

















































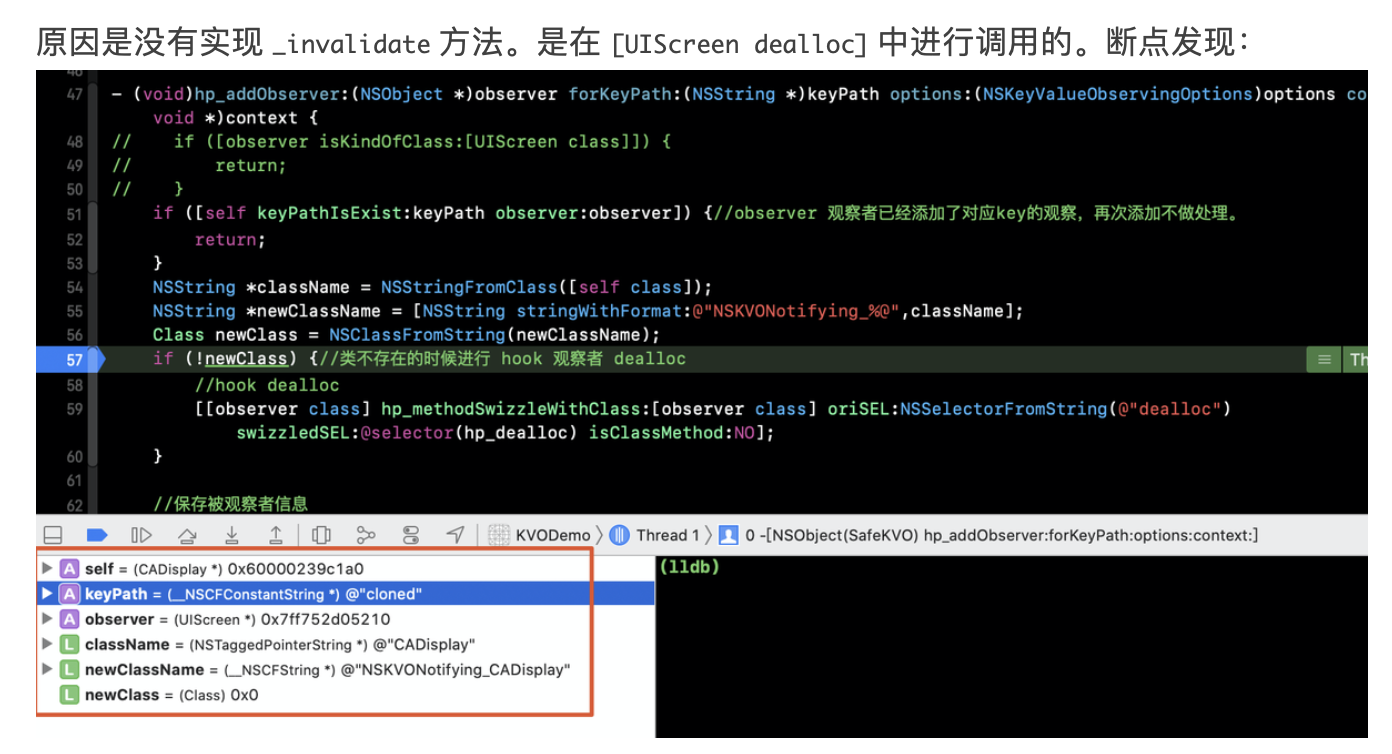
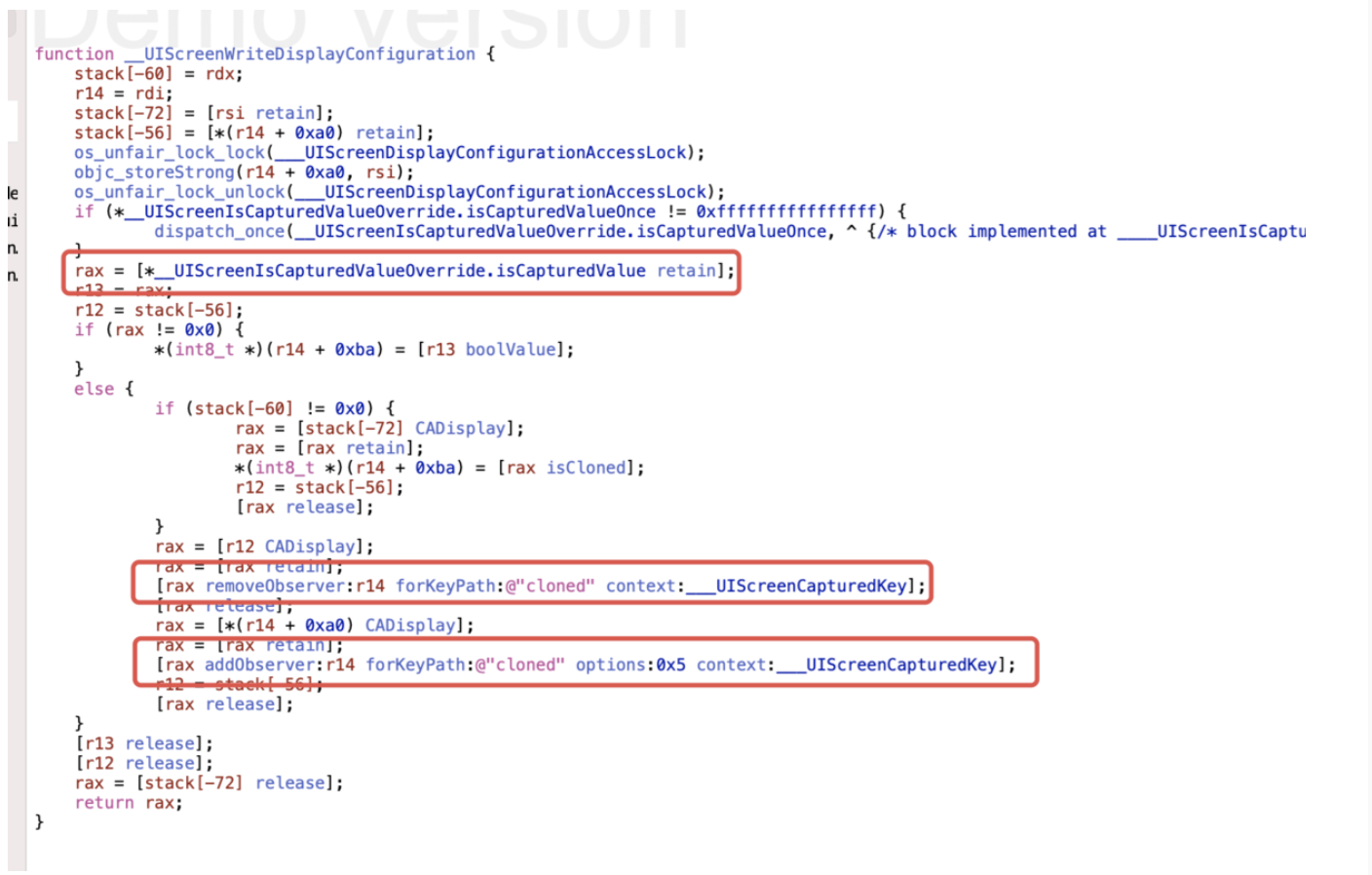

- DecorView何时绘制到屏幕中
- DecorView如何绘制到屏幕中(addView,removeView,upDateViewLayout)
- Activity是如何得到Touch事件的
DecorView何时绘制到屏幕中
在Activity的启动流程中提到执行Activity的performLaunchActivity方法执行的时,先是通过反射创建了Activity,然后会调用Activity的attach方法,在上一篇我们知道attach方法做了PhoneWindow的初始化操作,再然后才是执行生命周期onCreate,而setContent方法又是在onCreate执行后,看起来一切都很合理。
先创建一个Activity,然后再为这个Activity创建一个PhoneWindow,执行onCreate,最后再把我们写的XML设置进去。
一切都准备就绪,但是我们到目前还是看不到界面,因为我们知道,Activity真正可见是在执行onResume的时候。所以对于DecorView何时绘制到屏幕中问题,其实答案已经出来了,接下来需要去代码里进行验证。
看过我之前文章的人知道找Activity不同生命周期具体执行代码要去TransactionExecutor里看performLifecycleSequence方法。
Activity的onRemune具体执行是在Activity的handleResumeActivity方法中,我们去看看这里是怎么处理PhoneWindow的。
android.app.ActivityThread
@Override
public void handleResumeActivity(IBinder token, boolean finalStateRequest, boolean isForward,
String reason) {
......
