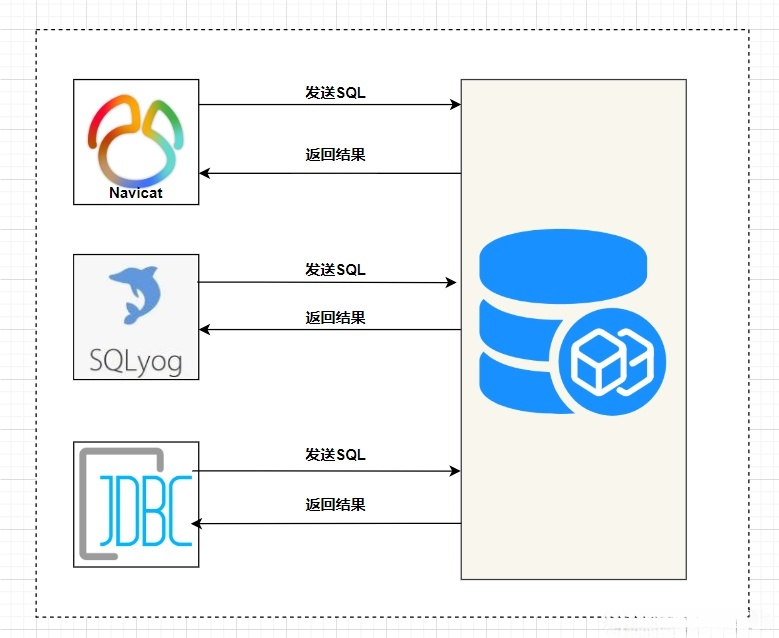
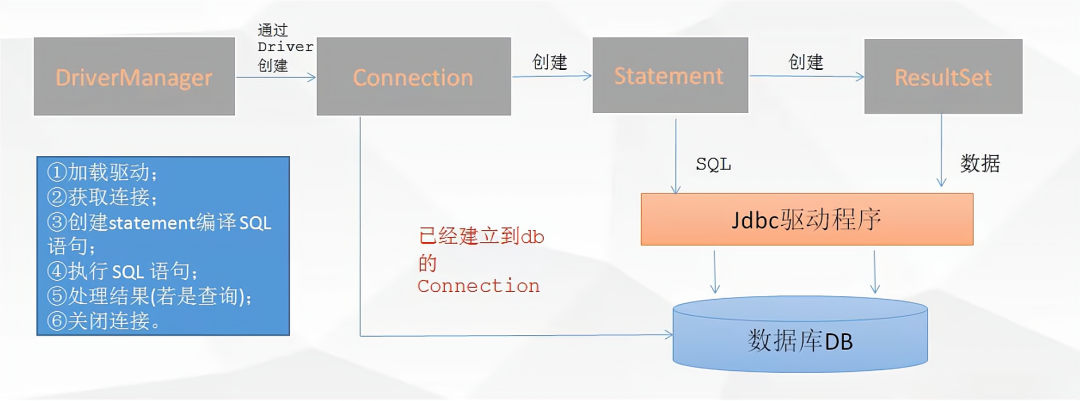
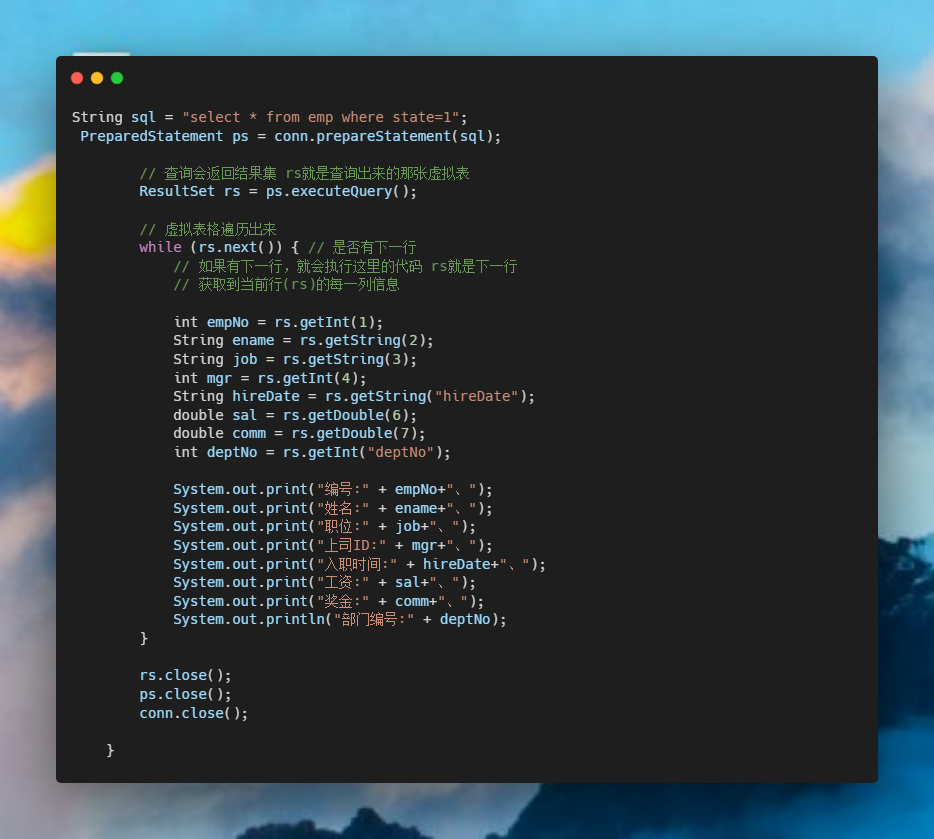
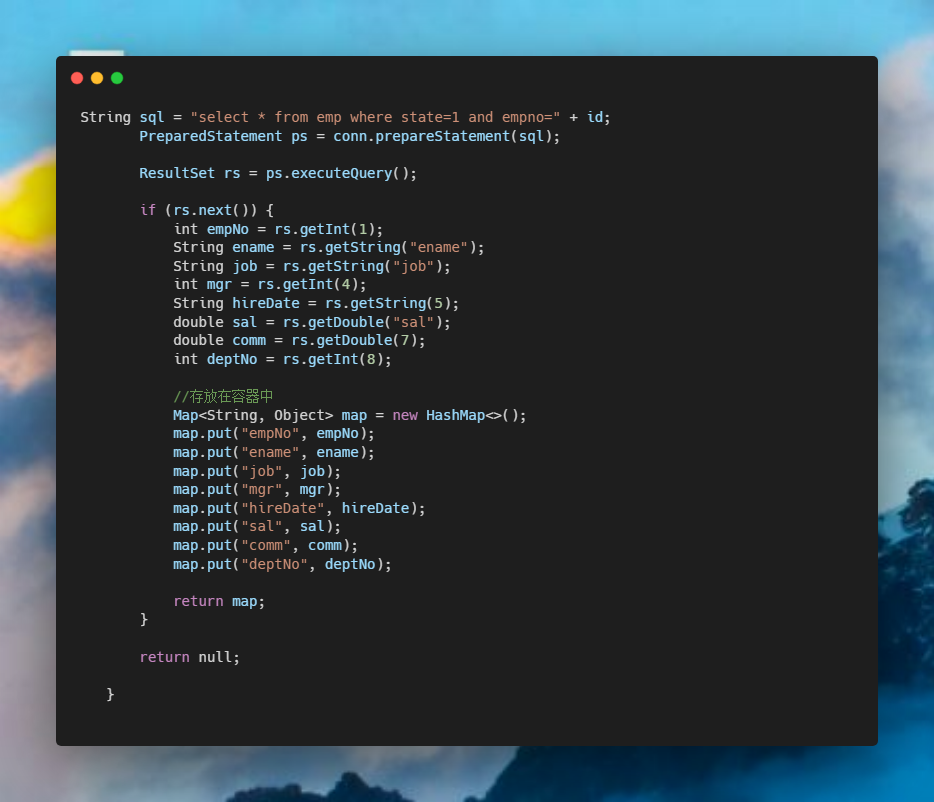
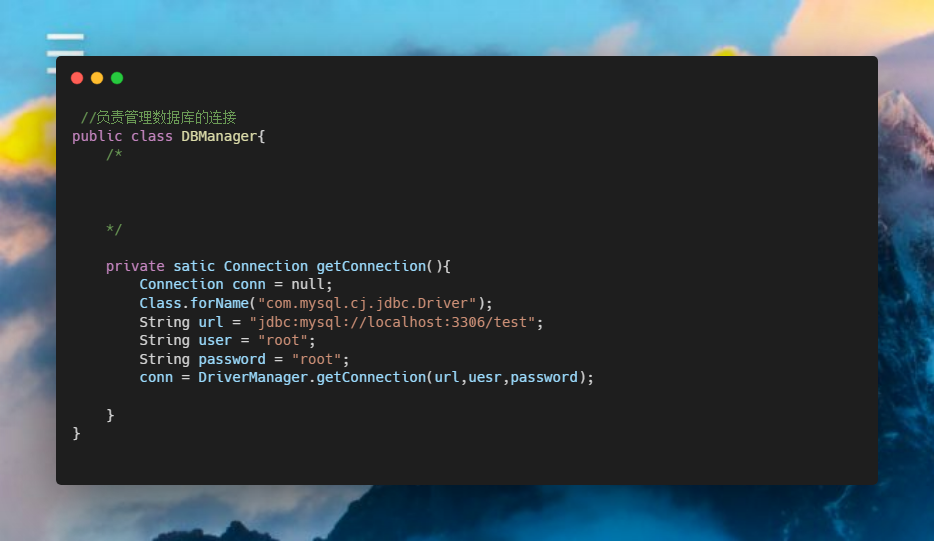
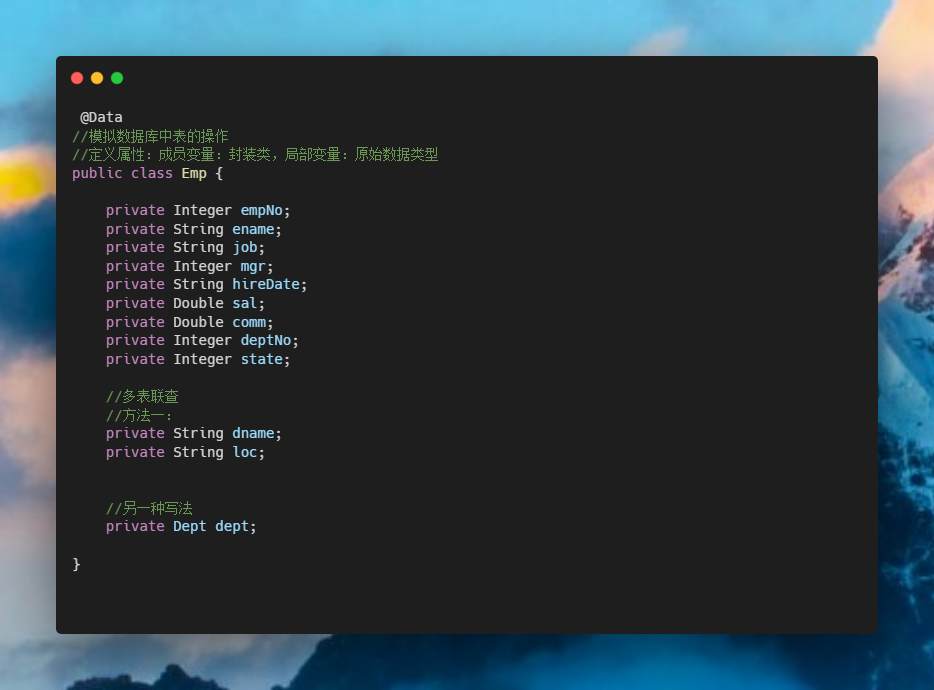
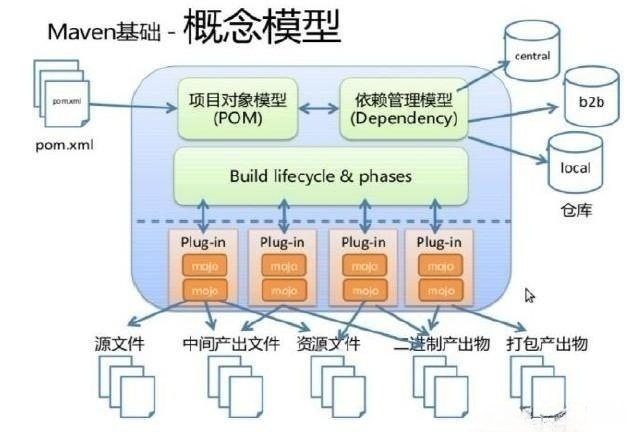
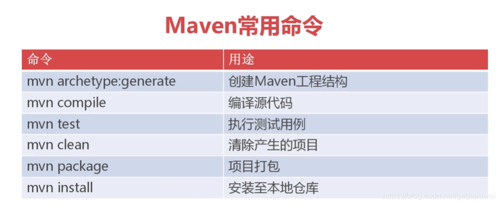
前情提要
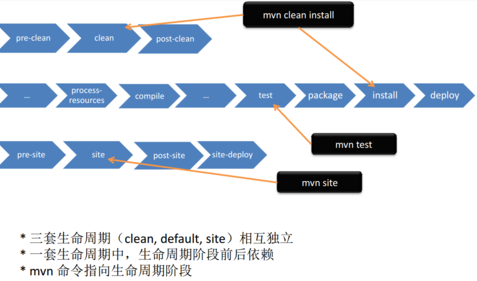
今天,产品找到我,说能不能实现这个图呢

众所周知,产品说啥就是啥,于是就直接开干。
小波折
为了实现我的需求做了下调研,看了d3还有x6之类的库,感觉都太重了,也不一定能实现我的需求。于是在沸点上寻求了下建议

掘友们建议canvas直接画

于是决定手撸
结果
之前没有使用canvas画过东西,于是花了一天边看文档,边画,最终画完了,效果如下:

代码及思路
首先构造数据集在画布上的节点位置
let stations = new Array(13).fill(null);
const cornerP = [
{ x: 20, y: 67.5, type: 'corner', showP: true },
{ x: 55, y: 47.5, type: 'corner', showP: false },
{ x: 337.5, y: 47.5, type: 'corner', showP: false },
{ x: 337.5, y: 112.5, type: 'corner', showP: false },
{ x: 55, y: 112.5, type: 'corner', showP: false },
{ x: 20, y: 92.5, type: 'corner', showP: true },
];
function getStationsPosition(): {
num: string;
status: number;
x: number;
y: number;
type?: string;
}[] {
const middleIndex = Math.floor(stations.length / 2);
const { width, height } = canvasRef.current as HTMLCanvasElement;
let centerPoint = { x: width - 20, y: height / 2 + 20 };
let leftArr = stations.filter((v, _i) => _i < middleIndex);
const leftWidth = (width - 40 - 35 - 32.5) / (leftArr.length - 1);
const leftP = leftArr.map((v, i) => ({
x: leftWidth * i + 55,
y: height / 2 + 20 - 32.5,
}));
const rightArr = stations.filter((v, _i) => _i > middleIndex);
