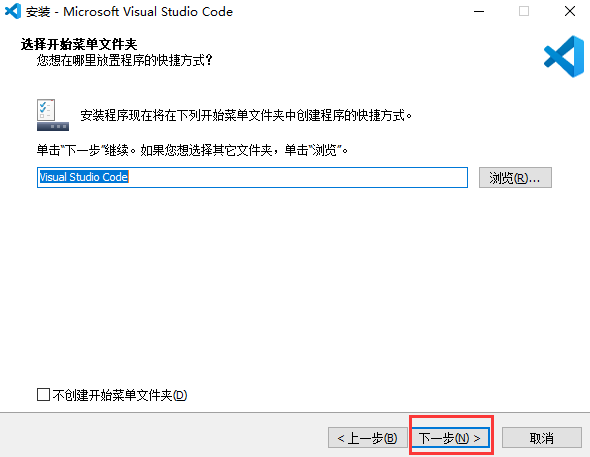
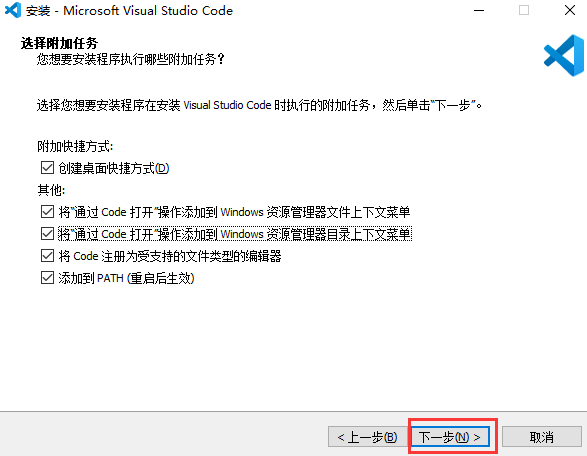
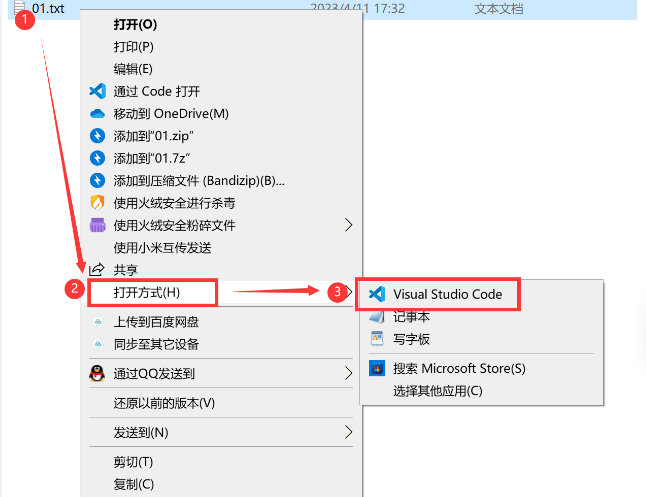
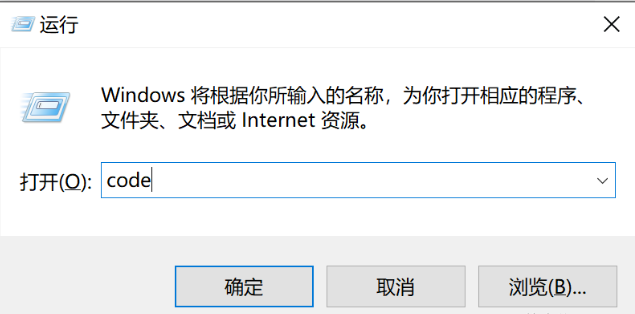
前言
过年期间在家里没事,把zustand的源码看了一遍,看完后我最大的收获就是ts水平突飞猛进,再去刷那些类型体操题目就变得简单了,下面和大家分享一下zustand库是怎么定义ts类型的。
ts类型推断
个人认为ts最大的作用有两个,一个是类型约束,另外一个是类型推断。
- 类型约束也叫类型安全,在编译阶段就能发现语法错误,可以有效减少低级错误。
- 类型推断,当你没有标明变量的类型时,编译器会根据一些简单的规则来推断你定义的变量的类型
这一篇主要和大家分享类型推断,类型推断主要有以下几种情况。
根据变量的值自动推导类型


