没有办法向前或向后跳着我们想要执行的代码处。但 Jump To Line 可以做到。
Jump To Line 是一个插件,所以,需要先安装它。

由于大明哥使用的 idea 版本是 2024.2,这个插件貌似不支持,所以就在网上借鉴了一张图:

在执行到 debug 处时,会出现一个黄颜色的箭头,我们可以将这个箭头拖动到你想执行的代码处就可以了。向前、向后都可以,是不是非常方便。
目前这 5 个 debug 技巧是大明哥在工作中运用最多的,还有一个就是远程 debug 调试,但是这个我个人认为是野路子,大部分公司一般是不允许这么做的,所以大明哥就不演示了!
来源:juejin.cn/post/7470185977434144778
产品:大哥,你这列表查询有问题啊!
前言
👳♂️产品大哥(怒气冲冲跑过来): “大哥你这查询列表有问题啊,每次点一下查询,返回的数据不一样呢”
👦我:“FKY 之前不是说好的吗,加了排序查询很卡,就取消了”
🧔技术经理:“卡主要是因为分页查询加了排序之后,mybatisPlus 生成的 count 也会有Order by就 很慢,自己实现一个count 就行了”
👦我:“分页插件在执行统计操作的时候,一般都会对Sql 简单的优化,会去掉排序的”
今天就来看看分页插件处理 count 的时候的优化逻辑,是否能去除order by;
同时 简单阐述一下 order by、limit 的运行原理
往期好文:最近发现一些同事的代码问题
mybatisPlus分页插件count 运行原理
分页插件都是基于MyBatis 的拦截器接口Interceptor实现,这个就不用多说了。下面看一下分页插件的处理count的代码,以及优化的逻辑。
详细代码见:
com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor.class
count sql 从获取到执行的主要流程
1.确认count sql MappedStatement 对象:
先查询Page对象中 是否有countId(countId 为mapper sql id),有的话就用自定义的count sql,没有的话就自己通过查询语句构建一个count MappedStatement
2.优化count sql:
得到countMs构建成功之后对count SQL进行优化,最后 执行count SQL,将结果 set 到page对象中。
public boolean willDoQuery(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
IPage<?> page = ParameterUtils.findPage(parameter).orElse(null);
if (page == null || page.getSize() < 0 || !page.searchCount()) {
return true;
}
BoundSql countSql;
// -------------------------------- 根据“countId”获取自定义的count MappedStatement
MappedStatement countMs = buildCountMappedStatement(ms, page.countId());
if (countMs != null) {
countSql = countMs.getBoundSql(parameter);
} else {
//-------------------------------------------根据查询ms 构建统计SQL的MS
countMs = buildAutoCountMappedStatement(ms);
//-------------------------------------------优化count SQL
String countSqlStr = autoCountSql(page, boundSql.getSql());
PluginUtils.MPBoundSql mpBoundSql = PluginUtils.mpBoundSql(boundSql);
countSql = new BoundSql(countMs.getConfiguration(), countSqlStr, mpBoundSql.parameterMappings(), parameter);
PluginUtils.setAdditionalParameter(countSql, mpBoundSql.additionalParameters());
}
CacheKey cacheKey = executor.createCacheKey(countMs, parameter, rowBounds, countSql);
//----------------------------------------------- 统计SQL
List<Object> result = executor.query(countMs, parameter, rowBounds, resultHandler, cacheKey, countSql);
long total = 0;
if (CollectionUtils.isNotEmpty(result)) {
// 个别数据库 count 没数据不会返回 0
Object o = result.get(0);
if (o != null) {
total = Long.parseLong(o.toString());
}
}
// ---------------------------------------set count ret
page.setTotal(total);
return continuePage(page);
}
count SQL 优化逻辑
主要优化的是以下两点:
- 去除 SQl 中的order by
- 去除 left join
哪些情况count 优化限制:
- SQL 中 有 这些集合操作的 INTERSECT,EXCEPT,MINUS,UNION 直接不优化count
- 包含groupBy 不去除orderBy
- order by 里带参数,不去除order by
- 查看select 字段中是否动态条件,如果有条件字段,则不会优化 Count SQL
- 包含 distinct、groupBy不优化
- 如果 left join 是子查询,并且子查询里包含 ?(代表有入参) 或者 where 条件里包含使用 join 的表的字段作条件,就不移除 join
- 如果 where 条件里包含使用 join 的表的字段作条件,就不移除 join
- 如果 join 里包含 ?(代表有入参) 就不移除 join
详情可阅读一下代码:
/**
* 获取自动优化的 countSql
*
* @param page 参数
* @param sql sql
* @return countSql
*/
protected String autoCountSql(IPage<?> page, String sql) {
if (!page.optimizeCountSql()) {
return lowLevelCountSql(sql);
}
try {
Select select = (Select) CCJSqlParserUtil.parse(sql);
SelectBody selectBody = select.getSelectBody();
// https://github.com/baomidou/mybatis-plus/issues/3920 分页增加union语法支持
//----------- SQL 中 有 这些集合操作的 INTERSECT,EXCEPT,MINUS,UNION 直接不优化count
if (selectBody instanceof SetOperationList) {
// ----lowLevelCountSql 具体实现: String.format("SELECT COUNT(*) FROM (%s) TOTAL", originalSql)
return lowLevelCountSql(sql);
}
....................省略.....................
if (CollectionUtils.isNotEmpty(orderBy)) {
boolean canClean = true;
if (groupBy != null) {
// 包含groupBy 不去除orderBy
canClean = false;
}
if (canClean) {
for (OrderByElement order : orderBy) {
//-------------- order by 里带参数,不去除order by
Expression expression = order.getExpression();
if (!(expression instanceof Column) && expression.toString().contains(StringPool.QUESTION_MARK)) {
canClean = false;
break;
}
}
}
//-------- 清除order by
if (canClean) {
plainSelect.setOrderByElements(null);
}
}
//#95 Github, selectItems contains #{} ${}, which will be translated to ?, and it may be in a function: power(#{myInt},2)
// ----- 查看select 字段中是否动态条件,如果有条件字段,则不会优化 Count SQL
for (SelectItem item : plainSelect.getSelectItems()) {
if (item.toString().contains(StringPool.QUESTION_MARK)) {
return lowLevelCountSql(select.toString());
}
}
// ---------------包含 distinct、groupBy不优化
if (distinct != null || null != groupBy) {
return lowLevelCountSql(select.toString());
}
// ------------包含 join 连表,进行判断是否移除 join 连表
if (optimizeJoin && page.optimizeJoinOfCountSql()) {
List<Join> joins = plainSelect.getJoins();
if (CollectionUtils.isNotEmpty(joins)) {
boolean canRemoveJoin = true;
String whereS = Optional.ofNullable(plainSelect.getWhere()).map(Expression::toString).orElse(StringPool.EMPTY);
// 不区分大小写
whereS = whereS.toLowerCase();
for (Join join : joins) {
if (!join.isLeft()) {
canRemoveJoin = false;
break;
}
.........................省略..............
} else if (rightItem instanceof SubSelect) {
SubSelect subSelect = (SubSelect) rightItem;
/* ---------如果 left join 是子查询,并且子查询里包含 ?(代表有入参) 或者 where 条件里包含使用 join 的表的字段作条件,就不移除 join */
if (subSelect.toString().contains(StringPool.QUESTION_MARK)) {
canRemoveJoin = false;
break;
}
str = subSelect.getAlias().getName() + StringPool.DOT;
}
// 不区分大小写
str = str.toLowerCase();
if (whereS.contains(str)) {
/*--------------- 如果 where 条件里包含使用 join 的表的字段作条件,就不移除 join */
canRemoveJoin = false;
break;
}
for (Expression expression : join.getOnExpressions()) {
if (expression.toString().contains(StringPool.QUESTION_MARK)) {
/* 如果 join 里包含 ?(代表有入参) 就不移除 join */
canRemoveJoin = false;
break;
}
}
}
// ------------------ 移除join
if (canRemoveJoin) {
plainSelect.setJoins(null);
}
}
}
// 优化 SQL-------------
plainSelect.setSelectItems(COUNT_SELECT_ITEM);
return select.toString();
} catch (JSQLParserException e) {
..............