const rightWidth = (width - 40 - 35 - 32.5) / (rightArr.length - 1);
const rightP = rightArr.map((v, i) => ({
x: 370 - 32.5 - rightWidth * i,
y: height / 2 + 20 + 32.5,
}));
return [
cornerP[0],
cornerP[1],
...leftP,
cornerP[2],
centerPoint,
cornerP[3],
...rightP,
cornerP[4],
cornerP[5],
].map((v, i) => ({
...v,
num: String(2),
status: i > 3 ? 0 : i > 2 ? 1 : 2,
}));
}
为了避免实际使用过程中,数据点位不够,上面的点位生成主动加入了拐角的点位。
然后画出背景路径
function drawBgLine(
points: ReturnType<typeof getStationsPosition>,
color?: string,
) {
const ctx = canvasRef.current?.getContext(
'2d',
) as unknown as CanvasRenderingContext2D;
points.forEach((item, index) => {
const next = points[index + 1];
if (next) {
if (next.y === item.y) {
ctx.beginPath();
ctx.moveTo(item.x, item.y);
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, )';
ctx.lineTo(next.x, next.y);
ctx.stroke();
} else if (Math.abs(next.y - item.y) === 32.5) {
ctx.beginPath();
if (next.x < item.x) {
ctx.arc(
next.x,
item.y,
32.5,
(Math.PI / 180) * 0,
(Math.PI / 180) * 90,
);
} else {
ctx.arc(
item.x,
next.y,
32.5,
(Math.PI / 180) * 270,
(Math.PI / 180) * 0,
);
}
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.stroke();
} else if (Math.abs(next.y - item.y) < 32.5) {
ctx.beginPath();
if (next.x < item.x) {
ctx.moveTo(item.x, item.y);
ctx.quadraticCurveTo(next.x, item.y, next.x, next.y);
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.stroke();
ctx.beginPath();
ctx.fillStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.arc(next.x, next.y, 4, 0, Math.PI * 2);
ctx.fill();
} else {