函数返回值自动推断

函数中如果有条件分支,推导出来的返回值类型是所有分支的返回值类型的联合类型

ts的类型推导方式是懒推导,也就是说不会实际执行代码。

上图中如果实际执行了,c的类型是能确认为null的。
使用范型推导

可以看到按照上面写法,对象合并推导不出来,如果能推导出来u3应该等于 {name: string, age: number}。
这时候我们可以借助范型来推导

可以给上面代码简写为这样,编辑器也能推导出来

实战
实现pick方法
从一个对象中,返回指定的属性名称。

上面代码中定义了两个范型T和U,T表示对象,U被限定为T的属性名(U extends keyof T),返回值的类型为{[K in U]: T[K]},in的作用就是遍历U这个数组。

可以看到数组元素被限制了只能是user对象里的key


也正确的推导出来了
实现useRequest
先看一个例子
import { useEffect, useState } from 'react';
function getUsers(): Promise<{ name: string }[]> {
return new Promise(resolve => {
setTimeout(() => {
resolve([
{
name: 'tom',
},
{
name: 'jack',
},
]);
}, 1000);
})
}
const App = () => {
const [loading, setLoading] = useState(true);
const [users, setUsers] = useState<Awaited<ReturnType<typeof getUsers>>>([]);
const [error, setError] = useState(false);
useEffect(() => {
setLoading(true);
getUsers().then((res) => {
setUsers(res);
}).catch(() => {
setError(true);
}).finally(() => {
setLoading(false);
})
}, []);
if (loading) {
return (
<div>loading...</div>
)
}
if (error) {
return (
<div>error</div>
)
}
return (
<div
>
{users.map(u => (
<div key={u.name}>{u.name}</div>
))}
</div>
);
};
export default App;
上面这个例子实现了从后端请求用户列表,然后渲染出来。为了提高用户体验,在加载数据时,加了一个loading,当请求出错时,告诉用户请求失败。
代码比较简单我就不一一讲解了,有行代码需要注意一下。
const [users, setUsers] = useState<Awaited<ReturnType<typeof getUsers>>>([]);
typeof getUsers 获取getUsers函数类型
ReturnType 获取某个函数的返回值
Awaited 如果函数返回值为Promise,这个可以获取到最终的值类型。


可以看到,正确的获取到了getUsers函数的返回值类型。
然而一个很简单的功能需要写那么多代码,肯定是不合理的,那么我们给简化一下。目前市面上已经有不少库来解决这个问题了,比如react-query或ahooks库里的useRequest,都可以解决这个问题,我这里分享的不是具体代码实现,而是怎么写ts。
封装useRequest
import { useEffect, useState } from 'react';
export function useRequest<T extends () => Promise<unknown>>(
fn: T,
): {
loading: boolean;
error: boolean;
data: Awaited<ReturnType<T>>;
} {
const [loading, setLoading] = useState(false);
const [error, setError] = useState(false);
const [data, setData] = useState<any>();
useEffect(() => {
setLoading(true);
fn().then(res => {
setData(res);
}).catch(() => {
setError(true);
}).finally(() => {
setLoading(false);
});
}, [fn])
return {
loading,
error,
data,
};
}
改造app.tsx文件,使用useRequest
import { useRequest } from './useRequest';
function getUsers(): Promise<{ name: string }[]> {
return new Promise(resolve => {
setTimeout(() => {
resolve([
{
name: 'tom',
},
{
name: 'jack',
},
]);
}, 1000);
})
}
const App = () => {
const { loading, data: users, error } = useRequest(getUsers);
if (loading) {
return (
<div>loading...</div>
)
}
if (error) {
return (
<div>error</div>
)
}
return (
<div
>
{users.map(u => (
<div
key={u.name}
>
{u.name}
</div>
))}
</div>
);
};
export default App;
对比最开始的代码,是不是简单了很多。
useRequest.tsx代码也很简单,首先使用了范型限制fn只能是一个函数,返回值还必须是Promise。这个hooks返回值loading和error就不说了,主要是data,这个data要求和传进来的方法返回值一致,前面说过,可以使用Awaited<ReturnType<T>>获取函数的返回类型。

