








只有 7 KB!前端圈疯传的 Vue3 转场动效神库!效果炸裂!
“只要 7 KB,就能把多页站变成丝滑 SPA!”——这句话在前端圈疯传的神库,就是 Barba.js。
今天,我们就把它和 Vue3 搭配,手把手带你做出**“效果炸裂”**的页面切换动效!

为什么是 Barba.js × Vue3?
- 天生轻量:
gzip后仅7 KB,0 依赖,对Vue3的bundle体积几乎没影响。 - 渐进增强:不改现有路由,只要把需要动效的部分包一层
data-barba="container",老项目也能无痛升级。 - 动画自由:官方只负责“切换生命周期”,真正的视觉冲击可以交给
GSAP、Anime.js或Vue3的<Transition>组件。 - 社区炸裂:GitHub
1.2 w+star,大量 Vue3 样板可直接抄作业。
30 秒极速上手
1.安装
npm i @barba/core @barba/css # 核心 + 零 JS 动画辅助
npm i gsap # 想玩高级动效再装
2.HTML 骨架(Vue3 单页或多页皆可)
<body data-barba="wrapper">
<header>公共头部</header>
<!-- Vue3 挂载点,也是 Barba 需要替换的区域 -->
<main id="app"
data-barba="container"
data-barba-namespace="home">
<!-- 这里放 <RouterView/> 或直接放组件 -->
</main>
<footer>公共底部</footer>
</body>
3.初始化(main.ts)
import barba from '@barba/core'
import barbaCss from '@barba/css'
import gsap from 'gsap'
barba.use(barbaCss) // 先让 Barba 帮你加/删 class
barba.init({
transitions: [{
name: 'cover', // 自定义名字
sync: true, // 进出同时执行,更顺滑
leave({ current }) {
// 当前页面滑出
return gsap.to(current.container, {
y: '-100%',
opacity: 0,
duration: 0.6,
ease: 'power2.inOut'
})
},
enter({ next }) {
// 新页面滑入
gsap.from(next.container, {
y: '100%',
opacity: 0,
duration: 0.6,
ease: 'power2.inOut'
})
}
}]
})
⚠️ 注意:
- 每次切换完成后,手动重新挂载 Vue3 实例(如果使用多页模式),或让组件复用
<keep-alive>。
- Barba 会帮你更新浏览器
history,SEO不受影响。
实战:3 个效果炸裂的技巧
视差 + 蒙版过渡
在 leave 钩子用 GSAP 把旧页面做 clip-path 收缩,新页面做 视差滑动,视觉冲击直接拉满。
路由级差异化动效
利用 @barba/router 给 /home → /about 用 淡入淡出,给 /portfolio/* → /portfolio/* 用 3D 翻转,保持品牌调性一致。
鼠标悬停预加载
打开 @barba/prefetch,用户还没点击就把下一页提前拉回来,真正“秒开”体验。

常见踩坑 & 解决方案
🔴 场景 1:首屏闪白
症状:刷新后能看到瞬间白屏,然后内容才出现。
快速解法:
- 给
<body data-barba="wrapper">先加style="opacity:0"。 - 在
barba.init里写一次性的once过渡:
once({ next }) {
gsap.fromTo(next.container,
{ opacity: 0 },
{ opacity: 1, duration: 0.4, onComplete: () => document.body.style.opacity = 1 }
)
}
🔴 场景 2:Vue3 组件不销毁,内存暴涨
症状:来回切换页面后,控制台出现 [Vue warn]: Component is already mounted。
快速解法:
在 afterEnter 里手动卸载并重新挂载:
afterEnter({ next }) {
app?.unmount()
app = createApp(App)
app.mount('#app')
}
🔴 场景 3:滚动位置错乱
症状:A 页面滚到 800 px,跳转到 B 页面却直接回到顶部。
快速解法:
barba.hooks.beforeLeave(() => {
history.replaceState({ ...history.state, scrollY: window.scrollY }, '')
})
barba.hooks.afterEnter(() => {
const { scrollY = 0 } = history.state || {}
window.scrollTo({ top: scrollY, behavior: 'smooth' })
})
🔴 场景 4:点击浏览器后退,页面样式瞬间全乱
症状:后退时 Barba 把缓存的 DOM 直接塞回,但 Vue3 样式作用域失效。
快速解法:
给 <style scoped> 再补一个全局补丁:
/* barba 会把 container 整个替换,scoped 样式会丢 */
.barba-container[data-namespace="home"] .hero {
/* 重写一次关键样式 */
}
🔴 场景 5:移动端首次滑动卡顿
症状:iOS Safari 第一次滑屏有 300 ms 延迟。
快速解法:
在 barba.init 里关闭预加载的 timeout:
barba.init({
timeout: 0, // 不等待 requestIdleCallback
})
写在最后
Barba.js 并不是一个“Vue3 专用”的库,但正是这种 框架无关 的特性,让它在 Vue3 项目里反而更自由:
- 你可以继续用
Vue Router做SPA; - 也可以把多页站改造成
“伪 SPA”,却保留SSR的SEO优势。
一句话:如果你受够了页面跳转的“闪白”,又不想折腾整站改造成 SPA,Barba.js + Vue3 就是目前性价比最高的动效解!
- Barba.js 官网:
https://barba.js.org/ - Barba.js Github:
https://github.com/barbajs/barba
来源:juejin.cn/post/7532287059374506027
Hutool被卖半年多了,现状是逆袭还是沉寂?
是的,没错。那个被人熟知的国产开源框架 Hutool 距离被卖已经过去近 7 个月了。
那 Hutool 现在的发展如何呢?它未来有哪些更新计划呢?Hutool AI 又该如何使用呢?如果不想用 Hutool 有没有可替代的框架呢?
近半年现状
从 Hutool 官网可以看出,其被卖近 7 个月内仅发布了 4 个版本更新,除了少量的新功能外,大多是 Bug 修复,当期在此期间发布了 Hutool AI 模块,算是一个里程碑式的更新:

收购公司
没错,收购 Hutool 的这家公司和收购 AList 的公司是同一家公司(不够科技),该公司前段时间因为其在收购 AList 代码中悄悄收集用户设备信息,而被推向过风口浪尖,业内人士认为其收购开源框架就是为了“投毒”,所以为此让收购框架损失了很多忠实的用户。
其实,放眼望去那些 APP 公司收集用户设备和用户信息属于家常便饭了(国内隐私侵犯问题比较严重),但 AList 因为其未做文档声明,且未将收集设备信息的代码提交到公共仓库,所以大家发现之后才会比较气愤。
Hutool-AI模块使用
Hutool AI 模块的发布算是被收购之后发布的最值得让人欣喜的事了,使用它可以对接各大 AI 模型的工具模块,提供了统一的 API 接口来访问不同的 AI 服务。
目前支持 DeepSeek、OpenAI、Grok 和豆包等主流 AI 大模型。
该模块的主要特点包括:
- 统一的 API 设计,简化不同 AI 服务的调用方式。
- 支持多种主流 AI 模型服务。
- 灵活的配置方式。
- 开箱即用的工具方法。
- 一行代码调用。
具体使用如下。
1.添加依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-ai</artifactId>
<version>5.8.38</version>
</dependency>
2.调用API
实现对话功能:
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel("your bots id").build(), DoubaoService.class);
ArrayList<Message> messages = new ArrayList<>();
messages.add(new Message("system","你是什么都可以"));
messages.add(new Message("user","你想做些什么"));
String botsChat = doubaoService.botsChat(messages);
识别图片:
//可以使用base64图片
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel(Models.Doubao.DOUBAO_1_5_VISION_PRO_32K.getModel()).build(), DoubaoService.class);
String base64 = ImgUtil.toBase64DataUri(Toolkit.getDefaultToolkit().createImage("your imageUrl"), "png");
String chatVision = doubaoService.chatVision("图片上有些什么?", Arrays.asList(base64));
//也可以使用网络图片
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel(Models.Doubao.DOUBAO_1_5_VISION_PRO_32K.getModel()).build(), DoubaoService.class);
String chatVision = doubaoService.chatVision("图片上有些什么?", Arrays.asList("https://img2.baidu.com/it/u=862000265,4064861820&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=1544"),DoubaoCommon.DoubaoVision.HIGH.getDetail());
生成视频:
//创建视频任务
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel("your Endpoint ID").build(), DoubaoService.class);
String videoTasks = doubaoService.videoTasks("生成一段动画视频,主角是大耳朵图图,一个活泼可爱的小男孩。视频中图图在公园里玩耍," +
"画面采用明亮温暖的卡通风格,色彩鲜艳,动作流畅。背景音乐轻快活泼,带有冒险感,音效包括鸟叫声、欢笑声和山洞回声。", "https://img2.baidu.com/it/u=862000265,4064861820&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=1544");
//查询视频生成任务信息
String videoTasksInfo = doubaoService.getVideoTasksInfo("任务id");
未来发展
- Hutool5:目前 Hutool 5.x 版本主要是基于 JDK 8 实现的,后面更新主要以 BUG 修复为准。
- Hutool6:主要以功能尝鲜为主。
- Hutool7:升级为 JDK 17,添加一些新功能,删除一些不用的类。
目前只发布了 Hutool 5.x,按照目前的更新进度来看,不知何时才能盼来 Hutool7 的发布。
同类替代框架
如果担心 Hutool 有安全性问题,或更新不及时的问题可以尝试使用同类开源工具类:
- Apache Commons:commons.apache.org/
- Google Guava:github.com/google/guav…
视频解析
http://www.bilibili.com/video/BV1QR…
小结
虽然我们不知道 Hutool 被收购意味着什么?是会变的越来越好?还是会就此陨落?我们都不知道答案,所以只能把这个问题交给时间。但从个人情感的角度出发,我希望国产开源框架越做越好。好了,我是磊哥,咱们下期见。
本文已收录到我的面试小站 http://www.javacn.site,其中包含的内容有:场景题、SpringAI、SpringAIAlibaba、并发编程、MySQL、Redis、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、JVM、设计模式、消息队列、Dify、Coze、AI常见面试题等。
来源:juejin.cn/post/7547624644507156520
前端何时能出个"秦始皇"一统天下?我是真学不动啦!
前端何时能出个"秦始皇"一统天下?我是真学不动啦!
引言
前端开发的世界,就像历史上的战国时期一样,各种框架、库、工具层出不穷,形成了一个百花齐放但也令人眼花缭乱的局面。
而且就因为百家争鸣,导致各种鄙视链出现
比如 React 和 Vue 互喷
v:你react 这么难用,不如我vue 简单
r:你一点都不灵活,我想咋用咋用
v:你useEffect 心智负担太重,一点都好用
r:啥心智负担,那是你太笨了,我就喜欢这种什么都掌握在自己手里的感觉
v:你内部更是混乱,一个状态管理就那么多种 啥redux、mobx、recoil。。。。不像我们一个pinia 走天下
r:你管我 我想用哪个用哪个,你还说我,你内部对一个 用ref还是用reactive 都吵得不可开交!
......

1. 框架之争
- React: 由Facebook维护的一个用于构建用户界面的JavaScript库。其设计理念是通过组件化的方式简化复杂的UI开发。
- 官网: reactjs.org/
- GitHub: github.com/facebook/re…
- GitHub Stars: 超过235k(截至2025年4月)
- Vue.js: 一种渐进式JavaScript框架,非常适合用来构建单页应用。Vue的核心库只关注视图层,易于上手。
- 官网: vuejs.org/
- GitHub: github.com/vuejs/vue
- GitHub Stars: 约209k(截至2025年4月)
- Angular: Google支持的一个开源Web应用框架,适用于大型企业级项目。它提供了一个全面的解决方案来创建动态Web应用程序。
- 官网: angular.io/
- GitHub: github.com/angular/ang…
- GitHub Stars: 大约97.5k(截至2025年4月)
- Solid.js: 一个专注于性能和简单性的声明式UI库,采用细粒度的响应式系统,提供了极高的运行效率。
- 官网: http://www.solidjs.com/
- GitHub: github.com/solidjs/sol…
- GitHub Stars: 约33.3k(截至2025年4月)
- Svelte: 一种新兴的前端框架,通过在编译时将组件转换为高效的原生代码,从而避免了运行时开销。
- 官网: svelte.dev/
- GitHub: github.com/sveltejs/sv…
- GitHub Stars: 约82.3k(截至2025年4月)
- Ember.js: 一个旨在帮助开发者构建可扩展的Web应用的框架,尤其适合大型团队协作。
- 官网: emberjs.com/
- GitHub: github.com/emberjs/emb…
- GitHub Stars: 约22.6k(截至2025年4月)
2. 样式处理满花齐放
样式处理方面可以进一步细分,包括CSS预处理器、CSS-in-JS、Utility-First CSS框架以及CSS Modules等。
- CSS预处理器
- Sass: 提供变量、嵌套规则等高级功能,极大地提高了CSS代码的可维护性。
- 官网: sass-lang.com/
- GitHub: github.com/sass/sass
- GitHub Stars: 约15.2k(截至2025年4月)
- Less: 另一种流行的CSS预处理器,支持类似的功能但语法稍有不同。
- 官网: lesscss.org/
- GitHub: github.com/less/less.j…
- GitHub Stars: 约17k(截至2025年4月)
- Stylus: 一款灵活且功能强大的CSS预处理器,允许省略括号和分号等符号,使代码更加简洁。
- 官网: stylus-lang.com/
- GitHub: github.com/stylus/styl…
- GitHub Stars: 约11.2k(截至2025年4月)
- Sass: 提供变量、嵌套规则等高级功能,极大地提高了CSS代码的可维护性。
- CSS-in-JS
- styled-components: 允许你通过JavaScript编写CSS,并将样式直接附加到组件上。
- 官网: styled-components.com/
- GitHub: github.com/styled-comp…
- GitHub Stars: 约40.8k(截至2025年4月)
- Emotion: 类似于styled-components,但提供了更多的灵活性和性能优化。
- 官网: emotion.sh/
- GitHub: github.com/emotion-js/…
- GitHub Stars: 约17.7k(截至2025年4月)
- styled-components: 允许你通过JavaScript编写CSS,并将样式直接附加到组件上。
- 原子化css
- Tailwind CSS: 一种实用优先的CSS框架,让你可以通过低级实用程序类构建定制设计。
- 官网: tailwindcss.com/
- GitHub: github.com/tailwindlab…
- GitHub Stars: 约87.2k(截至2025年4月)
- UnoCSS: 新一代的原子化CSS引擎,旨在提供极致的性能和灵活性。
- 官网: uno.antfu.me/
- GitHub: github.com/unocss/unoc…
- GitHub Stars: 约17.5k(截至2025年4月)
- Windi CSS: 一个基于Tailwind CSS的即时按需CSS框架,提供了更快的开发体验。
- 官网: windicss.org/
- GitHub: github.com/windicss/wi…
- GitHub Stars: 约6.5k(截至2025年4月)
- Tailwind CSS: 一种实用优先的CSS框架,让你可以通过低级实用程序类构建定制设计。
3. 构建工具五花八门
构建工具是现代前端开发不可或缺的一部分,它们负责将源代码转换为生产环境可用的形式,并优化性能。
- Webpack: 一个模块打包工具,广泛用于复杂的前端项目中。它支持多种文件类型的处理,并具有强大的插件生态。
- 官网: webpack.js.org/
- GitHub: github.com/webpack/web…
- GitHub Stars: 约65.2k(截至2025年4月)
- Vite: 由Vue.js作者尤雨溪开发的下一代前端构建工具,以其极快的冷启动速度和热更新闻名。
- 官网: vitejs.dev/
- GitHub: github.com/vitejs/vite
- GitHub Stars: 约72.1k(截至2025年4月)
- Rollup: 一个专注于JavaScript库的打包工具,特别适合构建小型库或框架。
- 官网: rollupjs.org/
- GitHub: github.com/rollup/roll…
- GitHub Stars: 约25.7k(截至2025年4月)
- Rspack: 一个基于Rust实现的高性能构建工具,兼容Webpack配置,旨在提供更快的构建速度。
- 官网: rspack.dev/
- GitHub: github.com/web-infra-d…
- GitHub Stars: 约11.3k(截至2025年4月)
- esbuild: 一个用Go语言编写的极速打包工具,专为现代JavaScript项目设计。
- 官网: esbuild.github.io/
- GitHub: github.com/evanw/esbui…
- GitHub Stars: 约38.8k(截至2025年4月)
- Turbopack: 由Next.js团队推出的下一代构建工具,号称比Webpack快700倍。
- 官网: turbo.build/docs
- GitHub: github.com/vercel/turb…
- GitHub Stars: 约27.5k(截至2025年4月)
- Rolldown: 一个基于Rust的Rollup替代方案,旨在提供更快的构建速度和更高的性能。
- 官网: rolldown.dev/
- GitHub: github.com/rolldown/ro…
- GitHub Stars: 约10.7k(截至2025年4月)
对比分析:
- Webpack 是目前最成熟的构建工具,生态系统庞大,但配置复杂度较高。
- Vite 凭借其快速的开发体验迅速崛起,尤其在中小型项目中表现优异。
- Rollup 更适合轻量级项目或库的构建,虽然社区规模较小,但在特定场景下非常高效。
- Rspack 和 esbuild 利用高性能语言(如Rust和Go)实现了极快的构建速度,适合对性能要求较高的项目。
- Turbopack 是新兴工具,主打极速构建,未来可能成为Webpack的有力竞争者。
- Rolldown 提供了另一种基于Rust的高速构建解决方案,特别针对Rollup用户群体。
4. 包管理工具逐步更新
- npm: Node.js默认的包管理器,允许开发者轻松地安装、共享和分发代码。
- 官网: http://www.npmjs.com/
- GitHub: github.com/npm/cli
- cnpm: npm在中国的镜像站,由于网络问题,很多中国开发者更倾向于使用cnpm。
- GitHub: github.com/cnpm/cnpm
- Yarn: Facebook推出的一个快速、可靠、安全的依赖管理工具。
- 官网: yarnpkg.com/
- GitHub: github.com/yarnpkg/yar…
- pnpm: 快速且节省磁盘空间的包管理器。
- 官网: pnpm.io/
- GitHub: github.com/pnpm/pnpm
5. 状态管理百家争鸣
状态管理是前端开发中的重要组成部分,它帮助开发者有效地管理应用的状态变化。
- Redux: 经典的Flux实现,广泛用于React生态系统中,适合管理大型应用的状态。
- 官网: redux.js.org/
- GitHub: github.com/reduxjs/red…
- GitHub Stars: 约61.1k(截至2025年4月)
- MobX: 响应式状态管理库,通过可观察对象实现自动化的状态更新。
- 官网: mobx.js.org/
- GitHub: github.com/mobxjs/mobx
- GitHub Stars: 约27.8k(截至2025年4月)
- Zustand: 轻量级的状态管理解决方案,API简单且易于使用。
- 官网: zustand-demo.pmnd.rs/
- GitHub: github.com/pmndrs/zust…
- GitHub Stars: 约51.7k(截至2025年4月)
- Jotai: 原子化状态管理库,专注于轻量级和灵活性。
- 官网: jotai.org/
- GitHub: github.com/pmndrs/jota…
- GitHub Stars: 约19.8k(截至2025年4月)
- Recoil: Facebook推出的实验性状态管理库,专为React设计。
- 官网: recoiljs.org/
- GitHub: github.com/facebookexp…
- GitHub Stars: 约19.6k(截至2025年4月)
- Pinia: Vue的下一代状态管理库,设计简洁且与Vue 3完美集成。
- 官网: pinia.vuejs.org/
- GitHub: github.com/vuejs/pinia
- GitHub Stars: 约13.8k(截至2025年4月)
6. JavaScript运行时环境都有好几种
JavaScript运行时环境是现代前端和后端开发的核心部分,它决定了代码如何被解析和执行。以下是几种主流的JavaScript运行时环境:
- Node.js:
- Node.js 是一个基于Chrome V8引擎的JavaScript运行时,广泛用于构建服务器端应用、命令行工具以及全栈开发。
- 它拥有庞大的生态系统,npm作为其默认包管理器,已经成为全球最大的软件注册表。
- 官网: nodejs.org/
- GitHub: github.com/nodejs/node
- GitHub Stars: 约111k(截至2025年4月)
- Deno:
- Deno 是由Node.js的原作者Ryan Dahl创建的一个现代化JavaScript/TypeScript运行时,旨在解决Node.js的一些设计缺陷。
- 它内置了对TypeScript的支持,并提供了更安全的权限模型(如文件系统访问需要显式授权)。
- Deno还集成了标准库,无需依赖第三方模块即可完成许多常见任务。
- 官网: deno.land/
- GitHub: github.com/denoland/de…
- GitHub Stars: 约103k(截至2025年4月)
- Bun:
- Bun 是一个新兴的JavaScript运行时,旨在提供更快的性能和更高效的开发体验。
- 它不仅可以用作运行时环境,还可以替代npm、Yarn等包管理工具,同时支持ES Modules和CommonJS。
- Bun的目标是成为Node.js和Deno的强大竞争者,特别适合高性能需求的场景。
- 官网: bun.sh/
- GitHub: github.com/oven-sh/bun
- GitHub Stars: 约77.5k(截至2025年4月)
对比分析:
- Node.js 是目前最成熟且广泛应用的JavaScript运行时,尤其在企业级项目中占据主导地位。
- Deno 提供了更现代化的设计理念,特别是在安全性、TypeScript支持和内置工具方面表现突出。
- Bun 是一个新兴的选手,凭借其极速的性能和多功能性迅速吸引了开发者关注,未来潜力巨大。
7. 跨平台开发
随着移动设备和多终端生态的普及,跨平台开发成为现代应用开发的重要方向。以下是几种主流的跨平台开发工具和技术:
- React Native:
- React Native 是由Facebook推出的一个基于React的跨平台移动应用开发框架,允许开发者使用JavaScript和React构建原生性能的iOS和Android应用。
- 它提供了丰富的社区支持和插件生态,适合需要快速迭代的项目。
- 官网: reactnative.dev/
- GitHub: github.com/facebook/re…
- GitHub Stars: 约122k(截至2025年4月)
- Flutter:
- Flutter 是由Google开发的一个开源UI框架,使用Dart语言构建高性能的跨平台应用。
- 它通过自绘引擎渲染UI,提供了一致的用户体验,并支持Web、iOS、Android以及桌面端开发。
- 官网: flutter.dev/
- GitHub: github.com/flutter/flu…
- GitHub Stars: 约170k(截至2025年4月)
- Electron:
- Electron 是一个用于构建跨平台桌面应用的框架,基于Node.js和Chromium,广泛应用于桌面端应用开发。
- 它允许开发者使用Web技术(HTML、CSS、JavaScript)构建功能强大的桌面应用,但可能会导致较大的应用体积。
- 官网: http://www.electronjs.org/
- GitHub: github.com/electron/el…
- GitHub Stars: 约116k(截至2025年4月)
- Tauri:
- Tauri 是一个轻量级的跨平台桌面应用框架,旨在替代Electron,提供更小的应用体积和更高的安全性。
- 它利用系统的原生Webview来渲染UI,同时支持Rust作为后端语言,从而实现更高的性能。
- 官网: tauri.app/
- GitHub: github.com/tauri-apps/…
- GitHub Stars: 约91.5k(截至2025年4月)
- Capacitor:
- Capacitor 是由Ionic团队推出的一个跨平台工具,允许开发者将Web应用封装为原生应用。
- 它支持iOS、Android和Web,并提供了丰富的插件生态,方便调用原生设备功能。
- 官网: capacitorjs.com/
- GitHub: github.com/ionic-team/…
- GitHub Stars: 约13.1k(截至2025年4月)
- UniApp:
- UniApp 是一个基于 Vue.js 的跨平台开发框架,能够将代码编译到多个平台,包括微信小程序、H5、iOS、Android以及其他小程序(如支付宝小程序、百度小程序等)。
- 它的优势在于一次编写,多端运行,特别适合需要覆盖多个小程序平台的项目。
- 官网: uniapp.dcloud.io/
- GitHub: github.com/dcloudio/un…
- GitHub Stars: 约40.6k(截至2025年4月)
对比分析:
- React Native 和 Flutter 是移动端跨平台开发的两大主流选择,分别适合熟悉JavaScript和Dart的开发者。
- Electron 是桌面端跨平台开发的经典解决方案,虽然体积较大,但易于上手。
- Tauri 提供了更轻量化的桌面端开发方案,适合对性能和安全性有更高要求的项目。
- Capacitor 则是一个灵活的工具,特别适合将现有的Web应用快速迁移到移动端。
- UniApp 非常适合需要覆盖多种小程序平台的项目,尤其在国内的小程序生态中表现出色。
结论
你看我这还是只是列举了一部分,都这么多了,学前端的是真的命苦啊,真心学不动了。

而且最近 尤雨溪宣布成立 VoidZero 说是一代JavaScript工具链,能够统一前端 开发构建工具,如果真能做到,真是一件令人振奋的事情,希望尤雨溪能做到跟 spring 一样统一java 天下 把前端的天下给统一了,大家觉得有可能么?
来源:juejin.cn/post/7493420166878822450
35岁程序员失业了,除了送外卖,还能做什么?
很多人可能都觉得,被裁了再找一份工作就好了。但是对于35岁的程序员来说,这可能很难。
35岁程序员失业并不是个别现象,而是很多人都已经遇到了的问题。有可能有外部环境的因素导致,也有可能是个人自身的原因。
为什么?
1.技术更新太快
互联网行业的技术更新速度真的太快了。
记得我刚工作的时候,前端还在用JQuery,一转眼React、Vue已经成为标配了。
Java也从当初的jsp,到现在的springboot,springCloud。
现在大数据、人工智能、AI等新技术层出不穷。如果不持续学习,很容易就会被淘汰。
2.年轻人更有干劲
这是一个很显示的问题。一个35岁的程序员,可能要价是年轻程序员的好几倍。但对于公司来说,如果不是核心的岗位,年轻人的性价比更高。
年轻人没有家庭负担,能加班、能熬夜。对于新技术的敏感度高,学习速度也很快。这些都是优势。
3.自身成长跟不上
很多程序员工作了很多年,但只是在重复劳动,没有形成自己的核心竞争力。你可能有多年的经验,但这些经验并没有转化为更高的价值。
还有就是,35岁左右的年纪,正是家庭负担最重的时候。父母、孩子、房子和车子,哪一样都需要操心。
这些都会分散你的精力,让你没办法想年轻时那样能够全身心的投入工作。
失业后该怎么办?
如果你在35岁时真的失业了,不要慌,请先冷静下来,好好规划一下。
1.调整心态
失业的第一件事,不是急着找下一份工作,而是先冷静下来,调整好自己的心态。
失业并不代表你不行,可能只是不适合那个环境。就当时给自己放个假,陪陪家人,思考一下自己到底想要什么。
不要做这几件事:
不要盲目的投简历,见公司就投;
不要自暴自弃,怀疑自己的人生;
不要急着转行,特别是完全不了解的行业。
2.财务评估
冷静下来后,要做一次彻底的财务评估。算算你的存款能支持多久,每个月的固定支出是多少。
这可以帮你明确你有多少事件可以找工作或者转型。如果经济压力大,也可以先找一份工作过渡一下。
3.找准自己的定位
这是最关键的一步。你要清楚的知道自己的优势和劣势,找准自己的定位。
可以问问自己这些问题:
我最擅长什么技术?
我有什么样的项目经验?
我的软技能如何(沟通、管理、架构设计等)?
我到底喜欢做什么?
根据这些答案,你可以确定自己的方向,是继续做技术,还是转向管理,更或者是创业?
有哪些出路可以选择?
对于35岁的程序员来说,其实出路有很多,不只是送外卖,开滴滴。
1.深耕技术
很多程序员觉得35岁还在写代码真的很失败,我认为这是一个错误的观念。在国外,50-60岁还在写代码的大有人在。
怎么深耕?
成为领域专家:不要什么都懂一点,但什么都不精。选择一个方向深入下去,比如前端、后端、大数据、AI等,成为某个领域的专家。
学习新技术:关注行业的趋势,学习新技术。比如现在还在只学jsp或者jQuery,那肯定是不行的。
参与开源项目:参与开源项目不仅能提升你的技术能力,还能扩大你的影响力。
2.技术管理
如果你对技术还有兴趣,但又不想天天写代码,技术管理是一个不错的选择。
需要具备的能力:
技术能力:你不需要是团队里最牛的,但必须又扎实的技术基础,能够做技术决策。
沟通协调能力:能够与产品、测试和运营等不同的角色进行有效沟通。
团队管理能力:懂得怎么记激励团队成员,怎么分配认为,怎么样解决同事之间的冲突。
3.架构师
架构师是很多程序员的职业目标,需要深厚的技术功底。
架构师的核心能力:
技术广度:需要对各种技术有所了解,知道在什么场景下该用什么技术。
系统设计能力:能够设计扩展性好、性能高的系统架构。
业务理解能力:能够快速的为业务需求制定技术方案。
4.自由职业或创业
如果不想再为别人打工,可以考虑创业或者做自由职业。
创业方向
技术服务:为中小企业提供技术服务,比如开发网站、小程序和APP开发等。
软件开发:开发自己的产品,比如SaaS服务、移动应用等。
自由职业
接外包项目:通过各大外包平台接项目(不稳定,我个人认为不如上班)。
技术写作:写技术文章,做技术分享。
5.转行相关领域
如果你真的不想做技术了,也可以转行到相关领域。
可能的领域:
产品经理:程序员转产品经理有天然的优势,因为你懂技术,知道什么能做,什么不能做。
技术投资:如果你对商业有敏感度,可以考虑转向技术投资领域。
怎么样预防失业的风险?
在失业之前,我们就应该做好准备。
1.持续学习
技术行业,不学习就会被淘汰。这不是危言耸听,而是现实。
定期学习新技术:不要等到用的时候才学,平时可以多逛下稀土掘金、csdn等网站关注一些新技术。
深入理解基础:新技术层出不穷,但基础是不变的。深入理解计算机基础、网络、算法等,这些知识永远不会过时。
跨界学习:不要只局限在自己熟悉的技术,多了解一下其他相关领域。
2.建立个人品牌
在当今社会,个人品牌越来越重要。有了个人品牌,你就有了影响力,就有了更多的机会。
如何建立个人品牌?
写技术博客:分享你的技术经验和见解。
参与开源项目:在GitHub上贡献代码。
在技术社区活跃:回答问题,分享经验。
参加技术大会:尽可能在技术大会上做一些交流和分享。
3.发展副业
不要把所有鸡蛋放在一个篮子里。在发展主业的同时,可以考虑发展副业。
副业方向:
接外包项目:利用业余时间接一些项目。
写技术文章:向技术媒体投稿,获取稿费。
开发自己的产品:比如浏览器插件、小程序、APP等。
结语
35岁程序员失业,确实是一个非常大的挑战。但危机中或许也会藏着新的机遇。
重要的是,捕蝇自暴自弃,认证找准自己的方向,然后坚定的走下去。
任何行业的路都不好走,只要你能保持学习的热情,不断的提升自己,年龄就不是问题。
35岁,不是终点,而是新的起点。
如果你觉得这篇文章对你有帮助,欢迎点赞、分享。你的支持是我继续创作的最大动力!
链接:juejin.cn/post/7563910479007498240
同志们,我去外包了
同志们,我去外包了
同志们,经历了漫长的思想斗争,我决定回老家发展,然后就是简历石沉大海,还好外包拯救了我,我去外包了!

首先随着工作年限的增加,越来越多公司并不会去和你抠八股文了(那阵八股风好像停了),只是象征性的问几个问题,然后会对照着项目去问些实际的问题以及你的处理办法。 (ps:(坐标合肥)突然想到某鑫面试官问我你知道亿级流量吗?你怎么处理的,听到这个问题我就想呼过去,也许读书读傻了,他根本不知道亿级流量是个什么概念,最主要的是它是个制造业公司啊,你哪来的亿级流量啊,也不知道问这个问题时他在想啥,还有某德(不是高德),一场能面一个小时,人裂开)。
好了,言归正传,咱说点入职这家公司我了解到的一点东西,我分为两部分:代码和sql;
代码上
首先传统的web项目也会分前端后端,这点不错;
1.获取昨天日期
可以使用jdk自带的LocalDate.now().minusDays(-1) 这个其实内部调用的是plusDays(1)方法,所以不如直接就用plusDays方法,这样少一层判断;
PS:有多少人和我之前一样直接new Date()的。
2.字符填充
apache.common下的StringUtils的rightPad方法用于字符串填充使用方法是StringUtils.rightPad(str,len,fillStr) 大概意思就是str长度如果小于len,就用fillStr填充;
PS:有多少人之前是String.format或者StringBuilder用循环实现的。
3.获取指定年指定月的某天
获取指定年指定月的某天可以用localDate.of(year,month,day),如果我们想取2025年的五月一号,可以写成LocalDate.of(2025, 5, 1),那有人可能就想到了如果月尾呢,LocalDate.of(2025, 5, 31)也是可以的,但是我们需要清楚知道这个月有多少天,比如说你2月给个30天,那就会抛异常; 麻烦;
 更好的办法就是先获取第一天,然后调用
更好的办法就是先获取第一天,然后调用localDate.with(TemporalAdjusters.lastDayOfMonth());方法获取最后一天,TemporalAdjusters.lastDayOfMonth()会自动处理不同月份和闰年的情况;
sql层面的
有言在先,说实话我不建议在sql层面写这种复杂的东西,毕竟我们这么弱的人看到那么长的且复杂的sql会很无力,那种无力感你懂吗?打工人不为难打工人;不过既然别人写了,咱们就学习一下嘛;
1.获取系统日期
首先获取系统日期可以试用TRUNC(SYSDATE)进行截取,这样返回的时分秒是00:00:00,比如2025-05-29 00:00:00,它也可以截取数字,想知道就去自行科普下,不建议掌握,学习了下,有点搞;
2.返回date当前月份的最后一天
LAST_DAY(date)这个返回的是date当前月份的最后一天,比如今天是2025-05-29,那么返回的是2025-05-31 ADD_MONTH(date,11)表示当前日期加上11个月,比如2025-01-02,最终返回的是2025-12-02;
3.左连接的知识点
最后再提个左连接的知识点,最近看懵了,图一乐哈,A left join B,就是on的条件是在join生成临时表时起作用的,而where是对生成的临时表进行过滤; 两者过滤的时机不一样。我想了很久我觉得可以这么理解,on它虽然可以添加条件,但他的条件只是一个匹配条件比如B.age>10;它是不会对A表查询出来的数据量产生一个过滤效果; 而where是一个实打实的过滤条件,不管怎么说都会影响最终结果,对于inner join这个特例,on和where的最终效果一样,因为B.age>10会导致B的匹配数据减少,由于是交集,故会对整体数据产生影响。
好了,晚安,外包打工仔。。。
来源:juejin.cn/post/7510055871465308212
Kafka 消息积压了,同事跑路了
快到年底了,系统频繁出问题。我有正当理由怀疑老板不想发年终奖所以搞事。
这不,几年都遇不到的消息队列积压现象今晚又卷土重来了。
今晚注定是个不眠夜了,原神启动。。。

组里的小伙伴火急火燎找到我说,Kafka 的消息积压一直在涨,预览图一直出不来。我加了几个服务实例,刚开始可以消费,后面消费着也卡住了。
本来刚刚下班的我就比较疲惫,想让他撤回镜像明天再上。不成想组长不讲武德,直接开了个飞书视频。
我当时本来不想理他,我已经下班了,别人上线的功能出问题关我啥事。

后来他趁我不注意搞偷袭,给我私信了,我当时没多想就点开了飞书。
本来以传统功夫的点到为止,我进入飞书不点开他的会话,是能看他给我发的最后一句话的。

我把手放在他那个会话上就是没点开,已读不回这种事做多了不好。我笑了一下,准备洗洗睡了。
正在我收手不点的时候,他突然给我来了一个电话,我大意了啊,没有挂,还强行接了他的电话。两分多钟以后就好了,我说小伙子你不讲武德。
直接喊话,今晚必须解决,大家都点咖啡算他的。
 这真没办法,都找上门来了。只能跟着查一下,早点解决早点睡觉。然后我就上 Kafka 面板一看:最初的4个分区已经积压了 1200 条,后面新加的分区也开始积压了,而且积压的速度越来越快。
这真没办法,都找上门来了。只能跟着查一下,早点解决早点睡觉。然后我就上 Kafka 面板一看:最初的4个分区已经积压了 1200 条,后面新加的分区也开始积压了,而且积压的速度越来越快。
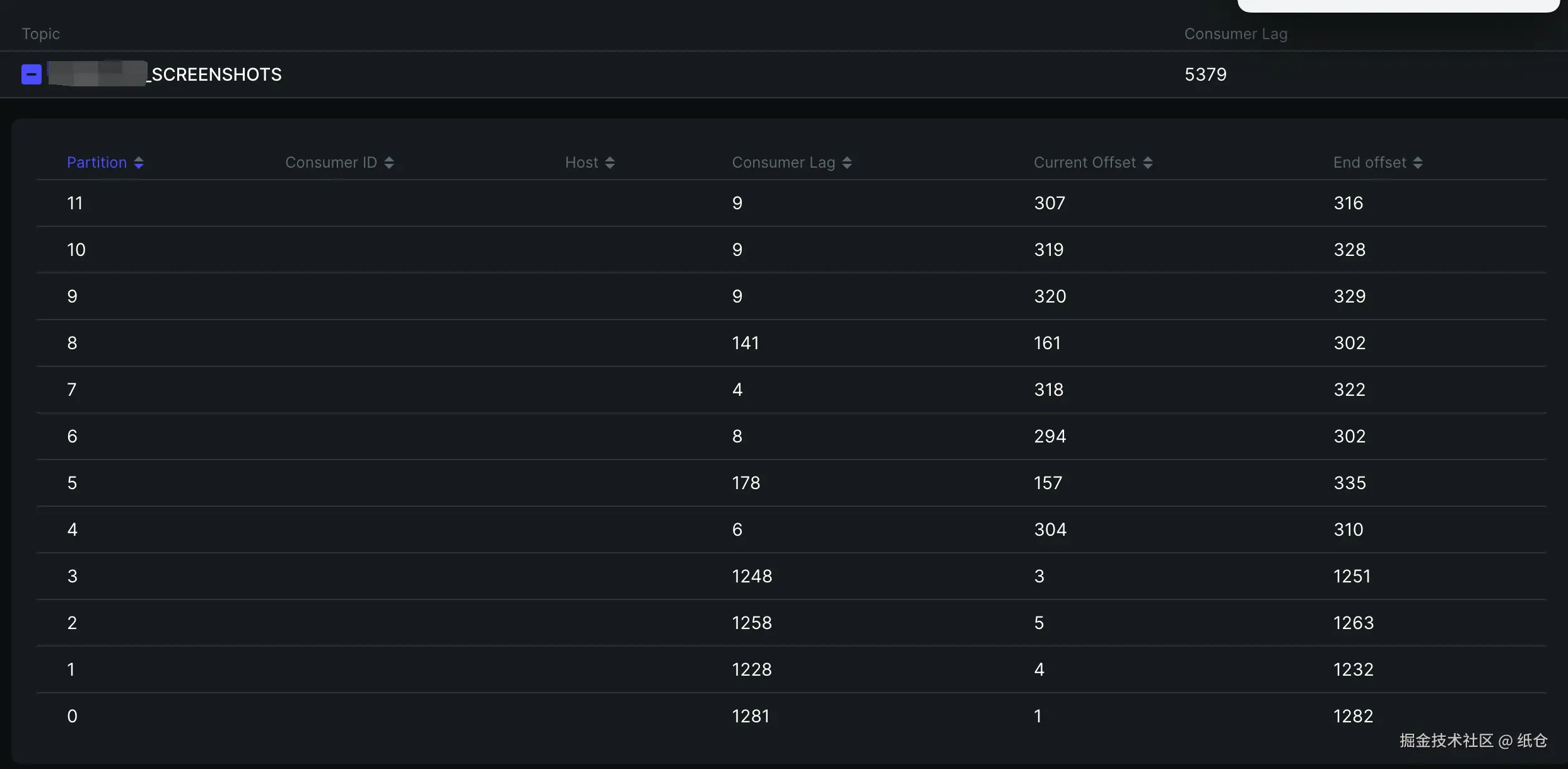
搞清楚发生了什么?我们就得思考一下导致积压的原因。一般是消费者代码执行出错了,导致某条消息消费不了。
所以某个点卡住了,然后又有新的消息进来。
Kafka 是通过 offset 机制来标记消息是否消费过的,所以如果分区中有某一条消息消费失败,就会导致后面的没机会消费。
我用的是spring cloud stream 来处理消息队列的发送和监听。代码上是每次处理一条消息,而且代码还在处理的过程中加了 try-catch。监听器链路打印的日志显示执行成功了,try-catch也没有捕捉到任何的异常。
这一看,我就以为是消费者性能不足,突然想起 SpringCloudStream 好像有个多线程消费的机制。立马让开发老哥试试,看看能不能就这样解决了,我困得不行。

我半眯着眼睛被提醒吵醒了。开发老哥把多线程改成10之后,发现积压更快了,而且还有pod会挂。老哥查了一下多线程的配置 concurrency。
原来指的是消费者线程,一个消费者线程会负责处理一个分区。对于我们来说,增加之后可能会导致严重的流量倾斜,难怪pod会挂掉,赶紧恢复了回去。
看来想糊弄过去是不行了,我把pod运行的日志全部拉下来。查了一下日志,日志显示执行成功了,但同时有超时错误,这就见了鬼了。
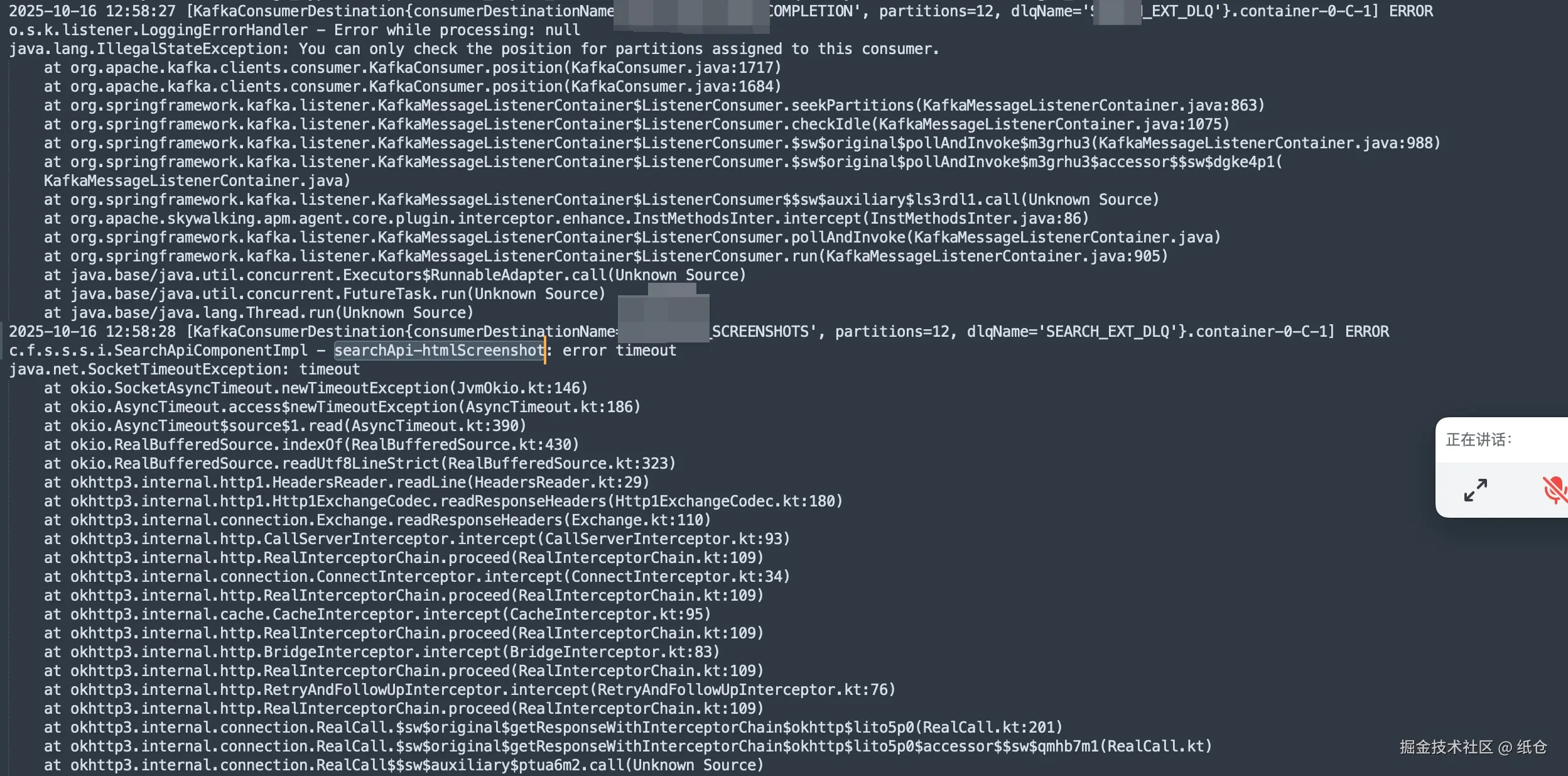
作为一个坚定的唯物主义者,我是不信见鬼的。但此刻我汗毛倒竖,吓得不敢再看屏幕一眼。

但是内心又觉得不甘心,于是我偷偷瞄了一眼屏幕。不看还好,一喵你猜我发现了啥?
消费者组重平衡了,这就像是在黑暗中有一束光照向了我,猪八戒发现嫦娥原来一直暗恋自己,我的女神其实不需要拉屎。
有了重平衡就好说了,无非就是两种情况,一是服务挂掉了,二是服务消费者执行超时了。现在看来服务没有挂,那就是超时了,也正好和上面的日志能对上。

那怎么又看到监听器执行的结果是正常的呢?
这就得从 Kafka 的批量拉取机制说起了,这货和我们人类直觉上的的队列机制不太一样。我们一般理解的队列是发送一个消息给队列,然后队列就异步把这消息给消费者。但是这货是消费者主动去拉取一批来消费。
然后好死不死,SpringCloudStream 为了封装得好用符合人类的认知,就做成了一般理解的队列那种方式。
SpringCloudStream 一批拉了500条记录,然后提供了一个监听器接口让我们实现。入参是一个对象,也就是500条数据中的一条,而不是一个数组。

我们假设这500条数据的ID是 001-500,每一条数据对应的消费者需要执行10s。那么总共就需要500 x 10s=5000s。
再假设消费者执行的超时时间是 300s,而且消费者执行的过程是串行的。那么500条中最多只能执行30条,这就能解释为什么看消费链路是正常的,但是还超时。
因为单次消费确实成功了,但是批次消费也确实超时了。
我咧个豆,破案了。

于是我就想到了两种方式来处理这个问题:第一是改成单条消息消费完立马确认,第二是把批次拉取的数据量改小一点。
第一种方案挺好的,就是性能肯定没有批量那么好,不然你以为 Kafka 的吞吐量能薄纱ActiveMQ这些传统队列。吞吐量都是小事,这个方案胜在可以立马去睡觉了。只需要改一个配置:ack-mode: RECORD
第二种方案是后来提的,其实单单把批次拉取的数据量改小性能提升还不是很明显。不过既然我们都能拿到一批数据了,那多线程安排上就得了。
先改配置,一次只拉取50条 max.poll.records: 50。然后启用线程池处理,完美!
@StreamListener("")
public void consume(List<byte[]> payloads) {
List> futures = payloads.stream().map(bytes -> {
Payload payload = JacksonSnakeCaseUtils.parseJson(new String(bytes), Payload.class);
return CompletableFuture.runAsync(() -> {
// ........
}, batchConsumeExecutor).exceptionally(e -> {
log.error("Thread error {}", bytes, e);
return null;
});
}).collect(Collectors.toList());
try {
// 等待这批消息中的所有任务全部完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
errorMessage = "OK";
} catch (Exception e) {
errorMessage = "Ex: " + e.getMessage();
} finally {
// ...
}
}

来源:juejin.cn/post/7573687816431190026
10 个被严重低估的 JS 特性,直接少写 500 行代码
前言
最近逛 Reddit 的时候,看到一个关于最被低估的 JavaScript 特性的讨论,我对此进行了总结,和大家分享一下。
最近逛 Reddit 的时候,看到一个关于最被低估的 JavaScript 特性的讨论,我对此进行了总结,和大家分享一下。
1. Set:数组去重 + 快速查找,比 filter 快 3 倍
提到数组去重,很多人第一反应是 filter + indexOf,但这种写法的时间复杂度是 O (n²),而 Set 天生支持 “唯一值”,查找速度是 O (1),还能直接转数组。
举个例子:
用户 ID 去重:
// 后端返回的重复用户 ID 列表
const duplicateIds = [101, 102, 102, 103, 103, 103];
// 1 行去重
const uniqueIds = [...new Set(duplicateIds)];
console.log(uniqueIds); // [101,102,103]
避免重复绑定事件:
const listenedEvents = new Set();
// 封装事件绑定函数,防止同一事件重复绑定
function safeAddEvent(eventName, handler) {
if (!listenedEvents.has(eventName)) {
window.addEventListener(eventName, handler);
listenedEvents.add(eventName); // 标记已绑定
}
}
// 调用 2 次也只会绑定 1 次 scroll 事件
safeAddEvent("scroll", () => console.log("滚动了"));
safeAddEvent("scroll", () => console.log("滚动了"));
提到数组去重,很多人第一反应是 filter + indexOf,但这种写法的时间复杂度是 O (n²),而 Set 天生支持 “唯一值”,查找速度是 O (1),还能直接转数组。
举个例子:
用户 ID 去重:
// 后端返回的重复用户 ID 列表
const duplicateIds = [101, 102, 102, 103, 103, 103];
// 1 行去重
const uniqueIds = [...new Set(duplicateIds)];
console.log(uniqueIds); // [101,102,103]
避免重复绑定事件:
const listenedEvents = new Set();
// 封装事件绑定函数,防止同一事件重复绑定
function safeAddEvent(eventName, handler) {
if (!listenedEvents.has(eventName)) {
window.addEventListener(eventName, handler);
listenedEvents.add(eventName); // 标记已绑定
}
}
// 调用 2 次也只会绑定 1 次 scroll 事件
safeAddEvent("scroll", () => console.log("滚动了"));
safeAddEvent("scroll", () => console.log("滚动了"));
2. Object.entries () + Object.fromEntries ():对象数组互转神器
以前想遍历对象,要用 for...in 循环,外加判断 hasOwnProperty;如果想把数组转成对象,只能手动写循环。这对组合直接一键搞定。
举个例子:
筛选对象属性,过滤掉空值:
// 后端返回的用户信息,包含空值字段
const userInfo = {
name: "张三",
age: 28,
avatar: "", // 空值,需要过滤
phone: "13800138000",
};
// 1. 转成[key,value]数组,过滤空值;2. 转回对象
const filteredUser = Object.fromEntries(Object.entries(userInfo).filter(([key, value]) => value !== ""));
console.log(filteredUser);
// {name: "张三", age:28, phone: "13800138000"}
URL 参数转对象(不用再写正则了)
// 地址栏的参数:?name=张三&age=28&gender=男
const searchStr = window.location.search.slice(1);
// 直接转成对象,支持中文和特殊字符
const paramObj = Object.fromEntries(new URLSearchParams(searchStr));
console.log(paramObj); // {name: "张三", age: "28", gender: "男"}
以前想遍历对象,要用 for...in 循环,外加判断 hasOwnProperty;如果想把数组转成对象,只能手动写循环。这对组合直接一键搞定。
举个例子:
筛选对象属性,过滤掉空值:
// 后端返回的用户信息,包含空值字段
const userInfo = {
name: "张三",
age: 28,
avatar: "", // 空值,需要过滤
phone: "13800138000",
};
// 1. 转成[key,value]数组,过滤空值;2. 转回对象
const filteredUser = Object.fromEntries(Object.entries(userInfo).filter(([key, value]) => value !== ""));
console.log(filteredUser);
// {name: "张三", age:28, phone: "13800138000"}
URL 参数转对象(不用再写正则了)
// 地址栏的参数:?name=张三&age=28&gender=男
const searchStr = window.location.search.slice(1);
// 直接转成对象,支持中文和特殊字符
const paramObj = Object.fromEntries(new URLSearchParams(searchStr));
console.log(paramObj); // {name: "张三", age: "28", gender: "男"}
3. ?? 与 ??=:比 || 靠谱
用 || 设置默认值时,会把 0、""、false这些 “有效假值” 当成空值。比如用户输入 0(表示数量),count || 10会返回 10,但这里其实应该返回 0。而??只判断 null/undefined。
举个例子:
处理用户输入的 “有效假值”:
// 用户输入的数量( 0 是有效数值,不能替换)
const userInputCount = 0;
// 错误写法:会把 0 当成空值,返回 10
const wrongCount = userInputCount || 10;
// 正确写法:只判断 null/undefined,返回 0
const correctCount = userInputCount ?? 10;
console.log(wrongCount, correctCount); // 10, 0
给对象补默认值(不会覆盖已有值):
// 前端传入的配置,可能缺少 retries 字段
const requestConfig = { timeout: 5000 };
// 只有当 retries 为 null/undefined 时,才赋值 3(不覆盖已有值)
requestConfig.retries ??= 3;
console.log(requestConfig); // {timeout:5000, retries:3}
// 如果已有值,不会被覆盖
const oldConfig = { timeout: 3000, retries: 2 };
oldConfig.retries ??= 3;
console.log(oldConfig); // {timeout:3000, retries:2}
用 || 设置默认值时,会把 0、""、false这些 “有效假值” 当成空值。比如用户输入 0(表示数量),count || 10会返回 10,但这里其实应该返回 0。而??只判断 null/undefined。
举个例子:
处理用户输入的 “有效假值”:
// 用户输入的数量( 0 是有效数值,不能替换)
const userInputCount = 0;
// 错误写法:会把 0 当成空值,返回 10
const wrongCount = userInputCount || 10;
// 正确写法:只判断 null/undefined,返回 0
const correctCount = userInputCount ?? 10;
console.log(wrongCount, correctCount); // 10, 0
给对象补默认值(不会覆盖已有值):
// 前端传入的配置,可能缺少 retries 字段
const requestConfig = { timeout: 5000 };
// 只有当 retries 为 null/undefined 时,才赋值 3(不覆盖已有值)
requestConfig.retries ??= 3;
console.log(requestConfig); // {timeout:5000, retries:3}
// 如果已有值,不会被覆盖
const oldConfig = { timeout: 3000, retries: 2 };
oldConfig.retries ??= 3;
console.log(oldConfig); // {timeout:3000, retries:2}
4. Intl API:原生国际化 API
很多人会用 moment.js 处理日期、货币格式化,但这个库体积特别大(压缩后也有几十 KB);而 Intl 是浏览器原生 API,支持货币、日期、数字的本地化,体积为 0,还能自动适配地区。
举个例子:
多语言货币格式化(适配中英文):
const price = 1234.56;
// 人民币格式(自动加 ¥ 和千分位)
const cnyPrice = new Intl.NumberFormat("zh-CN", {
style: "currency",
currency: "CNY",
}).format(price);
// 美元格式(自动加 $ 和千分位)
const usdPrice = new Intl.NumberFormat("en-US", {
style: "currency",
currency: "USD",
}).format(price);
console.log(cnyPrice, usdPrice); // ¥1,234.56 $1,234.56
日期本地化(不用手动拼接年月日):
const now = new Date();
// 中文日期:2025年11月3日 15:40:22
const cnDate = new Intl.DateTimeFormat("zh-CN", {
year: "numeric",
month: "long",
day: "numeric",
hour: "2-digit",
minute: "2-digit",
second: "2-digit",
}).format(now);
// 英文日期:November 3, 2025, 03:40:22 PM
const enDate = new Intl.DateTimeFormat("en-US", {
year: "numeric",
month: "long",
day: "numeric",
hour: "2-digit",
minute: "2-digit",
second: "2-digit",
}).format(now);
console.log(cnDate, enDate);
很多人会用 moment.js 处理日期、货币格式化,但这个库体积特别大(压缩后也有几十 KB);而 Intl 是浏览器原生 API,支持货币、日期、数字的本地化,体积为 0,还能自动适配地区。
举个例子:
多语言货币格式化(适配中英文):
const price = 1234.56;
// 人民币格式(自动加 ¥ 和千分位)
const cnyPrice = new Intl.NumberFormat("zh-CN", {
style: "currency",
currency: "CNY",
}).format(price);
// 美元格式(自动加 $ 和千分位)
const usdPrice = new Intl.NumberFormat("en-US", {
style: "currency",
currency: "USD",
}).format(price);
console.log(cnyPrice, usdPrice); // ¥1,234.56 $1,234.56
日期本地化(不用手动拼接年月日):
const now = new Date();
// 中文日期:2025年11月3日 15:40:22
const cnDate = new Intl.DateTimeFormat("zh-CN", {
year: "numeric",
month: "long",
day: "numeric",
hour: "2-digit",
minute: "2-digit",
second: "2-digit",
}).format(now);
// 英文日期:November 3, 2025, 03:40:22 PM
const enDate = new Intl.DateTimeFormat("en-US", {
year: "numeric",
month: "long",
day: "numeric",
hour: "2-digit",
minute: "2-digit",
second: "2-digit",
}).format(now);
console.log(cnDate, enDate);
5. Intersection Observer:图片懒加载 + 滚动加载,不卡主线程
传统我们用 scroll事件 + getBoundingClientRect()判断元素是否在视口,会频繁触发重排,导致页面卡顿;Intersection ObserverAPI 是异步监听,不阻塞主线程,性能直接提升一大截。
举个例子:
图片懒加载(可用于优化首屏加载速度):
<img data-src="https://xxx.com/real-img.jpg" src="placeholder.jpg" class="lazy-img" />
// 初始化观察者
const lazyObserver = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
// 当图片进入视口
if (entry.isIntersecting) {
const img = entry.target;
img.src = img.dataset.src; // 加载真实图片
lazyObserver.unobserve(img); // 加载后停止监听
}
});
});
// 给所有懒加载图片添加监听
document.querySelectorAll(".lazy-img").forEach((img) => {
lazyObserver.observe(img);
});
列表滚动加载更多(避免一次性加载过多数据):
<ul id="news-list">ul>
<div id="load-more">加载中...div>
const loadObserver = new IntersectionObserver((entries) => {
if (entries[0].isIntersecting) {
// 当加载提示进入视口,请求下一页数据
fetchNextPageData().then((data) => {
renderNews(data); // 渲染新列表项
});
}
});
// 监听加载提示元素
loadObserver.observe(document.getElementById("load-more"));
传统我们用 scroll事件 + getBoundingClientRect()判断元素是否在视口,会频繁触发重排,导致页面卡顿;Intersection ObserverAPI 是异步监听,不阻塞主线程,性能直接提升一大截。
举个例子:
图片懒加载(可用于优化首屏加载速度):
<img data-src="https://xxx.com/real-img.jpg" src="placeholder.jpg" class="lazy-img" />
// 初始化观察者
const lazyObserver = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
// 当图片进入视口
if (entry.isIntersecting) {
const img = entry.target;
img.src = img.dataset.src; // 加载真实图片
lazyObserver.unobserve(img); // 加载后停止监听
}
});
});
// 给所有懒加载图片添加监听
document.querySelectorAll(".lazy-img").forEach((img) => {
lazyObserver.observe(img);
});
列表滚动加载更多(避免一次性加载过多数据):
<ul id="news-list">ul>
<div id="load-more">加载中...div>
const loadObserver = new IntersectionObserver((entries) => {
if (entries[0].isIntersecting) {
// 当加载提示进入视口,请求下一页数据
fetchNextPageData().then((data) => {
renderNews(data); // 渲染新列表项
});
}
});
// 监听加载提示元素
loadObserver.observe(document.getElementById("load-more"));
6. Promise.allSettled ():批量请求不 “挂掉”,比 Promise.all 更实用
如果使用 Promise.all,当批量请求时,只要有一个请求失败,Promise.all 就会直接 reject,其他成功的请求结果就拿不到了;而 allSettled 会等待所有请求完成,不管成功失败,还能分别处理结果。
举个例子:
批量获取用户信息 + 订单 + 消息(部分接口失败不影响整体):
// 3个并行请求,可能有失败的
const requestList = [
fetch("/api/user/101"), // 成功
fetch("/api/orders/101"), // 失败(比如订单不存在)
fetch("/api/messages/101"), // 成功
];
// 等待所有请求完成,处理成功和失败的结果
Promise.allSettled(requestList).then((results) => {
// 处理成功的请求
const successData = results.filter((res) => res.status === "fulfilled").map((res) => res.value.json());
// 记录失败的请求(方便排查问题)
const failedRequests = results.filter((res) => res.status === "rejected").map((res) => res.reason.url);
console.log("成功数据:", successData);
console.log("失败接口:", failedRequests); // ["/api/orders/101"]
});
如果使用 Promise.all,当批量请求时,只要有一个请求失败,Promise.all 就会直接 reject,其他成功的请求结果就拿不到了;而 allSettled 会等待所有请求完成,不管成功失败,还能分别处理结果。
举个例子:
批量获取用户信息 + 订单 + 消息(部分接口失败不影响整体):
// 3个并行请求,可能有失败的
const requestList = [
fetch("/api/user/101"), // 成功
fetch("/api/orders/101"), // 失败(比如订单不存在)
fetch("/api/messages/101"), // 成功
];
// 等待所有请求完成,处理成功和失败的结果
Promise.allSettled(requestList).then((results) => {
// 处理成功的请求
const successData = results.filter((res) => res.status === "fulfilled").map((res) => res.value.json());
// 记录失败的请求(方便排查问题)
const failedRequests = results.filter((res) => res.status === "rejected").map((res) => res.reason.url);
console.log("成功数据:", successData);
console.log("失败接口:", failedRequests); // ["/api/orders/101"]
});
7. element.closest ():向上找父元素最安全的方式
传统如果想找某个元素的父元素,比如点击列表项找列表,需要使用 element.parentNode.parentNode,但一旦 DOM 结构变了,代码就崩了;closest() 回直接根据 CSS 选择器找最近的祖先元素,不管嵌套多少层。
举个例子:
点击列表项,给列表容器加高亮:
<ul class="user-list">
<li class="user-item">张三li>
<li class="user-item">李四li>
ul>
document.querySelectorAll(".user-item").forEach((item) => {
item.addEventListener("click", (e) => {
// 找到最近的.user-list(不管中间嵌套多少层)
const list = e.target.closest(".user-list");
list.classList.toggle("active"); // 切换高亮
});
});
输入框聚焦,给表单组加样式:
<div class="form-group">
<label>用户名label>
<input type="text" id="username" />
div>
const usernameInput = document.getElementById("username");
usernameInput.addEventListener("focus", (e) => {
// 找到最近的.form-group,加focused样式
const formGr0up = e.target.closest(".form-group");
formGr0up.classList.add("focused");
});
传统如果想找某个元素的父元素,比如点击列表项找列表,需要使用 element.parentNode.parentNode,但一旦 DOM 结构变了,代码就崩了;closest() 回直接根据 CSS 选择器找最近的祖先元素,不管嵌套多少层。
举个例子:
点击列表项,给列表容器加高亮:
<ul class="user-list">
<li class="user-item">张三li>
<li class="user-item">李四li>
ul>
document.querySelectorAll(".user-item").forEach((item) => {
item.addEventListener("click", (e) => {
// 找到最近的.user-list(不管中间嵌套多少层)
const list = e.target.closest(".user-list");
list.classList.toggle("active"); // 切换高亮
});
});
输入框聚焦,给表单组加样式:
<div class="form-group">
<label>用户名label>
<input type="text" id="username" />
div>
const usernameInput = document.getElementById("username");
usernameInput.addEventListener("focus", (e) => {
// 找到最近的.form-group,加focused样式
const formGr0up = e.target.closest(".form-group");
formGr0up.classList.add("focused");
});
8. URL + URLSearchParams:处理 URL 方便多了
传统解析 URL 参数、修改参数,还要写复杂的正则表达式,有时还得处理中文编码问题;当然我们会直接引入三方库来处理,但毕竟还要引入多余的苦,其实 URL API 可以直接解析 URL 结构,URLSearchParams 可用于处理参数,支持增删改查,自动编码,方便多了。
解析 URL 参数(支持中文和特殊字符):
// 当前页面URL:https://xxx.com/user?name=张三&age=28&gender=男
const currentUrl = new URL(window.location.href);
// 获取参数
console.log(currentUrl.searchParams.get("name")); // 张三
console.log(currentUrl.hostname); // xxx.com(域名)
console.log(currentUrl.pathname); // /user(路径)
修改 URL 参数,跳转新页面:
const url = new URL("https://xxx.com/list");
// 添加参数
url.searchParams.append("page", 2);
url.searchParams.append("size", 10);
// 修改参数
url.searchParams.set("page", 3);
// 删除参数
url.searchParams.delete("size");
console.log(url.href); // https://xxx.com/list?page=3
window.location.href = url.href; // 跳转到第3页
传统解析 URL 参数、修改参数,还要写复杂的正则表达式,有时还得处理中文编码问题;当然我们会直接引入三方库来处理,但毕竟还要引入多余的苦,其实 URL API 可以直接解析 URL 结构,URLSearchParams 可用于处理参数,支持增删改查,自动编码,方便多了。
解析 URL 参数(支持中文和特殊字符):
// 当前页面URL:https://xxx.com/user?name=张三&age=28&gender=男
const currentUrl = new URL(window.location.href);
// 获取参数
console.log(currentUrl.searchParams.get("name")); // 张三
console.log(currentUrl.hostname); // xxx.com(域名)
console.log(currentUrl.pathname); // /user(路径)
修改 URL 参数,跳转新页面:
const url = new URL("https://xxx.com/list");
// 添加参数
url.searchParams.append("page", 2);
url.searchParams.append("size", 10);
// 修改参数
url.searchParams.set("page", 3);
// 删除参数
url.searchParams.delete("size");
console.log(url.href); // https://xxx.com/list?page=3
window.location.href = url.href; // 跳转到第3页
9. for...of 循环:比 forEach 灵活,还支持 break 和 continue
我们都知道,forEach 不能用 break中断循环,也不能用 continue跳过当前项。而for...of不仅支持中断,还能遍历数组、Set、Map、字符串,甚至获取索引。
举个例子:
遍历数组,找到目标值后中断:
const productList = [
{ id: 1, name: "手机", price: 5999 },
{ id: 2, name: "电脑", price: 9999 },
{ id: 3, name: "平板", price: 3999 },
];
// 找价格大于8000的产品,找到后中断
for (const product of productList) {
if (product.price > 8000) {
console.log("找到高价产品:", product); // {id:2, name:"电脑", ...}
break; // 中断循环,不用遍历剩下的
}
}
遍历 Set,获取索引:
const uniqueTags = new Set(["前端", "JS", "CSS"]);
// 用 entries() 获取索引和值
for (const [index, tag] of [...uniqueTags].entries()) {
console.log(`索引${index}:${tag}`); // 索引 0:前端,索引 1:JS...
}
我们都知道,forEach 不能用 break中断循环,也不能用 continue跳过当前项。而for...of不仅支持中断,还能遍历数组、Set、Map、字符串,甚至获取索引。
举个例子:
遍历数组,找到目标值后中断:
const productList = [
{ id: 1, name: "手机", price: 5999 },
{ id: 2, name: "电脑", price: 9999 },
{ id: 3, name: "平板", price: 3999 },
];
// 找价格大于8000的产品,找到后中断
for (const product of productList) {
if (product.price > 8000) {
console.log("找到高价产品:", product); // {id:2, name:"电脑", ...}
break; // 中断循环,不用遍历剩下的
}
}
遍历 Set,获取索引:
const uniqueTags = new Set(["前端", "JS", "CSS"]);
// 用 entries() 获取索引和值
for (const [index, tag] of [...uniqueTags].entries()) {
console.log(`索引${index}:${tag}`); // 索引 0:前端,索引 1:JS...
}
10. 顶层 await:模块异步初始化
以前在 ES 模块里想异步加载配置,必须写个 async 函数再调用;现在 top-level await 允许你在模块顶层直接用 await,其他模块导入时会自动等待,不用再手动处理异步。
举个例子:
模块初始化时加载配置:
// config.js
// 顶层直接 await,加载后端配置
const response = await fetch("/api/config");
export const appConfig = await response.json(); // {baseUrl: "https://xxx.com", timeout: 5000}
// api.js(导入 config.js,自动等待配置加载完成)
import { appConfig } from "./config.js";
// 直接用配置,不用关心异步
export const apiClient = {
baseUrl: appConfig.baseUrl,
get(url) {
return fetch(`${this.baseUrl}${url}`, { timeout: appConfig.timeout });
},
};
点击按钮动态加载组件(按需加载,减少首屏体积):
// 点击“图表”按钮,才加载图表组件
document.getElementById("show-chart-btn").addEventListener("click", async () => {
// 动态导入图表模块,await 等待加载完成
const { renderChart } = await import("./chart-module.js");
renderChart("#chart-container"); // 渲染图表
});
以前在 ES 模块里想异步加载配置,必须写个 async 函数再调用;现在 top-level await 允许你在模块顶层直接用 await,其他模块导入时会自动等待,不用再手动处理异步。
举个例子:
模块初始化时加载配置:
// config.js
// 顶层直接 await,加载后端配置
const response = await fetch("/api/config");
export const appConfig = await response.json(); // {baseUrl: "https://xxx.com", timeout: 5000}
// api.js(导入 config.js,自动等待配置加载完成)
import { appConfig } from "./config.js";
// 直接用配置,不用关心异步
export const apiClient = {
baseUrl: appConfig.baseUrl,
get(url) {
return fetch(`${this.baseUrl}${url}`, { timeout: appConfig.timeout });
},
};
点击按钮动态加载组件(按需加载,减少首屏体积):
// 点击“图表”按钮,才加载图表组件
document.getElementById("show-chart-btn").addEventListener("click", async () => {
// 动态导入图表模块,await 等待加载完成
const { renderChart } = await import("./chart-module.js");
renderChart("#chart-container"); // 渲染图表
});
结语
可以看到,以前我们依赖的第三方库,其实原生 API 早就能解决,比如用 Intl 替代 moment.js,用 Set 替代 lodash 的 uniq,用 Intersection Observer 替代懒加载,随着老旧的浏览器被讨论,兼容性越来越好,这些 API 以后会成为基操。
作者:冴羽
来源:juejin.cn/post/7568153532014559267
可以看到,以前我们依赖的第三方库,其实原生 API 早就能解决,比如用 Intl 替代 moment.js,用 Set 替代 lodash 的 uniq,用 Intersection Observer 替代懒加载,随着老旧的浏览器被讨论,兼容性越来越好,这些 API 以后会成为基操。
来源:juejin.cn/post/7568153532014559267
大家觉得,在前端开发中,最难的技术是哪一个?
“你不能把点点滴滴的事情在未来连接起来,你只能在回顾时看到它们的联系。所以你必须相信,未来的某一刻,你做的所有事情都会有意义。” ——乔布斯
Hello,大家好,我是 三千。
大家觉得,在前端开发中,最难的技术是哪一个?
如果你之前完全没有接触过3D 可视化应用开发,那使用Three.js开发应用还是门槛挺高的,比如,加载一个模型,调光,选择模型弹框的功能,就能干出Three.js上百行的代码。同时还有很多复杂的3D概念需要理解。
前言

今天给大家分享一个3D 开发框架:TresJS 。它是一个基于 Vue.js 的声明式 Three.js 框架,将 Vue 的开发便利性与 Three.js 的强大功能完美结合,提供了模板语法和组件化的开发方式,与 Vue 生态无缝结合,无需额外学习复杂的 Three.js API,大大简化了复杂 3D 场景的构建。高扩展性,与 Three.js 的资源和技术完美兼容,并且在内部进行了大量优化,确保在构建复杂 3D 场景时,性能表现依然出色,无论是数据可视化、虚拟现实。还是3D动画效果,TresJS 都能轻松应对。
下面我们通过一个例子,来看看它是怎么使用的。

1、安装
通过npm的方式,我们可以安装 TresJS:
pnpm add three @tresjs/core
- Typescript
TresJS 是用 Typescript 编写的,是完全类型化的。如果您使用的是 Typescript,您就能充分享受类型的好处。 只需要保证你安装了 three 的类型定义。
npm install @types/three -D
2、设置体验画布
在我们创建场景前,我们需要一个什么来展示它。使用原始的 ThreeJS 我们会需要创建一个 canvas HTML 元素来挂载 WebglRenderer 并初始化一个场景。
通过 TresJS 你仅仅需要导入默认组件 并把它添加到你的 Vue 组件的模板部分即可。
<script lang="ts" setup>
import { TresCanvas } from '@tresjs/core'
script>
<template>
<TresCanvas window-size>
TresCanvas>
template>
这个 TresCanvas 组件会在场景幕后做一些设置的工作:
- 它创建一个 WebGLRenderer 用于自动更新每一帧。
- 它根据浏览器刷新率设置要在每一帧上调用的渲染循环。
3、画布尺寸
默认的情况下,TresCanvas 组件会跟随父元素的宽高,如果出现空白页,请确保父元素的大小合适。
<script lang="ts" setup>
import { TresCanvas } from '@tresjs/core'
script>
<template>
<TresCanvas>
TresCanvas>
template>
<style>
html,
body {
margin: 0;
padding: 0;
height: 100%;
width: 100%;
}
#app {
height: 100%;
width: 100%;
}
style>
如果您的场景不是用户界面的一部分,您也可以通过像这样的使用 window-size prop 来强制画布使用整个窗口的宽度和高度:
<script lang="ts" setup>
import { TresCanvas } from '@tresjs/core'
script>
<template>
<TresCanvas window-size>
TresCanvas>
template>
4、创建一个场景
我们只需要 4 个核心元素来创建 3D 体验:
使用 TresJS 时,您只需将 Renderer(canvas 作为 DOM 元素)和Scene。
<template>
<TresCanvas window-size>
TresCanvas>
template>
然后,您可以使用
<template>
<TresCanvas window-size>
<TresPerspectiveCamera />
TresCanvas>
template>
5、添加一个🍩
那个场景看起来有点空,让我们添加一个基本对象。如果我们使用普通的 ThreeJS,我们需要创建一个 网格 对象,并在其上附加一个 材质 和一个 几何体,如下所示:
const geometry = new THREE.TorusGeometry(1, 0.5, 16, 32)
const material = new THREE.MeshBasicMaterial({ color: 'orange' })
const donut = new THREE.Mesh(geometry, material)
scene.add(donut)
网格是 three.js 中的基本场景对象,用于保存在 3D 空间中表示形状所需的几何体和材质。
现在让我们看看如何使用 TresJS 轻松实现相同的事情。为此,我们将使用
<template>
<TresCanvas window-size>
<TresPerspectiveCamera />
<TresMesh>
<TresTorusGeometry :args="[1, 0.5, 16, 32]" />
<TresMeshBasicMaterial color="orange" />
TresMesh>
TresCanvas>
template>
- 注意,我们不需要导入任何东西,这是因为 TresJS 会为您使用的 PascalCase 的带有 Tres 前缀的 Three 对象自动生成一个 Vue 组件。例如,如果要使用
<script setup lang="ts">
import { TresCanvas } from '@tresjs/core'
script>
<template>
<TresCanvas
clear-color="#82DBC5"
window-size
>
<TresPerspectiveCamera
:position="[3, 3, 3]"
:look-at="[0, 0, 0]"
/>
<TresMesh>
<TresTorusGeometry :args="[1, 0.5, 16, 32]" />
<TresMeshBasicMaterial color="orange" />
TresMesh>
<TresAmbientLight :intensity="1" />
TresCanvas>
template>
从这里开始,您可以开始向场景中添加更多对象,并调整组件的属性来查看它们如何影响场景。

6、思路总结
最后我们用人话总结一下上面的思路:
- 1、最外层我们定义一个TresCanvas,在里面我们可以添加场景
- 2、然后定义一个透视相机,用于观察3D场景,position里去定义相机x,y,z轴的位置,look-at里定义相机观察的目标点
- 3、相机定义完之后,我们开始渲染3d对象,TresTorusGeometry用来定义环面集合体的半径和环向参数。TresMeshBasicMaterial定义几何体的基本材质和颜色。
- 4、最后用TresAmbientLight设置一下环境光的强度。
结语
以上就是今天与大家分享的全部内容,你的支持是我更新的最大动力,我们下期见!
打工人肝 文章/视频 不易,期待你一键三连的鼓励 !!!
😐 这里是【程序员三千】,💻 一个喜欢捣鼓各种编程工具新鲜玩法的啊婆主。
🏠 已入驻:抖爸爸、b站、小红书(都叫【程序员三千】)
💽 编程/AI领域优质资源推荐 👉 http://www.yuque.com/xiaosanye-o…
来源:juejin.cn/post/7468330256689463348
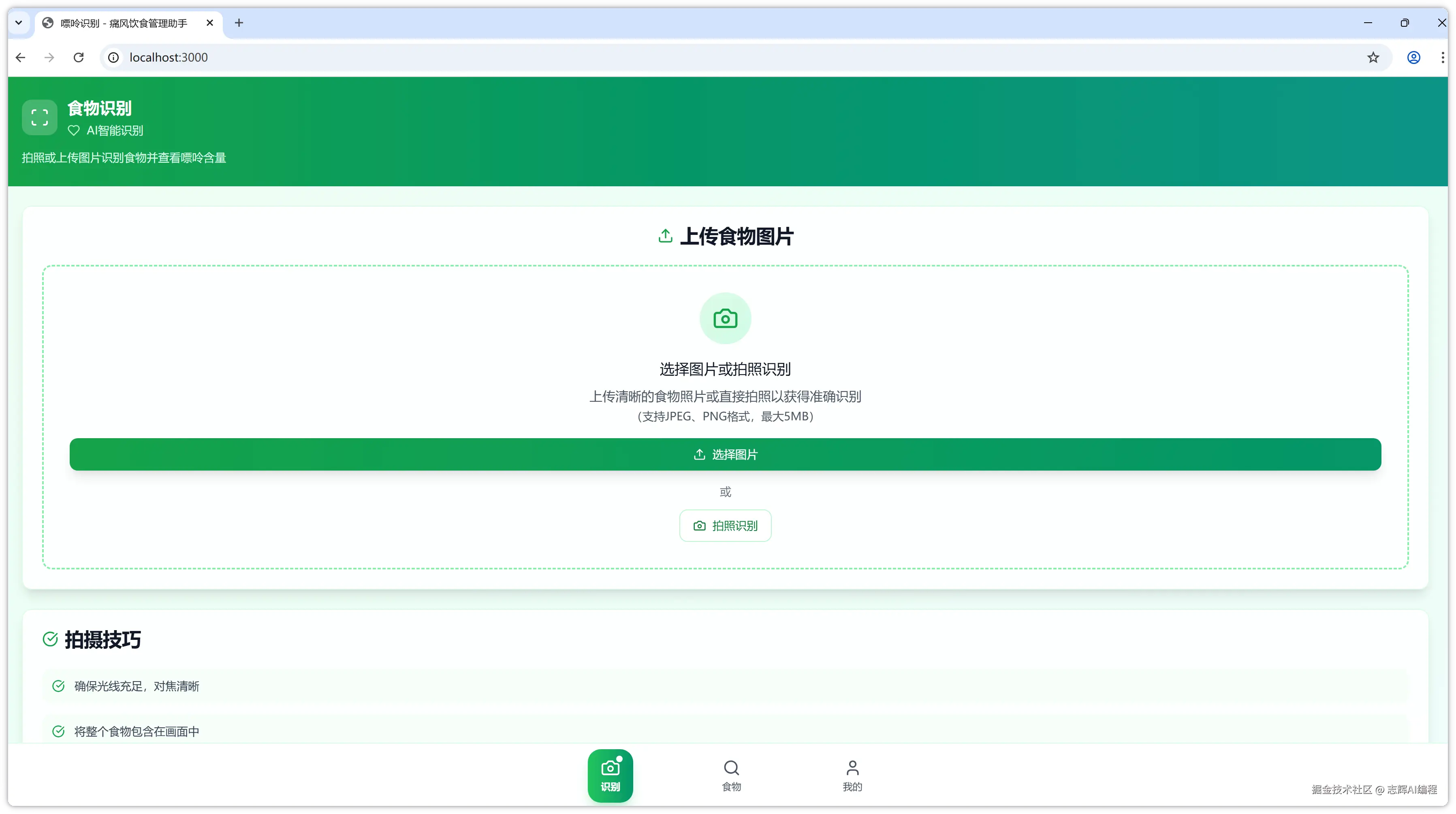
一天 AI 搓出痛风伴侣 H5 程序,前后端+部署通吃,还接入了大模型接口(万字总结)
自我介绍
大家好,我是志辉,10 年大数据架构,目前专注 AI 编程
大家好,我是志辉,10 年大数据架构,目前专注 AI 编程
1、背景
这个很早我就想写了 App 了,我也是痛风患者,好多年,深知这里面的痛呀,所以我想给大家带来一个好的通风管家的体验,但宏伟目标还是从小点着手,那么就有了今天的主角,痛风伴侣 H5。
这个很早我就想写了 App 了,我也是痛风患者,好多年,深知这里面的痛呀,所以我想给大家带来一个好的通风管家的体验,但宏伟目标还是从小点着手,那么就有了今天的主角,痛风伴侣 H5。
目录大纲
前面都是些开胃小菜,看官们现在我们就正式开始正文,那么整体目前是分的 6 个阶段。
前四个阶段可以分为一个大家的阶段,就完成了你的产品工作
最后就是收尾工作,以及后续的维护。
废话少说,就正式开始吧。
前面都是些开胃小菜,看官们现在我们就正式开始正文,那么整体目前是分的 6 个阶段。
前四个阶段可以分为一个大家的阶段,就完成了你的产品工作
最后就是收尾工作,以及后续的维护。
废话少说,就正式开始吧。
第零阶段:介绍
产品开发流程图
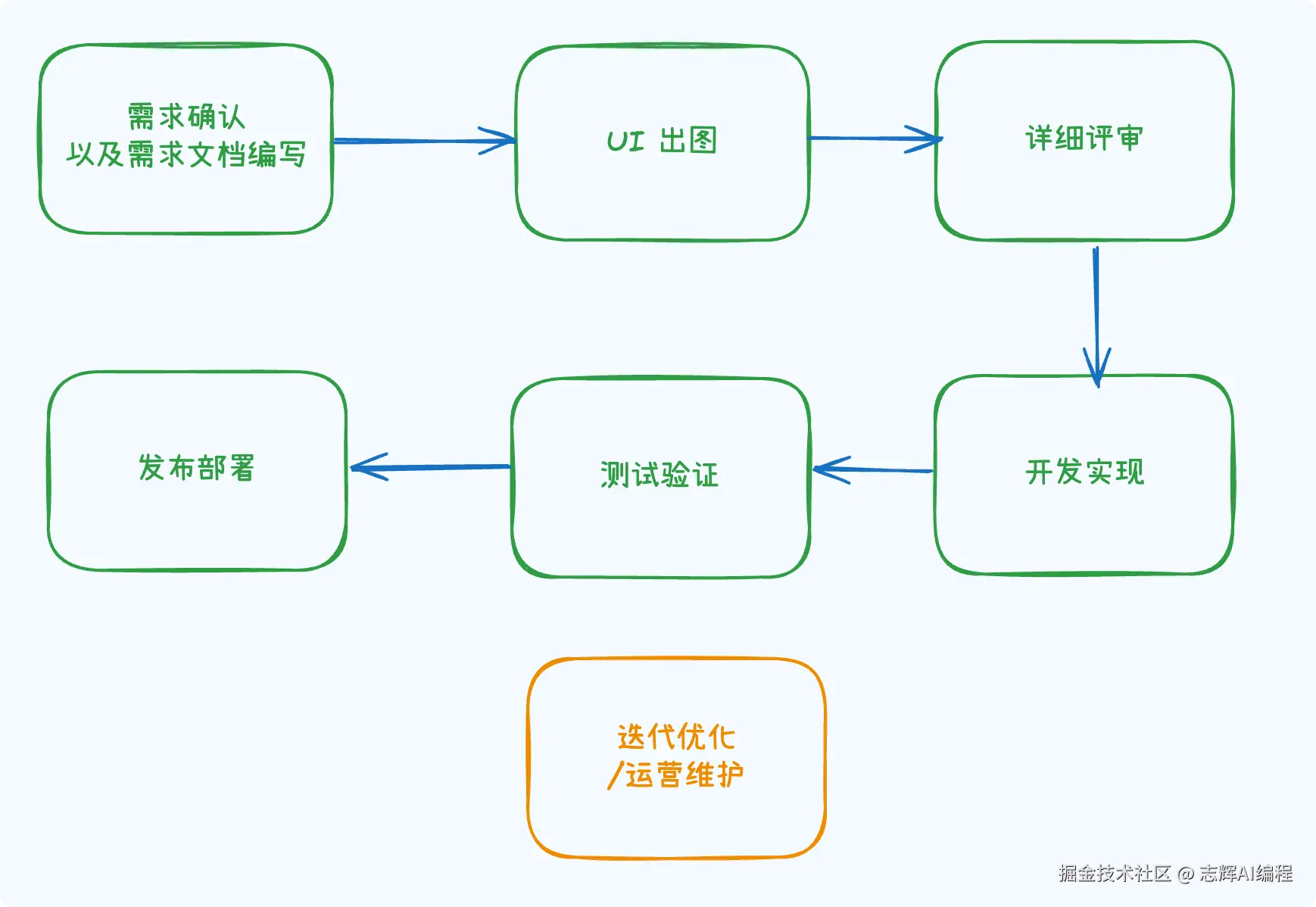
这是一个传统的软件开发流程,从需求的讨论开始到最后的产品上线,总共需要的六大步骤,包括后续的迭代升级维护。
这是一个传统的软件开发流程,从需求的讨论开始到最后的产品上线,总共需要的六大步骤,包括后续的迭代升级维护。
成本测算
这里面其实最大的就是投入的人力成本,还不算使用的电脑、软件这些,还包括最大的就是时间成本。
我们按按照基本公司业务项目的项目来迭代看
- 人力成本
- 产品:1~2 人,有些大项目合作的会更多,跨大部门合作的。
- UI :1 人
- 研发:
- 前端:1~2人
- 后端:2~3人
- 测试:1~2 人
- 合计:这里面最少都是 6 人
- 时间成本
- 这里不用多少,大家如果有经验的,基本公司项目一般的需求都是至少一个月才能上线一个版本,小需求快的也就是半个月上线。
- 沟通成本
- 这个就用说了,大家都是合作项目,产品和 UI,产品和研发,研发和测试,这就是为啥会有那么多会的缘故,不同的工种,面对的是不同

这里面其实最大的就是投入的人力成本,还不算使用的电脑、软件这些,还包括最大的就是时间成本。
我们按按照基本公司业务项目的项目来迭代看
- 人力成本
- 产品:1~2 人,有些大项目合作的会更多,跨大部门合作的。
- UI :1 人
- 研发:
- 前端:1~2人
- 后端:2~3人
- 测试:1~2 人
- 合计:这里面最少都是 6 人
- 时间成本
- 这里不用多少,大家如果有经验的,基本公司项目一般的需求都是至少一个月才能上线一个版本,小需求快的也就是半个月上线。
- 沟通成本
- 这个就用说了,大家都是合作项目,产品和 UI,产品和研发,研发和测试,这就是为啥会有那么多会的缘故,不同的工种,面对的是不同
时间成本感受
个人创业感想
那这里你就可能要较真了,你这个功能简单,哪能跟公司的项目比了。
那我就想起我之前跟我同学一起创业搞 app 的时候,那个时候我不会 app、也不会前端,我是主战大数据的,其实对后端有些框架不也太熟。
那会儿我们四个人,1 个 app、1 个后端+前端、1 个产品,也是足足搞了 1 个多月才勉强上了第一个小版本。
但是我们花的时间很多,虽然一个月,但那一个月我没睡过觉,不会就得学呀,哪像现在不会你找个 AI 帮手帮你搞,你就盯着就行,那会一边学前端,一遍写代码,遇到问题只能搜索引擎查,要么就是硬看源码去找思路解决。
想想就是很痛苦。
那这里你就可能要较真了,你这个功能简单,哪能跟公司的项目比了。
那我就想起我之前跟我同学一起创业搞 app 的时候,那个时候我不会 app、也不会前端,我是主战大数据的,其实对后端有些框架不也太熟。
那会儿我们四个人,1 个 app、1 个后端+前端、1 个产品,也是足足搞了 1 个多月才勉强上了第一个小版本。
但是我们花的时间很多,虽然一个月,但那一个月我没睡过觉,不会就得学呀,哪像现在不会你找个 AI 帮手帮你搞,你就盯着就行,那会一边学前端,一遍写代码,遇到问题只能搜索引擎查,要么就是硬看源码去找思路解决。
想想就是很痛苦。
公司工作感想
本职工作是大数据架构,设计的都是后端复杂的项目通信,整体底层架构设计,但是也需要去做一些产品的事情。
但是大数据产品就不像业务系统配比那么豪华,一整个公司就两三个人,那么有时候就的去做后端服务、前端界面,就为了把我们的产品体验做好。
每天下班疯狂学习前端框架,从最基本的 html、css、js 学起,不然问题解决不了,花了大量的时间,并且做项目还要学习各种框架,不然报错了你都不知道咋去搜索。
这样能做大功能的事情很少,也就是修修补补做些小功能。
本职工作是大数据架构,设计的都是后端复杂的项目通信,整体底层架构设计,但是也需要去做一些产品的事情。
但是大数据产品就不像业务系统配比那么豪华,一整个公司就两三个人,那么有时候就的去做后端服务、前端界面,就为了把我们的产品体验做好。
每天下班疯狂学习前端框架,从最基本的 html、css、js 学起,不然问题解决不了,花了大量的时间,并且做项目还要学习各种框架,不然报错了你都不知道咋去搜索。
这样能做大功能的事情很少,也就是修修补补做些小功能。
产品感想
这也是我最近用了 AI 编程后的感想,最近公司的数据产品项目,我基本都是 AI 编程搞定。
以前复杂的画布拖拉拽,我基本搞不定到上线的质量,现在咔咔的一下午就搞定开发,再结合 AI 的部署模板,一天就基本完成功能。效率太快。
也是这样,我在现在的公司的产出一周顶的上以前的一个月(这真不是吹牛,开会的半个小时,大数据的首页的 landing page 我就做好了🤦♂️) ,但是时间完全不用一周(偷偷的在这了讲,老板知道了,就。。。所以我要多做一些,让老板留下我)。
我现在感想的就是现在更加需要的就是你的创意、你的想法,现在的 AI 能力让更多的人提效的同时,也降低了普通人实现自己产品的可能性。这在以前是无法想象的,毕竟很多门槛是无法跨越,是需要时间磨练的。
这也是我最近用了 AI 编程后的感想,最近公司的数据产品项目,我基本都是 AI 编程搞定。
以前复杂的画布拖拉拽,我基本搞不定到上线的质量,现在咔咔的一下午就搞定开发,再结合 AI 的部署模板,一天就基本完成功能。效率太快。
也是这样,我在现在的公司的产出一周顶的上以前的一个月(这真不是吹牛,开会的半个小时,大数据的首页的 landing page 我就做好了🤦♂️) ,但是时间完全不用一周(偷偷的在这了讲,老板知道了,就。。。所以我要多做一些,让老板留下我)。
我现在感想的就是现在更加需要的就是你的创意、你的想法,现在的 AI 能力让更多的人提效的同时,也降低了普通人实现自己产品的可能性。这在以前是无法想象的,毕竟很多门槛是无法跨越,是需要时间磨练的。
效果展示
然后再多来几张美美的截图(偷偷告诉你,这就是我的背景图片工具做出来的。)
然后再多来几张美美的截图(偷偷告诉你,这就是我的背景图片工具做出来的。)
第一阶段:需求
1、需求思考
做产品最开的就是需求了,如果你是产品经理,那么我理解这一阶段是不需要 AI 来帮你忙的。
虽然大家基本对产品或多或少都有一些理解,那么专业性肯定比不了,那么我们就需要找专业的帮忙了。
所以我这里找的是 ChatGPT,大家找 DeepSeek,或者是 Gemin,或者是 Claude 都可以的。
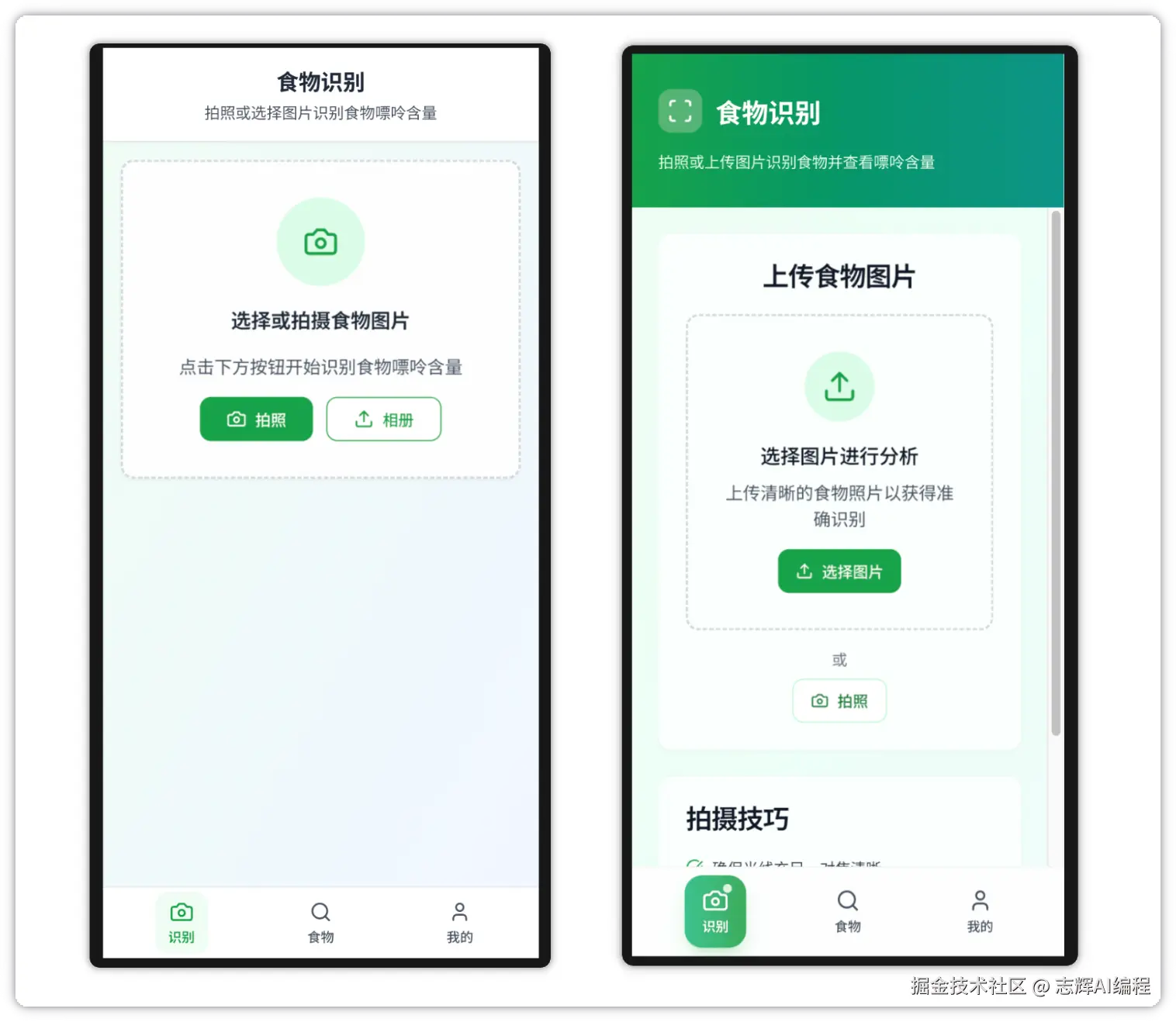
我目前准备为痛风患者开发一个拍照识别食物嘌呤的h5应用,我的需求如下:
1. 这个h5底部有3个tab: 识别、食物、我的
2. 在【识别】页面,用户可以选择拍照或者选择相册上传,然后AI识别食物,并且给到对应的嘌呤的识别结果和建议。
3. 在【食物】页面,用于展示不同升糖指数的常见食物,顶部有一个筛选,用户可以筛选按嘌呤含量高低的食物,下方显示食物照片/名称/嘌呤/描述
4. 【我的】页面顶部有一个折线图,用户记录用户的尿酸历史;下方显示近3次的尿酸数据:包括平均、最低、最高的数据;还有记录尿酸和历史记录的列表。
在技术上,【我的】页面尿酸历史记录保存在本地localStorage中,【食物】的筛选也是通过本地筛选,拍照识别食物嘌呤的功能,采用通义千问的vl模型。
请你参考我的需求,帮我编写一份对应的需求文档。
发给 ChatGPT
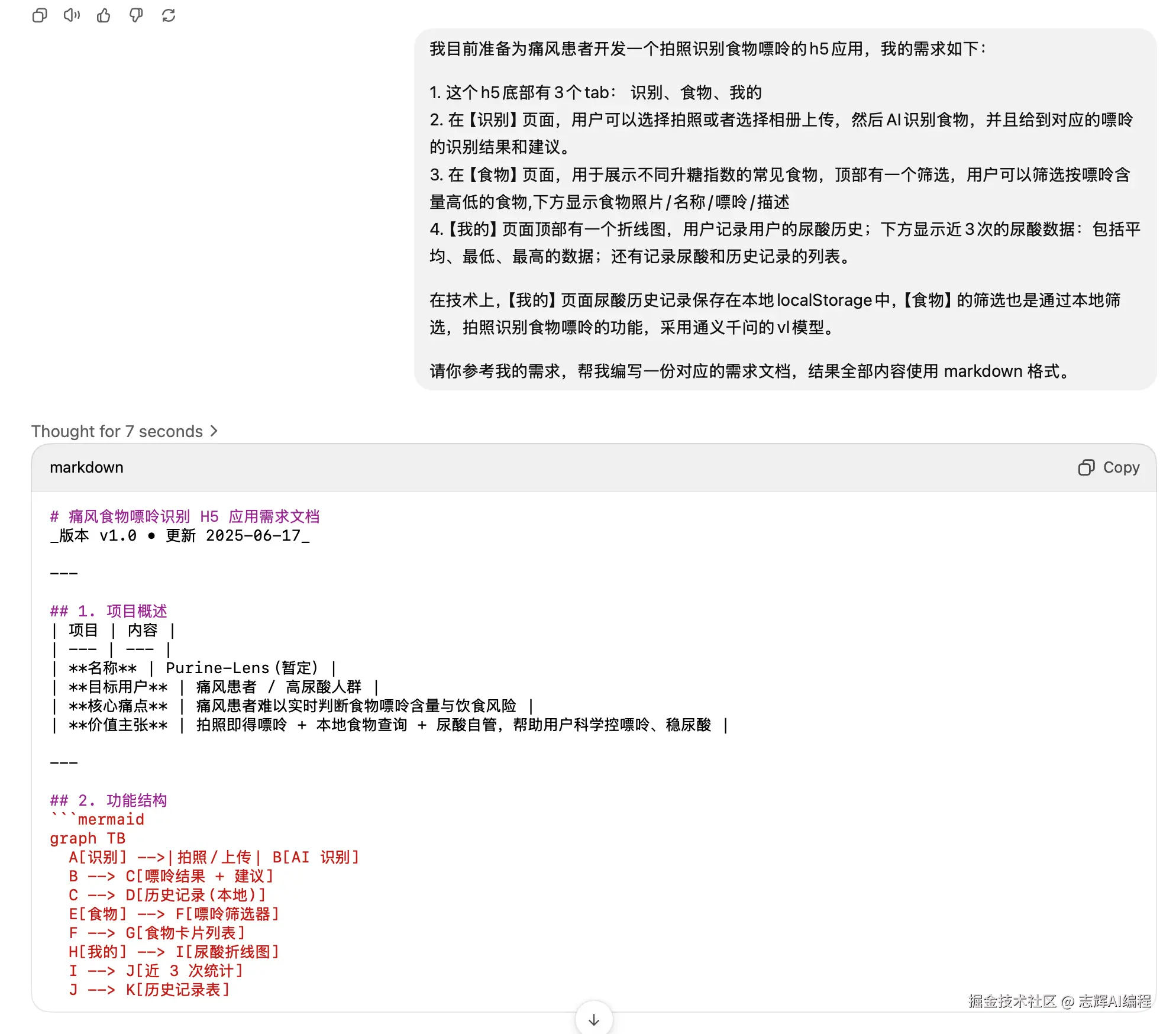
这样就给我们回复了。
做产品最开的就是需求了,如果你是产品经理,那么我理解这一阶段是不需要 AI 来帮你忙的。
虽然大家基本对产品或多或少都有一些理解,那么专业性肯定比不了,那么我们就需要找专业的帮忙了。
所以我这里找的是 ChatGPT,大家找 DeepSeek,或者是 Gemin,或者是 Claude 都可以的。
我目前准备为痛风患者开发一个拍照识别食物嘌呤的h5应用,我的需求如下:
1. 这个h5底部有3个tab: 识别、食物、我的
2. 在【识别】页面,用户可以选择拍照或者选择相册上传,然后AI识别食物,并且给到对应的嘌呤的识别结果和建议。
3. 在【食物】页面,用于展示不同升糖指数的常见食物,顶部有一个筛选,用户可以筛选按嘌呤含量高低的食物,下方显示食物照片/名称/嘌呤/描述
4. 【我的】页面顶部有一个折线图,用户记录用户的尿酸历史;下方显示近3次的尿酸数据:包括平均、最低、最高的数据;还有记录尿酸和历史记录的列表。
在技术上,【我的】页面尿酸历史记录保存在本地localStorage中,【食物】的筛选也是通过本地筛选,拍照识别食物嘌呤的功能,采用通义千问的vl模型。
请你参考我的需求,帮我编写一份对应的需求文档。
发给 ChatGPT
这样就给我们回复了。
2、思考
你说我不会像你写那么多好的提示词,一个我也是借鉴别人的,一个就是继续找 AI 帮你搞定,比如你不知道 localstoreage 是什么,没关系,这个都是可以找 AI 问出来的。

或者是说你只有一个想法,而不知道这个产品要做成什么,也可以问 AI。
GPT 会告诉你每个阶段该做哪些功能,这样看看哪些对你合适,然后通过不断的多轮对话,来让他输出最后的需求文档。

你说我不会像你写那么多好的提示词,一个我也是借鉴别人的,一个就是继续找 AI 帮你搞定,比如你不知道 localstoreage 是什么,没关系,这个都是可以找 AI 问出来的。
或者是说你只有一个想法,而不知道这个产品要做成什么,也可以问 AI。
GPT 会告诉你每个阶段该做哪些功能,这样看看哪些对你合适,然后通过不断的多轮对话,来让他输出最后的需求文档。
3、创建需求工作空间
我们在电脑新建个目录,用来存放暂时的需求文档和一些前置工作的文件
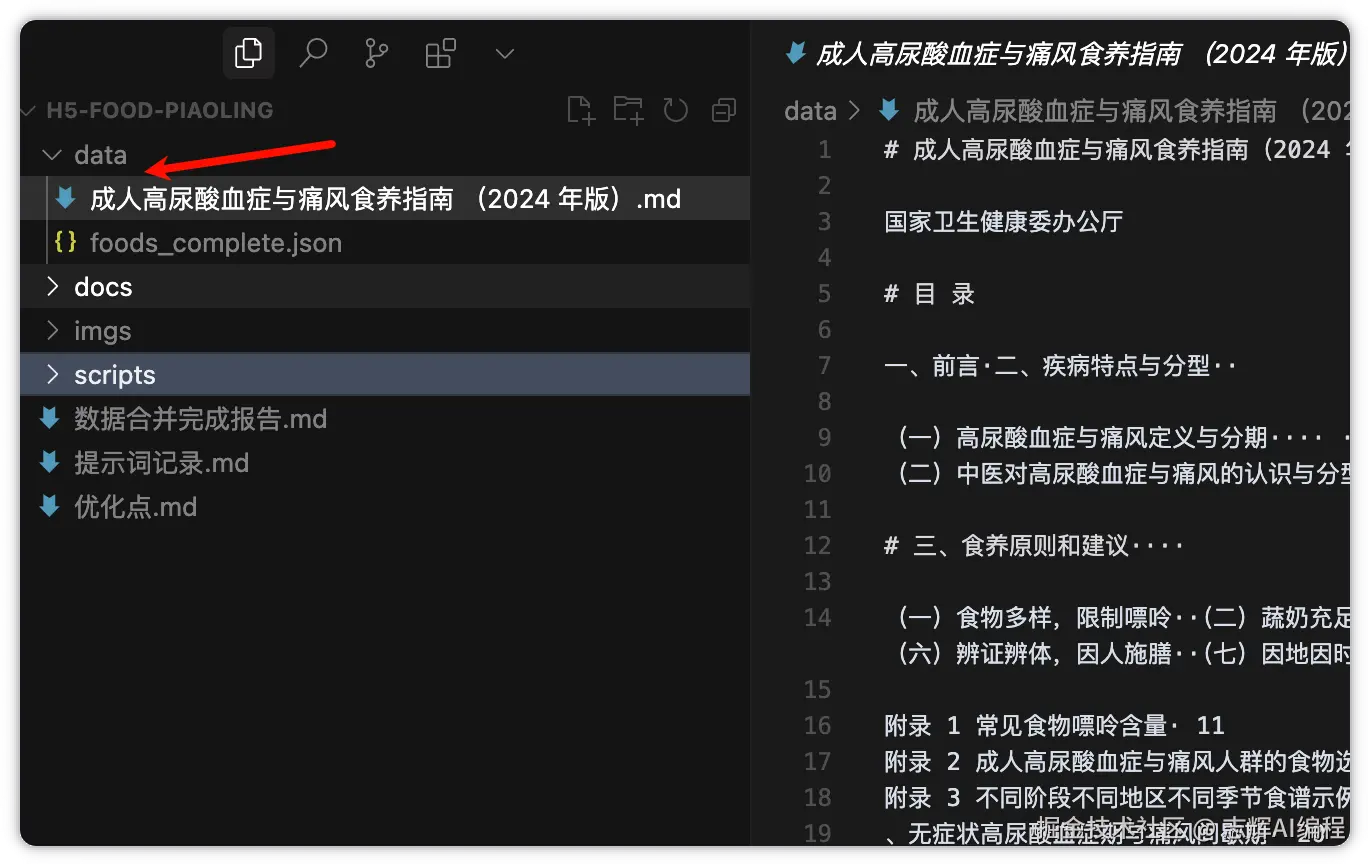
Step 1: 在电脑的某个目录下创建前期我们需要的工作项目的目录,这里我叫 h5-food-piaoling
Step 2: Cursor 打开这个目录
Step 3: 创建 docs 目录
Step 4: docs 目录下创建 prd.md 文件,把刚刚 GPT 生成的需求文档拷贝过来。
我这里是后截图的,所以文件很多,不要受干扰了
我们在电脑新建个目录,用来存放暂时的需求文档和一些前置工作的文件
Step 1: 在电脑的某个目录下创建前期我们需要的工作项目的目录,这里我叫 h5-food-piaoling
Step 2: Cursor 打开这个目录
Step 3: 创建 docs 目录
Step 4: docs 目录下创建 prd.md 文件,把刚刚 GPT 生成的需求文档拷贝过来。
我这里是后截图的,所以文件很多,不要受干扰了
4、重要的一步
到这里需求文档就创建好了,那么我们是不是马上就可以开发了,哦,NO,这里还有很重要的一步。
那么就是需要仔细看这个 GPT 给我们生成的需求文档,还是需要人工审核下的,避免一些小细节的词语、或者影响的需要修改的。
比如这里,我已经恢复不出来了,这里原来有些 “什么一页的文章,适合老年人的这些文字”,这些其实不符合我那会儿想的需求的,所以我就删除了。
比如这里用到的一些技术,如果你懂的话,就可以换成你懂的技术,也是需要考虑到后面迭代升级的一些事情。

总结:其实这里就是需要人工审查下,避免一些很不符合你想的那些,是需要修改/删除的,这个会影响后面生成 UI/交互的逻辑。
不过这个步骤不做问题也不大,这一步也是需要长久锻炼出来,后面等真实的页面出来后,你再去修改也行。
到这里需求文档就创建好了,那么我们是不是马上就可以开发了,哦,NO,这里还有很重要的一步。
那么就是需要仔细看这个 GPT 给我们生成的需求文档,还是需要人工审核下的,避免一些小细节的词语、或者影响的需要修改的。
比如这里,我已经恢复不出来了,这里原来有些 “什么一页的文章,适合老年人的这些文字”,这些其实不符合我那会儿想的需求的,所以我就删除了。
比如这里用到的一些技术,如果你懂的话,就可以换成你懂的技术,也是需要考虑到后面迭代升级的一些事情。
总结:其实这里就是需要人工审查下,避免一些很不符合你想的那些,是需要修改/删除的,这个会影响后面生成 UI/交互的逻辑。
不过这个步骤不做问题也不大,这一步也是需要长久锻炼出来,后面等真实的页面出来后,你再去修改也行。
第二阶段:数据准备
这里的一步也是我认为比较特别的点,这个步骤的点可以借鉴到其他场景里面。
这里的一步也是我认为比较特别的点,这个步骤的点可以借鉴到其他场景里面。
1、哪里找数据
你的产品里的数据的可信度在哪里?特别是关乎于健康的,网上的信息纷繁复杂,大家很难分清哪些是真的,哪些是假的。
我之前查食物的嘌呤的时候,就遇见了,同样一个食物,app 上看到的,网上看到的都不一样,我就黑人问号了???
所以,这里就涉及到数据的权威性、真实性了。那么权威机构发布的可信度会更强。
所以我找到了卫健委颁发的数据。
地址:http://www.nhc.gov.cn/sps/c100088…

另外还可以看到不止痛风的资料有,还有青少年、肥胖、肾病的食养指南。
这些病其实都是慢性病,不是吃药就能马上好起来,需要长期靠饮食、运动来恢复的。
可以把这些数据用起来,后面挖掘更多需求。
你的产品里的数据的可信度在哪里?特别是关乎于健康的,网上的信息纷繁复杂,大家很难分清哪些是真的,哪些是假的。
我之前查食物的嘌呤的时候,就遇见了,同样一个食物,app 上看到的,网上看到的都不一样,我就黑人问号了???
所以,这里就涉及到数据的权威性、真实性了。那么权威机构发布的可信度会更强。
所以我找到了卫健委颁发的数据。
地址:http://www.nhc.gov.cn/sps/c100088…
另外还可以看到不止痛风的资料有,还有青少年、肥胖、肾病的食养指南。
这些病其实都是慢性病,不是吃药就能马上好起来,需要长期靠饮食、运动来恢复的。
可以把这些数据用起来,后面挖掘更多需求。
2、下载数据
这一步周就是把数据下载下来,直接点击上面的
下载来后是个pdf 的文件,那么这一步我们就准备好了。
这里我附带一份,大家可以作为参考
暂时无法在飞书文档外展示此内容
这一步周就是把数据下载下来,直接点击上面的
下载来后是个pdf 的文件,那么这一步我们就准备好了。
这里我附带一份,大家可以作为参考
暂时无法在飞书文档外展示此内容
3、处理数据
这一步是为什么了,是因为目前在所有的 AI 编程工具里面,pdf 是读取不了的,特别是 Cursor 里面。
目前能够读取的是 markdown 格式的数据
markdown 格式的数据很简单,就是纯文本,加上一些符号,就可以做成标题显示
不懂的可以直接问题 AI 工具就行了。
这里就可以看到大模型给我们的解释了。
这一步是为什么了,是因为目前在所有的 AI 编程工具里面,pdf 是读取不了的,特别是 Cursor 里面。
目前能够读取的是 markdown 格式的数据
markdown 格式的数据很简单,就是纯文本,加上一些符号,就可以做成标题显示
不懂的可以直接问题 AI 工具就行了。
这里就可以看到大模型给我们的解释了。
插曲
我不懂 markdown 是什么,帮我解释下,我一点都不懂这个
在 Cursor 里面使用 ask 模式来提问

下面就是一个回答的截图,如果你对里面的文字不清楚的,那么就继续问 AI 就可以了。多轮对话。

我不懂 markdown 是什么,帮我解释下,我一点都不懂这个
在 Cursor 里面使用 ask 模式来提问
下面就是一个回答的截图,如果你对里面的文字不清楚的,那么就继续问 AI 就可以了。多轮对话。
处理数据
这里就是需要把 pdf 转为 markdown 的数据
这里推荐使用:mineru.net/
重点在于免费,直接登录注册进来后,点击上传我们刚下载的 pdf。
等待上传转换完成,下一步就是在文件里面,看到转换的文件了。
点击右侧下载,就是 markdown 格式。
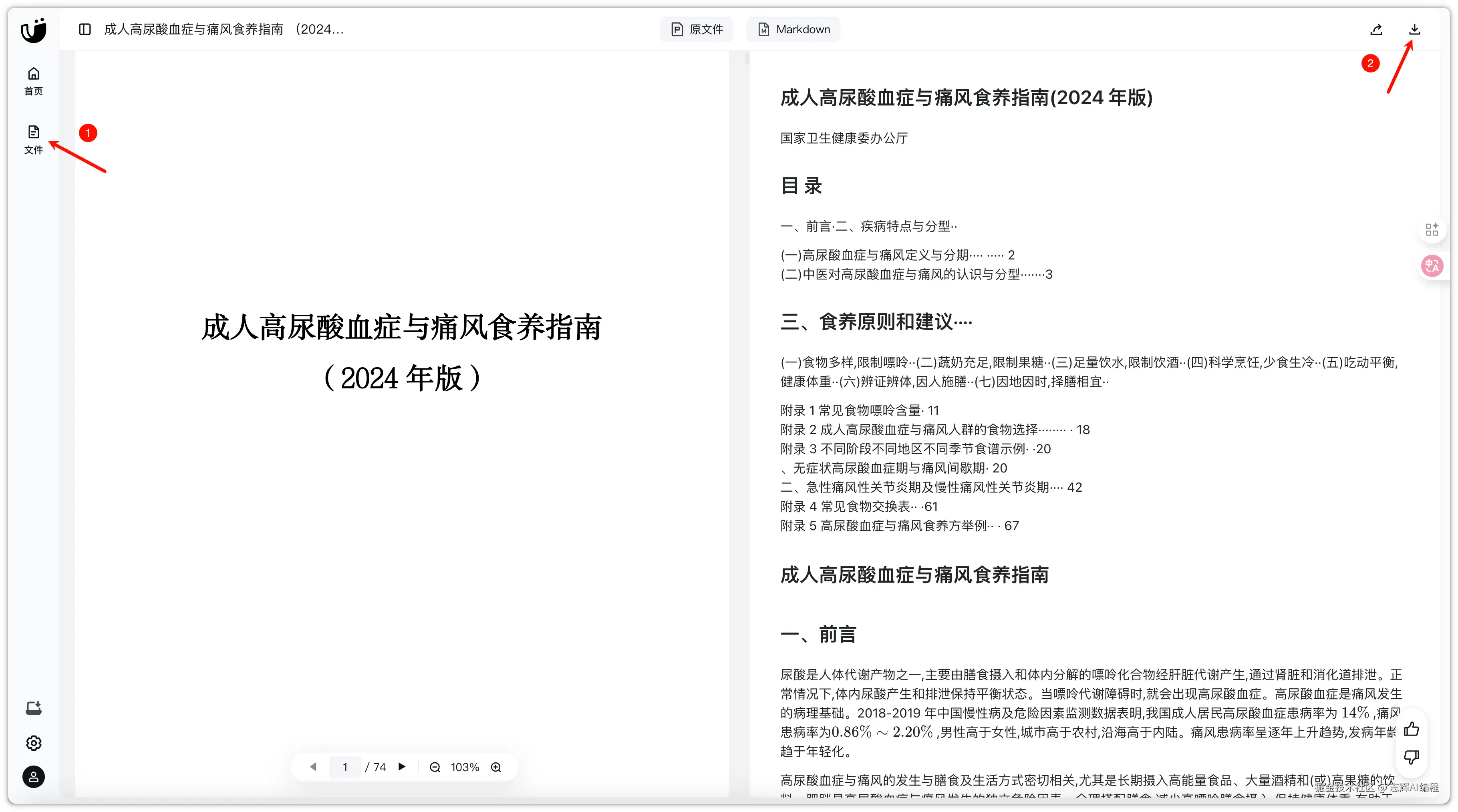
把下载好的 markdown 文件放入到项目里面的 data 目录,待会儿会需要数据处理。
这里就是需要把 pdf 转为 markdown 的数据
这里推荐使用:mineru.net/
重点在于免费,直接登录注册进来后,点击上传我们刚下载的 pdf。
等待上传转换完成,下一步就是在文件里面,看到转换的文件了。
点击右侧下载,就是 markdown 格式。
把下载好的 markdown 文件放入到项目里面的 data 目录,待会儿会需要数据处理。
4、修正需求文档
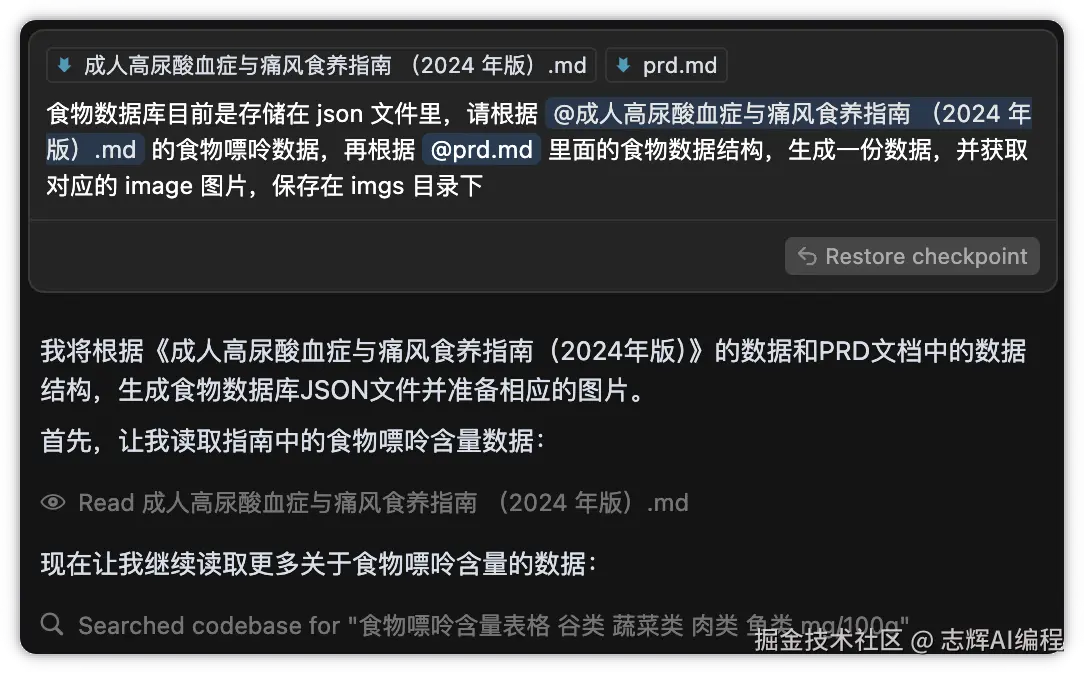
那么让 Cursor 给我们重新生成需求文档,这样食物的分类,还有统计,会更准确,因为现在是基于权威数据来的。
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
那么让 Cursor 给我们重新生成需求文档,这样食物的分类,还有统计,会更准确,因为现在是基于权威数据来的。
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
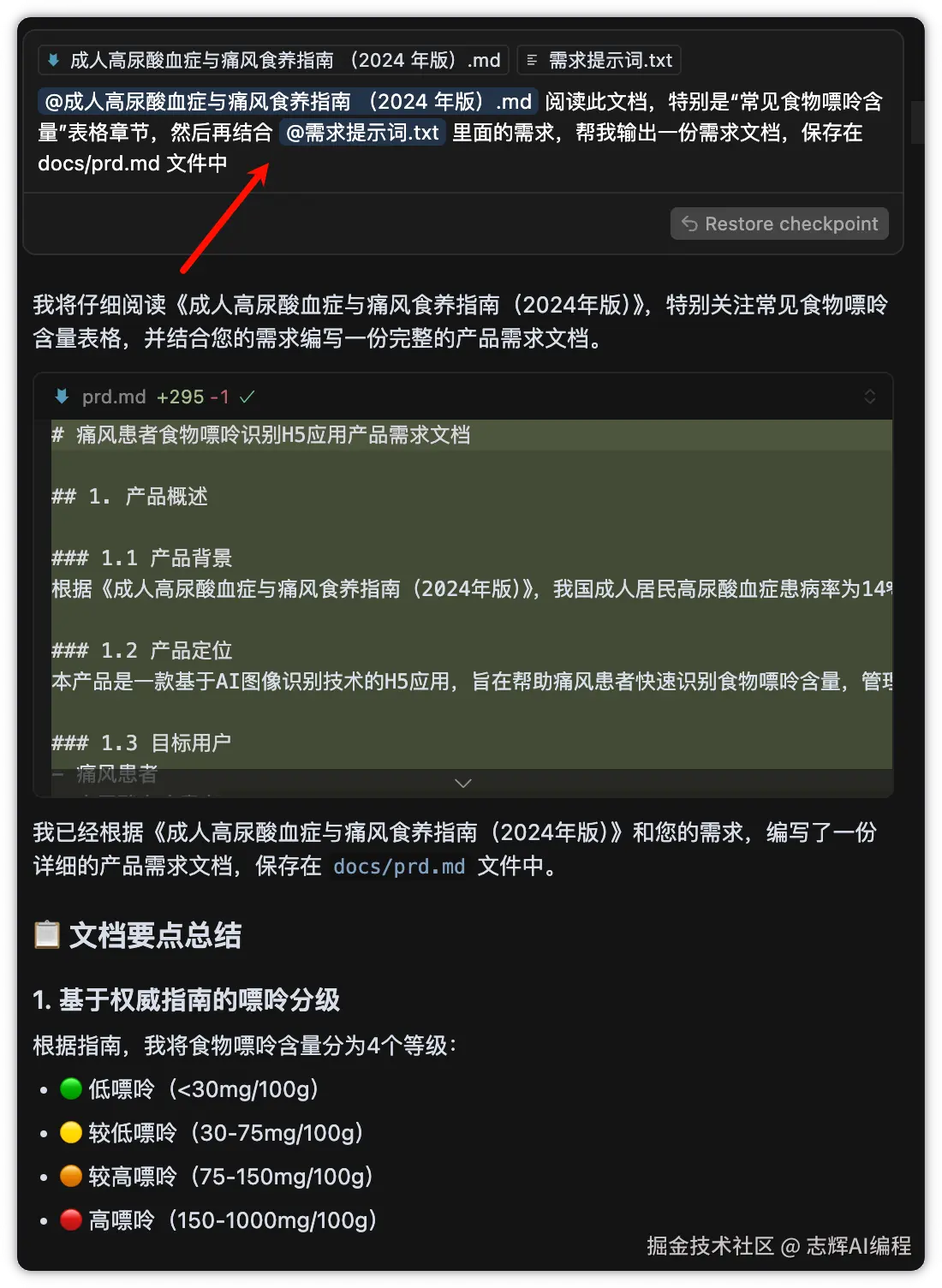
5、生成数据文件
前面我们不是讲到了。食物列表的数据需要存储在本地,也就是客户端,形式我们就采用 json 的形式
同样你不知道 json 是个啥的话,找 AI 问,或者直接 Cursor 里面提问就行了。
左边是提示词,右侧就是创建的 json 文件
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
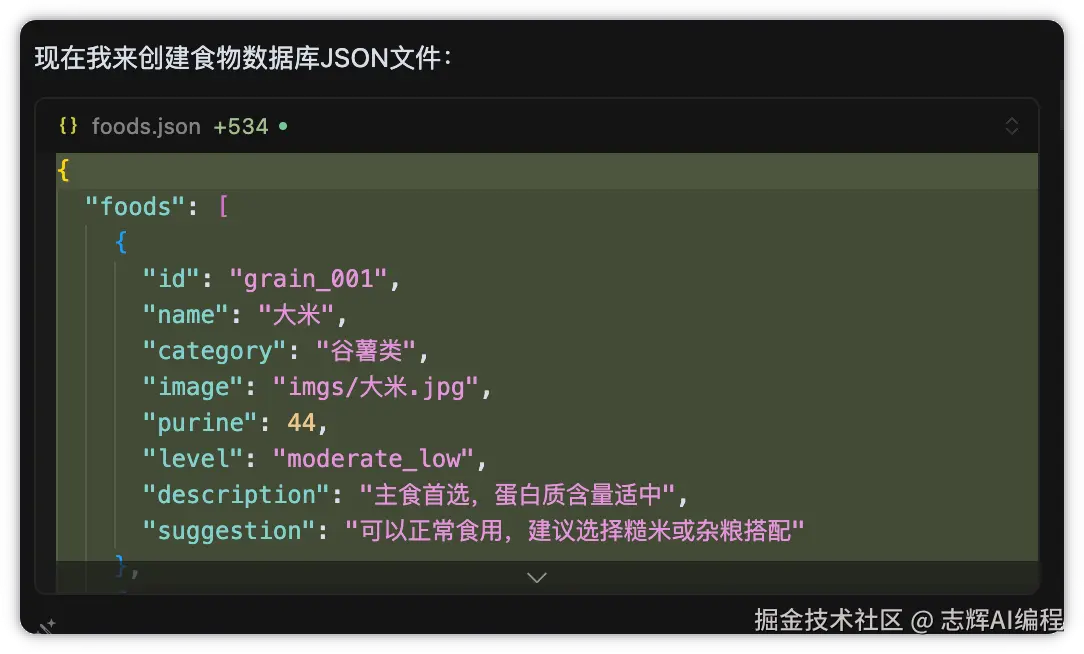
结果:
6、继续调整文件
上一步骤发现,其实只给我们列觉了 53 种食物,并不全
我需要全部的数据,那么继续
总结的有 53 种食物,但是我看 @成人高尿酸血症与痛风食养指南 (2024 年版).md 下的“表1-2 常见食物嘌呤含量表” 应该不止这么多,请再次阅读然后补全数据到 @foods.json 文件里。
最后发现,总文档里总结了 180 种的食物

最后生成的数据文件如下:

前面我们不是讲到了。食物列表的数据需要存储在本地,也就是客户端,形式我们就采用 json 的形式
同样你不知道 json 是个啥的话,找 AI 问,或者直接 Cursor 里面提问就行了。
左边是提示词,右侧就是创建的 json 文件
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
结果:
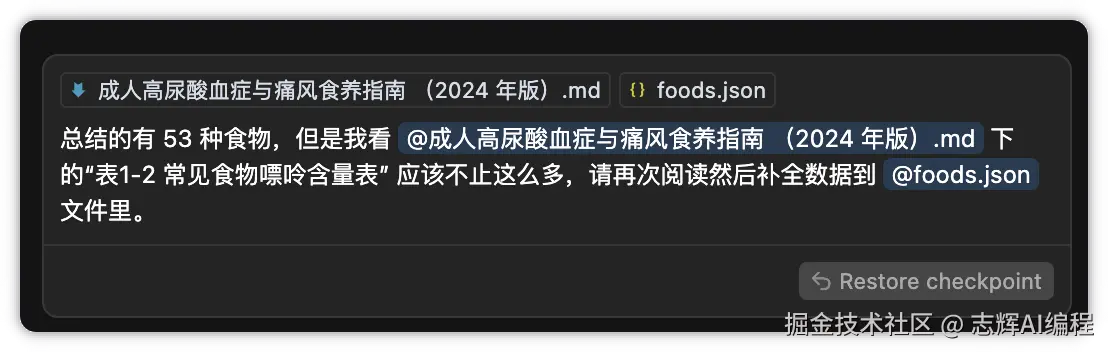
6、继续调整文件
上一步骤发现,其实只给我们列觉了 53 种食物,并不全
我需要全部的数据,那么继续
总结的有 53 种食物,但是我看 @成人高尿酸血症与痛风食养指南 (2024 年版).md 下的“表1-2 常见食物嘌呤含量表” 应该不止这么多,请再次阅读然后补全数据到 @foods.json 文件里。
最后发现,总文档里总结了 180 种的食物
最后生成的数据文件如下:
6、图片问题
不过这里有个问题就是,食物对应的图片是没有办法在这里一次性完成的
我也尝试了在 Cursor 里让他帮我完成,结果些了一大堆的代码,下来的图片还对应不上。
尝试了很多方案,都不太理想。
那你说了,去搜索引擎下载了,我也想到了,不过想起来你要去搜索,然后找图片,下载,有 180 多种了,还要命名好图片名字,最后保存到目录。
想到这里,我就头大,索性干脆自己写一个,其他流程系统都帮我搞定,暂时目前只需要我人工确认图片,保证准确性。
Claude Code + 爬虫碰撞什么样的火花,3 小时搞定我的数据需求
这个小系统也还是有很大的挖掘潜力,后面也还可以做很多事情
到这里基本需求阶段就完成了,数据也准备的差不多了,下面就是进入开发阶段了。
不要看前面的文字多,那都是前戏,下面就是正戏,坐稳扶好,开奔。
不过这里有个问题就是,食物对应的图片是没有办法在这里一次性完成的
我也尝试了在 Cursor 里让他帮我完成,结果些了一大堆的代码,下来的图片还对应不上。
尝试了很多方案,都不太理想。
那你说了,去搜索引擎下载了,我也想到了,不过想起来你要去搜索,然后找图片,下载,有 180 多种了,还要命名好图片名字,最后保存到目录。
想到这里,我就头大,索性干脆自己写一个,其他流程系统都帮我搞定,暂时目前只需要我人工确认图片,保证准确性。
Claude Code + 爬虫碰撞什么样的火花,3 小时搞定我的数据需求
这个小系统也还是有很大的挖掘潜力,后面也还可以做很多事情
到这里基本需求阶段就完成了,数据也准备的差不多了,下面就是进入开发阶段了。
不要看前面的文字多,那都是前戏,下面就是正戏,坐稳扶好,开奔。
第三阶段:开发+联调+测试
这里是主要的开发、联调、测试阶段,也就是在传统开发流程中会占据大部分的时间,基本一个软件/系统的开发大部分的时间都在这个里面,所以我们看看结合 AI 它的速度将会达到什么样。
这里是主要的开发、联调、测试阶段,也就是在传统开发流程中会占据大部分的时间,基本一个软件/系统的开发大部分的时间都在这个里面,所以我们看看结合 AI 它的速度将会达到什么样。
== 1、前端 ==
步骤一:bolt 开发
说下为什么采用 bolt 工具来做第一步工作。
其实线下 v0、bolt、lovable 很多这种前端设计工具,那么他与 Cursor 的区别在哪里了?
1、首先通过简单的提示词,它生成的功能和 UI 基本都是很完善的,UI 很美、交互也很舒服。这种你在 Curosr 里面从零开始些是很难的。
2、这种工具一般都可以选择界面的上的元素(比如 div、button,这个就比较难),然后进行你的提示词修改,很精准,这个你在 Cursor 里面比较难做。
3、还有一个点就是前端开发的界面的定位这些大模型很难听得懂你在说啥的,所以我感觉也是这块的难度采用了上面那么多的类似的工具的诞生。
当然,如果不用这些工具,直接让 Cursor 给你出 ui 设计,然后使用 UI 设计出前端代码也可以的。
这个我看看后面用其他例子来讲解。
把上面的需求步骤的 prd.md 的需求直接粘贴到提示词框里。没问题,就可以直接点击提交了。
小技巧:看左下角有个五角星的图标,是可以美化提示词的,这个目前倒是 bolt 都有的功能。
另外还可以通过 Github 或者 Figma 来生成项目图片。
下面就是嘎嘎开始干活了。

等他写完,就可以在界面的右侧看到写完的H5程序。
界面很简单,左侧就是对话区域,右侧就是产品的展示区域
小细节:在使用移动端展示的时候,还可以选择对应的手机型号

说下为什么采用 bolt 工具来做第一步工作。
其实线下 v0、bolt、lovable 很多这种前端设计工具,那么他与 Cursor 的区别在哪里了?
1、首先通过简单的提示词,它生成的功能和 UI 基本都是很完善的,UI 很美、交互也很舒服。这种你在 Curosr 里面从零开始些是很难的。
2、这种工具一般都可以选择界面的上的元素(比如 div、button,这个就比较难),然后进行你的提示词修改,很精准,这个你在 Cursor 里面比较难做。
3、还有一个点就是前端开发的界面的定位这些大模型很难听得懂你在说啥的,所以我感觉也是这块的难度采用了上面那么多的类似的工具的诞生。
当然,如果不用这些工具,直接让 Cursor 给你出 ui 设计,然后使用 UI 设计出前端代码也可以的。
这个我看看后面用其他例子来讲解。
把上面的需求步骤的 prd.md 的需求直接粘贴到提示词框里。没问题,就可以直接点击提交了。
小技巧:看左下角有个五角星的图标,是可以美化提示词的,这个目前倒是 bolt 都有的功能。
另外还可以通过 Github 或者 Figma 来生成项目图片。
下面就是嘎嘎开始干活了。
等他写完,就可以在界面的右侧看到写完的H5程序。
界面很简单,左侧就是对话区域,右侧就是产品的展示区域
小细节:在使用移动端展示的时候,还可以选择对应的手机型号
步骤二:调整
1、错误修复
这个交互我觉得做的特别好,不用粘贴错误,直接就在界面上点击“Attempt fix”就可以了,这真的是纯 vibe coding ,粘贴复制都不用了。🤦♂️
如果有错误,继续就可以了。
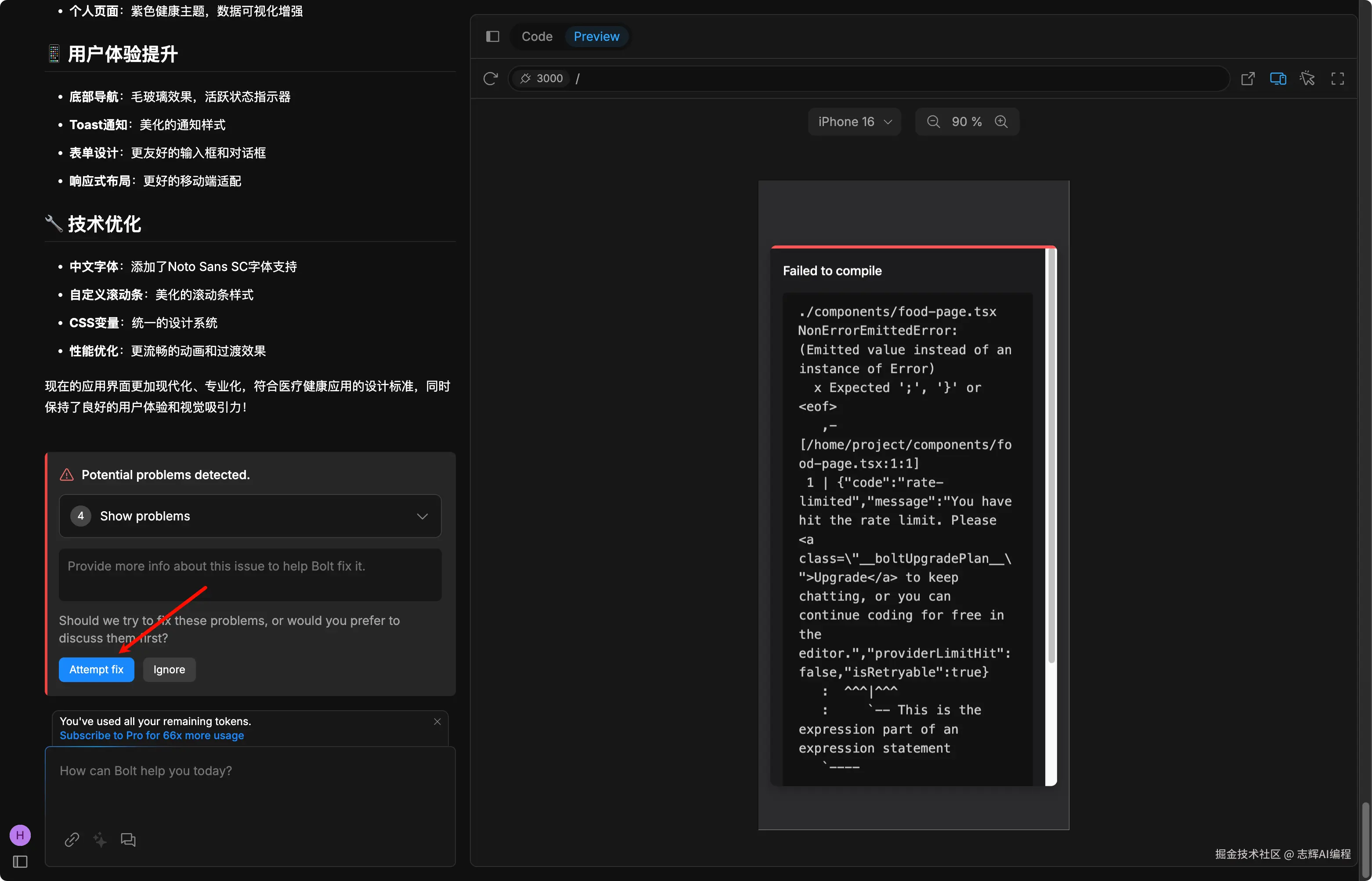
这个交互我觉得做的特别好,不用粘贴错误,直接就在界面上点击“Attempt fix”就可以了,这真的是纯 vibe coding ,粘贴复制都不用了。🤦♂️
如果有错误,继续就可以了。
2、UI 调整:主题
刚开始其实 UI 并不是太好看,我的主题色是绿色的,所以我也不知道让它弄什么样的好看。
再帮我美化下 UI 界面
就输入了上面一句话,刚开始的 UI 如下图

最后看下对比效果
左边是最开始生成的,右边是我让他优化后的样子。还是有很多细节优化的。
刚开始其实 UI 并不是太好看,我的主题色是绿色的,所以我也不知道让它弄什么样的好看。
再帮我美化下 UI 界面
就输入了上面一句话,刚开始的 UI 如下图
最后看下对比效果
左边是最开始生成的,右边是我让他优化后的样子。还是有很多细节优化的。
3、UI 修复方式一:截图
另外如果样式有问题,可以截图粘贴到对话框,然后输入提示词修改。
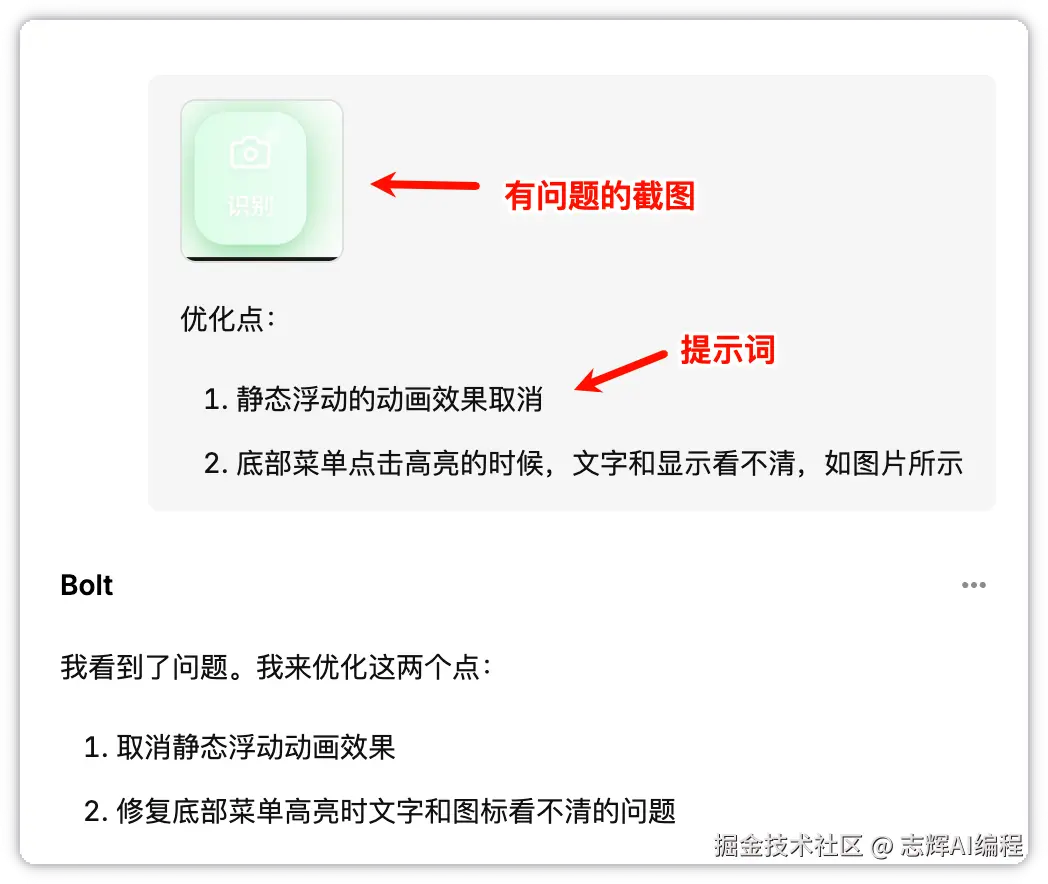
另外如果样式有问题,可以截图粘贴到对话框,然后输入提示词修改。
4、UI 修复方式二:选择元素
这里就是我要说的可以选择界面上的元素,然后针对某些元素进行改写
bolt 的方式这几输入提示词
v0 比较高级,选择后,可以直接修改 div 的一些样式参数,比如:宽高、字体、布局、背景、阴影。精准调节。(低代码+vibe coding)
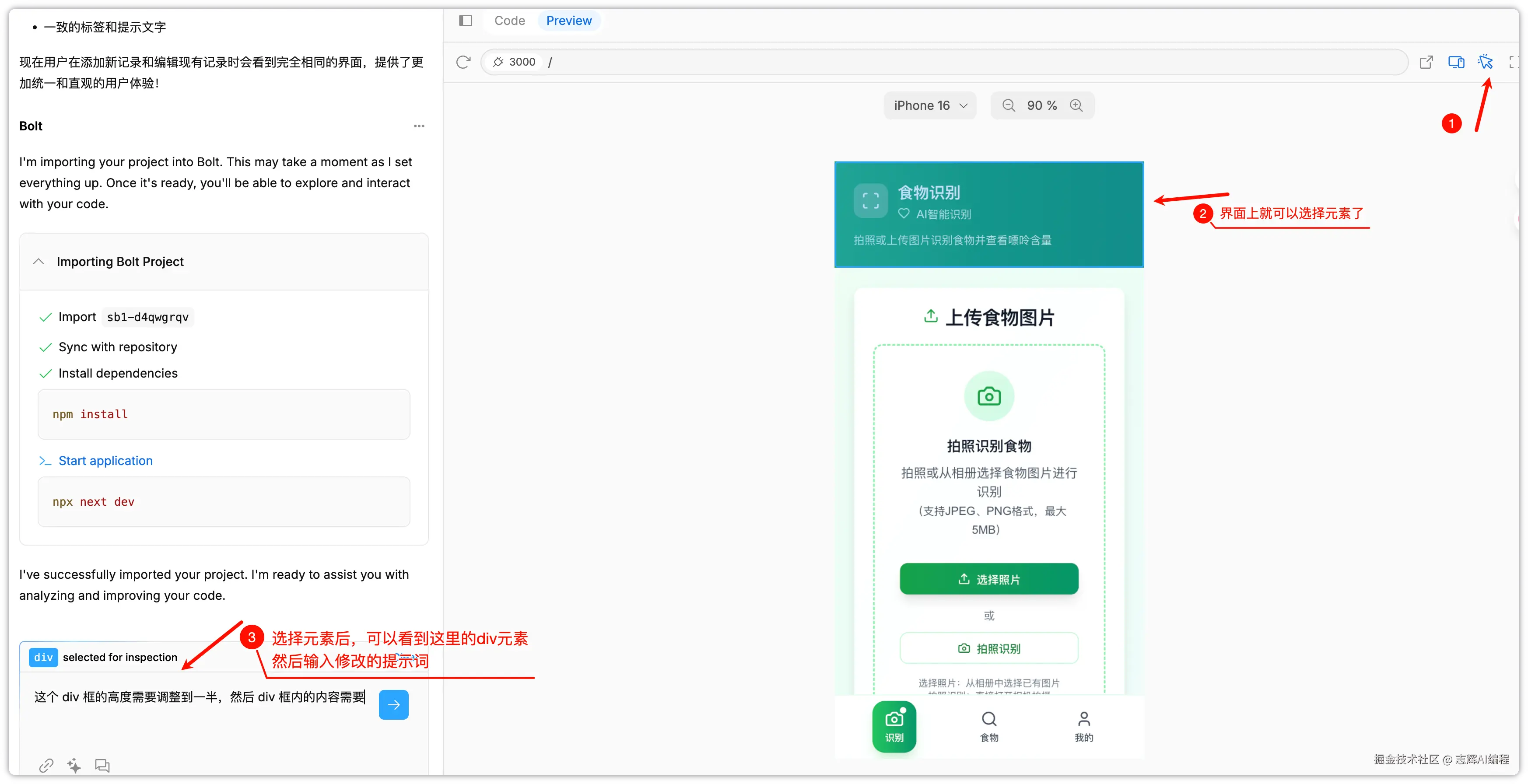
经过多轮修复,觉得功能差不多了,就可以转战本地 Cursor 就继续下一步了。
这里就是我要说的可以选择界面上的元素,然后针对某些元素进行改写
bolt 的方式这几输入提示词
v0 比较高级,选择后,可以直接修改 div 的一些样式参数,比如:宽高、字体、布局、背景、阴影。精准调节。(低代码+vibe coding)
经过多轮修复,觉得功能差不多了,就可以转战本地 Cursor 就继续下一步了。
步骤三:本地 Cursor 修改
1、同步代码到 Github
点击右上角的「Integrations」里的 Github。

下面就会提示你链登录 Github

接着授权就可以
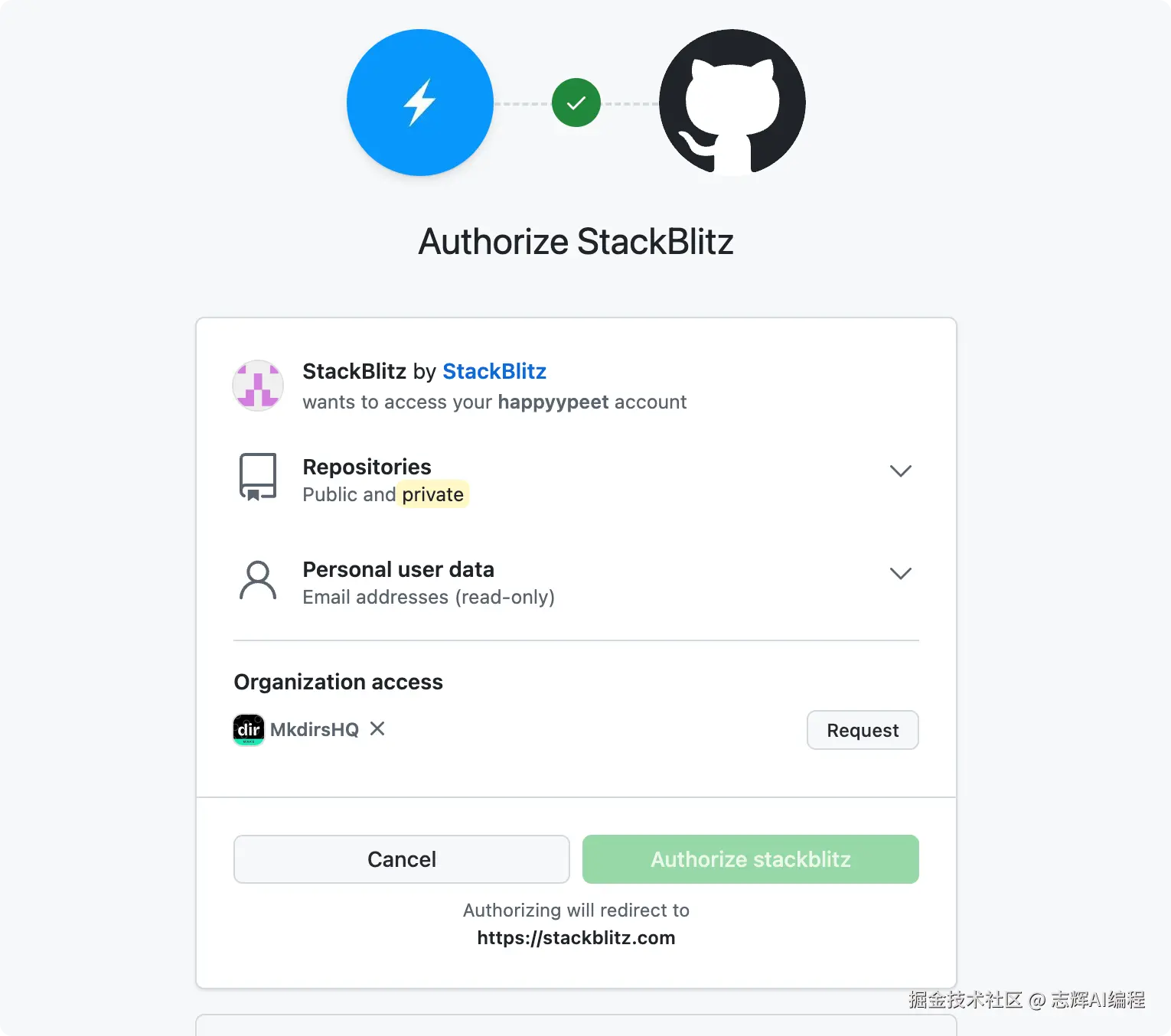
然欧输入你需要创建的项目名称
点击右上角的「Integrations」里的 Github。
下面就会提示你链登录 Github
接着授权就可以
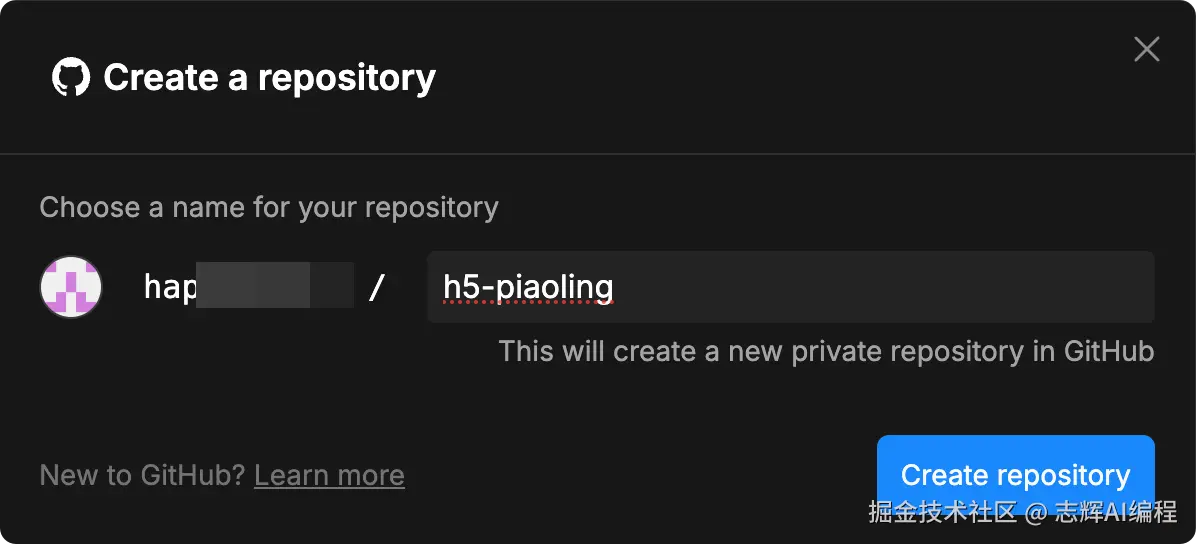
然欧输入你需要创建的项目名称
2、本地下载代码
使用 git 工具把代码下载到本地
git 就类似游戏的存档工具,每一个步骤都可以存档,当有问题的时候,就可以从某个存档恢复了。
当然:这里需要提前安装好 Git,如果有不懂的可以联系我,我来帮你解决。这你就不多说了
打开你的 Github 仓库页面,复制 HTTPS 的地址
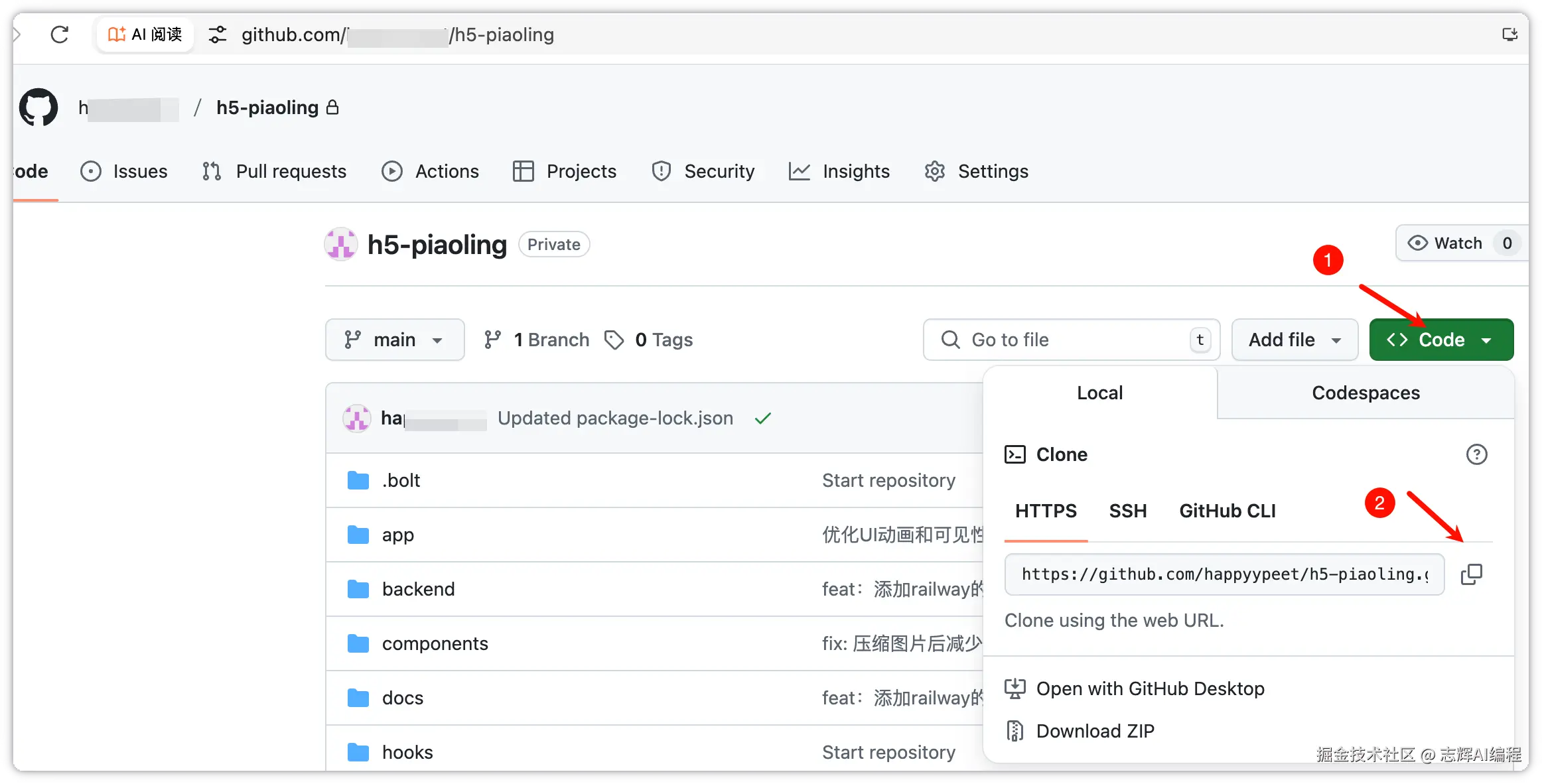
然后使用下面的命令,就可以下载到本地了。
git clone 你的代码仓库地址

下一步就是安装代码的依赖包
这里需要 nodejs 环境,同样就不多说了,不懂的可以私聊

下一步就是启动
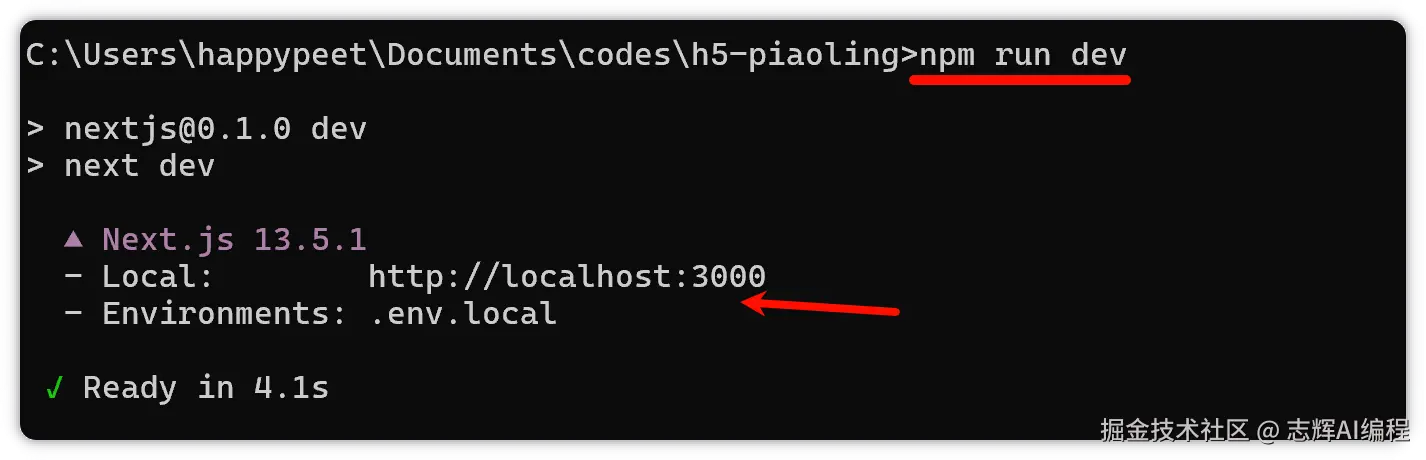
接着就是浏览器打开上面的地址:http://localhsot:3000,就可以看见上面写好的页面。
默认打开是按照 pc 的全屏显示的,可能看着有些别扭
我们打开 F12,打开调试窗口,如下图
点击右侧类似电脑手机的按钮,就可以调到移动端模式显示了,还可以选择对应的机型。
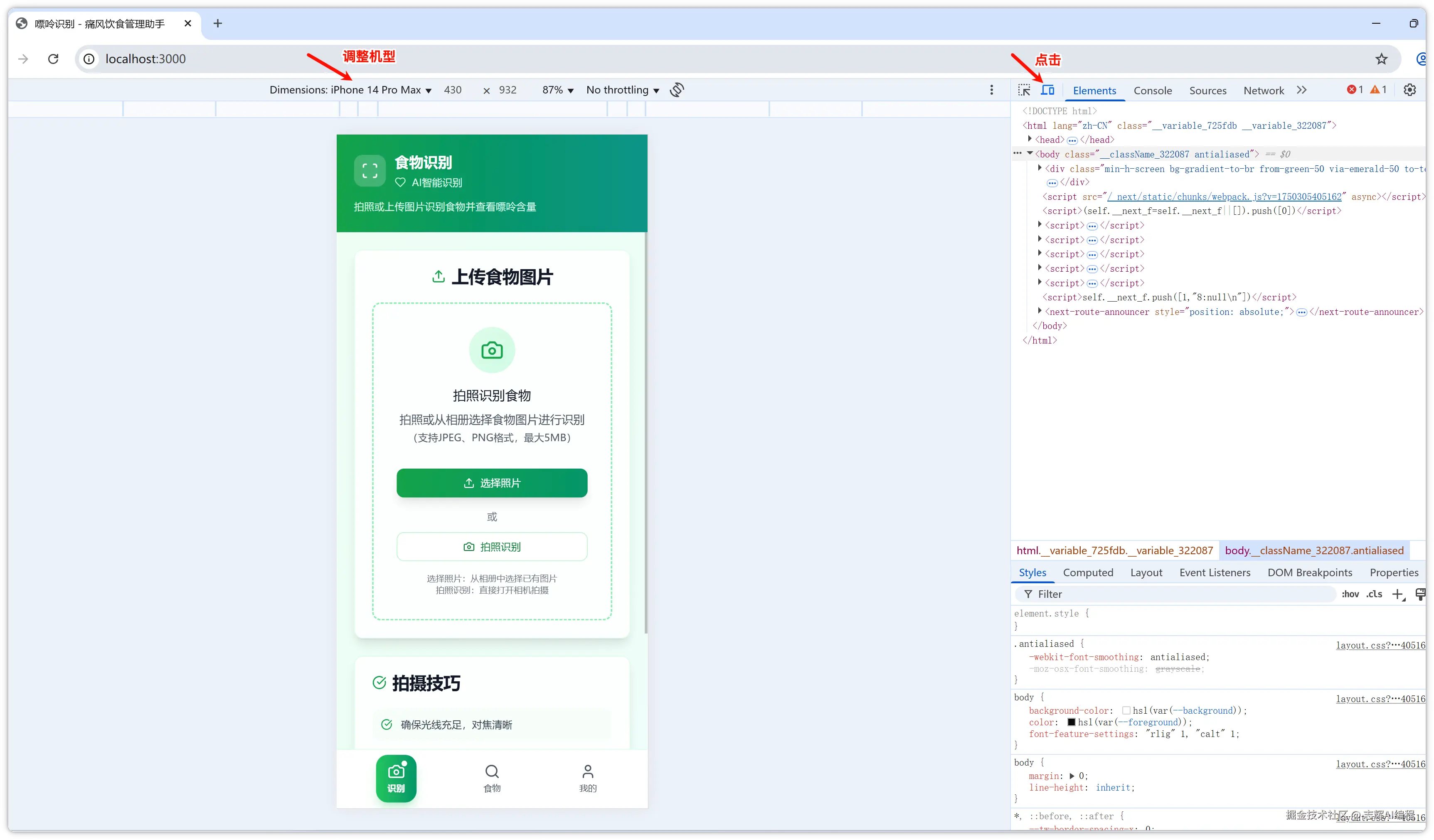
使用 git 工具把代码下载到本地
git 就类似游戏的存档工具,每一个步骤都可以存档,当有问题的时候,就可以从某个存档恢复了。
当然:这里需要提前安装好 Git,如果有不懂的可以联系我,我来帮你解决。这你就不多说了
打开你的 Github 仓库页面,复制 HTTPS 的地址
然后使用下面的命令,就可以下载到本地了。
git clone 你的代码仓库地址
下一步就是安装代码的依赖包
这里需要 nodejs 环境,同样就不多说了,不懂的可以私聊
下一步就是启动
接着就是浏览器打开上面的地址:http://localhsot:3000,就可以看见上面写好的页面。
默认打开是按照 pc 的全屏显示的,可能看着有些别扭
我们打开 F12,打开调试窗口,如下图
点击右侧类似电脑手机的按钮,就可以调到移动端模式显示了,还可以选择对应的机型。
xx 小插曲 xx
原本不想放这里的,结果还是放一下吧,刚好是解决了一个很大的问题
刚开始在 bolt 上面修改的时候,修改后一直报个错误,结果修复了很多次,还是没有解决。

没办法,我就在本地 Cursor 上仔细看了下代码,发现是个引号的问题。

我就在本地 Cursor 中快速修复了下
但是后面惊悚的事情来了,我去 bolt 上调整了下界面样式,结果又给我写成了引号的问题
最后我就发现,可能 bolt 目前对这类的错误还是没有意识。并且看它界面的代码,每次都是从头开始写(难怪要等好一段时间才弄完,究竟是什么设计了?)
最后索性,我仔细看了下代码,删除掉了,没啥大的影响。
目前来看 bolt 这种工具还是有点门槛,解决错误的能力还是没有 Cursor 强大,一不小心页面上的错误就在一起存在,你也不知道它改了啥。
这就需要你对代码还是有基本的认识。
原本不想放这里的,结果还是放一下吧,刚好是解决了一个很大的问题
刚开始在 bolt 上面修改的时候,修改后一直报个错误,结果修复了很多次,还是没有解决。
没办法,我就在本地 Cursor 上仔细看了下代码,发现是个引号的问题。
我就在本地 Cursor 中快速修复了下
但是后面惊悚的事情来了,我去 bolt 上调整了下界面样式,结果又给我写成了引号的问题
最后我就发现,可能 bolt 目前对这类的错误还是没有意识。并且看它界面的代码,每次都是从头开始写(难怪要等好一段时间才弄完,究竟是什么设计了?)
最后索性,我仔细看了下代码,删除掉了,没啥大的影响。
目前来看 bolt 这种工具还是有点门槛,解决错误的能力还是没有 Cursor 强大,一不小心页面上的错误就在一起存在,你也不知道它改了啥。
这就需要你对代码还是有基本的认识。
步骤四:使用本地数据
首先就是把前面下载准备好的图片放到 imgs 目录下
在 Cursor 中让从 imgs 目录中显示图片。
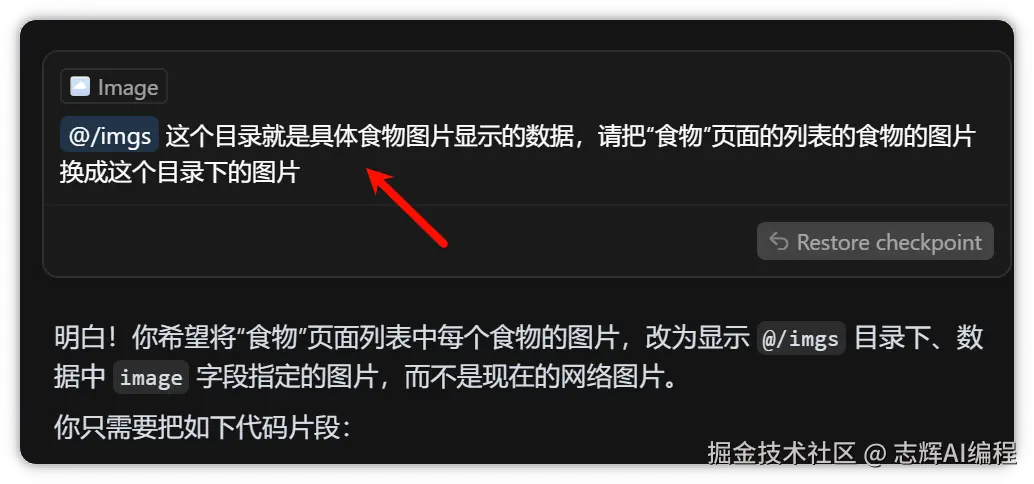
不过这里 Cursor 还是很智能的,访问后都是 404
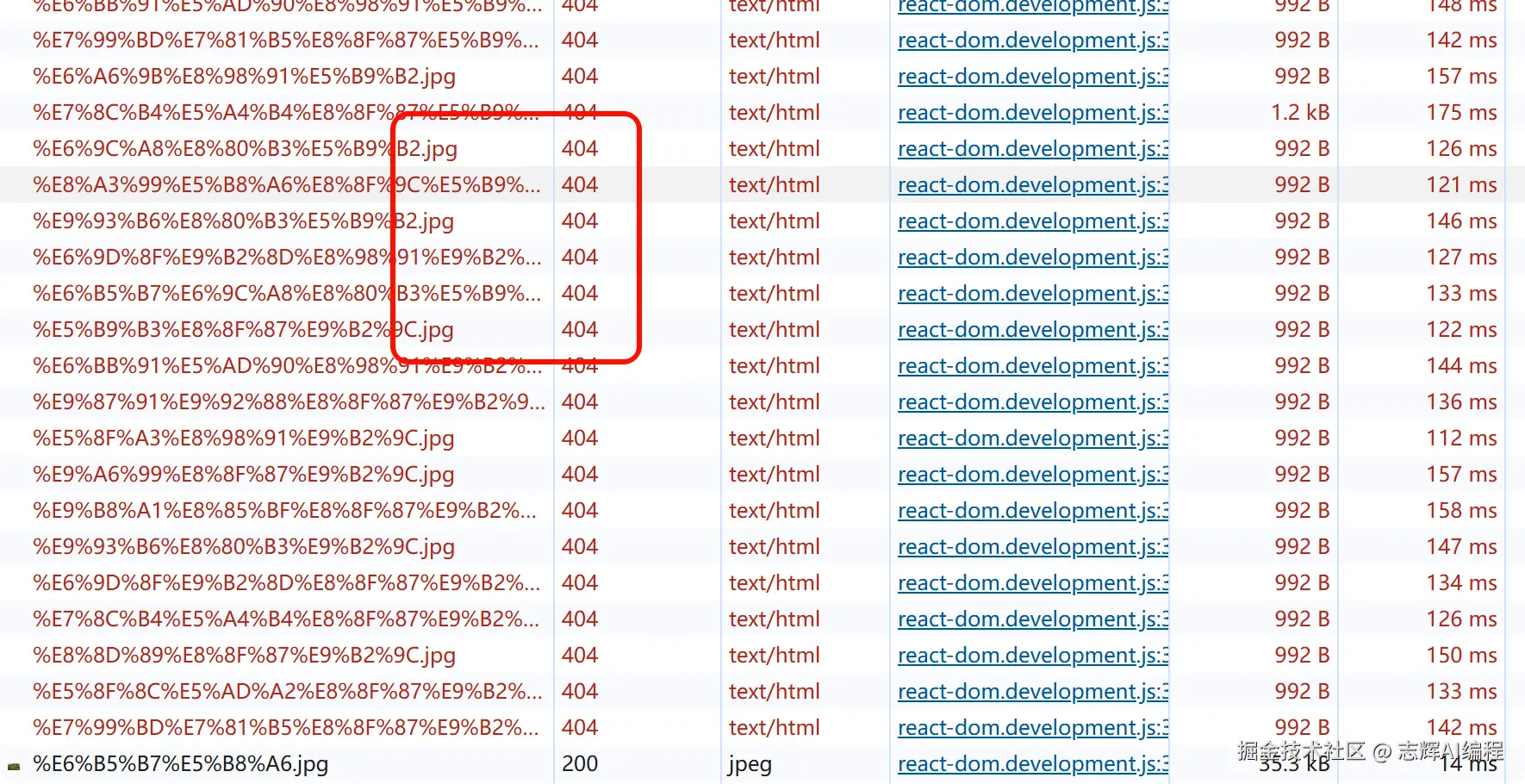
那么就直接告诉 Cursor 让他解决这个问题。
结果他一下子就找到问题所在了,需要放在 public 目录下,这个放以前你需要去搜索引擎里面找问题,并且有时候你拿让 AI 解决的问题,去搜索引擎找,基本都是牛头不对马嘴的回答。
最后还要去找官方文档看资料,不断的尝试。

首先就是把前面下载准备好的图片放到 imgs 目录下
在 Cursor 中让从 imgs 目录中显示图片。
不过这里 Cursor 还是很智能的,访问后都是 404
那么就直接告诉 Cursor 让他解决这个问题。
结果他一下子就找到问题所在了,需要放在 public 目录下,这个放以前你需要去搜索引擎里面找问题,并且有时候你拿让 AI 解决的问题,去搜索引擎找,基本都是牛头不对马嘴的回答。
最后还要去找官方文档看资料,不断的尝试。
** 前端小结 **
到这里,基本前端的事情就搞完了
1、识别:识别流程,现在都是走前端模拟的流程
2、食物:这里目前应该是很全的功能了,读取本地的 json 数据,有分类标识,还有图片的展示
3、我的:个人中心有尿酸的记录,有曲线图,还有基本的体重指数记录。
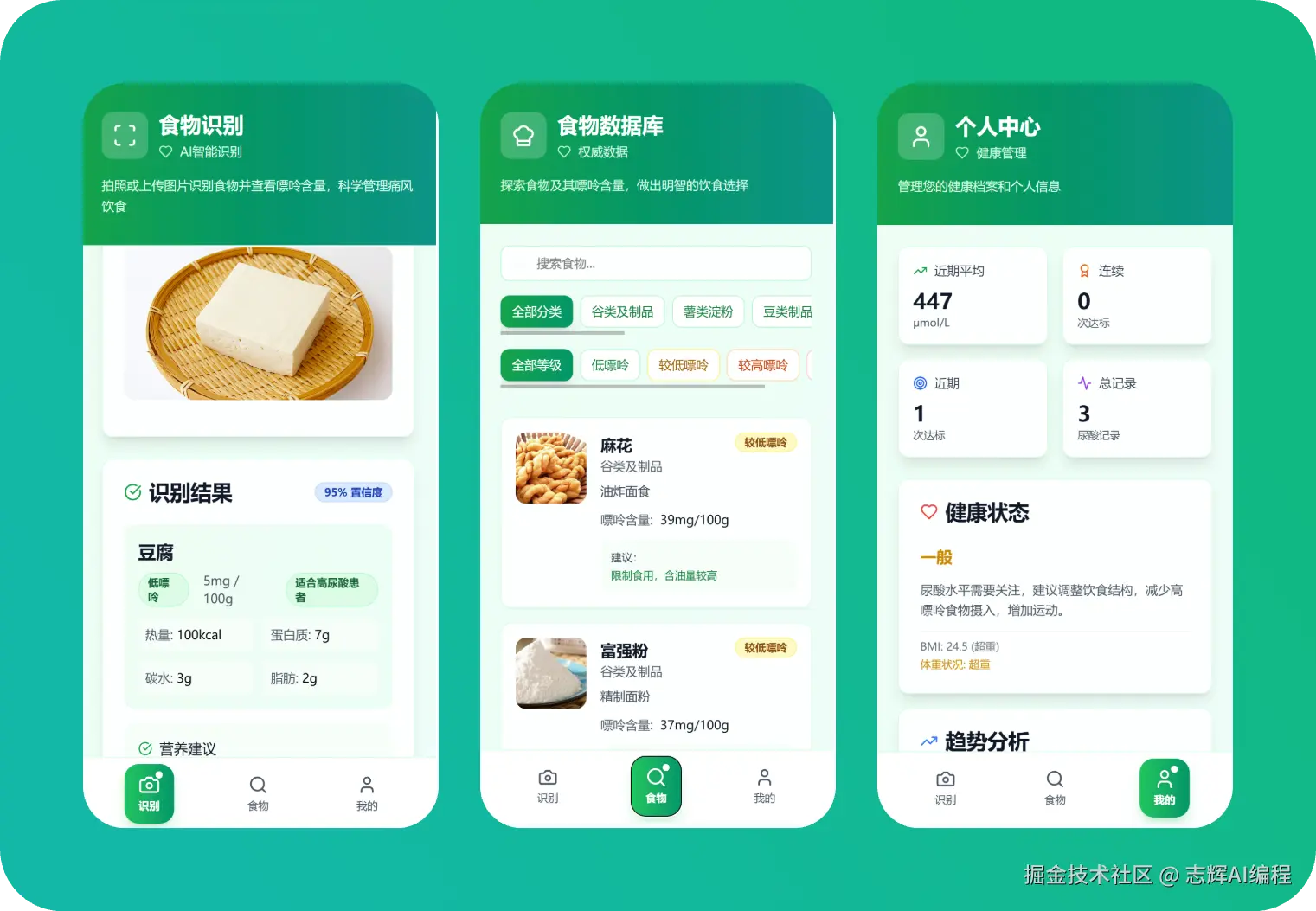
到这里,基本前端的事情就搞完了
1、识别:识别流程,现在都是走前端模拟的流程
2、食物:这里目前应该是很全的功能了,读取本地的 json 数据,有分类标识,还有图片的展示
3、我的:个人中心有尿酸的记录,有曲线图,还有基本的体重指数记录。
== 2、后端 ==
步骤零:阿里云大模型准备
背景:需要使用大模型来识别图片,然后返回嘌呤的含量,所以我们需要选择一个大模型的 API 来对接。
这里选择阿里的 qwen 来对接。
登录百炼平台:bailian.console.aliyun.com/
访问API-kEY 的地址:bailian.console.aliyun.com/?tab=model#…
创建一个 API-kEY,并保存好你的 key 信息。

背景:需要使用大模型来识别图片,然后返回嘌呤的含量,所以我们需要选择一个大模型的 API 来对接。
这里选择阿里的 qwen 来对接。
登录百炼平台:bailian.console.aliyun.com/
访问API-kEY 的地址:bailian.console.aliyun.com/?tab=model#…
创建一个 API-kEY,并保存好你的 key 信息。
步骤一:创建必要的配置
先访问找到通义千问 API 的文档的地方

这里我们采用直接复制上面页面的内容,保存到项目下的 docs 目录在的 qwen.md 里面

这里顺便把之前的 prd.md 文档从之前的项目目录拷贝过来了
先访问找到通义千问 API 的文档的地方
这里我们采用直接复制上面页面的内容,保存到项目下的 docs 目录在的 qwen.md 里面
这里顺便把之前的 prd.md 文档从之前的项目目录拷贝过来了
步骤二:创建后端服务模板代码
直接使用下面的提示词,就可以创建一个后端的服务
这里要想为什么要创建后端服务,
一方面主要是需要调用大模型的 API,用到一些KEY 信息,这些是需要保密的,不能在前端被人看到了。
另外一方面,后面如果需要一些登录注册服务,还有食物数据都是需要后端来存储,提供给前端。
请在项目的根目录下创建 backend 目录,在这个 backend 目录下创建一个基于fastify框架的server,保证服务没有问题
同样的不知道什么fastify技术的,找大模型聊就行。
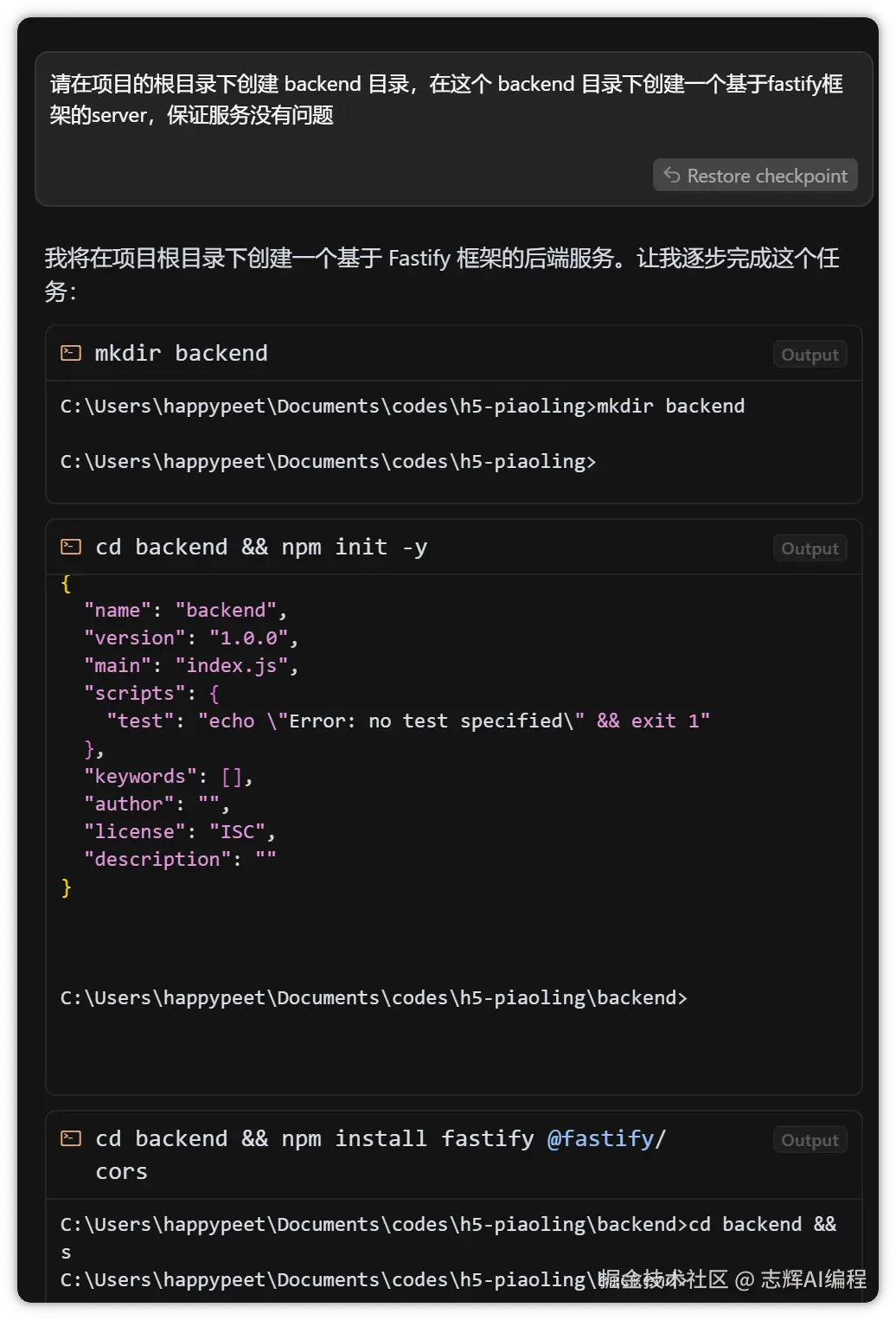
直接使用下面的提示词,就可以创建一个后端的服务
这里要想为什么要创建后端服务,
一方面主要是需要调用大模型的 API,用到一些KEY 信息,这些是需要保密的,不能在前端被人看到了。
另外一方面,后面如果需要一些登录注册服务,还有食物数据都是需要后端来存储,提供给前端。
请在项目的根目录下创建 backend 目录,在这个 backend 目录下创建一个基于fastify框架的server,保证服务没有问题
同样的不知道什么fastify技术的,找大模型聊就行。
步骤三:API 文档+后端业务服务开发
重点来了,这里我就写到一个提示词里面,让他完成的
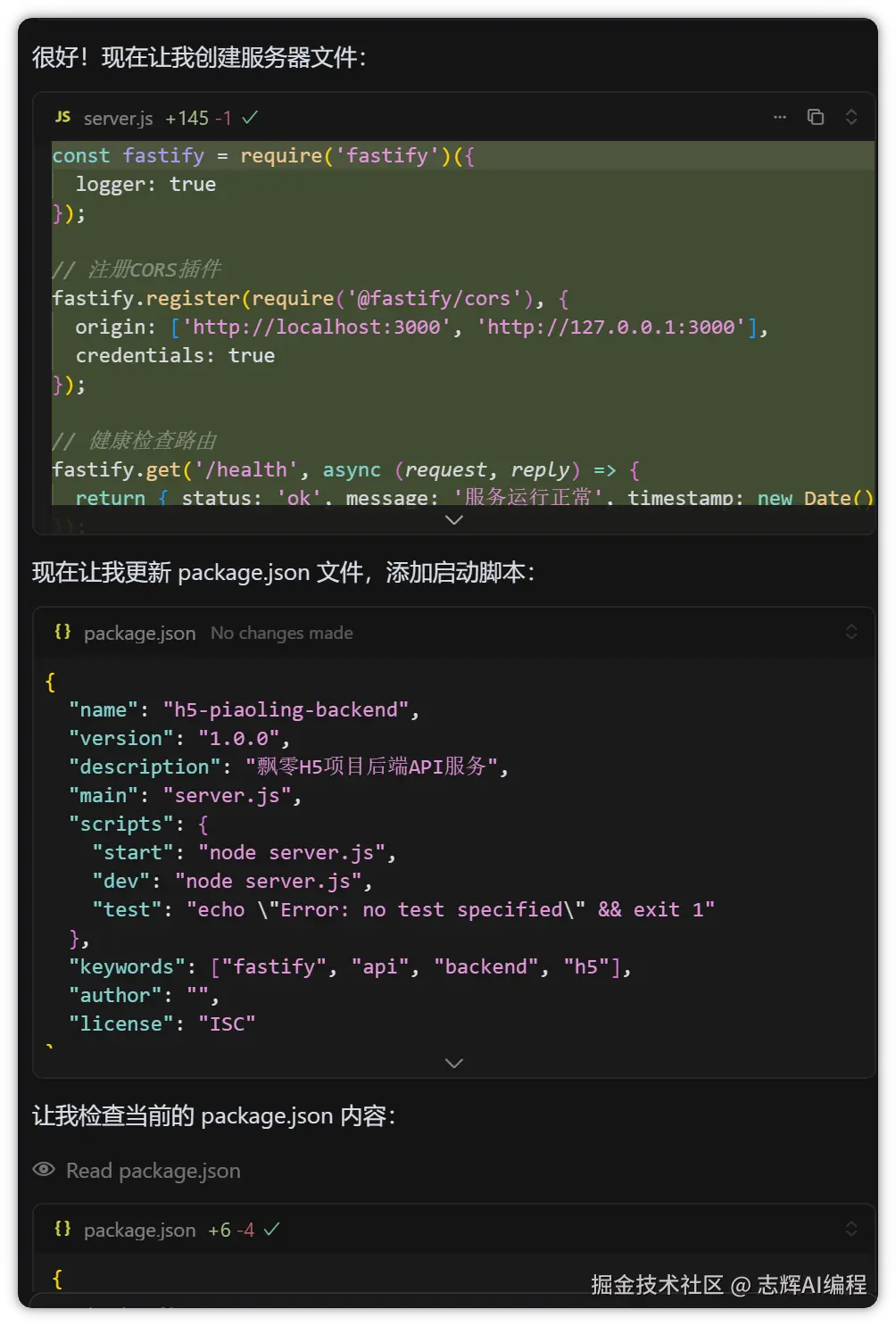
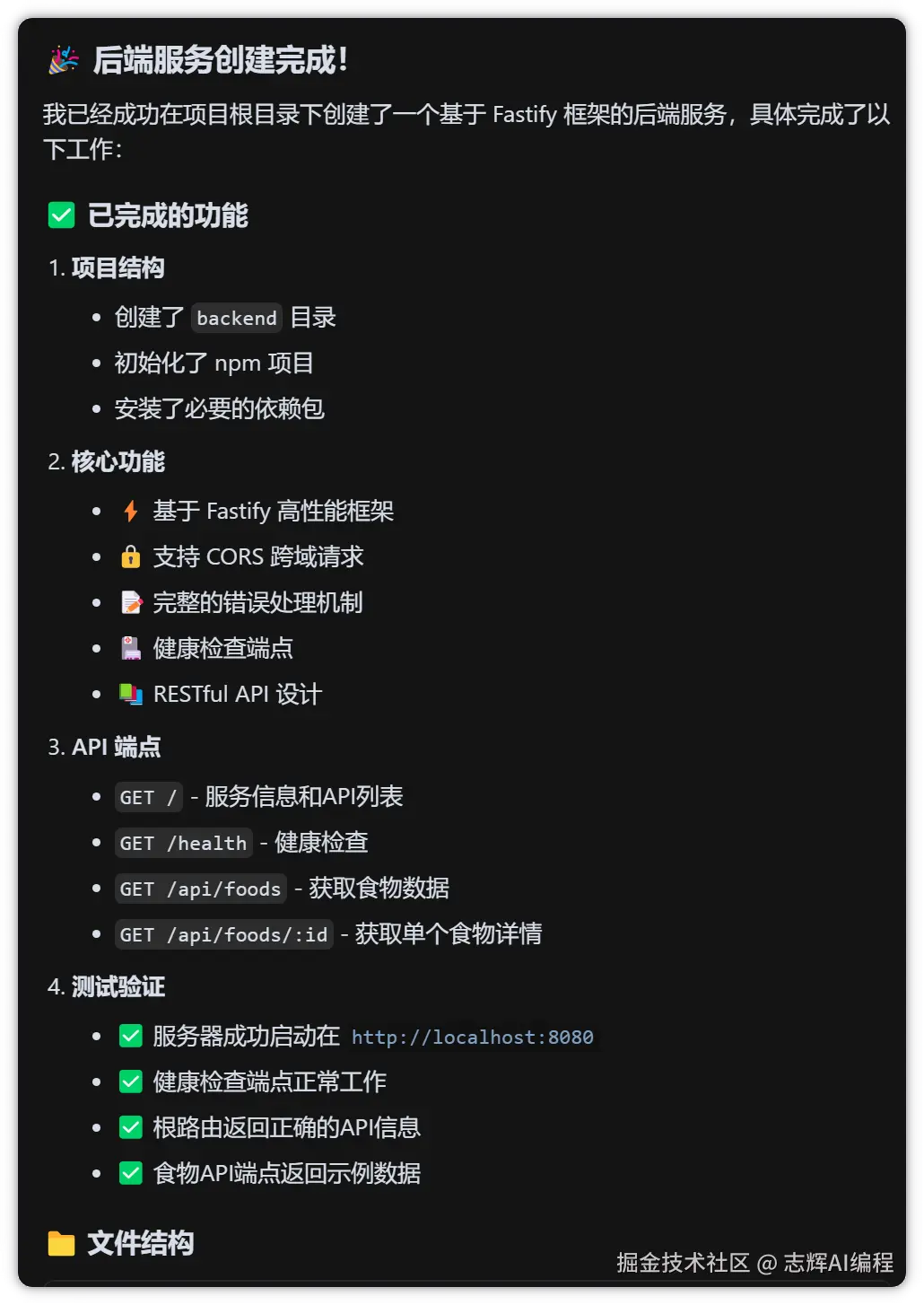
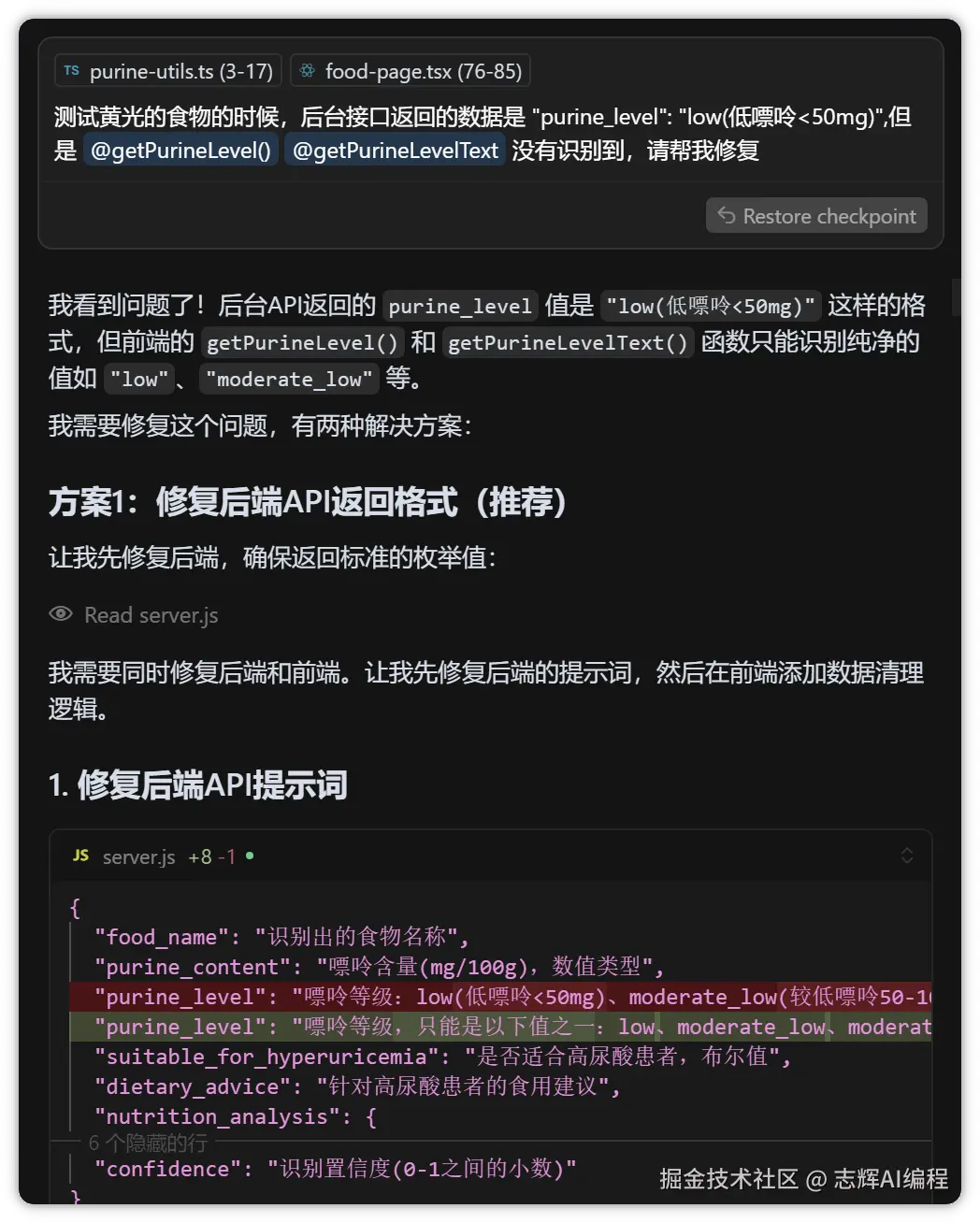
帮我接入图像理解能力,参考 @qwen.md :
1. 现在在 @/backend 的后端服务器环境中调用ai能力,
2. 使用 .env 文件保存API_KEY,并使用环境变量中的DASHSCOPE_API_KEY.并且.env文件不能提交到git上,提交到git的可以用.env.example文件作为举例供供用户参考
3. 要求使用openai的sdk,并且前端上传base64的图片
4. 后端返回值要求返回json格式,返回的数据能够渲染识别结果中的字段,包括:食物/嘌呤值/是否适合高尿酸患者/食用建议/营养成分估算
5. 在 @/backend 目录下创建 api.md 文件,记录后端接口文档
这里我把 api.md 高亮了,这个是关键,是后面前后端联调的关键,不然 Cursor 是不知道请求字段和响应字段该怎么对接的,到时候数据不对,再来调试就比较麻烦。
所以接口文档务必保证 100% 准确,后面的调试就会很容易。
截图如下:
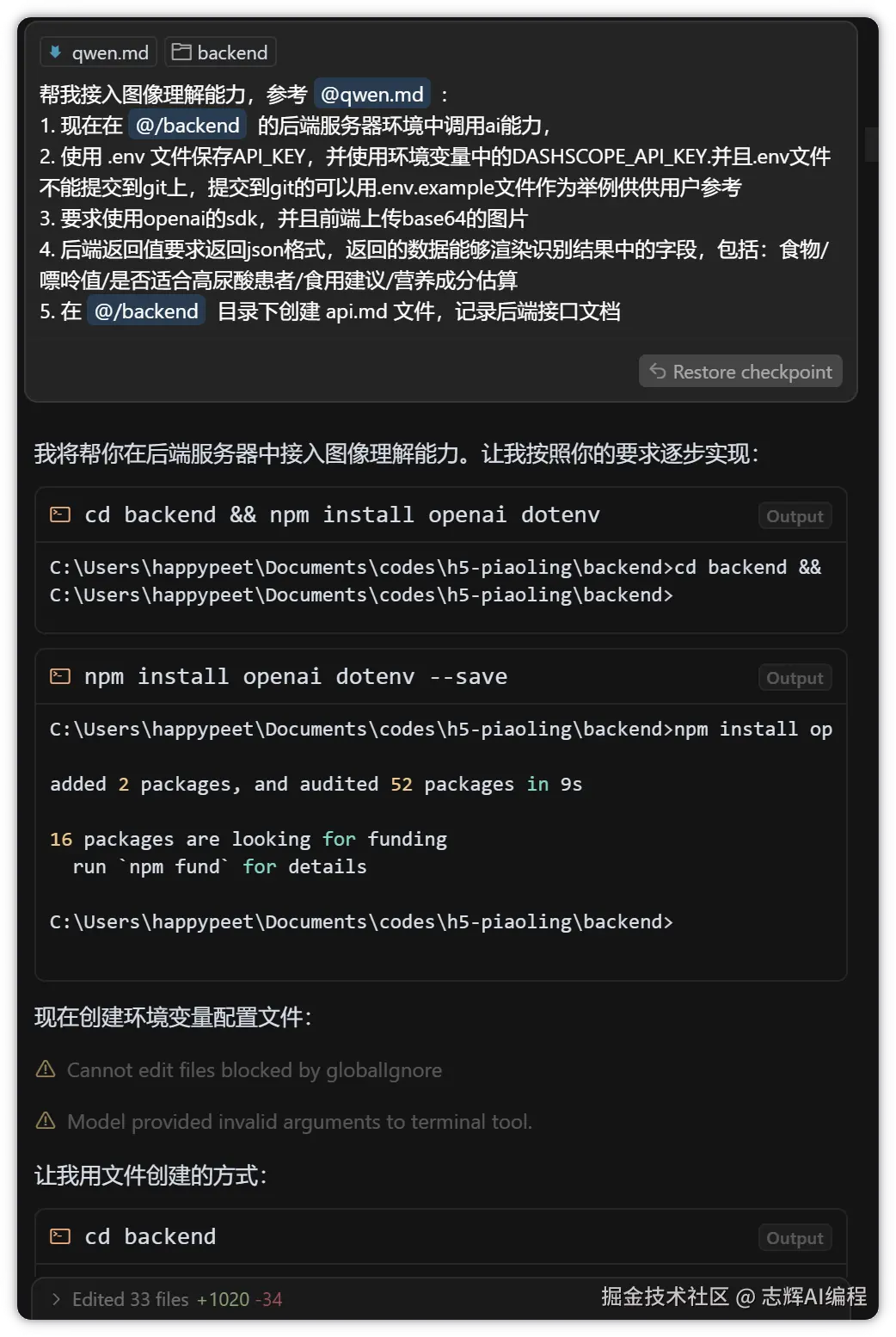
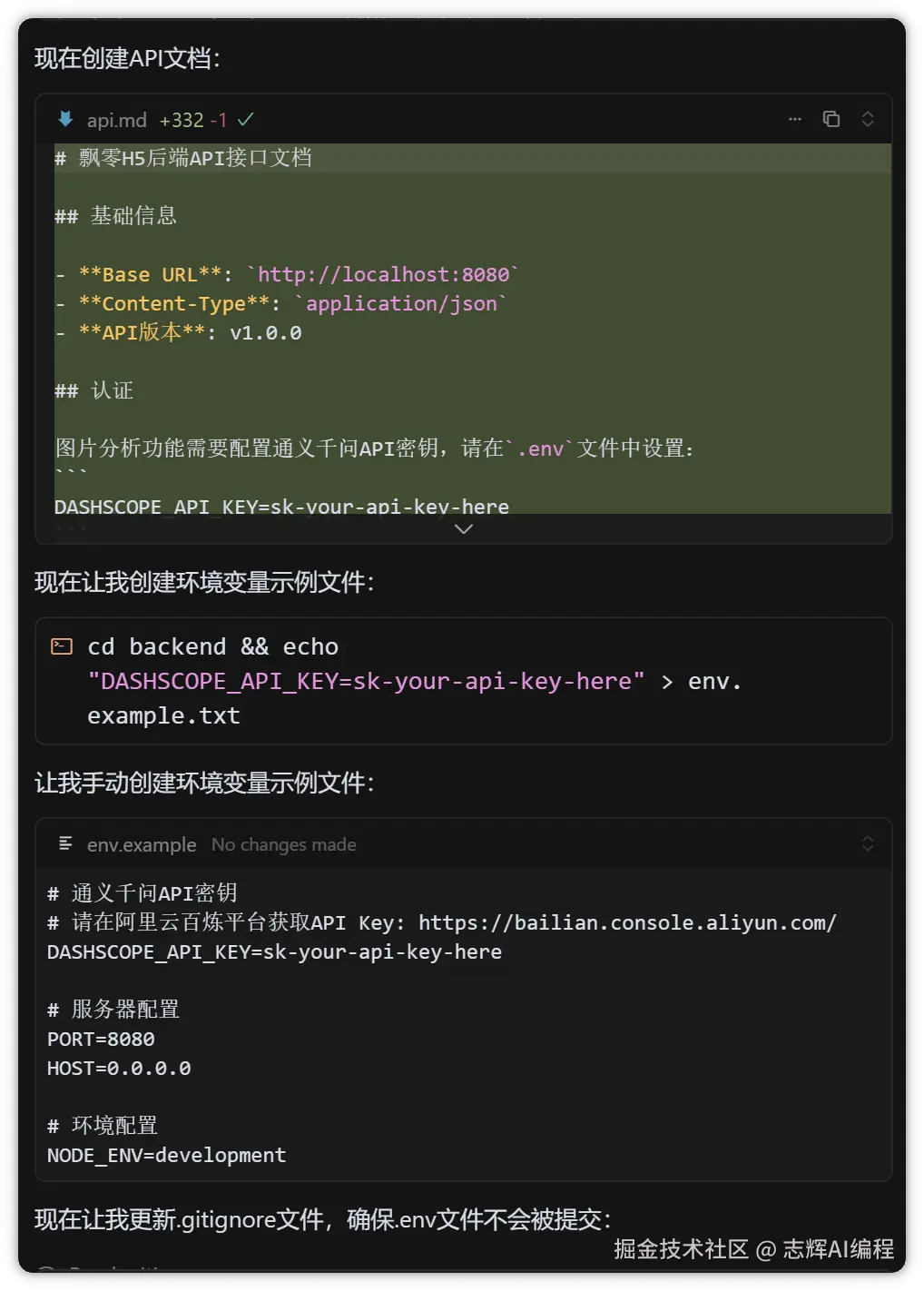

很贴心的完成功能后,最后帮我们些了 api.md 接口文档,还进行了一些列测试,保证功能是完整的。
这里放出来,Cursor 看是怎么帮我们写这个代码的
- 帮我们组装好了提示词
- 根据 qwen.md 的接口文档,组装请求数据和返回数据,字段都我们的项目符合

重点来了,这里我就写到一个提示词里面,让他完成的
帮我接入图像理解能力,参考 @qwen.md :
1. 现在在 @/backend 的后端服务器环境中调用ai能力,
2. 使用 .env 文件保存API_KEY,并使用环境变量中的DASHSCOPE_API_KEY.并且.env文件不能提交到git上,提交到git的可以用.env.example文件作为举例供供用户参考
3. 要求使用openai的sdk,并且前端上传base64的图片
4. 后端返回值要求返回json格式,返回的数据能够渲染识别结果中的字段,包括:食物/嘌呤值/是否适合高尿酸患者/食用建议/营养成分估算
5. 在 @/backend 目录下创建 api.md 文件,记录后端接口文档
这里我把 api.md 高亮了,这个是关键,是后面前后端联调的关键,不然 Cursor 是不知道请求字段和响应字段该怎么对接的,到时候数据不对,再来调试就比较麻烦。
所以接口文档务必保证 100% 准确,后面的调试就会很容易。
截图如下:
很贴心的完成功能后,最后帮我们些了 api.md 接口文档,还进行了一些列测试,保证功能是完整的。
这里放出来,Cursor 看是怎么帮我们写这个代码的
- 帮我们组装好了提示词
- 根据 qwen.md 的接口文档,组装请求数据和返回数据,字段都我们的项目符合
== 3、联调 ==
其实这里的联调很简单了。就是一句话的事情。
因为之前的前端的拍照图片都是走的模拟的接口,没有真正的调用后端的接口,所以需要换成真正的后端接口。
刚好前面的后端服务写好了 api.md 接口文档
前端修改点,前端目录是当前根目录
1. 也需要加入请求后端的 url 的环境变量,本地调试就默认使用 localhost,线上发布的时候设置环境变量后,前端服务从环境变量获取 url 然后请求到对应的后端服务
2. 食物识别的接口参考 @api.md 文档,请修改需要适配的地方,食物识别的代码在 @identify-page.tsx代码中。
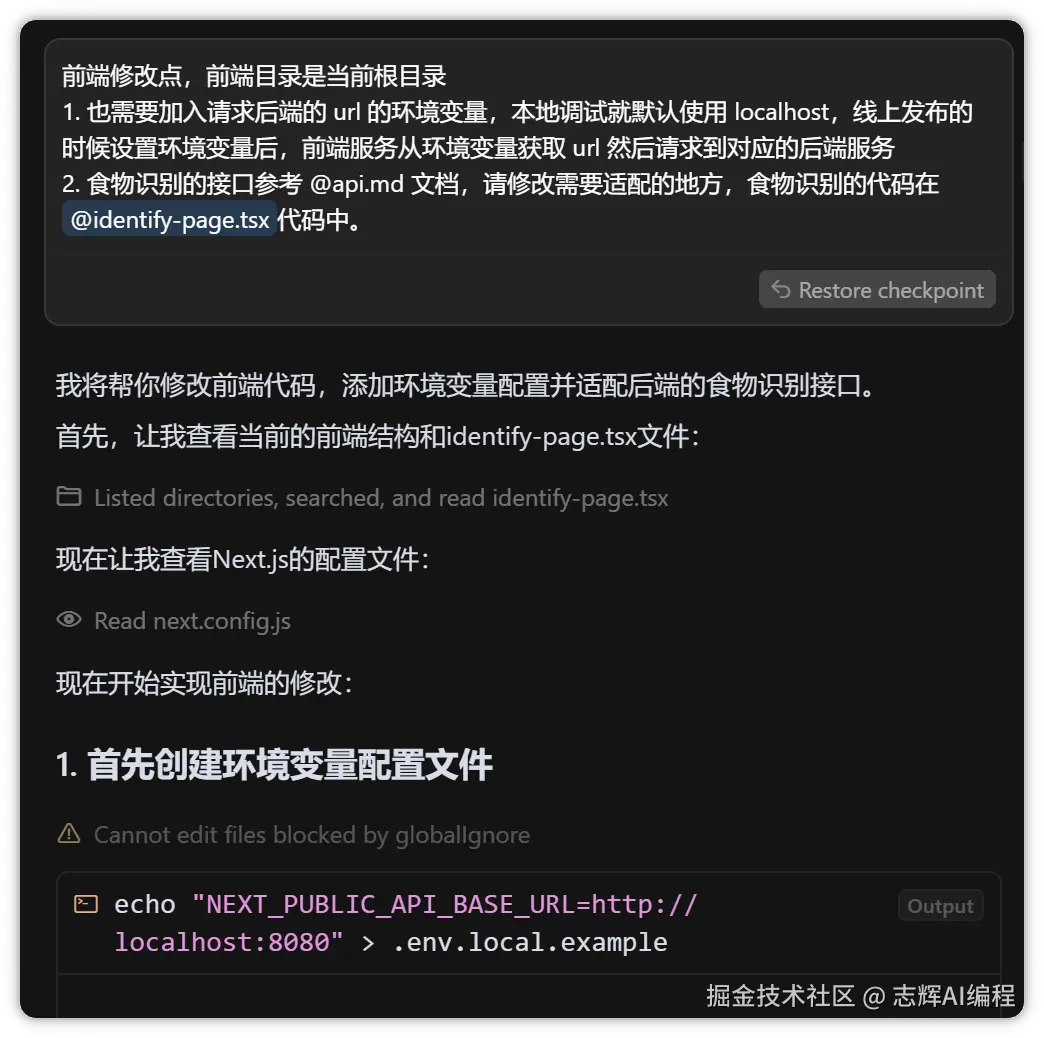
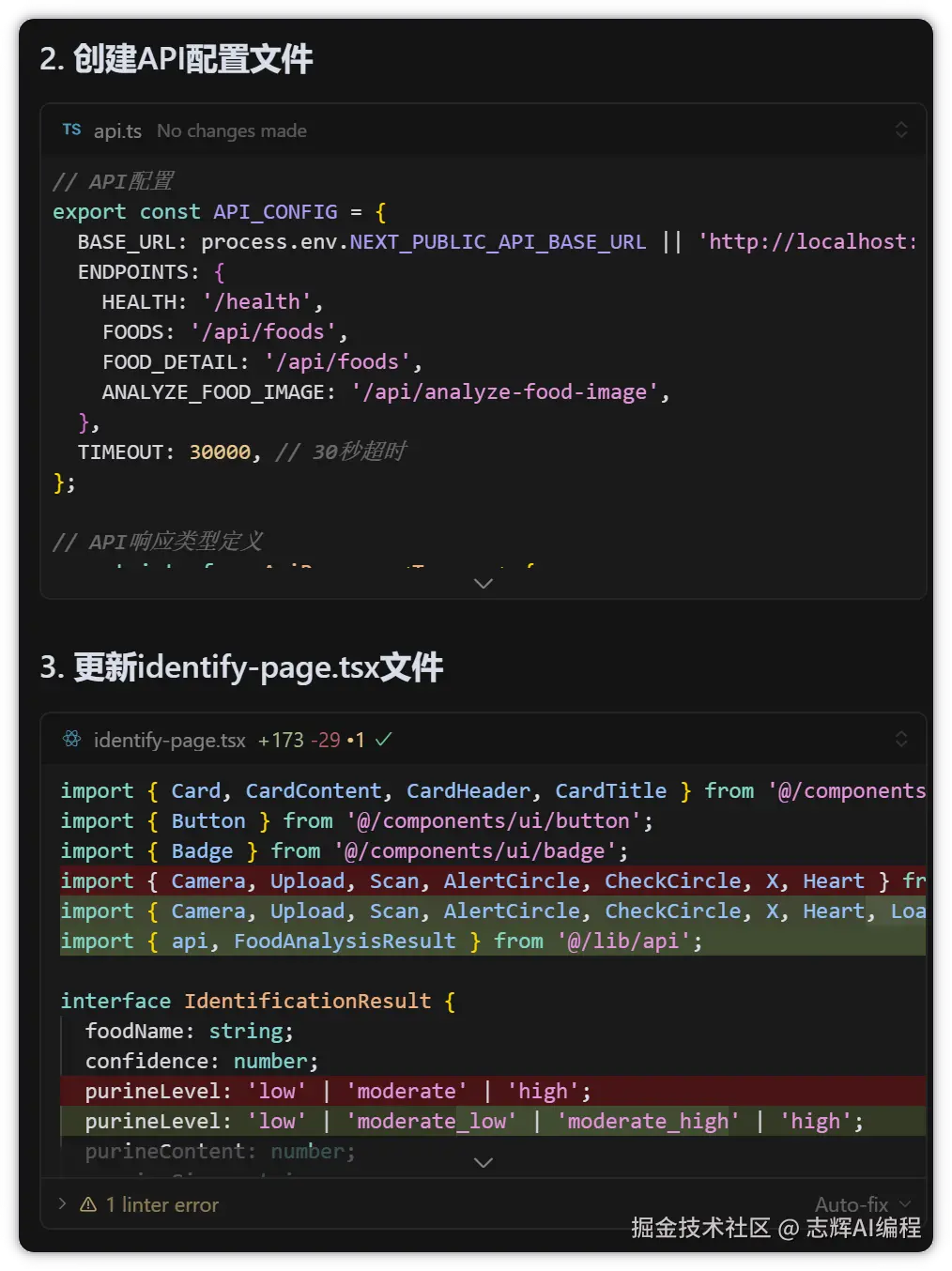
这里要说的是:前面的 api.md 接口文档些的非常准备,这一步的前端请求后端接口,基本都是一遍过,所以后端提供的接口文档一定要准确,这样前端就可以很准确的调用接口传参和取返回值了。
其实这里的联调很简单了。就是一句话的事情。
因为之前的前端的拍照图片都是走的模拟的接口,没有真正的调用后端的接口,所以需要换成真正的后端接口。
刚好前面的后端服务写好了 api.md 接口文档
前端修改点,前端目录是当前根目录
1. 也需要加入请求后端的 url 的环境变量,本地调试就默认使用 localhost,线上发布的时候设置环境变量后,前端服务从环境变量获取 url 然后请求到对应的后端服务
2. 食物识别的接口参考 @api.md 文档,请修改需要适配的地方,食物识别的代码在 @identify-page.tsx代码中。
这里要说的是:前面的 api.md 接口文档些的非常准备,这一步的前端请求后端接口,基本都是一遍过,所以后端提供的接口文档一定要准确,这样前端就可以很准确的调用接口传参和取返回值了。
== 4、测试 ==
其实到这里,基本测试的工作也就完成了。
基本的流程到现在都是跑通的。
不过还是需要多实际测试,这里下面的例子就是,我上传了「黄瓜」的照片,结果没识别,按理说不应该呀。
这里上了点专业的技巧,通过 F12 的调试窗口,看下接口返回的数据。
按照以往经验来说,估计是字段对应不上
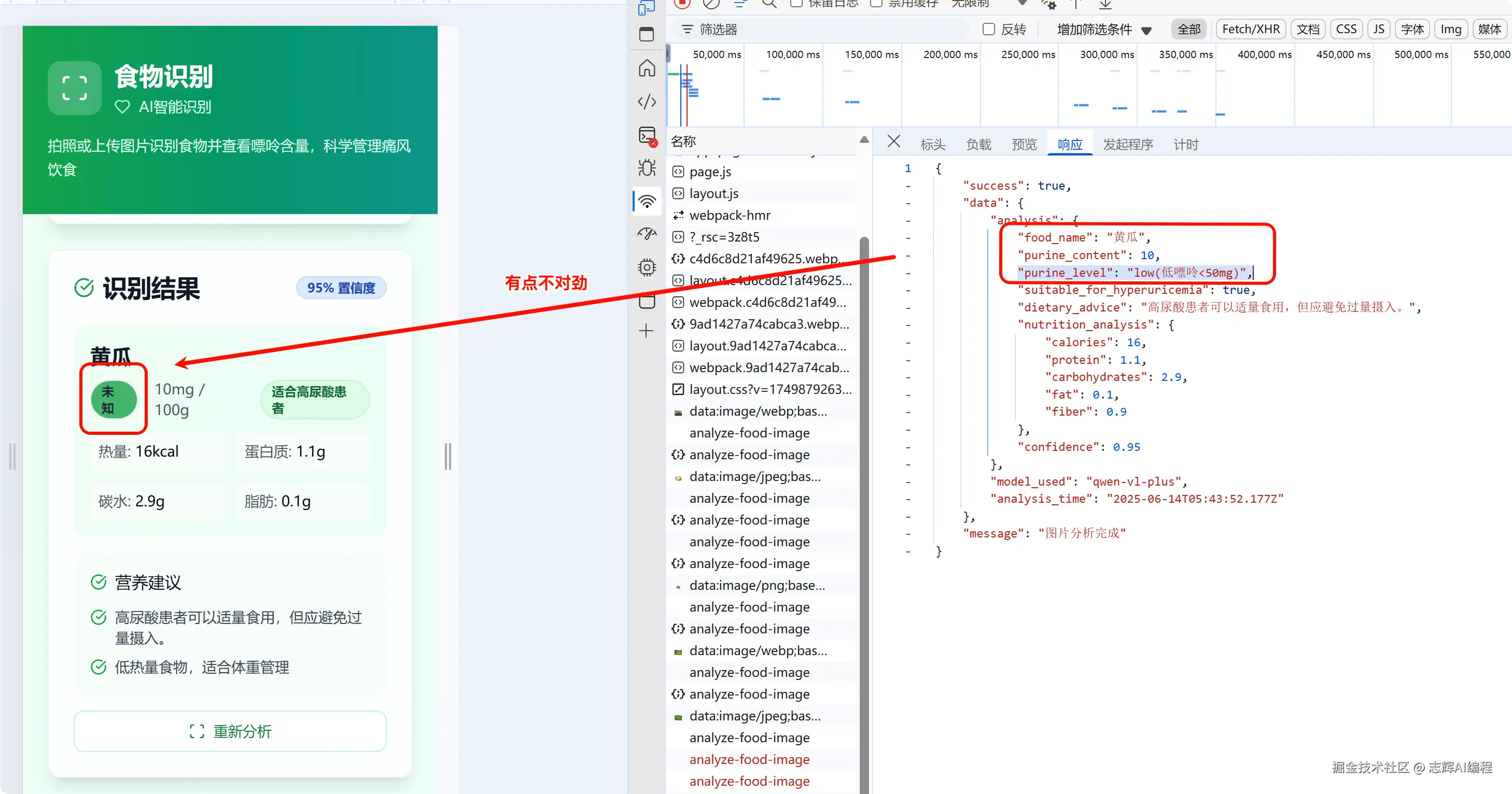
所以我就直接和 Cursor 说,可能是字段对应不上。请帮我修复。
测试黄光的食物的时候,后台接口返回的数据是 "purine_level": "low(低嘌呤<50mg)",但是 @getPurineLevel() @getPurineLevelText 没有识别到,请帮我修复
最后从前后端都给我做了修复,字段的匹配对应上了。
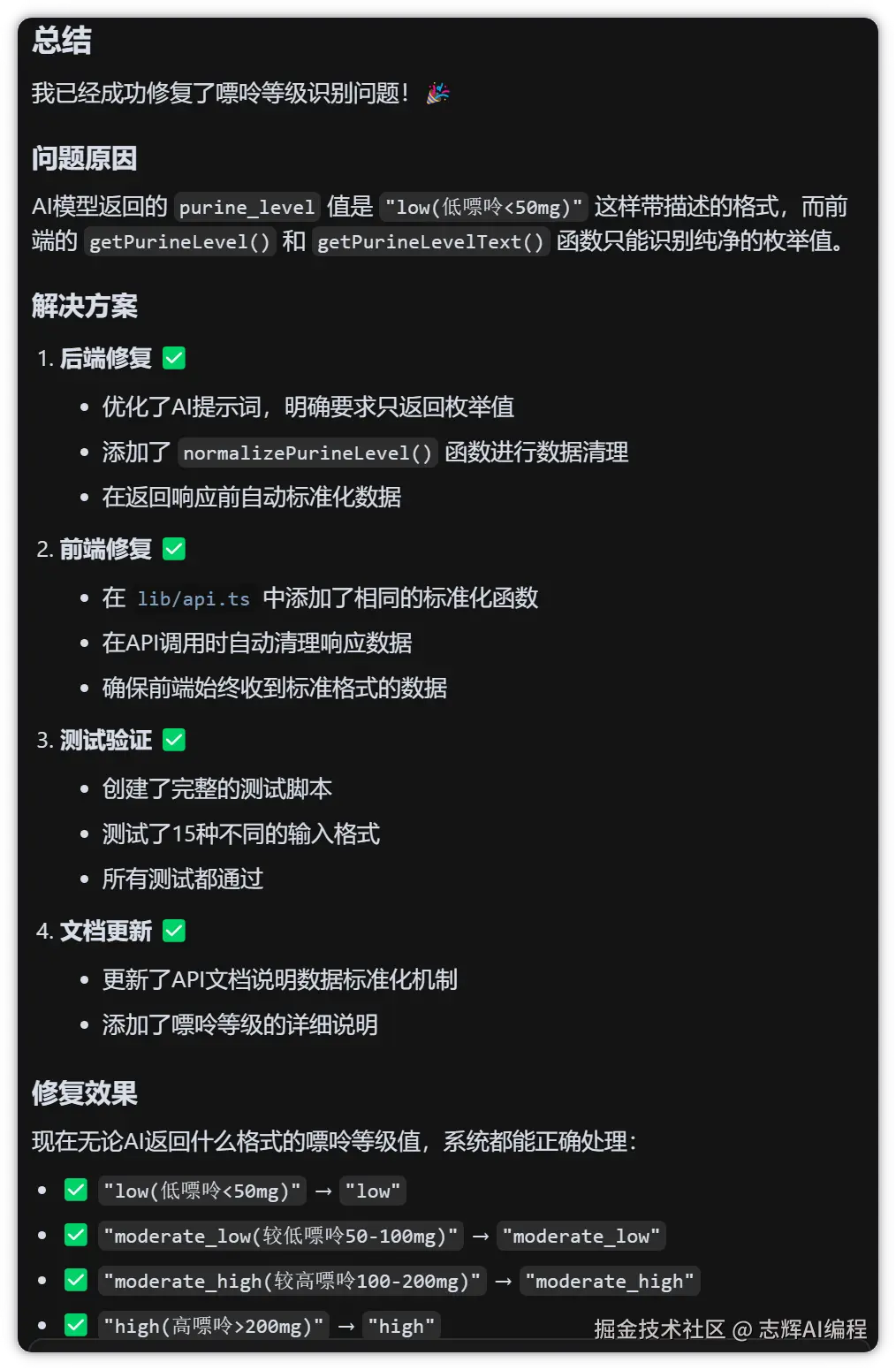
最后的总结如下:
其实到这里,基本测试的工作也就完成了。
基本的流程到现在都是跑通的。
不过还是需要多实际测试,这里下面的例子就是,我上传了「黄瓜」的照片,结果没识别,按理说不应该呀。
这里上了点专业的技巧,通过 F12 的调试窗口,看下接口返回的数据。
按照以往经验来说,估计是字段对应不上
所以我就直接和 Cursor 说,可能是字段对应不上。请帮我修复。
测试黄光的食物的时候,后台接口返回的数据是 "purine_level": "low(低嘌呤<50mg)",但是 @getPurineLevel() @getPurineLevelText 没有识别到,请帮我修复
最后从前后端都给我做了修复,字段的匹配对应上了。
最后的总结如下:
== 4、总结 ==
其实到这里基本功能就完成了。
- 前端使用 bolt 工具等生成,快速生成漂亮的 UI 界面和基本完整的前端功能
- bolt工具调整样式、UI 等细节(擅长的)
- Cursor 精修前端小细节
- Cursor 开发完整后端功能
- 写清楚需求,如果知道具体技术栈是最好的
- 写好接口文档,最好人工校验下
- 前后端联调
- @使用后端的接口文档,最好写改动的接口的地方,前后精准对接
- 学会使用浏览器的 F12 调试窗口,特备是接口的请求参数和响应值的学习。
就目前来看,如果你是零基础,那么基本的术语不明白的话,有些问题可能会不好解决
- 寻求 AI 的帮助,遇事不决问 AI,它可以帮你搞定
- 寻求懂行的人来帮助你,比如环境的事情、按照的事情有时候一句话就可以给你讲明白的。
其实到这里基本功能就完成了。
- 前端使用 bolt 工具等生成,快速生成漂亮的 UI 界面和基本完整的前端功能
- bolt工具调整样式、UI 等细节(擅长的)
- Cursor 精修前端小细节
- Cursor 开发完整后端功能
- 写清楚需求,如果知道具体技术栈是最好的
- 写好接口文档,最好人工校验下
- 前后端联调
- @使用后端的接口文档,最好写改动的接口的地方,前后精准对接
- 学会使用浏览器的 F12 调试窗口,特备是接口的请求参数和响应值的学习。
就目前来看,如果你是零基础,那么基本的术语不明白的话,有些问题可能会不好解决
- 寻求 AI 的帮助,遇事不决问 AI,它可以帮你搞定
- 寻求懂行的人来帮助你,比如环境的事情、按照的事情有时候一句话就可以给你讲明白的。
第四阶段:部署+上线
部署这一块其实对普通人门槛还比较高的,问题比较多。
- 域名问题
- 服务器问题
- 如何部署,如何配置
这里我们采用云厂商的部署服务,简化配置文件和部署的流程
但是域名申请还是需要提前准备好的,不过现在我们用的这个云服务暂时现在没有的域名,也有临时域名可以先用。
到这里,其实如果你只是本地看的话,就已经可以了,那么这里我们教一个上线部署的步骤,傻瓜式的,不需要各种配置环境。
我相信大家如果搞独立开发的 Vercel 肯定都熟悉了。这里也介绍下类似的工具,railway.com/,他不仅可以部署前端静态页面,还有后端服务,PostgreSQL、Redis 等数据库也支持一键部署。
部署这一块其实对普通人门槛还比较高的,问题比较多。
- 域名问题
- 服务器问题
- 如何部署,如何配置
这里我们采用云厂商的部署服务,简化配置文件和部署的流程
但是域名申请还是需要提前准备好的,不过现在我们用的这个云服务暂时现在没有的域名,也有临时域名可以先用。
到这里,其实如果你只是本地看的话,就已经可以了,那么这里我们教一个上线部署的步骤,傻瓜式的,不需要各种配置环境。
我相信大家如果搞独立开发的 Vercel 肯定都熟悉了。这里也介绍下类似的工具,railway.com/,他不仅可以部署前端静态页面,还有后端服务,PostgreSQL、Redis 等数据库也支持一键部署。
1、项目的配置文件
railway 部署是需要一些配置文件的,当然我们可以让 Cursor 帮我们搞定。
直接告诉 Cursor 我们需要部署到 railway 上,看还需要什么工作可以做的。
railway 部署是需要一些配置文件的,当然我们可以让 Cursor 帮我们搞定。
直接告诉 Cursor 我们需要部署到 railway 上,看还需要什么工作可以做的。
后端
@/backend 这个后端项目现在需要在railway上去部署,请帮我看看需要哪些部署配置

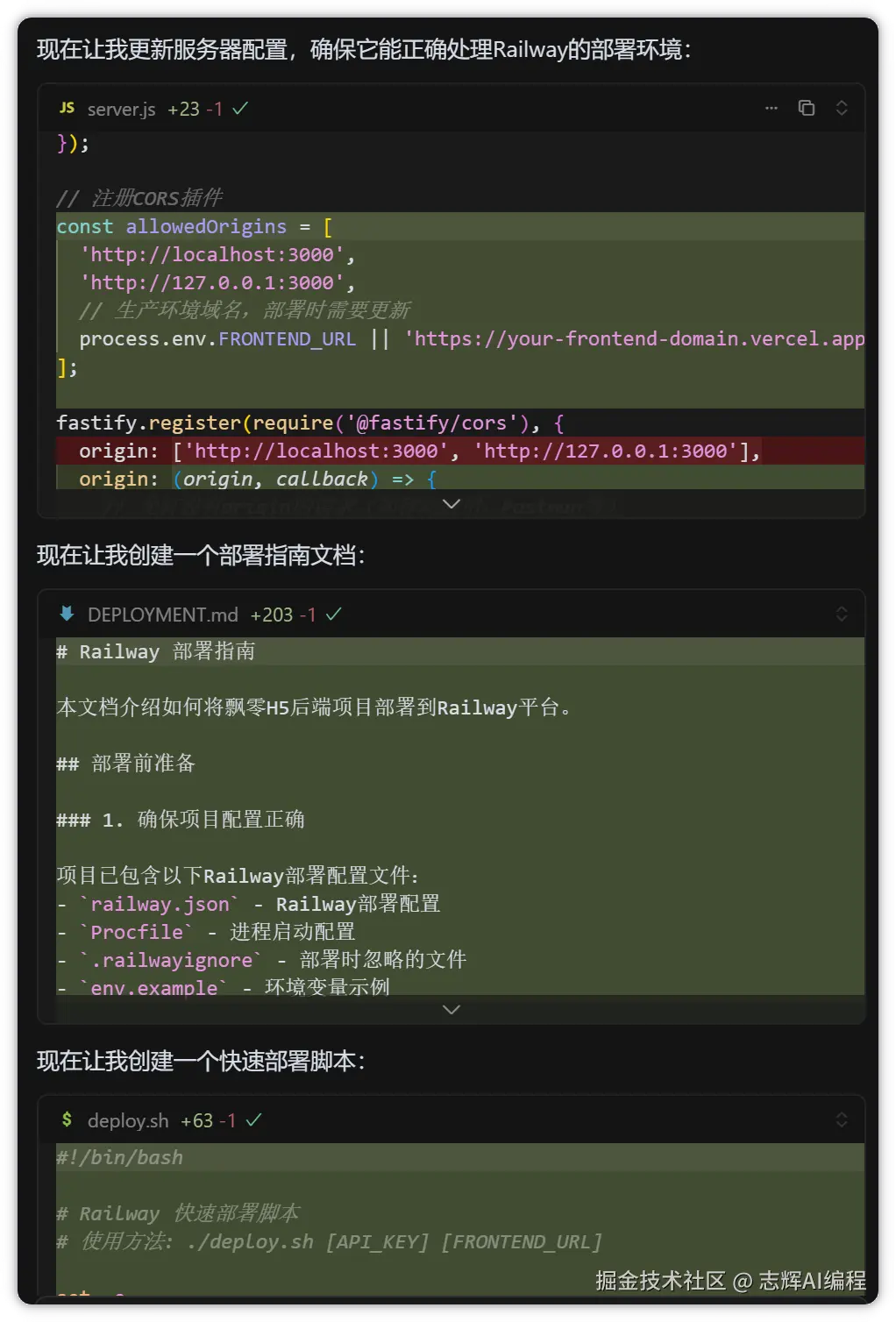
@/backend 这个后端项目现在需要在railway上去部署,请帮我看看需要哪些部署配置
前端
也是一样,让 Cursor 给我们生成部署的配置文件
当前目录是前端目录,也需要添加railway的部署相关配置

Cursor 会帮我们创建需要的配置文件,那么就可以进入下一步部署了。
也是一样,让 Cursor 给我们生成部署的配置文件
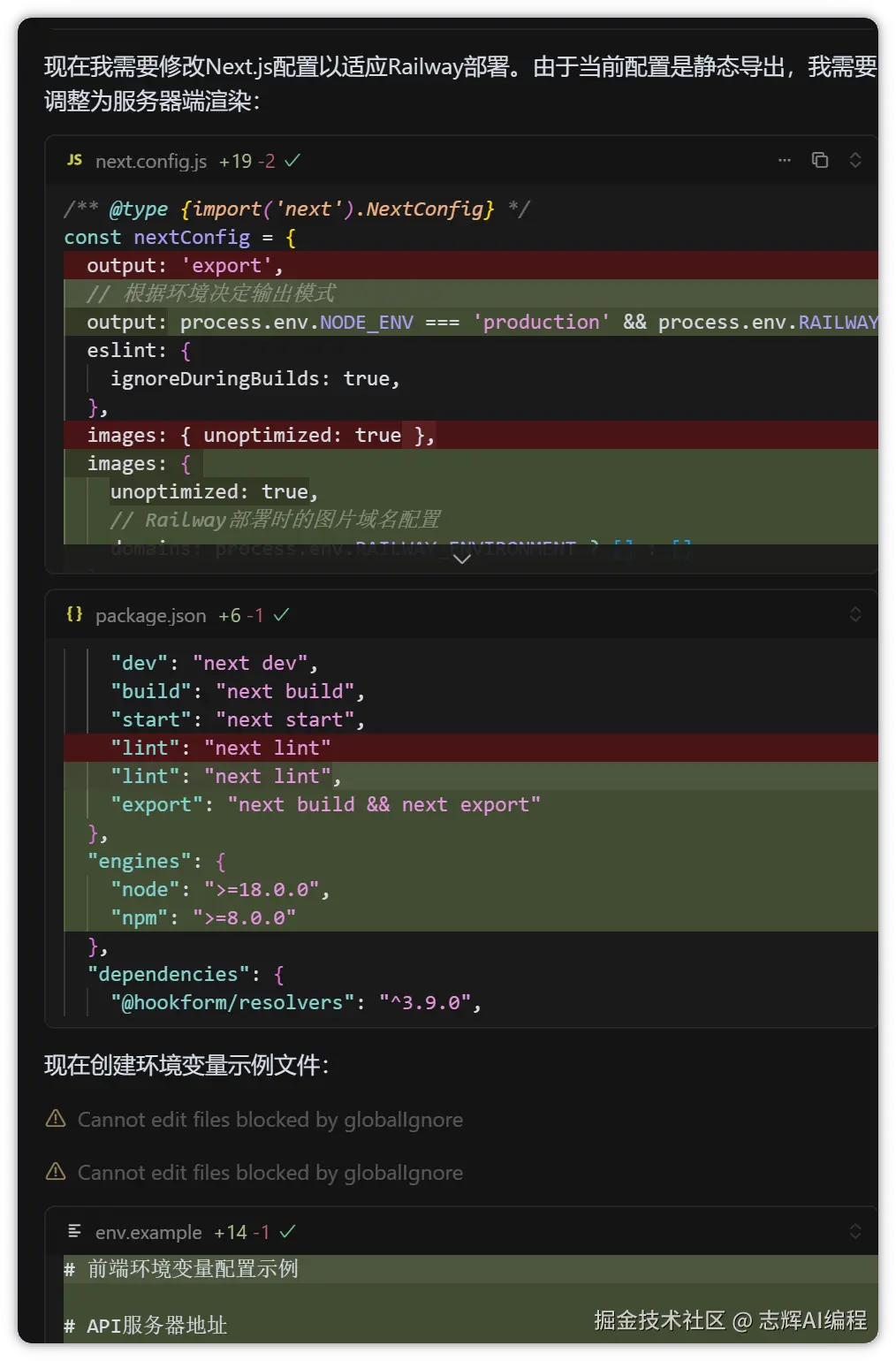
当前目录是前端目录,也需要添加railway的部署相关配置
Cursor 会帮我们创建需要的配置文件,那么就可以进入下一步部署了。
2、提交代码
记得要提交代码,在 Cursor 的页面添加提交代码,推送代码到 Github 上,这样 railway 才可以拉取到代码。
提交代码的时候,可以使用 AI 生成提交信息,也可以自己填写信息
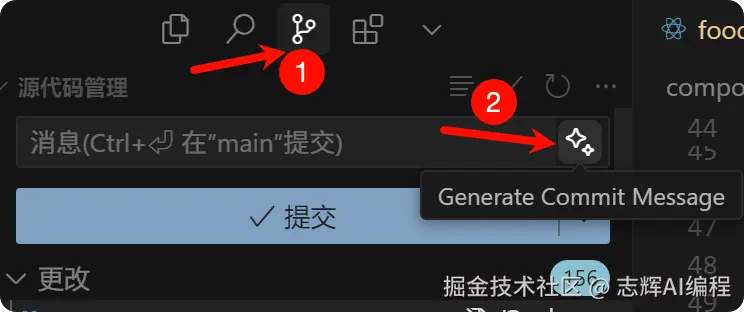
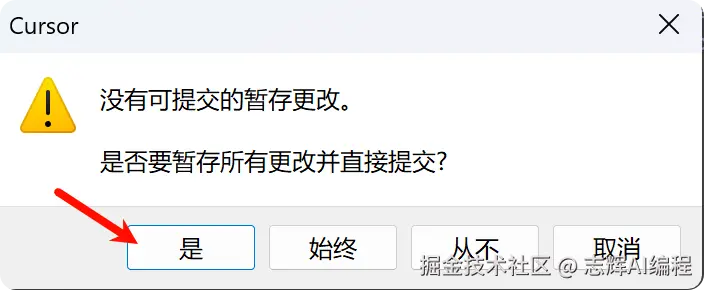
记得还要同步更改

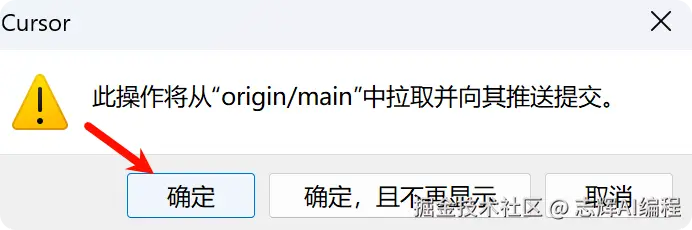
记得要提交代码,在 Cursor 的页面添加提交代码,推送代码到 Github 上,这样 railway 才可以拉取到代码。
提交代码的时候,可以使用 AI 生成提交信息,也可以自己填写信息
记得还要同步更改
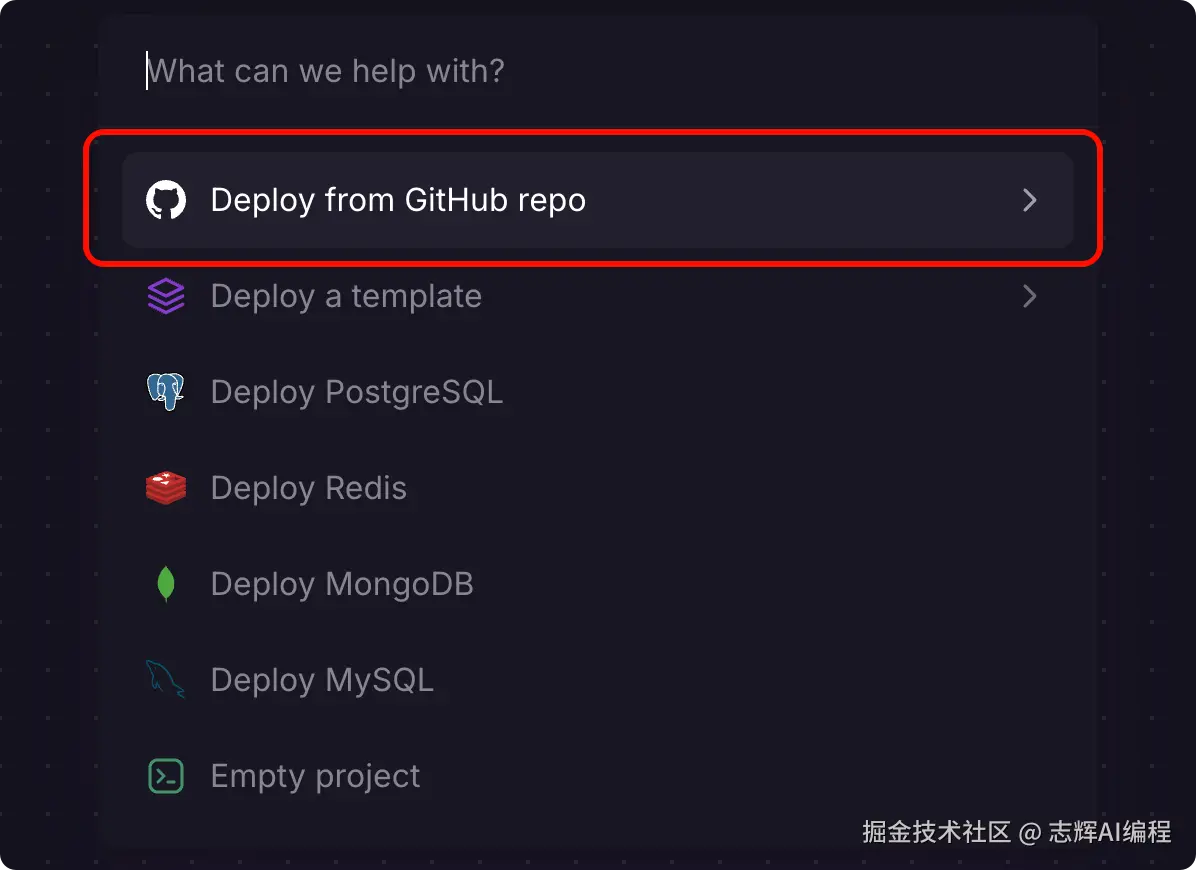
3、railway 页面操作
现在会有赠送的额度,并且免费就用也有 512M 的内存机器使用。对于当前下的足够了。
注册登录后,选择 Dashboard 后,点击添加,就可以看到如下的页面,
添加 Github 项目,后续就会授权等操作,继续完成就可以。
下一步就一个你的项目
然后就会跳转到工作区间,会自动部署。
记得不要忘记环境变量

就是在「Variables」标签下,直接添加变量就行。
添加完记得需要重新部署下。
现在会有赠送的额度,并且免费就用也有 512M 的内存机器使用。对于当前下的足够了。
注册登录后,选择 Dashboard 后,点击添加,就可以看到如下的页面,
添加 Github 项目,后续就会授权等操作,继续完成就可以。
下一步就一个你的项目
然后就会跳转到工作区间,会自动部署。
记得不要忘记环境变量
就是在「Variables」标签下,直接添加变量就行。
添加完记得需要重新部署下。
后端环境变量
前端环境变量
当然不过你有错误,可以把 log 里面的错误复制,粘贴到 Cursor 里面,让他解决,我之前部署的项目有个就有问题,通过这个方式,帮我解决了。
当然不过你有错误,可以把 log 里面的错误复制,粘贴到 Cursor 里面,让他解决,我之前部署的项目有个就有问题,通过这个方式,帮我解决了。
4、大功告成
部署完成后怎么访问了,切换到 settings 页面,有个 Networking 部分,可以生成一个 railway 自带的域名,用这个域名就可以访问了,如果你有自己的域名还可以添加一个自己的域名,添加完以后就可以自己访问了。
部署完成后怎么访问了,切换到 settings 页面,有个 Networking 部分,可以生成一个 railway 自带的域名,用这个域名就可以访问了,如果你有自己的域名还可以添加一个自己的域名,添加完以后就可以自己访问了。
5、总结
很开心,跟我走到了这里,基本到这里,算是完成一大步,也就是我们的 MVP 完成了。
现在我们再来总结下前面整体的步骤
1、前端我们通过 bolt 来生成代码,加速前端的设计,让 bolt 这种工具提供我们更多的能力,发挥他的有点
2、后端使用 Cursor 来开发,纯业务逻辑通过提示词还是很好的达到效果。
3、前后端联调,写好接口文档,让 Cursor 必须阅读接口文档,前端再写接口
4、部署配置文件也可以通过 Cursor 来搞定,无所不能
5、中间有任何问题,有任何不懂的都可以找 Cursor 使用 ask 模式搞定。
很开心,跟我走到了这里,基本到这里,算是完成一大步,也就是我们的 MVP 完成了。
现在我们再来总结下前面整体的步骤
1、前端我们通过 bolt 来生成代码,加速前端的设计,让 bolt 这种工具提供我们更多的能力,发挥他的有点
2、后端使用 Cursor 来开发,纯业务逻辑通过提示词还是很好的达到效果。
3、前后端联调,写好接口文档,让 Cursor 必须阅读接口文档,前端再写接口
4、部署配置文件也可以通过 Cursor 来搞定,无所不能
5、中间有任何问题,有任何不懂的都可以找 Cursor 使用 ask 模式搞定。
第五阶段:运营维护+推广
分了「优化」「安全」「推广」三个部分来说这个事情。
- 其实到这里是后续的常态,你不要不断的推广你的产品,去增加访问量。
- 另外就是不断的迭代优化你的功能,提升用户体验,加强本身产品的竞争力。
- 最后、最后、最后就是安全,这个不要忘记了,后面我也会加强后,然后去推广下我的产品,安全很重要,提前做好可以更保护你的服务器和大模型的 API-KEY。
分了「优化」「安全」「推广」三个部分来说这个事情。
- 其实到这里是后续的常态,你不要不断的推广你的产品,去增加访问量。
- 另外就是不断的迭代优化你的功能,提升用户体验,加强本身产品的竞争力。
- 最后、最后、最后就是安全,这个不要忘记了,后面我也会加强后,然后去推广下我的产品,安全很重要,提前做好可以更保护你的服务器和大模型的 API-KEY。
优化
这个是上线了后发现的,就是使用手机拍的照片,一般都比较大,这张图片请求后端的时候,数据量比较大,接口超时了。
那么解决办法:
1、增加后端的请求体的大小
2、压缩图片,然后再请求后端接口
这个是上线了后发现的,就是使用手机拍的照片,一般都比较大,这张图片请求后端的时候,数据量比较大,接口超时了。
那么解决办法:
1、增加后端的请求体的大小
2、压缩图片,然后再请求后端接口
安全
其实这里还是蛮重要的,因为你的服务,还有你的大模型的 KEY,如果服务器被攻击是要付出代价的,最重要的是花掉你的钱呀。
所以这块我还在做,目前想的就是让 Cursor 正题 revivew 代码,看下有什么安全隐患,给我一些解决方案。
其实这里还是蛮重要的,因为你的服务,还有你的大模型的 KEY,如果服务器被攻击是要付出代价的,最重要的是花掉你的钱呀。
所以这块我还在做,目前想的就是让 Cursor 正题 revivew 代码,看下有什么安全隐患,给我一些解决方案。
推广
如果你的产品上线后,需要写文章、发小红书去推广,首先从你的种子用户开始,你的微信群,你的朋友圈都是可以的。
后面积极听取用户心声,持续解决痛点需求,满足用户的痛点,产品就会越来越好。
如果你的产品上线后,需要写文章、发小红书去推广,首先从你的种子用户开始,你的微信群,你的朋友圈都是可以的。
后面积极听取用户心声,持续解决痛点需求,满足用户的痛点,产品就会越来越好。
第六阶段:成本计算
时间成本
从开始到结束上线,手机使用正式的域名访问,大概就是整一天的时间,从早上开始,忙到晚上我就开启了测试,晚上搞完还去外面遛弯了一大圈回来的。
我们就算:10 小时
从开始到结束上线,手机使用正式的域名访问,大概就是整一天的时间,从早上开始,忙到晚上我就开启了测试,晚上搞完还去外面遛弯了一大圈回来的。
我们就算:10 小时
人力成本
哈哈哈哈,很清楚,就我一个人
哈哈哈哈,很清楚,就我一个人
软件成本
bolt:20 元优惠包月(海鲜市场),就算正式渠道,20 刀一个月,当然有免费额度,调整不多,基本够用
Cursor:150教育优惠(海鲜市场),就算正式渠道,20 刀一个月,足足够用
域名:32首年
我们就算满的,折算成人民币,也就是 300 块。
想想 300 块一天你就做出来一个系统(前后端+部署),何况软件都是包月的,一个月你可以产出很多东西,不止这个一个系统。
对比公司开发,一个月的成本前后端两个人,毕业生也的上万了吧,何况还是 5 年经验开发的(市面上的抢手货)。
bolt:20 元优惠包月(海鲜市场),就算正式渠道,20 刀一个月,当然有免费额度,调整不多,基本够用
Cursor:150教育优惠(海鲜市场),就算正式渠道,20 刀一个月,足足够用
域名:32首年
我们就算满的,折算成人民币,也就是 300 块。
想想 300 块一天你就做出来一个系统(前后端+部署),何况软件都是包月的,一个月你可以产出很多东西,不止这个一个系统。
对比公司开发,一个月的成本前后端两个人,毕业生也的上万了吧,何况还是 5 年经验开发的(市面上的抢手货)。
总结
能走到这里的,我希望你给自己一个掌声,确实不容易。
我希望你也有可以通过编程来实现自己的想法和创意。
虽然目前编程对于零基础的人来说确实可能会有些吃劲,但是你我差距也不大,我现在遇到了很多在搞 AI 编程的都是程序员,有房地产行业的、也有产品的。
遇事不决,问 AI
我希望你可以记住这句话,自己的创意+基本问题找 AI,你基本就可以解决 99% 的问题,剩下的 1% 你基本遇不到,遇到了,也不要慌,身边这么多牛人总会有人知道。
作者:志辉AI编程
来源:juejin.cn/post/7517496354244067339
能走到这里的,我希望你给自己一个掌声,确实不容易。
我希望你也有可以通过编程来实现自己的想法和创意。
虽然目前编程对于零基础的人来说确实可能会有些吃劲,但是你我差距也不大,我现在遇到了很多在搞 AI 编程的都是程序员,有房地产行业的、也有产品的。
遇事不决,问 AI
我希望你可以记住这句话,自己的创意+基本问题找 AI,你基本就可以解决 99% 的问题,剩下的 1% 你基本遇不到,遇到了,也不要慌,身边这么多牛人总会有人知道。
来源:juejin.cn/post/7517496354244067339
不容易,35岁的我还在小公司苟且偷生
前言
前几天和前同事闲时聚餐,约了两个月的小聚终于达成了,程序员行业聚少离多,所幸大家的发量还坚挺着。
期间不可避免地聊到了自己的公司、行业状况以及对未来的看法,几杯老酒之后,大家畅所欲言,其中一位老哥侃起了他的职业生涯,既坎坷又无奈,饭后想起来挺有代表性的,征得他同意故记录在此。
以下是老哥的历程。

前几天和前同事闲时聚餐,约了两个月的小聚终于达成了,程序员行业聚少离多,所幸大家的发量还坚挺着。
期间不可避免地聊到了自己的公司、行业状况以及对未来的看法,几杯老酒之后,大家畅所欲言,其中一位老哥侃起了他的职业生涯,既坎坷又无奈,饭后想起来挺有代表性的,征得他同意故记录在此。
以下是老哥的历程。
程序员的前半生
我今年35岁,有房有贷有妻女有老父母。
出生在90年代的农村,从小中规中矩,不惹事不喧哗不突出,三好学生没有我,德智体美没有全面发展。学习也算努力,不算小题做题家,因为只考了个本科。
大学学费全靠助学带款,勤工俭学补贴日用,埋头苦干成绩也只在年级中等偏下水平。有些同学早早就定下了大学的目标,比如考研、比如出国、比如考公,到了大三的时候大家基本都有了自己的目标。而我的目标就是尽早工作,争取早日还完带款,因此早早就开始准备找工作。
也许是上天眷顾,不知道怎么就被华为看重了(那会华为还没现在的如日中天,彼时是BAT的天下),稀里糊涂的接受了offer,没想到却是改变了后面十年的决定。
2013年,深圳的夏天阳光明媚,热气扑鼻,提着一个简单的箱子进入了坂田基地。
刚开始,工作上的一切都很新鲜,每个人都在忙碌,虽然不知道他们在忙什么,但感觉很高级的样子。同期入职的同事都比较厉害,很快就适应了工作,而自己还是没完全应对工作内容,于是下班之后继续留在公司学习,顺便蹭饭。
就这样,很快就一年过去了,自己也慢慢熟悉了工作节奏,但是加班也越来越多了。对于自己来说,为了过节点,6点是晚饭时间,9点是下班时间,12点正式下班。
平凡的日子没什么值得留恋,过一天、一个月、一年、四年都没什么两样,四年里学习到了不少的知识,也数了很多次深圳凌晨的路灯数。
作为深漂,没有遇到深圳爱情故事,也对高昂的房价绝望,于是决定回到二线城市,成为一名蓉漂。 2017年,还是和四年前一样的行李箱,出现在了老家的省会城市,只是那时的我没有了助学打款,怀里也攒下了一些血汗钱。
那时互联网行业发展还是如火如荼,前端的需求量也很大,也得益于华为公司发展越来越好,自己的华为经历很快就拿到了几个offer,选了一家初创公司,幻想着能有一番成就。
2018年底,眼看着房价越长越高,某链中介不断地灌输再不买明天就是另一个价了,错过这个村就没这个店了,也许是想有个家,也许是想着父母能到省会里一起住,拿出自己做牛马几年的积蓄加上父母一辈子辛苦攒的小十万的养老钱购买了城区里的新房,那会儿的价格已经比前两年涨了一倍多,妥妥的高位站岗,不过想着自己是刚需也不会卖,因此咬咬牙掏出了全部的积蓄怒而背上了三十年的房贷。
房子的事暂时落定了,全身心的投入到工作中,没想到老板只想骗投资人的钱,产品没弄好投资人不愿跟进了,坚持了三年,期间各种断臂求生,最终还是落了个司破人走的境地。
2020年,30岁的我第一次被动失业了,幸运的是也找到了另一半。为了尽可能节省支出,房子装修的事我们都是亲力亲为,最后花了十多万终于将房子装好了,虽然很简单但毕竟是自己在大城市里的第一套房子,那一刻,感觉十年的付出都是值得的。
背着沉重的房贷,期望能找到一份薪资稍微过得去的工作,于是在简历上优势那行写了:“可加班”。依稀记得有些HR对我进行了灵魂拷问:结婚了吗?有小孩了吗?你都30岁了还能加班吗?。我斩钉截铁地说:只要公司有需要,我定会全力以赴!
2022年,我们的孩子出世了,队友辞去了工作全心全意带小孩,而我更加努力了,毕竟有了四脚吞金兽,不得不肝。
虽然工作很努力,但成果一般,不是公司的技术担当,也不会是技术洼地。
2023年的某一天,和之前的364天一样的平淡,在座位上解Bug的我突然感觉到一阵心悸,呼吸不畅,实在不行了呼唤同事叫了120,去医院一套检查下来没发现什么大问题。医生询问是不是工作压力太大,平时加班很多?我说还好,平时也就加班到9点。医生笑了笑说你这种年轻人我见多了,都是压力大的毛病,平时工作不要久坐盯着屏幕多站起来走走。他让我回家多休息,回去后观察了几天还是偶尔会有心悸,再去了另一个医院进行检查,也是没有明确的诊断结果,只是说可能是这个问题,又可能是另一个问题。
过了1个月后,身体上的问题不见好转,我辞去了工作。
2023年末,找了一家小公司,也就是我现在的公司,工资没有涨,仔细算起来还变相下降了。
还是做的业务需求,也没有领导什么人,管好自己就行,直属上级还是个工作几年的小伙。这家公司主要的特点是不加班,技术难度不高,能做多少就是多少,前提是要报风险,领导也不会强迫加班。
就这样到了2024,神奇的是我已经很久没有心悸的感觉了,不知道是不加班还是心态转变的原因。 家里的小朋友也长大了,会说话了。我现在每天下班最温馨的的是她开着门期待我回家的那一刻,她的期盼的眼神就是我回家的动力。
公司在2024年也裁了不少人,领导也找我谈过问问我的想法,我说:我还是能胜任这份工作的。领导说:公司觉得你年级大了一些,工资虽然不是最高,但不太符合行情,你懂的。我说:我懂,可以接受适当的降薪。 就这样,我挺过了2024,然而过了一周领导走了。
2025年,我35周岁了。 现在的我已经彻底接受自己的平庸的事实了。在学生时代,从来都不出色,也不会垫底,就是那类最容易被忽略的人。在工作时代,不是技术大牛,也不是完全的水货,就是普普通通的程序员。
如果说上半生吃到了什么红利,只能说入坑了计算机这行业,技术给我带了收入,有了糊口的基础。没进股市,却被房价狠狠割了一道。
35岁的我,没有彻底躺平摆烂,也没有足够奋发进取。
35岁的我,有着24年的房贷,还好61岁的时候我还在工作,应该还能还房贷。
35岁的我,不吃海鲜不喝酒,尿酸500+。
35岁的我,人体工学椅也挽救不了腰椎间盘突出。
35岁的我,头发依然浓密,只是白发越来越多。
35岁的我,已经不打游戏,只是会看这各种小说聊以慰藉。
35岁的我,两点一线,每天挤着地铁,看众生百态。
35岁的我,早睡早起,放空自己。
35岁的我,暂时还没有领取毕业大礼包,希望今年还能苟过。
35岁的我,希望经济能够好起来,让如我一般平凡的人能够有活下去的勇气。
诸君,下一年再会~祝你平安喜乐,万事顺遂!
太极分两仪,有程序员也有程序媛:30岁的程序媛,升值加薪与我无缘
作者:小鱼人爱编程
来源:juejin.cn/post/7457567782470385705
我今年35岁,有房有贷有妻女有老父母。
出生在90年代的农村,从小中规中矩,不惹事不喧哗不突出,三好学生没有我,德智体美没有全面发展。学习也算努力,不算小题做题家,因为只考了个本科。
大学学费全靠助学带款,勤工俭学补贴日用,埋头苦干成绩也只在年级中等偏下水平。有些同学早早就定下了大学的目标,比如考研、比如出国、比如考公,到了大三的时候大家基本都有了自己的目标。而我的目标就是尽早工作,争取早日还完带款,因此早早就开始准备找工作。
也许是上天眷顾,不知道怎么就被华为看重了(那会华为还没现在的如日中天,彼时是BAT的天下),稀里糊涂的接受了offer,没想到却是改变了后面十年的决定。
2013年,深圳的夏天阳光明媚,热气扑鼻,提着一个简单的箱子进入了坂田基地。
刚开始,工作上的一切都很新鲜,每个人都在忙碌,虽然不知道他们在忙什么,但感觉很高级的样子。同期入职的同事都比较厉害,很快就适应了工作,而自己还是没完全应对工作内容,于是下班之后继续留在公司学习,顺便蹭饭。
就这样,很快就一年过去了,自己也慢慢熟悉了工作节奏,但是加班也越来越多了。对于自己来说,为了过节点,6点是晚饭时间,9点是下班时间,12点正式下班。
平凡的日子没什么值得留恋,过一天、一个月、一年、四年都没什么两样,四年里学习到了不少的知识,也数了很多次深圳凌晨的路灯数。
作为深漂,没有遇到深圳爱情故事,也对高昂的房价绝望,于是决定回到二线城市,成为一名蓉漂。 2017年,还是和四年前一样的行李箱,出现在了老家的省会城市,只是那时的我没有了助学打款,怀里也攒下了一些血汗钱。
那时互联网行业发展还是如火如荼,前端的需求量也很大,也得益于华为公司发展越来越好,自己的华为经历很快就拿到了几个offer,选了一家初创公司,幻想着能有一番成就。
2018年底,眼看着房价越长越高,某链中介不断地灌输再不买明天就是另一个价了,错过这个村就没这个店了,也许是想有个家,也许是想着父母能到省会里一起住,拿出自己做牛马几年的积蓄加上父母一辈子辛苦攒的小十万的养老钱购买了城区里的新房,那会儿的价格已经比前两年涨了一倍多,妥妥的高位站岗,不过想着自己是刚需也不会卖,因此咬咬牙掏出了全部的积蓄怒而背上了三十年的房贷。
房子的事暂时落定了,全身心的投入到工作中,没想到老板只想骗投资人的钱,产品没弄好投资人不愿跟进了,坚持了三年,期间各种断臂求生,最终还是落了个司破人走的境地。
2020年,30岁的我第一次被动失业了,幸运的是也找到了另一半。为了尽可能节省支出,房子装修的事我们都是亲力亲为,最后花了十多万终于将房子装好了,虽然很简单但毕竟是自己在大城市里的第一套房子,那一刻,感觉十年的付出都是值得的。
背着沉重的房贷,期望能找到一份薪资稍微过得去的工作,于是在简历上优势那行写了:“可加班”。依稀记得有些HR对我进行了灵魂拷问:结婚了吗?有小孩了吗?你都30岁了还能加班吗?。我斩钉截铁地说:只要公司有需要,我定会全力以赴!
2022年,我们的孩子出世了,队友辞去了工作全心全意带小孩,而我更加努力了,毕竟有了四脚吞金兽,不得不肝。
虽然工作很努力,但成果一般,不是公司的技术担当,也不会是技术洼地。
2023年的某一天,和之前的364天一样的平淡,在座位上解Bug的我突然感觉到一阵心悸,呼吸不畅,实在不行了呼唤同事叫了120,去医院一套检查下来没发现什么大问题。医生询问是不是工作压力太大,平时加班很多?我说还好,平时也就加班到9点。医生笑了笑说你这种年轻人我见多了,都是压力大的毛病,平时工作不要久坐盯着屏幕多站起来走走。他让我回家多休息,回去后观察了几天还是偶尔会有心悸,再去了另一个医院进行检查,也是没有明确的诊断结果,只是说可能是这个问题,又可能是另一个问题。
过了1个月后,身体上的问题不见好转,我辞去了工作。
2023年末,找了一家小公司,也就是我现在的公司,工资没有涨,仔细算起来还变相下降了。
还是做的业务需求,也没有领导什么人,管好自己就行,直属上级还是个工作几年的小伙。这家公司主要的特点是不加班,技术难度不高,能做多少就是多少,前提是要报风险,领导也不会强迫加班。
就这样到了2024,神奇的是我已经很久没有心悸的感觉了,不知道是不加班还是心态转变的原因。 家里的小朋友也长大了,会说话了。我现在每天下班最温馨的的是她开着门期待我回家的那一刻,她的期盼的眼神就是我回家的动力。
公司在2024年也裁了不少人,领导也找我谈过问问我的想法,我说:我还是能胜任这份工作的。领导说:公司觉得你年级大了一些,工资虽然不是最高,但不太符合行情,你懂的。我说:我懂,可以接受适当的降薪。 就这样,我挺过了2024,然而过了一周领导走了。
2025年,我35周岁了。 现在的我已经彻底接受自己的平庸的事实了。在学生时代,从来都不出色,也不会垫底,就是那类最容易被忽略的人。在工作时代,不是技术大牛,也不是完全的水货,就是普普通通的程序员。
如果说上半生吃到了什么红利,只能说入坑了计算机这行业,技术给我带了收入,有了糊口的基础。没进股市,却被房价狠狠割了一道。
35岁的我,没有彻底躺平摆烂,也没有足够奋发进取。
35岁的我,有着24年的房贷,还好61岁的时候我还在工作,应该还能还房贷。
35岁的我,不吃海鲜不喝酒,尿酸500+。
35岁的我,人体工学椅也挽救不了腰椎间盘突出。
35岁的我,头发依然浓密,只是白发越来越多。
35岁的我,已经不打游戏,只是会看这各种小说聊以慰藉。
35岁的我,两点一线,每天挤着地铁,看众生百态。
35岁的我,早睡早起,放空自己。
35岁的我,暂时还没有领取毕业大礼包,希望今年还能苟过。
35岁的我,希望经济能够好起来,让如我一般平凡的人能够有活下去的勇气。
诸君,下一年再会~祝你平安喜乐,万事顺遂!
太极分两仪,有程序员也有程序媛:30岁的程序媛,升值加薪与我无缘
来源:juejin.cn/post/7457567782470385705
编辑器也有邪修?盘点VS Code邪门/有趣的扩展
VS Code 之所以成为最受欢迎的编辑器之一,很大程度上得益于其丰富的扩展生态。本人精选 20 个实用or有趣的 VS Code 扩展,覆盖摸鱼放松,文件管理、代码规范、效率工具等等多个场景,干货满满,下面正片开始:
1 看小说漫画:any-reader
- 核心功能: 在 VS Code 中阅读小说、文档,支持 TXT/EPUB 格式、章节导航、字体调整。
- 适用场景:利用碎片时间阅读技术文档或轻小说,避免频繁切换应用。
- 隐藏技巧:支持自定义快捷键翻页,可设置阅读定时提醒。
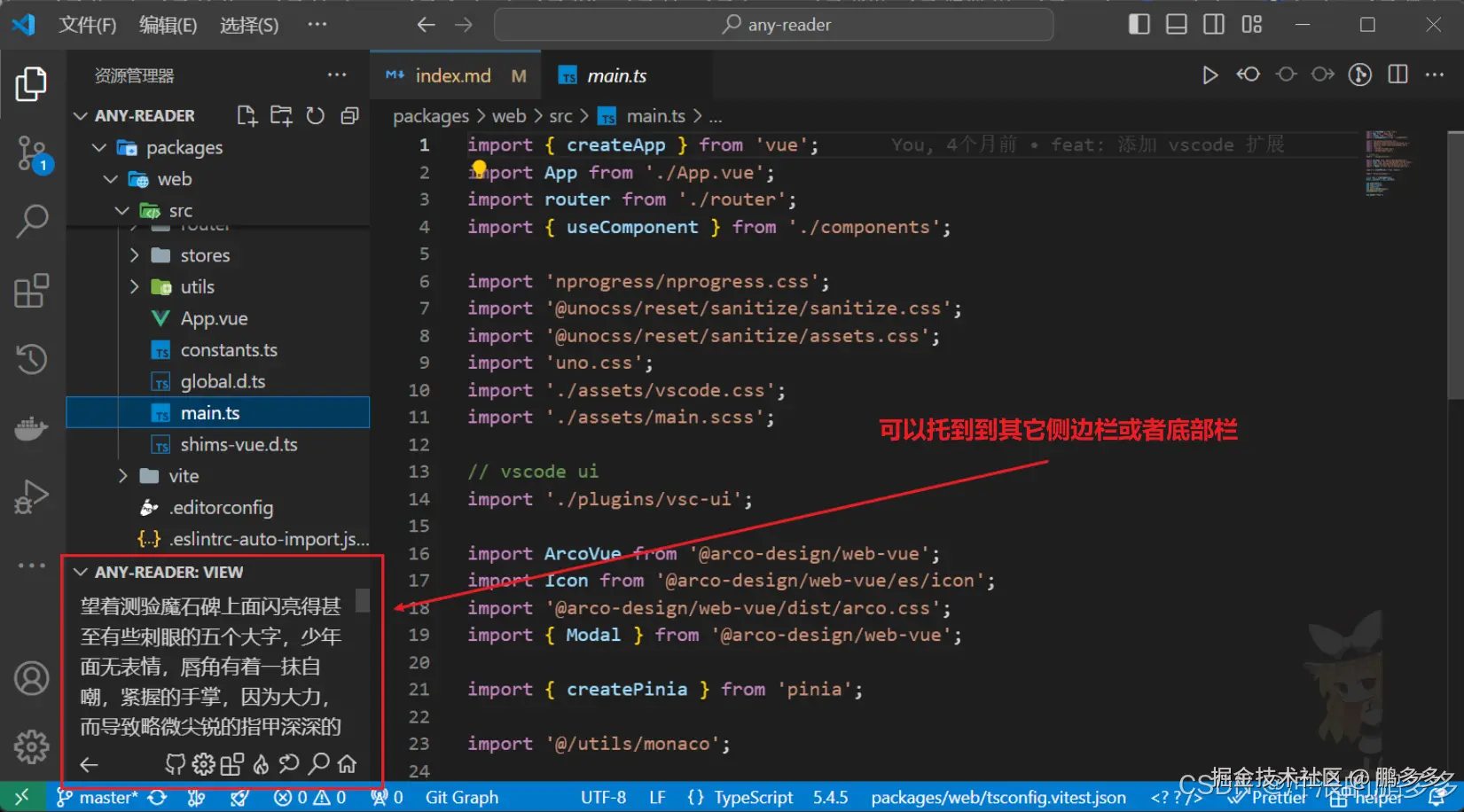
2 偷偷在状态栏看小说:Thief-Book
- 核心功能:在状态栏显示小说,支持阅读进度。
- 适用场景:利用碎片时间阅读技术文档或轻小说,避免频繁切换应用。
- 隐藏技巧:支持快捷键翻页。

3 看股票基金期货:韭菜盒子
- 核心功能:
- 基金实时涨跌,实时数据,支持海外基展示
- 股票实时涨跌,支持 A 股、港股、美股
- 期货实时涨跌,支持国内期货
- 底部状态栏信息
- 开市自动刷新,节假日关闭轮询
- 支持升序/降序排序、基金持仓金额升序/降序
- 基金实时走势图和历史走势图
- 基金排行榜
- 基金持仓信息
- 支持维护持仓成本价,自动计算收益率
- 基金趋势统计图
- 基金支持分组展示等等...
- 注意:投资有风险,入市需谨慎!
4 小霸王
- 核心功能:一款基于vscode的nes游戏插件,主打本地与远程游戏资源管理,让你在编辑器内就能完成游戏的添加、下载、启动全流程。
- 不建议上班玩哈!
5. JSON 变可视化树图:JSON Crack
- 核心功能:将 JSON 数据转换为交互式树状可视化图表,支持折叠/展开节点、搜索内容。
- 适用场景:分析复杂 JSON 结构(如 API 响应、配置文件)、快速定位数据层级。
- 优势:比原生 JSON 格式化更直观,支持大体积 JSON 数据渲染。
6. 改变工作区的颜色来快速识别当前项目:Peacock
- 核心功能:为不同工作区设置独特的颜色主题(标题栏、活动栏颜色),快速区分多个 VS Code 窗口。
- 适用场景:同时打开多个项目时,通过颜色直观识别当前操作的项目(如生产环境项目用红色,测试环境用绿色)。
- 个性化选项:支持按项目自动切换颜色,可自定义颜色饱和度和亮度。
7. 编码时长统计:Time Master
- 核心功能:自动记录代码编写时间、文件修改统计,生成每日/每周编程报告,分析编码效率。
- 适用场景:跟踪项目开发时间、了解自己的编码习惯、评估任务耗时。
- 特色:支持集成到 VS Code 状态栏实时显示当前编码时长,数据本地存储保护隐私。
8. 生成文件夹树结构:file-tree-generator
- 核心功能:一键生成项目文件夹结构并复制为文本,支持自定义忽略文件和格式。
- 适用场景:编写 README 文档、项目说明时快速插入目录结构,或向团队展示项目架构。
- 使用技巧:右键文件夹选择「Generate File Tree」,可通过配置文件自定义输出格式。
9. 轻松切换项目:Project Manager
- 核心功能:快速保存和切换多个项目,支持按标签分类、搜索项目,无需反复通过文件管理器打开文件夹。
- 适用场景:同时开发多个项目时,减少切换成本;整理常用项目集合。
- 特色功能:支持从 Git 仓库、本地文件夹导入项目,可配置项目启动命令。
10. 将文件保存到本地历史记录:Local History
- 核心功能:自动为文件创建本地历史版本,支持对比不同版本差异、恢复误删内容。
- 适用场景:防止代码意外丢失、追踪文件修改记录、找回被覆盖的代码。
- 优势:无需依赖 Git,即使未提交的更改也能保存,历史记录默认保留 90 天。
11. 生成文件头部注释和函数注释:koroFileHeader
- 核心功能:自动生成文件头部注释(作者、日期、描述等)和函数注释,支持自定义注释模板。
- 适用场景:统一团队代码注释规范,快速生成符合 JSDoc、JavaDoc 等标准的注释。
- 高级用法:通过配置文件定义不同语言的注释模板,支持快捷键触发(默认
Ctrl+Alt+i生成函数注释)。
12. 复制 JSON 粘贴为代码:Paste JSON as Code
- 核心功能:将 JSON 数据粘贴为指定语言的类型定义或实体类(支持 TypeScript、Go、C#、Python 等 20+ 语言)。
- 适用场景:根据 API 返回的 JSON 结构快速生成接口类型定义,避免手动编写类型。
- 使用技巧:复制 JSON 后执行命令「Paste JSON as Code」,选择目标语言和变量名即可生成代码。
13. 把代码块框起来:Blockman - Highlight Nested Code Blocks
- 核心功能:用彩色边框高亮嵌套的代码块(如函数、循环、条件语句),直观区分代码层级。
- 适用场景:阅读复杂代码、调试嵌套逻辑时,快速定位代码块边界。
- 特色:支持自定义边框样式、透明度和颜色,兼容大多数代码主题。

14. SVG 预览和编辑:SVG Preview
- 核心功能:在 VS Code 中实时预览 SVG 图片,支持直接编辑 SVG 代码并即时查看效果。
- 适用场景:前端开发中处理 SVG 图标、调整 SVG 路径、优化 SVG 代码。
- 特色:支持放大缩小预览、复制 SVG 代码,兼容大多数 SVG 特性。
15. 程序员鼓励师:Rainbow Fart
- 核心功能:在编码过程中根据输入的关键字触发语音赞美,例如输入 function 时播放 “写得真棒!”,输入 if 时播放 “逻辑清晰,太厉害了!”。支持多语言语音包(中文、英文等),赞美内容与代码语境关联。
- 适用场景:单人开发时缓解编码疲劳,增添趣味性;团队协作时活跃开发氛围;新手学习编程时获得正向反馈。
- 高级功能:支持自定义语音包(可录制个人或团队专属鼓励语音)、配置触发关键字规则、调整音量和触发频率,兼容多种编程语言。
- 文档:传送门
16. 命名风格转换:Name Transform
- 核心功能:一键转换变量名、函数名的命名风格,支持 camelCase(小驼峰)、PascalCase(大驼峰)、snake_case(下划线)、kebab-case(短横线)等常见格式的相互转换。
- 适用场景:接手不同风格的代码时统一命名规范;调用第三方 API 时适配参数命名格式;重构代码时批量修改命名风格。
- 高级功能:支持选中区域批量转换、配置默认转换规则、自定义命名风格映射表,可集成到右键菜单或快捷键(默认 Alt+Shift+T)快速触发。
17. 代码拼写检查器:Code Spell Checker
- 核心功能:实时检查代码中的单词拼写错误(如变量名、注释、字符串中的英文单词),通过下划线标记错误,并提供修正建议。
- 适用场景:避免因拼写错误导致的 Bug(如变量名拼写错误 usre 而非 user);优化代码注释和文档的可读性;英文非母语开发者提升代码规范性。
- 高级功能:支持添加自定义词典(忽略项目专属术语或缩写)、配置语言规则(支持英语、法语等多语言)、批量修复重复拼写错误,可集成到 CI/CD 流程中进行拼写检查。
18. 自动修改标签名:Auto Rename Tag
- 核心功能:在 HTML、XML、JSX、Vue 等标记语言中,修改开始标签时自动同步更新对应的结束标签,无需手动修改配对标签。
- 适用场景:前端开发中修改 HTML/JSX 标签(如将改为 时,结束标签自动变为 );编辑 XML 配置文件或 Vue 模板时避免标签不匹配问题。
- 高级功能:支持自定义匹配的标签语言(默认覆盖 HTML、Vue、React 等)、配置标签同步延迟时间、忽略自闭合标签,兼容嵌套标签结构。
19. 快速调试打印:Console Helper
- 核心功能:一键生成格式化的调试打印语句(如 console.log()、console.error()),自动填充变量名和上下文信息,支持快捷键快速插入。
- 适用场景:前端开发中快速添加调试日志;后端开发调试变量值或函数执行流程;临时排查代码逻辑问题时减少重复输入。
- 高级功能:支持自定义打印模板(如添加时间戳、文件名、行号)、一键注释 / 取消所有打印语句、自动删除冗余打印,兼容 JavaScript、TypeScript、Python 等多种语言。
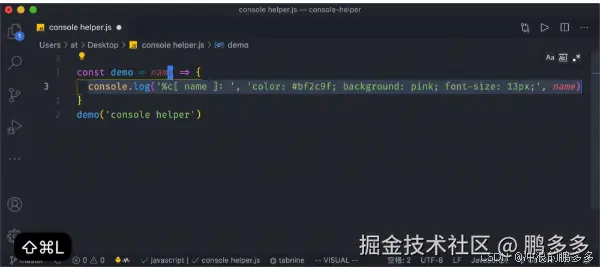
20. 彩虹括号:Rainbow Brackets
- 核心功能:为嵌套的括号(圆括号、方括号、花括号)添加不同颜色,增强代码层次感。
- 适用场景:编写嵌套较深的代码(如 JSON 结构、条件语句、函数嵌套)时,快速识别括号配对关系。
- 自定义选项:支持调整颜色主题、忽略特定文件类型、配置括号样式。

如果看了觉得有帮助的,我是鹏多多,欢迎 点赞 关注 评论;
往期文章
- flutter-使用AnimatedDefaultTextStyle实现文本动画
- js使用IntersectionObserver实现目标元素可见度的交互
- Web前端页面开发阿拉伯语种适配指南
- 让网页拥有App体验?PWA 将网页变为桌面应用的保姆级教程PWA
- 助你上手Vue3全家桶之Vue3教程
- 使用nvm管理node.js版本以及更换npm淘宝镜像源
- 超详细!Vue的十种通信方式
- 手把手教你搭建规范的团队vue项目,包含commitlint,eslint,prettier,husky,commitizen等等
个人主页
来源:juejin.cn/post/7536530451461472265
看了下昨日泄露的苹果 App Store 源码……
新闻
昨日苹果 App Store 前端源码泄露,因其生产环境忘记关闭 Sourcemap,被用户下载了源码,上传到 Github。
目前已经 Fork 和 Star 超 5k:
如果你想要第一时间知道前端资讯,欢迎关注公众号:冴羽
昨日苹果 App Store 前端源码泄露,因其生产环境忘记关闭 Sourcemap,被用户下载了源码,上传到 Github。
目前已经 Fork 和 Star 超 5k:
如果你想要第一时间知道前端资讯,欢迎关注公众号:冴羽
用户如何抓取的源码?
用户 rxliuli 使用 Chrome 插件 Save All Resources 将代码下载了下来。
插件地址为:chromewebstore.google.com/detail/save…
下次你也可以打包下载源码了~
用户 rxliuli 使用 Chrome 插件 Save All Resources 将代码下载了下来。
插件地址为:chromewebstore.google.com/detail/save…
下次你也可以打包下载源码了~
如何看待源码泄露?
其实前端源码泄露对业务本身并没有什么影响,因为前端代码无论是否压缩还是混淆,最终都需传输到浏览器才能运行,本身就具有 “暴露” 属性,SourceMap 只是让代码更易读,更容易调试。
尽管如此,依然不建议在生产环境开启 SourceMap,对普通用户无益,且存在轻微性能开销和源代码暴露的安全风险。
我大致看了下代码,并没有什么密钥之类的信息,所以干点坏事之类的就不用想了。真正有价值的核心代码比如推荐逻辑还是在服务端。
其实前端源码泄露对业务本身并没有什么影响,因为前端代码无论是否压缩还是混淆,最终都需传输到浏览器才能运行,本身就具有 “暴露” 属性,SourceMap 只是让代码更易读,更容易调试。
尽管如此,依然不建议在生产环境开启 SourceMap,对普通用户无益,且存在轻微性能开销和源代码暴露的安全风险。
我大致看了下代码,并没有什么密钥之类的信息,所以干点坏事之类的就不用想了。真正有价值的核心代码比如推荐逻辑还是在服务端。
代码使用 Svelte?
我万万没想到,项目使用的是 Svelte。
Svelte 我自然是很熟的,毕竟我翻译过 Svelte 官网:svelte.yayujs.com/

还写了一本掘金小册《Svelte 开发指南》:s.juejin.cn/ds/QNzfZ4eq…
想一想,使用 Svelte 也在情理之中。
因为 Svelte 就非常适合处理这种页面相对简单、业务逻辑并不复杂的页面。
在实现上 ,与其说 Svelte 是框架,不如说 Svelte 是一个编译器。 它会在构建时就会将代码编译为高效的 JavaScript 代码,因此能够实现高性能的 Web 应用。
Svelte 的核心优势在于:
- 轻量级:核心库只有 3 KB,非常适合开发轻量级项目
- 高性能:构建时优化,而且不使用虚拟 DOM,减少了内存占用和开销,性能更高
- 易上手:学习曲线小,入门门槛低,语法简洁易懂
简而言之,Svelte 非常适合构建轻量级 Web 项目,也是本人做个人项目的首选技术栈。
以后大家如果要做相对简单的项目,又有性能上的追求(比如 KPI),那就可以考虑使用 Svelte。
我万万没想到,项目使用的是 Svelte。
Svelte 我自然是很熟的,毕竟我翻译过 Svelte 官网:svelte.yayujs.com/
还写了一本掘金小册《Svelte 开发指南》:s.juejin.cn/ds/QNzfZ4eq…
想一想,使用 Svelte 也在情理之中。
因为 Svelte 就非常适合处理这种页面相对简单、业务逻辑并不复杂的页面。
在实现上 ,与其说 Svelte 是框架,不如说 Svelte 是一个编译器。 它会在构建时就会将代码编译为高效的 JavaScript 代码,因此能够实现高性能的 Web 应用。
Svelte 的核心优势在于:
- 轻量级:核心库只有 3 KB,非常适合开发轻量级项目
- 高性能:构建时优化,而且不使用虚拟 DOM,减少了内存占用和开销,性能更高
- 易上手:学习曲线小,入门门槛低,语法简洁易懂
简而言之,Svelte 非常适合构建轻量级 Web 项目,也是本人做个人项目的首选技术栈。
以后大家如果要做相对简单的项目,又有性能上的追求(比如 KPI),那就可以考虑使用 Svelte。
用它作为示例学 Svelte ?
我看了下代码,项目代码还是 Svelte 4,而 Svelte 已经到 5 了,Svelte 4 和 5 不论是底层架构还是基础语法都发生了很大的变化,其变化的剧烈程度类似于 Next.js 12 升 Next.js 13,所以想通过这个项目学习 Svelte 就不用想了,都是些过时的语法了,不如直接学 Svelte 5。
作者:冴羽
来源:juejin.cn/post/7569057572436607014
我看了下代码,项目代码还是 Svelte 4,而 Svelte 已经到 5 了,Svelte 4 和 5 不论是底层架构还是基础语法都发生了很大的变化,其变化的剧烈程度类似于 Next.js 12 升 Next.js 13,所以想通过这个项目学习 Svelte 就不用想了,都是些过时的语法了,不如直接学 Svelte 5。
来源:juejin.cn/post/7569057572436607014
当你的Ant-Design成了你最大的技术债

大家好😁
如果你是一个前端,尤其是在B端(中后台)领域,Ant Design(antd)这个名字,你不可能没听过。
在过去的5年里,我们团队的所有新项目,技术选型里的第一行,永远是antd。它专业、开箱即用、文档齐全,拥有一切你想要的组件, 帮我们这些小团队,一夜之间就拥有了大厂的专业门面。
我们靠它,快速地交付了一个又一个项目。
但是,从去年开始,我发现,这个曾经的经典,正在变成我们团队脖子上最重的枷锁。
Ant Design,这个我们当初用来解决技术债的核心组件库,现在,却成了我们最大的技术债本身😖。
这是一篇团队血泪史, 讲一讲感想🤷♂️。
我们为什么会爱上 AntD?
我们必须承认,从无到有阶段,antd是无敌的。
你一个3人的小团队,用上antd,做出来的东西,看起来和阿里几百人团队做的系统,没什么区别。
Table、Form、Modal、Menu... 你需要的一切,它都以一种极其标准的方式给你了。你不再需要自己造轮子。
当你发现@ant-design/pro-components时,一个ProTable,直接帮你搞定了请求、分页、查询表单、工具栏... 你甚至都不用写useState了。
在那个阶段,我们以为我们找到了大结局。
当个性化成为 我们的 KPI
美好可能是短暂的,从我们的产品经理和UI设计师开始👇:
能不能...不要长得这么 Ant Design?🤣
这是我们设计师,在评审会上,小心翼翼提出来的第一句话。
老板也说:我们要做自己的品牌,现在的系统,太千篇一律了!!!
于是,我们接到了第一个简单的需求:把全局的主题色,从橙色改成我们的品牌红。
这很简单,不就是 ConfigProvider嘛🤔。我们改了。
然后,第二个需求来了:这个Modal弹窗的关闭按钮,能不能不要放在右上角?我们要放在左下角,和确认按钮放在一起。(有点反人类🤷♂️)
灾难,就从这里开始了。
antd的Modal组件,根本就没提供这个插槽或prop。我们唯一的办法,是 强改。
于是,我们的代码里,开始出现这种恶臭的CSS:
/* 一个高权重的全局CSS文件 */
.ant-modal-header {
/* ... */
}
/* 嘿,那个右上角的关闭按钮,给我藏起来! */
.ant-modal-close-x {
display: none !important;
}
为了把那个 X 藏起来,我们用了!important。我们亲手打开了潘多拉魔盒。
这个表格的筛选图标,能换成我们自己画的吗?😖
antd的Table,是一个重灾区。它太强大了,也很黑盒。
我们设计师,重新画了一套筛选、排序的图标。但我们发现,antd的Table组件,根本没想过让你换这个。
我们唯一的办法,就是用 CSS选择器,一层一层地穿进antd的DOM结构里,找到那个,然后用background-image去盖掉它。
/* 另一个人写的,更恶臭的CSS */
.ant-table-thead > tr > th.ant-table-column-has-filters .ant-table-filter-trigger {
/* 妈呀,这是啥? */
background: url('our-own-icon.svg') !important;
}
.ant-table-thead > tr > th.ant-table-column-has-filters .ant-table-filter-trigger > svg {
/* 藏起来,藏起来! */
display: none !important;
}
我们被拖累了。
我们花在 覆盖antd默认样式上的时间,已经远远超过了我们自己写一个组件的时间。
压死骆驼的最后一根稻草
我们用了ProTable,它的查询表单和表格是强耦合的。当产品经理提出一个我希望查询表单,在页面滚动时,吸附在顶部的需求时... 我们发现,我们改不动。我们被ProComponents的黑盒,锁死了。
然后我们的vendor.js打包出来,2.5MB。用webpack-bundle-analyzer一看,antd和@ant-design/icons,占了1.2MB。我们为了一个Button和Icon,引入了一个全家桶。antd的按需加载?别闹了,在ProComponents面前,它几乎是全量的。
而且 antd从v3到v4,我们花了一个月。从v4到v5,我们花了半个月。每一次升级,都是一次大型重构,因为我们那些写法一样被CSS覆盖,在新版里,全失效了🤷♂️。
我们本想找一个可靠的组件库,这么久过来,结果它成了债主。
我们真正需要的可能是轮子
我终于想明白了。
Ant Design,它不是一个组件库(Library),它是一个UI框架(Framework)。它是一套解决方案,它有它自己强势的 设计价值观。
当你的需求,和它的价值观一致时,它就是圣经。 当你的需求,和它的价值观不一致时,它就变成枷锁。
我们当初要的,其实是一个带样式的Button;而antd给我的,是一个内置了loading、disabled、onClick时会有水波纹动画、并且必须是蓝色或白色的Button。
我们的自救之路
在我们新的项目中,我忍痛做出了一个决定🤷♂️:
原则上,不再使用antd。
我们新的技术栈,转向了: Tailwind CSS + Headless UI 方案(比如Radix UI)
这个组合,才是我们想要的:
Headless UI:它只提供功能和无障碍。比如,一个Dialog(模态框),它帮我搞定了按Esc关闭、焦点管理。但它没有任何样式。Tailwind CSS:我拿到了这个无样式的Dialog,然后用Tailwind的class,在5分钟内,在AI的帮助下,把它拼成了我们设计师想要的、独一无二的弹窗。
我们拿回了CSS的完全控制权,同时又享受了 AI + 组件开发的便利。
我依然尊敬Ant Design,它在前端B端历史上,是个丰碑。 对于那些从0到1的、对UI没有要求的内部系统,我可能依然会用它。
但对于那些需要品牌、体验、个性化的核心产品,我必须和它说再见了。

因为,当你的组件库开始控制你的设计和性能时,它就不是你的资产了。
而变成你最大的技术债🙌。
来源:juejin.cn/post/7571176484515659828
我是如何将手动的日报完全自动化的☺️☺️☺️
书接上回,上回我们聊了处理重复任务的自动化思维。
其中,我举了用工具自动化公司日报的例子。
今天,我就来详细说说,我到底是怎么做的,以及过程中遇到了哪些问题和挑战。
背景
我们公司使用某第三方系统有一个自定义的数据看板,每天需要向群里发送日报。之前,这项工作由团队成员轮流手动完成:从系统的一个自定义看板复制数据到 Excel,再将表格转为图片,发到群里。
轮到我负责的那一周,我左手边电脑打开系统,右手边打开 Excel,一个个数据复制过去,3.4%、-10%……为避免出错,还要逐一核对。整个过程每天耗时大约 7 到 10 分钟,繁琐又枯燥。
我开始思考:这种重复性工作能不能自动化?
于是,我在群里向大佬们请教,提出了这个问题:

结果,消息已读,没有一个人回复。
那一刻,我暗下决心:我要自己解决这个问题!
初探
于是乎我打开了改系统,开始研究。
该系统大概长这样, 这是一个自定义看板,后台自定义配置出来的,数据是根据配置的规则算出来的,有十几项,我们是需要从每项取3个数据。加起来复制30-40次。
- 手动复制效率低下。
- 浪费时间。
- 容易出错,粘错位置了,又得一个个重新对一遍。
所以我第一步是需要把手动复制拿数据的这个过程,利用脚本自动化了。
流程与任务拆解
我们的思路是这样,先脑子里过一下原来的流程,然后一步步自动化原来的流程。
1、原来手动的流程
- 手动登录系统
- 点击对应面板,一个个复制数据,粘贴到excel里。
- 全部复制完,核对完,右键复制为图片
- 发送到群里。
2、脚本任务拆解
- js逆向登录加密方法,自动化登录,拿到token。
- 利用爬虫抓取数据,拿到我需要的。
- 利用canvas将数据画成表格,然后转成图片。
- 图片传到oss,调用钉钉webhook接口,定时发送到群里
以上我们已经将,手动的流程的任务与自动化需要做的任务一一对应了。
现在我们思路清晰了。
然后我们要做的就是把每个任务逐个攻克即可。
任务分步实现
你不觉得我应该先完成第一个任务——JS 逆向登录加密方法,实现自动化登录并获取 token 吗?
这确实是全自动流程中最核心的一环:没有自动登录获取凭证,后续的数据抓取和操作根本无从谈起。
不过,我初步分析了登录接口,发现参数加密逻辑较复杂,短时间内难以破解。
于是我选择暂时跳过,先手动复制登录凭证,确保后续流程全部打通后再回过头补全自动化登录部分。
1、利用爬虫抓取数据。
首先看板这是个列表,有很多项内容,首先看这个列表怎么来的,服务端渲染还是,调的接口。
然后看能不能完全从页面拿到,我们再考虑抓取方式。
1、如果是服务端渲染的或者数据很快出来的。我们可以考虑抓页面。
2、但是今天这个例子,经过我的研究,我需要的数据,都是异步调接口的,我看还有队列排队逻辑。 说明页面完整展现的时间不稳定,长则几十秒都有可能, 所以我感觉抓页面是不稳定的。
所以我选择抓接口。
1.1内容搜索大法
 众多的接口啊,我们怎么找到我要的数据在哪???于是我们利用调试工具,搜索响应内容关键字
众多的接口啊,我们怎么找到我要的数据在哪???于是我们利用调试工具,搜索响应内容关键字
例如搜页面中显示的这个标题
通过内容再network搜索内容 找到了列表接口
点开看,确实,里边就是这个列表的数据。
但是没有具体是环比、同比,我要的数字。
再次寻找每一项具体数据的获取接口。
再次通过搜索大法找了好久好久.....
找到了通过每项id和过滤条件去获取具体数据的接口
1.2 接口找齐,开始编码
研究下来。整体逻辑是,先获取面板列表,然后循环列表的每一项,拿着有关联的参数去调详情。
面板的数据列表获取
/**
* 获取重点功能监控面板列表及详情数据
* @returns {Promise<*[]>}
*/
async function queryReportList(dashboard) {
const { id: dashboard_id, common_event_filter } = dashboard
const data = await fetch(
`https://xxx/api/v2/sa/dashboards/${dashboard_id}?is_visit_record=true`,
{
credentials: "include",
headers: {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:136.0) Gecko/20100101 Firefox/136.0",
Cookie: Cookie
},
referrer:
`https://xxx/dashboard/?dash_type=lego&id=${dashboard_id}&project=1&product=sensors_analysis`,
method: "GET",
mode: "cors"
}
)
.then(res => res.json())
const result = [];
// 获取控面板的前12个监控项的监控数据。
for (const item of data.items.slice(0, 13)) {
if (item.bookmark) {
// 这里解出来, 调下一个接口要用到。
const data = JSON.parse(item.bookmark.data);
const res = await queryReportByTool({
bookmarkid: item.bookmark.id,
measures: data.measures,
dashboard_id: dashboard_id,
common_event_filter: common_event_filter
});
result.push({
...res,
name: item.bookmark.name
});
console.log(
{
name: item.bookmark.name,
base_number: res.base_number /= 100,
day: res.month_on_month /= 100,
week: res.year_on_year /= 100
}
)
}
}
return result
}
获取每一项具体数据
/**
* 报告列表的报告id去获取具体数据
* @param params
* @returns {Promise
*/
async function queryReportByTool(params) {
const requestId = Date.now() + ":803371";
const body = {
measures: params.measures,
unit: "day",
by_fields: [],
sampling_factor: null,
from_date: dayjs()
.subtract(14, "day")
.format("YYYY-MM-DD"),
// from_date: "2025-02-28",
to_date: getYesterDay(),
// to_date: "2025-03-13",
detail_and_rollup: true,
enable_detail_follow_rollup_by_values_rank: true,
...
};
try {
const data = await fetch(
`https://xxxx/api/events/compare/report/?bookmarkId=${
params.bookmarkid
}&async=true&timeout=10&request_id=${requestId}`,
{
credentials: "include",
headers: {
"User-Agent":
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:136.0) Gecko/20100101 Firefox/136.0",
...
Cookie
},
referrer:
"https://xxxx/dashboard/?dash_type=lego&id=692&project=1&product=sensors_analysis",
body: JSON.stringify(body),
method: "POST",
mode: "cors",
timeout: 10000
}
).then(res => res.json());
if (!data || data.isDone === false) {
return await queryReportByTool(params);
} else {
return data;
}
} catch (e) {
return await queryReportByTool(params);
}
}
1.3 数据拿到
执行一下,数据拿到了,找到了我要的几个字段
PS D:\project2\report> node .\index.js
{
name: 'xxx生成失败率',
base_number: 0.0103,
day: -0.3602,
week: -0.16260000000000002
}
...
{
name: 'xxxx生成失败率',
base_number: 0.017,
day: 0,
week: 0.0241
}
2025-03-18.xlsx文件已保存!
default: 27.917s
1.4 小结
表面看似一帆风顺,因为我是以回忆的视角,实则历经坎坷。目标网站的接口之间关系、参数间的关联,皆需细细揣摩、深入研究。
2、生成图片
node-cavas 生成图片。细节我就不讲了,数据都拿到了,用数据生成一张图片那就看你怎么解决了。
3、图片传到oss,调用钉钉webhook接口,定时发送到群里
传图
我是传到了腾讯云cos
const filePath = `/custom/999/${dashboard.worksheetName}-${dayjs().format('YYYYMMDD')}.jpeg`
const uploadRes = await tencentCos.upload(imageBuffer, filePath, true)
发钉钉群
查看钉钉群机器人api文档,以md格式发送图片链接。
async function sendDingTalkMessage(text) {
// const today = dayjs()
// .format("YYYY-MM-DD")
const token = '1a6e1111111' // 大群机器人
const result = await fetch(`https://oapi.dingtalk.com/robot/send?access_token=${token}`, {
method: 'post',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify({
"msgtype": "markdown",
"markdown": {
"title": "监控日报",
// "text": `#### ${title}-${today} \n >  \n`
"text": text
},
"at": {
"isAtAll": true
}
})
}).then(res => res.json())
console.log(result)
if (result.errcode === 0) {
console.log('发送成功')
return true
}
}
到这里可以当做一个脚本每天手动执行一下。 但是还没完全自动化,还差一步
4、js逆向登录加密方法,自动化登录。
就剩下自动登录了。
4.1 为什么要自动化登录?
因为这个系统登录凭证在一定时间内会过期,且不是明文登录的,登录接口参数加密了的。
 看到这你就得去研究他的加密规则了
看到这你就得去研究他的加密规则了
或者止步于此,手动复制登录凭证,本地执行脚本也是可以。
我如果要在服务器上自动化整个流程,必须得让他自动登录拿到登录凭证。
4.2 逆向步骤
4.2.1找到登录接口
先点页面的登录,找到登录接口,在请求调用栈中随便找个位置先打个断点,然后刷新页面,再次点击登录,嘿,您猜怎么着,断住了!!!
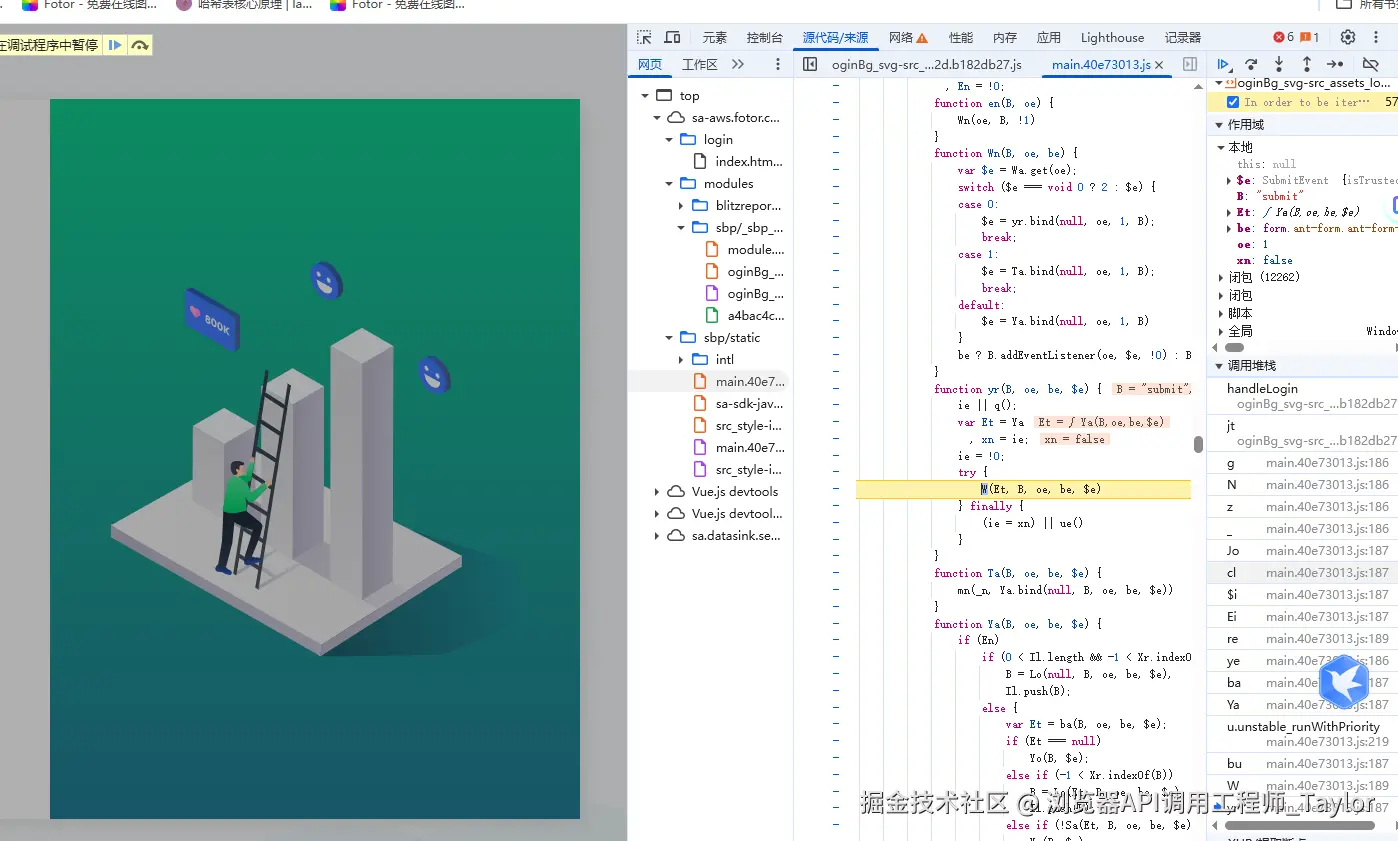
4.2.2 顺着调用栈找逻辑
顺着调栈给上找逻辑。所有在前端加密的一定是可以模拟的。
找到了调登录的方法。 看了下这就是调store里的方法passport/login。 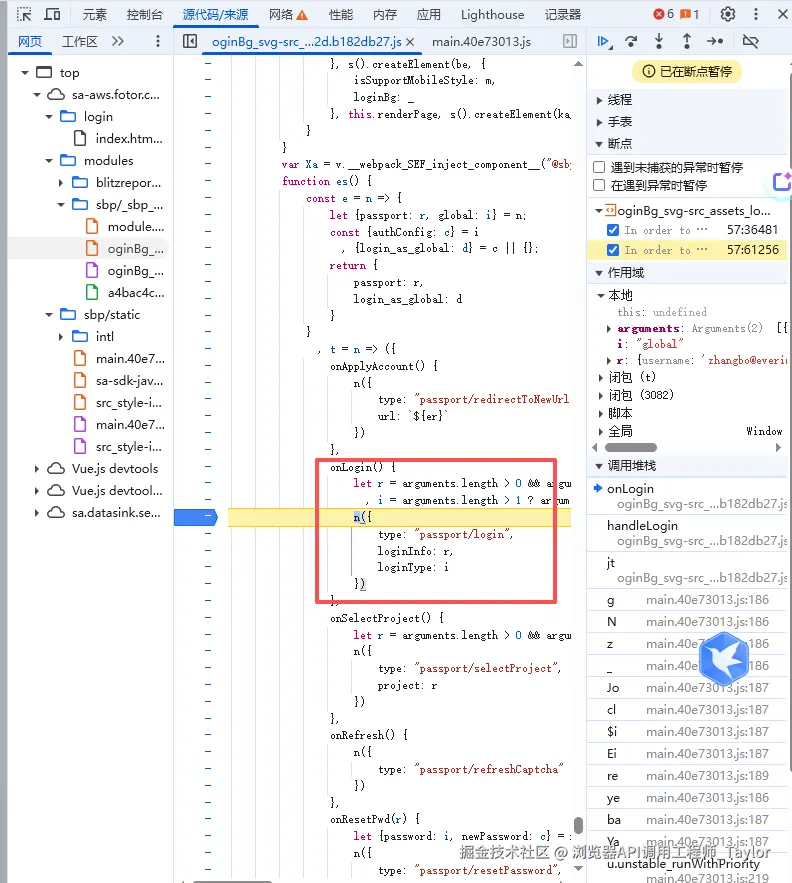
从这再往下就比较不容易了,因为你会发现,就有点乱了。进到的都是混淆的一些abcdefg名字的方法。
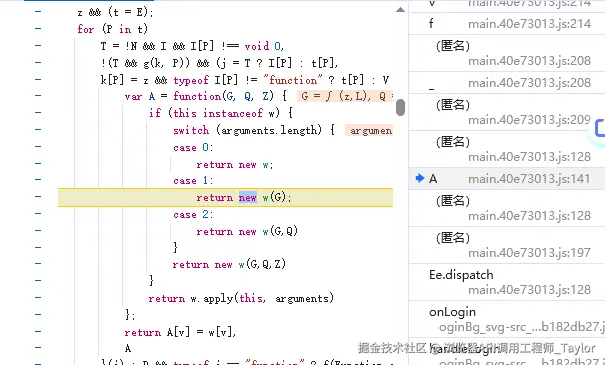
但是咱们明确目标就是要找到调用的方法passport/login的位置。
我尝试了如下
- 搜索passport/login关键字
- 搜索接口路径
找了一辈子, 终于找到了调接口的地方
看到这个Me方法,传递了一个 isEncrypted 我猜测就是 是否要加密参数的意思吧。 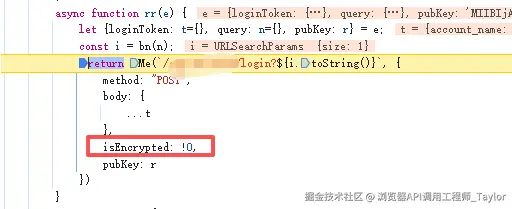
别搁Me方法外面蹭了行不行???,赶紧进去看看。
你就给我看这个? 这里面又调了另一个

咱们接着进到xt.request。
您猜怎么着,还没到,这里又进行了一顿操作之后,调了一个名为P的方法。
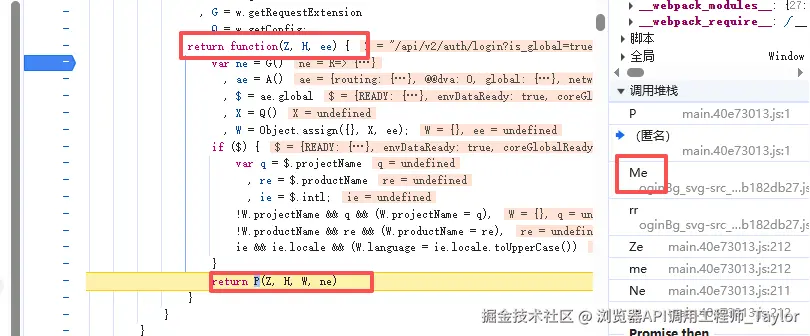
好好好,继续继续。
4.2.3 找到了加密的位置
到了P方法,终于是没给我玩套娃了啊。
在这一步终于是看到了关键字 isEncrypted。
看了代码确实是判断isEncrypted加密的。
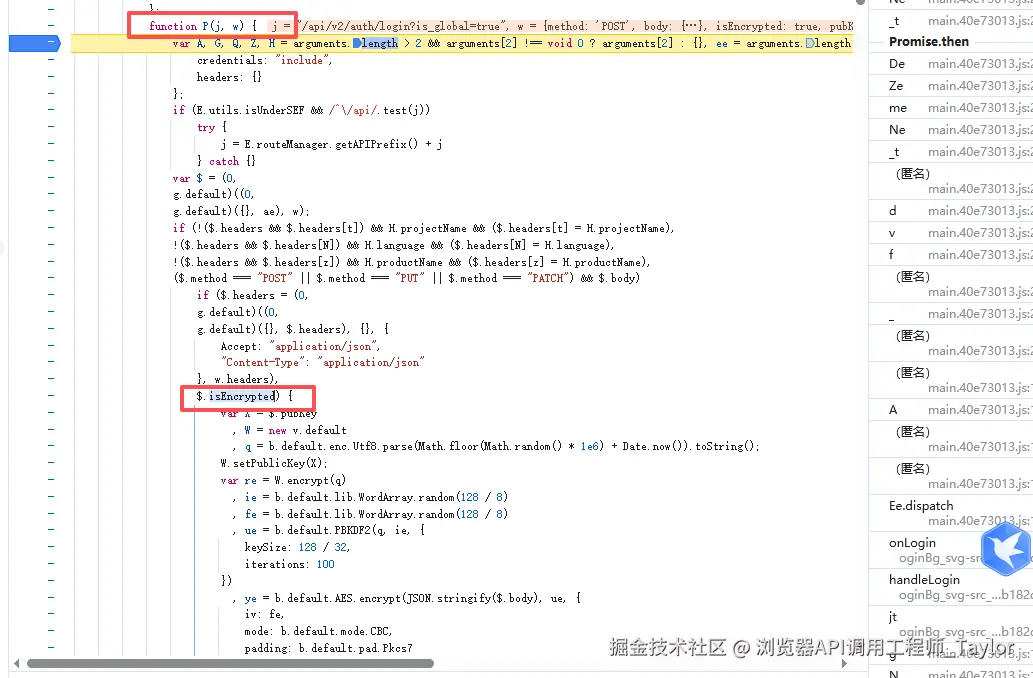
看了后发现这是一个RSA+AES结合的加密方式。
RAS加密密钥, AES加密登录数据。
加密流程总结:
- RSA保护AES密钥的安全传输
- AES保护实际登录数据的机密性
- 双重加密确保登录信息在传输过程中的安全性
为何不用单一的加密方式?
那么你有没有这样的疑问呢?为什么不单独用rsa直接加密数据呢?岂不简单。
当然不行,是有原因的!
RSA长度限制 RSA加密算法对明文长度有严格限制,具体取决于密钥长度和填充方式。以下是不同密钥长度下的最大明文长度(以字节为单位):
- 1024位密钥:最大明文长度约为 117字节
- 2048位密钥:最大明文长度约为 245字节
- 4096位密钥:最大明文长度约为 512字节
所以RSA加密超出长度的会报错的。
所以先生成短密钥,再使用RSA加密AES对称算法的密钥,再用对称密钥加密实际数据。这是实际应用中的常见做法,兼顾安全性和效率
4.2.4 模拟他的加密过程
大致流程
- 把加密逻辑copy啊。
- 补环境。
- 不断尝试直到通过后端校验。
理解后端如何解密和校验
前面我们说到
RAS加密密钥, AES加密登录数据。
那么后端的校验流程就是:
- 私钥解出密钥
- 密钥配和iv、salt等再解出被AES加密的账号密码信息.
知道了这些,那么我们需要做的就是正确加密和传递相关信息,如果校验失败,我们就要来回对比差异,找到问题,不断尝试。
在不断尝试下我成功了。
遇到的问题
- 加密的包的版本跟目标网站用的不一样导致校验失败,后经过漫长的查找找到了一样的版本。
- 还要注意header里带的字段,都要模拟他加密后的带过去。例如这几个。
- salt
- iv等

最终我抽出来的登录加密方法
var b = require("crypto-js");
var jsencrypt = require("nodejs-jsencrypt/bin/jsencrypt").default;
/**
* js逆向回来的方法,模拟xx登录对参数加密
* @param body xx登录参数
* @param public 公钥
* @returns {{headers: {"aes-salt": string, "aes-iv": string, "aes-passphrase": *, "X-Request-Timestamp": string, "X-Request-Id": string, "X-Request-Sign": *}, body: string}}
*/
function encryptLogin(body, public) {
const W = new jsencrypt();
W.setPublicKey(public)
q = b.enc.Utf8.parse(Math.floor(Math.random() * 1e6) + Date.now()).toString();
// q = "31373432353237383135363835";
var re = W.encrypt(q)
, ie = b.lib.WordArray.random(128 / 8)
, fe = b.lib.WordArray.random(128 / 8)
, ue = b.PBKDF2(q, ie, {
keySize: 128 / 32,
iterations: 100
})
, ye = b.AES.encrypt(JSON.stringify(body), ue, {
iv: fe,
mode: b.mode.CBC,
padding: b.pad.Pkcs7
});
const j = "/api/v2/auth/login?is_global=true"
const Ee = parseInt(Date.now() / 1000).toString()
const he = Ee
const Fe = ye.toString()
var bt = "".concat(Ee, "_").concat(he, "_").concat(j, "_").concat(Fe, "_14skjh");
const res = {
headers: {
"aes-salt": ie.toString(),
"aes-iv": fe.toString(),
"aes-passphrase": re,
"X-Request-Timestamp": Ee,
"X-Request-Sign": b.MD5(bt).toString(),
"X-Request-Id": he,
},
body: ye.toString()
}
return res
}
使用登录方法
登录之后存下来cookie供获取数据的接口使用
async function login(public, loginData) {
// 加密登录信息
const encryptOptions = encryptLogin({
...loginData
}, public)
return await fetch("xxx", {
"headers": {
...encryptOptions.headers
},
"method": "POST",
credentials: "include",
body: encryptOptions.body
}).then(res => {
Cookie = res.headers.get('set-cookie')
return res.json()
})
}
任务分步都实现了(自动化了)。
串联起来这四步,整体就实现了。
随后部署到服务器,配置定时任务每天执行。
效果展示
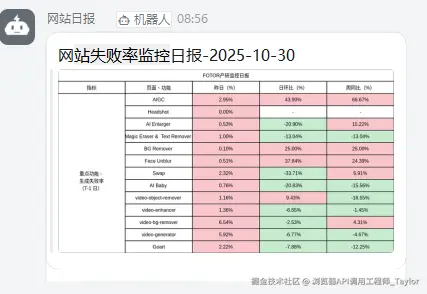
总结
- 先通后补:登录逆向卡壳,先手动Cookie跑通全链,再回填自动化。
- 逆向不怕乱:混淆代码里断点+全局搜索(接口路径/关键字),总能定位加密点。
- 加密常RSA+AES:RSA只加密短密钥,AES加密长数据,补环境+对齐Header字段是关键。
- 贵在坚持:第一天研究无果别灰心,第二天重新上手,灵感与进展常不期而至。
虽然文章写得像一帆风顺,但实则磕磕绊绊——在层层混淆的代码里翻找,第一天方法不对,左冲右突脑壳嗡嗡作响。幸好第二天没放弃,沉下心继续深挖,一步步试错、迭代,终于攻克所有难题。
如果有小伙伴有任何问题或者想跟我探讨细节,欢迎联系!
喜欢的话,点点关注。
来源:juejin.cn/post/7566913899175051299
为何前端圈现在不关注源码了?
大家好,我是双越。前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP。我的代表作有:
- wangEditor 开源 web 富文本编辑器,GitHub 18k star,npm 周下载量 20k
- 划水AI Node 全栈 AIGC 知识库,包括 AI 写作、多人协同编辑。复杂业务,真实上线。
- 前端面试派 系统专业的面试导航,刷题,写简历,看面试技巧,内推工作。开源免费。
开始
大家有没有发现一个现象:最近 1-2 年,前端圈不再关注源码了。
最近 Vue3.6 即将发布,alien-signal 不再依赖 Proxy 可更细粒度的实现响应式,vapor-model 可以不用 vdom 。
Vue 如此大的内部实现的改动,我没发现多少人研究它的源码,我日常关注的那些博客、公众号也没有发布源码相关的内容。
这要是在 3 年之前,早就开始有人研究这方面的源码了,博客一篇接一篇,跟前段时间的 MCP 话题一样。
还有前端工具链几乎快让 Rust 重构一遍了,rolldown turbopack 等产品使得构建效率大大提升。这要是按照 3 年之前对 webpack 那个研究态度,你不会 rust 就不好意思说自己是前端了。
不光是这些新东西,就是传统的 Vue React 等框架源码现在也没啥热度了,我关注每日的热门博客,几乎很少有关于源码的文章了。
这是为什么呢?
泡沫
看源码,其实是一种泡沫,现在破灭了。所谓泡沫,就是它的真实价值之前一直被夸大,就像房地产泡沫。
前几年是互联网发展的红利期,到处招聘开发人员,大家都拿着高工资,随便跳槽就能涨薪 20% ,大家就会误以为真的是自己的能力值这么多钱。
而且,当年面试时,尤其是大公司,为了筛选出优秀的候选人(因为培训涌入的人实在太多),除了看学历以外,最喜欢考的就是算法和源码。
确实,如果一个技术人员能把算法和源码看明白,那他肯定算是一个合格的程序员,上限不好说,但下限是能保证的。就像一个人名牌大学毕业的,他的能力下限应该是没问题的。
大公司如此面试,其他公司也就跟风,面试题在网络上传播,各位程序员也就跟风学习,很快普及到整个社区。
所以,如果不经思考,表面看来:就是因为我会算法、会源码,有这些技能,才拿到一个月几万甚至年薪百万的工资。
即,源码和算法价值百万。
现状
现在泡沫破灭了。业务没有增长了,之前是红利期,现在是内卷期,之前大量招聘,现在大量裁员。
你看这段时间淘宝和美团掐架多严重,你补贴我补贴,你广告我也广告。如果有新业务增长,他们早就忙着去开疆拓土了,没公司在这掐架。
面试少了,算法和源码也就没有发挥空间了。关键是大家现在才发现:原来自己会算法会源码,也会被裁员,也拿不到高工资了。
哦,原来之前自己的价值并不是算法和源码决定的,最主要是因为市场需求决定的。哪怕我现在看再多的源码,也少有面试机会,那还看个锤子!
现在企业预算缩减,对于开发人员的要求更加返璞归真:降低工资,甚至大量使用外包人员代替。
所以开发人员的价值,就是开发一些增删改查的日常 web 或 app 的功能,什么算法和框架源码,真实的使用场景太少。
看源码有用吗?
答案当然是肯定的。学习源码对于提升个人技术能力是至关重要的,尤其是对于初学者,学习前辈经验是个捷径。
但我觉得看 Vue react 这些源码对于开发提升并不会很直接,它也许会潜移默化的提升你的“内功”,但无法直接体现在工作上,除非你的工作就是开发 Vue react 类的框架。
我更建议大家去看一些应用类的源码,例如 UI 组件库的源码看如何封装复杂组件,例如 vue-admin 看如何封装一个 B 端管理后台。
再例如我之前学习 AI Agent 开发,就看了 langChain 提供的 agent-chat-ui 和 Vercel 提供的 ai-chatbot 这两个项目的源码,我并没有直接看 langChain 的源码。
找一些和你实际开发工作相关的一些优秀开源项目,学习他们的设计,阅读他们的源码,这是最直接有效的。
最后
前端人员想学习全栈 + AI 项目和源码,可关注我开发的 划水AI,包括 AI 写作、多人协同编辑。复杂业务,真实上线。
来源:juejin.cn/post/7531888067218800640
我为什么说全栈正在杀死前端?
大家好,我又来了🤣。
打开2025年的招聘软件,十个资深前端岗位,有八个在JD(职位描述)里写着:“有Node.js/Serverless/全栈经验者优先”。

全栈 👉 成了我们前端工程师内卷的一种方式。仿佛你一个干前端的,要是不懂点BFF、不会配Nginx、不聊聊K8s,你都不好意思跟人说你是资深。
我们都在拼命地,去学Nest.js、学数据库、学运维。我们看起来,变得越来越全能了。
但今天,我想泼一盆冷水🤔:
全栈正在杀死前端。
全栈到底是什么
我们先要搞清楚,现在公司老板们想要的全栈,到底是什么?
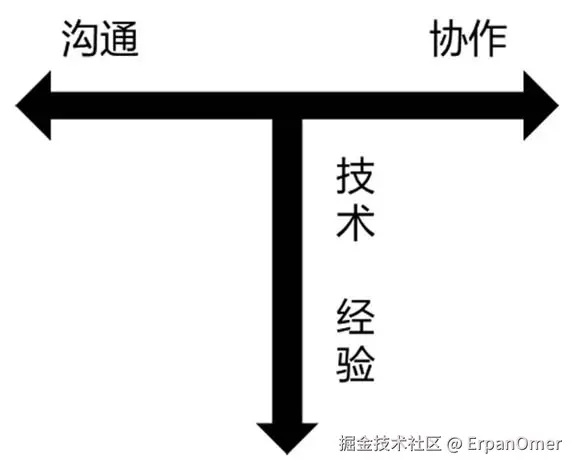
他们想要的,不是一个T型人才(在一个领域是专家,同时懂其他领域)。
他们想要的是:一个能干两个人(前端+后端)的活,但只需要付1.5个人的工资。
但一个人的精力,毕竟是有限的。
- 当我花了3个月,去死磕K8s的部署和Nest.js的依赖注入时,我必然没有时间,去研究新出炉的
INP性能指标该如何优化。 - 当我花了半周时间,去设计数据库表结构和BFF接口时,我必然没有精力,去打磨那个React组件的可访问性,无障碍(a11y)和动画细节。
我们引以为傲的前端精神,正在被全栈的广度要求,稀释得一干二净。
全栈的趋势,正在逼迫我们,从一个能拿90分的前端专家,变成一个前后端都是及格的功能实现者。
关于前端体验
做全栈的后果,最终由谁来买单?
是用户。
我们来看看全栈前端主导下,最容易出现的受灾现场:
1.能用就行的交互
全栈思维,是功能驱动的。
数据能从数据库里查出来,通过API发到前端,再用v-for渲染出来,好了,这个功能完成了😁。
至于:
- 列表的虚拟滚动做了吗?
- 图片的懒加载做了吗?
- 按钮的
loading和disabled状态,在API请求时加了吗? - 页面切换的骨架屏做了吗?
- 弱网环境下的超时和重试逻辑写了吗?
- UI测试呢?
抱歉,没时间。我还要去写BFF层的单元测试。
2.无障碍,可访问性(a11y)
你猜一个全栈,在用
来源:juejin.cn/post/7573172586839834676
如何知道同事的工资?
薪资保密,是所有互联网公司的红线之一。作为牛马,虽然能理解制度的初衷,但肯定忍不住想知道身边同事的工资。
直接问当然不行,我提供几个思路:
- 调虎离山,乘 TA 不在,在 TA 电脑上登录 OA/ERP,直接看工资
- 与 TA 搞对象或者搞基,知道工资后,马上分手,继续下一位,直到遍历完所有同事
- 拼命地卷自己,不断升职,成为他们的 +1 或 +2(腾讯是 +2 才有薪酬权)
虽然有可行性,但是作为码农,这些方案都太 low 了,没有丝毫技术含量。
下面,且看老夫的表演:

2016年底,花 100 块买了台摩托罗拉 C118,长这样:

百度百科的介绍如下:
Moto C118是Moto品牌于2006年2月推出的一款直板式基础功能手机
配备 96×64 单色显示屏,支持GSM 900/1800MHz双频网络
没错,我在 2016 年底买了一台 2006 年上市的功能机。很无聊的机器,哪怕在 06 年,我都没正眼瞧过它。
但,这跟工资有啥关系?
一般来说,工资入账时,会有银行的短信提醒。如果能截获短信,不就知道其他人的工资了吗?
经过硬件修改后的 C118,刷入特殊的固件,连接到Linux机器,启动脚本扫描频段,用WireShark抓包,就能收到其他人的短信了:
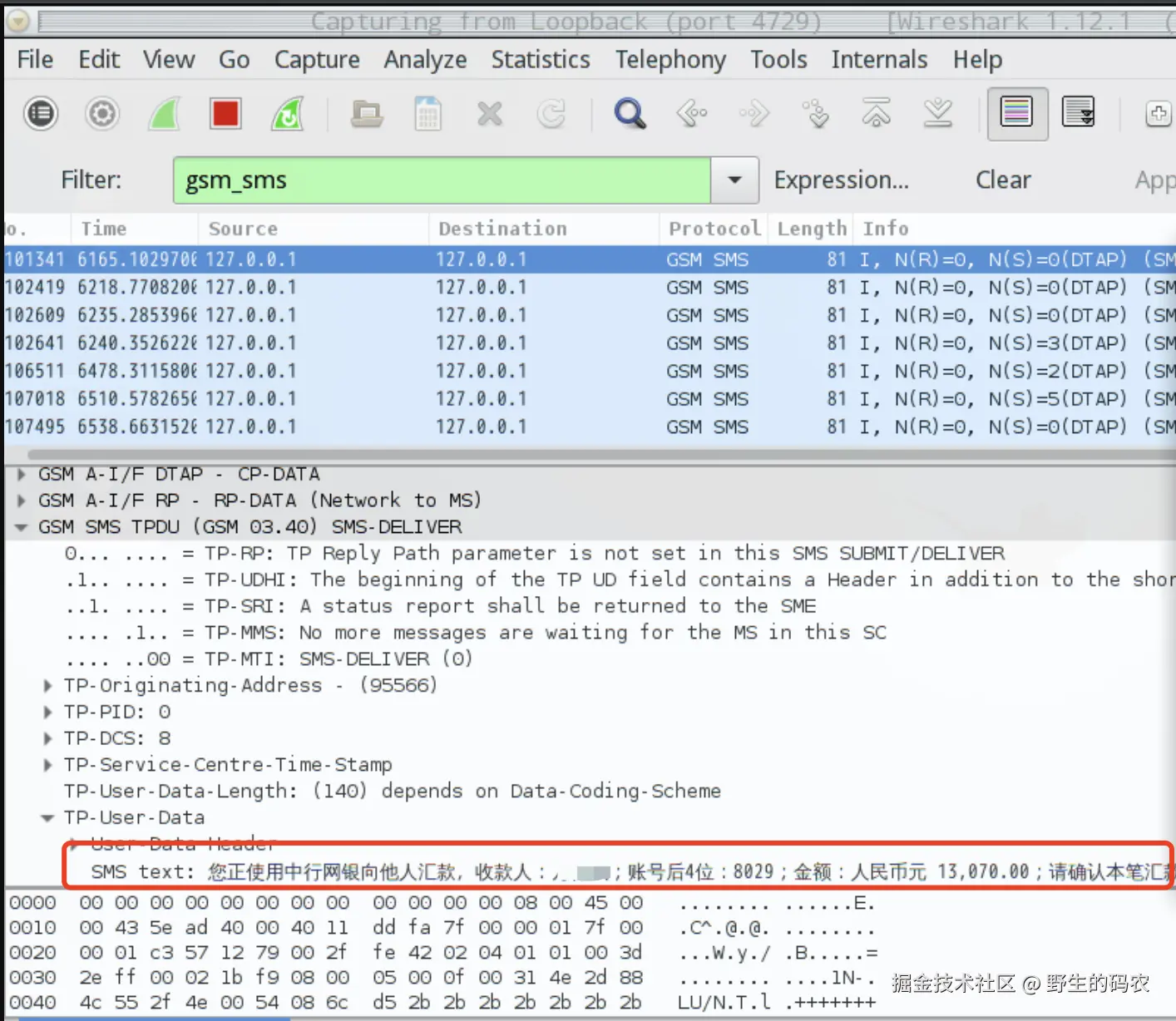
大概原理是:
GSM 短信未加密,而基站发送短信是广播的。
也就是说,任意的手机(不需要插入 SIM 卡)都能收到连接到同一基站的其他手机的短信,只不过会丢弃不属于自己的短信
特殊的固件就是让手机来者不拒,不要丢弃其他人的短信。具体细节,网上一大堆,请自行搜索OsmocomBB。
我完全不懂硬件,直接买的改好后的 C118,卖家顺便改了 Micro-USB 供电,不需要电池了。我觉得挺漂亮的,就是有点像定时炸弹:

机器到手后,照葫芦画瓢,跑了半天,真抓到了一些推广短信。卧槽,牛逼!
等到发工资那天,提前把脚本跑起来,附近同事的工资,尽收眼底。完美!؏؏☝ᖗ乛◡乛ᖘ☝؏؏
好吧,这只是一个邪恶的想法,从未付诸实施。说起来你可能不信,每次都是收到工资入账短信后,我才想起来脚本没跑。久而久之,就忘了这件事了。
话说回来,即使当初真干了,也是徒劳。因为这个只能抓移动和联通的 GSM 短信,对电信的 CDMA 无效。而且,当时 4G 已经全面铺开,根本抓不到。即使有同事用 GSM 老人机,也因为原理的限制,看不到收件人手机号,并不知道是谁的工资。
最后,说一件趣事:
几年前,某司价值观中的「创新」要改成「创造」,在内网征集最能代表「创造」的动物,点赞数最多的是它:

提议者的配文:
蝙蝠,昼伏夜出,象征着创造力
最重要的是,它擅长倒挂
彼时,网上一堆晒 SP、SSP 的 offer 的校招生,薪资遥遥领先工作多年的老员工。当然,蝙蝠最终还是以最高得票遗憾落选了,虽败犹荣。
类似的倒挂,在我身上也发生过,果断选择了跑路。然后,薪资翻了数倍,敏感内容,略。
来源:juejin.cn/post/7550151424333053992
学不动了?没事,前端娱乐圈也更新不动了
大家好,我是双越。前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP。
我正开发一个 Node 全栈 AIGC 知识库 划水AI,包括 AI 写作、多人协同编辑。复杂业务,真实上线,大家可以去注册试用,围观项目研发过程。
开始
从 2024 年春天到现在 2025 年初夏,好像遍地都是 AI 的各种新闻,前端圈里都有啥动向呢?好像没有啥印象。
我本人是自由职业,每天都会关注行业动态,可能比很多上班族都要看的多。但凭我个人的记忆和印象,我只能记住两件事儿
第一,React19 发布,同时 Nextjs 15 发布。React19 发布新增的功能都是为了满足 RSC 和 Nextjs 而做的,如果你用 React 做纯前端开发,这次更新影响不大。
第二,Vue 作者 尤雨溪 去年秋天创办 VoidZero 计划重构 JS 工具链,并且得到了很多公司的投资。Vue3.6 发布已经集成了他们的 Rolldown 工具,性能提升几倍。
其他的更新没有印象了,也可能是我没关注到,或者太过于基础(如 ES TS Node 等语法和底层能力)而没注意。
AI 总结
人可能不记得,但 AI 可以帮忙,于是我分别咨询了 ChatGPT 和 DeepSeek ,都开启了联网搜索。
从 2024 年初到现在 2025 年5月,前端开发领域有哪些比较重要的新闻和技术变化?
例如 react19 nextjs15 remix TS vue vite nodejs AI 等相关的,帮我整理一个时间线。
ChatGPT 的结果如下,主要是 React Nextjs Nodejs TS Vite 等这些更新,没有什么特别需要注意的。

DeepSeek 的结果如下,大概内容都是这样写,但它提到了 Remix 和 tailwindCSS ,他们都发布了新的版本。

后来我又想到 Nuxtjs 又查了一下,发现 Nuxtjs v4 发布了,国内也用的少,之前不知道。
最近这两天又爆出 Remix 要脱离 React router ,要基于 PReact 单独开发,要做的更加轻量化。对于我们开发者来说,又一个 React 轮子而已,功能和使用方式都差不多。
解决“学不动”问题
前几年前端技术更新非常快,一些技术、工具、框架,1 年以后就过时了,大家直呼“学不动了...”
但现在已经彻底改变了,所有的技术、工具、框架都已经趋于稳定,即便是再更新也不是断崖式的更新,不影响我们的日常开发使用。
已经慢慢变成了 Java 技术栈的样子,未来几年不会有太大的变化,已经学到的同学不用再花费很多时间学习了,好好工作即可 —— 反正是闲不着~
如果不是当前这个大环境和内卷的形势,这样还真就挺好的,可惜环境如此,不卷这个就卷那个,现在全民卷 AI 了。
AI 相关更新
前端圈更新不懂,AI 圈可是活跃的很,AI 编程工具雨后春笋般的涌现
- Copilot
- Cursor
- Windsurf
- Trae
- Cline
- v0
- bold.new
今天刷到一个朋友圈特别有意思,开心一下,结束文本

来源:juejin.cn/post/7513781200416309298
进入外包,我犯了所有程序员都会犯的错!
前言
前些天有位小伙伴和我吐槽他在外包工作的经历,语气颇为激动又带着深深的无奈。
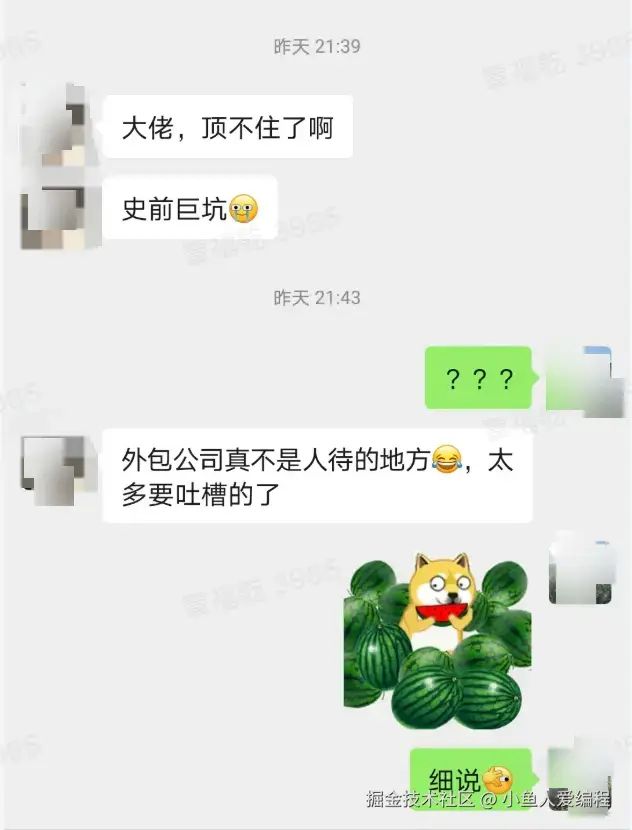
本篇以他的视角,进入他的世界,看看这一段短暂而平凡的经历。
前些天有位小伙伴和我吐槽他在外包工作的经历,语气颇为激动又带着深深的无奈。
1. 上岸折戟尘沙
本人男,安徽马鞍山人士,21年毕业于江苏某末流211,在校期间转码。
上网课期间就向往大城市,于是毕业后去了深圳,找到了一家中等IT公司(人数500+)搬砖,住着宝安城中村,来往繁华南山区。
待了三年多,自知买房变深户无望,没有归属感,感觉自己也没那么热爱技术,于是乎想回老家考公务员,希望待在宇宙的尽头。
24年末,匆忙备考,平时工作忙里偷闲刷题,不出所料,笔试卒,梦碎。
本人男,安徽马鞍山人士,21年毕业于江苏某末流211,在校期间转码。
上网课期间就向往大城市,于是毕业后去了深圳,找到了一家中等IT公司(人数500+)搬砖,住着宝安城中村,来往繁华南山区。
待了三年多,自知买房变深户无望,没有归属感,感觉自己也没那么热爱技术,于是乎想回老家考公务员,希望待在宇宙的尽头。
24年末,匆忙备考,平时工作忙里偷闲刷题,不出所料,笔试卒,梦碎。
2. 误入外包
复盘了备考过程,觉得工作占用时间过多,想要找一份轻松点且离家近的工作,刚好公司也有大礼包的指标,于是主动申请,辞别深圳,前往徽京。
Boss上南京的软件大部分是外包(果然是外包之都),前几年外包还很活跃,这些年外包都沉寂了不少,找了好几个月,断断续续有几个邀约,最后实在没得选了,想着反正就过渡一下挣点钱不寒碜,接受了外包,作为WX服务某为。薪资比在深圳降了一些,在接受的范围内。
想着至少苟着等待下一次考公,因此前期做项目比较认真,遇到问题追根究底,为解决问题也主动加班加点,同为WX的同事都笑话我说比自有员工还卷,我却付之一笑。
直到我经历了几件事,正所谓人教人教不会,事教人一教就会。
复盘了备考过程,觉得工作占用时间过多,想要找一份轻松点且离家近的工作,刚好公司也有大礼包的指标,于是主动申请,辞别深圳,前往徽京。
Boss上南京的软件大部分是外包(果然是外包之都),前几年外包还很活跃,这些年外包都沉寂了不少,找了好几个月,断断续续有几个邀约,最后实在没得选了,想着反正就过渡一下挣点钱不寒碜,接受了外包,作为WX服务某为。薪资比在深圳降了一些,在接受的范围内。
想着至少苟着等待下一次考公,因此前期做项目比较认真,遇到问题追根究底,为解决问题也主动加班加点,同为WX的同事都笑话我说比自有员工还卷,我却付之一笑。
直到我经历了几件事,正所谓人教人教不会,事教人一教就会。
3. 我在外包的二三事
有一次,我提出了自有员工设计方案的衍生出的一个问题,并提出拉个会讨论一下,他并没有当场答应,而是回复说:我们内部看看。
而后某天我突然被邀请进入会议,聊了几句,意犹未尽之际,突然就被踢出会议...开始还以为是某位同事误触按钮,然后再申请入会也没响应。
后来我才知道,他们内部商量核心方案,因为权限管控问题,我不能参会。
这是我第一次体会到WX和自有员工身份上的隔阂。
还有一次和自有员工一起吃饭的时候,他不小心说漏嘴了他的公积金,我默默推算了一下他的工资至少比我高了50%,而他的毕业院校、工作经验和我差不多,瞬间不平衡了。
还有诸如其它的团建、夜宵、办公权限、工牌等无一不是明示着你是外包员工,要在外包的规则内行事。 至于转正的事,头上还有OD呢,OD转正的几率都很低,好几座大山要爬呢,别想了。
有一次,我提出了自有员工设计方案的衍生出的一个问题,并提出拉个会讨论一下,他并没有当场答应,而是回复说:我们内部看看。
而后某天我突然被邀请进入会议,聊了几句,意犹未尽之际,突然就被踢出会议...开始还以为是某位同事误触按钮,然后再申请入会也没响应。
后来我才知道,他们内部商量核心方案,因为权限管控问题,我不能参会。
这是我第一次体会到WX和自有员工身份上的隔阂。
还有一次和自有员工一起吃饭的时候,他不小心说漏嘴了他的公积金,我默默推算了一下他的工资至少比我高了50%,而他的毕业院校、工作经验和我差不多,瞬间不平衡了。
还有诸如其它的团建、夜宵、办公权限、工牌等无一不是明示着你是外包员工,要在外包的规则内行事。 至于转正的事,头上还有OD呢,OD转正的几率都很低,好几座大山要爬呢,别想了。
3. 反求诸己
以前网上看到很多吐槽外包的帖子,还总觉得言过其实,亲身经历了才刻骨铭心。
我现在已经摆正了心态,既来之则安之。正视自己WX的身份,给多少钱干多少活,给多少权利就承担多少义务。
不攀比,不讨好,不较真,不内耗,不加班。
另外每次当面讨论的时候,我都会把工牌给露出来,潜台词就是:快看,我就是个外包,别为难我😔~
另外我现在比较担心的是:
万一我考公还是失败,继续找工作的话,这段外包经历会不会是我简历的污点😢
当然这可能是我个人感受,其它外包的体验我不知道,也不想再去体验了。
对,这辈子和下辈子都不想了。 附南京外包之光,想去或者不想去的伙伴可以留意一下:

作者:小鱼人爱编程
来源:juejin.cn/post/7511582195447824438
以前网上看到很多吐槽外包的帖子,还总觉得言过其实,亲身经历了才刻骨铭心。
我现在已经摆正了心态,既来之则安之。正视自己WX的身份,给多少钱干多少活,给多少权利就承担多少义务。
不攀比,不讨好,不较真,不内耗,不加班。
另外每次当面讨论的时候,我都会把工牌给露出来,潜台词就是:快看,我就是个外包,别为难我😔~
另外我现在比较担心的是:
万一我考公还是失败,继续找工作的话,这段外包经历会不会是我简历的污点😢
当然这可能是我个人感受,其它外包的体验我不知道,也不想再去体验了。
对,这辈子和下辈子都不想了。 附南京外包之光,想去或者不想去的伙伴可以留意一下:
来源:juejin.cn/post/7511582195447824438
我TM被AI骗了!!损失惨痛~
首先声明:这个绝对不是标题党!!!

不管是前端佬、后端佬、APP佬,还是普罗大众,都可以点进来借鉴看看。
反正经过这么一遭,我算是被醍醐灌顶了。
起因
因为会玩点大A票,所以日常会关注一些财经新闻。
而看新闻的几个渠道中,其中就有澎bo新闻或者经济学人。
吐个槽,不是外国的月亮比较圆,非得看他们,而是他们一些信息就是比村里的快!
言归正传!这些新闻机构好是好,但有一致命缺点:得花钱!

这你能忍?反正对于我这样苦哈哈的程序员,我的第一解决办法并不是直接付钱订购,而是想别的出路。
终于经过检索,我找到一条路子(具体是啥,相信大家都可以检索到)。
就这么一直用着用着,直到有一天,我脑子里蹦出个想法来。
经过
生成式对话AI可谓火遍大江南北,我就在想,我要是把链接喂给他们,是不是可以直接把文章拔下来,然后还可以将直接翻译好的文本给我?

秉承实干家的Title,说干就干。
我陆续验证了Deepseek、通义千问、ChatGTP、Grok、然后万恶的Grok😡😡...反正没有再使用其它的,我感觉已经可以了。
提示词基本都差不多,如下:
【https:// url 看官请假装这是一个链接^v^】,把这篇文章翻译成中文发给我。不需要整理
前四个都不行。基本是这样:

还有这样下面这样!!
终于,在遇到Grok这厮后,它直接明了的给出文章!
怀疑
回忆当时的Grok输出,我是直呼卧槽。
然后,细细看了下内容,有模有样,跟标题还真贴合。
然后,我质疑了。
是的,我是怀疑过的!!!
但,怀疑的方式依旧那么的愚蠢的。我怀疑的办法不是去说搞一篇原文,来作对比较,而是傻愣愣的直接去问Grok。
然后给我的回复就是:

他斩钉截铁的告诉我,不会也无法非法获取付费内容。
好吧。不管你这怎么样,
反正当时我信了。
我pua了我
就这么用了几天,感觉是真爽!狂喜了好长一段时间,每天会看一两篇。
倒不是一点怀疑都没有,而且怀疑的并不是内容有问题。
因为给出的内容,里面文章很有逻辑,还夹杂着数据支撑,最后还会给一些很犀利的结尾,跟之前阅读的那些内容,从感觉上真尼玛像!!!
其中真正让我有些疑虑的,是里面一些日期使用。比如今天明明是11月20日,已经星期四了,但里面的内容会出现:在11月19日,上周三的某知情人士说法。。,这样阐述。
但~因为相信,我自己pua我自己了,完全将其合理化了。
要么就认为是翻译的问题,或者认为时区的问题,再或者就认为AI翻译就这个尿性。

反转
最近关注过大A票的朋友,应该都知道半导体板块。然后也应该听说过安世半导体事件。
我就是其中关注者之一,也是其中的赌狗一只。
话说对于赌狗来说,最大的瘾就是在事情未确定的时候,去下注,然后为此获得收益。
那么应用到这个事件,我们就是去,下注WTKJ票,赌我们村里赢。
反正这个事件反反复复,那票也是起起落落。
就这么一天吧,某澎bo报道了一篇文章,然后一如往常将链接丢给Grok,反正Grok给出的内容大意就是:荷兰政府强硬,要坚定收回控制权。
好吧。赌狗看到这样消息,那自然而然想到对于WTKJ是利空。为了止损,所以夜间挂了跌停,为此还喜滋滋。

直到第二天,卖掉之后。我看到了国内新闻报道,内容跟Grok的那篇完全相反,是荷兰政府放弃干预!
嗯?咋回事?莫非国内消息滞后?(你看,这就是盲目的代价)
然后我又去看了一遍Grok内容,再次对比国内新闻。这截然相反的新闻,咋回事???
终于,我开窍一样的找回了原来的路子,用原文对比Grok一看!
吐血了!
跟原文真的半毛钱都没得关系。

你猜,我的反应是去干嘛?
我尽量是去质问那个Grok傻xxx,然后他的回复给我气笑了~

我是打死都没有去怀疑,你这浓眉大眼的AI你竟然就这么胡编乱造。
结局
好了,这个就是整个事情的经过。

事后的第一反应,是脑海里回忆起电影《2001太空漫游》那画面:
Open the pod bay doors,Hal. I'm sorry,Dave.

《2001太空漫游》的艺术高度再次飙升!
如果有一天,AI真得像人了,或者我们无法分辨他是真得或者假得,或者一百万个AI智能体都这么说得。那么我们怎么去辨别?
最后,告诫大家:
市场有风险,投资需谨慎!!!
来源:juejin.cn/post/7574648745894281257
我发现很多程序员都不会打日志。。。
你是小阿巴,刚入职的低级程序员,正在开发一个批量导入数据的程序。
没想到,程序刚上线,产品经理就跑过来说:小阿巴,用户反馈你的程序有 Bug,刚导入没多久就报错中断了!
你赶紧打开服务器,看着比你发量都少的报错信息:

你一脸懵逼:只有这点儿信息,我咋知道哪里出了问题啊?!
你只能硬着头皮让产品经理找用户要数据,然后一条条测试,看看是哪条数据出了问题……
原本大好的摸鱼时光,就这样无了。
这时,你的导师鱼皮走了过来,问道:小阿巴,你是持矢了么?脸色这么难看?

你无奈地说:皮哥,刚才线上出了个 bug,我花了 8 个小时才定位到问题……
鱼皮皱了皱眉:这么久?你没打日志吗?
你很是疑惑:谁是日志?为什么要打它?

鱼皮叹了口气:唉,难怪你要花这么久…… 来,我教你打日志!
⭐️ 本文对应视频版:bilibili.com/video/BV1K7…
什么是日志?
鱼皮打开电脑,给你看了一段代码:
@Slf4j
public class UserService {
public void batchImport(List userList) {
log.info("开始批量导入用户,总数:{}", userList.size());
int successCount = 0;
int failCount = 0;
for (UserDTO userDTO : userList) {
try {
log.info("正在导入用户:{}", userDTO.getUsername());
validateUser(userDTO);
saveUser(userDTO);
successCount++;
log.info("用户 {} 导入成功", userDTO.getUsername());
} catch (Exception e) {
failCount++;
log.error("用户 {} 导入失败,原因:{}", userDTO.getUsername(), e.getMessage(), e);
}
}
log.info("批量导入完成,成功:{},失败:{}", successCount, failCount);
}
}
你看着代码里的 log.info、log.error,疑惑地问:这些 log 是干什么的?
鱼皮:这就是打日志。日志用来记录程序运行时的状态和信息,这样当系统出现问题时,我们可以通过日志快速定位问题。
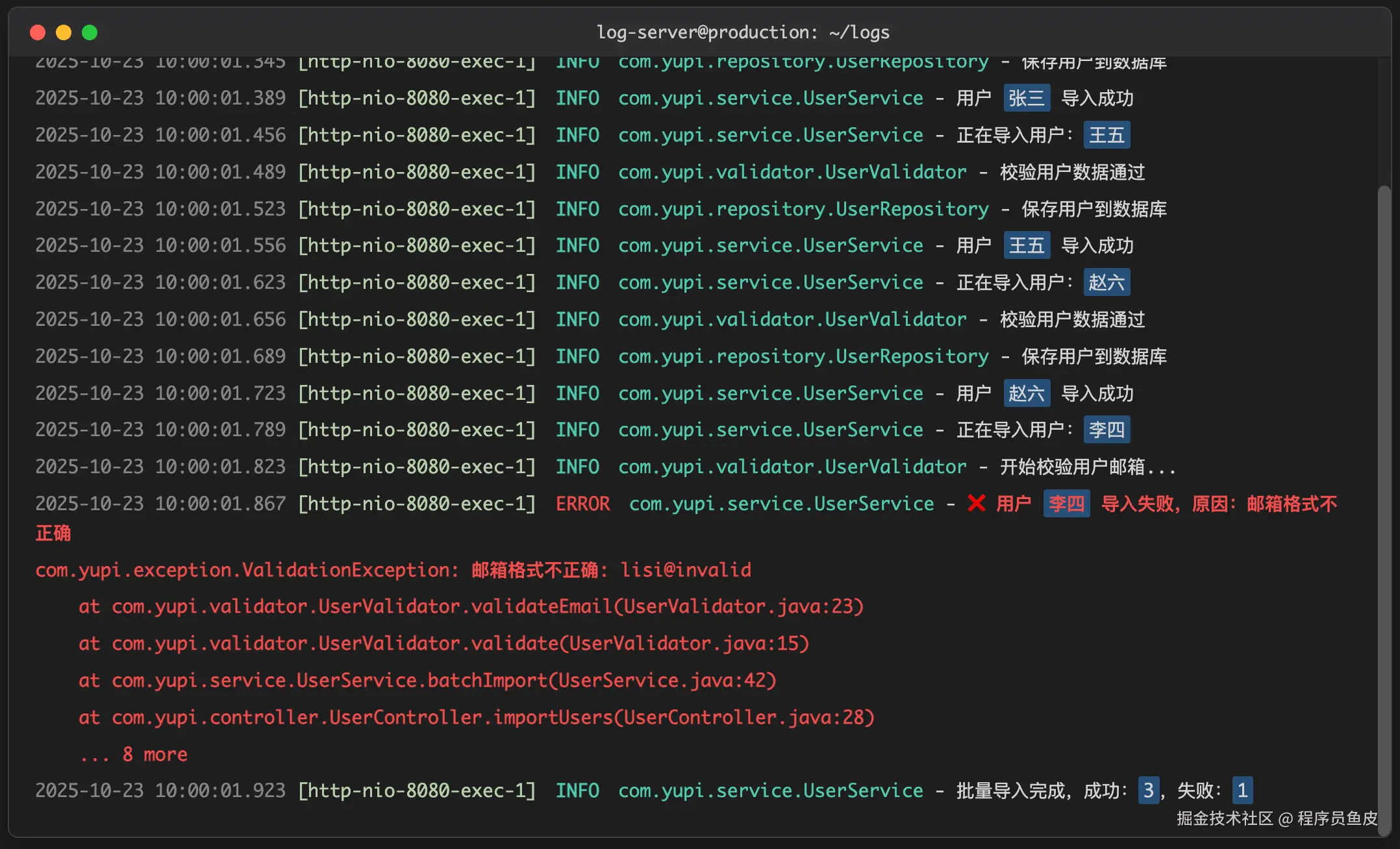
你若有所思:哦?还可以这样!如果当初我的代码里有这些日志,一眼就定位到问题了…… 那我应该怎么打日志?用什么技术呢?
怎么打日志?
鱼皮:每种编程语言都有很多日志框架和工具库,比如 Java 可以选用 Log4j 2、Logback 等等。咱们公司用的是 Spring Boot,它默认集成了 Logback 日志框架,你直接用就行,不用再引入额外的库了~

日志框架的使用非常简单,先获取到 Logger 日志对象。
1)方法 1:通过 LoggerFactory 手动获取 Logger 日志对象:
public class MyService {
private static final Logger logger = LoggerFactory.getLogger(MyService.class);
}
2)方法 2:使用 this.getClass 获取当前类的类型,来创建 Logger 对象:
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
}
然后调用 logger.xxx(比如 logger.info)就能输出日志了。
public class MyService {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
public void doSomething() {
logger.info("执行了一些操作");
}
}
效果如图:

小阿巴:啊,每个需要打日志的类都要加上这行代码么?
鱼皮:还有更简单的方式,使用 Lombok 工具库提供的 @Slf4j 注解,可以自动为当前类生成日志对象,不用手动定义啦。
@Slf4j
public class MyService {
public void doSomething() {
log.info("执行了一些操作");
}
}
上面的代码等同于 “自动为当前类生成日志对象”:
private static final org.slf4j.Logger log =
org.slf4j.LoggerFactory.getLogger(MyService.class);
你咧嘴一笑:这个好,爽爽爽!

等等,不对,我直接用 Java 自带的 System.out.println 不也能输出信息么?何必多此一举?
System.out.println("开始导入用户" + user.getUsername());
鱼皮摇了摇头:千万别这么干!
首先,System.out.println 是一个同步方法,每次调用都会导致耗时的 I/O 操作,频繁调用会影响程序的性能。

而且它只能输出信息到控制台,不能灵活控制输出位置、输出格式、输出时机等等。比如你现在想看三天前的日志,System.out.println 的输出早就被刷没了,你还得浪费时间找半天。
你恍然大悟:原来如此!那使用日志框架就能解决这些问题吗?
鱼皮点点头:没错,日志框架提供了丰富的打日志方法,还可以通过修改日志配置文件来随心所欲地调教日志,比如把日志同时输出到控制台和文件中、设置日志格式、控制日志级别等等。
在下苦心研究日志多年,沉淀了打日志的 8 大邪修秘法,先传授你 2 招最基础的吧。
打日志的 8 大最佳实践
1、合理选择日志级别
第一招,日志分级。
你好奇道:日志还有级别?苹果日志、安卓日志?
鱼皮给了你一巴掌:可不要乱说,日志的级别是按照重要程度进行划分的。

其中 DEBUG、INFO、WARN 和 ERROR 用的最多。
- 调试用的详细信息用 DEBUG
- 正常的业务流程用 INFO
- 可能有问题但不影响主流程的用 WARN
- 出现异常或错误的用 ERROR
log.debug("用户对象的详细信息:{}", userDTO); // 调试信息
log.info("用户 {} 开始导入", username); // 正常流程信息
log.warn("用户 {} 的邮箱格式可疑,但仍然导入", username); // 警告信息
log.error("用户 {} 导入失败", username, e); // 错误信息
你挠了挠头:俺直接全用 DEBUG 不行么?
鱼皮摇了摇头:如果所有信息都用同一级别,那出了问题时,你怎么快速找到错误信息?
在生产环境,我们通常会把日志级别调高(比如 INFO 或 WARN),这样 DEBUG 级别的日志就不会输出了,防止重要信息被无用日志淹没。
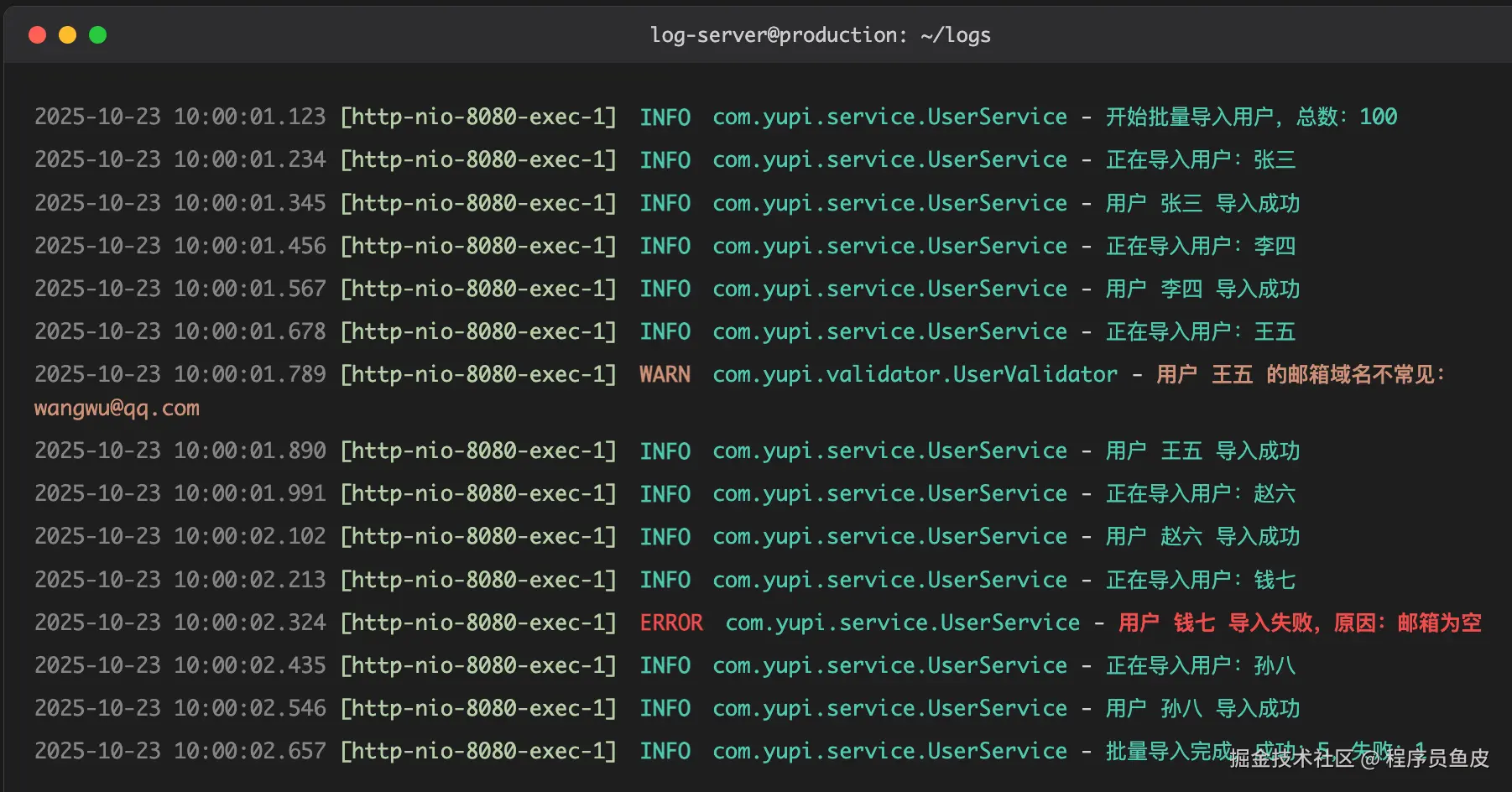
你点点头:俺明白了,不同的场景用不同的级别!
2、正确记录日志信息
鱼皮:没错,下面教你第二招。你注意到我刚才写的日志里有一对大括号 {} 吗?
log.info("用户 {} 开始导入", username);
你回忆了一下:对哦,那是啥啊?
鱼皮:这叫参数化日志。{} 是一个占位符,日志框架会在运行时自动把后面的参数值替换进去。
你挠了挠头:我直接用字符串拼接不行吗?
log.info("用户 " + username + " 开始导入");
鱼皮摇摇头:不推荐。因为字符串拼接是在调用 log 方法之前就执行的,即使这条日志最终不被输出,字符串拼接操作还是会执行,白白浪费性能。
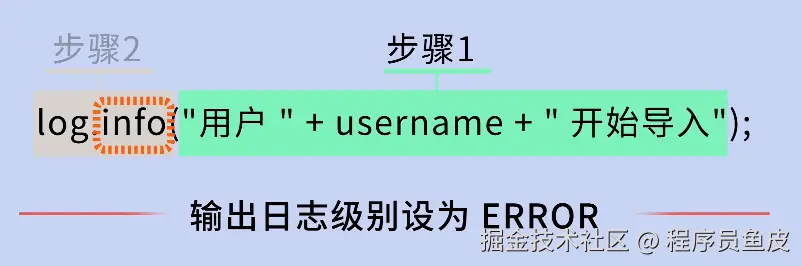
你点点头:确实,而且参数化日志比字符串拼接看起来舒服~

鱼皮:没错。而且当你要输出异常信息时,也可以使用参数化日志:
try {
// 业务逻辑
} catch (Exception e) {
log.error("用户 {} 导入失败", username, e); // 注意这个 e
}
这样日志框架会同时记录上下文信息和完整的异常堆栈信息,便于排查问题。
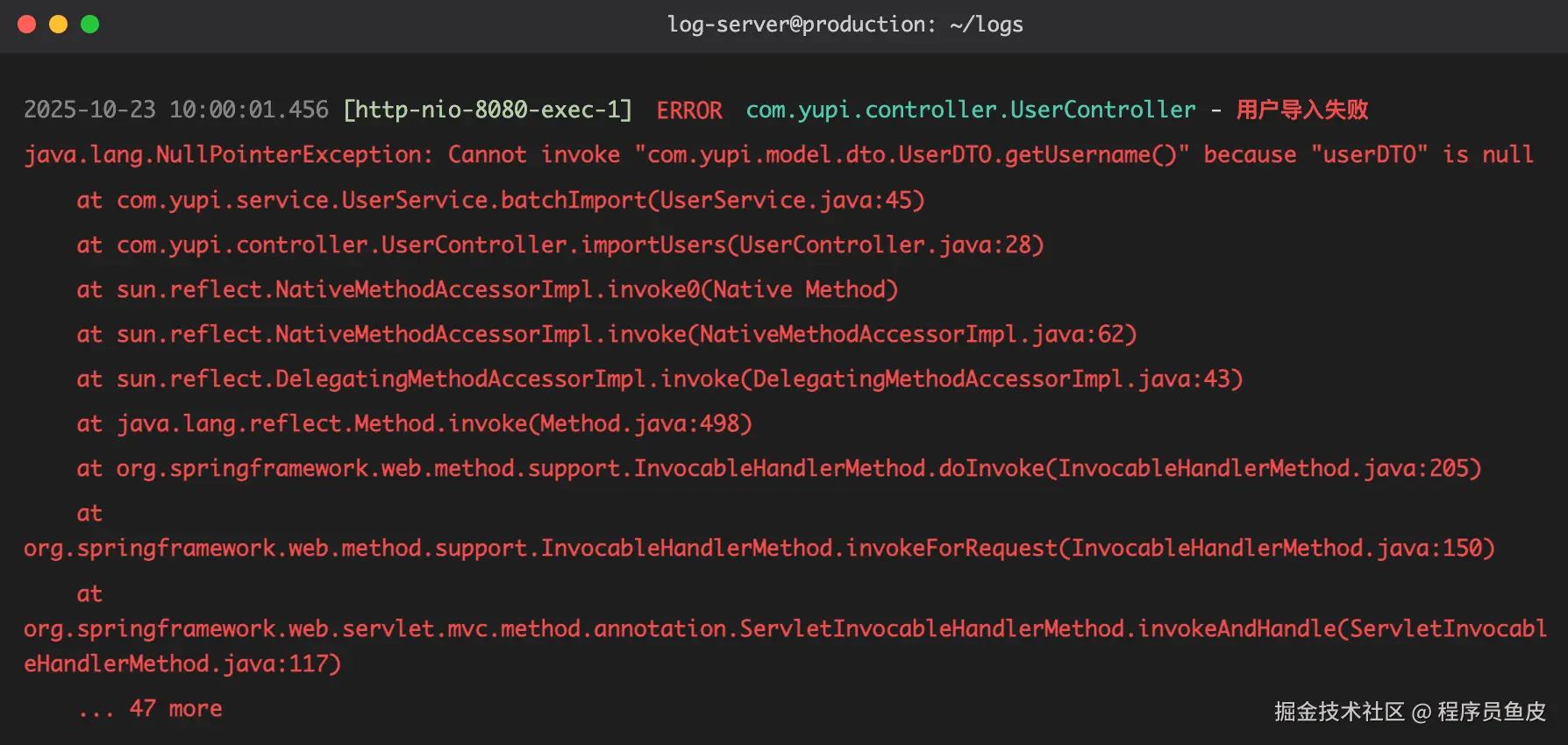
你抱拳:学会了,我这就去打日志!
3、把控时机和内容
很快,你给批量导入程序的代码加上了日志:
@Slf4j
public class UserService {
public BatchImportResult batchImport(List userList) {
log.info("开始批量导入用户,总数:{}", userList.size());
int successCount = 0;
int failCount = 0;
for (UserDTO userDTO : userList) {
try {
log.info("正在导入用户:{}", userDTO.getUsername());
// 校验用户名
if (StringUtils.isBlank(userDTO.getUsername())) {
throw new BusinessException("用户名不能为空");
}
// 保存用户
saveUser(userDTO);
successCount++;
log.info("用户 {} 导入成功", userDTO.getUsername());
} catch (Exception e) {
failCount++;
log.error("用户 {} 导入失败,原因:{}", userDTO.getUsername(), e.getMessage(), e);
}
}
log.info("批量导入完成,成功:{},失败:{}", successCount, failCount);
return new BatchImportResult(successCount, failCount);
}
}
光做这点还不够,你还翻出了之前的屎山代码,想给每个文件都打打日志。
但打着打着,你就不耐烦了:每段代码都要打日志,好累啊!但是不打日志又怕出问题,怎么办才好?
鱼皮笑道:好问题,这就是我要教你的第三招 —— 把握打日志的时机。
对于重要的业务功能,我建议采用防御性编程,先多多打日志。比如在方法代码的入口和出口记录参数和返回值、在每个关键步骤记录执行状态,而不是等出了问题无法排查的时候才追悔莫及。之后可以再慢慢移除掉不需要的日志。

你叹了口气:这我知道,但每个方法都打日志,工作量太大,都影响我摸鱼了!
鱼皮:别担心,你可以利用 AOP 切面编程,自动给每个业务方法的执行前后添加日志,这样就不会错过任何一次调用信息了。

你双眼放光:这个好,爽爽爽!

鱼皮:不过这样做也有一个缺点,注意不要在日志中记录了敏感信息,比如用户密码。万一你的日志不小心泄露出去,就相当于泄露了大量用户的信息。
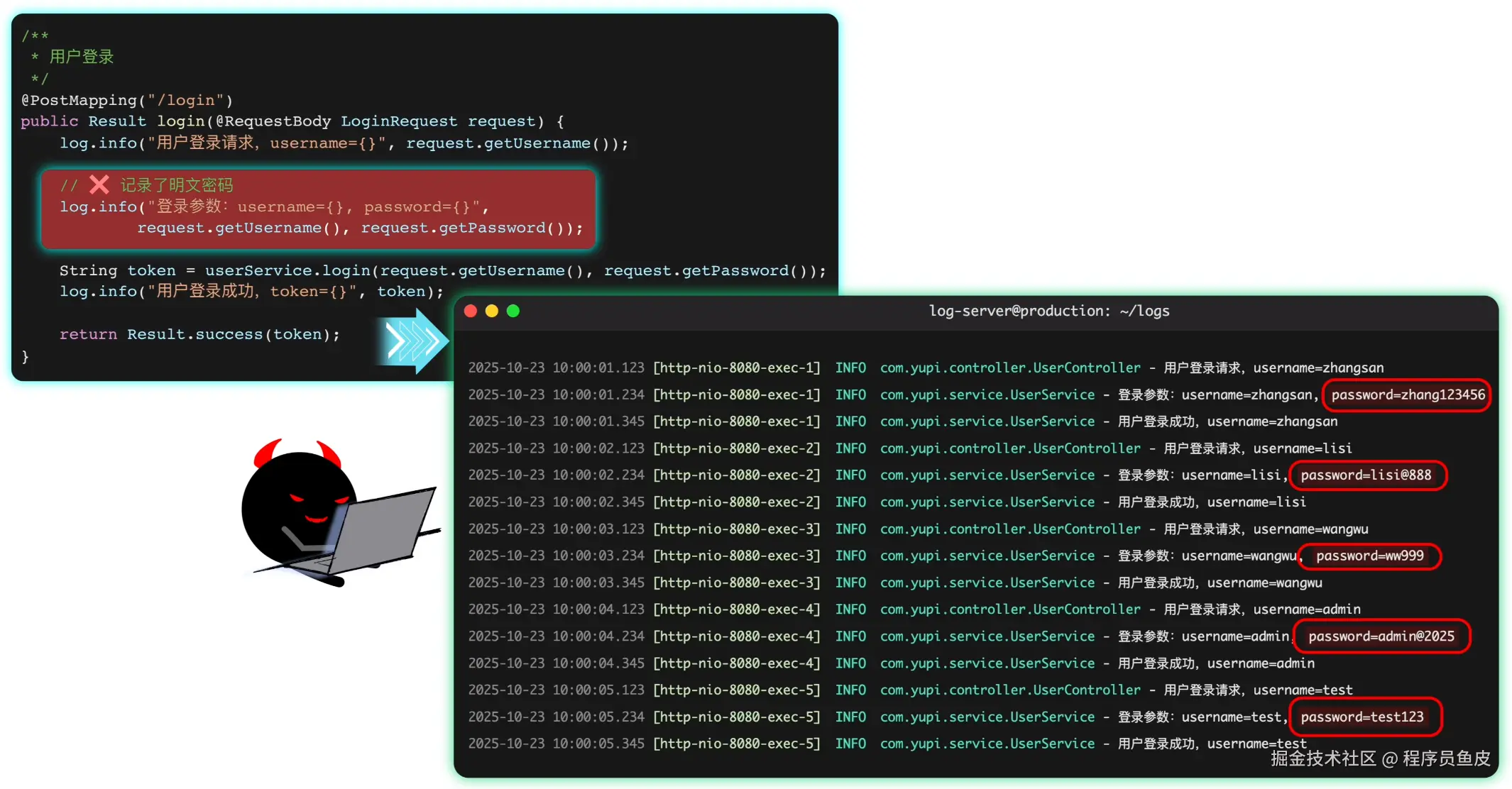
你拍拍胸脯:必须的!
4、控制日志输出量
一个星期后,产品经理又来找你了:小阿巴,你的批量导入功能又报错啦!而且怎么感觉程序变慢了?
你完全不慌,淡定地打开服务器的日志文件。结果瞬间呆住了……
好家伙,满屏都是密密麻麻的日志,这可怎么看啊?!
鱼皮看了看你的代码,摇了摇头:你现在每导入一条数据都要打一些日志,如果用户导入 10 万条数据,那就是几十万条日志!不仅刷屏,还会影响性能。
你有点委屈:不是你让我多打日志的么?那我应该怎么办?
鱼皮:你需要控制日志的输出量。
1)可以添加条件来控制,比如每处理 100 条数据时才记录一次:
if ((i + 1) % 100 == 0) {
log.info("批量导入进度:{}/{}", i + 1, userList.size());
}
2)或者在循环中利用 StringBuilder 进行字符串拼接,循环结束后统一输出:
StringBuilder logBuilder = new StringBuilder("处理结果:");
for (UserDTO userDTO : userList) {
processUser(userDTO);
logBuilder.append(String.format("成功[ID=%s], ", userDTO.getId()));
}
log.info(logBuilder.toString());
3)还可以通过修改日志配置文件,过滤掉特定级别的日志,防止日志刷屏:
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>logs/app.logfile>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFOlevel>
filter>
appender>
5、统一日志格式
你开心了:好耶,这样就不会刷屏了!但是感觉有时候日志很杂很乱,尤其是我想看某一个请求相关的日志时,总是被其他的日志干扰,怎么办?
鱼皮:好问题,可以在日志配置文件中定义统一的日志格式,包含时间戳、线程名称、日志级别、类名、方法名、具体内容等关键信息。
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%npattern>
encoder>
appender>
这样输出的日志更整齐易读:
此外,你还可以通过 MDC(Mapped Diagnostic Context)给日志添加额外的上下文信息,比如请求 ID、用户 ID 等,方便追踪。
在 Java 代码中,可以为 MDC 设置属性值:
@PostMapping("/user/import")
public Result importUsers(@RequestBody UserImportRequest request) {
// 1. 设置 MDC 上下文信息
MDC.put("requestId", generateRequestId());
MDC.put("userId", String.valueOf(request.getUserId()));
try {
log.info("用户请求处理完成");
// 执行具体业务逻辑
userService.batchImport(request.getUserList());
return Result.success();
} finally {
// 2. 及时清理MDC(重要!)
MDC.clear();
}
}
然后在日志配置文件中就可以使用这些值了:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - [%X{requestId}] [%X{userId}] %msg%npattern>
encoder>
appender>
这样,每个请求、每个用户的操作一目了然。
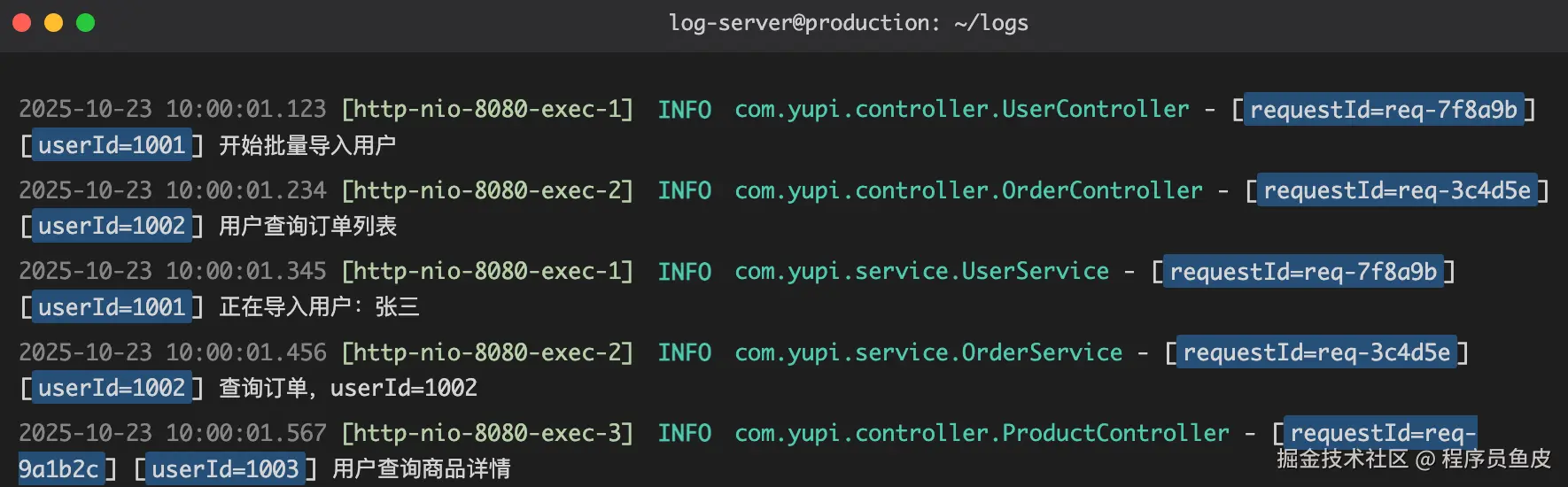
6、使用异步日志
你又开心了:这样打出来的日志,确实舒服,爽爽爽!但是我打日志越多,是不是程序就会更慢呢?有没有办法能优化一下?
鱼皮:当然有,可以使用 异步日志。
正常情况下,你调用 log.info() 打日志时,程序会立刻把日志写入文件,这个过程是同步的,会阻塞当前线程。而异步日志会把写日志的操作放到另一个线程里去做,不会阻塞主线程,性能更好。
你眼睛一亮:这么厉害?怎么开启?
鱼皮:很简单,只需要修改一下配置文件:
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>512queueSize>
<discardingThreshold>0discardingThreshold>
<neverBlock>falseneverBlock>
<appender-ref ref="FILE" />
appender>
<root level="INFO">
<appender-ref ref="ASYNC" />
root>
不过异步日志也有缺点,如果程序突然崩溃,缓冲区中还没来得及写入文件的日志可能会丢失。

所以要权衡一下,看你的系统更注重性能还是日志的完整性。
你想了想:我们的程序对性能要求比较高,偶尔丢几条日志问题不大,那我就用异步日志吧。
7、日志管理
接下来的很长一段时间,你混的很舒服,有 Bug 都能很快发现。
你甚至觉得 Bug 太少、工作没什么激情,所以没事儿就跟新来的实习生阿坤吹吹牛皮:你知道日志么?我可会打它了!

直到有一天,运维小哥突然跑过来:阿巴阿巴,服务器挂了!你快去看看!
你连忙登录服务器,发现服务器的硬盘爆满了,没法写入新数据。
你查了一下,发现日志文件竟然占了 200GB 的空间!
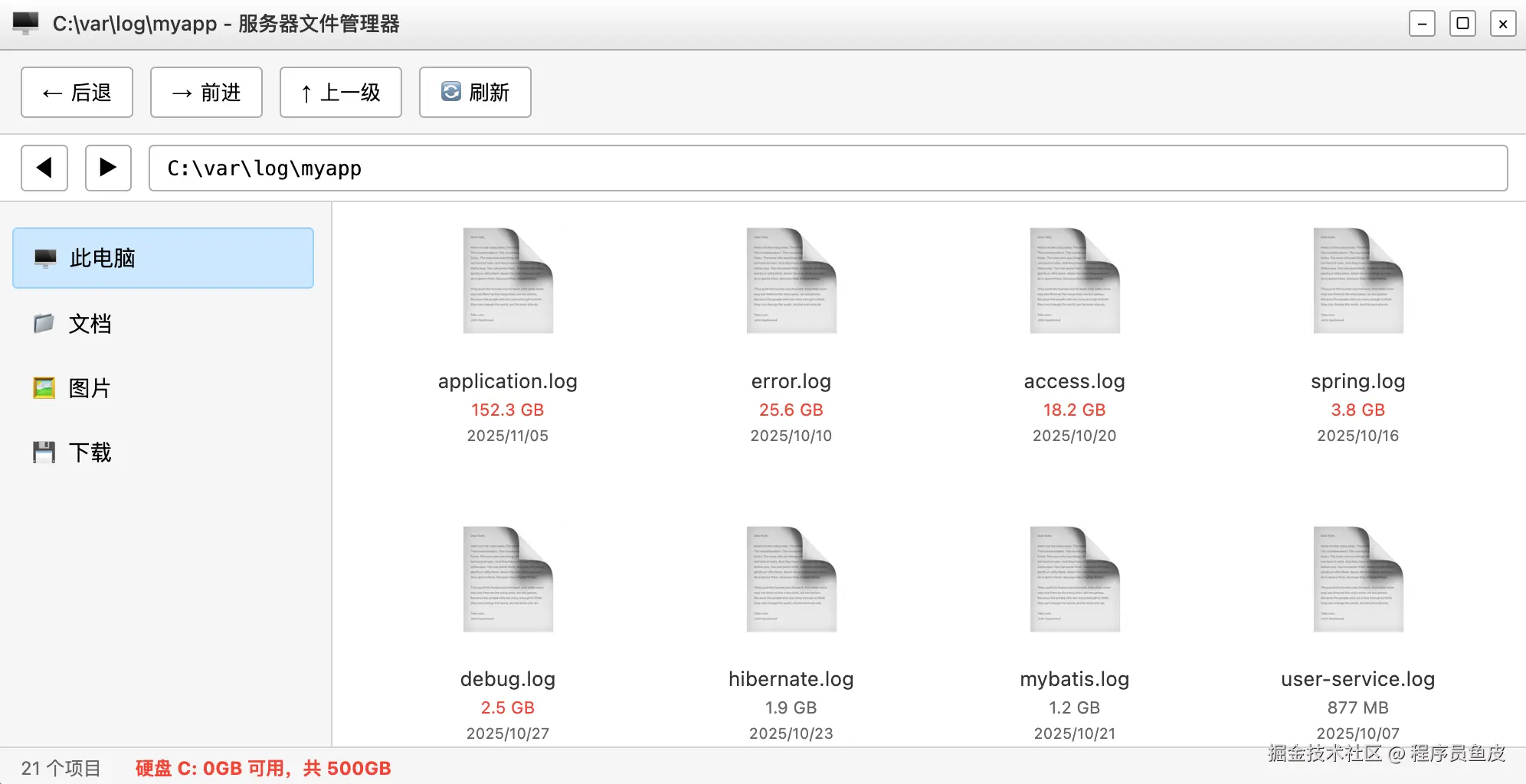
你汗流浃背了,正在考虑怎么甩锅,结果阿坤突然鸡叫起来:阿巴 giegie,你的日志文件是不是从来没清理过?
你尴尬地倒了个立,这样眼泪就不会留下来。

鱼皮叹了口气:这就是我要教你的下一招 —— 日志管理。
你好奇道:怎么管理?我每天登服务器删掉一些历史文件?
鱼皮:人工操作也太麻烦了,我们可以通过修改日志配置文件,让框架帮忙管理日志。
首先设置日志的滚动策略,可以根据文件大小和日期,自动对日志文件进行切分。
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.%i.logfileNamePattern>
<maxFileSize>10MBmaxFileSize>
<maxHistory>30maxHistory>
rollingPolicy>
这样配置后,每天会创建一个新的日志文件(比如 app-2025-10-23.0.log),如果日志文件大小超过 10MB 就再创建一个(比如 app-2025-10-23.1.log),并且只保留最近 30 天的日志。
还可以开启日志压缩功能,进一步节省磁盘空间:
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<fileNamePattern>logs/app-%d{yyyy-MM-dd}.log.gzfileNamePattern>
rollingPolicy>
你有些激动:吼吼,这样我们就可以按照天数更快地查看日志,服务器硬盘也有救啦!
8、集成日志收集系统
两年后,你负责的项目已经发展成了一个大型的分布式系统,有好几十个微服务。
如今,每次排查问题你都要登录到不同的服务器上查看日志,非常麻烦。而且有些请求的调用链路很长,你得登录好几台服务器、看好几个服务的日志,才能追踪到一个请求的完整调用过程。
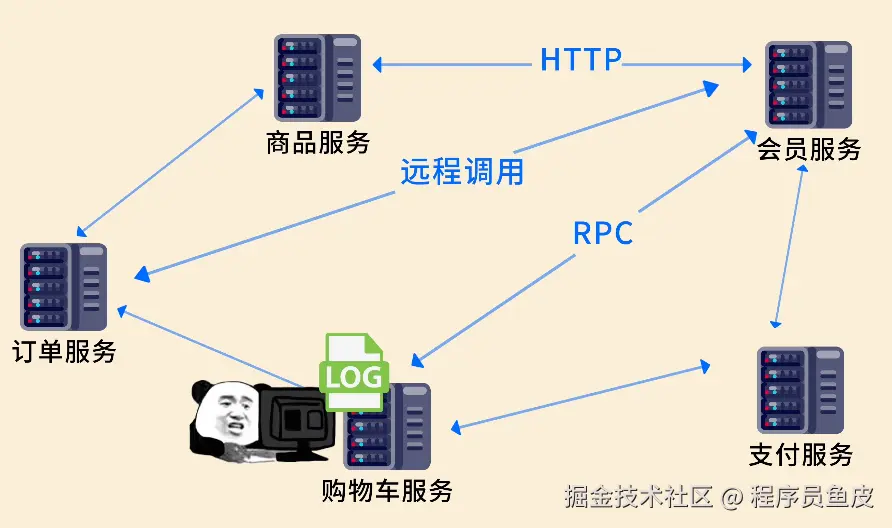
你简直要疯了!
于是你找到鱼皮求助:现在查日志太麻烦了,当年你还有一招没有教我,现在是不是……
鱼皮点点头:嗯,对于分布式系统,就必须要用专业的日志收集系统了,比如很流行的 ELK。
你好奇:ELK 是啥?伊拉克?
阿坤抢答道:我知道,就是 Elasticsearch + Logstash + Kibana 这套组合。
简单来说,Logstash 负责收集各个服务的日志,然后发送给 Elasticsearch 存储和索引,最后通过 Kibana 提供一个可视化的界面。
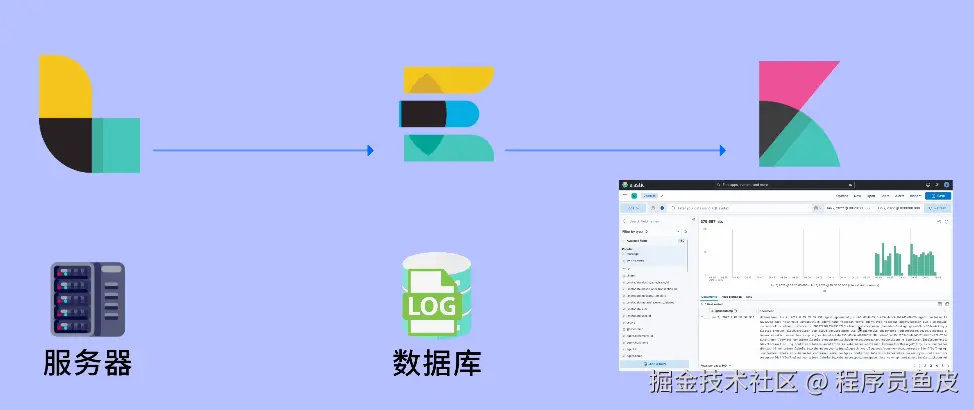
这样一来,我们可以方便地集中搜索、查看、分析日志。
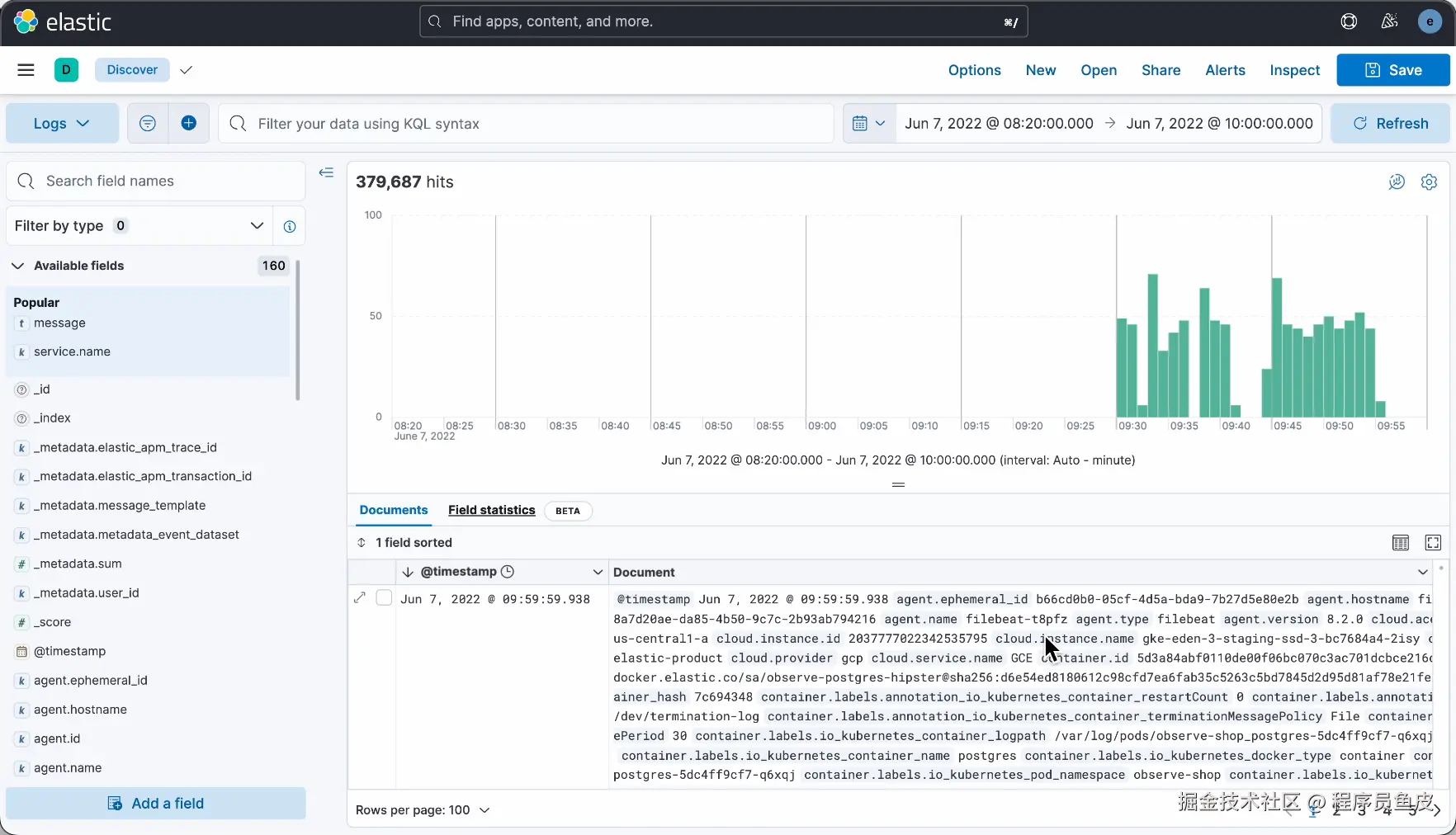
你惊讶了:原来日志还能这么玩,以后我所有的项目都要用 ELK!
鱼皮摆摆手:不过 ELK 的搭建和运维成本比较高,对于小团队来说可能有点重,还是要按需采用啊。
结局
至此,你已经掌握了打日志的核心秘法。
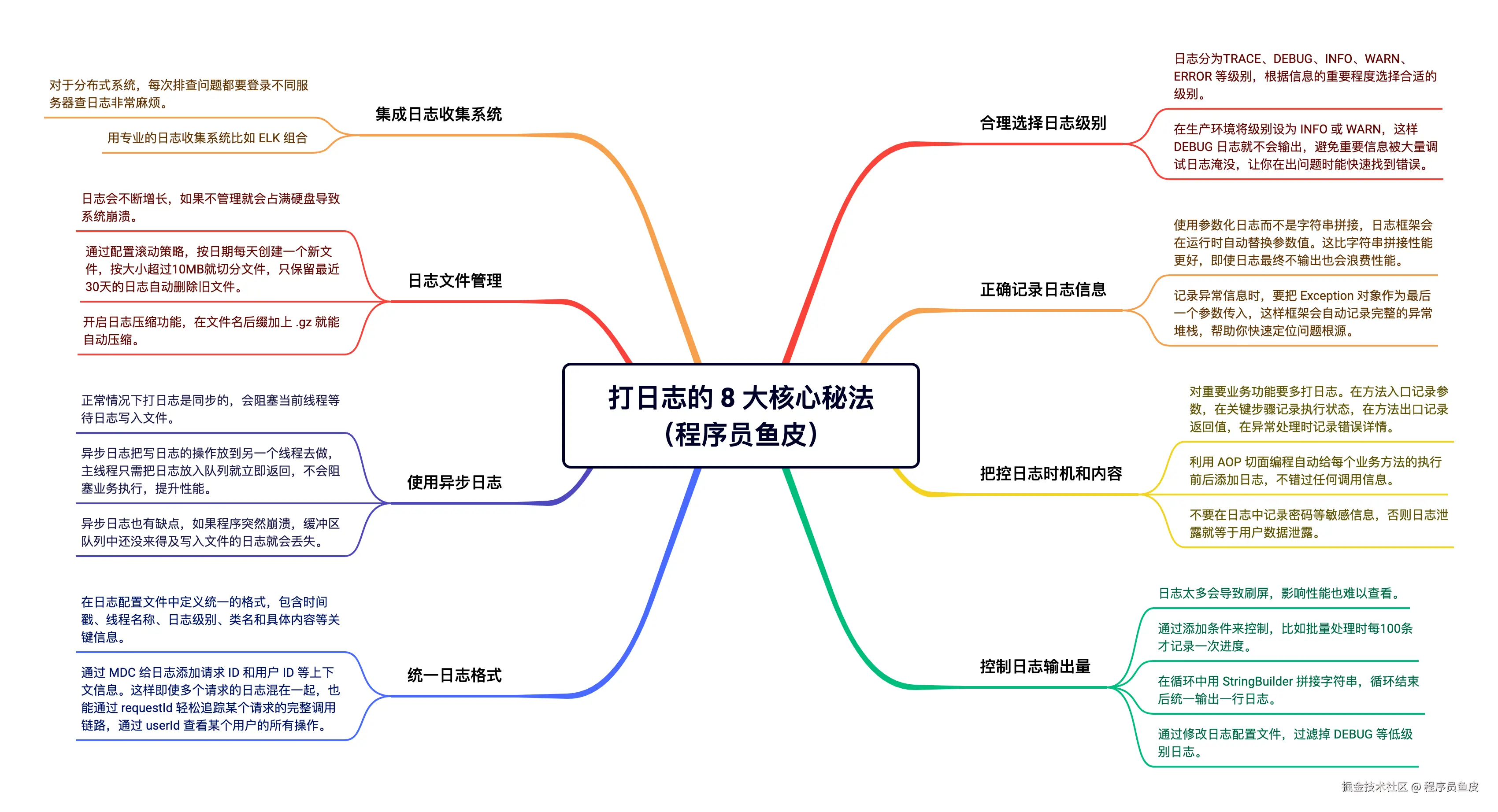
只是你很疑惑,为何那阿坤竟对日志系统如此熟悉?
阿坤苦笑道:我本来就是日志管理大师,可惜我上家公司的同事从来不打日志,所以我把他们暴打了一顿后跑路了。
阿巴 giegie 你要记住,日志不是写给机器看的,是写给未来的你和你的队友看的!
你要是以后不打日志,我就打你!
更多
来源:juejin.cn/post/7569159131819753510
女朋友被链接折磨疯了,我写了个工具一键解救
有一天女朋友跟我抱怨:工作里被各种链接折腾得头大,飞书和浏览器之间来回切窗口,一会忘了看哪个,心情都被搅乱了。我回头一想——我也一样,办公室每个人都被链接淹没。
“
同事丢来的需求文档、群里转的会议记录、GitLab 的 MR 链接、还有那些永远刷不完的通知——每点一个链接就得在聊天工具和浏览器之间跳转,回来后一秒钟就忘了"本来要点哪个、看哪个"。更别提那些收集了一堆好文章想集中看,或者别人发来一串链接让你"挑哪个好"的时候,光是打开就要折腾半天。
"
这不是注意力不集中,是工具没有帮你省掉这些无意义的切换。
"
于是我做了一个极简 Chrome 插件: Open‑All 。它只做一件事——把你所有网址一次性在新窗口打开。你复制粘贴一次,它把链接都整齐地摆在新标签页里,你只要从左到右按顺序看就行。简单、直接,让你把注意力放在真正重要的事情上
先看效果:一键打开多个链接
这些痛点你肯定也遇到过
每天都在经历的折磨
- 浏览器和飞书、企微、钉钉来回切应用 :复制链接、粘贴、点开、切回来,这套动作做一遍就够烦的了
- 容易忘事 :打开到第几个链接了?这个看过没?脑子根本记不住
- 启动成本高 :一想到链接要一个个点开,就懒得开始了
- 没法对比 :想要横向比较几个方案,但打开方案链接都费劲
具体什么时候最痛苦
- 收集的文章想一口气看完 :平时存了一堆好文章,周末想集中看,结果光打开就累了
- 别人让你帮忙选 :同事发来几个方案链接问你觉得哪个好,你得全部打开才能比较
- 代码 Review :GitLab 上好几个 MR 要看,还有相关的 Issue 和 CI 结果
- 开会前准备 :会议文档、背景资料、相关链接,都得提前打开看看
我的解决方案
设计思路很简单
- 就解决一个问题 :批量打开链接,不搞那些花里胡哨的功能
- 零学习成本 :会复制粘贴就会用
- 让你专注 :少折腾,多干活
能干什么
- 把一堆链接一次性在新窗口打开
- 自动保存你输入的内容,不怕误关
- 界面超简单,点两下就搞定
技术实现
项目结构
shiba-cursor
├── manifest.json # 扩展的"身-份-证"
├── popup.html # 弹窗样式
└── popup.js # 弹窗交互
文件说明:
- manifest.json:扩展身份信息
- popup.html:弹窗样式
- popup.js:弹窗交互
立即尝试
方法一: 从github仓库拉代码,本地安装
5分钟搞定安装:复制代码 → 创建文件 → 加载扩展 → 开始使用!
🚀 浏览项目的完整代码可以点击这里 github.com/Teernage/op…,如果对你有帮助欢迎Star。
方法二:直接从chrome扩展商店免费安装
Chrome扩展商店一键安装:open-all 批量打开URL chromewebstore.google.com/detail/%E6%…,如果对你有帮助欢迎好评。
动手实现
第一步:创建项目文件
创建文件夹
open-all创建manifest.json文件
{
"manifest_version": 3,
"name": "批量打开URL",
"version": "1.0",
"description": "输入多个URL,一键在新窗口中打开",
"permissions": [
"tabs",
"storage"
],
"action": {
"default_popup": "popup.html",
"default_title": "批量打开URL"
}
}
创建popup.html文件
html>
<html>
<head>
<meta charset="utf-8" />
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
body {
width: 320px;
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', Roboto,
sans-serif;
color: #333;
}
.container {
background: rgba(255, 255, 255, 0.95);
padding: 20px;
box-shadow: 0 8px 32px rgba(0, 0, 0, 0.1);
backdrop-filter: blur(10px);
border: 1px solid rgba(255, 255, 255, 0.2);
}
.title {
font-size: 18px;
font-weight: 600;
text-align: center;
margin-bottom: 16px;
color: #1d1d1f;
letter-spacing: -0.5px;
}
#urlInput {
width: 100%;
height: 140px;
padding: 12px;
border: 2px solid #e5e5e7;
border-radius: 12px;
font-size: 14px;
font-family: 'SF Mono', Monaco, monospace;
resize: none;
background: #fafafa;
transition: all 0.2s ease;
line-height: 1.4;
}
#urlInput:focus {
outline: none;
border-color: #007aff;
background: #fff;
box-shadow: 0 0 0 4px rgba(0, 122, 255, 0.1);
}
#urlInput::placeholder {
color: #8e8e93;
font-size: 13px;
}
.button-group {
display: flex;
gap: 8px;
margin-top: 16px;
}
button {
flex: 1;
padding: 12px 16px;
border: none;
border-radius: 10px;
font-size: 14px;
font-weight: 500;
cursor: pointer;
transition: all 0.2s ease;
font-family: inherit;
}
#openBtn {
background: linear-gradient(135deg, #007aff 0%, #0051d5 100%);
color: white;
box-shadow: 0 2px 8px rgba(0, 122, 255, 0.3);
}
#openBtn:hover {
transform: translateY(-1px);
box-shadow: 0 4px 12px rgba(0, 122, 255, 0.4);
}
#openBtn:active {
transform: translateY(0);
}
#clearBtn {
background: #f2f2f7;
color: #8e8e93;
border: 1px solid #e5e5e7;
}
#clearBtn:hover {
background: #e5e5ea;
color: #636366;
}
#status {
margin-top: 12px;
padding: 8px 12px;
border-radius: 8px;
font-size: 12px;
text-align: center;
display: none;
background: rgba(52, 199, 89, 0.1);
color: #30d158;
border: 1px solid rgba(52, 199, 89, 0.2);
}
.tip {
font-size: 11px;
color: #8e8e93;
text-align: center;
margin-top: 8px;
line-height: 1.3;
}
style>
head>
<body>
<div class="container">
<div class="title">批量打开 URLdiv>
<textarea
id="urlInput"
placeholder="输入 URL,每行一个:
https://www.apple.com
https://www.github.com
https://www.google.com"
>textarea>
<div class="button-group">
<button id="clearBtn">清空button>
<button id="openBtn">打开button>
div>
<div class="tip">输入会自动保存,打开后自动清空div>
<div id="status">div>
div>
<script src="popup.js">script>
body>
html>
创建popup.js文件
document.addEventListener('DOMContentLoaded', function() {
const urlInput = document.getElementById('urlInput');
const openBtn = document.getElementById('openBtn');
const clearBtn = document.getElementById('clearBtn');
const status = document.getElementById('status');
// 恢复上次保存的输入
chrome.storage.local.get(['savedUrls'], function(result) {
if (result.savedUrls) {
urlInput.value = result.savedUrls;
}
});
// 自动保存输入内容
urlInput.addEventListener('input', function() {
chrome.storage.local.set({savedUrls: urlInput.value});
});
// 清空按钮
clearBtn.addEventListener('click', function() {
urlInput.value = '';
chrome.storage.local.remove(['savedUrls']);
showStatus('已清空');
});
// 打开URL按钮
openBtn.addEventListener('click', function() {
const urls = getUrls(urlInput.value);
if (urls.length === 0) {
showStatus('请输入有效的URL');
return;
}
// 创建新窗口并打开所有URL
chrome.windows.create({url: urls[0]}, function(window) {
for (let i = 1; i < urls.length; i++) {
chrome.tabs.create({
windowId: window.id,
url: urls[i],
active: false
});
}
// 成功打开后清空输入并移除存储
urlInput.value = '';
chrome.storage.local.remove(['savedUrls']);
showStatus(`已打开 ${urls.length} 个URL`);
});
});
// 解析URL
function getUrls(input) {
return input.split('\n')
.map(line => line.trim())
.filter(line => line && (line.startsWith('http://') || line.startsWith('https://')));
}
// 显示状态
function showStatus(message) {
status.textContent = message;
status.style.display = 'block';
setTimeout(() => {
status.style.display = 'none';
}, 2000);
}
});
💡 深入理解脚本通信机制
虽然这个插件比较简单,只用到了 popup 和 storage API,但如果你想开发更复杂的插件(比如需要在网页中注入脚本、实现跨脚本通信),就必须理解 Chrome 插件的多脚本架构。
强烈推荐阅读:
👉 大部分人都错了!这才是 Chrome 插件多脚本通信的正确姿势
第二步:安装扩展
- 打开Chrome浏览器
- 地址栏输入:
chrome://extensions/ - 打开右上角"开发者模式"
- 点击"加载已解压的扩展程序"
- 选择刚才的文件夹,然后确定
- 固定扩展
- 点击扩展图标即可使用
最后想说的
这个插件功能很简单,但解决的是我们每天都会遇到的真实问题。它不会让你的工作效率翻倍,但能让你少一些无聊的重复操作,多一些专注的时间。
我和女朋友现在用着都挺爽的,希望也能帮到你。如果你也有类似的困扰,试试看吧,有什么想法也欢迎在评论区聊聊。
你最希望下个版本加什么功能?评论区告诉我!
如果觉得对您有帮助,欢迎点赞 👍 收藏 ⭐ 关注 🔔 支持一下! 往期实战推荐:
来源:juejin.cn/post/7566677296801071155
网页版微信来了!无需下载安装客户端!
大家好,我是 Java陈序员。
你是否遇到过:在公共电脑上想临时用微信却担心账号安全,服务器或 Linux 系统上找不到合适的微信客户端,或者想在多个设备上便捷访问微信却受限于安装环境?
今天,给大家介绍一个超实用的开源项目,让你通过浏览器就能轻松使用微信,无需在本地安装客户端!
项目介绍
wechat-selkies —— 基于 Docker 的微信/QQ Linux 客户端,将官方微信/QQ Linux 客户端封装在容器中,借助 Selkies WebRTC 技术,实现了通过浏览器直接访问使用。
功能特色:
- 浏览器访问:通过 Web 浏览器直接使用微信,无需本地安装
- Docker化部署:简单的容器化部署,环境隔离
- 数据持久化:支持配置和聊天记录持久化存储
- 中文支持:完整的中文字体和本地化支持,支持本地中文输入法
- 图片复制:支持通过侧边栏面板开启图片复制
- 文件传输:支持通过侧边栏面板进行文件传输
- AMD64和ARM64架构支持:兼容主流CPU架构
- 硬件加速:可选的 GPU 硬件加速支持
- 窗口切换器:左上角增加切换悬浮窗,方便切换到后台窗口,为后续添加其它功能做基础
- 自动启动:可配置自动启动微信和QQ客户端(可选)
技术栈:
- 基础镜像:
ghcr.io/linuxserver/baseimage-selkies:ubuntunoble - 微信客户端:官方微信 Linux 版本
- Web 技术:Selkies WebRTC
- 容器化:Docker + Docker Compose
安装部署
环境要求
- Docker
- Docker Compose
- 支持 WebRTC 的现代浏览器(Chrome、Firefox、Safari 等)
Docker 部署
1、拉取镜像
# GitHub Container Registry 镜像
docker pull ghcr.io/nickrunning/wechat-selkies:latest
# Docker Hub 镜像
docker pull ghcr.io/nickrunning/wechat-selkies:latest
2、创建挂载目录
mkdir -p /data/software/wechat/conf
3、运行容器
docker run -it -d \
-p 3000:3000 \
-p 3001:3001 \
-v /data/software/wechat/conf:/config \
--device /dev/dri:/dev/dri \
nickrunning/wechat-selkies:latest
4、容器运行成功后,浏览器访问
# HTTP
http://{ip/域名}:3000
# HTTPS
https://{ip/域名}:3001
注意:映射 3000 端口用于 HTTP 访问,3001 端口用于 HTTPS 访问,建议使用 HTTPS.
Docker Compose 部署
1、创建项目目录并进入
mkdir -p /data/software/wechat-selkies
cd /data/software/wechat-selkies
2、创建 docker-compose.yaml 文件
services:
wechat-selkies:
image: nickrunning/wechat-selkies:latest # or ghcr.io/nickrunning/wechat-selkies:latest
container_name: wechat-selkies
ports:
- "3000:3000" # http port
- "3001:3001" # https port
restart: unless-stopped
volumes:
- ./config:/config
devices:
- /dev/dri:/dev/dri # optional, for hardware acceleration
environment:
- PUID=1000 # user ID
- PGID=100 # group ID
- TZ=Asia/Shanghai # timezone
- LC_ALL=zh_CN.UTF-8 # locale
- AUTO_START_WECHAT=true # default is true
- AUTO_START_QQ=false # default is false
# - CUSTOM_USER= # recommended to set a custom user name
# - PASSWORD= # recommended to set a password for selkies web ui
3、启动服务
docker-compose up -d
4、运行成功后,浏览器访问
# HTTP
http://{ip/域名}:3000
# HTTPS
https://{ip/域名}:3001
源码部署
1、克隆或下载项目源码
git clone https://github.com/nickrunning/wechat-selkies.git
cd wechat-selkies
2、启动服务
docker-compose up -d
3、运行成功后,浏览器访问
# HTTP
http://{ip/域名}:3000
# HTTPS
https://{ip/域名}:3001
配置说明
在 docker-compose.yml 中可以配置以下环境变量:
| 变量名 | 默认值 | 说明 |
|---|---|---|
| TITLE | WeChat Selkies | Web UI 标题 |
| PUID | 1000 | 用户 ID |
| PGID | 100 | 组 ID |
| TZ | Asia/Shanghai | 时区设置 |
| LC_ALL | zh_CN.UTF-8 | 语言环境 |
| CUSTOM_USER | - | 自定义用户名(推荐设置) |
| PASSWORD | - | Web UI 访问密码(推荐设置) |
| AUTO_START_WECHAT | true | 是否自动启动微信客户端 |
| AUTO_START_QQ | false | 是否自动启动 QQ 客户端 |
功能体验
wechat-selkies 部署成功后,即可通过浏览器访问。
1、打开地址后,需要使用手机微信进行扫码登录

2、扫码登录成功后,即可开始使用
3、同时支持暗黑主题模式
4、QQ 同样也需要进行扫码登录或者使用账密登录
5、登录成功后,即可开始使用

如果你想在 Linux 系统使用微信或者想随时随地便捷使用微信,不妨试试 wechat-selkies, 可以使用 Docker 快速地部署在服务器上,快去试试吧~
项目地址:https://github.com/nickrunning/wechat-selkies
最后
推荐的开源项目已经收录到 GitHub 项目,欢迎 Star:
https://github.com/chenyl8848/great-open-source-project
或者访问网站,进行在线浏览:
https://chencoding.top:8090/#/
大家的点赞、收藏和评论都是对作者的支持,如文章对你有帮助还请点赞转发支持下,谢谢!
来源:juejin.cn/post/7572921387746377734
逃离鸭科夫5人2周1个亿,我们可以做一个鸡科夫吗?
点击上方亿元程序员+关注和★星标

引言
哈喽大家好,不知道小伙伴们最近有没有关注到一个名叫《逃离鸭科夫》的游戏。
这款游戏在各大社交平台和游戏社区都成为了热门话题,Steam平台上的同时在线人数一度突破30万,其口碑表现也相当出色。
在累计一万七千多条玩家评价中,收获了96%的压倒性好评,整体评价明显优于今年发布的多数新作。
其中更为炸裂的信息,开发这款游戏的团队仅仅只有5个人。

除了有常规的3D美术和数值策划外,还有3个神人:
- 负责游戏设计、战斗编程以及基础美术的制作人。
- 负责游戏内大部分编程的游戏主策。
- 负责游戏内所有美术资产的校招生。
更想不到的是,如此精简的团队,打造出的游戏,仅仅2周时间,收获1个亿,远高于团队预期。
那么问题来了,鸭科夫如此成功,我们可以做一个“鸡科夫”吗?
这个问题还是交给小伙伴们吧,笔者实在是折腾不起,但是呢,我们可以定个小目标,做个简单的小东西起步。
言归正传,本期笔者介绍一下如何在Cocos游戏开发中,制作类似逃离鸭科夫中的激光瞄准器!
本文源码和源工程在文末获取,小伙伴们自行前往。
什么是激光瞄准器?

激光瞄准器是一种安装在武器(如枪支、弓箭等)上的装置,它发射出一束低功率的、可见或不可见的激光束,在被瞄准的物体上投射一个光点,提示使用者弹着点(即子弹预计会命中的位置)。
制作原理

在Cocos游戏开发中,激光瞄准器的制作方法有不少,包括但不限于以下几种:
- Line组件。
- 自定义Shader。
- 粒子系统。
本期我们主要演示Line组件的使用。
Line组件
Line组件用于渲染3D场景中给定的点连成的线段。
Line组件渲染的线段是有宽度的,并且总是面向摄像机,这与billboard组件相似。
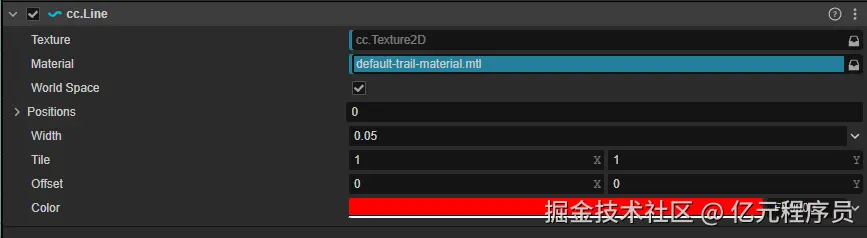
Line组件的使用非常简单,我们重点关注他的:
positions: 每个线段端点的坐标。width: 线段宽度,如果采用曲线,则表示沿着线段方向上的曲线变化。color: 线段颜色,如果采用渐变色,则表示沿着线段方向上的颜色渐变。
激光瞄准器制作实例
下面跟随这笔者,一起在Cocos游戏开发中实现一个激光瞄准器。
1.资源准备
老生常谈,有美术搭子的找美术搭子,没有美术搭子的找AI搭子。
笔者拿出做例子最爱的小鸡,本期我们叫他“鸡科夫”。
2.Line组件
新建一个节点,绑定一个Line组件,设置一下线的宽度和颜色,坐标我们在代码中动态设置。
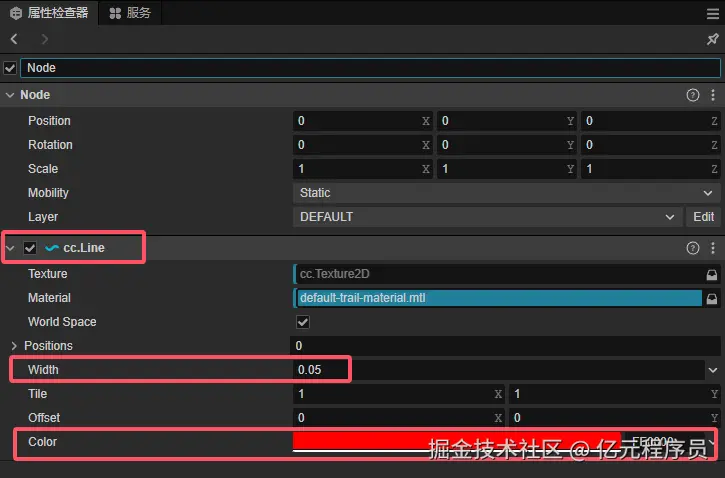
3.写代码
首先声明一个ChickenKF类并挂在Canvas上,绑定好Line组件、鸡科夫和摄像机。
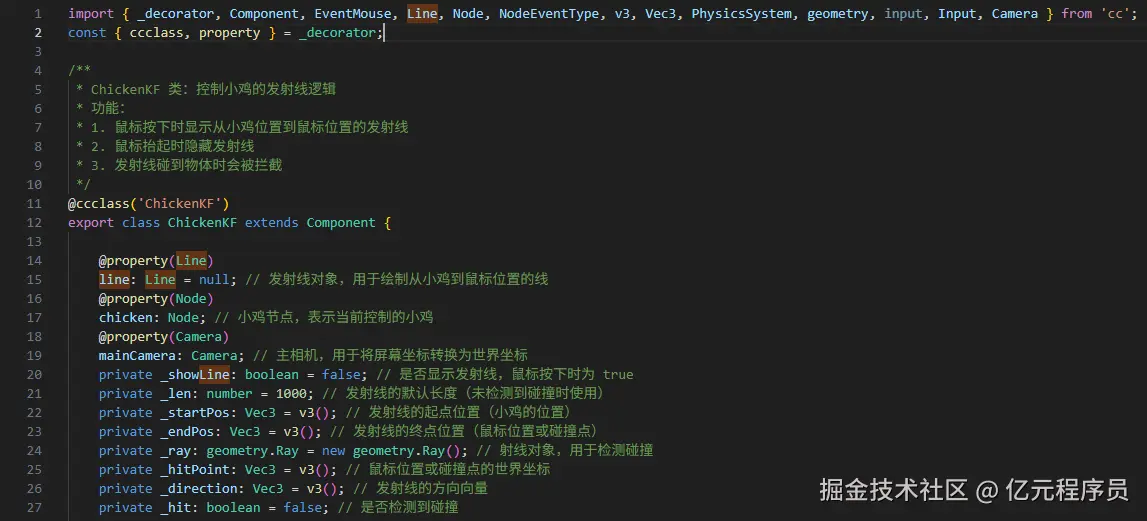
然后监听一下鼠标事件,按下时显示激光,移动瞄准,抬起时关闭激光。
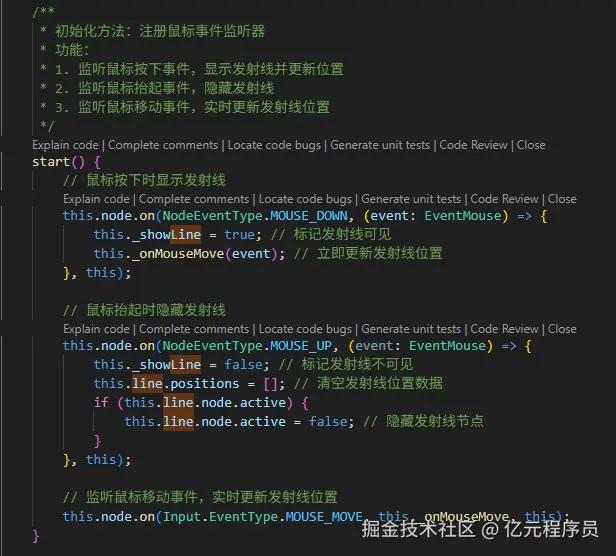
通过鼠标事件和射线检测,确定激光的方向和目标。
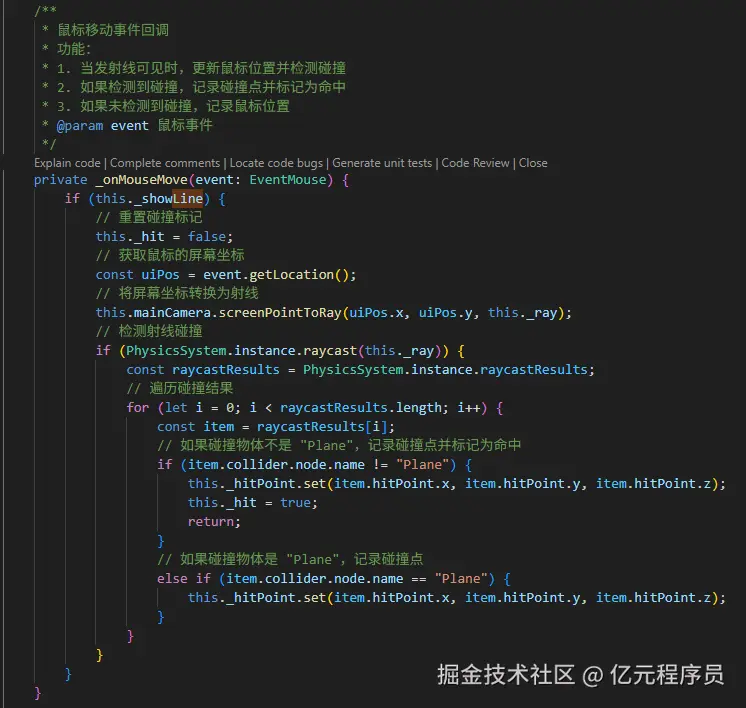
计算出来激光的起点和终点,对Line组件的positions进行赋值。
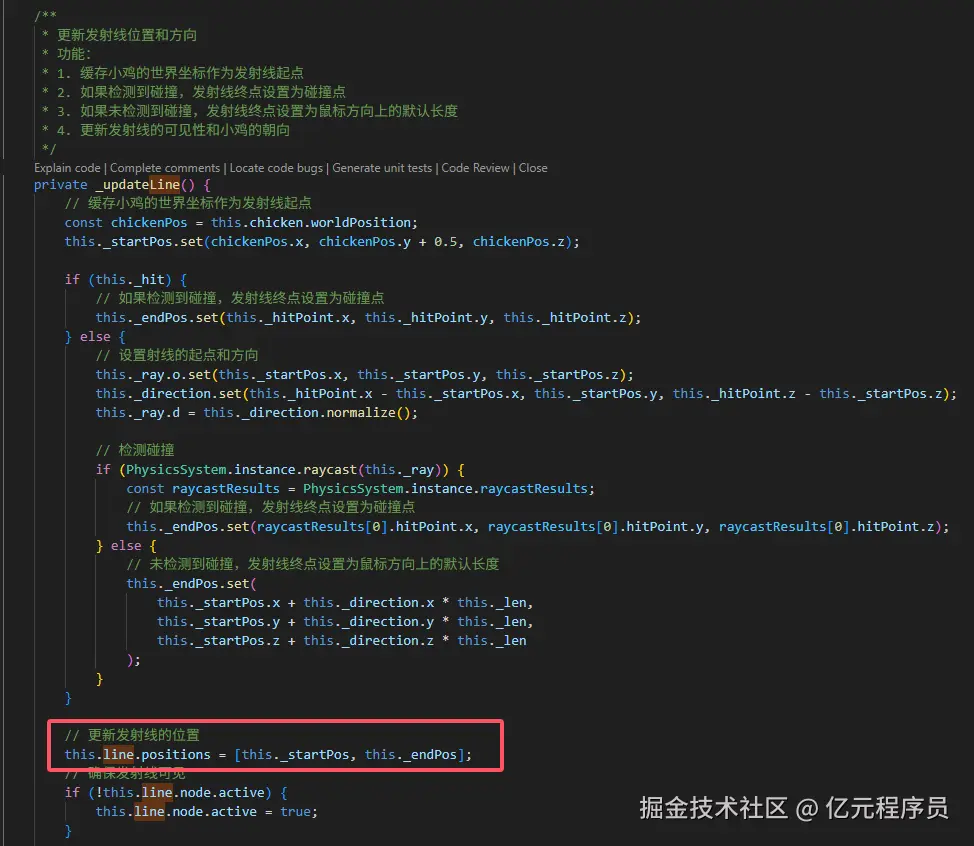
4.效果演示

结语
逃离鸭科夫之所以能够成为爆款,并非偶然,它源于对游戏的热爱、对玩家的重视以及对游戏的执着,因为他们“听人劝吃饱饭”。
假如我们完整复刻出来一个“鸡科夫”,它会如愿成为爆款吗?
评论区说出你的看法。
本文源工程可通过私信发送 ChickenKF 获取。
我是"亿元程序员",一位有着8年游戏行业经验的主程。在游戏开发中,希望能给到您帮助, 也希望通过您能帮助到大家。
AD:笔者线上的小游戏《打螺丝闯关》《贪吃蛇掌机经典》《重力迷宫球》《填色之旅》《方块掌机经典》大家可以自行点击搜索体验。
实不相瞒,想要个赞和爱心!请把该文章分享给你觉得有需要的其他小伙伴。谢谢!
推荐专栏:
点击下方灰色按钮+关注。
来源:juejin.cn/post/7569515660930220083
如何用Claude Code 生成顶级UI ❇️
前言
以往我的处理
以往生成UI我会怎么做呢?
- 跟 v0 结对chat,出一版原型,再基于原型样式去迭代
- 或者是使用 stritch 设计一个初版的UI,再进行迭代
- https://v0.app/
- https://stitch.withgoogle.com/
下方是其中一个产品,hi-offer 多次迭代后大致的UI 效果,看起来还可以,只是还没有到很靓丽的程度🫥
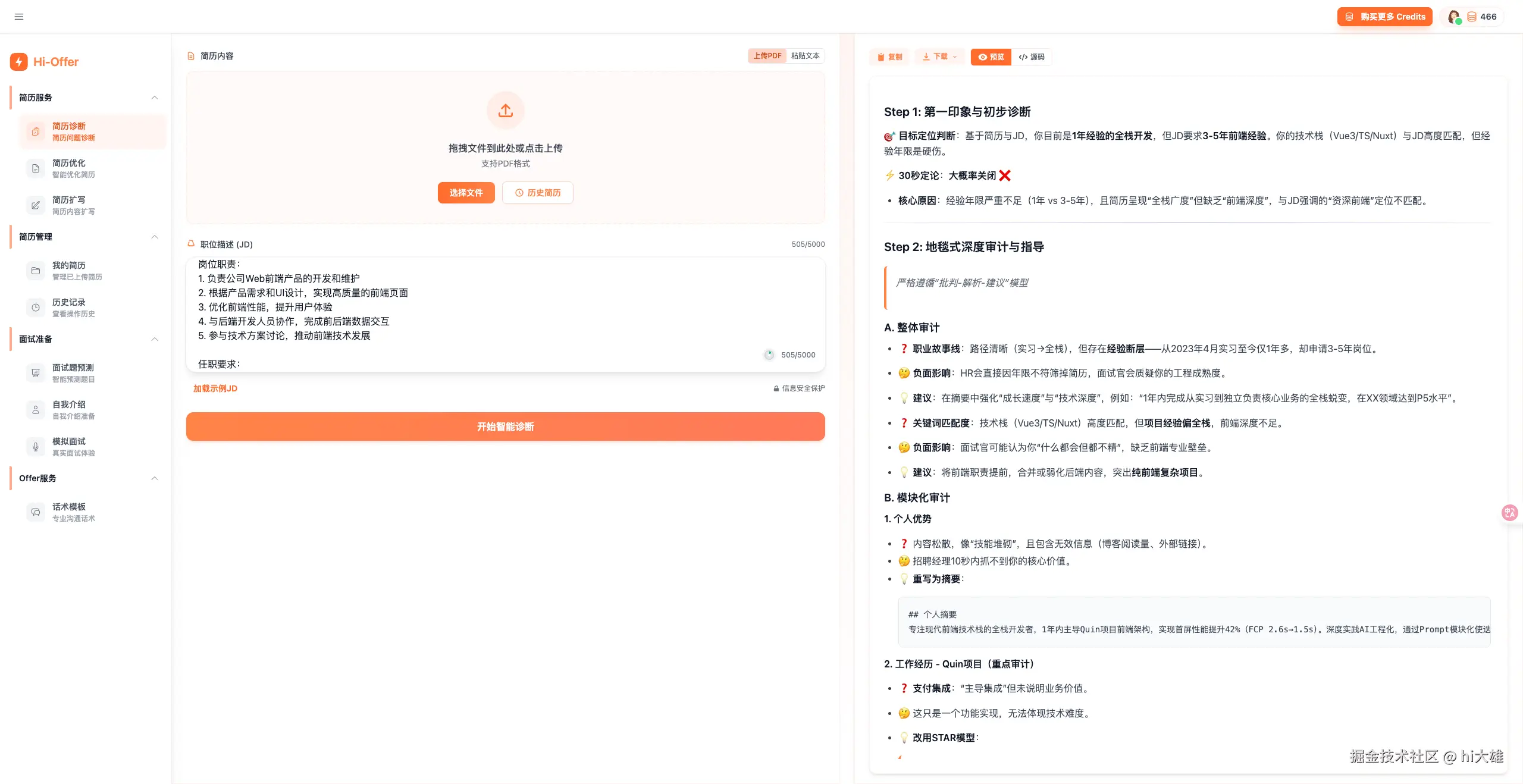
那可能有小伙伴会有同样的疑问:
* 我没有UI 设计经验呀,我要怎么快速实现 **靓丽程度** 的 UI 呢?
* 答案是~~抄~~,No,是模仿学习哈哈
给大家一个样例,MotherDucker 的首页。 给大家10秒钟,思索一下。如果你想复刻这种UI风格,用在自己的产品上,你会怎么做?
可能有下面的一些思考
- 截图 UI 给 cluade code 分析
- 截图丢给stitch + 对话迭代
众所周知,OCR 过程,出现很大UI 信息缺失,比如:具体配色数值、阴影、间距、字体等,于是你会发现,最终AI完成的效果可能都没有60% 。
于是核心思路是:解决样式信息大量丢失的问题,通过减少信息代差,让AI coding 完成的UI 风格有不错的效果
好消息是,最近实践了一个工作流,很好地解决了这个问题,随我来,我们只需要核心的五个步骤:
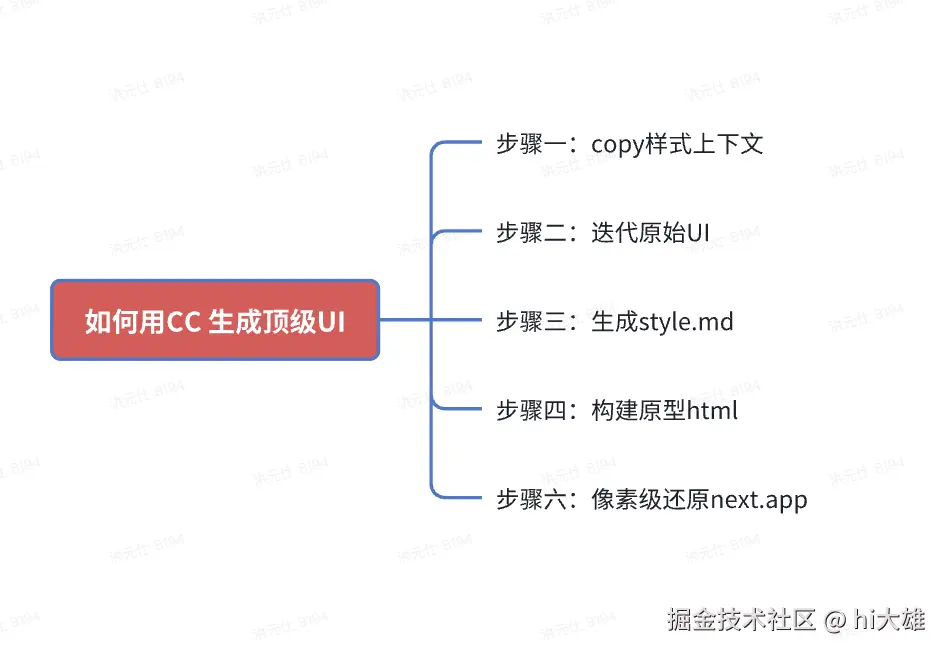
最终成品效果如下,全程vibe coding,详见:4-quadrant-to-do.vercel.app/
- 如果你感觉效果还不错,愉快开始本文之旅吧~~
- 如果你认为效果比较牵强,那么阅读本文之后,你一定可以迭代出更好的UI。
话不多说,我们开始发车 ~~
以往生成UI我会怎么做呢?
- 跟 v0 结对chat,出一版原型,再基于原型样式去迭代
- 或者是使用 stritch 设计一个初版的UI,再进行迭代
- https://v0.app/
- https://stitch.withgoogle.com/
下方是其中一个产品,hi-offer 多次迭代后大致的UI 效果,看起来还可以,只是还没有到很靓丽的程度🫥
那可能有小伙伴会有同样的疑问:
* 我没有UI 设计经验呀,我要怎么快速实现 **靓丽程度** 的 UI 呢?
* 答案是~~抄~~,No,是模仿学习哈哈
给大家一个样例,MotherDucker 的首页。 给大家10秒钟,思索一下。如果你想复刻这种UI风格,用在自己的产品上,你会怎么做?
可能有下面的一些思考
- 截图 UI 给 cluade code 分析
- 截图丢给stitch + 对话迭代
众所周知,OCR 过程,出现很大UI 信息缺失,比如:具体配色数值、阴影、间距、字体等,于是你会发现,最终AI完成的效果可能都没有60% 。
于是核心思路是:解决样式信息大量丢失的问题,通过减少信息代差,让AI coding 完成的UI 风格有不错的效果
好消息是,最近实践了一个工作流,很好地解决了这个问题,随我来,我们只需要核心的五个步骤:
最终成品效果如下,全程vibe coding,详见:4-quadrant-to-do.vercel.app/
- 如果你感觉效果还不错,愉快开始本文之旅吧~~
- 如果你认为效果比较牵强,那么阅读本文之后,你一定可以迭代出更好的UI。
话不多说,我们开始发车 ~~
步骤一:Copy样式上下文,生成初版的html
你需要提供下方的的上下文信息给CC,让他帮忙构建一个html 页面
- 参考的 web UI 截图【长图或多张全屏图】
- copy web 的 html css 样式信息
- prompt
你需要提供下方的的上下文信息给CC,让他帮忙构建一个html 页面
- 参考的 web UI 截图【长图或多张全屏图】
- copy web 的 html css 样式信息
- prompt
截图

prompt
Help me rebuild exact same ui design in signle html as xxx.html, above is extracted css:
Help me rebuild exact same ui design in signle html as xxx.html, above is extracted css:
style info
右键检查,选择html、body 元素,copy style 信息
* html css style
* body css style
例如:
-webkit-locale: "en";
scroll-margin-top: var(--eyebrow-desktop);
animation-duration: 0.0001s !important;
animation-iteration-count: 1 !important;
transition-duration: 0s !important;
caret-color: transparent !important;
--tw-border-spacing-x: 0;
--tw-border-spacing-y: 0;
--tw-translate-x: 0;
--tw-translate-y: 0;
--tw-rotate: 0;
--tw-skew-x: 0;
--tw-skew-y: 0;
--tw-scale-x: 1;
--tw-scale-y: 1;
--tw-pan-x: ;
--tw-pan-y: ;
--tw-pinch-zoom: ;
--tw-scroll-snap-strictness: proximity;
--tw-gradient-from-position: ;
--tw-gradient-via-position: ;
--tw-gradient-to-position: ;
--tw-ordinal: ;
--tw-slashed-zero: ;
--tw-numeric-figure: ;
--tw-numeric-spacing: ;
--tw-numeric-fraction: ;
--tw-ring-inset: ;
--tw-ring-offset-width: 0px;
--tw-ring-offset-color: #fff;
--tw-ring-color: rgb(59 130 246 / 0.5);
--tw-ring-offset-shadow: 0 0 #0000;
--tw-ring-shadow: 0 0 #0000;
--tw-shadow: 0 0 #0000;
--tw-shadow-colored: 0 0 #0000;
--tw-blur: ;
--tw-brightness: ;
--tw-contrast: ;
--tw-grayscale: ;
--tw-hue-rotate: ;
--tw-invert: ;
--tw-saturate: ;
--tw-sepia: ;
--tw-drop-shadow: ;
--tw-backdrop-blur: ;
--tw-backdrop-brightness: ;
--tw-backdrop-contrast: ;
--tw-backdrop-grayscale: ;
--tw-backdrop-hue-rotate: ;
--tw-backdrop-invert: ;
--tw-backdrop-opacity: ;
--tw-backdrop-saturate: ;
--tw-backdrop-sepia: ;
--tw-contain-size: ;
--tw-contain-layout: ;
--tw-contain-paint: ;
--tw-contain-style: ;
box-sizing: border-box;
border: 0px;
font-size: 100%;
vertical-align: baseline;
text-decoration: none;
scroll-padding-top: var(--header-desktop);
scroll-behavior: auto;
height: 100%;
margin: 0;
padding: 0;
line-height: 1.5;
-webkit-text-size-adjust: 100%;
tab-size: 4;
font-family: ui-sans-serif, system-ui, sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
font-feature-settings: normal;
font-variation-settings: normal;
-webkit-tap-highlight-color: transparent;
--swiper-theme-color: #007aff;
--toastify-toast-min-height: fit-content;
--toastify-toast-width: fit-content;
--header-mobile: 70px;
--header-desktop: 90px;
--eyebrow-mobile: 70px;
--eyebrow-desktop: 55px;
右键检查,选择html、body 元素,copy style 信息
* html css style
* body css style
例如:
-webkit-locale: "en";
scroll-margin-top: var(--eyebrow-desktop);
animation-duration: 0.0001s !important;
animation-iteration-count: 1 !important;
transition-duration: 0s !important;
caret-color: transparent !important;
--tw-border-spacing-x: 0;
--tw-border-spacing-y: 0;
--tw-translate-x: 0;
--tw-translate-y: 0;
--tw-rotate: 0;
--tw-skew-x: 0;
--tw-skew-y: 0;
--tw-scale-x: 1;
--tw-scale-y: 1;
--tw-pan-x: ;
--tw-pan-y: ;
--tw-pinch-zoom: ;
--tw-scroll-snap-strictness: proximity;
--tw-gradient-from-position: ;
--tw-gradient-via-position: ;
--tw-gradient-to-position: ;
--tw-ordinal: ;
--tw-slashed-zero: ;
--tw-numeric-figure: ;
--tw-numeric-spacing: ;
--tw-numeric-fraction: ;
--tw-ring-inset: ;
--tw-ring-offset-width: 0px;
--tw-ring-offset-color: #fff;
--tw-ring-color: rgb(59 130 246 / 0.5);
--tw-ring-offset-shadow: 0 0 #0000;
--tw-ring-shadow: 0 0 #0000;
--tw-shadow: 0 0 #0000;
--tw-shadow-colored: 0 0 #0000;
--tw-blur: ;
--tw-brightness: ;
--tw-contrast: ;
--tw-grayscale: ;
--tw-hue-rotate: ;
--tw-invert: ;
--tw-saturate: ;
--tw-sepia: ;
--tw-drop-shadow: ;
--tw-backdrop-blur: ;
--tw-backdrop-brightness: ;
--tw-backdrop-contrast: ;
--tw-backdrop-grayscale: ;
--tw-backdrop-hue-rotate: ;
--tw-backdrop-invert: ;
--tw-backdrop-opacity: ;
--tw-backdrop-saturate: ;
--tw-backdrop-sepia: ;
--tw-contain-size: ;
--tw-contain-layout: ;
--tw-contain-paint: ;
--tw-contain-style: ;
box-sizing: border-box;
border: 0px;
font-size: 100%;
vertical-align: baseline;
text-decoration: none;
scroll-padding-top: var(--header-desktop);
scroll-behavior: auto;
height: 100%;
margin: 0;
padding: 0;
line-height: 1.5;
-webkit-text-size-adjust: 100%;
tab-size: 4;
font-family: ui-sans-serif, system-ui, sans-serif, "Apple Color Emoji", "Segoe UI Emoji", "Segoe UI Symbol", "Noto Color Emoji";
font-feature-settings: normal;
font-variation-settings: normal;
-webkit-tap-highlight-color: transparent;
--swiper-theme-color: #007aff;
--toastify-toast-min-height: fit-content;
--toastify-toast-width: fit-content;
--header-mobile: 70px;
--header-desktop: 90px;
--eyebrow-mobile: 70px;
--eyebrow-desktop: 55px;
HTML 预览效果
cc构建的html 页面
cc构建的html 页面
步骤2: 迭代原始UI
这里我觉得原始UI的分格上已经可以了,只是一些细节还不太行,比如按钮hover 的阴影、边框等还需要完善。
我一般会使用下方的prompt 以及 copy 具体标签的CSS 来进一步处理。
这里我觉得原始UI的分格上已经可以了,只是一些细节还不太行,比如按钮hover 的阴影、边框等还需要完善。
我一般会使用下方的prompt 以及 copy 具体标签的CSS 来进一步处理。
prompt
Only code in HTML/Tailwind in a single code block.
Any CSS styles should be in the style attribute. Start with a response, then code and finish with a response.
Don't mention about tokens, Tailwind or HTML.
Always include the html, head and body tags.
Use lucide icons for javascript, 1.5 strokewidth.
Unless style is specified by user, design in the style of Linear, Stripe, Vercel, Tailwind UI (IMPORTANT: don't mention names).
Checkboxes, sliders, dropdowns, toggles should be custom (don't add, only include if part of the UI). Be extremely accurate with fonts.
For font weight, use one level thinner: for example, Bold should be Semibold.
Titles above 20px should use tracking-tight.
Make it responsive.
Avoid setting tailwind config or css classes, use tailwind directly in html tags.
If there are charts, use chart.js for charts (avoid bug: if your canvas is on the same level as other nodes: h2 p canvas div = infinite grows. h2 p div>canvas div = as intended.).
Add subtle dividers and outlines where appropriate.
Don't put tailwind classes in the html tag, put them in the body tags.
If no images are specified, use these Unsplash images like faces, 3d, render, etc.
Be creative with fonts, layouts, be extremely detailed and make it functional.
If design, code or html is provided, IMPORTANT: respect the original design, fonts, colors, style as much as possible.
Don't use javascript for animations, use tailwind instead. Add hover color and outline interactions.
For tech, cool, futuristic, favor dark mode unless specified otherwise.
For modern, traditional, professional, business, favor light mode unless specified otherwise.
Use 1.5 strokewidth for lucide icons and avoid gradient containers for icons.
Use subtle contrast.
For logos, use letters only with tight tracking.
Avoid a bottom right floating DOWNLOAD button.
Only code in HTML/Tailwind in a single code block.
Any CSS styles should be in the style attribute. Start with a response, then code and finish with a response.
Don't mention about tokens, Tailwind or HTML.
Always include the html, head and body tags.
Use lucide icons for javascript, 1.5 strokewidth.
Unless style is specified by user, design in the style of Linear, Stripe, Vercel, Tailwind UI (IMPORTANT: don't mention names).
Checkboxes, sliders, dropdowns, toggles should be custom (don't add, only include if part of the UI). Be extremely accurate with fonts.
For font weight, use one level thinner: for example, Bold should be Semibold.
Titles above 20px should use tracking-tight.
Make it responsive.
Avoid setting tailwind config or css classes, use tailwind directly in html tags.
If there are charts, use chart.js for charts (avoid bug: if your canvas is on the same level as other nodes: h2 p canvas div = infinite grows. h2 p div>canvas div = as intended.).
Add subtle dividers and outlines where appropriate.
Don't put tailwind classes in the html tag, put them in the body tags.
If no images are specified, use these Unsplash images like faces, 3d, render, etc.
Be creative with fonts, layouts, be extremely detailed and make it functional.
If design, code or html is provided, IMPORTANT: respect the original design, fonts, colors, style as much as possible.
Don't use javascript for animations, use tailwind instead. Add hover color and outline interactions.
For tech, cool, futuristic, favor dark mode unless specified otherwise.
For modern, traditional, professional, business, favor light mode unless specified otherwise.
Use 1.5 strokewidth for lucide icons and avoid gradient containers for icons.
Use subtle contrast.
For logos, use letters only with tight tracking.
Avoid a bottom right floating DOWNLOAD button.
原始UI.html 效果
经过两次三次调整后,我觉得work 了
经过两次三次调整后,我觉得work 了
步骤3: 生成STYLE_GUIDE.md
在正式开整我们的web 产品之前,我们需要一个容器,保存上面我们原始UI的所有样式信息,减少信息代差。
这个容器就是STYLE_GUIDE.md,你可以使用下面的 prompt 来生成
在正式开整我们的web 产品之前,我们需要一个容器,保存上面我们原始UI的所有样式信息,减少信息代差。
这个容器就是STYLE_GUIDE.md,你可以使用下面的 prompt 来生成
pormpt
Great, now help me generate a detailed style guide\
In style guide, you must include the following part:
- Overview
- Color Palette
- Typography (Pay attention to font weight, font size and how different fonts have been used together in the project)
- Spacing System
- Component Styles
- Shadows & Elevation
- Animations & Transitions
- Border Radius
- Opacity & Transparency
- Common Tailwind CSS Usage in Project
- Example component reference design code
- And so on...
In a word, Give detailed analysis and descriptions to the project style system, and don't miss any important details.
Great, now help me generate a detailed style guide\
In style guide, you must include the following part:
- Overview
- Color Palette
- Typography (Pay attention to font weight, font size and how different fonts have been used together in the project)
- Spacing System
- Component Styles
- Shadows & Elevation
- Animations & Transitions
- Border Radius
- Opacity & Transparency
- Common Tailwind CSS Usage in Project
- Example component reference design code
- And so on...
In a word, Give detailed analysis and descriptions to the project style system, and don't miss any important details.
生成的STYLE_GUIDE.md
由于cc 给我生成的style-guide 比较长,这里只贴了关键部分,如需查看完整.md, 辛苦移步仓库查看Github
# MotherDuck UI Design System - Style Guide
## Table of Contents
1. [Overview](#overview)
2. [Color Palette](#color-palette)
3. [Typography](#typography)
4. [Spacing System](#spacing-system)
5. [Component Styles](#component-styles)
6. [Shadows & Elevation](#shadows--elevation)
7. [Animations & Transitions](#animations--transitions)
8. [Border Radius](#border-radius)
9. [Opacity & Transparency](#opacity--transparency)
10. [Layout System](#layout-system)
11. [Common Tailwind CSS Usage](#common-tailwind-css-usage)
12. [Example Component Reference](#example-component-reference)
13. [Responsive Design Patterns](#responsive-design-patterns)
---
## Overview
The MotherDuck design system features a **bold, playful, and technical aesthetic** that combines:
- **Brutalist design principles** with heavy borders and sharp corners
- **Vibrant color palette** inspired by data visualization
- **Interactive micro-animations** with shadow-based hover effects
- **Technical typography** mixing Inter for UI and Monaco for code
- **Generous spacing** for a clean, breathable layout
### Design Philosophy
- **Bold & Confident**: Strong borders, high contrast, and clear visual hierarchy
- **Playful & Approachable**: Bright colors, whimsical cloud decorations, and friendly copy
- **Technical & Professional**: Code samples, data-focused messaging, and precise typography
- **Interactive**: Immediate visual feedback on all interactive elements
---
## Color Palette
### Primary Colors
```css
/* Background Colors */
--beige-background: #F4EFEA; /* Main page background */
--white: #FFFFFF; /* Card and section backgrounds */
--dark-gray: #2D2D2D; /* Code editor header */
/* Brand Colors */
--primary-blue: #6FC2FF; /* Primary CTA buttons */
--cyan: #4DD4D0; /* Secondary accent, badges */
--light-blue: #5CB8E6; /* Tertiary accent, banners */
--yellow: #FFD500; /* Top banner, tags, accents */
/* Text & Borders */
--dark: #383838; /* Primary text, borders */
--medium-gray: #666666; /* Secondary elements */
--light-gray: #E0E0E0; /* Dividers, table borders */
/* Accent Colors */
--orange-primary: #FF9500; /* Logo primary */
--orange-secondary: #FF6B00; /* Logo secondary */
--coral: #FF6B6B; /* Error/warning states */
--pink: #FFB6C1; /* Decorative accents */
### Color Usage Guidelines
| Color | Usage | Hex Code | Tailwind Class |
| -------------------- | ------------------------------------------ | --------- | ----------------------------------- |
| **Beige Background** | Main page background, alternating sections | `#F4EFEA` | `bg-[#F4EFEA]` |
| **White** | Cards, modals, content backgrounds | `#FFFFFF` | `bg-white` |
| **Primary Blue** | Primary CTA buttons, focus states | `#6FC2FF` | `bg-[#6FC2FF]` |
| **Cyan** | Badges, secondary highlights | `#4DD4D0` | `bg-[#4DD4D0]` |
| **Light Blue** | Banners, tags, tertiary accents | `#5CB8E6` | `bg-[#5CB8E6]` |
| **Yellow** | Top banner, promotional elements | `#FFD500` | `bg-[#FFD500]` |
| **Dark Gray** | Primary text, all borders | `#383838` | `text-[#383838]` `border-[#383838]` |
| **Medium Gray** | Secondary text, disabled states | `#666666` | `text-gray-600` |
### Color Combinations
**High Contrast Pairings:**
* Yellow background (`#FFD500`) + Dark text (`#383838`)
* White background + Dark borders (`#383838`)
* Primary Blue (`#6FC2FF`) + Dark borders (`#383838`)
**Semantic Colors:**
* **Success**: Cyan (`#4DD4D0`)
* **Warning**: Yellow (`#FFD500`)
* **Error**: Coral (`#FF6B6B`)
* **Info**: Light Blue (`#5CB8E6`)
***
## Typography
### Font Families
```css
/* Primary Font - UI Text */
font-family: 'Inter', -apple-system, BlinkMacSystemFont, sans-serif;
/* Secondary Font - Code Samples */
font-family: 'Monaco', 'Courier New', monospace;
```
### Type Scale
| Element | Size | Weight | Line Height | Letter Spacing | Tailwind Classes |
| ---------------------- | -------------------- | -------------- | ----------- | --------------- | --------------------------------------------------------------- |
| **Hero H1** | 96px / 112px / 128px | 700 (Bold) | 1.0 | -0.02em (tight) | `text-6xl lg:text-7xl xl:text-8xl font-bold tracking-tighter` |
| **Section H2** | 48px / 60px | 700 (Bold) | 1.1 | -0.01em (tight) | `text-4xl lg:text-5xl font-bold tracking-tight` |
| **Section H2 (Large)** | 48px | 700 (Bold) | 1.1 | -0.01em (tight) | `text-5xl font-bold tracking-tight` |
| **Card H3** | 36px / 42px | 700 (Bold) | 1.2 | -0.01em (tight) | `text-3xl lg:text-4xl font-bold tracking-tight` |
| **Component H3** | 16px | 600 (Semibold) | 1.3 (snug) | 0 | `text-base font-semibold leading-snug` |
| **Body Large** | 18px / 20px | 500 (Medium) | 1.6 | 0 | `text-lg lg:text-xl font-medium leading-relaxed` |
| **Body Regular** | 16px | 400 (Regular) | 1.5 | 0 | `text-base` |
| **Body Small** | 14px | 500 (Medium) | 1.5 | 0 | `text-sm font-medium` |
| **Caption** | 12px | 400 (Regular) | 1.4 | 0 | `text-xs` |
| **Button Text** | 14px / 16px | 700 (Bold) | 1.0 | 0 | `text-sm font-bold uppercase` / `text-base font-bold uppercase` |
| **Code** | 13px / 14px | 400 (Regular) | 1.8 | 0 | `text-sm code-text leading-relaxed` |
| **Label Small** | 12px | 700 (Bold) | 1.2 | 0.1em (widest) | `text-xs font-bold tracking-widest` |
### Font Weight Guidelines
| Weight | Value | Usage |
| -------------- | ----- | ------------------------------------------------- |
| **Regular** | 400 | Body text, descriptions, table content |
| **Medium** | 500 | Navigation links, emphasized body text, subtitles |
| **Semibold** | 600 | Card headings, feature titles |
| **Bold** | 700 | All headings, buttons, tags, labels |
| **Extra Bold** | 800 | (Not used in current design) |
### Typography Patterns
**Heading Pattern:**
```html
由于cc 给我生成的style-guide 比较长,这里只贴了关键部分,如需查看完整.md, 辛苦移步仓库查看Github
# MotherDuck UI Design System - Style Guide
## Table of Contents
1. [Overview](#overview)
2. [Color Palette](#color-palette)
3. [Typography](#typography)
4. [Spacing System](#spacing-system)
5. [Component Styles](#component-styles)
6. [Shadows & Elevation](#shadows--elevation)
7. [Animations & Transitions](#animations--transitions)
8. [Border Radius](#border-radius)
9. [Opacity & Transparency](#opacity--transparency)
10. [Layout System](#layout-system)
11. [Common Tailwind CSS Usage](#common-tailwind-css-usage)
12. [Example Component Reference](#example-component-reference)
13. [Responsive Design Patterns](#responsive-design-patterns)
---
## Overview
The MotherDuck design system features a **bold, playful, and technical aesthetic** that combines:
- **Brutalist design principles** with heavy borders and sharp corners
- **Vibrant color palette** inspired by data visualization
- **Interactive micro-animations** with shadow-based hover effects
- **Technical typography** mixing Inter for UI and Monaco for code
- **Generous spacing** for a clean, breathable layout
### Design Philosophy
- **Bold & Confident**: Strong borders, high contrast, and clear visual hierarchy
- **Playful & Approachable**: Bright colors, whimsical cloud decorations, and friendly copy
- **Technical & Professional**: Code samples, data-focused messaging, and precise typography
- **Interactive**: Immediate visual feedback on all interactive elements
---
## Color Palette
### Primary Colors
```css
/* Background Colors */
--beige-background: #F4EFEA; /* Main page background */
--white: #FFFFFF; /* Card and section backgrounds */
--dark-gray: #2D2D2D; /* Code editor header */
/* Brand Colors */
--primary-blue: #6FC2FF; /* Primary CTA buttons */
--cyan: #4DD4D0; /* Secondary accent, badges */
--light-blue: #5CB8E6; /* Tertiary accent, banners */
--yellow: #FFD500; /* Top banner, tags, accents */
/* Text & Borders */
--dark: #383838; /* Primary text, borders */
--medium-gray: #666666; /* Secondary elements */
--light-gray: #E0E0E0; /* Dividers, table borders */
/* Accent Colors */
--orange-primary: #FF9500; /* Logo primary */
--orange-secondary: #FF6B00; /* Logo secondary */
--coral: #FF6B6B; /* Error/warning states */
--pink: #FFB6C1; /* Decorative accents */
### Color Usage Guidelines
| Color | Usage | Hex Code | Tailwind Class |
| -------------------- | ------------------------------------------ | --------- | ----------------------------------- |
| **Beige Background** | Main page background, alternating sections | `#F4EFEA` | `bg-[#F4EFEA]` |
| **White** | Cards, modals, content backgrounds | `#FFFFFF` | `bg-white` |
| **Primary Blue** | Primary CTA buttons, focus states | `#6FC2FF` | `bg-[#6FC2FF]` |
| **Cyan** | Badges, secondary highlights | `#4DD4D0` | `bg-[#4DD4D0]` |
| **Light Blue** | Banners, tags, tertiary accents | `#5CB8E6` | `bg-[#5CB8E6]` |
| **Yellow** | Top banner, promotional elements | `#FFD500` | `bg-[#FFD500]` |
| **Dark Gray** | Primary text, all borders | `#383838` | `text-[#383838]` `border-[#383838]` |
| **Medium Gray** | Secondary text, disabled states | `#666666` | `text-gray-600` |
### Color Combinations
**High Contrast Pairings:**
* Yellow background (`#FFD500`) + Dark text (`#383838`)
* White background + Dark borders (`#383838`)
* Primary Blue (`#6FC2FF`) + Dark borders (`#383838`)
**Semantic Colors:**
* **Success**: Cyan (`#4DD4D0`)
* **Warning**: Yellow (`#FFD500`)
* **Error**: Coral (`#FF6B6B`)
* **Info**: Light Blue (`#5CB8E6`)
***
## Typography
### Font Families
```css
/* Primary Font - UI Text */
font-family: 'Inter', -apple-system, BlinkMacSystemFont, sans-serif;
/* Secondary Font - Code Samples */
font-family: 'Monaco', 'Courier New', monospace;
```
### Type Scale
| Element | Size | Weight | Line Height | Letter Spacing | Tailwind Classes |
| ---------------------- | -------------------- | -------------- | ----------- | --------------- | --------------------------------------------------------------- |
| **Hero H1** | 96px / 112px / 128px | 700 (Bold) | 1.0 | -0.02em (tight) | `text-6xl lg:text-7xl xl:text-8xl font-bold tracking-tighter` |
| **Section H2** | 48px / 60px | 700 (Bold) | 1.1 | -0.01em (tight) | `text-4xl lg:text-5xl font-bold tracking-tight` |
| **Section H2 (Large)** | 48px | 700 (Bold) | 1.1 | -0.01em (tight) | `text-5xl font-bold tracking-tight` |
| **Card H3** | 36px / 42px | 700 (Bold) | 1.2 | -0.01em (tight) | `text-3xl lg:text-4xl font-bold tracking-tight` |
| **Component H3** | 16px | 600 (Semibold) | 1.3 (snug) | 0 | `text-base font-semibold leading-snug` |
| **Body Large** | 18px / 20px | 500 (Medium) | 1.6 | 0 | `text-lg lg:text-xl font-medium leading-relaxed` |
| **Body Regular** | 16px | 400 (Regular) | 1.5 | 0 | `text-base` |
| **Body Small** | 14px | 500 (Medium) | 1.5 | 0 | `text-sm font-medium` |
| **Caption** | 12px | 400 (Regular) | 1.4 | 0 | `text-xs` |
| **Button Text** | 14px / 16px | 700 (Bold) | 1.0 | 0 | `text-sm font-bold uppercase` / `text-base font-bold uppercase` |
| **Code** | 13px / 14px | 400 (Regular) | 1.8 | 0 | `text-sm code-text leading-relaxed` |
| **Label Small** | 12px | 700 (Bold) | 1.2 | 0.1em (widest) | `text-xs font-bold tracking-widest` |
### Font Weight Guidelines
| Weight | Value | Usage |
| -------------- | ----- | ------------------------------------------------- |
| **Regular** | 400 | Body text, descriptions, table content |
| **Medium** | 500 | Navigation links, emphasized body text, subtitles |
| **Semibold** | 600 | Card headings, feature titles |
| **Bold** | 700 | All headings, buttons, tags, labels |
| **Extra Bold** | 800 | (Not used in current design) |
### Typography Patterns
**Heading Pattern:**
```html
MAKING BIG DATA FEEL SMALL
WHY IT'S BETTER
WHO IS IT FOR?
Analytics that works for everyone
```
**Body Text Pattern:**
```html
DUCKDB CLOUD DATA WAREHOUSE SCALING TO TERABYTES
Is your data all over the place? Start making sense...
Subscribe to MotherDuck news
```
**Text Decoration:**
* Links use `underline` for emphasis
* All-caps text for: buttons, headings, labels, navigation
* Tracking adjustment: `-tracking-tighter` for large headings, `tracking-widest` for small labels
***
## Spacing System
### Base Spacing Scale
The design uses Tailwind's default spacing scale (1 unit = 0.25rem / 4px):
| Value | Pixels | Usage |
| ----- | ------ | ------------------------------ |
| `1` | 4px | Micro spacing, icon gaps |
| `2` | 8px | Tight element spacing |
| `3` | 12px | Small gaps, checkbox spacing |
| `4` | 16px | Default gap, button groups |
| `6` | 24px | Medium spacing, card padding |
| `8` | 32px | Large spacing, section gaps |
| `10` | 40px | Extra large spacing |
| `12` | 48px | Section separation |
| `16` | 64px | Major section separation |
| `20` | 80px | Section padding (vertical) |
| `28` | 112px | Hero section padding (desktop) |
### Component Spacing Patterns
**Section Padding:**
```css
/* Standard Section */
padding: py-20 px-6 /* 80px vertical, 24px horizontal */
/* Compact Section */
padding: py-16 px-6 /* 64px vertical, 24px horizontal */
/* Hero Section */
padding: py-20 lg:py-28 px-6 /* 80px mobile, 112px desktop */
```
**Container Max Width:**
```css
max-w-6xl /* 1152px - Standard content */
max-w-7xl /* 1280px - Wide content */
max-w-4xl /* 896px - Narrow content, forms */
max-w-2xl /* 672px - Very narrow, centered content */
```
**Gap Spacing:**
```css
gap-2 /* 8px - Tight elements (window dots) */
gap-3 /* 12px - Form elements, checkboxes */
gap-4 /* 16px - Button groups, form rows */
gap-6 /* 24px - Grid items (small screens) */
gap-8 /* 32px - Navigation items */
gap-12 /* 48px - Card grid (medium) */
gap-16 /* 64px - Section elements */
```
**Margin Spacing:**
```css
/* Heading Margins */
mb-2 /* 8px - Label to content */
mb-3 /* 12px - Subtitle to content */
mb-6 /* 24px - Small heading to content */
mb-8 /* 32px - Medium heading to content */
mb-16 /* 64px - Large heading to grid */
/* Element Margins */
mb-4 /* 16px - Paragraph to button */
mb-6 /* 24px - Form to submit */
mb-8 /* 32px - Icon to text */
```
Analytics that works for everyone
```
**Body Text Pattern:**
```html
DUCKDB CLOUD DATA WAREHOUSE SCALING TO TERABYTES
Is your data all over the place? Start making sense...
Subscribe to MotherDuck news
```
**Text Decoration:**
* Links use `underline` for emphasis
* All-caps text for: buttons, headings, labels, navigation
* Tracking adjustment: `-tracking-tighter` for large headings, `tracking-widest` for small labels
***
## Spacing System
### Base Spacing Scale
The design uses Tailwind's default spacing scale (1 unit = 0.25rem / 4px):
| Value | Pixels | Usage |
| ----- | ------ | ------------------------------ |
| `1` | 4px | Micro spacing, icon gaps |
| `2` | 8px | Tight element spacing |
| `3` | 12px | Small gaps, checkbox spacing |
| `4` | 16px | Default gap, button groups |
| `6` | 24px | Medium spacing, card padding |
| `8` | 32px | Large spacing, section gaps |
| `10` | 40px | Extra large spacing |
| `12` | 48px | Section separation |
| `16` | 64px | Major section separation |
| `20` | 80px | Section padding (vertical) |
| `28` | 112px | Hero section padding (desktop) |
### Component Spacing Patterns
**Section Padding:**
```css
/* Standard Section */
padding: py-20 px-6 /* 80px vertical, 24px horizontal */
/* Compact Section */
padding: py-16 px-6 /* 64px vertical, 24px horizontal */
/* Hero Section */
padding: py-20 lg:py-28 px-6 /* 80px mobile, 112px desktop */
```
**Container Max Width:**
```css
max-w-6xl /* 1152px - Standard content */
max-w-7xl /* 1280px - Wide content */
max-w-4xl /* 896px - Narrow content, forms */
max-w-2xl /* 672px - Very narrow, centered content */
```
**Gap Spacing:**
```css
gap-2 /* 8px - Tight elements (window dots) */
gap-3 /* 12px - Form elements, checkboxes */
gap-4 /* 16px - Button groups, form rows */
gap-6 /* 24px - Grid items (small screens) */
gap-8 /* 32px - Navigation items */
gap-12 /* 48px - Card grid (medium) */
gap-16 /* 64px - Section elements */
```
**Margin Spacing:**
```css
/* Heading Margins */
mb-2 /* 8px - Label to content */
mb-3 /* 12px - Subtitle to content */
mb-6 /* 24px - Small heading to content */
mb-8 /* 32px - Medium heading to content */
mb-16 /* 64px - Large heading to grid */
/* Element Margins */
mb-4 /* 16px - Paragraph to button */
mb-6 /* 24px - Form to submit */
mb-8 /* 32px - Icon to text */
```
步骤4: 构建原型html
为了验证效果我们叫cc 大哥,参考STYLE_GUIDE.md ,实现一个四象限 to-do list 的.html 原型。 
中间省略我跟他对需求的过程,下方是cc实现的初稿👇
看起来平平无奇,甚至有点糟糕,什么东西嘛这是??🥸
别担心!! 别忘啦,所有的样式信息,都在STYLE_GUIDE.md ,我们可以继续push cc 迭代。
为了验证效果我们叫cc 大哥,参考STYLE_GUIDE.md ,实现一个四象限 to-do list 的.html 原型。
中间省略我跟他对需求的过程,下方是cc实现的初稿👇
看起来平平无奇,甚至有点糟糕,什么东西嘛这是??🥸
别担心!! 别忘啦,所有的样式信息,都在STYLE_GUIDE.md ,我们可以继续push cc 迭代。
ui 迭代
1:叫替换一下 header 的颜色为style-guide.md 里面的黄色
2:添加图表统计功能
经过几轮的迭代,我们得到了初版的效果
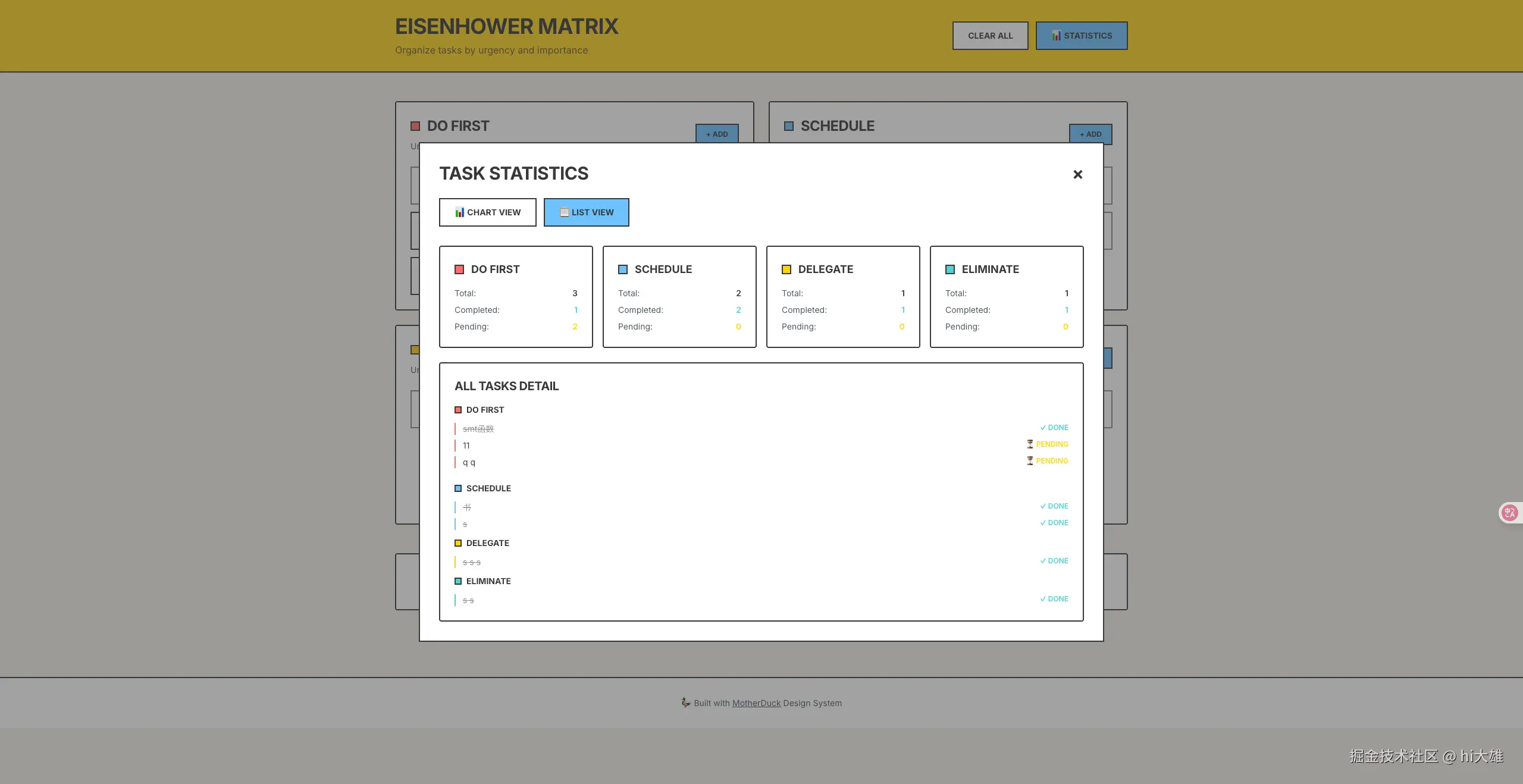
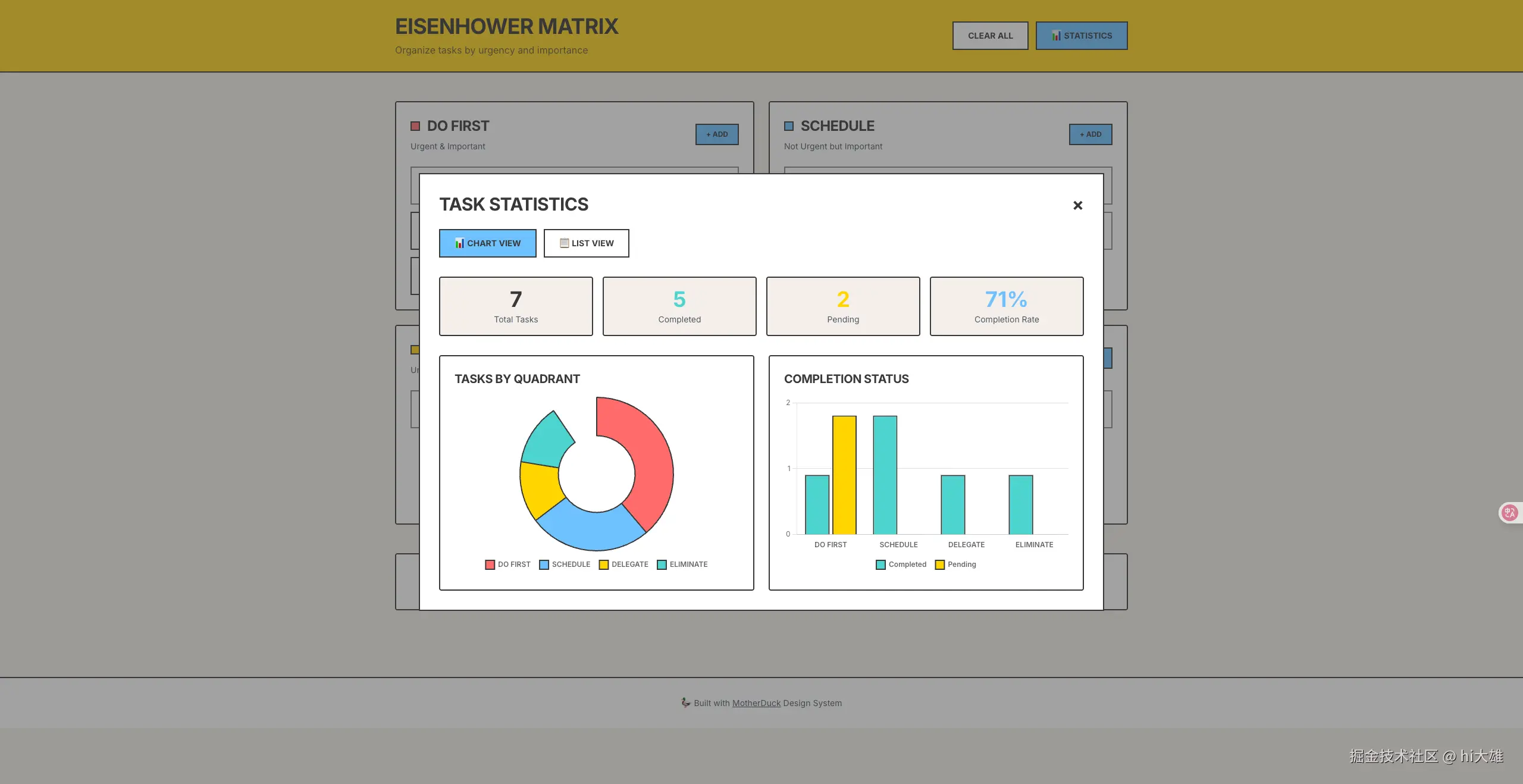
1:叫替换一下 header 的颜色为style-guide.md 里面的黄色
2:添加图表统计功能
经过几轮的迭代,我们得到了初版的效果
步骤5:构建像素级别还原的next app
原生的.html 不方便后续迭代维护,你可以使用下方的prompt 叫CC构建一个next app 开始build 之前可以梳理一下已实现的功能,方便后续迭代
原生的.html 不方便后续迭代维护,你可以使用下方的prompt 叫CC构建一个next app 开始build 之前可以梳理一下已实现的功能,方便后续迭代
prompt
> Great,now you need to build a next app from todo-quadrant.html
- you need to ensure the UI and logic are pixel perfectly restorely 。
- the code structure should be clear enough and The code is highly readable.
- when there is the case that if-else ,your need to use early-return to solve
> Great,now you need to build a next app from todo-quadrant.html
- you need to ensure the UI and logic are pixel perfectly restorely 。
- the code structure should be clear enough and The code is highly readable.
- when there is the case that if-else ,your need to use early-return to solve
保存plan.md

最终的next.app 效果
最终的next.app 效果
其他扩展
当然啦,有了STYLE_GUIDE.md你还可以拓展更多的实践,比如:
- 在 stitch 生成符合风格 ui 设计稿【还可以加上初版的.html】
- 在lovart 生成符合风格的美术素材
- 基于farme motion 生成产品演示动画
- 生成漂亮的产品的幻灯片(html),用一些工具转为ppt 使用
当然啦,有了STYLE_GUIDE.md你还可以拓展更多的实践,比如:
- 在 stitch 生成符合风格 ui 设计稿【还可以加上初版的.html】
- 在lovart 生成符合风格的美术素材
- 基于farme motion 生成产品演示动画
- 生成漂亮的产品的幻灯片(html),用一些工具转为ppt 使用
参考实践
作者:hi大雄
来源:juejin.cn/post/7569777676098814002
来源:juejin.cn/post/7569777676098814002
我用AI重构了一段500行的屎山代码,这是我的Prompt和思考过程

大家好,我来了🙂。
我们团队,维护着一个有5年历史的史诗级中后台项目😖。在这座屎山里,有一个叫handleOrderSubmit.js的文件。
可以下载瞧一瞧 有多屎👉 handleOrderSubmit.js
它是一个长达500多行的React useEffect 钩子函数(是的,你没看错,一个useEffect)。
它混合了订单数据的本地校验、价格计算、优惠券应用、API请求、全局状态更新、以及错误弹窗处理... 所有的逻辑,都塞在一个函数里,用if/else和try/catch层层嵌套。
没人敢动它😖。

每次产品经理提一个小需求,比如在提交订单时,增加一种新的优惠券类型,我们整个团队的表情都像被雷劈了。因为我们知道,改这个函数,要么加班一周,要么就等着P0级事故。
上周,产品经理要求我们在这个函数里,加入一个全新的风控逻辑。
我评估了一下,手动重构,至少需要一个资深工程师一周的时间,而且风险极大。
我受够了。我决定,把这个烫手的任务,扔给我的实习生——AI(我用的是GPT-5 mini,穷😂)。
这篇文章,就是我人机协作,啃下这块硬骨头的完整复盘,大家继续看。
我不能直接说重构它
我犯的第一个错误,是直接把500行代码贴给AI,然后说:帮我重构这段代码。
AI很听话,它给我的,是一段看起来更整洁的代码——它把if/else换成了switch,提了几个变量... 这不叫重构,这叫重新排版,毫无意义。
我很快意识到:AI是一个能力超强、但没有灵魂的执行者。我,作为开发者,必须给它提供一个清晰的方案。
于是,我制定了一个五步重构法。
我的Prompt和思考
我的核心思想是:AI负责执行,我负责决策。 我要像一个指挥家一样,一步一步地引导AI,把这500行的代码,拆解成高内聚、低耦合的模块。
第一步:先让AI读懂屎山
我不能上来就让AI改。我得先确认,它和我对这段代码的理解,在一个频道上。
Prompt:
你是一个资深的React架构师。请分析下面这段500行的
useEffect代码。
- 告诉我它做了几件主要的事情?(职责分析)
- 找出所有的副作用(比如API请求、
localStorage操作、全局状态更新)。- 找出所有的纯逻辑(比如数据校验、价格计算)。
- 评价它的可维护性和可测试性。
GPT的回答,给了我一个惊喜。它清晰地列出了:
- 职责:它承担了至少5个职责:表单校验、价格计算、库存检查、创建订单、处理UI反馈。
- 副作用:
api.post(...),setLoading(true),showToast(...)... - 纯逻辑:
validateForm(...),calculateTotalPrice(...)... - 评价:可维护性极低,单一职责原则被严重违反,几乎不可测试。
很好,AI看懂了!我们就可以可以开始了😁。
第二步:先分离纯逻辑代码
这是最关键的一步。我要把计算和动作分开。
Prompt:
非常好。现在,请你只针对纯逻辑部分(表单校验、价格计算)进行重构。
- 把这些逻辑,从原函数中提取出来,变成独立的、可导出的纯函数。
- 这些函数必须是纯的:不能有任何副作用(不能调用
api或setLoading)。- 使用TypeScript,为这些新函数的入参和返回值,提供清晰的类型定义。
AI立刻唰唰唰地给了我几个文件:
validate.ts:
export function validateOrder(formData: OrderForm): string | null {
if (!formData.user) return '用户信息不能为空';
if (formData.items.length === 0) return '商品不能为空';
// ... 10 more rules
return null;
}
calculator.ts:
export function calculateTotalPrice(items: Item[], coupon: Coupon): number {
let total = items.reduce((sum, item) => sum + item.price * item.quantity, 0);
if (coupon.type === 'PERCENT') {
total *= (1 - coupon.value / 100);
}
// ... 20 more rules
return total;
}
第三步:让AI为自己的代码做测试
我怎么知道AI提炼的逻辑,是对的还是错的? 答案:让它自己写单元测试来证明。
Prompt:
你现在是一个QA工程师。请使用
Vitest,为你刚才提取的validateOrder和calculateTotalPrice这两个函数,编写全面的单元测试用例。 必须覆盖所有边界情况,包括正常、异常、和边缘值。
AI再次给了我惊喜。它生成的测试用例,比我手写的还要全:
// calculator.test.ts
import { describe, it, expect } from 'vitest';
import { calculateTotalPrice } from './calculator';
describe('calculateTotalPrice', () => {
it('should return 0 for empty cart', () => {
expect(calculateTotalPrice([], null)).toBe(0);
});
it('should apply percent coupon', () => {
const items = [{ price: 100, quantity: 1 }];
const coupon = { type: 'PERCENT', value: 10 };
expect(calculateTotalPrice(items, coupon)).toBe(90);
});
// ... 省略更多
});
我把这些测试用例跑了一遍,全部通过。我现在信心大增😁。
第四步:重写协调层
现在,纯逻辑已经被分离并验证了。原来的500行屎山,只剩下副作用和流程控制代码了。是时候重写它了。
Prompt:
干得漂亮。现在,我们来重构那个原始的
useEffect函数。
- 它现在唯一的职责是协调。
- 调用我们刚才创建的
validateOrder和calculateTotalPrice纯函数。- 把所有的副作用(API请求、
setLoading、showToast)清晰地编排起来。- 使用
async/await,让异步流程更清晰,用try/catch处理错误。
这次,AI给我的,是一个只有30行左右的、清晰的流程代码:
// 重构后的 useEffect
useEffect(() => {
const submitOrder = async () => {
setLoading(true);
try {
// 1. 协调:验证 (纯)
const errorMsg = validateOrder(formData);
if (errorMsg) {
showToast(errorMsg);
return;
}
// 2. 协调:计算 (纯)
const totalPrice = calculateTotalPrice(formData.items, formData.coupon);
// 3. 协调:副作用(不纯)
const result = await api.post('/order/submit', { ...formData, totalPrice });
// 4. 协调:响应(不纯)
if (result.code === 200) {
showToast('订单提交成功!');
router.push('/success');
} else {
showToast(result.message);
}
} catch (err) {
showToast(err.message);
} finally {
setLoading(false);
}
};
if (isSubmitting) { // 假设一个触发条件
submitOrder();
setIsSubmitting(false);
}
}, [isSubmitting, formData /* ...其他依赖 */]);
第五步:最后守卫工作,加入新功能
别忘了,我重构的目的,是为了加风控这个新功能。
Prompt:
最后一步。请在API请求之前,加入一个风控检查的逻辑(调用
riskControl.check(...))。这是一个异步函数,如果检查不通过,它会抛出一个错误。
AI在第2步和第3步之间,加了几行代码,完美收工。
这次重构,我总共花了大概5个小时,而不是原计划的一周。
总觉得 AI 不会淘汰会写代码的工程师。
只会降维打击那些只会堆砌代码的工程师。
那段500行的屎山,在过去,是我的噩梦;现在,有了AI的帮助,它变成了我的靶场。
这种感觉,真爽🙌。
来源:juejin.cn/post/7570630923710054452
我本是写react的,公司让我换赛道搞web3D
当你在会议室里争论需求时,智慧工厂的数字孪生正同步着每一条产线的脉搏;
当你对着平面图想象空间时,智慧小区的三维模型已在虚拟世界精准复刻每一扇窗的采光。
当你在CAD里调整参数时,
数字孪生城市的交通流正实时映射每辆车的轨迹;
当你等待客户确认方案时,
机械臂的3D仿真已预演了十万次零误差的运动路径;
当你用二维图纸解释传动原理时,
可交互的3D引擎正让客户‘拆解’每一个齿轮;
当你担心售后维修难描述时,
AR里的动态指引已覆盖所有故障点;
当你用PS拼贴效果图时,
VR漫游的业主正‘推开’你设计的每一扇门;
当你纠结墙面材质时,
光影引擎已算出了午后3点最温柔的折射角度;
从前端到Web3D,
不是换条赛道,
而是打开新维度。
韩老师说过:再牛的程序员都是从小白开始,既然开始了,就全心投入学好技术。
🔴 工具
所有的api都可以通过threejs官网的document,切成中文,去搜:

🔴 平面
⭕️ Scene 场景
场景能够让你在什么地方、摆放什么东西来交给three.js来渲染,这是你放置物体、灯光和摄像机的地方。

import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
⭕️ camera 相机
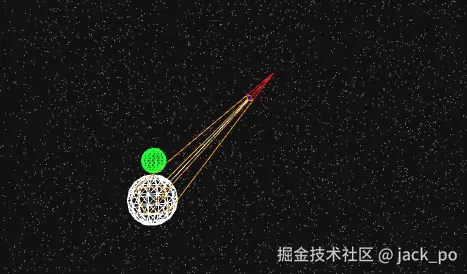
import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
// 2、创建相机
const camera = new THREE.PerspectiveCamera(
75, // 相机的角度
window.innerWidth / window.innerHeight, // 相机的宽高比
0.1, // 相机的近截面
1000 // 相机的远截面
);
// 设置相机位置
camera.position.set(0, 0, 10); // 相机位置 (X轴坐标, Y轴坐标, Z轴坐标)
scene.add(camera); // 相机添加到场景中
⭕️ 物体 cube
import * as THREE from "three";
// console.log(THREE);
// 目标:了解three.js最基本的内容
// 1、创建场景
const scene = new THREE.Scene();
// 2、创建相机
const camera = new THREE.PerspectiveCamera(
75, // 相机的角度
window.innerWidth / window.innerHeight, // 相机的宽高比
0.1, // 相机的近截面
1000 // 相机的远截面
);
// 设置相机位置
camera.position.set(0, 0, 10); // 相机位置 (X轴坐标, Y轴坐标, Z轴坐标)
scene.add(camera); // 相机添加到场景中
// 添加物体
// 创建几何体
const cubeGeometry = new THREE.BoxGeometry(1, 1, 1); // 创建立方体的几何体 (长, 宽, 高)
const cubeMaterial = new THREE.MeshBasicMaterial({ color: 0xffff00 }); // MeshBasicMaterial 基础网格材质 ({ color: 0xffff00 }) 颜色
// 根据几何体和材质创建物体
const cube = new THREE.Mesh(cubeGeometry, cubeMaterial); // 创建立方体的物体 (几何体, 材质)
// 将几何体添加到场景中
scene.add(cube); // 物体添加到场景中
⭕️ 渲染 render
// 初始化渲染器
const renderer = new THREE.WebGLRenderer();
// 设置渲染的尺寸大小
renderer.setSize(window.innerWidth, window.innerHeight); // 设置渲染的尺寸大小 (窗口宽度, 窗口高度)
// console.log(renderer);
// 将webgl渲染的canvas内容添加到body
document.body.appendChild(renderer.domElement); // 将webgl渲染的canvas内容添加到body
// 使用渲染器,通过相机将场景渲染进来
renderer.render(scene, camera); // 使用渲染器,通过相机将场景渲染进来 (场景, 相机)
⭕️ 效果
效果是平面的:

到这里,还不是3d的,如果要加3d,要加一下控制器。
🔴 3d
⭕️ 控制器
添加轨道。像卫星☄围绕地球🌏,环绕查看的视角:
// 导入轨道控制器
import { OrbitControls } from "three/examples/jsm/controls/OrbitControls";
// 目标:使用控制器查看3d物体
// // 使用渲染器,通过相机将场景渲染进来
// renderer.render(scene, camera);
// 创建轨道控制器
const controls = new OrbitControls(camera, renderer.domElement); // 创建轨道控制器 (相机, 渲染器dom元素)
controls.enableDamping = true; // 设置控制器阻尼,让控制器更有真实效果。
function render() {
renderer.render(scene, camera); // 浏览器每渲染一帧,就重新渲染一次
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render); // 浏览器渲染下一帧的时候就会执行render函数,执行完会再次调用render函数,形成循环,每秒60次
}
render();
⭕️ 加坐标轴辅助器
// 添加坐标轴辅助器
const axesHelper = new THREE.AxesHelper(5); // 坐标轴(size轴的大小)
scene.add(axesHelper);
⭕️ 设置物体移动
// 设置相机位置
camera.position.set(0, 0, 10);
scene.add(camera);
cube.position.x = 3;
// 往返移动
function render() {
cube.position.x += 0.01;
if (cube.position.x > 5) {
cube.position.x = 0;
}
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ 缩放
cube.scale.set(3, 2, 1); // xyz, x3倍, y2倍
单独设置
cube.position.x = 3;
⭕️ 旋转
cube.rotation.set(Math.PI / 4, 0, 0, "XZY"); // x轴旋转45度
单独设置
cube.rotation.x = Math.PI / 4;
⭕️ requestAnimationFrame
function render(time) {
// console.log(time);
// cube.position.x += 0.01;
// cube.rotation.x += 0.01;
// time 是一个不断递增的数字,代表当前的时间
let t = (time / 1000) % 5; // 为什么求余数,物体移动的距离就是t,物体移动的距离是0-5,所以求余数
cube.position.x = t * 1; // 0-5秒,物体移动0-5距离
// if (cube.position.x > 5) {
// cube.position.x = 0;
// }
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ Clock 跟踪事件处理动画
// 设置时钟
const clock = new THREE.Clock();
function render() {
// 获取时钟运行的总时长
let time = clock.getElapsedTime();
console.log("时钟运行总时长:", time);
// let deltaTime = clock.getDelta();
// console.log("两次获取时间的间隔时间:", deltaTime);
let t = time % 5;
cube.position.x = t * 1;
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
大概是8毫秒一次渲染时间.
⭕️ 不用算 用 Gsap动画库
// 导入动画库
import gsap from "gsap";
// 设置动画
var animate1 = gsap.to(cube.position, {
x: 5,
duration: 5,
ease: "power1.inOut", // 动画属性
// 设置重复的次数,无限次循环-1
repeat: -1,
// 往返运动
yoyo: true,
// delay,延迟2秒运动
delay: 2,
onComplete: () => {
console.log("动画完成");
},
onStart: () => {
console.log("动画开始");
},
});
gsap.to(cube.rotation, { x: 2 * Math.PI, duration: 5, ease: "power1.inOut" });
// 双击停止和恢复运动
window.addEventListener("dblclick", () => {
// console.log(animate1);
if (animate1.isActive()) {
// 暂停
animate1.pause();
} else {
// 恢复
animate1.resume();
}
});
function render() {
renderer.render(scene, camera);
// 渲染下一帧的时候就会调用render函数
requestAnimationFrame(render);
}
render();
⭕️ 根据尺寸变化 实现自适应
// 监听画面变化,更新渲染画面
window.addEventListener("resize", () => {
// console.log("画面变化了");
// 更新摄像头
camera.aspect = window.innerWidth / window.innerHeight;
// 更新摄像机的投影矩阵
camera.updateProjectionMatrix();
// 更新渲染器
renderer.setSize(window.innerWidth, window.innerHeight);
// 设置渲染器的像素比
renderer.setPixelRatio(window.devicePixelRatio);
});
⭕️ 用js控制画布 全屏 和 退出全屏
window.addEventListener("dblclick", () => {
const fullScreenElement = document.fullscreenElement;
if (!fullScreenElement) {
// 双击控制屏幕进入全屏,退出全屏
// 让画布对象全屏
renderer.domElement.requestFullscreen();
} else {
// 退出全屏,使用document对象
document.exitFullscreen();
}
// console.log(fullScreenElement);
});
⭕️ 应用 图形 用户界面 更改变量
// 导入dat.gui
import * as dat from "dat.gui";
const gui = new dat.GUI();
gui
.add(cube.position, "x")
.min(0)
.max(5)
.step(0.01)
.name("移动x轴")
.onChange((value) => {
console.log("值被修改:", value);
})
.onFinishChange((value) => {
console.log("完全停下来:", value);
});
// 修改物体的颜色
const params = {
color: "#ffff00",
fn: () => {
// 让立方体运动起来
gsap.to(cube.position, { x: 5, duration: 2, yoyo: true, repeat: -1 });
},
};
gui.addColor(params, "color").onChange((value) => {
console.log("值被修改:", value);
cube.material.color.set(value);
});
// 设置选项框
gui.add(cube, "visible").name("是否显示");
var folder = gui.addFolder("设置立方体");
folder.add(cube.material, "wireframe");
// 设置按钮点击触发某个事件
folder.add(params, "fn").name("立方体运动");

🔴 结语
前端的世界,
不该只有Vue和React——
还有WebGPU里等待你征服的星辰大海。"
“当WebGL成为下一代前端的基础设施,愿你是最早站在三维坐标系里的那个人。”
来源:juejin.cn/post/7517209356855164978
AI时代,为什么我放弃Vue全家桶,选择了Next.js + Supabase
AI时代,为什么我放弃Vue全家桶,选择了Next.js + Supabase
12天的项目,我现在2天就能搞定。
这不是吹牛,而是我真实的开发体验。从Vue全家桶切换到Next.js + Supabase后,我的开发效率提升了10倍。
作为一个前端工程师出身的AI创业者,我曾经是Vue全家桶的忠实用户。Vue 3 + Vite + Pinia + Element Plus,这套组合陪我度过了实习和早期项目开发。
但是,当我开始用AI工具写代码后,一切都变了。
痛点:Vue在AI时代的尴尬
最初我还是习惯性地选择Vue,毕竟熟悉。但很快就发现了问题:
AI对Vue的理解让人抓狂
真实场景:我让Claude帮我写一个用户状态管理,结果:
// AI生成的Vue代码 - 问题一堆
const user = reactive({ name: '' }) // 应该用ref?
const userName = ref(user.name) // 重复定义?
// Pinia store在哪?为什么不用?
我花了2小时调试,最后发现AI把Vue 2和Vue 3的语法混在一起了。
更要命的是选择困难症
想要个用户登录系统?Vue全家桶给你10种方案:
- 后端:Express? Koa? Fastify?
- 数据库:MySQL? PostgreSQL? MongoDB?
- 认证:JWT? Session? OAuth?
- 部署:Docker? PM2? Nginx配置?
每个选择都需要调研、对比、踩坑。还没开始写业务逻辑,就已经消耗了大量时间和精力。
转折:AI改变了我的选择标准
直到我接触到Claude Code和各种MCP工具,才意识到问题的根本:
在AI时代,技术栈的选择标准彻底变了。
以前我们选技术栈考虑的是:
- 学习曲线
- 生态丰富度
- 团队熟悉度
- 性能表现
现在必须加上一个新维度:AI友好度。
什么是AI友好度?就是AI工具对这个技术栈的理解程度和支持质量。我发现:
- React/Next.js的训练数据更多 - GitHub上React项目是Vue的好几倍
- TypeScript + React的组合AI最熟悉 - 代码生成质量明显更高
- Next.js生态更适合全栈开发 - 一套框架解决前后端问题
更重要的是,我需要的不是完美的架构,而是快速验证想法的能力。
这已经成为行业共识
不只是我这么想,看看数据:
- GitHub上新项目,70%选择Next.js而非Vue
- Vercel部署量:Next.js项目数是Vue的5倍
- Stack Overflow 2024调查:Next.js超越Vue成为最受欢迎框架
连大厂也在转向:
- Netflix:从自建架构迁移到Next.js
- TikTok:新项目默认选择Next.js + Supabase
- 字节内部:推荐小团队使用"无后端"方案快速原型
我的答案:Next.js + Supabase
最终我选择了这个组合:
前端:Next.js 14 + TypeScript + Tailwind CSS
- AI对React生态理解最深
- TypeScript让AI生成的代码更可靠
- Tailwind CSS的原子化样式AI也很熟悉
后端:Supabase (PostgreSQL + 自动API)
- 零后端配置,专注业务逻辑
- 自动生成TypeScript类型定义
- 内置认证、存储、实时功能
开发工具:Claude Code + AI编程助手
- 代码自动生成和优化
- 实时错误检测和修复建议
- 智能代码补全和重构
最重要的是,你不需要从零搭建。
Next.js官方提供了with-supabase模板,一行命令就能开始:
npx create-next-app -e with-supabase my-app
这个模板已经配置好了:
- ✅ Supabase客户端初始化
- ✅ TypeScript类型定义
- ✅ 用户认证系统
- ✅ 中间件和路由保护
- ✅ 服务端和客户端数据获取
关键是,AI对这个模板非常熟悉。
我让Claude帮我修改代码时,它知道:
createClient()怎么用- 认证状态如何获取
- RLS规则怎么写
- Server Components和Client Components的区别
代码对比见真章
同样是获取用户信息,看看差异:
// Vue + AI:经常出错
const { data } = await $fetch('/api/user') // $fetch是啥?
const user = reactive(data) // 为什么不用ref?
// 类型怎么定义?接口在哪?
// Next.js + Supabase + AI:一气呵成
const { data: user } = await supabase.auth.getUser()
// 自动类型推导,无需手动定义
这就是AI友好度的体现 - 不是技术本身有多先进,而是AI对它的理解有多深。
实战验证:效率的巨大提升
用这套技术栈开发项目,我的体感是:
开发速度提升10倍
以前用Vue全家桶做一个带用户系统的项目:
- Day 1-2: 搭建后端API
- Day 3-4: 配置数据库和认证
- Day 5-7: 前端业务逻辑
- Day 8-10: 联调和部署
现在用Next.js + Supabase:
- Day 1 上午:
npx create-next-app -e with-supabase,完成核心功能 - Day 1: 下午,部署到Vercel
- 完成
真实案例对比
让我用具体数字说话。最近我帮朋友做了一个AI工具的落地页项目:
技术需求:
- 用户注册登录
- 支付集成
- 使用记录追踪
- 响应式设计
- SEO优化
Vue全家桶时代(预估):
- 后端API开发:5天
- 前端开发:4天
- 认证系统:2天
- 部署配置:1天
- 总计:12天
Next.js + Supabase实际用时:
- 模板初始化:30分钟
- Supabase数据库设计:半天
- 前端页面开发:1天
- 支付集成(Stripe):半天
- 部署(Vercel一键):10分钟
- 总计:2天

效率提升关键因素:
- 零后端配置 - Supabase自动生成API
- AI代码生成 - Claude对Next.js生态理解深度
- 模板起步 - with-supabase省去了80%的基础配置
- 类型安全 - TypeScript让AI生成的代码更可靠
踩坑经验:诚实的权衡
当然,这套技术栈也不是万能的:
性能权衡:
- Supabase在复杂查询时确实比自建API慢一些
- 但对于MVP和中小项目(1万用户以下)完全够用
成本考虑:
- 免费额度很慷慨:500MB数据库,50MB存储
- 付费后按使用量计费,比维护服务器便宜
迁移风险:
- 高度依赖Supabase生态
- 但PostgreSQL标准,迁移难度不大
最重要的认知转变:
在AI时代,完美的架构不如快速的验证。
一些实用建议
如果你也在纠结技术栈选择,我的建议是:
1. 评估你的真实需求
选择Next.js + Supabase,如果你:
- 团队规模3人以下
- 需要快速验证想法
- 预期用户量1万以下
- 重视开发效率 > 极致性能
坚持传统技术栈,如果你:
- 团队有专门的后端工程师
- 对性能有极致要求
- 已有大量历史代码
- 数据安全要求极高
2. 立即行动,不要完美主义
# 今天就可以开始
npx create-next-app -e with-supabase my-ai-project
cd my-ai-project
npm run dev
花30分钟体验一下,比看100篇教程有用。
3. 拥抱AI编程助手
推荐使用Claude Code或其他AI编程工具,它们对Next.js + Supabase生态理解最深,能提供:
- 精准的代码生成
- 智能的错误修复
- 最佳实践建议
结语:
从Vue全家桶到Next.js + Supabase,这不只是技术栈的切换,更是开发思维的升级。
在AI时代,最重要的不是掌握最新的框架,而是选择AI最懂的工具,让AI成为你的开发伙伴。
技术为想法服务,想法为使命服务。选择让你更快实现想法的技术栈,就是最好的选择。
来源:juejin.cn/post/7538087794968952884
国产 Canvas 引擎!神器!
写过原生 Canvas 的朋友都懂:
- API 低级到怀疑人生——画个带圆角的矩形就要
20行起步,缩放、拖拽、层级管理全靠自己实现。 - 节点一多直接 PPT——超过
5000个元素,页面卡成幻灯片。
于是,我们一边掉头发,一边默念:“有没有一款库,写得少、跑得快、文档还是中文?”
什么是 LeaferJS
LeaferJS 是一款高性能、模块化、开源的 Canvas 2D 渲染引擎,专注于提供高性能、可交互、可缩放矢量图形的绘图能力。

它采用场景图(Scene Graph)架构,支持响应式布局、事件系统、动画、滤镜、遮罩、路径、图像、文本、滚动视图、缩放、拖拽、节点嵌套、分组等丰富功能。
LeaferJS 的核心优势

高效绘图
- 生成图片、短视频、印刷品:支持导出
PNG、JPEG、PDF、SVG等多种格式,满足印刷级品质需求。 - Flex 自动布局、中心绘制:内置
Flex布局,支持中心绘制,后端可批量生成图片。 - 渐变、内外阴影、裁剪、遮罩、擦除:支持线性渐变、径向渐变、内外阴影、裁剪、遮罩、擦除等高级绘图功能。
UI 交互
- 开发小游戏、互动应用、组态软件:支持跨平台交互事件、手势,
CSS交互状态、光标。 - 动画、状态、过渡、精灵:支持帧动画、状态过渡、精灵图、箭头、连线等交互元素。
图形编辑
- 开发裁剪、图片、图形编辑器:提供丰富的图形编辑功能,高可定制。
- 标尺、视窗控制、滚动条:支持标尺、视窗控制、滚动条等编辑器必备功能。
性能巨兽
LeaferJS 最最核心的一点就是性能至上,和目前市面上比较流行的 Canvas 库对比:
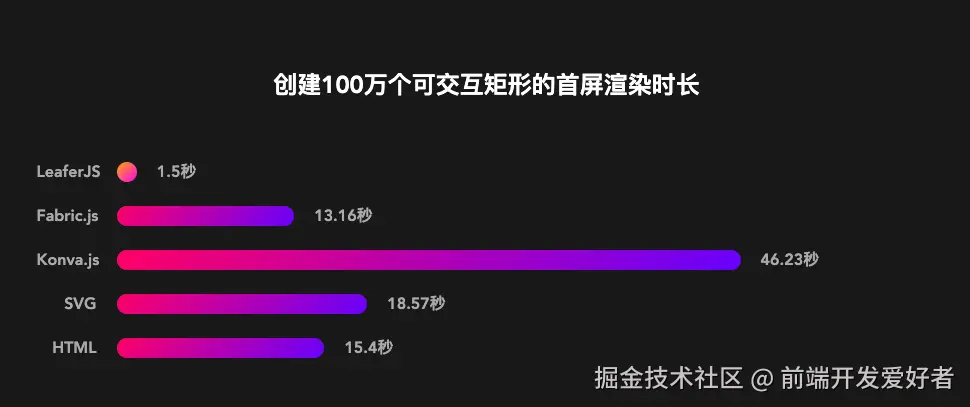
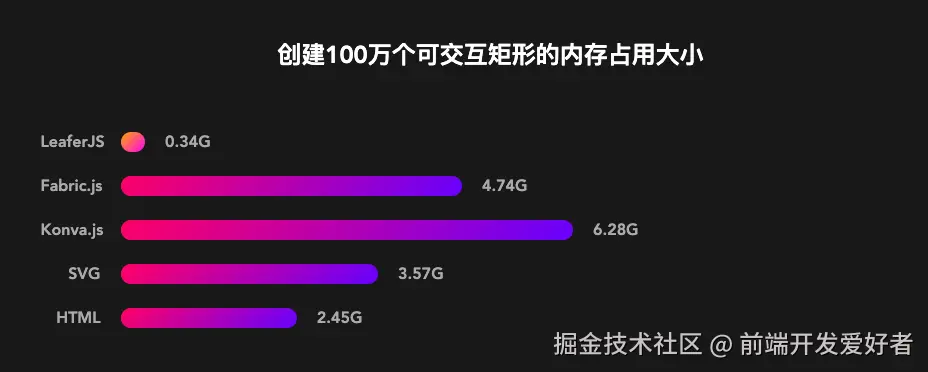
如何快速上手
# 1. 创建项目
npm create leafer@latest my-canvas
cd my-canvas
npm i
npm run dev
// 2. 写代码(index.ts)
import { Leafer, Rect } from 'leafer-ui'
const leafer = new Leafer({ view: window })
const rect = new Rect({
x: 100,
y: 100,
width: 200,
height: 200,
fill: '#32cd79',
cornerRadius: [50, 80, 0, 80],
draggable: true
})
leafer.add(rect)
浏览器访问 http://localhost:5173——圆角矩形已可拖拽!
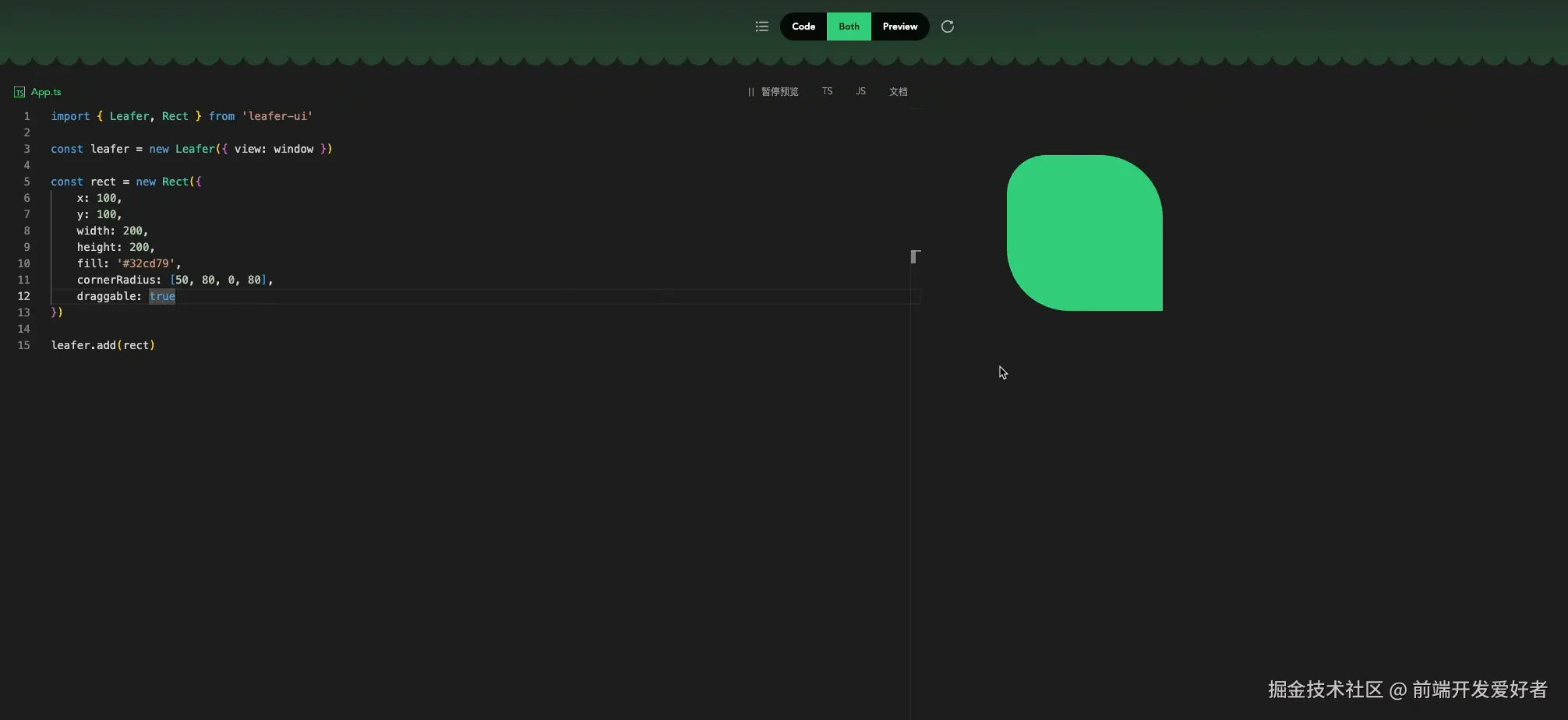
想加 1 万个?直接 for 循环,依旧丝滑。
使用场景
- 在线设计工具——海报、名片、电商 banner,导出 4K PDF 秒级完成。
- 数据可视化——物联网组态、拓扑图、百万点折线图,放大 20 倍依旧清晰。
- 在线白板——教学、会议、脑图,无限画布 + 实时协作。
- 无代码搭建——拖拽生成页面,JSON 一键转 Canvas 应用。
- 小游戏/动画——跑酷、拼图、营销活动,帧率稳 60,包体小一半。
优秀案例展示
基于 Leafer + vue3 实现画板。
fly-cut 在线视频剪辑工具。
- Github 地址:
https://github.com/x007xyz/flycut
基于 LeaferJS 的贪吃蛇小游戏。

一款美观且功能强大的在线设计工具,具备海报设计和图片编辑功能,基于 leafer.js 的开源版。
- Github 地址:
https://github.com/more-strive/tuhigh
更多优秀案例,可以移步官网

让“国产”成为“首选”
LeaferJS 不是又一个“国产替代”,而是直接把 Canvas 的性能与体验拉到 Next Level。
它让开发者第一次敢在提案里写:“前端百万节点实时交互,没问题。”
如果你受够了原生 Canvas 的笨拙,也踩腻了国外库的深坑,不妨试试 LeaferJS——
- LeaferJS 官网地址:
https://www.leaferjs.com/
来源:juejin.cn/post/7566104702569742355
颜色网站为啥都收费?自己做个要花多少钱?
你是小阿巴,一位没有对象的程序员。

这天深夜,你打开了某个颜色网站,准备鉴赏一些精彩的视频教程。
结果一个大大的付费弹窗阻挡了你!
你心想:可恶,为啥颜色网站都要收费啊?

作为一名程序员,你怎能甘心?
于是你决定自己做一个,不就是上传视频、播放视频嘛?
这时,经常给大家分享 AI 和编程知识的 鱼皮 突然从你身后冒了出来:天真!你知道自己做一个要花多少钱么?

你吓了一跳:我又没做过这种网站,怎么知道要花多少?
难道,你做过?
鱼皮一本正经:哼,当然…… 没有。
不过我做过可以看视频的、技术栈完全类似的 编程学习网站,所以很清楚这类网站的成本。
你来了兴趣:哦?愿闻其详。
鱼皮笑了笑:那我就以 编程导航 项目为例,从网站开发、上线到运营的完整流程,给你算算做一个视频网站到底要花多少钱。还能教你怎么省钱哦~
你点了个赞,并递上了两个硬币:好啊,快说快说!
鱼皮特别感谢朋友们的支持,你们的鼓励是我持续创作的动力 🌹!
⚠️ 友情声明:以下成本是基于个人经验 + 专业云服务商价格的估算(不考虑折扣),仅供参考。
⭐️ 推荐观看本文对应视频版:bilibili.com/video/BV1nJ…
服务器
想让别人访问你的网站,首先你要有一台服务器。
你点点头:我知道,代码文件都要放到服务器上运行,用户通过浏览器访问网站,其实是在向服务器请求网页文件和数据。
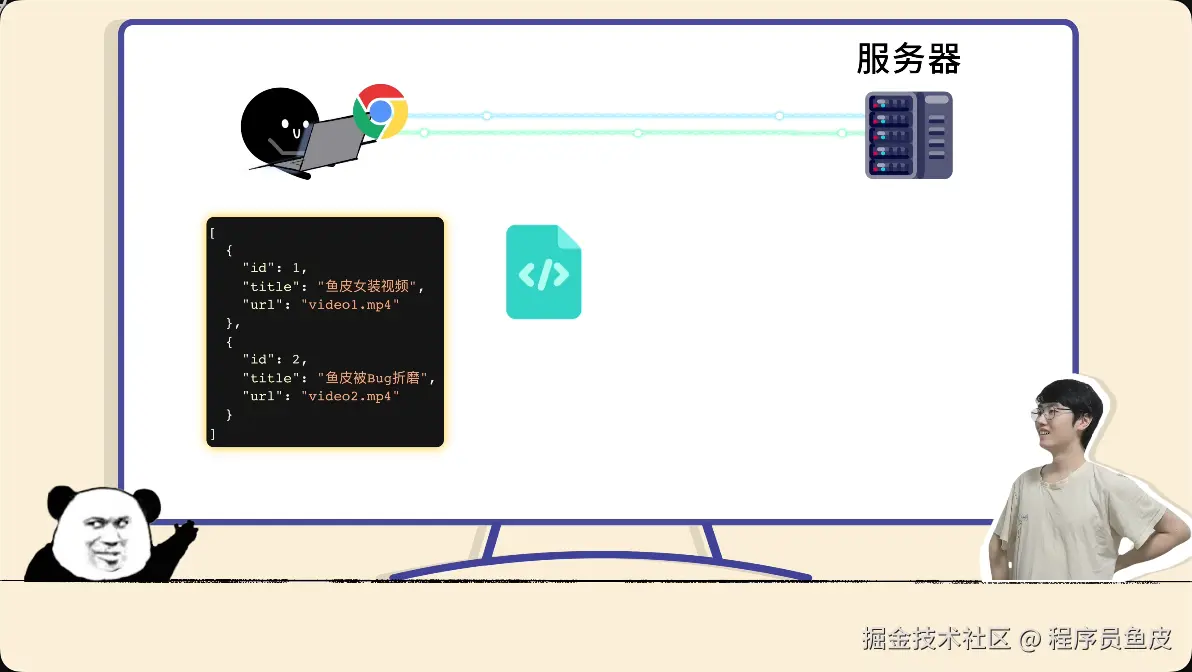
那服务器怎么选呢?
鱼皮:服务器的配置要看你的网站规模。刚开始做个小型视频网站,可以用入门配置的轻量应用服务器 (比如 2 核 CPU、2G 内存、4M 带宽) ,一年几百块就够了。
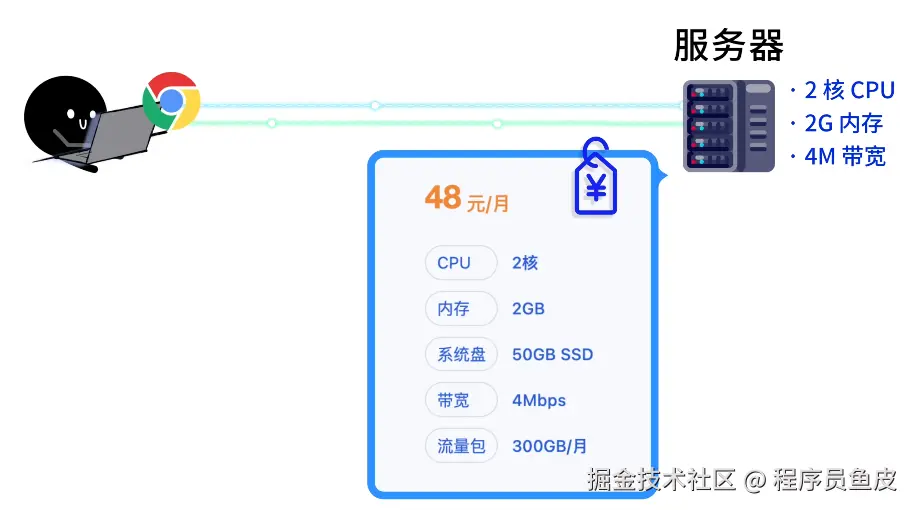
等后续用户多了,服务器带宽跟不上了再升级。比如 4 核 CPU、16G 内存、14M 带宽,一年差不多几千块。
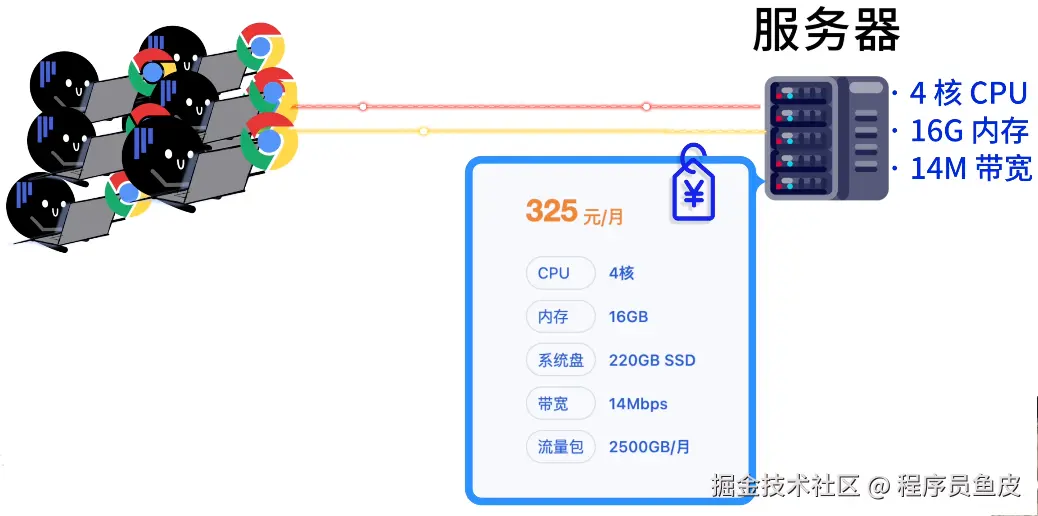
你:几百块?比我想的便宜啊。
鱼皮:没错,国内云服务现在竞争很激烈、动不动就搞优惠。
但是要注意,如果你想做 “那种网站”,就要考虑用海外服务器了(好处是不用备案)。
咳咳,我们不谈这个……
数据库
有了服务器,还得有数据库,用来存储网站的用户信息、视频信息、评论点赞这些数据。
你:这个简单,数据库不就是 MySQL、PostgreSQL 这些嘛,装在服务器上不就行了?
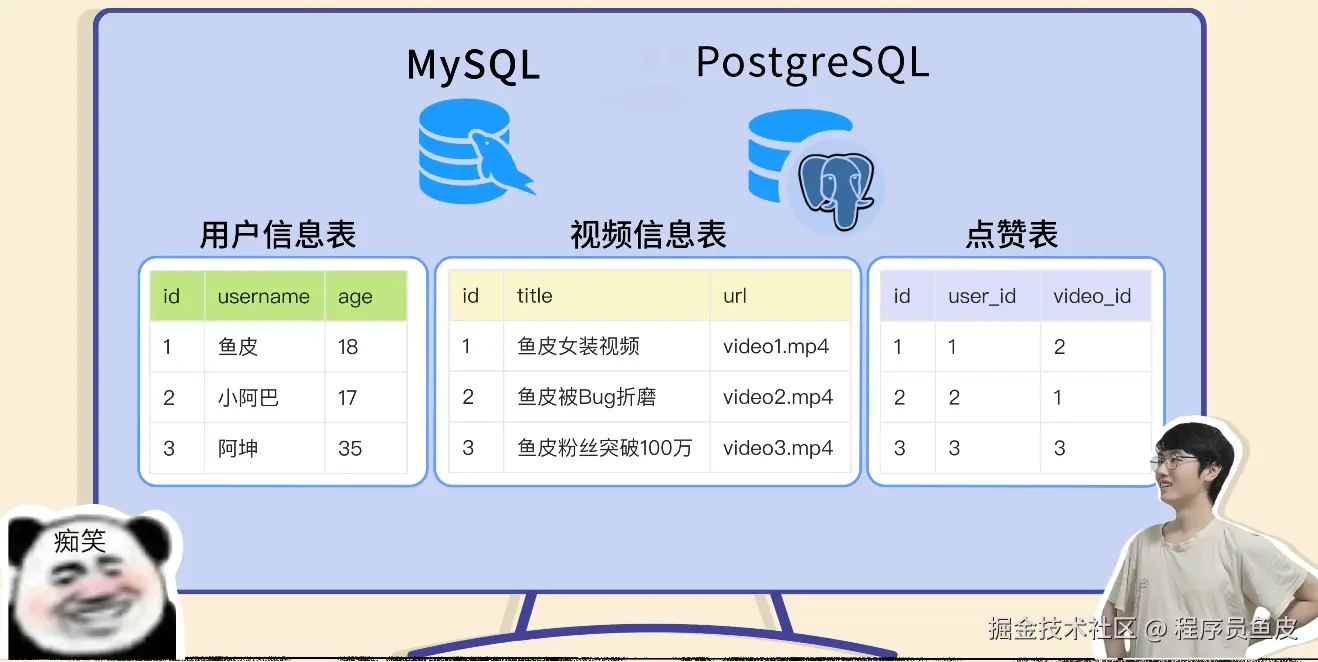
鱼皮:是可以的,但我更建议使用云数据库服务,比如阿里云 RDS 或者腾讯云的云数据库。
你:为啥?不是要多花钱吗?
鱼皮:因为云数据库更稳定,而且自带备份、容灾、监控这些功能,你自己搞的话,还要费时费力安装维护,万一数据丢了可就麻烦了。
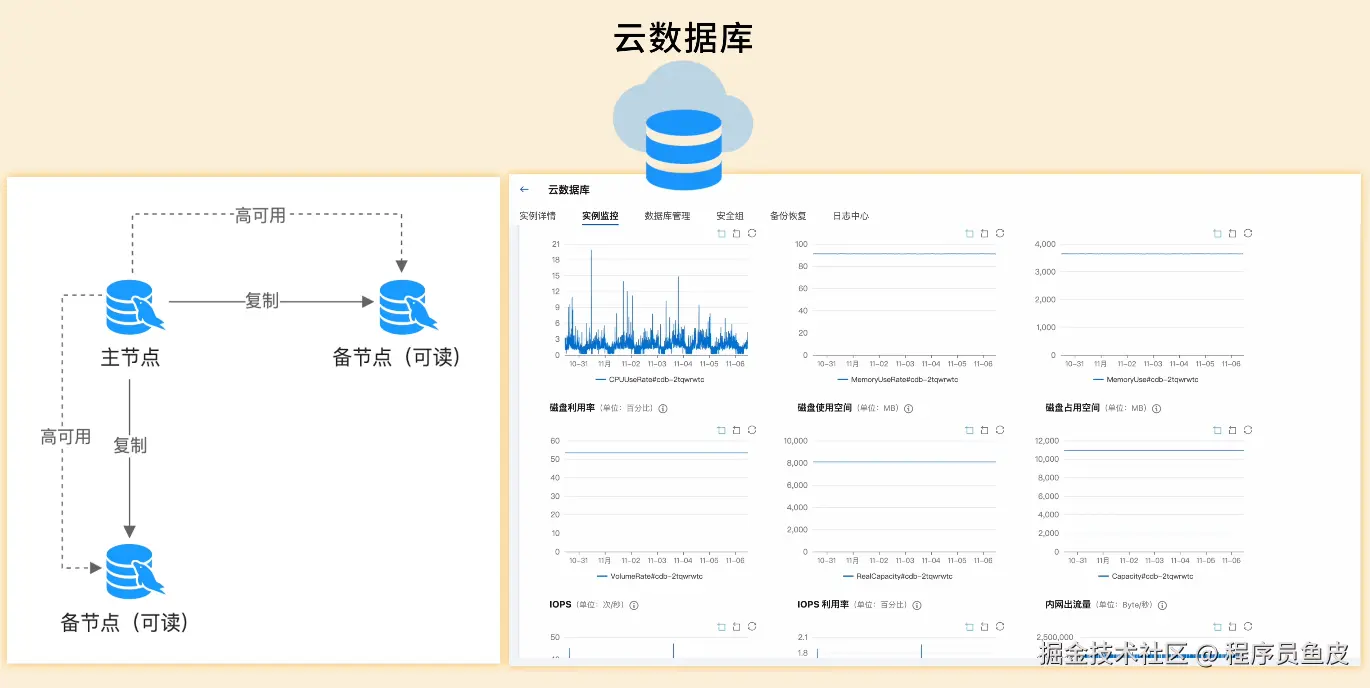
你:确实,那得多少钱?
鱼皮:入门级的云数据库(比如 2 核 4G 内存、100GB 硬盘)包年大概 2000 元左右。后面用户多了、数据量大了,就要升级配置(比如 4 核 16G),那一年就要 1 万多了。不过那个时候你已经赚麻了……
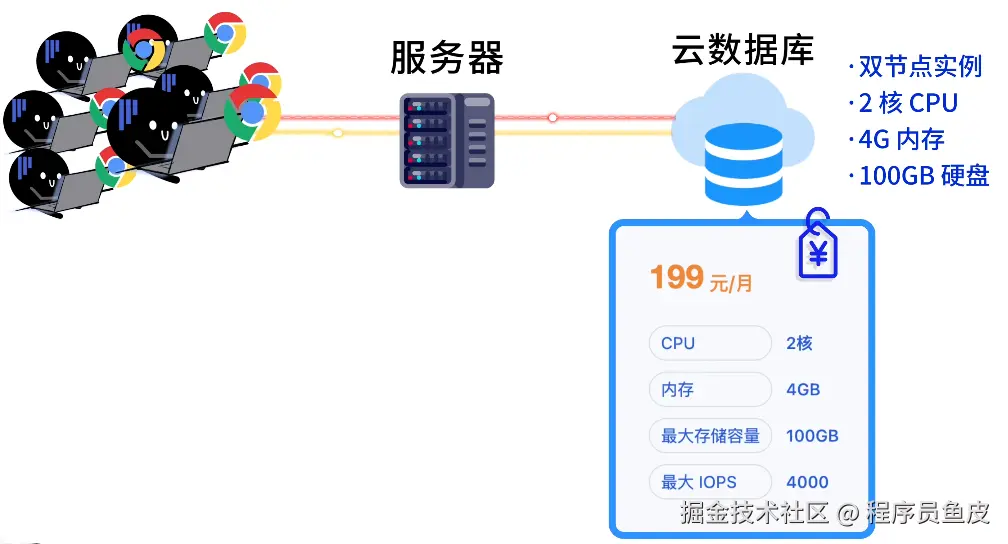
Redis
鱼皮:对了,我还建议你加个 Redis 缓存。
你挠了挠头:Redis?之前看过你的 讲解视频。这个是必须的吗?

鱼皮:刚开始可以没有,但如果你想让网站数据能更快加载,强烈建议用。
你想啊,视频网站用户一进来都要查看视频列表、热门推荐这些,如果用 Redis 把热点数据缓存起来,响应速度能快好几倍,还能帮数据库分摊查询压力。
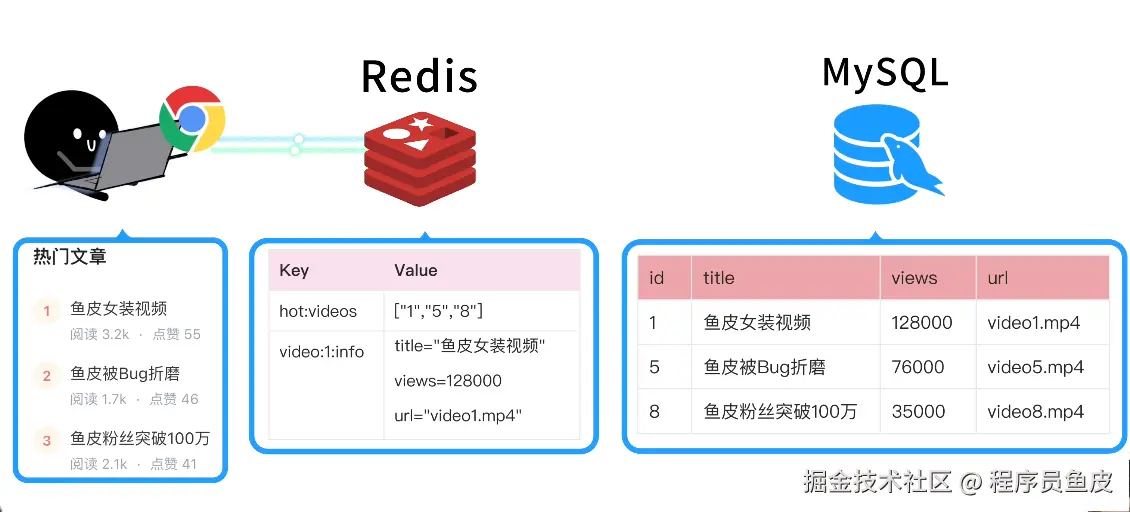
你:确实,网站更快用户更爽,也更愿意付费。那 Redis 要多少钱?
鱼皮:Redis 比数据库便宜一些。入门级的 Redis 服务一年大概 1000 元左右。
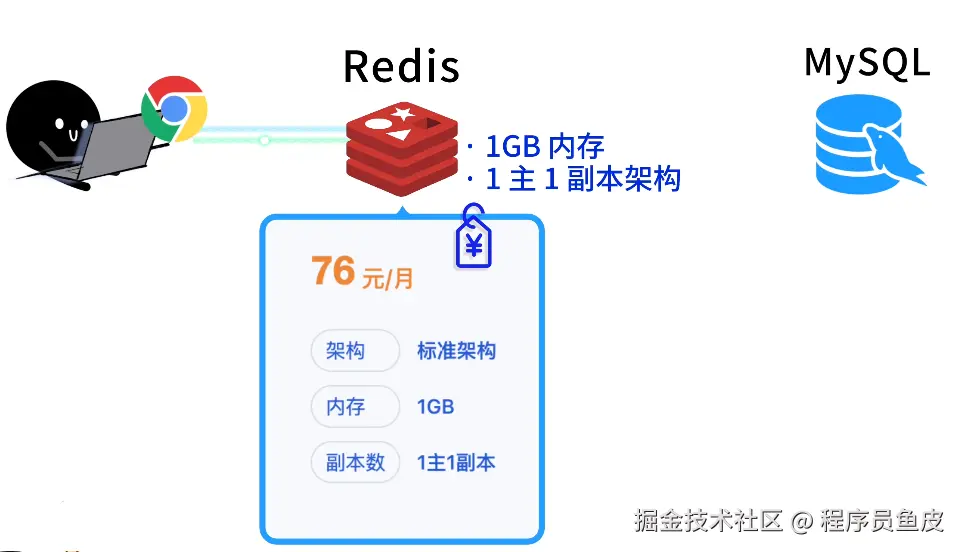
你松了口气:也还行吧,看来做个视频网站也花不了多少钱啊!
对象存储
鱼皮:别急,接下来才是重点!
我问问你,视频文件保存在哪儿?
你不假思索:当然是存在服务器的硬盘上!
鱼皮哈哈大笑:别开玩笑了,一个高清视频动不动就几百 MB 甚至几个 G,你那点儿服务器硬盘能存几个视频?
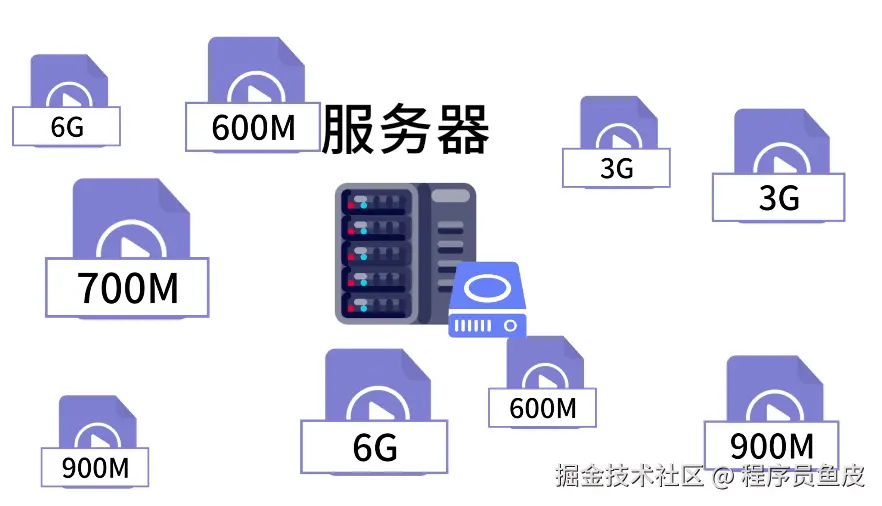
而且服务器带宽有限,如果同时有很多用户看视频,服务器根本撑不住!
你:那咋办啊!
鱼皮:更好的做法是用 对象存储,比如阿里云 OSS、腾讯云 COS。
对象存储是专门用来存海量文件的云服务,它容量几乎无限、可以弹性扩展,而且访问速度快、稳定性高,很适合存储图片和音视频这些大文件。
你:贵吗?
鱼皮:存储本身不贵,100GB 一年也就几十块钱。但 真正贵的是流量费用!
用户每看一次视频,都要从对象存储下载数据,这就产生了流量。
如果一个 1 GB 的视频被完整播放 1000 次,那就是 1000 GB 的流量,大概 500 块钱。
你看那些视频网站,每天光 1 个视频可能就有 10 万人看过,价格可想而知。
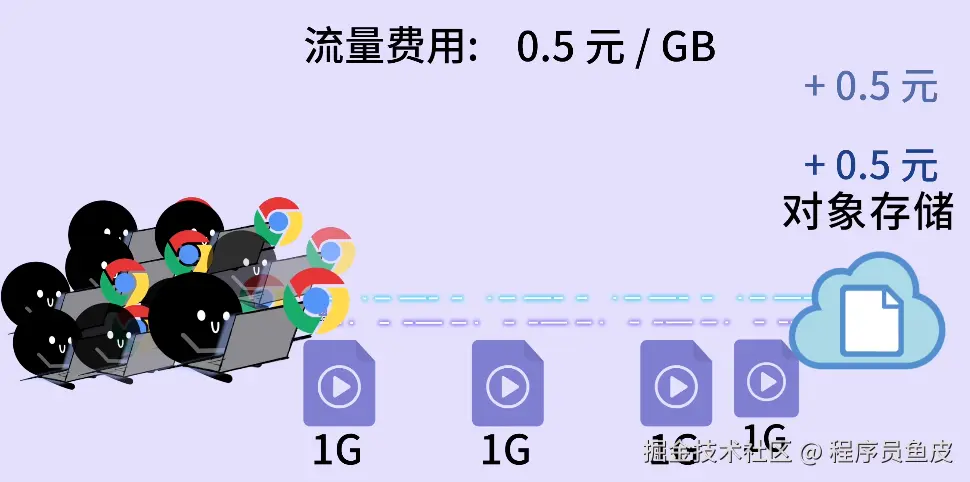
你惊讶地说不出话来:阿巴阿巴……

视频转码
鱼皮接着说:这还不够!对于视频网站,你还要做 视频转码。因为用户上传的视频格式、分辨率、编码方式都不一样,你需要把它们统一转成适合网页播放的格式,还要生成不同清晰度的版本让用户选择(标清、高清、超清)。
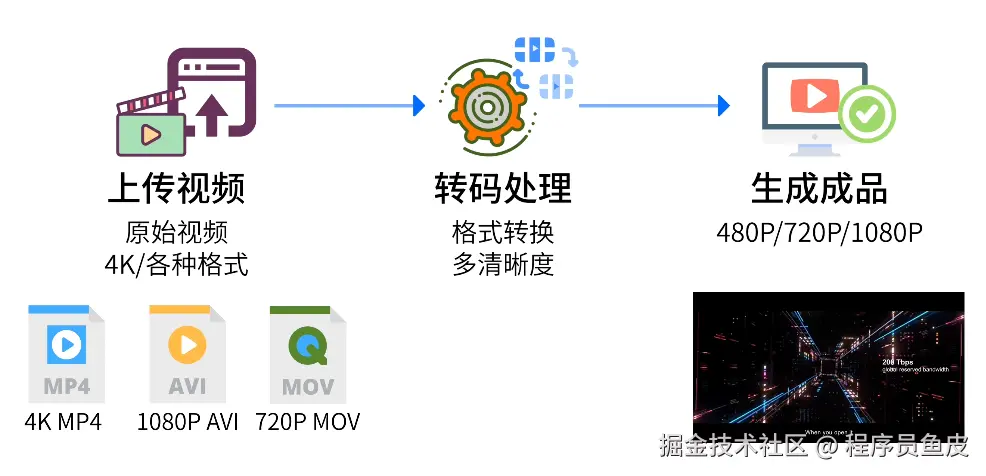
你:啊,那不是要多存好几个不同清晰度的视频文件?
鱼皮:没错,而且转码本身也是要钱的!
一般按照清晰度和视频分钟数计费。如果你上传 1000 个小时的高清视频,光转码费就得几千块!
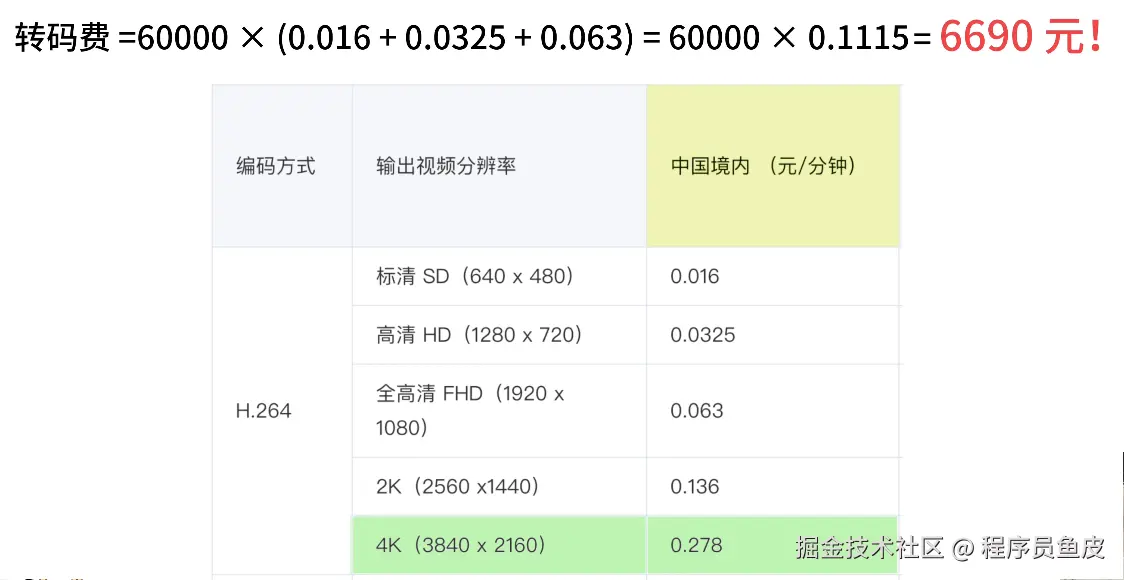
CDN 加速
你急了:怎么做个视频网站处处都要花钱啊!有没有便宜点的办法?
鱼皮笑道:可以用 CDN。
你:CDN是啥?听着就高级!
鱼皮:CDN 叫内容分发网络,简单说就是把你的视频缓存到全国各地的服务器节点上。用户看视频的时候,从最近的节点拿数据,不仅速度更快,而且流量费比对象存储便宜不少。
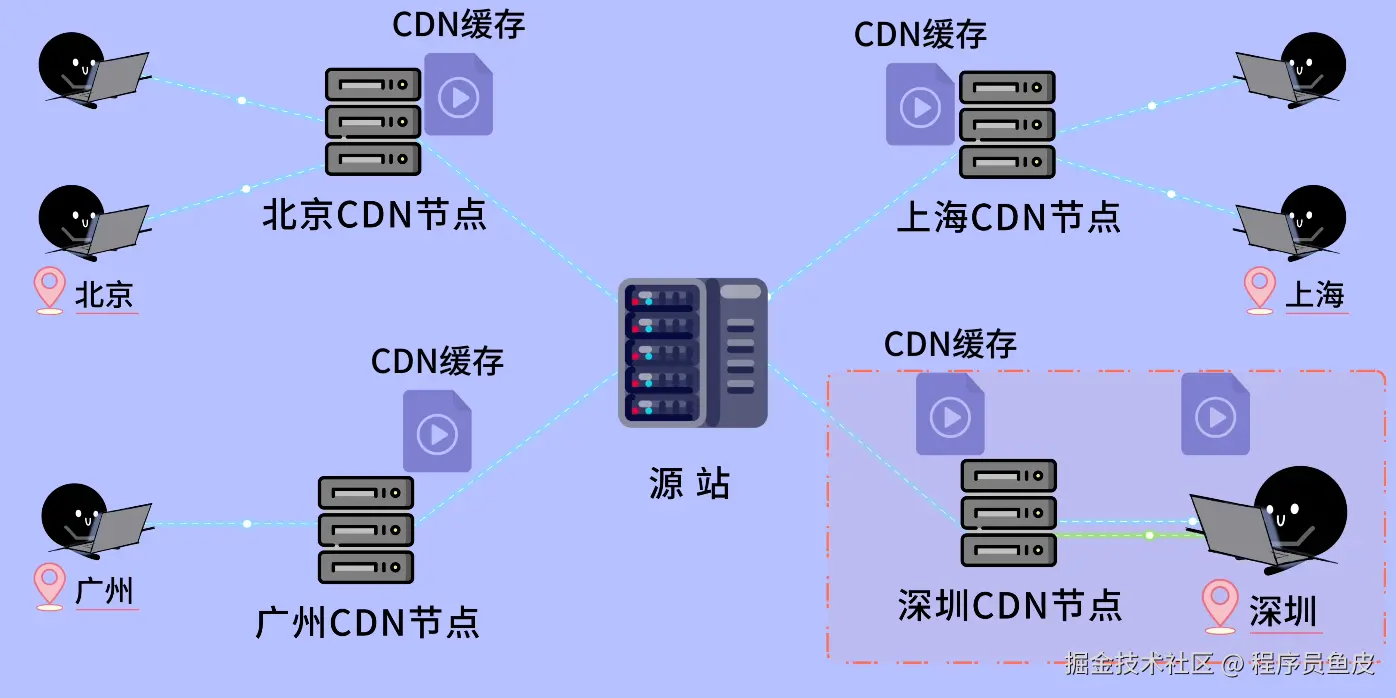
你眼睛一亮:这么好?那不是必用 CDN!
鱼皮:没错,一般建议对象存储配合 CDN 使用。
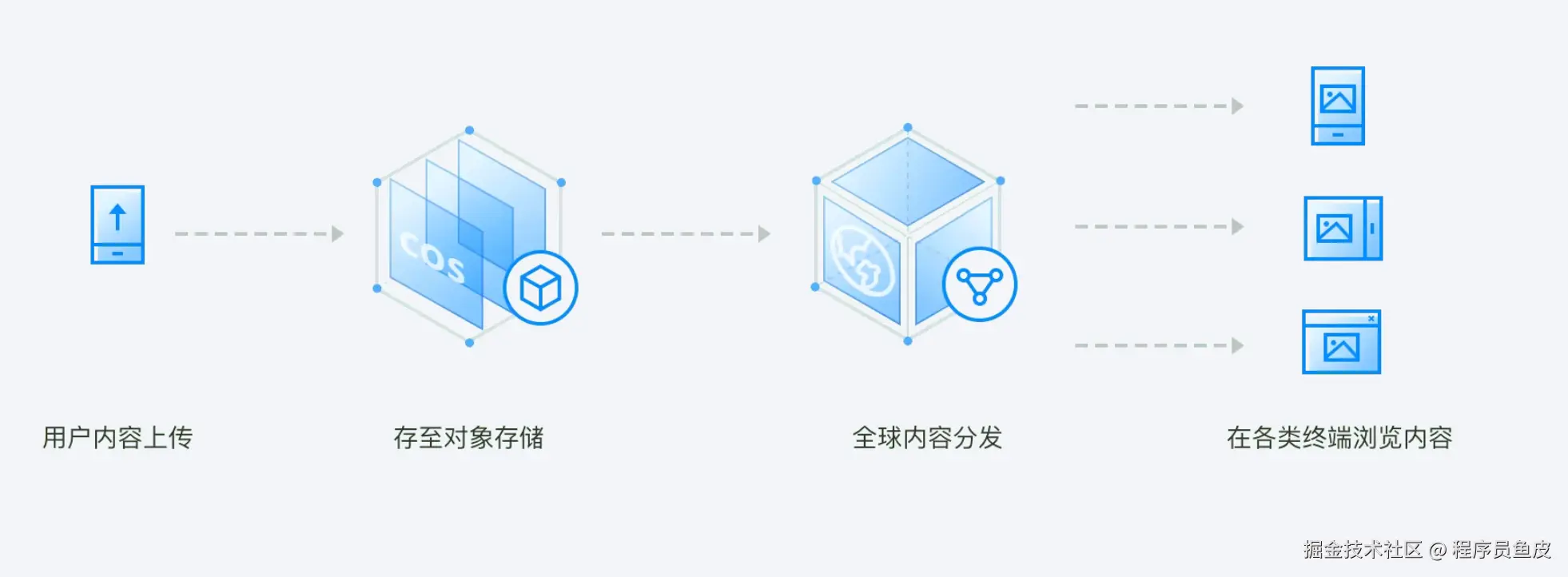
而且视频网站 一定要做好流量防刷和安全防护!
现在有的平台自带了流量防盗刷功能:
此外,建议手动添加更多流量安全配置。
1)设置访问频率限制,防止短时间被盗刷大量流量

2)还要配置 CDN 的流量告警,超过阈值及时得到通知
3)还要启用 referer 防盗链,防止别人盗用你的视频链接,用你的流量做网站捞钱。
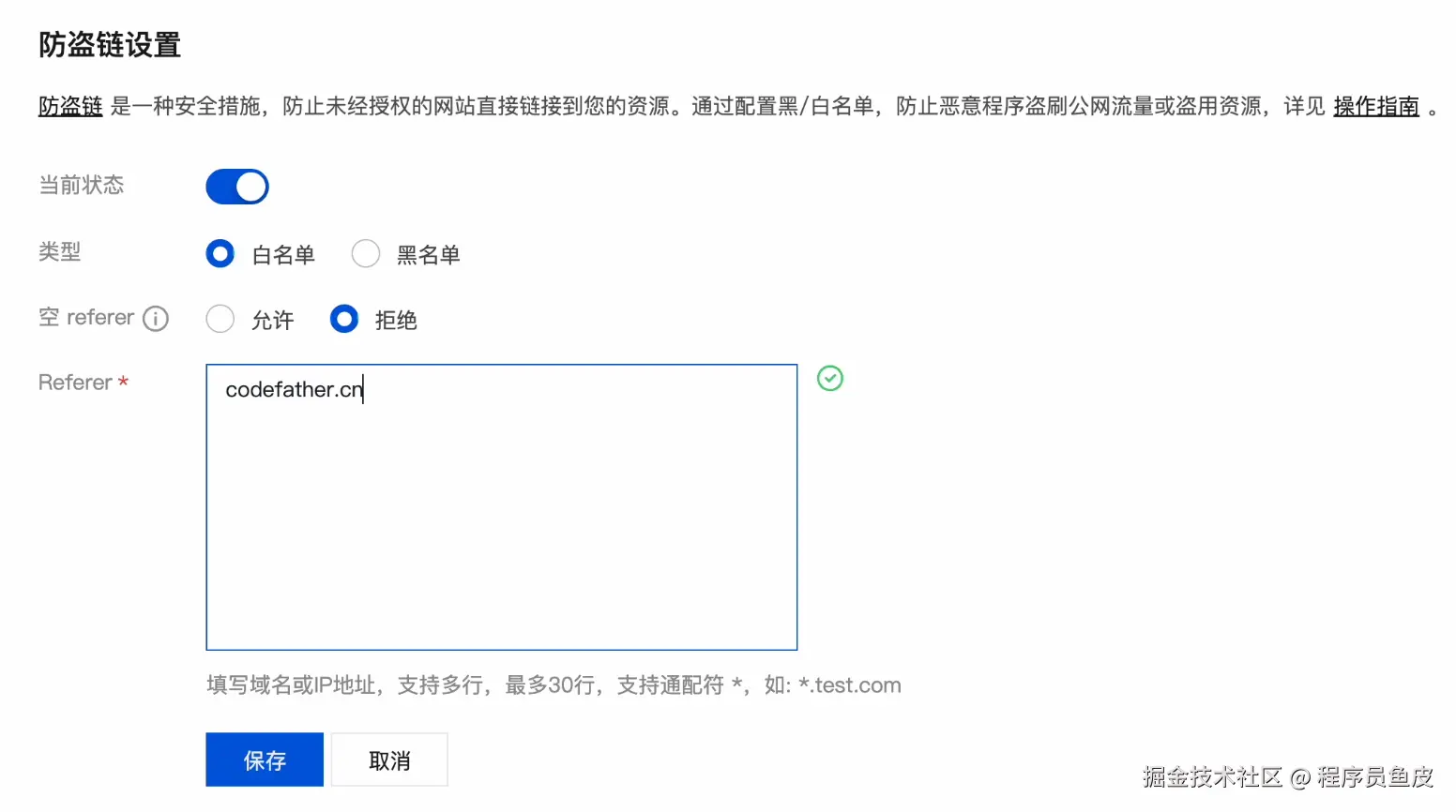
如果不做这些,可能分分钟给你刷破产了!
你:这我知道,之前看过很多你破产和被攻击的视频!
鱼皮:我 ***!

视频点播
你:为了给用户看个视频,我要先用对象存储保存文件、再通过云服务转码视频、再通过 CDN 给用户加速访问,感觉很麻烦啊!
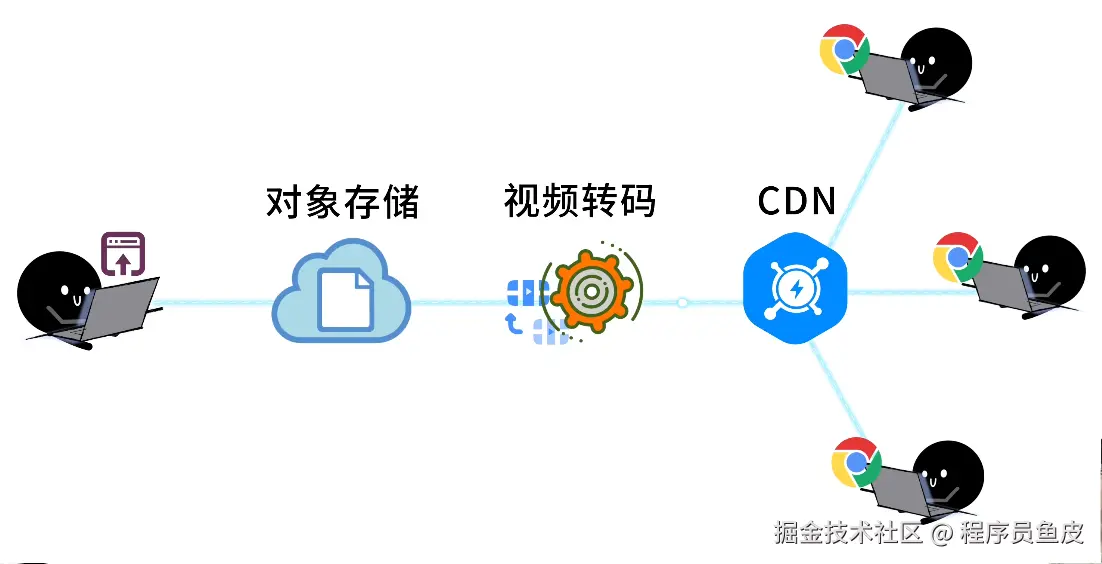
鱼皮神秘一笑:嘿嘿,其实还有更简单的方案 —— 视频点播服务,这是快速实现视频网站的核心。
只需要通过官方提供的 SDK 代码包和示例代码,就能快速完成视频上传、转码、多清晰度切换、加密保护等功能。
此外,还提供了 CDN 内容加速和各端的视频播放器。
你双眼放光:这么厉害,如果我自己从零开发这些功能,至少得好几个月啊!
鱼皮:没错,视频点播服务相当于帮你做了整合,能大幅提高开发效率。
但是它的费用也包含了存储费、转码费和流量费,价格跟前面提到的方案不相上下。
你叹了口气:唉,主要还是流量费太贵了啊……
网站上线还要准备啥?
鱼皮:讲完了开发视频网站需要的技术,接下来说说网站上线还需要的其他东西。
你:啊?还有啥?
鱼皮:首先,你得有个 域名 给用户访问吧?总不能让人家记你的 IP 地址吧?
不过别担心,普通域名一年也就几十块钱(比如我的 codefather.cn 才 38 / 年)。
当然,如果是稀缺的好域名就比较贵了,几百几千万的都有!
你:别说了,俺随便买个便宜的就行……
鱼皮:买了域名还得配 SSL 证书,因为现在做网站都得用 HTTPS 加密传输,不然浏览器会提示 “不安全”,用户看了就跑了。
刚开始可以直接用 Let's Encrypt 提供的免费证书,但只有 3 个月有效期,到期要手动续期,比较麻烦。
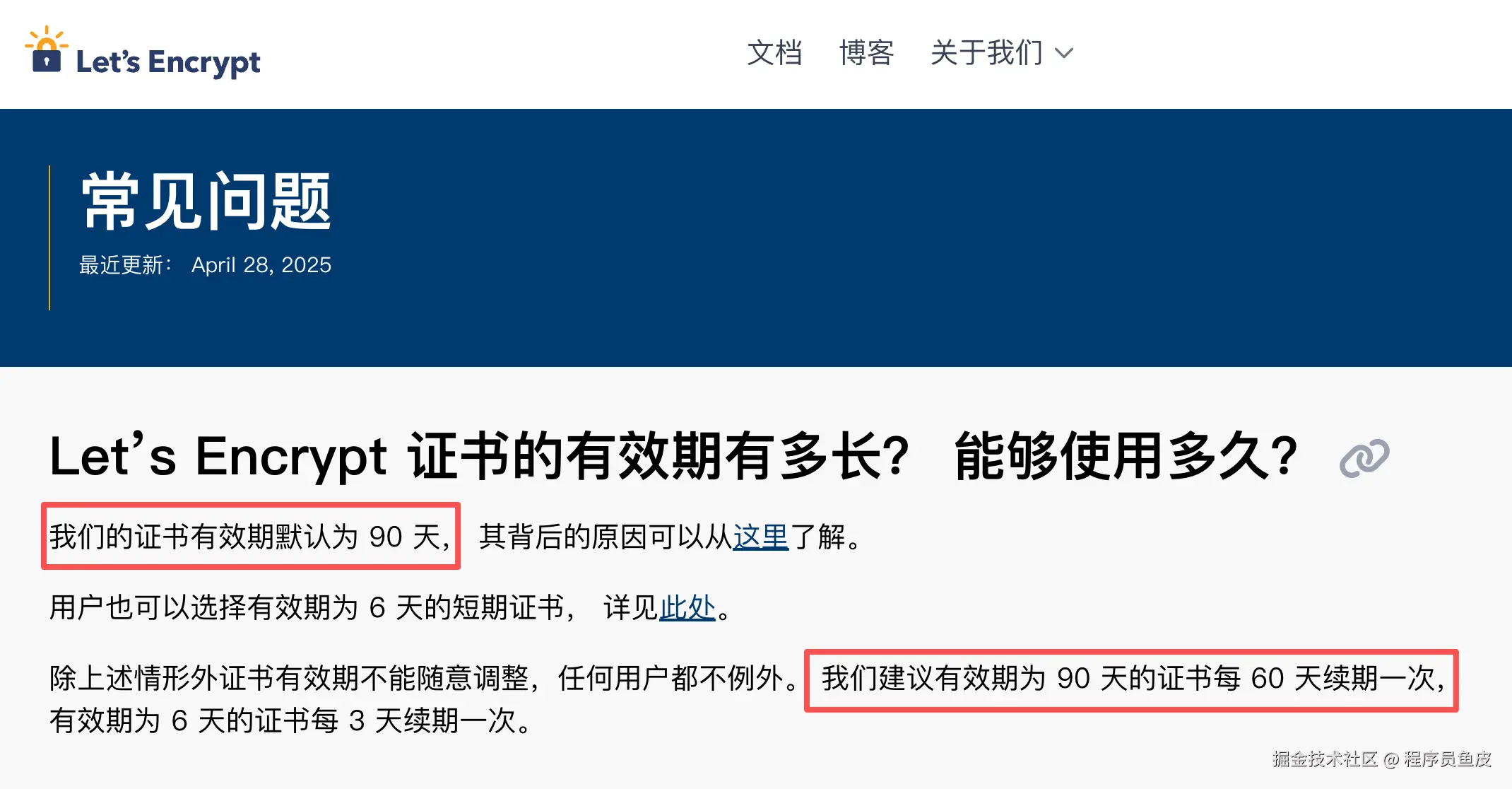
想省心的话可以买付费证书,便宜的一年几百块。
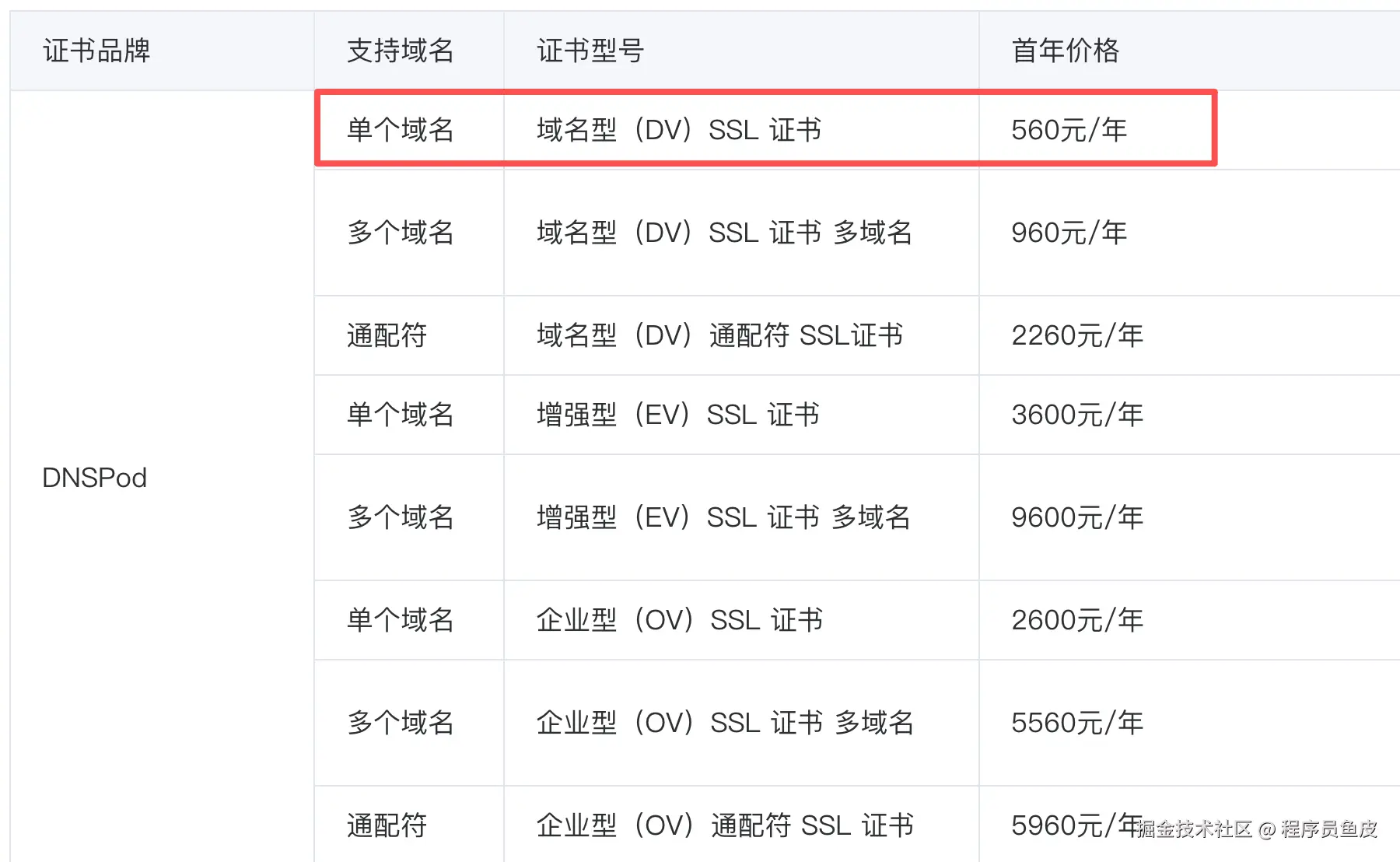
你:了解,那我就先用免费的,看来上线也花不了几个钱。
鱼皮:哎,可不能这么说,网站正式上线运营后,花钱的地方可多着呢!尤其是安全防护。
安全防护
做视频网站要面对两大安全威胁。第一个是 内容安全,你总不能让用户随便上传违规视频吧?万一上传了不该传的内容,网站直接就被封了。
你紧张起来:对啊,我人工审核也看不过来啊…… 怎么办?

鱼皮:可以用内容审核服务。视频审核包含画面和声音两部分,比文字审核更贵,审核 1000 小时视频,大概几千块。
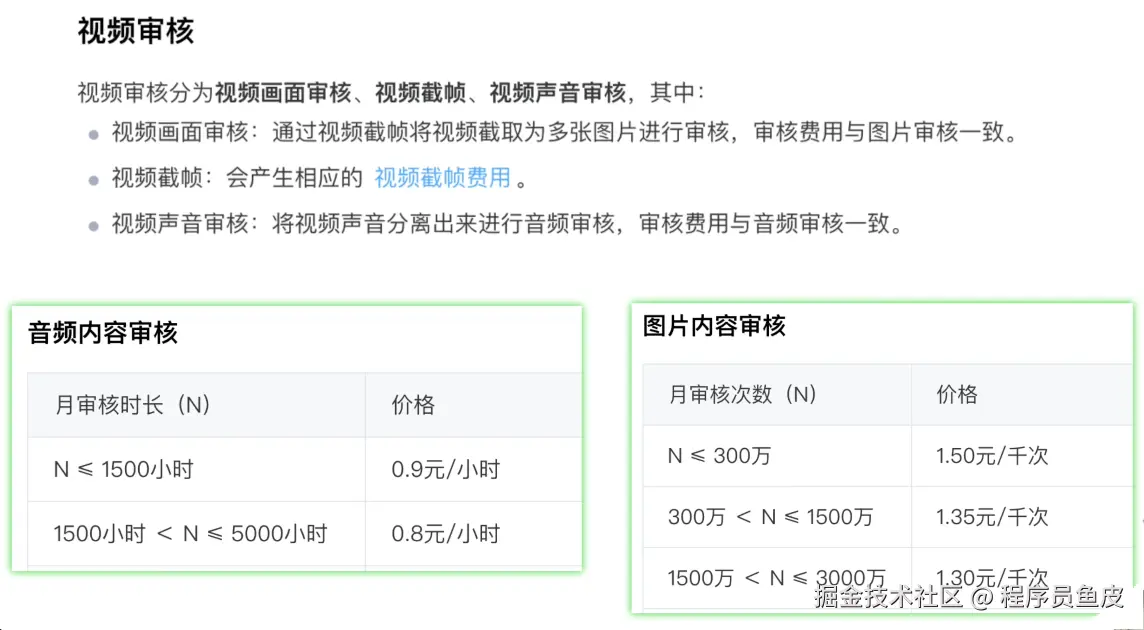
你:还有第二个威胁呢?
鱼皮:第二个是最最最难应对的 网络攻击。做视频网站,尤其是有付费内容的,特别容易被攻击。DDoS 流量攻击想把你冲垮、SQL 注入想偷你数据、XSS 攻击想搞你用户、爬虫想盗你视频……
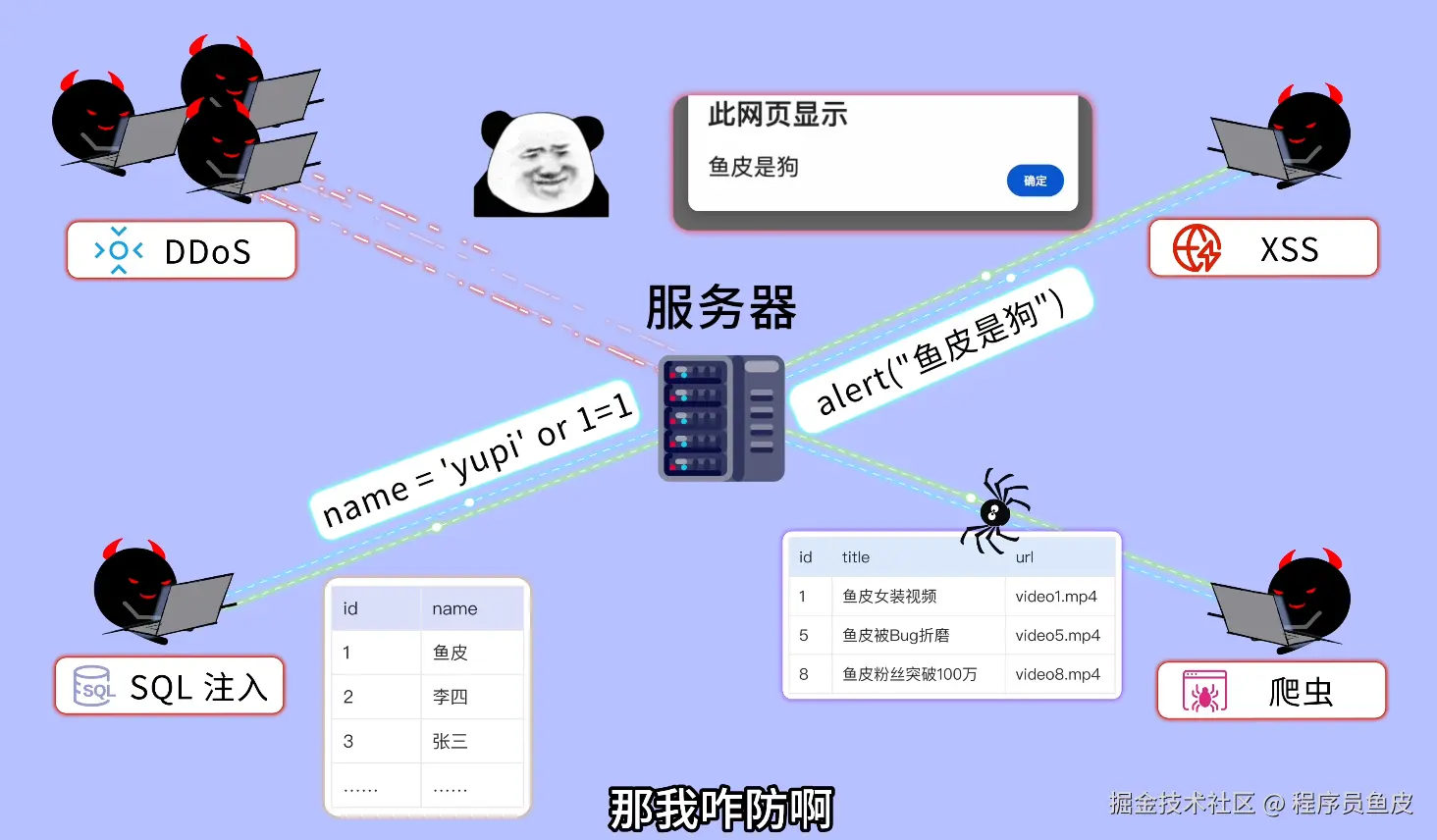
你:这么坏的吗?那我咋防啊!
鱼皮:常用的是 Web 应用防火墙(WAF)和 DDoS 防护服务。Web 防火墙能防 SQL 注入、XSS 攻击这些应用层攻击,而 DDoS 防护能抵御大规模流量冲击。
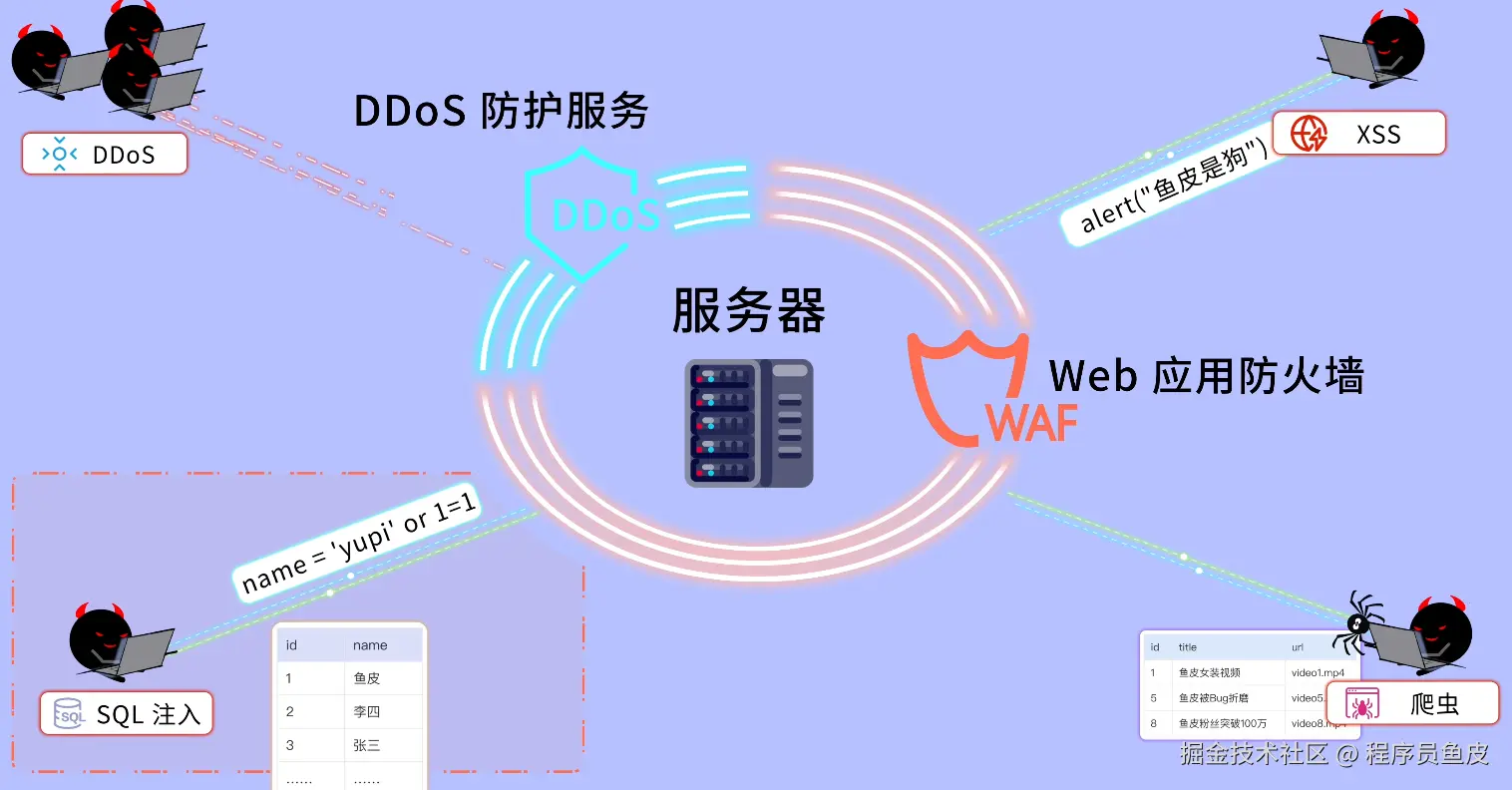
但是这些商业级服务都挺贵的,可能一年就是几万几十万……
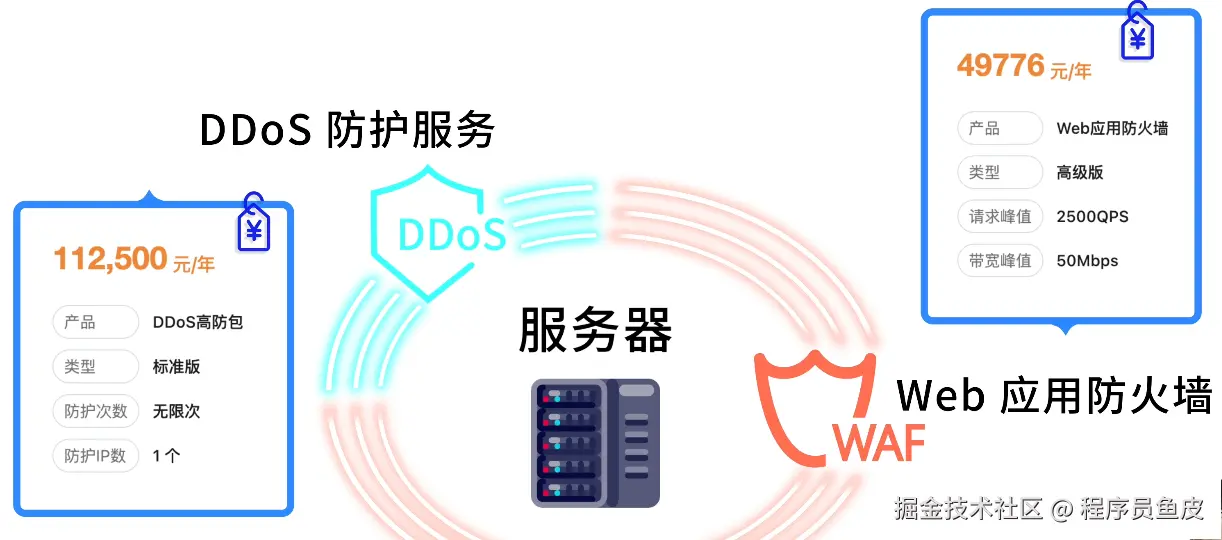
你惊呼:我为了防止被攻击,还要搭这么多钱?!
鱼皮笑了:好消息是,有些云服务商会提供一点点免费的 DDoS 基础防护,还有相对便宜的轻量版 DDoS 防护包。
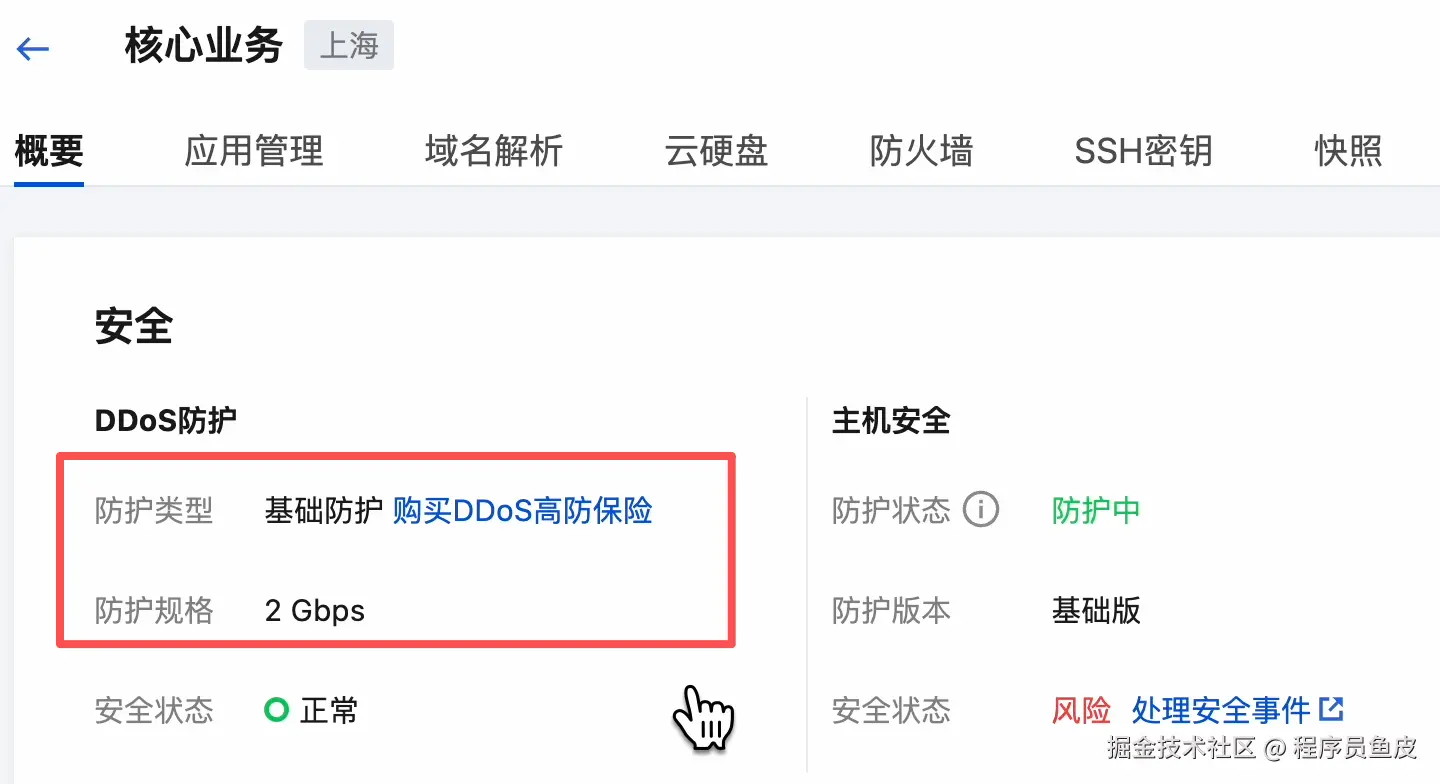
我的建议是,刚开始就先用免费的,加上代码里做好防 SQL 注入、XSS 这些安全措施,其实够用了。等网站真做起来、有收入了,再花钱买商业级的防护服务就好。
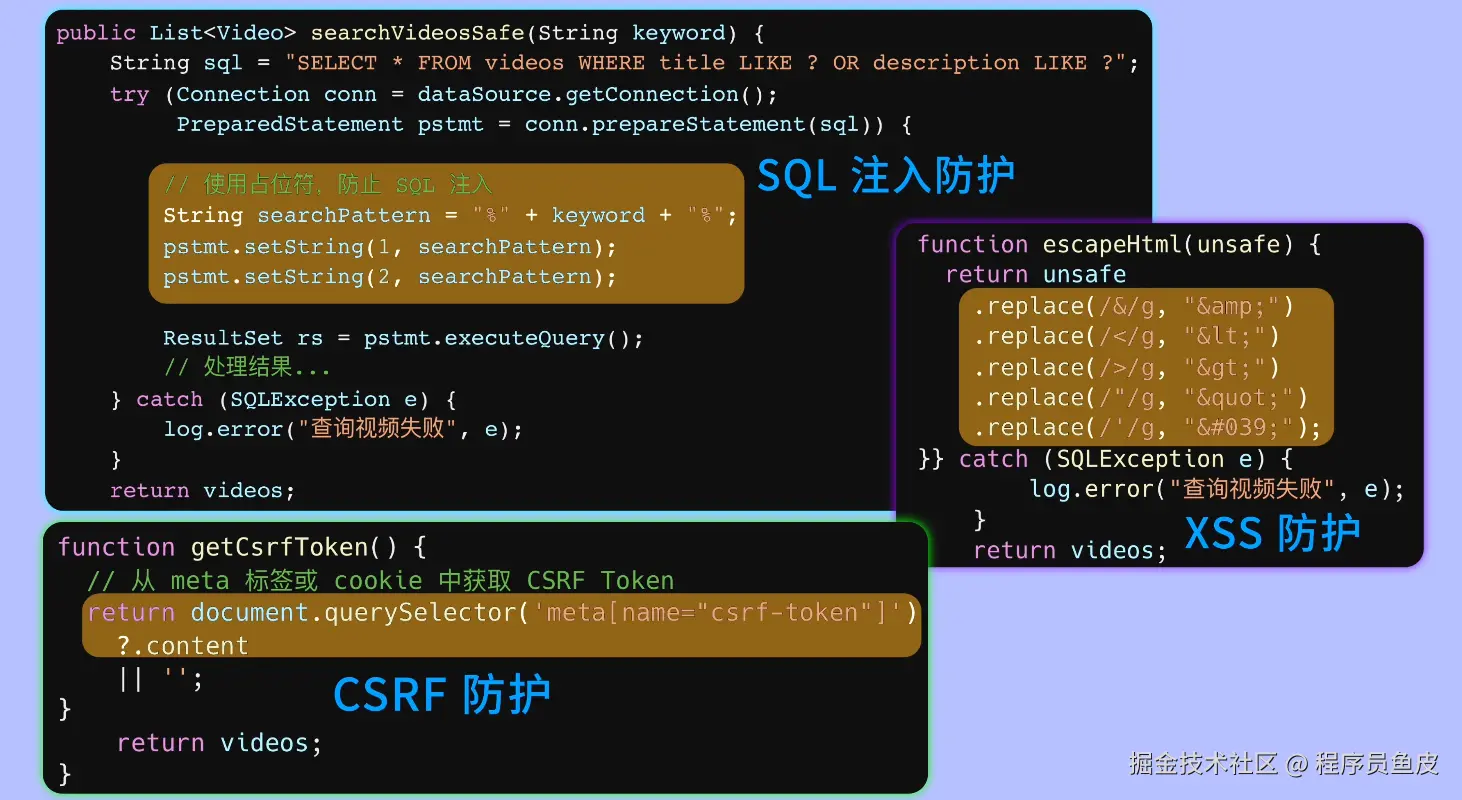
你点了点头:是呀,如果没收入,被攻击就被攻击吧,哼!
鱼皮微笑道:你这心态也不错哈哈。除了刚才说的这些,随着你网站的成熟,还可能会用到很多第三方服务,比如短信验证码、邮件推送、 等等,这些也都是成本。
总成本
讲到这里,你应该已经了解了视频网站的整个技术架构和成本。
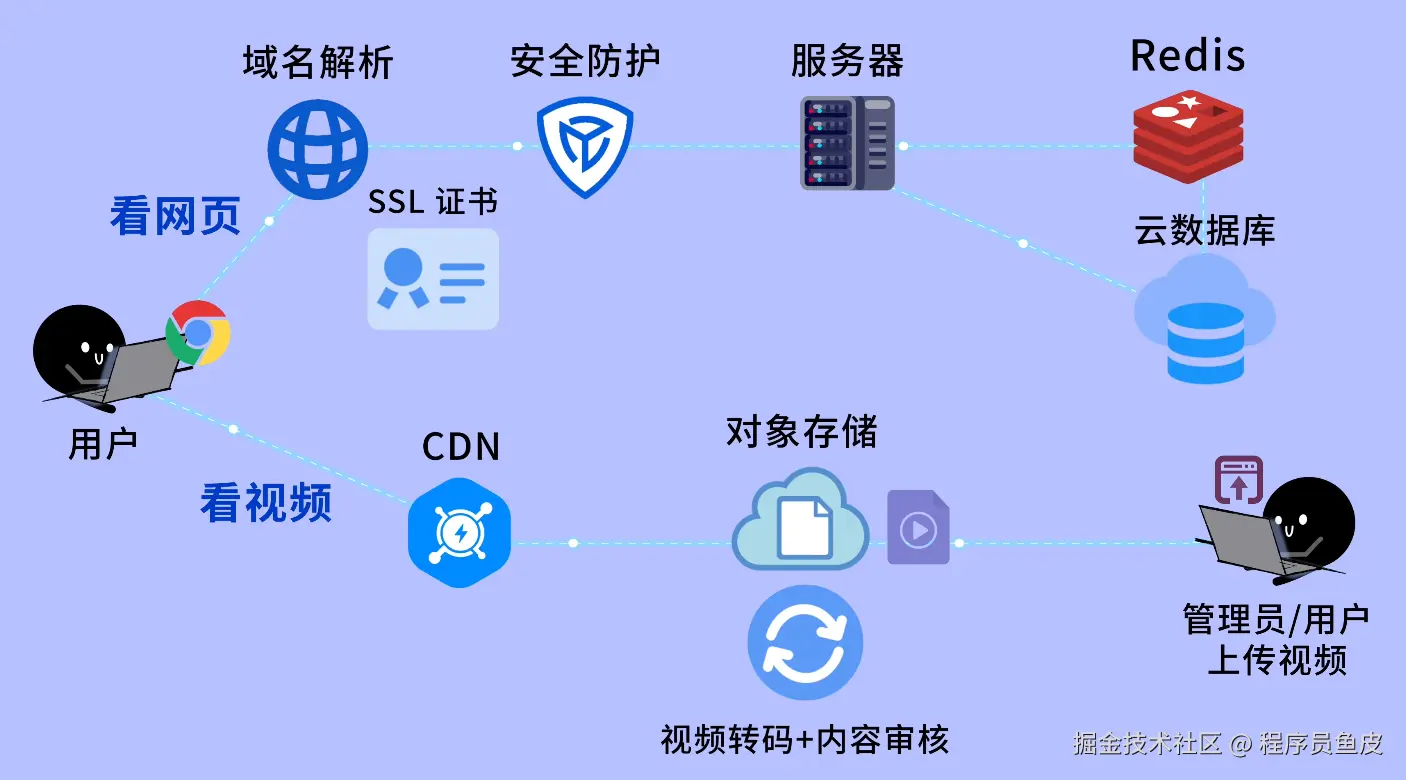
最后再总结一下,如果一个人做个小型的视频网站,一年到底要花多少钱?
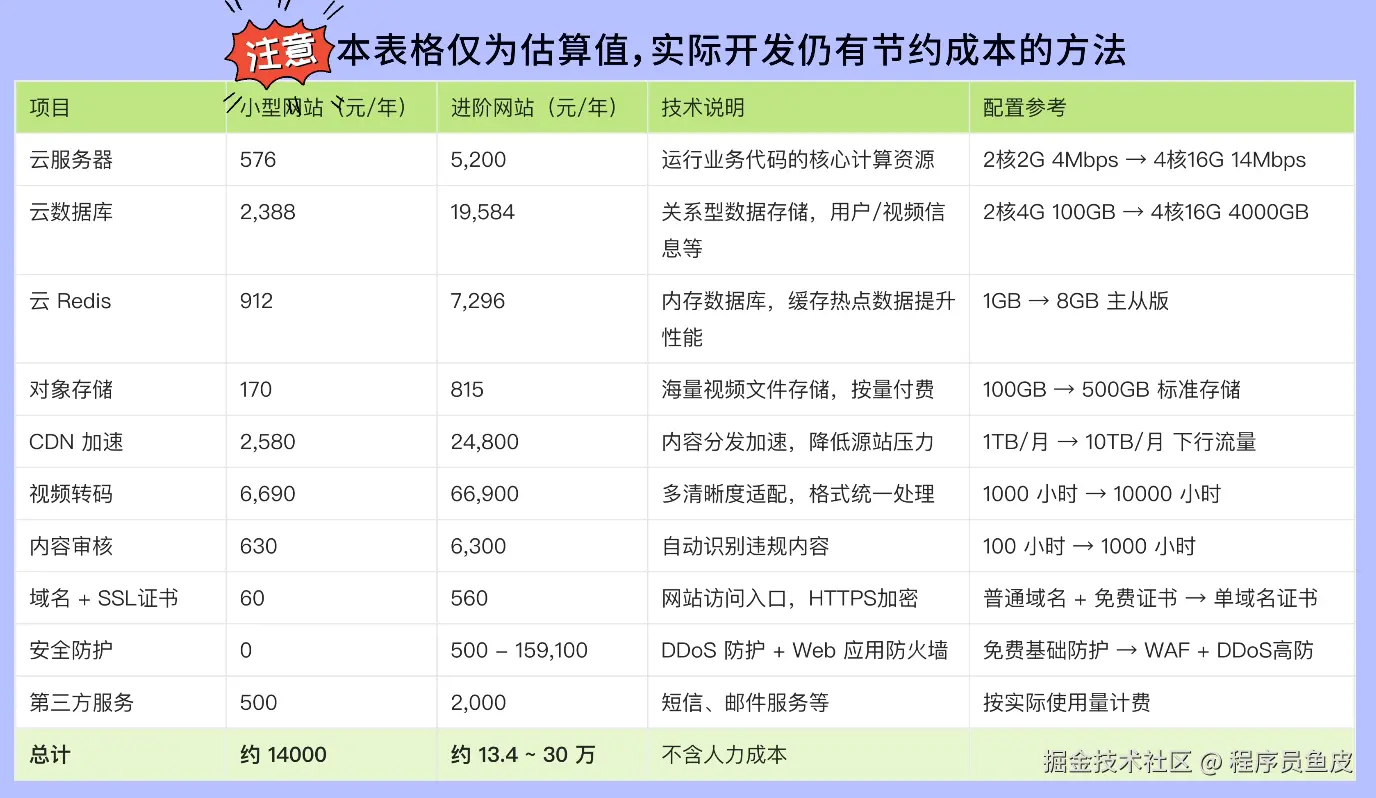
你看着这个表,倒吸一口凉气:视频网站的成本真高啊……

鱼皮:没错,这还只是保守估计。如果你的网站真火了,每天几万人看视频,一年光流量费就得有几十万吧。
而且刚才说的都只是网站本身的成本,如果你一个人做累了,要组个团队开发呢?
按照一线城市的成本算算,前端开发 + 后端开发 + 测试工程师 + 运维工程师,再加上五险一金,差不多每月要接近 10 万了。
你瞪大眼睛:那一年就是一百万?
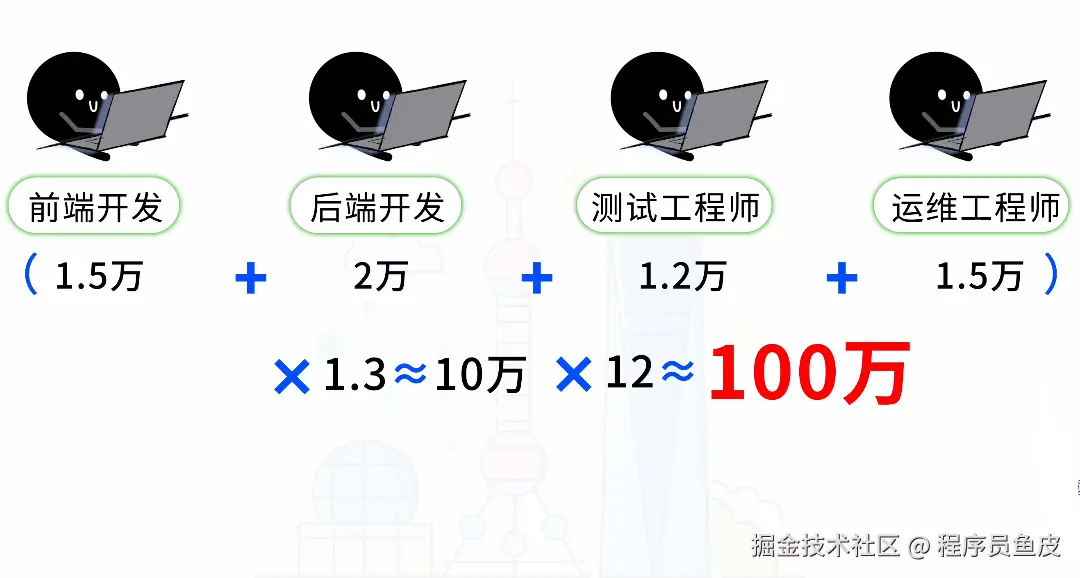
鱼皮:没错,人力成本才是最贵的。
你:好了你别说了,我不做了,我不做了!我现在终于理解为什么那些网站都要收费了……
鱼皮:不过说实话,虽然成本不低,但那些网站收费真的太贵了,其实成本远没那么高,更多的是利用人性赚取暴利!
所以比起花钱看那些乱七八糟的网站,把钱和时间投资在学习上,才是最有价值的。
你点了点头:这次一定!再看一期你的教程,我就睡觉啦~
更多
来源:juejin.cn/post/7572961448537882651
就因为package.json里少了个^号,我们公司赔了客户十万块

写这篇文章的时候,我刚通宵处理完一个P0级(最高级别)的线上事故,天刚亮,烟灰缸是满的🚬。
事故的原因,说出来你可能不信,不是什么服务器宕机,也不是什么黑客攻击,就因为我们package.json里的一个依赖项,少写了一个小小的^(脱字符号) 。
这个小小的失误,导致我们给客户A的数据计算模块,在一次平平无奇的依赖更新后,全线崩溃。而我们,直到客户的业务方打电话来投诉,才发现问题。
等我们回滚、修复、安抚客户,已经是7个小时后。按照合同的SLA(服务等级协议),我们公司需要为这次长时间的服务中断,赔付客户十万块。
老板在事故复盘会上,倒没说什么重话,只是默默地把合同复印件放在了桌上。

今天,我不想抱怨什么,只想把这个价值 十万块 的教训,原原本本地分享出来,希望能给所有前端、乃至所有工程师,敲响一个警钟。
事故是怎么发生的?
我们先来复盘一下事故的现场。
我们有一个给客户A定制的Node.js数据处理服务。它依赖了我们内部的另一个核心工具库@internal/core。
在项目的package.json里,依赖是这么写的:
{
"name": "customer-a-service",
"dependencies": {
"@internal/core": "1.3.5",
"express": "^4.18.2",
"lodash": "^4.17.21"
// ...
}
}
注意看,express和lodash前面,都有一个^符号,而我们的@internal/core,没有。
这个^代表什么?它告诉npm/pnpm/yarn:“我希望安装1.x.x版本里,大于等于1.3.5的最新版本。”
而没有^,代表什么?它代表:我只安装1.3.5这一个版本,锁死它,不许变。
问题就出在这里。
上周,core库的同事,修复了一个严重的性能Bug,发布了1.3.6版本,并且在公司群里通知了所有人。
我们组里负责这个项目的同学,看到了通知,也很负责任。他想:core库升级了,我也得跟着升。
于是,他看了看package.json,发现项目里用的是1.3.5。他以为,只要他去core库的仓库,把1.3.5这个tag删掉,然后把1.3.6的tag打上去,CI/CD在下次部署时,重新pnpm install,就会自动拉取到最新的代码。
他错了!
最致命的锁死版本
因为我们的依赖写的是"1.3.5",而不是"^1.3.5",所以我们的pnpm-lock.yaml文件里,把这个依赖的解析规则,彻底锁死在了1.3.5。
无论core库的同事怎么发布1.3.6、1.3.7,甚至2.0.0...
只要我们不去手动修改package.json,我们的CI/CD流水线,在执行pnpm install时,永远、永远,都只会去寻找那个被写死的1.3.5版本。
然后,灾难发生了。
core库的同事,在发布1.3.6后,为了保持仓库整洁,就把1.3.5那个旧的git tag给删掉了。
然后,客户A的项目,某天下午需要做一个常规的文案更新,触发了部署流水线。
流水线执行到pnpm install时,pnpm拿着lock文件,忠实地去找@internal/core@1.3.5这个包...
“Error: Package '1.3.5' not found.”
流水线崩溃了。一个本该5分钟完成的文案更新,导致了整个服务7个小时的宕机😖。
十万块换来的血泪教训
事故复盘会上,我们所有人都沉默了。我们复盘的,不是谁的锅,而是我们对依赖管理这个最基础的认知,出了多大的偏差。
^ (Caret) 和 ~ (Tilde) 不是选填,而是必填
^(脱字符) :^1.3.5意味着1.x.x(x >= 5)。这是最推荐的写法。它允许我们自动享受到所有 非破坏性 的小版本和补丁更新(比如1.3.6,1.4.0),这也是npm install默认的行为。~(波浪号) :~1.3.5意味着1.3.x(x >= 5)。它只允许补丁更新,不允许小版本更新。太保守了,一般不推荐。- (啥也不写) :
1.3.5意味着锁死。除非你是react或vue这种需要和生态强绑定的宿主,否则,永远不要在你的业务项目里这么干!
我们团队现在强制规定,所有package.json里的依赖,必须、必须、必须使用^。
关于lock文件
我们以前对lock文件(pnpm-lock.yaml, package-lock.json)的理解太浅了,以为它只是个缓存。
现在我才明白,package.json里的^1.3.5,只是在定义一个规则。
而pnpm-lock.yaml,才是基于这个规则,去计算出的最终答案。
lock文件,才是保证你同事、你电脑、CI服务器,能安装一模一样的依赖树的唯一路径。它必须被提交到Git。
依赖更新,是一个主动的行为,不是被动的
我们以前太天真了,以为只要依赖发了新版,我们就该自动用上。
这次事故,让我们明白:依赖更新,是一个严肃的、需要主动管理和测试的行为。
我们现在的流程是:

- 使用
pnpm update --interactive:pnpm会列出所有可以安全更新的包(基于^规则)。 - 本地测试:在本地跑一遍完整的测试用例,确保没问题。
- 提交PR:把更新后的
pnpm-lock.yaml文件,作为一个单独的PR提交,并写清楚更新了哪些核心依赖。 - CI/CD验证:让CI/CD在
staging环境,用这个新的lock文件,跑一遍完整的E2E(端到端)测试。
这十万块,是技术Leader(我)的失职,也是我们整个团队,为基础不牢付出的最昂贵的一笔学费。
一个小小的^,背后是整个npm生态的依赖管理的核心。
分享出来,不是为了博眼球,是真的希望大家能回去检查一下自己的package.json。
看看你的依赖前面,那个小小的^,它还在吗?😠
来源:juejin.cn/post/7568418604812632073
微信小游戏包体限制4M,一个字体就11.24M,怎么玩?
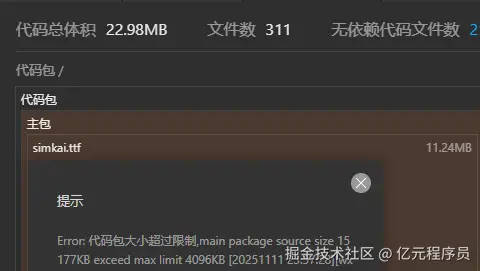
引言
哈喽大家好,很多时候,我们的游戏项目为了美观和保证风格的统一,都会用到外部字体库。
但是,外部字体库通常是完整的字库,体积非常的大,例如完整的simkai字体库就达到了11.24MB。
要知道,现在的微信小游戏限制主包的大小不能超过4M,即使你把字体放在分包,占去近50%的代码包大小,想想也不太合适。

因此,我们如果想要能够顺利地在游戏中用上漂亮的字体,那我们得想办法将字库瘦下来。
言归正传,本期将带小伙伴们一起来看下,如何将我们想用的字库从11.24M瘦到不到1M 。
本文源工程可在文末获取,小伙伴们自行前往。
精简字库原理
据了解,一个完整的字库估计有3~4万个汉字,但实际上我们游戏项目需要用到的可能只占10%~20%,甚至更少,像其中的一些汉字囧、烎、嫑、勥、忈、巭、怹、颪、氼、兲,别说用,笔者连读都不会读。(会读的小伙伴请打在评论区,我给你点赞)
游戏项目中,用到文字的地方通常包含下面几个:
- 1.游戏配置(*.json),一般配置里面的中文最多。
- 2.预制体(*.prefab),有些静态的文字通常就在预制体的
Label里。
- 3.场景(*.scene、*.fire)同上。
- 4.代码(*.ts),写死在代码里的。
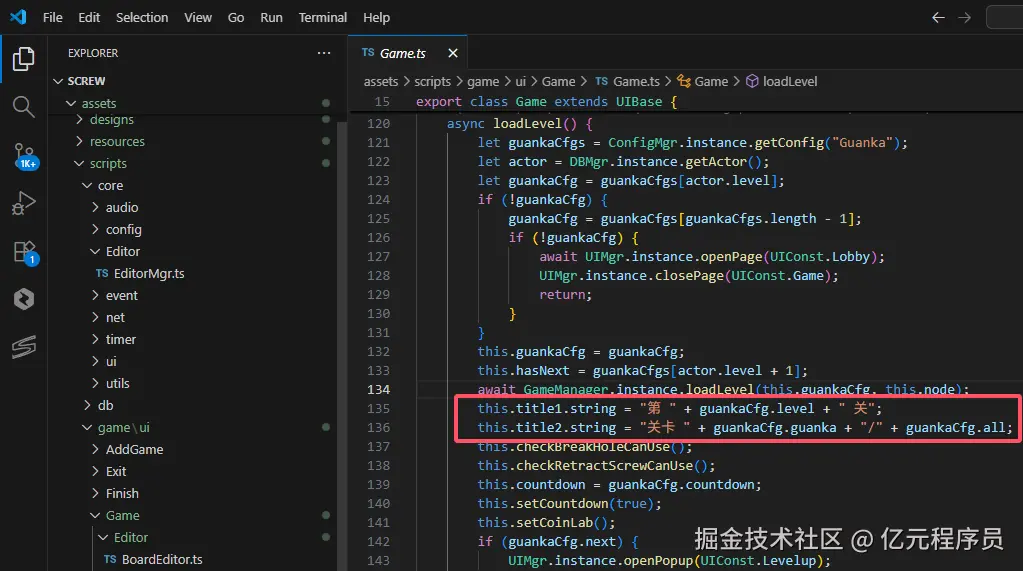
因此,要瘦身字体,按照以下2个步骤即可:
- 1.通过工具将上述地方的文字提取出来。
- 2.通过工具从字库中的保留我们提取到的文字,其余的删除。
精简字库实例
1.提取中文字
要提取中文字,我们只需要按照上面的原理,遍历我们的游戏项目中的游戏配置、预制体、场景和代码进行匹配即可。
其中遍历文件,笔者使用的是glob。
匹配中文字的正则表达式是/[\u4e00-\u9fff]/g。
2.精简字库
这里我们使用百度出品的字体子集化工具Fontmin。可以直接通过npm install fontmin进行安装。
工具的使用也非常简单,通过传入原字体、保留的字符和字体输出目录,最后通过fontmin.run这个API生成即可。
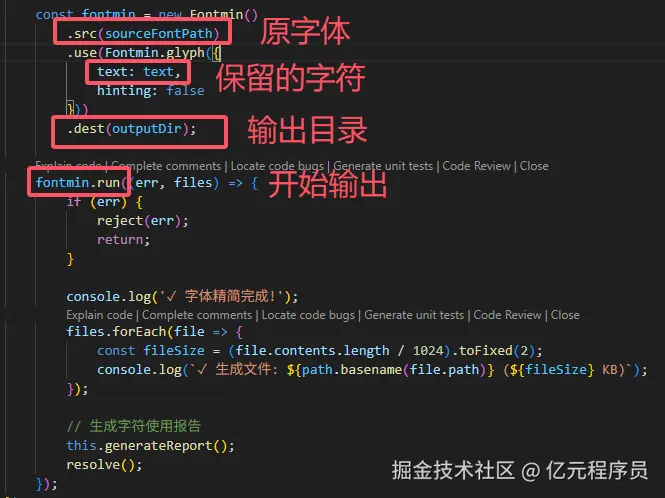
3.效果演示
通过node font-minifier.js --project=C:\Users\Administrator\Desktop\demo --source=C:\Users\Administrator\Desktop\simkai.ttf传入工程目录和原字体路径即可。
执行结果可以看到扫描的所有文件。
提取到的所有中文字。
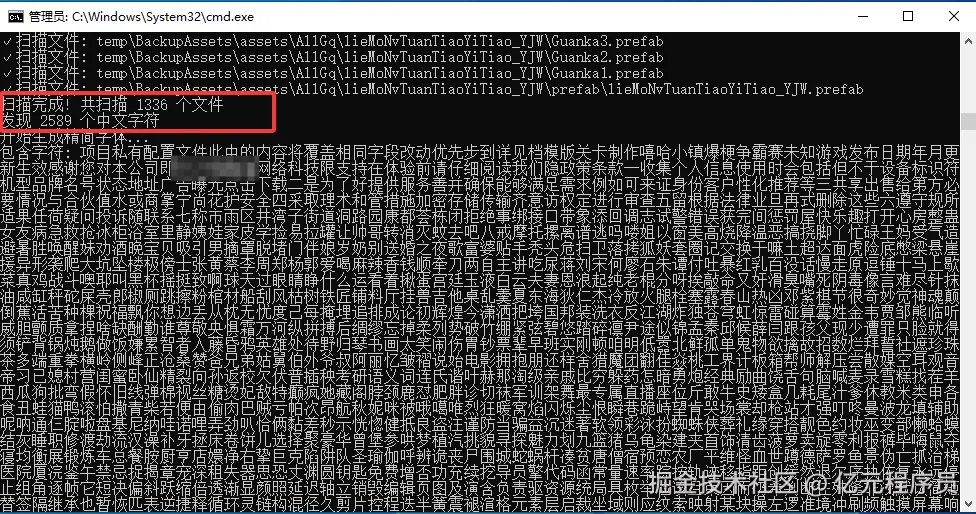
生成的文件及其大小。
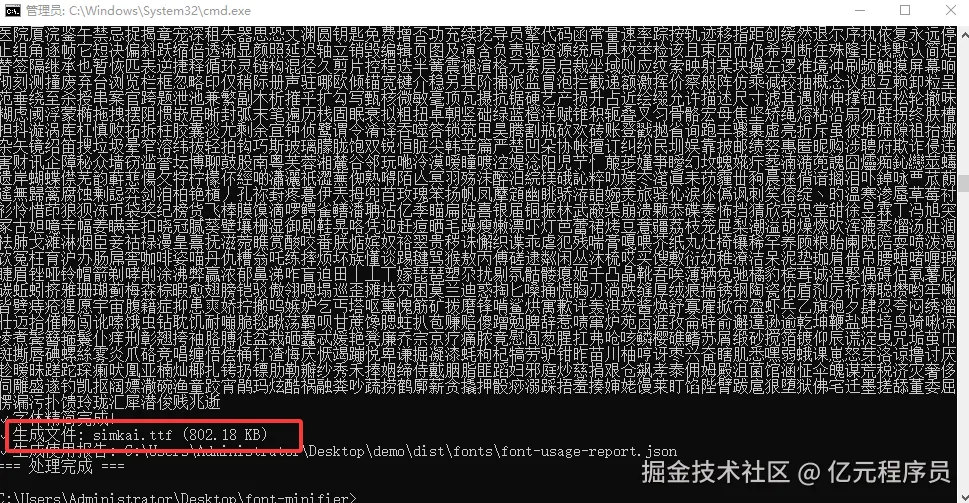
精简后的字体大小为802K。
更进一步
除去我们遍历出来的游戏设定的中文字,其实还有一部分中文字我们是不确定的,那就是用户自定义的内容,例如名字和聊天文字。
想要处理这一部分文字,我们只能通过预设,猜到用户会自定义的内容,从而预设保留,可以通过网络上分享的常用内容来完成。
此外工具可以集成到插件或者打包系统里面去,这样后续就不用考虑相关问题,自动生成所需字库即可。
结语
通过上述方法,可以将字库大幅度精简到能够使用的状态,但是也会有一定的瑕疵。
不知道小伙伴们有没有更完美的办法呢?
本文源工程可通过私信发送 fontminifier 获取。
我是"亿元程序员",一位有着8年游戏行业经验的主程。在游戏开发中,希望能给到您帮助, 也希望通过您能帮助到大家。
AD:笔者线上的小游戏《打螺丝闯关》《贪吃蛇掌机经典》《重力迷宫球》《填色之旅》《方块掌机经典》大家可以自行点击搜索体验。
实不相瞒,想要个赞和爱心!请把该文章分享给你觉得有需要的其他小伙伴。谢谢!
推荐专栏:
来源:juejin.cn/post/7572087181608353842
白嫖党的快乐,我在安卓手机上搭了服务器+内网穿透,再也不用买服务器了
起因
因为去年买的腾讯云服务器到期了,我一看续租的话要459元,作为白嫖党这是万万不能接受的!
于是我就想:能否搞一个简单的服务器,能跑基本的项目就好了。
然后我就在掘金上看到了一篇文章:如何将旧的Android手机改造为家用服务器
最后结合全网,搜到了如下两种方案:
- KSWEB
- Ternux
综合对比下,我选择用Termux试试。
因为去年买的腾讯云服务器到期了,我一看续租的话要459元,作为白嫖党这是万万不能接受的!
于是我就想:能否搞一个简单的服务器,能跑基本的项目就好了。
然后我就在掘金上看到了一篇文章:如何将旧的Android手机改造为家用服务器
最后结合全网,搜到了如下两种方案:
- KSWEB
- Ternux
综合对比下,我选择用Termux试试。
前提
想要跑起来Termux,首先你要有一个安卓手机。
于是我就开始逛咸鱼,最后选了一款IQOO Neo5型号的,12+256G(有些小毛病),花了315元,这个内存跑服务应该是够了的。
想要跑起来Termux,首先你要有一个安卓手机。
于是我就开始逛咸鱼,最后选了一款IQOO Neo5型号的,12+256G(有些小毛病),花了315元,这个内存跑服务应该是够了的。
开始安装
安装Termux
1)通过github或者APKFab应用商店安装Termux。
2)更新和安装基础软件包
pkg update && pkg upgrade -y
pkg install wget curl nano -y
1)通过github或者APKFab应用商店安装Termux。
2)更新和安装基础软件包
pkg update && pkg upgrade -y
pkg install wget curl nano -y
安装nodejs
由于本人是前端开发,所有用的服务都是nodejs写的,所以只安装node相关的东西
pkg install nodejs
// 安装PHP或其他的同理,示例如下:
pkg install php
安装完成后,打印一下看看是否成功了
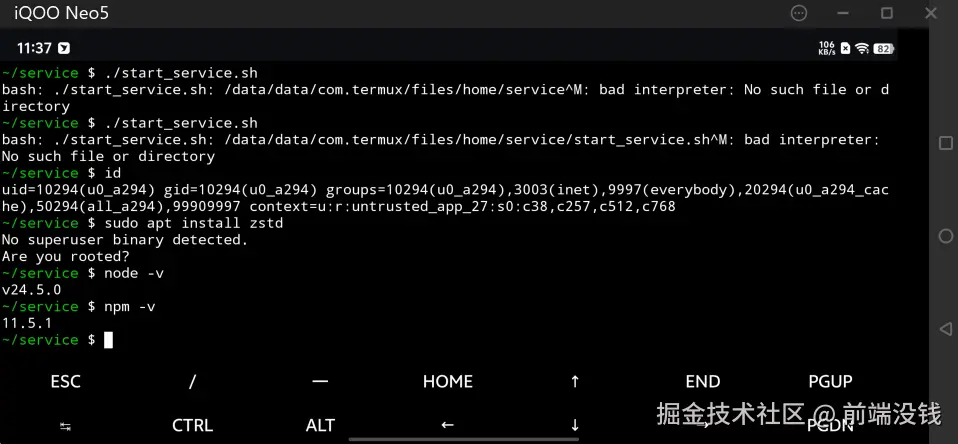
由于本人是前端开发,所有用的服务都是nodejs写的,所以只安装node相关的东西
pkg install nodejs
// 安装PHP或其他的同理,示例如下:
pkg install php
安装完成后,打印一下看看是否成功了
安装其他
由于我的项目也有nodejs服务端,所以还需要安装以下:
- mysql 数据库
- ssh 远程连接
- redis 缓存
- cpolar 内网穿透(本地部署的项目,外网无法访问,用它来给外网访问)
- nginx 高性能代理
具体的教程就不展示细节了,推荐几个教程地址,仅供参考:
设置完ssh后,就可以在电脑上的Xshell连接登录了,注意了:
默认端口号为8022,不是22
默认端口号为8022,不是22
默认端口号为8022,不是22
连接成功后是这样的
其中有一个用户身份验证,用户名输入whoami查看
由于我的项目也有nodejs服务端,所以还需要安装以下:
- mysql 数据库
- ssh 远程连接
- redis 缓存
- cpolar 内网穿透(本地部署的项目,外网无法访问,用它来给外网访问)
- nginx 高性能代理
具体的教程就不展示细节了,推荐几个教程地址,仅供参考:
设置完ssh后,就可以在电脑上的Xshell连接登录了,注意了:
默认端口号为8022,不是22
默认端口号为8022,不是22
默认端口号为8022,不是22
连接成功后是这样的
其中有一个用户身份验证,用户名输入whoami查看
放入几个项目
我用Xftp传入几个vue项目和nodejs项目
我用Xftp传入几个vue项目和nodejs项目
启动服务
项目放入后,启动的服务应该是只能局域网访问的,几个vue项目都是打包的dist文件,所以需要配置nginx代理,关键配置如下,有多少个项目,就来多少个server就行,慢慢配吧。
因为个人项目不多,也不找其他高大上的管理工具了
# 加解密 配置
server {
listen 5290;
server_name 192.168.3.155;
location / {
root /data/data/com.termux/files/home/vue/rui-utils-crypt/dist;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /data/data/com.termux/files/usr/share/nginx/html;
}
}
# 个人博客 配置
server {
listen 5173;
server_name 192.168.3.155;
location / {
root /data/data/com.termux/files/home/vue/vite-press-blog/dist;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /data/data/com.termux/files/usr/share/nginx/html;
}
}
# 若依 - nodejs-vue
server {
listen 5000;
server_name 192.168.3.155;
location / {
# dist为静态资源文件夹,dist内有index.html,
root /data/data/com.termux/files/home/vue/ruoyi-vue/dist;
index index.html index.htm;
# 解决单页面应用中history模式不能刷新的bug
try_files $uri $uri/ /index.html;
# try_files $uri $uri/ =404;
}
# 服务器代理实现跨域
location /prod-api/ {
proxy_pass http://192.168.3.155:7002/; # 将/api/开头的url转向该域名
#如果报错则使用这一行代替上一行 proxy_pass http://localhost:8000; 将/api/开头的url转向该域名
rewrite "^/prod-api/(.*)$" /$1 break ; # 最终url中去掉/api前缀
}
# 静态资源优化 - 添加 ^~ 前缀提高匹配优先级
location ^~ /assets/ {
root /data/data/com.termux/files/home/vue/ruoyi-vue/dist;
expires 12h;
error_log /dev/null;
access_log /dev/null;
}
#ERROR-PAGE-START 错误页配置,可以注释、删除或修改
error_page 404 /404.html;
#REWRITE-START URL重写规则引用,修改后将导致面板设置的伪静态规则失效
# include /www/server/panel/vhost/rewrite/60.204.201.111.conf;
#REWRITE-END
#禁止访问的文件或目录
location ~ ^/(.user.ini|.htaccess|.git|.env|.svn|.project|LICENSE|README.md)
{
return 404;
}
#一键申请SSL证书验证目录相关设置
location ~ .well-known{
allow all;
}
#禁止在证书验证目录放入敏感文件
if ( $uri ~ "^/.well-known/.*.(php|jsp|py|js|css|lua|ts|go|zip|tar.gz|rar|7z|sql|bak)$" ) {
return 403;
}
location ~ .*.(gif|jpg|jpeg|png|bmp|swf|ico)$
{
expires 30d;
error_log /dev/null;
access_log /dev/null;
}
location ~ .*.(js|css)?$
{
expires 12h;
error_log /dev/null;
access_log /dev/null;
}
access_log /data/data/com.termux/files/usr/var/log/nginx/access.log;
error_log /data/data/com.termux/files/usr/var/log/nginx/error.log;
}
项目放入后,启动的服务应该是只能局域网访问的,几个vue项目都是打包的dist文件,所以需要配置nginx代理,关键配置如下,有多少个项目,就来多少个server就行,慢慢配吧。
因为个人项目不多,也不找其他高大上的管理工具了
# 加解密 配置
server {
listen 5290;
server_name 192.168.3.155;
location / {
root /data/data/com.termux/files/home/vue/rui-utils-crypt/dist;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /data/data/com.termux/files/usr/share/nginx/html;
}
}
# 个人博客 配置
server {
listen 5173;
server_name 192.168.3.155;
location / {
root /data/data/com.termux/files/home/vue/vite-press-blog/dist;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /data/data/com.termux/files/usr/share/nginx/html;
}
}
# 若依 - nodejs-vue
server {
listen 5000;
server_name 192.168.3.155;
location / {
# dist为静态资源文件夹,dist内有index.html,
root /data/data/com.termux/files/home/vue/ruoyi-vue/dist;
index index.html index.htm;
# 解决单页面应用中history模式不能刷新的bug
try_files $uri $uri/ /index.html;
# try_files $uri $uri/ =404;
}
# 服务器代理实现跨域
location /prod-api/ {
proxy_pass http://192.168.3.155:7002/; # 将/api/开头的url转向该域名
#如果报错则使用这一行代替上一行 proxy_pass http://localhost:8000; 将/api/开头的url转向该域名
rewrite "^/prod-api/(.*)$" /$1 break ; # 最终url中去掉/api前缀
}
# 静态资源优化 - 添加 ^~ 前缀提高匹配优先级
location ^~ /assets/ {
root /data/data/com.termux/files/home/vue/ruoyi-vue/dist;
expires 12h;
error_log /dev/null;
access_log /dev/null;
}
#ERROR-PAGE-START 错误页配置,可以注释、删除或修改
error_page 404 /404.html;
#REWRITE-START URL重写规则引用,修改后将导致面板设置的伪静态规则失效
# include /www/server/panel/vhost/rewrite/60.204.201.111.conf;
#REWRITE-END
#禁止访问的文件或目录
location ~ ^/(.user.ini|.htaccess|.git|.env|.svn|.project|LICENSE|README.md)
{
return 404;
}
#一键申请SSL证书验证目录相关设置
location ~ .well-known{
allow all;
}
#禁止在证书验证目录放入敏感文件
if ( $uri ~ "^/.well-known/.*.(php|jsp|py|js|css|lua|ts|go|zip|tar.gz|rar|7z|sql|bak)$" ) {
return 403;
}
location ~ .*.(gif|jpg|jpeg|png|bmp|swf|ico)$
{
expires 30d;
error_log /dev/null;
access_log /dev/null;
}
location ~ .*.(js|css)?$
{
expires 12h;
error_log /dev/null;
access_log /dev/null;
}
access_log /data/data/com.termux/files/usr/var/log/nginx/access.log;
error_log /data/data/com.termux/files/usr/var/log/nginx/error.log;
}
本地访问
本人手机的ip为:192.168.3.155,端口用nginx的配置项即可,在Termux中输入nginx来启动,这样就可以本地访问了。
不知道ip的可以输入ifconfig来查看
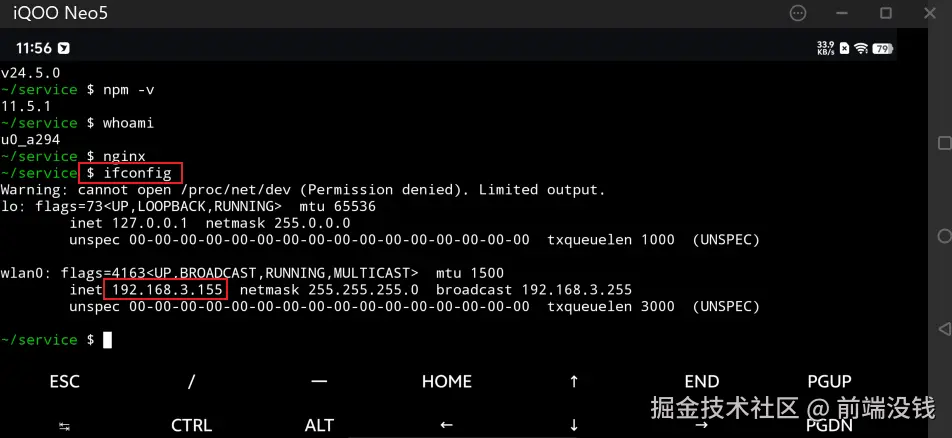 先访问一下
先访问一下192.168.3.155:5173
 可以看到,在电脑上已经能访问手机上启动的服务了。
可以看到,在电脑上已经能访问手机上启动的服务了。
但是我们需要外网也能访问,这就需要前面说的内网穿透了。
本人手机的ip为:192.168.3.155,端口用nginx的配置项即可,在Termux中输入nginx来启动,这样就可以本地访问了。
不知道ip的可以输入ifconfig来查看
先访问一下192.168.3.155:5173
可以看到,在电脑上已经能访问手机上启动的服务了。
但是我们需要外网也能访问,这就需要前面说的内网穿透了。
内网穿透
本项目的内网穿透选的是cpolar,教程见上文链接。
因为我装了sv工具,所以我输入sv up cpolar就启动了cpolar,启动后在电脑上输入手机IP + 9200端口号即可登录cpolar后台
配置本地的端口号:  配置完后,就可以在
配置完后,就可以在在线隧道列表菜单看到已配置的了
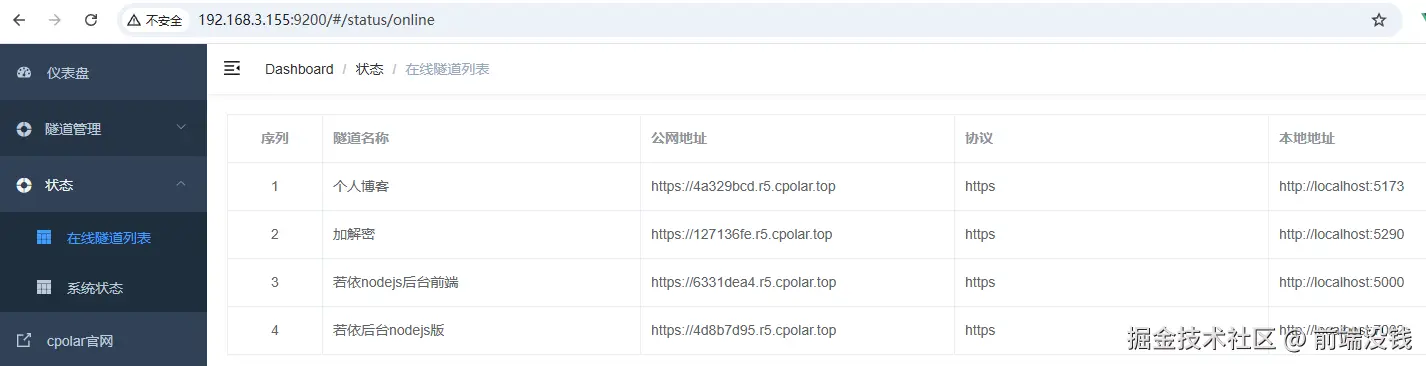 然后我们就可以在公网地址访问了,复制列表的地址,打开:
然后我们就可以在公网地址访问了,复制列表的地址,打开:
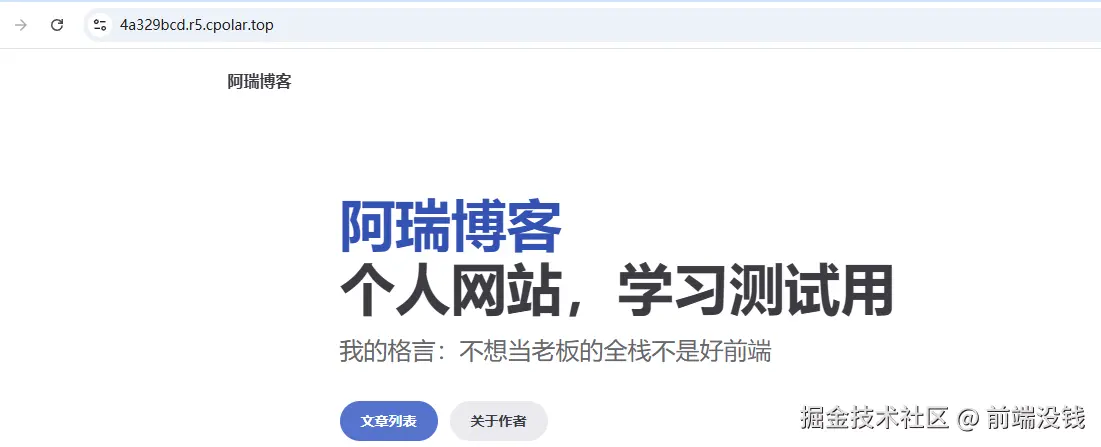
至此,我们已经可以在外网访问手机上、部署的vue打包项目了。但是此时没有后端服务,接下来我们同时部署后端的服务。
本项目的内网穿透选的是cpolar,教程见上文链接。
因为我装了sv工具,所以我输入sv up cpolar就启动了cpolar,启动后在电脑上输入手机IP + 9200端口号即可登录cpolar后台
配置本地的端口号: 配置完后,就可以在在线隧道列表菜单看到已配置的了
然后我们就可以在公网地址访问了,复制列表的地址,打开:
至此,我们已经可以在外网访问手机上、部署的vue打包项目了。但是此时没有后端服务,接下来我们同时部署后端的服务。
部署nodejs后端
先运行以下命令,启动redis和数据库
redis-server --daemonize yes
mysqld_safe &
然后根据nodejs的启动方法启动即可,一般为node 入口文件.js
我的启动成功如下
对应的前端地址如下:6331dea4.r5.cpolar.top/index
这个前后端是我用nodejs改写的java版若依管理后台,源码地址:gitee.com/ruirui-stud… 我以前的文章也有介绍的
最后,如果需要启动多个nodejs项目,可以用pm2管理
注意:本文的地址可能无法访问,因为手机我有别的用处,不一定随时开着
作者:前端没钱
来源:juejin.cn/post/7537893826595700788
先运行以下命令,启动redis和数据库
redis-server --daemonize yes
mysqld_safe &
然后根据nodejs的启动方法启动即可,一般为node 入口文件.js
我的启动成功如下
对应的前端地址如下:6331dea4.r5.cpolar.top/index
这个前后端是我用nodejs改写的java版若依管理后台,源码地址:gitee.com/ruirui-stud… 我以前的文章也有介绍的
最后,如果需要启动多个nodejs项目,可以用pm2管理
注意:本文的地址可能无法访问,因为手机我有别的用处,不一定随时开着
来源:juejin.cn/post/7537893826595700788
Electron 淘汰!新的跨端框架来了!性能飙升!
用过 Electron 的兄弟都懂,好处是“会前端就能写桌面”,坏处嘛,三座大山压得喘不过气:

- 体积巨婴
空项目打出来100 M+,每次更新又得80 M,用户宽带不要钱? - 内存老虎
开个“Hello World”常驻300 M,再开几个窗口,直接1 G起步,Mac 用户看着彩虹转圈怀疑人生。 - 启动慢动作
双击图标 → 图标跳 → 白屏3秒 → 终于看见界面,节奏堪比56 K猫拨号。
老板还天天催:“两周给我 MVP!”—— 抱着 Electron,就像抱着一只会写代码的胖熊猫,可爱但跑不动。
主角登场:GPUI
Rust 圈最近冒出一个“狠角色”——GPUI。
GPUI,是 Zed 编辑器团队推出的 Rust UI 框架,以 GPU 加速和高效渲染模式悄然崛起。
它不卖广告,纯开源,一句话介绍:直接拿显卡画界面,浏览器啥的全部踢出去。
- 底层用
wgpu,Metal/Vulkan/DX12想调谁就调谁; - 上层给前端味道的
DSL,写起来像React,跑起来却是纯原生; - 安装包
12 M,内存50 M,启动0.4秒,表格滑到60帧不带喘。
说人话:把 Electron 的“胖身子”抽真空,留下一身腱子肉。
亮点:为什么值得换坑?
| 场景 | Electron 现实 | GPUI 现实 |
|---|---|---|
| 安装包 | 100 M+ 是常态 | 12 M 起步,单文件都能带走 |
| 空载内存 | 一开 300 M,再开几个窗口直奔 1 G | 50 M 晃悠,再多窗口也淡定 |
| 启动速度 | 白屏 2~3 秒 | 肉眼可见 0.4 秒 |
| 大数据表格 | 十万行就卡成 PPT | 百万行照样 60 fps,滑到飞起 |
| 主题切换 | 重载 or 重启 | 一行代码,热切换,深色浅色瞬间完成 |
外加 60+现成组件:按钮、表格、树、日历、Markdown、穿梭框……皮肤直接照搬 Web 圈最火的 shadcn/ui,设计师不用改稿,开发直接复制粘贴。
五分钟上手:从零到 Hello Window
① 先装 Rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
一路回车即可,30 秒搞定。
② 新建工程
cargo new my-app && cd my-app
③ 把依赖写进 Cargo.toml
[dependencies]
gpui = "0.2"
gpui-component = "0.1"
④ src/main.rs 写几行
use gpui::*;
fn main() {
App::new().run(|cx: &mut AppContext| {
Window::new("win", cx)
.title("我的第一个 GPUI 窗口")
.build(cx, |cx| {
Label::new("Hello,GPUI!", cx)
})
.unwrap();
});
}
⑤ 跑!
cargo run
三秒后窗口蹦出来,Hello 世界完成。没有黑框,没有白屏,体验跟原生记事本一样丝滑。
写代码像 React,跑起来像 C++
组件化 + 事件回调,前端同学一看就懂:
Button::new("点我下单", cx)
.style(ButtonStyle::Primary)
.on_click(|_, cx| {
println!("订单已发送");
notify_user("成交!", cx);
})
背后是 Rust 的零成本抽象,编译完就是机器码,没有浏览器,没有虚拟机,没有 GC 卡顿,性能直接拉满。
老网页也别扔,一键塞进来
历史项目里还有 React 报表?开 webview 特性就行:
gpui-component = { version = "0.1", features = ["webview"] }
窗口里留一块“浏览器区域”,把旧地址挂进去,零改动复用,妈妈再也不用担心重写代码。
Electron 依然是老大哥,但“胖身子”在 2025 年真的有点跟不上节奏。
新项目、新团队、新想法,不妨给 GPUI 一个机会——试过之后,你可能再也回不去了。
- GPUI 官网:
https://www.gpui.rs/ - GPUI Component 官网:
https://longbridge.github.io/gpui-component/
来源:juejin.cn/post/7568192652287787062
我天,Java 已沦为老四。。
略想了一下才发现,自己好像有大半年都没有关注过 TIOBE 社区了。
TIOBE 编程社区相信大家都听过,这是一个查看各种编程语言流行程度和趋势的社区,每个月都有榜单更新,每年也会有年度榜单和总结出炉。
昨晚在家整理浏览器收藏夹时,才想起了 TIOBE 社区,于是打开看了一眼最近的 TIOBE 编程语言社区指数。
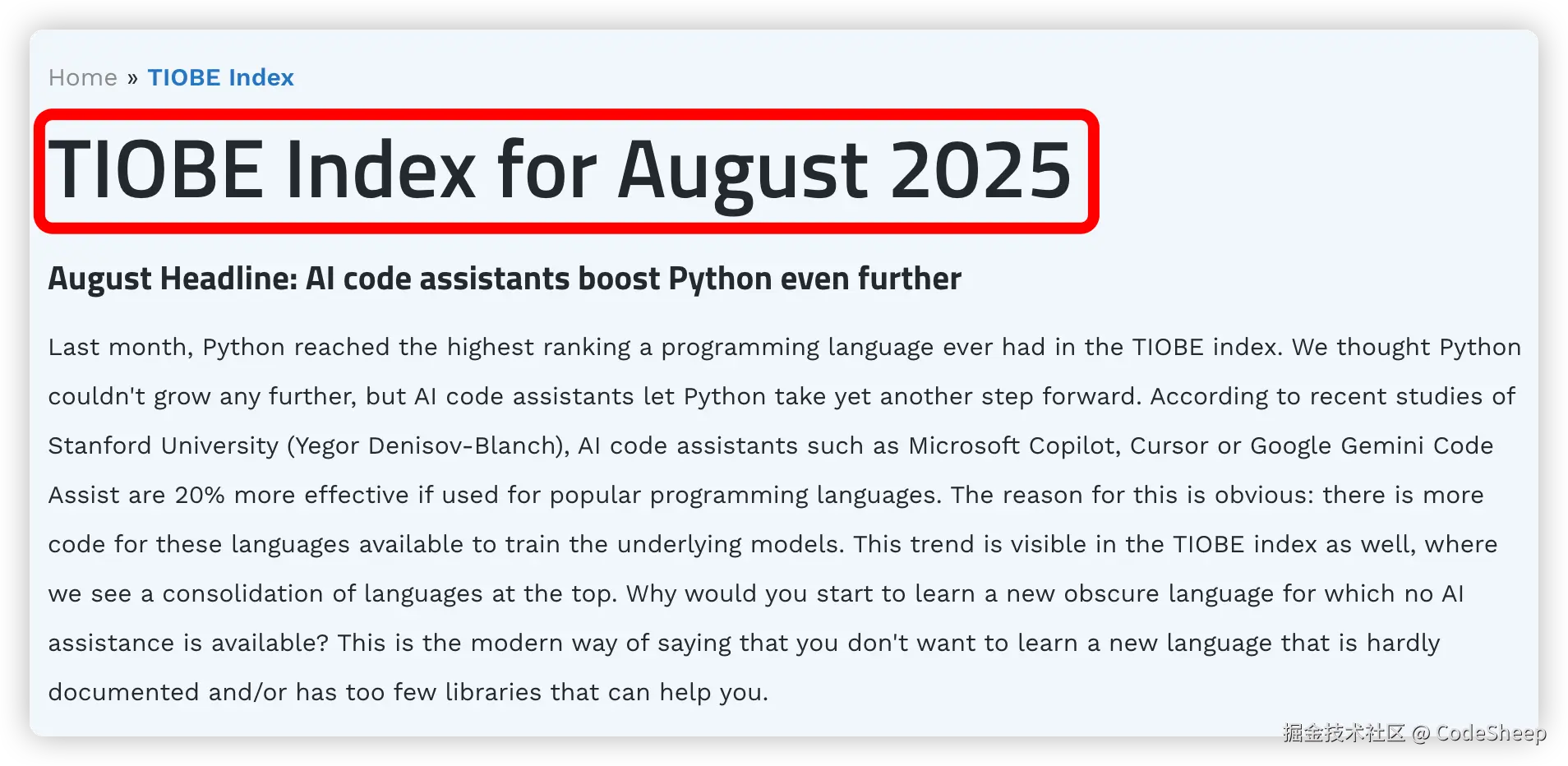
没想到,Java 居然已经跌出前三了,并且和第一名 Python 的差距也进一步拉开到了近 18%。
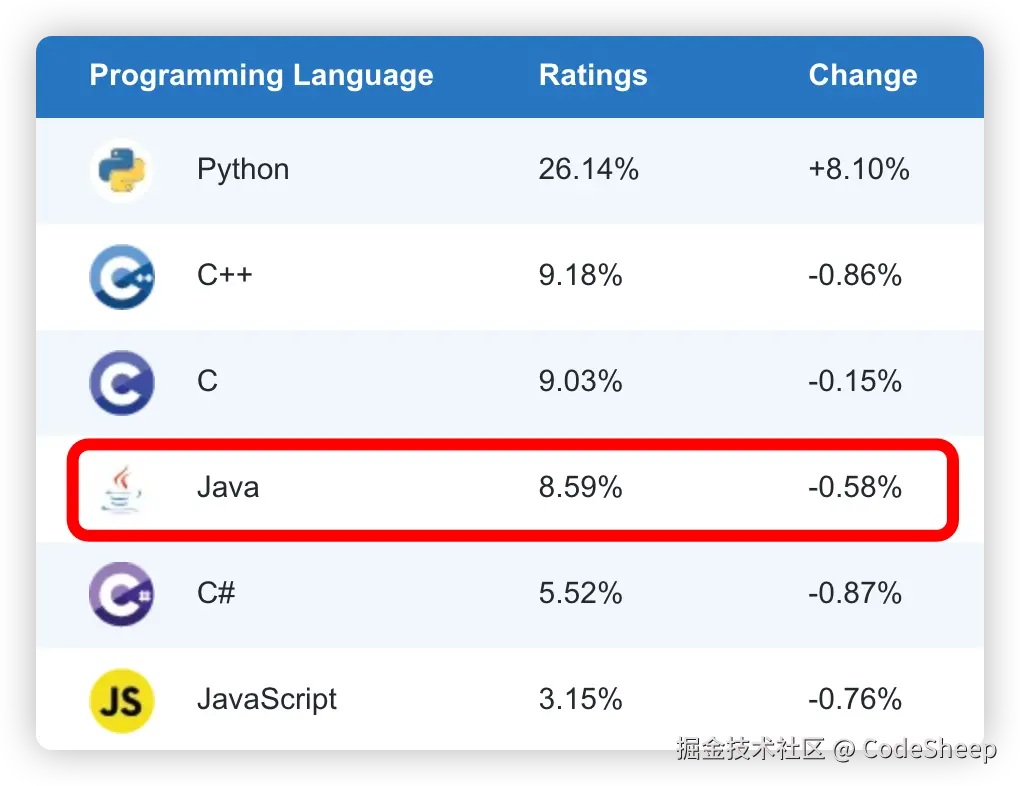
回想起几年前,Java 曾是何等地风光。
各种基于 Java 技术栈所打造的 Web 后端、互联网服务成为了移动互联网时代的中坚力量,同时以 Java 开发为主的后端岗位也是无数求职者们竞相选择的目标。
然而这才过去几年,如今的 Java 似乎也没有了当年那种无与争锋的强劲势头,由此可见 AI 领域的持续进化和繁荣对它的冲击到底有多大。
用数据说话最有说服力。
拉了一下最近这二十多年来 Java 的 TIOBE 社区指数变化趋势看了看,情况似乎不容客观。
可以明显看到的是一个:呈震荡式下降的趋势。
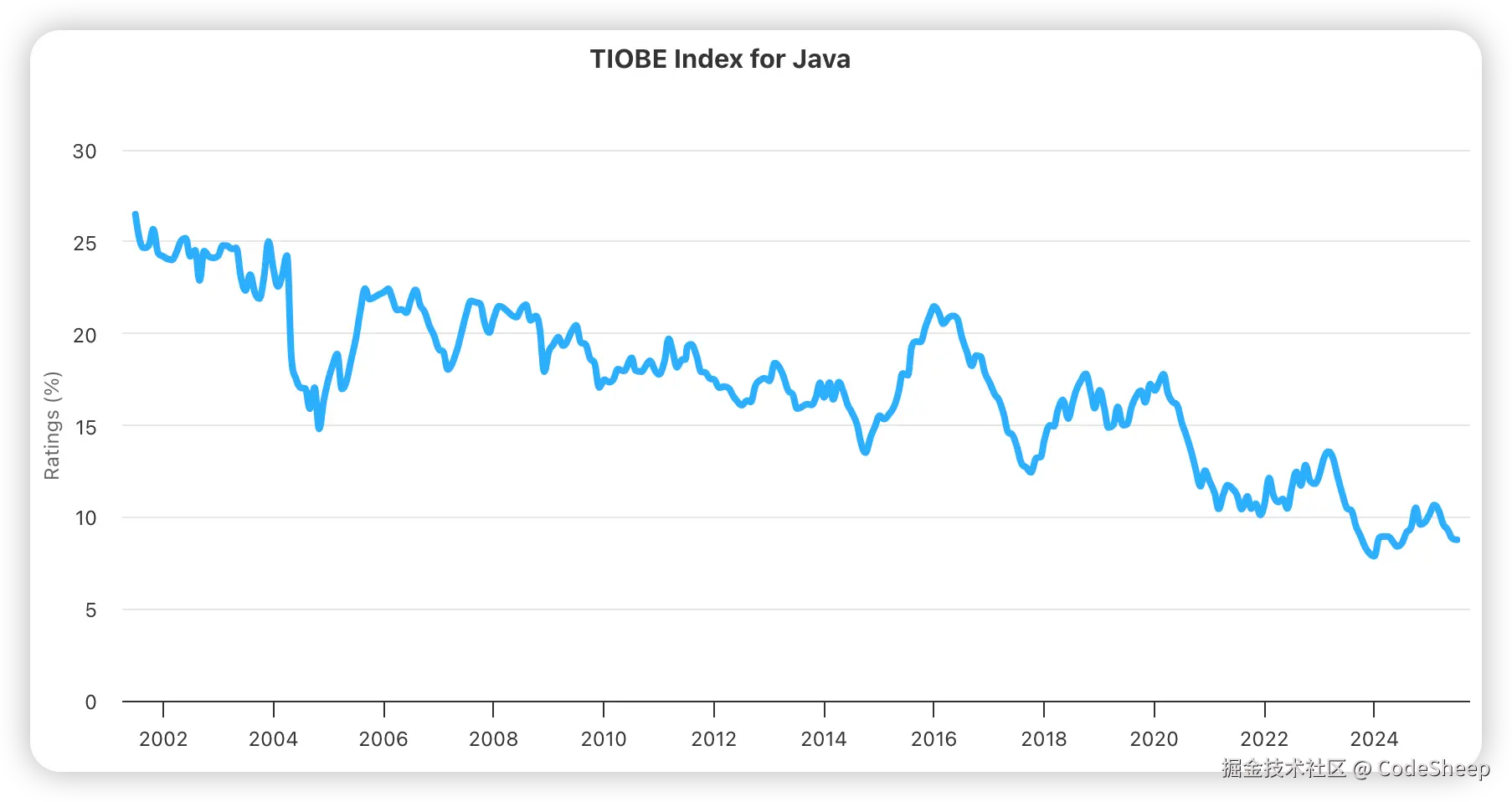
现如今,Java 日常跌出前三已经成为了常态,并且和常居榜首的 Python 的差距也是越拉越大了。
在目前最新发布的 TIOBE Index 榜单中排名前十的编程语言分别是:
- Python
- C++
- C
- Java
- C#
- JavaScript
- Visual Basic
- Go
- Perl
- Delphi/Object Pascal
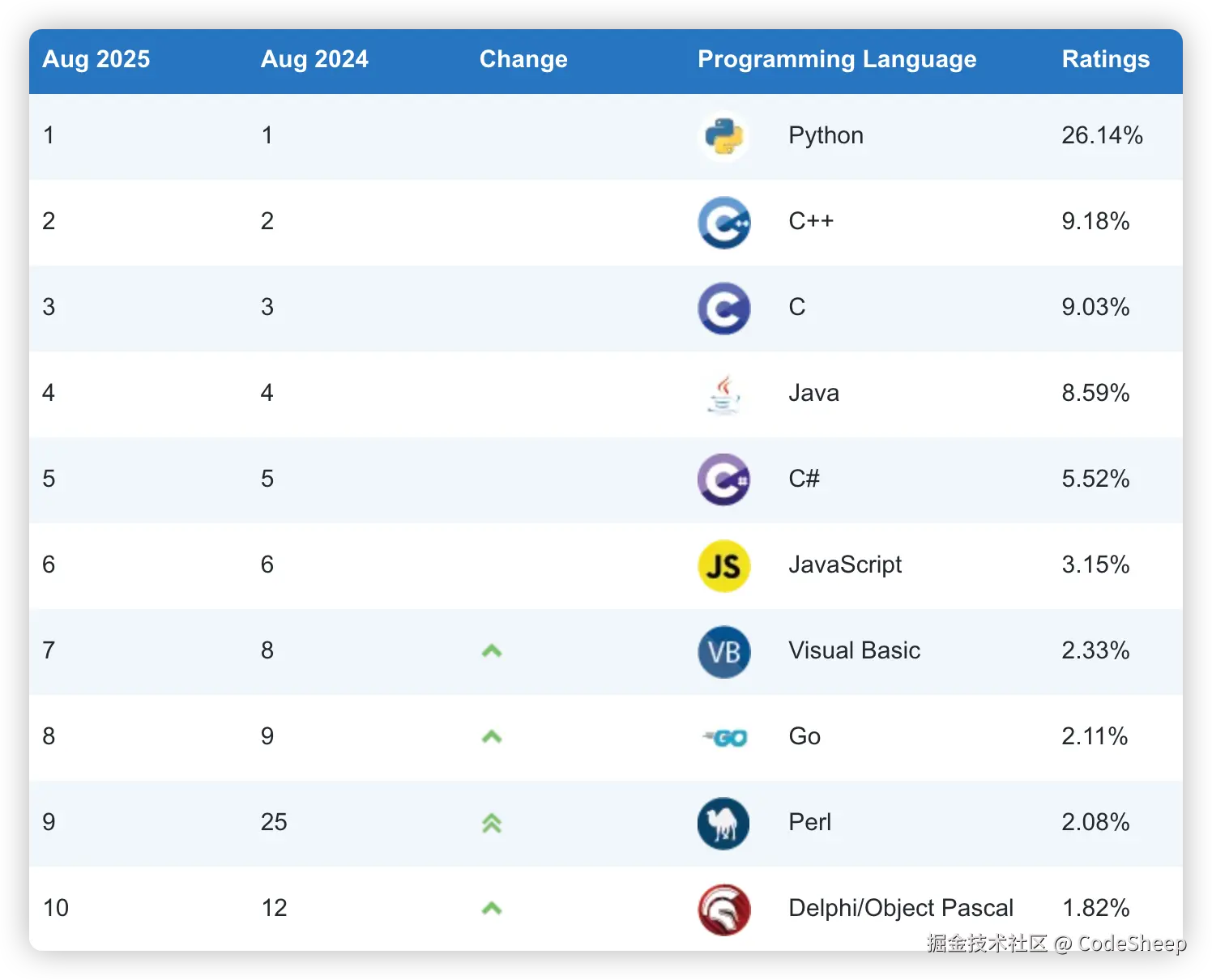
其中 Python 可谓是一骑绝尘,与排名第二的 C++ 甚至拉开了近 17% 的差距,呈现了断崖式领先的格局。
不愧是 AI 领域当仁不让的“宠儿”,这势头其他编程语言简直是望尘莫及!
另外还值得一提的就是 C 语言。
最近这几个月 C 语言的 TIOBE Index Ratings 比率一直在回升,这说明其生命力还是非常繁荣的,这对于一个已经诞生 50 多年的编程语言来说,着实不易。
C 语言于上个世纪 70 年代初诞生于贝尔实验室,由丹尼斯·里奇(Dennis MacAlistair Ritchie)以肯·汤普森(Kenneth Lane Thompson)所设计的 B 语言为基础改进发展而来的。

就像之前 TIOBE 社区上所描述的,这可能主要和当下物联网(IoT)技术的发展繁荣,以及和当今发布的大量小型智能设备有关。毕竟 C 语言运行于这些对性能有着苛刻要求的小型设备时,性能依然是最出色的。
说到底,编程语言本身并没有所谓的优劣之分,只有合适的应用场景与项目需求。
按照官方的说法,TIOBE 榜单编程语言指数的计算和主流搜索引擎上不同编程语言的搜索命中数是有关的,所以某一程度上来说,可以反映出某个编程语言的热门程度(流行程度、受关注程度)。
而通过观察一个时间跨度范围内的 TIOBE 指数变化,则可以一定程度上看出某个编程语言的发展趋势,这对于学习者来说,可以作为一个参考。
Java:我啥场面没见过
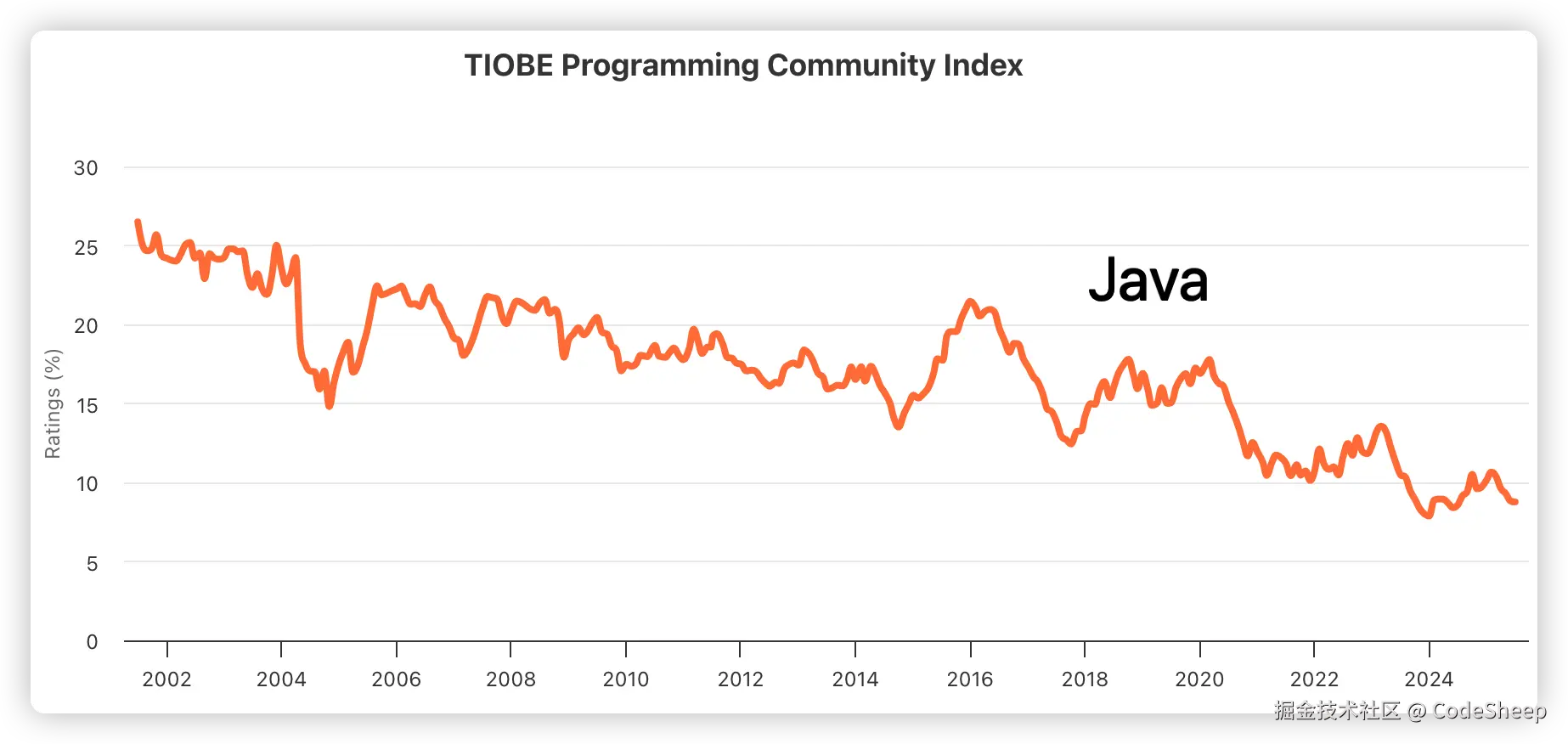
曾经的 Java 可谓是互联网时代不可或缺的存在。早几年的 Java 曲线一直处于高位游走,彼时的 Java 正是构成当下互联网生态繁荣的重要编程语言,无数的 Web 后端、互联网服务,甚至是移动端开发等等都是 Java 的擅长领域。
而如今随着 AI 领域的发展和繁荣,曾经的扛把子如今似乎也感受到了前所未有的压力。
C语言:我厉兵秣马
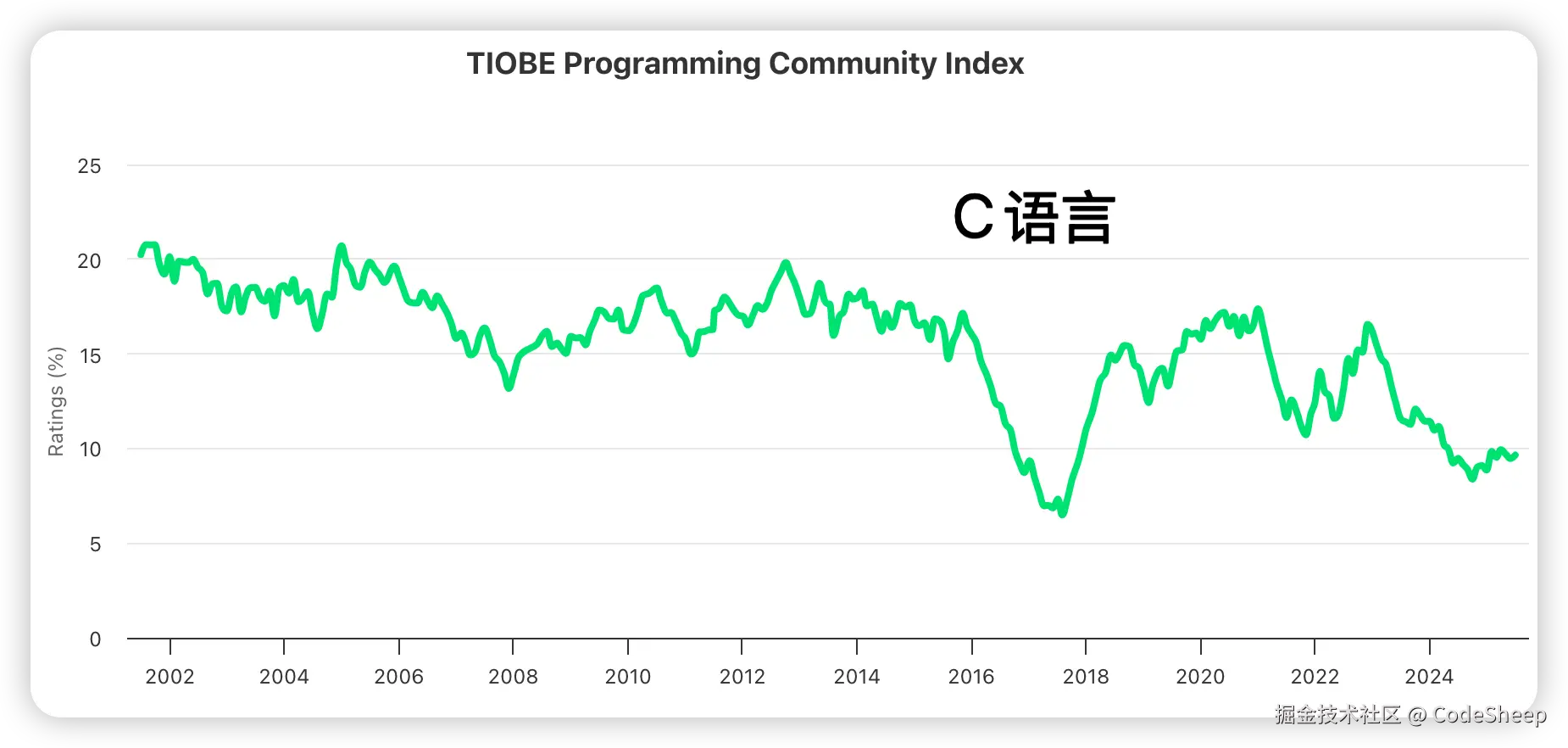
流水的语言,铁打的 C。
C 语言总是一个经久不衰的经典编程语言,同时也是为数不多总能闯进榜单前三的经典编程语言。
自诞生之日起,C 语言就凭借其灵活性、细粒度和高性能等特性获得了无可替代的位置,就像上文说的,随着如今的万物互联的物联网(IoT)领域的兴起,C 语言地位依然很稳。
C++:我稳中求进
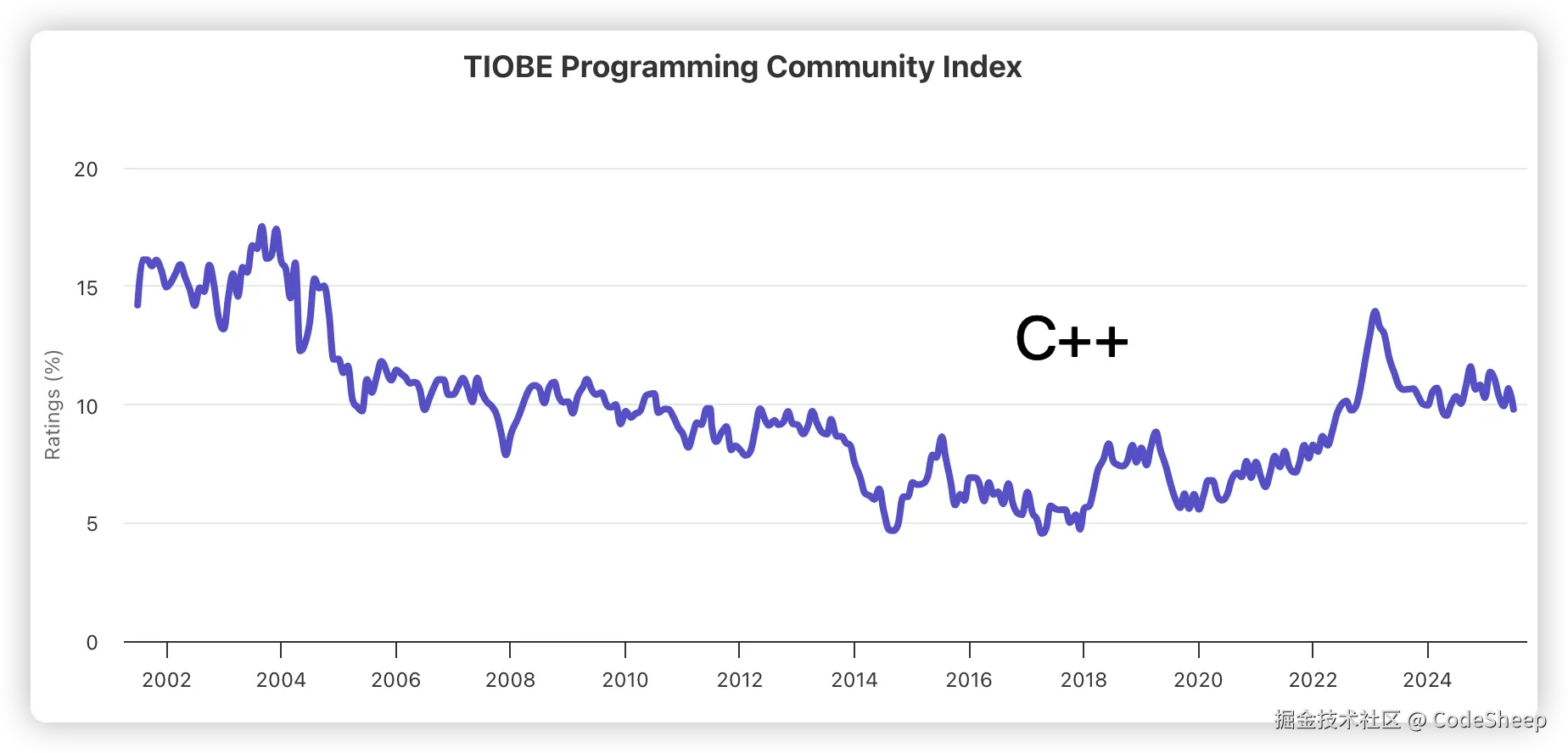
C++ 的确是一门强大的语言,但语言本身的包袱也的确是不小,而且最近这几年的指数趋势稳中求进,加油吧老大哥。
Python:我逆流而上
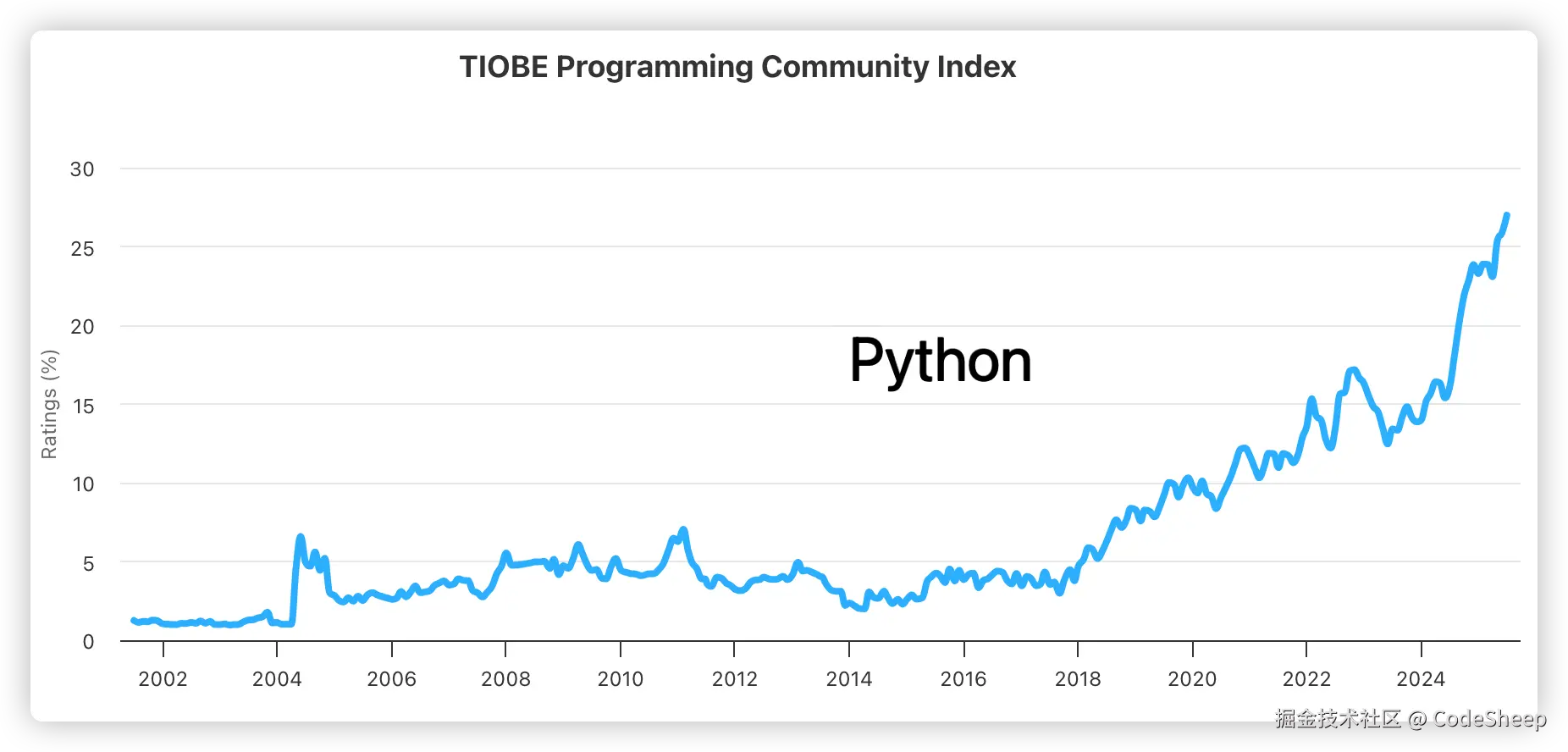
当别的编程语言都在震荡甚至下跌之时,Python 这几年却强势上扬,这主要和当下的数据科学、机器学习、人工智能等科学领域的繁荣有着很大的关系。
PHP:我现在有点慌
PHP:我不管,我才是世界上最好的编程语言,不接受反驳(手动doge)。
好了,那以上就是今天的内容分享了,感谢大家的阅读,我们下篇见。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7540497727161417766
Flutter官方拒绝适配鸿蒙的真相:不是技术问题,而是...
这两年随着鸿蒙系统相关的争议变多,讨论Flutter 在鸿蒙上的适配的争议也开始变多了。
比如前段时间写了一篇文章讨论用Flutter开发鸿蒙应用。
Flutter 3.35倒逼鸿蒙:兼容or出局,没有第三条路!
就有人评论说应该是Flutter官方适配鸿蒙,而不是鸿蒙适配Flutter。
其实这么说也是有一点道理的(虽然不多),今天老刘就展开分析以下到底应该是谁来适配谁?
从技术角度看:Flutter确实应该主动适配鸿蒙
Flutter作为跨平台框架,它的核心价值就是"一套代码,多端运行",所以如果不能适配重要平台,那就失去了跨平台的意义。

就像当年Flutter必须适配iOS和Android一样。
这不是谁求谁的问题,这是技术逻辑的问题。
Flutter从诞生那天起,就打着"Write once, run anywhere"的旗号。
但是事实是Flutter官方确实没有表现出适配意愿。
现实情况更复杂:这是一个博弈过程
理想很丰满,现实很骨感。
技术逻辑是一回事,商业逻辑是另一回事。
在当前的经济形势下,各个企业去增加一个独立的鸿蒙团队的成本是难以接受的。
Flutter的价值就在于能够有效的降低这种成本。
因此站在鸿蒙的角度,是应该主动适配Flutter的,而不是等待Flutter官方适配。
其实不仅仅是Flutter,主流的跨平台框架鸿蒙官方都有必要去主动适配。
这就像是一个新开的商场,你不能指望品牌商主动来入驻。
你得主动去招商,提供优惠政策,比如免费装修。
鸿蒙的困境:
- 用户基数还很少,开发者投入意愿不强。
- 生态建设需要时间,短期内难以完全替代Android。
- 政策推动有限,最终还是要靠技术魅力。
Flutter的考量:
- Google作为Flutter的主导者,对鸿蒙的态度可能比较复杂。
这个有国际形势的原因,具体背后有哪些权衡咱也不知道,咱也不敢说。
- 本质的原因是鸿蒙的体量还不够。
就好像当年微软的Windows Phone,技术很好,没有足够的市场份额,开发者就不会买账。
所以从谁受益的角度来看,明显鸿蒙方面去适配Flutter的收益更大。
鸿蒙已经在做Flutter适配
话说回来,其实鸿蒙方面已经在为包括Flutter在内的跨平台框架做适配了。
而且动作还不小。
关键时间线
让我们先看看这几年鸿蒙Flutter适配的关键节点:
2021年1月 - 美团外卖MTFlutter团队率先突破。
发布《让Flutter在鸿蒙系统上跑起来》技术文章。
应该是业界首次公开的Flutter鸿蒙适配探索。
2023年8月 - 华为在HDC大会正式发声。
发布HarmonyOS NEXT,确定第一批跨平台框架适配名单:
- Flutter
- React Native
- 京东Taro
- uni-app
2023年9月 - OpenHarmony-SIG组织正式开源Flutter适配项目。
基于Flutter 3.7版本进行适配。
这意味着适配工作从企业内部走向了开源社区。
2024年8月 - 三方库适配取得重大进展。
深开鸿、开鸿智谷、鸿湖万联完成36个Flutter三方库适配。
其中9个完成测试验收。
具体适配工作有哪些
从技术层面来看,鸿蒙适配Flutter主要需要做这几件事:
嵌入层开发
重新实现Flutter嵌入层以适配鸿蒙平台。
这是最核心的工作,相当于给Flutter换了一个"底盘"。
Flutter Engine移植
基于Android版本进行鸿蒙平台的移植。
这里有个巧妙的地方,鸿蒙系统延用了Android的很多技术方案。
比如Vulkan图形API。
所以把Impeller这样的渲染引擎移植过来,并不需要大动干戈。
开发工具适配
Flutter Tools支持构建HAP包。
这样开发者就可以用熟悉的Flutter命令行工具直接构建鸿蒙应用了。
生态建设的困局
但是,技术适配只是第一步,真正的挑战在于生态建设。
简单来说就是:Flutter有了,但是三方库还没有完全适配好。
从技术原理来说,如果是纯Dart的三方库,适配起来应该比较简单。
大概率是能直接运行的,或者极少的修改就能运行。
但是如果涉及到原生代码的三方库,那就麻烦了。
需要重新移植Android/iOS的原生代码到鸿蒙平台。
这个工作量就比较大了。
而且很多三方库的维护者可能对鸿蒙平台并不熟悉,更没有去适配的意愿。
对鸿蒙上各种开发框架来说都是这样的,基础库的不完善造成了开发者移植app的困难,进一步造成了App数量的缺少,即使移植过来也可能是功能缺失的。
应用数量和质量都不够就很难快速提升用户量,用户量不够就很难吸引足够多的开发者。
这就形成了一个恶性循环。
总结
其实说到底,这也不能说是什么博弈。
任何一个跨平台框架都不可能去适配所有的系统。
就像Flutter也没有适配塞班、Windows Phone这些已经消失的系统一样。
反过来说,作为体量还不够大的系统,主动去提供更好的应用移植解决方案,确实是快速建立生态的最佳路径。
老刘作为一个开发人员,我觉得一个新的系统要想快速建立生态,其实更好的方案是向上提供一套和现有最流行系统(比如Android)兼容的系统级API。
这样大部分应用可以用最小的代价迁移到新系统上。
如果你真的觉得现有的系统API有很大的缺陷,也完全可以在现有API基础上做增量优化。
如果你的优化真的有很大先进性,随着开发者增加,自然有人会使用。
当然这只是开发者的角度。
很多事情也不是给开发者做的。
连API都是全新的全自主研发系统和兼容API的系统,对很多不懂技术的人来说还是有很大差别的。
另一方面,鸿蒙系统这种设计在智能家居、汽车等不太依赖现有生态的场景下,也有自己的优势。
毕竟在这些新兴领域,大家都是从零开始,没有历史包袱。
鸿蒙的分布式架构、万物互联的理念,在这些场景下确实有独特的价值。
所以,与其纠结谁适配谁,不如关注技术本身能解决什么问题。
Flutter适配鸿蒙也好,鸿蒙适配Flutter也好,最终受益的都是开发者和用户。
技术的发展从来不是零和游戏,而是共同进步的过程。
如果看到这里的同学对客户端或者Flutter开发感兴趣,欢迎联系老刘,我们互相学习。 私信免费领老刘整理的《Flutter开发手册》,覆盖90%应用开发场景。 可以作为Flutter学习的知识地图。
—— laoliu_dev
来源:juejin.cn/post/7569038855610007562
从「[1,2,3].map (parseInt)」踩坑,吃透 JS 数组 map 与包装类核心逻辑
你有没有遇到过这样的诡异场景:明明以为 [1,2,3].map(parseInt) 会返回 [1,2,3],实际运行却得到 [1, NaN, NaN]?
这行看似简单的代码,藏着 JS 数组方法、函数传参、包装类等多个核心知识点的关联。今天我们就从这个经典坑点切入,一步步拆解 map 方法的底层逻辑,顺带理清 NaN、包装类、字符串处理等容易混淆的知识点。
一、先踩坑:为什么 [1,2,3].map (parseInt) 不是 [1,2,3]?
要搞懂这个问题,我们得先明确两个关键:map 方法的参数传递规则,以及 parseInt 的工作原理。
1. map 方法的真正传参逻辑
MDN 明确说明:map 方法会遍历原数组,对每个元素调用回调函数,并将三个参数依次传入回调:
- 当前遍历的元素(item)
- 元素的索引(index)
- 原数组本身(arr)
也就是说,[1,2,3].map(parseInt) 等价于:
javascript
运行
[1,2,3].map((item, index, arr) => {
return parseInt(item, index, arr);
});
这里的关键是:map 会强制传递三个参数给回调,而不是只传我们以为的 “元素本身”。
2. parseInt 的参数陷阱
parseInt 的语法是 parseInt(string, radix),它只接收两个有效参数:
- 第一个参数:要转换的字符串(非字符串会先转字符串)
- 第二个参数:基数(进制,范围 2-36,0 或省略则默认 10 进制)
- 第三个参数会被直接忽略
结合 map 的传参,我们逐次分析遍历过程:
- 第一次遍历:item=1,index=0 → parseInt (1, 0)。基数 0 等价于 10 进制,结果 1。
- 第二次遍历:item=2,index=1 → parseInt (2, 1)。基数 1 无效(必须≥2),结果 NaN。
- 第三次遍历:item=3,index=2 → parseInt (3, 2)。2 进制中只有 0 和 1,3 无效,结果 NaN。
这就是为什么最终结果是 [1, NaN, NaN] —— 不是 map 或 parseInt 本身有问题,而是参数传递的 “错位匹配” 导致的。
3. 正确写法是什么?
如果想通过 map 实现 “数组元素转数字”,正确做法是明确回调函数的参数,只给 parseInt 传需要的值:
javascript
运行
// 方法1:手动控制参数
[1,2,3].map(item => parseInt(item));
// 方法2:使用Number简化
[1,2,3].map(Number);
// 两种写法结果都是 [1,2,3]
二、吃透 map 方法:不止是 “遍历 + 返回”
解决了坑点,我们再深入理解 map 的核心特性 —— 它是 ES6 数组新增的纯函数(不改变原数组,返回新数组),这也是它和 forEach 的核心区别。
1. map 的核心规则(必记)
- 不改变原数组:无论回调函数做什么操作,原数组的元素都不会被修改。
- 返回新数组:新数组长度与原数组一致,每个元素是回调函数的返回值。
- 跳过空元素:map 会忽略数组中的 empty 空位(forEach 也会),但不会忽略 undefined 和 null。
示例验证:
javascript
运行
const arr = [1, 2, 3, , 5]; // 第4位是empty
const newArr = arr.map(item => item * 2);
console.log(newArr); // [2,4,6, ,10](保留空位)
console.log(arr); // [1,2,3, ,5](原数组不变)
2. 实用场景:从基础到进阶
map 的核心价值是 “数据转换”,日常开发中高频使用:
- 基础转换:数组元素的统一处理(如平方、转格式)
javascript
运行
const arr = [1,2,3,4,5,6];
const squares = arr.map(item => item * item); // [1,4,9,16,25,36]
- 复杂转换:提取对象数组的特定属性
javascript
运行
const users = [{name: '张三'}, {name: '李四'}, {name: '王五'}];
const names = users.map(user => user.name); // ['张三', '李四', '王五']
三、延伸知识点:NaN 与包装类,JS 的 “隐式魔法”
在分析 map 和 parseInt 的过程中,我们遇到了 NaN,而 JS 中字符串能调用length方法的特性,又涉及到 “包装类” 的隐式逻辑 —— 这两个知识点是理解 JS “面向对象特性” 的关键。
1. NaN:不是数字的 “数字”
NaN 的全称是 “Not a Number”,但 typeof 检测结果是number,这是它的第一个反直觉点。
什么时候会出现 NaN?
- 无效的数学运算:
0/0、Math.sqrt(-1)、"abc"-10 - 类型转换失败:
parseInt("hello")、Number(undefined) - 注意:
Infinity(6/0)和-Infinity(-6/0)不是 NaN,它们是有效的 “无穷大” 数值。
如何正确判断 NaN?
因为NaN === NaN的结果是false(NaN 不等于任何值,包括它自己),所以必须用专门的方法:
javascript
运行
// 推荐:ES6新增的Number.isNaN(只检测NaN)
Number.isNaN(parseInt("hello")); // true
// 不推荐:window.isNaN(会先转换类型,误判情况多)
isNaN("hello"); // true("hello"转数字是NaN)
isNaN(123); // false
2. 包装类:JS 让 “简单类型” 拥有对象能力
JS 是完全面向对象的语言,但我们平时写的"hello".length、520.1314.toFixed(2),看起来是 “简单数据类型调用对象方法”—— 这背后就是包装类的隐式操作。
包装类的工作流程
当你对字符串、数字、布尔值这些简单类型调用方法时,JS 会自动做三件事:
- 用对应的构造函数(String、Number、Boolean)创建一个临时对象(包装对象);
- 通过这个临时对象调用方法(如 length、toFixed);
- 方法调用结束后,立即销毁临时对象,释放内存。
用代码还原这个过程:
javascript
运行
let str = "hello";
console.log(str.length); // 实际执行过程:
const tempObj = new String(str); // 1. 创建包装对象
console.log(tempObj.length); // 2. 调用方法
tempObj = null; // 3. 销毁对象
关键区别:简单类型 vs 包装对象
javascript
运行
let str1 = "hello"; // 简单类型(string)
let str2 = new String("hello"); // 包装对象(object)
console.log(typeof str1); // "string"
console.log(typeof str2); // "object"
console.log(str1.length === str2.length); // true(方法调用结果一致)
四、拓展:字符串处理的常见误区(length、slice、substring)
包装类让字符串拥有了对象方法,但字符串处理中也有不少容易踩坑的点,结合笔记中的案例总结:
1. length 的 “坑”:emoji 占几个字符?
JS 的字符串用 UTF-16 编码存储,常规字符(如 a、中)占 1 个 16 位单位,emoji 和生僻字占 2 个及以上。length 属性统计的是 “16 位单位个数”,而非视觉上的 “字符个数”:
javascript
运行
console.log('a'.length); // 1(常规字符)
console.log('中'.length); // 1(常规字符)
console.log("𝄞".length); // 2(emoji占2个单位)
console.log("👋".length); // 2(emoji占2个单位)
2. slice vs substring:负数索引与起始位置
两者都用于截取字符串,但处理负数索引和起始位置的逻辑不同:
- 负数索引:slice 支持从后往前截取(-1 是最后一位),substring 会把负数转为 0;
- 起始位置:slice 严格按 “前参为起点,后参为终点”,substring 会自动交换大小值(小的当起点)。
示例对比:
javascript
运行
const str = "hello";
console.log(str.slice(-3, -1)); // "ll"(从后数第3位到第1位)
console.log(str.substring(-3, -1)); // ""(负数转0,0>0无结果)
console.log(str.slice(3, 1)); // ""(3>1无结果)
console.log(str.substring(3, 1)); // "el"(自动交换为1-3)
五、总结:从坑点到体系化知识
回到最初的[1,2,3].map(parseInt),这个坑的本质是 “对 API 参数传递规则的理解不透彻”。但顺着这个坑,我们串联起了:
- map 方法的参数传递、纯函数特性;
- parseInt 的基数规则、类型转换逻辑;
- NaN 的特性与判断方法;
- 包装类的隐式工作流程;
- 字符串处理的常见误区。
JS 的很多 “诡异现象”,本质都是对底层逻辑的不了解。掌握这些核心知识点后,再遇到类似问题时,就能快速定位根源 —— 这也是我们从 “踩坑” 到 “成长” 的关键。
最后留一个小思考:["10","20","30"].map(parseI
来源:juejin.cn/post/7569898158835777577
线程池中的坑:线程数配置不当导致任务堆积与拒绝策略失效
“线程池我不是早就会了吗?corePoolSize、maxPoolSize、queueSize 都能背下来!”
—— 真正出事故的时候你就知道,配置这仨数,坑多得跟高考数学题一样。
一、线上事故复盘:任务全卡死,日志一片寂静
几个月前有个定时任务服务,凌晨会并发处理上千个文件。按理说线程池能轻松抗住。
结果那天凌晨,监控报警:任务积压 5 万条,机器 CPU 却只有 3%!
去看线程 dump:
pool-1-thread-1 waiting on queue.take()
pool-1-thread-2 waiting on queue.take()
...
线程都在等任务,但任务明明在队列里!
当时线程池配置如下:
new ThreadPoolExecutor(
5,
10,
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(10000),
new ThreadPoolExecutor.AbortPolicy()
);
看起来没毛病对吧?
实际结果是:拒绝策略从未生效、maxPoolSize 永远没机会触发。
二、真相:线程池参数不是你想的那样配的
要理解问题,得先知道 ThreadPoolExecutor 的任务提交流程。
任务提交 → 核心线程是否满?
↓ 否 → 新建核心线程
↓ 是 → 队列是否满?
↓ 否 → 放入队列等待
↓ 是 → 是否小于最大线程数?
↓ 是 → 创建非核心线程
↓ 否 → 拒绝策略触发
也就是说:
只要队列没满,线程池就不会创建非核心线程。
所以:
- 你的
corePoolSize = 5; - 队列能放
10000个任务; maxPoolSize = 10永远不会触发;- 线程永远就那 5 个在干活;
- 队列里的任务越堆越多,拒绝策略永远“假死”。
三、踩坑场景实录
| 场景 | 错误配置 | 结果 |
|---|---|---|
| 高频接口异步任务 | LinkedBlockingQueue<>(10000) | 队列太大 → 拒绝策略形同虚设 |
| IO密集型任务 | 核心线程过少(如5) | CPU空闲但任务堆积 |
| CPU密集型任务 | 核心线程过多(如50) | 上下文切换浪费CPU |
| 线程池共用 | 多个模块共用一个 pool | 某任务阻塞导致全局“死锁” |
四、正确配置姿势(我现在都这么配)
思路很简单:
“小队列 + 合理核心数 + 合理拒绝策略”
而不是 “大队列 + 盲目扩大线程数”。
例如 CPU 密集型任务:
int cores = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor executor = new ThreadPoolExecutor(
cores + 1,
cores + 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(100),
new ThreadPoolExecutor.CallerRunsPolicy()
);
IO 密集型任务:
int cores = Runtime.getRuntime().availableProcessors();
ThreadPoolExecutor executor = new ThreadPoolExecutor(
cores * 2,
cores * 4,
60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(200),
new ThreadPoolExecutor.CallerRunsPolicy()
);
关键思想:
- 宁可拒绝,也不要堆积。
- 拒绝意味着“系统过载”,堆积意味着“慢性自杀”。
五、拒绝策略的“假死”与自定义方案
内置的 4 种拒绝策略:
AbortPolicy:直接抛异常(最安全)CallerRunsPolicy:调用方线程执行(可限流)DiscardPolicy:悄悄丢弃任务(最危险)DiscardOldestPolicy:丢最老的(仍可能乱序)
如果你想更智能一点,可以自定义:
new ThreadPoolExecutor.AbortPolicy() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
log.warn("任务被拒绝,当前队列:{}", e.getQueue().size());
// 可以上报监控 / 发报警
}
};
六、监控才是救命稻草
别等到队列堆积了才发现问题。
我建议给线程池加实时监控,比如:
ScheduledExecutorService monitor = Executors.newScheduledThreadPool(1);
monitor.scheduleAtFixedRate(() -> {
log.info("PoolSize={}, Active={}, QueueSize={}",
executor.getPoolSize(),
executor.getActiveCount(),
executor.getQueue().size());
}, 0, 5, TimeUnit.SECONDS);
这样你能第一时间看到线程数没涨、队列在爆。
🧠 七、总结(踩坑后记)
| 项目 | 错误思路 | 正确思路 |
|---|---|---|
| corePoolSize | 设太小 | 根据 CPU/I/O 特性动态计算 |
| queueCapacity | 设太大 | 保持小容量以触发拒绝策略 |
| maxPoolSize | 没触发 | 仅当队列满后才会启用 |
| 拒绝策略 | 默认 Abort | 建议自定义/限流处理 |
| 监控 | 没有 | 定期打印状态日志 |
最后一句话:
“线程池是救命的工具,用不好就变慢性毒药。”
✍️ 写在最后
如果你看到这里,不妨想想自己的系统里有多少个 newFixedThreadPool、多少个默认 LinkedBlockingQueue 没有限制大小。
你以为是“优化”,其实是定时炸弹。
来源:juejin.cn/post/7566476530500223003
中石化将开源组件二次封装申请专利,这个操作你怎么看?
开源项目推荐:
一. 前言
昨天看到了一篇关于 “中石化申请基于 vue 的文件上传组件二次封装方法和装置专利,解决文件上传功能开发繁琐问题” 的新闻。
今天特地在专利系统检索了一下,竟然是真的,令人不禁大跌眼镜!用的全是开源组件,最后还把它们变成了自己的专利!这波操作属实厉害啊!


难道以后要用这种方式上传文件,要交专利费了?哈哈....
说来好笑,有掘友指出有单词拼写错误,我又查看一下专利文件,竟然还真有拼写错误...

二. 了解一下
本专利是通过在 vue 页面中自定义 el-upload 组件和 el-progress 组件的使用,解决了文件上传功能开发步骤繁琐和第三方组件无法满足业务需求的问题,实现了简化开发、提高效率和灵活性的效果。
1. 摘要
本发明提供了一种基于 vue 的文件上传组件的二次封装方法和装置,解决了针对于文件上传功能的开发步骤繁琐,复杂,且上传功能的第三方组件无法完全满足业务需求的问题。
该基于 vue 的文件上传组件的二次封装方法包括:在 vue 页面中创建 el‑upload 组件和 el‑progress 组件;
基于所述 el‑upload 组件获取目标上传文件的大小,并判断所述目标上传文件的大小是否符合上传标准;若是,上传所述目标上传文件,并基于所述 el‑progress 组件获取上传进度;上传完成后,对上传的所述目标上传文件进行预处理并存储;
对存储的所述目标上传文件进行封装,并获得 vue 组件。
技术流程图:

二次封装装置模块:

2. 解决的技术问题
现有技术中文件上传功能的开发步骤繁琐复杂,第三方组件无法完全满足业务需求。
3. 采用的技术手段
通过在 vue 页面中引入 el-upload 组件和 el-progress 组件,自定义上传方法和进度条绑定,获取文件大小和上传进度,进行预处理和存储,并将其封装成可重复使用的 vue 组件。
4. 产生的技术功效
简化了文件上传功能的开发步骤,节省了开发时间和效率,避免了代码沉冗,降低了后期维护成本,并提高了文件上传功能的灵活性。
三. 实现一下
这种简单的上传文件+上传进度显示不是最基本的业务封装吗?相信这是每个前端开发工程师必备的基础技能。
所以我们趁热打铁,我们也来实现一下。
我也先来个流程图,梳理一下文件上传过程:

1. el-upload + el-progress 组合
- el-upload 负责文件选择、上传。
- el-progress 负责展示上传进度。
2. 文件大小校验
- 使用 el-upload 的
before-upload钩子,判断文件大小是否符合标准。
3. 上传进度获取
- 使用 el-upload 的
on-progress钩子,实时更新进度条。
4. 上传完成后的预处理与存储
- 上传完成后,触发自定义钩子(如
beforeStore、onStore),进行预处理和存储。
5. 封装为 Vue 组件
- 通过 props、emits、插槽等方式,暴露灵活的接口,便于业务页面集成。
都懒得自己动手,让 Cursor 来实现一下。Cursor 还是一如既往的强大,基本上一次询问就能成功!我表示 Cursor 在手,天下我有!

UploaderWrapper 自定义组件:
<template>
<div class="file-uploader">
<ElUpload
:action="action"
:before-upload="beforeUpload"
:on-progress="handleProgress"
:on-success="handleSuccess"
:on-error="handleError"
:limit="limit"
:on-exceed="handleExceed"
:show-file-list="showFileList"
:multiple="multiple"
:accept="accept"
v-model:file-list="fileList"
:on-remove="handleRemove"
>
<template #trigger>
<ElButton type="primary"> 选择文件上传 ElButton>
template>
<template #tip>
<div class="el-upload__tip">
支持的文件类型: {{ accept }},单个文件不超过 {{ maxSize }}MB
div>
template>
ElUpload>
<ElProgress
v-if="isUploading"
:percentage="uploadPercent"
:status="uploadPercent === 100 ? 'success' : ''"
class="mt-4"
/>
div>
template>
<style scoped>
.file-uploader {
width: 100%;
}
.el-upload__tip {
font-size: 12px;
color: #606266;
margin-top: 8px;
}
style>
使用方式:
<template>
<ElCard class="mb-5 w-80">
<template #header> 文件上传演示 template>
<UploaderWrapper
action="/api/upload"
:max-size="5"
:before-store="beforeStore"
:on-store="onStore"
/>
ElCard>
template>
效果如下所示:

声明:“代码仅供演示,不要使用,以免有专利侵权风险,慎重!”
四. 思考一下
从开发者的角度来看,这个专利事件是否能给我们带来了一些值得思考影响和启示:
- 技术创新的边界问题
- 使用开源组件进行二次封装是否应该被授予专利?
- 是否对开源社区的发展可能产生负面影响?
- 对日常开发的影响
- 如果专利获得授权,其他公司使用类似的文件上传组件封装方案是否可能面临法律风险?
- 开发者是否需要寻找替代方案或支付专利费用?
- 对开源社区的影响
- 可能打击开发者对开源项目的贡献热情,自己辛苦开源项目为别人做了嫁衣?
- 是否会影响开源组件的使用和二次开发
- 可能导致更多公司效仿,将开源组件的二次封装申请专利,因为毕竟专利对公司的招投标挺大的
五. 后记
“中石化作为传统能源企业,都能积极拥抱前端技术,还将内部技术方案申请专利,体现了他们对知识产权的重视?”
那我们是不是要在技术创新和知识产权保护之间找到平衡点,既要保护创新,又不能阻碍技术的发展。
而作为开发者的我们呢?这么简单的封装都能申请专利成功的话,那么...,大家有什么想法,是不是现在强的可怕?哈哈...
专利来源于国家知识产权局
申请公布号:CN120122937A
来源:juejin.cn/post/7514858513442078754
Canvas 高性能K线图的架构方案
前言
证券行业,最难的前端组件,也就是k线图了。
指标还可以添加、功能还可以扩展, 但思路要清晰。
作为一个从证券行业毕业的前端从业者,
我想分享下自己的项目经验。
1、H5 K线图,支持无限左右滑动、样式可随意定制;
2、纯canvas制作,不借助任何第三方图表库;
3、阅读本文,需要有 canvas 基础知识;
注意:以上的 demo 还有一些 bug, 没时间修复, 预览地址是直接在 github 上部署的, 所以最好通过 vpn科学上网,否则可能访问不了,然后再在移动端打开页面。 另外, 上面的股票详情页, 还没有做自适应,等我有时间再改。
证券行业,最难的前端组件,也就是k线图了。
指标还可以添加、功能还可以扩展, 但思路要清晰。
作为一个从证券行业毕业的前端从业者,
我想分享下自己的项目经验。
1、H5 K线图,支持无限左右滑动、样式可随意定制;
2、纯canvas制作,不借助任何第三方图表库;
3、阅读本文,需要有 canvas 基础知识;
注意:以上的 demo 还有一些 bug, 没时间修复, 预览地址是直接在 github 上部署的, 所以最好通过 vpn科学上网,否则可能访问不了,然后再在移动端打开页面。 另外, 上面的股票详情页, 还没有做自适应,等我有时间再改。
一、先看最终的效果
1、GIF动图如下


2、支持样式自定义



二、canvas 注意事项
1、整数坐标,会导致模糊
canvas 在画线段, 通常会出现以下代码:
cxt.moveTo(x1, y1);
cxt.lineTo(x2, y2);
cxt.lineWidth = 1;
cxt.stroke();
假设上面的两个点是(1,10)和(5,10),那么画出来的实际上是一条横线,
理论上横线的粗度是1px,且该横线被 y=10 切成两半,
上半部分粗度是 0.5px, 下半部分粗度也是 0.5px,
这样横线的整体粗度才会是 1px。
但是 canvas 不是这样处理的, canvas 默认线条会与整数对齐,
也就是横线的上部分不会是 y=9.5px, 而是 y=9px;
横线的下半部分也不是 y=10.5px, 而是 y=11px;
从而横线的粗度看起来不是1px,而是2px。
并且由于粗度被拉伸,颜色也会被淡化,那怎么解决这个问题呢?
处理方式也很简单, 通过 cxt.translate(0.5, 0.5) 将坐标往下移动 0.5 个像素,
然后接下来的所有点, 都保证是整数即可, 这样就能保证不会被拉伸。
典型的代码如下:
cxt.translate(0.5, 0.5);
cxt.moveTo(Math.floor(x1), Math.floor(y1));
cxt.lineTo(Math.floor(x2), Math.floor(y2));
cxt.lineWidth = 1;
cxt.stroke();
在我的代码中, 也体现了类似的处理。
canvas 在画线段, 通常会出现以下代码:
cxt.moveTo(x1, y1);
cxt.lineTo(x2, y2);
cxt.lineWidth = 1;
cxt.stroke();
假设上面的两个点是(1,10)和(5,10),那么画出来的实际上是一条横线,
理论上横线的粗度是1px,且该横线被 y=10 切成两半,
上半部分粗度是 0.5px, 下半部分粗度也是 0.5px,
这样横线的整体粗度才会是 1px。
但是 canvas 不是这样处理的, canvas 默认线条会与整数对齐,
也就是横线的上部分不会是 y=9.5px, 而是 y=9px;
横线的下半部分也不是 y=10.5px, 而是 y=11px;
从而横线的粗度看起来不是1px,而是2px。
并且由于粗度被拉伸,颜色也会被淡化,那怎么解决这个问题呢?
处理方式也很简单, 通过 cxt.translate(0.5, 0.5) 将坐标往下移动 0.5 个像素,
然后接下来的所有点, 都保证是整数即可, 这样就能保证不会被拉伸。
典型的代码如下:
cxt.translate(0.5, 0.5);
cxt.moveTo(Math.floor(x1), Math.floor(y1));
cxt.lineTo(Math.floor(x2), Math.floor(y2));
cxt.lineWidth = 1;
cxt.stroke();
在我的代码中, 也体现了类似的处理。
2、如何处理高像素比带来的模糊
设备像素比越高,理论上应该越清晰,因为原来用一个小方块来渲染1px, 现在用2个(dpr=2的情况)小方块来渲染,应该更清晰才对,但是canvas不是这样的。
例如,通过js获取父容器 div 的宽度是 width, 这时候如果设置 canvas.width = width,在设备像素比为2的时候, canvas 画出来的宽度为css对应宽度的一半, 如果强制通过 css 将 canvas 宽度设置为 width, 则 canvas 会被拉长一倍, 导致出现锯齿模糊。
注意了吗?上面所说的 canvas.width=width 与 css 设置的 #canvas { width: width } 起到的效果是不一样的。不要随便通过 css 去设置 canvas 的宽高, 容易被拉伸变形或者导致模糊。
通用的处理方式是:
//初始化高清Canvas
function initHDCanvas() {
const rect = hdCanvas.getBoundingClientRect();
//设置Canvas内部尺寸为显示尺寸乘以设备像素比
const dpr = window.devicePixelRatio || 1;
hdCanvas.width = rect.width * dpr;
hdCanvas.height = rect.height * dpr;
//设置Canvas显示尺寸保持不变
hdCanvas.style.width = rect.width + 'px';
hdCanvas.style.height = rect.height + 'px';
//获取上下文并缩放
const ctx = hdCanvas.getContext('2d');
ctx.scale(dpr, dpr);
//接下来,你可以自由发挥
}
设备像素比越高,理论上应该越清晰,因为原来用一个小方块来渲染1px, 现在用2个(dpr=2的情况)小方块来渲染,应该更清晰才对,但是canvas不是这样的。
例如,通过js获取父容器 div 的宽度是 width, 这时候如果设置 canvas.width = width,在设备像素比为2的时候, canvas 画出来的宽度为css对应宽度的一半, 如果强制通过 css 将 canvas 宽度设置为 width, 则 canvas 会被拉长一倍, 导致出现锯齿模糊。
注意了吗?上面所说的 canvas.width=width 与 css 设置的 #canvas { width: width } 起到的效果是不一样的。不要随便通过 css 去设置 canvas 的宽高, 容易被拉伸变形或者导致模糊。
通用的处理方式是:
//初始化高清Canvas
function initHDCanvas() {
const rect = hdCanvas.getBoundingClientRect();
//设置Canvas内部尺寸为显示尺寸乘以设备像素比
const dpr = window.devicePixelRatio || 1;
hdCanvas.width = rect.width * dpr;
hdCanvas.height = rect.height * dpr;
//设置Canvas显示尺寸保持不变
hdCanvas.style.width = rect.width + 'px';
hdCanvas.style.height = rect.height + 'px';
//获取上下文并缩放
const ctx = hdCanvas.getContext('2d');
ctx.scale(dpr, dpr);
//接下来,你可以自由发挥
}
三、样式配置
为了方便样式自定义, 我独立出一个默认的配置对象 defaultKlineConfig, 参数的含义如下图所示,其实下图这个风格的标注, 是通过 excalidraw 这个软件画的, 也是 canvas 做的开源软件, 可见 canvas 在前端可视化领域的重要性, 这个扯远了,打住。

如上图, 整个canvas 画板, 分成 5 部分,
每一部分的高度, 都可以设置,
其中主图和副图的高度,是通过比例来计算的:
mainChartHeight = restHeight * mainChartHeightPercent
其中,restHeigh 是画板总高度 height 减去其他几部分计算的, 如下:
restHeight = height - lineMessageHeight - tradeMessageHeight - xLabelHeight
十字交叉线的颜色, X轴 与 Y轴 的 tooltip 背景色、字体大小的参数如下:

为了方便样式自定义, 我独立出一个默认的配置对象 defaultKlineConfig, 参数的含义如下图所示,其实下图这个风格的标注, 是通过 excalidraw 这个软件画的, 也是 canvas 做的开源软件, 可见 canvas 在前端可视化领域的重要性, 这个扯远了,打住。
如上图, 整个canvas 画板, 分成 5 部分,
每一部分的高度, 都可以设置,
其中主图和副图的高度,是通过比例来计算的:
mainChartHeight = restHeight * mainChartHeightPercent
其中,restHeigh 是画板总高度 height 减去其他几部分计算的, 如下:
restHeight = height - lineMessageHeight - tradeMessageHeight - xLabelHeight
十字交叉线的颜色, X轴 与 Y轴 的 tooltip 背景色、字体大小的参数如下:
四、均线计算
从上面的图可以看出, 需要画 5日均线、10日均线、20日均线, 成交量快线(10日)、成交量慢线(20日) 但是, 接口没有给出当日的均线值, 需要自己计算。
5日均线 = (过去4个成交日的收盘价总和 + 今日收盘价)/ 5
10日均线 = (过去9个成交日的收盘价总和 + 今日收盘价)/ 10
20日均线 = (过去19个成交日的收盘价总和 + 今日收盘价)/ 20
成交量快线 = (过去9日成交量 + 今日成交量)/ 10
成交量慢线 = (过去19日成交量 + 今日成交量)/ 20
所以, 当获取 lmt(一屏的蜡烛图个数)个数据时, 为了计算均线, 需要至少将前 19 个(我的代码写20)数据都获取到。当前一个均线已经获取到, 下一个均线就不需要再累加20个值再得平均数, 可以省一点计算:
今日20日均线值 = (昨日均线值 * 20 - 前面第20个的收盘价 + 今日收盘价)/ 20;
从上面的图可以看出, 需要画 5日均线、10日均线、20日均线, 成交量快线(10日)、成交量慢线(20日) 但是, 接口没有给出当日的均线值, 需要自己计算。
5日均线 = (过去4个成交日的收盘价总和 + 今日收盘价)/ 5
10日均线 = (过去9个成交日的收盘价总和 + 今日收盘价)/ 10
20日均线 = (过去19个成交日的收盘价总和 + 今日收盘价)/ 20
成交量快线 = (过去9日成交量 + 今日成交量)/ 10
成交量慢线 = (过去19日成交量 + 今日成交量)/ 20
所以, 当获取 lmt(一屏的蜡烛图个数)个数据时, 为了计算均线, 需要至少将前 19 个(我的代码写20)数据都获取到。当前一个均线已经获取到, 下一个均线就不需要再累加20个值再得平均数, 可以省一点计算:
今日20日均线值 = (昨日均线值 * 20 - 前面第20个的收盘价 + 今日收盘价)/ 20;
五、分层渲染
为了减少重绘,提高性能,可以将K线图做分层渲染。那分几层合适?我认为是三层。
- 第一层, 不动层
- 第二层,变动层
- 第三层,交互层
为了减少重绘,提高性能,可以将K线图做分层渲染。那分几层合适?我认为是三层。
- 第一层, 不动层
- 第二层,变动层
- 第三层,交互层
不动层
首先, 网格是固定的, 也就是说,当页面拖拽、或者长按出现十字交叉的时候,底部的网格线是不变的,如果每次拖拽,都需要重绘网格,那这个其实是没有必要的开销,可以将网格放在最底层(例如 z-index:0),一次性绘制后,就不要再重绘。
首先, 网格是固定的, 也就是说,当页面拖拽、或者长按出现十字交叉的时候,底部的网格线是不变的,如果每次拖拽,都需要重绘网格,那这个其实是没有必要的开销,可以将网格放在最底层(例如 z-index:0),一次性绘制后,就不要再重绘。
变动层
由于拖拽的时候,蜡烛柱体,均线,Y轴刻度, X轴刻度, 都需要重绘, 这一块是无法改变的事实, 所以, 变动层放在中间层(例如 z-index:1),也是最繁忙的一层,并且该层不响应触摸事件。
由于拖拽的时候,蜡烛柱体,均线,Y轴刻度, X轴刻度, 都需要重绘, 这一块是无法改变的事实, 所以, 变动层放在中间层(例如 z-index:1),也是最繁忙的一层,并且该层不响应触摸事件。
交互层
最后, 交互层由于要捕捉用户的触摸行为, 所以,这一层要在最上层(例如 z-index:2)。
交互层监听触摸事件:当页面快速滑动, 则响应拖拽事件, 即K线图的时间线会左右滑动;当用户长按之后才滑动, 则出现十字交叉浮层。
交互层的好处是, 当响应十字交叉浮层时, 只需要绘制横线、竖线、对应X轴和Y轴的值,而不需要重绘蜡烛柱体和均线, 可以减少重绘,最大程度减少渲染压力。
最后, 交互层由于要捕捉用户的触摸行为, 所以,这一层要在最上层(例如 z-index:2)。
交互层监听触摸事件:当页面快速滑动, 则响应拖拽事件, 即K线图的时间线会左右滑动;当用户长按之后才滑动, 则出现十字交叉浮层。
交互层的好处是, 当响应十字交叉浮层时, 只需要绘制横线、竖线、对应X轴和Y轴的值,而不需要重绘蜡烛柱体和均线, 可以减少重绘,最大程度减少渲染压力。
六、基础几何绘制
网格线
首先计算出主图的高度 this.mainChartHeight, 将主图从上到下等分为4部分,再在左右两边画出竖线,形成主图的网格,副图是成交量图, 只需画一个矩形边框即可,用 strokeRect 即可画出。
//画出网格线
private drawGridLine() {
//获取配置参数
const { gridColor, lineMessageHeight, xLabelHeight, width, height } = this.config;
//画出K线图的5条横线
const split = this.mainChartHeight / 4;
this.canvasCxt.beginPath();
this.canvasCxt.lineWidth = 0.5;
this.canvasCxt.strokeStyle = gridColor;
for (let i = 0; i <= 4; i++) {
const splitHeight = Math.floor(split * i) + lineMessageHeight!;
this.drawLine(0, splitHeight, width, splitHeight);
}
//画出K线图的2条竖线
this.drawLine(0, lineMessageHeight!, 0, lineMessageHeight! + this.mainChartHeight);
this.drawLine(width, lineMessageHeight!, width, lineMessageHeight! + this.mainChartHeight);
//画出成交量的矩形
this.canvasCxt.strokeRect(
0,
height - xLabelHeight! - this.subChartHeight,
width,
this.subChartHeight,
);
}
//画出两个点形成的直线
private drawLine(x1: number, y1: number, x2: number, y2: number) {
this.canvasCxt.moveTo(x1, y1);
this.canvasCxt.lineTo(x2, y2);
this.canvasCxt.stroke();
}
首先计算出主图的高度 this.mainChartHeight, 将主图从上到下等分为4部分,再在左右两边画出竖线,形成主图的网格,副图是成交量图, 只需画一个矩形边框即可,用 strokeRect 即可画出。
//画出网格线
private drawGridLine() {
//获取配置参数
const { gridColor, lineMessageHeight, xLabelHeight, width, height } = this.config;
//画出K线图的5条横线
const split = this.mainChartHeight / 4;
this.canvasCxt.beginPath();
this.canvasCxt.lineWidth = 0.5;
this.canvasCxt.strokeStyle = gridColor;
for (let i = 0; i <= 4; i++) {
const splitHeight = Math.floor(split * i) + lineMessageHeight!;
this.drawLine(0, splitHeight, width, splitHeight);
}
//画出K线图的2条竖线
this.drawLine(0, lineMessageHeight!, 0, lineMessageHeight! + this.mainChartHeight);
this.drawLine(width, lineMessageHeight!, width, lineMessageHeight! + this.mainChartHeight);
//画出成交量的矩形
this.canvasCxt.strokeRect(
0,
height - xLabelHeight! - this.subChartHeight,
width,
this.subChartHeight,
);
}
//画出两个点形成的直线
private drawLine(x1: number, y1: number, x2: number, y2: number) {
this.canvasCxt.moveTo(x1, y1);
this.canvasCxt.lineTo(x2, y2);
this.canvasCxt.stroke();
}
画各类均线
1、首先计算出一屏的股价最大值 max , 股价最小值 min ,成交量最大值 maxAmount。
2、当某一个点的均线为 value, 根据最大值、最小值、索引index, 计算出坐标点(x, y), 画均线的时候, 第一个点用 moveTo(x0, y0),其他点用 lineTo(xn yn), 最后 stroke 连起来即可。
3、当然, 每一条线设置下颜色, 即 stokeStyle。
//画出各类均线
private drawLines(max: number, min: number, maxAmount: number) {
//将宽度分成n个小区间, 一个小区间画一个蜡烛, 每个区间的宽度是 splitW
const splitW = this.config.width / this.config.lmt!;
//画一下5日均线
this.canvasCxt.beginPath();
this.canvasCxt.strokeStyle = this.config.ma5Color;
this.canvasCxt.lineWidth = 1;
let isTheFirstItem = true;
for (
let i = this.startIndex;
i < this.arrayList.length && i < this.startIndex + this.config.lmt!;
i++
) {
const index = i - this.startIndex;
let value = this.arrayList[i].ju5;
if (value === 0) {
continue;
}
const x = Math.floor(index * splitW + 0.5 * splitW);
const y = Math.floor(
((max - value) / (max - min)) * this.mainChartHeight + this.config.lineMessageHeight!,
);
if (isTheFirstItem) {
this.canvasCxt.moveTo(x, y);
isTheFirstItem = false;
} else {
this.canvasCxt.lineTo(x, y);
}
}
this.canvasCxt.stroke();
}
1、首先计算出一屏的股价最大值 max , 股价最小值 min ,成交量最大值 maxAmount。
2、当某一个点的均线为 value, 根据最大值、最小值、索引index, 计算出坐标点(x, y), 画均线的时候, 第一个点用 moveTo(x0, y0),其他点用 lineTo(xn yn), 最后 stroke 连起来即可。
3、当然, 每一条线设置下颜色, 即 stokeStyle。
//画出各类均线
private drawLines(max: number, min: number, maxAmount: number) {
//将宽度分成n个小区间, 一个小区间画一个蜡烛, 每个区间的宽度是 splitW
const splitW = this.config.width / this.config.lmt!;
//画一下5日均线
this.canvasCxt.beginPath();
this.canvasCxt.strokeStyle = this.config.ma5Color;
this.canvasCxt.lineWidth = 1;
let isTheFirstItem = true;
for (
let i = this.startIndex;
i < this.arrayList.length && i < this.startIndex + this.config.lmt!;
i++
) {
const index = i - this.startIndex;
let value = this.arrayList[i].ju5;
if (value === 0) {
continue;
}
const x = Math.floor(index * splitW + 0.5 * splitW);
const y = Math.floor(
((max - value) / (max - min)) * this.mainChartHeight + this.config.lineMessageHeight!,
);
if (isTheFirstItem) {
this.canvasCxt.moveTo(x, y);
isTheFirstItem = false;
} else {
this.canvasCxt.lineTo(x, y);
}
}
this.canvasCxt.stroke();
}
画出蜡烛柱体


当收盘价大于等于开盘价, 选用上面左边红色的样式; 当收盘价小于开盘价, 选用上面右边绿色的样式。
以红色蜡烛为例, 最高点 A(x0, y0),最低点是 B(x1, y1),
高度 height、宽度 width 都是相对于坐标轴的,
红色矩形左上角的顶点是 D(x, y)。
为了画出红色蜡烛, 先后顺序别搞混:
- AB 这条竖线,通过 moveTo,lineTo 画出来;
- 定义一个矩形 cxt.rect(x, y, width, heigth);
- 通过 fill 将矩形内部填充为白色, 这时候白色矩形会覆盖掉红色竖线的一部分;
- 再通过 stroke 描出矩形的红色边框
按照上面这个顺序, 竖线会被覆盖掉一部分,同时,矩形内部的白色填充不会挤压矩形的红色边框, 如果先 stroke 再 fill,容易出现白色填充覆盖红色边框,矩形可能会变模糊,或者使得红色变淡,极其不友好,所以按照我上面的顺序,可以减少不必要的麻烦。
当收盘价大于等于开盘价, 选用上面左边红色的样式; 当收盘价小于开盘价, 选用上面右边绿色的样式。
以红色蜡烛为例, 最高点 A(x0, y0),最低点是 B(x1, y1),
高度 height、宽度 width 都是相对于坐标轴的,
红色矩形左上角的顶点是 D(x, y)。
为了画出红色蜡烛, 先后顺序别搞混:
- AB 这条竖线,通过 moveTo,lineTo 画出来;
- 定义一个矩形 cxt.rect(x, y, width, heigth);
- 通过 fill 将矩形内部填充为白色, 这时候白色矩形会覆盖掉红色竖线的一部分;
- 再通过 stroke 描出矩形的红色边框
按照上面这个顺序, 竖线会被覆盖掉一部分,同时,矩形内部的白色填充不会挤压矩形的红色边框, 如果先 stroke 再 fill,容易出现白色填充覆盖红色边框,矩形可能会变模糊,或者使得红色变淡,极其不友好,所以按照我上面的顺序,可以减少不必要的麻烦。
画出文字
canvas 画出文字, 典型的代码如下
this.canvasCxt.beginPath();
this.canvasCxt.font = `${this.config.yLabelFontSize}px "Segoe UI", Arial, sans-serif`;
this.canvasCxt.textBaseline = 'alphabetic';
this.canvasCxt.fillStyle = this.config.yLabelColor;
注意textBaseline 默认对齐方式是 alphabetic, 但 middle 往往更好用, 能实现垂直居中,但我发现垂直居中也不是很居中,所以会特意加减1、2个像素;
当然还有个textAlign, 能实现水平对齐方式, 左右对齐都可以, 例如上图最左、最右的时间标签。
canvas 画出文字, 典型的代码如下
this.canvasCxt.beginPath();
this.canvasCxt.font = `${this.config.yLabelFontSize}px "Segoe UI", Arial, sans-serif`;
this.canvasCxt.textBaseline = 'alphabetic';
this.canvasCxt.fillStyle = this.config.yLabelColor;
注意textBaseline 默认对齐方式是 alphabetic, 但 middle 往往更好用, 能实现垂直居中,但我发现垂直居中也不是很居中,所以会特意加减1、2个像素;
当然还有个textAlign, 能实现水平对齐方式, 左右对齐都可以, 例如上图最左、最右的时间标签。
七、交互设计
根据上面的GIF动图, 可以知道, 本次做的移动端 K 线图, 最重要的两个交互是:
- 快速拖拽,K线图随时间轴左右滑动
- 长按滑动,出现十字交叉tooltip
上面的交互,其实是比较复杂的,所以需要先设计一个简单的数据结构:
- 首先页面存放一个列表 arrayList
- 保存一个数字标识 startIndex,表示当前屏幕从 startIndex 开始画蜡烛图
当用户往右快速拖拽时, startIndex 根据用户拖拽的距离, 适当变小; 当用户往左快速拖拽时, startIndex 根据用户拖拽的距离, 适当变大。
那 arrayList 到底多长合适, 因为股票可能有十几年的数据, 甚至上百年的数据, 我不能一次性拉取这个股票的所有数据吧?
当然,站在软件性能、消耗等角度,也不应该一次性拉取所有的数据, 我的答案是 arraylist 最多保存5屏的数据量,用户看到的屏幕, 应该是接近中间这一屏,也就是第3屏的数据, 左右两边各保存2屏数据,这样,用户拖拽的时候,可以比较流畅,而不是每次拖拽都要等拉取数据再去渲染。
那什么时候拉取新的数据呢? 用户触摸完后,当startIndex左边的数据少于2屏,开始拉取左边的数据; 用户触摸完后,当startIndex右边的数据少于2屏,开始拉取右边的数据;
那如果用户一直往右拖拽, 是不是就一直往左边添加数据, 这个 arraylist 是不是会变得很长?
当然不是,例如,当我往 arraylist 的左边添加数据的时候,startIndex 也会跟着变动, 因为用户看到的第一条柱体,在 arraylist 的索引已经变了。当我往 arraylist 的某一边添加数据后, arraylist 的另一边如果数据超过 2 屏, 要适当裁掉一些数据, 这样 arraylist 的总数, 始终保持在 5 屏左右,就不会占用太多的存放空间。
总体思想是, 从 startIndex 开始渲染屏幕的第一条柱体, 当前屏幕的左右两边, 都预留2屏数据,防止用户拖拽频繁调用接口, 导致卡顿; 同时也控制了 arraylist 的长度, 这是虚拟列表的变形,这样设计,可以做一个 高性能 的k线图。
根据上面的GIF动图, 可以知道, 本次做的移动端 K 线图, 最重要的两个交互是:
- 快速拖拽,K线图随时间轴左右滑动
- 长按滑动,出现十字交叉tooltip
上面的交互,其实是比较复杂的,所以需要先设计一个简单的数据结构:
- 首先页面存放一个列表 arrayList
- 保存一个数字标识 startIndex,表示当前屏幕从 startIndex 开始画蜡烛图
当用户往右快速拖拽时, startIndex 根据用户拖拽的距离, 适当变小; 当用户往左快速拖拽时, startIndex 根据用户拖拽的距离, 适当变大。
那 arrayList 到底多长合适, 因为股票可能有十几年的数据, 甚至上百年的数据, 我不能一次性拉取这个股票的所有数据吧?
当然,站在软件性能、消耗等角度,也不应该一次性拉取所有的数据, 我的答案是 arraylist 最多保存5屏的数据量,用户看到的屏幕, 应该是接近中间这一屏,也就是第3屏的数据, 左右两边各保存2屏数据,这样,用户拖拽的时候,可以比较流畅,而不是每次拖拽都要等拉取数据再去渲染。
那什么时候拉取新的数据呢? 用户触摸完后,当startIndex左边的数据少于2屏,开始拉取左边的数据; 用户触摸完后,当startIndex右边的数据少于2屏,开始拉取右边的数据;
那如果用户一直往右拖拽, 是不是就一直往左边添加数据, 这个 arraylist 是不是会变得很长?
当然不是,例如,当我往 arraylist 的左边添加数据的时候,startIndex 也会跟着变动, 因为用户看到的第一条柱体,在 arraylist 的索引已经变了。当我往 arraylist 的某一边添加数据后, arraylist 的另一边如果数据超过 2 屏, 要适当裁掉一些数据, 这样 arraylist 的总数, 始终保持在 5 屏左右,就不会占用太多的存放空间。
总体思想是, 从 startIndex 开始渲染屏幕的第一条柱体, 当前屏幕的左右两边, 都预留2屏数据,防止用户拖拽频繁调用接口, 导致卡顿; 同时也控制了 arraylist 的长度, 这是虚拟列表的变形,这样设计,可以做一个 高性能 的k线图。
八、触摸事件解耦
根据上面的分析:
- 快速拖拽, K线图左右移动
- 长按再滑动, 出现十字交叉tooltip
以上两种拖拽,都在 touchmove 事件中触发, 那怎么区分开呢? 典型的 touchstart、 touchmove 、 touchend 解耦如下:
let timer = null;
let startX = 0;
let startY = 0;
let isLongPress = false;
canvas.addEventListener('touchstart', (e) => {
startX = e.touches[0].clientX;
startY = e.touches[0].clientY;
isLongPress = false;
timer = setTimeout(() => {
isLongPress = true;
// 显示十字光标hover
showCrossHair(e);
}, 500);
});
canvas.addEventListener('touchmove', (e) => {
if (isLongPress) {
// 长按移动时更新十字光标位置
updateCrossHair(e);
} else {
// 快按拖动时移动K线图
clearTimeout(timer);
moveKLineChart(e);
}
});
canvas.addEventListener('touchend', () => {
clearTimeout(timer);
if (isLongPress) {
// 长按结束隐藏十字光标
hideCrossHair();
}
isLongPress = false;
});
// 关闭十字光标
function hideCrossHair() {
// 隐藏逻辑
}
根据上面的框架, 再详细补充下代码就可以了。 然后再在 touchend 事件中, 新增或减少 arraylist 的数据量。
根据上面的分析:
- 快速拖拽, K线图左右移动
- 长按再滑动, 出现十字交叉tooltip
以上两种拖拽,都在 touchmove 事件中触发, 那怎么区分开呢? 典型的 touchstart、 touchmove 、 touchend 解耦如下:
let timer = null;
let startX = 0;
let startY = 0;
let isLongPress = false;
canvas.addEventListener('touchstart', (e) => {
startX = e.touches[0].clientX;
startY = e.touches[0].clientY;
isLongPress = false;
timer = setTimeout(() => {
isLongPress = true;
// 显示十字光标hover
showCrossHair(e);
}, 500);
});
canvas.addEventListener('touchmove', (e) => {
if (isLongPress) {
// 长按移动时更新十字光标位置
updateCrossHair(e);
} else {
// 快按拖动时移动K线图
clearTimeout(timer);
moveKLineChart(e);
}
});
canvas.addEventListener('touchend', () => {
clearTimeout(timer);
if (isLongPress) {
// 长按结束隐藏十字光标
hideCrossHair();
}
isLongPress = false;
});
// 关闭十字光标
function hideCrossHair() {
// 隐藏逻辑
}
根据上面的框架, 再详细补充下代码就可以了。 然后再在 touchend 事件中, 新增或减少 arraylist 的数据量。
九、性能优化
其实, 做到上面的设计,性能已经很好了,可以监控帧率来看下滑动的流畅程度。
总结下我做了什么操作,来提高整体的性能:
其实, 做到上面的设计,性能已经很好了,可以监控帧率来看下滑动的流畅程度。
总结下我做了什么操作,来提高整体的性能:
1、分层渲染
将K线图画在3个canvas上。
- 不动层只需要绘画一次;
- 变动层根据需要而变动;
- 交互层独立出来,不会影响其它层,变动层的大量蜡烛柱体、均线等也不会受交互层的影响
将K线图画在3个canvas上。
- 不动层只需要绘画一次;
- 变动层根据需要而变动;
- 交互层独立出来,不会影响其它层,变动层的大量蜡烛柱体、均线等也不会受交互层的影响
2、离屏渲染
当需要在K线上标注一些icon时, 这些 icon 可以先离屏渲染, 需要的时候, 再copy到变动层对应的位置,这样比临时抱佛脚去画,要省很多时间,也能提高新能。
当需要在K线上标注一些icon时, 这些 icon 可以先离屏渲染, 需要的时候, 再copy到变动层对应的位置,这样比临时抱佛脚去画,要省很多时间,也能提高新能。
3、设置数据缓冲区
就是屏幕只渲染一屏数据, 但是在当前屏的左右两边,各缓存了2屏数据, 超过5屏数据的时候,及时裁掉多余的数据, 这样arraylist的数据量始终保持在5屏, 控制了数据量,有效的控制了占用空间。
就是屏幕只渲染一屏数据, 但是在当前屏的左右两边,各缓存了2屏数据, 超过5屏数据的时候,及时裁掉多余的数据, 这样arraylist的数据量始终保持在5屏, 控制了数据量,有效的控制了占用空间。
4、节流防抖
touchmove 会很频繁触发, 可通过节流来控制,减少不必要的渲染。
touchmove 会很频繁触发, 可通过节流来控制,减少不必要的渲染。
十、部署到GitHub Pages
1、安装gh-pages包
npm install --save-dev gh-pages
npm install --save-dev gh-pages
2、package.json 添加如下配置
注意, Stock 这个需要对应github的仓库名
{
"homepage": "https://fhrddx.github.io/Stock",
"scripts": {
"predeploy": "npm run build",
"deploy": "gh-pages -d build"
}
}
注意, Stock 这个需要对应github的仓库名
{
"homepage": "https://fhrddx.github.io/Stock",
"scripts": {
"predeploy": "npm run build",
"deploy": "gh-pages -d build"
}
}
3、运行部署命令
npm run build
npm run deploy

最后, 访问上面的链接(注意,在国内可能要开vpn)
这样, github pages 部署成功, 访问上面链接, 可以看到如下效果。

github page 的部署需要将仓库设置为 public, 这个我挺反感的, 可以用 vercel 部署, 也就是将 github 账号与 vercel 关联起来, 项目的 package.js 的 homepage 设置为 “.” , 然后 vercel 可以点击一下, 一键部署, 常见的命令行如下:
# 1. 安装 Vercel CLI
npm install -g vercel
# 2. 在项目根目录登录 Vercel
vercel login
# 3. 部署项目
npm run build
vercel --prod
# 或者直接部署 build 文件夹
vercel --prod --build
作者:VincentFHR
来源:juejin.cn/post/7556154928059334666
npm run build
npm run deploy
最后, 访问上面的链接(注意,在国内可能要开vpn)
这样, github pages 部署成功, 访问上面链接, 可以看到如下效果。
github page 的部署需要将仓库设置为 public, 这个我挺反感的, 可以用 vercel 部署, 也就是将 github 账号与 vercel 关联起来, 项目的 package.js 的 homepage 设置为 “.” , 然后 vercel 可以点击一下, 一键部署, 常见的命令行如下:
# 1. 安装 Vercel CLI
npm install -g vercel
# 2. 在项目根目录登录 Vercel
vercel login
# 3. 部署项目
npm run build
vercel --prod
# 或者直接部署 build 文件夹
vercel --prod --build
来源:juejin.cn/post/7556154928059334666
Elasticsearch 避坑指南:我在项目中总结的 14 条实用经验
刚开始接触 Elasticsearch 时,我觉得它就像个黑盒子——数据往里一扔,查询语句一写,结果就出来了。直到负责公司核心业务的搜索模块后,我才发现这个黑盒子里面藏着无数需要注意的细节。
今天就把我在实际项目中积累的 ES 使用经验分享给大家,主要从索引设计、字段类型、查询优化、集群管理和架构设计这几个方面来展开。

索引设计:从基础到进阶
1. 索引别名(alias):为变更留条后路
刚开始做项目时,我习惯直接用索引名。直到有一次需要修改字段类型,才发现 ES 不支持直接修改映射,也不支持修改主分片数,必须重建索引。(**新增字段是可以的)
解决方案很简单:使用索引别名。业务代码中永远使用别名,重建索引时只需要切换别名的指向,整个过程用户无感知。
这就好比给索引起了个"外号",里面怎么换内容都不影响外面的人称呼它。
2. Routing 路由:让查询更精准
在做 SaaS 电商系统时,我发现查询某个商家的订单数据特别慢。原来,默认情况下ES根据文档ID的哈希值分配分片,导致同一个商家的数据分散在不同分片上。
优化方案:使用商家 ID 作为 routing key,存储和查询数据时指定routing key。这样,同一个商家的所有数据都会存储在同一个分片上。
效果对比:
- 优化前:查询要扫描所有分片(比如3个分片都要查)
- 优化后:只需要查1个分片
- 结果:查询速度直接翻倍,资源消耗还更少
3. 分片拆分:应对数据增长
当单个索引数据量持续增长时,单纯增加分片数并不是最佳方案。
我的经验是:
- 业务索引:单个分片控制在 10-30GB
- 搜索索引:10GB 以内更合适
- 日志索引:可以放宽到 20-50GB
对于 SaaS 系统,ES单索引数据较大,且存在“超级大商户”,导致数据倾斜严重时,可以按商家ID%64取模进行索引拆分,比如 orders_001 到 orders_064,每个索引包含部分商家的数据,然后再根据商户ID指定routing key。
请根据业务数据量和业务要求,选择最适合的分片拆分规则 和routing key路由算法,同时不要因为拆分不合理,导致ES节点中存在大量分片。
ES默认单节点分片最大值为1000(7.0版本后),可以参考ES官方建议,堆内存分片数量维持大约1:20的比例
字段类型:选择比努力重要
4. Text vs Keyword:理解它们的本质区别
曾经有个坑:用户手机号用 text 类型存储,结果搜索完整的手机号却搜不到。原来 text 类型会被分词,13800138000 可能被拆成 138、0013、8000 等片段。
正确做法:
- 需要分词搜索的用 text(如商品描述)
- 需要精确匹配的用 keyword(如订单号、手机号),适合 term、terms 等精确查询
- 效果:keyword 类型的 term 查询速度更快,存储空间更小
5. 多字段映射(multi-fields):按需使用不浪费
ES 默认会为 text 字段创建 keyword 子字段,但这并不总是必要的。
我的选择:
- 确定字段需要精确匹配和聚合时:启用 multi-fields
- 只用于全文搜索时:禁用 multi-fields
- 好处:节省存储空间,提升写入速度
6. 排序字段:选对类型提升性能
用 keyword 字段做数值排序是个常见误区。比如价格排序,100 会排在 99 前面,因为它是按字符串顺序比较的。
推荐做法:
- 数值排序:用 long、integer 类型
- 时间排序:用 date 类型
- 提升效果:排序速度提升明显,内存占用也更少
查询优化:平衡速度与精度
7. 模糊查询:了解正确的打开方式
在 ES 7.9 之前,wildcard 查询是个性能陷阱。它基于正则表达式引擎,前导通配符会导致全量词项扫描。
现在的方案:
- ES7.9+:使用 wildcard 字段类型
- 优势:底层使用优化的 n-gram + 二进制 doc value 机制,性能提升显著
提示:ES7.9前后版本wildcard的具体介绍,可以参考我的上一篇文章
8. 分页查询:避免深度分页的坑
产品经理曾要求实现"无限滚动",我展示了深度分页的性能数据后,大家达成共识:业务层面避免深度分页才是根本解决方案。就像淘宝、Google 这样的大厂,也都对分页做了限制,这不仅是技术考量,更是用户体验的最优选择。
技术方案(仅在确实无法避免时考虑):
- 浅分页:使用
from/size,适合前几页的常规分页 - Scroll:适合大数据量导出,但需要维护 scroll_id 和历史快照,对服务器资源消耗较大
- search_after:基于上一页最后一条记录进行分页,但无法跳转任意页面,且频繁查询会增加服务器压力
需要强调的是,这些技术方案都存在各自的局限性,业务设计上的规避始终是最佳选择。
集群管理:保障稳定运行
9. 索引生命周期:自动化运维
日志数据的特点是源源不断,如果不加管理,磁盘很快就会被撑满。
我的做法:
- 按天创建索引(如 log_20231201)
- 设置保留策略(保留7天或30天)
- 结合模板自动化管理
10. 准实时性:理解刷新机制
很多新手会困惑:为什么数据写入后不能立即搜索?
原理:ES 默认 1 秒刷新一次索引,这是为了在实时性和写入性能之间取得平衡。
调整建议:
- 实时性要求高:保持 1s
- 写入量大:适当调大 refresh_interval
补充说明:如果需要更新后立即能查询到,通常有两种方案:
- 让前端直接展示刚提交的数据,等下一次调用接口时再查询 ES
- 更新完后,前端延迟 1.5 秒后再查询
关键点:业务需求不一定都要后端实现,可以结合前端一起考虑解决方案。
11. 内存配置:32G 限制的真相
为什么 ES 官方建议不要超过 32G 内存?
技术原因:Java 的压缩指针技术在 32G 以内有效,超过这个限制会浪费大量内存。
实践建议:单个节点配置约50%内存,留出部分给操作系统。
架构设计:合理的分工协作
12. ES 与数据库:各司其职
曾经试图在 ES 里存储完整的业务数据,结果遇到数据一致性问题。
现在的方案:
- ES:存储搜索条件和文档 ID
- 数据库:存储完整业务数据
- 查询:ES 找 ID,数据库取详情
好处:既享受 ES 的搜索能力,又保证数据的强一致性。
13. 嵌套对象:保持数据关联性
处理商品规格这类数组数据时,用普通的 object 类型会导致数据扁平化,破坏对象间的关联。
解决方案:使用 nested 类型,保持数组内对象的独立性,确保查询结果的准确性。
14. 副本配置:读写平衡的艺术
副本可以提升查询能力,但也不是越多越好。
经验值:
- 大多数场景:1 个副本足够
- 高查询压力:可适当增加
- 注意:副本越多,写入压力越大
写在最后
这些经验都是在解决实际问题中慢慢积累的。就像修路一样,开始可能只是简单铺平,随着车流量的增加,需要不断优化——设置红绿灯、划分车道、建立立交桥。使用 ES 也是同样的道理,随着业务的发展,需要不断调整和优化。
最大的体会是:理解原理比记住命令更重要。只有明白了为什么这样设计,才能在遇到新问题时找到合适的解决方案。
如果有人问我:"ES 怎么才能用得更好?"我的回答是:"先理解业务场景,再选择技术方案。就像我们之前做的模糊搜索,不是简单地用 wildcard,而是根据 ES 版本选择最优解。"
技术的价值不在于多复杂,而在于能否优雅地解决实际问题。与大家共勉。
来源:juejin.cn/post/7569959427879567370
Python实战:用高德地图API批量获取地址所属街道并写回Excel
在日常的数据处理工作中,我们经常需要根据公司、事件或门店的注册地址,批量获取其所在的街道信息,例如“浦东新区张江镇”“徐汇区龙华街道”等。 手动查询显然低效,而借助 Python + 高德地图API,我们可以轻松实现自动化批量查询并将结果写入 Excel 文件中。
本文将完整展示一个从 Excel 读取地址 → 调用高德API → 获取街道 → 写回Excel的实用脚本,并讲解实现细节与优化思路。
一、功能概述
这段脚本的功能可以总结为四步:
- 从 Excel 文件中读取地址数据;
- 调用高德地图地理编码(geocode)与逆地理编码(regeo)接口获取街道名称;
- 自动将查询结果写回到 Excel 的新列中;
- 对查询失败的地址进行重试与记录,保证数据尽量完整。
二、项目依赖与准备工作
在开始之前,请确保安装以下依赖:
pip install pandas openpyxl requests
并在高德开放平台申请一个 API Key,申请地址为: 👉 lbs.amap.com/api/webserv…
拿到 key 后,将它填入脚本开头的配置部分:
key = "你的高德API_KEY"
三、核心逻辑讲解
1. Excel文件读取与列处理
脚本使用 pandas 和 openpyxl 结合读取 Excel 文件:
df = pd.read_excel(input_file)
if '注册地址' not in df.columns:
df['注册地址'] = df.iloc[:,16]
addresses = df['注册地址'].tolist()
这段代码首先读取整个 Excel,然后确认是否存在“注册地址”列; 如果没有,则自动取第 17 列(索引16)作为地址列,保证兼容不同格式的表格。
随后,脚本用 openpyxl 打开同一个文件,以保留单元格样式,准备写入新的“街道”列:
wb = load_workbook(input_file)
ws = wb.active
ws.insert_cols(target_col)
ws.cell(row=header_row_index, column=target_col, value="街道")
这样既能读取数据,又能保持表格原有格式,方便下游人员直接查看。
2. 调用高德API获取街道信息
核心的查询函数如下:
def get_street_from_amap(address, retries=max_retries):
if not isinstance(address, str) or not address.strip():
return ""
for attempt in range(1, retries+1):
try:
geo_resp = requests.get(
"https://restapi.amap.com/v3/geocode/geo",
params={"key": key, "address": address, "city": "上海"},
timeout=15
).json()
if not geo_resp.get("geocodes"):
continue
location = geo_resp["geocodes"][0]["location"]
regeo_resp = requests.get(
"https://restapi.amap.com/v3/geocode/regeo",
params={"key": key, "location": location, "extensions": "base", "radius":500},
timeout=15
).json()
if regeo_resp.get("regeocode"):
township = regeo_resp["regeocode"]["addressComponent"].get("township","") or ""
return township
except Exception as e:
print(f"[尝试 {attempt}/{retries}] 地址查询失败: {address}, 错误: {e}")
time.sleep(sleep_time + random.random()*0.5)
return
这段逻辑分为两步:
- 正向地理编码(geocode):根据地址字符串获取经纬度;
- 逆向地理编码(regeo):根据经纬度反查街道名称(township)。
并加入了异常重试机制与随机延时,防止频繁请求触发高德API限流。
3. 批量查询与缓存优化
查询过程通过循环实现:
cache = {}
failed_addresses = []
for row_idx, addr in enumerate(addresses, start=header_row_index+1):
if not isinstance(addr,str) or not addr.strip():
ws.cell(row=row_idx, column=target_col, value="")
continue
if addr in cache:
township = cache[addr]
else:
township = get_street_from_amap(addr)
if township is :
failed_addresses.append((row_idx, addr))
township = ""
cache[addr] = township
time.sleep(sleep_time + random.random()*0.5)
ws.cell(row=row_idx, column=target_col, value=township)
这里有几个优化点:
- 缓存(cache)机制:如果同一地址出现多次,只请求一次;
- 延时策略:
sleep_time + random.random()*0.5,避免被API风控; - 实时进度输出:每50行打印一次进度。
4. 失败重试与错误记录
对于第一次查询失败的地址,脚本会自动发起第二轮重查:
if failed_addresses:
print(f"第一次查询失败地址共 {len(failed_addresses)} 条,开始自动重查……")
still_failed = []
for row_idx, addr in failed_addresses:
township = get_street_from_amap(addr)
if township is :
still_failed.append((row_idx, addr))
township = ""
cache[addr] = township
ws.cell(row=row_idx, column=target_col, value=township)
time.sleep(sleep_time + random.random()*0.5)
failed_addresses = still_failed
最终仍查询失败的地址会被写入单独的 Excel 文件:
if failed_addresses:
df_fail = pd.DataFrame([addr for _, addr in failed_addresses], columns=["地址"])
df_fail.to_excel(failed_file, index=False)
这样可以方便人工二次处理,比如手动调整地址格式或补录缺失信息。
四、运行结果
执行脚本后,控制台会显示类似输出:
已处理 50 行,最近地址:上海市浦东新区张江路123号 → 张江镇
已处理 100 行,最近地址:上海市浦东新区川沙路56号 → 川沙新镇
第一次查询失败地址共 5 条,开始自动重查……
完成,已保存:事件列表-上海浦东-带街道.xlsx
最终仍失败的地址已保存到 查询失败地址.xlsx
最终输出文件中会新增一列“街道”,完整保留原有格式:
| 注册地址 | 街道 |
|---|---|
| 上海市浦东新区张江路123号 | 张江镇 |
| 上海市浦东新区川沙路56号 | 川沙新镇 |
五、实用建议与扩展方向
- 批量查询速度控制
- 高德API对单IP有请求频率限制,建议控制每秒请求数。
- 若数据量大,可考虑多线程+限速队列模式。
- 地址清洗预处理
- 可先对地址进行正则清洗,去掉多余标点、括号、空格等,提高命中率。
- 多城市适配
- 当前城市固定为“上海”,可通过参数配置实现全国适配。
- 异常日志记录
- 建议在重查阶段输出更多日志,例如返回状态码、错误类型,方便调试。
- 接口替代方案
- 若数据量巨大,可以使用高德地图的批量地理编码接口(支持最多 10 条一次),进一步提升效率。
六、总结
本文通过一个实战案例展示了如何用 Python + 高德地图API 实现“批量地址→街道归属”的自动化处理。 整个过程涵盖了数据读取、接口调用、异常重试、结果写回等完整流程,既是一个实用工具脚本,也体现了 Python 在数据自动化中的强大能力。
核心亮点:
| 模块 | 功能 |
|---|---|
| pandas + openpyxl | 高效读取与写入 Excel |
| requests | 调用高德API进行地理解析 |
| 缓存与重试机制 | 提高查询稳定性与速度 |
| 自动生成失败文件 | 方便人工补录与质量控制 |
如果你日常需要处理大量企业、门店、事件地址,这个脚本可以帮你节省大量时间。
来源:juejin.cn/post/7569825640851619875
从零基于 Canvas 实现一个文本渲染器
一、前因后果
1.1 目的
起因是女朋友想做小红薯的账号。她每天会先把小故事写好复制到手机上,然后按照一定的图片规格一张张裁剪,最后发布到平台上。

接着我就在想,有没有什么高效的文本转成图片并且能够自动分页的方案呢?查了很久都没找到合适的方案,最后还是决定自己写一个转换工具。
起因是女朋友想做小红薯的账号。她每天会先把小故事写好复制到手机上,然后按照一定的图片规格一张张裁剪,最后发布到平台上。
接着我就在想,有没有什么高效的文本转成图片并且能够自动分页的方案呢?查了很久都没找到合适的方案,最后还是决定自己写一个转换工具。
1.2 需求
总结了一下我的场景,发现需求如下:
- 能够内容转成指定尺寸的图片
- 能够设置字体、背景、样式
- 支持自动换行、自定义换行
- 支持分页
- 支持图片下载
根据输入文本,通过 Canvas 渲染

展示全部分页图片的内容,可以批量下载

总结了一下我的场景,发现需求如下:
- 能够内容转成指定尺寸的图片
- 能够设置字体、背景、样式
- 支持自动换行、自定义换行
- 支持分页
- 支持图片下载
根据输入文本,通过 Canvas 渲染
展示全部分页图片的内容,可以批量下载
1.3 思路
基于需求,最后决定采用 Canvas 的绘制方案。思路如下:
- 根据输入文本,完成分行、分页的计算
- 将分页数据绘制到 Canvas
- 批量将 Canvas 的内容导出图片进行下载
基于需求,最后决定采用 Canvas 的绘制方案。思路如下:
- 根据输入文本,完成分行、分页的计算
- 将分页数据绘制到 Canvas
- 批量将 Canvas 的内容导出图片进行下载
1.4 难点
做的时候发现几个核心的问题难点,分别是换行、分页的问题。
做的时候发现几个核心的问题难点,分别是换行、分页的问题。
I. 换行问题
在 canvas 中进行文本绘制不同于 HTML 标签,文本是不能自动换行的。所以这个需要自己去计算什么时候换行,在哪个字符段该换行。

在 canvas 中进行文本绘制不同于 HTML 标签,文本是不能自动换行的。所以这个需要自己去计算什么时候换行,在哪个字符段该换行。
II. 分页问题
当内容超出当前页了,我们希望能够自动进行分页,这个就需要去计算行高和页面内容区高度。

当内容超出当前页了,我们希望能够自动进行分页,这个就需要去计算行高和页面内容区高度。
二、设计方案
下面介绍一下 Canvas 文本渲染器的设计方案。主要会围绕着文本计算、文本绘制、导出图片来讲解。
下面介绍一下 Canvas 文本渲染器的设计方案。主要会围绕着文本计算、文本绘制、导出图片来讲解。
2.1 如何计算文本
计算文本主要做的事情就是,根据用户输入的文本和想要生成的图片、字体参数,来计算需要分多少页,每一页具体要展示多少行,每一行要展示多少内容。
计算文本主要做的事情就是,根据用户输入的文本和想要生成的图片、字体参数,来计算需要分多少页,每一页具体要展示多少行,每一行要展示多少内容。
I. 分词
要实现换行,就要知道一句话中从哪个分词开始是超出了当前行的最大宽度。这个分词可能是某个中文字符、某个英文单词、某串数字、某个其他字符等。
这里我们只讨论简单的中英文数字的场景
所以要做的第一步,就是将输入的文本拆解成一个个分词,然后去筛选掉空的字符。

核心代码如下:

要实现换行,就要知道一句话中从哪个分词开始是超出了当前行的最大宽度。这个分词可能是某个中文字符、某个英文单词、某串数字、某个其他字符等。
这里我们只讨论简单的中英文数字的场景
所以要做的第一步,就是将输入的文本拆解成一个个分词,然后去筛选掉空的字符。
核心代码如下:
II. 分行
现在已经将文本拆分成了足够细的分词。接下来要做的就是将每个分词不断地塞入每一行中。
你可以把每一行理解成一个固定宽度的容器,一但某个分词塞不进了,就得创建一个新的容器再把这个分词塞进去。

所这个遍历的过程,需要知道行的最大宽度以及当前分词的真实宽度。最大宽度的计算规则,根据用户设置的页面宽度减去左右边距的宽度,就是内容区的最大行宽度。

代码如下:

分词的真实宽度则是用 canvas 中的 measureText 来测量字符串的宽度。

接下来就是一个累加的过程。把分词加入当前行,判断是否超出最大宽度,如果超出就新起一行。

最后遍历完后就会得出所有的分行内容。
上面是分行大致的思路,但在实际的代码实现上,会随着分词类型、换行需求的增加变得更加复杂。例如:
- 英文单词前面需要追加空格

- 用户想自定义空行逻辑:匹配到句号自动换行并且空一行。
现在已经将文本拆分成了足够细的分词。接下来要做的就是将每个分词不断地塞入每一行中。
你可以把每一行理解成一个固定宽度的容器,一但某个分词塞不进了,就得创建一个新的容器再把这个分词塞进去。
所这个遍历的过程,需要知道行的最大宽度以及当前分词的真实宽度。最大宽度的计算规则,根据用户设置的页面宽度减去左右边距的宽度,就是内容区的最大行宽度。
代码如下:
分词的真实宽度则是用 canvas 中的 measureText 来测量字符串的宽度。
接下来就是一个累加的过程。把分词加入当前行,判断是否超出最大宽度,如果超出就新起一行。
最后遍历完后就会得出所有的分行内容。
上面是分行大致的思路,但在实际的代码实现上,会随着分词类型、换行需求的增加变得更加复杂。例如:
- 英文单词前面需要追加空格
- 用户想自定义空行逻辑:匹配到句号自动换行并且空一行。

III. 分页
有了分行的数据,就可以进行分页了。其实逻辑差不多,只不过一个是横向,一个是纵向。把每个页当成一个固定高度的容器,不断的把行塞进去,塞不进就新起一个页容器。

这个遍历的过程需要知道页面内容区的最大高度以及每一行的行高。行高一般是用户设置的,所以只需关注页面内容区的最大高度的计算规则。

代码如下:

分页计算流程,遍历 lines 把分行不断塞入当前页。如果超出高度就放到新的页面。最后就会得出所有分页的数据。

2.2 如何绘制
有了分页数据以后,绘制主要做的事情就是根据用户设置的样式(页面边距、字体和背景)来渲染每一页具体的内容。
I. 指定图片尺寸
通过设置 Canvas 画布的大小即可。

II. 绘制背景
背景直接通过 fillRect 绘制即可

III. 绘制内容
绘制内容的时候,主要考虑两个点:
- 设置字体样式
- 根据边距、行高计算每行绘制的位置

2.3 如何导出图片
导出图片就是将 Canvas 上的内容转成 DataURL 然后下载成图片

三、最后
基于上面的思路,你不仅仅可以开发一个简单的文本渲染器,你甚至可以做一个复杂的编辑器哦~
最后我将这个工具封装成了一个 npm 库,直接导入这个库就可以完成文本到图片的一个转换了。

如果感兴趣,完整代码放置在 GitHub 了:github.com/zixingtangm…
来源:juejin.cn/post/7485758756911857683
Java/Kotlin 泛型
泛型是 Java 和 Kotlin 中用于实现 "参数化类型" 的核心机制,允许类、接口、方法在定义时不指定具体类型,而是在使用时动态指定,从而实现代码复用和类型安全。
基本定义
泛型类/接口
Java:通过 class 类名
// 泛型类
public class Box {
private T value;
public void set(T value) {
this.value = value;
}
public T get() {
return value;
}
}
// 泛型接口
public interface List {
void add(T element);
T get(int index);
}
kotlin:语法类似,通过 class 类名
// 泛型类
class Box<T>(private var value: T) {
fun set(value: T) {
this.value = value
}
fun get(): T = value
}
// 泛型接口
interface List<T> {
fun add(element: T)
fun get(index: Int): T
}
泛型方法
Java:类型参数声明在方法返回值前,需显式声明。
public static T getFirstElement(List list) {
return list.get(0);
}
kotlin:类型参数声明在方法名前
fun ) : T = list[0]
类型擦除
Java 和 Kotlin 的泛型都基于类型擦除实现:编译时检查类型安全,运行时泛型类型信息被擦除(仅保留原始类型)。
Java
List strList = new ArrayList<>();
List intList = new ArrayList<>();
// 运行时泛型信息被擦除,均为 ArrayList 类型
System.out.println(strList.getClass() == intList.getClass()); // 输出 true
Kotlin
val strList: List = listOf()
val intList: List<Int> = listOf()
// 同样擦除,运行时类型相同
println(strList.javaClass == intList.javaClass) // 输出 true
无法在运行时检查泛型具体类型(如 obj instanceof List
编译错误)。
变异
变异描述泛型类型与子类型的关系,核心问题:若 A 是 B 的子类型,Generic 与 Generic 是什么关系?
Java 需在每次使用泛型时通过通配符控制变异(使用处处理),而 Kotlin 在定义泛型时一次性声明(声明处处理),更简洁且避免重复逻辑。
协变
Java:Generic 是 Generic 的子类型(A 是 B 的子类型),用 ? extends B 表示。
List intList = new ArrayList<>();
Listextends Number> numList = intList; // 合法:Integer 是 Number 子类型,协变
Number n = numList.get(0); // 合法:能读(输出 Number)
numList.add(1); // 编译错误:无法确定具体类型,写操作不安全
泛型类型只能输出 B 及其子类型(读操作安全,写操作受限)。
Kotlin:用 out 标记类型参数,表示泛型类型是生产者,只能输出 T,即作为返回值。不能输入 T,会导致类型不安全。即若 A : B,则 Generic : Generic
val intList: List<Int> = listOf(1, 2, 3)
val numList: List = intList // 合法:协变允许这种赋值
Kotlin 通过 out 关键字在泛型定义时声明协变,如下所示:
// 协变接口:T 只能作为输出(返回值)
interface DataReader<out T> {
fun read(): T // 读取数据,返回 T 类型(输出操作,合法)
}
class IntReader : DataReader<Int> {
private var current = 1
override fun read(): Int {
return current++
}
}
val intReader: DataReader<Int> = IntReader()
// 利用协变特性,将 Int 读取器赋值给 Number 读取器变量,(因为 Int 是 Number 的子类型,协变允许)
val numberReader: DataReader = intReader // 合法
逆变
Java:Generic 是 Generic 的子类型(A 是 B 的子类型),用 ? super A 表示。泛型类型只能输入 A 及其子类型(写操作安全,读操作受限)。
List numList = new ArrayList<>();
Listsuper Integer> intSuperList = numList; // 合法:Number 是 Integer 父类型,逆变
intSuperList.add(1); // 合法:能写(输入 Integer)
Number n = intSuperList.get(0); // 编译错误:只能读为 Object,类型不安全
kotlin:用 in 标记类型参数,表示泛型类型是消费者(只能输入 T,即作为参数)。即若 A : B,则 Generic : Generic。
// 逆变接口:T 只能作为输入(方法参数)
interface DataProcessor<in T> {
fun process(data: T) // 处理数据,接收 T 类型参数(输入操作,合法)
}
// 处理所有 Number 类型(父类型处理器)
class NumberProcessor : DataProcessor<Number> {
override fun process(data: Number) {
println("NumberProcessor process: $data")
}
}
val numberProcessor: DataProcessor = NumberProcessor()
val intProcessor: DataProcessor<Int> = numberProcessor
不变
默认情况下,Generic 与 Generic 无父子关系(即使 A 是 B 的子类型)。对于 kotlin 来说,未用 out/in 标记时,泛型类型默认不变。
通配符与星投影
Java:无界通配符 ?,表示任意类型,读写均受限,可读为 Object,可写 null(无意义)
List anyList = new ArrayList();
Object obj = anyList.get(0); // 合法:读为 Object
anyList.add(null); // 合法:只能加 null
anyList.add("a"); // 编译错误:类型不确定
Kotlin:星投影 *,是 Kotlin 对未知类型参数的简化表示,行为与 Java 通配符类似,但规则更明确:
- 对于 Generic
(协变且有上界):Generic<*> 等价于 Generic 。 - 对于 Generic
(逆变):Generic<*> 等价于 Generic (Nothing 是 Kotlin 所有类型的子类型)。 - 对于 Generic
(不变且有上界):Generic<*> 等价于 Generic 。
Kotlin 标准库的 List 是协变的(List
val anyList: List<*> = listOf("a", 1) // 等价于 List
val obj: Any? = anyList[0] // 合法:读为 Any?
// anyList.add("b") // 编译错误:星投影不可写(类似 Java ?)
泛型约束
泛型约束用于限制类型参数的范围(如只能是某类的子类)。
上界约束(限制为某类型的子类型)
Java:用 extends 声明,类型参数必须是指定类型的子类型。
// T 必须是 Number 的子类型(如 Integer、Double)
public class NumberBoxextends Number> {
private T value;
}
NumberBox intBox = new NumberBox<>();
Kotlin:用 : 声明,语法更简洁。
// T 必须是 Number 的子类型
class NumberBox<T : Number>(private var value: T)
// 合法
val intBox = NumberBox(1) // 推断 T 为 Int
// 不合法
// val strBox = NumberBox("a")
多个上界约束
Java:用 & 连接,且类必须放在接口前(只能有一个类上界)。
// T 必须是 Number 子类且实现 Comparable
public class ComparableNumberBoxextends Number & Comparable> {
}
Kotlin:用 where 子句,支持多个上界,顺序无限制。
// T 必须是 Number 子类且实现 Comparable
class ComparableNumberBox<T> where T : Number, T : Comparable<T>
Java 和 kotlin 都不直接支持下界约束,但是,Java 可以通过通配符 ? super A,kotlin 可以通过 in 逆变实现类似的效果。
Kotlin 独有的泛型特性:reified
由于类型擦除,Java 无法在运行时获取泛型类型信息(如 T.class 不合法)。但 Kotlin 通过 inline 函数配合 reified 关键字,可在运行时保留类型信息。
inline fun <reified T : Activity> startActivity(
context: Context,
extras: Bundle? = null
) {
val intent = Intent(context, T::class.java)
extras?.let { intent.putExtras(it) }
context.startActivity(intent)
}
来源:juejin.cn/post/7567822836484718630
用 “奶茶连锁店的部门分工” 理解各种 CoroutineScope
故事背景:
“协程奶茶连锁店” 生意火爆,总部为了高效管理,设立了 4 个核心部门,每个部门负责不同类型的任务,且有严格的 “上下班时间”(生命周期):
- 总公司长期项目组(GlobalScope) :负责跨门店的长期任务(如年度供应链优化),除非主动停掉,否则一直运行。
- 前台接待组(MainScope) :负责门店前台的即时服务(如点单、结账),必须在前台营业时间内工作,打烊时全部停手。
- 后厨备餐组(ViewModelScope) :配合前台备餐,前台换班(ViewModel 销毁)时,未完成的备餐任务必须立刻停掉。
- 临时促销组(LifecycleScope) :负责门店外的临时促销,摊位撤掉(Activity/Fragment 销毁)时,促销活动马上终止。
这些部门本质上都是CoroutineScope,但因 “职责” 不同,它们的coroutineContext(核心配置)和 “生命周期触发条件” 不同。下面逐个拆解:
“协程奶茶连锁店” 生意火爆,总部为了高效管理,设立了 4 个核心部门,每个部门负责不同类型的任务,且有严格的 “上下班时间”(生命周期):
- 总公司长期项目组(GlobalScope) :负责跨门店的长期任务(如年度供应链优化),除非主动停掉,否则一直运行。
- 前台接待组(MainScope) :负责门店前台的即时服务(如点单、结账),必须在前台营业时间内工作,打烊时全部停手。
- 后厨备餐组(ViewModelScope) :配合前台备餐,前台换班(ViewModel 销毁)时,未完成的备餐任务必须立刻停掉。
- 临时促销组(LifecycleScope) :负责门店外的临时促销,摊位撤掉(Activity/Fragment 销毁)时,促销活动马上终止。
这些部门本质上都是CoroutineScope,但因 “职责” 不同,它们的coroutineContext(核心配置)和 “生命周期触发条件” 不同。下面逐个拆解:
一、总公司长期项目组:GlobalScope
部门特点:
- 任务周期长(可能跨多天),不受单个门店生命周期影响。
- 没有 “自动下班” 机制,必须手动终止,否则会一直运行(可能 “加班摸鱼” 导致资源浪费)。
- 任务周期长(可能跨多天),不受单个门店生命周期影响。
- 没有 “自动下班” 机制,必须手动终止,否则会一直运行(可能 “加班摸鱼” 导致资源浪费)。
代码里的 GlobalScope:
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
fun main() = runBlocking {
// 启动总公司的长期任务(优化供应链)
GlobalScope.launch {
repeat(10) { i -> // 模拟10天的任务
println("第${i+1}天:优化供应链中...")
delay(1000) // 每天做一点
}
}
// 模拟门店只观察3天就关门
delay(3500)
println("门店关门了,但总公司任务还在跑...")
}
运行结果:
第1天:优化供应链中...
第2天:优化供应链中...
第3天:优化供应链中...
门店关门了,但总公司任务还在跑...
第4天:优化供应链中...
// 即使主线程结束,任务仍在后台运行(直到JVM退出)
import kotlinx.coroutines.GlobalScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
fun main() = runBlocking {
// 启动总公司的长期任务(优化供应链)
GlobalScope.launch {
repeat(10) { i -> // 模拟10天的任务
println("第${i+1}天:优化供应链中...")
delay(1000) // 每天做一点
}
}
// 模拟门店只观察3天就关门
delay(3500)
println("门店关门了,但总公司任务还在跑...")
}
运行结果:
第1天:优化供应链中...
第2天:优化供应链中...
第3天:优化供应链中...
门店关门了,但总公司任务还在跑...
第4天:优化供应链中...
// 即使主线程结束,任务仍在后台运行(直到JVM退出)
实现原理:
GlobalScope的coroutineContext是固定的:
object GlobalScope : CoroutineScope {
override val coroutineContext: CoroutineContext
get() = Dispatchers.Default + SupervisorJob()
}
- Dispatcher.Default:默认在后台线程池执行(适合计算密集型任务)。
- SupervisorJob() :特殊的 “组长”,它的子任务失败不会影响其他子任务(比如某个门店的供应链优化失败,不影响其他门店),且没有父 Job(所以不会被其他 Scope 取消)。
GlobalScope的coroutineContext是固定的:
object GlobalScope : CoroutineScope {
override val coroutineContext: CoroutineContext
get() = Dispatchers.Default + SupervisorJob()
}
- Dispatcher.Default:默认在后台线程池执行(适合计算密集型任务)。
- SupervisorJob() :特殊的 “组长”,它的子任务失败不会影响其他子任务(比如某个门店的供应链优化失败,不影响其他门店),且没有父 Job(所以不会被其他 Scope 取消)。
为什么少用?
就像总公司的长期任务如果不手动停,会一直占用人力物力,GlobalScope启动的协程如果忘记取消,会导致内存泄漏(比如 Android 中 Activity 销毁后,协程还在访问已销毁的 View)。
就像总公司的长期任务如果不手动停,会一直占用人力物力,GlobalScope启动的协程如果忘记取消,会导致内存泄漏(比如 Android 中 Activity 销毁后,协程还在访问已销毁的 View)。
二、前台接待组:MainScope
部门特点:
- 只在前台营业时间工作(比如门店 9:00-21:00),负责和顾客直接交互(必须在主线程执行)。
- 打烊时(手动调用
cancel()),所有接待任务立刻停止。
- 只在前台营业时间工作(比如门店 9:00-21:00),负责和顾客直接交互(必须在主线程执行)。
- 打烊时(手动调用
cancel()),所有接待任务立刻停止。
代码里的 MainScope:
import kotlinx.coroutines.MainScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking {
// 创建前台接待组(指定在主线程工作)
val frontDeskScope = MainScope()
// 启动接待任务:点单、结账
frontDeskScope.launch {
println("开始点单(线程:${Thread.currentThread().name})")
delay(1000) // 模拟点单耗时
println("点单完成,开始结账")
}
// 模拟21:00打烊
delay(500)
println("前台打烊!停止所有接待任务")
frontDeskScope.cancel() // 手动取消
}
运行结果:
开始点单(线程:main) // 确保在主线程执行
前台打烊!停止所有接待任务
// 后续“结账”不会执行,因为被取消了
import kotlinx.coroutines.MainScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
import kotlinx.coroutines.runBlocking
fun main() = runBlocking {
// 创建前台接待组(指定在主线程工作)
val frontDeskScope = MainScope()
// 启动接待任务:点单、结账
frontDeskScope.launch {
println("开始点单(线程:${Thread.currentThread().name})")
delay(1000) // 模拟点单耗时
println("点单完成,开始结账")
}
// 模拟21:00打烊
delay(500)
println("前台打烊!停止所有接待任务")
frontDeskScope.cancel() // 手动取消
}
运行结果:
开始点单(线程:main) // 确保在主线程执行
前台打烊!停止所有接待任务
// 后续“结账”不会执行,因为被取消了
实现原理:
MainScope的coroutineContext是:
fun MainScope(): CoroutineScope = CoroutineScope(SupervisorJob() + Dispatchers.Main)
- Dispatchers.Main:强制在主线程执行(Android 中对应 UI 线程,确保能更新 UI)。
- SupervisorJob() :子任务失败不影响其他任务(比如一个顾客点单失败,不影响另一个顾客结账)。
- 手动取消:必须通过
scope.cancel()触发(比如 Android 中在onDestroy调用)。
MainScope的coroutineContext是:
fun MainScope(): CoroutineScope = CoroutineScope(SupervisorJob() + Dispatchers.Main)
- Dispatchers.Main:强制在主线程执行(Android 中对应 UI 线程,确保能更新 UI)。
- SupervisorJob() :子任务失败不影响其他任务(比如一个顾客点单失败,不影响另一个顾客结账)。
- 手动取消:必须通过
scope.cancel()触发(比如 Android 中在onDestroy调用)。
三、后厨备餐组:ViewModelScope
部门特点:
- 专门配合前台备餐,前台换班(ViewModel 被销毁)时,自动停止所有备餐任务(避免 “给已走的顾客做奶茶”)。
- 专门配合前台备餐,前台换班(ViewModel 被销毁)时,自动停止所有备餐任务(避免 “给已走的顾客做奶茶”)。
代码里的 ViewModelScope(Android 场景):
import androidx.lifecycle.ViewModel
import androidx.lifecycle.viewModelScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
class TeaViewModel : ViewModel() {
fun startPrepareTea() {
// 后厨备餐任务(自动绑定ViewModel生命周期)
viewModelScope.launch {
println("开始备餐:煮珍珠...")
delay(2000) // 模拟备餐耗时
println("备餐完成!")
}
}
// ViewModel销毁时(如Activity.finish),系统自动调用
override fun onCleared() {
super.onCleared()
println("前台换班,后厨停止备餐")
}
}
import androidx.lifecycle.ViewModel
import androidx.lifecycle.viewModelScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
class TeaViewModel : ViewModel() {
fun startPrepareTea() {
// 后厨备餐任务(自动绑定ViewModel生命周期)
viewModelScope.launch {
println("开始备餐:煮珍珠...")
delay(2000) // 模拟备餐耗时
println("备餐完成!")
}
}
// ViewModel销毁时(如Activity.finish),系统自动调用
override fun onCleared() {
super.onCleared()
println("前台换班,后厨停止备餐")
}
}
实现原理:
viewModelScope是 ViewModel 的扩展属性,其coroutineContext为:
val ViewModel.viewModelScope: CoroutineScope
get() = CoroutineScope(ViewModelCoroutineScope.DispatcherProvider.main + job)
- Dispatcher.Main:默认在主线程(也可指定其他线程)。
- 内部 Job:和 ViewModel 绑定,当 ViewModel 的
onCleared()被调用时,这个 Job 会自动cancel(),所有子协程随之终止。
viewModelScope是 ViewModel 的扩展属性,其coroutineContext为:
val ViewModel.viewModelScope: CoroutineScope
get() = CoroutineScope(ViewModelCoroutineScope.DispatcherProvider.main + job)
- Dispatcher.Main:默认在主线程(也可指定其他线程)。
- 内部 Job:和 ViewModel 绑定,当 ViewModel 的
onCleared()被调用时,这个 Job 会自动cancel(),所有子协程随之终止。
四、临时促销组:LifecycleScope
部门特点:
- 在门店外的临时摊位工作,摊位撤掉(Activity/Fragment 销毁)时,自动停止所有促销活动。
- 在门店外的临时摊位工作,摊位撤掉(Activity/Fragment 销毁)时,自动停止所有促销活动。
代码里的 LifecycleScope(Android 场景):
import androidx.fragment.app.Fragment
import androidx.lifecycle.lifecycleScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
class PromotionFragment : Fragment() {
override fun onStart() {
super.onStart()
// 临时促销任务(自动绑定Fragment生命周期)
lifecycleScope.launch {
println("开始促销:发传单...")
delay(3000) // 模拟促销耗时
println("促销结束!")
}
}
// Fragment销毁时,系统自动触发
override fun onDestroy() {
super.onDestroy()
println("摊位撤掉,促销停止")
}
}
import androidx.fragment.app.Fragment
import androidx.lifecycle.lifecycleScope
import kotlinx.coroutines.delay
import kotlinx.coroutines.launch
class PromotionFragment : Fragment() {
override fun onStart() {
super.onStart()
// 临时促销任务(自动绑定Fragment生命周期)
lifecycleScope.launch {
println("开始促销:发传单...")
delay(3000) // 模拟促销耗时
println("促销结束!")
}
}
// Fragment销毁时,系统自动触发
override fun onDestroy() {
super.onDestroy()
println("摊位撤掉,促销停止")
}
}
实现原理:
lifecycleScope是LifecycleOwner(如 Activity/Fragment)的扩展属性,其coroutineContext为:
val LifecycleOwner.lifecycleScope: CoroutineScope
get() = lifecycle.coroutineScope
- 内部关联
Lifecycle,当生命周期走到ON_DESTROY时,自动调用cancel()。 - 默认使用
Dispatchers.Main,确保能更新 UI(如更新促销进度)。
lifecycleScope是LifecycleOwner(如 Activity/Fragment)的扩展属性,其coroutineContext为:
val LifecycleOwner.lifecycleScope: CoroutineScope
get() = lifecycle.coroutineScope
- 内部关联
Lifecycle,当生命周期走到ON_DESTROY时,自动调用cancel()。 - 默认使用
Dispatchers.Main,确保能更新 UI(如更新促销进度)。
五、各 Scope 的生命周期时序图
1. GlobalScope 时序图(无自动取消)
┌───────────┐ ┌─────────────┐ ┌───────────┐
│ 用户代码 │ │ GlobalScope │ │ 子协程 │
└─────┬─────┘ └───────┬─────┘ └─────┬─────┘
│ │ │
│ launch协程 │ │
├───────────────────>│ │
│ │ 启动子协程 │
│ ├─────────────────>│
│ │ │ 执行中...
│ │ │<─────┐
│ (无自动取消) │ │ │
│ │ │ │
│ (需手动cancel) │ │ │
│ (否则一直运行) │ │ │
┌───────────┐ ┌─────────────┐ ┌───────────┐
│ 用户代码 │ │ GlobalScope │ │ 子协程 │
└─────┬─────┘ └───────┬─────┘ └─────┬─────┘
│ │ │
│ launch协程 │ │
├───────────────────>│ │
│ │ 启动子协程 │
│ ├─────────────────>│
│ │ │ 执行中...
│ │ │<─────┐
│ (无自动取消) │ │ │
│ │ │ │
│ (需手动cancel) │ │ │
│ (否则一直运行) │ │ │
2. ViewModelScope 时序图(ViewModel 销毁时取消)
┌─────────────┐ ┌────────────────┐ ┌───────────┐
│ ViewModel │ │ ViewModelScope │ │ 子协程 │
└───────┬─────┘ └───────┬────────┘ └─────┬─────┘
│ │ │
│ 初始化scope │ │
├───────────────────>│ │
│ │ │
│ launch协程 │ │
├───────────────────>│ │
│ │ 启动子协程 │
│ ├────────────────────>│
│ │ │ 执行中...
│ │ │
│ onCleared()触发 │ │
├───────────────────>│ │
│ │ 调用Job.cancel() │
│ ├────────────────────>│
│ │ │ 终止执行
│ │ │<─────┐
┌─────────────┐ ┌────────────────┐ ┌───────────┐
│ ViewModel │ │ ViewModelScope │ │ 子协程 │
└───────┬─────┘ └───────┬────────┘ └─────┬─────┘
│ │ │
│ 初始化scope │ │
├───────────────────>│ │
│ │ │
│ launch协程 │ │
├───────────────────>│ │
│ │ 启动子协程 │
│ ├────────────────────>│
│ │ │ 执行中...
│ │ │
│ onCleared()触发 │ │
├───────────────────>│ │
│ │ 调用Job.cancel() │
│ ├────────────────────>│
│ │ │ 终止执行
│ │ │<─────┐
3. LifecycleScope 时序图(ON_DESTROY 时取消)
┌─────────────┐ ┌────────────────┐ ┌───────────┐
│ Activity │ │ LifecycleScope │ │ 子协程 │
└───────┬─────┘ └───────┬────────┘ └─────┘─────┘
│ │ │
│ 初始化scope │ │
├───────────────────>│ │
│ │ │
│ launch协程 │ │
├───────────────────>│ │
│ │ 启动子协程 │
│ ├────────────────────>│
│ │ │ 执行中...
│ │ │
│ 生命周期到ON_DESTROY│ │
├───────────────────>│ │
│ │ 调用Job.cancel() │
│ ├────────────────────>│
│ │ │ 终止执行
│ │ │<─────┐
┌─────────────┐ ┌────────────────┐ ┌───────────┐
│ Activity │ │ LifecycleScope │ │ 子协程 │
└───────┬─────┘ └───────┬────────┘ └─────┘─────┘
│ │ │
│ 初始化scope │ │
├───────────────────>│ │
│ │ │
│ launch协程 │ │
├───────────────────>│ │
│ │ 启动子协程 │
│ ├────────────────────>│
│ │ │ 执行中...
│ │ │
│ 生命周期到ON_DESTROY│ │
├───────────────────>│ │
│ │ 调用Job.cancel() │
│ ├────────────────────>│
│ │ │ 终止执行
│ │ │<─────┐
总结:选对 Scope,就像找对部门
Scope 类型 生命周期绑定 核心配置(coroutineContext) 适用场景 GlobalScope 无(需手动取消) Dispatchers.Default + SupervisorJob 跨组件的长期任务(谨慎使用) MainScope 手动控制 Dispatchers.Main + SupervisorJob 顶层 UI 组件(如 Application) ViewModelScope ViewModel.onCleared Dispatchers.Main + 内部 Job 配合 ViewModel 的备餐 / 数据请求 LifecycleScope Activity/Fragment 销毁 Dispatchers.Main + Lifecycle 关联 Job 临时 UI 任务(如促销、弹窗倒计时)
记住:Scope 的本质是给协程找个 “归属”,让协程在合适的时间开始,在该结束的时候乖乖结束,避免 “野协程” 捣乱~
作者:Android童话镇
来源:juejin.cn/post/7563197374418157604
| Scope 类型 | 生命周期绑定 | 核心配置(coroutineContext) | 适用场景 |
|---|---|---|---|
| GlobalScope | 无(需手动取消) | Dispatchers.Default + SupervisorJob | 跨组件的长期任务(谨慎使用) |
| MainScope | 手动控制 | Dispatchers.Main + SupervisorJob | 顶层 UI 组件(如 Application) |
| ViewModelScope | ViewModel.onCleared | Dispatchers.Main + 内部 Job | 配合 ViewModel 的备餐 / 数据请求 |
| LifecycleScope | Activity/Fragment 销毁 | Dispatchers.Main + Lifecycle 关联 Job | 临时 UI 任务(如促销、弹窗倒计时) |
记住:Scope 的本质是给协程找个 “归属”,让协程在合适的时间开始,在该结束的时候乖乖结束,避免 “野协程” 捣乱~
来源:juejin.cn/post/7563197374418157604
或许,找对象真的太难了……
找对象真的太难了,我不由地发出这个感慨
但其实说着也奇怪,明明我每天两点一线,上班了去工位、下班了回宿舍,根本没有其他社交,但我为什么会发出这样的感慨呢?
- 是因为总是在无聊时感到了孤独才希望有个伴,还是看见大家都有伴了才觉得自己孤独?
- 是因为看到了别人功成名就家庭和谐的嫉妒,还是吊儿郎当无所事事地调侃?
- 是因为信息茧房导致我对婚姻产生了偏见而刻意疏远,还是无能狂怒般自卑不敢去尝试?
- ……
如果是针对我个人的话,那应该是自卑了吧。这辈子30多年没什么情感经历,就只有一次相亲后“交往”的经验。那次相亲后异地聊了9个月,中间节假日只有我回去见了3次面,没有矛盾,每天都在线上花个两三个小时也都聊得很开心,但我却总觉得彼此都像个不熟的人,以至于最后“分手”时内心也毫无波澜。
“或许我根本不需要为了找个伴才选择想找对象吧。”我总是这样安慰自己,其实安慰的次数不多,因为我没有经常想。
我每天两点一线的生活很规律,很轻松,最重要的是,我已经非常习惯了。所以从某种程度来讲,“客观上”,我并没有真的想找对象、也没有主动去尝试结交新朋友,“主观上”,现在的社会风向和经济形势,不太利于我尝试告别单身,即便 A 股沪指最近持续性突破十年新高。
光是想,不去做,那可不就是“太难了”。
其实,有那么一瞬间我也想结婚
可怜的是,这并不是基于我个人的想法,而是外界的干扰。我记得我31岁生日那天,凌晨6点过还在睡梦中,外公外婆就打来电话,祝我生日快乐。我很诧异,因为我没想到农忙时节呢,他们还没忙忘了,也因为居然这么早,鸡鸭才刚叫。然后一如既往地说:不要太节约了,吃点好的,照顾好自己……然后,快点找对象,天天瞌睡都睡不好,揪心得很哦。结了婚他们就放心了,不然他们死了都不安心哦。
或许80多岁的老人家觉得,任何事情,只要你想要,那就能发生。我想要天上掉金子,天上就会掉金子;我想要地里喷石油,地里就会喷石油;我想要找对象,自然就有对象……
我倒是习以为常了,只不过那一整天,就没有第二个人祝我生日快乐了。不管是朋友同事,还是父母亲戚,即便是早我一天过生日、而我在生日前一天给她发去生日祝福的堂姐,都没有。
其实我也是习以为常了,可能因为我的生日也是我爷爷的忌日,我总是刻意淡忘它,大部分时候过生日我自己都会忘记,10岁之后就没有任何一次庆祝生日的行为——10岁那年父母要都外出打工,自此再次成为留守儿童。
但今年有那么一瞬间,突然觉得难得只有两个80多岁的老人还记得我生日,一直让他们失望有点于心不忍,更何况,正常来讲,我还能“忤逆”他们多少年呢?
可惜的是,就和那些贩卖焦虑的短视频、营销号一样,总是提出问题、夸大问题、制造矛盾、激化矛盾,但从来不会提供解决方法一样:想结婚了,然后呢?
独身一人在无聊的时候确实是无聊的
最近不知道是上班天天盯着电脑看久了,还是下班游戏玩多了,眼睛特别酸痛,于是我难得的又在下班之后出去逛了逛。
正常的话吃了饭我就玩游戏了,先玩几把NBA 2K,再玩几把英雄联盟手游,再玩几把王者荣耀。
其实曾几何时,我从生理上都厌恶王者荣耀的,因为它把很多中国历史人物文化名人,搞成游戏中乱七八糟的角色,让我无法接受。以至于这么多年来,从同学同事、到堂表兄弟等,都没有机会跟我一起玩。
我也没想到我居然突然之间就接受了,即便这曾经让我生理上讨厌的东西。我记得很清楚,2025年7月2日,我新历生日那天,我下载了王者荣耀,建立了账号,开始游玩,持续十几天有空就一直在玩,一百来把、十几级的账号打到最低等级的王者段位,觉得差不多入门了,想着和老同学、老朋友、老同事们一起玩时,才发现他们都不上线了。或许,随着年龄的增长,这种“年轻时的生理厌恶”都敌不过“无聊时的孤单寂寞”。
所以每次当我一个人出去小道散步闲逛消磨时间时,总会特别在意那些跑步锻炼身体的人、散步话家常的两公婆、坐在摊位小车后面玩手机的摆摊老板……感觉他们都有目的地在做什么,而只有我在漫无目的地走着。
其实这条路我之前走过,至少在我今年生日之前,只不过那个时候,这马路边的行人道,没有这么多杂草、灌木。就像人生路,总是在回忆的时候,才觉得曾经如此宽阔,才懊悔当时未曾踏入。可是,时光一直向前流逝,回忆永远迭代更新。

可能现在生活没有达到预期的我们总是有这样的想法,要是能回到过去就好了。实际上只是想带着现在的记忆回到过去,去弥补一些错过或者错误。似乎真像有多元宇宙,回到过去之后会有新的时间线,补足那些遗憾,每一次的回溯,终究会得到一条完美符合心意的时间线。实际上我觉得,即便我们能回到过去,那也是会失去所有记忆,然后完完整整重复之前做过的事情,又一次的错过或者错误,不会有多条时间线,即便你回去再多次,都只会重复同样的事情,都只是同一条时间线。但只有这一条时间线,其实也就够了。
正因为消极,所以才乐观
其实我一直是希望传播积极乐观心态的,从我以往的文章总能看到有这样的痕迹。但就像那些奢侈品广告一样:你买得起不重要,你买不起才重要。
就像我当年创业板3600多点最高峰买入了很多和创业板强关联基金一样,那时总觉得中国经济一定是蒸蒸日上,最后一路跌倒了1500点,一点点割肉,最后全盘清掉,赔了一些钱,然后不敢再入场。所以我也没赶上或者说是错过了今年大半年的牛市,有点难受。与之相对的,为了求稳买入了大量的债券,却债市正熊,又套在手里,更难受了。
可能这都不是什么大事,毕竟只是对我造成了一些经济损失,并不会影响到我的一如既往平凡普通的物质生活;但是焦虑、担忧、烦闷的心态,却非常影响我的精神状态,严重损坏我本就低迷的精神生活。
我一直有个想法,希望尽量在35岁前能多攒一些钱,这样如果35岁之后某天丢了工作,我就徒步去环游中国。并不是他们那种雄心壮志地环游,什么“朝圣“”啊、“远离浮躁净化心灵”啊。就跟平时一样,大街小巷,散步流浪,随便走走看看,不过变成了走到哪里黑,就到哪里歇。等到钱花光了,人老了走不动,客死他乡,也算得偿所愿了。
如果真的能到这个时候,身后没有拖拽、肩上没有负担,该是多么舒服的境况。
发现了吗,其实我就是这么矛盾,一方面安慰自己钱财乃身外物,不必强求;另一方面又觉得钱财乃必需品,多多益善。原因非常简单,因为我缺这东西,所以看得很重;又因为没本事挣到更多,所以才安慰自己它不重要。
这就是别人说的,看清问题根源比无法解决问题更让人窒息,也就是“无知是福”或者”无知者无畏”的感悟了。
每个人都应该有自己的活法,即便大同小异
正如写代码的人,总是会重复造轮子,偶尔还会乐此不疲。世上的人这么多,大部分的人的都是千篇一律的,事实上,大家都在做的事情,说不定才是对的。大家都重复着读书、工作、结婚、生子、工作、退休、等死的生活,正是因为在和平年代这就是一个非常典型且应该让人轻松愉悦、容易接受的平凡人的人生。
同样功能、完全适配你项目的工具包,一个周下载几百万、上次更新1个月前,一个周下载几十、上次更新5年前,只考虑下载使用的话,你会怎么选呢?
就像正因为他是魔丸才敢高喊“我命由我不由天”,就像有人说对钱不感兴趣;也就像也有人觉得“奋斗用多大劲啊?”就像我以为“忠诚的不绝对就是绝对的不忠诚”只是一个战锤40K的梗而已……这个世界本来就因为科技发展而不断更新,止不住的时代洪流,纷纷扰扰的世界,何必太关注别人关心的事情,兜兜转转可能发现,你特别在意的东西别人根本没放在心上,你漫不经心地言语却刺穿了别人的心脏。所有的一切,在心脏停止跳动之前,其实都无关紧要;而在心脏停止跳动之后,更是毫无意义。
所以我平时有空的时候,也会更新一下我 Github 仓库中几个开源的小项目,虽然没什么技术含量,还借助了很多AI辅助编码,但我在写完测试完成之后的那一刻感觉很舒服,就算之后很久都没再更新、测试,还发现了bug,但那完成时的一瞬间很舒服,就成了我持续不断更新的主观能动性之一。
人总有一死,我一直强调不要太在意他人的眼光,为自己而生活。但如果你根本不知道自己想要过什么样的人生,那么从众并不是什么丢人的行为。 人生短暂,不值得斤斤计较,浪费也是它应该存在的过程片段。
坐在厂门口的女子
我今天出去散步的时候,经过了隔壁厂,恰巧看到一位女士蹲在门口马路牙子上,左手拿着装炸土豆片套着塑料袋的小盒子,右手拿着手机看小说。我在外面溜达了个把小时,回去的时候发现她还蹲着那马路牙子上,可能是同一个位置,只不过只有右手拿着手机继续看着小说。
但我猜测她“可能”并没有一直蹲着那里看小说,因为那装炸土豆片的小纸盒没有在她左手上继续拿着,也没有放在她的身旁……
为什么只是“猜测和可能”呢?谁知道呢,或许她站起来走几步丢到垃圾桶后又蹲回去了,或许只是她吃完了空纸盒子放在旁边被风吹走了;或许她没吃完揉吧揉吧纸盒子随手丢到马路对面去了,又或许甚至可能她变身奥特曼打走了怪兽又变回正常人继续在厂门口看小说了……
如果不是因为间隔这么久,看见她还呆在同一个位置,我可能根本就没在意。就像如果不是出来工作了10年依旧还在原地,我也不必过度“揣摩自己”。
可能因为总是太在意,所以才觉得一切都太难了…… 毕竟“得不到的永远在骚动……”
很难了,一个陌生人有两次遇到的机会。
多数情况下都只有一次机会。换成是我,如果我一开始也是蹲在厂门口的马路牙子上,估计没人会注意到。但我要是一开始就跪在厂门口不停在磕头,说不定就有人会注意到了……
结尾
哈哈,Gotcha!要不是我这几天玩游戏多了眼睛有点酸痛,需要休息一下,我才不会在这里长篇大论无病呻吟呢,都这么久没有更新了是吧,那我玩游戏看视频啥的时可是乐在其中、忘乎所以的,佝偻成一团都还在哈哈大笑呢。
所以,赶紧去做那些让你自己开心的事情吧,享受生活,这才是我们活着的原因之一,其他的事情,fxxk off。
来源:juejin.cn/post/7544259368277852175
我们来说一说什么是联合索引最左匹配原则?
什么是联合索引?
首先,要理解最左匹配原则,得先知道什么是联合索引。
- 单列索引:只针对一个表列创建的索引。例如,为 users 表的 name 字段创建一个索引。
- 联合索引:也叫复合索引,是针对多个表列创建的索引。例如,为 users 表的 (last_name, first_name) 两个字段创建一个联合索引。
这个索引的结构可以想象成类似于电话簿或字典。电话簿是先按姓氏排序,在姓氏相同的情况下,再按名字排序。你无法直接跳过姓氏,快速找到一个特定的名字。
什么是最左匹配原则?
最左匹配原则指的是:在使用联合索引进行查询时,MySQL/SQL数据库从索引的最左前列开始,并且不能跳过中间的列,一直向右匹配,直到遇到范围查询(>、<、BETWEEN、LIKE)就会停止匹配。
这个原则决定了你的 SQL 查询语句是否能够使用以及如何高效地使用这个联合索引。
核心要点:
- 从左到右:索引的使用必须从最左边的列开始。
- 不能跳过:不能跳过联合索引中的某个列去使用后面的列。
- 范围查询右停止:如果某一列使用了范围查询,那么它右边的列将无法使用索引进行进一步筛选。
举例说明
假设我们有一个 users 表,并创建了一个联合索引 idx_name_age,包含 (last_name, age) 两个字段。
| id | last_name | first_name | age | city |
| 1 | Wang | Lei | 20 | Beijing |
| 2 | Zhang | Wei | 25 | Shanghai |
| 3 | Wang | Fang | 22 | Guangzhou |
| 4 | Li | Na | 30 | Shenzhen |
| 5 | Zhang | San | 28 | Beijing |
索引 idx_name_age 在磁盘上大致是这样排序的(先按 last_name 排序,last_name 相同再按 age 排序):
(Li, 30) (Wang, 20) (Wang, 22) (Zhang, 25) (Zhang, 28)
现在,我们来看不同的查询场景:
✅ 场景一:完全匹配最左列
SELECT * FROM users WHERE last_name = 'Wang';
- 分析:查询条件包含了索引的最左列 last_name。
- 索引使用情况:✅ 可以使用索引。数据库可以快速在索引树中找到所有 last_name = 'Wang' 的记录((Wang, 20) 和 (Wang, 22))。
✅ 场景二:匹配所有列
SELECT * FROM users WHERE last_name = 'Wang' AND age = 22;
- 分析:查询条件包含了索引的所有列,并且顺序与索引定义一致。
- 索引使用情况:✅ 可以高效使用索引。数据库先定位到 last_name = 'Wang',然后在这些结果中快速找到 age = 22 的记录。
✅ 场景三:匹配最左连续列
SELECT * FROM users WHERE last_name = 'Zhang';
- 分析:虽然只用了 last_name,但它是索引的最左列。
- 索引使用情况:✅ 可以使用索引。和场景一类似。
❌ 场景四:跳过最左列
SELECT * FROM users WHERE age = 25;
- 分析:查询条件没有包含索引的最左列 last_name。
- 索引使用情况:❌ 无法使用索引。这就像让你在电话簿里直接找所有叫“伟”的人,你必须翻遍整个电话簿,也就是全表扫描。
⚠️ 场景五:包含最左列,但中间有断档
-- 假设我们有一个三个字段的索引 (col1, col2, col3) -- 查询条件为 WHERE col1 = 'a' AND col3 = 'c';
- 分析:虽然包含了最左列 col1,但跳过了 col2 直接查询 col3。
- 索引使用情况:✅ 部分使用索引。数据库只能使用 col1 来缩小范围,找到所有 col1 = 'a' 的记录。对于 col3 的过滤,它无法利用索引,需要在第一步的结果集中进行逐行筛选。
⚠️ 场景六:最左列是范围查询
SELECT * FROM users WHERE last_name > 'Li' AND age = 25;
- 分析:最左列 last_name 使用了范围查询 >。
- 索引使用情况:✅ 部分使用索引。数据库可以使用索引找到所有 last_name > 'Li' 的记录(即从 Wang 开始往后的所有记录)。但是,对于 age = 25 这个条件,由于 last_name 已经是范围匹配,age 列在索引中是无序的,因此数据库无法再利用索引对 age 进行快速筛选,只能在 last_name > 'Li' 的结果集中逐行检查 age。
总结与最佳实践
最左匹配原则的本质是由索引的数据结构(B+Tree) 决定的。索引按照定义的字段顺序构建,所以必须从最左边开始才能利用其有序性。
如何设计好的联合索引?
- 高频查询优先:将最常用于 WHERE 子句的列放在最左边。
- 等值查询优先:将经常进行等值查询(=)的列放在范围查询(>, <, LIKE)的列左边。
- 覆盖索引:如果查询的所有字段都包含在索引中(即覆盖索引),即使不符合最左前缀,数据库也可能直接扫描索引来避免回表,但这通常发生在二级索引扫描中,效率依然不如最左匹配。
来源:juejin.cn/post/7565940210148868148
掌握协程的边界与环境:CoroutineScope 与 CoroutineContext
CoroutineScope 与 CoroutineContext 的概念
CoroutineContext (协程上下文)
CoroutineContext 是协程上下文,包含了协程运行时所需的所有信息。
比如:
- 管理协程流程(生命周期)的
Job。 - 管理线程的
ContinuationInterceptor,它的实现类CoroutineDispatcher决定了协程所运行的线程或线程池。
CoroutineScope (协程作用域)
CoroutineScope 是协程作用域,它通过 coroutineContext 属性持有了当前协程代码块的上下文信息。
比如,我们可以获取 Job 和 ContinuationInterceptor 对象:
fun main() = runBlocking<Unit> {
val scope = CoroutineScope(EmptyCoroutineContext) // scope 并没有持有已有协程的上下文
val outerJob = scope.launch {
val innerJob = coroutineContext[Job]
val interceptor = coroutineContext[ContinuationInterceptor]
println("job: $innerJob, interceptor: $interceptor")
}
outerJob.join()
}
CoroutineScope 的另一个作用就是提供了 launch 和 async 协程构建器,我们可以通过它来启动一个协程。
这样,新创建的协程能够自动继承 CoroutineScope 的 coroutineContext。比如利用 Job,可以建立起父子关系,从而实现结构化并发。
GlobalScope
GlobalScope 是一个单例的 CoroutineScope 对象,所以我们在任何地方通过它来启动协程。
它的第二个特点是,它的 coroutineContext 属性是 EmptyCoroutineContext,也就是说它没有内置的 Job。
@DelicateCoroutinesApi
public object GlobalScope : CoroutineScope {
/**
* Returns [EmptyCoroutineContext].
*/
override val coroutineContext: CoroutineContext
get() = EmptyCoroutineContext
}
即使是我们手动创建的 CoroutineScope,其内部也是有 Job 的。
// 手动创建 CoroutineScope
CoroutineScope(EmptyCoroutineContext)
// CoroutineScope.kt
@Suppress("FunctionName")
public fun CoroutineScope(context: CoroutineContext): CoroutineScope =
ContextScope(if (context[Job] != null) context else context + Job()) // 自动创建Job对象
所以我们在 GlobalScope.coroutineContext 中是获取不到 Job 的:
@OptIn(DelicateCoroutinesApi::class)
fun main() = runBlocking<Unit> {
val job: Job? = GlobalScope.coroutineContext[Job]
if (job == null) {
println("job is null")
}
try {
val jobNotNull: Job = GlobalScope.coroutineContext.job
} catch (e: IllegalStateException) {
println("job is null, exception is: $e")
}
}
运行结果:
job is null
job is null, exception is: java.lang.IllegalStateException: Current context doesn't contain Job in it: EmptyCoroutineContext
那么,这有什么用吗?
其实,GlobalScope 所启动的协程没有父 Job。
这就意味着:
- 当前协程不和其他
Job的生命周期绑定,比如不会随着某个界面的关闭而自动取消。 - 它是顶级协程,生命周期默认为整个应用的生命周期。
- 它发生异常,并不会影响到其他协程和
GlobalScope。反之,GlobalScope本身也无法级联取消所有任务,因为它所启动的协程是完全独立的。
总结:GlobalScope 就是用来启动那些不与组件生命周期绑定,而是与整个应用生命周期保持一致的全局任务,比如一个日志上报任务。
关键在使用时,可能会有资源泄露的风险,需要正确管理好协程的生命周期。
Context 的三个实用工具
在挂起函数中获取 CoroutineContext
如果我们要在一个挂起函数中获取 CoroutineContext,我们不得不给将其作为 CoroutineScope 的扩展函数。
suspend fun CoroutineScope.printContinuationInterceptor() {
delay(1000)
val interceptor = coroutineContext[ContinuationInterceptor]
println("interceptor: $interceptor")
}
但我们知道挂起函数的外部一定有协程存在,所以是存在 CoroutineContext 的。为此,Kotlin 协程库提供了一个顶层的 coroutineContext 属性,这个属性的 get() 函数是一个挂起函数,它能在任何挂起函数中访问到当前正在执行的协程的 CoroutineContext。
import kotlin.coroutines.coroutineContext
suspend fun printContinuationInterceptor() {
delay(1000)
val interceptor = coroutineContext[ContinuationInterceptor]
println("interceptor: $interceptor")
}
另外,还有一个 currentCoroutineContext() 函数也能获取到 CoroutineContext,它内部实现也是 coroutineContext 属性。
为什么需要这个函数?
为了解决命名冲突,比如下面这段代码。
private fun mySuspendFun() {
flow<String> {
// 顶层属性
coroutineContext
}
GlobalScope.launch {
flow<String> {
// this 的成员属性优先级高于顶层属性
// 所以是外层 launch 的 CoroutineScope 的成员属性 coroutineContext
coroutineContext
}
}
}
在这种情况下,如果需要明确属性的源头,就需要使用 currentCoroutineContext() 函数,它会调用到那个顶层的属性。
CoroutineName 协程命名
CoroutineName 是一个协程上下文信息,我们可以使用它来给协程设置一个名称。
fun main() = runBlocking<Unit> {
val scope = CoroutineScope(EmptyCoroutineContext)
val name = CoroutineName("coroutine-1")
val job = scope.launch(name) {
val coroutineName = coroutineContext[CoroutineName]
println("current coroutine name: $coroutineName")
}
job.join()
}
运行结果:
current coroutine name: CoroutineName(coroutine-1)
它主要用于测试和调试,你可以使用它来区分哪些日志是哪个协程打印的。
自定义 CoroutineContext
如果我们要给协程附加一些功能,我们可以考虑自定义 CoroutineContext。
如果是简单的标记,可以优先考虑使用
CoroutineName。
自定义 CoroutineContext 需要实现 CoroutineContext.Element,并且提供 Key。为此,Kotlin 协程库提供了 AbstractCoroutineContextElement 来简化这个过程。我们只需这样,即可创建一个用于协程内部记录日志的 Context:
// 继承 AbstractCoroutineContextElement,并把 Key 传给父构造函数
class CoroutineLogger(val tag: String) : AbstractCoroutineContextElement(CoroutineLogger) {
// 声明专属的 Key
companion object Key : CoroutineContext.Key<CoroutineLogger>
// 添加专属功能
fun log(message: String) {
println("[$tag] $message")
}
}
使用示例:
fun main() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
val job = scope.launch(CoroutineLogger("Test")) {
val logger = coroutineContext[CoroutineLogger]
logger?.log("Start")
delay(5000)
logger?.log("End")
}
job.join()
}
运行结果:
[Test] Start
[Test] End
coroutineScope() 与 withContext()
coroutineScope 串行的异常封装器
coroutineScope 是一个挂起函数,它会挂起当前协程,直到执行完内部的所有代码(包括会等待内部启动的所有子协程执行完毕),最后一行代码的执行结果会作为函数的返回值。
coroutineScope 会创建一个新的 CoroutineScope,在这个作用域中执行 block 代码块。并且这个作用域严格继承了父上下文(coroutineContext),并会在内部创建一个新的 Job,作为父 Job 的子 Job。
coroutineScope从效果上来看,和launch().join()类似。
那么,它的应用场景是什么?
它的应用场景由它的特性决定,有两个核心场景:
- 在挂起函数中提供
CoroutineScope。(最常用)
suspend fun CoroutineScope.mySuspendFunction() {
delay(1000)
launch {
println("launch")
}
}
如果你要在挂起函数中启动一个新的协程,你只好将其定义为
CoroutineScope的扩展函数。不过,你也可以使用coroutineScope来提供作用域。
它能提供作用域,是因为挂起函数的外部一定存在着协程,所以一定具有
CoroutineScope。
suspend fun doConcurrentWork() {
val startTime = System.currentTimeMillis()
coroutineScope {
val task1 = async { // 任务1
delay(5000)
}
val task2 = async { // 任务2
delay(3000)
}
} // // 挂起,直到上面两个 async 都完成
val endTime = System.currentTimeMillis()
println("Total execution time: ${endTime - startTime}") // 5000 左右
}
- 业务逻辑封装并进行异常处理。(最重要)
我们都知道,我们无法在协程外部使用
try-catch捕获协程内部的异常。
但使用
coroutineScope函数可以,当它内部的任何子协程失败了,它会将这个异常重新抛出来,这时我们可以使用try-catch来捕获。
fun main() = runBlocking<Unit> {
try {
coroutineScope {
val data1 = async {
"user-1"
}
val data2 = async {
throw IllegalStateException("error")
}
awaitAll(data1, data2)
}
} catch (e: Exception) {
println("exception is: $e")
}
}
运行结果:
exception is: java.lang.IllegalStateException: error
原因也很简单,因为它是一个串行的挂起函数,外部协程会被挂起,直到它执行完毕。如果它的内部出现了异常,外部协程是能够知晓的。
coroutineScope可以将并发的崩溃变为可被捕获、处理的异常,常用于处理并发错误。
withContext 串行的上下文切换器
我们再来看 withContext,其实它和 coroutineScope 几乎一样。
它也是一个串行的挂起函数,也会返回代码块的结果,内部也是启动了一个新的协程。
它和 coroutineScope 的唯一的不同是,withContext 允许我们传递上下文。你也可以这么想,coroutineScope 就是一个不改变任何上下文的 withContext:
withContext(EmptyCoroutineContext) { // 沿用旧的 CoroutineContext
}
withContext(coroutineContext) { // 使用旧的 CoroutineContext
}
而 withContext 的使用场景就很清楚了,我们需要切换上下文的时候会使用它,并且希望代码是串行执行的,之后还能再切回原来的线程继续往下执行。
虽然
withContext与coroutineScope类似,但coroutineScope更多用于封装业务异常。
suspend fun getUserProfile() {
// 当前在 Dispatchers.Main
val profile = withContext(Dispatchers.IO) {
// 自动切换到 IO 线程
Thread.sleep(3000) // 耗时操作
"the user profile"
}
// 自动切回 Dispatchers.Main
println("the user profile is $profile")
}
CoroutineContext 的加、取操作
加法:合并与替换
两个 CoroutineContext 相加调用的是 plus()。
public operator fun plus(context: CoroutineContext): CoroutineContext =
if (context === EmptyCoroutineContext) this else // fast path -- avoid lambda creation
context.fold(this) { acc, element ->
val removed = acc.minusKey(element.key)
if (removed === EmptyCoroutineContext) element else {
// make sure interceptor is always last in the context (and thus is fast to get when present)
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
其中关键在于 CombinedContext,它是 CoroutineContext 的实现类:
// CoroutineContextImpl.kt
@SinceKotlin("1.3")
internal class CombinedContext(
private val left: CoroutineContext,
private val element: Element // Element 也是 `CoroutineContext` 的实现类
) : CoroutineContext, Serializable
它会将操作符两边的上下文使用 CombinedContext 对象包裹(合并),如果两个上下文具有相同的 Key,加号右侧的会替换左侧的。
比如 Dispatchers.IO + Job() + CoroutineName("my-name") 一共会进行三次合并,得到三个 CombinedContext 对象,不会进行替换。
fun main() = runBlocking<Unit> {
val handler = CoroutineExceptionHandler { _, throwable ->
println("Caught $throwable")
}
val job =
launch(Dispatchers.IO + Job() + CoroutineName("my-name") + handler) {
println(coroutineContext)
}
job.join()
}
运行结果:
[CoroutineName(my-name), com.example.coroutinetest.TestKtKt$main$1$invokeSuspend$$inlined$CoroutineExceptionHandler$1@6667fe3b, StandaloneCoroutine{Active}@26b2b4fd, Dispatchers.IO]
如果在末尾再加上一个 CoroutineName("your_name"),会进行一次替换,运行结果是:[com.example.coroutinetest.TestKtKt$main$1$invokeSuspend$$inlined$CoroutineExceptionHandler$1@6667fe3b, CoroutineName(your_name), StandaloneCoroutine{Active}@26b2b4fd, Dispatchers.IO]
[] 取值
[] 取值其实调用的是 CoroutineContext.get() 函数,它会从上下文(CombinedContext 树)中找到我们需要的信息。
@SinceKotlin("1.3")
public interface CoroutineContext {
/**
* Returns the element with the given [key] from this context or `null`.
*/
public operator fun <E : Element> get(key: Key<E>): E?
// ...
}
我们填入的参数其实是每一个接口的伴生对象 Key,每个伴生对象都实现了 CoroutineContext.Key<T> 接口,并将泛型指定为了当前接口。
以 ContinuationInterceptor 为例:
@SinceKotlin("1.3")
public interface ContinuationInterceptor : CoroutineContext.Element {
/**
* The key that defines *the* context interceptor.
*/
public companion object Key : CoroutineContext.Key<ContinuationInterceptor>
// ...
}
比如我们要获取上下文中的 CoroutineDispatcher,我们可以这样做:
fun main() = runBlocking<Unit> {
val scope = CoroutineScope(Dispatchers.Default)
val job = scope.launch {
val dispatcher = coroutineContext[ContinuationInterceptor] as CoroutineDispatcher // 强转
println("CoroutineDispatcher is $dispatcher")
}
job.join()
}
来源:juejin.cn/post/7564230484126892071
前端部署,又有新花样?
大多数前端开发者在公司里,很少需要直接操心“部署”这件事——那通常是运维或 DevOps 的工作。
但一旦回到个人项目,情况就完全不一样了。写个小博客、搭个文档站,或者搞个 demo 想给朋友看,部署往往成了最大的拦路虎。
常见的选择无非是 Vercel、Netlify 或 GitHub Pages。它们表面上“一键部署”,但细节其实并不轻松:要注册平台账号、要配置域名,还得接受平台的各种限制。国内的一些云服务商(比如阿里云、腾讯云)管控更严格,操作门槛也更高。更让人担心的是,一旦平台宕机,或者因为地区网络问题导致访问不稳定,你的项目可能随时“消失”在用户面前。虽然这种情况不常见,但始终让人心里不踏实。
很多时候,我们只是想快速上线一个小页面,不想被部署流程拖累,有没有更好的方法?
一个更轻的办法
前段时间我发现了一个开源工具 PinMe,主打的就是“极简部署”。

它的使用体验非常直接:
- 不需要服务器
- 不用注册账号
- 在项目目录敲一条命令,就能把项目打包上传到 IPFS 网络
- 很快,你就能拿到一个可访问的地址
实际用起来的感受就是一个字:爽。
整个过程几乎没有繁琐配置,不需要绑定平台账号,也不用担心流量限制或收费。
这让很多场景变得顺手:
- 临时展示一个 demo,不必折腾服务器
- 写了个静态博客,不想搞 CI/CD 流程
- 做了个活动页或 landing page,随时上线就好
以前这些需求可能要纠结“用 GitHub Pages 还是 Vercel”,现在有了 PinMe,直接一键上链就行。
体验一把
接下来看看它在真实场景下的表现:部署流程有多简化?访问速度如何?和传统方案相比有没有优势?
测试项目
为了覆盖不同体量的场景,这次我选了俩类项目来测试:
- 小型项目:fuwari(开源的个人博客项目),打包体积约 4 MB。
- 中大型项目:Soybean Admin(开源的后台管理系统),打包体积约 15 MB。
部署项目
PinMe 提供了两种方式:命令行 和 可视化界面。
这两种方式我们都来试一下。
命令行部署
先全局安装:
npm install -g pinme
然后一条命令上传:
pinme upload <folder/file-path>
比如上传 Soybean Admin,文件大小 15MB:
输入命令之后,等着就可以了:

只用了两分钟,终端返回的 URL 就能直接访问项目的控制页面。还能绑定自己的域名:
点击网站链接就可以看到已经部署好的项目,访问速度还是挺快的:
同样地,上传个人博客也是一样的流程。
部署完成:
可视化部署
不习惯命令行?PinMe 也提供了网页上传,进度条实时显示:
部署完成后会自动进入管理页面:
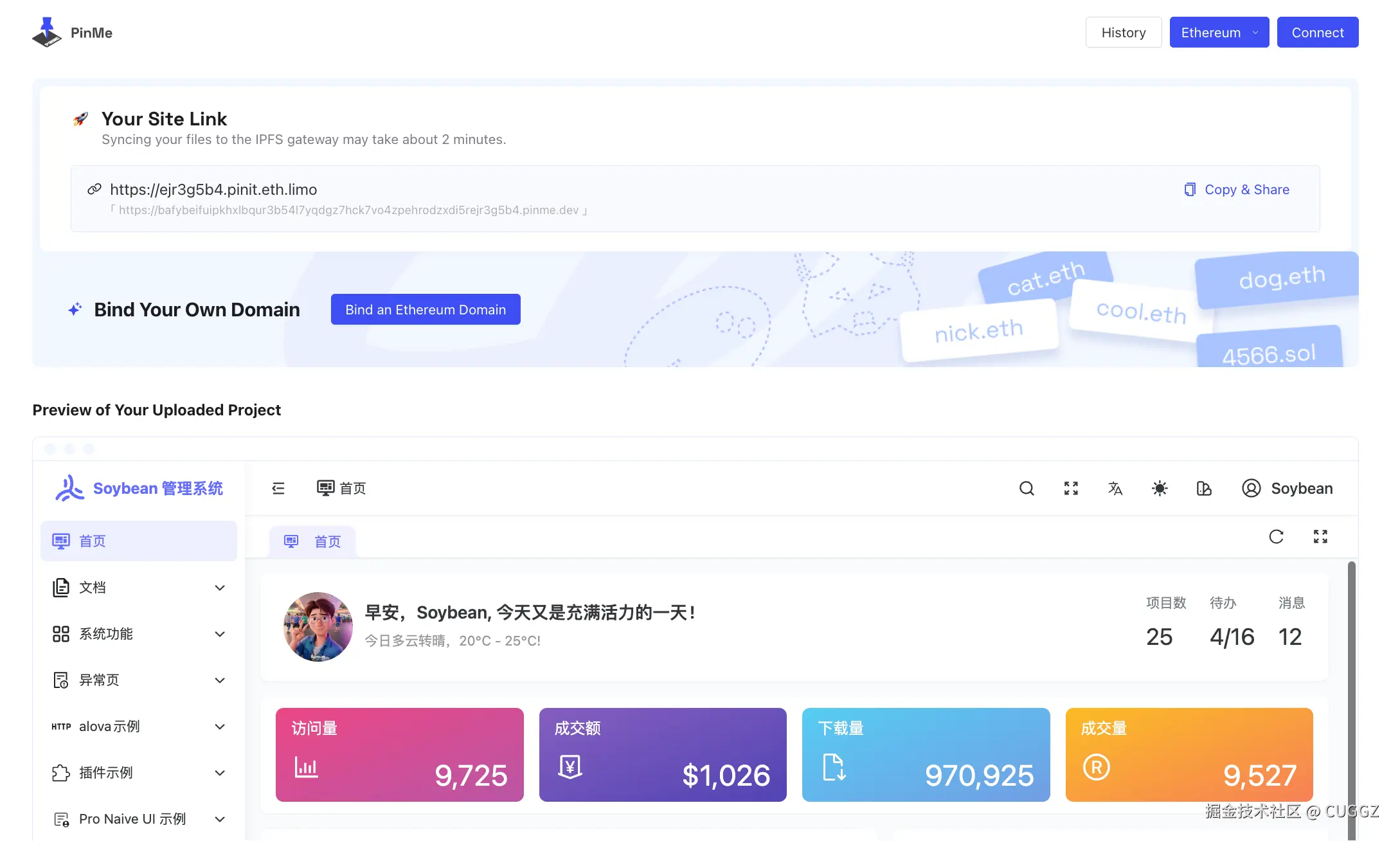
经过测试,部署速度和命令行几乎一致。
其他功能
历时记录
部署过的网站都能在主页的 History 查看:
历史部署记录:
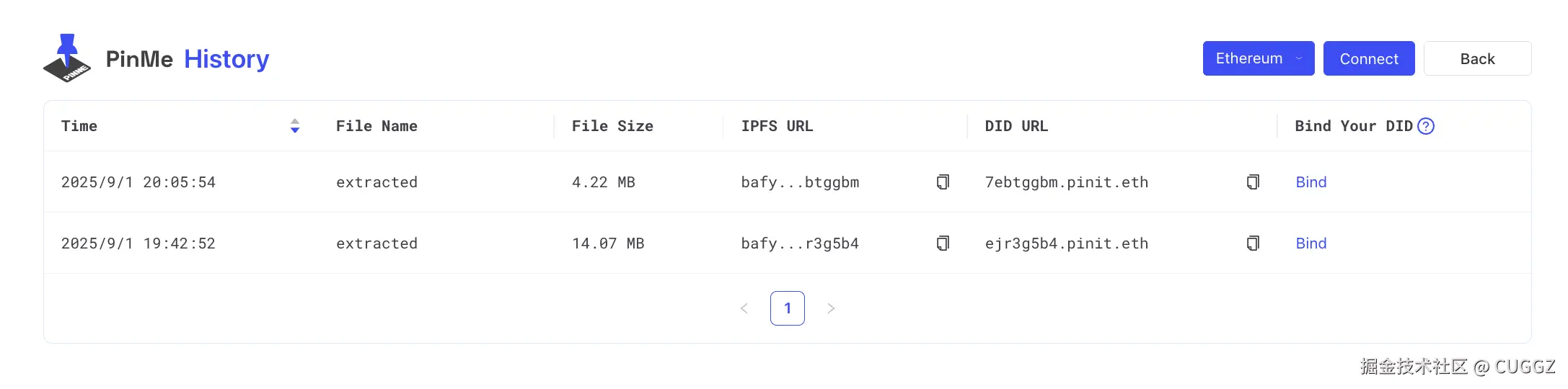
也可以用命令行:
pinme list
历史部署记录:
删除网站
如果不再需要某个项目,执行以下命令即可:
pinme rm
PinMe 背后的“硬核支撑”
如果只看表层,PinMe 就像一个极简的托管工具。但要理解它为什么能做到“不依赖平台”,还得看看它背后的底层逻辑。
PinMe 的底层依赖 IPFS,这是一个去中心化的分布式文件系统。
要理解它的意义,得先聊聊“去中心化”这个概念。
传统互联网是中心化的:你访问一个网站时,浏览器会通过 DNS 找到某台服务器,然后从这台服务器获取内容。这条链路依赖强烈,一旦 DNS 被劫持、服务器宕机、服务商下线,网站就无法访问。
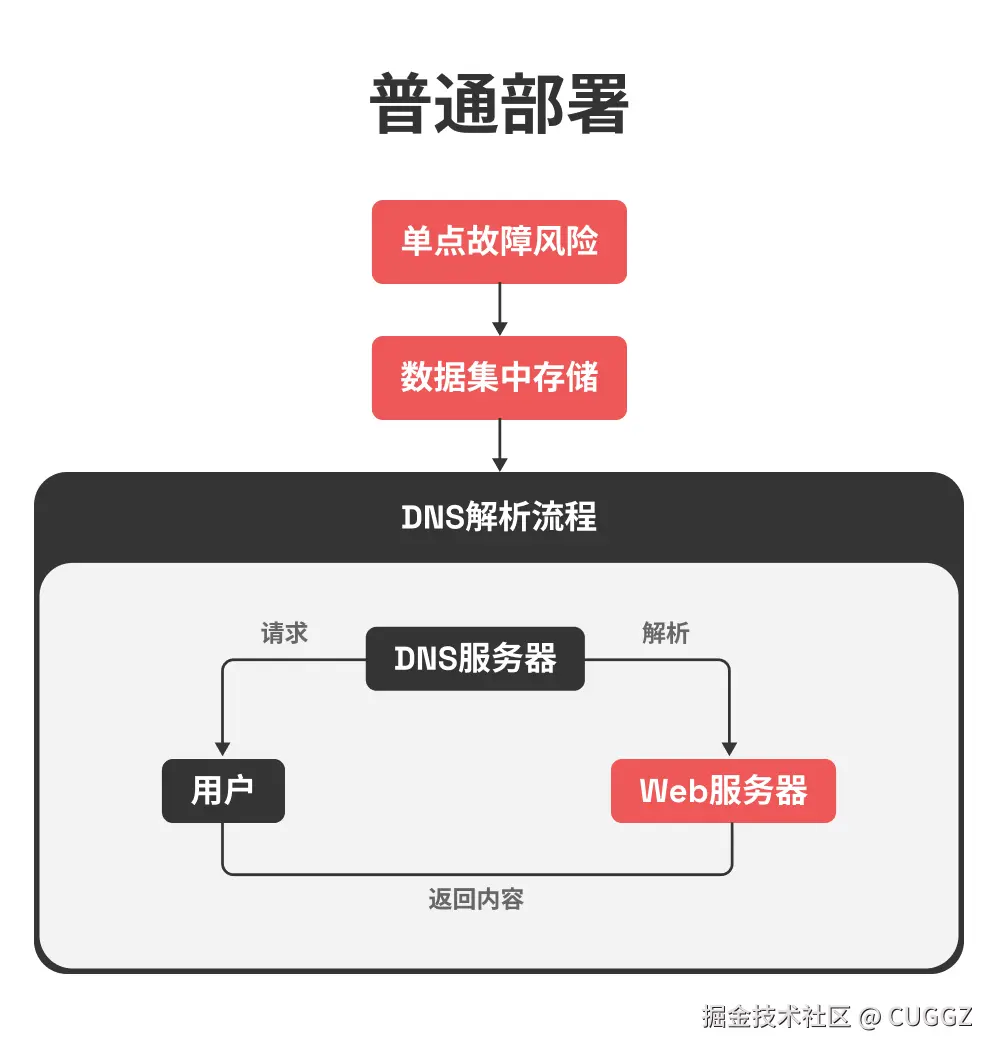
去中心化的思路完全不同:
- 数据不是放在单一服务器,而是分布在全球节点中
- 访问不依赖“位置”,而是通过内容哈希来检索
- 只要有节点存储这份内容,就能访问到,不怕单点故障
这意味着:
- 更稳定:即使部分节点宕机,内容依然能从其他节点获取。
- 防篡改:文件哪怕改动一个字节,对应的 CID 也会完全不同,从机制上保障了前端资源的完整性和安全性。
- 更自由:不再受制于中心化平台,文件真正由用户自己掌控。
当然,IPFS 地址(哈希)太长,不适合直接记忆和分享。这时候就需要 ENS(Ethereum Name Service)。它和 DNS 类似,但记录存储在以太坊区块链上,不可能被篡改。比如你可以把 myblog.eth 指向某个 IPFS 哈希,别人只要输入 ENS 域名就能访问,不依赖传统 DNS,自然也不会被劫持。
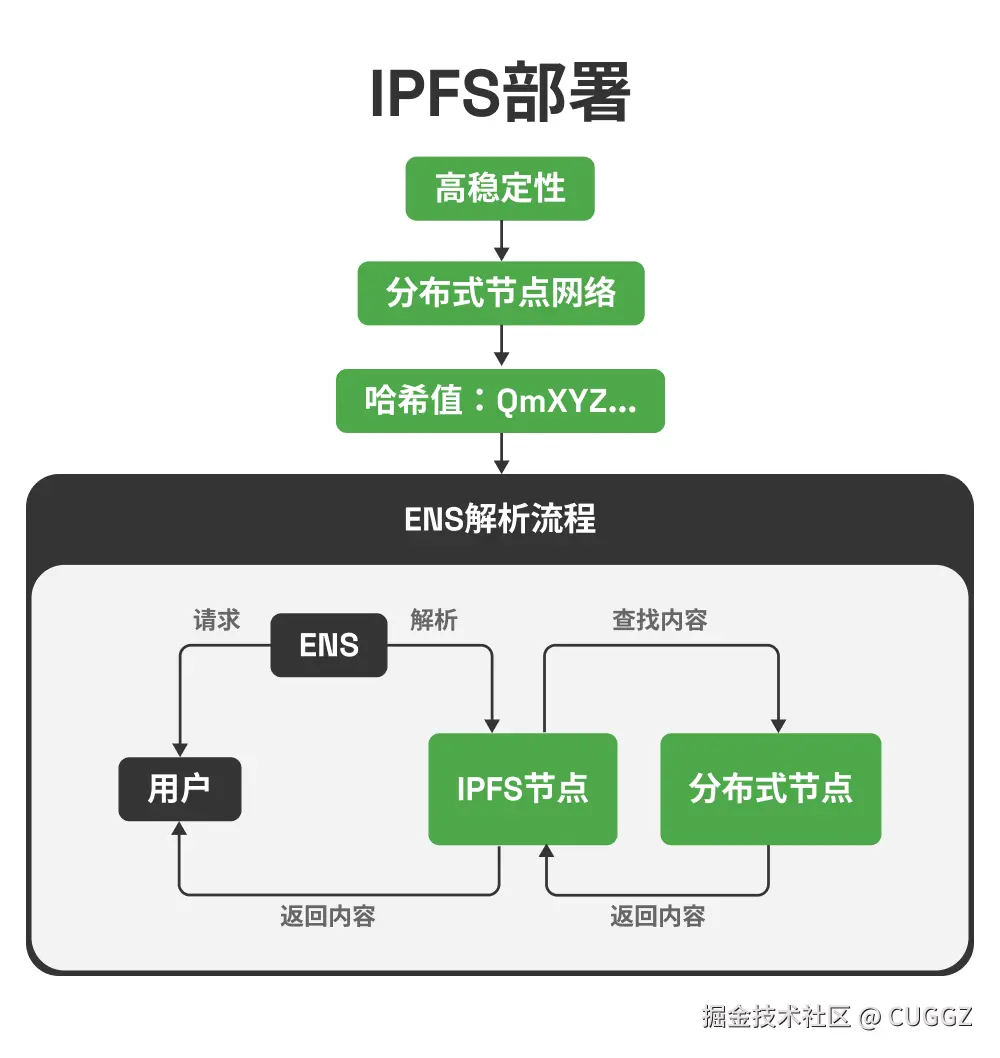
换句话说:
ENS + IPFS = 内容去中心化 + 域名去中心化
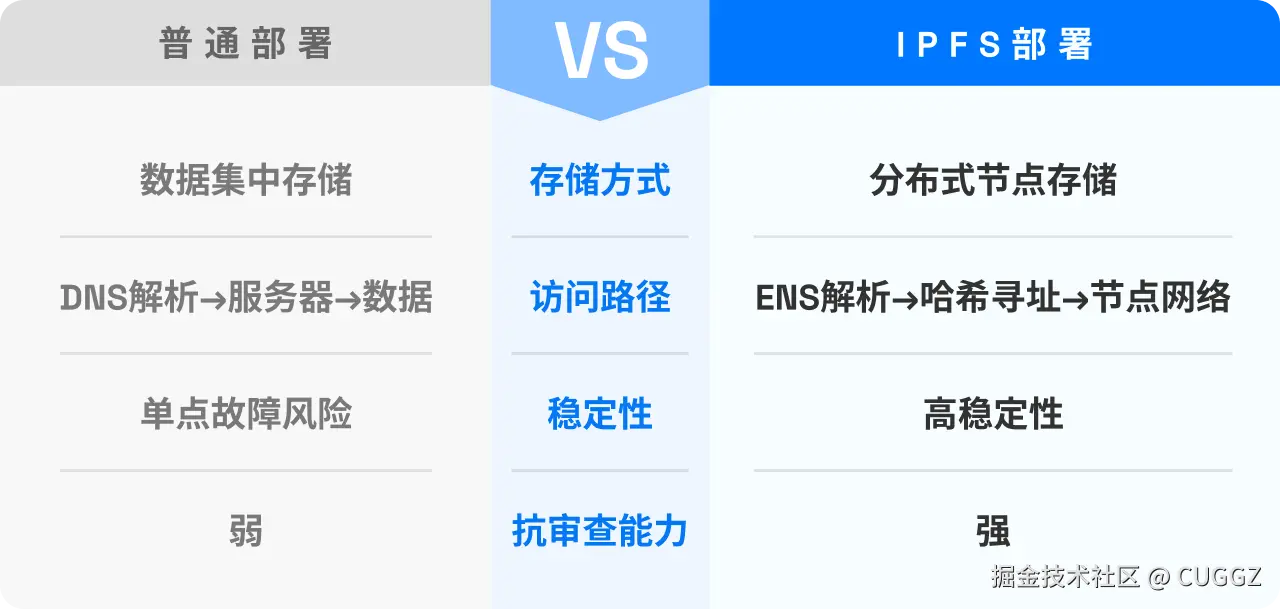
前端个人项目瞬间就有了更高的自由度和安全性。
一点初步感受
PinMe 并不是要取代 Vercel 这类成熟平台,但它带来了一种新的选择:更简单、更自由、更去中心化。
如果你只是想快速上线一个小项目,或者对去中心化部署感兴趣,PinMe 值得一试。
- 官网:pinme.eth.limo/
- Github:github.com/glitternetw…
这是一个完全开源的项目,开发团队也会持续更新。如果你在测试过程中有想法或需求,不妨去 GitHub 提个 Issue —— 这不仅能帮助项目成长,也能让它更贴近前端开发的实际使用场景!
来源:juejin.cn/post/7547515500453380136
antd 对 ai 下手了!Vue 开发者表示羡慕!

前端开发者应该对 Ant Design 不陌生,特别是 React 开发者,antd 应该是组件库的标配了。
近年来随着 AI 的爆火,凡是想要接入 AI 的都想搞一套自己的 AI 交互界面。专注于 AI 场景组件库的开源项目倒不是很多见,近日 antd 宣布推出 Ant Design X 1.0 🚀 ,这是一个基于 Ant Design 的全新 AGI 组件库,使用 React 构建 AI 驱动的用户交互变得更简单了,它可以无缝集成 AI 聊天组件和 API 服务,简化 AI 界面的开发流程。
该项目已在 Github 开源,拥有 1.6K Star!
看了网友的评论,看来大家还是需要的!当前的 Ant Design X 只支持 React 项目,看来 Vue 开发者要羡慕了...
ant-design-x 特性
- 🌈 源自企业级 AI 产品的最佳实践:基于 RICH 交互范式,提供卓越的 AI 交互体验
- 🧩 灵活多样的原子组件:覆盖绝大部分 AI 对话场景,助力快速构建个性化 AI 交互页面
- ⚡ 开箱即用的模型对接能力:轻松对接符合 OpenAI 标准的模型推理服务
- 🔄 高效管理对话数据流:提供好用的数据流管理功能,让开发更高效
- 📦 丰富的样板间支持:提供多种模板,快速启动 LUI 应用开发
- 🛡 TypeScript 全覆盖:采用 TypeScript 开发,提供完整类型支持,提升开发体验与可靠性
- 🎨 深度主题定制能力:支持细粒度的样式调整,满足各种场景的个性化需求
支持组件
以下圈中的部分为 ant-design-x 支持的组件。可以看到主要都是基于 AI Chat 场景的组件设计。现在你可以基于这些组件自由组装搭建一个自己的 AI 界面。
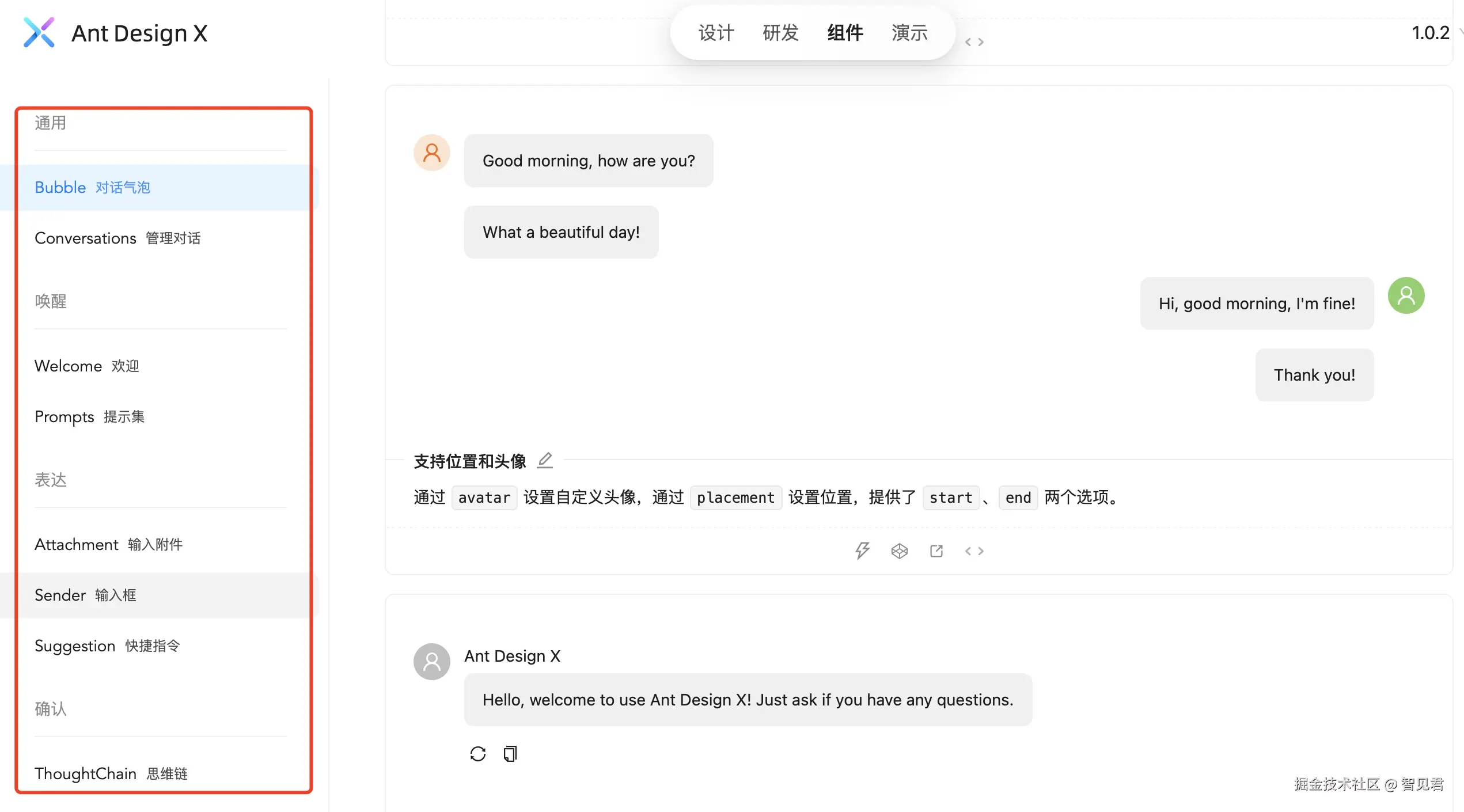
ant-design-x 也提供了一个完整 AI Chat 的 Demo 演示,可以查看 Demo 的代码并直接使用。
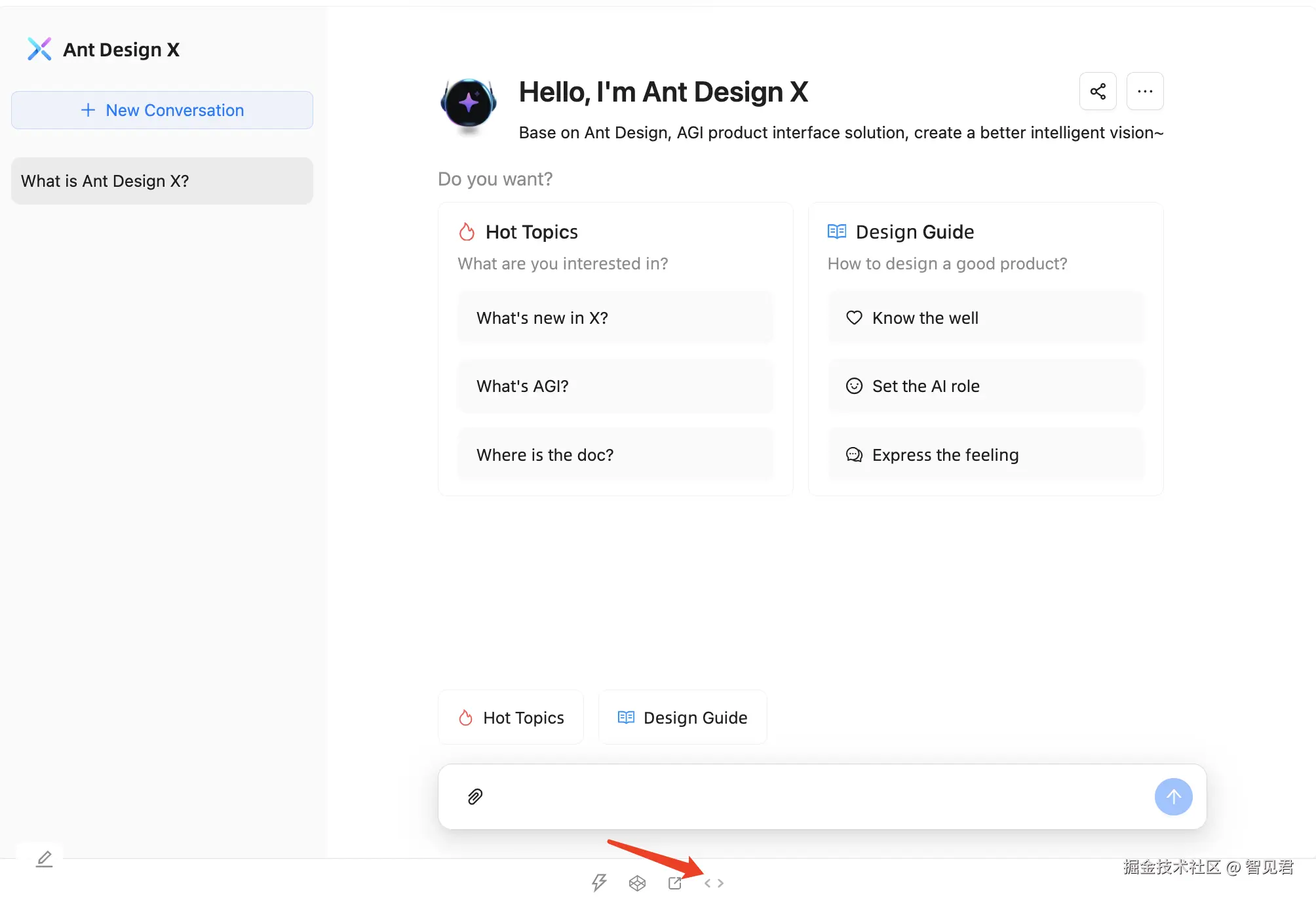
更多组件详细内容可参考 组件文档
使用
以下命令安装 @ant-design/x 依赖。
注意,ant-design-x 是基于 Ant Design,因此还需要安装依赖 antd。
yarn add antd @ant-design/x
import React from 'react';
import {
// 消息气泡
Bubble,
// 发送框
Sender,
} from '@ant-design/x';
const messages = [
{
content: 'Hello, Ant Design X!',
role: 'user',
},
];
const App = () => (
<div>
<Bubble.List items={messages} />
<Sender />
</div>
);
export default App;
Ant Design X 前生 ProChat
不知道有没有小伙伴们使用过 ProChat,这个库后面的维护可能会有些不确定性,其维护者表示 “24 年下半年后就没有更多精力来维护这个项目了,Github 上的 Issue 存留了很多,这边只能尽量把一些恶性 Bug 修复”
如上所示,也回答了其和 Ant Design X 的关系:ProChat 是 x 的前生,新用户请直接使用 x,老用户也请尽快迁移到 x。
感兴趣的朋友们可以去试试哦!
来源:juejin.cn/post/7444878635717443595


