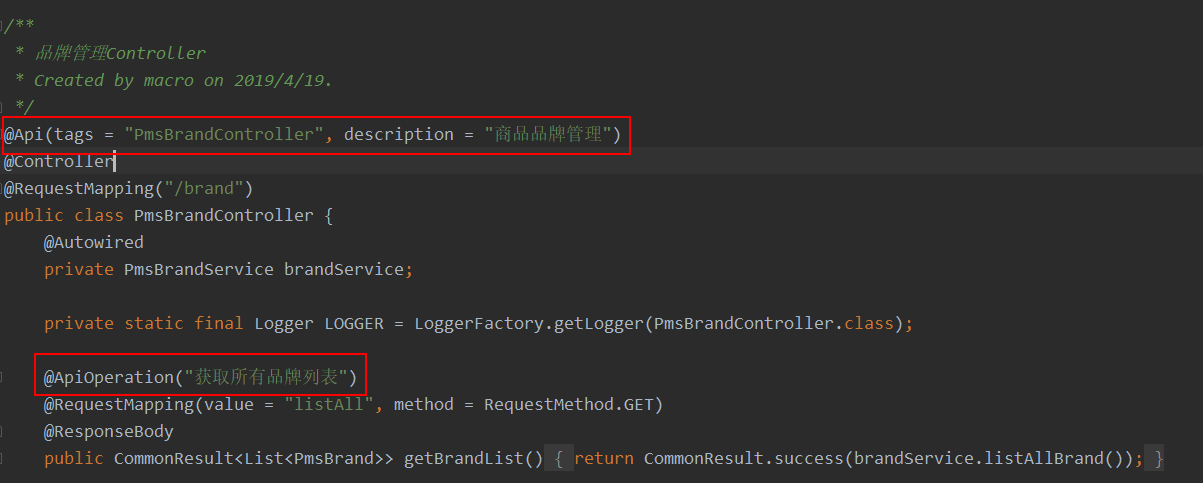
1. http 链接到断开的过程?
第一步:TCP建立连接:三次握手
HTTP 是应用层协议,他的工作还需要数据层协议的支持,最常与它搭配的就是 TCP 协议(应用层、数据层是 OSI 七层模型中的,以后有机会会说到的)。TCP 协议称为数据传输协议,是可靠传输,面向连接的,并且面向字节流的。
面向连接:通信之前先建立连接,确保双方在线。 可靠传输:在网络正常的情况下,数据不会丢失。 面向字节流:传输灵活,但是 TCP 的传输存在粘包问题,没有明显的数据约定。
在正式发送请求之前,需要先建立 TCP 连接。建立 TCP 连接的过程简单地来说就是客户端和服务端之间发送三次消息来确保连接的建立,这个过程称为三次握手。
第二步:浏览器发送请求命令
TCP 连接建立完成后,客户端就可以向服务端发送请求报文来请求了
请求报文分为请求行、请求头、空行、请求体,服务端通过请求行和请求头中的内容获取客户端的信息,通过请求体中的数据获取客户端的传递过来的数据。
第三步:应答响应
在接收到客户端发来的请求报文并确认完毕之后。服务端会向客户端发送响应报文
响应报文是有状态行、响应头、空行和响应体组成,服务端通过状态行和响应头告诉客户端请求的状态和如何对数据处理等信息,真正的数据则在响应体中传输给客户端。
第四步:断开 TCP 连接
当请求完成后,还需要断开 tcp 连接,断开的过程
断开的过程简单地说就算客户端和服务端之间发送四次信息来确保连接的断开,所以称为四次挥手。
延伸:
一、单向请求 HTTP 请求是单向的,是只能由客户端发起请求,由服务端响应的请求-响应模式。(如果你需要双向请求,可以用 socket)
二、基于 TCP 协议 HTTP 是应用层协议,所以其数据传输部分是基于 TCP 协议实现的。
三、无状态 HTTP 请求是无状态的,即没有记忆功能,不能获取之前请求或响应的内容。起初这种简单的模式,能够加快处理速度,保证协议的稳定,但是随着应用的发展,这种无状态的模式会使我们的业务实现变得麻烦,比如说需要保存用户的登录状态,就得专门使用数据库来实现。于是乎,为了实现状态的保持,引入了 Cookie 技术来管理状态。
四、无连接 HTTP 协议不能保存连接状态,每次连接只处理一个请求,用完即断,从而达到节约传输时间、提高并发性。在 TCP 连接断开之后,客户端和服务端就像陌生人一样,下次再发送请求,就得重新建立连接了。有时候,当我们需要发送一段频繁的请求时,这种无连接的状态反而会耗费更多的请求时间(因为建立和断开连接本身也需要时间),于是乎,HTTP1.1 中提出了持久连接的概念,可以在请求头中设置 Connection: keep-alive 来实现。
2. 深拷贝、浅拷贝
深拷贝、浅拷贝实例说明?
深拷贝:是对对象本身的拷贝; 浅拷贝:是对指针的拷贝;
在 oc 中父类的指针可以指向子类的对象,这是多态的一个特性 声明一个 NSString 对象,让它指向一个 NSMutableString 对象,这一点是完全可以的,因为 NSMutableString 的父类就是 NSString。NSMutableString 是一个可以改变的对象,如果我们用 strong 修饰,NSString 对象强引用了 NSMutableString 对象。假如我们在其他的地方修改了这个 NSMutableString 对象,那么 NSString 的值会随之改变。
关于copy修饰相关
1、对 NSString 进行 copy -> 这是一个浅拷贝,但是因为是不可变对象,后期值也不会改变;
2、对 NSString 进行 mutableCopy -> 这是一个深拷贝,但是拷贝出来的是一个可变的对象 NSMutableString;
3、对 NSMutableString 进行 copy -> 这是一个深拷贝,拷贝出来一个不可变的对象;
4、对 NSmutableString 进行 mutableCopy -> 这是一个深拷贝,拷贝出来一个可变的对象;
总结:
对对象进行 mutableCopy,不管对象是可变的还是不可变的都是深拷贝,并且拷贝出来的对象都是可变的;
对对象进行 copy,copy 出来的都是不可变的。
对于系统的非容器类对象,我们可以认为,如果对一不可变对象复制,copy 是指针复制(浅拷贝)和 mutableCopy 就是对象复制(深拷贝)。如果是对可变对象复制,都是深拷贝,但是 copy 返回的对象是不可变的。
指 NSArray,NSDictionary 等。对于容器类本身,上面讨论的结论也是适用的,需要探讨的是复制后容器内对象的变化。
//copy返回不可变对象,mutablecopy返回可变对象
NSArray *array1 = [NSArray arrayWithObjects:@"a",@"b",@"c",nil];
NSArray *arrayCopy1 = [array1 copy];
//arrayCopy1是和array同一个NSArray对象(指向相同的对象),包括array里面的元素也是指向相同的指针
NSLog(@"array1 retain count: %d",[array1 retainCount]);
NSLog(@"array1 retain count: %d",[arrayCopy1 retainCount]);
NSMutableArray *mArrayCopy1 = [array1 mutableCopy];
mArrayCopy1 是 array1 的可变副本,指向的对象和 array1 不同,但是其中的元素和 array1 中的元素指向的是同一个对象。
mArrayCopy1 还可以修改自己的对象 [mArrayCopy1 addObject:@"de"];
[mArrayCopy1 removeObjectAtIndex:0]; array1 和 arrayCopy1 是指针复制,而 mArrayCopy1 是对象复制,mArrayCopy1 还可以改变期内的元素:删除或添加。但是注意的是,容器内的元素内容都是指针复制。
NSArray *mArray1 = [NSArray arrayWithObjects:[NSMutableString stringWithString:@"a"],@"b",@"c",nil];
NSArray *mArrayCopy2 = [mArray1 copy];
NSMutableArray *mArrayMCopy1 = [mArray1 mutableCopy];
NSMutableString *testString = [mArray1 objectAtIndex:0];
[testString appendString:@" tail"];
NSLog(@"%@-%@-%@",mArray1,mArrayMCopy1,mArrayCopy2);
结果:mArray1,mArrayMCopy1,mArrayCopy2三个数组的首元素都发生了变化!
补充:来自开发者留言
面试时我有时会问说说 copy 和 mutableCopy,候选人几乎 100% 说你是说深拷贝和浅拷贝啊 ....,我会说不是!
> 下面用 NSArray、NSMutableArray 举例,因为 NSString、NSMutableString 并不会再引用其它对象,因此不足以说明问题。
1、NSArray 等类型的 copy 实际并没有 copy,或者最多只能说 copy 了引用,因为 copy 方法只返回了 self,这是对内存的优化;
2、而 NSMutableArray 的 copy 确实 copy 了,得到的是新的 NSArray 对象,但并不是所谓的深拷贝,因为它只浅浅地 copy 了一个 NSArray,其中的内容仍然是 NSMutableArray 的内容,可以用 == 直接判等;
3、NSArray 和 NSMutableArray 的 mutableCopy 与 2 相似,只是结果是个 NSMutableArray;
4、以上说法一般只适用于 Foundation 提供的一些类型,很多时候并不适用于自己写的类 —— 思考一下你自己写的类是怎么实现 NSCopying 协议的?有实现 NSMutableCopying 协议吗?
所以 ObjC 并没有所谓的深拷贝,要想实现真正的深拷贝,基本上只能依赖序列化+反序列化,这样得到的结果才是深到见底的深拷贝。
如果你说道理大家都懂,深拷贝、浅拷贝只是一种叫法而已,那我只能说你太不严谨了,官方文档从来没这么教过;而且这种说法也不利于初学者理解,以及再学习其它语言时触类旁通,比如 Java。
所以建议严谨一点可以叫引用拷贝和浅拷贝,深拷贝很少用到;或者非要两个互为反义词,可以叫真拷贝和假拷贝。
3. load 和 initialize 区别
load方法和initialize方法区别,以及在子类、父类、分类中调用顺序?
+(void)load
1、+load 方法加载顺序:父类> 子类> 分类 (load 方法都会加载)注意:(如果分类中有 A, B,顺序要看 A, B 加入工程中顺序) ,可能结果:( 父类> 子类> 分类A> 分类B ) 或者( 父类> 子类> 分类B> 分类A )
2、+load 方法不会被覆盖(比如有父类,子类,分类A,分类B,这四个 load 方法都会加载)。
3、+load 方法调用在 main函数前
+(void)initialize
1、分类 (子类没有 initialize 方法,父类存在或者没有 1initialize 方法)
2、分类> 子类 (多个分类就看编译顺序,只有存在一个)
3、父类> 子类 (分类没有 initialize 方法)
4、父类 (子类,分类都没有 initialize 方法)
总结 +initialize:
1、当调用子类的 + initialize 方法时候,先调用父类的,如果父类有分类, 那么分类的 + initialize 会覆盖掉父类的
2、分类的 + initialize 会覆盖掉父类的
3、子类的 + initialize 不会覆盖分类的
4、父类的 + initialize 不一定会调用, 因为有可能父类的分类重写了它
5、发生在main函数后。
4. 同名方法调用顺序
同名方法在子类、父类、分类的调用顺序?
注意:+load 方法是根据方法地址直接调用,并不是经过 objc_msgSend 函数调用(通过 isa 和 superclass 找方法),所以不会存在方法覆盖的问题。
5. 事件响应链
事件响应链(同一个控制器有三个view,如何判断是否拥有相同的父视图)
iOS 系统检测到手指触摸( Touch )操作时会将其打包成一个 UIEvent 对象,并放入当前活动 Application 的事件队列,单例的 UIApplication 会从事件队列中取出触摸事件并传递给单例的 UIWindow 来处理,UIWindow 对象首先会使用 hitTest:withEvent: 方法寻找此次 Touch 操作初始点所在的视图(View),即需要将触摸事件传递给其处理的视图,这个过程称之为 hit-test view。
UIAppliction --> UIWiondw -->递归找到最适合处理事件的控件-->控件调用 touches 方法-->判断是否实现 touches 方法-->没有实现默认会将事件传递给上一个响应者-->找到上一个响应者。
UIResponder 是所有响应对象的基类,在 UIResponder 类中定义了处理上述各种事件的接口。我们熟悉的 UIApplication、 UIViewController、 UIWindow 和所有继承自 UIView 的 UIKit 类都直接或间接的继承自 UIResponder,所以它们的实例都是可以构成响应者链的响应者对象。
//如何获取父视图
UIResponder *nextResponder = gView.nextResponder;
NSMutableString *p = [NSMutableString stringWithString:@"--"];
while (nextResponder) {
NSLog(@"%@%@", p, NSStringFromClass([nextResponder class]));
[p appendString:@"--"];
nextResponder = nextResponder.nextResponder;
}
如果有父视图则 nextResponder 指向父视图如果是控制器根视图则指向控制器;
控制器如果在导航控制器中则指向导航控制器的相关显示视图最后指向导航控制器;
如果是根控制器则指向 UIWindow;
UIWindow 的 nexResponder 指向 UIApplication 最后指向 AppDelegate。
6.TCP丢包
TCP 会不会丢包?该怎么处理?网络断开会断开链接还是一直等待,如果一直网络断开呢?
TCP 在不可靠的网络上实现可靠的传输,必然会有丢包。TCP 是一个“流”协议,一个详细的包将会被 TCP 拆分为好几个包上传,也是将会把小的封裝成大的上传,这就是说 TCP 粘包和拆包难题。
7.自动释放池
自动释放池创建和释放的时机,在子线程是什么时候创建释放的?
默认主线程的运行循环(runloop)是开启的,子线程的运行循环(runloop)默认是不开启的,也就意味着子线程中不会创建 autoreleasepool,所以需要我们自己在子线程中创建一个自动释放池。(子线程里面使用的类方法都是 autorelease,就会没有池子可释放,也就意味着后面没有办法进行释放,造成内存泄漏。)
在主线程中如果产生事件那么 runloop 才回去创建 autoreleasepool,通过这个道理我们就知道为什么子线程中不会创建自动释放池了,因为子线程的 runloop 默认是关闭的,所以他不会自动创建 autoreleasepool,需要我们手动添加。
如果你生成一个子线程的时候,要在线程开始执行的时候,尽快创建一个自动释放池,否则会内存泄露。因为子线程无法访问主线程的自动释放池。
8.计算机编译流程
源文件: 载入.h、.m、.cpp 等文件
预处理: 替换宏,删除注释,展开头文件,产生 .i 文件
编译: 将 .i 文件转换为汇编语言,产生 .s 文件
汇编: 将汇编文件转换为机器码文件,产生 .o 文件
链接: 对 .o 文件中引用其他库的地方进行引用,生成最后的可执行文件