ctx.moveTo(item.x, item.y);
ctx.quadraticCurveTo(item.x, next.y, next.x, next.y);
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.stroke();
ctx.beginPath();
ctx.fillStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.arc(item.x, item.y, 4, 0, Math.PI * 2);
ctx.fill();
}
}
}
});
}
此处主要的思路是根据相领点位的高低差,来画不同的路径
然后画进度图层
function drawProgressBgLine(points: ReturnType<typeof getStationsPosition>) {
const ctx = canvasRef.current?.getContext(
'2d',
) as unknown as CanvasRenderingContext2D;
const index = points.findIndex((v) => v.status === 0);
const newArr = points.slice(0, index);
const lastEl = points[index];
const curEl = points[index - 1];
console.log(lastEl, curEl);
if (lastEl) {
if (lastEl.y === curEl.y) {
if (lastEl.x > curEl.x) {
const centerP = {
x: (lastEl.x - curEl.x) / 2 + curEl.x,
y: curEl.y,
};
const img = new Image();
img.src = carIcon;
img.onload = function () {
ctx.drawImage(img, centerP.x - 12, centerP.y - 32, 19, 24);
};
ctx.beginPath();
ctx.moveTo(curEl.x, curEl.y);
ctx.lineTo(centerP.x, centerP.y);
ctx.lineTo(centerP.x, centerP.y - 2);
ctx.lineTo(centerP.x + 3, centerP.y);
ctx.lineTo(centerP.x, centerP.y + 2);
ctx.lineTo(centerP.x, centerP.y);
ctx.fillStyle = 'rgba(107, 255, 236, 1)';
ctx.fill();
ctx.lineWidth = 4;
ctx.strokeStyle = 'rgba(107, 255, 236, 1)';
ctx.stroke();
}
}
}
drawBgLine(newArr, 'rgba(107, 255, 236, 1)');
}
主要是已经走过的路径线路变蓝,未走过的,获取两点中间位置,添加图标,箭头。这里箭头判断我未补全,等待实际使用补全
最后画出节点就可以了
function draw() {
if (!canvasRef.current) {
return;
}
const ctx = canvasRef.current?.getContext(
