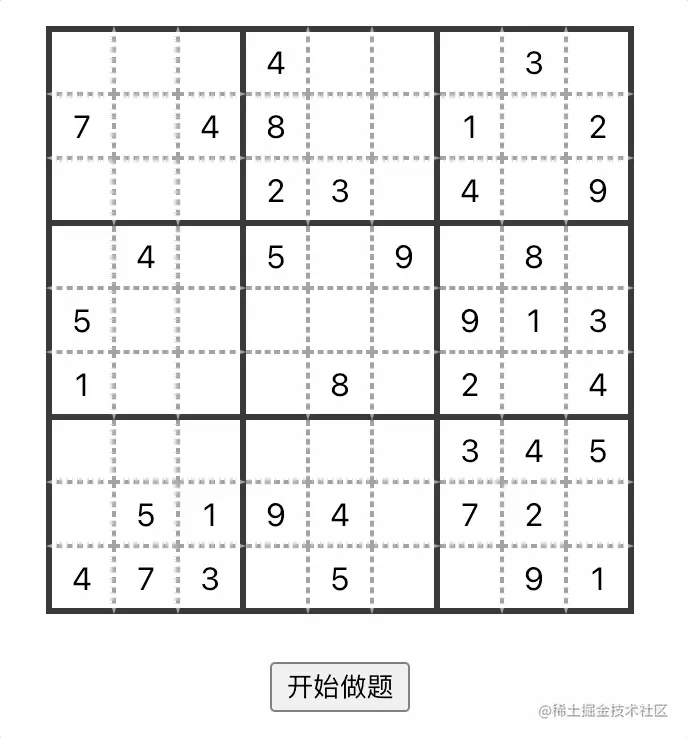
最近看到老婆天天在手机上玩数独,突然想起 N 年前刷 LeetCode 的时候,有个类似的算法题(37.解数独),是不是可以把这个算法进行可视化。
说干就干,经过一个小时的实践,最终效果如下:
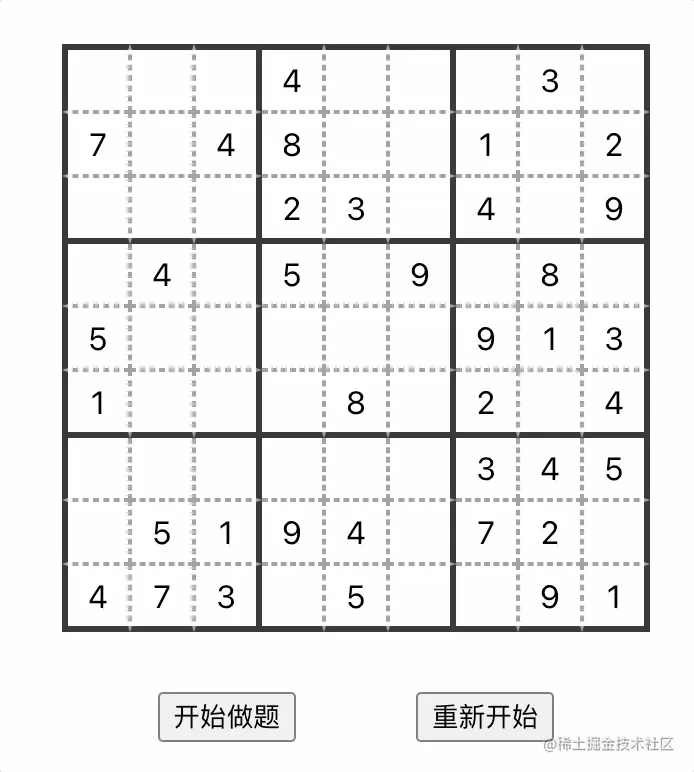
怎么解数独
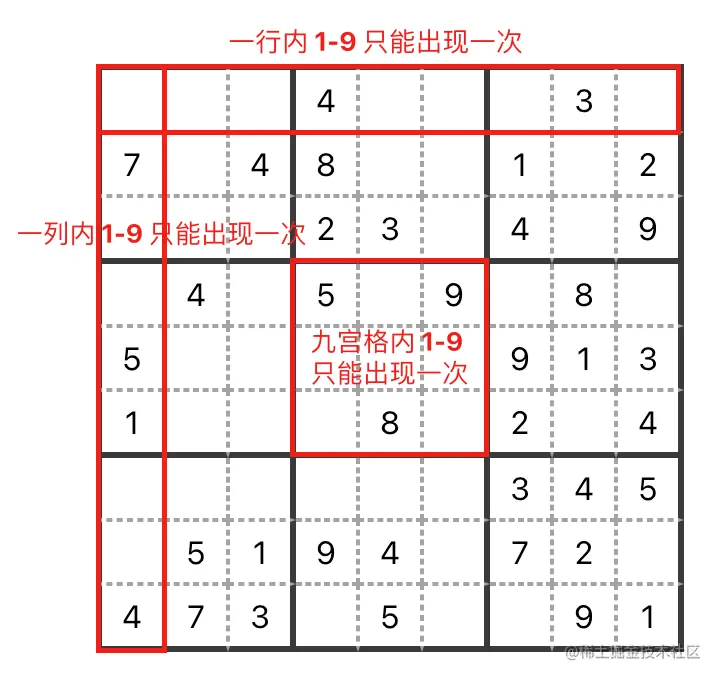
解数独之前,我们先了解一下数独的规则:
- 数字
1-9 在每一行只能出现一次。
- 数字
1-9 在每一列只能出现一次。
- 数字
1-9 在每一个以粗实线分隔的九宫格( 3x3 )内只能出现一次。
接下来,我们要做的就是在每个格子里面填一个数字,然后判断这个数字是否违反规定。
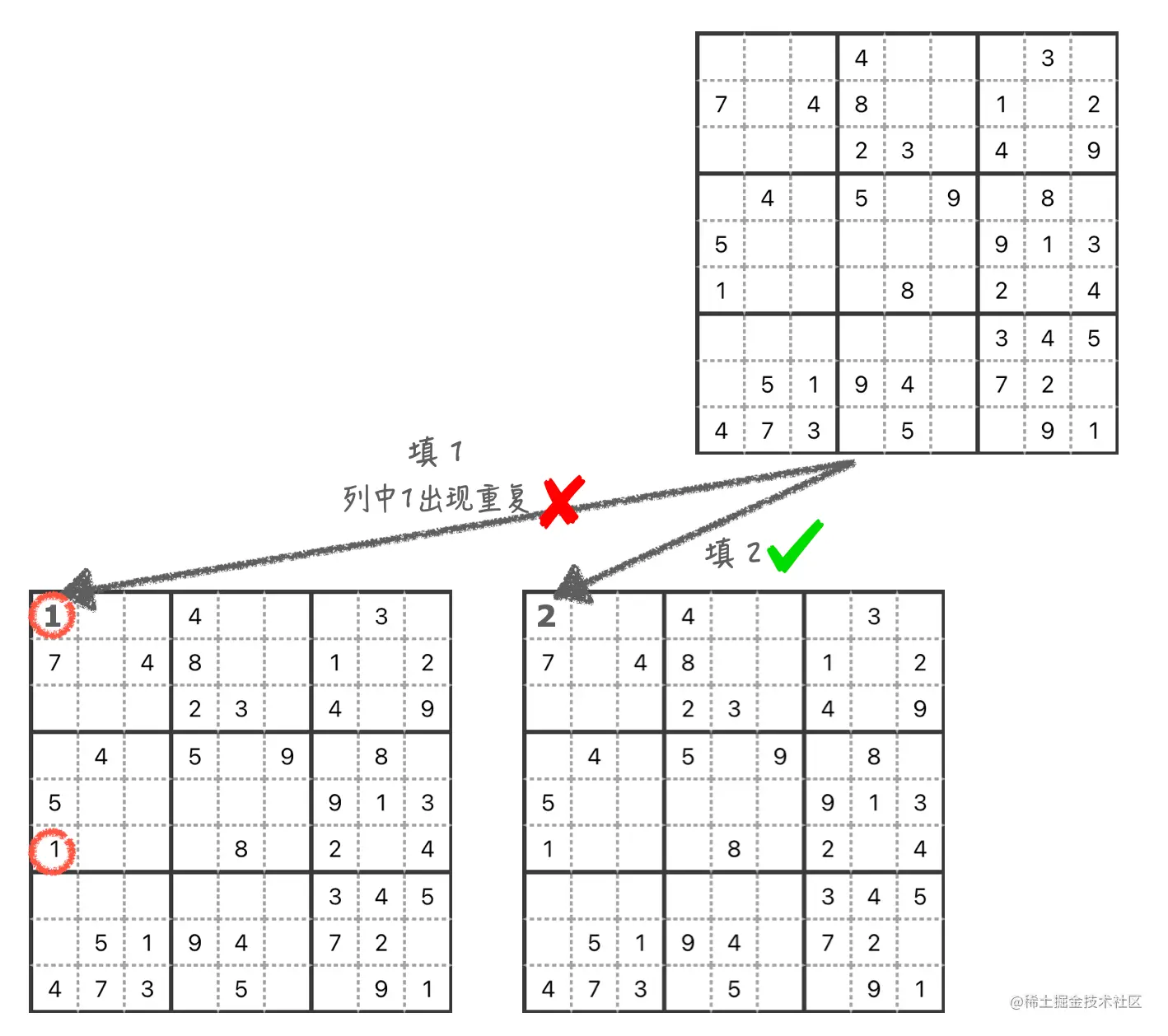
填第一个格子
首先,在第一个格子填 1,发现在第一列里面已经存在一个 1,此时就需要擦掉前面填的数字 1,然后在格子里填上 2,发现数字在行、列、九宫格内均无重复。那么这个格子就填成功了。
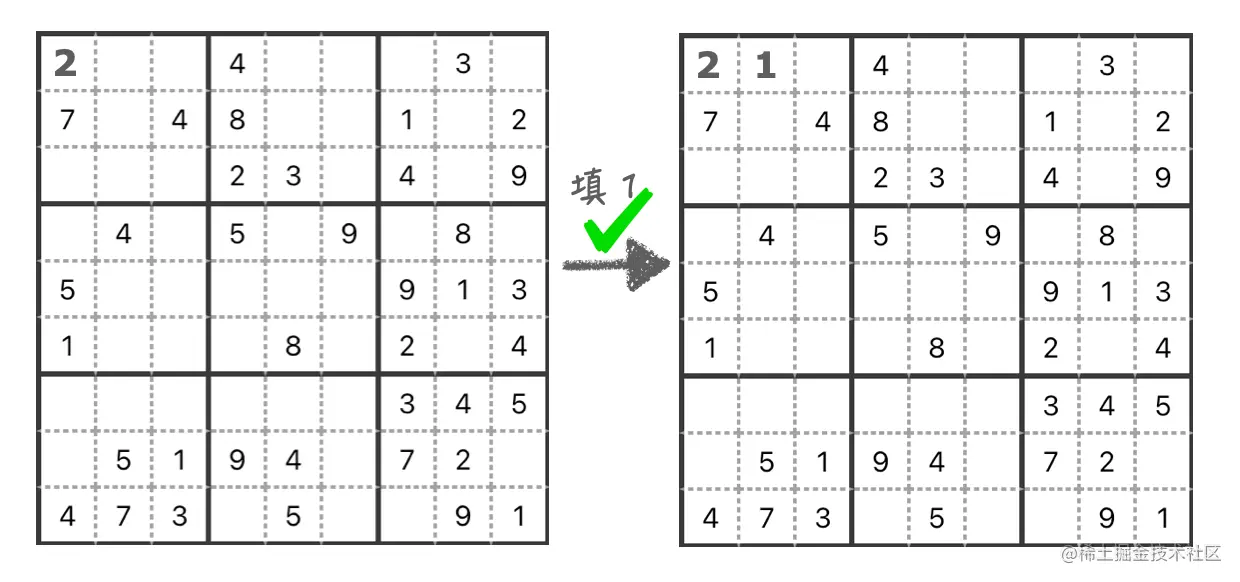
填第二个格子
下面看第二个格子,和前面一样,先试试填 1,发现在行、列、九宫格内的数字均无重复,那这个格子也填成功了。
填第三个格子
下面看看第三个格子,由于前面两个格子,我们已经填过数字 1、2,所以,我们直接从数字 3 开始填。填 3 后,发现在第一行里面已经存在一个 3,然后在格子里填上 4,发现数字 4 在行和九宫格内均出现重复,依旧不成功,然后尝试填上数字 5,终于没有了重复数字,表示填充成功。
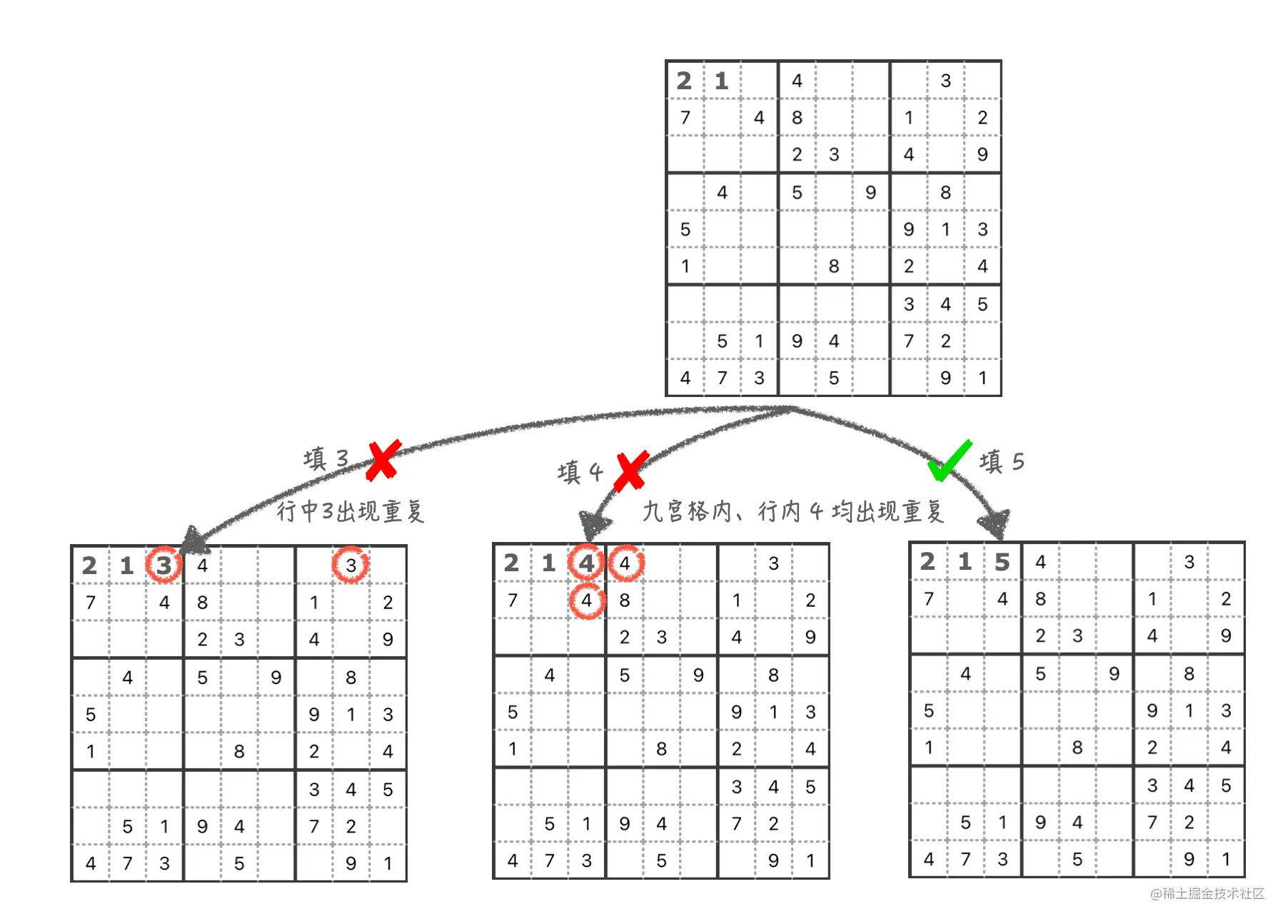
一直填,直到填到第九个格子
照这个思路,一直填到第九个格子,这个时候,会发现,最后一个数字 9 在九宫格内冲突了。而 9 已经是最后一个数字了,这里没办法填其他数字了,只能返回上一个格子,把第七个格子的数字从 8 换到 9,发现在九宫格内依然冲突。
