








MacOS14.4 + Java = 崩溃!!!
使用Mac开发Java的好兄弟们,最近你们还好吗,不知道你们对下面这张图熟不熟悉。

我是很熟悉啊,而且今天就遇到了两次0.0,那么到底是怎么回事呢?
1.场景复现
下午起床,洗把脸开始上班。很有感觉哈,思考问题脑子变快了,手上的代码也快了起来。正当我洋洋得意感觉就要大功告成的时候,突然,很快啊,我他喵的IDEA没了。突然返回到了桌面,我甚至都没反应过来发生了什么事,然后就弹出了上面那个非常让人想把它枪毙五分钟的弹窗。我IDEA崩溃了!!!不过,还好,IDEA向来智能,还会自动保存。然后我就点击了重新打开,打开后我是真的傻眼了。
我代码呢???啊???IDEA我代码呢???说好的自动保存呢?

然后我又找了下本地历史,发现也没有记录,真的G了,快一个小时的汗水白流了。。。我直接想骂街。那又能怎么办呢,只能在跟同事吐槽几句后,重新来过。
生活就是这样,每时每刻都在发生我们无法控制的事情,尽管你很委屈,尽管那是你努力很久很久的东西,但是我们无能为力。我们只能选择擦干眼泪,重新再来。你要习惯,这就是生活。
2.情景再现
就在我感慨完之后,又是一顿行云流水写完了代码,然后点击小虫子按钮准备DeBug时,好家伙,他又来了。 不过好消息是,这次大部分代码还在,只有一小部分丢失了。

3.抓到罪魁祸首
总是感觉不太对劲,从做开发到现在,说实话还从未遇到如此场景。心里除了崩溃之外还存在着疑惑,到底是什么导致一天出现两次这种情况。
晚上逛掘金的时候让我找到了这个答案。
感谢@程序猿DD的文章:juejin.cn/post/734700…
原来是你,我最信赖的MacOS。
原来官方早在3.15就发布了一篇博客,里面讲解了macos14.4中运行java程序会有导致崩溃的情况。大致意思是,在macos14.4之前,系统会向访问受保护区域的进程发送两种信号SIGBUS和SIGSEGV,进程可以选择处理信号并继续运行。但是在macos14.4中,这个信号变了,变成了新的信号SIGKILL,然后我们的java进程没法处理这个信号,所以进程就被无条件的杀死了。
而且影响从 Java 8 到 JDK 22 的早期访问版本的所有 Java 版本。并且目前没有可用的解决方法。

(帮好兄弟们翻译一下)

再看看我的系统版本,好家伙,没谁了,帮苹果测试系统兼容性了。

4.懊悔ing
现在的我已经想象到未来一段时间IDEA接连崩溃的情况了

来源:juejin.cn/post/7347957860087250996
用 Maven 还是 Gradle?
大家好,我是风筝
作为Java 开发者,你平时用 Maven 还是 Gradle?
我一直用的都是 Maven,但是前几天做了一个小项目,用的是 Gradle,因为项目创建出来默认就是用的 Gradle,而且功能足够简单,我也就没动。

实话说,以前也接触过 Gradle。最早是我想学学 Android 开发,Android 项目默认就是用 Gradle,其实那时候我对Gradle 的印象就不是很好。
本来下载 Android SDK 就够慢的了,我记得第一次搭Android 环境,弄了足足一天。好不容易 SDK下载完了,就想写了 Hello World 跑一下,结果发现本地没有 Gradle,这时候Android Stuido 其实会自动下载 Gradle 的(就是一个 Gradle.zip的文件,相信很多人对这个文件有阴影),但是国内的网络死活就是下载不下来。(ps: 现在下载 Gradle 应该是问题不大了,因为 Gradle 开通了国内的 CDN)
大哥,我就想跑个 Hello World,何罪之有啊!后来一顿搜索,跟着好几个教程,好歹是跑起来了。
在那儿之后,我就没碰过 Gradle 了。直到有一天,看到 Spring 和 Spring Boot 都从 Maven 切换到 Gradle了。诶,难不成 Gradle 已经这么厉害了,让 Spring 团队都抛弃 Maven 了。
然后我把 Spring Boot 最新仓库 clone 下来,结果一构建,一堆报错,解决一个又一个呀,就这?
我把原因归结于 Gradle 使用门槛过高,外加自己能力不行。直到有一天看到有人说:“有几个 Gradle 项目能一次性构建成功跑起来的吗?”
当然这不能就说 Gradle 不好用,Gradle 老鸟们基本上不存在这样的问题,说到底还是理解的不够到位。
为什么 Spring 放着好好的 Maven 不用,要费大力气切到 Gradle呢?Spring 这么大的项目,切到 Gradle 也没那么容易,也是在很多人(包括Gradle 团队成员)的帮助下才迁移完成的。据官方介绍,迁移的主要原因就是为了减少构建时间,构建速度确实是 Gradle 强于 Maven的一大优势,尤其是对于大项目更是如此。
Maven
Maven 是一个项目管理和构建工具,主要用于 Java 项目的构建、依赖管理和项目生命周期管理。Maven 的核心是包管理工具,至于项目构建其实是依靠插件来完成的,比如 maven-compiler-plugin插件等。 
Maven 遵循“约定优于配置”的原则,提供了一套默认的项目结构和构建流程。如果开发者遵循这些约定,Maven 就能自动处理很多配置工作,从而减少开发者的配置负担。
Maven 使用 XML 文件的形式管理依赖包,也就是项目中的 pom.xml,整个 XML 文件的格式都是固定的,仓库怎么引入、依赖怎么引入、插件怎么引入都是约定好的,照着做就好了,一个项目的 pom 文件,复制到另一个项目中,改一下包依赖、改一下基本项目信息,其他的基本完全复用。
Gradle
Gradle 是一个构建自动化工具,广泛用于软件项目的构建、依赖管理和项目生命周期的管理。它最初是为了构建 Java 项目而设计的,但如今它支持多种编程语言和技术,包括 Java、Kotlin、Groovy、Scala、Android 等。 
其在自动化构建能力上更强,包管理只是其中的一个功能。
Gradle 采用基于 Groovy 或 Kotlin 的领域特定语言(DSL),允许开发者通过编写脚本来自定义构建过程。相比其他构建工具(如 Maven),Gradle 更加灵活和强大。这就是它灵活性所在,但是也是它的门槛所在,也就是说你要使用它,还要理解 Groovy 或 Kotlin,理解的不到位可能会带来很多问题。这也是很多人吐槽它的原因,过于灵活的副作用就是门槛过高。
优缺点比较
其实通过上面的介绍也能看出一些端倪了。
学习门槛
首先在学习门槛上,显然 Gradle 更高。一般项目, Maven 加几行 XML 就行了,构建插件也就那么几个,只需要复制粘贴就可以了,而 Gradle 中多少要了解一点 Groovy 或 Kotlin 吧。
灵活性
Gradle 的灵活度更高,Maven 则是中规中举。如果你的构建行为比较复杂,可能纯靠 Maven 自己的配置文件没办法实现,就需要你自己写一些辅助脚本了。而用 Gradle 的话,你可以使用它的 DSL 能力定制非常复杂的构建流程。
性能
这个不得不承认,Gradle 的性能更高。据官方介绍,一般的项目使用 Gradle 构建的速度是Maven 的至少2倍,而一些大型项目的复杂构建,在极端情况下能达到 Maven 的100倍,这好像有点儿夸张了,不过快几倍应该是有的,这也是为什么 Spring 切换到 Gradle 的理由,切换到 Gradle 后,构建时间大概是20多分钟,可想而知,使用 Maven 的话,应该要一个小时以上了。
性能好是有代价的,除了原理不一样外,Gradle 会有一些后台进程,所以,对于一些性能不怎么样的开发机来说,使用 Gradle 反而会觉得卡。
用户体验
用户体验是个很主观的东西,有人就觉得 Maven 好,即使慢一点,也是它好。有人就觉得 Gradle 好,灵活,而且门槛高,用它说明我技术好啊。
但是 Maven 的稳定性是非常好的,一个 Maven 3.5 用好几年也没啥问题,但是 Gradle 不一样,好多版本是不做兼容的。比如我本地安装了新版本,但是有一个项目用的是老版本,那很可能这个项目是没办法跑起来的,只能去安装和这个项目适配的版本。这也是 Gradle 被疯狂吐槽的一个点,即使是 Gradle 用户。
最后
作为开发者如何选择呢?对我来说,我就老实的用 Maven 就好了,反正我也基本上做不了那么大型的、构建一次几个小时的应用,使用 Maven 就图个省心。安心写代码就好了,构建的事儿交给Maven、交给插件就好了。典型的实用主义。
一家之言啊,作为开发者来说,第一肯定是要跟着公司的规定来,公司如果用 Gradle ,那你也不能坚持用 Maven。同理,公司用 Maven,你也不能另辟蹊径的用 Gradle 。
其实到最后可能就是习惯问题了,如果一个工具用的时间超过几个月,那基本上所有的问题都不是问题了。
来源:juejin.cn/post/7424302125460619298
微信小程序、h5、微信公众号之间的跳转
一、微信小程序不同页面之间的跳转
wx.switchTab
跳转到 tabBar 页面,并关闭所有非 tabBar 页面。
wx.switchTab({
url: '', // app.json 里定义的 tabBar 页面路径,不可传参数
success: function() {},
fail: function() {},
complete: function() {}
});
wx.reLaunch
关闭所有页面,跳转到指定页面。
wx.reLaunch({
url: '', // app.json 里定义页面路径,可传参数,例如 'path?key1=val1&key2=val2'
success: function() {},
fail: function() {},
complete: function() {}
});
// url 上传递的参数可以在被打开页面的 onLoad 生命周期中接收
Page({
onLoad(options) {
// your code...
}
});
如果传递的参数有中文,为了避免乱码,可以先
encodeURIComponent,再decodeURIComponent
wx.redirectTo
关闭当前页跳转到指定页面,但是不允许跳转到 tabbar 页。
wx.redirectTo({
url: '', // app.json 里定义页面路径,可传参数,例如 'path?key1=val1&key2=val2'
success: function() {},
fail: function() {},
complete: function() {}
});
// url 上传递的参数可以在被打开页面的 onLoad 生命周期中接收
Page({
onLoad(options) {
// your code...
}
});
wx.navigateTo
保留当前页面,跳转到应用内的某个页面。但是不能跳到 tabbar 页面。使用 wx.navigateBack 可以返回到原页面。小程序中页面栈最多十层。
wx.navigateTo({
url: '', // app.json 里定义页面路径,可传参数,例如 'path?key1=val1&key2=val2'
events: {
// 为指定事件添加一个监听器,获取被打开页面传送到当前页面的数据
acceptDataFromOpenedPage: function(data) {
console.log(data);
},
someEvent: function(data) {
console.log(data);
}
},
success: function(res) {
// 通过eventChannel向被打开页面传送数据
res.eventChannel.emit('acceptDataFromOpenerPage', { data: 'test' });
},
fail: function() {},
complete: function() {}
});
// eventChannel 传递的参数可以在被打开页面的 onLoad 生命周期中接收
Page({
onLoad(options) {
console.log('options', options);
const eventChannel = this.getOpenerEventChannel();
eventChannel.emit('acceptDataFromOpenedPage', {data: 'test'});
eventChannel.emit('someEvent', {data: 'test'});
// 监听acceptDataFromOpenerPage事件,获取上一页面通过eventChannel传送到当前页面的数据
eventChannel.on('acceptDataFromOpenerPage', function(data) {
console.log(data)
})
}
});
wx.navigateBack
关闭当前页面,返回上级页面或多级页面,可以通过 getCurrentPages 获取当前的页面栈,决定返回几层。
const pages = getCurrentPages();
const prevPages = pages[pages.length -2];
// 向跳转页面传递参数
prevPages.setData({...});
wx.navigateBack({
delta: 1, // 返回的页面数,默认是 1,如果 delta 大于现有页面,则返回到首页
success: function() {},
fail: function() {},
complete: function() {}
});
二、微信小程序和H5之间的跳转
微信小程序跳转到 H5
使用微信小程序自身提供的 web-view 组件,它作为承载网页的容器,会自动铺满整个小程序页面。
// app.json
{
pages: [
"pages/webView/index"
]
}
// webView/index.wxml
"{{url}}">
// webView/index.js
Page({
data: {
url: ''
},
onLoad: function(options) {
this.setData({
url: options.url
});
}
})
H5 跳转微信小程序
wx-open-launch-weapp 用于H5页面中提供一个可以跳转小程序的按钮。
在使用wx-open-launch-weapp这个标签之前,需要先引入微信JSSDK,通过 wx.config 接口注入权限验证配置,然后通过 openTagList 字段申请所需要的开放标签。
<wx-open-launch-weapp class="dialog-footer" id="iKnow" username="跳转的小程序原始id" path="所需跳转的小程序内页面路径及参数">
<style>style>
<template>
<div class="dialog-footer" style="font-size: 2rem; text-align: center;">前往小程序div>
template>
wx-open-launch-weapp>
<script src="https://res.wx.qq.com/open/js/jweixin-1.6.0.js">script>
const IKnowElem = document.querySelector("#iKnow");
IKnowElem.addEventListener("launch", function (e) {
console.log("success", e);
});
IKnowElem.addEventListener("error", function (e) {
console.log("fail", e.detail);
});
function jsApiSignature() {
return post(
"/api/mp/jsapi/signature",
{ url: location.href }
).then((resp) => {
if (resp.success) {
const data = resp.data;
wx.config({
appId: appid,
timestamp: data.timestamp,
nonceStr: data.nonceStr,
signature: data.signature,
openTagList: ["wx-open-launch-weapp"],
jsApiList: [],
});
wx.ready(function () {
console.log("ready");
// config信息验证后会执行ready方法,所有接口调用都必须在config接口获得结果之后,config是一个客户端的异步操作,所以如果需要在页面加载时就调用相关接口,则须把相关接口放在ready函数中调用来确保正确执行。对于用户触发时才调用的接口,则可以直接调用,不需要放在ready函数中
});
wx.error(function (res) {
console.error("授权失败", res);
// config信息验证失败会执行error函数,如签名过期导致验证失败,具体错误信息可以打开config的debug模式查看,也可以在返回的res参数中查看,对于SPA可以在这里更新签名
});
}
});
}
三、H5 和微信公众号之间的相互跳转
H5 跳转到微信公众号
在微信公众号里打开的 H5 页面执行 closeWindow 关闭窗口事件即可。
const handleFinish = function () {
console.log("handleFinish");
document.addEventListener(
"WeixinJSBridgeReady",
function () {
WeixinJSBridge.call("closeWindow");
},
false
);
WeixinJSBridge.call("closeWindow");
};
如有问题,欢迎指正~~
来源:juejin.cn/post/7314546931863240723
如何从任意地方点击链接跳转到微信公众号?
一、微信内部点击链接
微信公众号主页链接:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=XXX#wechat_redirect
微信公众号主页链接:
https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=XXX#wechat_redirect
1.1 action
action 代表当前路径前端框架的哪个页面
- home:当前路径前端框架首页
action 代表当前路径前端框架的哪个页面
- home:当前路径前端框架首页
1.2 __biz
__biz 代表微信公众号 ID
__biz 代表微信公众号 ID
1.2.1 __biz 的获取方式
- 在网页中打开该公众号的任意一篇推文 ➡️ 右击鼠标选择检查 ➡️ 在元素下搜素
__biz

org:url 表示当前内容链接
- 从公众平台进入公众号 ➡️ 公众号设置页,右键打开检查 ➡️ 搜索 uin_base64

- 在网页中打开该公众号的任意一篇推文 ➡️ 右击鼠标选择检查 ➡️ 在元素下搜素
__biz
org:url 表示当前内容链接
- 从公众平台进入公众号 ➡️ 公众号设置页,右键打开检查 ➡️ 搜索 uin_base64
二、微信外部点击链接
目前微信官方没有提供相应的功能,但是有的第三方平台可以实现,比如天天外链

但是需要注意,配置的网页地址不能是公众号首页或关注页,必须是永久公众号文章链接。
来源:juejin.cn/post/7216518492613656636
成为海王的日子——我做了一个微信自动聊天的工具
一直幻想着能够成为一个海王,于是做了一个微信自动聊天的工具。
测试微信版本:wechat 3.9.12.17
采用技术:
- Bmob后端云(AI对话和存储需要自动聊天的人和prompt)
- uiautomation
- pyautogui
开发语言:
- python,conda环境下运行
最终的效果大家可以看B站:http://www.bilibili.com/video/BV1yK…
一、获取微信对话内容
这里采用了网上的一些开源项目进行修改,写了一个自己的WeChat控制类,采用的是uiautomation和pyautogui组件进行UI的控制,模拟人的操作。
WeChat控制类的内容比较多,为了方便阅读,这里只呈现一部分,有需要的朋友可以联系我获取。
class WeChat:
def __init__(self, path, locale="zh-CN"):
# 微信打开路径
self.path = path
# 用于复制内容到剪切板
self.app = QApplication([])
self.lc = WeChatLocale(locale)
# 鼠标移动到控件上
def move(self,element):
x, y = element.GetPosition()
auto.SetCursorPos(x, y)
# 鼠标快速点击控件
def click(self,element):
x, y = element.GetPosition()
auto.Click(x, y)
# 鼠标右键点击控件
def right_click(self,element):
x, y = element.GetPosition()
auto.RightClick(x, y)
# 鼠标快速点击两下控件
def double_click(self,element):
x, y = element.GetPosition()
auto.SetCursorPos(x, y)
element.DoubleClick()
# 打开微信客户端
def open_wechat(self):
subprocess.Popen(self.path)
# 搜寻微信客户端控件
def get_wechat(self):
return auto.WindowControl(Depth=1, Name=self.lc.weixin)
# 防止微信长时间挂机导致掉线
def prevent_offline(self):
self.open_wechat()
self.get_wechat()
search_box = auto.EditControl(Depth=8, Name=self.lc.search)
self.click(search_box)
# 搜索指定用户
def get_contact(self, name):
self.open_wechat()
self.get_wechat()
search_box = auto.EditControl(Depth=8, Name=self.lc.search)
self.click(search_box)
pyperclip.copy(name)
auto.SendKeys("{Ctrl}v")
# 等待客户端搜索联系人
time.sleep(0.3)
search_box.SendKeys("{enter}")
# 鼠标移动到发送按钮处点击发送消息
def press_enter(self):
# 获取发送按钮
send_button = auto.ButtonControl(Depth=15, Name=self.lc.send)
self.click(send_button)
# 检测微信发新消息的用户
def check_new_user(self):
self.open_wechat()
self.get_wechat()
users = []
# 获取左侧聊天按钮
chat_btn = auto.ButtonControl(Name=self.lc.chats)
self.double_click(chat_btn)
# 持续点击聊天按钮,直到获取完全部新消息
item = auto.ListItemControl(Depth=10)
prev_name = item.ButtonControl().Name
while True:
# 判断该联系人是否有新消息
pane_control = item.PaneControl()
if len(pane_control.GetChildren()) == 3:
users.append(item.ButtonControl().Name)
self.click(item)
# 跳转到下一个新消息
self.double_click(chat_btn)
item = auto.ListItemControl(Depth=10)
# 已经完成遍历,退出循环
if prev_name == item.ButtonControl().Name:
break
prev_name = item.ButtonControl().Name
return users
二、获取需要自动聊天的人和对应的prompt
这部分信息我存储在Bmob后端云上面,对应的表结构(表名为:autochat,创建的字段为:name、prompt)和测试的内容如下:

获取信息的时候,我采用了子线程的方式,每隔300秒获取一次新的需要自动对话的微信和对应的prompt,代码如下:
# Bmob对象
bmob = Bmob(config['bmob_appid'], config['bmob_secret'])
# 存储从Bmob后端云获取到的自动对话的微信名和对应的prompt
name_prompts = {}
# 从Bmob后端云获取自动聊天的微信名和prompt
def get_user_prompt():
users = bmob.findObjects('autochat')
name_prompts.clear()
for user in users:
name_prompts[user.name] = user.prompt
# 每隔5分钟获取一次要自动聊天微信名称和对应的prompt
def run_with_interval():
while True:
get_user_prompt()
time.sleep(300)
if __name__ == "__main__":
t = threading.Thread(target=run_with_interval)
t.start()
三、组装对话上下文和自动对话
这里主要用到了WeChat类的获取新对话人名字、获取某个人历史聊天记录的方法,和Bmob后端云的AI功能,具体代码如下:
# 执行自动聊天功能
def main():
wechat = WeChat(path=config['wechat_path'])
# 创建一个锁
lock = threading.Lock()
while True:
try:
comtypes.CoInitialize()
# 确保微信操作的线程安全
with lock:
wechat.click(auto.ButtonControl(Name=wechat.lc.facorites))
users = wechat.check_new_user()
if len(users) <= 0:
time.sleep(5)
print("暂时没有新消息")
continue
for user in users:
if user not in name_prompts.keys():
time.sleep(5)
print(f"{user}不在需要自动问答的名单上")
continue
else:
# 获取聊天记录,30这个数字可以调整,越大的话,AI会越了解你,但消耗的token也越多
msgList = wechat.get_dialogs(user, 30)
if len(msgList) <= 0:
continue
# 组装上下文对话记录
ai = []
ai.append({"content": name_prompts[user], "role": "system"})
for msg in msgList:
chatmsg = msg[2].replace('[动画表情]','')
if chatmsg=='':
continue
if msg[1] == user:
ai.append({"content": chatmsg, "role": "user"})
else:
ai.append({"content": chatmsg, "role": "assistant"})
bmob.connectAI()
to = bmob.chat2(ai)
bmob.closeAI()
print('ai:'+to)
if to != "":
wechat.send_msg(user, to)
except Exception as e:
print(e)
来源:juejin.cn/post/7422401535215435788
Next.js 使用 Hono 接管 API
直入正题,Next.js 自带的 API Routes (现已改名为 Route Handlers) 异常难用,例如当你需要编写一个 RESTful API 时,尤为痛苦,就像这样

这还没完,当你需要数据验证、错误处理、中间件等等功能,又得花费不小的功夫,所以 Next.js 的 API Route 更多是为你的全栈项目编写一些简易的 API 供外部服务,这也可能是为什么 Next.js 宁可设计 Server Action 也不愿为 API Route 提供传统后端的能力。
但不乏有人会想直接使用 Next.js 来编写这些复杂服务,恰好 Hono.js 便提供相关能力。
这篇文章就带你在 Next.js 项目中要如何接入 Hono,以及开发可能遇到的一些坑点并如何优化。
Next.js 中使用 Hono
可以按照 官方的 cli 搭建或者照 next.js 模版 github.com/vercel/hono… 搭建,核心代码 app/api/[[...route]]/route.ts 的写法如下所示。
import { Hono } from 'hono'
import { handle } from 'hono/vercel'
const app = new Hono().basePath('/api')
app.get('/hello', (c) => {
return c.json({
message: 'Hello Next.js!',
})
})
export const GET = handle(app)
export const POST = handle(app)
export const PUT = handle(app)
export const DELETE = handle(app)
从 hono/vercel 导入的 handle 函数会将 app 实例下的所有请求方法导出,例如 GET、POST、PUT、DELETE 等。
一开始的 User CRUD 例子,则可以将其归属到一个文件内下,这里我不建议将后端业务代码放在 app/api 下,因为 Next.js 会自动扫描 app 下的文件夹,这可能会导致不必要的热更新,并且也不易于服务相关代码的拆分。而是在根目录下创建名为 server 的目录,并将有关后端服务的工具库(如 db、redis、zod)放置该目录下以便调用。

至此 next.js 的 api 接口都将由 hono.js 来接管,接下来只需要按照 Hono 的开发形态便可。
数据效验
zod 可以说是 TS 生态下最优的数据验证器,hono 的 @hono/zod-validator 很好用,用起来也十分简单。
import { z } from 'zod'
import { zValidator } from '@hono/zod-validator'
import { Hono } from 'hono'
const paramSchema = z.object({
id: z.string().cuid(),
})
const jsonSchema = z.object({
status: z.boolean(),
})
const app = new Hono().put(
'/users/:id',
zValidator('param', paramSchema),
zValidator('json', jsonSchema),
(c) => {
const { id } = c.req.valid('param')
const { status } = c.req.valid('json')
// 逻辑代码...
return c.json({})
},
)
export default app
支持多种验证目标(param,query,json,header 等),以及 TS 类型完备,这都不用多说。
但此时触发数据验证失败,响应的结果令人不是很满意。下图为访问 /api/todo/xxx 的响应结果(其中 xxx 不为 cuid 格式,因此抛出数据验证异常)

所返回的响应体是完整的 zodError 内容,并且状态码为 400
:::tip
数据验证失败的状态码通常为 422
:::
因为 zod-validator 默认以 json 格式返回整个 result,代码详见 github.com/honojs/midd…
这就是坑点之一,返回给客户端的错误信息肯定不会是以这种格式。这里我将其更改为全局错误捕获,做法如下
- 复制 zod-validator 文件并粘贴至
server/api/validator.ts,并将 return 语句更改为 throw 语句。
if (!result.success) {
- return c.json(result, 400)
}
if (!result.success) {
+ throw result.error
}
- 在
server/api/error.ts中,编写 handleError 函数用于统一处理异常。(后文前端请求也需要统一处理异常)
import { z } from 'zod'
import type { Context } from 'hono'
import { HTTPException } from 'hono/http-exception'
export function handleError(err: Error, c: Context): Response {
if (err instanceof z.ZodError) {
const firstError = err.errors[0]
return c.json(
{ code: 422, message: `\`${firstError.path}\`: ${firstError.message}` },
422,
)
}
// handle other error, e.g. ApiError
return c.json(
{
code: 500,
message: '出了点问题, 请稍后再试。',
},
{ status: 500 },
)
}
- 在
server/api/index.ts,也就是 hono app 对象中绑定错误捕获。
const app = new Hono().basePath('/api')
app.onError(handleError)
- 更改 zValidator 导入路径。
- import { zValidator } from '@hono/zod-validator'
+ import { zValidator } from '@/server/api/validator'
这样就将错误统一处理,且后续自定义业务错误也同样如此。

:::note 顺带一提
如果需要让 zod 支持中文错误提示,可以使用 zod-i18n-map
:::
RPC
Hono 有个特性我很喜欢也很好用,可以像 TRPC 那样,导出一个 client 供前端直接调用,省去编写前端 api 调用代码以及对应的类型。
这里我不想在过多叙述 RPC(可见我之前所写有关 TRPC 的使用),直接来说说有哪些注意点。
链式调用
还是以 User CRUD 的代码为例,不难发现 .get .post .put 都是以链式调用的写法来写的,一旦拆分后,此时接口还是能够调用,但这将会丢失此时路由对应的类型,导致 client 无法使用获取正常类型,使用链式调用的 app 实例化对象则正常。

替换原生 Fetch 库
hono 自带的 fetch 或者说原生的 fetch 非常难用,为了针对业务错误统一处理,因此需要选用请求库来替换,这里我的选择是 ky,因为他的写法相对原生 fetch 更友好一些,并且不会破坏 hono 原有类型推导。
在 lib/api-client.ts 编写以下代码
import { AppType } from '@/server/api'
import { hc } from 'hono/client'
import ky from 'ky'
const baseUrl =
process.env.NODE_ENV === 'development'
? 'http://localhost:3000'
: process.env.NEXT_PUBLIC_APP_URL!
export const fetch = ky.extend({
hooks: {
afterResponse: [
async (_, __, response: Response) => {
if (response.ok) {
return response
} else {
throw await response.json()
}
},
],
},
})
export const client = hc<AppType>(baseUrl, {
fetch: fetch,
})
这里我是根据请求状态码来判断本次请求是否为异常,因此使用 response.ok,而响应体正好有 message 字段可直接用作 Error message 提示,这样就完成了前端请求异常处理。
至于说请求前自动添加协议头、请求后的数据转换,这就属于老生常谈的东西了,这里就不多赘述,根据实际需求编写即可。
请求体与响应体的类型推导
配合 react-query 可以更好的获取类型安全。此写法与 tRPC 十分相似,相应代码 → Inferring Types
// hooks/users/use-user-create.ts
import { client } from '@/lib/api-client'
import { InferRequestType, InferResponseType } from 'hono/client'
import { useMutation } from '@tanstack/react-query'
import { toast } from 'sonner'
const $post = client.api.users.$post
type BodyType = InferRequestType<typeof $post>['json']
type ResponseType = InferResponseType<typeof $post>['data']
export const useUserCreate = () => {
return useMutation<ResponseType, Error, BodyType>({
mutationKey: ['create-user'],
mutationFn: async (json) => {
const { data } = await (await $post({ json })).json()
return data
},
onSuccess: (data) => {
toast.success('User created successfully')
},
onError: (error) => {
toast.error(error.message)
},
})
}
在 app/users/page.tsx 中的使用
'use client'
import { useUserCreate } from '@/features/users/use-user-create'
export default function UsersPage() {
const { mutate, isPending } = useUserCreate()
const handleSubmit = (e: React.FormEvent
e.preventDefault()
const formData = new FormData(e.currentTarget)
const name = formData.get('name') as string
const email = formData.get('email') as string
mutate({ name, email })
}
return (
<form onSubmit={handleSubmit}>
<div>
<label htmlFor='name'>Name:label>
<input type='text' id='name' name='name' />
div>
<div>
<label htmlFor='email'>Email:label>
<input type='email' id='email' name='email' />
div>
<button type='submit' disabled={isPending}>
Create User
button>
form>
)
}
OpenAPI 文档
这部分我已经弃坑了,没找到一个很好的方式为 Hono 写 OpenAPI 文档。不过对于 TS 全栈开发者,似乎也没必要编写 API 文档(接口自给自足),更何况还有 RPC 这样的黑科技,不担心接口的请求参数与响应接口。
如果你真要写,那我说说几个我遇到的坑,也是我弃坑的原因。
首先就是写法上,你需要将所有的 Hono 替换成 OpenAPIHono (来自 @hono/zod-openapi, 其中 zod 实例 z 也是)。以下是官方的示例代码,我将其整合到一个文件内
import { createRoute, OpenAPIHono, z } from '@hono/zod-openapi'
import { swaggerUI } from '@hono/swagger-ui'
const app = new OpenAPIHono()
const ParamsSchema = z.object({
id: z
.string()
.min(3)
.openapi({
param: {
name: 'id',
in: 'path',
},
example: '123',
}),
})
const UserSchema = z
.object({
id: z.string().openapi({ example: '123' }),
name: z.string().openapi({ example: 'John Doe' }),
})
.openapi('User')
const route = createRoute({
method: 'get',
path: '/api/users/{id}',
request: {
params: ParamsSchema,
},
responses: {
200: {
content: {
'application/json': {
schema: UserSchema,
},
},
description: 'Retrieve the user',
},
},
})
app.openapi(route, async (c) => {
const { id } = c.req.valid('param')
// 逻辑代码...
const user = {
id,
name: 'Ultra-man',
}
return c.json(user)
})
从上述代码的可读性来看,第一眼你很难看到清晰的看出这个接口到底是什么请求方法、请求路径,并且在写法上需要使用 .openapi 方法,传入一个由 createRoute 所创建的 router 对象。并且写法上不是在原有基础上扩展,已有的代码想要通过代码优先的方式来编写 OpenAPI 文档将要花费不小的工程,这也是我为何不推荐的原因。
定义完接口(路由)之后,只需要通过 app.doc 方法与 swaggerUI 函数,访问 /api/doc 查看 OpenAPI 的 JSON 数据,以及访问 /api/ui 查看 Swagger 界面。
import { swaggerUI } from '@hono/swagger-ui'
app.doc('/api/doc', {
openapi: '3.0.0',
info: {
version: '1.0.0',
title: 'Demo API',
},
})
app.get('/api/ui', swaggerUI({ url: '/api/doc' }))

从目前来看,OpenAPI 文档的生成仍面临挑战。我们期待 Hono 未来能推出一个功能,可以根据 app 下的路由自动生成接口文档(相关Issue已存在)。
仓库地址
附上本文中示例 demo 仓库链接(这个项目就不搞线上访问了)
后记
其实我还想写写 Auth、DB 这些服务集成的(这些都在我实际工作中实践并应用了),或许是太久未写 Blog 导致手生了不少,这篇文章也是断断续续写了好几天。后续我将会出一版完整的我个人的 Nextjs 与 Hono 的最佳实践模版。
也说说我为什么会选用 Hono.js 作为后端服务, 其实就是 Next.js 的 API Route 实在是太难用了,加之轻量化,你完全可以将整个 Nextjs + Hono 服务部署在 Vercel 上,并且还能用上 Edge Functions 的特性。(就是有点小贵)
但不过从我的 Nest.js 开发经验来看(也可能是习惯了 Spring Boot 那套三层架构开发形态),总觉得 Hono 差了点意思,说不出来的体验,可能这就是所谓的全栈框架的开发感受吧。
来源:juejin.cn/post/7420597224516812837
农行1面:Java如何保证线程T1,T2,T3 顺序执行?
你好,我是猿java。
线程是 Java执行的最小单元,通常意义上来说,多个线程是为了加快速度且无需保序,这篇文章,我们来分析一道农业银行的面试题目:如要保证线程T1, T2, T3顺序执行?
考察意图
在面试中出现这道问题,通常是为了考察候选人的以下几个知识点:
1. 多线程基础知识: 希望了解候选人是否熟悉Java多线程的基本概念,包括线程的创建、启动和同步机制。
2. 同步机制的理解:候选人需要展示对Java中各种同步工具的理解,如join()、CountDownLatch、Semaphore、CyclicBarrier等,并知道如何在不同场景下应用这些工具。
3. 线程间通信:希望候选人理解线程间通信的基本原理,例如如何使用wait()和notify()来协调线程。
4. 对Java并发包的熟悉程度: 希望候选人了解Java并发包(java.util.concurrent)中的工具和类,展示其对现代Java并发编程的掌握。
保证线程顺序执行的方法
在分析完面试题的考察意图之后,我们再分析如何保证线程顺序执行,这里列举了几种常见的方式。
join()
join()方法是Thread类的一部分,可以让一个线程等待另一个线程完成执行。 当你在一个线程T上调用T.join()时,调用线程将进入等待状态,直到线程T完成(即终止)。因此,可以通过在每个线程启动后调用join()来实现顺序执行。
如下示例代码,展示了join()如何保证线程顺序执行:
Thread t1 = new Thread(() -> {
// 线程T1的任务
});
Thread t2 = new Thread(() -> {
// 线程T2的任务
});
Thread t3 = new Thread(() -> {
// 线程T3的任务
});
t1.start();
t1.join(); // 等待t1完成
t2.start();
t2.join(); // 等待t2完成
t3.start();
t3.join(); // 等待t3完成
CountDownLatch
CountDownLatch通过一个计数器来实现,初始时,计数器的值由构造函数设置,每次调用countDown()方法,计数器的值减1。当计数器的值变为零时,所有等待在await()方法上的线程都将被唤醒,继续执行。
CountDownLatch是Java并发包(java.util.concurrent)中的一个同步辅助类,用于协调多个线程之间的执行顺序。它允许一个或多个线程等待另外一组线程完成操作。
如下示例代码,展示了CountDownLatch如何保证线程顺序执行:
CountDownLatch latch1 = new CountDownLatch(1);
CountDownLatch latch2 = new CountDownLatch(1);
Thread t1 = new Thread(() -> {
// 线程T1的任务
latch1.countDown(); // 完成后递减latch1
});
Thread t2 = new Thread(() -> {
try {
latch1.await(); // 等待T1完成
// 线程T2的任务
latch2.countDown(); // 完成后递减latch2
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread t3 = new Thread(() -> {
try {
latch2.await(); // 等待T2完成
// 线程T3的任务
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
t1.start();
t2.start();
t3.start();
CountDownLatch关键方法解析:
- CountDownLatch(int count) : 构造函数,创建一个CountDownLatch实例,计数器的初始值为count。
- void await() : 使当前线程等待,直到计数器的值变为零。
- boolean await(long timeout, TimeUnit unit) : 使当前线程等待,直到计数器的值变为零或等待时间超过指定的时间。
- void countDown() : 递减计数器的值。当计数器的值变为零时,所有等待的线程被唤醒。
Semaphore
Semaphore通过一个计数器来管理许可,计数器的初始值由构造函数指定,表示可用许可的数量。线程可以通过调用acquire()方法请求许可,如果许可可用则授予访问权限,否则线程将阻塞。使用完资源后,线程调用release()方法释放许可,从而允许其他阻塞的线程获取许可。
如下示例代码,展示了Semaphore如何保证线程顺序执行:
Semaphore semaphore1 = new Semaphore(0);
Semaphore semaphore2 = new Semaphore(0);
Thread t1 = new Thread(() -> {
// 线程T1的任务
semaphore1.release(); // 释放一个许可
});
Thread t2 = new Thread(() -> {
try {
semaphore1.acquire(); // 获取许可,等待T1完成
// 线程T2的任务
semaphore2.release(); // 释放一个许可
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
Thread t3 = new Thread(() -> {
try {
semaphore2.acquire(); // 获取许可,等待T2完成
// 线程T3的任务
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
t1.start();
t2.start();
t3.start();
Semaphore关键方法分析:
- Semaphore(int permits) :构造一个具有给定许可数的Semaphore。
- Semaphore(int permits, boolean fair) :构造一个具有给定许可数的Semaphore,并指定是否是公平的。公平性指的是线程获取许可的顺序是否是先到先得。
- void acquire() :获取一个许可,如果没有可用许可,则阻塞直到有许可可用。
- void acquire(int permits) :获取指定数量的许可。
- void release() :释放一个许可。
- void release(int permits) :释放指定数量的许可。
- int availablePermits() :返回当前可用的许可数量。
- boolean tryAcquire() :尝试获取一个许可,立即返回true或false。
- boolean tryAcquire(long timeout, TimeUnit unit) :在给定的时间内尝试获取一个许可。
单线程池
单线程池(Executors.newSingleThreadExecutor())可以确保任务按提交顺序依次执行。所有任务都会在同一个线程中运行,保证了顺序性。
如下示例代码展示了单线程池如何保证线程顺序执行:
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(new T1());
executor.submit(new T2());
executor.submit(new T3());
executor.shutdown();
单线程这种方法简单易用,适合需要顺序执行的场景。
synchronized
synchronized 是Java中的一个关键字,用于实现线程同步,确保多个线程对共享资源的访问是互斥的。它通过锁机制来保证同一时刻只有一个线程可以执行被Synchronized保护的代码块,从而避免数据不一致和线程安全问题。
如下示例代码,展示了synchronized如何保证线程顺序执行:
class Task {
synchronized void executeTask(String taskName) {
System.out.println(taskName + " 执行");
}
}
public class Main {
public static void main(String[] args) {
Task task = new Task();
new Thread(() -> task.executeTask("T1")).start();
new Thread(() -> task.executeTask("T2")).start();
new Thread(() -> task.executeTask("T3")).start();
}
}
总结
本文,我们分析了5种保证线程T1,T2,T3顺序执行的方法,依次如下:
- join()
- CountDownLatch
- Semaphore
- 单线程池
- synchronized
在实际开发中,这种需要在业务代码中去保证线程执行顺序的情况几乎不会出现,因此,这个面试题其实缺乏实际的应用场景,纯粹是为了面试存在。尽管是面试题,还是可以帮助我们更好地去了解和掌握线程。
来源:juejin.cn/post/7423196076507562023
丰富的诗词资源!一个现代化诗词学习网站!
大家好,我是 Java陈序员。
之前,给大家推荐过一个古诗文起名工具,利用古诗文进行起名。
今天,给大家介绍一个现代化诗词学习网站,完美适用于自身、孩子学习背诵古诗词!
关注微信公众号:【Java陈序员】,获取开源项目分享、AI副业分享、超200本经典计算机电子书籍等。
项目介绍
aspoem —— 现代化诗词学习网站,一个更加注重UI和阅读体验的诗词网站。收集了丰富的诗词资源,用户可以通过作者、诗词、名句快速查找诗词。

功能特色:
- 提供丰富的中国古典诗词资源
- 提供诗词欣赏与学习、拼音标注、注释和白话文翻译
- 提供全站搜索、诗人及词牌名索引以及标签系统方便查找相关主题诗词
- 界面友好,便于用户使用,支持暗黑模式和多种主题
- 注重移动端的适配,支持 PC 和手机端访问
技术栈:
- React
- Next
- Tailwind CSS
- PostgreSQL
项目体验
诗词
丰富的诗词:aspoem 目前已经收集了 6000+ 首诗词。

诗词鉴赏:提供拼音标注、注释和白话文等的展示方式,使诗词更加易于阅读。

摘抄卡片:提供高清大图,支持免费下载。

诗人
海量的诗人:aspoem 目前汇总了 700+ 个诗人、词人。

诗人介绍:提供诗人介绍,以及创作的诗词,方便有针对性的学习。

词牌名&标签&片段
词牌名:收集了多种多样的词牌名,并汇总对应的诗词。


标签:按照近体诗、书籍、诗经、节日、情感等分类进行打标签,方便检索查询。


片段:摘抄经典的名片诗句、词句。

其他功能
检索查询:查找诗人、诗词、名句。

暗黑模式

多种主题

适配移动端
 |  |
|---|
本地运行
前期准备
1、下载代码
git clone https://github.com/meetqy/aspoem.git
2、复制一份 .env.example 并重命名为 .env
aspoem提供了是否集成 PostgreSQL 两种版本,可自行挑选。
集成 PostgreSQL
1、修改配置文件 .env 中的 PostgreSQL 连接信息
# 后台操作需要的 Token, http://localhost:3000/create?token=v0
TOKEN="v0"
# 本地
POSTGRES_PRISMA_URL="postgresql://meetqy@localhost:5432/aspoem"
POSTGRES_URL_NON_POOLING="postgresql://meetqy@localhost:5432/aspoem"
# 统计相关 没有可不填 不会加载对应的代码
# google analytics id
NEXT_PUBLIC_GA_ID="G-PYEC5EG749"
# microsoft-clarity-id
NEXT_PUBLIC_MC_ID="ksel7bmi48"
2、安装依赖
pnpm install
3、启动项目
pnpm run dev
4、浏览器访问 http://localhost:3000
不集成 PostgreSQL
1、修改 .env
POSTGRES_PRISMA_URL="postgresql://meetqy@localhost:5432/aspoem"
POSTGRES_URL_NON_POOLING="postgresql://meetqy@localhost:5432/aspoem"
改为
POSTGRES_PRISMA_URL="file:./db.sqlite"
POSTGRES_URL_NON_POOLING="file:./db.sqlite"
2、修改 prisma/schema.prisma 中的
datasource db {
provider = "postgresql"
url = env("POSTGRES_PRISMA_URL")
directUrl = env("POSTGRES_URL_NON_POOLING")
}
改为
datasource db {
provider = "sqlite"
url = env("POSTGRES_PRISMA_URL")
directUrl = env("POSTGRES_URL_NON_POOLING")
}
3、将 prisma/sample.sqlite 改为 db.sqlite
4、安装依赖并启动,推荐使用 pnpm
pnpm i
pnpm db:push
pnpm dev
Docker 部署
aspoem 项目提供 Dockerfile 和 docker-compose.yml 文件。Dockfile 用于构建 aspoem 服务镜像,docker-compose.yml 用于启动 aspoem 和一个 PostgresSQl.
执行以下命令,一键启动项目:
cd aspoem
docker compose up
aspoem 一个致力于分享诗词的平台,为用户提供了一个良好的诗词阅读体验!对于喜欢中国诗词的朋友们来说,真的是一个宝藏。它不仅资源丰富,而且界面简洁,使用起来非常友好。大家快去体验吧~
项目地址:https://github.com/meetqy/aspoem
最后
推荐的开源项目已经收录到 GitHub 项目,欢迎 Star:
https://github.com/chenyl8848/great-open-source-project
或者访问网站,进行在线浏览:
https://chencoding.top:8090/#/

