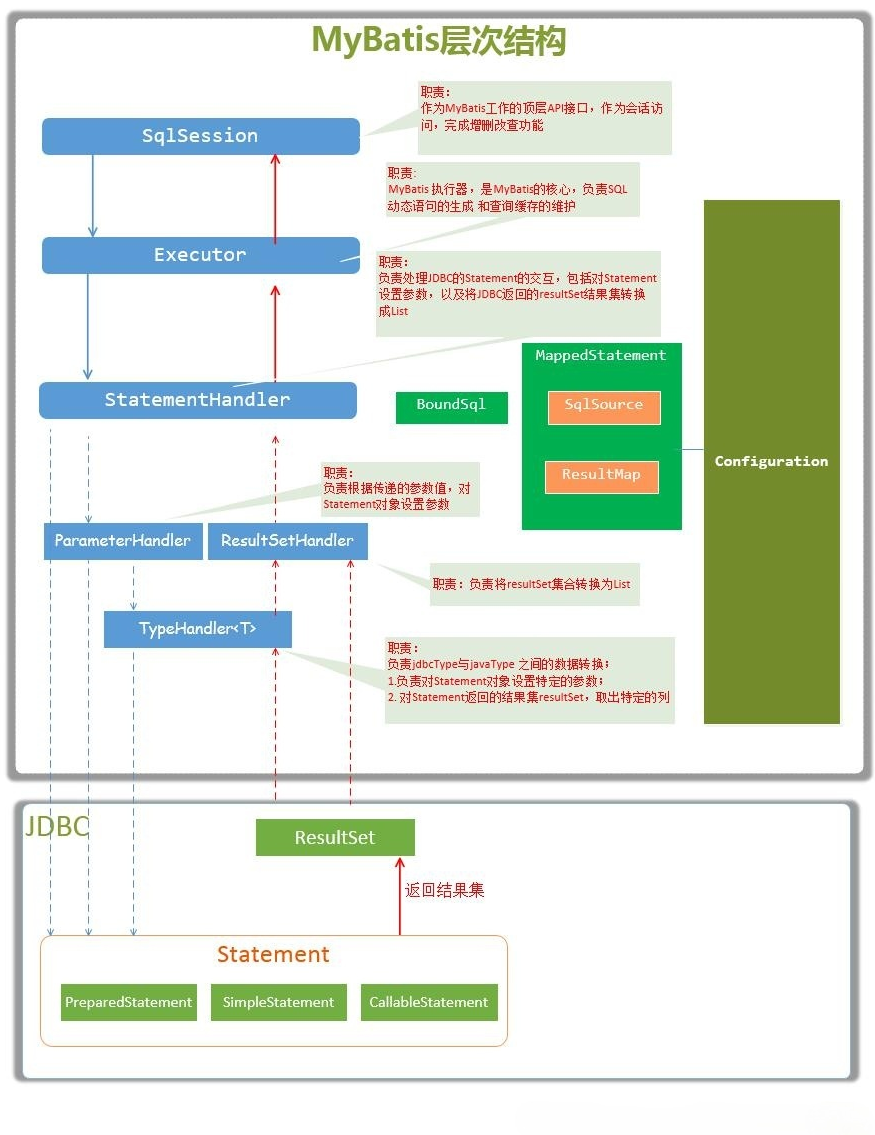
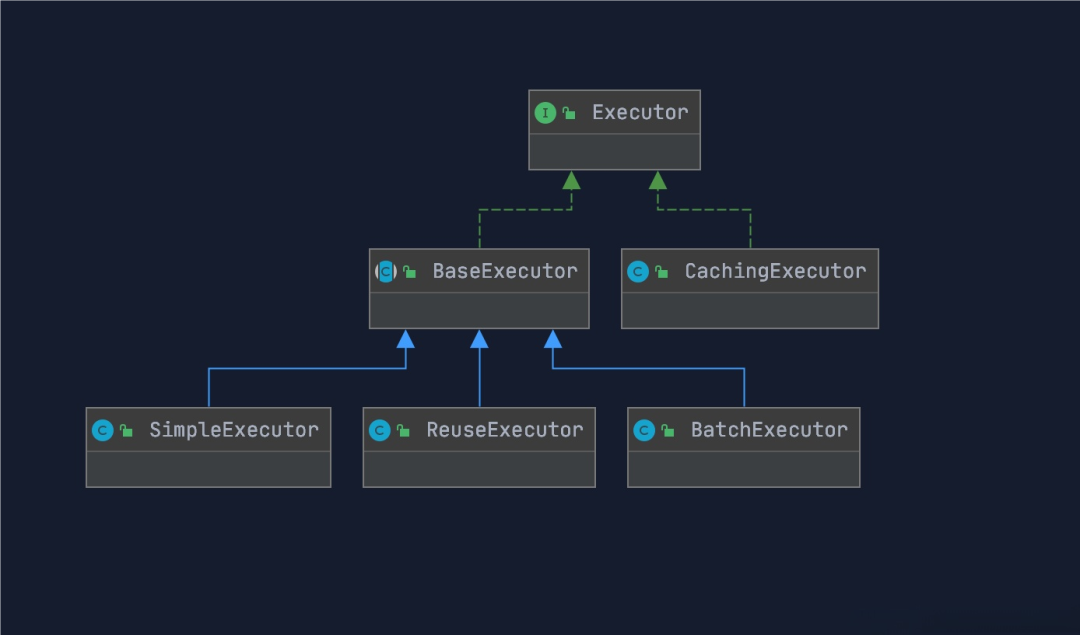
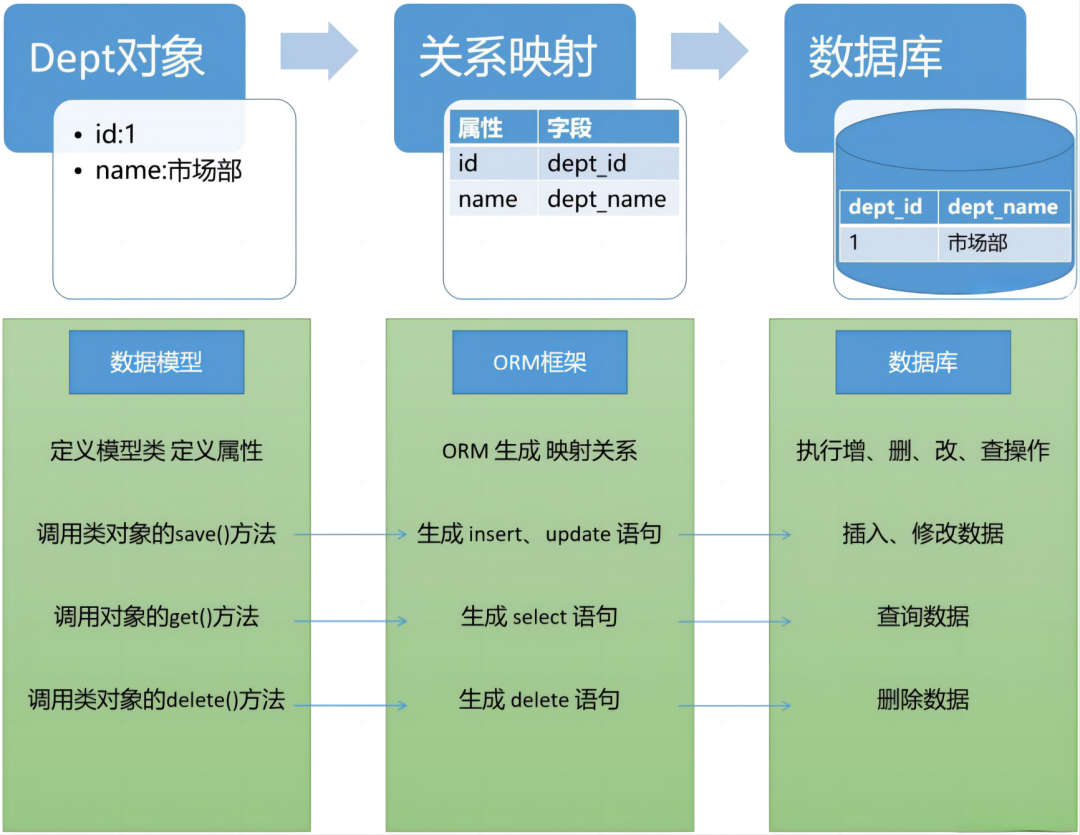
背景
年前的时候,开发一个电子杂志项目,功能需求是通过上传pdf文件,将其转为图片格式,所以杂志的内容其实就是一张张图片
不过当时技术要求用后端实现,所以使用的是PHP实现该功能。项目完成后,寻思着在前端是否也能实现pdf转图片的功能。一番研究后,果真可行。以下就分享如何通过前端js将pdf文件转为图片格式,并且支持翻页预览、以及图片打包下载
效果预览
 |
|---|
所需工具
- pdf.js(负责API解析,可将pdf文件渲染成canvas实现预览)
- pdf.worker.js(负责核心解析)
- jszip.js(将图片打包成生成.zip文件)
- Filesaver.js(保存下载zip文件)
工具下载
一、pdf.js及pdf.worker.js下载地址:
mozilla.github.io/pdf.js/gett…
1.选择稳定版下载

2.解压后将bulid中的pdf.js及pdf.worker.js拷贝到项目中

二、jszip.js及Filesaver.js下载地址:
stuk.github.io/jszip/
1.点击download.JSZip

2.解压后将dist文件夹下的jszip.js文件以及vendor文件夹下的FileSaver.js文件拷贝到项目中

至此,所需工具已齐全。以下直接附上项目完整代码(代码可直接复制使用,查看效果。 对应的文件需自行下载引入)
源代码: 嫌麻烦的小伙伴可以直接在公众号后回复: pdf转图片
代码实现
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>PDF文件转图片</title>
<script src="https://cdn.staticfile.org/jquery/1.10.2/jquery.min.js"></script>
<script type="text/javascript" src="js/pdf.js"></script>
<script type="text/javascript" src="js/pdf.worker.js"></script>
<script type="text/javascript" src="js/jszip.js"></script>
<script type="text/javascript" src="js/FileSaver.js"></script>
<style type="text/css">
button {
width: 120px;
height: 30px;
background: none;
border: 1px solid #b1afaf;
border-radius: 5px;
font-size: 12px;
font-weight: 1000;
color: #384240;
cursor: pointer;
outline: none;
margin: 0 0.5%
}
button:hover {
background: #ccc;
}
#container {
width: 600px;
height: 780px;
margin-top: 1%;
border-radius: 2px;
border: 2px solid #a29b9b;
}
.pdfInfos {
margin: 0 2%;
}
</style>
</head>
<body>
<div style="margin-top:1%">
<button id="prevpage">上一页</button>