'2d',
) as unknown as CanvasRenderingContext2D;
ctx.clearRect(0, 0, canvasRef.current?.width, canvasRef.current?.height);
if (ctx) {
ctx.font = '12px serif';
ctx.fillStyle = '#fff';
ctx.fillText(text, 10, canvasRef.current?.height / 2 + 24);
const points = getStationsPosition();
drawBgLine(points);
drawProgressBgLine(points);
points.forEach((item) => {
if (item.type !== 'corner') {
ctx.clearRect(item.x - 6, item.y - 6, 12, 12);
ctx.beginPath();
ctx.moveTo(item.x, item.y);
ctx.fillStyle =
item.status === 2
? 'rgba(255, 157, 31, 1)'
: item.status === 1
? 'rgba(107, 255, 236, 1)'
: 'rgba(55, 59, 62, 1)';
ctx.arc(item.x, item.y, 4, 0, Math.PI * 2);
ctx.fill();
ctx.beginPath();
ctx.lineWidth = 1;
ctx.strokeStyle = 'rgba(55, 59, 62, 1)';
ctx.arc(item.x, item.y, 6, 0, Math.PI * 2);
ctx.stroke();
ctx.closePath();
ctx.fillStyle = '#fff';
ctx.fillText(item.num, item.x - 4, item.y - 12);
}
});
}
}
最后贴一下全部代码
import carIcon from '@/assets/images/map/map_car1.png';
import { useEffect, useRef } from 'react';
const LineCanvas = () => {
const canvasRef = useRef<HTMLCanvasElement>(null);
let text = '第3遍(15:00-18:00)';
let stations = new Array(13).fill(null);
const cornerP = [
{ x: 20, y: 67.5, type: 'corner', showP: true },
{ x: 55, y: 47.5, type: 'corner', showP: false },
{ x: 337.5, y: 47.5, type: 'corner', showP: false },
{ x: 337.5, y: 112.5, type: 'corner', showP: false },
{ x: 55, y: 112.5, type: 'corner', showP: false },
{ x: 20, y: 92.5, type: 'corner', showP: true },
];
function getStationsPosition(): {
