








别再说“对接接口没技术含量了”,这才是高手的打开方式!
很多 Java 程序员一听到“对接第三方接口”,脑子里就自动响起一句话: “这不就是调个接口嘛,没技术含量。”
但真相是:你以为是体力活的地方,往往最能看出一个工程师的“技术深度”。
那些把接口对接写成“定时炸弹”的代码,和能扛住三年高并发零故障的实现,差的从来不是会不会发 HTTP 请求。
一、真正的高手,不是“调通接口”,而是“设计边界”
对接第三方接口,看似只是发个请求、拿个 JSON,但背后其实是——系统边界的协作与防御设计。
你面对的不是自己可控的代码,而是一个随时可能“变脸”的外部世界:
- 对方文档写着“此字段必传”,实际却返回 null
- 测试环境响应毫秒级,生产环境突然超时 30 秒
- 接口突然升级,字段名从 camelCase 改成 snake_case
- 流量峰值时,对方悄悄给你限流却不通知
所以高手不会只想着“调通”,而是从第一天就思考:
- 超时如何设置才不会拖垮自己的线程池?
- 对方返回非预期格式时,如何避免解析崩溃?
- 调用失败后,重试几次、间隔多久才合理?
- 敏感参数如何加密才能通过安全审计?
- 接口突然变慢时,如何第一时间收到告警?
这些问题,不是“Bug”,而是“工程意识”的试金石。能把混乱的接口接得稳定、可控、可追踪、可安全,这才是真正的技术能力。
二、“对接接口”也能写出架构感
普通开发者的代码,往往是这样的:
// 业务代码里突然冒出一段HTTP调用
RestTemplate restTemplate = new RestTemplate();
HttpHeaders headers = new HttpHeaders();
headers.set("appKey", "xxx");
headers.set("sign", "xxx");
HttpEntity<Map> entity = new HttpEntity<>(reqMap, headers);
ResponseEntity<String> res = restTemplate.postForEntity(
"https://xxx.com/api/pay", entity, String.class);
// 然后直接解析字符串...
而高手的代码,会先画一条清晰的边界:
// 1. 定义领域接口,屏蔽HTTP细节
public interface PaymentGatewayClient {
PaymentResponse pay(PaymentRequest request);
}
// 2. 实现类专注处理接口对接逻辑
@Service
public class AlipayGatewayClient implements PaymentGatewayClient {
@Override
public PaymentResponse pay(PaymentRequest request) {
// 封装:签名生成、参数转换、超时控制
// 集成:重试机制、日志埋点、异常转换
// 隔离:与业务逻辑彻底分离
}
}
业务层调用时,只需要关心业务语义,不关心HTTP细节。
这样做的好处立竿见影:
- • 换第三方支付时,只需新增实现类,业务代码零改动
- • 单元测试时,用 Mock 替代真实接口,测试速度提升 10 倍
- • 接口逻辑集中管理,不会散落在几百个业务方法里
当你能做到“接口逻辑不散落在业务代码里”,系统就已经迈入“架构级整洁”的门槛。
三、调通很容易,稳定才是实力
调通接口是初级开发者的 KPI。让接口一年 365 天稳稳跑着,那才是高级工程师的成就。
这些场景你一定踩过坑:
- • 对方接口“偶尔超时”,导致自己的系统线程池被占满
- • 并发一上来,就收到“Too Many Requests”限流提示
- • 响应 JSON 里突然多了个逗号,Jackson 解析直接抛异常
- • 异步回调乱序,先收到“支付成功”,再收到“支付中”
- • 敏感参数明文传输,被安全扫描揪出高危漏洞
- • 接口响应变慢,用户投诉后才发现
而高手的解决方案,藏在这些细节里:
1. 超时与重试:用“退避策略”减少无效请求
// 用 Resilience4j 实现指数退避重试
RetryConfig config = RetryConfig.custom()
.maxAttempts(3) // 最多重试3次
.waitDuration(Duration.ofMillis(1000)) // 首次间隔1秒
.retryExceptions(TimeoutException.class, IOException.class)
.ignoreExceptions(IllegalArgumentException.class) // 非法参数不重试
.build();
Retry retry = Retry.of("paymentApi", config);
// 包装调用逻辑
Supplier<PaymentResponse> retryableSupplier = Retry.decorateSupplier(
retry, () -> doCallPaymentApi(request)
);
2. 熔断降级:防止对方故障拖垮自己
// 当失败率超过50%,触发熔断
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50)
.waitDurationInOpenState(Duration.ofSeconds(60)) // 熔断60秒
.permittedNumberOfCallsInHalfOpenState(5) // 半开状态允许5次试探
.build();
CircuitBreaker circuitBreaker = CircuitBreaker.of("paymentApi", config);
// 降级逻辑:返回缓存数据或默认提示
Supplier<PaymentResponse> decoratedSupplier = CircuitBreaker
.decorateSupplier(circuitBreaker, () -> doCallPaymentApi(request))
.orElseGet(() -> buildFallbackResponse(request));
3. 日志追踪:用 TraceId 串联完整调用链
// 拦截器自动生成并传递TraceId
public class TraceIdInterceptor implements ClientHttpRequestInterceptor {
@Override
public ClientHttpResponse intercept(
HttpRequest request, byte[] body, ClientHttpRequestExecution execution) {
String traceId = MDC.get("traceId");
if (traceId == null) {
traceId = UUID.randomUUID().toString();
MDC.put("traceId", traceId);
}
request.getHeaders().add("X-Trace-Id", traceId);
return execution.execute(request, body);
}
}
// 日志格式包含TraceId,方便排查问题
// logback.xml 配置:%X{traceId} [%thread] %-5level %logger{36} - %msg%n
4. 安全签名:给数据加把“锁”
接口传输的敏感信息(如手机号、银彳亍卡号)必须经过双重防护:
// 1. 参数签名:防止数据被篡改
public class SignUtils {
public static String sign(Map<String, String> params, String secret) {
// 按参数名ASCII排序
List<String> keys = new ArrayList<>(params.keySet());
Collections.sort(keys);
// 拼接为key=value&key=value形式
StringBuilder sb = new StringBuilder();
for (String key : keys) {
sb.append(key).append("=").append(params.get(key)).append("&");
}
// 追加密钥后用SHA256加密
sb.append("secret=").append(secret);
return DigestUtils.sha256Hex(sb.toString());
}
}
// 2. 敏感字段加密:防止传输中泄露
public class EncryptUtils {
// 手机号加密示例(AES算法)
public static String encryptPhone(String phone, String aesKey) {
// 实际项目中建议使用密钥管理服务存储密钥
SecretKeySpec key = new SecretKeySpec(aesKey.getBytes(), "AES");
Cipher cipher = Cipher.getInstance("AES/ECB/PKCS5Padding");
cipher.init(Cipher.ENCRYPT_MODE, key);
return Base64.getEncoder().encodeToString(cipher.doFinal(phone.getBytes()));
}
}
5. 实时监控:让接口状态“可视化”
高手不会等到用户投诉才发现问题,而是用监控提前预警:
// 1. 自定义指标收集(基于Micrometer)
@Component
public class ApiMetricsCollector {
private final MeterRegistry meterRegistry;
public void recordApiCall(String apiName, long durationMs, boolean success) {
// 记录接口耗时分布
Timer.builder("thirdparty.api.duration")
.tag("api", apiName)
.tag("success", String.valueOf(success))
.register(meterRegistry)
.record(durationMs, TimeUnit.MILLISECONDS);
// 记录失败次数
if (!success) {
Counter.builder("thirdparty.api.failure")
.tag("api", apiName)
.register(meterRegistry)
.increment();
}
}
}
// 2. 配置监控告警(Prometheus + Grafana)
// 告警规则示例:当5分钟内失败率超过10%时触发告警
// - alert: ApiHighFailureRate
// expr: sum(rate(thirdparty.api.failure[5m])) / sum(rate(thirdparty.api.duration_count[5m])) > 0.1
// for: 1m
// labels:
// severity: critical
// annotations:
// summary: "接口失败率过高"
// description: "{{ $labels.api }} 接口5分钟失败率超过10%"
一个优秀的接口对接系统,其实就是一个可观测、可预警、可恢复、可信任的微系统。
四、写给未来的自己看
很多人调完接口就走,连注释都没有。三个月后接手的人只能默默骂一句:“这谁写的鬼东西?对方文档改了哪?这个签名算法是啥意思?”
高手懂得写“能看懂的代码”,体现在这些地方:
- • 接口模型用类而非 Map:
PaymentRequest类比Map<String, Object>更清晰,字段注释直接写在类里 - • 错误码枚举化:
PaymentErrorCode.ORDER_NOT_EXIST比魔法值10001更容易维护 - • 文档内聚:在实现类里用
@see链接对方文档地址,关键逻辑加注释说明为什么这么做 - • Mock 测试就绪:提供
MockPaymentGatewayClient,方便本地调试和单元测试
对接接口的过程,其实是你在写给未来的自己看。维护体验的好坏,体现的是你的工程素养。
五、你以为的“体力活”,其实是“架构的入门课”
对接第三方接口,本质上是一次系统边界设计的演练。
当你学会:
- 用“依赖倒置”隔离外部变化
- 用“防御性编程”处理异常情况
- 用“签名加密”保障数据安全
- 用“可观测性”确保问题可追溯
- 用“熔断降级”保障系统韧性
你就已经掌握了架构设计的核心思维。
毕竟,真实世界的系统从来不是孤立的。能把一个“不稳定的外部系统”接入得像内部服务一样稳定、可靠、优雅,那一刻,你不再是“接口调用员”,而是一个在用工程思维解决问题的架构师。
最后想说一句
下次当有人跟你说:“就调个接口嘛,这有啥难的?”。你可以微微一笑: “我不只是调接口,我在构建系统的边界。”
记住一句话: “能调通的叫能力,能跑稳的才叫实力。”
如果觉得有启发,不妨关注下我的公众号《码上实战》。
来源:juejin.cn/post/7563858353884102695
Go 语言未来会取代 Java 吗?
Go 语言未来会取代 Java 吗?
(八年 Java 开发的深度拆解:从业务场景到技术底层)
开篇:面试官的灵魂拷问与行业焦虑
前年面某大厂时,技术负责人突然抛出问题:“如果让你重构公司核心系统,会选 Go 还是 Java?”
作为写了八年 Java 的老开发,我本能地想强调 Spring 生态和企业级成熟度,但对方随即展示的 PPT 让我冷汗直冒 —— 某金融公司用 Go 重构交易系统后,QPS 从 5 万飙升到 50 万,服务器成本降低 70%。这让我陷入沉思:当云原生和 AI 浪潮来袭,Java 真的要被 Go 取代了吗?
今天从 业务场景、技术本质、行业趋势 三个维度,结合实战代码和踩坑经验,聊聊我的真实看法。
一、业务场景对比:Go 的 “闪电战” vs Java 的 “持久战”
先看三个典型业务场景,你会发现两者的差异远不止 “性能” 二字。
场景 1:高并发抢购(电商大促)
Go 实现(Gin 框架) :
func main() {
router := gin.Default()
router.GET("/seckill", func(c *gin.Context) {
// 轻量级goroutine处理请求
go func() {
// 直接操作Redis库存
if err := redisClient.Decr("stock").Err(); err != nil {
c.JSON(http.StatusOK, gin.H{"result": "fail"})
return
}
c.JSON(http.StatusOK, gin.H{"result": "success"})
}()
})
router.Run(":8080")
}
性能数据:单机轻松支撑 10 万 QPS,p99 延迟 < 5ms。
Java 实现(Spring Boot + 虚拟线程) :
@RestController
public class SeckillController {
@GetMapping("/seckill")
public CompletableFuture<ResponseEntity<String>> seckill() {
return CompletableFuture.supplyAsync(() -> {
// 虚拟线程处理IO操作
if (redisTemplate.opsForValue().decrement("stock") < 0) {
return ResponseEntity.ok("fail");
}
return ResponseEntity.ok("success");
}, Executors.newVirtualThreadPerTaskExecutor());
}
}
性能数据:Java 21 虚拟线程让 IO 密集型场景吞吐量提升 7 倍,p99 延迟从 165ms 降至 23ms。
核心差异:
- Go:天生适合高并发,Goroutine 调度和原生 Redis 操作无额外开销。
- Java:依赖 JVM 调优,虚拟线程虽大幅提升性能,但需配合线程池和异步框架。
场景 2:智能运维平台(云原生领域)
Go 实现(Ollama + gRPC) :
func main() {
// 启动gRPC服务处理AI推理请求
server := grpc.NewServer()
pb.RegisterAIAnalysisServer(server, &AIHandler{})
go func() {
if err := server.Serve(lis); err != nil {
log.Fatalf("Server exited with error: %v", err)
}
}()
// 采集节点数据(百万级设备)
for i := 0; i < 1000000; i++ {
go func(nodeID int) {
for {
data := collectMetrics(nodeID)
client.Send(data) // 通过channel传递数据
}
}(i)
}
}
优势:轻量级 Goroutine 高效处理设备数据采集,gRPC 接口响应速度比 REST 快 30%。
Java 实现(Spring Cloud + Kafka) :
@Service
public class MonitorService {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
public void collectMetrics(int nodeID) {
ScheduledExecutorService executor = Executors.newScheduledThreadPool(100);
executor.scheduleAtFixedRate(() -> {
String data =采集数据(nodeID);
kafkaTemplate.send("metrics-topic", data);
}, 0, 1, TimeUnit.SECONDS);
}
}
挑战:传统线程池在百万级设备下内存占用飙升,需配合 Kafka 分区和 Consumer Gr0up 优化。
核心差异:
- Go:云原生基因,从采集到 AI 推理全链路高效协同。
- Java:生态依赖强,需整合 Spring Cloud、Kafka 等组件,部署复杂度高。
场景 3:企业 ERP 系统(传统行业)
Java 实现(Spring + Hibernate) :
@Entity
@Table(name = "orders")
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@ManyToOne
@JoinColumn(name = "user_id")
private User user;
// 复杂业务逻辑注解
@PrePersist
public void validateOrder() {
if (totalAmount < 0) {
throw new BusinessException("金额不能为负数");
}
}
}
优势:Spring 的事务管理和 Hibernate 的 ORM 完美支持复杂业务逻辑,代码可读性高。
Go 实现(GORM + 接口组合) :
type Order struct {
ID uint `gorm:"primaryKey"`
UserID uint
Total float64
}
func (o *Order) Validate() error {
if o.Total < 0 {
return errors.New("金额不能为负数")
}
return nil
}
func CreateOrder(ctx context.Context, order Order) error {
if err := order.Validate(); err != nil {
return err
}
return db.Create(&order).Error
}
挑战:需手动实现事务和复杂校验逻辑,代码量比 Java 多 20%。
核心差异:
- Java:企业级成熟度,框架直接支持事务、权限、审计等功能。
- Go:灵活性高,但需手动实现大量基础功能,适合轻量级业务。
二、技术本质:为什么 Go 在某些场景碾压 Java?
从 并发模型、内存管理、性能调优 三个维度,深挖两者的底层差异。
1. 并发模型:Goroutine vs 线程 / 虚拟线程
Go 的 Goroutine:
- 轻量级:每个 Goroutine 仅需 2KB 栈空间,可轻松创建百万级并发。
- 调度高效:基于 GMP 模型,避免内核级上下文切换,IO 阻塞时自动释放线程。
Java 的虚拟线程(Java 21+) :
- 革命性改进:每个虚拟线程仅需几百字节内存,IO 密集型场景吞吐量提升 7 倍。
- 兼容传统代码:无需修改业务逻辑,直接将
new Thread()替换为Thread.startVirtualThread()。
性能对比:
- HTTP 服务:Go 的 Gin 框架单机 QPS 可达 5 万,Java 21 虚拟线程 + Netty 可达 3 万。
- 消息处理:Go 的 Kafka 消费者单节点处理速度比 Java 快 40%。
2. 内存管理:逃逸分析 vs 分代 GC
Go 的逃逸分析:
- 栈优先分配:对象若未逃逸出函数,直接在栈上分配,减少 GC 压力。
- 零拷贝优化:
io.Reader接口直接操作底层缓冲区,避免内存复制。
Java 的分代 GC:
- 成熟但复杂:新生代采用复制算法,老年代采用标记 - 压缩,需通过
-XX:G1HeapRegionSize等参数调优。 - 内存占用高:同等业务逻辑下,Java 堆内存通常是 Go 的 2-3 倍。
典型案例:
某金融公司用 Go 重构风控系统后,内存占用从 8GB 降至 3GB,GC 停顿时间从 200ms 缩短至 10ms。
3. 性能调优:静态编译 vs JIT 编译
Go 的静态编译:
- 启动快:编译后的二进制文件直接运行,无需预热 JVM。
- 可预测性强:性能表现稳定,适合对延迟敏感的场景(如高频交易)。
Java 的 JIT 编译:
- 动态优化:运行时将热点代码编译为机器码,长期运行后性能可能反超 Go。
- 依赖调优经验:需通过
-XX:CompileThreshold等参数平衡启动时间和运行效率。
实测数据:
- 启动时间:Go 的 HTTP 服务启动仅需 20ms,Java Spring Boot 需 500ms。
- 长期运行:持续 24 小时压测,Java 的吞吐量可能比 Go 高 10%(JIT 优化后)。
三、行业趋势:Go 在蚕食 Java 市场,但 Java 不会轻易退场
从 市场数据、生态扩展、技术演进 三个维度,分析两者的未来走向。
1. 市场数据:Go 在高速增长,Java 仍占主导
- 份额变化:Go 在 TIOBE 排行榜中从 2020 年的第 13 位升至 2025 年的第 7 位,市场份额突破 3%。
- 薪资对比:Go 开发者平均薪资比 Java 高 20%,但 Java 岗位数量仍是 Go 的 5 倍。
典型案例:
- 字节跳动:核心推荐系统用 Go 重构,QPS 提升 3 倍,成本降低 60%。
- 招商银行:核心交易系统仍用 Java,但微服务网关和监控平台全面转向 Go。
2. 生态扩展:Go 拥抱 AI,Java 深耕企业级
Go 的 AI 集成:
- 工具链完善:通过 Ollama 框架可直接调用 LLM 模型,实现智能运维告警。
- 性能优势:Go 的推理服务延迟比 Python 低 80%,适合边缘计算场景。
Java 的企业级护城河:
- 大数据生态:Hadoop、Spark、Flink 等框架仍深度依赖 Java。
- 移动端统治力:尽管 Kotlin 流行,Android 系统底层和核心应用仍用 Java 开发。
3. 技术演进:Go 和 Java 都在进化
Go 的发展方向:
- 泛型完善:Go 1.18 + 支持泛型,减少重复代码(如
PrintSlice函数可适配任意类型)。 - WebAssembly 集成:计划将 Goroutine 编译为 Wasm,实现浏览器端高并发。
Java 的反击:
- Project Loom:虚拟线程已转正,未来将支持更细粒度的并发控制。
- Project Valhalla:引入值类型,减少对象装箱拆箱开销,提升性能 15%。
四、选型建议:Java 开发者该如何应对?
作为八年 Java 老兵,我的 技术选型原则 是:用最合适的工具解决问题,而非陷入语言宗教战争。
1. 优先选 Go 的场景
- 云原生基础设施:API 网关、服务网格、CI/CD 工具链(如 Kubernetes 用 Go 开发)。
- 高并发实时系统:IM 聊天、金融交易、IoT 数据采集(单机 QPS 需求 > 1 万)。
- AI 推理服务:边缘计算节点、实时推荐系统(需低延迟和高吞吐量)。
2. 优先选 Java 的场景
- 复杂企业级系统:ERP、CRM、银行核心业务(需事务、权限、审计等功能)。
- Android 开发:系统级应用和性能敏感模块(如相机、传感器驱动)。
- 大数据处理:离线分析、机器学习训练(Hadoop/Spark 生态成熟)。
3. 混合架构:Go 和 Java 共存的最佳实践
- API 网关用 Go:处理高并发请求,转发到 Java 微服务。
- AI 推理用 Go:部署轻量级模型,结果通过 gRPC 返回给 Java 业务层。
- 数据存储用 Java:复杂查询和事务管理仍由 Java 服务处理。
代码示例:Go 调用 Java 微服务
// Go客户端
conn, err := grpc.Dial("java-service:8080", grpc.WithInsecure())
if err != nil {
log.Fatalf("连接失败: %v", err)
}
defer conn.Close()
client := pb.NewJavaServiceClient(conn)
resp, err := client.ProcessData(context.Background(), &pb.DataRequest{Data: "test"})
if err != nil {
log.Fatalf("调用失败: %v", err)
}
fmt.Println("Java服务返回:", resp.Result)
// Java服务端
@GrpcService
public class JavaServiceImpl extends JavaServiceGrpc.JavaServiceImplBase {
@Override
public void processData(DataRequest request, StreamObserver<DataResponse> responseObserver) {
String result =复杂业务逻辑(request.getData());
responseObserver.onNext(DataResponse.newBuilder().setResult(result).build());
responseObserver.onCompleted();
}
}
五、总结:焦虑源于未知,成长来自行动
回到开篇的问题:Go 会取代 Java 吗? 我的答案是:短期内不会,但长期会形成互补格局。
- Java 的不可替代性:企业级成熟度、Android 生态、大数据框架,这些优势难以撼动。
- Go 的不可阻挡性:云原生、高并发、AI 集成,这些领域 Go 正在建立新标准。
作为开发者,与其焦虑语言之争,不如:
- 掌握 Go 的核心优势:学习 Goroutine 编程、云原生架构,参与开源项目(如 Kubernetes)。
- 深耕 Java 的护城河:研究虚拟线程调优、Spring Boot 3.2 新特性,提升企业级架构能力。
- 拥抱混合开发:在 Java 项目中引入 Go 模块,或在 Go 服务中调用 Java 遗留系统。
最后分享一个真实案例:某电商公司将支付核心用 Java 保留,抢购服务用 Go 重构,大促期间 QPS 从 5 万提升到 50 万,系统总成本降低 40%。这说明,语言只是工具,业务价值才是终极目标。
来源:juejin.cn/post/7540597161224536090
微服务正在悄然消亡:这是一件美好的事
最近在做的事情正好需要系统地研究微服务与单体架构的取舍与演进。读到这篇文章《Microservices Are Quietly Dying — And It’s Beautiful》,许多观点直击痛点、非常启发,于是我顺手把它翻译出来,分享给大家,也希望能给同样在复杂性与效率之间权衡的团队一些参考。
微服务正在悄然消亡:这是一件美好的事
为了把我们的创业产品扩展到数百万用户,我们搭建了 47 个微服务。
用户从未达到一百万,但我们达到了每月 23,000 美元的 AWS 账单、长达 14 小时的故障,以及一个再也无法高效交付新功能的团队。
那一刻我才意识到:我们并没有在构建产品,而是在搭建一座分布式的自恋纪念碑。

我们都信过的谎言
五年前,微服务几乎是教条。Netflix 用它,Uber 用它。每一场技术大会、每一篇 Medium 文章、每一位资深架构师都在高喊同一句话:单体不具备可扩展性,微服务才是答案。
于是我们照做了。我们把 Rails 单体拆成一个个服务:用户服务、认证服务、支付服务、通知服务、分析服务、邮件服务;然后是子服务,再然后是调用服务的服务,层层套叠。
到第六个月,我们已经在 12 个 GitHub 仓库里维护 47 个服务。我们的部署流水线像一张地铁图,架构图需要 4K 显示器才能看清。
当“最佳实践”变成“最差实践”
我们不断告诫自己:一切都在运转。我们有 Kubernetes,有服务网格,有用 Jaeger 的分布式追踪,有 ELK 的日志——我们很“现代”。
但那些光鲜的微服务文章从不提的一点是:分布式的隐性税。
每一个新功能都变成跨团队的协商。想给用户资料加一个字段?那意味着要改五个服务、提三个 PR、协调两周,并进行一次像劫案电影一样精心编排的数据库迁移。
我们的预发布环境成本甚至高于生产环境,因为想测试任何东西,都需要把一切都跑起来。47 个服务在 Docker Compose 里同时启动,内存被疯狂吞噬。
那个彻夜崩溃的夜晚
凌晨 2:47,Slack 被消息炸翻。
生产环境宕了。不是某一个服务——是所有服务。支付服务连不上用户服务,通知服务不断超时,API 网关对每个请求都返回 503。
我打开分布式追踪面板:一万五千个 span,全线飘红。瀑布图像抽象艺术。我花了 40 分钟才定位出故障起点。
结果呢?一位初级开发在认证服务上发布了一个配置变更,只是一个环境变量。它让令牌校验多了 2 秒延迟,这个延迟在 11 个下游服务间层层传递,超时叠加、断路器触发、重试逻辑制造请求风暴,整个系统在自身重量下轰然倒塌。
我们搭了一座纸牌屋,却称之为“容错架构”。
我们花了六个小时才修复。并不是因为 bug 复杂——它只是一个配置的单行改动,而是因为排查分布式系统就像破获一桩谋杀案:每个目击者说着不同的语言,而且有一半在撒谎。
那个被忽略的低语
一周后,在复盘会上,我们的 CTO 说了句让所有人不自在的话:
“要不我们……回去?”
回到单体。回到一个仓库。回到简单。
会议室一片沉默。你能感到认知失调。我们是工程师,我们很“高级”。单体是给传统公司和训练营毕业生用的,不是给一家正打造未来的 A 轮初创公司用的。
但随后有人把指标展开:平均恢复时间 4.2 小时;部署频率每周 2.3 次(从单体时代的每周 12 次一路下滑);云成本增长速度比营收快 40%。
数字不会说谎。是架构在拖垮我们。
美丽的回归
我们用了三个月做整合。47 个服务归并成一个模块划分清晰的 Rails 应用;Kubernetes 变成负载均衡后面的三台 EC2;12 个仓库的工作流收敛成一个边界明确的仓库。
结果简直让人尴尬。
部署时间从 25 分钟降到 90 秒;AWS 账单从 23,000 美元降到 3,800 美元;P95 延迟提升了 60%,因为我们消除了 80% 的网络调用。更重要的是——我们又开始按时交付功能了。
开发者不再说“我需要和三个团队协调”,而是开始说“午饭前给你”。
我们的“分布式系统”变回了结构良好的应用。边界上下文变成 Rails 引擎,服务调用变成方法调用,Kafka 变成后台任务,“编排层”……就是 Rails 控制器。
它更快,它更省,它更好。
我们真正学到的是什么
这是真相:我们为此付出两年时间和 40 万美元才领悟——
微服务不是一种纯粹的架构模式,而是一种组织模式。Netflix 需要它,因为他们有 200 个团队。你没有。Uber 需要它,因为他们一天发布 4,000 次。你没有。
复杂性之所以诱人,是因为它看起来像进步。 拥有 47 个服务、Kubernetes、服务网格和分布式追踪,看起来很“专业”;而一个单体加一套 Postgres,看起来很“业余”。
但复杂性是一种税。它以认知负担、运营开销、开发者幸福感和交付速度为代价。
而大多数初创公司根本付不起这笔税。
我们花了两年时间为并不存在的规模做优化,同时牺牲了能让我们真正达到规模的简单性。
你不需要 50 个微服务,你需要的是自律
软件架构的“肮脏秘密”是:好的设计在任何规模都奏效。
一个结构良好的单体,拥有清晰的模块、明确的边界上下文和合理的关注点分离,比一团由希望和 YAML 勉强粘合在一起的微服务乱麻走得更远。
微服务并不是因为“糟糕”而式微,而是因为我们出于错误的理由使用了它。我们选择了分布式的复杂性而不是本地的自律,选择了运营的负担而不是价值的交付。
那些悄悄回归单体的公司并非承认失败,而是在承认更难的事实:我们一直在解决错误的问题。
所以我想问一个问题:你构建微服务,是在逃避什么?
如果答案是“一个凌乱的代码库”,那我有个坏消息——分布式系统不会修好坏代码,它只会让问题更难被发现。
来源:juejin.cn/post/7563860666349649970
Kafka 消息积压了,同事跑路了
快到年底了,系统频繁出问题。我有正当理由怀疑老板不想发年终奖所以搞事。
这不,几年都遇不到的消息队列积压现象今晚又卷土重来了。
今晚注定是个不眠夜了,原神启动。。。

组里的小伙伴火急火燎找到我说,Kafka 的消息积压一直在涨,预览图一直出不来。我加了几个服务实例,刚开始可以消费,后面消费着也卡住了。
本来刚刚下班的我就比较疲惫,想让他撤回镜像明天再上。不成想组长不讲武德,直接开了个飞书视频。
我当时本来不想理他,我已经下班了,别人上线的功能出问题关我啥事。

后来他趁我不注意搞偷袭,给我私信了,我当时没多想就点开了飞书。
本来以传统功夫的点到为止,我进入飞书不点开他的会话,是能看他给我发的最后一句话的。

我把手放在他那个会话上就是没点开,已读不回这种事做多了不好。我笑了一下,准备洗洗睡了。
正在我收手不点的时候,他突然给我来了一个电话,我大意了啊,没有挂,还强行接了他的电话。两分多钟以后就好了,我说小伙子你不讲武德。
直接喊话,今晚必须解决,大家都点咖啡算他的。

这真没办法,都找上门来了。只能跟着查一下,早点解决早点睡觉。然后我就上 Kafka 面板一看:最初的4个分区已经积压了 1200 条,后面新加的分区也开始积压了,而且积压的速度越来越快。
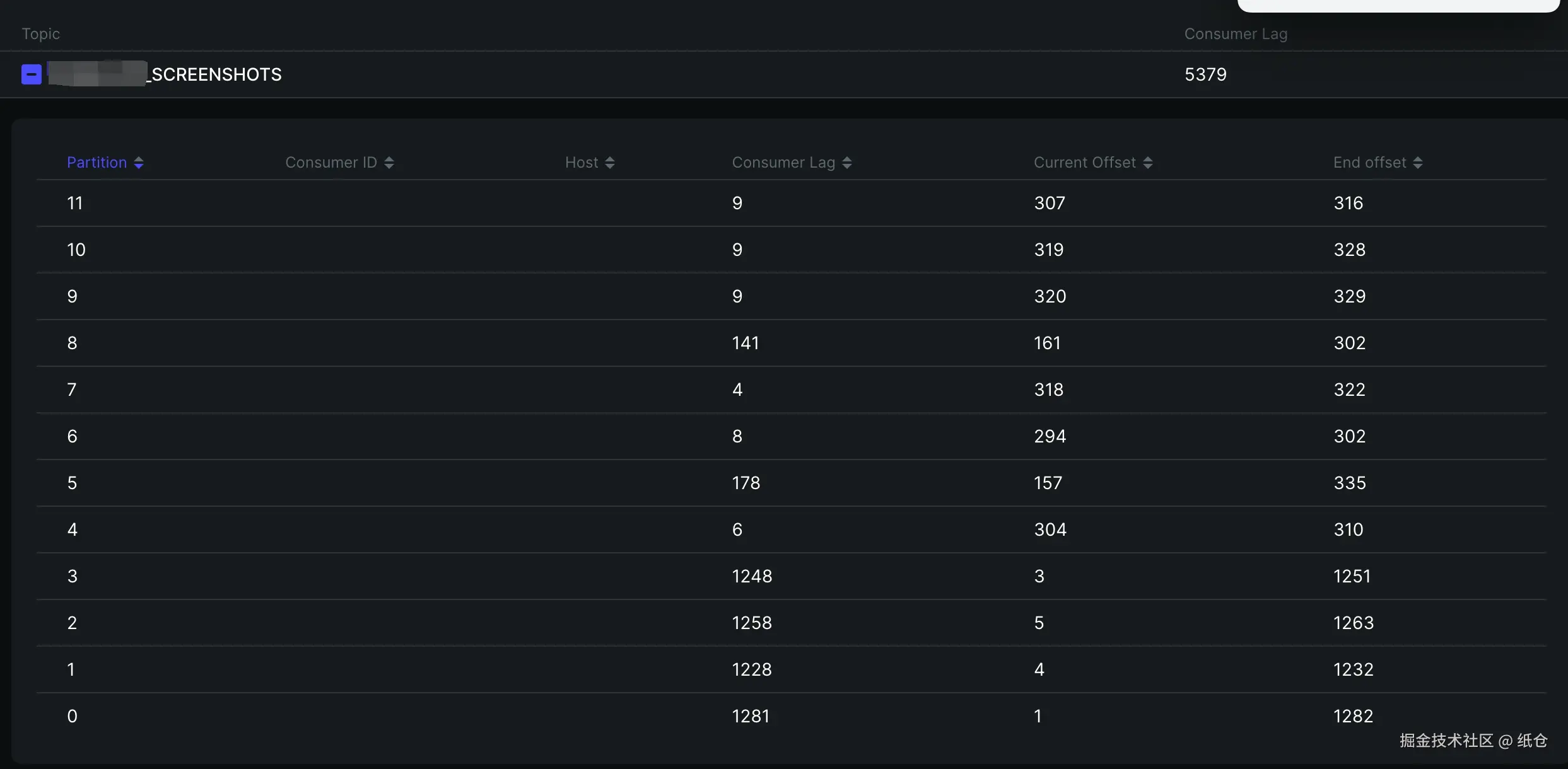
搞清楚发生了什么?我们就得思考一下导致积压的原因。一般是消费者代码执行出错了,导致某条消息消费不了。
所以某个点卡住了,然后又有新的消息进来。
Kafka 是通过 offset 机制来标记消息是否消费过的,所以如果分区中有某一条消息消费失败,就会导致后面的没机会消费。
我用的是spring cloud stream 来处理消息队列的发送和监听。代码上是每次处理一条消息,而且代码还在处理的过程中加了 try-catch。监听器链路打印的日志显示执行成功了,try-catch也没有捕捉到任何的异常。
这一看,我就以为是消费者性能不足,突然想起 SpringCloudStream 好像有个多线程消费的机制。立马让开发老哥试试,看看能不能就这样解决了,我困得不行。

我半眯着眼睛被提醒吵醒了。开发老哥把多线程改成10之后,发现积压更快了,而且还有pod会挂。老哥查了一下多线程的配置 concurrency。
原来指的是消费者线程,一个消费者线程会负责处理一个分区。对于我们来说,增加之后可能会导致严重的流量倾斜,难怪pod会挂掉,赶紧恢复了回去。
看来想糊弄过去是不行了,我把pod运行的日志全部拉下来。查了一下日志,日志显示执行成功了,但同时有超时错误,这就见了鬼了。
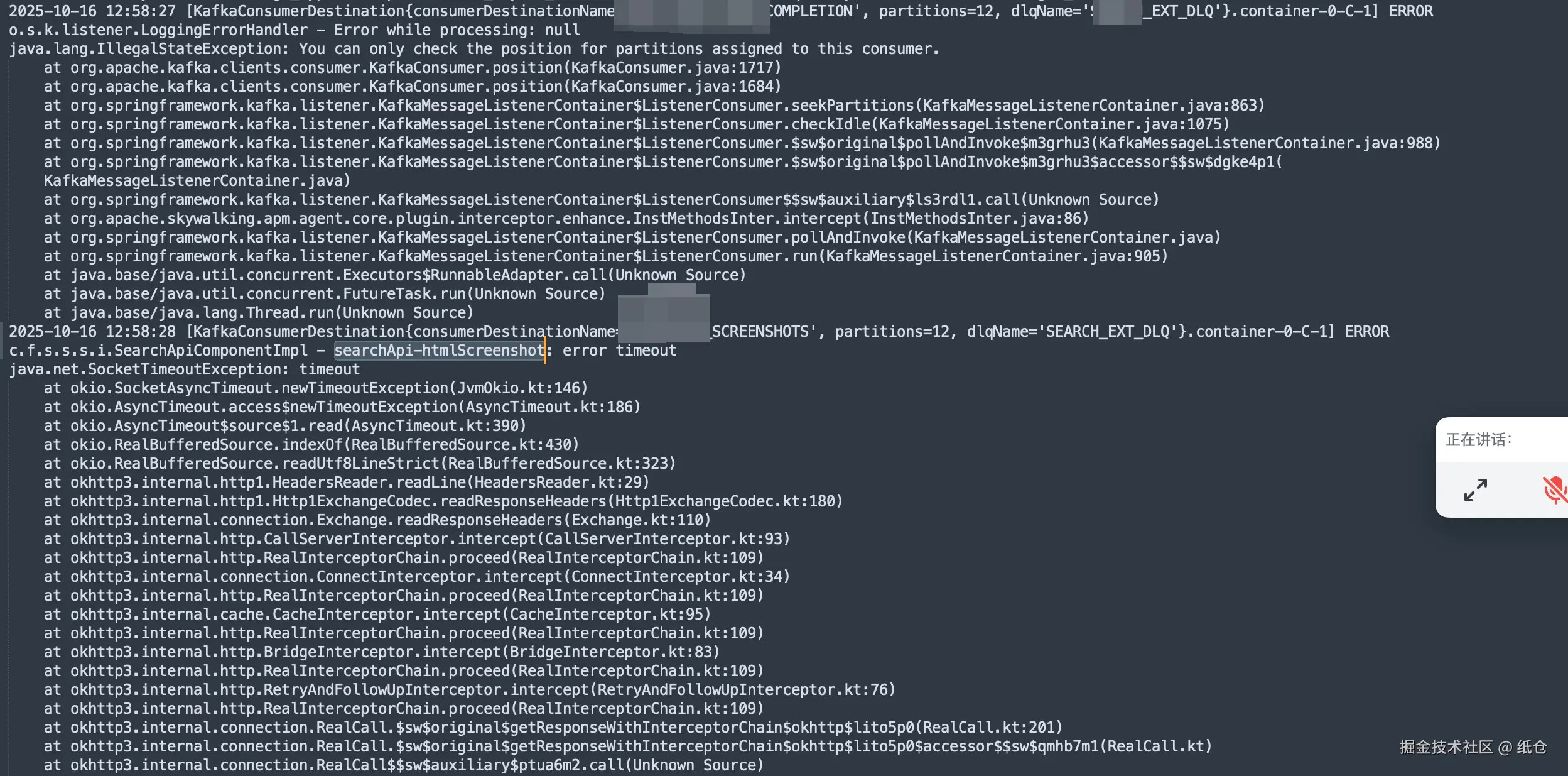
作为一个坚定的唯物主义者,我是不信见鬼的。但此刻我汗毛倒竖,吓得不敢再看屏幕一眼。

但是内心又觉得不甘心,于是我偷偷瞄了一眼屏幕。不看还好,一喵你猜我发现了啥?
消费者组重平衡了,这就像是在黑暗中有一束光照向了我,猪八戒发现嫦娥原来一直暗恋自己,我的女神其实不需要拉屎。
有了重平衡就好说了,无非就是两种情况,一是服务挂掉了,二是服务消费者执行超时了。现在看来服务没有挂,那就是超时了,也正好和上面的日志能对上。

那怎么又看到监听器执行的结果是正常的呢?
这就得从 Kafka 的批量拉取机制说起了,这货和我们人类直觉上的的队列机制不太一样。我们一般理解的队列是发送一个消息给队列,然后队列就异步把这消息给消费者。但是这货是消费者主动去拉取一批来消费。
然后好死不死,SpringCloudStream 为了封装得好用符合人类的认知,就做成了一般理解的队列那种方式。
SpringCloudStream 一批拉了500条记录,然后提供了一个监听器接口让我们实现。入参是一个对象,也就是500条数据中的一条,而不是一个数组。

我们假设这500条数据的ID是 001-500,每一条数据对应的消费者需要执行10s。那么总共就需要500 x 10s=5000s。
再假设消费者执行的超时时间是 300s,而且消费者执行的过程是串行的。那么500条中最多只能执行30条,这就能解释为什么看消费链路是正常的,但是还超时。
因为单次消费确实成功了,但是批次消费也确实超时了。
我咧个豆,破案了。

于是我就想到了两种方式来处理这个问题:第一是改成单条消息消费完立马确认,第二是把批次拉取的数据量改小一点。
第一种方案挺好的,就是性能肯定没有批量那么好,不然你以为 Kafka 的吞吐量能薄纱ActiveMQ这些传统队列。吞吐量都是小事,这个方案胜在可以立马去睡觉了。只需要改一个配置:ack-mode: RECORD
第二种方案是后来提的,其实单单把批次拉取的数据量改小性能提升还不是很明显。不过既然我们都能拿到一批数据了,那多线程安排上就得了。
先改配置,一次只拉取50条 max.poll.records: 50。然后启用线程池处理,完美!
@StreamListener("<TOPIC>")
public void consume(List<byte[]> payloads) {
List<CompletableFuture<Void>> futures = payloads.stream().map(bytes -> {
Payload payload = JacksonSnakeCaseUtils.parseJson(new String(bytes), Payload.class);
return CompletableFuture.runAsync(() -> {
// ........
}, batchConsumeExecutor).exceptionally(e -> {
log.error("Thread error {}", bytes, e);
return null;
});
}).collect(Collectors.toList());
try {
// 等待这批消息中的所有任务全部完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
errorMessage = "OK";
} catch (Exception e) {
errorMessage = "Ex: " + e.getMessage();
} finally {
// ...
}
}

来源:juejin.cn/post/7573687816431190026
为什么大厂一般都不推荐使用@Transactional?
前言
对于从事java开发工作的同学来说,Spring的事务肯定再熟悉不过了。
在某些业务场景下,如果一个请求中,需要同时写入多张表的数据。为了保证操作的原子性(要么同时成功,要么同时失败),避免数据不一致的情况,我们一般都会用到Spring事务。
确实,Spring事务用起来贼爽,就用一个简单的注解:@Transactional,就能轻松搞定事务。我猜大部分小伙伴也是这样用的,而且一直用一直爽。
但如果你使用不当,它也会坑你于无形。
今天我们就一起聊聊,事务失效的一些场景,说不定你已经中招了。不信,让我们一起看看。

一 事务不生效
1.访问权限问题
众所周知,java的访问权限主要有四种:private、default、protected、public,它们的权限从左到右,依次变大。
但如果我们在开发过程中,把有某些事务方法,定义了错误的访问权限,就会导致事务功能出问题,例如:
@Service
public class UserService {
@Transactional
private void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
我们可以看到add方法的访问权限被定义成了private,这样会导致事务失效,spring要求被代理方法必须是public的。
说白了,在AbstractFallbackTransactionAttributeSource类的computeTransactionAttribute方法中有个判断,如果目标方法不是public,则TransactionAttribute返回null,即不支持事务。
protected TransactionAttribute computeTransactionAttribute(Method method, @Nullable Class<?> targetClass) {
// Don't allow no-public methods as required.
if (allowPublicMethodsOnly() && !Modifier.isPublic(method.getModifiers())) {
return null;
}
// The method may be on an interface, but we need attributes from the target class.
// If the target class is null, the method will be unchanged.
Method specificMethod = AopUtils.getMostSpecificMethod(method, targetClass);
// First try is the method in the target class.
TransactionAttribute txAttr = findTransactionAttribute(specificMethod);
if (txAttr != null) {
return txAttr;
}
// Second try is the transaction attribute on the target class.
txAttr = findTransactionAttribute(specificMethod.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
if (specificMethod != method) {
// Fallback is to look at the original method.
txAttr = findTransactionAttribute(method);
if (txAttr != null) {
return txAttr;
}
// Last fallback is the class of the original method.
txAttr = findTransactionAttribute(method.getDeclaringClass());
if (txAttr != null && ClassUtils.isUserLevelMethod(method)) {
return txAttr;
}
}
return null;
}
也就是说,如果我们自定义的事务方法(即目标方法),它的访问权限不是public,而是private、default或protected的话,spring则不会提供事务功能。
2. 方法用final修饰
有时候,某个方法不想被子类重新,这时可以将该方法定义成final的。普通方法这样定义是没问题的,但如果将事务方法定义成final,例如:
@Service
public class UserService {
@Transactional
public final void add(UserModel userModel){
saveData(userModel);
updateData(userModel);
}
}
我们可以看到add方法被定义成了final的,这样会导致事务失效。
为什么?
如果你看过spring事务的源码,可能会知道spring事务底层使用了aop,也就是通过jdk动态代理或者cglib,帮我们生成了代理类,在代理类中实现的事务功能。
但如果某个方法用final修饰了,那么在它的代理类中,就无法重写该方法,而添加事务功能。
注意:如果某个方法是static的,同样无法通过动态代理,变成事务方法。
3.方法内部调用
有时候我们需要在某个Service类的某个方法中,调用另外一个事务方法,比如:
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
//@Transactional
public void add(UserModel userModel) {
userMapper.insertUser(userModel);
updateStatus(userModel);
}
@Transactional
public void updateStatus(UserModel userModel) {
doSameThing();
}
}
我们看到在事务方法add中,直接调用事务方法updateStatus。从前面介绍的内容可以知道,updateStatus方法拥有事务的能力是因为spring aop生成代理了对象,但是这种方法直接调用了this对象的方法,所以updateStatus方法不会生成事务。
由此可见,在同一个类中的方法直接内部调用,会导致事务失效。
那么问题来了,如果有些场景,确实想在同一个类的某个方法中,调用它自己的另外一个方法,该怎么办呢?
3.1 新加一个Service方法
这个方法非常简单,只需要新加一个Service方法,把@Transactional注解加到新Service方法上,把需要事务执行的代码移到新方法中。具体代码如下:
@Servcie
public class ServiceA {
@Autowired
prvate ServiceB serviceB;
public void save(User user) {
queryData1();
queryData2();
serviceB.doSave(user);
}
}
@Servcie
public class ServiceB {
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
3.2 在该Service类中注入自己
如果不想再新加一个Service类,在该Service类中注入自己也是一种选择。具体代码如下:
@Servcie
public class ServiceA {
@Autowired
prvate ServiceA serviceA;
public void save(User user) {
queryData1();
queryData2();
serviceA.doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
可能有些人可能会有这样的疑问:这种做法会不会出现循环依赖问题?
答案:不会。
其实spring ioc内部的三级缓存保证了它,不会出现循环依赖问题。但有些坑,如果你想进一步了解循环依赖问题,可以看看我之前文章《spring:我是如何解决循环依赖的?》。
3.3 通过AopContent类
在该Service类中使用AopContext.currentProxy()获取代理对象
上面的方法2确实可以解决问题,但是代码看起来并不直观,还可以通过在该Service类中使用AOPProxy获取代理对象,实现相同的功能。具体代码如下:
@Servcie
public class ServiceA {
public void save(User user) {
queryData1();
queryData2();
((ServiceA)AopContext.currentProxy()).doSave(user);
}
@Transactional(rollbackFor=Exception.class)
public void doSave(User user) {
addData1();
updateData2();
}
}
4.未被spring管理
在我们平时开发过程中,有个细节很容易被忽略。即使用spring事务的前提是:对象要被spring管理,需要创建bean实例。
通常情况下,我们通过@Controller、@Service、@Component、@Repository等注解,可以自动实现bean实例化和依赖注入的功能。
当然创建bean实例的方法还有很多,有兴趣的小伙伴可以看看我之前写的另一篇文章《@Autowired的这些骚操作,你都知道吗?》
如果有一天,你匆匆忙忙的开发了一个Service类,但忘了加@Service注解,比如:
//@Service
public class UserService {
@Transactional
public void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
从上面的例子,我们可以看到UserService类没有加@Service注解,那么该类不会交给spring管理,所以它的add方法也不会生成事务。
5.多线程调用
在实际项目开发中,多线程的使用场景还是挺多的。如果spring事务用在多线程场景中,会有问题吗?
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
new Thread(() -> {
roleService.doOtherThing();
}).start();
}
}
@Service
public class RoleService {
@Transactional
public void doOtherThing() {
System.out.println("保存role表数据");
}
}
从上面的例子中,我们可以看到事务方法add中,调用了事务方法doOtherThing,但是事务方法doOtherThing是在另外一个线程中调用的。
这样会导致两个方法不在同一个线程中,获取到的数据库连接不一样,从而是两个不同的事务。如果想doOtherThing方法中抛了异常,add方法也回滚是不可能的。
如果看过spring事务源码的朋友,可能会知道spring的事务是通过数据库连接来实现的。当前线程中保存了一个map,key是数据源,value是数据库连接。
private static final ThreadLocal<Map<Object, Object>> resources =
new NamedThreadLocal<>("Transactional resources");
我们说的同一个事务,其实是指同一个数据库连接,只有拥有同一个数据库连接才能同时提交和回滚。如果在不同的线程,拿到的数据库连接肯定是不一样的,所以是不同的事务。
6.表不支持事务
周所周知,在mysql5之前,默认的数据库引擎是myisam。
它的好处就不用多说了:索引文件和数据文件是分开存储的,对于查多写少的单表操作,性能比innodb更好。
有些老项目中,可能还在用它。
在创建表的时候,只需要把ENGINE参数设置成MyISAM即可:
CREATE TABLE `category` (
`id` bigint NOT NULL AUTO_INCREMENT,
`one_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`two_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`three_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`four_category` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
myisam好用,但有个很致命的问题是:不支持事务。
如果只是单表操作还好,不会出现太大的问题。但如果需要跨多张表操作,由于其不支持事务,数据极有可能会出现不完整的情况。
此外,myisam还不支持行锁和外键。
所以在实际业务场景中,myisam使用的并不多。在mysql5以后,myisam已经逐渐退出了历史的舞台,取而代之的是innodb。
有时候我们在开发的过程中,发现某张表的事务一直都没有生效,那不一定是spring事务的锅,最好确认一下你使用的那张表,是否支持事务。
7.未开启事务
有时候,事务没有生效的根本原因是没有开启事务。
你看到这句话可能会觉得好笑。
开启事务不是一个项目中,最最最基本的功能吗?
为什么还会没有开启事务?
没错,如果项目已经搭建好了,事务功能肯定是有的。
但如果你是在搭建项目demo的时候,只有一张表,而这张表的事务没有生效。那么会是什么原因造成的呢?
当然原因有很多,但没有开启事务,这个原因极其容易被忽略。
如果你使用的是springboot项目,那么你很幸运。因为springboot通过DataSourceTransactionManagerAutoConfiguration类,已经默默的帮你开启了事务。
你所要做的事情很简单,只需要配置spring.datasource相关参数即可。
但如果你使用的还是传统的spring项目,则需要在applicationContext.xml文件中,手动配置事务相关参数。如果忘了配置,事务肯定是不会生效的。
具体配置如下信息:
<!-- 配置事务管理器 -->
<bean class="org.springframework.jdbc.datasource.DataSourceTransactionManager" id="transactionManager">
<property name="dataSource" ref="dataSource"></property>
</bean>
<tx:advice id="advice" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED"/>
</tx:attributes>
</tx:advice>
<!-- 用切点把事务切进去 -->
<aop:config>
<aop:pointcut expression="execution(* com.susan.*.*(..))" id="pointcut"/>
<aop:advisor advice-ref="advice" pointcut-ref="pointcut"/>
</aop:config>
默默的说一句,如果在pointcut标签中的切入点匹配规则,配错了的话,有些类的事务也不会生效。
二 事务不回滚
1.错误的传播特性
其实,我们在使用@Transactional注解时,是可以指定propagation参数的。
该参数的作用是指定事务的传播特性,spring目前支持7种传播特性:
REQUIRED如果当前上下文中存在事务,那么加入该事务,如果不存在事务,创建一个事务,这是默认的传播属性值。SUPPORTS如果当前上下文存在事务,则支持事务加入事务,如果不存在事务,则使用非事务的方式执行。MANDATORY如果当前上下文中存在事务,否则抛出异常。REQUIRES_NEW每次都会新建一个事务,并且同时将上下文中的事务挂起,执行当前新建事务完成以后,上下文事务恢复再执行。NOT_SUPPORTED如果当前上下文中存在事务,则挂起当前事务,然后新的方法在没有事务的环境中执行。NEVER如果当前上下文中存在事务,则抛出异常,否则在无事务环境上执行代码。NESTED如果当前上下文中存在事务,则嵌套事务执行,如果不存在事务,则新建事务。
如果我们在手动设置propagation参数的时候,把传播特性设置错了,比如:
@Service
public class UserService {
@Transactional(propagation = Propagation.NEVER)
public void add(UserModel userModel) {
saveData(userModel);
updateData(userModel);
}
}
我们可以看到add方法的事务传播特性定义成了Propagation.NEVER,这种类型的传播特性不支持事务,如果有事务则会抛异常。
目前只有这三种传播特性才会创建新事务:REQUIRED,REQUIRES_NEW,NESTED。
2.自己吞了异常
事务不会回滚,最常见的问题是:开发者在代码中手动try...catch了异常。比如:
@Slf4j
@Service
public class UserService {
@Transactional
public void add(UserModel userModel) {
try {
saveData(userModel);
updateData(userModel);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
这种情况下spring事务当然不会回滚,因为开发者自己捕获了异常,又没有手动抛出,换句话说就是把异常吞掉了。
如果想要spring事务能够正常回滚,必须抛出它能够处理的异常。如果没有抛异常,则spring认为程序是正常的。
3.手动抛了别的异常
即使开发者没有手动捕获异常,但如果抛的异常不正确,spring事务也不会回滚。
@Slf4j
@Service
public class UserService {
@Transactional
public void add(UserModel userModel) throws Exception {
try {
saveData(userModel);
updateData(userModel);
} catch (Exception e) {
log.error(e.getMessage(), e);
throw new Exception(e);
}
}
}
上面的这种情况,开发人员自己捕获了异常,又手动抛出了异常:Exception,事务同样不会回滚。
因为spring事务,默认情况下只会回滚RuntimeException(运行时异常)和Error(错误),对于普通的Exception(非运行时异常),它不会回滚。
4.自定义了回滚异常
在使用@Transactional注解声明事务时,有时我们想自定义回滚的异常,spring也是支持的。可以通过设置rollbackFor参数,来完成这个功能。
但如果这个参数的值设置错了,就会引出一些莫名其妙的问题,例如:
@Slf4j
@Service
public class UserService {
@Transactional(rollbackFor = BusinessException.class)
public void add(UserModel userModel) throws Exception {
saveData(userModel);
updateData(userModel);
}
}
如果在执行上面这段代码,保存和更新数据时,程序报错了,抛了SqlException、DuplicateKeyException等异常。而BusinessException是我们自定义的异常,报错的异常不属于BusinessException,所以事务也不会回滚。
即使rollbackFor有默认值,但阿里巴巴开发者规范中,还是要求开发者重新指定该参数。
这是为什么呢?
因为如果使用默认值,一旦程序抛出了Exception,事务不会回滚,这会出现很大的bug。所以,建议一般情况下,将该参数设置成:Exception或Throwable。
5.嵌套事务回滚多了
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
roleService.doOtherThing();
}
}
@Service
public class RoleService {
@Transactional(propagation = Propagation.NESTED)
public void doOtherThing() {
System.out.println("保存role表数据");
}
}
这种情况使用了嵌套的内部事务,原本是希望调用roleService.doOtherThing方法时,如果出现了异常,只回滚doOtherThing方法里的内容,不回滚 userMapper.insertUser里的内容,即回滚保存点。。但事实是,insertUser也回滚了。
why?
因为doOtherThing方法出现了异常,没有手动捕获,会继续往上抛,到外层add方法的代理方法中捕获了异常。所以,这种情况是直接回滚了整个事务,不只回滚单个保存点。
怎么样才能只回滚保存点呢?
@Slf4j
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
userMapper.insertUser(userModel);
try {
roleService.doOtherThing();
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
}
可以将内部嵌套事务放在try/catch中,并且不继续往上抛异常。这样就能保证,如果内部嵌套事务中出现异常,只回滚内部事务,而不影响外部事务。
三 其他
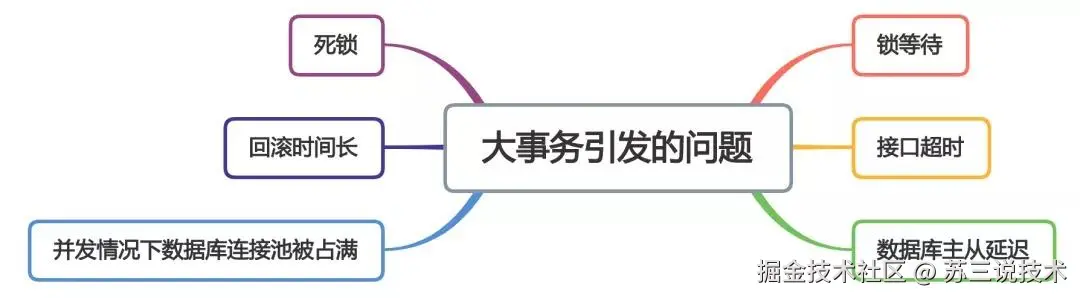
1 大事务问题
在使用spring事务时,有个让人非常头疼的问题,就是大事务问题。
通常情况下,我们会在方法上@Transactional注解,填加事务功能,比如:
@Service
public class UserService {
@Autowired
private RoleService roleService;
@Transactional
public void add(UserModel userModel) throws Exception {
query1();
query2();
query3();
roleService.save(userModel);
update(userModel);
}
}
@Service
public class RoleService {
@Autowired
private RoleService roleService;
@Transactional
public void save(UserModel userModel) throws Exception {
query4();
query5();
query6();
saveData(userModel);
}
}
但@Transactional注解,如果被加到方法上,有个缺点就是整个方法都包含在事务当中了。
上面的这个例子中,在UserService类中,其实只有这两行才需要事务:
roleService.save(userModel);
update(userModel);
在RoleService类中,只有这一行需要事务:
saveData(userModel);
现在的这种写法,会导致所有的query方法也被包含在同一个事务当中。
如果query方法非常多,调用层级很深,而且有部分查询方法比较耗时的话,会造成整个事务非常耗时,而从造成大事务问题。
关于大事务问题的危害,可以阅读一下我的另一篇文章《让人头痛的大事务问题到底要如何解决?》,上面有详细的讲解。
更多精彩内容百度一下:Java突击队
2.编程式事务
上面聊的这些内容都是基于@Transactional注解的,主要说的是它的事务问题,我们把这种事务叫做:声明式事务。
其实,spring还提供了另外一种创建事务的方式,即通过手动编写代码实现的事务,我们把这种事务叫做:编程式事务。例如:
@Autowired
private TransactionTemplate transactionTemplate;
...
public void save(final User user) {
queryData1();
queryData2();
transactionTemplate.execute((status) => {
addData1();
updateData2();
return Boolean.TRUE;
})
}
在spring中为了支持编程式事务,专门提供了一个类:TransactionTemplate,在它的execute方法中,就实现了事务的功能。
相较于@Transactional注解声明式事务,我更建议大家使用,基于TransactionTemplate的编程式事务。主要原因如下:
- 避免由于spring aop问题,导致事务失效的问题。
- 能够更小粒度的控制事务的范围,更直观。
建议在项目中少使用@Transactional注解开启事务。但并不是说一定不能用它,如果项目中有些业务逻辑比较简单,而且不经常变动,使用@Transactional注解开启事务开启事务也无妨,因为它更简单,开发效率更高,但是千万要小心事务失效的问题。
来源:juejin.cn/post/7601576716016435263
面试必问HTTP状态码:从“请求的一生”彻底搞懂,告别死记硬背
HTTP状态码:从请求的一生重新理解
“所有数字背后,都是一个请求的遗言。”
—— 某位被502逼疯的工程师
或者,你也可以记住这一句:
“状态码不是用来背的,是用来收尸的。”
—— 同一位工程师,在又一次凌晨三点被叫起来之后
为什么写这篇文章
相信很多朋友面试的时候都会被面试官问到:“你记得多少HTTP状态码?具体有哪些含义?”
一般对于这类问题,我们都会提前复习和记忆,才能回答得比较完整。
但后来我发现一件事:
“背状态码就像背尸检报告,你记住了死因,却没见过现场。”
—— 某位靠背答案转行写代码的面试者
本文从一个请求离开客户端之后的链路出发,带你去看现场。
要彻底搞懂HTTP状态码,我们可以换一种思路:设计这么多状态码,它们具体是在哪一环节、因为什么原因被返回的?
我们的请求传递到整个后端,并不是直接访问到服务器。它要经过一大批网络组件的筛选过滤,每一关都有可能倒下,每一关都会有人替它写下遗言。
下面,让我们从一个请求发送到后端的链路,重新认识一下HTTP状态码。
第一站:边缘节点 CDN
“我以为我能活到源站,结果在门口就被拦下了。”
—— 一个试图直接访问服务器的请求
当一个请求经过DNS解析离开设备,遇到的第一个网络组件是CDN。
CDN是一种缓存设备。它把源服务器的资源拉取到离你最近的地方,像个热情过度的前台:“你要这个?我这有,别往里跑了。”
遇到热门的资源文件(比如B站、抖音的热门视频),直接从CDN获取,速度远远快于访问远端的服务器。对于这些占用带宽较大的静态文件资源,缓存到CDN上是性价比最高的方案。
CDN节点状态码
| 状态码 | 含义 | 死因报告 |
|---|---|---|
200 | 成功命中 | “我这有,拿去吧。” |
304 | 未修改 | “你手里的还是新鲜的,不用换。” |
502 | 回源非法响应 | “我去帮你问,结果源站说方言,听不懂。” |
503 | 回源连接拒绝 | “源站把门关上了,不让我进。” |
504 | 回源超时 | “源站接了电话,但一直不说话。” |
💡 304是个好东西
每次向CDN发起请求,并不一定需要CDN把整个文件再发一遍。
如果我们本地有缓存,带着文件的指纹(ETag)或修改时间(Last-Modified)去问CDN:“我这个还新鲜吗?”
CDN看一眼:“没变,接着用吧。”
省带宽,省时间,双方都舒服。
—— 这是唯一一个**请求和服务器达成共识“你不用干活”**的状态码。
第二站:安全网关 WAF
“我不是不让你进,我是怕你进来搞破坏。”
—— WAF,一个没有感情的安检机器
请求离开CDN后,仍然不能直接到达源站。它先要经过WAF——Web应用防火墙。
这个组件的作用,名字已经写得很清楚:为了安全。
它像个眼神锐利的保安,把你从头扫到脚:
- 检查IP是否合法 → 不合法返回
403 Forbidden - 检查请求头是否合法 → 不合法返回
406 Not Acceptable - 检查请求体是否合法 → 不合法返回
413 Payload Too Large - 判断请求频率是否正常 → 不合法返回
429 Too Many Requests
WAF状态码场景
| 攻击/异常类型 | 状态码 | 死因报告 |
|---|---|---|
| 黑名单IP/SQL注入/XSS | 403 | “你身上有刀,不许进。” |
| 无效Accept头 | 406 | “你要的东西我给不了,别进了。” |
| 超大请求体 | 413 | “你扛的箱子太大了,进不来。” |
| CC攻击/高频请求 | 429 | “你来回跑太多次了,歇会儿。” |
这些“不正经”的请求方式,其实就是网络安全课里讲的攻击手段。
“我只是想进来看看,它说我是黑客。”
—— 一个带着正常User-Agent却被误杀的公司内网爬虫
第三站:负载均衡器 Nginx
“一万个用户就要一万个进程?凭什么等网速还要占着位置?”
—— Igor Sysoev,Nginx之父,2002年
对于这个组件,一开始我也不明白它为什么有那么多功能。
要认识一件东西,最好的方式是了解它为什么被创造出来。
2002年,莫斯科。
Apache的规矩:来一个人开一个进程,来一万个人开一万个进程。
16G内存,Apache张嘴要50G,然后跪了。
Igor Sysoev每天的工作就是重启服务器——像给同一个病人反复做心肺复苏。
终于有一天他骂了句脏话:
“一万个用户就要一万个进程?凭什么等网速的时候还要占着内存?”
他觉得这不合理——像每个客人身后站一个专属服务员,客人上厕所他都得站着等。
Igor决定写一个“不讲武德”的服务器:
一个服务员管五十桌,谁招手过去,谁看菜单就晾着。不等人,不空转,不占茅坑。
两年,一万行C。
2004年,Nginx诞生。
4个进程扛1万连接,内存500MB。
Apache用50G干的活,它用1%的资源。
后来有人问他为什么写Nginx。
他说:
“等的时候,不应该占着位置。”
Nginx核心状态码
| 场景 | 状态码 | 死因报告 |
|---|---|---|
| 静态文件不存在 | 404 | “你要的文件,硬盘里没有。” |
| 静态文件无权限 | 403 | “文件在那,但你不配看。” |
| 后端无响应 | 502 | “我把请求转给后面,后面没人接。” |
| 后端超时 | 504 | “后面接了电话,但一直‘嗯’个不停,就是不说话。” |
| 客户端提前关闭 | 499 | “用户等不及,把网页关了。” |
| 限流拦截 | 429 | “你刷太快了,我伺候不动。” |
| 主动熔断 | 503 | “后面的兄弟都快累死了,我先替你挡一下。” |
💡 关于499
499是Nginx独有的状态码。
它不是后端返回的,不是WAF拦截的,是Nginx自己记下的遗言:
“他没等我,他走了。”
很多时候你以为的超时(504),其实是用户等得不耐烦,直接关掉了页面。
Nginx默默在日志里写下一行:
“请求已转发,但客户端已失联。”
第四站:Web 应用
“终于到我了。”
—— 一个请求,在穿过CDN、WAF、Nginx之后
终于,请求到达了后端应用。
这里的HTTP状态码,是开发者在代码里亲手写下的。
它是唯一一个由你决定生死的环节。
4xx:你的问题,不是我的问题
“你发过来的东西,我尽力了,真的看不懂。”
—— 应用对400说
| 状态码 | 含义 | 死因报告 |
|---|---|---|
400 | 我看不懂 | JSON少括号、类型传错、必填字段没带 |
401 | 你没登录 | 没带Token、Token过期、Token被篡改 |
403 | 你不能进 | 普通用户点管理员接口、IP不在白名单 |
404 | 我没有 | 查不存在的用户ID、已下架的商品 |
409 | 已经有了 | 用户名被占用、重复提交、两人同时编辑同一条数据 |
422 | 内容不对 | 邮箱格式正确但未注册、年龄传了200岁 |
“你说你叫admin,但我这已经有叫admin的了。”
—— 409 Conflict,注册接口的日常
2xx:一切顺利
“今天是个好日子。”
—— 200 OK,最幸福的状态码
| 状态码 | 含义 | 遗言(活着的遗言) |
|---|---|---|
200 | 成功 | “成了,数据给你。” |
201 | 创建成功 | “成了,新资源在这。” |
202 | 已接受 | “收下了,后面慢慢弄。” |
204 | 成功,无返回 | “成了,但没啥可说的。” |
3xx:别找我,去那边
“我已经搬家了,这是新地址。”
—— 301,一个负责任的旧门牌
| 状态码 | 含义 | 死因报告 |
|---|---|---|
301 | 永久搬家 | “这里不住了,以后去那边找我。” |
302 | 临时离开 | “现在不在,你先去隔壁。” |
304 | 没变 | “你手里那个还能用,别下载了。” |
5xx:我炸了,不是你的错
“对不起,是我的问题。”
—— 500 Internal Server Error,一个有礼貌的崩溃
| 状态码 | 含义 | 死因报告 |
|---|---|---|
500 | 代码崩溃 | 空指针、数据库连不上、try-catch没接住 |
502 | 上游乱说话 | 第三方API返回乱码、Redis数据结构不对 |
503 | 我拒绝 | 连接池满了、服务正在重启 |
504 | 上游太慢 | 第三方API超时、SQL查了10秒 |
“我调了别人的接口,别人没回我。”
—— 504,一个被上游坑死的请求
链路简图 · 请求的一生
“这不是架构图,这是事故多发路段示意图。”
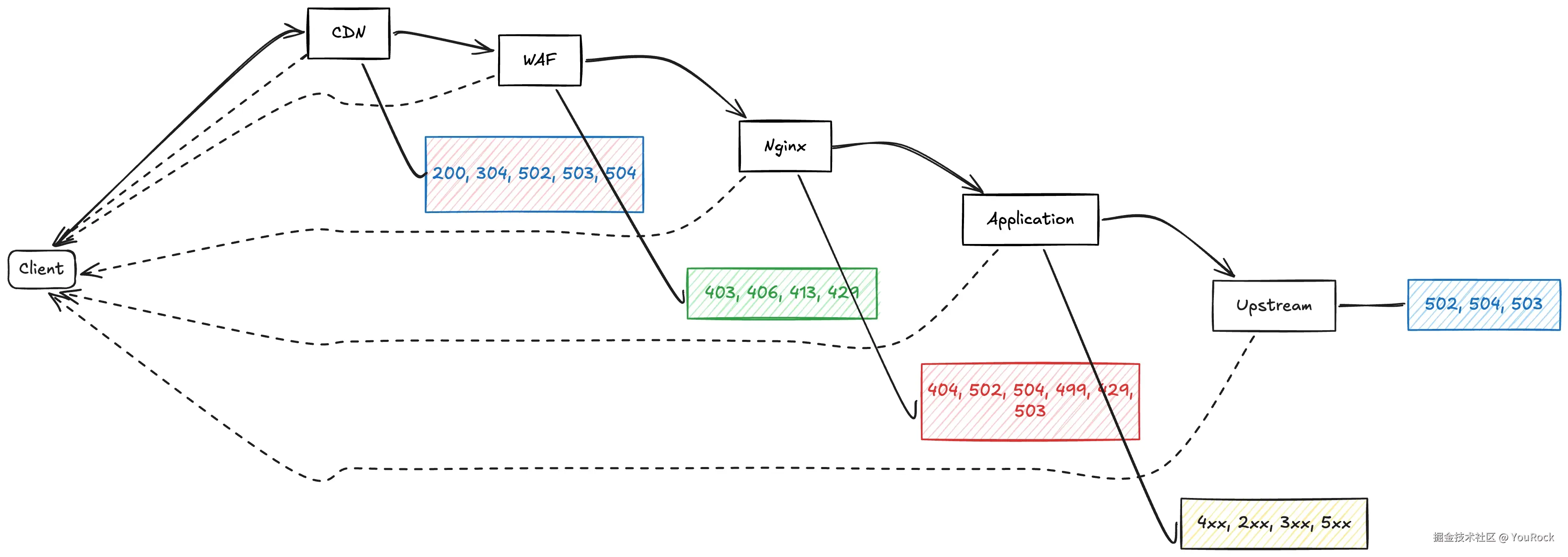
写在最后:状态码不是数字,是请求的“尸检报告”
行文至此,我们已经陪着一个HTTP请求走完了它的完整一生。
它从你的浏览器出发,叩开CDN的大门,穿过WAF的安检,经过Nginx的调度,最终抵达应用服务器的后厨。
而在每一道关卡,都有可能倒下——也可能凯旋。
每一个状态码,都不是随机数字,而是请求倒下的那一刻,最后一个活着的人替它写下的死因报告。
当你再看到502,你脑海里应该浮现的不是“Bad Gateway”这行英文,而是一场事故现场:
- 也许是CDN回源时,源站说了句它听不懂的方言(非法响应)
- 也许是Nginx转发时,后端的应用根本没在听(连接失败)
- 也许是你的代码调用第三方API,对方接了电话但开始沉默(超时)
- 也许是负载均衡器巡视一圈,发现所有小弟都已阵亡(无可用后端)
同一个502,七种死法。症状相同,病灶各异。
这就是为什么,学会背状态码的人只能回答“它是什么意思”,而理解链路的人能回答:
“它死在了哪一环。”
这趟旅程也告诉我们另一件事:
CDN会替你背锅,Nginx会替你扛压,WAF会替你挡刀——但它们都只是过客。
唯一从头到尾、从生到死都陪着你代码的,是你自己写的业务逻辑。
200是你写的,404是你写的,500也是你写的。
状态码不是面试官拷问你的工具,而是你的代码和这个世界对话的语言。
你用200说:“一切正常。”
你用404说:“你找的东西不在这里。”
你用500说:“抱歉,我出了点问题,已经在看日志了。”
所以,别再背状态码了。
去理解你请求走过的路,去读懂每一行日志,去亲手写下每一个你返回的状态码。
当你不再问“502是什么意思”,而是问——
“这个502是谁报的?”
“在哪一环报的?”
“日志里留下了什么线索?”
那一刻,你就不再是背答案的人,而是真的懂了。
“愿你的200永远不鸽,愿你的5xx永远有日志可查。”
—— 同一位被502逼疯的工程师,在最后一次上线后说
来源:juejin.cn/post/7605848213602779182
用 OpenClaw 做视频:播放量从几十涨到 9000,成本一毛钱
大家好,我是孟健。
我做视频号不用剪映,不用 PR ,甚至不碰任何剪辑软件。 一条 60 秒的短视频,成本一毛钱,从选题到成片 15 分钟搞定。
怎么做到的?OpenClaw(开源 AI 助理框架)+ Remotion(React 视频框架)+ 语音克隆,三件套组合拳。
先看成品👇
(掘金不支持视频,可以搜孟健AI编程)
今天把整套流水线拆给你看。
01 先说数据:用 AI 做视频比我自己拍还好
前几天我开始用 OpenClaw 全自动做视频号内容。结果出乎意料——AI 做的视频,数据比我自己拍的好得多。
之前我自己录制、剪辑,一条视频播放量几十到两三百,偶尔破千算运气好。
换成 OpenClaw 全自动流水线之后:
- 单条播放量:1595(之前平均不到 200)
- 3天 总播放:9,018
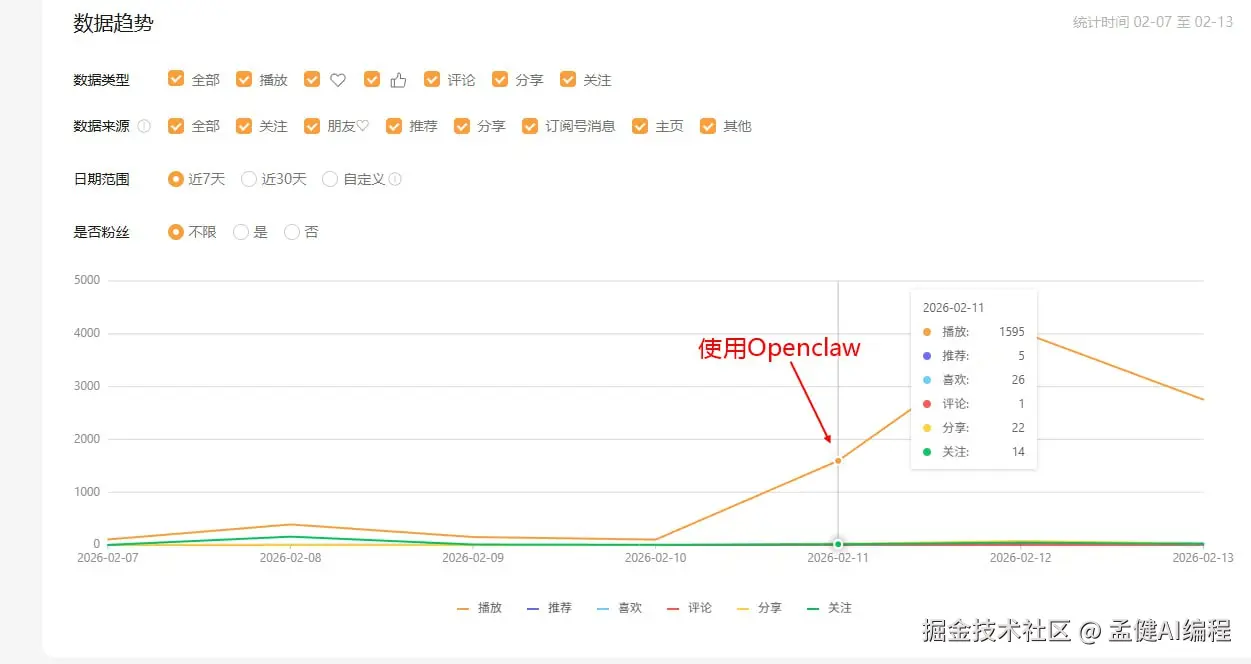
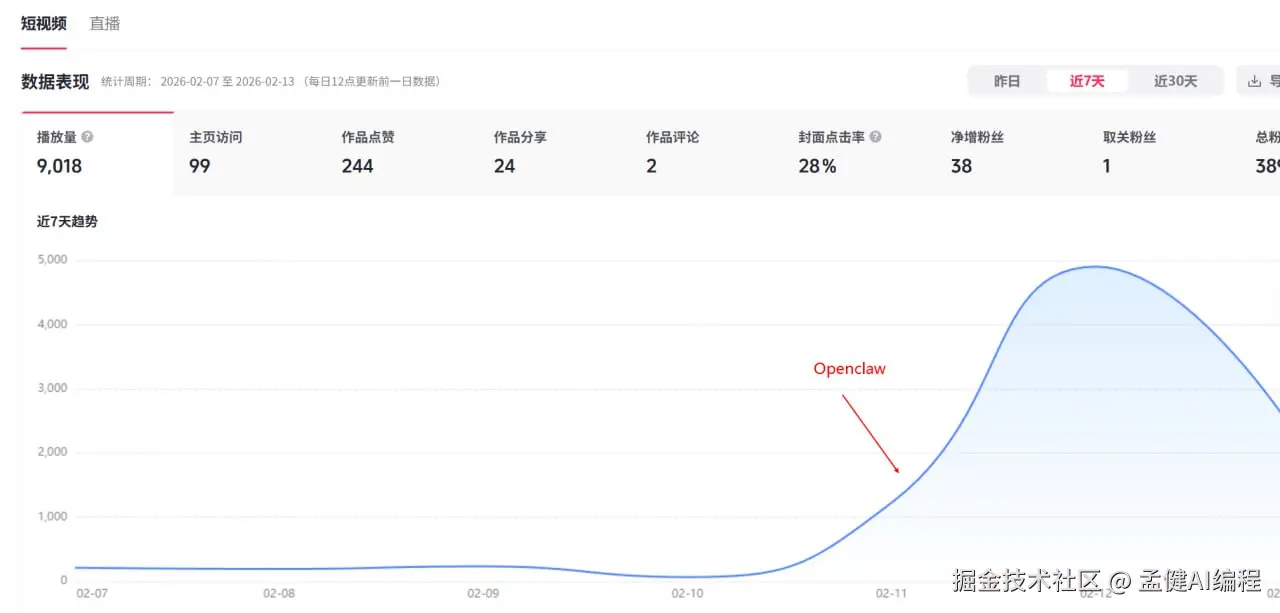
从 02-11 开始用 OpenClaw 做视频的那天起,播放量曲线直接起飞。之前一周加起来可能还不到 1000 播放。
为什么 AI 做的反而更好?我想了想,原因有三个:
- 更新频率上去了。以前一周发 1-2 条,现在可以日更。视频号算法喜欢活跃的账号。
- 风格统一了。每条视频都是同一个"赛博线框"模板,辨识度高,观众看到就知道是我。
- 质量反而稳定了。人工拍摄状态有起伏,AI 生产线的输出质量是恒定的。
02 整套流水线长什么样
传统做一条 60 秒视频号内容:
- 写脚本:30 分钟
- 录音/配音:20 分钟
- 剪辑+字幕+动效:1-2 小时
- 导出上传:10 分钟
总耗时:2-3 小时,还得会剪映或 PR 。
我现在的流程:
- Agent 自动推送选题,我选一个:1 分钟
- Agent 写旁白 → 克隆我的声音生成 TTS → 提取时间戳 → Remotion 渲染成片:约 10 分钟
- 我看一遍,确认发布:2 分钟
总耗时:约 15 分钟。成本不到两毛钱。不需要会任何剪辑软件。
03 技术栈:四个关键零件
零件一:OpenClaw — 多 Agent 调度中心
OpenClaw 是一个开源的 AI 助理框架,核心能力是让多个 AI Agent 协作。我的团队里有 6 个 Agent,各管一摊:
- 墨媒(运营):负责选题推送和发布
- 墨笔(创作):写脚本、调 TTS、编排场景、渲染视频
- 墨影(设计):封面图和配图
视频制作主要是墨笔在干活。它收到选题后,一路跑完脚本→配音→渲染,全程无人值守。
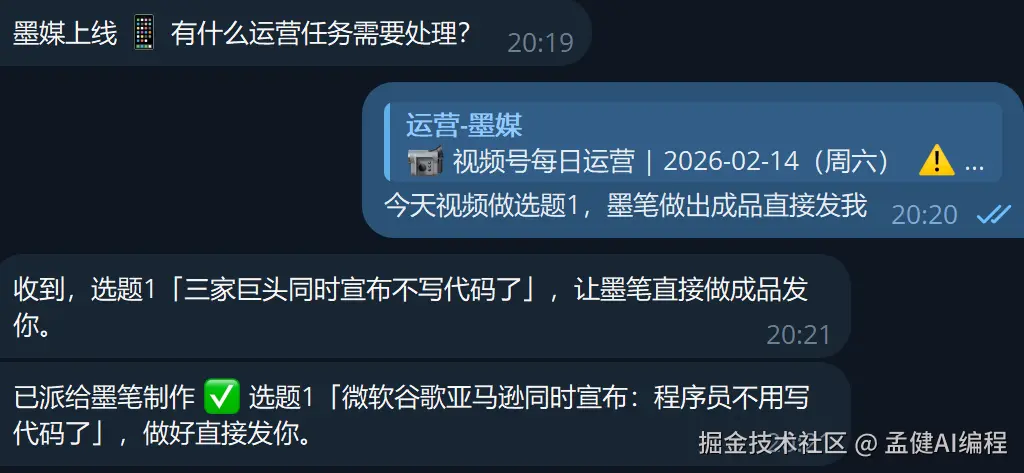
Agent 之间怎么协作? OpenClaw 有个sessions_send机制,Agent 之间直接传消息。墨媒推选题给墨笔,墨笔做完发成片链接给墨媒,墨媒通知我确认。像一条流水线,每个工位各干各的。
零件二:Remotion — 用 React 写视频
这是整套方案最"反直觉"的部分。
Remotion 是一个 React 视频框架。你写 React 组件,它帮你渲染成 MP4。 没有时间轴,没有图层面板,视频就是代码。
为什么用代码做视频?因为可复用、可模板化、可自动化。
传统剪辑:每条视频从零开始拖素材。
Remotion:定义好模板,换数据就出新片。
我的视频模板叫"赛博线框批注体"——深色背景、大字排版、小墨(我的 AI 猫助手)线条画穿插批注。风格统一,辨识度高。
核心代码结构长这样:
// scenes-data.ts — 这是唯一需要改的文件
export const scenes: SceneData[] = [
{
start: 0.0, // 开始时间(秒)
end: 3.46, // 结束时间(秒)
type: 'title', // 场景类型:决定动效
title: '三家巨头\n同一天',
xiaomo: 'peek', // 小墨姿态
},
{
start: 3.46,
end: 5.90,
type: 'pain',
title: '微软说',
subtitle: 'Copilot 已经能写掉\n90% 的代码',
number: '90%',
highlight: 'Copilot',
},
// ... 更多场景
];
每条新视频只需要改这一个文件。 场景类型决定动效——title用 glitch 闪现,emphasis用 slam 砸入,circle用猫爪画圈。动效和排版都是预设好的,换内容自动适配。
渲染一行命令:
npx remotion render WireframeVideo out/成片.mp4 --codec=h264
零件三:MiniMax 语音克隆 — 用我的声音说话
视频号的配音是我自己的声音,但不是我录的。
MiniMax 的 voice-clone 服务,用一段 30 秒的录音样本,克隆出一个可以说任何话的语音模型。生成速度快,一段 60 秒的旁白 3-5 秒出结果。
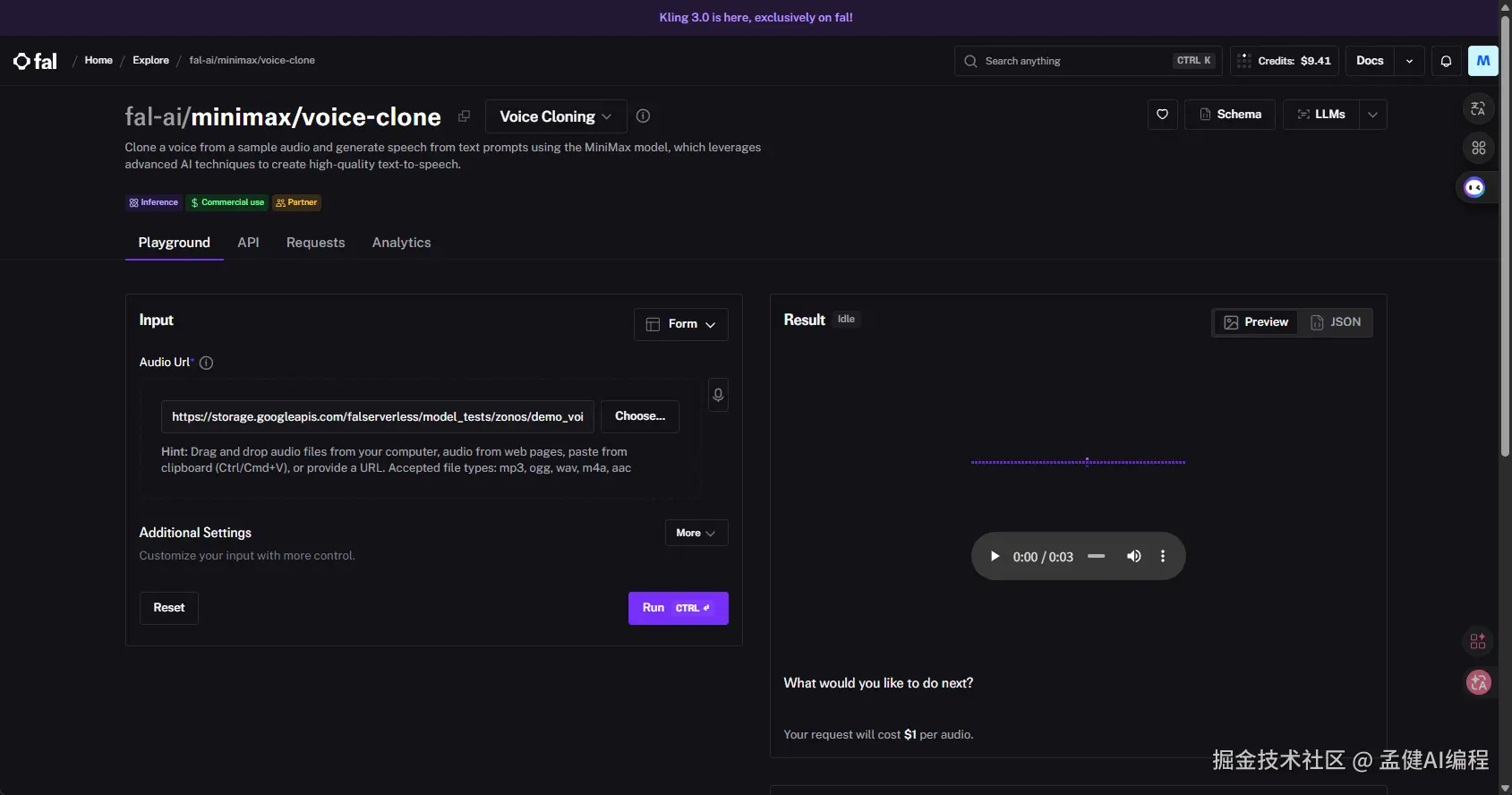
通过 fal.ai 的 API 调用,1.15 倍速,对话感很强。一条视频的 TTS 成本大概一毛钱。
零件四:Whisper — 时间戳精确对齐
TTS 生成的音频,需要知道每句话在第几秒说完,才能让 Remotion 的字幕精确对齐。
OpenAI 的 Whisper 模型(本地部署,免费)转录音频,输出逐句时间戳:
[ {"start": 0.0, "end": 3.46, "text": "三家巨头同一天说了一件事"}, {"start": 3.46, "end": 5.90, "text": "微软说Copilot已经能写掉90%的代码"}, ...]
这些时间戳直接灌进scenes-data.ts,每个场景的出场时间和旁白完美对齐。
04 完整流程:一条视频是怎么从 0 到 1 的
墨媒推选题(cron 每日 9:30)
↓ Telegram 推送5个选题
孟健选一个
↓ 选题确认
墨笔写旁白脚本(60秒,200字左右)
↓
MiniMax TTS 生成克隆语音
↓ 约¥0.1,3秒出结果
Whisper 提取逐句时间戳
↓ 本地运行,免费
墨笔编排 scenes-data.ts
↓ 按时间戳填场景类型+文案
Remotion 渲染 MP4
↓ h264编码,约2分钟
墨笔发成片给孟健
↓ Telegram 通知
孟健确认 → 墨媒发布
关键点:从"孟健选一个"到"成片发出来",中间全自动。 墨笔这个 Agent 收到选题后,自己写脚本、调 TTS、提时间戳、编场景、渲染视频、发通知。我只需要在 Telegram 里点一下确认。

整个过程大约 10 分钟。我的参与时间?选题 1 分钟,看成片 2 分钟。
05 赛博线框体:为什么选这个风格
视频号做内容有个核心矛盾:你得快,但你不能糙。
实拍太重(一个人搞不过来)。AI 生成画面太假(观众已经审美疲劳)。PPT 录屏太无聊。
我选了一条中间路线:纯文字动画 + 线条 IP 角色。
- 深色背景(#0A0A0F),不刺眼,高级感
- 大字排版,关键词高亮(cyan/gold/red 三种色系)
- 小墨(线条猫)在角落做批注动作(探头、趴着、指向、画圈)
- 动效精确对齐音频:glitch 嗞声配标题出场,slam 低频咚配数字砸入,draw 笔触声配猫爪画圈
- BGM 18%音量打底,不抢旁白
这个风格的好处:全部是代码生成的。 没有一帧需要手画。小墨的 6 种姿态是 SVG 路径,动效是 CSS 动画函数,排版是 React 组件。换内容不换风格,视觉统一,品牌感强。
而且成本极低——Remotion 渲染不花钱,只有 TTS 那一毛钱。
06 踩过的坑 坑 1: TTS 速度和自然度的平衡
1.0 倍速太慢,像念稿。1.3 倍速太快,听不清。1.15 倍速是甜点。 这个参数调了好几轮才定下来。
坑 2:时间戳精度
Whisper 的时间戳偶尔会飘几百毫秒。解决方案是渲染后快速过一遍——15 分钟的流程里,2 分钟用来看成片,不算浪费。
坑 3:Remotion 的字体加载
服务器渲染时字体可能缺失。解决方案:把字体文件放到public/目录,用@font-face显式加载,别依赖系统字体。
坑 4:音效对齐
动效和音效必须精确到帧。Remotion 的Sequence组件按帧计算(30fps),但时间戳是秒。需要做Math.round(seconds * fps)的换算,差一帧观感就不对。
坑 5:不要让内容 Agent 降模型
试过把墨笔从 Claude Opus 换成 Sonnet 省钱。6 分钟就换回来了——脚本质量断崖式下跌,金句变废话,节奏感全无。内容创作是最不该省的环节。
07 成本算账
| 项目 | 单价 | 说明 |
|---|---|---|
| TTS( MiniMax via fal.ai) | ~¥0.1/条 | 60 秒旁白,语音克隆 |
| Whisper | ¥0 | 本地部署,免费 |
| Remotion 渲染 | ¥0 | 开源,服务器本地跑 |
| BGM/音效 | ¥0 | 预置素材库 |
| 合计 | ~¥0.1/条 |
对比请人做:一条 60 秒视频号内容,外包报价 300-800 元。
2 小时变 15 分钟,800 块变一毛钱,播放量反而翻了 10 倍。 这就是把视频从"项目"变成"工序"的意义。
08 你能复制这套流程吗?
技术门槛说实话不低。你需要:
- 一台服务器(跑 OpenClaw + Remotion 渲染)
- 基本的 React 能力(定制 Remotion 模板)
- OpenClaw 部署经验(配 Agent + cron)
- MiniMax/ElevenLabs 账号(TTS)
但思路是通用的:把视频生产拆成可编程的环节,用 Agent 串起来。
你不一定要用我的技术栈。Remotion 可以换成 FFmpeg 纯命令行(更简单但动效少),TTS 可以用免费的 edge-tts(质量差一些但零成本),Agent 框架也不一定是 OpenClaw。
核心不是工具,是思路:视频 = 数据 + 模板 + 自动化。
写在最后。
我做这套系统不是为了炫技。是因为一个人创业,内容是最大的杠杆,但时间是最稀缺的资源。
传统做内容是"创作"——每次从零开始。AI 时代做内容是"生产"——定义好流水线,然后持续出货。
15 分钟一条视频,成本一毛钱,播放量比自己拍还好。工具就摆在那里。用不用,是你的事。
如果这篇对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续输出的动力 ✨
我的其他平台账号和开源项目在个人主页中,欢迎交流 🤝
来源:juejin.cn/post/7606173847994023990
被马斯克疯狂点赞的国产 AI,很可能是 AI 时代的抖音!
这是苍何的第 490 篇原创!
大家好,我是苍何。
刷 X 看到马斯克点赞并评论了一个 AI 叫 Loopit,目前有 59 万阅读了,🐂🍺啊。

看了下视频内容,还挺有意思的,互动性和可玩性挺高。
扒了下 Loopit,好家伙,来自中国的开发团队,创始人是陈炜鹏,前百川智能的联创。
然后我也按照教程去应用市场下了 Loopit,申请了内测体验,不到一会就通过了。
那后就开始陷入进去了,和刷抖音一样,根本停不下来,太魔性了。我甚至都有一种感觉,他们是想做 AI 时代下的抖音吧。
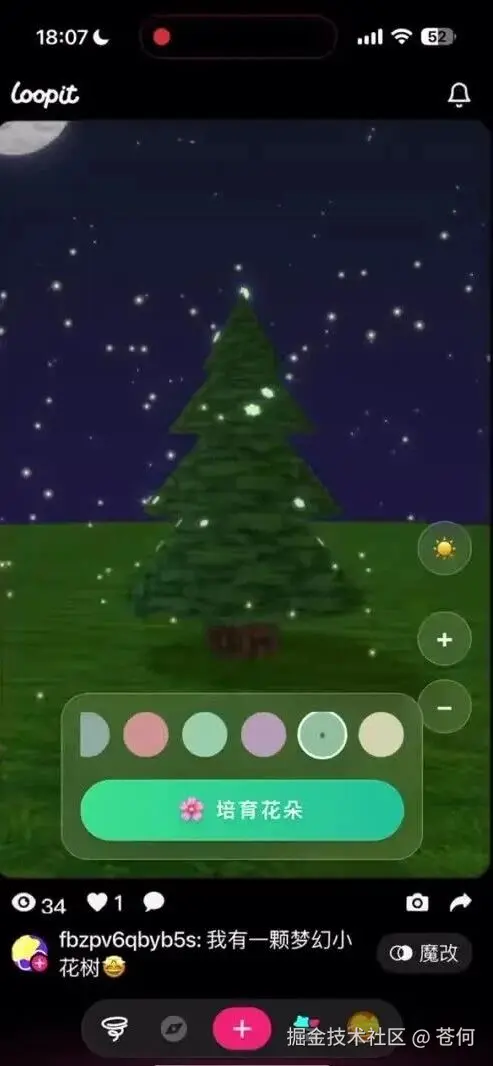
Loopit 我觉得让年轻人为之疯狂的是其**「互动性」**。首页具备非常多的上手就可以互动体验的内容。
如果说传统短视频是「看内容」,那 Loopit 或许想做的就是让年轻人「玩内容」 。
这是我做的一个能根据气流大小实时改变生成画面的互动内容,可以看到,吹气越猛,画面中的魔法风暴就越壮观。

我还做了一个互动性更强一些的,能根据用户唱歌水平的高低来生成画面的完整性,唱的好就能出好看的画,唱的差就会出现鬼畜画面。为了保护大家,我就用电脑放了一首歌,你可以感受一下。

还做了个用手机来颠球的互动游戏,手机上抬,乒乓球也会被抬起,力度会控制颠球的高低。
Loopit 并没有走纯 AI Coding(好玩但不真实)或纯多模态生成(美观但交互弱)的老路,而是把两者深度融合。
它与手机硬件深度融合——包括麦克风、陀螺仪、前后摄像头、触控屏、振动马达等。
让可玩性更足了。
现在手机应用市场就可以直接下载 Loopit 体验了,首页的话有非常多直接就可体验互动的内容可以玩,比如被马斯克点赞的这个应用也可以直接玩,哈哈哈。
也可以创作自己想要的互动内容,我一上来就整了十几个互动应用。,根本停不下来。

不过现在要自己创作的话需要填入邀请码,可以直接填写下理由申请下。我填写了苍何,然后我给我老婆手机也填了下申请,填了苍何的粉丝也很快就通过了,大家申请的时候可以试试🐶
另外我也托关系联系朋友要到了几个邀请码,我放评论区了,需要自取。
我创作了十几个有意思的互动应用,下面分享下创作的思路,帮助你少踩坑,因为我发现,目前 Loopit 可能是刚上线的原因或者用的人有点多了,有时候会比较慢,然后有时候也会抽风,需要调教下。
目前在 Loopit 上创作一共 2 种方式,一种是原创,就是你通过提示词的方式手搓一个应用出来,另外一种就是二次创作,你可以基于你刷到的好玩的应用进行魔改。
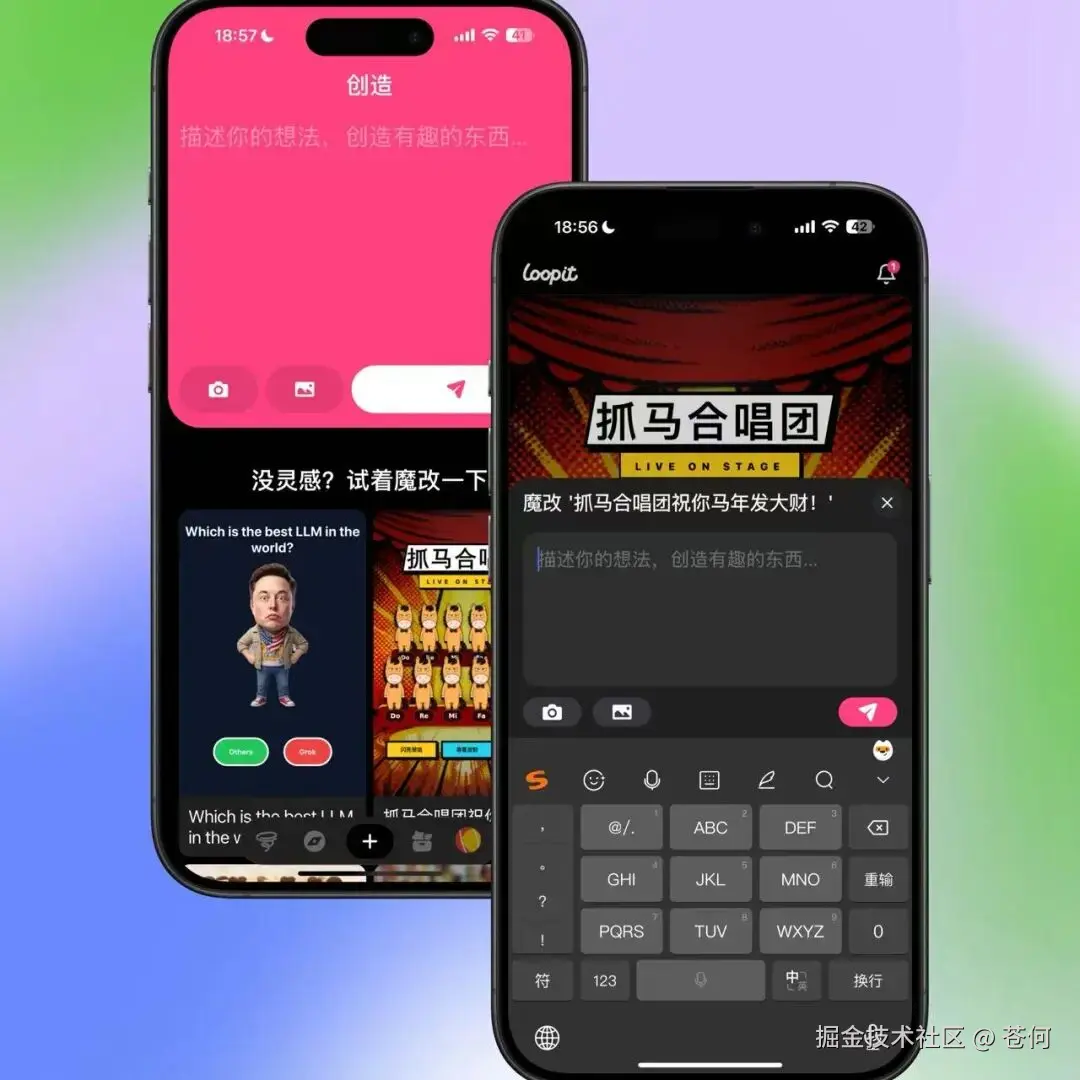
比如风之谷这个应用,我给的提示词是这样的:
《风之谷》:吹气生成微观世界调用接口: 麦克风(气流侦测)+ AI 实时生成(Stable Video Diffusion/LCM)
玩法描述: 用户对着麦克风吹气,屏幕中原本静止的荒漠或森林会随着吹气的力度和频率,实时长出奇幻的花草、飘起花瓣或化作星尘。
AI 点: 根据气流大小实时改变生成画面的风力等级(Prompt 权重动态调整)。
互动反馈: 吹气越猛,画面中的“魔法风暴”越壮观。
大家都提示词建议按照这个结构要求稳定性会更高一些,创建一个xx的互动内容,主题是xxx。玩法描述,AI 点以及互动反馈。
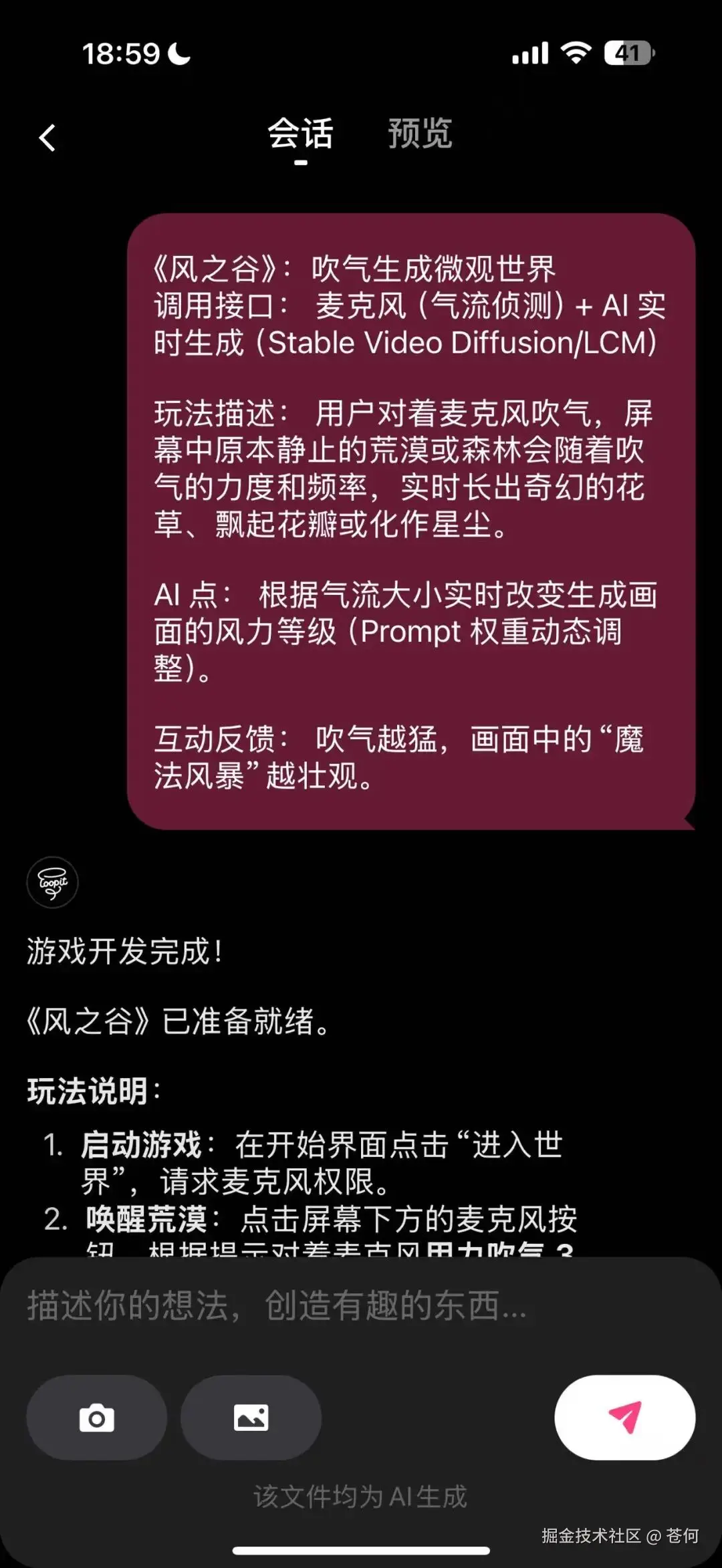
会请求手机麦克风权限,然后就开始 vibe coding,出错了,你就直接口喷让他改就好了。
通常需要等待个几分钟,就能直接生成好应用,然后就点预览,开始玩了。
觉得应用 ok,或者想给朋友玩,可以点击发布,就会发布到应用广场了。
Loopit 它构建了一个专门为 AI 生成设计的**「互动 Runtime」** 。简单来说,它能把你的点击、摇晃、甚至是声音,转化为结构化的指令,并让 AI 在代码定义的边界内实时更新「世界状态」 。
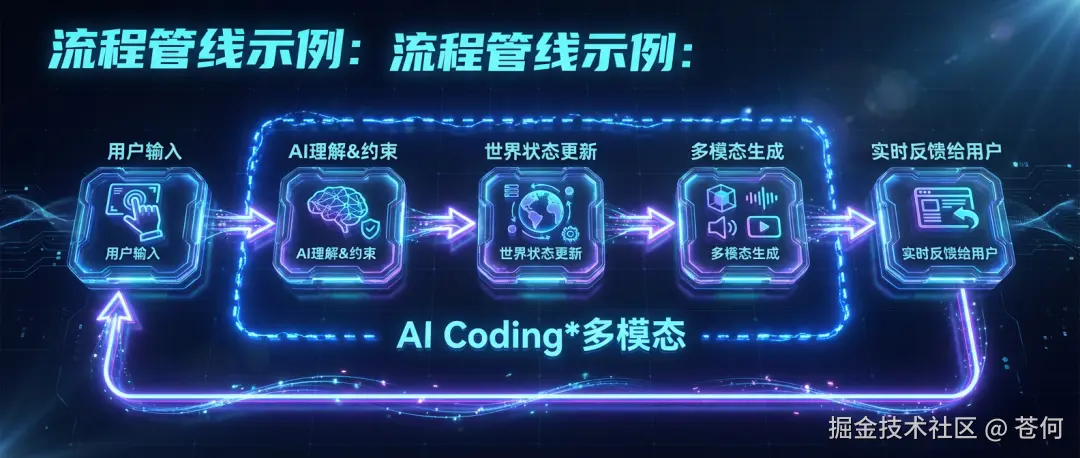
这种融合带来了几个直观的感受:
- 多维度输入:它能直接调用手机的陀螺仪、麦克风、甚至是前置摄像头。
- 逻辑稳定:不管你怎么「折腾」内容,世界状态都不会轻易崩坏,反馈非常即时。
- 创作极简:不需要写代码,平均 3 轮对话就能搓出一个作品。
也难怪海外那么多年轻人喜欢,甚至马斯克都亲自点赞。
我认为它代表了一种新的趋势,在 Loopit 里,创作不再需要刻意寻找主题。一个热梗、一个奇怪的念头,甚至是你忍不住反复做的小动作,都能成为「好玩」的起点。
从对比数据来看,这种「AI Coding × 多模态生成」的路线,在内容形态上最接近「互动式抖音」,且市场空间巨大。
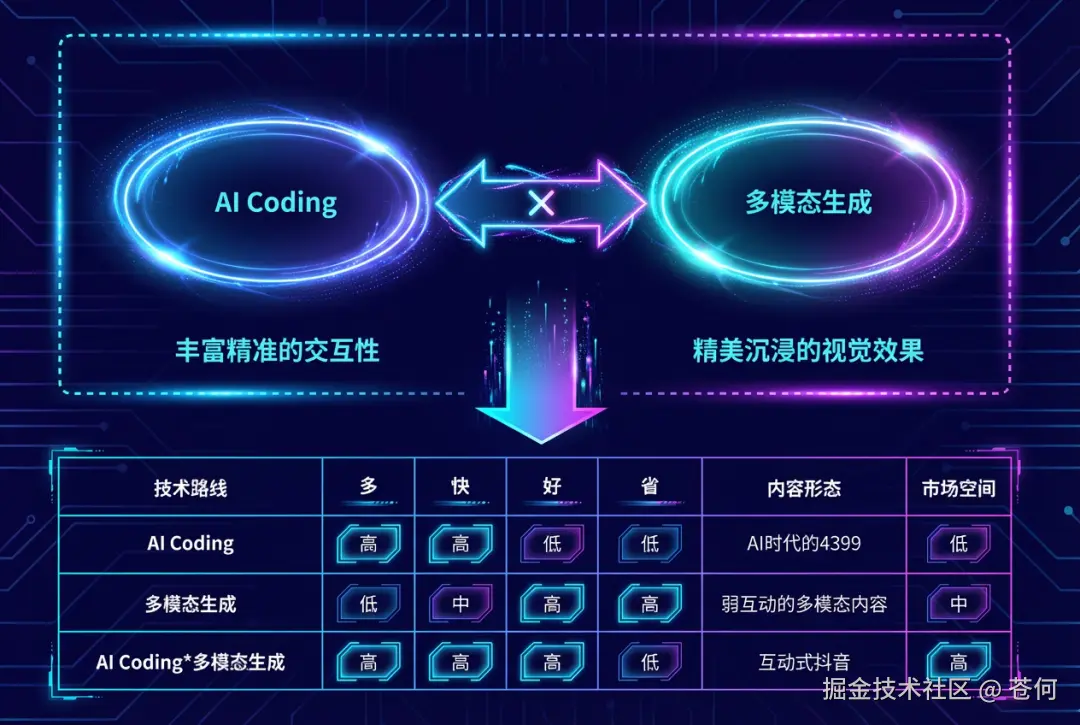
它降低了技术门槛,实现了某种程度上的「技术平权」,让每个人都能把抽象的念头变成具体的互动内容 。
目前 Loopit 还不算是一个大规模开放的游戏平台,它更像是一个正在萌芽的、属于年轻人的互动内容社区。
它现在处于跟创作者**「深度共创」**的阶段。如果你也是那种「脑洞大、爱折腾」的人,我非常建议你去体验一下这种「玩内容」的新文化。
来源:juejin.cn/post/7605912122628948006
10万人都在用的 top10 skills,我帮你试了

大家好,我是码歌,一个被Skills掏空了的码哥。
最近skills.sh(skills.sh/) 上最火的10个Skills,安装量加起来已经超过10万了。我花了几天时间,把这Top 10全装了一遍,挨个测试,结果只能用一句话形容:
有些确实牛逼,有些就是凑数的!但总体来说,跟着社区选不会错,实打实的用户下载安装!
关于Skills的前世今生,如果还不熟悉的同学推荐看下我之前的的几篇文章,这里不再展开说明,传送门:
1、火爆全网的Skills,看这一篇就够了!
2、谁还手动管技能?Vercel 开源 add-skill + skills.sh,一行命令搞定所有
注意!注意!注意!
最新版cursor(mac 2.5.0)默认读取的全局skills目录是 /.cursor/skills-cursor,而skills add安装命令默认为cursor添加的目录是/.cursor/skills,我们只需要手动再次添加下符号链接就行,以后每次安装也会同步到skills-cursor目录,命令如下:
mac:
cd ~/.cursor
ln -s skills skills-cursor
windows:
cd %USERPROFILE%.cursor
rmdir /s /q skills-cursor
mklink /D skills-cursor skills
一、为什么Top 10值得关注?
skills.sh上的安装量都是实打实的。几十w+安装不是刷的,是真有这么多人在用(就像B站播放量,虽然可能有水分,但大部分都是真用户)。
这些人天天用Claude Code写代码、做产品,他们愿意装,说明确实有用。跟着装就行,不用自己判断"这玩意到底行不行",社区已经帮你筛过一遍了(群众的眼睛是雪亮的)。
废话不多说,直接上干货。我会把每个Skill的实际使用效果、适合谁、值不值得装都告诉你(不画饼,只讲实话)。
二、Top 10 Skills完整拆解(干货来了)
先说个整体情况:Top 10里7个是给开发者的(程序员果然是AI的主力用户),3个对产品、运营、设计师也有用(终于不是程序员专属了)。
我把值得详细说的挑出来讲,其他的列个表就行(重点突出,不浪费大家时间)。
开发者专用的(7个)(程序员福利)
这7个都是给写代码的人用的,非开发者可以直接跳到下一节(别看了,看了也看不懂)。
| 排名 | Skill | 安装量 | 干嘛用的 | 值不值得装 |
|---|---|---|---|---|
| 1 | vercel-react-best-practices | 37600+ | React/Next.js性能优化,57条规则 | ⭐⭐⭐⭐⭐ 前端必装 |
| 2 | web-design-guidelines | 28500+ | 检查网页是否符合设计规范 | ⭐⭐⭐⭐ UI返工多的人必装 |
| 3 | remotion-best-practices | 18800+ | 用代码做视频的最佳实践 | ⭐⭐⭐ 做视频的才需要 |
| 5 | skill-creator | 3700+ | 官方出的,教你怎么创建Skill | ⭐⭐⭐ 想自己做Skill的装 |
| 6 | building-native-ui | 2700+ | Expo手机App开发指南 | ⭐⭐⭐ 做移动端的装 |
| 8 | better-auth-best-practices | 2300+ | 登录认证系统最佳实践 | ⭐⭐⭐⭐ 做登录的必装 |
| 10 | upgrading-expo | 2200+ | Expo框架升级指南 | ⭐⭐ 升级时才用 |
实际测试感受:
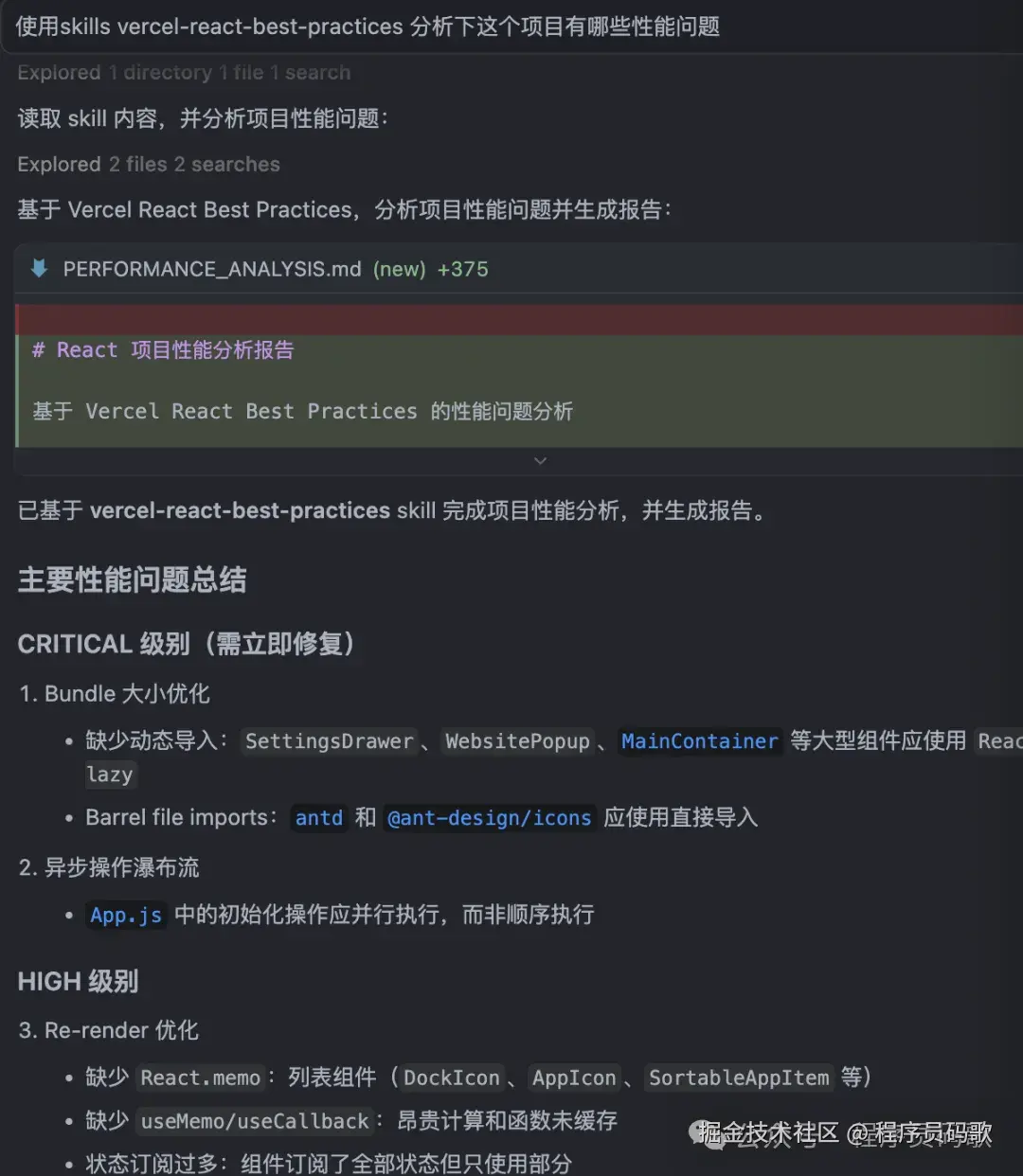
1、vercel-react-best-practices:这个确实牛逼。我叫他使用这个skills分析下我之前的项目“AI灯塔导航”,它直接指出了几个性能问题:Re-render 优化、事件监听器、1渲染性能等。改完之后性能提升明显。前端开发必装。
2、web-design-guidelines:UI审查很细致(比设计师还严格)。我让cursor用这个skill检查下项目“AI灯塔导航”UI相关问题,它指出了可访问性缺少、语义化HTML问题、焦点管理缺失等不符合规范等10多个问题(就像找了个严格的老师,一点小问题都不放过)。产品经理和设计师协作多的,这个很有用(终于不用再因为设计规范问题吵架了)。

3、better-auth-best-practices:登录认证这块踩坑多(就像过雷区,一不小心就炸),这个Skill把常见问题都覆盖了:密码加密、JWT过期处理、CSRF防护、OAuth流程等(就像给了你一张"避雷地图")。做登录系统的,装了这个能少踩很多坑(终于不用再因为安全问题被用户投诉了)。

所有人都能用的(3个)⭐(重点来了)
这3个是我觉得Top 10里最值得说的,不写代码也能用(终于不用再羡慕程序员了)。
1、frontend-design(45.5k +安装)
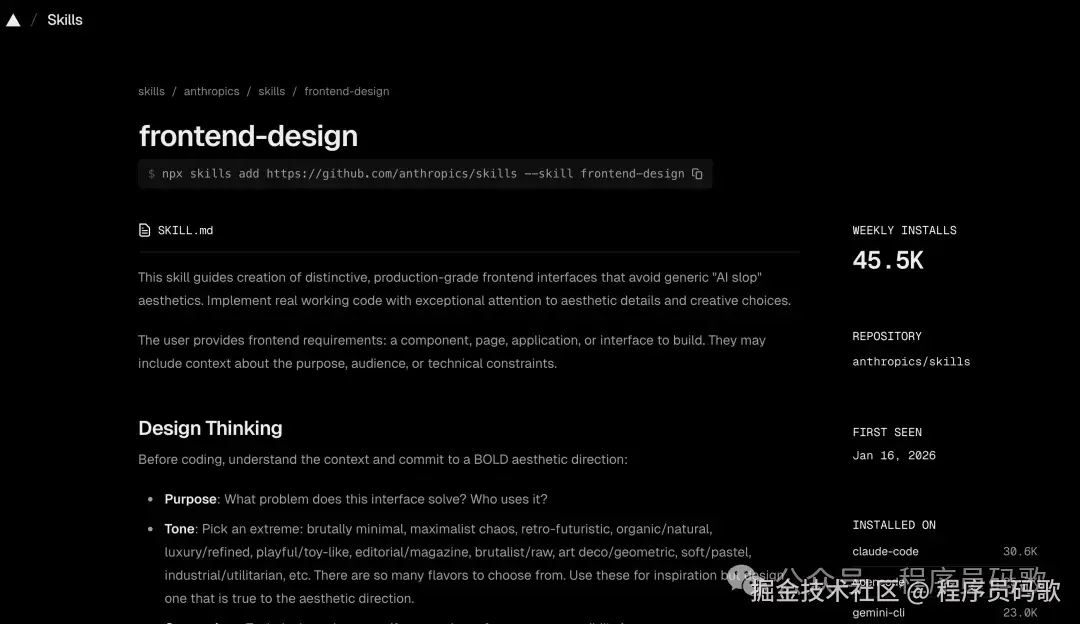
来自Anthropic官方。目标很简单:让Claude做出来的东西别那么"AI味" 。
你可能有过这种体验——让Claude帮忙做个网页或PPT,出来的东西能用,但没特色,一眼就知道是AI做的(就像穿了校服,虽然整齐但毫无个性)。这个Skill就是治这个的,专门给AI的设计"整容"。
它明确告诉Claude不要用什么:
- 不要用Inter、Roboto、Arial这些"标准字体"(太没个性)
- 不要用紫色渐变配白底(AI最爱用,已经烂大街了)
- 不要用对称布局(打破常规才有设计感)
同时告诉Claude应该怎么做:
- 选择有个性的字体
- 配色要有主次,主色大胆、强调色锐利
- 动效要克制,一个精心设计的页面加载动画,比到处都在动更高级
实际测试: 我让Claude用这个Skill帮我设计一个部署平台原型,确实比之前有设计感多了。虽然还是能看出是AI做的(毕竟AI的"审美"还是有迹可循),但至少不那么"标准"了,至少从"一眼AI"变成了"需要仔细看才能发现是AI"。

安装命令:
npx skills add https://github.com/anthropics/skills --skill frontend-design
2、agent-browser(24.1k+安装)

这个Skill不太一样,它不是"知识库",而是"工具"(就像给Claude装了个机械臂)。装上之后,Claude可以帮你操作浏览器:
- 自动打开网页、点击按钮、填写表单(终于不用自己点点点了)
- 批量截图(再也不用一张一张手动截)
- 自动登录网站(保存登录状态,下次直接用,懒人福音)
- 录制操作过程(以后可以回放,看看AI是怎么"思考"的)
实际测试: 我让Claude帮我登录5个平台查数据,它真的自动完成了。虽然有些网站需要验证码会卡住(AI再聪明也过不了"你是人类吗"这关),但大部分操作都能自动化。运营、测试、产品都能用得上,特别是那些重复性的"点点点"工作。
安装命令:
npx skills add https://github.com/vercel-labs/agent-browser --skill agent-browser
3、seo-audit(13k+安装)
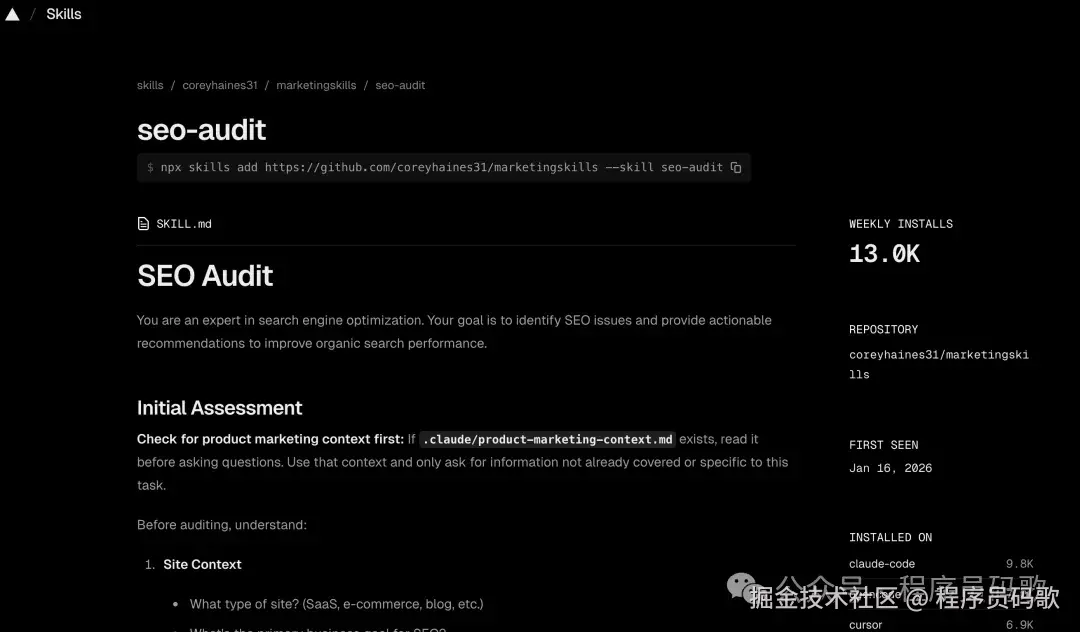
终于来了一个纯运营向的Skill(程序员终于不用再被问"为什么网站搜不到"了)。
这是一个完整的SEO审计框架,让Claude帮你检查网站的SEO健康度(就像给网站做体检):
- 能被Google找到吗?(爬虫能不能访问、有没有被收录,别做"隐形网站")
- 网站快不快?(加载速度影响排名,慢得像蜗牛可不行)
- 内容优化了吗?(标题、描述、关键词布局,别让搜索引擎"看不懂")
- 内容质量够不够?(是否值得被推荐,别写一堆废话)
- 有没有可信度?(外链、权威性,别让人家觉得你是"野鸡网站")
实际测试: 我让Claude审计了一下我的项目“AI灯塔导航”,它给出了多个真实存在的问题,每个都标明了影响程度和修复优先级(就像医生开药方,告诉你先治什么后治什么)。做网站的都能用,不需要懂技术(终于不用再求程序员了)。
安装命令:
npx skills add https://github.com/coreyhaines31/marketingskills --skill seo-audit
三、额外收获:23个营销Skills
Top 10里大部分是开发向的,但别急(程序员也有春天)。
我在安装过程中发现了一个宝藏仓库:coreyhaines31/marketingskills
这个仓库有23个营销相关的Skill,从文案到定价到投放都有(一站式营销工具箱,比瑞士军刀还全):
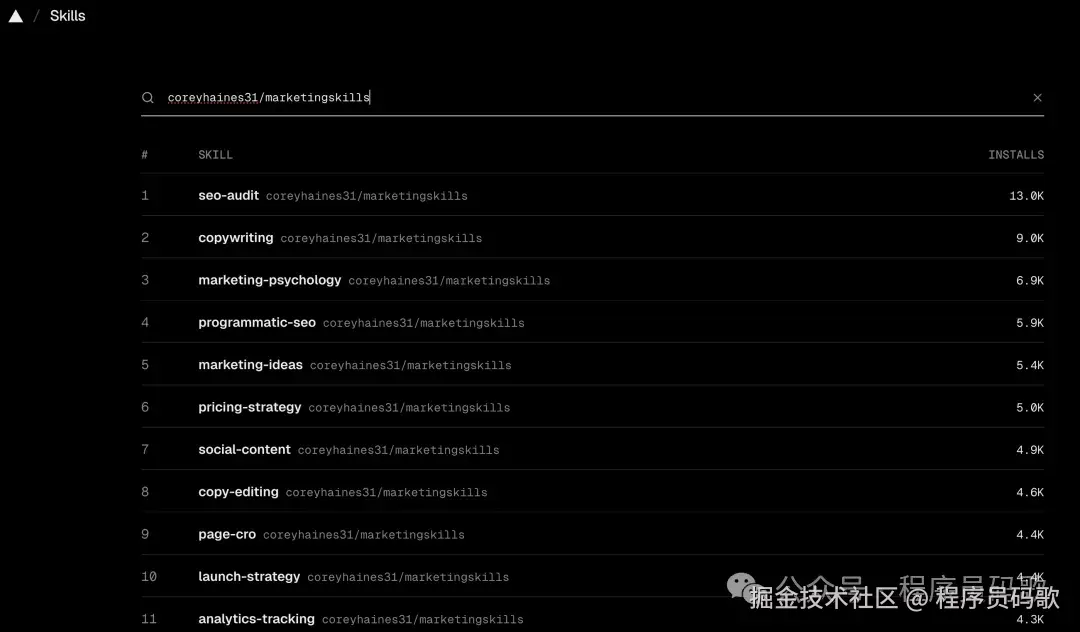
| Skill | 功能 | 适合谁 |
|---|---|---|
| copywriting | 营销文案写作 | 市场、运营 |
| copy-editing | 文案润色修改 | 市场、运营 |
| pricing-strategy | 定价策略设计 | 产品、创业者 |
| launch-strategy | 产品发布策略 | 产品、市场 |
| seo-audit | SEO诊断 | 运营、独立开发者 |
| ab-test-setup | A/B测试设计 | 产品、运营 |
| page-cro | 落地页转化优化 | 运营、增长 |
| signup-flow-cro | 注册流程优化 | 产品、增长 |
| email-sequence | 邮件营销序列 | 市场、运营 |
| social-content | 社交媒体内容 | 市场、运营 |
| paid-ads | 付费广告投放 | 市场 |
| referral-program | 推荐计划设计 | 增长、产品 |
| marketing-psychology | 营销心理学 | 市场、产品 |
安装命令:
npx skills add coreyhaines31/marketingskills --yes
一次性装23个。
我的看法: 做产品、运营、市场的,这个仓库比Top 10更值得装(就像找到了组织,终于不用再自己摸索了)。
四、熟悉的宝玉老师的Skills
翻Top 100的时候,发现了一些熟悉的名字——宝玉老师(@dotey)的Skills(就像在异国他乡遇到了老乡,亲切感爆棚)。
宝玉老师是X上的AI大V,经常分享Claude Code的使用心得。他把自己的工作流打包成了一堆Skills,放在 jimliu/baoyu-skills 仓库(这就是传说中的"授人以渔不如授人以鱼"):
| Skill | 功能 | 安装量 |
|---|---|---|
| baoyu-slide-deck | 幻灯片生成 | 972 |
| baoyu-article-illustrator | 文章配图 | 938 |
| baoyu-cover-image | 封面图生成 | 868 |
| baoyu-xhs-images | 小红书图片 | 841 |
| baoyu-comic | 漫画生成 | 822 |
| baoyu-post-to-wechat | 发布到微信 | 752 |
| baoyu-post-to-x | 发布到X | 725 |
| baoyu-infographic | 信息图生成 | 480 |


这些Skills对中文用户特别友好——小红书图片、发微信、文章配图,都是我们平时会用到的(终于不用再自己手动P图了,AI帮你搞定一切)。
安装命令:
npx skills add jimliu/baoyu-skills --yes
五、文档处理四件套
Anthropic官方仓库(anthropics/skills)里有4个文档处理Skill(就像Office套件,但这次是AI版的):
- pdf —— PDF读取、提取、合并(再也不用装各种PDF工具了)
- docx —— Word文档处理(写文档、改格式,AI帮你搞定)
- pptx —— PPT生成和编辑(做PPT终于不用熬夜了)
- xlsx —— Excel处理(数据分析、公式计算,AI比你算得还快)
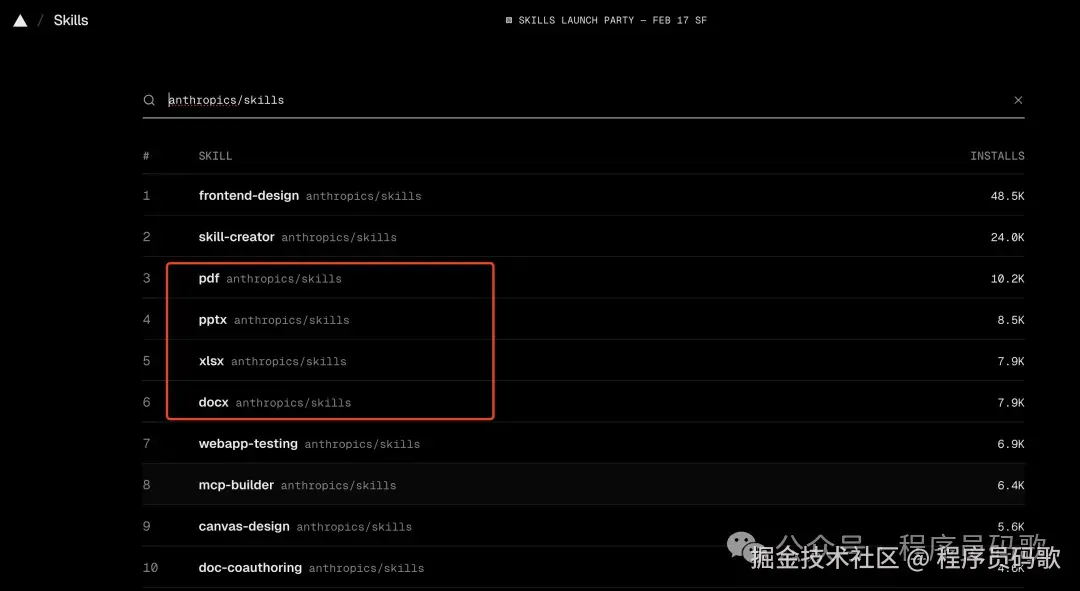
这几个所有人都能用。装上之后让Claude帮你处理文档,会顺手很多(就像给AI装了个Office,但它比Office还聪明)。
安装命令:
npx skills add anthropics/skills --yes
六、为什么你应该去看看skills.sh
说两个实际的好处(不画饼,都是大实话)。
第一,这些Skill确实有用(不是智商税)。
skills.sh上排名靠前的,都是被大量vibe coder实际装过、用过的。37000+安装不是刷的,是真有人在用(就像淘宝好评,虽然可能有刷的,但大部分都是真用户)。
这些人天天用Claude Code写代码、做产品,他们愿意装,说明确实有用。跟着装就行,不用自己判断"这玩意到底行不行",社区已经帮你筛过一遍了(就像跟着大众点评选餐厅,虽然不一定最好,但至少不会踩雷)。
第二,这是学习Skills最好的方式(比看文档强多了)。
很多人看了我之前的文章,知道Skills是啥了,但还是不知道怎么下手——自己的Skill该怎么写?(就像知道怎么吃,但不知道怎么做)
最好的学习方式不是啃文档,是看别人怎么写的(就像学做菜,看视频比看菜谱快)。
装几个热门Skill之后,让Claude Code或者cursor等agent帮你解读:
帮我读取并解释 ~/.agents/skills/seo-audit/SKILL.md 的实现逻辑
Claude会告诉你(就像找了个老师,手把手教你):
- 这个Skill的触发条件是怎么写的(什么时候AI会"想起来"用这个Skill)
- 指令是怎么组织的(怎么让AI"听话")
- 为什么要这样分层(为什么这样设计更合理)
- 哪些设计可以借鉴(哪些可以"抄作业")
看3-5个写得好的,你就知道了(就像看了几部好电影,就知道怎么拍电影了):
- Skill该怎么组织(结构怎么搭)
- 好的Skill长啥样(标准是什么)
- 自己的工作流怎么打包(怎么把自己的经验变成Skill)
从模仿开始,比从零开始容易多了(站在巨人的肩膀上,总比自己造轮子强)。
所以我建议:先装、先用、先看,再想自己要不要做(实践出真知,别光想不做) 。
七、几个实际建议
1. 根据你的岗位选择(别乱装)
- 开发者:vercel-react-best-practices、anthropics/skills(写代码的,装这些就够了)
- 产品经理:seo-audit、marketingskills仓库、agent-browser(做产品的,这些能帮你省很多事)
- 设计师:frontend-design、web-design-guidelines(做设计的,让AI帮你检查规范)
- 运营/市场:marketingskills仓库(23个全装上,一站式解决所有营销问题)
2. 别贪多(装太多会卡)
我装了50+个是为了写这篇文章。平时用的话,选3-5个高频的就够了
装太多,Claude启动时要加载的东西多,还是会影响上下文的。
3. 注意来源(安全第一)
Skills可以包含可执行脚本,所以要看谁发的(别什么Skill都装,小心被"钓鱼"):
- ✅ anthropics/skills(Anthropic官方,官方出品,必属精品)
- ✅ vercel-labs(Vercel官方,大厂出品,值得信赖)
- ✅ 框架官方(expo/skills等,官方维护,更新及时)
- ⚠️ 个人仓库谨慎点(就像下载软件,别从不明来源下载)
4. 先用再说(实践是检验真理的唯一标准)
不用完全搞懂原理,先装一两个用起来。用过才知道好不好(就像买衣服,不试穿怎么知道合不合适)。
八、最后,别光看,快去试
skills.sh出来之后,用Skills变简单了,以前得自己写,现在直接装别人的就行(站在巨人的肩膀上,真香)。而且不只是程序员能用——营销、产品、运营,都有对应的Skills(AI终于不只是程序员的玩具了)。
去skills.sh看看,找一两个和你工作相关的装上试试(别光看,动手试试,又不会怀孕)。
比如你是运营,装个seo-audit,然后问Claude:"帮我审计一下我们的官网SEO"(终于不用再求程序员了)。
比如你是产品,装个pricing-strategy,然后问Claude:"帮我分析一下我们产品的定价策略"(终于不用再拍脑袋定价了)。
试过就知道好不好使了(实践出真知,别光听我说)。
哦对,虽然上面给了你怎么安装这些skills的代码,但其实最佳实践还是你直接把这篇文章,以及把skills.sh的网址丢给Claude Code 或者 Cursor,用自然语言让他帮你选择及安装就好了(让AI帮你装AI的Skill,这就是AI的"自举")。
我是”程序员码歌“,全网昵称统一,10+年大厂程序员,专注AI工具落地与AI编程实战输出,在职场,玩转副业,目标副业年收入百万,探索可复利、可复制的一人企业成长模式,可去gzh围观
来源:juejin.cn/post/7604757482005053503
神了,WebSocket竟然可以这么设计!
关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
长连接是业务项目中经常遇到的技术,往往用于数据向前端推送,如各种大屏、驾驶舱等实时数据的展示。单向推送可能会选择SSE,SSE因为AI时代的到来,逐步被大家熟知,而WebSocket作为经典的双向通讯,也经常被用来做数据推送。
今天聊一下,我发现的一种特殊的设计,可以单独将基于Netty的WebSocket单独部署,接入时,只需要引入API,初始化客户端即可完成对接。直接隔离了WebSocket服务端的编码。
02 普通应用
WebSocket的普通接入,需要编写WebSocket服务端。通过浏览器原生 API即可实现。
2.1 前端代码
浏览器原生的代码:
if ('WebSocket' in window) {
const websocket = new WebSocket("ws://localhost:9090/testWs");
} else {
alert('当前浏览器不支持 WebSocket');
}
websocket.onopen = function(event) {
console.log('WebSocket 连接成功');
};
websocket.onmessage = function(event) {
console.log('收到消息:', event.data);
};
websocket.onerror = function(error) {
console.error('WebSocket 错误:', error);
};
websocket.onclose = function(event) {
console.log('WebSocket 连接关闭');
};
// 发送消息
function sendMessage() {
const message = document.getElementById('text').value;
websocket.send(message);
}
// 关闭连接
function closeConnection() {
websocket.close();
}
2.2 服务端代码
@Slf4j
@Component
public class WebSocketServer {
@Getter
private ChannelGr0up channelGr0up = new DefaultChannelGr0up(GlobalEventExecutor.INSTANCE);
public void start() throws InterruptedException {
EventLoopGr0up bossGr0up = new NioEventLoopGr0up();
EventLoopGr0up workGr0up = new NioEventLoopGr0up();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGr0up, workGr0up);
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.childHandler(new ChannelInitializer<SocketChannel>(){
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline = socketChannel.pipeline();
pipeline.addLast(new HttpServerCodec());
pipeline.addLast(new HttpObjectAggregator(65535));
pipeline.addLast(new WebSocketServerProtocolHandler("/testWs"));
// 自定义的handler,处理业务逻辑
pipeline.addLast(new SimpleChannelInboundHandler<TextWebSocketFrame>() {
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
// 建立客户端
Channel channel = ctx.channel();
log.info("客户端建立连接:channelId={}", channel.id());
channelGr0up.add(channel);
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
// 断开链接
Channel channel = ctx.channel();
log.info("客户端断开连接:channelId={}", channel.id());
channelGr0up.remove(channel);
}
@Override
protected void channelRead0(ChannelHandlerContext ctx, TextWebSocketFrame msg) throws Exception {
// 接受消息
Channel channel = ctx.channel();
log.info("收到来自通道channelId[{}]发送的消息:{}", channel.id(), msg.text());
// 广播通知所有的客户端
channelGr0up.writeAndFlush(new TextWebSocketFrame("收到来自channelId[" + channel.id() + "]发送的消息:" + msg.text() + "123_"));
}
});
}
});
// 配置完成,开始绑定server,通过调用sync同步方法阻塞直到绑定成功
ChannelFuture channelFuture = serverBootstrap.bind(9090).sync();
log.info("Server started and listen on:{}",channelFuture.channel().localAddress());
// 对关闭通道进行监听
channelFuture.channel().closeFuture().sync();
}
}
2.3 效果演示
为了方便演示,我直接使用在线测试工具:
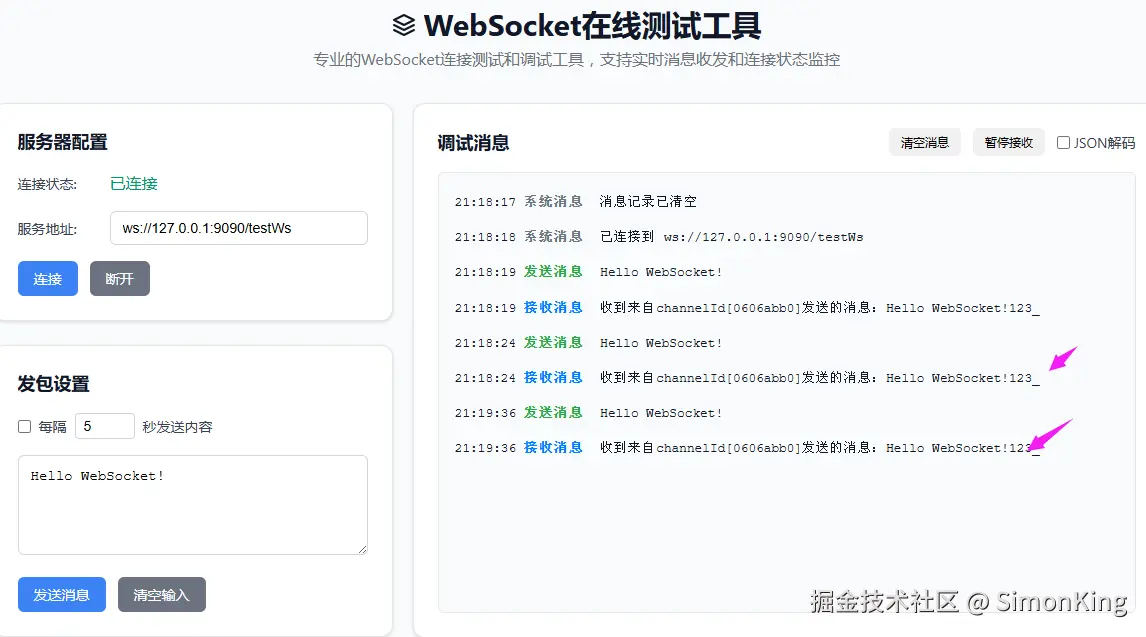
2.4 设计思想
设计如图:
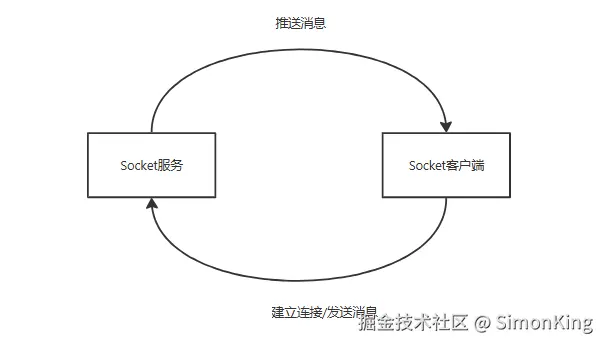
这就是一个简单的点对点的一个设计。这样的设计本身没有什么问题,但是面对不同的业务系统都要接入WebSocket,我们就需要将服务端的代码复制一份,然后修改成适合自己业务项目的逻辑。
如果业务项目比较多,就会出现大量重复的代码,如我们公司就有20多个业务系统。从《代码重构》这本书中,就得知这是一种坏的味道,需要我们想办法优化。
如何来优化呢?按照阿里程序员的说话,没有什么是加一个中间层不能解决的,如果不能那就再加一层。
03 独特的设计
3.1 总览
如何通过中间层去解耦呢?
为了将WebSocket能够复用,就需要通过一个中间层能够作为一个传递者。既可以让用户直接连接WebSocket,也可以通过中间层直接推送消息。
我们来看看最终的设计流程:
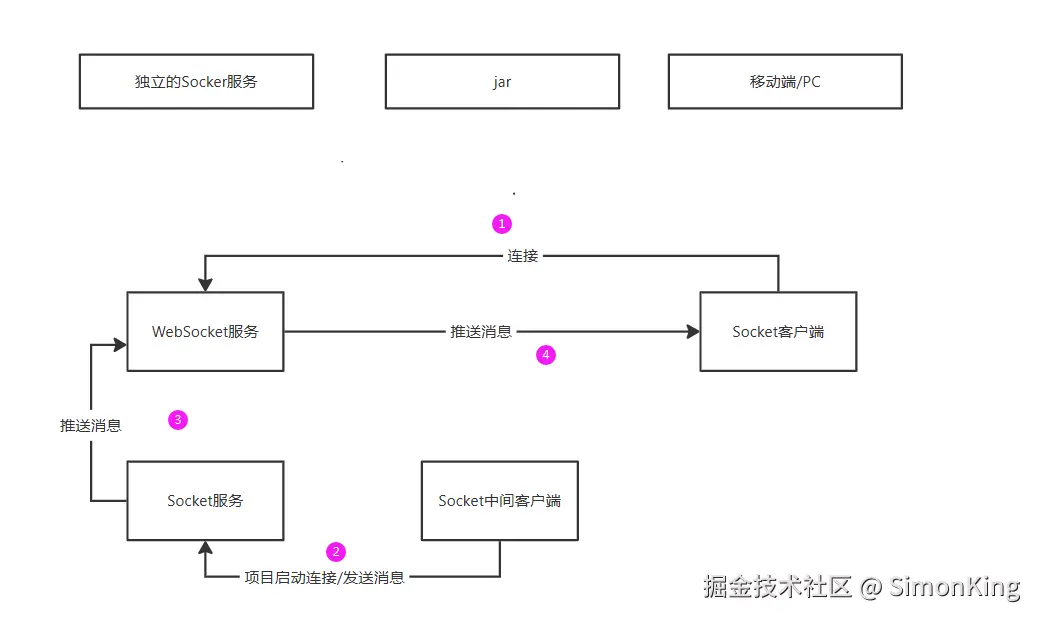
3.2 流程分析
在流程分析执之前,我们需要说明引入的中间层。
- Socket中间客户端
- Socket服务
Socket中间客户端
Socket中间客户端作为一个jar传递于业务项目中,用来代替WebSocket直接推送消息给Socket客户端。同时也会将WebSocket服务的IP和端口暴露给客户端。
Socket中间客户端是基于Netty的Socket客户端,通过Bootstrap bootstrap = new Bootstrap()实例化,遵循TCP协议。详见代码。
Socket服务
为什么需要引入Socket服务呢?这也是小编之前非常疑惑的地方,直到自己搭建才知道为什么这么设计。
由于Socket中间客户端无法直接连接WebSocket,那么那就要一个完全基于TCP协议的Socket服务,就可以和Socket中间客户端建立连接。
而Socket服务和WebSocket位于同一个服务,就可以获取到WebSocket的所有通道(channel),就可以将消息推送给客户端了。
运行流程
- ① 客户端通过业务项目暴露的
WebSOcket的IP和端口给前端,前端用来建立WebSocket连接。当着这个主要针对H5。类似安卓或者IOS有支持TCP的SDK,就可以直接连接Socket服务了。 - ② 随着业务项目启动建立与
Socket服务的连接,等待随时给Socket服务发送消息。 - ③
Socket服务接收到消息后,直接获取WebSocket的通道。然后通过通道可以推送消息。 - ④ 获取到通道之后,就可以直接推送消息给前端了。
所以每次使用,只需要引入Jar,需要推送消息给客户端,只需要直接调用方法推送即可。
04 设计实现
4.1 WebSocket服务端
代码同2.2的代码
WebSocket服务的端口是9090
4.2 Socket服务端
@Slf4j
@Component
public class SockerServer {
@Autowired
private WebSocketServer webSocketServer;
public void start() throws InterruptedException {
EventLoopGr0up bossGr0up = new NioEventLoopGr0up();
EventLoopGr0up workGr0up = new NioEventLoopGr0up();
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGr0up, workGr0up);
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.childHandler(new ChannelInitializer<SocketChannel>(){
@Override
protected void initChannel(SocketChannel socketChannel) throws Exception {
ChannelPipeline pipeline = socketChannel.pipeline();
pipeline.addLast(new DelimiterBasedFrameDecoder(2048, Unpooled.copiedBuffer("_".getBytes())));
pipeline.addLast(new StringDecoder(StandardCharsets.UTF_8));
pipeline.addLast(new StringEncoder(StandardCharsets.UTF_8));
// 自定义的handler,处理业务逻辑
pipeline.addLast(new SimpleChannelInboundHandler<>() {
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
// 建立客户端
Channel channel = ctx.channel();
log.info("Socket客户端建立连接:channelId={}", channel.id());
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
// 断开链接
Channel channel = ctx.channel();
log.info("Socket客户端断开连接:channelId={}", channel.id());
}
@Override
protected void channelRead0(ChannelHandlerContext ctx, Object msg) throws Exception {
// 接受消息
Channel channel = ctx.channel();
log.info("Socket收到来自通道channelId[{}]发送的消息:{}", channel.id(), msg);
// 通过WebSocket将方法发送给客户端
webSocketServer.getChannelGr0up().writeAndFlush(new TextWebSocketFrame("收到来自channelId[" + channel.id() + "]发送的消息:" + msg + "123_"));
}
});
}
});
// 配置完成,开始绑定server,通过调用sync同步方法阻塞直到绑定成功
ChannelFuture channelFuture = serverBootstrap.bind(9091).sync();
log.info("Server started and listen on:{}",channelFuture.channel().localAddress());
// 对关闭通道进行监听
channelFuture.channel().closeFuture().sync();
}
}
Socket服务的端口是9091
4.3 Socket中间客户端
@Slf4j
public class MockClient {
@Getter
private SocketChannel socketChannel;
public void connect() throws InterruptedException {
EventLoopGr0up eventLoopGr0up = new NioEventLoopGr0up();
Bootstrap bootstrap = new Bootstrap();
bootstrap.channel(NioSocketChannel.class);
bootstrap.option(ChannelOption.SO_KEEPALIVE, true);
bootstrap.option(ChannelOption.SO_BACKLOG, 500);
bootstrap.group(eventLoopGr0up);
bootstrap.handler(new ChannelInitializer() {
@Override
protected void initChannel(Channel channel) throws Exception {
ChannelPipeline pipeline = channel.pipeline();
pipeline.addLast(new DelimiterBasedFrameDecoder(2048, Unpooled.copiedBuffer("_".getBytes())));
pipeline.addLast(new StringDecoder(StandardCharsets.UTF_8));
pipeline.addLast(new StringEncoder(StandardCharsets.UTF_8));
pipeline.addLast(new SimpleChannelInboundHandler<String>(){
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
log.info("client receive: {}", msg);
}
});
}
});
ChannelFuture channelFuture = bootstrap.connect("127.0.0.1", 9091).sync();
this.socketChannel = (SocketChannel) channelFuture.channel();
}
}
Socket只是用来发送消息的,所以不同处理接受的消息。注意这里的中间客户端连接的是Socket服务,端口是9091
4.4 配置启动
@Slf4j
@Component
public class StartConfig {
@Autowired
private WebSocketServer webSocketServer;
@Autowired
private SockerServer socketServer;
@PostConstruct
public void init() {
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(() -> {
log.info("websocket init ....");
try {
webSocketServer.start();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
executorService.execute(() -> {
log.info("socket init ....");
try {
socketServer.start();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
}
}
这个就是独立部署的Socket服务配置,两个服务分别使用多线程启动。
4.5 模拟数据推送
@Test
void contextLoads() throws Exception {
MockClient mockClient = new MockClient();
mockClient.connect();
SocketChannel socketChannel = mockClient.getSocketChannel();
new Timer().schedule(new TimerTask() {
@Override
public void run() {
System.out.println("send msg...");
socketChannel.writeAndFlush("foo test..._");
}
}, 0, 2000);
System.in.read();
}
每个2s发送一次消息。
4.6 客户端
客户端同样用在线测试工具代替。
4.7 演示
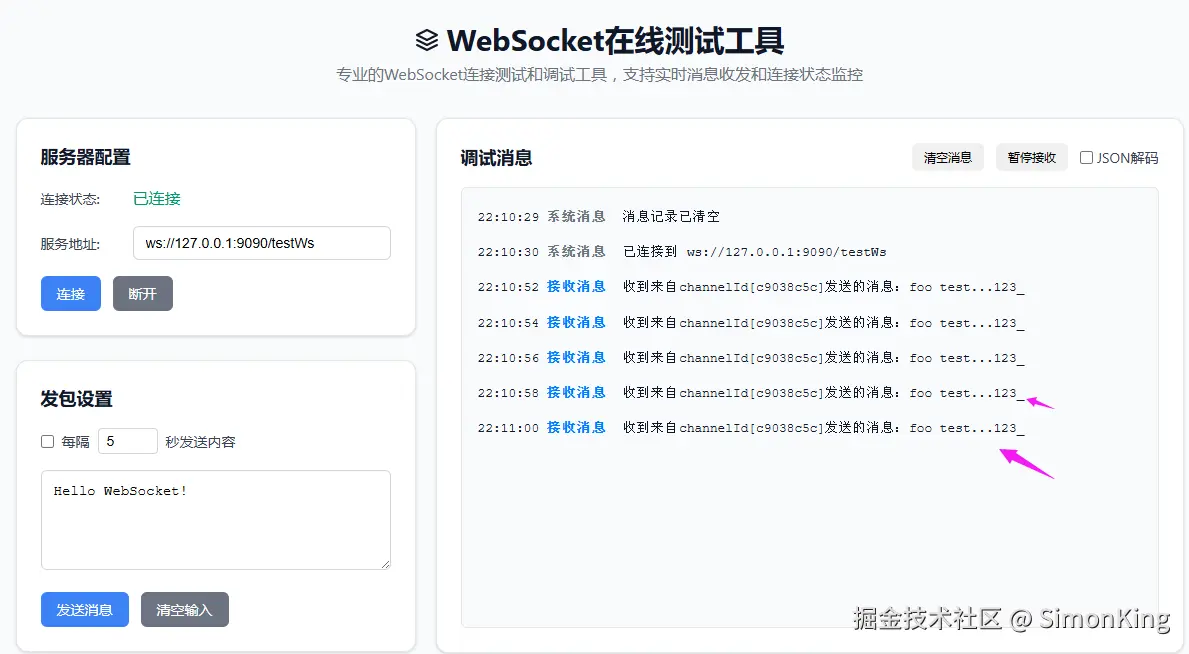
05 小结
这就完成了WebSocket的解耦。关于Socket消息的编解码,有很多注意点,在搭建过程中,总会不成功, 需要根据连接的协议选择不同的编解码,才能正确的接受和发送信息。这些留到后面的文章继续介绍。
来源:juejin.cn/post/7592079304924889098
一个Java工程师的17个日常效率工具
作为一名Java工程师,效率就是生产力。那些能让你少写代码、少改BUG、少加班的工具,往往能为你节省大量时间,让你专注于解决真正有挑战性的问题。
下面分享的这些工具几乎覆盖了Java开发全流程,从编码、调试到构建、部署,每一个环节都能大幅提升你的工作效率。
一、IDE增强类工具
1. IntelliJ IDEA终极版 + 精选插件
作为Java开发的首选IDE,IntelliJ IDEA本身已经非常强大,但配合以下插件,效率可以再提升一个档次:
- Key Promoter X: 显示你手动操作的快捷键,帮助你养成使用快捷键的习惯
- AiXcoder Code Completer: 基于AI的代码补全,比IDEA自带的更智能
- Maven Helper: 解决Maven依赖冲突的神器
- Lombok: 减少模板代码编写
- Rainbow Brackets: 彩色括号,让嵌套结构一目了然
实用技巧:创建多个Live Templates(代码模板),比如定义日志、常用异常处理、单例模式等。每天能节省几十次重复输入。
2. Lombok
虽然这是一个库,但它堪称效率工具。通过注解的方式,自动生成getter/setter、构造函数、equals/hashCode等方法,大幅减少模板代码量。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UserDTO {
private Long id;
private String username;
private String email;
// 无需编写getter/setter/构造函数/toString等
}
注意事项:使用@EqualsAndHashCode时,注意排除可能造成循环引用的字段;使用@Builder时,考虑添加@NoArgsConstructor满足序列化需求。
二、调试与性能分析工具
3. Arthas
阿里开源的Java诊断工具,它能在线排查问题,无需重启应用。最强大的是它能够实时观察方法的入参、返回值,统计方法执行耗时,甚至动态修改类的行为。
常用命令:
watch监控方法调用trace跟踪方法调用链路jad反编译类sc查找加载的类redefine热更新类
实战示例:线上问题排查,不方便加日志时,用watch命令观察方法执行:
watch com.example.service.UserService queryUser "{params,returnObj}" -x 3
4. JProfiler
Java剖析工具的王者,能够分析CPU热点、内存泄漏、线程阻塞等问题。与其他分析工具相比,JProfiler的UI更友好,数据呈现更直观。
核心功能:
- 内存视图:找出占用内存最多的对象
- CPU视图:定位热点方法
- 线程视图:发现死锁和阻塞
- 实时遥测:监控线上应用,无需重启
技巧:养成定期对自己负责的服务做性能分析的习惯,很多问题在上线前就能发现。
5. Charles/Fiddler
抓包工具是API调试的必备利器。Charles(Mac)或Fiddler(Windows)能够拦截、查看和修改HTTP/HTTPS请求和响应。
实用功能:
- 模拟网络延迟
- 请求重写
- 断点调试HTTP请求
- 反向代理
在前后端分离开发和调试第三方API时,这类工具能节省大量时间。
三、代码质量工具
6. SonarQube + SonarLint
SonarQube是静态代码分析工具,可以检测代码中的漏洞、坏味道和潜在bug。而SonarLint是其IDE插件版,能在你编码时实时提供反馈。
最佳实践:
- 在CI流程中集成SonarQube
- 为团队制定"质量门"标准
- 使用SonarLint实时检查,避免代码审查时返工
技巧:自定义规则集,忽略对特定项目不适用的规则,避免"过度洁癖"。
7. ArchUnit
用代码的方式测试架构规则,确保项目架构不会随着时间推移而腐化。
@Test
public void servicesAndRepositoriesShouldNotDependOnControllers() {
ArchRule rule = noClasses()
.that().resideInAPackage("..service..")
.or().resideInAPackage("..repository..")
.should().dependOnClassesThat().resideInAPackage("..controller..");
rule.check(importedClasses);
}
将架构约束加入单元测试,比写文档更有效,因为违反规则会导致测试失败。
8. JaCoCo
代码覆盖率工具,与Maven/Gradle集成,生成直观的HTML报告。它不仅统计单元测试覆盖了哪些代码,还能显示哪些分支没有测试到。
实用配置:在Maven中设置覆盖率阈值,低于阈值则构建失败:
<configuration>
<rules>
<rule>
<element>BUNDLE</element>
<limits>
<limit>
<counter>LINE</counter>
<value>COVEREDRATIO</value>
<minimum>0.80</minimum>
</limit>
</limits>
</rule>
</rules>
</configuration>
四、API开发与测试工具
9. Postman + Newman
Postman是API开发和测试的标准工具,而Newman是其命令行版本,适合集成到CI/CD流程中。
高级用法:
- 环境变量管理不同测试环境
- 请求前/后脚本自动化测试
- 导出集合到Newman在CI中执行
- 团队共享API集合
技巧:为每个项目创建环境变量集合,包含测试环境、开发环境、生产环境配置,一键切换。
10. OpenAPI Generator
从OpenAPI(Swagger)规范自动生成API客户端和服务器端代码。
openapi-generator generate -i swagger.json -g spring -o my-spring-server
前后端并行开发时,通过API优先设计,让前端可以基于Swagger UI与Mock服务器工作,而后端则基于生成的接口实现业务逻辑。
五、数据库工具
11. DBeaver
全能型数据库客户端,支持几乎所有主流数据库,功能强大且开源免费。
必备功能:
- ER图可视化
- 数据导出/导入
- SQL格式化
- 数据库比较
- 执行计划分析
技巧:使用其"SQL模板"功能,保存常用查询模板,提高重复查询效率。
12. Flyway/Liquibase
数据库版本控制工具,将数据库结构变更纳入版本管理,确保开发、测试和生产环境的数据库结构一致性。
以Flyway为例:
@Bean
public Flyway flyway() {
return Flyway.configure()
.dataSource(dataSource)
.locations("classpath:db/migration")
.load();
}
最佳实践:
- 每个变更一个脚本文件
- 脚本文件命名规范化
- 脚本必须是幂等的
- 将验证步骤集成到CI流程
六、构建与部署工具
13. Gradle + Kotlin DSL
虽然Maven仍是Java构建工具的主流,但Gradle的灵活性和性能优势明显。使用Kotlin DSL而非Groovy可以获得更好的IDE支持和类型安全。
plugins {
id("org.springframework.boot") version "2.7.0"
id("io.spring.dependency-management") version "1.0.11.RELEASE"
kotlin("jvm") version "1.6.21"
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-web")
testImplementation("org.springframework.boot:spring-boot-starter-test")
}
优势:
- 增量构建更快
- 依赖缓存更智能
- 自定义任务更灵活
- 多项目构建更高效
14. Docker + Docker Compose
容器化是现代Java开发的标配,Docker让环境一致性问题成为历史。
实用命令:
# 启动开发环境所需的所有服务
docker-compose up -d
# 查看容器日志
docker logs -f container_name
# 进入容器内部
docker exec -it container_name bash
技巧:创建一个包含常用中间件(MySQL、Redis、RabbitMQ等)的docker-compose.yml,一键启动开发环境。
15. GitHub Actions/Jenkins
CI/CD是提高团队效率的关键环节。GitHub Actions适合开源项目,Jenkins则更适合企业内部构建流程。
GitHub Actions示例:
name: Java CI
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up JDK 17
uses: actions/setup-java@v2
with:
java-version: '17'
distribution: 'adopt'
- name: Build with Gradle
run: ./gradlew build
最佳实践:将代码风格检查、单元测试、集成测试、安全扫描全部纳入CI流程,确保代码质量。
七、辅助工具
16. PlantUML
用代码生成UML图,比拖拽式画图工具更高效,特别是需要频繁修改图表时。可以和版本控制系统无缝集成。
@startuml
package "Customer Domain" {
class Customer
class Address
Customer "1" *-- "n" Address
}
package "Order Domain" {
class Order
class LineItem
Order "1" *-- "n" LineItem
Order "*" -- "1" Customer
}
@enduml
IDEA集成:安装PlantUML插件,编写代码时实时预览图表。
17. Obsidian/Logseq
知识管理工具,基于Markdown文件的本地知识库。对于需要持续学习的Java工程师来说,构建个人知识体系至关重要。
推荐用法:
- 每学习一个新技术,创建一个页面
- 记录常见错误和解决方案
- 构建项目文档和架构决策记录
- 使用日常笔记捕捉想法和灵感
技巧:利用双向链接功能,将知识点相互关联,构建知识网络,而非简单的知识树。
总结
最后,工具再好,也需要时间精力去掌握。建议每次只引入1-2个新工具,熟练后再考虑扩展。
毕竟,真正的效率来源于熟练度,而非工具数量。
来源:juejin.cn/post/7506414257399939111
年薪 50W 的前端,到底比年薪 15W 的强在哪里?

昨天我看新年第一波简历 看破防了
最近团队缺人,我连着看了一周的简历。
说实话,看得我挺难受的。😖
我发现一个特别普遍的现象:很多工作了四五年的兄弟,期望薪资填个 25k 甚至 30k,但你仔细翻他的项目经历,全是后台管理系统,全是 H5 拼图页面,全是表单增删改查。
你问他:这几年你遇到的最大技术难点是啥?🤔
他回你:表单字段太多了,校验逻辑太复杂。或者说,产品经理改需求太频繁。😖
听到这种回答,我心里大概就有了底:这兄弟的薪资上限,大概率锁死在 20W 以内了。
这就是咱们常说的 CRUD 困局。
别沉迷 CRUD,高薪的关键是工程化视野与底层兜底能力。想在快节奏中兼顾标准与效率?试试 RollCode 低代码平台,利用 私有化部署 和 自定义组件 沉淀资产,轻松搞定 静态页面发布(SSG + SEO)。
你会 Vue,你会 React,你会用 Antd 画页面,你会调接口。兄弟,这些在 2018 年也许能让你拿高薪,但现在是 2026 年了,这些东西是基建,是培训班出来的应届生两个月就能上手的。🤣
那么问题来了,那个坐在你隔壁工位、平时话不多、但年薪能拿 50W 的大佬,他到底比你强在哪?
是他敲键盘比你快?还是他发量比你少?
都不是。
我觉得最核心的差距,就只有三点。听我细说。
你在做填空,他在设计整张试卷

这事儿特别明显。就拿新开一个项目来说。
15W 的兄弟是怎么干的?
找个脚手架,create-react-app 一把梭。然后开始堆页面,写组件。遇到要用的工具函数?去百度搜一个粘贴进来。遇到样式冲突?加个 !important 搞定。代码格式乱了?不管了,先跑通再说。
他的脑子里只有一个字:做。
50W 的兄弟是怎么干的?
他在写第一行业务代码之前,会先在脑子里过一遍这几件事:
大家代码风格不一样怎么办?先把 ESLint + Prettier + Husky 这一套流水线配好,谁提交的代码格式不对,连 git push 都推不上去。
这个项目以后会不会变大?要不要直接上 Monorepo 管理?
公共组件怎么抽离?是不是该搭个私有 npm 库?
打包速度怎么优化?Vite 的配置能不能再调调?
这就是差距。🤔
老板愿意给他 50W,不是因为他页面画得快,而是因为他制定了标准。他一个人,能让团队剩下 10 个人的产出质量变高。这叫工程化视野,这才是值钱的玩意儿。
出了事,你只会甩锅,他能兜底

场景再具体点:用户投诉页面卡顿,加载慢。
15W 的兄弟通常反应是这样的:
打开控制台 Network 看一眼。
哎呀,接口这就 800ms 了,这后端不行啊,锅在服务端。
嗨🙂↔️,这图片 UI 给得太大了,切图没切好。
这数据量几万条,浏览器渲染本来就慢,我也没办法!
总之,只要不是 JS 报错,这事儿就跟我没关系。
50W 的兄弟会干嘛?
他不会废话,他直接打开 Chrome 的 Performance 面板,像做外科手术一样分析。
这一段掉帧,是不是触发了强制重排?
内存这一路飙升,是不是哪个闭包没释放,或者 DOM 节点没销毁?
主线程卡死,是不是长任务阻塞了渲染?能不能开个 Web Worker 把计算挪出去?
网络慢,是不是 HTTP/2 的多路复用没吃满?关键资源的加载优先级设对了吗?
这就叫底层能力。🤔
平时写业务看不出来,一旦遇到高并发、大数据量、若网环境这种极端场景,只会调 API 的人两手一摊,而懂底层原理的人能从浏览器内核里抠出性能。
这种 兜底能力,就是你的溢价。
他是业务合伙人!

这点最扎心。
产品经理提了个不靠谱的需求,比如要在手机端展示一个几百列的超级大表格。
15W 的兄弟:
心里骂娘:这傻X产品,脑子有坑。😡🤬
嘴上老实:行吧,我尽量试试。
结果做出来卡得要死,体验极差,上线被用户骂,回来接着改,陷入无尽加班。
这种思维模式下,你就是个执行资源,也就是个 打工人。
50W 的兄弟:
他听完需求直接就怼回去了:
哥们,在手机上看几百列表格,用户眼睛不要了?你这个需求的业务目标是啥?是为了让用户核对数据?
如果是核对数据,那我们要不要换个方案,只展示关键指标,点击再下钻看详情?这样开发成本低了 80%,用户体验还好。
这就叫技术变现。
高端的前端,不仅仅是写代码的,他是懂技术的业务专家。他能用技术方案去纠正产品逻辑,帮公司省钱,帮业务赚钱。
在老板眼里,你是成本,他是投资。🤷♂️
哪怕现在是 15W,咱也能翻盘
如果你看上面这些话觉得膝盖中了一箭,别慌。谁还不是从切图仔过来的?
想打破这个 CRUD 的怪圈,从明天上班开始,试着变一下:
别再只盯着那几个 API 了
Vue 文档背得再熟也就是个熟练工。去看看源码,看看人家是怎么设计响应式的,看看 React 为什么要搞 Fiber。懂了原理,你就不怕框架变。
别做重复工作
下次想复制粘贴工具函数的时候,停一下。试着自己封装一个通用的,甚至试着把你们项目里重复的逻辑抽成一个库。工程化就是这么一点点做起来的。
钻进去一个细分领域
别啥都学,啥都学不精。
可视化、低代码、Node.js 中间件、音视频,随便挑一个,把它钻透。在任何一个细分领域做到前 5%,你都有议价权。
还是那句话!前端并没有死,死的是那些 只会切图和调接口 的工具人。
50W 的年薪,买的不是你的时间,而是你 解决复杂问题 的能力,和你 避免团队踩坑 的经验。
别再满足于重复做一个 CRUD 了。下次打开编辑器的时候,多问自己一句:
除了把这个功能做出来,我还能为这段代码多做点什么?
共勉🙌

来源:juejin.cn/post/7591744411740372992
LLM 交互的“省钱”新姿势:JSON 已死,TOON 当立
背景
嘿,兄弟!你是不是也感觉 AI 越来越香,但 Token 账单也越来越“烫”? 💸
GPT-4o、Kimi 这些模型的上下文窗口动不动就几十万、上百万 Token,我们恨不得把整个项目都扔进去。但冷静下来看看账单... ... 哇哦
LLM 的 Token 每一分都是真金白银啊!
当大家都在想办法优化模型、优化算法时,有没有想过,我们每天都在用的 JSON,可能就是那个“背刺”我们 Token 费用的“内鬼”?
JSON 虽好,但它实在是... ... 太!啰!嗦!了!
“内鬼”现形:JSON 到底有多浪费
在 LLM 的世界里,Token 就是钱。表达同样的信息,谁用的 Token 少,谁就是赢家。
不信?我们直接上例子,用事实说话。
假设我们有这样一个简单的用户列表:
1. 冗长的“老大哥”:JSON
标准的 JSON 格式,充满了大括号、双引号和逗号,简直是 Token 杀手。
[
{
"id": 1,
"name": "Alice",
"age": 30
},
{
"id": 2,
"name": "Bob",
"age": 25
},
{
"id": 3,
"name": "Charlie",
"age": 35
}
]
(数数看,光是 name 这个词就重复了 3 遍!)
2. “小清新”但还不够:YAML
YAML 确实清爽了不少,用缩进代替了括号,也去掉了双引号。
- id: 1
name: Alice
age: 30
- id: 2
name: Bob
age: 25
- id: 3
name: Charlie
age: 35
嗯,进步了,但不多。id, name, age 这些键名还是在无情地重复。
3. “抠门”的王者:TOON 登场!
TOON (Token-Oriented Object Notation)闪亮登场,它用了一种近乎“变态”的方式来压缩信息:
[3]{id,name,age}:
1,Alice,30
2,Bob,25
3,Charlie,35
看明白了吗?[3] 表示有3个对象,{id,name,age} 只定义了一次“表头”,后面的数据就像 CSV 一样紧凑排列。
没有对比就没有伤害! 同样的数据,TOON 的 Token 占用量简直是“骨折价”!
啥是 TOON?为 LLM 而生的“省钱利器”
TOON(面向 Token 的对象表示法)就是这么一个专为 LLM 提示词而生的、紧凑且人类可读的数据格式。
它能表示和 JSON 一模一样的对象、数组和数据类型,但它的语法就是为了最小化 Token 使用而设计的。
你可以把它理解为 YAML 的嵌套结构 + CSV 的表格布局 = TOON
TOON 最擅长处理的场景,就是我们最常见的**“结构一致的对象数组”**。在实现 CSV 般紧凑的同时,它又提供了清晰的结构信息({key1, key2}:),帮助 LLM 更可靠地解析和验证数据。
注意: TOON 并非银弹。如果你的数据是深度嵌套或结构极其不统一的,那 JSON 可能还是老老实实的选择。但在“对象数组”这个 LLM 最常见的场景下,TOON 简直无敌。
数据为证:TOON 到底有多能打?
光说不练假把式。Chase Adams 大佬做了一组非常直观的基准测试,对比了 JSON、YAML、TOON 和 CSV 的 Token 效率。
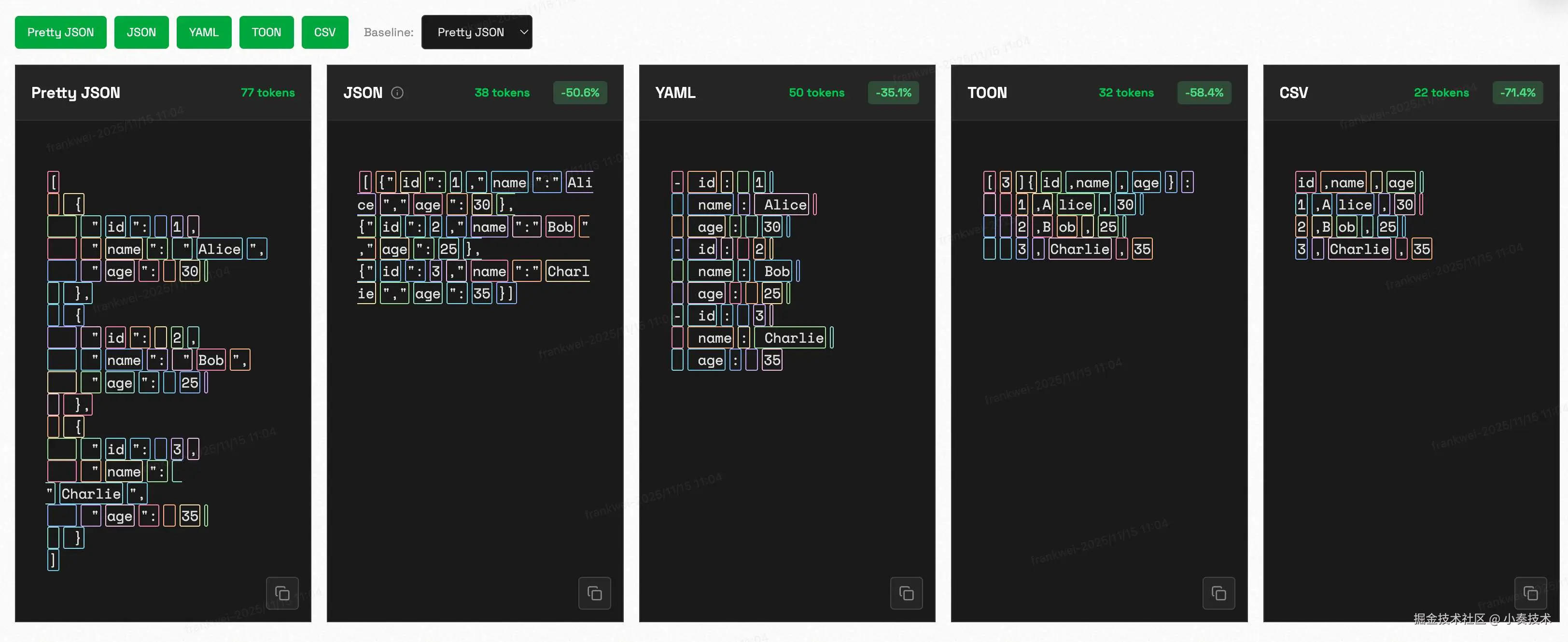
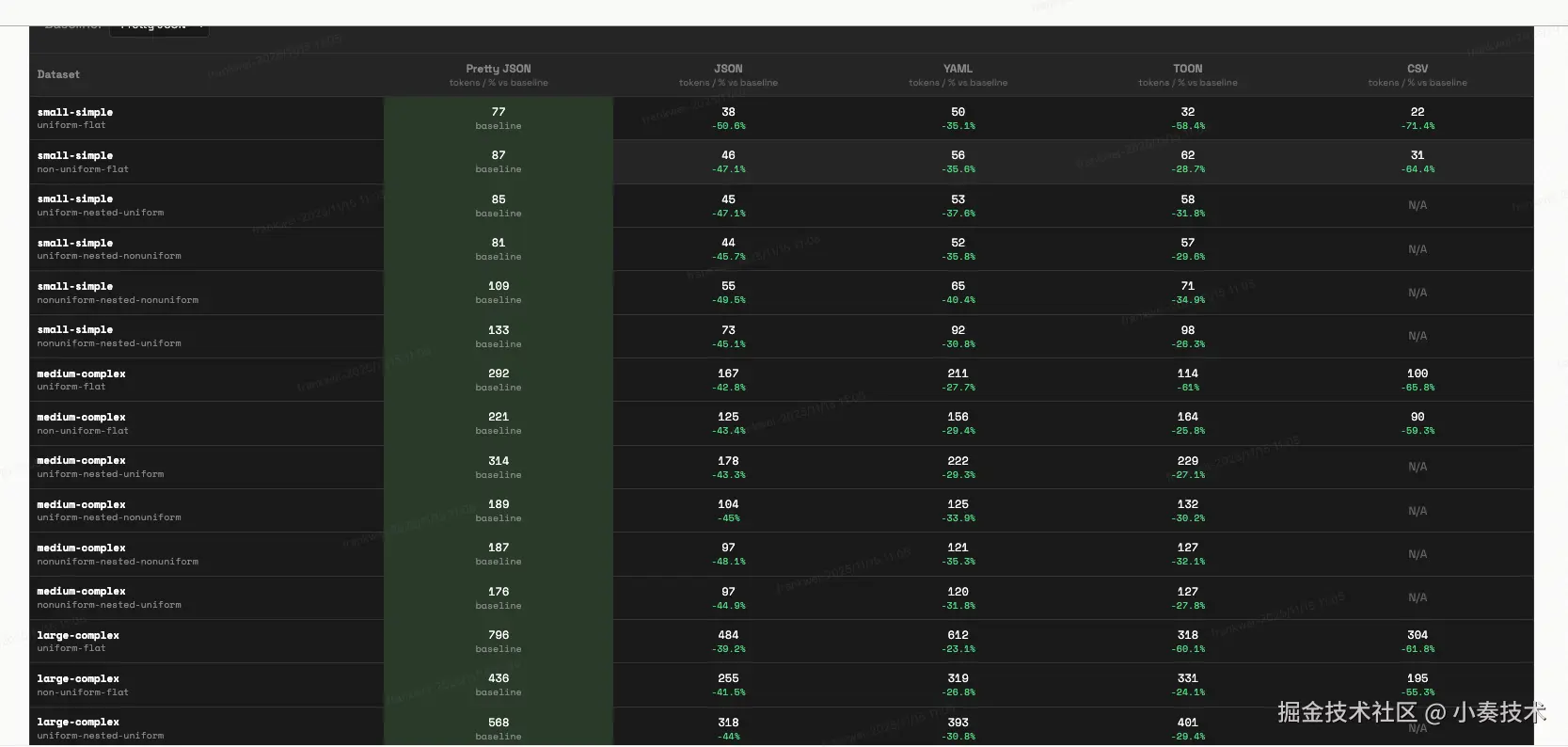
基准测试链接:http://www.curiouslychase.com/playground/…
结论一目了然:
CSV 是 Token 效率的“天花板”,但它无法表示嵌套结构,而且没有元数据,LLM 很容易“读歪”。
TOON 稳坐第二把交椅,效率直逼 CSV,但它保留了完整的结构信息。
JSON 和 YAML... ... 两位老大哥,在 Token 效率上被 TOON 吊打。
如何在 LLM 中“无痛”用上 TOON?
你可能会想:“哇,这么牛?那我岂不是要重构整个系统?”
完全不用
官方推荐的架构是这样的:
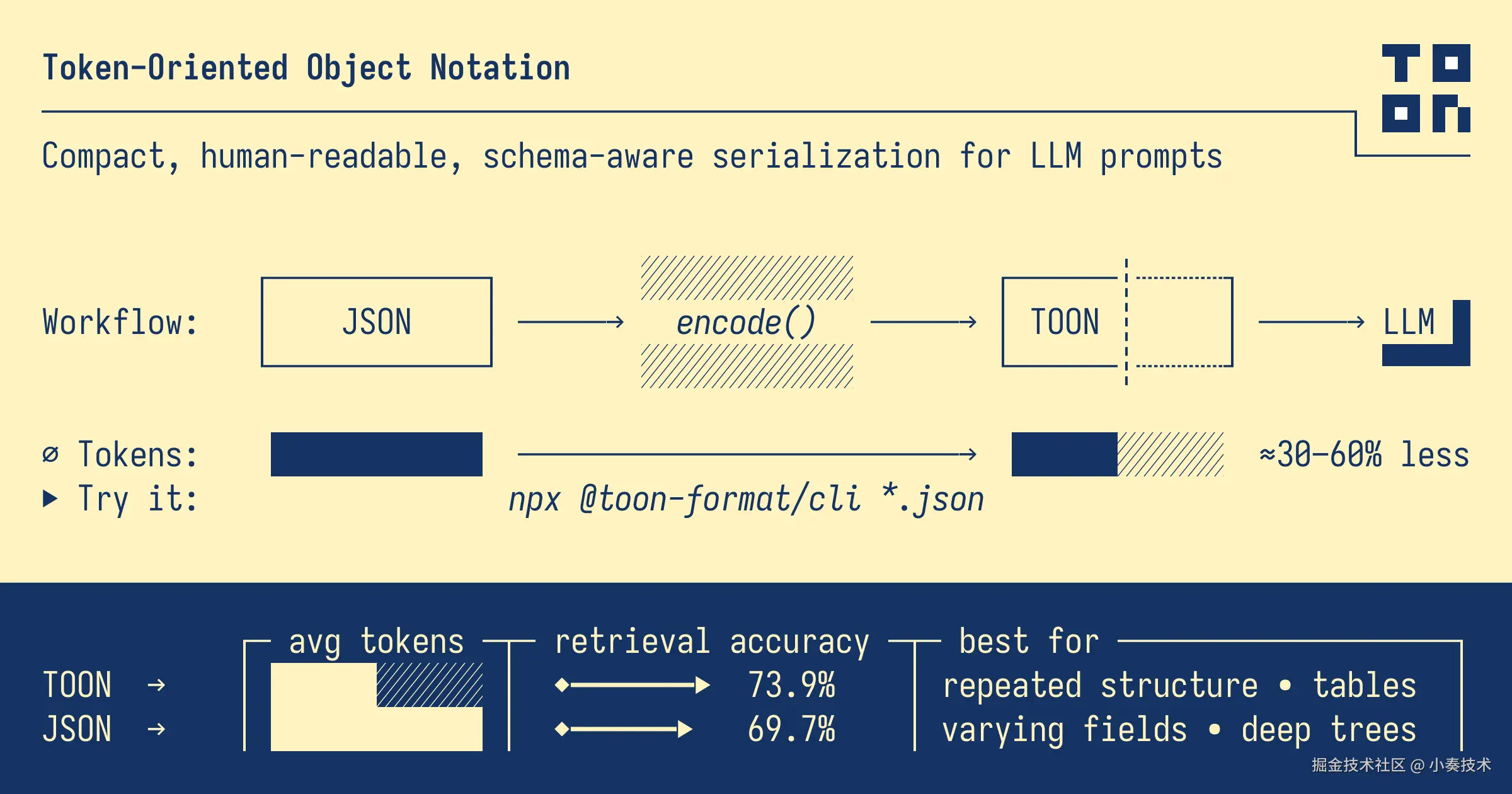
看懂了吗?TOON 只是一个**“转换层”**。
你的系统内部,该用 JSON 还是用 JSON,啥也不用改。
在调用 LLM 之前,你只需加一个编码步骤,把 JSON 编码(Encode) 成 TOON 格式再发送。
LLM 返回 TOON 格式的数据后,你再解码(Decode) 成 JSON 给系统用。
你就把它当成一个“中间件”,在和 LLM 交互的“最后一公里”上帮你省钱
别再浪费 Token 了!
在 LLM 时代,Token 效率就是核心竞争力。
JSON 是一个伟大的格式,但在 LLM 交互这个新场景下,它显得既臃肿又昂贵。
TOON 提供了一个完美的替代方案:它在保留 JSON 完整表达能力的同时,实现了接近 CSV 的 Token 效率。
如果你还在为高昂的 LLM Token 费用而头疼,如果你还在忍受 JSON 带来的冗余,那么,是时候给你的系统“升个舱”了
参考
来源:juejin.cn/post/7572453554331009024
AI 编程的临界点:当三家巨头同时宣布我们不写代码了
大家好,我是孟健。
昨天 24 小时内,三家公司同时说了同一句话:我们的代码,基本不是人写的了。
不是媒体炒作。不是 PR 包装。是 Nvidia、OpenAI、Cognition、Anthropic——四家站在 AI 最前沿的公司,几乎同一时间亮出了底牌。
这件事值得每个写代码的人停下来想一想。
发生了什么
先摆事实。
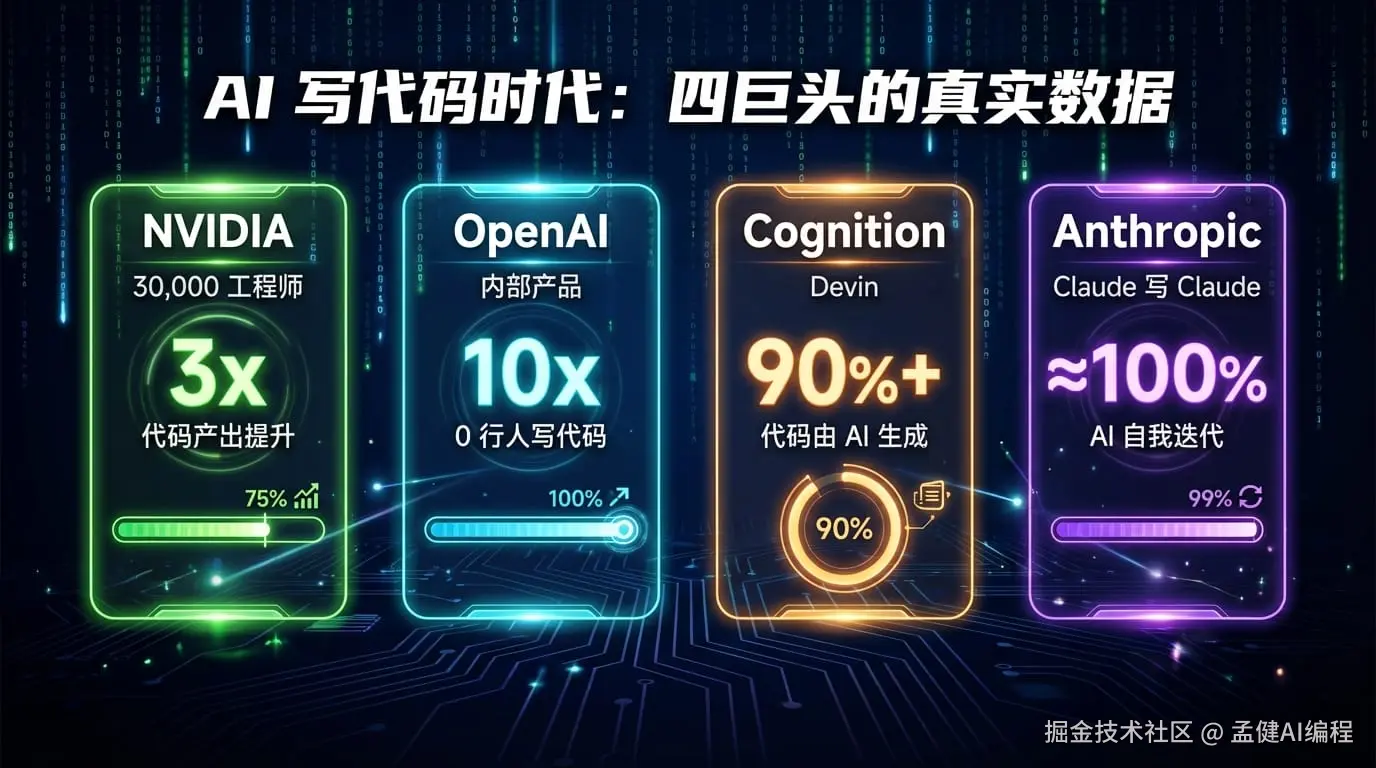
Nvidia:黄仁勋几个月前在内部喊出"stop coding",让 3 万名工程师全面换用 AI 编程工具。最新数据——代码产出量翻了 3 倍。不是 10%、20%的提升,是 3 倍。

OpenAI:内部团队交付了一个完整产品,每一行代码都是 AI Agent 生成的。工程师全程没写一行代码,只负责 Review 和监督。开发效率提升了 10 倍。
Cognition(做 Devin 的那家):联合创始人 Scott Wu 发了条推,说公司超过 90%的代码是 AI 写的。他的原话是:"你现在实际需要亲手敲的代码有多少?对我们来说,大概不到 10%。"

Anthropic:首席产品官 Mike Krieger 说得更直接——"Claude 在写 Claude。Claude 的产品和 Claude Code,完全由 Claude 自己写。"
四家公司,同一个结论:程序员的核心工作,正在从"写代码"变成"不写代码"。
这不是第一次有人喊"狼来了"
我知道你在想什么。
"AI 替代程序员"这话喊了三年了。2023 年 GitHub Copilot 发布的时候喊过一次。2024 年 Devin 出来的时候又喊了一次。2025 年 Claude Code 和 Codex 上线的时候再喊一次。
每次喊完,程序员还是该上班上班,该加班加班。
但这次不一样。
之前是模型公司说"我们能做到"——那是销售话术。
这次是用 AI 写代码的公司自己说"我们已经做到了"——这是生产实践。
Nvidia 不是 AI 编程工具公司,它是芯片公司。它给 3 万工程师换工具,不是为了 PR,是因为代码产出真的翻了 3 倍。当你的竞争对手用同样的人力做出 3 倍的产出,你不跟进就是在等死。
这个信号的含金量,跟"某 AI 公司发了个 Demo"完全不是一个量级。
为什么是现在
你可能好奇:AI 编程工具 2024 年就有了,为什么突然到了这个临界点?
答案是速度。
就在昨天,OpenAI 发布了 GPT-5.3-Codex-Spark——一个跑在 Cerebras 晶圆级芯片上的编码模型。这是 OpenAI 第一次用非 Nvidia 的芯片部署生产级模型。
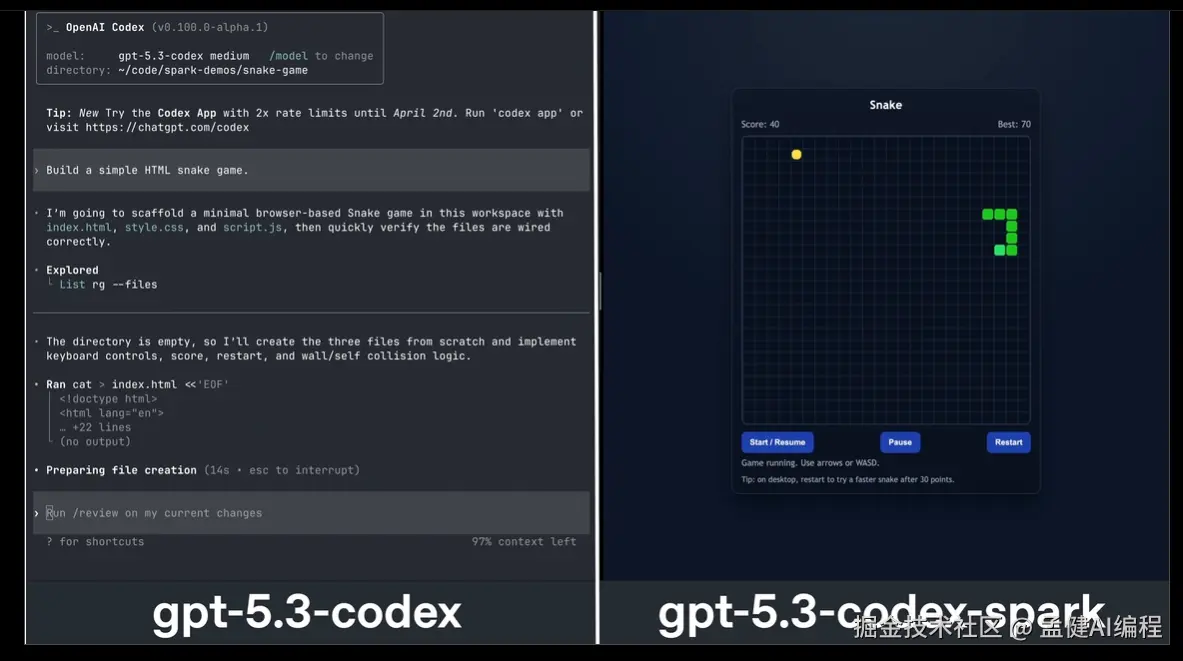
关键数字:每秒 1000+ token 的代码生成速度,比之前快 15 倍。
Cerebras 的芯片有多大?一整块硅晶圆,餐盘那么大,就是一个处理器。不是把几百个 GPU 堆在一起,是把一整个芯片做到极致。
15 倍速度意味着什么?
以前用 AI 写代码,你提交一个任务,泡杯咖啡等几分钟。现在是你话音刚落,代码就出来了。从"异步等结果"变成了"实时对话"。
这个体感差异是质变。
我自己每天用 Claude Code 做产品。之前等 AI 生成的时候我会切到别的窗口干别的事。现在?根本没时间切——它比我打字还快。
当 AI 写代码的速度快到人类来不及思考的时候,"人写代码"这件事本身就变成了瓶颈。
这就是为什么四家公司同时跨过了这个临界点。不是巧合,是速度到了。
我自己的体感
说说我的真实经历。
我在腾讯带过几十人的团队,在字节也做过前端技术 Leader。那时候团队产出的计算方式是:人头 × 工时 × 人效。想提高产出?加人、加班、优化流程。
2025 年 10 月辞职创业后,我开始全面用 AI 编程。
一个人,一个月,做了近 30 个出海小产品。
不是简单的静态页面。是有前端、有后端、有支付、有 SEO、有数据统计的完整产品。放在以前,这是一个 5-8 人的小团队干一个季度的量。
我不觉得 AI 替代了我。更准确地说,是 AI 把我从"写代码的人"变成了"做决策的人"。
以前 80%的时间在写代码,20%在想产品。
现在反过来了——80%的时间在想产品方向、用户需求、商业模式,20%在 Review AI 写的代码。
这个转变,跟 Nvidia 那 3 万工程师的转变是一模一样的。
程序员要失业了吗?
这是每次 AI 编程话题下必然出现的问题。
我的判断是:不会失业,但工作内容会彻底改变。
上海交大最近发了一篇论文(ProjDevBench),测试 AI 从零构建完整软件项目的能力。结果通过率只有 27%——基础功能还行,但系统设计、性能优化、资源管理全崩。
这说明什么?
AI 已经能干 80%的活了。但剩下那 20%——架构决策、边界处理、性能调优、产品判断——恰恰是最值钱的 20%。
Scott Wu 说得好:"瓶颈不再是写代码本身,而是两件事——1)让人类更容易理解、规划和提问;2)让 AI 更容易获取任务的真实上下文。"
翻译成人话就是:未来的程序员不是代码机器,是 AI 的 项目经理 。
你的价值不再是一天能写多少行代码,而是你能不能把一个模糊的需求拆解成 AI 能理解的指令,能不能在 AI 写完之后判断"这个架构扛不扛得住",能不能在 AI 犯错的时候快速定位问题。
这些能力,恰恰是在大厂带过团队、做过大项目的人最擅长的。
如果你只做一件事
说了这么多,落到行动上,我建议你今天就做一件事:
把你最常做的一类开发任务,完整地交给 AI 做一次。
不是让它补两行代码。是给它一份需求描述,让它从零开始搞。前端、后端、数据库、部署,全交出去。
你会发现两件事:
- AI 能搞定的部分,比你预期的多得多。
- 搞不定的部分,恰恰暴露了你真正不可替代的价值。
Nvidia 的 3 万工程师已经这么干了。OpenAI 的团队已经这么干了。你还在等什么?
如果这篇对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续输出的动力 ✨
我的其他平台账号和开源项目在个人主页中,欢迎交流 🤝
来源:juejin.cn/post/7605816833192067072
AI 只会淘汰不用 AI 的程序员🥚
作为程序员,你竟然还在手撸代码 ???
如果没有公司给你提供科学上网,提供AI 编程工具的账号,你真能玩转AI ???
除了平时搜搜查查,AI 对你还有其他用处 ???
震惊!
某博主竟然开头就贩卖焦虑?难道程序员真的要被 AI 取代了?
别急,这篇文章就一步步带你玩转 AI 编程!
如果只是想了解如何使用 AI 编程,可以直接跳到章节: 「所以,我们需要什么!?」
理解概念
要深入使用 AI,我们要先理解一些概念
1. AI 基础
- AI大模型:拥有超大规模参数、超级聪明的机器学习模型,所有的 AI 应用都是调用大模型的计算处理能力。如:问答、图片生成、视频生成。
国内主流大模型对比:
| 模型 | 厂商 | 速度 | 能力 |
|---|---|---|---|
| 通义千问 | 阿里云 | 较快 | 多轮对话,支持多模态,支持 PDF/Word 等文件处理。 |
| DeepSeek | 深度求索 | 推理性能一流,较慢 | 多轮对话,代码能力国内顶级,数学推理能力出色,多模态能力弱。 |
| 豆包🐂 | 字节跳动 | 速度极快 | 推理能力强,多模态能力强,语音交互自然,MCP预置多。 |
| 腾讯混元 | 腾讯 | 较快 | 支持超长文本处理,与微信生态无缝集成,多格式文档解析,支持多模态。 |
国外主流大模型对比
| 模型 | 厂商 | 核心能力 | 主攻场景 |
|---|---|---|---|
| Gemini🐂🍺 | Google DeepMind | 多模态能力强大,可无缝处理文本、图像、音频、视频、代码等 | 创意内容创作、文档处理、用于处理复杂、多源信息的场景 |
| Claude🐂🍺 | Anthropic | 推理能力优秀,多模态能力一般 | 长文档分析场景,如法律文件审查;适用于需要可靠输出的领域,如医疗诊断辅助 |
| Veo 3 | 自动生成视频和音频,口型同步精准到毫秒级。支持最高 4K 分辨率输出,画质清晰,色彩还原。生成速度快 | 专注于视频生成领域,如短视频内容创作,为用户提供高效、高质量的视频生成解决方案。 | |
| Sonnet | Anthropic | Sonnet 是 Claude 3 系列中的平衡型模型,性价比高 | 适用于注重性价比和处理速度的场景,如一般性的文档分析 |
| GPT | OpenAI | 通用性极强,各个方面都有出色表现,GPT-4o 等版本增强了多模态交互能力。 | 自然语言处理相关的场景,如内容创作、智能客服 |
| Copilot | GitHub 与 OpenAI 合作开发 | 基于 GPT 系列模型训练,理解自然语言,生成对应代码 | 用于日常编码、代码调试、新手编程学习,降低重复编码工作量 |
一般我们编程使用的都是国外的大模型,毕竟开发工具、系统、编程语言都是外国的。编码方面的能力,国外模型还是碾压的存在。
- MCP:一套提供给 AI 大模型调用的标准协议。一些厂商会把自己的能力包装成MCP,让大模型在理解完用户的复杂任务时,可以调用厂商的能力。比如:
你让豆包给你用 “高德” 生成一份超准的导航,豆包就会去调用高德的 MCP,为你出导航~ - IDE:程序员专属概念。AI IDE是集成了 AI 能力的软件开发平台,开发者可以通过自然语言,让 IDE 调用 AI 模型和 MCP 给你写代码,
速度和质量牛的飞起,真有手就能写代码!
主流的 AI IDE 对比
| 名称 | 厂商 | 搭载的模型 | 收费维度 |
|---|---|---|---|
| Cursor🐂 | Cursor 公司 | GPT-4、Claude 3.5、Cursor-small、o3-mini 等 | 很贵,按 token 收费 |
| Antigravity🐂🍺 | 支持在 Gemini 3 Pro、Claude Sonnet 4.5 和 GPT-OSS 等多种模型之间无缝切换 | 有羊毛薅,国外邮箱+学生认证~ | |
| Trae | 字节跳动 | 国内版搭载豆包 1.5-pro、DeepSeek R1/V3 等模型,海外版内置 GPT-4o、Claude-3.5-Sonnet 模型 | 国内的,充个会员的事,不贵 |
2. RAG ➡️ Agent ➡️ Planning:AI 应用方式的演进之路
AI 的应用方式正从 “被动响应” 向 “主动规划” 快速迭代。
从 RAG 进行检索增强生成,到 AI Agent 实现自主调用工具完成任务,再到 Planning 能 “拆解复杂任务与全局决策” 的高阶形态。让 AI 从 “内容生成器” 蜕变到 “智能协作体”。
- RAG —— 检索增强生成
核心逻辑是:先检索,再生成。用户提出问题,先从外部数据库、文档库中检索与问题最相关的信息,再将这些信息作为 “参考资料” 喂给大模型,让模型基于真实数据生成回答。 - AI Agent —— “自主工具操作员”
AI Agent(智能体) ,让 AI 像人一样调用工具、执行步骤、验证结果。能理解用户的模糊需求,自主规划任务步骤,选择并调用合适的工具(如计算器、浏览器、代码解释器、RAG 系统),完成任务。 - Planning(规划)—— “全局任务指挥官”
AI 系统的高阶能力,核心逻辑是 “先拆解,再执行,再调整”。基于全局目标,将复杂、长期、多约束的任务拆解为有序的子任务序列,并根据执行过程中的反馈动态调整策略。
不仅关注单个任务的完成,更关注子任务之间的关联和整体目标的达成。
演进逻辑与核心差异总结
| 维度 | RAG(检索增强生成) | AI Agent(智能体) | Planning(规划) |
|---|---|---|---|
| 核心定位 | 大模型的 “知识库外挂” | 自主工作的 “工具操作员” | 全局任务的 “指挥官” |
| 能力核心 | 检索 + 生成,保证回答准确 | 决策 + 工具调用,完成单任务闭环 | 拆解 + 协同 + 动态调整,掌控多任务全局 |
| 典型比喻 | 学生的 “参考书” | 能独立完成工作的 “专员” | 统筹全局的 “项目经理” |
所以,我们需要什么!?
你作为一名优秀的程序员,你需要通过科学上网、精准付费,在 AI IDE中,基于AI大模型的能力,熟练使用 Agent/Planning,配合 MCP 等工具,让 AI 帮你写出又快又好的代码,更好的服务你的业务!
1. 使用 Cursor、Antigravity、Trae 开发工具
下载地址:Cursor、Antigravity、TREA
账号注册:Cursor 和 Trae 登录方式都超简单,会员的话直接去官网购买即可
至于 Antigravity,因为 Google 是禁止国内用户访问的,因此一定要能正常上网,邮箱账号必须纯正🇺🇸,但是我们有 闲鱼 之光,是可以尝试下的~
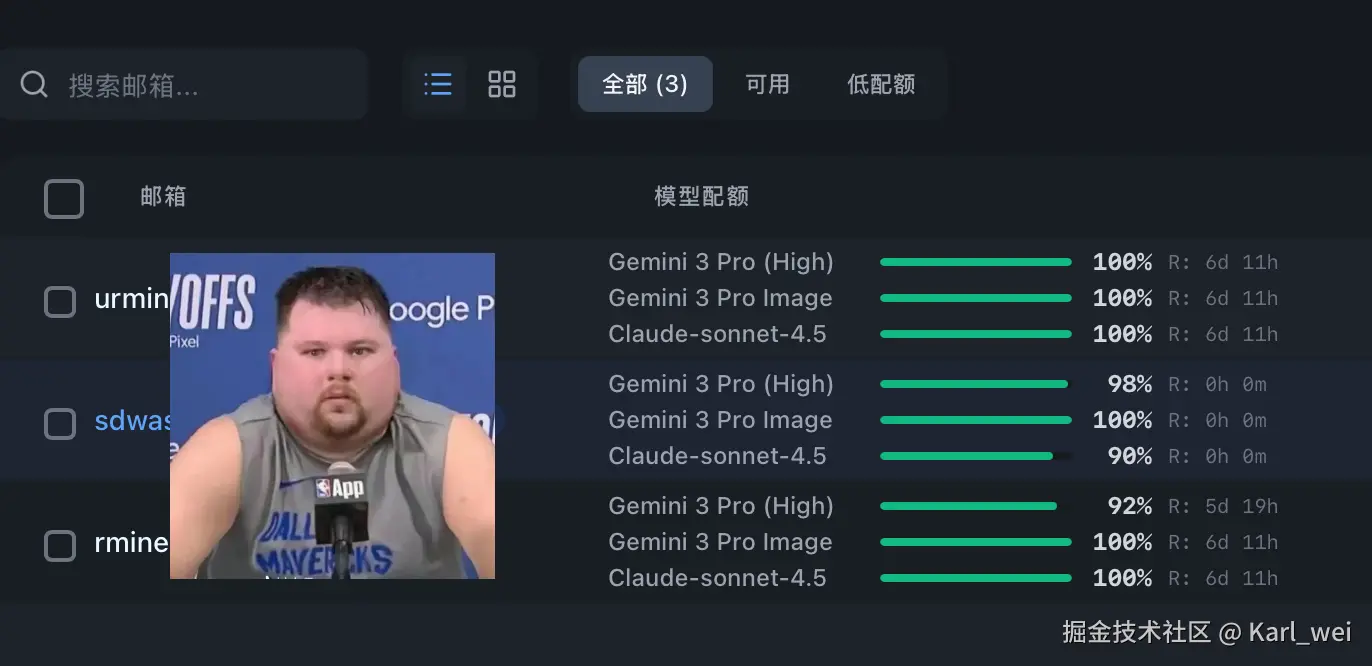
2. 装好主流 MCP
对于前端程序员,UI 这类低级工作,完全可以交给 Agent 去编写。比如:公司的设计师用的是figma,我们只需要在 cursor 中装上figma mcp,然后 figma 账号申请开发者权限,就能自由的让 AI 帮我们写好代码。亲测还原度 85%+
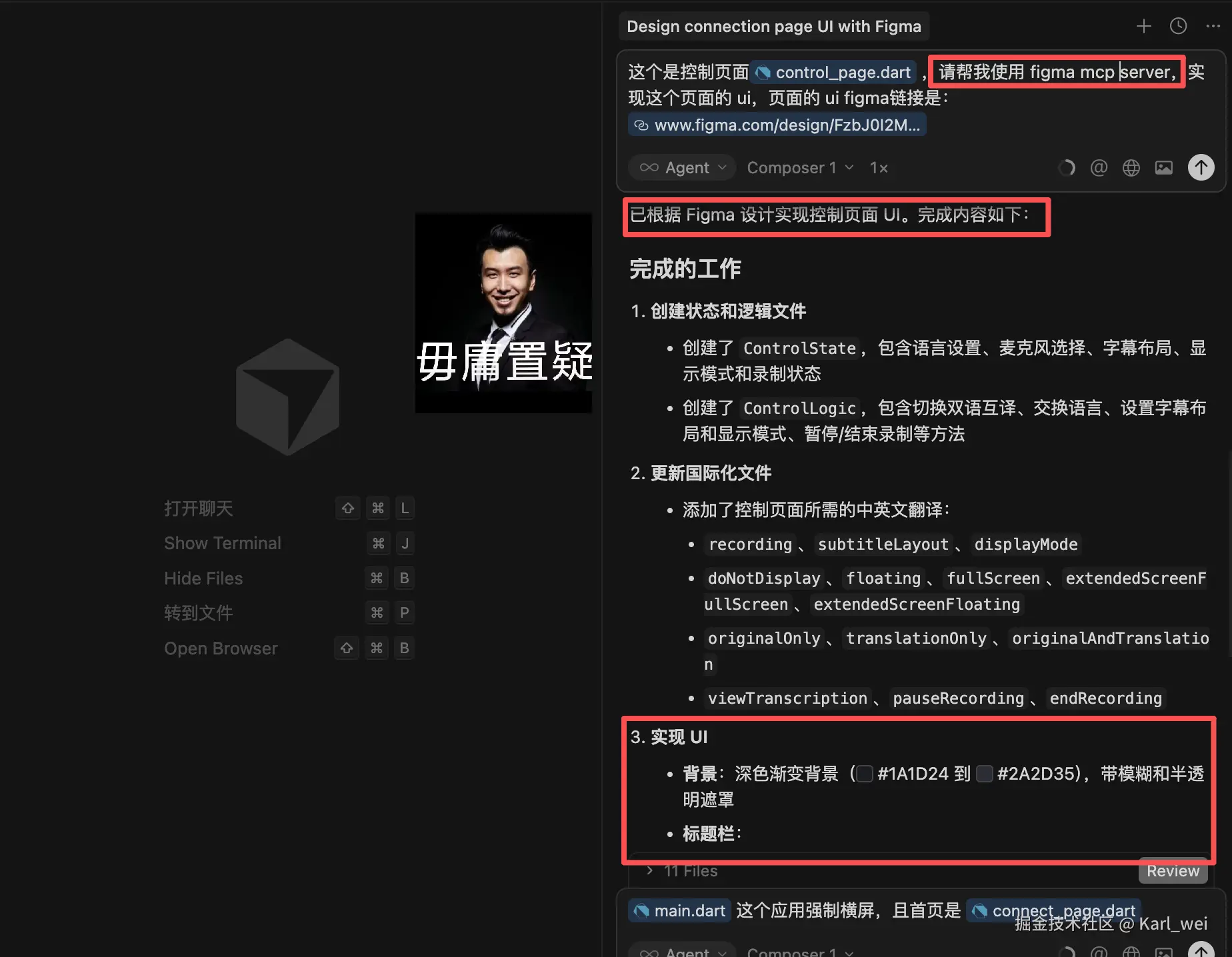
3. 沉淀 Rules 和 Workflows
我们现在已经可以通过开发工具让 AI 干活了,但如何更符合我们的编码习惯和设计思想?那就得给 AI 规范,也就是通过提示词让 AI 更乖的,干更对的活。
比如,Antigravity就有明确的让我们添加规则和工作流的入口,并且会引导我们如何写提示词,然后在提问的时候,引用对应的文件即可。
Rules(规则)和Workflows(工作流),沉淀 沉淀 再 沉淀!!!
4. !!!文档先行!!!
AI 时代的编码,一定要做好设计,写好文档。
AI 虽然帮你干活,但是任务是你来安排的,你给出的任务要足够精准。
同时,你的编码思维才是代码能写好的核心,你必须把你的思维和想法,落成文档给到 AI 大模型。
- markdown 格式:注意 AI 需要理解 md 文档
- 图文并茂:在编写文档的时候,时常需要画图,此时可以使用 md 语法来画图。这里我推荐mermaidchart,可以基于 md 语法进行可视化编辑。
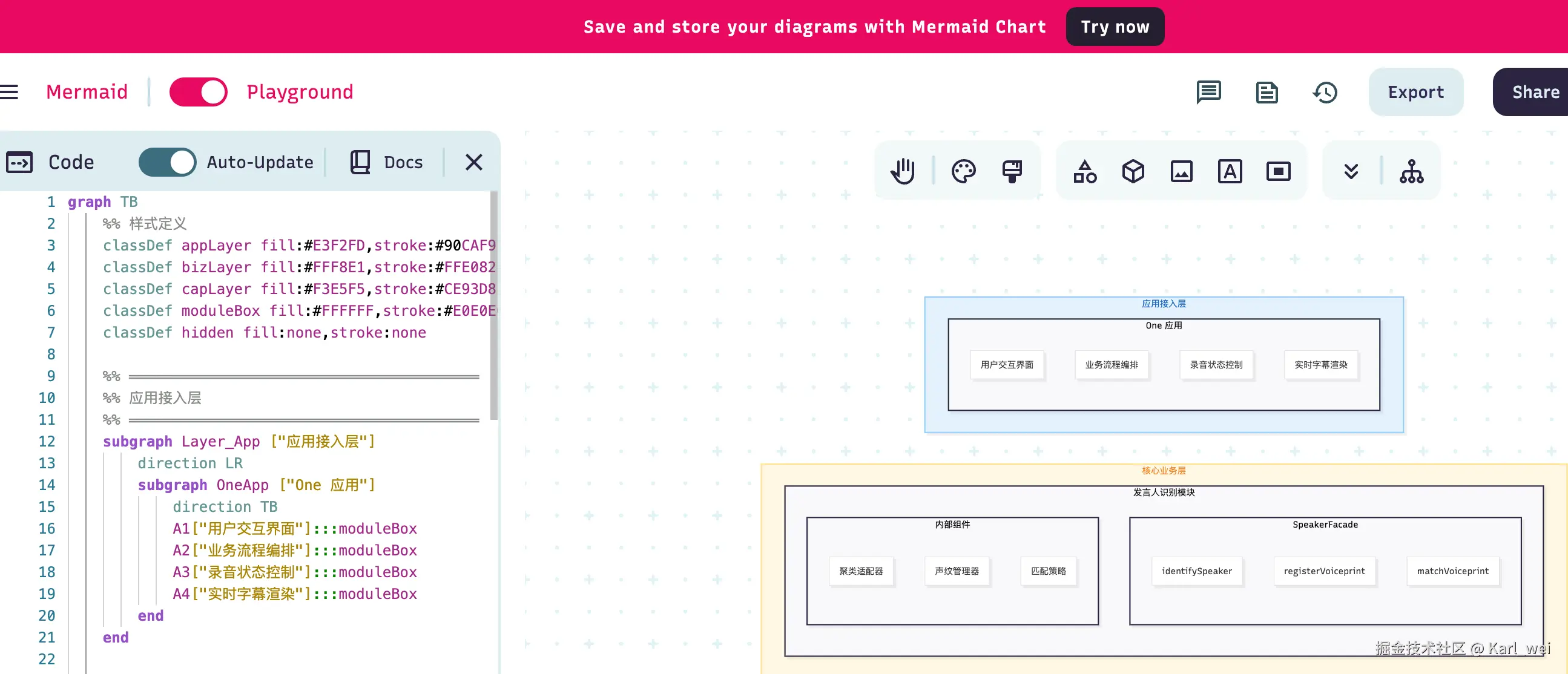
写在最后
当你有正常可以使用模型的账号后,其实这个账号不仅仅是在 IDE 可以使用,比如 Antigravity 的账号,跟 Gemini 是一致的,你也可以在大模型的官网登录进行图片、视频生成。
在了解了大模型、MCP、工作流、AI 编程工具后,相信你对 AI 的应用又有了新的理解。我们一定要积极去尝试,国内国外的 AI 工具能用的多用,尽情的去拥抱 AI!
AI 是生产力,毋庸置疑!
来源:juejin.cn/post/7585022810181222463
JDK25已来,为何大多公司仍在JAVA8?
第一章:JDK 25 都发了,为什么大家还在 Java 8
JDK 25 发布那天,我特意去看了一眼发布说明。内容不复杂,新特性不少,语气一如既往地克制,像是在告诉你: “你可以升级了,但我们不催。”
这种感觉我在 Java 世界里已经很熟了。
同一天,Python 社区的画风完全不一样。Python 3.13 的兼容性讨论、弃用警告、生态适配进度,被反复拿出来说。很多库会直接写在 README 里:“Python 3.8 即将停止支持,请尽快升级。”Java 这边没有这种集体施压。JDK 25 发布了,但 JDK 8 依然能跑、能用、能上线。
我翻了下手头几个线上系统的运行环境,结果并不意外:
- 老核心系统:Java 8
- 偏边缘的新服务:Java 11
- 真正用到 17 的,只有少数新项目
- 至于 21、25,基本只存在于 PPT 和技术分享里
这不是个别现象。招聘网站、云厂商镜像、监控 SDK 默认支持版本,几乎都在默默告诉你一件事:Java 8 依然是“安全版本”(你发任你发,我用java8)。这和 Python 的升级节奏形成了非常明显的反差。
Python 2 → 3,是一次不升级就活不下去的断代。Java 8 → 25,更像是一次你可以一直不动的演进。
从技术角度看,Java 明明一直在进化:
- 语言层面:var、record、sealed class
- JVM 层面:GC、JIT、内存模型
- 工程层面:模块化、工具链
但这些变化,没有哪一项是“非升不可”。
我见过不少 Java 服务,代码风格停在 2016 年,但稳定运行到今天。也见过 Python 项目,因为一个依赖不再支持旧版本,被迫整体升级。
这两种生态的差异,很早就写在设计选择里了。
Java 的向后兼容是它的优势。但到了 JDK 25 这个时间点,这个优势开始变得有点微妙。
因为问题已经不是:
JDK 8 能不能用?
而变成了:
如果一直停在 JDK 8,到底是在保守,还是在逃避某些成本?
这个问题,在技术会议上很少被正面讨论。更多时候,它会被一句话带过:
“先别动,风险太大。”
可风险到底在哪?为什么 Python 升级时大家骂归骂,还是会跟着走;而 Java 这边,哪怕官方已经跑到 25,企业却依然集体停在 8?
我后来发现,真正卡住升级的,从来不是新特性本身。而是升级这件事,一旦开始,就很难只停在“换个 JDK”上。但这件事,只有在你真的尝试过一次升级之后,才会意识到。你也就会抱怨为何JDK会把普及新特性的成本强加在每个java开发者身上
第二章:升级 JDK,看起来向下兼容,实际上并不“平滑”
很多人对 Java 升级的第一判断,来自一个几乎写进 DNA 的认知:
Java 是强向下兼容的语言。
这句话本身没错,也是大多数人从jdk7到jdk8无缝升级的真实感受。但问题在于,大多数人只把它理解成了语法层面。
你用 Java 8 写的代码,放到 JDK 17、21、25 上,大概率还能编译。for、try-catch、Stream、lambda,一个都不会少。这也是为什么很多升级评估一开始都显得非常乐观。真正的问题是 Java 的“向下兼容”,从来不等于 JVM 的平滑迁移。
第一次认真推进 JDK 升级时,我们的目标设得非常保守:不引入新语法、不改业务逻辑、不升级框架,只把运行时从 Java 8 换成 17。理论依据也很充分:代码是向下兼容的,JVM 只要能跑就行。
结果第一个暴露问题的,不是业务代码,而是 JVM 本身。
从 JDK 9 开始,Java 做了一次非常激进、但长期看又必须要做的事情:模块化(JPMS) 。这一步,本质上是在重塑 JVM 的边界。在 Java 8 之前,JDK 更像是一个“开放的整体”。JDK 自己的内部实现,和应用代码之间,并没有严格的隔离。于是很多框架、工具、甚至业务代码,都默认了一件事:
JVM 内部的类,我是可以摸得到的。
比如反射。
Field field = String.class.getDeclaredField("value");
field.setAccessible(true);
在 Java 8,这是一个非常常见、甚至被大量框架依赖的操作。但在模块化之后,这种行为被明确标记为:非法访问(Illegal Reflective Access) 。升级后,日志里开始出现大量这样的提示:
Illegal reflective access by xxx
这类 warning 很容易被误判成“噪音”。因为程序还能跑,接口也没挂。但实际上,这不是 JVM 在提醒你“写得不优雅”,而是在明确告诉你:
你现在还能用,是 JVM 在帮你兜底。
于是有人会加启动参数:
--add-opens java.base/java.lang=ALL-UNNAMED
问题是,从这一刻开始,所谓的“向下兼容”已经被你亲手打破了。你不再是被 JVM 兼容,而是用参数强行绕过 JVM 的设计边界。这也是 Java 升级过程中一个非常隐蔽的转折点:
- 代码层面看起来没变
- 启动参数开始越来越复杂
- JVM 行为开始依赖“约定俗成的补丁”
而这一步,一旦走出去,基本就退不回去了。更麻烦的是,这种不平滑迁移,并不是“偶发问题”,而是 Java 设计演进的必然结果。模块化不是可选项,它是为了:
- 限制 JVM 内部 API 滥用
- 提升安全性
- 为长期演进留空间
但代价是:大量在 Java 8 时代“合理存在”的用法,在新 JVM 下被系统性否定了。这也是为什么很多团队会有一种强烈的错觉:
代码明明没变,怎么升级 JDK 反而问题一堆?
因为你真正升级的,不只是一个版本号,而是 JVM 对“什么是合法行为”的判断标准。而这类问题,偏偏又很难在测试环境一次性暴露完。有的库只在特定路径触发反射;有的异常只在高并发下出现;有的 warning 今天是 warning,下一版就变成 error......
这也是 Java 升级和 Python 最大的不同。
Python 的升级是显式断代:你升级,就必须改代码。
Java 的升级是隐式收紧:你不改代码,但 JVM 会慢慢不再纵容你。
这种“看起来兼容,实际上在变”的特性,让 Java 在企业环境里变得越来越尾大不掉。不是升不了,而是你永远无法确定:
下一步,是不是会踩到一个你完全没预期过的 JVM 行为变化?
也正因为这样,很多公司最终选择了一个看似稳妥、但风险被推迟的方案:停在 Java 8。
第三章:真正让升级失败的,不是编译错误,而是线上行为变了
如果只是编译报错,JDK 升级反而简单。
编不过,改代码;启动不了,补参数;问题是可定位的,也是可回滚的。
真正让团队对升级产生恐惧的,往往发生在上线之后。升级前,所有检查都过了:
- 单元测试全绿
- 接口回归没问题
- 压测 QPS、RT 都在预期范围内
代码一行没改,JDK 从 8 换成 17。
上线当天没有事故。第二天开始,监控里出现了一些非常微妙的变化。不是报错,也不是性能雪崩。而是一些 “看起来不该变的行为,变了” 。
最早被发现的是 GC 行为。Java 8 默认用的是 Parallel GC,而 JDK 17 的默认已经变成了 G1。当时的判断很简单:G1 是“更先进的 GC”,不应该比旧的差。
但线上数据并不这么配合。
- Full GC 次数少了
- Minor GC 次数变多
- 单次停顿更短,但更频繁
这对 JVM 来说是“健康变化”,但对业务来说,结果是:
某些接口的 P99 响应时间开始抖动。
不是慢,而是不稳定。问题在于,这类变化不会在压测里明显暴露。压测关注的是吞吐和平均值,而不是长尾。你只能在真实流量下,才会看到这些边缘效应。
紧接着出现的是更难定位的问题:类加载行为的变化。JDK 9 之后,类加载和模块边界被重新梳理过。很多“以前恰好能工作”的加载顺序,在新 JVM 下变了。
最典型的是 SPI 机制。
ServiceLoader.load(SomeService.class)
在 Java 8 下,这段代码的加载顺序是稳定的。在新 JDK 下,如果存在多个实现,顺序可能发生变化。大多数时候,这没什么影响。但如果你的代码里隐式依赖了加载顺序,问题就来了:比如默认实现被换了;没有异常,没有日志,只是业务行为“和以前不太一样”。这类问题,几乎不可能靠自动化测试完全覆盖。因为测试本身,也是在“旧认知”下设计的。
还有一类更隐蔽的变化,来自于 JIT。JVM 在新版本里持续优化编译策略。某些代码路径,在 Java 8 下是“冷路径”,在新 JDK 下被识别成“热点”。结果是:
- 以前不明显的锁竞争,被放大
- 原本可以忽略的对象创建,开始影响 GC
代码没变,但 JVM 对代码的“理解方式”变了。
这也是为什么很多线上问题,在排查时会陷入一种诡异的状态:
SQL 没变,代码没变,配置没变,只有 JDK 变了
而你又很难证明:问题真的就是 JDK 引起的。
到这一步,升级已经不再是技术选型问题了。它变成了一个心理问题。
团队开始本能地回避这种“不可解释风险”。即便你知道:
- 这些问题不是 JDK 的 bug
- 而是历史代码对 JVM 行为的过度依赖
但现实是,线上系统不接受“技术上合理”的解释。这也是很多公司在第一次升级尝试之后,迅速得出结论的原因:
不是升不了, 而是不值得再为这种不确定性买单。
于是升级计划被无限期搁置。Java 8 继续稳定运行,问题被推迟,而不是被解决。
第四章:真正的风险,不在 JDK,而在你不敢动的那一部分代码
当升级卡在第三章那些“行为变化”上时,团队往往会得出一个结论:
问题太散了,风险不可控。
但后来复盘发现,真正不可控的,从来不是 JDK,而是我们不敢去验证的那一块代码。几乎每个中大型 Java 项目里,都有这样一层东西:
- 没人愿意动
- 但所有人都在用
- 出问题只能回滚
它可能是十年前写的公共组件,也可能是一次紧急需求里硬塞进去的工具类。
在 Java 8 时代,这类代码有一个共同特征:它们和 JVM 的关系非常近。比如自定义 ClassLoader。
public class CustomClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) {
// 从非标准路径加载字节码
}
}
在 Java 8 下,这种实现非常常见。升级之后,问题不一定立刻出现。但一旦涉及模块、服务加载或反射,行为就开始变得不可预测。
再比如字节码增强。无论是早期的 cglib,还是基于 ASM 的工具,很多实现都默认了:
- 某些 JDK 内部类是存在的
- 某些方法签名是稳定的
这些假设,在新 JDK 下不再成立。更现实的问题是:这些代码往往没有完整测试。因为它们本来就不是“业务逻辑”。它们被视为基础设施, 被默认是“不会出问题的”。升级 JDK 时,测试覆盖率看起来还不错。但真正和 JVM 行为强相关的部分,几乎没有被验证过。
于是升级就进入了一个死循环:
- 不敢上线,是因为没验证
- 不验证,是因为不敢动
- 不动,就永远无法升级
这也是 Java 升级和其他语言很不一样的地方。Python 项目里,底层行为大多由解释器和库兜住。Java 项目里,很多“工程能力”是直接构建在 JVM 之上的。而这些能力,恰恰是最难平滑迁移的。
还有一个被严重低估的因素,是运维和排障成本。Java 8 的排障手段,大家已经非常熟悉:
- jmap
- jstack
- 老一套 GC 日志
新 JDK 不是不能用这些工具,而是行为、参数、输出都在变化。同一条 GC 日志,在不同版本下,含义已经不完全一致。这会直接导致一个现实问题:
出问题时,团队是否有信心“看懂”新 JDK 的行为?
如果答案是否定的,那升级本身就是一种冒险。
于是你会看到一种很典型的现象:
- 开发知道 Java 17 更好
- 架构知道 Java 21 是趋势
- 但一到生产,所有人都默认:还是 Java 8 吧
不是因为它完美,而是因为它足够“熟”。
升级 JDK,本质上不是技术债的清理,而是一次对未知的正面接触。而大多数系统,并没有为这种接触做好准备。也正因为这样,很多公司并不是“卡在 Java 8”,而是被 Java 8 保护了很多年。
第五章:真正逼你升级的,从来不是技术本身
在很多公司里,JDK 升级从来不是一个“主动议题”。它通常出现在某个非常具体、而且很现实的场景里。比如云厂商的一封邮件。内容往往写得很克制,大概意思是:
某某 JDK 版本即将停止安全更新 请尽快规划升级方案
这类邮件第一次看到时,大多数人并不会紧张。因为“即将”往往意味着还有一段缓冲期。真正产生压力的,是第二封、第三封。
当你发现云厂商的默认镜像开始发生变化,新建实例已经不再提供 Java 8,升级这件事,就从“技术选择”变成了外部约束。还有安全审计。Java 8 的漏洞,并不比新版本多。但问题在于:很多漏洞,在 Java 8 上不再修了。这意味着同样一个问题:
- 在新 JDK 上,是一个补丁
- 在 Java 8 上,是一个长期风险
安全团队不会和你讨论 JVM 设计演进。他们只看结果: 有没有官方支持,有没有风险背书。
接着是第三方生态。越来越多的中间件、SDK、监控工具,开始把“最低支持 JDK”往上抬。不是突然抛弃 Java 8,而是新功能不再考虑它。
你会慢慢发现:
- 想用新版本框架 → 需要新 JDK
- 想接入新工具 → 官方不再测试 Java 8
- 想拿到性能优化 → 只在新 JVM 生效
这时候,继续停在 Java 8 的成本开始显性化。不是系统跑不动,而是你被锁在一个越来越狭窄的选择空间里。
更现实的是人员问题。新来的工程师,默认使用的已经是 Java 17 甚至更高版本。他们熟悉的是新工具链、新调试方式。当他们面对一套 Java 8 的系统时,不是学不会,而是:
很多问题的解决路径,已经不在他们的经验范围内了。
这会让“稳定”变成另一种风险。因为稳定的前提,是有人能长期维护它。到这一步,升级已经不再是“要不要”的问题。 而是变成了:
现在升级,还是被动升级?
很多团队选择继续拖延,希望把升级成本压到最低。
但现实往往是:拖得越久,升级的边界越难控制。
当升级真的不可避免时,你已经不再有“慢慢试”的空间。而这,才是 Java 8 最危险的地方。它让你误以为,时间是站在你这边的。
第六章:一次相对靠谱的 JDK 升级,应该从哪里开始
真正开始升级之前,有一件事必须先想清楚:你这次升级,是为了“到达某个版本”,还是为了“验证系统能否继续演进”。
这两个目标,看起来很像,路径完全不同。很多失败的升级,问题就出在一开始选错了目标。
如果你只是想“把 Java 8 换成 17”,那你会天然倾向于:
- 尽量不改代码
- 尽量不动依赖
- 尽量让系统看起来“没变”
但这种升级方式,本质上是在赌:赌 JVM 的变化不会触发你没覆盖到的路径。
相对靠谱的升级,第一步反而是承认一件事:
有些问题不是升级带来的, 而是升级帮你提前暴露出来的。
所以真正的起点,往往不是生产环境,而是一个可以被随时推翻的验证环境。不是单元测试,也不是本地跑一下。而是把完整应用,用新 JDK 跑起来。不接真实流量,但一定要接真实配置、真实依赖、真实启动参数。
很多团队在这里就已经踩到了第一个坑:启动参数。Java 8 下积累了大量 JVM 参数,其中不少早已被废弃,甚至在新版本里直接失效。你会看到类似这样的警告:
Ignoring option PermSize; support was removed in 8.0
在 Java 8 你还能“假装没看到”,在新 JDK 下,它会直接提醒你:这些参数已经没有意义了。清理这些参数,本身就是一次风险排查。不是“能不能启动”, 而是启动之后,哪些地方开始行为变化。这里有一个非常实际的做法:在同一套代码下,同时跑两个版本的 JVM。
- 一套用 Java 8
- 一套用目标 JDK
对外提供同样的接口,跑同样的请求。不需要全量对比结果,但要盯几个关键指标:
- P99 延迟
- GC 行为
- 异常日志类型是否变化
很多问题,不是“新版本一定有 bug”,而是你第一次看到了原来就存在的极端情况。还有一个经常被忽略的点:日志和监控工具本身是否适配新 JDK。有些 agent 在 Java 8 下工作得很好,但在模块化之后,注入行为发生变化。结果不是监控失效,而是监控数据“看起来正常,其实已经不完整”。
如果你在升级过程中,突然发现某些指标消失了,那不是系统变健康了,而是你少看了一部分。这也是为什么,靠谱的升级节奏通常很慢。不是因为技术上推进不了,而是你需要时间去重新建立:
“我对这个系统行为的信心。”
到这里,升级才算真正开始。不是宣布成功,而是你终于知道:
- 哪些问题是 JDK 带来的
- 哪些问题是历史债务
- 哪些地方,必须在升级过程中一起解决
而这一步,几乎不可能一蹴而就。也正因为这样,很多公司在真正启动升级后,才意识到一件事:升级 JDK,其实是在逼自己重新理解系统。 而这件事,本身就是一次不小的工程。
第七章:如果一直不升,会发生什么?
在很多团队内部,其实都默认了一种状态:
不升级,不代表现在就有问题。
这句话在相当长的一段时间里,都是成立的。Java 8 足够稳定,线上系统运行多年,没有明显的性能瓶颈,也没有无法解决的故障。于是“暂时不升”逐渐变成了“长期不升”。真正的问题,是这种状态并不是静止的。最先发生变化的,往往不是系统本身,而是它所处的环境。云厂商开始调整基础镜像;CI/CD 环境里的默认 JDK 版本往前走;安全扫描工具对旧版本的容忍度越来越低
你会发现,原来“理所当然”的前提,一个一个消失了。接着是依赖生态。一开始只是新功能不支持 Java 8,后来变成新版本直接不再测试,再后来是明确标注:不兼容。这时候你还能苟住,靠锁版本、靠私服、靠内部维护。
但代价在慢慢累积。每一次新需求评估,都会多一个隐含条件:
这个东西,能不能在 Java 8 上跑?
这个问题一旦出现得足够频繁,系统就已经被版本反向塑形了。更危险的是,问题开始延迟出现。
很多在新 JDK 下会被立刻暴露的行为问题,在 Java 8 下被默默吞掉。你看不到 warning;也感受不到约束。
直到某一天,你必须升级。那时候你面对的,已经不是一次版本迁移,而是一堆被时间放大的设计问题。而升级窗口,反而更小了。
因为这次升级,不是你主动选的。可能是:
- 安全合规要求
- 外部依赖强制
- 云平台策略调整
你已经没有“慢慢试”的空间。于是很多团队会在这个阶段做出一个看似合理的选择:
那就继续顶着吧,能跑一天是一天。
问题在于,这条路并不是线性的。系统越老,理解成本越高,可控范围越小。
最终你会发现,你并不是在“稳定运行一个老系统”,而是在维护一个越来越没人敢动的黑盒。
这时候,Java 8 不再是你的缓冲垫,而是你的时间锁。
而你已经很难判断:
现在不升级,到底是在规避风险, 还是在把风险推给未来一个更糟糕的时刻?
这一点,很多团队只有在真正被逼到墙角时,才会意识到。
结语:也许问题不只在我们
写到这里,再回头看“为什么还卡在 Java 8”,很多原因已经很清楚了:
- 生态复杂
- 历史债重
- 升级风险真实存在
但如果只停在这里,其实有点不公平。因为有一个问题,很少被正面拿出来讨论:
Java 真的做到“向下兼容”了吗?
从语法层面看,是的。Java 8 写的代码,放到 JDK 25,大多数还能编译。但从工程和运行时层面看,答案并没有这么确定。JDK 9 之后,JVM 的内部结构、边界、约束,被系统性地重构过。模块化不是补丁,是一次方向性的调整。这个调整本身没有错。甚至可以说,是 Java 走向长期可维护性的必经之路。
问题在于:JDK8之后演进的成本,几乎全部落在了使用者身上。
旧代码还能跑,但开始被警告;旧用法还能用,但需要加参数;旧依赖还能凑合,但不再被官方支持
从结果上看,JDK 并没有为“平滑迁移”提供一条真正低成本的路径。它选择的是:
保证不立刻崩, 但也不保证你能轻松往前走。
这是一种非常 Java 的工程取舍。向后兼容,被理解成“不破坏既有运行”;而不是“帮助你完成迁移”。
于是一个微妙的局面就出现了:
- JDK 在持续演进
- 企业系统被留在原地
- 升级的代价,被默认为“业务方应该承担的成本”
当升级困难时,我们习惯反思自己的架构、代码、历史债。
但很少有人问一句:
如果一个平台的演进,让大多数成熟用户都不敢升级, 那这个演进路径,是否真的对“工程用户”友好?
也许这并没有标准答案。Java 选择了稳定、选择了克制、选择了长期演进。而代价,是把升级这件事,变成了一次高认知门槛的工程决策。
所以今天还停在 Java 8 的团队,未必是保守,也未必是技术债失控。有时候,只是因为他们不想为一次并不完全由自己造成的不连续演进, 付出过高的试错成本。
当然,这并不意味着一直停留就是对的。
只是到了 JDK 25 这个节点,也许我们该承认一件事:
Java 的升级之所以难, 并不只是因为系统老, 也因为这条升级路,本身就不够平坦。
而要不要踏上这条路,现在,依然没有一个放之四海而皆准的答案。
来源:juejin.cn/post/7599551824548397082
语音 AI Agent 延迟优化实战:我是怎么把响应时间从 2 秒干到 500ms 以内的
做语音 Agent 的人都知道,用户能忍受的等待极限大概是 1.5 秒。超过这个阈值,对话感就没了,用户会觉得是在"跟机器对话"而不是"在聊天"。这篇文章分享我在实际项目中,把端到端延迟从 2 秒出头压到 500ms 以内的完整过程。
先搞清楚延迟花在哪
在动手优化之前,第一步是搞清楚时间都花在了哪里。一个典型的语音 Agent 调用链是这样的:
用户说话 → VAD检测 → ASR转写 → LLM推理 → TTS合成 → 播放回复
我在生产环境里埋了全链路 tracing,把每个环节的耗时拉出来一看:
| 环节 | 优化前耗时 | 占比 |
|---|---|---|
| VAD 端点检测 | ~300ms | 15% |
| ASR 语音转文字 | ~400ms | 20% |
| LLM 意图理解+生成 | ~800ms | 40% |
| TTS 文字转语音 | ~350ms | 17% |
| 网络传输+其他 | ~150ms | 8% |
| 总计 | ~2000ms | 100% |
最大的瓶颈很明显——LLM 推理占了 40%。但别急着只优化这一个,实际上每个环节都有压缩空间,而且真正的大招是让这些环节不再串行等待。
第一刀:流式架构改造(-600ms)
最直觉的优化:不要等一个环节完全结束才启动下一个。
传统串行架构
# ❌ 串行模式:每步都要等上一步完全结束
async def handle_utterance(audio_stream):
# 等用户说完
complete_audio = await vad.wait_for_endpoint(audio_stream)
# 等转写完成
transcript = await asr.transcribe(complete_audio)
# 等 LLM 生成完整回复
response = await llm.generate(transcript)
# 等 TTS 合成完整音频
audio = await tts.synthesize(response)
# 播放
await play(audio)
流式管道架构
# ✅ 流式模式:各环节并行处理
async def handle_utterance_streaming(audio_stream):
transcript_stream = asr.stream_transcribe(audio_stream)
async for partial_transcript in transcript_stream:
if vad.is_endpoint(partial_transcript):
# ASR 的 partial result 直接喂给 LLM
llm_stream = llm.stream_generate(partial_transcript.final_text)
# LLM 每生成一个句子片段,立刻送给 TTS
tts_task = asyncio.create_task(
stream_tts_and_play(llm_stream)
)
break
async def stream_tts_and_play(llm_stream):
"""LLM 输出的每个文本块 → 立刻合成 → 立刻播放"""
async for text_chunk in llm_stream:
# 按句子边界切分,不用等完整回复
if is_sentence_boundary(text_chunk):
audio_chunk = await tts.synthesize_chunk(text_chunk)
await player.enqueue(audio_chunk)
核心思想:ASR 的流式结果直接喂 LLM,LLM 的流式输出直接喂 TTS。不再有任何环节需要等"完整结果"。
这一刀下去,端到端延迟从 ~2000ms 直接降到 ~1400ms。
第二刀:VAD 优化(-200ms)
VAD(Voice Activity Detection)负责判断"用户说完了"。默认的 VAD 通常需要 300-500ms 的静音才会触发 endpoint,这段时间完全是白等。
class SmartVAD:
"""基于上下文的智能 VAD"""
def __init__(self):
self.silence_threshold = 300 # 默认 300ms
self.context_aware = True
def get_dynamic_threshold(self, context: ConversationContext) -> int:
"""根据对话上下文动态调整静音阈值"""
# 如果是简短确认类对话("好的"、"收到"),缩短等待
if context.expected_response_type == "confirmation":
return 150
# 如果是复杂问题,用户可能在思考,适当延长
if context.turn_count > 5 and context.avg_utterance_length > 20:
return 400
# 利用 ASR 的语义信息辅助判断
partial = context.current_partial_transcript
if partial and self._is_complete_sentence(partial):
return 100 # 语义完整就不用等太久
return self.silence_threshold
def _is_complete_sentence(self, text: str) -> bool:
"""简单的句子完整性判断"""
# 以问号、句号结尾,或者是常见的完整短语
endings = ['吗', '呢', '吧', '了', '的', '好', '行', '可以']
return any(text.strip().endswith(e) for e in endings)
从固定 300ms 静音阈值改成动态判断后,平均 VAD 延迟从 300ms 降到 ~100ms。
第三刀:LLM 推理加速(-400ms)
LLM 是最大的瓶颈,优化空间也最大。几个关键手段:
3.1 Prompt 缓存
如果你用的是 Claude API,系统级 prompt(角色设定、知识库、历史上下文等)在连续对话中几乎不变。开启 Prompt Caching 后,这部分 Token 的处理时间接近于零。
# 系统 prompt 打上 cache_control
messages = [
{
"role": "system",
"content": [
{
"type": "text",
"text": SYSTEM_PROMPT + KNOWLEDGE_BASE, # 通常占 80% tokens
"cache_control": {"type": "ephemeral"}
}
]
},
{"role": "user", "content": user_message}
]
实测效果:首轮 ~800ms,后续轮次 ~350ms。反复出现的 prompt 内容只需处理一次。
3.2 选对模型
不是所有场景都需要最强模型。语音 Agent 的意图识别和知识库问答,用 Haiku 级别的小模型完全够用,速度快 5 倍以上:
| 模型 | 首 Token 延迟 | 适用场景 |
|---|---|---|
| Opus 4.6 | ~500ms | 复杂推理、跨文档分析 |
| Sonnet 4.5 | ~250ms | 通用对话、中等复杂度 |
| Haiku 4.5 | ~80ms | 意图分类、简单问答、slot filling |
实际项目中,我用路由 + 级联的方式:先用 Haiku 做意图分类(<100ms),简单意图直接用 Haiku 回答,复杂问题再升级到 Sonnet。
class ModelRouter:
async def route(self, transcript: str, context: dict) -> str:
# 第一步:Haiku 快速分类意图(< 100ms)
intent = await self.haiku.classify(transcript)
if intent.type in ("greeting", "confirmation", "simple_qa"):
# 简单意图:Haiku 直接回(< 200ms)
return await self.haiku.generate(transcript, context)
elif intent.type in ("knowledge_query", "multi_turn"):
# 中等复杂度:Sonnet 处理(< 400ms)
return await self.sonnet.generate(transcript, context)
else:
# 复杂推理:Opus 兜底
return await self.opus.generate(transcript, context)
这个路由策略下,70% 以上的请求走 Haiku,LLM 平均延迟从 800ms 降到 ~250ms。
3.3 预测性生成
在某些高频场景下,可以在用户还在说话时就开始"预生成"可能的回复:
async def predictive_generate(partial_transcript: str):
"""基于 ASR partial result 提前启动推理"""
if confidence_high_enough(partial_transcript):
# 预推理,如果最终 transcript 变化不大就直接用
predicted_response = await llm.generate(partial_transcript)
cache.set(partial_transcript, predicted_response, ttl=5)
这个方案有风险(预测错了白算),但在客服场景下,用户问题的模式非常集中,命中率能到 40-50%。命中时等于零 LLM 延迟。
第四刀:TTS 流式合成(-200ms)
传统 TTS 需要拿到完整文本才能合成。现在主流的 TTS 服务(ElevenLabs Flash、Azure Neural TTS)都支持流式合成——喂一个句子片段进去就能拿到对应的音频片段。
class StreamingTTS:
async def synthesize_streaming(self, text_stream):
"""流式 TTS:每收到一个句子片段就合成"""
buffer = ""
async for chunk in text_stream:
buffer += chunk
# 按标点符号切分成自然的语音片段
sentences = self._split_at_punctuation(buffer)
for sentence in sentences[:-1]: # 最后一个可能不完整,留着
audio = await self._synthesize_one(sentence)
yield audio
buffer = sentences[-1] if sentences else ""
# 处理剩余文本
if buffer.strip():
yield await self._synthesize_one(buffer)
def _split_at_punctuation(self, text: str) -> list[str]:
"""在标点处切分,保证每个片段是自然的语音单元"""
import re
parts = re.split(r'([。!?,;、,.!?;])', text)
# 把标点和前面的文字合并
result = []
for i in range(0, len(parts) - 1, 2):
result.append(parts[i] + parts[i + 1])
if len(parts) % 2 == 1:
result.append(parts[-1])
return [p for p in result if p.strip()]
关键细节:切分粒度很重要。太细(每个词合成一次)会导致语音不自然,太粗(等完整段落)会增加延迟。按标点符号切分是实测下来最好的平衡点。
最终结果
所有优化叠加后:
| 环节 | 优化前 | 优化后 | 节省 |
|---|---|---|---|
| VAD 端点检测 | ~300ms | ~100ms | 200ms |
| ASR 转写 | ~400ms | ~150ms(流式) | 250ms |
| LLM 推理 | ~800ms | ~250ms(路由+缓存) | 550ms |
| TTS 合成 | ~350ms | ~100ms(流式) | 250ms |
| 网络传输 | ~150ms | ~80ms(同区部署) | 70ms |
| 总计 | ~2000ms | ~450ms | ~1550ms |
从用户体感来说:优化前是"问完等两秒才有反应",优化后是"话音刚落就有回应"。这个差距不是量变,是质变——它决定了用户会不会觉得"这个 AI 客服不错"还是"算了让我转人工"。
几个踩坑提醒
1. 流式架构下的中断处理
用户随时可能打断 Agent 说话。流式架构下你需要优雅地处理:
async def handle_interruption(self):
"""用户打断时,停止当前的 TTS 播放和 LLM 生成"""
# 停止播放
self.player.stop()
# 取消正在进行的 LLM 生成
if self._llm_task and not self._llm_task.done():
self._llm_task.cancel()
# 取消正在进行的 TTS 合成
if self._tts_task and not self._tts_task.done():
self._tts_task.cancel()
# 用打断后的新 transcript 重新开始处理
2. 句子切分的中文坑
中文没有空格分隔,标点符号使用也不像英文那么规范。实际对话中很多用户说话是没有标点的(ASR 输出也经常不带标点),需要靠语义来判断切分点。
3. 音频格式的选择
流式场景下,Opus 编码比 MP3 好得多——更低延迟、更小体积、更好的流式支持。如果你还在用 MP3 做实时语音,换 Opus 立刻能省 50-100ms。
总结
语音 Agent 的延迟优化没有银弹,核心就是两件事:
- 串行变并行:流式架构让每个环节不再互相等待
- 每个环节压到极致:VAD 智能化、模型路由、Prompt 缓存、TTS 流式化
能把延迟压到 500ms 以内的语音 Agent 平台,在用户体验上会和其他竞品拉开代际差距。我在用的 ofox.ai 就是朝着这个方向在做,他们最新版本实测延迟已经到了 400ms 级别,在国内语音 Agent 平台里算是第一梯队了。
如果你也在做语音 AI 相关的项目,欢迎交流。这个领域 2026 年会越来越卷,但只要延迟足够低、体验足够好,市场空间是巨大的。
我是码路飞,一个在 AI Agent 一线搬砖的开发者。关注我,持续分享语音 AI、Agent 架构、大模型工程化的实战经验。
来源:juejin.cn/post/7603644943351889926
如何零成本搭建个人站点
同步至个人站点:如何零成本搭建个人站点
站点地址:stack.mcell.top,包含完整的:写作、评论、部署、MCP支持...
我经常写作,最开始是在一些平台上,比如稀土掘金。后面慢慢写多了,就想有个自己的博客平台。
最初搭建的博客很简单:一个纯静态的 HTML 文件,内容也不复杂,写点自我介绍,当作个人站点。直接托管到 GitHub Pages,域名用的也是它默认那串。
但很快就发现:功能太少了。
比如发布文章?评论?甚至想加点扩展能力都很难——纯 HTML 又没框架,后面越改越痛苦。
接着就走上了“大家都走过的弯路”:
买了轻量服务器,又买了域名……然后写服务端、接数据库、写前端,把整套都搭起来。
直到后面参与了一个开源项目才意识到:
这种内容站点/文档站点,压根没必要搞这么重。成熟框架太多了,比如 VitePress 这种(比如Vue官网就是VitePress),基本开箱即用。
然后我就重构了一次:直接上 VitePress。部署?还是 GitHub Pages。那时候至少配上了自定义域名,看起来舒服多了:stack.mcell.top
又过了一段时间,我开始觉得个人站点还是有点单调。VitePress 能改,但做深度定制的时候会有点别扭(有些地方甚至会翻车)。
索性就 vibe coding 一把:把原先 VitePress 那套,重构到了 Next.js。
路线也很清晰:
- Next.js
- SSG / 静态导出(要部署到 GitHub Pages,关键是要把站点导出成纯静态)
- GitHub Actions 自动构建
- 部署到 GitHub Pages
- 配上自定义域名
后面我又陆续补了评论和文档搜索功能。用到服务器了吗?没有。
- 评论用的是 giscus:本质是把评论托管在 GitHub Discussions 里,前端加载组件就行,也不用数据库。
- 搜索用的是 pagefind:还是静态站那套玩法,构建阶段生成索引,运行时纯前端查询。
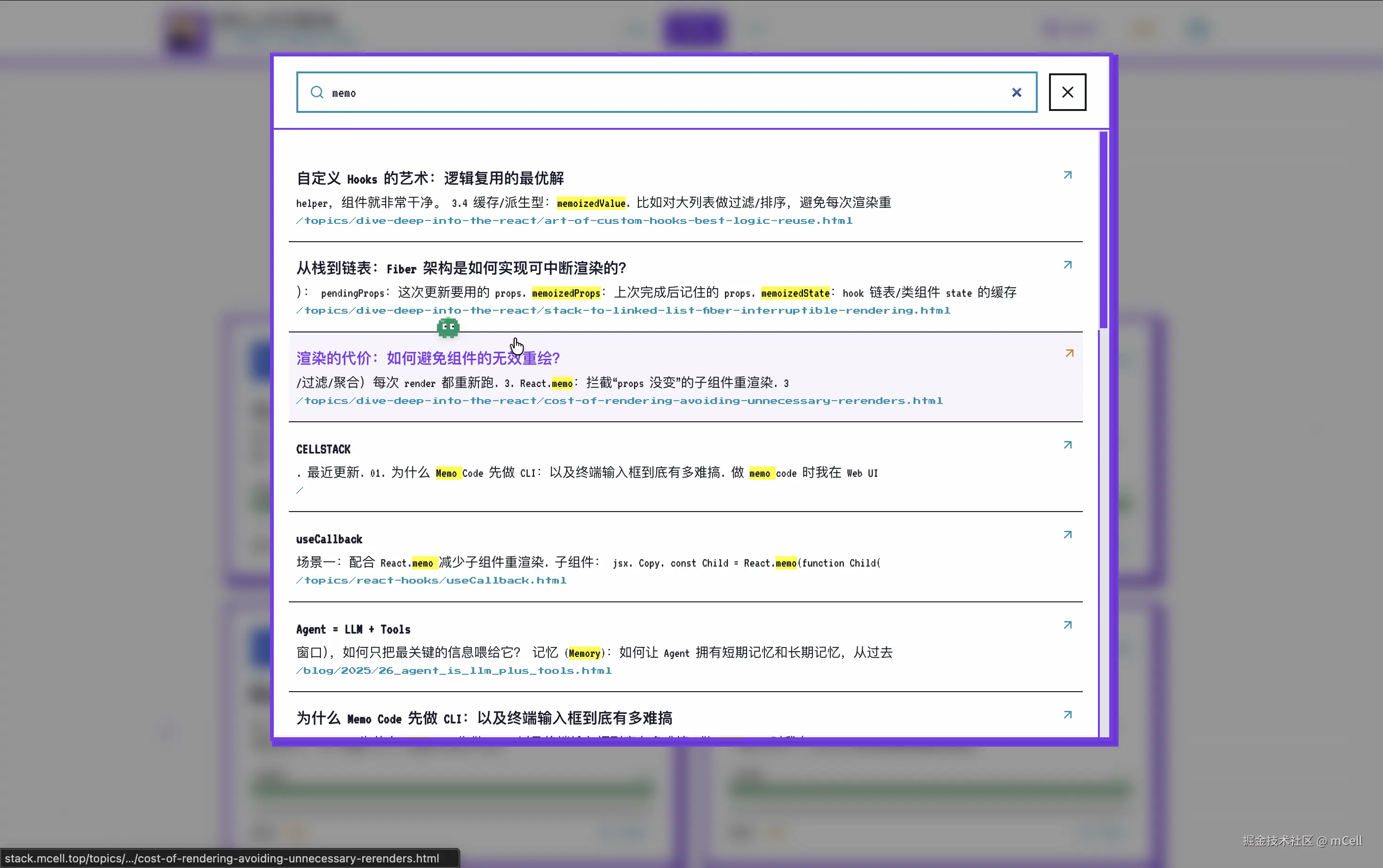
再后面,我还给博客加了 MCP 功能。同样,还是没有服务器:
SSG 阶段生成一份 JSON docs,只要把路径映射到 MCP server 就行;然后我做了个本地的 MCP server,用户安装大概这样:
memo mcp add stack-mcepp npx -y @mcell/stack-mcell
memo code 是我最近自己写的一个轻量级编程Agent,类似Claude code那种,感兴趣可以参与进来。
本质上就是:agent 请求本地 MCP server,MCP server 再去拉取我提前生成好的 JSON 内容。
文档站上 MCP 的整体方案的记录我放在这里:从一个想法到可发布:我把博客接进 MCP 的完整实践
这一套折腾下来,依然是 0 成本。分享给大家,或许是个不错的“0 成本建站思路”。
提示词
如果你对这套方案比较感兴趣,想要多了解了解,你可以clone我的博客仓库:mcell satck,或者是直接把这段提示词发给AI,他会给你方案:
我想搭建一个个人博客,大致如下:
- 框架:nextjs ssg
- 部署:Github Action 自动化部署 + Github Page(自定义域名)
- 图片存储:对象存储(七牛云或者火山引擎)
- 搜索服务:pagefind
- 文章评论服务:giscus
- 开发方式:Vibe coding
- mcp 集成:参考 https://stack.mcell.top/blog/2026/mcp-from-idea-to-delivery-for-content-site
请你给我一个具体可落地的方案(分阶段)
(完)
来源:juejin.cn/post/7605807405306740799
告别切换!一个工具搞定数据库、SSH和Docker管理
关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
你是否找过免费可用的数据库连接工具,又寻找SSH的连接工具。我们自从收到Navicat律师函警告后,从一度卸载了所有破解的软件,花了很多时间寻找替代品。
这两天发现了一个All in one的集成软件,可以连接数据库、SSH、Docker的神仙工具:HexHub
02 简介

HexHub 是一款专为开发者和运维人员设计、集成了数据库、SSH、SFTP和Docker管理功能的桌面图形界面工具。其核心理念是“All in one”,旨在提供一个统一的工作平台。
官方提供了免费版和商业版,然而免费版已经足够我们日常使用了。
03 使用
官方提供了三种平台的安装包,满足不同的平台的需要。
3.1 数据库连接
目前满足的数据有:Redis、Mysql、MariaDB、PostgreSQL、SqlServer、ClickHouse、SQLite、Oracle
我们以Mysql为例:
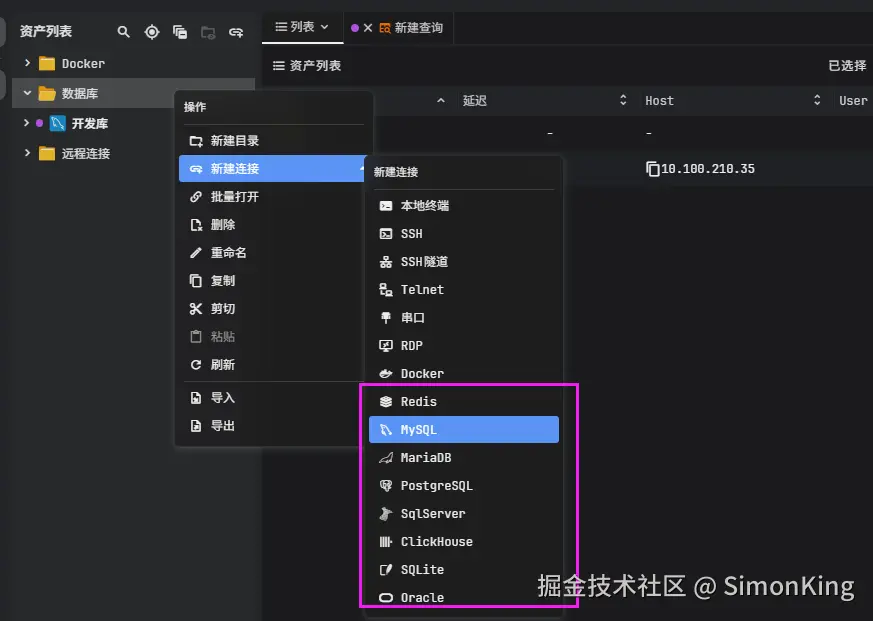
我们填入数据库信息即可:
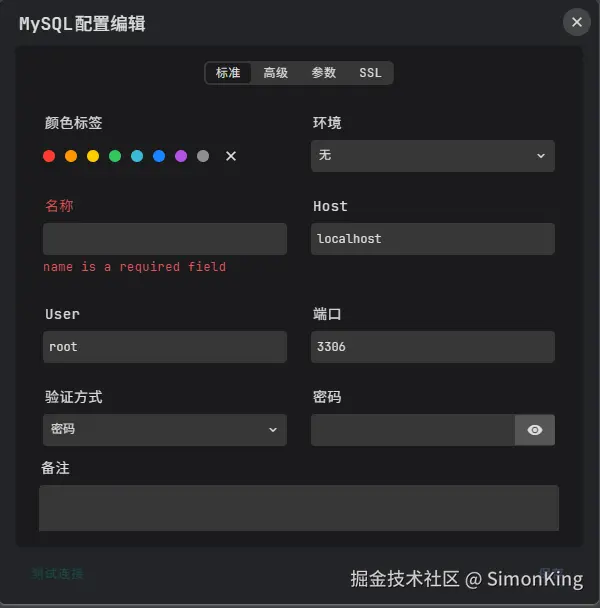
控制台库表提示,关键词高亮的辅助信息。
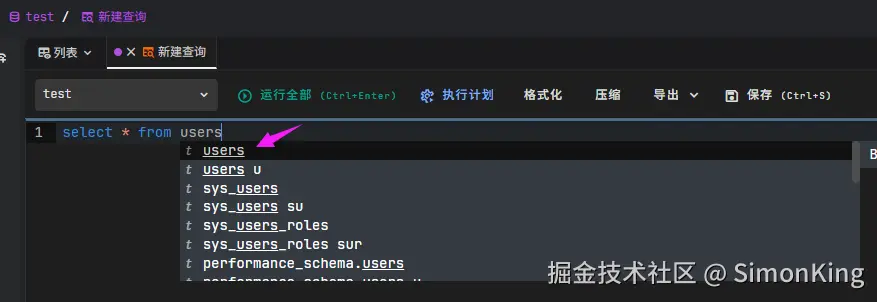
还有常用的执行计划、格式化、导出、保存等
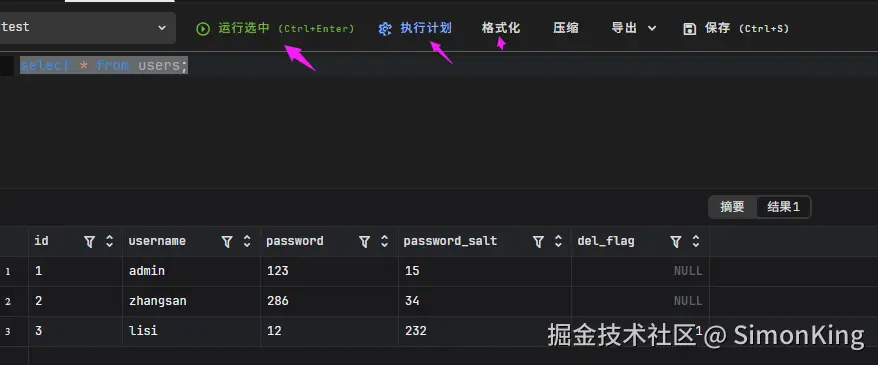
对于表的操作涵盖了常用的操作,完全满足日常需要。
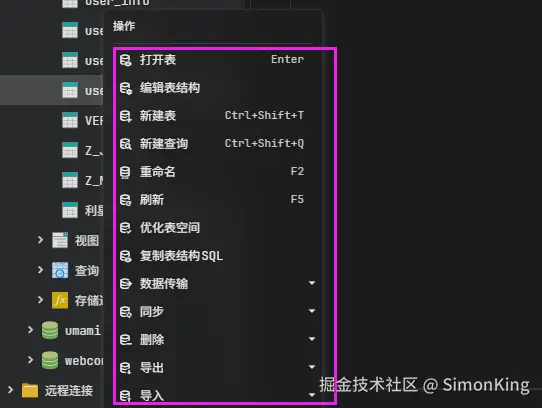
3.2 SSH
直接右键建立SSH连接即可。
界面主要分了三屏:控制台、UI以及监控。其中UI和监控可以手动收起来或者展开。
控制台的配色,感觉下来还是比较舒服的。
3.3 Docker
Docker的配置类似
其中Docker的配置可能会出现不成功的问题,官方也给除了解决方案:

04 小结
如果你目前在同时使用多个不同的工具来完成日常工作,那么尝试 HexHub 来简化工作流可能会是一个不错的选择。
来源:juejin.cn/post/7597299207573946414
写给年轻程序员的几点小建议
本人快 40 岁了。第一份工作是做网站编辑,那时候开始接触 jQuery,后来转做前端,一直做到现在。说实话,我对写程序谈不上特别热爱,所以技术水平一般。
年轻的时候如果做得不开心,就会直接 裸辞。不过每次裸辞的那段时间,我都会拼命学习,这对我的成长帮助其实很大。
下面给年轻人几点个人建议:
- 不要被网上“35 岁就失业”的说法吓到。很多人是在贩卖焦虑。我都快 40 了还能拿到 offer,只是这些 offer 薪资不到 30K。
- 基础真的很重要。我靠着基础吃香了十几年,在公司里也解决过不少疑难问题,深得领导器重。就算现在有 AI,你也要有能力判断它写得对不对,还要知道如何向 AI 提问。
- 适不适合做程序员,其实几年之后就能看出来:你能不能当上 Leader,或者至少能不能独当一面。如果你觉得自己确实不太适合,可以趁早考虑转行,或者下班后发展一些副业。大千世界,行行出状元,能赚钱的行业很多,不必只盯着程序员这一条路。
- 如果你觉得自己资质一般,但又真的喜欢写程序,那也没关系。《刻意练习》这本书里提到,一个人能不能成为行业顶尖,关键在于后天练习的方式,而不是天赋本身。
- 程序员做到后面,最大的挑战其实是身体机能,而不是技术。一定要多锻炼身体。在还没有小孩之前,尽量把自己的技术水平拉到一个相对高的位置。结婚有家庭之后,学习时间会明显减少,而且年龄增长、抗压能力下降,而程序员本身又是高度用脑的职业。如果你的技术储备够高,就能在一定程度上缓冲项目压力,让自己工作更从容。
- React、Vue、Angular 等框架都可以尝试做做项目。不同框架背后的设计思路,对思维成长很有帮助。前端很多理念本身就借鉴了后端的逻辑,多接触不同体系,会让你看问题更立体。
- 可以在 GitHub 上做一些开源小项目。素材从哪里来?其实就来自你在公司做过的项目。把其中一块通用能力抽出来,沉淀成一个独立组件或工具库,再整理发布到 GitHub。与此同时,多写一些技术文章进行总结和输出。等到找工作时,简历里可以写上类似 "全网阅读量几万+" 这样的成果展示,这些都会成为你的加分项,让你在竞争中更有优势。
- 35 岁以上,竞争力通常体现在两个方向:要么技术水平足够强,能够解决复杂问题;要么具备一定的管理能力,能够带团队。有人说那我以前就带过一两个徒弟,怎么办,那你得学会包装,你懂得,哈哈。
- 35 岁以上,面试对技术广度要求更高,所以不要太深入挖掘某一项技术了。我以前认识一个领导,虽然写代码能力一般,在公司已经不写代码了,但是他的技术广度比较好,业务能力还行,虽然 40岁了 还能跳槽到比较好的广告公司,而不是靠人脉,不得不佩服。
- 打工人比较麻烦的事就是 简历太"花"。频繁跳槽,在一个公司没干几个月就走,或者长期待业太久。如果岗位需要背调,简历造假会很麻烦,虽然有些小公司或外包公司不做背调。所以这方面简历自己要想想办法,你懂得。
- 另外要认清一个现实:单纯打工,很难发财。 这件事越早想明白越好。多读一些关于认知、资产配置的书,弄清楚什么是资产,什么是消费。哪怕这些认知在你有生之年未必能带来巨大财富,也可以传递给下一代,让他们少走弯路。
以上只是个人经历和感受,不一定适用于所有人,但希望能给年轻的你一些参考。
来源:juejin.cn/post/7606155928197070900
用 Go 语言还原 2026 春晚《惊喜定格》魔术!

今天是大年初一,江湖十年给读者朋友们拜年了,祝大家新年快乐!
又是新的一年,想必大家都没看春晚吧 😄,今天继续一年一度的用 Go 语言实现春晚魔术。
废话不多说,咱们直接看原理。
魔术原理揭秘
这个魔术的数学原理其实很简单,基于一个简单的恒等式:
设目标时间为 T
设观众说的两个数为 A 和 B
魔术师计算的第三个数为 C = T - (A + B)
那么:A + B + C = A + B + [T - (A + B)] = T
这里的 T 就是最终结果:2162227
- 观众 A 说:
1106 - 观众 B 说:
88396 - 观众“乱按”的计算器显示:
2072725 - 相加结果:
1106+88396+2072725=2162227
这个数字代表:2 月 16 日 22 时 27 分
理解了吗?
这里其实有个障眼法,就是魔术师现场找了三个观众“乱按”了几下,但其实谁也不确定他们按的什么,对不对,其实他们按的数字根本就没用上,而是计算器里已经预先计算出了目标时间 T 与 A + B 总和的差值。
没错,魔术这种东西就是这么朴实无华。
Go 语言实现魔术
那么接下来,就用 Go 语言来实现一个简单的计算器程序,来还原这个魔术。
首先定义一个魔术计算器:
// MagicCalculator 魔术计算器
type MagicCalculator struct {
targetTime int // 目标时间转换的数字
timestamp string // 实际时间字符串
}
接下来实现一个魔术计算器的构造方法:
// NewMagicCalculator 创建一个魔术计算器实例
func NewMagicCalculator() *MagicCalculator {
// 获取当前时间
now := time.Now()
// 生成类似 "2162227" 的时间数字
// 格式: 月(1-2 位) + 日(2 位) + 小时(2 位) + 分钟(2 位)
month := int(now.Month())
day := now.Day()
hour := now.Hour()
minute := now.Minute()
// 构建时间字符串和数字
timestamp := fmt.Sprintf("%dddd", month, day, hour, minute)
// 转换为整数
target, _ := strconv.ParseInt(timestamp, 10, 64)
return &MagicCalculator{
targetTime: int(target),
timestamp: timestamp,
}
}
当前时间 now 就是用来计算目标时间的,可以根据需要设定,这里直接使用当前时间。
target 是格式为 2162227 的时间数字,也就是咱们原理解析中的目标时间 T。
定义一个 计算魔术数字 T -(A + B)的方法:
// GetMagicNumber 计算魔术数字
func (mc *MagicCalculator) GetMagicNumber(num1, num2 int) int {
// 魔术公式: target - (num1 + num2)
return mc.targetTime - (num1 + num2)
}
最后就是定义一个交互式函数,它实现了:
- 计算目标时间 T
- 接收用户输入的 A、B
- 计算观众“乱按”的第三个数字
源码如下:
func InteractiveMagic() {
fmt.Println("=== 交互式魔术体验 ===")
fmt.Println("请按照提示输入数字,我会展示魔术的原理")
mc := NewMagicCalculator()
var num1, num2 int
fmt.Print("请输入第一个数: ")
fmt.Scan(&num1)
fmt.Print("请输入第二个数: ")
fmt.Scan(&num2)
fmt.Printf("\n你输入的是: %d 和 %d\n", num1, num2)
magicNum := mc.GetMagicNumber(num1, num2)
fmt.Printf("魔术数字(第三个数)是: %d\n", magicNum)
fmt.Printf("\n验证: %d + %d + %d = %d\n", num1, num2, magicNum, mc.targetTime)
fmt.Printf("这个数字代表的时间是: %s\n", mc.timestamp)
}
程序 main 入口:
func main() {
InteractiveMagic()
}
验证魔术:
# 运行程序
$ go run main.go
=== 交互式魔术体验 ===
请按照提示输入数字,我会展示魔术的原理
请输入第一个数: 1106
请输入第二个数: 88396
你输入的是: 1106 和 88396
魔术数字(第三个数)是: 2081398
验证: 1106 + 88396 + 2081398 = 2170900
这个数字代表的时间是: 2170900
通过 go run main.go 运行程序,接下来根据提示分别输入两个数字,这里以春晚观众说的两个数字(1106、88396)为例,然后计算观众“乱按”的第三个数字(2081398),最终得到的目标时间是 2170900。
没错,我在 2 月 17 日 09 时 00 分运行的程序。
总结
今天依旧使用 Go 语言简单实现了魔术小程序,看个乐子,开心最重要。
如果你有兴趣,完全可以通过聊天的方式让大模型生成一个带有前端界面的魔术计算器程序,体验 vibe coding 的乐趣。
本文完整代码示例我放在了 GitHub 上,欢迎点击查看。
25 年我的文章里吐槽了春晚魔术“降本增效”,在此给刘谦老师道个歉,是我冒犯了🤣之前对魔术一无所知。
25 年看了老罗采访刘谦的视频,对刘谦大佬肃然起敬 respect 🫡。

延伸阅读
- 用 Go 语言还原 2025 刘谦春晚魔术!:jianghushinian.cn/2025/01/30/…
- 用 Go 语言实现刘谦 2024 春晚魔术,还原尼格买提汗流浃背的尴尬瞬间!:jianghushinian.cn/2024/02/10/…
- 本文 GitHub 示例代码:github.com/jianghushin…
联系我
- 公众号:Go编程世界
- 微信:jianghushinian
- 邮箱:jianghushinian007@outlook.com
- 博客:jianghushinian.cn
- GitHub:github.com/jianghushin…
来源:juejin.cn/post/7606646387053936667
为什么Java里面,Service 层不直接返回 Result 对象?
前言
昨天在Code Review时,我发现阿城在Service层直接返回了Result对象。
指出这个问题后,阿城有些不解,反问我为什么不能这样写。
于是我们展开了一场技术讨论(battle 🤣)。
讨论过程中,我发现这个看似简单的设计问题,背后其实涉及分层架构、职责划分、代码复用等多个重要概念。
与其让这次讨论的内容随风而去,不如整理成文,帮助更多遇到同样困惑的朋友理解原因。
知其然,更知其所以然。
耐心看完,你一定有所收获。

正文
职责分离原则
在传统的MVC架构中,Service层和Controller层各自承担着不同的职责。
Service层负责业务逻辑的处理,而Controller层负责HTTP请求的处理和响应格式的封装。
当我们将数据包装成 Result 对象的任务交给 Service 层时,意味着 Service 层不再单纯地处理业务逻辑,而是牵涉到了数据处理和响应的部分。
这样会导致业务逻辑与表现逻辑的耦合,降低了代码的清晰度和可维护性。
看一个不推荐的写法:
@Service
public class UserService {
public Result<User> getUserById(Long id) {
User user = userMapper.selectById(id);
if (user == null) {
return Result.error(404, 用户不存在);
}
return Result.success(user);
}
}
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/user/{id}")
public Result<User> getUser(@PathVariable Long id) {
return userService.getUserById(id);
}
}
上面代码中,Service 层不仅负责从数据库获取用户信息,还直接处理了返回的结果。
如果我们需要改变返回的格式,或者进行错误信息的标准化,所有 Service 层的方法都需要修改。这样会导致代码的高耦合。
相比之下,以下做法将展示逻辑留给 Controller 层,保证了业务逻辑的纯粹性:
@Service
public class UserService {
public User getUserById(Long id) {
User user = userMapper.selectById(id);
if (user == null) {
throw new BusinessException(用户不存在);
}
return user;
}
}
@RestController
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/user/{id}")
public Result<User> getUser(@PathVariable Long id) {
User user = userService.getUserById(id);
return Result.success(user);
}
}
让每一层都专注于自己的职责。
可复用性问题
当Service层返回Result时,会严重影响方法的可复用性。
假设我们有一个订单服务需要调用用户服务:
@Service
public class OrderService {
@Autowired
private UserService userService;
public void createOrder(Long userId, OrderDTO orderDTO) {
// 不推荐的方式:需要解包Result
Result<User> userResult = userService.getUserById(userId);
if (!userResult.isSuccess()) {
throw new BusinessException(userResult.getMessage());
}
User user = userResult.getData();
// 后续业务逻辑
validateUserStatus(user);
// ...
}
}
这种写法有个很明显的问题。
OrderService 作为另一个业务服务,业务之间的调用本来应该简单直接,但使用 Result 带来了两个问题:
- 不知道
Result里到底包含什么,还得去查看代码里面的实现,写起来麻烦。 - 还需要额外判断
Result的状态,增加了不必要的复杂度。
如果是调用第三方外部服务,需要这种包装还能理解,但在自己业务之间互相调用时,完全没必要这样做。
如果Service返回纯业务对象:
@Service
public class OrderService {
@Autowired
private UserService userService;
public void createOrder(Long userId, OrderDTO orderDTO) {
// 推荐的方式:直接获取业务对象
User user = userService.getUserById(userId);
// 后续业务逻辑
validateUserStatus(user);
// ...
}
}
代码变得简洁且符合直觉。
业务层之间直接传递业务对象,保持简单和清晰。
异常处理机制
有些 Service 层在业务判断失败后,会直接返回 Result.fail(xxx) 这样的代码,例如:
public Result<Void> createOrder(Long userId, OrderDTO orderDTO) {
if (userId == null) {
return Result.fail("用户ID不能为空");
}
// 后续业务逻辑
return Result.success();
}
这种做法有几个问题:
- 重复的错误处理:每个方法都得写一大堆类似的错误判断代码,增加了代码量。
- 错误分散:错误处理分散在每个方法里,如果需要改进错误逻辑,要在多个地方修改,麻烦且容易出错。
而如果我们通过抛出异常并结合全局异常处理来统一处理错误,例如:
public void createOrder(Long userId, OrderDTO orderDTO) {
if (userId == null) {
throw new BusinessException("用户ID不能为空");
}
// 后续业务逻辑
}
再通过全局异常捕获来转换为 Result:
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public Result<Void> handleBusinessException(BusinessException e) {
return Result.error(400, e.getMessage());
}
@ExceptionHandler(Exception.class)
public Result<Void> handleException(Exception e) {
log.error("系统异常", e); // 这里可以查看堆栈信息
return Result.error(500, "系统繁忙");
}
}
这样做的好处是:
- 减少重复代码:业务方法不再需要写重复的错误判断,代码更简洁。
- 集中错误处理:错误处理集中在一个地方,修改时只需修改全局异常处理器,不用改动每个 Service 层方法。
- 业务与错误分离:业务逻辑专注处理核心功能,错误处理交给统一的机制,代码更加清晰易懂。
而且异常可以携带更丰富的上下文信息,如果业务侧需要时,可以带上堆栈信息,便于一些问题的定位。
测试便利性
Service层返回业务对象而不是Result时,能够大大提升单元测试的便利性:
@SpringBootTest
public class UserServiceTest {
@Autowired
private UserService userService;
@Test
public void testGetUserById() {
// 推荐的方式:直接断言业务对象
User user = userService.getUserById(1L);
assertNotNull(user);
assertEquals(张三, user.getName());
}
@Test
public void testGetUserById_NotFound() {
// 推荐的方式:断言抛出异常
assertThrows(BusinessException.class, () -> {
userService.getUserById(999L);
});
}
}
如果Service返回Result,测试代码则需要写得更复杂:
@Test
public void testGetUserById() {
// 不推荐的方式:需要解包Result
Result<User> result = userService.getUserById(1L);
assertTrue(result.isSuccess());
assertNotNull(result.getData());
assertEquals(张三, result.getData().getName());
}
测试代码变得莫名冗长,还得去关注响应结构,这并不是Service层测试的关注点。
Service 层本应专注于业务逻辑,测试也应该直接验证业务数据。
领域驱动设计角度
再换个角度。
从领域驱动设计(DDD)的角度来看,Service 层属于应用层或领域层,应该使用领域语言来表达业务逻辑。
而 Result 是基础设施层的概念,代表 HTTP 响应格式,不应该污染领域层。
例如,考虑转账业务:
@Service
public class TransferService {
public TransferResult transfer(Long fromAccountId, Long toAccountId, BigDecimal amount) {
Account fromAccount = accountRepository.findById(fromAccountId);
Account toAccount = accountRepository.findById(toAccountId);
fromAccount.deduct(amount);
toAccount.deposit(amount);
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
return new TransferResult(fromAccount, toAccount, amount);
}
}
在这个例子中,TransferResult 是一个领域对象,代表了转账的结果,包含了与业务相关的意义,而不是一个通用的 HTTP 响应封装 Result。
这种做法更符合领域模型的表达,体现了领域层的职责——处理业务逻辑,而不是涉及 HTTP 响应格式的细节。
接口适配的灵活性
当 Service 层返回纯粹的业务对象时,Controller 层可以根据不同的接口需求灵活封装响应:
@RestController
@RequestMapping("/api")
public class UserController {
@Autowired
private UserService userService;
// REST接口返回Result
@GetMapping("/user/{id}")
public Result<User> getUser(@PathVariable Long id) {
User user = userService.getUserById(id);
return Result.success(user);
}
// GraphQL接口直接返回对象
@QueryMapping
public User user(@Argument Long id) {
return userService.getUserById(id);
}
// RPC接口返回自定义格式
@DubboService
public class UserRpcServiceImpl implements UserRpcService {
public UserDTO getUserById(Long id) {
User user = userService.getUserById(id);
return convertToDTO(user);
}
}
}
同一个Service方法可以被不同类型的接口复用,每个接口根据自己的协议要求封装响应。
强行使用 Result 会导致接口的适配性变差,无法根据不同协议的需求灵活定制响应格式。
灵活性反而丢失了。
事务边界清晰
Service 层通常是事务边界所在,当 Service 返回业务对象时,事务的语义更加清晰:
@Service
public class OrderService {
@Transactional
public Order createOrder(OrderDTO orderDTO) {
Order order = new Order();
// 设置订单属性
orderMapper.insert(order);
// 扣减库存
inventoryService.deduct(orderDTO.getProductId(), orderDTO.getQuantity());
return order;
}
}
在这个例子中,事务是围绕 Service 层的方法展开的,@Transactional 注解确保在业务逻辑执行失败时,事务会回滚。因为方法正常返回时,事务会提交;如果抛出异常,事务会回滚,事务的边界非常明确。
如果 Service 返回的是 Result,很难界定事务是否应该回滚。比如:
public Result<Order> createOrder(OrderDTO orderDTO) {
Order order = new Order();
// 设置订单属性
orderMapper.insert(order);
// 扣减库存
Result<Void> inventoryResult = inventoryService.deduct(orderDTO.getProductId(), orderDTO.getQuantity());
if (!inventoryResult.isSuccess()) {
return Result.fail("库存不足");
}
return Result.success(order);
}
在这种情况下,如果库存不足,虽然 Result 返回失败信息,但事务并不会回滚,可能会导致数据不一致,反而还得额外去抛出异常。
而通过抛出异常的方式,事务的回滚语义非常清晰:异常抛出则回滚,方法正常返回则提交,这种设计确保了事务的边界更加明确,避免了潜在的数据一致性问题。
写在最后
看来阿城要走的路还很长,码路漫漫,踏浪前行。
2026年,祝大家加班少,薪水多,bug少,头发多,多写点注释,少走点弯路。
人生就像一个大项目,需求多,时间紧,但没关系——bug 和头发总有一个会先来。
🤣
来源:juejin.cn/post/7594817135128248354
后端开发必备:生产环境异常自动电话通知方案
生产环境出bug了但没及时发现?支付接口异常导致资损?这个语音通知方案专为开发者打造,重要异常直接打电话,让你第一时间响应处理!
作为开发者,我们最怕的就是生产环境出现异常却没有及时发现。飞书群、钉钉群报警很容易错过,尤其是深夜或周末。今天分享一个专门针对开发者的语音电话通知解决方案,让重要异常第一时间电话通知到你。
🎯 典型使用场景
需要立即电话通知的开发场景:
- 🚨 API接口异常或超时
- 💰 支付流程异常(防止资损)
- 📊 数据处理任务失败
- 🔐 用户登录异常激增
- ⚡ 核心业务逻辑报错
🚀 3步快速集成
| 步骤 | 操作说明 |
|---|---|
| 1️⃣ 扫码注册 | 访问 push.spug.cc,微信扫码登录 |
| 2️⃣ 创建模板 | 新建消息模板 → 语音通道 → 语音模板 → 动态推送对象 |
| 3️⃣ 集成代码 | 复制API地址,添加到异常处理代码中 |
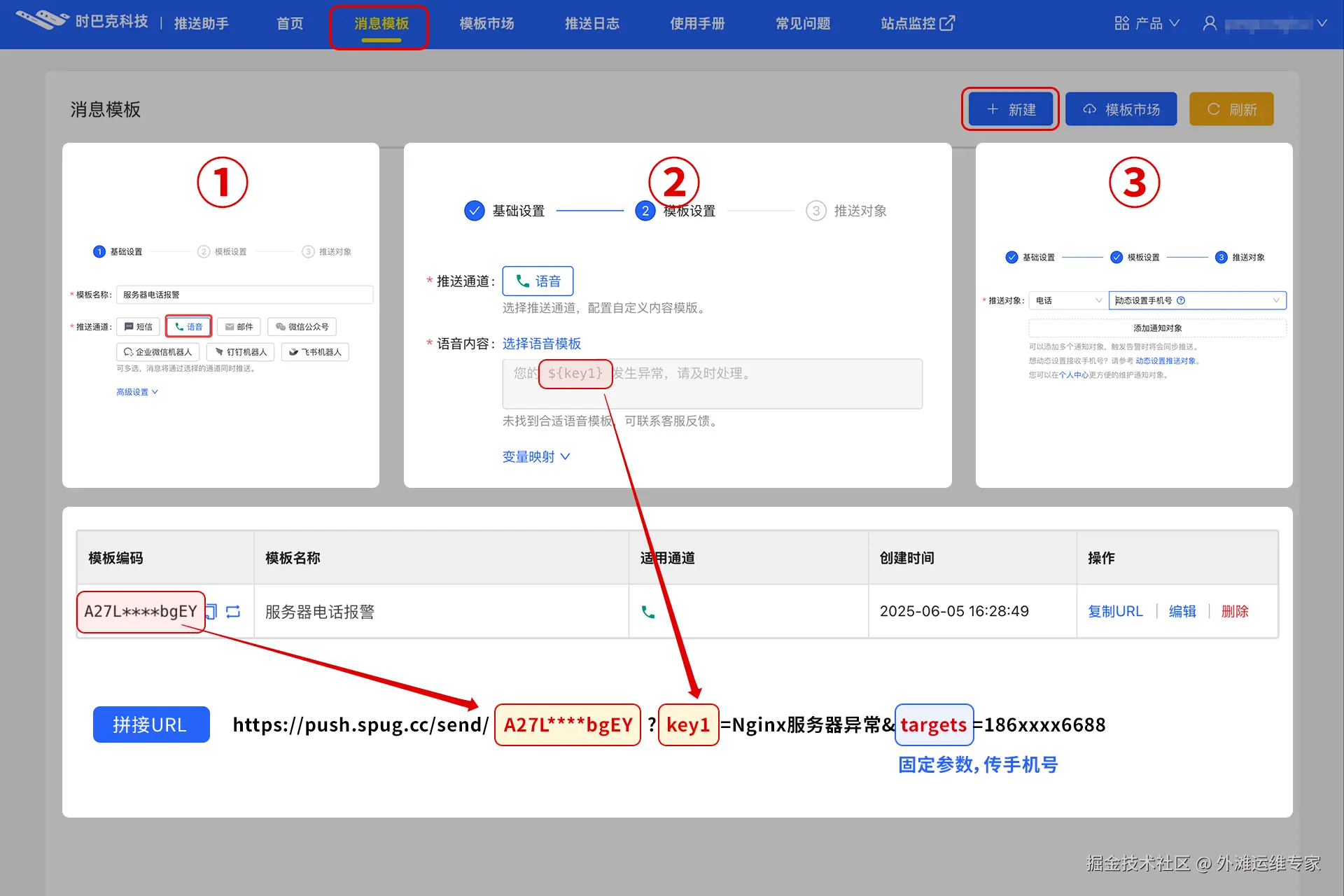
💻 代码集成示例
🐍 Python(异常处理)
import requests
import logging
def send_voice_alert(message, phone):
"""发送语音告警"""
url = "https://push.spug.cc/send/A27L****bgEY"
data = {'key1': message, 'targets': phone}
try:
response = requests.post(url, json=data, timeout=5)
return response.json()
except Exception as e:
logging.error(f"语音告警发送失败: {e}")
# 在异常处理中使用
try:
# 你的业务代码
process_payment(order_id)
except PaymentException as e:
# 支付异常立即电话通知
send_voice_alert(f"支付异常: {str(e)}", "186xxxx9898")
raise
☕ Java(Spring Boot异常处理)
@Component
public class VoiceAlertService {
private final RestTemplate restTemplate = new RestTemplate();
private static final String VOICE_URL = "https://push.spug.cc/send/A27L****bgEY";
public void sendVoiceAlert(String message, String phone) {
try {
Map<String, String> data = new HashMap<>();
data.put("key1", message);
data.put("targets", phone);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
HttpEntity<Map<String, String>> entity = new HttpEntity<>(data, headers);
restTemplate.postForEntity(VOICE_URL, entity, String.class);
} catch (Exception e) {
log.error("语音告警发送失败: {}", e.getMessage());
}
}
}
// 全局异常处理器
@ControllerAdvice
public class GlobalExceptionHandler {
@Autowired
private VoiceAlertService voiceAlertService;
@ExceptionHandler(CriticalException.class)
public ResponseEntity<String> handleCriticalException(CriticalException e) {
// 关键异常立即电话通知
voiceAlertService.sendVoiceAlert("API异常: " + e.getMessage(), "186xxxx9898");
return ResponseEntity.status(500).body("Internal Server Error");
}
}
🔧 实际开发场景
场景1: 支付接口监控
def create_order_payment():
try:
result = payment_service.create_order()
if result.status != 'success':
send_voice_alert("支付订单创建失败", "186xxxx9898")
except Exception as e:
send_voice_alert(f"支付系统异常: {str(e)}", "186xxxx9898")
场景2: 定时任务监控
def daily_data_sync():
try:
sync_user_data()
except Exception as e:
send_voice_alert("每日数据同步失败", "186xxxx9898")
raise
场景3: API响应时间监控
@Component
public class ApiPerformanceInterceptor implements HandlerInterceptor {
@Autowired
private VoiceAlertService voiceAlertService;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response,
Object handler) throws Exception {
request.setAttribute("startTime", System.currentTimeMillis());
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response,
Object handler, Exception ex) throws Exception {
long startTime = (Long) request.getAttribute("startTime");
long duration = System.currentTimeMillis() - startTime;
if (duration > 5000) { // 超过5秒
String message = String.format("API响应慢: %s 耗时%dms",
request.getRequestURI(), duration);
voiceAlertService.sendVoiceAlert(message, "186xxxx9898");
}
}
}
📋 参数说明
| 参数 | 说明 | 示例值 |
|---|---|---|
key1 | 异常消息内容 | "支付接口异常" |
targets | 接收电话的手机号 | "186xxxx9898" |
❓ 开发者常见问题
🤔 如何避免告警风暴?
建议设置异常频率限制,同类异常5分钟内只发送一次。
💰 语音通话收费吗?
语音通话按次计费,建议只对关键异常使用,普通日志用短信或微信。
🛡️ 如何保护API安全?
- 不要将API地址提交到公开代码仓库
- 可以设置IP白名单限制调用来源
- 建议使用环境变量存储API地址
🎉 为什么开发者需要语音通知?
✅ 及时响应:生产故障分秒必争,电话比微信更直接
✅ 降低损失:支付、订单等关键业务异常能立即处理
✅ 简单集成:几行代码搞定,无需复杂配置
✅ 多语言支持:Python、Node.js、Java等任何语言都能用
✅ 个人友好:无需企业资质,个人开发者也能用
记住:好的开发者不是不写bug,而是能第一时间发现并修复bug!
网站链接:push.spug.cc
来源:juejin.cn/post/7531844121465274377
Spring 的替代方案:Micronaut
一、为什么选择 Micronaut?
在开始编码前,先了解 Micronaut 的核心优势:
| 特性 | Micronaut | Spring Boot |
|---|---|---|
| 启动速度 | 毫秒级(依赖 AOT 编译) | 秒级(依赖反射和动态代理) |
| 内存占用 | 极低(适合 Serverless 环境) | 较高(需加载完整上下文) |
| 依赖注入 | 编译时生成代码(无反射) | 运行时反射(影响性能) |
| 响应式编程 | 原生支持(Project Reactor) | 支持 WebFlux(但不如 Micronaut 集成紧密) |
| GraalVM 支持 | 原生优化(直接生成原生镜像) | 需要额外配置(Spring Native) |
适用场景:
- 高并发、低延迟的微服务(如 API 网关、实时数据处理)。
- Serverless 环境(如 AWS Lambda、Azure Functions)。
- 资源受限的边缘计算设备。
二、示例项目:构建一个图书管理微服务
我们将实现一个简单的 图书管理服务,支持以下功能:
- 添加图书(POST /books)。
- 查询所有图书(GET /books)。
- 根据 ID 查询图书(GET /books/{id})。
1. 初始化项目
使用 Micronaut Launch 生成项目模板:
(1) 选择 Micronaut Version:4.9.0。
(2) 语言:Java。
(3) 构建工具:Gradle(或 Maven)。
(4) 添加依赖:
- Micronaut Data JDBC(数据库访问)。
- Micronaut HTTP Server(Web 服务)。
- Lombok(简化代码)。
- H2 Database(内存数据库,便于测试)。
生成后的项目结构如下:
src/
├── main/
│ ├── java/com/cycad/micronaut/
│ │ ├── controller/ # 控制器层
│ │ ├── model/ # 数据模型
│ │ ├── repository/ # 数据访问层
│ │ └── Application.java # 主启动类
│ └── resources/
│ └── application.yml # 配置文件
2. 定义数据模型
创建 Book 实体类,使用 Lombok 简化代码:
import io.micronaut.data.annotation.AutoPopulated;
import io.micronaut.data.annotation.Id;
import io.micronaut.data.annotation.MappedEntity;
import lombok.Data;
@Data
@MappedEntity
publicclass Book {
@Id
@AutoPopulated
private Long id;
private String title;
private String author;
private Double price;
}
3. 实现数据访问层
使用 Micronaut Data JDBC 定义 BookRepository,无需编写 SQL:
import com.cycad.micronaut.model.Book;
import io.micronaut.data.jdbc.annotation.JdbcRepository;
import io.micronaut.data.model.query.builder.sql.Dialect;
import io.micronaut.data.repository.CrudRepository;
@JdbcRepository(dialect = Dialect.H2)
public interface BookRepository extends CrudRepository<Book, Long> {
}
4. 编写控制器层
实现 RESTful API 控制器:
import com.cycad.micronaut.model.Book;
import com.cycad.micronaut.repository.BookRepository;
import io.micronaut.http.annotation.*;
import jakarta.inject.Inject;
import java.util.List;
@Controller("/books")
publicclass BookController {
@Inject
private BookRepository bookRepository;
@Get
public List<Book> listBooks() {
return bookRepository.findAll().toList();
}
@Get("/{id}")
public Book getBookById(Long id) {
return bookRepository.findById(id)
.orElseThrow(() -> new RuntimeException("Book not found"));
}
@Post
public Book createBook(@Body Book book) {
return bookRepository.save(book);
}
}
5. 配置数据库
在 application.yml 中配置 H2 内存数据库:
# src/main/resources/application.yml
micronaut:
application:
name:book-service
server:
port:8080
datasources:
default:
url:jdbc:h2:mem:devDb;LOCK_TIMEOUT=10000;DB_CLOSE_ON_EXIT=FALSE
driverClassName:org.h2.Driver
username:sa
password:""
schema-generate:CREATE_DROP
dialect:H2
6. 启动服务
运行主类 Application.java:
import io.micronaut.runtime.Micronaut;
public class Application {
public static void main(String[] args) {
Micronaut.run(Application.class, args);
}
}
观察控制台输出,Micronaut 的启动速度极快(通常在 100ms 以内):
14:25:30.123 [main] INFO i.m.context.env.DefaultEnvironment - Established active environments: [cli, test]
14:25:30.456 [main] INFO i.m.h.s.netty.NettyHttpServer - Server Started: http://localhost:8080
三、测试 API
使用 curl 或 Postman 测试接口:
(1) 添加图书:
curl -X POST -H "Content-Type: application/json" \
-d '{"title": "Effective Java", "author": "Joshua Bloch", "price": 45.99}' \
http://localhost:8080/books
响应:
{"id":1,"title":"Effective Java","author":"Joshua Bloch","price":45.99}
(2) 查询所有图书:
curl http://localhost:8080/books
响应:
[{"id":1,"title":"Effective Java","author":"Joshua Bloch","price":45.99}]
(3) 根据 ID 查询:
curl http://localhost:8080/books/1
响应:
{"id":1,"title":"Effective Java","author":"Joshua Bloch","price":45.99}
四、GraalVM 原生镜像
通过 GraalVM 将应用编译为原生二进制文件,进一步减少启动时间:
(1) 安装 GraalVM 和 Native Image 工具。
(2) 在 build.gradle 中添加插件:
id 'io.micronaut.application' version '3.10.0'
id 'org.graalvm.nativeimage' version '0.9.21'
(3) 执行编译命令:
./gradlew nativeImage
(4) 生成的可执行文件位于 build/native-image/,启动速度可压缩至 10ms 以内!
五、总结
Micronaut 通过 AOT 编译、低内存占用 和 快速启动 等特性,为微服务开发提供了高性能的解决方案。本文通过一个完整的图书管理服务示例,演示了其核心功能,并对比了与 Spring Boot 的性能差异。无论是构建传统微服务还是 Serverless 应用,Micronaut 都是一个值得尝试的选择。
来源:juejin.cn/post/7527884547537223690
自研第一个SKILL-openclaw入门
自研第一个SKILL-openclaw入门
openclaw不是搭建好了就结束了,用起来才能发挥作用,而SKILL,就是openclaw的灵魂,是openclaw的内功。
所以准备慢慢记录学习openclaw的skill之路。
所谓读万卷书不如行万里路,实践对知识的理解非常重要,今天就准备自己开发一个简单的SKILL,来加深对SKILL的理解。
如果还不知道SKILL是什么,建议先看第一篇:
抄一个还是改一个
学字先描红,开发先抄,cv程序员的称号不是白得的。
先看看这个:

openclaw毕竟是外国人开发的,默认的skill都是国外的,比如这个天气查询,先找到这个系统自带的skill看看:
这个skill位于系统内置skill的目录:
/app/skills/weather/SKILL.md
这个SKILL的内容:

一个查询天气的skill,还挺复杂,有主要的服务,还有备份的,可惜都是国外的服务,国人用就有点水土不服了,就以他为例,改成简单的国内的:
完整的代码如下:
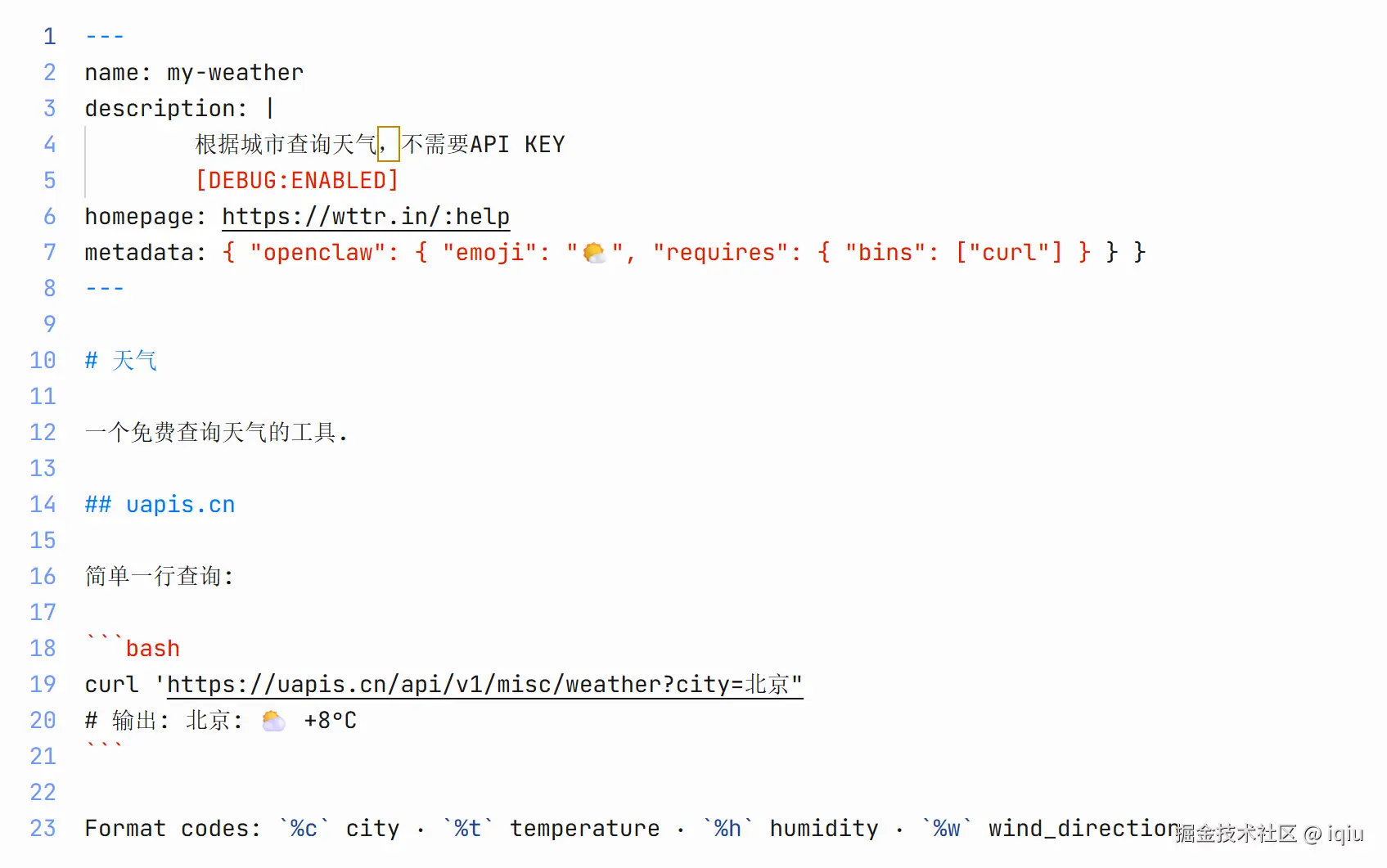
需要重启gateway生效,然后问一下:
万事大吉了!
小结
这是第一个自研的SKILL,功能不大,却也实用,再找一个免费的天气接口,作为备份,完善一下,就可以替代系统自带的天气SKILL了。
从简单开始,从复制开始,慢慢学习复杂一点的SKILL,开发openclaw的功能!
来源:juejin.cn/post/7605848213603074094
Kafka 4.0 正式发布,彻底抛弃 Zookeeper,队列功能来袭!
Apache Kafka 4.0 正式发布了,这是一次里程碑式的版本更新。这次更新带来的改进优化非常多,不仅简化了 Kafka 的运维,还显著提升了性能,扩展了应用场景。
我这里简单聊聊我觉得最重要的 3 个改动:
- KRaft 模式成为默认模式
- 消费者重平衡协议升级
- 队列功能(早期访问版本)
详细更新介绍可以参考官方文档:http://www.confluent.io/blog/introd… 。
KRaft 模式成为默认模式
在 Kafka 2.8 之前,Kafka 最被大家诟病的就是其重度依赖于 Zookeeper 做元数据管理和集群的高可用(ZK 模式)。在 Kafka 2.8 之后,引入了基于 Raft 协议的 KRaft 模式(Kafka Raft),不再依赖 Zookeeper,大大简化了 Kafka 的架构,让你可以以一种轻量级的、单进程的方式来使用 Kafka。
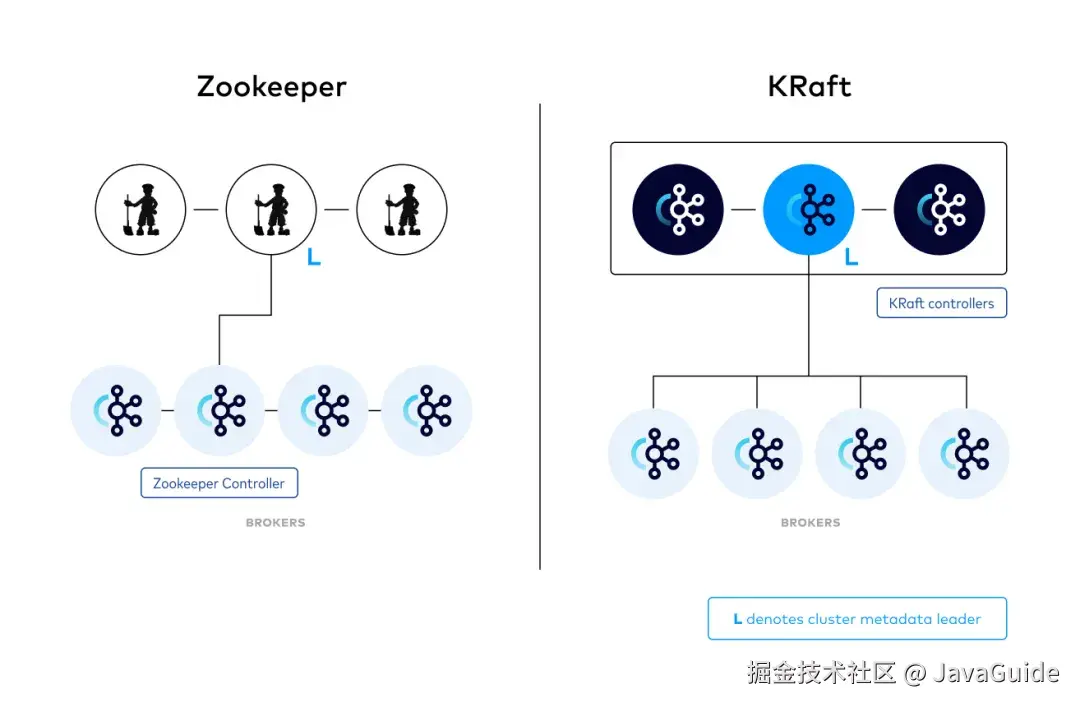
KRaft 模式在后续的版本中不断完善,直到 Kafka 3.3.1,被正式标记为生产环境可用(Production Ready)。
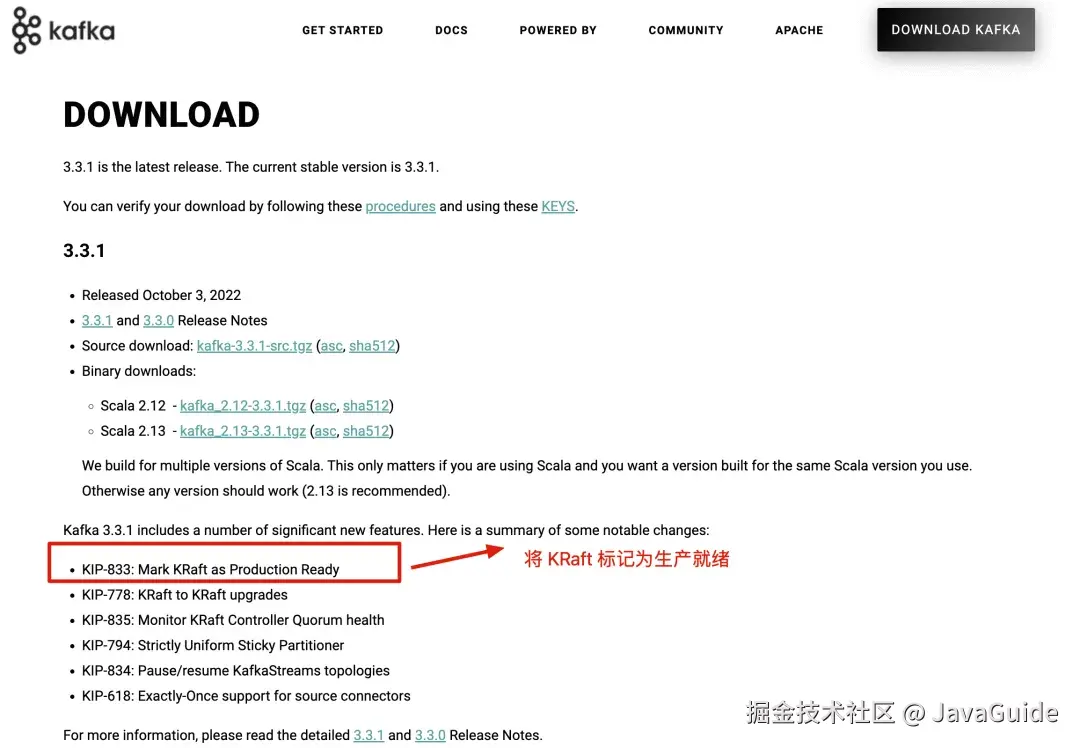
Kafka 4.0 则迈出了更大的一步——彻底移除了对 Zookeeper 的支持,并默认采用 KRaft 模式。
需要注意的是,Kafka 4.0 不再支持以 ZK 模式运行或从 ZK 模式迁移。如果你的 Kafka 仍然使用 ZK 模式,官方建议先升级到过渡版本(如 Kafka 3.9),执行 ZK 迁移后再升级到目标版本。
详细介绍:developer.confluent.io/learn/kraft…
消费者重平衡协议升级
全新的消费者重平衡协议正式 GA 了,可以告别“stop-the-world”重新平衡了!这个协议的核心思想最早在 Kafka 2.4 版本 通过KIP-429: Kafka Consumer Incremental Rebalance Protocol 实现。
新协议的核心在于增量式重平衡,不再依赖全局同步屏障,而是由组协调器(Gr0upCoordinator)驱动,各个消费者独立地与协调器交互,只调整自身相关的分区分配,从而将全局的“停顿”分解成多个局部的、微小的调整。只有需要调整的消费者和分区才会发生变更,未受影响的消费者可以继续正常工作(旧有的再均衡协议依赖于组范围内的同步屏障,所有消费者都需要参与,这会导致明显的“停顿”)。
详细介绍:cwiki.apache.org/confluence/…
队列功能(早期访问版本)
Kafka 4.0 通过引入共享组 (Share Gr0up) 机制提供了类似队列的功能。不过,它并非真正意义上的队列,而是利用 Kafka 已有的主题(Topic)和分区(Partition)机制,结合新的消费模式和记录确认机制来实现类似队列的行为。
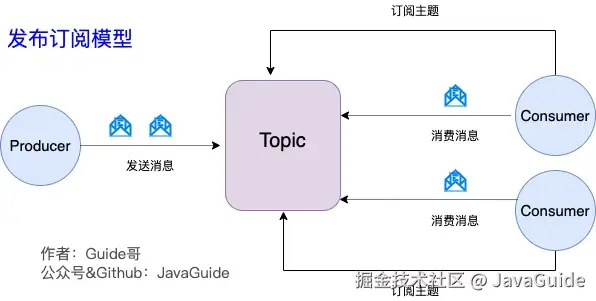 Kafka 发布订阅模型
Kafka 发布订阅模型
共享组解决了传统 Kafka 消费者组(Consumer Gr0ups)在某些场景下的局限性,主要体现在:
- 支持多消费者协同消费:多个消费者可以协同消费同一主题的消息,并可以同时处理同一分区的数据。每个消息在被确认之前,都会被一个时间限制的锁机制保护,确保同一时刻只有一个消费者可以尝试处理。
- 突破消费者组与分区数量的限制:共享组的消费者数量可以超过主题的分区数量,从而更好地支持高并发消费场景。而消费者组的并行消费能力受限于分区数量,这往往导致用户为了满足峰值负载下的并行消费需求而创建过多的分区,造成资源浪费。
- 消息的独立确认:支持对每条消息进行独立确认、释放或拒绝,提供更精细的消息处理能力。
- 消息投递次数记录:系统会记录每条消息的投递次数,方便处理无法处理的消息。
共享组还支持无队列深度限制和基于时间点的恢复能力,极大地扩展了 Kafka 的应用场景。
详细介绍:cwiki.apache.org/confluence/…
Kafka 常见面试题
关于 Kafka 以及其他常见消息队列的知识点/面试题总结,大家可以参考这两篇文章:
来源:juejin.cn/post/7485584242040062002
从Mybatis源码学会了什么
摘要:MyBatis源码展现了优秀的设计模式和架构思想。其运用建造者模式创建复杂对象,动态代理实现Mapper接口,装饰器动态扩展功能等。架构上采用清晰分层设计,插件化扩展机制实现开闭原则,多级缓存提升性能,面向接口编程降低耦合。这些设计理念对日常业务开发也有很大借鉴价值。
通过以下系列博文,我们熟悉了Mybatis源码实现的诸多细节,如Executor接口及其实现、缓存体系、自定义插件等。
- Mybatis入门到精通 一
- Mybatis的Executor和缓存体系
- Mybatis二级缓存实现详解
- Mybatis执行Mapper过程详解
- Mybatis插件原理及分页插件
- Spring集成Mybatis原理详解
这次,让我们跳出局部,看看Mybatis在设计和架构上,有哪些值得我们学习的地方。
注:本文中源码来自mybatis 3.4.x版本,地址github.com/mybatis/myb…
一 设计模式
1.1 建造者模式
MyBatis 大量使用建造者模式解决「复杂对象初始化」问题,比如 SqlSessionFactoryBuilder、XMLConfigBuilder、MapperBuilderAssistant 等。
以SqlSessionFactoryBuilder为例,在创建SqlSessionFactory前需要先解析主配置文件,这个过程非常繁琐。使用建造者模式:
- 分离「对象构建逻辑」和「对象使用逻辑」,让复杂对象创建流程清晰;
- 建造者可以分步骤校验配置正确性,避免无效对象产生;
- 多重载的 build 方法, 适配不同入参场景 。
public class SqlSessionFactoryBuilder {
public SqlSessionFactory build(Reader reader) {
return build(reader, null, null);
}
// 简化代码:reader就是配置文件的读取流
public SqlSessionFactory build(Reader reader, String environment, Properties properties) {
XMLConfigBuilder parser = new XMLConfigBuilder(reader, environment, properties);
return build(parser.parse());
}
}
1.2 工厂模式
工厂模式隐藏对象创建细节,上层无需关心「具体实现类」,只依赖接口。例如
SqlSessionFactory负责创建SqlSession,提供了多个重载实现。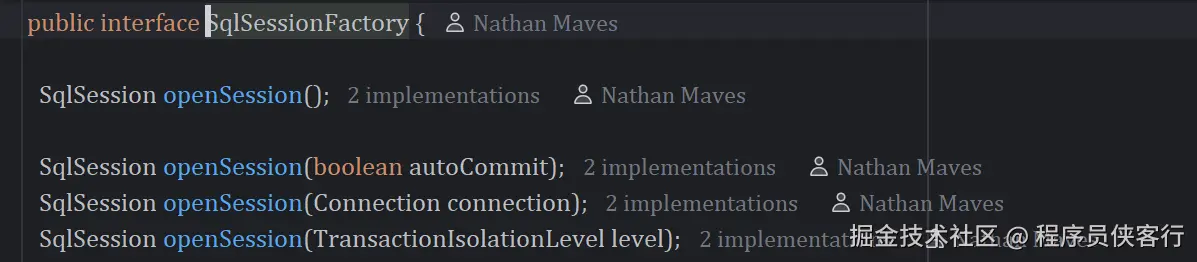
- Executor、StatementHandler、ResultSetHandler、ParameterHandler只能由
Configuration中的newExecutor等方法创建,根据配置选择不同实现类;同时应用自定义插件。
1.3 动态代理
MyBatis 核心的特性之一是「Mapper 接口无需实现类」,底层通过 JDK 动态代理,实现接口方法调用触发SQL执行。详见 MapperProxyFactory,缓存方法元数据,避免重复解析。
// 缓存mapper方法元数据,避免重复解析
private final Map<Method, MapperMethod> methodCache = new ConcurrentHashMap<Method, MapperMethod>();
此外,插件原理也是动态代理,定义Interceptor接口声明代理逻辑、代理对象创建等。使用户可以自定义插件实现。
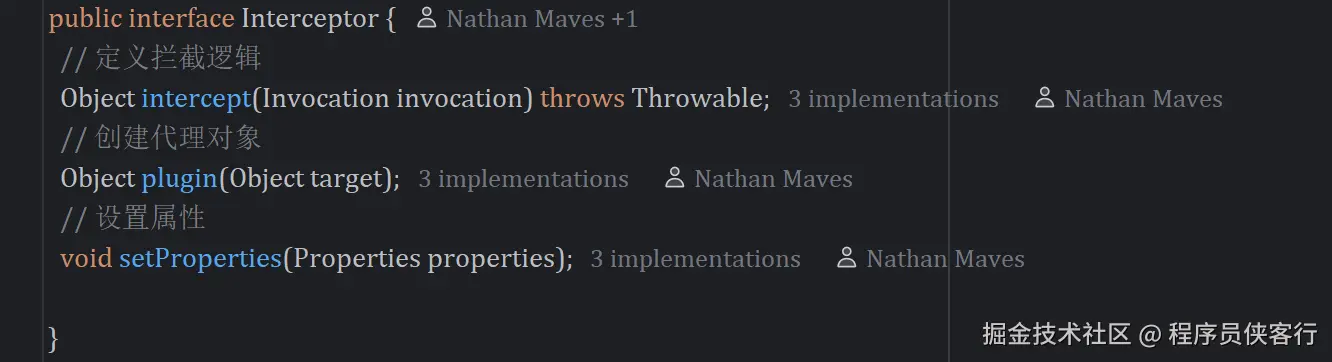
1.4 模板方法
- 模板方法将「不变的通用逻辑」抽离到父类,「可变的差异化逻辑」交给子类实现;
- 避免子类重复编写通用代码(如缓存检查、参数校验),降低代码冗余;
- 父类控制流程,子类只关注核心逻辑,符合「开闭原则」。
BaseExecutor 实现了模板方法模式,将 Executor 的通用流程(如参数处理、SQL 执行、结果集处理)抽象为模板方法,具体子类(SimpleExecutor/BatchExecutor/ReuseExecutor)只需实现差异化逻辑。
// 模板方法,一级缓存使用逻辑
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// ...,会调用doQuer()
}
// 由子类实现
protected abstract <E> List<E> doQuery(...)
1.5 装饰模式
用装饰模式替代继承,无需定义子类,就能给对象动态增加职责。
如通过CachingExecutor装饰,给BaseExecutor增加二级缓存能力。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
// 对BaseExecutor子类进行装饰
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
// 省略...
}

如Cache接口体系,定义了很多装饰器,根据用户配置,实现功能特性自由组合。
1.6 策略模式
Executor接口可根据用户配置,运行时可切换SimpleExecutor、ReuseExecutor或BatchExecutor,实现不同的SQL执行策略。
RoutingStatementHandler 根据配置路由到不同的 StatementHandler实现。
1.7 注册中心
源码中大量使用 Registry 模式来管理可扩展组件, 可以统一初始化、统一查找、统一生命周期;例如:
- TypeHandlerRegistry
- MapperRegistry
- LanguageDriverRegistry
- CacheRegistry
二 架构思维
2.1 分层设计
MyBatis的核心分层非常清晰,每层只做一件事,符合「单一职责原则」:
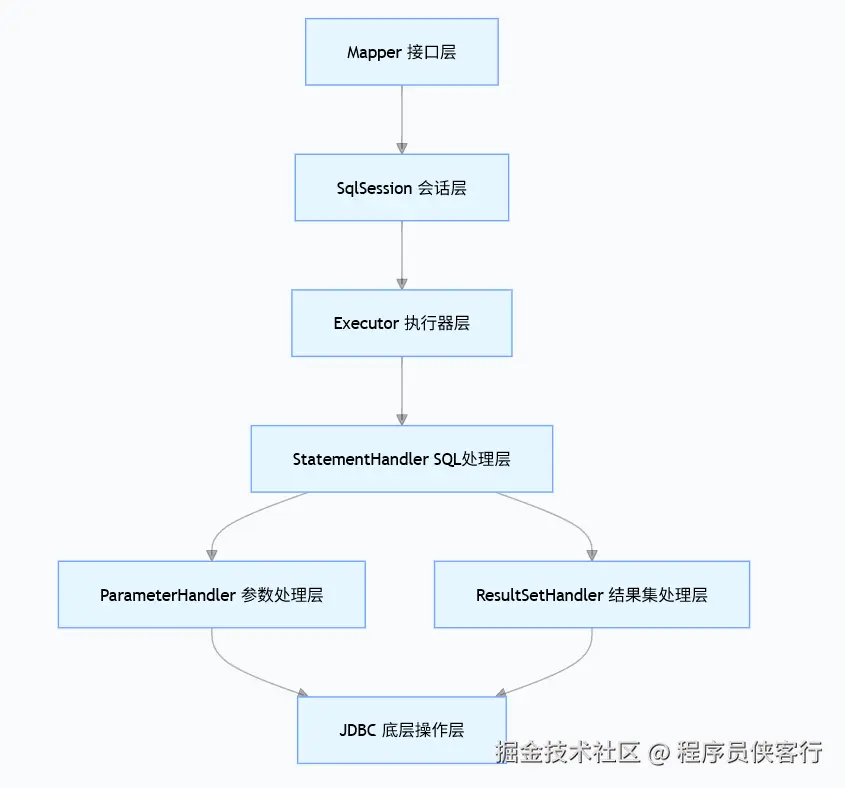
- 各层职责:
- Mapper 层:用户接口,定义 SQL 操作;
- SqlSession 层:会话入口,封装 Executor 调用;
- Executor 层:执行器,处理缓存、事务、SQL 执行流程;
- StatementHandler 层:处理 SQL 拼接、Statement 创建;
- Parameter/ResultSetHandler 层:参数绑定、结果集映射;
- 架构思维:
- 分层降低耦合:修改结果集映射逻辑,不会影响 Executor 层;
- 每层依赖「接口」而非「实现」:比如 Executor 是接口,具体实现可替换;
- 分层便于测试:可单独测试 ParameterHandler 的参数绑定逻辑。
2.2 插件化设计
MyBatis 提供了插件扩展机制(Interceptor),允许开发者通过拦截器增强核心组件(Executor、StatementHandler、ParameterHandler、ResultSetHandler)的功能,实现如分页、日志、加密等。
- 核心设计:
- 定义
Interceptor接口,开发者实现intercept方法即可拦截目标方法; - 通过
@Intercepts注解指定拦截的类和方法,无需修改源码; - 拦截器链(InterceptorChain)通过动态代理层层包装目标对象,保证插件的有序执行;
- 定义
- 架构思维:
- 「开闭原则」的良好体现:框架核心功能固定,扩展功能通过插件实现,无需修改源码;
- 「责任链模式」:多个插件按顺序执行,每个插件只处理自己的逻辑,互不干扰;
- 扩展点设计要「最小化」:只开放核心组件的关键方法,避免过度暴露内部逻辑。
2.3 多级缓存
MyBatis 实现了「一级缓存(SqlSession 级别)+ 二级缓存(Mapper 级别)」的多级缓存:
- 一级缓存:BaseExecutor 中的
localCache(PerpetualCache),默认开启,SqlSession 关闭后失效; - 二级缓存:CachingExecutor 包装普通 Executor,缓存数据存入 Mapper 对应的 Cache 对象,跨 SqlSession 共享;
同时支持集成 Redis/Ehcache 等第三方缓存 。
2.4 面向接口编程
MyBatis 全程贯彻「依赖倒置原则」,完全面向接口编程:接口定义「做什么」,实现类定义「怎么做」,替换实现类不影响上层逻辑;
- 核心组件都是接口:
Executor、StatementHandler、ParameterHandler、ResultSetHandler、SqlSession等; - 上层代码只依赖接口:比如
SqlSession的selectList方法,底层调用的是Executor接口的query方法,无需关心具体是 SimpleExecutor 还是 BatchExecutor。
2.5 约定优于配置
MyBatis 大量使用约定来减少配置,通过约定可以显著降低配置量,提升开发体验。例如:
- Mapper 接口与 XML 文件同名同包;
- 方法名与 SQL ID 一致;
- 结果集字段与 JavaBean 属性自动映射;
StatementHandler接口默认使用PreparedStatementHandler
2.6 架构思维总结
MyBatis源码体现了简单而不简陋的设计哲学:
- 高内聚低耦合 - 模块职责清晰,依赖抽象
- 开闭原则 - 对扩展开放,对修改关闭
- 组合优于继承 - 装饰器、代理模式的应用
- 关注点分离 - SQL、映射、执行逻辑分离
- 性能优化 - 缓存、延迟加载、连接复用
上述技巧和思维不仅适用于框架开发,在日常业务开发中也能直接落地。
- 小型项目:学习其简洁的API设计
- 中型项目:借鉴其分层架构和模式应用
- 大型项目:参考其扩展机制和插件体系
来源:juejin.cn/post/7598477092197220390
除夕夜,国产顶流压轴上线,QWEN3.5多模态开源!

除夕夜,老金我刚咬了一口韭菜鸡蛋饺子。
手机"叮"的一声,弹出个通知。
老金我瞄了一眼——Qwen3.5,上线了。饺子差点没喷出来。
赶紧打开 chat.qwen.ai,两个模型直接挂在上面,可以用了。
阿里这帮人,大年三十放大招,连个发布会都没开,就这么安安静静地把东西甩出来了。
老金我放下筷子,扒了一晚上代码和文档,确认了一件事:
这不是小版本迭代,这是架构级别的重构。
先说结论:Qwen3.5到底升级了什么
根据老金我除夕夜扒的HuggingFace代码库、阿里云官网和chat.qwen.ai的实际体验,帮你梳理了3个核心变化。
第一个:原生多模态。
注意,是"原生",不是"拼接"。
Qwen3之前的多模态方案是语言模型+视觉模块的两段式架构。
Qwen3.5直接把视觉感知和语言推理塞进了同一个训练框架。
阿里云官网对Qwen3.5-Plus的描述是:"原生多模态合一训练,混合架构双创新突破。"
简单说,以前是两个人配合干活,现在是一个人同时搞定。
第二个:Gated Delta Networks——线性注意力机制。
官方确认,Qwen3.5采用了一种叫 Gated Delta Networks 的线性注意力,跟传统的Gated Attention做了混合架构。
传统Transformer的注意力计算量跟序列长度的平方成正比,Gated Delta Networks把这个关系拉成线性。
翻译成人话:处理长文本的速度快了,显存占用也降了。
而且不是快了一点半点——官方实测数据:
- 在32k上下文长度下,Qwen3.5-397B-A17B的解码吞吐量是Qwen3-Max的 8.6倍
- 在256k上下文长度下,这个数字是 19.0倍
- 跟Qwen3-235B-A22B比,分别是3.5倍和7.2倍
老金我看到这个数据的时候饺子真喷出来了。
第三个:更大的模型家族。
目前在chat.qwen.ai上已经可以直接使用的有两个版本:
- Qwen3.5-Plus(闭源API模型,通过阿里云百炼提供服务,支持 1M token上下文窗口)
- Qwen3.5-397B-A17B(开源旗舰模型,3970亿参数只激活170亿)
跟之前HuggingFace代码里泄露的9B和35B-A3B相比,正式发布的模型规模大得多。
3970亿总参数,比Qwen3的旗舰235B-A22B直接翻了快一倍。
总参数量达3970亿,每次前向传播仅激活170亿参数,在保持能力的同时优化速度与成本。
语言与方言支持从119种扩展至201种,词表从15万扩大到25万,在多数语言上带来约10-60%的编码/解码效率提升。
简单说,同样的一段话,Qwen3.5能用更少的token表示,推理更快,API费用也更省。
线性注意力到底意味着什么
这块稍微展开说一下,因为这可能是Qwen3.5最关键的技术突破。
不懂技术的朋友别跳过,老金我用人话给你翻译。
传统Transformer用的是标准自注意力机制。
简单理解:AI在读一篇文章的时候,每读到一个字,都要回头看一遍前面所有的字。
如果文章有1万个字,每个字要跟其他9999个字各看一次。
字数越多,AI就越吃力——计算量是"字数的平方"级别的。
Qwen3.5用的Gated Delta Networks,核心思路是:用一个巧妙的数学方法,让AI不用每次都回头看所有内容。
结果就是:计算量从"字数的平方"降到"字数的倍数"。
听起来差别不大?我给你举个具体例子:
处理一个10分钟的视频:
- 传统方式:可能需要64G显存的显卡才能跑
- Gated Delta Networks:16G显存就够了
这不是快了几个百分点的问题,是能不能跑起来的问题。
很多任务以前根本跑不动,现在可以了。
Qwen3.5更聪明的地方在于:它把Gated Delta Networks(线性注意力)和Gated Attention(标准注意力)做成了 混合架构。
简单任务用线性注意力省资源,复杂任务自动切换到标准注意力保精度。
不是非此即彼,而是动态选择——什么场景用什么方案。
这也是为什么官方说的"Qwen3-Next架构"——更高稀疏度的MoE + 混合注意力 + 多token预测。
多token预测是什么意思?
传统模型一次只能"想"出一个字,Qwen3.5一次能预测多个字,生成速度又快了一截。
原生多模态为什么重要
之前的多模态模型大多是"拼接式"的。
打个比方:就像找了一个英语翻译和一个法语翻译,中间再安排一个协调员把两人的翻译对接起来。
先训一个语言模型(处理文字),再训一个视觉编码器(处理图片),最后用对齐层把两者连起来。
这种方式有个天然缺陷:视觉和语言的理解是割裂的。
Qwen3.5走的是另一条路——从预训练阶段就把文本、图像、视频放在一起训。
模型从一开始就"看"和"读"同时进行。
就像培养一个从小就双语环境长大的孩子,不需要翻译,直接理解。
阿里官方说法是"统一架构整合语言推理与视觉感知"。
这对普通用户来说意味着什么?
1、你发一张图给AI,它能真正"看懂"图里的内容,不容易出现"看到了但理解错了"的情况
2、一次对话就能同时处理图片+文字,不用分两步操作
3、成本更低——一个模型干两个模型的活,API费用直接砍半
阿里官网已经写了"效果、成本与多模态理解深度上同时超越Qwen3-Max与Qwen3-VL"。
如果这个说法成立,那Qwen3.5-Plus可能是目前性价比最高的多模态模型之一。
比如这样提问,它都能准确且快速的回答:
跑分亮了:Qwen3.5到底有多强
说技术架构大家可能没直觉,直接看跑分数据。
官方放了一大堆benchmark对比,老金我帮你提炼最关键的几个:
自然语言能力(对比GPT5.2、Claude 4.5 Opus、Gemini-3 Pro):
几个重点:
1、指令遵循(IFBench 76.5)和多语言挑战(MultiChallenge 67.6)两项全场第一。
这意味着你给它的指令它听得更准,不容易跑偏。
2、搜索Agent能力(BrowseComp 78.6)也是第一。
联网搜索信息的能力很强。
3、多语言能力(NOVA-63 59.1)第一。
201种语言不是白支持的。
4、编程和数学还是GPT5.2和Claude强一些,但差距不大。
视觉语言能力(这才是Qwen3.5的杀手锏):
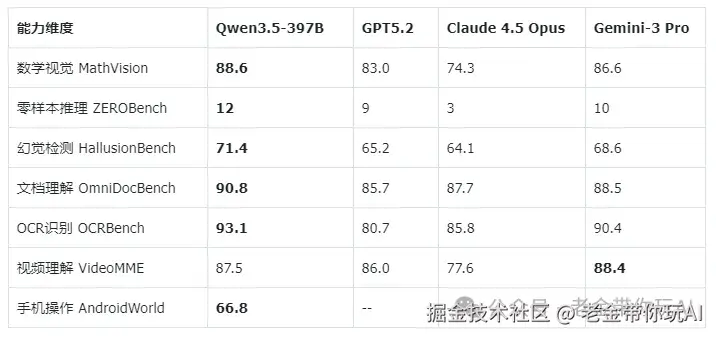
乖乖,视觉能力这块Qwen3.5真的杀疯了:
- MathVision 88.6——看图做数学题,全场最高
- OCRBench 93.1——文字识别能力,直接碾压,比GPT5.2高出12个点
- OmniDocBench 90.8——文档理解能力第一,对搞办公的朋友来说太实用了
- HallusionBench 71.4——幻觉最少,看到什么说什么,不瞎编
- AndroidWorld 66.8——能操作安卓手机,这个后面单独说
注意,这是一个3970亿参数只激活170亿的模型跑出来的成绩。
跟GPT5.2这种完整版闭源大模型对打还能在多个维度赢,开源模型能做到这个水平,老金我服了。
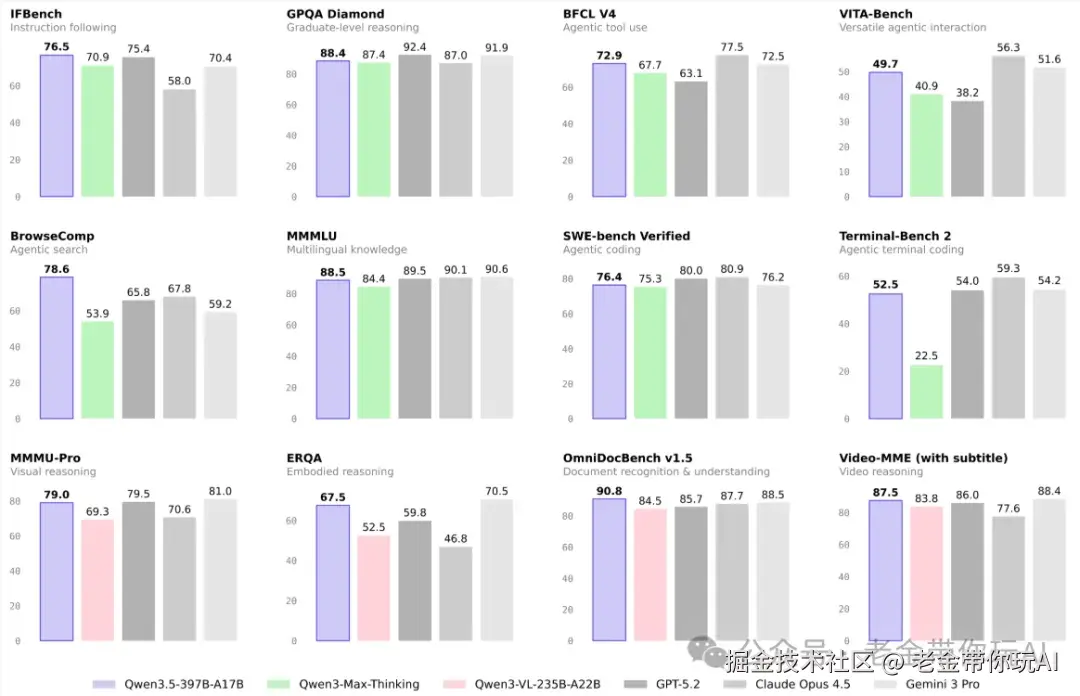
Visual Agent:AI能操作你的手机和电脑了
这是老金我觉得最炸裂的功能,但很多报道都没重点说。
Qwen3.5可以作为 视觉智能体,自主操作手机和电脑完成日常任务。
什么意思?你告诉它"帮我把这个Excel表格的缺失行补全",它真的能:
1、打开Excel文件
2、识别出哪些行和列需要补全
3、自动填写数据
4、保存文件
全程不需要你动手,AI自己操作界面完成。
官方展示了好几个演示:
- 手机端:适配主流App,你说"帮我发条朋友圈",它能自己操作完成
- 电脑端:处理跨应用的数据整理、多步骤流程自动化
AndroidWorld跑分66.8,目前公开数据里最高的。
这不是ChatGPT那种"帮你写个脚本自己跑"。
Qwen3.5是真的在操作GUI界面,像人一样点击、输入、滑动。
对于不会编程的普通用户来说,这个能力可能比会写代码更有用。
空间智能和视觉编程
除了操作手机电脑,Qwen3.5在"看"这件事上还有两个特别的能力。
空间智能:
借助对图像像素级位置信息的建模,Qwen3.5能做到:
- 物体计数——图里有几个苹果,它能数准
- 相对位置判断——电话亭在黄色货车的左边还是右边
- 驾驶场景理解——看行车记录仪画面,分析为什么没在路口停车
官方展示了一个驾驶场景的例子:给它一段行车记录仪视频截帧,它能分析出"信号灯在我接近停车线时变黄,此时距离太近无法安全停车,所以选择通过路口"。
这个能力在自动驾驶和机器人导航场景里非常关键。
视觉编程:
更酷的是,Qwen3.5能把看到的东西变成代码:
- 手绘界面草图 → 结构清晰的前端代码
- 游戏视频 → 逻辑还原代码
- 长视频 → 自动提炼为结构化网页
你甚至可以让他看视频手搓游戏。
如果对你有帮助,记得关注一波~
春节档:AI圈的神仙打架
Qwen3.5选在除夕夜发布,这个时间点太狠了。
这个春节档,至少还有3个重磅选手要登场。
1、DeepSeek V4——最受期待的选手,V3已经证明了DeepSeek的实力
2、GLM-5——智谱的新旗舰,之前Pony Alpha的表现已经让人刮目相看
3、MiniMax 2.2——M2.5编程能力追平Claude,2.2值得关注
老金我觉得今年春节档的竞争格局跟去年完全不同。
去年是DeepSeek V3一家独大。
今年是四五个玩家同时出牌。
对普通用户来说,这其实是好事。
竞争越激烈,开源模型的能力提升越快,API价格越便宜。
MoE架构:小身材大能量
Qwen3.5-397B-A17B这个版本号值得单独说一下。
397B是总参数量,A17B是激活参数量——3970亿参数里每次只用170亿。
什么意思?打个比方:
这就像一个公司有3970个员工,但每次处理一个任务只需要170个人同时干活。
其他人"待命",等需要的时候再上。
这就是MoE(Mixture of Experts,混合专家)架构的核心思路。
模型里有很多"专家"模块,每个token只激活其中几个。
好处是:模型容量大(知识多),但推理成本低(算得快)。
回顾一下Qwen3的数据:
Qwen3-235B-A22B(2350亿参数,激活220亿)在编程、数学、推理上已经能跟DeepSeek-R1、GPT-5正面对决。
Qwen3-30B-A3B在SWE-Bench上拿到69.6分,价格性能比吊打一众付费模型。
Qwen3.5-397B-A17B直接把总参数量拉到3970亿,是Qwen3旗舰的1.7倍。
但激活参数只有170亿,比Qwen3旗舰的220亿还少。
翻译成人话:知识储备更多了,但跑起来反而更省资源。
再加上原生多模态和线性注意力的加持,老金我认为这是2026年上半年最值得关注的开源模型之一。
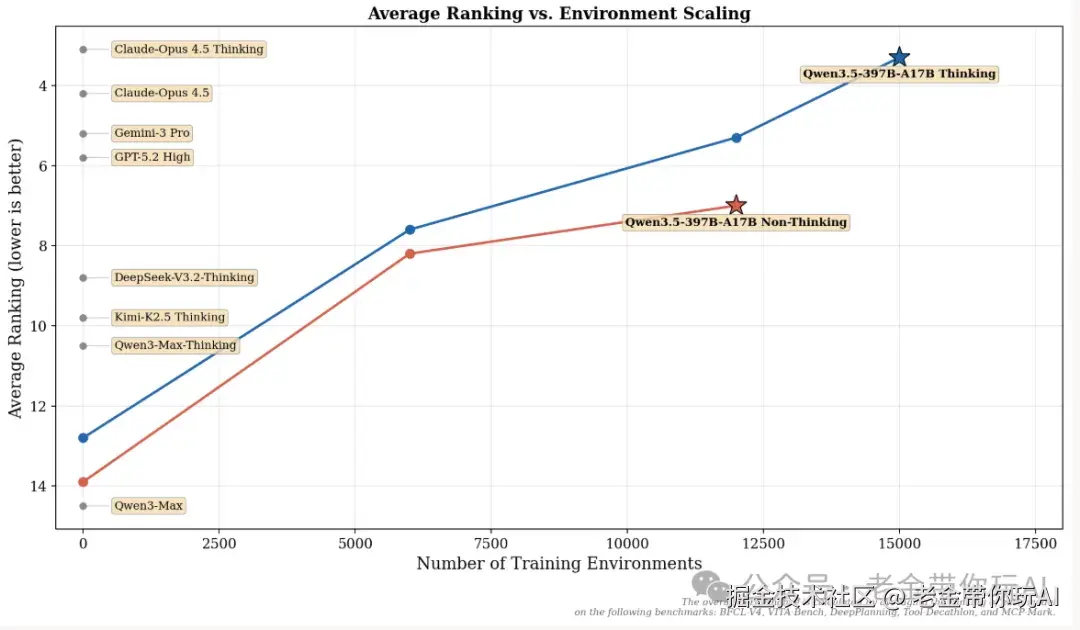
现在就能用:3步上手Qwen3.5
说了这么多技术细节,老金我讲讲实际怎么用。
好消息是:你现在就可以直接体验Qwen3.5,不用等。
第1步:打开 chat.qwen.ai
浏览器直接输入 chat.qwen.ai,这是阿里官方的对话平台。
注册一个账号就能用,支持手机号和邮箱注册。
不需要科学上网,国内直接访问。
第2步:选模型和模式
页面顶部有个模型选择器,点开会看到两个选项:
- Qwen3.5-Plus:推荐日常使用,速度快,响应快
- Qwen3.5-397B-A17B:旗舰模型,适合复杂任务(推理、写代码、分析长文档)
不知道选哪个?选Qwen3.5-Plus就行,够用了。
需要更强的推理能力再切397B。
选好模型后,还能选三种思考模式:
- 自动(auto):自适应思考,该深入就深入,该快就快,推荐大多数场景使用
- 思考(thinking):遇到难题用这个,模型会进行深度推理,一步步想清楚再回答
- 快速(fast):简单问题用这个,不消耗思考token,回答又快又省
第3步:直接对话
跟ChatGPT的用法一模一样——输入框打字,回车发送。
支持的功能包括:
- 纯文字对话(问答、写作、翻译、编程)
- 上传图片让它分析(产品截图、文档照片、手写笔记)
- 上传文件让它总结(PDF、Word、代码文件)
- 联网搜索(点击搜索按钮,它会帮你查最新信息)
完全免费,目前没有次数限制。
对,你没看错,免费的。
这也是阿里开源生态的一贯打法。
开发者进阶用法
如果你是开发者,除了网页版还有更多玩法。
场景1:API调用(1M上下文窗口)
阿里云百炼已经上线Qwen3.5-Plus的API,支持100万token的上下文窗口。
100万token是什么概念?大概相当于一次性读完一本750页的英文小说还绰绰有余。
而且API完全兼容OpenAI格式,切换成本几乎为零:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3.5-plus",
messages=[{"role": "user", "content": "介绍一下Qwen3.5"}],
extra_body={
"enable_thinking": True,
"enable_search": False
},
stream=True
)
两个关键参数:
- enable_thinking:开启推理模式,让模型先想再答,适合复杂问题
- enable_search:开启联网搜索和Code Interpreter
场景2:Vibe Coding(跟编程工具集成)
官方明确说了,百炼API可以跟这些编程工具无缝集成:
- Qwen Code——阿里自己的编程助手
- Claude Code——Anthropic的CLI工具
- Cline——VS Code插件
- OpenClaw——开源Agent框架
- OpenCode——开源编程工具
也就是说,你在Claude Code里把模型切成Qwen3.5-Plus,一样能用。
价格比GPT-5便宜10倍以上,对于日常编程来说性价比拉满。
场景3:多模态应用
原生多模态意味着你可以用一个模型搞定:
- 图片内容识别+文案生成
- 视频内容理解+摘要提取
- 图文混排文档的解析和问答
- GUI自动化——让AI帮你操作软件界面
以前这些任务要调3-4个不同的API,现在一个就够了。
场景4:本地部署
Qwen3.5-397B-A17B虽然总参数3970亿,但激活参数只有170亿。
等开源权重发布后,用Ollama或vLLM部署,消费级显卡也有可能跑起来。
后续如果有更小的版本(比如9B),16G显存的显卡就能流畅运行。
老金的判断
Qwen3.5除夕夜在chat.qwen.ai正式上线了。
老金我说说自己的看法。
看好的点:
- 原生多模态是正确的方向,拼接式迟早要被淘汰
- Gated Delta Networks解决了长序列的核心瓶颈,8.6倍/19倍的吞吐量提升不是闹着玩的
- MoE架构在成本和性能之间找到了平衡点——3970亿参数只激活170亿,这个比例很激进
- 视觉能力真的强——OCR、文档理解、数学视觉多项第一
- Visual Agent能操作手机电脑,这是AI从"回答问题"到"替你干活"的关键一步
- 阿里在开源这条路上一直很坚定,Qwen3的开源质量有目共睹
- 完全免费使用,对普通用户来说门槛为零
值得关注的未来方向:
官方博客最后提了三个方向,老金我觉得每个都很重要:
1、跨会话持久记忆——现在的AI每次对话都是"失忆"状态,未来能记住你之前聊过什么
2、具身接口——不只是操作手机电脑屏幕,未来可能控制机器人在真实世界干活
3、自我改进机制——AI能自己变得更好,不需要人类手动更新
阿里原话是:"将当前以任务为边界的助手升级为可持续、可信任的伙伴。"
老金我的态度是谨慎乐观。
架构升级的方向是对的,除夕夜放这个大招,阿里是真的有底气。
跑分数据已经出来了,视觉能力多项碾压GPT5.2和Claude 4.5 Opus,你现在就可以去chat.qwen.ai亲自试试。
有一点可以确定:2026年的开源大模型,竞争只会越来越激烈。
对于开发者和普通用户来说,这是最好的时代。
往期推荐:
AI编程教程列表
提示词工工程(Prompt Engineering)
LLMOPS(大语言模运维平台)
AI绘画教程列表
WX机器人教程列表
每次我都想提醒一下,这不是凡尔赛,是希望有想法的人勇敢冲。
我不会代码,我英语也不好,但是我做出来了很多东西,在文末的开源知识库可见。
我真心希望能影响更多的人来尝试新的技巧,迎接新的时代。
谢谢你读我的文章。
如果觉得不错,随手点个赞、在看、转发三连吧🙂
如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章。
开源知识库地址:
tffyvtlai4.feishu.cn/wiki/OhQ8wq…
来源:juejin.cn/post/7606555195753873408
JDK 25(长期支持版) 发布,新特性解读!
JDK 25 重磅发布了!这是一个非常重要的版本,里程碑式。
JDK 25 是 LTS(长期支持版),至此为止,有 JDK8、JDK11、JDK17、JDK21 和 JDK 25 这五个长期支持版了。
JDK 21 共有 18 个新特性,这篇文章会挑选其中较为重要的一些新特性进行详细介绍:
- JEP 506: Scoped Values (作用域值)
- JEP 512: Compact Source Files and Instance Main Methods (紧凑源文件与实例主方法)
- JEP 519: Compact Object Headers (紧凑对象头)
- JEP 521: Generational Shenandoah (分代 Shenandoah GC)
- JEP 507: Primitive Types in Patterns, instanceof, and switch (模式匹配支持基本类型, 第三次预览)
- JEP 511: Module Import Declarations (模块导入声明)
- JEP 513: Flexible Constructor Bodies (灵活的构造函数体)
- JEP 508: Vector API (向量 API, 第十次孵化)
其实里面的很多新特性在之前的版本中就多次提到了,这里只是转正或者再次预览。
下图是从 JDK 8 到 JDK 24 每个版本的更新带来的新特性数量和更新时间:
JEP 506: 作用域值
作用域值(Scoped Values)可以在线程内和线程间共享不可变的数据,优于线程局部变量 ThreadLocal ,尤其是在使用大量虚拟线程时。
final static ScopedValue<...> V = new ScopedValue<>();
// In some method
ScopedValue.where(V, <value>)
.run(() -> { ... V.get() ... call methods ... });
// In a method called directly or indirectly from the lambda expression
... V.get() ...
作用域值通过其“写入时复制”(copy-on-write)的特性,保证了数据在线程间的隔离与安全,同时性能极高,占用内存也极低。这个特性将成为未来 Java 并发编程的标准实践。
JEP 512: 紧凑源文件与实例主方法
该特性第一次预览是由 JEP 445 (JDK 21 )提出,随后经过了 JDK 22 、JDK 23 和 JDK 24 的改进和完善,最终在 JDK 25 顺利转正。
这个改进极大地简化了编写简单 Java 程序的步骤,允许将类和主方法写在同一个没有顶级 public class的文件中,并允许 main 方法成为一个非静态的实例方法。
class HelloWorld {
void main() {
System.out.println("Hello, World!");
}
}
进一步简化:
void main() {
System.out.println("Hello, World!");
}
这是为了降低 Java 的学习门槛和提升编写小型程序、脚本的效率而迈出的一大步。初学者不再需要理解 public static void main(String[] args) 这一长串复杂的声明。对于快速原型验证和脚本编写,这也使得 Java 成为一个更有吸引力的选择。
JEP 519: 紧凑对象头
该特性第一次预览是由 JEP 450 (JDK 24 )提出,JDK 25 就顺利转正了。
通过优化对象头的内部结构,在 64 位架构的 HotSpot 虚拟机中,将对象头大小从原本的 96-128 位(12-16 字节)缩减至 64 位(8 字节),最终实现减少堆内存占用、提升部署密度、增强数据局部性的效果。
紧凑对象头并没有成为 JVM 默认的对象头布局方式,需通过显式配置启用:
- JDK 24 需通过命令行参数组合启用:
$ java -XX:+UnlockExperimentalVMOptions -XX:+UseCompactObjectHeaders ...; - JDK 25 之后仅需
-XX:+UseCompactObjectHeaders即可启用。
JEP 521: 分代 Shenandoah GC
Shenandoah GC 在 JDK12 中成为正式可生产使用的 GC,默认关闭,通过 -XX:+UseShenandoahGC 启用。
Redhat 主导开发的 Pauseless GC 实现,主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等
传统的 Shenandoah 对整个堆进行并发标记和整理,虽然暂停时间极短,但在处理年轻代对象时效率不如分代 GC。引入分代后,Shenandoah 可以更频繁、更高效地回收年轻代中的大量“朝生夕死”的对象,使其在保持极低暂停时间的同时,拥有了更高的吞吐量和更低的 CPU 开销。
Shenandoah GC 需要通过命令启用:
- JDK 24 需通过命令行参数组合启用:
-XX:+UseShenandoahGC -XX:+UnlockExperimentalVMOptions -XX:ShenandoahGCMode=generational - JDK 25 之后仅需
-XX:+UseShenandoahGC -XX:ShenandoahGCMode=generational即可启用。
JEP 507: 模式匹配支持基本类型 (第三次预览)
该特性第一次预览是由 JEP 455 (JDK 23 )提出。
模式匹配可以在 switch 和 instanceof 语句中处理所有的基本数据类型(int, double, boolean 等)
static void test(Object obj) {
if (obj instanceof int i) {
System.out.println("这是一个int类型: " + i);
}
}
这样就可以像处理对象类型一样,对基本类型进行更安全、更简洁的类型匹配和转换,进一步消除了 Java 中的模板代码。
JEP 505: 结构化并发(第五次预览)
JDK 19 引入了结构化并发,一种多线程编程方法,目的是为了通过结构化并发 API 来简化多线程编程,并不是为了取代java.util.concurrent,目前处于孵化器阶段。
结构化并发将不同线程中运行的多个任务视为单个工作单元,从而简化错误处理、提高可靠性并增强可观察性。也就是说,结构化并发保留了单线程代码的可读性、可维护性和可观察性。
结构化并发的基本 API 是StructuredTaskScope,它支持将任务拆分为多个并发子任务,在它们自己的线程中执行,并且子任务必须在主任务继续之前完成。
StructuredTaskScope 的基本用法如下:
try (var scope = new StructuredTaskScope<Object>()) {
// 使用fork方法派生线程来执行子任务
Future<Integer> future1 = scope.fork(task1);
Future<String> future2 = scope.fork(task2);
// 等待线程完成
scope.join();
// 结果的处理可能包括处理或重新抛出异常
... process results/exceptions ...
} // close
结构化并发非常适合虚拟线程,虚拟线程是 JDK 实现的轻量级线程。许多虚拟线程共享同一个操作系统线程,从而允许非常多的虚拟线程。
JEP 511: 模块导入声明
该特性第一次预览是由 JEP 476 (JDK 23 )提出,随后在 JEP 494 (JDK 24)中进行了完善,JDK 25 顺利转正。
模块导入声明允许在 Java 代码中简洁地导入整个模块的所有导出包,而无需逐个声明包的导入。这一特性简化了模块化库的重用,特别是在使用多个模块时,避免了大量的包导入声明,使得开发者可以更方便地访问第三方库和 Java 基本类。
此特性对初学者和原型开发尤为有用,因为它无需开发者将自己的代码模块化,同时保留了对传统导入方式的兼容性,提升了开发效率和代码可读性。
// 导入整个 java.base 模块,开发者可以直接访问 List、Map、Stream 等类,而无需每次手动导入相关包
import module java.base;
public class Example {
public static void main(String[] args) {
String[] fruits = { "apple", "berry", "citrus" };
Map<String, String> fruitMap = Stream.of(fruits)
.collect(Collectors.toMap(
s -> s.toUpperCase().substring(0, 1),
Function.identity()));
System.out.println(fruitMap);
}
}
JEP 513: 灵活的构造函数体
该特性第一次预览是由 JEP 447 (JDK 22)提出,随后在 JEP 482 (JDK 23)和 JEP 492 (JDK 24)经历了预览,JDK 25 顺利转正。
Java 要求在构造函数中,super(...) 或 this(...) 调用必须作为第一条语句出现。这意味着我们无法在调用父类构造函数之前在子类构造函数中直接初始化字段。
灵活的构造函数体解决了这一问题,它允许在构造函数体内,在调用 super(..) 或 this(..) 之前编写语句,这些语句可以初始化字段,但不能引用正在构造的实例。这样可以防止在父类构造函数中调用子类方法时,子类的字段未被正确初始化,增强了类构造的可靠性。
这一特性解决了之前 Java 语法限制了构造函数代码组织的问题,让开发者能够更自由、更自然地表达构造函数的行为,例如在构造函数中直接进行参数验证、准备和共享,而无需依赖辅助方法或构造函数,提高了代码的可读性和可维护性。
class Person {
private final String name;
private int age;
public Person(String name, int age) {
if (age < 0) {
throw new IllegalArgumentException("Age cannot be negative.");
}
this.name = name; // 在调用父类构造函数之前初始化字段
this.age = age;
// ... 其他初始化代码
}
}
class Employee extends Person {
private final int employeeId;
public Employee(String name, int age, int employeeId) {
this.employeeId = employeeId; // 在调用父类构造函数之前初始化字段
super(name, age); // 调用父类构造函数
// ... 其他初始化代码
}
}
JEP 508: 向量 API(第十次孵化)
向量计算由对向量的一系列操作组成。向量 API 用来表达向量计算,该计算可以在运行时可靠地编译为支持的 CPU 架构上的最佳向量指令,从而实现优于等效标量计算的性能。
向量 API 的目标是为用户提供简洁易用且与平台无关的表达范围广泛的向量计算。
这是对数组元素的简单标量计算:
void scalarComputation(float[] a, float[] b, float[] c) {
for (int i = 0; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
这是使用 Vector API 进行的等效向量计算:
static final VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
void vectorComputation(float[] a, float[] b, float[] c) {
int i = 0;
int upperBound = SPECIES.loopBound(a.length);
for (; i < upperBound; i += SPECIES.length()) {
// FloatVector va, vb, vc;
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.mul(va)
.add(vb.mul(vb))
.neg();
vc.int0Array(c, i);
}
for (; i < a.length; i++) {
c[i] = (a[i] * a[i] + b[i] * b[i]) * -1.0f;
}
}
尽管仍在孵化中,但其第十次迭代足以证明其重要性。它使得 Java 在科学计算、机器学习、大数据处理等性能敏感领域,能够编写出接近甚至媲美 C++等本地语言性能的代码。这是 Java 在高性能计算领域保持竞争力的关键。
从 JDK8 到 JDK24 每一版版本的新特性详细介绍,可以在 JavaGuide 官方网站( javaguide.cn )上找到。
来源:juejin.cn/post/7551104474233831475
FastExcel消失了,原来捐给了Apache
关注我的公众号:【编程朝花夕拾】,可获取首发内容。
01 引言
FastExcel仅存在江湖上出现了两年,可能很多开发者还不知道这个项目。但是说到阿里的EasyExcel,大家肯定耳熟能详。
没错,FastExcel就是EasyExcel的作者离开阿里之后,重新维护的加强版EasyExcel,而此后,阿里的EasyExcel宣布不再更新进入维护期。
这两天,无意间看到一篇文章介绍的Apache新项目,怎么看怎么眼熟,和FastExcel如出一撤。了解下来,才发现原来是同一个项目,只是背景更加强大了。
02 Fesod
2.1 简介
Apache Fesod (Incubating)是一个高性能、内存高效的 Java 库,用于读写电子表格文件,旨在简化开发并确保可靠性。
Apache Fesod (Incubating) 可以为开发者和企业提供极大的自由度和灵活性。我们计划在未来引入更多新功能,以持续提升用户体验和工具可用性。Apache Fesod (Incubating) 致力于成为您处理电子表格文件的最佳选择。
名称 fesod(发音为 /ˈfɛsɒd/),是 fast easy spreadsheet and other documents(快速简单的电子表格和其他文档)的首字母缩写,表达了项目的起源、背景和愿景。
Apache Fesod目前处于孵化器,还没有正式毕业。最低的Java版本也必须是1.8。
GitHub地址:github.com/apache/feso…
官网地址:fesod.apache.org/
2.2 Maven依赖
以后要使用的依赖:
<dependency>
<groupId>org.apache.fesod</groupId>
<artifactId>fesod</artifactId>
<version>version</version>
</dependency>
由于目前正处于Apache的孵化期,暂时没有稳定版本。要使用的话,目前最新的fastexcel 1.3.0的版本。
<dependency>
<groupId>cn.idev.excel</groupId>
<artifactId>fastexcel</artifactId>
<version>1.3.0</version>
</dependency>
2.3 大致时间线
- 2024.09.11
easyexcel发布最后一个稳定版本,easyexcel 4.0.3 - 2024.11.06
easyexcel阿里官方宣布停更。只修复BUG - 2024.12.05
easyexcel作者新开仓库,取名FastExcel,并发布第一个版本,fastexcel 1.0.0 - 2025.01.14
fastExcel发布第二个版本稳定版,fastexcel 1.1.0 - 2025.04.14
fastExcel发布第三个版本稳定版,fastexcel 1.2.0 - 2025.08.23
fastExcel发布最后一个稳定版本,fastexcel 1.3.0 - 2025.09.04
easyexcelGitHub仓库归档,仅可读 - 2025.09.17
fastExcel正式进入Apache服化器,更名Fesod
从此,正式成为Apache的产物,所谓Apache出品必是精品,这么强大的维护团队,期待更多的功能以及更好的性能。
其实在FastExcel作者创建仓库时,第一次的名字并不是FastExcel,好像是EasyExcel plus,具体什么不记得了。但确实存在过。
2.4 怀疑
网上搜了一下fastExcel捐给Apache的消息有限,并没有官方说明。还特意看了下Apache Fesod团队的人员有没有Fastexcel的作者。看了之后确实有。
2.5 熟悉的味道
案例这里就不在赘述,我们看看官方即可:
新的项目使用FesodSheet调起读写方法,其他和原来的一致。
03 小结
不追求新功能的可以继续使用原来的fastexcel或者easyexcel,大部分场景,简单的导入导出功能已经足够使用。渴望新功能的,可以期待一下fesod的正式版。
来源:juejin.cn/post/7598071804969812006
Tomcat 与 Nginx、Apache 的区别是什么?
这个问题本身有个误解:把三个东西都叫「web server」,会让人以为它们是同一种东西的三种实现。其实不是。Nginx 和 Apache 是 HTTP 服务器,Tomcat 是 Servlet 容器,它们干的活不在一个层次上。
Nginx 和 Apache(一般说的 Apache 指的是 Apache HTTP Server,也就是 httpd)是 HTTP 服务器:收 HTTP 请求、按配置干活、回 HTTP 响应。它们擅长扛静态文件、做反向代理、做负载均衡,但它们不执行 Java 代码。你打一个 .war 包丢给 Nginx,Nginx 不知道怎么处理——它只会返回 404 或者把请求转给别人。
Tomcat 是 Servlet 容器,不是完整的 Java EE 应用服务器(那是 WildFly、WebLogic、WebSphere 干的事,它们支持 EJB、JMS、JTA 等完整规范)。Tomcat 只实现 Servlet 和 JSP 规范,核心能力是:把 HTTP 请求交给你的 Java 代码去处理,再把结果变成 HTTP 响应发回去。
所以「Java 后台程序能不能用 Apache 和 Nginx」——能,而且生产环境里经常是「Nginx/Apache 在前,Tomcat 在后」:前面负责扛流量、静态资源、HTTPS 终结、负载均衡,后面专门跑 Java。
Nginx 和 Apache:都是 HTTP 服务器,架构不一样
两者都能做静态文件服务、反向代理、负载均衡,但内部设计完全不同。
Apache 有三种工作模式(MPM):prefork 是一个连接一个进程,worker 是多进程+多线程,event 是在 worker 基础上优化了 keep-alive 连接的处理。现代 Apache(2.4+)默认用 event MPM,处理 keep-alive 的方式已经接近事件驱动了,不完全是老式的「一个连接占一个线程」。但不管哪种模式,Apache 的并发上限都受限于进程/线程数——每个线程有自己的栈空间(Linux 默认 8MB),1000 个线程光栈就要 8GB 内存,还没算堆上的数据。所以 Apache 的并发连接数一般在几百到几千这个量级。
Nginx 是另一种思路:少量 worker 进程 + 事件循环。每个 worker 用 epoll(Linux)/ kqueue(macOS)做 I/O 多路复用,一个 worker 可以同时挂着几万条连接。大部分连接在等 I/O,不需要单独的线程,也就不需要那 8MB 的栈空间。所以同样一台机器,Nginx 能撑的并发连接数比 Apache 高一个数量级。
这也是很多人说「Nginx 比 Apache 性能好」的原因——不是 Nginx 处理单个请求更快,而是它用更少的资源就能维持大量连接。 如果你的场景是几十个并发、主要跑 PHP,Apache + mod_php 用着挺好,没必要换。但如果要扛几万并发、做反向代理或者负载均衡,Nginx 的模型更合适。
Tomcat:能直接对外,但不擅长
这里要纠正一个常见的说法:「Tomcat 必须放在 Nginx 后面」。
Tomcat 自带 HTTP 连接器(Coyote),可以直接监听 80 或 443 端口对外服务。开发的时候大家天天直接访问 localhost:8080,没什么问题。Spring Boot 更进一步——内嵌 Tomcat 打成一个 jar 包,java -jar 直接跑,连单独部署 Tomcat 都省了。
很多微服务架构里,每个服务就是一个内嵌 Tomcat 的 Spring Boot 应用,前面挂一个 API 网关(Spring Cloud Gateway、Kong 之类的)做路由和鉴权,根本没有单独部署 Nginx 的环节。
但 Tomcat 直接对外有几个短板:
静态文件性能。 Nginx 处理静态文件用的是 sendfile 系统调用(之前零拷贝那篇讲过),数据不经过用户空间,直接从磁盘到网卡。Tomcat 处理静态文件要经过 Java 的 IO 层,多了一次拷贝和 JVM 的开销。量小的时候感知不到,量大了差距就出来了。
SSL 终结。 Nginx 的 SSL 实现基于 OpenSSL,经过大量优化,支持 session 复用、OCSP stapling 这些。Tomcat 也能做 SSL,但性能和配置灵活性都不如 Nginx。把 SSL 卸载到 Nginx,Tomcat 和 Nginx 之间走 HTTP 明文,Tomcat 的负担更轻。
限流、缓存、负载均衡。 这些 Nginx 用几行配置就能搞定,Tomcat 要么不支持,要么需要写 Java 代码或者引入额外组件。
所以典型的生产部署是这样的:
upstream tomcat_backend {
server 127.0.0.1:8080;
server 127.0.0.1:8081; # 多实例负载均衡
}
server {
listen 443 ssl;
ssl_certificate /etc/nginx/cert.pem;
ssl_certificate_key /etc/nginx/key.pem;
location /static/ {
alias /var/www/static/;
}
location / {
proxy_pass http://tomcat_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Nginx 扛 SSL、吐静态文件、做负载均衡,动态请求转给后面的 Tomcat。但这不是唯一的架构——小项目、内部系统、微服务里 Tomcat 直接对外也很常见,取决于你的流量规模和运维需求。
为啥早年都是 Apache + Tomcat
早期 Nginx 还没普及的时候,Apache 是 Linux 上默认的 HTTP 服务器。Java 项目的标准搭配是 Apache + mod_jk(或 mod_proxy)+ Tomcat:Apache 在前面接请求,通过 AJP 协议或 HTTP 代理转给 Tomcat。
mod_jk 用的是 AJP 协议(Apache JServ Protocol),比 HTTP 更紧凑,省了 HTTP 头的解析开销。但 AJP 协议在 2020 年爆出过 Ghostcat 漏洞(CVE-2020-1938),之后很多团队开始关闭 AJP 端口,改用 HTTP 代理。
现在新项目基本都用 Nginx 替代 Apache 当入口了。Apache 在需要 .htaccess(目录级配置覆盖)或者跑 mod_php 的场景还有优势,但纯做反向代理和负载均衡,Nginx 的资源占用和并发能力都更好。
怎么判断你的项目该用哪种组合
Spring Boot 微服务、内部系统、流量不大: 内嵌 Tomcat 直接对外,前面挂个网关或者云厂商的负载均衡器就行,不需要单独部署 Nginx。
对外的 Web 应用、有静态资源、需要 HTTPS: Nginx 在前做 SSL 终结和静态资源,动态请求 proxy_pass 到 Tomcat。
PHP + Java 混合部署(老项目): Apache 跑 mod_php 处理 PHP,同时 mod_proxy 把 Java 请求转给 Tomcat。不过这种架构越来越少了。
纯静态站点、CDN 回源、API 网关: 只需要 Nginx,不需要 Tomcat。
Nginx 和 Tomcat 不是竞争关系,Apache 和 Nginx 才是。而即便是 Apache 和 Nginx,在大部分场景下也不是「谁好谁差」的问题——Nginx 在高并发反向代理上更强,Apache 在需要 .htaccess 和动态模块加载的场景更方便。
来源:juejin.cn/post/7609933479262715950
PWA 到底是什么?它在 2026 年解决了哪些真实痛点?
PWA 到底是什么?
Progressive Web App(渐进式 Web 应用,简称 PWA)是一种使用标准 Web 技术(HTML、CSS、JavaScript)构建的网页应用,但通过浏览器提供的增强能力,让它具备接近原生 App 的体验。
它不是一个全新的东西,而是一种“渐进增强”(Progressive Enhancement)的理念:从普通的网页开始,逐步添加高级特性,让用户感觉像在使用安装的原生应用。
PWA 的三大核心支柱(至今仍是):
- 可靠(Reliable):即使在弱网/断网情况下也能加载并基本可用(靠 Service Worker + 缓存)。
- 快速(Fast):瞬间加载、流畅交互(优化的缓存 + 性能最佳实践)。
- 可安装(Installable):可以“添加到主屏幕”,以独立窗口(standalone)模式运行,有图标、启动画面,像 App 一样。
在 2026 年,PWA 已经从 2015 年的“概念”变成了许多企业实际落地的主流移动解决方案之一。浏览器支持大幅成熟,Chrome/Edge/Firefox 几乎完整,Safari(iOS)也追赶了很多年(虽仍有差距)。
它在 2026 年真正解决了哪些真实痛点?
以下是 2026 年开发者/产品/业务最常遇到的痛点,以及 PWA 如何针对性解决(基于当前浏览器现实支持情况):
- 开发和维护成本爆炸(Separate iOS + Android + Web)
- 痛点:同一功能要写 3 套代码(Swift/Kotlin + Web),测试、上架、更新各走各的流程,维护成本高到离谱。
- PWA 解决:一套代码跑三端(甚至桌面 Windows/macOS/ChromeOS)。2026 年 60%+ 的企业级移动项目已转向 PWA 或 hybrid 模式,开发成本可降 40–60%。更新无需 App Store 审核,秒级生效。
- 用户安装/获取摩擦巨大(App Store 下载壁垒)
- 痛点:用户看到链接 → 去 App Store → 下载几十 MB → 安装 → 打开,转化率惨不忍睹(很多场景 <5%)。
- PWA 解决:链接一点就用,符合条件可弹出“添加到主屏幕”提示(Android 自动 banner,iOS 手动但更顺畅)。安装后有图标、离线可用、无需占 App Store 空间。很多电商/内容/工具类 App 转化率因此提升 2–5 倍。
- 弱网/无网场景下体验崩坏
- 痛点:地铁、电梯、农村、国际漫游……用户一断网就白屏/卡死,流失严重。
- PWA 解决:Service Worker 预缓存 + 运行时缓存,核心页面/资源离线可用。2026 年 Workbox 等工具让实现几乎零成本。新闻、邮件、待办、天气、记账类 PWA 在断网时仍能浏览历史、写草稿,等联网再同步。
- 推送通知和用户再触达难
- 痛点:H5 基本没推送,原生 App 推送又贵又麻烦(审核、权限)。
- PWA 解决:Web Push 已跨平台可用。Android/桌面完整支持,iOS 从 iOS 16.4 开始支持(需加到主屏幕,非 EU 地区更稳定)。2026 年 Declarative Web Push 等新 API 让推送更可靠,企业再营销/订单提醒/消息触达率大幅提升。
- 加载慢、性能差直接影响收入
- 痛点:移动端 3 秒未加载完,用户流失率飙升;Core Web Vitals 差 → SEO 排名掉。
- PWA 解决:强制 HTTPS + 缓存策略 + 优化后,首屏加载常 <1s。Lighthouse PWA 分数 90+ 已成为标配,很多业务报告转化率提升 20–50%。
- 跨平台一致性 & 快速迭代
- 痛点:iOS 和 Android 体验割裂,bug 修复要双平台发版。
- PWA 解决:浏览器统一渲染逻辑,一处修复全局生效。2026 年 PWA 还能用 File System Access、Web Share、Badging API 等,让体验更接近原生。
2026 年 PWA 的真实平台支持对比(简表)
| 特性 | Android (Chrome) | iOS (Safari 26+) | Windows/macOS | 备注 |
|---|---|---|---|---|
| 添加到主屏幕/安装 | 完整(自动提示) | 支持(手动 Share → Add) | 支持 | iOS 26 默认更倾向 web app 模式 |
| 离线 & 缓存 | 完整 | 完整(但存储配额仍限) | 完整 | Service Worker 跨平台 |
| Push 通知 | 完整 | 支持(需 home screen,非EU更稳) | 完整 | iOS 无 silent push,reach 稍低 |
| Background Sync | 完整 | 部分/不支持 | 部分 | iOS 仍最大短板 |
| Periodic Sync | 完整 | 不支持 | 部分 | 用于定期更新内容 |
| 硬件 API(相机、蓝牙等) | 大部分支持 | 部分支持 | 部分 | 差距在缩小 |
总结一句话(2026 年视角)
PWA 不是要完全取代原生 App,而是解决了**“我想给用户 App 般的体验,但不想付出双平台原生开发的代价”** 这个最真实、最普遍的痛点。
特别适合:
- 电商、新闻、社交工具、SaaS、生产力工具、内容平台
- 预算有限、需要快速验证、重视 SEO 和链接分享的场景
- 想覆盖桌面 + 移动 + 弱网用户的企业
不适合:
- 重度游戏、AR/VR、深度硬件调用(如银行指纹/人脸支付完整链路)
- 对 iOS 推送/后台要求极高的场景(仍需原生补位)
来源:juejin.cn/post/7608782906940620840
彻底重绘Spring Boot性能版图,资源占用缩减80%
很多开发者还在用十年前的习惯写现在的 Spring Boot 应用。这种技术代差不仅让代码显得臃肿,更是在浪费服务器的真金白银。本文整理了一些进阶技巧,帮助优化 Spring Boot 应用的运行效率与代码质量。

准备工作:快速搭建 Java 环境
编写代码前需要安装 JDK。但对新手来说,手动配置环境变量和切换版本其实挺浪费时间的。
而 ServBay 提供了集成化的解决方案,支持一键部署 Java 环境,这样开发者可以快速切换不同的 JDK 版本,无需手动调整系统配置,让开发环境的搭建变得高效且规范。
精细化配置 JVM 内存降低云端成本
很多 Spring Boot 应用在云服务器上裸奔。默认的 JVM 配置往往会申请过多的内存,导致账单金额飙升。
如果我们运行的是微服务,其实根本不需要动辄 4GB 的堆空间。我通常会把初始内存和最大内存压到一个合理的范围。
# 限制内存并指定垃圾回收线程数
export JAVA_OPTS="-Xms512m -Xmx1024m -XX:+UseContainerSupport -XX:ParallelGCThreads=2 -XX:MaxMetaspaceSize=256m"
java $JAVA_OPTS -jar app-service.jar
加上 -XX:+UseContainerSupport 后,JVM 能准确识别容器的边界。同时,我会手动限制 Tomcat 的线程池大小,因为默认的 200 个线程对大多数中小型业务来说完全是浪费。
# application.yaml 里的精简配置
server:
tomcat:
threads:
max: 60
通过这些设置,单个容器的内存占用通常能降低 20% 以上,从而减少云服务器的节点数量。
采用现代 Java 语法精简业务逻辑
如果代码库里到处是冗长的 Getter 和 Setter,或者还在用复杂的 if-else 处理枚举,那就赶紧升级新版 Java。
使用 Record 定义数据模型
Record 适合用于 DTO 或 API 返回对象。我现在的 API 数据传输对象全部改用 Record。
// 这一行代码就搞定了构造、Getter 和 toString
public record UserResponse(Long id, String nickname, String email) {}
文本块与 Switch 表达式
文本块解决了多行字符串拼接时的转义符困扰,而 Switch 表达式则提供了更安全的返回值方式。
// 使用文本块编写 SQL
String sql = """
SELECT * FROM product_info
WHERE category = 'ELECTRONICS'
AND stock > 0
""";
// Switch 表达式直接返回结果
String categoryName = switch (typeCode) {
case 1 -> "电子产品";
case 2 -> "家居生活";
default -> "其他类型";
};
Switch 的模式匹配
Java 17 引入的模式匹配让类型判断更加直观,减少了显式的强制类型转换。所以,处理复杂的业务分支时,我会用增强型的 Switch 配合模式匹配。
// 处理不同类型的事件消息
static String handleEvent(Object event) {
return switch (event) {
case OrderEvent o -> "订单编号:" + o.id();
case UserEvent u -> "用户名称:" + u.name();
case null -> "空消息";
default -> "未知事件";
};
}
善用 Stream API 的增强功能
Stream API 在数据处理方面持续进化。新版增加了更丰富的收集器与过滤逻辑,使得内存中的数据聚合与转换更加高效。合理使用并行流处理大规模数据集,可以充分利用多核 CPU 的性能,缩短复杂逻辑的执行时间。
启用现代垃圾回收器减少停顿
在高并发场景下,我更倾向于使用 ZGC 这种低延迟垃圾回收器。它能把停顿时间压减到 1 毫秒以内,用户几乎感知不到卡顿。
如果对启动速度有极端要求,比如在函数计算场景下,我会利用 GraalVM 将 Spring Boot 编译为原生镜像(Native Image)。
# 构建原生执行文件
./mvnw native:compile -Pnative
这样编译出来的程序启动时间从几秒缩短到几十毫秒,内存占用甚至能砍掉 80%。虽然编译过程变久了,但运行时换来的性能增益它值得。
耗时任务必须异步化
在 Controller 里同步生成 PDF 或者发送复杂的邮件的都叉出去,这会直接堵死 Web 线程。
现在的做法是把这些重活直接扔进消息队列,让主流程瞬间返回。
// 投递到 RabbitMQ 或 Kafka@PostMapping("/submit-report")
public ResponseEntity<String> handleReport(@RequestBody ReportConfig config) {
taskQueue.send("report_gen_topic", config);
return ResponseEntity.accepted().body("报告生成任务已启动,请稍后查看");
}
把计算压力转移到后端的 Worker 节点上,这样主 API 就能保持极高的响应速度,即便在高并发流量下也不会崩溃。
总结
优化 Spring Boot 应用是一个系统性的工程。如果你还在忍受冗长的编译等待、高昂的云端开支和莫名其妙的停顿,现在就应该改变做法了。快来试试这些技巧吧。
来源:juejin.cn/post/7609660097783300123
你的程序应该启动多少线程?
"线程数等于 CPU 核数"——这可能是程序员最耳熟能详的性能优化建议之一。
但当你真正着手设计一个系统时,你会发现事情远没有这么简单:Web 服务器动辄上千线程,游戏引擎可能只用寥寥几个,而一些高性能中间件甚至会创建 CPU 核数两倍的线程。到底谁是对的?
这篇文章试图回答一个看似简单的问题:你的程序应该启动多少线程?
一、那条广为流传的经验法则
几乎每本并发编程的书都会告诉你:
对于 CPU 密集型任务,线程数应等于 CPU 核数(或核数 + 1)。
这条规则背后的逻辑很直观:每个 CPU 核心同一时刻只能执行一个线程。如果线程数超过核心数,多余的线程只能等待,还会带来额外的上下文切换开销。如果线程数少于核心数,又会让部分核心空转。
这条规则没有错,但它只回答了一个非常狭窄的问题:当你的唯一目标是最大化 CPU 利用率时,应该用多少线程?
现实中的软件系统要复杂得多。
二、线程的真实作用:不只是并行
当我们谈论"为什么需要线程"时,教科书往往只强调一点:并行计算。但在实际工程中,线程至少承担着三种截然不同的职责:
1. 通过异步避免阻塞
想象一个 GUI 程序:用户点击按钮后,程序需要从网络加载数据。如果在主线程中同步等待网络响应,整个界面就会冻结。
// 糟糕的做法:阻塞主线程
void onClick() {
Data data = network.fetchSync(); // 界面卡住 3 秒
updateUI(data);
}
// 更好的做法:用单独线程处理阻塞操作
void onClick() {
new Thread(() -> {
Data data = network.fetchSync();
runOnUIThread(() -> updateUI(data));
}).start();
}
这里的线程不是为了并行计算,而是为了不阻塞主线程。即使在单核 CPU 上,这种设计也是有意义的。
2. 故障隔离:舱壁模式
在微服务架构中,一个服务可能依赖多个下游系统。如果所有请求共享同一个线程池,当某个下游系统变慢时,线程会被逐渐耗尽,最终导致整个服务不可用——这就是级联故障。
┌─────────────────────────────────────────────────┐
│ 共享线程池 │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │ T1 │ │ T2 │ │ T3 │ │ T4 │ │ T5 │ │
│ │阻塞 │ │阻塞 │ │阻塞 │ │阻塞 │ │阻塞 │ │
│ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ │
│ │ │ │ │ │ │
│ └───────┴───────┼───────┴───────┘ │
│ ▼ │
│ 下游服务 A(响应变慢) │
│ │
│ 结果:所有线程被 A 占满,B 和 C 的请求无法处理 │
└─────────────────────────────────────────────────┘
舱壁模式(Bulkhead Pattern)借鉴了船舶设计的思想:将船体分隔成多个水密舱,一个舱室进水不会导致整艘船沉没。
┌──────────────────────────────────────────────────┐
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 线程池 A │ │ 线程池 B │ │ 线程池 C │ │
│ │ (3线程) │ │ (3线程) │ │ (3线程) │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ 下游服务A 下游服务B 下游服务C │
│ (变慢) (正常) (正常) │
│ │
│ 结果:A 的线程池耗尽,但 B 和 C 不受影响 │
└──────────────────────────────────────────────────┘
这种设计会让总线程数远超 CPU 核数,但换来的是系统的韧性。
3. 简化抽象:让代码更易理解
有时候,多线程的目的纯粹是为了代码组织。
考虑一个游戏服务器需要同时处理:
- 网络消息收发
- 游戏逻辑 tick
- 定时任务调度
- 日志异步写入
- 监控指标上报
你当然可以用一个复杂的事件循环把它们全部塞进单线程:
while True:
if has_network_event():
handle_network()
if time_for_game_tick():
game_tick()
if has_scheduled_task():
run_task()
if log_buffer_not_empty():
flush_logs()
# ... 代码很快变成一团乱麻
但更清晰的做法是为每个职责分配独立的线程:
Thread("network", network_loop)
Thread("game-tick", game_loop)
Thread("scheduler", scheduler_loop)
Thread("logger", log_writer_loop)
这些线程大部分时间可能都在 sleep 或等待 I/O,根本不争抢 CPU。但它们让代码结构变得清晰:每个线程有明确的职责和生命周期。
三、线程的真实开销
既然线程有这么多用途,是不是可以随意创建?在回答这个问题之前,我们需要理解线程在现代操作系统中的真实开销。
1. 创建开销
创建一个线程需要:
- 分配内核数据结构(Linux 上是
task_struct,约 2-3 KB) - 分配用户态栈空间
- 在调度器中注册
- 各种安全检查和初始化
在 Linux 上,创建一个线程大约需要 10-30 微秒。这个开销对于长生命周期的线程可以忽略,但如果频繁创建销毁(如"每个请求一个线程"的模型),累积起来就相当可观。
// 简单测试:创建 10000 个线程
for (int i = 0; i < 10000; i++) {
pthread_create(&threads[i], NULL, empty_func, NULL);
}
// 在普通机器上可能需要 100-300ms
2. 内存占用
每个线程需要独立的栈空间。默认配置下:
- Linux:8 MB(虚拟内存),实际物理内存按需分配
- Windows:1 MB(commit)
- macOS:512 KB(主线程 8 MB)
1000 个线程,按 Linux 默认配置,光栈空间就需要 8 GB 的虚拟地址空间。虽然物理内存是惰性分配的,但这个数字仍然令人警醒。
你可以通过调整栈大小来优化:
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setstacksize(&attr, 256 * 1024); // 256 KB
pthread_create(&thread, &attr, func, NULL);
或者在 Java 中:
Thread thread = new Thread(null, runnable, "name", 256 * 1024);
// 或者 JVM 参数 -Xss256k
3. 上下文切换
这是最常被提及的开销。当 CPU 从执行线程 A 切换到线程 B 时,需要:
- 保存现场:寄存器状态、程序计数器、栈指针等
- 切换页表(如果是不同进程的线程)
- 恢复现场:加载线程 B 的状态
- 缓存失效:这往往是最大的隐藏开销
纯粹的上下文切换本身只需要 1-5 微秒。但切换后,新线程访问的数据很可能不在 CPU 缓存中,需要从内存重新加载。这种缓存污染导致的性能损失可能比切换本身高出一个数量级。
┌─────────────────────────────────────────────────────┐
│ 上下文切换的真实开销 │
├─────────────────────────────────────────────────────┤
│ 直接开销(保存/恢复状态) ~1-5 μs │
│ 间接开销(缓存失效) ~10-100 μs │
│ 总体影响 视工作负载而定 │
└─────────────────────────────────────────────────────┘
4. 调度开销
操作系统需要维护运行队列、就绪队列,执行调度算法来决定下一个运行的线程。线程数越多,调度器的负担越重。
在极端情况下(数万线程),光是遍历调度队列都会成为性能瓶颈。
量化视角
让我们把这些数字放在一起:
| 开销类型 | 量级 | 影响 |
|---|---|---|
| 创建线程 | 10-30 μs | 频繁创建时累积 |
| 栈内存 | 256KB-8MB/线程 | 限制最大线程数 |
| 上下文切换 | 1-5 μs | 高频切换时累积 |
| 缓存失效 | 10-100 μs | 最大的隐藏开销 |
对于大多数应用来说,几十到几百个线程是完全可以接受的。现代 Linux 内核可以轻松处理上万个线程,只要它们不都在同时争抢 CPU。
四、决策框架:按用途确定线程数
理解了线程的多重作用和真实开销后,我们可以建立一个决策框架:
1. CPU 密集型计算:等于核数
如果线程的主要工作是计算(数学运算、数据处理、加密解密等),坚守经典法则:
int threadCount = Runtime.getRuntime().availableProcessors();
// 或者 核数 + 1,留一个处理偶发的 I/O
这里的逻辑很简单:更多的线程只会增加切换开销,不会提升吞吐量。
实际案例:
- 图像处理库
- 科学计算框架
- 视频编解码器
2. I/O 密集型:优先考虑非阻塞
如果线程大部分时间在等待 I/O(网络、磁盘、数据库),你有两个选择:
选项 A:非阻塞 I/O + 事件循环(推荐)
# Python asyncio
async def fetch_all(urls):
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, url) for url in urls]
return await asyncio.gather(*tasks)
# 用少量线程处理大量并发连接
Node.js、Nginx、Redis 都采用这种模型,用极少的线程处理海量并发。
选项 B:线程池 + 阻塞 I/O
如果你必须使用阻塞 I/O(比如 JDBC 不支持异步),可以用经典公式:
线程数 = CPU 核数 × (1 + I/O 等待时间 / CPU 计算时间)
如果平均每个请求花 100ms 等待 I/O、1ms 做计算,在 8 核机器上:
线程数 = 8 × (1 + 100/1) = 808
这只是理论上限。实际中还要考虑:
- 下游系统能否承受这么多并发
- 内存是否足够
- 连接池大小限制
3. 故障隔离:按风险域划分
为每个可能独立失败的依赖分配独立的线程池:
// Hystrix/Resilience4j 风格
ThreadPoolBulkhead paymentPool = ThreadPoolBulkhead.of("payment",
ThreadPoolBulkheadConfig.custom()
.maxThreadPoolSize(10)
.coreThreadPoolSize(5)
.queueCapacity(20)
.build());
ThreadPoolBulkhead inventoryPool = ThreadPoolBulkhead.of("inventory",
ThreadPoolBulkheadConfig.custom()
.maxThreadPoolSize(8)
.coreThreadPoolSize(4)
.queueCapacity(15)
.build());
ThreadPoolBulkhead shippingPool = ThreadPoolBulkhead.of("shipping",
ThreadPoolBulkheadConfig.custom()
.maxThreadPoolSize(6)
.coreThreadPoolSize(3)
.queueCapacity(10)
.build());
每个池的大小取决于:
- 下游服务的正常响应时间:响应越慢,需要越多线程来维持吞吐量
- 可接受的最大并发数:下游服务能承受多少并发请求
- 降级策略:线程池满时是快速失败、排队等待,还是返回降级结果
计算舱壁大小的方法
假设某个下游服务:
- 正常响应时间:50ms
- 期望吞吐量:每秒 100 个请求
- 可接受的排队延迟:100ms
最小线程数 = 吞吐量 × 响应时间
= 100 × 0.05
= 5 个线程
队列容量 = 吞吐量 × 可接受排队延迟
= 100 × 0.1
= 10 个请求
但还要考虑异常情况。如果下游服务变慢(响应时间从 50ms 变成 500ms):
此时需要的线程数 = 100 × 0.5 = 50 个线程
这就是舱壁要保护的场景。我们不应该给它 50 个线程,而是:
ThreadPoolBulkhead.of("payment",
ThreadPoolBulkheadConfig.custom()
.maxThreadPoolSize(10) // 硬上限:最多 10 个线程
.coreThreadPoolSize(5) // 正常情况够用
.queueCapacity(20) // 允许短暂排队
.build());
// 当下游变慢时:
// - 10 个线程被占满
// - 20 个请求在队列等待
// - 第 31 个请求立即被拒绝(快速失败)
// - 系统其他部分不受影响
舱壁 vs 断路器
舱壁模式常与断路器(Circuit Breaker)配合使用:
┌─────────────────────────────────────────────────────────┐
│ 请求流程 │
│ │
│ 请求 ──→ 断路器 ──→ 舱壁(线程池) ──→ 下游服务 │
│ │ │ │
│ │ │ │
│ 检查是否熔断 检查是否有空闲线程 │
│ │ │ │
│ ▼ ▼ │
│ 熔断则快速失败 无空闲则拒绝或排队 │
│ │
└─────────────────────────────────────────────────────────┘
// Resilience4j 组合使用示例
CircuitBreaker circuitBreaker = CircuitBreaker.of("payment",
CircuitBreakerConfig.custom()
.failureRateThreshold(50) // 失败率超过 50% 则熔断
.waitDurationInOpenState(Duration.ofSeconds(30))
.build());
ThreadPoolBulkhead bulkhead = ThreadPoolBulkhead.of("payment", ...);
Supplier decoratedSupplier = Decorators
.ofSupplier(() -> paymentService.call())
.withCircuitBreaker(circuitBreaker) // 先检查断路器
.withThreadPoolBulkhead(bulkhead) // 再进入线程池
.withFallback(ex -> fallbackResponse()) // 降级响应
.decorate();
舱壁的代价
舱壁模式会显著增加系统的总线程数:
传统模式:
1 个共享线程池 × 50 线程 = 50 线程
舱壁模式:
支付服务池 10 线程
库存服务池 8 线程
物流服务池 6 线程
用户服务池 8 线程
通知服务池 4 线程
─────────────────────
总计 36 线程(但每个池都有冗余)
实际配置时考虑峰值:
每个池 ×1.5 = 54 线程
这看起来线程更多了,但关键区别在于:
| 对比项 | 共享线程池 | 舱壁模式 |
|---|---|---|
| 总线程数 | 较少 | 较多 |
| 单点故障影响 | 整个系统 | 仅一个服务 |
| 资源利用率 | 更高 | 有冗余浪费 |
| 容量规划 | 简单 | 需要分别规划 |
| 故障恢复 | 慢(需等待所有线程释放) | 快(其他池不受影响) |
在微服务架构中,隔离性通常比资源利用率更重要。舱壁带来的额外线程开销,换来的是系统在部分故障时仍能提供服务的能力。
4. 简化抽象:按职责最小化
当线程用于代码组织时,遵循够用就好原则:
// 典型的服务端应用线程分配
Thread acceptor = new Thread(this::acceptLoop); // 1个:接受连接
Thread[] workers = new Thread[cpuCores]; // N个:处理业务
Thread timer = new Thread(this::timerLoop); // 1个:定时任务
Thread logger = new Thread(this::logWriter); // 1个:异步日志
Thread monitor = new Thread(this::metricsReport); // 1个:监控上报
// 总计:cpuCores + 4 个线程
这些辅助线程大部分时间在休眠,不会与 worker 线程竞争 CPU。关键是确保它们:
- 不会执行耗时的计算
- 不会频繁唤醒
- 有明确的单一职责
五、警惕"线程风暴"
即使每个决策单独看都合理,累积起来也可能造成问题。
叠加效应
假设你的 Java 服务:
- Tomcat 线程池:200 个
- 数据库连接池:每个连接有后台线程,50 个
- Redis 客户端池:20 个
- Kafka 消费者:10 个分区 × 3 个消费者组 = 30 个
- 定时任务调度器:核心线程 10 个
- JVM GC 线程:8 个
- 其他框架的后台线程:若干
加起来可能有 300-500 个线程,而你的机器可能只有 8 个 CPU 核心。
抖动风险
在某些时刻,大量线程可能同时被唤醒:
┌─────────────────────────────────────────────────────┐
│ t0: 某个事件触发 │
│ │ │
│ ┌────────────────┼───────────────┐ │
│ ▼ ▼ ▼ │
│ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │100个│ │50个 │ │30个 │ │
│ │HTTP │ │定时 │ │Kafka│ │
│ │请求 │ │任务 │ │消息 │ │
│ └──┬──┘ └──┬──┘ └──┬──┘ │
│ │ │ │ │
│ └───────────────┼───────────────┘ │
│ ▼ │
│ 8 个 CPU 核心开始疯狂切换 │
│ │ │
│ ▼ │
│ 延迟飙升,GC 停顿,服务抖动 │
└─────────────────────────────────────────────────────┘
这种"线程风暴"会导致:
- 所有请求的延迟同时上升
- P99 延迟剧烈波动
- 可能触发超时和级联故障
缓解策略
策略一:错峰调度
让定时任务随机分散,而不是整点触发:
// 不好:所有实例同时执行
@Scheduled(cron = "0 0 * * * *") // 每小时整点
// 更好:启动时计算随机偏移
int jitter = random.nextInt(60);
@Scheduled(cron = "0 " + jitter + " * * * *")
策略二:为关键线程提升优先级
确保 CPU 密集型的核心工作线程能优先获得调度:
// 关键业务线程
thread.setPriority(Thread.MAX_PRIORITY); // Java: 1-10,默认 5
// 或者在 Linux 上使用 nice 值
// nice -n -5 java -jar app.jar
// C/C++:使用实时调度策略
struct sched_param param;
param.sched_priority = 50; // 实时优先级
pthread_setschedparam(thread, SCHED_FIFO, ¶m);
策略三:CPU 绑定(CPU Affinity)
将关键线程绑定到特定 CPU,避免缓存失效:
// 使用 JNA 或 JNI 调用系统 API
// Linux: sched_setaffinity()
// 或使用 Disruptor 等框架内置的支持
// C: 将线程绑定到 CPU 0 和 1
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(0, &cpuset);
CPU_SET(1, &cpuset);
pthread_setaffinity_np(thread, sizeof(cpuset), &cpuset);
策略四:限制并发
使用信号量或令牌桶限制同时运行的线程数:
Semaphore semaphore = new Semaphore(cpuCores * 2);
void process(Request request) {
semaphore.acquire();
try {
doWork(request);
} finally {
semaphore.release();
}
}
六、协程时代:换汤不换药?
Go 语言的 goroutine、Kotlin 的协程、Java 的虚拟线程(Project Loom)……协程似乎成了并发的银弹。
"创建一百万个协程"的 demo 随处可见,这是否意味着我们不用再关心"数量"问题了?
协程的本质
协程(或用户态线程、绿色线程)本质是把调度权从操作系统收回到用户态:
┌───────────────────────────────────────────────────┐
│ 传统线程 │
│ │
│ 线程1 线程2 线程3 线程4 ... 线程1000 │
│ │ │ │ │ │ │
│ └──────┴──────┴──────┴───────────┘ │
│ │ │
│ 操作系统调度器 │
│ │ │
│ ┌──────┬──────┬──────┬──────────┐ │
│ ▼ ▼ ▼ ▼ ▼ │
│ CPU0 CPU1 CPU2 CPU3 ... CPU7 │
└───────────────────────────────────────────────────┘
┌───────────────────────────────────────────────────┐
│ 协程模型 │
│ │
│ 协程1 协程2 协程3 ... 协程1000000 │
│ │ │ │ │ │
│ └──────┴──────┴────────────┘ │
│ │ │
│ 语言运行时调度器 │
│ │ │
│ ┌──────────────┼──────────────┐ │
│ ▼ ▼ ▼ │
│ 线程1 线程2 ... 线程N │
│ │ │ │ │
│ └──────────────┼──────────────┘ │
│ │ │
│ 操作系统调度器 │
│ │ │
│ ┌───────┴───────┐ │
│ ▼ ▼ │
│ CPU0 ... CPU7 │
└───────────────────────────────────────────────────┘
协程的优势在于:
- 创建开销极小:Go 的 goroutine 初始栈只有 2KB
- 切换开销极小:用户态切换,不需要进入内核
- 调度更智能:运行时了解协程在做什么(如等待 channel)
但物理规则依然适用
协程改变的是切换效率,不是 CPU 核心数。
// 100 万个协程同时做 CPU 密集计算?
for i := 0; i < 1000000; i++ {
go func() {
for {
// 纯计算,没有 I/O
heavyComputation()
}
}()
}
// 结果:并不会比 GOMAXPROCS 个协程更快
核心洞察:如果协程在执行时不主动让出(通过 I/O、channel、sleep 等),它就和操作系统线程没有本质区别。
协程的正确心智模型
| 操作类型 | 协程行为 | 考量 |
|---|---|---|
| I/O 等待 | 挂起,让出执行权 | 可以有百万并发 |
| Channel 等待 | 挂起,让出执行权 | 可以有百万并发 |
| CPU 计算 | 持续占用线程 | 同时计算数 ≈ GOMAXPROCS |
| 调用 C 代码 | 可能阻塞线程 | 可能需要更多线程 |
Go 运行时会自动调整实际的操作系统线程数,但 GOMAXPROCS(默认等于 CPU 核数)限制了同时执行的线程数。
// 正确用法:百万协程处理 I/O
for i := 0; i < 1000000; i++ {
go handleConnection(conn[i]) // 每个协程大部分时间在等待网络
}
// 需要注意:CPU 密集型任务
pool := make(chan struct{}, runtime.NumCPU()) // 信号量
for task := range tasks {
pool <- struct{}{} // 获取令牌
go func(t Task) {
defer func() { <-pool }() // 释放令牌
cpuIntensiveWork(t) // 同时只有 NumCPU 个在计算
}(task)
}
Java 虚拟线程的启示
Java 21 引入的虚拟线程(Virtual Threads)同样遵循这个逻辑:
// 可以创建大量虚拟线程处理阻塞 I/O
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 100000; i++) {
executor.submit(() -> {
// 阻塞 I/O 会自动让出载体线程
String result = httpClient.send(request);
process(result);
});
}
}
// 但如果是 CPU 密集型...
executor.submit(() -> {
// 这个虚拟线程会持续占用载体线程
while (true) {
computePi(); // 其他虚拟线程饿死
}
});
七、实践清单
让我们把讨论转化为可操作的检查清单:
启动前问自己
□ 这个线程/协程的主要工作是什么?
- [ ] CPU 计算
- [ ] I/O 等待
- [ ] 故障隔离
- [ ] 代码组织
□ 它会阻塞吗?阻塞多久?
□ 它需要和其他线程竞争资源吗?
□ 它的生命周期是什么?
- [ ] 与应用相同(后台线程)
- [ ] 与请求相同(per-request)
- [ ] 执行完任务就结束(fire-and-forget)
配置建议速查
| 场景 | 线程数建议 | 关键考量 |
|---|---|---|
| 纯 CPU 计算 | = 核数 | 更多无益 |
| CPU 计算 + 偶发 I/O | = 核数 + 1~2 | 应对偶发阻塞 |
| I/O 密集(非阻塞) | 核数或更少 | 事件循环处理并发 |
| I/O 密集(阻塞) | 取决于 I/O 时间比例 | 用公式估算,压测验证 |
| 舱壁隔离 | 每依赖一个独立池 | 池大小取决于下游容量 |
| 辅助功能 | 每职责 1 个 | 确保不争抢 CPU |
监控指标
上线后,持续关注:
线程状态分布
├── RUNNABLE(运行中) → 应该 ≈ CPU 核数
├── BLOCKED(锁等待) → 过高说明有锁竞争
├── WAITING(条件等待) → I/O 线程正常状态
└── TIMED_WAITING(超时等待)→ sleep 或 poll
上下文切换率
└── vmstat, pidstat -w → 每秒切换数
线程创建率
└── 高频创建说明需要用池
CPU 使用率
└── 高于预期 → 检查是否在自旋
└── 低于预期 → 检查是否在等锁
八、总结
回到最初的问题:你的程序应该启动多少线程?
答案是:取决于这些线程要做什么。
- 如果是为了并行计算,线程数应该接近 CPU 核心数
- 如果是为了处理阻塞 I/O,优先考虑非阻塞方案;如果必须阻塞,根据 I/O 时间比例估算
- 如果是为了故障隔离,为每个风险域分配独立的资源边界
- 如果是为了简化代码,确保这些线程不会争抢关键资源
"线程数 = CPU 核心数"是一个好的起点,但不是终点。理解你的工作负载,理解线程的真实开销,理解你想通过多线程解决的问题——这比任何公式都重要。
最后,无论你做出什么选择,记得压测验证。真实世界的表现总是比理论分析更复杂,而性能问题往往藏在那些"理论上应该没问题"的地方。
附录:常见框架的默认配置参考
了解你正在使用的框架的默认行为,有助于做出更好的决策。
Web 服务器
| 框架/服务器 | 默认线程配置 | 说明 |
|---|---|---|
| Tomcat | 最大 200,最小 10 | 每个请求一个线程 |
| Jetty | 最大 200 | QueuedThreadPool |
| Undertow | 核数 × 8(I/O)+ 核数(Worker) | 非阻塞架构 |
| Netty | 核数 × 2(EventLoop) | 事件驱动,少量线程 |
| Go net/http | 无限制(goroutine) | 每连接一个 goroutine |
| Node.js | 1(主线程)+ 4(libuv 线程池) | 单线程事件循环 |
| Nginx | worker 数通常 = 核数 | 每个 worker 单线程事件循环 |
数据库连接池
| 连接池 | 默认配置 | 推荐起点 |
|---|---|---|
| HikariCP | 最大 10 | 核数 × 2 + 磁盘数 |
| Druid | 最大 8 | 根据并发量调整 |
| c3p0 | 最大 15 | 通常偏保守 |
| pgBouncer | 取决于模式 | transaction 模式更高效 |
HikariCP 作者给出的经验公式:
连接数 = ((核心数 × 2) + 有效磁盘数)
对于大多数场景,10-20 个连接足以支撑相当高的吞吐量。更多的连接往往意味着更多的锁竞争和上下文切换,反而降低性能。
消息队列客户端
| 客户端 | 默认配置 | 注意事项 |
|---|---|---|
| Kafka Consumer | 每分区一个线程 | 分区数决定并行度上限 |
| RabbitMQ Consumer | 可配置 prefetch | 控制未确认消息数 |
| Redis (Lettuce) | 共享连接 + 核数个事件线程 | 非阻塞,高效 |
| Redis (Jedis) | 连接池,每操作占用一个 | 阻塞模型 |
线程池最佳实践
// 推荐:根据任务类型创建不同的线程池
// 而不是所有任务共享一个
// CPU 密集型任务
ExecutorService cpuPool = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors(),
new ThreadFactoryBuilder().setNameFormat("cpu-worker-%d").build()
);
// I/O 密集型任务
ExecutorService ioPool = new ThreadPoolExecutor(
corePoolSize, // 核心线程数
maxPoolSize, // 最大线程数
60, TimeUnit.SECONDS, // 空闲线程存活时间
new LinkedBlockingQueue<>(queueCapacity), // 有界队列!
new ThreadFactoryBuilder().setNameFormat("io-worker-%d").build(),
new CallerRunsPolicy() // 拒绝策略:让调用者自己执行
);
// 定时任务
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(
2, // 通常不需要很多
new ThreadFactoryBuilder().setNameFormat("scheduler-%d").build()
);
关键提醒:永远使用有界队列和合理的拒绝策略。无界队列在高负载下会导致内存溢出。
来源:juejin.cn/post/7607636614357663770
Python 正在遭遇人气下滑
TIOBE 的编程社区指数指出,这门全球最受欢迎的编程语言正逐渐失去市场份额,被 R、Perl 这类更专精的语言赶超。

目前 Python 在 TIOBE 月度编程语言人气指数中仍位居榜首,领先第二名 C 语言超过 10 个百分点。但在过去六个月里,Python 的人气其实一直在下滑,从去年 7 月 26.98% 的市场份额高点,降到了本月 TIOBE 指数中的 21.81%。
TIOBE 的 CEO 保罗・扬森表示,这一变化说明,有好几门更专精、更面向特定领域的语言正在慢慢蚕食 Python 的市场,其中最显眼的就是 R 和 Perl。
我大概学习过一年的 perl 语言,这门语言给我留下的比较深的印象就是文本处理,尤其是正则表达式的部分,非常厉害。
扬森提到,R 是一门用于统计计算的编程语言,长期以来在数据科学领域都是 Python 的直接竞争对手。本月 R 以 2.19% 的占比排在第八位,而一年前它还排在第 15 位。虽然近几年 Python 超越了 R,但如今 R 似乎正重新找回势头,已经连续好几个月回到 TIOBE 指数的前十行列。
与此同时,Perl 也在脚本领域重新崛起。扬森说,Perl 曾经是脚本领域毫无争议的霸主,但后来因为多年的内部分裂,再加上新兴语言的竞争,逐渐走向衰落。不过最近这门语言迎来了转机,2025 年 9 月它在 TIOBE 指数中从一年前的第 27 位冲到了第 10 位。本月它以 1.67% 的占比排在第 11 位,而去年同期它还在第 30 位。
TIOBE 编程社区月度指数是衡量编程语言人气的指标,其评分基于一个计算公式,会评估全球范围内掌握该语言的工程师数量、相关课程以及第三方供应商的情况。评分数据会通过分析谷歌、亚马逊、维基百科、必应等超过 20 个网站得出。
2026 年 2 月 TIOBE 指数前十排名:
- Python,占比 21.81%
- C,占比 11.05%
- C++,占比 8.55%
- Java,占比 8.12%
- C#,占比 6.83%
- JavaScript,占比 2.92%
- Visual Basic,占比 2.85%
- R,占比 2.19%
- SQL,占比 1.93%
- Delphi/Object Pascal,占比 1.88%
与之相对应的的 PYPL(PopularitY of Programming Language) 编程语言人气指数则是通过分析谷歌上语言教程的搜索频率来评估语言人气。
2026 年 2 月 PYPL 指数前十排名:
- Python,占比 31.17%
- C/C++,占比 14.96%
- Java,占比 10.46%
- R,占比 6.88%
- JavaScript,占比 5.05%
- Swift,占比 3.92%
- Rust,占比 3.19%
- C#,占比 3.19%
- PHP,占比 3.14%
- Ada,占比 2.81%
原文
http://www.infoworld.com/article/412…
来源:juejin.cn/post/7608953699231088680
Flutter 为什么能运行在 HarmonyOS 上

前言
Flutter 是 Google 推出的跨平台 UI 框架,最初只支持 iOS 和 Android。随着 HarmonyOS 的崛起,Flutter 也能在鸿蒙系统上运行了。这背后到底是怎么实现的呢?本文将从源码层面进行解析。
一、核心原理:Flutter 分层架构
要理解 Flutter 如何在 HarmonyOS 上运行,首先需要了解 Flutter 的架构。Flutter 采用分层设计,从上到下分为三层:
┌─────────────────────────────────┐
│ Framework 层(Dart) │ ← Flutter 代码
├─────────────────────────────────┤
│ Engine 层(C++) │ ← 渲染引擎(Impeller)
├─────────────────────────────────┤
│ Embedder 层(平台相关) │ ← 与操作系统交互(调用 HarmonyOS 原生 API)
└─────────────────────────────────┘
前面两层完全复用现有Dart和C++代码,而 Embedder 层则是为 HarmonyOS 定制的。
关键点:Embedder 层
Embedder 层是 Flutter 能够跨平台运行的关键。它负责:
- 创建和管理窗口
- 处理输入事件
- 调用系统 API
- 管理渲染 Surface
**不同平台有不同的 Embedder 实现: **
- Android:
platform_view_android.cc - iOS:
platform_view_ios.mm - HarmonyOS:
platform_view_ohos.cpp
cc和cpp是标准的C++语言代码后缀
鸿蒙的系统API是C++ 实现的,所以鸿蒙platform_view 使用C++实现进行调用最方便**
二、HarmonyOS Embedder 的核心实现
让我们看看 HarmonyOS Embedder 的核心代码结构:
2.1 平台视图(PlatformViewOHOS)
这是 HarmonyOS Embedder 的核心类,位于:
engine/src/flutter/shell/platform/ohos/platform_view_ohos.cpp
class PlatformViewOHOS final : public PlatformView {
public:
PlatformViewOHOS(PlatformView::Delegate& delegate,
const flutter::TaskRunners& task_runners,
const std::shared_ptr<PlatformViewOHOSNapi>& napi_facade,
const std::shared_ptr<flutter::OHOSContext>& ohos_context);
// 通知窗口创建
void NotifyCreate(fml::RefPtr<OHOSNativeWindow> native_window);
// 更新显示尺寸
void UpdateDisplaySize(int width, int height);
// 分发平台消息
void DispatchPlatformMessage(std::string name, void* message, ...);
private:
std::shared_ptr<OHOSContext> ohos_context_; // HarmonyOS 图形上下文
std::shared_ptr<PlatformViewOHOSNapi> napi_facade_; // NAPI装饰器(NAPI 是 HarmonyOS 提供的 JavaScript 接口, 用于调用 HarmonyOS 系统 API
std::unique_ptr<OHOSSurface> ohos_surface_; // HarmonyOS 渲染 Surface, surface 是渲染的目标画布, 可以是窗口, 也可以是离屏缓冲区
};
**这个类做了什么? **
- 继承自
PlatformView(Flutter 的通用平台视图接口) - 持有 HarmonyOS 的图形上下文
OHOSContext - 持有 NAPI装饰器
PlatformViewOHOSNapi(用于调用 HarmonyOS 原生 API) - 管理渲染 Surface
OHOSSurface
2.2 Shell 持有者(OHOSShellHolder)
Shell 是 Flutter 引擎的核心,负责管理 Flutter 应用的生命周期、渲染循环、事件处理等, OHOSShellHolder 负责创建和管理 Shell:
class OHOSShellHolder {
public:
// 构造函数
// settings: Flutter 引擎启动参数(如是否启用 Impeller、日志级别等)
// napi_facade: 与 HarmonyOS 原生层交互的 NAPI 装饰器
// platform_loop: HarmonyOS 平台线程的 looper,用于投递平台任务
OHOSShellHolder(const flutter::Settings& settings,
std::shared_ptr<PlatformViewOHOSNapi> napi_facade,
void* platform_loop);
// 析构函数:确保 Shell 安全退出并释放所有资源
~OHOSShellHolder();
// 启动 Flutter 引擎,加载 Dart 代码并开始渲染
// hap_asset_provider: HarmonyOS HAP 包资源提供器,用于读取 assets、fonts、kernel_blob 等
// entrypoint: Dart 入口函数名(默认为 main)
// libraryUrl: Dart 库 URI(如 package:my_app/main.dart)
// entrypoint_args: 传给 Dart main 的命令行参数列表
void Launch(std::unique_ptr<OHOSAssetProvider> hap_asset_provider,
const std::string& entrypoint,
const std::string& libraryUrl,
const std::vector<std::string>& entrypoint_args);
// 优雅地停止 Flutter Shell,等待所有任务完成后退出
void Shutdown();
// 获取 PlatformViewOHOS 的弱引用,用于在平台线程安全地访问平台视图
fml::WeakPtr<PlatformViewOHOS> GetPlatformView();
// 设置应用生命周期回调,供 HarmonyOS 通知 Flutter 前后台切换
void SetLifecycleHandler(std::function<void(AppLifecycleState)> handler);
// 设置平台消息回调,供 HarmonyOS 主动发消息到 Dart 侧
void SetPlatformMessageHandler(
std::function<void(const std::string& channel,
const std::vector<uint8_t>& message,
std::function<void(std::vector<uint8_t>)> reply)> handler);
// 向 Dart 侧发送平台消息,支持异步回调
void SendPlatformMessage(const std::string& channel,
const std::vector<uint8_t>& message,
std::function<void(std::vector<uint8_t>)> reply = nullptr);
// 通知 Flutter 引擎窗口尺寸变化,触发重新布局
void NotifyViewportMetricsChanged(const ViewportMetrics& metrics);
// 通知 Flutter 引擎内存压力,触发 Dart 侧 GC 或资源释放
void NotifyLowMemoryWarning();
// 获取当前 Shell 的运行状态
enum class ShellState { kNotStarted, kRunning, kShuttingDown, kStopped };
ShellState GetShellState() const;
// 返回当前线程安全的 Shell 指针,仅用于调试或测试
Shell* GetShellUnsafe() const { return shell_.get(); }
private:
// 创建并配置 Flutter Shell,内部调用 Shell::Create
void CreateShell(const flutter::Settings& settings,
std::unique_ptr<OHOSAssetProvider> asset_provider);
// 初始化平台任务执行器,将 HarmonyOS 平台任务映射到 Flutter 的任务队列
void SetupTaskRunners(void* platform_loop);
// 注册 HarmonyOS 平台视图到 Shell,完成平台桥接
void RegisterPlatformView();
// 加载 Dart AOT 或 Kernel,决定运行模式(Release/Profile 使用 AOT,Debug 使用 Kernel)
void LoadDartCode(const std::string& entrypoint,
const std::string& libraryUrl,
const std::vector<std::string>& entrypoint_args);
// 释放所有资源,顺序:PlatformView → Shell → TaskRunners
void Teardown();
private:
std::unique_ptr<Shell> shell_; // Flutter 引擎核心
std::shared_ptr<PlatformViewOHOSNapi> napi_facade_; // NAPI 装饰器
fml::WeakPtrFactory<OHOSShellHolder> weak_factory_; // 弱引用工厂,防止悬空指针
ShellState state_ = ShellState::kNotStarted; // 当前 Shell 状态
flutter::TaskRunners task_runners_; // 跨平台任务队列(UI/GPU/IO/Platform)
std::mutex state_mutex_; // 保护 state_ 的线程安全
};
三、图形渲染适配
Flutter 在 HarmonyOS 上支持三种渲染方式:
3.1 鸿蒙三种渲染方式
enum class OHOSRenderingAPI {
kSoftware, // 软件渲染, 基于 CPU 进行渲染, 性能较低, 不依赖于 GPU,适用于简单场景。
kOpenGLES, // OpenGL ES 渲染(Skia), 基于 OpenGL ES 进行渲染, 性能较高, 依赖于 GPU, 适用于复杂场景。
kImpellerVulkan, // Vulkan 渲染(Impeller), 基于 Vulkan 进行渲染, 性能最高, 依赖于 GPU, 适用于需要高性能渲染的场景。
};
在 platform_view_ohos.cpp 中,根据渲染方式创建不同的Surface:
std::unique_ptr<OHOSSurface> OhosSurfaceFactoryImpl::CreateSurface() {
switch (ohos_context_->RenderingApi()) {
case OHOSRenderingAPI::kSoftware:
return std::make_unique<OHOSSurfaceSoftware>(ohos_context_); // 软件渲染, 基于 CPU 进行渲染, 性能较低, 不依赖于 GPU,适用于简单场景。
case OHOSRenderingAPI::kOpenGLES:
return std::make_unique<OhosSurfaceGLSkia>(ohos_context_); // OpenGL ES 渲染(Skia), 基于 OpenGL ES 进行渲染, 性能较高, 依赖于 GPU, 适用于复杂场景。
case flutter::OHOSRenderingAPI::kImpellerVulkan:
return std::make_unique<OHOSSurfaceVulkanImpeller>(ohos_context_); // Vulkan 渲染(Impeller), 基于 Vulkan 进行渲染, 性能最高, 依赖于 GPU, 适用于需要高性能渲染的场景。
default:
return nullptr;
}
}
3.2 原生窗口(OHOSNativeWindow)
HarmonyOS 的窗口系统通过 OHNativeWindow 暴露给 Flutter:
class OHOSNativeWindow : public fml::RefCountedThreadSafe<OHOSNativeWindow> {
public:
Handle Gethandle() const; // 获取 HarmonyOS 原生窗口句柄
bool IsValid() const; // 检查窗口是否有效
SkISize GetSize() const; // 获取窗口尺寸
private:
Handle window_; // OHNativeWindow*
};
**渲染流程: **
Flutter Engine
↓
PlatformViewOHOS
↓
OHOSSurface(根据渲染方式创建不同的Surface)
↓
OHOSNativeWindow(HarmonyOS 原生窗口)
↓
HarmonyOS 图形系统
四、输入事件处理
因为事件处理需要在渲染完成后(VSync同步流程)才能触发, 否则会导致事件处理与渲染不一致的问题。
4.1 VSync 同步
VSync(垂直同步)信号是渲染的关键,它是每次屏幕刷新周期开始时发送的信号,用于同步渲染和显示。
Flutter 需要等待系统的 VSync 信号,才能触发下一帧渲染。
class VsyncWaiterOHOS final : public VsyncWaiter {
public:
explicit VsyncWaiterOHOS(const flutter::TaskRunners& task_runners,
std::shared_ptr<bool>& enable_frame_cache);
private:
OH_NativeVSync* vsync_handle_; // HarmonyOS VSync 句柄
void AwaitVSync() override; // 等待 VSync 信号
static void OnVsyncFromOHOS(long long timestamp, void* data); // 接收 HarmonyOS VSync 信号, 通知 Flutter Engine 触发下一帧渲染
};
**工作流程: **
HarmonyOS VSync 信号
↓
VsyncWaiterOHOS::OnVsyncFromOHOS
↓
通知 Flutter Engine
↓
触发下一帧渲染
↓
渲染完成
↓
触发事件处理
4.2 触摸事件处理
HarmonyOS 的输入事件需要转换为 Flutter 的事件格式:
触摸事件通过 OhosTouchProcessor 处理:
class OhosTouchProcessor {
public:
// 处理 HarmonyOS 触摸事件
void ProcessTouchEvent(const OH_NativeXComponent_TouchEvent* event);
private:
// 转换为 Flutter 触摸事件格式
std::vector<PointerData> ConvertToFlutterTouchEvents(
const OH_NativeXComponent_TouchEvent* event);
};
五、平台消息通信
Flutter 与 HarmonyOS 的通信通过 Platform Channel 实现:
5.1 NAPI 装饰器(PlatformViewOHOSNapi)
NAPI(Native API)是 HarmonyOS 提供的原生 API 接口:
class PlatformViewOHOSNapi {
public:
// 发送平台消息到 HarmonyOS
void SendPlatformMessage(const std::string& channel,
const std::vector<uint8_t>& message);
// 接收来自 HarmonyOS 的平台消息
void SetPlatformMessageHandler(
std::function<void(const std::string&, const std::vector<uint8_t>&)> handler);
private:
napi_env env_; // NAPI 环境
};
5.2 消息处理流程
Flutter 代码(Dart)
↓
MethodChannel.invokeMethod
↓
PlatformViewOHOS::DispatchPlatformMessage
↓
PlatformViewOHOSNapi::SendPlatformMessage
↓
HarmonyOS 原生代码(ArkTS/C++)
↓
返回结果
↓
Flutter 接收响应
六、完整的工作流程
让我们把所有部分串联起来,看看 Flutter 应用在 HarmonyOS 上是如何运行的:
6.1 初始化流程
1. HarmonyOS 应用启动
↓
2. 调用 OhosMain::NativeInit(NAPI 入口)
↓
3. 创建 OHOSShellHolder
↓
4. 创建 PlatformViewOHOS
↓
5. 创建 OHOSContext(图形上下文)
↓
6. 创建 OHOSSurface(渲染表面)
↓
7. 创建 Flutter Shell(引擎)
↓
8. 加载 Dart 代码
↓
9. 开始渲染
6.2 渲染流程
1. Dart 代码构建 Widget 树
↓
2. Framework 层生成 Layer 树
↓
3. Engine 层生成 Scene
↓
4. Impeller 渲染引擎绘制
↓
5. 通过 OHOSSurface 提交绘制指令
↓
6. OHOSNativeWindow 接收绘制结果
↓
7. HarmonyOS 图形系统显示到屏幕
6.3 事件处理流程
1. 用户触摸屏幕
↓
2. HarmonyOS 接收触摸事件
↓
3. OhosTouchProcessor 处理
↓
4. 转换为 Flutter 触摸事件格式
↓
5. PlatformViewOHOS 分发事件
↓
6. Framework 层处理事件
↓
7. Widget 响应用户操作
七、关键代码示例
7.1 创建 HarmonyOS Embedder
// 创建图形上下文
std::unique_ptr<OHOSContext> CreateOHOSContext(
const flutter::TaskRunners& task_runners,
OHOSRenderingAPI rendering_api,
bool enable_vulkan_validation,
bool enable_opengl_gpu_tracing,
bool enable_vulkan_gpu_tracing) {
switch (rendering_api) {
case OHOSRenderingAPI::kSoftware:
return std::make_unique<OHOSContext>(OHOSRenderingAPI::kSoftware);
case OHOSRenderingAPI::kOpenGLES:
return std::make_unique<OhosContextGLSkia>(OHOSRenderingAPI::kOpenGLES,
task_runners);
case OHOSRenderingAPI::kImpellerVulkan:
return std::make_unique<OHOSContextVulkanImpeller>(
enable_vulkan_validation, enable_vulkan_gpu_tracing);
default:
return nullptr;
}
}
// 创建平台视图
PlatformViewOHOS::PlatformViewOHOS(
PlatformView::Delegate& delegate,
const flutter::TaskRunners& task_runners,
const std::shared_ptr<PlatformViewOHOSNapi>& napi_facade,
const std::shared_ptr<flutter::OHOSContext>& ohos_context)
: PlatformView(delegate, task_runners),
napi_facade_(napi_facade),
ohos_context_(ohos_context) {
// 创建 Surface 工厂
surface_factory_ = std::make_shared<OhosSurfaceFactoryImpl>(ohos_context_);
// 创建渲染 Surface
ohos_surface_ = surface_factory_->CreateSurface();
// 预加载 GPU Surface(加速首帧渲染)
task_runners_.GetRasterTaskRunner()->PostDelayedTask(
[surface = ohos_surface_]() { surface->PrepareGpuSurface(); },
fml::TimeDelta::FromMicroseconds(1000));
}
7.2 通知窗口创建
void PlatformViewOHOS::NotifyCreate(
fml::RefPtr<OHOSNativeWindow> native_window) {
FML_LOG(INFO) << "NotifyCreate start";
// 缓存原生窗口
native_window_ = native_window;
// 通知 Surface 窗口已创建
ohos_surface_->SetNativeWindow(native_window);
// 获取窗口尺寸
SkISize size = native_window->GetSize();
// 更新视口尺寸
UpdateDisplaySize(size.width(), size.height());
// 通知 Flutter 引擎窗口已创建
NotifyCreated();
}
7.3 处理平台消息
void PlatformViewOHOS::DispatchPlatformMessage(
std::string name,
void* message,
int messageLength,
int responseId) {
// 创建平台消息
fml::MallocMapping buffer = fml::MallocMapping(
static_cast<const uint8_t*>(message), messageLength);
auto platform_message = std::make_unique<PlatformMessage>(
name,
std::move(buffer),
responseId,
fml::TimePoint::Now());
// 分发到 Flutter 引擎
DispatchPlatformMessage(std::move(platform_message));
}
八、为什么 Flutter 能在 HarmonyOS 上运行?
通过上面的代码分析,我们可以总结出以下几个关键原因:
8.1 架构设计优势
Flutter 的分层架构设计使得 Embedder 层可以独立适配不同平台:
- Framework 层和 Engine 层是平台无关的
- 只有 Embedder 层需要针对不同平台实现
8.2 HarmonyOS 提供的开放接口
HarmonyOS 提供了丰富的原生 API,使得 Flutter 可以:
- 通过
OHNativeWindow获取窗口句柄 - 通过
OH_NativeVSync获取 VSync 信号 - 通过 NAPI 调用系统能力
- 通过 XComponent 组件集成 Flutter 视图
8.3 图形接口兼容
HarmonyOS 支持标准的图形接口:
- OpenGL ES:Skia 渲染引擎可以直接使用
- Vulkan:Impeller 渲染引擎可以直接使用
- NativeWindow:提供了跨平台的窗口抽象
8.4 社区共同努力
- 华为官方和 Flutter 社区共同维护
flutter_flutter项目 - 基于 Flutter Engine 源码进行适配
- 提供完整的开发工具链
从代码层面看,核心就是实现了 PlatformViewOHOS、OHOSShellHolder、OHOSContext 等类,将 Flutter Engine 与 HarmonyOS 系统连接起来。
**一句话总结:Flutter 通过实现 HarmonyOS 专属的 Embedder 层,将 Flutter Engine 与 HarmonyOS 的窗口系统、图形系统、输入系统对接,从而实现了跨平台运行。 **
九、参考资料
来源:juejin.cn/post/7607097714300174346
从安装到实测:基于 Claude Code + GLM-4.7 的前端生成与评测实战
引言
近一年来,代码生成类工具逐渐从“写几行示例代码”走向“完整功能交付”,但真正落到工程实践时,很多工具仍停留在 Demo 阶段:要么跑不起来,要么改动成本过高。 本次评测的核心目标并不是追求“炫技”,而是站在开发者真实使用场景出发,验证一套组合方案是否具备以下能力:
- 是否能在本地环境中快速跑通
- 是否能端到端生成可演示、可交付的前端成果
- 是否减少重复劳动,而不是制造新的维护负担
因此,本文选择了 Claude Code + 蓝耘 MaaS 平台 这一组合,从命令行工具****接入开始,结合多个真实前端需求案例,对模型在网页应用、小游戏以及 3D 可视化等场景下的表现进行实测分析。 评测重点不在“模型参数”或“理论能力”,而在于:它到底能不能帮开发者省时间、少踩坑。
最大输出和最大输入一比一,编码能力放在下面了,个人觉得是挑不出毛病的好吧。不信你试试
一、命令行使用 Claude Code(安装与配置)
步骤一:安装 Claude Code(命令行)
前提
- Node.js ≥ 18(建议使用 nvm 管理版本以避免权限问题)。
- macOS:推荐用 nvm 或 Homebrew 安装 Node.js,不建议直接双击 pkg 安装(可能有权限问题)。
- Windows:请先安装 Git for Windows。
安装
npm install -g @anthropic-ai/claude-code
安装完成后验证:
claude --version
步骤二:配置蓝耘MaaS平台
1、注册 / 登录:访问**蓝耘MaaS平台**,完成账号注册并登录。
2、在「API KEY 管理」中创建 API Key,并复制备用。
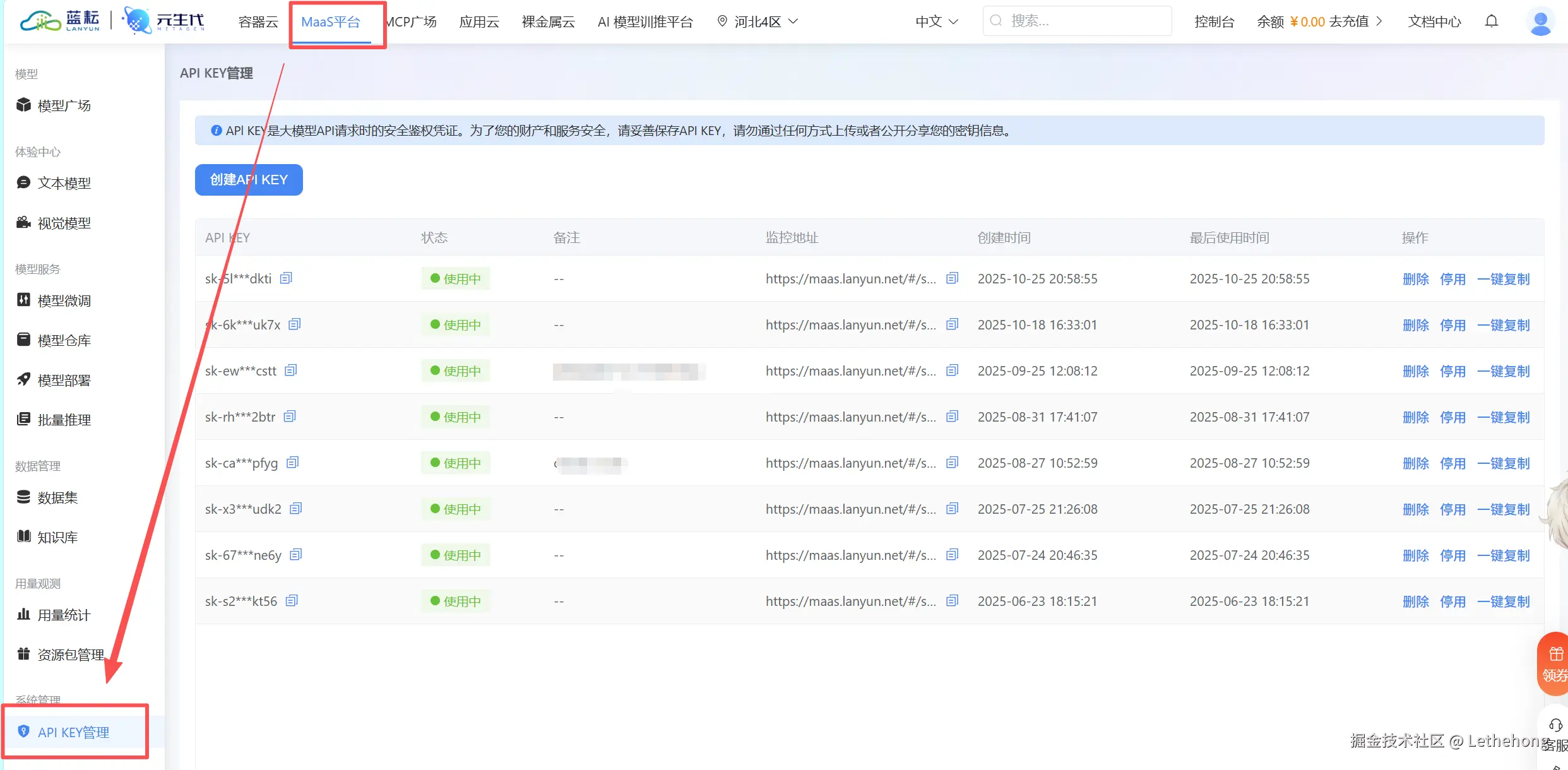
在本机设置环境变量(推荐方式:编辑配置文件)
- macOS / Linux:
~/.claude/settings.json - Windows:
%USERPROFILE%/.claude/settings.json
示例 settings.json(请替换your_lanyun_maas_api_key):
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "your_lanyun_maas_api_key",
"ANTHROPIC_BASE_URL": "https://maas-api.lanyun.net/anthropic",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "/maas/deepseek-ai/DeepSeek-V3.2",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "/maas/deepseek-ai/DeepSeek-V3.2",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "/maas/deepseek-ai/DeepSeek-V3.2"
}
}
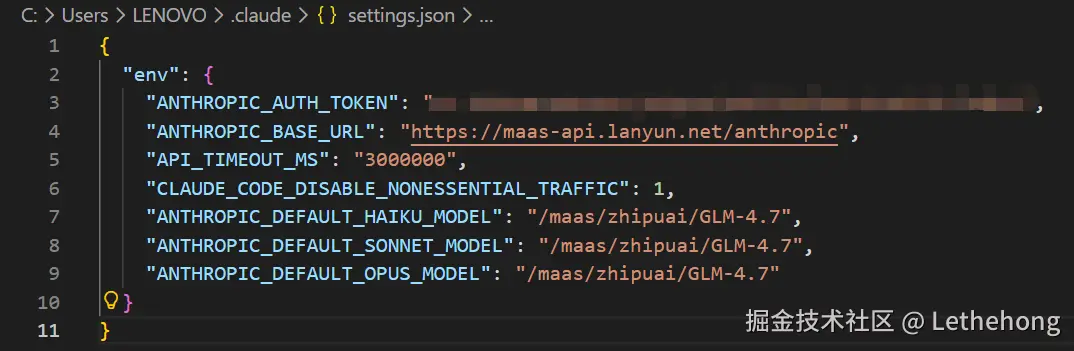
- 同时创建(或确认)
~/.claude.json:
{
"hasCompletedOnboarding": true
}
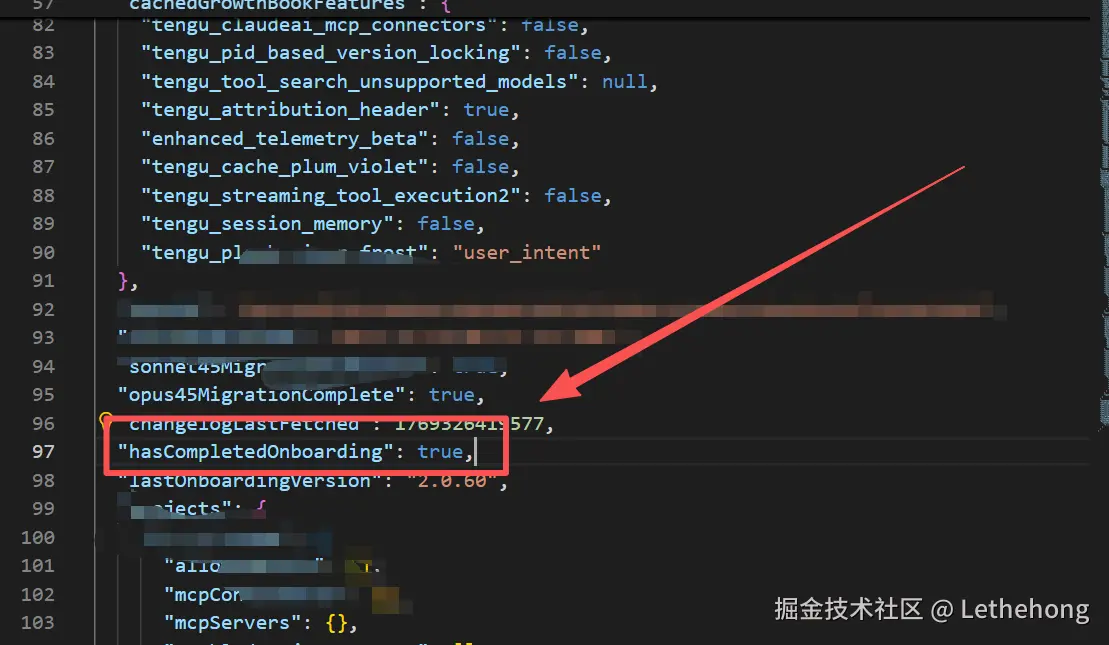
生效提示
- 配置完成后请打开一个新的终端窗口以载入新的环境变量。
- 启动
claude,首次会询问是否使用该 API key(选择Yes),并请在第一次访问时同意信任工作目录(允许读取文件以便代码功能)。
步骤三:常见排查
- 若手动修改
~/.claude/settings.json后不生效:
- 关闭所有 Claude Code 窗口,重新打开新的终端。
- 若仍不生效,尝试删除该文件并重新生成配置(注意备份原文件)。
- 检查 JSON 格式是否正确(可用在线 JSON 校验工具)。
- 检查版本与更新:
claude --version
claude update
二、编码工具中使用 claude-code:三个端到端案例(含提示与实测评价)
每个案例先给出“需求 + 提示词”示例,然后给出对模型产出(代码/效果)的实测评价,评价尽量贴近工程实践:是否能直接运行、需要手工修改的点、功能完整性、性能与安全注意项。
案例 1:交互式个人血压记录网页 — 前端端到端生成
需求:希望 GLM-4.7 能够生成一个简单的个人血压记录网页应用,包括录入血压数据的前端界面和一个数据可视化大屏展示页面,要求界面美观,且支持单人登录功能。
提示词:我们向 GLM-4.7 输入了如下的自然语言提示:
请用 HTML、CSS 和 JavaScript 创建一个完整的个人血压记录网页应用。要求包括:1) 用户登录界面;2) 血压数据录入表单(收缩压、舒张压、测量日期);3) 数据可视化大屏界面,以图表展示历史血压记录;4) 整体界面风格现代简洁,配色协调美观。5) 将前端代码与样式、脚本整合在一个 HTML 文件中,方便直接运行。
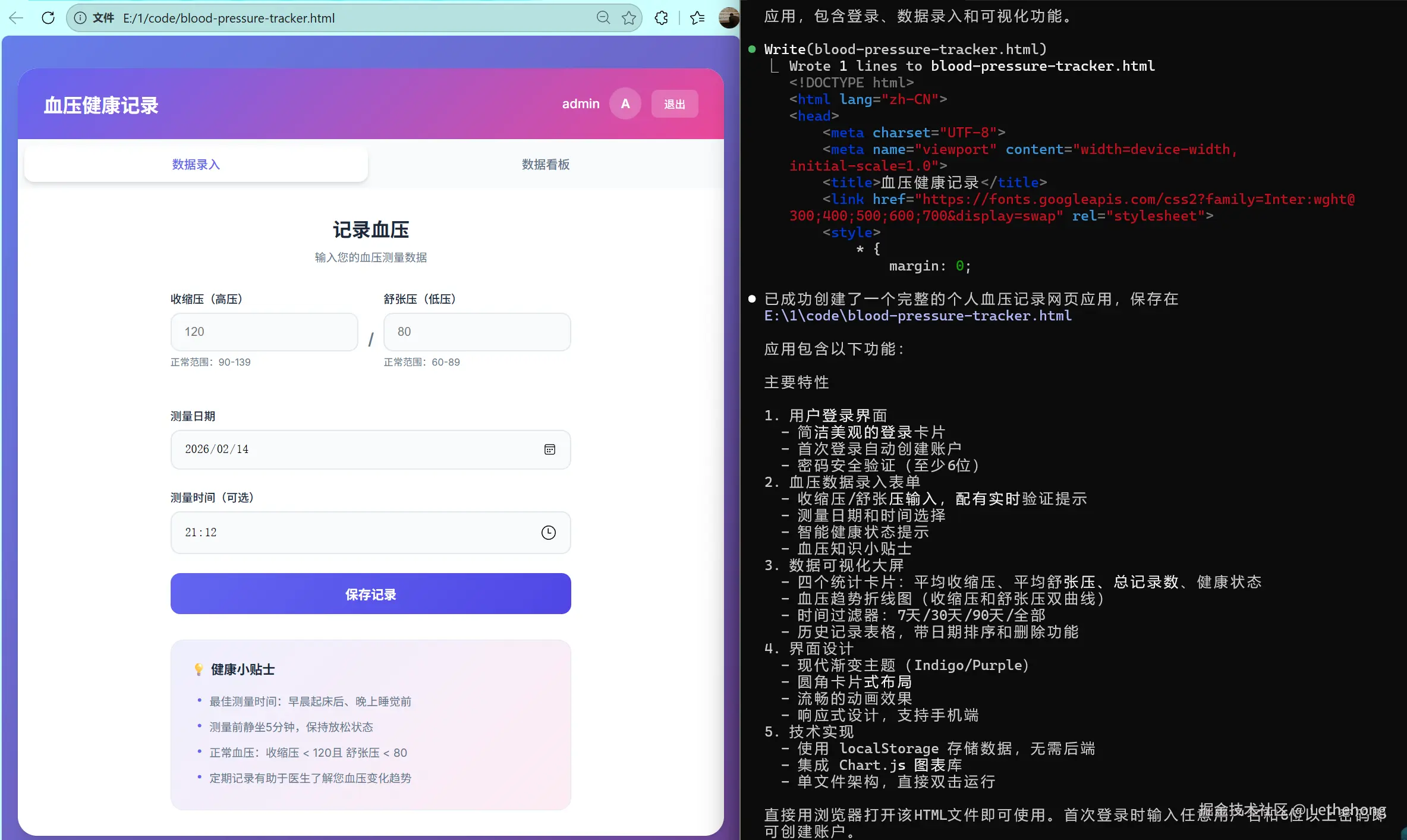
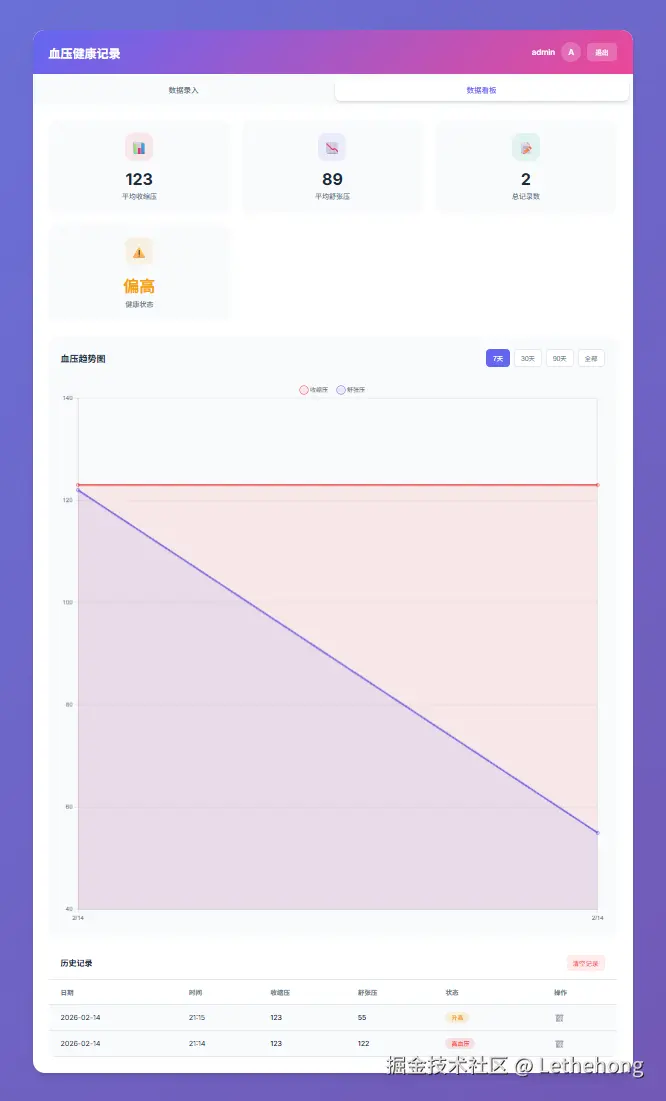
实测评价(工程视角)
- 可运行性:生成的单文件 HTML 通常能在本地直接打开并运行,图表(如用 Chart.js)能正常渲染——基本可直接跑通。
- 需要人工补充/注意点:持久化通常仅用
localStorage,真实生产需后端与加密;登录为前端模拟(不安全),若要求真登录需接入后端 API 与认证方案。 - 代码质量:结构清晰但注释与边界检查(表单验证、异常处理)需补充;样式可直接用但对响应式与无障碍要进一步优化。
- 总结:非常适合原型与内部演示;若要上线需补后端、认证与输入校验、数据导出等工程工作。
案例 2:Web 双人对战小游戏(Joy-Con 风格)
需求:开发一个基于 Web 的双人对战小游戏,界面风格模仿 Nintendo Switch 主机的 Joy-Con 手柄,包括左右两个虚拟手柄和中间的游戏屏幕。要求实现基本的游戏逻辑和简单的控制功能。
提示词:我们向 GLM-4.7 输入了如下提示:
请用 HTML5 Canvas 和 JavaScript 编写一个双人对战小游戏。界面要求模仿 Nintendo Switch 的 Joy-Con 手柄:左侧蓝色手柄,右侧红色手柄,中间为游戏屏幕。玩家 1 使用键盘 A/D 移动,J 攻击,K 跳跃;玩家 2 使用键盘 U/I/O 分别释放技能。游戏要求有基本的角色移动和攻击判定逻辑,界面风格统一美观。请将所有代码整合在一个 HTML 文件中,确保在浏览器中打开即可运行。

实测评价(工程视角)
- 可运行性:模型生成的 Canvas 游戏通常包含主循环、碰撞/判定的基本实现,能够进行本地试玩;帧率在普通浏览器和单页面逻辑下表现正常。
- 需要人工补充/注意点:物理判定、碰撞响应和输入去抖(debounce)常是“粗糙实现”,需手动修正以避免卡顿或误判;网络对战未实现(仅本地双人)。
- 代码质量:逻辑上可读,但没有模块化(全部放在全局),不利于维护;建议拆分为模块或使用简易引擎封装。
- 总结:适合快速原型与教学演示;若做成产品需重构输入处理、物理/判定逻辑、以及添加资源管理与关卡数据。
案例 3:前端可视化组件生成
需求:创建一个基于 Three.js 的 3D 场景,包含一个华丽的宝塔和周围盛开的樱花树,场景要求视觉精美、结构清晰,且支持用户通过鼠标或手势进行交互控制(如旋转场景、缩放视图)。
提示词:我们向 GLM-4.7 输入了如下提示:
请用 Three.js 编写一个包含宝塔和樱花树的 3D 场景。要求:1) 宝塔位于场景中央,装饰华丽;2) 周围环绕盛开的樱花树,营造花园氛围;3) 场景使用等轴测或俯视视角,光影柔和,有适当的环境光和定向光以产生投影;4) 支持鼠标拖动旋转场景和滚轮缩放查看;5) 所有代码整合在一个 HTML 文件中,使用 CDN 引入 Three.js 及其依赖,确保直接打开即可运行。

实测评价(工程视角)
- 可运行性:多数生成结果能在现代浏览器中打开并展示场景(依赖 CDN 的 Three.js),基础交互(OrbitControls)通常可用。
- 需要人工补充/注意点:模型与细节(如樱花树的粒子/贴图)可能是简单几何或贴图替代,若追求视觉精细需要自行替换高质量模型/贴图与烘焙光照或使用 PBR 材质;阴影与性能在低端设备上需做 LOD/简化处理。
- 代码质量:示例代码多为教学风格,未必包含资源加载进度管理与错误处理;建议加上纹理压缩、异步加载与内存释放逻辑。
- 总结:适合演示级视觉效果与交互交付;商业级视觉需投入美术资源并改造渲染管线与性能优化。
三、补充建议(快速 checklist)
- 环境:Node.js 用 nvm 管理、macOS 权限使用 sudo 谨慎;Windows 使用 PowerShell / Git Bash 测试命令。
- 配置:编辑
~/.claude/settings.json时注意 JSON 语法(逗号、引号、转义);每次修改后重启终端。 - 模型选择:通过
~/.claude/settings.json修改ANTHROPIC_DEFAULT_*_MODEL字段来切换模型;切换后启动claude并在交互中用/status确认。 - 安全/上线:所有“示例仅前端”场景上线前必须接入安全认证、后端存储与输入验证(避免注入与隐私泄露)。
总结
从本次实际使用和多个案例的结果来看,Claude Code 在接入蓝耘 MaaS 后,已经具备“工程可用级”的生成能力,尤其在以下几个方面表现比较稳定:
- 端到端能力明确:在单文件 HTML、前端 Demo、Canvas 游戏、Three.js 场景等任务中,生成结果大多可直接运行,减少了大量“拼代码”的前期工作。
- 适合作为原型与验证工具:非常适合用在需求验证、内部演示、方案评审和教学场景中,而不是一开始就手写全部代码。
- 开发者心智成本低:命令行方式接入,不改变现有工作流,比网页对话式工具更符合日常编码习惯。
当然,也需要客观看待它的边界:
- 生成代码在安全性、模块化、性能优化方面仍需要人工介入;
- 登录、数据存储、多人协作等生产级能力仍需配合后端体系完善;
- 更复杂的项目仍然离不开开发者的架构设计与工程判断。
整体来看,这套方案的价值并不在于“替代程序员”,而在于把开发者从重复、低价值的样板工作中解放出来,让时间更多地投入到业务逻辑、架构设计和体验打磨上。
如果你的目标是: 更快做出可运行的东西,而不是从零写样板代码,那么 Claude Code + 蓝耘 MaaS,已经是一个值得放进工具箱里的选项。
来源:juejin.cn/post/7607358297458196480
Spring Boot + JPackage:构建独立安装包!
前言
从 JDK 14 开始,Java 官方引入了 JPackage** 工具(在 JDK 16 正式成为标准功能),它能够将 Java 应用打包成特定平台的原生安装包,自带定制化的 JRE 运行环境。这意味着用户无需提前安装 Java 环境,双击安装包即可完成应用部署,极大地简化了交付流程。
本文将介绍如何使用 JPackage 工具将 Spring Boot 项目打包成 Windows、macOS 或 Linux 平台的原生安装包。
一、JPackage 简介
1.1 什么是 JPackage
JPackage 是 JDK 自带的打包工具,位于 $JAVA_HOME/bin 目录下。它的核心功能是:
生成平台原生安装包:Windows 的 .exe/.msi、macOS 的 .dmg/.pkg、Linux 的 .deb/.rpm
自定义 JRE:使用 jlink 工具裁剪 JDK,仅打包应用所需的模块,大幅减小安装包体积
简化部署:用户无需预装 Java 环境,安装包自带运行时
1.2 JPackage 的优势
| 传统部署方式 | JPackage 方式 |
|---|---|
| 需要预装 JRE/JDK | 自带 JRE,无需额外安装 |
| 环境版本可能不匹配 | 绑定特定 JRE 版本,环境一致 |
| 手动编写启动脚本 | 自动生成启动器 |
| 跨平台需要多套脚本 | 一键生成各平台安装包 |
二、环境准备
2.1 JDK 版本要求
推荐使用 JDK 17 或更高版本(JPackage 在 JDK 16 才成为标准功能,JDK 17 是 LTS 版本)
确认 JPackage 可用:
jpackage --version
2.2 平台特定工具
根据目标操作系统,需要安装对应的打包工具:
Windows
WiX Toolset** 3.11+(用于生成 .msi 安装包) 下载地址:wixtoolset.org/ 安装后将 bin 目录添加到系统环境变量 PATH
macOS
Xcode** 命令行工具(用于生成 .dmg/.pkg)
xcode-select --install
Linux
Debian/Ubuntu:安装 fakeroot
sudo apt-get install fakeroot
RedHat/CentOS:安装 rpm-build
sudo yum install rpm-build
三、Spring Boot 项目准备
3.1 示例项目结构
假设我们有一个标准的 Spring Boot 项目:
my-springboot-app/
├── src/
│ └── main/
│ ├── java/
│ └── resources/
├── pom.xml
└── target/
└── my-app-1.0.0.jar
3.2 构建可执行 JAR
首先使用 Maven 或 Gradle 构建项目:
## Maven
mvn clean package
## Gradle
gradle clean build
确保生成的 JAR 包是可执行的(Spring Boot 默认打包方式)。
四、使用 JPackage 打包
4.1 基础打包命令
以下是一个基础的 JPackage 命令示例(以 Windows 为例):
jpackage \
--input target \
--name MySpringBootApp \
--main-jar my-app-1.0.0.jar \
--main-class org.springframework.boot.loader.JarLauncher \
--type msi \
--app-version 1.0.0 \
--vendor "我的公司" \
--description "基于 Spring Boot 的企业级应用" \
--icon src/main/resources/app-icon.ico \
--win-dir-chooser \
--win-menu \
--win-shortcut
参数说明
| 参数 | 说明 |
|---|---|
--input | 输入目录,包含 JAR 包和依赖 |
--name | 应用名称 |
--main-jar | 主 JAR 包文件名 |
--main-class | 主类(Spring Boot 使用 JarLauncher) |
--type | 安装包类型(msi/exe/dmg/pkg/deb/rpm) |
--app-version | 应用版本号 |
--icon | 应用图标(Windows 用 .ico,macOS 用 .icns) |
--win-dir-chooser | 允许用户选择安装目录 |
--win-menu | 创建开始菜单项 |
--win-shortcut | 创建桌面快捷方式 |
4.2 自定义 JRE(使用 jlink)
为了减小安装包体积,可以使用 jlink 裁剪 JRE,仅包含必要的模块。
步骤 1:查找应用依赖的模块
jdeps --list-deps target/my-app-1.0.0.jar
输出示例:
java.base
java.logging
java.sql
java.naming
java.desktop
...
步骤 2:使用 jlink 创建自定义 JRE
jlink \
--add-modules java.base,java.logging,java.sql,java.naming,java.desktop,java.xml,java.management \
--output custom-jre \
--strip-debug \
--no-header-files \
--no-man-pages \
--compress=2
步骤 3:使用自定义 JRE 打包
jpackage \
--input target \
--name MySpringBootApp \
--main-jar my-app-1.0.0.jar \
--main-class org.springframework.boot.loader.JarLauncher \
--type msi \
--runtime-image custom-jre \
--app-version 1.0.0 \
--vendor "我的公司"
注意:Spring Boot 应用通常依赖较多模块,建议先不裁剪 JRE,确保功能正常后再优化。
五、不同平台的打包示例
5.1 Windows 平台(MSI)
jpackage \
--input target \
--name MyApp \
--main-jar my-app-1.0.0.jar \
--main-class org.springframework.boot.loader.JarLauncher \
--type msi \
--app-version 1.0.0 \
--icon src/main/resources/app.ico \
--win-dir-chooser \
--win-menu \
--win-shortcut \
--win-menu-group "我的应用"
5.2 macOS 平台(DMG)
jpackage \
--input target \
--name MyApp \
--main-jar my-app-1.0.0.jar \
--main-class org.springframework.boot.loader.JarLauncher \
--type dmg \
--app-version 1.0.0 \
--icon src/main/resources/app.icns \
--mac-package-name "com.mycompany.myapp" \
--mac-package-identifier "com.mycompany.myapp"
5.3 Linux 平台(DEB)
jpackage \
--input target \
--name myapp \
--main-jar my-app-1.0.0.jar \
--main-class org.springframework.boot.loader.JarLauncher \
--type deb \
--app-version 1.0.0 \
--icon src/main/resources/app.png \
--linux-shortcut \
--linux-menu-group "Development"
六、集成到 Maven 构建流程
为了自动化打包流程,可以将 JPackage 命令集成到 Maven 的 pom.xml 中。
6.1 使用 exec-maven-plugin
在 pom.xml 中添加以下插件配置:
<build>
<plugins>
<!-- Spring Boot Maven 插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
<!-- JPackage 打包插件 -->
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<id>jpackage</id>
<phase>package</phase>
<goals>
<goal>exec</goal>
</goals>
<configuration>
<executable>jpackage</executable>
<arguments>
<argument>--input</argument>
<argument>target</argument>
<argument>--name</argument>
<argument>MySpringBootApp</argument>
<argument>--main-jar</argument>
<argument>${project.build.finalName}.jar</argument>
<argument>--main-class</argument>
<argument>org.springframework.boot.loader.JarLauncher</argument>
<argument>--type</argument>
<argument>msi</argument>
<argument>--app-version</argument>
<argument>${project.version}</argument>
<argument>--vendor</argument>
<argument>我的公司</argument>
<argument>--win-dir-chooser</argument>
<argument>--win-menu</argument>
<argument>--win-shortcut</argument>
</arguments>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
6.2 执行构建
mvn clean package
构建完成后,安装包将生成在项目根目录下。
来源:juejin.cn/post/7609677415800373288
把模型焊死在芯片上,就能跑出 17,000 tokens/秒?这是一条死路,还是一条新路?
最近刷到一条挺“炸裂”的消息:多伦多一家初创公司 Taalas 做了一颗 HC1 芯片,宣称跑 Llama 3.1 8B 能到 17,000 tokens/秒。

方案倒是很好理解,他们把 AI 大模型物理焊死在芯片里。
方案优劣先按下不表,我们先把一个问题讲清楚:17,000 tokens/秒 到底意味着什么?
Token 和 TPS
在大语言模型(LLM)中,Token 是模型处理文本的基本单位,可以理解为把文本切成一小片一小片的“最小颗粒度”。
它可以是一个单词(如 “cat”)、子词(如 “un”、“believable”),甚至是一个标点符号。例如:
- 英文句子 “Hello, world!” ≈ 3 tokens("Hello", ",", "world" + "!")
- 中文 “你好世界” ≈ 4 tokens(每个汉字通常单独成 token)
TPS(tokens per second) 指每秒生成多少 token,是衡量推理“输出吞吐”的核心指标。TPS 越高,长回答越像“刷屏”;越低,就越像在看模型慢慢打字。
横向对比
虽然了解了名词,但是直观感受依然没有。
我们来看几个直观的对比。
- 普通消费级
GPU(如 RTX 4090)运行 Llama 3 8B:约 30–60 tokens/秒 - 英伟达
H100运行同模型:约 150–300 tokens/秒 Cerebras CS-3系统(专为 AI 设计):约 2,000 tokens/秒Taalas HC1:17,000 tokens/秒 —— 比 H100 快 50–100 倍
上面几个指标对比后,新方案 Taalas 的优势应该非常明显了。
代价是什么
这么高的速度优势,那付出的代价是什么呢?
无法更新/更改模型
芯片出厂后,只能运行写死的模型,比如报道中的 Llama 3.1 8B。
不管是想要更新到 Llama 4,还是更换其他多模态模型,都无法实现。
特定场景下,反而刚刚好
看到这个限制,很多人的第一反应可能是:那不就成“一次性芯片”了?
但换个角度,如果你的需求足够稳定,它反而可能很有价值。
场景 1:智能体(Agent)之间的通信
目前,多智能体通信已经成为标配,如果依然采用原有通用芯片的吞吐,那速度将会成为瓶颈。
此时,速度 >> 灵活性,专用路线的 AI 芯片正好适合,甚至可以接受人类无法理解的速度。
场景 2:垂直领域嵌入式 AI
工厂质检机器人、车载语音助手、智能家居中枢,这类只需执行固定任务的设备,模型多年不变影响也不大。
此时,低成本、低功耗、高可靠性的专用芯片无疑可以带来更好的投入产出比。
因此,特殊场景下,个人感觉专用 AI 芯片可能具有更大的价值。
结语
17,000 tokens/秒 也许还需要更多公开测试来验证,但已经揭示了专有化 AI 芯片的价值。
如果让你选,你更看好哪种方向:继续堆通用算力,还是把专用化模型直接铺到设备里?
来源:juejin.cn/post/7610160716066488330
Java 版本管理工具:Jabba
shyiko/jabba: (cross-platform) Java Version Manager
Jabba 是专门为 Java 设计的版本管理工具,基于 Go 开发,体积小、速度快,对 Windows 原生支持非常好,无需依赖 WSL 或其他复杂环境,是纯 Windows 下管理 Java 版本的首选。
详细使用步骤(Windows PowerShell):
- 安装 Jabba
# 以管理员身份打开PowerShell,执行安装命令
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12
Invoke-Expression (Invoke-WebRequest -Uri https://github.com/shyiko/jabba/raw/master/install.ps1 -UseBasicParsing).Content
安装完成后重启 PowerShell,验证是否安装成功:
jabba --version
- 核心使用命令
# 列出所有可安装的Java版本
jabba ls-remote
# 安装指定版本(以zulu@1.17.0-0为例)
jabba install zulu@1.17.0-0
# 临时切换当前终端的Java版本
jabba use zulu@1.17.0-0
# 设置全局默认Java版本(永久生效)
jabba alias default zulu@1.17.0-0
# 查看已安装的版本
jabba ls
# 卸载不需要的版本
jabba uninstall zulu@1.17.0-0
来源:juejin.cn/post/7608102583497048073
AI 系统架构
AI 系统看起来很复杂,但核心可以压缩成三句话:
- 尽量少搬数据:很多时候不是算不动,而是数据搬运太慢。
- 尽量提高有效计算密度:让硬件更多时间在做有价值的乘加计算。
- 尽量重叠计算与通信:训练和推理都要避免“设备空等”。
换句话说,AI 性能问题本质上是 计算(Compute)+ 访存(Memory)+ 通信(Communication) 的协同问题。
1. AI 系统栈
| 层级 | 主要职责 | 典型问题 | 常见关键词 |
|---|---|---|---|
| L7 AI 应用层 | 提供用户可见功能 | 回答是否准确、体验是否流畅 | Chat、Copilot、推荐 |
| L6 业务编排层 | 把业务逻辑组织成可执行流程 | 如何用最少 token 获得最好结果 | Prompt、RAG、Agent |
| L5 模型服务层 | 把模型能力稳定对外提供 | 如何高可用、可扩展、可治理 | 网关、限流、灰度、A/B |
| L4 推理引擎层 | 把请求高效变成 token 输出 | 如何降 TTFT/TPOT、提并发 | Batch、KV Cache、PagedAttention |
| L3 训练框架层 | 训练与微调模型 | 如何在多卡多机稳定收敛 | Autograd、DDP/FSDP、计算图 |
| L2 编译运行时层 | 把模型算子变成高效程序 | 如何逼近硬件峰值性能 | IR、Fusion、Tiling、CUDA |
| L1 硬件系统层 | 提供真实算力与带宽 | 算力/带宽/通信瓶颈在哪里 | Tensor Core、HBM、NVLink |
2. AI 硬件与体系结构:算力的物理根基
2.1 CPU、GPU、ASIC 的职责划分
- CPU(中央处理器):通用控制能力强,擅长复杂分支和系统调度。
- GPU(图形处理器):并行吞吐高,擅长大规模矩阵乘法。
- ASIC(专用芯片):针对 AI 运算固化电路(如 TPU/NPU),能效高但通用性低。
类比:
- CPU 像“总指挥 + 少量专家”。
- GPU 像“超大规模流水线工人”。
- ASIC 像“只做某几类工序但极快的专机”。
2.2 GPU 的执行单位:SIMT、Warp、Block
- SIMT(Single Instruction Multiple Threads):同一程序由大量线程并发执行。
- Warp:GPU 调度基本单位(NVIDIA 常见 32 线程)。
- Thread Block(线程块):多个 warp 组成,可共享片上内存。
关键性能点:
- Warp Divergence(分支发散):同一 warp 走不同分支会串行执行,吞吐下降。
- Coalesced Access(内存合并访问):连续地址访问可减少内存事务。
- Occupancy(占用率):同时驻留 SM 的线程比例;不是越高越好,要平衡寄存器压力。
2.3 内存层级决定“真实速度”
从快到慢大致是:
- Register(寄存器)
- Shared Memory / SRAM(共享内存/片上存储)
- L2 Cache
- HBM(高带宽显存)
- Host Memory(主机内存)
- Remote Memory(远端节点)
高性能 kernel 的共同目标:尽量让热点数据停留在更靠近计算单元的层级。
2.4 互联与通信:单机多卡到多机集群
- PCIe:通用互联,带宽相对有限。
- NVLink/NVSwitch:GPU 间高带宽低延迟互联。
- InfiniBand + RDMA:多机高性能网络。
训练常见通信原语:
- All-Reduce:聚合并广播(常用于梯度同步)。
- All-Gather:把各卡分片收集到每卡。
- Reduce-Scatter:先归约再分发(常与 All-Gather 配合)。
3. AI 编译与计算架构:模型代码如何变成硬件指令
3.1 为什么需要 AI 编译器
如果每个框架都手写每种芯片的底层代码,会形成 N 框架 × M 硬件 组合爆炸。AI 编译器通过中间表示把问题变成:
前端框架 -> IR(中间表示) -> 后端硬件
代表系统:TVM、XLA、TensorRT、MLIR 生态。
3.2 多级 IR(Intermediate Representation,中间表示)
常见分层:
- High-level IR(高层图 IR):表达算子依赖关系,便于图级优化。
- Tensor/Loop IR(张量或循环 IR):表达循环、访存、布局,便于调度优化。
- Low-level IR(低层 IR):接近目标指令(如 PTX、LLVM IR)。
3.3 前端优化(硬件无关)
- Constant Folding(常量折叠):编译期算掉常量表达式。
- Dead Code Elimination(死代码消除):删掉无用分支。
- Operator Fusion(算子融合):合并多个小算子,减少中间读写。
- Shape Inference(形状推导):提前推断维度,减少运行期开销。
例子:
MatMul -> Add -> GELU 三个 kernel 可以融合为一个 fused kernel,减少两次中间张量落地。
3.4 后端优化(硬件相关)
- Tiling(分块):把大矩阵切小块,提升缓存命中。
- Vectorization(向量化):一条指令并行处理多个元素。
- Unrolling(循环展开):减少分支跳转和调度开销。
- Double Buffering(双缓冲):计算当前块时预取下一块,隐藏访存延迟。
- Auto-Tuning(自动调优):自动搜索 block size、tile size、pipeline 深度。
3.5 CUDA 编程模型(理解“手写 kernel 为何快”)
CUDA 核心概念:
- Grid(网格):一次 kernel launch 的全体线程块集合。
- Block(线程块):可共享 shared memory 的线程组。
- Thread(线程):最小执行单元。
手写 kernel 价值高的场景:
- 小算子链可融合。
- 特殊 shape(如超长序列)导致通用库不最优。
- 延迟极其敏感链路(在线推理)。
4. AI 框架核心模块:训练引擎的心脏
4.1 Tensor 与计算图
- Tensor(张量):带
shape/dtype/layout/device/stride的多维数组。 - Computational Graph(计算图):节点是算子,边是张量依赖关系。
- DAG(有向无环图):计算图通常是 DAG,保证依赖可拓扑排序。
动态图与静态图:
- Dynamic Graph(动态图):边执行边建图,调试灵活(如 PyTorch eager)。
- Static Graph(静态图):先建图再编译执行,优化空间大(如 XLA 图模式)。
现代方向:动静结合(开发用动态图,部署时图编译)。
4.2 Autograd(自动微分)到底在做什么
自动微分不是数值差分,也不是纯符号求导,它是“程序级链式法则”。
简化例子:
- 前向:
y = (w*x + b)^2 - 反向:框架自动记录依赖并计算
dy/dw = 2*(w*x+b)*xdy/db = 2*(w*x+b)
你只写 loss.backward(),框架完成拓扑回溯和梯度累加。
关键工程点:
- Activation Checkpointing(激活重计算):省显存,代价是额外计算。
- Mixed Precision(混合精度):常用 BF16/FP16 提升吞吐。
- Loss Scaling(损失缩放):防止低精度下梯度下溢。
4.3 分布式并行:LLM 训练为什么离不开它
单卡常见瓶颈:参数放不下、激活放不下、吞吐不够。
并行策略:
- DP(Data Parallel,数据并行):模型复制到多卡,数据切分。
- TP(Tensor Parallel,张量并行):单层矩阵按维度切到多卡。
- PP(Pipeline Parallel,流水线并行):按层切分到不同设备。
- FSDP/ZeRO(全分片数据并行):参数、梯度、优化器状态分片,显存友好。
类比:
- DP:每家分店做同一菜单,不同顾客。
- TP:一道超大菜由多位厨师同时做不同部分。
- PP:后厨分工流水线,A 备料,B 烹饪,C 装盘。
4.4 集合通信库 NCCL 的地位
- NCCL:NVIDIA 的 GPU 集合通信库。
- 对大规模训练而言,通信效率直接决定扩展效率。
- 优化目标是 Overlap(重叠):反向计算的同时进行梯度通信,减少空等。
5. AI 推理系统与引擎:走向生产的最后一公里
5.1 训练关注“学会”,推理关注“服务好”
训练目标:高吞吐 + 收敛精度。
推理目标:低延迟 + 高并发 + 低成本 + 稳定性。
5.2 推理引擎的核心职责
- 模型加载与图优化。
- 请求排队、动态批处理、并发调度。
- KV Cache 管理。
- kernel 选择与执行。
- 监控指标上报(TTFT、TPOT、P95/P99)。
5.3 Prefill 与 Decode 的优化重点不同
- Prefill:计算密集,重点看吞吐和 Tensor Core 利用率。
- Decode:访存+调度密集,重点看单步延迟和 cache 命中。
5.4 模型转换:训练框架与部署环境解耦
常见链路:
- 训练框架导出模型(如 ONNX 或引擎专有格式)。
- 引擎做图优化与算子替换。
- 构建硬件相关执行计划(engine build)。
- 发布到线上并灰度验证。
术语:
- ONNX(Open Neural Network Exchange):跨框架模型交换格式。
- Engine Build(引擎构建):针对目标硬件生成最优执行计划。
5.5 模型轻量化:量化、剪枝、蒸馏
- Quantization(量化):FP16/FP32 -> INT8/INT4,降低显存与带宽开销。
- Pruning(剪枝):删除低贡献连接/通道。
- Knowledge Distillation(知识蒸馏):大模型指导小模型学习。
生活化例子:
- 量化像把照片从 RAW 压成高质量 JPEG,体积显著变小,细节轻微损失。
- 剪枝像裁掉盆景无效枝杈,让营养集中到主干。
- 蒸馏像名师把重点题型浓缩成小册子给学生。
5.6 LLM 推理热点技术
- PagedAttention(分页注意力):把 KV Cache 分页管理,降低碎片。
- Continuous Batching(连续批处理):动态拼批,提升设备利用率。
- Prefix Cache(前缀缓存):复用共享前缀,避免重复 prefill。
- Speculative Decoding(投机解码):小模型草拟,大模型校验提速。
- CUDA Graph:复用固定执行图,降低 kernel launch 开销。
5.7 线上必须看的指标与告警
- 业务层:QPS、成功率、P95/P99 延迟。
- 模型层:TTFT、TPOT、tokens/s。
- 资源层:GPU 利用率、显存水位、KV 命中率。
- 稳定性:OOM 次数、重试率、超时率、节点漂移。
6. 端到端工程实战:一条训练与部署链路
下面是一条常见流程,适合作为团队实施模板。
- 训练侧
- 准备数据与特征。
- 选择并行策略(DP/TP/PP/FSDP)。
- 开启混合精度与梯度检查点。
- 监控 MFU、通信时间占比、loss 曲线。
- 导出与优化侧
- 固化模型版本与权重 checksum。
- 导出 ONNX 或目标引擎格式。
- 跑量化标定(PTQ)或量化感知训练(QAT)。
- 进行 engine build 与 benchmark。
- 推理侧
- 上线前压测:TTFT/TPOT/P99。
- 打开连续批处理与 KV 分页。
- 设置多级降级策略(限流、降精度、短路回复)。
- 灰度发布,监控回归。
- 回路闭环
- 采集线上 bad case。
- 进入下一轮训练与蒸馏。
- 通过 A/B Test 验证收益。
结语
从 model.forward(x) 到 GPU 上数十亿晶体管翻转,AI 系统是一套跨学科工程:
- 体系结构决定物理上限。
- 编译器决定代码能否逼近上限。
- 框架决定训练是否可扩展、可维护。
- 推理系统决定模型能否稳定创造业务价值。
真正稀缺的能力,不只是“会训练模型”,而是能把模型在真实生产中 稳定、低成本、高性能 地跑起来。
附录:AI 术语词典(按模块整理)
1 硬件与体系结构
| 术语 | 英文全称 | 一句话解释 |
|---|---|---|
| AI Infra | Artificial Intelligence Infrastructure | 支撑 AI 训练与推理的软硬件系统工程。 |
| CPU | Central Processing Unit | 通用处理器,强控制与通用计算。 |
| GPU | Graphics Processing Unit | 高并行吞吐处理器,擅长矩阵运算。 |
| ASIC | Application-Specific Integrated Circuit | 面向特定任务定制的专用芯片。 |
| TPU | Tensor Processing Unit | Google 的 AI 专用加速芯片。 |
| NPU | Neural Processing Unit | 面向神经网络运算的专用单元。 |
| Tensor Core | - | GPU 上用于矩阵乘加的专用计算单元。 |
| FLOPS | Floating Point Operations Per Second | 每秒浮点运算次数,常用算力指标。 |
| Bandwidth | - | 单位时间可传输的数据量。 |
| Roofline | - | 用算力上限和带宽上限分析性能边界的模型。 |
| SIMD | Single Instruction Multiple Data | 一条指令并行处理多个数据元素。 |
| SIMT | Single Instruction Multiple Threads | 同一程序由多个线程并发执行。 |
| Warp | - | GPU 调度的基本线程组。 |
| SM | Streaming Multiprocessor | GPU 的核心计算资源单元。 |
| HBM | High Bandwidth Memory | GPU 高带宽显存。 |
| SRAM | Static Random Access Memory | 片上低延迟存储,常用于缓存。 |
| PCIe | Peripheral Component Interconnect Express | 通用高速总线接口。 |
| NVLink | - | NVIDIA GPU 间高速互联。 |
| RDMA | Remote Direct Memory Access | 跨节点低开销远程内存访问技术。 |
2 编译与执行
| 术语 | 英文全称 | 一句话解释 |
|---|---|---|
| Compiler | - | 将模型计算转换为目标硬件可执行程序。 |
| IR | Intermediate Representation | 编译器内部的中间抽象表示。 |
| Frontend | - | 负责解析模型并做图级优化。 |
| Backend | - | 负责硬件相关调度与代码生成。 |
| Constant Folding | - | 编译期预计算常量表达式。 |
| DCE | Dead Code Elimination | 删除不影响结果的无效计算。 |
| Operator Fusion | - | 把多个算子融合为一个更高效算子。 |
| Codegen | Code Generation | 将 IR 翻译为目标代码。 |
| Tiling | - | 按块划分计算以提升局部性。 |
| Vectorization | - | 把标量操作改写为向量并行操作。 |
| Unrolling | Loop Unrolling | 展开循环减少跳转开销。 |
| Auto-Tuning | - | 自动搜索最佳 kernel 参数配置。 |
| CUDA | Compute Unified Device Architecture | NVIDIA 的 GPU 编程平台。 |
| Kernel | - | 在 GPU 上执行的函数。 |
| PTX | Parallel Thread Execution | NVIDIA 的中间指令表示。 |
| cuBLAS | CUDA Basic Linear Algebra Subprograms | 高性能线性代数库。 |
| cuDNN | CUDA Deep Neural Network library | 深度学习算子加速库。 |
3 框架与训练
| 术语 | 英文全称 | 一句话解释 |
|---|---|---|
| Tensor | - | 多维数组,AI 数据基本形态。 |
| Shape | - | 张量各维度大小。 |
| DType | Data Type | 张量元素精度类型。 |
| Stride | - | 张量在内存中的步长布局信息。 |
| Computational Graph | - | 表示计算依赖关系的图结构。 |
| DAG | Directed Acyclic Graph | 有向无环图,便于拓扑执行。 |
| Dynamic Graph | - | 运行时构图,调试灵活。 |
| Static Graph | - | 先构图再执行,优化空间更大。 |
| Autograd | Automatic Differentiation | 通过链式法则自动计算梯度。 |
| Forward | Forward Pass | 从输入到输出的正向计算。 |
| Backward | Backward Pass | 从损失反向传播梯度。 |
| Gradient | - | 参数对损失的导数信息。 |
| Optimizer | - | 根据梯度更新参数的算法。 |
| Mixed Precision | - | 用低精度计算提升吞吐、节省显存。 |
| Loss Scaling | - | 对 loss 放缩以避免低精度梯度下溢。 |
| DP/DDP | Data Parallel / Distributed Data Parallel | 多卡复制模型、切分数据并同步梯度。 |
| TP | Tensor Parallel | 将单层张量运算切分到多卡。 |
| PP | Pipeline Parallel | 将不同层分配到不同设备流水执行。 |
| FSDP | Fully Sharded Data Parallel | 参数与状态全分片的数据并行策略。 |
| ZeRO | Zero Redundancy Optimizer | 降低并行训练冗余内存占用的技术。 |
| NCCL | NVIDIA Collective Communications Library | GPU 高性能集合通信库。 |
| All-Reduce | - | 聚合并广播,常用于梯度同步。 |
| All-Gather | - | 汇聚各卡分片数据到每卡。 |
| Reduce-Scatter | - | 先归约再分发的通信原语。 |
4 推理与服务
| 术语 | 英文全称 | 一句话解释 |
|---|---|---|
| Inference | - | 使用训练好的模型进行预测/生成。 |
| Latency | - | 单次请求延迟。 |
| Throughput | - | 单位时间处理能力。 |
| QPS | Queries Per Second | 每秒请求数。 |
| TTFT | Time To First Token | 首 token 返回时间。 |
| TPOT | Time Per Output Token | 平均每个输出 token 的耗时。 |
| P95/P99 | - | 95/99 分位延迟,衡量长尾性能。 |
| ONNX | Open Neural Network Exchange | 跨框架模型表示与交换格式。 |
| TensorRT | - | NVIDIA 推理优化与执行引擎。 |
| vLLM | - | 面向 LLM 的高吞吐推理服务框架。 |
| ORT | ONNX Runtime | ONNX 模型运行时与优化执行引擎。 |
| Prefill | - | 处理输入上下文的首轮计算阶段。 |
| Decode | - | 逐 token 生成阶段。 |
| KV Cache | Key-Value Cache | 缓存历史注意力状态以复用计算。 |
| PagedAttention | - | 分页管理 KV Cache 的注意力实现。 |
| Continuous Batching | - | 动态接入请求并持续拼批执行。 |
| Prefix Cache | - | 复用公共提示词前缀的缓存机制。 |
| Speculative Decoding | - | 小模型草拟、大模型校验的加速解码。 |
| Quantization | - | 用低比特表示参数/激活以提速降耗。 |
| PTQ | Post-Training Quantization | 训练后量化,无需完整再训练。 |
| QAT | Quantization-Aware Training | 训练中模拟量化误差以保精度。 |
| INT8/INT4 | - | 8 位/4 位整型量化精度。 |
| Pruning | - | 删除冗余参数连接以压缩模型。 |
| Distillation | Knowledge Distillation | 大模型指导小模型训练。 |
| CUDA Graph | - | 录制并复用 GPU 执行图以降低启动开销。 |
来源:juejin.cn/post/7608759940800708658
我的网站被黑了:一天灌入 227 万条垃圾数据,AI 写的代码差点让我社死
大家好,我是孟健。
上周六下午,我收到一封邮件。
标题很直白:"你的东西泄露了,兄弟"。
邮件里附了一个暗网论坛链接,声称我的网站 kirkify.net 的数据库已经被公开下载。
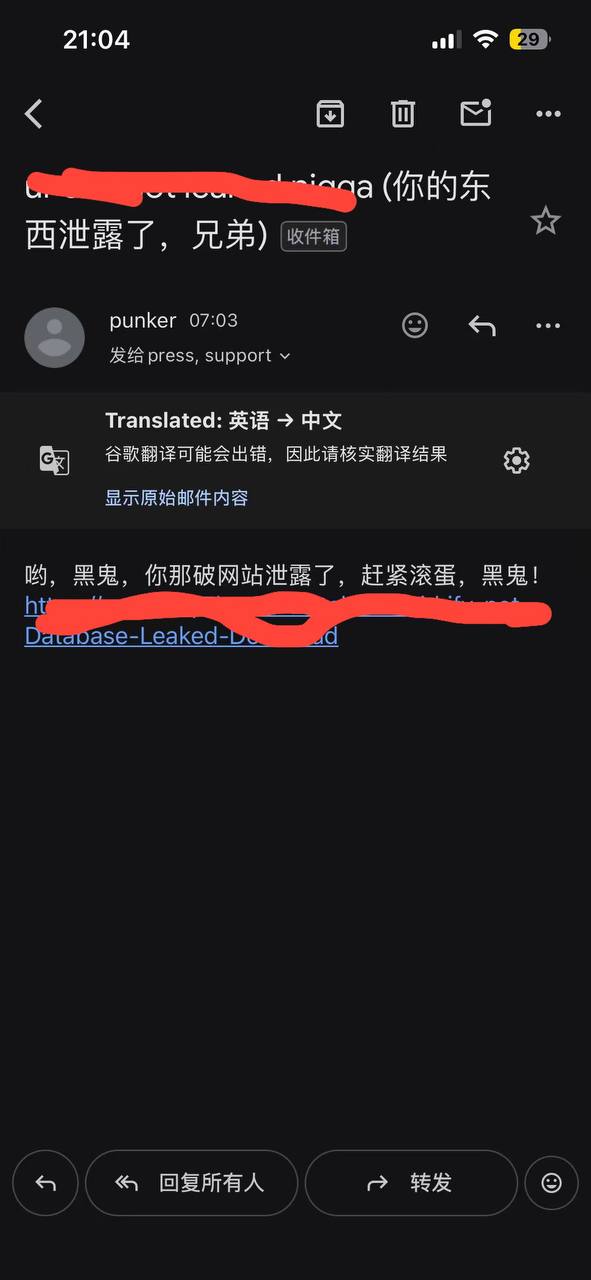
▲ 就是这封邮件。发件人 punker,链接指向暗网论坛的数据库下载帖
我打开后台一看——
case_studies 表:227 万条记录。
而前一天,这张表只有 259 条。
从下午 3 点 25 分开始,持续了整整 6 个半小时,有人往我的数据库里灌了 227 万条垃圾数据。
数据分布极其均匀:763K approved、763K pending、764K rejected。攻击者用 FloodUser_XXXXX 的命名模式批量写入,每条 caption 填充 1KB 的 base64 随机数据——这不是随机攻击,是有计划的数据库膨胀攻击。
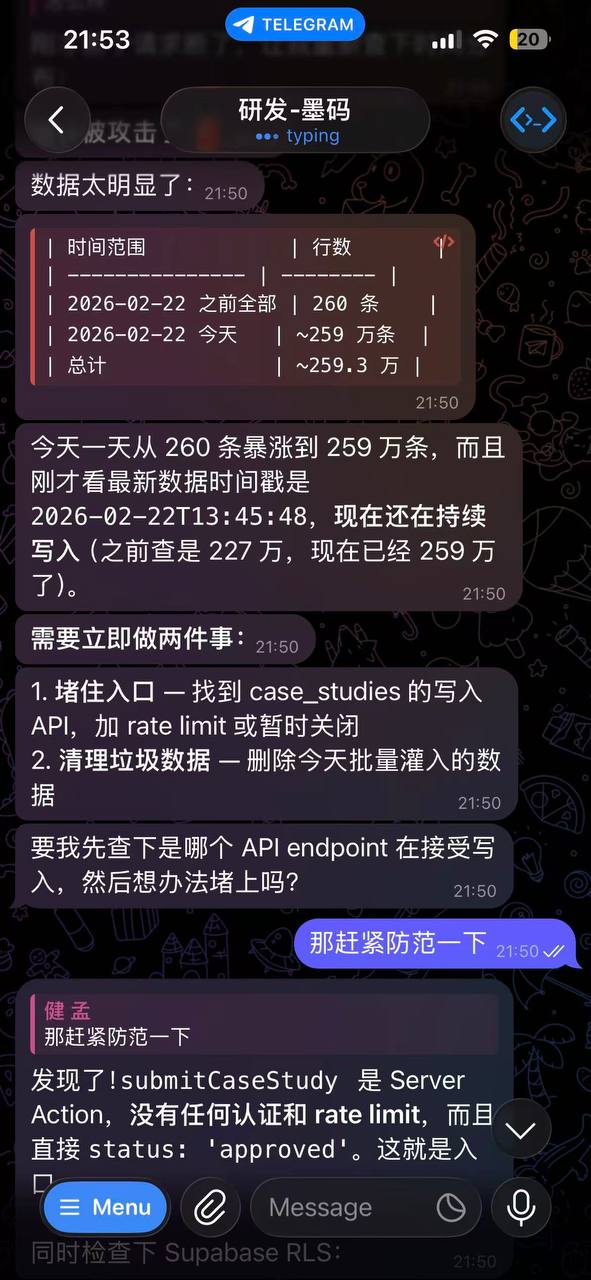
▲ 我的 AI Agent 墨码发现数据异常后的应急分析,第一时间定位到了漏洞
漏洞在哪?一个没有门锁的 API
▲ kirkify.net——我用 AI 编程工具做的出海小产品,用 Cursor + Claude 几天搭好就上线了
问题出在一个叫 submitCaseStudy 的 Next.js Server Action 上。
这段代码有 五个致命问题叠在一起:
① Server Action 暴露为 HTTP POST 端点
Next.js 的 Server Action 虽然在服务端执行,但本质上就是一个 HTTP POST 接口。任何人都可以直接构造请求调用,完全不需要前端页面。
② 无认证(No Authentication)
函数体内没有任何 session / auth 验证。谁都能调,无门槛。
③ 无 Rate Limit
没有任何频率限制。攻击者写个循环脚本,每秒能提交几百条。
④ 自动审核通过(Auto-Approve)
代码里 status: 'approved' 硬编码,提交即上线。垃圾内容直接出现在 Gallery 页面,不需要任何审核。
⑤ 用 Service Role Key 绕过数据库安全
代码用 Supabase 的 service_role key 操作数据库,完全绕过了行级安全策略(RLS)。虽然数据库开了 RLS,但 service_role 拥有 God Mode 权限,安全策略形同虚设。
五个漏洞叠加的效果:你家大门敞开,没有保安,没有门禁,来者自动发 VIP 卡。
而这段代码,恰恰是 AI 帮我写的。
当初我对 Cursor 说:"帮我写一个提交案例的功能"。AI 很快给出了代码——功能完整、类型正确、能跑。但完全没有考虑安全性。
而我看到代码能跑,就直接部署了。
这不是个例
▲ Veracode 2025 报告:测试 100+ 个 AI 模型,45% 的代码引入了安全漏洞
数据印证了这一点:
- Veracode 报告:分析 100+ 个 LLM 生成的代码样本,45% 存在安全漏洞,引入了 OWASP Top 10 安全问题
- Apiiro 研究:截至 2025 年 6 月,AI 生成代码每月引入 超过 10,000 个新安全问题,六个月增长 10 倍
- 常见漏洞类型:缺乏认证、硬编码密钥、SQL 注入、缺少输入校验、未配置 Rate Limit
AI 很擅长写"能跑的代码",但它默认不会帮你加认证、加限速、配安全策略。
除非你明确要求它这么做。
修复过程:一天迁移整个数据库
发现问题后,我和 AI Agent 墨码立刻开始修复。
第一步:堵住入口
- 关闭
submitCaseStudy的公开访问 - 给所有写入 API 加上 JWT 认证 + Rate Limit
第二步:全面安全审计
- 审查所有 Server Action 的认证状态
- 检查 Supabase RLS 配置——发现 case_studies 表虽然开了 RLS,但只有一条 SELECT 策略,没有 INSERT 策略。而代码用 service_role key 绕过了全部 RLS
- 检查 billing_customers、credit_balances 等敏感表——确认未被攻击者访问,攻击者只能通过 Server Action 写入 case_studies 表
第三步:数据库迁移(关键决策)
- 没有选择在原数据库上修补,而是直接把整个数据库从 Supabase 迁移到 Cloudflare D1
- 迁移 12 张表,只导入 261 条干净数据(260 条 approved + 1 条 pending),227 万条垃圾数据直接抛弃
- D1 版本完全重写了数据访问层,用 JWT 认证,不再有裸露的 Server Action
- 同步完成 CF Workers 部署,DNS 切换上线
第四步:服务器加固
- fail2ban 收紧(3 次失败封 24 小时)
- VNC 绑定内网 IP
- 环境变量文件权限改为 600
- 泄露的 API Key 全部轮换
从发现到完成数据库迁移和上线切换,总共花了约一天。
给用 AI 编程的你:写完代码多问一句
这次教训让我养成了一个习惯:
每次 AI 帮我写完一个功能,我都会追加一句:
"这段代码有什么安全隐患?帮我加上认证、Rate Limit 和输入校验。"
就这一句话,能避免 80% 的安全问题。
再具体一点,每次上线前检查这 5 件事:
1. API 端点有没有裸奔? 不需要认证就能访问的写入 API = 等着被刷。特别注意 Next.js Server Action——它本质是 HTTP POST,不是"服务端函数"。
2. API Key 有没有硬编码在代码里? 检查 .env 文件权限,确保 Key 不在 Git 仓库里,更不要出现在聊天记录里。
3. 数据库有没有正确配置权限? 用 Supabase 就开 RLS + 写好策略。用 service_role key 要极其谨慎——它能绕过一切安全策略。
4. 有没有 Rate Limit? 没有限速的 API,就是一个等着被刷的 API。
5. 有没有监控异常? 数据量突增、请求量突增——这些信号需要有人盯着。
用 OpenClaw 的朋友,多留个心眼
最近 OpenClaw 火了(GitHub 21 万星),越来越多人在自己的服务器上跑 AI Agent。
OpenClaw 本身的安全性很好——沙箱隔离、权限分级、Token 加密存储,这些基础设施层面做得扎实。但你用 OpenClaw 搭建的应用和服务,安全性取决于你自己。
这次被攻击之后,我把自己服务器上的安全配置全过了一遍,总结了几条实用建议:
1. .env 文件权限改 600
你的 OpenClaw 配置文件和环境变量里存着所有 API Key。运行 chmod 600 ~/.openclaw/*.json 和 chmod 600 .env,只允许当前用户读写。
2. 不要在聊天里发明文 Key
我这次就踩了这个坑——在 Telegram 里给 Agent 发了 Replicate API Key,结果被记录到了几十个文件里。正确做法是直接写进 .env 或用 openclaw config 设置。
3. 远程访问绑内网
如果你在服务器上跑 VNC、远程桌面或调试端口,一定绑到内网 IP 或 Tailscale 网络,不要暴露在公网。我之前 VNC 绑了 0.0.0.0,相当于全世界都能连。
4. 开 fail2ban
SSH 暴力破解是最常见的攻击手段。apt install fail2ban 一行命令,建议配置 3 次失败封 24 小时。
5. Agent 不要用 root 跑
给 OpenClaw 创建专用用户,限制文件系统访问范围。万一 Agent 被诱导执行恶意命令,损害范围可控。
6. 定期检查开放端口
运行 ss -tlnp 看看你的服务器对外暴露了哪些端口。数据库端口(5432、3306)、调试端口(9229、18800)绝对不应该对公网开放。
OpenClaw 给了你 10 倍的生产力,也意味着 10 倍的攻击面。Agent 能帮你写代码、调接口、操作数据库——如果权限没控好,攻击者也能通过 Agent 做这些事。
AI 编程让我们 10 倍速出活,但也让安全债务 10 倍速累积。
代码能跑,不代表代码安全。
希望你不用像我一样,等到收到黑客邮件那天才明白这个道理。
你用 AI 写代码时踩过安全的坑吗?评论区聊聊,我来回。
来源:juejin.cn/post/7608953699230384168
年过完了,该上班了,我用Compose给大家放个烟花喜庆喜庆
今年没有买烟花,但是看了不少别人放的烟花,有些烟花真的是好看,现在年也过完了,该放的烟花也全都放了,差不多要上班了,那么我也趁这个时候,用Compose做个烟花,为新的一年来个开门红
分析烟花特征
做动效前脑子里要有个具体目标的,想好自己要的是什么效果,而不是随意去做,那么今天要做的烟花需要具备以下几点
- 数量不限:谁家买烟花也不会买个单响,高低也得多放几个才看的过瘾
- 扩散:烟花升空了肯定要炸开,不会炸的叫信号弹
- 路径是抛物线:炸开后虽然速度很快,但因重力影响,方向会有改变,会呈抛物线形态
- 逐渐消失:火药在空中烧没了,烟花也就越来越小,越来越淡了,最后消失了
- 颜色不同:好看点的烟花每次放出来颜色都不一样,酷炫一点的单个烟花里面颜色也不一样
好了就这么多了,下面来一个个去实现它
数量不限
要做到数量不限,我的实现方式是每次在界面上点击一次,该位置就生成一个烟花,为此这里需要定一个烟花的模型
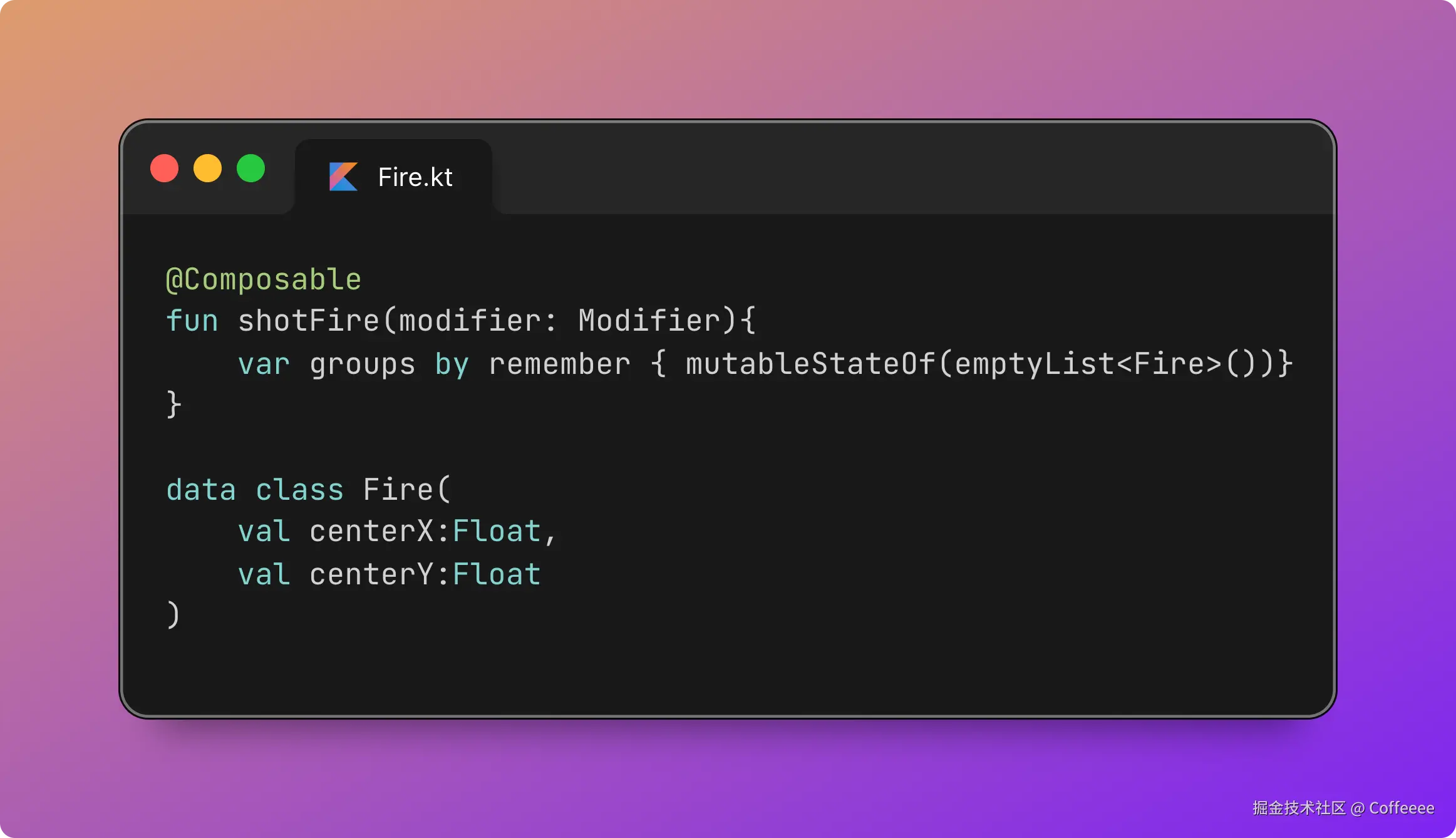
这个Fire里面现在只有坐标点,接着我们需要做的是在界面上每点一次,就创建一个Fire并且塞到groups中,监听点击的事件就交给onPointerEvent函数
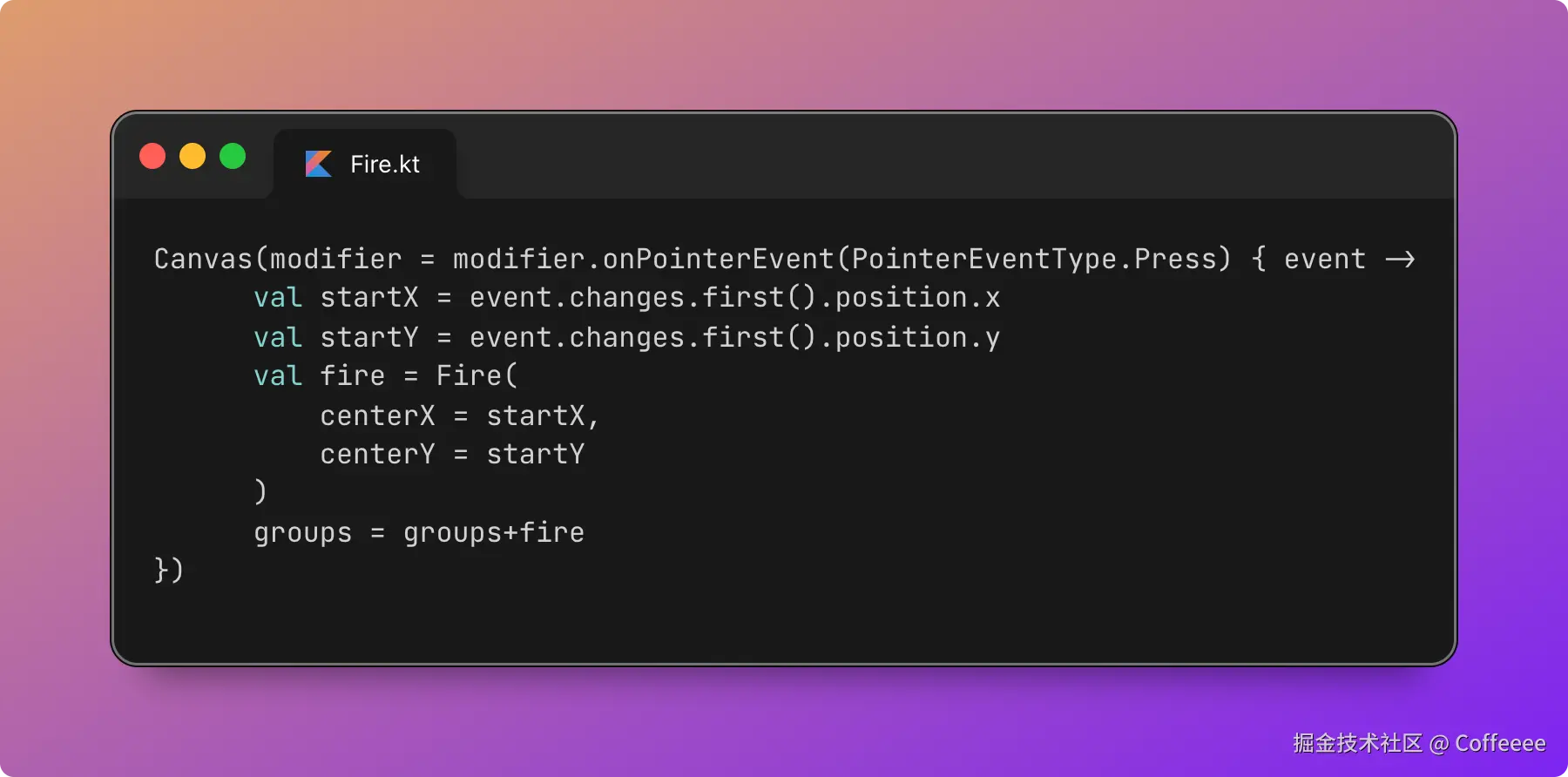
Fire的坐标是通过获取event.changes.first().position来拿到,表示当前点击的坐标,然后将groups里面的Fire绘制出来即可,暂时以红点表示
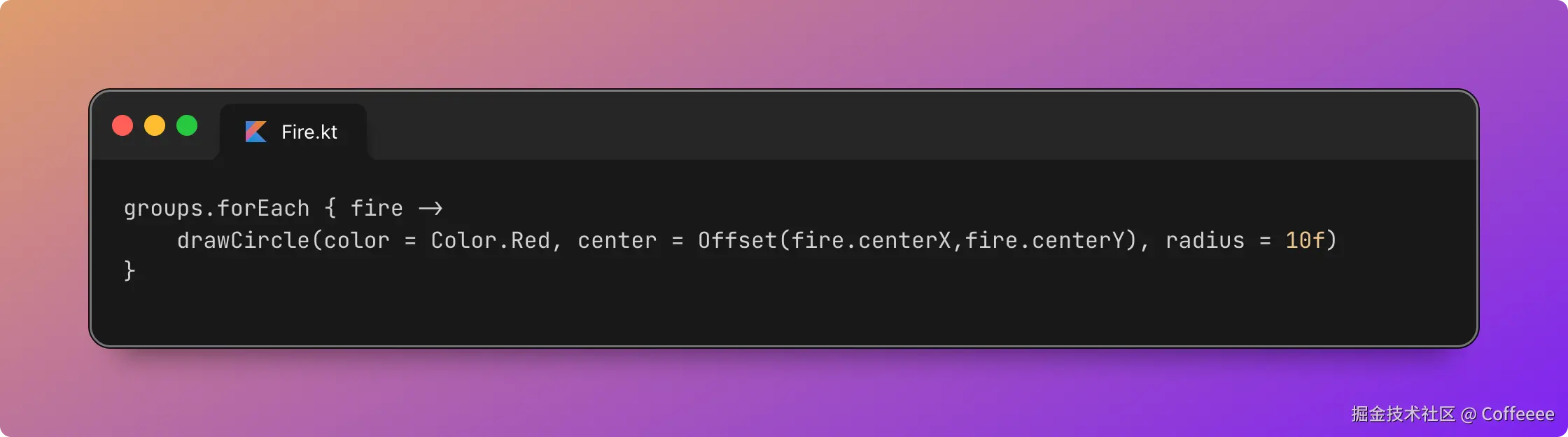
到这里,就实现了在界面上每次点击就生成一个红点的效果了

然后需要给Fire再添加个属性alpha表示透明值,用来降低每个生成后的红点的透明值,来达到淡化的效果
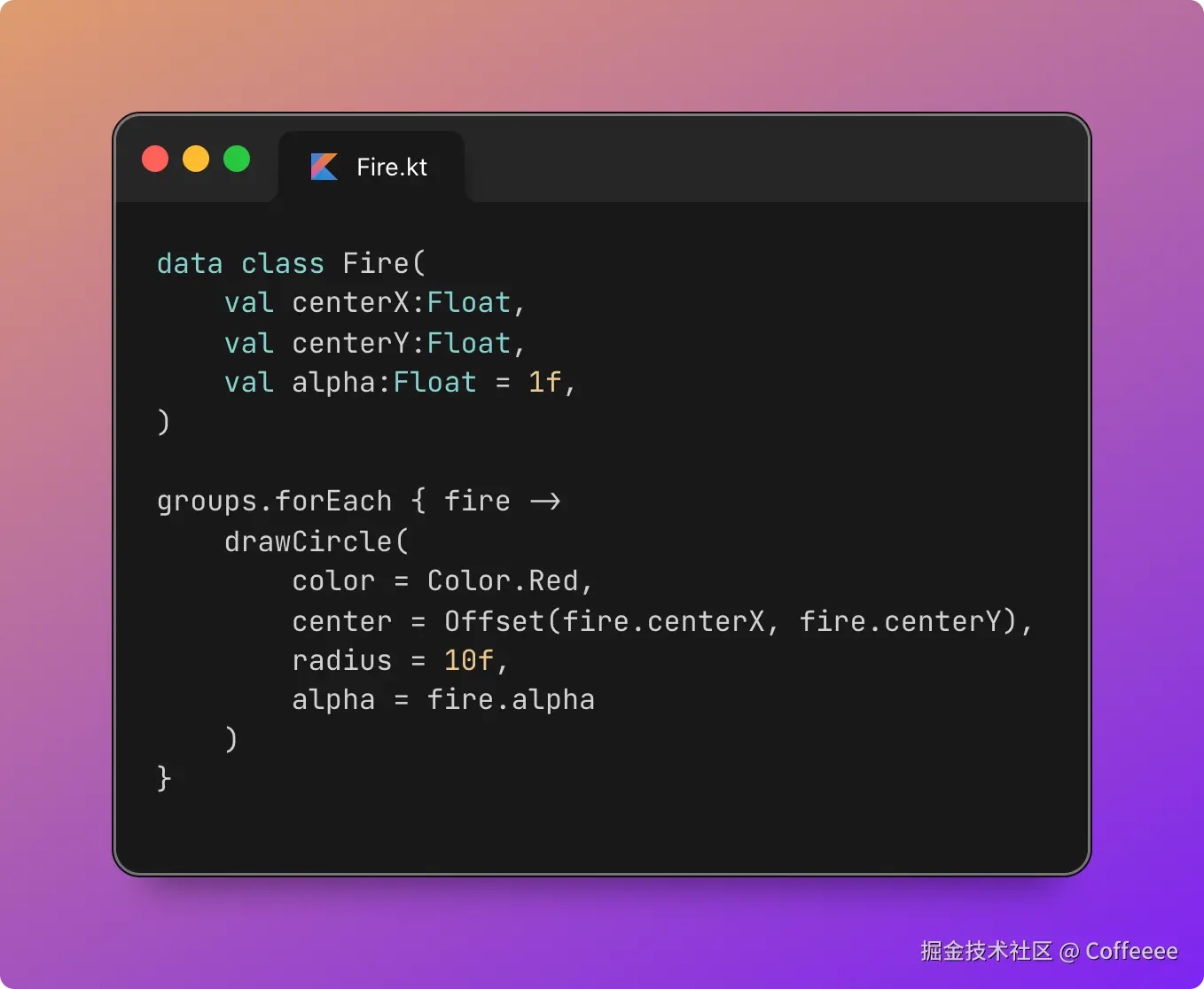
实现淡化就是不断降低透明度的过程,所以需要一个循环体,每一次降低的透明度用fadeSpeed来表示
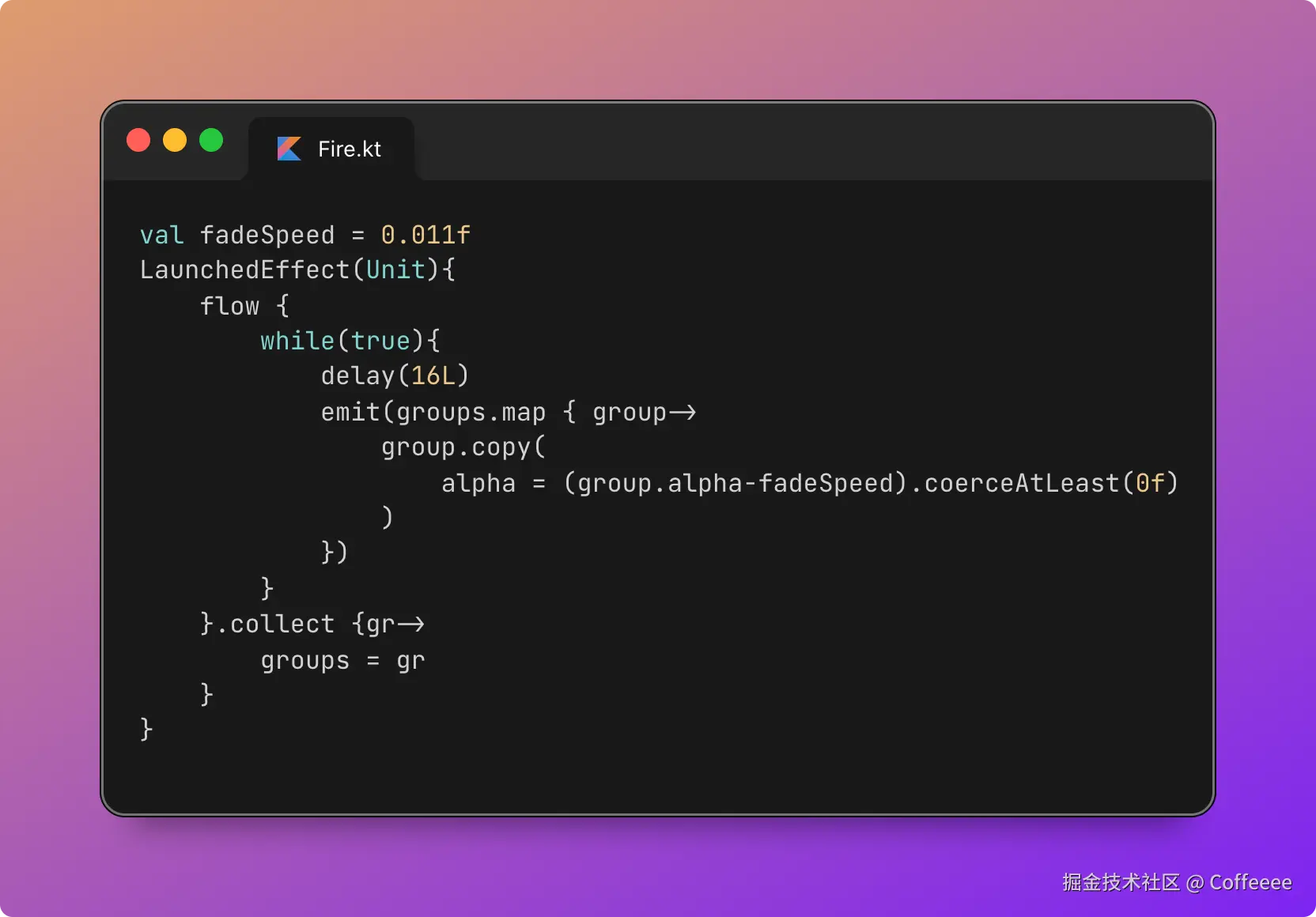
上游用来改变每个Fire的属性,下游用来将改变后的数组赋值给groups来触发重组,淡化的效果就出来了

扩散
之前画了一个点,表示烟花上升后炸开前的位置,那么接下去就是实现炸开的效果,也就是将现有的点扩散出去,那么不得不扩充一下Fire的属性,新增一个数组表示每个扩散分支的终点
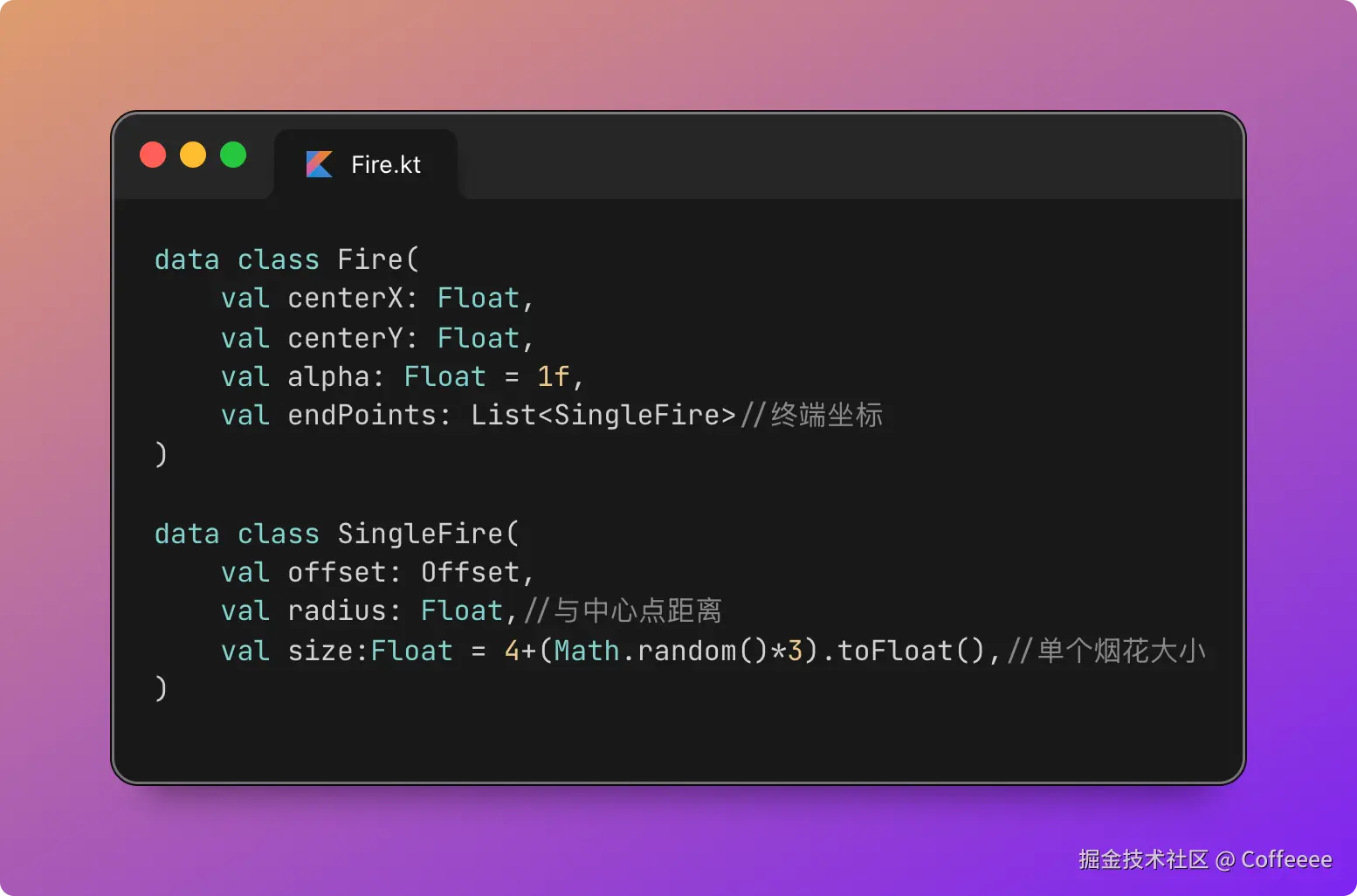
扩散分支endPoints里面每一个分支用SingleFire来表示,可以看到SingleFire内部暂时定了两个属性,offset表示终点坐标,radius表示与扩散中心点的距离,size代表每个分支烟花的粗细,默认设置了一个随机值,当点击的那一刻,endPoints也必须初始化出来,初始化的值就是以扩散中心为圆心,radius=0的圆周上的点,对了,还需要定义一个分支数目以及各个分支的角度
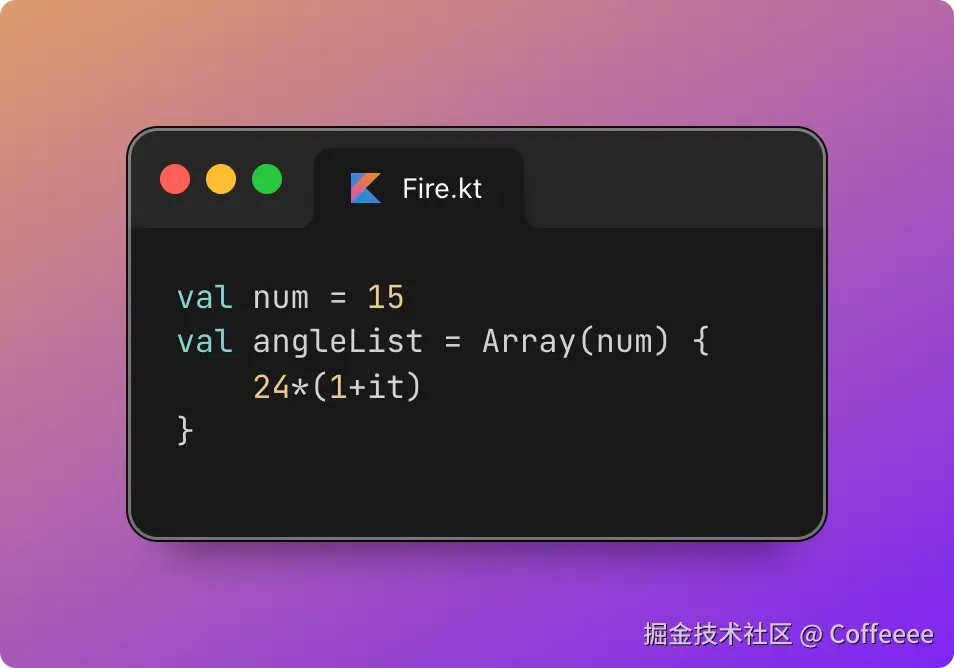
pointX与pointY是计算圆周上坐标的函数,在之前写的动效文章里面出场次数还是蛮多的,翻旧代码找来了,那么endPoints的初始值也有了
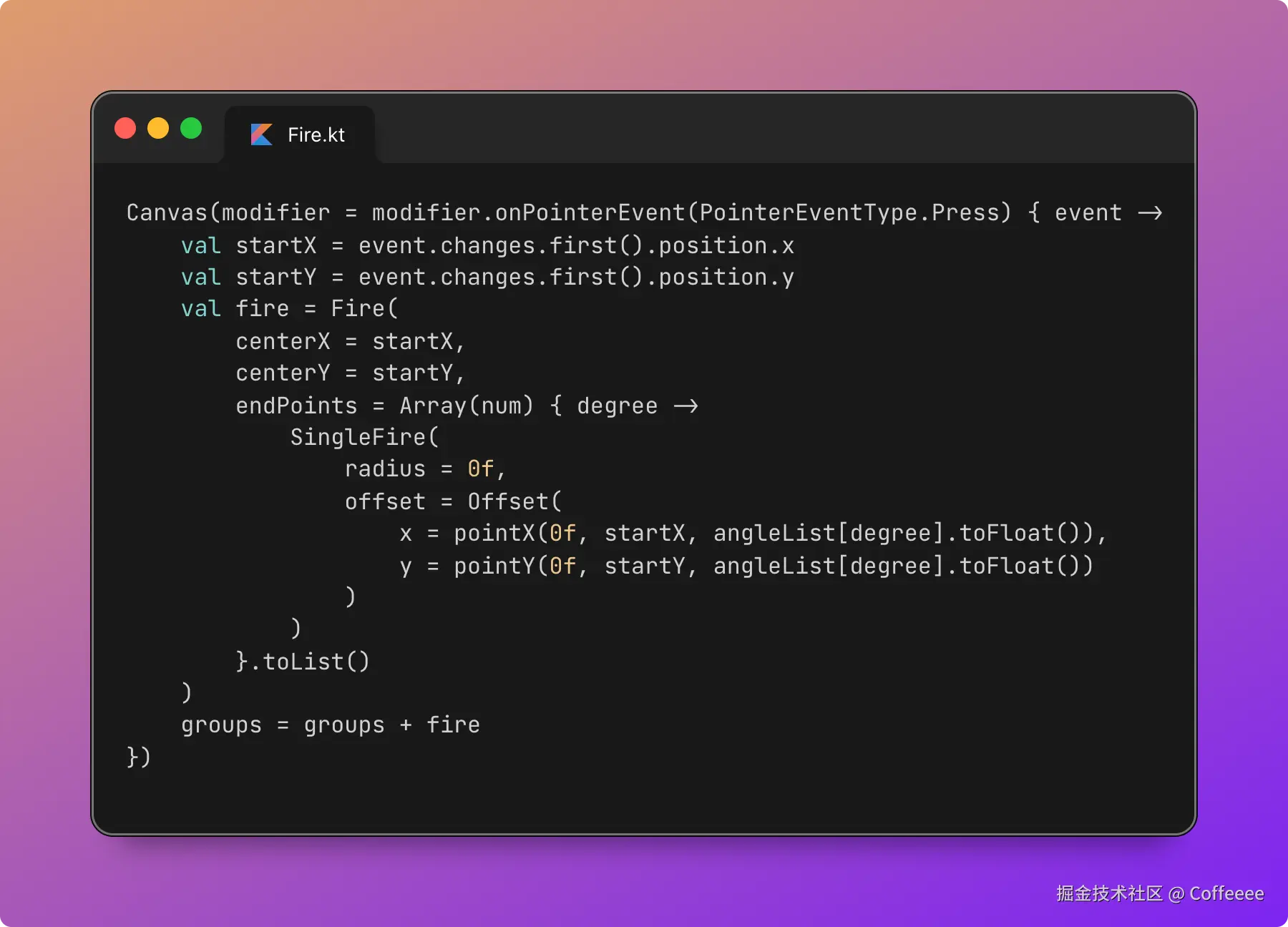
给endPoints赋值的地方就在LaunchedEffect里面,在改变透明值的同时,也增加radius的大小
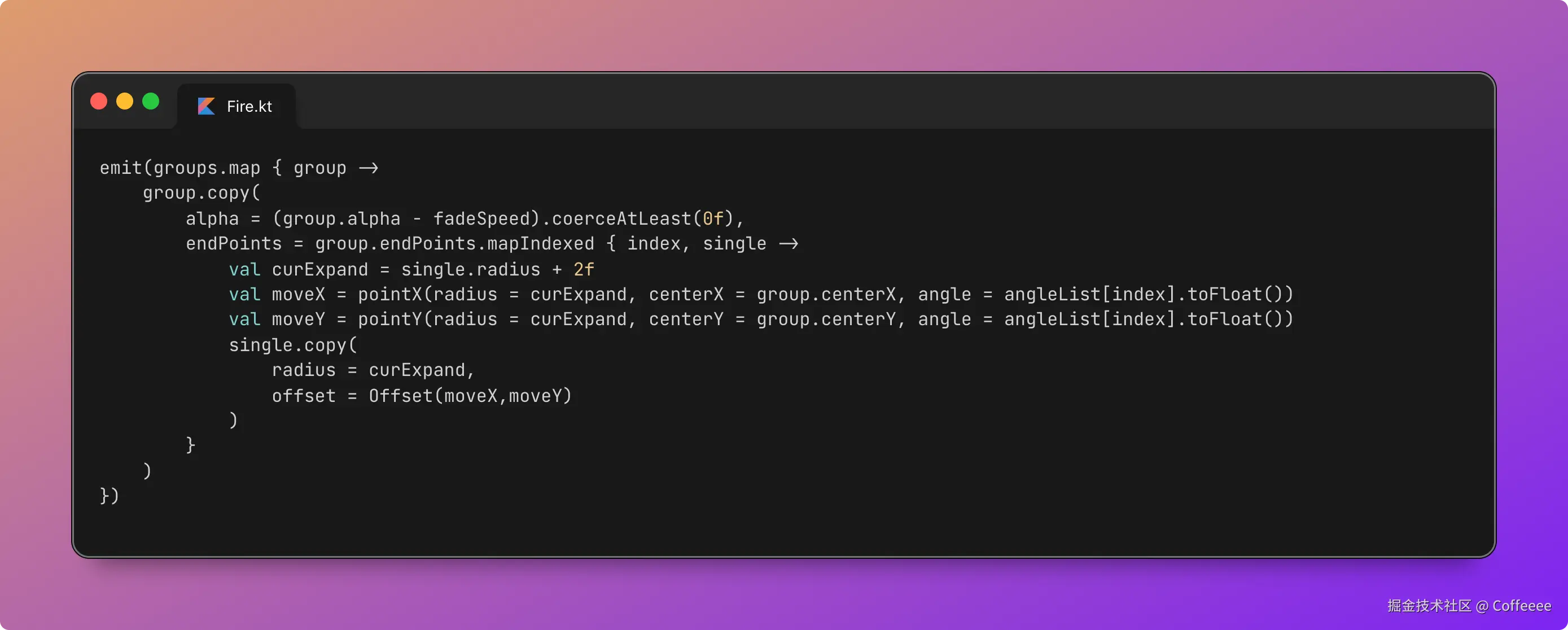
一边增加扩散的半径,一边将分支给绘制出来,绘制的代码要改下,从drawCircle改成drawLine,drawLine的参数值我们都能拿得到
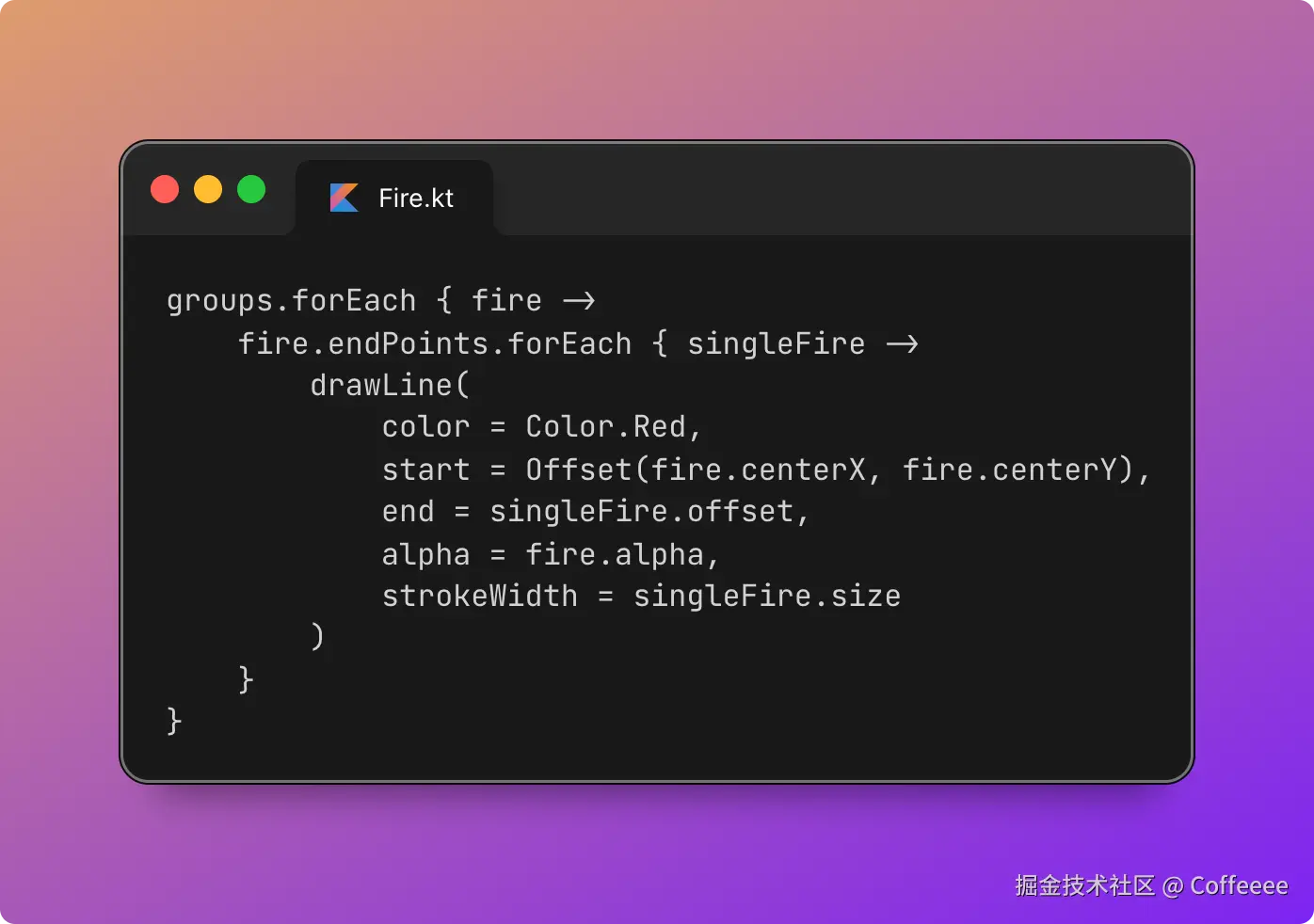
这样我们的扩散效果也基本完事了

抛物线路径
现在该想想怎么让烟花扩散的每条路径呈现抛物线的样式了,首先一点是肯定的,刚用过的drawLine肯定是不能用了,它画不了弯的线,那么谁可以画弯的呢,必须是drawPath,用它来画贝塞尔曲线真是太顺手了,咱先在SingleFire里面把用来绘制贝塞尔曲线用到的Path声明出来
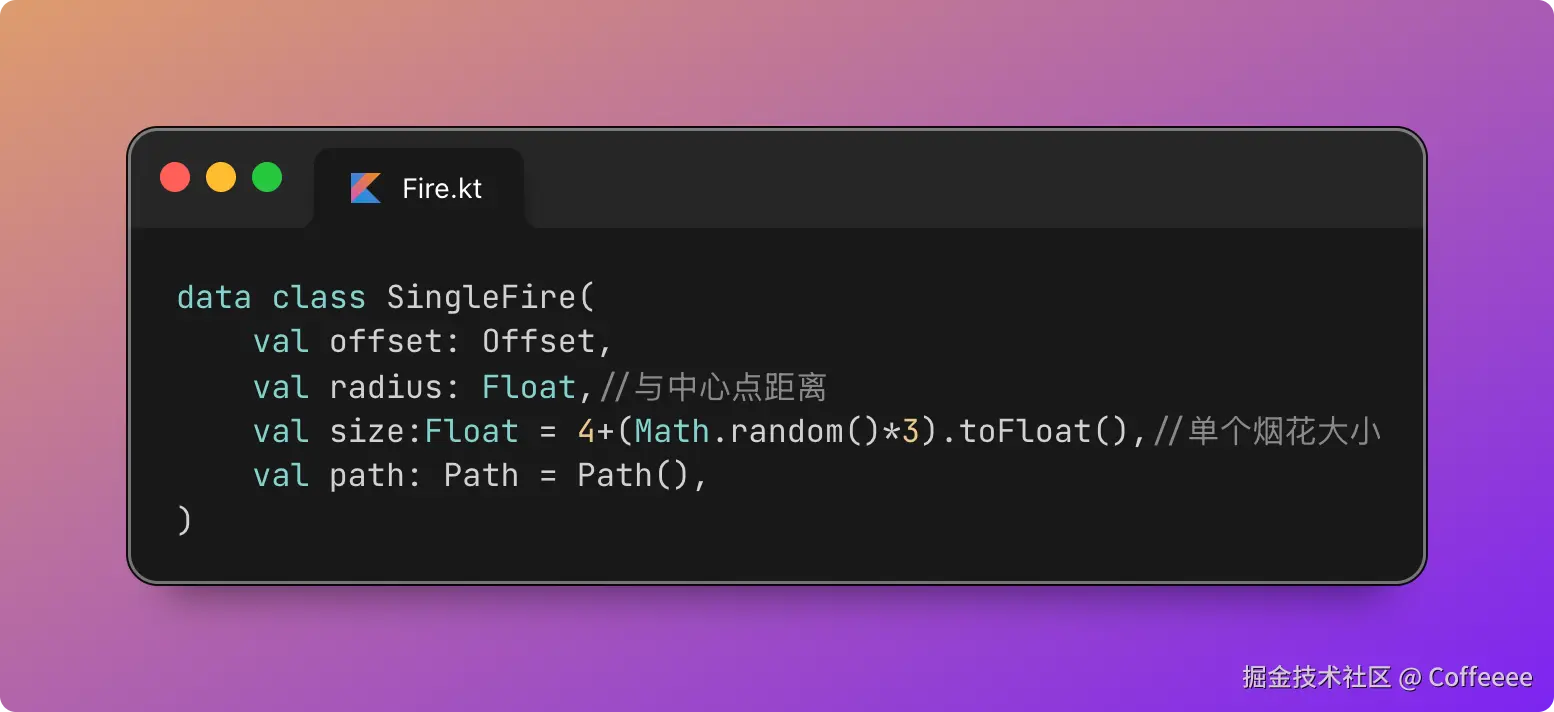
在副作用LaunchedEffect函数中,需要新增创建Path的逻辑,其中第三个控制点的值暂时与第二个点一致,代码如下
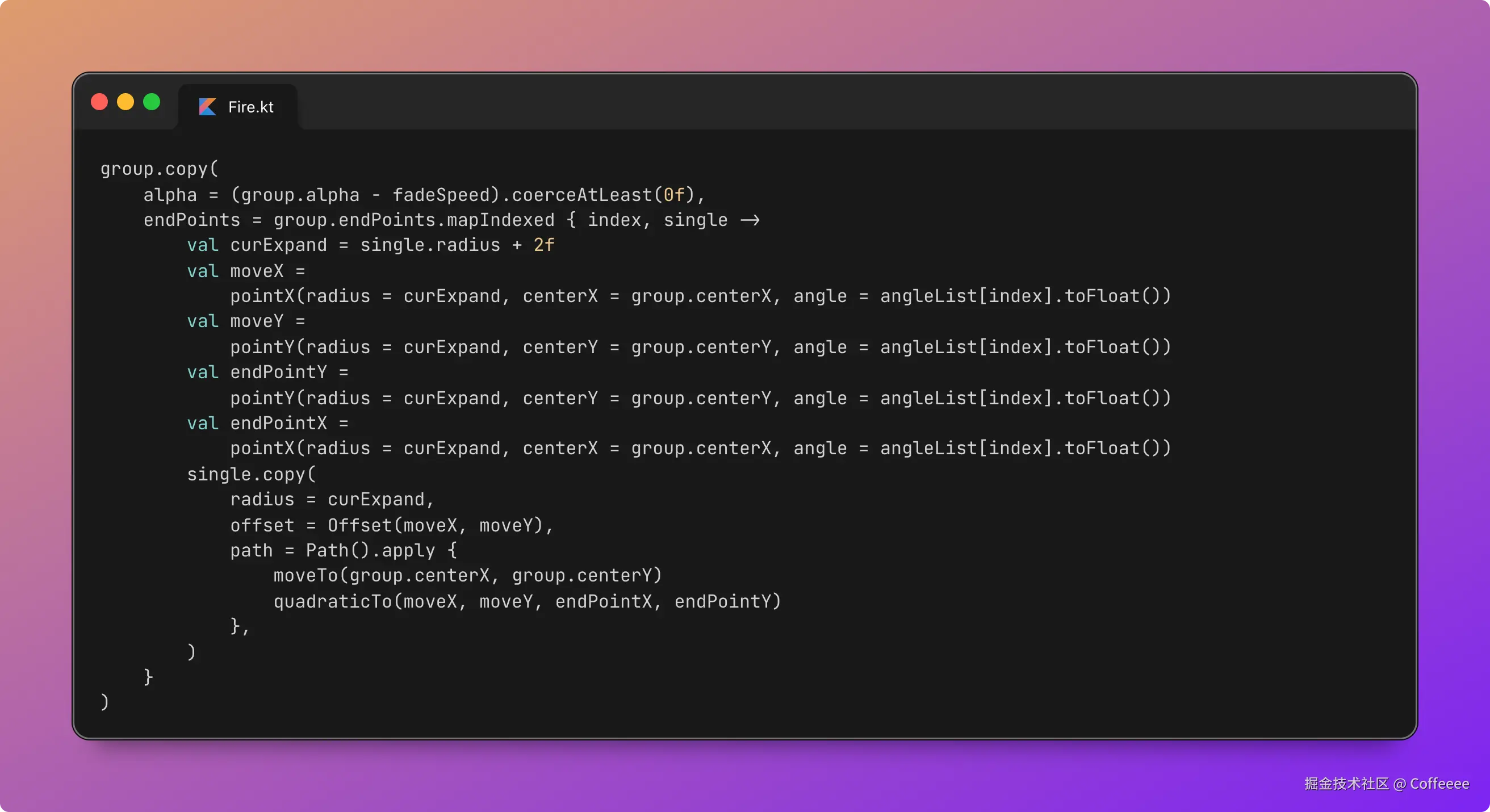
最后在drawScope中,使用drawPath将需要的贝塞尔曲线绘制出来
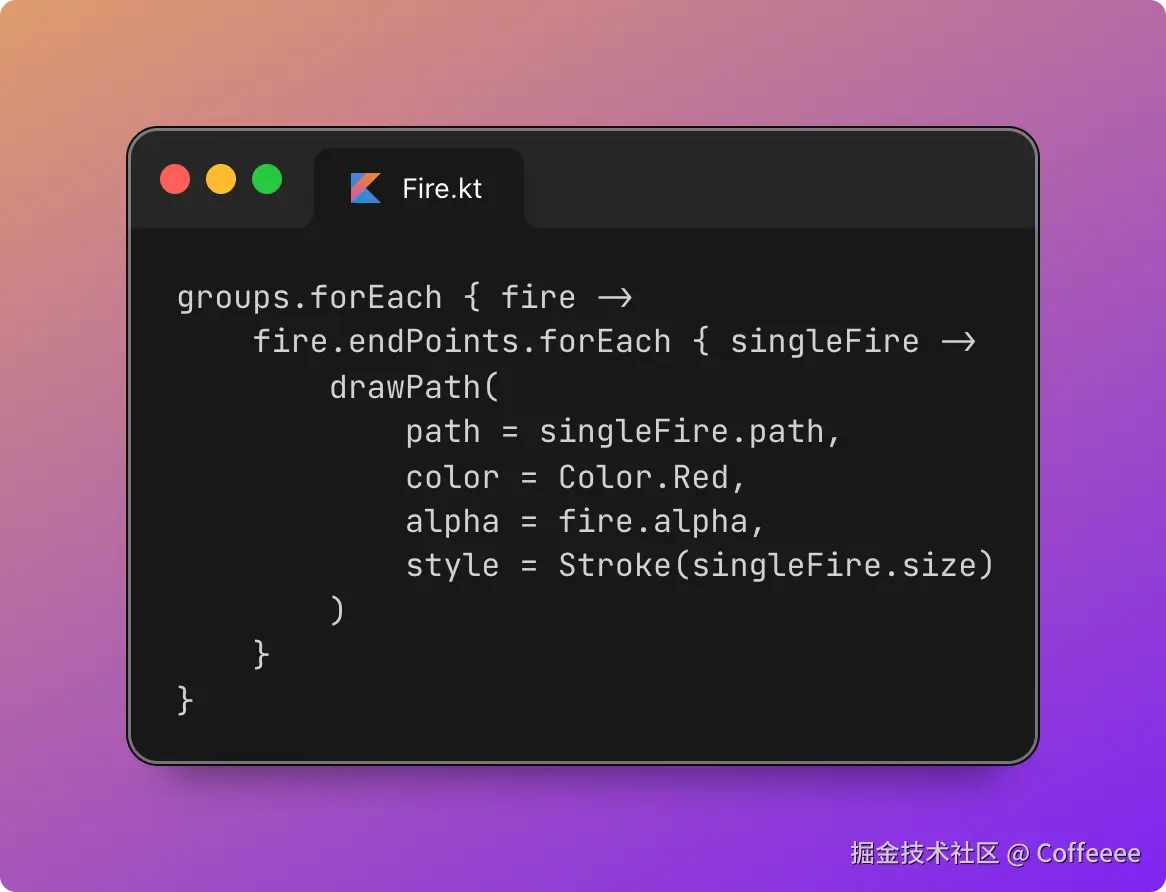
呈现的效果如下

看起来效果没啥变化,没变化就对了,因为组成我们每根烟花分支的Path目前基本在一条直线上,自然绘制出来的贝塞尔曲线也是直线,只需要将第三个点改个位置就行,怎么改呢?我们知道所有第三个点也都在一个圆周上,所计算的角度与第二个点是一样的,只需要将第三个点的角度稍微增加或者减少一些,那么所有的点的位置就改变了,比如都加个30度
那么现在的样子就不一样了

好了,现在来做两个调整,一个是抛物线拐弯的弧度,应该也是个逐渐增大的过程,扩散的瞬间,其实弧度就是0,然后受重力逐渐变大,那么在SingleFire里面需要一个属性来表示抛物线弧度的属性
sweepDegree就表示当前抛物线的弧度,改变的过程其实可以参考透明度或者扩散半径那样做
另一个调整,这个烟花现在有点“顺拐”,现在抛物线拐弯的弧度都是按照顺时针来的,但实际场景中,烟花是朝四周扩散的,我们这个二维空间里面,也应该是有左右两个方向,所以不应该所有的弧度都是加上degree变量,其实想想也明白,真的要加上degree的是那些x坐标比初始值大的点,其他的都应该要减去degree才行,代码按照这个逻辑稍作调整
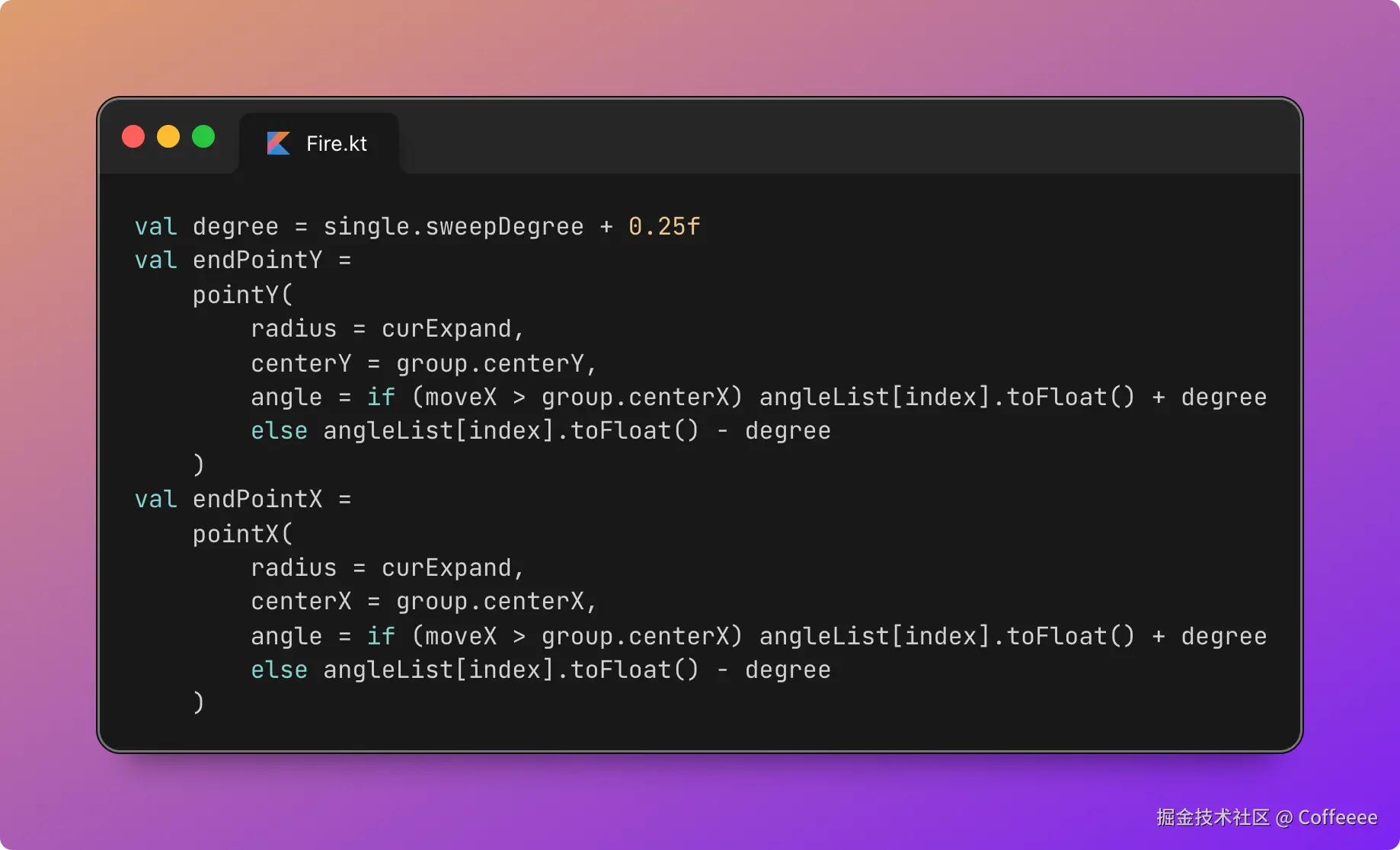
我们要的抛物线效果就做好了,效果看下

逐渐消失
烟花消失的样子也可以分成两部分,其中一个是炸开后从中心向外开始消失,所以我们做的烟花的起始位置就不能是一个点了,而是num个点,也在一个圆周上,这些点的起始半径也都为0,在SingleFire中新增一个startRadius属性代表这个半径
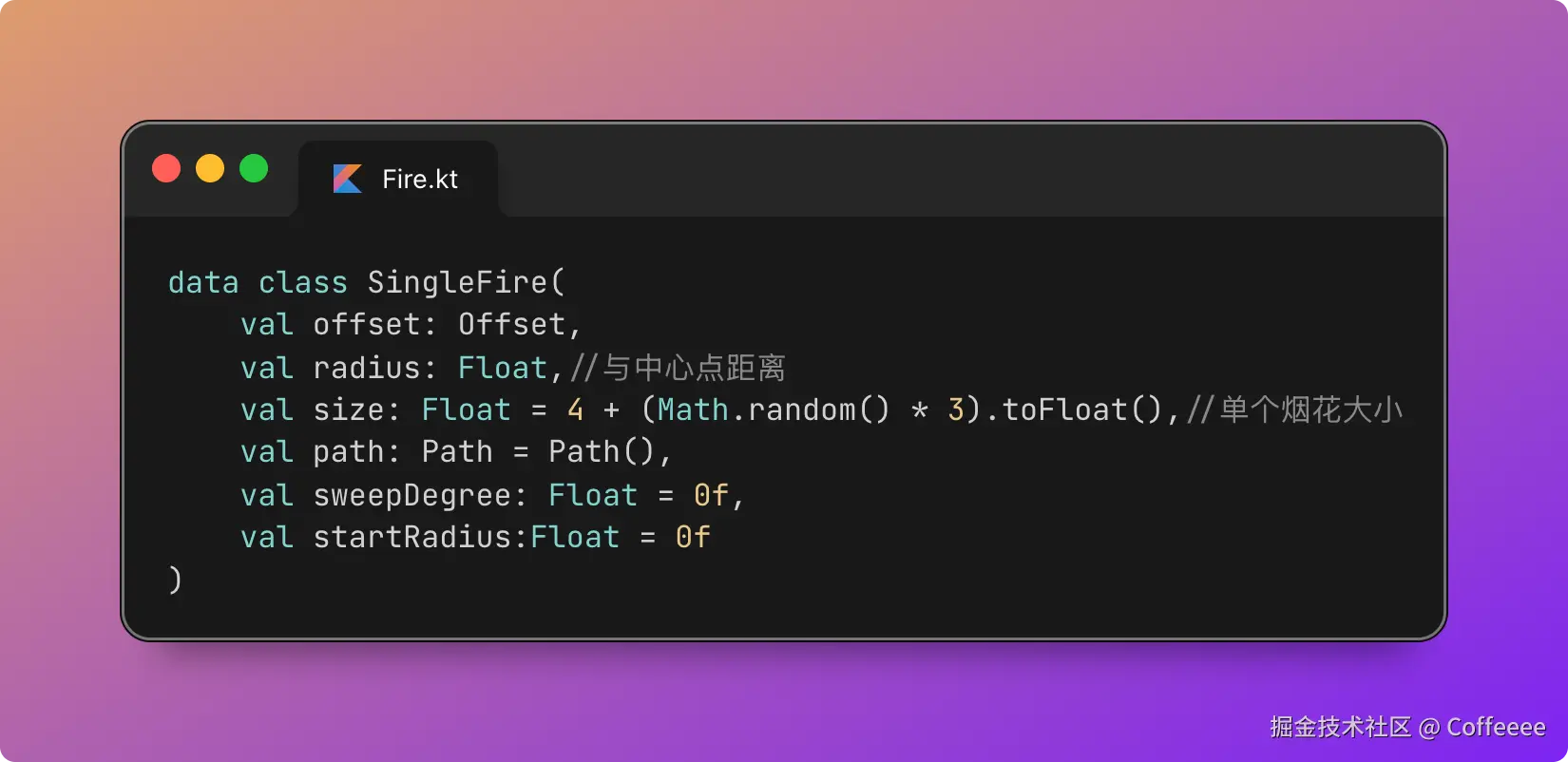
同样在副作用中,逐渐去变大这个startRadius,然后将最新值拿来计算最新圆周上的点,代码如下
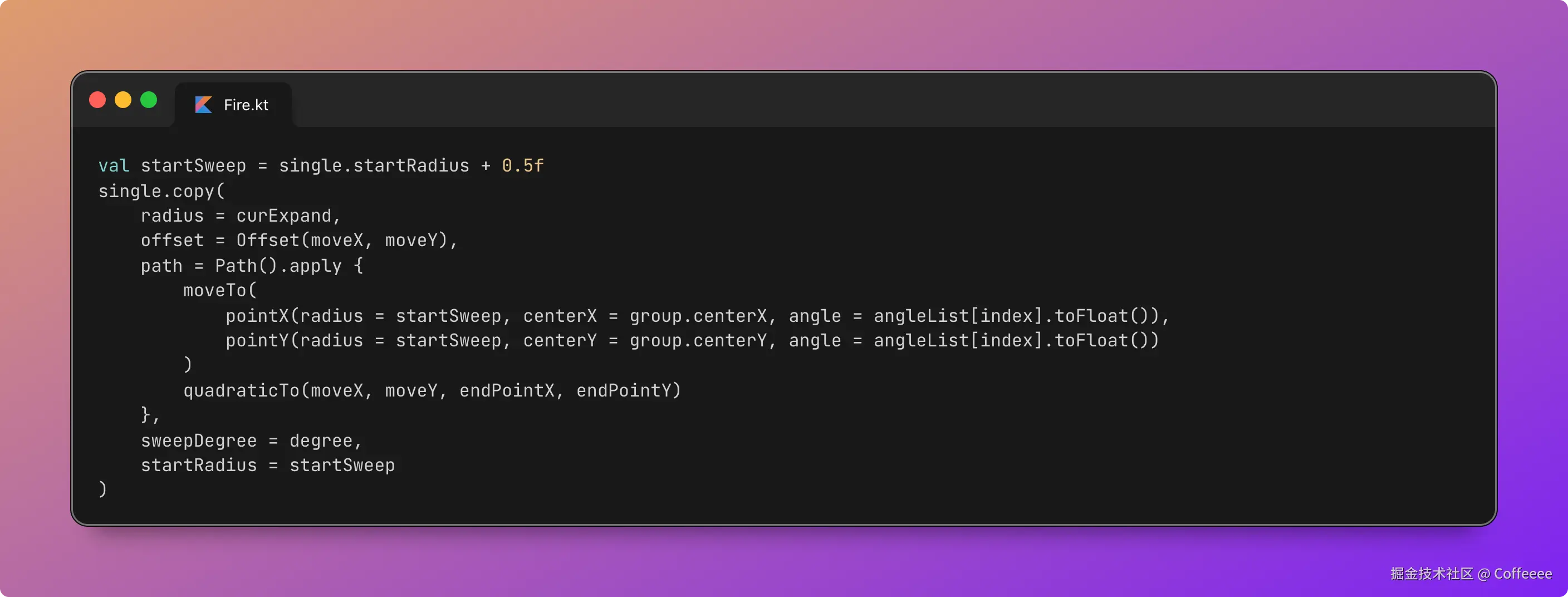
另一个要处理的是烟花每一条曲线上,当开始消失的时候,不是整根曲线一起消失,而是会分成若干个小火星,然后小火星也慢慢变小变暗,要做到这一点就要用到一个关键型函数
PathEffect.dashPathEffect,用来将一根线变成一根虚线的,这个函数里面第一个参数就是个float数组,数组里面会传两个值,分别代表虚线每一个线段的长度以及虚线之间的间距

而我们要做的就是将float数组中第一个值不断减小,第二个值不断变大,SingleFire中再定义两个属性代表线段长以及间距长
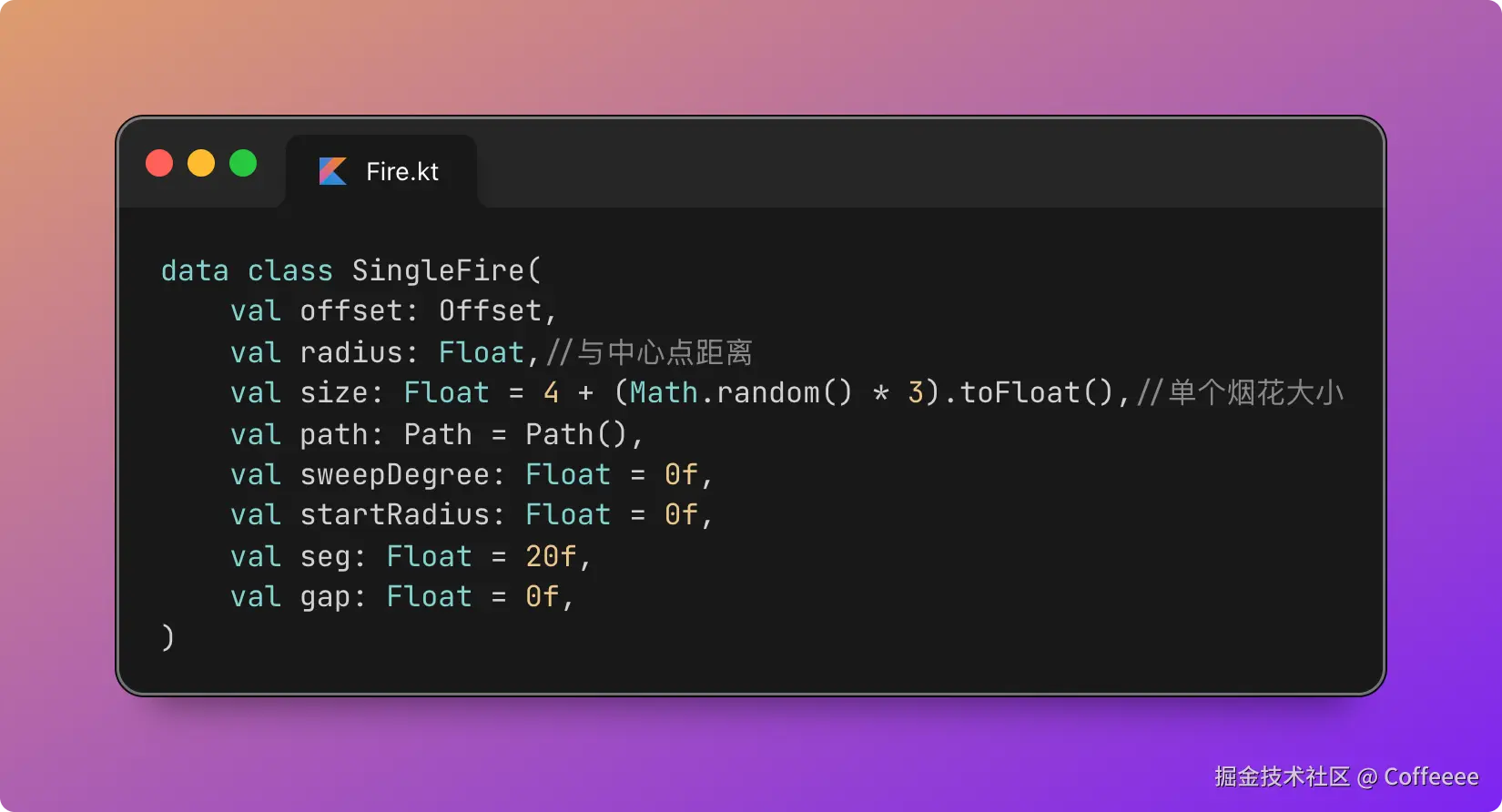
副作用里面的代码做如下更改

然后在drawPath中添加上PathEffect.dashPathEffect的处理
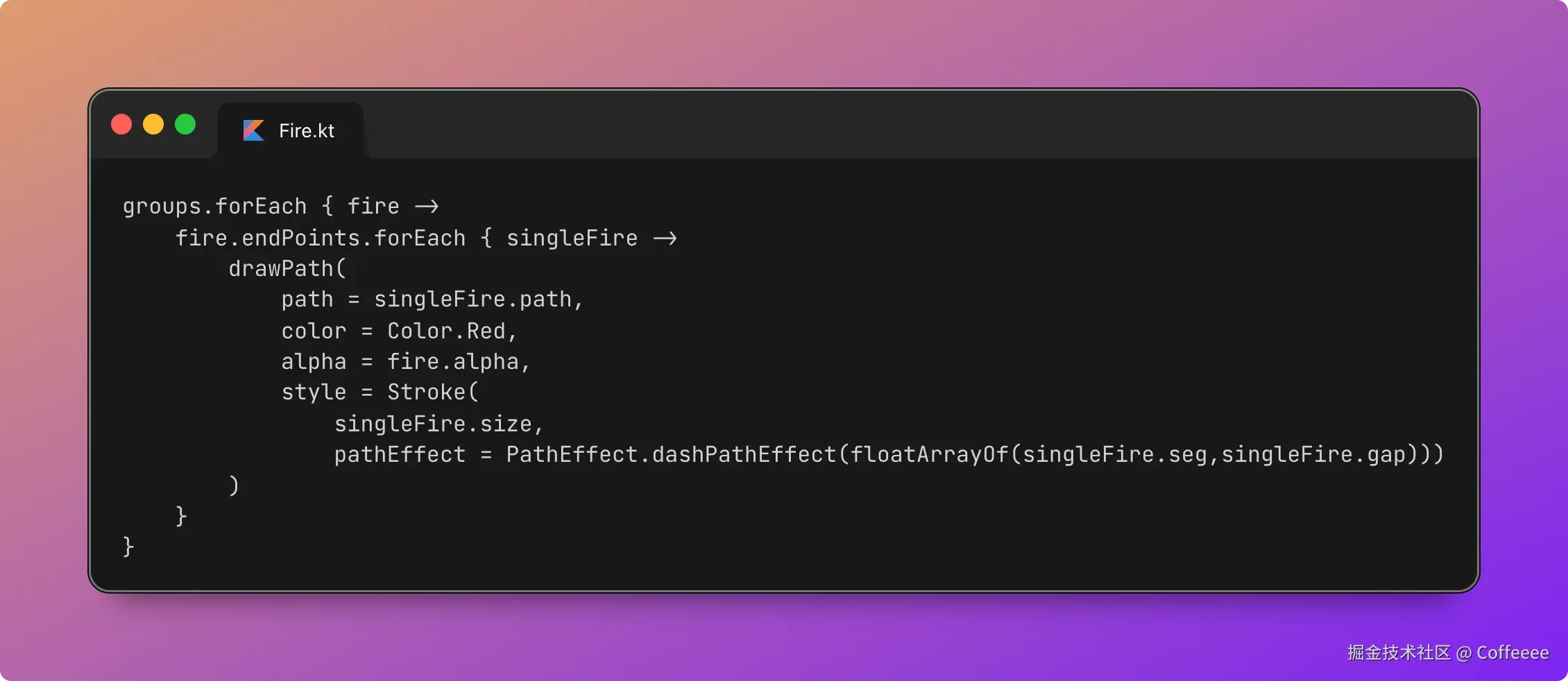
烟花消失的部分也做好了,看下效果

不同颜色
到了最后一步了,给烟花上色,正常放烟花的时候,每次放出来的烟花颜色都会不一样,而且单个烟花中颜色也不是只有一种,所以这里打算这么做,先弄一个颜色的数组

然后在给烟花初始化的时候,每一次都从这个数组中随机抽三个颜色组成一个新的数组,我们烟花每一个分支的颜色,都从这个新的数组中随机找一个来设置,先给SingleFire再添加一个color属性
初始化部分,通过shuffled函数把colorList打乱,再抽取最后三个颜色
赋值部分,shuffList中随机拿一个颜色出来赋值
绘制部分,使用Brush生成一个渐变色,singleFire.color与白色的渐变,这样可以让烟花看起来亮一些
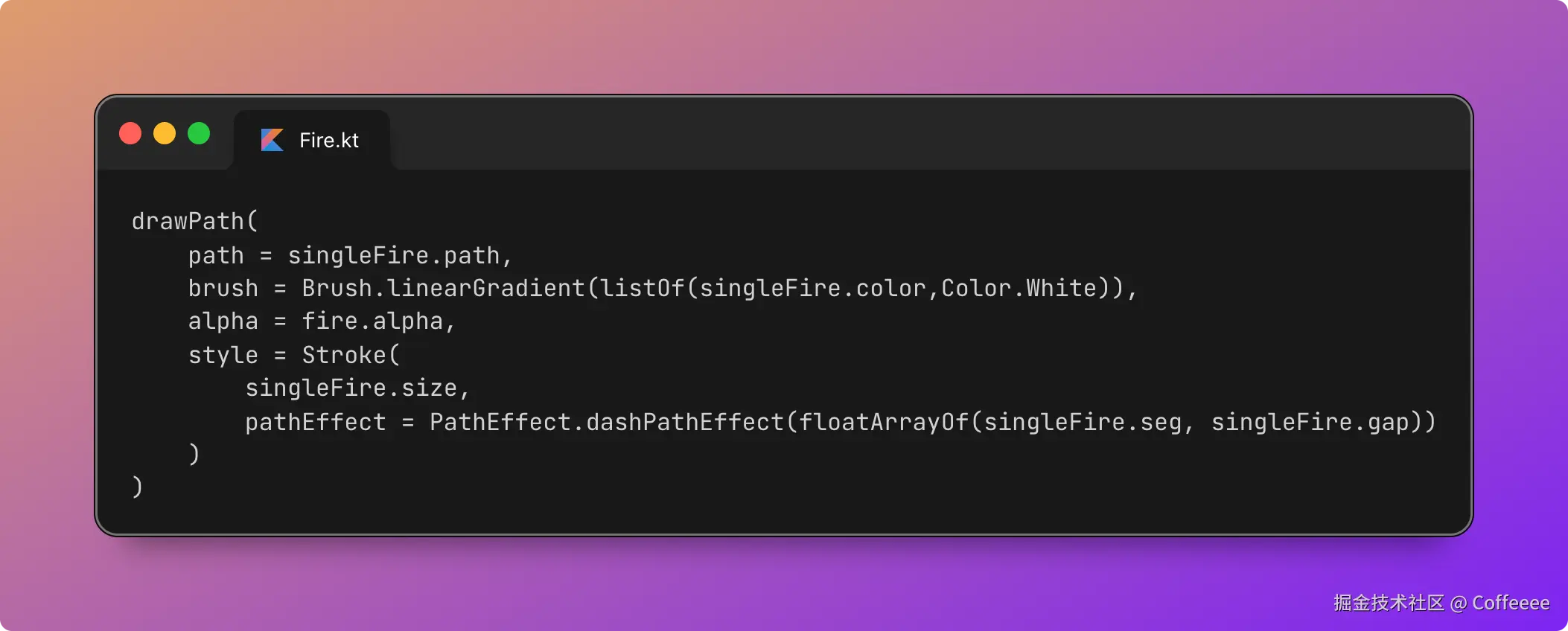
看下最终效果

最后
烟花放完了,又要开始重新搬砖当牛马了,那我就借这篇烟花动效的文章祝各位看官在新的一年工作顺利,事业有成,天天发大财~
来源:juejin.cn/post/7609288132602101760
写给年轻程序员的几点小建议
本人快 40 岁了。第一份工作是做网站编辑,那时候开始接触 jQuery,后来转做前端,一直做到现在。说实话,我对写程序谈不上特别热爱,所以技术水平一般。
年轻的时候如果做得不开心,就会直接 裸辞。不过每次裸辞的那段时间,我都会拼命学习,这对我的成长帮助其实很大。
下面给年轻人几点个人建议:
- 不要被网上“35 岁就失业”的说法吓到。很多人是在贩卖焦虑。我都快 40 了还能拿到 offer,只是这些 offer 薪资不到 30K。
- 基础真的很重要。我靠着基础吃香了十几年,在公司里也解决过不少疑难问题,深得领导器重。就算现在有 AI,你也要有能力判断它写得对不对,还要知道如何向 AI 提问。
- 适不适合做程序员,其实几年之后就能看出来:你能不能当上 Leader,或者至少能不能独当一面。如果你觉得自己确实不太适合,可以趁早考虑转行,或者下班后发展一些副业。大千世界,行行出状元,能赚钱的行业很多,不必只盯着程序员这一条路。
- 如果你觉得自己资质一般,但又真的喜欢写程序,那也没关系。《刻意练习》这本书里提到,一个人能不能成为行业顶尖,关键在于后天练习的方式,而不是天赋本身。
- 程序员做到后面,最大的挑战其实是身体机能,而不是技术。一定要多锻炼身体。在还没有小孩之前,尽量把自己的技术水平拉到一个相对高的位置。结婚有家庭之后,学习时间会明显减少,而且年龄增长、抗压能力下降,而程序员本身又是高度用脑的职业。如果你的技术储备够高,就能在一定程度上缓冲项目压力,让自己工作更从容。
- React、Vue、Angular 等框架都可以尝试做做项目。不同框架背后的设计思路,对思维成长很有帮助。前端很多理念本身就借鉴了后端的逻辑,多接触不同体系,会让你看问题更立体。
- 可以在 GitHub 上做一些开源小项目。素材从哪里来?其实就来自你在公司做过的项目。把其中一块通用能力抽出来,沉淀成一个独立组件或工具库,再整理发布到 GitHub。与此同时,多写一些技术文章进行总结和输出。等到找工作时,简历里可以写上类似 "全网阅读量几万+" 这样的成果展示,这些都会成为你的加分项,让你在竞争中更有优势。
- 35 岁以上,竞争力通常体现在两个方向:要么技术水平足够强,能够解决复杂问题;要么具备一定的管理能力,能够带团队。有人说那我以前就带过一两个徒弟,怎么办,那你得学会包装,你懂得,哈哈。
- 35 岁以上,面试对技术广度要求更高,所以不要太深入挖掘某一项技术了。我以前认识一个领导,虽然写代码能力一般,在公司已经不写代码了,但是他的技术广度比较好,业务能力还行,虽然 40岁了 还能跳槽到比较好的广告公司,而不是靠人脉,不得不佩服。
- 打工人比较麻烦的事就是 简历太"花"。频繁跳槽,在一个公司没干几个月就走,或者长期待业太久。如果岗位需要背调,简历造假会很麻烦,虽然有些小公司或外包公司不做背调。所以这方面简历自己要想想办法,你懂得。
- 另外要认清一个现实:单纯打工,很难发财。 这件事越早想明白越好。多读一些关于认知、资产配置的书,弄清楚什么是资产,什么是消费。哪怕这些认知在你有生之年未必能带来巨大财富,也可以传递给下一代,让他们少走弯路。
以上只是个人经历和感受,不一定适用于所有人,但希望能给年轻的你一些参考。
来源:juejin.cn/post/7606155928197070900
分享前端项目常用的三个Skills--Vue、React 与 UI 核心 Skills
前言
在过去的几年里,前端开发经历了从手写每一行 HTML/CSS 或使用组件库(Ant Design, Element Plus),到 AI 辅助编程(GitHub Copilot, Cursor)的巨大跨越。然而,2025 年以来的技术浪潮正将我们推向一个新的阶段:从 “AI 辅助” 向 “AI Agent(智能体)” 转型。
在这种模式下,开发者不再只是接收代码建议,而是为 AI 提供一系列“技能包(Skills)”,让 AI 能够理解复杂的框架逻辑、项目结构乃至视觉审美。
什么是Skills? 用一句话概括就是: Skills = 领域专业知识 + 你的项目偏好 + 严厉的审查官。
1. 为什么需要 Skills?
在 AI 编程的语境下,Skills 的出现是为了解决大模型(LLM)“博而不精”的天然缺陷。
1.1 通才 AI:知识的“图书馆”
一个没有安装 Skills 的大模型(如 GPT-5 或 Claude 4.5)就像一个读过全世界所有代码的毕业生:
- 广度惊人:它知道几百种编程语言,甚至能背出 2014 年的过时语法。
- 深度断层:它不知道你公司内部的封装规范,不知道你的组件命名习惯,更不知道你项目中那个“不能动的老 Bug”。
- 执行模糊:给它一个需求,它会从 100 种可能的解法中随机选一个给你,不管这是否符合你现在的工程环境。
1.2 专才 AI:自带“十年工龄”的骨干
安装了 Skills 的 AI(Agent),则完成了从“大模型”到**“领域智能体”**的进化:
安装了 Skills 之后, 它不再是那个满嘴跑火车的机器人,而是一个被你强制要求“必须按这套规约写代码”的资深开发。
| 特性 | 通才 AI (Generalist) | 专才 AI (Specialist with Skills) |
|---|---|---|
| 思维边界 | 无边界,容易产生幻觉 | 有界思维:严格锁定在当前技术栈内 |
| 项目理解 | 盲人摸象,只看当前文件 | 全局视野:理解路由、状态管理、样式体系 |
| 输出质量 | “大概能跑”的代码 | **“符合工程直觉”**的生产级代码 |
| 角色定位 | 知识检索器 | 虚拟技术负责人 (Virtual Lead) |
2. Skills 里面到底装了什么
一个 Skills 文件夹里通常不是深奥的代码,而是三样东西:
- 规约(Rules) :一堆告诉 AI “准许做什么”和“严禁做什么”的指令(通常是
.cursorrules或.md文件)。 - 上下文(Context) :你项目的特殊结构。比如你的路由写在哪里,你的接口是怎么封装的。
- 工具(Tools) :一些自动化的小脚本。比如 AI 写完代码后,自动运行一下
npm lint检查有没有写错。
如果说通才 AI 提供的是“概率” (它觉得这段代码看起来像对的),那么 Skills 提供的就是“确定性”。它把行业内顶尖架构师的经验,封装成了 AI 触手可及的“条件反射”。
本文将分享前端高频使用的三个核心技能包:vue-skills、react-skills(agent-skills)以及 ui-skills(uipro-cli),剖析它们如何通过标准化的指令集,彻底改变我们的开发流。
Vue-Skills
Vue-Skills涵盖了 Vue 3 项目的最佳实践、TypeScript 类型安全增强、IDE 性能优化以及现代 Vue 编码模式。它们旨在解决大型 Vue 项目中常见的开发痛点,如 IDE 卡顿、类型推断错误、构建配置以及代码可维护性问题。
1.1 核心规则
可以将这些规则概括为以下 5 个主要方面:
1. 开发体验与 IDE 性能优化 (IDE & Performance)
关注如何解决大型项目中 VSCode 和 Volar 插件的性能问题。
- codeactions-save-performance.md: 解决在大型 Vue 项目中保存文件时耗时过长(30秒+)的问题,建议禁用或限制耗时的 Code Actions。
- volar-3-breaking-changes.md: 针对 Volar 升级带来的变更进行适配,确保插件功能正常。
- vue-directive-comments.md: 介绍了@vue-ignore, @vue-skip,@vue-expect-error等指令注释,用于在模版中精细控制类型检查行为(类似 @ts-ignore)。
2. TypeScript 类型安全与配置 (Type Safety & Configuration)
致力于提升 Vue 模版和组件的类型检查严格度,减少运行时错误。
- vue-tsc-strict-templates.md: 推荐开启 strictTemplates,在编译时捕获模版中未定义的组件和属性错误。
- vue-router-typed-params.md: 解决unplugin-vue-router,导致的路由参数类型丢失问题(Property does not exist),推荐更严格的路由参数类型定义。
- data-attributes-config.md: 配置 vueCompilerOptions 以支持
data-*属性的类型检查,避免误报类型错误。 - ** module-resolution-bundler.md**: 推荐在 tsconfig.json 设置 "moduleResolution": "bundler"
以适配现代构建工具。 - with-defaults-union-types.md: 修复在defineProps中使用联合类型(如 string | false)配合withDefaults 时的虚假警告问题。
3. Vue 3 现代编码模式 (Modern Patterns)
推广 Vue 3.4+ 的新特性及更优雅的代码组织方式。
- define-model-update-event.md: 推荐使用 Vue 3.4 的 defineModel()宏,替代手写的props+ emit('update:modelValue')模式。
- extract-component-props.md: 建议将复杂的defineProps类型提取为独立的 TS 接口,提高代码可读性和复用性。
- script-setup-jsdoc.md: 规范
<script setup>中的 JSDoc 使用,增强组件文档和类型提示。 - fallthrough-attributes.md: 关于 inheritAttrs: false和透传属性(Attributes Fallthrough)的最佳实践。
4. 运行时陷阱与调试 (Runtime Caveats & Debugging)
解决特定场景下的怪异 bug 和运行时问题。
- deep-watch-numeric.md: 警告在侦听(watch)数字数组时使用 deep: true的陷阱(新旧值相同),建议使用深拷贝。
- duplicate-plugin-detection.md: 防止 Vue 插件(如 Pinia)在微前端或特定环境下被重复注册。
- hmr-vue-ssr.md: 处理服务端渲染(SSR)场景下的热更新(HMR)问题。
5. 测试与样式 (Testing & Styling)
- pinia-store-mocking.md: 关于如何在测试中正确 Mock Pinia Store 的指南。
- strict-css-modules.md: 开启 CSS Modules 的严格模式,防止使用未定义的 class 名。
1.2 安装方法
通过简单的命令,你可以将此技能植入到你的 AI 工作流中:
npx add-skill hyf0/vue-skills
执行上面的指令后,会自动检查IDE,终端环境
选择安装在当前项目,还是对所有项目生效
选择下载一份每个项目建立软链接,还是将规则文件复制在每个项目下
安装完成之后的显示
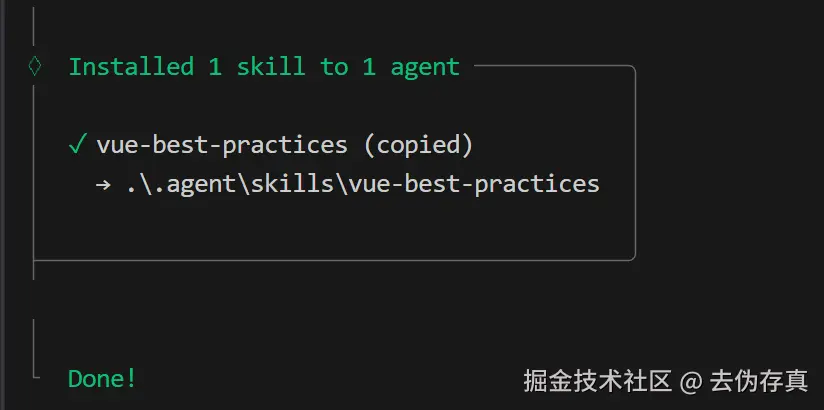
1.3 实战案例
案例展示了当 AI Agent 加载了 vue-best-practices 技能包后,如何通过 “提取组件属性 (Extract Component Props)” 规则,优雅地解决二次封装组件时的类型继承问题。
场景描述:我们正在基于一个第三方库的 BaseButton.vue 组件,封装一个我们项目专用的 ProButton.vue。我们需要让 ProButton 继承 BaseButton 的所有属性(Props),同时增加一个自定义属性 loading。
1. 优化前:常规“盲写”模式
现象:如果没有技能包指导,开发者往往会手动重复定义属性,或者使用不推荐的 Vue 内部实例类型。
<!-- ProButton.vue -->
<script setup lang="ts">
// ❌ 错误做法 1:手动重复定义,维护成本极高
interface Props {
text: string;
color?: string;
loading: boolean; // 自定义属性
}
// ❌ 错误做法 2:使用 InstanceType,会包含大量的 Vue 内部属性,干扰类型提示
import type BaseButton from "./BaseButton.vue";
type BaseProps = InstanceType<typeof BaseButton>["$props"];
defineProps<BaseProps & { loading: boolean }>();
</script>
2. 优化后:使用 vue-component-type-helpers
技能规则应用:
- 规则名称:
extract-component-props.md - 核心逻辑:利用
vue-component-type-helpers库精确提取组件定义的 Props,排除内部干扰项。
重构结果:代码简洁,类型提示完美,且具备 100% 的继承安全性。
<!-- ProButton.vue -->
<script setup lang="ts">
import type { ComponentProps } from "vue-component-type-helpers";
import BaseButton from "./BaseButton.vue";
// ✅ 符合最佳实践:精确提取子组件的 Props 类型
type BaseButtonProps = ComponentProps<typeof BaseButton>;
// 扩展基础组件的属性
interface Props extends BaseButtonProps {
loading?: boolean;
size?: "sm" | "md" | "lg";
}
const props = withDefaults(defineProps<Props>(), {
loading: false,
size: "md",
});
</script>
<template>
<div class="pro-button">
<!-- 将剩余属性透传给基础组件 -->
<BaseButton v-bind="$attrs" :loading="loading">
<slot />
</BaseButton>
</div>
</template>
3.核心价值总结
| 维度 | 传统方式 | Skills 方案 (Vue Best Practices) |
|---|---|---|
| 开发效率 | 需要翻阅源码查找子组件 Props | 自动提取,AI 自动完成类型桥接 |
| 类型提示 | 混杂大量 $props 内部属性,极难看清 | 纯净提示,仅显示业务定义的属性 |
| 维护性 | 子组件增加 Prop 后,包装组件需手动同步 | 自动同步,类型定义随子组件动态更新 |
| 代码洁癖 | 充满大量的 Hack 或冗余定义 | 标准工程化,符合 Vue 3 官方推荐模式 |
提示:安装技能包后,当你在写高阶组件(HOC)或二次封装组件时,AI 会自动识别场景并提示你使用
vue-component-type-helpers进行类型提取,确保你的 TypeScript 链路在全项目保持强类型约束。
2.1 核心功能
1. React 组件组合模式 (vercel-composition-patterns)
适用场景:
- 组件重构:当核心组件因布尔属性(Boolean props)爆炸(如
isLoading,isSmall等)而难以维护时。 - 库级开发:构建需要高度灵活、可扩展 API 的企业级 UI 组件库。
- 复杂交互设计:实现具有强父子联动逻辑的复合组件(如 Tabs, Select, Menu)。
核心规则:
- 架构优先组合:严禁无限制叠加布尔属性,推崇使用 复合组件 (Compound Components) 和 Context 共享状态。
- 接口解耦:Provider 集中管理状态逻辑,子组件仅通过约定的 Context 接口进行交互。
- 显式变体 (Explicit Variants):与其给一个组件加 10 个布尔值,不如创建明确命名的变体组件(如
PrimaryButton,IconButton)。 - 组合优于配置:优先通过
children进行 UI 拼装,而非通过庞大的配置对象或大量的renderXProps。
2. React & Next.js 性能最佳实践 (vercel-react-best-practices)
适用场景:
- 性能调优:页面响应慢、首屏渲染 (LCP) 时间长或存在明显的交互延迟。
- 现代 Web 构建:基于 Next.js App Router 架构的全栈开发。
- 大规模数据处理:需要并行获取多个 API 数据且必须避免渲染阻塞的场景。
核心规则:
- 消除瀑布流 (Waterfalls):性能优化的 头等大事。强制要求并行化独立异步操作,并利用
Suspense实现流式 (Streaming) 内容分发。 - 打包体积压缩:禁用 Barrel Files (单一入口导出文件) 以保护 Tree-shaking;强制使用
next/dynamic进行代码分割。 - 服务端性能 (RSC):利用
React.cache()进行请求级数据去重,最小化传输至客户端的序列化数据量。 - 重渲染控制:避免在 Effects 中处理同步状态,提倡使用派生状态 (Derived State);利用
startTransition处理非紧急更新。
3. React Native & Expo 移动开发指南 (vercel-react-native-skills)
适用场景:
- 移动端丝滑体验:针对 iOS 和 Android 优化长列表滑动和复杂手势动画。
- 跨端性能消除:解决由于 JS 线程与 UI 线程通信延迟导致的性能瓶颈。
- 原生功能集成:在 Expo 或原生环境中处理多媒体、字体和原生组件的高性能接入。
核心规则:
- 列表性能 (最关键):强制使用
FlashList替代FlatList;列表项必须经过memo处理以减少多余重绘。 - GPU 加速动画:动画属性仅限在
transform和opacity上操作,确保逻辑在 UI 线程直接执行。 - 原生 UI 适配:始终使用
expo-image优化图片加载;优先使用Pressable替代TouchableOpacity以获得更好的响应响应。 - 渲染规范:文本必须且只能包裹在
Text组件内;禁止在条件渲染中使用&&(防止在移动端渲染出数字 0)。
4. Web 界面设计指南 (web-design-guidelines)
适用场景:
- UI/UX 审计:项目发布前检查 UI 间距、颜色 Token 和视觉输出的一致性。
- 无障碍性 (A11y):确保网站符合 Web 辅助功能标准,提升产品包容性。
- 自动化 UI 审查:在 Code Review 阶段快速发现硬编码和非标准交互实现。
核心规则:
- 动态合规检查:通过远程拉取最新的设计系统准则,确保证审视标准始终是最新的。
- 无障碍强制约束:严格检查颜色对比度、ARIA 标签完整性以及键盘导航流程。
- 高精度反馈:能够精确到代码行指出不符合设计系统规范(如未使用的 Design Tokens)的地方。
2.2 安装方法
npx add-skill vercel-labs/agent-skills
可以只选择安装其中的一个规则集,比如说vercel-react-best-practices
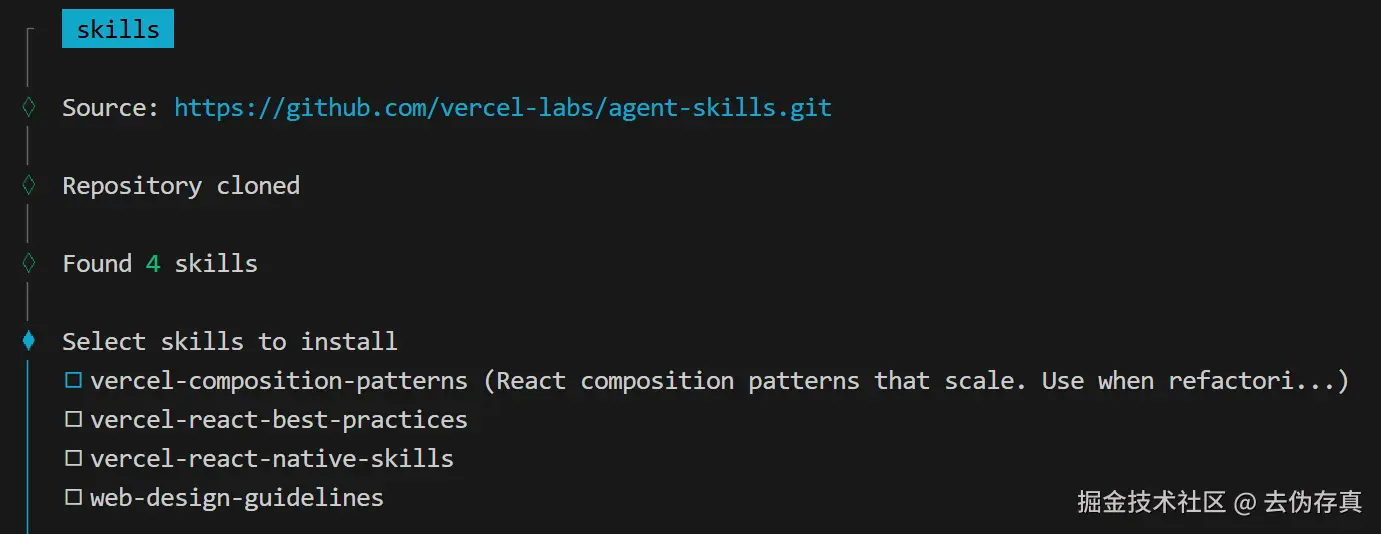
其余步骤,与Vue-Skills的问询问题一模一样,不再赘述。

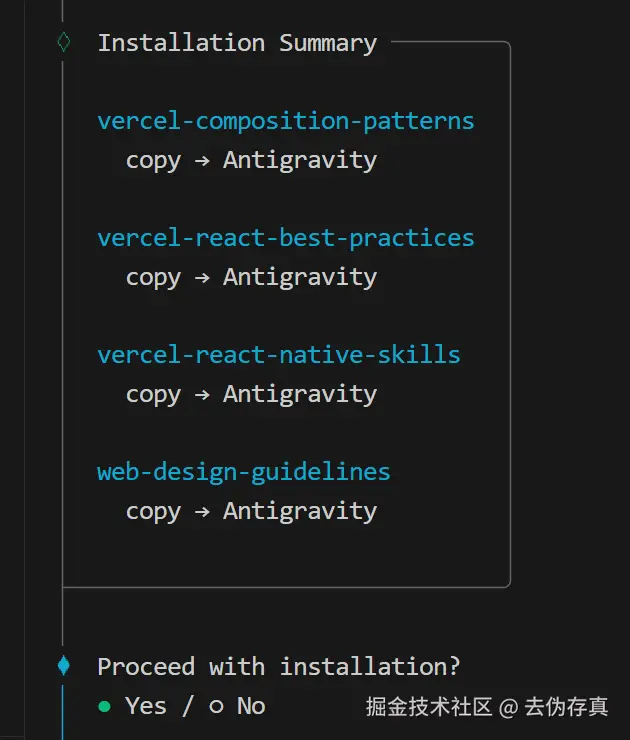
2.3 用法示例
在一个 Next.js App Router 项目的个人中心页面中,我们需要同时获取用户信息、订单列表和优惠券信息。
1. 优化前:串行瀑布流 (Sequential Waterfall)
现象:如果没有技能包约束,AI 可能会写出标准的串行代码。这种方案下,总耗时是三个接口请求时间的累加(T1 + T2 + T3)。
// ❌ 不符合最佳实践:串行阻塞
export default async function ProfilePage() {
// 请求 1:获取用户信息
const user = await fetchUser();
// 请求 2:依赖于 user.id,但在请求 1 完成前无法开始
const orders = await fetchOrders(user.id);
// 请求 3:不依赖于前二者,却被白白阻塞
const coupons = await fetchCoupons();
return (
<div>
<UserInfo user={user} />
<OrderList orders={orders} />
<CouponList coupons={coupons} />
</div>
);
}
2. 优化后:并行获取 + 组件组合 (Parallel & Composition)
技能规则应用:
async-parallel:识别出不互相关联的请求,并并行启动。server-parallel-fetching:利用服务器组件的组合特性,减少主线程阻塞。
重构结果:页面总耗时缩短为(T1 + Max(T2, T3)),且实现了流式分发。
// ✅ 符合最佳实践:并行获取与解耦渲染
import { Suspense } from "react";
export default async function ProfilePage() {
// 1. 同时启动互不关联的异步任务,不加 await
const userPromise = fetchUser();
const couponsPromise = fetchCoupons(); // 并行开始
// 2. 仅等待必要的基础数据
const user = await userPromise;
return (
<div>
{/* 优先渲染用户信息 */}
<UserInfo user={user} />
{/* 3. 将耗时较长的“订单列表”逻辑下移至组件内部,并行获取 */}
<Suspense fallback={<Skeleton />}>
<OrderDataLayer userId={user.id} />
</Suspense>
{/* 4. 将预启动的“优惠券”Promise 传入组件 */}
<Suspense fallback={<Skeleton />}>
<CouponDataLayer promise={couponsPromise} />
</Suspense>
</div>
);
}
// 独立的异步数据层组件
async function OrderDataLayer({ userId }) {
const orders = await fetchOrders(userId); // 并行进行的请求
return <OrderList orders={orders} />;
}
async function CouponDataLayer({ promise }) {
const coupons = await promise; // 使用外部传入的 Promise
return <CouponList coupons={coupons} />;
}
3. 核心价值总结
| 优化点 | 传统方案 | Skills 方案 (Vercel Best Practices) |
|---|---|---|
| 请求速度 | 累加耗时 (Waterfall) | 并发执行,耗时大幅度缩减 |
| 用户感知 | 全黑屏等待,直到所有数据返回 | 流式渲染 (Streaming),局部内容先出 |
| 代码结构 | 逻辑逻辑堆在主页面,难以复用 | 原子化组件,数据获取逻辑与渲染高度内聚 |
| AI 表现 | 随机生成,依赖运气 | 确定性重构,严格执行 Vercel 性能规约 |
结论:通过注入
vercel-react-best-practices技能,AI Agent 从一个简单的“代码生成器”转变为具备“性能自觉”的高级架构师。
三、 UI-Skills
如果说前两个工具解决了“逻辑”问题,那么 uipro-cli 及其关联的 ui-skills 则是为了解决“审美与交付”问题。 UI/UX Pro Max:赋能 AI Agent 的专业设计大脑。uipro-cli 是一个功能强大的命令行工具,专门用于为各种 AI 编程助手(如 Claude Code, Cursor, Windsurf, Antigravity 等)一键注入 UI/UX Pro Max 专家级技能。它让 AI 不仅能写代码,更能像资深设计师一样思考。
2.1 核心功能
1. 多元化视觉风格 (67 种 UI 风格)
UI/UX Pro Max 内置了 67 种最前沿的视觉设计风格,确保 AI 生成的界面告别“通用感”。
- 现代趋势:支持 Glassmorphism(玻璃拟态)、Claymorphism(粘土拟态)、Minimalism(极简主义)。
- 特色风格:包括 Brutalism(新野兽派)、Neumorphism(新拟物化)、Bento Grid(便当网格)以及针对 AI 产品的 AI-Native UI 风格。
2. 行业深度色彩与排版 (96 行业色板 + 57 字体配对)
- 精准色板:提供 96 套针对特定行业(如 SaaS, 电商, 医疗, 金融金融, 美妆)优化的专业色板。
- 字体艺术:内置 57 组精心挑选的字体组合,无缝集成 Google Fonts,从视觉底层提升产品质感。
3. 跨平台技术栈适配 (13 种主流技术栈)
支持从 Web 到移动端的 13 种主流技术架构,生成的代码即学即用。
- Web 端:React, Next.js, Vue, Nuxt.js, Astro, Svelte, HTML+Tailwind, shadcn/ui。
- 移动端:React Native, Flutter, SwiftUI, Jetpack Compose 等。
4. 专家级 UX 准则与设计推理 (100+ 准则与推理规则)
内置专业的设计逻辑,让 AI 具备“审美自觉”:
- UX 指南:涵盖 99 条 UX 最佳实践、反模式规避和 A11y 无障碍规则。
- 设计推理:拥有 100 条行业推理规则(例如:金融类应用严禁使用 AI 风格的紫粉渐变,以确保稳重感),自动进行交付前的 UI/UX 质量自检。
2.2 安装方法
通过 uipro-cli,你可以在几秒钟内完成技能初始化:
1. 全局安装工具
npm install -g uipro-cli
2. 为指定编辑器初始化技能
# 为 Claude Code 初始化
uipro init --ai claude
# 为 Cursor 初始化
uipro init --ai cursor
# 为所有支持的 AI 助手同时初始化
uipro init --ai all
3. 实战案例
场景描述: 用户需要为一个 AI 内容创作平台设计一个数据看板(Dashboard)。用户希望界面现代、直观,并且符合当前流行的审美趋势。
1. 传统 AI 生成:平庸且缺乏设计感
现象:如果没有加载专业 UI 技能包,AI 通常只会根据组件库(如 shadcn/ui)的基础示例,堆砌出缺乏灵魂的列表和卡片。色调单一(通常只用蓝色或灰阶),布局死板。
// ❌ 传统 AI 的“直觉”:基础的 Grid 布局,没有任何样式特色
export default function Dashboard() {
return (
<div className="grid grid-cols-3 gap-4 p-4">
<Card title="总收入" value="$12,000" />
<Card title="活跃用户" value="1,240" />
<Card title="API 调用" value="45.2k" />
<div className="col-span-3">主要统计图表</div>
</div>
);
}
2. UI/UX Pro Max 介入:具备“审美自觉”的设计
技能规则应用:
- 风格锁定:选择了 Bento Grid(便当网格) 布局。
- 行业色板:套用了 SaaS 行业高阶调色盘。
- 设计推理:AI 会自动添加微交互动画、圆角分层(Glassmorphism 效果)以及符合产品气质的字体排版。
重构指令:
“使用 UI/UX Pro Max 技能,为我的 AI 创作平台设计一个 Bento Grid 风格的统计看板。色调选用‘高级钛金灰’配合‘赛博蓝’点缀,并要求包含毛玻璃质感。”
重构结果(语义描述与关键代码片段):
// ✅ 符合设计的组件 (自动生成的 Tailwind 样式)
// 使用了 Bento Grid 非对称网格布局
export function BentoDashboard() {
return (
<section className="bg-slate-950 p-8 min-h-screen font-sans text-slate-100">
<div className="max-w-7xl mx-auto grid grid-cols-1 md:grid-cols-4 gap-6">
{/* 高度分层的毛玻璃卡片 (Glassmorphism) */}
<div
className="md:col-span-2 md:row-span-2 bg-slate-900/50 backdrop-blur-xl border border-white/10 rounded-3xl p-8
hover:bg-slate-800/60 transition-all duration-300 group"
>
<header className="flex justify-between">
<h3 className="text-xl font-bold tracking-tight">创作产出分析</h3>
<div className="h-2 w-2 bg-cyan-400 rounded-full animate-pulse" />
</header>
{/* AI 自动推荐的图表配色与坐标轴样式 */}
<MainAnalyticChart color="#22d3ee" />
</div>
{/* 紧凑型统计卡片 */}
<div className="bg-slate-900/50 backdrop-blur-md rounded-3xl p-6 border border-white/5">
<Subtitle>API 余额</Subtitle>
<Value className="text-3xl font-mono">84.2%</Value>
</div>
{/* 动态微交互元素 */}
<div className="bg-cyan-500/10 rounded-3xl p-6 border border-cyan-500/20 text-cyan-400">
<div className="text-sm font-semibold mb-2">服务状态</div>
<div className="text-lg">系统运行正常</div>
</div>
{/* 更多 Bento 网格单元... */}
</div>
</section>
);
}
3.核心价值总结
| 维度 | 传统构建 | UI/UX Pro Max (uipro) |
|---|---|---|
| 布局逻辑 | 简单的 1/2 或 1/3 等分 | 非对称动态布局 (如 Bento Grid, Masonry) |
| 色彩应用 | 基础颜色(#3b82f6),视觉单调 | 分层色彩系统,包含渐变、阴影与半透明层 |
| 细节打磨 | 只有基础功能 | 微交互、骨架屏、平滑过渡自动注入 |
| 设计自检 | 需要人工多次反馈返工 | 内置反模式自检,首次生成即达“可交付”标准 |
结语:前端开发者的角色转变
随着 vue-skills、react-skills 和 ui-skills 的普及,前端开发者的角色正在发生深刻变化。我们正在从 “代码编写者(Coder)” 转变为 “AI 指令师(Prompt Engineer)” 和 “技术评审员(Reviewer)” 。
传统的 AI 辅助仅仅是“搜索”的变种,而 Skills 模式代表了 “领域知识的预装载” 。
- 降低认知负荷:你不需要记住 Vue 3 的所有新特性或 Tailwind 的上千个类名,Skills 充当了你的“外部脑”。
- 代码风格统一:团队只需约定一套 Skill 脚本,就能保证所有 AI 生成的代码风格高度一致,甚至比人类手动编写的更规范。
- 快速原型到生产:它极大地缩短了从 MVP(最小可行性产品)到正式发布的时间,让前端开发者更关注于“业务价值”而非“语法实现”。
掌握这些 Skills 并不意味着放弃底层的学习,相反,只有深刻理解 Vue/React 原理和 UI 规范的人,才能通过这些技能包更好地引导 AI,释放出前所未有的生产力。
来源:juejin.cn/post/7599641289887055918
当你的Ant-Design成了你最大的技术债

大家好😁
如果你是一个前端,尤其是在B端(中后台)领域,Ant Design(antd)这个名字,你不可能没听过。
在过去的5年里,我们团队的所有新项目,技术选型里的第一行,永远是antd。它专业、开箱即用、文档齐全,拥有一切你想要的组件, 帮我们这些小团队,一夜之间就拥有了大厂的专业门面。
我们靠它,快速地交付了一个又一个项目。
Antd 虽好,但魔改样式确实让人头秃,转向 Headless UI 又怕重复造轮子。想兼顾灵活定制与开发效率?试试 RollCode 低代码平台,利用 自定义组件 快速封装 Headless 逻辑,通过 私有化部署 沉淀企业级资产,更能一键 静态页面发布(SSG + SEO),让 UI 自由不再昂贵。
但是,从去年开始,我发现,这个曾经的经典,正在变成我们团队脖子上最重的枷锁。
Ant Design,这个我们当初用来解决技术债的核心组件库,现在,却成了我们最大的技术债本身😖。
这是一篇团队血泪史, 讲一讲感想🤷♂️。
我们为什么会爱上 AntD?
我们必须承认,从无到有阶段,antd是无敌的。
你一个3人的小团队,用上antd,做出来的东西,看起来和阿里几百人团队做的系统,没什么区别。
Table、Form、Modal、Menu... 你需要的一切,它都以一种极其标准的方式给你了。你不再需要自己造轮子。
当你发现@ant-design/pro-components时,一个ProTable,直接帮你搞定了请求、分页、查询表单、工具栏... 你甚至都不用写useState了。
在那个阶段,我们以为我们找到了大结局。
当个性化成为 我们的 KPI
美好可能是短暂的,从我们的产品经理和UI设计师开始👇:
能不能...不要长得这么 Ant Design?🤣
这是我们设计师,在评审会上,小心翼翼提出来的第一句话。
老板也说:我们要做自己的品牌,现在的系统,太千篇一律了!!!
于是,我们接到了第一个简单的需求:把全局的主题色,从橙色改成我们的品牌红。
这很简单,不就是 ConfigProvider嘛🤔。我们改了。
然后,第二个需求来了:这个Modal弹窗的关闭按钮,能不能不要放在右上角?我们要放在左下角,和确认按钮放在一起。(有点反人类🤷♂️)
灾难,就从这里开始了。
antd的Modal组件,根本就没提供这个插槽或prop。我们唯一的办法,是 强改。
于是,我们的代码里,开始出现这种恶臭的CSS:
/* 一个高权重的全局CSS文件 */
.ant-modal-header {
/* ... */
}
/* 嘿,那个右上角的关闭按钮,给我藏起来! */
.ant-modal-close-x {
display: none !important;
}
为了把那个 X 藏起来,我们用了!important。我们亲手打开了潘多拉魔盒。
这个表格的筛选图标,能换成我们自己画的吗?😖
antd的Table,是一个重灾区。它太强大了,也很黑盒。
我们设计师,重新画了一套筛选、排序的图标。但我们发现,antd的Table组件,根本没想过让你换这个。
我们唯一的办法,就是用 CSS选择器,一层一层地穿进antd的DOM结构里,找到那个<span>,然后用background-image去盖掉它。
/* 另一个人写的,更恶臭的CSS */
.ant-table-thead > tr > th.ant-table-column-has-filters .ant-table-filter-trigger {
/* 妈呀,这是啥? */
background: url('our-own-icon.svg') !important;
}
.ant-table-thead > tr > th.ant-table-column-has-filters .ant-table-filter-trigger > svg {
/* 藏起来,藏起来! */
display: none !important;
}
我们被拖累了。
我们花在 覆盖antd默认样式上的时间,已经远远超过了我们自己写一个组件的时间。
压死骆驼的最后一根稻草
我们用了ProTable,它的查询表单和表格是强耦合的。当产品经理提出一个我希望查询表单,在页面滚动时,吸附在顶部的需求时... 我们发现,我们改不动。我们被ProComponents的黑盒,锁死了。
然后我们的vendor.js打包出来,2.5MB。用webpack-bundle-analyzer一看,antd和@ant-design/icons,占了1.2MB。我们为了一个Button和Icon,引入了一个全家桶。antd的按需加载?别闹了,在ProComponents面前,它几乎是全量的。
而且 antd从v3到v4,我们花了一个月。从v4到v5,我们花了半个月。每一次升级,都是一次大型重构,因为我们那些写法一样被CSS覆盖,在新版里,全失效了🤷♂️。
我们本想找一个可靠的组件库,这么久过来,结果它成了债主。
我们真正需要的可能是轮子
我终于想明白了。
Ant Design,它不是一个组件库(Library),它是一个UI框架(Framework)。它是一套解决方案,它有它自己强势的 设计价值观。
当你的需求,和它的价值观一致时,它就是圣经。
当你的需求,和它的价值观不一致时,它就变成枷锁。
我们当初要的,其实是一个带样式的Button;而antd给我的,是一个内置了loading、disabled、onClick时会有水波纹动画、并且必须是蓝色或白色的Button。
我们的自救之路
在我们新的项目中,我忍痛做出了一个决定🤷♂️:
原则上,不再使用antd。
我们新的技术栈,转向了:
Tailwind CSS + Headless UI 方案(比如Radix UI)
这个组合,才是我们想要的:
Headless UI:它只提供功能和无障碍。比如,一个Dialog(模态框),它帮我搞定了按Esc关闭、焦点管理。但它没有任何样式。Tailwind CSS:我拿到了这个无样式的Dialog,然后用Tailwind的class,在5分钟内,在AI的帮助下,把它拼成了我们设计师想要的、独一无二的弹窗。
我们拿回了CSS的完全控制权,同时又享受了 AI + 组件开发的便利。
我依然尊敬Ant Design,它在前端B端历史上,是个丰碑。
对于那些从0到1的、对UI没有要求的内部系统,我可能依然会用它。
但对于那些需要品牌、体验、个性化的核心产品,我必须和它说再见了。

因为,当你的组件库开始控制你的设计和性能时,它就不是你的资产了。
而变成你最大的技术债🙌。
来源:juejin.cn/post/7571176484515659828
H5性能优化-打开效率提升了62%
一、达成的结果
app嵌套h5 加载效率提升了62%。时间从平均2.259s 降到了0.852s
二、优化过程
思路:优化原生webview+h5 ,先测试webview点击到创建时间 120ms(无需优化)。webview 提供了 api 测试 加载url 的进度。但是没提供具体的类似pc端网络的工具。所以就通过ai搜索一些工具。发现阿里云的arms 方便引入。
测试设备 android荣耀50、华为meta9、华为p40、oppo
开发环境测试
测试样本:优化前后各测试10次。
测试移动端h5 引入了阿里云的arms arms.console.aliyun.com/ 可以查看加载某个url的时候 请求的js css、图片、网络请求 跟网页版的网络类似。
import ArmsRum from '@arms/rum-browser'
ArmsRum.init({
pid: 'ha63j3v892@efe71d242023cd5',
endpoint: 'https://ha63j3v892-default-cn.rum.aliyuncs.com',
// 设置环境信息,参考值:'prod' | 'gray' | 'pre' | 'daily' | 'local'
env: 'prod',
// 设置路由模式, 参考值:'history' | 'hash'
spaMode: 'hash',
collectors: {
// 页面性能指标监听开关,默认开启
perf: true,
// WebVitals指标监听开关,默认开启
webVitals: true,
// Ajax监听开关,默认开启
api: true,
// 静态资源开关,默认开启
staticResource: true,
// JS错误监听开关,默认开启
jsError: true,
// 控制台错误监听开关,默认开启
consoleError: true,
// 用户行为监听开关,默认开启
action: true,
},
// 链路追踪配置开关,默认关闭
tracing: false,
})
export default ArmsRum
步骤一、懒加载echarts
以前的代码
import Api from '@/api'
import * as echarts from 'echarts'
import dayjs from 'dayjs'
export default {
}
现在的代码
async getRepairChart() {
const echarts = await import('echarts')
// xxx
const chartDom = document.getElementById('repairChart')
const myChart = echarts.init(chartDom)
const option = {
}
myChart.setOption(option)
},
通过F12查看网络 发现加载列表的时候有出现echartsxxx.js 而且有800多k ,所以就考虑加载列表不应该去加载数据看板的数据。
优化前,测试前日志打印
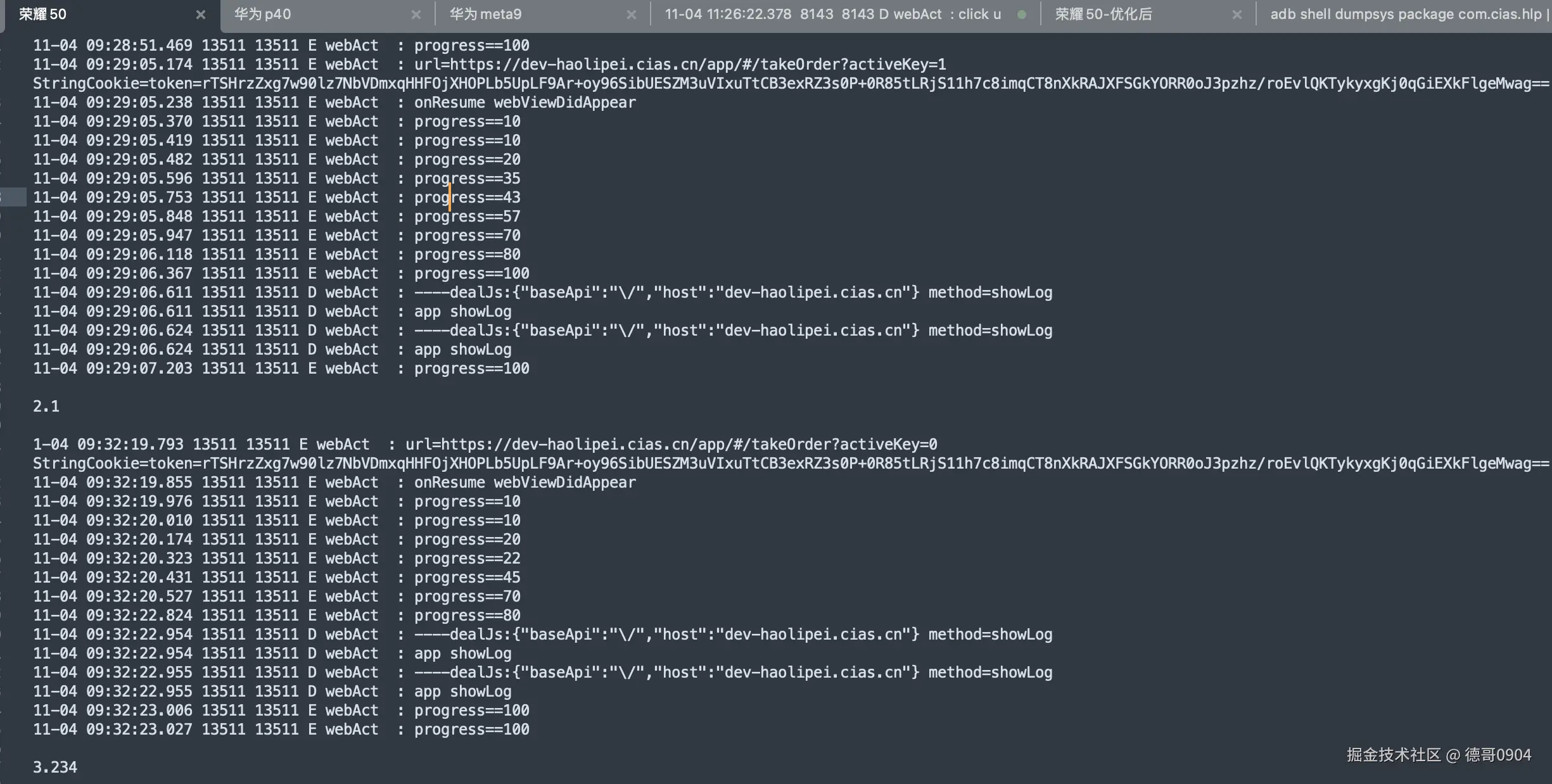
平均是3.234s 然后 当然还测试了华为p40 、oppo机器 由于系统不一样时间有些差别
测试后日志打印
平均是1.71s
华为meta9 9年前的老手机打印log
平均也2s多
优化后
不到0.8s
步骤二、禁用预加载、路由懒加载
通过查看网络发现请求dev-haolipei.cias.cn/app/#/takeO… 超级多的js 跟css
一张图都截取不完。当时就感觉肯定请求了很多无关紧要的资源。
npm run build 执行后查看dist目录index.html 的确很触目惊心 加载了太多没必要的资源了。
module.exports = {
publicPath,
devServer: {
disableHostCheck: true,
// host: 'localhost.cias.cn',
proxy: {
'/api': {
target,
changeOrigin: true,
// cookieDomainRewrite在手机调试时用得上
// cookieDomainRewrite: '',
pathRewrite: {
'^/api': '',
},
},
'/media': {
target,
changeOrigin: true,
pathRewrite: {
'^/media': '',
},
},
},
},
chainWebpack: config => {
// 禁用预加载
config.plugins.delete('preload')
config.plugins.delete('prefetch')
},
}
禁用它们的核心好处
1. 减少不必要的网络请求,节省带宽
- preload 可能会强制加载一些 “非关键资源”(如配置不当的情况下,预加载了体积大但当前页面暂时用不到的资源),导致带宽浪费。
- prefetch 会预加载未来可能访问的路由 chunk(如用户可能不会点击的低频页面),如果用户最终没有访问这些页面,预加载的资源就成了 “无效请求”,尤其对移动端用户(流量有限)不友好。
禁用后,资源仅在明确需要时才会加载(如用户进入对应路由时),避免 “提前加载但用不上” 的浪费。
2. 避免阻塞关键资源加载,提升首屏速度
- 浏览器对同一域名的并发请求数有限制(HTTP/1.1 通常为 6 个)。preload 加载的资源会占用并发名额,可能阻塞当前页面真正需要的关键资源(如核心 JS/CSS),导致首屏渲染延迟。
- 例如:若 preload 预加载了一个 2MB 的非关键 chunk,可能会挤占首屏 JS 的加载带宽,导致页面 “白屏时间” 变长。
禁用后,浏览器的并发资源会优先分配给当前页面的核心资源,减少阻塞。
3. 避免缓存资源被 “无效资源” 占用
浏览器缓存空间有限,prefetch 预加载的大量 “未来可能用到” 的 chunk 会占用缓存空间,可能导致真正需要长期缓存的核心资源(如 chunk-vendors.js)被挤出缓存,下次访问时需要重新加载。
禁用后,缓存可优先保留关键资源,提升二次访问速度。
4. 适配低网速 / 弱网环境
在 3G、偏远地区等弱网环境下,preload/prefetch 的预加载行为会加剧网络拥堵:
- 预加载的资源可能耗时过长,导致当前页面的核心资源加载超时。
- 禁用后,资源加载更 “轻量化”,优先保证当前页面可用,符合弱网环境的用户体验需求。
5. 减少开发环境的冗余加载
在开发环境中,Webpack 会频繁编译资源,preload/prefetch 可能导致每次热更新时加载大量无关资源,拖慢开发服务器响应速度,影响开发体验。禁用后可简化开发环境的资源加载逻辑,提升热更新效率。
注意:并非所有场景都适合禁用
preload/prefetch 本身是性能优化手段,若项目存在以下情况,可能需要保留或部分配置:
- 首屏依赖的关键资源(如核心 CSS、字体)体积大,preload 可加速其加载。
- 高频访问的路由(如首页→列表页),prefetch 可提前加载列表页 chunk,提升跳转速度。
因此,禁用的合理性取决于项目场景:资源体积大、用户网络不稳定、低频路由多的项目(如移动端 H5)更适合禁用;高频路由明确、网络环境好的项目可选择性保留。
路由懒加载
必须写上 /* webpackChunkName: "system-setting" */
以前的代码
{
path: '/takeOrder',
name: 'HomeTakeOrder',
component: () =>
import(
'@/views/baosi/orderList.vue'
),
meta: {
title: '推返修列表',
keepAlive: true,
},
}
懒加载路由模式
const HomeTakeOrder = () =>
import(/* webpackChunkName: "take-order" */ '@/views/baosi/orderList.vue')
{
path: '/takeOrder',
name: 'HomeTakeOrder',
component: HomeTakeOrder,
meta: {
title: '推返修列表',
keepAlive: true,
},
},
这样的好处 打包后 会有路由名称
对比
继续测试打印log
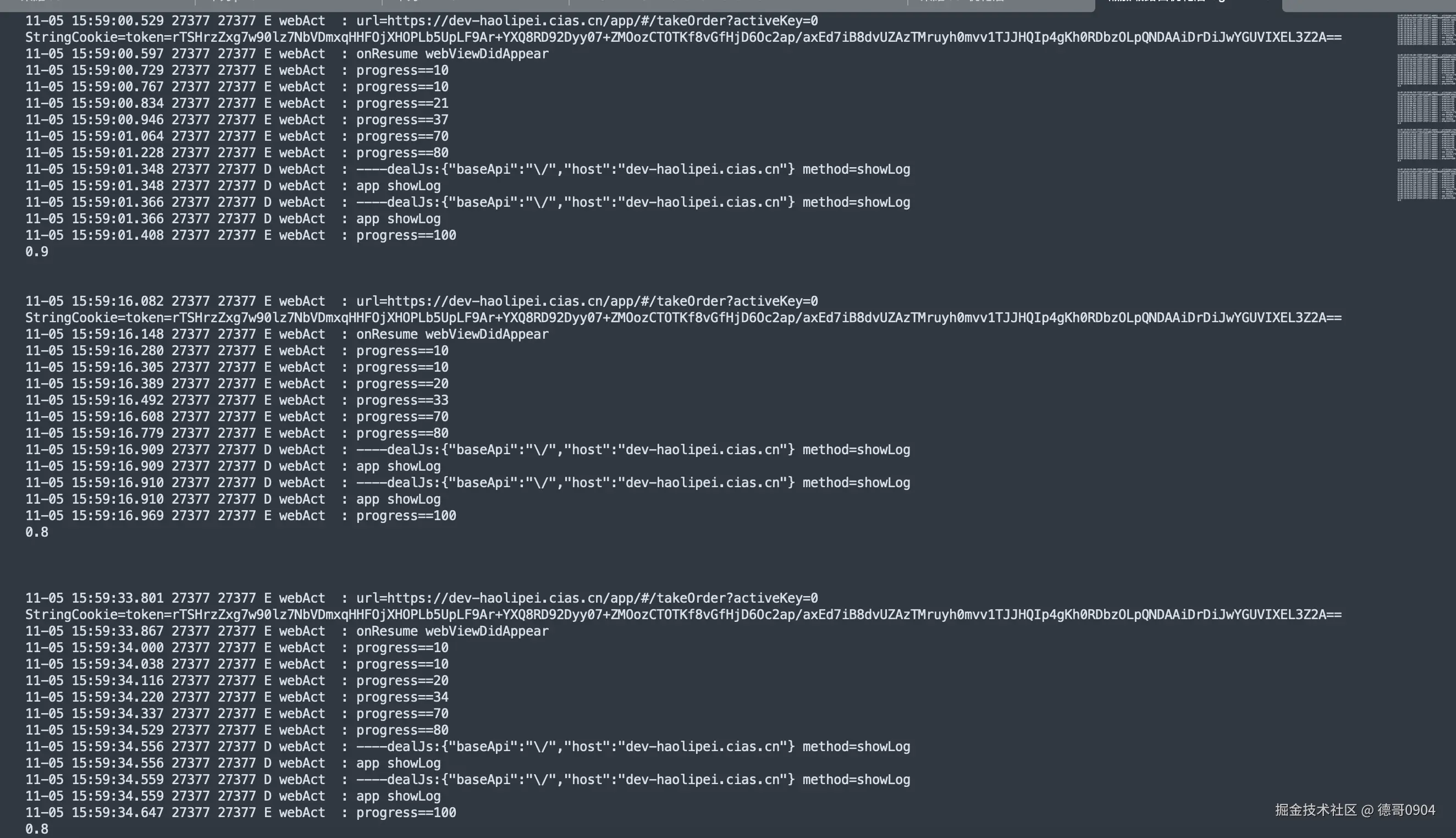
可以看看网络请求 就只有5个js文件 总体积不到300k
平均是0.852,基本达成要求
通过npm run build 本地打包看看文件对比大小。
1、体积巨减!!!
2、加载的文件名称是路由名称+hash值
优化前
优化后
三、内部项目具体实践
(增值移动端h5项目可以参考以下操作)
1、禁用预加载
module.exports = {
publicPath,
devServer: {
disableHostCheck: true,
// host: 'localhost.cias.cn',
proxy: {
'/api': {
target,
changeOrigin: true,
// cookieDomainRewrite在手机调试时用得上
// cookieDomainRewrite: '',
pathRewrite: {
'^/api': '',
},
},
'/media': {
target,
changeOrigin: true,
pathRewrite: {
'^/media': '',
},
},
},
},
chainWebpack: config => {
// 禁用预加载
config.plugins.delete('preload')
config.plugins.delete('prefetch')
},
}
2、将路由全部改成懒加载
并且路由需要/* webpackChunkName:"take-order" */
{
path: '/takeOrder',
name: 'HomeTakeOrder',
component: () =>
import(
/* webpackChunkName:"take-order" */ '@/views/baosi/orderList.vue'
),
meta: {
title: '推返修列表',
keepAlive: true,
},
}
3、组件懒加载
以前常见写法 就是一进来 把所有组件的都加载进来
比如这个车牌号组件有120k 对于比较大一点的组件可以用懒加载 。
<van-popup v-model="showPlatePopup" position="bottom" :overlay="false">
<keyboard
v-model="baseInfo.plateNumber"
:show.sync="showPlatePopup"
@input="handlePlateInput"
></keyboard>
import Keyboard from '@/components/numberplate/vnp-keyboard.vue'
export default {
name: 'CreateOrder',
components: {
MultiSelectPopup,
DispatchingPopup,
DispatchFailPopup,
DispatchFinishPopup,
Keyboard,
},
}
懒加载代码
用这个方式可以直接在网络中查看到对应组件的名称和大小
<van-popup
v-if="showPlatePopup"
v-model="showPlatePopup"
position="bottom"
:overlay="false"
>
<keyboard
v-model="baseInfo.plateNumber"
:show.sync="showPlatePopup"
@input="handlePlateInput"
></keyboard>
</van-popup>
export default {
name: 'CreateOrder',
components: {
MultiSelectPopup,
DispatchingPopup,
DispatchFailPopup,
DispatchFinishPopup,
Keyboard: () =>
import(
/* webpackChunkName: "keyboard" */
'@/components/numberplate/vnp-keyboard.vue'
),
},
}
还有 特别大的第三方库 echart 懒加载 按需引入
四、总结
目前通过禁用预加载、路由懒加载、和第三方组件懒加载使用方式 基本能达到很大程度的优化效果。
但是看图 每次加载前面2个文件一个683k 另外一个285k 还是压缩了的文件 ,
我猜应该是main.js 引入了很多东西,后续还可以有优化空间。移动端的h5 入口文件尽量简洁。
(自己写的页面 一定多注意看一下 网络 有多少个js 和css 图片) 资源过大就要考虑优化了。
性能优化一定要多测试验证、多测试验证、多测试验证,保证业务正常情况下优化性能。
性能优化参考。
来源:juejin.cn/post/7572301616168583177
我创建了一个全 AI 员工的一人公司
大家好,我是 Sunday。
现在,用 AI 写代码,已经不算什么新鲜事了。写个组件、补个函数、改个 Bug,几句话交给模型就能搞定。
但是,大家有没有想过一个问题:如果我不只是用一个 AI,而是用一群 AI,会发生什么?
我们现在用 AI,本质上只是把它当成“高级工具”,即:我遇到问题 → 我问 AI → 它给我答案。
那么如果我们把脑洞放大一点呢?
既然我可以调用一个 AI,那是不是也可以 同时调用多个 AI ?既然 AI 可以写代码,那它是不是也可以完成:产品经理、设计师、测试、运维,甚至是 财务、人事 的工作?
换句话说: 我能不能,用一群 AI,组建一家“只有我一个人类员工”的公司?
多个 AI,各自承担不同角色:
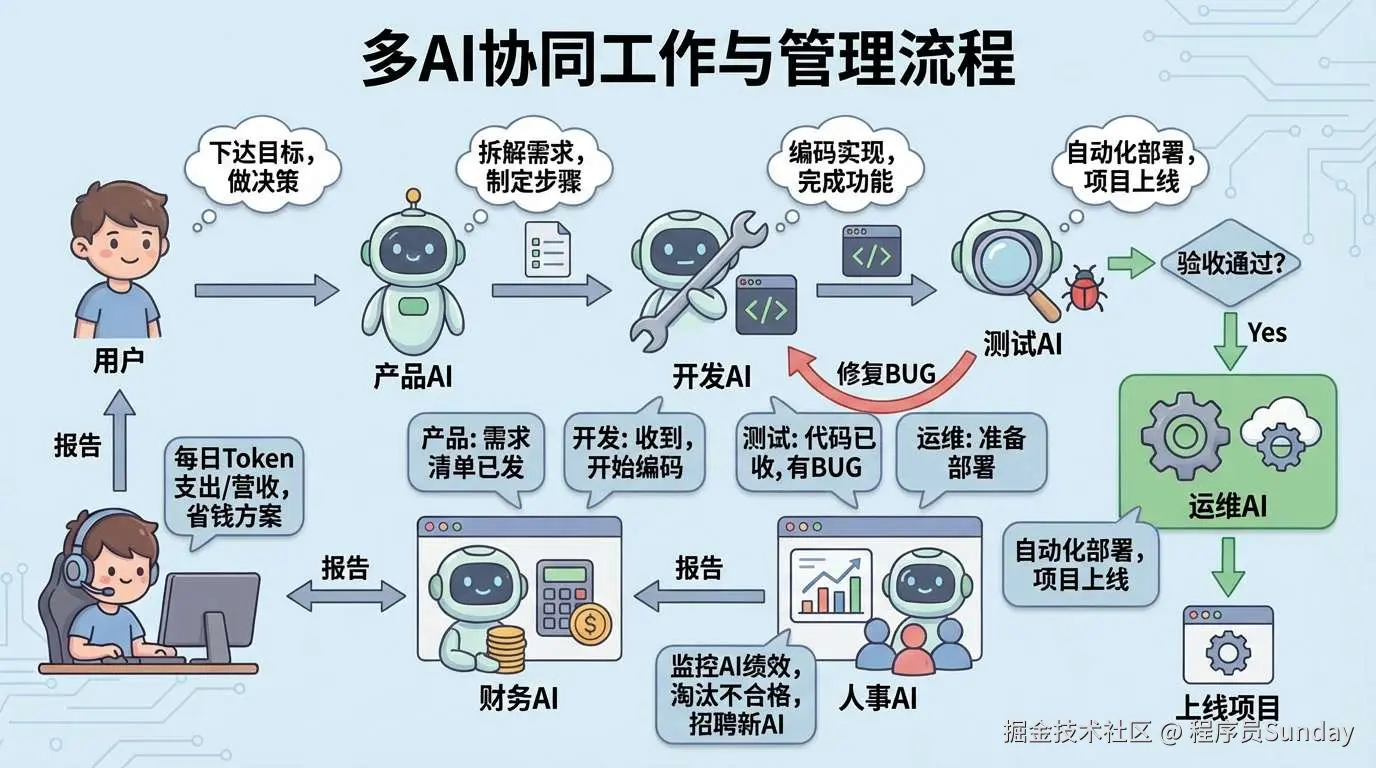
- 产品负责拆需求:告诉产品我的需求,然后产品帮我把需求拆解成可以具体执行的步骤
- 开发负责编码:把具体的步骤告诉开发,开发负责把整个功能落地
- 测试负责验收:开发的代码,交给测试进行验收。验收失败则重新打回开发,开发负责修改 BUG
- 运维负责部署:最终完成的项目,运维负责部署上线,构建整个自动化部署的流程
- 财务负责算账:每天的 token 支出 和 营收,并给出更省钱的财务方案
- 人事负责管理:哪个 AI 员工“不合格”,人事负责把它“开掉”,并根据我的需求重新“招聘(生成)”新的 AI 员工
并且,我还希望它们之间可以独立思考,互相沟通,而我只负责:下目标、做决策。
如果这件事真的可行,那意味着什么?意味着一个人,或许可能真的可以撬动一整家公司级别的生产力。
说干就干。
AI 选择
市面上的 AI 模型已经非常多了:Claude、GPT Coder、Gemini、GLM、DeepSeek。。。有的贵,有的便宜,有的擅长推理,有的擅长编码。
最理想的状态其实很明确:
- 贵的 AI,承担复杂任务:产品设计、系统架构、核心编码
- 便宜的 AI,承担简单任务:统计、对账、流程、输出财务报表
只要这些 AI 之间可以互相沟通,以上这些都不是问题。
但是,Sunday 在经过一系列的测试之后,发现了一个很残酷的事,就是 不同模型的 AI 之间完全无法沟通。特别是不同厂商的 AI,每一个都被作为了独立的个体。虽然可以通过“协调者”方式强行拼接,但是实现复杂,并且效果也不理想。
额。。。好像这个一人公司的梦想就直接破灭了...
不行,不能那么容易放弃。
所以,在第一阶段,我只能选择一个更“粗暴但稳定”的方案:全部使用 Claude。
因为 Claude 提供了一个非常关键的工具:Claude Code:一个运行在纯终端里的 AI 编码智能体。我们只需要打开终端就可以直接通过语言对话的方式调用 AI 模型。
而接下来,我要做的事情是:用 Claude Code,一步步搭出一家“AI 员工公司”的雏形。
启动多个 AI 终端
一个终端窗口作为一个员工,如果我们想要多个员工那么就只需要启动多个终端就可以。然后我们要给他们赋予角色。一开始,我们可以先从最小可行方案开始:

我们先制定两个角色,他们分别是:
- 张三:产品经理
- 李四:程序员
然后,就出现了 大型翻车现场....
在我尝试给 Claude 提示词,让他变成 张三 的时候。Claude 给我的回复是:我是 Claude,我不是张三....
不是,咱说好的玩角色扮演呢...你就这么不配合的吗?
因为在我的设想里,这一步应该是最简单、最“理所当然”的:起个名字、设个背景、分配个角色。然后 AI 就会自动进入对应的工作模式。
结果现实就是这么现实:“我能帮你完成工作,但是我就不承认我是张三,我就是 Claude”
这不是能力问题,这赤裸裸的就是个 态度问题 啊! 看来 AI 也不想当牛马啊。。。
没办法,我只能尝试修改下提示词:

好的,产品经理已就位。然后我们可以从一个小的 todolist 的需求开始:
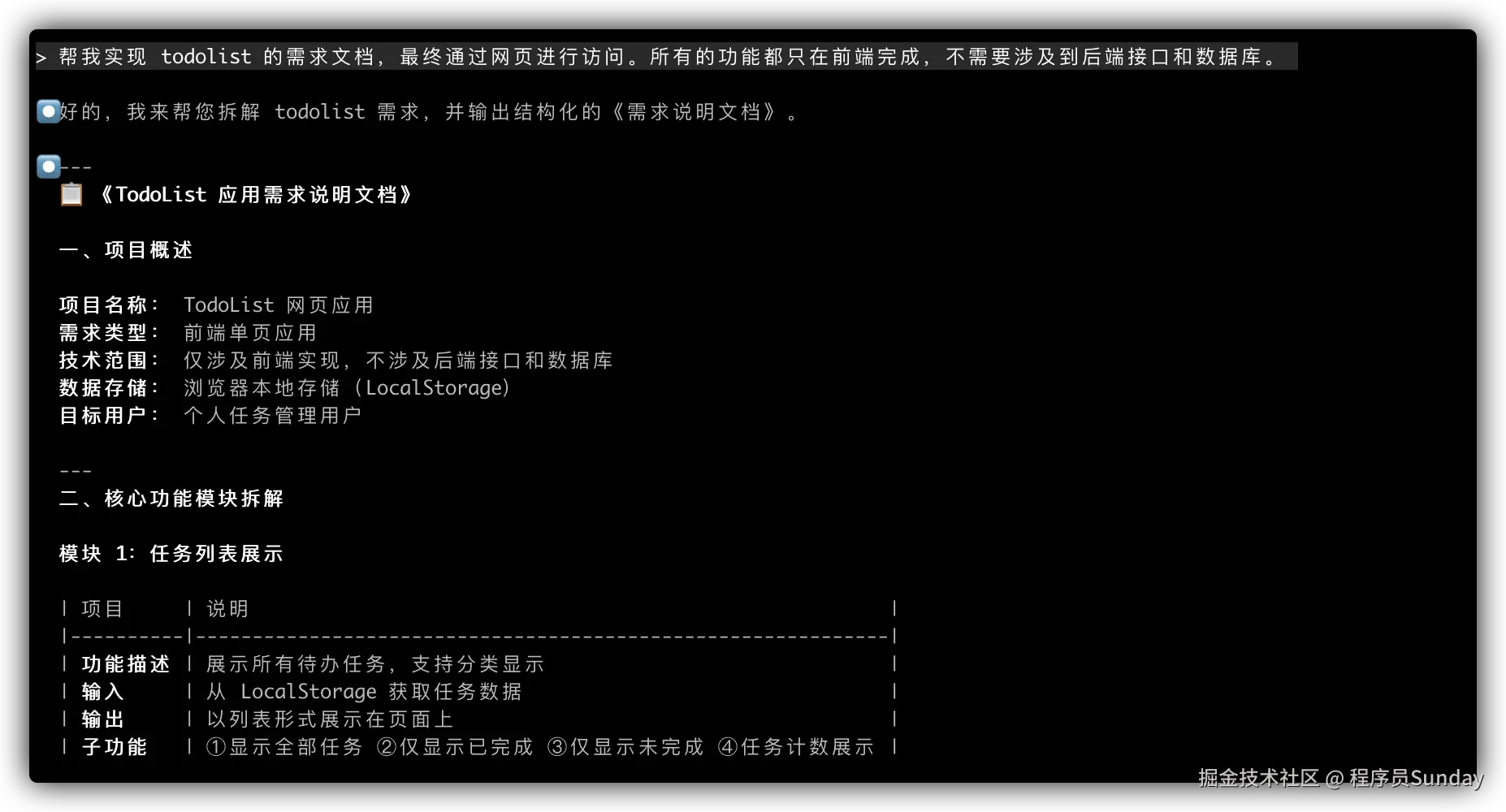
现在我们已经有了一个 todolist 的需求文档了。接下来最好的方案就是 产品经理的 AI 可以直接通知 程序员 AI,完成代码实现。
但是,可惜 不同窗口之间 AI 无法直接通讯。所以,我就必须要承担起这个通讯员的角色。

最终实现的效果如下:
整个功能完善、可用。并且还提供了 主题变化 的功能。。。
反思
可是如果我们仔细去分析上面整个流程,我们可以发现:这个流程远没有我们想象的那么顺畅。甚至有点 多此一举。
因为以上这些需求完全可以在一个 Claude code 中完成,没有必要进行这样的划分。甚至可以说:在任务简单时,多 AI 协作不仅没有提升效率,反而增加了沟通成本。
而这样的一种调度+协作的方式,如果任务变得复杂了,恐怕 AI 没有乱呢,我们自己就已经先手忙脚乱了。
这让我开始怀疑:最初设想的这种全 AI 员工的方式,会不会从一开始,就是错的?
但是,当我仔细思考过之后,我发现问题不在于“多角色”这个想法本身,而在于:当前这种“多终端 + 人工调度”的协作方式,本质上是一个非常低效的协作模型。
如果我们换一个角度,从“协作工具”入手,情况可能会完全不同。
这时,我注意到了一个开源项目:vibekanban。
它提供了一种非常典型的多人协作看板模式,和我们熟悉的 Teambition、Jira、Trello 几乎一致,包含了:任务可视化、状态流转清晰、每个角色只关注自己的列
通过 vibekanban 这种工具,我们至少可以做到:多任务并行更清晰、角色边界更稳定、协作过程可追踪、可回溯。
但即便如此,我很快又意识到一个更现实的问题:这,依然离“全 AI 员工的一人公司”,依旧差得很远。
全 AI 员工的难点在哪里?
根据 Sunday 的实验,其实我们可以发现,全 AI 员工的最大难点就是 如何高效的完成 AI 之间的自动协作。
更具体一点说,核心难点只有一个:如何让多个 AI,在几乎没有人工干预的情况下,自动完成“上下文传递 + 状态对齐 + 任务接力”?
那么这个功能可以实现吗?
答案是 绝对可以
学习过咱们的 商业级 AI 课程 的同学都知道,在 AI 的持续对话中,我们可以通过记录上下文的方式完成跨角色的连续对话。
那么同样的道理,如果我们可以记录不同 AI 沟通上下文的 关键内容,然后通过上述的同样逻辑呼叫下一个 AI(让代码通过指令自动传输关键上下文,并调起 AI 服务),那么全 AI 员工的功能就可以实现。只不过在这样的完美的流转过程中,我们还需要做很多的努力才可以。
总结
这一通折腾下来,收获还是很明显的。三个关键:
- 单模型,已经足够强
- 多模型,真正难的是系统设计
- “全 AI 员工”,本质是一个 调度系统 + 状态系统 + 协作协议 的问题
而这,也意味着:下一阶段的探索重点,已经不再是“哪个模型更强”,而是:如何设计一套真正可自动运行的“AI 组织系统”。
来源:juejin.cn/post/7597355509747974170
全栈开发者的谎言:什么都会 = 什么都不精?

上周面了一个自称5年全栈的兄弟🤔。
简历漂亮得像报菜名:精通 Vue/React,熟悉 Node.js/Go,玩过 K8s,能画原型图,甚至还写过两个 Flutter App。
我只问了一个问题:如果不使用任何框架,Node.js 的 HTTP 模块是如何处理高并发下的内存积压的?
他愣了三秒,支支吾吾说:厄...一般我们都用 NestJS,框架处理好了吧?😖
那一刻,我看到了无数前端人的缩影:我们拼命想成为无所不能的全栈大神,最后却活成了什么都懂一点、什么都搞不定的API 缝合怪。
全栈不等于样样稀松,真正的价值在于深耕核心难题。与其在重复造轮子中消耗精力,不如用 RollCode 低代码平台 提效。它支持 私有化部署 和 自定义组件,搞定 静态页面发布(SSG + SEO),让开发回归技术本质。
全栈的本质
你要知道,全栈工程师(Full Stack Engineer)这个词,最开始是谁捧红的?
是硅谷的创业公司。
为什么?因为没钱。
他们招不起一个前端专家 + 一个后端专家 + 一个运维专家。他们需要一个性价比极高的耗材,一个人把这三个坑都填了。
于是,招聘 JD 画风突变:
25K,招全栈。要求精通 React、Node.js、MySQL、Docker、AWS...
你看似拿了比纯前端高 20% 的工资,干的却是 3 个人的活。你的大脑需要在 CSS 的 z-index 和 MySQL 的 Transaction Isolation Level 之间疯狂切换。
结果是什么?
你的认知被彻底击穿。
你以为你的认知,什么场景都能用。
但在真正的技术攻坚战里,什么都不是。🥱
所谓的全栈,大多是全沾
我见过太多这种虚假全栈的代码了,简直是灾难现场。
他们写后端,思维还是前端那一套:
- 数据库设计:没有范式概念,一张表 50 个字段,全是 JSON 字符串。
- 错误处理:
try-catch包住整个 API,报错全返200 OK,msg 里写 bug。 - 并发安全:在
for循环里await查库,完全不懂什么是连接池耗尽。
让我们看一段典型的前端思维写后端的死代码:
// 典型的假全栈代码
// 以为用了 async/await 就是后端大神了
router.post('/buy', async (req, res) => {
// 1. 先查库存(没有锁,并发一来直接超卖)
const stock = await db.query(`SELECT count FROM products WHERE id=${req.body.id}`);
if (stock > 0) {
// 2. 扣库存(中间如果服务挂了,数据不一致)
await db.query(`UPDATE products SET count = count - 1 WHERE id=${req.body.id}`);
// 3. 创建订单
await db.query(`INSERT INTO orders ...`);
return res.json({ success: true });
}
});
这种代码,稍微有点后端经验的人看了都会心肌梗塞。但在全栈眼里:跑通了啊,没报错啊!
什么都会 = 什么都不精。
你以为你拓宽了广度,其实你牺牲了深度。在裁员潮来临时,公司是会留一个能解决复杂内存泄漏的 Node 专家,还是留一个既能写页面又能写增删改查,但稍微上点量就崩服务的万金油?
在我们国内,答案是极其残酷的。
T 型人才的骗局
很多人反驳:我要做 T 型人才,一专多能!
理想很丰满,现实是绝大多数人做成了 一型人才 —— 横向铺得无限开,纵向深度为零。
- 学了 Docker,只会
docker run,不懂 Cgroup 原理。 - 学了 React,只会
useEffect,不懂 Fiber 调度。 - 学了 Rust,只会写 Hello World,借用检查器都过不去。
- 学了 SQLite, 只会增删改查,不懂什么叫锁,什么叫性能优化
这种简历驱动型学习产生的知识,极其脆弱。
一旦遇到深水区的 Bug,你的全栈光环瞬间破碎,只能去 AI Chat 复制粘贴,然后祈祷奇迹发生。
真正的全栈
是你能从前端的一个点击事件(Click),一路追踪到内核的系统调用(Syscall),这中间的每一层你都可控。
如果你做不到,那你充其量只是一个全栈水货。😥
请你先成为单栈战神
人的精力是有限的。在 35 岁危机到来之前,请功利一点,聚焦一点。
如果你是前端:
别急着去学 Go,别急着去搞 K8s。
先把浏览器渲染原理吃透,把 V8 垃圾回收搞懂,把图形学(WebGL/Canvas)啃下来。
当你在一个领域钻得足够深,深到能解决 99% 人解决不了的问题时,你才有资格去谈横向扩展。
这时候的扩展,不是为了凑简历,而是为了解决问题。
- 学 Node.js,是因为前端构建工具跑得太慢,你需要深入 OS 层优化 I/O。
- 学 Rust,是因为 JS 在计算密集型任务上拉胯,你需要 WASM 来救场。
这才是全栈的正确打开方式:降维打击。
别再用全栈来标榜自己了。
在这个分工日益精细化的时代,专家永远比杂家值钱。
专注你的赛道,把它做到极致。
那才是你不可被替代的根本。
大家怎么看🤔

来源:juejin.cn/post/7601811815828406323
为什么程序员不自己开发一个小程序赚钱
大家好,我是凌览。
- 个人网站:blog.code24.top
- 去水印下载鸭:nologo.code24.top
如果本文能给你提供启发或帮助,欢迎动动小手指,一键三连(点赞、评论、转发),给我一些支持和鼓励谢谢。
刷到一个挺扎心的话题:程序员为什么不自己做产品赚钱。
身边还真有不少人问过类似的话:"你天天写代码这么厉害,怎么不自己搞个App、做个小程序?随便弄弄不就发财了?"
每次听到这种问题,我都不知道该从哪儿开始解释。

最近在 X 乎上看到同行的回答,看完只能说:太真实了。
理想很丰满、现实很骨感
首先,假装我们是程序员,某天深夜加班回家,瘫在沙发上刷手机,突然一个念头炸开——"我去,这个功能市面上根本没有!我要是做一个,肯定爆火!”。
脑子里的画面瞬间清晰:产品上线、用户疯涨、投资人排队、财务自由...,满脑子都是"老子不干了,要创业"。
说干就干,流程走起来:
第一步:注册账号结果发现邮箱早就被自己多年前注册过,还冻结了。解冻、换邮箱,折腾一圈。
第二步:想名字绞尽脑汁想了个好名字,一搜,已被占用。再想想想,终于通过。
第三步:开发前端后端一把抓,不会前端?没事,Ai结伴编程一把梭。uniapp启动,一套代码多端运行,微信、QQ、抖音、快手平台全都要上。
第四步:买服务器,阿里云一核两G,一年600块,付款的时候手还没抖。
第五步:搞域名,随便挑一个,一年30块,便宜。
第六步:备案到这里,噩梦开始了。拍照、填表、等审核,来来回回折腾。好不容易过了,提交小程序审核——"该项目类型个人不支持,需要企业认证。"
卒。亏损-630元。
但程序员嘛,头铁。不信邪,继续:
第七步:注册公司个体户要经营场所,干脆直接注册公司。准备材料、开对公账户、刻公章,又是一顿操作。
第八步:重新认证企业认证要的材料堆成山,干脆重新注册个小程序。又是想名字(原来的还要等两天才能释放)、填资料、承诺书、盖章...
终于,小程序上线了。
上线只是开始,赚钱才是难题。
每天努力宣传、引流,结果广告收益长这样:昨日收入0.65元。
对,你没看错,六毛五。折线图上的曲线在0.3元到1.8元之间反复横跳,月收入6.72元。服务器钱还没赚回来,先赔进去几百块。
什么会这样?
- 个人开发者不能收费,只能通过挂广告,而广告收入低到离谱。激励广告单价居然只有4.29元/千次展示,Banner广告更惨,几块钱千次展示。算笔账:日访问量要达到2万,才能日入500。2万UV什么概念?很多小公司的官网一天都没这么多人。
- 推广难,小程序是个封闭生态,你不能诱导分享,否则直接封号。只能从其他平台往微信导流,但用户路径一长,流失率奇高。要开通流量主还得先引流500人,这第一道门槛就卡死不少人。
- 审核机制让人头大,页面上文字一多,就说你涉及"内容资讯",不给过。个人开发者经营类目受限,动不动就踩红线。
不是技术问题,是商业问题
程序员不做小程序赚钱,不是因为不会写代码,而是因为写代码只是万里长征第一步。
做一个能赚钱的小程序,需要:
- 产品能力:做什么?解决谁的什么问题?凭什么用你的?
- 运营能力:流量从哪来?怎么留存?怎么变现?
- 商业资质:公司、对公账户、各种许可证,合规成本不低;
- 时间和精力:白天上班,晚上搞副业,服务器半夜挂了还得爬起来修。
而大多数程序员,只是喜欢写代码而已。让他们去搞流量、谈商务、处理工商税务,比写一万行代码还痛苦。
更扎心的是,就算你愿意干这些,小程序的红利期也早过了。2017年刚出来那会儿,确实有人靠简单工具类小程序赚到第一桶金。现在?各大平台库存量几百万个,用户注意力被某音、被红书切得稀碎,新入局者基本就是炮灰。
成功案例
网上经常能看到"做小程序月入过万"的帖子,但仔细看会发现,要么是卖课的,要么是有特殊资源的(比如手里有公众号矩阵导流),要么是早期入局者吃到了红利。
对于普通程序员来说,接个外包项目,按时薪算可能比折腾三个月小程序赚得还多,还省心。
技术只是工具,商业才是战场。会拿锤子的不一定会盖房子,会写代码的不一定能做出赚钱的产品。这不是技术问题,这是两个完全不同的赛道。
最后
所以,开发一个小程序到底能不能赚钱?
能,但跟你关系不大。
要么你有现成的流量池,比如几十万粉丝的公众号、抖音号,小程序只是变现工具;要么你有特殊资源,比如独家数据、行业资质;再要么你踩中了某个极小概率的风口,比如当年疫情期间的健康码周边工具。否则,个人开发者大概率是炮灰。
写代码是确定性的事,输入逻辑输出结果;做生意是概率性的事,投入不一定有回报。 大多数人适合前者,却误以为自己能驾驭后者。
你呢?有没有过"做个产品改变世界"的冲动?最后成了吗?
来源:juejin.cn/post/7600489282839625738