此时需要替换上上个格子的数字(第六个格子)。直到没有冲突为止,所以在这个过程中,不仅要往后填数字,还要回过头看看前面的数字有没有问题,不停地尝试。
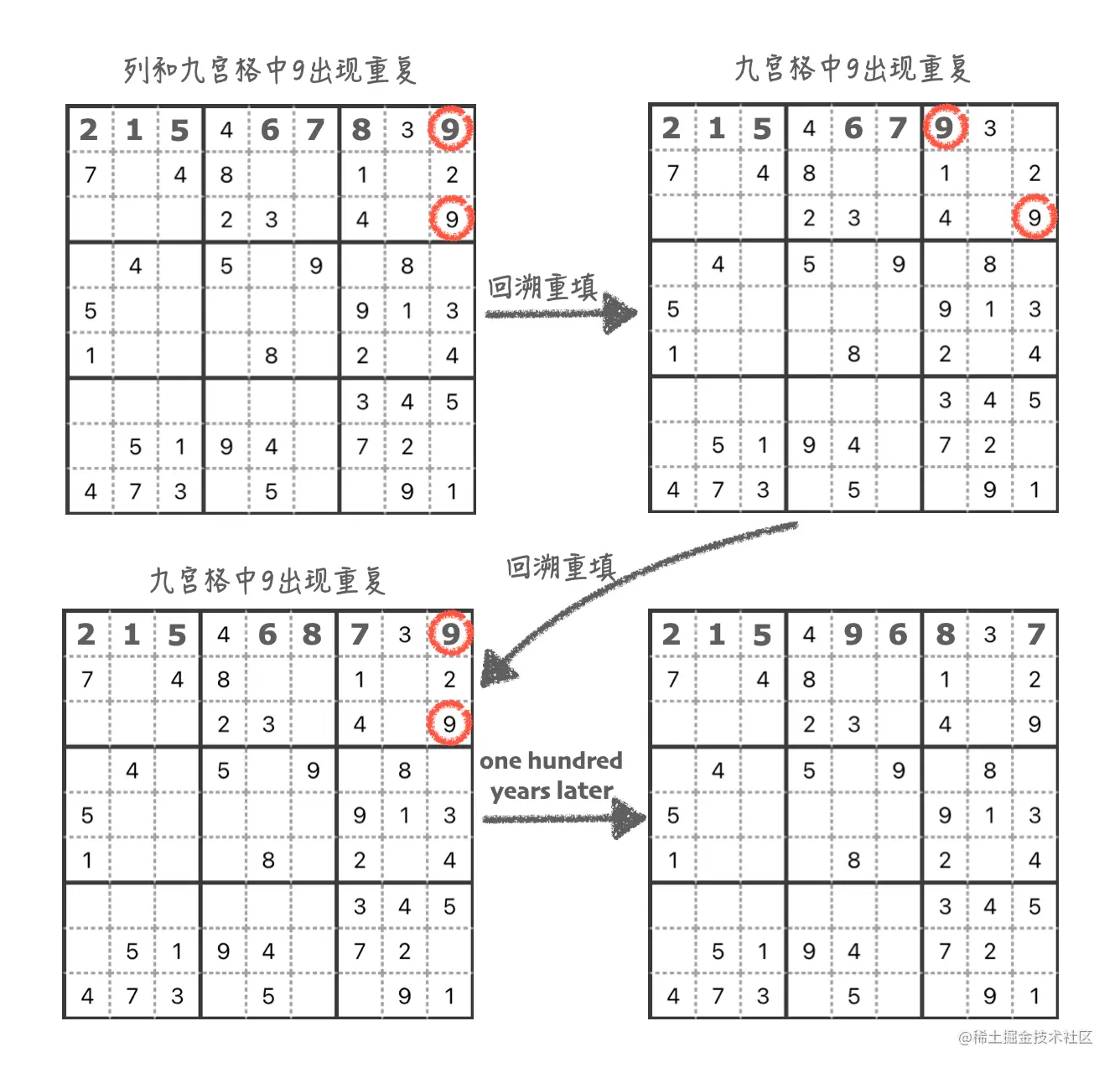
综上所述
解数独就是一个不断尝试的过程,每个格子把数字 1-9 都尝试一遍,如果出现冲突就擦掉这个数字,直到所有的格子都填完。
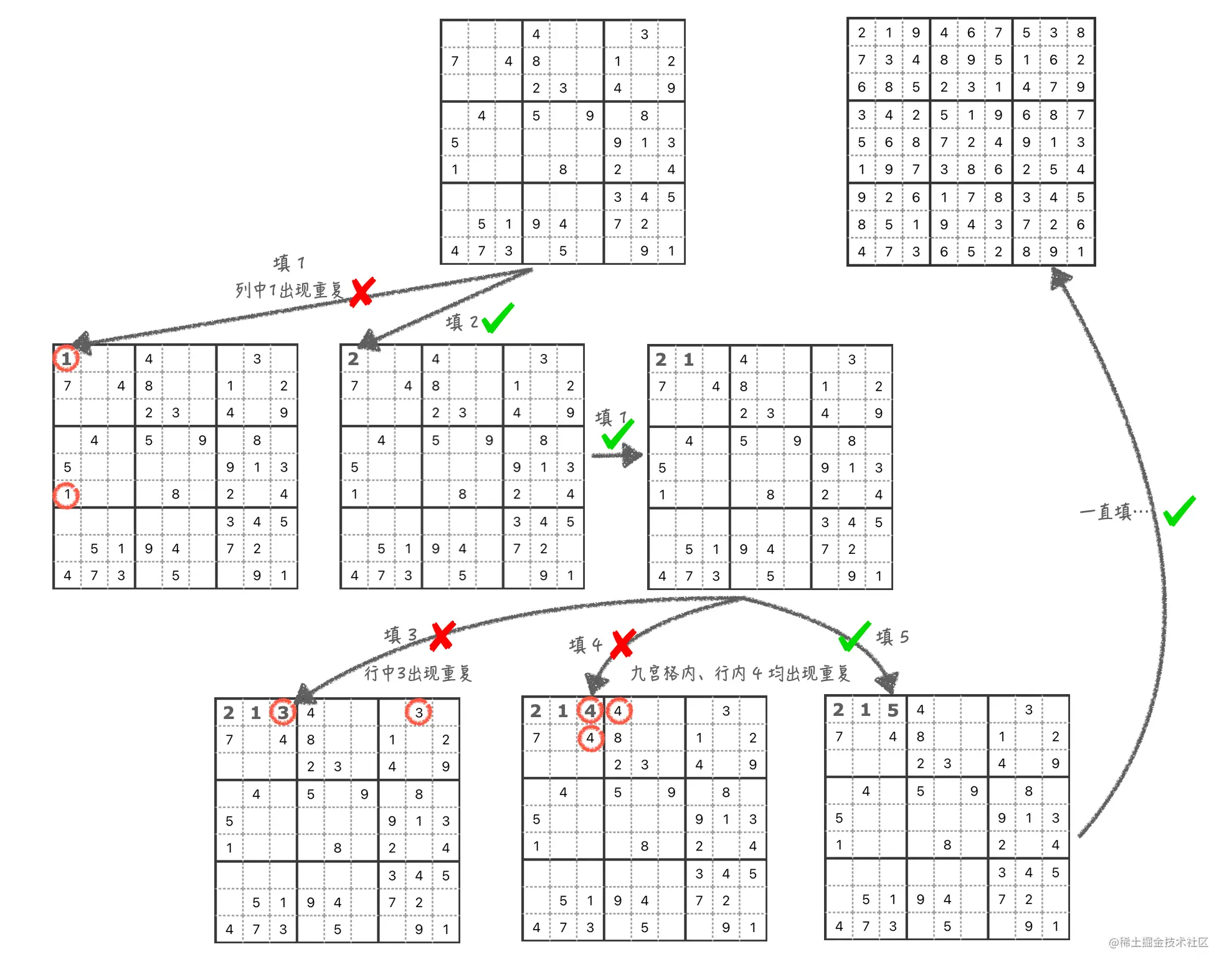
通过代码来实现
把上面的解法反映到代码上,就需要通过 递归 + 回溯 的思路来实现。
在写代码之前,先看看怎么把数独表示出来,这里参考 leetcode 上的题目:37. 解数独。
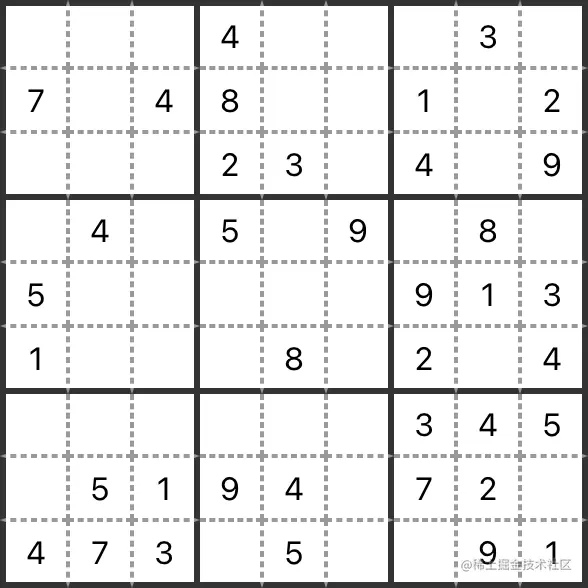
前面的这个题目,可以使用一个二维数组来表示。最外层数组内一共有 9 个数组,表示数独的 9 行,内部的每个数组内 9 字符分别对应数组的列,未填充的空格通过字符('.' )来表示。
const sudoku = [
['.', '.', '.', '4', '.', '.', '.', '3', '.'],
['7', '.', '4', '8', '.', '.', '1', '.', '2'],
['.', '.', '.', '2', '3', '.', '4', '.', '9'],
['.', '4', '.', '5', '.', '9', '.', '8', '.'],
['5', '.', '.', '.', '.', '.', '9', '1', '3'],
['1', '.', '.', '.', '8', '.', '2', '.', '4'],
['.', '.', '.', '.', '.', '.', '3', '4', '5'],
['.', '5', '1', '9', '4', '.', '7', '2', '.'],
['4', '7', '3', '.', '5', '.', '.', '9', '1'],
]
知道如何表示数组后,我们再来写代码。
const sudoku = [……]
// 方法接受行、列两个参数,用于定位数独的格子
function solve(row, col) {
