








牛逼,一款 996 代码分析工具
程序员是一个创作型的职业,频繁的加班并不能增加产出,而国内 996 的公司文化,真的一言难尽。但是如果你进到一家公司,你能从哪些观察来判断这家公司的工作强度的(加班文化)?是看大家走得早不早吗?有一定的参考意义,但是如果走得晚呢,可能是大家不敢提前走而在公司耗时间。
今天要推荐一个代码分析工具 code996,它可以统计 Git 项目的 commit 时间分布,进而推导出这个项目的编码工作强度。这算是一种对项目更了解的方式,杜绝 996 从了解数据开始。
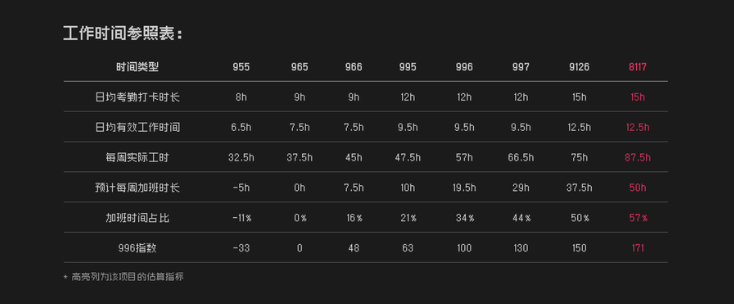
我们先来看 code996 分析出来的结果示例,以下是分析项目的基本情况:

通过图表查看 commit 提交分布:

对比项目工作时间类型:
如果你对 code996 是如何工作的,以下是作者的说明:

因为代码是公司的很重要的资产,泄露是肯定不行的,为了解决大家的后顾之忧,该项目是完全安全的。

code996 除了能够分析项目的实际工作强度,也能用来分析我们代码编写的情况,对自身了解自己代码编写效率的时段、最近的工作强度等都是非常好的一个输入。
更多项目详情请查看如下链接。
开源项目地址:https://github.com/hellodigua/code996
开源项目作者:hellodigua
收起阅读 »如何从0到1构建一个稳定、高性能的Redis集群
这篇文章我想和你聊一聊 Redis 的架构演化之路。
现如今 Redis 变得越来越流行,几乎在很多项目中都要被用到,不知道你在使用 Redis 时,有没有思考过,Redis 到底是如何稳定、高性能地提供服务的?
你也可以尝试回答一下以下这些问题:
- 我使用 Redis 的场景很简单,只使用单机版 Redis 会有什么问题吗?
- 我的 Redis 故障宕机了,数据丢失了怎么办?如何能保证我的业务应用不受影响?
- 为什么需要主从集群?它有什么优势?
- 什么是分片集群?我真的需要分片集群吗?
- …
如果你对 Redis 已经有些了解,肯定也听说过数据持久化、主从复制、哨兵这些概念,它们之间又有什么区别和联系呢?
如果你存在这样的疑惑,这篇文章,我会从 0 到 1,再从 1 到 N,带你一步步构建出一个稳定、高性能的 Redis 集群。
在这个过程中,你可以了解到 Redis 为了做到稳定、高性能,都采取了哪些优化方案,以及为什么要这么做?
掌握了这些原理,这样平时你在使用 Redis 时,就能够做到「游刃有余」。
这篇文章干货很多,希望你可以耐心读完。

从最简单的开始:单机版 Redis
首先,我们从最简单的场景开始。
假设现在你有一个业务应用,需要引入 Redis 来提高应用的性能,此时你可以选择部署一个单机版的 Redis 来使用,就像这样:

这个架构非常简单,你的业务应用可以把 Redis 当做缓存来使用,从 MySQL 中查询数据,然后写入到 Redis 中,之后业务应用再从 Redis 中读取这些数据,由于 Redis 的数据都存储在内存中,所以这个速度飞快。
如果你的业务体量并不大,那这样的架构模型基本可以满足你的需求。是不是很简单?
随着时间的推移,你的业务体量逐渐发展起来了,Redis 中存储的数据也越来越多,此时你的业务应用对 Redis 的依赖也越来越重。
但是,突然有一天,你的 Redis 因为某些原因宕机了,这时你的所有业务流量,都会打到后端 MySQL 上,这会导致你的 MySQL 压力剧增,严重的话甚至会压垮 MySQL。

这时你应该怎么办?
我猜你的方案肯定是,赶紧重启 Redis,让它可以继续提供服务。
但是,因为之前 Redis 中的数据都在内存中,尽管你现在把 Redis 重启了,之前的数据也都丢失了。重启后的 Redis 虽然可以正常工作,但是由于 Redis 中没有任何数据,业务流量还是都会打到后端 MySQL 上,MySQL 的压力还是很大。
这可怎么办?你陷入了沉思。
有没有什么好的办法解决这个问题?
既然 Redis 只把数据存储在内存中,那是否可以把这些数据也写一份到磁盘上呢?
如果采用这种方式,当 Redis 重启时,我们把磁盘中的数据快速恢复到内存中,这样它就可以继续正常提供服务了。
是的,这是一个很好的解决方案,这个把内存数据写到磁盘上的过程,就是「数据持久化」。
数据持久化:有备无患
现在,你设想的 Redis 数据持久化是这样的:

但是,数据持久化具体应该怎么做呢?
我猜你最容易想到的一个方案是,Redis 每一次执行写操作,除了写内存之外,同时也写一份到磁盘上,就像这样:

没错,这是最简单直接的方案。
但仔细想一下,这个方案有个问题:客户端的每次写操作,既需要写内存,又需要写磁盘,而写磁盘的耗时相比于写内存来说,肯定要慢很多!这势必会影响到 Redis 的性能。
如何规避这个问题?
我们可以这样优化:Redis 写内存由主线程来做,写内存完成后就给客户端返回结果,然后 Redis 用另一个线程去写磁盘,这样就可以避免主线程写磁盘对性能的影响。
这确实是一个好方案。除此之外,我们可以换个角度,思考一下还有什么方式可以持久化数据?
这时你就要结合 Redis 的使用场景来考虑了。
回忆一下,我们在使用 Redis 时,通常把它用作什么场景?
是的,缓存。
把 Redis 当做缓存来用,意味着尽管 Redis 中没有保存全量数据,对于不在缓存中的数据,我们的业务应用依旧可以通过查询后端数据库得到结果,只不过查询后端数据的速度会慢一点而已,但对业务结果其实是没有影响的。
基于这个特点,我们的 Redis 数据持久化还可以用「数据快照」的方式来做。
那什么是数据快照呢?
简单来讲,你可以这么理解:
- 你把 Redis 想象成一个水杯,向 Redis 写入数据,就相当于往这个杯子里倒水
- 此时你拿一个相机给这个水杯拍一张照片,拍照的这一瞬间,照片中记录到这个水杯中水的容量,就是水杯的数据快照

也就是说,Redis 的数据快照,是记录某一时刻下 Redis 中的数据,然后只需要把这个数据快照写到磁盘上就可以了。
它的优势在于,只在需要持久化时,把数据「一次性」写入磁盘,其它时间都不需要操作磁盘。
基于这个方案,我们可以定时给 Redis 做数据快照,把数据持久化到磁盘上。

其实,上面说的这些持久化方案,就是 Redis 的「RDB」和「AOF」:
- RDB:只持久化某一时刻的数据快照到磁盘上(创建一个子进程来做)
- AOF:每一次写操作都持久到磁盘(主线程写内存,根据策略可以配置由主线程还是子线程进行数据持久化)
它们的区别除了上面讲到的,还有以下特点:
- RDB 采用二进制 + 数据压缩的方式写磁盘,这样文件体积小,数据恢复速度也快
- AOF 记录的是每一次写命令,数据最全,但文件体积大,数据恢复速度慢
如果让你来选择持久化方案,你可以这样选择:
- 如果你的业务对于数据丢失不敏感,采用 RDB 方案持久化数据
- 如果你的业务对数据完整性要求比较高,采用 AOF 方案持久化数据
假设你的业务对 Redis 数据完整性要求比较高,选择了 AOF 方案,那此时你又会遇到这些问题:
- AOF 记录每一次写操作,随着时间增长,AOF 文件体积会越来越大
- 这么大的 AOF 文件,在数据恢复时变得非常慢
这怎么办?数据完整性要求变高了,恢复数据也变困难了?有没有什么方法,可以缩小文件体积?提升恢复速度呢?
我们继续来分析 AOF 的特点。
由于 AOF 文件中记录的都是每一次写操作,但对于同一个 key 可能会发生多次修改,我们只保留最后一次被修改的值,是不是也可以?
是的,这就是我们经常听到的「AOF rewrite」,你也可以把它理解为 AOF 「瘦身」。
我们可以对 AOF 文件定时 rewrite,避免这个文件体积持续膨胀,这样在恢复时就可以缩短恢复时间了。

再进一步思考一下,还有没有办法继续缩小 AOF 文件?
回顾一下我们前面讲到的,RDB 和 AOF 各自的特点:
- RDB 以二进制 + 数据压缩方式存储,文件体积小
- AOF 记录每一次写命令,数据最全
我们可否利用它们各自的优势呢?
当然可以,这就是 Redis 的「混合持久化」。
具体来说,当 AOF rewrite 时,Redis 先以 RDB 格式在 AOF 文件中写入一个数据快照,再把在这期间产生的每一个写命令,追加到 AOF 文件中。因为 RDB 是二进制压缩写入的,这样 AOF 文件体积就变得更小了。

此时,你在使用 AOF 文件恢复数据时,这个恢复时间就会更短了!
Redis 4.0 以上版本才支持混合持久化。
这么一番优化,你的 Redis 再也不用担心实例宕机了,当发生宕机时,你就可以用持久化文件快速恢复 Redis 中的数据。
但这样就没问题了吗?
仔细想一下,虽然我们已经把持久化的文件优化到最小了,但在恢复数据时依旧是需要时间的,在这期间你的业务应用还是会受到影响,这怎么办?
我们来分析有没有更好的方案。
一个实例宕机,只能用恢复数据来解决,那我们是否可以部署多个 Redis 实例,然后让这些实例数据保持实时同步,这样当一个实例宕机时,我们在剩下的实例中选择一个继续提供服务就好了。
没错,这个方案就是接下来要讲的「主从复制:多副本」。
主从复制:多副本
此时,你可以部署多个 Redis 实例,架构模型就变成了这样:

我们这里把实时读写的节点叫做 master,另一个实时同步数据的节点叫做 slave。
采用多副本的方案,它的优势是:
- 缩短不可用时间:master 发生宕机,我们可以手动把 slave 提升为 master 继续提供服务
- 提升读性能:让 slave 分担一部分读请求,提升应用的整体性能

这个方案不错,不仅节省了数据恢复的时间,还能提升性能,那它有什么问题吗?
你可以思考一下。
其实,它的问题在于:当 master 宕机时,我们需要「手动」把 slave 提升为 master,这个过程也是需要花费时间的。
虽然比恢复数据要快得多,但还是需要人工介入处理。一旦需要人工介入,就必须要算上人的反应时间、操作时间,所以,在这期间你的业务应用依旧会受到影响。
怎么解决这个问题?我们是否可以把这个切换的过程,变成自动化呢?
对于这种情况,我们需要一个「故障自动切换」机制,这就是我们经常听到的「哨兵」所具备的能力。
哨兵:故障自动切换
现在,我们可以引入一个「观察者」,让这个观察者去实时监测 master 的健康状态,这个观察者就是「哨兵」。
具体如何做?
- 哨兵每间隔一段时间,询问 master 是否正常
- master 正常回复,表示状态正常,回复超时表示异常
- 哨兵发现异常,发起主从切换

有了这个方案,就不需要人去介入处理了,一切就变得自动化了,是不是很爽?
但这里还有一个问题,如果 master 状态正常,但这个哨兵在询问 master 时,它们之间的网络发生了问题,那这个哨兵可能会误判。

这个问题怎么解决?
答案是,我们可以部署多个哨兵,让它们分布在不同的机器上,它们一起监测 master 的状态,流程就变成了这样:
- 多个哨兵每间隔一段时间,询问 master 是否正常
- master 正常回复,表示状态正常,回复超时表示异常
- 一旦有一个哨兵判定 master 异常(不管是否是网络问题),就询问其它哨兵,如果多个哨兵(设置一个阈值)都认为 master 异常了,这才判定 master 确实发生了故障
- 多个哨兵经过协商后,判定 master 故障,则发起主从切换
所以,我们用多个哨兵互相协商来判定 master 的状态,这样一来,就可以大大降低误判的概率。
哨兵协商判定 master 异常后,这里还有一个问题:由哪个哨兵来发起主从切换呢?
答案是,选出一个哨兵「领导者」,由这个领导者进行主从切换。
问题又来了,这个领导者怎么选?
想象一下,在现实生活中,选举是怎么做的?
是的,投票。
在选举哨兵领导者时,我们可以制定这样一个选举规则:
- 每个哨兵都询问其它哨兵,请求对方为自己投票
- 每个哨兵只投票给第一个请求投票的哨兵,且只能投票一次
- 首先拿到超过半数投票的哨兵,当选为领导者,发起主从切换
其实,这个选举的过程就是我们经常听到的:分布式系统领域中的「共识算法」。
什么是共识算法?
我们在多个机器部署哨兵,它们需要共同协作完成一项任务,所以它们就组成了一个「分布式系统」。
在分布式系统领域,多个节点如何就一个问题达成共识的算法,就叫共识算法。
在这个场景下,多个哨兵共同协商,选举出一个都认可的领导者,就是使用共识算法完成的。
这个算法还规定节点的数量必须是奇数个,这样可以保证系统中即使有节点发生了故障,剩余超过「半数」的节点状态正常,依旧可以提供正确的结果,也就是说,这个算法还兼容了存在故障节点的情况。
共识算法在分布式系统领域有很多,例如 Paxos、Raft,哨兵选举领导者这个场景,使用的是 Raft 共识算法,因为它足够简单,且易于实现。
现在,我们用多个哨兵共同监测 Redis 的状态,这样一来,就可以避免误判的问题了,架构模型就变成了这样:

好了,到这里我们先小结一下。
你的 Redis 从最简单的单机版,经过数据持久化、主从多副本、哨兵集群,这一路优化下来,你的 Redis 不管是性能还是稳定性,都越来越高,就算节点发生故障,也不用担心了。
你的 Redis 以这样的架构模式部署,基本上就可以稳定运行很长时间了。
…
随着时间的发展,你的业务体量开始迎来了爆炸性增长,此时你的架构模型,还能够承担这么大的流量吗?
我们一起来分析一下:
- 稳定性:Redis 故障宕机,我们有哨兵 + 副本,可以自动完成主从切换
- 性能:读请求量增长,我们可以再部署多个 slave,读写分离,分担读压力
- 性能:写请求量增长,但我们只有一个 master 实例,这个实例达到瓶颈怎么办?
看到了么,当你的写请求量越来越大时,一个 master 实例可能就无法承担这么大的写流量了。
要想完美解决这个问题,此时你就需要考虑使用「分片集群」了。
分片集群:横向扩展
什么是「分片集群」?
简单来讲,一个实例扛不住写压力,那我们是否可以部署多个实例,然后把这些实例按照一定规则组织起来,把它们当成一个整体,对外提供服务,这样不就可以解决集中写一个实例的瓶颈问题吗?
所以,现在的架构模型就变成了这样:

现在问题又来了,这么多实例如何组织呢?
我们制定规则如下:
- 每个节点各自存储一部分数据,所有节点数据之和才是全量数据
- 制定一个路由规则,对于不同的 key,把它路由到固定一个实例上进行读写
而分片集群根据路由规则所在位置的不同,还可以分为两大类:
- 客户端分片
- 服务端分片
客户端分片指的是,key 的路由规则放在客户端来做,就是下面这样:

这个方案的缺点是,客户端需要维护这个路由规则,也就是说,你需要把路由规则写到你的业务代码中。
如何做到不把路由规则耦合在业务代码中呢?
你可以这样优化,把这个路由规则封装成一个模块,当需要使用时,集成这个模块就可以了。
这就是 Redis Cluster 的采用的方案。

Redis Cluster 内置了哨兵逻辑,无需再部署哨兵。
当你使用 Redis Cluster 时,你的业务应用需要使用配套的 Redis SDK,这个 SDK 内就集成好了路由规则,不需要你自己编写了。
再来看服务端分片。
这种方案指的是,路由规则不放在客户端来做,而是在客户端和服务端之间增加一个「中间代理层」,这个代理就是我们经常听到的 Proxy。
而数据的路由规则,就放在这个 Proxy 层来维护。
这样一来,你就无需关心服务端有多少个 Redis 节点了,只需要和这个 Proxy 交互即可。
Proxy 会把你的请求根据路由规则,转发到对应的 Redis 节点上,而且,当集群实例不足以支撑更大的流量请求时,还可以横向扩容,添加新的 Redis 实例提升性能,这一切对于你的客户端来说,都是透明无感知的。
业界开源的 Redis 分片集群方案,例如 Twemproxy、Codis 就是采用的这种方案。

分片集群在数据扩容时,还涉及到了很多细节,这块内容不是本文章重点,所以暂不详述。
至此,当你使用分片集群后,对于未来更大的流量压力,都可以从容面对了!
总结
好了,我们来总结一下,我们是如何一步步构建一个稳定、高性能的 Redis 集群的。
首先,在使用最简单的单机版 Redis 时,我们发现当 Redis 故障宕机后,数据无法恢复的问题,因此我们想到了「数据持久化」,把内存中的数据也持久化到磁盘上一份,这样 Redis 重启后就可以从磁盘上快速恢复数据。
在进行数据持久化时,我们又面临如何更高效地将数据持久化到磁盘的问题。之后我们发现 Redis 提供了 RDB 和 AOF 两种方案,分别对应了数据快照和实时的命令记录。当我们对数据完整性要求不高时,可以选择 RDB 持久化方案。如果对于数据完整性要求较高,那么可以选择 AOF 持久化方案。
但是我们又发现,AOF 文件体积会随着时间增长变得越来越大,此时我们想到的优化方案是,使用 AOF rewrite 的方式对其进行瘦身,减小文件体积,再后来,我们发现可以结合 RDB 和 AOF 各自的优势,在 AOF rewrite 时使用两者结合的「混合持久化」方式,又进一步减小了 AOF 文件体积。
之后,我们发现尽管可以通过数据恢复的方式还原数据,但恢复数据也是需要花费时间的,这意味着业务应用还是会受到影响。我们进一步优化,采用「多副本」的方案,让多个实例保持实时同步,当一个实例故障时,可以手动把其它实例提升上来继续提供服务。
但是这样也有问题,手动提升实例上来,需要人工介入,人工介入操作也需要时间,我们开始想办法把这个流程变得自动化,所以我们又引入了「哨兵」集群,哨兵集群通过互相协商的方式,发现故障节点,并可以自动完成切换,这样就大幅降低了对业务应用的影响。
最后,我们把关注点聚焦在如何支撑更大的写流量上,所以,我们又引入了「分片集群」来解决这个问题,让多个 Redis 实例分摊写压力,未来面对更大的流量,我们还可以添加新的实例,横向扩展,进一步提升集群的性能。
至此,我们的 Redis 集群才得以长期稳定、高性能的为我们的业务提供服务。
这里我画了一个思维导图,方便你更好地去理解它们之间的关系,以及演化的过程。

后记
看到这里,我想你对如何构建一个稳定、高性能的 Redis 集群问题时,应该会有自己的见解了。
其实,这篇文章所讲的优化思路,围绕的主题就是「架构设计」的核心思想:
- 高性能:读写分离、分片集群
- 高可用:数据持久化、多副本、故障自动切换
- 易扩展:分片集群、横向扩展
当我们讲到哨兵集群、分片集群时,这还涉及到了「分布式系统」相关的知识:
- 分布式共识:哨兵领导者选举
- 负载均衡:分片集群数据分片、数据路由
当然,除了 Redis 之外,对于构建任何一个数据集群,你都可以沿用这个思路去思考、去优化,看看它们到底是如何做的。
例如当你在使用 MySQL 时,你可以思考一下 MySQL 与 Redis 有哪些不同?MySQL 为了做到高性能、高可用,又是如何做的?其实思路都是类似的。
我们现在到处可见分布式系统、数据集群,我希望通过这篇文章,你可以理解这些软件是如何一步步演化过来的,在演化过程中,它们遇到了哪些问题,为了解决这些问题,这些软件的设计者设计了怎样的方案,做了哪些取舍?
你只有了解了其中的原理,掌握了分析问题、解决问题的能力,这样在以后的开发过程中,或是学习其它优秀软件时,就能快速地找到「重点」,在最短的时间掌握它,并能在实际应用中发挥它们的优势。
其实这个思考过程,也是做「架构设计」的思路。在做软件架构设计时,你面临的场景就是发现问题、分析问题、解决问题,一步步去演化、升级你的架构,最后在性能、可靠性方面达到一个平衡。虽然各种软件层出不穷,但架构设计的思想不会变,我希望你真正吸收的是这些思想,这样才可以做到以不变应万变。
来源:mp.weixin.qq.com/s/q79ji-cgfUMo7H0p254QRg
收起阅读 »Go语言负责人离职后,一门国产语言诞生了
1 事件回顾
上周,谷歌Go语言项目负责人Steve Francia宣布辞去职务,而他给出理由是:Go项目的工作停滞不前,让他感到难受。
有意思的是,部分国内的Gopher(Go语言爱好者的自称)对Go语言也产生了新想法。比如,国内第一批Go语言爱好者之一的柴树杉、全球Go贡献者榜上长期排名TOP 50的史斌等Gopher,他们决定以Go语言为蓝本,发起新的编程语言:凹语言™(凹读音“Wa”)。
目前凹语言™的代码已经在Github开源,并且提供了简单可执行的示例。根据其仓库的介绍,凹语言™的设计目标有以下几个:
1、披着Go和Rust语法外衣的C++语言
2、凹语言™源码文件后缀为.wa
3、凹语言™编译器兼容WaGo语法,凹语法与WaGo语法在AST层面一致(二者可生成相同的AST并无损的互相转换)
4、凹语言™支持中文/英文双语关键字,即任一关键字均有中文版和英文版,二者在语法层面等价

凹语言™示意,图片来源@GitHub
据柴树杉、史斌等人的说法,Go语言“克制”的风格是他们对编程语言审美的最大公约数。因此,凹语言™项目启动时大量借鉴了Go的设计思想和具体实现。
当然,他们也表示,选择Go语言作为初始的蓝本,是在有限投入下不得不作出的折衷。他们希望随着项目的发展,积累更多原创的设计,为自主创新的大潮贡献一点力量。
虽说柴树杉、史斌等人是资深的Gopher,偏爱Go语言并不难理解,但我们还是忍不住好奇:究竟Go语言有多神奇,让他们对Go语言这么着迷?
2 为什么选中Go语言
从许多使用过Go语言的开发者对Go的评价上看,Go语言在设计上有以下四个特点。
1、简单易用
不同于那些通过相互借鉴而不断增加新特性的主流编程语言(如C++、Java等),Go的设计者们在语言设计之初就拒绝走语言特性融合的道路,而选择了“做减法”。
他们把复杂留给了语言自身的设计和实现,留给了Go核心开发组,而将简单、易用和清晰留给了广大使用Go语言的开发者。因此,Go语言呈现出:
简洁、常规的语法(不需要解析符号表),仅有25个关键字;
没有头文件;
显式依赖(package);
没有循环依赖(package);
常量只是数字;
首字母大小写决定可见性;
任何类型都可以拥有方法(没有类);
没有子类型继承(没有子类);
没有算术转换;
没有构造函数或析构函数;
赋值不是表达式;
在赋值和函数调用中定义的求值顺序(无“序列点”概念);
没有指针算术;
内存总是初始化为零值;
没有类型注解语法(如C++中的const、static等)
……
2、偏好组合
C++、Java等主流面向对象语言,通过庞大的自上而下的类型体系、继承、显式接口实现等机制,将程序的各个部分耦合起来,但在Go语言中我们找不到经典面向对象的语法元素、类型体系和继承机制。
那Go语言是如何将程序的各个部分耦合在一起呢?是组合。
在语言设计层面,Go使用了正交的语法元素,包括Go语言无类型体系,类型之间是独立的,没有子类型的概念;每个类型都可以有自己的方法集合,类型定义与方法实现是正交独立的。
各类型之间通过类型嵌入,将已经实现的功能嵌入新类型中,以快速满足新类型的功能需求。在通过新类型实例调用方法时,方法的匹配取决于方法名字,而不是类型。
另外,通过在接口的定义中嵌入接口类型来实现接口行为的聚合,组成大接口,这种方式在标准库中尤为常用,并且已经成为Go语言的一种惯用法。
这是Go语言的一个创新设计:接口只是方法集合,且与实现者之间的关系是隐式的,如此可让程序各个部分之间的耦合降至最低。
3、并发和轻量
Go语言的三位设计者Rob Pike、Robert Griesemer和Ken Thompson曾认为C++标准委员会在思路上是短视的,因为硬件很可能在未来十年内发生重大变化,将语言与当时的硬件紧密耦合起来是十分不明智的,是没法给开发人员在编写大规模并发程序时带去太多帮助的。
因而他们把将面向多核、原生内置并发支持作为新语言的设计原则之一。
Go语言原生支持并发的设计哲学体现在下面两点。
(1)Go语言采用轻量级协程并发模型,使得Go应用在面向多核硬件时更具可扩展性。
(2)Go语言为开发者提供的支持并发的语法元素和机制。
4、面向工程
Go语言的设计者在Go语言最初设计阶段,就将解决工程问题作为Go的设计原则之一,进而考虑Go语法、工具链与标准库的设计,这也是Go与那些偏学院派、偏研究性编程语言在设计思路上的一个重大差异。
这让Go语言的规范足够简单灵活,有其他语言基础的程序员都能迅速上手。更重要的是Go自带完善的工具链,大大提高了团队协作的一致性。比如Gofmt自动排版Go代码,很大程度上杜绝了不同人写的代码排版风格不一致的问题。把编辑器配置成在编辑存档的时候自动运行Gofmt,这样在编写代码的时候可以随意摆放位置,存档的时候自动变成正确排版的代码。此外还有Gofix,Govet等非常有用的工具。
总之,Go在语言层面的简单让Go收获了不逊于C++/Java等的表现力的同时,还获得了更好的可读性、更高的开发效率等在软件工程领域更为重要的元素。
3 凹语言™的未来
虽然今天,Go凭借其优越的性能,已经成为主流编程语言之一(超过75%的CNCF项目,包括Kubernetes和Istio,都是用Go编写的,另外,Go也是主要的云应用程序语言之一),Go语言在中国也相当受欢迎,但我们还是不禁担心脱胎于Go的凹语言™,会有美好的未来吗?
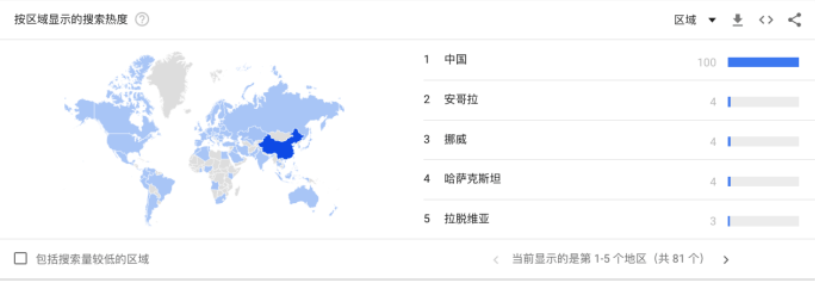
Go语言搜索热度,图片来源@Google Trend
预测未来从来都是困难的,不过,好在凹语言™的前面有一个先行者——Go+语言,我们不妨基于Go+的发展,来大致推测凹语言™的未来。
Go+是七牛云CEO许式伟发明的编程语言,于2020年7月正式发布,2021年10月推出1.0版本,目前最新发布版本是今年6月13日发布的1.1版本。也就是说,从正式发布到现在,经过近两年的时间,Go+还处于初始阶段,距离大规模应用还有一定距离,那么可以预见,凹语言™在未来相当长的时间里,不会进入广大开发者的视野中。
另外,据ECUG Con 2022大会上许式伟发表的看法,虽然大家都比较看重编程语言的性能,但单从性能来看的话,许式伟认为Python在脚本语言里面只能算二流,Python其实并不快。
在许式伟看来,对新生的语言来说,最重要它选择的目标人群。
Go+选择的目标人群是全民,许式伟称其为“连儿童也能掌握的语言”,因而Go+从工程与STEM教育的一体化开始奠定用户基础。
正是Go+的这几个特性,让一部分开发者看好Go+的未来。而对Go+的正向预期,会成为Go+进一步发展的助力。
对凹语言™来说,这个道理也是适用的:凹语言™的发展重点可能不在于性能,而在于其选择哪些人群作为目标受众,以及通过何种方式获得种子用户。
如果日后凹语言™的项目方会公布这些消息,那么凹语言™的未来还是可以期待的。
来源:武穆、信远(51CTO技术栈)
收起阅读 »快速搭建一个网关服务,动态路由、鉴权的流程,看完秒会(含流程图)
最近发现网易号有盗掘金文章的,xdm有空可以关注一下这个问题,希望帮助到大家同时能够保障自己权益。
前言
本文记录一下我是如何使用Gateway搭建网关服务及实现动态路由的,帮助大家学习如何快速搭建一个网关服务,了解路由相关配置,鉴权的流程及业务处理,有兴趣的一定看到最后,非常适合没接触过网关服务的同学当作入门教程。
搭建服务
框架
SpringBoot 2.1
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.0.RELEASE</version>
</parent>Spring-cloud-gateway-core
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-gateway-core</artifactId>
</dependency>common-lang3
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>路由配置
网关作为请求统一入口,路由就相当于是每个业务系统的入口,通过路由规则则可以匹配到对应微服务的入口,将请求命中到对应的业务系统中
server:
port: 8080
spring:
cloud:
gateway:
enabled: true
routes:
- id: demo-server
uri: http://localhost:8081
predicates:
- Path=/demo-server/**
filters:
- StripPrefix= 1routes
| 配置项 | 描述 |
|---|---|
| id | 路由唯一id,使用服务名称即可 |
| uri | 路由服务的访问地址 |
| predicates | 路由断言 |
| filters | 过滤规则 |
解读配置
现在有一个服务demo-server部署在本机,地址和端口为127.0.0.1:8081,所以路由配置uri为http://localhost:8081
使用网关服务路由到此服务,predicates -Path=/demo-server/**,网关服务的端口为8080,启动网关服务,访问localhost:8080/demo-server,路由断言就会将请求路由到demo-server
直接访问demo-server的接口localhost:8081/api/test,通过网关的访问地址则为localhost:8080/demo-server/api/test,predicates配置将请求断言到此路由,filters-StripPrefix=1代表将地址中/后的第一个截取,所以demo-server就截取掉了
使用gateway通过配置文件即可完成路由的配置,非常方便,我们只要充分的了解配置项的含义及规则就可以了;但是这些配置如果要修改则需要重启服务,重启网关服务会导致整个系统不可用,这一点是无法接受的,下面介绍如何通过Nacos实现动态路由
动态路由
使用nacos结合gateway-server实现动态路由,我们需要先部署一个nacos服务,可以使用docker部署或下载源码在本地启动,具体操作可以参考官方文档即可
Nacos配置
groupId: 使用网关服务名称即可
dataId: routes
配置格式: json
[{
"id": "xxx-server",
"order": 1, #优先级
"predicates": [{ #路由断言
"args": {
"pattern": "/xxx-server/**"
},
"name": "Path"
}],
"filters":[{ #过滤规则
"args": {
"parts": 0 #k8s服务内部访问容器为http://xxx-server/xxx-server的话,配置0即可
},
"name": "StripPrefix" #截取的开始索引
}],
"uri": "http://localhost:8080/xxx-server" #目标地址
}]json格式配置项与yaml中对应,需要了解配置在json中的写法
比对一下json配置与yaml配置
{
"id":"demo-server",
"predicates":[
{
"args":{
"pattern":"/demo-server/**"
},
"name":"Path"
}
],
"filters":[
{
"args":{
"parts":1
},
"name":"StripPrefix"
}
],
"uri":"http://localhost:8081"
}
spring:
cloud:
gateway:
enabled: true
routes:
- id: demo-server
uri: http://localhost:8081
predicates:
- Path=/demo-server/**
filters:
- StripPrefix= 1代码实现
Nacos实现动态路由的方式核心就是通过Nacos配置监听,配置发生改变后执行网关相关api创建路由
@Component
public class NacosDynamicRouteService implements ApplicationEventPublisherAware {
private static final Logger LOGGER = LoggerFactory.getLogger(NacosDynamicRouteService.class);
@Autowired
private RouteDefinitionWriter routeDefinitionWriter;
private ApplicationEventPublisher applicationEventPublisher;
/** 路由id */
private static List<String> routeIds = Lists.newArrayList();
/**
* 监听nacos路由配置,动态改变路由
* @param configInfo
*/
@NacosConfigListener(dataId = "routes", groupId = "gateway-server")
public void routeConfigListener(String configInfo) {
clearRoute();
try {
List<RouteDefinition> gatewayRouteDefinitions = JSON.parseArray(configInfo, RouteDefinition.class);
for (RouteDefinition routeDefinition : gatewayRouteDefinitions) {
addRoute(routeDefinition);
}
publish();
LOGGER.info("Dynamic Routing Publish Success");
} catch (Exception e) {
LOGGER.error(e.getMessage(), e);
}
}
/**
* 清空路由
*/
private void clearRoute() {
for (String id : routeIds) {
routeDefinitionWriter.delete(Mono.just(id)).subscribe();
}
routeIds.clear();
}
@Override
public void setApplicationEventPublisher(ApplicationEventPublisher applicationEventPublisher) {
this.applicationEventPublisher = applicationEventPublisher;
}
/**
* 添加路由
*
* @param definition
*/
private void addRoute(RouteDefinition definition) {
try {
routeDefinitionWriter.save(Mono.just(definition)).subscribe();
routeIds.add(definition.getId());
} catch (Exception e) {
LOGGER.error(e.getMessage(), e);
}
}
/**
* 发布路由、使路由生效
*/
private void publish() {
this.applicationEventPublisher.publishEvent(new RefreshRoutesEvent(this.routeDefinitionWriter));
}
}过滤器
gateway提供GlobalFilter及Ordered两个接口用来定义过滤器,我们自定义过滤器只需要实现这个两个接口即可
GlobalFilter filter() 实现过滤器业务
Ordered getOrder() 定义过滤器执行顺序
通常一个网关服务的过滤主要包含 鉴权(是否登录、是否黑名单、是否免登录接口...) 限流(ip限流等等)功能,我们今天简单介绍鉴权过滤器的流程实现
鉴权过滤器
需要实现鉴权过滤器,我们先得了解登录及鉴权流程,如下图所示
由图可知,我们鉴权过滤核心就是验证token是否有效,所以我们网关服务需要与业务系统在同一个redis库,先给网关添加redis依赖及配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis-reactive</artifactId>
</dependency>
spring:
redis:
host: redis-server
port: 6379
password:
database: 0代码实现
1.定义过滤器AuthFilter
2.获取请求对象 从请求头或参数或cookie中获取token(支持多种方式传token对于客户端更加友好,比如部分web下载请求会新建一个页面,在请求头中传token处理起来比较麻烦)
3.没有token,返回401
4.有token,查询redis是否有效
5.无效则返回401,有效则完成验证放行
6.重置token过期时间、添加内部请求头信息方便业务系统权限处理
@Component
public class AuthFilter implements GlobalFilter, Ordered {
@Autowired
private RedisTemplate<String, String> redisTemplate;
private static final String TOKEN_HEADER_KEY = "auth_token";
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求对象
ServerHttpRequest request = exchange.getRequest();
// 2.获取token
String token = getToken(request);
ServerHttpResponse response = exchange.getResponse();
if (StringUtils.isBlank(token)) {
// 3.token为空 返回401
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
// 4.验证token是否有效
String userId = getUserIdByToken(token);
if (StringUtils.isBlank(userId)) {
// 5.token无效 返回401
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
// token有效,后续业务处理
// 从写请求头,方便业务系统从请求头获取用户id进行权限相关处理
ServerHttpRequest.Builder builder = exchange.getRequest().mutate();
request = builder.header("user_id", userId).build();
// 延长缓存过期时间-token缓存用户如果一直在操作就会一直重置过期
// 这样避免用户操作过程中突然过期影响业务操作及体验,只有用户操作间隔时间大于缓存过期时间才会过期
resetTokenExpirationTime(token, userId);
// 完成验证
return chain.filter(exchange);
}
@Override
public int getOrder() {
// 优先级 越小越优先
return 0;
}
/**
* 从redis中获取用户id
* 在登录操作时候 登陆成功会生成一个token, redis得key为auth_token:token 值为用户id
*
* @param token
* @return
*/
private String getUserIdByToken(String token) {
String redisKey = String.join(":", "auth_token", token);
return redisTemplate.opsForValue().get(redisKey);
}
/**
* 重置token过期时间
*
* @param token
* @param userId
*/
private void resetTokenExpirationTime(String token, String userId) {
String redisKey = String.join(":", "auth_token", token);
redisTemplate.opsForValue().set(redisKey, userId, 2, TimeUnit.HOURS);
}
/**
* 获取token
*
* @param request
* @return
*/
private static String getToken(ServerHttpRequest request) {
HttpHeaders headers = request.getHeaders();
// 从请求头获取token
String token = headers.getFirst(TOKEN_HEADER_KEY);
if (StringUtils.isBlank(token)) {
// 请求头无token则从url获取token
token = request.getQueryParams().getFirst(TOKEN_HEADER_KEY);
}
if (StringUtils.isBlank(token)) {
// 请求头和url都没有token则从cookies获取
HttpCookie cookie = request.getCookies().getFirst(TOKEN_HEADER_KEY);
if (cookie != null) {
token = cookie.getValue();
}
}
return token;
}
}总结
Gateway通过配置项可以实现路由功能,整合Nacos及配置监听可以实现动态路由,实现GlobalFilter, Ordered两个接口可以快速实现一个过滤器,文中也详细的介绍了登录后的请求鉴权流程,如果有不清楚地方可以评论区见咯。
来源:juejin.cn/post/7004756545741258765
收起阅读 »七夕节马上要到了,前端工程师,后端工程师,算法工程师都怎么哄女朋友开心?
这篇文章的前提是,你得有个女朋友,没有就先收藏着吧!
七夕节的来源是梁山伯与祝英台的美丽传说,化成了一对蝴蝶~ 美丽的神话!虽然现在一般是过214的情人节了,但是不得不说,古老的传统的文化遗产,还是要继承啊~
在互联网公司中,主要的程序员品种包括:前端工程师,后端工程师,算法工程师。
对于具体的职业职能划分还不是很清楚的,我们简单的介绍一下不同程序员岗位的职责:
前端程序员:绘制UI界面,与设计和产品经理进行需求的对接,绘制特定的前端界面推向用户
后端程序员:接收前端json字符串,与数据库对接,将json推向前端进行显示
算法工程师:进行特定的规则映射,优化函数的算法模型,改进提高映射准确率。
七夕节到了,怎么结合自身的的专业技能,哄女朋友开心呢?
前端工程师:我先来,画个动态的晚霞页面!
1.定义样式风格:
.star {
width: 2px;
height: 2px;
background: #f7f7b6;
position: absolute;
left: 0;
top: 0;
backface-visibility: hidden;
}2.定义动画特性
@keyframes rotate {
0% {
transform: perspective(400px) rotateZ(20deg) rotateX(-40deg) rotateY(0);
}
100% {
transform: perspective(400px) rotateZ(20deg) rotateX(-40deg) rotateY(-360deg);
}
}3.定义星空样式数据
export default {
data() {
return {
starsCount: 800, //星星数量
distance: 900, //间距
}
}
}4.定义星星运行速度与规则:
starNodes.forEach((item) => {
let speed = 0.2 + Math.random() * 1;
let thisDistance = this.distance + Math.random() * 300;
item.style.transformOrigin = `0 0 ${thisDistance}px`;
item.style.transform =
`
translate3d(0,0,-${thisDistance}px)
rotateY(${Math.random() * 360}deg)
rotateX(${Math.random() * -50}deg)
scale(${speed},${speed})`;
});前端预览效果图:
后端工程师看后,先点了点头,然后表示不服,画页面太肤浅了,我开发一个接口,定时在女朋友生日的时候发送祝福邮件吧!
1.导入pom.xml 文件
<!-- mail邮件服务启动器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>2.application-dev.properties内部增加配置链接
#QQ\u90AE\u7BB1\u90AE\u4EF6\u53D1\u9001\u670D\u52A1\u914D\u7F6E
spring.mail.host=smtp.qq.com
spring.mail.port=587
## qq邮箱
spring.mail.username=#yourname#@qq.com
## 这里填邮箱的授权码
spring.mail.password=#yourpassword#3.配置邮件发送工具类 MailUtils.java
@Component
public class MailUtils {
@Autowired
private JavaMailSenderImpl mailSender;
@Value("${spring.mail.username}")
private String mailfrom;
// 发送简单邮件
public void sendSimpleEmail(String mailto, String title, String content) {
// 定制邮件发送内容
SimpleMailMessage message = new SimpleMailMessage();
message.setFrom(mailfrom);
message.setTo(mailto);
message.setSubject(title);
message.setText(content);
// 发送邮件
mailSender.send(message);
}
}4.测试使用定时注解进行注释
@Component
class DemoApplicationTests {
@Autowired
private MailUtils mailUtils;
/**
* 定时邮件发送任务,每月1日中午12点整发送邮件
*/
@Scheduled(cron = "0 0 12 1 * ?")
void sendmail(){
// 定制邮件内容
StringBuffer content = new StringBuffer();
content.append("HelloWorld");
//分别是接收者邮箱,标题,内容
mailUtils.sendSimpleEmail("123456789@qq.com","自定义标题",content.toString());
}
}@scheduled注解 使用方法: cron:秒,分,时,天,月,年,* 号表示 所有的时间均匹配
5.工程进行打包,部署在服务器的容器中运行即可。
算法工程师,又开发接口,又画页面,我就训练一个自动写诗机器人把!
1.定义神经网络RNN结构
def neural_network(model = 'gru', rnn_size = 128, num_layers = 2):
cell = tf.contrib.rnn.BasicRNNCell(rnn_size, state_is_tuple = True)
cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple = True)
initial_state = cell.zero_state(batch_size, tf.float32)
with tf.variable_scope('rnnlm'):
softmax_w = tf.get_variable("softmax_w", [rnn_size, len(words)])
softmax_b = tf.get_variable("softmax_b", [len(words)])
embedding = tf.get_variable("embedding", [len(words), rnn_size])
inputs = tf.nn.embedding_lookup(embedding, input_data)
outputs, last_state = tf.nn.dynamic_rnn(cell, inputs, initial_state = initial_state, scope = 'rnnlm')
output = tf.reshape(outputs, [-1, rnn_size])
logits = tf.matmul(output, softmax_w) + softmax_b
probs = tf.nn.softmax(logits)
return logits, last_state, probs, cell, initial_state2.定义模型训练方法:
def train_neural_network():
logits, last_state, _, _, _ = neural_network()
targets = tf.reshape(output_targets, [-1])
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [targets], \
[tf.ones_like(targets, dtype = tf.float32)], len(words))
cost = tf.reduce_mean(loss)
learning_rate = tf.Variable(0.0, trainable = False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), 5)
#optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer = tf.train.AdamOptimizer(learning_rate)
train_op = optimizer.apply_gradients(zip(grads, tvars))
Session_config = tf.ConfigProto(allow_soft_placement = True)
Session_config.gpu_options.allow_growth = True
trainds = DataSet(len(poetrys_vector))
with tf.Session(config = Session_config) as sess:
sess.run(tf.global_variables_initializer())
saver = tf.train.Saver(tf.global_variables())
last_epoch = load_model(sess, saver, 'model/')
for epoch in range(last_epoch + 1, 100):
sess.run(tf.assign(learning_rate, 0.002 * (0.97 ** epoch)))
#sess.run(tf.assign(learning_rate, 0.01))
all_loss = 0.0
for batche in range(n_chunk):
x,y = trainds.next_batch(batch_size)
train_loss, _, _ = sess.run([cost, last_state, train_op], feed_dict={input_data: x, output_targets: y})
all_loss = all_loss + train_loss
if batche % 50 == 1:
print(epoch, batche, 0.002 * (0.97 ** epoch),train_loss)
saver.save(sess, 'model/poetry.module', global_step = epoch)
print (epoch,' Loss: ', all_loss * 1.0 / n_chunk)3.数据集预处理
poetry_file ='data/poetry.txt'
# 诗集
poetrys = []
with open(poetry_file, "r", encoding = 'utf-8') as f:
for line in f:
try:
#line = line.decode('UTF-8')
line = line.strip(u'\n')
title, content = line.strip(u' ').split(u':')
content = content.replace(u' ',u'')
if u'_' in content or u'(' in content or u'(' in content or u'《' in content or u'[' in content:
continue
if len(content) < 5 or len(content) > 79:
continue
content = u'[' + content + u']'
poetrys.append(content)
except Exception as e:
passpoetry.txt文件中存放这唐诗的数据集,用来训练模型
4.测试一下训练后的模型效果:
藏头诗创作:“七夕快乐”
模型运算的结果
哈哈哈,各种节日都是程序员的表(zhuang)演(bi) 时间,不过这些都是锦上添花,只有实实在在,真心,才会天长地久啊~
提前祝各位情侣七夕节快乐!
作者:千与编程
来源:juejin.cn/post/6995491512716918814
安全对等问题:确保移动应用跨平台安全性
一段时间以来,人们都“知道”,作为移动平台的 Android 不如 iOS 安全,这已经成为常识。似乎除了消费者,每个人都知道。2021 年 8 月对 10000 名移动消费者进行的一项全球调查发现,iOS 和 Android 用户的安全期望基本一致。
然而,尽管消费者有这样的期望,而且从本质上讲,一个移动平台并不一定比另一个平台更安全,但移动应用很少能实现 Android 和 iOS 的安全功能对等。事实上,许多移动应用甚至缺少最基本的安全保护措施。让我们看看这是为什么。
1
移动应用安全需要多层次防御
大多数安全专家和第三方标准组织都会同意,移动应用安全需要多层次防御,包括以下核心领域的多种安全特性:
代码混淆和应用护盾(Application Shielding):保护移动应用的二进制文件和源代码,防止逆向工程。
数据加密:保护应用中存储和使用的数据。
安全通信:保护在应用和应用后端之间传递的数据,包括确保用于建立可信连接的数字证书的真实性和有效性。
操作系统防护:保护应用免受未经授权的操作系统修改(如 rooting 和越狱)所影响。
开发人员应该在应用的 iOS 和 Android 版本中均衡地实现这些功能的组合,形成一致的安全防御。而且,他们应该在开发周期的早期添加这些功能——这个概念被称为安全“左移”。听起来很容易吧?理论上,是的,但在实践中,如果使用“传统”方法,要实现移动应用多层次安全防御实际上是相当困难的。
多年来,移动开发人员一直试图使用传统的工具集来实现应用内移动应用安全,包括第三方开源库、商业移动应用安全 SDK 或专用编译器。第一个主要的挑战是,移动应用的安全从来无法通过“银弹”实现。由于移动应用在不受保护的环境中运行,并存储和处理大量有价值的信息,有许多方法可以攻击它们。黑客有无穷无尽的、免费提供而又非常强大的工具集可以使用,而且可以全天候地研究和攻击应用而不被发现。
2
移动安全要求
因此,为了构建一个强大的防御体系,移动开发人员需要实施一个既“广”且“深”的多层次防御。所谓“广”,我指的是不同保护类别的多种安全特性,它们彼此相互补充,如加密和混淆。所谓“深”,我指的是每个安全特性都应该有多种检测或保护方法。例如,一个越狱检测 SDK 如果只在应用启动时进行检查,就不会很有效,因为攻击者很容易绕过。
或者考虑下反调试,这是一种重要的运行时防御,可以防止攻击者使用调试器来执行动态分析——他们会在一个受控的环境中运行应用,为的是了解或修改应用的行为。有许多类型的调试器——有一些基于 LLDB——是针对原生代码的,如 C++ 或 Objective C,其他的在 Java 或 Kotlin 层进行检查,诸如此类。每个调试器连接和分析应用的工作方式都略有不同。因此,为了使反调试防御奏效,应用需要识别正在使用的多种调试方法,并动态地进行恰当的防御,因为黑客会继续尝试不同的调试工具或方法,直到他们找到一个可以成功的。
3
防篡改
安全要求清单并不仅限于此。每个应用都需要防篡改功能,如校验和验证、预防二进制补丁,以及应用的重新打包、重新签名、模拟器和仿真器,等等。毫不夸张,仅是针对一个操作系统研究和实现这些功能或保护方法中的一项,就需要至少几个人周的开发时间。而且还要有一个前提,就是移动开发人员已经拥有特定安全领域的专业知识,但情况往往并非如此。复杂度可能会快速增加,到目前为止,我们只讨论了一个保护类别——运行时或动态保护。想象一下,如果提到的每个功能都需要一到两周的开发时间,那么实现全部安全特性得付出多大的时间成本。
4
防越狱 /Rooting
接下来,你还需要操作系统层面的保护,如防越狱 /rooting,在移动操作系统遭破坏的情况下保护应用。越狱 /rooting 使移动应用容易受到攻击,因为它允许对操作系统和文件系统进行完全的管理控制,破坏了整个安全模型。而且,仅仅检测越狱 /rooting 已经不够了,因为黑客们一直在不断地改进他们的工具。要说最先进的越狱和 rooting 工具,在 iOS 上是 Checkra1n,在 Android 上是 Magisk——还有许多其他的工具。其中,还有一些工具用于隐藏或掩盖活动及管理超级用户权限——通常授予恶意应用。朋友们,如果你使用 SDK 或第三方库实现了越狱或 rooting 检测,那么你的保护措施很有可能已经过时或者很容易被绕过,尤其是在没有对应用的源代码进行充分混淆的情况下。
5
代码混淆
如果你使用 SDK 或第三方库来实现安全防护,那在未混淆的应用中几乎没什么用——为什么?因为黑客使用 Hopper、IDA-pro 等开源工具,就可以很容易地反编译或反汇编,找到 SDK 的源代码,或使用类似 Frida 这样的动态二进制工具箱,注入他们自己的恶意代码,修改应用的行为,或简单地禁用安全 SDK。
代码混淆可以防止攻击者了解移动应用的源代码。而且,我们总是建议使用多种混淆方法,包括混淆本地代码或非本地代码和库,以及混淆应用的逻辑结构或控制流。例如,可以使用控制流混淆或重命名函数、类、方法、变量等来实现。不要忘了还要混淆调试信息。
从现实世界的数据中可以看出,大多数移动应用都缺乏足够的混淆,只混淆了应用的一小部分代码,这项对超过 100 万个 Android 应用的研究清楚地说明了这一点。正如该研究指出的那样,造成这种情况的原因是,对于大多数移动开发人员来说,依赖专用编译器的传统混淆方法实在是太复杂和费时,难以全面实施。相反,许多开发人员只实现了单一的混淆功能,或者只混淆了代码库的一小部分。在这项研究中,研究人员发现,大多数应用只实现了类名混淆,这本身很容易被攻陷。拿书打个比方,类名混淆本身就像是混淆了一本书的“目录”,但书中所有实际的页和内容却并没有混淆。这种表面的混淆相当容易被绕过。
6
数据保护和加密
接着说数据保护,你还需要借助加密来保护应用和用户数据——在移动应用中,有很多地方存储着数据,包括沙盒、内存以及应用的代码或字符串。要自己实现加密,有很多棘手的问题需要解决,包括密钥衍生(key derivation)、密码套件和加密算法组合、密钥大小及强度。许多应用使用了多种编程语言,每一种都需要不同的 SDK,或者会导致你无法控制的不兼容性,又或是需要你无法访问的依赖。而数据类型的差异也有复杂性增加和性能下降的风险。
然后,还有一个典型的问题,即在哪里存储加密密钥。如果密钥存储在应用内部,那它们可能会被反向工程的攻击者发现,然后他们就可以用来解密数据。这就是为什么我们说动态密钥生成是一个非常重要的功能。通过动态密钥生成,加密密钥只在运行时生成,而不会存储在应用或移动设备上。此外,密钥只使用一次,可以防止攻击者发现或截获它们。
那么传输中的数据呢?仅靠 TLS 是不够的,因为有很多方法可以侵入应用的连接。检查和验证 TLS 会话和证书很重要,这可以确保所有的证书和 CA 都是有效且真实的,受到行业标准加密的保护。这可以防止黑客获得 TLS 会话的控制权。然后还有证书固定,可以防止连接到遭到入侵的服务器,或保护服务器,拒绝遭到入侵的应用连接(例如,如果你的应用被变成了一个恶意机器人)。
7
欺诈、恶意软件、防盗版
最后,还有反欺诈、反恶意软件和反盗版保护,你可以在上述基线保护的基础上增加防护层,用于防止非常高级或专门的威胁。这些保护措施可能包括可以防止应用覆盖攻击、自动点击器、钩子框架和动态二进制工具、内存注入、键盘记录器、密钥注入或可访问性滥用的功能,所有这些都是移动欺诈或移动恶意软件的常用武器。
不难想象,即使是实现上述功能的一个子集,也需要大量的时间和资源。到目前为止,我只是谈了一个强大的安全防御所需的特性和功能。即使你内部有资源和所需的技能组合,那么拼凑出一个防御体系的行动挑战又是什么呢?让我们探讨一下开发团队可能会遇到的一些实施挑战。
8
不同平台和框架之间的实现差异
鉴于用于构建移动应用的 SDK/ 库及原生或非原生编程语言之间存在无数的框架差异和不兼容,开发人员将面临的下一个问题是如何分别为 Android 和 iOS 实现这些安全功能。虽然软件开发工具包(SDK)提供了一些标准安全功能,但没有 SDK 能普遍覆盖所有的平台或框架。
当开发人员试图使用 SDK 或开源库来实现移动应用安全时,所面临的一个主要挑战在于,这些方法都依赖于源代码,需要对应用代码进行修改。而结果是,这些方法中的每一个都明确地与应用所使用的特定编程语言绑定,并且还暴露给了各种编程语言或是这些语言和框架的包“依赖”。
通常,iOS 应用使用 Objective-C 或 Swift 构建,而 Android 应用使用 Java 或 Kotlin 以及使用 C 和 C++ 编写原生库。例如,假如你想对存储在 Android 和 iOS 应用中的数据进行加密。如果你找到了一些第三方 Android 加密库亦或是 Java 或 Kotlin 的 SDK,它们不一定适用于应用中使用的 C 或 C++ 代码部分(原生库)。
在 iOS 中也是如此。你浏览 StackOverflow 时可能会发现,在 Swift 中常用的 Cryptokit 框架对 Objective C 不起作用。
那么,非原生或跨平台应用呢?它们是完全不同的赛道,因为你要处理的是 JavaScript 等 Web 技术和 React Native、Cordova、Flutter 或 Xamarin 等非原生框架,它们无法直接(或根本不能)使用为原生语言构建的 SDK 或库。此外,对于非原生应用,你可能无法获得相关的源代码文件,从源头实现加密。
关于这个问题,有一个真实的例子,请看 Stack Overflow 上的这篇帖子。开发人员需要在一个 iOS 应用中实现代码混淆,其中 React Native(一个非原生框架)和 Objective C(一种原生编码语言)之间存在多个依赖关系。由于 iOS 项目中没有可以混淆 React Native 代码的内置库,开发人员需要使用一个外部包(依赖关系 #1)。此外,该外部包还依赖下游的一个库或包来混淆 JavaScript 代码(依赖关系 #2)。现在,如果第三方库的开发人员决定废弃该解决方案,会发生什么?我们的一个客户就面临着这样的问题,这导致他们的应用不符合 PCI 标准。
那么,你认为需要多少开发人员来实现我刚才描述的哪怕是一小部分功能?又需要多长时间?你有足够的时间在现有的移动应用发布过程中实现所需的安全功能吗?
9
DevOps 是敏捷 + 自动化,传统安全是单体 + 手动
移动应用是在一个快节奏、灵活且高度自动化的敏捷模式下开发和发布的。为了使构建和发布更快速、更简单,大多数 Android 和 iOS DevOps 团队都围绕 CI/CD 和其他自动化工具构建了最佳管道。另一方面,安全团队无法访问或查看 DevOps 系统,而且大多数安全工具并不是针对敏捷方法构建的,因为它们在很大程度上依赖于手动编程或实施,在这种情况下,单个安全功能的实施时间可能会长于发布时间表允许的时间。
为了弥补这些不足,一些组织在向公共应用商店发布应用之前,会使用代码扫描和渗透测试,以深入探查漏洞和其他移动应用问题。当发现漏洞时,企业就会面临一个艰难的决定:是在未进行必要保护的情况下发布应用,还是推迟发布,让开发人员有时间来解决安全问题。当这种情况发生时,推荐的安全保护措施往往会被忽视。
开发人员并不懒惰,而是他们用于实现安全保护的系统和工具根本无法匹配现代敏捷 /DevOps 开发的快节奏。
10
实现强大的移动应用安全和平台对等的五个步骤
一般来说,自动化是实现安全对等和强大的移动应用安全的关键所在。以下是在应用发布周期内将移动应用安全打造为应用组成部分的五个步骤。
开发、运营和安全团队必须就移动安全预期达成一致。对于组织作为起点的安全目标,人们要有一个共同的理解,如 OWASP Mobile Top 10、TRM 移动应用安全指南和移动应用安全验证标准(MASVS)。一旦确定了目标并选择了标准,所有团队成员都要知道这对他们的工作流有何影响。
安全非常复杂,手动编码很慢,而且容易出错。评估并利用自动化系统,借助人工智能和机器学习(ML)将安全集成到移动应用中。通常情况下,这些都是无代码平台,可以自动将安全构建到移动应用中,它们通常被称为安全构建系统。
移动应用安全模型左移是指,移动开发人员需要在构建应用的同时构建安全特性。
一旦选择了自动化安全实施平台,就应该将其整合到团队的持续集成(CI)和持续交付(CD)流程中,这可以加速开发生命周期,所有团队——开发、运营和安全——在整个冲刺期间都应该保持密切合作。此外,企业可以为每个 Android 和 iOS 应用所需的特定安全特性创建可重复使用的移动安全模板,从而更接近实现平台对等。
如果没有办法即时验证所需的安全功能是否包含在发布中,那么在发布会议上就会出现争执,可能导致应用发布或更新延期。验证和确认应该自动记录,防止最后一刻的发布混乱。
开发团队需要可预测性和明确的预算。通过采用自动化的安全方法,应用开发团队可以减少人员和开发费用的意外变化,因为它消除了手动将安全编码到移动应用时固有的不确定性。
11
小结
安全对等问题是一个大问题,但它是一个更大问题的一部分,即移动应用普遍缺乏安全性。通过在安全实现中采用与特性开发相同或更高程度的自动化,开发人员可以确保他们针对每个平台发布的每一个应用都免受黑客、骗子和网络犯罪分子的侵害。
作者简介:
Alan Bavosa 是 Appdome 的安全产品副总裁。长期以来,他一直担任安全产品执行官,曾是 Palerra(被 Oracle 收购)和 Arcsight(被 HP 收购)的产品主管。
原文链接:
https://www.infoq.com/articles/secure-mobile-apps-parity-problem/
MySQL:max_allowed_packet 影响了什么?
max_allowed_packet 表示 MySQL Server 或者客户端接收的 packet 的最大大小,packet 即数据包,MySQL Server 和客户端上都有这个限制。
数据包
每个数据包,都由包头、包体两部分组成,包头由 3 字节的包体长度、1 字节的包编号组成。3 字节最多能够表示 2 ^ 24 = 16777216 字节(16 M),也就是说,一个数据包的包体长度必须小于等于 16M 。
如果要发送超过 16M 的数据怎么办?
当要发送大于 16M 的数据时,会把数据拆分成多个 16M 的数据包,除最后一个数据包之外,其它数据包大小都是 16M。而 MySQL Server 收到这样的包后,如果发现包体长度等于 16M ,它就知道本次接收的数据由多个数据包组成,会先把当前数据包的内容写入缓冲区,然后接着读取下一个数据包,并把下一个数据包的内容追加到缓冲区,直到读到结束数据包,就接收到客户端发送的完整数据了。
那怎样算一个数据包?
一个 SQL 是一个数据包
返回查询结果时,一行数据算一个数据包
解析的 binlog ,如果用 mysql 客户端导入,一个 SQL 算一个数据包
在复制中,一个 event 算一个数据包
下面我们通过测试来讨论 max_allowed_packet 的实际影响。
导入 SQL 文件受 max_allowed_packet 限制吗?
如果 SQL 文件中有单个 SQL 大小超过 max_allowed_packet ,会报错:
##导出时设置 mysqldump --net-buffer-length=16M,这样保证导出的sql文件中单个 multiple-row INSERT 大小为 16M
mysqldump -h127.0.0.1 -P13306 -uroot -proot --net-buffer-length=16M \
--set-gtid-purged=off sbtest sbtest1 > /data/backup/sbtest1.sql
##设置max_allowed_packet=1M
##导入报错
[root@localhost data]# mysql -h127.0.0.1 -P13306 -uroot -proot db3 < /data/backup/sbtest1.sql
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 1153 (08S01) at line 41: Got a packet bigger than 'max_allowed_packet' bytes导入解析后的 binlog 受 max_allowed_packet 限制吗?
row 格式的 binlog,单个SQL修改的数据产生的 binlog 如果超过 max_allowed_packet,也会报错。
在恢复数据到指定时间点的场景,解析后的binlog单个事务大小超过1G,并且这个事务只包含一个SQL,此时一定会触发 max_allowed_packet 的报错。但是恢复数据的任务又很重要,怎么办呢?可以将 binlog 改名成 relay log,用 sql 线程回放来绕过这个限制。
查询结果受 max_allowed_packet 限制吗?
查询结果中,只要单行数据不超过客户端设置的 max_allowed_packet 即可:
##插入2行20M大小的数据
[root@localhost tmp]# dd if=/dev/zero of=20m.img bs=1 count=0 seek=20M
记录了0+0 的读入
记录了0+0 的写出
0字节(0 B)已复制,0.000219914 秒,0.0 kB/秒
[root@localhost tmp]# ll -h 20m.img
-rw-r--r-- 1 root root 20M 6月 6 15:15 20m.img
mysql> create table t1(id int auto_increment primary key,a longblob);
Query OK, 0 rows affected (0.03 sec)
mysql> insert into t1 values(NULL,load_file('/tmp/20m.img'));
Query OK, 1 row affected (0.65 sec)
mysql> insert into t1 values(NULL,load_file('/tmp/20m.img'));
Query OK, 1 row affected (0.65 sec)
##mysql客户端默认 --max-allowed-packet=16M,读取失败
mysql> select * from t1;
ERROR 2020 (HY000): Got packet bigger than 'max_allowed_packet' bytes
##设置 mysql 客户端 --max-allowed-packet=22M,读取成功
[root@localhost ~]# mysql -h127.0.0.1 -P13306 -uroot -proot --max-allowed-packet=23068672 sbtest -e "select * from t1;" > /tmp/t1.txt
[root@localhost ~]# ll -h /tmp/t1.txt
-rw-r--r-- 1 root root 81M 6月 6 15:30 /tmp/t1.txtload data 文件大小受 max_allowed_packet 限制吗?
load data 文件大小、单行大小都不受 max_allowed_packet 影响:
##将上一个测试中的数据导出,2行数据一共81M
mysql> select * int o outfile '/tmp/t1.csv' from t1;
Query OK, 2 rows affected (0.57 sec)
[root@localhost ~]# ll -h /tmp/t1.csv
-rw-r----- 1 mysql mysql 81M 6月 6 15:32 /tmp/t1.csv
##MySQL Server max_allowed_packet=16M
mysql> select @@max_allowed_packet;
+----------------------+
| @@max_allowed_packet |
+----------------------+
| 16777216 |
+----------------------+
1 row in set (0.00 sec)
##load data 成功,不受 max_allowed_packet 限制
mysql> load data infile '/tmp/t1.csv' into table t1;
Query OK, 2 rows affected (1.10 sec)
Records: 2 Deleted: 0 Skipped: 0 Warnings: 0binlog 中超过 1G 的 SQL ,是如何突破 max_allowed_packet 复制到从库的?
从库 slave io 线程、slave sql 线程可以处理的最大数据包大小由参数 slave_max_allowed_packet 控制。这是限制 binlog event 大小,而不是单个 SQL 修改数据的大小。
主库 dump 线程会自动设置 max_allowed_packet为1G,不会依赖全局变量 max_allowed_packet。用来控制主库 DUMP 线程每次读取 event 的最大大小。
具体可以参考:mp.weixin.qq.com/s/EfNY_UwEthiu-DEBO7TrsA
另外超过 4G 的大事务,从库心跳会报错:https://opensource.actionsky.com/20201218-mysql/
作者:胡呈清,爱可生 DBA 团队成员,擅长故障分析、性能优化
来源:jianshu.com/u/a95ec11f67a8
收起阅读 »慢 SQL 分析与优化
背景介绍
从系统设计角度看,一个系统从设计搭建到数据逐步增长,SQL 执行效率可能会出现劣化,为继续支撑业务发展,我们需要对慢 SQL 进行分析和优化,严峻的情况下甚至需要对整个系统进行重构。所以我们往往需要在系统设计前对业务进行充分调研、遵守系统设计规范,在系统运行时定期结合当前业务发展情况进行系统瓶颈的分析。
从数据库角度看,每个 SQL 执行都需要消耗一定 I/O 资源,SQL 执行的快慢,决定了资源被占用时间的长短。假如有一条慢 SQL 占用了 30%的资源共计 1 分钟。那么在这 1 分钟时间内,其他 SQL 能够分配的资源总量就是 70%,如此循环,当资源分配完的时候,所有新的 SQL 执行将会排队等待。所以往往一条慢 SQL 会影响到整个业务。
本文仅讨论 MySQL-InnoDB 的情况。
优化方式
SQL 语句执行效率的主要因素
数据量
SQL 执行后返回给客户端的数据量的大小;
数据量越大需要扫描的 I/O 次数越多,数据库服务器的 IO 更容易成为瓶颈。
取数据的方式
数据在缓存中还是在磁盘上;
是否能够通过全局索引快速寻址;
是否结合谓词条件命中全局索引加速扫描。
数据加工的方式
排序、子查询、聚合、关联等,一般需要先把数据取到临时表中,再对数据进行加工;
对于数据量比较多的计算,会消耗大量计算节点的 CPU 资源,让数据加工变得更加缓慢;
是否选择了合适的 join 方式
优化思路
减少数据扫描(减少磁盘访问)
尽量在查询中加入一些可以提前过滤数据的谓词条件,比如按照时间过滤数据等,可以减少数据的扫描量,对查询更友好;
在扫描大表数据时是否可以命中索引,减少回表代价,避免全表扫描。
返回更少数据(减少网络传输或磁盘访问)
减少交互次数(减少网络传输)
将数据存放在更快的地方
某条查询涉及到大表,无法进一步优化,如果返回的数据量不大且变化频率不高但访问频率很高,此时应该考虑将返回的数据放在应用端的缓存当中或者 Redis 这样的缓存当中,以提高存取速度。
减少服务器 CPU 开销(减少 CPU 及内存开销)
避免大事务操作
利用更多资源(增加资源)
优化案例
数据分页优化
sele ct * from table_demo where type = ? limit ?,?;优化方式一:偏移 id
lastId = 0 or min(id)
do {
sele ct * from table_demo where type = ? and id >{#lastId} limit ?;
lastId = max(id)
} while (isNotEmpty)
优化方式二:分段查询
该方式较方式一的优点在于可并行查询,每个分段查询互不依赖;较方式一的缺点在于较依赖数据的连续性,若数据过于分散,代价较高。
minId = min(id) maxId = max(id)
for(int i = minId; i<= maxId; i+=pageSize){
sele ct * from table_demo where type = ? and id between i and i+ pageSize;
}
优化 GROU P BY
提高 GROU P BY 语句的效率, 可以通过将不需要的记录在 GROU P BY 之前过滤掉.下面两个查询返回相同结果但第二个明显就快了许多。
低效:
sele ct job , avg(sal) from table_demo grou p by job having job = ‘manager'高效:
sele ct job , avg(sal) from table_demo where job = ‘manager' grou p by job范围查询
联合索引中如果有某个列存在范围(大于小于)查询,其右边的列是否还有意义?
expla in sele ct count(1) from statement where org_code='1012' and trade_date_time >= '2019-05-01 00:00:00' and trade_date_time<='2020-05-01 00:00:00'
expla in sele ct * from statement where org_code='1012' and trade_date_time >= '2019-05-01 00:00:00' and trade_date_time<='2020-05-01 00:00:00' limit 0, 100
expla in sele ct * from statement where org_code='1012' and trade_date_time >= '2019-05-01 00:00:00' and trade_date_time<='2020-05-01 00:00:00'
使用单键索引 trade_date_time 的情况下
从索引里找到所有 trade_date_time 在'2019-05-01' 到'2020-05-01' 区间的主键 id。假设有 100 万个。
对这些 id 进行排序(为的是在下面一步回表操作中优化 I/O 操作,因为很多挨得近的主键可能一次磁盘 I/O 就都取到了)
回表,查出 100 万行记录,然后逐个扫描,筛选出 org_code='1020'的行记录
使用联合索引 trade_date_time, org_code -联合索引 trade_date_time, org_code 底层结构推导如下:

以查找 trade_date_time >='2019-05-01' and trade_date_time <='2020-05-01' and org_code='1020'为例:
在范围查找的时候,直接找到最大,最小的值,然后进行链表遍历,故仅能用到 trade_date_time 的索引,无法使用到 org_code 索引
基于 MySQL5.6+的索引下推特性,虽然 org_code 字段无法使用到索引树,但是可以用于过滤回表的主键 id 数。
小结:对于该 case, 索引效果[org_code,trade_date_time] > [trade_date_time, org_code]>[trade_date_time]。实际业务场景中,检索条件中 trade_date_time 基本上肯定会出现,但 org_code 却不一定,故索引的设计还需要结合实际业务需求。
优化 Order by
索引:
KEY `idx_account_trade_date_time` (`account_number`,`trade_date_time`),
KEY `idx_trade_date_times` (`trade_date_time`)
KEY `idx_createtime` (`create_time`),
慢 SQL:
SELE CT id,....,creator,modifier,create_time,update_time FROM statement
WHERE (account_number = 'XXX' AND create_time >= '2022-04-24 06:03:44' AND create_time <= '2022-04-24 08:03:44' AND dc_flag = 'C') ORDER BY trade_date_time DESC,id DESC LIMIT 0,1000;
优化前:SQL 执行超时被 kill 了
SELE CT id,....,creator,modifier,create_time,upda te_time FROM statement
WHERE (account_number = 'XXX' AND create_time >= '2022-04-24 06:03:44' AND create_time <= '2022-04-24 08:03:44' AND dc_flag = 'C') ORDER BY create_time DESC,id DESC LIMIT 0,1000;
优化后:执行总行数为:6 行,耗时 34ms。
MySQL使不使用索引与所查列无关,只与索引本身,where条件,order by 字段,grou p by 字段有关。索引的作用一个是查找,一个是排序。业务拆分
sele ct * from order where status='S' and update_time < now-5min limit 500拆分优化:
随着业务数据的增长 status='S'的数据基本占据数据的 90%以上,此时该条件无法走索引。我们可以结合业务特征,对数据获取按日期进行拆分。
date = now; minDate = now - 10 days
while(date > minDate) {
sele ct * from order where order_date={#date} and status='S' and upda te_time < now-5min limit 500
date = data + 1
}
数据库结构优化
范式优化:表的设计合理化(符合 3NF),比如消除冗余(节省空间);
反范式优化:比如适当加冗余等(减少 join)
拆分表:分区将数据在物理上分隔开,不同分区的数据可以制定保存在处于不同磁盘上的数据文件里。这样,当对这个表进行查询时,只需要在表分区中进行扫描,而不必进行全表扫描,明显缩短了查询时间,另外处于不同磁盘的分区也将对这个表的数据传输分散在不同的磁盘 I/O,一个精心设置的分区可以将数据传输对磁盘 I/O 竞争均匀地分散开。对数据量大的表可采取此方法,可按月建表分区。
SQL 语句优化
SQL 检查状态及分数计算逻辑
尽量避免使用子查询
用 IN 来替换 OR
读取适当的记录 LIMIT M,N,而不要读多余的记录
禁止不必要的 Order By 排序
总和查询可以禁止排重用 union all
避免随机取记录
将多次插入换成批量 Insert 插入
只返回必要的列,用具体的字段列表代替 sele ct * 语句
区分 in 和 exists
优化 Grou p By 语句
尽量使用数字型字段
优化 Join 语句
大表优化
分库分表(水平、垂直)
读写分离
数据定期归档
原理剖析
MySQL 逻辑架构图:

索引的优缺点
优点
提高查询语句的执行效率,减少 IO 操作的次数
创建唯一性索引,可以保证数据库表中每一行数据的唯一性
加了索引的列会进行排序,在使用分组和排序子句进行查询时,可以显著减少查询中分组和排序的时间
缺点
索引需要占物理空间
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
当对表中的数据进行增删改查时,索引也要动态的维护,这样就降低了数据的更新效率
索引的数据结构
主键索引

普通索引

组合索引

索引页结构

索引页由七部分组成,其中 Infimum 和 Supremum 也属于记录,只不过是虚拟记录,这里为了与用户记录区分开,还是决定将两者拆开。

数据行格式:
MySQL 有 4 种存储格式:
Compact
Redundant (5.0 版本以前用,已废弃)
Dynamic (MySQL5.7 默认格式)
Compressed

Dynamic 行存储格式下,对于处理行溢出(当一个字段存储长度过大时,会发生行溢出)时,仅存放溢出页内存地址。
索引的设计原则
哪些情况适合建索引
数据又数值有唯一性的限制
频繁作为 where 条件的字段
经常使用 grou p by 和 order by 的字段,既有 gro up by 又有 order by 的字段时,建议建联合索引
经常作为 upda te 或 dele te 条件的字段
经常需要 distinct 的字段
多表连接时的字段建议创建索引,也有注意事项
连接表数量最好不要超过 3 张,每增加一张表就相当于增加了一次嵌套循环,数量级增长会非常快
对多表查询时的 where 条件创建索引
对连接字段创建索引,并且数据类型保持一致
在确定数据范围的情况下尽量使用数据类型较小的,因为索引会也会占用空间
对字符串创建索引时建议使用字符串的前缀作为索引
这样做的好处是:
能节省索引的空间,
虽然不能精确定位,但是能够定位到相同的前缀,然后通过主键查询完整的字符串,这样既能节省空间,又减少了字符串的比较时间,还能解决排序问题。
区分度高(散列性高)的字段适合作为索引。
在多个字段需要创建索引的情况下,联合索引优先于单值索引。使用最频繁的列作为索引的最左侧 。
哪些情况下不需要使用索引
在 where 条件中用不到的字段不需要。
数据量小的不需要建索引,比如数据少于 1000 条。
由大量重复数据的列上不要建索引,比如性别字段中只有男和女时。
避免在经常更新的表或字段中创建过多的索引。
不建议主键使用无序的值作为索引,比如 uuid。
不要定义冗余或重复的索引
例如:已经创建了联合索引 key(id,name)后就不需要再单独建一个 key(id)的索引
索引优化之 MRR
例如有一张表 user,主键 id,普通字段 age,为 age 创建非聚集索引,有一条查询语句 sele ct* user from table where age > 18;(注意查询语句中的结果是*)
在 MySQL5.5 以及之前的版本中如何查询呢?先通过非聚集索引查询到 age>18 的第一条数据,获取到了主键 id;然后根据非聚集索引中的叶子节点存储的主键 id 去聚集索引中查询行数据;根据 age>18 的数据条数每次查询聚集索引,这个过程叫做回表。
上述的步骤有什么缺点呢?如何 age>18 的数据非常多,那么每次回表都需要经过 3 次 IO(假设 B+树的高度是 3),那么会导致查询效率过低。
在 MySQL5.6 时针对上述问题进行了优化,优化器先查询到 age>3 的所有数据的主键 id,对所有主键的 id 进行排序,排序的结果缓存到 read_rnd_buffer,然后通过排好序的主键在聚簇索引中进行查询。
如果两个主键的范围相近,在同一个数据页中就可以之间按照顺序获取,那么磁盘 io 的过程将会大大降低。这个优化的过程就叫做 Multi Range Read(MRR) 多返回查询。
索引下推
假设有索引(name, age), 执行 SQL: sele ct * from tuser where name like '张%' and age=10;

MySQL 5.6 以后, 存储引擎根据(name,age)联合索引,找到,由于联合索引中包含列,所以存储引擎直接在联合索引里按照age=10过滤。按照过滤后的数据再一一进行回表扫描。

索引下推使用条件
只能用于
range、ref、eq_ref、ref_or_null访问方法;只能用于
InnoDB和MyISAM存储引擎及其分区表;对存储引擎来说,索引下推只适用于二级索引(也叫辅助索引);
索引下推的目的是为了减少回表次数,也就是要减少 IO 操作。对于的聚簇索引来说,数据和索引是在一起的,不存在回表这一说。
引用了子查询的条件不能下推;
引用了存储函数的条件不能下推,因为存储引擎无法调用存储函数。
思考:
MySQL 一张表到底能存多少数据?
为什么要控制单行数据大小?
优化案例 4 中优化前的 SQL 为什么走不到索引?
总结
抛开数据库硬件层面,数据库表设计、索引设计、业务代码逻辑、分库分表策略、数据归档策略都对 SQL 执行效率有影响,我们只有在整个设计、开发、运维阶段保持高度敏感、追求极致,才能让我们系统的可用性、伸缩性不会随着业务增长而劣化。
参考资料
来源:字节跳动技术团队
收起阅读 »B站:2021.07.13 我们是这样崩的
至暗时刻
2021年7月13日22:52,SRE收到大量服务和域名的接入层不可用报警,客服侧开始收到大量用户反馈B站无法使用,同时内部同学也反馈B站无法打开,甚至APP首页也无法打开。基于报警内容,SRE第一时间怀疑机房、网络、四层LB、七层SLB等基础设施出现问题,紧急发起语音会议,拉各团队相关人员开始紧急处理(为了方便理解,下述事故处理过程做了部分简化)。
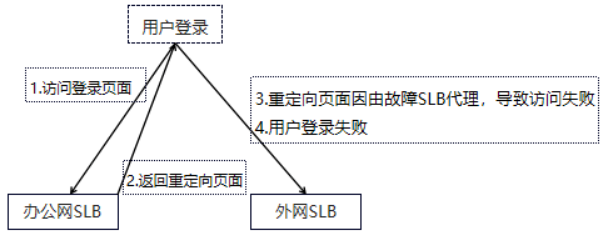
初因定位
22:55 远程在家的相关同学登陆VPN后,无法登陆内网鉴权系统(B站内部系统有统一鉴权,需要先获取登录态后才可登陆其他内部系统),导致无法打开内部系统,无法及时查看监控、日志来定位问题。
22:57 在公司Oncall的SRE同学(无需VPN和再次登录内网鉴权系统)发现在线业务主机房七层SLB(基于OpenResty构建) CPU 100%,无法处理用户请求,其他基础设施反馈未出问题,此时已确认是接入层七层SLB故障,排除SLB以下的业务层问题。
23:07 远程在家的同学紧急联系负责VPN和内网鉴权系统的同学后,了解可通过绿色通道登录到内网系统。
23:17 相关同学通过绿色通道陆续登录到内网系统,开始协助处理问题,此时处理事故的核心同学(七层SLB、四层LB、CDN)全部到位。
故障止损
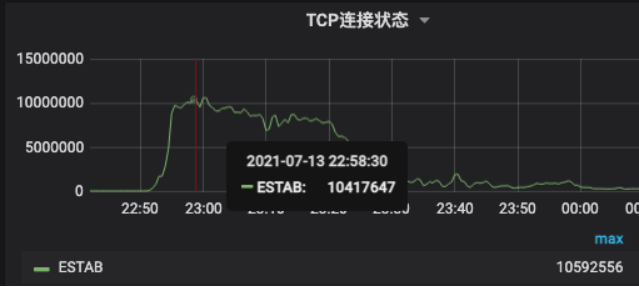
23:20 SLB运维分析发现在故障时流量有突发,怀疑SLB因流量过载不可用。因主机房SLB承载全部在线业务,先Reload SLB未恢复后尝试拒绝用户流量冷重启SLB,冷重启后CPU依然100%,未恢复。
23:22 从用户反馈来看,多活机房服务也不可用。SLB运维分析发现多活机房SLB请求大量超时,但CPU未过载,准备重启多活机房SLB先尝试止损。
23:23 此时内部群里同学反馈主站服务已恢复,观察多活机房SLB监控,请求超时数量大大降低,业务成功率恢复到50%以上。此时做了多活的业务核心功能基本恢复正常,如APP推荐、APP播放、评论&弹幕拉取、动态、追番、影视等。非多活服务暂未恢复。
23:25 - 23:55 未恢复的业务暂无其他立即有效的止损预案,此时尝试恢复主机房的SLB。
我们通过Perf发现SLB CPU热点集中在Lua函数上,怀疑跟最近上线的Lua代码有关,开始尝试回滚最近上线的Lua代码。
近期SLB配合安全同学上线了自研Lua版本的WAF,怀疑CPU热点跟此有关,尝试去掉WAF后重启SLB,SLB未恢复。
SLB两周前优化了Nginx在balance_by_lua阶段的重试逻辑,避免请求重试时请求到上一次的不可用节点,此处有一个最多10次的循环逻辑,怀疑此处有性能热点,尝试回滚后重启SLB,未恢复。
SLB一周前上线灰度了对 HTTP2 协议的支持,尝试去掉 H2 协议相关的配置并重启SLB,未恢复。
新建源站SLB
00:00 SLB运维尝试回滚相关配置依旧无法恢复SLB后,决定重建一组全新的SLB集群,让CDN把故障业务公网流量调度过来,通过流量隔离观察业务能否恢复。
00:20 SLB新集群初始化完成,开始配置四层LB和公网IP。
01:00 SLB新集群初始化和测试全部完成,CDN开始切量。SLB运维继续排查CPU 100%的问题,切量由业务SRE同学协助。
01:18 直播业务流量切换到SLB新集群,直播业务恢复正常。
01:40 主站、电商、漫画、支付等核心业务陆续切换到SLB新集群,业务恢复。
01:50 此时在线业务基本全部恢复。
恢复SLB
01:00 SLB新集群搭建完成后,在给业务切量止损的同时,SLB运维开始继续分析CPU 100%的原因。
01:10 - 01:27 使用Lua 程序分析工具跑出一份详细的火焰图数据并加以分析,发现 CPU 热点明显集中在对 lua-resty-balancer 模块的调用中,从 SLB 流量入口逻辑一直分析到底层模块调用,发现该模块内有多个函数可能存在热点。
01:28 - 01:38 选择一台SLB节点,在可能存在热点的函数内添加 debug 日志,并重启观察这些热点函数的执行结果。
01:39 - 01:58 在分析 debug 日志后,发现 lua-resty-balancer模块中的 _gcd 函数在某次执行后返回了一个预期外的值:nan,同时发现了触发诱因的条件:某个容器IP的weight=0。
01:59 - 02:06 怀疑是该 _gcd 函数触发了 jit 编译器的某个 bug,运行出错陷入死循环导致SLB CPU 100%,临时解决方案:全局关闭 jit 编译。
02:07 SLB运维修改SLB 集群的配置,关闭 jit 编译并分批重启进程,SLB CPU 全部恢复正常,可正常处理请求。同时保留了一份异常现场下的进程core文件,留作后续分析使用。
02:31 - 03:50 SLB运维修改其他SLB集群的配置,临时关闭 jit 编译,规避风险。
根因定位
11:40 在线下环境成功复现出该 bug,同时发现SLB 即使关闭 jit 编译也仍然存在该问题。此时我们也进一步定位到此问题发生的诱因:在服务的某种特殊发布模式中,会出现容器实例权重为0的情况。
12:30 经过内部讨论,我们认为该问题并未彻底解决,SLB 仍然存在极大风险,为了避免问题的再次产生,最终决定:平台禁止此发布模式;SLB 先忽略注册中心返回的权重,强制指定权重。
13:24 发布平台禁止此发布模式。
14:06 SLB 修改Lua代码忽略注册中心返回的权重。
14:30 SLB 在UAT环境发版升级,并多次验证节点权重符合预期,此问题不再产生。
15:00 - 20:00 生产所有 SLB 集群逐渐灰度并全量升级完成。
原因说明
背景
B站在19年9月份从Tengine迁移到了OpenResty,基于其丰富的Lua能力开发了一个服务发现模块,从我们自研的注册中心同步服务注册信息到Nginx共享内存中,SLB在请求转发时,通过Lua从共享内存中选择节点处理请求,用到了OpenResty的lua-resty-balancer模块。到发生故障时已稳定运行快两年时间。
在故障发生的前两个月,有业务提出想通过服务在注册中心的权重变更来实现SLB的动态调权,从而实现更精细的灰度能力。SLB团队评估了此需求后认为可以支持,开发完成后灰度上线。
诱因
在某种发布模式中,应用的实例权重会短暂的调整为0,此时注册中心返回给SLB的权重是字符串类型的"0"。此发布模式只有生产环境会用到,同时使用的频率极低,在SLB前期灰度过程中未触发此问题。
SLB 在balance_by_lua阶段,会将共享内存中保存的服务IP、Port、Weight 作为参数传给lua-resty-balancer模块用于选择upstream server,在节点 weight = "0" 时,balancer 模块中的 _gcd 函数收到的入参 b 可能为 "0"。
根因