<button id="nextpage">下一页</button>
<button id="exportImg">导出图片</button>
<button onclick="choosePdf()">选择一个pdf文件</button>
<input style="display:none" id='chooseFile' type='file' accept="application/pdf">
</div>
<div style="margin-top:1%">
<span class="pdfInfos">页码:<span id="currentPages"></span><span id="totalPages"></span></span>
<span class="pdfInfos">文件名:<span id="fileName"></span></span>
<span class="pdfInfos">文件大小:<span id="fileSize"></span></span>
</div>
<div style="position: relative;">
<div id="container"></div>
<img id="imgloading" style="position: absolute;top: 20%;left: 2%;display:none" src="loading.gif">
</div>
</body>
<script>
var currentPages,totalPages //声明一个当前页码及总页数变量
var scale = 2; //设置缩放比例,越大生成图片越清晰
$('#chooseFile').change(function() {
var pdfFilePath = $('#chooseFile').val();
if(pdfFilePath) {
$("#imgloading").css('display','block');
$("#container").empty(); //清空上一PDF文件展示图
currentPages=1; //重置当前页数
totalPages=0; //重置总页数
var filesdata = $('#chooseFile')[0].files; //jquery获取到文件 返回属性的值
var fileSize = filesdata[0].size; //文件大小
var mb;
if(fileSize) {
mb = fileSize / 1048576;
if(mb > 10) {
alert("文件大小不能>10M");
return;
}
}
$("#fileName").text(filesdata[0].name);
$("#fileSize").text(mb.toFixed(2) + "Mb");
var reader = new FileReader();
reader.readAsDataURL(filesdata[0]); //将文件读取为 DataURL
reader.onload = function(e) { //文件读取成功完成时触发
pdfjsLib.getDocument(this.result).then(function(pdf) { //调用pdf.js获取文件
if(pdf) {
totalPages = pdf.numPages; //获取pdf文件总页数
$("#currentPages").text("1/");
$("#totalPages").text(totalPages);
//遍历动态创建canvas
for(var i = 1; i <= totalPages; i++) {
var canvas = document.createElement('canvas');