if (col >= 9) {
// 超过第九列,表示这一行已经结束了,需要另起一行
col = 0
row += 1
if (row >= 9) {
// 另起一行后,超过第九行,则整个数独已经做完
return true
}
}
if (sudoku[row][col] !== '.') {
// 如果该格子已经填过了,填后面的格子
return solve(row, col + 1)
}
// 尝试在该格子中填入数字 1-9
for (let num = 1; num <= 9; num++) {
if (!isValid(row, col, num)) {
// 如果是无效数字,跳过该数字
continue
}
// 填入数字
sudoku[row][col] = num.toString()
// 继续填后面的格子
if (solve(row, col + 1)) {
// 如果一直到最后都没问题,则这个格子的数字没问题
return true
}
// 如果出现了问题,solve 返回了 false
// 说明这个地方要重填
sudoku[row][col] = '.' // 擦除数字
}
// 数字 1-9 都填失败了,说明前面的数字有问题
// 返回 FALSE,进行回溯,前面数字要进行重填
return false
}
上面的代码只是实现了递归、回溯的部分,还有一个 isValid 方法没有实现。该方法主要就是按照数独的规则进行一次校验。
const sudoku = [……]
function isValid(row, col, num) {
// 判断行里是否重复
for (let i = 0; i < 9; i++) {
if (sudoku[row][i] === num) {
return false
}
}
// 判断列里是否重复
for (let i = 0; i < 9; i++) {
if (sudoku[i][col] === num) {
return false
}
}
// 判断九宫格里是否重复
const startRow = parseInt(row / 3) * 3
const startCol = parseInt(col / 3) * 3