Lua 是动态类型语言,常用习惯里变量不需要定义类型,只需要为变量赋值即可。
Lua在对一个数字字符串进行算术操作时,会尝试将这个数字字符串转成一个数字。
在 Lua 语言中,如果执行数学运算 n % 0,则结果会变为 nan(Not A Number)。
_gcd函数对入参没有做类型校验,允许参数b传入:"0"。同时因为"0" != 0,所以此函数第一次执行后返回是 _gcd("0",nan)。如果传入的是int 0,则会触发[ if b == 0 ]分支逻辑判断,不会死循环。
_gcd("0",nan)函数再次执行时返回值是 _gcd(nan,nan),然后Nginx worker开始陷入死循环,进程 CPU 100%。
问题分析
\1. 为何故障刚发生时无法登陆内网后台?
事后复盘发现,用户在登录内网鉴权系统时,鉴权系统会跳转到多个域名下种登录的Cookie,其中一个域名是由故障的SLB代理的,受SLB故障影响当时此域名无法处理请求,导致用户登录失败。流程如下:
事后我们梳理了办公网系统的访问链路,跟用户链路隔离开,办公网链路不再依赖用户访问链路。
\2. 为何多活SLB在故障开始阶段也不可用?
多活SLB在故障时因CDN流量回源重试和用户重试,流量突增4倍以上,连接数突增100倍到1000W级别,导致这组SLB过载。后因流量下降和重启,逐渐恢复。此SLB集群日常晚高峰CPU使用率30%左右,剩余Buffer不足两倍。如果多活SLB容量充足,理论上可承载住突发流量, 多活业务可立即恢复正常。此处也可以看到,在发生机房级别故障时,多活是业务容灾止损最快的方案,这也是故障后我们重点投入治理的一个方向。
\3. 为何在回滚SLB变更无效后才选择新建源站切量,而不是并行?
我们的SLB团队规模较小,当时只有一位平台开发和一位组件运维。在出现故障时,虽有其他同学协助,但SLB组件的核心变更需要组件运维同学执行或review,所以无法并行。
\4. 为何新建源站切流耗时这么久?
我们的公网架构如下:
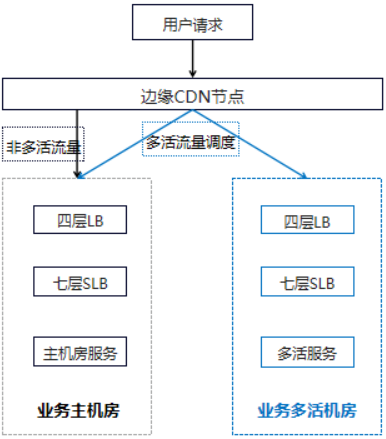
此处涉及三个团队:
SLB团队:选择SLB机器、SLB机器初始化、SLB配置初始化
四层LB团队:SLB四层LB公网IP配置
CDN团队:CDN更新回源公网IP、CDN切量
SLB的预案中只演练过SLB机器初始化、配置初始化,但和四层LB公网IP配置、CDN之间的协作并没有做过全链路演练,元信息在平台之间也没有联动,比如四层LB的Real Server信息提供、公网运营商线路、CDN回源IP的更新等。所以一次完整的新建源站耗时非常久。在事故后这一块的联动和自动化也是我们的重点优化方向,目前一次新集群创建、初始化、四层LB公网IP配置已经能优化到5分钟以内。
\5. 后续根因定位后证明关闭jit编译并没有解决问题,那当晚故障的SLB是如何恢复的?
当晚已定位到诱因是某个容器IP的weight="0"。此应用在1:45时发布完成,weight="0"的诱因已消除。所以后续关闭jit虽然无效,但因为诱因消失,所以重启SLB后恢复正常。
如果当时诱因未消失,SLB关闭jit编译后未恢复,基于定位到的诱因信息:某个容器IP的weight=0,也能定位到此服务和其发布模式,快速定位根因。
优化改进
此事故不管是技术侧还是管理侧都有很多优化改进。此处我们只列举当时制定的技术侧核心优化改进方向。
1. 多活建设
在23:23时,做了多活的业务核心功能基本恢复正常,如APP推荐、APP播放、评论&弹幕拉取、动态、追番、影视等。故障时直播业务也做了多活,但当晚没及时恢复的原因是:直播移动端首页接口虽然实现了多活,但没配置多机房调度。导致在主机房SLB不可用时直播APP首页一直打不开,非常可惜。通过这次事故,我们发现了多活架构存在的一些严重问题:
多活基架能力不足
机房与业务多活定位关系混乱。
CDN多机房流量调度不支持用户属性固定路由和分片。
业务多活架构不支持写,写功能当时未恢复。
部分存储组件多活同步和切换能力不足,无法实现多活。
业务多活元信息缺乏平台管理
哪个业务做了多活?
业务是什么类型的多活,同城双活还是异地单元化?
业务哪些URL规则支持多活,目前多活流量调度策略是什么?
上述信息当时只能用文档临时维护,没有平台统一管理和编排。
多活切量容灾能力薄弱
多活切量依赖CDN同学执行,其他人员无权限,效率低。
无切量管理平台,整个切量过程不可视。
接入层、存储层切量分离,切量不可编排。
无业务多活元信息,切量准确率和容灾效果差。
我们之前的多活切量经常是这么一个场景:业务A故障了,要切量到多活机房。SRE跟研发沟通后确认要切域名A+URL A,告知CDN运维。CDN运维切量后研发发现还有个URL没切,再重复一遍上面的流程,所以导致效率极低,容灾效果也很差。
所以我们多活建设的主要方向:
多活基架能力建设
优化多活基础组件的支持能力,如数据层同步组件优化、接入层支持基于用户分片,让业务的多活接入成本更低。
重新梳理各机房在多活架构下的定位,梳理Czone、Gzone、Rzone业务域。
推动不支持多活的核心业务和已实现多活但架构不规范的业务改造优化。
多活管控能力提升
统一管控所有多活业务的元信息、路由规则,联动其他平台,成为多活的元数据中心。
支持多活接入层规则编排、数据层编排、预案编排、流量编排等,接入流程实现自动化和可视化。
抽象多活切量能力,对接CDN、存储等组件,实现一键全链路切量,提升效率和准确率。
支持多活切量时的前置能力预检,切量中风险巡检和核心指标的可观测。
2. SLB治理
架构治理
故障前一个机房内一套SLB统一对外提供代理服务,导致故障域无法隔离。后续SLB需按业务部门拆分集群,核心业务部门独立SLB集群和公网IP。
跟CDN团队、四层LB&网络团队一起讨论确定SLB集群和公网IP隔离的管理方案。
明确SLB能力边界,非SLB必备能力,统一下沉到API Gateway,SLB组件和平台均不再支持,如动态权重的灰度能力。
运维能力
SLB管理平台实现Lua代码版本化管理,平台支持版本升级和快速回滚。
SLB节点的环境和配置初始化托管到平台,联动四层LB的API,在SLB平台上实现四层LB申请、公网IP申请、节点上线等操作,做到全流程初始化5分钟以内。
SLB作为核心服务中的核心,在目前没有弹性扩容的能力下,30%的使用率较高,需要扩容把CPU降低到15%左右。
优化CDN回源超时时间,降低SLB在极端故障场景下连接数。同时对连接数做极限性能压测。
自研能力
运维团队做项目有个弊端,开发完成自测没问题后就开始灰度上线,没有专业的测试团队介入。此组件太过核心,需要引入基础组件测试团队,对SLB输入参数做完整的异常测试。
跟社区一起,Review使用到的OpenResty核心开源库源代码,消除其他风险。基于Lua已有特性和缺陷,提升我们Lua代码的鲁棒性,比如变量类型判断、强制转换等。
招专业做LB的人。我们选择基于Lua开发是因为Lua简单易上手,社区有类似成功案例。团队并没有资深做Nginx组件开发的同学,也没有做C/C++开发的同学。
3. 故障演练
本次事故中,业务多活流量调度、新建源站速度、CDN切量速度&回源超时机制均不符合预期。所以后续要探索机房级别的故障演练方案:
模拟CDN回源单机房故障,跟业务研发和测试一起,通过双端上的业务真实表现来验收多活业务的容灾效果,提前优化业务多活不符合预期的隐患。
灰度特定用户流量到演练的CDN节点,在CDN节点模拟源站故障,观察CDN和源站的容灾效果。
模拟单机房故障,通过多活管控平台,演练业务的多活切量止损预案。
4. 应急响应
B站一直没有NOC/技术支持团队,在出现紧急事故时,故障响应、故障通报、故障协同都是由负责故障处理的SRE同学来承担。如果是普通事故还好,如果是重大事故,信息同步根本来不及。所以事故的应急响应机制必须优化:
优化故障响应制度,明确故障中故障指挥官、故障处理人的职责,分担故障处理人的压力。
事故发生时,故障处理人第一时间找backup作为故障指挥官,负责故障通报和故障协同。在团队里强制执行,让大家养成习惯。
建设易用的故障通告平台,负责故障摘要信息录入和故障中进展同步。
本次故障的诱因是某个服务使用了一种特殊的发布模式触发。我们的事件分析平台目前只提供了面向应用的事件查询能力,缺少面向用户、面向平台、面向组件的事件分析能力:
跟监控团队协作,建设平台控制面事件上报能力,推动更多核心平台接入。
SLB建设面向底层引擎的数据面事件变更上报和查询能力,比如服务注册信息变更时某个应用的IP更新、weight变化事件可在平台查询。
扩展事件查询分析能力,除面向应用外,建设面向不同用户、不同团队、不同平台的事件查询分析能力,协助快速定位故障诱因。
总结
此次事故发生时,B站挂了迅速登上全网热搜,作为技术人员,身上的压力可想而知。事故已经发生,我们能做的就是深刻反思,吸取教训,总结经验,砥砺前行。
此篇作为“713事故”系列之第一篇,向大家简要介绍了故障产生的诱因、根因、处理过程、优化改进。后续文章会详细介绍“713事故”后我们是如何执行优化落地的,敬请期待。
最后,想说一句:多活的高可用容灾架构确实生效了。
来源:哔哩哔哩技术
收起阅读 »大家好啊,世界您好啊,请多关照哈
大家好啊,世界您好啊,请多关照哈,,,,,,,,,,,
Logstash:如何在 Elasticsearch 中查找和删除重复文档
许多将数据驱动到 Elasticsearch 中的系统将利用 Elasticsearch 为新插入的文档自动生成的 id 值。 但是,如果数据源意外地将同一文档多次发送到Elasticsearch,并且如果将这种自动生成的 id 值用于 Elasticsearch 插入的每个文档,则该同一文档将使用不同的id值多次存储在 Elasticsearch 中。 如果发生这种情况,那么可能有必要找到并删除此类重复项。 因此,在此博客文章中,我们介绍如何通过
使用 Logstash
使用 Python 编写的自定义代码从 Elasticsearch 中检测和删除重复文档
示例文档结构
就本博客而言,我们假设 Elasticsearch 集群中的文档具有以下结构。 这对应于包含代表股票市场交易的文档的数据集。
{
"_index": "stocks",
"_type": "doc",
"_id": "6fo3tmMB_ieLOlkwYclP",
"_version": 1,
"found": true,
"_source": {
"CAC": 1854.6,
"host": "Alexanders-MBP",
"SMI": 2061.7,
"@timestamp": "2017-01-09T02:30:00.000Z",
"FTSE": 2827.5,
"DAX": 1527.06,
"time": "1483929000",
"message": "1483929000,1527.06,2061.7,1854.6,2827.5\r",
"@version": "1"
}
}给定该示例文档结构,出于本博客的目的,我们任意假设如果多个文档的 [“CAC”,“FTSE”,“SMI”] 字段具有相同的值,则它们是彼此重复的。
使用 Logstash 对 Elasticsearch 文档进行重复数据删除
这种方法已经在之前的文章 “Logstash:处理重复的文档” 已经描述过了。Logstash 可用于检测和删除 Elasticsearch 索引中的重复文档。 在那个文章中,我们已经对这个方法进行了详述,也做了展示。我们也无妨做一个更进一步的描述。
在下面的示例中,我编写了一个简单的 Logstash 配置,该配置从 Elasticsearch 集群上的索引读取文档,然后使用指纹过滤器根据 ["CAC", "FTSE", "SMI"] 字段的哈希值为每个文档计算唯一的 _id 值,最后将每个文档写回到同一 Elasticsearch 集群上的新索引,这样重复的文档将被写入相同的 _id 并因此被消除。
此外,通过少量修改,相同的 Logstash 过滤器也可以应用于写入新创建的索引的将来文档,以确保几乎实时删除重复项。这可以通过更改以下示例中的输入部分以接受来自实时输入源的文档,而不是从现有索引中提取文档来实现。
请注意,使用自定义 id 值(即不是由 Elasticsearch 生成的 _id)将对索引操作的[写入性能产生一些影响](https://www.elastic.co/guide/en/elasticsearch/reference/master/tune-for-indexing-speed.html#use_auto_generated_ids)。
另外,值得注意的是,根据所使用的哈希算法,此方法理论上可能会导致 id 值的[哈希冲突数](https://en.wikipedia.org/wiki/Collision(computer_science))不为零,这在理论上可能导致两个不相同的文档映射到相同的_id,因此导致这些文档之一丢失。对于大多数实际情况,哈希冲突的可能性可能非常低。对不同哈希函数的详细分析不在本博客的讨论范围之内,但是应仔细考虑指纹过滤器中使用的哈希函数,因为它将影响提取性能和哈希冲突次数。
下面给出了使用指纹过滤器对现有索引进行重复数据删除的简单 Logstash 配置。
input {
# Read all documents from Elasticsearch
elasticsearch {
hosts => "localhost"
index => "stocks"
query => '{ "sort": [ "_doc" ] }'
}
}
# This filter has been updated on February 18, 2019
filter {
fingerprint {
key => "1234ABCD"
method => "SHA256"
source => ["CAC", "FTSE", "SMI"]
target => "[@metadata][generated_id]"
concatenate_sources => true # <-- New line added since original post date
}
}
output {
stdout { codec => dots }
elasticsearch {
index => "stocks_after_fingerprint"
document_id => "%{[@metadata][generated_id]}"
}
}用于 Elasticsearch 文档重复数据删除的自定义 Python 脚本
内存有效的方法
如果不使用 Logstash,则可以使用自定义 python 脚本有效地完成重复数据删除。 对于这种方法,我们计算定义为唯一标识文档的["CAC","FTSE","SMI"] 字段的哈希值 (Hash)。 然后,我们将此哈希用作 python 字典中的键,其中每个字典条目的关联值将是映射到同一哈希的文档 _id 的数组。
如果多个文档具有相同的哈希,则可以删除映射到相同哈希的重复文档。 另外,如果你担心哈希值冲突的可能性,则可以检查映射到同一散列的文档的内容,以查看文档是否确实相同,如果是,则可以消除重复项。
检测算法分析
对于 50GB 的索引,如果我们假设索引包含平均大小为 0.4 kB 的文档,则索引中将有1.25亿个文档。 在这种情况下,使用128位 md5 哈希将重复数据删除数据结构存储在内存中所需的内存量约为128位x 125百万= 2GB 内存,再加上160位_id将需要另外160位x 125百万= 2.5 GB 的内存。 因此,此算法将需要4.5GB 的 RAM 数量级,以将所有相关的数据结构保留在内存中。 如果可以应用下一节中讨论的方法,则可以大大减少内存占用。
算法增强
在本节中,我们对算法进行了增强,以减少内存使用以及连续删除新的重复文档。
如果你要存储时间序列数据,并且知道重复的文档只会在彼此之间的一小段时间内出现,那么您可以通过在文档的子集上重复执行该算法来改善该算法的内存占用量在索引中,每个子集对应一个不同的时间窗口。例如,如果您有多年的数据,则可以在datetime字段(在过滤器上下文中以获得最佳性能)上使用范围查询,一次仅一周查看一次数据集。这将要求算法执行52次(每周一次)-在这种情况下,这种方法将使最坏情况下的内存占用减少52倍。
在上面的示例中,你可能会担心没有检测到跨星期的重复文档。假设你知道重复的文档间隔不能超过2小时。然后,您需要确保算法的每次执行都包含与之前算法执行过的最后一组文档重叠2小时的文档。对于每周示例,因此,您需要查询170小时(1周+ 2小时)的时间序列文档,以确保不会丢失任何重复项。
如果你希望持续定期从索引中清除重复的文档,则可以对最近收到的文档执行此算法。与上述逻辑相同-确保分析中包括最近收到的文档以及与稍旧的文档的足够重叠,以确保不会无意中遗漏重复项。
用于检测重复文档的 Python 代码
以下代码演示了如何可以有效地评估文档以查看它们是否相同,然后根据需要将其删除。 但是,为了防止意外删除文档,在本示例中,我们实际上并未执行删除操作。 这样的功能的实现将是非常直接的。
可以在 github 上找到用于从 Elasticsearch 中删除文档重复数据的代码。
#!/usr/local/bin/python3
import hashlib
from elasticsearch import Elasticsearch
es = Elasticsearch(["localhost:9200"])
dict_of_duplicate_docs = {}
# The following line defines the fields that will be
# used to determine if a document is a duplicate
keys_to_include_in_hash = ["CAC", "FTSE", "SMI"]
# Process documents returned by the current search/scroll
def populate_dict_of_duplicate_docs(hits):
for item in hits:
combined_key = ""
for mykey in keys_to_include_in_hash:
combined_key += str(item['_source'][mykey])
_id = item["_id"]
hashval = hashlib.md5(combined_key.encode('utf-8')).digest()
# If the hashval is new, then we will create a new key
# in the dict_of_duplicate_docs, which will be
# assigned a value of an empty array.
# We then immediately push the _id onto the array.
# If hashval already exists, then
# we will just push the new _id onto the existing array
dict_of_duplicate_docs.setdefault(hashval, []).append(_id)
# Loop over all documents in the index, and populate the
# dict_of_duplicate_docs data structure.
def scroll_over_all_docs():
data = es.search(index="stocks", scroll='1m', body={"query": {"match_all": {}}})
# Get the scroll ID
sid = data['_scroll_id']
scroll_size = len(data['hits']['hits'])
# Before scroll, process current batch of hits
populate_dict_of_duplicate_docs(data['hits']['hits'])
while scroll_size > 0:
data = es.scroll(scroll_id=sid, scroll='2m')
# Process current batch of hits
populate_dict_of_duplicate_docs(data['hits']['hits'])
# Update the scroll ID
sid = data['_scroll_id']
# Get the number of results that returned in the last scroll
scroll_size = len(data['hits']['hits'])
def loop_over_hashes_and_remove_duplicates():
# Search through the hash of doc values to see if any
# duplicate hashes have been found
for hashval, array_of_ids in dict_of_duplicate_docs.items():
if len(array_of_ids) > 1:
print("********** Duplicate docs hash=%s **********" % hashval)
# Get the documents that have mapped to the current hashval
matching_docs = es.mget(index="stocks", doc_type="doc", body={"ids": array_of_ids})
for doc in matching_docs['docs']:
# In this example, we just print the duplicate docs.
# This code could be easily modified to delete duplicates
# here instead of printing them
print("doc=%s\n" % doc)
def main():
scroll_over_all_docs()
loop_over_hashes_and_remove_duplicates()
main()结论
在此博客文章中,我们展示了两种在 Elasticsearch 中对文档进行重复数据删除的方法。 第一种方法使用 Logstash 删除重复的文档,第二种方法使用自定义的 Python 脚本查找和删除重复的文档。
来源:https://blog.csdn.net/UbuntuTouch/article/details/106643400
原文: How to Find and Remove Duplicate Documents in Elasticsearch | Elastic Blog
收起阅读 »DevOps之【持续集成】
引言
对于客户或者需求方来说,可以集成交付的软件才是有价值的。
每个软件都有集成的过程,如果软件规模比较小,比如只有一个人而且没有外部依赖,那集成没什么问题。随着软件变得复杂,依赖变多,开发人员变多,那么早集成、常集成,就可以尽早暴露问题,做出相应的调整,防止在软件后期才发现问题,从而导致软件失败。
定义
大师Martin Fowler对持续集成是这样定义的:
持续集成是一种软件开发实践,即团队开发成员经常集成它们的工作,通常每个成员每天至少集成一次,也就意味着每天可能会发生多次集成。每次集成都通过自动化的构建(包括编译,发布,自动化测试)来验证,从而尽快地发现集成错误。许多团队发现这个过程可以大大减少集成的问题,让团队能够更快的开发内聚的软件。
优点
降低软件风险 早集成,常集成,并且做了有效的测试,有利于尽早暴露问题和软件缺陷,了解软件的健康情况。假定越少的软件,对于维护和新业务开发都是有利的。 如果botslab每一个品类的设备都单独分支开发,不能及时集成进来,依赖问题、冲突问题、业务复用问题不能尽早解决,问题累积到一定程度解决成本会变大,业务发展是不会为代码重构让路的,那么软件质量的降低是必然的,很多项目都是这样失败的
减少重复过程 软件集成的过程看起来简单,但是做起来难。软件的编译,测试,审查,部署,反馈,这些重复劳动是非常耗时,且没有意义的,自动化集成可以让开发解放出来,做一些用脑袋的事情。 如果出现疏漏,会给下游的参与者带来额外工作量和项目质量的误判。软件的输出质量是会影响项目计划的,所以持续集成很重要的一点就是自动化
随时生成可以部署的软件 持续集成可以随时随地输出可以部署的软件,这一点对于需求方或客户是明显的好处。我们可以对客户说软件有多么好的架构,多么高质量的代码,但是对于客户来说,一个可以使用的软件才是他的实际资产。持续交付可以尽早的暴露产品问题和开发方向,客户才能给出有效的意见和开发重点。
软件是透明的 持续集成会生成软件构建状态和品质信息,经常集成可以看到一些趋势,预测一些软件质量走向。
团队信心 持续集成可以建立团队的信心,开发清楚的知道自己的代码产生了什么影响,测试对软件质量的预测稳定,产品或客户可以放心的需求了
步骤
统一的代码库
自动构建
自动测试
每个人每天都要向代码库主干提交代码
每次代码递交后都会在持续集成服务器上触发一次构建
保证快速构建
模拟生产环境的自动测试
每个人都可以很容易的获取最新可执行的应用程序
每个人都清楚正在发生的状况
自动化的部署
原则
所有的开发人员需要在本地机器上做本地构建,然后再提交的版本控制库中,从而确保他们的变更不会导致持续集成失败。
开发人员每天至少向版本控制库中提交一次代码。
开发人员每天至少需要从版本控制库中更新一次代码到本地机器。
需要有专门的集成服务器来执行集成构建,每天要执行多次构建。
每次构建都要100%通过。
每次构建都可以生成可发布的产品。
修复失败的构建是优先级最高的事情。
作者:QiShare
来源:juejin.cn/post/6986884632222384141
[PHP 安全] pcc —— PHP 安全配置检测工具
背景
在 PHP 安全测试中最单调乏味的任务之一就是检查不安全的 PHP 配置项。作为一名 PHP 安全海报的继承者,我们创建了一个脚本用来帮助系统管理员如同安全专家一样尽可能快速且全面地评估 php.ini 和相关主题的状态。在下文中,该脚本被称作“PHP 安全配置项检查器”,或者 pcc。
概念
- 一个便于分发的单文件
- 有对每个安全相关的 ini 条目的简单测试
- 包含一些其他测试 - 但不太复杂
- 兼容 PHP >= 5.4, 或者 >= 5.0
- 没有复杂/过度设计的代码,例如没有类/接口,测试框架,类库等等。它应该第一眼看上去是显而易见的-甚至对于新手-这个工具怎么使用能用来做什么。
- 没有(或者少量的)依赖
使用 / 安装
- CLI:简单调用
php phpconfigcheck.php。然后,添加参数-a以便更好的查看隐藏结果,-h以 HTML 格式输出,-j以 JSON 格式输出. - WEB: 复制这个脚本文件到你的服务器上的任意一个可访问目录,比如 root 目录。参见下面的“防护措施”。
在非 CLI 模式下默认输出 HTML 格式。可以通过修改设置环境变量PCC_OUTPUT_TYPE=text或者PCC_OUTPUT_TYPE=json改变这个行为。
一些测试用例默认是被隐藏的,特别是skipped、ok和 unknown/untested这些。要显示全部结果,可以用phpconfigcheck.php?showall=1,但这并不适用于 JSON 输出,它默认返回全部结果。
在 WEB 模式下控制输出格式用phpconfigcheck.php?format=...,format的值可以是text,html或者json中的一个,例如:phpconfigcheck.php?format=text。format参数优先于 PCC_OUTPUT_TYPE。
保障措施
大多数情况下,最好是自己来关注与安全性相关的问题比如PHP的配置。脚本已实现下列保障措施:
- mtime检查:脚本在非CLI环境中只能工作两天。可以通过
touch phpconfigcheck.php或者将脚本文件再次复制到你的服务器(例如通过SCP)来重新进行mtime检查。可以通过设置环境量:PCC_DISABLE_MTIME=1,比如在apache的.htaccess文件中设置SetEnv PCC_DISABLE_MTIME 1来禁用mtime检查。 - 来源IP检查:默认情况下,只有localhost (127.0.0.1 和 ::1)才能访问这个脚本。其他主机可以通过在
PCC_ALLOW_IP中添加IP地址或者通配符表达式的方式来访问脚本,比如在.htaccess文件中设置SetEnv PCC_ALLOW_IP 10.0.0.*。你还可以选择通过SSH端口转发访问您的web服务器, 比如ssh -D或者ssh -L。
下载
可以通过github下载第一个完整的开发版: https://github.com/sektioneins/pcc
如果有好的建议或者遇到bug请给我们提issue:
截图
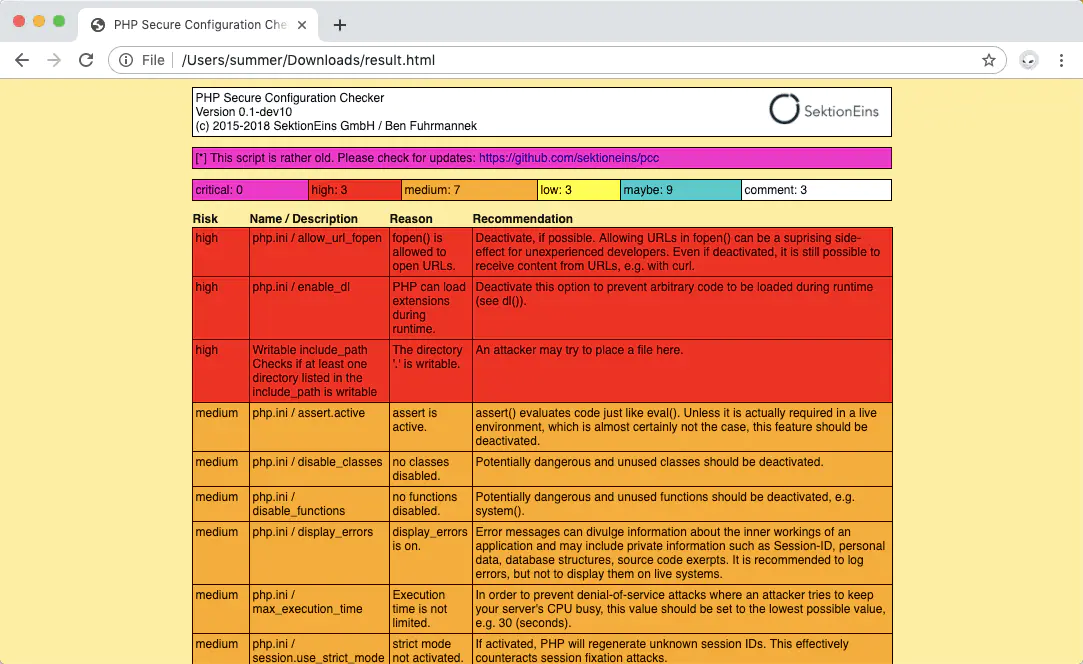
HTML输出的列表是根据问题严重性排序的,通过颜色代码的形式列出了所有建议。列表顶部的状态行会显示问题的数量。
转载自: https://cloud.tencent.com/developer/article/1911011
收起阅读 »Vue2全家桶之一:vue-cli
都说Vue2简单上手容易,的确,看了官方文档确实觉得上手很快,除了ES6语法和webpack的配置让你感到陌生,重要的是思路的变换,以前用jq随便拿全局变量和修改dom的锤子不能用了,vue只用关心数据本身,不用再频繁繁琐的操作dom,注册事件、监听事件、取消事件。。。。(确实很烦)。vue的官方文档还是不错的,由浅到深,如果不使用构建工具确实用的很爽,但是这在实际项目应用中是不可能的,当用vue-cli构建一个工程的时候,发现官方文档还是不够用,需要熟练掌握es6,而vue的全家桶(vue-cli,vue-router,vue-resource,vuex)还是都要上的。
vue.js有著名的全家桶系列,包含了vue-router,vuex, vue-resource,再加上构建工具vue-cli,就是一个完整的vue项目的核心构成。
vue-cli这个构建工具大大降低了webpack的使用难度,支持热更新,有webpack-dev-server的支持,相当于启动了一个请求服务器,给你搭建了一个测试环境,只关注开发就OK。
1.安装vue-cli
① 使用npm(需要安装node环境)全局安装webpack,打开命令行工具输入:npm install webpack -g或者(npm install -g webpack),安装完成之后输入 webpack -v,如下图,如果出现相应的版本号,则说明安装成功。
② 全局安装vue-cli,在cmd中输入命令:
npm install --global vue-cli安装成功:
安装完成之后输入 vue -V(注意这里是大写的“V”),如下图,如果出现相应的版本号,则说明安装成功。
打开C:\Users\Andminster\AppData\Roaming\npm目录下可以看到:
打开node_modules也可以看到:
2.用vue-cli来构建项目
① 我首先在D盘新建一个文件夹(dxl_vue)作为项目存放地,然后使用命令行cd进入到项目目录输入:
vue init webpack baogebaoge是自定义的项目名称,命令执行之后,会在当前目录生成一个以该名称命名的项目文件夹。
输入命令后,会跳出几个选项让你回答:
- Project name (baoge): -----项目名称,直接回车,按照括号中默认名字(注意这里的名字不能有大写字母,如果有会报错Sorry, name can no longer contain capital letters),阮一峰老师博客为什么文件名要小写 ,可以参考一下。
- Project description (A Vue.js project): ----项目描述,也可直接点击回车,使用默认名字
- Author (): ----作者,输入dongxili
接下来会让用户选择: - Runtime + Compiler: recommended for most users 运行加编译,既然已经说了推荐,就选它了
Runtime-only: about 6KB lighter min+gzip, but templates (or any Vue-specificHTML) are ONLY allowed in .vue files - render functions are required elsewhere 仅运行时,已经有推荐了就选择第一个了 - Install vue-router? (Y/n) 是否安装vue-router,这是官方的路由,大多数情况下都使用,这里就输入“y”后回车即可。
- Use ESLint to lint your code? (Y/n) 是否使用ESLint管理代码,ESLint是个代码风格管理工具,是用来统一代码风格的,一般项目中都会使用。
接下来也是选择题Pick an ESLint preset (Use arrow keys) 选择一个ESLint预设,编写vue项目时的代码风格,直接y回车 - Setup unit tests with Karma + Mocha? (Y/n) 是否安装单元测试,我选择安装y回车
- Setup e2e tests with Nightwatch(Y/n)? 是否安装e2e测试 ,我选择安装y回车
回答完毕后上图就开始构建项目了。
② 配置完成后,可以看到目录下多出了一个项目文件夹baoge,然后cd进入这个文件夹:
安装依赖:
npm install ( 如果安装速度太慢。可以安装淘宝镜像,打开命令行工具,输入:
npm install -g cnpm --registry=https://registry.npm.taobao.org
然后使用cnpm来安装 )
npm install :安装所有的模块,如果是安装具体的哪个个模块,在install 后面输入模块的名字即可。而只输入install就会按照项目的根目录下的package.json文件中依赖的模块安装(这个文件里面是不允许有任何注释的),每个使用npm管理的项目都有这个文件,是npm操作的入口文件。因为是初始项目,还没有任何模块,所以我用npm install 安装所有的模块。安装完成后,目录中会多出来一个node_modules文件夹,这里放的就是所有依赖的模块。
然后现在,baoge文件夹里的目录是这样的:
解释下每个文件夹代表的意思(仔细看一下这张图):
image.png
3.启动项目
npm run dev
如果浏览器打开之后,没有加载出页面,有可能是本地的 8080 端口被占用,需要修改一下配置文件 config里的index.js
还有,如果本地调试项目时,建议将build 里的assetsPublicPath的路径前缀修改为 ' ./ '(开始是 ' / '),因为打包之后,外部引入 js 和 css 文件时,如果路径以 ' / ' 开头,在本地是无法找到对应文件的(服务器上没问题)。所以如果需要在本地打开打包后的文件,就得修改文件路径。
我的端口没有被占用,直接成功(服务启动成功后浏览器会默认打开一个“欢迎页面”):
注意:在进行vue页面调试时,一定要去谷歌商店下载一个vue-tool扩展程序。
4.vue-cli的webpack配置分析
- 从
package.json可以看到开发和生产环境的入口。
- 可以看到dev中的设置,build/webpack.dev.conf.js,该文件是开发环境中webpack的配置入口。
- 在webpack.dev.conf.js中出现webpack.base.conf.js,这个文件是开发环境和生产环境,甚至测试环境,这些环境的公共webpack配置。可以说,这个文件相当重要。
- 还有config/index.js 、build/utils.js 、build/build.js等,具体请看这篇介绍:
https://segmentfault.com/a/1190000008644830
5.打包上线
注意,自己的项目文件都需要放到 src 文件夹下。
在项目开发完成之后,可以输入 npm run build 来进行打包工作。
npm run build另:
1.npm 开启了npm run dev以后怎么退出或关闭?
ctrl+c
2.--save-dev
自动把模块和版本号添加到模块配置文件package.json中的依赖里devdependencies部分
3. --save-dev 与 --save 的区别
--save 安装包信息将加入到dependencies(生产阶段的依赖)
--save-dev 安装包信息将加入到devDependencies(开发阶段的依赖),所以开发阶段一般使用它打包完成后,会生成 dist 文件夹,如果已经修改了文件路径,可以直接打开本地文件查看。
项目上线时,只需要将 dist 文件夹放到服务器就行了。
转载自: https://cloud.tencent.com/developer/article/1896690
收起阅读 »Java Exception
Java异常
异常指不期而至的各种状况,如:文件找不到、网络连接失败、非法参数等。异常是一个事件,它发生在程序运行期间,干扰了正常的指令流程。Java通 过API中Throwable类的众多子类描述各种不同的异常。因而,Java异常都是对象,是Throwable子类的实例,描述了出现在一段编码中的 错误条件。当条件生成时,错误将引发异常。
Java异常类层次结构图:
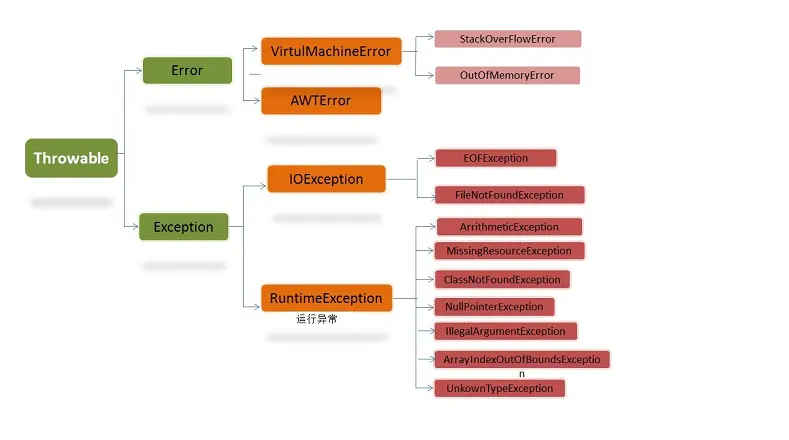
图1 Java异常类层次结构图
在 Java 中,所有的异常都有一个共同的祖先 Throwable(可抛出)。Throwable 指定代码中可用异常传播机制通过 Java 应用程序传输的任何问题的共性。 Throwable: 有两个重要的子类:Exception(异常)和 Error(错误),二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Error(错误):是程序无法处理的错误,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
Exception(异常):是程序本身可以处理的异常。
Exception 类有一个重要的子类 RuntimeException。RuntimeException 类及其子类表示“JVM 常用操作”引发的错误。例如,若试图使用空值对象引用、除数为零或数组越界,则分别引发运行时异常(NullPointerException、ArithmeticException)和 ArrayIndexOutOfBoundException。
注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。
通常,Java的异常(包括Exception和Error)分为可查的异常(checked exceptions)和不可查的异常(unchecked exceptions)。
可查异常(编译器要求必须处置的异常):正确的程序在运行中,很容易出现的、情理可容的异常状况。可查异常虽然是异常状况,但在一定程度上它的发生是可以预计的,而且一旦发生这种异常状况,就必须采取某种方式进行处理。
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于可查异常。这种异常的特点是Java编译器会检查它,也就是说,当程序中可能出现这类异常,要么用try-catch语句捕获它,要么用throws子句声明抛出它,否则编译不会通过。
不可查异常(编译器不要求强制处置的异常):包括运行时异常(RuntimeException与其子类)和错误(Error)。
Exception 这种异常分两大类运行时异常和非运行时异常(编译异常)。程序中应当尽可能去处理这些异常。
运行时异常:都是RuntimeException类及其子类异常,如NullPointerException(空指针异常)、IndexOutOfBoundsException(下标越界异常)等,这些异常是不检查异常,程序中可以选择捕获处理,也可以不处理。这些异常一般是由程序逻辑错误引起的,程序应该从逻辑角度尽可能避免这类异常的发生。
运行时异常的特点是Java编译器不会检查它,也就是说,当程序中可能出现这类异常,即使没有用try-catch语句捕获它,也没有用throws子句声明抛出它,也会编译通过。 非运行时异常 (编译异常):是RuntimeException以外的异常,类型上都属于Exception类及其子类。从程序语法角度讲是必须进行处理的异常,如果不处理,程序就不能编译通过。如IOException、SQLException等以及用户自定义的Exception异常,一般情况下不自定义检查异常。
4.处理异常机制
在 Java 应用程序中,异常处理机制为:抛出异常,捕捉异常。
抛出异常:当一个方法出现错误引发异常时,方法创建异常对象并交付运行时系统,异常对象中包含了异常类型和异常出现时的程序状态等异常信息。运行时系统负责寻找处置异常的代码并执行。
捕获异常 :在方法抛出异常之后,运行时系统将转为寻找合适的异常处理器(exception handler)。潜在的异常处理器是异常发生时依次存留在调用栈中的方法的集合。当异常处理器所能处理的异常类型与方法抛出的异常类型相符时,即为合适 的异常处理器。运行时系统从发生异常的方法开始,依次回查调用栈中的方法,直至找到含有合适异常处理器的方法并执行。当运行时系统遍历调用栈而未找到合适 的异常处理器,则运行时系统终止。同时,意味着Java程序的终止。
对于运行时异常、错误或可查异常,Java技术所要求的异常处理方式有所不同。
由于运行时异常的不可查性,为了更合理、更容易地实现应用程序,Java规定,运行时异常将由Java运行时系统自动抛出,允许应用程序忽略运行时异常。
对于方法运行中可能出现的Error,当运行方法不欲捕捉时,Java允许该方法不做任何抛出声明。因为,大多数Error异常属于永远不能被允许发生的状况,也属于合理的应用程序不该捕捉的异常。
对于所有的可查异常,Java规定:一个方法必须捕捉,或者声明抛出方法之外。也就是说,当一个方法选择不捕捉可查异常时,它必须声明将抛出异常。
能够捕捉异常的方法,需要提供相符类型的异常处理器。所捕捉的异常,可能是由于自身语句所引发并抛出的异常,也可能是由某个调用的方法或者Java运行时 系统等抛出的异常。也就是说,一个方法所能捕捉的异常,一定是Java代码在某处所抛出的异常。简单地说,异常总是先被抛出,后被捕捉的。
任何Java代码都可以抛出异常,如:自己编写的代码、来自Java开发环境包中代码,或者Java运行时系统。无论是谁,都可以通过Java的throw语句抛出异常。
从方法中抛出的任何异常都必须使用throws子句。
捕捉异常通过try-catch语句或者try-catch-finally语句实现。
总体来说,Java规定:对于可查异常必须捕捉、或者声明抛出。允许忽略不可查的RuntimeException和Error。
4.1 捕获异常:try、catch 和 finally
1.try-catch语句
在Java中,异常通过try-catch语句捕获。其一般语法形式为:
try {
// 可能会发生异常的程序代码
} catch (Type1 id1){
// 捕获并处置try抛出的异常类型Type1
}
catch (Type2 id2){
//捕获并处置try抛出的异常类型Type2
} 关键词try后的一对大括号将一块可能发生异常的代码包起来,称为监控区域。Java方法在运行过程中出现异常,则创建异常对象。将异常抛出监控区域之 外,由Java运行时系统试图寻找匹配的catch子句以捕获异常。若有匹配的catch子句,则运行其异常处理代码,try-catch语句结束。
匹配的原则是:如果抛出的异常对象属于catch子句的异常类,或者属于该异常类的子类,则认为生成的异常对象与catch块捕获的异常类型相匹配。
例1 捕捉throw语句抛出的“除数为0”异常。
public class TestException {
public static void main(String[] args) {
int a = 6;
int b = 0;
try { // try监控区域
if (b == 0) throw new ArithmeticException(); // 通过throw语句抛出异常
System.out.println("a/b的值是:" + a / b);
}
catch (ArithmeticException e) { // catch捕捉异常
System.out.println("程序出现异常,变量b不能为0。");
}
System.out.println("程序正常结束。");
}
} 制运行结果:程序出现异常,变量b不能为0。
程序正常结束。
例1 在try监控区域通过if语句进行判断,当“除数为0”的错误条件成立时引发ArithmeticException异常,创建 ArithmeticException异常对象,并由throw语句将异常抛给Java运行时系统,由系统寻找匹配的异常处理器catch并运行相应异 常处理代码,打印输出“程序出现异常,变量b不能为0。”try-catch语句结束,继续程序流程。
事实上,“除数为0”等ArithmeticException,是RuntimException的子类。而运行时异常将由运行时系统自动抛出,不需要使用throw语句。
例2 捕捉运行时系统自动抛出“除数为0”引发的ArithmeticException异常。
public static void main(String[] args) {
int a = 6;
int b = 0;
try {
System.out.println("a/b的值是:" + a / b);
} catch (ArithmeticException e) {
System.out.println("程序出现异常,变量b不能为0。");
}
System.out.println("程序正常结束。");
}
} 制运行结果:程序出现异常,变量b不能为0。
程序正常结束。
例2 中的语句:
System.out.println("a/b的值是:" + a/b);
在运行中出现“除数为0”错误,引发ArithmeticException异常。运行时系统创建异常对象并抛出监控区域,转而匹配合适的异常处理器catch,并执行相应的异常处理代码。
由于检查运行时异常的代价远大于捕捉异常所带来的益处,运行时异常不可查。Java编译器允许忽略运行时异常,一个方法可以既不捕捉,也不声明抛出运行时异常。
例3 不捕捉、也不声明抛出运行时异常。
public class TestException {
public static void main(String[] args) {
int a, b;
a = 6;
b = 0; // 除数b 的值为0
System.out.println(a / b);
}
} 复制运行结果:
Exception in thread "main" java.lang.ArithmeticException: / by zero at Test.TestException.main(TestException.java:8)
例4 程序可能存在除数为0异常和数组下标越界异常。
public class TestException {
public static void main(String[] args) {
int[] intArray = new int[3];
try {
for (int i = 0; i <= intArray.length; i++) {
intArray[i] = i;
System.out.println("intArray[" + i + "] = " + intArray[i]);
System.out.println("intArray[" + i + "]模 " + (i - 2) + "的值: "
+ intArray[i] % (i - 2));
}
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("intArray数组下标越界异常。");
} catch (ArithmeticException e) {
System.out.println("除数为0异常。");
}
System.out.println("程序正常结束。");
}
} 运行结果:
intArray[0] = 0
intArray[0]模 -2的值: 0
intArray[1] = 1
intArray[1]模 -1的值: 0
intArray[2] = 2
除数为0异常。
程序正常结束。
例4 程序可能会出现除数为0异常,还可能会出现数组下标越界异常。程序运行过程中ArithmeticException异常类型是先行匹配的,因此执行相匹配的catch语句:
catch (ArithmeticException e){
System.out.println("除数为0异常。");
} 需要注意的是,一旦某个catch捕获到匹配的异常类型,将进入异常处理代码。一经处理结束,就意味着整个try-catch语句结束。其他的catch子句不再有匹配和捕获异常类型的机会。
Java通过异常类描述异常类型,异常类的层次结构如图1所示。对于有多个catch子句的异常程序而言,应该尽量将捕获底层异常类的catch子 句放在前面,同时尽量将捕获相对高层的异常类的catch子句放在后面。否则,捕获底层异常类的catch子句将可能会被屏蔽。
RuntimeException异常类包括运行时各种常见的异常,ArithmeticException类和ArrayIndexOutOfBoundsException类都是它的子类。因此,RuntimeException异常类的catch子句应该放在 最后面,否则可能会屏蔽其后的特定异常处理或引起编译错误。
使用 C# 开发 node.js 插件
项目需求
最近在开发一个 electron 程序,其中有用到和硬件通讯部分;硬件厂商给的是 .dll 链接库做通讯桥接,
第一版本使用 C 写的 Node.js 扩展 😁;由于有异步任务的关系,实现使用了 N-API 提供的多线程做异步任务调度,
虽然功能实现了,但是也有些值得思考的点。
- 纯 C 编程效率低,木有 trycatch 的语言调试难度也大 (磕磕绊绊的)
- 编写好的 .node 扩展文件,放在 electron 主进程中运行会有一定的隐患稍有差错会导致软件闪退 (后来用子进程隔离运行)
- 基于 N-API 方式去编写 Node.js 插件会显得有所束缚,木有那种随心所欲写 C 的那种“顺畅”;尤其是多线程部分
综上考虑,加上通讯功能又是调用 .dll 文件,索性转战 C#,对于 windows 来说再合适不过了;但是问题是 C# 咋编译到 Node.js 中?
答案是“编译不了”。
插件实现的功能只是收到命令后调用 .dll 去操作硬件,再时时能把结果返回即可。
基于这个需求我们用 C# 去调用 .dll 文件,然后再解决派发命令、实时获取结果的通讯问题就OK了,剩下的就都是好处啦
- C# 编写难度低于 C,又是 windows 亲儿子,基于
.NET Framework编译后的程序仅 19KB (C实现同样功能编出来的.node文件 565KB) - 基于 C# 的插件独立于 Node.js 运行环境,程序出了问题不会影响 electron 应用
- 木有任何的编程束缚,~亲想咋写就咋写
通讯问题
说这个之前我们还忽略了一个问题,这个 C# 的程序(.exe文件)如果启动?
既然是一个程序(.exe文件),我们双击即可执行;既然双击即可执行,我们就可以用 child_process 模块提供的
spawn 去拉起程序(代替鼠标双击);
好!程序已经启动了,那么该到了如果通讯的环节了。
spawn 的执行就是开启了一个单独的进程,通讯问题也就是进程通讯问题。之前如果你用过 spawn 启动过 Node.js 程序(.js文件),那么你肯定知道通讯使用 send 方法即可;这个是 Node.js 内置的方式
我们启动的进程是 C# 程序,通讯问题只能我们自己来解决了;进程通讯的方式有好多这里不展开。对于前端(web)攻城狮来讲,我们最熟悉的莫过于 http 通讯方式了;就用它!
- C# 程序端启动开启一个
http服务等待 Node.js 端发送请求过来;根据参数决定要干啥 -
spawn启动的应用(进程),会返回一个ChildProcessWithoutNullStreams(这个我也不能很明确的理解);能够接收到标准的stdio输入/输出
那我们就利用这点使用ChildProcessWithoutNullStreams.stdout.on('data', chunk => console.log(chunk.toString()))的方式就可以收到 C# 通过stdio即Console.WriteLine()发过来的数据;
哇!好方便~ - 可能有人会想到用双工的
web socket实现通讯,很棒!实现方式确实有很多种,这里用Console.WriteLine()通过标准的stdio方式实现,算不算是一个开发成本不高的讨巧做法呢!
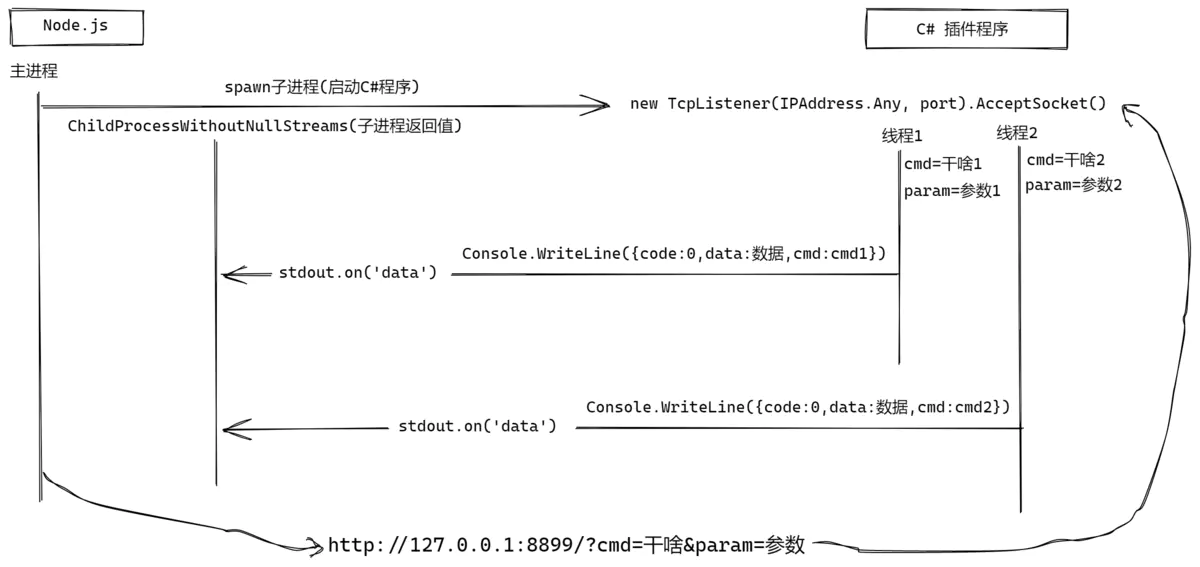
大致流程
- 如果觉得这篇文章有难度,可以看简单版的哦 Node.js 利用 stdio 标准输入/输出实现与 C# 程序通讯
开发环境
- C# 代码部分使用 Visual Studio 2017
- test.js 代码部分使用 VsCode
using System;
using System.Collections.Generic;
using System.Linq; using System.Text;
using System.Net;
using System.Net.Sockets;
using System.Threading;
using System.Text.RegularExpressions;
namespace NodeAddons {
class Program {
static TcpListener listener;
static int port = 8899;
static string now = DateTime.Now.ToString("yyyy-MM-dd HH:mm:ss");
static void Main(string[] args){
listener = new TcpListener(IPAddress.Any, port);
listener.Start();
// 启用服务器线程
new Thread(new ThreadStart(StartServer)).Start();
Console.WriteLine("Http server run at {0}.", port);
}
// Http 服务器
static void StartServer() {
while(true) {
// 这里会阻塞线程,直到接受到一个请求
Socket socket = listener.AcceptSocket();
// 将请求单独开一个线程处理;while(true)会回到等待下一个请求状态,周而复始
new Thread(new ParameterizedThreadStart(HandleRequest)).Start(socket);}}// 处理一个请求static void HandleRequest(object args) {Socket socket = (Socket)args;byte[] receive = new byte[1024];socket.Receive(receive, receive.Length, SocketFlags.None);string httpRawTxt = Encoding.ASCII.GetString(receive);// 通过 stdio(Console.WriteLine) 实现与 node.js 通讯// ## 开头、结尾,方便区分这个条输出是给 node.js 通讯用的Console.WriteLine("##" + httpRawTxt + "##");SendToBrowser(ref socket, now);}// 发送数据static void SendToBrowser(ref Socket socket, string body){string header = "HTTP/1.1 200 OK\r\n" + "Content-Type: text/html\r\n" + "Content-Length: " + body.Length + "\r\n" + "Access-Control-Allow-Origin:*\r\n"// 支持跨域 + "\r\n";// 响应头与响应体分界byte[] data = Encoding.ASCII.GetBytes(header + body);if (socket.Connected) {int res = socket.Send(data, data.Length, SocketFlags.None);if (res == -1){Console.WriteLine("Socket Error cannot Send Packet.");}else{Console.WriteLine(">> [{0}]", now);}socket.Close();}}}}
Node.js 部分
const http = require('http');
const cp = require('child_process');
const path = require('path');
// const handel = cp.spawn(path.join(__dirname, 'dist/NodeAddons.exe'));
const handel = cp.spawn(path.join(__dirname, 'dist/NodeAddons_WithConsole.exe')); handel.stdout.on('data', chunk => { const str = chunk.toString();
// 约定 ##数据## 的字符串为通讯数据
let res = str.match(/##([\S\s]*)##/g);
if (!Array.isArray(res)) return;
res = res[0].match(/(?<=(\?))(.*)(?=(\sHTTP\/1.1))/);
if (!Array.isArray(res)) return;
console.log('[stdout queryString]', res[0]); });
function query(param, cb) {
http.get(`http://127.0.0.1:8899/?${(new URLSearchParams(param)).toString()}`, res => { res.on('data', chunk => { cb(chunk.toString()); });
}); }
query({ name: 'anan', age: 29, time: Date.now() }, httpRawTxt => { console.log('[http response]', httpRawTxt); });
// 监听 Ctrl + c process.on('SIGINT', () => { handel.kill(); process.exit(0); });测试一下
- 当然程序不会自己停下来哈,毕竟子进程的 http 服务一直在运行!
$ node test.js [stdout queryString] name=anan&age=29&time=1595134635733 [http response] 2020-07-19 12:57:15

本文转载自 https://www.jianshu.com/p/9ac4f9ef9625
收起阅读 »分享4个Linux中Node.js的进程管理器
Node.js进程管理器是一个有用的工具,可以确保Node.js进程或脚本连续(永久)运行,并使其能够在系统引导时自动启动。
它允许您监视正在运行的服务,它有助于执行常见的系统管理任务(例如重新启动失败,停止,重新加载配置而无需停机,修改环境变量/设置,显示性能指标等等)。它还支持应用程序日志记录,群集和负载平衡,以及许多其他有用的流程管理功能。
另请参阅:2019年为开发人员提供的14个最佳NodeJS框架
包管理器尤其适用于在生产环境中部署Node.js应用程序。 在本文中,我们将回顾Linux系统中Node.js应用程序管理的四个进程管理器。
1. PM2
PM2是一个开源,高级,功能丰富,跨平台和最流行的Node.js生产级流程管理器,内置负载均衡器。它允许您列出,监视和处理所有已启动的Nodejs进程,并支持群集模式。

安装PM2以在Linux中运行Nodejs应用程序
它支持应用程序监视:提供一种监视应用程序资源(内存和CPU)使用情况的简单方法。它支持您的流程管理工作流,允许您通过流程文件配置和调整每个应用程序的行为(支持的格式包括Javascript,JSON和YAML)。
应用程序日志始终是生产环境中的关键,在这方面,PM2允许您轻松管理应用程序的日志。它提供了分别处理和显示日志的不同方式和格式。您可以实时显示日志,刷新日志,并在需要时重新加载日志。
重要的是,PM2支持启动脚本,您可以将其配置为在预期或意外的计算机重新启动时自动启动进程。它还支持在当前目录或其子目录中修改文件时自动重新启动应用程序。
此外,PM2还带有一个模块系统,允许用户为Nodejs进程管理创建自定义模块。例如,您可以为日志轮换模块或负载平衡创建模块等等。
最后但同样重要的是,如果您使用Docker容器,PM2允许容器集成,并提供允许您以编程方式使用它的API系统。
2. StrongLoop PM
StrongLoop PM也是一个开源的高级生产过程管理器,用于Node.js应用程序,内置负载平衡,就像PM2一样,它可以通过命令行或图形界面使用。
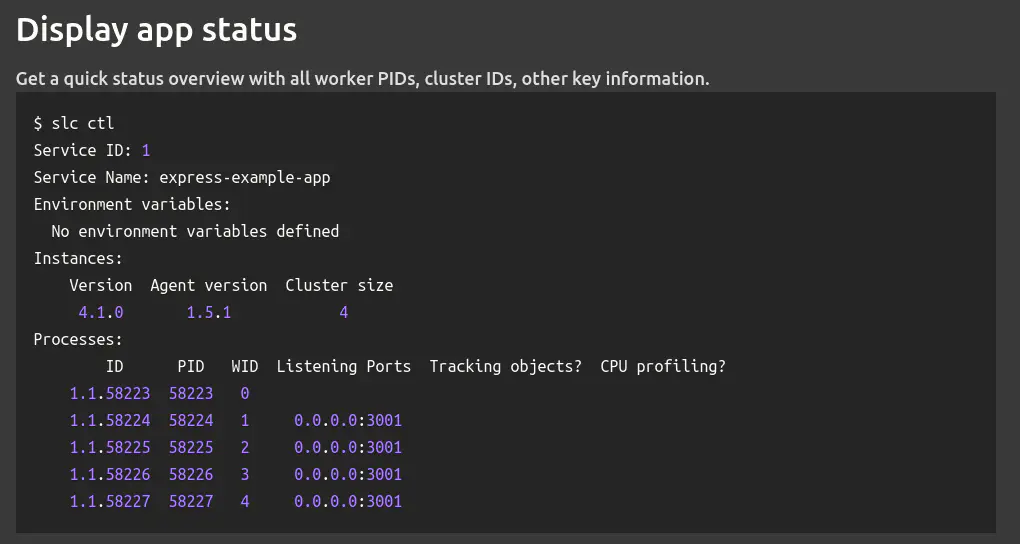
用于Nodejs的StrongLoop PM进程管理器
它支持应用程序监视(查看性能指标,如事件循环时间、CPU和内存消耗)、多主机部署、集群模式、零停机应用程序重启和升级、故障时自动进程重启以及日志聚合和管理。
此外,它附带Docker支持,允许您将性能指标导出到与状态兼容的服务器,并在第三方控制台(如DataDog、石墨、Splunk以及Syslog和原始日志文件)中查看。
3. Forever
Forever是一个开源,简单且可配置的命令行界面工具,可以连续(Forever)运行给定的脚本。它适用于运行Node.js应用程序和脚本的较小部署。您可以通过两种方式永久使用:通过命令行或将其嵌入代码中。

Forever运行脚本
它允许您管理(启动,列出,停止,停止所有,重新启动,重新启动所有等等。)Node.js进程,它支持监视文件更改,调试模式,应用程序日志,终止进程和退出信号自定义等等。此外,它还支持多种使用选项,您可以直接从命令行传递或将它们传递到JSON文件中。
4. Systemd - 服务和系统管理器
在Linux中,Systemd是一个守护程序,用于管理系统资源,例如进程和文件系统的其他组件。 systemd管理的任何资源都称为一个单元。有不同类型的单元,包括服务,设备,插座,安装,目标和许多其他单元。
Systemd通过称为单元文件的配置文件管理单元。因此,为了像任何其他系统服务一样管理Node.js服务器,您需要为它创建一个单元文件,在这种情况下它将是一个服务文件。
为Node.js服务器创建服务文件后,可以启动它,启用它以在系统引导时自动启动,检查其状态,重新启动(停止并再次启动它)或重新加载其配置,甚至像任何其他系统服务一样停止它。
摘要
Node.js包管理器是在生产环境中部署项目的有用工具。它使应用程序永远存在,并简化了如何控制它。在本文中,我们回顾了Node.js的四个包管理器。如果您有任何疑问或问题,请使用下面的反馈表与我们联系。
Node.js编写组件的几种方式
Node.js编写组件的几种方式
本文主要备忘为Node.js编写组件的三种实现:纯js实现、v8 API实现(同步&异步)、借助swig框架实现。
关键字:Node.js、C++、v8、swig、异步、回调。
简介
首先介绍使用v8 API跟使用swig框架的不同:
(1)v8 API方式为官方提供的原生方法,功能强大而完善,缺点是需要熟悉v8 API,编写起来比较麻烦,是js强相关的,不容易支持其它脚本语言。
(2)swig为第三方支持,一个强大的组件开发工具,支持为python、lua、js等多种常见脚本语言生成C++组件包装代码,swig使用者只需要编写C++代码和swig配置文件即可开发各种脚本语言的C++组件,不需要了解各种脚本语言的组件开发框架,缺点是不支持javascript的回调,文档和demo代码不完善,使用者不多。
二、纯JS实现Node.js组件
(1)到helloworld目录下执行npm init 初始化package.json,各种选项先不管,默认即可,更多package.json信息参见:https://docs.npmjs.com/files/package.json。
(2)组件的实现index.js,例如:
module.exports.Hello = function(name) {
console.log('Hello ' + name);
}(3)在外层目录执行:npm install ./helloworld,helloworld于是安装到了node_modules目录中。
(4)编写组件使用代码:
var m = require('helloworld');
m.Hello('zhangsan'); //输出: Hello zhangsan三、 使用v8 API实现JS组件——同步模式
(1)编写binding.gyp, eg:
{ "target_name": "hello", "sources": [ "hello.cpp" ]
}
]
}关于binding.gyp的更多信息参见:https://github.com/nodejs/node-gyp
(2)编写组件的实现hello.cpp,eg:
#include <node.h>
namespace cpphello { using v8::FunctionCallbackInfo; using v8::Isolate; using v8::Local; using v8::Object; using v8::String; using v8::Value; void Foo(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
args.GetReturnValue().Set(String::NewFromUtf8(isolate, "Hello World"));
} void Init(Local<Object> exports) {
NODE_SET_METHOD(exports, "foo", Foo);
}
NODE_MODULE(cpphello, Init)
}(3)编译组件
node-gyp configure
node-gyp build./build/Release/目录下会生成hello.node模块。
(4)编写测试js代码
const m = require('./build/Release/hello')
console.log(m.foo()); //输出 Hello World(5)增加package.json 用于安装 eg:
{ "name": "hello", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "node test.js" }, "author": "", "license": "ISC" }(5)安装组件到node_modules
进入到组件目录的上级目录,执行:npm install ./helloc //注:helloc为组件目录
会在当前目录下的node_modules目录下安装hello模块,测试代码这样子写:
var m = require('hello');
console.log(m.foo());四、 使用v8 API实现JS组件——异步模式
上面三的demo描述的是同步组件,foo()是一个同步函数,也就是foo()函数的调用者需要等待foo()函数执行完才能往下走,当foo()函数是一个有IO耗时操作的函数时,异步的foo()函数可以减少阻塞等待,提高整体性能。
异步组件的实现只需要关注libuv的uv_queue_work API,组件实现时,除了主体代码hello.cpp和组件使用者代码,其它部分都与上面三的demo一致。
hello.cpp:
/* * Node.js cpp Addons demo: async call and call back.
* gcc 4.8.2
* author:cswuyg
* Date:2016.02.22
* */ #include <iostream> #include <node.h> #include <uv.h> #include <sstream> #include <unistd.h> #include <pthread.h>
namespace cpphello { using v8::FunctionCallbackInfo; using v8::Function; using v8::Isolate; using v8::Local; using v8::Object; using v8::Value; using v8::Exception; using v8::Persistent; using v8::HandleScope; using v8::Integer; using v8::String; // async task
struct MyTask{
uv_work_t work; int a{0}; int b{0}; int output{0};
unsigned long long work_tid{0};
unsigned long long main_tid{0};
Persistent<Function> callback;
}; // async function
void query_async(uv_work_t* work) {
MyTask* task = (MyTask*)work->data;
task->output = task->a + task->b;
task->work_tid = pthread_self();
usleep(1000 * 1000 * 1); // 1 second
} // async complete callback
void query_finish(uv_work_t* work, int status) {
Isolate* isolate = Isolate::GetCurrent();
HandleScope handle_scope(isolate);
MyTask* task = (MyTask*)work->data; const unsigned int argc = 3;
std::stringstream stream;
stream << task->main_tid;
std::string main_tid_s{stream.str()};
stream.str("");
stream << task->work_tid;
std::string work_tid_s{stream.str()};
Local<Value> argv[argc] = {
Integer::New(isolate, task->output),
String::NewFromUtf8(isolate, main_tid_s.c_str()),
String::NewFromUtf8(isolate, work_tid_s.c_str())
};
Local<Function>::New(isolate, task->callback)->Call(isolate->GetCurrentContext()->Global(), argc, argv);
task->callback.Reset(); delete task;
} // async main
void async_foo(const FunctionCallbackInfo<Value>& args) {
Isolate* isolate = args.GetIsolate();
HandleScope handle_scope(isolate); if (args.Length() != 3) {
isolate->ThrowException(Exception::TypeError(String::NewFromUtf8(isolate, "arguments num : 3"))); return;
} if (!args[0]->IsNumber() || !args[1]->IsNumber() || !args[2]->IsFunction()) {
isolate->ThrowException(Exception::TypeError(String::NewFromUtf8(isolate, "arguments error"))); return;
}
MyTask* my_task = new MyTask;
my_task->a = args[0]->ToInteger()->Value();
my_task->b = args[1]->ToInteger()->Value();
my_task->callback.Reset(isolate, Local<Function>::Cast(args[2]));
my_task->work.data = my_task;
my_task->main_tid = pthread_self();
uv_loop_t *loop = uv_default_loop();
uv_queue_work(loop, &my_task->work, query_async, query_finish);
} void Init(Local<Object> exports) {
NODE_SET_METHOD(exports, "foo", async_foo);
}
NODE_MODULE(cpphello, Init)
}异步的思路很简单,实现一个工作函数、一个完成函数、一个承载数据跨线程传输的结构体,调用uv_queue_work即可。难点是对v8 数据结构、API的熟悉。
test.js
// test helloUV module
'use strict';
const m = require('helloUV')
m.foo(1, 2, (a, b, c)=>{
console.log('finish job:' + a);
console.log('main thread:' + b);
console.log('work thread:' + c);
}); /* output:
finish job:3
main thread:139660941432640
work thread:139660876334848 */五、swig-javascript 实现Node.js组件
利用swig框架编写Node.js组件
(1)编写好组件的实现:.h和.cpp **
eg:
namespace a { class A{ public: int add(int a, int y);
}; int add(int x, int y);
}(2)编写.i,用于生成swig的包装cpp文件*
eg:
/* File : IExport.i */
%module my_mod
%include "typemaps.i"
%include "std_string.i"
%include "std_vector.i"
%{
#include "export.h"
%}
%apply int *OUTPUT { int *result, int* xx};
%apply std::string *OUTPUT { std::string* result, std::string* yy };
%apply std::string &OUTPUT { std::string& result };
%include "export.h"
namespace std {
%template(vectori) vector<int>;
%template(vectorstr) vector<std::string>;
};上面的%apply表示代码中的 int* result、int* xx、std::string* result、std::string* yy、std::string& result是输出描述,这是typemap,是一种替换。
C++导出函数返回值一般定义为void,函数参数中的指针参数,如果是返回值的(通过*.i文件中的OUTPUT指定),swig都会把他们处理为JS函数的返回值,如果有多个指针,则JS函数的返回值是list。
%template(vectori) vector
swig支持的更多的stl类型参见:https://github.com/swig/swig/tree/master/Lib/javascript/v8
(3)编写binding.gyp,用于使用node-gyp编译
**(4)生成warpper cpp文件 **生成时注意v8版本信息,eg:swig -javascript -node -c++ -DV8_VERSION=0x040599 example.i
(5)编译&测试
难点在于stl类型、自定义类型的使用,这方面官方文档太少。
六、其它
在使用v8 API实现Node.js组件时,可以发现跟实现Lua组件的相似之处,Lua有状态机,Node有Isolate。
Node实现对象导出时,需要实现一个构造函数,并为它增加“成员函数”,最后把构造函数导出为类名。Lua实现对象导出时,也需要实现一个创建对象的工厂函数,也需要把“成员函数”们加到table中。最后把工厂函数导出。
Node的js脚本有new关键字,Lua没有,所以Lua对外只提供对象工厂用于创建对象,而Node可以提供对象工厂或者类封装。
转载自 https://cloud.tencent.com/developer/article/1929669
收起阅读 »从零打造node.js版scf客户端
node.js是一个划时代的技术,它在原有的Web前端和后端技术的基础上总结并提炼出了许多新的概念和方法,堪称是十多年来Web开发经验的集大成者。转转公司在使用node.js方面,一起走在前沿。8月16日,转转公司的FE王澍老师,在镜泊湖会议室进行了一场主题为《nodejs全栈之路》的讲座。优秀的语言、平台、工具只有在优秀的程序员的手中才能显现出它的威力。一直听说转转公司在走精英化发展战略,所以学习下转转对node.js的使用方式,就显得很有必要。
对于大多数人使用node.js上的直观感受,就是模块、工具很齐全,要什么有什么。简单request一下模块,就可以开始写javasript代码了。然而出自58同城的转转,同样存在大量服务,使用着58自有的rpc框架scf。scf无论从设计还是实际效果,都算得上业内领先。只不过在跨平台的基础建设上,略显不足。从反编译的源码中,可以找到支持的平台有.net、java、c、php。非java平台的scf版本更新,也有些滞后。之前还听说肖指导管理的应用服务部,以“兼职”的方式开发过c++版客户端。而且也得到umcwrite等服务的实际运用。所以node.js解决好调用scf服务,是真正广泛应用的前提。这也正是我最关心的问题。
王澍老自己的演讲过程并没有介绍scf调用的解决方案,但在提问环节中,进行了解答。我能记住的内容是,目前的采用的方案是使用node-java模块,启动一个jvm进程,最终还是在node.js的项目中编写的java代码,性能尚可接受,但使用中内存占用很大;王澍老师也在尝试自己使用c++开发模块来弃用node-java。
这确实很让我很失望,我所理解的node.js应该是与性能有关的部分,几乎全部是c++编写的。之前肖指导要求发布公共服务,改写成使用scf提供的异步方式执行,借那次机会,我也阅读了一部分反编译的scf源码。感觉如果只是解决node.js调用scf的问题,不应该是个很难的事情。像管理平台、先知等外围功能,可以后期一点点加入。正巧我一直在质疑自己是不是基础差的问题,干脆写一个node.js版的scf客户端,来试试自己的水准。
结合自己之前对node.js的零散知识(其实现在也很零散)。对这次实践提出如下的一些设计要点:
1、序列化版本使用scfv3,虽然难度应该是最大的,但应该能在较长的时间内避免升级序列化版本的琐事。
2、使用管理平台读取配置,禁用scf.config类似的本地配置。想想之前许多部门,推进禁用线上服务直连的过程,就觉得很有必要(管理平台也用线下环境,线下调试根本不是阻碍)。
3、客户端支持全类型,之前偶尔听说了c++版客户端不支持枚举类型,使得有些服务只能调整接口。
4、c++使用libuv库,具备跨平台开发、调试能力。c++版客户端听说只支持linux平台。
5、只提供异步接口,这是当然的,不然node.js就别想用了。
现有的c++客户端,在3、4、5上与我的设想不符合,所以我决定亲自编写。
先是搜了本介绍libuv的pdf——《An Introduction to libuv》,看了几天,对libuv的使用方式有所了解,用上的只有tcp相关接口。(比起java,node.js的资料还是少,介绍的也少有深入的,像这样的底层类库,资料就更少了)
在58作为rd,如果不是做ios,是少有配macbook的员工的。所以我本次是在windows上编写的。不得不说node.js就是霸道,自动安装时,默认全部安装最新的版本。这样在windows平台上编译c++时,就要求visual studio不能低于2015。
网上搜索c++开发node.js模块,基本总是能找到那个addon的示例。可能是由于v8引擎的接口也有过变化,addon的示例使用的类型、接口也存在几种,终于还是试出了自己可以编译过的了。
首先在addon的基础上,写个运用libuv连接tcp的逻辑,一旦试通了,就可以一点点抄写反编译的scf客户端源码了。
在开发过程中,我的设计也进行了一些修改:
1、反序列化逻辑,通过tcp连接,交由一个java程序来执行(基于netty开发)。由于反序列化时,scf的二进制数据是没有足够的类型信息的。大体上,当读取到一个typeid时,如果本地没有对应的类型信息,完全不知道下一个字节是做什么用的。(我其实只希望得到一个类似多叉树的嵌套格式,也做不到。)如果非要使用c++来执行反序列化,也并非不可能。需要将scf反序列化用到的类型信息,整理成一种新的数据格式,存放于c++程序的内存中。为此需要开发一个输出类型配置数据的java离线工具,node.js模块需要开发:读取这个类型配置文件到内存,再将scf反序列化的逻辑使用c++抄一遍。综上来看,使用一个java的反序列化辅助进程,可以在性能几乎无损的情况下,极大的减少了开发量,同时避免了许多反序列化过程中的bug。这不正是一个极简的微服务嘛。
2、javascript入参对象中,需要自带scf序列化相关的类型信息,这样就能在全类型的支持scf对象了。当然我也设想过,有没有机会将序列化,也交由java辅助进程。那样就需要设计一个java对象在javascript中的表示形式,由java辅助进程,先转换为java对象,再序列化。再加上两次额外tcp传输。在没有减少工作量的情况下,浪费了不少性能。当然如果十分拒绝c++开发的话,倒是能因此少写些c++代码。
后续可以做的一些事情:
1、完善的重连、超时处理;
2、管理平台配置热更新;
3、管理平台数据上报;
4、先知;
5、加密、压缩(似乎和node.js的非计算密集场景有些冲突,而且公司的scf配置默认都是关闭这两个的。scf良好的用了这么些年,不开启这两个功能的功劳应该也不小)
当然已开发的内容中,也一定满是bug。等有人用了,我再考虑改bug的事。生产环境下的试错机会,才能让程序真正成长。
收起阅读 »React-Native与原生模块间的几种通信方式
每种语言都有自己的设计理念、语法、运行环境,这也导致了不同语言间相互交流通信时必须要有中介来翻译,如JAVA与C/C++通过JNI来交流、OC与C/C++需要在.mm文件混编、而JAVA/OC与Lua通信时需要通过C/C++语言来做中介。那么在React-Native中JSX是如何与底层模块进行通信的呢?这里主要以iOS系统来做说明。
原理
通信本质上是信息的交流,具体到计算机语言则是数据的流动。应用中数据在React-Native与原生模块间的流动与共享,完成了与用户的交互,达成了应用的目标。React-Native与OC间通信的数据只能是下面的几种类型(前为JS类型,后为OC类型):
- string-NSString
- number - int/NSInteger/float/double/NSNumber
- boolean - BOOL/NSNumber
- array - NSArray
- object - NSDictionary(NSString型key, value可以为这里的其它类型)
- func - RCTResponseSenderBlock
其它类型的数据需要通过一定的规则转换成这几种类型后(一般都会转换成JSON串)再通信.
React-Native本质是通过JavaScriptCore.framework实现JS代码与OC代码间的互动。因此下面说的几种方式在本质原理上都是相同的,不同的地方只是在于实现形式与方法的差别。
函数调用
在将原生模块封装并提供给React-Native使用时,可以通过RCT_EXPORT_METHOD()宏向React-Native侧定义其可以调用的接口函数,完成两模块间的通信。
//定义了startVPN接口,React-Native将VPN的具体参数通过该接口传入到原生模块,开启指定的VPN
RCT_EXPORT_METHOD(startVPN:(NSDictionary*)config)
{
LSShadowSocksDataMode* mode = [[LSShadowSocksDataMode alloc] initWithDictionary:config];
[self.manager startVPN:mode];
}除了传入数据外,通过可以通过这种方式从原生侧获取数据。最容易想到的是通过返回值获取,可惜的是RCT_EXPORT_METHOD宏不支持返回值,不过其提供了另外一种实现返回值的方式:
RCT_EXPORT_METHOD(isOpen:(RCTResponseSenderBlock)callback)
{
BOOL open = [self.manager status];
callback(@[[NSNull null], @[@(open)]]);
}通过回调函数的形式实现返回值的效果,达到了数据交换的目的。
属性共享
这种方式主要针对于UI控件来说的。React-Native中最基础的UI类型是RCTRootView,该类有一个初始化方法initWithBridge:moduleName:initialProperties:,第三个参数initialProperties表示的是UI控件的初始属性值,类型为NSDictionary,其最终会被同步到由第二个参数定义的React-Native类的props中,即完成了两个模块间的数据交流。
NSArray *imageList = @[@"http://foo.com/bar1.png",
@"http://foo.com/bar2.png"];
NSDictionary *props = @{@"images" : imageList};
RCTRootView *rootView = [[RCTRootView alloc] initWithBridge:bridge
moduleName:@"ImageBrowserApp"
initialProperties:props];import React, { Component } from 'react';
import {
AppRegistry,
View,
Image,
} from 'react-native';
class ImageBrowserApp extends Component {
renderImage(imgURI) {
return (
<Image source={{uri: imgURI}} />
);
}
render() {
return (
<View>
{this.props.images.map(this.renderImage)}
</View>
);
}
}
AppRegistry.registerComponent('ImageBrowserApp', () => ImageBrowserApp);初始化接口只能在UI组件建立时使用,如果需要在UI组件的生命周期内通信呢,RCTRootView提供了appProperties这样一种机制:
NSArray *imageList = @[@"http://foo.com/bar3.png",
@"http://foo.com/bar4.png"];
rootView.appProperties = @{@"images" : imageList};通知
OC中使用NSNotificationCenter向整个应用发送通知,所有对该通知感兴趣的对象都会获得该通知并执行相应的动作。React-Native中也提供有类似的机制:RCTEventEmitter。原生模块继承该类后,就可以向React-Native侧发送通知,而React-Native就能够接收到该通知,并处理一并传送过来的数据了。
-(void)vpnStatusChanged:(NSNotification*)notification
{
NEVPNStatus status = [self.manager status];
NSString* value = nil;
switch (status) {
case NEVPNStatusReasserting:
value = @"重新连接中";
break;
case NEVPNStatusConnecting:
value = @"连接中";
break;
case NEVPNStatusConnected:
value = @"已连接";
break;
case NEVPNStatusDisconnecting:
value = @"断开连接中";
break;
case NEVPNStatusDisconnected:
case NEVPNStatusInvalid:
value = @"末连接";
break;
default:
break;
}
if(value){
[self sendEventWithName:@"VpnStatus" body:@{@"status":value}];
}
}这里将V**的状态通过通知发送到React-Native侧,由React-Native将V**的状态显示的UI界面上。
转载自 https://cloud.tencent.com/developer/article/1930848
收起阅读 »Java VS .NET:Java与.NET的特点对比
一、前言
为什么要写Java跟.NET对比?
.NET出生之后就带着Java的影子。从模仿到创新,.NET平台也越来越成熟。他们不同的支持者也经常因为孰弱孰强的问题争论不休。但是本文并不是为了一分高下。而是针对Java平台跟.NET平台做一些对比。主要围绕项目构建、Web框架、项目部署展开讨论。相信经过这些讨论可以让Java/.NET工程师对Java平台、.NET平台有更好的了解。
二、项目构建
项目构建工具
工欲善其事必先利其器。开发环境配置+工具使用当然要先讲了。
1、表面上的工具
平台工具ken.io的解释
.NETVisual Studio微软官方IDE,它具备了开发.NET应用程序的几乎所有工具
JavaIdea/EclipseIDE,负责管理项目以及代码的运行调试等,依赖于JDK
JavaMaven负责管理项目模板、打包(jar包等),依赖于JDK
JavaJDKJRE(Java项目运行环境),Java工具(编译器等)
.NET工程师要开展工作,安装Visual Studio(后面简称:VS)就可以进行开发了。但是Java开发,只安装IDE是不行的,就算某些IDE会自动安装JDK,甚至是Maven,但是这些还是需要自己配置,不然还可能会踩坑。从开发环境的配置来说,.NET工程师操作上确实简单一些,一直下一步,等待安装完成即可。Java工程师就先要了解下工具,以及各个工具的职责。然后逐一配置。
从这个点上来说,Java的入门曲线会稍陡一些,但是Java工程师也会比.NET工程师更早关注到项目构建的重要环节。
2、实际上的工具
职责.NET平台Java平台ken.io的解释
项目管理VSIDEA/Eclips.NET只有微软官方IDE,Java没有官方的IDE,没有VS好用,但是有多个选择
项目模板VS+MSBuildIDE+Maven.NET项目的模板是VS自带的,是直接符合MSBuild(编译器)标准的,项目由sln+csproj文件组织,Java平台编译器的标准是公开的,目前主流项目都是基于Maven模板来创建,项目由pom.xml文件组织。
编译&调试VS+MSBuild+SDKIDE+Maven+SDK.NET平台的编译器是独立的,Java平台的编译器是集成在JDK中,Maven模板的项目是由pom.xml文件组织,但是编译器并不是认识pom.xml,所以编译需要Maven的参与
Package管理NuGetMavenNuget是微软官方开源的VS插件,Maven是Apache下的开源项目。ken.io觉得Maven更灵活、强大。NuGet容易上手。
打包/发布VS+MSBuild+SDKIDE+Maven+SDK.NET平台的编译器是独立的,Java平台的编译器是集成在JDK中,Maven模板的项目是由pom.xml文件组织的,但是编译器并不是认识pom.xml,所以打包需要Maven的参与。IDE主要是提供图形化界面替代命令操作
从项目管理上说。VS这个IDE更好用一些,项目模板上,.NET项目模板由于有Visual Studio的存在,可以说简单易用而且丰富,Java平台的Maven模板灵活。
其实大部分差异都是编译器跟模板带来的差异。.NET平台的编译器是独立的,编译器MSBuild有一套标准, 而且Visual Studio提供了丰富好用的项目模板。
Java平台的编译器的编译配置是xml文档,由于Java官方没有项目模板,IDE只负责帮你组织项目,但是并没有模板,你可以将任意目录指定为SourceRoot(代码根目录),ResourceRoot(资源文件根目录:比如配置文件)也可以任意指定,编译的时候,IDE会将你的项目代码,以及编译器所需要的编译描述/配置xml文档告诉编译器该如何编译你的项目。确实非常灵活,但是也增加了项目管理的成本。包的管理也非常麻烦,还好有Maven结束了这个混沌的Java世界。
编码特点
—.NETJava
类的组织namespace:命名空间,name跟目录无关Package:name跟目录名一致
类.cs文件:类名跟文件名无关.java文件,类名跟文件名无关,但一个类文件只能定义一个public类
编译产出.dll,.exe文件.jar,.war文件
三、框架
.NET的Web框架基本上都是微软官方的,官方的框架也最为流行,而Java平台,除了官方提供的Servlet API(相当于.NET的System.Web)其他的基本都由Spring大家族统治了。本次我们主要对比目前Web开发最常用的MVC框架以及持久层框架
功能.NETJavaken.io的说明
Web核心ASP.NETServlet—
Web框架ASP.NET MVCSpring MVCASP.NET MVC是微软官方框架,Srping MVC框架隶属于Spring大家族,依赖于Spring
视图引擎RazorThymeleaf/FreeMarkerRazor是微软官方的视图引擎,非常好用,Spring MVC并没有视图引擎,但是有Thymeleaf,FreeMarker。ken.io更喜欢Razor的风格
持久层Entity FrameworkMyBatisEF是微软官方的持久层框架,易上手、开发效率高、但侵入性强。MyBatis配置灵活,无侵入性。各有利弊。
.NET平台的框架由于都是微软官方的,比较好组织,上手容易。Java平台的框架,灵活可配置。这也是Java平台一贯的风格。但是ken.io不得不吐槽的是,Spring MVC作为一个MVC框架,竟然没有自己的视图引擎,那MVC种的View去哪了?
可能是因为Java作为Web后端的主力平台,确实很少关注视图层,但是Spring MVC没有View层引擎,还是感觉不合适。Thymeleaf跟FreeMarker,ken.io更推荐FreeMarker。因为ken.io更喜欢FreeMaker的语法。可能是用惯了Razor的缘故。
四、项目部署
对于项目部署。.NET平台貌似没得选,只能选Windows+IIS,虽然有Mono,但毕竟不是支持所有的类库。而Java平台既可以选择Windows+Tomcat,也可以选择Linux+Tomcat。但是通常会选择Linux+Tomcat毕竟成本低。
职责.NETJava
操作系统Windows ServerWindows Server、Linux Server
Web服务器IISTomcat(Tomcat是目前最主流的,也有其他的Servlet容易例如:JBoss)
不过Java平台的特性,Java项目的部署会比.NET项目部署偏麻烦一些。
IIS图形化界面一直下一步,再调整下应用程序池的版本就行了。而Tomcat不论是在Windows,还是在Linux,都通过修改配置文件完成站点配置
转载自:https://cloud.tencent.com/developer/article/1926747
收起阅读 »ASP.NET MVC 与 ASP.NET Web Form 的介绍与区别
1 ASP.NET MVC
是微软提供的以MVC模式为基础的ASP.NET Web应用程序开发框架。
MVC 模式分别为:
Model:领域模型 处理应用程序数据逻辑部分,获取数据,处理数据
View:视图 用于处理实际返回给用户的页面
Controller:控制器 通过Model 读取处理数据,通过View 将结果返回。
2 ASP.NET Webform
在 ASP.NET 框架下的一种基于事件模型的开发模式,有开发速度快,容易上手等特点。
3 两者的区别和各自优缺点
ASP.NET 作为微软的Web程序开发框架,MVC与Webform 是不同时期的开发模式,
在ASP.NET 运行处理原理 基本一致.
Webform 优点:可以基于事件模型开发,类似Winform中,所有请求使用ViewState和页面生命周期来维持控件状态,同时控件的开发,加快了开发速度,整体Webform的内部封装比较高。
Webform 缺点: 正是由于封装程度高,Webform非常难扩展,开发人员便利了解内部运行原理,不容易被测试。同时控件的ViewState 增加了网站服务器的传输量,一定程度上影响程序的效率。
MVC 优点 :易于扩展,易于单元测试,易于测试驱动开发。MVC中的一个路由的存在,可以做一些链接伪静态的处理。
总结: MVC 不是取代了Webform,两者适用于不同的开发环境下,都是简单三层中的表示层的开发框架,都是ASP.NET 框架下的开发模式。
1 页面处理流程:
MCV的页面处理流程依旧在ASP.NET原有上有扩展,MVC通过特定的IHttpModule和IHttpHandler 来处理请求,与Webform不同的,Webform中每个aspx页面都会有是一个IHttphandler实例。MVC中 Controller都比是IHttpHandler的子类实例,Action是在MvcHandler中通过MVC的工厂反射执行的,MvcHandler可以自定义。
2 上下文 请求对象: Context Session Request Response Cookie 基本一致
3 配置文件基本一致,但不通用
4 部分服务器控件并不是不可以在MVC中使用
5 在ASP.NET MVC中,包括Membership,healthMonitoring,httpModule,trace在内的内置和自定义的组件模块仍然是继续可用。
附图 :MVC 原理图和介绍