但是上面代码可能会导致bug,看下面代码,如果请求失败,users应该是空的,直接这样使用就会报错了。改造一下,当error为false的时候data为正常类型,error为true的时候data为null,这里可以使用联合类型。




加了一个判断后,下面就不会报错了。ts在某些时候,真的可以避免一些低级错误,我相信如果没有这个限制,肯定有人在写代码的时候不加判断直接用users。
如果请求接口的函数需要参数怎么办,下面来实现一下。

使用Parameters获取传入函数的参数类型


多个参数也是支持的

zustand
zustand是一个react状态管理库,使用起来比较简单没啥心智负担,所以我一直在用。
上面带着大家入门了ts的类型推断,下面给大家分享一下zustand的ts定义。我看完zustand源码后,发现这个库的ts定义比功能实现还复杂,这里我只给大家分享ts,具体实现掘金已经有很多大佬写过了,我就不分享了。
先从一个最简单的例子开始
import { create } from 'zustand';
interface State {
count: number;
}
interface Action {
inc: () => void;
}
export const useStore = create<State & Action>((set) => ({
count: 1,
inc: () => set((state) => ({count: state.count + 1})),
}));

create方法的定义
type Create = {
<T, Mos extends [StoreMutatorIdentifier, unknown][] = []>(
initializer: StateCreator<T, [], Mos>,
): UseBoundStore<Mutate<StoreApi<T>, Mos>>
<T>(): <Mos extends [StoreMutatorIdentifier, unknown][] = []>(
initializer: StateCreator<T, [], Mos>,
) => UseBoundStore<Mutate<StoreApi<T>, Mos>>
<S extends StoreApi<unknown>>(store: S): UseBoundStore<S>
}
可以看到create有三个重载方法,最后一个废弃不用了,上面例子使用的是第一个方法,第二个重载方法可以这样使用。

这样做的意义和中间件有关系,这个后面再说。
<T, Mos extends [StoreMutatorIdentifier, unknown][] = []>(
initializer: StateCreator<T, [], Mos>,
): UseBoundStore<Mutate<StoreApi<T>, Mos>>
我们先看第一个方法,定义了两个范型,T表示返回值类型,对应上面例子中create<State & Action>,Mos是给中间件用的,这个等会再说。
create方法的参数initializer定义
initializer: StateCreator<T, [], Mos>
参数initializer对应的类型是StateCreator
export type StateCreator<
T,
Mis extends [StoreMutatorIdentifier, unknown][] = [],
Mos extends [StoreMutatorIdentifier, unknown][] = [],
U = T,
> = ((
setState: Get<Mutate<StoreApi<T>, Mis>, 'setState', never>,
getState: Get<Mutate<StoreApi<T>, Mis>, 'getState', never>,
store: Mutate<StoreApi<T>, Mis>,
) => U) & { $$storeMutators?: Mos }
StateCreator定义了4个范型,T还是表示返回值类型,其余三个暂时用不到。
((
setState: Get<Mutate<StoreApi<T>, Mis>, 'setState', never>,
getState: Get<Mutate<StoreApi<T>, Mis>, 'getState', never>,
store: Mutate<StoreApi<T>, Mis>,
) => U) & { $$storeMutators?: Mos }
这段ts表明,initializer是一个函数,并且有三个参数,& { $$storeMutators?: Mos }表示交叉类型,也就是说这个函数可能会有$$storeMutators属性。
举个例子:

因为函数上没有$$name属性,所以报错了,下面给函数加上属性就可以了

setState: Get<Mutate<StoreApi<T>, Mis>, 'setState', never>
type Get<T, K, F> = K extends keyof T ? T[K] : F
定义了一个Get类型,表示K如果在T对象的可以中,则返回K属性对应的值类型,如果不在返回F。
看个例子