for (let i = startRow; i < startRow + 3; i++) {
for (let j = startCol; j < startCol + 3; j++) {
if (sudoku[i][j] === num) {
return false
}
}
}
return true
}
通过上面的代码,我们就能解出一个数独了。
const sudoku = [
['.', '.', '.', '4', '.', '.', '.', '3', '.'],
['7', '.', '4', '8', '.', '.', '1', '.', '2'],
['.', '.', '.', '2', '3', '.', '4', '.', '9'],
['.', '4', '.', '5', '.', '9', '.', '8', '.'],
['5', '.', '.', '.', '.', '.', '9', '1', '3'],
['1', '.', '.', '.', '8', '.', '2', '.', '4'],
['.', '.', '.', '.', '.', '.', '3', '4', '5'],
['.', '5', '1', '9', '4', '.', '7', '2', '.'],
['4', '7', '3', '.', '5', '.', '.', '9', '1']
]
function isValid(row, col, num) {……}
function solve(row, col) {……}
solve(0, 0) // 从第一个格子开始解
console.log(sudoku) // 输出结果

动态展示做题过程
有了上面的理论知识,我们就可以把这个做题的过程套到 react 中,动态的展示做题的过程,也就是文章最开始的 Gif 中的那个样子。
这里直接使用 create-react-app 脚手架快速启动一个项目。
npx create-react-app sudoku
cd sudoku
打开 App.jsx ,开始写代码。
import React from 'react';