// TODO Push resumeArgs into the activity for consideration
performResumeActivity内会触发Activity的onResume生命周期
final ActivityClientRecord r = performResumeActivity(token, finalStateRequest, reason);
......
r.window = r.activity.getWindow();
//获取到当前PhoneWindow的DecorView
View decor = r.window.getDecorView();
decor.setVisibility(View.INVISIBLE);
ViewManager wm = a.getWindowManager();
......
关键代码
wm.addView(decor, l);
......
}
关键代码只有简单的一句wm.addView(decor, l);
找出WindowManagerImpl
这个wm是ViewManager类型,然后获取他的方法是Activity的WindowManager。先来搞清楚一下WindowManager和ViewManager是什么关系。
假装分析一波,能用ViewManager去接收WindowManager,说明WindowManager要么是ViewManager的子类,要么是实现了ViewManager接口。而且会使用wm.addView。就说明这个addView方法ViewManager里被定义了,在WindowManager中没有,否则不会这么去写。
其实也不用想这么多,各自点进去看看就知道了。
android.view.ViewManager
public interface ViewManager
{
public void addView(View view, ViewGroup.LayoutParams params);
public void updateViewLayout(View view, ViewGroup.LayoutParams params);
public void removeView(View view);
}
android.view.WindowManager
@SystemService(Context.WINDOW_SERVICE)
public interface WindowManager extends ViewManager {
......
}
ViewManager是个接口,里面虽然只有三个方法,但是我们却非常熟悉,这三个方法的重要性就不用多说了。
让我没想到的是WindowManager居然也是个接口......那addView具体的实现在哪呢。只能去getWindowManager具体找找了。
android.app.Activity
......
private WindowManager mWindowManager;
......
public WindowManager getWindowManager() {
return mWindowManager;
}
而的赋值操作在attach里
final void attach(......){
mWindow = new PhoneWindow(this, window, activityConfigCallback);
mWindow.setWindowControllerCallback(mWindowControllerCallback);
mWindow.setCallback(this);
mWindow.setOnWindowDismissedCallback(this);
mWindow.getLayoutInflater().setPrivateFactory(this);
......
给PhoneWindow设置一个WindowManager
mWindow.setWindowManager((WindowManager)context.getSystemService(Context.WINDOW_SERVICE),
mToken, mComponent.flattenToString(),
(info.flags & ActivityInfo.FLAG_HARDWARE_ACCELERATED) != 0);
if (mParent != null) {
mWindow.setContainer(mParent.getWindow());
}
取出WindowManager来赋值给mWindowManager
mWindowManager = mWindow.getWindowManager();
}
所以想知道mWindowManager到底是啥还得看mWindow.getWindowManager。而mWindow.getWindowManager返回的又是上面的一行mWindow.setWindowManager,所以去setWindowManager看看吧
android.view.Window
......
private WindowManager mWindowManager;
......
public void setWindowManager(WindowManager wm, IBinder appToken, String appName,
boolean hardwareAccelerated) {
mAppToken = appToken;
mAppName = appName;
mHardwareAccelerated = hardwareAccelerated;
if (wm == null) {
wm = (WindowManager)mContext.getSystemService(Context.WINDOW_SERVICE);
}
关键代码
mWindowManager = ((WindowManagerImpl)wm).createLocalWindowManager(this);
}
......
public WindowManager getWindowManager() {
return mWindowManager;
}
真相浮出水面
mWindowManager的真实对象是WindowManagerImpl
addView
这一小节我们来看看Window的添加过程
找了这么久我们就是为了弄明白wm.addView(decor, l);的wm到底是个啥。下面去看看addView到底把我们的DecorView怎么了。
android.view.WindowManagerImpl
public final class WindowManagerImpl implements WindowManager {
@UnsupportedAppUsage
private final WindowManagerGlobal mGlobal = WindowManagerGlobal.getInstance();
......
@Override
public void addView(@NonNull View view, @NonNull ViewGroup.LayoutParams params) {
applyDefaultToken(params);
mGlobal.addView(view, params, mContext.getDisplayNoVerify(), mParentWindow,
mContext.getUserId());
}
......
