StrictMode是Android开发过程中一个必不可缺的性能检测工具,他能帮助开发检测出一些不合理的代码块。
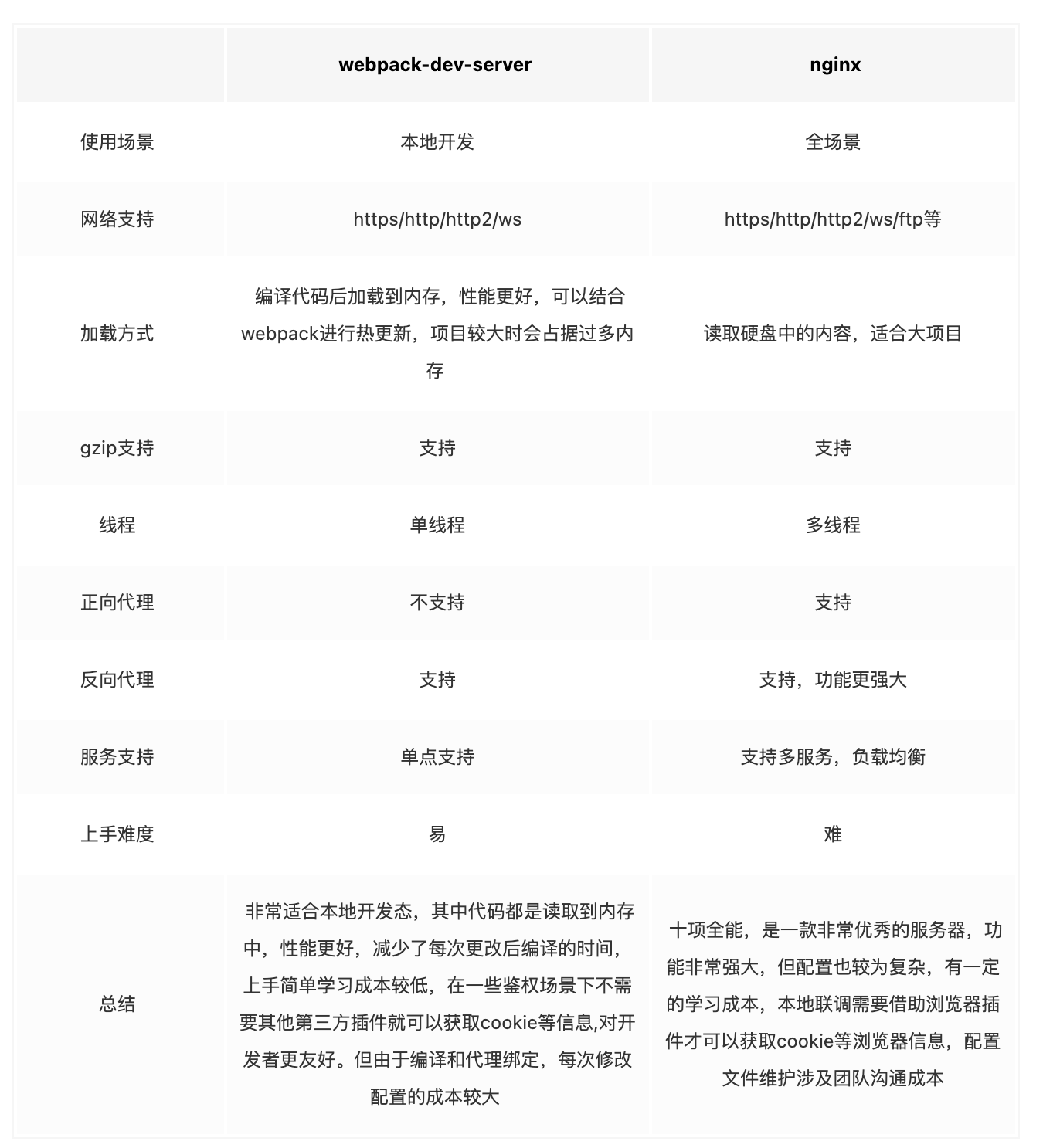
策略分类
StrictMode分为线程策略(ThreadPolicy)和虚拟机策略(VmPolicy)
线程策略(ThreadPolicy)
线程策略主要包含了以下几个方面
- detectNetwork:监测主线程使用网络(重要)
- detectCustomSlowCalls:监测自定义运行缓慢函数
- penaltyLog:输出日志
- penaltyDialog:监测情况时弹出对话框
- detectDiskReads:检测在UI线程读磁盘操作 (重要)
- detectDiskWrites:检测在UI线程写磁盘操作(重要)
- detectResourceMismatches:检测发现资源不匹配 (api>22)
- detectAll:检测所有支持检测等项目(如果太懒,不想一一列出来,可以通过这个方式)
- permitDiskReads:允许UI线程在磁盘上读操作
虚拟机策略(VmPolicy)
虚拟机策略主要包含了以下几个方面
- detectActivityLeaks:检测Activity 的内存泄露情况(重要)(api>10)
- detectCleartextNetwork:检测明文的网络 (api>22)
- detectFileUriExposure:检测file://或者是content:// (api>17)
- detectLeakedClosableObjects:检测资源没有正确关闭(重要)(api>10)
- detectLeakedRegistrationObjects:检测BroadcastReceiver、ServiceConnection是否被释放 (重要)(api>15)
- detectLeakedSqlLiteObjects:检测数据库资源是否没有正确关闭(重要)(api>8)
- setClassInstanceLimit:设置某个类的同时处于内存中的实例上限,可以协助检查内存泄露(重要)
- penaltyLog:输出日志
- penaltyDeath:一旦检测到应用就会崩溃
代码
private void enabledStrictMode() {
//开启Thread策略模式
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder().detectNetwork()//监测主线程使用网络io
.detectCustomSlowCalls()//监测自定义运行缓慢函数
.detectDiskReads() // 检测在UI线程读磁盘操作
.detectDiskWrites() // 检测在UI线程写磁盘操作
.penaltyLog() //写入日志
.penaltyDialog()//监测到上述状况时弹出对话框
.build());
//开启VM策略模式
StrictMode.setVmPolicy(new StrictMode.VmPolicy.Builder().detectLeakedSqlLiteObjects()//监测sqlite泄露
.detectLeakedClosableObjects()//监测没有关闭IO对象
.setClassInstanceLimit(MainActivity.class, 1) // 设置某个类的同时处于内存中的实例上限,可以协助检查内存泄露
.detectActivityLeaks()
.penaltyLog()//写入日志
.penaltyDeath()//出现上述情况异常终止
.build());
}
案例1
public class MainActivity extends Activity {
private Handler mHandler = new Handler();
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
if (BuildConfig.DEBUG) {
enabledStrictMode();
}
mHandler.postDelayed(new Runnable() {
@Override
public void run() {
Log.d("MainActivity", "我来了");
}
}, 10 * 1000);
TextView tv = new TextView(this);
tv.setText("不错啊");
}
private void enabledStrictMode() {
//开启Thread策略模式
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder().detectNetwork()//监测主线程使用网络io
.detectCustomSlowCalls()//监测自定义运行缓慢函数
.detectDiskReads() // 检测在UI线程读磁盘操作
.detectDiskWrites() // 检测在UI线程写磁盘操作
.penaltyLog() //写入日志
.penaltyDialog()//监测到上述状况时弹出对话框