}
return lowLevelCountSql(sql);
}
order by 运行原理
order by 排序,具体怎么排取决于优化器的选择,如果优化器认为走索引更快,那么就会用索引排序,否则,就会使用filesort (执行计划中extra中提示:using filesort),但是能走索引排序的情况并不多,并且确定性也没有那么强,很多时候,还是走的filesort
索引排序
索引排序,效率是最高的,就算order by 后面的字段是 索引列,也不一定就是通过索引排序。这个过程是否一定用索引,完全取决于优化器的选择。
filesort 排序
如果不能走索引排序, MySQL 会执行filesort操作以读取表中的行并对它们进行排序。
在进行排序时,MySQL 会给每个线程分配一块内存用于排序,称为 sort_buffer,它的大小是由sort_buffer_size控制的。
sort_buffer_size的大小不同,会在不同的地方进行排序操作:
- 如果要排序的数据量小于 sort_buffer_size,那么排序就在内存中完成。
- 如果排序数据量大于sort_buffer_size,则需要利用磁盘临时文件辅助排序。
采用多路归并排序的方式将磁盘上的多个有序子文件合并成一个有序的结果集
filesort 排序 具体实现方式
FileSort是MySQL中用于对数据进行排序的一种机制,主要有以下几种实现方式:
全字段排序
- 原理:将查询所需的所有字段,包括用于排序的字段以及其他
SELECT列表中的字段,都读取到排序缓冲区中进行排序。这样可以在排序的同时获取到完整的行数据,减少访问原表数据的次数。 - 适用场景:当排序字段和查询返回字段较少,并且排序缓冲区能够容纳这些数据时,全字段排序效率较高。
行指针排序
- 原理:只将排序字段和行指针(指向原表中数据行的指针)读取到排序缓冲区中进行排序。排序完成后,再根据行指针回表读取所需的其他字段数据。
- 适用场景:当查询返回的
字段较多,而排序缓冲区无法容纳全字段数据时,行指针排序可以减少排序缓冲区的占用,提高排序效率。但由于需要回表操作,可能会增加一定的I/O开销。
多趟排序
- 原理:如果数据量非常大,即使采用行指针排序,排序缓冲区也无法一次容纳所有数据,MySQL会将数据分成多个较小的部分,分别在排序缓冲区中进行排序,生成多个有序的临时文件。然后再将这些临时文件进行多路归并,最终得到完整的有序结果。
- 适用场景:适用于处理超大数据量的排序操作,能够在有限的内存资源下完成排序任务,但会产生较多的磁盘I/O操作,
性能相对较低。
优先队列排序
- 原理:结合优先队列数据结构进行排序。对于带有
LIMIT子句的查询,MySQL会创建一个大小为LIMIT值的优先队列。在读取数据时,将数据放入优先队列中,根据排序条件进行比较和调整。当读取完所有数据或达到一定条件后,优先队列中的数据就是满足LIMIT条件的有序结果。 - 适用场景:特别适用于需要获取少量排序后数据的情况,如查询排名前几的数据。可以避免对大量数据进行全量排序,提高查询效率。
❗所以减少查询字段 ,以及 减少 返回的行数,对于排序SQL 的优化也是非常重要
❗以及order by 后面尽量使用索引字段,以及行数限制
limit 运行原理
limit执行过程
对于 SQL 查询中 LIMIT 的使用,像 LIMIT 10000, 100 这种形式,MySQL 的执行顺序大致如下:
- 从数据表中读取所有符合条件的数据(包括排序和过滤)。
- 将数据按照 ORDER BY 排序。
- 根据 LIMIT 参数选择返回的记录:
- 跳过前 10000 行数据(这个过程是通过丢弃数据来实现的)。
- 然后返回接下来的 100 行数据。
所以,LIMIT 是先检索所有符合条件的数据,然后丢弃掉前面的行,再返回指定的行数。这解释了为什么如果数据集很大,LIMIT 会带来性能上的一些问题,尤其是在有很大的偏移量(比如 LIMIT 10000, 100)时。
总结
本篇文章分析,mybatisPlus 分页插件处理count sql 的逻辑,以及优化过程,同时也简单分析order by 和 limit 执行原理。
希望这篇文章能够让你对SQL优化 有不一样的认知,最后感谢各位老铁一键三连!
ps: 云服务器找我返点;面试宝典私;收徒ING;
来源:juejin.cn/post/7457934738356338739