canvas.id = "pageNum" + i;
$("#container").append(canvas);
var context = canvas.getContext('2d');
renderImg(pdf,i,context);
}
}
});
};
}
});
//渲染生成图片
function renderImg(pdfFile,pageNumber,canvasContext) {
pdfFile.getPage(pageNumber).then(function(page) { //逐页解析PDF
var viewport = page.getViewport(scale); // 页面缩放比例
var newcanvas = canvasContext.canvas;
//设置canvas真实宽高
newcanvas.width = viewport.width;
newcanvas.height = viewport.height;
//设置canvas在浏览中宽高
newcanvas.style.width = "100%";
newcanvas.style.height = "100%";
//默认显示第一页,其他页隐藏
if (pageNumber!=1) {
newcanvas.style.display = "none";
}
var renderContext = {
canvasContext: canvasContext,
viewport: viewport
};
page.render(renderContext); //渲染生成
});
$("#imgloading").css('display','none');
return;
};
//上一页
$("#prevpage").click(function(){
if (!currentPages||currentPages <= 1) {
return;
}
nowpage=currentPages;
currentPages--;
$("#currentPages").text(currentPages+"/");
var prevcanvas = document.getElementById("pageNum"+currentPages);
var currentcanvas = document.getElementById("pageNum"+nowpage);
currentcanvas.style.display = "none";
prevcanvas.style.display = "block";
})
//下一页
$("#nextpage").click(function(){
if (!currentPages||currentPages>=totalPages) {
return;
}
nowpage=currentPages;
currentPages++;
$("#currentPages").text(currentPages+"/");
var nextcanvas = document.getElementById("pageNum"+currentPages);
var currentcanvas = document.getElementById("pageNum"+nowpage);
currentcanvas.style.display = "none";
nextcanvas.style.display = "block";
})
//导出图片
$("#exportImg").click(function() {
if (!$('#chooseFile').val()) {
alert('请先上传pdf文件')
return false;
}
$("#imgloading").css('display','block');