大家的点赞、收藏和评论都是对作者的支持,如文章对你有帮助还请点赞转发支持下,谢谢!
来源:juejin.cn/post/7419267723782570022
Chrome 浏览器惊现严重漏洞
近期,Chrome 又爆出了一个惊天漏洞,其内部的 JavaScript 引擎 V8 存在不恰当的实现让远程攻击者可以通过精心设计的 HTML 页面对堆损坏进行潜在的攻击。
前置知识
V8 引擎是 Google 开发的开源 JavaScript 引擎,最初是为 Chrome 浏览器设计的,现在也被 Node.js 和许多其他项目广泛使用。值得注意的是,从 2020 年开始,Edge 浏览器转而使用了 Chromium 项目,这意味着现在的 Microsoft Edge 浏览器确实使用 V8 引擎来执行 JavaScript 代码,与 Google Chrome 浏览器相同。
堆损坏(Heap Corruption)是一种常见的内存错误,发生在程序错误地操作堆内存时。堆是动态内存分配的区域,程序在运行时可以从堆中分配或释放内存。如果程序不正确地处理这些操作,就可能导致堆损坏。攻击者可能利用堆损坏来执行任意代码,这是许多安全攻击的基础。
漏洞信息
| 漏洞名称 | Google Chrome 安全漏洞 | 威胁等级 | 高 |
|---|---|---|---|
| 影响产品 | Chromium(Edge、Chrome等) | 影响版本 | 小于等于128.0.6613.84 |
该漏洞已经在新版本的 Chrome 和 Edge 修复,可以更新至最新版本预防该威胁。
漏洞分析
以下是为 ARM64 设备设计的漏洞利用原型,用于触发该漏洞:
var arrx = new Array(150);
arrx[0] = 1.1;
var fake = new Uint32Array(10);
fake[0]= 1;
fake[1] =3;
fake[2]=2;
fake[3] = 4;
fake[4] = 5;
fake[5] = 6;
fake[6] = 7;
fake[7] = 8;
fake[8] = 9;
var tahir = 0x1;
function poc(a) {
var oob_array = new Array(5);
oob_array[0] = 0x500;
let just_a_variable = fake[0];
let another_variable3 = fake[7];
if(a % 7 == 0)
another_variable3 = 0xff00000000; //spray high bytes
another_variable3 = Math.max(another_variable3,tahir);
another_variable3 = another_variable3 >>> 0;
var index = fake[3];
var for_phi_modes = fake[6];
let c = fake[1];
//giant loop for generate cyclic graph
for(var i =0;i<10;i++) {
if( a % 3 == 0){
just_a_variable = c;
}
if( a % 37 == 0) {
just_a_variable = fake[2];
}
if( a % 11 == 0){
just_a_variable = fake[8];
}
if( a % 17 == 0){
just_a_variable = fake[5];
}
if( a % 19 == 0){
just_a_variable = fake[4];
}
if( a % 7 == 0 && i>=5){
for_phi_modes = just_a_variable;
just_a_variable = another_variable3;
}
if(i>=6){
for(let j=0;j<5;j++){
if(a % 5 == 0) {
index = for_phi_modes;
oob_array[index] = 0x500; //zero extends before getting value
}
}
}
for_phi_modes = c;
c = just_a_variable;
}
//zero extend
return [index,BigInt(just_a_variable)];
}
for(let i = 2; i<0x500;i++) {
poc(i); //compile using turbofan
}
poc(7*5);
通过复杂的数组操作和循环逻辑,企图达到越界访问或者修改内存的目的,从而可能实现任意代码执行。脚本的核心部分是利用 TurboFan 编译器优化的特性,通过特定的数据操作来破坏内存结构。
代码分析
首先代码对如下几个变量进行了初始化,分别为:
- arrx 是一个长度为
150的数组,初始化第一个元素为 1.1。 - fake 是一个长度为
10的 Uint32Array,用于存储一系列整数。 - tahir 是一个十六进制的整数值 0x1。
然后就是函数部分,包含了复杂的逻辑和条件判断,主要用于操作和修改 oob_array 和 fake 数组的元素。主要有以下几点信息:
- oob_array 是一个长度为 5 的数组,用于存储操作结果。
- 函数内部使用了多个
局部变量来从 fake 数组中读取数据,并根据输入参数 a 的不同值改变这些数据。 - 特别是在 a % 5 == 0 的条件下,代码尝试访问
oob_array[index],其中 index 是从 fake 数组中获取的。这可能导致越界访问,因为 index 的值可能超出 oob_array 的索引范围。
最后就是通过多次调用 poc 函数,并且特意让 TurboFan 编译器优化这些循环调用。在一些优化过程中,编译器可能未能处理好边界条件,导致安全问题。
关键点
- TurboFan 编译器优化:
TurboFan是 V8 引擎中的优化编译器,通过频繁调用 poc 函数,脚本试图诱导TurboFan生成的代码在边界检查上产生漏洞,从而实现越界访问或写入。 - 内存破坏:通过复杂的条件控制流,脚本试图创建出一种可以操纵内存指针的情况(如
index和for_phi_modes),从而进行越界写入,可能导致内存破坏,进一步用于任意代码执行。 - 条件分支与循环:脚本中多次使用复杂的条件判断和循环逻辑来混淆内存操作,可能意在规避一些简单的防护机制,并诱导编译器优化过程中出现漏洞。
来源:juejin.cn/post/7416517826041790514
地表最强全息 AR 眼镜问世!Meta 十年绝密豪赌烧 10 亿,现场开箱老黄亲测
【新智元导读】就在刚刚,小扎携掉最强 AR 眼镜 Orion 登场!Meta 首款 AR 眼镜,苦研十年后,终于诞生了,成本高达 10000 美元。果然,小扎让我们离元宇宙又近了一步。这会是一次全新的范式转变吗?
Meta 首款 AR 眼镜,终于亮相了!
酝酿十年,烧钱数十亿,作为小扎元宇宙宏图大业的一部分,我们今日终于得见 Meta AR 眼镜的真容。

这款名为 Orion 的产品,由带 MicroLED 投影的眼镜、人机交互的腕带、提供计算能力的小盒子组成。
轻快的外观,领先行业的 AR 体验,Meta 再为业内做出开创性的壮举。虚拟现实世界的入口,元宇宙的雏形,或许就是这般样子。
有趣的是,因为制作成本高达 10000 美元,这款眼镜本次仅做展示之用,是产品原型,并不会正式发售。

英伟达老黄已经试戴上了
每个计算平台,都会带来我们与设备交互方式的范式转变。上一次是鼠标、智能手机,这一次,会是 AR 眼镜吗?
此外,在 Meta Connect 2024 发布会上,其他重要产品也悉数亮相——
Meta Quest 3S 头显眼镜发布;Meta Ray-Ban 眼镜上线新功能;Meta 首个拥有多模态能力的开源大模型 Llama 3.2 亮相。
AR 眼镜:元宇宙入口的新范式?
地表最强 AR 眼镜,终于诞生了!

在昨晚的发布会上,小扎激动地向全世界展示了这款地表最强 AR 眼镜。

研发过程,经历了整整十年。目标很简单,但技术挑战却极其艰巨。
目标有多简单,无非是要满足是眼镜而非头戴设备、无线、重量不超过 100g、宽广视野、全息显示、清晰度够高、能捕捉到细节、亮度足、在不同光线下都能看清、显示面积够大、足以呈现电影银幕或多个工作用显示器、能透过它看到外界这些要求罢了。
研发工程师们呕心沥血了整整十年,终于做出了 Orion。

注意,这不是透视效果,这是物理世界上面叠加了全息图
如果收到消息,你不必掏出手机,只要在全息图中做出几个手势,就可以回复了。

远方的人,可以以全息图的形式瞬间传送到你身边。

敲敲手指,你就可以玩纸牌、象棋、全息乒乓球了。

小扎表示,Orion 会给未来的元宇宙世界提供更多入口。

可以说,它包含着 AI 空间计算终极形态的野心。
比起苹果过于笨重的 Vision Pro,Orion 的确有了未来空间计算 AI 设备的雏形。
此次发布的 Orion,具有宽视野显示器,内置无线 AI,是 Meta 十年来一直致力实现的事。

显示器
在 Orion 中,Meta 选择了微型 LED 显示器。

可以说,这款 AR 眼镜的最大挑战,就是显示器。
由于需要以不符合原理的方式弯曲光束,团队需要建造一个全新的显示架构。
它可以让眼镜框架中的微型投影仪将光线射入波导,将纳米级 3D 结构打印到透镜中,使光线发生折射,从而在我们的环境中显示不同深度和尺寸的全息图。

为此,团队没有使用玻璃光学器件,而是使用了碳化硅的新材料。
后者很轻,不会产生奇怪的光学伪影或 C stray 散光,且具有非常高的折射率,这,就是实现大视野和有效利用光子的关键。
散热
另一个挑战就是散热。我们不可能把风扇塞进一副眼镜里,怎么办呢?
唯一消除热量的方式,就是将其辐射出去。
团队做了两件事。首先,框架由散热材料镁制成。其次,Orion 中的许多定制组件也是用镁材料设计。
而且团队构建了数十个定制硅芯片,不仅节能,还能针对 AI 机器感知和图形算法进行优化。
这样,Orion 就可以采用手眼跟踪以及 slam 算法,大大降低了算法所需的功耗。
外形
Orion 的尺寸为一英尺,具有光学对准功能,精度达到了人类头发丝厚度的 1/10。
它有七个微型摄像头和传感器,尺寸很小,因而可以嵌入镜框边缘。

Meta 表示,在目前最小的眼镜外形中,他们实现了可用的最大视野。
这使得数字内容能与我们所看到的世界融为一体。

全新互动模式:肌电图腕带
传统的 AR 眼镜,是用语音控制和手眼跟踪来导航用户界面。
但 Meta 认为,我们还需要一种更谨慎、私密的全新方式,跟 AR 眼镜进行交流。
这就是全新上线的肌电图腕带和眼球注视功能。

腕带会检测你的神经运动信号,这样你就可以用手势进行点击。

只需看着目标,就可以进行选定。

总之,Orion 的输入和交互系统,将语音、眼镜注视、手部追踪和 EMG 腕带无缝结合,让我们可以更轻松、更快、更舒适地操作。
AR 眼镜能否成为主流?Meta 表示,只要解决了这两个问题,就能实现。
第一,能否实现根本性的技术突破,比如将大显示屏融入一副普通眼镜中?
第二,什么用例是你只能在 AR 眼镜上操作,不能在其他设备上完成的?
而 Orion 原型,就是 Meta 对这两个问题的回答。这个原型是对未来的一瞥,现实已触手可及。
虽然作为消费产品,它的价格仍然昂贵得吓人,但毫无疑问,它可能是未来最先进的消费电子产品,是自智能手机以来最有影响力的新设备。
在下一波以人为本的计算浪潮中,借助 Orion,Meta 又迈出了重要一步。
与此同时,戴上头显办公,也是一个不错的选择。
Meta 将微软办公软件集成到应用之中,画布延展,多人协作,打工人都不曾想到,未来办公这么美好。
很快,Quest 头显也将轻松连接到 Windows 11 个人电脑上,通过键盘直接配对。
电脑屏不够用,也不用外接显示屏了,一个 Quest 头显就能实现。

Meta 称,我们正在建设的:不是下一个游戏平台,而是下一个计算平台。
在这个平台中,你可以看电影、听音乐、做电子表格、与朋友一起玩游戏,闲逛,甚至聊天。
因此,计算平台系统 Horizon OS,便是开启这一幕最理想的界面。
会上,Meta 还公布了基于 Horizon OS 平台上工具更新。
主要有扩展混合显示功能的套件,比如音频到表情、声线追踪(ART)、微手势、直通摄像头访问 API 等。
如下,是通过微手势触发移动的示例。

另外,在虚拟化身上更新,Meta 计划让照片在虚拟空间动起来。
这就非常类似,苹果 Vision Pro 中的「空间视频」。
这里,Meta 将其称之为 Hypersscape,可以将你带入照片中的虚拟世界,就像是在一个平行时空中的自己。
这背后就利用高斯渲染技术,通过云渲染和流媒体方式,让其在 Quest 3 头显中活灵活现。

小扎在主旨演讲中,展示了纽约 Daniel Arsham 的艺术家工作室。
通过手机扫描房间,并在 Horizon 中便可轻松将物理世界,带到数字世界中。

根据官方定价,配备 128GB 入门级 Quest3S,仅需 299.99 美元。256GB 存储空间,售价 399.99 美元。
想要直通顶级体验,那就得配上 512 GB Quest 3。

新增记忆能力,Ray-Ban 眼镜再升级
另一边,首发自研 AR 眼镜之外,Meta 还为 Ray-Ban 眼镜更新了一些新功能。

几个月前,集成 Meta AI 助手眼镜,大秀了一场。
这次,Meta 称不用说「嘿,Meta」,直接用唤醒词即可开启对话,让人与设备之间交谈更丝滑。
比如,当你拿起面前这件衣服,盯着它并表示,「帮我记住这件夹克,这样我就可以向 Nas 展示」。

同时,Ray-Ban 眼镜新增了记忆功能。
假设当你打飞的到了某个地方时,不必绞尽脑汁记住自己在哪里,眼镜就可以为你代劳了。
而且,更贴心的是,你可以用自己声音设置一个提醒——安全着陆时,三个小时内给妈妈发短信。
眼睛看哪,Ray-Ban 便会指向哪。
比如,看着传单上的电话号码、或者二维码,眼镜可以根据你所看内容,采取行动。
另外,眼镜的视频输入正添加 Meta AI 助手支持,方便获得实时的帮助。
当你去另一座城市,遇到新的地标,或者想要了解下一步旅行计划,直接可以与 Meta AI 实时交流。

大会上,Meta 还预告了下一个新功能——实时翻译。
当你与西班牙语、法语、意大利语的人交谈时,可以通过眼镜的开耳扬声器,直接听到的是「英语」的版本。
小扎现场和同事演示了,西班牙语和英语如何无缝交流精彩一幕。

这简直就是异域旅行者们的福音,完全无障碍畅玩全世界。
总结一波:Quest 3S 头显、雷朋智能眼镜、全息 AR 眼镜、Llama 3.2 大模型…… 这届 Meta Connect 2024 大会,小扎赢麻了。
参考资料:
来源:juejin.cn/post/7418507128871993363
高质量数据不够用,合成数据是打开 AGI 大门的金钥匙吗?
编者按: 人工智能技术的发展离不开高质量数据的支持。然而,现有可用的高质量数据资源已日渐接近枯竭边缘。如何解决训练数据短缺的问题,是当前人工智能领域亟待解决的一个较为棘手的问题。
本期文章探讨了一种经实践可行的解决方案 —— 合成数据(Synthetic Data)。如 AlphaZero、Sora 等已初步证实了合成数据具备的巨大潜力。对于语言模型来说,虽然要生成高质量的合成文本存在一定难度,但通过优化现有数据、从多模态数据中学习等策略,或许能够大幅降低对新数据的需求量。
如果合成数据真的能解决训练数据匮乏的难题,其影响必将是极其深远的。文章进一步分析了可能产生的影响:如互联网行业可能会被重塑、反垄断审查可能进一步加强、公共数据资源会获得更多投资等。不过现在做出这些预测或许还为时尚早,我们需要保持冷静,耐心观察合成数据这一技术在未来会取得何种突破性进展。
本文直指人工智能发展面临的一大瓶颈 —— “高质量数据的日益枯竭”,并提出了一种有争议但值得探索的解决方案,极具启发意义。我们后续会持续关注这一技术领域的最新进展,敬请期待!
作者 | Nabeel S. Qureshi
编译 | 岳扬

大语言模型是在海量数据上完成训练的,数据集规模堪比众多图书馆的藏书总和。然而,如果有一天我们用尽了所有可用的数据,该怎么办呢?图片来源:Twitter[1]
01 数据不够用?
现代大语言模型(LLMs)的一个关键事实可概括总结为:数据为王。人工智能模型的行为很大程度上取决于其训练所用的数据集;其他细节(诸如模型架构等),只是为数据集提供计算能力的一种手段。拥有一份干净的、高品质的数据集,其价值不可估量。[1]
数据的重要地位在人工智能行业的商业实践(AI business practice)中可见一斑。OpenAI 近期宣布与 Axel Springer、Elsevier、美联社及其它内容出版商和媒体巨头达成数据合作;《纽约时报》(NYT)最近起诉 OpenAI,要求停用利用 NYT 数据训练的 GPT 模型。与此同时,苹果公司正以超过五千万美元的价格,寻求与内容出版商(publishers)的数据合作。在当前的边际效益**(译者注:边际效益(Marginal Benefit)是一个经济学概念,指的是在增加一单位的某种投入(如生产中的劳动力、原材料或者服务中的员工时间)时,所获得的额外收益或价值的增加。)下,模型从更多数据中获取的利益远超单纯扩大模型规模带来的收益。
训练语料库(training corpora)的扩容速度令人咋舌。世界上首个现代 LLM 是在维基百科这一知识宝库上训练完成的。GPT-3 在 3000 亿个 tokens(包括单词、词根或标点等)上进行训练,而 GPT-4 的训练数据量更是达到了惊人的13万亿个 tokens 。自动驾驶汽车是在数千小时的视频录像资料中学习、掌握驾驶技巧的;在编程辅助方面,OpenAI 的 Copilot,依托的是来自 Github 上数百万行人类编写的代码。
这种情况会一直持续下去吗?2022 年发表在 arXiv[2] 上的一项研究表明:我们正逼近耗尽高质量数据的边缘,这一转折点预计会在2023年至2027年间到来。 (这里所谓的“高质量数据”,涵盖了维基百科(Wikipedia)、新闻(news)、代码(code)、科学文献(scientific papers)、书籍(books)、社交媒体对话内容(social media conversations)、精选网页(filtered web pages)以及用户原创内容(如 Reddit 上的内容)。)
研究估计,这些高质量数据的存量约为 9e12 个单词,并且每年以 4 %到 5 %的速度增长。 9e12 具体有多大?举个例子,莎士比亚全集的字数约为 90 万(即9e5),相比之下,9e12 这个数量足足是莎翁作品字数总和的 1000 万倍之巨。
据粗略估计,要达到真正意义上的人类级人工智能(human-level AI),所需数据量可能是当前数据量的 5 到 6 个数量级之上,换言之,至少需要 10 万至 100 万倍的数据量扩充。
回顾一下,GPT-4 使用了 13 万亿个 tokens 。不过还有很多尚未充分开采的领域里潜藏着丰富的数据等待挖掘,比如音频与视频资料、非英语数据资料、电子邮件、短信、推特动态、未数字化的书籍,以及企业私有数据。通过这些渠道,我们或许能再获得比目前有用数据多 10 倍甚至 100 倍的数据,然而,要再获得多 10 万倍的数据却如同天方夜谭。
一句话,我们手中的数据还远远不够。
除此之外,还有一系列现有的不利因素可能让获取优质数据变得更加棘手:
- 那些依赖用户来生成内容(User-generated content, UGC)的网站,比如Reddit、Stack Overflow、Twitter/X等,纷纷关上了免费获取数据大门,对数据使用权开出了天价的的许可费。
- 作家、艺术家,甚至像《纽约时报》这样的媒体巨头,都在维权路上高歌猛进,抗议其作品未经许可就被大语言模型拿去“学习”。
- 有人担忧,互联网正逐渐被大语言模型生成的低质内容所淹没,这不仅可能引发模型的“drift”(译者注:在模型持续学习或微调的过程中,如果新增数据质量不高,可能引导模型产生不理想的变化。),还会直接拉低模型响应的质量。
02 合成数据:超级智能的新曙光?
基于前文的分析,我们或许会得出一个比较悲观的结论:我们目前拥有的数据不足以训练出超级智能(superintelligence)。然而,现在做出这样的判断未免操之过急。解决这一问题的关键可能就在于合成数据的创造——即机器为了自训练(self-training)而自主生成的数据。
尽管听上去像是天方夜谭,但事实上,一些前沿的现代 AI 系统都是通过合成数据训练出来的:
- 专攻棋类的 AlphaZero[3] 就是使用合成数据训练出来的。具体而言,AlphaZero 通过与自身对战来生成数据,并从这些对局中汲取教训,不断优化策略。(这种数据之所以被称为合成数据,是因为它完全不需要借鉴真实人类的棋局记录。)
- 再来看看 OpenAI 的最新成果之一 —— Sora[4],这款视频生成模型能够依据简单的文字指令,创造出长达 1 分钟的虚拟视频。它的训练很可能是基于电子游戏引擎(大概率是Unreal Engine 5)生成的合成数据。也就是说,Sora 不仅通过 YouTube 视频或现实世界的电影来学习,游戏引擎构建的虚拟环境同样成为了它的学习素材。
所以,这项技术已在棋类博弈与视频生成应用中得到了证实;真正的问题在于它能否同样适用于文本处理。 在某些方面,制作供训练使用的高质量视频数据,比生成文字训练数据容易得多:只需一部 iPhone,就能拍摄视频捕捉现实生活的真实面貌。然而,要想让合成的文本数据成为有效的训练数据,它必须是高质量、有趣的,而且在某种意义上是 "真实的"。
关键的一点是,创造有价值的合成数据,不仅仅就是从无到有的创作文本那么简单。比如,一份最新发表的论文[5](2024年1月)指出,利用大语言模型改进抓取到的网络数据的表达方式,不仅能优化训练效果,还能提升训练效率。有时,仅通过筛选并移除数据集中质量最差的数据(这一过程称为“数据集剪枝”),就能大幅增强大语言模型的表现。有一项针对图像数据的研究更是惊人地发现,要达到模型的峰值性能(peak model performance),甚至需要舍弃数据集中高达90%的非关键信息!
如今,我们已拥有能像孩童般从视频中观察与学习的大语言模型。当我们弄清楚如何获取更高质量的多模态数据(包括视频、音频、图像及文本)的技巧,我们可能会惊喜地发现,大语言模型填补其世界观缺失部分所需的训练数据量,远比原先设想的要少得多。
03 解决合成数据生成问题将带来的影响
- 攻克合成数据的生成这一难题将极大加速人工智能领域的进步:考虑到当前研究者们对合成数据开发的投入、解决这一问题的巨大动力以及这一难题在其他领域已取得的成功,我们有理由相信,在未来几个月至数年内合成数据的生成将取得重大进展,进一步推动 AI 技术的飞速发展。而这一方面的技术突破,很可能会被各大企业严密保护为商业机密。
- 互联网行业或将重塑,减少对广告的依赖程度:传统上严重依赖广告收入的互联网企业,可能转向一种全新的商业模式,聚焦于训练数据的生成、创造。如 Reddit 这家近期申请 IPO(S-1) 的互联网巨头,其收入的 10%(即约 6000 万美元)来源于数据销售,且预计这一比例将持续上升。互联网上的用户数据源源不断(包括 reviews、tweets、comments 等),获取这些新鲜数据将非常有价值。如果这一点正确,各大企业将竞相采取措施,收集更多高价值的人工生成数据,助力人工智能模型的训练。
- 反垄断审查将趋严:独占如 Reddit、Elsevier 这类高价值数据源所引发的反垄断问题,预期将受到更为严格的审查。大型科技公司凭借其雄厚的财力和庞大的数据集,将进一步巩固其市场主导地位,加剧小规模企业参与竞争的难度。
- 开源项目可能会落后:监管部门需思考如何确保数据集的公平获取途径,可能会将数据集视作公共基础设施,或在特定条件下强制执行数据共享相关要求。构建更多高质量、经过筛选和整理的数据集,对学术界和开源社区维持竞争力尤为重要。各国政府也许会主动建立中央数据资源库,供所有大语言模型(LLM)开发者使用,从而帮助创造公平的竞争环境。不过短期内,开源项目开发者只能继续在 private labs (译者注:由私营企业或非公有实体运营的研究实验室,它们的工作成果、研发的技术和产生的数据往往被视为公司的知识产权,对外保密。)制作的优秀模型基础上对其进行微调,这意味着开源项目在可预见的未来仍可能落后于 private labs 。
- 数据被共享为公共资源:某些类型的数据具备公共属性,往往因投资不足而未得到充分开发。比如,一个汇集人类伦理道德偏好(human ethical preferences),通过对比分析形成的公共数据集,便是一个适宜公开资助或 AI 慈善项目投资的对象。类似的案例不胜枚举。
在科幻小说《沙丘》中,迷幻剂 melange(小说中俗称“香料”),被誉为银河系中的无价之宝。基于以上种种,埃隆·马斯克(Elon Musk)不久前在推特上的言论[6]——“数据即是香料(data is the spice.)”——便显得极为意味深长。AI 实验室都对此心领神会,正紧锣密鼓地“捣鼓”数据。
【注释】有一篇由 OpenAI 研究员撰写的题目为《the ‘it’ in AI models is the dataset(AI模型的核心在于数据集)》( nonint.com/2023/06/10/… )的精彩博客文章,作者一针见血地指出:
“AI 模型的行为特征并非取决于其架构设计、超参数设置或是优化器算法的选择。真正起决定作用的是数据集本身,除此之外别无他物。所有的架构、参数和优化方法,归根结底都是为了更高效地处理数据,逼近数据集的真实表现。”
Thanks for reading!
Nabeel S. Qureshi is a Visiting Scholar at Mercatus. His research focuses on the impacts of AI in the 21st century.
END
参考资料
[3]en.wikipedia.org/wiki/AlphaZ…
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
来源:juejin.cn/post/7384347818384850984
前端可以玩“锁”🔐了
大家好,我是CC,在这里欢迎大家的到来~
“锁”经常使用在多进程的语言理和数据库事务的架构当中,现在 Web API 当中也提供了“锁”- Web Locks API。
领域
在浏览器多标签页或 worker 中运行的脚本中获取锁,执行工作时保持锁,最后释放锁。
锁的范围仅限于同一源内
请求锁
同一源下,当持有锁时,其他相同锁的请求将排队,仅当锁被释放时第一个排队的请求才会被授予锁。
回调函数执行完毕后锁会自动释放
navigator.locks.request('mylock', {}, async (lock) => {
console.log(lock);
});
在这里我们能看到 request 方法的第二个参数(可选),可以在请求锁时传递一些选项,这个我们在后边会介绍到。
监控锁
判断锁管理器的状态,有利于调试;返回结果是一个锁管理器状态的快照,标识了持有锁和请求中的锁的有关数据,像名称、client_id和模式。
navigator.locks.query().then((locks) => {
console.log(locks);
});
实现
接下来将使用请求锁的可选参数实现以下内容:
从异步任务返回值
request() 方法本身返回一个 Promise,一旦锁被释放,该 Promise 就会 resolve。
const result = await navigator.locks.request('ccmama'}, async (lock) => {
// 任务
return data;
});
// 拿到内部回调函数返回的 data
console.log(result);
共享锁和独占锁模式
配置项 mode 默认是 'exclusive',可选项还有 'shared'。
锁只能有一个持有者,但是可以同时授权多个共享。
在读写模式中经常使用 'shared' 模式进行读取,'exclusive' 模式用于写入。
navigator.locks.request('ccmama', {
mode: 'shared',
}, async (lock) => {
// 任务
});
📢
持有 'exclusive' 锁,同名 'exclusive' 锁排队等候
持有 'exclusive' 锁,同名 'shared' 锁排队等候
持有 'shared' 锁,同名 'shared' 锁也可访问同一资源
持有 'shared' 锁,同名 'exclusive' 锁排队等候
条件获取
配置项 ifAvailable 默认 false,当设置 true 时锁请求仅在不需要排队时才会被授予,也就是说在任务没有其他等待的情况下锁请求才会被授予,否则返回 null。
navigator.locks.request('ccmama', { ifAvailable: true }, async lock => {
if (!lock) return;
// 任务
});
注意:同名锁
防止死锁的应急通道
配置项 steal 默认 false,当设置为 true 时任何持有的同名锁将被释放,并且请求将被授权,抢占任何排队中的锁请求。
navigator.locks.request('ccmama', { steal: true }, async lock => {
// 任务
});
⚠️
使用要小心。之前在锁内运行的代码会继续运行,并且可能与现在持有锁的代码发生冲突。
中止锁定请求
配置项 signal 是 AbortSignal 类型;如果指定并且 AbortController 被中止,则锁请求将被丢弃。
try {
const controller = new AbortController();
setTimeout(() => controller.abort(), 400);
navigator.locks.request('ccmama', { signal: controller.signal }, async lock => {
// 任务
});
} catch(ex) {}
// 或
try {
navigator.locks.request('ccmama', { signal: AbortSignal.timeout(1000) }, async lock => {
// 任务
});
} catch(ex) {}
⚠️
超时时会报出一个异常错误,需要使用 try catch 捕获
参考文章
可能理解并不一定到位,欢迎交流。
来源:juejin.cn/post/7382640456109490211
为什么年轻人要珍惜机会窗口

今天来跟大家分享一下什么是机会窗口以及为什么要珍惜机会窗口?首先从我个人的经验出发,我觉得不管是在学习,在职业,在投资,现在社会各个方面都是有很多非常好的机会的。但是这些好的机会又不经常有,那到底如何定义好机会,又如何抓住机会?那这里面先说一下什么叫好的机会。
什么是好机会
就以职业的成长性来说,互联网整个行业的二十年蓬勃发展就是极好的一个机会,大概从20年起到如今这个时间段都有一个非常好的机会,那指的就是哪怕你的能力稍微弱一点,你都能够在这个机会里面找到自己的红利。比如我有很多稍微找我几届的同事或者主管,他们可能在学历或者能力方面都没有特别高,但是正因为赶上了红利,他们的晋升特别快,拿到了股票也特别多,我好几个同事基本上在上海或者杭州都有两三套房,并且还有大量的现金。甚至有一些大专的同事,都拿到大量的股票,接近财富自由。
所以这种机会窗口是整个行业变革,整个现代社会发展带来的,它打开了一扇可以改变命运的窗口。这种时间窗口相对来说会比较长,特别是相对一个人的职业三十年来说。而且这种行业的机会,可能就有持续五年或者十年这样的时间。而在这样的机会窗口内,你不管是哪个点入局都能吃到一定的发展红利。
比如我记得早个五六年,很多人在找工作的时候,往往会纠结于去百度还是腾讯或者是阿里,但实际上我们发现站在更高,更长远的角度来说,他们选择任何一个公司收获到的都非常的丰厚,相比现在的毕业生,哪怕是双985可能也是无法找到一份工作,想想那时候是不是很幸福?在这种大背景下,在机会窗口来临的时候,你选错了,选的不是很好,都没有关系,你都能够收获到足够的红利,最多就是你赚50万还是100万的区别,而时代没有的话,上限就是赚10万。
除了这个例子之外,还有一个红利机会点就是房地产。我知道在差不多2005年~2018年这个时间段里面,只要你买房基本上都是赚的,所以我很多同学往往都有一个非常巨大的认知论,就认为他买房赚钱是因为他牛逼,他地段选的好,户型选的好,他完全归因于他买的房价大涨是因为眼光好,怎么样怎么样才能赚到钱,而实际上这只是时代给他的红利而已,其实再往回倒个七八年你在哪里买房都是赚的。但实际上以我的经验来看,不管那个时候,哪怕你在小城市买一套房子,涨幅可能都是两三倍的。
所以当时的眼光和认知和选择能力确实会决定了你的资产增值多少,但是只要在那个红利周期内,你做的选择大概率都不会太差,这也是雷军所说,站在风口上的猪也可以飞起来,说的就是这个道理。

这就是整个时代给我们的窗口,这个窗口可能会给的特别大,而且很多时候在这个周期里面,你根本感觉不到这是时代给你的机会,你只是做你正常的操作,到了指定的时间去指定的公司,去选合适热门专业,去买认为合适的房子,你觉得很自然,但实际上从后面再看,你会发现你在十年前做的选择和十年后做的选择成本、难度以及你付出的代价完全不一样。同样是89平米的房子,放在2010年就是3000一平米,放在现在就是8万一平米。同样是去阿里巴巴,以前大专就行,现在本硕985都直接被Pass。
上面说的都是比较大的机会,那我再说一个相对来说比较小的窗口。这些非常大的机会窗口还是依赖于各种不同不一样的大背景,但是有很多机会并没有像这种时代给的机会一样,可以有长达五年,十年你可以认真去选,你可以去大胆的犯错和试错,选错了你重新再来一次就可以了,但是我们在实际工作里面,我们碰到的一些机会点,其实时间窗口非常的短。如果你稍微不慎,可能就错过了这个机会,而等待下一个机会就不知道猴年马月了,所以我们就要在这个地方要抓住那稍纵即逝的机会窗口。

我举一个例子,比如说这两年是低代码的元年,而这个时候如果你之前刚好一直在从事低代码或者低代码相关的工作,那么到了这两年,你的议价空间是非常大的,因为很多公司都在如火如荼的去做这块的业务,在短时间内是没有办法慢慢培养出或者招聘到这类专才,所以往往公司愿意溢价去花费大价钱去购买和招聘相关的同学,所以这个时候如果你抓住了机会,你可以得到一个很高的议价,比如说层级直接变高了一层或者你的总包直接变成了两倍,甚至非常有机会作为骨干负责人拉起一支团队,那么你进入管理岗位也就水到渠成了。
为什么机会有窗口
而这种机会窗口往往只有半年,一年或者最多两年,因为到了一两年之后,有很多的同学也感知到了这个先机,往往就会把自己的精力投到这一块来,那么意味着供需就发生了变化,供应方就会越来越多,那么就使得需求方有溢价的能力,这个时候到了两年之后可能就完全拉平了,这个低代码行业跟其他行业变得完全一样,甚至再往后人才堆积的更加的过分,你可能连这个机会都没有了,只剩下被选择的命运。历史历代,都演绎着完全相同的剧本。
到了直播行业也是一样,在直播刚刚兴起的时候,如果你恰巧做的是相关业务,这个时候你跳过去往往会能够涨薪特别高,工资的幅度也是特别高,所以在这个时候你有充分的议价权,但是窗口我们也知道往往只有几年,而且在互联网这么变化快的情况下的话,时间可能会进一步缩短,比如这两年已经到了直播的红海,基本上该用直播的用户已经到顶了,这个时候虽然还有大把的招聘,但需求实际上已经是强弩之末了。
随着人口红利到底的时候,我们所谓的互联网这些机会的窗口实际上已经是没了,变得普普通通的一份职业而已,而且这个时候入局往往有可能会遭受灭顶之灾,比如说最近就听说到整个直播行业要整顿,一旦业务发生了整顿,对人才的需求的调整就会变得非常的明显,往往再激烈一点可能就会快速裁员,不要说红利了,拿到的全部是负债。
再往小的一些说,可能针对每个人的职业窗口也是不一样的,比如说对于有些大企业,有一些管理的岗位,但往往是因为原管理的同学离职或者新增的岗位,这个时候会有短时间的招聘名额来等待这个位置,而一旦你错过了这个机会以后,这个位置没了以后,可能这个坑位就不需要人了。这个时候不是你能力好不好的问题,是有没有坑位的问题。
所以好机会往往只是一瞬间而已,很多同学担心稳定性,希望在一个地方一直苟着求稳定,这个其实跟体制内没有任何的区别。风险和收益从哲学层面上来说,都是相对的,或者说没有决定的风险,也没有决定的稳定,风险和稳定阶段性只能取其一,长期看稳定和风险是互相转化的。我经常听到有人说大厂稳定,但是实际上我们在分析背后的原因,大厂稳定本身就是个伪命题。又稳定,又高薪,又轻松,这是不可能的。所以我称之为「工作不可能的三角特点」。
但很多人说我能否要里面的两个因素,我要稳定要高薪但是我愿意加班吃苦。
对不起,这个其实也是不可能的。我们可以站在企业的角度来考虑一下,一旦我这个工作特别的高薪又稳定的情况下的话,那虽然你干的很苦,但我始终在人力成本特别充分的情况下的话,公司能找到更好的替代者来。同样的工作量,但是花更少的钱来解决,说白了大部分所谓的高薪岗位没有什么严格的技术壁垒。
所以我们说过的,站在更大的角度来说,互联网也是一个机会窗口,因为过了这个窗口之后,可能你想加班加点熬夜,你可能都拿不到这样的一个薪水和待遇。
如何抓住机会窗口
反而换一个角度来说,我们一定要抓住这样的机会窗口,这样的机会窗口可以给我们的发展带来一个质的变化,当然也有很多时候我们会做一些错误的选择,比如说我们找到了一个我们认为好的机会,但实际上这个机会是有问题的,比如说我去了某一个创业公司,原本以为会有巨大的发展,但是后面倒闭了。当然这个也是一种博弈,这里面非常考核一个同学的综合的认知能力、选择能力和纠错能力。不仅要判断能否找到合适的机会,还要在碰到了困难的时候能够去快速的去纠错。
从我的例子来看,如敢于去挑战这种新机会的同学,哪怕其中有一些不如意的变动,但是大概率他的结果大概率不会太差。比如我有个同学从集团跳槽到蚂蚁国际,呆了一年就觉得部门有问题,后面又去了字节头条,现在也非常稳定。还有一个同学出去创业,也不顺利,但是后面又折腾成了另外一个大型公司的高级主管。
反而是事事求稳,稳住某一个大厂,稳住某一个职位,稳住每一个薪水,到了最后往往收益会越来越小,直到最后完全被动。整体上来看,整个社会会把更多的报酬分向于这些敢于挑战,敢于冒险,敢于拼搏的人的,而不会把大量的资源分享到又稳定,又顽固,又不愿意改变的这群人,这是当前社会的游戏规则。这个在大数据上面完全是合理的,只不过落到每个人的头上的尺度和比例会有点不一样。
所以站在我现在的角度上来看,我觉得所有的想向上奋进的同学都应该主动抓住变革的机会。因为这个好机会可能对在你的人生来说,几十年可能就这么一两次,甚至有些都是完全为你量身定做的机会,如果你一旦错过了以后,可能你抓住下一个机会的成本和代价就变得会非常的大。

尤其是年轻人更应该去折腾,因为你的试错的成本会非常低,当你发现了你的错误决策以后,你能够快速的去更正,去变化,所以在年轻的时候往往就应该多折腾一点,善于去准备好去等待好的机会,如果机会来了,大胆的出击。
来源:juejin.cn/post/7296865632166805513
【实现环信 SDK登陆跳转至Harmony 底部导航栏】
1.在 Index.ets 的 aboutToApper 方法中 实现环信SDK 初始化

代码块(可直接 copy):
let optionss = new ChatOptions("输入管理后台注册的环信 APPkey");
//管理后台网址:https://console.easemob.com/user/login
//环信初始化
ChatClient.getInstance().init(getContext(),optionss)2.登录环信SDK并跳转至少导航栏页面
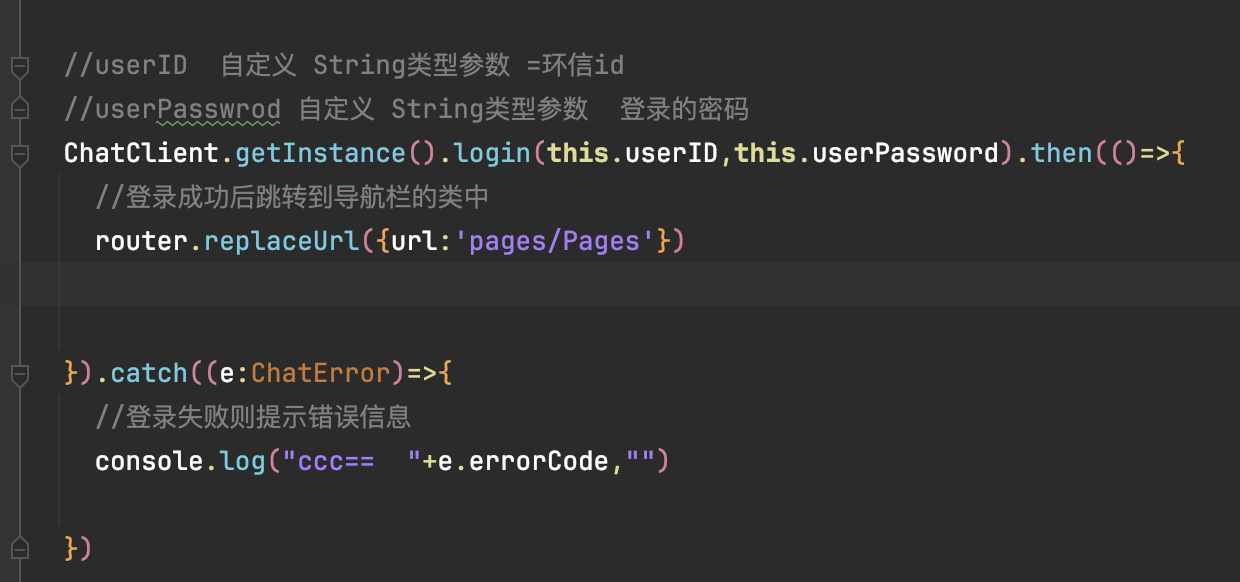
代码块://userID 自定义 String类型参数 =环信id
//userPasswrod 自定义 String类型参数 登录的密码
ChatClient.getInstance().login(this.userID,this.userPassword).then(()=>{
//登录成功后跳转到导航栏的指定类中
router.replaceUrl({url:'pages/Pages'})
}).catch((e:ChatError)=>{
//登录失败则提示错误信息
console.log("ccc== "+e.errorCode,"")
})3.在 Harmony 平台下自定义容器
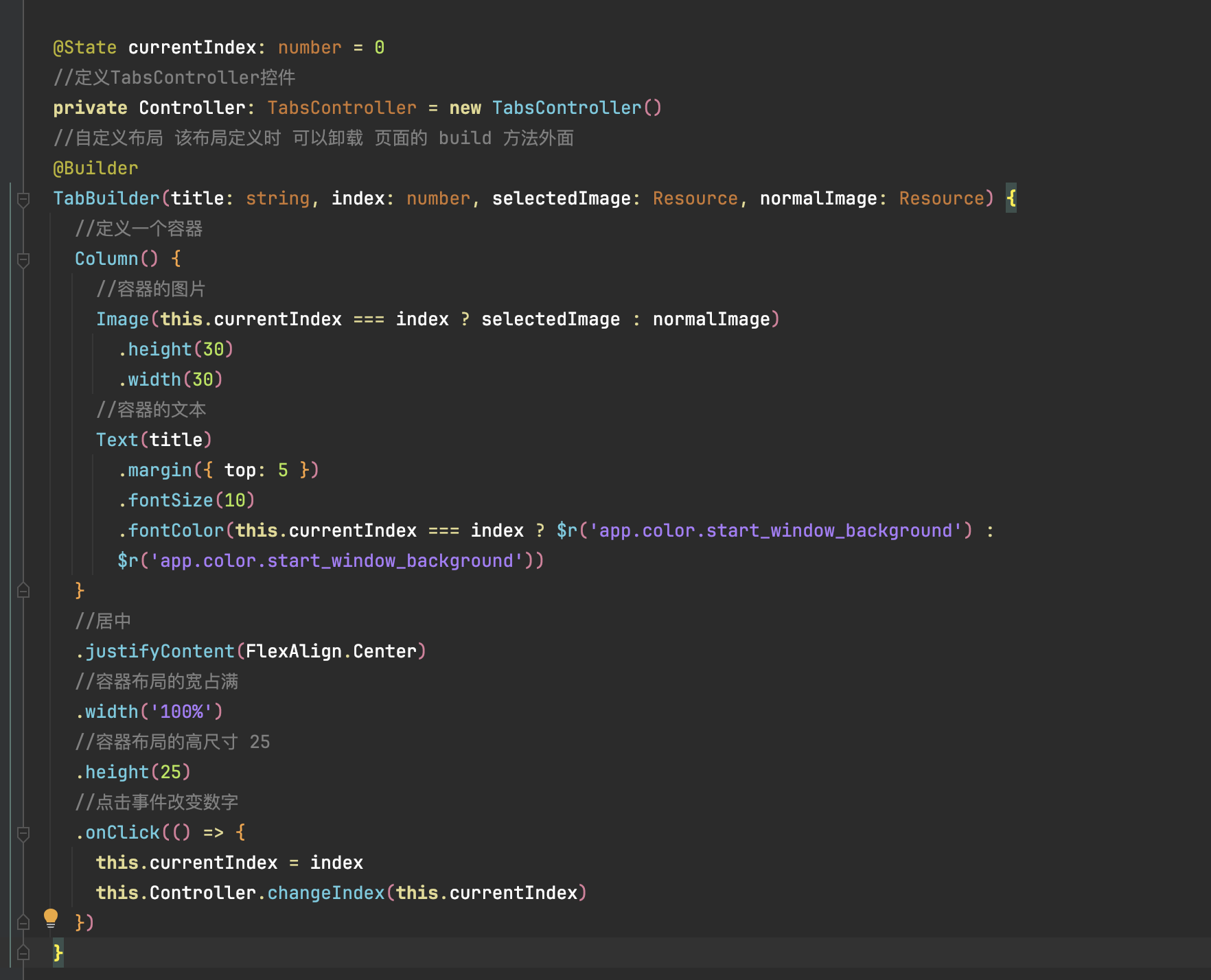
代码块:
@State currentIndex: number = 0
//定义TabsController控件
private Controller: TabsController = new TabsController()
//自定义布局 该布局定义时 可以卸载 页面的 build 方法外面
@Builder
TabBuilder(title: string, index: number, selectedImage: Resource, normalImage: Resource) {
//定义一个容器
Column() {
//容器的图片
Image(this.currentIndex === index ? selectedImage : normalImage)
.height(30)
.width(30)
//容器的文本
Text(title)
.margin({ top: 5 })
.fontSize(10)
.fontColor(this.currentIndex === index ? $r('app.color.start_window_background') :
$r('app.color.start_window_background'))
}
//居中
.justifyContent(FlexAlign.Center)
//容器布局的宽占满
.width('100%')
//容器布局的高尺寸 25
.height(25)
//点击事件改变数字
.onClick(() => {
this.currentIndex = index
this.Controller.changeIndex(this.currentIndex)
})
}4.build 中通过 Tabs 组件实现底部导航栏
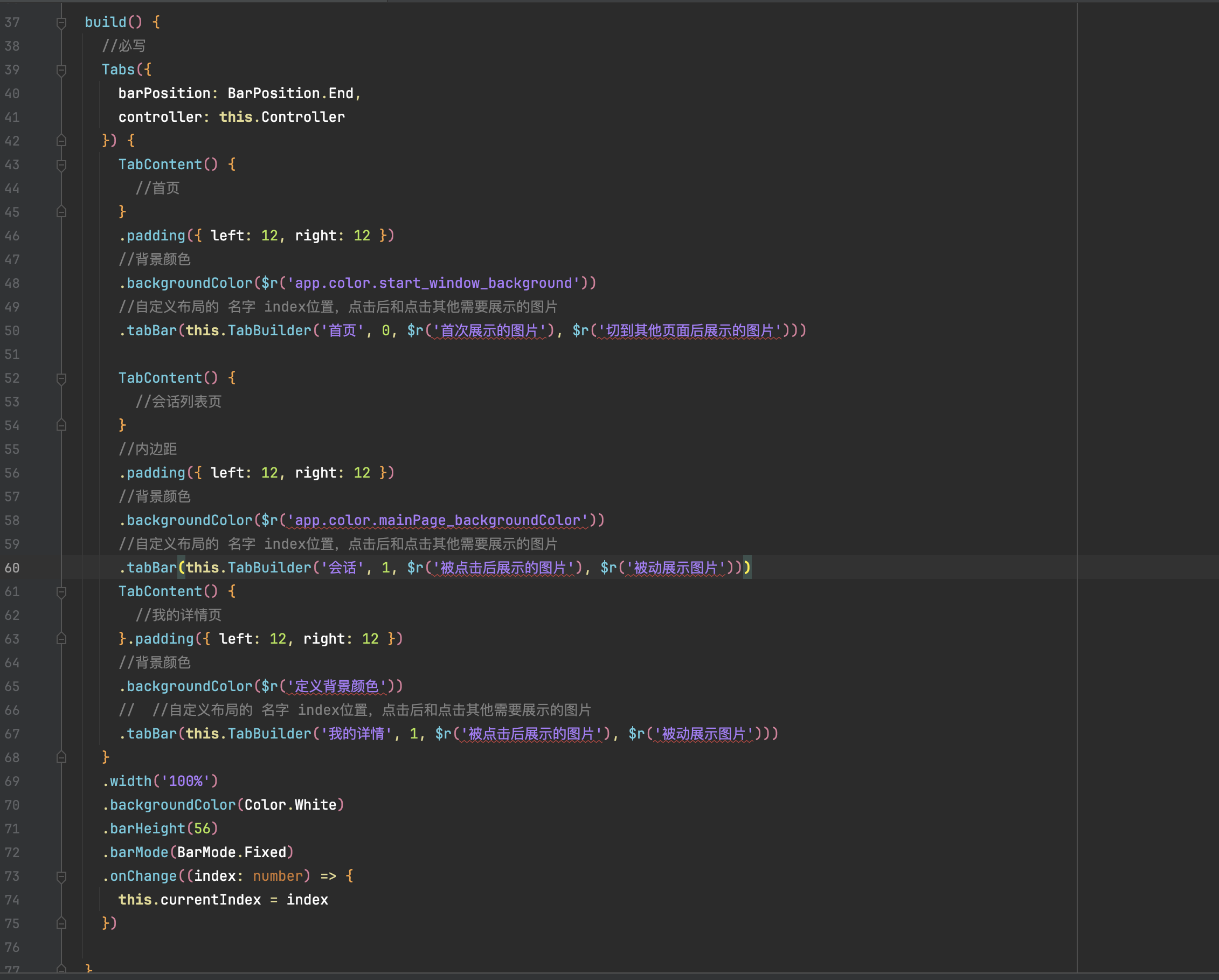
代码块:
build() {
//必写
Tabs({
barPosition: BarPosition.End,
controller: this.Controller
}) {
TabContent() {
//首页
}
.padding({ left: 12, right: 12 })
//背景颜色
.backgroundColor($r('app.color.start_window_background'))
//自定义布局的 名字 index位置,点击后和点击其他需要展示的图片
.tabBar(this.TabBuilder('首页', 0, $r('首次展示的图片'), $r('切到其他页面后展示的图片')))
TabContent() {
//会话列表页
}
//内边距
.padding({ left: 12, right: 12 })
//背景颜色
.backgroundColor($r('app.color.mainPage_backgroundColor'))
//自定义布局的 名字 index位置,点击后和点击其他需要展示的图片
.tabBar(this.TabBuilder('会话', 1, $r('被点击后展示的图片'), $r('被动展示图片')))
TabContent() {
//我的详情页
}.padding({ left: 12, right: 12 })
//背景颜色
.backgroundColor($r('定义背景颜色'))
// //自定义布局的 名字 index位置,点击后和点击其他需要展示的图片
.tabBar(this.TabBuilder('我的详情', 1, $r('被点击后展示的图片'), $r('被动展示图片')))
}
.width('100%')
.backgroundColor(Color.White)
.barHeight(56)
.barMode(BarMode.Fixed)
.onChange((index: number) => {
this.currentIndex = index
})
}向全栈靠齐的前端分享
背景与思考
前端在很多后端开发人员中,总是觉得没啥技术含量。尤其是在老java眼中,深深感觉存在严重的鄙视链。然后就是自己的职业规划,也不想一直做前端敲代码。毕竟自己的付出不少,也想收获属于自己的成就感。然后自己的横向发展就成了必然。
后端技术首推Node
- 前后端编程环境和语法一致,上手非常快。
- 轻量级,部署简单。
- 生态丰富,文档颇多,碰到问题,百度查询方便。
- 高效的异步I/O模型,易处理大并发和连接。
Node框架推荐Koa

- 相对于express,Koa更加的轻便,上手主打一个简单易学好用。
- 语法上它的中间件和前端的模块化很像,开发思路一致。
- 前端熟悉的async await,promise方式,很好的解决了多层嵌套,地狱回调问题。
- 借助 co 和 generator,很好地解决了异步流程控制和异常捕获问题。
学习推荐
我当初学习也是想看了一下官网,发现确实如介绍般的简单,但是对于入门者来说,有点简单的过分了。在此推荐阮一峰老师的网络日志(不是打广告,确实是我当初前端起步阶段的老师之一,受益匪浅)。
主要代码解析
项目结构

app.js源码
const Koa = require('koa');
const Router = require('koa-router');
// 跨域模块
var cors = require('koa2-cors');
//文件模块
const fs = require('fs');
const { historyApiFallback } = require('koa2-connect-history-api-fallback');
//静态文件加载
const serve = require('koa-static');
//路径管理
const path = require('path');
//koa-body对文件上传进行配置
const koaBody = require('koa-body')
//实例化koa
const app = new Koa();
app.use(historyApiFallback());
app.use(cors());
const router = new Router();
const bodyParser = require('koa-bodyparser');
const controller = require('./controller');
app.use(async (ctx, next) => {
ctx.set("Access-Control-Allow-Origin", "*")
await next()
})
app.use(bodyParser());
// 处理跨域
app.use(controller());
app.use(koaBody({
multipart:true,
formidable:{
maxFileSize:50000*1024*1024, //设置上传文件大小最大限制,默认为2m,2000*1024*1024
keepExtensions: true // 保留文件拓展名
}
}))
// 1.主页静态网页 把静态页统一放到public中管理
const main = serve(path.join(__dirname) + '/build');
//配置路由
app.use(router.routes()).use(router.allowedMethods());
const port = 5000;
app.use(main)
app.listen(port, () => {
console.log(`server started on ${port}`)
});
依赖包讲解
const Koa = require('koa');
这是引入koa框架,这是重中之重,只有引入了才能够在项目中使用。在项目中会通过new来实例化,比如代码中的const app = new Koa();。然后再定义一个监听的端口,app.listen()方法来进行监听。
const fs = require('fs');
这是koa自带的文件模块,如果你想对系统文件进行读取,修改。或者文件上传保存,都离不开整个fs模块,fs.readFile和fs.readFileSync。
const koaBody = require('koa-body')
Koa-body是基于Koa的中间件模型构建的,主要用于文件上传,以及在中间件中对请求体的解析。对请求体的解析中,我们主要使用koa-bodyparser,它可以将http请求中的数据,解析成我们需要的JavaScript对象。
const Router = require('koa-router');
```门口
Router模块就是路由,此路由和前端路由有差异,此路由可以理解为前端理解的api接口,只是叫法不一样而已。
```js
const { historyApiFallback } = require('koa2-connect-history-api-fallback');
koa2-connect-history-api-fallback是一个专门为 Koa2 框架设计的中间件,它的主要目的是在SPA应用中处理URL重定向,尤其是在用户直接输入或者通过后退按钮访问非根URL时。 这个中间件会将所有未匹配到特定路由的请求转发到默认HTML文件(通常是 index.html),确保SPA可以正常启动并处理路由。还记得当初自己终于完成了一整套的项目线上部署,可把自己开心坏了,但是同事在一次用着发现,刷新页面时,页面直接变成了404,你说吓不吓人。盘查一下发现自己在vue前端中的路由为何在后端中变成了一个get请求。

controller.js源码
const fs = require('fs')
// add url-route in /controllers:
function addMapping (router, mapping) {
for (var url in mapping) {
if (url.startsWith('GET ')) {
var path = url.substring(4)
router.get(path, mapping[url])
// console.log(`register URL mapping: GET ${path}`);
} else if (url.startsWith('POST ')) {
var path = url.substring(5)
router.post(path, mapping[url])
// console.log(`register URL mapping: POST ${path}`);
} else if (url.startsWith('PUT ')) {
var path = url.substring(4)
router.put(path, mapping[url])
// console.log(`register URL mapping: PUT ${path}`);
} else if (url.startsWith('DELETE ')) {
var path = url.substring(7)
router.del(path, mapping[url])
// console.log(`register URL mapping: DELETE ${path}`);
} else {
// console.log(`invalid URL: ${url}`);
}
}
}
function addControllers (router, dir) {
fs.readdirSync(__dirname + '/' + dir)
.filter(f => {
return f.endsWith('.js')
})
.forEach(f => {
// console.log(`process controller: ${f}...`);
let mapping = require(__dirname + '/' + dir + '/' + f)
addMapping(router, mapping)
})
}
module.exports = function (dir) {
let controllers_dir = dir || 'controllers',
router = require('koa-router')()
addControllers(router, controllers_dir)
return router.routes`()`
}
controller讲解
在这个controller中,我们主要做了一件事,那就是路由映射逻辑处理。
function addControllers()
这个方法用于自动加载指定目录下的js文件,它使用fs.readdirSync读取目录,然后通过filter和forEach方法来处理每个文件名,只选择以.js结尾的文件,并将这些文件的路由映射添加到router上
function addMapping()
这个函数用于将HTTP方法(如GET、POST、PUT、DELETE)和对应的URL路径映射到处理函数上。它遍历传入的mapping对象,根据URL的前缀(如GET 、POST 等)来确定使用哪个HTTP方法,并将路径和处理函数注册到router上。
controllers下路由POST方法
const jwt = require('jsonwebtoken')
module.exports = {
'POST /login': async (ctx, next) => {
var key = ctx.request.body
if (key.username && key.password) {
return new Promise(function (resolve, reject) {
var MongoClient = require('mongodb').MongoClient
var MG_URL = 'mongodb://***********/'
MongoClient.connect(
MG_URL,
{ useUnifiedTopology: true },
function (err, db) {
if (err) throw err
var dbo = db.db('website')
dbo
.collection('user')
.find({ username: key.username, password: key.password })
.toArray(function (err, result) {
if (result.length) {
const TOKEN = jwt.sign(
{
name: result[0].username
},
'MY_TOKEN',
{ expiresIn: '24h' }
)
let data = {
username: result[0].username,
token: TOKEN
}
ctx.response.body = {
result: 1,
status: 200,
code: 200,
data: data
}
} else {
ctx.response.body = {
result: 0,
status: 200,
code: 0,
msg: '该用户不存在'
}
}
if (err) throw err
resolve(result)
db.close()
})
}
)
})
} else {
ctx.response.body = {
result: 0,
status: 200,
code: 0,
msg: 'error'
}
}
}
}
这是一个登录的login方法,用POST进行请求。在这个地方用了一下mongodb数据库存储。在api接口请求login方法时,获取请求中所携带的参数进行解析,并判断此用户以及密码是否在我们的数据库中,如果存在返回成功的提示以及相关数据,如果错误,则提示错误。当然如果还不会数据库的使用,可以去除数据库相关部分,直接用本地json数据,这个比较简单,就是fs读取本地json文件,然后返回给api接口。不在此做详细说明。
controllers下路由GET方法
module.exports = {
'GET /getNews': async (ctx, next) => {
return new Promise(function (resolve, reject) {
var MongoClient = require('mongodb').MongoClient
var MG_URL = 'mongodb://********'
MongoClient.connect(
MG_URL,
{ useUnifiedTopology: true },
function (err, db) {
if (err) throw err
var dbo = db.db('website')
dbo
.collection('news')
.find({})
.toArray(function (err, result) {
if (result.length) {
ctx.response.body = {
result: 1,
status: 200,
code: 1,
data: result
}
} else {
ctx.response.body = {
result: 0,
status: 200,
code: 0,
msg: '暂无数据'
}
}
if (err) throw err
resolve(result)
db.close()
})
}
)
})
}
}
这是一个获取新闻的getNews方法,用GET请求。主要用来查询数据库中的list的信息。DELETE,PUT等方法不在此处贴出更多源码。
数据库首推mondodb

- 面向集合存储,易存储对象类型的数据。
- 模式自由。
- 高性能、易部署、易使用。
- 文档型数据结构灵活,适应不同类型的数据。
- 支持动态查询。
- 非关系型数据库。
学习推荐
为啥选择MongoDB数据库,相对来说操作还是比较简单,而且存储的数据类型都是对象的形式,前端可以轻松拿捏。在这里直接推荐菜鸟的mongodb教程,看名字就知道,这是一个适合菜鸟初步学习的地方。讲解也比较详细,学完上面的内容,用mongodb数据库进行基本的数据存储和操作已经没有问题了。
总结
通过以上的分享,其实对大多数前端来说,开启一个简单的后端服务和接口请求,已经可以开箱即用了。想要完整的学习代码,也可以私信我。虽然不是很完善,但麻雀虽小五脏俱全。
思考
在前端行业已经接7载。曾经害怕java的恐惧而转入前端行业,所有受到鄙视也是有一部分原因吧,毕竟自己曾经年少无知,害怕吃苦选择了一个稍微简单的前端就稀里糊涂的就业了,保命要紧。但是在后来又想改变这个鄙视链,自己就开始了nodejs的学习,python的学习,数据库MongoDB,MySQL,PostgreSQL。学不完,压根学不完。
后面再无尽的内卷中,有的做开发不是自己的路,也想做做管理,毕竟前端做到前端组长就已经是极限了,在公司以java为尊的环境下,想做更高的级别几乎不可能。毕竟自己算是耿直死宅,不善交际,讨不到大领导的喜爱。然后又开始了原型的学习,PMP项目管理证书的考取(进行中),也曾有单独出去做产品的想法,面试过一个,但是与自己的预期薪资相差太大,没去。
来源:juejin.cn/post/7415654362993639439
如果你使用的第三方库有bug,你会怎么办
早上好,中午好,晚上好
在当今的前端工程化领域,第三方库的使用已经成为标配。然而,不可避免的是,这些库可能会存在bug,或者是库的一些功能并不能满足需要,需要修改库的某个功能,或添加功能。当遇到这种情况时,我们应该如何应对?本文将介绍三种解决第三方库bug的方法,并重点介绍使用patch-package库来修复bug的全过程。
在当今的前端工程化领域,第三方库的使用已经成为标配。然而,不可避免的是,这些库可能会存在bug,或者是库的一些功能并不能满足需要,需要修改库的某个功能,或添加功能。当遇到这种情况时,我们应该如何应对?本文将介绍三种解决第三方库bug的方法,并重点介绍使用patch-package库来修复bug的全过程。
方法一:提issues给第三方库的作者,让作者修复
这个方式是比较常见的解决方式了,但有几个缺点:
- 库作者不维护这个库了,那提issues自然就没有人close了,gg
- 库作者很忙,或者项目缺乏活跃的贡献者,导致问题可能长时间都不懂响应,那如果你这个项目很急的话,那gg
- bug或者功能的优先级不高,库作者先解决其他高优先级的,或者他不接受你的建议或者及时修复问题,那gg
- 还有可能出现的沟通成本,以确保库作者完全理解了问题的本质和重要性。
那如果库作者很勤奋,每天都在维护,对issues的问题,都满怀热情的进行解决,那我们可以按照以下流程进行提issues:
- 发现bug:在使用第三方库时,发现了一个bug。
- 复现bug:在本地环境中尝试复现该bug,并记录详细的复现步骤。
- 提交issues:访问第三方库的GitHub仓库,点击“New issue”按钮,填写以下信息:
- 标题:简洁地描述bug现象。
- 描述:详细描述bug的复现步骤、预期结果和实际结果。
- 环境:列出你的操作系统、浏览器版本、库的版本等信息。
- 等待回复:作者可能会要求你提供更多信息,或者告诉你解决方案。耐心等待并积极配合。nice
这个方式是比较常见的解决方式了,但有几个缺点:
- 库作者不维护这个库了,那提issues自然就没有人close了,gg
- 库作者很忙,或者项目缺乏活跃的贡献者,导致问题可能长时间都不懂响应,那如果你这个项目很急的话,那gg
- bug或者功能的优先级不高,库作者先解决其他高优先级的,或者他不接受你的建议或者及时修复问题,那gg
- 还有可能出现的沟通成本,以确保库作者完全理解了问题的本质和重要性。
那如果库作者很勤奋,每天都在维护,对issues的问题,都满怀热情的进行解决,那我们可以按照以下流程进行提issues:
- 发现bug:在使用第三方库时,发现了一个bug。
- 复现bug:在本地环境中尝试复现该bug,并记录详细的复现步骤。
- 提交issues:访问第三方库的GitHub仓库,点击“New issue”按钮,填写以下信息:
- 标题:简洁地描述bug现象。
- 描述:详细描述bug的复现步骤、预期结果和实际结果。
- 环境:列出你的操作系统、浏览器版本、库的版本等信息。
- 等待回复:作者可能会要求你提供更多信息,或者告诉你解决方案。耐心等待并积极配合。nice
方法二:fork第三方库,修复好bug后,发布到npm,项目下载自己发布的npm包
这个方式也有局限性:
- 维护负担:一旦你fork了库,你需要负责维护这个分支,包括合并上游的更新和修复新出现的bug。
- 长期兼容性:随着时间的推移,原库和新fork的库可能会出现分歧,使得合并更新变得更加困难。
- 版本管理:需要管理自己发布的npm包版本,确保它与其他依赖的兼容性。
- 社区隔离:使用自己的fork可能会减少与原社区的合作机会,错过原库的其他改进和特性。
那如果你觉得这个方式很不错,那最佳实践是这样的:
这个方式也有局限性:
- 维护负担:一旦你fork了库,你需要负责维护这个分支,包括合并上游的更新和修复新出现的bug。
- 长期兼容性:随着时间的推移,原库和新fork的库可能会出现分歧,使得合并更新变得更加困难。
- 版本管理:需要管理自己发布的npm包版本,确保它与其他依赖的兼容性。
- 社区隔离:使用自己的fork可能会减少与原社区的合作机会,错过原库的其他改进和特性。
那如果你觉得这个方式很不错,那最佳实践是这样的:
步骤 1: Fork 原始库
- 访问原始库的GitHub页面。
- 点击页面上的“Fork”按钮,将库复制到你的GitHub账户下。
- 访问原始库的GitHub页面。
- 点击页面上的“Fork”按钮,将库复制到你的GitHub账户下。
步骤 2: 克隆你的Fork
git clone https://github.com/your-username/original-repo.git
cd original-repo
git clone https://github.com/your-username/original-repo.git
cd original-repo
步骤 3: 设置上游仓库
git remote add upstream https://github.com/original-owner/original-repo.git
这样当作者更新维护库的时候,可以获取上游仓库的最新更新。
git remote add upstream https://github.com/original-owner/original-repo.git
这样当作者更新维护库的时候,可以获取上游仓库的最新更新。
步骤 4: 创建特性分支
git checkout -b fix-bug-branch
git checkout -b fix-bug-branch
步骤 5: 修复Bug
在这个分支上,进行必要的代码更改来修复bug。
在这个分支上,进行必要的代码更改来修复bug。
步骤 6: 测试更改
在本地环境中测试你的更改,确保修复了bug并且没有引入新的问题。
在本地环境中测试你的更改,确保修复了bug并且没有引入新的问题。
步骤 7: 提交并推送更改
git add .
git commit -m "Fix bug description"
git push origin fix-bug-branch
git add .
git commit -m "Fix bug description"
git push origin fix-bug-branch
步骤 8: 创建Pull Request(可选)
如果你希望原始库接受你的修复,可以向上游仓库创建一个Pull Request。
如果你希望原始库接受你的修复,可以向上游仓库创建一个Pull Request。
步骤 9: 发布到NPM
如果原始库没有接受你的PR,或者你需要立即使用修复,可以发布到NPM:
- 登录到NPM。
npm login
这个地方有个坑点,就是你使用了npm镜像需要将镜像更改为npm官方仓库:
npm config set registry https://registry.npmjs.org
- 修改
package.json中的名称,避免与原始库冲突,例如添加你的用户名前缀。
{
"name": "@your-username/original-repo",
// ...
}
- 更新版本号。
npm version patch
- 发布到NPM。
npm publish
如果原始库没有接受你的PR,或者你需要立即使用修复,可以发布到NPM:
- 登录到NPM。
npm login
这个地方有个坑点,就是你使用了npm镜像需要将镜像更改为npm官方仓库:
npm config set registry https://registry.npmjs.org
- 修改
package.json中的名称,避免与原始库冲突,例如添加你的用户名前缀。
{
"name": "@your-username/original-repo",
// ...
}
npm version patch
npm publish
步骤 10: 在你的项目中使用Forked库
在你的项目package.json中,将依赖项更改为你的forked版本。
{
"dependencies": {
"original-repo": "^1.0.0",
"@your-username/original-repo": "1.0.1"
}
}
步骤 11: 维护你的Fork
定期从上游仓库合并更新到你的fork,以保持与原始库的同步。
git checkout master
git pull upstream master
git push origin master
最佳实践总结
- 保持与上游仓库的同步。
- 清晰地记录你的更改和发布。
- 为你的fork创建文档,说明它与原始库的区别。
- 考虑长期维护策略,如果可能,尽量回归到官方版本。
方法三:使用patch-package库来修复
patch-package 是一个非常有用的 npm 包,它允许我们在没有修改原始 npm 依赖包的情况下,对 npm 依赖进行修复或自定义。这在以下场景中特别有用:
- 当你发现一个第三方库的 bug,但作者还没有修复它,或者修复后的版本尚未发布。
- 当你需要对第三方库进行微小的定制,而不想维护一个完整的分支或分叉。
patch-package 的工作原理
patch-package 的工作流程通常如下:
- 修改
node_modules中的依赖包文件。 - 运行
patch-package命令,它会生成一个补丁文件,通常是.patch文件,保存在项目根目录下的patches文件夹中。 - 在
package.json的scripts部分添加一个脚本来应用这些补丁,通常是在postinstall阶段。 - 将生成的
.patch文件提交到版本控制系统中。 - 当其他开发者运行
npm install或yarn安装依赖时,或者 CI/CD 系统构建项目时,这些补丁会被自动应用。
但使用这种方式也有前提:
1. 潜在冲突:如果第三方库的官方更新解决了相同的bug,但采用了不同的方法,那么你的补丁可能会与这些更新冲突
2. 库没有源码:这种方式是在node_modules里对应的包进行修改,如果包是压缩后的,那就没办法改了,所以只能针对node_modules里的包有源码的情况下。
最佳实践:
步骤 1:安装patch-package postinstall-postinstall
postinstall-postinstall,作用是 postinstall 脚本在 Yarn 安装过程中运行。
yarn add patch-package postinstall-postinstall --dev
步骤 2:配置 package.json
在你的 package.json 文件中,添加一个 postinstall 脚本来确保在安装依赖后应用补丁:
"scripts": {
"postinstall": "patch-package"
}
步骤 3:修复依赖包中的 bug
假如vue3有个bug,我们直接在 node_modules/vue/xxx 中修复这个 bug。
步骤 4:创建补丁
修复完成后,我们运行以下命令来生成补丁:
npx patch-package example-lib
这会在项目根目录下创建一个 patches 文件夹,并在其中生成一个名为 vue+3.4.29.patch 的文件(假设vue当前库的版本是3.4.29)。
步骤 5:提交补丁文件到代码库中
现在,我们将 patches 文件夹和里面的 .patch 文件提交到版本控制系统中。
git add patches/example-lib+1.0.0.patch
git commit -m "Add patch for vue3.4.29"
git push
步骤 6:安装依赖并应用补丁
就是其他同事在下载项目或者更新依赖后,postinstall 脚本会自动运行,并应用补丁。
npm install
# 或者
yarn install
当 npm install 或 yarn install 完成后,patch-package 会自动检测 patches 文件夹中的补丁,并将其应用到对应的依赖上。
志哥我想说
遇到第三方库的bug时,我们可以选择提issues、fork并发布自己的npm包,或者使用patch-package进行本地修复。当然你还可以有:
- 使用替代库
- 社区支持
每种方法都有其适用场景,根据实际情况选择最合适的方法。希望本文能帮助你更好地应对第三方库的bug问题,或者面试或者技术分享等。
来源:juejin.cn/post/7418797840796254271
抖音自动进入直播间的动画挺有意思的,看看有多少种方式可以实现
在刷抖音的时候,发现有一个直播的专属导航页签,切换到这个页签之后,刷出来的内容全都是直播,不过都是在“门外”观看,没有进入直播间;
短暂的停留之后,会出现一个自动进入直播间的提示,并且有一个描边动画,动画结束之后,就会进入直播间,今天我就尝试通过多种方式来实现这个动画效果。
1. 渐变实现

效果如上图所示,渐变需要使用到的是conic-gradient锥形渐变,文档地址:conic-gradient
代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
html,
body {
height: 100%;
margin: 0;
}
body {
display: flex;
justify-content: center;
align-items: center;
background: linear-gradient(90deg, #1F1C2C 0%, #928DAB 100%);
color: #fff;
}
.wrap {
position: relative;
background-color: rgba(255, 255, 255, 0.2);
width: fit-content;
padding: 10px 20px;
border-radius: calc(1em + 10px);
}
/*使用自定义属性来控制进度*/
@property --offset {
syntax: "<length-percentage>";
inherits: false;
initial-value: 0;
}
.wrap.gradient-animation {
overflow: hidden;
/*和普通 css 变量一样使用即可*/
background-image:
conic-gradient(
#fff 0%,
#fff var(--offset),
transparent var(--offset) 100%
);
}
/*需要使用一个遮挡来挡住多余的部分,只保留描边部分*/
.wrap.gradient-animation::before {
content: ' ';
position: absolute;
top: 2px;
left: 2px;
right: 2px;
bottom: 2px;
background: #1F1C2C;
border-radius: inherit;
z-index: 0;
}
.wrap.gradient-animation:hover {
animation: gradient 5s linear 1 forwards;
}
@keyframes gradient {
0% {
--offset: 0;
}
100% {
--offset: 100%;
}
}
</style>
</head>
<body>
<div class="wrap gradient-animation">
<!-- 需要控制层级显示 -->
<span style="position: relative; z-index: 1;">自动进入直播间</span>
</div>
</body>
</html>
conic-gradient的技术细节就不展开了,感兴趣的可以自行查阅文档,这里主要的技术点在于--offset这个自定义属性,因为渐变本身是不支持动画的,所以需要借助这个自定义属性来实现动画效果,文档地址:@property
这里的效果其并不是很理想,因为conic-gradient的渐变是一个圆形的渐变,而实际效果是边框的一个描边,所以需要使用一个遮罩来挡住多余的部分,只保留描边部分。
由于使用了伪元素来实现遮罩,所以还需要控制层级显示,避免遮罩挡住了文字,并且原效果是透明的背景,这里使用遮罩层之后背景就不能是透明的了,而且动画在每一个部分执行的时间都不连贯。
可以说这种方式有很多的局限性,所以我们来看看下一种方式。
2. 渐变加 mask 实现

渐变加mask的实现思路和上面的类似,主要是解决了上面的背景半透明的问题,文档地址:mask
代码如下:
<div class="wrap gradient-mask">
<span style="position: relative; z-index: 1;">自动进入直播间</span>
</div>
.wrap.gradient-mask::before {
content: ' ';
position: absolute;
inset: 0;
background-color: rgba(255, 255, 255, 0.1);
background-image: conic-gradient(
#fff 0%,
#fff var(--offset),
transparent var(--offset) 100%
);
border-radius: inherit;
mask-image: url("data:image/svg+xml;utf8,<svg xmlns='http://www.w3.org/2000/svg'><rect width='150' x='1' y='1' height='40' rx='20' fill='transparent' stroke='red' stroke-width='2' stroke-alignment='outside'/></svg>");
mask-size: 100% 100%;
mask-repeat: no-repeat;
}
.wrap.gradient-mask:hover::before {
animation: gradient 5s linear 1 forwards;
}
这里把效果整体迁移到了::before伪元素上,使用mask-image里面加了一个svg来处理描边的问题,这样就不需要使用遮罩来挡住多余的部分,只保留描边部分。
但是这里的问题也很明显,那就是svg并不能很好的响应式,而且因为svg的其他原因,导致描边的边宽有点被裁剪,这里也只是提供一个思路,并不是最佳实践。
3. 使用 svg 实现

上面都已经使用到了svg作为遮罩,那么直接使用svg更简单直接,这种情况个人也比较推荐,代码如下:
<div class="wrap svg">
<svg xmlns="http://www.w3.org/2000/svg">
<rect width="150" x="1" y="1" height="40" rx="20" stroke="rgba(255, 255, 255, 0.1)" stroke-width="2" />
<rect width="150" x="1" y="1" height="40" rx="20" class="rect" />
</svg>
<span style="position: relative; z-index: 1;">自动进入直播间</span>
</div>
.wrap.svg svg {
position: absolute;
inset: 0;
width: 100%;
height: 100%;
}
.wrap.svg svg > rect {
width: calc(100% - 2px);
height: calc(100% - 2px);
fill: transparent;
stroke-width: 2;
}
.wrap.svg svg > .rect {
stroke-dasharray: 350;
stroke-dashoffset: 350;
stroke: white;
stroke-width: 2;
}
.wrap.svg:hover svg > .rect {
transition: stroke-dashoffset 5s linear;
stroke-dashoffset: 0;
}
svg的描边效果主要是通过stroke-dasharray和stroke-dashoffset来实现的,svg描边效果也是一个非常有趣的实现。
stroke-dasharray是用来控制虚线的,这个值越大,虚线之间的间隔也越大,大到一定程度这个虚线就正好将整个形状包裹住。
stroke-dashoffset是用来控制虚线的偏移量,当这个值等于stroke-dasharray的时候,虚线就会完全消失,等于0的时候,虚线就会完全显示。
根据svg的特性,描边是在形状的外部,所以最外层有一个半透明的边框路径显示的并不完全,需要通过一些技巧来处理。

所以上面的代码会有两个rect,一个是用来描边的,一个是用来做半透明的边框的,这样就可以实现一个比较完美的描边动画效果。
但是上面的描边起点和终点都是在左上角,如果需要在中间的话,可以通过path来实现,感兴趣的可以自行尝试,这里提供path的代码:
<svg viewBox="0 0 600 150" xmlns="http://www.w3.org/2000/svg">
<path d="M 100 0 L 500 0 A 50 50 0 1 1 500 150 L 100 150 A 50 50 0 1 1 100 0 Z" fill="transparent" stroke="rgba(255, 255, 255, 0.1)" stroke-width="2" />
</svg>
path需要微调,因为没有贴边,可以使用一些在线网站来进行调整,比如:svg-path-editor,可自行探索。
总结
这一篇文章通过多种方式来实现一个描边动画效果,主要技术有:
conic-gradient锥形渐变,本身渐变是不支持动画的,但是我们可以通过自定义属性来实现动画效果;mask遮罩,mask本身其实和背景图的使用方式差不多,但是mask主要用来遮挡多余的部分,在这里我们使用mask来遮挡主要部分,只保留描边部分来实现动画效果;svg描边,svg描边是一个非常有趣的技术,通过stroke-dasharray和stroke-dashoffset来实现描边动画效果,这种方式是最推荐的。
当然肯定还有其他的方式来实现这个效果,这里只是提供了一些思路,希望对大家有所帮助。
来源:juejin.cn/post/7420814883576414259
开源生态:谁在提供中文翻译?
前言
不知道大家有没有发现,几乎所有的有名有姓的开源仓库,都有英文文档,即使是国人开源的,也会一本正经的机翻一个英文文档,更有甚者将readme默认语言以英文展示

我们如此自觉的为全世界提供英文文档,那谁为我们提供中文文档?
中文文档翻译生态
虽然
像vue这种由国人发起的项目,自然而然的会有中英或更多语言的文档。
vuejs-translations/docs-zh-cn 是vue官方团队的开源翻译文档,由社区维护更新,至今已有700+人参与贡献

人多力量大,我们看到了质量非常高的 vue 中文文档。

但是
老外开源的项目却很难有自觉撰写中文文档的积极性,比如 mapboxGL 退出后,至今还没有一个对标官方文档的中文站,即使它在国内仍旧可用。
但是但是
开发者在网络上冲浪的时候,发现我们常用的开源库,基本也都有中文文档,那么这些文档是哪来的呢?当然是有一批兴趣使然,不求回报,为爱发电的开源字幕组了。
开源字幕组
他们或是有三三两两的小团体,或是社区性的向一个仓库贡献,或是独立完成翻译,这其中最难得的,当属个人独立翻译了。
独立翻译不光考验外语功底,还要有足够的耐心和毅力,耐得住寂寞,更要持之以恒。如果说把文档机翻一遍相当于在一座山外挑了两桶水,那么足够细致且同步原版文档更新就相当于每天挑两桶水,且不洒出一滴。
@远方OS 是 Vue 和 VueUse 的官方团队成员

vue-draggable-plus、v-scale-screen 的开源作者,会飞

此人对开源的热爱达到了狂热的地步


远方OS 目前维护了两个开源库的中文翻译:
一个是他所在的 vueuse 团队的中文文档,地址:vueuse.pages.dev/
一个是 unocss 的中文文档:unocss-cn.pages.dev/
其质量之高,各位可以自行观之
甚至还配备了演武场unocss-cn.pages.dev/play/,
交互式文档:unocss-cn.pages.dev/interactive…
还有专门给读者解惑的微信群,可谓大义。
他的翻译完全对标英文原版文档


并且约每周会同步更新一次,保证文档的及时性。
为爱发电
做开源是没有稳定回报的,做开源翻译亦是如此,也曾有人尝试过收费翻译,但是在网友的群攻之下,也是取消了收费,开源大佬们需要一边上班糊口,一边为爱发电,作为受益者,我们有义务表示尊重和支持。
结语
此文章没有收钱,没有收钱

作为掘金第一营销怪,我义不容辞。
来源:juejin.cn/post/7387291151734980617
拿去吧你!Flutter 仿抖音个人主页下拉拖拽效果
引言
最近产品经理看到抖音的个人主页下拉效果很不错,让我也实现一个,如果是native还好办,开源成熟的库一大堆,可我是Flutter呐🤣,业内成熟可用的库非常有限,最终跟产品经理batte失败后,没办法只能参考native代码硬肝出来。
效果图