123123123.jpg
1 客户端发出请求给IIS(mvc中为集成模式),执行HttpRunTime的ProcessRequest方法
2 创建了一批MvcApplication对象,存放在应用程序池中,执行第一个MvcApplication对象实例中的 Application的Application_Start()方法、
RouteConfig.RegisterRountes(RouteTable.Routes)-->向路由规则集合注册一条默认的路由规则
3 调用Application对象实例的ProcessRequest方法 ,传入上下文对象HttpContext,开始执行19个管道事件
4 第七个管道事件:
UrlRouting过滤器:
1 获取当前Reuqest对象中的RawUrl:此时 /Home/Index
2 去扫描当前路由规则集合中的所,从上而下开始匹配,匹配成功了--{controller}/{action}/{id}这条路由规则,MVC底层就会根据路由规则解析出控制器名称
HomeController action:Index
3 调用DefaultControllerFactory反射创建控制器类的对象实例,存入RemapHandler中
4 将 控制器和action名称以字符串的形式存入RouteData中5 第八个管道事件
1 判断当前RemapHandler是否为null, 不为null直接跳过执行后面的管道事件
2 为null继续创建页面类对象6 第十一,十二个管道事件
1 获取上下文的RemapHandler中的控制器类的对象实例
2从RoutData中取出当前请求action名称
3 以反射的方式动态执行action方法
4 action返回类型分为:
4.1 如果是一个视图类型:调用具体的视图(.cshtml)编译成页面类,在调用页面类的Excute()方法,将所有的代码执行后写入到Response中
4.2如果是一个非视图类型,直接将结果写入到Response中即可NodeJS 入门了解
1 NodeJS 是什么
- NodeJS 是 javascript 的一种运行环境,是对 Google V8 引擎进行的封装。是一个服务器端的 javascript 解释器;
- NodeJS 使用事件驱动,非阻塞 I/O 模型;
什么是非阻塞 I/O 模型:
- 阻塞:I/O 时进程休眠等待 I/O 完成后再进行下一步;
- 非阻塞 I/O :I/O 时函数立即返回,进程不等待 I/O 完成;
什么是事件驱动:
I/O 等异步操作结束后的通知。
2 NodeJS 和 npm 的关系
包含关系,NodeJS 中含有 npm,比如说你安装好 NodeJS,你打开 cmd 输入 npm -v 会发现出 npm 的版本号,说明 npm 已经安装好。
引用大神的总结:
其实 npm 是 NodeJS 的包管理器(package manager)。我们在 NodeJS 上开发时,会用到很多别人已经写好的 javascript 代码,如果每当我们需要别人的代码时,都根据名字搜索一下,下载源码,解压,再使用,会非常麻烦。
于是就出现了包管理器 npm。大家把自己写好的源码上传到 npm 官网上,如果要用某个或某些个,直接通过 npm 安装就可以了,不用管那个源码在哪里。并且如果我们要使用模块 A,而模块 A 又依赖模块 B,模块 B 又依赖模块 C 和 D,此时 npm 会根据依赖关系,把所有依赖的包都下载下来并且管理起来。试想如果这些工作全靠我们自己去完成会多么麻烦!
3 NodeJS 的安装
直接网上下载安装就可以了。环境配置,其实就是在 path,加入 NodeJS 的安装目录,这样就可以在控制台使用 NodeJS 的命令。验证,可以在控制台输入:node -v 和 npm -v
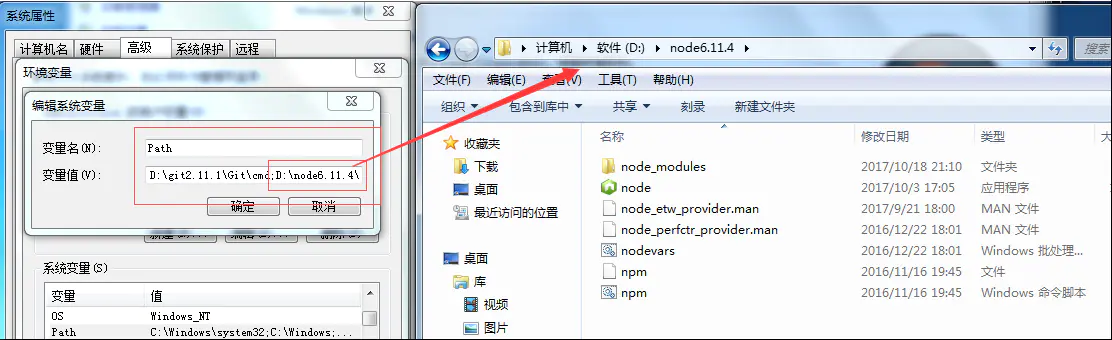
4 初始化 npm 环境
首先保证有 node 和 npm 环境,运行 node -v 和 npm -v 查看
进入项目目录,运行 npm init 按照步骤填写最终生成 package.json 文件,所有使用 npm 做依赖管理的项目,根目录下都会有一个这个文件,该文件描述了项目的基本信息以及一些第三方依赖项(插件)。详细的使用说明可查阅官网文档。
5 安装插件
已知我们将使用 webpack 作为构建工具,那么就需要安装相应插件,运行 npm install webpack webpack-dev-server --save-dev 来安装两个插件。
又已知我们将使用 React ,也需要安装相应插件,运行 npm i react react-dom --save 来安装两个插件。其中 i 是 install 的简写形式。
安装完成之后,查看 package.json 可看到多了 devDependencies 和 dependencies 两项,根目录也多了一个 node_modules 文件夹。
6 --save 和 --save-dev 的区别
npm i 时使用 --save 和 --save-dev,可分别将依赖(插件)记录到 package.json 中的 dependencies 和 devDependencies 下面。
dependencies 下记录的是项目在运行时必须依赖的插件,常见的例如 react 、jquery 等,即及时项目打包好了、上线了,这些也是需要用的,否则程序无法正常执行。
devDependencies 下记录的是项目在开发过程中使用的插件,例如这里我们开发过程中需要使用 webpack 打包,而我在工作中使用 fis3 打包,但是一旦项目打包发布、上线了之后,webpack 和 fis3 就都没有用了,可卸磨杀驴。
延伸一下,我们的项目有 package.json,其他我们用的项目如 webpack 也有 package.json,见 ./node_modules/webpack/package.json,其中也有 devDependencies 和 dependencies。当我们使用 npm i webpack 时,./node_modules/webpack/package.json 中的dependencies 会被 npm 安装上,而 devDependencies 也没必要安装。
参考:http://www.imooc.com/article/14499
7 CommonJS
CommonJS 是 node 的模块管理规范
- 每个文件都是一个模块,有自己的作用域;
- 在模块内部
module变量代表模块本身; module.exports属性代表模块对外接口;
require 规则
/表示绝对路径,./表示相对路径;- 支持
js、json、node扩展名,不写依次尝试; - 不写路径则认为是
build-in模块或者各级node_modules内的第三方模块
require 特性
- module 被加载的时候执行,加载后缓存;
- 一旦出现某个模块被循环加载,就只输出已经执行的部分,还未执行的部分不会输出
8 global
node 全局对象 global,相当于 web 的 window 对象。
- CommonJS
- Buffer、process、console
- timer
nodeJS操纵数据库
Node.exe的安装
下载nodeJS,安装
检测是否安装成功 node -v
另外一种安装我们node的方式
使用nvm这个软件来安装
node version manger,如果你想同时安装多个node版本
教程:http://www.jianshu.com/p/07c3456e875a
步骤:
1、安装nvm这个软件: https://github.com/coreybutler/nvm-windows/releases
2、使用上面装好的nvm软件,安装我们需要的node版本了
指令:
nvm install 具体的版本号就行了
nvm uninstall 具体的版本号
nvm list 查看当前安装了哪些版本
nvm use 具体版本号,切换到某个版本
建议:
安装一个高一点的稳定的版本即可,因为软件都是向下兼容
系统环境变量及其作用
系统环境变量
每个系统都会提供一种叫做环境变量的东西,用来简化我们去
访问某一个应用程序可执行文件(.exe)的操作
我们配置了环境变量能做到什么事呢?
在我们终端的任何一个目录下,都可以访问,配置在系统
环境变量里面的可执行文件
如何将一个软件的可执行文件配置在我们的系统环境变量中?
步骤:
1、拷贝一个可执行文件所在的目录,比如:
node.exe所在的目录 C:\Program Files\nodejs
2、系统 > 高级系统设置 > 高级 > 环境变量 >
系统变量 > Path > 填写上你的目录
注意事项:
如果更改了系统的环境变量,就必须把终端重新启动
启动node.exe执行js代码
启动(相当于启动Apache服务器)
1、在我们的node的安装目录下,去双击我们node.exe
2、在终端输入 node即可 node.exe
退出我们的node.exe
1、在终端中输入.exit
2、连续按住两次 CTRL + C
怎么去执行js代码
1、直接在我们启动的node.exe中写代码(在开启的REPL环境中写代码执行)
缺点:
书写不方便,阅读起来也不方便
因为在我们的cmd中写的代码,是放在内存中的,
一旦我们退出了node.exe,原先写的代码都没有了
2、把我们写好的代码放在一个单独的js文件中去执行
在终端中输入 node.exe +执行的文件名称
注意:
1、我们js代码不是在终端中运行的,只是借助终端
去启动我们node.exe,并且最终将结果展现在终端里面而已
2、在运行时候,首先你的终端的目录得切换到你要
执行的文件的目录下面去,然后使用node 文件名称执行即可
我们nodejs的代码是在一个叫做REPL环境中,执行的
REPL
JS的执行
执行js在浏览器端,我是是要依靠浏览器(js的解析引擎)
在服务器端 nodejs开启的REPL环境
官网的解释:
参考:http://shouce.qdfuns.com/nodejs/repl.html
REPL就是当通过node.exe启动之后开辟的一块内存空间,
在这块内容空间里面就可以解释执行我们的js代码
例如:
在终端中输入了 node abc.js 做的事情就是,将abc.js中
写好的js的逻辑代码扔在启动好的node的内容空间中去运行,
我们把启动好的node的这块内存空间称之为REPL环境
模块化思想
为什么前端需要有模块化
1、解决全局变量名污染的问题
2、把相同功能的代码放在一个模块(一个js文件中)方便后期维护
3、便于复用
NodeJS中如何体现模块化
1、Node本身是基于CommonJS规范,
参考:http://javascript.ruanyifeng.com/nodejs/module.html#toc0
2、Node作者在设计这门语言的时候,就严格按照CommonJS
的规范,将它的API设计成模块化了,比如它将开启Web服务这
个功能所有代码都放入一个http模块中
3、Node本质来说就是将相同功能的代码放入到一个.js文件中管理
常用NodeJS中的模块
模块 作用
http 开启一个Web服务,给浏览器提供服务
url 给浏览器发送请求用,还可以传递参数(GET)
querystring 处理浏览器通过GET/POST发送过来的参数
path 查找文件的路径
fs 在服务器端读取文件用的
上面五大核心模块加上其它一些第三方的模块,就可以完成基本的数据库操作了nodeJS核心模块及其操作
http
使用http模块开启web服务
步骤:
//1、导入我们需要的核心模块(NodeJS提供的模块我们称之为核心模块)
var http = require('http');
//2、利用获取到的核心模块的对象,创建一个server对象
var server = http.createServer();
//3、利用server对象监听浏览器的请求,并且处理(请求-处理-响应)
server.on('request',function(req,res){
res.end("welcome");
});
//4、开启web服务开始监听
server.listen(8080,'127.0.0.1',function(){
console.log('开启服务器成功');
});url
1、导入url这个核心模块
2、调用url.parse(url字符串,true),如果是true的话代表把我们
的username=zhangsan&pwd=123 字符串解析成js对象
// 使用url模块获取url中的一些相关信息
const url = require('url')
var testURL = http://127.0.0.1:8899/login?username=zhangsan&pwd=123
console.log(url.parse(testURL,true))//{username:zhangsan,pwd:123}QueryString
作用:
将GET/POST传递过来的参数,进行解析
GET : ?username=zhangsan&pwd=123
POST : username=zhangsan&pwd=123
使用:
const querystring = require('querystring')
const paramsObj = querystring.parse(键值对的字符串)GET&POST
相同点:
都是HTTP协议的方法
都能传递参数给服务器
不同点:
1、传参的方式不一样
GET 放在路径后面 ?开始,后面键值对
POST 放在请求体 键值对的方式
2、传参的限制不一样
GET 2048B
POST 2M
3、GET有缓存,POST没有
4、GET传参不安全,POST相对安全
建议:
如果只是单纯的获取数据,就用GET,因为GET有缓存效率高
如果是要向服务器提交数据,就用POST
fs&path
path
作用:获取路径
path.join(__dirname,'你要读取的文件夹下面的文件名称即可')
__dirname全局属性,代表当前文件所在的文件夹路径
path.join会自动判断文件的路径,并且给他加上`/`fs
作用:读取服务器硬盘上面的某一个文件(操作文件)
fs.readFile : 异步读取服务器硬盘上面的某一个文件fs:node去读取服务器硬盘中的文件(操作文件)
path:获取文件的路径
上面两个基本上配合起来用自定义模块
CommonJS规范认为,一个.js文件就可以看成一个模块,如果我们想把模块中定义的变量,方法,对象给外面的js使用,就必须使用CommonJS提供module将我们需要给外面用的东西,导出去
注意点
在commonjs中导入模块用 require
在commonjs中在模块中导出 使用module.exports
如果是自定义模块,在导入自定义模块的时候,得把路径写完整
require导入的东西,就是别的文件modulu.exports导出的东西
Express 框架
基本概念
它是对HTTP封装,用来简化我们网络功能那一块
官网:http://www.expressjs.com.cn/ 官方解释:
基于 Node.js 平台,快速、开放、极简的 web 开发框架。
重点
1、如何去接收GET/POST传递过来的参数
2、如何通过Express进行分门别类的处理路由
3、静态资源的处理
使用
1、Hello World 案例
步骤:
1、导入包
2、创建一个app
3、请求处理响应
4、开启web服务,开始监听
2、获取GET/POST参数
GET参数:登录 http://127.0.0.1:3000/login?username=zhangsan&pwd=123
可以直接在我们的req.query中就可以获取了
POST参数:因为express没有直接提供获取POST参数的方法,需要借助一个第三方包 body-parser
参考: https://www.npmjs.com/package/body-parser
步骤:
1、npm install body-parser --save
2、导包
3、实现某些方法
最后通过req.body即可以获取到post提交过来的参数
路由处理
前端路由:
作用:当触发了某个超链接之后,根据路由的配置,决定
跳转到哪个页面,最终将这个页面呈现出来
后台的路由
作用:就是用来分门别类的出路用户发送过来的请求
http://127.0.0.1:3000/login
http://127.0.0.1:3000/register
http://127.0.0.1:3000/getGoodsList
http://127.0.0.1:3000/getGoodsInfo
jd购物
男士:(专门创建一个man.js文件来实现男士区域商品的请求)
http://www.jd.com/man/xz
http://www.jd.com/man/ld
http://www.jd.com/man/px
女士:(专门创建一个girl.js文件来实现女士区域商品的请求)
http://www.jd.com/girl/xs
http://www.jd.com/girl/bag
http://www.jd.com/girl/khexpress中代码实现?
步骤:
1、先要创建一个单独的路由(js文件),来处理某一类
请求下面的所有用户请求,并且需要导出去
1.1 导入包 express
1.2 创建一个路由对象
const manRouter = express.Router()
1.3 在具体的路由js中处理属于我们该文件的路由
manRouter.get(xxx)
manRouter.post(xxx)
1.4 将上面创建的路由对象导出去,在入口文件中使用
2、在入口文件中,导入我们的路由文件,并且使用就可以了
//导入路由文件
const manRouter = require(path.join(__dirname,"man/manRouter.js"))
//在入口文件中使用
app.use('/man',manRouter)
```
## Express中静态资源的处理
Express希望对我们后台静态资源处理,达到简单的目的,
然后只希望我们程序员写一句话就能搞定
步骤:
1、在我们入口文件中设置静态资源的根目录
注意点:一定要在路由处理之前设置app.use(express.static(path.join(__dirname,'statics')))
```
2、在我们的页面中,按照我们Express的规则来请求后台
静态资源数据
写link的href,script的src写的时候,除开静态资源根
路径之外,按照他在服务器上面的路径规则写
mongodb数据库
数据库
保存数据的仓库,数据库本质也是一个文件,只是说和普通的
文件不太一样,他有自己的存储规则,让我们保存数据和查询
数据更加方便
存储文件的介质
localStorage 文本文件
大型数据或是海量数据的时候必须要用到数据库
数据库的分类
客户端:
iOS/Android/前端
iOS/Android SQLite 在iOS/Android存储App的数据
服务端:
关系型数据库
部门---员工
mysql
sqlserver
oracle
非关系型数据库
JSON对象的形式来存储
MongoDB : 简单,你会js、JSON就能操作 Redis Memcached
数据库的作用
1、保存应用程序产生的数据(用户注册数据,用户的个人信息等等)
2、当应用程序需要数据的时候,提供给应用程序去展示
安装mongodb服务端
步骤:
1、安装mongodb服务端软件
2、设置mongodb的环境变量,重启终端验证 mongo -version
3、建立一个文件夹,用来存储mongodb数据库产生的数
据(建议放在C盘根目录 mongodb_datas)
4、启动
mongod --dbpath c:/mongodb_datas
启动服务端有几种方式
1、方式一,直接在cmd中输入 mongod --dbpath c:/mongodb_datas
32位: mongod --dbpath c:/mongodb_datas --journal --storageEngine=mmapv1
2、方式二,可以把mongod --dbpath c:/mongodb_datas做成一个批处理文件
32位: mongod --dbpath c:/mongodb_datas --journal --storageEngine=mmapv1
使用robomongo这个小机器人来操作我们的数据库中的数据
步骤:
1、连接到我们mongodb数据库服务端,并且连接成功之
后,服务端会给我们返回一个操作数据库的db对象
2、拿着上一步返回的db对象,对mongodb数据库中的数据进行操作了
连接成功之后,我们要来操作数据的话
1、创建一个数据库 (相当于在excel中创建空白工作簿)
2、创建集合 (相当于在excel创建工作表单)
数据的一个集合,把相关联的数据放在一个集合中
3、确立表头,插入数据、删除数据、修改数据、查询数据
MongoDB数据库中的概念
数据库 : 一个App中对应一个数据库
集合:相当于Excel中表单,一堆数据的集合,相关联的数据,
会放在一个集合中
文档:相当于excel中的每一行数据
一个数据中可以有多个集合(学生集合、食品集合)
一个集合可以有多条文档(多条数据)
在NodeJS中使用mongodb这个第三方包来操作我们mongodb数据库中的数据
参考: https://www.npmjs.com/package/mongodb
前提准备:
1、使用npm i mongodb --save来安装
正式集成:
1、导入包
2、拿到我们mongoClient对象
3、使用mongoClient连接到mongodb的服务端,返回操作数据库的db对象
4、通过db对象,拿到数据集合
db.collection('集合的名称')
5、调用集合的增,删,改,查的方法,来操作数据库中的数据
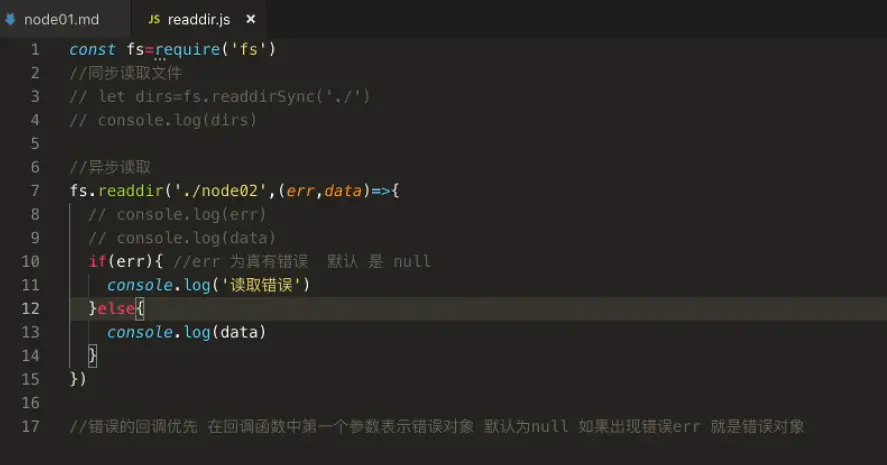
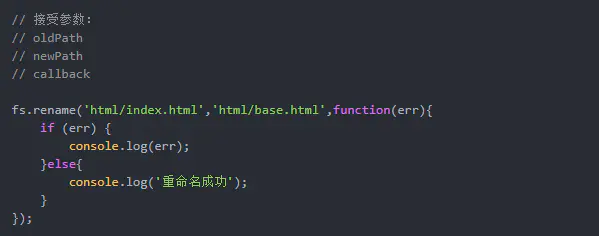
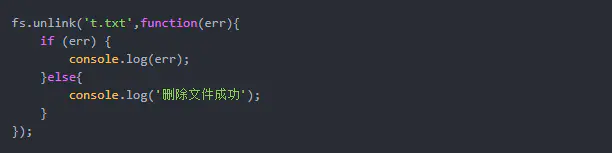
解析Python爬虫赚钱方式
Python爬虫怎么挣钱?解析Python爬虫赚钱方式,想过自己学到的专业技能赚钱,首先需要你能够数量掌握Python爬虫技术,专业能力强才能解决开发过程中出现的问题,Python爬虫可以通过Python爬虫外包项目、整合信息数据做产品、独立的自媒体三种方式挣钱。
Python爬虫怎么挣钱?
一、Python爬虫外包项目
网络爬虫最通常的的挣钱方式通过外包网站,做中小规模的爬虫项目,向甲方提供数据抓取,数据结构化,数据清洗等服务。新入行的程序员大多都会先尝试这个方向,直接靠技术手段挣钱,这是我们技术人最擅长的方式,因项目竞价的人太多,外包接单网站上的爬虫项目被砍到了白菜价也是常有的事。
二、整合信息数据做产品
利用Python爬虫简单说就是抓取分散的信息,整合后用网站或微信或APP呈现出来,以通过网盟广告,电商佣金,直接售卖电商产品或知识付费来变现。
三、最典型的就是找爬虫外包活儿
网络爬虫最通常的的挣钱方式通过外包网站,做中小规模的爬虫项目,向甲方提供数据抓取,数据结构化,数据清洗等服务。新入行的程序员大多都会先尝试这个方向,直接靠技术手段挣钱,这是我们技术人最擅长的方式,因项目竞价的人太多,外包接单网站上的爬虫项目被砍到了白菜价也是常有的事。
接着又去琢磨了其他的挣钱方法
四、爬数据做网站
那会儿开始接触运营,了解到一些做流量,做网盟挣钱的一些方法。挺佩服做运营的热,觉得鬼点子挺多的(褒义),总是会想到一些做流量的方法,但是他们就是需要靠技术去帮忙实现,去帮忙抓数据,那会我就在思考我懂做网站,抓数据都没问题,只要我能融汇运营技巧,就可以靠个人来挣钱钱了,于是就学习了一些SEO,和做社群的运营方法。
开始抓数据,来做网站挣钱,每个月有小几千块钱,虽然挣得不多,但做成之后不需要怎么维护,也算是有被动收入了。当然如果你技术学的还不够好,暂时就不要做了,可以先去小编的专栏简介的学习小天地,里面很多新教程项目多练习
五、去股市里浪一下【股市有风险,谨慎入市】
年龄越来越大了,有点余钱了就想投资一下,就去研究了下美股,买了一阵美股,挣了点钱,就想挣得更多,就在想有没有方法通过IT技术手段来辅助一下,那时喜欢买shopitify (类似国内的有赞)这类高成长,财报季股价波动大的股票。因为他是依附于facebook这类社交网站的,就是那些facebook上的网红可以用shopitify开店,来给他们的粉丝卖商品。
所以shopitify有个特点就是在社交媒体上的讨论量和相关话题度能反应一些这家公司这个季度的销售近况,这会影响它这个季度的财报,所以就想方设法就facebook上抓数据,来跟往期,历史上的热度来对比,看当季的财报是否OK,就用这种方法来辅助我买卖(是辅助,不是完全依靠)。
当初战绩还是可以,收益基本2-3倍于本金,心里挺喜滋滋的,后面由于我的风险控制意识不够,大亏了2次,亏到吐血。所以印证了那句话,股市有风险,谨慎入市。
六、在校大学生
最好是数学或计算机相关专业,编程能力还可以的话,稍微看一下爬虫知识,主要涉及一门语言的爬虫库、html解析、内容存储等,复杂的还需要了解URL排重、模拟登录、验证码识别、多线程、代理、移动端抓取等。由于在校学生的工程经验比较少,建议找一些少量数据抓取的项目,而不要去接一些监控类的项目、或大规模抓取的项目。慢慢来,步子不要迈太大。
七、在职人员
如果你本身就是爬虫工程师,挣钱很简单。如果你不是,也不要紧。只要是做IT的,稍微学习一下爬虫应该不难。
在职人员的优势是熟悉项目开发流程,工程经验丰富,能对一个任务的难度、时间、花费进行合理评估。可以尝试去找一些大规模抓取任务、监控任务、移动端模拟登录并抓取任务等,收益想对可观一些。
八、独立的自媒体号
做公众号、自媒体、独立博客,学Python写爬虫的人越来越多,很多是非计算机科班出身。所以把用Python写爬虫的需求增大了,工作上的实践经验多一点,可以多写一些教程和学习经验总结。
以上就是关于Python爬虫赚钱的方式介绍,掌握专业技能除本职工作外还可以兼职接单哦。
掌握python爬虫、Web前端、人工智能与机器学习、自动化开发、金融分析、网络编程等技能,零基础python找到工作也就不难了的哦。
两个textinput 切换不用点两下
核心代码
//添加手势监听
componentWillMount(){
this._panResponder = PanResponder.create({
onStartShouldSetPanResponder: () => true,
onPanResponderRelease: (evt,gs)=>{
console.log(gs);
{/*处理事件*/}
if (gs.y0<46+38 && gs.y0>46) {
this.refs.textInputs.focus()
};
}
})
}将手势监听给一个组件
{...this._panResponder.panHandlers}
将组建和事件写出来
ref='textInputs'
onFocus={() => {this.refs.textInputs.focus()}}
即可
🌰
/**
* Sample React Native App
* https://github.com/facebook/react-native
* @flow
*/
import React, { Component } from 'react';
import {
AppRegistry,
StyleSheet,
View,
ScrollView,
PanResponder,
TextInput,
Text
} from 'react-native';
export default class button extends Component {
constructor(props) {
//加载父类方法,不可省略
super(props);
//设置初始的状态
this.state = {
top:0,
left:0,
};
}
componentWillMount(){
this._panResponder = PanResponder.create({
onStartShouldSetPanResponder: () => true,
onPanResponderRelease: (evt,gs)=>{
console.log(gs);
if (gs.y0<46+38 && gs.y0>46) {
this.refs.textInputs.focus()
};
}
})
}
render(){
return (
{...this._panResponder.panHandlers}
keyboardShouldPersistTaps={false}>
联系方式
style={styles.telTextInput}
autoCapitalize = "none"
autoCorrect={false}
multiline = {true}
keyboardType = "default"
ref='textInputs'
placeholder = "请输入手机号或邮箱"
placeholderTextColor = "#999"
onFocus={() => {this.refs.textInputs.focus()}}
>
style={styles.telTextInput}
autoCapitalize = "none"
autoCorrect={false}
multiline = {true}
keyboardType = "default"
ref='textInput'
placeholder = "请输入手机号或邮箱"
placeholderTextColor = "#999"
onFocus={() => {this.refs.textInput.focus()}}
>
);
}
}
const styles = StyleSheet.create({
container: {
flex:1,
flexDirection: 'column',
//marginTop:64,
backgroundColor:'white'
},
line3:{
height:46,
paddingHorizontal:15,
paddingVertical:15,
borderBottomColor:'#E0E0E0',
borderBottomWidth:1
},
fdcontext:{
color:'#aaa',
fontSize:14
},
line5:{
flexDirection: 'column',
flex:1,
height: 38*2,
borderBottomColor:'#E0E0E0',
borderBottomWidth:1,
},
telTextInput:{
height:37,
fontSize: 12,
color:'#aaa',
paddingHorizontal:15,
paddingVertical:6,
}
});
AppRegistry.registerComponent('button', () => button);原创声明,本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
10行代码实现一个爬虫
跟我学习Python爬虫系列开始啦。带你简单快速高效学习Python爬虫。
一、快速体验一个简单爬虫
以抓取简书首页文章标题和链接为例
简书首页
就是以上红色框内文章的标签,和这个标题对应的url链接。当然首页还包括其他数据,如文章作者,文章评论数,点赞数。这些在一起,称为结构化数据。我们先从简单的做起,先体验一下Python之简单,之快捷。
1)环境准备
当然前提是你在机器上装好了Python环境,初步掌握和了解Python语法。如果还没有装好Python环境,对Python语言法不了解,可以先看《然学科技 Python基础系列》文章:https://www.jianshu.com/nb/20496406
2)安装相应包
快速入门我们使用的是requests包和BeautifulSoup包。简单解释一下,requests功能强大,代码少,封装了网络请求request(发起请求)和response(网络响应),request就像打开浏览器地址栏输入你想要访问的网站,浏览器中马上就可以看到内容一样(response)。
爬虫可以抓到大量数据(结构化的数据),存到数据库中(或excel, csv文件),再进行清洗整理,进行其他工作,如数据分析等。数据抓取也是数据分析前提和基础。
- 安装
requests
pip install requests- 安装
beautifulsoup4
pip install beautifulsoup4 - 可以查看一下你安装了哪些包
pip list3)代码:
# _*_ coding:utf-8 _*_
import requests
from bs4 import BeautifulSoup
URL='http://www.jianshu.com'
def simple_crawel():
html = requests.get(URL).content
soup = BeautifulSoup(html, 'lxml')
titles = soup.find_all('a',class_="title")
for t in titles:
print t.text+' -->>> '+'https://www.jianshu.com'+t['href']
if __name__ == '__main__':
simple_crawel()运行这个文件:
python demo.py结果:
抓取到的数据
代码解析:
html = requests.get(URL).content发起一个请求,获到到页面的内容(文本),对的就是一行代码就抓取到网页的全部内容。下一步就是要对页面进行解析。
titles = soup.find_all('a',class_="title")这行代码表示,寻找页面上所有class属性为title的a标签,就是文章标题所对应的标签。怎样才能找到文章标题对就是的哪个标题呢?很简单,在chrome浏览器中右键“检查”中查看就知道。看下图:
文章标题所对应的标签
然后再循环遍历,就得到每一个文章标题的a标签对象,在循环中取出文章标题的内容'text'和链接href就行了。
就这么简单,10行代码就抓取到首页热门文章的标题和URL打印在屏幕上。
二、学习爬虫需要的相关知识
代码很少,涉及到的知识点却很多。如果想要入门系统学习Python爬虫需要哪些知识呢?
- Python语言基础
- Python爬虫相关库
- HTTP请求响应模式
- HTML基础(HTML+CSS)
- 数据库基础
以上内容,都会在《跟我学Python爬虫》逐步讲。也可以把Python爬虫作为Python语言学习的起点,来了解和学习这门“人工智能的第一语言”,进而打开爬虫、数据分析、数据可视化、深度学习、人工智能的大门。
新建一个简单的React-Native工程
一、环境配置
(1)需要一台Mac(OSX)
(2)在Mac上安装Xcode
(3)安装node.js:https://nodejs.org/download/
(4)建议安装watchman,终端命令:brew install watchman
(5)安装flow:brew install flow
ok,按照以上步骤,你应该已经配置好了环境。
二、Hello, React-Native
现在我们需要创建一个React-Native的项目,因此可以按照下面的步骤:
打开终端,开始React-Native开发的旅程吧。
(1)安装命令行工具:sudo npm install -g react-native-cli
(2)创建一个空项目:react-native init HelloWorld
(3)找到创建的HelloWorld项目,双击HelloWorld.xcodeproj即可在xcode中打开项目。xcodeproj是xcode的项目文件。
(4)在xcode中,使用快捷键cmd + R即可启动项目。基本的Xcode功能可以熟悉,比如模拟器的选择等。
启动完成后,你会看到React-Packger和iOS模拟器,具体的效果如下,说明你创建项目成功了。
Xcode10 上创建RN工程报错:error: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src: Permission deniederror: couldn't create directory /Users/dmy/HelloWorld/node_modules/react-native/third-party/glog-0.3.5/src:
解决办法:
不要直接使用 react-native init HelloWorld 创建项目,
后面加个 --version 0.45.0 之前的版本就好了,
比如:
react-native init HelloWorld --version 0.44.0
React-Native 20分钟入门指南
背景
为什么需要React-Native?
在React-Native出现之前移动端主流的开发模式是原生开发和Hybrid开发(H5混合原生开发),Hybrid app相较于native app的优势是开发成本低开发速度快(H5页面开发跨平台,无需重新写web、android、ios代码),尽管native app在开发上需要更多时间,但却带来了更好的用户体验(页面渲染、手势操作的流畅性),也正是基于这两点Facebook在2015年推出了React-Native
What we really want is the user experience of the native mobile platforms, combined with the developer experience we have when building with React on the web.
上文摘自React-Native发布稿,React-Native的开发既保留了React的开发效率又拥有媲美原生的用户体验,其运行原理并非使用webview所以不属于Hybrid开发,想了解的可以查看React Native运行原理解析这篇文章。React-Native提出的理念是‘learn once,write every where’,之所以不是‘learn once, run every where’,是因为不同平台的用户体验有所不同,因此要运行全平台仍需要一些额外的适配,这里是Occhino对React-Native的介绍。
React-Native在Github的Star数
React-Native的npm下载数
上面两张图展示了React-Native的对于开发者的热门程度,且官方对其的开发状态一直更新,这也是其能抢占原生开发市场的重要因素。
搭建开发环境
在创建项目前我们需要先搭建React-Native所需的开发环境。
第一步需要先安装nodejs、python2、jdk8(windows有所不同,推荐使用macos开发,轻松省事)
brew install node //macos自带python和jdk
第二步安装React Native CLI
npm install -g react-native-cli
第三步安装Android Studio,参考官方的开发文档
创建第一个应用
使用react-native命令创建一个名为HelloReactNative的项目
react-native init HelloReactNative
等待其下载完相关依赖后,运行项目
react-native run-ios
or
react-native run-android
成功运行后的出现的界面是这样的
react-native-helloworld.png
基本的JSX和ES6语法
先看一下运行成功后的界面代码
/**
* Sample React Native App
* https://github.com/facebook/react-native
* @flow
*/
import React, {Component} from 'react';
import {
Platform,
StyleSheet,
Text,
View
} from 'react-native';
const instructions = Platform.select({
ios: 'Press Cmd+R to reload,\n' +
'Cmd+D or shake for dev menu',
android: 'Double tap R on your keyboard to reload,\n' +
'Shake or press menu button for dev menu',
});
//noinspection BadExpressionStatementJS
type
Props = {};
//noinspection JSAnnotator
export default class App extends Component<Props> {
render() {
return (
<View style={styles.container}>
<Text style={styles.welcome}>
Welcome to React Native!
</Text>
<Text style={styles.instructions}>
To get started, edit App.js
</Text>
<Text style={styles.instructions}>
{instructions}
</Text>
</View>
);
}
}
const styles = StyleSheet.create({
container: {
flex: 1,
justifyContent: 'center',
alignItems: 'center',
backgroundColor: '#F5FCFF',
},
welcome: {
fontSize: 20,
textAlign: 'center',
margin: 10,
},
instructions: {
textAlign: 'center',
color: '#333333',
marginBottom: 5,
},
});代码中出现的import、export、extends、class以及未出现的() =>箭头函数均为ES6需要了解的基础语法,import表示引入需要的模块,export表示导出模块,extends表示继承自某个父类,class表示定义一个类,()=>为箭头函数,用此语法定义的函数带有上下文信息,因此不必再处理this引用的问题。
<Text style={styles.welcome}>Welcome to React Native!</Text>这段代码是JSX语法使用方式,和html标记语言一样,只不过这里引用的是React-Native的组件,Text是一个显示文本的组件,可以看到style={styles.welcome}这是JSX的另一个语法可以将有效的js表示式放入大括号内,Welcome to React Native!为其内容文本,可以尝试修改他的内容为Hello React Native!,刷新界面后
react-native-text.png
熟悉更多的ES6语法有助于更有效率的开发。
组件的属性和状态
在了解了一些基本的JSX和ES6语法后,我们还需要了解两个比较重要的概念即props和state,props为组件的属性,state为组件的状态,两者间的区别在于,props会在组件被实例化时通过构造参数传入,所以props的传递为单向传递,且只能由父组件控制,state为组件的内部状态由组件自己管理,不受外界影响。props和state都能修改组件的状态,两者的改变会导致相关引用的组件状态改变,也就是说在组件的内部存在子组件引用了props和state,那么当发生改变时相应子组件会重新渲染,其实这里也可以看出props和state的使用联系,父组件可以通过setState修改state,并将其传递到子组件的props中使子组件重新渲染从而使父组件重新渲染。
组件生命周期
image
组件的生命周期会经历三个阶段
Mounting:挂载
Updating:更新
Unmounting:移除对应的生命周期回调方法为
componentWillMount()//组件将要挂载时调用
render()//组件渲染时调用
componentDidMount()//组件挂载完成时调用
componentWillReceiveProps(object nextProps)//组件props和state改变时调用
shouldComponentUpdate(object nextProps,object nextState)//返回false不更新组件,一下两个方法不执行
componentWillUpdate(object nextProps,object nextState)//组件将要更新时调用
componentDidUpdate(object nextProps,object nextState)//组件完成更新时调用
componentWillUnmount()//组件销毁时调用这里我们需要重点关注的地方在于组件运行的阶段,组件每一次状态收到更新都会调用render()方法,除非shouldComponentUpdate方法返回false,可以通过此方法对组件做一些优化避免重复渲染带来的性能消耗。
样式
React-Native样式实现了CSS的一个子集,样式的属性与CSS稍有不同,其命名采用驼峰命名,对前端开发者来说基本没差。使用方式也很简单,首先使用StyleSheet创建一个styles
const styles = StyleSheet.create({
container:{
flex:1
}
})然后将对应的style传给组件的style属性,例如<View style={styles.container}/>
常用组件
在日常开发中最常使用的组件莫过于View,Text,Image,TextInput的组件。
View基本上作为容器布局,在里面可以放置各种各样的控件,一般只需要为其设置一个style属性即可,常用的样式属性有flex,width,height,backgroundColor,flexDirector,margin,padding更多可以查看Layout Props。
Text是一个显示文本的控件,只需要在组件的内容区填写文字内容即可,例如<Text>Hello world</Text>,可以为设置字体大小和颜色<Text style={{fontSize:14,color:'red'}}>Hello world</Text>,同时也支持嵌套Text,例如
<Text style={{fontWeight: 'bold'}}>
I am bold
<Text style={{color: 'red'}}>
and red
</Text>
</Text>TextInput是文本输入框控件,其使用方式也很简单
<TextInput
style={{width:200,height:50}}
onChangeText={(text)=>console.log(text)}
/>style设置了他的样式,onChangeText传入一个方法,该方法会在输入框文字发生变化时调用,这里我们使用console.log(text)打印输入框的文字。
Image是一个图片控件,几乎所有的app都会使用图片作为他们的个性化展示,Image可以加载本地和网络上的图片,当加载网络图片时必须设定控件的大小,否则图片将无法展示
加载本地图片,图片地址为相对地址
<Image style={{width:100,height:100}} source={require('../images/img001.png')}/>
加载网络图片
<Image style={{width:100,height:100}} source={{uri:'https://facebook.github.io/react-native/docs/assets/favicon.png'}}/>react-native自定义原生组件
使用react-native的时候能够看到不少函数调用式的组件,像LinkIOS用来呼起url请求
LinkIOS.openUrl('http://www.163.com');actionSheetIOS用来实现ios客户端底部弹起的选择对话框
ActionSheetIOS.showActionSheetWithOptions({
options: BUTTONS,
cancelButtonIndex: CANCEL_INDEX,
destructiveButtonIndex: DESTRUCTIVE_INDEX,
},
(buttonIndex) => { this.setState({ clicked: BUTTONS[buttonIndex] });
});这些组件的使用方式都大同小异,通过声明一个native module,然后在这个组件内部通过底层实现方法的具体内容
像ActionSheetIOS在使用的时候,首先需要在工程的pod库中添加ActionSheetIOS对应的RCTActionSheet
pod 'React', :path => 'node_modules/react-native', :subspecs => ['Core','RCTActionSheet'# Add any other subspecs you want to use in your project]我们可以看到RCTActionSheet相关的实现的代码是放在react-native/Libraries/ActionSheetIOS下的
整个工程包含3个代码文件,ActionSheetIOS.js、RCTActionSheetManager.h、RCTActionSheetManager.m
ActionSheetIOS.js内容很简单,先是定义了引用oc代码的方式
var RCTActionSheetManager = require('NativeModules').ActionSheetManager;然后定义了ActionSheetIOS组件,并export
var ActionSheetIOS = {
showActionSheetWithOptions(options: Object, callback: Function) {
invariant( typeof options === 'object' && options !== null, 'Options must a valid object'
);
invariant( typeof callback === 'function', 'Must provide a valid callback'
);
RCTActionSheetManager.showActionSheetWithOptions(
{...options, tintColor: processColor(options.tintColor)},
callback
);
},
.....,
};module.exports = ActionSheetIOS;我们看到关键是引入底层oc的方式,其他的跟写前端没啥差别
然后再看RCTActionSheetManager的实现
#import "RCTBridge.h"@interface RCTActionSheetManager : NSObject@end主要是实现了RCTBridgeModule这个协议,这个协议是实现前端js-》oc的主要中间件,感兴趣的可以看看实现,
然后就是对RCTActionSheetManager的实现的代码,关键几句
@implementation RCTActionSheetManager
{
// Use NSMapTable, as UIAlertViews do not implement // which is required for NSDictionary keys
NSMapTable *_callbacks;}
RCT_EXPORT_MODULE()
...
RCT_EXPORT_METHOD(showActionSheetWithOptions:(NSDictionary *)options
callback:(RCTResponseSenderBlock)callback)
{
...
}主要是RCT_EXPORT_MODULE用来注册react-native module ,然后具体的实现方法放在RCT_EXPORT_METHOD开头的函数内
RCT开头的宏用来区分react-native函数与原声的函数,jspatch的bang有过具体分析,感兴趣的可以看看
http://blog.cnbang.net/tech/2698/
所以我们自己实现一个原生的react-native组件的时候,完全可以照着actionSheetIOS来做
在前端自定义一个js,通过require('NativeModules').XXX 引入
然后在底层实现RCTBridgeModule的类,在类里把RCT_EXPORT_MODULE、RCT_EXPORT_METHOD加上即可
转载自 https://cloud.tencent.com/developer/article/1896500
收起阅读 »100w的数据表比1000w的数据表查询更快吗?
当我们对一张表发起查询的时候,是不是这张表的数据越少,查询的就越快?
答案是不一定,这和mysql B+数索引结构有一定的关系。
innodb逻辑存储结构
从Innodb存储引擎的逻辑存储结构来看,所有数据都被逻辑的放在一个表空间(tablespace)中,默认情况下,所有的数据都放在一个表空间中,当然也可以设置每张表单独占用一个表空间,通过innodb_file_per_table来开启。
mysql> show variables like 'innodb_file_per_table';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
1 row in set (0.00 sec)
表空间又是由各个段组成的,常见的有数据段,索引段,回滚段等。因为innodb的索引类型是b+树,那么数据段就是叶子结点,索引段为b+的非叶子结点。
段空间又是由区组成的,在任何情况下,每个区的大小都为1M,innodb引擎一般默认页的大小为16k,一般一个区中有64个连续的页(64*16k=1M)。
通过段我们知道,还存在一个最小的存储单元页。它是innodb管理的最小的单位,默认是16K,当然也可以通过innodb_page_size来设置为4K、8K...,我们的数据都是存在页中的
mysql> show variables like 'innodb_page_size';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
1 row in set (0.00 sec)
所以innodb的数据结构应该大致如下:

B+ 树
b+树索引的特点就是数据存在叶子结点上,并且叶子结点之间是通过双向链表方式组织起来的。
假设存在这样一张表:
CREATE TABLE `user` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL DEFAULT '',
`age` int(10) NOT NULL DEFAULT 0,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
聚集索引
对于主键索引id,假设它的b+树结构可能如下:

此时树的高度是2
叶子节点之间双向链表连接
叶子结点除了id外,还存了name、age字段(叶子结点包含整行数据)
我们来看看 select * from user where id=30 是如何定位到的。
首先根据id=30,判断在第一层的25-50之间
通过指针找到在第二层的p2中
把p2再加载到内存中
通过二分法找到id=30的数据
总结:可以发现一共发起两次io,最后加载到内存检索的时间忽略不计。总耗时就是两次io的时间。
非聚集索引
通过表结构我们知道,除了id,我们还有name这个非聚集索引。所以对于name索引,它的结构可能如下:

此时树的高度是2
叶子节点之间双向链表连接
叶子结点除了name外,还有对应的主键id
我们来看看 select * from user where name=jack 是如何定位到的。
首先根据
name=jack,判断在第一层的mary-tom之间通过指针找到在第二层的p2中
把p2再加载到内存中
通过二分法找到
name=jack的数据(只有name和id)因为是
select *,所以通过id再去主键索引查找同样的原理最终在主键索引中找到所有的数据
总结:name查询两次io,然后通过id再次回表查询两次io,加载到内存的时间忽略不计,总耗时是4次io。另外,搜索公众号GitHub猿后台回复“天猫”,获取一份惊喜礼包。
一棵树能存多少数据
以上面的user表为例,我们先看看一行数据大概需要多大的空间:通过show table status like 'user'\G
mysql> show table status like 'user'\G
*************************** 1. row ***************************
Name: user
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 10143
Avg_row_length: 45
Data_length: 458752
Max_data_length: 0
Index_length: 311296
Data_free: 0
Auto_increment: 10005
Create_time: 2021-07-11 17:22:56
Update_time: 2021-07-11 17:31:52
Check_time: NULL
Collation: utf8mb4_general_ci
Checksum: NULL
Create_options:
Comment:
1 row in set (0.00 sec)
我们可以看到Avg_row_length=45,那么一行数据大概占45字节,因为一页的大小是16k,那么一页可以存储的数据是16k/45b = 364行数据,这是叶子结点的单page存储量。
以主键索引id为例,int占用4个字节,指针大小在InnoDB中占6字节,这样一共10字节,从root结点出来多少个指针,就可以知道root的下一层有多少个页。因为root结点只有一页,所以此时就是16k/10b = 1638个指针。
如果树的高度是2,那么能存储的数据量就是
1638 * 364 = 596232条如果树的高度是3,那么能存储的数据量就是
1638 * 1638 * 364 = 976628016条

如何知道一个索引树的高度
innodb引擎中,每个页都包含一个PAGE_LEVEL的信息,用于表示当前页所在索引中的高度。默认叶子节点的高度为0,那么root页的PAGE_LEVEL + 1就是这棵索引的高度。

那么我们只要找到root页的PAGE_LEVEL就行了。
通过以下sql可以定位user表的索引的page_no:
mysql> SELECT b.name, a.name, index_id, type, a.space, a.PAGE_NO FROM information _schema.INNODB_SYS_INDEXES a, information _schema.INNODB_SYS_TABLES b WHERE a.table_id = b.table_id AND a.space <> 0 and b.name='test/user';
+-----------+---------+----------+------+-------+---------+
| name | name | index_id | type | space | PAGE_NO |
+-----------+---------+----------+------+-------+---------+
| test/user | PRIMARY | 105 | 3 | 67 | 3 |
| test/user | name | 106 | 0 | 67 | 4 |
+-----------+---------+----------+------+-------+---------+
2 rows in set (0.00 sec)
可以看到主键索引的page_no=3,因为PAGE_LEVEL在每个页的偏移量64位置开始,占用两个字节。所以算出它在文件中的偏移量:16384*3 + 64 = 49152 + 64 =49216,再取前两个字节就是root的PAGE_LEVEL了。
通过以下命令找到ibd文件目录
show global variables like "%datadir%" ;
+---------------+-----------------------+
| Variable_name | Value |
+---------------+-----------------------+
| datadir | /usr/local/var/mysql/ |
+---------------+-----------------------+
1 row in set (0.01 sec)
user.ibd在 /usr/local/var/mysql/test/下。
通过hexdump来分析data文件。
hexdump -s 49216 -n 10 user.ibd
000c040 00 01 00 00 00 00 00 00 00 69
000c04a
000c040 00 01 00 00 00 00 00 00 00 69
00 01就是说明PAGE_LEVEL=1,那么树的高度就是1+1=2。
回到题目
100w的数据表比1000w的数据表查询更快吗?通过查询的过程我们知道,查询耗时和树的高度有很大关系。如果100w的数据如果和1000w的数据的树的高度是一样的,那其实它们的耗时没什么区别。
来源:juejin.cn/post/6984034503362609165
收起阅读 »PHP语法和PHP变量
一.PHP语言标记
在一个后缀为.php的文件立马,以<?php ?>开始和结束的文件,就是php标记文件,具体格式如下:
1.xml风格,是PHP的标准风格,推荐使用
2.简短风格,遵循SGML处理。需要在php.ini中将指令short_open_tag打开,或者在php编译时加入–enable-short-tags.如果你想你的程序移植性好,就抛弃这种风格,它就比1.1少了个php
3.ASP 风格(已移除)
种标记风格与 ASP 或 ASP.NET 的标记风格相同,默认情况下这种风格是禁用的。如果想要使用它需要在配置设定中启用了 asp_tags 选项。
不过该标记风格在 PHP7 中已经不再支持,了解即可。
4.SCRIPT 风格(已移除)
种标记风格是最长的,如果读者使用过 JavaScript 或 VBScript,就会熟悉这种风格。该标记风格在 PHP7 中已经不再支持,了解即可。
注意:如果文件内容是纯 PHP 代码,最好将文件末尾的 PHP 结束标记省略。这样可以避免在 PHP 结束标记之后,意外插入了空格或者换行符之类的误操作,而导致输出结果中意外出现空格和换行。
位置
可以将PHP语言放在后缀名为.php的HTML文件的任何地方。注意了,是以.php结尾的HTML文件。比如
PHP 注释规范
单行注释 每行必须单独使用注释标记,称为单行注释。它用于进行简短说明,形如 //php
多行注释
多行注释用于注释多行内容,经常用于多行文本的注释。注释的内容需要包含在(/* 和 */)中,以“/*”开头,以“*/结尾
php里面常见的几种注释方式
1.文件头的注释,介绍文件名,功能以及作者版本号等信息
2.函数的注释,函数作用,参数介绍及返回类型
3.类的注释
二.PHP变量
什么是变量呢?
程序中的变量源于数学,在程序语言中能够储存结果或者表示抽象概念。简单理解变量就是临时存储值的容器,它可以储存数字、文本、或者一些复杂的数据等。变量在 PHP 中居于核心地位,是使用 PHP 的关键所在,变量的值在程序运行中会随时发生变化,能够为程序中准备使用的一段数据起一个简短容易记的名字,另外它还可以保存用户输入的数据或运算的结果。
声明(创建)变量
因为 PHP 是一种弱类型的语言,所以使用变量前不用提前声明,变量在第一次赋值时会被自动创建,这个原因使得 PHP 的语法和C语言、Java 等强类型语言有很大的不同。声明 PHP 变量必须使用一个美元符号“$”后面跟变量名来表示,然后再使用“=”给这个变量赋值。如下所示