因为T对象中没有count属性,所以返回never,never表示不存在的类型。

因为T对象中有name属性,所以返回name字段对应的类型string。
Mutate<StoreApi<T>, Mis>
Mutate这个类型很复杂,是为了解决中间件类型提示出现的,后面再说,没有使用中间件的情况下可以把这段代码简化为StoreApi<T>。
export interface StoreApi<T> {
setState: SetStateInternal<T>
getState: () => T
getInitialState: () => T
subscribe: (listener: (state: T, prevState: T) => void) => () => void
destroy: () => void
}
type SetStateInternal<T> = {
_(
partial: T | Partial<T> | { _(state: T): T | Partial<T> }['_'],
replace?: boolean | undefined,
): void
}['_']
到这里我们就看到前面例子中set的定义了,set方法有两个参数,第一个参数可以是前面范型定义的一个对象,可以是对象中的一些属性,也可以是一个函数。第二个属性表示是否覆盖整个对象。
这里的["_"]让我有点迷惑,不知道有啥作用,也可以写成下面这样。
type SetStateInternal<T> = (
partial: T | Partial<T> | { _(state: T): T | Partial<T> }['_'],
replace?: boolean | undefined,
) => void
set竟然可以直接设置值,看完源码后,我才知道可以这样用,一般我都是用函数,然后使用函数返回值更新值。

create方法的返回值类型定义
UseBoundStore<Mutate<StoreApi<T>, Mos>>
上面说了没有中间件的情况下,可以简化为:UseBoundStore<StoreApi<T>>
export type UseBoundStore<S extends WithReact<ReadonlyStoreApi<unknown>>> = {
(): ExtractState<S>
<U>(selector: (state: ExtractState<S>) => U): U
<U>(
selector: (state: ExtractState<S>) => U,
equalityFn: (a: U, b: U) => boolean,
): U
} & S
type ExtractState<S> = S extends { getState: () => infer T } ? T : never
create返回值是一个函数,这个函数有三个重载方法,并且方法上还有一些属性,(& S)表示这些属性。
第一个重载方法表示没有参数时直接返回ExtractState<S>,ExtractState其实就是获取S对象中getState的返回值类型。

第二个重载方法有一个参数,可以返回自定义属性。

第三个重载方法废弃了,就不说了。

上图中useStore之所以有setState和getState等属性,就是上面& S的作用。
create第二个重载方法的作用
zustand支持使用中间件和编写中间件,看完官方持久化persist中间件的ts定义后,直接把我CPU干烧了,太复杂。
先看一下前面说过的,为啥create方法加了一个重载方法。
<T>(): <Mos extends [StoreMutatorIdentifier, unknown][] = []>(
initializer: StateCreator<T, [], Mos>,
) => Mutate<StoreApi<T>, Mos>
这个重载方法主要是给使用了中间件的情况下使用的,看一个例子。


上面例子中使用了官方提供的持久化中间件,如果使用第一种重载方法会报错,使用第二种就会报错,下面我们来分析一下为啥会这样。
先给上面代码简化一下
function a() {
console.log('hello');
}
type Fn = {
<T, U extends any[] = []>(name: U): T;
<T>(): <U extends any[] = []>(name: U) => T;
};
const b = a as Fn;
b(['hello'])

这时候我们调用第一个重载方法没有报错,加了范型后就报错了。

这是因为不使用范型的时候,编辑器会自动推导类型,如果传了一个范型,那么 U extends any[] = []会强制使用默认值[],所以传['hello']会报错。传[]就不会报错了。第二个重载方法的意义就是给两个范型拆开,这样设置了T不会应用U。