整体构思
实现拖拽滑动功能,关键在于对手势事件的识别。在 Flutter 中,可使用Listener来监听触摸事件,如下所示:
Listener(
onPointerDown: (result) {
},
onPointerMove: (result) {
},
onPointerUp: (_) {
}
在手指滑动的过程中不断的刷新背景图高度是不是就可以实现图片的拉伸效果呢?我们这里图片加载库使用CachedNetworkImage,高度在156的基础上动态识别手指的滑动距离extraPicHeight
CachedNetworkImage(
width: double.infinity,
height: 156 + extraPicHeight,
imageUrl: backgroundUrl,
fit: fitType,
)
识别到手指滑动就不断的刷新拉伸高度extraPicHeight,flutter setState 内部已经做了优化,不用担心性能问题,实际效果体验很不错。
setState(() {
extraPicHeight;
});
经过实验思路是没有问题,那么监听哪些事件,extraPicHeight到底怎么计算,有什么边界值还考虑到呢?我们从手势的顺序开始梳理一下。
首先按压屏幕会识别到触碰屏幕起点,也就是initialDx initialDy,对于下拉拖拽我们关心更多的是纵向坐标result.position.dy
onPointerDown: (result) {
initialDy = result.position.dy;
initialDx = result.position.dx;
},
当手指在屏幕滑动会触发onPointerMovew,result.position.dy代表的就是手势滑动的位置
onPointerMove: (result) {
//手指的移动时
// updatePicHeight(result.position.dy); //自定义方法,图片的放大由它完成。
},
这边处理逻辑比较复杂,我们先抽成函数updatePicHeight
updatePicHeight(changed) {
//。。。已省略不重要细节代码
extraPicHeight += changed - prev_dy; //新的一个y值减去前一次的y值然后累加,作为加载到图片上的高度。
debugPrint('extraPicHeight updatePicHeight : $extraPicHeight');
//这里是为了限制我们的最大拉伸效果
if (extraPicHeight > 300) {
extraPicHeight = 300;
}
if (extraPicHeight > 0) {
setState(() {
prev_dy = changed;
});
}
}
这里简化了很多细节逻辑,核心目的就是要不断的累加我们的拖动距离来计算extraPicHeight高度,这里的changed是我们手指的y坐标,滑动的距离需要减去上次滑动的回调y,所以我们必须声明一个过去y坐标的变量也就是prev_dy,通过通过 changed - prev_dy就可以得出真正滑动的距离,然后我们不断累加 extraPicHeight += changed - prev_dy就是图片的拉伸距离。
手指下拉以后图片确实拉伸了,但是松开手后发现回不去了🤣因为我们还需要处理图回去的问题,既然可以通过setState把图片高度拉高,我们也可以通过setState把图片高度刷回去,核心要思考的是如何平滑的让图片自己缩回去呢?有经验的你一定想到动画了。
flutter这里的动画库是Tween,Tween可以通过addListener监听距离的回调,当距离变化不断刷新图片高度
anim = Tween(begin: extraPicHeight, end: 0.0).animate(animationController)
..addListener(() {
setState(() {
extraPicHeight = anim.value;
fitType = BoxFit.cover;
});
});
prev_dy = 0; //同样归零
动画的效果最终由控制器animationController来决定,这里给了一个300ms的时间还不错,可以根据自己业务扩展
animationController = AnimationController(
vsync: this, duration: const Duration(milliseconds: 300));
所有在手抬起的时候执行我们的动画runAnimate函数即可
onPointerUp: (_) {
//当手指抬起离开屏幕时
if (isVerticalMove) {
if (extraPicHeight < 0) {
extraPicHeight = 0;
prev_dy = 0;
return;
}
debugPrint('extraPicHeight onPointerUp : $extraPicHeight');
runAnimate(); //动画执行
animationController.forward(from: 0); //重置动画
}
},
整体的技术方案履完了,之后就是细节问题了
问题1:横行稍微有倾角的滑动也会导致页面拖拽,比如侧滑返回上一页面
这是由于手指滑动的角度没有限制, 这里我们计算一下滑动倾角,超过45度无效,角度计算通过x,y坐标计算tan函数即可
onPointerMove: (result) {
double deltaY = result.position.dy - initialDy;
double deltaX = result.position.dx - initialDx;
double angle =
(deltaY == 0) ? 90 : atan(deltaX.abs() / deltaY.abs()) * 180 / pi;
debugPrint('onPointerMove angle : $angle');
if (angle < 45) {
isVerticalMove = true; // It's a valid vertical movement
updatePicHeight(result
.position.dy); // Custom method to handle vertical movement
} else {
isVerticalMove =
false; // It's not a valid vertical movement, ignore it
}
}
问题2:图片高度变了,为啥没有拉伸啊!
图片拉伸取决于你图片库的加载配置,以flutter举例,我们的图片库是CachedNetworkImage
CachedNetworkImage(
width: double.infinity,
height: 156 + extraPicHeight,
imageUrl: backgroundUrl,
fit: fitType,
)
加载效果取决于fit,默认不变形我们使用cover,拉伸时使用fitHeight或者fill
updatePicHeight(changed) {
if (prev_dy == 0) {
//如果是手指第一次点下时,我们不希望图片大小就直接发生变化,所以进行一个判定。
prev_dy = changed;
}
if (extraPicHeight > 0) {
//当我们加载到图片上的高度大于某个值的时候,改变图片的填充方式,让它由以宽度填充变为以高度填充,从而实现了图片视角上的放大。
fitType = BoxFit.fitHeight;
} else {
fitType = BoxFit.cover;
}
extraPicHeight += changed - prev_dy; //新的一个y值减去前一次的y值然后累加,作为加载到图片上的高度。
debugPrint('extraPicHeight updatePicHeight : $extraPicHeight');
if (extraPicHeight > 300) {
extraPicHeight = 300;
}
if (extraPicHeight > 0) {
setState(() {
prev_dy = changed;
fitType = fitType;
});
}
}
最后看下组件如何布局
CustomScrollView(
physics: const NeverScrollableScrollPhysics(),
slivers: <Widget>[
SliverToBoxAdapter(
child: buildTopWidget(),
),
SliverToBoxAdapter(
child: Column(
children: contents,
),
)
]
),
)
整个列表使用CustomScrollView,因为在flutter上用他才能实现这种变化效果,未来还可以扩展顶部导航栏的变化需求。buildTopWidget就是我们头部组件,包括内部的背景图,但是整个组件和背景图的高度都是依赖extraPicHeight变化的,contents是我们的内容,当头部组件挤压,会正常跟随滑动到底部。
全局变量依赖以下参数就够了,核心要注意的就是边界值问题,什么时候把状态值重置问题。
//初始坐标
double initialDy = 0;
double initialDx = 0;
double extraPicHeight = 0; //初始化要加载到图片上的高度
late double prev_dy; //前一次滑动y
//是否是垂直滑动
bool isVerticalMove = false;
//动画器
late AnimationController animationController;
late Animation<double> anim;
技术语言不是我分享的核心,解决这个需求的技术思维路线是我们大家可以借鉴学习的。
如果你有任何疑问可以通过掘金联系我,如果文章对你有所启发,希望能得到你的点赞、关注和收藏,这是我持续写作的最大动力。Thanks~
来源:juejin.cn/post/7419248277382021135
抛弃 `!important` 吧,一个更友好的技巧让你的 CSS 优先级变大

原文:Double your specificity with this one weird trick
在一个理想的世界里,我们的 CSS 代码组织得井井有条,易于维护。然而,现实往往大相径庭。你的 CSS 代码是完美的,但其他人那些烦人的 CSS 可能会与你的风格冲突,或者应用了你不需要的样式。
此外,你可能也无法修改那些 CSS。也许它来自你正在使用的 UI 库,也许是一些第三方的小组件。
更糟糕的是,HTML 也不受你控制,添加一些额外的 class 或 id 属性来覆盖样式也并不可行。
不知不觉中,你被卷入了一场 CSS 优先级之战。你的选择器需要优先于他们的选择器。开发者很容易被『诱惑 😈』去使用 !important,但你知道这是不好的实践,我们能不能有一种更优雅的方式来实现我们覆盖的诉求?
本文将教给你一个技巧,可以用一种不是很 hacky 的方式应对这些情况 👩💻。
示例 🔮
假设你正在开发一个网站,该网站有一个新闻订阅表单。它包含一个复选框,但复选框的位置有点偏。你需要修正这个问题,但注册表单是一个嵌入到页面上的第三方组件,你无法直接修改它的 CSS。
通过浏览器检查复选框,确定只要改变它的 top 位置即可。当前的位置是通过选择器.newsletter .newsletter__checkbox .checkbox__icon 设置的,它的权重为 (0,3,0)。

一开始你可能会使用相同的选择器来修改 top 值:
/* 覆盖新闻通讯复选框的顶部位置 */
.newsletter .newsletter__checkbox .checkbox__icon {
top: 5px;
}
当 CSS 的顺序是固定的,并且你可以保证你的 CSS 规则一定在他们的后面的情况下,这足够了。因为『后来居上』:即如果有多个相同的 CSS 选择器选择了同一个DOM元素,那么最后出现的将“获胜”。
然而,大多数时候你无法保证代码顺序。此时你需要增加选择器的优先级。你可以在 DOM 中寻找一些额外的类名,一般从父元素中添加:
/* 更多的类名!权重现在是(0,4,0) */
.parent-thing .newsletter .newsletter__checkbox .checkbox__icon {
top: 5px;
}
或者你发现这个元素恰好是一个 ,可以将其加入选择器提高优先级:
/* 权重现在是 (0,3,1) */
.newsletter .newsletter__checkbox span.checkbox__icon {
top: 5px;
}
但所有这些方法都有副作用,都会使你的代码变得脆弱。如果 .parent-thing 突然不见了呢,比如你升级了某个外部依赖(比如 antd 😅)?或者如果 .checkbox__icon 从 span 改成了不同的元素怎么办?突然间,你的高优先级选择器什么也选不到了!
当浏览器计算 CSS 选择器优先级时,它们本质上是在计算你组合了多少 ID、类、元素或等效选择器。实际上可以多次重复同一个选择器,每次重复都会增加权重。CSS 选择器 Level 4 规范 写到:
CSS 选择器允许多次出现相同的简单选择器,而且可以增加权重。
因此,你可以通过重复(三次、四次……)相同的选择器提高权重:
/* 双重 .checkbox__icon!权重现在是 (0,4,0) */
.newsletter .newsletter__checkbox .checkbox__icon.checkbox__icon {
top: 5px;
}
注意
.checkbox__icon.checkbox__icon中没有空格!它是一个选择器,因为你针对的是具有那个类的单个元素
现在你可以简单地重复几次选择器来提升优先级!
译者注:该技巧其实在 MDN !important 章节 有示例(以下示例重复了3次
#myElement):
#myElement#myElement#myElement .myClass.myClass p:hover {
color: blue;
}
p {
color: red !important;
}
在 HTML 中重复 🚫
注意,这个技巧只在 CSS 中有效!在 HTML 中重复相同的类名对优先级没有任何影响。
<div class="badger badger badger">
Mushroom!
div>
总结 🎯
CSS 可以多次重复同一个选择器,每次重复都会增加权重 🏋️♂️
这种 CSS 技巧是否有点 hack?也许是。然而我认为它让我们:
- 避免诉诸于
!important - 『就近原则』提高可读性:重复多次的选择器,这样代码的意图对读者来说更清晰
- 这种模式让你很容易在代码中找到其他人的 CSS 覆盖,如果不再需要我们可以放心删除
只要你不过度使用它,我认为这是一个完全合法且 Robust 的技巧至少相比我们之前学会的所有技巧,下次处理棘手的覆盖三方样式情况时可以考虑用一用。
是否还有更好的解决办法?其实有,@layer 是官方推荐的最佳实践但是兼容性不好 Chrome>=99,而且使用场景有限。
来源:juejin.cn/post/7411686792342618153
英伟达 5090 被曝 32G 大显存、核心是 5080 的两倍!网友:怕不是 B200 双芯封装技术下放
32GB GDDR7 内存,CUDA 核心数 21760 个——
关于英伟达下一代旗舰消费级显卡 5090,知名消息人士 kopite7kimi 给出了最新爆料。
同时,5080 被曝内存容量为 16G,是 5090 的一半。

当然 5080 恰好是 5090 一半的还不只是内存,所以有人怀疑 5090 的 GPU 会不会像 B200 等服务器 GPU 一样,是两块芯片拼接出来的产物。

另外按 kopite7kimi 的爆料,5090 的(TGP)功耗将达到 600W,比 450W 的 4090 多出了三分之一。
老牌科技网站 Gizmodo 更是调侃说,5090 一启动,周围街区的灯都会变暗。

虽然功耗问题确实明显,但不妨碍还是有网友预计 5090 会大卖——
一方面,对于游戏玩家,他们虽然不一定需要如此高的性能,但会有强烈的购买欲望;
另一方面,它可以满足 AI/ML 从业者的算力需求,可以用来运行本地模型。

5090 和 5080 配置怎样?
对比着目前英伟达已有型号中最先进的 4090,我们来看下 5090 和 5080 被爆料的配置。

GPU 上,两款显卡都将采用 3nm 制程 Blackwell 架构的 GPU,5090 和 5080 分别将使用 GB202-300 和 GB203-400。
还是据 kopite7mimi 的爆料,GB202 共有 96 个 TPC,支持 512bit GDDR7 显存,GB203 的 TPC 数量则为 42 个,支持的 GDDR7 显存则为 256bit。

kopite7mimi 对网友的回复显示,这两款 GPU 芯片在今年 5 月底时已经流片。

内存方面,两款显卡都将采用最新一代的 GDDR7 内存,2022 年业内就一开始讨论,但最终的 JEDEC 规范发布时间是今年 3 月。
而上一代 GDDR6 的发布时间是 2018 年,4090 中采用的 GDDR6X 为 GDDR6 的升级版,G6X 的发布时间距今也已超过四年。
容量上看,kopite7mimi 的说法是 5090 和 5080 将分别使用 32 和 16GB 内存,也就是说 5080 的内存容量要小于 4090 的 24GB。
但在 chipcell 论坛上,另一名叫做 PolyMorph 的爆料者称,之后 5080 也会推出 24GB 版本。

这一消息还被 Tom’sHardware 引用,然而另一家科技媒体 VideoCardz 将其标记为了 “传闻”。

当然关于英伟达的爆料本就众说纷纭,加上其自身也可能对某些规格做出更改,所以在正式发布之前,消息无法被证实或证伪。
至于发布时间,kopite7mimi 曾表示,CES(2025 年 1 月)之前是没指望了。

另外,50 系显卡的插槽是今年刚出的 PCIe5.0,这意味着,如果手里只有 PCIe 4.0 的话,想体验 50 系显卡就得连主板一同更换。
不过可以肯定的是,5090 将能进一步满足 AI/ML 领域日益增长的算力需要,满足本地化的模型运行需求。
游戏方面,网友认为高端游戏显卡市场或将饱和——随着 4K 分辨率逐渐普及,游戏画质提升空间变小,游戏玩家对更高性能显卡的需求可能见顶。
但是随着游戏中 AI 技术的引入,未来游戏也可能对 GPU 产生更新的需求。

另外对于 5090 的功耗问题,有网友表示,如果这种(不管功耗猛堆料的)趋势得不到遏制,那么未来的显卡可能都是外置的了,这非常糟糕……

另外,高功耗也可能带来噪音和散热问题,影响使用体验。
有网友用表情包调侃,按照这个趋势,等到 8090 的时候,显卡恐怕是要像空调外机一样装在室外了。

爆料者曾预言 Blackwell 架构
5090 和 5080 的爆料者,在 X 上叫 kopite7kimi,他时业界非常著名的爆料人士,被 Gizmodo 等媒体认为是英伟达爆料者中消息最可信的。
甚至 5090 和 5080 据传采用的 Blackwell 架构,kopite7kimi 在 2021 年就给出了爆料。
当然表述上没有那么直白,只是发了一张美国数学家和统计学家 David Blackwell 的照片。

但还是有人看出了背后的含义,在评论区询问是不是英伟达架构的名称,kopite7kimi 则回复说:
也许就是 Ampere(当时的最新架构)的下下代。

而英伟达这边在 Ampere 之后,相继推出了 Ada Lovelace 和 Hopper,但 Hopper 主要用于数据中心而不是消费级显卡。
考虑到这一点的话,那就真的和 kopite7kimi 的预测一模一样了。
参考链接:
[1]gizmodo.com/the-leaked-…
[2]videocardz.com/newz/nvidia…
[3]http://www.tomshardware.com/pc-componen…
[4]news.ycombinator.com/item?id=416…
— 完 —
来源:juejin.cn/post/7419907933255352339
想弄一个节日头像,结果全是广告!带你用 Canvas 自己制作节日头像
一、为什么要自己制作节日头像?
很多人想为节日换上特别的头像,尤其是在国庆这样的节日气氛中,给自己的WX头像添加节日元素成为了不少人的选择。最初我也以为只需通过一些WX公众号简单操作,就能轻松给头像加上节日图案,比如国庆节、圣诞节头像等。然而,实际体验却很糟糕——广告无处不在!每一步操作几乎都被强制插入广告打断,不仅浪费时间,体验也非常差。
为了避开这些广告,享受更自由、更个性化的制作过程,我决定分享一个不用看广告的好方法:使用 Canvas 自己动手制作一个专属的节日头像!
很多人想为节日换上特别的头像,尤其是在国庆这样的节日气氛中,给自己的WX头像添加节日元素成为了不少人的选择。最初我也以为只需通过一些WX公众号简单操作,就能轻松给头像加上节日图案,比如国庆节、圣诞节头像等。然而,实际体验却很糟糕——广告无处不在!每一步操作几乎都被强制插入广告打断,不仅浪费时间,体验也非常差。
为了避开这些广告,享受更自由、更个性化的制作过程,我决定分享一个不用看广告的好方法:使用 Canvas 自己动手制作一个专属的节日头像!
二、源码 & 在线体验
三、 实现的功能与后续发展
在解决了广告干扰的问题后,我通过 Canvas 实现了多个实用功能,让大家可以轻松制作个性化的节日头像:
- 头像裁剪功能
- 头像与框架的拼接
- 头像框透明度调节
- 头像框颜色过滤(可自定义头像框)
- 后续发展:Fabric.js 自定义贴图功能
- 后续发展:更新更多节日的头像 & 贴图
在解决了广告干扰的问题后,我通过 Canvas 实现了多个实用功能,让大家可以轻松制作个性化的节日头像:
- 头像裁剪功能
- 头像与框架的拼接
- 头像框透明度调节
- 头像框颜色过滤(可自定义头像框)
- 后续发展:Fabric.js 自定义贴图功能
- 后续发展:更新更多节日的头像 & 贴图
四、当前素材及投稿征集
展示目前头像框素材,也欢迎大家投稿,我也会陆续更进头像框(项目中头像框已进行分类,这里为了方便展示,也可以自定义头像框)
展示目前头像框素材,也欢迎大家投稿,我也会陆续更进头像框(项目中头像框已进行分类,这里为了方便展示,也可以自定义头像框)
1. 头像框

2. 贴图
五、代码实现
整体逻辑非常简单 : 头像 + 头像框 = 所需头像
整体逻辑非常简单 : 头像 + 头像框 = 所需头像
1. 头像裁剪功能
页面部分
- 使用
:width 来根据设备类型设置宽度(device === DeviceEnum.MOBILE ? '95%' : '42%')。 - 底部有文件上传和旋转按钮。
<template>
<el-dialog
v-model="dialog.visible"
:width="device === DeviceEnum.MOBILE ? '95%' : '42%'"
class="festival-avatar-upload-dialog"
destroy-on-close
draggable
overflow
title="上传头像"
>
<div style="height: 45vh">
<vue-cropper
ref="cropper"
:autoCrop="true"
:centerBox="true"
:fixed="true"
:fixedNumber="[1,1]"
:img="imgTemp"
:outputType="'png'"
/>
div>
<template #footer>
<div class="festival-avatar-dialog-options">
<el-button @click="uploadAvatar">
<el-icon style="margin-right: 5px;">
<UploadFilled/>
el-icon>
上传头像
<input ref="avatarUploaderRef" accept="image/*" class="avatar-uploader" name="file" type="file"
@change="handleFileChange">
el-button>
<el-button @click="rotateLeft">
<el-icon><RefreshLeft/>el-icon>
el-button>
<el-button @click="rotateRight">
<el-icon><RefreshRight/>el-icon>
el-button>
<el-button type="primary" @click="submitForm">提 交el-button>
div>
template>
el-dialog>
template>
- 使用
:width来根据设备类型设置宽度(device === DeviceEnum.MOBILE ? '95%' : '42%')。 - 底部有文件上传和旋转按钮。
<template>
<el-dialog
v-model="dialog.visible"
:width="device === DeviceEnum.MOBILE ? '95%' : '42%'"
class="festival-avatar-upload-dialog"
destroy-on-close
draggable
overflow
title="上传头像"
>
<div style="height: 45vh">
<vue-cropper
ref="cropper"
:autoCrop="true"
:centerBox="true"
:fixed="true"
:fixedNumber="[1,1]"
:img="imgTemp"
:outputType="'png'"
/>
div>
<template #footer>
<div class="festival-avatar-dialog-options">
<el-button @click="uploadAvatar">
<el-icon style="margin-right: 5px;">
<UploadFilled/>
el-icon>
上传头像
<input ref="avatarUploaderRef" accept="image/*" class="avatar-uploader" name="file" type="file"
@change="handleFileChange">
el-button>
<el-button @click="rotateLeft">
<el-icon><RefreshLeft/>el-icon>
el-button>
<el-button @click="rotateRight">
<el-icon><RefreshRight/>el-icon>
el-button>
<el-button type="primary" @click="submitForm">提 交el-button>
div>
template>
el-dialog>
template>
代码逻辑部分(核心部分)
imgTemp 用来存储上传的临时图片数据。handleFileChange 处理文件上传事件,校验文件类型并使用 FileReader 读取图片数据,并本地存储。rotateLeft 和 rotateRight 分别用于左旋和右旋图片。
// 省略部分属性定义
const imgTemp = ref<string>("") // 临时图片数据
const cropper = ref(); // 裁剪实例
const avatarUploaderRef = ref<HTMLInputElement | null>(null); // 上传头像 input 引用
// 上传头像功能
function uploadAvatar() {
avatarUploaderRef.value?.click(); // 点击 input 触发上传
}
// 上传文件前校验 : 略
// 处理文件上传
function handleFileChange(event: Event) {
const input = event.target as HTMLInputElement;
if (input.files && input.files[0]) {
const file = input.files[0];
if (!beforeAvatarUpload(file)) return;
const reader = new FileReader();
reader.onload = (e: ProgressEvent
imgTemp.value = e.target?.result as string; // 读取的图片数据赋给 imgTemp
};
reader.readAsDataURL(file);
}
}
// 旋转功能
function rotateLeft() {
cropper.value?.rotateLeft();
}
const rotateRight = () => {
cropper.value?.rotateRight();
};
imgTemp用来存储上传的临时图片数据。handleFileChange处理文件上传事件,校验文件类型并使用FileReader读取图片数据,并本地存储。rotateLeft和rotateRight分别用于左旋和右旋图片。
// 省略部分属性定义
const imgTemp = ref<string>("") // 临时图片数据
const cropper = ref(); // 裁剪实例
const avatarUploaderRef = ref<HTMLInputElement | null>(null); // 上传头像 input 引用
// 上传头像功能
function uploadAvatar() {
avatarUploaderRef.value?.click(); // 点击 input 触发上传
}
// 上传文件前校验 : 略
// 处理文件上传
function handleFileChange(event: Event) {
const input = event.target as HTMLInputElement;
if (input.files && input.files[0]) {
const file = input.files[0];
if (!beforeAvatarUpload(file)) return;
const reader = new FileReader();
reader.onload = (e: ProgressEvent
imgTemp.value = e.target?.result as string; // 读取的图片数据赋给 imgTemp
};
reader.readAsDataURL(file);
}
}
// 旋转功能
function rotateLeft() {
cropper.value?.rotateLeft();
}
const rotateRight = () => {
cropper.value?.rotateRight();
};
实现效果图

2. 头像与头像框合并
页面部分 (核心部分)
compositeAvatar 为组合头像 , avatarData 为头像数据 ,compositeCanvas 头像 Canvas , avatarFrameCanvas 头像框 Canvas- 在没有
compositeAvatar 的时候展示 avatarData , 没有 avatarData 提示用户点击 PLUS 的图片
<div class="festival-avatar-preview">
<div class="festival-avatar-preview__plus" @click="openAvatarDialog">
<img v-if="compositeAvatar" :src="compositeAvatar" alt="合成头像"/>
<img v-else-if="avatarData" :src="avatarData" alt="头像"/>
<el-icon v-else color="#8c939d" size="28">
<Plus>Plus>
el-icon>
div>
div>
<canvas ref="compositeCanvas" style="display: none;">canvas>
<canvas ref="avatarFrameCanvas" style="display: none;">canvas>
compositeAvatar为组合头像 ,avatarData为头像数据 ,compositeCanvas头像 Canvas ,avatarFrameCanvas头像框 Canvas- 在没有
compositeAvatar的时候展示avatarData, 没有avatarData提示用户点击PLUS的图片
<div class="festival-avatar-preview">
<div class="festival-avatar-preview__plus" @click="openAvatarDialog">
<img v-if="compositeAvatar" :src="compositeAvatar" alt="合成头像"/>
<img v-else-if="avatarData" :src="avatarData" alt="头像"/>
<el-icon v-else color="#8c939d" size="28">
<Plus>Plus>
el-icon>
div>
div>
<canvas ref="compositeCanvas" style="display: none;">canvas>
<canvas ref="avatarFrameCanvas" style="display: none;">canvas>
逻辑部分 (核心部分)
- 通过
toDataURL 转换后合成为组合头像 , 通过 drawImage 合并 avatarFrameCanvas 和上文中avatarData 进行合并
const context = getCanvasContext(compositeCanvas); // 获取主 Canvas 上下文
const frameContext = getCanvasContext(avatarFrameCanvas); // 获取头像框 Canvas 上下文
// 省略非相关逻辑 , context 中写入 avatarData 内容
// 将处理后的头像框绘制到主 Canvas 上
context.drawImage(avatarFrameCanvas.value, 0, 0, avatarImg.width, avatarImg.height);
// 将合成后的图片转换为数据 URL
compositeAvatar.value = compositeCanvas.value!.toDataURL('image/png');
- 通过
toDataURL转换后合成为组合头像 , 通过drawImage合并avatarFrameCanvas和上文中avatarData进行合并
const context = getCanvasContext(compositeCanvas); // 获取主 Canvas 上下文
const frameContext = getCanvasContext(avatarFrameCanvas); // 获取头像框 Canvas 上下文
// 省略非相关逻辑 , context 中写入 avatarData 内容
// 将处理后的头像框绘制到主 Canvas 上
context.drawImage(avatarFrameCanvas.value, 0, 0, avatarImg.width, avatarImg.height);
// 将合成后的图片转换为数据 URL
compositeAvatar.value = compositeCanvas.value!.toDataURL('image/png');
实现效果
当我们点击头像框的时候,合并头像

当我们点击头像框的时候,合并头像
3. 头像框透明度调整
页面部分 与上文一样 , 通过调整 avatarFrameCanvas 的内容而调整头像框
页面部分 与上文一样 , 通过调整 avatarFrameCanvas 的内容而调整头像框
逻辑部分 (核心部分)
通过 context 中 globalAlpha 属性设置全局透明度。
setFrameOpacity(frameContext, frameOpacity.value); // 设置头像框透明度
/**
* 设置 Canvas 的透明度
* @param context Canvas 的 2D 上下文
* @param opacity 透明度值
*/
function setFrameOpacity(context: CanvasRenderingContext2D, opacity: number) {
context.globalAlpha = opacity; // 设置全局透明度
}
通过 context 中 globalAlpha 属性设置全局透明度。
setFrameOpacity(frameContext, frameOpacity.value); // 设置头像框透明度
/**
* 设置 Canvas 的透明度
* @param context Canvas 的 2D 上下文
* @param opacity 透明度值
*/
function setFrameOpacity(context: CanvasRenderingContext2D, opacity: number) {
context.globalAlpha = opacity; // 设置全局透明度
}
实现效果

4. 头像框颜色过滤
页面部分 与上文一样 , 通过调整 avatarFrameCanvas 的内容而调整头像框
服务对象 我们有自定义头像框功能,但是自己找的头像很容易有白底的问题,所以更新此功能。
页面部分 与上文一样 , 通过调整 avatarFrameCanvas 的内容而调整头像框
服务对象 我们有自定义头像框功能,但是自己找的头像很容易有白底的问题,所以更新此功能。
逻辑部分 (核心部分)
filterColorToTransparent 函数
- 作用:将与指定颜色相近的像素变为透明。
colorDistance 函数
- 作用:计算两种颜色(RGB 值)之间的距离。距离越小,颜色越相似。
- 计算方式:使用欧几里得距离公式计算两个 RGB 颜色向量之间的距离,如果距离小于一定的容差值(
tolerance),则认为两种颜色足够接近。 
rgbStringToArray 函数
- 作用:将 RGB 字符串(例如
'rgb(255,255,255)')转换为包含 r, g, b 值的对象。
/**
* 将指定颜色过滤为透明
* @param context Canvas 的 2D 上下文
* @param width Canvas 宽度
* @param height Canvas 高度
*/
function filterColorToTransparent(context: CanvasRenderingContext2D, width: number, height: number) {
const frameImageData = context.getImageData(0, 0, width, height);
const data = frameImageData.data;
const targetColor = rgbStringToArray(colorFilter.value.color); // 将目标颜色转换为 RGB 数组
// 遍历所有像素点
for (let i = 0; i < data.length; i += 4) {
const r = data[i];
const g = data[i + 1];
const b = data[i + 2];
const distance = colorDistance({r, g, b}, targetColor); // 计算当前颜色与目标颜色的差距
// 如果颜色差距在容差范围内,则将其透明度设为 0
if (distance <= colorFilter.value.tolerance) {
data[i + 3] = 0; // 设置 alpha 通道为 0(透明)
}
}
// 将处理后的图像数据放回 Canvas
context.putImageData(frameImageData, 0, 0);
}
/**
* 计算两种颜色之间的距离(欧几里得距离)
* @param color1 颜色 1,包含 r、g、b 属性
* @param color2 颜色 2,包含 r、g、b 属性
* @returns number 返回颜色之间的距离
*/
function colorDistance(color1: { r: number; g: number; b: number }, color2: { r: number; g: number; b: number }) {
return Math.sqrt(
(color1.r - color2.r) ** 2 +
(color1.g - color2.g) ** 2 +
(color1.b - color2.b) ** 2
);
}
/**
* 将 RGB 字符串转换为 RGB 数组
* @param rgbString RGB 字符串(例如 'rgb(255,255,255)')
* @returns 返回一个包含 r、g、b 值的对象
*/
function rgbStringToArray(rgbString: string) {
const result = rgbString.match(/\d+/g)?.map(Number) || [0, 0, 0]; // 匹配并转换 RGB 值
return {r: result[0], g: result[1], b: result[2]}; // 返回 r、g、b 对象
}
filterColorToTransparent 函数
- 作用:将与指定颜色相近的像素变为透明。
colorDistance 函数
- 作用:计算两种颜色(RGB 值)之间的距离。距离越小,颜色越相似。
- 计算方式:使用欧几里得距离公式计算两个 RGB 颜色向量之间的距离,如果距离小于一定的容差值(
tolerance),则认为两种颜色足够接近。
rgbStringToArray 函数
- 作用:将 RGB 字符串(例如
'rgb(255,255,255)')转换为包含r, g, b值的对象。
/**
* 将指定颜色过滤为透明
* @param context Canvas 的 2D 上下文
* @param width Canvas 宽度
* @param height Canvas 高度
*/
function filterColorToTransparent(context: CanvasRenderingContext2D, width: number, height: number) {
const frameImageData = context.getImageData(0, 0, width, height);
const data = frameImageData.data;
const targetColor = rgbStringToArray(colorFilter.value.color); // 将目标颜色转换为 RGB 数组
// 遍历所有像素点
for (let i = 0; i < data.length; i += 4) {
const r = data[i];
const g = data[i + 1];
const b = data[i + 2];
const distance = colorDistance({r, g, b}, targetColor); // 计算当前颜色与目标颜色的差距
// 如果颜色差距在容差范围内,则将其透明度设为 0
if (distance <= colorFilter.value.tolerance) {
data[i + 3] = 0; // 设置 alpha 通道为 0(透明)
}
}
// 将处理后的图像数据放回 Canvas
context.putImageData(frameImageData, 0, 0);
}
/**
* 计算两种颜色之间的距离(欧几里得距离)
* @param color1 颜色 1,包含 r、g、b 属性
* @param color2 颜色 2,包含 r、g、b 属性
* @returns number 返回颜色之间的距离
*/
function colorDistance(color1: { r: number; g: number; b: number }, color2: { r: number; g: number; b: number }) {
return Math.sqrt(
(color1.r - color2.r) ** 2 +
(color1.g - color2.g) ** 2 +
(color1.b - color2.b) ** 2
);
}
/**
* 将 RGB 字符串转换为 RGB 数组
* @param rgbString RGB 字符串(例如 'rgb(255,255,255)')
* @returns 返回一个包含 r、g、b 值的对象
*/
function rgbStringToArray(rgbString: string) {
const result = rgbString.match(/\d+/g)?.map(Number) || [0, 0, 0]; // 匹配并转换 RGB 值
return {r: result[0], g: result[1], b: result[2]}; // 返回 r、g、b 对象
}
实现效果


六、结束语
开发很容易,祝大家各个节日快乐 !!!
来源:juejin.cn/post/7419223935005605914
我的车被划了,看我实现简易监控拿捏他!node+DroidCam+ffmpeg
某天我骑着我的小电驴下班回到我那出租屋,习惯性的看了一眼我那停在门口的二手奥拓,突然发现有点不对劲,走近一看引擎盖上多了一大条划痕,顿时恶向胆边生,是谁!!!为此我决定用现有条件做一套简易的监控系统来应对日后的情况,于是有了这篇文章。
一 准备工作
由于是要做监控,硬件是必不可少的,所以首先想到的就是闲置的手机了,找了一台安卓8.1的古董出来,就决定是你了。因为之前在公司使用过
DroidCam这款软件用来进行webRTC的开发,所以这次就顺理成章的装了这款软件,连上家里的wifi后打开就相当于有了一台简易的视频服务器。那么硬件搞定了,接下来的就是软件了。梳理下来的话只有以下几点了
- 拉取DroidCam上的视频流
- 将拉取到的内容做存储
由于本人是个前端,因此这里就顺理成章的使用node来作为软件实现的第一方案了。
二 获取视频流,啊?怎么是这玩意儿

怎么获取它传过来的视频流呢?看了一下上打开的软件界面,发现给了两个地址,ip端口 和 ip端口/video,不出意料的这两个里面肯定是有能用的东西,挨个打开后发现不带video的地址是相当于一个控制台,带video的是视频的接口地址。那就好办了,我满怀激动的以为一切都很容易的时候,打开控制台一看,咦,这是啥玩意儿?它的所谓的视频是现在img标签里的,这在之前可是没见过哦,再看一眼接口地址,咦,这是一个长链接?点开详情看了一眼,好吧,又学到新东西了。它的Content-Type是multipart/x-mixed-replace;boundary='xxxx',这是啥呀,搜索了一下资料后如下。
MJPEG(Motion Joint Photographic Experts Gr0up)是一种视频压缩格式,其中每一帧图像都分别使用JPEG编码,不使用帧间编码,压缩率通常在20:1-50:1范围内。它的原理是把视频镜头拍成的视频分解成一张张分离的jpg数据发送到客户端。当客户端不断显示图片,即可形成相应的图像。
大致意思懂了,就是这就是一张张的图像呗。后面又看了一下服务端是如何生成这玩意儿的,这里就不细说了。
知道了是啥东西,那就要想怎么把它搞出来了
三 使用ffmpeg 获取每一帧
ffmpeg相信大家都不陌生,使用前需要先在本机上安装,安装方法的话这里就不赘述了。
安装后在系统环境变量高级设置中,增加path变量的值为ffmpeg在电脑上的路径。后续就可以使用了。


随便新建一个js文件
const fs = require('fs')
const path = require('path')
//截取的视频帧的存储路径和命名方式
const outputFilePattern = path.join(__dirname + '/newFrame', 'd.jpg');
//视频服务器地址
const mjpegUrl = 'http://192.168.2.101:4747/video?1920x1080';
//通过child_process的spawn调用外部文件,执行ffmpeg,并传入参数
//下方代码执行后在连接到服务后不手动停止的情况下期间会不断的在指定目录下生成获取到的图片
const ffmpeg = require('child_process').spawn('ffmpeg', [
'-i',
mjpegUrl,
'-vf',
'fps=24',//设置帧率
'-q:v',
'1', // 调整此值以更改输出质量(较低的值表示更好的质量)
outputFilePattern // %d 将被替换为帧编号
], { windowsHide: true });//调用时不显示cmd窗口
//错误监听
ffmpeg.on('error', function (err) {
throw err;
});
//关闭监听
ffmpeg.on('close', function (code) {
console.log('ffmpeg exited with code ' + code);
});
//数据
ffmpeg.stderr.on('data', function (data) {
console.log('stderr: ' + data.toString());
//执行合并图片操作
//....
});
上述代码运行后如果能正常连接上服务的话你会在指定目录下看到不断生成的图片。
四 将图片生成为视频
光有图片是不够的,我最终的预期是生成视频以供查看,所以添加以下的代码将图片合并为视频
//上面生成图片后存放的位置
let filePath = path.join(__dirname + '/newFrame', 'd.jpg');
let comd = [
'-framerate',
'24',
'-i',
filePath,
'-c:v',
'libx264',
'-pix_fmt',
'yuv420p',
`${__dirname}/outVideo/${new Date().getFullYear()}-${(new Date().getMonth() + 1).toString().padStart(2, '0')}-${new Date().getDate().toString().padStart(2, '0')}_${new Date().getHours().toString().padStart(2, '0')}${new Date().getMinutes().toString().padStart(2, '0')}${new Date().getSeconds().toString().padStart(2, '0')}.mp4`
]
const ffmpeg = require('child_process').spawn('ffmpeg', comd,{ windowsHide: true });
ffmpeg.on('close', function (code) {
console.log('ffmpeg exited with code ' + code);
console.log('任务执行结束,开始删除')
});
我这里定的是每2000张图片组合成视频,因此将第三步中的
ffmpeg.stderr.on('data', function (data) {
console.log('stderr: ' + data.toString());
});
改成

ffmpeg.stderr.on('data', function (data) {
console.log('stderr: ' + data.toString());
//打印结果 =>>frame= 1474 fps= 14 q=1.0 size=N/A time=00:01:01.41 bitrate=N/A speed=0.57x
let arr = data.toString().split('fps')
try {
//获取frame数量用来计数
frameCount = arr[0].split('=')[1].trim()
console.log(frameCount)
//为什么这里用大于而不是等于呢,因为获取frame可能不是总会计数到我们想要的值,踩过坑,注意
if (frameCount > 2000) {
console.log('数量满足')
//关闭本次获取流
ffmpeg.kill('SIGKILL');
//这里执行合并文件的操作
//...
}
} catch (e) { }
});
到这里如果你一切顺利的话就能在指定的文件夹里看到合并完成后的MP4视频了。

五 合并完成后删除上次获取的图片
将第四步的
ffmpeg.on('close', function (code) {
console.log('ffmpeg exited with code ' + code);
console.log('任务执行结束,开始删除')
});
改为
ffmpeg.on('close', async function (code) {
console.log('ffmpeg exited with code ' + code);
console.log('任务执行结束,开始删除')
try {
await fsE.emptyDir('your folderPath');
console.log(`已清空文件夹`);
//重新执行第二步
//...
} catch (err) {
console.error(`无法清空文件夹: ${err}`);
}
});
这里的fsE是 const fsE = require('fs-extra');,需要安装并且导入
到这里为止,整个基本的流程就完成了
六 总结
整个程序到目前为止已经能基本满足我的需求,但是还存在不足,比如频繁的往硬盘上读写文件、容错处理等等,后续我的想法是把图片保存到内存中,在满足条件后再写入硬盘,减少文件的I/O操作,加入对人体的识别,接入之前写过的邮件通知,有人靠近自动记录时间点并发送到邮箱。当然了,我这个肯定比不了市面上的那些成熟产品,就是自己写着好玩的,请各位大佬轻喷!有错误和意见欢迎指正!

来源:juejin.cn/post/7419887017164767268
有了小孩后,对我的影响还是挺大的
张雪峰曾经说: 闺女是上帝对父母的恩赐,儿子是上帝对父母的惩罚。
2023年8月9日,上帝惩罚了我。
事情的经过是这样的
我和我媳妇其实很早就领证结婚了,但是一直没要宝宝,因为那个时候感觉两个人过日子真是太滋润了,周六日可以睡到自然醒,也可以夜里12点去泡澡,一脚油门想去哪去哪。

2022年房子装修好了,除完甲醛后就搬进来住了。“正好”那个时间又赶上了疫情,很多小区就封了,我们小区也不不例外。我记得那个时候买了好多肉和吃的,所以吃喝不用担心,再加上我和媳妇都是干的程序员,可以居家办公,家庭收入也没受到影响,总之那段时间过得还是挺爽😍。
也就是在这段很爽的时间里,我们有了宝宝😂。
怀孕的这段时间
除了正常的产检外,还拍了很多B超,不小心摔着了拍个B超,肚子疼了去拍个B超,胎动异常了去拍个B超🤓...
总之也是一块不小的支出

小插曲
到了孕晚期,我媳妇的胎位不正,不能顺产,但是我媳妇又想顺产,然后医生说可以做外道转手术,把胎位移正。
然后发了5000大洋,在医院住了三天,终于把胎位搞正了。

谁承想回到家不到一个星期,自己又掉转过来了😹
最后还是选择了剖腹产
看来干什么事情都要顺其自然,强求不来
宝宝顺利出生了
时间过得最慢的就是媳妇推进手术室做剖腹产,我们在外面等着的时候,真是度秒如年,生怕出了什么意外。

好在最后一切顺利

当爸爸的第一个晚上,真是一夜没睡,因为没有任何经验,什么东西都得现学,比如如何喂奶,如何包裹小孩...
所以干什么还是提前做好功课为好
现在已经一岁多啦
现在宝宝已经一岁一个月了,时间过得既快又慢,经历了很多很多。
下面就谈谈有了孩子后的感受吧!
可支配的时间越来越少
有了孩子后最大的变化就是,自己可支配的时间越来越少了。没有孩子之前,我和媳妇还可以有时间看电影,泡温泉啥的,有了孩子后二人世界彻底崩塌😭
还有就是
说来也奇怪,有了孩子后,基本上对学习没啥动力了,除非是工作中要用到的一些技术,可能有时间会自己研究下(很少),大部分时间都不会再关注技术,有点时间就想着刷刷抖音,打打游戏😑

我之所以打算写点东西,很大一部分原因就是为了减少我刷抖音的时间😶
越来越像爸爸
有小孩的前三个月,我媳妇有产假,加上我妈也来共同照护孩子,所以在带小孩上我基本上没怎么操心。有些时候为了睡好觉就直接一个人跑到次卧去,做个甩手装柜。
后来我媳妇也上班了,加上她离公司比较远,基本上都是我先下班,所以我也要承担一部分照护小孩的责任。
怎么说呢,这种感觉很奇妙,就是你陪伴孩子的时间越长,你就会越喜欢哄小孩,然后小孩也会越来越喜欢你

每当孩子有什么头疼发烧啥的,当父母的就像心里压住个千斤顶,这个做父母的应该都懂吧。
现在就希望孩子可以快点长大,我有更多的时间和精力干我自己感兴趣的事。
来源:juejin.cn/post/7420001862487654409
入职第一天,看了公司代码,牛马沉默了
入职第一天就干活的,就问还有谁,搬来一台N手电脑,第一分钟开机,第二分钟派活,第三分钟干活,巴适。。。。。。

打开代码发现问题不断
- 读取配置文件居然读取两个配置文件,一个读一点,不清楚为什么不能一个配置文件进行配置


 一边获取WEB-INF下的配置文件,一边用外部配置文件进行覆盖,有人可能会问既然覆盖,那可以全在外部配置啊,问的好,如果全用外部配置,咱们代码获取属性有的加上了项目前缀(上面的两个put),有的没加,这样配置文件就显得很乱不可取,所以形成了分开配置的局面,如果接受混乱,就写在外部配置;不能全写在内部配置,因为
一边获取WEB-INF下的配置文件,一边用外部配置文件进行覆盖,有人可能会问既然覆盖,那可以全在外部配置啊,问的好,如果全用外部配置,咱们代码获取属性有的加上了项目前缀(上面的两个put),有的没加,这样配置文件就显得很乱不可取,所以形成了分开配置的局面,如果接受混乱,就写在外部配置;不能全写在内部配置,因为
prop_c.setProperty(key, value);
value获取外部配置为空的时候会抛出异常;properties底层集合用的是hashTable
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
}
- 很多参数写死在代码里,如果有改动,工作量会变得异常庞大,举例权限方面伪代码
role.haveRole("ADMIN_USE")
- 日志打印居然sout和log混合双打


先不说双打的事,对于上图这个,应该输出包括堆栈信息,不然定位问题很麻烦,有人可能会说e.getMessage()最好,可是生产问题看多了发现还是打堆栈好;还有如果不是定向返回信息,仅仅是记录日志,完全没必要catch多个异常,一个Exception足够了,不知道原作者这么写的意思是啥;还是就是打印日志要用logger,用sout打印在控制台,那我日志文件干啥;
4.提交的代码没有技术经理把关,下发生产包是个人就可以发导致生产环境代码和本地代码或者数据库数据出现不一致的现象,数据库数据的同步是生产最容易忘记执行的一个事情;比如我的这家公司上传文件模板变化了,但是没同步,导致出问题时开发环境复现问题真是麻烦;
5.随意更改生产数据库,出不出问题全靠开发的职业素养;
6.Maven依赖的问题,Maven引pom,而pom里面却是另一个pom文件,没有生成的jar供引入,是的,我们可以在dependency里加上
<type>pom
来解决这个问题,但是公司内的,而且实际也是引入这个pom里面的jar的,我实在不知道这么做的用意是什么,有谁知道;求教 
以上这些都是我最近一家公司出现的问题,除了默默接受还能怎么办;
那有什么优点呢:
- 不用太怎么写文档
- 束缚很小
- 学到了js的全局调用怎么写的(下一篇我来写,顺便巩固一下)
解决之道
怎么解决这些问题呢,首先对于现有的新项目或升级的项目来说,spring的application.xml/yml 完全可以写我们的配置,开发环境没必要整外部文件,如果是生产环境我们可以在脚本或启动命令添加 nohup java -Dfile.encoding=UTF-8 -Dspring.config.location=server/src/main/config/application.properties -jar xxx.jar & 来告诉jar包引哪里的配置文件;也可以加上动态配置,都很棒的,
其次就是规范代码,养成良好的规范,跟着节奏,不要另辟蹊径;老老实实的,如果原项目上迭代,不要动源代码,追加即可,没有时间去重构的;
我也曾是个快乐的童鞋,也有过崇高的理想,直到我面前堆了一座座山,脚下多了一道道坑,我。。。。。。!
来源:juejin.cn/post/7371986999164928010
强大的一笔的Hermes引擎,是如何让你的 App 脱颖而出的!
Hermes 是一款由 Facebook 开源的轻量级 JavaScript 引擎,专门针对 React Native 应用进行了优化。与传统的 JavaScript 引擎(例如 JavaScriptCore 和 V8)相比,Hermes 具有以下优势:
启动时间更快: Hermes 使用预编译字节码(AOT),而不是即时编译(JIT),这可以显著缩短应用的启动时间。
更小的内存占用: Hermes 的体积小巧,占用内存更少,这对于移动设备尤为重要。
更小的应用包大小: 由于 Hermes 的体积小巧,因此可以减小 React Native 应用的包大小。

高效的性能的原因
先看下面这幅图:

Hermes Engine 的设计初衷是为了优化 React Native 应用的性能。它通过对 JavaScript 代码的提前编译,将其转化为字节码,从而减少了运行时的解析时间。这种预编译机制使得应用启动速度显著提升,用户体验更加流畅。

在 CPU 利用率方面,Hermes 也有显著的优势。
通过优化 JavaScript 执行和垃圾回收过程,Hermes 提供了更快的启动时间和更低的内存占用。研究表明,使用 Hermes 的应用在性能上有显著提升,用户体验更加流畅
内存占用和包大小优化

Hermes 采用了优化的内存管理机制,如内存池和高效的垃圾回收算法,能够减少应用在运行时的内存占用。这对于资源受限的移动设备尤为关键。使用 Hermes 编译的应用包体积通常更小。这对于需要快速下载安装的应用很有优势,也有助于提高应用在应用商店的排名。上图就是 Stock RN 应用基于 Hermes 引擎的内存优化后的实际效果。
良好的兼容性
Hermes 提供了强大的调试工具,帮助开发者快速定位和解决问题。其集成的调试功能使得开发者能够实时监控应用的性能,及时发现并修复潜在的性能瓶颈。
Hermes 得到了 Facebook 和开源社区的广泛支持,拥有丰富的文档和活跃的开发者社区。开发者可以轻松获取资源和支持,促进了 Hermes 的快速发展和普及。
一些小众第三方库不支持 Hermes 引擎
虽然,大多数比较有名的第三方库都是支持 Hermes引擎的,但是有一个小小的问题,有些比较小众的第三方库,是不支持 hermes 引擎的,这个时候,你可需要想办法自己改写下这个第三方库,或者给作者提建议。
如,腾讯云 cos ,React Native 的库,就是不支持 Hermes 引擎的。相关issue 在这里:

不过,对于这个问题,你完全可以使用 restful api 呀,所以,解决问题的方式太多了,不要因为一个小众的三方库而放弃恐怖的性能提升,多少有点不值当。
实际应用案例
许多知名应用已经开始采用 Hermes Engine,以提升其性能。例如,Facebook 和 Instagram 的部分功能已成功迁移至 Hermes,用户反馈显示应用的启动时间和流畅度均有显著改善。这些成功案例进一步验证了 Hermes 的强大实力。
如何用上Hermes 引擎
如果你在使用 Expo 做移动端跨端研发,那么恭喜你,默认就是使用的 Hermes 引擎,无需任何配置,如果你想显式配置,也无妨,甚至你可以指定 ios 使用jsc 引擎。
{
"expo": {
"jsEngine": "hermes",
"ios": {
"jsEngine": "jsc"
}
}
}
如果你使用的是 React Native 0.70 或更高版本,则 Hermes 引擎将默认启用。如果你使用的是较早版本的 React Native,则可以按照 React Native 文档 中的说明启用 Hermes 引擎。配置简单的就啰嗦。小伙伴们,React Native 要吊打 Flutter了 吗?拍拍砖?
来源:juejin.cn/post/7394095950383743015
Vite 为何短短几年内变成这样?
给前端以福利,给编程以复利。大家好,我是大家的林语冰。
00. 观前须知
在 Web 开发领域,Vite 如今已如雷贯耳。
自 2020 年 4 月发布以来,Vite 的人气蒸蒸日上。目前 Vite 在 GitHub 上的收藏数量已超过 64k,每周下载量超过 1200 万次,现在为 Nuxt、Remix、Astro 等大多数开源框架提供支持。
尽管众口嚣嚣,我们意识到许多开发者可能仍然不熟悉 Vite 是什么鬼物,也不熟悉 Vite 在推动现代 Web 框架和工具的开发中扮演的重要角色。
在本文中,我们将科普 Vite 的知识储备,以及 Vite 如何在短短几年后发展成为现代 Web 的重量级角色。

免责声明
本文属于是语冰的直男翻译了属于是,略有删改,仅供粉丝参考。英文原味版请传送 What is Vite (and why is it so popular)?。
01. Vite 是什么鬼物?
Vite 的发音为 /vit/,在法语中是“快速”或“迅捷”的意思,不得不说 Vite 名副其实。
简而言之,Vite 是一种现代 JS 构建工具,为常见 Web 模式提供开箱即用的支持和构建优化,兼具 rollup 的自由度和成熟度。
Vite 还与 esbuild 和原生 ES 模块强强联手,实现快速无打包开发服务器。
Vite 是由“Vue 之父”尤雨溪(Evan You)构思出来的,旨在通过减少开发者在启动开发服务器和处理文件编辑后重载时遭遇的性能瓶颈,简化打包过程。
02. Vite 的核心特性

运行 Vite 时,你会注意到的第一个区别在于,开发服务器会即时启动。
这是因为,Vite 采用按需方法将你的应用程序提供给浏览器。Vite 不会首先打包整个源码,而是响应浏览器请求,将你编写的模块即时转换为浏览器可以理解的原生 ESM 模块。
Vite 为 TS、PostCSS、CSS 预处理器等提供开箱即用的支持,且可以通过不断增长的插件生态系统进行扩展,支持所有你喜欢的框架和工具。
每当你在开发期间更改项目中的任意文件时,Vite 都会使用应用程序的模块图,只热重载受影响的模块(HMR)。这允许开发者预览他们的更改,及其对应用程序的影响。
Vite 的 HMR 速度惊人,可以让编辑器自动保存,并获得类似于在浏览器开发工具中修改 CSS 时的反馈循环。
Vite 还执行 依赖预构建(dependency pre-bundling)。在开发过程中,Vite 使用 esbuild 来打包你的依赖并缓存,加快未来服务器的启动速度。
此优化步骤还有助于加快 lodash 等导出许多迷你模块的依赖的加载时间,因为浏览器只加载每个依赖的代码块(chunk)。这还允许 Vite 在依赖中支持 CJS 和 UMD 代码,因为它们被打包到原生 ESM 模块中。
当你准备好部署时,Vite 将使用优化的 rollup 设置来构建你的应用程序。Vite 会执行 CSS 代码分割,添加预加载指令,并优化异步块的加载,无需任何配置。
Vite 提供了一个通用的 rollup 兼容插件 API,适用于开发和生产,使你可以更轻松地扩展和自定义构建过程。
03. Vite 的优势
使用 Vite 有若干主要优势,包括但不限于:
03-1. 开源且独立
Vite 由开源开发者社区“用爱发电”,由来自不同背景的开发者团队领导,Vite 核心仓库最近贡献者数量已突破 900 人。
Vite 得到积极的开发和维护,不断实现新功能并解决错误。
03-2. 本地敏捷开发
开发体验是 Vite 的核心,每次点击保存时,你都能感受到延迟。我们常常认为重载速度是理所当然的。
但随着您的应用程序增长,且重载速度逐渐停止,你将感恩 Vite 几乎能够保持瞬间重载,而无论应用程序大小如何。
03-3. 广泛的生态系统支持
Vite 的方案人气爆棚,大多数框架和工具都默认使用 Vite 或拥有一流的支持。通过选择使用 Vite 作为构建工具,这些项目维护者可以在它们之间共享一个统一基建,且随着时间的推移共同改良 Vite。
因此,它们可以花更多的时间开发用户需要的功能,而减少重新造轮子的时间。
03-4. 易于扩展
Vite 对 rollup 插件 API 的押注得到了回报。插件允许下游项目共享 Vite 核心提供的功能。
我们有很多高质量的插件可供使用,例如 vite-plugin-pwa 和 vite-imagetools。
03-5. 框架构建难题中的重要角色
Vite 是现代元框架构建的重要组成部分之一,这是一个更大的工具生态系统的一部分。
Volar 提供了在代码编辑器中为 Vue、MDX 和 Astro 等自定义编程语言构建可靠且高性能的编辑体验所需的工具。Volar 允许框架向用户提供悬停信息、诊断和自动补全等功能,并共享 Volar 作为为它们提供支持的通用基建。
另一个很好的例子是 Nitro,它是一个服务器工具包,用于创建功能齐全的 Web 服务器,开箱即用地支持每个主要部署平台。Nitro 是一个与框架无关的库 UnJS 的奇妙集合的一部分。
04. Vite 的未来

在最近的 ViteConf 大会的演讲中,尤雨溪表示,虽然 Vite 取得了巨大进展,但仍面临一些已知的问题和挑战。
Vite 目前使用 rollup 进行生产构建,这比 esbuild 或 Bun 等原生打包器慢得多。
Vite 还尽可能减少开发和生产环境之间的不一致性,但考虑到 rollup 和 esbuild 之间的差异,某些不一致性无法避免。
尤雨溪现在领导一个新团队开发 rolldown,这是一个基于 Rust 的 rollup 移植,在 “JS 氧化编译器 OXC”之上构建了最大的兼容性。
这个主意是用 rolldown 替代 Vite 中的 rollup 和 esbuild。Vite 将拥有一个单独基建,兼具 rollup 的自由度和 esbuild 的速度,消除不一致性,使代码库更易于维护,并加快构建时间。
rolldown 目前处于早期阶段,但已经显示出有希望的结果。rolldown 现已开源,rolldown 团队正在寻找贡献者来辅助实现这一愿景。
与此同时,Vite 团队在每个版本中不断改良 Vite。这项工作从上游的为 Vitest 和 Nuxt Dev SSR 提供动力的引擎 vite-node 开始,现已发展成为框架作者对 Vite API 的完整修订版。
新版 Environment API 预计在 Vite 6 中发布,这将是自 Vite 2 发布以来 Vite 最大的变化之一。这将允许在任意数量的环境中通过 Vite 插件管道运行代码,解锁对 worker、RSC 等的一流支持。
Vite 正在开辟一条前进的道路,并迅速成为 JS 生态系统事实上的构建工具。
参考文献
- Vite:vitejs.dev
- Blog:blog.stackblitz.com/posts/what-…
- Rolldown:rolldown.rs
粉丝互动
本期话题是:如何评价人气爆棚的 Vite,你最喜欢或期待 Vite 的哪个功能?你可以在本文下方自由言论,文明科普。
欢迎持续关注“前端俱乐部”,给前端以福利,给编程以复利。
坚持阅读的小伙伴可以给自己点赞!谢谢大家的点赞,掰掰~

来源:juejin.cn/post/7368836713965486119
因为编辑器没做草稿,老板崩溃了。。。
现场
大家好,我是多喝热水。
事情是这样的,那天晚上老板在群里吐槽说他在手机上写了将近 1000 字的评论不小心点了一下黑屏,然后内容就突然没了,如下:

原来是我们编辑器没有做草稿能力,导致关闭后原本编辑的内容都消失了,确实这个体验不太好,想想怎么把这里优化一下。
调研
像我们平时用得比较多的社交平台,比如某音、某书等,先从它们的评论区入手,看看主流的平台是怎么做的。
1)某音
某音的效果是,在某条视频下评论后划走,再划回来编辑的内容就不在了,看样子是没有做草稿能力,如图:

2)某书
某书的效果是,在某个笔记下面评论然后划走,再回来的时候内容是还在的。而且每条评论都有自己的编辑态,互不干扰,如图:

好看真好看,呸好用真好用,既然体验上某书更好,我决定仿照某书的方案来实现。

既然要做成某书的效果,那我们就需要解决两个问题:
1)他们评论区草稿内容是怎么存的?
2)存在哪里了?
内容怎么存?
先说说我的看法,如果要让每条评论都拥有独立的编辑态,那么肯定是需要一个唯一标识的,那我能想到的唯一标识就是ID。
内容存哪里?
存后端还是存前端?存前端的话又存哪里?这里我简单总结了一下:
存后端
优势:数据真正的持久化、安全性高
缺陷:需要网络连接,依赖后端,开发成本高
存前端
优势:简单易用、性能好、脱机可用
缺陷:无法真正持久化、存储空间有限、不安全
方案选择
回归到需求本身,我们不需要实时性多么高,所以存前端就已经可以满足我们的需求了。
但在前端存储还有一个存储空间问题,需要考虑一下存储内容的有效时间,过期了就得删除,不然会存在很多冗余数据,所以我们又面临新的问题,前端用什么来存?
浏览器常用的存储方案:cookie、localStorage、sessionStorage
1)cookie 是可以设置过期时间的,但如果存 cookie,那它的容量只有5kb,有点太小了,并且每次发请求 cookie 都会被携带上,无疑是增加了额外的带宽开销
2)sessionStorage 存储空间最大支持5MB,但窗口被关闭后数据就过期了,有效期仅仅是窗口会话期间,万一用户不小心关闭了窗口,数据也消失了,所以这个方案也不太妥当
3)相比之下 localStorage 的容量也有 5MB,足够大,但是它本身不支持设置过期时间(默认永久有效),需要人为去控制,好在这个成本并不高,综合之下我们还是选择存 localStorage 了
开发
选好方案后,就可以开始动手开发了!先把支持控制过期时间 的 localStorage 逻辑写一下。
写之前我们需要考虑一下代码的复用性,因为在我们网站中,有很多地方都用到了编辑器,比如评论区、交流内容发布等,如果每一处都写一遍的话,那这个代码就太冗余了,所以将它封装为一个 hook 是一个不错的选择,代码如下:
import { CACHE_TYPE, EXPIRES_TIME } from './constants';
/**
* 缓存数据
* @param key
* @returns
*/
export default function useCache(key: string = CACHE_TYPE.ESSAY_CONTENT) {
/**
* 删除缓存数据
*/
const removeCache = () => {
localStorage.removeItem(key);
};
/**
* 设置缓存数据
* @param data 数据内容
* @param expires 过期时间(毫秒)
*/
const setCache = (data: any, expires: number = EXPIRES_TIME) => {
const cacheData = {
value: data,
expires: expires ? Date.now() + expires : null, // 计算过期时间戳
};
localStorage.setItem(key, JSON.stringify(cacheData));
};
/**
* 获取缓存数据
* @returns 缓存数据或 null
*/
const getCache = () => {
const cachedString = localStorage.getItem(key);
if (!cachedString) {
return null;
}
const cachedObject = JSON.parse(cachedString);
// 检查是否设置了过期时间并且是否已经过期
if (cachedObject.expires && Date.now() > cachedObject.expires) {
removeCache(); // 删除已过期的数据
return null;
}
return cachedObject.value;
};
return { removeCache, setCache, getCache };
}
简单解释一下上面的代码:
1)useCache 函数主要接收一个 KEY,删除、获取、设置草稿数据都会用到这个 KEY,且我们保证它是唯一的
2)在设置需要缓存内容时(setCache),会给出一个 expires 的参数用于控制该数据的有效时间
3)获取数据的时候会校验一下有效时间,如果已经过期了则返回 null
在编辑器中应用
最后我们需要在用到编辑器的地方使用这个 hook。
可能有些小伙伴会觉得我们网站中用到编辑器的地方很多,这一步才是一个大工程,其实不然,因为我们所有用到编辑器的地方都是用的同一个组件,我们需要改动的地方就是那个公共的编辑器组件!
这时候封装带来的便捷性就体现的淋漓尽致,省去了不少时间用来摸鱼!!!
改动代码如下(伪代码):
type GeneralContentEditorProps = {
targetId?: string; // 缓存ID
// 省略不相关代码...
};
/**
* 通用的内容编辑器
* @param props
* @returns
*/
export default function GeneralContentEditor({
targetId,
// 省略不相关代码...
}: GeneralContentEditorProps) {
// 省略不相关代码...
const [content, setContent] = useState('')
const { getCache, setCache, removeCache } = useCache(targetId);
useEffect(() => {
setContent(getCache() ?? '')
}, [])
}
简单解释一下上面的代码:
1)给编辑器新增了一个属性 targetId,这个 targetId 用来作为缓存的唯一标识,由使用方提供给我们
2)初始化的时候去调 getCache 函数读取缓存的数据
3)有内容变更的时候调 setCache 函数去更新缓存的数据
到这里流程已经跑通了,但还缺少重要的一步,需要定时清空一下缓存的数据,因为现在的逻辑是如果我们不主动去获取这个数据,它还是占据着存储空间。
清空冗余数据
其实我们也不需要专门去写定时器来清空,只需要在编辑器初始化的时候去检测一遍就可以,所以代码还需加点料,如下图:

到这一步编辑器草稿能力就完善的差不多了,已经能够正常使用了,我们看看效果,如下:

nice,没有什么问题,好了,我要去摸鱼了 😋

来源:juejin.cn/post/7419598991119532043
老板想集成地图又不想花钱,于是让我...
前言
在数字化时代,地图服务已成为各类应用的标配,无论是导航、位置分享还是商业分析,地图都扮演着不可或缺的角色。然而,高质量的地图服务往往伴随着不菲的授权费用。公司原先使用的是国内某知名地图服务,但随着业务的扩展和成本的考量,老板决定寻找一种成本更低的解决方案。于是,我们的目光转向了免费的地图服务——天地图。
天地图简介
天地图(lbs.tianditu.gov.cn/server/guid…
是中国领先的在线地图服务之一,提供全面的地理信息服务。它的API支持地理编码、逆地理编码、周边搜索等多种功能,且完全免费。这正是我们需要的。
具体实现代码
为了将天地图集成到我们的系统中,我们需要进行一系列的开发工作。以下是实现过程中的关键代码段。
1. 逆地理编码
逆地理编码是将经纬度转换为可读的地址。在天地图中,这一功能可以通过以下代码实现:
public static MapLocation reverseGeocode(String longitude, String latitude) {
Request request = new Request();
LocateInfo locateInfo = GCJ02_WGS84Utils.gcj02_To_Wgs84(Double.valueOf(latitude), Double.valueOf(longitude));
longitude = String.valueOf(locateInfo.getLongitude());
latitude = String.valueOf(locateInfo.getLatitude());
String postStr = String.format(REVERSE_GEOCODE_POST_STR, longitude, latitude);
String encodedPostStr = null;
try {
encodedPostStr = URLEncoder.encode(postStr, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
String url = REVERSE_GEOCODE_URL + "?tk=" + TK + "&type=" + GEOCODE + "&postStr=" + encodedPostStr;
request.setUrl(url);
Response<String> response = HttpClientHelper.getWithoutUserAgent(request, null);
if (response.getSuccess()) {
String body = response.getBody();
JSONObject jsonObject = JSON.parseObject(body);
String status = jsonObject.getString("status");
if (!"0".equals(status)) {
return null;
}
JSONObject resultObject = jsonObject.getJSONObject("result");
MapLocation mapLocation = new MapLocation();
String formattedAddress = resultObject.getString("formatted_address");
mapLocation.setAddress(formattedAddress);
String locationStr = resultObject.getString("location");
JSONObject location = JSON.parseObject(locationStr);
String lon = location.getString("lon");
String lat = location.getString("lat");
locateInfo = GCJ02_WGS84Utils.wgs84_To_Gcj02(Double.valueOf(lat), Double.valueOf(lon));
lon = String.valueOf(locateInfo.getLongitude());
lat = String.valueOf(locateInfo.getLatitude());
mapLocation.setLongitude(lon);
mapLocation.setLatitude(lat);
JSONObject addressComponent = resultObject.getJSONObject("addressComponent");
String address = addressComponent.getString("address");
mapLocation.setName(address);
mapLocation.setCity(addressComponent.getString("city"));
return mapLocation;
}
return null;
}
2. 周边搜索
周边搜索允许我们根据一个地点的经纬度搜索附近的其他地点。实现代码如下:
public static List<MapLocation> nearbySearch(String query, String longitude, String latitude, String radius) {
LocateInfo locateInfo = GCJ02_WGS84Utils.gcj02_To_Wgs84(Double.valueOf(latitude), Double.valueOf(longitude));
longitude = String.valueOf(locateInfo.getLongitude());
latitude = String.valueOf(locateInfo.getLatitude());
Request request = new Request();
String longLat = longitude + "," + latitude;
String postStr = String.format(NEARBY_SEARCH_POST_STR, query, Integer.valueOf(radius), longLat);
String encodedPostStr = null;
try {
encodedPostStr = URLEncoder.encode(postStr, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
String url = SEARCH_URL + "?tk=" + TK + "&type=" + QUERY + "&postStr=" + encodedPostStr;
request.setUrl(url);
Response<String> response = HttpClientHelper.getWithoutUserAgent(request, null);
List<MapLocation> list = new ArrayList<>();
if (response.getSuccess()) {
String body = response.getBody();
JSONObject jsonObject = JSON.parseObject(body);
JSONObject statusObject = jsonObject.getJSONObject("status");
String infoCode = statusObject.getString("infocode");
if (!"1000".equals(infoCode)) {
return new ArrayList<>();
}
String resultType = jsonObject.getString("resultType");
String count = jsonObject.getString("count");
if (!"1".equals(resultType) || "0".equals(count)) {
return new ArrayList<>();
}
JSONArray poisArray = jsonObject.getJSONArray("pois");
for (int i = 0; i < poisArray.size(); i++) {
JSONObject poiObject = poisArray.getJSONObject(i);
MapLocation mapLocation = new MapLocation();
mapLocation.setName(poiObject.getString("name"));
mapLocation.setAddress(poiObject.getString("address"));
String lonlat = poiObject.getString("lonlat");
String[] lonlatArr = lonlat.split(",");
locateInfo = GCJ02_WGS84Utils.wgs84_To_Gcj02(Double.valueOf(lonlatArr[1]), Double.valueOf(lonlatArr[0]));
String lon = String.valueOf(locateInfo.getLongitude());
String lat = String.valueOf(locateInfo.getLatitude());
mapLocation.setLongitude(lon);
mapLocation.setLatitude(lat);
list.add(mapLocation);
}
}
return list;
}
3. 文本搜索
文本搜索功能允许用户根据关键词搜索地点。实现代码如下:
public static List<MapLocation> searchByText(String query, String mapBound) {
Request request = new Request();
String postStr = String.format(SEARCH_BY_TEXT_POST_STR, query, mapBound);
String encodedPostStr = null;
try {
encodedPostStr = URLEncoder.encode(postStr, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
String url = SEARCH_URL + "?tk=" + TK + "&type=" + QUERY + "&postStr=" + encodedPostStr;
request.setUrl(url);
Response<String> response = HttpClientHelper.getWithoutUserAgent(request, null);
List<MapLocation> list = new ArrayList<>();
if (response.getSuccess()) {
String body = response.getBody();
JSONObject jsonObject = JSON.parseObject(body);
JSONObject statusObject = jsonObject.getJSONObject("status");
String infoCode = statusObject.getString("infocode");
if (!"1000".equals(infoCode)) {
return new ArrayList<>();
}
String resultType = jsonObject.getString("resultType");
String count = jsonObject.getString("count");
if (!"1".equals(resultType) || "0".equals(count)) {
return new ArrayList<>();
}
JSONArray poisArray = jsonObject.getJSONArray("pois");
for (int i = 0; i < poisArray.size(); i++) {
JSONObject poiObject = poisArray.getJSONObject(i);
MapLocation mapLocation = new MapLocation();
mapLocation.setName(poiObject.getString("name"));
mapLocation.setAddress(poiObject.getString("address"));
String lonlat = poiObject.getString("lonlat");
String[] lonlatArr = lonlat.split(",");
LocateInfo locateInfo = GCJ02_WGS84Utils.wgs84_To_Gcj02(Double.valueOf(lonlatArr[1]), Double.valueOf(lonlatArr[0]));
String lon = String.valueOf(locateInfo.getLongitude());
String lat = String.valueOf(locateInfo.getLatitude());
mapLocation.setLongitude(lon);
mapLocation.setLatitude(lat);
list.add(mapLocation);
}
}
return list;
}
4. 坐标系转换
由于天地图使用的是WGS84坐标系,而国内常用的是GCJ-02坐标系,因此我们需要进行坐标转换。以下是坐标转换的工具类:
/**
* WGS-84:是国际标准,GPS坐标(Google Earth使用、或者GPS模块)
* GCJ-02:中国坐标偏移标准,Google Map、高德、腾讯使用
* BD-09:百度坐标偏移标准,Baidu Map使用(经由GCJ-02加密而来)
* <p>
* 这些坐标系是对真实坐标系统进行人为的加偏处理,按照特殊的算法,将真实的坐标加密成虚假的坐标,
* 而这个加偏并不是线性的加偏,所以各地的偏移情况都会有所不同,具体的内部实现是没有对外开放的,
* 但是坐标之间的转换算法是对外开放,在网上可以查到的,此算法的误差在0.1-0.4之间。
*/
public class GCJ02_WGS84Utils {
public static double pi = 3.1415926535897932384626;//圆周率
public static double a = 6378245.0;//克拉索夫斯基椭球参数长半轴a
public static double ee = 0.00669342162296594323;//克拉索夫斯基椭球参数第一偏心率平方
/**
* 从GPS转高德
* isOutOfChina 方法用于判断经纬度是否在中国范围内,如果不在中国范围内,则直接返回原始的WGS-84坐标。
* transformLat 和 transformLon 是辅助函数,用于进行经纬度的转换计算。
* 最终,wgs84ToGcj02 方法返回转换后的GCJ-02坐标系下的经纬度。
*/
public static LocateInfo wgs84_To_Gcj02(double lat, double lon) {
LocateInfo info = new LocateInfo();
if (isOutOfChina(lat, lon)) {
info.setChina(false);
info.setLatitude(lat);
info.setLongitude(lon);
} else {
double dLat = transformLat(lon - 105.0, lat - 35.0);
double dLon = transformLon(lon - 105.0, lat - 35.0);
double radLat = lat / 180.0 * pi;
double magic = Math.sin(radLat);
magic = 1 - ee * magic * magic;
double sqrtMagic = Math.sqrt(magic);
dLat = (dLat * 180.0) / ((a * (1 - ee)) / (magic * sqrtMagic) * pi);
dLon = (dLon * 180.0) / (a / sqrtMagic * Math.cos(radLat) * pi);
double mgLat = lat + dLat;
double mgLon = lon + dLon;
info.setChina(true);
info.setLatitude(mgLat);
info.setLongitude(mgLon);
}
return info;
}
//从高德转到GPS
public static LocateInfo gcj02_To_Wgs84(double lat, double lon) {
LocateInfo info = new LocateInfo();
LocateInfo gps = transform(lat, lon);
double lontitude = lon * 2 - gps.getLongitude();
double latitude = lat * 2 - gps.getLatitude();
info.setChina(gps.isChina());
info.setLatitude(latitude);
info.setLongitude(lontitude);
return info;
}
// 判断坐标是否在国外
private static boolean isOutOfChina(double lat, double lon) {
if (lon < 72.004 || lon > 137.8347)
return true;
if (lat < 0.8293 || lat > 55.8271)
return true;
return false;
}
//转换
private static LocateInfo transform(double lat, double lon) {
LocateInfo info = new LocateInfo();
if (isOutOfChina(lat, lon)) {
info.setChina(false);
info.setLatitude(lat);
info.setLongitude(lon);
return info;
}
double dLat = transformLat(lon - 105.0, lat - 35.0);
double dLon = transformLon(lon - 105.0, lat - 35.0);
double radLat = lat / 180.0 * pi;
double magic = Math.sin(radLat);
magic = 1 - ee * magic * magic;
double sqrtMagic = Math.sqrt(magic);
dLat = (dLat * 180.0) / ((a * (1 - ee)) / (magic * sqrtMagic) * pi);
dLon = (dLon * 180.0) / (a / sqrtMagic * Math.cos(radLat) * pi);
double mgLat = lat + dLat;
double mgLon = lon + dLon;
info.setChina(true);
info.setLatitude(mgLat);
info.setLongitude(mgLon);
return info;
}
//转换纬度所需
private static double transformLat(double x, double y) {
double ret = -100.0 + 2.0 * x + 3.0 * y + 0.2 * y * y + 0.1 * x * y
+ 0.2 * Math.sqrt(Math.abs(x));
ret += (20.0 * Math.sin(6.0 * x * pi) + 20.0 * Math.sin(2.0 * x * pi)) * 2.0 / 3.0;
ret += (20.0 * Math.sin(y * pi) + 40.0 * Math.sin(y / 3.0 * pi)) * 2.0 / 3.0;
ret += (160.0 * Math.sin(y / 12.0 * pi) + 320 * Math.sin(y * pi / 30.0)) * 2.0 / 3.0;
return ret;
}
//转换经度所需
private static double transformLon(double x, double y) {
double ret = 300.0 + x + 2.0 * y + 0.1 * x * x + 0.1 * x * y + 0.1
* Math.sqrt(Math.abs(x));
ret += (20.0 * Math.sin(6.0 * x * pi) + 20.0 * Math.sin(2.0 * x * pi)) * 2.0 / 3.0;
ret += (20.0 * Math.sin(x * pi) + 40.0 * Math.sin(x / 3.0 * pi)) * 2.0 / 3.0;
ret += (150.0 * Math.sin(x / 12.0 * pi) + 300.0 * Math.sin(x / 30.0 * pi)) * 2.0 / 3.0;
return ret;
}
}
结论
通过上述代码,我们成功地将天地图集成到了我们的系统中,不仅满足了功能需求,还大幅降低了成本。这一过程中,我们深入理解了地图服务的工作原理,也提升了团队的技术能力。
注意事项
- 确保在使用天地图API时遵守其服务条款,尤其是在商业用途中。
- 由于网络或其他原因,天地图API可能存在访问延迟或不稳定的情况,建议在生产环境中做好异常处理和备用方案。
- 坐标系转换是一个复杂的过程,确保使用可靠的算法和工具进行转换,以保证定位的准确性。
通过这次集成,我们不仅为公司节省了成本,还提升了系统的稳定性和用户体验。在未来的开发中,我们将继续探索更多高效、低成本的技术解决方案。
来源:juejin.cn/post/7419524888041472009
js中的finally一定会执行吗?
背景
在我们程序开发中,我们的代码会出现这种或那种的错误,我们使用try...catch进行捕获。如果需要不管是成功还是失败都需要执行,我们可能需要finally。
那么有一个问题,无论是否发生错误,在finally中的代码一定会执行吗?
下面我们看一个案例:
1. 案例
场景:请求一个接口,如果接口没有正确返回,我们使用try...finally包裹代码,代码如下:
function getMember(num) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (num === 1) {
resolve(num)
}
if (num === 0) {
reject()
}
}, 2000)
})
}
async function init() {
try {
console.log('打印***start')
await getMember(0)
console.log('打印***end')
} catch (err) {
console.log('打印***err')
} finally {
console.log('打印***finally')
}
}
结果如下:

上述案例中,如果请求传入的num由另外一个接口返回,num的值不是0或者1,上述的getMember就一直处于pengding状态,接下来的finally也不会执行。
我们也可以这样理解,当在处理Promise问题时,我们需要确保Promise始终得到结果,不管是成功还是失败。
上述代码可以完善如下:
function getMember(num) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (num === 1) {
resolve(num);
} else if (num === 0) {
reject(new Error('Num is 0'));
} else {
// 默认情况,也解决Promise
resolve('Some default value');
}
}, 2000);
});
}
async function init() {
try {
console.log('打印***start');
const result = await getMember(2); // 传递一个非0非1的值
console.log('打印***end', result);
} catch (err) {
console.log('打印***err', err);
} finally {
console.log('打印***finally'); // 这行总是会被执行
}
}
init();
修改后的例子中,无论num的值是什么,Promise都会被解决(要么通过resolve,要么通过reject),,确保Promise被正常处理,才能确保finally执行。
2. try...catch注意点
2.1 仅对运行时的 error 有效
要使得 try...catch 能工作,代码必须是可执行的。换句话说,它必须是有效的 JavaScript 代码。
如果代码包含语法错误,那么 try..catch 将无法正常工作,例如含有不匹配的花括号:
try {
{
{
} catch (err) {
alert("引擎无法理解这段代码,它是无效的");
}
结果如下:

JavaScript 引擎首先会读取代码,然后运行它。在读取阶段发生的错误被称为“解析时间(parse-time)”错误,并且无法恢复(从该代码内部)。这是因为引擎无法理解该代码。
所以,try...catch 只能处理有效代码中出现的错误。这类错误被称为“运行时的错误(runtime errors)”,有时被称为“异常(exceptions)”。
2.2 try...catch 同步执行
如果在定时代码中发生异常,例如在 setTimeout 中,则 try...catch 不会捕获到异常:
try {
setTimeout(function () {
noSuchVariable; // 脚本将在这里停止运行
}, 1000);
} catch (err) {
alert("不工作");
} finally {
console.log('打印***finally')
}
结果如下:

因为 try...catch 包裹了计划要执行的函数,该函数本身要稍后才执行,这时引擎已经离开了 try...catch 结构。
为了捕获到计划的(scheduled)函数中的异常,那么 try...catch 必须在这个函数内:
try {
setTimeout(function () {
try {
noSuchVariable; // 脚本将在这里停止运行
} catch (error) {
console.log(error)
}
}, 1000);
} catch (err) {
alert("不工作");
} finally {
console.log('打印***finally')
}
结果如下:

总结
在使用try...catch...finally的时候,无论是否发生异常(即是否执行了catch块),finally块中的代码总是会被执行,除非在try、catch或finally块中发生了阻止程序继续执行的情况(如Promsie一直处理pending状态)。
如有错误,请指正O^O!
来源:juejin.cn/post/7419524503200677898
这个评论系统设计碉堡了
先赞后看,南哥助你Java进阶一大半
geeksforgeeks.org官网给出了Facebook评论系统的高级设计图,Facebook的评论竟然是支持实时刷新的。也就是说用户不用刷新帖子,只要帖子有新的评论就会自动推送到用户端,这里Facebook使用的便是每天在全球有超过20亿设备在使用的WebSocket技术。

我是南哥,一个Java学习与进阶的领路人。
相信对你通关面试、拿下Offer进入心心念念的公司有所帮助。
⭐⭐⭐本文收录在《Java学习/进阶/面试指南》:https://github/JavaSouth
精彩文章推荐
- 面试官没想到一个ArrayList,我都能跟他扯半小时
- 《我们一起进大厂》系列-Zookeeper基础
- 再有人问你WebSocket为什么牛逼,就把这篇文章发给他!
- 全网把Kafka概念讲的最透彻的文章,别无二家
- 可能是最漂亮的Java I/O流详解
1. 评论系统设计
1.1 评论表如何设计
评论系统的表要这么设计,每条评论的id标识要么是根评论id、要么是回复评论id。如果是根评论,那parent_comment_id字段就为空;而回复别人的评论,parent_comment_id字段指向根评论id。
CREATE TABLE `comments` (
`comment_id` INT AUTO_INCREMENT PRIMARY KEY, -- 评论唯一ID
`user_id` INT NOT NULL, -- 用户ID
`content` TEXT NOT NULL, -- 评论内容
`parent_comment_id` INT DEFAULT NULL, -- 如果是回复,则指向原始评论ID
`post_id` INT NOT NULL, -- 被评论的帖子或内容ID
`like_count` INT DEFAULT 0, -- 点赞数量
`create_time` TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 评论创建时间
);
我们还要给评论加上点赞数,南哥给大家看看抖音的评论设计。
用户可以给每条评论打上点赞,所以我们应该再设计一个点赞表。其实抖音这种评论模式叫嵌套式评论结构,嵌套式评论注重用户对话交流,用户可以很方便地查看一个对话里的所有回复,我们看下抖音评论里有着展开10条回复的按钮。

其他评论模式设计还有平铺式评论结构,像微信朋友圈,或者Github的issue都是平铺式评论结构。这种设计更适合用户关注重点在发布的内容本身,而不是对话。大家有没发现微信朋友圈的特点是对话比较少点,点赞反而更多。
来看看点赞表设计。
CREATE TABLE `comment_likes` (
`user_id` INT NOT NULL, -- 点赞用户ID
`comment_id` INT NOT NULL, -- 被点赞的评论ID
`liked_timeMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 点赞时间
);
1.2 评论数据存储
抖音每天产生视频几百万、上千万,每个视频的评论高的甚至有上万条评论,要怎么样的数据查询设计才能支持每天亿级的评论?
南哥先假设我们用MySQL作为实际的数据存储,这么高的并发肯定不能让查询直接冲击数据库 。再分库分表也是没用。

Elasticsearch官网这么宣传它的产品:
Elasticsearch 极其快速,快到不可思议
当用户发表评论时,我们首先把评论写入MySQL数据库,再使用异步机制把评论同步到Elasticsearch中。当在用户请求查询评论时,优先从 Elasticsearch 中进行查询。
// 评论存储到MySQL、Elasticsearch
public void storeComment(Comment comment) {
// 将评论存入 MySQL
commentRepository.save(comment);
// 异步将评论同步到 Elasticsearch
CompletableFuture.runAsync(() -> {
elasticsearchService.indexComment(comment);
});
}
1.3 事务控制
大家想一想以上设计,有哪些需要进行事务控制?
例如comment_likes点赞表的插入和comment评论表的更新,用户为某一个评论点赞,会在comment_likes表插入一条新记录,同时会更新comment表的点赞数量。
但是,从用户需求的角度来看,用户并不在意点赞数的强一致性和实时性,这点不使用事务也可以接受。
我曾经和老外程序员在论坛聊过,他说他们的点赞后端分布式服务用的本地缓存,即使每一个服务的本地缓存相对不太一致,对系统完全没有影响。
// 事务控制
@Transactional
public void likeComment(int commentId, int userId) {
// 插入一条点赞记录
commentLikesRepository.insert(userId, commentId);
// 更新评论表中的点赞数量,假设有一个专门的方法来处理这个更新
commentRepository.incrementLikeCount(commentId);
}
1.4 点赞数加入Redis
点赞数相比评论来说,量更加巨大,用户点赞时直接落到MySQL数据库肯定不合理,服务器扛不住也没必要扛。
假如点赞数没有进行事务控制。南哥打算这样处理,用户点赞后,后端服务接受到点赞请求,把用户内容、点赞数放到Redis里,这里采用Redis五大基本类型之一:Map。
// Map结构
comment_like_key = [comment_id_6:like_count = 66, comment_id_7:like_count = 77]
我们需要查询点赞数时直接从高性能内存数据库Redis查询。
当然这还没完,MySQL数据库和Elasticsearch的点赞量需要去同步更新,我们设置定时任务每个一段时间完成数据同步任务。上文的comment_likes点赞记录表同样需要记录,把点赞放到Redis时进行异步添加点赞记录即可。
// 定时任务数据同步任务
@Scheduled(fixedRate = 10000)
public void syncLikes() {
// 从 Redis 中读取最新的点赞数据
Map<Integer, Integer> likes = redisService.fetchAllLikes();
// 同步到 MySQL 和 Elasticsearch
likes.forEach((commentId, likeCount) -> {
commentRepository.updateLikeCount(commentId, likeCount);
elasticsearchService.updateLikeCount(commentId, likeCount);
});
}
戳这,《JavaSouth》作为一份涵盖Java程序员所需掌握核心知识、面试重点的神秘文档。
我是南哥,南就南在Get到你的点赞点赞。

创作不易,不妨点赞、收藏、关注支持一下,各位的支持就是我创作的最大动力❤️
来源:juejin.cn/post/7418084847615737868
2024 最新最全 VS Code 插件推荐!
Visual Studio Code 是由微软开发的一款开源的代码编辑器,它有了一个丰富的插件市场,提供了很多实用的插件。本文就来分享 2024 年开发必备的 VS Code 插件!

功能强化
驼峰翻译助手
纠结怎么取变量? 中文一键翻译转换成常用大小驼峰等格式。

change-case
Change-case插件提供了一种简单的方法来将单词或变量名更改为各种情况,包括驼峰命名(camelCase)、下划线命名(snake_case)、标题命名(TitleCase)等多种格式。

Codelf
变量命名神器,搜索 Github、Bitbucket、Google Code、Codeplex、Sourceforge、Fedora Project、GitLab 中的项目以查找实际使用的变量名称。

Surround
用于在代码块周围添加包装代码片段。该插件支持语言标识符、多选区操作、完全可自定义、自定义包装代码片段,并为每个包装代码片段单独分配快捷键。

Duplicate Action
一键复制并创建文件或文件夹,提高了开发过程中的文件操作效率。

CSS Peek
它允许开发者直接从HTML文档中快速跳转到匹配的CSS样式定义,并提供预览功能,从而大大提高CSS样式的查找和编辑效率。

Regex Previewer
可以实时预览正则表达式匹配结果,并适用于多种前端框架和语言,同时提供快捷键操作、全局和多行选项等便捷功能,以提升开发效率。

Code Spell Checker
Code Spell Checker 插件可以检查单词拼写是否出现错误,检查的规则遵循 camelCase (驼峰拼写法)。

Markdown Preview Enhanced
支持实时预览 Markdown 文件效果,并具备导出 PDF、支持数学公式、流程图等多种高级功能,提供了丰富的定制选项和兼容性,极大地提升了 Markdown 文档的编辑和预览体验。

Markdown All in One
用于提供Markdown编辑的全方位支持,包括实时预览、语法提示、目录生成、表格生成等多种功能。

i18n-ally
主要用于国际化多语言开发,提供内联提示、快速修改key值对应的语言文件、统一管理翻译、自动翻译等功能。

GitHub Repositories
在 VS Code 中快速打开 Github 仓库,无需克隆到本地。

Turbo Console Log
一键生成有意义的 console.log 消息,支持多语言、多光标操作,提供可定制的日志类型和输出格式,提高调试效率。

indent-rainbow
一款代码缩进可视化插件,它通过为文本前面的缩进着色,使缩进更具可读性。

Remote-SSH
允许开发者通过 SSH 协议连接到远程服务器或虚拟机,直接在本地 VS Code 编辑器中操作远程服务器上的代码,实现无缝的远程开发体验。主要功能包括远程连接、无缝的代码编辑和调试、扩展兼容性、多种连接选项、优化的性能以及支持多个远程服务器同时连接等。

前端框架
ES7+ React/Redux/React-Native snippets
提供了许多速记前缀来加速开发并帮助开发人员为 React、Redux、GraphQL 和 React Native 创建代码片段和语法。

Typescript React Code Snippets
此插件包含了使用 Typescript 的 React 代码片段,它支持 Typescript(.ts) 或 TypeScript React (.tsx) 等语言。以下是使用 TypeScript 创建 React 组件的两个片段。
- 默认导出 React:

- 导出 React 组件:

Vue - Official
Vue 官方扩展。

Vue 3 Snippets
这个插件包含了所有的 Vue.js 2 和 Vue.js 3 的 api 对应的代码片段。

Vue VSCode Snippets
此插件将 Vue 2 Snippets 和 Vue 3 Snippets 添加到 Visual Studio Code 中。

React Native Tools
允许在不同的模拟器或仿真器上轻松运行和调试代码,从命令面板快速运行 react-native 命令,而无需在终端中手动运行命令,并使用 IntelliSense 浏览 React Native 的函数、对象和参数等。

JavaScript (ES6) code snippets
通过此插件可以使用预定义的 ES6 语法片段速记,从而提高开发效率。这个 VS Code 插件可以自定义,因为它不特定于任何框架。

Tailwind CSS IntelliSense
专为使用 Tailwind CSS 的开发者设计,提供实时的类名建议、自动完成、文档预览等功能,以提升 Tailwind CSS 的开发效率和代码质量。

Git 集成
GitLens
该插件增强了 VS Code 中的 Git,并从每个存储库中释放隐藏数据。可以快速查看代码的编写者、轻松导航和探索 Git 存储库、通过丰富的可视化效果和强大的比较命令获取有效信息,以及执行更多操作,帮助我们更好地理解代码。

Git History
该插件用于查看 Git 日志和文件历史记录并比较分支或提交。

Git Graph
Git Graph 插件用于可视化查看存储库的 Git 操作,并从图形中轻松执行Git操作。

统计分析
Import Cost
在项目中导入多个包时可能会出现性能问题,Import Cost 就用于查看将特定库导入项目的成本。该插件会显示导入库的大小,如果大小为绿色,则表示库很小,而红色表示库很大。

Time Master
从编程活动中自动生成的指标、见解和时间跟踪。它是一个开源项目,独立于网络环境,安全轻量。

VS Code Counter
VS Code Counter 插件用于统计项目代码的行数,安装插件之后,右键点击需要统计代码的文件夹,选择“Count lines in directory”,这时就会在项目根目录出现一个名为 .VSCodeCounter 的文件夹,包含了不同格式的结果,编辑器会打开其中的的 .md 格式。结果中会显示代码总行数,不同格式文件行数,不同路径文件函数等。代码行数中有纯代码行数、空白行数、注释行数。

AI 编程辅助
GitHub Copilot
GitHub Copilot 是 Github 推出的一款 AI 结对编程工具,可以帮助开发者更快、更智能地编写代码,不过该插件并不是免费的。

Tabnine
Tabnine 是一款 AI 代码助手,可加速和简化软件开发,同时保证代码的私密性、安全性和合规性。

Codeium
一个基于 AI 技术的免费代码加速工具包,为VSCode提供70多种语言的快速自动补全、聊天和搜索功能,支持IDE内聊天和多种编程语言的建议。

TONGYI Lingma
通义灵码是阿里云推出的一款基于通义大模型的智能编码辅助工具,提供实时续写、自然语言生成代码、单元测试生成、代码注释生成、代码解释、研发智能问答、异常报错排查等能力。

CodeGeeX
CodeGeeX 是一款基于大模型的智能编程助手,它完善了代码的生成与补全,自动为代码添加注释,此外,它还针对代码问题的智能问答,当然还包括代码解释,实现代码,修复代码bug等非常丰富的功能。

代码美化
Highlight Matching Tag
用于实时高亮显示匹配的标签对,方便用户在 HTML 或 XML 代码中快速找到配对的标签。它可以在点击一个标签时,自动显示配对的标签,并通过下划线或其他样式来指示它们之间的对应关系。

TODO Highlight
实时高亮显示代码中的TODO、FIXME等标记,支持自定义关键字和正则表达式匹配,方便开发者快速识别、管理和追踪待办事项。

Todo Tree
用于在Visual Studio Code中搜索、管理和高亮代码中的待办事项标记(如TODO、FIXME等)。它支持自定义标签、颜色编码、实时更新、过滤与排序等功能,并以可视化的树形结构展示待办事项列表,方便开发者快速定位、编辑和跟踪代码中的待办事项。

Better comments
该插件对不同类型的注释会附加了不同的颜色,更加方便区分,帮助我们在代码中创建更人性化的注释。

Colorize
Colorize 会给颜色代码增加一个当前匹配代码颜色的背景。它通过 CSS 变量、预处理器变量、hsl/hsla 颜色、跨浏览器颜色、exa、rgb、rgba和argb的彩色背景将 CSS 颜色可视化,帮助开发者快速区分颜色。

Image preview
通过此插件,当鼠标悬浮在图片的链接上时,可以实时预览该图片,除此之外,还可以看到图片的大小和分辨率。

CodeSnap
CodeSnap 用于对代码的进行截图和共享。屏幕截图可以用文本或形状进行注释,并通过链接共享或包含在网站或文档中。只需使用 ctrl + shift + P 并输入 CodeSnap,然后按回车键,CodeSnap 窗口就会打开。

Error Lens
Error Lens 是一款把代码检查(错误、警告、语法问题)进行突出显示的插件。Error Lens 通过使诊断更加突出,增强了语言的诊断功能,突出显示了由该语言生成的诊断所在的整行,并在代码行的位置以行方式在线打印了诊断消息。

Pretty TypeScript Errors
Pretty TypeScript Errors 旨在使 TypeScript 的错误信息更易读、更人性化。随着 TypeScript 类型复杂性的增加,错误消息可能会变得混乱不堪,充满了难以理解的括号和“...”。这个扩展通过重新格式化或解释 TypeScript 编译器产生的原始错误信息,来帮助开发者更容易地理解发生了什么。

编辑器美化
Power Mode
Power Mode 旨在通过添加视觉特效来增强编程体验,通过了诸如粒子效果、烟火、火焰、魔法效果等特效,让编程过程更加生动有趣。

One Dark Pro
一款编辑器主题。

Dracula Official
一款编辑器主题。

GitHub Theme
一款编辑器主题。

Winter Is Coming Theme
一款编辑器主题。

Ayu
一款编辑器主题。

vscode-icons
VSCode 官方出品的图标库。

Material Icon Theme
该插件根据最新的 Material Design 主题为文件和文件夹提供图标。它可以帮助我们识别文件并为编辑器添加自定义的外观。

Peacock
允许开发者为 Visual Studio Code 的工作区界面(如侧边栏、底栏和标题栏)自定义颜色,以区分不同的项目或编码环境。

来源:juejin.cn/post/7384765023343394827
与其造神,不如依靠群体的力量:这家公司走出了一条不同于 OpenAI 的 AGI 路线
看过剧版《三体》的读者或许都记得一个名场面:来自三体的智子封锁了人类科技,还向地球人发出了「你们是虫子」的宣告。但没有超能力的普通人史强却在蝗群漫天飞舞的麦田中喊出:「把我们人类看成是虫子的三体人,他们似乎忘了一个事实,那就是虫子从来就没有被真正地战胜过」。

三体人看到的是单个虫子脆弱的一面 —— 你可以轻松踩死一只蚂蚁,打死一只蝗虫、蜜蜂。但他们没有看到的是,当这些虫子集结在一起时,它们可以涌现出远超个体简单相加的力量。

科学家们很早就发现了这种力量,并将其命名为「群体智能」(Swarm Intelligence)。这种智能不是由某个中央大脑控制,而是通过个体间的简单互动和信息交换自然形成的。它是一种集体智慧的体现,是自然界中一种奇妙而高效的协作方式。
其实,从宏观上说,人类社会的不断发展和演化也是一种群体智能现象,绝大多数文明成果都是人类个体在长期群体化、社会化的生产生活中逐渐演化形成的产物。
那么,人工智能的发展能否借鉴这种模式?答案自然是「能」。但长期以来,由于机器的个体智能化程度较低等原因,「群体智能」迟迟难以涌现。
生成式 AI 的发展或许可以推动这些问题的解决,也让「群体智能」获得了新一轮的关注。
「这波生成式 AI 相当于把个体的智能化水平提升上去了。而个体智能的提升,意味着群体的智能有望实现指数级增长。」在近期的一次访谈中,RockAI CEO 刘凡平向机器之心表达了这样的观点。

RockAI 是一家成立于 2023 年 6 月的 AI 初创,他们自研了国内首个非 Attention 机制的 Yan 架构通用大模型,并将这个大模型部署在了手机、PC、无人机、机器人等多种端侧设备上,还尝试让自己的大模型在这些设备上实现「自主学习」能力。
而这一切均服务于一个宏大的目标 —— 让每一台设备都拥有自己的智能,而且是可以像人类一样实时学习、个性化自主进化的系统。刘凡平认为,当这些拥有不同能力、不同个性的智能单元得以协同,即可完成数据共享、任务分配和策略协调,涌现出更为宏大、多元的群体智能,最终实现个性化与群体智能的和谐统一,开启人与机器的智能新时代。
那这一切怎么去实现呢?在访谈中,刘凡平和邹佳思(RockAI 联合创始人)向机器之心分享了他们的路线图和最新进展。
一条不同于 OpenAI 的 AGI 路线
前面提到,「群体智能」的研究进展受限于单个个体的智能化程度,所以研究者们首先要解决的问题就是让单个个体变得足够聪明。
要说「聪明」,OpenAI 的模型可以说是出类拔萃。但从目前的情况来看,他们似乎更侧重于训练出拥有超级智能的单个大模型。而且,这条路线走起来并不容易,因为它高度依赖海量的数据和计算资源,这在能源、数据和成本上都带来了可持续性的问题。
此外,通过一个超级智能模型来处理所有任务是一种高度中心化的模式,这在实践中容易出现智能增长的瓶颈,因为单一模型缺乏灵活的适应能力和协作效应,导致其智能提升速度受到限制。
那么,OpenAI 未来有没有可能也走群体智能的路线?这个问题目前还没有明确答案。但可以看到的一点是,以该公司和其他大部分公司当前采用的 Transformer 架构去构建群体智能的单个个体可能会遇到一些障碍。
首先是高算力需求的障碍。以 Attention 机制为基础的 Transformer 架构对计算资源的需求非常高,其计算复杂度为 O (n^2)(n 为序列长度)。这意味着随着输入序列的增长,计算成本急剧增加。在构建群体智能时,我们需要多个单元大模型协同工作,而这些单元大模型往往部署在低算力的设备上(如无人机、手机、机器人等)。如果不经过量化、裁剪等操作,Transformer 架构的模型很难在低算力设备上直接部署。所以我们看到,很多公司都是通过这些操作让模型成功在端侧跑起来。
但对于群体智能来说,光让模型跑起来还不够,还要让它们具备自主学习的能力。在刘凡平看来,这一点至关重要。
他解释说,在一个没有自主学习的群体中,最聪明的个体会主导其他智能体的决策,其他智能体只能跟随它的指引。这种情况下,群体智能的上限就是最聪明个体的水平,无法超越。但通过自主学习,每个智能体都可以独立提升自身的智能水平,并逐渐接近最聪明的个体。而且,自主学习促进了知识共享,类似于人类的知识传承。这样,群体中的所有智能体都会变得更聪明,群体整体的智能水平有望实现指数级增长,远远超出简单的个体累加。
而量化、裁剪等操作最致命的问题,就是破坏了模型的这种自主学习能力。「当一个模型被压缩、量化、裁剪之后,这个模型就不再具备再学习的能力了,因为它的权重已经发生了变化,这种变化基本是不可逆的。这就像我们把一个螺丝钉钉入墙中,如果在敲入的过程中螺丝钉受到损坏,那么想要把它取出来重新使用就变得很困难,让它变得更锋利就变得不可能。」刘凡平解释说。
讲到这里,实现群体智能的路线其实就已经非常清晰了:
- 首先,你要在架构层面做出改变,研发出一种可以克服 Transformer 缺陷的新架构。
- 然后,你要将基于这个架构的模型部署到各种端侧设备上,让模型和这些设备高度适配。
- 接下来,更重要的一点是,这个架构的模型要能够在各种端侧设备上自主学习,不断进化。
- 最后,这些模型与端侧设备结合成的智能体要能够自主协作,共同完成任务。
这其中的每个阶段都不简单:
- 在第一阶段,新架构不止要具备低算力、部署到端侧原生无损的特点,还要具备可以媲美 Transformer 架构的性能,保证单个个体足够聪明且可以自主学习。
- 在第二阶段,「大脑和身体」的高度适配涉及感知层面和数据处理的不同模态,每种设备有着不同的需求,这增加了模型和设备适配的复杂性。
- 在第三阶段,让模型部署之后还可以学习就意味着要挑战现有的训练、推理完全分离的机制,让模型参数在端侧也可以调整,且调整足够快、代价足够小。这就涉及到对传统反向传播机制的挑战,需要的创新非常底层。
- 在第四阶段,主要挑战是如何实现智能体之间的有效协作。这个过程要求智能体自主发现并形成完成任务的最佳方案,而不是依赖于人为设定或程序预设的方案。智能体需要根据自己的智能水平来决定协作的方式。
这些难点就决定了,RockAI 必须走一条不同于 OpenAI 的路线,挑战一些传统的已经成为「共识」的方法。
刘凡平提到,在前两个阶段,他们已经做出了一些成果,针对第三、四个阶段也有了一些实验和构想。

群体智能的单元大模型 ——Yan 1.3
第一阶段的标志性进展是一个采用 Yan 架构(而非 Transformer 架构或其变体)的大模型。这个模型的 1.0 版本发布于今年的 1 月份,为非 Attention 机制的通用自然语言大模型。据了解,该模型有相较于同等参数 Transformer 的 7 倍训练效率、5 倍推理吞吐和 3 倍记忆能力。而且,这一模型 100% 支持私有化部署应用,不经裁剪和压缩即可在主流消费级 CPU 等端侧设备上无损运行。
经过半年多的攻关,这一模型刚刚迎来了最新版本 ——Yan 1.3。

Yan 1.3 是一个 3B 参数的多模态模型,能够处理文本、语音、视觉等多种输入,并输出文本和语音,实现了多模态的模拟人类交互。

尽管参数量较小,但其效果已超越 Llama 3 8B 的模型。而且,它所用的训练语料比 Llama 3 要少,训练、推理算力也比 Llama 3 低很多。这在众多非 Transformer 架构的模型中是一个非常领先的成绩,其训练、推理的低成本也让它比其他架构更加贴近工业化和商业化。

这些出色的性能得益于高效的架构设计和算法创新。
在架构层面,RockAI 用一个名叫 MCSD(multi-channel slope and decay)的模块替换了 Transformer 中的 Attention 机制,同时保留 Attention 机制中 token 之间的关联性。在信息传递过程中,MCSD 强调了有效信息的传递,确保只有最重要的信息被传递给后续步骤,而且是以 O (n) 的复杂度往下传,这样可以提高整体效率。在验证特征有效性和 token 之间的关联性方面,MCSD 表现优秀。

**在算法层面,RockAI 提出了一种类脑激活机制。**这是一种分区激活的机制,就像人开车和写字会分别激活脑部的视觉区域和阅读区域一样,Yan 1.3 会根据学习的类型和知识范围来自适应调整部分神经元,而不是让全量的参数参与训练。推理时也是如此。具体有哪些神经元来参与运算是由仿生神经元驱动的算法来决定的。

在今年的 GTC 大会上,Transformer 论文作者之一 Illia Polosukhin 提到,像 2+2 这样的简单问题可能会使用大模型的万亿参数资源。他认为自适应计算是接下来必须出现的事情之一,我们需要知道在特定问题上应该花费多少计算资源。RcokAI 的类脑激活机制是自适应计算的一种实现思路。
这或许听起来和 MoE 有点像。但刘凡平解释说,类脑激活机制和 MoE 有着本质的区别。MoE 是通过「专家」投票来决定任务分配,每个「专家」的网络结构都是固定的,其结果是可预测的。而类脑激活机制没有「专家」,也没有「专家」投票的过程,取而代之的是神经元的选择过程。其中的每个神经元都是有价值的,选择的过程也是一个自学习的过程。
这种分区激活机制在 MCSD 的基础上进一步降低了 Yan 架构模型的训练、推理计算复杂度和计算量。
「这也符合人类大脑的运行方式。人脑的功耗只有二十几瓦,如果全部的 860 亿个神经元每次都参与运算,大脑产生的生物电信号肯定是不够用的。」刘凡平说道。目前,他们的类脑激活机制已经得到了脑科学团队的理论支持和实际论证,也申请到了相关专利。
以端侧设备为载体,迈向群体智能
在 Yan 1.3 的发布现场,我们看到了该模型在 PC、手机、机器人、无人机等端侧设备的部署情况。鉴于 Yan 1.2 发布时甚至能在树莓派上运行,这样的端侧部署进展并不令我们感到意外。
部署了 Yan 1.3 的机器人。机器人内置硬件为 Intel Core i3。
而且我们知道,这些端侧智能体的潜力才刚刚显露。毕竟,以上创新的目标不只是让模型能够在端侧跑起来(当前很多模型都能做到这一点),而是使其具备自主学习的能力,作为「群体智能的单元大模型」持续进化。无论是 Yan 架构的「0 压缩、0 裁剪」无损部署,还是分区激活的高效计算,都是服务于这一目标。这是 RockAI 和其他专注于端侧 AI 的公司的一个本质区别。
「如果我们拿一个 10 岁的孩子和一个 30 岁的博士来比,那肯定 30 岁的博士知识面更广。但是,我们不能说这个 10 岁的孩子在未来无法达到甚至超越这位博士的成就。因为如果这个 10 岁的孩子自我学习能力足够高,他的未来成长速度可能比 30 岁的博士还要快。所以我们认为,自主学习能力才是衡量一个模型智能化程度的重要标志。」刘凡平说道。可以说,这种自主学习能力才是 RockAI 追求的「scaling law」。
为了实现这种自主学习能力,RockAI 的团队提出了一种「训推同步」机制,即让模型可以在推理的同时,实时有效且持续性地进行知识更新和学习,最终建立自己独有的知识体系。这种「训推同步」的运行方式类似于人类在说话的同时还能倾听并将其内化为自己的知识,对底层技术的要求非常高。
为此,RockAI 的团队正在寻找反向传播的更优解,方法也已经有了一些原型,并且在世界人工智能大会上进行过展示。不过,他们的方法原型目前仍面临一些挑战,比如延迟。在后续 Yan 2.0 的发布中,我们有望见到原型升级版的演示。
那么,在每一台设备都拥有了智能后,它们之间要怎么联结、交互,从而涌现出群体智能?对此,刘凡平已经有了一些初步构想。
首先,它们会组成一个去中心化的动态系统。在系统中,每台设备都拥有自主学习和决策的能力,而不需要依赖一个中央智能来控制全局。同时,它们之间又可以共享局部数据或经验,并通过快速的通信网络互相传递信息,从而在需要时发起合作,并利用其他智能体的知识和资源来提升任务完成的效率。
路线「小众」,挑战与机遇并存
纵观国内 AI 领域,RockAI 走的路可以说非常「小众」,因为里面涉及到非常底层的创新。在硅谷,有不少人在做类似的底层研究,就连「神经网络之父」Hint0n 也对反向传播的一些限制表示过担忧,特别是它与大脑的生物学机制不符。不过,大家目前都还没有找到特别有效的方法,因此这一方向还没有出现明显的技术代差。对于 RockAI 这样的国内企业来说,这既是挑战,也是机遇。
对于群体智能,刘凡平相信,这是一条迈向更广泛的通用人工智能的路线,因为它的理论基础是非常坚实的,「如果没有群体智能,就没有人类社会的文明,更不会有科技的发展」。
而且,刘凡平认为,群体智能所能带来的生产力变革比拥有超级智能的单个大模型所能带来的更全面、更多样。随着自主架构大模型的研发成功和多元化硬件生态的构建,他们相信自己正在逐渐接近这一目标。
我们也期待看到这家公司的后续进展。
参考链接:
news.sciencenet.cn/sbhtmlnews/…
http://www.shxwcb.com/1205619.htm…
© THE END
来源:juejin.cn/post/7418813003783929868
腾讯开源利器:让iOS UI调试更高效
最近逛G站,偶然发现一款 iOS UI 调试工具,那就是腾讯 QMUI团队 开源的LookinSever[1]。初步体验了一下,功能还是非常强大,简单记录并分享一下。
简介
腾讯的LookinServer[2]是一款专为iOS开发者设计的UI调试工具,类似于 Xcode 自带的 UI Inspector 工具,或者以前常用的另一款软件Reveal。

基本功能
1、实时UI查看: LookinServer可以实时捕捉并显示iOS应用的UI层级结构。这包括所有的视图(Views)、控件(Controls)以及它们的属性(Properties)等。
2、层级视图展示: 通过图形化界面,开发者可以方便地浏览UI的层级关系。这有助于快速定位UI问题,例如某些视图被错误地覆盖或布局不正确。
3、属性编辑: 开发者可以直接在LookinServer中修改视图的属性(如frame、color等),并立即在应用中看到效果。这种所见即所得的调试方式大大加快了UI调整的效率。
4、视图调试: LookinServer支持对单个视图进行详细调试,包括查看其布局约束、事件响应链、以及性能指标等。
工作原理
1、数据抓取: LookinServer会将目标iOS应用中的UI数据抓取下来。这通常涉及到通过iOS的运行时(Runtime)机制和反射机制来获取应用当前的UI层级和视图信息。
2、通信机制: LookinServer客户端与iOS应用之间通过网络通信进行数据传输。应用中集成的LookinServer SDK会将视图层级、属性等数据打包发送到LookinServer客户端进行展示。
3、动态更新: 当开发者在LookinServer客户端中修改视图属性时,修改指令会通过通信机制发送回iOS应用,应用立即应用这些修改并更新显示。通过这种方式,实现了实时的UI调试。
使用场景
1、UI布局调试: 快速发现并修正UI布局问题,例如视图错位、层级不正确等。
2、UI性能优化: 查看每个视图的性能指标,找出性能瓶颈并进行优化。
3、快速迭代: 在开发过程中频繁修改UI时,通过LookinServer可以快速预览效果,减少编译和重启应用的时间。
优势
1、提高效率: 实时查看和修改UI,大大减少了传统调试方式的时间成本。
2、直观可视化: 图形化的视图层级展示,让开发者可以更直观地理解UI结构。
3、易于集成: LookinServer Framework易于集成到现有项目中,支持CocoaPods、 Swift Package Manager以及手动集成,支持OC和Swift,不需要对项目做大的改动。
小试牛刀
1、安装Lookin: 官网[3]下载并安装Lookin Mac客户端。
2、安装 LookinServer Framework:
- • 通过 CocoaPods
- • Swift项目:pod 'LookinServer', :subspecs => ['Swift'], :configurations => ['Debug']
- • ObjC项目:pod 'LookinServer', :configurations => ['Debug']
- • 通过 Swift Package Manager:github.com/QMUI/Lookin…
- • 手动集成:下面以
OC项目为例。 将下载的源码导入项目中,注意Swift文件夹里面的可以删除,或者将文件LKS_SwiftTraceManager.swift不加到target里参与编译。

在Debug模式下,打开SHOULD_COMPILE_LOOKIN_SERVER宏定义。

3、简单使用: 建个项目,拖几个控件,运行,打开第一步安装的LookinMac 软件,监测到运行的项目,可以看到视图层级关系、target-action、手势、常见属性设置等,UI及时同步刷新。

注意事项
1、需要在 Debug 模式下使用
2、使用 1.0.6及以后 的版本
总结
腾讯的LookinServer是一个强大的iOS UI调试工具,其通过实时查看、编辑和调试视图层级和属性,极大地提高了UI开发和调试的效率。通过掌握其原理和使用方法,开发者可以更高效地处理UI问题,提高应用的整体质量。
引用链接
[1] LookinSever: github.com/QMUI/Lookin…
[2] LookinServer: lookin.work/
[3] 官网: lookin.work/
来源:juejin.cn/post/7376586649982091301
听我一句劝,业务代码中,别用多线程。
你好呀,我是歪歪。
前几天我在网上冲浪,看到一个哥们在吐槽,说他工作三年多了,没使用过多线程。
虽然八股文背的滚瓜烂熟,但是没有在实际开发过程中写的都是业务代码,没有使用过线程池,心里还是慌得一比。
我只是微微一笑,这不是很正常吗?
业务代码中一般也使不上多线程,或者说,业务代码中不知不觉你以及在使用线程池了,你再 duang 的一下搞一个出来,反而容易出事。
所以提到线程池的时候,我个人的观点是必须把它吃得透透的,但是在业务代码中少用或者不用多线程。
关于这个观点,我给你盘一下。
Demo
首先我们还是花五分钟搭个 Demo 出来。
我手边刚好有一个之前搭的一个关于 Dubbo 的 Demo,消费者、生产者都有,我就直接拿来用了:

这个 Demo 我也是跟着网上的 quick start 搞的:
cn.dubbo.apache.org/zh-cn/overv…

可以说写的非常详细了,你就跟着官网的步骤一步步的搞就行了。
我这个 Demo 稍微不一样的是我在消费者模块里面搞了一个 Http 接口:

在接口里面发起了 RPC 调用,模拟从前端页面发起请求的场景,更加符合我们的开发习惯。
而官方的示例中,是基于了 SpringBoot 的 CommandLineRunner 去发起调用:

只是发起调用的方式不一样而已,其他没啥大区别。
需要说明的是,我只是手边刚好有一个 Dubbo 的 Demo,随手就拿来用了,但是本文想要表达的观点,和你使不使用 Dubbo 作为 RPC 框架,没有什么关系,道理是通用的。
上面这个 Demo 启动起来之后,通过 Http 接口发起一次调用,看到控制台服务提供方和服务消费方都有对应的日志输出,准备工作就算是齐活儿了:

上菜
在上面的 Demo 中,这是消费者的代码:

这是提供者的代码:

整个调用链路非常的清晰:

来,请你告诉我这里面有线程池吗?
没有!
是的,在日常的开发中,我就是写个接口给别人调用嘛,在我的接口里面并没有线程池相关的代码,只有 CRUD 相关的业务代码。
同时,在日常的开发中,我也经常调用别人提供给我的接口,也是一把梭,撸到底,根本就不会用到线程池。
所以,站在我,一个开发人员的角度,这个里面没有线程池。
合理,非常合理。
但是,当我们换个角度,再看看,它也是可以有的。
比如这样:

反应过来没有?
我们发起一个 Http 调用,是由一个 web 容器来处理这个请求的,你甭管它是 Tomcat,还是 Jetty、Netty、Undertow 这些玩意,反正是个 web 容器在处理。
那你说,这个里面有线程池吗?
在方法入口处打个断点,这个 http-nio-8081-exec-1 不就是 Tomcat 容器线程池里面的一个线程吗:

通过 dump 堆栈信息,过滤关键字可以看到这样的线程,在服务启动起来,啥也没干的情况下,一共有 10 个:

朋友,这不就是线程池吗?
虽然不是你写的,但是你确实用了。
我写出来的这个 test 接口,就是会由 web 容器中的一个线程来进行调用。所以,站在 web 容器的角度,这里是有一个线程池的:

同理,在 RPC 框架中,不管是消费方,还是服务提供方,也都存在着线程池。
比如 Dubbo 的线程池,你可以看一下官方的文档:
cn.dubbo.apache.org/zh-cn/overv…

而对于大多数的框架来说,它绝不可能只有一个线程池,为了做资源隔离,它会启用好几个线程池,达到线程池隔离,互不干扰的效果。
比如参与 Dubbo 一次调用的其实不仅一个线程池,至少还有 IO 线程池和业务线程池,它们各司其职:

我们主要关注这个业务线程池。
反正站在 Dubbo 框架的角度,又可以补充一下这个图片了:

那么问题来了,在当前的这个情况下?
当有人反馈:哎呀,这个服务吞吐量怎么上不去啊?
你怎么办?
你会 duang 的一下在业务逻辑里面加一个线程池吗?

大哥,前面有个 web 容器的线程池,后面有个框架的线程池,两头不调整,你在中间加个线程池,加它有啥用啊?
web 容器,拿 Tomcat 来说,人家给你提供了线程池参数调整的相关配置,这么一大坨配置,你得用起来啊:
tomcat.apache.org/tomcat-9.0-…

再比如 Dubbo 框架,都给你明说了,这些参数属于性能调优的范畴,感觉不对劲了,你先动手调调啊:

你把这些参数调优弄好了,绝对比你直接怼个线程池在业务代码中,效果好的多。
甚至,你在业务代码中加入一个线程池之后,反而会被“反噬”。
比如,你 duang 的一下怼个线程池在这里,我们先只看 web 容器和业务代码对应的部分:

由于你的业务代码中有线程池的存在,所以当接受到一个 web 请求之后,立马就把请求转发到了业务线程池中,由线程池中的线程来处理本次请求,从而释放了 web 请求对应的线程,该线程又可以里面去处理其他请求。
这样来看,你的吞吐量确实上去了。
在前端来看,非常的 nice,请求立马得到了响应。
但是,你考虑过下游吗?
你的吞吐量上涨了,下游同一时间处理的请求就变多了。如果下游跟不上处理,顶不住了,直接就是崩给你看怎么办?

而且下游不只是你一个调用方,由于你调用的太猛,导致其他调用方的请求响应不过来,是会引起连锁反应的。
所以,这种场景下,为了异步怼个线程池放着,我觉得还不如用消息队列来实现异步化,顶天了也就是消息堆积嘛,总比服务崩了好,这样更加稳妥。
或者至少和下游勾兑一下,问问我们这边吞吐量上升,你们扛得住不。
有的小伙伴看到这里可能就会产生一个疑问了:歪师傅,你这个讲得怎么和我背的八股文不一样啊?
巧了,你背过的八股文我也背过,现在我们来温习一下我们背过的八股文。
什么时候使用线程池呢?
比如一个请求要经过若干个服务获取数据,且这些数据没有先后依赖,最终需要把这些数据组合起来,一并返回,这样经典的场景:

用户点商品详情,你要等半天才展示给用户,那用户肯定骂骂咧咧的久走了。
这个时候,八股文上是怎么说的:用线程池来把串行的动作改成并行。

这个场景也是增加了服务 A 的吞吐量,但是用线程池就是非常正确的,没有任何毛病。
但是你想想,我们最开始的这个案例,是这个场景吗?

我们最开始的案例是想要在业务逻辑中增加一个线程池,对着一个下游服务就是一顿猛攻,不是所谓的串行改并行,而是用更多的线程,带来更多的串行。
这已经不是一个概念了。
还有一种场景下,使用线程池也是合理的。
比如你有一个定时任务,要从数据库中捞出状态为初始化的数据,然后去调用另外一个服务的接口查询数据的最终状态。

如果你的业务代码是这样的:
//获取订单状态为初始化的数据(0:初始化 1:处理中 2:成功 3:失败)
//select * from order where order_status=0;
ArrayList initOrderInfoList = queryInitOrderInfoList();
//循环处理这批数据
for(OrderInfo orderInfo : initOrderInfoList){
//捕获异常以免一条数据错误导致循环结束
try{
//发起rpc调用
String orderStatus = queryOrderStatus(orderInfo.getOrderId);
//更新订单状态
updateOrderInfo(orderInfo.getOrderId,orderStatus);
} catch (Exception e){
//打印异常
}
}
虽然你框架中使用了线程池,但是你就是在一个 for 循环中不停的去调用下游服务查询数据状态,是一条数据一条数据的进行处理,所以其实同一时间,只是使用了框架的线程池中的一个线程。
为了更加快速的处理完这批数据,这个时候,你就可以怼一个线程池放在 for 循环里面了:
//循环处理这批数据
for(OrderInfo orderInfo : initOrderInfoList){
//使用线程池
executor.execute(() -> {
//捕获异常以免一条数据错误导致循环结束
try {
//发起rpc调用
String orderStatus = queryOrderStatus(orderInfo.getOrderId);
//更新订单状态
updateOrderInfo(orderInfo.getOrderId, orderStatus);
} catch (Exception e) {
//打印异常
}
});
}

需要注意的是,这个线程池的参数怎么去合理的设置,是需要考虑的事情。
同时这个线程池的定位,就类似于 web 容器线程池的定位。
或者这样对比起来看更加清晰一点:

定时任务触发的时候,在发起远程接口调用之前,没有线程池,所以我们可以启用一个线程池来加快数据的处理。
而 Http 调用或者 RPC 调用,框架中本来就已经有一个线程池了,而且也给你提供了对应的性能调优参数配置,那么首先考虑的应该是把这个线程池充分利用起来。
如果仅仅是因为异步化之后可以提升服务响应速度,没有达到串行改并行的效果,那么我更加建议使用消息队列。
好了,本文的技术部分就到这里啦。
下面这个环节叫做[荒腔走板],技术文章后面我偶尔会记录、分享点生活相关的事情,和技术毫无关系。我知道看起来很突兀,但是我喜欢,因为这是一个普通博主的生活气息。
荒腔走板

不知道你看完文章之后,有没有产生一个小疑问:最开始部分的 Demo 似乎用处并不大?
是的,我最开始构思的行文结构是是基于 Demo 在源码中找到关于线程池的部分,从而引出其实有一些我们“看不见的线程池”的存在的。
原本周六我是有一整天的时间来写这篇文章,甚至周五晚上还特意把 Demo 搞定,自己调试了一番,该打的断点全部打上,并写完 Demo 那部分之后,我才去睡觉的,想得是第二天早上起来直接就能用。
按照惯例周六睡个懒觉的,早上 11 点才起床,自己慢条斯理的做了一顿午饭,吃完饭已经是下午 1 点多了。
本来想着在沙发上躺一会,结果一躺就是一整个下午。期间也想过起来写一会文章,坐在电脑前又飞快的躺回到沙发上,就是觉得这个事情索然无味,当下的那一刻就想躺着,然后无意识的刷手机,原本是拿来写文章中关于源码的部分的时间就这样浪费了。
像极了高中时的我,周末带大量作业回家,准备来个悬梁刺股,弯道超车,结果变成了一睡一天,捏紧刹车。
高中的时候,时间浪费了是真的可惜。
现在,不一样了。
荒腔走板这张图片,就是我躺在沙发上的时候,别人问我在干什么时随手拍的一张。
我并不为躺了一下午没有干正事而感到惭愧,浪费了的时间,才是属于自己的时间。
很久以前我看到别人在做一些浪费时间的事情的时候,我心里可能会嘀咕几句,劝人惜时。
这两年我不会了,允许自己做自己,允许别人做别人。
来源:juejin.cn/post/7297980721590272040
iframe嵌入页面实现免登录思路(以vue为例)
背景:
最近实现一个功能需要使用iframe嵌入其它系统内部的一个页面,但嵌入后出现一个问题,就是一打开这个页面就会自动跳转到登录页,原因是被嵌入系统没有登录(没有token)肯定不让访问内部页面的,本文就是解决这个问题的。
附带相关文章:只要用iframe必遇到这6种"坑"之一(以Vue为例)
选择的技术方案:
本地系统使用iframe嵌入某个系统内部页面,那就证明被嵌入系统是安全的可使用的,所以可以通过通讯方式带一个token过去实现免登录,我用vue项目作为例子具体如下:
方法一通过url传:
// 发送方(本地系统):
<div>
<iframe :src="url" id="childFrame" importance="high" name="demo" ></iframe>
</div>
//被嵌入页面进行接收
url = `http://localhost:8080/dudu?mytoken={mytoken}` //
接收方:直接使用window.location.search接收,然后对接收到的进行处理
注意:
- 如果使用这个方法最好把
token加密一下,要不然直接显示在url是非常危险的行为,所以我更推荐下面方法二 - 上面接收方要在在
APP.vue文件的created生命周期接收,在嵌入页面接收是不行的,这里与VUE的执行流程有关就不多说了
方法二通过iframe的通讯方式传(推荐):
// 发送方(本地系统):
var params = {
type: "setToken",
token: "这是伟过去的token"
}
window.parent.postMessage(params, "*");
// 接收方(被嵌入系统):在APP.vue文件的created生命周期接收
window.addEventListener( "message",
(e)=>{
if(e.data.type === 'setToken'){
//这里拿到token,然后放入缓存实在免登录即可
}
}
false);
注意: 上面接收方要在在APP.vue文件的created生命周期接收,在嵌入页面接收是不行的,这里与VUE的执行流程有关就不多说了
补充:
看着评论不少疑问,所以我就按我个人的思路去补充回答一下,但不绝对实用,欢迎互相指导
(1)如果不同源系统怎么办?
正常使用上述方法二进行通迅,但不带token过去因为不同源根本无法通用,直接在被嵌入页面请求token,这个要和后端沟通好怎么获取
// 接收方(被嵌入系统):在APP.vue文件的created生命周期接收
window.addEventListener( "message",
(e)=>{
if(e.data.type === 'setToken'){
//这里在被嵌入页面请求接口获取这个系统的token,然后放到缓存中免登录
}
}
false);
(2)如果两个系统保存token字段相当怎么办?
例如:主系统本地存储的token叫:access_token , iframe嵌入的系统采用的token也叫:access_token
这分为两种情况:(1)同源并且token字段相同 (2)不同源并且token字段相当
(1)同源并且token字段相同
这种情况同源+token字段相同,根本不会出现需要登录的情况,因为同一个浏览器缓存都能拿到并且又是通用token
(2)不同源并且token字段相当
这种情况只有嵌入系统和本地系统两种情况它们并不会同时出现的,那么只要判断当前是那个情况就行,然后给对应的token
方案:请求在拦截器那里判断当前请求来自那个系统的页面,然后给对应的token
例如:两个系统都要传my_token字段给后端,如果都放缓存就会覆盖,所以直接本地系统放到token1缓存,嵌入系统放到token2缓存,拦截器判断后如果本来系统页面 my_token=token1,嵌入页面 my_token=token2
来源:juejin.cn/post/7350876924393209894
啊,富文本没做安全处理被XSS攻击了啊
前言
相信很多前端小伙伴项目中都用到了富文本,但你们有没有做防XSS攻击处理?最近的项目由于比较紧急我也没有处理而是直接正常使用,但公司内部有专门的安全部门针对测试,然后测出来富文本被XSS攻击了,而且危险级别为高。
啊这....,那我就去解决一下吧,顺便从XSS和解决方案两个角度记录到下来毕竟好久没更新文章了。
先说说什么是XSS攻击?
简述:XSS全称Cross-Site Scripting也叫跨站脚本攻击,是最最最常见的网络安全漏洞,其实就是攻击者在受害者的浏览器中注入恶意脚本执行。这种攻击通常发生在 Web 应用程序未能正确过滤用户输入的情况下,导致恶意脚本被嵌入到合法的网页中。
执行后会产生窃取信息、篡改网页、和传播病毒与木马等危害,后果相当严重。
XSS又有三大类
1、存储型 XSS即Stored XSS
恶意的脚本被放置在目标服务器上面,通过正常的网页请求返回给用户端执行。
例如 在观看某个私人博客评论中插入恶意脚本,当其他用户访问该页面时,脚本会执行危险操作。
2、反射型 XSS即Reflected XSS
恶意的脚本通过 URL 参数或一些输入的字段传递给目标的服务器,用户在正常请求时会返回并且执行。
例如 通过链接中的参数后面注入脚本,当用户点击此链接时,脚本就会在用户的浏览器中执行危险操作。
3、DOM 基于的 XSS即DOM-based XSS
恶意的脚本利用 DOM(Document Object Model)操作来修改页面内容。
这种类型的 XSS 攻击不涉及服务器端的代码操作,仅仅是通过客户端插入 JavaScript 代码实现操作。
富文本就是属于第一种,把脚本藏在代码中存到数据库,然后用户获取时会执行。
富文本防XSS的方式?
网上一大堆不明不白的方法还有各种插件可以用,但其实自己转义一下就行,根本不需要复杂化。
当我们不做处理时传给后台的富文本数据是这样的。

上面带有标签,甚至有src和script之类的操作,在里面放一些脚本真的太简单了。
因此,我们创建富文本成功提交给后台的时候把各种<>/\之类危险符号转义成指定的字符就能防止脚本了。
如下所示,方法参数value就是要传递给后台的富文本内容。
export const getXssFilter = (value: string): string => {
// 定义一个对象来存储特殊字符及其对应的 HTML 实体
const htmlEntities = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
'\'': ''',
'\\': '\',
'|': '|',
';': ';',
'$': '$',
'%': '%',
'@': '@',
'(': '(',
')': ')',
'+': '+',
'\r': ' ',
'\n': ' ',
',': ',',
};
// 使用正则表达式替换所有特殊字符
let result = value.replace(/[&<>"'\\|;$%@()+,]/g, function (match) {
return htmlEntities[match] || match;
});
return result;
};
此时传给后台的富文本参数是这样的,把敏感符号全部转义。

但展现给用户看肯定要看正常的内容啊,这里就要把内容重新还原了,这步操作可以在前端完成,也可以在后端完成。
如果是前端完成可以用以下方法把获取到的数据进行转义。
// 还原特殊字符
export const setXssFilter = (input) => {
return input
.replace(/|/g, '|')
.replace(/&/g, '&')
.replace(/;/g, ';')
.replace(/$/g, '$')
.replace(/%/g, '%')
.replace(/@/g, '@')
.replace(/'/g, '\'')
.replace(/"/g, '"')
.replace(/\/g, '\\')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/(/g, '(')
.replace(/)/g, ')')
.replace(/+/g, '+')
.replace(/ /g, '\r')
.replace(/ /g, '\n')
.replace(/,/g, ',');
}
但是。。。。
上面只适合使用于纯富文本的场景,如果在普通文本的地方回显会依然触发危险脚本。如下所示

其实直接转义后不还原即可解决,但由于是富文本这种情况比较特殊情况,不还原就失去文本样式了,怎么办??
最终解决方案是对部分可能造成XSS攻击的特殊字符和标签进行转义处理,例如:script、iframe等。
示例代码
export const getXssFilter = (value: string): string => {
// 定义一个对象来存储特殊字符及其对应的 HTML 实体
const htmlEntities = {
'&': '&',
'\'': ''',
'\r': ' ',
'\n': ' ',
'script': 'script',
'iframe': 'iframe',
// 'img': 'img',
'object': 'ojst',
'embed': 'embed',
'on': 'on',
'javascript': 'javascript',
'expression': 'expresssion',
'video': 'video',
'audio': 'audio',
'svg': 'svg',
'background-image': 'background-image',
};
// 使用正则表达式替换所有特殊字符
let result = value.replace(/[&<>"'\\|;$%@()+,]/g, function (match) {
return htmlEntities[match] || match;
});
// 额外处理 `script`、`iframe`、`img` 等关键词
result = result.replace(/script|iframe|object|embed|on|javascript|expression|background-image/gi, function (match) {
return htmlEntities[match] || match;
});
return result;
};
效果只会对敏感部分转义

但这种方案不用还原转义,因为做的针对性限制。
小结
其实就是对特殊符号转换后还原的思路,相当的简单。
如果那里写的不好或者有更好的建议,欢迎大佬指点啦。
来源:juejin.cn/post/7415911762128404480
大厂必问 · 如何防止订单重复?
在电商系统或任何涉及订单操作的场景中,用户多次点击“提交订单”按钮可能会导致重复订单提交,造成数据冗余和业务逻辑错误,导致库存问题、用户体验下降或财务上的错误。因此,防止订单重复提交是一个常见需求。
常见的重复提交场景
- 网络延迟:用户在提交订单后未收到确认,误以为订单未提交成功,连续点击提交按钮。
- 页面刷新:用户在提交订单后刷新页面,触发订单的重复提交。
- 用户误操作:用户无意中点击多次订单提交按钮。
防止重复提交的需求
- 幂等性保证:确保相同的请求多次提交只能被处理一次,最终结果是唯一的。
- 用户体验保障:避免由于重复提交导致用户感知的延迟或错误。
常用解决方案
前端防重机制:在前端按钮点击时禁用按钮或加锁,防止用户多次点击。
后端幂等处理:
- 利用Token机制:在订单生成前生成一个唯一的Token,保证每个订单提交时只允许携带一次Token。
- 基于数据库的唯一索引:通过对订单字段(如订单号、用户ID)创建唯一索引来防止重复数据的插入。
- 分布式锁:使用Redis等分布式缓存加锁,保证同一时间只允许处理一个订单请求。
功能实践
Spring Boot 提供了丰富的工具和库,今天我们基于Spring Boot框架,可以利用 Token机制 和 Redis分布式锁 来防止订单的重复提交。
功能原理与技术实现
通过Redis的原子性操作,我们可以确保高并发情况下多个请求对同一个订单的操作不会冲突。

Token机制
Token机制是一种常见的防止重复提交的手段,通常的工作流程如下:
- Token生成:在用户开始提交订单时,服务器生成一个唯一的
OrderToken并将其存储在 Redis 等缓存中,同时返回给客户端。 - Token验证:用户提交订单时,客户端会将
OrderToken发送回服务器。服务器会验证此OrderToken是否有效。 - Token销毁:一旦验证通过,服务器会立即销毁
OrderToken,防止重复使用同一个Token提交订单。
这种机制确保每次提交订单时都需要一个有效且唯一的Token,从而有效防止重复提交。
Redis分布式锁
在多实例的分布式环境中,Token机制可以借助 Redis 来实现更高效的分布式锁:
- Token存储:生成的Token可以存储在Redis中,Token的存活时间通过设置TTL(如10分钟),保证Token在一定时间内有效。
- Token校验与删除:当用户提交订单时,服务器通过Redis查询该Token是否存在,并立即删除该Token,确保同一个订单只能提交一次。
流程设计
- 用户发起订单请求时,后端生成一个唯一的Token(例如UUID),并将其存储在Redis中,同时将该Token返回给前端。
- 前端提交订单时,将Token携带至后端。
- 后端校验该Token是否有效,若有效则执行订单创建流程,同时删除Redis中的该Token,确保该Token只能使用一次。
- 如果该Token已被使用或过期,则返回错误信息,提示用户不要重复提交。
功能实现
依赖配置(pom.xml)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
application. properties
# Thymeleaf ??
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.suffix=.html
spring.thymeleaf.mode=HTML
spring.thymeleaf.encoding=UTF-8
spring.thymeleaf.cache=false
spring.redis.host=127.0.0.1
spring.redis.port=23456
spring.redis.password=pwd
订单Token生成服务
生成Token并存储到Redis: 当用户请求生成订单页面时,服务器生成一个唯一的UUID作为订单Token,并将其与用户ID一起存储在Redis中。
package com.example.demo.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import java.util.UUID;
import java.util.concurrent.TimeUnit;
@Service
@Slf4j
public class OrderTokenService {
@Autowired
private RedisTemplate<String, String> redisTemplate;
// 生成订单Token
public String generateOrderToken(String userId) {
String token = UUID.randomUUID().toString();
// 将Token存储在Redis中,设置有效期10分钟
redisTemplate.opsForValue().set("orderToken:" + userId, token, 10, TimeUnit.MINUTES);
return token;
}
// 验证订单Token
public boolean validateOrderToken(String userId, String token) {
String redisToken = redisTemplate.opsForValue().get("orderToken:" + userId);
log.info("@@ 打印Redis中记录的redisToken :{} `VS` @@ 打印当前请求过来的token :{}", redisToken, token);
if (token.equals(redisToken)) {
// 验证成功,删除Token
redisTemplate.delete("orderToken:" + userId);
return true;
}
return false;
}
}
订单控制器
订单提交与验证Token: 提交订单时,系统会检查用户传递的Token是否有效,若有效则允许提交并删除该Token,确保同一Token只能提交一次。
package com.example.demo.controller;
import com.example.demo.entity.Order;
import com.example.demo.service.OrderTokenService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderTokenService orderTokenService;
// 获取订单提交的Token
@GetMapping("/getOrderToken")
public ResponseEntity<String> getOrderToken(@RequestParam String userId) {
String token = orderTokenService.generateOrderToken(userId);
return ResponseEntity.ok(token);
}
// 提交订单
@PostMapping("/submitOrder")
public ResponseEntity<String> submitOrder(Order order) {
// 校验Token
if (!orderTokenService.validateOrderToken(order.getUserId(), order.getOrderToken())) {
return ResponseEntity.status(HttpStatus.BAD_REQUEST).body("订单重复提交,请勿重复操作");
}
// 此处处理订单逻辑
// ...
// 假设订单提交成功
return ResponseEntity.ok("订单提交成功");
}
}
前端实现
前端通过表单提交订单,并在每次提交前从服务器获取唯一的订单Token:
<script>
document.getElementById('orderForm').addEventListener('submit', function(event) {
event.preventDefault();
const userId = document.getElementById('userId').value;
if (!userId) {
alert("请填写用户ID");
return;
}
// 先获取Token,再提交订单
fetch(`/order/getOrderToken?userId=${userId}`)
.then(response => response.text())
.then(token => {
document.getElementById('orderToken').value = token;
// 提交订单请求
const formData = new FormData(document.getElementById('orderForm'));
fetch('/order/submitOrder', {
method: 'POST',
body: formData
})
.then(response => response.text())
.then(result => {
document.getElementById('message').textContent = result;
})
.catch(error => {
document.getElementById('message').textContent = '订单提交失败,请重试';
});
})
.catch(error => {
document.getElementById('message').textContent = '获取Token失败';
});
});
</script>
为了验证功能,我们在代码中增加 Thread.sleep(2000); 来进行阻塞。

然后快速点击提交表单,可以看到提示表单重复提价的信息

**技术选型与优化:**通过Redis结合Token机制,我们有效地防止了订单的重复提交,并通过Token的唯一性和时效性保证了订单操作的幂等性。
- Redis缓存:通过Redis的分布式锁和高并发处理能力,确保系统在高并发情况下仍然可以正常运行,并发订单提交的场景中不会出现Token重复使用问题。
- UUID:使用UUID生成唯一的Token,保证Token的唯一性和安全性。
- Token时效性:Token通过设置Redis的TTL(过期时间)来控制有效期,避免无效Token长期占用资源。
总结
防止订单重复提交的关键在于:
- Token的唯一性与时效性:确保每次订单提交前都有唯一且有效的Token。
- Token的原子性验证与删除:在验证Token的同时删除它,防止同一个Token被多次使用。
- Redis的高效存储与分布式锁:通过Redis在高并发环境中提供稳定的锁机制,保证并发提交的准确性。
这套基于Token机制和Redis的解决方案具有简单、高效、可扩展的特点,适合各种高并发场景下防止重复订单提交。
来源:juejin.cn/post/7418776600738840628
现在前端组长都是这样做 Code Review
前言
Code Review 是什么?
Code Review 通常也简称 CR,中文意思就是 代码审查
一般来说 CR只关心代码规范和代码逻辑,不关心业务
但是,如果CR的人是组长,建议有时间还是看下与自己组内相关业务,能避免一些生产事故的发生
作为前端组长做 Code Review 有必要吗?
主要还是看公司业务情况吧,如果前端组长需求不多的情况,是可以做下CR,能避免一些生产事故
- 锻炼自己的
CR能力 - 看看别人的代码哪方面写的更好,学习总结
- 和同事交流,加深联系
- 你做了
CR,晋升和面试,不就有东西吹了不是
那要怎么去做Code Review呢?
可以从几个方面入手
- 项目架构规范
- 代码编写规范
- 代码逻辑、代码优化
- 业务需求
具体要怎么做呢?
传统的做法是PR时查看,对于不合理的地方,打回并在PR中备注原因或优化方案
每隔一段时间,和组员开一个简短的CR分享会,把一些平时CR过程中遇到的问题做下总结
当然,不要直接指出是谁写出的代码有问题,毕竟这不是目的,分享会的目的是交流学习
人工CR需要很大的时间精力,与心智负担
随着 AI 的发展,我们可以借助一些 AI 来帮我们完成CR
接下来,我们来看下,vscode中是怎么借助 AI 工具来 CR 的
安装插件 CodeGeex

新建一个项目
mkdir code-review
cd code-review
创建 test.js 并用 vscode 打开
cd .>test.js
code ./

编写下 test.js
function checkStatus() {
if (isLogin()) {
if (isVip()) {
if (isDoubleCheck()) {
done();
} else {
throw new Error("不要重复点击");
}
} else {
throw new Error("不是会员");
}
} else {
throw new Error("未登录");
}
}
这是连续嵌套的判断逻辑,要怎么优化呢?
侧边栏选择这个 AI 插件,选择我们需要CR的代码
输入 codeRiview,回车

我们来看下 AI 给出的建议

AI 给出的建议还是很不错的,我们可以通过更多的提示词,优化它给出的修改建议,这里就不过多赘述了
通常我们优化这种类型的代码,基本优化思路也是,前置校验逻辑,正常逻辑后置
除了CodeGeex外,还有一些比较专业的 codeRiview 的 AI 工具
比如:CodeRabbit
那既然都有 AI 工具了,我们还需要自己去CR 吗?
还是有必要的,借助 AI 工具我们可以减少一些阅读大量代码环节,提高效率,减少 CR 的时间
但是仍然需要我们根据 AI 工具的建议进行改进,并且总结,有利于拓宽我们见识,从而写出更优质的代码
具体 CR 实践
判断逻辑优化
1. 深层对象判空
// 深层对象
if (
store.getters &&
store.getters.userInfo &&
store.getters.userInfo.menus
) {}
// 可以使用 可选链进行优化
if (store?.getters?.userInfo?.menus) {}
2. 空函数判断
优化之前
props.onChange && props.onChange(e)
支持 ES11 可选链写法,可这样优化,js 中需要这样,ts 因为有属性校验,可以不需要判断,当然也特殊情况
props?.onChange?.(e)
老项目,不支持 ES11 可以这样写
const NOOP = () => 8
const { onChange = NOOP } = props
onChange(e)
3. 复杂判断逻辑抽离成单独函数
// 复杂判断逻辑
function checkGameStatus() {
if (remaining === 0 ||
(remaining === 1 && remainingPlayers === 1) ||
remainingPlayers === 0) {
quitGame()
}
}
// 复杂判断逻辑抽离成单独函数,更方便阅读
function isGameOver() {
return (
remaining === 0 ||
(remaining === 1 && remainingPlayers === 1) ||
remainingPlayers === 0
);
}
function checkGameStatus() {
if (isGameOver()) {
quitGame();
}
}
4. 判断处理逻辑正确的梳理方式
// 判断逻辑不要嵌套太深
function checkStatus() {
if (isLogin()) {
if (isVip()) {
if (isDoubleCheck()) {
done();
} else {
throw new Error('不要重复点击');
}
} else {
throw new Error('不是会员');
}
} else {
throw new Error('未登录');
}
}
这个是不是很熟悉呀~
没错,这就是使用 AI 工具 CR的代码片段
通常这种,为了处理特殊状况,所实现的判断逻辑,都可以采用 “异常逻辑前置,正常逻辑后置” 的方式进行梳理优化
// 将判断逻辑的异常逻辑提前,将正常逻辑后置
function checkStatus() {
if (!isLogin()) {
throw new Error('未登录');
}
if (!isVip()) {
throw new Error('不是会员');
}
if (!isDoubleCheck()) {
throw new Error('不要重复点击');
}
done();
}
函数传参优化
// 形参有非常多个
const getMyInfo = (
name,
age,
gender,
address,
phone,
email,
) => {
// ...
}
有时,形参有非常多个,这会造成什么问题呢?
- 传实参是的时候,不仅需要知道传入参数的个数,还得知道传入顺序
- 有些参数非必传,还要注意添加默认值,且编写的时候只能从形参的后面添加,很不方便
- 所以啊,那么多的形参,会有很大的心智负担
怎么优化呢?
// 行参封装成对象,对象函数内部解构
const getMyInfo = (options) => {
const { name, age, gender, address, phone, email } = options;
// ...
}
getMyInfo(
{
name: '张三',
age: 18,
gender: '男',
address: '北京',
phone: '123456789',
email: '123456789@qq.com'
}
)
你看这样是不是就清爽了很多了
命名注释优化
1. 避免魔法数字
// 魔法数字
if (state === 1 || state === 2) {
// ...
} else if (state === 3) {
// ...
}
咋一看,这 1、2、3 又是什么意思啊?这是判断啥的?
语义就很不明确,当然,你也可以在旁边写注释
更优雅的做法是,将魔法数字改用常量
这样,其他人一看到常量名大概就知道,判断的是啥了
// 魔法数字改用常量
const UNPUBLISHED = 1;
const PUBLISHED = 2;
const DELETED = 3;
if (state === UNPUBLISHED || state === PUBLISHED) {
// ...
} else if (state === DELETED) {
// ...
}
2. 注释别写只表面意思
注释的作用:提供代码没有提供的额外信息
// 无效注释
let id = 1 // id 赋值为 1
// 有效注释,写业务逻辑 what & why
let id = 1 // 赋值文章 id 为 1
3. 合理利用命名空间缩短属性前缀
// 过长命名前缀
class User {
userName;
userAge;
userPwd;
userLogin() { };
userRegister() { };
}
如果我们把前面的类里面,变量名、函数名前面的 user 去掉
似乎,也一样能理解变量和函数名称所代表的意思
代码却,清爽了不少
// 利用命名空间缩短属性前缀
class User {
name;
age;
pwd;
login() {};
register() {};
}
分支逻辑优化
什么是分支逻辑呢?
使用 if else、switch case ...,这些都是分支逻辑
// switch case
const statusMap = (status: string) => {
switch(status) {
case 'success':
return 'SuccessFully'
case 'fail':
return 'failed'
case 'danger'
return 'dangerous'
case 'info'
return 'information'
case 'text'
return 'texts'
default:
return status
}
}
// if else
const statusMap = (status: string) => {
if(status === 'success') return 'SuccessFully'
else if (status === 'fail') return 'failed'
else if (status === 'danger') return 'dangerous'
else if (status === 'info') return 'information'
else if (status === 'text') return 'texts'
else return status
}
这些处理逻辑,我们可以采用 映射代替分支逻辑
// 使用映射进行优化
const STATUS_MAP = {
'success': 'Successfull',
'fail': 'failed',
'warn': 'warning',
'danger': 'dangerous',
'info': 'information',
'text': 'texts'
}
return STATUS_MAP[status] ?? status
【扩展】
?? 是 TypeScript 中的 “空值合并操作符”
当前面的值为 null 或者 undefined 时,取后面的值
对象赋值优化
// 多个对像属性赋值
const setStyle = () => {
content.body.head_style.style.color = 'red'
content.body.head_style.style.background = 'yellow'
content.body.head_style.style.width = '100px'
content.body.head_style.style.height = '300px'
// ...
}
这样一个个赋值太麻烦了,全部放一起赋值不就行了
可能,有些同学就这样写
const setStyle = () => {
content.body.head_style.style = {
color: 'red',
background: 'yellow',
width: '100px',
height: '300px'
}
}
咋一看,好像没问题了呀?那 style 要是有其他属性呢,其他属性不就直接没了吗~
const setStyle = () => {
content.body.head_style.style = {
...content.body.head_style.style
color: 'red',
background: 'yellow',
width: '100px',
height: '300px'
}
}
采用展开运算符,将原属性插入,然后从后面覆盖新属性,这样原属性就不会丢了
隐式耦合优化
// 隐式耦合
function responseInterceptor(response) {
const token = response.headers.get("authorization");
if (token) {
localStorage.setItem('token', token);
}
}
function requestInterceptor(response) {
const token = localStorage.getItem('token');
if (token) {
response.headers.set("authorization", token);
}
}
这个上面两个函数有耦合的地方,但是不太明显
比如这样的情况,有一天,我不想在 responseInterceptor 函数中保存 token 到 localStorage了
function responseInterceptor(response) {
const token = response.headers.get("authorization");
}
function requestInterceptor(response) {
const token = localStorage.getItem('token');
if (token) {
response.headers.set("authorization", token);
}
}
会发生什么?
localStorage.getItem('token')一直拿不到数据,requestInterceptor 这个函数就报废了,没用了
函数 responseInterceptor改动,影响到函数 requestInterceptor 了,隐式耦合了
怎么优化呢?
// 将隐式耦合的常数抽离成常量
const TOKEN_KEY = "authorization";
const TOKEN = 'token';
function responseInterceptor(response) {
const token = response.headers.get(TOKEN_KEY);
if (token) {
localStorage.setItem(TOKEN_KEY, token);
}
}
function requestInterceptor(response) {
const token = localStorage.getItem(TOKEN_KEY);
if (token) {
response.headers.set(TOKEN_KEY, token);
}
}
这样做有什么好处呢?比刚才好在哪里?
还是刚才的例子,我去掉了保存 localStorage.setItem(TOKEN_KEY, token)
我可以根据TOKEN_KEY这个常量来查找还有哪些地方用到了这个 TOKEN_KEY,从而进行修改,就不会出现冗余,或错误
不对啊,那我不用常量,用token也可以查找啊,但你想想 token 这个词是不是得全局查找,其他地方也会出现token
查找起来比较费时间,有时可能还会改错了
用常量的话,全局查找出现重复的概率很小
而且如果你是用 ts 的话,window 下鼠标停在常量上,按 ALT 键就能看到使用到这个常量的地方了,非常方便
小结
codeRiview(代码审查)不仅对个人技能的成长有帮助,也对我们在升职加薪、面试有所裨益
CR 除了传统的方式外,也可以借助 AI 工具,来简化其中流程,提高效率
上述的优化案例,虽然优化方式不同,但是核心思想都是一样,都是为了代码 更简洁、更容易理解、更容易维护
当然了,优化方式还有很多,如果后期遇到了也会继续补充进来
来源:juejin.cn/post/7394792228215128098
简单的 Web 端实时日志实现

背景
cron service 在执行定时任务时,需要能够实时查看该任务的执行日志以确保程序正确的工作。为了能够在尽可能短的时间内实现该功能,我们需要一个足够简单的方案。
方案如何选择?
我相信大多数开发者第一个想到的就是 WebSocket ,然后是 HTTP/SSE 。WebSocket 在很多情况下是实至名归的万金油选择。但这这里他太重了,对服务端和客户端具有侵入性需要花费额外的时间来集成到项目中。
那么 SSE 呢,为什么不是他?
虽然 SSE 即轻量又实时,但 SSE 无法设置请求头。这导致无法使用缓存和通过请求头设置的 Token。而且作为长链接他还一直占用并发额度。
WebSocket:❌
- 优势:
- 实时性高
- 不会占用 HTTP 并发额度
- 劣势:
- 复杂度较高,需要在客户端和服务器端都进行特殊的处理
- 消耗更多的服务器资源。
- 优势:
SSE(Server-Sent Events):❌
- 优势:
- 基于HTTP协议,不需要在服务端和客户端做额外的处理
- 实时性高
- 劣势:
- 无法设置请求头
- 占用 HTTP 并发额度
- 优势:
HTTP:✅
- 优势:
- 简单易用,不需要在服务端和客户端做额外的处理。
- 支持的功能丰富,如缓存,压缩,认证等功能。
- 劣势:
- 实时性差,取决于轮询时间间隔。
- 每次HTTP请求都需要建立新的连接(仅针对 HTTP/0.x 而言)并可能阻塞同源的其他请求而导致性能问题。12
- HTTP/1.x 支持持久连接以避免每次请求都重新建立 TCP 连接,但数据通信是串行的。
- HTTP/2.x 支持持久连接且支持并行的数据通信。
- 优势:
以上列出的优缺点是仅对于本文所讨论的场景(即Web 端的实时日志)而言,这三种数据交互技术在其他场景中的优缺点不在本文讨论范围内。
实现
HTTP 轮询已经是老熟人了,不再做介绍。本文的着重于实时日志的实现及优化。
sequenceDiagram
participant 浏览器
participant 服务器
Note right of 浏览器: 首先,获取日志文件最后 X bytes 的内容
浏览器->>服务器: 最新的日志文件有多大?
服务器->>浏览器: 日志文件大小: Y bytes
浏览器->>服务器: 从 Y - X bytes 处返回内容
服务器->>浏览器: 日志文件大小: Y1 bytes, 日志内容: XXXX
loop 持续轮询获取最新的日志
浏览器->>服务器: 从 Y1 bytes 处返回内容
服务器->>浏览器: 日志文件大小: Y2 bytes, 日志内容: XXXX
end
上方是基本工作原理的流程图。
实现的关键点在于
- 前端如何知道日志文件当前的大小
- 服务端如何从指定位置获取日志文件内容
这两点都可以通过 HTTP Header 来解决。Content-Range HTTP 响应头会包含完整文件的大小,而 Range HTTP 请求头可以指示服务器返回指定位置的文件内容。
因此在服务端不需要额外的逻辑,仅通过 Web 端代码就可以实现实时日志功能。
代码实现
篇幅限制,代码不会处理异常情况
首先,根据上述流程图。我们需要获取日志文件的大小。
const res = await fetch(URL, {
method: "GET",
headers: { Range: "bytes=0-0" }
});
const contentRange = res.headers.get("Content-Range") || "";
const match = /bytes (\d+)-(\d+)\/(\d+)/.exec(contentRange);
// 日志文件大小
const total = Number.parseInt(match[3], 10);
Range: "bytes=0-0"指定仅获取第一个字节的内容,以免较大的日志文件导致响应时间过长。
我们发起了一个 GET 请求并将 Range 请求头设置为 bytes=0-0 如果服务器能够正确处理 Range 请求头,响应中将包含一个 Content-Range 列其中将包含日志文件的完整大小,可以通过正则解析拿到。
现在我们已经拿到了日志文件的大小并存储在名为 total 的变量中。然后根据 total 获取到最后 10 KB 的日志内容。
const res = await fetch(url, {
method: "GET",
headers: {
Range: `bytes=${total - 1000 * 10}-`
}
});
const contentRange = res.headers.get("Content-Range") || "";
const match = /bytes (\d+)-(\d+)\/(\d+)/.exec(contentRange);
// 下一次请求的起始位置
const start = Number.parseInt(match[2], 10) + 1;
// 日志内容
const content = await res.text();
现在我们发起了一个 GET 请求并将 Range 请求头设置为 bytes=${total - 1000 * 10}- 以获取最后 10 KB 的日志内容。并且通过正则解析拿到了下一次请求的起始位置。
现在我们已经拿到了日志文件的大小和最后 10 KB 的日志内容。接下来就是持续轮询去获取最新的日志。轮询代码区别仅在于将 Range 标头设置为 bytes=${start}- 以便获取最新的日志。
const res = await fetch(url, {
method: "GET",
headers: {
Range: `bytes=${start}-`
}
});
const contentRange = res.headers.get("Content-Range") || "";
const match = /bytes (\d+)-(\d+)\/(\d+)/.exec(contentRange);
// 下一次请求的起始位置
start = Number.parseInt(match[2], 10) + 1;
// 日志内容
const content = await res.text();
以上,基本的功能已经实现了。日志内容保存在名为 content 的变量中。
优化
HTTP 轮询常因其高延迟为人诟病,我们可以通过指数退避的方式来尽可能的降低延时且不会显著的增加服务器负担。
指数退避是一种常见的网络重试策略,它会在每次重试时将等待时间乘以一个固定的倍数。这样做的好处是,当网络出现问题时,重试的时间间隔会逐渐增加,直到达到最大值。
一个简单的实现如下:
/**
* 使用指数退避策略获取日志.
*/
export class ExponentialBackoff {
private readonly base: number;
private readonly max: number;
private readonly factor: number;
private retries: number;
/**
* @param base 基础延迟时间 默认 1000ms (1秒)
* @param max 最大延迟时间 默认 60000ms (1分钟)
* @param factor 延迟时间增长因子 默认 2
*/
constructor(base: number = 1000, max: number = 60000, factor: number = 2) {
this.base = base;
this.max = max;
this.factor = factor;
this.retries = 0;
}
/**
* 获取下一次重试的延迟时间.
*/
next() {
const delay = Math.min(this.base * Math.pow(this.factor, this.retries), this.max);
this.retries++;
return delay;
}
/**
* 重置重试次数.
*/
reset() {
this.retries = 0;
}
}
值得一提的是带有 Range 标头的请求成功时会返回 206 Partial Content 状态码。而在请求的范围超出文件大小时会返回 416 Range Not Satisfiable 状态码。我们可以通过这两个状态码来判断请求是否成功。
成功时调用 reset 方法重置重试次数,失败时调用 next 方法获取下一次重试的延迟时间。
总结
即使再优秀的方案也不是银弹,真正合适的方案需要考虑的不仅仅是技术本身,还有业务场景,团队技术栈,团队技术水平等等。在选择技术方案时,我们需要权衡各种因素,而不是盲目的选择最流行的技术。
当我们责备现有的技术方案为何如此糟糕时,或许在那个时间点上,这个方案是最合适的。

感谢以下网友的帮助和建议:齐洛格德
Footnotes
来源:juejin.cn/post/7337519776796295177
方寸之间窥万象——这样的Tooltip,你会开发吗?
序言
提示信息(tooltip)是一种常见的 GUI 元素。在可视化领域,tooltip 通常指用户将鼠标悬停在图元上或者图表区域时弹出的明细数据信息框。如果是桌面环境,通常会在用户将指针悬停在元素上而不单击它时显示 tooltip;如果是移动环境,通常会在长按(即点击并按住)元素时显示 tooltip。
这样一个小小的组件,却可以十分有效地丰富图表的数据展现能力和图表交互效果,同时在实际业务领域的用途也非常广泛。
近些年来,业界主要图表库(如ECharts、G2等)都提供了 tooltip 的配置能力和默认渲染能力,以达到开箱即用的效果。VChart 更不例外,提供了更加灵活的 tooltip 展示与配置方案。
通过使用 VChart,你既可以显示图表中任何系列的图元所携带的数据信息(mark tooltip):

也可以显示某个特定维度项下的所有图元的数据信息(dimension tooltip):

乃至可以灵活地自定义 tooltip,甚至在其中插入子图表,拓展交互的边界:

本文将通过一些实战案例,详细讲述 VChart 提示信息的重点用法、自定义方式以及设计细节。
示例一:可触及的 tooltip,与 Amazon 的安全三角形
为了不对用户的鼠标交互进行干扰,VChart 的 tooltip 默认不会响应鼠标事件。但是在某些情况,用户却希望鼠标可以移到 tooltip 中进行一些额外的交互行为,比如点击 tooltip 中的按钮和链接,或者选取并复制一些数据。
为了满足这类需求,tooltip 支持在 spec 中配置 enterable 属性。如果不配置或者配置 enterable: false,默认效果是这样的,鼠标无法移到 tooltip 元素内:

而如果配置 enterable: true,效果如以下截图所示:

图表简化版 spec 为:
const spec = {
type: 'waterfall',
data: [], // 数据略
legends: { visible: true, orient: 'bottom' },
xField: 'x',
yField: 'y',
seriesField: 'type',
total: {
type: 'field',
tagField: 'total'
},
title: {
visible: true,
text: 'Chinese quarterly GDP in 2022'
},
tooltip: {
enterable: true // TOOLTIP SPEC
}
};
const vchart = new VChart(spec, { dom: CONTAINER_ID });
vchart.renderSync();
简单对比两个 tooltip 的效果,可以发现后者在鼠标靠近 tooltip 时,tooltip 便适时地停住了。
这个小小的交互细节里却有些文章,灵感来源直接来自 Amazon 的官网实现。
这个例子也许已经为人熟知,我们简单回顾一下。这首先要从普通网站的下拉菜单开始讲起:

在一个设计欠佳的菜单组件里(如 bootstrap),鼠标从一级菜单移入二级菜单往往是很困难的,很容易触发二级菜单的隐藏策略,从而变成一场无聊的打地鼠游戏。
但是 Amazon 早期官网的菜单,由于用户使用频率高,根本无法接受这样的体验。于是他们完美地解决了这个问题,并成为一个交互优化的经典案例。
其思路的核心,便是检测鼠标移动的方向。如果鼠标移动到下图的蓝色三角形中,当前显示的子菜单将继续打开一小会儿:

在鼠标的每个位置,你可以想象鼠标当前位置与下拉菜单的右上角和右下角之间形成一个三角形。如果下一个鼠标位置在该三角形中,说明用户可能正在将鼠标移向当前显示的子菜单。Amazon 利用这一点实现了很好的效果。只要鼠标停留在该蓝色三角形中,当前子菜单就会保持打开。如果鼠标移出该三角形,他们会立即切换子菜单,使其感觉非常敏捷。
整体效果类似于下图所示:

正所谓,上帝在细节中(God is in the details)。从这个交互优化里,我们看到的不仅是一个精妙的算法,而是一个科技巨头对于产品和用户体验的态度。Amazon 的数百亿市值有多少是从这些很小很小,但是明显很用心的产品细节中积累起来的呢?

VChart 的 tooltip 也一样,着重参考了 Amazon 的交互优化。如果配置 enterable: true,在每个时刻,都会存在一个这样的“安全三角形”,三个顶点分别是鼠标光标以及 tooltip 的两个端点,取面积最大的三角形:

如果鼠标在下一刻滑到这个三角形区域中, tooltip 便为鼠标“停留一会儿”,直到鼠标移到 tooltip 区域内。

但是在鼠标移到 tooltip 区域之前,tooltip 并不会永远停下来等待鼠标。如果鼠标过于缓慢地靠近 tooltip,tooltip 还是会离开的(变成一场失败、却又在意料之中的奔赴)。这样便可以同时保证用户鼠标有足够的行动自由度。以下示例特地将鼠标移动速度放慢,便可以实现既进入三角形区域,又不会被 tooltip “挡路”:

作为对比,ECharts 的 tooltip 虽然同样支持 enterable 属性,但是 ECharts 主要通过简单的 tooltip 缓动来支持鼠标移入,鼠标仍需要不停地“追逐” tooltip 才能移至其中,灵活性便打了折扣。以下为 ECharts 的效果:

示例二:灵活的 pattern,内容与样式的自由配置
为了尽最大可能满足更多业务方的需求,VChart 的 tooltip 支持比较灵活的内容和样式配置。下文将以官网 demo(http://www.visactor.io/vchart/demo…

在这个图表中,用户配置了一条 y=10000 的标注线。同时要求在 dimension tooltip 中实现:
- 数据项从大到小排序;
- 比标注线高的数据项标红(条件格式);
- 在 tooltip 内容的最后一行加上标注线所代表的数据。
同时,这个 tooltip 的位置还拥有以下特征:
- dimension tooltip 的位置固定在光标上方;
- mark tooltip 的位置固定在数据项下方。
如以下动图所示:

这个示例实际上代表了很多不同类型的业务需求。下面拆解来看一下:
基本 tooltip 内容配置
首先,剥去自定义内容和样式的部分,这个图表的最简 spec 和基本 tooltip 配置如下:
const markLineValue = 10000;
const spec = {
type: 'line',
data: {
values: [
{ type: 'Nail polish', country: 'Africa', value: 4229 },
// 其他数据略
]
},
stack: false,
xField: 'type',
yField: 'value',
seriesField: 'country',
legends: [{ visible: true, position: 'middle', orient: 'bottom' }],
markLine: [
{
y: markLineValue,
endSymbol: { visible: false },
line: { style: { /* 样式配置略 */ }}
}
],
tooltip: { // TOOLTIP SPEC
mark: {
title: {
value: datum => datum.type
},
content: [
{
key: datum => datum.country,
value: datum => datum.value
}
]
},
dimension: {
title: {
value: datum => datum.type
},
content: [
{
key: datum => datum.country,
value: datum => datum.value
}
]
}
}
};
const vchart = new VChart(spec, { dom: CONTAINER_ID });
vchart.renderSync();
显示效果如下:

观察 spec 不难发现,mark tooltip 和 dimension tooltip 分别用回调方式配置了 tooltip 的显示内容。其中:
- title.value 显示的是数据项中对应于
xField的内容; - content.key 显示的是数据项中对应于
seriesField(也是区分出图例项的 field)的内容; - content.value 显示的是数据项中对应于
yField的内容。
回调是 tooltip 内容的基本配置方式,用户可以在 title 和 content 中自由配置回调函数来实现数据绑定和字符串的格式化。
Tooltip 内容的排序、增删、条件格式
我们再来看一下 dimension tooltip 的 spec:
{
tooltip: { // TOOLTIP SPEC
mark: { /* ...略 */ },
dimension: {
title: {
value: datum => datum.type
},
content: [
{
key: datum => datum.country,
value: datum => datum.value
}
]
}
}
}
不难发现,content 配置的数组只包含 1 个对象,但是上图显示出来却有 4 行内容。为什么呢?
其实在 dimension tooltip 中发生了和折线图元类似的 data join 过程:由于在数据中,seriesField 划分出了 4 个数据组(图例项有 4 个),因此在经过笛卡尔积后,真实 tooltip 内容行数为 content 数组成员数量乘以 4。在数据组装过程中,每个数据组都要依次走一遍 content 数组成员里的回调。
我们把 spec 中的 tooltip 内容配置称为 TooltipPattern,tooltip 所需数据称为 TooltipData,最终的 tooltip 结构称为 TooltipActual。数据组装过程可以表示为:
在本例中,经过这个过程,TooltipPattern 中的回调在 TooltipActual 中消失(回调已被执行 4 次),且由 1 行变成了 4 行。
这个过程完整的执行流程如下:

那么回到示例中的用户需求,用户希望将 tooltip 内容行由大到小排序。那么这个步骤自然要在 TooltipActual 生成之后执行,也就是上图中的 “updateTooltipContent” 过程。
Tooltip spec 中支持配置 updateContent 回调来对 TooltipActual 的 content 部分进行操作。排序可以这样写:
{
tooltip: { // TOOLTIP SPEC
mark: { /* ...略 */ },
dimension: {
title: {
value: datum => datum.type
},
content: [
{
key: datum => datum.country,
value: datum => datum.value
}
],
updateContent: prev => {
// 排序
prev.sort((a, b) => b.value - a.value);
}
}
}
}
updateContent 回调的第一个参数为已经计算好的 TooltipActual。加上回调以后,排序生效:

在 tooltip 中实现条件格式以及新增一行也是一样的方法,可以直接在 updateContent 回调中处理:
{
updateContent: prev => {
// 排序
prev.sort((a, b) => b.value - a.value);
// 条件格式:比标注线高的数据项标红
prev.forEach(item => {
if (item.value >= markLineValue) {
item.valueStyle = {
fill: 'red'
};
}
});
// 新增一行
prev.push({
key: 'Mark Line',
value: markLineValue,
keyStyle: { fill: 'orange' },
valueStyle: { fill: 'orange' },
// 自定义 shape 的 svg path
shapeType: 'M44.3,22.1H25.6V3.3h18.8V22.1z M76.8,3.3H58v18.8h18.8V3.3z M99.8,3.3h-9.4v18.8h9.4V3.3z M12.9,3.3H3.5v18.8h9.4V3.3z',
shapeColor: 'orange',
hasShape: true
});
}
}
调试 spec,回调生效,最后效果如下:

Tooltip 样式和位置
VChart tooltip 支持将 tooltip 固定于某图元附近或者鼠标光标附近。在本例中,mark tooltip 固定于图元的下方,而 dimension tooltip 固定于鼠标光标的上方,可以这样配置:
{
tooltip: { // TOOLTIP SPEC
mark: {
// 其他配置略
position: 'bottom' // 显示在下方
positionAt: 'mark' // 固定在图元附近,由于这是默认值,这行可以删掉
},
dimension: {
// 其他配置略
position: 'top', // 显示在上方
positionAt: 'pointer' // 固定在鼠标光标附近
}
}
}
而样式配置可以在 tooltip spec 上的 style 配置项下进行自定义。style 支持配置 tooltip 组件各个组成部分的统一样式,详细配置项可参考官网文档(http://www.visactor.io/vchart/opti…
最后效果如下,完整 spec 可见官网 demo(http://www.visactor.io/vchart/demo…

示例三:锦上添花,可按需修改的 tooltip dom 树
VChart 的 tooltip 共支持两种渲染模式:
- Dom 渲染,适用于桌面或移动端浏览器环境;
- Canvas 渲染,适用于移动端小程序、node 环境等非浏览器环境。
对于 dom 版本的 tooltip,为了更好的支持业务方的自定义需求,VChart 开放了对 tooltip dom 树的修改接口。下文将以官网 demo(http://www.visactor.io/vchart/demo…

在这个示例中,用户要求在 tooltip 的底部增加一个超链接,用户点击链接后,便可以自动跳转到 Google,对 tooltip 标题进行进一步搜索。这个示例要求两个能力:
- 示例一介绍的 enterable 能力,开启后鼠标会被允许滑入 tooltip 区域,这是在 tooltip 中实现交互的前提;
- 在默认 tooltip 上绘制自定义的 dom 元素。
为了实现第二个能力,tooltip 支持了回调 updateElement,这个回调配在 tooltip spec 顶层。这个示例的 tooltip 配置如下:
{
tooltip: { // TOOLTIP SPEC
enterable: true,
updateElement: (el, actualTooltip, params) => {
// 自定义元素只加在 dimension tooltip 上
if (actualTooltip.activeType === 'dimension') {
const { changePositionOnly, dimensionInfo } = params;
// 判断本次 tooltip 显示是否仅改变了位置,如果是的话退出
if (changePositionOnly) { return; }
// 改变默认 tooltip dom 的宽高策略
el.style.width = 'auto';
el.style.height = 'auto';
el.style.minHeight = 'auto';
el.getElementsByClassName('value-box')[0].style.flex = '1';
for (const valueLabel of el.getElementsByClassName('value')) {
valueLabel.style.maxWidth = 'none';
}
// 删除上次执行回调添加的自定义元素
if (el.lastElementChild?.id === 'button-container') {
el.lastElementChild.remove();
}
// 添加新的自定义元素
const div = document.createElement('div');
div.id = 'button-container';
div.style.margin = '10px -10px 0px';
div.style.padding = '10px 0px 0px';
div.style.borderTop = '1px solid #cccccc';
div.style.textAlign = 'center';
div.innerHTML = `href="https://www.google.com/search?q=${dimensionInfo[0]?.value}"
style="text-decoration: none"
target="_blank"
>Search with Google`;
el.appendChild(div);
} else {
// 对于 mark tooltip,删除上次执行回调添加的自定义元素
if (el.lastElementChild?.id === 'button-container') {
el.lastElementChild.remove();
}
}
}
}
}
updateElement在每次 tooltip 被激活或者更新时触发,在触发时,TooltipActual 已经计算完毕,且 dom 节点也已经准备好。回调的第一个参数便是本次将要显示的 tooltip dom 根节点。目前不支持替换该节点,只支持对该节点以及其孩子进行修改。
这个配置的设计最大限度地复用了 VChart tooltip 的内置逻辑,同时提供了足够自由的自定义功能。你可以随心所欲地定制 tooltip 显示内容,并且复用任何你没有覆盖的逻辑。
比如,你可以对 tooltip 的大小进行重新定义,而不用关心窗口边界的躲避策略是否会出问题。事实上 VChart 会自动把 tooltip 定位逻辑复用在修改过的 dom 上:

这个回调还可以进一步封装,比如在 react-vchart 中将用户侧的 react 组件插入 tooltip。目前这个封装主要由业务侧自主进行,后续 VChart 也有计划提供官方支持。
示例四:完全自定义,由业务托管 tooltip 渲染
若要更进一步,VChart tooltip 最高级别的自定义,便是让 VChart 完全将 tooltip 渲染交给用户。有以下两种方式可以选择:
- 用户自定义 tooltip handler
- 用户使默认 tooltip 失效,监听 tooltip 事件
再结合示例二、示例三的铺垫,便可以带出整个 tooltip 模块的设计架构。熟悉了架构便更容易了解每条渲染路径以及各个层级的关系。

由上图可见,示例三对应的是 “Custom DOM Render” 的自定义,示例二对应了 “Custom TooltipActual” 部分的自定义。而示例四,便是对应整个 “Tooltip Events” 以及 “Custom TooltipHandler” 的自定义。
由于上图中,“Tooltip Events” 和 “Custom TooltipHandler” 纵跨了多个层级,因此它覆盖的默认逻辑是最多的,体现在:
- 当给图表设置了自定义 tooltip handler 后,内置的 tooltip 将不再起作用。
- VChart 不感知、不托管自定义 tooltip 的渲染,需要自行实现 tooltip 渲染,包括处理原始数据、tooltip 内容设计,以及根据项目环境创建组件并设置样式。
- 当图表删除时会调用当前 tooltip handler 的
release函数,需要自行实现删除。
目前,火山引擎 DataWind 正是使用自定义 tooltip handler 的方式实现了自己的图表 tooltip。DataWind 支持用户对tooltip 进行富文本渲染,甚至支持了 tooltip 内渲染图表的能力。

另外,也可以参考官网示例(http://www.visactor.io/vchart/demo…

自定义 tooltip handler 的核心是调用 VChart 实例方法 setTooltipHandler,部分示例代码如下:
vchart.setTooltipHandler({
showTooltip: (activeType, tooltipData, params) => {
const tooltip = document.getElementById('tooltip');
tooltip.style.left = params.event.x + 'px';
tooltip.style.top = params.event.y + 'px';
let data = [];
if (activeType === 'dimension') {
data = tooltipData[0]?.data[0]?.datum ?? [];
} else if (activeType === 'mark') {
data = tooltipData[0]?.datum ?? [];
}
tooltipChart.updateData(
'tooltipData',
data.map(({ type, value, month }) => ({ type, value, month }))
);
tooltip.style.visibility = 'visible';
},
hideTooltip: () => {
const tooltip = document.getElementById('tooltip');
tooltip.style.visibility = 'hidden';
},
release: () => {
tooltipChart.release();
const tooltip = document.getElementById('tooltip');
tooltip.remove();
}
});
其他特性一览
VChart tooltip 包含一些其他的高级特性,下文将简要介绍。
在任意轴上触发 dimension tooltip
Dimension tooltip 一般最适合用于离散轴,ECharts 同时支持连续轴上的 dimension tooltip(axis tooltip)。而 VChart 支持了在连续轴、时间轴乃至在一个图表中的任意一个轴上触发 dimension tooltip。
以下示例展示了 dimension tooltip 在连续轴(时间轴)上汇总离散数据的能力(这个 case 和一般的 dimension tooltip 刚好相反):

一般的 dimension tooltip 会在离散轴(纵轴)触发 tooltip,汇总连续数据(对应于时间轴)。而 VChart 同时支持这两种方式的 tooltip。
Demo 地址:http://www.visactor.io/vchart/demo…
长内容支持:换行和局部滚动
过长的内容在 tooltip 上一般是 bad case。但是为了使长内容的浏览体验更好,VChart tooltip 可以配置多行文本以及内容区域局部滚动。如以下示例:

局部滚动 Demo 地址:http://www.visactor.io/vchart/demo…
多行文本配置项:http://www.visactor.io/vchart/opti…
结语
Tooltip 在提升用户浏览图表的体验中扮演着重要的角色。本文介绍了 VChart tooltip 的基本使用方法、技术设计以及多层面的自定义方案。然而为了保证行文清晰,VChart tooltip 还有一些其他的用法细节本文没有涉及,想了解更多可以查阅官网 demo 以及文档。
然而需要提醒的是,虽然 tooltip 能够有效传递数据与信息、以及增加图表的互动能力,但过分依赖它们可能会导致用户体验下降。合理地利用 tooltip,让它们在需要时出现而不干扰用户的主要任务,是设计和开发中应保持的平衡。
希望本文能为你在配置 VChart tooltip 时提供有用的指导。愿你在图表中创造更加直观、轻松且愉快的用户体验时,VChart 能成为你强大的伙伴。

github:github.com/VisActor/VC…
相关参考:
来源:juejin.cn/post/7337963242416422924
寒门子弟想跨越阶层有多难
快要高考了,最近身边发生了不少事,感触颇深,我想记录一下。大家都知道高考是唯一公平竞争的机会,也是寒门贵子唯一一次想翻身的机会。但是,每个人情况和起点不一致,考试是公平的,但出身是不公平的,出身在河南落后的农村的小镇做题家和出身在上海的繁华大都市的国际学校的先进教育资源一样吗?答案可想而知。
身边有个亲人出身河南农村,这几天刚大学本科毕业,通过校招拿到了某物流领域独角兽公司的offer,base杭州,待遇是6k左右底薪,思考再三,他弟弟选择拒掉了offer,原因是,觉得靠自己这个收入全年无休也买不起杭州的房子,还要跟对象常年异地(对象在老家教师),于是选择去卷老家的编制岗,至少不用考虑买房,还能顾上了家庭,但是他的父母却表示不理解:说一辈子都没出息了,作为农民出身辛苦一辈子供出来的大学生,还要继续留在那个贫穷落后的小地方。为此他感到很苦恼,如何做才能不负如来不负卿!
同样,他说,比起其他同样出身在农村的孩子已经好很多了,至少有个月薪三千的稳定工作,很多农村的孩子都是提前辍学,进厂打螺丝或者失业待家,甚至娶不起农村媳妇,只能通过玩游戏,对抗父母证明自己的存在感,不然要被周围人的流言蜚语的唾沫星子淹死。提到这里甚至还有一丝欣慰。
他说,你不懂,像我这样出身农村的底层孩子,大多数在高考前就已经被淘汰掉了,因为太多穷苦老百姓,觉得读书没有直接去社会上进厂打工来的实在,孩子叛逆不想上学,也不会管太多,更不会觉得人生被毁掉了,相反,早点出去打过工挣钱才是农村人的常态,就这样,穷人的孩子干着穷苦的工作,攒点钱早点结婚生子,一代又一代,恶性循环,也不会觉得有任何不对,因为身边的环境和周围的人大多命运也都是这样。
形成鲜明对比的是,另一个同学,出身在江浙沪独生子,他说,从小只要学习不好,父母就感觉天塌了,因为他父母是很早一批的大学生,虽然他父母也是农村人的孩子,但是是最早一批的大学生,吃到了知识改变命运的红利,甚至不惜任何代价,帮他找资源,托关系,请到了他的老师给他在家补课开小灶,他说他学习一直不好,但是就是这么一路走过来的,甚至他父亲还帮他联系到了211院校的校长,讲到这里,大家意识到差距了吧。他说他学习很差,但被父母一路逼下去读到了研究生。。。毕业后家人关系托底去了某国有五大行,待遇不用多说大家也都懂。
同样,出身农村,学习很差就要回农村继续种地,娶个媳妇生个娃,干着廉价的劳动力,甚至都不知道好日子好工作是什么意思,因为资源和眼界有限,接触不到,也没见过,也无法给孩子形容出来,更没法用言语具体说服叛逆期的孩子。只好为了多挣钱去大城市,离开家人,最后挣点钱回到家了,孩子不理解,继续叛逆,等到了懂事的年纪,已经没有机会翻身了。这里声明:并不是我歧视农村,农村环境好,农村人淳朴,农村土地辽阔,除了经济医疗交通教育不发达,农家乐也非常有趣。

别的行业咱不敢说,至少计算机行业对比传统行业,给了穷人一次走向小康的机会,但这种机会也不会一直都有,互联网寒冬的背景下,即使选择了计算机专业,大多数底层出身的孩子也无法真正的跨越阶层,因为那个时代的红利,已经褪去了。。。
最近看到了一条新闻,说曾经在衡水中学的高考状元,出身农村,声称自己是“乡下的土猪拱了城里的白菜”,报考了浙大计算机专业,三年过后了,这位高考状元却迷茫了,因为他对计算机专业并没有兴趣,当初仅仅因为觉得这个行业高薪才报名的,但是行业在变化,在这个时代下,计算机行业已经发展迅速,没有了昨日的如日中天,相反,他的眼里没有光,他厌倦了这种一天都坐在电脑面前的工作,但是未来何去何从,他依然迷茫,他只知道学习高考,却没有好好规划自己的人生,没有认真思考自己的定位,不懂得人生价值,只知道脱离贫苦。这点也许是大多数底层出身孩子的迷茫吧!
回过神来,今年高考,如果再给你一次机会,你还会像曾经一样,没有把高考当成唯一一次公平翻身的机会吗?寒门贵子想跨越阶层到底有多难?大多数人的机会,也许就这么一次吧。
来源:juejin.cn/post/7376407925646770239
总算体会到jsx写法为啥灵活
前言
大家好,我是你不会困,写代码就不会困,今天分享的是总算体会到jsx写法为啥灵活
什么是jsx写法?
当谈到JavaScript中的JSX写法时,人们往往会想到React和Vue这样的流行前端框架。JSX作为一种在JavaScript中编写类似于HTML的语法,为前端开发者提供了更灵活和直观的方式来构建用户界面。
JSX的灵活性体现在多个方面。首先,JSX允许开发者在JavaScript中嵌入HTML标记,使得代码更易读和维护。通过使用JSX,开发者可以在同一个文件中编写JavaScript逻辑和界面布局,而无需频繁切换不同的文件。这种混合编程风格提高了开发效率,同时也方便了代码的组织和调试。
其次,JSX支持在标记中使用JavaScript表达式,这使得动态生成界面变得更加简单。开发者可以在JSX中直接使用JavaScript变量、函数调用和逻辑控制语句,从而动态地渲染页面内容。这种灵活性使得开发者能够根据不同的数据状态和条件来动态展示内容,提升了用户体验。
另外,JSX还支持在标记中使用循环和条件语句,比如map函数和条件渲染,从而实现列表展示、条件展示等常见的UI需求。这种功能使得开发者可以更方便地处理复杂的UI逻辑,同时简化了代码的编写和维护。
此外,JSX的组件化特性也为前端开发带来了很多好处。通过将UI拆分成独立的组件,开发者可以更好地组织和管理代码,提高代码的重用性和可维护性。JSX中的组件可以嵌套使用,形成复杂的UI结构,同时每个组件可以单独管理自己的状态和逻辑,使得代码更加清晰和可扩展。
今天在开发的时候发现,这两个即可开启总计列
show-summary
:summary-method="getSummaries"
但是产品的需求比较麻烦,需要渲染多行,查了相关的文档,好像没有这种渲染的demo,翻看项目的代码,有一部分代码的实现比较巧妙,使用的是jsx写法,然后就尝试着去实现
要在vue里面使用jsx写法,在script标签使用<script lang="jsx">,即可使用
getSummaries(param) {
const { columns } = param
const sums = []
const nullHtml = '-'
columns.forEach((column, index) => {
if (index === 0) {
sums[index] = '总计'
return
}
if (this.totalSum.summaryReceivableComparisons) {
sums[index] = (
<div>
{this.totalSum.summaryReceivableComparisons.map((item) => (
<div class='cell-item' key={item.invoiceCurrency}>
<p>
{this.formatValue(
item[column.property],
column.property.includes('Ratio')
? 'percentage'
: 'thousandth'
)}
</p>
</div>
))}
</div>
)
} else {
sums[index] = nullHtml
return
}
})
return sums
},
上面的代码使用了map来遍历,将对应的html返回,el-table的总计列即可生效,来应对不同的需求
总结
总的来说,JSX作为JavaScript中的一种扩展语法,为前端开发带来了更灵活、直观和高效的开发体验。通过使用JSX,开发者可以更轻松地构建交互丰富、动态变化的用户界面,同时提高了代码的可读性和可维护性。JSX的灵活性和表现力使其成为现代前端开发中不可或缺的一部分。
来源:juejin.cn/post/7410672790020800548
JDK23,带来了哪些新功能?
前言
2024年9月17日,Java开发者们迎来了期待已久的JDK23版本。
下载地址:jdk.java.net/23/
文档地址:jdk.java.net/23/release-…

为 JDK 21 之后的第一个非 LTS 版本,最终的 12 个 JEP 特性包括:
JEP 455:模式、instanceof 和 switch 中的原始类型(Primitive Types in Patterns, instanceof, and switch,预览)
JEP 466:类文件 API(Class-File API,第二轮预览)
JEP 467:Markdown 文档注释(Markdown Documentation Comments)
JEP 469:Vector API(第八轮孵化)
JEP 471:废弃 sun.misc.Unsafe 中的内存访问方法以便于将其移除(Deprecate the Memory-Access Methods in sun.misc.Unsafe for Removal)
JEP 473:流收集器(Stream Gatherers,第二轮预览)
JEP 474:ZGC:默认的分代模式(ZGC: Generational Mode by Default)
JEP 476:模块导入声明(Module Import Declarations,预览)
JEP 477:隐式声明的类和实例主方法(Implicitly Declared Classes and Instance Main Methods,第三轮预览)
JEP 480:结构化并发(Structured Concurrency,第三轮预览)
JEP 481:作用域值(Scoped Values,第三轮预览)
JEP 482:灵活的构造函数体(: Flexible Constructor Bodies,第二轮预览)
基本上每次JDK的升级,在带来一些新功能的同时,也会提升一些性能。
一些优秀的语法,也能提升开发效率。
除了编程语言升级能提升开发效率之外,一些好的开发工具或者设备,也可以。
2 提升开发效率
显示器可以提升开发效率?
答:是真的。
2.1 屏幕尺寸
在之后的一段时间内,我尝试过一些不同品牌和型号的外接显示器。
常见的显示器的屏幕比是16:9。
而我现在正在用的明基RD280U显示器的屏幕比是3:2。

跟我的笔记本电脑屏幕相比,高度是笔记本电脑的两倍了。
我第一次使用时,就明显感觉到,明基RD240Q显示器的屏幕更高一些,一屏可以多看十几行代码。
在开发过程中,每次滚动屏幕,都可以多看几行代码,如果次数多了,可以多看很多行代码,真的可以提高开发效率。
2.2 专业编程模式
我后来才知道明基RD280U是一个专业的编程显示器,专门给程序员设计的。
屏幕正下方的这个按键,可以调整编程模式,可以优化IDE上代码的显示效果,让代码更加清晰:

2.3 背光灯
我们之前在晚上编程的时候,经常需要打开台灯,才能让屏幕看到更清楚。
为了解决这个问题,明基RD280U提供了Moonhalo背光灯的功能,下面这张图是我在关灯的情况下拍摄的:

可以看到屏幕有黄色的背景灯光。
下面的这张灯光图更直观:

可以让你沉浸在开发中,不被打扰。
3 全方位呵护
明基RD280U显示器使用了莱茵认证护眼技术,实现了:低蓝光、无屏闪的效果。
3.1 护眼模式
在夜间开发,可以切换夜间保护模式:

如果切换成自动模式,当外面环境变亮时,屏幕会自动变暗。当外面环境变暗时,屏幕会自动变暗。
保护我们的眼睛。
智慧蓝光模式是为了减少蓝光对眼睛的刺激,提供更舒适的视觉体验。

我们可以调节让自己眼睛感到舒服的蓝光。
3.2 抗反射面板
当我们的屏幕出现其他的灯光直射时,笔记本电脑的效果是这样的:

代码完全看不清楚。
而明基RD280U显示器,即使遇到强光也能看清代码。

这是我非常喜欢的设计。
4 软件协同
明基RD280U显示器为了方便我们操作,还提供了一个驱动软件:Display Pilot2。
里面包含了画面切换,快速搜索,桌面分区和键盘快速切换功能。

我们可以在电脑上直接控制显示器:

文章前面介绍的这些功能,都可以直接在电脑上通过Display Pilot2进行控制。
比如开启显示器的Moonhalo背光灯。

新增的flow功能可以设置特定时间场景下的一些显示器的参数。

5 总结
本文主要介绍了JDK23的12项新特性,涵盖了语言预览、API增强、性能优化等多个方面,可能会对开发者的工作流程和编程习惯产生深远的影响。
同时也介绍了我正在使用的明基RD280U显示器的一些优秀的功能,比如:屏幕尺寸更大、专业编程模式、Moonhalo背光灯、护眼功能(夜间防护功能、智慧蓝光)、抗反射面板、display pilot2功能,能够提升开发效率和保护我们的眼睛。
来源:juejin.cn/post/7418072992838500362
如何组装一台高性价比的电脑

前言
最近想配置一台电脑,由于在这方面是小白,就花了一部分时间以及精力在这方面,相信你看完,也能轻轻松松装电脑。
目标
高性价比、小钱办大事
电脑配置基础知识
组装一台台式机需要考虑多个组件,以下是一份基本的装机配置清单,包括了主要硬件和一些可选配件
我把他们划分为必须和非必须(可理解为表单的必填或者非必填)
有了必须项目的配置就可以组装出一台电脑,非必须项目属于个人需求(可理解为个性化定制)
必须项
- 处理器(CPU) :
- 选择适合需求的处理器,如Intel Core系列或AMD Ryzen系列。
- 显卡(GPU) :
- 集成显卡或独立显卡,如NVIDIA GeForce或AMD Radeon系列。
- 主板(Motherboard) :
- 根据CPU选择相应插槽类型的主板,如ATX、Micro-ATX或Mini-ITX规格。
- 内存(RAM) :
- 至少8GB DDR4内存,更高需求可以选择16GB或32GB。
- 固态硬盘(SSD) :
- 用于安装操作系统和常用软件,256GB或更大容量。
- 散热器(Cooler) :
- CPU散热器,盒装CPU可能附带散热器。
- 电源供应器(PSU) :
- 根据系统需求选择合适的功率,如500W、600W等,并确保有80 PLUS认证。
- 机箱(Case) :
- 根据主板规格和个人喜好选择机箱。
机箱严格来讲属于非必须,因为你用纸箱子也能行,但是对于小白来说还是整个便宜的比较好
- 外围设备:
- 显示器、键盘、鼠标。
- 音频设备:
- 耳机、扬声器。
非必须项
- 机械硬盘(HDD, 可选) :
- 用于数据存储,1TB或更大容量。
- 机箱风扇(可选) :
- 用于改善机箱内部空气流通。
- 光驱(可选) :
- 如有需要,可以选择DVD或蓝光光驱。
- 无线网卡(可选) :
- 如果主板不支持无线连接,可以添加无线网卡。
- 声卡(可选) :
- 如果需要更好的音频性能,可以添加独立声卡。
- 扩展卡(可选) :
- 如网络卡、声卡、图形卡等。
- 机箱装饰(可选) :
- RGB灯条、风扇等。
处理器(CPU)天梯图

显卡(GPU)天梯图

如何选择显示器
选择电脑显示器时,有几个关键因素需要考虑:
- 分辨率:分辨率决定了显示器的清晰度。常见的有1080p(全高清)、1440p(2K)、2160p(4K)等。分辨率越高,画面越清晰,但同时对显卡的要求也越高。
- 屏幕尺寸:根据你的使用习惯和空间大小来选择。大屏幕可以提供更宽广的视野,但也需要更大的桌面空间。
- 刷新率:刷新率表示显示器每秒可以刷新多少次画面。常见的有60Hz、144Hz、240Hz等。高刷新率可以提供更流畅的视觉效果,特别适合游戏玩家。
- 响应时间:响应时间指的是像素从一种状态变化到另一种状态所需的时间,通常以毫秒(ms)为单位。响应时间越短,画面变化越快,越适合快速变化的游戏或视频。
- 面板类型:主要有TN、IPS、VA三种面板。TN面板响应速度快,但色彩表现一般;IPS面板色彩表现好,视角宽,但响应时间相对较慢;VA面板则介于两者之间。
- 连接接口:确保显示器的连接接口与你的电脑兼容,常见的有HDMI、DisplayPort、DVI、VGA等。
- 色彩准确性:如果你的工作涉及到图像或视频编辑,那么选择色彩准确性高的显示器非常重要。
- 附加功能:一些显示器可能提供额外的功能,如USB接口、扬声器、可调节支架等。
- 预算:根据你的预算来决定购买哪种类型的显示器。通常来说,价格越高,显示器的性能和功能也越全面。
- 品牌和售后服务:选择知名品牌的显示器通常可以保证较好的质量和售后服务。
根据你的具体需求和预算,综合考虑上述因素,选择最适合你的显示器。 并不是配置越高越好,重点是根据你的显卡和CPU来看,实现极致性价比,需要对应电脑配置能带动的最大区间,比方说 英特尔 i5-12400F(6核心12线程,睿频4.4GHz)+ 华硕DUAL-RTX 4060-8G游戏显卡能带起来的刷星率极限基本就是165Hz左右,那么你配置2K,180Hz的显示器就够用了,当然你有钱也可以整个4K,200+Hz的
关于外围设备(键鼠、耳机、音响等)
这个看个人喜好以及预算来决定吧,比方说有线还是无线,机械还是非机械等等....
不同价位装机性价比清单(根据目前市场上)
装机其实主要花费就在显卡(GPU)和处理器(CPU)上,显卡(GPU)金额占比超过50%比比皆是,处理器(CPU)金额占比一般是在百分之20%~30%,其他配件金额占比20%~30%左右。
如果预算足够建议优先升级显卡
CPU分为盒装和散片,预算充足盒装,预算不足散片也能用
3K推荐
- CPU: Intel 12代酷睿i5 12400F
- 显卡: 华硕DUAL RTX 3050 6G
- 内存: 威刚D4 16GB 3200MHz
- 硬盘: 英睿达 500GB PCI-E 4.0 M.2
- 主板: 圣旗H610M
- 电源: 爱国者额定500W
- 跑分: 107W±
- 合计:3.5K左右
4K极致性价比
4K-6K这个价位其实CPU最佳的就是就是在下图区间 同理可自行对比GPU天梯图


- CPU: 英特尔 i5-12400F(6核心12线程,睿频4.4GHz)
- 显卡: 华硕DUAL-RTX 4060-8G游戏显卡 升级选项: +299元升级至华硕TX-RTX 4060-O8G-GAMING天选白三风扇
- 散热: 动力火车四铜管白色强劲散热器
- 主板: 华硕PRIME B760M-FD4(支持AURA神光同步)
- 内存: 雷克沙DDR4 16GB 3200MHz高频内存
- 硬盘: 雷克沙500GB NVMe PCIe SSD(读速高达3300MB/S)
- 电源: 源之力静音大师额定600W安规3C白色
- 机箱: 动力火车琉璃海景房
- 合计:4K左右

5K极致性价比



6K极致性价比

7K极致性价比

8K极致性价比

1W极致性价比
1W预算以上可能考虑的不单单是配置了,还有外观之类的,可以DIY定制之类的


1.2W极致性价比

1.3w极致性价比

总结下,其实根据CPU、GPU天梯图就可以找到自己的目标区间,其他配置看个人预算来就行,核心就是两大件!如果有装机高手,欢迎留言交流,有不懂的,欢迎提问。后续会根据问题持续补充
来源:juejin.cn/post/7379420157670670372
Electron实现静默打印小票
Electron实现静默打印小票
静默打印流程

1.渲染进程通知主进程打印
//渲染进程 data是打印需要的数据
window.electron.ipcRenderer.send('handlePrint', data)
2.主进程接收消息,创建打印页面
//main.ts
/* 打印页面 */
let printWindow: BrowserWindow | undefined
/**
* @Author: yaoyaolei
* @Date: 2024-06-07 09:27:22
* @LastEditors: yaoyaolei
* @description: 创建打印页面
*/
const createPrintWindow = () => {
return new Promise<void>((resolve) => {
printWindow = new BrowserWindow({
...BASE_WINDOW_CONFIG,
title: 'printWindow',
webPreferences: {
preload: join(__dirname, '../preload/index.js'),
sandbox: false,
nodeIntegration: true,
contextIsolation: false
}
})
printWindow.on('ready-to-show', () => {
//打印页面创建完成后不需要显示,测试时可以调用show查看页面样式(下面有我处理的样式图片)
// printWindow?.show()
resolve()
})
printWindow.webContents.setWindowOpenHandler((details: { url: string }) => {
shell.openExternal(details.url)
return { action: 'deny' }
})
if (is.dev && process.env['ELECTRON_RENDERER_URL']) {
printWindow.loadURL(`${process.env['ELECTRON_RENDERER_URL']}/print.html`)
} else {
printWindow.loadFile(join(__dirname, `../renderer/print.html`))
}
})
}
ipcMain.on('handlePrint', (_, obj) => {
//主进程接受渲染进程消息,向打印页面传递数据
if (printWindow) {
printWindow!.webContents.send('data', obj)
} else {
createPrintWindow().then(() => {
printWindow!.webContents.send('data', obj)
})
}
})
3.打印页面接收消息,拿到数据渲染页面完成后通知主进程开始打印
<!doctype html>
<html>
<head>
<meta charset="UTF-8" />
<title>打印</title>
<style>
</style>
</head>
<body>
</body>
<script>
window.electron.ipcRenderer.on('data', (_, obj) => {
//这里是接受的消息,处理完成后将html片段放在body里面完成后就可以开始打印了
//样式可以写在style里,也可以内联
console.log('event, data: ', obj);
//这里自由发挥
document.body.innerHTML = '处理的数据'
//通知主进程开始打印
window.electron.ipcRenderer.send('startPrint')
})
</script>
</html>
这个是我处理完的数据样式,这个就是print.html


4,5.主进程接收消息开始打印,并且通知渲染进程打印状态
ipcMain.on('startPrint', () => {
//这里如果不指定打印机使用的是系统默认打印机,如果需要指定打印机,
//可以在初始化的时候使用webContents.getPrintersAsync()获取打印机列表,
//然后让用户选择一个打印机,打印的时候将打印机名称传过来
printWindow!.webContents.print(
{
silent: true,
margins: { marginType: 'none' }
//deviceName:如果要指定打印机传入打印机名称
},
(success) => {
//通知渲染进程打印状态
if (success) {
mainWindow.webContents.send('printStatus', 'success')
} else {
mainWindow.webContents.send('printStatus', 'error')
}
}
)
})

完毕~
来源:juejin.cn/post/7377645747448365091
我的 Electron 客户端被第三方页面入侵了...
问题描述
公司有个内部项目是用 Electron 来开发的,有个功能需要像浏览器一样加载第三方站点。
本来一切安好,但是某天打开某个站点的链接,导致 整个客户端直接变成了该站点的页面。
这一看就是该站点做了特殊的处理,经排查网页源码后,果然发现了有这么一句代码。
if (window.top !== window.self) {
window.top.location = window.location;
}
翻译一下就是:如果当前窗口不是顶级窗口的话,将当前窗口设置为顶级窗口。
奇怪的是两者不是 跨域 了吗,为什么 iframe 还可以影响顶级窗口。
先说一下我当时的一些解决办法:
- 用
webview替换iframe - 给
iframe添加sandbox属性
后续内容就是一点复盘工作。
场景复现(Web端)
一开始怀疑是客户端的问题,所以我用在纯 Web 上进行了一次对比验证。
这里我们新建两个文件:1.html 和 2.html,我们称之为 页面A 和 页面B。
然后起了两个本地服务器来模拟同源与跨域的情况。
页面A:http://127.0.0.1:5500/1.html
页面B:http://127.0.0.1:5500/2.html 和 http://localhost:3000/2.html
符合同源策略
<body>
<h1>这是页面A</h1>
<!-- 这是同源的情况 -->
<iframe id="iframe" src="http://127.0.0.1:5500/2.html" />
<script>
iframe.onload = () => {
console.log('iframe loaded..')
console.log('子窗口路径', iframe.contentWindow.location.href)
}
</script>
</body>
<body>
<h2>这是页面B</h2>
<script>
console.log('page2...')
console.log(window === window.top)
console.log('顶部窗口路径', window.top.location.href)
</script>
</body>
我们打开控制台可以看到 页面A 和 页面B 是可以 互相访问 到对方窗口的路径。

如果这个时候在 页面B 加上文章开头提到的 代码片段,那么显然页面将会发生变化。

跨域的情况
这时候我们修改 页面A 加载 页面B 的地址,使其不符合同源策略。

理所应当的是,两个页面不能够相互访问了,这才是正常的,否则内嵌第三方页面可以互相修改,那就太不安全了。
场景复现(客户端)
既然 Web 端是符合预期的,那是不是 Electron 自己的问题呢?
我们通过 electron-vite 快速搭建了一个 React模板的electron应用,版本为:electron@22.3.27,并且在 App 中也嵌入了刚才的 页面B。
function App(): JSX.Element {
return (
<>
<h1>这是Electron页面</h1>
<iframe id="iframe" src="http://localhost:3000/2.html"/>
</>
)
}
export default App

对不起,干干净净的 Electron 根本不背这个锅,在它身上的表现如同 Web端 一样,也受同源策略的限制。
那么肯定是我的项目里有什么特殊的配置,通过对比主进程的代码,答案终于揭晓。
new BrowserWindow({
...,
webPreferences: {
...,
webSecurity: false // 就是因为它
}
})
Electron 官方文档 里是这么描述 webSecurity 这个配置的。
webSecurityboolean (可选) - 当设置为false, 它将禁用同源策略 (通常用来测试网站), 如果此选项不是由开发者设置的,还会把allowRunningInsecureContent设置为true. 默认值为true。
也就是说,Electron本身是有一层屏障的,但当该属性设置为 false 的时候,我们的客户端将会绕过同源策略的限制,这层屏障也就消失了,因此 iframe 的行为表现得像是嵌套了同源的站点一样。
解决方案
把这个配置去掉,确实是可以解决这个问题,但考虑到可能对其他功能造成的影响,只能采取其他方案。
如文章开头提到的,用 webview 替换 iframe。
webview 是 Electron的一个自定义元素(标签),可用于在应用程序中嵌入第三方网页,它默认开启安全策略,直接实现了主应用与嵌入页面的隔离。
因为目前这个需求是仅作展示,不需要与嵌套页面进行交互以及复杂的通信,因此在一开始的开发过程中,并没有使用它,而是直接采用了 iframe。
而 iframe 也能够实现类似的效果,只需要添加一个 sandbox 属性可以解决。
MDN 中提到,sandbox 控制应用于嵌入在 <iframe> 中的内容的限制。该属性的值可以为空以应用所有限制,也可以为空格分隔的标记以解除特定的限制。
如此一来,就算是同源的,两者也不会互相干扰。
总结
这不是一个复杂的问题,发现后及时修复了,并没有造成很大的影响(还好是自己人用的平台)。
写这篇文章的主要目的是为了记录这次事件,让我意识到在平时开发过程中,把注意力过多的放在了 业务、样式、性能等这些看得见的问题上,可能很少关注甚至忽略了 安全 这一要素,以为前端框架能够防御像 XSS 这样的攻击就能安枕无忧。
谨记,永远不要相信第三方,距离产生美。
如有纰漏,欢迎在评论区指出。
来源:juejin.cn/post/7398418805971877914
如何将用户输入的名称转成艺术字体-fontmin.js
写在开头
日常我们在页面中使用特殊字体,一般操作都是直接由前端来全量引入设计师提供的整个字体包即可,具体操作如下:
<template>
<div class="font">橙某人</div>
</template>
<style scoped>
@font-face {
font-family: "orange";
src: url("./orange.ttf");
}
.font {
font-family: "orange";
}
</style>
很简单吧🤡,但有时应用场景不同,可能需要我们考虑一下性能问题。
一般来说,我们常见的字体包整个是非常大的,小的有几M到十几M,大的可能去到上百M都有,特别是中文类的字体包会相对英文类的要更大一些。
如本文案例,我们仅需在用户输入完后加载对应的字体包即可,这样能避免性能的损耗。
为此,我们需要把整个字体包拆分、细致化、子集化,让它能达到按需引入的效果。
那么这要如何来做这个事情呢?这个方案单单前端可做不了,我们需要配合后端一起,下面就来看看具体的实现过程吧。😗
前端
前端小编用 Vue 来编写,具体如下:
<template>
<div>
<input v-model="name" />
<button @click="handleClick">生成</button>
<div v-if="showName" class="font">{{ showName }}</div>
</div>
</template>
<script>
export default {
data() {
return {
name: "",
showName: "",
};
},
methods: {
handleClick() {
// 创建link标签
const linkElement = document.createElement("link");
linkElement.setAttribute("rel", "stylesheet");
linkElement.setAttribute("type", "text/css");
linkElement.href = `http://localhost:3000?name=${encodeURIComponent(this.name)}`;
document.body.appendChild(linkElement);
// 优化显示效果
setTimeout(() => {
this.showName = this.name;
}, 300);
},
},
};
</script>
<style>
.font {
font-family: orange;
font-size: 50px;
}
</style>
应该都能看懂吧,主要就是生成了一个 <link /> 标签并插入到文档中,标签的请求地址指向我们服务端,至于服务端会返回什么你可以先猜一猜。👻
服务端
服务端小编选择用 Koa2 来编写,你也可以选择 Express 或者 Egg ,甚至 Node 也是可以的,差异不大,具体逻辑如下:
const koa = require("koa2");
const fs = require("fs");
const FontMin = require("fontmin");
const app = new koa();
/** @name 优化,缓存已经加载过的字体包进内存 **/
const fontFamilyMap = {};
/** @name 加载字体包 **/
function loadFontLibrary(fontPath, fontFamily) {
if (fontFamilyMap[fontFamily]) return fontFamilyMap[fontFamily];
return new Promise((resolve, reject) => {
fs.readFile(fontPath, (error, file) => {
if (error) {
reject(new Error(error.message));
} else {
fontFamilyMap[fontFamily] = file;
resolve(file);
}
});
});
}
app.use(async (ctx) => {
const { name } = ctx.query;
// 设置返回文件类型
ctx.set("Content-Type", "text/css");
const fontPath = "./font/orange.ttf";
const fontFamily = "orange";
if (!fs.existsSync(fontPath)) return (ctx.body = "字体包读取失败");
const fontMin = new FontMin();
const fontFile = await loadFontLibrary(fontPath, fontFamily);
fontMin.src(fontFile);
const getFontCSS = () => {
return new Promise((resolve) => {
fontMin
.use(FontMin.glyph({ text: name }))
.use(FontMin.css({ base64: true, fontFamily }))
.run((error, files) => {
if (error) {
console.log("error", error.message);
} else {
const fontContent = files?.[1]?.contents;
resolve(fontContent);
}
});
});
};
const fontCSS = await getFontCSS();
ctx.body = fontCSS;
});
app.listen(3000);
console.log("服务器开启: http://localhost:3000/");
我们主要是采用了 Fontmin 库来完成整个字体包的按需加载功能,这个库是第一个纯 JavaScript 字体子集化方案。
可能有后端是
Java或者其他技术栈的小伙伴,你们也不用担心,据小编和公司后端同事了解,不同技术栈也是有对应的库可以解决的,需要的可以自行查查看。
至此,本篇文章就写完啦,撒花撒花。

希望本文对你有所帮助,如有任何疑问,期待你的留言哦。
老样子,点赞+评论=你会了,收藏=你精通了。
来源:juejin.cn/post/7293151700869038099
登录问题——web端
问题描述:
在集成环信SDK的过程中,大家可能会遇到一个令人困惑的问题:明明已经通过open登录成功了,但是在调用api时却总是报错,错误类型为type28或者type700或者type39 not login。本文将详细分析这个问题的原因,并提供相应的解决方案。


原因分析:
要解决这个问题,我们首先需要了解环信SDK的登录机制。登录过程实际上分为两个步骤:
1. 请求Token:这是open登录操作的第一步,即在open.then或者success回调中返回token。
2. 建立长连接:即建立WebSocket连接,触发onOpened或者onConnected回调。只有当onOpened或者onConnected回调被触发,才算是真正与环信服务器建立了连接。
SDK在拿到token后,会将其设置进入SDK并尝试建立连接。如果在onOpened或者onConnected回调触发之前就执行了api的调用,那么token可能还没有被正确设置进入SDK,从而导致后续的HTTP请求报token无效的错误。也就是出现type28或者type700或者type 39的报错。
解决方案:
为了避免这个问题,我们需要调整代码逻辑,确保在onOpened或者onConnected回调触发后再去请求一系列的接口。以下是具体的调整步骤:
1. 监听连接状态:在SDK初始化后,监听onOpened或者onConnected回调。
2. 延迟调用api操作:不要在open.then或者success回调中立即执行api的调用,而是等待onOpened或者onConnected回调触发后再执行。
3. 检查SDK状态:调用api前检查SDK是否已经成功建立连接。
可以用以下三种方法中的一种判断检查SDK是否已经成功建立连接~
1、WebIM.conn方法下有一个logOut字段,该字段为true时表明未登录状态,该字段为false时表明登录;
2、WebIM.conn.isOpened () 方法有三个状态,undefined为未登录状态,true为已登录状态,false为未登录状态,可以根据这三个状态去判断是否登录;
3、通过onOpened 这个回调来判断,只要执行了就说明登录成功了,输出的话,输出的是undefined
183天打造行业新标杆!BOE(京东方)国内首条第8.6代AMOLED生产线提前全面封顶
2024年9月25日,BOE(京东方)投建的国内首条第8.6代AMOLED生产线全面封顶仪式在成都市高新区举行,该生产线从开工到封顶仅用183天,以科学、高效、高质的速度再树行业新标杆。这不仅是BOE(京东方)创新突破、打造新质生产力的又一重大举措,也是OLED领域的里程碑事件,极大推动OLED显示产业快速迈进中尺寸发展阶段,对促进半导体显示产业优化升级、引领行业高质量发展具有重要意义。京东方科技集团董事长陈炎顺出席并宣布仪式启动,项目总指挥刘晓东、项目执行总指挥杨国波等领导及中建三局集团有限公司、中国建筑一局(集团)有限公司、中国电子工程设计院股份有限公司、四川华凯工程项目管理有限公司等相关单位领导共同出席封顶仪式。

BOE(京东方)第8.6代AMOLED生产线项目总指挥刘晓东在致辞中表示:“BOE(京东方)第8.6代AMOLED生产线自今年初正式开工以来,始终秉持‘五同时、五确保、五典范’建设原则,以坚韧不拔的意志和团结协作的精神,历时183天,提前达成全面封顶目标,标志着该生产线正式迈入新阶段。BOE(京东方)第8.6代AMOLED生产线必将成为行业标杆工程,为企业发展注入新的活力与动力。我们有信心、有能力打造全球最具竞争力的第8.6代AMOLED生产线,为全球显示产业进步贡献重要力量。”

BOE(京东方)第8.6代AMOLED生产线总投资630亿元,是四川省迄今投资体量最大的单体工业项目,设计产能每月3.2万片玻璃基板(尺寸2290mm×2620mm),主要生产笔记本电脑、平板电脑等智能终端高端触控OLED显示屏。BOE(京东方)通过采用低温多晶硅氧化物(LTPO)背板技术与叠层发光器件制备工艺,使OLED屏幕实现更低的功耗和更长的使用寿命,也将带动下游笔记本及平板电脑产品的迭代升级。目前,BOE(京东方)已在成都、重庆、绵阳投建了三条第6代柔性AMOLED生产线,再加上国内首条第8.6代AMOLED生产线的投建,全面展现了其全球领先的技术实力和行业影响力。值得关注的是,截至2023年,BOE(京东方)柔性OLED出货量已连续多年稳居国内第一,全球第二(数据来源:Omdia),柔性OLED相关专利申请超3万件。BOE(京东方)柔性显示技术不仅应用于手机领域,还持续拓展笔记本、车载、可穿戴等领域,折叠屏、滑卷屏、全面屏等柔性显示解决方案已覆盖国内外众多头部终端品牌,进一步确立BOE(京东方)在OLED领域的全球领先地位。
2024年,BOE(京东方)面向下一个三十年的新征程全新出发,公司将始终坚持“传承、创新、发展”的企业文化内核,坚定信念、创新变革,持续探索契合市场需求的企业发展“第N曲线”。BOE(京东方)第8.6代AMOLED生产线也将汇聚新型显示产业人才,发挥引擎作用,打造以柔性显示为核心的“世界柔谷”,在持续提升竞争力的同时,谱写行业高质发展的新篇章。
收起阅读 »

