













2025 AI原生编程挑战赛收官,5500+战队攻关AIOps工程化闭环
1月14日, 由阿里云主办、云原生应用平台承办的“2025 AI原生编程挑战赛”圆满收官。历经2个多月的角逐,6支队伍从5500多支报名战队中脱颖而出,在云原生环境下跑通AIOps Agent核心技术闭环,成功晋级决赛。最终,来自汽车行业的企业级战队“V-AI”获得总冠军。

AI原生编程挑战赛由发展历程超过10年的“云原生编程挑战赛”升维而来。自2015年创办至今已连续举办十一届,累计吸引全球10余个国家和地区的96,000多支战队参与。
作为国内聚焦AI原生编程与运维场景融合的重磅赛事,本次大赛自启动就展现出“破圈”影响力,参赛选手遍布包括清华大学、中科院等在内的180多所国内外高校及120多家企业。大赛核心命题在于将大模型的推理潜能引入运维实战。选手基于部署在阿里云跨可用区的真实电商服务,通过官方提供的真实多模态可观测数据(Log、Metric、Trace、Entity、Event)构建AI驱动的智能运维Agent,实现对复杂云原生系统中未知故障的自动根因诊断。
为广邀全球开发者共赴“让天下没有难查的故障”的技术实践,大赛组委会提供了通过云监控2.0白屏化操作、通过SPL/SQL语句分析诊断、Workflow/Agent自动化三种解题路径,配以最小可复现步骤、示例查询与产出要求指导,帮助选手借助AI快速、准确、低成本地进行故障根因诊断,收获参赛作品超1000份。
总决赛现场,阿里云智能集团副总裁、基础设施事业部负责人蒋江伟,阿里云智能集团副总裁、市场营销部负责人刘湘雯为冠军战队“V-AI”颁奖。

蒋江伟表示,这次AI原生编程挑战赛见证了AI Agent在处理复杂运维问题上的潜力。选手们在大赛中释放出的创新活力与技术灵感,让我们看到AI与研发、测试与运维全链路的深度融合,正在为构建标准化、可规模化扩展的智能运维新范式夯实根基。
刘湘雯在祝贺获奖战队时指出,从云原生到AI原生,大赛的愿景随着技术的演进不断迭代。希望参赛开发者以本次大赛作为起点,继续勇敢破界,在实战中打磨,让更多创新构想精准落地。
来自华中科技大学计算机学院的“HUST-B507”战队及个人开发者战队“我就看看不参加” 分获亚军和季军,阿里云智能集团资深技术专家司徒放、云原生应用平台负责人周琦为获奖战队颁奖。


阿里云智能云原生应用平台运营负责人王荣刚、产品营销市场负责人陆俊为3支个人开发者战队“scaner”、 “皮卡丘的皮卡”、“那个男孩儿” 颁发优胜奖,鼓励选手在智能运维领域持续探索。

代表冠军战队V-AI分享的车企领域架构师朱迪表示:“工作中的大量IT运维工作,让我们面对提升效率、降低成本的挑战。在这次比赛中我们不仅提升了技术,也加深了对阿里云可观测产品的理解,加速解决实际故障的效率。通过比赛,我们更加相信AI与运维的融合是必然趋势。感谢组委会的支持,期待与阿里云继续携手共进,迎接更加智能的未来。”
多位参赛队伍及选手分享经验时提到,阿里云云监控2.0提供的产品和服务,为参赛提供了稳定的数据底座。其中,UModel作为云监控2.0的核心建模基础,提出基于图模型的统一可观测数据建模范式,不仅解决了传统可观测系统中“数据孤岛”、“语义割裂”、“建模复杂”等痛点,还为AI原生运维(AIOps)、智能根因分析、跨域关联等高级能力提供了结构化、可推理的数据底座,是阿里云为AI时代打造的运维世界本体,让可观测系统从“被动响应”走向“主动认知与优化”。
本次大赛的技术深度也赢得了学术界的关注,其技术逻辑与实验环境已获得中科院等知名高校机构认可,并被正式引入相关科研课题实践,为AIOps产业长期发展储备高质量人才。
阿里云智能资深技术专家、云原生应用平台负责人周琦表示,“AIOps编程挑战赛希望以大模型与AI技术为新起点,帮助开发者开启在Operation Intelligence广阔赛道上的探索,将传统依赖经验的‘老中医式’运维转变为智能化的问题解决能力,实现从被动响应向主动预测的升级。感谢各位参赛选手的创意和创新,和阿里云一同推动AIOps Agent的发展,创造智能运维的未来。”
大赛中沉淀的技术标准与人才生态将持续赋能企业向AI原生演进。阿里云将以云监控2.0为核心智能运维体系,帮助企业在AI时代以更智能、更高效、更低成本的方式构建全栈可观测体系。
收起阅读 »大小仅 1KB!超级好用!计算无敌!
js 原生的数字计算是一个令人头痛的问题,最常见的就是浮点数精度丢失。
// 1. 加减运算
0.1 + 0.2 // 结果:0.30000000000000004(预期 0.3)
0.7 - 0.1 // 结果:0.6000000000000001(预期 0.6)
// 2. 乘法精度偏移
0.1 * 0.2 // 结果:0.020000000000000004(预期 0.02)
3 * 0.3 // 结果:0.8999999999999999(预期 0.9)
// 3. 除法结果异常
0.3 / 0.; // 结果:2.9999999999999996(预期 3)
1.2 / 0.2 // 结果:5.999999999999999(预期 6)
在金额计算的场景中出现这种问题是很危险的,例如「0.1 元 + 0.2 元」本应等于 0.3 元,原生计算却会得出 0.30000000000000004 元,直接导致金额显示错误或支付逻辑异常。
不少人会用toFixed四舍五入,保留 2 位小数来格式化数字,它本质上是 字符串格式化工具,而非精度修复工具,而且还会带来新的精度问题 —— toFixed的四舍五入规则是 “银行家舍入法”,无法解决底层计算的精度误差。
// 问题1. 四舍五入规则不符合预期
1.005.toFixed(2); // 结果:"1.00"(预期 "1.01")
2.005.toFixed(2); // 结果:"2.00"(同样问题)
1.235.toFixed(2); // 结果:"1.23"(预期 "1.24")
// 问题2. 无法修复底层计算误差
const sum = 0.1 + 0.2; // 0.30000000000000004
sum.toFixed(2); // 结果:"0.30"(表面正确,但误差仍存在,后续再运算仍然有问题)
sum.toFixed(10); // 结果:"0.3000000000"(仅隐藏误差,未消除)
而 number-precision 能解决这些问题。
number-precision 的优势在哪?
- 轻量化,大小仅
1kb - API 极简化,只有
加减乘除和四舍五入 - 专注精度问题,无额外心智负担
兼容性好,无额外依赖
适用场景
- 中小型项目、仅需解决基础加减乘除精度问题的场景(如电商、金融类简单计算)
- 对包体积敏感的前端项目。
如何使用?
pnpm install number-precision
import NP from 'number-precision'
NP.strip(0.09999999999999998); // = 0.1
NP.plus(0.1, 0.2); //加法计算 = 0.3, not 0.30000000000000004
NP.plus(2.3, 2.4); //加法计算 = 4.7, not 4.699999999999999
NP.minus(1.0, 0.9); //减法计算 = 0.1, not 0.09999999999999998
NP.times(3, 0.3); //乘法计算 = 0.9, not 0.8999999999999999
NP.times(0.362, 100); //乘法法计算 = 36.2, not 36.199999999999996
NP.divide(1.21, 1.1); //除法计算 = 1.1, not 1.0999999999999999
NP.round(0.105, 2); //四舍五入,保留2位小数 = 0.11, not 0.1
混合的计算:
import NP from 'number-precision'
// (0.8-0.5)x1000,保留2位小数
NP.round(NP.times(NP.minus(0.8, 0.5), 1000), 2)
// 计算股票收益率
NP.round(NP.times(NP.divide(NP.minus(+price, +cost), +cost), 100),2)
更复杂的计算场景用什么
number-precision有短小精悍的优势在,基本的运算都能拿捏,但那些要求更高的计算场景用什么库呢?
总结了目前社区流行的几款计算库,大家按需取用。
| 库 | 特点场景 | 库体积 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|---|---|
toFixed | 内置方法,仅用于数字格式化,不解决底层精度问题 | 0 | 无需额外引入,使用便捷 | 无法修复计算误差,四舍五入规则非标准 | 非精确场景的临时格式化 |
number-precision | 轻量化,提供加减乘除、四舍五入基础功能,无多余 | 1KB | 体积极小,API 极简,学习成本低 | 不支持超大整数,无复杂数学运算 | 电商价格计算、表单数字校验 |
big.js | 专注十进制浮点数运算,API 简洁,默认精度可配置 | 6KB | 平衡体积与功能,兼容性好 | 功能少于 decimal.js | 中小型项目精确计算、数据统计 |
decimal.js | 功能全面,支持高精度控制、大数字处理、进制转换、三角函数等,可自定义精度配置 | 32KB | 精度极高,功能覆盖全,灵活性强 | 体积较大,API 较复杂 | 金融核心计算、科学计算 |
math.js | 全能型数学库,支持表达式解析、矩阵运算、单位转换等复杂数学能力 | 160KB | 综合数学能力强,场景覆盖广 | 体积庞大,性能开销高 | 数据可视化、工程计算 |
附上地址:
number-precision:github.com/nefe/number…
big.js:github.com/MikeMcl/big…
decimal.js:github.com/MikeMcl/dec…
math.js:github.com/josdejong/m…
作品推荐
Haotab 新标签页,一个优雅的新标签页
静待你的体验❤
来源:juejin.cn/post/7555400502711320576
做个大屏既要不留白又要不变形还要没滚动条,我直接怒斥领导,大屏适配就这四种模式
在前端开发中,大屏适配一直是个让人头疼的问题。领导总是要求大屏既要不留白,又要不变形,还要没有滚动条。这看似简单的要求,实际却压根不可能。今天,我们就来聊聊大屏适配的四种常见模式,以及如何根据实际需求选择合适的方案。
一、大屏适配的困境
在大屏项目中,适配问题几乎是每个开发者都会遇到的挑战。屏幕尺寸的多样性、设计稿与实际屏幕的比例差异,都使得适配变得复杂。而领导的“既要...又要...还要...”的要求,更是让开发者们感到无奈。不过,我们可以通过合理选择适配模式来尽量满足这些需求。
二、四种适配模式
在大屏适配中,常见的适配模式有以下四种:
(以下截图中模拟视口1200px*500px和800px*600px,设计稿为1920px*1080px)
1. 拉伸填充(fill)
- 特点:内容会被拉伸变形,以完全填充视口框。这种方式可以确保视口内没有空白区域,但可能会导致内容变形。
- 适用场景:适用于对内容变形不敏感的场景,例如全屏背景图。
2. 保持比例(contain)
- 特点:内容保持原始比例,不会被拉伸变形。如果内容的宽高比与视口不一致,会在视口内出现空白区域(黑边)。这种方式可以确保内容不变形,但可能会留白。
- 适用场景:适用于需要保持内容原始比例的场景,例如视频或图片展示。
3. 滚动显示(scroll)
- 特点:内容不会被拉伸变形,当内容超出视口时会添加滚动条。这种方式可以确保内容完整显示,但用户需要滚动才能查看全部内容。
- 适用场景:适用于内容较多且需要完整显示的场景,例如长列表或长文本。
4. 隐藏超出(hidden)
- 特点:内容不会被拉伸变形,当内容超出视口时会隐藏超出部分。这种方式可以避免滚动条的出现,但可能会隐藏部分内容。
- 适用场景:适用于内容较多但不需要完整显示的场景,例如仪表盘。
三、为什么不能同时满足所有要求?
这四种适配模式各有优缺点,但它们在逻辑上是相互矛盾的。具体来说:
- 不留白:要求内容完全填充视口,没有任何空白区域。这通常需要拉伸或缩放内容以适应视口的宽高比。
- 不变形:要求内容保持其原始宽高比,不被拉伸或压缩。这通常会导致内容无法完全填充视口,从而出现空白区域(黑边)。
- 没滚动条:要求内容完全适应视口,不能超出视口范围。这通常需要隐藏超出部分或限制内容的大小。
这三个要求在逻辑上是相互矛盾的:
- 如果内容完全填充视口(不留白),则可能会变形。
- 如果内容保持原始比例(不变形),则可能会出现空白区域(留白)。
- 如果内容超出视口范围,则需要滚动条或隐藏超出部分。
四、【fitview】插件快速实现大屏适配
fitview 是一个视口自适应的 JavaScript 插件,它支持多种适配模式,能够快速实现大屏自适应效果。
github地址:github.com/pbstar/fitv…
在线预览:pbstar.github.io/fitview
以下是它的基本使用方法:
配置
- el: 需要自适应的 DOM 元素
- fit: 自适应模式,字符串,可选值为 fill、contain(默认值)、scroll、hidden
- resize: 是否监听元素尺寸变化,布尔值,默认值 true
安装引入
npm 安装
npm install fitview
esm 引入
import fitview from "fitview";
cdn 引入
<script src="https://unpkg.com/fitview@[version]/lib/fitview.umd.js"></script>
使用示例
<div id="container">
<div style="width:1920px;height:1080px;"></div>
</div>
const container = document.getElementById("container");
new fitview({
el: container,
});
五、总结
大屏适配是一个复杂的问题,不同的项目有不同的需求。虽然不能同时满足“不留白”“不变形”和“没滚动条”这三个要求,但可以通过合理选择适配模式来尽量满足大部分需求。在实际开发中,我们需要根据项目的具体需求和用户体验来权衡,选择最合适的适配方案。
在选择适配方案时,fitview 这个插件可以提供很大的帮助。它支持多种适配模式,能够快速实现大屏自适应效果。如果你正在寻找一个简单易用的适配工具,fitview 值得一试。你可以通过 npm 安装或直接使用 CDN 引入,快速集成到你的项目中。
希望这篇文章能帮助你更好地理解和选择大屏适配方案。如果你有更多问题或建议,欢迎在评论区留言。
来源:juejin.cn/post/7513059488417497123
Vue3 生态再一次加强,网站开发无敌!
如果你正在做官网开发,还在辛苦的手动实现那些动画特效,那今天推荐的这个库,至少让你提前4小时开始摸鱼!
以前,面对设计师的那些炫酷动画,实现起来是最耗头发的;产品经理还时不时的说一下,这效果不好看,我要的是五彩斑斓的黑!
还抱着 Element UI + Animate.css 在那里辛苦调试,苦苦思考好好的效果怎么到了 safari 就变形了呢 ?
现如今,时代变了!
什么是 Inspira UI
Inspira UI 是专门为 Vue3/Nuxt 开发的可复用的动画组件集合。
- 完全免费和开源
- 完美支持
vue3/Nuxt3 - 包括
按钮、输入框、背景、卡片、设备模拟、光标、2D/3D效果等120+个特效组件 - 样式基于
TailwindCSS - 动画使用
motion-v、gsap实现 - 对移动设备特别优化
来欣赏一下效果:

视频文字
图库
3d文字

走马灯
spline
Inspira UI 的优势
1.兼顾视觉与功能
以**「轻量动效组件库」为定位,核心组件覆盖基础 UI(按钮、输入框等)和模块(3D 交互、动态背景等),所有组件均内置微交互**设计。动效无需额外开发完美适配企业官网、电商页面等需视觉增强的场景,实现 “拿即用” 的开发体验。

Liquid Logo
2.基于Tailwind CSS V4
底层基于 Tailwind CSS 构建组件基础样式,确保原子类叠加的灵活性;支持浅色、深色模式一键切换;支持 ypeScript,所有组件与 API 均提供完整类型定义。

浅色模式
3.深度兼容 Vue/Nuxt 生态,性能提升
无论是 Vue 单页应用还是 Nuxt 服务端渲染项目,都能无缝融入现有技术栈,降低开发者的学习与迁移成本。
同时基于 Vue 3.4+ 新增的 defineModel 与 watchEffect 语法重构,减少了至少 30% 的响应式依赖开销;
4.多端性能优化
对于 3D 组件,在支持 WebGPU 的浏览器中,渲染帧率较旧版 WebGL 提升 2-3 倍.
而对于移动端设备、低配置设备会自动调节动效帧率,性能大大提高;同时,对所有组件做了 “懒加载 + 预渲染” 优化,首屏加载速度较旧版提升 35%
如何使用?
Inspira UI 官方文档支持中文,写的也很接地气,通俗易懂 5 分钟就能上手!
- 安装依赖
# 安装 tainlwind
pnpm install tailwindcss @tailwindcss/vite
# 安装 tailwindcss 库和实用工具
pnpm install -D clsx tailwind-merge class-variance-authority tw-animate-css
# 安装 VueUse 和其他支持库
pnpm install @vueuse/core motion-v
- 配置 vite
import { defineConfig } from 'vite'
import tailwindcss from '@tailwindcss/vite'
export default defineConfig({
plugins: \[
tailwindcss(),
],
})
- 配置主题
可以根据需要自由配置主题色。
@import tailwindcss;
@import tw-animate-css;
@custom-variant dark (&:is(.dark *));
:root {
--card: oklch(1 0 0);
--card-foreground: oklch(0.141 0.005 285.823);
}
.dark {
--background: oklch(0.141 0.005 285.823);
--foreground: oklch(0.985 0 0);
}
@theme inline {
--color-background: var(--background);
}
@layer base {
* {
@apply border-border outline-ring/50;
}
body {
@apply bg-background text-foreground;
}
}
html {
color-scheme: light dark;
}
html.dark {
color-scheme: dark;
}
html.light {
color-scheme: light;
}
最后一步,可以复制源码或者通过 Cli 来安装。
- 直接使用源码
找到想要的组件,复制粘贴到自己的项目中即可。
- 通过 Cli 安装
pnpm dlx shadcn-vue\@latest add "https://registry.inspira-ui.com/gradient-button.json>"
然后,你就有了一个炫酷的按钮。

Gradient Button 效果
最后
Vue3/Nuxt3开发者再也不用羡慕 React生态的 Aceternity UI、Magic UI 了。
Inspira UI 直接填补了 vue3 生态中动效开发这一块的缺陷,可以将这些奇妙的设计应用在企业官网、特效开发中,大大节省开发成本。
让 Vue3 生态再一次得到加强,快去试试这个炫酷的项目把!
附上官网地址:inspira-ui.com/docs/cn
作品推荐
Haotab 新标签页,一个优雅的新标签页
静待你的体验❤
来源:juejin.cn/post/7554572856147984424
放下你手里的 GIF,这才是前端动画最终的归宿!!
一、前端动画的"至暗时刻":每个像素都在燃烧经费
618 前夕,我的 PM 突然发来灵魂拷问:"菜鸡,这个购物车弹性动画,为什么安卓和 iOS 的抖动幅度不一样?还有这个圣诞飘雪特效,为什么 iPhone 13 Pro Max 的耗电量能煎鸡蛋?"
我默默擦掉额头的冷汗,回想起被这些需求支配的恐惧:
- GIF地狱:
- 一个3秒的 loading 动画,设计师随手甩来的 GIF 居然有
5MB - 在安卓低端机上播放时,仿佛在看 PPT 版的《黑客帝国》
- 一个3秒的 loading 动画,设计师随手甩来的 GIF 居然有
- SVG炼狱:
- 设计师用 AE 做的酷炫路径动画,转成
SVG + CSS后变成了毕加索抽象画 - 当产品要求动态修改渐变色时,我仿佛听到了 CPU 的惨叫声
- 设计师用 AE 做的酷炫路径动画,转成
- 平台鸿沟:
- iOS 工程师用 Core Animation 优雅实现的弹性动画
- Android 同学用 ValueAnimator 艰难复刻
- Web 端同事的 CSS transition 在 Safari 上直接摆烂
直到某天,隔壁组的前端突然拍案而起:"用Lottie!这玩意能直接吃AE动画!" —— 那一刻,我仿佛看到了前端动画的文艺复兴曙光。
二、Lottie:动画界的 Rosetta Stone(罗塞塔石碑)
1. 打破巴别塔诅咒的技术本质
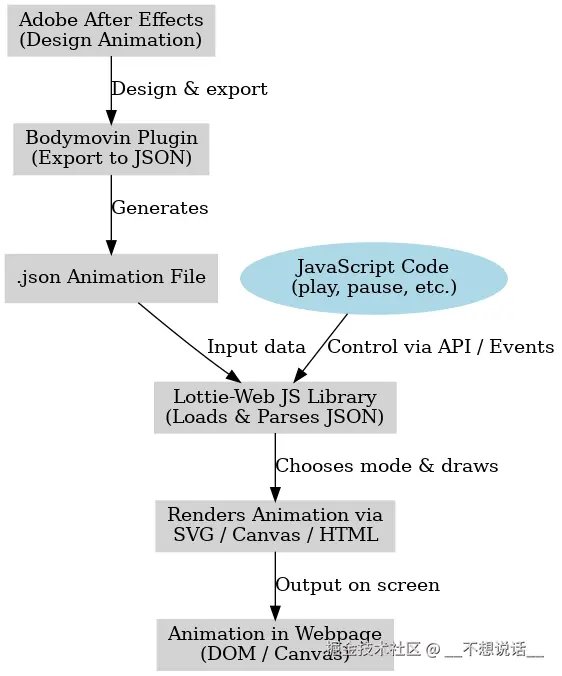
Lottie的魔法可以拆解为三个核心环节:
- 魔法卷轴(JSON文件):
设计师在AE中使用 Bodymovin插件 导出的动画配方,包含所有图层、关键帧、路径等元数据,体积通常只有GIF的1/10 - 咒语解析器(Lottie Runtime):
各平台的解析引擎(Web/iOS/Android/Flutter等),像精密的手术刀般逐帧解析JSON指令 - 元素召唤阵(Canvas/SVG/OpenGL):
根据设备性能自动选择最优渲染方案,低端机用轻量SVG,旗舰机秀Canvas魔法
2. 那些年被 Lottie 拯救的惨案现场
| 传统方案 | Lottie解决方案 | 性能对比 |
|---|---|---|
| 序列帧动画 | 矢量路径动画 | 体积减少90% |
| CSS关键帧 | 复杂贝塞尔曲线运动 | 渲染速度提升300% |
| GIF动图 | 透明通道+高清显示 | 内存占用降低80% |
| Lottie的跨平台特性让设计还原度达到99.99%,从此告别"安卓特供版动画"的尴尬 |
三、Lottie 的文艺复兴之路:从加载动画到元宇宙门票
1. 业务舞台的常青树场景
- 轻量级演出:
Loading 动画、按钮微交互、表情包(微信的[呲牙]动画仅28KB) - 重量级剧场:
新手引导流程、电商促销动效、直播礼物特效(某直播平台的火箭升空动画仅182KB) - 沉浸式演出:
游戏化运营活动、元宇宙3D场景过渡(某电商 App 的虚拟试衣间加载动画)
2. 那些让程序员笑醒的代码片段
Web 端 React 全家桶套餐:
import { Player } from '@lottiefiles/react-lottie-player';
<Player
src="/emoji.lottie.json"
style={{ height: '300px' }}
autoplay
loop
onEvent={event => {
if (event === 'complete') console.log('老板说这个动画要播10086遍')
}}
/>
Vue3 优雅食用姿势:
<template>
<Lottie :animation-data="rocketJSON" @ready="startLaunch" />
</template>
<script setup>
import { Lottie } from 'lottie-web-vue';
import rocketJSON from './rocket-launch.json';
const startLaunch = (anim) => {
anim.setSpeed(1.5);
anim.play();
}
</script>
微信小程序性能优化版:
<lottie
animationData="{{lottieData}}"
path="https://static.example.com/animations/coupon.json"
autoPlay="{{true}}"
css="{{'width: 100%; height: 300rpx;'}}"
bind:ready="onAnimReady"
/>
四、打开 Lottie 的正确姿势:从青铜到王者的进阶之路
1. 设计师的防跑偏指南
- AE图层命名规范:禁止出现"最终版-真的不改了-V12"这类薛定谔命名
- 合理使用预合成:嵌套层级不要超过俄罗斯套娃的极限
- 动态属性标记:需要运行时修改的颜色/文字要提前标注
2. 工程师的性能调优包
压缩黑科技三件套:
# 使用 lottie-tools 进行瘦身
npx lottie-tools compress animation.json -o animation.min.json
# 删除无用元数据
npx lottie-tools remove-unused animation.json
# 提取公共资源
npx lottie-tools split animation.json --output-dir ./assets
按需加载策略:
const loadLottie = async () => {
const animation = await import(
/* webpackPrefetch: true */
/* webpackChunkName: "lottie-animation" */
'./animation.json'
);
lottie.loadAnimation({
container: document.getElementById('lottie'),
animationData: animation.default
});
}
五、当Lottie遇到次元壁:那些年我们填过的坑
1. 跨平台兼容性排雷手册
| 问题现象 | 解决方案 | 原理剖析 |
|---|---|---|
| iOS 闪退 | 检查 mask 路径是否闭合 | CoreAnimation 的路径容错较低 |
| 安卓颜色失真 | 禁用硬件加速 | 某些 GPU 对渐变支持不完善 |
| 微信小程序渲染错位 | 使用 px 单位替代 rpx | 部分机型 transform-origin 计算 bug |
2. 性能优化急救包
// 帧率节流大法
animation.addEventListener('enterFrame', () => {
if(performance.now() - lastTime < 16) return;
lastTime = performance.now();
// 真正执行渲染逻辑
});
// 内存泄漏防护
useEffect(() => {
const anim = lottie.loadAnimation({...});
return () => anim.destroy(); // 比卸载微信还干净
}, []);
六、未来展望:Lottie的元宇宙野望
当我在AR眼镜里看到Lottie渲染的3D购物动画时,突然意识到这个技术正在打开新次元:
- Lottie 3D Beta:
支持 AE 的 3D 图层导出,在WebGL中渲染立体动画 - 动态数据绑定:
实时修改3D模型的材质参数,实现千人千面的营销动画 - 物理引擎集成:
给动画元素添加重力、碰撞等物理特性,让每个像素都遵循真实世界法则
也许不久的将来,我们能用Lottie在元宇宙里复刻《盗梦空间》的折叠城市动画——当然,得先确保产品经理不会要求实时修改地心引力参数。
总结
从被 GIF 支配的恐惧,到用 JSON 驾驭动画的自由,Lottie 让我们离"设计即代码"的理想国又近了一步。下次当设计师又甩来 500MB 的 AE 工程时,你可以优雅地打开 Bodymovin 插件:"亲爱的,这次咱们换个姿势加载。"
来源:juejin.cn/post/7506418053997428751
“改个配置还要发版?”搞个配置后台不好吗
前言
之前我们公司有个项目组搞了个 AI 大模型推荐功能,眼看就要上架了,结果产品突然找过来说:
“那个 AI 推荐的模块先别放了,先隐藏吧,怕上架审核出问题。”
为了赶时间,技术那边就临时加了个判断,把入口在前端藏起来,赶紧发了个版本,算是暂时搞定。
结果没过几天,又说要发版本。我一问咋了?技术一脸生无可恋:
“产品又说 AI 那个功能现在可以公测了,要放出来了。”
好吧,那就再发一次......
然后没几天,产品又说要隐藏掉,说模型结果不稳定要临时下线。
“先别公测了,发现有问题,先关掉再说。”
听说那天技术已经气到跟产品去厕所单挑了……
我当时的内心 OS 是:这也太反复了吧?到底是想上还是不想上?
这种“上线前隐藏,上线后又展示,再隐藏”的操作,不是一次两次了。
所以我们当时就想了:
既然这些需求只是改个显示开关、调个默认值,为啥不干脆给他们一个“自助按钮”?别每次都让我们改代码发版本,产品自己调着玩不好吗?
于是我们开始在后台做一套简单的业务配置中心,目标就是:
- 产品、运营可以自己配置功能开关、文案、参数,不用找开发
- 配置修改能实时生效,不用再发版本
- 支持输入类型、下拉选项、开关按钮、范围数值,想怎么配就怎么配
这不是为了什么“大中台”,就是想解决那些一天三改、两小时一调的需求,把这些琐碎从开发日常里剥离出去。
这些配置,说改就改,好烦人
其实像上面的这个事情 在我们日常开发中太常见了。
举几个我亲身经历的例子就知道为啥我们非得搞个配置中心:
- 登录要不要加图形验证码?
一开始为了用户体验不加,结果突然哪天注册量暴涨,一查是黑产在刷。产品急了:“赶紧加验证码!”
技术临时改、测试、上线……黑产已经溜了,下次再刷又得重来一遍。为啥不做个开关自己控制? - 推荐功能的参数一天一个样
有一版产品说“默认推荐 5 个兴趣标签”,隔两天又改成 3 个,再过几天又要回 4 个,说“现在运营数据反馈不一样了”。
我寻思你都能自己看数据了,那你为啥不能自己改参数? - 短信通道经常切换
阿里、腾讯、网易云信……一个月能换仨。原因也很实在,要么是价格问题,要么是运营说“昨天验证码收不到”。
每次换通道都得技术去代码里改templateId、signName,我真想把接口都写成配置项,让你们爱换谁换谁。 - 活动逻辑说改就改
运营:“这个弹窗逻辑改一下,注册就弹。”
上了之后运营又说:“太打扰用户了,还是调成登录 3 天之后再弹。”
这不就一行逻辑的事,但每次都要发版真心烦。
像这些情况,改的不是业务逻辑,就是个值、个条件、个开关。但只要没抽出来配置,就只能靠技术手动改代码,一点都不优雅,还特别浪费时间。
所以后来我们就想,还是干脆统一搞个配置后台吧,把这些“天天改、随时调”的破事都收进去,让配置能看得见、改得了、控得住,技术这边也能轻松点。
之前我们配置到底怎么管的?说实话,说出来都不太好意思:
- 有的直接写死在代码里,变量名都不带解释的,谁写的谁才知道啥意思;
- 稍微规范一点的,会统一搞个 config 文件,但也只是“技术自己看得懂”的那种;
- 更混乱的是,有的配置写在 yml,有的塞在数据库,还有的干脆“哪里用到就哪里写”,找都找不到;
- 最离谱的是:业务运营类的配置和技术底层的配置,全堆一起,切短信通道这种运营配置放在 core-service 的 application.yml 里,看得人脑壳疼。
等到要改配置的时候,产品和运营根本不知道去哪改,开发也得翻半天才能定位是哪段逻辑控制的,甚至还会不小心把技术底层配置给动了……这种时候就明白了,没有一套清晰、隔离、可视化的配置系统,迟早乱套。
配置也要讲规矩,不能啥都往后台扔
当然,配置中心也不是说所有配置都往后台一丢就完事了。
我们踩过这个坑。
最早的时候我们也想偷懒,把所有配置(技术的、业务的、运营的)都塞在统一的配置文件里,比如 config.php 或 application.yml 里,统一读就完了,听起来挺美的。
但实际用下来,真的是——乱!成!一!锅!粥!
一方面,业务/运营配的东西,是给人看的,得讲人话。
比如:
- 推荐位默认展示几个内容?
- 某个功能在特定版本下是否开启?
- 发奖的触发条件设置为几天内登录?
这些运营同学自己都能理解,也希望自己能控制,那就该做成后台可配置、能预览、能实时生效的。
但另一方面,有些配置就不能乱动,或者干脆不应该给后台看到:
- MQ 消费 topic 名
- 数据库连接池配置
- 是否启用 debug 模式
- 线上某些敏感接口的限频值
如果我们把这些放给业务方看,他们可能都不知道是干嘛的,不小心点了一下,系统都能给整崩了……
所以后来我们就统一了一套大致的“配置分级规则”:
有些配置是纯技术底层的,比如 MQ 的 topic 名、接口限流的阈值、日志采样比例、数据库连接池大小……
这些属于“动一下系统都可能出事”的类型,不给任何后台入口,完全由技术团队内部维护,最好写死或写进 yml 里。
然后是那种纯运营向的配置,比如功能开关、首页推荐展示几个卡片、某段文案内容、活动弹窗的显示时间等等。
这些配置逻辑上不会出啥大问题,但会被运营天天来回调整,必须放后台让他们自己搞,不然技术早晚被烦死。
还有一种是产品经常会动的业务规则类配置,比如:
- 某个功能灰度给哪些版本开放;
- 某个打点逻辑的间隔时间怎么设;
- 是否对新用户显示某个引导。
这些其实也不属于“技术配置”,而是产品为了做 A/B 测试、做用户分群、验证效果临时改的,技术只负责“支持能力”,真正的“值”还是应该交给产品自己配。
我们就按照这个思路,把技术底层的隐藏掉,只暴露运营类和业务类配置给后台,谁负责谁管理。改错了好歹还能找到人。
这样一来,配置中心的边界清晰了,技术也不用再被无限兜底,系统也能跑得更稳定,团队分工也更顺。
配置中心该长啥样?我们定了几个目标
前面说了那么多需求、痛点、吵架场面(划掉),那我们到底想要一个什么样的配置中心呢?
说白了,我们的目标很简单:
能分清模块,分清人,分清配置类型,能改能看能预览,最好技术都不用管。
那我们是怎么拆功能的呢?最初的设计版本是这样的:
1. 配置要能分模块
不能全堆一起。
我们一个项目,最少有这些模块:系统相关、用户系统、运营活动、AI 任务、通知推送、发奖逻辑……每个模块都有自己的配置。
所以我们一开始就支持“按模块分组”,一个模块里挂多个配置项,清清楚楚谁负责啥,谁爱改啥自己管。
2. 每个配置项要有“类型”
这个最开始我们踩过坑。
最初只做了输入框,结果运营输入一堆错格式的东西,改出 bug。后来我们就定了:所有配置项必须类型化,根据使用场景来限定可选值/格式。
目前我们支持的类型大概是这几种:
- 输入框:最普通的文本输入,比如标题、url、提示语。
- 范围值:像“10~100”这种,就搞个最小|最大格式,自动校验。
- 下拉框:适合选模板、选模型、选渠道。
- 单选框:跟下拉差不多,看场景展示方式不同。
- 开关:很直观,是否开启、是否显示,一眼看懂。
- 多选框:比如支持多个渠道、多种规则生效。
每种类型不仅能展示、还能实时预览效果,这样产品在后台改的时候,不会因为“看不懂这个字段到底是啥”而填错。
3. 每个配置项还要有说明、默认值、排序、是否启用这些“附加属性”
比如说明字段是给人看的,告诉我们这个配置是干嘛的。
默认值是防止读取失败时兜底的。
排序值让我们在后台列表里好找,不然一堆配置乱七八糟的。
“是否启用”是加的一个保险,有些配置值可以保留但临时不生效,方便灰度切换或者留作备选。
4. 最重要的:配置改完必须能“立刻生效”
要是改完还得等发版、等服务重启,那这配置中心跟笔记本有啥区别?
所以我们后面加了热更新机制(这部分我后面会细讲),让配置一改,业务侧立刻拿到新值。
配置中心的数据库设计,我们是这么搞的
配置中心的本质,其实就是“配置的结构化存储 + 可控修改 + 有上下文管理”。
所以数据库是核心。我们一共设计了两个主表:模块表 + 配置项表。当然后续可以加变更记录表之类的,这里先讲核心结构。
1. 模块表:配置的分组归属
配置不能全堆一起,所以我们做了个“模块管理”表,每个模块代表一类业务,比如用户系统、AI 推荐、通知设置、发奖逻辑等。
表结构像下面这样:
CREATE TABLE `config_module` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(100) NOT NULL COMMENT '模块名称',
`sort` int(11) DEFAULT '0' COMMENT '排序值,越小越靠前',
`status` tinyint(4) DEFAULT '1' COMMENT '状态 1启用 0禁用',
`create_time` int(11) NOT NULL,
`update_time` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='配置模块分组';
字段说明一下:
id就是主键name是模块名,比如“用户系统”、“活动发奖”sort控制在前端显示顺序,方便找status是不是启用这个模块的配置- 时间字段保留是为了后续查操作记录
2.配置项表:一条配置的所有核心信息
模块分好了之后,接下来就是每个模块下面的具体配置项。我们所有的配置内容,都存在这张 config 表里。
我们当时在设计的时候,就围绕几个问题来定字段的:
- 这个配置是给谁看的?(产品、运营、开发)
- 他们需要怎么填?(输入框?下拉?多选?)
- 填的时候怎么确保不出错?(要不要加参数说明?校验?默认值?)
- 配置项能不能启用/禁用?排序顺序怎么控制?
- 有没有必要展示说明/备注?
最终我们定下了下面这个表结构:
CREATE TABLE `config` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`pid` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '所属模块ID',
`name` varchar(100) NOT NULL COMMENT '配置项名称(展示用)',
`key` varchar(100) NOT NULL COMMENT '配置项key(英文唯一标识)',
`value` text COMMENT '配置项当前值',
`input_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '输入类型:1输入框 2范围 3下拉 4单选 5开关 6多选',
`param` text COMMENT '参数说明:选项或范围,如 "A-1|B-2|C-3"',
`desc` varchar(255) DEFAULT '' COMMENT '配置项说明/备注',
`sort` int(11) DEFAULT '0' COMMENT '排序值(越小越前)',
`status` tinyint(4) DEFAULT '1' COMMENT '状态:1启用 0禁用',
`create_time` int(11) NOT NULL,
`update_time` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `key` (`key`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='系统配置项表';
字段说明:
id:自增主键,没啥说的。pid:配置项属于哪个模块(模块表里的 id)。name:配置项的中文名,比如“是否展示弹窗”。key:这个是英文标识,用来在代码里读取,比如home.pop.enabled。value:配置的当前值,比如1(开启)或{"a":1,"b":2}。input_type:决定这个配置项在后台怎么展示:
- 1 = 输入框
- 2 = 范围(比如“10|100”)
- 3 = 下拉框
- 4 = 单选按钮
- 5 = 开关
- 6 = 多选框
param:这个字段就很灵活了,用来定义下拉/单选/多选的选项,或者范围的上下限,比如:
"中文-zh|英文-en""10|100"
desc:配置项的说明,告诉用户这个配置干嘛的,防止乱填。sort:排序值,配置项多了之后按顺序展示比较清楚。status:这个配置当前是否启用,方便临时关闭某个配置而不删除它。create_time/update_time:时间戳,用来做修改记录、日志追踪之类的。UNIQUE KEY (key):保证每个配置 key 唯一,不会撞名。
总体来说,这张表的核心就是:一个配置项,长什么样、值是多少、长得像啥、能不能动,都在这张表里写清楚了。
模块设计:把配置管得清清楚楚,落到后台页面里
前面我们提到,配置中心一定要支持“按模块分组”,不然配置一多,找起来比翻快递单还费劲。
这里就简单说下我们是怎么把“模块”这个概念,真正落到后台界面和数据库结构里的。
我们每个模块其实就是一个大分类,比如:
- 系统配置
- 用户配置
- AI 相关配置
- 活动发奖配置
- 通知推送相关……
每个模块下可以挂多个配置项,类似“一个文件夹里放一类东西”。
我们后台页面上的模块管理界面,大概就长这样:

这里我们可以设计的支持排序、状态控制、修改、删除这些操作。
点击“新增模块”就会弹出这个表单:
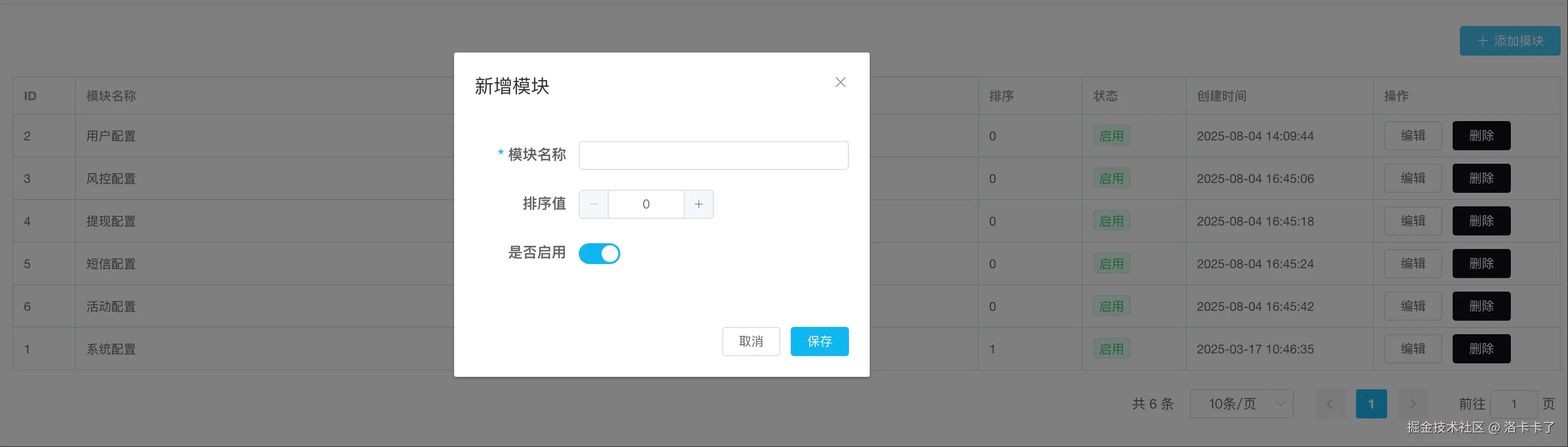
看起来非常简洁对不对。上面的模块表结构对应的核心字段就三个:
- 模块名称:展示用,方便识别
- 排序值:用来控制前端列表显示顺序
- 是否启用:可以临时禁用整个模块下的配置项
后台页面支持模块的增删改查,基础功能已足够覆盖大多数业务配置需求。
当然,如果业务后续需要更复杂的结构(比如“系统配置 → 登录模块 → 登录相关配置”这种),我们也可以扩展支持二级模块或模块分组。当前只是保留了基础能力,足够轻量、上手快。
配置项怎么设计的?
有了模块分组之后,接下来的重头戏就是:配置项的核心玩法。
每个配置项,本质上就是一个“可调参数”。比如这些熟悉的问题:
- 用户登录要不要启用谷歌验证?
- 运营活动的推荐数值范围是多少?
- 发奖逻辑该切哪个短信商?
以前这些配置,不是写死在代码里,就是散落在 yml、env 文件里,甚至不同环境各一份,改一次还得发版,改完还得祈祷别出问题。
这次我们干脆做成可视化配置项,页面上就能:
新增、修改、启用/禁用
设置不同类型的输入方式
即填即预览,所见即所得
我们支持的配置类型包括:
- 输入框:适合输入纯文本,比如一个 URL、token、默认值等。
- 范围:用
最小值|最大值格式,比如推荐人数限制就写成10|100。 - 下拉选择:多个固定选项,用
|分隔,比如中文-zh|英文-en。 - 单选按钮:和下拉差不多,但前端展示为横向圆点,更直观。
- 开关:布尔值场景,1 是开启,0 是关闭。
- 多选框:允许选多个选项,比如某功能适用于多个角色、多个平台。
每种类型在新增配置时都有专属提示,比如范围要填最小|最大,下拉要写选项清单,填完之后还能看到实时预览,确保填的值就是我们想要的。
接下来我们就一个个举例,一边介绍场景,一边实际新增配置项来看效果。
类型一:输入框
适用场景:
输入框是最通用、最基础的配置类型,适合填写纯文本、数字、链接、key 等,不需要做复杂校验,直接存直接用。
常见场景举例:
default_jump_url:默认跳转链接,比如用户扫码登录后跳去哪个页面。login_timeout:用户登录状态超时时间,单位秒。system_notice:系统公告文案。token_prefix:JWT 或其它 token 的前缀标识。
我们现在来新增一个配置项:
- 所属模块:系统配置
- 配置名称:登录超时(秒)
- 配置 Key:
login_timeout - 输入类型:输入框
- 默认值:600
- 参数说明:留空(输入框不需要)
- 描述:用户登录后多少秒内无操作将自动退出
- 排序值:0
- 是否启用:是
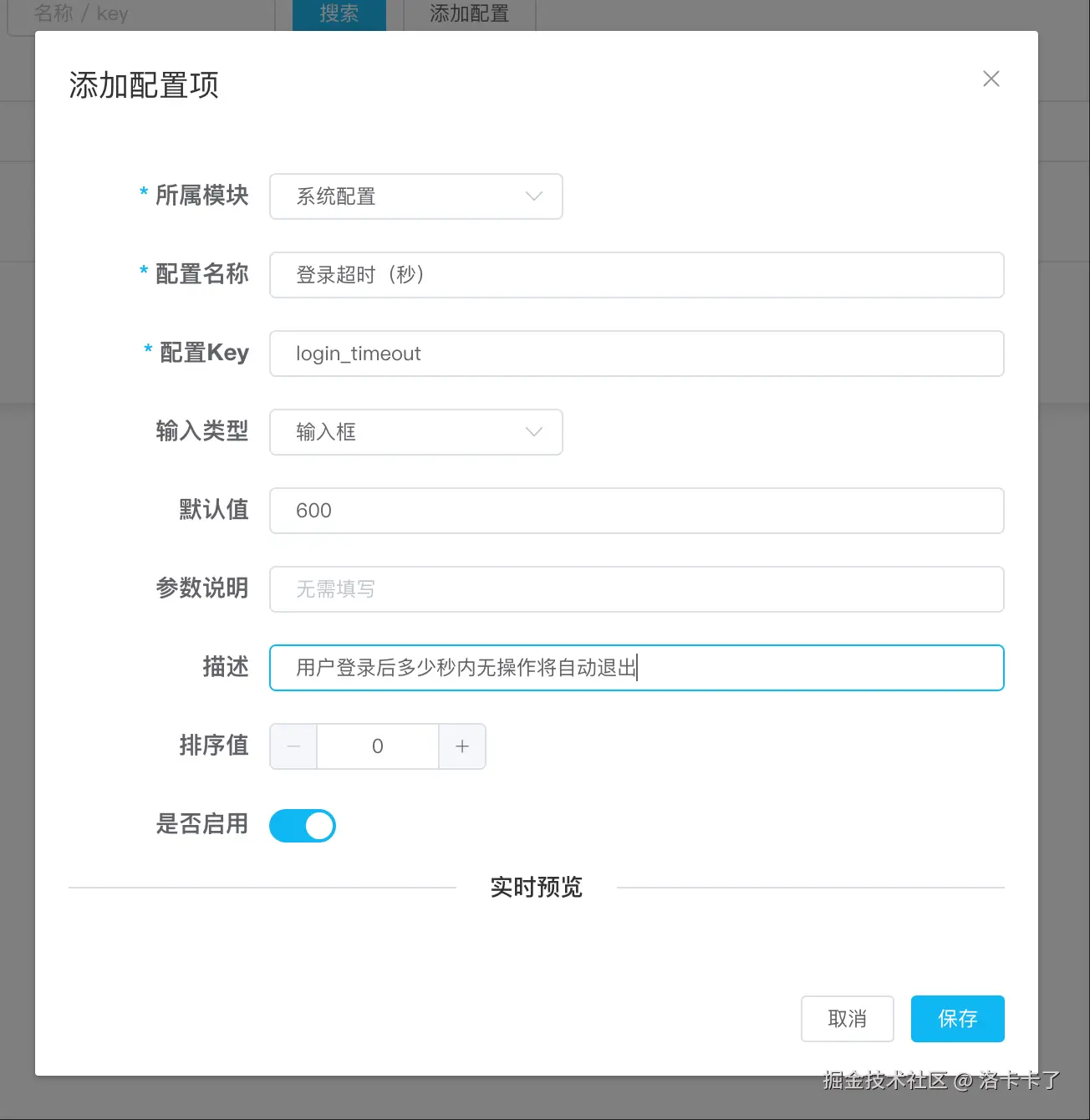
类型二:范围(最小值 | 最大值)
适用场景:
范围类型适合那种“值不能随便填,必须在某个区间内”的配置,比如:
- 推荐系统中:每天最多推荐多少次?
- 活动配置中:用户每次最多能抽几次奖?
- 发奖逻辑中:奖励金额必须在一个上下限之间。
用配置来写这种规则,业务方只要改数字就行,不用再去翻代码或改逻辑,非常方便。
示例配置:推荐数值范围
假设我们现在要配置一个推荐值范围:
- 所属模块:系统配置
- 配置名称:每日推荐数量范围
- 配置 Key:
recommend_count_range - 输入类型:范围
- 默认值:50
- 参数说明:
10|100(表示最小值是 10,最大值是 100) - 描述:控制推荐系统每天给用户推荐的最小/最大条数
- 排序值:0
- 是否启用:是
我们在页面中选择「输入类型:范围」之后,系统会提示填写参数格式为:
最小值|最大值,例如:10|100
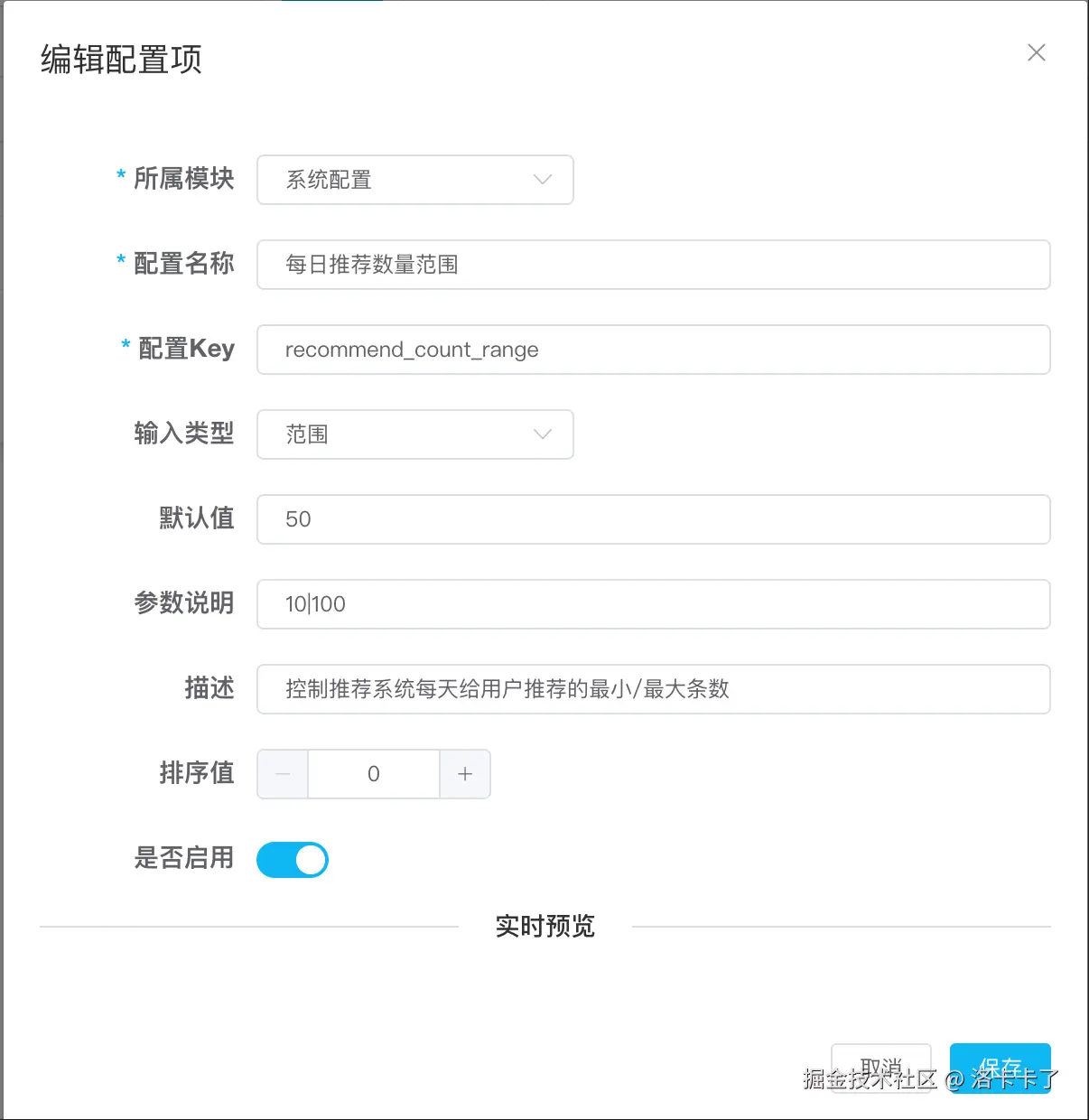
类型三:下拉选择(select)
适用场景:
如果某个配置值只能从一组选项中选一个,比如:
- 默认语言:中文 / 英文 / 日文
- 消息推送渠道:极光 / 个推 / 小米推送
- 推荐策略:粗放型 / 精细化 / AB 测试组
这类配置,业务经常调整,但必须选“规定范围内”的值,用下拉最合适。
示例配置:默认语言设置
我们现在来配置一个「默认语言」的选项:
- 所属模块:系统配置
- 配置名称:默认语言
- 配置 Key:
default_language - 输入类型:下拉选择
- 默认值:
zh - 参数说明:
中文-zh|英文-en|日文-jp - 描述:系统默认语言,决定用户首次进入时的显示语言
- 排序值:0
- 是否启用:是
注意参数说明的格式:
每个选项写成“名称-值”,多个选项用 | 隔开,比如:
中文-zh|英文-en|日文-jp
我们可以随意扩展选项,只要格式统一就行。
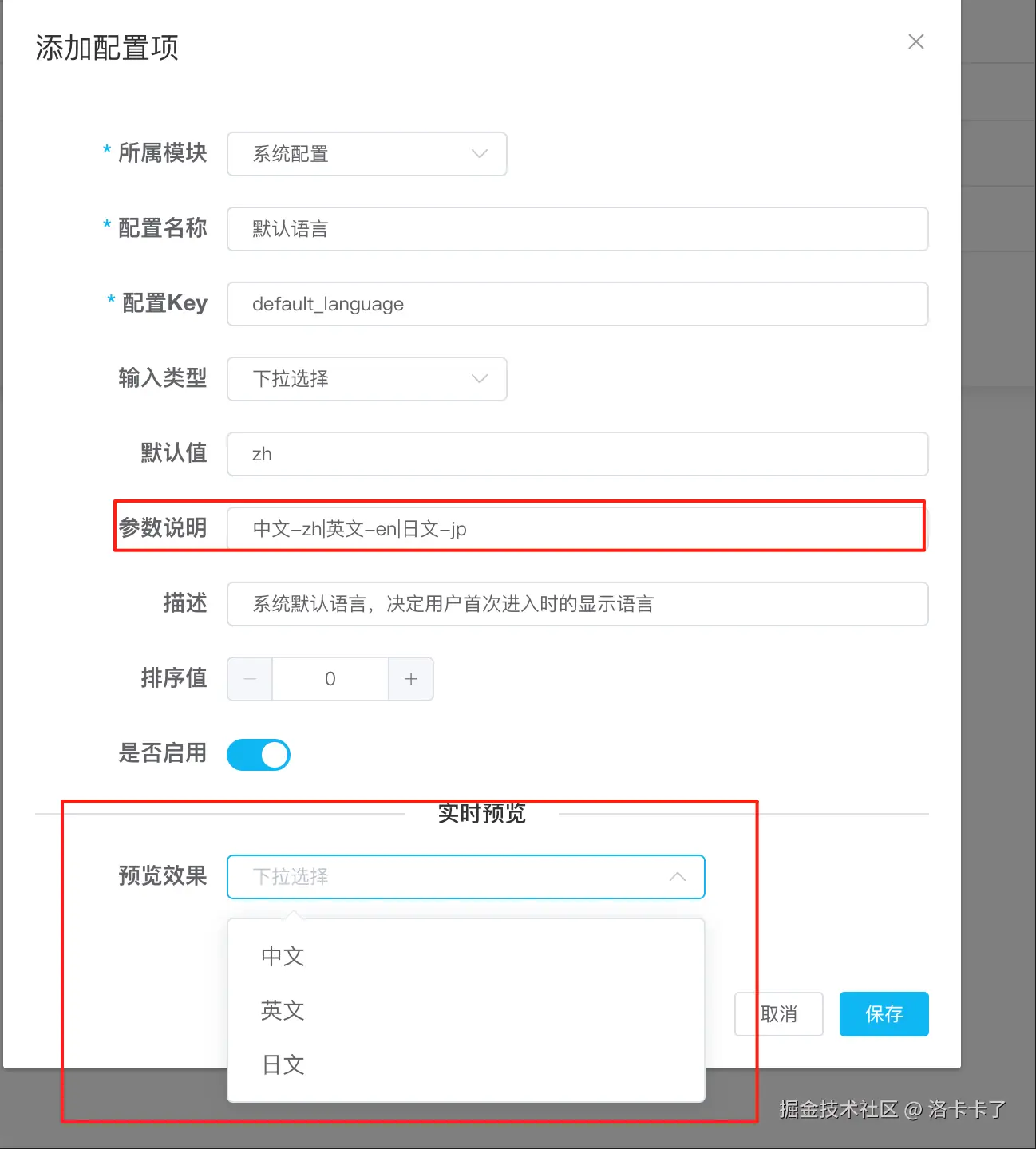
类型四:单选按钮(radio)
适用场景:
单选按钮适合那种选项数量不多、用户希望“一眼看清楚当前选的是啥”的配置,比如:
- 登录方式:密码 / 验证码 / 三方授权
- 首页布局:列表 / 瀑布流
- 推送等级:重要 / 普通 / 弱提示
相比下拉,单选按钮更直接,不用点一下再展开,适合管理后台中高频使用的布尔或枚举项
示例配置:登录方式选择
假设我们想设置一个登录方式的配置:
- 所属模块:系统配置
- 配置名称:登录方式
- 配置 Key:
login_method - 输入类型:单选按钮
- 默认值:
pwd - 参数说明:
密码登录-pwd|验证码登录-code|三方授权-oauth - 描述:控制用户使用哪种方式登录
- 排序值:0
- 是否启用:是
参数说明格式:
和下拉一样,用 名称-值 的格式写选项,多个用 | 分隔:
密码登录-pwd|验证码登录-code|三方授权-oauth

类型五:开关(switch)
适用场景:
布尔型逻辑的最爱!
只要我们有 “开关类” 配置,比如:
- 是否开启 AI 推荐功能
- 是否启用登录验证码
- 是否允许用户取消订单
- 是否开启调试日志打印
这些“启用 / 禁用”型的业务控制,都可以直接用开关来配置,后台切换一次立即生效,不用发版,非常方便。
示例配置:启用登录验证码
这次我们来添加一个“是否启用图片验证码”的配置:
- 所属模块:系统配置
- 配置名称:启用图片验证码
- 配置 Key:
login_captcha_enabled - 输入类型:开关
- 默认值:
1(1 表示启用,0 表示关闭) - 参数说明:留空(开关类型不需要)
- 描述:是否对用户登录行为开启图形验证码验证
- 排序值:0
- 是否启用:是
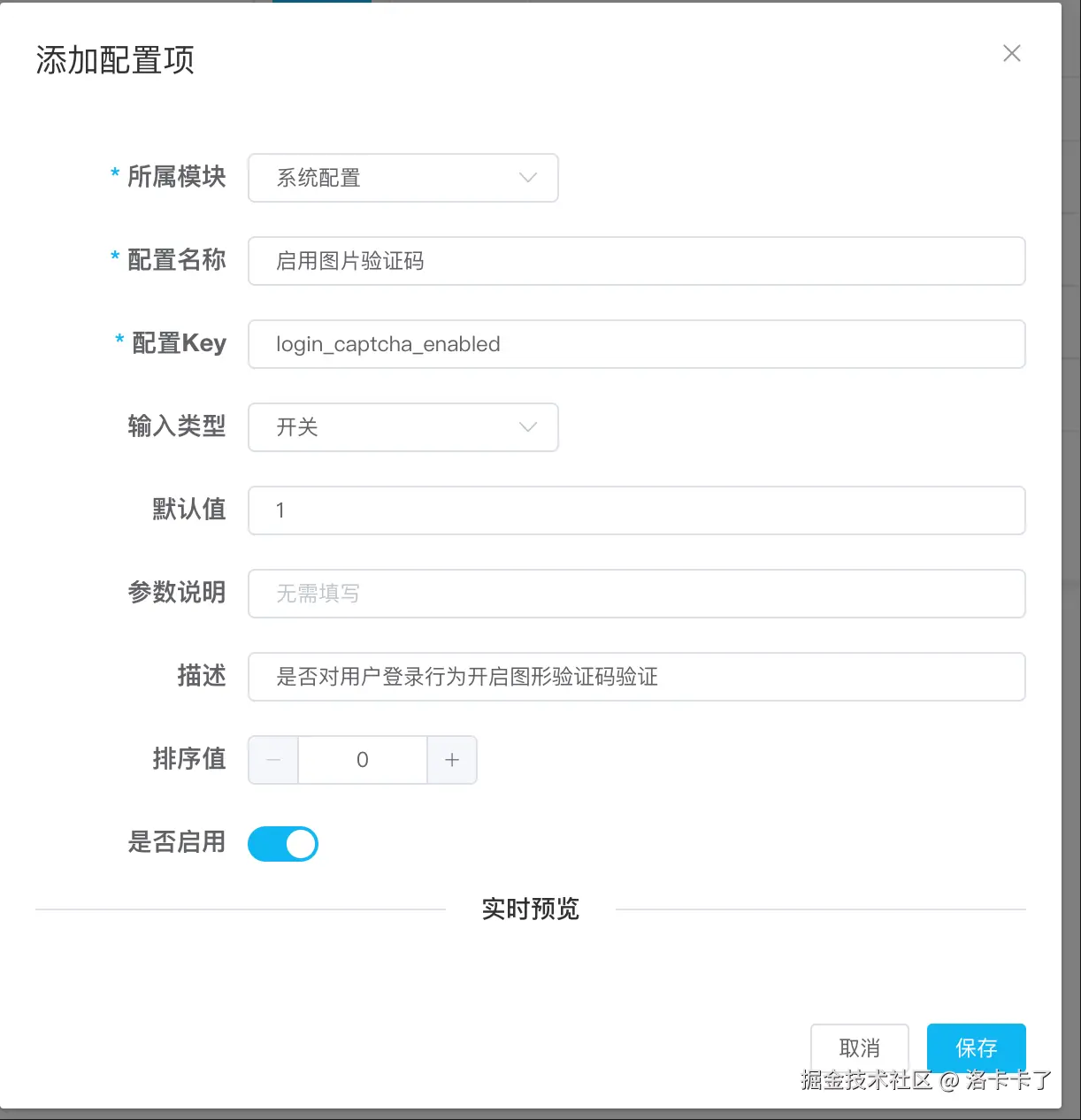
这类配置用处非常多,一些 灰度开关、紧急兜底、临时下线功能 都可以通过这个来做,非常适合给非技术人员使用。
类型六:多选框(checkbox)
适用场景:
当我们希望用户可以勾选多个选项时,单选就不够用了,比如:
- 消息推送支持的渠道:短信 / App / 微信 / 邮件
- 用户允许绑定的第三方平台:微信 / QQ / 微博
- 内容推荐的标签:热门 / 最新 / AI / 精选
多选框让这些“可以组合”的配置变得灵活,谁要开就勾谁,要多选就多选,不受限制。
示例配置:允许的推送渠道
我们来配置一个「支持的消息推送渠道」:
- 所属模块:系统配置
- 配置名称:推送渠道
- 配置 Key:
push_channels - 输入类型:多选框
- 默认值:
app,wechat(多个值用英文逗号隔开) - 参数说明:
短信-sms|App-app|微信-wechat|邮件-mail - 描述:平台支持的推送方式,可多选
- 排序值:0
- 是否启用:是
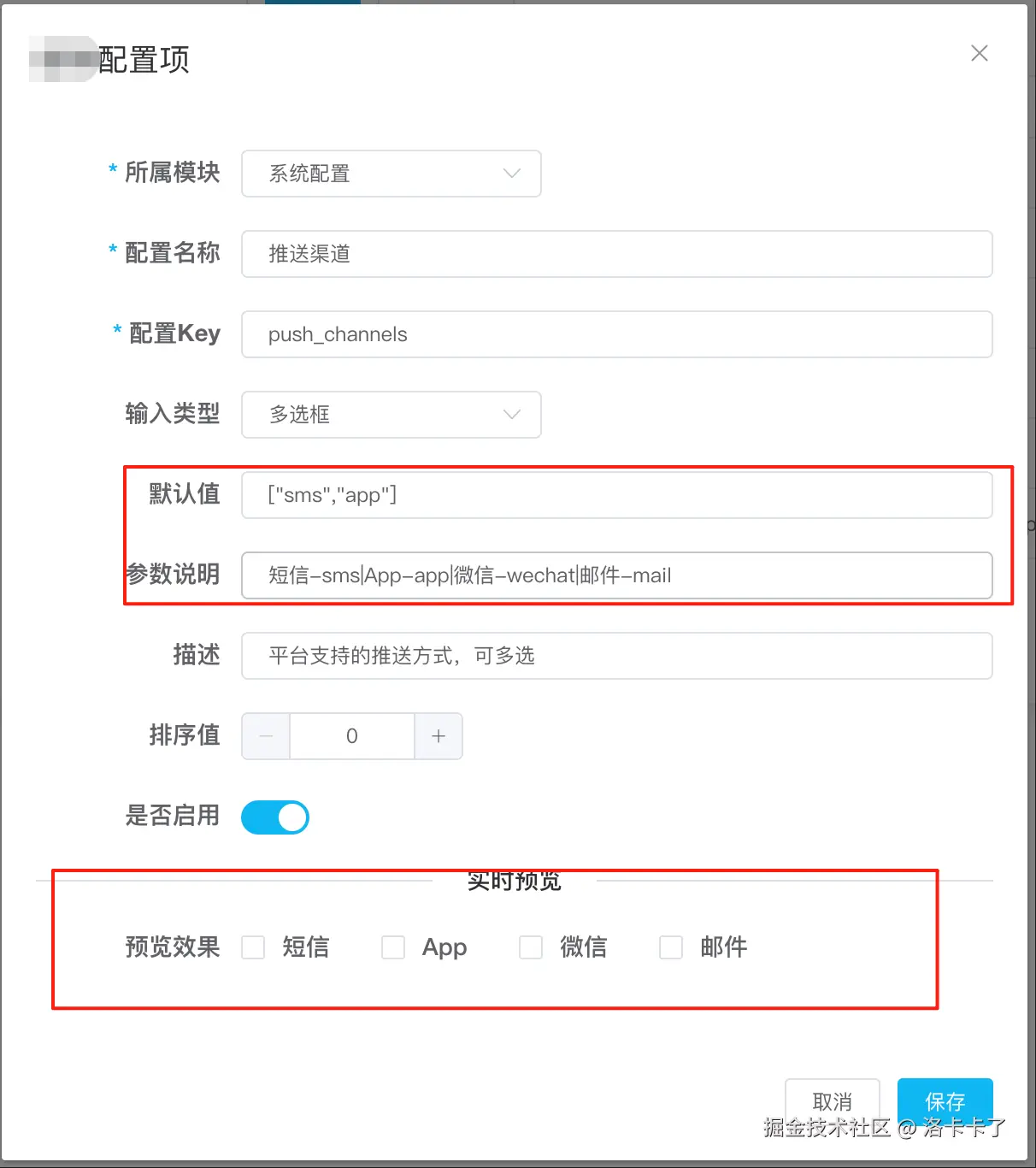
参数说明格式 & 默认值说明
- 参数格式:
展示文本-值用|分隔
短信-sms|App-app|微信-wechat|邮件-mail
- 默认值:用英文逗号
,隔开多个值,必须是参数里定义过的值
app,wechat
配置项列表展示效果(后台页面)
配置添加完以后,在后台配置中心的列表中展示是这样:
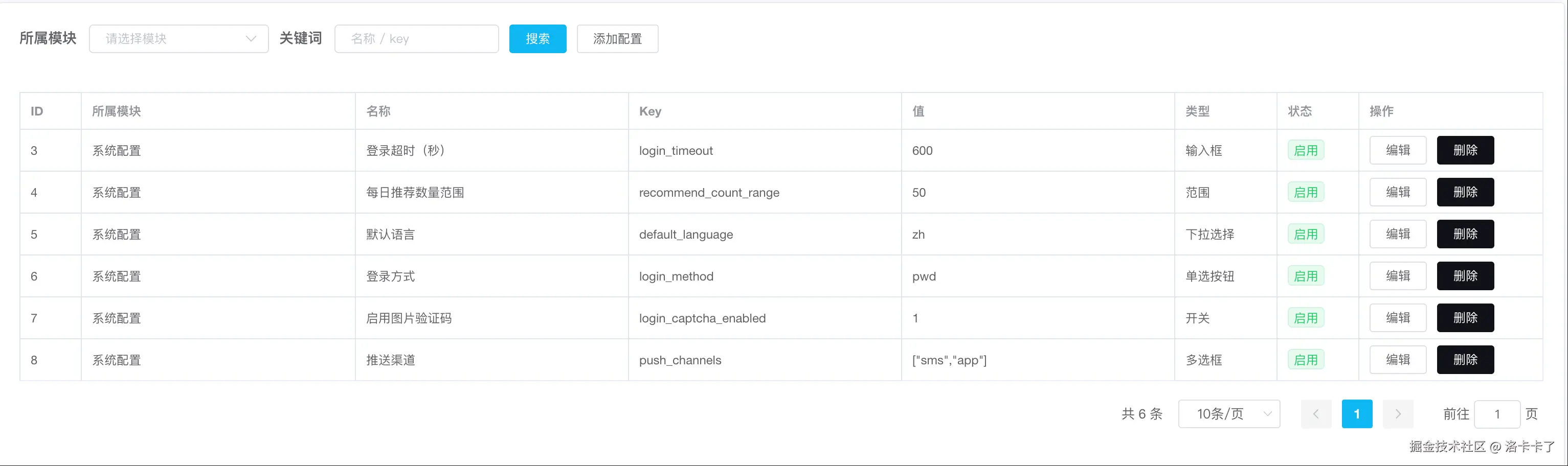
每一项都根据类型展示了不同的 UI 组件,页面清晰、可读、可点、可编辑,操作起来一目了然。
而我们的数据库记录示例(config 表)存储为这样的:

每条记录都绑定了模块 ID(这里都挂在“系统配置”模块下),并且通过 input_type 字段区分了类型,param 字段为配置项的结构补充说明(下拉/单选/多选专用),desc 字段用于给配置者提示用途。
至于页面上的 UI 展示逻辑、预览区域怎么动态渲染、后端接口怎么接收和保存这些配置,我这边就不展开一一举例了。
说到底,这套配置中心的重点不是“多高级的交互”,而是“足够简单、稳定、好用”,让我们能快速落地配置项、快速修改参数,而不是天天写死在代码里改个值还要发版。
给产品和运营用的“安全编辑页”
配置项都建好了,页面也能预览,那产品和运营想调参数的时候,是直接去编辑配置项吗?
当然不能。
你想啊,运营只是想把推荐数从 100 调成 50,结果点到 key 了,把 recommend_range 改成 recommend_rang,那后端一拿不到值,整个推荐系统直接罢工了。
所以我们专门做了一套“参数调整页”,就像上图这样的界面,产品和运营只需要点点选项、输个值、开个关,完全不用接触 key 和底层结构,修改也更安全。
这个页面其实是对配置项的“业务层封装”——模块和配置项的创建,还是需要研发来做的。因为只有开发才能知道每个 key 该怎么在代码里接,哪些是支持实时生效的,哪些改了之后要重启服务,业务逻辑怎么走,这些都不是运营自己能处理的。
换句话说:
- 配置项创建时,研发定义 key + 类型 + 默认值 + 参数说明。
- 产品和运营后续修改时,只改值,不动结构,不容易出错。
那我们既然添加了配置项之后,下一步就是把它展示出来,让运营和产品能方便地修改配置、实时查看效果。
我们设计了一个专门的页面,用来承载这些配置项的「操作界面」。页面整体是按模块分 tab 展开的,每个模块下展示自己对应的配置项,表单类型跟配置项定义时保持一致,比如输入框、开关、下拉、多选等一应俱全。
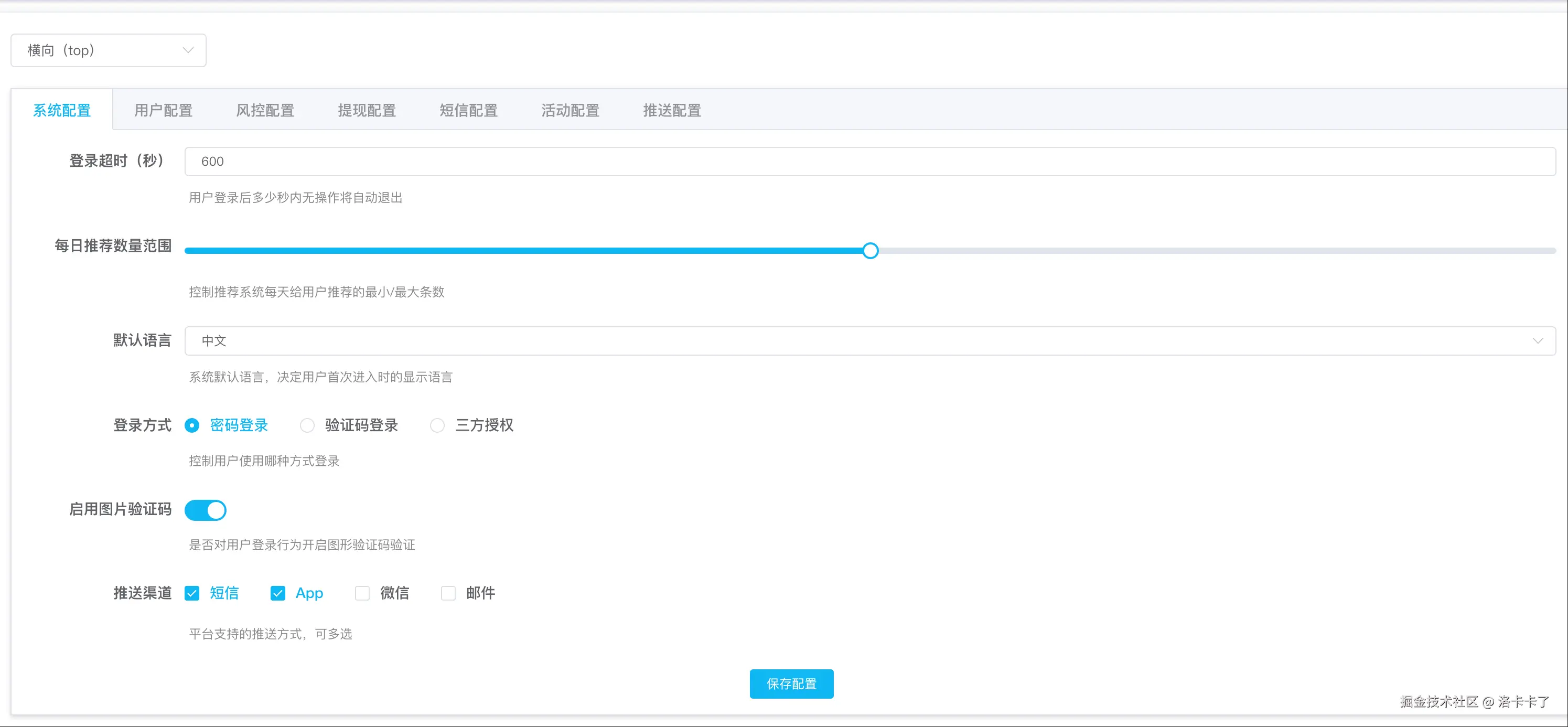
如下图所示,就是我们系统初版配置模块下的实际页面效果:
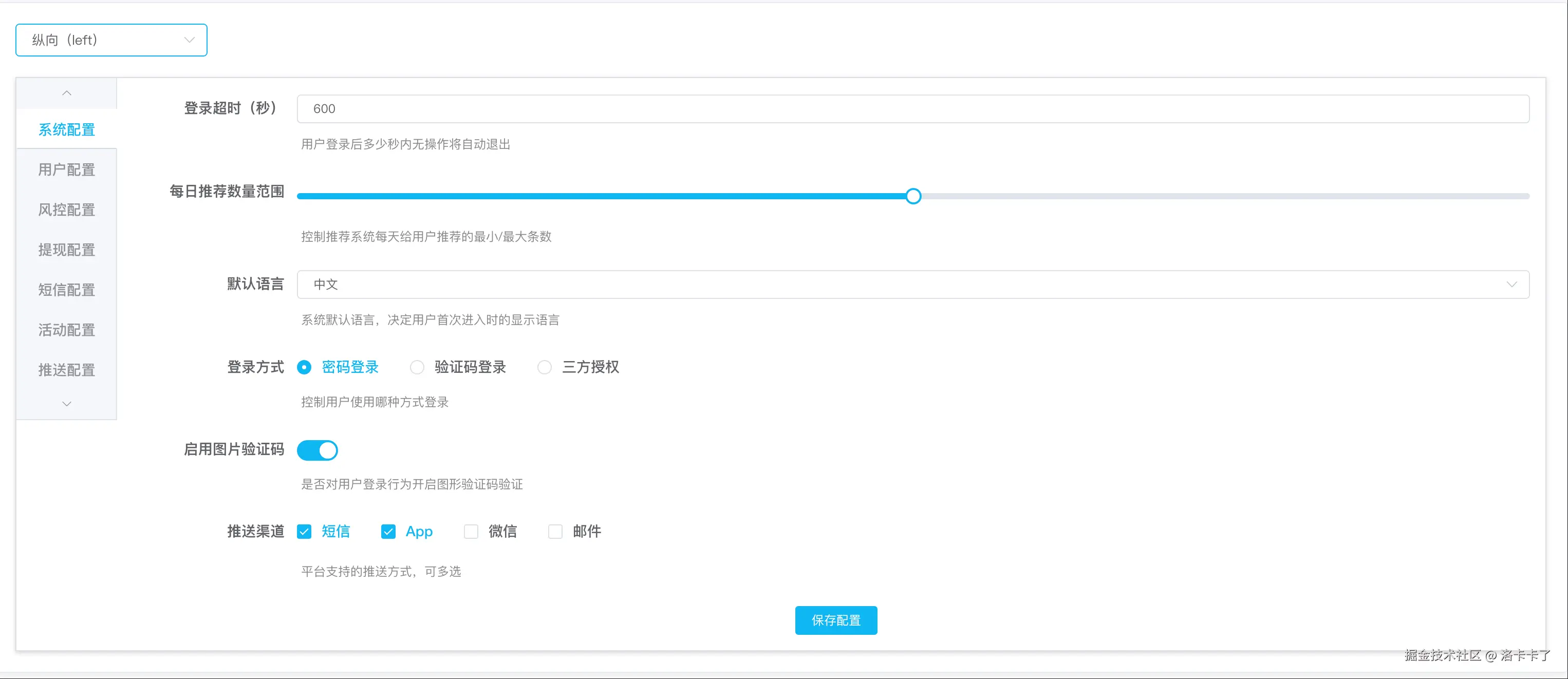
当然如果某个模块配置太多我们也可以切换为纵向展示:
从上图我们可以看到:
- 每个配置项都有自己的「说明文案」,方便使用者理解配置含义;
- 类型化配置项有明确的 UI 控件,比如「每日推荐数量范围」就是滑动条;
- 实时编辑,保存即生效(根据配置项定义的类型和读取方式);
- 页面左上角还能切换模块,快速定位。
这个页面是专门为非技术人员设计的,不需要他们懂 key 是什么,也不用关心类型怎么定义,他们只管调值就行了,一切都变得可控又安全。
有了这个配置页之后,产品和运营基本上就能脱离研发,自主修改参数了。接下来我们来聊聊配置值在后端是怎么被接入的。
配置中心只是“存”,真正怎么“用”还得看后端
配置中心做得再强大,最终目的还是要服务业务逻辑。
页面上填的那些 key 和 value 并不是为了好看,它们必须在后端代码里“用起来”,才算真正落地。
那后端是怎么接这些配置的呢?其实就两件事:
- 读取配置值
- 根据 key 做对应逻辑处理
比如我们在后台新增了一个配置项:
key: enable_google_auth
value: 1
表示用户登录时是否开启 Google 验证。那后端代码里就可能是这样写的:
func ShouldUseGoogleAuth() bool {
val := configService.Get("enable_google_auth")
return val == "1"
}
而且每次新建一个配置项,一定要先让开发把读取逻辑写好,配置才能真正生效。不然页面配得再漂亮,后端代码不接,等于白改。
因此,我们建议配置项的新增一定要有“二次审核”机制——业务逻辑没走通之前,别急着让配置项上线。
配置读取:要读得快,还要改得稳
我们虽然只是做了一个小小的配置中心,但依旧严格遵守几个“配置铁律”:
| 原则 | 含义 |
|---|---|
| 读快写稳 | 配置是读多写少,必须优先保障读取性能 |
| 缓存兜底 | 数据库抗不了高并发,缓存必须做主力 |
| 更新可控 | 配置改动要支持热更新,不能等发版 |
| 不信网络 | 避免每次都走 RPC / HTTP,配置必须能“本地感知” |
所以我们最后的设计是:
所有配置值都先读 Redis,Redis 没有再查数据库,查出来的值再写回 Redis。
我们可以简单封装了一个方法来统一读取配置:
func (s *ConfigService) Get(key string) string {
val, err := redisClient.Get(ctx, "config:"+key).Result()
if err == redis.Nil {
val = db.GetConfigFromDB(key)
redisClient.Set(ctx, "config:"+key, val, time.Hour) // 缓存 1 小时
}
return val
}
这样做的好处:
- 性能好:Redis 读取速度快,尤其适合配置这种读多写少的场景;
- 调用方便:业务方不需要知道配置在哪,直接调
configService.Get(); - 支持热更新:后台一改配置,Redis 一更新,后端逻辑立刻用上新的值。
配置改错了怎么办?我们加了「刷新机制」来兜底
想象一下,有个产品小哥在后台把短信通道从 A 改成了 B,然后 Redis 秒同步,结果是 B 接口根本没打通……
“线上短信全挂了”+“谁改的都不知道”+“运营拉着技术去机房单挑”
这事我们也不是没经历过。
为了防止“手滑即事故”,我们可以引入了 配置刷新机制。
也就是说,后台页面改配置只是“提交更新”,真正生效得靠一个“刷新动作” 。
我们可以设计一种配置刷新方案:保存 ≠ 生效,需要“手动刷新”才能同步
比如我们之前初版采用的模式,更保险一些:
- 后台页面改配置,只写入数据库,不同步 Redis;
- 系统标记这个配置为“待刷新”;
- 产品或运营点“刷新”按钮,才真正写入 Redis;
- 同步操作记录 & 通知消息,方便追踪。
优点是:
- 不怕误操作,有一步确认机会;
- 可接入审批流程;
- 所有操作都有记录,排查问题不含糊。
当然我们也可以设计一个“刷新 API”:
POST /api/config/refresh?key=xxx
POST /api/config/refresh_all
支持单个或批量刷新,用于后台管理或开发联调。
安全兜底机制
除了“刷新机制”,我们还需要做几件事:
| 功能 | 说明 |
|---|---|
| 操作记录 | 谁改了什么,啥时候改的,值变了多少 |
| 修改通知 | 配置一改,系统自动发钉钉提醒相关同事 |
| 关键配置加锁 | 比如短信、支付相关配置默认加锁,解锁需审批 |
| 限制字段编辑 | 页面上只能改 value,不允许改 key,防止配置失效 |
总的来说呢,配置中心不是“你点保存我就给你改”,而是一个受控的配置发布系统。
读得快、改得稳、改完能溯源、有通知有审计——这才是一个靠谱的配置中心。
最后的碎碎念
说实话,这套配置中心,说难也不难,说重要吧,也不是业务核心。
但对我们来说,真的很刚需。纯粹就是日常工作中被“配置这点事儿”折磨太久了。 尤其是对业务开发流程不规范的公司来说。
以前在小公司,改个配置就得发版,发版就有几率中奖,一不小心就全服出事。久了大家都怕动,连产品都不敢随便提需求,说白了就是被流程和风险绑住手脚。
后来我们才想明白,像“推荐数量改一下”“开关先关一阵看看效果”这种,完全没必要动代码、改逻辑、走上线流程。给他们一个地方自己调就好了嘛。
所以这套配置中心,说不上啥高级架构,也不是啥大厂必备,但就是解决了我们日常那些“看起来不重要但天天遇到”的小问题。
业务推进更顺了,产品改需求也不再靠嘴说,技术也不用动不动上线连夜发包。这不比啥都强?
更多架构实战、工程化经验和踩坑复盘,我会在公众号 「洛卡卡了」 持续更新。
如果内容对你有帮助,欢迎关注我,我们一起每天学一点,一起进步。
来源:juejin.cn/post/7534632857504989238
Vue3 防重复点击指令 - clickOnce
Vue3 防重复点击指令 - clickOnce
一、问题背景
在实际的 Web 应用开发中,我们经常会遇到以下问题:
- 用户快速多次点击提交按钮:导致重复提交表单,产生多条相同数据
- 异步请求未完成时再次点击:可能导致数据不一致或服务器压力增大
- 用户体验不佳:没有明确的加载状态反馈,用户不知道操作是否正在进行
这些问题在以下场景中尤为常见:
- 表单提交(注册、登录、创建订单等)
- 数据保存操作
- 文件上传
- 支付操作
- API 调用
二、解决方案
clickOnce 指令通过以下机制解决上述问题:
1. 节流机制
使用 @vueuse/core 的 useThrottleFn,在 1.5 秒内只允许执行一次点击操作。
2. 按钮禁用
点击后立即禁用按钮,防止用户再次点击。
3. 视觉反馈
自动添加 Element Plus 的 Loading 图标,让用户明确知道操作正在进行中。
4. 智能恢复
- 如果绑定的函数返回 Promise(异步操作),则在 Promise 完成后自动恢复按钮状态
- 如果是同步操作,则立即恢复
三、核心特性
✅ 自动防重复点击:1.5秒节流时间
✅ 自动 Loading 状态:无需手动管理 loading 变量
✅ 支持异步操作:自动检测 Promise 并在完成后恢复
✅ 优雅的清理机制:组件卸载时自动清理事件监听
✅ 类型安全:完整的 TypeScript 支持
四、技术实现
关键技术点
- Vue 3 自定义指令:使用
Directive类型定义 - VueUse 节流:
useThrottleFn提供稳定的节流功能 - 动态组件渲染:使用
createVNode和render动态创建 Loading 图标 - Promise 检测:自动识别异步操作并在完成后恢复状态
工作流程
用户点击按钮
↓
节流检查(1.5秒内只执行一次)
↓
禁用按钮 + 添加 Loading 图标
↓
执行绑定的函数
↓
检测返回值是否为 Promise
↓
Promise 完成后(或同步函数执行完)
↓
移除 Loading + 恢复按钮状态
五、使用方法
1. 注册指令
// main.ts
import clickOnce from '@/directives/clickOnce'
app.directive('click-once', clickOnce)
2. 在组件中使用
<template>
<!-- 异步操作示例 -->
<el-button
type="primary"
v-click-once="handleSubmit">
提交表单
</el-button>
<!-- 带参数的异步操作 -->
<el-button
type="success"
v-click-once="() => handleSave(formData)">
保存数据
</el-button>
</template>
<script setup lang="ts">
const handleSubmit = async () => {
// 模拟 API 调用
await api.submitForm(formData)
ElMessage.success('提交成功')
}
const handleSave = async (data: any) => {
await api.saveData(data)
ElMessage.success('保存成功')
}
</script>
六、优势对比
传统方式
<template>
<el-button
type="primary"
:loading="loading"
:disabled="loading"
@click="handleSubmit">
提交
</el-button>
</template>
<script setup lang="ts">
const loading = ref(false)
const handleSubmit = async () => {
if (loading.value) return
loading.value = true
try {
await api.submit()
} finally {
loading.value = false
}
}
</script>
问题:
- 需要手动管理 loading 状态
- 每个按钮都要写重复代码
- 容易遗漏 finally 清理逻辑
使用 clickOnce 指令
<template>
<el-button
type="primary"
v-click-once="handleSubmit">
提交
</el-button>
</template>
<script setup lang="ts">
const handleSubmit = async () => {
await api.submit()
}
</script>
优势:
- 代码简洁,无需管理状态
- 自动处理 loading 和禁用
- 统一的用户体验
七、注意事项
- 仅用于异步操作:该指令主要为异步操作设计,同步操作会立即恢复
- 绑定函数必须返回 Promise:对于异步操作,确保函数返回 Promise
- 节流时间固定:当前节流时间为 1.5 秒,可根据需求调整
THROTTLE_TIME常量 - 依赖 Element Plus:使用了 Element Plus 的 Loading 图标和样式
八、适用场景
✅ 适合使用:
- 表单提交按钮
- 数据保存按钮
- 文件上传按钮
- API 调用按钮
- 支付确认按钮
❌ 不适合使用:
- 普通导航按钮
- 切换/开关按钮
- 需要快速连续点击的场景(如计数器)
九、指令源码
import type { Directive } from 'vue'
import { createVNode, render } from 'vue'
import { useThrottleFn } from '@vueuse/core'
import { Loading } from '@element-plus/icons-vue'
const THROTTLE_TIME = 1500
const clickOnce: Directive<HTMLButtonElement, () => Promise<unknown> | void> = {
mounted(el, binding) {
const handleClick = useThrottleFn(
() => {
// 如果元素已禁用,直接返回(双重保险)
if (el.disabled) return
// 禁用按钮
el.disabled = true
// 添加 loading 状态
el.classList.add('is-loading')
// 创建 loading 图标容器
const loadingIconContainer = document.createElement('i')
loadingIconContainer.className = 'el-icon is-loading'
// 使用 Vue 的 createVNode 和 render 来渲染 Loading 组件
const vnode = createVNode(Loading)
render(vnode, loadingIconContainer)
// 将 loading 图标插入到按钮开头
el.insertBefore(loadingIconContainer, el.firstChild)
// 将 loading 图标存储到元素上,以便后续移除
;(el as any)._loadingIcon = loadingIconContainer
;(el as any)._loadingVNode = vnode
// 执行绑定的函数(应返回 Promise 或普通函数)
const result = binding.value?.()
const removeLoading = () => {
el.disabled = false
// 移除 loading 状态
el.classList.remove('is-loading')
const icon = (el as any)._loadingIcon
if (icon && icon.parentNode === el) {
// 卸载 Vue 组件
render(null, icon)
el.removeChild(icon)
delete (el as any)._loadingIcon
delete (el as any)._loadingVNode
}
}
// 如果返回的是 Promise,则在完成时恢复;否则立即恢复
if (result instanceof Promise) {
result.finally(removeLoading)
} else {
// 非异步操作,立即恢复(或根据需求决定是否恢复)
// 通常建议只用于异步操作,所以这里也可以不处理,或给出警告
removeLoading()
}
},
THROTTLE_TIME,
)
// 将 throttled 函数存储到元素上,以便在 unmount 时移除
;(el as any)._throttledClick = handleClick
el.addEventListener('click', handleClick)
},
beforeUnmount(el) {
const handleClick = (el as any)._throttledClick
if (handleClick) {
el.removeEventListener('click', handleClick)
// 取消可能还在等待的 throttle
handleClick.cancel?.()
delete (el as any)._throttledClick
}
},
}
export default clickOnce
十、总结
clickOnce 指令通过封装防重复点击逻辑,提供了一个开箱即用的解决方案,让开发者可以专注于业务逻辑,而不用担心重复点击的问题。它结合了节流、状态管理和视觉反馈,为用户提供了更好的交互体验。
来源:juejin.cn/post/7589839767816355878
2026年的IT圈,看看谁在“裸泳”,谁在“吃肉”
Hello,兄弟们,我是V哥!
最近不少粉丝私信问我:“V哥,现在这行情卷得跟麻花似的,35岁危机就在眼前,你说咱们搞IT的,到了2026年还有出路吗?这技术迭代快得像坐火箭,我到底该往哪边押注?”
V哥我就一句话:焦虑个屁!机会全是给有准备的人留着的。
你们现在看是“寒冬”,V哥我看是“洗牌”。等到2026年,IT行业的格局早就翻天覆地了。那些只会写重复代码的“代码搬运工”确实该慌,但懂趋势、会借力的兄弟,那会儿绝对是香饽饽。
今天,V哥我就掏心窝子地聊聊,2026年咱们这行的几大“风口”。特别是最后两块大肉,听进去了,你下半年的年终奖就稳了。
一、 AI智能体开发:2026年的“新物种”
兄弟们,先把“ChatGPT”这种对话机器人放一边。V哥告诉你,2026年是AI智能体爆发的一年。
啥叫智能体?现在的AI像个博学的书呆子,你问它答。而智能体,那是带着“脑子”和“手脚”的打工人。它不仅能理解你的意图,还能自己拆解任务、自己去调用工具、自己反思纠错,最后把活儿干完了给你交差。
- 现在是: 你写代码,AI帮你补全一行。
- 2026年是: 你说“帮我做个电商后台”,智能体自己写代码、自己测、自己部署、甚至自己写文档。
V哥的研判:
到了2026年,不会开发智能体的程序员,就像2010年不会用智能手机的人一样落伍。你不需要自己去造一个大模型(那是大厂的事儿),你需要做的是做中间的“Controller”(控制器)。怎么用LangChain(或者那时候更牛的框架)把大模型串起来?怎么给智能体挂载API接口?怎么设计它的“记忆”和“规划”能力?
这块儿目前还是蓝海,谁能率先把“数字员工”搞定,谁就是那个省下百万人力成本的老板眼里的红人。

二、 鸿蒙开发:国产操作系统的“成年礼”
这块儿,V哥必须得敲黑板!这可能是未来几年里,中国普通程序员最大的红利期。
别总盯着Android和iOS卷了,那是存量市场,杀得头破血流。你看华为现在的动作,HarmonyOS NEXT(纯血鸿蒙) 已经切断了对安卓代码的依赖。这意味什么?意味着这不仅仅是换个皮肤,这是一套全新的、独立的生态!
V哥的预言:
到了2026年,鸿蒙不再是手机的配角,而是全场景(手机、车机、家电、工控)的霸主。
- 技术栈: 赶紧把ArkTS(Ark TypeScript)学熟了,ArkUI这套声明式开发范式非常顺手。
- 机会在哪? 现在市面上大量的APP都需要重构鸿蒙原生版。这中间有一个巨大的缺口!前两年进去的那批人,现在都成技术总监了。2026年,随着万物互联真正落地,鸿蒙开发者的薪资会比同级别的安卓开发高出至少30%。
V哥我一直说,技术要跟着国运走。鸿蒙这条路,不仅是写代码,更是在参与基础设施建设。这碗饭,香!

三、 后端开发:告别“CRUD”,拥抱“编排”
兄弟们,别再笑话写Java/Go的后端枯燥了。虽然简单的增删改查(CRUD)真的会被AI干掉,但后端的逻辑核心地位永远不会动摇。
2026年的后端,不再是单纯的写接口,而是做“AI时代的管家”。
以前你的服务是给前端APP用的,2026年,你的服务大部分是给上面的“AI智能体”用的。智能体需要调用你的数据库、调用你的业务逻辑。你的接口设计得更规范、更原子化、响应更快。
V哥建议:
Go语言和Rust会在后端越来越火(因为性能好、并发强)。而且,后端得懂点云原生,容器化、Service Mesh(服务网格)这些都是标配。你得学会怎么把一个庞大的系统拆得碎碎的,还能用AI把它们管得服服帖帖。

四、 前端开发:从“画页面”到“造体验”
前端死了吗?V哥告诉你,前端才刚刚开始“性感”起来。
写HTML/CSS这种活儿,2026年估计UI设计师直接说一句话,AI就生成了。那前端干嘛?前端负责“交互的灵魂”。
随着WebGPU的普及,浏览器里能跑3D大作、能跑复杂的物理引擎。鸿蒙的ArkUI也是跨端的前端技术。未来的前端,更多是图形学、人机交互和3D可视化。你打开一个网页,不再是看图文,而是进入一个虚拟空间,这背后全是前端工程师的功力。
V哥一句话: 放下jQuery,搞深Three.js,搞透React/Vue原理,往图形学和全栈方向发展。

五、 嵌入式开发:软硬件结合的“硬核浪漫”
以前搞嵌入式感觉是“修收音机的”,2026年搞嵌入式那是“造智能机器人”的。
因为上面说的鸿蒙和AI,最后都要落脚到硬件上。智能眼镜、智能家电、自动驾驶,哪个离得开嵌入式?
重点来了: 嵌入式未来会和AI深度融合,叫TinyML(微型机器学习)。在芯片上跑小型的AI模型,让摄像头能识别人脸,让传感器能听懂声音。如果你既懂C语言底层,又懂一点AI算法部署,你是各大硬件厂抢着要的“国宝”。

六、 大数据开发:从“存数据”到“喂AI”
大数据没凉,只是换了个活法。
前几年大家搞Hadoop、Spark,是为了存日志、做报表。2026年,搞大数据主要是为了给AI当“饲养员”。
AI需要高质量的数据清洗、向量化处理。这就涉及到向量数据库、数据湖、实时计算流。怎么把企业的几十亿条数据,变成AI能看懂的“知识”,这是大数据工程师的新活儿。不懂AI的数据工程师,未来路会越走越窄。

七、 AI运维与 AI测试:机器管机器
最后说说这两个容易被忽视的领域。
- AI运维: 以前服务器报警了,运维兄弟半夜爬起来看日志。2026年,AI运维系统会自动定位故障、自动修复、自动扩容。运维工程师不需要敲那么多命令了,而是负责训练这个“运维AI”,制定策略。这叫SRE(站点可靠性工程)的进化版。
- AI测试: 测试不仅是找Bug,更是“攻防演练”。用AI去生成几万条变态测试用例去轰炸你的系统,甚至用AI去对抗AI生成的代码。只有AI才能测出AI写的Bug。
V哥总结一下
兄弟们,2026年其实并不远。
V哥我看了一圈,未来的趋势就两个字:融合。
- 鸿蒙是万物互联的底座,必须要抓;
- AI智能体是提升效率的神器,必须要懂;
- 其他所有的后端、前端、嵌入式、数据,都要围绕着这两者去进化。
别再纠结Java还是Python,Go还是Rust了。语言只是工具,解决问题的思路才是王道。从今天起,试着用AI去帮你干活,试着去了解一下鸿蒙的ArkTS,试着把你的工作流程“智能化”。
等到了2026年,当别人还在为裁员瑟瑟发抖时,V哥希望看到你已经站在风口上,笑傲江湖!
我是V哥,带你不仅看懂技术,更看懂未来。
来源:juejin.cn/post/7593139476839874566
用 npm 做免费图床,这操作绝了!
最近发现了一个骚操作 —— 用 npm 当图床,完全免费,还带全球 CDN 加速。分享一下具体实现过程。
为啥要用 npm 做图床?
先说说背景,我经常在各大平台写文章,需要上传图片。但:
- 免费图床不稳定,容易挂
- 自建图床成本高
- 其他平台限制多
然后想到 npm,这不就是现成的 CDN 吗?全球访问速度还快。
怎么实现的?
1. 基本原理
npm 包本质上就是一堆文件,我们可以把图片放进去。发布后,npm 的 CDN 会自动分发这些文件。
访问方式:
# unpkg
https://unpkg.com/包名@版本号/图片路径
# jsdelivr
https://cdn.jsdelivr.net/npm/包名@版本号/图片路径
# PS
https://unpkg.com/cosmium@latest/images/other/npm-pic.png
2. 自动化发布npm包
每次提交图片后都需要手动发布到 npm那不是很烦, 别急github Actions可以帮我们自动发包, 可以直接fork 我的项目:github.com/Cosmiumx/co…
name: Publish to npm
on:
push:
branches:
- master
jobs:
....
3. 配置步骤
- Fork 本项目
- 将本项目 Fork 到你的 GitHub 账号下。
- 修改包名
- 编辑
package.json,将包名改为你自己的:
- 编辑
{
"name": "your-package-name",
"version": "0.0.1",
...
}
注意:包名必须是 npm 上未被占用的名称。
- 创建 npm token
- 访问 npmjs.com,
- 进入 Access Tokens 页面
- 点击 Generate New Token → 选择 Bypass 2FA 类型 (npm最新规则token最长只能设置90天)
- 记住这个 token,只显示一次
- 配置 GitHub Secrets
- 在你 Fork 的仓库中:
- 仓库 Settings → Secrets and variables → Actions
- 添加
NPM_TOKEN,值为刚才的 token
- 上传图片
- 把图片放到
images目录 - 提交代码,工作流自动发布
- 把图片放到
4. 访问方式
发布后,图片可通过以下 CDN 访问:
# unpkg
https://unpkg.com/cosmium@latest/images/your-image.png
# jsdelivr
https://cdn.jsdelivr.net/npm/cosmium@latest/images/your-image.png
实际体验
优点:
- 完全免费,npm 不收费
- 全球 CDN,访问速度快
- 自动化流程,上传图片后自动发布
- 版本管理清晰
注意事项:
- ⚠️ npm 包一旦发布无法删除,版本号会永久保留
- ⚠️ 不要上传敏感信息,npm 包是完全公开的
- ⚠️ 遵守 npm 使用条款,不要滥用 CDN 服务
- ⚠️ 图片版权,确保你有权使用并分发上传的图片
总结
这个方案算是找到了一个不错的图床替代方案,特别适合经常写技术文章的同学。虽然有点折腾,但效果不错。
有兴趣的可以 fork 我的项目:github.com/Cosmiumx/co…
配置好之后,以后上传图片就只是 git push 的事情了,还是很方便的。
如果这个方法对你有帮助,别忘了点赞支持一下~
来源:juejin.cn/post/7594385386740629523
浏览器中如何摆脱浏览器下12px的限制
目前Chrome浏览器依然没有放开12px的限制,但Chrome仍然是使用人数最多的浏览器。
在笔者开发某个项目时突发奇想:如果实际需要11px的字体大小怎么办?这在Chrome中是实现不了的。关于字体,一开始想到的就是rem等非px单位。但是rem只是为了响应式适配,并不能突破这一限制。
em、rem等单位只是为了不同分辨率下展示效果提出的换算单位,常见的库
px2rem也只是利用了js将px转为rem。包括微信小程序提出的rpx单位也是一样!
这条路走不通,就只剩下一个方法:改变视觉大小而非实际大小。
理论基础
css中有一个属性:transform: scale();
- 值的绝对值>1,就是放大,比如2,就是放大2倍
- 值的绝对值 0<值<1,就是缩小,比如0.5,就是原来的0.5倍;
- 值的正负,负值表示图形翻转。
默认情况下,scale(x, y):以x/y轴进行缩放;如果y没有值,默认y==x;
也可以分开写:scaleX() scaleY() scaleZ(),分开写的时候,可以对Z轴进行缩放
第二种写法:transform: scale3d(x, y, z)该写法是上面的方法的复合写法,结果和上面的一样。
但使用这个属性要注意一点:scale 缩放的时候是以“缩放元素所在空间的中心点”为基准的。
所以如果用在改变元素视觉大小的场景下,一般还需要利用另一个元素来“恢复位置”:
transform-origin: top left;
语法上说,transform-origin 拥有三个属性值:
transform-origin: x-axis y-axis z-axis;
默认为:
transform-origin:50% 50% 0;
属性值可以是百分比、em、px等具体的值,也可以是top、right、bottom、left和center这样的关键词。作用就是更改一个元素变形的原点。
实际应用
<div class="mmcce__info-r">
<!-- 一些html结构 -->
<div v-show="xxx" class="mmcce-valid-mj-period" :class="{'mmcce-mh': showStr}">
<div class="mmcce-valid-period-child">xxx</div><!-- 父级结构,点击显示下面内容 -->
<div class="mmcce-valid-pro" ref="mmcceW">
<!-- 下面内容在后面有讲解 -->
<div class="mmcce-text"
v-for="(item, index) in couponInfo.thresholdStr"
:key="index"
:index="index"
:style="{height: mTextH[index] + 'px'}"
>{{item}}</div>
</div>
</div>
</div>
.mmcce-valid-mj-period {
max-height: 15px;
transition: all .2s ease;
&.mmcce-mh {
max-height: 200px;
}
.mmcce-valid-pro {
display: flex;
flex-direction: column;
padding-bottom: 12px;
.mmcce-text {
width: 200%; // !
font-size: 22px;
height: 15px;
line-height: 30px;
color: #737373;
letter-spacing: 0;
transform : scale(.5);
transform-origin: top left;
}
}
}
.mmcce-valid-period-child {
position: relative;
width : 200%;
white-space: nowrap;
font-size : 22px;
color : #979797;
line-height: 30px;
transform : scale(.5);
transform-origin: top left;
//xxx
}

可以明确说明的是,这样的 hack 需要明确规定缩放元素的height值 !!!
上面代码中为什么.mmcce-valid-mj-period类中要用max-height ?为什么对展开元素中的文字类.mmcce-text中使用height?
我将类.mmcce-text中的height去掉后,看下效果:

(使用min-height是一样的效果)
OK,可以看到,占高没有按我们想的“被缩放”。影响到了下面的元素位置。
本质上是“视觉大小改变了但实际(占位)大小无变化”。
这时候,宽高实际也被缩放了的。这一点通过代码中width:200%也可以看出来。或者你设置了overflow:hidden;也可以有相应的效果!
这一点需要注意,一般来说,给被缩放元素显式设置一个大于等于其font-size的height值即可。
缩放带来的其它问题
可能在很多人使用的场景中是不会考虑到这个问题的:被缩放元素限制高度以后如果元素换行那么会出现文字重叠的现象。
为此,我采用了在mounted生命周期中获取父元素宽度,然后动态计算是否需要换行以及换行的行数,最后用动态style重新渲染每一条数据的height值。
这里有三点需要注意:
- 这里用的是一种取巧的方法:用
每个文字的视觉font-size值*字符串长度。因为笔者遇到的场景不会出现问题所以可以这么用。在不确定场景中更推荐用canvas或dom实际计算每个字符的宽度再做判断(需要知道文字、字母和数字的宽度是不一样的); - 需要注意一些特殊机型的展示,比如三星的galaxy fold,这玩意是个折叠屏,它的计算会和一般的屏幕计算的不一致;
- 在vue生命周期中,mounted可以操作dom,你可以通过
this.$el获取元素。但要注意:在这个时期被获取的元素不能用v-if(即:必须存在于虚拟tree中)。这也是上面代码中笔者使用v-show和opacity的原因。
关于第三点,还涉及到加载顺序的问题。比如刚进入页面时要展示弹窗,弹窗是一个组件。那你在index.vue中是获取不到这个组件的。但是你可以将比如header也拆分出来,然后在header组件的mounted中去调用弹窗组件暴露出的方法。
mounted(){
let thresholdStr = this.info.dropDownTextList;
let minW = false;
if(this.$el.querySelector('.mmcce-valid-pro').clientWidth < 140) { // 以iPhone5位准,再小于其中元素宽度的的机型就要做特殊处理了
minW = true
}
let mmcw = this.$el.querySelector('.mmcce-valid-pro').getBoundingClientRect().width;
let mmch = [];
for(let i=0;i<thresholdStr.length;i++) {
// 11是指缩放后文字的font-size值,这是一种取巧的方式
if(11*(thresholdStr[i].length) > mmcw) {
if(minW) {
mmch[i] = Math.floor((11*thresholdStr[i].length) / mmcw) * 15;
}else {
mmch[i] = Math.floor((11*(thresholdStr[i].length) + 40) / mmcw) * 15;
}
}else {
mmch[i] = 15;
}
}
this.mTextH = mmch;
},
笔者前段时间弄了一个微信公众号:前端Code新谈。里面暂时有webrtc、前端面试和用户体验系列文章,最近暂时搁置了webrtc,新开了一个系列“three.js”,欢迎关注!希望能够帮到大家,也希望能互相交流!一起学习共同进步
来源:juejin.cn/post/7596276978808389675
微服务正在悄然消亡:这是一件美好的事
最近在做的事情正好需要系统地研究微服务与单体架构的取舍与演进。读到这篇文章《Microservices Are Quietly Dying — And It’s Beautiful》,许多观点直击痛点、非常启发,于是我顺手把它翻译出来,分享给大家,也希望能给同样在复杂性与效率之间权衡的团队一些参考。
微服务正在悄然消亡:这是一件美好的事
为了把我们的创业产品扩展到数百万用户,我们搭建了 47 个微服务。
用户从未达到一百万,但我们达到了每月 23,000 美元的 AWS 账单、长达 14 小时的故障,以及一个再也无法高效交付新功能的团队。
那一刻我才意识到:我们并没有在构建产品,而是在搭建一座分布式的自恋纪念碑。

我们都信过的谎言
五年前,微服务几乎是教条。Netflix 用它,Uber 用它。每一场技术大会、每一篇 Medium 文章、每一位资深架构师都在高喊同一句话:单体不具备可扩展性,微服务才是答案。
于是我们照做了。我们把 Rails 单体拆成一个个服务:用户服务、认证服务、支付服务、通知服务、分析服务、邮件服务;然后是子服务,再然后是调用服务的服务,层层套叠。
到第六个月,我们已经在 12 个 GitHub 仓库里维护 47 个服务。我们的部署流水线像一张地铁图,架构图需要 4K 显示器才能看清。
当“最佳实践”变成“最差实践”
我们不断告诫自己:一切都在运转。我们有 Kubernetes,有服务网格,有用 Jaeger 的分布式追踪,有 ELK 的日志——我们很“现代”。
但那些光鲜的微服务文章从不提的一点是:分布式的隐性税。
每一个新功能都变成跨团队的协商。想给用户资料加一个字段?那意味着要改五个服务、提三个 PR、协调两周,并进行一次像劫案电影一样精心编排的数据库迁移。
我们的预发布环境成本甚至高于生产环境,因为想测试任何东西,都需要把一切都跑起来。47 个服务在 Docker Compose 里同时启动,内存被疯狂吞噬。
那个彻夜崩溃的夜晚
凌晨 2:47,Slack 被消息炸翻。
生产环境宕了。不是某一个服务——是所有服务。支付服务连不上用户服务,通知服务不断超时,API 网关对每个请求都返回 503。
我打开分布式追踪面板:一万五千个 span,全线飘红。瀑布图像抽象艺术。我花了 40 分钟才定位出故障起点。
结果呢?一位初级开发在认证服务上发布了一个配置变更,只是一个环境变量。它让令牌校验多了 2 秒延迟,这个延迟在 11 个下游服务间层层传递,超时叠加、断路器触发、重试逻辑制造请求风暴,整个系统在自身重量下轰然倒塌。
我们搭了一座纸牌屋,却称之为“容错架构”。
我们花了六个小时才修复。并不是因为 bug 复杂——它只是一个配置的单行改动,而是因为排查分布式系统就像破获一桩谋杀案:每个目击者说着不同的语言,而且有一半在撒谎。
那个被忽略的低语
一周后,在复盘会上,我们的 CTO 说了句让所有人不自在的话:
“要不我们……回去?”
回到单体。回到一个仓库。回到简单。
会议室一片沉默。你能感到认知失调。我们是工程师,我们很“高级”。单体是给传统公司和训练营毕业生用的,不是给一家正打造未来的 A 轮初创公司用的。
但随后有人把指标展开:平均恢复时间 4.2 小时;部署频率每周 2.3 次(从单体时代的每周 12 次一路下滑);云成本增长速度比营收快 40%。
数字不会说谎。是架构在拖垮我们。
美丽的回归
我们用了三个月做整合。47 个服务归并成一个模块划分清晰的 Rails 应用;Kubernetes 变成负载均衡后面的三台 EC2;12 个仓库的工作流收敛成一个边界明确的仓库。
结果简直让人尴尬。
部署时间从 25 分钟降到 90 秒;AWS 账单从 23,000 美元降到 3,800 美元;P95 延迟提升了 60%,因为我们消除了 80% 的网络调用。更重要的是——我们又开始按时交付功能了。
开发者不再说“我需要和三个团队协调”,而是开始说“午饭前给你”。
我们的“分布式系统”变回了结构良好的应用。边界上下文变成 Rails 引擎,服务调用变成方法调用,Kafka 变成后台任务,“编排层”……就是 Rails 控制器。
它更快,它更省,它更好。
我们真正学到的是什么
这是真相:我们为此付出两年时间和 40 万美元才领悟——
微服务不是一种纯粹的架构模式,而是一种组织模式。Netflix 需要它,因为他们有 200 个团队。你没有。Uber 需要它,因为他们一天发布 4,000 次。你没有。
复杂性之所以诱人,是因为它看起来像进步。 拥有 47 个服务、Kubernetes、服务网格和分布式追踪,看起来很“专业”;而一个单体加一套 Postgres,看起来很“业余”。
但复杂性是一种税。它以认知负担、运营开销、开发者幸福感和交付速度为代价。
而大多数初创公司根本付不起这笔税。
我们花了两年时间为并不存在的规模做优化,同时牺牲了能让我们真正达到规模的简单性。
你不需要 50 个微服务,你需要的是自律
软件架构的“肮脏秘密”是:好的设计在任何规模都奏效。
一个结构良好的单体,拥有清晰的模块、明确的边界上下文和合理的关注点分离,比一团由希望和 YAML 勉强粘合在一起的微服务乱麻走得更远。
微服务并不是因为“糟糕”而式微,而是因为我们出于错误的理由使用了它。我们选择了分布式的复杂性而不是本地的自律,选择了运营的负担而不是价值的交付。
那些悄悄回归单体的公司并非承认失败,而是在承认更难的事实:我们一直在解决错误的问题。
所以我想问一个问题:你构建微服务,是在逃避什么?
如果答案是“一个凌乱的代码库”,那我有个坏消息——分布式系统不会修好坏代码,它只会让问题更难被发现。
来源:juejin.cn/post/7563860666349649970
🚀从 autofit 到 vfit:Vue 开发者该选哪个大屏适配工具?

在数据可视化和大屏开发中,"适配"永远是绕不开的话题。不同分辨率下如何保持元素比例、位置精准,往往让开发者头疼不已。
autofit.js 作为老牌适配工具,早已在许多项目中证明了价值;而新晋的 vfit 则专为 Vue 3 量身打造。今天我们就来深入对比这两款工具,看看谁更适合你的场景。
一、核心定位:通用方案 vs Vue 专属
首先得明确两者的定位差异:
- autofit.js:无框架依赖的通用缩放工具,通过计算容器与设计稿的比例,对整个页面进行缩放处理,核心逻辑是
transform: scale(ratio)的全局应用。 - vfit.js:专为 Vue 3 设计的轻量方案,不仅提供全局缩放,更通过组件化思想解决精细定位问题,是"缩放+定位"的一体化方案。
二、核心能力对比
1. 缩放逻辑:全局统一 vs 灵活可控
autofit.js 的缩放逻辑相对直接:
- 计算容器宽高与设计稿的比例(取宽/高比例的最小值或按配置选择)
- 对目标容器应用整体缩放,实现"一缩全缩"
vfit.js 则提供了更灵活的缩放策略:
// vfit 初始化配置
createFitScale({
target: '#app', // 监听缩放的容器
designHeight: 1080, // 设计稿高度
designWidth: 1920, // 设计稿宽度
scaleMode: 'auto' // 缩放模式:auto/height/width
})
-
auto模式会自动对比容器宽高比与设计稿比例,智能选择按宽或按高缩放 - 支持在组件内通过
useFitScale()获取当前缩放值,实现局部自定义缩放
2. 定位能力:粗犷适配 vs 精细控制
这是两者最核心的差异。
autofit.js 由于是全局缩放,元素定位依赖原始 CSS 布局,在复杂场景下容易出现:
- 固定像素定位的元素在缩放后偏离预期位置
- 相对定位元素在不同分辨率下比例失调
vfit.js 则通过 FitContainer 组件解决了这个痛点,支持两种定位单位:
<!-- 百分比定位:位置不受缩放影响,适合居中场景 -->
<FitContainer :top="50" :left="50" unit="%">
<div class="card" style="transform: translate(-50%, -50%)">居中内容</div>
</FitContainer>
<!-- 像素定位:位置随缩放自动计算,适合固定布局 -->
<FitContainer :top="90" :left="90" unit="px">
<div class="box">固定位置元素</div>
</FitContainer>
-
unit="%":位置基于容器百分比,适合居中、靠边等相对位置 -
unit="px":位置会自动乘以当前缩放值,保证设计稿像素与实际显示一致
更贴心的是,vfit.js 还支持通过 right/bottom 定位,并自动处理不同原点的缩放计算(比如右上角、右下角)。
3. 框架融合:独立工具 vs Vue 生态
autofit.js 作为独立库,需要手动在 Vue 项目中处理初始化时机(通常在 onMounted 中),且无法直接与 Vue 的响应式系统结合。
vfit.js 则完全融入 Vue 3 生态:
- 通过
app.use()安装,自动处理初始化时机 - 缩放值通过
Ref实现响应式,组件内可实时获取 FitContainer组件支持 props 动态更新,适配动态布局场景
三、适用场景分析
| 场景 | 更推荐 | 原因 |
|---|---|---|
| Vue 3 项目开发 | vfit.js | 组件化开发更自然,响应式集成更顺畅 |
| 非 Vue 项目(React/原生) | autofit.js | 无框架依赖,通用性更强 |
| 简单大屏(整体缩放即可) | 两者均可 | autofit 配置更简单,vfit 稍重 |
| 复杂布局(多元素精细定位) | vfit.js | 两种定位单位+组件化,解决位置偏移问题 |
| 需局部自定义缩放 | vfit.js | useFitScale() 可灵活控制局部元素 |
四、迁移成本与上手难度
- autofit.js:API 简单,几行代码即可初始化,学习成本低,适合快速接入简单场景。
- vfit.js:需要理解组件化定位思想,初期有一定学习成本,但对于复杂场景,后期维护成本更低。
如果你从 autofit.js 迁移到 vfit.js,只需:
- 替换初始化方式(
app.use(createFitScale(...))) - 将需要定位的元素用
FitContainer包裹 - 根据需求调整
top/left与单位
总结:没有最好,只有最合适
autofit.js 胜在通用性和简单直接,适合非 Vue 项目或简单的全局缩放场景;而 vfit.js 则在 Vue 3 生态中展现了更强的针对性,通过组件化和精细定位,解决了复杂大屏的适配痛点。
如果你是 Vue 开发者,且正在为元素定位偏移烦恼,不妨试试 vfit——它可能正是你寻找的"Vue 大屏适配最优解"。
官网地址:web-vfit.netlify.app,可以直接在线体验效果~
github:github.com/v-plugin/vf…
来源:juejin.cn/post/7577970969395445801
一张 8K 海报差点把首屏拖垮
你给后台管理系统加了一个「企业风采」模块,运营同学一口气上传了 200 张 8K 宣传海报。首屏直接飙到 8.3 s,LCP 红得发紫。
老板一句「能不能像朋友圈那样滑到哪看到哪?」——于是你把懒加载重新翻出来折腾了一轮。
解决方案:三条技术路线,你全踩了一遍
1. 最偷懒:原生 loading="lazy"
一行代码就能跑,浏览器帮你搞定。
<img
src="https://cdn.xxx.com/poster1.jpg"
loading="lazy"
decoding="async"
width="800" height="450"
/>
🔍 关键决策点
loading="lazy"2020 年后现代浏览器全覆盖,IE 全军覆没。- 必须写死
width/height,否则 CLS 会抖成 PPT。
适用场景:内部系统、用户浏览器可控,且图片域名已开启 Accept-Ranges: bytes(支持分段加载)。
2. 最稳妥:scroll 节流 + getBoundingClientRect
老项目里还有 5% 的 IE11 用户,我们只能回到石器时代。
// utils/lazyLoad.js
const lazyImgs = [...document.querySelectorAll('[data-src]')];
let ticking = false;
const loadIfNeeded = () => {
if (ticking) return;
ticking = true;
requestAnimationFrame(() => {
lazyImgs.forEach((img, idx) => {
const { top } = img.getBoundingClientRect();
if (top < window.innerHeight + 200) { // 提前 200px 预加载
img.src = img.dataset.src;
lazyImgs.splice(idx, 1); // 🔍 及时清理,防止重复计算
}
});
ticking = false;
});
};
window.addEventListener('scroll', loadIfNeeded, { passive: true });
🔍 关键决策点
- 用
requestAnimationFrame把 30 ms 的节流降到 16 ms,肉眼不再掉帧。 - 预加载阈值 200 px,实测 4G 网络滑动不白屏。
缺点:滚动密集时 CPU 占用仍高,列表越长越卡。
3. 最优雅:IntersectionObserver 精准观测
新项目直接上 Vue3 + TypeScript,我们用 IntersectionObserver 做统一调度。
// composables/useLazyLoad.ts
export const useLazyLoad = (selector = '.lazy') => {
onMounted(() => {
const imgs = document.querySelectorAll<HTMLImageElement>(selector);
const io = new IntersectionObserver(
(entries) => {
entries.forEach((e) => {
if (e.isIntersecting) {
const img = e.target as HTMLImageElement;
img.src = img.dataset.src!;
img.classList.add('fade-in'); // 🔍 加过渡动画
io.unobserve(img); // 观测完即销毁
}
});
},
{ rootMargin: '100px', threshold: 0.01 } // 🔍 提前 100px 触发
);
imgs.forEach((img) => io.observe(img));
});
};
- 浏览器合成线程把「目标元素与视口交叉状态」异步推送到主线程。
- 主线程回调里只做一件事:把
data-src搬到src,然后unobserve。 - 整个滚动期间,零事件监听,CPU 占用 < 1%。
原理剖析:从「事件驱动」到「观测驱动」
| 维度 | scroll + 节流 | IntersectionObserver |
|---|---|---|
| 触发时机 | 高频事件(~30 ms) | 浏览器内部合成帧后回调 |
| 计算量 | 每帧遍历 N 个元素 | 仅通知交叉元素 |
| 线程占用 | 主线程 | 合成线程 → 主线程 |
| 兼容性 | IE9+ | Edge79+(可 polyfill) |
| 代码体积 | 0.5 KB | 0.3 KB(含 polyfill 2 KB) |
一句话总结:把「我每隔 16 ms 问一次」变成「浏览器你告诉我啥时候到」。
应用扩展:把懒加载做成通用指令
在 Vue3 项目里,我们干脆封装成 v-lazy 指令,任何元素都能用。
// directives/lazy.ts
const lazyDirective = {
mounted(el: HTMLImageElement, binding) {
const io = new IntersectionObserver(
([entry]) => {
if (entry.isIntersecting) {
el.src = binding.value; // 🔍 binding.value 就是 data-src
io.disconnect();
}
},
{ rootMargin: '50px 0px' }
);
io.observe(el);
},
};
app.directive('lazy', lazyDirective);
模板里直接写:
<img v-lazy="item.url" :alt="item.title" />
举一反三:三个变体场景思路
- 无限滚动列表
把IntersectionObserver绑在「加载更多」占位节点上,触底即请求下一页,再把新节点继续observe,形成递归观测链。 - 广告曝光统计
广告位 50% 像素可见且持续 1 s 才算一次曝光。设置threshold: 0.5并在回调里用setTimeout延迟 1 s 上报,离开视口时clearTimeout。 - 背景图懒加载
背景图没有src,可以把真实地址塞在style="--bg: url(...)",交叉时把background-image设成var(--bg),同样零回流。
小结
- 浏览器新特性能救命的,就别再卷节流函数了。
- 写死尺寸、加过渡、及时
unobserve,是懒加载不翻车的三件套。 - 把观测器做成指令/组合式函数,后续业务直接零成本接入。
现在你的「企业风采」首屏降到 1.2 s,老板滑得开心,运营继续传 8K 图,世界和平。
来源:juejin.cn/post/7530854092869615635
🤦♂️ 产品又来了:"能不能把Table的滚动条放到页面底部?
😅 又是熟悉的对话
产品:"小王,这个表格用户体验不好啊,用户要滚动到底部才能看到横向滚动条,能不能把滚动条固定在页面底部?"
我:"emmm... 这个... 技术上可以实现,但是..."
产品:"那就这么定了!明天上线!"
我:"😭"
相信很多前端同学都遇到过类似的场景。面对超宽的 el-table,用户确实需要先滚动到表格底部才能进行左右滚动,体验确实不够友好。
💡干!
于是一个通用的水平滚动条组件 vue-horizontal-scrollbar 诞生了!
🌟 快速体验
想看看实际效果?访问 在线演示
🚀 最终的解决方案
<template>
<el-table style="width: 100%">
</el-table>
<HorizontalScrollbar
:target-selector="getSelector('.el-table__body-wrapper .el-scrollbar .el-scrollbar__wrap')"
:content-selector="getSelector('.el-table__body-wrapper .el-scrollbar .el-scrollbar__view')"
/>
</template>
<script setup>
import { ref } from 'vue'
import { VueHorizontalScrollbar } from 'vue-horizontal-scrollbar'
import "vue-horizontal-scrollbar/dist/style.css"
function getSelector(selector: string) {
const elements = document.querySelectorAll<HTMLElement>(selector) // 兼容展开行
if (elements.length) {
return elements[elements.length - 1]
}
else {
console.warn(`Selector "${selector}" did not match any elements.`)
return null
}
}
// 💡 tips: 如果是有侧边菜单的管理系统需要动态修改vue-horizontal-scrollbar-container的left
</script>
✨ 这样做的好处
🎯 用户体验升级
- 滚动条始终可见,无需滚动页面
- 位置固定,操作便捷
- 支持键盘和鼠标滚轮操作
🛠️ 开发体验友好
- 一行代码解决问题
- 不破坏原有组件结构
- 支持任意 DOM 元素
🎨 高度可定制
<template>
<div>
<!-- Your scrollable content -->
<div id="scroll-container" style="overflow-x: auto; width: 100%;">
<div id="scroll-content" style="width: 2000px; height: 200px;">
<!-- Wide content here -->
<p>This content is wider than the container...</p>
</div>
</div>
<!-- Horizontal Scrollbar -->
<VueHorizontalScrollbar
target-selector="#scroll-container"
content-selector="#scroll-content"
:auto-show="true"
@scroll="onScroll"
/>
</div>
</template>
<script setup>
import { VueHorizontalScrollbar } from 'vue-horizontal-scrollbar'
import "vue-horizontal-scrollbar/dist/style.css"
function onScroll(info) {
console.log('Scroll info:', info)
// { scrollLeft: 100, maxScroll: 1000, scrollPercent: 10 }
}
</script>
✨ Features
- 🎯 Vue 3 & TypeScript - Full TypeScript support with Vue 3 Composition API
- 🎨 Customizable - Flexible styling and configuration options
- ♿ Accessible - ARIA labels and keyboard navigation support
- 📱 Touch Friendly - Mobile-friendly touch gestures
- 🚀 Performance - Optimized with throttling and efficient updates
- 🎪 Flexible - Works with any scrollable content
- 🎛️ Event Rich - Comprehensive event system for interactions
- 📦 Lightweight - Minimal dependencies
📖 API Reference
Props
| Prop | Type | Default | Description |
|---|---|---|---|
targetSelector | string | Function | — | Required. CSS selector or function returning the scroll container element |
contentSelector | string | Function | — | Required. CSS selector or function returning the content element |
autoShow | boolean | true | Auto show/hide scrollbar based on content width |
minScrollDistance | number | 50 | Minimum scroll distance to show scrollbar (when autoShow is true) |
height | number | 16 | Scrollbar height in pixels |
enableKeyboard | boolean | true | Enable keyboard navigation (Arrow keys, Home, End) |
scrollStep | number | 50 | Scroll step for keyboard navigation |
minThumbWidth | number | 30 | Minimum thumb width in pixels |
throttleDelay | number | 16 | Throttle delay for scroll events in milliseconds |
zIndex | number | 9999 | Z-index for the scrollbar |
disabled | boolean | false | Disable the scrollbar |
ariaLabel | string | 'Horizontal scrollbar' | ARIA label for accessibility |
teleportTo | string | 'body' | Teleport to target element |
🎪 更多有趣的玩法
除了解决表格滚动问题,这个组件还能用在:
- 商品展示:电商网站的商品横向滚动
- 图片画廊:摄影作品展示
- 时间轴:项目进度展示
- 标签导航:当标签太多时的横向滚动
📦 立即使用
bash
npm install vue-horizontal-scrollbar
🎉 结语
从此以后,再也不怕产品提这种"奇葩"需求了!
产品:"这个滚动条能不能再加个渐变效果?"
我:"没问题!改个 CSS 就行!"
产品:"能不能支持触摸滑动?"
我:"早就支持了!"
项目地址:GitHub
NPM 包:vue-horizontal-scrollbar
如果这个组件帮到了你,记得给项目点个 ⭐ 哦!让我们一起让前端开发变得更轻松!🎉
来源:juejin.cn/post/7521922500773789747
一个大龄程序员的地铁日记(第5期),几乎都关于读书
最近一个月地铁上,输出内容几乎都围绕着某个主题,于是本篇内容当中都有小标题。
1、读什么书可以让人变得平静、淡定?
以我的经验——过去5年,读了一些书,整个人变得内敛沉稳安静很多——来看,似乎变化与某一本书的关系不大,而仅仅只关于持续阅读这件事,只要持续阅读,过个三五年,整个人便会平静、淡定许多。
我这结论,大概是很主观的,我一时说不太清变化如何发生,但我将尽量将发生在我身上的变化说清楚。
首先,我以为仅仅读一本书,是不能做到改变的,不管是认知还是行为,都不行。
《学习之道》,是一位世界冠军两次夺得冠军的个人传记,作者在书中分享了他的学习之道——一切都基于重复练习,练习过程中需要辅以热爱。读完本书前后几个月,我是真有按照作者的分享去行事的,篮球从微小动作调整,台球也一点一滴进步,但这些微小调整只持续两三个月便被抛之脑后。
《人性的弱点》,是教导与人为善的一本书。阅读当时的我,天天脸带笑意,认真倾听,耐烦讨论。但这些善良的特点,在几个月后也慢慢消退。
即从书中收获的认知影响自己一段时间行为后,并不能持续。
然后,是“几乎所有的书都是有关联的”。这些慢慢退化的认知,在后来的读书当中,又被强化与巩固。
《天才假象》也在说重复练习与热爱,《乔布斯传》甚至将热爱化作极致,《废邮存底》说读书写作如是。总之,这“基于热爱的重复练习是成功/熟练的必要条件”认知,慢慢在我内心变得巩固。
类似的认知,如沉稳、如安静、如三思而后行、如换位思考……都在读书当中慢慢变得巩固。被巩固的认知,会不自觉体现在行为当中,于是,便自然而然的平静且淡定了。
这过程无关某一本书,只在于持续阅读。
2、看过的人物传记当中,你最推荐的是哪一本?
我目前看过的人物传记,有这样几本:《曾国藩传》《人生随时可以重来》《从文自传》《一个瑜伽行者的自传》《乔布斯传》《漫漫回家路》《为奴十二年》《多余的话》《人生由我》《我的前半生》以及《我曾走在崩溃的边缘》。
这些书当中,我最喜欢的,是沈从文先生的《从文自传》,喜欢的缘由很简单,一是沈先生的文字简单真实且真诚,二是从这传记当中所感受到的安静与顽强。
对的,沈先生生命中的那些变化,在他的文字当中显得安静自然;顽强,则来自于安静背后的变化,那些变化(比如真正成为一个靠文字养活自己的作家),是需要很强生命力很强执行力的。
这些书当中,我最想要推荐的,是溥仪先生的《我的前半生》。
诚然,末代皇帝做过许多于中国很不好的错事,但他终于在人生后半段意识到自己错误并反省并给予后人以反省。
我自己读《我的前半生》过程,恰似以第一人称视角看正发生的历史。皇帝到底每天在想什么?皇帝失势后会怎样?
原来皇帝也慌张荒唐,皇帝也会焦虑到睡不着觉。
我想自己,看到了一位很真实的皇帝。
到全书最末尾,溥仪先生有体验到一种人生真谛,即“吃得下饭,睡得着觉”是人生最完美状态。看完全书,我是有感受到自己多出一种“任其自然”态度的:“既然连皇帝都追求吃饱穿暖睡好,为何我自己不珍惜正拥有的人生状态呢?”
《我的前半生》已经看了许久,好些即时体验记不太住,但当下这一刻,它是我看过人物传记当中最被推荐的那本。
3、今年看了哪些书?
今年读完的书,大概(不确定的意思,是其中有两本书大概是前些年读完但没记录的)是25本,它们分作这样几个类别:
心理学有《行为主义》《无条件养育》《十分钟冥想》《幸福的勇气》《甘于平凡的勇气》《爱的艺术》和《亲密关系》。心理学书籍,依然帮助我更好的认识自己。
历史有《秦谜》《五代十国全史》《细说宋朝》。这些书,我依然对照着《国史大纲》来看,我以为现在的自己,虽然依然记不住五代十国有哪些人、宋朝如何变化,但心中对这两个朝代是多出许多印象的,五代十国最黑暗,而宋积贫积弱。
传记以及记录自己或他人生活事的书有《闭经记》《我曾走在崩溃的边缘》《瓦尔登湖》《初老的女人》《沈从文评传》《我的老师沈从文》。
我依然喜欢看人物传记,我以为读人物传记这选择真不错,它们总给予我一种借鉴:我经历过的,前人也经历过。
关于沈从文先生的书,我新加入书架的还有《执拗的拓荒者》以及《沈从文全传》。
小说有《额尔古纳河右岸》《活着》《多情剑客无情剑》《长安的荔枝》。这几本小说,都短短的;《额尔古纳河右岸》和《活着》,我都哭着读完。
其它类别暂时只有一本,只是《人体简史》,这是一本很值得推荐的关于人体的科普书。
我正在阅读,或许在不久将来会读完的书,有《我看见的世界》《苏东坡新传》《李自成》《安娜·卡列尼娜》《金钱心理学》以及《高效能人士的七个习惯》。
4、电子书有哪些优点?
对我来说,现在电子书已经完完全全代替了纸质书。我买纸质书,更多只为“收藏”,我想要的,只是在某个比较闲散时间,找一找翻书的感觉。
对我来说,电子书相较纸质书有以下优点:
首先,也是最重要的那一点,电子书很方便。现在我已经在《微信读书》上连续阅读三年多(之前在《京东读书》连续阅读一年多),我的碎片时间——地铁上、卫生间、等电梯——都能拿出手机看书,使用手机读书,那许多的碎片时间都慢慢攒成帮助我进步的阶梯。
其次,基于碎片化阅读,电子书更容易帮助养成读书习惯。不管纸质书或者Kindle,身上多带一个设备,看书的门槛总是高了许多。
然后,是电子书相较纸质书便宜许多。我在微读的第一年,买一年付费会员只花168元,这会员可以阅读所有在微读上架的出版书。后来,微读开通了50块钱挑战赛(花50块钱,每天阅读持续一年,累积时长达到300小时),我便只需要50块钱,便能读成千上万本我想读的书了。
然后,是笔记与重新翻阅的方便。微读上面读书,可以在给予自己感触内容下方划线或者写上自己的即时感悟,这些感悟被收集在一起,可以搜索,可以直接定位。当书中内容记不太清需要回顾时,直接搜索笔记,直接搜索全书即可。
总之,电子书于我,是方便许多的。
5、一篇日记
现在时间是晚上的9点05分,我已经在回家地铁上前进两站。三站过后我要转车,我打算再去拼一拼下一趟列车的及时——在它关门之前——上车,我于是站在距离转站路线最近那个口子,只待列车到站。
我的右手边,大概是两个小学生(或者是初中生)正坐地上,他们的对话内容,我有听到两三句:
“那个别人刚走了的座位还是热乎的,如果坐了就会长痔疮。”
“我下一站就到红旗河沟了。反正没作业……反正没作业。”
对于今天的准时上车,我是很有些骄傲的。我似乎已经好久好久,没有9点准时下班。
(我跑过换乘路线,下一趟列车还有一分钟,今天的换乘计划成功了。)
今天的工作,又是和提示词作斗争的一天。
今天的新闻,大概只有一条:我的同事说,他的一位朋友从外地回重庆,Offer年包已经过了60。啊哈?所以重庆还是开得起工资的?
嗐!又有人在地铁上开很大声的外放,他应该正在玩某一种打枪游戏。
说起地铁外放,我想重庆和北京(上周去了北京出差)是真有一些差距的,我在北京一周坐地铁次数不多(大概五六七次),从没听到过手机外放,而重庆?每一趟地铁,我都得和外放侠做一点小小斗争:那些不能专心的时间,我总告诉自己“没关系的,不听不听”。
最近两天的晚饭,都是地铁口的一碗洋芋,7块钱。吃洋芋很快,于是我可以在晚饭时间向家里打几个电话。身体健康,就该是最高优的事情。
还有其它的应该记录的内容么?好像没有的。
不对,还有一条。
最近的读书时间,全部给了小说,一本是《安娜·卡列尼娜》,一本是《李自成》。这两本小说,都好长好长。
6、读书会忘记应该怎么办呢?
基于我现在的读书认知(过去五年日均阅读一小时多一点,读书类型多种多样,累积读完大概120本书)来看,我以为记住书中内容这件事,仿佛是可以不需要刻意追求的。
那些我们想要记住的,总能够印象不熄。
以《学习之道》里面的“Zone概念”为例,投篮不管怎么投都有,台球不管怎么打都进,全没有技巧,只凭借着一种感觉,这种感觉是可以有方法做到频繁进入的。
如何进入,带着热爱,练习不止即可。
还有些内容,是读过便忘记的,但这忘记的内容,可以通过一种简单的方法被记住。这简单的方法是不停地读,读相关联的书,看相关联的内容。
这内容当中的一个示例,是算法“快慢指针”,最初我并不知道如何探测链表是否循环,第一次刷题后也很快忘记。直到在《剑指Offer》《我的第一本算法书》《程序员面试金典》中多次强化,它被刻在脑子里。
我想自己,读过书当中可能超过99%,是都被我忘记的。这些被忘记的内容,如何能够被更好的记住,我知道的方法来自于《津巴多普通心理学》名叫“精细复述”,即将自己学到的知识,用自己的话认真地重新组织一遍,这件事做完,便能将知识记得更久些。
这样记住的内容,有“将愤怒或者悲伤写成文字,能够缓解自己的情绪”“记忆能力可以不随年龄变化,只需要一些组装技巧”……
最后,现在的我真的以为“读书想要记住”这件事是可以不强求的,只要不停看,外加一些思考,就好的。
7、推荐几本能够快速读完的小书吧?
看到这个问题,我脑子里冒出来两三本小书,它们都是我读完认为不错不厚甚至很薄的三本小书:《宝贵的人生建议》《受戒》以及《活出生命的意义》。
《宝贵的人生建议》,是一位老者(作者名字以及生平我并不能记住,记住的只是作者是一位六十多岁的老人)写给他子女以及孙辈的人生建议。每一条建议,都不长。
我记住的建议有好些,比如老生常谈的“种一棵树的最好时机是十年前,其次是现在”,比如“写不出文章时,假装以讲故事形式说给朋友听,当写完后删去朋友名字,便是一篇不错草稿”。(此处只是自己的复述,并非书中原文。)
我以为《宝贵的人生建议》是一本好书的缘由在于作者在末尾所说“书中建议恰似帽子,可能并不适用每一个人,选择自己喜欢的那顶就好”,即作者并不强迫读者接受他的认知。
不强迫,便是长者风范。
《受戒》是汪曾祺先生的短篇小说,我大概看完过不下五遍,全书很短,或许不到一小时便能读完。每一遍阅读,我都感受到一种简单的美好:明子和英子的爱情,唯美、自然,充满活力。
《活出生命的意义》,是一本短短传记,我从书中收获的认知有两个:
- 拥有希望是一个人活下去的最基本条件;
- 不管怎样的绝望场景,我们都拥有最后的自由,选择以何种态度面对这绝望的自由。
以上三本书,如果快一点,或许一两天内可以全部读完。但回味无穷。
8、怎样做到坚持阅读?
大概靠一点惯性,一点贪念,以及对书中内容的许多期待。
惯性,来源于过去五年的作息,以及用手机的习惯。
过去五年以来,我有两年半上班通勤是坐地铁的。地铁上的时间,都被我用来看书,这时间的看书,毫无心理负担。
上班路上:“我正要去公司干活呢,现在通勤路上肯定不会有人找。”
下班路上:“今天的事情已经都有了交代,看点轻松的书打发下时间吧。”
于是看书,专注且有趣。
当看书次数变多,很自然便会打开手机上的《微信读书》,于是再看两分钟。
贪念,也可以说成是对认知的渴求。五年以前,我想着靠自己的生活日记换取流量,只写两周便发现没了东西可写,于是找书来看。
我的看书,是为写作言之有物,是为更新(我给自己定下目标,不管是怎样内容,每周必须完成一篇更新)有内容可写,是为内容能够被人阅读换成收入。
于是看书,与写作相辅相成,世俗又带目的。
期待,是对书中内容最纯粹的期待,我仅仅想知道,书中那人物、事物、理论的未来是怎样的。
《崇祯传》里的崇祯怎么就亡国了?《安娜·卡列尼娜》里的安娜和弗隆斯基有未来么?《我曾走在崩溃的边缘》中俞敏洪老师是怎样不崩溃的?《也许你该找个人聊聊》当中心理咨询师每天都做些什么?
总之,那些无尽的期盼与好奇牵着我,看书不停。
9、糖醋排骨怎么做呢?
最近刚刚试过再做一次糖醋排骨,不脆,但依然有点好吃。制作步骤如下,每一步骤后面括号中是我当下存在的疑惑:
选排骨。(这一步很重要,上一次做时排骨都骨头中间肉包周边,成品好看许多。这一次买的打六折的排骨,成品则很不规则。)
排骨洗净焯水再用热水洗一洗。(这个步骤我从网上学来的,其实没掌握原理,也不确定不焯水味道是否不一样?焯水出锅后用冷水洗是否真的会柴?甚至焯水之后有必要洗么?)
锅中放油,小火放糖,把糖炒出糖色。(这个步骤我想自己油放多了些而糖放少了点,于是糖色不黑,排骨不甜。当然,没有饭店里面的甜,却似乎更符合自己的口味。)
下排骨,不停地翻翻翻翻,直到排骨有些焦黄。
下入没过排骨再深一指的热水,加入调味的盐、醋、酱油,焖。(什么时候放盐依然是一个问题,我看到一条高赞视频说提前放盐排骨会柴,但真正制作时,会忘记这注意事项。又由于没有天天做,于是不能验证。)
水快干,再翻翻翻,收汁。尝一下,不够甜再加一点糖。出锅,撒一点葱粒、红椒粒,增香增色。
最终成品,不嫩,有一点柴,有嚼劲,颜色不深,但依然好吃的。
下次做时的优化:少一点油多一点糖。
10、最近正阅读的书有哪些?
我最近正阅读的书,是这几本:
《李自成》和《崇祯传》,《安娜·卡列尼娜》,《高效能人士的七个习惯》,以及《亲密关系》。
目前《李自成》刚刚看到四分之一,我对于书中作者对崇祯的评价——刚愎自用、犹疑猜忌——不太相信,于是先读《崇祯传》。
《崇祯传》也正读到四分之一处,崇祯灭了魏忠贤,已经杀掉袁崇焕,现在不信任大臣,正启用宦官到各处监督。
现在崇祯给予我的印象,是勤劳皇帝做了一个错误决定(杀袁崇焕),以及身边帮手很不够。
《安娜·卡列尼娜》正听到六分之五处,基迪和列文正在莫斯科等待他们的第一个小孩出生;安娜和弗隆斯基在乡下生活,弗隆斯基感受到安娜限制着他,安娜刚刚给丈夫卡列宁写信申请离婚。
到现在,我以为安娜和弗隆斯基之间,似乎也并非是真正的爱情,在最初的激情、温情过后,当真正回到生活当中,他们的关系也是并不稳定的。或许安娜并不是出轨状态,此种情况会好一些?
《高效能人士的七个习惯》已经看到最后一个习惯——不断更新——了。虽然我对作者在书中的那些佐证并不很信服,但随着阅读时长增加,我以为这七个习惯是真有效的,它们是智慧,来自于生活、历史中积攒的经验。
《亲密关系》,我之前已经听完一遍有声书,现在刚刚读到第二章。我想要的,是在未来将这本书中内容理解的更多些。
对的,《亲密关系》看两遍的原因是,它是我超级推荐的一本书,我想自己理解更多些后再给出有理有据的推荐理由。
对的,书读第二遍,速度慢许多许多。
来源:juejin.cn/post/7587245616754343987
uni-app使用瓦片实现离线地图的两种方案
最近接到一个安卓App的活儿,虽然功能上不算复杂,但因为原本没怎么做过安卓端,所以也是"摸着石头过河"。简单写一下踩过的坑和淌的水吧~
uni-app实现离线地图主要用 leafletjs 实现,但是因为在安卓端运行,存在渲染问题,所以还要用上 renderjs。
实现方案一:web-view
因为uni-app引入第三方可以采用传统的 NPM 安装的方式,也可以采用引入打包完的js文件的方式。
这里采用 leafletjs 打包完的文件,将 leafletjs 放入 static 文件夹内。
在网上下载了公开的瓦片地图图片,以 {z}/{x}/{y} 的目录结构放入 tiles 文件夹中,将 tiles 放入 static 文件夹内。
在static文件夹下新建一个 offline-map.html 文件
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>离线地图</title>
<link rel="stylesheet" href="./leaflet/leaflet.css" />
<style>
html,
body {
margin: 0;
padding: 0;
}
#map {
height: 100vh;
width: 100vw;
margin: 0;
padding: 0;
}
</style>
</head>
<body>
<div id="map"></div>
<script src="./leaflet/leaflet.js"></script>
<script>
const baseUrl = './tiles/{z}/{x}/{y}.jpg';
const map = L.map('map').setView([23.56, 113.23], 15);
L.tileLayer(baseUrl, {
minZoom: 15,
maxZoom: 18,
tms: true,
attribution: 'Offline Tiles',
errorTileUrl: ''
}).addTo(map);
</script>
</body>
</html>
找到 pages/index/index.vue 文件,采用 web-view 引用的方式引入上述 html 文件。
// pages/index/index.vue
<template>
<view class="content">
<web-view src="/static/offline-map.html"></web-view>
</view>
</template>
<style>
.content {
width: 100%;
height: 100%;
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
}
</style>
实现方案二:renderjs
仍然将 leafletjs 和 瓦片图片文件夹tiles 放入 static 文件夹中。
// pages/index/index.vue
<view class="content">
<view id="map" class="map-container"></view>
</view>
<script module="leaflet" lang="renderjs">
import '@/static/leaflet/leaflet.css';
import * as L from "@/static/leaflet/leaflet.js";
export default {
mounted() {
this.initMap();
},
methods: {
initMap() {
const baseUrl = 'static/tiles/{z}/{x}/{y}.jpg'
map = L.map('map').setView([23.56, 113.23], 15);
L.tileLayer(baseUrl, {
minZoom: 15,
maxZoom: 18,
tms: true,
attribution: 'Offline Tiles',
errorTileUrl: ''
}).addTo(map);
},
}
}
</script>
这里需要注意的是一定要在 renderjs 中实现上述代码,如果在常规 script 中实现,在 H5端 没有任何问题,但是运行到真机上会白屏。(这个问题我反复试了好几次都不行,结果还是上传到 Trae 上解决了这个问题)。
导致这种情况的原因是在常规 sctipt 中的代码,在真机上是运行在 逻辑层 的代码,无法干扰到 视图层 的结构,这一点和Web是不同的。
而 renderjs 是运行在 视图层 的js,具备操作 DOM 的能力。
其次是引用 static 文件的路径,import static 中的文件可以使用 @/static 的方式,但是在代码中引用 static 文件需要采用 static/ 的形式。
总结
最后我做完以后让 Trae 给了一下评价,Trae 表示不建议采用这种方式实现离线地图,首先瓦片地图文件一般非常大,我用的仅仅是其中的一小部分,也超过了 60MB,打包出来的 App 包太大了。
其次无论是 web-view 还是 renderjs 本质上是一样的。在app-vue环境下,视图层由webview渲染,而renderjs就是运行在视图层的。
所以无论是渲染效率还是开发上基本没差。
来源:juejin.cn/post/7592531796044185615
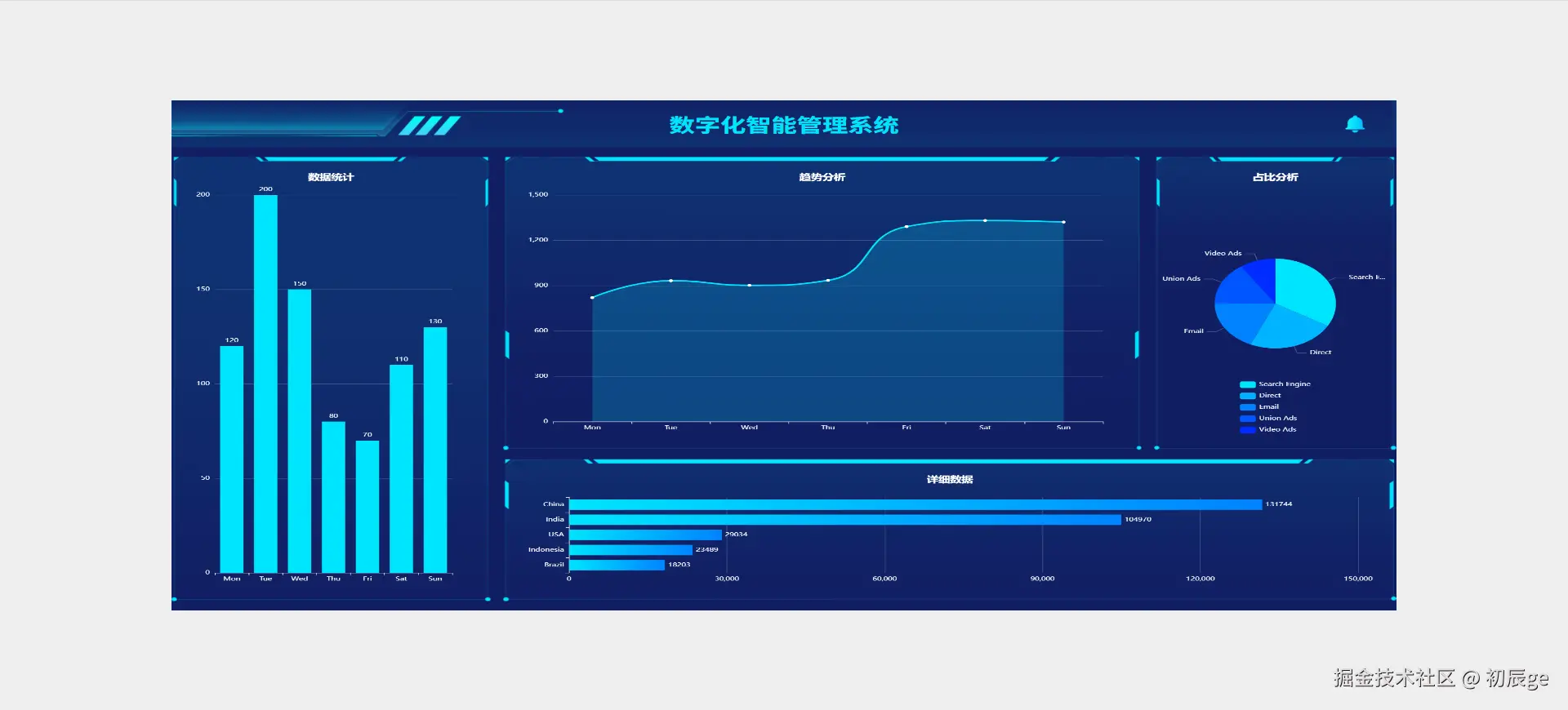
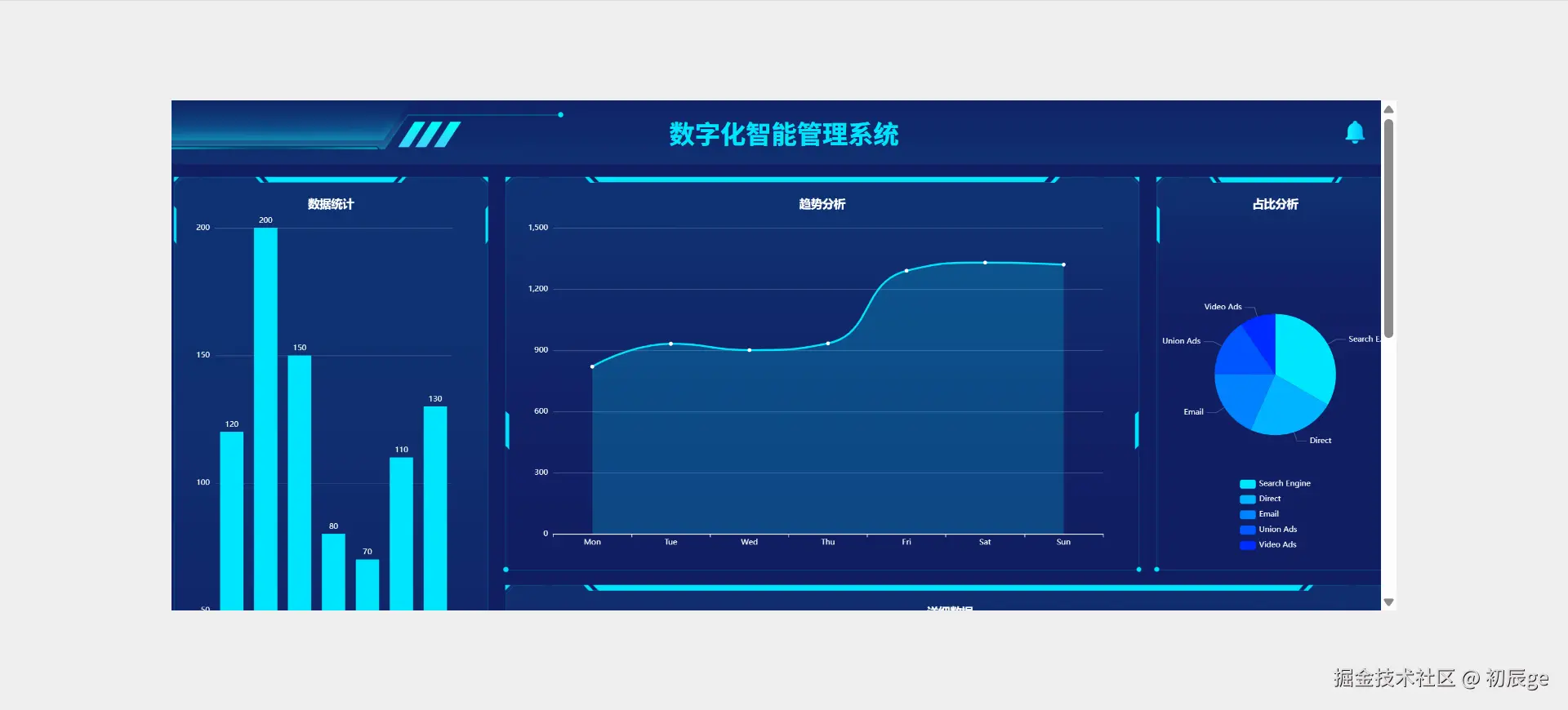
巧用辅助线,轻松实现类拼多多的 Tab 吸顶效果
前言:吸顶交互的挑战
在移动端开发中,Tab 吸顶是一种非常常见的交互效果:页面滚动时,位于内容区域的 Tab 栏会“吸附”在顶部导航栏下方,方便用户随时切换。比如拼多多百亿补贴 H5 的效果如下:

要实现这个效果、并处理其他关联吸顶的效果,开发者通常需要精确处理两个问题:
- 状态判断:如何准确判断 Tab 栏是否应进入或退出吸顶状态?
- 临界值计算:页面滚动到哪个位置时,才是触发吸顶的精确临界点?
传统的方案往往依赖于监听页面的 scroll 事件,在回调中频繁计算元素位置,不仅逻辑复杂、容易出错,还可能引发性能问题。那么,有没有一种更简单、更优雅的方式呢?
本文将介绍一种巧妙的思路,仅用一条辅助线,就能轻松解决上述两个问题,极大简化实现逻辑。
我是印刻君,一位前端程序员,关注我,了解更多有温度的轻知识,有深度的硬内容。
核心思路:一条辅助线
我们的核心方法是:在 Tab 组件的父容器内,放置一条辅助线。这条线的高度可以忽略(例如 1px),定位在 Tab 上方,与 Tab 的距离正好等于顶部导航栏的高度(navbarHeight)。
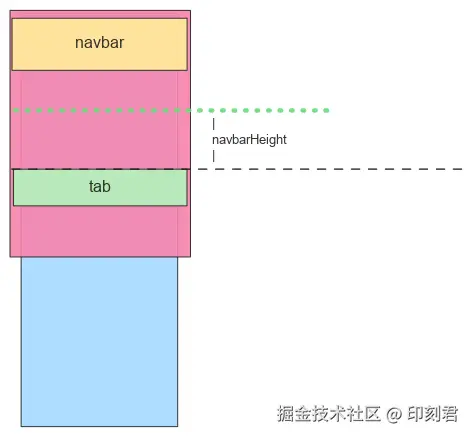
这条看似简单的辅助线,为我们提供了两个至关重要的信息:
- 判断吸顶状态:当页面滚动,导致这条辅助线完全离开视窗顶部时,恰好就是 Tab 栏需要吸顶的时刻。我们可以使用
IntersectionObserverAPI 来监听其可见性变化,从而轻松更新吸顶状态。
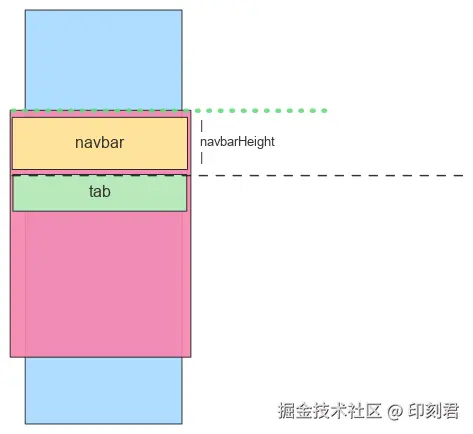
- 获取吸顶临界值:在页面初始布局完成后,该辅助线距离页面顶部的偏移量(
offsetTop),就等于触发 Tab 吸顶时页面的滚动距离(scrollTop)。我们无需计算,直接获取即可。
原理与实现
1. 判断吸顶状态
IntersectionObserver 是一个现代浏览器 API,可以异步观察目标元素与其祖先或顶级视窗的交叉状态,而无需在主线程上执行高频计算。
在我们的方案中,我们将辅助线作为观察目标。当它向上滚动并与视窗顶部完全分离(isIntersecting 变为 false)时,就意味着 Tab 栏的顶部即将触碰到导航栏的底部。此时,我们只需更新一个状态(例如 isSticky = true),即可触发 Tab 吸顶。这种方式性能优异且逻辑清晰。
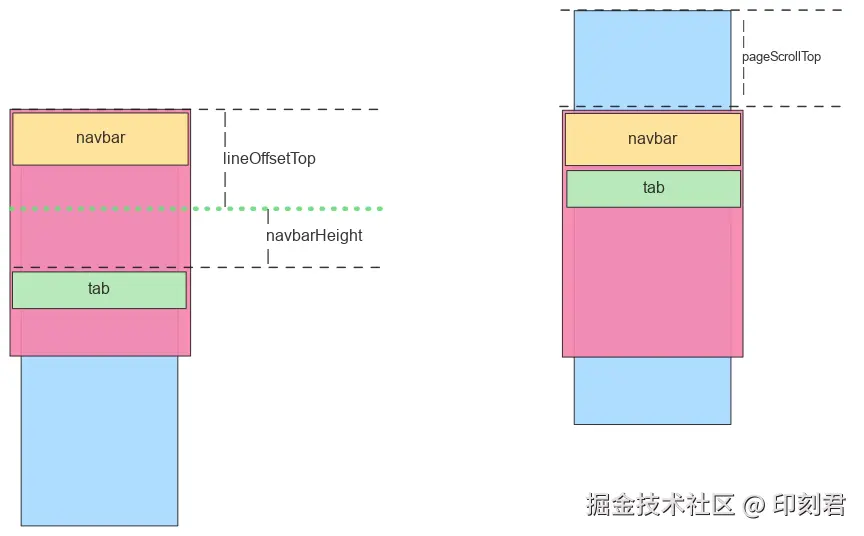
2. 获取吸顶临界值
为什么辅助线的 offsetTop 就是吸顶时的滚动距离呢?让我们通过简单的几何关系来证明。
- 吸顶临界点:如图所示,当 Tab 栏的顶部需要滚动到导航栏(
navbar)的底部时,页面滚动的距离pageScrollTop应为:pageScrollTop = tabOffsetTop - navbarHeight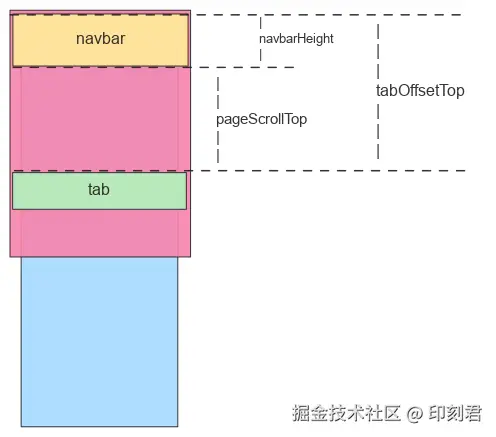
- 辅助线的位置:根据我们的设计,辅助线位于 Tab 上方
navbarHeight的位置。因此,它距离页面顶部的距离lineOffsetTop为:lineOffsetTop = tabOffsetTop - navbarHeight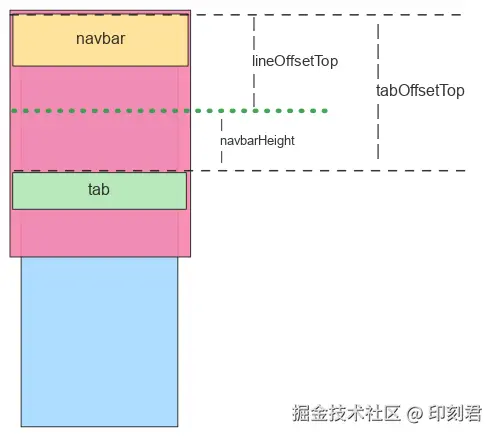
结合以上两个等式,可以清晰地得出:
pageScrollTop = lineOffsetTop
这证明了我们可以在页面加载后,直接通过读取辅助线的 offsetTop 属性,预先获得精确的吸顶滚动临界值。
3. 代码示例:React Hooks 实现
下面是一个基于 React Hooks 的简单实现,展示了如何将上述原理付诸实践。
import React, { useState, useEffect, useRef } from 'react';
const StickyTabs = ({ navbarHeight }) => {
const [isSticky, setIsSticky] = useState(false);
const [stickyScrollTop, setStickyScrollTop] = useState(0);
// Ref 指向我们的辅助线
const helperLineRef = useRef(null);
useEffect(() => {
const helperLineEl = helperLineRef.current;
if (!helperLineEl) {
return;
}
// 1. 获取吸顶临界值:页面加载后,直接读取 offsetTop
setStickyScrollTop(helperLineEl.offsetTop);
// 2. 监听辅助线可见性,判断吸顶状态
const observer = new IntersectionObserver(
([entry]) => {
// 当辅助线与视窗不再交叉时,意味着 Tab 需要吸顶
setIsSticky(!entry.isIntersecting);
},
// root: null 表示观察与视窗的交叉
// threshold: 0 表示元素刚进入或刚离开视窗时触发
{ root: null, threshold: 0 }
);
observer.observe(helperLineEl);
return () => observer.disconnect();
}, [navbarHeight]);
return (
<div>
{/* ... 其他页面内容 ... */}
<div style={{ position: 'relative' }}>
{/* 辅助线:绝对定位到 Tab 上方 navbarHeight 的位置 */}
<div
ref={helperLineRef}
style={{ position: 'absolute', top: -`${navbarHeight}px`, height: '1px' }}
/>
{/* Tab 组件 */}
<div
style={{
position: isSticky ? 'fixed' : 'static',
top: isSticky ? `${navbarHeight}px` : 'auto',
width: '100%',
zIndex: 10,
// ... 其他样式
}}
>
{/* Tabs... */}
div>
div>
{/* ... 列表等内容 ... */}
div>
);
};
在这个例子中:
helperLineRef指向我们的辅助线。useEffect在组件挂载后执行:- 通过
helperLineRef.current.offsetTop一次性获取并存储吸顶临界值stickyScrollTop。 - 创建
IntersectionObserver监听辅助线,当它离开视窗时,将isSticky设为true,反之则为false。
- 通过
- Tab 组件的
position样式根据isSticky状态动态切换,从而实现吸顶和取消吸顶的效果。
总结
通过引入一条简单的辅助线,我们将一个动态、复杂的滚动计算问题,巧妙地转化为了一个静态、简单的布局问题。
这种方法的优势显而易见:
- 逻辑清晰:用
IntersectionObserver判断状态,用offsetTop获取临界值,职责分明,代码易于理解和维护。 - 性能更优:避免了高频的
scroll事件监听和其中复杂的计算,将性能开销降到最低。 - 实现简单:无需引入复杂的第三方库,仅依靠浏览器原生 API 即可优雅地实现功能。
我是印刻君,一位前端程序员,关注我,了解更多有温度的轻知识,有深度的硬内容。
来源:juejin.cn/post/7572539461479546923
为什么有些人边框不用border属性
1) border 会改变布局(占据空间)
border 会参与盒模型,增加元素尺寸。
例如,一个宽度 200px 的元素加上 border: 1px solid #000,实际宽度会变成:
200 + 1px(left) + 1px(right) = 202px
如果不想影响布局,就很麻烦。
使用 box-shadow: 0 0 0 1px #000不会改变大小,看起来像 border,但不占空间。
2) border 在高 DPI 设备上容易出现“模糊/不齐”
特别是 0.5px border(发丝线),在某些浏览器上有锯齿、断线。
transform: scale(0.5) 或伪元素能做更稳定的发丝线。
3) border 圆角 + 发丝线 常出现不规则效果
border + border-radius 在不同浏览器的渲染不一致,容易出现不均匀、颜色不一致的问题。
用 outline / box-shadow 圆角更稳定。
4) border 不适合做阴影/多层边框
如果你需要两层边框:
双层边框用 border 很难做
而用:
box-shadow: 0 0 0 1px #333, 0 0 0 2px #999;
非常简单。
5) border 和背景裁剪一起用时容易出 bug
比如 background-clip、overflow: hidden 配合 border 会出现背景被挤压、不应该被裁剪却裁剪等问题。
6) hover/active 等状态切换时会“跳动”
因为 border 会改变元素大小。
例子:
.btn { border: 0; }
.btn:hover { border: 1px solid #000; }
鼠标移上去会抖动,因为尺寸变大了。
用 box-shadow 的话就不会跳。
25/11/25更新,来自评论区大佬补充
除了动态外有时候 overflow 也会导致原本刚刚好的布局不会删除滚动条,由于有了 border 1px 导致刚好出现滚动条但其实根本滚不了。
总结
边框可以分别使用border、outline、box-shadow三种方式去实现,其中outline、box-shadow不会像border一样占据空间。而box-shadow可以用来解决两个元素相邻时边框变宽的问题。不使用border并不是因为它不好,而是因为outline和box-shadow的兼容性和灵活性相对border会更好一点。
来源:juejin.cn/post/7575065042158633010
如果产品经理突然要你做一个像抖音一样流畅的H5
从前端到爆点!抖音级 H5 如何炼成?
在万物互联的时代,H5 页面已成为产品推广的利器。当产品经理丢给你一个“像抖音一样流畅的 H5”任务时,是挑战还是机遇?别慌,今天就带你走进抖音 H5 的前端魔法世界。
一、先看清本质:抖音 H5 为何丝滑?
抖音 H5 之所以让人欲罢不能,核心在于两点:极低的卡顿率和极致的交互反馈。前者靠性能优化,后者靠精心设计的交互逻辑。比如,你刷视频时的流畅下拉、点赞时的爱心飞舞,背后都藏着前端开发的“小心机”。
二、性能优化:让页面飞起来
(一)懒加载与预加载协同作战
懒加载是 H5 性能优化的经典招式,只在用户即将看到某个元素时才加载它。但光靠懒加载还不够,聪明的抖音 H5 还会预加载下一个可能进入视野的元素。以下是一个基于 IntersectionObserver 的懒加载示例:
document.addEventListener('DOMContentLoaded', () => {
const lazyImages = [].slice.call(document.querySelectorAll('img.lazy'));
if ('IntersectionObserver' in window) {
let lazyImageObserver = new IntersectionObserver((entries) => {
entries.forEach((entry) => {
if (entry.isIntersecting) {
let lazyImage = entry.target;
lazyImage.src = lazyImage.dataset.src;
lazyImageObserver.unobserve(lazyImage);
}
});
});
lazy Images.forEach((lazyImage) => {
lazyImageObserver.observe(lazyImage);
});
}
});
(二)图片压缩技术大显神威
图片是 H5 的“体重”大户。抖音 H5 常用 WebP 格式,它在保证画质的同时,能将图片体积压缩到 JPEG 的一半。你可以用以下代码轻松实现图片格式转换:
function compressImage(inputImage, quality) {
return new Promise((resolve) => {
const canvas = document.createElement('canvas');
const ctx = canvas.getContext('2d');
canvas.width = inputImage.naturalWidth;
canvas.height = inputImage.naturalHeight;
ctx.drawImage(inputImage, 0, 0, canvas.width, canvas.height);
const compressedImage = new Image();
compressedImage.src = canvas.toDataURL('image/webp', quality);
compressedImage.onload = () => {
resolve(compressedImage);
};
});
}
三、交互设计:让用户欲罢不能
(一)微动画营造沉浸感
在点赞、评论等关键操作上,抖音 H5 会加入精巧的微动画。比如点赞时的爱心从手指位置飞出,这其实是一个 CSS 动画加 JavaScript 事件监听的组合拳。以下是一个简易版的点赞动画代码:
@keyframes flyHeart {
0% {
transform: scale(0) translateY(0);
opacity: 0;
}
50% {
transform: scale(1.5) translateY(-10px);
opacity: 1;
}
100% {
transform: scale(1) translateY(-20px);
opacity: 0;
}
}
.heart {
position: fixed;
width: 30px;
height: 30px;
background-image: url('../assets/heart.png');
background-size: contain;
background-repeat: no-repeat;
animation: flyHeart 1s ease-out;
}
document.querySelector('.like-btn').addEventListener('click', function(e) {
const heart = document.createElement('div');
heart.className = 'heart';
heart.style.left = e.clientX + 'px';
heart.style.top = e.clientY + 'px';
document.body.appendChild(heart);
setTimeout(() => {
heart.remove();
}, 1000);
});
(二)触摸事件优化
在移动设备上,触摸事件的响应速度直接影响用户体验。抖音 H5 通过精准控制触摸事件的捕获和冒泡阶段,减少了延迟。以下是一个优化触摸事件的示例:
const touchStartHandler = (e) => {
e.preventDefault(); // 防止页面滚动干扰
// 处理触摸开始逻辑
};
const touchMoveHandler = (e) => {
// 处理触摸移动逻辑
};
const touchEndHandler = (e) => {
// 处理触摸结束逻辑
};
const element = document.querySelector('.scrollable-container');
element.addEventListener('touchstart', touchStartHandler, { passive: false });
element.addEventListener('touchmove', touchMoveHandler, { passive: false });
element.addEventListener('touchend', touchEndHandler);
四、音频处理:让声音为 H5 增色
抖音 H5 的音频体验也很讲究。它会根据用户的操作实时调整音量,甚至在不同视频切换时平滑过渡音频。以下是一个简单的声音控制示例:
const audioContext = new (window.AudioContext || window.webkitAudioContext)();
const audioElement = document.querySelector('audio');
const audioSource = audioContext.createMediaElementSource(audioElement);
const gainNode = audioContext.createGain();
audioSource.connect(gainNode);
gainNode.connect(audioContext.destination);
// 调节音量
function setVolume(level) {
gainNode.gain.value = level;
}
// 音频淡入效果
function fadeInAudio() {
gainNode.gain.setValueAtTime(0, audioContext.currentTime);
gainNode.gain.linearRampToValueAtTime(1, audioContext.currentTime + 1);
}
// 音频淡出效果
function fadeOutAudio() {
gainNode.gain.linearRampToValueAtTime(0, audioContext.currentTime + 1);
}
五、跨浏览器兼容:让 H5 无处不在
抖音 H5 能在各种浏览器上保持一致的体验,这离不开前端开发者的兼容性优化。常用的手段包括使用 Autoprefixer 自动生成浏览器前缀、为老浏览器提供 Polyfill 等。以下是一个为 CSS 动画添加前缀的示例:
const autoprefixer = require('autoprefixer');
const postcss = require('postcss');
const css = '.example { animation: slidein 2s; } @keyframes slidein { from { transform: translateX(0); } to { transform: translateX(100px); } }';
postcss([autoprefixer]).process(css).then(result => {
console.log(result.css);
/*
输出:
.example {
animation: slidein 2s;
}
@keyframes slidein {
from {
-webkit-transform: translateX(0);
transform: translateX(0);
}
to {
-webkit-transform: translateX(100px);
transform: translateX(100px);
}
}
*/
});
打造一个像抖音一样的流畅 H5,需要前端开发者在性能优化、交互设计、音频处理和跨浏览器兼容等方面全方位发力。希望这些技术点能为你的 H5 开发之旅提供助力,让你的产品在激烈的市场竞争中脱颖而出!
来源:juejin.cn/post/7522090635908251686
写 CSS 用 px?这 3 个单位能让页面自动适配屏幕
在网页开发中,CSS 单位是控制元素尺寸、间距和排版的基础。
长期以来,px(像素)因其直观、精确而被广泛使用。
然而,随着设备屏幕尺寸和用户需求的多样化,单纯依赖 px 已难以满足现代 Web 对可访问性、灵活性和响应式能力的要求。
什么是 px?
px 是 CSS 中的绝对长度单位,代表像素(pixel)。
在标准密度屏幕上,1px 通常对应一个物理像素点。
开发者使用 px 可以精确控制元素的大小,例如:
.container {
width: 320px;
font-size: 16px;
padding: 12px;
}
这种写法简单直接,在固定尺寸的设计稿还原中非常高效。但问题也正源于它的绝对性。
px 存在哪些问题?
1. 缺乏响应能力
px 的值是固定的,不会随屏幕宽度、容器大小或用户设置而变化。
在一个 320px 宽的手机上显示良好的按钮,在 4K 显示器上可能显得微不足道,反之亦然。
2. 不利于可访问性
许多用户(尤其是视力障碍者)会调整浏览器的默认字体大小。
但使用 px 定义的字体不会随之缩放,导致内容难以阅读。
相比之下,使用相对单位(如 rem)能尊重用户的偏好设置。
更好的选择
为解决上述问题,CSS 提供了一系列更智能、更灵活的单位和功能。以下是几种核心方案:
1. 相对单位:rem 与 em
rem(root em):相对于根元素()的字体大小。默认情况下,1rem = 16px,但可通过设置html { font-size: 18px }改变基准。em:相对于当前元素或其父元素的字体大小,常用于局部缩放。
示例:
html {
font-size: 16px; /* 基准 */
}
.title {
font-size: 1.5rem; /* 24px */
margin-bottom: 1em; /* 相对于自身字体大小 */
}
优势:支持用户自定义缩放,便于构建比例一致的排版系统。
2. 视口单位:vw、vh、vmin、vmax
这些单位基于浏览器视口尺寸:
1vw= 视口宽度的 1%1vh= 视口高度的 1%vmin取宽高中较小者,vmax取较大者
用途:适合全屏布局、动态高度标题等场景。
示例:
.hero {
height: 80vh; /* 占视口高度的 80% */
font-size: 5vw; /* 字体随屏幕宽度缩放 */
}
注意:在移动端,vh 可能受浏览器地址栏影响,需谨慎使用。
3. clamp() 函数:实现流体响应
clamp() 是 CSS 的一个重要进步,允许你在一个属性中同时指定最小值、理想值和最大值:
font-size: clamp(16px, 4vw, 32px);
含义:
- 在小屏幕上,字体不小于 16px;
- 在中等屏幕,按 4vw 动态计算;
- 在大屏幕上,不超过 32px。
这行代码即可替代多个 @media 查询,实现平滑、连续的响应效果。
更推荐结合相对单位使用:
font-size: clamp(1rem, 2.5vw, 2rem);
这样既保留了可访问性,又具备响应能力。
4. 容器查询(Container Queries)
过去,响应式布局只能基于整个视口(通过 @media)。
但组件常常需要根据自身容器的大小来调整样式——这就是容器查询要解决的问题。
使用步骤:
- 为容器声明
container-type:
.card-wrapper {
container-type: inline-size; /* 基于内联轴(通常是宽度) */
}
- 使用
@container编写查询规则:
@container (min-width: 300px) {
.card-title {
font-size: 1.25rem;
}
}
@container (min-width: 500px) {
.card-title {
font-size: 1.75rem;
}
}
现在,只要 .card-wrapper 的宽度变化,内部元素就能自动响应,无需关心页面整体布局。这对构建可复用的 UI 组件库至关重要。
容器查询已在主流浏览器(Chrome 105+、Firefox 116+、Safari 16+)中得到支持。
建议
- 避免在字体大小、容器宽度、内边距等关键布局属性中使用纯
px。 - 优先使用
rem作为全局尺寸基准,em用于局部比例。 - 对需要随屏幕缩放的元素,使用
clamp()+vw/rem组合。 - 构建组件时,考虑启用容器查询,使其真正“自适应”。
- 保留
px仅用于不需要缩放的场景,如边框(border: 1px solid)、固定图标尺寸等。
本文首发于公众号:程序员大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
📌往期内容
ThreadLocal 在实际项目中的 6 大用法,原来可以这么简单
重构了20个SpringBoot项目后,总结出这套稳定高效的架构设计
来源:juejin.cn/post/7593292445300899859
CSS终于支持渐变色的过渡了🎉
背景
在做项目时,总会遇到UI给出渐变色的卡片或者按钮,但在做高亮的时候,由于没有过渡,显得尤为生硬。
过去的解决方案
在过去,我们如果要实现渐变色的过渡,通常会使用如下几种方法:
- 添加遮罩层,通过改变遮罩层的透明度做出淡入淡出的效果,实现过渡。
- 通过
background-size/position使得渐变色移动,实现渐变色移动的效果。 - 通过
filter: hue-rotate滤镜实现色相旋转,实现过渡。
但这几种方式都有各自的局限性:
- 遮罩层的方式看似平滑,但不是真正的过渡,差点意思。
background-size/position的方式需要计算好background-size和background-position,否则会出现渐变不完整的情况。并且只是实现了渐变的移动,而不是过渡。filter: hue-rotate也需要计算好旋转角度,实现复杂度高,过渡的也不自然。
@property新规则
@property规则可以定义一个自定义属性,并且可以指定该属性的语法、是否继承、初始值等。
@property --color {
syntax: '<color>';
inherits: false;
initial-value: #000000;
}
我们只需要把这个自定义属性--color应用到linear-gradient中,在特定的时候改变它的值,非常轻松就可以实现渐变色的过渡了。
我们再看看@property规则中这些属性的含义。
Syntax语法描述符
Syntax用于描述自定义属性的数据类型,必填项,常见值包括:
<number>数字(如0,1,2.5)<percentage>百分比(如0%,50%,100%)<length>长度单位(如px,em,rem)<color>颜色值<angle>角度值(如deg,rad)<time>时间值(如s,ms)<image>图片<*>任意类型
Inherits继承描述符
Inherits用于描述自定义属性是否从父元素继承值,必填项:
true从父元素继承值false不继承,每个元素独立
Initial-value初始值描述符
Initial-value用于描述自定义属性的初始值,在Syntax为通用时为可选。
兼容性
@property目前仍是实验性规则,但主流浏览器较新版本都已支持。
总结与展望
@property规则的出现,标志着CSS在动态样式控制方面迈出了重要一步。它不仅解决了渐变色过渡的技术难题,更为未来的CSS动画和交互设计开辟了新的可能性。
随着浏览器支持的不断完善,我们可以期待:
- 更丰富的动画效果
- 更简洁的代码实现
- 更好的性能表现
来源:juejin.cn/post/7591697558377873450
浅谈 import.meta.env 和 process.env 的区别
这是一个前端构建环境里非常核心、也非常容易混淆的问题。下面我们从来源、使用场景、编译时机、安全性四个维度来谈谈 import.meta.env 和 process.env 的区别。
一句话结论
process.env是 Node.js 的环境变量接口import.meta.env是 Vite(ESM)在构建期注入的前端环境变量
一、process.env 是什么?
1️⃣ 本质
- 来自 Node.js
- 运行时读取 服务器 / 构建机的系统环境变量
- 本身 浏览器里不存在
console.log(process.env.NODE_ENV);
2️⃣ 使用场景
- Node 服务
- 构建工具(Webpack / Vite / Rollup)
- SSR(Node 端)
3️⃣ 前端能不能用?
👉 不能直接用
浏览器里没有 process:
// 浏览器原生环境 ❌
Uncaught ReferenceError: process is not defined
4️⃣ 为什么 Webpack 项目里能用?
因为 Webpack 帮你“编译期替换”了
process.env.NODE_ENV
// ⬇️ 构建时被替换成
"production"
本质是 字符串替换,不是运行时读取。
二、import.meta.env 是什么?
1️⃣ 本质
- Vite 提供
- 基于 ES Module 的
import.meta - 构建期 + 运行期可用(但值是构建期确定的)
console.log(import.meta.env.MODE);
2️⃣ 特点
- 浏览器里 原生支持
- 不依赖 Node 的
process - 更符合现代 ESM 规范
三、两者核心区别对比(重点)
| 维度 | process.env | import.meta.env |
|---|---|---|
| 来源 | Node.js | Vite |
| 标准 | Node API | ESM 标准扩展 |
| 浏览器可用 | ❌(需编译替换) | ✅ |
| 注入时机 | 构建期 | 构建期 |
| 是否运行时读取 | ❌ | ❌ |
| 推荐前端使用 | ❌ | ✅ |
⚠️ 两者都不是“前端运行时读取服务器环境变量”
四、Vite 中为什么不用 process.env?
1️⃣ 因为 Vite 不再默认注入 process
// Vite 项目中 ❌
process.env.API_URL
会直接报错。
2️⃣ 官方设计选择
- 避免 Node 全局污染
- 更贴近浏览器真实环境
- 更利于 Tree Shaking
五、Vite 环境变量的正确用法(非常重要)
1️⃣ 必须以 VITE_ 开头
# .env
VITE_API_URL=https://api.example.com
console.log(import.meta.env.VITE_API_URL);
❌ 否则 不会注入到前端
2️⃣ 内置变量
import.meta.env.MODE // development / production
import.meta.env.DEV // true / false
import.meta.env.PROD // true / false
import.meta.env.BASE_URL
六、安全性
⚠️ 重要警告
import.meta.env里的变量 ≠ 私密
它们会:
- 被 打进 JS Bundle
- 可在 DevTools 直接看到
❌ 不要这样做
VITE_SECRET_KEY=xxxx
✅ 正确做法
- 前端:只放“公开配置”(API 域名、开关)
- 私密变量:只放在 Node / 服务端
七、SSR / 全栈项目里怎么区分?
在 Vite + SSR(如 Nuxt / 自建 SSR):
Node 端
process.env.DB_PASSWORD
浏览器端
import.meta.env.VITE_API_URL
两套环境变量是刻意分开的。
为什么必须分成两套?(设计原因)
1️⃣ 执行环境不同(这是根因)
| 位置 | 运行在哪 | 能访问什么 |
|---|---|---|
| SSR Server | Node.js | process.env |
| Client Bundle | 浏览器 | import.meta.env |
浏览器里 永远不可能安全地访问服务器环境变量。
2️⃣ SSR ≠ 浏览器
很多人误解:
“SSR 是不是浏览器代码先在 Node 跑一遍?”
❌ 不完全对
SSR 实际是:
Node.js 先跑一份 → 生成 HTML
浏览器再跑一份 → hydrate
这两次执行:
- 环境不同
- 变量来源不同
- 安全级别不同
在 Vite + SSR 中,变量的“真实流向”
1️⃣ Node 端(SSR Server)
// server.ts / entry-server.ts
const dbPassword = process.env.DB_PASSWORD;
✔️ 真实运行时读取
✔️ 不会进 bundle
✔️ 只存在于服务器内存
2️⃣ Client 端(浏览器)
// entry-client.ts / React/Vue 组件
const apiUrl = import.meta.env.VITE_API_URL;
✔️ 构建期注入
✔️ 会打进 JS
✔️ 用户可见
3️⃣ 中间那条“禁止通道”
// ❌ 绝对禁止
process.env.DB_PASSWORD → 浏览器
SSR 不会、也不允许,自动帮你“透传”环境变量
SSR 中最容易踩的 3 个坑(重点)
❌ 坑 1:在“共享代码”里直接用 process.env
// utils/config.ts(被 server + client 共用)
export const API = process.env.API_URL; // ❌
问题:
- Server OK
- Client 直接炸(或被错误替换)
✅ 正确方式:
export const API = import.meta.env.VITE_API_URL;
或者:
export const API =typeof window === 'undefined'
? process.env.INTERNAL_API
: import.meta.env.VITE_API_URL;
❌ 坑 2:误以为 SSR 可以“顺手用数据库变量”
// Vue/React 组件里
console.log(process.env.DB_PASSWORD); // ❌
哪怕你在 SSR 模式下,这段代码:
- 最终仍会跑在浏览器
- 会被打包
- 是严重安全漏洞
❌ 坑 3:把“环境变量”当成“运行时配置”
// ❌ 想通过部署切换 API
import.meta.env.VITE_API_URL
🚨 这是 构建期值:
build 时确定
→ CDN 缓存
→ 所有用户共享
想运行期切换?只能:
- 接口返回配置
- HTML 注入 window.CONFIG
- 拉 JSON 配置文件
SSR 项目里“正确的分层模型”(工程视角)
┌──────────────────────────┐
│ 浏览器 Client │
│ import.meta.env.VITE_* │ ← 公开配置
└───────────▲──────────────┘
│
HTTP / HTML
│
┌───────────┴──────────────┐
│ Node SSR Server │
│ process.env.* │ ← 私密配置
└───────────▲──────────────┘
│
内部访问
│
┌───────────┴──────────────┐
│ DB / Redis / OSS │
└──────────────────────────┘
这是一条 单向、安全的数据流。
Nuxt / 自建 SSR 的对应关系
| 类型 | 用途 |
|---|---|
| runtimeConfig | Server-only |
| runtimeConfig.public | Client 可见 |
| process.env | 仅 server |
👉 Nuxt 本质也是在帮你维护这条边界
八、常见误区总结
❌ 误区 1
import.meta.env是运行时读取
❌ 错,仍是构建期注入
❌ 误区 2
可以用它动态切换环境
❌ 不行,想动态只能:
- 接口返回配置
- 或运行时请求 JSON
❌ 误区 3
Vite 里还能继续用
process.env
❌ 除非你手动 polyfill(不推荐)
九、总结
- 前端(Vite)只认
import.meta.env.VITE_* - 服务端(Node)只认
process.env - 永远不要把秘密放进前端 env
来源:juejin.cn/post/7592062873829916722
Maven 4 终于快来了,新特性很香!
大家好,我是 Guide!在 Java 生态中,Maven 绝对是大家每天都要打交道的“老朋友”。
InterviewGuide 这个开源 AI 项目中,我使用了 Gradle。不过,根据大家的反馈来看还是更愿意使用 Maven 一些。
目前(2026 年 1 月)Maven 4.0 仍处于 Release Candidate 阶段,最新版本为 4.0.0-rc-5(2025 年 11 月 08 日发布),尚未正式 GA(General Availability)。

虽然目前 Maven 4 还处于 Release Candidate(RC)阶段,但它展现出来的特性足以让我们这些长期被 Maven 3 “历史债”折磨的开发者感到兴奋。
一句话总结:Maven 4 要求最低 Java 17 运行环境,通过分离构建与消费模型、树形生命周期等黑科技,彻底告别了臃肿且难以维护的 POM。
下面简单介绍一下 Maven 4 的最重要新特性(基于官方文档和发布记录):
Build POM 与 Consumer POM 的分离
这是 Maven 4 解决的最大痛点。在 Maven 3 时代,你发布的 pom.xml 既要管“怎么构建”,又要管“别人怎么依赖”,导致发布的元数据极其臃肿,甚至带有大量的 profile 和本地路径。
Maven 4 解决方案:
- Build POM:这就是你本地编辑的
pom.xml(模型升级至 4.1.0)。它包含所有的构建细节,比如插件配置、私有 profile 等。 - Consumer POM:当你执行
deploy时,Maven 4 会自动生成一个“纯净版”的pom.xml(固定为 4.0.0 模型)。它去掉了所有插件、build 逻辑和 parent 继承关系,仅保留 GAV 坐标和核心依赖。
默认关闭 ,需显式开启:
mvn deploy -Dmaven.consumer.pom.flatten=true
或在项目根 .mvn/maven-user.properties 中永久配置:
maven.consumer.pom.flatten=true
这样的话,发布的 artifact 更干净,依赖解析更快,生态(Gradle、sbt、IDE、Sonatype 等)兼容性更好,无需再依赖 flatten-maven-plugin 等 hack 方案。

POM 模型升级到 4.1.0 + 多项简化语法
Maven 4 引入了全新的命名空间(**maven.apache.org/POM/4.1.0**…
1. 自动发现子项目
- 新标签
<subprojects>:正式取代了容易产生术语混淆的<modules>(标记为 deprecated)。 - 隐式发现 :如果父项目
packaging=pom且没有声明子项目,Maven 4 会自动扫描包含pom.xml的直接子目录。再也不用手动一行行写子模块名了!
2. 坐标推断(Inference)
在 <parent> 中,如果你按默认路径放置项目,可以省略 version、groupId 甚至整个坐标。Maven 会自动从相对路径推断父 POM 坐标。
3. CI 友好变量原生支持
${revision}、${sha1} 等变量现在是原生一等公民,不需要再写 hack 插件就能直接在命令行定义版本。
构建性能:从线性生命周期到树形并发
Maven 3 的生命周期是线性的,这意味着如果你的项目很大,构建过程就像“老牛拉破车”。
1. 树形生命周期与钩子
Maven 4 将生命周期升级为树形结构,并引入了 before:xxx 和 after:xxx 阶段。你可以更精准地在每个阶段前后绑定插件。
默认还是 Maven 3 时代的线性行为(向后兼容)。
要真正用上树形 + 更细粒度并发,必须显式加参数 -b concurrent(或 --builder concurrent)。
2. 并发构建器 (-b concurrent)
传统的并发构建往往受限于父子依赖。Maven 4 的并发构建器只要依赖模块进入 “Ready” 状态就会立即开跑,不再傻等父模块完成所有阶段。
开发者体验优化
1. 构建恢复 (-r / --resume)
大型项目构建到 90% 挂了?在 Maven 4 里直接 -r 即可从失败处继续,自动跳过已成功的模块。这简直是多模块项目的“救命稻草”。
2. 延迟发布 (deployAtEnd 默认开启)
为了防止出现“半成品”发布(一部分模块发了,另一部分报错没发),Maven 4 默认会在所有模块全部构建成功后才进行最后的统一发布。

3. 官方迁移助手 (mvnup)
担心升级出问题?官方直接给了 mvnup 工具,自动扫描并建议如何将你的 3.x 项目迁移到 4.1.0 模型。
现在该升级吗?
- 生产环境:由于目前还在 RC 阶段,且最低要求 Java 17,建议观望,等正式 GA 之后再小范围灰度。
- 新项目/个人实验:强烈建议开启 POM 4.1.0 进行尝试。特别是 Build/Consumer POM 的分离,能让你的项目元数据管理水平提升一个档次。
- 大厂多模块项目:如果你深陷“Maven 构建慢、POM 维护难”的泥潭,Maven 4 的并发构建和自动子项目发现正是你需要的解药。
面对 Maven 二十年来最大的变动,你最期待哪个功能?或者你已经转向了 Gradle?欢迎在评论区留言,我们一起“对齐”一下!
相关地址:
- Maven 发布记录:maven.apache.org/ref/
- 迁移到 Maven4:maven.apache.org/guides/mini…
- Maven4 介绍:maven.apache.org/whatsnewinm…
来源:juejin.cn/post/7595527937832157238
一些我推荐的前端代码写法
使用解构赋值简化变量声明
const obj = {
a:1,
b:2,
c:3,
d:4,
e:5,
}
// 不好的写法
const a = obj.a;
const b = obj.b;
const c = obj.c;
const d = obj.d;
const e = obj.e;
// 我推荐的
const {a: newA = '',b,c,d,e} = obj || {};
- 要注意解构的对象不能为
undefined、null。否则会报错。所以可以给个空对象作为默认值 - 解构的 key 如果不存在,可以给个默认值,避免后续逻辑出错
合并数据
const a = [1,2];
const b = [3,4];
const obj1 = {
a:1,
}
const obj2 = {
b:1,
}
// 一般的写法
const c = a.concat(b);
const obj = Object.assign({}, obj1, obj2);
// 我推荐的写法
const c = [...arr1, ...arr2];
const obj = { ...obj1, ...obj2 };
Object.assign 和 Array.concat 其实也可以,只不过拓展运算符的优势如下:
- 更简洁,阅读性更好
- 会创建新的对象/数组,不会污染原数据(避免副作用)
- 支持深层次嵌套结构的合并
- 类型安全,编译时检查
条件判断
条件判断的话有几种情况,第一种是常见的多个条件判断
// 不好的写法
if(
type == 1 ||
type == 2 ||
type == 3 ||
type == 4 ||
){
//...
}
// 我推荐的
const typeArr = [1,2,3,4]
if (typeArr.includes(type)) {
//...
}
这样写代码会更简洁。如果其他地方也有相同的条件判断逻辑,当需要同时修改时,只需要修改 typeArr 即可。
第二种是三目运算符的条件判断,三目运算符我个人认为如果是简单的判断可以写,但是稍微复杂或着未来会改动的判断,最好不要使用三目运算符。容易三目运算符无限嵌套
let c = 1, d = 2, e = 3
// 不好的写法
const obj = {
a: 1,
b: (c === 1 || d === 1) ? 'bb' : d === 2 ? 'vv' : e === 3 ? '66' : null
}
// 我推荐的写法1
const obj = {
a: 1,
}
if (c === 1 || d === 1) {
obj.b = 'bb'
} else if (d === 2) {
obj.b = 'vv'
} else if (e === 3) {
obj.b = '66'
} else {
obj.b = null
}
// 我推荐的写法2
const valueMap = [
{ condition: (c, d, e) => c === 1 || d === 1, value: 'bb' },
{ condition: (c, d, e) => d === 2, value: 'vv' },
{ condition: (c, d, e) => e === 3, value: '66' }
];
function getValueByMap(c, d, e) {
const match = valueMap.find(item => item.condition(c, d, e));
return match ? match.value : null;
}
getValueByMap(c, d, e
// 我推荐的写法3
const conditionConfig = {
rules: [
{ name: 'rule1', check: (c, d, e) => c === 1 || d === 1, result: 'bb' },
{ name: 'rule2', check: (c, d, e) => d === 2, result: 'vv' },
{ name: 'rule3', check: (c, d, e) => e === 3, result: '66' }
],
defaultValue: null
};
function evaluateConditions(c, d, e, config) {
for (const rule of config.rules) {
if (rule.check(c, d, e)) {
return rule.result;
}
}
return config.defaultValue;
}
evaluateConditions(c, d, e, conditionConfig)
写法1、写法2、写法3都可以,具体可以看团队代码规范。
一般来说,写法1适用于比较简单的条件判断,比如请求参数时,可能会不同的情况添加额外的参数
写法2适用于条件比较多的情况
写法3使用于条件判断经常改的情况,这种情况可以使用配置化的方式封装条件判断。(ps:甚至在后续迭代时,如果产品跟你battle,你可以拿代码怼回去。兜底留痕)
纯函数
最好一个函数只做一件事,可以组合可以拆分
// 不好的写法
function createObj(name, temp) {
if (temp) {
fs.create(`./temp/${name}`);
} else {
fs.create(name);
}
}
// 我推荐的写法
function createFile(name) {
fs.create(name);
}
function createTempFile(name) {
createFile(`./temp/${name}`)
}
不好的写法不满足纯函数的概念,相同的输入有了不同的输出
再举一个例子:
//不好的写法
function emailClients(clients) {
clients.forEach((client) => {
const clientRecord = database.lookup(client);
if (clientRecord.isActive()) {
email(client);
}
});
}
//我推荐的写法
function emailClients(clients) {
clients
.filter(isClientRecord)
.forEach(email)
}
function isClientRecord(client) {
const clientRecord = database.lookup(client);
return clientRecord.isActive()
}
这样写逻辑更清晰,易读。
- 巧用filter函数,把filter的回调单开一个函数进行条件处理,返回符合条件的数据
- 符合条件的数据再巧用forEach,执行email函数
函数参数个数不要超过2个
就我个人而言,当函数的参数个数超过2个时,我会以对象的形式作为参数传入
// 不好的写法
function create(p1, p2, p3, p4) {
// ...
}
create(1,'2',true,[])
// 我推荐的写法
const config = {
p1: 1,
p2: '2',
p3: true,
p4: []
}
function create(config) {
}
create(config)
这样写在调用函数时,代码更简洁,可读性更好。
获取对象属性值
// 不好的写法
const name = obj && obj.name;
// 我推荐的写法
const name = obj?.name;
可选链让语法更简洁
箭头函数简化
// 传统函数定义
function add(a, b) {
return a + b;
}
// 箭头函数简化
const add = (a, b) => a + b;
需要注意的时,如果函数体涉及到了 this,则需要注意箭头函数 this 的指向问题
简化函数参数
// 不好的写法
function greet(name) {
const finalName = name || 'Guest';
console.log(`Hello, ${finalName}!`);
}
// 我推荐的写法
function greet({ name = 'Guest' }) {
console.log(`Hello, ${name}!`);
}
过滤操作
前端一般会涉及到过滤操作,比如精准过滤
const a = [1,2,3,4,5];
// 不好的写法
const result = a.filter(
item => {
return item === 3
}
)
// 我推荐的写法
const result = a.find(item => item === 3)
find相较于 filter 来说,有结果时不会继续遍历数组,性能更好
非空条件判断
有些时候,我们要判断值是否是 null、undefined 时,可以通过 ?? 判断
// 一般的写法
if (a !== null && a !== undefined) {
const b = 'BBBB'
}
// 我推荐的写法
const b = a ?? 'BBBB'
??运算符是当左侧是 null 或者 undefined 时,会取右侧的值
注释
在适当的地方写上注释,方便后续迭代
来源:juejin.cn/post/7563391880802320436
从一个程序员的角度告诉你:“12306”有多牛逼?
每到节假日期间,一二线城市返乡、外出游玩的人们几乎都面临着一个问题:抢火车票!
12306 抢票,极限并发带来的思考
虽然现在大多数情况下都能订到票,但是放票瞬间即无票的场景,相信大家都深有体会。
尤其是春节期间,大家不仅使用 12306,还会考虑“智行”和其他的抢票软件,全国上下几亿人在这段时间都在抢票。
“12306 服务”承受着这个世界上任何秒杀系统都无法超越的 QPS,上百万的并发再正常不过了!
笔者专门研究了一下“12306”的服务端架构,学习到了其系统设计上很多亮点,在这里和大家分享一下并模拟一个例子:如何在 100 万人同时抢 1 万张火车票时,系统提供正常、稳定的服务。
Github代码地址:
https://github.com/GuoZhaoran/spikeSystem
大型高并发系统架构
高并发的系统架构都会采用分布式集群部署,服务上层有着层层负载均衡,并提供各种容灾手段(双火机房、节点容错、服务器灾备等)保证系统的高可用,流量也会根据不同的负载能力和配置策略均衡到不同的服务器上。
下边是一个简单的示意图:
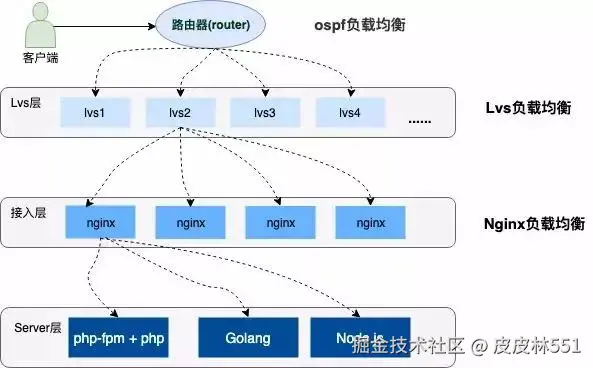
负载均衡简介
上图中描述了用户请求到服务器经历了三层的负载均衡,下边分别简单介绍一下这三种负载均衡。
①OSPF(开放式最短链路优先)是一个内部网关协议(Interior Gateway Protocol,简称 IGP)
OSPF 通过路由器之间通告网络接口的状态来建立链路状态数据库,生成最短路径树,OSPF 会自动计算路由接口上的 Cost 值,但也可以通过手工指定该接口的 Cost 值,手工指定的优先于自动计算的值。
OSPF 计算的 Cost,同样是和接口带宽成反比,带宽越高,Cost 值越小。到达目标相同 Cost 值的路径,可以执行负载均衡,最多 6 条链路同时执行负载均衡。
②LVS (Linux Virtual Server)
它是一种集群(Cluster)技术,采用 IP 负载均衡技术和基于内容请求分发技术。
调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。
③Nginx
想必大家都很熟悉了,是一款非常高性能的 HTTP 代理/反向代理服务器,服务开发中也经常使用它来做负载均衡。
Nginx 实现负载均衡的方式主要有三种:
- 轮询
- 加权轮询
- IP Hash 轮询
下面我们就针对 Nginx 的加权轮询做专门的配置和测试。
Nginx 加权轮询的演示
Nginx 实现负载均衡通过 Upstream 模块实现,其中加权轮询的配置是可以给相关的服务加上一个权重值,配置的时候可能根据服务器的性能、负载能力设置相应的负载。
下面是一个加权轮询负载的配置,我将在本地的监听 3001-3004 端口,分别配置 1,2,3,4 的权重:
#配置负载均衡
upstream load_rule {
server 127.0.0.1:3001 weight=1;
server 127.0.0.1:3002 weight=2;
server 127.0.0.1:3003 weight=3;
server 127.0.0.1:3004 weight=4;
}
...
server {
listen 80;
server_name load_balance.com http://www.load_balance.com;
location / {
proxy_pass http://load_rule;
}
}
我在本地 /etc/hosts 目录下配置了 http://www.load_balance.com 的虚拟域名地址。
接下来使用 Go 语言开启四个 HTTP 端口监听服务,下面是监听在 3001 端口的 Go 程序,其他几个只需要修改端口即可:
package main
import (
"net/http"
"os"
"strings"
)
func main() {
http.HandleFunc("/buy/ticket", handleReq)
http.ListenAndServe(":3001", nil)
}
//处理请求函数,根据请求将响应结果信息写入日志
func handleReq(w http.ResponseWriter, r *http.Request) {
failedMsg := "handle in port:"
writeLog(failedMsg, "./stat.log")
}
//写入日志
func writeLog(msg string, logPath string) {
fd, _ := os.OpenFile(logPath, os.O_RDWR|os.O_CREATE|os.O_APPEND, 0644)
defer fd.Close()
content := strings.Join([]string{msg, "\r\n"}, "3001")
buf := []byte(content)
fd.Write(buf)
}
我将请求的端口日志信息写到了 ./stat.log 文件当中,然后使用 AB 压测工具做压测:
ab -n 1000 -c 100 http://www.load_balance.com/buy/ticket
统计日志中的结果,3001-3004 端口分别得到了 100、200、300、400 的请求量。
这和我在 Nginx 中配置的权重占比很好的吻合在了一起,并且负载后的流量非常的均匀、随机。
具体的实现大家可以参考 Nginx 的 Upsteam 模块实现源码,这里推荐一篇文章《Nginx 中 Upstream 机制的负载均衡》:
https://www.kancloud.cn/digest/understandingnginx/202607
秒杀抢购系统选型
回到我们最初提到的问题中来:火车票秒杀系统如何在高并发情况下提供正常、稳定的服务呢?
从上面的介绍我们知道用户秒杀流量通过层层的负载均衡,均匀到了不同的服务器上,即使如此,集群中的单机所承受的 QPS 也是非常高的。如何将单机性能优化到极致呢?
要解决这个问题,我们就要想明白一件事: 通常订票系统要处理生成订单、减扣库存、用户支付这三个基本的阶段。
我们系统要做的事情是要保证火车票订单不超卖、不少卖,每张售卖的车票都必须支付才有效,还要保证系统承受极高的并发。
这三个阶段的先后顺序该怎么分配才更加合理呢?我们来分析一下:
下单减库存
 当用户并发请求到达服务端时,首先创建订单,然后扣除库存,等待用户支付。
当用户并发请求到达服务端时,首先创建订单,然后扣除库存,等待用户支付。
这种顺序是我们一般人首先会想到的解决方案,这种情况下也能保证订单不会超卖,因为创建订单之后就会减库存,这是一个原子操作。
但是这样也会产生一些问题:
- 在极限并发情况下,任何一个内存操作的细节都至关影响性能,尤其像创建订单这种逻辑,一般都需要存储到磁盘数据库的,对数据库的压力是可想而知的。
- 如果用户存在恶意下单的情况,只下单不支付这样库存就会变少,会少卖很多订单,虽然服务端可以限制 IP 和用户的购买订单数量,这也不算是一个好方法。
支付减库存

如果等待用户支付了订单在减库存,第一感觉就是不会少卖。但是这是并发架构的大忌,因为在极限并发情况下,用户可能会创建很多订单。
当库存减为零的时候很多用户发现抢到的订单支付不了了,这也就是所谓的“超卖”。也不能避免并发操作数据库磁盘 IO。
预扣库存

从上边两种方案的考虑,我们可以得出结论:只要创建订单,就要频繁操作数据库 IO。
那么有没有一种不需要直接操作数据库 IO 的方案呢,这就是预扣库存。先扣除了库存,保证不超卖,然后异步生成用户订单,这样响应给用户的速度就会快很多;那么怎么保证不少卖呢?用户拿到了订单,不支付怎么办?
我们都知道现在订单都有有效期,比如说用户五分钟内不支付,订单就失效了,订单一旦失效,就会加入新的库存,这也是现在很多网上零售企业保证商品不少卖采用的方案。
订单的生成是异步的,一般都会放到 MQ、Kafka 这样的即时消费队列中处理,订单量比较少的情况下,生成订单非常快,用户几乎不用排队。
扣库存的艺术
从上面的分析可知,显然预扣库存的方案最合理。我们进一步分析扣库存的细节,这里还有很大的优化空间,库存存在哪里?怎样保证高并发下,正确的扣库存,还能快速的响应用户请求?
在单机低并发情况下,我们实现扣库存通常是这样的:
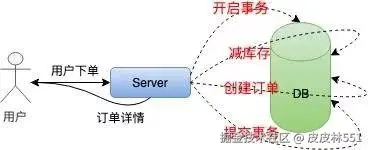
为了保证扣库存和生成订单的原子性,需要采用事务处理,然后取库存判断、减库存,最后提交事务,整个流程有很多 IO,对数据库的操作又是阻塞的。
这种方式根本不适合高并发的秒杀系统。接下来我们对单机扣库存的方案做优化:本地扣库存。
我们把一定的库存量分配到本地机器,直接在内存中减库存,然后按照之前的逻辑异步创建订单。
改进过之后的单机系统是这样的:
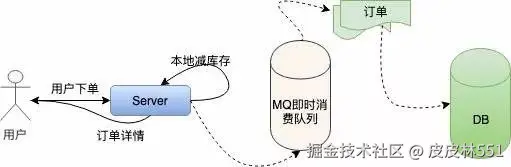
这样就避免了对数据库频繁的 IO 操作,只在内存中做运算,极大的提高了单机抗并发的能力。
但是百万的用户请求量单机是无论如何也抗不住的,虽然 Nginx 处理网络请求使用 Epoll 模型,c10k 的问题在业界早已得到了解决。
但是 Linux 系统下,一切资源皆文件,网络请求也是这样,大量的文件描述符会使操作系统瞬间失去响应。
上面我们提到了 Nginx 的加权均衡策略,我们不妨假设将 100W 的用户请求量平均均衡到 100 台服务器上,这样单机所承受的并发量就小了很多。
然后我们每台机器本地库存 100 张火车票,100 台服务器上的总库存还是 1 万,这样保证了库存订单不超卖,下面是我们描述的集群架构:
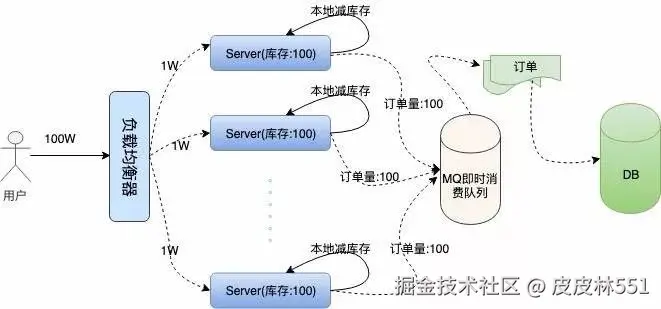 问题接踵而至,在高并发情况下,现在我们还无法保证系统的高可用,假如这 100 台服务器上有两三台机器因为扛不住并发的流量或者其他的原因宕机了。那么这些服务器上的订单就卖不出去了,这就造成了订单的少卖。
问题接踵而至,在高并发情况下,现在我们还无法保证系统的高可用,假如这 100 台服务器上有两三台机器因为扛不住并发的流量或者其他的原因宕机了。那么这些服务器上的订单就卖不出去了,这就造成了订单的少卖。
要解决这个问题,我们需要对总订单量做统一的管理,这就是接下来的容错方案。服务器不仅要在本地减库存,另外要远程统一减库存。
有了远程统一减库存的操作,我们就可以根据机器负载情况,为每台机器分配一些多余的“Buffer 库存”用来防止机器中有机器宕机的情况。
我们结合下面架构图具体分析一下:
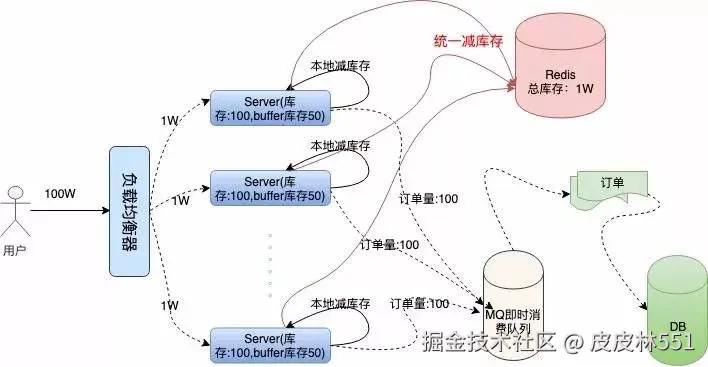
我们采用 Redis 存储统一库存,因为 Redis 的性能非常高,号称单机 QPS 能抗 10W 的并发。
在本地减库存以后,如果本地有订单,我们再去请求 Redis 远程减库存,本地减库存和远程减库存都成功了,才返回给用户抢票成功的提示,这样也能有效的保证订单不会超卖。
当机器中有机器宕机时,因为每个机器上有预留的 Buffer 余票,所以宕机机器上的余票依然能够在其他机器上得到弥补,保证了不少卖。
Buffer 余票设置多少合适呢,理论上 Buffer 设置的越多,系统容忍宕机的机器数量就越多,但是 Buffer 设置的太大也会对 Redis 造成一定的影响。
虽然 Redis 内存数据库抗并发能力非常高,请求依然会走一次网络 IO,其实抢票过程中对 Redis 的请求次数是本地库存和 Buffer 库存的总量。
因为当本地库存不足时,系统直接返回用户“已售罄”的信息提示,就不会再走统一扣库存的逻辑。
这在一定程度上也避免了巨大的网络请求量把 Redis 压跨,所以 Buffer 值设置多少,需要架构师对系统的负载能力做认真的考量。
代码演示
Go 语言原生为并发设计,我采用 Go 语言给大家演示一下单机抢票的具体流程。
初始化工作
Go 包中的 Init 函数先于 Main 函数执行,在这个阶段主要做一些准备性工作。
我们系统需要做的准备工作有:初始化本地库存、初始化远程 Redis 存储统一库存的 Hash 键值、初始化 Redis 连接池。
另外还需要初始化一个大小为 1 的 Int 类型 Chan,目的是实现分布式锁的功能。
也可以直接使用读写锁或者使用 Redis 等其他的方式避免资源竞争,但使用 Channel 更加高效,这就是 Go 语言的哲学:不要通过共享内存来通信,而要通过通信来共享内存。
Redis 库使用的是 Redigo,下面是代码实现:
...
//localSpike包结构体定义
package localSpike
type LocalSpike struct {
LocalInStock int64
LocalSalesVolume int64
}
...
//remoteSpike对hash结构的定义和redis连接池
package remoteSpike
//远程订单存储健值
type RemoteSpikeKeys struct {
SpikeOrderHashKey string //redis中秒杀订单hash结构key
TotalInventoryKey string //hash结构中总订单库存key
QuantityOfOrderKey string //hash结构中已有订单数量key
}
//初始化redis连接池
func NewPool() *redis.Pool {
return &redis.Pool{
MaxIdle: 10000,
MaxActive: 12000, // max number of connections
Dial: func() (redis.Conn, error) {
c, err := redis.Dial("tcp", ":6379")
if err != nil {
panic(err.Error())
}
return c, err
},
}
}
...
func init() {
localSpike = localSpike2.LocalSpike{
LocalInStock: 150,
LocalSalesVolume: 0,
}
remoteSpike = remoteSpike2.RemoteSpikeKeys{
SpikeOrderHashKey: "ticket_hash_key",
TotalInventoryKey: "ticket_total_nums",
QuantityOfOrderKey: "ticket_sold_nums",
}
redisPool = remoteSpike2.NewPool()
done = make(chanint, 1)
done <- 1
}
本地扣库存和统一扣库存
本地扣库存逻辑非常简单,用户请求过来,添加销量,然后对比销量是否大于本地库存,返回 Bool 值:
package localSpike
//本地扣库存,返回bool值
func (spike *LocalSpike) LocalDeductionStock() bool{
spike.LocalSalesVolume = spike.LocalSalesVolume + 1
return spike.LocalSalesVolume < spike.LocalInStock
}
注意这里对共享数据 LocalSalesVolume 的操作是要使用锁来实现的,但是因为本地扣库存和统一扣库存是一个原子性操作,所以在最上层使用 Channel 来实现,这块后边会讲。
统一扣库存操作 Redis,因为 Redis 是单线程的,而我们要实现从中取数据,写数据并计算一些列步骤,我们要配合 Lua 脚本打包命令,保证操作的原子性:
package remoteSpike
......
const LuaScript = `
local ticket_key = KEYS[1]
local ticket_total_key = ARGV[1]
local ticket_sold_key = ARGV[2]
local ticket_total_nums = tonumber(redis.call('HGET', ticket_key, ticket_total_key))
local ticket_sold_nums = tonumber(redis.call('HGET', ticket_key, ticket_sold_key))
-- 查看是否还有余票,增加订单数量,返回结果值
if(ticket_total_nums >= ticket_sold_nums) then
return redis.call('HINCRBY', ticket_key, ticket_sold_key, 1)
end
return0
`
//远端统一扣库存
func (RemoteSpikeKeys *RemoteSpikeKeys) RemoteDeductionStock(conn redis.Conn) bool {
lua := redis.NewScript(1, LuaScript)
result, err := redis.Int(lua.Do(conn, RemoteSpikeKeys.SpikeOrderHashKey, RemoteSpikeKeys.TotalInventoryKey, RemoteSpikeKeys.QuantityOfOrderKey))
if err != nil {
returnfalse
}
return result != 0
}
我们使用 Hash 结构存储总库存和总销量的信息,用户请求过来时,判断总销量是否大于库存,然后返回相关的 Bool 值。
在启动服务之前,我们需要初始化 Redis 的初始库存信息:
hmset ticket_hash_key "ticket_total_nums" 10000 "ticket_sold_nums" 0
响应用户信息
我们开启一个 HTTP 服务,监听在一个端口上:
package main
...
func main() {
http.HandleFunc("/buy/ticket", handleReq)
http.ListenAndServe(":3005", nil)
}
上面我们做完了所有的初始化工作,接下来 handleReq 的逻辑非常清晰,判断是否抢票成功,返回给用户信息就可以了。
package main
//处理请求函数,根据请求将响应结果信息写入日志
func handleReq(w http.ResponseWriter, r *http.Request) {
redisConn := redisPool.Get()
LogMsg := ""
<-done
//全局读写锁
if localSpike.LocalDeductionStock() && remoteSpike.RemoteDeductionStock(redisConn) {
util.RespJson(w, 1, "抢票成功", nil)
LogMsg = LogMsg + "result:1,localSales:" + strconv.FormatInt(localSpike.LocalSalesVolume, 10)
} else {
util.RespJson(w, -1, "已售罄", nil)
LogMsg = LogMsg + "result:0,localSales:" + strconv.FormatInt(localSpike.LocalSalesVolume, 10)
}
done <- 1
//将抢票状态写入到log中
writeLog(LogMsg, "./stat.log")
}
func writeLog(msg string, logPath string) {
fd, _ := os.OpenFile(logPath, os.O_RDWR|os.O_CREATE|os.O_APPEND, 0644)
defer fd.Close()
content := strings.Join([]string{msg, "\r\n"}, "")
buf := []byte(content)
fd.Write(buf)
}
前边提到我们扣库存时要考虑竞态条件,我们这里是使用 Channel 避免并发的读写,保证了请求的高效顺序执行。我们将接口的返回信息写入到了 ./stat.log 文件方便做压测统计。
单机服务压测
开启服务,我们使用 AB 压测工具进行测试:
ab -n 10000 -c 100 http://127.0.0.1:3005/buy/ticket
下面是我本地低配 Mac 的压测信息:
This is ApacheBench, Version 2.3 <$revision: 1826891="">
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 127.0.0.1 (be patient)
Completed 1000 requests
Completed 2000 requests
Completed 3000 requests
Completed 4000 requests
Completed 5000 requests
Completed 6000 requests
Completed 7000 requests
Completed 8000 requests
Completed 9000 requests
Completed 10000 requests
Finished 10000 requests
Server Software:
Server Hostname: 127.0.0.1
Server Port: 3005
Document Path: /buy/ticket
Document Length: 29 bytes
Concurrency Level: 100
Time taken for tests: 2.339 seconds
Complete requests: 10000
Failed requests: 0
Total transferred: 1370000 bytes
HTML transferred: 290000 bytes
Requests per second: 4275.96 [#/sec] (mean)
Time per request: 23.387 [ms] (mean)
Time per request: 0.234 [ms] (mean, across all concurrent requests)
Transfer rate: 572.08 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 8 14.7 6 223
Processing: 2 15 17.6 11 232
Waiting: 1 11 13.5 8 225
Total: 7 23 22.8 18 239
Percentage of the requests served within a certain time (ms)
50% 18
66% 24
75% 26
80% 28
90% 33
95% 39
98% 45
99% 54
100% 239 (longest request)
根据指标显示,我单机每秒就能处理 4000+ 的请求,正常服务器都是多核配置,处理 1W+ 的请求根本没有问题。
而且查看日志发现整个服务过程中,请求都很正常,流量均匀,Redis 也很正常:
//stat.log
...
result:1,localSales:145
result:1,localSales:146
result:1,localSales:147
result:1,localSales:148
result:1,localSales:149
result:1,localSales:150
result:0,localSales:151
result:0,localSales:152
result:0,localSales:153
result:0,localSales:154
result:0,localSales:156
...
总结回顾
总体来说,秒杀系统是非常复杂的。我们这里只是简单介绍模拟了一下单机如何优化到高性能,集群如何避免单点故障,保证订单不超卖、不少卖的一些策略
完整的订单系统还有订单进度的查看,每台服务器上都有一个任务,定时的从总库存同步余票和库存信息展示给用户,还有用户在订单有效期内不支付,释放订单,补充到库存等等。
我们实现了高并发抢票的核心逻辑,可以说系统设计的非常的巧妙,巧妙的避开了对 DB 数据库 IO 的操作。
对 Redis 网络 IO 的高并发请求,几乎所有的计算都是在内存中完成的,而且有效的保证了不超卖、不少卖,还能够容忍部分机器的宕机。
我觉得其中有两点特别值得学习总结:
①负载均衡,分而治之
通过负载均衡,将不同的流量划分到不同的机器上,每台机器处理好自己的请求,将自己的性能发挥到极致。
这样系统的整体也就能承受极高的并发了,就像工作的一个团队,每个人都将自己的价值发挥到了极致,团队成长自然是很大的。
②合理的使用并发和异步
自 Epoll 网络架构模型解决了 c10k 问题以来,异步越来越被服务端开发人员所接受,能够用异步来做的工作,就用异步来做,在功能拆解上能达到意想不到的效果。
这点在 Nginx、Node.JS、Redis 上都能体现,他们处理网络请求使用的 Epoll 模型,用实践告诉了我们单线程依然可以发挥强大的威力。
服务器已经进入了多核时代,Go 语言这种天生为并发而生的语言,完美的发挥了服务器多核优势,很多可以并发处理的任务都可以使用并发来解决,比如 Go 处理 HTTP 请求时每个请求都会在一个 Goroutine 中执行。
总之,怎样合理的压榨 CPU,让其发挥出应有的价值,是我们一直需要探索学习的方向。
来源:juejin.cn/post/7541770924800163875
如何优雅地实现每 5 秒轮询请求?
在做实时监控系统时,比如服务器状态面板、订单处理中心或物联网设备看板,每隔 5 秒自动拉取最新数据是再常见不过的需求了。
但你有没有遇到过这些问题?
- 页面切到后台还在疯狂发请求,浪费资源
- 上一次请求还没回来,下一次又发了,接口雪崩
- 用户切换标签页回来,发现数据“卡”在旧状态
- 页面销毁了定时器还在跑,内存泄漏
今天我就以一个运维监控平台的真实场景为例,带你从“能用”做到“好用”。
一、问题场景:设备在线状态轮询
假设我们要做一个 IDC 机房设备监控页,需求如下:
- 每 5 秒查询一次所有服务器的在线状态
- 接口
/api/servers/status响应较慢(平均 1.2s) - 用户可能切换到其他标签页处理邮件
- 页面关闭时必须停止轮询
如果直接写个 setInterval,很容易踩坑。我们一步步来优化。
二、第一版:基础轮询(能跑,但有隐患)
import { ref, onMounted, onUnmounted } from 'vue'
const servers = ref([])
let timer = null
onMounted(() => {
const poll = () => {
fetch('/api/servers/status')
.then(res => res.json())
.then(data => {
servers.value = data
})
}
poll() // 首次立即执行
timer = setInterval(poll, 5000) // 每5秒轮询
})
onUnmounted(() => {
clearInterval(timer) // 🔍 清理定时器
})
✅ 实现了基本功能
❌ 但存在三个致命问题:
- 接口未完成就发起下一次请求 → 可能雪崩
- 页面不可见时仍在轮询 → 浪费带宽和电量
- 异常未处理 → 网络错误可能导致后续不再轮询
三、第二版:可控轮询 + 可见性优化
我们改用“请求完成后再延迟 5 秒”的策略,避免并发:
import { ref, onMounted, onUnmounted } from 'vue'
const servers = ref([])
let abortController = null // 用于取消请求
const poll = async () => {
try {
// 支持取消上一次请求
abortController?.abort()
abortController = new AbortController()
const res = await fetch('/api/servers/status', {
signal: abortController.signal
})
if (!res.ok) throw new Error('Network error')
const data = await res.json()
servers.value = data
} catch (err) {
if (err.name !== 'AbortError') {
console.warn('轮询失败,将重试...', err)
}
} finally {
// 🔍 请求结束后再等5秒发起下一次
setTimeout(poll, 5000)
}
}
onMounted(() => {
poll() // 启动轮询
})
onUnmounted(() => {
abortController?.abort()
})
🔍 关键点解析:
finally中setTimeout实现“串行轮询”,避免并发AbortController可在组件卸载时主动取消进行中的请求- 错误被捕获后仍继续轮询,保证稳定性
四、第三版:智能节流 —— 页面可见性控制
现在解决“页面不可见时是否轮询”的问题。我们引入 visibilitychange 事件:
let isVisible = true
const handleVisibilityChange = () => {
isVisible = !document.hidden
console.log('页面可见性:', isVisible ? '可见' : '隐藏')
}
onMounted(() => {
// 监听页面可见性
document.addEventListener('visibilitychange', handleVisibilityChange)
const poll = async () => {
try {
abortController?.abort()
abortController = new AbortController()
const res = await fetch('/api/servers/status', {
signal: abortController.signal
})
const data = await res.json()
servers.value = data
} catch (err) {
if (err.name !== 'AbortError') {
console.warn('轮询失败:', err)
}
} finally {
// 🔍 只有页面可见时才继续轮询
if (isVisible) {
setTimeout(poll, 5000)
} else {
// 页面隐藏,等待恢复后再请求
document.addEventListener('visibilitychange', function waitVisible() {
if (!document.hidden) {
document.removeEventListener('visibilitychange', waitVisible)
setTimeout(poll, 1000) // 恢复后1秒再查
}
}, { once: true })
}
}
}
poll()
})
🔍 这里做了两层控制:
- 页面隐藏时,不再自动发起下一轮请求
- 页面重新可见时,延迟 1 秒触发一次查询,避免瞬间唤醒过多资源
五、封装成可复用的轮询 Hook
把这套逻辑抽象成通用 usePolling Hook:
// composables/usePolling.js
import { ref } from 'vue'
export function usePolling(fetchFn, interval = 5000) {
const data = ref(null)
const loading = ref(false)
const error = ref(null)
let abortController = null
let isVisible = true
const poll = async () => {
if (loading.value) return // 防止重复执行
loading.value = true
error.value = null
try {
abortController?.abort()
abortController = new AbortController()
const result = await fetchFn(abortController.signal)
data.value = result
} catch (err) {
if (err.name !== 'AbortError') {
error.value = err
console.warn('Polling error:', err)
}
} finally {
loading.value = false
// 🔍 根据可见性决定是否继续
if (isVisible) {
setTimeout(poll, interval)
}
}
}
const start = () => {
// 移除旧监听避免重复
document.removeEventListener('visibilitychange', handleVisibility)
document.addEventListener('visibilitychange', handleVisibility)
poll()
}
const stop = () => {
abortController?.abort()
document.removeEventListener('visibilitychange', handleVisibility)
}
const handleVisibility = () => {
isVisible = !document.hidden
if (isVisible) {
setTimeout(poll, 1000)
}
}
return { data, loading, error, start, stop }
}
使用方式极其简洁:
<script setup>
import { usePolling } from '@/composables/usePolling'
const fetchStatus = async (signal) => {
const res = await fetch('/api/servers/status', { signal })
return res.json()
}
const { data, loading } = usePolling(fetchStatus, 5000)
// 自动在 onMounted 启动
</script>
<template>
<div v-if="loading">加载中...</div>
<ul v-else>
<li v-for="server in data" :key="server.id">
{{ server.name }} - {{ server.status }}
</li>
</ul>
</template>
六、对比主流轮询方案
| 方案 | 实现方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
setInterval | 固定间隔触发 | 简单直观 | 不考虑响应时间,易并发 | 快速原型 |
| 串行 setTimeout | 请求完再延时 | 避免并发,稳定 | 周期不严格 | 多数业务场景 ✅ |
| WebSocket | 服务端推送 | 实时性最高 | 成本高,兼容性差 | 股票行情、聊天 |
| Server-Sent Events | 单向流式推送 | 轻量级实时 | 不支持 IE | 日志流、通知 |
| 智能轮询(本方案) | 可见性+串行控制 | 节能、稳定、用户体验好 | 略复杂 | 生产环境推荐 ✅ |
七、举一反三:三个变体场景实现思路
- 动态轮询频率
如网络异常时降频至 30s 一次,正常后恢复 5s。可在finally中根据error.value动态调整setTimeout时间。 - 多接口协同轮询
多个 API 轮询但希望错峰发送。可用Promise.all组合请求,在finally统一控制下一轮时机,避免瞬间并发。 - 离线重连机制
当检测到网络断开(fetch 超时),改为指数退避重试(1s → 2s → 4s → 8s),恢复后再切回 5s 正常轮询。
小结
实现“每 5 秒轮询”看似简单,但要做到稳定、节能、用户体验好,需要考虑:
- ✅ 使用 串行 setTimeout 替代 setInterval,避免请求堆积
- ✅ 利用 AbortController 主动取消无用请求
- ✅ 结合 页面可见性 API 节省资源
- ✅ 封装为 可复用 Hook,提升工程化水平
记住一句话:好的轮询,是“聪明地少做事”,而不是“拼命做事情”。
下次当你接到“每隔 X 秒刷新”的需求时,别急着写 setInterval,先问问自己:用户真的需要这么频繁吗?能不能用 WebSocket?页面看不见的时候还要刷吗?
来源:juejin.cn/post/7530948113120624675
妙啊!Js的对象属性居然还能这么写
Hi,我是石小石~
静态属性获取的缺陷
前段时间在做项目国际化时,遇到一个比较隐蔽的问题:
我们在定义枚举常量时,直接调用了 i18n 的翻译方法:
export const OverdueStatus: any = {
ABOUT_TO_OVERDUE: {
value: 'ABOUT_TO_OVERDUE',
name: i18n.global.t('common.about_to_overdue'),
color: '#ad0000',
bgColor: '#ffe1e1'
},
}
结果发现翻译始终不生效。排查后才发现原因很简单 —— OverdueStatus 对象的初始化早于 i18n 实例的生成,因此取到的翻译结果是空的。
虽然最后我通过封装自定义 Vue 插件的方式彻底解决了问题,但排查过程中其实还有一个可选思路。
当时我想到的最直接办法是:让 name 在被访问时再去执行 i18n.global.t,而不是在对象定义时就执行。比如把 OverdueStatus 定义为函数:
export const OverdueStatus = () => ({
ABOUT_TO_OVERDUE: {
value: 'ABOUT_TO_OVERDUE',
name: i18n.global.t('common.about_to_overdue'),
color: '#ad0000',
bgColor: '#ffe1e1'
},
})
这样在调用时:
OverdueStatus().ABOUT_TO_OVERDUE.name
就能确保翻译逻辑在 i18n 实例创建完成之后再执行,从而避免初始化顺序的问题。不过,这种方式也有明显的缺点:所有类似的枚举都要改成函数,调用时也得多加一层执行,整体代码会变得不够简洁。
如何优雅地实现“动态获取属性”?
上面提到的“把枚举改成函数返回”虽然能解决问题,但在实际业务中显得有些笨拙。有没有更优雅的方式,让属性本身就支持 动态计算 呢?
其实,JavaScript 本身就为我们提供了解决方案 —— getter。
举个例子,我们可以把枚举对象改写成这样:
export const OverdueStatus: any = {
ABOUT_TO_OVERDUE: {
value: 'ABOUT_TO_OVERDUE',
get name() {
return i18n.global.t('common.about_to_overdue')
},
color: '#ad0000',
bgColor: '#ffe1e1'
},
}
这样一来,在访问 name 属性时,才会真正执行 i18n.global.t,确保翻译逻辑在 i18n 实例创建完成后才生效,完美解决问题。
访问器属性的原理
在 JavaScript 规范里,get 定义的属性叫 访问器属性,区别于普通的 数据属性 (Data Property) 。简单来说getter 其实就是对象属性的一种特殊定义方式。
当我们写:
const obj = {
get foo() {
return "bar"
}
}
等价于用 Object.defineProperty:
const obj = {}
Object.defineProperty(obj, "foo", {
get: function() {
return "bar"
}
})
所以访问 obj.foo 时,其实是触发了这个 get 函数,而不是读取一个固定的值。
类比Vue的computed
在 Vue 里,我们经常写 computed 计算属性,其实就是 getter 的思想。
import { computed, ref } from "vue"
const firstName = ref("Tom")
const lastName = ref("Hanks")
const fullName = computed(() => `${firstName.value} ${lastName.value}`)
computed 内部其实就是包装了一个 getter 函数。
注意点
- getter 不能跟属性值同时存在:
const obj = {
get name() { return "石小石" },
name: "石小石Orz" // 会报错
}
- getter 是只读的,如果你想支持赋值,需要配合
setter:
const obj = {
_age: 18,
get age() { return this._age },
set age(val) { this._age = val }
}
obj.age = 20
console.log(obj.age) // 20
其他实用场景
延迟计算
有些值计算比较复杂,但只有在真正使用时才去算,可以提升性能
const user = {
firstName: "石",
lastName: "小石",
get fullName() {
// 类比一个计算,实现开发中,一个很复杂的计算才使用此方法
console.log("计算了一次 fullName")
return `${this.firstName} ${this.lastName}`
}
}
console.log(user.fullName) // "石小石"
这种写法让 API 看起来更自然,不需要调用函数 user.getFullName(),而是 user.fullName。
数据封装与保护
有些属性可能并不是一个固定字段,而是基于内部状态计算出来的:
const cart = {
items: [100, 200, 300],
get total() {
return this.items.reduce((sum, price) => sum + price, 0)
}
}
console.log(cart.total) // 600
这样 cart.total 永远是最新的,不用担心手动维护,你也不用写一个函数专门去更新这个值。
来源:juejin.cn/post/7543300730116325403
分库分表正在被淘汰
前言
“分库分表这种架构模式会逐步的被淘汰!” 不知道在哪儿看到的观点
如果我们现在在搭建新的业务架构,如果说你们未来的业务数据量会达到千万 或者上亿的级别 还在一股脑的使用分库分表的架构,那么你们的技术负责人真的就应该提前退休了🙈
如果对未来的业务非常有信心,单表的数据量能达到千万上亿的级别,请使用NewSQL 数据库,那么NewSQL 这么牛,分布库分表还有意义吗?
今天虽然写的是一篇博客,但是更多的是抱着和大家讨论的心态来的,所以大家目前有深度参与分库分表,或者NewSQL 的都可以在评论区讨论!
什么是NewSQL
NewSQL 是21世纪10年代初出现的一个术语,用来描述一类新型的关系型数据库管理系统(RDBMS)。它们的共同目标是:在保持传统关系型数据库(如Oracle、MySQL)的ACID事务和SQL模型优势的同时,获得与NoSQL系统类似的、弹性的水平扩展能力
NewSQL 的核心理念就是 将“分库分表”的复杂性从应用层下沉到数据库内核层,对上层应用呈现为一个单一的数据库入口,解决现在 分库分表的问题;
分库分表的问题
分库分表之后,会带来非常多的问题;比如需要跨库联查、跨库更新数据如何保证事务一致性等问题,下面就来详细看看分库分表都有那些问题
- 数据库的操作变得复杂
- 跨库 JOIN 几乎不可行:原本简单的多表关联查询,因为表被分散到不同库甚至不同机器上,变得异常困难。通常需要拆成多次查询,在应用层进行数据组装,代码复杂且性能低下。
- 聚合查询效率低下:
COUNT(),SUM(),GR0UP BY,ORDER BY等操作无法在数据库层面直接完成。需要在每个分片上执行,然后再进行合并。 - 分页问题:
LIMIT 20, 10这样的分页查询会变得非常诡异。你需要从所有分片中获取前30条数据,然后在应用层排序后取第20-30条。页码越大,性能越差。
- 设计上需要注意的问题
- 分片键(Sharding Key)的选择:如果前期没有设计好,后期数据倾斜比较严重
- 全局唯一ID需要提前统一设计,规范下来
- 分布式事务问题,需要考虑使用哪种方式去实现(XA协议,柔性事务)
选择TiDB还是采用mysql 分库分表的设计
数据量非常大,需要满足OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 且预算充足(分布式数据库的成本也是非常高的这一点非常的重要),并且是新业务新架构落地 优先推荐使用TiDB。
当然实际上选择肯定是需要多方面考虑的,大家有什么观点都可以在评论区讨论。
可以看看一个资深开发,深度参与TiDB项目,他对TiDB的一些看法:
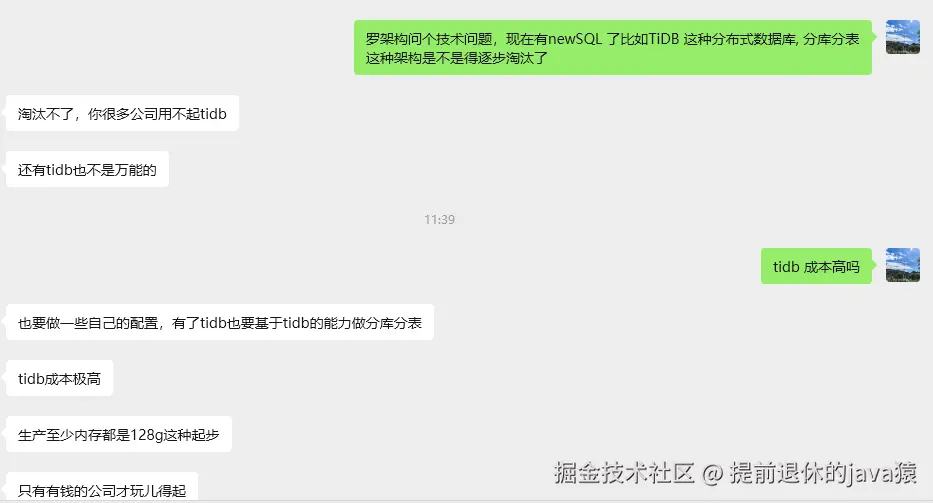


1 什么是TiDB?
TiDB是PingCAP公司研发的开源分布式关系型数据库,采用存储计算分离架构,支持混合事务分析处理(HTAP) 。它与MySQL 5.7协议兼容,并支持MySQL生态,这意味着使用MySQL的应用程序可以几乎无需修改代码就能迁移到TiDB。
🚀目标是为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解决方案。TiDB 适合高可用、强一致要求较高、数据规模较大等各种应用场景。
官方文档:docs.pingcap.com/zh/tidb/dev…
TiDB五大核心特性
TiDB之所以在分布式数据库领域脱颖而出,得益于其五大核心特性:
- 一键水平扩容或缩容:得益于存储计算分离的架构设计,可按需对计算、存储分别进行在线扩容或缩容,整个过程对应用透明。
- 金融级高可用:数据采用多副本存储,通过Multi-Raft协议同步事务日志,只有多数派写入成功事务才能提交,确保数据强一致性。
- 实时HTAP:提供行存储引擎TiKV和列存储引擎TiFlash,两者之间的数据保持强一致,解决了HTAP资源隔离问题。
- 云原生分布式数据库:通过TiDB Operator可在公有云、私有云、混合云中实现部署工具化、自动化。
- 兼容MySQL 5.7协议和生态:从MySQL迁移到TiDB无需或只需少量代码修改,极大降低了迁移成本。
2 TiDB与MySQL的核心差异
虽然TiDB兼容MySQL协议,但它们在架构设计和适用场景上存在根本差异。以下是它们的详细对比:
2.1 架构差异
表1:TiDB与MySQL架构对比
| 特性 | MySQL | TiDB |
|---|---|---|
| 架构模式 | 集中式架构 | 分布式架构 |
| 扩展性 | 垂直扩展,主从复制 | 水平扩展,存储计算分离 |
| 数据分片 | 需要分库分表 | 自动分片,无需sharding key |
| 高可用机制 | 主从复制、MGR | Multi-Raft协议,多副本 |
| 存储引擎 | InnoDB、MyISAM等 | TiKV(行存)、TiFlash(列存) |
2.2 性能表现对比
性能方面,TiDB与MySQL各有优势,主要取决于数据量和查询类型:
- 小数据量简单查询:在数据量百万级以下的情况下,MySQL的写入性能和点查点写通常优于TiDB。因为TiDB的分布式架构在少量数据时无法充分发挥优势,却要承担分布式事务的开销。
- 大数据量复杂查询:当数据量达到千万级以上,TiDB的性能优势开始显现。一张千万级别表关联查询,MySQL可能需要20秒,而TiDB+TiKV只需约5.57秒,使用TiFlash甚至可缩短到0.5秒。
- 高并发场景:MySQL性能随着并发增加会达到瓶颈然后下降,而TiDB性能基本随并发增加呈线性提升,节点资源不足时还可通过动态扩容提升性能。
2.3 扩展性与高可用对比
MySQL的主要扩展方式是一主多从架构,主节点无法横向扩展(除非接受分库分表),从节点扩容需要应用支持读写分离。而TiDB的存储和计算节点都可以独立扩容,支持最大512节点,集群容量可达PB级别。
高可用方面,MySQL使用增强半同步和MGR方案,但复制效率较低,主节点故障会影响业务处理[]。TiDB则通过Raft协议将数据打散分布,单机故障对集群影响小,能保证RTO(恢复时间目标)不超过30秒且RPO(恢复点目标)为0,真正实现金融级高可用。
2.4 SQL功能及兼容性
虽然TiDB高度兼容MySQL 5.7协议和生态,但仍有一些重要差异需要注意:
不支持的功能包括:
- 存储过程与函数
- 触发器
- 事件
- 自定义函数
- 全文索引(计划中)
- 空间类型函数和索引
有差异的功能包括:
- 自增ID的行为(TiDB推荐使用AUTO_RANDOM避免热点问题)
- 查询计划的解释结果
- 在线DDL能力(TiDB更强,不锁表支持DML并行操作)
3 如何选择:TiDB还是MySQL?
选择数据库时,应基于实际业务需求和技术要求做出决策。以下是具体的选型建议:
3.1 选择TiDB的场景
TiDB在以下场景中表现卓越:
- 数据量大且增长迅速的OLTP场景:当单机MySQL容量或性能遇到瓶颈,且数据量达到TB级别时,TiDB的水平扩展能力能有效解决问题。
例如,当业务数据量预计将超过TB级别,或并发连接数超过MySQL合理处理范围时。 - 实时HTAP需求:需要同时进行在线事务处理和实时数据分析的场景。
传统方案需要OLTP数据库+OLAP数据库+ETL工具,TiDB的HTAP能力可简化架构,降低成本和维护复杂度。 - 金融级高可用要求:对系统可用性和数据一致性要求极高的金融行业场景。
TiDB的多副本和自动故障转移机制能确保业务连续性和数据安全。 - 多业务融合平台:需要将多个业务数据库整合的统一平台场景。
TiDB的资源管控能力可以按照RU(Request Unit)大小控制资源总量,实现多业务资源隔离和错峰利用。 - 频繁的DDL操作需求:需要频繁进行表结构变更的业务。
TiDB的在线DDL能力在业务高峰期也能平稳执行,对大表结构变更尤其有效。
3.2 选择MySQL的场景
MySQL在以下情况下仍是更合适的选择:
- 中小规模数据量:数据量在百万级以下,且未来增长可预测。
在这种情况下,MySQL的性能可能更优,且总拥有成本更低。 - 简单读写操作为主:业务以点查点写为主,没有复杂的联表查询或分析需求。
- 需要特定MySQL功能:业务依赖存储过程、触发器、全文索引等TiDB不支持的功能。
- 资源受限环境:硬件资源有限且没有分布式数据库管理经验的团队。
MySQL的运维管理相对简单,学习曲线较平缓。
3.3 决策参考框架
为了更直观地帮助决策,可以参考以下决策表:
| 考虑因素 | 倾向TiDB | 倾向MySQL |
|---|---|---|
| 数据规模 | TB级别或预计快速增长 | GB级别,增长稳定 |
| 并发需求 | 高并发(数千连接以上) | 低至中等并发 |
| 查询类型 | 复杂SQL,多表关联 | 简单点查点写 |
| 可用性要求 | 金融级(RTO<30s,RPO=0) | 常规可用性要求 |
| 架构演进 | 微服务、云原生、HTAP | 传统单体应用 |
| 运维能力 | 有分布式系统管理经验 | 传统DBA团队 |
4 迁移注意事项
如果决定从MySQL迁移到TiDB,需要注意以下关键点:
- 功能兼容性验证:检查应用中是否使用了TiDB不支持的MySQL功能,如存储过程、触发器等。
- 自增ID处理:将AUTO_INCREMENT改为AUTO_RANDOM以避免写热点问题。
- 事务大小控制:注意TiDB对单个事务的大小限制(早期版本限制较严,4.0版本已提升到10GB)。
- 迁移工具选择:使用TiDB官方工具如DM(Data Migration)进行数据迁移和同步。
- 性能测试:迁移前务必进行充分的性能测试,特别是针对业务关键查询的测试。
5 总结
TiDB和MySQL是适用于不同场景的数据库解决方案,没有绝对的优劣之分。MySQL是优秀的单机数据库,适用于数据量小、架构简单的场景;数据量大了之后需要做分库分表。而TiDB作为分布式数据库,专注于解决大数据量、高并发、高可用性需求下的数据库瓶颈问题,但是成本也是非常的高
本人没有使用过NewSQL ,还望各位大佬批评指正
来源:juejin.cn/post/7561245020045918249
vue也支持声明式UI了,向移动端kotlin,swift看齐,抛弃html,pug升级版,进来看看新语法吧
众所周知,新生代的ui框架(如:kotlin,swift,flutter,鸿蒙)都已经抛弃了XML这类的结构化数据标记语言改为使用声明式UI
只有web端还没有支持此类ui语法,此次我开发的ovsjs为前端也带来了此类声明式UI语法的支持,语法如下
项目地址
语法插件地址:
marketplace.visualstudio.com/items?itemN…
新语法如下:
我认为更强的地方是我的新设计除了为前端带来了声明式UI,还支持了 #{ } 不渲染代码块的设计,支持在 声明式UI中编写代码,这样UI和逻辑之间的距离更近,维护更方便,抽象组件也更容易
对比kotlin,swift,flutter,鸿蒙语法如下:
kotlin的语法
import kotlinx.browser.*
import kotlinx.html.*
import kotlinx.html.dom.*
fun main() {
document.body!!.append.div {
h1 {
+"Welcome to Kotlin/JS!"
}
p {
+"Fancy joining this year's "
a("https://kotlinconf.com/") {
+"KotlinConf"
}
+"?"
}
}
}
swiftUI的语法
import SwiftUI
struct ContentView: View {
var body: some View {
VStack(spacing: 16) {
Text("Hello SwiftUI")
.font(.largeTitle)
.fontWeight(.bold)
Text("Welcome to SwiftUI world")
Button("Click Me") {
print("Button clicked")
}
}
.padding()
}
}
flutter的语法
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
body: Center(
child: Column(
mainAxisSize: MainAxisSize.min,
children: [
const Text(
"Hello Flutter",
style: TextStyle(fontSize: 28, fontWeight: FontWeight.bold),
),
const SizedBox(height: 12),
const Text("Welcome to Flutter world"),
const SizedBox(height: 16),
ElevatedButton(
onPressed: () {
print("Button clicked");
},
child: const Text("Click Me"),
)
],
),
),
),
);
}
}
鸿蒙 arkts
@Entry
@Component
struct Index {
@State message: string = 'Hello ArkUI'
build() {
Column() {
Text(this.message)
.fontSize(28)
.fontWeight(FontWeight.Bold)
Text('Welcome to HarmonyOS')
.margin({ top: 12 })
Button('Click Me')
.margin({ top: 16 })
.onClick(() => {
console.log('Button clicked')
})
}
.padding(20)
}
}
原理实现
简述一下实现原理,就是通过parser支持了新语法,然后将新语法转义为 iife包裹的vue的h函数
为什么要iife包裹
因为要支持不渲染代码块
ovs图中的代码对应的编译后的代码是这样的
import {defineOvsComponent} from "/@fs/D:/project/qkyproject/test-volar/ovs/ovs-runtime/src/index.ts";
import {$OvsHtmlTag} from "/@fs/D:/project/qkyproject/test-volar/ovs/ovs-runtime/src/index.ts";
import {ref} from "/node_modules/.vite/deps/vue.js?v=76ca4127";
export default defineOvsComponent(props => {
const msg = "You did it!";
let count = ref(0);
const timer = setInterval(() => {
count.value = count.value + 1;
},1000);
return $OvsHtmlTag.div({class:'greetings',onClick(){
count.value = 0;
}},[
$OvsHtmlTag.h1({class:'green'},[msg]),
count,
$OvsHtmlTag.h3({},[
"You've successfully created a project with ",
$OvsHtmlTag.a({href:'https://vite.dev/',target:'_blank',rel:'noopener'},['Vite']),
' + ',
$OvsHtmlTag.a({href:'https://vuejs.org/',target:'_blank',rel:'noopener'},['Vue 3']),
' + ',
$OvsHtmlTag.a({href:'https://github.com/alamhubb/ovsjs',target:'_blank',rel:'noopener'},['OVS']),
'.'
])
]);
});
parser是我自己写的,抄了 chevortain 的设计,写了个subhuti,支持定义peg语法
slimeparser,支持es2025语法的parser,基于subhuti,声明es2025语法就行
然后就是ovs继承slimeparser,添加了ovs的语法支持,并且在ast生成的时候将代码转为vue的渲染函数,运行时就是运行的vue的渲染函数的代码,所以完美支持vue的生态
感兴趣的可以试试,入门教程
由于本人能力有先,文中存在错误不足之处,请大家指正,有对新语法感兴趣的欢迎留言和我交流
来源:juejin.cn/post/7580287383788585003
让用户愿意等待的秘密:实时图片预览
你有没有经历过这样的场景?点击“上传头像”,选了一张照片,页面却毫无反应——没有提示,没有图像,只有一个静默的按钮。你开始怀疑:是没选上?网速慢?还是系统出错了?于是你犹豫要不要再点一次,甚至直接关掉页面。
而如果在你选择文件的瞬间,一张清晰的缩略图立刻出现在眼前,哪怕后端还在处理,你也会安心地等待下去。
不是用户没耐心,而是他们需要一点“确定性”来支撑等待的理由。
图片预览,正是那个微小却关键的信号:你的操作已被接收,一切正在按预期进行。
得到程序正在运行的信号之后用户才会有等待的欲望。
今天,我们就来亲手实现一个图片预览功能。
先思考:要让一张用户选中的本地图片显示在网页上,我们到底需要做些什么?
第一步:我们要显示图片,那肯定得有个 <img> 标签吧?
没错。想在页面上看到图片,最直接的方式就是用 <img :src="xxx" />。但问题来了:用户刚从电脑里选了一张照片,这张照片还在他本地硬盘上,还没传到服务器,也没有公开 URL。那 src 该填什么?
这时候你可能会想:“能不能把这张本地文件直接塞进 src?”
答案是:不能直接塞 File 对象,但——我们可以把它“变成”一个 URL。
第二步:用户选了图,我们怎么拿到它?
通常我们会用 <input type="file" accept="image/*"> 让用户选择图片。在 Vue 中,为了能“拿到”这个 input 元素本身(而不仅仅是它的值),我们会用到 ref。
<input
type="file"
ref="uploadImage"
accept="image/*"
@change="updateImageData"
/>
这里,ref="uploadImage" 就像给这个 input 贴了个标签。之后在 script 里,我们就能通过 uploadImage.value 拿到它的真实 DOM 引用。
于是,在 updateImageData 函数里,我们可以这样取到用户选中的文件:
const input = uploadImage.value;
const file = input.files[0]; // 用户选的第一张图
注意:不是 input.file,而是 input.files —— 这是一个常见的笔误,也是很多初学者卡住的地方。
第三步:有了 File 对象,怎么变成 <img> 能识别的 src?
现在我们手里有一个 File 对象,但它不能直接赋给 img.src。我们需要把它转成一种浏览器能直接渲染的格式。
这时候,FileReader 就登场了。
const reader = new FileReader();
reader.readAsDataURL(file);
readAsDataURL 会把文件内容读取为一个 Data URL,格式类似:
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA...
这串字符串可以直接作为 <img> 的 src!是不是很巧妙?
那什么时候能拿到这个结果呢?FileReader 是异步的,所以我们监听它的 onloadend 事件:
reader.onloadend = (e) => {
imgPreview.value = e.target.result; // 这就是 Data URL
}
而我们的模板中早已准备好了一个 <img>:
<img :src="imgPreview" alt="" v-if="imgPreview" />
当 imgPreview 有值时,图片就自动显示出来了!
完整逻辑串起来
把这些碎片拼在一起,整个流程就清晰了:
- 用户点击 input 选择图片;
@change触发updateImageData;- 通过
ref拿到 input,取出files[0]; - 用
FileReader读取为 Data URL; - 把结果存到响应式变量
imgPreview; - Vue 自动更新
<img :src="imgPreview">,图片就出来了。
这整个过程完全在前端完成,不需要上传到服务器,也不依赖任何第三方库——只用了浏览器原生 API 和 Vue 的响应式系统。
最后:完整实例
在vue中实现图片预览的完整代码及效果
来源:juejin.cn/post/7585534343562608690
Arco Design 停摆!字节跳动 UI 库凉了?
1. 引言:设计系统的“寒武纪大爆发”与 Arco 的陨落
在 2019 年至 2021 年间,中国前端开发领域经历了一场前所未有的“设计系统”爆发期。伴随着企业级 SaaS 市场的崛起和中后台业务的复杂度攀升,各大互联网巨头纷纷推出了自研的 UI 组件库。这不仅是技术实力的展示,更是企业工程化标准的话语权争夺。在这一背景下,字节跳动推出了 Arco Design,这是一套旨在挑战 Ant Design 霸主地位的“双栈”(React & Vue)企业级设计系统。
Arco Design 在发布之初,凭借其现代化的视觉语言、对 TypeScript 的原生支持以及极具创新性的“Design Lab”设计令牌(Design Token)管理系统,迅速吸引了大量开发者的关注。它被定位为不仅仅是一个组件库,而是一套涵盖设计、开发、工具链的完整解决方案。然而,就在其社区声量达到顶峰后的短短两年内,这一曾被视为“下一代标准”的项目却陷入了令人费解的沉寂。
截至 2025 年末,GitHub 上的 Issue 堆积如山,关键的基础设施服务(如 IconBox 图标平台)频繁宕机,官方团队的维护活动几乎归零。对于数以万计采用了 Arco Design 的企业和独立开发者而言,这无疑是一场技术选型的灾难。
本文将深入剖析 Arco Design 从辉煌到停摆的全过程。我们将剥开代码的表层,深入字节跳动的组织架构变革、内部团队的博弈(赛马机制)、以及中国互联网大厂特有的“KPI 开源”文化,为您还原整件事情的全貌。
2. 溯源:Arco Design 的诞生背景与技术野心
要理解 Arco Design 为何走向衰败,首先必须理解它诞生时的宏大野心及其背后的组织推手。Arco 并不仅仅是一个简单的 UI 库,它是字节跳动为了解决特定业务线极其复杂的后台需求而孵化的产物。
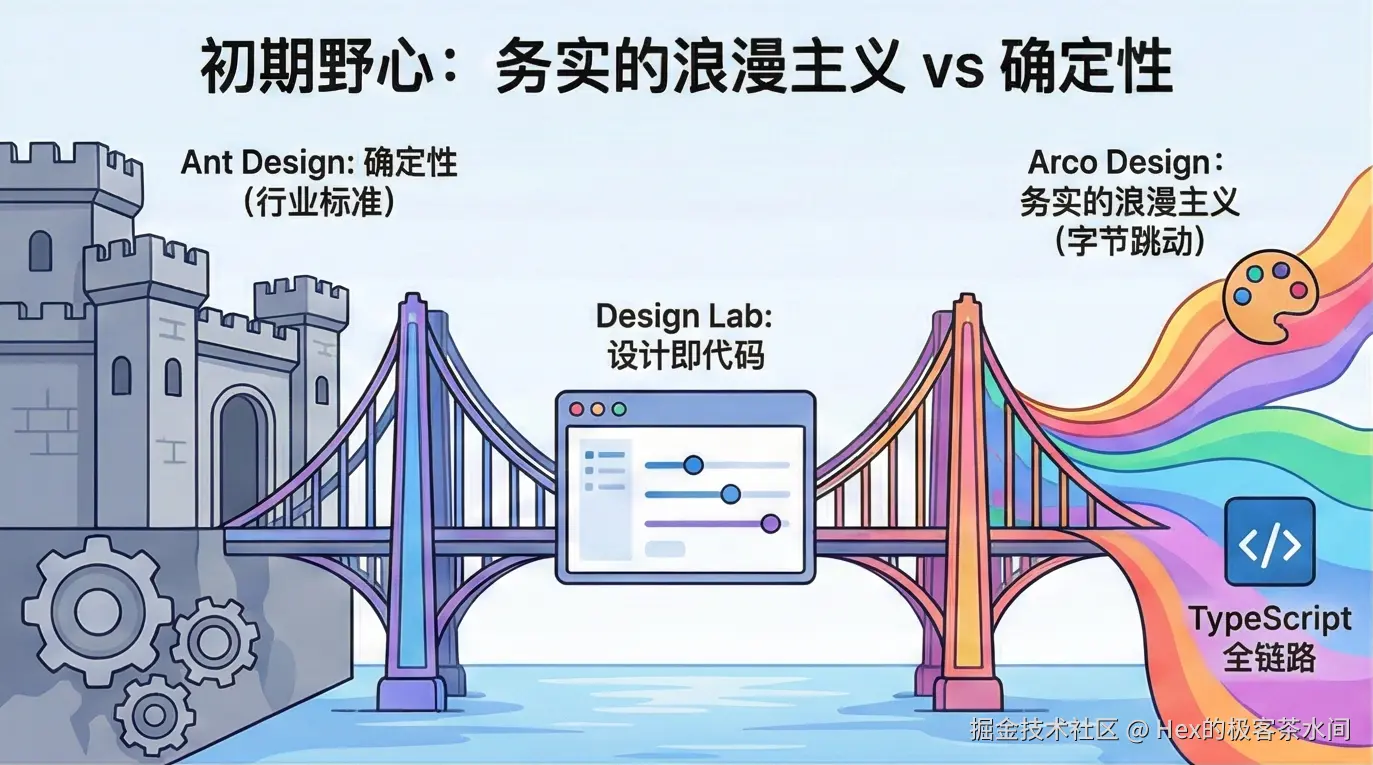
2.1 “务实的浪漫主义”:差异化的产品定位
Arco Design 在推出时,鲜明地提出了“务实的浪漫主义”这一设计哲学。这一口号的提出,实际上是为了在市场上与阿里巴巴的 Ant Design 进行差异化竞争。
- Ant Design 的困境:作为行业标准,Ant Design 以“确定性”著称,其风格克制、理性,甚至略显单调。虽然极其适合金融和后台管理系统,但在需要更强品牌表达力和 C 端体验感的场景下显得力不从心。
- Arco 的切入点:字节跳动的产品基因(如抖音、TikTok)强调视觉冲击力和用户体验的流畅性。Arco 试图在中后台系统中注入这种基因,主张在解决业务问题(务实)的同时,允许设计师发挥更多的想象力(浪漫)。
这种定位在技术层面体现为对 主题定制(Theming) 的极致追求。Arco Design 并没有像传统库那样仅仅提供几个 Less 变量,而是构建了一个庞大的“Design Lab”平台,允许用户在网页端通过可视化界面细粒度地调整成千上万个 Design Token,并一键生成代码。这种“设计即代码”的早期尝试,是 Arco 最核心的竞争力之一。
2.2 组织架构:GIP UED 与架构前端的联姻
Arco Design 的官方介绍中明确指出,该系统是由 字节跳动 GIP UED 团队 和 架构前端团队(Infrastructure FrontEnd Team) 联合推出的。这一血统注定了它的命运与“GIP”这个业务单元的兴衰紧密绑定。
2.2.1 解密 GIP:通用信息平台 (General Information Platform)
GIP 全称为 General Information Platform(通用信息平台)。这是字节跳动早期的核心业务支柱,主要包含以下以“图文与中长视频”为核心的信息分发产品:
- 今日头条:字节跳动的起家之作,智能推荐资讯平台。
- 西瓜视频:中长视频平台。
- 番茄小说:免费网文阅读平台。
2.2.2 业务对技术的反哺与制约
GIP 的业务特点是高信息密度。今日头条的内容审核后台、广告投放系统(早期巨量引擎)、创作者管理平台(头条号后台)都需要处理海量的文本数据和复杂的表格操作。因此,Arco Design 从诞生起就带有浓重的“B 端中后台”基因,强调紧凑、理性和高效率,这正是为了服务于 GIP 庞大的内部系统需求。
在 2019-2020 年,GIP 仍是公司的绝对核心与营收主力。Arco Design 的推出,实际上是字节跳动“长子”(头条系)试图确立公司内部技术标准的一次有力尝试。
2.3 黄金时代的技术堆栈
在 2021 年左右,Arco Design 的技术选型是极具前瞻性的,这也是它能迅速获得 5.5k Star 的原因之一:
- 全链路 TypeScript:所有组件均采用 TypeScript 编写,提供了优秀的类型推导体验,解决了当时 Ant Design v4 在某些复杂场景下类型定义不友好的痛点。
- 双框架并进:@arco-design/web-react 和 @arco-design/web-vue 保持了高度统一的 API 设计和视觉风格。这对于那些技术栈不统一的大型公司极具吸引力,意味着设计规范可以跨框架复用。
- 生态闭环:除了组件库,Arco 还发布了 arco-cli(脚手架)、Arco Pro(中后台模板)、IconBox(图标管理平台)以及 Material Market(物料市场)。这表明团队不仅是在做一个库,而是在构建一个类似 Salesforce Lightning 或 SAP Fiori 的企业级生态。
然而,正是这种庞大的生态铺设,为日后的维护埋下了巨大的隐患。当背后的组织架构发生震荡时,维持如此庞大的产品矩阵所需的资源将变得不可持续。
3. 停摆的证据:基于数据与现象的法医式分析
尽管字节跳动从未发布过一份正式的“Arco Design 停止维护声明”,但通过对代码仓库、社区反馈以及基础设施状态的深入分析,我们可以断定该项目已进入实质性的“脑死亡”状态。
3.1 代码仓库的“心跳停止”
对 GitHub 仓库 arco-design/arco-design (React) 和 arco-design/arco-design-vue (Vue) 的提交记录分析显示,活跃度在 2023 年底至 2024 年初出现了断崖式下跌。
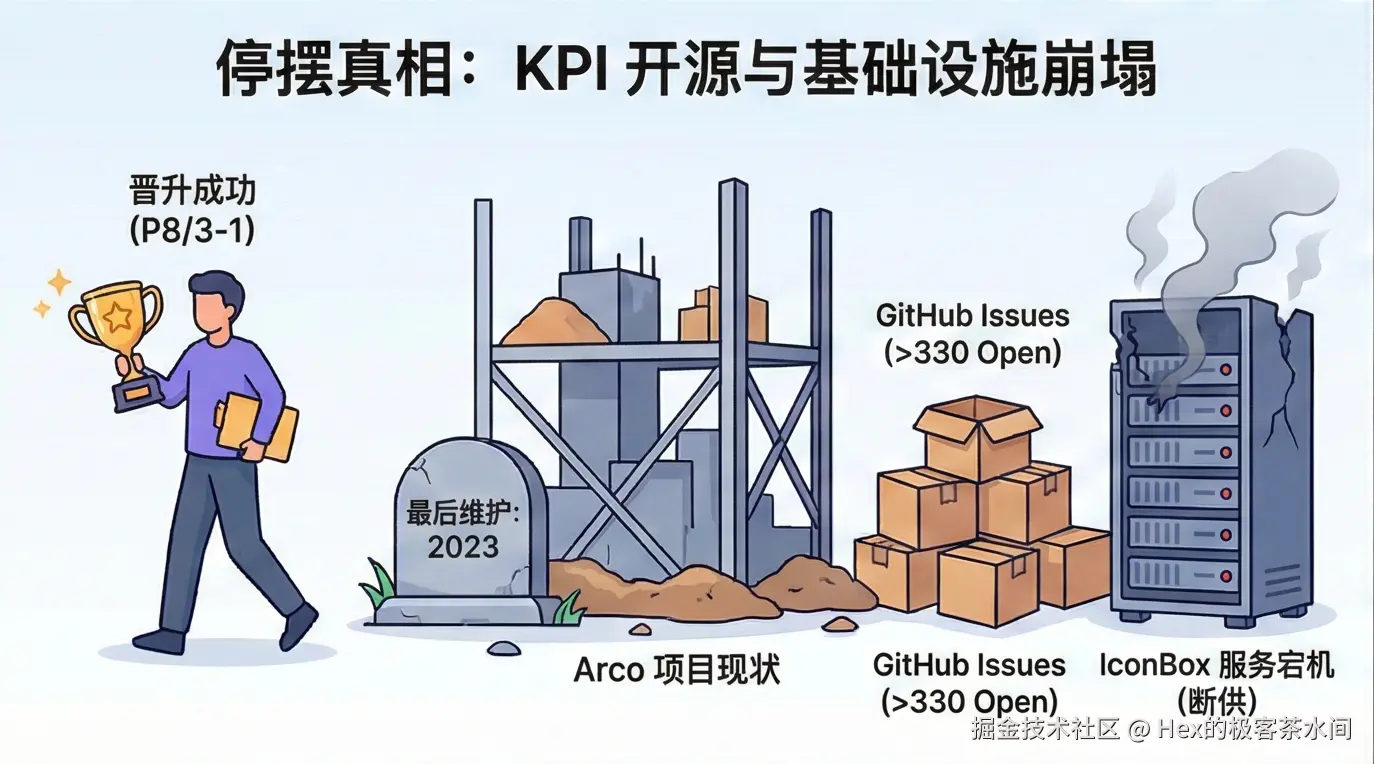
3.1.1 提交频率分析
虽然 React 版本的最新 Release 版本号为 2.66.8(截至文章撰写时),但这更多是惯性维护。
- 核心贡献者的离场:早期的高频贡献者(如 sHow8e、jadelike-wine 等)在 2024 年后的活跃度显著降低。许多提交变成了依赖项升级(Dependabot)或极其微小的文档修复,缺乏实质性的功能迭代。
- Vue 版本的停滞:Vue 版本的状态更为糟糕。最近的提交多集中在构建工具迁移(如迁移到 pnpm)或很久以前的 Bug 修复。核心组件的 Feature Request 长期无人响应。
3.1.2 积重难返的 Issue 列表
Issue 面板是衡量开源项目生命力的体温计。目前,Arco Design 仓库中积累了超过 330 个 Open Issue。
- 严重的 Bug 无人修复:例如 Issue #3091 “tree-select 组件在虚拟列表状态下搜索无法选中最后一个” 和 Issue #3089 “table 组件的 default-expand-all-rows 属性设置不生效”。这些都是影响生产环境使用的核心组件 Bug,却长期处于 Open 状态。
- 社区的绝望呐喊:Issue #3090 直接以 “又一个没人维护的 UI 库” 为题,表达了社区用户的愤怒与失望。更有用户在 Discussion 中直言 “这个是不是 KPI 项目啊,现在维护更新好像都越来越少了”。这种负面情绪的蔓延,通常是一个项目走向终结的社会学信号。
3.2 基础设施的崩塌:IconBox 事件
如果说代码更新变慢还可以解释为“功能稳定”,那么基础设施的故障则是项目被放弃的直接证据。
- IconBox 无法发布:Issue #3092 指出 “IconBox 无法发布包了”。IconBox 是 Arco 生态中用于管理和分发自定义图标的 SaaS 服务。这类服务需要后端服务器、数据库以及运维支持。
- 含义解读:当一个大厂开源项目的配套 SaaS 服务出现故障且无人修复时,这不仅仅是开发人员没时间的问题,而是意味着服务器的预算可能已经被切断,或者负责运维该服务的团队(GIP 相关的基建团队)已经被解散。这是项目“断供”的最强物理证据。
3.3 文档站点的维护降级
Arco Design 的文档站点虽然目前仍可访问,但其内容更新已经明显滞后。例如,关于 React 18/19 的并发特性支持、最新的 SSR 实践指南等现代前端话题,在文档中鲜有提及。与竞争对手 Ant Design 紧跟 React 官方版本发布的节奏相比,Arco 的文档显得停留在 2022 年的时光胶囊中。
4. 深层归因:组织架构变革下的牺牲品
Arco Design 的陨落,本质上不是技术失败,而是组织架构变革的牺牲品。要理解这一点,我们需要将视线从 GitHub 移向字节跳动的办公大楼,审视这家巨头在过去三年中发生的剧烈动荡。
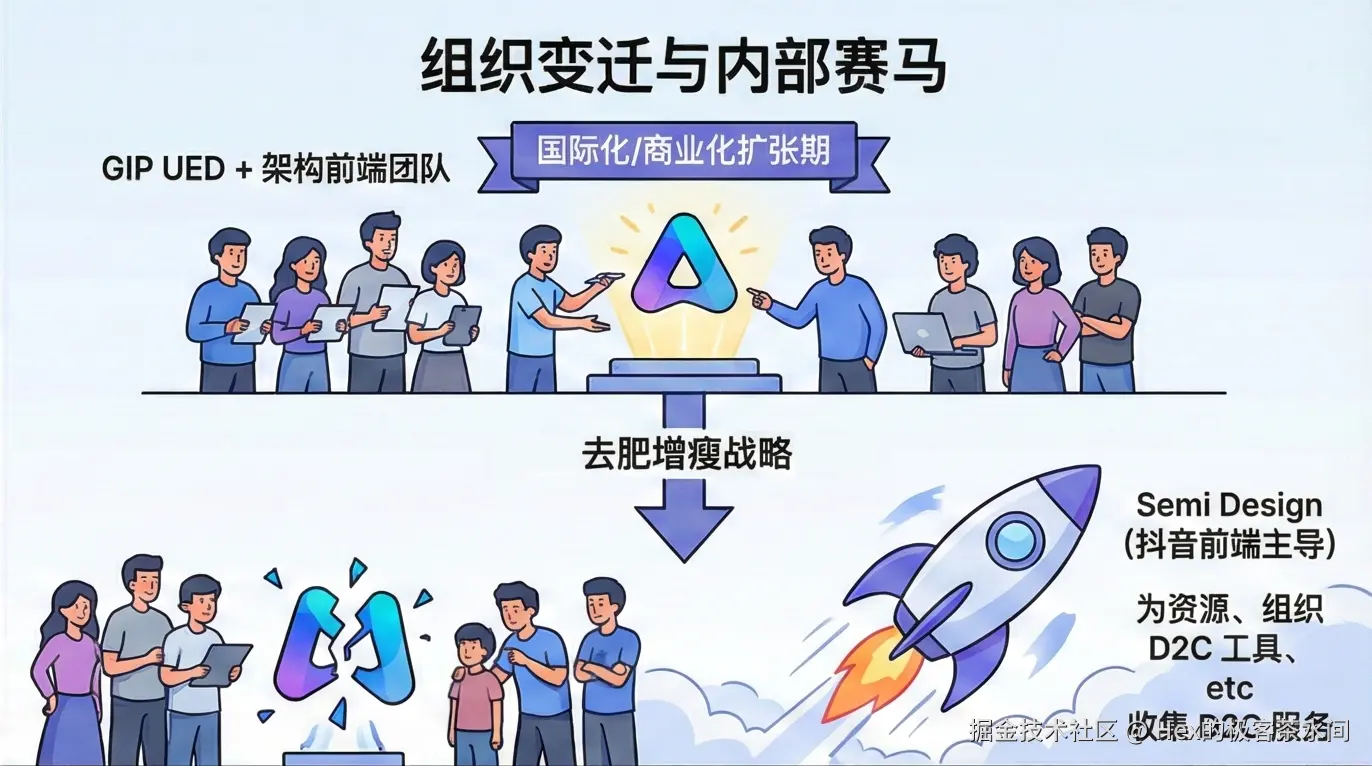
4.1 战略重心的转移:从“头条”到“抖音”
2021 年底至 2024 年,字节跳动进行了多次大规模的组织架构调整。其中最关键的变化是战略重心从图文资讯(今日头条)全面转向短视频与直播(抖音/TikTok)以及后来的 AI 大模型。
- GIP 的边缘化:随着移动互联网进入存量时代,今日头条和西瓜视频的用户增长见顶,战略地位从“增长引擎”退化为“现金牛”甚至“存量维持”业务。
- 资源的抽离:GIP UED 和相关前端团队面临缩编或重组。维护 Arco Design 这样一套庞大的开源系统需要持续的人力投入。当母体部门本身都在进行“去肥增瘦”时,一个无法直接带来商业增量的开源 KPI 项目,自然成为了裁员的首选目标。
4.2 内部赛马机制:Arco Design vs. Semi Design
字节跳动素以“APP 工厂”和“内部赛马”文化著称。这种文化不仅存在于 C 端产品中,也渗透到了技术基建领域。Arco Design 的停摆,很大程度上是因为它在与内部竞争对手 Semi Design 的博弈中败下阵来。
4.2.1 Semi Design 的崛起
Semi Design 是由 抖音前端团队 与 MED 产品设计团队 联合推出的设计系统。
- 出身显赫:与 GIP 不同,Semi Design 背靠的是字节跳动的绝对核心——抖音。抖音前端团队拥有极其充裕的资源和稳固的业务地位。
- 技术路线之争:Semi Design 在架构上更为先进,采用了 Foundation/Adapter 模式,实现了逻辑与渲染分离,能以更低的成本适配不同框架。同时,Semi 深度集成了 D2C(Design-to-Code)工具链,更符合公司对 AI 和人效的追求。
4.2.2 为什么 Arco 输了?
在资源整合期,公司高层显然不需要维护两套功能高度重叠的企业级 UI 库。
- 业务绑定:Semi Design 宣称服务了内部 10 万+ 用户和近千个平台产品,深度嵌入在抖音的内容生产与运营流中。
- 结局:随着 GIP 业务权重的下降和团队的调整,Arco Design 失去了维护的资源,而 Semi Design 成为了事实上的内部标准。
4.3 中国大厂的“KPI 开源”陷阱
Arco Design 的命运也折射出中国互联网大厂普遍存在的“KPI 开源”现象。
- 晋升阶梯:在阿里的 P7/P8 或字节的 2-2/3-1 晋升答辩中,主导一个“行业领先”的开源项目是极具说服力的业绩。因此,很多工程师或团队 Leader 会发起此类项目,投入巨大资源进行推广(刷 Star、做精美官网)。
- 晋升后的遗弃:一旦发起人成功晋升、转岗或离职,该项目的“剩余价值”就被榨干了。接手的新人往往不愿意维护“前人的功劳簿”,更愿意另起炉灶做一个新的项目来证明自己。
- Arco 的轨迹:Arco 的高调发布(2021年)恰逢互联网泡沫顶峰。随着 2022-2024 年行业进入寒冬,晋升通道收窄,维护开源项目的 ROI(投入产出比)变得极低,导致项目被遗弃。
5. 社区自救的幻象:为何没有强有力的 Fork?
面对官方的停摆,用户自然会问:既然代码是开源的(MIT 协议),为什么没有人 Fork 出来继续维护?调查显示,虽然存在一些零星的 Fork,但并未形成气候。
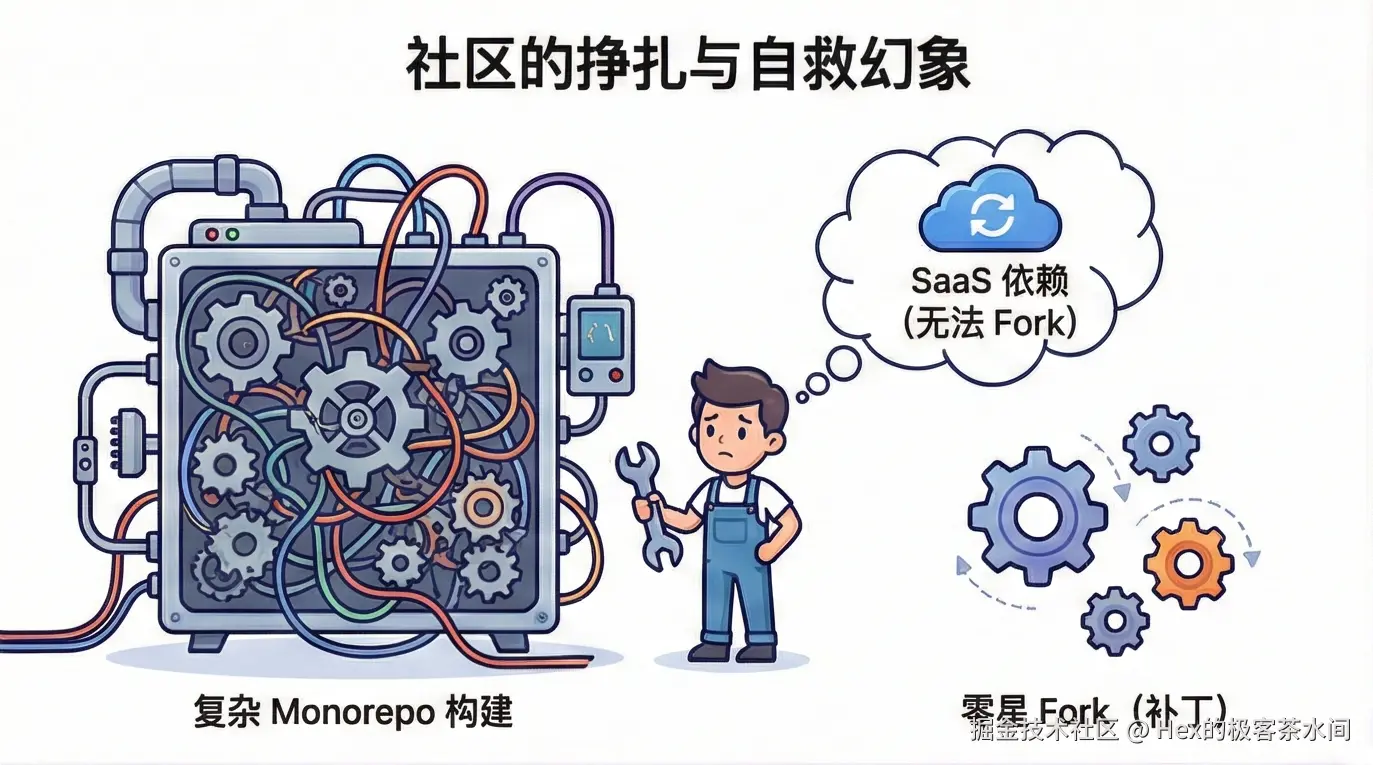
5.1 Fork 的现状调查
通过对 GitHub 和 Gitee 的检索,我们发现了一些 Fork 版本,但并未找到具备生产力的社区继任者。
- vrx-arco:这是一个名为 vrx-arco/arco-design-pro 的仓库,声称是 "aro-design-vue 的部分功能扩展"。然而,这更像是一个补丁集,而不是一个完整的 Fork。它主要解决特定开发者的个人需求,缺乏长期维护的路线图。
- imoty_studio/arco-design-designer:这是一个基于 Arco 的表单设计器,并非组件库本身的 Fork。
- 被动 Fork:GitHub 显示 Arco Design 有 713 个 Fork。经抽样检查,绝大多数是开发者为了阅读源码或修复单一 Bug 而进行的“快照式 Fork”,并没有持续的代码提交。
5.2 为什么难以 Fork?
维护一个像 Arco Design 这样的大型组件库,其门槛远超普通开发者的想象。
- Monorepo 构建复杂度:Arco 采用了 Lerna + pnpm 的 Monorepo 架构,包含 React 库、Vue 库、CLI 工具、图标库等多个 Package。其构建脚本极其复杂,往往依赖于字节内部的某些环境配置或私有源。外部开发者即使拉下来代码,要跑通完整的 Build、Test、Doc 生成流程都非常困难。
- 生态维护成本:Arco 的核心优势在于 Design Lab 和 IconBox 等配套 SaaS 服务。Fork 代码容易,但 Fork 整个后端服务是不可能的。失去了 Design Lab 的 Arco,就像失去了灵魂的空壳,吸引力大减。
- 技术栈锁定:Arco 的一些底层实现可能为了适配字节内部的微前端框架或构建工具(如 Modern.js)做了特定优化,这增加了通用化的难度。
因此,社区更倾向于迁移,而不是接盘。
6. 用户生存指南:现状评估与迁移策略
对于目前仍在使用 Arco Design 的团队,局势十分严峻。随着 React 19 的临近和 Vue 3 生态的演进,Arco 将面临越来越多的兼容性问题。
6.1 风险评估表
| 风险维度 | 风险等级 | 具体表现 |
|---|---|---|
| 安全性 | 🔴 高危 | 依赖的第三方包(如 lodash, async-validator 等)若爆出漏洞,Arco 不会发版修复,需用户手动通过 resolutions 强行覆盖。 |
| 框架兼容性 | 🔴 高危 | React 19 可能会废弃某些 Arco 内部使用的旧生命周期或模式;Vue 3.5+ 的新特性无法享受。 |
| 浏览器兼容性 | 🟠 中等 | 新版 Chrome/Safari 的样式渲染变更可能导致 UI 错位,无人修复。 |
| 基础设施 | ⚫ 已崩溃 | IconBox 无法上传新图标,Design Lab 可能随时下线,导致主题无法更新。 |
6.2 迁移路径推荐
方案 A:迁移至 Semi Design(推荐指数:⭐⭐⭐⭐)
如果你是因为喜欢字节系的设计风格而选择 Arco,那么 Semi Design 是最自然的替代者。
- 优势:同为字节出品,设计语言的命名规范和逻辑有相似之处。Semi 目前维护活跃,背靠抖音,拥有强大的 D2C 工具链。
- 劣势:API 并非 100% 兼容,仍需重构大量代码。且 Semi 主要是 React 优先,Vue 生态支持相对较弱(主要靠社区适配)。
方案 B:迁移至 Ant Design v5/v6(推荐指数:⭐⭐⭐⭐⭐)
如果你追求极致的稳定和长期的维护保障,Ant Design 是不二之选。
- 优势:行业标准,庞大的社区,Ant Gr0up 背书。v5 版本引入了 CSS-in-JS,在定制能力上已经大幅追赶 Arco 的 Design Lab。
- 劣势:设计风格偏保守,需要设计师重新调整 UI 规范。
方案 C:本地魔改(推荐指数:⭐)
如果项目庞大无法迁移,唯一的出路是将 @arco-design/web-react 源码下载到本地 packages 目录,作为私有组件库维护。
- 策略:放弃官方更新,仅修复阻塞性 Bug。这需要团队内有资深的前端架构师能够理解 Arco 的源码。
7. 结语与启示
Arco Design 的故事是现代软件工程史上的一个典型悲剧。它证明了在企业级开源领域,康威定律(Conway's Law) 依然是铁律——软件的架构和命运取决于开发它的组织架构。
当 GIP 部门意气风发时,Arco 是那颗最耀眼的星,承载着“务实浪漫主义”的理想;当组织收缩、业务调整时,它便成了由于缺乏商业造血能力而被迅速遗弃的资产。对于技术决策者而言,Arco Design 的教训是惨痛的:在进行技术选型时,不能仅看 README 上的 Star 数或官网的精美程度,更要审视项目背后的组织生命力和维护动机。

目前来看,Arco Design 并没有复活的迹象,社区也没有出现强有力的接棒者。这套组件库正在数字化浪潮的沙滩上,慢慢风化成一座无人问津的丰碑。
来源:juejin.cn/post/7582879379441745963
前端图像五兄弟:网络 URL、Base64、Blob、ArrayBuffer、本地路径,全整明白!
你有没有在写前端的时候,突然迷糊了:
- 为啥这张图片能直接
src="https://xxx.jpg"就能展示? - 为啥有时候图片是乱七八糟的一串 Base64?
- 有的还整出来个 Blob,看不懂但好像很高级?
- 有时还来个
ArrayBuffer,这又是哪位大哥? - 最离谱的是:我本地图片路径写进去,怎么就不生效?
这些,其实都和“图像在前端的存在形式”有关。今天咱们就像唠家常一样,一口气整明白这几个常见的前端图像形式,用最接地气的方式讲明白,配上实例、场景分析,帮你彻底建立系统认知!
一、网络 URL:最熟悉的那张脸
<img src="https://example.com/image.jpg" />
这就是我们最常见的方式:网络地址。
📦 本质上是啥?
一个 HTTP(S) 请求,浏览器去服务器上拉图片回来。
👍 优点:
- 用起来最简单,能连网就能显示
- 浏览器会缓存,提高加载效率
- 图片不占你的 HTML 或 JS 文件大小
👎 缺点:
- 依赖网络,断网就 GG
- 跨域可能出问题(特别是 canvas 想处理图片时)
- 没法离线用
🧩 常见场景:
- 图床、CDN 图片
- 用户头像、商品封面等动态内容
二、本地 URL(相对路径):常被坑的老兄
<img src="./images/logo.png" />
听起来像本地文件,实际上也是被打包进项目的资源文件路径。
⚙️ 本质上是啥?
开发时是相对路径,生产环境通常会被 Webpack、Vite 等构建工具“处理成”一个真实可访问的路径,比如 dist/assets/logo.abcd1234.png。
👀 你可能踩过的坑:
- 路径写错,或者构建工具没配置资源处理,图片加载失败
- 静态服务器没开,直接打开 HTML 无法访问文件(浏览器出于安全考虑禁止 file 协议访问)
💡 使用建议:
- 放到
public目录,或者使用 import 静态资源方式处理 - 建议使用构建工具配置 alias 简化路径
三、Base64:字节转码“图片串”
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA..." />
这是把图片数据编码成 Base64 的字符串,直接塞进 HTML 或 JS 文件里。
🔬 本质上是啥?
Base64 是一种将二进制数据编码成 ASCII 字符串的方式。
✅ 优点:
- 免请求!嵌入式图片,一起打包进页面
- 没有跨域问题
- 非常适合小图标、loading 动画、SVG
❌ 缺点:
- 体积暴涨,大概比原图多 33%
- 可读性差,不利于维护
- 页面初始加载变慢
🧩 常见场景:
CSS background-image- 富文本编辑器中的粘贴图像
- 邮件嵌入图像
四、Blob:文件对象,前端造图必备
const blob = new Blob([arrayBuffer], { type: 'image/png' });
const url = URL.createObjectURL(blob);
img.src = url;
这是处理文件流时常见的一种格式。
🔍 本质上是啥?
Blob 是浏览器提供的一种二进制大对象,可以把它看作 JS 里的“文件”。
💪 优点:
- 可由 JS 动态生成,支持下载、预览、上传
- 可控制 MIME 类型,灵活性强
- 可以通过
URL.createObjectURL()生成临时地址
📉 缺点:
- 是内存对象,页面刷新就没了
- 不能跨页面共享(临时的)
🧩 常见场景:
- 前端截图(
canvas.toBlob()) - 文件上传预览
- 后台生成图片后前端下载
五、ArrayBuffer / Uint8Array:最低层的图像数据表示
fetch('image.jpg')
.then(res => res.arrayBuffer())
.then(buffer => {
// 可以转为 blob 或 base64 再显示
});
这是最底层的图像数据,直接以字节数组的形式存在。
🧠 本质上是啥?
ArrayBuffer 是一段原始的内存区域,常用于处理二进制数据,Uint8Array 是对它的视图(读取用)。
🧰 常见用途:
- 图像处理(比如 AI 模型的图片输入)
- 自定义图片加载器(如通过 WASM 解码)
- 二进制传输协议
🔄 转换方式:
- 转为 Blob:
new Blob([buffer]) - 转为 Base64:
btoa(String.fromCharCode(...new Uint8Array(buffer)))
🔄 图像形式转换总结表格
| 形式 | 可直接显示 | 是否跨域限制 | 是否可本地预览 | 推荐用途 |
|---|---|---|---|---|
| 网络 URL | ✅ | 有 | ❌ | 最常见场景 |
| 本地路径 | ✅ | 无 | ✅(需本地服务器) | 项目资源图 |
| Base64 | ✅ | 无 | ✅ | 小图标、嵌入图 |
| Blob | ✅ | 无 | ✅ | 前端生成图 |
| ArrayBuffer | ❌ | 无 | ✅ | 图像底层处理 |
🧠 最后的总结:选哪种图像形式?
- ✅ 展示外部图 → 用 URL
- ✅ 项目图标/静态资源 → 本地路径
- ✅ 上传/预览/截图 → Blob
- ✅ 处理图像数据 → ArrayBuffer
- ✅ 小图或嵌入内容 → Base64
掌握这些图像“存在形式”,不仅能帮你写出更高效、稳定的代码,更能在项目中灵活切换,游刃有余!
如果你觉得这篇有点帮助,别忘了点个赞或者收藏一下~
来源:juejin.cn/post/7495549439035195402
🔥3 kB 换 120 ms 阻塞? Axios 还是 fetch?
0. 先抛结论,再吵不迟
| 指标 | Axios 1.7 | fetch (原生) |
|---|---|---|
| gzip 体积 | ≈ 3.1 kB | 0 kB |
| 阻塞时间(M3/4G) | 120 ms | 0 ms |
| 内存峰值(1000 并发) | 17 MB | 11 MB |
| 生产 P1 故障(过去一年) | 2 次(拦截器顺序 bug) | 0 次 |
| 开发体验(DX) | 10 分 | 7 分 |
结论:
- 极致性能/SSG/Edge → fetch 已足够;
- 企业级、需要全局拦截、上传进度 → Axios 仍值得;
- 二者可共存:核心链路与首页用 fetch,管理后台用 Axios。
1. 3 kB 到底贵不贵?
2026 年 1 月,HTTP Archive 最新采样(Chrome 桌面版)显示:
- 中位 JS 体积 580 kB,3 kB 似乎“九牛一毛”;
- 但放到首屏预算 100 kB 的站点(TikTok 推荐值),3 kB ≈ 3 % 预算,再加 120 ms 阻塞,LCP 直接从 1.5 s 飙到 1.62 s,SEO 评级掉一档。
“ bundle 每 +1 kB,4G 下 FCP +8 ms”——Lighthouse 2025 白皮书。
2. 把代码拍桌上:差异只剩这几行
下面 4 个高频场景,全部给出“可直接复制跑”的片段,差异一目了然。
2.1 自动 JSON + 错误码
// Axios:零样板
const {data} = await axios.post('/api/login', {user, pwd});
// fetch:两行样板
const res = await fetch('/api/login', {
method:'POST',
headers:{'Content-Type':'application/json'},
body:JSON.stringify({user, pwd})
});
if (!res.ok) throw new Error(res.status);
const data = await res.json();
争议:
- Axios 党:少写两行,全年少写 3000 行。
- fetch 党:gzip 后 3 kB 换两行?ESLint 模板一把就补全。
2.2 超时 + 取消
// Axios:内置
const source = axios.CancelToken.source();
setTimeout(() => source.cancel('timeout'), 5000);
await axios.get('/api/big', {cancelToken: source.token});
// fetch:原生 AbortController
const ctl = new AbortController();
setTimeout(() => ctl.abort(), 5000);
await fetch('/api/big', {signal: ctl.signal});
2025 之后 Edge/Node 22 已全支持,AbortSignal.timeout(5000) 一行搞定:
await fetch('/api/big', {signal: AbortSignal.timeout(5000)});
结论:语法差距已抹平。
2.3 上传进度条
// Axios:progress 事件
await axios.post('/upload', form, {
onUploadProgress: e => setProgress(e.loaded / e.total)
});
// fetch:借助 `xhr` 或 `ReadableStream`
// 2026 仍无原生简易方案,需要封装 `xhr` 才能拿到 `progress`。
结论:大文件上传场景 Axios 仍吊打 fetch。
2.4 拦截器(token、日志)
// Axios:全局拦截
axios.interceptors.request.use(cfg => {
cfg.headers.Authorization = `Bearer ${getToken()}`;
return cfg;
});
// fetch:三行封装
export const $get = (url, opts = {}) => fetch(url, {
...opts,
headers: {...opts.headers, Authorization: `Bearer ${getToken()}`}
});
经验:拦截器一旦>2 个,Axios 顺序地狱频发;fetch 手动链式更直观。
3. 实测!同一个项目,两套 bundle
测试场景
- React 18 + Vite 5,仅替换 HTTP 层;
- 构建目标:es2020 + gzip + brotli;
- 网络:模拟 4G(RTT 150 ms);
- 采样 10 次取中位。
| 指标 | Axios | fetch |
|---|---|---|
| gzip bundle | 46.7 kB | 43.6 kB |
| 首屏阻塞时间 | 120 ms | 0 ms |
| Lighthouse TTI | 2.1 s | 1.95 s |
| 内存峰值(1000 并发请求) | 17 MB | 11 MB |
| 生产报错(过去一年) | 2 次拦截器顺序错乱 | 0 |
数据来自 rebrowser 2025 基准 ;阻塞时间差异与 51CTO 独立测试吻合 。
4. 什么时候一定要 Axios?
- 需要上传进度(onUploadProgress)且不想回退 xhr;
- 需要请求/响应拦截链 >3 层,且团队对“黑盒”可接受;
- 需要兼容 IE11(2026 年政务/银行仍存);
- 需要Node 16 以下老版本(fetch 需 18+)。
5. 共存方案:把 3 kB 花在刀刃上
// core/http.js
export const isSSR = typeof window === 'undefined';
export const HTTP = isSSR || navigator.connection?.effectiveType === '4g'
? { get: (u,o) => fetch(u,{...o, signal: AbortSignal.timeout(5000)}) }
: await import('axios'); // 动态 import,只在非 4G 或管理后台加载
结果:
- 首屏 0 kB;
- 管理后台仍享受 Axios 拦截器;
- 整体 bundle 下降 7 %,LCP −120 ms。
6. 一句话收尸
2026 年的浏览器,fetch 已把“缺的课”补完:取消、超时、Node 原生、TypeScript 完美。
3 kB 的 Axios 不再是“默认”,而是“按需”。
上传进度、深链拦截、老浏览器——用 Axios;
其余场景,让首页飞一把,把 120 ms 还给用户。
来源:juejin.cn/post/7590011643297005606
这 5 个冷门 HTML 标签,让我直接删了100 行 JS 代码!
在写前端的时候,我们实现的比较多的一些基础交互,比如折叠面板、弹窗、输入提示、进度条或颜色选择等等,会不得不引入 JavaScript。
但其实,HTML 自己也内置了不少功能强大的原生标签,它们开箱即用、语义清晰,还能大幅减少 JS 的代码量。
下面介绍 5 个冷门但实用的 HTML 标签。
1. <details> 和 <summary> - 可折叠内容
替代: 手风琴效果、折叠面板、FAQ部分
<details>
<summary>点击查看详情</summary>
<p>隐藏的内容,无需JS实现展开/收起</p>
</details>
实现效果:

使用场景
- FAQ 折叠面板
- 设置项分组展开
- 移动端“查看更多”区域
注意事项
- 默认是关闭状态;添加
open属性可默认展开:<details open> - 可通过 CSS 的
details[open]选择器定制展开样式 - 支持键盘操作(Enter/Space 触发),无障碍友好
2. <dialog> - 原生对话框
替代:div模拟模态框 + 背景遮罩 + 关闭逻辑
<dialog id="modal">
<p>这是原生弹窗</p>
<button onclick="document.getElementById('modal').close()">关闭</button>
</dialog>
<button onclick="document.getElementById('modal').showModal()">打开弹窗</button>
实现效果:

使用场景
- 确认提示框
- 登录/注册弹窗
- 临时信息展示
注意事项
.showModal()会自动创建半透明遮罩(可通过::backdrop自定义).show()是非模态显示(不锁定背景)- 聚焦自动管理:打开时聚焦第一个可聚焦元素,关闭后焦点返回触发按钮
- 兼容性:Chrome/Firefox/Edge 支持良好;Safari 15.4+ 支持;IE 不支持
3. <datalist> - 输入建议列表
替代:监听input事件 + 动态生成下拉列表
<input list="browsers" placeholder="选择或输入浏览器">
<datalist id="browsers">
<option value="Chrome">
<option value="Firefox">
<option value="Safari">
</datalist>
实现效果:
使用场景
- 搜索建议(非强制选项)
- 表单字段预填(如城市、产品名)
- 快速输入辅助
注意事项
- 用户仍可输入不在列表中的值(与
<select>不同) - 浏览器会自动根据输入过滤匹配项
- 移动端会调出带建议的软键盘(部分浏览器支持)
4. <meter> & <progress> - 进度指示器
替代:div模拟进度条 + JS更新宽度
<!-- 已知范围内的标量值(如磁盘使用率) -->
<meter min="0" max="100" value="70">70%</meter>
<!-- 任务完成进度(如文件上传) -->
<progress value="50" max="100">50%</progress>
实现效果:
使用场景
- 搜索建议(非强制选项)
- 表单字段预填(如城市、产品名)
- 快速输入辅助
注意事项
- 用户仍可输入不在列表中的值(与
<select>不同) - 浏览器会自动根据输入过滤匹配项
- 移动端会调出带建议的软键盘(部分浏览器支持)
5. <input type="color"> - 颜色选择器
替代:自定义颜色选择器UI + 色值转换逻辑
<input type="color" value="#ff0000">
实现效果:

使用场景
- 主题配色设置
- 图表颜色配置
- 设计工具中的拾色功能
注意事项
- 返回值始终为 小写 7 位十六进制(如
#ff5733) - 移动端会调出系统级颜色选择器
- 无法自定义 UI,但可通过
::-webkit-color-swatch微调样式(有限)
总结
<details>/<summary>:实现折叠内容<dialog>:原生弹窗,自带遮罩和焦点管理<datalist>:输入建议选择<meter>/<progress>:进度展示无需手动计算宽度<input type="color">:系统级颜色选择器开箱即用
这些原生 HTML 标签虽然不太起眼,但用好它们,不仅能省去大量 JavaScript 逻辑,还能让页面更语义化、更友好。
本文首发于公众号:程序员大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
来源:juejin.cn/post/7594742976712179746
推荐8个牛逼的SpringBoot项目
前言
最近两年左右的时间,我一口气肝了8个实现项目。
包含了各种业界常见的技术,比如:SpringBoot、SpringCloud、SpringCloud Alibaba、Mybatis、JPA、Redis、MongoDB、ElasticSearch、MySQL、PostgreSQL、Minio、Caffine、RocketMQ、Prometheus、Grafana、ELK、skywalking、Sentinel、Nacos、Redisson、shardingsphere、HikariCP、guava、WebFlux、nacos、Sentinel、WebSocket、Gateway、Nginx、Docker、Spring AI、Spring AI Alibaba等等,非常值得一看。
今天给大家介绍一下这些项目,感兴趣的小伙伴,可以一起交流学习一下,干货满满。
1 100万QPS短链系统
使用技术:JDK21、SpringBoot3.5.3、JPA、Redis、布隆过滤器、Sentinel、Nacos、Redisson、shardingsphere、HikariCP、guava、Prometheus等。
目前设计了32个数据库,每个数据库包含了256张表。
每天可支持2.6亿以上的数据写入。
100万QPS短链系统的系统架构图如下:
技术亮点:
该项目的亮点是:
- 使用了最新的JDK21和SpringBoot3.5.3
- 100万QPS的超高并发请求
- 数据库分库分表设计
- 多级布隆过滤器设计
- 限流和熔断的使用
- Redis分片集群
- 改进后的雪花算法
- Redis分布式锁的使用
- Redis Stream的使用
- 多级缓存设计
- 多线程的处理
- 完整的单元测试覆盖
- 使用Prometheus对项目实时监控
- 使用Grafana创建监控仪表盘
- 使用AlertManager实现自动报警功能
- 接入钉钉报警
- 基于时间片的布隆过滤器
- 系统平滑扩容
- 基于Docker容器化部署
- 支持多种短链生成算法
- 接口幂等性设计
基于时间片的布隆过滤器流程图如下:
短链系统平滑扩容方案如下:
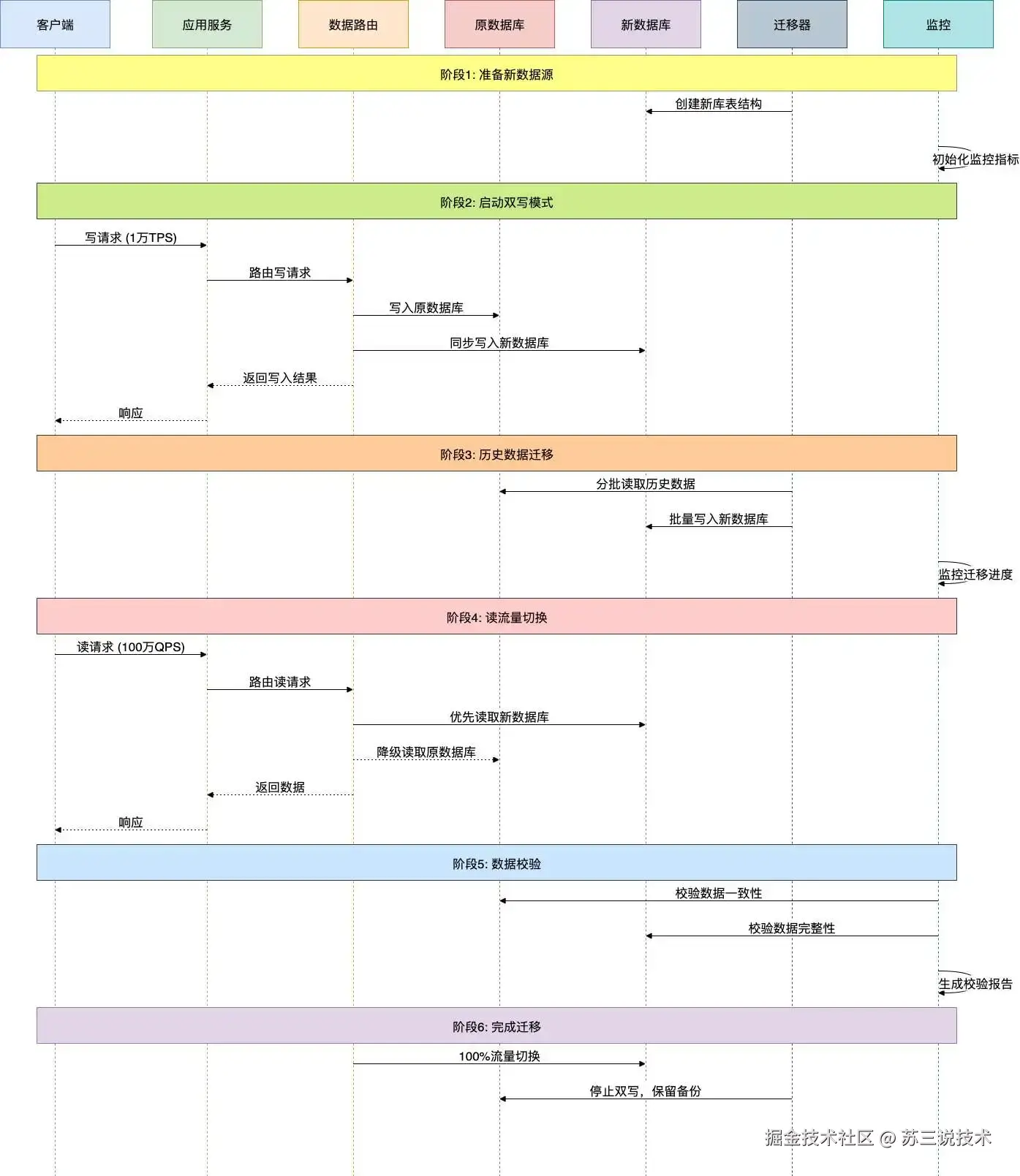
通过这个项目,可以学到很多高并发、流量评估、分库分表、多级缓存、多级布隆过滤器、限流、熔断、多线程、监控、报警、数据扩容、集群、广播消息、单元测试编写等多方面的知识。
目前这个项目包含两端代码:
- 后端服务
- 前端服务
想进大厂的小伙伴们,一定不要错过这个项目,里面有很多加分项。
点击这里获取项目源代码和教程:www.susan.net.cn/project
2 SaaS点餐系统
使用技术:JDK21、SpringBoot3.4.3、SpringCloud、SpringCloud Alibaba、Gateway、Mybatis、PostgesSQL、Redis、RocketMQ、ElasticSearch、Knife4j、Prometheus、Grafana、Minio、数据隔离等。
SaaS点餐系统是一套:DDD开发模式+多租户+PostgesSQL 的复杂微服务系统。
包含了9个微服务。
系统整体架构如下:
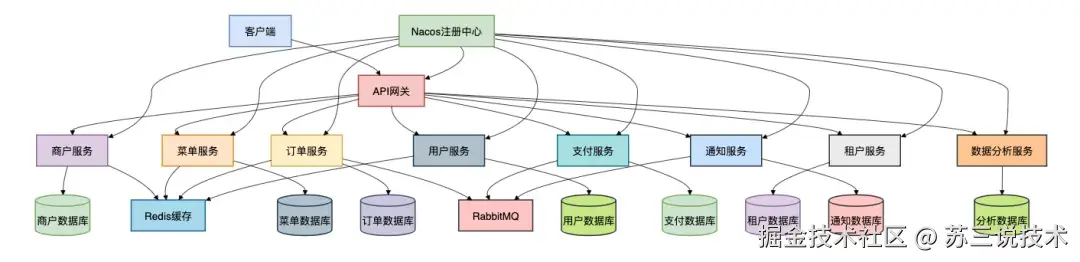
数据隔离方案如下:
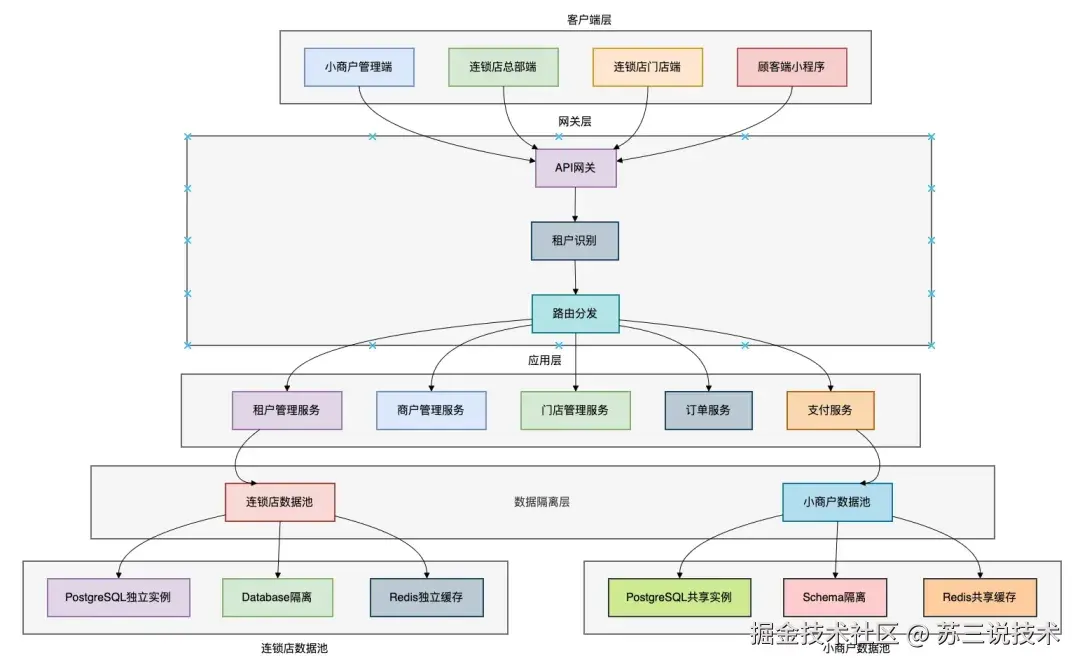
DDD开发模式的代码示例:
通过这个项目可以掌握DDD开发模型、多租户数据隔离的方案实现、PostgresSQL数据库的使用,还有微服务之间的数据交换,网关服务的统一处理,以及复杂系统的职责领域的划分。
运行效果:
3 商城微服务系统
susan_mall_cloud是微服务项目。
使用了目前业界比较新的技术:JDK17、Spring6、SpringBoot3.3.5、SpringCloud2024、SpringCloud Alibaba2023.0.1.0。
微服务后端包含了:
- susan-mall-common (公共文件)
- susan-mall-gateway (网关服务)
- susan-mall-basic (基础服务)
- susan-mall-auth (权限服务,包含用户和权限相关的)
- susan-mall-product (商品服务)
- susan-mall-order (订单服务)
- susan-mall-pay (支付服务)
- susan-mall-member (会员服务)
- susan-mall-marketing (营销服务)
- susan-mall-admin(后台管理系统API)
- susan-mall-mobile(移动端API)
这个版本在商城已有技术基础之上,又增加了:SpringCloud Gateway、WebFlux、Seata、Skywaking、OpenFeign、Loadbalancer、Sentinel、Nacos、Canal、xxl-job、Prometheus、K8S等。
项目架构图:
目前包含了多端代码:
- 服务端的网关服务和6个微服务。
- 后台管理系统。
- uniapp小程序。
下面是商城小程序真实的截图:

看起来是不是非常专业?
商城微服务项目很复杂,包含了目前业界微服务分布式系统中使用最主流的技术,强烈推荐一下。
无论在工作中,还是面试中,都可以作为加分项。
特别是SpringCloud Gateway中WebFlux的使用,微服务之间的异常处理,以及微服务之间的通信,都很值得一看。
4 商城系统
商城系统目前包含了:SpringBoot后端 + Vue管理后台 + uniapp小程序 ,三个端的完整代码。
商城项目中包含了:基于Docker部署教程、域名解析教程、按环境隔离、网络爬虫、推荐算法、支付宝支付、分库分表、分片算法优化、手写动态定时任务、手写通用分页组件、JWT登录验证、数据脱敏、动态workId、hanlp敏感词校验,手写分布式ID生成器、分布式限流、手写Mybatis插件、两级缓存提升性能、MQ消息通信、ES商品搜索、OSS服务对接、失败自动重试机制、接口幂等性处理、百万数据excel导出、WebSocket消息推送、用户异地登录检测、freemarker模版邮件发送、代码生成工具、重复请求自动拦截、自定义金额校验注解等等一系列功能。
使用的技术:

商城系统的系统架构图如下:

包含了:
- 应用层:小程序、移动端H5、管理后台
- 网关层:Nginx反向代理和负载均衡
- 服务层:API服务、Job服务 & mq消费者服务
- 数据存储层:susan_mall库MySQL主从、susan_mall_order库MySQL分库分表、MongoDB保存商品详情、Minio存储文件
- 中间件层:Redis集群、RocketMQ、ElasticSearch、Nacos(注册中间 & 配置中心)
商城系统的技术架构图如下:
使用的都是目前业界非常主流和常用的技术,这些技术大部分公司目前都在使用。
商城系统可以帮你真正增加很多企业级项目经验。
功能亮点:
商城项目无论是毕业设计,还是面试,还是实际工作中,都非常值得一看。
商城项目使用了目前非常主流的技术,手写了很多底层的代码,设计模式、自定义了很多拦截器、过滤器、转换器、监听器等,很多代码可以搬到实际的工作中。
目前星球中包含了商城项目从0~1的完整开发教程,小白也可以直接上手。
星球中有些小伙伴,通过这个项目拿到了非常不错的offer。
点击这里获取项目源代码和教程:www.susan.net.cn/project
5. 秒杀系统
苏三的秒杀系统是专门为高并发而生的。
目前使用的技术有:SpringBoot、Redis、Redission、lua、RocketMQ、ElasticSearch、JWT、freemarker、themelaf、html、vue、element-ui等。
功能包括:商品预热、商品秒杀、分布式锁、MQ异步下单、限流、失败重试、预扣库存、数据一致性处理等。
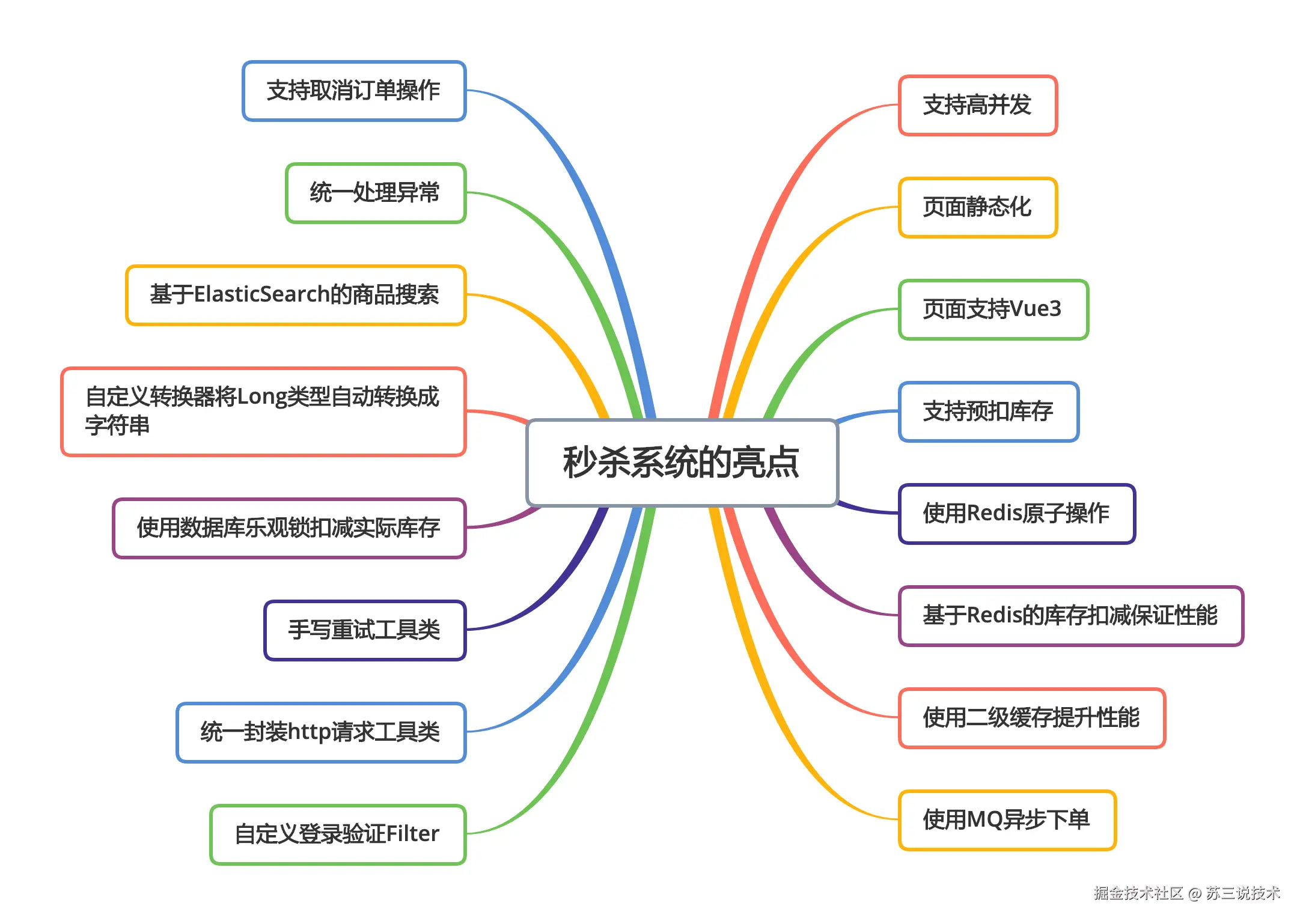
涉及到了高并发的多种技术,特别是对页面静态化,倒计时、秒杀按钮控制、分布式锁、预扣库存、MQ处理、数据一致性等,会有比较大的收获。
秒杀系统的系统架构图:
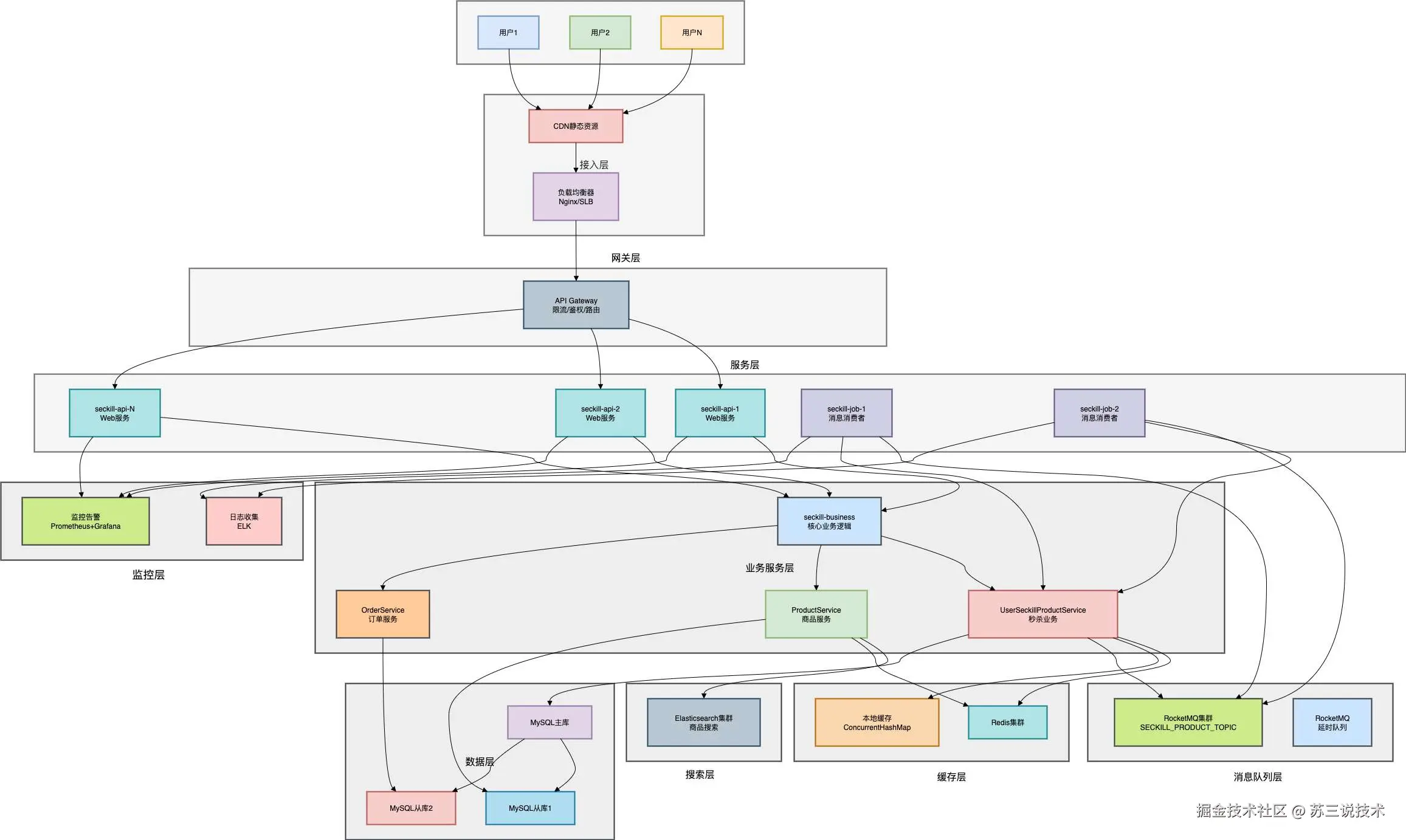
可以帮你增加高并发的工作经验,也可以写到你的简历中。
秒杀系统在面试或者工作中,会经常遇到,非常有参考价值。
6 刷题吧小程序
IT刷题吧是我用AI花了几天时间,设计和开发了一款小程序。
效果图如下:
为了帮助大家能够快速的掌握使用AI开发项目的技巧,提升开发效率,能够先人一步,变成全栈开发工程师。
无论是自己接私活,还是开发公司的项目,都能够用更少的时间,写出更多,更有价值的代码。
苏三在知识星球中给小伙伴们,通过IT刷题吧项目,专门开设了一个AI开发课程。
你看完之后,会发现打开了一扇通向新世界的大门。(有很多惊喜)
这个课程会包含如下内容:
- 如何用AI设计产品原型的?
- 如何用AI生成小程序端和后端的代码结构的?
- 如何用AI生成后端的表结构?
- 如何用AI生成小程序和后端代码?
- 如何生成一套完整的可运行的代码?
- 如何基于图片生成想要的代码?
- 如何搞定小程序页面中的图片问题?
- 如何让小程序端和后端代码调通?
- 生成的代码不理想怎么办?
- 如果在开发过程中遇到了一些问题,用AI如何解决问题?
- 如何生成测试数据?
- 如何制定代码开发规范?
- AI开发工具的使用方法
- AI开发工具卡顿怎么办?
- 如何运行项目?
- 如何上线部署项目?
等等。。。
星球中会交付如下内容:
- IT刷题吧小程序
- SpringBoot后端代码
- 用AI开发项目的完整流程
目前已经全部开发完。
使用AI开发这个项目,从0~1的开发和部署教程。
问题答疑。
通过这个项目,你可以学到使用AI开发项目的具体方法。
如果你掌握了这些方法,开发其他的小程序绰绰有余。
这个项目有极大的价值。
授人予鱼,不如授人以渔。
光是学会这个项目,就有极大的价值。
7. 苏三的demo项目
这个项目包含了一些工作中常用的技术点,有很多非常有参考价值的示例。
涵盖:Spring、Mybatis、多线程、事务、常用工具、设计模式、http请求、lamda、io、excel、泛型、注解等多个方面。
本项目的宗旨是分享实际工作中,非常实用的代码技巧,能够让你写出更优雅高效的代码。
此外,后面会收录一下面试中,尤其是笔试中经常会被问题到的代码片段和算法。
8. 代码生成器项目
这是一个基于Spring Boot的智能代码生成器,能够根据数据库表结构自动生成完整的Java Web项目代码,极大提升开发效率,让开发者专注于业务逻辑而非重复的CRUD代码编写。
我们用这个代码生成器,可以通过数据库表,一键直接生成controller、service、mapper、entity、菜单sql、vue页面等。
使用的技术:SpringBoot、MyBatis、Apache Velocity、Swagger2、Lombok、Druid、Maven等。
我们在日常开发中,把数据库表设计好了之后,然后通过该工具,能够快速生成一个可以直接运行的CRUD代码。
毫不夸张的说,如果在项目中使用它,可以让你的开发效率快速提升,我们真的可以少写30%的代码。

在实际工作中,非常有价值。
来源:juejin.cn/post/7588022226739724338
一行生成绝对唯一 ID:别再依赖 Date.now() 了!
在前端开发中,“生成唯一 ID” 是高频需求 —— 从列表项标识、表单临时存储,到数据缓存键值,都需要一个 “绝对不重复” 的标识符。但看似简单的需求下,藏着很多容易踩坑的实现方式,稍有不慎就会引发数据冲突、逻辑异常等问题。
今天我们就来拆解常见误区,带你掌握真正可靠的唯一 ID 生成方案。
一、为什么 “唯一 ID” 比想象中难?
唯一 ID 的核心要求是 “全局不重复”,但前端环境的特殊性(无状态、多标签页、高并发操作),让很多看似合理的方案在实际场景中失效。
下面两种常见实现,其实都是 “伪唯一” 陷阱。
❌ 误区 1:时间戳 + 随机数(Date.now() + Math.random())
很多开发者会直觉性地将 “时间唯一性” 和 “随机唯一性” 结合,写出这样的代码:
// 错误示例:看似合理的“伪唯一”方案
function generateNaiveId() {
// 时间戳转36进制(缩短长度)+ 随机数截取
return Date.now().toString(36) + Math.random().toString(36).substr(2);
}
// 示例输出:l6n7f4v2am50k9m7o4
这种方案的缺陷在高并发场景下会暴露无遗:
- 时间戳精度不足:
Date.now()的精度是毫秒级(1ms),如果同一毫秒内调用多次(比如循环生成、高频接口回调),ID 的 “时间部分” 会完全重复; - 伪随机性风险:
Math.random()生成的是 “非加密级随机数”,其算法可预测,在短时间内可能生成重复的序列,进一步增加冲突概率。
结论:仅适用于低频次、非核心场景(如临时展示用 ID),绝对不能用于生产环境的核心数据标识。
❌ 误区 2:全局自增计数器
另一种思路是维护一个全局变量自增,看似能保证 “有序唯一”:
// 错误示例:自增计数器方案
let counter = 0;
function generateIncrementId() {
return `id-${counter++}`;
}
// 示例输出:id-0、id-1、id-2...
但在浏览器环境中,这个方案的缺陷更致命:
- 无状态丢失:页面刷新、路由跳转后,
counter会重置为 0,之前的 ID 序列会重复; - 多标签页冲突:用户打开多个相同页面时,每个页面的
counter都是独立的,会生成完全相同的 ID(比如两个页面同时生成id-0)。
结论:浏览器环境中几乎毫无实用价值,仅能用于单次会话、单页面的临时标识。
二、王者方案:一行代码实现绝对唯一 —— crypto.randomUUID()
既然简单方案不可靠,我们需要借助浏览器原生提供的 “加密级” 能力。crypto.randomUUID() 就是 W3C 标准推荐的官方解决方案,彻底解决 “唯一 ID” 难题。
1. 用法:一行代码搞定
crypto 是浏览器内置的全局对象(无需引入任何库),专门提供加密相关能力,randomUUID() 方法可直接生成符合 RFC 4122 v4 规范 的 UUID(通用唯一标识符):
// 正确示例:生成绝对唯一ID
const uniqueId = crypto.randomUUID();
// 示例输出:3a6c4b2a-4c26-4d0f-a4b7-3b1a2b3c4d5e
2. 为什么它是 “绝对唯一” 的?
crypto.randomUUID() 的可靠性源于三个核心优势:
- 极低碰撞概率:v4 UUID 由 122 位随机数构成,组合数量高达
2^122(约 5.3×10^36),相当于 “在地球所有沙滩的沙粒中,选中某一颗特定沙粒” 的概率,实际场景中碰撞概率趋近于 0; - 加密级随机性:基于 “密码学安全伪随机数生成器(CSPRNG)”,随机性远优于
Math.random(),无法被预测或破解,避免恶意伪造重复 ID; - 跨环境兼容:生成的 UUID 是全球通用标准格式(8-4-4-4-12 位字符),前端、后端(Node.js、Java 等)、数据库(MySQL、MongoDB)都能直接识别,无需格式转换。
3. 兼容性:覆盖所有现代环境
crypto.randomUUID() 的支持范围已经非常广泛,完全满足绝大多数新项目需求:
- 浏览器:Chrome 92+、Firefox 90+、Safari 15.4+(2022 年及以后发布的版本);
- 服务器:Node.js 14.17+(LTS 版本均支持);
- 框架:Vue 3、React 18、Svelte 等现代框架无任何兼容性问题。
三、兼容性兜底方案(针对旧环境)
如果需要兼容旧浏览器(如 IE11)或低版本 Node.js,可以使用第三方库 uuid(轻量、无依赖),其底层逻辑与 crypto.randomUUID() 一致:
安装依赖:
npm install uuid
# 或 yarn add uuid
使用方式:
// 旧环境兜底方案
import { v4 as uuidv4 } from 'uuid';
const uniqueId = uuidv4();
// 示例输出:同标准UUID格式
四、总结:唯一 ID 生成的 “最佳实践”

对于 2023 年后的新项目,直接使用 crypto.randomUUID() 即可 —— 一行代码、零依赖、绝对可靠,彻底告别 “ID 重复” 的烦恼!
来源:juejin.cn/post/7561781514922688522
前端的AI路其之三:用MCP做一个日程助理
前言
话不多说,先演示一下吧。大概功能描述就是,告诉AI“添加日历,今天下午五点到六点,我要去万达吃饭”,然后AI自动将日程同步到日历。
准备工作
开发这个日程助理需要用到MCP、Mac(mac的日历能力)、Windsurf(运行mcp)。技术栈是Typescript。
思路
基于MCP我们可以做很多。关于这个日程助理,其实也是很简单一个尝试,其实就是再验证一下我对MCP的使用。因为Siri的原因,让我刚好有了这个想法,尝试一下自己搞个日程助理。关于MCP可以看我前面的分享
# 前端的AI路其之一: MCP与Function Calling# 前端的AI路其之二:初试MCP Server 。
我的思路如下: 让大模型理解一下我的意图,然后执行相关操作。这也是我对MCP的理解(执行相关操作)。因此要做日程助理,那就很简单了。首先搞一个脚本,能够自动调用mac并添加日历,然后再包装成MCP,最后引入大模型就ok了。顺着这个思路,接下来就讲讲如何实现吧
实现
第一步:在mac上添加日历
这里我们需要先明确一个概念。mac上给日历添加日程,其实是就是给对应的日历类型添加日程。举个例子

左边红框其实就是日历类型,比如我要添加一个开发日程,其实就是先选择"开发"日历,然后在该日历下添加日程。因此如果我们想通过脚本形式创建日程,其实就是先看日历类型存在不存在,如果存在,就在该类型下添加一个日程。
因此这里第一步,我们先获取mac上有没有对应的日历,没有的话就创建一个。
1.1 查找日历
参考文档 mac查找日历
假定我们的日历类型叫做 日程助手。 这里我使用了applescript的语法,因为JavaScript的方式我这运行有问题。
import { execSync } from 'child_process';
function checkCalendarExists(calendarName) {
const Script = `tell application "Calendar"
set theCalendarName to "${calendarName}"
set theCalendar to first calendar where its name = theCalendarName
end tell`;
// 执行并解析结果
try {
const result = execSync(`osascript -e '${Script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log(result);
return true;
} catch (error) {
console.error('检测失败:', error.message);
return false;
}
}
// 使用示例
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
附赠检验结果
现在我们知道了怎么判断日历存不存在,那么接下来就是,在日历不存在的时候创建日历
1.2 日历创建
参考文档 mac 创建日历
import { execSync } from 'child_process';
// 创建日历
function createCalendar(calendarName) {
const script = `tell application "Calendar"
make new calendar with properties {name:"${calendarName}"}
end tell`;
try {
execSync(`osascript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (e) {
console.log('create fail', e)
return false;
}
}
// 检查日历是否存在
function checkCalendarExists(calendarName) {
....
}
// 使用示例
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
if (!exists) {
const res = createCalendar(calendarName);
console.log(res ? '✅ 创建成功' : '❌ 创建失败')
}
运行结果

接下来就是第三步了,在日历“日程助手”下创建日程
1.3 创建日程
import { execSync } from 'child_process';
// 创建日程
function createCalendarEvent(calendarName, config) {
const script = `var app = Application.currentApplication()
app.includeStandardAdditions = true
var Calendar = Application("Calendar")
var eventStart = new Date(${config.startTime})
var eventEnd = new Date(${config.endTime})
var projectCalendars = Calendar.calendars.whose({name: "${calendarName}"})
var projectCalendar = projectCalendars[0]
var event = Calendar.Event({summary: "${config.title}", startDate: eventStart, endDate: eventEnd, description: "${config.description}"})
projectCalendar.events.push(event)
event`
try {
console.log('开始创建日程');
execSync(` osascript -l JavaScript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log('✅ 日程添加成功');
} catch (error) {
console.error('❌ 执行失败:', error);
}
}
// 创建日历
function createCalendar(calendarName) {
....
}
// 检查日历是否存在
function checkCalendarExists(calendarName) {
...
}
这里我们完善一下代码
import { execSync } from 'child_process';
function handleCreateEvent(config) {
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
// console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
if (!exists) {
const createRes = createCalendar(calendarName);
console.log(createRes ? '✅ 创建日历成功' : '❌ 创建日历失败')
if (createRes) {
createCalendarEvent(calendarName, config)
}
} else {
createCalendarEvent(calendarName, config)
}
}
// 创建日程
function createCalendarEvent(calendarName, config) {
const script = `var app = Application.currentApplication()
app.includeStandardAdditions = true
var Calendar = Application("Calendar")
var eventStart = new Date(${config.startTime})
var eventEnd = new Date(${config.endTime})
var projectCalendars = Calendar.calendars.whose({name: "${calendarName}"})
var projectCalendar = projectCalendars[0]
var event = Calendar.Event({summary: "${config.title}", startDate: eventStart, endDate: eventEnd, description: "${config.description}"})
projectCalendar.events.push(event)
event`
try {
console.log('开始创建日程');
execSync(` osascript -l JavaScript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log('✅ 日程添加成功');
} catch (error) {
console.error('❌ 执行失败:', error);
}
}
// 创建日历
function createCalendar(calendarName) {
const script = `tell application "Calendar"
make new calendar with properties {name:"${calendarName}"}
end tell`;
try {
execSync(`osascript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (e) {
console.log('create fail', e)
return false;
}
}
// 检查日历是否存在
function checkCalendarExists(calendarName) {
const Script = `tell application "Calendar"
set theCalendarName to "${calendarName}"
set theCalendar to first calendar where its name = theCalendarName
end tell`;
// 执行并解析结果
try {
const result = execSync(`osascript -e '${Script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (error) {
return false;
}
}
// 运行示例
const eventConfig = {
title: '团队周会',
startTime: 1744183538021,
endTime: 1744442738000,
description: '每周项目进度同步',
};
handleCreateEvent(eventConfig)
运行结果

这就是一个完善的,可以直接在终端运行的创建日程的脚本的。接下来我们要做的就是,让大模型理解这个脚本,并学会使用这个脚本
第二步: 定义MCP
基于第一步,我们已经完成了这个日程助理的基本功能,接下来就是借助MCP的能力,教会大模型知道有这个函数,以及怎么调用这个函数
// 引入 mcp
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
// 声明MCP服务
const server = new McpServer({
name: "mcp_calendar",
version: "1.0.0"
});
...
// 添加日历函数 也就是告诉大模型 有这个东西以及怎么用
server.tool("add_mac_calendar", '给mac日历添加日程, 接受四个参数 startTime, endTime是起止时间(格式为YYYY-MM-DD HH:MM:SS) title是日历标题 description是日历描述', { startTime: z.string(), endTime: z.string(), title: z.string(), description: z.string() },
async ({ startTime, endTime, title, description }) => {
const res = handleCreateEvent({
title: title,
description: description,
startTime: new Date(startTime).getTime(),
endTime: new Date(endTime).getTime()
});
return {
content: [{ type: "text", text: res ? '添加成功' : '添加失败' }]
}
})
// 初始化服务
const transport = new StdioServerTransport();
await server.connect(transport);
这里附上完整的ts代码
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { execSync } from 'child_process';
import { z } from "zod";
export interface EventConfig {
// 日程标题
title: string;
// 日程开始时间 毫秒时间戳
startTime: number;
// 日程结束时间 毫秒时间戳
endTime: number;
// 日程描述
description: string;
}
const server = new McpServer({
name: "mcp_calendar",
version: "1.0.0"
});
function handleCreateEvent(config: EventConfig) {
const calendarName = '日程助手';
const exists = checkCalendarExists(calendarName);
// console.log(`日历 "${calendarName}" 存在:`, exists ? '✅ 是' : '❌ 否');
let res = false;
if (!exists) {
const createRes = createCalendar(calendarName);
console.log(createRes ? '✅ 创建日历成功' : '❌ 创建日历失败')
if (createRes) {
res = createCalendarEvent(calendarName, config)
}
} else {
res = createCalendarEvent(calendarName, config)
}
return res
}
// 创建日程
function createCalendarEvent(calendarName: string, config: EventConfig) {
const script = `var app = Application.currentApplication()
app.includeStandardAdditions = true
var Calendar = Application("Calendar")
var eventStart = new Date(${config.startTime})
var eventEnd = new Date(${config.endTime})
var projectCalendars = Calendar.calendars.whose({name: "${calendarName}"})
var projectCalendar = projectCalendars[0]
var event = Calendar.Event({summary: "${config.title}", startDate: eventStart, endDate: eventEnd, description: "${config.description}"})
projectCalendar.events.push(event)
event`
try {
console.log('开始创建日程');
execSync(` osascript -l JavaScript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
console.log('✅ 日程添加成功');
return true
} catch (error) {
console.error('❌ 执行失败:', error);
return false
}
}
// 创建日历
function createCalendar(calendarName: string) {
const script = `tell application "Calendar"
make new calendar with properties {name:"${calendarName}"}
end tell`;
try {
execSync(`osascript -e '${script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (e) {
console.log('create fail', e)
return false;
}
}
// 检查日历是否存在
function checkCalendarExists(calendarName: string) {
const Script = `tell application "Calendar"
set theCalendarName to "${calendarName}"
set theCalendar to first calendar where its name = theCalendarName
end tell`;
// 执行并解析结果
try {
const result = execSync(`osascript -e '${Script}'`, {
encoding: 'utf-8',
stdio: ['pipe', 'pipe', 'ignore'] // 忽略错误输出
});
return true;
} catch (error) {
return false;
}
}
server.tool("add_mac_calendar", '给mac日历添加日程, 接受四个参数 startTime, endTime是起止时间(格式为YYYY-MM-DD HH:MM:SS) title是日历标题 description是日历描述', { startTime: z.string(), endTime: z.string(), title: z.string(), description: z.string() },
async ({ startTime, endTime, title, description }) => {
const res = handleCreateEvent({
title: title,
description: description,
startTime: new Date(startTime).getTime(),
endTime: new Date(endTime).getTime()
});
return {
content: [{ type: "text", text: res ? '添加成功' : '添加失败' }]
}
})
const transport = new StdioServerTransport();
await server.connect(transport);
第三步: 导入Windsurf
在前文已经讲过如何引入到Windsurf,可以参考前文# 前端的AI路其之二:初试MCP Server ,这里就不过多赘述了。 其实在build之后,完全可以引入其他支持MCP的软件基本都是可以的。
接下来就是愉快的调用时间啦。
总结
这里其实是对前文# 前端的AI路其之二:初试MCP Server 的再次深入。算是大概讲明白了Tool方式怎么用,MCP当然不止这一种用法,后面也会继续输出自己的学习感悟,也欢迎各位大佬的分享和指正。
祝好。
来源:juejin.cn/post/7495598542405550107
Web PWA的极致,比App更像App
这是一个平平无奇的音乐App Vooh,你可以在里面搜索歌曲,添加播放列表,播放音乐。

你可以滑动返回上一级页面,就像任何一个普通的App那样。

你可以流畅地展开音乐播放面板,看着歌词随着播放时间滚动。

当然,你也可以在电脑端,或者iPad上使用这个App。

而它与App的唯一不同,在于安装它不需要下载庞大的安装文件,只需要一个链接。音乐播放器Vooh的本体,只是一个网页。
作为一个诞生了好几年的老技术,PWA(Progressive Web Application)自诞生以来一直都不温不火,Google对它的愿景是最终所有的网页都能做到和App一致的体验,但直到现在,它都像是一道可有可无的饭后甜点。对于网页来说,即用即走似乎是它与生俱来的诅咒,用户既没有将Web安装到桌面的必要,也没有这个耐心,毕竟对于网络延迟增加1秒都可能导致访问量降低80%的地狱难度模式的网页用户生态而言,让一个浏览器用户点击一个陌生的“Install as application”的按钮简直是天方夜谭。尽管它就在那里,但乐于尝试的人似乎总是寥寥无几。既然PWA和纯网页能做的事情相差无几,那为什么还要浪费桌面空间增加一个以后可能再也不会使用的图标呢?
我一直认为,PWA应该朝着更像App的方向努力,才能体现出它的价值。然而,目前的许多PWA,看起来只是把普通的网页做成了全屏,与在浏览器中的体验别无二致,做不出差异化,用户自然没有动力去安装PWA,PWA那些听起来十分美好的特性便成了空中楼阁,无源之水,这个名字也越来越将从人们的视野中慢慢淡去。
如何才能让PWA更像APP,这是一个问题。毕竟浏览器的交互逻辑和原生App相比,有着很大的区别,用户早已习惯了移动浏览器中的前进后退,页面加载时的白屏,以及几乎不存在的手势交互,似乎在说,没关系,这就是网页,它做到这个份上已经足够了。然而,若要把这份体验带到模仿原生App的PWA中去,那势必将迎来用户预期低落的反噬,连这样那样的交互体验都没有,还能叫App?
为了了解目前的PWA究竟能做到何种地步,我开发了Vooh,一个竭尽可能模仿原生App实现的PWA音乐播放器。它尽力实现了一个原生App应该具备的一切交互细节,包括页面间自然的动画过渡,跟手的手势交互,为触屏优化的样式细节等等,我尽可能将它的每个细节都尽可能地做到与App别无二致,就是为了探索Web能力的极限。而在这之后,我也打算将Vooh的实现原理整理出来,并且准备逐步将之前的做过的项目“App化”,来一窥Google期待的未来,究竟是什么样子。
无处不在的过渡动画
尽管Vue,React以及原生CSS都提供了方便的方式实现过渡动画,但是对于大多数网页来说,一个Loading动画可能就是整个页面里动画最多的地方了。这对于网页来说的确无关紧要,毕竟用户们早已习惯了浏览器里生硬的切换效果,没有成体系的交互反馈,以及突然消失出现的页面区域。尽管在许多成熟组件库慢慢开始注重交互动画的优化之后,这样的情况在慢慢改善,但是依然难以改变用户的刻板印象。因此,为用户的预期提供动画反馈是伪装成原生App的一个关键步骤,否则,缺少反馈的使用体验会一下子将用户安装和使用PWA的欲望拉得很低。
除去老生常谈的按钮悬浮、按下时的动画,页面间的过渡动画也是不可缺少的一环。如果你仔细观察iOS的Tab页面,就能发现在切换Tab的时候,也会有细微的不易察觉的缩放淡出渐变,正是这种细致入微的动画组成了iOS App丝滑体验中重要的一部分。
表单组件的动画效果也很重要,Vooh尽可能地使用了iOS风格的表单组件,例如Button,Switch等,以贴合用户的日常视觉体验。

手势交互
手势是网页与App的重要差异点,一般来说,很少会有网页支持用户的滑动返回,长按呼出菜单等复杂的手势操作,而这正是让你的PWA丝般顺滑的关键。
需要注意的是,由于大部分移动浏览器和JS本身单线程的限制,手势交互依赖监听器的执行速度,而很难跑满设备屏幕的帧率上限,尤其是iOS设备上,开启低电量模式的情况下,监听器的帧率可能只有不到30 FPS,肉眼可见的卡顿。目前为止,也没有看到任何浏览器厂商有关于优化手势交互的提案,手势交互就像一道横亘在网页与App之间的鸿沟,没有丝毫跨越的可能,只能尽可能地模仿。

离线访问
没有哪个用户能接受打开App时整个页面全部消失无法操作,APP的最大优点就是离线可用,好在Service Worker的推出让这一点不再是问题,通过Service Worker对网页资源进行缓存,可以实现在低网速甚至离线环境下,也能继续使用PWA,就像真正的App那样。
然而不幸的是,在iOS设备上,Service Worker离线缓存不再可用,开启飞行模式或者关闭网络连接后将无法访问任何网页,包括已经安装在桌面上的PWA,
偶遇现代IE厂商,拼尽全力无法战胜。
细节之外的细节
而Vooh在这些基础能力之外,还增加了许多其他的细节设计,让整个App在模仿原生App时更进一步。
1,存储占用管理
在移动设备上,PWA与App的存储占用是分隔开的,而且往往要经过十分复杂的步骤才能看到PWA的实际空间占用,因此对于音乐播放器这种高度依赖本地资源的应用来说,一个显而易见的存储占用管理系统能有效缓解用户的存储焦虑。

2,接入系统播放器
隆重介绍Media Session API,它能让JS直接接入系统播放器控件,即使在后台也可以允许用户通过系统自带的播放器控制媒体的播放,例如下一曲、播放暂停等,在iOS设备上,还能直接适配灵动岛,这下谁还能分辨谁是原生App。

3,深色模式
在Apple等手机厂商的推动下,大部分的App都已经适配深色模式,而网页对于深色模式的适配比起App要更为简单,毕竟CSS实在是太灵活了,Vooh当然也做了适配,在不同的模式下都能完美贴合系统的主体模式。
为了提升Vooh与其他原生播放器的(根本不存在的)竞争力,我也煞费苦心地加入了许多的细节,来让用户有真正使用它的动力,例如根据歌曲封面动态取色,自动识别的滚动歌词等,希望能让它在用户的手机桌面上多待一段时间。
未竟之事
不过,即使是做到了这个地步,PWA的能力始终是有极限的。有些App轻易能做到的事,对于PWA而言犹如天堑一般遥不可及,包括但不限于:
1,后台活动
在移动设备上,网页也好,PWA也好,基本上没有任何后台活动能力,甚至上面提到的Media Session API,在iOS上顶多也只最多能支持后台播放1~2首歌曲,然后就会被强行停止,更不用说后台导航,推送通知这种活在梦里的API了,这方面浏览器天生就是残废,未来也看不到有任何改进的可能,因此在开发PWA时,一定要远离这些方向。在js都能跑虚拟机,剪视频的当下,Web开发者们推送一条通知的希冀却只能在另一个平行时空实现了。
2,跳转到PWA
据说Andriod Chrome支持使用PWA来打开特定的链接,不过在iOS上就别想了。
3,触感反馈
同样,Web也只能使用早已被淘汰的Vibrate,细腻的振动反馈和Taptic Engine对网页来说也是天方夜谭。
4,调用原生功能
还有无数浩如烟海的功能是PWA完全无法实现的,例如系统级的音量调节,亮度调节等,我能理解这是浏览器对恶意网站的限制,但这也确实极大限制了Web的发展,比如奠定了Web安全基础的跨域限制,如今成为了许多大型Web应用的掣肘。我由衷地希望某天浏览器能制定一个更宽松的PWA标准,例如安装到桌面后能提供更多的权限,提供一个无跨域限制的fetch代替品等等,然而即使对Web上心如Google,也没有考虑过这个方向的可能性。JS正在和越来越宽松的宿主环境(Tuari,Electron)一步步蚕食着原生GUI开发的领地,而它的发源地,浏览器却只能被所谓的安全性限制,成为一个只负责播放动画的花瓶。
总结
正如所说,一切能由javascript实现的终将会用javascript实现。如今,越来越多的平台小程序,快应用,乃至于H5套壳的App越来越多,随着浏览器性能的进一步提升,Web能做到的事越来越多,但是Web的交互性却并没有随着javascript的繁荣而被重视起来,受限于javascript的单线程特性,要完全模拟App的使用体验还是有一定的差距,一个劲地往原生体验上靠,有时也并不一定是最好的选择,Vooh的出现只是给了开发者们一个可能的方向,Web的轻量,优秀的可触达性与PWA有机结合,才是Web的发展方向。同时也希望各家浏览器厂商们能加快适配新的Web特性,能够让程序们在写代码时少掉一些头发,便是最大的善事了
如果对Vooh的实现方式有兴趣的话,欢迎关注我的专栏或者博客,后续的代码也会一并开源,涉及到音乐版权相关,目前的Vooh只开放了2首免费无版权音乐的使用,代码也不会涉及版权相关的领域。
来源:juejin.cn/post/7490977437674651683
视频播放弱网提示实现
作者:陈盛靖
一、背景
业务群里面经常反馈,视频播放卡顿,视频播放总是停留在某一时刻就播放不了了。后面经过排查,发现这是因为弱网导致的。然而,用户数量众多,隔三差五总有人在群里反馈,有时问题一时半会好不了,用户就会怀疑不是网络,而是我们的系统问题。因此,我们希望能在弱网的时候展示提示,这样用户体验会更友好,同时也能减少一定的客诉。
二、现状分析
我们使用的播放器是chimee(http://www.chimee.org/index.html)。遗憾的是,chimee并没有视频播放卡顿自动展示loading的功能,不过我们可以通过其插件能力,来编写一个自定义video-loading的插件。
三、方案设计
使用NetworkInformation
常见的方法就是我们通过设定一个标准,然后检测用户设备的网络速度,在到达一定阈值时展示弱网提示。这里需要确定一个重要的点:什么情况下才算弱网?
我们的应用是h5,这里我们可以使用window对象中的NetworkInformation(developer.mozilla.org/zh-CN/docs/…),我们可以通过浏览器的debug工具,打印window.naviagtor.connection,这个对象内部就存储着网络信息:

其中各个属性含义如下表所示:
| 属性 | 含义 |
|---|---|
| downlink | 返回以兆比特每秒为单位的有效带宽估计,四舍五入到最接近的 25 千比特每秒的倍数。 |
| downlinkMax | 返回底层连接技术的最大下行速度,以兆比特每秒(Mbps)为单位。 |
| effectiveType | 返回连接的有效类型(意思是“slow-2g”、“2g”、“3g”或“4g”中的一个)。此值是使用最近观察到的往返时间和下行链路值的组合来确定的。 |
| rtt | 返回当前连接的有效往返时间估计,四舍五入到最接近的 25 毫秒的倍数。 |
| saveData | 如果用户在用户代理上设置了减少数据使用的选项,则返回 true。 |
| type | 返回设备用于网络通信的连接类型。它会是以下值之一: bluetooth cellular ethernet none wifi wimax other unknown |
| onchange | 接口的 change 事件在网络连接信息发生变化时被触发,并且该事件由 NetworkInformation(developer.mozilla.org/zh-CN/docs/…) 对象接收。 |
其中,我们可以通过effectiveType判断当前网络的大体情况,并且可以拿到一个预估的网络带宽(downlink)。我们可以通过监听onchange事件,在网络变差的时候,展示对应的弱网提示。
这个方案的优点是:
- 浏览器环境原生支持
- 实现相对简单
但缺点却十分明显:
- 网络状态变化非实时
effectiveType的变化可能是分钟级别的,对于短暂的网络波动,状态没办法做更精细的把控
- 存在兼容性问题
对于不同一些主流浏览器不支持,例如Firefox、Safari等
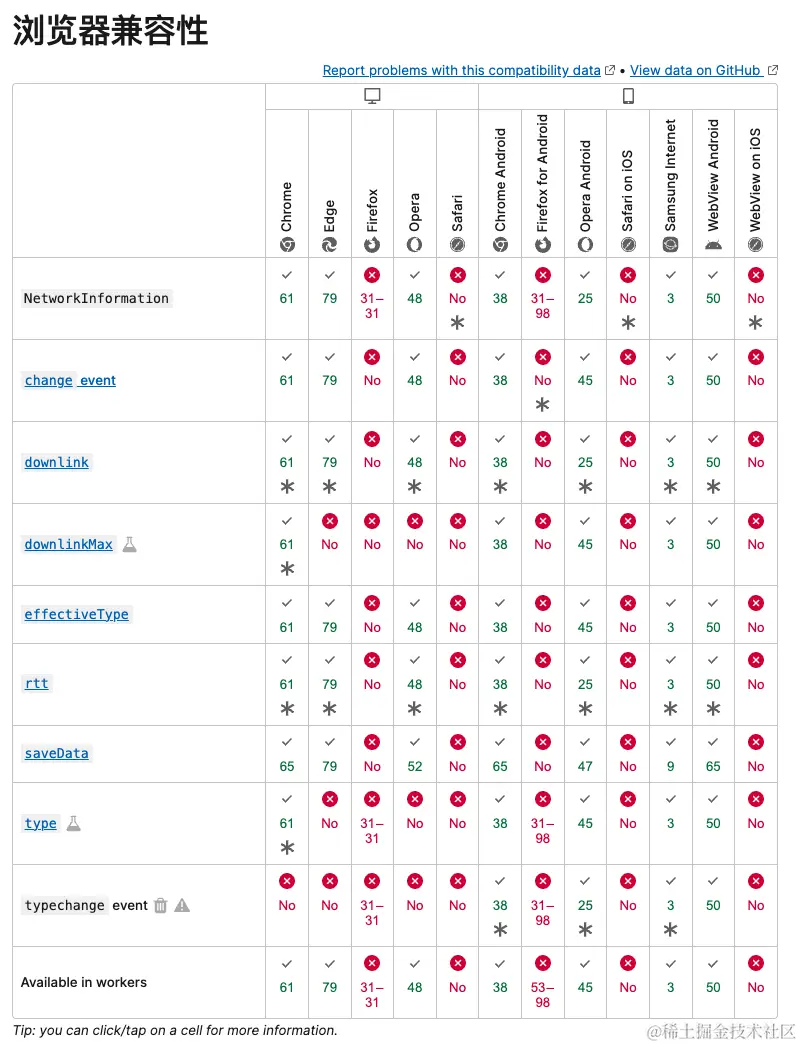
- 不同设备间存在差异
不同的设备和浏览器,由于其差异,在不同的网络情况下,视频的播放情况是不一样的,如果我们固定一个标准,可能会导致在不同设备下,同一个网络速度,有人明明正常播放视频,但是却提示网络异常,这样用户会感到疑惑。
那有没有更好的方法呢?
监听Video元素事件
chimee底层也是在html video上进行的二次封装,我们可以在插件的生命周期中,拿到对应的video元素节点。而在video标签中,存在这样两个事件:waiting和canplay。
其事件描述如下图所示:
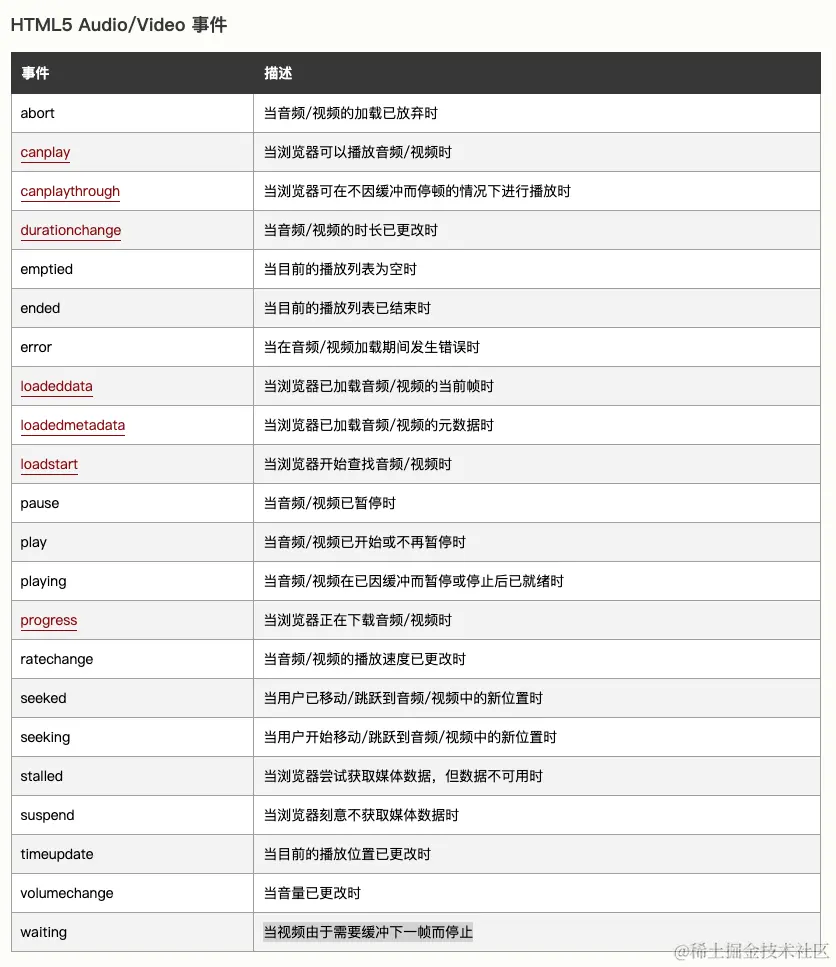
当视频播放卡顿时,会触发waiting事件;而当视频播放恢复正常时,会触发canplay事件。只要监听这两个事件,我们就可以实现对应的功能了。
四、功能拓展
我们知道,现在大多数网站的视频在提示弱网的时候,都会展示当前设备的网络速度是多少。因此我们也希望在展示对应的信息。那么怎么实现网络速度的检测呢?
一个简单的方法是,我们可以通过获取一张固定大小的图片资源(不一定是图片,也可以是别的类型的资源),并统计请求该资源的请求速度,从而计算当前网络的带宽是多少。当然,图片大小要尽可能小一点,一是为了节省用户流量,二是为了避免在网络不好的情况下,图片请求太慢导致一直计算不出来。
具体代码如下:
funtion calculateSpeed() {
// 图片大小772Byte
const fileSize = 772;
// 拼接时间戳,避免缓存
const imgUrl = `https://xxx.png?timestamp=${new Date().getTime()}`;
return new Promise((resolve, reject) => {
let start = 0;
let end = 1000;
let img = document.createElement('img');
start = new Date().getTime();
img.onload = function (e) {
end = new Date().getTime();
// 计算出来的单位为 B/s
const speed = fileSize / (end > start ? end - start : 1000) * 1000;
resolve(speed);
}
img.src = imgUrl;
}).catch(err => { throw err });
}
function translateUnit(speed) {
if(speed === 0) return '0.00 B/s';
if(speed > 1024 * 1024) return `${(speed / 1024 / 1024).toFixed(2)} MB/s`;
if(speed > 1024) return `${(speed / 1024).toFixed(2)} KB/s`;
else return `${speed.toFixed(2)} B/s`;
}
我们可以通过setInterval来轮询调用该函数,从而实时展示当前网络情况。系统流程图如下:
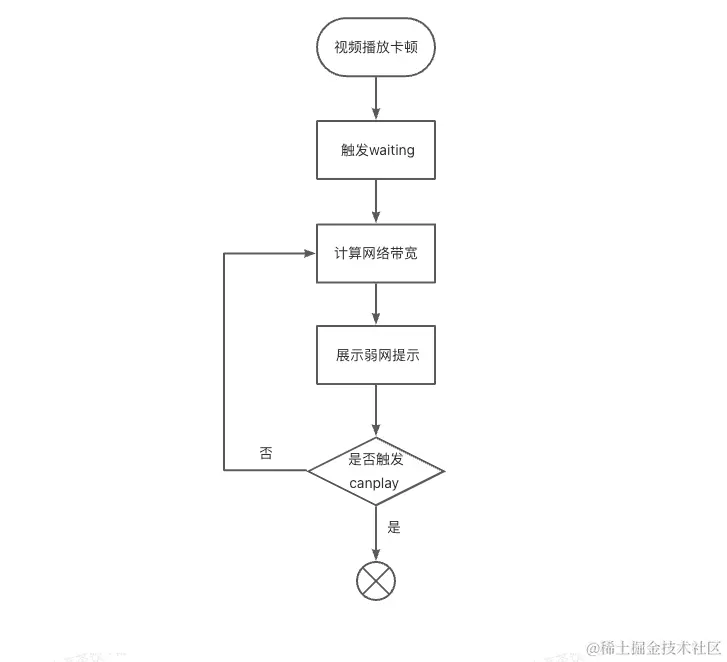
五、总结
我们可以通过Chrome浏览器开发者工具中的Network中的网络配置来模拟弱网情况

具体效果如下:

成功实现视频弱网提示,完结撒花🎉🎉🎉🎉🎉🎉。
来源:juejin.cn/post/7593550315254218758
富文本编辑器技术选型,到底是 Prosemirror 还是 Tiptap 好 ❓❓❓
我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于
Tiptap的富文本编辑器、NestJs后端服务、AI集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了Tiptap的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
在前端开发中,撤销和重做功能是提升用户体验的重要特性。无论是文本编辑器、图形设计工具,还是可视化搭建平台,都需要提供历史操作的回退和前进能力。这个功能看似简单,但实现起来需要考虑性能、内存占用、用户体验等多个方面。
在构建富文本编辑器时,Tiptap 和 ProseMirror 是两个常见的技术选择。两者都强大且灵活,但它们在设计理念、易用性、扩展性等方面存在差异。对于开发者来说,选择合适的工具对于项目的成功至关重要。本文将深入探讨两者的异同,并通过实际代码示例帮助你理解它们的差异,从而根据具体需求做出决策。
ProseMirror 的优势与挑战
ProseMirror 是一个 JavaScript 库,用于构建复杂的富文本编辑器。它的设计非常底层,提供了一个高效且灵活的文档模型,开发者可以完全控制编辑器的行为和界面。ProseMirror 本身并不提供任何 UI 或组件,而是一个核心库,开发者需要自行实现具体的编辑器功能。
作为一个底层框架,ProseMirror 允许开发者完全控制编辑器的各个方面,包括文档结构、输入行为、UI 样式等。它提供了丰富的 API,可以处理复杂的编辑需求,如数学公式、代码块、图片、链接等。开发者可以为几乎任何功能编写插件,并且可以在已有插件的基础上进行二次开发。基于虚拟 DOM 的设计,使其在大文档和复杂结构下能够提供较高的性能。
然而,由于其底层设计,ProseMirror 的 API 复杂,学习曲线陡峭。开发者需要深入理解其文档模型、事务管理、节点和视图的关系。由于不提供任何 UI 组件,开发者需要从零开始构建编辑器的界面和交互,配置和初始化过程也较为复杂,需要手动处理许多底层逻辑。
ProseMirror 基础使用示例
首先需要安装必要的包:
npm install prosemirror-state prosemirror-view prosemirror-model prosemirror-schema-basic prosemirror-schema-list prosemirror-commands
创建一个基本的 ProseMirror 编辑器需要配置 schema、state 和 view:
import { EditorState } from "prosemirror-state";
import { EditorView } from "prosemirror-view";
import { Schema, DOMParser } from "prosemirror-model";
import { schema } from "prosemirror-schema-basic";
import { addListNodes } from "prosemirror-schema-list";
import { exampleSetup } from "prosemirror-example-setup";
// 扩展基础 schema,添加列表支持
const mySchema = new Schema({
nodes: addListNodes(schema.spec.nodes, "paragraph block*", "block"),
marks: schema.spec.marks,
});
// 创建编辑器状态
const state = EditorState.create({
schema: mySchema,
plugins: exampleSetup({ schema: mySchema }),
});
// 创建编辑器视图
const view = new EditorView(document.querySelector("#editor"), {
state,
});
如果需要添加自定义命令,比如一个格式化工具条,需要手动实现:
import { toggleMark } from "prosemirror-commands";
import { schema } from "prosemirror-schema-basic";
// 创建加粗命令
const toggleBold = toggleMark(schema.marks.strong);
// 手动创建工具栏按钮
function createToolbar(view) {
const toolbar = document.createElement("div");
toolbar.className = "toolbar";
const boldBtn = document.createElement("button");
boldBtn.textContent = "Bold";
boldBtn.onclick = () => {
toggleBold(view.state, view.dispatch);
view.focus();
};
toolbar.appendChild(boldBtn);
return toolbar;
}
ProseMirror 自定义插件示例
创建一个自定义插件需要理解 ProseMirror 的插件系统:
import { Plugin } from "prosemirror-state";
// 创建一个字符计数插件
function characterCountPlugin() {
return new Plugin({
view(editorView) {
const counter = document.createElement("div");
counter.className = "char-counter";
const updateCounter = () => {
const text = editorView.state.doc.textContent;
counter.textContent = `字符数: ${text.length}`;
};
updateCounter();
return {
update(view) {
updateCounter();
},
destroy() {
counter.remove();
},
};
},
});
}
// 使用插件
const state = EditorState.create({
schema: mySchema,
plugins: [characterCountPlugin(), ...exampleSetup({ schema: mySchema })],
});
Tiptap 的便捷开发
Tiptap 是基于 ProseMirror 构建的富文本编辑器框架,它简化了 ProseMirror 的复杂性,提供了现成的 UI 组件和更易于使用的 API。Tiptap 旨在让开发者能够快速实现丰富的富文本编辑器,同时保持较高的灵活性和扩展性。
Tiptap 提供了简洁的 API,开发者不需要深入学习 ProseMirror 的底层概念即可实现基本的富文本编辑功能。它通过封装 ProseMirror 的复杂性,使得开发过程更加直观和简便。开箱即用的 UI 组件,如文本格式化、列表、图片插入等,极大地方便了开发者的使用,减少了开发时间。清晰的文档和活跃的开源社区,也为开发者提供了良好的支持和资源。虽然 Tiptap 进行了封装,但它仍然保留了 ProseMirror 的插件系统,开发者可以根据需要定制功能,并且可以轻松地集成其他插件。此外,Tiptap 可以与 Yjs 或其他 CRDT 库结合,支持实时协作编辑功能,这是 ProseMirror 本身不具备的特性。
不过,由于 Tiptap 封装了 ProseMirror 的很多底层功能,灵活性相对较低。对于一些需要极高自定义的需求,Tiptap 可能不如 ProseMirror 灵活。虽然在大多数情况下性能良好,但在处理超大文档或复杂操作时,性能可能不如直接使用 ProseMirror。
Tiptap 基础使用示例
Tiptap 的安装和使用相对简单:
npm install @tiptap/react @tiptap/starter-kit @tiptap/pm
在 React 中使用 Tiptap:
import { useEditor, EditorContent } from "@tiptap/react";
import StarterKit from "@tiptap/starter-kit";
function TiptapEditor() {
const editor = useEditor({
extensions: [StarterKit],
content: "<p>Hello World!</p>",
});
if (!editor) {
return null;
}
return (
<div>
<div className="toolbar">
<button
onClick={() => editor.chain().focus().toggleBold().run()}
disabled={!editor.can().chain().focus().toggleBold().run()}
className={editor.isActive("bold") ? "is-active" : ""}
>
Bold
</button>
<button
onClick={() => editor.chain().focus().toggleItalic().run()}
disabled={!editor.can().chain().focus().toggleItalic().run()}
className={editor.isActive("italic") ? "is-active" : ""}
>
Italic
</button>
<button
onClick={() => editor.chain().focus().toggleBulletList().run()}
className={editor.isActive("bulletList") ? "is-active" : ""}
>
Bullet List
</button>
</div>
<EditorContent editor={editor} />
</div>
);
}
Tiptap 的 Vue 版本同样简洁:
<template>
<div>
<div class="toolbar">
<button
@click="editor.chain().focus().toggleBold().run()"
:disabled="!editor.can().chain().focus().toggleBold().run()"
:class="{ 'is-active': editor.isActive('bold') }"
>
Bold
</button>
<button
@click="editor.chain().focus().toggleItalic().run()"
:class="{ 'is-active': editor.isActive('italic') }"
>
Italic
</button>
</div>
<editor-content :editor="editor" />
</div>
</template>
<script>
import { useEditor, EditorContent } from "@tiptap/vue-3";
import StarterKit from "@tiptap/starter-kit";
export default {
components: {
EditorContent,
},
setup() {
const editor = useEditor({
extensions: [StarterKit],
content: "<p>Hello World!</p>",
});
return { editor };
},
};
</script>
Tiptap 扩展功能示例
Tiptap 支持多种扩展,添加图片功能非常简单:
import Image from "@tiptap/extension-image";
import { useEditor, EditorContent } from "@tiptap/react";
import StarterKit from "@tiptap/starter-kit";
function EditorWithImage() {
const editor = useEditor({
extensions: [
StarterKit,
Image.configure({
inline: true,
allowBase64: true,
}),
],
});
const addImage = () => {
const url = window.prompt("图片URL");
if (url) {
editor.chain().focus().setImage({ src: url }).run();
}
};
return (
<div>
<button onClick={addImage}>添加图片</button>
<EditorContent editor={editor} />
</div>
);
}
创建自定义扩展也很直观:
import { Extension } from "@tiptap/core";
import { Plugin } from "prosemirror-state";
const CharacterCount = Extension.create({
name: "characterCount",
addProseMirrorPlugins() {
return [
new Plugin({
view(editorView) {
const counter = document.createElement("div");
counter.className = "char-counter";
const updateCounter = () => {
const text = editorView.state.doc.textContent;
counter.textContent = `字符数: ${text.length}`;
};
updateCounter();
return {
update(view) {
updateCounter();
},
destroy() {
counter.remove();
},
};
},
}),
];
},
});
// 使用自定义扩展
const editor = useEditor({
extensions: [StarterKit, CharacterCount],
});
Tiptap 实时协作示例
Tiptap 与 Yjs 集成实现实时协作非常简单:
npm install yjs y-prosemirror @tiptap/extension-collaboration @tiptap/extension-collaboration-cursor
import { useEditor, EditorContent } from "@tiptap/react";
import StarterKit from "@tiptap/starter-kit";
import Collaboration from "@tiptap/extension-collaboration";
import CollaborationCursor from "@tiptap/extension-collaboration-cursor";
import * as Y from "yjs";
import { WebrtcProvider } from "y-webrtc";
// 创建 Yjs 文档和提供者
const ydoc = new Y.Doc();
const provider = new WebrtcProvider("room-name", ydoc);
function CollaborativeEditor() {
const editor = useEditor({
extensions: [
StarterKit,
Collaboration.configure({
document: ydoc,
}),
CollaborationCursor.configure({
provider,
}),
],
});
return <EditorContent editor={editor} />;
}
从代码看差异
让我们通过实现一个带工具栏的编辑器来对比两者的代码复杂度:
在 ProseMirror 中,需要手动管理所有状态和命令:
import { EditorState, Plugin } from "prosemirror-state";
import { EditorView } from "prosemirror-view";
import { schema } from "prosemirror-schema-basic";
import { toggleMark } from "prosemirror-commands";
const state = EditorState.create({ schema });
const toolbarPlugin = new Plugin({
view(editorView) {
const toolbar = document.createElement("div");
toolbar.className = "toolbar";
const boldBtn = document.createElement("button");
boldBtn.textContent = "B";
boldBtn.onclick = (e) => {
e.preventDefault();
const { state, dispatch } = editorView;
const command = toggleMark(schema.marks.strong);
if (command(state, dispatch)) {
editorView.focus();
}
};
toolbar.appendChild(boldBtn);
document.body.insertBefore(toolbar, editorView.dom);
return {
destroy() {
toolbar.remove();
},
};
},
});
const view = new EditorView(document.querySelector("#editor"), {
state: EditorState.create({
schema,
plugins: [toolbarPlugin],
}),
});
而在 Tiptap 中,相同的功能实现更加简洁:
const editor = useEditor({
extensions: [StarterKit],
});
return (
<div>
<button
onClick={() => editor.chain().focus().toggleBold().run()}
className={editor.isActive("bold") ? "is-active" : ""}
>
B
</button>
<EditorContent editor={editor} />
</div>
);
如何做出选择
选择 Tiptap 还是 ProseMirror,关键在于项目需求和开发团队的技术能力。
如果你的目标是快速构建一个功能丰富、用户友好的富文本编辑器,且不希望花费过多时间在底层细节上,Tiptap 是一个理想的选择。它提供了简洁的 API 和现成的 UI 组件,可以快速启动和开发。如果你的编辑器需要一些定制功能,但不需要完全控制每个底层细节,Tiptap 提供了足够的灵活性,同时保持了开发的简便性。如果需要实现多人实时协作,Tiptap 内建的对 Yjs 等库的支持可以简化实现过程。
如果你需要完全控制编辑器的行为、界面和性能,ProseMirror 提供了更高的自由度。它适合那些有特定需求的项目,比如自定义文档结构、输入行为或非常复杂的编辑操作。在处理非常大的文档或需要极高性能的场景下,ProseMirror 能提供更好的优化和性能。如果你的项目需要完全自定义插件,或者你想对编辑器进行深度定制,ProseMirror 提供了更高的灵活性。
性能考虑
对于大文档处理,ProseMirror 提供了更细粒度的控制:
// ProseMirror 中可以精确控制更新
const state = EditorState.create({
schema,
plugins: [
// 可以精确控制哪些插件启用
// 可以自定义更新逻辑
new Plugin({
state: {
init() {
return {};
},
apply(tr, value) {
// 自定义状态更新逻辑
return value;
},
},
}),
],
});
而 Tiptap 虽然性能良好,但在极端场景下可能不如直接使用 ProseMirror 优化:
// Tiptap 的性能优化选项
const editor = useEditor({
extensions: [StarterKit],
editorProps: {
attributes: {
class:
"prose prose-sm sm:prose lg:prose-lg xl:prose-2xl mx-auto focus:outline-none",
},
// 可以传递 ProseMirror 的原生配置
},
// 但仍然受到封装层的限制
});
生态系统和社区支持
Tiptap 拥有丰富的扩展生态系统:
# Tiptap 官方扩展
npm install @tiptap/extension-image
npm install @tiptap/extension-link
npm install @tiptap/extension-table
npm install @tiptap/extension-code-block-lowlight
npm install @tiptap/extension-placeholder
npm install @tiptap/extension-character-count
npm install @tiptap/extension-typography
而 ProseMirror 的插件需要通过 prosemirror-* 包系列来获取,或者自己实现。官方提供了基础插件,但高级功能需要社区插件或自行开发。
实际项目场景建议
对于博客平台、内容管理系统、笔记应用等常见场景,Tiptap 通常是最佳选择。它的快速开发和丰富的功能足以满足大多数需求。代码示例展示了如何在几分钟内搭建一个功能完整的编辑器。
对于需要特殊文档结构(如学术论文编辑器、代码编辑器、专业排版工具)或对性能有极致要求的场景,ProseMirror 提供了必要的底层控制能力。但需要投入更多时间学习其 API 和概念。
如果你的团队时间有限,或者希望快速迭代,Tiptap 是明智的选择。如果团队有富文本编辑器开发经验,或者有充足时间进行深度定制,ProseMirror 可以带来更高的灵活性和性能。
总结
Tiptap 是一个基于 ProseMirror 的富文本编辑器框架,适合需要快速开发、易用且功能丰富的场景。它封装了 ProseMirror 的复杂性,让开发者能够专注于业务逻辑,而无需关心底层实现细节。通过本文的代码示例可以看出,Tiptap 的 API 设计更加直观,学习曲线平缓,适合大多数项目需求。
ProseMirror 则是一个底层框架,适合那些需要完全控制文档结构、编辑行为和性能优化的高级开发者。它更灵活,但学习曲线较陡峭,适合复杂或定制化需求较强的项目。从代码示例中可以看到,使用 ProseMirror 需要处理更多的底层细节,但同时也获得了更高的控制权。
如果你的项目需要快速构建编辑器并具备一定的自定义能力,Tiptap 是一个更为理想的选择。而如果你的项目需要完全的定制化和高性能处理,ProseMirror 将更符合你的需求。最终的选择应基于你的开发需求、项目规模以及团队的技术能力。建议通过实际代码尝试两者,根据你的具体场景做出最适合的选择。
来源:juejin.cn/post/7593573617647796276
瞧瞧别人家的日志打印,那叫一个优雅!
前言
这篇文章跟大家一起聊聊打印优质日志的10条军规,希望对你会有所帮助。

第1条:格式统一
反例(管理看到会扣钱):
log.info("start process");
log.error("error happen");
无时间戳,无上下文。
正解代码:
<!-- logback.xml核心配置 -->
<pattern>
%d{yy-MM-dd HH:mm:ss.SSS}
|%X{traceId:-NO_ID}
|%thread
|%-5level
|%logger{36}
|%msg%n
</pattern>
在logback.xml中统一配置了日志的时间格式、tradeId,线程、等级、日志详情都信息。
日志的格式统一了,更方便点位问题。

第2条:异常必带堆栈
反例(同事看了想打人):
try {
processOrder();
} catch (Exception e) {
log.error("处理失败");
}
出现异常了,日志中没打印任何的异常堆栈信息。
相当于自己把异常吃掉了。
非常不好排查问题。
正确姿势:
log.error("订单处理异常 orderId={}", orderId, e); // e必须存在!
日志中记录了出现异常的订单号orderId和异常的堆栈信息e。
第3条:级别合理
反面教材:
log.debug("用户余额不足 userId={}", userId); // 业务异常应属WARN
log.error("接口响应稍慢"); // 普通超时属INFO
接口响应稍慢,打印了error级别的日志,显然不太合理。
正常情况下,普通超时属INFO级别。
级别定义表:
| 级别 | 正确使用场景 |
|---|---|
| FATAL | 系统即将崩溃(OOM、磁盘爆满) |
| ERROR | 核心业务失败(支付失败、订单创建异常) |
| WARN | 可恢复异常(重试成功、降级触发) |
| INFO | 关键流程节点(订单状态变更) |
| DEBUG | 调试信息(参数流水、中间结果) |
第4条:参数完整
反例(让运维骂娘):
log.info("用户登录失败");
上面这个日志只打印了“用户登录失败”这个文案。
谁在哪登录失败?
侦探式日志:
log.warn("用户登录失败 username={}, clientIP={}, failReason={}",
username, clientIP, "密码错误次数超限");
登录失败的业务场景,需要记录哪个用户,ip是多少,在什么时间,登录失败了,失败的原因是什么。
时间在logback.xml中统一配置了格式。
这样才方便快速定位问题:

第5条:数据脱敏
血泪案例:
某同事打印日志泄露用户手机号被投诉。
我在记录的日志中,需要对一下用户的个人敏感数据做脱敏处理。
例如下面这样:
// 脱敏工具类
public class LogMasker {
public static String maskMobile(String mobile) {
return mobile.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
}
}
// 使用示例
log.info("用户注册 mobile={}", LogMasker.maskMobile("13812345678"));
第6条:异步保性能
问题复现
某次秒杀活动中直接同步写日志,导致大量线程阻塞:
log.info("秒杀请求 userId={}, itemId={}", userId, itemId);
高并发下IO阻塞。
致命伤害分析:
- 同步写日志导致线程上下文切换频繁
- 磁盘IO成为系统瓶颈
- 高峰期日志打印耗时占总RT的25%
正确示范(三步配置法)
步骤1:logback.xml配置异步通道
<!-- 异步Appender核心配置 -->
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志的阈值:当队列剩余容量<此值时,TRACE/DEBUG级别日志将被丢弃 -->
<discardingThreshold>0</discardingThreshold>
<!-- 队列深度:建议设为 (最大并发线程数 × 2) -->
<queueSize>4096</queueSize>
<!-- 关联真实Appender -->
<appender-ref ref="FILE"/>
</appender>
步骤2:日志输出优化代码
// 无需前置判断,框架自动处理
log.debug("接收到MQ消息:{}", msg.toSimpleString()); // 自动异步写入队列
// 不应做复杂计算后再打印(异步前仍在业务线程执行)
// 错误做法:
log.debug("详细内容:{}", computeExpensiveLog());
流程图如下:

步骤3:性能关键参数公式
最大内存占用 ≈ 队列长度 × 平均单条日志大小
推荐队列深度 = 峰值TPS × 容忍最大延迟(秒)
例如:10000 TPS × 0.5s容忍 ⇒ 5000队列大小
风险规避策略
- 防队列堆积:监控队列使用率,达80%触发告警
- 防OOM:严格约束大对象toString()的调用
- 紧急逃生:预设JMX接口用于快速切换同步模式
第7条:链路追踪
混沌场景:
跨服务调用无法关联日志。
我们需要有链路追踪方案。
全链路方案:
// 拦截器注入traceId
MDC.put("traceId", UUID.randomUUID().toString().substring(0,8));
// 日志格式包含traceId
<pattern>%d{HH:mm:ss} |%X{traceId}| %msg%n</pattern>
可以在MDC中设置traceId。
后面可以通过traceId全链路追踪日志。
流程图如下:

第8条:动态调参
半夜重启的痛:
线上问题需要临时开DEBUG日志,比如:查询用户的某次异常操作的日志。
热更新方案:
@GetMapping("/logLevel")
public String changeLogLevel(
@RequestParam String loggerName,
@RequestParam String level) {
Logger logger = (Logger) LoggerFactory.getLogger(loggerName);
logger.setLevel(Level.valueOf(level)); // 立即生效
return "OK";
}
有时候我们需要临时打印DEBUG日志,这就需要有个动态参数控制了。
否则每次调整打印日志级别都需要重启服务,可能会影响用户的正常使用。
journey
title 日志级别动态调整
section 旧模式
发现问题 --> 修改配置 --> 重启应用 --> 丢失现场
section 新模式
发现问题 --> 动态调整 --> 立即生效 --> 保持现场
第9条:结构化存储
混沌日志:
用户购买了苹果手机 订单号1001 金额8999
上面的日志拼接成了一个字符串,虽说中间有空格分隔了,但哪些字段对应了哪些值,看起来不是很清楚。
我们在存储日志的时候,需要做结构化存储,方便快速的查询和搜索。
机器友好式日志:
{
"event": "ORDER_CREATE",
"orderId": 1001,
"amount": 8999,
"products": [{"name":"iPhone", "sku": "A123"}]
}
这里使用了json格式存储日志。
日志中的数据一目了然。
第10条:智能监控
最失败案例:
某次用户开通会员操作,错误日志堆积3天才被发现,黄花菜都凉了。
我们需要在项目中引入智能监控。
ELK监控方案:

报警规则示例:
ERROR日志连续5分钟 > 100条 → 电话告警
WARN日志持续1小时 → 邮件通知
总结
研发人员的三大境界:
- 青铜:
System.out.println("error!") - 钻石:标准化日志 + ELK监控
- 王者:
- 日志驱动代码优化
- 异常预测系统
- 根因分析AI模型
最后的灵魂拷问:
下次线上故障时,你的日志能让新人5分钟定位问题吗?
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
来源:juejin.cn/post/7593232758128246790
一杯奶茶钱,PicGo + 阿里云 OSS 搭建永久稳定的个人图床
大家好,我是老刘
今天不聊Flutter开发,聊聊程序员常用的markdown工具。
最近这两天是用阿里云oss搞了个图床,发现还是有很多细节问题的,给大家分享一下。
这件事的起因是之前一直用的写文章的在线服务出了点问题,现在想直接在本地Trae或者Obsidian中写文章(markdown格式),但是为了复制到公众号方便,要自己搞一个图床,否则图片就不能直接复制到公众号和其它平台了。
研究了一圈后最终选择了PicGo 配合阿里云 OSS(对象存储)。
为啥选阿里云 OSS?
这目前最稳定、速度最快且性价比极高的图床方案之一。
而且是目前还有3个月的免费试用。
虽然它不是完全免费(需要极少的存储费和流量费,个人使用通常一年不到一杯奶茶钱),但带来的体验升级远超免费图床。
阿里云 OSS 是按量付费的,主要包含两部分:
- 存储费 : 存多少收多少,个人博客通常只有几百 MB,一个月0.12元。
- 流量费 : 有人访问你的图片才收费 。
- 00:00 - 08:00 (闲时): 0.25元/GB
- 08:00 - 24:00 (忙时): 0.50元/GB

- 注:不同地域价格微调,以上为参考。
为啥不选免费图床?
- GitHub 的问题: 由于国内网络原因,GitHub 的链接经常超时。这会导致发布平台抓取图片失败,最后不得不一张张手动重新上传图片,效率极低。
- Gitee 的问题:
- PicGo本身默认移除了 Gitee 官方支持(旧版可能有,新版需插件)。
- Gitee 为了防止滥用,限制了文件的外链访问,也就是访问量大有可能失败。(这个是听人说的,我自己在Obsidian笔记中用没有发现)
- 担心如果被系统判定为图床仓库,可能会导致仓库甚至账号被封禁。
接下来是 从零开始配置 PicGo + 阿里云 OSS 的详细保姆级教程。
配置方案
第一阶段:阿里云 OSS 配置 (只需做一次)
1. 开通 OSS 服务
- 登录 http://www.aliyun.com/
- 搜索 "对象存储 OSS",点击进入控制台。
- 点击 "开通服务"(如果已开通则跳过)。
2. 创建 Bucket (存储桶)
- 在 OSS 控制台左侧菜单,点击 Bucket 列表 -> 创建 Bucket。
- 填写配置:
- Bucket 名称: 起个名字(例如
oss_img)。 - 地域 (Region): 选择离你或者你的用户访问地点最近的(例如
华北2 (北京))。记住这个地域,后面要用。 - 存储类型: 标准存储。
- 读写权限 (ACL): 公共读 (Public Read)。这一点非常重要,否则图片链接发给别人无法访问。
- 其他选项默认即可。
- Bucket 名称: 起个名字(例如
- 点击确定创建。
3. 获取 AccessKey (密钥)
为了安全,不建议使用主账号的 Key,建议创建一个专门用于 OSS 的子账号。
回到 OSS 控制台的主界面,注意不是Bucket管理界面。
- 鼠标悬停在右上角头像,选择 AccessKey 管理 -> 使用RAM用户 AccessKey。
- 进入 RAM 访问控制台,点击 创建用户。
- 登录名称: 例如
picgo-user。 - 访问方式: 勾选 API 访问。
- 登录名称: 例如
- 点击确定,立即复制保存
AccessKey ID和AccessKey Secret(Secret 只显示这一次,丢了要重新建)。 - 给子用户授权:
- 在用户列表页面,找到刚才创建的
picgo-user,点击右侧 添加权限。 - 搜索
OSS,选择AliyunOSSFullAccess(或者更精细的权限,简单起见选 FullAccess)。 - 点击确定。
- 在用户列表页面,找到刚才创建的
第二阶段:PicGo 客户端/插件配置
我是用的是PicGo 桌面版,因为一方面我的场景是在Trae和Obsidian中都要用,另一方面,vs-picgo插件已经好几年没更新了。
所以如果你经常要在 Typora、Obsidian 等多个软件里用图床,建议配置桌面版。
而且日常使用我都是通过快捷键操作,桌面版和插件的操作复杂度是一样的,桌面版还有更全面的功能。
配置 PicGo 桌面版
- 下载并安装 PicGo 桌面版。
- 打开 PicGo -> 图床设置 -> 阿里云 OSS。
- 填写配置:
- 设定 KeyId:
AccessKey ID - 设定 KeySecret:
AccessKey Secret - 设定存储空间名: Bucket 名称 (例如
oss_img) - 确认存储区域: 也就是 Area,例如
oss-cn-beijing。 - 指定存储路径:
img/
- 设定 KeyId:
- 点击 确定 和 设为默认图床。
第三阶段:验证与使用
- 测试上传:
- 拖拽一张图片到 PicGo 主窗口。
- 或者随便截张图,然后按
Ctrl+Shift+P自动上传 看到上传成功的提示后生成的链接已经自动复制到剪贴板。
- 检查链接:
- 如果你看到生成的链接类似
https://oss_img.oss-cn-beijing.aliyuncs.com/img/xxx.png,且能在浏览器中正常打开图片,说明配置成功!
- 如果你看到生成的链接类似
其它事项
本地冗余还是同城冗余
对于 个人图床 (博客、笔记图片)这种场景,答案非常明确,请选择本地冗余 (LRS)
- 更便宜 (核心理由)
- 本地冗余 (LRS): 价格较低(标准存储约 0.12元/GB/月)。
- 同城冗余 (ZRS): 价格较高(标准存储约 0.15元/GB/月),比本地冗余贵约 25%。
- 对于个人用户,没必要多花这份钱,特别是存储量大的时候差距还是比较大的。
- 可靠性已经足够高
- 本地冗余的意思是:你的数据会存在阿里云同一个机房内的不同设备上。除非这整个机房发生灾难性毁灭(如大地震彻底摧毁机房),否则数据不会丢。数据可靠性高达 99.999999999% (11个9)。
- 同城冗余的意思是:你的数据会存在同一个城市的三个不同机房里。只有当这个城市的三个机房同时全挂了,数据才会丢。数据可靠性高达 12个9。
对于个人博客图片,本地冗余 (11个9) 的安全性已经远远溢出了。即使真的遇到极小概率的机房故障,阿里云通常也有修复手段。为了那几十块钱的图片去买“抗核弹级”的同城冗余,属于过度消费。
如果你实在不放心,就写个脚本定期把图片备份到其它平台即可。
防坑指南
特别注意:不要把 AccessKey 泄露给别人。
阿里云 OSS 是按量付费的,主要包含两部分:
- 存储费: 存多少收多少,个人博客通常只有几百 MB,这个很少。
- 流量费: 有人访问你的图片才收费。
如果你的图片是自己使用,比如Obsidian笔记,或者发布到公众号文章,那么问题不大。
比如老刘自己的Obsidian笔记只有几台电脑和手机同步使用,用量很小。
如果发布到公众号、csdn等平台也问题不大,因为各个平台都会抓取你的图片,发布的文章中使用的是平台的图片链接,而不是你自己的图片链接。
但是如果你是自建的个人博客,要注意一下访问量。
- 如果你的博客访问量非常巨大(每天几万),流量费会是一笔开支。对于普通个人博客,一年通常也就几十块钱。
- 可以在阿里云后台设置 “消费预警”,例如设置消费超过 10 元发短信通知,防止被恶意刷流量。
最后再说两句
折腾这么一圈,其实就为了一个目的:让写作回归写作本身。
我们花时间去配置图床、优化流程,不是为了成为工具大师,而是为了在灵感迸发的那一刻,不会因为图片上传失败这种破事而打断思路。
工具最好的状态,就是当你用它的时候,你根本感觉不到它的存在。
配置好 PicGo + 阿里云 OSS,把琐碎的技术细节丢给自动化工具,剩下的,就是尽情释放你的创造力了。
毕竟,内容,才是一切的王道。
如果看到这里的同学对客户端或者Flutter开发感兴趣,欢迎联系老刘,我们互相学习。
私信免费领老刘整理的《Flutter开发手册》,覆盖90%应用开发场景。
可以作为Flutter学习的知识地图。
—— laoliu_dev
来源:juejin.cn/post/7594000527510093865
MCP 是最大骗局?Skills 才是救星?
尤记得上半年大家对 MCP 的狂热,遇人就会和我聊到 MCP。然而从落地使用上似乎不是这么个情况。社区里面流传着一句话:MCP 是一个开发者远超使用者的功能。那么 MCP 真的是世上最大骗局吗?

如果你是 AI 工具的用户(而不是开发者),这篇文章可能会从另一角度来尝试解释:为什么 MCP 这么火,但你用起来总觉得”没什么用”?Skills 为什么可能才是你真正需要的东西。
一、MCP:开发者的狂欢,用户的懵圈
MCP(Model Context Protocol)在 2024 年底由 Anthropic 发布,号称是 AI 领域的”USB-C”——一个标准化的协议,让 AI 可以连接各种外部工具。
听起来很美好。但现实是社区里充斥着对 MCP 的嘲讽,称其为”最大骗局”。
MCP 可能是唯一开发者比使用者还多的技术 开发者为什么吐槽 MCP 协议?

这意味着什么?
大量开发者在「研究」MCP,但真正能给用户用的工具少得可怜。
SDK 月下载量 9700 万次,Registry 增长 407%——开发者热情高涨。但作为用户,你打开 Claude 或 Cursor,想找个好用的 MCP 工具,大概率还是会失望。
这不是 MCP 的错。这是它的「基因」决定的。
二、协议的「基因」决定了谁受益
为什么 MCP 对用户不友好?也许答案藏在协议设计本身。
我们对比下 MCP 和 Skills(Agent Skills)两个协议的规范:
| 维度 | MCP | Skills |
|---|---|---|
| 协议规定的是 | 开发者怎么写工具 | AI 怎么用能力 |
| 规范内容 | API、Schema、SDK | Markdown、Instructions |
| 开发者上手门槛 | 懂 JSON Schema + SDK | 会写 Markdown |
来源:modelcontextprotocol.io / agentskills.io
MCP 协议规定的是「开发者怎么写工具」——API 接口怎么定义、数据结构怎么传递、SDK 怎么集成。这些对开发者很重要,但普通用户根本不关心。
Skills 协议规定的是「AI 怎么用能力」——什么时候加载、怎么理解指令、如何执行任务。这些直接影响用户体验。

即使开发者来说,Skill 的上手成本也都远低于 MCP。甚至简单的 Skills,使用者可以在使用过程中无缝切换为开发者,边用边优化。
一句话总结:MCP 面向开发者,尽力优化了开发体验,在 Agent 如何使用这些工具上却没有给出太多指导;Skill 面向使用者,优化使用体验(包括成本),在 Agent 如何使用这些工具上给出了很多指导。
协议的设计目标,决定了谁能从中获益。
三、Skills 的杀手锏:渐进式披露
除了设计目标不同,Skills 还有一个技术上的优势:渐进式披露(Progressive Disclosure) 。
这是什么意思?用一个类比来解释:图书馆找书。
想象你去图书馆找资料:
MCP 方式:管理员把整个书架的书全搬到你面前。结果:信息过载,找不到重点 📚📚📚
Skill 方式:管理员先给你一本目录,你说要哪本再拿哪本。结果:精准高效 📋→📖

AI 的「脑容量」有限(Context Window)。
- 传统方式:一次性加载所有工具定义。假设有 100 个工具,可能占用几十万 tokens。
- Skill 方式:启动时只加载名称和描述(约 100 tokens/skill)。需要哪个,再加载哪个的详细指令。
- 元数据层:~100 tokens/skill
- 完整指令:建议 <5000 tokens
这意味着什么?100 个 Skills,启动时只需要约 10,000 tokens 的元数据。而不是一股脑塞进去几十万 tokens。
- AI 不会被无关信息干扰,更聪明
- 响应更快
- 能支持更多工具
四、两者不是对手,是搭档
说了这么多 Skills 的好话,是不是意味着 MCP 没用了?不是。
MCP 和 Skills 解决的是不同层次的问题:
- MCP = 工具箱:定义了「能连接什么」——数据库、API、文件系统、第三方服务
- Skills = 使用手册:定义了「怎么聪明地用这些工具」——工作流程、最佳实践、按需加载

它们也可以结合使用:
用 Skills 的渐进式披露来管理 MCP 工具。
MCP 负责「连接」,Skills 负责「智慧」。组合是一个好的解决方案。
五、给用户的建议
- 别光被 MCP 的热度带节奏。22000+ 个仓库听起来很多,但落地的有多少呢?
- 关注 Skills 生态。如果你用 Claude Code 等工具(近期 Kwaipilot 也会支持),Skills 可能比 MCP 更能直接提升你的体验。
- 两者都关注。长期来看,MCP + Skills 的组合可能是一种选择。MCP 提供连接能力,Skills 提供使用智慧。
- 2026 年:渐进式披露和动态上下文管理会成为 AI 工具的标配。近期我的一个实践 —— 基于 20w 字的 Specs 来让 Agent 实现一个 10pd 需求 —— 也是通过渐进式披露 Specs。Cursor 也已经给出了很好的解释。
结语
MCP 是最大骗局吗?不是。它也是一个优秀的开发者协议。
Skills 是救星吗?对用户来说,目前来说可能是的。
协议的设计目标,决定了谁能从中获益。 MCP 让开发者更容易写工具,Skills 让用户更容易用工具。
如果你是用户,别纠结 MCP 为什么”不好用”了。去看看 Skills 吧。
参考链接
来源:juejin.cn/post/7594420277449015323
🌸 入职写了一个月全栈next.js 感想
背景介绍
- 最近组内要做0-1的新ai产品, 招我进来就是负责这个ai产品,启动的时候这个季度就剩下两个月了,天天开会对齐进度,一个月就已经把基础版本给做完了,想要接入到现有的业务上面,时间方面就特别紧张,技术选型怎么说呢, leader用ai写了一个版本 我们在现有的代码进行二次开发这样, 全栈next.js 要学习的东西太多了 又没有前端基础,没有ai coding很难完成任务(十几分钟干完我一天的工作 claude4.5效果还不错 进度推的特别快), 自从trae下架了claude,后面就一直cursor claude 4.5了。
- nextjs+ts+tailwindcss+shadcn ui现在是mvp套餐,startup在梭哈,时间就是生产力哪需要那么多差异化样式直接一把,有的💰才开始做细节,你会发现慢慢也💩化了。
- Nextjs 是全栈框架 可以很快把一个MVP从零到一完整跑起来。 你要是抬杠说什么高并发负载均衡啥的,你的用户数量真多到需要考虑性能的时候,你已经不需要自己考虑了(小红书看到的一段话 挺符合场景的)
- next.js 写后端 确实比较轻量 只能做一些curd的操作 socket之类的不太合适 其他api 还是随便开发 给我的感受就是前端能够直接操作db,前后端仓库可以不分离,业务逻辑还是一定要分离的 看看开源的next.js 项目的架构设计结构是怎么样的 学习/模仿/改造。
- 语言只是工具,适合最重要,技术没有银弹
- nextjs.org/ github.com/vercel/next…
项目的时间线
项目从启动到这周 大概是5周的时间
- 10/28-10/31 Week 1
- 项目初始化/需求讨论/设计文档/
- 后端next.js, typescript技术熟悉 项目运行/调试
- 基础框架搭建 设计表结构ddl, 集成mysql, 编写crud接口阶段
- 11/03-11/07 Week 2
- 产品PRD 提供
- xxxx等表设计
- 11/10-11/14 Week 3
- xxxxx 基本功能完结
- @xxxx 讲解项目结构/规范
- 11/17-11/21 Week 4
- 首页样式/逻辑 优化
- 集成统一登录调研
- 部署完成
- 11/24-11/28 Week 5
- 服务推理使用Authorization鉴权 对内接口使用Cookies (access_token) 鉴权 开发
- xxxx 表设计表设计 逻辑开发
- xxx设计 设计开发
- 联调xxxx
5周时间 功能基本完成了 剩下的就是部署到线上 进行场景实践了
前端技术栈
- Next.js 14:选择 App Router 架构,支持服务端渲染和 API Routes
- TypeScript 5.4:强类型语言提升代码质量和可维护性
- React 18:利用并发特性和 Suspense 提升用户体验
- Zustand:轻量级状态管理,替代 Redux 降低复杂度
- Ant Design + Radix UI:组件库组合,平衡美观性和可访问性
React + TypeScript react.dev/
- 优势:类型安全:TypeScript 提供编译时类型检查,减少运行时错误 ✅ 组件化开发:高度可复用的组件设计 ✅ 生态成熟:丰富的第三方库和工具链 ✅ 开发体验:优秀的 IDE 支持和调试工具
- 劣势: ❌ 学习曲线:TypeScript 对新手有一定门槛 ❌ 编译时间:大型项目编译可能较慢 ❌ 配置复杂:类型定义需要额外维护
UI 组件方案 Ant Design + Radix UI 混合方案
- 优势: ✅ 快速开发:Ant Design 提供完整的企业级组件 ✅ 无障碍性:Radix UI 提供符合 WAI-ARIA 标准的组件 ✅ 定制灵活:Radix UI 无样式组件便于自定义 ✅ 中文支持:Ant Design 对中文界面友好
- 劣势: ❌ 包体积大:两个 UI 库增加了打包体积 ❌ 样式冲突:需要注意两个库的样式隔离❌ 维护成本:需要同时维护两套组件系统
Tailwind CSS
- 优势: ✅ 开发效率高:原子化类名,快速构建 UI ✅ 体积优化:生产环境自动清除未使用的样式 ✅ 一致性:设计系统内置,确保视觉一致 ✅ 响应式:便捷的响应式设计工具
- 劣势: ❌ 类名冗长:HTML 可能变得难以阅读 ❌ 学习成本:需要记忆大量类名 ❌ 非语义化:类名不直观反映元素意义
ant design x
ahooks
后端技术栈
- Prisma 6.18:现代化 ORM,类型安全且支持 Migration
- MySQL:成熟的关系型数据库,满足复杂查询需求
- Redis (ioredis) :高性能缓存,支持多种数据结构
- Winston:企业级日志系统,支持日志轮转和结构化输出
- Zod:运行时类型验证,保障 API 数据安全
Next.js API Routes
- 优势: ✅ 统一代码库:前后端在同一项目中 ✅ 类型共享:TypeScript 类型可在前后端复用 ✅ 开发效率:无需配置跨域、代理等 ✅ 部署简单:单一应用部署
- 劣势: ❌ 扩展性限制:无法独立扩展后端服务 ❌ 性能瓶颈:Node.js 单线程可能成为瓶颈 ❌ 微服务困难:不适合复杂的微服务架构
Prisma ORM
- 优势: ✅ 类型安全:自动生成 TypeScript 类型 ✅ 迁移管理:声明式 schema,易于版本控制 ✅ 查询性能:生成优化的 SQL 查询 ✅ 关系处理:直观的关系查询 API ✅ 多数据库支持:支持 MySQL、PostgreSQL、SQLite 等
- 劣势: ❌ 复杂查询:某些复杂 SQL 可能需要原始查询 ❌ 生成代码体积:生成的 client 文件较大 ❌ 版本升级:大版本升级可能需要迁移
踩坑记录
主要是记录一些开发过程中踩坑 和设计问题
- node js 项目 jean部署
- 自定义配置/dockerfile配置 没有类似项目参考 健康检查问题 加上环境变量配置多环境 一步一步
- next.js 中 用middleware进行接口拦截鉴权 里面有prisma path import 直接出现了Edge Runtime 异常 自定义auth 解决
- npm build 项目 踩坑
- 静态渲染流程 动态api 警告 强制动态渲染
- 其他组件 document 不支持build问题
- 保存多场景模式+构建版本管理第一版考虑的太少了,发现有问题 后面又重构了一版本
- xxx日志目前还没有接入 要不就是日志文件 要不就是console.log 目前看日志的方式是去容器化运行日志看了 后续集群部署就比较麻烦了
- ant design 版本降低到6.0以下 ant-design x 用不了2.0.0 的一些对话组件
Next.js实践的项目记录
苏州 trae friends线下黑客松 📒
- 去Trae pro-Solo模式 苏州线下hackathon一趟, 基本都是一些独立开发者,一人一公司,三个小时做出一个产品用Trae-solo coder模式,不得不说trae内部集成的vercel部署很丝滑 react项目一键deploy访问 完全不用关系域名服务器, solo模式其实就是混合多种model使用进行输出 想要的效果还是得不断的调试 thiking太长,对于前后端分离项目 也能够同时关联进行思考规划。
- 1点多到4点 coding时间 从0-1生成项目 使用trae pro solo模式 就3个小时 做不了什么大的东西 那就做个日语50音的网站呗 现场酒店的网基本用不了 我数据也很卡 用的旁边干中学老师的热点 用next.js tailwindcss ant design deepseek搭建的网页 够用了 最后vercel部署 trae自带集成 挺方便的 solo模式还是太慢了 接受不了 网站地址是 traekanastudio1ssw.vercel.app/ 功能就是假名+ai生成例句和单词 我都没有路演 最后拿优秀奖可能是我部署了吧 大部分人没部署 优秀奖就是卫衣了 蹭了一天的饭加零食 爽吃
- http://www.xiaohongshu.com/explore/692… 小红书当时发的帖子 可以领奖品
Typescript的AI方向 langchain/langgraph支持ts
- 最近在看的ts的ai框架 发现langchain 是支持ts的, langchain-chat 主要是使用langchain+langgraph 对ts进行实践 traechat-apps4y6.vercel.app/
- 部署还踩坑了 MCP 在 Vercel 上不生效是因为 Vercel 是 serverless 环境,不支持运行持久的子进程。让我帮你解决这个问题:
- 主要是对最近项目组内要用的到mcp/function call 进行实践操作 使用modelscope 上面开源的mcp进行尝试 使用vercel进行部署。
- 最近看到小红书上面的3d 粒子 圣诞树有点火呀,自己也尝试下 效果很差 自己弄的提示词 可以去看看帖子上的提示词去试试 他们都是gemini pro 3玩的 我也去弄个gemini pro 3 账号去玩玩。
- 还有一个3d粒子 跟着音乐动的的效果 下面的提示词可以试试
帮我构建一个极简科幻风格的 3D 音乐可视化网页。
视觉上参考 SpaceX 的冷峻美学,全黑背景,去装饰化。核心是一个由数千个悬浮粒子组成的‘生命体’,它必须能与声音建立物理连接:低音要像心脏搏动一样冲击屏幕,高音要像电流一样瞬间穿过点阵。
重点实现一种‘ACID 流体’视觉引擎:让粒子表面的颜色不再是静态的,而是像两种粘稠的荧光液体一样,在失重环境下互相吞噬、搅拌、流动,且流速由音乐能量驱动。

- docs.langchain.com/oss/javascr…
- http://www.modelscope.ai/home
- vercel.com
- http://www.modelscope.ai/mcp

ai方向 总结
- a2a解决的是agent之间如何配合工作的问题 agent card定义名片 名称 版本 能力 语言 格式 task委托书 通信方式http 用户 客户端是主控 接受用户需求 制定具体任务 向服务器发出需求 任务分发 接受响应 服务器是各类部署好的agent 遵循一套结构化模式
- mcp 解决的llm自主调用功能和工具问题
- mcp 是解决 function call 协议的碎片化问题,多 agent 主要是为了做上下文隔离
- 比如说手机有一个system agent 然后各个app有一个agent,用户语音输入买咖啡,然后system agent调用瑞幸agent 这样就是非侵入式 让app暴露系统a2a接口,感觉比mcp要更合理一点,不是单纯让app暴露tools,系统agent只需要做路由
- 而且有一点我觉得挺有意思的,就是自己的agent花的token是自己的钱,如果自己的agent找别人的agent,让它执行任务啥的,花的不就是别人的钱……
- Dify:更像宜家的模块化家具,提供可视化工作流、预置模板,甚至支持“拖拽式”编排AI能力。比如,你想做一
个智能客服,只需在界面里连接对话模型、知识库和反馈按钮,无需写一行代码
python 和ts 在ai上面的比较
- Python 依然是 AI 训练和科研的王者,PyTorch、TensorFlow、scikit-learn 这些生态太厚实了,训练大模型你离不开它。
- TS 在底层 AI 能力上还没那么能打,GPU 加速、模型优化这些,暂时还得靠 Python 打底。
- Python 搞理论和模型,TypeScript卷体验和交付
个人学习记录
主要还是前端和ai方面的知识点学习的比较多吧
- Typescript 语法基础+进阶 / Next.js 开发指南/React 开发指南
- ahooks 组件 使用 ahooks.js.org/zh-CN/hooks…
- ant design x 使用 ant-design-x.antgroup.com/components/…
- prisma orm框架 +mysql github.com/prisma/pris…
- dotenv 读取配置文件 github.com/dotenvx/dot…
- fastmcp 项目构建使用 原理
- Agent2Agent google协议内部详情
- swagger.io/specificati… OpenAPI 规范 一个 OpenAPI 描述(OAD)可以由一个 JSON 或 YAML 文档组成
- github.com/yossi-lee/s… 根据Swagger3规范,一键将Web服务转换为MCP
- http://www.jsonrpc.org/specificati… JSON-RPC 是一种无状态、轻量级的远程过程调用(RPC)协议
- github.com/agno-agi/ag… 多智能体框架
- roadmap.sh/ai-engineer ai工程师的roadmap 很全
- github.com/ChromeDevTo… *可以集成到cursorz中 *AI 能够直接控制和调试真实的 Chrome 浏览器
- http://www.nano-banana.ai/ Nano Banana Pro (V2) 文生图 图生图
- aistudio.google.com/prompts/new… gemini ai studio
Vibe Coding
- 先叠甲, 我没有前端的开发经验,第一次写前端项目,项目里面90%的前端代码都是ai 生成的,能够让你一个不会前端的同学也快速完成mvp版本/需求任务。我虽然很推ai coding 很喜欢用, 即时反馈带来的成就感, 但是对于生成的代码是不是屎山 大概率可能是了, 因为前期 AI速度快,制造屎山的速度更快。无论架构设计多优秀,也难避免屎山代码的宿命: 需求一直在变,你的架构设计是针对老的需求,随着新的需求增加,老的架构慢慢的就无法满足了,需要重构。
- 一起开发的前端同事都说ai生成那些样式互相影响了,样式有tailwindcss 有自定义的css 每个模块又有不同 大概率出问题 有冲突,就是💩山。
- 最大的开发障碍就是内心的偏见 不愿意放弃现在所擅长的东西 带着这份偏见不愿意去学习
对于ai coding 的话 用过trae-pro/cursor/qoder/copilot/codex等等 最终还是cursor claude 4.5用的最舒服
- 基本一周一个cursor pro账号 买号都花了快1k了。
You have used up your included usage and are on pay-as-you-go which is charged based on model API rates. You have spent $0.00 in on-demand usage this month.
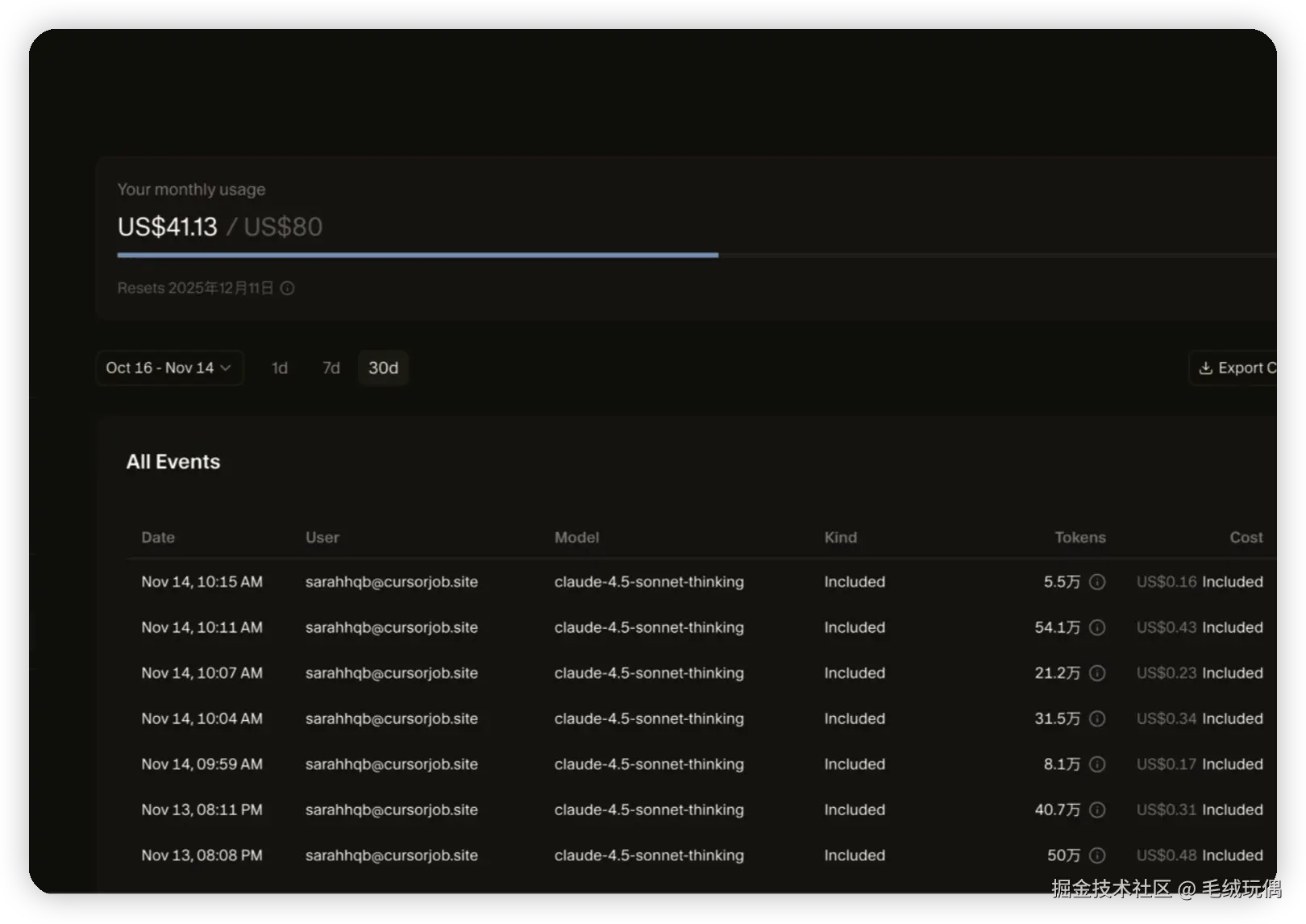

- 最后就是需要学好英语 前端的技术文档都是英文的 虽然有中文的翻译版本, 但没有自己直接去看官方的强 难免有差异, 我现在都是用插件进行web翻译去看的 很累。
- 现在时间是凌晨 11/30/02:36 喝了两瓶酒。这个周末我要重温甜甜的恋爱 给我也来一颗药丸 给时间是时间 让过去过去, 年底想去日本跨年了


来源:juejin.cn/post/7577713754562838580
为什么越来越多 Vue 项目用起了 UnoCSS?
Vue 开发者可能都注意到,UnoCSS 的讨论频率越来越高。它不像 Tailwind 那样有营销声势,不像 Windi 那样起得早,却在 2024 年之后逐渐“渗透”进越来越多的 Vue 项目中。很多团队从 Tailwind、Windi CSS、SCSS 等方案“迁徙”到了 UnoCSS。看似只是换了个工具,实际上却是一种更深层次的开发范式迁移。
为什么 UnoCSS 会被 Vue 项目偏爱?它到底解决了哪些问题?又会引发哪些新的思维变化?这篇文章,我们来拆开 UnoCSS 背后的真实诱因。
🎯 UnoCSS 到底是什么?一句话不够解释
如果你只把 UnoCSS 理解为“一个类 Tailwind 的原子化 CSS 工具”,那你可能漏掉了它真正颠覆的部分。
UnoCSS 是一个:
- 即写即用的原子 CSS 引擎,没有预定义 class(tailwind.config.js?你可以不用)
- 即时编译(on-demand generation) ,不扫描模板、不打包 CSS 文件,运行时动态生成样式表
- 支持任意规则组合,语义可扩展,能自动拼装
hover:bg-red-500/30 md:rounded-xl这种复杂 class - 插件式运行机制,样式规则 = 插件,想加功能不用改源码
简单说:UnoCSS 就像是原子 CSS 界的「Vite」,更轻,更快,更灵活。
🧩 Vue 项目迁移 UnoCSS 的几个主要诱因
1. 开箱即用,没有冗余配置
Tailwind 开发中一个不成文的痛点是配置文件维护成本:你几乎必须写一堆 tailwind.config.js 来扩展自己的颜色、字体、断点。
而 UnoCSS 有个“离谱”的特性:
你甚至可以不用写 config 文件。
举例:
<div class="text-lg font-bold text-[#3a7afe] hover:opacity-80">
颜色?随便写 HEX。你想用 shadow-[0_0_12px_rgba(0,0,0,0.2)]?它也认。基本告别 theme.extend。
这对 Vue 项目尤其友好 —— 组件就是 class 的封装,不需要额外定义 token。
2. 它更像 JS,而不是传统 CSS 工具
UnoCSS 本质上是一组「语法规则 + 解析器」,所有东西都是基于插件机制动态生成的。这点非常 Vue-ish。
比如你想扩展 btn-primary:
rules: [
['btn-primary', 'px-4 py-2 rounded bg-blue-500 text-white']
]
配合 Vue + Script Setup,甚至可以做到“功能指令式”的组件:
<button class="btn-primary hover:bg-blue-600">提交</button>
这是 Tailwind 无法比拟的灵活度,尤其当你想跨多个组件“语义复用”样式,而又不想搞复杂的 SCSS。
3. Vue SFC 中语法体验更佳
UnoCSS 不依赖 Preflight,不污染全局,也不会把所有 class 编译成一大坨 CSS 文件。
更关键的是,在 Vue SFC 中,它可以配合原子类的组合器变得非常语义化。
<div class="grid grid-cols-[1fr_auto] gap-4 items-center sm:(grid-cols-1 gap-2)">
括号组合、嵌套媒体查询、状态嵌套,全都写在 class 中,无需管理额外 CSS 文件,非常适合组件化开发。
4. 和 Vue 生态绑定更深
UnoCSS 的创作者之一是 Anthony Fu,也就是 VueUse、Vitesse、Vitest 的作者。
换句话说:UnoCSS 是为 Vue 项目天生设计的原子 CSS 工具,生态协同、理念统一。
你可以在 VitePress、Nuxt、Vitesse、VueUse 所有项目中一键集成 UnoCSS,毫不费力。插件如 @unocss/nuxt、@unocss/vite 也都官方维护,集成体验比 Tailwind 更丝滑。
📉 传统方案的反衬:你为什么“受够了 Tailwind”
- 写多了
text-sm text-neutral-700 font-medium leading-relaxed tracking-wide,你会厌烦堆 class - 为了统一样式,你又开始封装 btn、card、tag 等组件,但 Tailwind 里没法抽离 class 成变量
- 你想写一些自由样式(如
text-[rgba(0,0,0,0.75)]),却必须配置 tailwind.config.js,开发体验断层
UnoCSS 这时候就像一口“无限制自助餐”:你想吃什么,厨房就给你端上来。
🧪 真正让它爆红的项目:Nuxt 生态
Nuxt 3 和 UnoCSS 简直天作之合。
如果你用 Nuxt,安装 UnoCSS 就一行命令:
npm i -D @unocss/nuxt
甚至不需要配置,直接写:
<template>
<section class="text-center text-4xl text-gradient from-pink-500 to-yellow-500">
Hello, UnoCSS
</section>
</template>
想封装组件?直接写 variant 和 shortcuts,体验跟设计 token 一样自然:
shortcuts: {
'btn': 'px-4 py-2 font-bold rounded',
'btn-primary': 'btn bg-blue-500 text-white hover:bg-blue-600'
}
🧠 真正带来的范式转变
UnoCSS 不只是工具上的优化,它还改变了我们使用 CSS 的方式:
- 从维护样式表 → 动态生成样式
- 从配置颜色 → 直接在组件中定义 token
- 从 class 管理 → 到语义表达
传统做法是围绕“命名”,而 UnoCSS 更像是在写“表达式”。这种范式变化,决定了它会逐渐成为 Vue 项目的原子化首选。
📌 使用 UnoCSS 时的真实建议
- 如果你的项目刚启动,用 UnoCSS 会极大加快开发速度
- 如果你在维护大型 Vue 项目,建议先从局部引入,避免和 Tailwind 冲突
- 如果你对设计规范要求较高,UnoCSS 支持
theme、rules、shortcuts构建完全定制化体系 - 建议启用 VSCode 插件,否则开发体验会下降
✅为什么 UnoCSS 会流行?
因为它比 Tailwind 更轻,比 Windi 更快,比 SCSS 更灵活。而且,它是为 Vue 项目量身定制的。
不再“配置样式”,而是“表达样式”;不再围着类名转,而是围着组件转。
UnoCSS 不只是一个工具,而是一种更贴近 Vue 哲学的“开发语言”。
来源:juejin.cn/post/7512392168783659071
UI小姐姐要求有“Duang~Duang”的效果怎么办?

设计小姐姐: “搞一下这样的回弹效果,你行不行?”
我:“行!直接梭哈 50 行 keyframes + transform + 各种百分比,搞定 ”
设计小姐姐:“太硬(撇嘴),不够 Q 弹(鄙视)”
我:(裂开)
隔壁老王:这么简单你都不行,我来一行贝塞尔 cubic-bezier(0.3, 1.15, 0.33, 1.57) 秒了😎
设计小姐姐:哇哦!(兴奋)好帅!(星星眼🌟)好Q弹!(一脸崇拜😍)
我:“???”
🧠 一、为什么一行贝塞尔就能“Duang”起来?
1️⃣ cubic-bezier 是什么?
在 CSS 动画里,我们经常写:
transition: all 0.5s ease;
但其实 ease、linear、ease-in-out 这些都只是封装好的贝塞尔曲线。
底层原理是:
cubic-bezier(x1, y1, x2, y2)
这四个参数定义了时间函数曲线,控制动画速度的变化。
x:时间轴(必须在 0~1 之间)y:数值轴(可以超出 0~1!)
👉 当 y 超过 1 或小于 0 时,动画值就会冲过终点再回弹,
这就是“回弹感”的核心。
2️⃣ 回弹的本质:过冲 + 衰减
想象一个球掉下来:
- 过冲:球落地时会压扁(超出终点)
- 回弹:然后反弹回来,再逐渐稳定
在动画中,这个“过冲”就是 y>1 的部分,
而“回弹”就是曲线回到 y=1 的过程。
🧪 二、一行贝塞尔的魔法
✅ 火箭发射

<div class="bounce">🚀发射!</div>
<style>
.bounce {
transition: transform 0.8s cubic-bezier(0.68, -0.55, 0.27, 1.55);
}
.bounce:hover {
transform: translateY(-500px);
}
</style>
💡 参数解析:
- y1 = -0.55 → 先轻微反向缩小
- y2 = 1.55 → 再冲过头 55%,最后回弹到原位
🧩 四、常用贝塞尔参数
| 效果描述 | 贝塞尔参数 | 备注 |
|---|---|---|
| 微回弹(按钮) | cubic-bezier(0.34, 1.31, 0.7, 1) | 轻柔弹性 |
| 强回弹(卡片) | cubic-bezier(0.68, -0.55, 0.27, 1.55) | 爆发力强 |
| 柔和出入 | cubic-bezier(0.4, 0, 0.2, 1.4) | iOS 风 |
| 弹性放大 | cubic-bezier(0.175, 0.885, 0.32, 1.275) | 弹簧感 |
| 火箭猛冲 | cubic-bezier(0.68, -0.55, 0.27, 1.55) | 推背感 |
🧰 五、调试神器推荐
- 🎨 cubic-bezier.com
拖动手柄实时预览动画,复制参数一键搞定。 - ⚙️ easings.net
收录各种 easing 函数(含物理弹簧、阻尼等)。
来源:juejin.cn/post/7576264484688379944
WebRTC 实现视频通话的前端开发步骤
你好,我是木亦。我不知道你是否了解过 WebRTC(Web Real - Time Communication),但不得不承认,WebRTC 凭借其无需安装插件、支持浏览器间直接通信的显著优势,已成为实现网页端视频通话的不二之选。对于前端开发者而言,深入掌握 WebRTC 实现视频通话的开发流程,能够为用户打造出更加丰富多元、即时高效的互动体验。这篇文章将会向你介绍使用 WebRTC 实现视频通话的开发步骤。
一、项目初始化
在开启开发之旅前,首要任务是创建一个全新的前端项目。你可以借助常见的项目初始化工具,像create-react-app(适用于 React 项目)、vue-cli(适用于 Vue 项目),或者直接创建一个简洁的 HTML 页面。
使用 create-react-app 初始化项目
npx create-react-app webrtc-video-call
cd webrtc-video-call
使用 vue-cli 初始化项目
npm install - g @vue/cli
vue create webrtc-video-call
cd webrtc-video-call
如果选择直接创建 HTML 页面,其基本结构如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF - 8">
<title>WebRTC Video Call</title>
</head>
<body>
<!-- 后续添加视频通话相关元素 -->
</body>
</html>
二、引入 WebRTC 库
WebRTC 作为现代浏览器的内置功能,无需额外引入第三方库。在编写 JavaScript 代码时,可直接调用 WebRTC 提供的 API。
检测浏览器支持
if ('RTCPeerConnection' in window && 'RTCSessionDescription' in window && 'navigator.mediaDevices' in window) {
// 浏览器支持WebRTC
console.log('WebRTC is supported');
} else {
console.log('WebRTC is not supported in this browser');
}
通过上述代码,可快速判断当前浏览器是否支持 WebRTC,确保开发工作在兼容的环境下进行。
三、获取媒体设备权限
实现视频通话的第一步,是获取用户摄像头和麦克风的使用权限。
使用 navigator.mediaDevices.getUserMedia ()
const constraints = {
video: true,
audio: true
};
navigator.mediaDevices.getUserMedia(constraints)
.then((stream) => {
// 成功获取媒体流,可用于视频显示
const videoElement = document.createElement('video');
videoElement.srcObject = stream;
videoElement.autoplay = true;
document.body.appendChild(videoElement);
})
.catch((error) => {
console.error('Error accessing media devices:', error);
});
在这段代码中,constraints对象明确指定了需要获取视频和音频权限。getUserMedia()方法返回一个 Promise,当操作成功时,会返回包含媒体流的stream对象,随后便可将其绑定到video元素上,实现本地视频的实时显示。
四、建立对等连接
WebRTC 通过 RTCPeerConnection 对象建立对等连接,实现双方媒体数据的高效传输。
创建 RTCPeerConnection 对象
// 创建RTCPeerConnection对象
const peerConnection = new RTCPeerConnection({
iceServers: [
{ urls:'stun:stun.l.google.com:19302' }
]
});
这里借助了 STUN(Session Traversal Utilities for NAT)服务器辅助建立连接,stun.l.google.com:19302是 Google 提供的公共 STUN 服务器,能有效帮助穿越网络地址转换(NAT)设备。
处理 ICE 候选
在连接建立过程中,处理 ICE(Interactive Connectivity Establishment)候选至关重要,这有助于寻找到最佳的连接路径。
peerConnection.onicecandidate = (event) => {
if (event.candidate) {
// 将ICE候选发送给对方
// 这里需要实现发送逻辑,例如通过信令服务器
console.log('ICE candidate:', event.candidate);
}
};
当有 ICE 候选生成时,需及时将其发送给对方,实际应用中通常借助信令服务器完成这一操作。
交换 SDP(Session Description Protocol)
SDP 用于详细描述媒体会话的各项参数,双方需交换 SDP 以协商媒体格式、编解码方式等关键信息。
// 创建Offer
peerConnection.createOffer()
.then((offer) => {
return peerConnection.setLocalDescription(offer);
})
.then(() => {
// 将本地的SDP发送给对方
// 这里需要实现发送逻辑,例如通过信令服务器
console.log('Local SDP:', peerConnection.localDescription);
})
.catch((error) => {
console.error('Error creating offer:', error);
});
// 接收对方的SDP并设置为远程描述
peerConnection.setRemoteDescription(new RTCSessionDescription(receivedSDP))
.then(() => {
// 接收对方的Offer后,创建Answer
return peerConnection.createAnswer();
})
.then((answer) => {
return peerConnection.setLocalDescription(answer);
})
.then(() => {
// 将本地的Answer发送给对方
// 这里需要实现发送逻辑,例如通过信令服务器
console.log('Local SDP (Answer):', peerConnection.localDescription);
})
.catch((error) => {
console.error('Error setting remote description or creating answer:', error);
});
这部分代码展示了创建 Offer、设置本地描述、发送本地 SDP,以及接收对方 SDP 并创建 Answer、设置本地描述、发送本地 Answer 的完整流程。
五、显示远程视频
当双方成功建立连接并完成 SDP 交换后,便可接收对方的媒体流,实现远程视频的显示。
监听 track 事件
peerConnection.ontrack = (event) => {
const remoteVideoElement = document.createElement('video');
remoteVideoElement.srcObject = event.streams[0];
remoteVideoElement.autoplay = true;
document.body.appendChild(remoteVideoElement);
};
一旦接收到对方的媒体流,ontrack事件就会被触发,此时将接收到的媒体流绑定到新创建的video元素上,即可实时显示远程视频画面。
六、信令服务器的作用与实现
在 WebRTC 视频通话中,信令服务器承担着交换 SDP 和 ICE 候选等关键信息的重要职责。尽管 WebRTC 实现了媒体数据的直接传输,但信令的交互仍需借助服务器来完成。
信令服务器的选择
可选用 WebSocket、Socket.IO 等技术搭建信令服务器。以 Socket.IO 为例,搭建一个简易信令服务器的步骤如下:
npm install socket.io
简单的 Socket.IO 信令服务器示例
const io = require('socket.io')(3000);
io.on('connection', (socket) => {
socket.on('offer', (offer) => {
// 这里可以实现将offer转发给目标客户端
console.log('Received offer:', offer);
});
socket.on('answer', (answer) => {
// 这里可以实现将answer转发给目标客户端
console.log('Received answer:', answer);
});
socket.on('ice - candidate', (candidate) => {
// 这里可以实现将ice - candidate转发给目标客户端
console.log('Received ice - candidate:', candidate);
});
});
在前端代码中,需引入 Socket.IO 客户端库,并精心编写与服务器的通信逻辑,实现将 SDP 和 ICE 候选发送至服务器,以及从服务器接收对方的 SDP 和 ICE 候选。
WebRTC 实现视频通话的前端开发涵盖多个关键环节,从项目初始化、获取媒体设备权限,到建立对等连接、交换 SDP 和 ICE 候选,再到显示远程视频和搭建信令服务器。通过逐步掌握这些核心步骤,前端开发者能够构建出功能完备的视频通话应用,为用户提供流畅、实时的视频通信体验。在实际开发过程中,还需依据具体需求和应用场景,对代码进行优化与扩展,以充分满足多样化的业务需求。
5@2x.png" loading="lazy" src="https://www.imgeek.net/uploads/article/20260118/718ea69cb7313b0faba4510956153837.jpg"/>
来源:juejin.cn/post/7474124938526900262
五年自学前端到京东终面:我才明白自己不是范进,连范进都不如
1. 京东终面后,我在群里被恭喜了
2025年4月,京东HR在BOSS上找我,岗位写的是「iOS开发」,我心想这HR真他妈不专业,但还是回了句:「您好,我是前端,可以面试吗?」
没想到就这么稀里糊涂面了五轮,终面见部门老大,聊得还行。面完群里几个「未来同事」加我微信,有人说「稳了,等offer吧」,我也觉得这次该轮到我了吧?
然后,就没有然后了。
HR说「流程中」,一等就是一个月。这一个月我啥也没干,就刷邮箱等消息,像个傻逼一样。
这时候我才懂范进——你以为自己中了,其实屁都没有。
2. 我这五年,就是一部「选择比努力重要」的失败史
① 2020年:1万块我就觉得牛逼了
毕业那年进了个区块链小公司,老板说转正给1万,我他妈高兴坏了——「我同学花两三万培训还找不到工作呢!」
现在看真是蠢。那时候滴滴应届生「白菜价」都20k了,我还在为1万沾沾自喜。
问题不是钱,是起点——你第一份工作在小公司,后面想进大厂,难如登天。
② 2021-2023年:被裁了才知道害怕
后来跳槽涨了50%,进了个中型公司,终于知道什么叫「团队协作」了。结果没两年公司不行了,领了几万块钱「毕业大礼包」。
2023年再找工作,行情已经烂了。我怕失业,涨了40%多又去了个小公司,继续写垃圾代码。
这时候我才明白:小公司呆久了,你的简历就废了。
③ 2025年:面京东,我才知道自己多菜
今年我认真准备了半年,八股文、项目难点、架构设计,甚至刷了LeetCode。面京东时,人家问「你们日活多少?QPS多少?」
我他妈哪知道?我们公司就几十个人用,需要个屁的高并发!
大厂要的是「大厂经验」,你没有,就是没有。
3. 我认命了,但你们别学我
我现在进了一家还算稳定的公司,薪资也还行,但心里明白——我这辈子可能都进不去大厂了。
不是我不努力,是一开始选错了。如果毕业就进大厂,现在跳槽随便涨50%。但在小公司呆过?难。
但有一点让我没完全废掉:我写技术博客
真的,这几年每次面试,人家都会问我博客上的东西。那些在小公司用不上的「高端技术」,我全靠自己折腾,写在博客里。
所以如果你也在小公司:
- 别混日子,自己搞点有难度的项目
- 写博客,这玩意儿真能当简历用
- 早点跳,在小公司呆三年以上,简历就臭了
4. 最后说句实话
我知道你们想听「坚持就能进大厂」,但现实是——有些人就是没这个命。
我现在马上30岁了,五年经验,没大厂背景,以后更难。
前面卡技术经验,卡大厂背景,后面卡年龄限制,一开始没走好路,后面真的特别艰难
现在还背上了房贷,要结婚,要有小孩,后面压力更大,现在只想稳定一点 😭😭😭
但至少我还能写代码,还能靠技术吃饭。比起范进,我至少没疯。
最后贴几张图吧,就当看电子榨菜了
- 京东是真远,来回四个小时

- 不靠谱的面试


- 一直等不到的消息,我都感觉我问烦了
- 来自群友的关心,我当时已经是范进的心态了

- 别人的起点,或许就是你的终点
- 为什么拿京东说事
因为别的大厂也没约我面试,除了美团,小红书的外包 😭😭😭
- 新公司
来新公司上班快一个月了,已经轻车熟路,同事关系处的不错,已经开始穿拖鞋了(你们应该知道这句话的含金量)
结束语
后面会更新一些,新的学习的技术,如果对面经感兴趣的,也可以单独写一篇半年的面试经历以及总结~
来源:juejin.cn/post/7533801117521772582
2025快手直播至暗时刻:当黑产自动化洪流击穿P0防线,我们前端能做什么?🤷♂️
兄弟们,前天的瓜都吃了吗?🤣

说实话,作为一名还在写代码的打工仔,看到前天晚上快手那个热搜,我手里捧着的咖啡都不香了,后背一阵发凉。
12月22日晚上10点,正是流量最猛的时候,快手直播间突然失控。不是服务器崩了,而是内容崩了——大量视频像洪水一样灌进来。紧接着就是官方无奈的拔网线,全站直播强行关停。第二天开盘,股价直接跌了3个点。
这可不是普通的 Bug,这是P0 级中的 P0。
很多群里在传内鬼或者0day,但看了几位安全圈大佬(360、奇安信)的复盘,我发现这事儿比想象中更恐怖:这是一次教科书级别的黑产自动化降维打击。
今天不谈公关,咱们纯从技术角度复盘一下:假如这事儿发生在你负责的项目里,你的前端代码能抗住几秒?
当脚本比真人还多还快时?
这次事故最骚的地方在于,黑产根本不按套路出牌。
以前的攻击是 DDoS,打你的带宽,让你服务不可用。
这次是 Content DDoS(内容拒绝服务)。
1. 前端防线形同虚设
大家有没有想过,黑产是怎么把视频发出来的?
他们绝对不会坐在手机前,一个一个点开始直播。他们用的是群控、是脚本、是无头浏览器(Headless Browser)。
这意味着什么?
意味着你前端写的那些 if (user.isLogin)、那些漂亮的 UI 拦截、那些弹窗提示,在黑客眼里全是空气。他们直接逆向了你的 API,拿到了推流接口,然后几万个并发调用。
2. 审核系统被饱和式攻击
后端通常有人工+AI 审核。平时 QPS 是 1万,大家相安无事。
昨晚,黑产可能瞬间把 QPS 拉到了 100万。
云端 AI 审核队列直接爆了,人工审核员估计鼠标都点冒烟了也审不过来。一旦阈值被击穿,脏东西就流到了用户端。
那前端背锅了吗?
虽然核心漏洞肯定在后端鉴权和风控逻辑(大概率是接口签名泄露),但咱们前端作为 离黑客最近的一层皮,如果做得好,绝对能把攻击成本拉高 100 倍。
来,如果不幸遇到了这种自动化脚本攻击,咱们前端手里还有什么牌?🤔
别把 Sign 算法直接写在 JS 里!
很多兄弟写接口签名,直接在 request.js 里写个 md5(params + salt) 完事。
大哥,Chrome F12 一开,Sources 一搜,断点一打,你的盐(Salt)就裸奔了。
防范操作:直接上 WASM (WebAssembly)
把核心的加密、签名逻辑,用 C++ 或 Rust 写,编译成 .wasm 文件给前端调。
黑客想逆向 WASM?那成本可比读 JS 代码高太多了。这就是给他们设的第一道坎。
你的用户,可能根本不是人
黑产用的是脚本。脚本和真人的操作是有本质区别的。
不要只会在登录页搞个滑块,没用的,现在的图像识别早破了。
要在 关键操作(比如点击开始直播) 前,采集一波数据:
- 鼠标轨迹:真人的轨迹是曲线(贝塞尔曲线),脚本通常是直线。
- 点击间隔:脚本是毫秒级的固定间隔,人是有随机抖动的。
// 伪代码,简单的是不是人检测
function isHuman(events) {
// 如果鼠标轨迹过于平滑或呈绝对直线 -> 机器人
if (analyzeTrajectory(events) === 'perfect_linear') return false;
// 如果点击时间间隔完全一致 -> 机器人
if (checkTiming(events) === 'fixed_interval') return false;
return true;
}
把这些行为数据打分,随着请求发给后端。分低的,直接拒绝推流。
既然防不住内鬼,那就给他打标
这次很多人怀疑是内部泄露了接口文档或密钥。说实话,这种事防不胜防。
但是,前端可以搞 盲水印。
在你的 Admin 管理后台、文档平台,加上肉眼看不见的 Canvas 水印(把员工 ID 编码进背景图的 RGB 微小差值里,具体大家自己去探索😖)。
一旦截图流出,马上就能解码出是哪个员工泄露的。威慑力 > 技术本身。
或者试试这个技巧 👉 如何用隐形字符给公司内部文档加盲水印?(抓内鬼神器🤣)
安全复盘
这次快手事件,其实就死在了一个逻辑上: 后端太信任通过了前端流程的请求。
我们写代码时常犯的错误:
- 前端校验过手机号格式了,后端不用校验了吧?
- 必须点了按钮才能触发这个请求,所以这个接口很安全。
大错特错!
2025 年了,兄弟们。在 Web 的世界里,不相信前端 才是保命法则。
任何从客户端发来的数据,都要默认它是有毒的。
之前我都发过类似的文章:为什么永远不要相信前端输入?绕过前端验证,只需一个 cURL 命令!
希望对你们有帮助👆
这次是快手,下次可能就是咱们的公司。
尤其是年底了,黑灰产也要冲业绩(虽然这个业绩有点缺德😖)。
建议大家上班时看看这几件事:
- 查一下核心接口(支付、发帖、推流)有没有做签名校验。
- 看看有没有做频率限制(Rate Limiting),前端后端都要看。
- 搜一下你们的代码仓库,看看有没有把公司的 Key 或者源码传上去(这个真的很常见!)。
前端不只是画页面的,关键时刻,咱们也是安全防线的一部分。
别等到半夜被运维电话叫醒,那时候就真只能甚至想重写简历了🤣。

来源:juejin.cn/post/7586944874526539814