}
WindowManagerImpl居然又是个空壳,大部分操作都给了单例类WindowManagerGlobal去处理,
android.view.WindowManagerGlobal
private final ArrayList<View> mViews = new ArrayList<View>();
private final ArrayList<ViewRootImpl> mRoots = new ArrayList<ViewRootImpl>();
private final ArrayList<WindowManager.LayoutParams> mParams =
new ArrayList<WindowManager.LayoutParams>();
private final ArraySet<View> mDyingViews = new ArraySet<View>();
public void addView(View view, ViewGroup.LayoutParams params,Display display,
Window parentWindow, int userId) {
......
ViewRootImpl root;
View panelParentView = null;
synchronized (mLock) {
进行参数检查
if (view == null) {
throw new IllegalArgumentException("view must not be null");
}
if (display == null) {
throw new IllegalArgumentException("display must not be null");
}
if (!(params instanceof WindowManager.LayoutParams)) {
throw new IllegalArgumentException("Params must be WindowManager.LayoutParams");
}
final WindowManager.LayoutParams wparams = (WindowManager.LayoutParams) params;
如果是子Windowh还需要进行布局参数的调整
if (parentWindow != null) {
parentWindow.adjustLayoutParamsForSubWindow(wparams);
}
......
创建ViewRootImpl
root = new ViewRootImpl(view.getContext(), display);
view.setLayoutParams(wparams);
mViews.add(view);
mRoots.add(root);
mParams.add(wparams);
// do this last because it fires off messages to start doing things
try {
//把DecorView交给ViewRootImpl
root.setView(view, wparams, panelParentView, userId);
} catch (RuntimeException e) {
// BadTokenException or InvalidDisplayException, clean up.
if (index >= 0) {
removeViewLocked(index, true);
}
throw e;
}
}
}
首先我们看到WindowManagerGlobal维护了4个集合
mViews :存储了所有Window所对应的View
mRoots :存储的是所以Window所对应的ViewRootImpl
mParams:存储的是所有Window所对应的布局参数
mDyingViews:存储的是那些正在被删除的View
在addView中后面的关键代码创建了ViewRootImpl,并将我们的DecorView交给了它。
android.view.ViewRootImpl
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView,
int userId) {
synchronized (this) {
if (mView == null) {
mView = view;
}
......
触发一次屏幕刷新
requestLayout();
try {
将最后的操作给mWindowSession
res = mWindowSession.addToDisplayAsUser(mWindow, mSeq, mWindowAttributes,
getHostVisibility(), mDisplay.getDisplayId(), userId, mTmpFrame,
mAttachInfo.mContentInsets, mAttachInfo.mStableInsets,
mAttachInfo.mDisplayCutout, inputChannel,
mTempInsets, mTempControls);
setFrame(mTmpFrame);
} ......
// Set up the input pipeline.
输入事件处理
CharSequence counterSuffix = attrs.getTitle();
mSyntheticInputStage = new SyntheticInputStage();
InputStage viewPostImeStage = new ViewPostImeInputStage(mSyntheticInputStage);
InputStage nativePostImeStage = new NativePostImeInputStage(viewPostImeStage,
"aq:native-post-ime:" + counterSuffix);
InputStage earlyPostImeStage = new EarlyPostImeInputStage(nativePostImeStage);
InputStage imeStage = new ImeInputStage(earlyPostImeStage,
"aq:ime:" + counterSuffix);
InputStage viewPreImeStage = new ViewPreImeInputStage(imeStage);
InputStage nativePreImeStage = new NativePreImeInputStage(viewPreImeStage,
"aq:native-pre-ime:" + counterSuffix);
......