num: string;
status: number;
x: number;
y: number;
type?: string;
}[] {
const middleIndex = Math.floor(stations.length / 2);
const { width, height } = canvasRef.current as HTMLCanvasElement;
let centerPoint = { x: width - 20, y: height / 2 + 20 };
let leftArr = stations.filter((v, _i) => _i < middleIndex);
const leftWidth = (width - 40 - 35 - 32.5) / (leftArr.length - 1);
const leftP = leftArr.map((v, i) => ({
x: leftWidth * i + 55,
y: height / 2 + 20 - 32.5,
}));
const rightArr = stations.filter((v, _i) => _i > middleIndex);
const rightWidth = (width - 40 - 35 - 32.5) / (rightArr.length - 1);
const rightP = rightArr.map((v, i) => ({
x: 370 - 32.5 - rightWidth * i,
y: height / 2 + 20 + 32.5,
}));
return [
cornerP[0],
cornerP[1],
...leftP,
cornerP[2],
centerPoint,
cornerP[3],
...rightP,
cornerP[4],
cornerP[5],
].map((v, i) => ({
...v,
num: String(2),
status: i > 3 ? 0 : i > 2 ? 1 : 2,
}));
}
function drawBgLine(
points: ReturnType<typeof getStationsPosition>,
color?: string,
) {
const ctx = canvasRef.current?.getContext(
'2d',
) as unknown as CanvasRenderingContext2D;
points.forEach((item, index) => {
const next = points[index + 1];
if (next) {
if (next.y === item.y) {
ctx.beginPath();
ctx.moveTo(item.x, item.y);
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.lineTo(next.x, next.y);
ctx.stroke();
} else if (Math.abs(next.y - item.y) === 32.5) {
ctx.beginPath();
if (next.x < item.x) {
ctx.arc(
next.x,
item.y,
32.5,
(Math.PI / 180) * 0,
(Math.PI / 180) * 90,
);
} else {
ctx.arc(
item.x,
next.y,
32.5,
(Math.PI / 180) * 270,
(Math.PI / 180) * 0,
);
}
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.stroke();
} else if (Math.abs(next.y - item.y) < 32.5) {
ctx.beginPath();
if (next.x < item.x) {
ctx.moveTo(item.x, item.y);
ctx.quadraticCurveTo(next.x, item.y, next.x, next.y);
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.stroke();
ctx.beginPath();
ctx.fillStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.arc(next.x, next.y, 4, 0, Math.PI * 2);
ctx.fill();
} else {
ctx.moveTo(item.x, item.y);
ctx.quadraticCurveTo(item.x, next.y, next.x, next.y);
ctx.lineWidth = 4;
ctx.strokeStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.stroke();
ctx.beginPath();
ctx.fillStyle = color ?? 'rgba(55, 59, 62, 0.5)';
ctx.arc(item.x, item.y, 4, 0, Math.PI * 2);
ctx.fill();
}
}
}
});
}
function drawProgressBgLine(points: ReturnType<typeof getStationsPosition>) {
const ctx = canvasRef.current?.getContext(
'2d',
) as unknown as CanvasRenderingContext2D;
const index = points.findIndex((v) => v.status === 0);
const newArr = points.slice(0, index);
const lastEl = points[index];
const curEl = points[index - 1];
console.log(lastEl, curEl);
if (lastEl) {
if (lastEl.y === curEl.y) {
if (lastEl.x > curEl.x) {
const centerP = {
x: (lastEl.x - curEl.x) / 2 + curEl.x,
y: curEl.y,
};
const img = new Image();
img.src = carIcon;
img.onload = function () {
ctx.drawImage(img, centerP.x - 12, centerP.y - 32, 19, 24);
};
ctx.beginPath();
ctx.moveTo(curEl.x, curEl.y);
ctx.lineTo(centerP.x, centerP.y);
