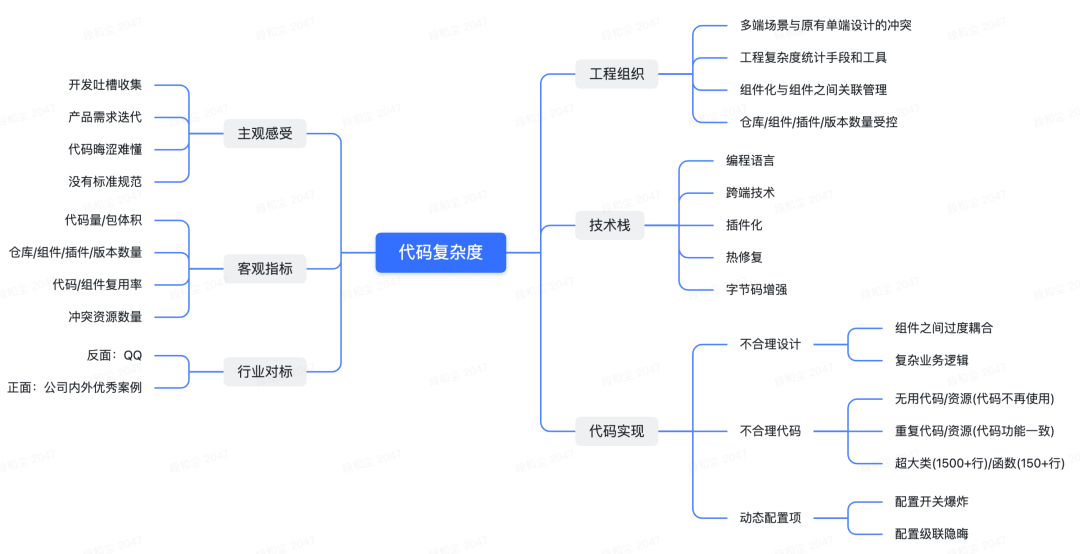
什么是Flutter Modular?
随着应用项目发展和变得越来越复杂,保持代码和项目结构可维护和可复用越来越难。Modular提供了一堆适配Flutter的解决方案来解决这些问题,比如依赖注入,路由系统和“一次性单例”系统(也就是说,当注入模块超出范围时,模块化自动配置注入模块)。
Modular的依赖注入为任何状态管理系统提供了开箱即用的支持,管理你应用的内存。
Modular也支持动态路由和相对路由,像在Web一样。
Modular结构
Modular结构由分离和独立的模块组成,这些模块将代表应用程序的特性。
每个模块都位于自己的目录中,并控制自己的依赖关系、路由、页面、小部件和业务逻辑。因此,您可以很容易地从项目中分离出一个模块,并在任何需要的地方使用它。
Modular支柱
这是Modular关注的几个方面:
- 自动内存管理
- 依赖注入
- 动态和相对路由
- 代码模块化
在项目中使用Modular
安装
打开你项目的pubspec.yaml并且添加flutter_modular作为依赖:
dependencies:
flutter_modular: any
在一个新项目中使用
为了在新项目中使用Modular,你必须做一些初始化步骤:
用MaterialApp创建你的main widget并且调用MaterialApp().modular()方法。
import 'package:flutter/material.dart';
import 'package:flutter_modular/flutter_modular.dart';
class AppWidget extends StatelessWidget {
@override
Widget build(BuildContext context) {
return MaterialApp(
initialRoute: "/",
).modular();
}
}
创建继承自Module的你项目的main module文件:
class AppModule extends Module {
@override
final List binds = [];
@override
final List routes = [];
}
在main.dart文件中,将main module包裹在ModularApp中以使Modular初始化它:
import 'package:flutter/material.dart';
import 'package:flutter_modular/flutter_modular.dart';
import 'app/app_module.dart';
void main() => runApp(ModularApp(module: AppModule(), child: AppWidget()));
完成!你的应用已经设置完成并且准备好和Modular一起工作!