}
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
scheduleTraversals();
}
}
setView方法先是做了个刷新布局的操作,内部执行的scheduleTraversals() 就是View绘制的入口,调用此方法后 ViewRootImpl 所关联的 View 也执行 measure - layout - draw 操作,确保在 View 被添加到 Window 上显示到屏幕之前,已经完成测量和绘制操作。至此由ViewRootImpl完成了添加View到Window的操作。 然后将调用mWindowSession的addToDisplayAsUser方法来完成Window的添加过程,内部真实执行的地方在WMS(WindowManagerService)
View的事件如何反馈到Activity
对于后面的输入事件处理的代码我也不是很明白,但是之前好像在哪里看过,所有对于利用管道和系统底层通信的机制有点印象。 这一块的简单的理解就是:这里是设置了一系列的输入通道。因为一个触屏事件的发生是肯定是由屏幕发起,再经过驱动层一系列的计算处理最后通过 Socket 跨进程通知 Android Framework 层。 其实看到这一块我一开始是不打算继续深入了,因为的也知道我的能力差不多就这了,但是抱着好奇的心点了进去想看看ViewPostImeInputStage是个啥。结果却有了意想不到的收获。
android.view.ViewRootImpl
final class ViewPostImeInputStage extends InputStage {
public ViewPostImeInputStage(InputStage next) {
super(next);
}
@Override
protected int onProcess(QueuedInputEvent q) {
if (q.mEvent instanceof KeyEvent) {
return processKeyEvent(q);
} else {
final int source = q.mEvent.getSource();
if ((source & InputDevice.SOURCE_CLASS_POINTER) != 0) {
只看这里,其实下面的两个都是类似
return processPointerEvent(q);
} else if ((source & InputDevice.SOURCE_CLASS_TRACKBALL) != 0) {
return processTrackballEvent(q);
} else {
return processGenericMotionEvent(q);
}
}
}
}
private int processPointerEvent(QueuedInputEvent q) {
final MotionEvent event = (MotionEvent)q.mEvent;
mAttachInfo.mUnbufferedDispatchRequested = false;
mAttachInfo.mHandlingPointerEvent = true;
boolean handled = mView.dispatchPointerEvent(event);
......
return handled ? FINISH_HANDLED : FORWARD;
}
注意一下参数的传递就知道这个mView其实就是一开始我们DecorView。但是dispatchPointerEvent是在View定义的。
android.view.View
public final boolean dispatchPointerEvent(MotionEvent event) {
if (event.isTouchEvent()) {
return dispatchTouchEvent(event);
} else {
return dispatchGenericMotionEvent(event);
}
}
返回了dispatchTouchEvent和dispatchGenericMotionEvent的执行。所以去DecorView看看
com.android.internal.policy.DecorView
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
final Window.Callback cb = mWindow.getCallback();
return cb != null && !mWindow.isDestroyed() && mFeatureId < 0
? cb.dispatchTouchEvent(ev) : super.dispatchTouchEvent(ev);
}
@Override
public boolean dispatchTrackballEvent(MotionEvent ev) {
final Window.Callback cb = mWindow.getCallback();
return cb != null && !mWindow.isDestroyed() && mFeatureId < 0
? cb.dispatchTrackballEvent(ev) : super.dispatchTrackballEvent(ev);
}
@Override
public boolean dispatchGenericMotionEvent(MotionEvent ev) {
final Window.Callback cb = mWindow.getCallback();
return cb != null && !mWindow.isDestroyed() && mFeatureId < 0
? cb.dispatchGenericMotionEvent(ev) : super.dispatchGenericMotionEvent(ev);
}
我们发现不管是哪个方法,最后都是从mWindow获取一个回调cb,然后把事回调出去。不知道读者对之前在Activity的attach里的时候的代码 mWindow.setCallback(this);还有没有印象,方法接收的参数类型是Window内部的一个接口Callback而我们的Activity实现了这个接口。所以mWindow.setCallback就是把Activity设置了进去,所以这个cb就是我们的Activity,所以DecorView的事件,就这样传递给了Activity
removeView
android.view.WindowManagerGlobal
@UnsupportedAppUsage
public void removeView(View view, boolean immediate) {
if (view == null) {
throw new IllegalArgumentException("view must not be null");
}
synchronized (mLock) {
找到需要删除View的索引
int index = findViewLocked(view, true);
View curView = mRoots.get(index).getView();
真的执行删除操作
removeViewLocked(index, immediate);
if (curView == view) {
return;
}
throw new IllegalStateException("Calling with view " + view
+ " but the ViewAncestor is attached to " + curView);
}
}
Window的删除过程页是在WindowManagerGlobal中。先是找到需要删除View的索引,然后传递到removeViewLocked方法里。
private void removeViewLocked(int index, boolean immediate) {
ViewRootImpl root = mRoots.get(index);
View view = root.getView();
if (root != null) {
root.getImeFocusController().onWindowDismissed();
}
boolean deferred = root.die(immediate);
if (view != null) {
view.assignParent(null);
if (deferred) {
mDyingViews.add(view);
}
}
}
removeViewLocked内部也是通过ViewRootImpl來完成刪除操作的。 在removeView方法里我们就看到了mRoots.get(index).getView(),里面又有View view = root.getView();ViewRootImpl的getView返回的View其实就是上面setView方法里,传进来的我们的顶层视图DecorView。
看看ViewRootImpl的die方法
Params:immediate – True, do now if not in traversal. False, put on queue and do later.
