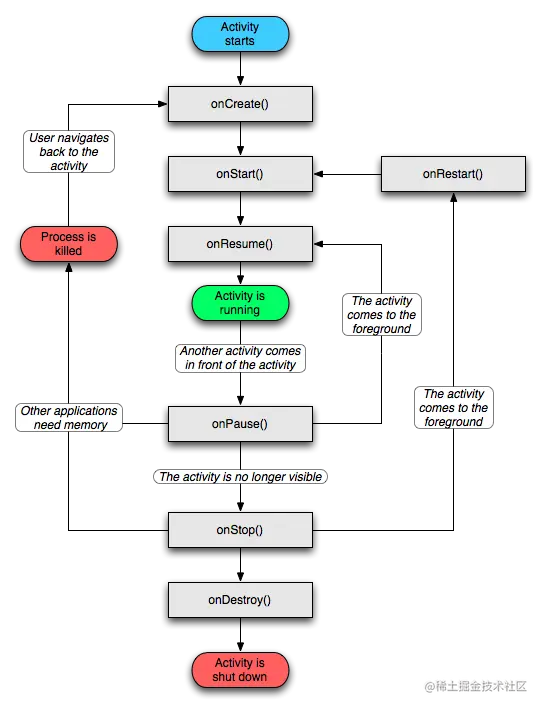
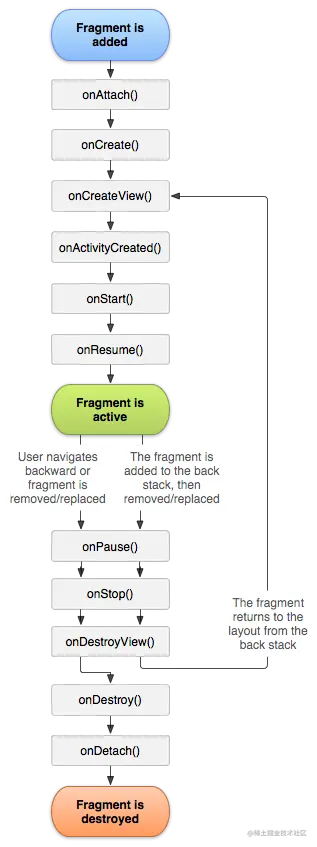
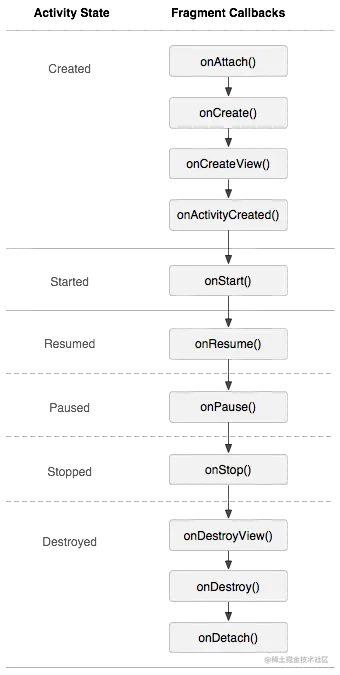
Jetpack Compose的预览版出来已经有很长时间了,相信很多读者都进行了一番尝试。注意:下文如无特殊说明,Compose均指代Jetpack Compose
可以说,Compose在声明布局时,其风格和React的JSX、Flutter 等非常的相似。
而且有一个高频出现的内容: Modifier,即 修饰器,顾名思义,它是一种修饰器, 在Compose的设计中,和UI相关的内容都涉及到它,例如:尺寸,形状 等
这一篇文章,我们一起学习两部分内容:
- Modifier的源码和设计
- SDK中既有的Modifier实现概览
当然,最全面的学习文档当属:官方API文档 , 后续查询API的含义和设计细节等都会用到,建议收藏
文中的代码均源自 1.0.1 版本
先放大招,Modifier的45行代码
其实有效代码行大约20行。
先举个使用示例:
Modifier.height(320.dp).fillMaxWidth()
这里的 Modifier 是接口 androidx.compose.ui.Modifier 的匿名实现,这也是一个很有意思的实用技巧。
我们先简单的概览下源码,再进行解读:
interface Modifier {
// ...