import './App.css';
class App extends React.Component {
state = {
// 在 state 中配置一个数独二维数组
sudoku: [
['.', '.', '.', '4', '.', '.', '.', '3', '.'],
['7', '.', '4', '8', '.', '.', '1', '.', '2'],
['.', '.', '.', '2', '3', '.', '4', '.', '9'],
['.', '4', '.', '5', '.', '9', '.', '8', '.'],
['5', '.', '.', '.', '.', '.', '9', '1', '3'],
['1', '.', '.', '.', '8', '.', '2', '.', '4'],
['.', '.', '.', '.', '.', '.', '3', '4', '5'],
['.', '5', '1', '9', '4', '.', '7', '2', '.'],
['4', '7', '3', '.', '5', '.', '.', '9', '1']
]
}
// TODO:解数独
solveSudoku = async () => {
const { sudoku } = this.state
}
render() {
const { sudoku } = this.state
return (
<div className="container">
<div className="wrapper">
{/* 遍历二维数组,生成九宫格 */}
{sudoku.map((list, row) => (
{/* div.row 对应数独的行 */}
<div className="row" key={`row-${row}`}>
{list.map((item, col) => (
{/* span 对应数独的每个格子 */}
<span key={`box-${col}`}>{ item !== '.' && item }</span>
))}
</div>
))}