变量命名规则
变量名并不是可以随意定义的,一个有效的变量名应该满足以下几点要求:
1. 变量必须以 $ 符号开头,其后是变量的名称,$ 并不是变量名的一部分;
2. 变量名必须以字母或下划线开头;
3. 变量名不能以数字开头;
4.变量名只能包含字母(A~z)、数字(0~9)和下划线(_);
5.与其它语言不通的是,PHP 中的一些关键字也可以作为变量名(例如 $true、$for)。
注意:PHP 中的变量名是区分大小写的,因此 $var 和 $Var 表示的是两个不同的变量
错误的变量命名示范
下划线命名法:将构成变量名的单词以下划线分割,例如 $get_user_name、$set_user_name;
驼峰式命名法(推荐使用):第一个单词全小写,后面的单词首字母小写,例如 $getUserName、$getDbInstance;
帕斯卡命名法:将构成变量名的所有单词首字母大写,例如 $Name、$MyName、$GetName。
PHP 基本语法2
一、PHP 标记
PHP 也是通过标记来识别的,像 JSP 的 <% %> 的一样,PHP 的最常用的标记是:<?php php 代码 ?> 。
以 “<?” 开始,“?>”结束。
该风格是最简单的标记风格,默认是禁止的,可以通过修改 short_open_tag 选项来允许使用这种风格。
[捂脸哭] 我们其实目前不需要去配置这个风格哈,老老实实用 <?php php 代码 ?> 就够了~
二、基础语法
1. PHP 语句都以英文分号【;】结束。
2. PHP 注释
大体上有三种:
<?php
/*
多行注释
*/
echo "string";// 单行注释
echo "string";# 单行注释
?>sublime text 3 神奇快捷键:ctrl shift d => 复制当前行到下一行
3. 输出语句:echo
<?php
echo "string";
echo("string");
?>PHP 可以嵌套在 HTML 里面写,所以也可以输出 HTML、CSS、JavaScript 语句等。
<font id="testPhpJs"></font>
<?php
echo "<style type='text/css'>#testPhpJs {color: red}</style>";
echo "<h1>一级标题</h1>";
echo "<script>var font = document.getElementById('testPhpJs');font.innerText='php输出js填充的文字';</script>";
?>
<input type="text" name="test" value="<?php echo "123"; ?>">
网页输出结果:
4. 变量及变量类型
PHP 的类型有六种,整型、浮点型、字符串、布尔型、数组、对象。
但是定义的方式只有一种:$ 变量名。PHP 变量的类型会随着赋值的改变而改变(动态类型)
<?php
$variable = 1; //整型
$variable = 1.23; //浮点型
$variable = "字符串"; //字符串 ""
$variable = '字符串'; //字符串 ''
$variable = false; //布尔型
?>特殊的变量(见附录)。
5. 字符串
关于字符串,我们还有几点需要说的:
a. 双引号和单引号
这两者包起来的都是字符串:'阿'、"阿"。注意单引号里不能再加单引号,双引号里不能再加双引号,实在要加的话记得用转义符 “ \”
b. 定界符
如果想输出很大一段字符串,那么就需要定界符来帮忙。定界符就是由头和尾两部分。
<?php
echo <<<EOT
hello world!
lalala~
EOT;
// 这个定界符的尾巴和前面<<<后面的字符应该一样
// !定界符的尾巴必须靠在最左边
?>定界符的名字是自己起的,乐意叫啥就叫啥,但是它的尾巴必须靠在最左边,不能有任何其他的字符!空格也不行:
<?php
//定界符的名字随便起
echo <<<ERROR
ERROR;
//但是尾巴必须靠左,前面不能有任何东西。比如这样就是错的 ↑
?>看!上面这个注释都变成绿色了~ 它都报错了,大家写的时候可不能这么写哦~O(∩_∩)O哈哈~
6. 字符串连接
不同于 Java 的 “+” 号连接符,PHP 用的是点【.】。在做数据库查询语句的时候,常会遇到要与变量拼接的情况。这里给个小技巧:
在数据库相关软件中先用一个数据例子写好查询语句,并测试直到执行成功:
然后将数据换成变量:
- 将 sql 语句用字符串变量存储。
- 将写死的数据换成两个双引号
- 在双引号中间加两个连接符 点【.】
- 在连接符中间将变量放入
<?php
$isbn = "9787508353937";//存储isbn的变量
$sql = "SELECT * FROM bookinfo WHERE isbn = '9787508353937'";
// $sql = "SELECT * FROM bookinfo WHERE isbn = '""'";
// $sql = "SELECT * FROM bookinfo WHERE isbn = '".."'";
$sql = "SELECT * FROM bookinfo WHERE isbn = '".$isbn."'";
//修改完成
?>保证不会出错哈哈(这个多用于数据库的增删改查,避免 sql 语句的错误)
7. 表单数据
表单在提交数据的时候,method 有两种方式:post & get。所以 PHP 有几种不同的方式来获取表单数据:
<?php
$_POST['表单控件名称'] //对应POST方式提交的数据
$_GET['表单控件名称'] //对应GET方式提交的数据
$_REQUEST['表单控件名称'] //同时适用于两种方式
?>8. 运算符
运算符和其他语言基本一致,如果不了解的可以去看看我的 java 运算符(https://blog.csdn.net/ahanwhite/article/details/89461167)。
但这里还是有一个比较特殊的:
字符串连接赋值:【.=】
<?php
$str = "这是连接";
$str .= "字符串的运算符";
// 那么现在的$str = "这是连接字符串的运算符";
?>9. 分支与选择
同样和其他语言差别不大,有兴趣可以看我的 java 控制语句(https://blog.csdn.net/ahanwhite/article/details/89461652)
10. PHP 函数
PHP 的函数和 Java 还是有点儿区别,定义的格式:
<?php
function 函数名($参数) {
函数体;
}
?>a. 函数参数可以为空
b. 如果需要修改函数的值,可以使用引用参数传递,但是需要在参数前面加上【&】
c. 函数的参数可以使用默认值,在定义函数是参数写成: $ 参数 =“默认值”; 即可。(默认值又叫缺省值)。
<?php
//改变参数变量的值
function myName(&$name) {
$name = "baibai";
echo $name;
}
$name = "huanhuan";
myName($name);
//设置默认参数值
function myName2($name="baibai") {
echo "<br>".$name;
}
//不传参测试默认值
myName2();
?>
输出结果:
d. PHP 也有一些自己的系统函数(比如 echo),这里再列几个常用的字符串函数:
- 字符串长度计算
$a = mb_strlen("abdsd");
$b = mb_strlen("lalalal",'UTF-8')我一般用后面这个,按 utf-8 编码计算长度。
- 在一个字符串中查找另一个字符串
strstr(字符串1,字符串2)补充一个函数 var_dump() 【实名感谢石老师】
用来判断一个变量的类型与长度, 并输出变量的数值, 如果变量有值输的是变量的值并回返数据类型. 此函数显示关于一个或多个表达式的结构信息,包括表达式的类型与值。数组将递归展开值,通过缩进显示其结构。
<?php
$a = strstr("asgduiashufai","dui");
$b = strstr("asgduiashufai","?");
echo var_dump($a);
echo "<br>";
echo var_dump($b);
?>如果存在前面的字符串里存在后面的字符串,那么会返回字符串 2 以及在字符串 1 里后面的所有字符。如果不存在,就会返回 false(但是不能直接输出,直接输出好像是空值,判断一下再输出提示信息会比较好)
- 按照 ASCII 码比较两个字符串大小
strcmp("字符串1","字符串2")
//1比2打,返回大于0,2比1打,返回小于0,一样大的话返回等于0- 将 html 标记作为字符串输出
htmlspecialchars("字符串")- 改变字符串大小写
strtolower("字符串");//将字符串全变成小写
strtoupper("字符串");//将字符串全变成大写- 加密函数
md5() 将一个字符串进行 MD5 加密计算。(没有解密的函数,用于密码,检验时将用户提交的密码加密之后进行对比)
$a = md5("字符串");附录
特殊的变量
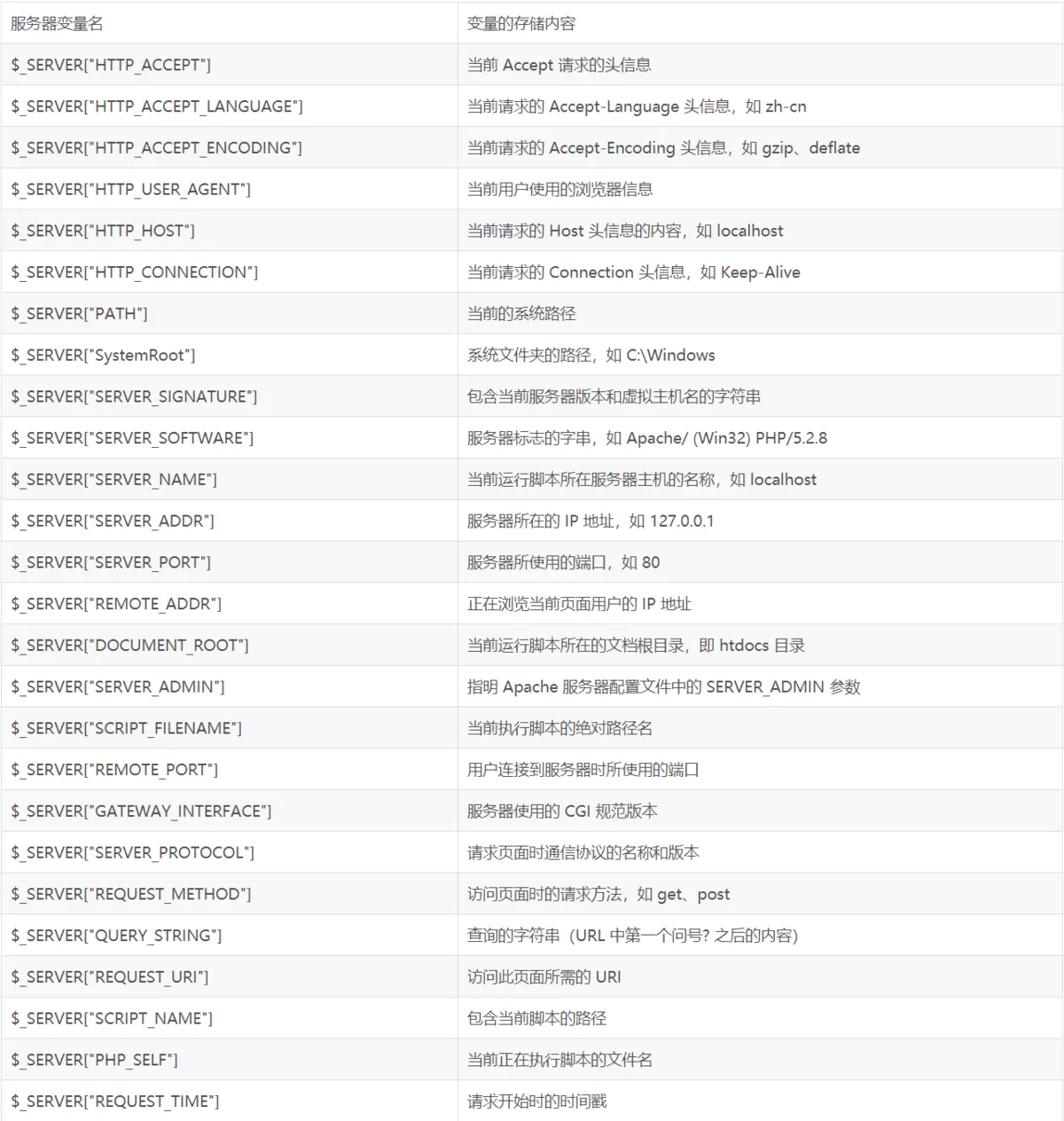
PHP-Beast 加密你的PHP源代码
前言
首先说说为什么要用PHP-Beast?
有时候我们的代码会放到代理商上, 所以很有可能代码被盗取,或者我们写了一个商业系统而且不希望代码开源,所以这时候就需要加密我们的代码。
另外PHP-Beast是完全免费和开源的, 当其不能完成满足你的需求时, 可以修改其代码而满足你的要。
编译安装如下
注意:如果你需要使用,首先修改key。可以参考下文
Linux编译安装:
$ wget https://github.com/liexusong/php-beast/archive/master.zip
$ unzip master.zip
$ cd php-beast-master
$ phpize
$ ./configure
$ sudo make && make install编译好之后修改php.ini配置文件, 加入配置项: extension=beast.so, 重启php-fpm 。
配置项:
beast.cache_size = size
beast.log_file = "path_to_log"
beast.log_user = "user"
beast.enable = Onbeast.log_level支持参数:
1. DEBUG
2. NOTICE
3. ERROR支持的模块有:
1. AES
2. DES
3. Base64通过测试环境:
Nginx + Fastcgi + (PHP-5.2.x ~ PHP-7.1.x)怎么加密你的项目
加密方案1:
安装完 php-beast 后可以使用 tools 目录下的 encode_files.php 来加密你的项目。使用 encode_files.php 之前先修改 tools 目录下的 configure.ini 文件,如下:
; source path
src_path = ""
; destination path
dst_path = ""
; expire time
expire = ""
; encrypt type (selection: DES, AES, BASE64)
encrypt_type = "DES"src_path 是要加密项目的路径,dst_path 是保存加密后项目的路径,expire 是设置项目可使用的时间 (expire 的格式是:YYYY-mm-dd HH:ii:ss)。encrypt_type是加密的方式,选择项有:DES、AES、BASE64。 修改完 configure.ini 文件后就可以使用命令 php encode_files.php 开始加密项目。
加密方案2:
使用beast_encode_file()函数加密文件,函数原型如下:
beast_encode_file(string $input_file, string $output_file, int expire_timestamp, int encrypt_type)。- $input_file: 要加密的文件
- $output_file: 输出的加密文件路径
- $expire_timestamp: 文件过期时间戳
- $encrypt_type: 加密使用的算法(支持:BEAST_ENCRYPT_TYPE_DES、BEAST_ENCRYPT_TYPE_AES)
制定自己的php-beast
php-beast 有多个地方可以定制的,以下一一列出:
- 使用 header.c 文件可以修改 php-beast 加密后的文件头结构,这样网上的解密软件就不能认识我们的加密文件,就不能进行解密,增加加密的安全性。
- php-beast 提供只能在指定的机器上运行的功能。要使用此功能可以在 networkcards.c 文件添加能够运行机器的网卡号,例如:
char *allow_networkcards[] = {
"fa:16:3e:08:88:01",
NULL,
};这样设置之后,php-beast 扩展就只能在 fa:16:3e:08:88:01 这台机器上运行。另外要注意的是,由于有些机器网卡名可能不一样,所以如果你的网卡名不是 eth0 的话,可以在 php.ini 中添加配置项: beast.networkcard = "xxx" 其中 xxx 就是你的网卡名,也可以配置多张网卡,如:beast.networkcard = "eth0,eth1,eth2"。
- 使用 php-beast 时最好不要使用默认的加密key,因为扩展是开源的,如果使用默认加密key的话,很容易被人发现。所以最好编译的时候修改加密的key,aes模块 可以在 aes_algo_handler.c 文件修改,而 des模块 可以在 des_algo_handler.c 文件修改。
函数列表 & Debug
开启debug模式:
可以在configure时加入 --enable-beast-debug 选项来开启debug模式。开启debug模式后需要在php.ini配置文件中加入配置项:beast.debug_path 和 beast.debug_mode。beast.debug_mode 用于指定是否使用debug模式,而 beast.debug_path 用于输出解密后的php脚本源码。这样就可以在 beast.debug_path 目录中看到php-beast解密后的源代码,可以方便知道扩展解密是否正确。
函数列表:
- beast_encode_file(): 用于加密一个文件
- beast_avail_cache(): 获取可以缓存大小
- beast_support_filesize(): 获取beast支持的最大可加密文件大小
- beast_file_expire(): 获取一个文件的过期时间
- beast_clean_cache(): 清空beast的所有缓存(如果有文件更新, 可以使用此函数清空缓存)
修改默认加密的key
1,修改加密后的文件头结构:打开header.c文件,找到以下代码:
char encrypt_file_header_sign[] = {
0xe8, 0x16, 0xa4, 0x0c,
0xf2, 0xb2, 0x60, 0xee
};int encrypt_file_header_length = sizeof(encrypt_file_header_sign);
自定义修改以下代码(其中的数字的范围为:0-8,字母的范围为:a-f):
0xe8, 0x16, 0xa4, 0x0c,
0xf2, 0xb2, 0x60, 0xee2,修改aes模块加密key:
打开php-beast-master/aes_algo_handler.c文件,找到以下代码:
static uint8_t key[] = {
0x2b, 0x7e, 0x61, 0x16, 0x28, 0xae, 0xd2, 0xa6,
0xab, 0xi7, 0x10, 0x88, 0x09, 0xcf, 0xef, 0xxc,
};自定义修改以下代码(其中的数字的范围为:0-8,字母的范围为:a-f):
0x2b, 0x7e, 0x61, 0x16, 0x28, 0xae, 0xd2, 0xa6,
0xab, 0xi7, 0x10, 0x88, 0x09, 0xcf, 0xef, 0xxc,3,修改des模块加密key:
打开php-beast-master/des_algo_handler.c文件,找到以下代码:
static char key[8] = {
0x21, 0x1f, 0xe1, 0x1f,
0xy1, 0x9e, 0x01, 0x0e,
};自定义修改以下代码(其中的数字的范围为:0-8,字母的范围为:a-f):
0x21, 0x1f, 0xe1, 0x1f,
0xy1, 0x9e, 0x01, 0x0e,4,修改base64模块加密key:
打开php-beast-master/base64_algo_handler.c文件,自定义修改以下代码:
static const short base64_reverse_table[256] = {
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1,
-1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,
15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1,
-1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,
-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1
};php-beast自定义加密模块
一,首先创建一个.c的文件。例如我们要编写一个使用base64加密的模块,可以创建一个名叫base64_algo_handler.c的文件。然后在文件添加如下代码:
#include "beast_module.h"
int base64_encrypt_handler(char *inbuf, int len, char **outbuf, int *outlen)
{
...
}
int base64_decrypt_handler(char *inbuf, int len, char **outbuf, int *outlen)
{
...
}
void base64_free_handler(void *ptr)
{
...
}
struct beast_ops base64_handler_ops = {
.name = "base64-algo",
.encrypt = base64_encrypt_handler,
.decrypt = base64_decrypt_handler,
.free = base64_free_handler,
};模块必须实现3个方法,分别是:encrypt、decrypt、free方法。
encrypt方法负责把inbuf字符串加密,然后通过outbuf输出给beast。
decrypt方法负责把加密数据inbuf解密,然后通过outbuf输出给beast。
free方法负责释放encrypt和decrypt方法生成的数据
二,写好我们的加密模块后,需要在global_algo_modules.c添加我们模块的信息。代码如下:
#include <stdlib.h>
#include "beast_module.h"
extern struct beast_ops des_handler_ops;
extern struct beast_ops base64_handler_ops;
struct beast_ops *ops_handler_list[] = {
&des_handler_ops,
&base64_handler_ops, /* 这里是我们的模块信息 */
NULL,
};三,修改config.m4文件,修改倒数第二行,如下代码:
PHP_NEW_EXTENSION(beast, beast.c des_algo_handler.c beast_mm.c spinlock.c cache.c beast_log.c global_algo_modules.c * base64_algo_handler.c *, $ext_shared)
base64_algo_handler.c的代码是我们添加的,这里加入的是我们模块的文件名。
现在大功告成了,可以编译试下。如果要使用我们刚编写的加密算法来加密php文件,可以修改php.ini文件的配置项,如下:
``
beast.encrypt_handler = "base64-algo"`
名字就是我们模块的name。
转载自:https://cloud.tencent.com/developer/article/1911039
收起阅读 »Java中的数据类型
Java是强类型语言
什么是强类型语言?
就是一个变量只能对应一种类型。而不是模棱两可的类型符号。
下面我通过一个例子来解释一下这个现象.
- javascript中可以用var表示许多数据类型
// 此时a为number
var a = 1;
// 此时a为字符串形式的'1'
var a = '1';可以看到,javascript里面,可以用var来承载各种数据类型,但是在Java,你必须对变量声明具体的数据类型(Java10中也开放了var,目前我们讨论的版本为Java8) 。
8大数据类型
基本类型 | 存储所需大小 | 取值范围 |
|---|---|---|
int | 4字节 | -2147483648~2147483647 |
short | 2字节 | -32768~32767 |
long | 8字节 | -9223372036854775808~9223372036854775807 |
byte | 1字节 | -128~127 |
float | 4字节 | 1.4e-45f~ 3.4028235e+38f |
double | 8字节 | 4.9e-324~1.7976931348623157e+308 |
char | 2字节 | \u0000~\uFFFF |
boolean | 根据JVM的编译行为会有不同的结果(1/4) | 布尔(boolean)类型的大小没有明确的规定,通常定义为取字面值 “true” 或 “false” |
NaN与无穷大
- NaN
在浮点数值计算中,存在一个NaN来表示该值不是一个数字
/**
* @author jaymin<br>
* 如何表示一个值不是数字
* 2021/3/21 14:54
*/
public class NaNDemo {
public static void main(String[] args) {
Double doubleNaN = new Double(0.0/0.0);
// 一个常数,其值为double类型的非数字(NaN)值
Double nan = Double.NaN;
System.out.println(doubleNaN.isNaN());
System.out.println(nan.isNaN());
}
}- 正负无穷大
private static void isPositiveInfinityAndNegativeInfinity(){
double positiveInfinity = Double.POSITIVE_INFINITY;
double negativeInfinity = Double.NEGATIVE_INFINITY;
System.out.println(positiveInfinity);
System.out.println(negativeInfinity);
}Result:
Infinity
-Infinity浮点数存在精度问题
Java中无法用浮点数值来表示分数,因为浮点数值最终采用二进制系统表示。
/**
* @author jaymin<br>
* 浮点数无法表示分数
* @since 2021/3/21 15:07
*/
public class PrecisionDemo {
public static void main(String[] args) {
System.out.println(2.0 - 1.1);
// 如何解决?使用BigDecimal
BigDecimal a = BigDecimal.valueOf(2.0);
BigDecimal b = BigDecimal.valueOf(1.1);
System.out.println(a.subtract(b));
}
}精度
向上转型和向下强转
- 向上转型
/**
*
*
* @author jaymin
* @since 2021/3/21 15:40
*/
public class ForcedTransfer {
public static void main(String[] args) {
int n = 123456789;
// 整型向上转换丢失了精度
float f = n;
System.out.println(f);
int n1 = 1;
float f1 = 2.2f;
// 不同类型的数值进行运算,将向上转型
System.out.println(n1 + f1);
}
}这里我们看到两个现象:
- 整型可以赋值给浮点型,但是可能会丢失精度.
- 整形和浮点数进行相加,先将整型向上转型为float,再进行float的运算.
层级关系:double>float>long>int
- 面试官经常问的一个细节
此处能否通过编译?
short s1= 1;
s1 = s1 + 1;答案是不能的,如果我们对小于 int 的基本数据类型(即 char、byte 或 short)执行任何算术或按位操作,这些值会在执行操作之前类型提升为 int,并且结果值的类型为 int。若想重新使用较小的类型,必须使用强制转换(由于重新分配回一个较小的类型,结果可能会丢失精度).
可以简单理解为: 比int类型数值范围小的数做运算,最终都会提升为int,当然,使用final可以帮助你解决这种问题.
- 正确示例
short s1= 1;
// 1. 第一个种解决办法
s1 = (short) (s1 + 1);
// 2. 第二种解决办法
s1+=1; final short a1 = 1;
final short a2 = 2;
short result = a1 + a2;- 向下转型(强制转换)
场景: 在程序中得到了一个浮点数,此时将其转成整形,那么你就可以使用强转.
/**
* 数值之间的强转
*
* @author jaymin
* @since 2021/3/21 15:40
*/
public class ForcedTransfer {
public static void main(String[] args) {
double x = 2021.0321;
// 强转为整型
int integerX = (int) x;
System.out.println(integerX);
x = 2021.8888;
// 四舍五入
int round = (int) Math.round(x);
System.out.println(round);
}
}Result:
2021
2022如果强转的过程中,上层的数据类型范围超出了下层的数据类型范围,那么会进行截断.
可以执行以下程序来验证这个问题.
long l = Long.MAX_VALUE;
int l1 = (int) l;
System.out.println(l1);
int i = 300;
byte b = (byte) i;
// 128*2 = 256,300-256=44
System.out.println(b);Reuslt:
-1
44初始值
基本数据类型都会有默认的初始值.
基本类型 | 初始值 |
|---|---|
boolean | false |
char | \u0000 (null) |
byte | (byte) 0 |
short | (short) 0 |
int | 0 |
long | 0L |
float | 0.0f |
double | 0.0d |
在定义对象的时候,如果你使用了基本类型,那么类在初始化后,如果你没有显性地赋值,那么就会为默认值。这在某些场景下是不对的(比如你需要在http中传输id,当对方没有传输id时,你应该报错,但是由于使用了基本的数据类型,id拥有了默认值0,那么此时程序就会发生异常)
定义对象的成员,最好使用包装类型,而不是基础类型.
Integer对象的缓存区
在程序中有些值是需要经常使用的,比如定义枚举时,经常会使用1,2,3作为映射值.Java的语言规范JLS中要求将-128到127的值进行缓存。(高速缓存的大小可以由-XX:AutoBoxCacheMax = <size>选项控制。在VM初始化期间,可以在sun.misc.VM类的私有系统属性中设置并保存java.lang.Integer.IntegerCache.high属性。)
- 使用==比较Integer可能会出现意想不到的结果
public static void main(String[] args) {
Integer a1 = Integer.valueOf(127);
Integer a2 = Integer.valueOf(127);
System.out.println(a1==a2);
Integer a3 = Integer.valueOf(128);
Integer a4 = Integer.valueOf(128);
System.out.println(a3==a4);
}Result:
true
false解决的办法很简单,使用equals来进行比较即可,Integer内部重写了equals和hashcode.
常用的一些转义字符
在字符串中,如果你想让输出的字符串换行,你就需要用到转义字符
转义字符 | Unicode | 含义 |
|---|---|---|
\b | \u0008 | 退格 |
\t | \u0009 | 制表 |
\n | \u000a | 换行 |
\r | \u000d | 回车 |
\" | \u0022 | 双引号 |
\' | \u0027 | 单引号 |
\\ | \u005c | 反斜杠 |
\\. | - | . |
- 换行输出字符串
System.out.println("我马上要换行了\n我是下一行");潜力APP新品推荐:Vibetoon——人人都可以是音乐视频创作人
1、Vibetoon——人人都可以是音乐视频创作人

不同于在大多数人都在布局 3D Avatar 和虚拟数字人,Vibetoon 另辟蹊径选择用“2D Avatar+音乐+短视频”的模式为自己开路。并成功吸引了 Will Smith、Martin Lawrence、Dj Jazzy Jeff、BLXST、Dave East、Macaulay Culkin 等多名音乐人、唱作人、明星们使用和宣传,同时也同华纳、Redbull等知名唱片公司达成合作。
而根据 Vibetoon 联合创始人 Veronica 表示,“Vibetoon 设立的初衷是希望每一个音乐人都可以不受资金和时间的限制,拥有自己专属的MV”。
而 Vibetoon 的使用方法也非常简单,用户只需要完成“Avatar 头像创作、场景选择和上传音乐”三步就可以创作一个专属自己的音乐视频了。
关于Avatar,用户可以自由选择选择 Avatar 的性别、体型、肤色、发色、眉毛、眼睛形状、虹膜颜色、眉毛、鼻子、嘴唇、睫毛、妆容、胡子、帽子、眼镜、耳饰、项链、手链、服装等内容。尽管每个类目提供的选项不是很丰富,但是也给出了一定的差异化空间,至少可以帮助创作者保留一定特点。
在场景上,Vibetoon 提供了沙发一角、跑车1(自然风光)、跑车2(城市风光)、录音房、泳池、阳台、地铁、沙滩等 8 个场景选择。
而除了场景本身,用户还可以加上如吸烟、弹吉他、敲电子键盘、打游戏、喝东西、写东西等不同的动画效果,选择不同的动画场景即可触发不同的动画效果。
从笔者个人的直观感受来看,Vibetoon 提供的金链子、编发、夸张耳饰、公路跑车等个性化选项,似乎更贴近“说唱”风格,这可能也是为何会多次在 Twitter 上被说唱歌手翻牌的原因。
Vibetoon 支持用户以不同比例的格式导出音乐视频并上传至 Instagram、YouTube 等不同社交媒体平台。

目前 Vibetoon 正处于努力众筹阶段,会将筹措资金用于更多场景、动作、服装和新功能的研发和探索中。
全球越来越多的用户习惯用短视频的方法来进行表达,而 Vibetoon 似乎在短视频生态链路中找到了一条垂直,且被公司、创作者和普通用户同时需要的路线。
收起阅读 »视频直播技术干货:一文读懂主流视频直播系统的推拉流架构、传输协议等
本文由蘑菇街前端开发工程师“三体”分享,原题“蘑菇街云端直播探索——启航篇”,有修订。
1、引言
随着移动网络网速的提升与资费的降低,视频直播作为一个新的娱乐方式已经被越来越多的用户逐渐接受。特别是最近这几年,视频直播已经不仅仅被运用在传统的秀场、游戏类板块,更是作为电商的一种新模式得到迅速成长。
本文将通过介绍实时视频直播技术体系,包括常用的推拉流架构、传输协议等,让你对现今主流的视频直播技术有一个基本的认知。

2、蘑菇街的直播架构概览
目前蘑菇街直播推拉流主流程依赖于某云直播的服务。
云直播提供的推流方式有两种:
1)一是通过集成SDK的方式进行推流(用于手机端开播);
2)另一种是通过RTMP协议向远端服务器进行推流(用于PC开播端或专业控台设备开播)。
除去推拉流,该云平台也提供了云通信(IM即时通讯能力)和直播录制等云服务,组成了一套直播所需要的基础服务。
3、推拉流架构1:厂商SDK推拉流

如上题所示,这一种推拉流架构方式需要依赖腾讯这类厂商提供的手机互动直播SDK,通过在主播端APP和用户端APP都集成SDK,使得主播端和用户端都拥有推拉流的功能。
这种推拉流架构的逻辑原理是这样的:
1)主播端和用户端分别与云直播的互动直播后台建立长连接;
2)主播端通过UDT私有协议向互动直播后台推送音视频流;
3)互动直播后台接收到音视频流后做转发,直接下发给与之建立连接的用户端。
这种推拉流方式有几点优势:
1)只需要在客户端中集成SDK:通过手机就可以开播,对于主播开播的要求比较低,适合直播业务快速铺开;
2)互动直播后台仅做转发:没有转码,上传CDN等额外操作,整体延迟比较低;
3)主播端和用户端都可以作为音视频上传的发起方:适合连麦、视频会话等场景。
4、推拉流架构2:旁路推流
之前介绍了通过手机SDK推拉流的直播方式,看起来在手机客户端中观看直播的场景已经解决了。
那么问题来了:如果我想要在H5、小程序等其他场景下观看直播,没有办法接入SDK,需要怎么处理呢?
这个时候需要引入一个新的概念——旁路推流。
旁路推流指的是:通过协议转换将音视频流对接到标准的直播 CDN 系统上。
目前云直播开启旁路推流后,会通过互动直播后台将音视频流推送到云直播后台,云直播后台负责将收到音视频流转码成通用的协议格式并且推送到CDN,这样H5、小程序等端就可以通过CDN拉取到通用格式的音视频流进行播放了。

目前蘑菇街直播旁路开启的协议类型有HLS、FLV、RTMP三种,已经可以覆盖到所有的播放场景,在后续章节会对这几种协议做详细的介绍。
5、推拉流架构3:RTMP推流
随着直播业务发展,一些主播逐渐不满足于手机开播的效果,并且电商直播需要高保真地将商品展示在屏幕上,需要通过更加高清专业的设备进行直播,RTMP推流技术应运而生。
我们通过使用OBS等流媒体录影程序,对专业设备录制的多路流进行合并,并且将音视频流上传到指定的推流地址。由于OBS推流使用了RTMP协议,因此我们称这一种推流类型为RTMP推流。
我们首先在云直播后台申请到推流地址和秘钥,将推流地址和秘钥配置到OBS软件当中,调整推流各项参数,点击推流以后,OBS就会通过RTMP协议向对应的推流地址推送音视频流。
这一种推流方式和SDK推流的不同之处在于音视频流是直接被推送到了云直播后台进行转码和上传CDN的,没有直接将直播流转推到用户端的下行方式,因此相比SDK推流延迟会长一些。

总结下来RTMP推流的优势和劣势比较明显。
优势主要是:
1)可以接入专业的直播摄像头、麦克风,直播的整体效果明显优于手机开播;
2)OBS已经有比较多成熟的插件,比如目前蘑菇街主播常用YY助手做一些美颜的处理,并且OBS本身已经支持滤镜、绿幕、多路视频合成等功能,功能比手机端强大。
劣势主要是:
1)OBS本身配置比较复杂,需要专业设备支持,对主播的要求明显更高,通常需要一个固定的场地进行直播;
2)RTMP需要云端转码,并且本地上传时也会在OBS中配置GOP和缓冲,延时相对较长。
6、高可用架构方案:云互备
业务发展到一定阶段后,我们对于业务的稳定性也会有更高的要求,比如当云服务商服务出现问题时,我们没有备用方案就会出现业务一直等待服务商修复进度的问题。
因此云互备方案就出现了:云互备指的是直播业务同时对接多家云服务商,当一家云服务商出现问题时,快速切换到其他服务商的服务节点,保证业务不受影响。

直播业务中经常遇到服务商的CDN节点下行速度较慢,或者是CDN节点存储的直播流有问题,此类问题有地域性,很难排查,因此目前做的互备云方案,主要是备份CDN节点。
目前蘑菇街整体的推流流程已经依赖了原有云平台的服务,因此我们通过在云直播后台中转推一路流到备份云平台上,备份云在接收到了直播流后会对流转码并且上传到备份云自身的CDN系统当中。一旦主平台CDN节点出现问题,我们可以将下发的拉流地址替换成备份云拉流地址,这样就可以保证业务快速修复并且观众无感知。
7、视频直播数据流解封装原理
介绍流协议之前,先要介绍我们从云端拿到一份数据,要经过几个步骤才能解析出最终需要的音视频数据。

如上图所示,总体来说,从获取到数据到最终将音视频播放出来要经历四个步骤。
*第一步:*解协议。
协议封装的时候通常会携带一些头部描述信息或者信令数据,这一部分数据对我们音视频播放没有作用,因此我们需要从中提取出具体的音视频封装格式数据,我们在直播中常用的协议有HTTP和RTMP两种。
*第二步:*解封装。
获取到封装格式数据以后需要进行解封装操作,从中分别提取音频压缩流数据和视频压缩流数据,封装格式数据我们平时经常见到的如MP4、AVI,在直播中我们接触比较多的封装格式有TS、FLV。
*第三步:*解码音视频。
到这里我们已经获取了音视频的压缩编码数据。
我们日常经常听到的视频压缩编码数据有H.26X系列和MPEG系列等,音频编码格式有我们熟悉的MP3、ACC等。
之所以我们能见到如此多的编码格式,是因为各种组织都提出了自己的编码标准,并且会相继推出一些新的议案,但是由于推广和收费问题,目前主流的编码格式也并不多。
获取压缩数据以后接下来需要将音视频压缩数据解码,获取非压缩的颜色数据和非压缩的音频抽样数据。颜色数据有我们平时熟知的RGB,不过在视频的中常用的颜色数据格式是YUV,指的是通过明亮度、色调、饱和度确定一个像素点的色值。音频抽样数据通常使用的有PCM。
*第四步:*音视频同步播放。
最后我们需要比对音视频的时间轴,将音视频解码后的数据交给显卡声卡同步播放。
8、视频直播传输协议1:HLS
首先介绍一下HLS协议。HLS是HTTP Live Streaming的简写,是由苹果公司提出的流媒体网络传输协议。
从名字可以明显看出:这一套协议是基于HTTP协议传输的。
说到HLS协议:首先需要了解这一种协议是以视频切片的形式分段播放的,协议中使用的切片视频格式是TS,也就是我们前文提到的封装格式。
在我们获取TS文件之前:协议首先要求请求一个M3U8格式的文件,M3U8是一个描述索引文件,它以一定的格式描述了TS地址的指向,我们根据M3U8文件中描述的内容,就可以获取每一段TS文件的CDN地址,通过加载TS地址分段播放就可以组合出一整段完整的视频。

使用HLS协议播放视频时:首先会请求一个M3U8文件,如果是点播只需要在初始化时获取一次就可以拿到所有的TS切片指向,但如果是直播的话就需要不停地轮询M3U8文件,获取新的TS切片。
获取到M3U8后:我们可以看一下里面的内容。首先开头是一些通用描述信息,比如第一个分片序列号、片段最大时长和总时长等,接下来就是具体TS对应的地址列表。如果是直播,那么每次请求M3U8文件里面的TS列表都会随着最新的直播切片更新,从而达到直播流播放的效果。

HLS这种切片播放的格式在点播播放时是比较适用的,一些大的视频网站也都有用这一种协议作为播放方案。
首先:切片播放的特性特别适用于点播播放中视频清晰度、多语种的热切换。比如我们播放一个视频,起初选择的是标清视频播放,当我们看了一半觉得不够清晰,需要换成超清的,这时候只需要将标清的M3U8文件替换成超清的M3U8文件,当我们播放到下一个TS节点时,视频就会自动替换成超清的TS文件,不需要对视频做重新初始化。
其次:切片播放的形式也可以比较容易地在视频中插入广告等内容。

在直播场景下,HLS也是一个比较常用的协议,他最大的优势是苹果大佬的加持,对这一套协议推广的比较好,特别是移动端。将M3U8文件地址喂给video就可以直接播放,PC端用MSE解码后大部分浏览器也都能够支持。但是由于其分片加载的特性,直播的延迟相对较长。比如我们一个M3U8有5个TS文件,每个TS文件播放时长是2秒,那么一个M3U8文件的播放时长就是10秒,也就是说这个M3U8播放的直播进度至少是10秒之前的,这对于直播场景来说是一个比较大的弊端。

HLS中用到的TS封装格式,视频编码格式是通常是H.264或MPEG-4,音频编码格式为AAC或MP3。
一个ts由多个定长的packtet组成,通常是188个字节,每个packtet有head和payload组成,head中包含一些标识符、错误信息、包位置等基础信息。payload可以简单理解为音视频信息,但实际上下层还有还有两层封装,将封装解码后可以获取到音视频流的编码数据。

9、视频直播传输协议2:HTTP-FLV
HTTP-FLV协议,从名字上就可以明显看出是通过HTTP协议来传输FLV封装格式的一种协议。
FLV是Flash Video的简写,是一种文件体积小,适合在网络上传输的封包方式。FlV的视频编码格式通常是H.264,音频编码是ACC或MP3。

HTTP-FLV在直播中是通过走HTTP长连接的方式,通过分块传输向请求端传递FLV封包数据。

在直播中,我们通过HTTP-FLV协议的拉流地址可以拉取到一段chunked数据。
打开文件后可以读取到16进制的文件流,通过和FLV包结构对比,可以发现这些数据就是我们需要的FLV数据。
首先开头是头部信息:464C56转换ASCII码后是FLV三个字符,01指的是版本号,05转换为2进制后第6位和第8位分别代表是否存在音频和视频,09代表头部长度占了几个字节。
后续就是正式的音视频数据:是通过一个个的FLV TAG进行封装,每一个TAG也有头部信息,标注这个TAG是音频信息、视频信息还是脚本信息。我们通过解析TAG就可以分别提取音视频的压缩编码信息。
FLV这一种格式在video中并不是原生支持的,我们要播放这一种格式的封包格式需要通过MSE对影视片的压缩编码信息进行解码,因此需要浏览器能够支持MSE这一API。由于HTTP-FLV的传输是通过长连接传输文件流的形式,需要浏览器支持Stream IO或者fetch,对于浏览器的兼容性要求会比较高。
FLV在延迟问题上相比切片播放的HLS会好很多,目前看来FLV的延迟主要是受编码时设置的GOP长度的影响。
这边简单介绍一下GOP:在H.264视频编码的过程中,会生成三种帧类型:I帧、B帧和P帧。I帧就是我们通常说的关键帧,关键帧内包括了完整的帧内信息,可以直接作为其他帧的参考帧。B帧和P帧为了将数据压缩得更小,需要由其他帧推断出帧内的信息。因此两个I帧之间的时长也可以被视作最小的视频播放片段时长。从视频推送的稳定性考虑,我们也要求主播将关键帧间隔设置为定长,通常是1-3秒,因此除去其他因素,我们的直播在播放时也会产生1-3秒的延时。

10、视频直播传输协议3:RTMP
RTMP协议实际可以与HTTP-FLV协议归做同一种类型。
他们的封包格式都是FlV,但HTTP-FLV使用的传输协议是HTTP,RTMP拉流使用RTMP作为传输协议。
RTMP是Adobe公司基于TCP做的一套实时消息传输协议,经常与Flash播放器匹配使用。
RTMP协议的优缺点非常明显。
RTMP协议的优点主要是:
1)首先和HTTP-FLV一样,延迟比较低;
2)其次它的稳定性非常好,适合长时间播放(由于播放时借用了Flash player强大的功能,即使开多路流同时播放也能保证页面不出现卡顿,很适合监控等场景)。
但是Flash player目前在web端属于墙倒众人推的境地,主流浏览器渐渐都表示不再支持Flash player插件,在MAC上使用能够立刻将电脑变成烧烤用的铁板,资源消耗很大。在移动端H5基本属于完全不支持的状态,兼容性是它最大的问题。

11、视频直播传输协议4:MPEG-DASH
MPEG-DASH这一协议属于新兴势力,和HLS一样,都是通过切片视频的方式进行播放。
他产生的背景是早期各大公司都自己搞自己的一套协议。比如苹果搞了HLS、微软搞了 MSS、Adobe还搞了HDS,这样使用者需要在多套协议封装的兼容问题上痛苦不堪。
于是大佬们凑到一起,将之前各个公司的流媒体协议方案做了一个整合,搞了一个新的协议。
由于同为切片视频播放的协议,DASH优劣势和HLS类似,可以支持切片之间多视频码率、多音轨的切换,比较适合点播业务,在直播中还是会有延时较长的问题。

12、如何选择最优的视频直播传输协议
视频直播协议选择非常关键的两点,在前文都已经有提到了,即低延时和更优的兼容性。
首先从延时角度考虑:不考虑云端转码以及上下行的消耗,HLS和MPEG-DASH通过将切片时长减短,延时在10秒左右;RTMP和FLV理论上延时相当,在2-3秒。因此在延时方面HLS ≈ DASH > RTMP ≈ FLV。
从兼容性角度考虑:HLS > FLV > RTMP,DASH由于一些项目历史原因,并且定位和HLS重复了,暂时没有对其兼容性做一个详尽的测试,被推出了选择的考虑范围。
综上所述:我们可以通过动态判断环境的方式,选择当前环境下可用的最低延迟的协议。大致的策略就是优先使用HTTP-FLV,使用HLS作为兜底,在一些特殊需求场景下通过手动配置的方式切换为RTMP。
对于HLS和HTTP-FLV:我们可以直接使用 hls.js 和 flv.js 做做解码播放,这两个库内部都是通过MSE做的解码。首先根据视频封装格式提取出对应的音视频chunk数据,在MediaSource中分别对音频和视频创建SourceBuffer,将音视频的编码数据喂给SourceBuffer后SourceBuffer内部会处理完剩下的解码和音视频对齐工作,最后MediaSource将Video标签中的src替换成MediaSource 对象进行播放。

在判断播放环境时我们可以参照flv.js内部的判断方式,通过调用MSE判断方法和模拟请求的方式判断MSE和StreamIO是否可用:
// 判断MediaSource是否被浏览器支持,H.264视频编码和Acc音频编码是否能够被支持解码
window.MediaSource && window.MediaSource.isTypeSupported('video/mp4; codecs="avc1.42E01E,mp4a.40.2"');
如果FLV播放不被支持的情况下:需要降级到HLS,这时候需要判断浏览器环境是否在移动端,移动端通常不需要 hls.js 通过MSE解码的方式进行播放,直接将M3U8的地址交给video的src即可。如果是PC端则判断MSE是否可用,如果可用就使用hls.js解码播放。
这些判读可以在自己的逻辑里提前判断后去拉取对应解码库的CDN,而不是等待三方库加载完成后使用三方库内部的方法判断,这样在选择解码库时就可以不把所有的库都拉下来,提高加载速度。
13、同层播放如何解决

电商直播需要观众操作和互动的部分比起传统的直播更加多,因此产品设计的时候很多的功能模块会悬浮在直播视频上方减少占用的空间。这个时候就会遇到一个移动端播放器的老大难问题——同层播放。
同层播放问题:是指在移动端H5页面中,一些浏览器内核为了提升用户体验,将video标签被劫持替换为native播放器,导致其他元素无法覆盖于播放器之上。
比如我们想要在直播间播放器上方增加聊天窗口,将聊天窗口通过绝对定位提升z-index置于播放器上方,在PC中测试完全正常。但在移动端的一些浏览器中,video被替换成了native播放器,native的元素层级高于我们的普通元素,导致聊天窗口实际显示的时候在播放器下方。
要解决这个问题,首先要分多个场景。
首先在iOS系统中:正常情况下video标签会自动被全屏播放,但iOS10以上已经原生提供了video的同层属性,我们在video标签上增加playsinline/webkit-playsinline可以解决iOS系统中大部分浏览器的同层问题,剩下的低系统版本的浏览器以及一些APP内的webview容器(譬如微博),用上面提的属性并不管用,调用三方库iphone-inline-video可以解决大部分剩余问题。
在Android端:大部分腾讯系的APP内置的webview容器用的都是X5内核,X5内核会将video替换成原生定制的播放器已便于增强一些功能。X5也提供了一套同层的方案(该方案官方文档链接已无法打开),给video标签写入X5同层属性也可以在X5内核中实现内联播放。不过X5的同层属性在各个X5版本中表现都不太一样(比如低版本X5中需要使用X5全屏播放模式才能保证MSE播放的视频同层生效),需要注意区分版本。
在蘑菇街App中,目前集成的X5内核版本比较老,在使用MSE的情况下会导致X5同层参数不生效。但如果集成新版本的X5内核,需要对大量的线上页面做回归测试,成本比较高,因此提供了一套折中的解决方案。通过在页面URL中增加一个开关参数,容器读取到参数以后会将X5内核降级为系统原生的浏览器内核,这样可以在解决浏览器视频同层问题的同时也将内核变动的影响范围控制在单个页面当中。
来源:http://www.blogjava.net/jb2011/archive/2022/05/31/450754.html
收起阅读 »MapperStruct:一款CURD神器
前言
相信绝大多数的业务开发同学,日常的工作都离不开写getter、setter方法。要么是将下游的RPC结果通过getter、setter方法进行获取组装。要么就是将自己系统内部的处理结果通过getter、setter方法处理成前端所需要的VO对象。
public UserInfoVO originalCopyItem(UserDTO userDTO){
UserInfoVO userInfoVO = new UserInfoVO();
userInfoVO.setUserName(userDTO.getName());
userInfoVO.setAge(userDTO.getAge());
userInfoVO.setBirthday(userDTO.getBirthday());
userInfoVO.setIdCard(userDTO.getIdCard());
userInfoVO.setGender(userDTO.getGender());
userInfoVO.setIsMarried(userDTO.getIsMarried());
userInfoVO.setPhoneNumber(userDTO.getPhoneNumber());
userInfoVO.setAddress(userDTO.getAddress());
return userInfoVO;
}传统的方法一般是采用硬编码,将每个对象的值都逐一设值。当然为了偷懒也会有采用一些BeanUtil简约代码的方式:
public UserInfoVO utilCopyItem(UserDTO userDTO){
UserInfoVO userInfoVO = new UserInfoVO();
//采用反射、内省机制实现拷贝
BeanUtils.copyProperties(userDTO, userInfoVO);
return userInfoVO;
}但是,像BeanUtils这类通过反射、内省等实现的框架,在速度上会带来比较严重的影响。尤其是对于一些大字段、大对象而言,这个速度的缺陷就会越明显。针对速度这块我还专门进行了测试,对普通的setter方法、BeanUtils的拷贝以及本次需要介绍的mapperStruct进行了一次对比。得到的耗时结果如下所示:(具体的运行代码请见附录)
| 运行次数 | setter方法耗时 | BeanUtils拷贝耗时 | MapperStruct拷贝耗时 |
|---|---|---|---|
| 1 | 2921528(1) | 3973292(1.36) | 2989942(1.023) |
| 10 | 2362724(1) | 66402953(28.10) | 3348099(1.417) |
| 100 | 2500452(1) | 71741323(28.69) | 2120820(0.848) |
| 1000 | 3187151(1) | 157925125(49.55) | 5456290(1.711) |
| 10000 | 5722147(1) | 300814054(52.57) | 5229080(0.913) |
| 100000 | 19324227(1) | 244625923(12.65) | 12932441(0.669) |
以上单位均为毫微秒。括号内的为当前组件同Setter比较的比值。可以看到BeanUtils的拷贝耗时基本为setter方法的十倍、二十倍以上。而MapperStruct方法拷贝的耗时,则与setter方法相近。由此可见,简单的BeanUtils确实会给服务的性能带来很大的压力。而MapperStruct拷贝则可以很好的解决这个问题。
使用教程
maven依赖
首先要导入mapStruct的maven依赖,这里我们选择最新的版本1.5.0.RC1。
...
<properties>
<org.mapstruct.version>1.5.0.RC1</org.mapstruct.version>
</properties>
...
//mapStruct maven依赖
<dependencies>
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>${org.mapstruct.version}</version>
</dependency>
</dependencies>
...
//编译的组件需要配置
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source> <!-- depending on your project -->
<target>1.8</target> <!-- depending on your project -->
<annotationProcessorPaths>
<path>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct-processor</artifactId>
<version>${org.mapstruct.version}</version>
</path>
<!-- other annotation processors -->
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>
</build>在引入maven依赖后,我们首先来定义需要转换的DTO及VO信息,主要包含的信息是名字、年龄、生日、性别等信息。
@Data
public class UserDTO {
private String name;
private int age;
private Date birthday;
//1-男 0-女
private int gender;
private String idCard;
private String phoneNumber;
private String address;
private Boolean isMarried;
}
@Data
public class UserInfoVO {
private String userName;
private int age;
private Date birthday;
//1-男 0-女
private int gender;
private String idCard;
private String phoneNumber;
private String address;
private Boolean isMarried;
}紧接着需要编写相应的mapper类,以便生成相应的编译类。
@Mapper
public interface InfoConverter {
InfoConverter INSTANT = Mappers.getMapper(InfoConverter.class);
@Mappings({
@Mapping(source = "name", target = "userName")
})
UserInfoVO convert(UserDTO userDto);
}需要注意的是,因为DTO中的name对应的其实是VO中的userName。因此需要在converter中显式声明。在编写完对应的文件之后,需要执行maven的complie命令使得IDE编译生成对应的Impl对象。(自动生成)
到此,mapperStruct的接入就算是完成了~。我们就可以在我们的代码中使用这个拷贝类了。
public UserInfoVO newCopyItem(UserDTO userDTO, int times) {
UserInfoVO userInfoVO = new UserInfoVO();
userInfoVO = InfoConverter.INSTANT.convert(userDTO);
return userInfoVO;
}怎么样,接入是不是很简单~
FAQ
1、接入项目时,发现并没有生成对应的编译对象class,这个是什么原因?
答:可能的原因有如下几个:
忘记编写对应的@Mapper注解,因而没有生成
没有配置上述提及的插件maven-compiler-plugin
没有执行maven的Compile,IDE没有进行相应编译
2、接入项目后发现,我项目内的Lombok、@Data注解不好使了,这怎么办呢?
由于Lombok本身是对AST进行修改实现的,但是mapStruct在执行的时候并不能检测到Lombok所做的修改,因此需要额外的引入maven依赖lombok-mapstruct-binding。
......
<org.mapstruct.version>1.5.0.RC1</org.mapstruct.version>
<lombok-mapstruct-binding.version>0.2.0</lombok-mapstruct-binding.version>
<lombok.version>1.18.20</lombok.version>
......
......
<dependency>
<groupId>org.mapstruct</groupId>
<artifactId>mapstruct</artifactId>
<version>${org.mapstruct.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok-mapstruct-binding</artifactId>
<version>${lombok-mapstruct-binding.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
</dependency>更详细的,mapperStruct在官网中还提供了一个实现Lombok及mapStruct同时并存的案例
3、更多问题:
欢迎查看MapStruct官网文档,里面对各种问题都有更详细的解释及解答。
实现原理
在聊到mapstruct的实现原理之前,我们就需要先回忆一下JAVA代码运行的过程。大致的执行生成的流程如下所示:
可以直观的看到,如果我们想不通过编码的方式对程序进行修改增强,可以考虑对抽象语法树进行相应的修改。而mapstruct也正是如此做的。具体的执行逻辑如下所示:
为了实现该方法,mapstruct基于JSR 269实现了代码。JSR 269是JDK引进的一种规范。有了它,能够在编译期处理注解,并且读取、修改和添加抽象语法树中的内容。JSR 269使用Annotation Processor在编译期间处理注解,Annotation Processor相当于编译器的一种插件,因此又称为插入式注解处理。想要实现JSR 269,主要有以下几个步骤:
继承AbstractProcessor类,并且重写process方法,在process方法中实现自己的注解处理逻辑。
在META-INF/services目录下创建javax.annotation.processing.Processor文件注册自己实现的Annotation Processor。
通过实现AbstractProcessor,在程序进行compile的时候,会对相应的AST进行修改。从而达到目的。
public void compile(List<JavaFileObject> sourceFileObjects,
List<String> classnames,
Iterable<? extends Processor> processors)
{
if (processors != null && processors.iterator().hasNext())
explicitAnnotationProcessingRequested = true;
// as a JavaCompiler can only be used once, throw an exception if
// it has been used before.
if (hasBeenUsed)
throw new AssertionError("attempt to reuse JavaCompiler");
hasBeenUsed = true;
// forcibly set the equivalent of -Xlint:-options, so that no further
// warnings about command line options are generated from this point on
options.put(XLINT_CUSTOM.text + "-" + LintCategory.OPTIONS.option, "true");
options.remove(XLINT_CUSTOM.text + LintCategory.OPTIONS.option);
start_msec = now();
try {
initProcessAnnotations(processors);
//此处会调用到mapStruct中的processor类的方法.
delegateCompiler =
processAnnotations(
enterTrees(stopIfError(CompileState.PARSE, parseFiles(sourceFileObjects))),
classnames);
delegateCompiler.compile2();
delegateCompiler.close();
elapsed_msec = delegateCompiler.elapsed_msec;
} catch (Abort ex) {
if (devVerbose)
ex.printStackTrace(System.err);
} finally {
if (procEnvImpl != null)
procEnvImpl.close();
}
} 关键代码,在mapstruct-processor包中,有个对应的类MappingProcessor继承了AbstractProcessor,并实现其process方法。通过对AST进行相应的代码增强,从而实现对最终编译的对象进行修改的方法。
@SupportedAnnotationTypes({"org.mapstruct.Mapper"})
@SupportedOptions({"mapstruct.suppressGeneratorTimestamp", "mapstruct.suppressGeneratorVersionInfoComment", "mapstruct.unmappedTargetPolicy", "mapstruct.unmappedSourcePolicy", "mapstruct.defaultComponentModel", "mapstruct.defaultInjectionStrategy", "mapstruct.disableBuilders", "mapstruct.verbose"})
public class MappingProcessor extends AbstractProcessor {
public boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnvironment) {
if (!roundEnvironment.processingOver()) {
RoundContext roundContext = new RoundContext(this.annotationProcessorContext);
Set<TypeElement> deferredMappers = this.getAndResetDeferredMappers();
this.processMapperElements(deferredMappers, roundContext);
Set<TypeElement> mappers = this.getMappers(annotations, roundEnvironment);
this.processMapperElements(mappers, roundContext);
} else if (!this.deferredMappers.isEmpty()) {
Iterator var8 = this.deferredMappers.iterator();
while(var8.hasNext()) {
MappingProcessor.DeferredMapper deferredMapper = (MappingProcessor.DeferredMapper)var8.next();
TypeElement deferredMapperElement = deferredMapper.deferredMapperElement;
Element erroneousElement = deferredMapper.erroneousElement;
String erroneousElementName;
if (erroneousElement instanceof QualifiedNameable) {
erroneousElementName = ((QualifiedNameable)erroneousElement).getQualifiedName().toString();
} else {
erroneousElementName = erroneousElement != null ? erroneousElement.getSimpleName().toString() : null;
}
deferredMapperElement = this.annotationProcessorContext.getElementUtils().getTypeElement(deferredMapperElement.getQualifiedName());
this.processingEnv.getMessager().printMessage(Kind.ERROR, "No implementation was created for " + deferredMapperElement.getSimpleName() + " due to having a problem in the erroneous element " + erroneousElementName + ". Hint: this often means that some other annotation processor was supposed to process the erroneous element. You can also enable MapStruct verbose mode by setting -Amapstruct.verbose=true as a compilation argument.", deferredMapperElement);
}
}
return false;
}
}如何断点调试:
因为这个注解处理器是在解析->编译的过程完成,跟普通的jar包调试不太一样,maven框架为我们提供了调试入口,需要借助maven才能实现debug。所以需要在编译过程打开debug才可调试。
在项目的pom文件所在目录执行mvnDebug compile
接着用idea打开项目,添加一个remote,端口为8000
打上断点,debug 运行remote即可调试。
附录
测试代码如下,采用Spock框架 + JAVA代码实现。Spock框架作为当前最火热的测试框架,你值得学习一下。 Spock框架初体验:更优雅地写好你的单元测试
// @Resource
@Shared
MapperStructService mapperStructService
def setupSpec() {
mapperStructService = new MapperStructService()
}
@Unroll
def "test mapperStructTest times = #times"() {
given: "初始化数据"
UserDTO dto = new UserDTO(name: "笑傲菌", age: 20, idCard: "1234",
phoneNumber: "18211932334", address: "北京天安门", gender: 1,
birthday: new Date(), isMarried: false)
when: "调用方法"
// 传统的getter、setter拷贝
long startTime = System.nanoTime();
UserInfoVO oldRes = mapperStructService.originalCopyItem(dto, times)
Duration originalWasteTime = Duration.ofNanos(System.nanoTime() - startTime);
// 采用工具实现反射类的拷贝
long startTime1 = System.nanoTime();
UserInfoVO utilRes = mapperStructService.utilCopyItem(dto, times)
Duration utilWasteTime = Duration.ofNanos(System.nanoTime() - startTime1);
long startTime2 = System.nanoTime();
UserInfoVO mapStructRes = mapperStructService.newCopyItem(dto, times)
Duration mapStructWasteTime = Duration.ofNanos(System.nanoTime() - startTime2);
then: "校验数据"
println("times = "+ times)
println("原始拷贝的消耗时间为: " + originalWasteTime.getNano())
println("BeanUtils拷贝的消耗时间为: " + utilWasteTime.getNano())
println("mapStruct拷贝的消耗时间为: " + mapStructWasteTime.getNano())
println()
where: "比较不同次数调用的耗时"
times || ignore
1 || null
10 || null
100 || null
1000 || null
}测试的Service如下所示:
public class MapperStructService {
public UserInfoVO newCopyItem(UserDTO userDTO, int times) {
UserInfoVO userInfoVO = new UserInfoVO();
for (int i = 0; i < times; i++) {
userInfoVO = InfoConverter.INSTANT.convert(userDTO);
}
return userInfoVO;
}
public UserInfoVO originalCopyItem(UserDTO userDTO, int times) {
UserInfoVO userInfoVO = new UserInfoVO();
for (int i = 0; i < times; i++) {
userInfoVO.setUserName(userDTO.getName());
userInfoVO.setAge(userDTO.getAge());
userInfoVO.setBirthday(userDTO.getBirthday());
userInfoVO.setIdCard(userDTO.getIdCard());
userInfoVO.setGender(userDTO.getGender());
userInfoVO.setIsMarried(userDTO.getIsMarried());
userInfoVO.setPhoneNumber(userDTO.getPhoneNumber());
userInfoVO.setAddress(userDTO.getAddress());
}
return userInfoVO;
}
public UserInfoVO utilCopyItem(UserDTO userDTO, int times) {
UserInfoVO userInfoVO = new UserInfoVO();
for (int i = 0; i < times; i++) {
BeanUtils.copyProperties(userDTO, userInfoVO);
}
return userInfoVO;
}
}参考文献
踩坑BeanUtils.copy**()导致的业务处理速度过慢
作者:DrLauPen
来源:https://juejin.cn/post/7103135968256851976
零侵入性:一个注解,优雅的实现循环重试功能
前言
在实际工作中,重处理是一个非常常见的场景,比如:
发送消息失败。
调用远程服务失败。
争抢锁失败。
这些错误可能是因为网络波动造成的,等待过后重处理就能成功.通常来说,会用try/catch,while循环之类的语法来进行重处理,但是这样的做法缺乏统一性,并且不是很方便,要多写很多代码.然而spring-retry却可以通过注解,在不入侵原有业务逻辑代码的方式下,优雅的实现重处理功能.
一、@Retryable是什么?
spring系列的spring-retry是另一个实用程序模块,可以帮助我们以标准方式处理任何特定操作的重试。在spring-retry中,所有配置都是基于简单注释的。
二、使用步骤
1.POM依赖
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
2.启用@Retryable
@EnableRetry
@SpringBootApplication
public class HelloApplication {
public static void main(String[] args) {
SpringApplication.run(HelloApplication.class, args);
}
}
3.在方法上添加@Retryable
import com.mail.elegant.service.TestRetryService;
import org.springframework.retry.annotation.Backoff;
import org.springframework.retry.annotation.Retryable;
import org.springframework.stereotype.Service;
import java.time.LocalTime;
@Service
public class TestRetryServiceImpl implements TestRetryService {
@Override
@Retryable(value = Exception.class,maxAttempts = 3,backoff = @Backoff(delay = 2000,multiplier = 1.5))
public int test(int code) throws Exception{
System.out.println("test被调用,时间:"+LocalTime.now());
if (code==0){
throw new Exception("情况不对头!");
}
System.out.println("test被调用,情况对头了!");
return 200;
}
}
来简单解释一下注解中几个参数的含义:
value:抛出指定异常才会重试
include:和value一样,默认为空,当exclude也为空时,默认所有异常
exclude:指定不处理的异常
maxAttempts:最大重试次数,默认3次
backoff:重试等待策略,默认使用@Backoff,@Backoff的value默认为1000L,我们设置为2000L;multiplier(指定延迟倍数)默认为0,表示固定暂停1秒后进行重试,如果把multiplier设置为1.5,则第一次重试为2秒,第二次为3秒,第三次为4.5秒。
当重试耗尽时还是失败,会出现什么情况呢?
当重试耗尽时,RetryOperations可以将控制传递给另一个回调,即RecoveryCallback。Spring-Retry还提供了@Recover注解,用于@Retryable重试失败后处理方法。如果不需要回调方法,可以直接不写回调方法,那么实现的效果是,重试次数完了后,如果还是没成功没符合业务判断,就抛出异常。
4.@Recover
@Recover
public int recover(Exception e, int code){
System.out.println("回调方法执行!!!!");
//记日志到数据库 或者调用其余的方法
return 400;
}
可以看到传参里面写的是 Exception e,这个是作为回调的接头暗号(重试次数用完了,还是失败,我们抛出这个Exception e通知触发这个回调方法)。对于@Recover注解的方法,需要特别注意的是:
方法的返回值必须与@Retryable方法一致
方法的第一个参数,必须是Throwable类型的,建议是与@Retryable配置的异常一致,其他的参数,需要哪个参数,写进去就可以了(@Recover方法中有的)
该回调方法与重试方法写在同一个实现类里面
5. 注意事项
由于是基于AOP实现,所以不支持类里自调用方法
如果重试失败需要给@Recover注解的方法做后续处理,那这个重试的方法不能有返回值,只能是void
方法内不能使用try catch,只能往外抛异常
@Recover注解来开启重试失败后调用的方法(注意,需跟重处理方法在同一个类中),此注解注释的方法参数一定要是@Retryable抛出的异常,否则无法识别,可以在该方法中进行日志处理。
总结
本篇主要简单介绍了Springboot中的Retryable的使用,主要的适用场景和注意事项,当需要重试的时候还是很有用的。
作者:Memory小峰
来源:blog.csdn.net/h254931252/article/details/109257998
收起阅读 »源码阅读原则
源码阅读原则
不是绝对的,只是提供一种大致的思路
见名之意
大致的了解一个类、方法、字段所代表的含义
切入点
明确你需要了解某个功能A的实现,越具体越好,列出切入点,然后从上至下的分析
分支
对于行数庞大、逻辑复杂的源码,我们在追踪时遇到非相关源码是必定的,可以简单追踪几个层级,给自己定一个界限,否则容易丢失目标,淹没在源码的海洋中
分支字段
追踪有没有直接返回该字段的方法,通过方法注释,直接快速了解该字段的作用。
对于没有向外暴露的字段,我们追踪它的usage:
数量较少:可以通过各
usage处的方法名大致了解,又或者是直接阅读源码数量较多:建议另辟蹊径,实在没办法再逐一攻破
分支方法
首先是阅读方法注释,有几种情况:
涉及新术语:在类中搜索关键字找到相关方法或类
涉及新的类:看
分支类非
功能A相关:略过
分支类
先阅读理解类注释,有以下几种情况:
涉及到新的领域:通过查看继承树的方式,大致了解它规模体系和作用
不确定和
功能A是否有关联:可查阅官方文档或者搜索引擎做确定
断点调试
动态分析的数据能够帮助我们去验证我们的理解是否正确,实践是检验真理的唯一标准
usage截止点
当你从某个方法出发,寻找它是在何处调用时,请记住你的目的,我们应该在脱离了强相关功能方法处截止,继续usage的意义不大。
比如RecyclerView中scrapOrRecycleView,我们的目的是:寻找什么时候触发了回收View
应该在onLayoutChildren处停止,再继续usage时,你的目的就变成了:寻找什么时候布置Adapter所有相关的子View
作者:土猫少侠
来源:juejin.cn/post/7100806273460863006
Base64编码解码原理
Base64编码与解码
原理涉及的算法
1、短除法
短除法运算方法是先用一个除数除以能被它除尽的一个质数,以此类推,除到商是质数为止。通过短除法,十进制数可以不断除以2得到多个余数。最后,将余数从下到上进行排列组合,得到二进制数。
实例:以字符n对应的ascII编码110为例。
110 / 2 = 55...0
55 / 2 = 27...1
27 / 2 = 13...1
13 / 2 = 6...1
6 / 2 = 3...0
3 / 2 = 1...1
1 / 2 = 0...1
将余数从下到上进行排列组合,得到字符n对应的ascII编码110转二进制为1101110,因为一字节对应8位(bit), 所以需要向前补0补足8位,得到01101110。其余字符同理可得。
2、按权展开求和
按权展开求和, 8位二进制数从右到左,次数是0到7依次递增, 基数*底数次数,从左到右依次累加,相加结果为对应十进制数。我们已二进制数01101110转10进制为例:
(01101110)2=0∗20+1∗21+1∗22+1∗23+0∗24+1∗25+1∗26+0∗27(01101110)_2 = 0 * 2^0 + 1 * 2 ^ 1 + 1 * 2^2 + 1 * 2^3 + 0 * 2^4 + 1 * 2^5 + 1 * 2^6 + 0 * 2^7(01101110)2=0∗20+1∗21+1∗22+1∗23+0∗24+1∗25+1∗26+0∗27
3、位概念
二进制数系统中,每个0或1就是一个位(bit,比特),也叫存储单元,位是数据存储的最小单位。其中 8bit 就称为一个字节(Byte)。
4、移位运算符
移位运算符在程序设计中,是位操作运算符的一种。移位运算符可以在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种:<<(左移)、>>(带符号右移)和>>>(无符号右移)。在base64的编码和解码过程中操作的是正数,所以仅使用<<(左移)、>>(带符号右移)两种运算符。
左移运算:是将一个二进制位的操作数按指定移动的位数向左移动,移出位被丢弃,右边移出的空位一律补0。【左移相当于一个数乘以2的次方】
右移运算:是将一个二进制位的操作数按指定移动的位数向右移动,移出位被丢弃,左边移出的空位一律补0,或者补符号位,这由不同的机器而定。在使用补码作为机器数的机器中,正数的符号位为0,负数的符号位为1。【右移相当于一个数除以2的次方】
// 左移
01101000 << 2 -> 101000(左侧移出位被丢弃) -> 10100000(右侧空位一律补0)
// 右移
01101000 >> 2 -> 011010(右侧移出位被丢弃) -> 00011010(左侧空位一律补0)
5、与运算、或运算
与运算、或运算都是计算机中一种基本的逻辑运算方式。
与运算:符号表示为&。运算规则:两位同时为“1”,结果才为“1”,否则为0
或运算:符号表示为|。运算规则:两位只要有一位为“1”,结果就为“1”,否则为0
什么是base64编码
2^6=64\
\
Base64编码是将字符串以每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节(6比特有效字节,最左边两个永远为0,其实也是8比特的字节)子序列,再将得到的子序列查找Base64的编码索引表,得到对应的字符拼接成新的字符串的一种编码方式。
每3个8比特(bit)的字节子序列拆分成4个6比特(bit)的字节的拆分过程如下图所示:
为什么base64编码后的大小是原来的4/3倍
因为6和8的最大公倍数是24,所以3个8比特的字节刚好可以拆分成4个6比特的字节,3 x 8 = 6 x 4。计算机中,因为一个字节需要8个存储单元存储,所以我们要把6个比特往前面补两位0,补足8个比特。如下图所示:
补足后所需的存储单元为32个,是原来所需的24个的4/3倍。这也就是base64编码后的大小是原来的4/3倍的原因。
为什么命名为base64呢?
因为6位(bit)的二进制数有2的6次方个,也就是二进制数(00000000-00111111)之间的代表0-63的64个二进制数。
不是说一个字节是用8位二进制表示的吗,为什么不是2的8次方?
因为我们得到的8位二进制数的前两位永远是0,真正的有效位只有6位,所以我们所能够得到的二进制数只有2的6次方个。
Base64字符是哪64个?
Base64的编码索引表,字符选用了"A-Z、a-z、0-9、+、/" 64个可打印字符来代表(00000000-00111111)这64个二进制数。即
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'编码原理
要把3个字节拆分成4个字节可以怎么做?
流程图
思路
分析映射关系:abc → xyzi。我们从高位到低位添加索引来分析这个过程
x: (前面补两个0)a的前六位 => 00a7a6a5a4a3a2
y: (前面补两个0)a的后两位 + b的前四位 => 00a1a0b7b6b5b4
z: (前面补两个0)b的后四位 + c的前两位 => 00b3b2b1b0c7c6
i: (前面补两个0)c的后六位 => 00c5c4c3c2c1c0
通过上述的映射关系,得到实现思路:
将字符对应的AscII编码转为8位二进制数
将每三个8位二进制数进行以下操作
将第一个数右移位2位,得到第一个6位有效位二进制数
将第一个数 & 0x3之后左移位4位,得到第二个6位有效位二进制数的第一个和第二个有效位,将第二个数 & 0xf0之后右移位4位,得到第二个6位有效位二进制数的后四位有效位,两者取且得到第二个6位有效位二进制
将第二个数 & 0xf之后左移位2位,得到第三个6位有效位二进制数的前四位有效位,将第三个数 & 0xC0之后右移位6位,得到第三个6位有效位二进制数的后两位有效位,两者取且得到第三个6位有效位二进制
将第三个数 & 0x3f,得到第四个6位有效位二进制数
将获得的6位有效位二进制数转十进制,查找对呀base64字符
代码实现
以hao字符串为例,观察base64编码的过程,将上面转换通过代码逻辑分析实现
// 输入字符串
let str = 'hao'
// base64字符串
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
// 定义输入、输出字节的二进制数
let char1, char2, char3, out1, out2, out3, out4, out
// 将字符对应的ascII编码转为8位二进制数
char1 = str.charCodeAt(0) & 0xff // 104 01101000
char2 = str.charCodeAt(1) & 0xff // 97 01100001
char3 = str.charCodeAt(2) & 0xff // 111 01101111
// 输出6位有效字节二进制数
out1 = char1 >> 2 // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 // 6 000110
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6 // 5 000101
out4 = char3 & 0x3f // 47 101111
out = base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4] // aGFv算法剖析
out1: char1 >> 2
01101000 -> 00011010
复制代码out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4
// 且运算
01101000 01100001
00000011 11110000
-------- --------
00000000 01100000
// 移位运算后得
00000000 00000110
// 或运算
00000000
00000110
--------
00000110
复制代码
第三个字符第四个字符同理
整理上述代码,扩展至多字符字符串
// 输入字符串
let str = 'haohaohao'
// base64字符串
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
// 获取字符串长度
let len = str.length
// 当前字符索引
let index = 0
// 输出字符串
let out = ''
while(index < len) {
// 定义输入、输出字节的二进制数
let char1, char2, char3, out1, out2, out3, out4
// 将字符对应的ascII编码转为8位二进制数
char1 = str.charCodeAt(index++) & 0xff // 104 01101000
char2 = str.charCodeAt(index++) & 0xff // 97 01100001
char3 = str.charCodeAt(index++) & 0xff // 111 01101111
// 输出6位有效字节二进制数
out1 = char1 >> 2 // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 // 6 000110
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6 // 5 000101
out4 = char3 & 0x3f // 47 101111
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4] // aGFv
}
原字符串长度不是3的整倍数的情况,需要特殊处理
...
char1 = str.charCodeAt(index++) & 0xff // 104 01101000
if (index == len) {
out2 = (char1 & 0x3) << 4
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + '=='
return out
}
char2 = str.charCodeAt(index++) & 0xff // 97 01100001
if (index == len) {
out1 = char1 >> 2 // 26 011010
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4 // 6 000110
out3 = (char2 & 0xf) << 2
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + '='
return out
}
...
全部代码
function base64Encode(str) {
// base64字符串
let base64EncodeChars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'
// 获取字符串长度
let len = str.length
// 当前字符索引
let index = 0
// 输出字符串
let out = ''
while(index < len) {
// 定义输入、输出字节的二进制数
let char1, char2, char3, out1, out2, out3, out4
// 将字符对应的ascII编码转为8位二进制数
char1 = str.charCodeAt(index++) & 0xff
out1 = char1 >> 2
if (index == len) {
out2 = (char1 & 0x3) << 4
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + '=='
return out
}
char2 = str.charCodeAt(index++) & 0xff
out2 = (char1 & 0x3) << 4 | (char2 & 0xf0) >> 4
if (index == len) {
out3 = (char2 & 0xf) << 2
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + '='
return out
}
char3 = str.charCodeAt(index++) & 0xff
// 输出6位有效字节二进制数
out3 = (char2 & 0xf) << 2 | (char3 & 0xc0) >> 6
out4 = char3 & 0x3f
out = out + base64EncodeChars[out1] + base64EncodeChars[out2] + base64EncodeChars[out3] + base64EncodeChars[out4]
}
return out
}
base64Encode('haohao') // aGFvaGFv
base64Encode('haoha') // aGFvaGE=
base64Encode('haoh') // aGFvaA==解码原理
逆向推导,由每4个6位有效位的二进制数合并成3个8位二进制数,根据ascII编码映射到对应字符后拼接字符串
思路
分析映射关系 xyzi -> abc
a: x后六位 + y第三、四位 => x5x4x3x2x1x0y5y4
b: y后四位 + z第三、四、五、六位 => y3y2y1y0z5z4z3z2
c: z后两位 + i后六位 => z1z0i5i4i3i2i1i0
将字符对应的base64字符集的索引转为6位有效位二进制数
将每四个6位有效位二进制数进行以下操作
第一个二进制数左移位2位,得到新二进制数的前6位,第二个二进制数 & 0x30之后右移位4位,取或集得到第一个新二进制数
第二个二进制数 & 0xf之后左移位4位,第三个二进制数 & 0x3c之后右移位2位,取或集得到第二个新二进制数
第二个二进制数 & 0x3之后左移位6位,与第四个二进制数取或集得到第二个新二进制数
根据ascII编码映射到对应字符后拼接字符串
代码实现
// base64字符串
let str = 'aGFv'
// base64字符集
let base64CharsArr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.split('')
// 获取索引值
let char1 = base64CharsArr.findIndex(char => char==str[0]) & 0xff // 26 011010
let char2 = base64CharsArr.findIndex(char => char==str[1]) & 0xff // 6 000110
let char3 = base64CharsArr.findIndex(char => char==str[2]) & 0xff // 5 000101
let char4 = base64CharsArr.findIndex(char => char==str[3]) & 0xff // 47 101111
let out1, out2, out3, out
// 位运算
out1 = char1 << 2 | (char2 & 0x30) >> 4
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
out3 = (char3 & 0x3) << 6 | char4
console.log(out1, out2, out3)
out = String.fromCharCode(out1) + String.fromCharCode(out2) + String.fromCharCode(out3)
遇到有用'='补过位的情况时
function base64decode(str) {
// base64字符集
let base64CharsArr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.split('')
let char1 = base64CharsArr.findIndex(char => char==str[0])
let char2 = base64CharsArr.findIndex(char => char==str[1])
let out1, out2, out3, out
if (char1 == -1 || char2 == -1) return out
char1 = char1 & 0xff
char2 = char2 & 0xff
let char3 = base64CharsArr.findIndex(char => char==str[2])
// 第三位不在base64对照表中时,只拼接第一个字符串
if (char3 == -1) {
out1 = char1 << 2 | (char2 & 0x30) >> 4
out = String.fromCharCode(out1)
return out
}
let char4 = base64CharsArr.findIndex(char => char==str[3])
// 第三位不在base64对照表中时,只拼接第一个和第二个字符串
if (char4 == -1) {
out1 = char1 << 2 | (char2 & 0x30) >> 4
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
out = String.fromCharCode(out1) + String.fromCharCode(out2)
return out
}
// 位运算
out1 = char1 << 2 | (char2 & 0x30) >> 4
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
out3 = (char3 & 0x3) << 6 | char4
console.log(out1, out2, out3)
out = String.fromCharCode(out1) + String.fromCharCode(out2) + String.fromCharCode(out3)
return out
}解码整个字符串,整理代码后
function base64decode(str) {
// base64字符集
let base64CharsArr = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.split('')
let i = 0
let len = str.length
let out = ''
while(i < len) {
let char1 = base64CharsArr.findIndex(char => char==str[i])
i++
let char2 = base64CharsArr.findIndex(char => char==str[i])
i++
let out1, out2, out3
if (char1 == -1 || char2 == -1) return out
char1 = char1 & 0xff
char2 = char2 & 0xff
let char3 = base64CharsArr.findIndex(char => char==str[i])
i++
// 第三位不在base64对照表中时,只拼接第一个字符串
out1 = char1 << 2 | (char2 & 0x30) >> 4
if (char3 == -1) {
out = out + String.fromCharCode(out1)
return out
}
let char4 = base64CharsArr.findIndex(char => char==str[i])
i++
// 第三位不在base64对照表中时,只拼接第一个和第二个字符串
out2 = (char2 & 0xf) << 4 | (char3 & 0x3c) >> 2
if (char4 == -1) {
out = out + String.fromCharCode(out1) + String.fromCharCode(out2)
return out
}
// 位运算
out3 = (char3 & 0x3) << 6 | char4
console.log(out1, out2, out3)
out = out + String.fromCharCode(out1) + String.fromCharCode(out2) + String.fromCharCode(out3)
}
return out
}
base64decode('aGFvaGFv') // haohao
base64decode('aGFvaGE=') // haoha
base64decode('aGFvaA==') // haoh上述解码核心是字符与base64字符集索引的映射,网上看到过使用AscII编码索引映射base64字符索引的方法
let base64DecodeChars = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1]
//
let char1 = 'hao'.charCodeAt(0) // h -> 104
base64DecodeChars[char1] // 33 -> base64编码表中的h
由此可见,base64DecodeChars对照accII编码表的索引存放的是base64编码表的对应字符的索引。
jdk1.8之前的方式
Base64编码与解码时,会使用到JDK里sun.misc包套件下的BASE64Encoder类和BASE64Decoder类
sun.misc包所提供的Base64编码解码功能效率不高,因此在1.8之后的jdk版本已经被删除了
// 编码器
final BASE64Encoder encoder = new BASE64Encoder();
// 解码器
final BASE64Decoder decoder = new BASE64Decoder();
final String text = "字串文字";
final byte[] textByte = text.getBytes("UTF-8");
//编码
final String encodedText = encoder.encode(textByte);
System.out.println(encodedText);
//解码
System.out.println(new String(decoder.decodeBuffer(encodedText), "UTF-8"));
Apache Commons Codec包的方式
Apache Commons Codec 有提供Base64的编码与解码功能,会使用到 org.apache.commons.codec.binary 套件下的Base64类别,用法如下
1、引入依赖
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-compress</artifactId>
<version>1.21</version>
</dependency>
2、代码实现
final Base64 base64 = new Base64();
final String text = "字串文字";
final byte[] textByte = text.getBytes("UTF-8");
//编码
final String encodedText = base64.encodeToString(textByte);
System.out.println(encodedText);
//解码
System.out.println(new String(base64.decode(encodedText), "UTF-8"));
jdk1.8之后的方式
与sun.misc包和Apache Commons Codec所提供的Base64编解码器方式来比较,Java 8提供的Base64拥有更好的效能。实际测试编码与解码速度,Java 8提供的Base64,要比
sun.misc套件提供的还要快至少11倍,比Apache Commons Codec提供的还要快至少3倍。
// 解码器
final Base64.Decoder decoder = Base64.getDecoder();
// 编码器
final Base64.Encoder encoder = Base64.getEncoder();
final String text = "字串文字";
final byte[] textByte = text.getBytes(StandardCharsets.UTF_8);
//编码
final String encodedText = encoder.encodeToString(textByte);
System.out.println(encodedText);
//解码
System.out.println(new String(decoder.decode(encodedText), StandardCharsets.UTF_8));
总结
Base64 是一种数据编码方式,可做简单加密使用,可以t通过改变base64编码映射顺序来形成自己独特的加密算法进行加密解密。
编码表
Base64编码表
AscII码编码表

作者:loginfo
来源:juejin.cn/post/7100421228644532255
推荐一款超棒的SpringCloud 脚手架项目
之前接个私活,在网上找了好久没有找到合适的框架,不是版本低没人维护了,在不就是组件相互依赖较高。所以我自己搭建一个全新spingCloud框架,里面所有组件可插拔的,集成多个组件供大家选择,喜欢哪个用哪个
一、系统架构图
二、快速启动
1.本地启动nacos: http://127.0.0.1:8848
sh startup.sh -m standalone2.本地启动sentinel: http://127.0.0.1:9000
nohup java -Dauth.enabled=false -Dserver.port=9000 -jar sentinel-dashboard-1.8.1.jar &3.本地启动zipkin: http://127.0.0.1:9411/
nohup java -jar zipkin-server-2.23.2-exec.jar &三、项目概述
springboot+springcloud
注册中心:nacos
网关:gateway
RPC:feign
以下是可插拔功能组件
流控熔断降级:sentinel
全链路跟踪:sleth+zipkin
分布式事务:seata
封装功能模块:全局异常处理、日志输出打印持久化、多数据源、鉴权授权模块、zk(分布式锁和订阅者模式)
maven:实现多环境打包、直推镜像到docker私服。
这个项目整合了springcloud体系中的各种组件。以及集成配置说明。同时将自己平时使用的功能性的封装以及工具包都最为模块整合进来。可以避免某些技术点长时间不使用后的遗忘。
另一方面现在springboot springcloud 已经springcloud-alibaba的版本迭代速度越来越快。
为了保证我们的封装和集成方式在新版本中依然正常运行,需要用该项目进行最新版本的适配实验。这样可以更快的在项目中集合工程中的功能模块。
四、项目预览
五、新建业务工程模块说明
由于springboot遵循 约定大于配置的原则。所以本工程中所有的额类都在的包路径都在com.cloud.base下。
如果新建的业务项目有规定使用指定的基础包路径则需要在启动类增加包扫描注解将com.cloud.base下的所有类加入到扫描范围下。
@ComponentScan(basePackages = "com.cloud.base")如果可以继续使用com.cloud.base 则约定将启动类放在该路径下即可。
六、模块划分
父工程:
cloud-base - 版本依赖管理 <groupId>com.cloud</groupId>
|
|--common - 通用工具类和包 <groupId>com.cloud.common</groupId>
| |
| |--core-common 通用包 该包包含了SpringMVC的依赖,会与WebFlux的服务有冲突
| |
| |--core-exception 自定义异常和请求统一返回类
|
|--dependency - 三方功能依赖集合 无任何实现 <groupId>com.cloud.dependency</groupId>
| |
| |--dependency-alibaba-cloud 关于alibaba-cloud的依赖集合
| |
| |--dependency-mybatis-tk 关于ORM mybatis+tk.mybatis+pagehelper的依赖集合
| |
| |--dependency-mybatis-plus 关于ORM mybatis+mybatis—plus+pagehelper的依赖集合
| |
| |--dependency-seata 关于分布式事务seata的依赖集合
| |
| |--dependency-sentinel 关于流控组件sentinel的依赖集合
| |
| |--dependency-sentinel-gateway 关于网关集成流控组件sentinel的依赖集合(仅仅gateway网关使用该依赖)
| |
| |--dependency-sleuth-zipkin 关于链路跟踪sleuth-zipkin的依赖集合
|
|--modules - 自定义自实现的功能组件模块 <groupId>com.cloud.modules</groupId>
| |
| |--modules-logger 日志功能封装
| |
| |--modules-multi-datasource 多数据功能封装
| |
| |--modules-lh-security 分布式安全授权鉴权框架封装
| |
| |--modules-youji-task 酉鸡-分布式定时任务管理模块
| |
|
|
|
| 以下是独立部署的应用 以下服务启动后配合前端工程使用 (cloud-base-angular-admin)
|
|--cloud-gateway 应用网关
|
|--authorize-center 集成了modules-lh-security 的授权中心,提供统一授权和鉴权
|
|--code-generator 代码生成工具
|
|--user-center 用户中心 提供用户管理和权限管理的相关服务
|
|--youji-manage-server 集成了modules-youji-task 的定时任务管理服务端
七、版本使用说明
<springboot.version>2.4.2</springboot.version>
<springcloud.version>2020.0.3</springcloud.version>
<springcloud-alibaba.version>2021.1</springcloud-alibaba.version>
八、多环境打包说明
在需要独立打包的模块resources资源目录下增加不同环境的配置文件
application-dev.yml
application-test.yml
application-prod.yml
修改application.yml
spring:
profiles:
active: @profileActive@
在需要独立打包的模块下的pom文件中添加一下打包配置。
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>${springboot.version}</version>
<configuration>
<fork>true</fork>
<addResources>true</addResources>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<delimiters>
<delimiter>@</delimiter>
</delimiters>
<useDefaultDelimiters>false</useDefaultDelimiters>
</configuration>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
<profiles>
<profile>
<id>dev</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<profileActive>dev</profileActive>
</properties>
</profile>
<profile>
<id>test</id>
<properties>
<profileActive>test</profileActive>
</properties>
</profile>
<profile>
<id>prod</id>
<properties>
<profileActive>prod</profileActive>
</properties>
</profile>
</profiles>
mvn打包命令
# 打开发环境
mvn clean package -P dev -Dmaven.test.skip=ture
# 打测试环境
mvn clean package -P test -Dmaven.test.skip=ture
# 打生产环境
mvn clean package -P prod -Dmaven.test.skip=ture
九、构建Docker镜像
整合dockerfile插件,可直接将jar包构建为docker image 并推送到远程仓库
增加插件依赖
<!-- docker image build -->
<plugin>
<groupId>com.spotify</groupId>
<artifactId>dockerfile-maven-plugin</artifactId>
<version>1.4.10</version>
<executions>
<execution>
<id>default</id>
<goals>
<!--如果package时不想用docker打包,就注释掉这个goal-->
<!-- <goal>build</goal>-->
<goal>push</goal>
</goals>
</execution>
</executions>
<configuration>
<repository>49.232.166.94:8099/example/${project.artifactId}</repository>
<tag>${profileActive}-${project.version}</tag>
<username>admin</username>
<password>Harbor12345</password>
<buildArgs>
<JAR_FILE>target/${project.build.finalName}.jar</JAR_FILE>
</buildArgs>
</configuration>
</plugin>
在pom.xml同级目录下增加Dockerfile
FROM registry.cn-hangzhou.aliyuncs.com/lh0811/lh0811-docer:lh-jdk1.8-0.0.1
MAINTAINER lh0811
ADD ./target/${JAR_FILE} /opt/app.jar
RUN chmod +x /opt/app.jar
CMD java -jar /opt/app.jar
十、源码获取
作者:我先失陪了
来源:https://juejin.cn/post/7100457917115007013
软件开发生命周期(SDLC)完全指南:6个典型阶段+6个常用开发模型
本文和您讨论了SDLC的6个典型阶段、以及6个常用开发模型,并给出如何根据不同的项目特征,选择这些开发方法的建议。
译者 | 陈峻
审校 | 孙淑娟
软件开发生命周期(Software Development Life Cycle,SDLC)包含了软件从开始到发布的不同阶段。它定义了一种用于提高待开发软件质量和效率的过程。因此,SDLC旨在通过最少的资源,交付出高质量的软件。为了避免产生严重项目失败后果,软件开发的生命周期通常可以被划分为如下六个阶段:
需求收集
设计
软件开发
测试和质量保证
部署
维护
值得注意的是,这些阶段并非是静态的,它们可以进一步地被分解成多个子类别,以适应独特的开发需求与流程。

图 1 软件开发生命周期
需求收集
这是整个周期中其他阶段的基础。在此阶段,所有利益相关者(包括客户、产品负责人等)都会去收集与待开发软件相关的信息。对此,项目经理和相关方会频繁召开会议。尽管此过程可能比较耗时,但是我们不可急于求成,毕竟大家需要对将要开发的产品有个清晰的了解。
利益相关方需要将收集到的所有信息,记录到软件需求规范(Software Requirement Specification,SRS)文档中。在完成了需求收集后,开发团队需要进行可行性研究,以确定项目是否能够被完成。
设计
此阶段旨在模拟软件应用的工作方式,并设计出软件蓝图。负责软件高级设计的开发人员将组成设计团队,并通过由上个阶段产生的SRS文档,来指导设计过程,并最终完成满足要求的体系结构。此处的高级设计是指包括用户界面、用户流程、通信设计等方面在内的基础要素。
软件开发
在此阶段,具有不同专业知识(例如前端和后端)的开发人员或工程师,会通过处理设计的需求,来构建和实现软件。这既能够由一个人,也可以由一个大型团队来执行,具体取决于项目的规模。
后端开发人员负责构建数据库结构和其他必要组件。最后,由前端开发人员根据设计去构建用户界面,并按需与后端进行对接。
在配套文档方面,用户指南会被创建,源代码中也应适当地留下相应的注释。也就是说,为了保证良好的代码质量,适当的开发指南和政策也是必不可少的。
测试
专门的测试人员协同开发团队在此阶段开展测试工作。测试既可以与开发同时进行,也可以在开发阶段结束时再开展。通常,开发人员在开发软件时就会进行单元测试,以便检查每个源代码单元是否能够按照预期工作。同时,此阶段也包括如下其他测试:
系统测试--通过测试系统,以验证其是否满足所有指定的需求。
集成测试--将各个模块组合到一起进行测试。测试团队通过单击按钮,并执行滚动和滑动操作,来与软件交互。当然,他们并不需要了解后端的工作原理。
用户验收测试--是在启动软件之前,邀请潜在用户或客户进行的最终测试。此类测试可以验证目标软件,是否能够根据需求的规范,处理各种真实的场景。
测试对于软件开发生命周期是至关重要的。倘若无法以正确的方式开展,则会让软件项目团队反复在开发和测试阶段之间徘徊,进而影响到成本和时间。
部署
完成测试后,我们就需要通过部署软件,来方便用户使用了。在此阶段,部署团队需要通过遵循若干流程,来确保部署流程的成功。无论是简单的流程,还是复杂的部署,都会涉及到创建诸如安装指南、系统用户指南等相关部署文档。
维护
作为开发周期的最后阶段,维护涉及到报告并修复在测试期间未能发现的错误。在修复方式上,我们既能够采取立即纠正错误的方式,也可以将其作为常规性的软件更新。
此外,软件项目团队还会在此阶段从用户处收集反馈,以协助软件的改进,并提高用户的软件使用体验。
SDLC方法
虽然SDLC通常都会遵从上述步骤,但是它们在实现方式上略有不同。下面,我将介绍排名靠前的6种SDLC方法:
瀑布
敏捷
精益
迭代
螺旋
DevOps方法
瀑布方法
图 2 瀑布方法
作为最古老、也是最直接的SDLC方法,瀑布方法遵循的是线性执行顺序。如上图所示,从需求收集到维护,逐步依次推进,且不存在任何逆转或倒退的步骤。也就是说,只有当上一步完成后,才能继续下一步。
由于在设计阶段之后,该方法不存在任何变化或调整的余地,因此,我们需要在需求收集阶段,收集到有关项目的所有信息,即制作软件蓝图。可见,对于经验不足的开发团队而言,如果能够保证软件的需求从项目开始就精确且稳定的话,便可以采用瀑布方法。也就是说,瀑布模型的成功,在很大程度上取决于需求收集阶段的输出是否清晰。当然,它也比较适合那些耗时较长的项目。
瀑布的优势
需求在初始阶段就能够被精心设计。
具有容易理解的线性结构。
易于管理。
瀑布的缺点
既不灵活,又不支持变更。
任何阶段一旦出现延迟,都会导致项目无法推进。
由于较为死板,因此项目总体时间较长。
并不鼓励在初始阶段之后,利益相关者进行积极地沟通。
敏捷方法
图 3 敏捷方法生命周期
敏捷(Agile)即为快速轻松的移动能力。以沟通和灵活性为中心的敏捷原则与方法,提倡以更短的周期和增量式地进行部署与发布。
在敏捷开发的生命周期中,每个阶段都有一个“仪式(ceremony)”,以便从开发团队和参与项目的其他利益相关者处获取反馈。其中包括:冲刺(sprint)计划、每日scrum、冲刺评审、以及冲刺回顾。
总地说来,敏捷开发是在各个“冲刺”中进行的,每个冲刺通常持续大约2到4周。每个冲刺的目标不一定是构建MVP(最小可行产品,Minimum Viable Product),而是构建可供客户使用的软件的一小部分。其交付出来的可能只是某个功能,而非具有完全功能的产品。也就是说,交付成果可能只是一个将来能够被慢慢增加的功能性服务,而不一定是MVP。
图 4 构建最小可行产品的示例
在每个冲刺结束后的冲刺审查阶段,如果利益相关者对开发的功能感到满意的话,方可开展下一轮冲刺。虽然新的功能是在冲刺中被开发的,但是整个项目期间的冲刺数量并不受限。它往往取决于项目和团队的规模。因此,敏捷方法最适用于那些从一开始就无法明确所有要求的项目。
敏捷的优势
适合不断变化的需求。
鼓励利益相关者之间的反馈和持续沟通。
由于采用了增量式方法,因此更易于管理各种潜在风险。
敏捷的缺点
最少量的文档。
需要具有高技能的资源。
如果沟通低效,则可能拖慢项目的速度。
如果过度依赖客户的互动,则可能会导致项目走向错误的方向。
精益方法
软件开发领域的精益方法源于精益制造的原则。这种方法旨在减少生产过程中的浪费和成本,从而实现利润的最大化。该方法虽与敏捷开发类似,但是侧重于效率、快速交付、以及迭代式开发。而区别在于,敏捷方法更专注于持续沟通和协作,以体现价值;而精益方法更专注于消除浪费,以创造客户价值。
精益方法的七个核心概念:
消除浪费--鼓励开发团队尽可能多地消除浪费。这种方法在某种程度上并不鼓励多任务处理。这意味着它只需要完成“份内”的处理工作,并通过节省构建所谓“锦上添花”的功能,来节省时间。同时在所有开发阶段都避免了不必要的文档和会议。
鼓励学习--通过鼓励创建一个有利于所有相关成员学习的环境,来促进团队对软件开发过程予以反馈。
推迟决定--在做出决定之前,应仔细考虑各种事实。
尽快交付--由于交付是基于时间的,因此它会专注于满足交付期限的增量式交付,而非大礼包式的发布。
团队授权--它避开了针对团队的微观管理,而是鼓励大家积极地参与到决策过程中,让彼此感到参与了重要的项目。它不但为团队成员提供了指导方向,而且为失败留出了足够的空间。
构建质量--由于在开发周期的所有阶段都关注客户价值,因此它会定期进行有关质量保证的各项测试。
整体优化--通过关注整个项目,而不是单独的项目模块,来有效地将组织战略与项目方案相结合。
精益方法的优势
由于团队参与到了决策之中,因此创造力得到了激发。
能够尽早地消除浪费,降低成本,并加快交付的速度。
精益方法的缺点
对于纪律性较差的团队而言,它不一定是最佳选择。
项目目标和重点可能会受到诸多灵活性的影响。
迭代方法
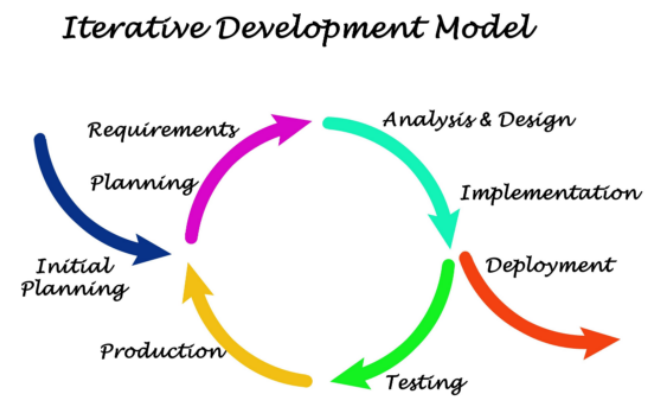
图 5 迭代开发模型
开发界引入迭代方法作为瀑布模型的替代方案。它通过添加迭代式重复性开发周期,来克隆瀑布方法的所有步骤。由于最终产品的各个部分在完成后,才在每次迭代结束时发布的,因此这种方法也属于增量式。具体而言,迭代方法的初始阶段是计划,而最后一个阶段是部署。介于两者之间的是:计划、设计、实施、测试和评估的循环过程。
迭代方法虽与敏捷方法类似,但是它涉及的客户参与度较少,并且具有预定义的增量范围。
迭代的优点
在早期阶段,它能够生成产品的可运行版本。
其变更的成本更低。
由于产品被分成较小的部分,因此更易于管理。
迭代的缺点
可能需要更多的资源。
有必要全面了解各项需求。
不适合小型项目。
螺旋方法
作为一种具有风险意识的软件开发方法,螺旋方法侧重于降低软件开发过程中的各项风险。它属于一种迭代的开发方法,在循环中不断推进。由于结合了瀑布模型和原型设计,因此螺旋方法是最灵活的SDLC方法,并具有如下四个主要阶段:
第一阶段--定义项目目标并收集需求。
第二阶段--该方法的核心是进行全面的风险分析和计划,消减已发现的风险。产品原型会在本阶段交付出来。
第三阶段--执行开发和测试。
第四阶段--涉及评估已开发的内容,并计划开展下一次迭代。
螺旋方法主要适用于高度定制化的软件开发。此外,用户对于原型的反馈可以在迭代后期(在开发阶段)扩展各项功能。
螺旋方法的优势
由于引入了广泛的风险分析,因此尽可能地避免了风险。
它适用于较大型的项目。
可以在迭代后期添加其他功能。
螺旋方法的缺点
它更关注成本收益。
它比其他SDLC方法更复杂。
它需要专家进行风险分析。
由于严重依赖风险分析,因此倘若风险分析不到位,则可能会使整个项目变得十分脆弱。
DevOps方法
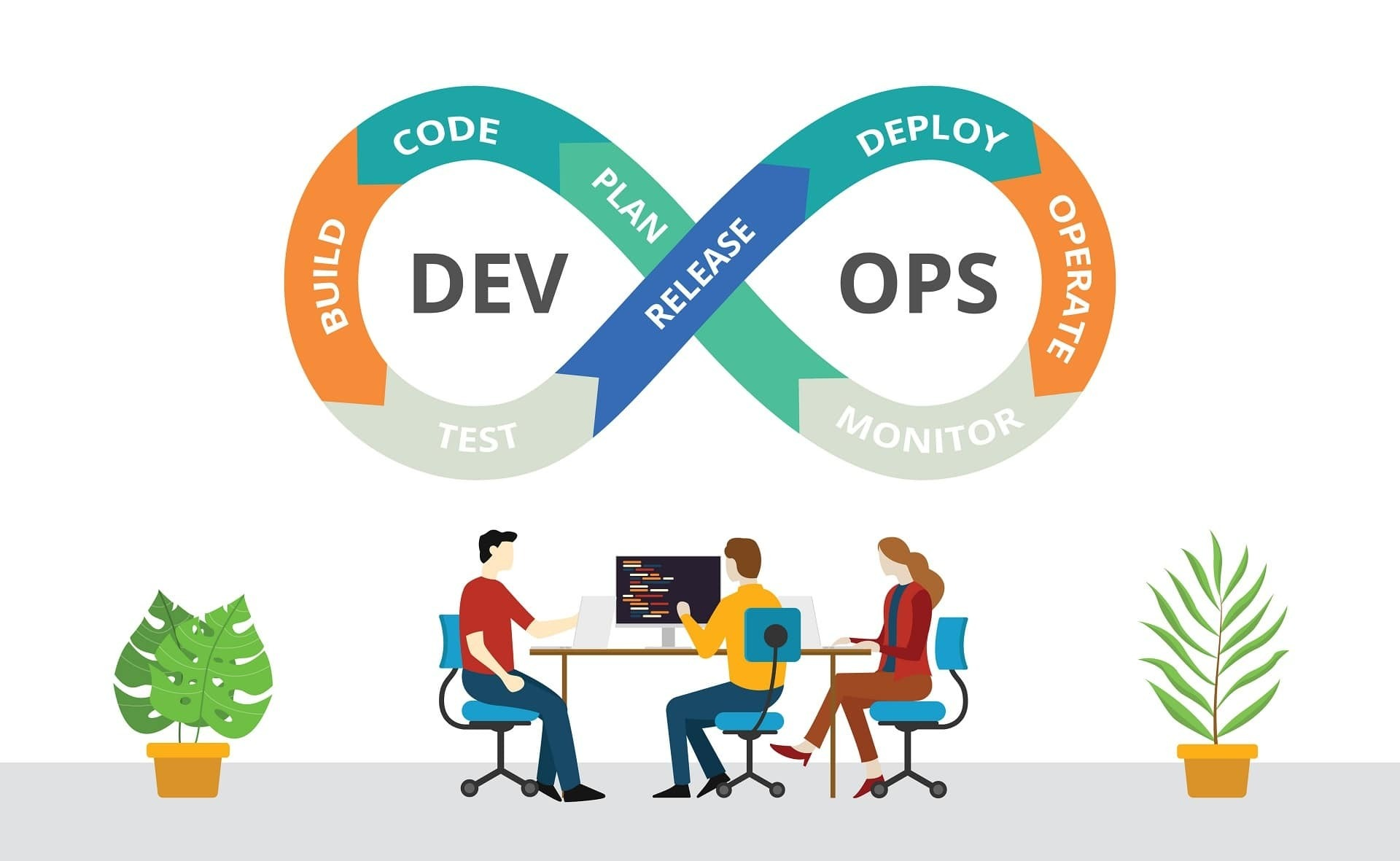
图 6 DevOps方法
在传统的软件开发方法中,开发人员和运维人员之间几乎没有协作。特别是在运营过程中,开发人员往往被视为“构建者”的角色。这就造成了沟通和协作上的差距,以及在反馈过程中出现混淆。而软件开发的DevOps方法恰好弥合了两者之间的沟通鸿沟。其目标是通过将开发和运营团队有效地结合起来,以快速地开发出更可靠的优质软件。值得一提的是,DevOps也是一种将手动开发转换为自动化软件开发的方法。通常,DevOps方法会被划分为如下5个阶段:
持续开发--此阶段涉及到软件应用的规划和开发。
持续集成—此阶段会将新的功能性代码与现有的代码相集成。
持续测试--开发团队和QA测试人员会使用maven和TestNG等自动化工具开展测试,以确保在新的功能中扫清缺陷。自动化测试为各种测试用例的执行节省了大量时间。
持续部署--此阶段会使用类似puppet的配置管理工具、以及容器化工具,将代码部署到生产环境(即服务器上)。它们还将协助安排服务器上的更新,并保持配置的一致性。
持续监控—运营团队会在此阶段通过使用Nagios、Relix和Splunk等工具,主动监控用户活动中的错误、异常、不当的软件行为、以及软件的性能。所有在此阶段被发现的问题都会被传递给开发团队,以便在持续开发阶段进行修复,进而提高软件的质量。
DevOps的优势
促进了合作。
通过持续开发和部署,更快地向市场交付软件。
最大化地利用Relix。
DevOps的缺点
当各个团队使用不同的环境时,将无法保证软件的安全。
涉及到人工输入的过程时,可能会减慢整体运营的速度。
小结
综上所述,软件开发生命周期中的每一个阶段都是非常重要的。我们只有正确地执行了每个步骤,才能最大限度地利用现有资源,并交付出高质量、可靠的软件。
事实上,软件开发并没有所谓的“最佳”方法,它们往往各有利弊。因此在选择具体方法之前,您需要了解待选方法对手头项目的实用性。当然,为了尽可能地采用最适合现有流程的方法,许多公司会同时使用两种不同方法的组合,通过取长补短来实现有效的融合,并相辅相成地完成软件的交付任务。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:The Complete Guide to SDLC,作者:Mario Olomu
收起阅读 »B站崩的那晚,连夜谋划了这场稳定性保障SRE升级之战
本文分享主题是B站SRE在稳定性方面的运营实践。
随着B站近几年的快速发展,业务规模越来越大,迭代速度越来越快,系统运行复杂度也越来越高。线上每天都会发生各种各样的故障,且发生的场景越来越刁钻。为了应对这种情况,保障业务在任何时刻都能将稳定性维持在一个高基线之上,B站专门成立了SRE体系团队,在提升业务稳定性领域进行了全方位、体系化的积极探索,从理论性支撑和能力化建设进行着手,从故障应急响应、事件运营、容灾演练、意识形态等多方面进行稳定性运营体系的构筑。
本次分享主题是B站SRE在稳定性方面的运营实践,分享内容分为以下几个部分:
案例剖析
从应急响应看稳定性运营
核心运营要素有哪些
两个运营载体:OnCall与事件运营中心
挑战与收益
一、案例剖析
多年来业界同仁针对稳定性这一话题进行了大量的探索和实践,业界不乏针对稳定性保障相关的讨论和研究。在围绕稳定性的实践上,大家也经常听到诸如混沌工程、全链路压测、大促活动保障和智能监控等话题的分享。B站在这些方面也做了很多建设工作,今天我将从应急响应的角度切入,和大家分享B站在稳定性运营方面所做的工作。
我们先来看两个案例,案例以真实事件为依托,相关敏感内容进行了改写。
案例一

1)背景
一个手机厂商的发布会在某天晚上12点举办,B站承接了该品牌的线上发布会直播。公司的运营同学提前就配置好了12点的直播活动页面以及准点的应用内Push消息。在12点到来之后,直播活动页推送生效,大量用户收到应用内推送消息,点击进入直播活动页面。
2)故障始末
12点01分,直播活动页内嵌的播放器无法支持部分用户正常加载播放。
12点03分,研发同学李四收到了异常的报警,开始介入处理。
12点04分,客服同学收到了大量有关发布会无法正常播放的用户反馈,常规处理方法无法解决用户问题。
影响持续到12点15分,研发同学李四还在排查问题的具体原因,没有执行相对应的止损预案(该种问题有对应预案),问题持续在线上造成影响。
直到12点16分,老板朋友找到了老板反馈今晚B站的某品牌手机直播发布会页面视频无法正常播放,此时老板开始从上往下询问,研发leader知道了这件事,开始联系SRE同学介入问题处理,并及时执行了相关的切换预案,直播活动页面播放恢复正常。
3)问题
在这个案例中,暴露了以下一些问题:
故障的相关告警虽然及时,但是并没有通知到足够多对的人。
该故障的告警,在短时间没有处理响应后,并未进行有效的结构性升级(管理升级,及时让更高level的人参与进来,知晓故障影响,协调处理资源)和职能性升级(技术升级,让更专业和更对口的人来参与响应处理,如team leader、SRE等)。
一线同学往往容易沉迷于查找问题根因,不能及时有效地对故障部位进行预案执行。
案例二

1)背景
一个平淡无奇的周末晚上,23点30分,监控系统触发大量告警,几乎全业务线、各架构层都在触发告警。
2)故障始末
23点40分,企业微信拉了有十几个群,原有的业务沟通群、基础服务OnCall群,都在不停地转发告警,询问情况。整个技术线一片恐慌,起初以为是监控系统炸了。此时相关故障的SRE同学已经被拉到某一个语音会议中。
注意,此时公司的多个BU业务线同学都炸锅了,到处咨询发生了什么,业务怎么突然就不炸了。又过了几分钟,资深的SRE同学又拉了一个大群,把相关业务对接人都拉进群里,开始整体说明故障情况。此时,该同学也比较纠结如何通报和说明这个问题,因为此时没有一个明确故障定位,语言很难拿捏,各个高level的老板也都在问(已上热搜)。并且,负责恢复入口服务的一线同学把故障预案执行了个遍,发现无济于事。后续在GSLB调度层,执行了整个跨机房的流量有损切换才让服务逐渐恢复正常。
凌晨之后,原有机房的问题定位出来了,补丁迅速打上,异常的问题彻底修复了。后续,在对此事件进行复盘时,发现困难重重。因为故障处理过程中,涉及到大量的服务、组件和业务方,并且大家当时拉了一堆群,同样的消息被发送到了很多群。参与处理故障的同学在语音、电话和企微群都有进行过沟通和处理进展发布,整个事件的细节整理起来非常耗费人力和精力,准确性也很难保障。
3)问题
在上面这个案例中,我们可以看到整个故障从发生、处置到结束后复盘,都存在以下问题:
当一个影响面比较大的故障产生时,大家没有统一的故障进展同步方式,依托原始的人工拉群,人工找相关人员电话联系,导致了故障最新的进展情况只能够在小范围传播扩散,无法统一对外公布,并且在传播过程中,很容易消息失真;
在故障处理过程中,缺少主要协调人(故障指挥官)。像这种大型故障,需要有一个人能够去协调各层人员分工、消息收敛、服务业务情况等,这个人需要能够掌控整个故障的所有消息和全貌进展;
在故障处理过程中,缺乏故障上下文的信息关联,大家难以知晓故障发生的具体位置,只是感知到自己的业务受损了,自己的服务可能有异常,这导致整个故障的定位时间被拉长;
在故障恢复之后,我们对这个故障进行复盘时,发现故障处理过程中的信息太过零散,复盘成本很高。
案例剖析
通过对上述两个案例的分析我们能够发现,在故障发生前、处理中和结束后,各个阶段都会有很多因素导致我们的故障不能被快速解决,业务不能快速恢复。
这里我们从故障的前、中、后三个阶段总结可能存在的一些问题。
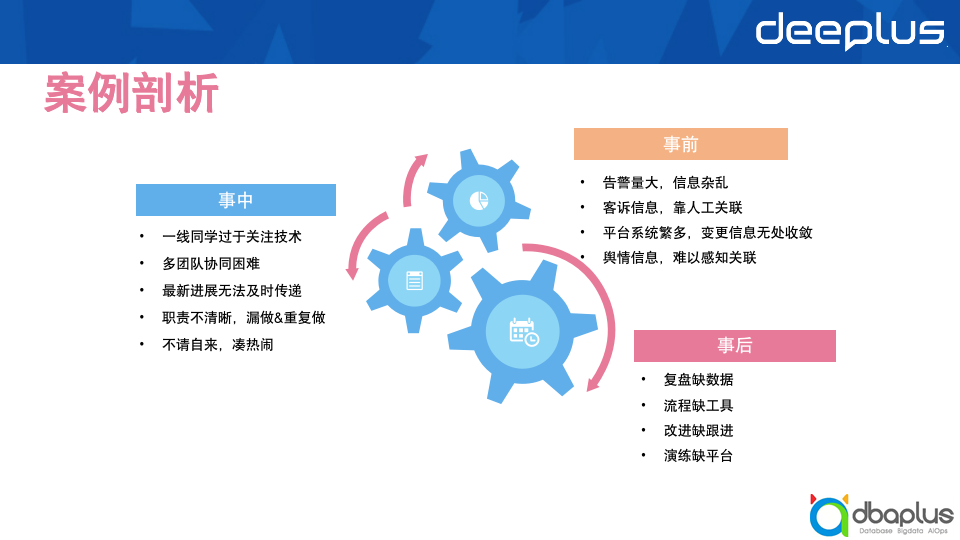
1)事前
告警信息量大,信息太过杂乱;
平台系统繁多,变更信息无处收敛;
客服反馈的信息,需要靠人工去关联,并反馈到技术线;
和公司舆情相关的信息,技术线很难感知到。
2)事中
一线同学过于关注技术,沉迷问题解决;
当一个故障影响面扩大之后,涉及多个团队的协同非常困难,最新的进展消息无法及时有效地传递到相关人员手中;
当参与一个故障处理的人员多了之后,多个人员之间缺乏协调,导致职责不清晰,产生事情漏做、重复做的问题;
故障处理过程中,会有一些不请自来,凑热闹的同学。
3)事后
当我们开展复盘时,发现故障处理时又是群、又是电话、又是口头聊,又是操作各种平台和工具,做了很多事情,产生了很多信息,梳理时间线很繁琐,还会遗漏,写好一份完整的复盘报告非常麻烦;
拉一大堆人进行复盘的时候,因为缺少结构化的复盘流程,经常是想到什么问什么。当某场复盘会,大家状态好的时候,能挖掘的点很多。如果状态不好或者大家意识上轻视时,复盘的效果就较差;
复盘后产出的改进事项,未及时统一地记录跟进,到底有没有完成,什么时间应该完成,完成的情况是否符合预期都不得而知;
对于已经修复的问题,是否需要演练验收确保真正修复。
以上三个阶段中可能发生的各种各样的问题,最终只会导致一个结果:服务故障时间增长,服务的SLA降低。
二、从应急响应看稳定性运营
针对上述问题,如何进行有效改善?这是本部分要重点分享的内容,从应急响应看稳定性运营。