var zip = new JSZip(); //创建一个JSZip实例
var images = zip.folder("images"); //创建一个文件夹用来存放图片
//遍历canvas,将其生成图片放进文件夹images中
$("canvas").each(function(index, ele) {
var canvas = document.getElementById("pageNum" + (index + 1));
//将图片放进文件夹images中
//参数1为图片名称,参数2为图片数据(格式为base64,需去除base64前缀 data:image/png;base64)
images.file("" + (index + 1) + ".png", splitBase64(canvas.toDataURL("image/png", 1.0)), {
base64: true
});
})
//打包下载
zip.generateAsync({
type: "blob"
}).then(function(content) {
saveAs(content, "picture.zip"); //saveAs依赖的js文件是FileSaver.js
$("#imgloading").css('display','none');
});
});
//截取base64前缀
function splitBase64(dataurl) {
var arr = dataurl.split(',')
return arr[1]
}
function choosePdf(){
$("#chooseFile").click()
}
</script>
</html>
项目实现原理分析
- 首先利用pdf.js将上传的pdf文件转化成canvas
- 然后使用jszip.js将canvas打包图片生成.zip文件
- 最后使用Filesaver.js将zip文件保存下载
项目注意要点
- 由于pdf文件是通过上传的,因此需要通过js的FileReader()对象将其读取为DataURL,pdf.js文件才可读取渲染
- JSZip对象的.file()函数中第二个参数传入的是base64格式图片,但是要去掉base64前缀标识
作者:程序员Winn
来源:juejin.cn/post/7238442926334918711
来源:juejin.cn/post/7238442926334918711





 命令行执行后出现这个界面表示服务启动成功了,然后访问我自己的ip+端口,再点击顶部
命令行执行后出现这个界面表示服务启动成功了,然后访问我自己的ip+端口,再点击顶部 去创建一个测试项目,建一个最简单的
去创建一个测试项目,建一个最简单的
 左下角出现
左下角出现 点击调试,就可以看到这个项目的一些实时调试信息,但是还没加什么代码。
点击调试,就可以看到这个项目的一些实时调试信息,但是还没加什么代码。 现在改一下我们的代码,加一些输出信息。
现在改一下我们的代码,加一些输出信息。 Console控制台的信息
Console控制台的信息 直接输出用户端代码变量的实时的值
直接输出用户端代码变量的实时的值 加个定时器试试,也是实时输出的
加个定时器试试,也是实时输出的
 再来看看Storage信息
再来看看Storage信息
 Element信息
Element信息 调个接口试试
调个接口试试

































![Video_20240120111316[00_00_12--00_00_15].gif](https://www.imgeek.net/uploads/article/20240122/ecbc3eb75e88f01b243fe5938a0de9f3.jpg)