<button onClick={this.solveSudoku}>开始做题</button>
</div>
</div>
);
}
}
九宫格样式
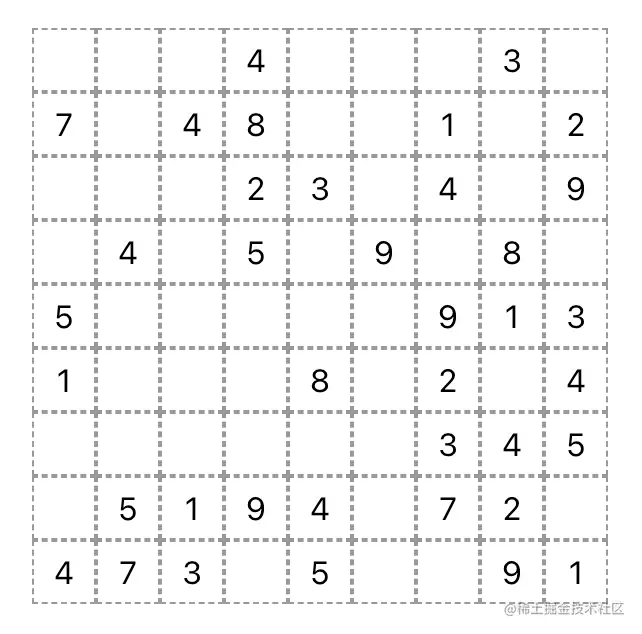
给每个格子加上一个虚线的边框,先让它有一点九宫格的样子。
.row {
display: flex;
direction: row;
/* 行内元素居中 */
justify-content: center;
align-content: center;
}
.row span {
/* 每个格子宽高一致 */
width: 30px;
min-height: 30px;
line-height: 30px;
text-align: center;
/* 设置虚线边框 */
border: 1px dashed #999;
}
可以得到一个这样的图形:
接下来,需要给外边框和每个九宫格加上实线的边框,具体代码如下:
/* 第 1 行顶部加上实现边框 */
.row:nth-child(1) span {
border-top: 3px solid #333;
}
/* 第 3、6、9 行底部加上实现边框 */
.row:nth-child(3n) span {
border-bottom: 3px solid #333;
}
/* 第 1 列左边加上实现边框 */
.row span:first-child {
border-left: 3px solid #333;
}
/* 第 3、6、9 列右边加上实现边框 */
.row span:nth-child(3n) {
border-right: 3px solid #333;
}
这里会发现第三、六列的右边边框和第四、七列的左边边框会有点重叠,第三、六行的底部边框和第四、七行的顶部边框也会有这个问题,所以,我们还需要将第四、七列的左边边框和第三、六行的底部边框进行隐藏。
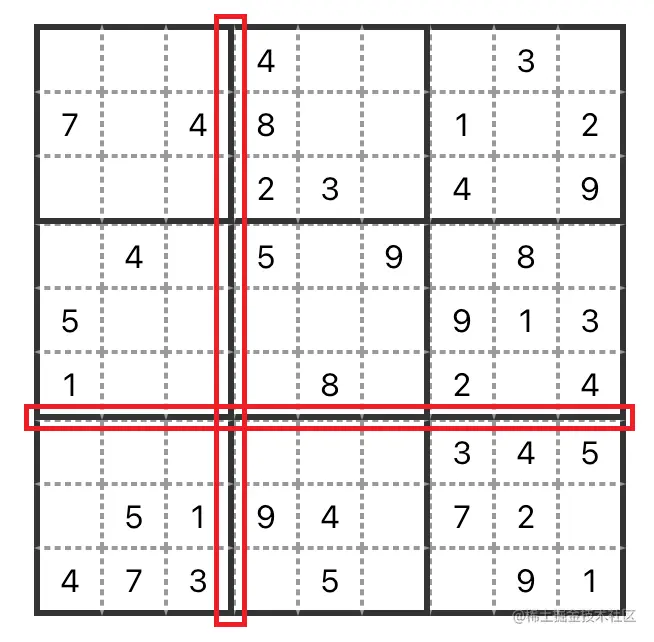
.row:nth-child(3n + 1) span {
border-top: none;
}
.row span:nth-child(3n + 1) {