ctx.lineTo(centerP.x, centerP.y - 2);
ctx.lineTo(centerP.x + 3, centerP.y);
ctx.lineTo(centerP.x, centerP.y + 2);
ctx.lineTo(centerP.x, centerP.y);
ctx.fillStyle = 'rgba(107, 255, 236, 1)';
ctx.fill();
ctx.lineWidth = 4;
ctx.strokeStyle = 'rgba(107, 255, 236, 1)';
ctx.stroke();
}
}
}
drawBgLine(newArr, 'rgba(107, 255, 236, 1)');
}
function draw() {
if (!canvasRef.current) {
return;
}
const ctx = canvasRef.current?.getContext(
'2d',
) as unknown as CanvasRenderingContext2D;
ctx.clearRect(0, 0, canvasRef.current?.width, canvasRef.current?.height);
if (ctx) {
ctx.font = '12px serif';
ctx.fillStyle = '#fff';
ctx.fillText(text, 10, canvasRef.current?.height / 2 + 24);
const points = getStationsPosition();
drawBgLine(points);
drawProgressBgLine(points);
points.forEach((item) => {
if (item.type !== 'corner') {
ctx.clearRect(item.x - 6, item.y - 6, 12, 12);
ctx.beginPath();
ctx.moveTo(item.x, item.y);
ctx.fillStyle =
item.status === 2
? 'rgba(255, 157, 31, 1)'
: item.status === 1
? 'rgba(107, 255, 236, 1)'
: 'rgba(55, 59, 62, 1)';
ctx.arc(item.x, item.y, 4, 0, Math.PI * 2);
ctx.fill();
ctx.beginPath();
ctx.lineWidth = 1;
ctx.strokeStyle = 'rgba(55, 59, 62, 1)';
ctx.arc(item.x, item.y, 6, 0, Math.PI * 2);
ctx.stroke();
ctx.closePath();
ctx.fillStyle = '#fff';
ctx.fillText(item.num, item.x - 4, item.y - 12);
}
});
}
}
useEffect(() => {
draw();
}, []);
return <canvas ref={canvasRef} width="390" height="120"></canvas>;
};
export default LineCanvas;
转载请注明出处!
作者:MshengYang_lazy
来源:juejin.cn/post/7312723512724439094