.build());
//开启VM策略模式
StrictMode.setVmPolicy(new StrictMode.VmPolicy.Builder().detectLeakedSqlLiteObjects()//监测sqlite泄露
.detectLeakedClosableObjects()//监测没有关闭IO对象
.setClassInstanceLimit(MainActivity.class, 1) // 设置某个类的同时处于内存中的实例上限,可以协助检查内存泄露
.detectActivityLeaks()
.penaltyLog()//写入日志
.penaltyDeath()//出现上述情况异常终止
.build());
}
}
如代码所示,我在MainActivity(启动模式为singleTask且为app的启动Activity)中创建一个Handler(非静态),然后执行一个delay了10s的任务。
现在我不断的启动和退出MainActivity,结果发现如下图所示
可以看出MainActivity创建了多份实例(此图使用了MAT中的OQL,以后的章节会详细的讲解),我们的预期是只能有一个这样的MainActivity实例。将其中某个对象实例引用路径列出来,见下图。
通过上图我们可以发现,是Handler持有了此MainActivity实例,导致这个MainActivity无法被释放。
改造
public class MainActivity extends Activity {
private static class InnerHandler extends Handler {
private final WeakReference<MainActivity> mWeakreference;
InnerHandler(MainActivity activity) {
mWeakreference = new WeakReference<>(activity);
}
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
final MainActivity activity = mWeakreference.get();
if (activity == null) {
return;
}
Log.d("MainActivity","执行msg");
}
}
private Handler mHandler = new InnerHandler(this);
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
if (BuildConfig.DEBUG) {
enabledStrictMode();
}
mHandler.postDelayed(new Runnable() {
@Override
public void run() {
Log.d("MainActivity", "我来了");
}
}, 10 * 1000);
TextView tv = new TextView(this);
tv.setText("我来了");
setContentView(tv);
}
@Override
protected void onDestroy() {
mHandler.removeCallbacksAndMessages(null);
super.onDestroy();
}
private void enabledStrictMode() {
//开启Thread策略模式
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder().detectNetwork()//监测主线程使用网络io
.detectCustomSlowCalls()//监测自定义运行缓慢函数
.detectDiskReads() // 检测在UI线程读磁盘操作
.detectDiskWrites() // 检测在UI线程写磁盘操作
.penaltyLog() //写入日志
.penaltyDialog()//监测到上述状况时弹出对话框
.build());
//开启VM策略模式
StrictMode.setVmPolicy(new StrictMode.VmPolicy.Builder().detectLeakedSqlLiteObjects()//监测sqlite泄露
.detectLeakedClosableObjects()//监测没有关闭IO对象
.setClassInstanceLimit(MainActivity.class, 1) // 设置某个类的同时处于内存中的实例上限,可以协助检查内存泄露
.detectActivityLeaks()
.penaltyLog()//写入日志
.build());
}
}
将Handler实现为静态内部类,且通过弱引用的方式将当前Activity持有,在onDestory出调用removeCallbacksAndMessages(null)方法,此处填null,表示将Handler中所有的消息都清空掉。
运行代码后,通过MAT分析见下图
由图可见,当前有且仅有一个MainActivity,达到代码设计预期。
备注