Returns:True, request has been queued. False, request has been completed.
boolean die(boolean immediate) {
// Make sure we do execute immediately if we are in the middle of a traversal or the damage
// done by dispatchDetachedFromWindow will cause havoc on return.
if (immediate && !mIsInTraversal) {
doDie();
return false;
}
if (!mIsDrawing) {
destroyHardwareRenderer();
} else {
Log.e(mTag, "Attempting to destroy the window while drawing!\n" +
" window=" + this + ", title=" + mWindowAttributes.getTitle());
}
mHandler.sendEmptyMessage(MSG_DIE);
return true;
}
参数immediates表示是否立即删除,返回false表示删除已完成,返回true表示加入待删除的队列里。看removeViewLocked的最后,将返回true加入了待删除的列表mDyingViews就明白了。 如果是需要立即删除则执行doDie,如果是是异步删除,则发送个消息,ViewRootImpl内部Handle接收消息的处理还是执行doDie。
现在看来doDie才是真正执行删除操作的地方。
void doDie() {
checkThread();
if (LOCAL_LOGV) Log.v(mTag, "DIE in " + this + " of " + mSurface);
synchronized (this) {
if (mRemoved) {
return;
}
mRemoved = true;
if (mAdded) {
关键代码
dispatchDetachedFromWindow();
}
......
全局单例WindowManagerGlobal也执行对应方法
WindowManagerGlobal.getInstance().doRemoveView(this);
}
void dispatchDetachedFromWindow() {
内部完成视图的移除
mView.dispatchDetachedFromWindow();
try {
内部通过WMA完成Window的删除
mWindowSession.remove(mWindow);
} catch (RemoteException e) {}
}
在dispatchDetachedFromWindow方法内部通过View的dispatchDetachedFromWindow方法完成View的删除,同时在通过mWindowSession来完成Window的删除
updateViewLayout
android.view.WindowManagerGlobal
public void updateViewLayout(View view, ViewGroup.LayoutParams params) {
if (view == null) {
throw new IllegalArgumentException("view must not be null");
}
if (!(params instanceof WindowManager.LayoutParams)) {
throw new IllegalArgumentException("Params must be WindowManager.LayoutParams");
}
final WindowManager.LayoutParams wparams = (WindowManager.LayoutParams)params;
更新View参数
view.setLayoutParams(wparams);
synchronized (mLock) {
int index = findViewLocked(view, true);
ViewRootImpl root = mRoots.get(index);
mParams.remove(index);
mParams.add(index, wparams);
更新ViewRootImpl参数
root.setLayoutParams(wparams, false);
}
}
updateViewLayout内部做的事情比较简单,先是更新View的参数,然后更新ViewRootImpl的参数。
- setLayoutParams内部会触发scheduleTraversals来对View重新布局,scheduleTraversals一旦触发,就会执行relayoutWindow方法,触发WMS来更新Window视图。我就不贴代码了,太多了,附上调用路径吧。
- scheduleTraversals->mTraversalRunnable(TraversalRunnable)->doTraversal->performTraversals->relayoutWindow->内部执行mWindowSession.relayout通知WMS更新Window
总结
- DecorView在Activity的handleResumeActivity方法执行通过wm.addView完成操作。执行时机是在onResume后面一点点
- DecorView存在于PhoneWindow中,DecorView的添加删除更新曹组是由ViewRootImpl负责,而PhoneWindow的添加删除更新操作由WMS负责
- PhoneWindow的事件通过Callback接口回调给Activity






































 图1.2 图层的树状结构(左边)以及对应的视图层级(右边)
图1.2 图层的树状结构(左边)以及对应的视图层级(右边)