回到上面问题再看一下create方法的参数类型

因为传了一个范型约束,所以第二个参数使用默认值[]了

然而persist中间件返回值类型Mos不为[],所以报错了

针对这个问题,有两个解决方案
第一个方案是把范型去掉,把范型写在persist上。

第二个方案是用第二个重载方法

中间件返回值的类型定义
前面有个东西没说,create返回值里的Mutate<StoreApi<T>, Mos>是干嘛用的,先看下代码
export type Mutate<S, Ms> = number extends Ms['length' & keyof Ms]
? S
: Ms extends []
? S
: Ms extends [[infer Mi, infer Ma], ...infer Mrs]
? Mutate<StoreMutators<S, Ma>[Mi & StoreMutatorIdentifier], Mrs>
: never
第一次看这个的时候,直接给我看懵了,这是啥,怎么还有递归,然后恶补了一下ts类型体操知识,顺便把github上类型体操题目刷了一下,然后再回来看这个类型体操就很简单了。
先写一个简单的例子让大家入门一下类型体操,合并数组中的对象类型。
type a = [{ name: string }, { age: number }];
type C<T extends any[] = [], S = {}> = T extends [infer F, ...infer R] ? C<R, S & F> : S

理解了这个,那上面Mutate也就好理解了。
number extends Ms['length' & keyof Ms] ? S : : Ms extends [] ? S : ...这段表示如果Ms的类型为any[]则返回S,如果Ms为[]也返回S。
正常我们没有使用中间件的时候,Ms是[],所以直接返回S也就是StoreApi<State & Action>。
当使用中间件的时候,我们先看下persist返回值类型。

persist中间件源码中的类型定义

根据create方法initializer参数定义Mos被自动推导成了[["zustand/persist", State & Action]],Mos对应Mutate里的Ms。

Ms extends [[infer Mi, infer Ma], ...infer Mrs]
对比上面的Ms类型,Mi为"zustand/persist",Ma为State & Action,Mrs为[]。
Mutate<StoreMutators<S, Ma>[Mi & StoreMutatorIdentifier], Mrs>
接下来开始递归了,StoreMutators<S, Ma>[Mi & StoreMutatorIdentifier],把Mi替换成"zustand/persist",变成StoreMutators<S, Ma>["zustand/persist" & StoreMutatorIdentifier]。

最开始这段代码让很迷惑,因为StoreMutators在项目里定义的是空对象,上面这种写法取不到任何东西。然后我去persist中间件源码里看了一下,原来在persist里给StoreMutators扩展了。

这几个类型定义可以简单理解为是给Mutate里S添加了persist属性。而persist属性有下面这些方法。

type Write<T, U> = Omit<T, keyof U> & U
Write表示合并两个类型,如果有重复的key,用后面的覆盖前面。

可以看到两个对象合并了key,并且name被覆盖成了number类型。
所以当使用persist中间件时,Mutate<StoreApi<T>, Mos>最终类型为StoreApi<T> & { persist: { ... } },所以我们能create返回的值里调用persist里的方法。

自定义中间件
模拟per中间件,自己也写一个,没有写具体实现,只写了类型定义。
import { StateCreator, StoreMutatorIdentifier } from 'zustand';
type Test = <
T,
Mps extends [StoreMutatorIdentifier, unknown][] = [],
Mcs extends [StoreMutatorIdentifier, unknown][] = [],
U = T
>(
initializer: StateCreator<T, [...Mps, ['test', unknown]], Mcs>
) => StateCreator<T, Mps, [['test', U], ...Mcs]>;
type Write<T, U> = Omit<T, keyof U> & U;
declare module 'zustand' {
interface StoreMutators<S, A> {
test: Write<S, {test: {log: () => void}}>;
}
}
function a() {
console.log(444);
}
export const test = a as unknown as Test;

在中间件中也可以重写setState方法


总结
到此终于结束了,最复杂的create方法讲完了,其他都是简单的,就不分享了。说实话ts类型定义比代码实现难理解多了,也有可能是我开始的水平不够,所以看起来比较费劲。为了看懂这些ts,我把ts体操类型刷了一遍,现在我感觉自己ts提升了很多。找个时间看一下zod的源码,学习一下它的ts定义。
我看一些ts教程的文章下面,很多人吐槽说TypeScript没有用,个人觉得公司里的业务代码或者个人小项目确实可以不用,但是如果你要开发一个开源框架或组件库,我觉得ts或jsdoc还是有必要的,类型推断和准确的代码提示可以方便用户使用。
作者:前端小付
来源:juejin.cn/post/7339364757386264612



































































































































































 `
`









































































 代码如下:
代码如下:






