在我们编写Android程序时,OkHttp已经成为了我们必不可少的部分,但我们往往知道OkHttp怎么用,不知其原理。在本篇中,我将通过如下方式带你深入其原理。
OkHttp 介绍
OkHttp 调用流程
socket 连接池复用机制
高并发请求队列:任务分发
责任链模式拦截器设计
1.0 OkHttp 介绍
由Square公司贡献的一个处理网络请求的开源项目,是目前Android使用最广泛的网络框架。从Android4.4开始HttpURLConnection的底层实现采用的是OkHttp。
谷歌官方在6.0以后再android sdk已经移除了httpclient,加入了okhttp。
很多知名网络框架,比如 Retrofit 底层也是基于OkHttp实现的。
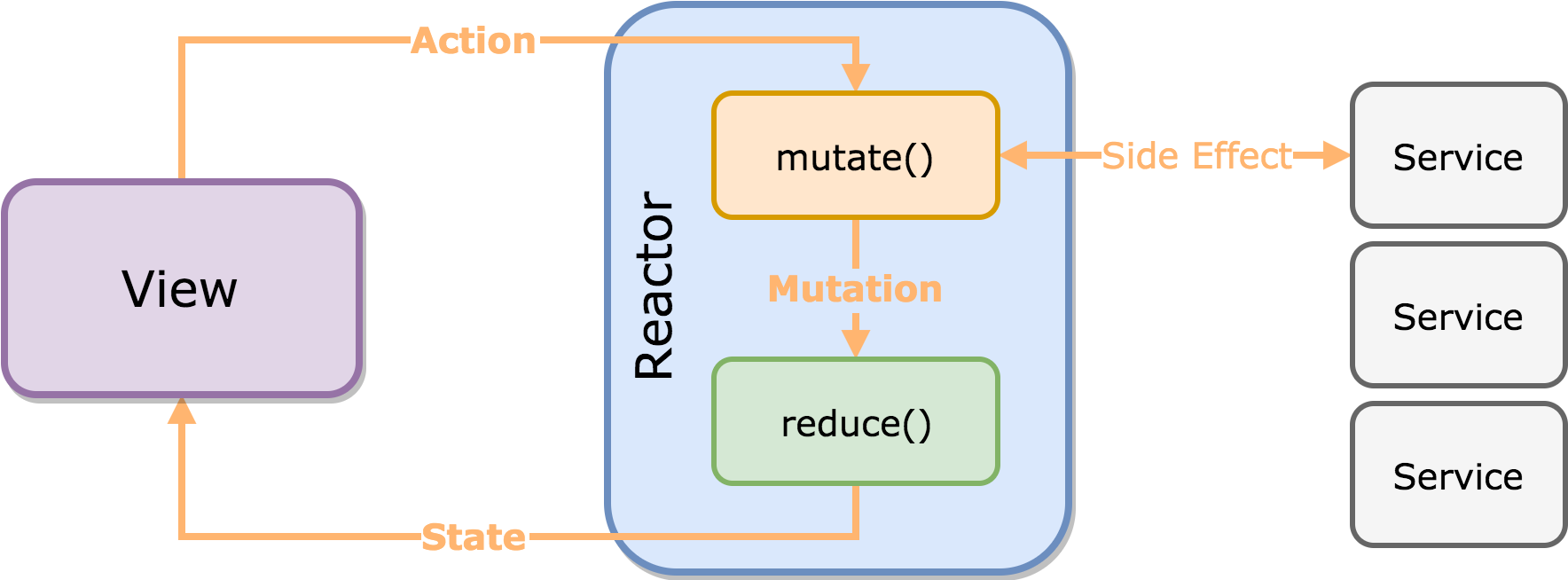
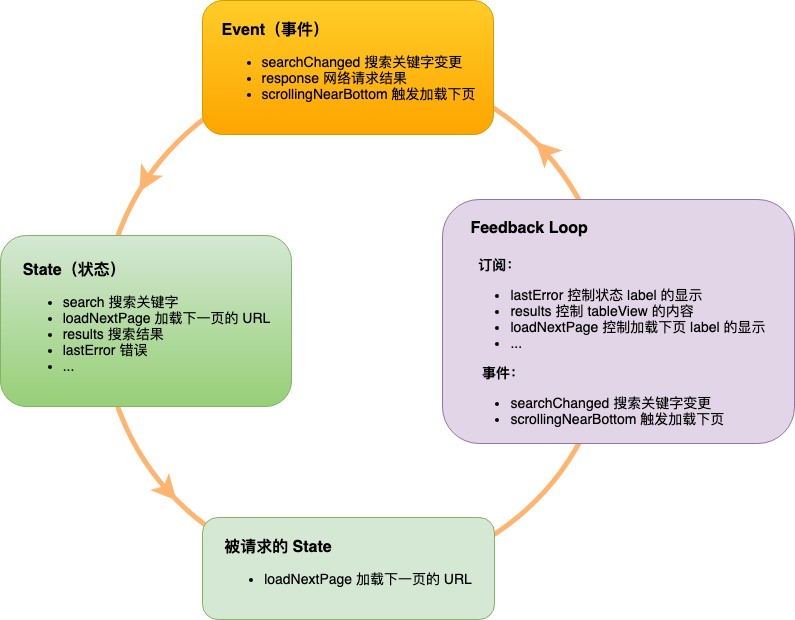
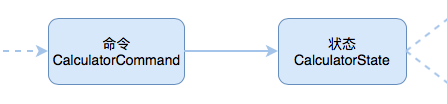
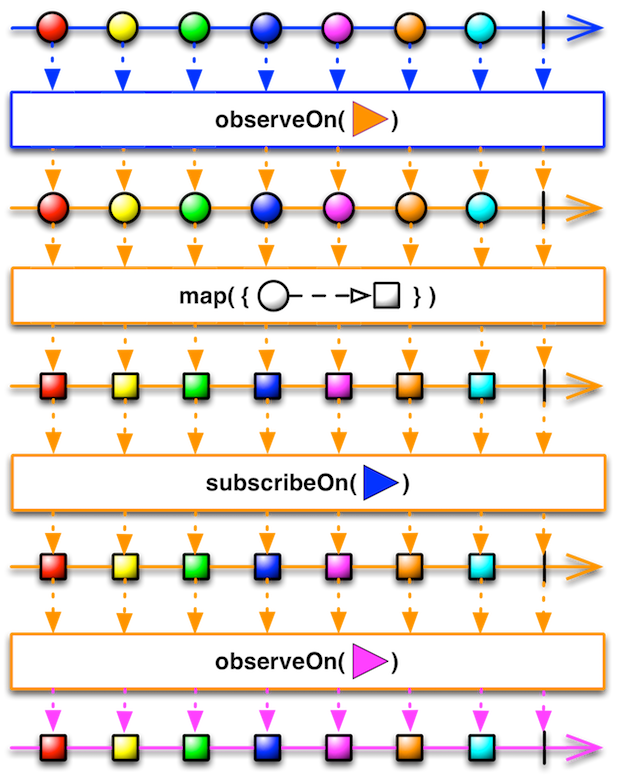
1.1 OkHttp 调用流程
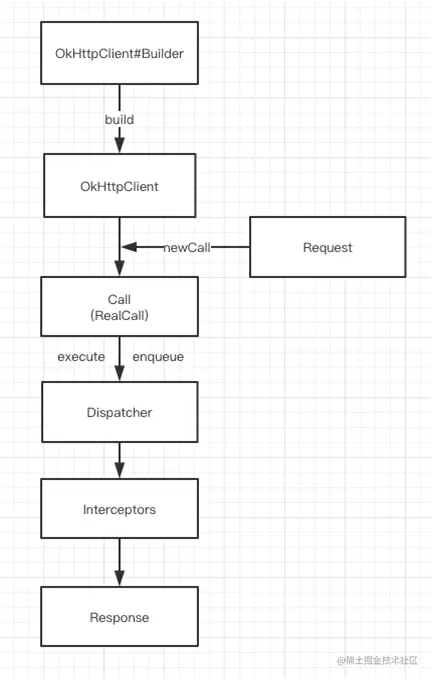
如图所示:
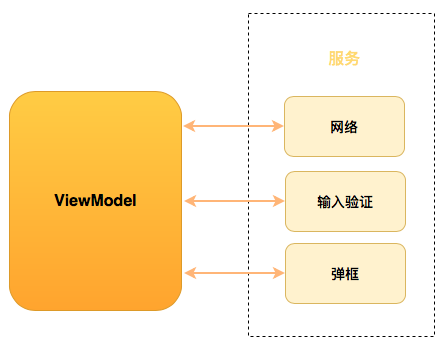
OkHttp请求过程中最少只需要接触OkHttpClient、Request、Call、Response,但是框架内部进行大量的逻辑处理。
所有的逻辑大部分集中在拦截器中,但是在进入拦截器之前还需要依靠分发器来调配请求任务。
- . 分发器:内部维护队列与线程池,完成请求调配;
- . 拦截器:五大默认拦截器完成整个请求过程。
1.2 socket 连接池复用机制
在了解socket 的复用连接池之前,我们首先要了解几个概念。
- TCP 三次握手
- TCP 四次挥手
1.2.1 TCP三次握手
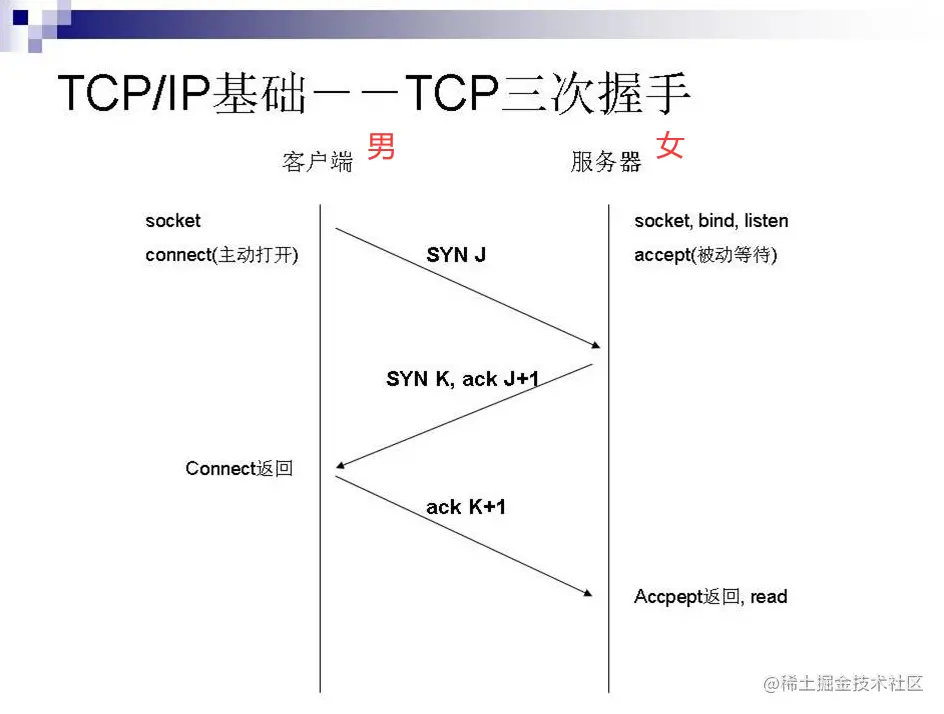
如图所示
我们把客户端比喻成男生,服务器比喻成女生。男生在追求女生的时候,男生发送了求偶的信号,女生在接受到求偶信号后,表示愿意接受男生,于是向男生发送了我愿意,但你要给我彩礼钱的信号。男生收到女生愿意信号后,表示也愿意给彩礼钱,向女生递交了彩礼钱。
整个过程双方必须秉持着相互了解对方的意图并且相互同意的情况下,才能相互连接。连接成功后,将会保持一段时间的长连接,就好如男女朋友在一起的一段时间,当发现彼此不合时,就迎来了TCP四次挥手(分手)
1.2.2 TCP四次挥手
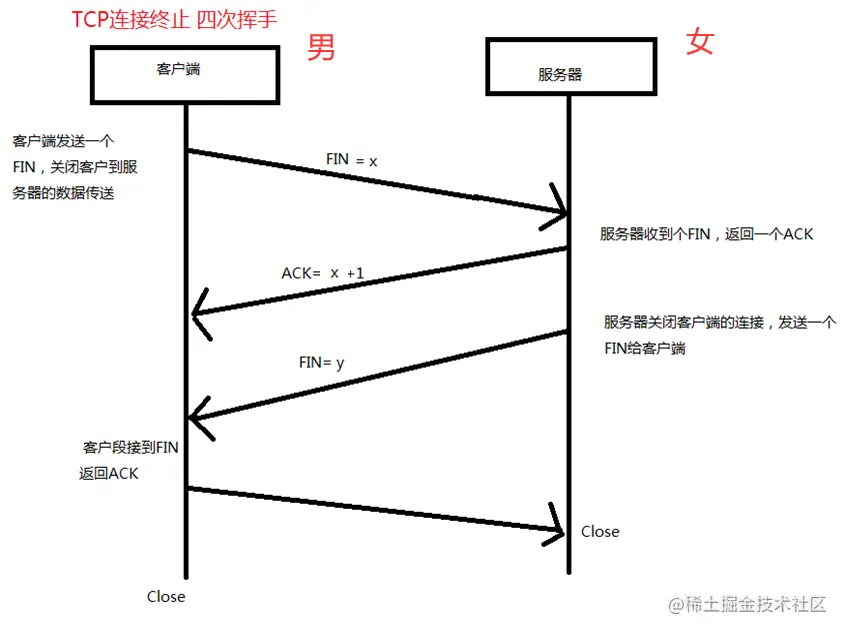
如图所示
我们依然将客户端比喻成男生,服务器比喻成女生。当男生发现女生太做作了,不合适时,就向女生提出了分手,女生第一时间给男生反应,你为什么要分手?过后女生也想明白了,就再次问男生是不是确定要分手?男生实在不想继续下去了,于是就向女生表明了确定要分手。
在整个TCP四次挥手过程中,只要有一方提出了断开连接,另一方在收了到断开连接信息后,先是表明已经收到了断开连接提示,然后再次提出方发送是否确认断开的提示,当收到确认断开信息时,双方才能断开整个TCP连接。
所以为什么会有连接复用?或者说连接复用为什么会提高性能?
通常我们在发起http请求的时候首先要完成tcp的三次握手,然后传输数据,最后再释放连接。三次握手的过程可以参考这里 TCP三次握手详解及释放连接过程。 一次Http响应的过程 
如图所示:
在高并发的请求连接情况下或者同个客户端多次频繁的请求操作,无限制的创建会导致性能低下。 因此http有一种叫做keepalive connections的机制,它可以在传输数据后仍然保持连接,当客户端需要再次获取数据时,直接使用刚刚空闲下来的连接而不需要再次握手。

Okhttp支持5个并发KeepAlive,默认链路生命为5分钟(链路空闲后,保持存活的时间)。
1.2.3 连接池(ConnectionPool)分析
public final class ConnectionPool {
/**
* Background threads are used to cleanup expired connections. There will be at most a single
* thread running per connection pool. The thread pool executor permits the pool itself to be
* garbage collected.
*/
private static final Executor executor = new ThreadPoolExecutor(0 /* corePoolSize */,
Integer.MAX_VALUE /* maximumPoolSize */, 60L /* keepAliveTime */, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp ConnectionPool", true));
/** The maximum number of idle connections for each address. */
//每个地址的最大空闲连接数。
private final int maxIdleConnections;
//每个地址的最长保持时间
private final long keepAliveDurationNs;
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
// 双向队列
private final Deque<RealConnection> connections = new ArrayDeque<>();
final RouteDatabase routeDatabase = new RouteDatabase();
boolean cleanupRunning;
....
源码解析
- Executor executor:线程池,用来检测闲置socket并对其进行清理。
- Deque connections:缓存池。Deque 是一个双端列表,支持在头尾插入元素,这里用作LIFO(后进先出)堆栈,多用于缓存数据。
- RouteDatabase routeDatabase:用来记录连接失败的router。
1、缓存操作
ConnectionPool提供对Deque进行操作的方法分别对put、get、connectionBecameIdle、evictAll几个操作。分别对应放入连接、获取连接、移除连接、移除所有连接操作。这里举例put和get操作。
put操作
void put(RealConnection connection) {
assert (Thread.holdsLock(this));
if (!cleanupRunning) {
cleanupRunning = true;
//下文重点讲解
executor.execute(cleanupRunnable);
}
connections.add(connection);
}
源码解析
可以看到在新的connection 放进列表之前执行清理闲置连接的线程。 既然是复用,那么看下他获取连接的方式。
get操作
/**
* Returns a recycled connection to {@code address}, or null if no such connection exists. The
* route is null if the address has not yet been routed.
*/
@Nullable RealConnection get(Address address, StreamAllocation streamAllocation, Route route) {
assert (Thread.holdsLock(this));
for (RealConnection connection : connections) {
if (connection.isEligible(address, route)) {
streamAllocation.acquire(connection, true);
return connection;
}
}
return null;
}
源码解析
遍历connections缓存列表,当某个连接计数的次数小于限制的大小以及request的地址和缓存列表中此连接的地址完全匹配。则直接复用缓存列表中的connection作为request的连接。
2、连接池清理和回收
上文我们讲到 Executor 线程池,用来清理闲置socket连接的。我们在put新连接到队列的时候会先执行清理闲置线程连接的线程,调用的是: executor.execute(cleanupRunnable),接下来我们就来分析:cleanupRunnable。
private final Runnable cleanupRunnable = new Runnable() {
@Override public void run() {
while (true) {
long waitNanos = cleanup(System.nanoTime());
if (waitNanos == -1) return;
if (waitNanos > 0) {
long waitMillis = waitNanos / 1000000L;
waitNanos -= (waitMillis * 1000000L);
synchronized (ConnectionPool.this) {
try {
ConnectionPool.this.wait(waitMillis, (int) waitNanos);
} catch (InterruptedException ignored) {
}
}
}
}
}
};
源码解析
线程中不停调用Cleanup 清理的动作并立即返回下次清理的间隔时间。继而进入wait 等待之后释放锁,继续执行下一次的清理。所以可能理解成他是个监测时间并释放连接的后台线程。 所以在这只要了解cleanup动作的过程,就清楚了这个线程池是如何回收的了
3、总结
到这,整个socket连接池复用机制讲完了。连接池复用的核心就是用Deque来存储连接,通过put、get、connectionBecameIdle、evictAll几个操作。另外通过判断连接中的计数对象StreamAllocation来进行自动回收连接。
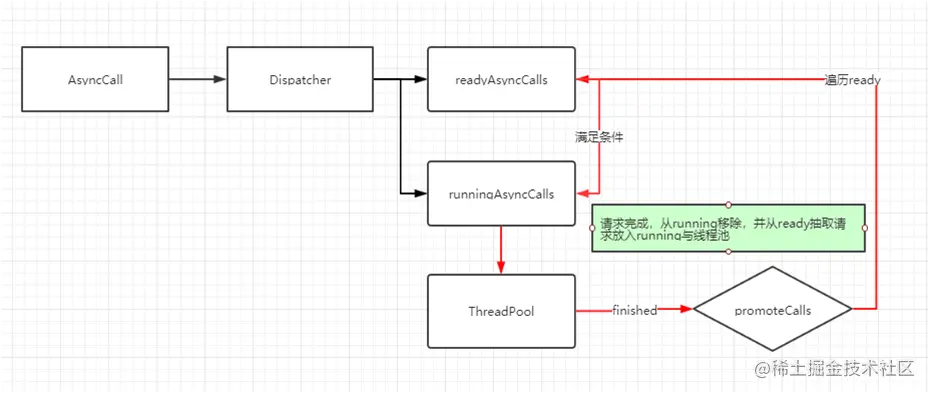
1.3 高并发请求队列:任务分发
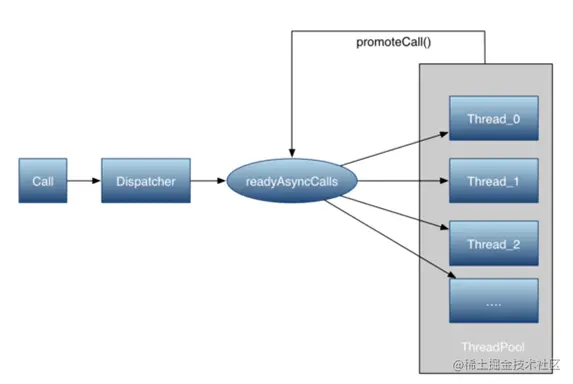
如图所示
当我们进行多网络接口请求时,将会通过对应任务分发器分派对应的任务。在解读源码之前,将会先手写一份直播任务分发的小demo,先理解何为分发器,方便后面更容易理解OkHttp是如何进行分发的。
1.3.1、手写直播分发demo
需求整理:
当用户进入直播界面的时候,用户首先能看到主播流所展示的页面,其次红包流、购物车流、以及其他流所展示的界面布局。而且这些附加流可动态控制,每个模块也必须单独做自己模块的事。
先定义 直播任务分发器
public abstract class LivePart {
public abstract void dispatch(BaseEvent event);
}
public abstract class BaseEvent {
}
//用于通知开播事件类
public class LiveEvent extends BaseEvent{
}
定义对应直播流
//事件分发机制
public class SmallVideoPart extends LivePart {
@Override
public void dispatch(BaseEvent event) {
if(event instanceof LiveEvent){
System.out.println("主播流来了,其他小视频窗口流要渲染出来了");
//可在这执行直播流相关的逻辑
}
}
}
//红包部件干他自己的事情
public class RedPackPart extends LivePart {
@Override
public void dispatch(BaseEvent event) {
if(event instanceof LiveEvent) {
System.out.println("直播流来了,红包准备开始");
//可在这执行红包相关的逻辑
}
}
}
哈哈哈,看到这是不是游刃有余呢?不过这里与同步请求不同的是,这里有俩个队列,一个正在执行的队列,一个为等待队列。 从这段代码里可知,什么时候进正在执行队列,什么时候进等待队列。 那么问题来了,已经进入等待队列里面的请求,什么时候迁移到执行队列里面来呢? 答案就在于这个方法的请求参 AsyncCall ,其实它就是一个Runnable ,进去寻找答案。
final class AsyncCall extends NamedRunnable {
private final Callback responseCallback;
String host() {
return originalRequest.url().host();
}
Request request() {
return originalRequest;
}
RealCall get() {
return RealCall.this;
}
AsyncCall(Callback responseCallback) {
super("OkHttp %s", redactedUrl());
this.responseCallback = responseCallback;
}
@Override protected void execute() {
boolean signalledCallback = false;
try {
//后面会重点讲解这getResponseWithInterceptorChain 方法
Response response = getResponseWithInterceptorChain();
if (retryAndFollowUpInterceptor.isCanceled()) {
signalledCallback = true;
responseCallback.onFailure(RealCall.this, new IOException("Canceled"));
} else {
signalledCallback = true;
responseCallback.onResponse(RealCall.this, response);
}
} catch (IOException e) {
if (signalledCallback) {
// Do not signal the callback twice!
Platform.get().log(INFO, "Callback failure for " + toLoggableString(), e);
} else {
eventListener.callFailed(RealCall.this, e);
responseCallback.onFailure(RealCall.this, e);
}
} finally {
// 当请求执行完成调用了Dispatcher的finished方法
client.dispatcher().finished(this);
}
}
}
源码分析
这里就是网络请求的核心类,不过在这不用看那么多,只需要看最后 finally 调用了 finished 方法。也就是说每个网络请求结束时,都会调用该方法,这还没完全找到答案,继续追进dispatcher的 finished方法。
/** Used by {@code AsyncCall#run} to signal completion. */
void finished(AsyncCall call) {
finished(runningAsyncCalls, call, true);
}
继续深入
private <T> void finished(Deque<T> calls, T call, boolean promoteCalls) {
int runningCallsCount;
Runnable idleCallback;
synchronized (this) {
if (!calls.remove(call)) throw new AssertionError("Call wasn't in-flight!");
// promoteCalls这里是true, 执行promoteCalls()
if (promoteCalls) promoteCalls();
runningCallsCount = runningCallsCount();
idleCallback = this.idleCallback;
}
if (runningCallsCount == 0 && idleCallback != null) {
idleCallback.run();
}
}
这里第三个变量为true,也就是 promoteCalls 这个方法是必然执行的,那么进这个方法看看。
private void promoteCalls() {
// 如果执行的队列请求数量超过64个,直接return
if (runningAsyncCalls.size() >= maxRequests) return; // Already running max capacity.
// 如果等待的队列请求数量为空,直接return
if (readyAsyncCalls.isEmpty()) return; // No ready calls to promote.
// 遍历等待队列
for (Iterator<AsyncCall> i = readyAsyncCalls.iterator(); i.hasNext(); ) {
AsyncCall call = i.next();
// 检查一下正在执行的同一host的请求数量是不是不满5个
if (runningCallsForHost(call) < maxRequestsPerHost) {
// 满足条件,当前等待任务移出等待队列
i.remove();
//当前被移除等待队列的任务加入正在执行队列
runningAsyncCalls.add(call);
//直接执行请求任务!
executorService().execute(call);
}
if (runningAsyncCalls.size() >= maxRequests) return; // Reached max capacity.
}
}
1.3.3、总结
哈哈哈哈,相信能看到这,上面提的问题直接迎刃而解。是不是很简单?再来一张图总结一下。
1.4 责任链模式拦截器设计
在上文讲解 Dispatcher 分发器的时候,里面讲解了异步请求,并且贴出了 AsyncCall 代码段,再次在这里贴一次。
final class AsyncCall extends NamedRunnable {
...略
@Override protected void execute() {
boolean signalledCallback = false;
try {
Response response = getResponseWithInterceptorChain();
...略
} catch (IOException e) {
...略
} finally {
client.dispatcher().finished(this);
}
}
}
同步调用
@Override public Response execute() throws IOException {
...略
try {
client.dispatcher().executed(this);
Response result = getResponseWithInterceptorChain();
if (result == null) throw new IOException("Canceled");
return result;
} catch (IOException e) {
eventListener.callFailed(this, e);
throw e;
} finally {
client.dispatcher().finished(this);
}
}
源码分析
这里可以看出 同步、异步调用 代码段里面,都调用了 getResponseWithInterceptorChain 方法。既然都调用了这方法,那我们进入一探究竟。
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
//开发者自定义拦截器
interceptors.addAll(client.interceptors());
// RetryAndFollowUpInterceptor (重定向拦截器)
interceptors.add(retryAndFollowUpInterceptor);
// BridgeInterceptor (桥接拦截器)
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//CacheInterceptor (缓存拦截器)
interceptors.add(new CacheInterceptor(client.internalCache()));
// ConnectInterceptor (连接拦截器)
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//开发者自定义拦截器
interceptors.addAll(client.networkInterceptors());
}
//CallServerInterceptor(读写拦截器)
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
return chain.proceed(originalRequest);
}
源码分析
这段代码,我们可以理解成添加了一系列责任链拦截器。那么问题又来了。 何为责任链?何为拦截器?它们有什么作用? 在本篇里,先让你理解这些,然后在下一篇里具体详解每一个拦截器。 如果理解什么是责任链拦截器的读者也可以选择跳过下面内容,直接看下一篇 Android 架构之OkHttp源码解读(中)
在本篇里,我准备了俩个小demo,相信看完后应该能有所收获。
1.4.1 模拟公司员工报销Demo
需求整理
现在要写一个报销系统,其中组长报销额度为1000;主管报销额度为5000;经理报销额度为10000;boos报销额度为10000+。
代码如下
1、Leader
public abstract class Leader {
//上级领导
public Leader nextHandler;
/**
* 处理报账请求
* @param money 能批复的报账额度
*/
public final void handleRequest(int money){
System.out.println(getLeader());
if(money <=limit()){
handle(money);
}else{
System.out.println("报账额度不足,提交领导");
if(null != nextHandler){
nextHandler.handleRequest(money);
}
}
}
/**
* 自身能批复的额度权限
* @return 额度
*/
public abstract int limit();
/**
* 处理报账行为
* @param money 具体金额
*/
public abstract void handle(int money);
/**
* 获取处理者
* @return 处理者
*/
public abstract String getLeader();
}
代码分析
该类可看作为 领导基类,具有报销功能的人。
2、组长
//组长(额度1000)
public class GroupLeader extends Leader {
@Override
public int limit() {
return 1000;
}
@Override
public void handle(int money) {
System.out.println("组长批复报销"+ money +"元");
}
@Override
public String getLeader() {
return "当前是组长";
}
}
3、主管
//主管(额度5000):
public class Director extends Leader {
@Override
public int limit() {
return 5000;
}
@Override
public void handle(int money) {
System.out.println("主管批复报销"+ money +"元");
}
@Override
public String getLeader() {
return "当前是主管";
}
}
4、经理
//经理(额度10000)
public class Manager extends Leader {
@Override
public int limit() {
return 10000;
}
@Override
public void handle(int money) {
System.out.println("经理批复报销"+ money +"元");
}
@Override
public String getLeader() {
return "当前是经理";
}
}
5、boos
//老板
public class Boss extends Leader {
@Override
public int limit() {
return Integer.MAX_VALUE;
}
@Override
public void handle(int money) {
System.out.println("老板批复报销"+ money +"元");
}
@Override
public String getLeader() {
return "当前是老板";
}
}
6、开始报销
//员工要报销 员工-》组长-》主管-》经理-》老板
//员工报销8000块
private void bxMoney(){
GroupLeader groupLeader = new GroupLeader();
Director director = new Director();
Manager manager = new Manager();
Boss boss = new Boss();
//设置上级领导处理者对象,组长的上级为主管
groupLeader.nextHandler = director;
//设置主管上级为经理
director.nextHandler = manager;
//设置经理上级为boos
manager.nextHandler = boss;
//这种责任链不好,还需要指定下一个处理对象
//发起报账申请
groupLeader.handleRequest(8000);
}
7、运行效果
I/System.out: 当前是组长
I/System.out: 报账额度不足,提交领导
I/System.out: 当前是主管
I/System.out: 报账额度不足,提交领导
I/System.out: 当前是经理
I/System.out: 经理批复报销8000元
8、总结
到这,相信你对责任链有了一个初步的认知,上一级做不好的交给下一级,但是这种责任链并不好,因为要通过代码手动指定责任链下一级到底是谁,而我们看到的OkHttp框架里面并不是用的这种模式。所以就迎来了第二个demo。
1.4.2 模拟支付场景Demo
需求整理
小明去超市里面买东西,结账的时候发现微信和支付宝的余额都不足,但是支付宝和微信里面余额加起来能够付款,于是小明 选择了微信、支付宝混合支付;小白也去超市买东西,但他的支付宝、微信金额都远远大于结账金额,于是他可以任选其一支付。
代码如下
1、定义一个具有支付能力的基类
public abstract class AbstractPay {
/**
* 支付宝支付
*/
public static int ALI_PAY = 1;
/**
* 微信支付
*/
public static int WX_PAY = 2;
/**
* 两者支付方式
*/
public static int ALL_PAY = 3;
/**
* 条码支付
*
* @param payRequest
* @param abstractPay
*/
abstract protected void barCode(PayRequest payRequest, AbstractPay abstractPay);
}
2、支付宝支付
public class AliPay extends AbstractPay {
@Override
public void barCode(PayRequest payRequest, AbstractPay abstractPay) {
if (payRequest.getPayCode() == ALI_PAY) {
System.out.println("支付宝扫码支付");
} else if(payRequest.getPayCode() == ALL_PAY){
System.out.println("支付宝扫码支付完成,等待下一步");
abstractPay.barCode(payRequest, abstractPay);
}else {
abstractPay.barCode(payRequest, abstractPay);