companion object : Modifier {
override fun
override fun
override fun any(predicate: (Element) -> Boolean): Boolean = false
override fun all(predicate: (Element) -> Boolean): Boolean = true
override infix fun then(other: Modifier): Modifier = other
override fun toString() = "Modifier"
}
}
而本身的接口则为:
package androidx.compose.ui
import androidx.compose.runtime.Stable
interface Modifier {
fun
fun
fun any(predicate: (Element) -> Boolean): Boolean
fun all(predicate: (Element) -> Boolean): Boolean
infix fun then(other: Modifier): Modifier =
if (other === Modifier) this else CombinedModifier(this, other)
}
Modifier接口默认实现赏析
先看Modifier接口,和Java8类似,Kotlin的接口可以提供默认实现, 显然, foldIn 和 foldOut 在这里是看不出门道的,必须结合 operation来看,先略过。
any 和 all 也是看不出啥的,毕竟我把注释都删了 而 then 方法则有点意思,接收一个 Modifier 接口实例, 如果该实例是Modifier的内部默认实现,则认为是无效操作,依旧返回自身,否则则返回一个 CombinedModifier实例 将自身和 other 结合在一起。
从这里,我们可以读出一点 味道 : 设计者一定会将一系列的Modifier设计成一个类似链表的结构,并且希望我们从Modifier的 companion实现开始进行构建。
其实,结合注释,我们可以知道Modifier确实会组成一个链表,并且 any 和 all 是对链表的元素运行判断表达式。
Modifier companion实现赏析
再回过头来看 companion实现。then、foldIn,foldOut 都是给啥返回啥, 再结合先前的接口默认实现,我们可以推断: 正常使用的话,最终的链表中不包含 companion实现 ,这从它的 any 和 all 的实现也可见一斑。
很显然这是一个有意思的技巧,这里不做过多解析,但既然我这样描述,一定可以让它进入链表中的。
CombinedModifier 实现
package androidx.compose.ui
import androidx.compose.runtime.Stable
class CombinedModifier(
private val outer: Modifier,
private val inner: Modifier
) : Modifier {
override fun
inner.foldIn(outer.foldIn(initial, operation), operation)
override fun
outer.foldOut(inner.foldOut(initial, operation), operation)
override fun any(predicate: (Modifier.Element) -> Boolean): Boolean =
outer.any(predicate) || inner.any(predicate)
override fun all(predicate: (Modifier.Element) -> Boolean): Boolean =
outer.all(predicate) && inner.all(predicate)
override fun equals(other: Any?): Boolean =
other is CombinedModifier && outer == other.outer && inner == other.inner
override fun hashCode(): Int = outer.hashCode() + 31 * inner.hashCode()
override fun toString() = "[" + foldIn("") { acc, element ->
if (acc.isEmpty()) element.toString() else "$acc, $element"
} + "]"
}
目前依旧缺乏有效的信息来解读 foldIn 和 foldOut 最终会干点啥,但可以看出其执行的次序,另外可以看出 any 和 all 没啥幺蛾子。
看完 Modifier.Element 之后我们赏析下 foldIn 和 foldOut的递归
Modifier.Element
不出意外,SDK内部的各种修饰效果都将实现这一接口,同样没啥幺蛾子。
package androidx.compose.ui
interface Modifier {
//...
interface Element : Modifier {
override fun
operation(initial, this)
override fun
operation(this, initial)
override fun any(predicate: (Element) -> Boolean): Boolean = predicate(this)
override fun all(predicate: (Element) -> Boolean): Boolean = predicate(this)
}
}
foldIn 和 foldOut 赏析
这里举一个栗子来看 foldIn 和 foldOut 的递归:
class A : Modifier.Element
class B : Modifier.Element
class C : Modifier.Element
fun Modifier.a() = this.then(A())
fun Modifier.b() = this.then(B())
fun Modifier.c() = this.then(C())
那么 Modifier.a().b().c() 的到的是什么呢?为了看起来直观点,我们 以 CM 代指 CombinedModifier
CM (
outer = CM (
outer = A(),
inner = B()
),
inner = C()
)
结合前面阅读源码获得的知识,我们再假设一个operation:
val initial = StringBuilder()
val operation: (StringBuilder, Element) -> StringBuilder = { builder, e ->
builder.append(e.toString()).append(";")
builder
}
显然:
Modifier.a().b().c().foldIn(initial, operation)
所得到的执行过程为:
val ra = operation.invoke(initial,A())
val rb = operation.invoke(ra,B())
return operation.invoke(rb,C())
从链表的头部执行到链表的尾部。
而foldOut 则相反,从链表的尾部执行到链表的头部。
当然,真正使用时,我们不一定会一直返回 initial。 但这和Modifier没啥关系,只影响到你对哪个对象使用Modifier。
SDK中既有的Modifier实现概览
上文中,我们在 Modifier的源码和设计细节 上花费了很长的篇幅,相信各位读者也已经彻底理解,下面我们看点轻松的。
很显然,下面这部分内容 混个脸熟 即可,就像在Android中的原生布局,一时间遗忘了布局属性的具体拼写也无伤大雅,借助SDK文档可以很快的查询到, 但是 不知道有这些属性 就会影响到开发了。
三个重要的包
- androidx.compose.foundation.layout: Modifier和布局相关的扩展
- androidx.compose.ui.draw: Modifier和绘制相关的扩展
- androidx.compose.foundation:Modifier的基础包,其中扩展部分主要为点击时间、背景、滑动等
API文档的内容是很枯燥的,如果读者仅仅是打算先混个脸熟,可以泛读下文内容,如果打算仔细的结合API文档进行研究,可以Fork 我的WorkShop项目 ,将源码和效果对照起来
foundation-layout库 -- androidx.compose.foundation.layout
具体的API列表和描述见 Api文档
这个包中,和布局相关,诸如:尺寸、边距、盒模型等,很显然,其中的内容非常的多。关于Modifier的内容,我们不罗列API。
正如同 DSL 的设计初衷,对于Compose而言,了解Android原生开发的同学,或者对前端领域有一丁点了解的同学,70%的DSL-API可以一眼看出其含义, 而剩下来的部分,多半需要实际测试下效果。
ui库 -- androidx.compose.ui.draw
这部分大多和绘制相关,类比Android原生技术栈,部分内容是比较深入的,是 自定义时 使用的 工具,所幸这部分API不太多,我们花费一屏来罗列下, 混个脸熟。
具体的API列表和描述见 Api文档
- 透明度
Modifier.alpha(alpha: Float)
- 按形状裁切
Modifier.clip(shape: Shape)
- 按照指定的边界裁切内容, 类似Android中的子View内容不超过父View
Modifier.clipToBounds()
Clip the content to the bounds of a layer defined at this modifier.
- 在此之后进行一次指定的绘制
Modifier.drawBehind(onDraw: DrawScope.() -> Unit)
Draw into a Canvas behind the modified content.
- 基于缓存绘制, 用于尺寸未发生变化,状态未发生变化时
Modifier.drawWithCache(onBuildDrawCache: CacheDrawScope.() -> DrawResult)
- 人为控制在布局之前或者之后进行指定的绘制
Modifier.drawWithContent(onDraw: ContentDrawScope.() -> Unit)
- 利用Painter 进行绘制
Modifier.paint(painter: Painter, sizeToIntrinsics: Boolean, alignment: Alignment, contentScale: ContentScale, alpha: Float, colorFilter: ColorFilter?)
- 围绕中心进行旋转
Modifier.rotate(degrees: Float)
- 缩放
Modifier.scale(scaleX: Float, scaleY: Float)
- 等比缩放
Modifier.scale(scale: Float)
- 绘制阴影
Modifier.shadow(elevation: Dp, shape: Shape, clip: Boolean)
foundation库 -- androidx.compose.foundation
所幸这部分也不太多,罗列下
- 设置背景
Modifier.background(color: Color, shape: Shape = RectangleShape)
Modifier.background(brush: Brush, shape: Shape = RectangleShape, alpha: Float = 1.0f)
Brush 是渐变的,Color是纯色的
- 设置边界,即描边效果
Modifier.border(border: BorderStroke, shape: Shape = RectangleShape)
Modifier.border(width: Dp, color: Color, shape: Shape = RectangleShape)
Modifier.border(width: Dp, brush: Brush, shape: Shape)
- 点击效果
Modifier.clickable(enabled: Boolean = true, onClickLabel: String? = null, role: Role? = null, onLongClickLabel: String? = null, onLongClick: () -> Unit = null, onDoubleClick: () -> Unit = null, onClick: () -> Unit)
Modifier.clickable(enabled: Boolean = true, interactionState: InteractionState, indication: Indication?, onClickLabel: String? = null, role: Role? = null, onLongClickLabel: String? = null, onLongClick: () -> Unit = null, onDoubleClick: () -> Unit = null, onClick: () -> Unit)
长按、单击、双击均包含在内
- 可滑动
Modifier.horizontalScroll(state: ScrollState, enabled: Boolean = true, reverseScrolling: Boolean = false)
Modifier.verticalScroll(state: ScrollState, enabled: Boolean = true, reverseScrolling: Boolean = false)
结语
这篇博客算是正式开始学习Jetpack Compose。
这是一个全新的内容,要真正的全面掌握还需要积累很多的知识,就如同最开始入门Android开发那样,各类控件的使用都需要学习和记忆
但它也仅局限于:一种新的声明式、响应式UI构建框架,并不用过于畏惧,虽然有一定的上手成本,但还没有颠覆整个Android客户端的开发方式。
另:WorkShop中的演示代码会跟随整个Compose系列的问题,我是兴致来了就更新一部分,这意味着可能会出现:有些效果博客中提到了,但WorkShop中没有写进去