应急响应的概念较早来源于《信息安全应急相应计划规范GB/T24363-2009》中提到的安全相关的应急响应,整体定义是“组织为了应对突发/重大信息安全事件的发生所作的准备,以及在事件发生后所采取的措施”。从这个概念我们延伸到稳定性上就产生了新的定义,“一个组织为了应对各种意外事件的发生所作的准备以及在事件发生后所采取的措施和行为”。这些措施和行为,通常用来减小和阻止事件带来的负面影响及不良后果。
三、核心运营要素有哪些

做好应急响应工作的核心目标是提升业务的稳定性。在这个过程中,我们核心关注4大要素。核心点是事件,围绕事件有三块抓手,分别是人、流程和工具/平台。
人作为应急响应过程中参与和执行的主体,对其应急的意识和心态有很高要求。特别是在一些重大的故障处理过程中,不能因为压力大或紧张导致错误判断。
流程将应急响应的流程标准化,期望响应人能够按照既定阶段的既定章程进行有效的推进和处理。
工具/平台支撑人和流程的高效合规运行,并将应急响应的过程、阶段进行度量,进而分析和运营,推进人和流程的改进。
事件
1)生命周期划分
要对故障进行有效运营,就需要先明确故障的生命周期。通过划分故障的生命周期,我们可以针对不同的周期阶段进行精准聚焦,更有目的性地开展稳定性提升工作。
针对故障生命周期的划分有很多种方式,按故障的状态阶段划分,可以分为事前、事中和事后。

按故障的流程顺序划分,可以分为故障防御、故障发生、故障响应、故障定位和故障恢复、复盘改进等阶段。
这里我围绕故障的时间阶段,从故障不同阶段的形态变化做拆分,将故障拆分为四个阶段。
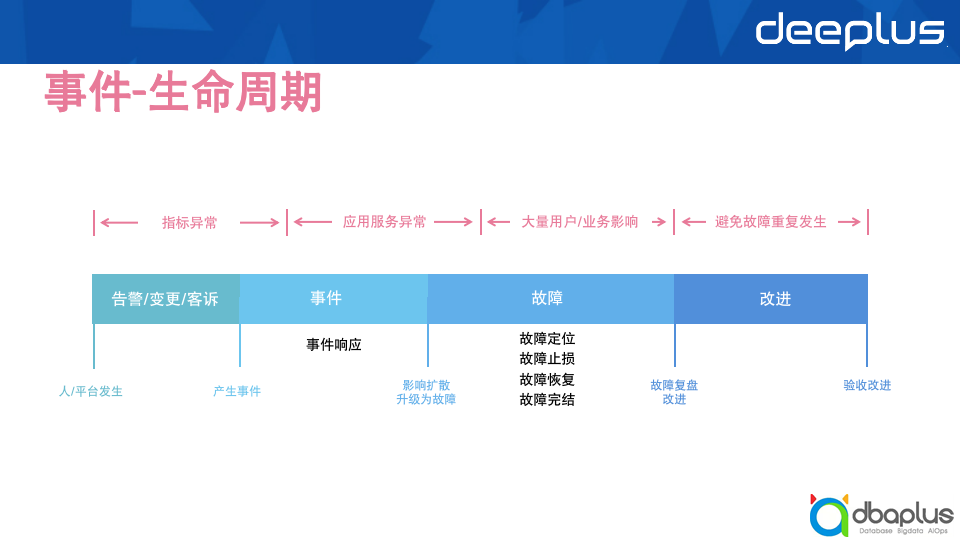
告警/变更/客诉
当故障还未被确认时,它可能是一个告警、变更或客诉。
事件
当这个告警、变更、客诉被上报后,会产生一个事件,我们需要有人去响应这个事件,此时一个真正的事件就形成了。
故障
当事件的影响范围逐渐扩散,这时往往有大量的用户、业务受到影响,我们需要将事件升级成故障,触发故障的应急协同,进行一系列的定位、止损等工作。
改进
故障最终会被恢复,接下来我们要对故障进行复盘,产生相关改进项,在改进项被完成之后,还需要进行相关的验收工作。
2)阶段度量
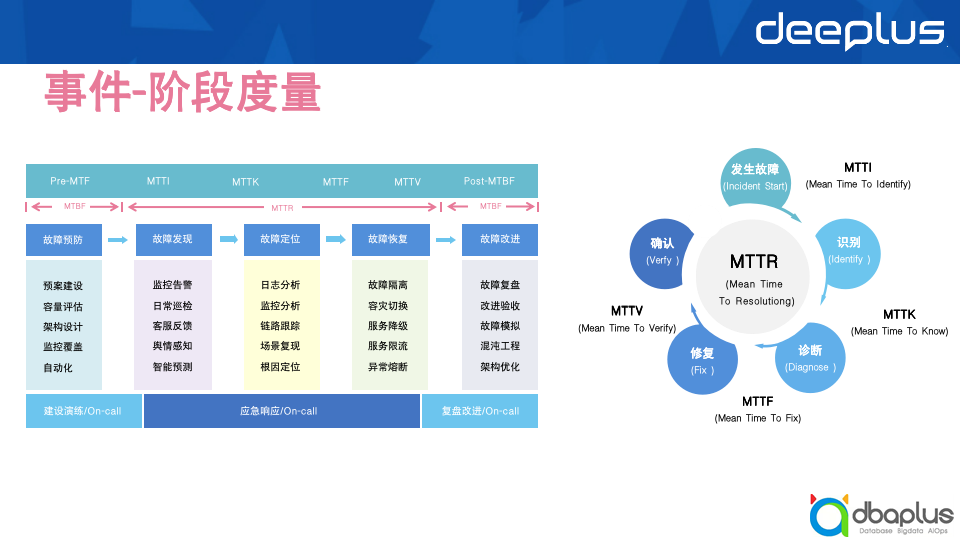
从更科学的角度看,我们知道在运营工作中,度量是很关键的一点。管理学大师彼得·德鲁克曾经说过:“你如果无法度量它,就无法管理它”。有效的度量指标定义,可以帮助我们更好更快地开展运营工作、评估价值成果。上文中我们提到的3个阶段是比较笼统的阶段,接下来我将介绍更加具体和可执行的量化拆分方法。
如上图所示,从故障预防依次到故障发现,故障定位,故障恢复,最后到故障改进,整体有两个大的阶段:MTBF(平均无故障时间)和MTTR(平均故障恢复时间)。我们进行业务稳定性运营的核心目标就是降低MTTR,增加MTBF。根据Google的定义,我们将MTTR进一步拆分为以下4个阶段:
MTTI:平均故障发现时间,指的是故障发生到我们发现的时间。
MTTK:平均故障定位时间,指的是我们发现故障到定位出原因的时间。
MTTF:平均故障修复时间,指的是我们采取恢复措施到故障彻底恢复的时间。
MTTV:平均故障修复验证时间,指的是故障恢复之后通过监控、用户验证真实恢复的时间。
3)关键节点
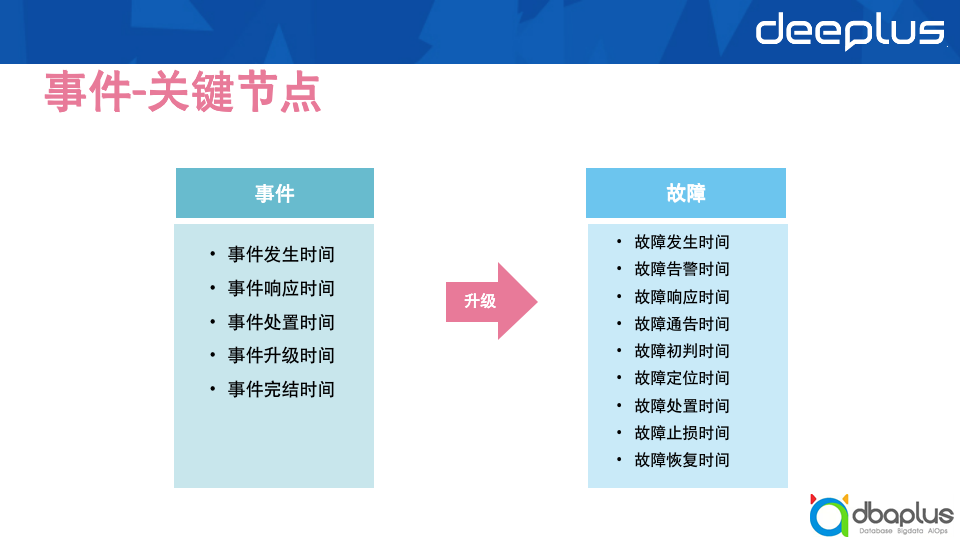
基于阶段度量的指标,我们能够得到一系列的关键时间节点。在不同的阶段形态,事件和故障会存在一些差异。故障因为形态更丰富,所存在的时间节点更多。上图中定下来的时间,均是围绕MTTR进行计算的。主要是为了通过度量事件、故障的处理过程,发现过程中存在的问题点,并对问题点进行精准优化,避免不知道如何切入去提升MTTR的问题,也方便我们对SRE的工作进行侧面考核。
人

人作为事件的一个主体,负责参与事件的响应、升级、处置和消息传播。

人通过上文中我们讲到的OnCall参与到应急响应中。我们在内部通过一套OnCall排班系统进行这方面的管理。这套系统明确了内部的业务、职能和人员团队,确保人员知道什么时间去值什么业务的班。下面的工具/平台部分会展开介绍。对参与人的要求,主要有以下几点:
具备良好的响应意识和处理心态。
具备熟练地响应执行的经验。
满足以上特征,才能做到故障来临时响应不慌乱,有条不紊地开展响应工作。
流程
那么针对人的要求如何实现?人员如何参与到应急响应的环节中去?人员的意识如何培养呢?

首先,我们内部制定了应急响应白皮书,明确了以下内容:
响应流程;
基于事件大小,所要参与的角色和角色对应的职责;
周边各个子系统SOP制定的标准规范;
针对应急过程中的对外通告内容模板;
故障过程的升级策略。
之后,我们会周期性地在部门内部、各BU进行应急响应宣讲,确保公司参与OnCall的同学能够学习和掌握。另外,我们也会将其作为一门必修课加入新同学的入职培训中。最后就是故障演练,通过实操,让没有参与过故障处理的新同学能够实际性地参与应急响应的过程,避免手生。
平台
平台作为支撑人与流程进行高效、稳定执行的载体,我将在下一部分进行具体描述。
四、两个运营载体:OnCall与事件运营中心
这部分我将向大家分享B站在应急响应方面落地的两个运营性平台。
OnCall系统
OnCall系统,即值班系统。值班系统在日常运转过程中的作用往往被低估,SRE、工程效率做这部分建设时,很容易基于二维的方式对人和事进行基于日历的值班管理,并通过网页、OpenAPI等方式对外提供数据服务。
下面我们通过几个例子来说明OnCall的必要性。
在日常工作中,当我们使用公司某个平台功能时,可能会习惯性找熟悉的同学,不管他这一天是不是oncall。这可能给那位同学带来困扰,他可能上周才值完班,这周要专心于研发或者项目的推进,你随时找他可能打断他的工作节奏。还有一种情况是新同学不知道该去找谁,我们内部之前经常有这种情况,一个新来的同学接手一套系统之后,有问题不知道该找谁,经常要转好几手,才能找到对的人,这一过程很痛苦。

以上内容总结起来就是总找一个人,总找不到人,除此之外,还会出现平台找不到人的情况。这些问题的根源是什么呢?无非就是who、when、what和how的问题,不能在正确的时间为正确的事找到正确的人。
那么OnCall系统的重要性和必要性都体现在哪些方面呢?
有问题找不到人
随着公司业务规模的扩大和领域的细分,一些新的同学和新业务方往往会出现一个问题。不知道是哪些人负责,需要咨询很多人才能找到具体解决问题的人。这一问题不仅限于故障,更存在于日常琐事中。特别是SRE同学的日常,经常会被研发同学咨询找人拉群,戏称拉群工程师。
下班不下岗
当人们遇到问题时,经常会下意识找熟悉的人。这就导致一些能力强、服务意识好的同学,总是在被人找。不论他今天值不值班,他将无时无刻都要面临被人打扰的问题。除了被人找之外,内部的监控系统、流程系统,也会给不值班的同学发送监控告警和流程审批信息。这也将SRE同学有50%的时间用于工程这一愿景变成泡影。
1)设计
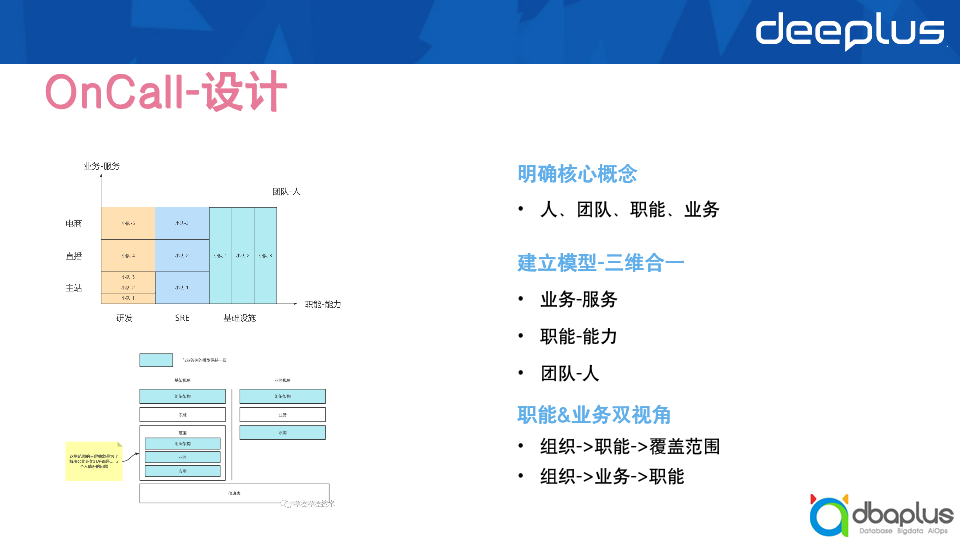
① 明确关联逻辑
针对上述两种情况,我们对公司的业务、服务、职能和组织架构进行了分析建模,明确了人、团队、职能和业务之间的关联关系。
② 建立三维合一模型
我们构建起了一套三维合一的模型。由组织-业务、职能-人员、组织-职能的关联关系,产生交汇点。值班人员会通过值班小队的方式,落在这些交汇点上,并且基于业务和基础架构的异同点,通过业务视角和职能视角分别对外提供服务。
以我们公司内部主站业务为例,我们会有专门的SRE小队进行日常的值班响应,这个小队只负责主站业务的值班响应。通过这样的对应关系,当人或平台有需求的时候,都可以通过业务和职能关联到对应实践的值班小队,最终定位到具体的人,这样也帮助我们将人藏了起来,更有利于后续SRE轮岗机制的推进落地。
③ 双视角提供服务
通过双视角的设计,区分了职能型和业务型的不同值班方式和关注点。原因在于B站的业务层级组织模式是按照“组织->业务->应用”这三级进行组织的,所有的应用归属到业务,业务归属到具体的组织架构。
职能视角
前端采用树型展示,组成结构为组织->职能->覆盖范围(组织->业务->服务),值班表具体挂载在覆盖范围下,覆盖范围可以只有一级组织也可以精确到组织下面的业务或业务下面的服务。
业务视角
前端采用树型展示,组织结构为组织->业务->职能,值班表具体挂载在职能下面。
在日常工作中,基础架构相关的服务,比如SRE、DBA、微服务、监控、计算平台等强职能型服务会通过职能视角对外提供值班信息。当业务人员有具体问题时,可以通过职能树快速定位到具体的值班人员。而对于业务服务来讲,日常的工作模式是围绕业务开展的,因此会通过业务进行展开,提供该业务下相关职能的对应值班信息。
这两个视角的底层数据是相通的,强职能相关服务提供方只需要维护好职能视角的值班信息,业务视角下的关联会自动生成。
2)功能展示
基于以上设计,我们内部做了一套OnCall排班的系统。

这套系统是管理业务、职能和人的系统。我们基于上文中提到的几个核心概念,在这些概念间建立了关系,分别是两条线,一条是职能-团队和人,另外一条是职能-业务和服务。
系统提供了排班班组的管理,支持基于日历的排班,同时支持班组设置主备oncall角色。在排班的细节上,我们支持基于时段进行自动排班计划生成,也支持在一个职能里多个班组混合排班。另外,也支持对已经排好班的班组,进行覆盖排班和换班,这个主要应对oncall同学突然有事请假的情况。在oncall通知方面,我们支持了企业微信、电话等通知方式,并且支持虚拟号码的方式,保护员工号码不对外泄露。同时也避免了因为熟悉导致的频繁被打扰的情况。
在周边生态方面,这套OnCall系统完全依赖周边系统的接入。我们目前对接了内部的告警系统、流程系统,确保告警和流程能够只通知oncall人,而不形成骚扰。在企业微信的服务号中,也进行了H5的页面嵌入,在用户通过企业微信反馈问题、找人时,知道当下该找谁。在各个接入的平台,也内嵌了OnCall的卡片页面,明确告诉用户本平台当前是谁值班。通过这套OnCall系统的落地,我们明确了人、团队、职能和业务的概念,并将这些概念进行了关系建立和对应。人员通过排班班组统一对外为某个业务提供某项职能的值班响应。通过前端的可视化,提供了日历的值班展示效果,可以直观看到某个业务所需要的某块职能在某个时间点是由哪个班组在服务,周边的各个系统也都对接OnCall系统,实现了人员响应的统一管理,解决了某些人员认人不认事,不通过正规流程处理的问题。
事件运营中心

事件运营中心这套系统是我们基于ITIL、SRE、信息安全应急计划的事件管理体系,为了满足公司对重大事件/故障的数字化管理,实现信息在线、数据在线和协同在线,使组织能够具备体系化提升业务连续性能力所做的产品平台。这个平台的定位是一站式的SRE事件运营中心,数字化运营业务连续性的目标是提升MTBF,降低MTTR,提高SLA。
1)架构设计
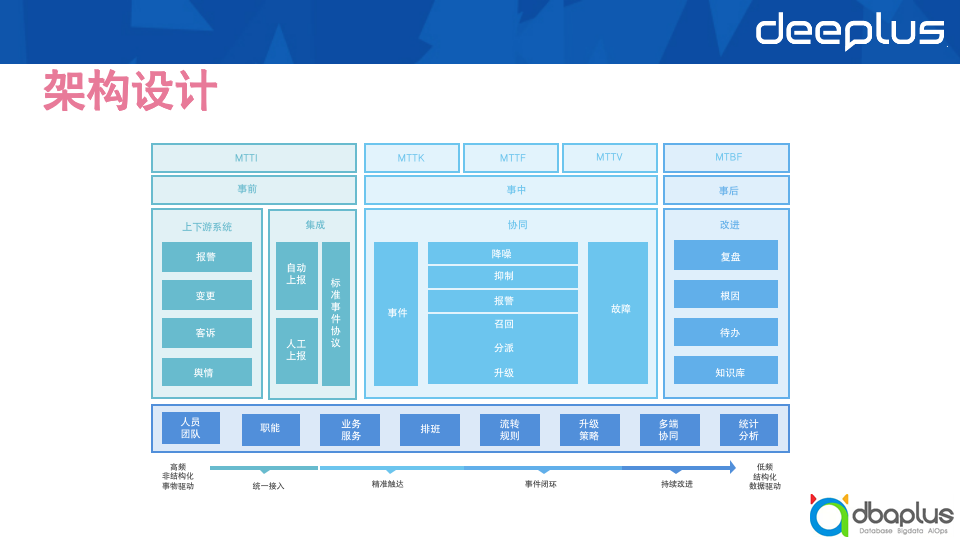
上图是我们平台的模块架构图,整体上还是围绕上文提到的事件的事前、事中和事后三个阶段拆分,覆盖了一个事件产生、响应、复盘、改进的全生命周期。
事前
我们对事件进行了4大类型的拆分,分别是告警、变更、客诉和舆情,然后通过设计标准的事件上报协议,以集成的方式将我们内部的各个系统打通,将事件信息统一收集到一起。在收集的过程中,进行二次处理,实现事件的结构化转储。
事中
我们会对接入的4大类型信息进行事件转化,然后通过预定义的规则对事件进行降噪,抑制、报警、召回、分派和升级等相关操作。在这个过程中,如果一个事件被判定影响到业务,我们会将它升级成一个故障,然后触发故障的应急响应流程。这里就进入到对故障响应处理过程中的一个阶段,在这个阶段我们会产生各种角色,例如故障指挥官、故障通讯人员、故障恢复人员等,相关人员明确认领角色,参与故障的止损。止损过程中,通过平台一键拉群创建应急响应指挥部,通过平台的进展同步进行相关群和业务人员的通告,通过记录簿实现故障信息的信息传递和记录。
事后
在故障结束之后,就进入到我们整体的改进环节。平台可以基于故障一键创建复盘报告,自动关联故障处理过程中的专家数据。平台提供预制的故障复盘问答模板,以确认各阶段是否按照预期的目标进行。复盘产生的待办列表,平台会进行定期的状态提醒和处理进度跟进。最终的这些都会以知识的形式,沉淀在我们的知识库。帮助日常On-Call问答和公司内部员工的培训学习。整体这样一套平台流程下来,就实现了将一些日常高频的非结构性事务驱动,通过统一接入、精准触达、事件闭环和持续改进等环节,转化为低频的结构化数据驱动方式。
2)场景覆盖
下面我们介绍平台在各个场景的覆盖。
① 集约化
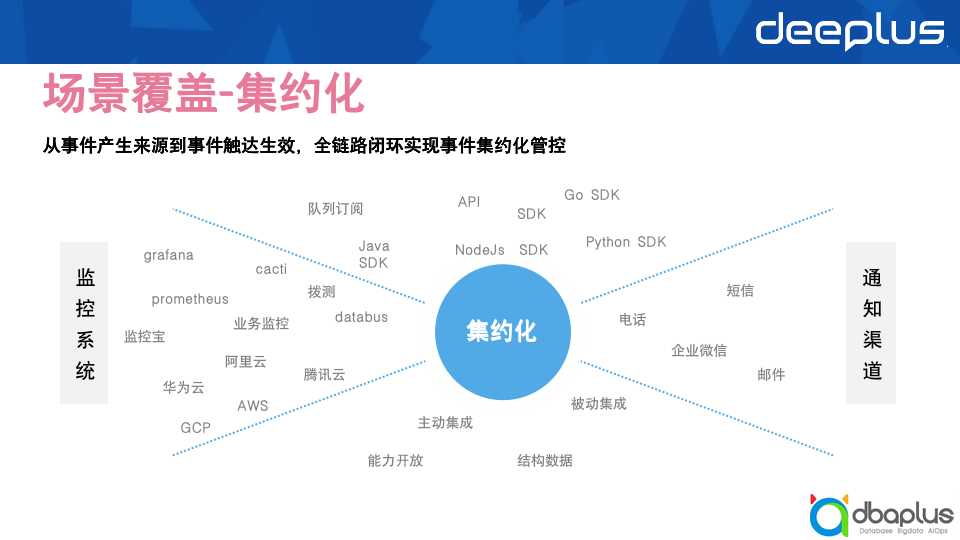
对事件产生的上游来源进行集约化管理,通过队列订阅、API和SDK的方式,将内部的监控,Prometheus、监控宝等各个云平台的监控都通过前面的4大类型定义收归到一起,然后统一进行通知触达。
② 标准事件类型

为了实现各个渠道消息的结构化规约,我们设计了标准的事件模型,通过这个事件模型,我们将周边各个系统/工具/平台进行收集,并且实现了事件的关联操作。模型主要分为4部分:
base是一些事件的基础信息字段;
who是指这一事件来自哪里,有哪些相关方;
when是指事件发生或产生影响的时间;
where是指事件来源于哪个业务、影响了哪些业务;
what是指这个事件的具体内容,它的操作对象是什么等等。
③ 降噪聚类
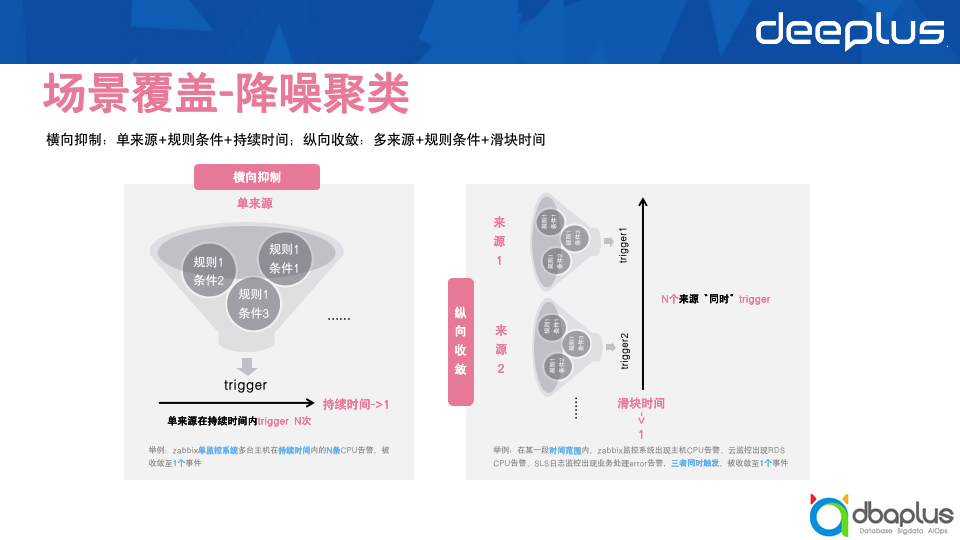
由于我们对事件的上报结构进行了标准化,并且预埋了关联字段,通过这些关联字段,我们就建立起了事件的关联关系,从而可以做事件的降噪聚类。
降噪聚类在执行上,主要分为两部分。
横向抑制
我们支持对单个来源的事件、告警,通过定义的规则进行收敛,比如Prometheus报警出一个服务在某个持续时间内持续报了N条一样的告警信息,平台会收敛到一个事件中去。
纵向抑制
这对上文中提到的底层系统故障十分有效,可以将底层故障导致的上层业务告警都统一收到一个事件中,避免大量告警使大家造成混淆。
④ 协同在线

在协同在线的场景下,我们通过一个面板将人、业务、组件和系统信息进行了汇总,通过一个事件详情页,将整个事件当下的处理人、关联业务和服务组件、当下的一些信息统一展示在一起。在协同能力上,我们提供了一键创建应急响应群的功能,建群时会自动关联该故障相关oncall同学,对故障感兴趣的同学也可以通过面板加入响应群。在故障页面,清晰看到故障当前的指挥官是谁,当下的处理人是哪些同学。彻底解决了之前靠人工拉语音、打电话、面对面交流的原始协作方式。
平台的各方面能力实现了事件全生命周期的闭环管理。监控告警、故障发现、应急响应、故障定位、故障恢复、故障复盘和故障改进,全阶段都通过平台能力去承载。
故障响应时,支持了故障的全局应急通告,提供了多种通告渠道,信息实时同步不延误,避免人工同步,漏同步、同步内容缺漏等问题;
故障跟踪阶段,平台可以实时展示最新的故障进展;故障影响面、当下处置情况,各阶段时间等等;
故障结束的复盘阶段,通过定义好的结构化、阶段化的复盘过程,确保复盘过程中,该问的问题不遗漏,该确认的点都确认到;
故障改进阶段,通过对改进项的平台化录入,关联相关责任方、验收方,确保改进的有效执行和落实。
上图中是协同相关的一些示例,当一个故障被创建出来时,会自动关联该故障涉及到的业务、组件、基础设施的oncall同学,这些同学可能是SRE、研发等,平台会记录他们是否有响应这些问题,并且当下所负责的角色是什么。因为角色决定了在该事件中所担负的事项和责任;下方一键拉群,可以将相关人员,自动拉入到一个群内,方便大家进行沟通协同,并且事件、故障的相关最新进展也会定期在群内同步;涉及到事件的参与人员,事件运营中心的服务号也会定期推送最新进展,确保不会丢失消息。
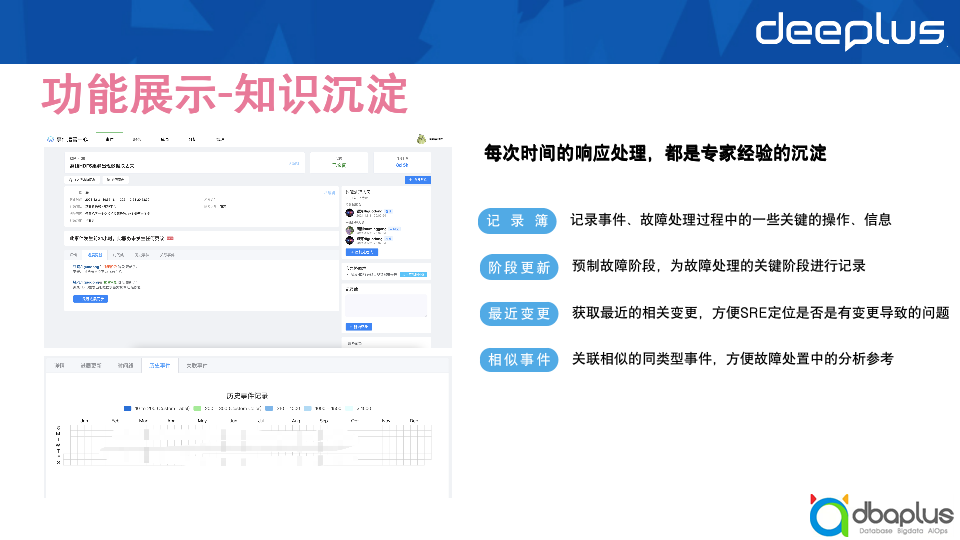
上图是我们内部的故障协同的详情页面,提供了记录簿、故障阶段更新、最近变更信息和相似事件,确保每次的响应处理,都能形成一个专家经验的沉淀,帮助后续新来的同学进行故障响应过程的学习。
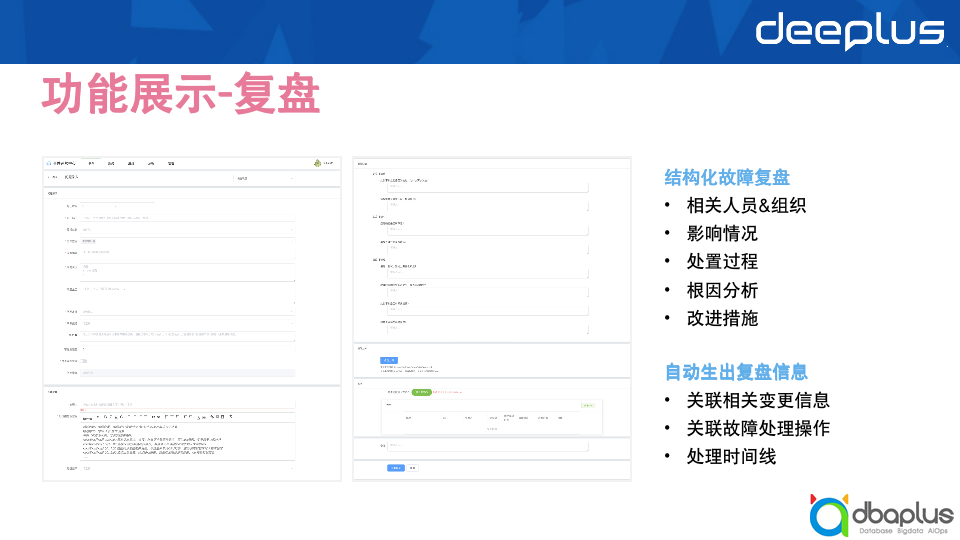
复盘方面,我们定义了结构化的故障复盘模板,像相关人员、组织、影响情况、处置过程、根因分析(在根因分析里面,我们设置了6问,确保对问题能够有深度地挖掘),改进措施等。在复盘效率方面,我们关联了相关的变更信息、故障处理时的一些变更操作,以及处理时间线,帮助复盘同学快速生成故障的相关信息,减少人工录入负担。
五、挑战与收益
挑战
在业务稳定性运营体系的建设过程中,团队也踩了很多坑,面临着诸多技术之外的挑战。鉴于业界对于技术相关的分享比较丰富,这里就针对体系逻辑和人员方面的挑战进行分享。
元信息统一
稳定性是个大话题,我们在落地整体体系时会发现,设计的上下游系统太多了。每个系统里面都会有人、业务、职能的使用需求。在初期,我们内部在服务、业务和人的关联这块没有形成统一的数据基准,导致我们在应急协同的诸多特性上难以落地,诸如故障的有效通知、群内的有效传递、故障画像的拓扑关联计算缺少映射关系等等。
在这种情况下,我们重新梳理了服务树和OnCall系统,通过服务树将组织、业务和服务的映射关系维护好,通过OnCall系统将组织、职能、业务和人的映射关系维护好,来确保找人的时候能找到人,找服务的时候能找到服务。
工作模式改变
新的应急响应流程,将故障过往对人的依赖转移到靠系统来自行驱动,这导致现有人员的工作模式产生了很大变化。传统故障处理时,响应人员手动拉群、语音或现场找人,现在变成了优先在系统内升级已有事件或录入故障信息,然后通过系统自动进行人员关联和邀请。群内的随意沟通,变成了在平台进行阶段性进展同步。原有的故障升级逻辑变成了平台定时通知,这给故障处理人员带了一定的压迫感。整体形式上更加严肃和标准,在落地初期给大家带来了一定的不适应感。针对这种情况,我们一方面通过在系统的文案描述上进行改善,交互逻辑上进行优化,尽可能在推行新标准的同时,适应旧的使用习惯。例如,常规应急协同群会先于平台的故障通告建立,这就会与平台创建的故障协同群发生冲突。此时,我们通过增加现有群关联来实现已有故障协同群和故障的关联。另外一方面,我们通过定期持续的宣讲,给大家介绍新的应急响应流程和平台使用方法,帮助大家适应新的应急响应模式。
收益
以上就是B站在业务稳定性运营方面所做的相关工作。通过体系化建设,已经在组织、流程和平台层面实现强效联动,具备了数字化运营业务稳定性的能力,建立了科学有效的稳定性评估提升量化标准,让稳定性提升有数据可依托。将故障应急响应流程从由人工驱动升级到由平台系统驱动,应急响应人员可以更专心处理故障,大幅提升故障恢复时间。后续我们将会持续探索更科学有效的管理运营方法,期望通过引入AI的能力,提升故障辅助定位能力、提早发现故障隐患,联动预案平台实现更多场景的故障自愈。
责任编辑:张燕妮来源: dbaplus社群
收起阅读 »API 工程化分享
概要
本文是学习B站毛剑老师的《API 工程化分享》学习笔记,分享了 gRPC 中的 Proto 管理方式,Proto 分仓源码方式,Proto 独立同步方式,Proto git submodules 方式,Proto 项目布局,Proto Errors,服务端和客户端的 Proto Errors,Proto 文档等等
目录
Proto IDL Management
IDL Project Layout
IDL Errors
IDL Docs
Proto IDL Management
Proto IDL
Proto 管理方式
Proto 分仓源码方式
Proto 独立同步方式
Proto git submodules 方式
Proto IDL
gRPC 从协议缓冲区使用接口定义语言 (IDL)。协议缓冲区 IDL 是一种与平台无关的自定义语言,具有开放规范。 开发人员会创作 .proto 文件,用于描述服务及其输入和输出。 然后,这些 .proto 文件可用于为客户端和服务器生成特定于语言或平台的存根,使多个不同的平台可进行通信。 通过共享 .proto 文件,团队可生成代码来使用彼此的服务,而无需采用代码依赖项。
Proto 管理方式
煎鱼的一篇文章:真是头疼,Proto 代码到底放哪里?
文章中经过多轮讨论对 Proto 的存储方式和对应带来的优缺点,一共有如下几种方案:
代码仓库
独立仓库
集中仓库
镜像仓库
镜像仓库
在我自己的微服务仓库里面,有一个 Proto 目录,就是放我自己的 Proto,然后在我提交我的微服务代码到主干或者某个分支的时候,它可能触发一个 mirror 叫做自动同步,会镜像到这个集中的仓库,它会帮你复制过去,相当于说我不需要把我的源码的 Proto 开放给你,同时还会自动复制一份到集中的仓库
在煎鱼的文章里面的集中仓库还是分了仓库的,B站大仓是一个统一的仓库。为什么呢?因为比方像谷歌云它整个对外的 API 会在一个仓库,不然你让用户怎么找?到底要去哪个 GitHub 下去找?有这么多 project 怎么找?根本找不到,应该建统一的一个仓库,一个项目就搞定了
我们最早衍生这个想法是因为无意中看到了 Google APIs 这个仓库。大仓可以解决很多问题,包括高度代码共享,其实对于 API 文件也是一样的,集中在一个 Repo 里面,很方便去检索,去查阅,甚至看文档,都很方便
我们不像其他公司喜欢弄一个 UI 的后台,我们喜欢 Git,它很方便做扩展,包括 CICD 的流程,包括 coding style 的 check,包括兼容性的检测,包括 code review 等等,你都可以基于 git 的扩展,gitlab 的扩展,GitHub 的一些 actions,做很多很多的工作
Proto 分仓源码方式
过去为了统一检索和规范 API,我们内部建立了一个统一的 bapis 仓库,整合所有对内对外 API。它只是一个申明文件。
API 仓库,方便跨部门协作;
版本管理,基于 git 控制;
规范化检查,API lint;
API design review,变更 diff;
权限管理,目录 OWNERS;
集中式仓库最大的风险是什么呢?是谁都可以更改
大仓的核心是放弃了读权限的管理,针对写操作是有微观管理的,就是你可以看到我的 API 声明,但是你实际上调用不了,但是对于迁入 check in,提到主干,你可以在不同层级加上 owner 文件,它里面会描述谁可以合并代码,或者谁负责 review,两个角色,那就可以方便利用 gitlab 的 hook 功能,然后用 owner 文件做一些细粒度的权限管理,针对目录级别的权限管理
最终你的同事不能随便迁入,就是说把文件的写权限,merge 权限关闭掉,只允许通过 merge request 的评论区去回复一些指令,比方说 lgtm(looks good to me),表示 review 通过,然后你可以回复一个 approve,表示这个代码可以被成功 check in,这样来做一些细粒度的权限检验
怎么迁入呢?我们的想法是在某一个微服务的 Proto 目录下,把自己的 Proto 文件管理起来,然后自动同步进去,就相当于要写一个插件,可以自动复制到 API 仓库里面去。做完这件事情之后,我们又分了 api.go,api.java,git submodule,就是把这些代码使用 Google protobuf,protoc 这个编译工具生成客户端的调用代码,然后推到另一个仓库,也就是把所有客户端调用代码推到一个源码仓库里面去
Proto 独立同步方式
移动端采用自定义工具方式,在同步代码阶段,自动更新最新的 proto 仓库到 worksapce 中,之后依赖 bazel 进行构建整个仓库
业务代码中不依赖 target 产物,比如 objective-c 的 .h/.a 文件,或者 Go 的 .go 文件(钻石依赖、proto 未更新问题)
源码依赖会引入很多问题
依赖信息丢失
proto 未更新
钻石依赖
依赖信息丢失
在你的工程里面依赖了其他服务,依赖信息变成了源码依赖,你根本不知道依赖了哪个服务,以前是 protobuf 的依赖关系,现在变成了源码依赖,服务依赖信息丢失了。未来我要去做一些全局层面的代码盘点,比方说我要看这个服务被谁依赖了,你已经搞不清楚了,因为它变成了源码依赖
proto 未更新
如果我的 proto 文件更新了,你如何保证这个人重新生成了 .h/.a 文件,因为对它来说这个依赖信息已经丢失,为什么每次都要去做这个动作呢?它不会去生成 .h/.a 文件
钻石依赖
当我的 A 服务依赖 B 服务的时候,通过源码依赖,但是我的 A 服务还依赖 C 服务,C 服务是通过集中仓库 bapis 去依赖的,同时 B 和 C 之间又有一个依赖关系,那么这个时候就可能出现对于 C 代码来说可能会注册两次,protobuf 有一个约束就是说重名文件加上包名是不允许重复的,否则启动的时候就会 panic,有可能会出现钻石依赖
A 依赖 B
A 依赖 C
A 和 B 是源码依赖
A 和 C 是 proto 依赖
B 和 C 之间又有依赖
那么它的版本有可能是对不齐的,就是有风险的,这就是为什么 google basic 构建工具把 proto 依赖的名字管理起来,它并没有生成 .go 文件再 checkin 到仓库里面,它不是源码依赖,它每一次都要编译,每次都要生成 .go 文件的原因,就是为了版本对齐
Proto git submodules 方式
经过多次讨论,有几个核心认知:
proto one source of truth,不使用镜像方式同步,使用 git submodules 方式以仓库中目录形式来承载;
本地构建工具 protoc 依赖 go module 下的相对路径即可;
基于分支创建新的 proto,submodules 切换分支生成 stub 代码,同理 client 使用联调切换同一个分支;
维护 Makefile,使用 protoc + go build 统一处理;
声明式依赖方式,指定 protoc 版本和 proto 文件依赖(基于 BAZEL.BUILD 或者 Yaml 文件)
proto one source of truth
如果只在一个仓库里面,如果只有一个副本,那么这个副本就是唯一的真相并且是高度可信任的,那如果你是把这个 proto 文件拷来拷去,最终就会变得源头更新,拷贝的文件没办法保证一定会更新
镜像方式同步
实际上维护了本地微服务的目录里面有一个 protobuf 的定义,镜像同步到集中的仓库里面,实际上是有两个副本的
使用 git submodules 方式以仓库中目录形式来承载
子模块允许您将 Git 存储库保留为另一个 Git 存储库的子目录。这使您可以将另一个存储库克隆到您的项目中并保持您的提交分开。
图中 gateway 这个目录就是以本地目录的形式,但是它是通过 git submodules 方式给承载进来的
如果公司内代码都在一起,api 的定义都在一起,那么大仓绝对是最优解,其次才是 git submodules,这也是 Google 的建议
我们倾向于最终 proto 的管理是集中在一个仓库里面,并且只有一份,不会做任何的 copy,通过 submodules 引入到自己的微服务里面,也就是说你的微服务里面都会通过 submodules 把集中 API 的 git 拷贝到本地项目里面,但是它是通过 submodeles 的方式来承载的,然后你再通过一系列 shell 的工具让你的整个编译过程变得更简单
IDL Project Layout
Proto Project Layout
在统一仓库中管理 proto,以仓库为名
根目录:
目录结构和 package 对齐;
复杂业务的功能目录区分;
公共业务功能:api、rpc、type;
目录结构和 package 对齐
我们看一下 googleapis 大量的 api 是如何管理的?
第一个就是在 googleapis 这个项目的 github 里面,它的第一级目录叫 google,就是公司名称,第二个目录是它的业务域,业务的名称
目录结构和 protobuf 的包名是完全对齐的,方便检索
复杂业务的功能目录区分
v9 目录下分为公共、枚举、错误、资源、服务等等
公共业务功能:api、rpc、type
在 googleapis 的根目录下还有类似 api、rpc、type 等公共业务功能
IDL Errors
Proto Errors
Proto Errors:Server
Proto Errors:Client
Proto Errors
使用一小组标准错误配合大量资源
错误传播
用简单的协议无关错误模型,这使我们能够在不同的 API,API 协议(如 gRPC 或 HTTP)以及错误上下文(例如,异步,批处理或工作流错误)中获得一致的体验。
使用一小组标准错误配合大量资源
服务器没有定义不同类型的“找不到”错误,而是使用一个标准 google.rpc.Code.NOT_FOUND 错误代码并告诉客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息。
我们以前自己的业务代码关于404,关于某种资源找不到的错误码,定义了上百上千个,请问为什么大家在设计 HTTP restful 或者 grpc 接口的时候不用人家标准的状态码呢?人家有标准的404,或者 not found 的状态码,用状态码去映射一下通用的错误信息不好吗?你不可能调用一个接口,返回几十种具体的错误码,你根本对于调用者来说是无法使用的。当我的接口返回超过3个自定义的错误码,你就是面向错误编程了,你不断根据错误码做不同的处理,非常难搞,而且你每一个接口都要去定义
这里的核心思路就是使用标准的 HTTP 状态码,比方说500是内部错误,503是网关错误,504是超时,404是找不到,401是参数错误,这些都是通用的,非常标准的一些状态码,或者叫错误码,先用它们,因为不是所有的错误都需要我们叫业务上 hint,进一步处理,也就是说我调你的服务报错了,我大概率是啥都不做的,因为我无法纠正服务端产生的一个错误,除非它是带一些业务逻辑需要我做一些跳转或者做一些特殊的逻辑,这种不应该特别多,我觉得两个三个已经非常多了
所以说你会发现大部分去调用别人接口的时候,你只需要用一个通用的标准的状态码去映射,它会大大降低客户端的逻辑复杂性,同时也不限制说你包含一些可操作的 hint 的一些信息,也就是说你可以包含一些指示你接下来要去怎么做的一些信息,就是它不冲突
错误传播
如果您的 API 服务依赖于其他服务,则不应盲目地将这些服务的错误传播到您的客户端。
举个例子,你现在要跟移动端说我有一个接口,那么这个接口会返回哪些错误码,你始终讲不清楚,你为什么讲不清楚呢?因为我们整个微服务的调用链是 A 调 B,B 调 C,C 调 D,D 的错误码会一层层透传到 A,那么 A 的错误码可能会是 ABCD 错误码的并集,你觉得你能描述出来它返回了哪些错误码吗?根本描述不出来
所以对于一个服务之间的依赖关系不应该盲目地将下游服务产生的这些错误码无脑透传到客户端,并且曾经跟海外很多公司,像 Uber,Twitter,Netflix,跟他们很多的华人的朋友交流,他们都不建议大家用这种全局的错误码,比方 A 部门用 01 开头,B 部门用 02 开头,类似这样的方式去搞所谓的君子契约,或者叫松散的没有约束的脆弱的这种约定
在翻译错误时,我们建议执行以下操作:
隐藏实现详细信息和机密信息
调整负责该错误的一方。例如,从另一个服务接收 INVALID_ARGUMENT 错误的服务器应该将 INTERNAL 传播给它自己的调用者。
比如你返回的错误码是4,代表商品已下架,我对这个错误很感兴趣,但是错误码4 在我的项目里面已经被用了,我就把它翻译为我还没使用的错误码6,这样每次翻译的时候就可以对上一层你的调用者,你就可以交代清楚你会返回错误码,因为都是你定义的,而且是你翻译的,你感兴趣的才翻译,你不感兴趣的通通返回 500 错误,就是内部错误,或者说 unknown,就是未知错误,这样你每个 API 都能讲清楚自己会返回哪些错误码
在 grpc 传输过程中,它会要求你要实现一个 grpc states 的一个接口的方法,所以在 Kraots 的 v2 这个工程里面,我们先用前面定义的 message Error 这个错误模型,在传输到 grpc 的过程中会转换成 grpc 的 error_details.proto 文件里面的 ErrorInfo,那么在传输到 client 的时候,就是调用者请求服务,service 再返回给 client 的时候再把它转换回来
也就是说两个服务使用一个框架就能够对齐,因为你是基于 message Error 这样的错误模型,这样在跨语言的时候同理,经过 ErrorInfo 使用同样的模型,这样就解决了跨语言的问题,通过模型的一致性
Proto Errors:Server
errors.proto 定义了 Business Domain Error 原型,使用最基础的 Protobuf Enum,将生成的源码放在 biz 大目录下,例如 biz/errors
biz 目录中核心维护 Domain,可以直接依赖 errors enum 类型定义;
data 依赖并实现了 biz 的 Reporisty/ACL,也可以直接使用 errors enum 类型定义;
TODO:Kratos errors 需要支持 cause 保存,支持 Unwrap();
在某一个微服务工程里面,errors.proto 文件实际上是放在 API 的目录定义,之前讲的 API 目录定义实际上是你的服务里面的 API 目录,刚刚讲了一个 submodules,现在你可以理解为这个 API 目录是另外一个仓库的 submodules,最终你是把这些信息提交到那个 submodules,然后通过 reference 这个 submodules 获取到最新的版本,其实你可以把它打成一个本地目录,就是说我的定义声明是在这个地方
这个 errors.proto 文件其实就列举了各种错误码,或者叫错误的字符串,我们其实更建议大家用字符串,更灵活,因为一个数字没有写文档前你根本不知道它是干啥的,如果我用字符串的话,我可以 user_not_found 告诉你是用户找不到,但是我告诉你它是3548,你根本不知道它是什么含义,如果我没写文档的话
所以我们建议使用 Protobuf Enum 来定义错误的内容信息,定义是在这个地方,但是生成的代码,按照 DDD 的战术设计,属于 Domain,因为业务设计是属于领域的一个东西,Domain 里面 exception 它最终的源码会在哪?会在 biz 的大目录下,biz 是 business 的缩写,就是在业务的目录下,举个例子,你可以放在 biz 的 errors 目录下
有了这个认知之后我们会做三个事情
首先你的 biz 目录维护的是领域逻辑,你的领域逻辑可以直接依赖 biz.errors 这个目录,因为你会抛一些业务错误出去
第二,我们的 data 有点像 DDD 的 infrastructure,就是所谓的基础设施,它依赖并实现了 biz 的 repository 和 acl,repository 就是我们所谓的仓库,acl 是防腐层
因为我们之前讲过它的整个依赖倒置的玩法,就是让我们的 data 去依赖 biz,最终让我们的 biz 零依赖,它不依赖任何人,也不依赖基础设施,它把 repository 和 acl 的接口定义放在 biz 自己目录下,然后让 data 依赖并实现它
也就是说最终我这个 data 目录也可以依赖 biz 的 errors,我可能通过查 mysql,结果这个东西查不到,会返回一个 sql no rows,但肯定不会返回这个错误,那我就可以用依赖 biz 的这个 errors number,比如说 user_not_found,我把它包一个 error 抛出去,所以它可以依赖 biz 的 errors
目前 Kratos 还不支持根因保存,根因保存是什么呢?刚刚说了你可能是 mysql 报了一个内部的错误,这个内部错误你实际上在最上层的传输框架,就是 HTTP 和 grpc 的 middleware 里面,你可能会把日志打出来,就要把堆栈信息打出来,那么根因保存就是告诉你最底层发生的错误是什么
不支持 Unwrap 就是不支持递归找根因,如果支持根因以后呢,就可以让 Kratos errors 这个 package 可以把根因传进去,这样子既能搞定我们 go 的 wrap errors,同时又支持我们的状态码和 reason,大类错误和小类错误,大类错误就是状态码,小类错误就是我刚刚说的用 enum 定义的具体信息,比方说这个商品被下架,这种就不太好去映射一个具体的错误码,你可能是返回一个500,再带上一个 reason,可能是这样的一个做法
Proto Errors:Client
从 Client 消费端只能看到 api.proto 和 error.proto 文件,相应的生成的代码,就是调用测的 api 以及 errors enum 定义
使用 Kratos errors.As() 拿到具体类型,然后通过 Reason 字段进行判定;
使用 Kratos errors.Reason() helper 方法(内部依赖 errors.As)快速判定;
拿到这两个文件之后你可以生成相应代码,然后调用 api
举个例子,图中的代码是调用服务端 grpc 的某一个方法,那么我可能返回一个错误,我们可以用 Kratos 提供的一个 Reason 的 short car,一个快捷的方法,然后把 error 传进去,实际上在内部他会调用标准库的 error.As,把它强制转换成 Kratos 的 errors 类型,然后拿到里面的 Reason 的字段,然后再跟这个枚举值判定,这样你就可以判定它是不是具体的一个业务错误
第二种写法你可以拿到原始的我们 Kratos 的 Error 模型,就是以下这个模型
new 出来之后用标准库的 errors.As 转换出来,转换出来之后再用 switch 获取它里面的 reason 字段,然后可以写一些业务逻辑
这样你的 client 代码跨语言,跨传输,跨协议,无论是 grpc,http,同样是用一样的方式去解决
IDL Docs
Proto Docs
Proto Docs
基于 openapi 插件 + IDL Protobuf 注释(IDL 即定义,IDL 即代码,IDL 即文档),最终可以在 Makefile 中使用 make api 生成 openapi.yaml,可以在 gitlab/vscode 插件直接查看
API Metadata 元信息用于微服务治理、调试、测试等;
因为我们可以在 IDL 文件上面写上大量的注释,那么当讲到这个地方,你就明白了 IDL 有什么样的好处?
IDL 文件它既定义,同时又是代码,也就是说你既做了声明,然后使用 protoc 可以去生成代码,并且是跨语言的代码,同时 IDL 本身既文档,也就是说它才真正满足了 one source of truth,就是唯一的事实标准
最终你可以在 Makefile 中定义一个 api 指令,然后生成一个 openapi.yaml,以前是 swagger json,现在叫 openapi,用 yaml 声明
生成 yaml 文件以后,现在 gitlab 直接支持 openapi.yaml 文件,所以你可以直接打开 gitlab 去点开它,就能看到这样炫酷的 UI,然后 VSCode 也有一个插件,你可以直接去查看
还有一个很关键的点,我们现在的 IDL 既是定义,又是代码,又是文档,其实 IDL 还有一个核心作用,这个定义表示它是一个元信息,是一个元数据,最终这个 API 的 mate data 元信息它可以用于大量的微服务治理
因为你要治理的时候你比方说对每个服务的某个接口进行路由,进行熔断进行限流,这些元信息是哪来的?我们知道以前 dubbo 2.x,3.x 之前都是把这些元信息注册到注册中心的,导致整个数据中心的存储爆炸,那么元信息在哪?
我们想一想为什么 protobuf 是定义一个文件,然后序列化之后它比 json 要小?因为它不是自描述的,它的定义和序列化是分开的,就是原始的 payload 是没有任何的定义信息的,所以它可以高度的compressed,可被压缩,或者说叫更紧凑
所以说同样的道理,IDL 的定义和它的元信息,和生成代码是分开的话,意味着你只要有 one source of truth 这份唯一的 pb 文件,基于这个 pb 文件,你就有办法把它做成一个 api 的 metadata 的服务,你就可以用于做微服务的治理
你可以选一个服务,然后看它有些什么接口,然后你可以通过一个管控面去做熔断、限流等功能,然后你还可以基于这个元信息去调试,你做个炫酷的 UI 可以让它有一些参数,甚至你可以写一些扩展,比方说这个字段叫 etc,建议它是什么样的值,那么你在渲染 UI 的时候可以把默认值填进去,那你就很方便做一些调试,甚至包含测试,你基于这个 api 去生成大量的 test case
参考
API 工程化分享 http://www.bilibili.com/video/BV17m…
接口定义语言 docs.microsoft.com/zh-cn/dotne…
真是头疼,Proto 代码到底放哪里? mp.weixin.qq.com/s/cBXZjg_R8…
git submodules git-scm.com/book/en/v2/…
kratos github.com/go-kratos/k…
error_details.proto github.com/googleapis/…
pkg/errors github.com/pkg/errors
Modifying gRPC Services over Time
作者:郑子铭_
来源:juejin.cn/post/7097866377460973599
算法图解-读书笔记
前言
首先要说明的是: 这本书的定义是一本算法入门书,更多的是以简单地描述和示例介绍常见的数据结构和算法以及其应用场景,所以如果你在算法上有了一定造诣或者想深入学习算法,这本书很可能不太适合你。
但如果你对算法感兴趣,但是不知从何学起或者感觉晦涩难懂,这本书绝对是一本很好的入门书,它以简单易懂的描述和示例,配以插画,向我们讲解了常见的算法及其应用场景。
本文是我基于自己的认知总结本书比较重点的部分,并不一定准确,更不一定适合所有人,所以如果你对本书的内容感兴趣,推荐阅读本书,本书总计180+页,而且配以大量示例和插画讲解,相信你很快就可以读完。
第一章:算法简介
算法是一组完成任务的指令。任何代码片段都可以视为算法。
二分查找
二分查找是一种用来在有序列表中快速查找指定元素的算法,每次判断待查找区间的中间元素和目标元素的关系,如果相同,则找到了目标元素,如果不同,则根据大小关系缩短了一半的查找区间。
相比于从头到尾扫描有序列表,一一对比的方式,二分查找无疑要快很多。
大O表示法
大O表示法是一种特殊的表示法,指出了算法的运行时间或者需要的内存空间,也就是时间复杂度和空间复杂度。
比如冒泡排序,
export default function bubbleSort(original:number[]) {
const len = original.length
for (let i = 0; i < len - 1; i++) {
for (let j = 1; j < len - i; j++) {
if (original[j - 1] > original[j]) {
[original[j - 1], original[j]] = [original[j], original[j - 1]]
}
}
}
}需要两层循环,每次循环的长度为 n(虽然并不完全等于n),那它的时间复杂度就是 O(n²)。同时因为需要创建常数量的额外变量(len,i,j),所以它的空间复杂度是 O(1)。
第二章:选择排序
内存的工作原理
当我们去逛商场或者超市又不想随身携带着背包或者手提袋时,就需要将它们存入寄存柜,寄存柜有很多柜子,每个柜子可以放一个东西,你有两个东西寄存,就需要两个柜子,也就是计算机内存的工作原理。计算机就像是很多柜子的集合,每个柜子都有地址。
数组和链表
有时我们需要在内存中存储一系列元素,应使用数组还是链表呢?
想要搞清楚这个问题,就需要知道数组和链表的区别。
数组是一组元素的集合,其中的元素都是相邻的,创建数组的时候需要指定其长度(这里不包括JavaScript中的数组)。可以理解为数组是一个大柜子,里边有固定数量的小柜子。
而链表中的元素则可以存储在任意位置,无需相邻,也不需要在创建的时候指定长度。
对应到电影院选座问题,
数组需要在初始就确定几个人看电影,并且必须是邻座。而一旦选定,此时如果再加一人,就需要重新选座,因为之前申请的位置坐不下现在的人数。而且如果没有当前数量的相邻座位,那么这场电影就没办法看了。
而链表则不要求指定数量和相邻性,所以如果是两个人,则只要还有大于等于两个空座,就可以申请座位,同样,如果此时再加一个人,只要还有大于等于一个空座,同样可以申请座位。\
数组因为可以通过索引获取元素,所以其读取元素的时间复杂度为O(1),但是因为其连续性,在中间插入或者删除元素涉及到其他元素的移动,所以插入和删除的时间复杂度为O(n)。
链表因为只存储了链表的头节点,获取元素需要从头节点开始向后查找,所以读取元素的时间复杂度为O(1),因为其删除和插入元素只需要改变前一个元素的next指针,所以其插入和删除的时间复杂度为O(1)。
选择排序
选择排序就是每次找出待排序区间的最值,放到已排序区间的末尾,比较简单,这里不做赘述了。
第三章:递归
个人理解,递归就是以相同的逻辑重复处理更深层的数据,直到满足退出条件或者处理完所有数据。
其中退出条件又称为基线条件,其他情况则属于递归条件,即需要继续递归处理剩余数据。
栈
这里主要讲的是调用栈,因为递归函数是不断调用自身,所以就导致调用栈也来越大,因为每次函数调用都会占用内存,当调用栈很高,就会导致内存占用很大的问题。解决这个问题通常有两种方法:
将递归改写为循环
使用尾递归
第四章:快速排序
快速排序使用的是分而治之的策略。
分而治之
简单理解,分治就是将大规模的问题,拆解为小规模的问题,直到规模小到很容易处理,然后对小规模问题进行处理后,再将处理结果合并,得到大规模问题的处理结果。
关于快排这里也不做赘述,感兴趣的可以看我之前的文章,需要注意的是,递归的方式更容易理解,但是会存在上述递归调用栈及多个子数组占用内存过高的问题。
第五章:散列表
散列表类似于JavaScript中的array、object和map,只不过作为上层语言,JavaScript帮我们做了很多工作,不需要我们自己实现散列函数,而散列函数,简单理解就是传入数据,会返回一个数字,而这个数字可以作为数组的索引下标,我们就可以根据得到的索引将数据存入索引位置。一个好的散列函数应该保证每次传入相同的数据,都返回相同的索引,并且计算的索引应该均匀分布。
常见的散列表的应用有电话簿,域名到IP的映射表,用户到收货地址的映射表等等。
冲突
散列表还有一个比较重要的问题是解决冲突,比如传入字符串"abc",散列函数返回1,然后我们将"abc"存储在索引1的位置,而传入"def",散列函数同样返回1,此时索引1的位置已经存储了"abc",此时怎么办呢?
一种常见的解决方案是在每个索引的位置存储一个链表,这样就可以在一个索引位置,存储多个元素。
第六章:广度优先搜索
图
如果我们要从A去往B,而A去往B的路线可能很多条,这些路线就可以抽象成图,图中每个地点是图中的节点,地点与地点之间的连接线称为边。而如果我们要找出从A去往B的最近路径,需要两个步骤:
使用图来建立问题模型
使用广度优先搜索求解最短路径
广度优先搜索
所谓广度优先搜索,顾名思义,就是搜索过程中以广度优先,而不是深度,对于两点之间最短路径的问题,就是首先从出发点,走一步,看看是否有到达B点的路径,如果没有,就从第一步走到的所有点在走一步,看看有没有到达B点的路径,依此类推,直到到达B点。
实际算法中,广度优先搜索通常需要借助队列实现,即不停的把下一次能到达的点加入队列,并每次取出队首元素判断是否是B点,如果不是,再把它的下一个地点加入队列。
第七章:狄克斯特拉算法
在上一章我们可以使用广度优先搜索计算图的最短路径,但是如果图的每一条边都有相应的权重,也就是加权图,那么广度优先搜索求得的只是边数最少的路径,但是不一定是加权图中的最短路径,这个时候,想要求得最短路径,就需要狄克斯特拉算法。
狄克斯特拉算法的策略是:
每次都寻找下一个开销最小的节点
更新该节点的邻居节点的开销
重复这个过程,直到对图中每个节点都这样做
计算最终路径
但是要注意的是狄克斯特拉算法只适合权重为正的情况下使用,如果图中有负权边,要使用贝尔曼-福德算法。
第八章:贪婪算法
所谓贪婪算法,就是每一步都采用最优解,当所有的局部解都是最优解,最终所有局部最优解组合得到的全局解就是近似的全局最优解。
要注意的是,贪婪算法得到的并不一定是最优解,但是是近似最优解的结果。
可能你会有疑问,为什么不使用可以准确得到最优解的算法呢?这是因为有些问题很难求出准确的最优解,比如书中的城市路线问题。
如果只有2个城市,则会有2条路线
3个城市会有6条路线
4个城市会有24条路线
5个城市会有120条路线
6个城市会有720条路线
你会发现随着城市的增加,路线总数是城市数量的阶乘,当城市数量增加到一定程度,要枚举所有路线几乎是不可能的,这个时候就需要用贪婪算法求得一个近似的最优解。
第九章:动态规划
动态规划的主要思路是将一个大问题拆成相同的小问题,通过不断求解小问题,最后得出大问题的结果。
解题过程通常分为两步,状态定义和转移方程。
所谓状态定义,即抽象出一个状态模型,来表示某个状态下的结果值。
所谓转移方程,即推导出状态定义中的状态模型可以由什么计算得出。
以LeetCode 746. 使用最小花费爬楼梯为例: 因为最小花费只和台阶层数有关,所以可以定义 dp[i] 表示第i层台阶所需花费,这就是状态定义。
又因为第i层台阶可能从i-2上来,也可能从i-1上来,所以第i层台阶的最小花费等于前面两层台阶中花费更小的那个加上本层台阶的花费,即dp[i] = Math.min(dp[i-1],dp[i-2])+cost[i],这就是转移方程。
完整解题代码如下:
var minCostClimbingStairs = function(cost) {
const dp = [cost[0],cost[1]]
for(let i = 2;i<cost.length;i++){
dp[i] = Math.min(dp[i-1],dp[i-2])+cost[i]
}
return Math.min(dp.at(-1),dp.at(-2))
}这里我讲解的方式和本书中画网格求解的方式并不一致,但是道理相同,一个是思考推导,一个是画网格推导。
第十章:K最近邻算法
K最近邻算法通常用来实现推荐系统,预测数值等。它的主要思想就是通过特征抽离,将节点绘制在坐标系中,当我们预测某个节点的数值或喜好时,通过对它相邻K个节点的数值和喜好的数据进行汇总求平均值,大概率就是它的数值和喜好。
比如常见的视频网站,社交网站,都会要求我们选择自己感兴趣的方面,或者在我们使用过程中记录我们的喜好,然后基于这些数据抽离我们的特征,然后根据相同特征的用户最近的观影记录或者话题记录,向我们推荐相同的电影和话题,也就是常见的猜你喜欢。还有机器学习的训练过程,也是提供大量数据给程序,让它进行特征抽离和记录,从而完善它的特征数据库,所以就有了机器越来越聪明的表现。
第十一章:接下来如何做
本章列举了本书没有单独拿出来讲但是依然很重要的数据结构和算法。
树
这里没有介绍树的基本概念,而是直接基于前面章节的二分查找引申出二叉查找树,这种树的性质是对于任意一个节点,它的左子树中的节点值都小于它,它的右子树的节点值都大于它。从而如果把整个树压平,就是一个升序的结果。然后还提到了B树,红黑树,堆和伸展树。
傅里叶变换
一个对傅里叶变换的比喻是:给她一杯冰沙,它能告诉你其中包含哪些成分。类似于给定一首歌曲,傅里叶变换能够将其中的各种频率分离出来。
常见的应用场景有音频、图片压缩。以音频为例,因为可以将歌曲分解为不同的频率,然后可以通过强调关系的部分,减弱或者隐藏不关心的部分,实现各种音效,也可以通过删除一些不重要的部分,实现压缩。
并行算法
因为笔记本和台式机都有多核处理器,那为了提高算法的速度,我们可以让它在多个内核中并行执行,这就是并行算法。
MapReduce
分布式算法是一种特殊的并行算法,并行算法通常是指在一台计算机上的多个内核中运行,而如果我们的算法复杂到需要数百个内核呢?这个时候就需要在多台计算机上运行,这就是分布式算法,MapReduce就是一种流行的分布式算法。
映射函数
映射函数接受一个数组,对其中的每个元素执行同样的操作。
归并函数
归并是指将多项合并于一项的操作,这可能不太好理解,但是你可以回想下归并排序和递归快排在回溯过程中合并结果数组的过程。
布隆过滤器 和 HyperLogLog
布隆过滤器 是一种概率型数据结构,它提供的答案有可能不对,但很可能是正确的。
比如Google负责搜集网页,但是它只需要搜集新出现的网页,因此需要判断该网页是否搜集过。固然我们可以使用一个散列表存储网页是否已经搜集过,查找和插入的时间复杂度都是O(1),一切看起来很不错,但是因为网页会有数以万亿个,所以这个散列表会非常大,需要极大的存储空间,而这个时候,布隆过滤器就是一个不错的选择,它只需要占用很少的存储空间,提供的结果又很可能准确,对于网页是否搜集过的问题,可能出现误报的情况,即给出答案这个网页已搜集过,但是没有搜集,但是如果给出的答案是没有搜集,就一定没有搜集。\
HyperLogLog 是一种类似于布隆过滤器的算法,比如Google要计算用户执行的不同搜索的数量,要回答这个问题,就需要耗费大量的空间存储日志,HyperLogLog可以近似的计算集合中不同的元素数,与布隆过滤器一样,它不能给出准确的答案,但是近似准确答案,但是占用空间小很多。
以上两者,都适用于不要求答案绝对准确,但是数据量很大的场景。
哈希算法
这里介绍的就是哈希算法,常见的就是对文件进行哈希计算,判断两个文件是否相同,比如大文件上传中就可以通过计算文件的哈希值与已上传文件的散列表或者布隆过滤器比对,如果上传过,则直接上传成功,实现秒传。
还有一种应用场景就是密码的加密,通常用户输入的密码并不会进行明文传输,而是通过哈希算法进行加密,这样即使传输报文并黑客拦截,他也并不能知道用户的密码。书中还引申了局部敏感的散列函数,对称加密,非对称加密。
线性规划
线性规划用于在给定约束条件下最大限度的改善指定的指标。
比如你的公司生产两种产品,衬衫和手提袋。衬衫每件利润2元,需要消耗1米布料和5粒扣子;手提袋每个利润3元,需要消耗2米布料和2粒扣子。现在有11米布料和20粒扣子,为了最大限度提高利润,该生产多少衬衫好手提袋呢?
以上就是个人对 《算法图解》 这本书的读书总结,如果能给你带来一点帮助,那就再好不过了。
保持学习,不断进步!一起加油鸭!💪
作者:前端_奔跑的蜗牛
来源:https://juejin.cn/post/7097881646858240007
美团面试官问我一个字符的String.length()是多少,我说是1,面试官说你回去好好学一下吧
public class testT {
public static void main(String [] args){
String A = "hi你是乔戈里";
System.out.println(A.length());
}
}以上结果输出为7。
小萌边说边在IDEA中的win环境下选中String.length()函数,使用ctrl+B快捷键进入到String.length()的定义。
/**
* Returns the length of this string.
* The length is equal to the number of Unicode
* code units in the string.
*
* @return the length of the sequence of characters represented by this
* object.
*/
public int length() {
return value.length;
}接着使用google翻译对这段英文进行了翻译,得到了大体意思:返回字符串的长度,这一长度等于字符串中的 Unicode 代码单元的数目。
小萌:乔戈里,那这又是啥意思呢?乔哥:前几天我写的一篇文章:面试官问你编码相关的面试题,把这篇甩给他就完事!)里面对于Java的字符使用的编码有介绍:
Java中 有内码和外码这一区分简单来说
- 内码:char或String在内存里使用的编码方式。
- 外码:除了内码都可以认为是“外码”。(包括class文件的编码)
而java内码:unicode(utf-16)中使用的是utf-16.所以上面的那句话再进一步解释就是:返回字符串的长度,这一长度等于字符串中的UTF-16的代码单元的数目。
代码单元指一种转换格式(UTF)中最小的一个分隔,称为一个代码单元(Code Unit),因此,一种转换格式只会包含整数个单元。UTF-X 中的数字 X 就是各自代码单元的位数。
UTF-16 的 16 指的就是最小为 16 位一个单元,也即两字节为一个单元,UTF-16 可以包含一个单元和两个单元,对应即是两个字节和四个字节。我们操作 UTF-16 时就是以它的一个单元为基本单位的。
你还记得你前几天被面试官说菜的时候学到的Unicode知识吗,在面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜这里面提到,UTF-16编码一个字符对于U+0000-U+FFFF范围内的字符采用2字节进行编码,而对于字符的码点大于U+FFFF的字符采用四字节进行编码,前者是两字节也就是一个代码单元,后者一个字符是四字节也就是两个代码单元!
而上面我的例子中的那个字符的Unicode值就是“U+1D11E”,这个Unicode的值明显大于U+FFFF,所以对于这个字符UTF-16需要使用四个字节进行编码,也就是使用两个代码单元!
所以你才看到我的上面那个示例结果表示一个字符的String.length()长度是2!
来看个例子!
public class testStringLength {
public static void main(String [] args){
String B = "𝄞"; // 这个就是那个音符字符,只不过由于当前的网页没支持这种编码,所以没显示。
String C = "\uD834\uDD1E";// 这个就是音符字符的UTF-16编码
System.out.println(C);
System.out.println(B.length());
System.out.println(B.codePointCount(0,B.length()));
// 想获取这个Java文件自己进行演示的,可以在我的公众号【程序员乔戈里】后台回复 6666 获取
}
}可以看到通过codePointCount()函数得知这个音乐字符是一个字符!
几个问题:0.codePointCount是什么意思呢?1.之前不是说音符字符是“U+1D11E”,为什么UTF-16是"uD834uDD1E",这俩之间如何转换?2.前面说了UTF-16的代码单元,UTF-32和UTF-8的代码单元是多少呢?
一个一个解答:
第0个问题:
codePointCount其实就是代码点数的意思,也就是一个字符就对应一个代码点数。
比如刚才音符字符(没办法打出来),它的代码点是U+1D11E,但它的代理单元是U+D834和U+DD1E,如果令字符串str = "u1D11E",机器识别的不是音符字符,而是一个代码点”/u1D11“和字符”E“,所以会得到它的代码点数是2,代码单元数也是2。
但如果令字符str = "uD834uDD1E",那么机器会识别它是2个代码单元代理,但是是1个代码点(那个音符字符),故而,length的结果是代码单元数量2,而codePointCount()的结果是代码点数量1.
第1个问题
上图是对应的转换规则:
- 首先 U+1D11E-U+10000 = U+0D11E
- 接着将U+0D11E转换为二进制:0000 1101 0001 0001 1110,前10位是0000 1101 00 后10位是01 0001 1110
- 接着套用模板:110110yyyyyyyyyy 110111xxxxxxxxxx
- U+0D11E的二进制依次从左到右填入进模板:110110 0000 1101 00 110111 01 0001 1110
- 然后将得到的二进制转换为16进制:d834dd1e,也就是你看到的utf-16编码了
第2个问题
- 同理,UTF-32 以 32 位一个单元,它只包含这一种单元就够了,它的一单元自然也就是四字节了。
- UTF-8 的 8 指的就是最小为 8 位一个单元,也即一字节为一个单元,UTF-8 可以包含一个单元,二个单元,三个单元及四个单元,对应即是一,二,三及四字节。
参考
作者:程序员乔戈里
来源:juejin.cn/post/6844904036873814023 收起阅读 »
一次关于架构的“嘴炮”
文章标题很随意,些微有一些骗点击的“贼意”;但内容却是充满了诚意,想必你已经感受到了。
这是一次源于头条 Android 客户端软件架构问题的探讨,之所以冠上“嘴炮”之名,是因为它有一些务虚;同时又夹杂了一些方法论,不仅适用于客户端软件架构,也适用于其他工作场景,希望对大家有所帮助。
为了拉满读者的带入感,且以“我们”为主语,来看架构的挑战、判断和打法。
我们的挑战
期望高
优秀的公司对架构都有着很高的期许,都希望有一个良好的顶层设计,从上到下有统一的认知,遵循共同的规范,写出让人舒适的代码,甚至有那么一丢偷懒,有没有“一劳永逸”的架构设计可保基业长青?
然而高期望意味着高落差,面对落差,我们容易焦虑:
代码什么时候能写的看上去本就应该是那个样子;而现在怎么就像是在攀登“屎山”呢?
文档什么时候能写的既简明又详细;而现在怎么就简明的看不懂,详细的很多余呢?
工具什么时候能更好用更强大一点;而现在怎么就动不动掉链子,没有想要的功能常年等排期呢?
“我”什么时候能从架构工作中找到成就感,而不是搞一搞就想着跑路呢?
责任大
大量问题的最终归因都是代码问题:设计不合理、使用不规范、逻辑太晦涩、编码“坑”太多。
没有一个单一的团队能承担这些问题的责任,我们收到过很多“吐槽”:
这尼玛谁写的,简直不堪入目,看小爷我推倒重来展现一把真正的实力
XX 在这里埋了颗雷,但 XX 已经不管了,事到如今,我也只能兜底搞一把
这压根就不应该这么用,本来的设计又不是为了这个场景,乱搞怪我咯?
卧槽,这特么是隐藏技能啊,编译时悄悄改了老子的代码,找瞎了都没找到在哪过环节渗透进来的
一方面,口嗨一时爽,我们“吐槽”历史代码得到了一时的舒缓;另一方面,也意味着责任也传递到了我们:处理得好,我们的产出可能还是一样会被当作糟粕,但如果处理不好,我们就断送了业务发展的前程。
事情难
架构面临的从来不是单一的业务问题,而是多个业务多人协作的交叉问题,负重前行是常态。
业务历久弥新,历史包袱叠加新的场景,随便动动刀子就拔出萝卜带出泥。譬如:头条 2021 年 10 月的版本有 XXXX 组件,相比一年前已经翻倍;类个数 XXXXX;插件 XX 个;仓库数量 XX 个;ttmain 仓库权限 XXX 人。(XX 代表数量级,隐去了具体数字,_)
技术栈层出不穷,一方面要保持成熟稳定,一方面要积极探索落地。架构的同学要熟悉多种技术栈,譬如:跨端技术在客户端业务中通常都是多种共存(H5/Hybrid/小程序/Lynx/Flutter),一个业务到底选用哪种技术栈进行承载,需要耗费多少成本?选定技术栈后存在什么局限,是否存在不可逾越的障碍?
疗效慢
我们经常说代码复杂度高,并把降复杂度作为架构方向的重点工作之一;但影响复杂度的因子众多,从外部来看,有主观感受、客观指标、行业对标三个角度;从内部来看,有工程组织、代码实现和技术栈三个角度。即便我们很好的优化了工程结构这个因子,短时间内也很难感受到复杂度有一个明显的下降。
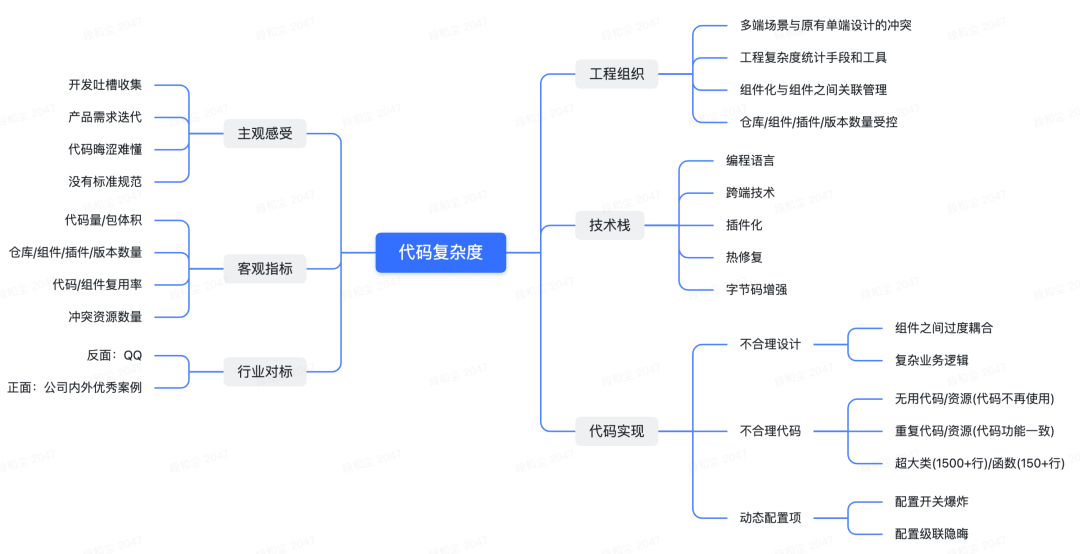
我们常说治理,其实是设计一种机制,在这种机制下运转直到治愈。
就像老中医开方子,开的不是特效药,而是应对病症的方法,是不是有用的方子,终究还是需要通过实践和时间的检验。希望我们不要成为庸医,瞎抓几把药一炖,就吹嘘药到病除。
我们的判断
架构问题老生常谈
谁来复盘架构问题,都免不了炒一炒“冷饭”;谁来规划架构方向,都逃不出了“减负”、“重构”、“复用”、“规范”这些关键词。难点在于把冷饭炒热,把方向落实。