这个案例在我们分析过程中,会爆出android instances=2; limit=1字样的StrictMode信息,原因是由于我们在启动退出MainActivity的过程中,系统正在回收MainActivity的实例(回收是需要时间的),即此对象正在被FinalizerReference引用,而我们正在启动另外一项MainActivity,故报两个实例。
案例2
public class MainActivity extends Activity {
@Override
protected void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
if (BuildConfig.DEBUG) {
enabledStrictMode();
}
TextView tv = new TextView(this);
tv.setText("我来了");
setContentView(tv);
newThread();
takeTime();
}
private void newThread() {
for (int i = 0; i < 50; i++) {
new Thread(new Runnable() {
@Override
public void run() {
takeTime();
}
}).start();
}
}
private void takeTime() {
try {
File file = new File(getCacheDir(), "test");
if (file.exists()) {
file.delete();
}
file.createNewFile();
FileOutputStream fileOutputStream = new FileOutputStream(file);
final String content = "hello 我来了";
StringBuffer buffer = new StringBuffer();
for (int i = 0; i < 100; i++) {
buffer.append(content);
}
fileOutputStream.write(buffer.toString().getBytes());
fileOutputStream.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
protected void onDestroy() {
super.onDestroy();
}
private void enabledStrictMode() {
//开启Thread策略模式
StrictMode.setThreadPolicy(new StrictMode.ThreadPolicy.Builder().detectNetwork()//监测主线程使用网络io
.detectCustomSlowCalls()//监测自定义运行缓慢函数
.detectDiskReads() // 检测在UI线程读磁盘操作
.detectDiskWrites() // 检测在UI线程写磁盘操作
.penaltyLog() //写入日志
.penaltyDialog()//监测到上述状况时弹出对话框
.build());
//开启VM策略模式
StrictMode.setVmPolicy(new StrictMode.VmPolicy.Builder().detectLeakedSqlLiteObjects()//监测sqlite泄露
.detectLeakedClosableObjects()//监测没有关闭IO对象
.setClassInstanceLimit(MainActivity.class, 1) // 设置某个类的同时处于内存中的实例上限,可以协助检查内存泄露
.detectActivityLeaks()
.penaltyLog()//写入日志
.build());
}
}
运行以上代码,弹出警告对话框
点击确定后,查看StrictMode日志见附图
从日志信息我们可以得到,程序在createNewFile、openFile、writeFile都花了75ms时间,这对于程序来说是一个较为耗时的操作。接着继续我们的日志
从字面上意思我们知道,是文件流没有关闭,通过日志我们能很快的定位问题点:
fileOutputStream.write(buffer.toString().getBytes());
fileOutputStream.flush();
文件流flush后,没有执行close方法,这样会导致这个文件资源一直被此对象持有,资源得不到释放,造成内存及资源浪费。
总结
StrictMode除了上面的案例情况,还可以检测对IO、网络、数据库等相关操作,而这些操作恰恰是Android开发过程中影响App性能最常见因素(都比较耗时、CPU占用时间、占用大量内存),所以在开发过程中时刻关注StrictMode变化是一个很好的习惯——一方面可以检测项目组员代码质量,另一方面也可以让自己在Android开发过程中形成一些良好的写代码的思维方式。在StrictMode检测过程中,我们要时刻关注日志的变换(如方法执行时间长短),尤其要对那些红色的日志引起注意,因为这些方法引发的问题是巨大的。