}
}
}
3、微信支付
public class WxPay extends AbstractPay {
@Override
public void barCode(PayRequest payRequest, AbstractPay abstractPay) {
if (payRequest.getPayCode() == WX_PAY) {
System.out.println("微信扫码支付");
} else if(payRequest.getPayCode() == ALL_PAY){
System.out.println("微信扫码支付完成,等待下一步");
abstractPay.barCode(payRequest, abstractPay);
}else {
abstractPay.barCode(payRequest, abstractPay);
}
}
}
4、待支付的商品
/**
* 待支付商品
*/
public class PayRequest {
//待选择的支付方式
private int payCode=0;
public int getPayCode() {
return payCode;
}
public void setPayCode(int payCode) {
this.payCode = payCode;
}
}
5、支付操作类
public class PayChain extends AbstractPay {
/**
* 完整责任链列表
*/
private List<AbstractPay> list = new ArrayList<>();
/**
* 索引
*/
private int index = 0;
/**
* 添加责任对象
*
* @param abstractPay
* @return
*/
public PayChain add(AbstractPay abstractPay) {
list.add(abstractPay);
return this;
}
@Override
public void barCode(PayRequest payRequest, AbstractPay abstractPay) {
// 所有遍历完了,直接返回
if (index == list.size()) {
System.out.println("支付全部完成,请取商品");
return;
}
// 获取当前责任对象
AbstractPay current = list.get(index);
// 修改索引值,以便下次回调获取下个节点,达到遍历效果
index++;
// 调用当前责任对象处理方法
current.barCode(payRequest, this);
}
}
6、开始支付
private void scanMoney() {
PayRequest payRequest = new PayRequest();
//1、支付宝支付;2、微信支付;3、两者支付方式
payRequest.setPayCode(3);
PayChain chain = new PayChain();
chain.add(new AliPay());
chain.add(new WxPay());
chain.barCode(payRequest, chain);
}
7、运行效果
I/System.out: 支付宝扫码支付完成,等待下一步
I/System.out: 微信扫码支付完成,等待下一步
I/System.out: 支付全部完成,请取商品
看这段代码结构是否似曾相识?这不就是OkHttp添加拦截器的格式么? 那么是不是可以假设一下,OkHttp添加的拦截器,是否也按照demo的方式执行的? 在这里再次贴一下OkHttp添加拦截器的代码段。
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
//开发者自定义拦截器
interceptors.addAll(client.interceptors());
// RetryAndFollowUpInterceptor (重定向拦截器)
interceptors.add(retryAndFollowUpInterceptor);
// BridgeInterceptor (桥接拦截器)
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//CacheInterceptor (缓存拦截器)
interceptors.add(new CacheInterceptor(client.internalCache()));
// ConnectInterceptor (连接拦截器)
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
//开发者自定义拦截器
interceptors.addAll(client.networkInterceptors());
}
//CallServerInterceptor(读写拦截器)
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(interceptors, null, null, null, 0,
originalRequest, this, eventListener, client.connectTimeoutMillis(),
client.readTimeoutMillis(), client.writeTimeoutMillis());
return chain.proceed(originalRequest);
}
源码解读
这里看添加方式几乎和demo一样,那么使用呢?源码最后一句调用了RealInterceptorChain.proceed方法,我们进去看看。
@Override public Response proceed(Request request) throws IOException {
return proceed(request, streamAllocation, httpCodec, connection);
}
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
if (index >= interceptors.size())
throw new AssertionError();
...略
calls++;
...略
// Call the next interceptor in the chain.
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
Interceptor interceptor = interceptors.get(index);
Response response = interceptor.intercept(next);
...略
return response;
}
源码解读
看这,具体使用也和demo如出一辙,拦截器使用完了,demo选择的return结束,okHttp选择抛异常结束;每当一个拦截器使用完了,就会继续切换下一个拦截器。好了,本篇文章就到这差不多结束了,最后再来个总结。
8、总结
相信看到这里的小伙伴,你应该理解了OkHttp的重要性、调用流程、连接池复用、任务分发、以及这样添加责任链拦截器的原因。



















































{kind=link}