创建child modules
你可以在你的项目中创建任意多module:
class HomeModule extends Module {
@override
final List binds = [
Bind.singleton((i) => HomeBloc()),
];
@override
final List routes = [
ChildRoute('/', child: (_, args) => HomeWidget()),
ChildRoute('/list', child: (_, args) => ListWidget()),
];
}
你可以通过module参数将子模块传递给你main module中的一个Route。
class AppModule extends Module {
@override
final List routes = [
ModuleRoute('/home', module: HomeModule()),
];
}
我们建议你讲代码分散到不同模块中,例如一个AuthModule,并将与此模块相关的所有路由放入其中。通过这样做,维护和与其他项目分享你的代码将变得更加容易。
**注意:**使用ModuleRoute对象创建复杂的路由。
添加路由
模块路由是通过覆盖routes属性来提供的。
class AppModule extends Module {
@override
final List binds = [];
@override
final List routes = [
ChildRoute('/', child: (_, __) => HomePage()),
ChildRoute('/login', child: (_, __) => LoginPage()),
];
}
**注意:**使用ChildRoute对象来创建简单路由。
动态路由
你可以使用动态路由系统来提供参数给你的Route:
// 使用 :参数名 语法来为你的路由提供参数。
// 路由参数可以通过' args '获得,也可以在' params '属性中访问,
// 使用方括号符号 (['参数名']).
@override
final List routes = [
ChildRoute(
'/product/:id',
child: (_, args) => Product(id: args.params['id']),
),
];
当调用给定路由时,参数将是模式匹配的。例如:
Modular.to.pushNamed('/product/1');
你也可以在多个界面中使用它。例如:
@override
final List routes = [
ChildRoute(
'/product/:id/detail',
child: (_, args) => DetailPage(id: args.params['id']),
),
ChildRoute(
'/product/:id/rating',
child: (_, args) => RatingPage(id: args.params['id']),
),
];
与第一个实例相同,我们只需要调用这个路由。例如:
Modular.to.navigate('/product/1/detail');
Modular.to.navigate('/product/1/rating');
然而,这种表示法只对简单的文字有效。
发送对象
如果你想传递一个复杂对象给你的路由,通过arguments参数传递给它::
Modular.to.navigate('/product', arguments: ProductModel());
并且,它将通过args.data属性提供而不是args.params:
@override
final List routes = [
ChildRoute(
'/product',
child: (_, args) => Product(model: args.data),
),
];
你可以直接通过binds来找回这些参数:
@override
final List binds = [
Bind.singleton((i) => MyController(data: i.args.data)),
];
路由泛型类型
你可以从导航返回一个值,就像.pop。为了实现这个,将你期望返回的参数作为类型参数传递给Route:
@override
final List routes = [
// This router expects to receive a `String` when popped.
ChildRoute('/event', child: (_, __) => EventPage()),
]
现在,使用.pop就像你使用Navigator.pop:
String name = await Modular.to.pushNamed('/event');
Modular.to.pop('banana');
路由守卫
路由守卫是一种类似中间件的对象,允许你从其它路由控制给定路由的访问权限。你通过让一个类implements RouteGuard可以实现一个路由守卫.
例如,下面的类只允许来自/admin的路由的重定向:
class MyGuard implements RouteGuard {
@override
Future canActivate(String url, ModularRoute route) {
if (url != '/admin'){
return Future.value(true);
} else {
return Future.value(false);
}
}
}
要在路由中使用你的RouteGuard,通过guards参数传递:
@override
final List routes = [
final ModuleRoute('/', module: HomeModule()),
final ModuleRoute(
'/admin',
module: AdminModule(),
guards: [MyGuard()],
),
];
如果你设置到module route上,RouteGuard将全局生效。
如果RouteGuard验证失败,添加guardedRoute属性来添加路由选择路由:
@override
final List routes = [
ChildRoute(
'/home',
child: (context, args) => HomePage(),
guards: [AuthGuard()],
guardedRoute: '/login',
),
ChildRoute(
'/login',
child: (context, args) => LoginPage(),
),
];
什么时候和如何使用navigate或pushNamed
你可以在你的应用中使用任何一个,但是需要理解每一个。
pushNamed
无论何时使用,这个方法都将想要的路由放在当前路由的上面,并且您可以使用AppBar上的后退按钮返回到上一个页面。 它就像一个模态,它更适合移动应用程序。
假设你需要深入你的路线,例如:
Modular.to.pushNamed('/home');
Modular.to.pushNamed('/home/user');
Modular.to.pushNamed('/home/user/profile');
最后,您可以看到返回到前一页的back按钮,这加强了模态页面在前一页上面的想法。
navigate
它删除堆栈中先前的所有路由,并将新路由放到堆栈中。因此,在本例中,您不会在AppBar中看到后退按钮。这更适合于Web应用程序。
假设您需要为移动应用程序创建一个注销功能。这样,您需要从堆栈中清除所有路由。
Modular.to.pushNamed('/home');
Modular.to.pushNamed('/home/user');
Modular.to.pushNamed('/home/user/profile');
Modular.to.navigate('/login');
Relative Navigation
要在页面之间导航,请使用Modular.to.navigate。
Modular.to.navigate('/login');
你可以使用相对导航来导航,就像在web程序一样:
Modular.to.navigate('/home/product/list');
Modular.to.navigate('/home/product/detail/3');
Modular.to.navigate('detail/3');
Modular.to.navigate('../config');
您仍然可以使用旧的Navigator API来堆叠页面。
Navigator.pushNamed(context, '/login');
或者,您可以使用Modular.to.pushhnamed,你不需要提供BuildContext:
Modular.to.pushNamed('/login');
Flutter Web URL routes (Deeplink-like)
路由系统可以识别URL中的内容,并导航到应用程序的特定部分。动态路由也适用于此。例如,下面的URL将打开带有参数的Product视图。args.params['id']设置为1。
https://flutter-website.com/
它也可以处理查询参数或片段:
https://flutter-website.com/
路由过渡动画
通过设置Route的转换参数,提供一个TransitionType,您可以选择在页面转换中使用的动画类型。
ModuleRoute('/product',
module: AdminModule(),
transition: TransitionType.fadeIn,
),
如果你在一个Module中指定了一个过渡动画,那么该Module中的所有路由都将继承这个过渡动画。
自定义过渡动画路由
你也可以通过将路由器的transition和customTransition参数分别设置为TransitionType.custom和你的CustomTransition来使用自定义的过渡动画:
import 'package:flutter/material.dart';
import 'package:flutter_modular/flutter_modular.dart';
CustomTransition get myCustomTransition => CustomTransition(
transitionDuration: Duration(milliseconds: 500),
transitionBuilder: (context, animation, secondaryAnimation, child){
return RotationTransition(turns: animation,
child: SlideTransition(
position: Tween(
begin: const Offset(-1.0, 0.0),
end: Offset.zero,
).animate(animation),
child: ScaleTransition(
scale: Tween(
begin: 0.0,
end: 1.0,
).animate(CurvedAnimation(
parent: animation,
curve: Interval(
0.00,
0.50,
curve: Curves.linear,
),
),
),
child: child,
),
),
)
;
},
);
依赖注入
可以通过重写Module的binds的getter将任何类注入到Module中。典型的注入例子有BLoCs、ChangeNotifier实例或(MobX)。
一个Bind对象负责配置对象注入。我们有4个Bind工厂类型和一个AsyncBind。
class AppModule extends Module {
// Provide a list of dependencies to inject into your project
@override
List get binds => [
Bind((i) => AppBloc()),
Bind.factory((i) => AppBloc()),
Bind.instance(myObject),
Bind.singleton((i) => AppBloc()),
Bind.lazySingleton((i) => AppBloc()),
AsyncBind((i) => SharedPreferences.getInstance())
];
...
}
Factory
每当调用类时实例化它。
@override
List get binds => [
Bind.factory((i) => AppBloc()),
];
Instance
使用已经实例化的对象。
@override
List get binds => [
Bind.instance((i) => AppBloc()),
];
Singleton
创建一个类的全局实例。
@override
List get binds => [
Bind.singleton((i) => AppBloc()),
];
LazySingleton
只在第一次调用类时创建一个全局实例。
@override
List get binds => [
Bind.lazySingleton((i) => AppBloc()),
];
AsyncBind
若干类的一些方法返回一个Future。要注入那些特定方法返回的实例,你应该使用AsyncBind而不是普通的同步绑定。使用Modular.isModuleReady()等待所有AsyncBinds解析,以便放开Module供使用。
重要:如果有其他异步绑定的相互依赖,那么AsyncBind的顺序很重要。例如,如果有两个AsyncBind,其中A依赖于B, AsyncBind B必须在A之前声明。注意这种类型的顺序!
import 'package:flutter_modular/flutter_modular.dart' show Disposable;
class AppBloc extends Disposable {
final controller = StreamController();
@override
void dispose() {
controller.close();
}
}
isModuleReady
如果你想确保所有的AsyncBinds都在Module加载到内存之前被解析,isModuleReady是一个方法。使用它的一种方法是使用RouteGuard,将一个AsyncBind添加到你的AppModule中,并将一个RouteGuard添加到你的ModuleRoute中。
class AppModule extends Module {
@override
List get binds => [
AsyncBind((i)=> SharedPreferences.getInstance()),
];
@override
List get routes => [
ModuleRoute(Modular.initialRoute, module: HomeModule(), guards: [HomeGuard()]),
];
}
然后,像下面这样创建一个RouteGuard。这样,在进入HomeModule之前,模块化会评估你所有的异步依赖项。
import 'package:flutter_modular/flutter_modular.dart';
class HomeGuard extends RouteGuard {
@override
Future canActivate(String path, ModularRoute router) async {
await Modular.isModuleReady();
return true;
}
}
在视图中检索注入的依赖项
让我们假设下面的BLoC已经定义并注入到我们的模块中(就像前面的例子一样):
import 'package:flutter_modular/flutter_modular.dart' show Disposable;
class AppBloc extends Disposable {
final controller = StreamController();
@override
void dispose() {
controller.close();
}
}
注意:Modular自动调用这些Binds类型的销毁方法:Sink/Stream, ChangeNotifier和[Store/Triple]
有几种方法可以检索注入的AppBloc。
class HomePage extends StatelessWidget {
@override
Widget build(BuildContext context) {
final appBloc = Modular.get();
final share = Modular.getAsync();
}
}
使用Modular小部件检索实例
ModularState
在本例中,我们将使用下面的MyWidget作为页面,因为这个页面需要是StatefulWidget。
让我们来了解一下ModularState的用法。当我们定义类_MyWidgetState扩展ModularState时,我们正在为这个小部件(在本例中是HomeStore)将Modular与我们的Store链接起来。当我们进入这个页面时,HomeStore将被创建,store/controller变量将被提供给我们,以便在MyWidget中使用。
在此之后,我们可以使用存储/控制器而没有任何问题。在我们关闭页面后,模块化将自动处理HomeStore。
class MyWidget extends StatefulWidget {
@override
_MyWidgetState createState() => _MyWidgetState();
}
class _MyWidgetState extends ModularState {
store.myVariableInsideStore = 'Hello!';
controller.myVariableInsideStore = 'Hello!';
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text("Modular"),
),
body: Center(child: Text("${store.counter}"),),
);
}
}
WidgetModule
WidgetModule具有与Module相同的结构。如果你想要一个带有Modular页面的TabBar,这是非常有用的。
class TabModule extends WidgetModule {
@override
List binds => [
Bind((i) => TabBloc(repository: i())),
Bind((i) => TabRepository()),
];
final Widget view = TabPage();
}
Mock导航系统
我们认为,在使用Modular.to和Modular.link时,提供一种native方式来mock导航系统会很有趣。要做到这一点,您只需实现IModularNavigator并将您的实现传递给Modular.navigatorDelegate。
使用 Mockito示例:
main() {
var navigatorMock = MyNavigatorMock();
Modular.navigatorDelegate = navigatorMock;
test('test navigator mock', () async {
when(navigatorMock.pushNamed('/test')).thenAnswer((_) async => {});
Modular.to.pushNamed('/test');
verify(navigatorMock.pushNamed('/test')).called(1);
});
}
class MyNavigatorMock extends Mock implements IModularNavigator {
@override
Future pushNamed(String? routeName, {Object? arguments, bool? forRoot = false}) =>
(super.noSuchMethod(Invocation.method(#pushNamed, [routeName], {#arguments: arguments, #forRoot: forRoot}), returnValue: Future.value(null)) as Future);
}
本例使用手动实现,但您也可以使用 代码生成器来创建模拟。
RouterOutlet
每个ModularRoute都可以有一个ModularRoute列表,这样它就可以显示在父ModularRoute中。反映这些内部路由的小部件叫做RouterOutlet。每个页面只能有一个RouterOutlet,而且它只能浏览该页面的子页面。
class StartModule extends Module {
@override
List get binds => [];
@override
List get routes => [
ChildRoute(
'/start',
child: (context, args) => StartPage(),
children: [
ChildRoute('/home', child: (_, __) => HomePage()),
ChildRoute('/product', child: (_, __) => ProductPage()),
ChildRoute('/config', child: (_, __) => ConfigPage()),
],
),
];
}
@override
Widget build(BuildContext context) {
return Scaffold(
body: RouterOutlet(),
bottomNavigationBar: BottomNavigationBar(
onTap: (id) {
if (id == 0) {
Modular.to.navigate('/start/home');
} else if (id == 1) {
Modular.to.navigate('/start/product');
} else if (id == 2) {
Modular.to.navigate('/start/config');
}
},
currentIndex: currentIndex,
items: const [
BottomNavigationBarItem(
icon: Icon(Icons.home),
label: 'Home',
),
BottomNavigationBarItem(
icon: Icon(Icons.control_camera),
label: 'product',
),
BottomNavigationBarItem(
icon: Icon(Icons.settings),
label: 'Config',
),
],
),
);
}














 。
。
















 ~
~














{kind=link}
{kind=link}