架构方向一直存在
架构并不只局限于一个产品的初始阶段,而是伴随着产品的整个生命周期。架构也不是一成不变的,它只适合于特定的场景,过去的架构不一定适合现在,当下的架构不一定能预测未来,架构是随着业务不断演进的,不会出现架构方向做到头了、没有事情可搞了的情况,架构永远生机勃勃。
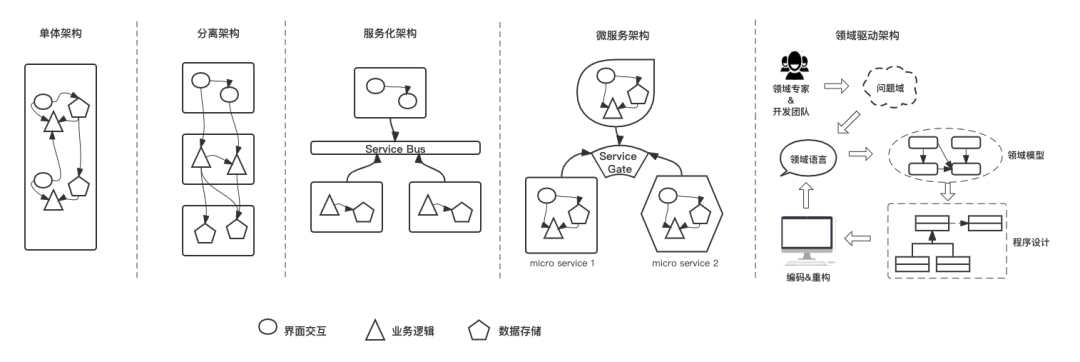

强制遵循规范: 通常会要求业务公共的组件逐渐下沉到基础组件层,但随着时间的推移,这个规范很容易被打破
需要成熟的团队: 领域专家(对业务细节非常熟悉的角色)和开发团队需紧密协作,构建出核心领域模型是关键。但盲目尝试 DDD 往往容易低估领域驱动设计这套方法论的实践成本,譬如将简单问题复杂化、陷入过分强调技术模型的陷阱
迄今为止,用于商业应用程序的最流行的软件架构设计模式是大泥球(Big Ball of Mud, BBoM),BBoM 是“…一片随意构造、杂乱无章、凌乱、任意拼贴、毫无头绪的代码丛林。”
泥球模式将扼杀开发,即便重构令人担忧,但也被认为是理所应当。然而,如果还是缺乏对领域知识应有的关注和考量,新项目最终也会走向泥球。没有开发人员愿意处理大泥球,对于企业而言,陷入大泥球就会丧失快速实现商业价值的能力。
——《领域驱动设计模式、原理与实践》Scott Millett & Nick Tune
复杂系统熵增不断
只要业务继续发展,越来越复杂就是必然趋势,这贴合热力学的熵增定律。
可以从两个维度来看复杂度熵增的过程:理解成本变高和预测难度变大。
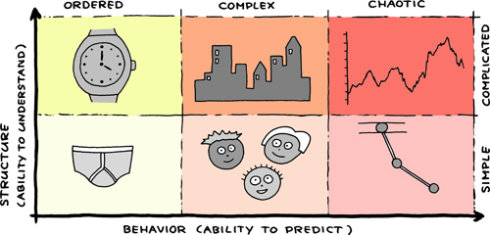
理解成本:规模和结构是影响理解成本的两个因素
宏大的规模是不好理解的,譬如:在城市路网中容易迷路,但在乡村中就那么几条道
复杂的结构是不好理解的,譬如:一个钟表要比一条内裤难以理解
当需求增多时,软件系统的规模也会增大,且这种增长趋势并非线性增长,会更加陡峭。倘若需求还产生了事先未曾预料到的变化,我们又没有足够的风险应对措施,在时间紧迫的情况下,难免会对设计做出妥协,头疼医头、脚疼医脚,在系统的各个地方打上补丁,从而欠下技术债(Technical Debt)。当技术债务越欠越多,累积到某个临界点时,就会由量变引起质变,整个软件系统的复杂度达到巅峰,步入衰亡的老年期,成为“可怕”的遗留系统。
正如饲养场的“奶牛规则”:奶牛逐渐衰老,最终无奶可挤;然而与此同时,饲养成本却在上升。
——《实现领域驱动设计 - 深入理解软件的复杂度》张逸
预测难度:当下的筹码不足以应对未来的变化
业务变化不可预测,譬如:头条一开始只是一个单端的咨询流产品,5 年前谁也不会预先设计 Lite 版、抖音、懂车帝等,多端以及新的业务场景带来的变化是无法预测的。很多时候,我们只需要在当下做到“恰当”的架构设计,但需要尽可能保持“有序”,一旦脱离了“有序”,那必将走向混乱,变得愈加不可预测
技术变化不可预测,譬如:作为一个 Java 开发人员,Lambda 表达式的简洁、函数式编程的快感、声明式/响应式 UI 的体验,都是“真香”的技术变化,而陈旧的 Java 版本以及配套的依赖都需要升级,一旦升级,伴随着的就是多版本共存、依赖地狱(传递升级)等令人胆颤的问题。很多时候,我们不需要也没办法做出未来技术的架构设计,但需要让架构保持“清晰”,这样我们能更快的拥抱技术的变化
既然注定是逆风局,那跑到最后就算赢。
过多的流程规范反倒会让大家觉得是自己是牵线木偶,牵线木偶注定会随风而逝。
我们应该更多“强调”一些原则,譬如:分而治之、控制规模、保持结构的清晰与一致,而不是要求大家一定要按照某一份指南进行架构设计,那既降低不了复杂度,又跟不上变化。“强调”并不直接解决问题,而是把重要的问题凸显出来,让大家在一定的原则下自己找到问题的解决办法。
我们的打法
我们的套路是:定义问题 → 确定架构 → 方案落地 → 结果复盘。越是前面的步骤,就越是重要和抽象,也越是困难,越能体现架构师的功力。所以,我们打法的第一步就是要认清问题所在。
认清问题
问题分类
架构的问题是盘根错节的,将所有问题放在一起,就有轻重缓急之分,就有类别之分。区分问题的类别,就能在一定的边界内,匹配上对应的人来解决问题。
工程架构:
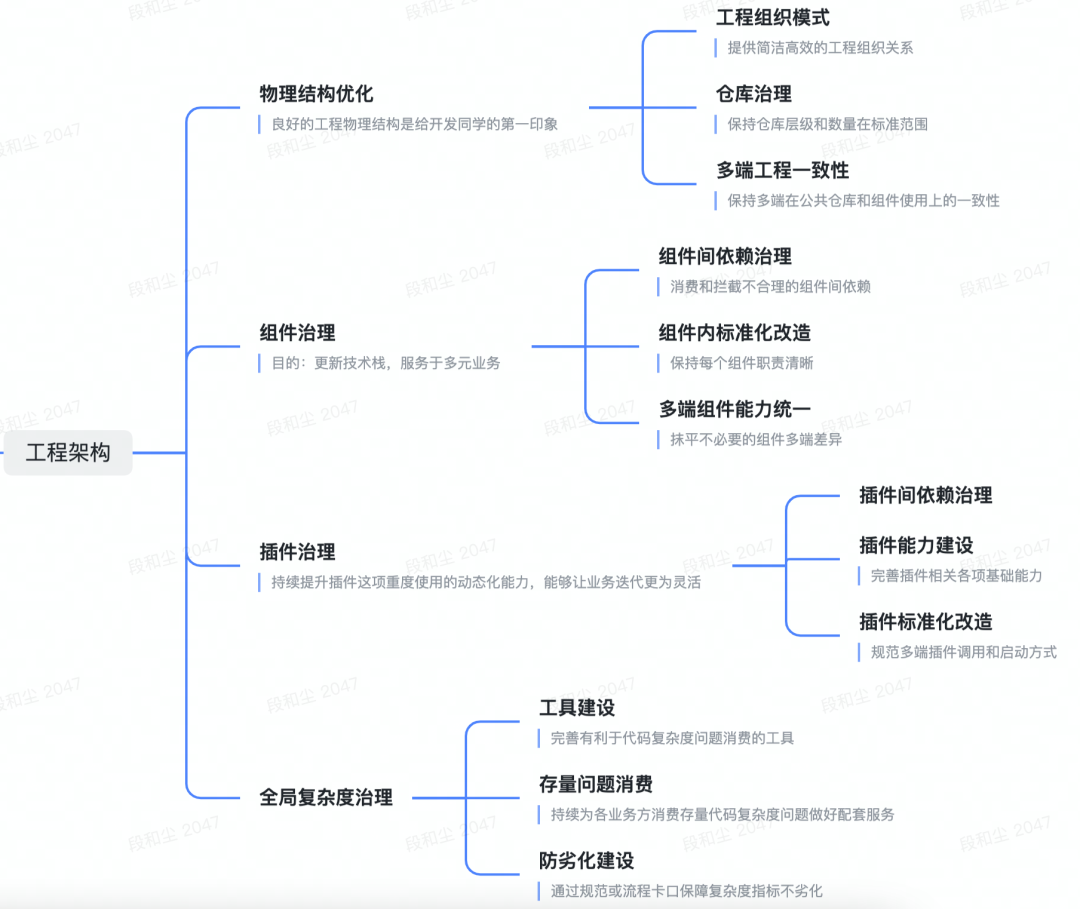
业务架构:

基础能力:
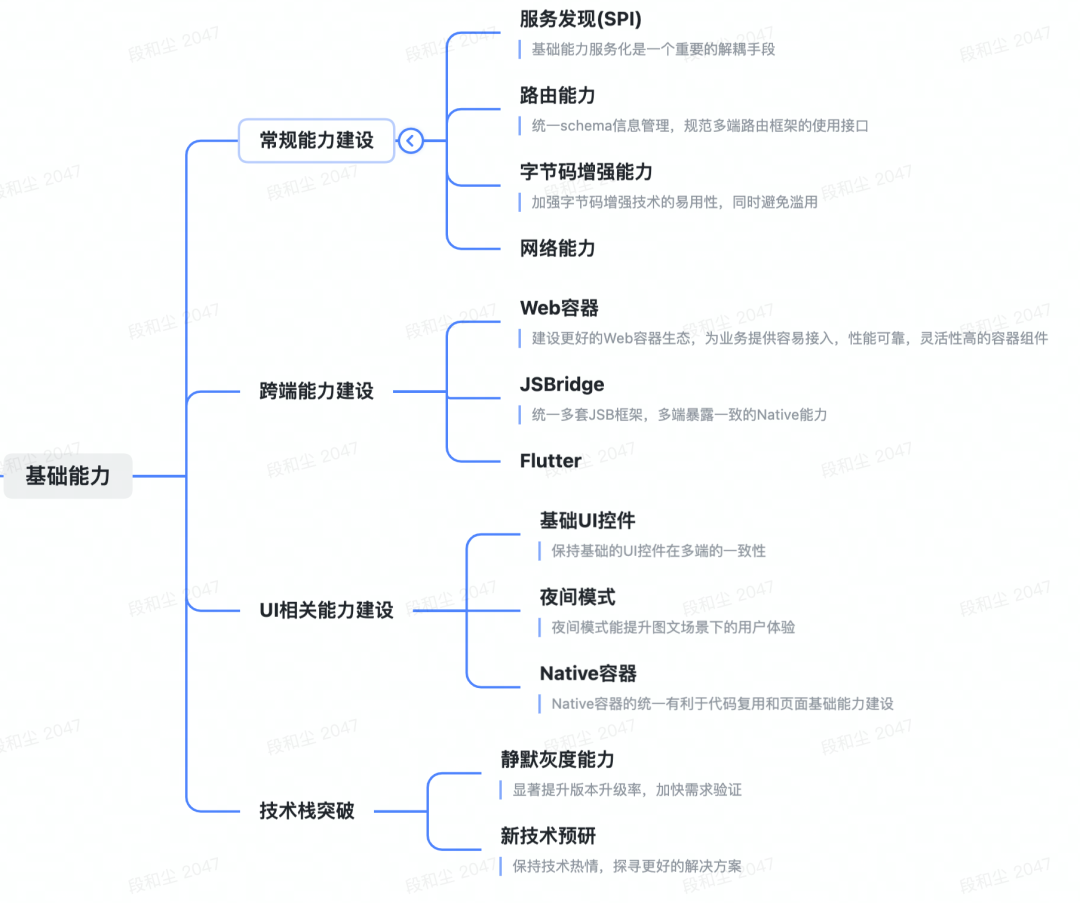
标准化:
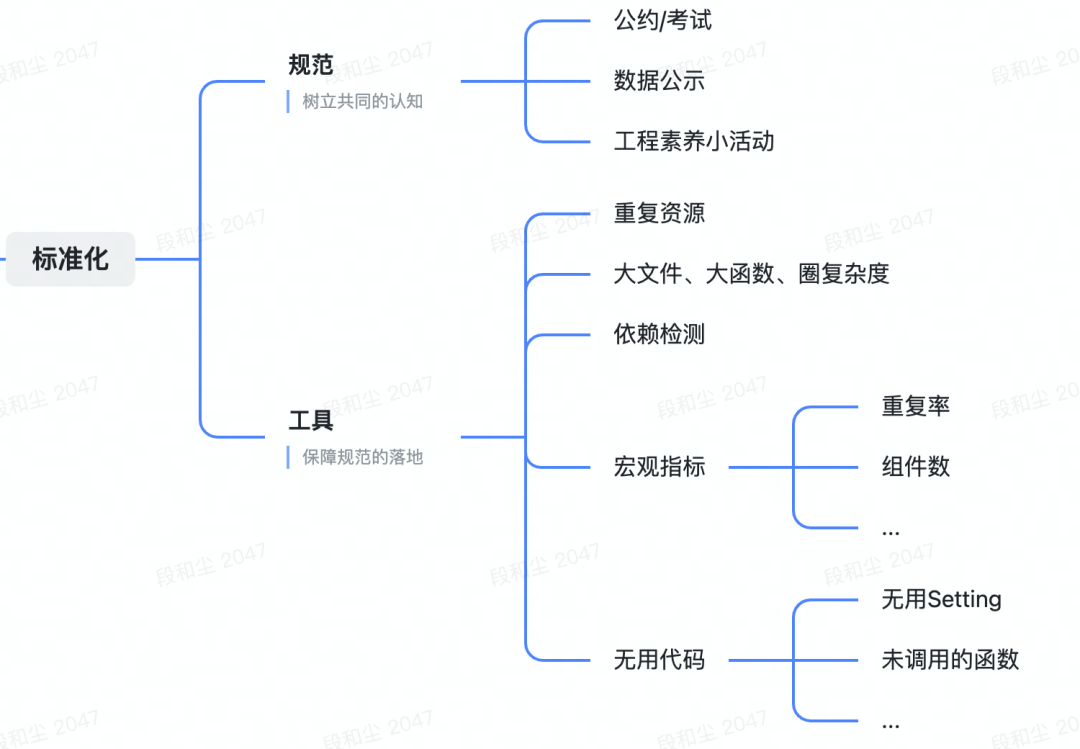
问题分级
挑战、问题、手段这些经常混为一谈,哪些是挑战?哪些是问题?那些是手段?其实这些都是一回事,就是矛盾,只是不同场景下,矛盾所在的层级不同,举一个例子:

我们判断当前的研发体验不能满足业务日渐延伸的需要,这是一个矛盾,既是当下的挑战,也是当下的一级问题。要处理好这个矛盾,我们得拆解它,于是就有了二级问题:我们的代码逻辑是否已经足够优化?研发流程是否已经足够便捷?文档工具是否已经足够完备?二级问题也是矛盾,解决好二级问题就是我们处理一级矛盾的手段。这样层层递进下去,我们就能把握住当前我们要重点优化和建设的一些基础能力:插件化、热更新、跨端能力。
在具体实践过程中,基础技术能力还需要继续拆解,譬如:热更新能力有很多(Java 层的 Robust/Qzone 超级补丁/Tinker 等,Native 层的 Sophix/ByteFix 等),不同热更方案各有优劣,适用场景也不尽相同。我们要结合现状做出判断,从众多方案汲取长处,要么做出更大的技术突破创新,要么整合已有的技术方案进行组合创新。
勤于思考问题背后的问题
亨利福特说,如果我问客户需要什么,他们会告诉我,他们需要一匹更快的马。从亨利福特的这句话,我们可以提炼出一个最直接的问题:客户需要一匹更快的马。立足这个问题本身去找解决方案,可能永远交不出满意的答卷:寻找更好的品种,更科学的训马方式。
思考问题背后的问题,为什么客户需要一匹更快的马?可能客户想要更快的日常交通方式,上升了一个层次后,我们立刻找到了更好的解决方案:造车。
我们不能只局限于问题本身,还需要看到问题背后的问题,然后才能更容易找到更多的解决方案。
认知金字塔
引用认知金字塔这个模型,谨以此共勉,让我们能从最原始数据中,提炼出解决问题的智慧。
DATA: 金字塔的最底层是数据。数据代表各种事件和现象。数据本身没有组织和结构,也没有意义。数据只能告诉你发生了什么,并不能让你理解为什么会发生。
INFORMATION: 数据的上一层是信息。信息是结构化的数据。信息是很有用的,可以用来做分析和解读。
KNOWLEDGE: 信息再往上一层是知识。知识能把信息组织起来,告诉我们事件之间的逻辑联系。有云导致下雨,因为下雨所以天气变得凉快,这都是知识。成语典故和思维套路都是知识。模型,则可以说是一种高级知识,能解释一些事情,还能做预测。
WISDOM: 认知金字塔的最上一层,是智慧。智慧是识别和选择相关知识的能力。你可能掌握很多模型,但是具体到这个问题到底该用哪个模型,敢不敢用这个模型,就是智慧。
这就是“DIKW 模型”。
循序渐进
架构的问题不能等,也不能急。一个大型应用软件,并非要求所有部分都是完美设计,针对一部分低复杂性的区域或者不太可能花精力投入的区域,满足可用的条件即可,不需要投入高质量的构建成本。
以治理头条复杂度为例:
长期的架构目标:更广(多端复用)、更快(单端开发速度)、更好(问题清理和前置拦截)
当下的突出问题:业务之间耦合太重、缺少标准规范、代码冗余晦涩

细节已打码,请读者不要在意。重点在于厘清问题之后,螺旋式上升,做到长期有方向,短期有反馈。
最后
一顿输出之后,千万不能忘却了人文关怀,毕竟谋事在人。架构狮得供起来,他们高瞻远瞩,运筹帷幄;但架构人,却是更需要被点亮的,他们可能常年在“铲屎”,他们期望得到认可,他们有的还没有对象…干着干着,架构的故事还在,但人却仿佛早已翻篇。
来源:字节跳动技术团队 blog.csdn.net/ByteDanceTech/article/details/123700599
收起阅读 »新的图形框架可以带来什么? 揭秘OpenHarmony新图形框架
3月30日,OpenHarmony v3.1 Release版本正式发布了。此版本为大家带来了全新的图形框架,实现了UI框架显示、多窗口、流畅动画等基础能力,夯实了OpenHarmony系统能力基座。下面就带大家详细了解新图形框架。
一、完整能力视图
新图形框架的能力在持续构建中,图1展示了新图形框架当前及未来提供的完整能力视图。
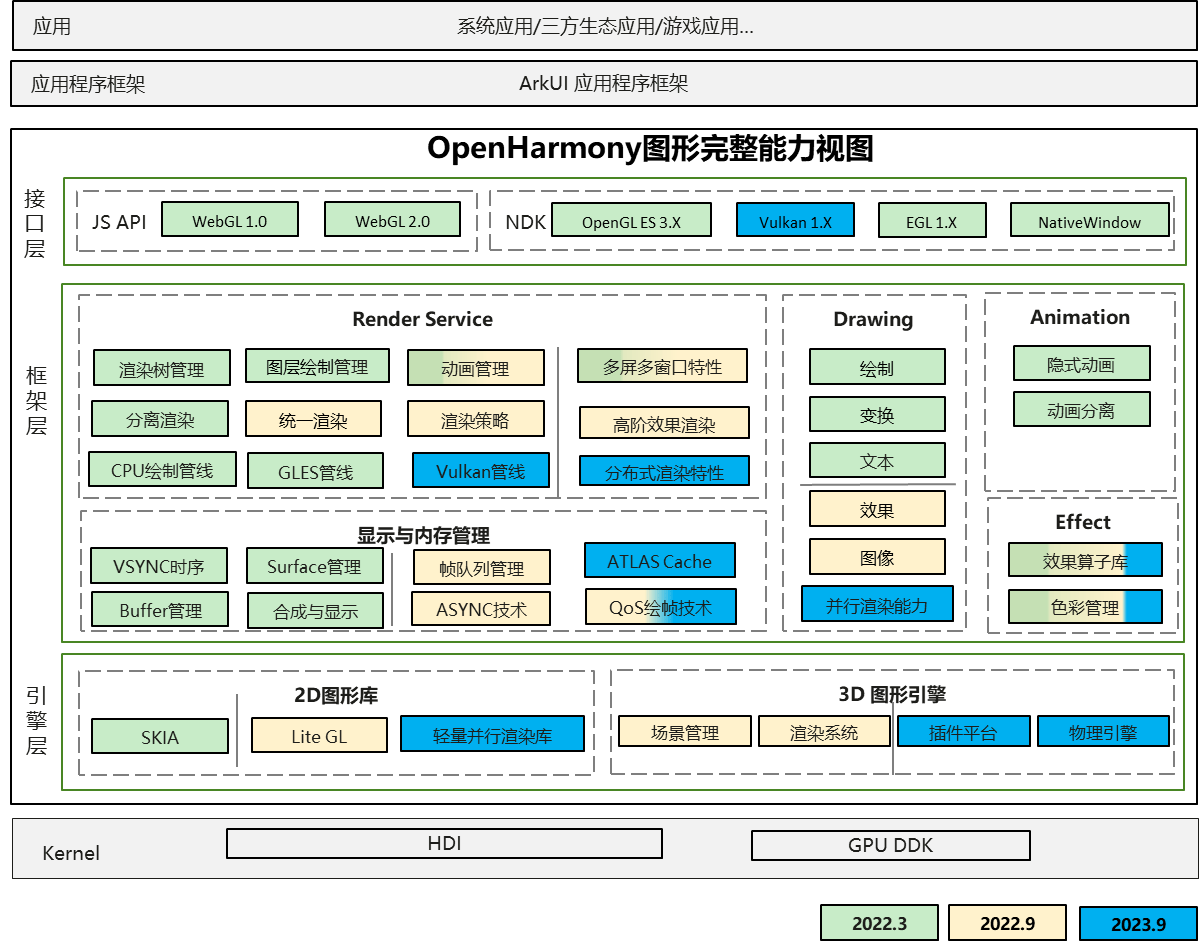
图1 OpenHarmony图形完整能力视图
按照分层抽象和轻模块化的架构设计原则,新图形框架分为接口层、架构层和引擎层。各层级说明如下:
● 接口层:提供图形NDK(native development kit,原生开发包)能力,包括OpenGL ES、Native Drawing等绘制接口能力。
● 框架层:由Render Service、Animation、Effect、Drawing、显示与内存管理等核心模块组成。框架层各模块说明如下:
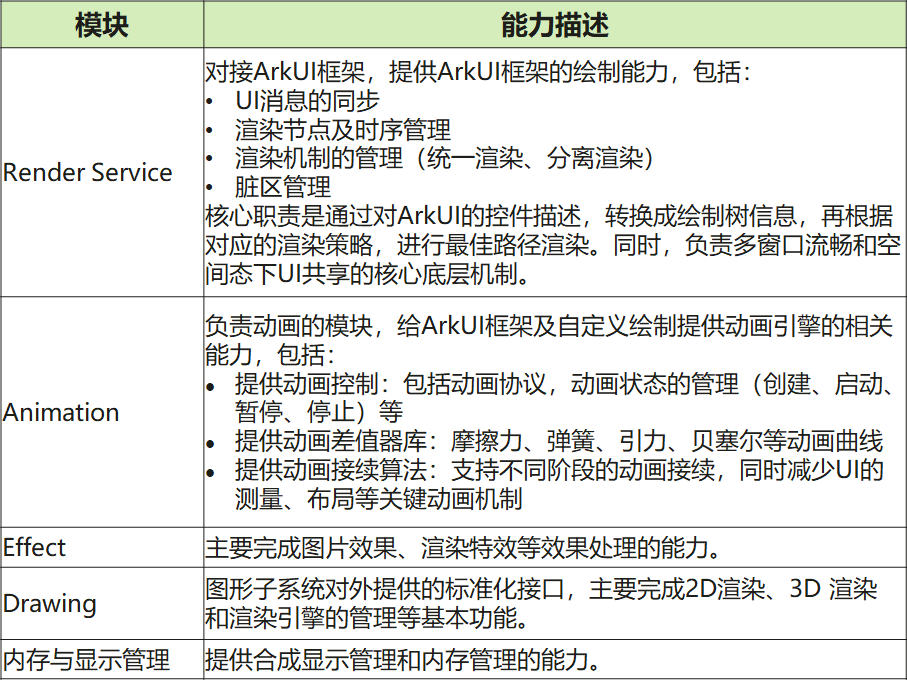
● 引擎层:包括2D图形库和3D图形引擎两个模块。2D图形库提供2D图形绘制底层API,支持图形绘制与文本绘制底层能力。3D图形引擎能力尚在构建中。
二、新图形框架的亮点
经过上一节介绍,我们对新图形框架的完整能力有了基本的了解。那么,新图形框架有什么亮点呢?
新图形框架在渲染、动画流畅性、接口方面重点发力:
(1)渲染方面
通常来讲,UI界面显示分为两个部分:一是描述的UI元素在应用内部显示,二是多个应用的界面在屏幕上同时显示。对此,新图形框架从功能上做了相应的设计:控件级渲染和窗口级渲染。“控件级渲染”重点考虑如何跟UI框架前端进行对接,需要将ArkUI框架的控件描述转换成绘制指令,并提供对应的节点管理以及渲染能力。而“窗口级渲染”重点考虑如何将多个应用合成显示到同一个屏幕上。
(2)动画流畅性方面
我们深挖动画处理流程中的各个环节,对新图形框架进行了新的动画实现设计,提升动画的流畅性体验。
(3)接口方面
新图形框架在接口层提供了更丰富的接口能力。
下面为大家一一详细介绍新图形框架的亮点特性。
1. 控件级渲染
新图形框架实现了基于RenderService(简称RS)的控件级渲染功能,如图2所示。
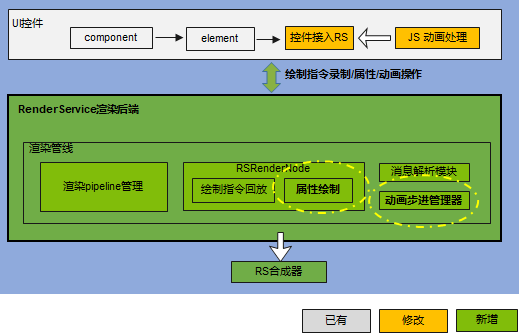
图2 控件级渲染
控件级渲染功能具有以下特点:
● 支持GPU渲染,提升渲染性能。
● 动画逻辑从主线程中剥离,提供独立的步进驱动机制。
● 将渲染节点属性化,属性与内容分离。
2. 窗口级渲染
新图形框架实现了基于RenderService的窗口级渲染功能,如图3所示。
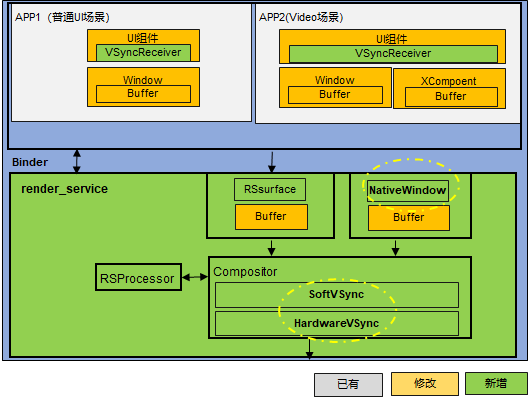
图3 窗口级渲染
窗口级渲染功能具有以下特点:
● 取代Weston合成框架,实现RS新合成框架。
● 支持硬件VSync/软件Vsync。
● 支持基于NativeWindow接入EGL/GLES的能力。
● 更灵活的合成方式,支持硬件在线合成/CPU合成/混合合成(GPU合成即将上线)。
● 支持多媒体图层在线overlay。
3. 更流畅的动画体验
动画流畅性是一项很基本、也很关键的特性,直接影响用户体验。为了提升动画的流畅性体验,我们深挖动画处理流程中的各个环节,对新图形框架进行了新的动画实现设计。
如图4所示,传统动画的实现流程如下:
(1) 应用创建动画,设置动画参数。
(2) 每帧回调,修改控件参数,重新测量、布局、绘制。
(3) 内容渲染。
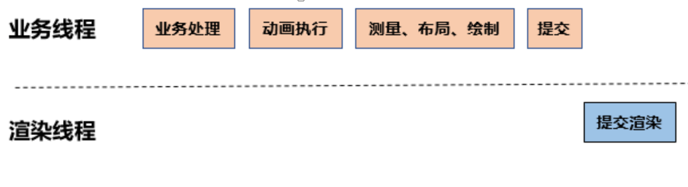
图4 传统动画实现
经过深入分析,我们发现传统动画实现存在以下缺点:
(1)UI与动画一起执行,UI的业务阻塞会影响动画的执行,导致动画卡顿。
(2)每帧回调修改控件属性,会触发测量布局录制,导致耗时增加。
针对以上两点缺陷,我们对新图形框架进行了新的动画实现设计,如图5所示。
图5 新框架的动画实现
(1)动画与UI分离。
动画在渲染线程步进,与UI业务线程分离。
(2)动画仅测量、布局、绘制一次,降低动画负载。
通过计算最终界面属性值,对有改变的控件添加动画,动画过程中不测量、布局、绘制,提升性能。
4. 对外提供的接口
新图形框架提供了丰富的接口:
(1)SDK:支持WebGL 1.0、WebGL 2.0,满足JS开发者的3D开发的需求。
WebGL开发指导:
(2)NDK:支持OpenGL ES3.X,可以通过XComponent提供的nativewindow创建EGL/OPENGL绘制环境,满足游戏引擎等开发者对3D绘图能力的需求。
图6 OpenGL ES使用示例
新图形框架还处于不断完善过程中,我们将基于新框架提供更多的能力,相信以后会给大家带来更多的惊喜,敬请期待~
收起阅读 »