border-left: none;
}
做题逻辑
样式写好后,就可以继续完善做题的逻辑了。
class App extends React.Component {
state = {
// 在 state 中配置一个数独二维数组
sudoku: [……]
}
solveSudoku = async () => {
const { sudoku } = this.state
// 判断填入的数字是否有效,参考上面的代码,这里不再重复
const isValid = (row, col, num) => {
……
}
// 递归+回溯的方式进行解题
const solve = async (row, col) => {
if (col >= 9) {
col = 0
row += 1
if (row >= 9) return true
}
if (sudoku[row][col] !== '.') {
return solve(row, col + 1)
}
for (let num = 1; num <= 9; num++) {
if (!isValid(row, col, num)) {
continue
}
sudoku[row][col] = num.toString()
this.setState({ sudoku }) // 填了格子之后,需要同步到 state
if (solve(row, col + 1)) {
return true
}
sudoku[row][col] = '.'
this.setState({ sudoku }) // 填了格子之后,需要同步到 state
}
return false
}
// 进行解题
solve(0, 0)
}
render() {
const { sudoku } = this.state
return (……)
}
}
对比之前的逻辑,这里只是在对数独的二维数组填空后,调用了 this.setState 将 sudoku 同步到了 state 中。
function solve(row, col) { …… sudoku[row][col] = num.toString()+ this.setState({ sudoku }) …… sudoku[row][col] = '.'+ this.setState({ sudoku }) // 填了格子之后,需要同步到 state}
在调用 solveSudoku 后,发现并没有出现动态的效果,而是直接一步到位的将结果同步到了视图中。
这是因为 setState 是一个伪异步调用,在一个事件任务中,所有的 setState 都会被合并成一次,需要看到动态的做题过程,我们需要将每一次 setState 操作放到该事件流之外,也就是放到 setTimeout 中。更多关于 setState 异步的问题,可以参考我之前的文章:React 中 setState 是一个宏任务还是微任务?
solveSudoku = async () => {
const { sudoku } = this.state
// 判断填入的数字是否有效,参考上面的代码,这里不再重复
const isValid = (row, col, num) => {
……
}
// 脱离事件流,调用 setState
const setSudoku = async (row, col, value) => {
sudoku[row][col] = value
return new Promise(resolve => {
setTimeout(() => {
this.setState({
sudoku
}, () => resolve())
})
})
}
// 递归+回溯的方式进行解题
const solve = async (row, col) => {
……
for (let num = 1; num <= 9; num++) {
if (!isValid(row, col, num)) {
continue
}
await setSudoku(row, col, num.toString())
if (await solve(row, col + 1)) {
return true
}
await setSudoku(row, col, '.')
}
return false
}
// 进行解题
solve(0, 0)
}
最后效果如下: