








国企三年我现在怎么样了
前言
我是[提前退休的java猿],一名7年java开发经验的开发组长,分享工作中的各种问题!
23年年初来到现在公司,已经三年了。没错公司的薪资稳定得离谱。从来没涨过,你说我能力不行表现不好嘛,我也拿过优秀员工。现在明显感觉到35岁危机的压力了,买房、结婚、生子现在也是我最近要考虑的问题了。要想收入提高一个等级对我来说现在很难了.........
因为目前对我来说想要收入提高一个小等级比如收入提高(50%),要么996,要么拥抱AI冲一波然后跳槽。这两条路都不在我的规划中,放弃技术 实现睡后收入😂才是我的目标(不撞南墙不回头)。
三年我都在干嘛
这三年,每一年我的状态还是有很大区别的。第一年努力工作站稳脚跟,第二年闲暇时间写文章开始接触短视频,第三年(25年)年初公司裁员庆幸自己没有被优化。第三年裁员之后,也是过得最舒服的一年。
今年(25年)开始把更多的精力花在了个人探索上,做自媒体(粉丝3600😭)。因为长期的写文章做视频,也算是接了两个广子。不怕大家笑话一共赚了不到2000块。
在工作期间我也花了很多的时间去思考以后的路怎么走,既然来了这养老公司,就得利用闲暇时间探索出一条路来!然而三年过去了,没有什么起色!
最大的收获: 就是行动起来了,通过坚持写文章,做视频让自己有了独立思考,有了独立做事儿的能力,有了独立做事儿的信心。
我的牺牲:
对我的工作影响其实还是有的。因为在上班期间我的思路的是并行的,没法专注的干一件事儿,好在工作上的事儿,借助现在的AI 能够轻松高效的完成。我现在写接口基本上都不会自测了😂。最大的影响就是自己干的活儿、做的业务记不住,因为思维没有深度参与其中,有时候看着代码自己都没有印象,因为代码基本也都是AI写的加上自己注意力不够专注。
无所谓了既然做了决定来了这养老公司,并且没有涨薪升职的机会,工作上的事儿能完成就行了。
26年怎么做
3年了,还是没有找到一个方向坚定的做下去!今年的目标抖音粉丝先破1万,然后探索独立开发,利用AI 快速形成自己的一套全栈开发流程。以后能不能独立接单或者维护一些自己的小产品。如果能找到志同道合的兄弟一起干那就是最好的呢。
总结
在职场当一个混子,向着目标出发!聚焦一个方向!
每年一篇年终总结:
在国企待了一年了,吐槽一下吧
入职国企快2年了,分享一下我最近的状态吧
来源:juejin.cn/post/7599868109086867498
2026年了,前端到底算不算“夕阳行业”?
你有没有在朋友圈或者知乎上看到过这样的声音:“前端这行是不是快没前途了?”、“前端是夕阳行业,学不起来就晚了”。听起来很吓人吧?今天周五公司不忙~ 所以就想就想聊聊,为什么这些说法有点夸张,而且,实际上,前端比你想的要活跃、要有意思得多。
前端行业现状与就业趋势深入分析
其他废话少说,我先列出一组数据。
市场数据说明:招聘活跃度与求职热度
在判定某个岗位是否是“夕阳行业”前,我们得看看实实在在的数据,而不是空谈。虽然我们没有官方完整的每月统计数据,但从招聘平台侧面指标可以窥见市场动态:
BOSS直聘平台整体使用频次趋势(2024 年)
数据来自行业研究监测,反映招聘平台月度活跃度(平台月访问次数,单位为万次)。它可以折射出用户在找工作和发布岗位的活跃程度:
| 月份 | Boss直聘(万次) | 前程无忧(万次) | 智联招聘(万次) |
|---|---|---|---|
| 2024‑01 | 1212.8 | 503.3 | 381.6 |
| 2024‑03 | 2271.8 | 958.5 | 660.3 |
| 2024‑05 | 1892.9 | 730.1 | 496.5 |
| 2024‑09 | 1861.9 | 695.1 | 465.5 |
| 2024‑12 | 1492.8 | 665.7 | 432.8 |
从这张表可以看到几个趋势:
- 春节前后及 3 月、4 月经常会有求职与招聘高峰,这与校园招聘和年终奖金兑现周期有关。
- Boss直聘的整体使用频次明显高于其他招聘平台,表明它在人才市场中具有更高的活跃度。
这说明整体就业市场并没有冷却到技术岗位“没市场”的程度,但伴随着整体求职竞争压力也在增加(尤其毕业季之后)。
2024–2025 前端岗位薪资与供需情况(综合公开数据)
下面给出一个简要的薪资与供需趋势对比,是基于公开行业报告和招聘平台上职位薪资调研整理的(单位:人民币):
前端薪资水平(2024–2025)
| 类型 | 数据来源 | 平均薪资(月) | 说明 |
|---|---|---|---|
| 全国前端平均薪资 | 招聘求职网站综合数据 | ~20,877 元/月 | 2024 年全国平均数据,样本规模较大 |
| 数字前端工程师高薪技术岗位 | 脉脉高聘年度报告 | ~67,728 元/月 | 仅针对极高端职位薪资榜首人才 |
| BOSS直聘高级前端岗位示例 | 招聘岗位样例 | 20K–50K /月 | 典型一线城市高级薪资范围 |
| 企业大厂前端薪资 | 公司薪资水平数据 | ~57–65 万/年 | P6(技术中高级)年薪典型值 |
小结:大厂或高级岗位薪资明显高于平均,而整体前端岗薪资按城市和经验差异明显(北上深等一线城市更高)。中高级工程师薪资已进入较高收入层。
前端岗位供需趋势(24 年–25 年)
真实可公开的按月份招聘/求职人数统计不容易直接获得(需付费或数据授权),但我们可以根据人才供需比报告和其他间接指标构建趋势理解:
人才供需比(供给 vs 需求)变化
| 数据年份/区间 | 人才供需比(整体技术类) | 解读 |
|---|---|---|
| 2022 全年 | 1.29 | 约 1.3 求职者争一岗 |
| 2023 全年 | 2.00 | 竞争更激烈 |
| 2024 1‑10 月 | 2.06 | 职位竞争仍然紧张 |
供需比上升意味着“求职者数量增速快于岗位数量”,这反映就业市场总体竞争压力上升,但这主要是整体技术类岗位,不仅限前端。技术类岗位中核心和稀缺型(例如 AI、架构方向)仍然紧缺。 开源中国
招聘/求职活跃度趋势示意
timeline
title
2024 : 招聘需求 ↑, 求职人数 ↑
2025 : 招聘需求 ↓, 求职人数 ↑↑
- 招聘需求在 2024/2025 年虽整体活跃,但增长略收敛。
- 求职人数增速仍然高(尤其高校毕业生和转行人才增多)。 PDF 文档助手+1
“前端到底是做什么的”
以前的前端,其实很简单——写页面。你写几个 HTML、CSS,再加上点 JS,页面能跑就算完成任务。大部分人只要会写代码,基本就能找到工作。那时候,技术门槛不高,但随之而来的问题是:大家都能做,稀缺性不强。
到了现在,前端已经不是单纯写页面那么简单了。现在你需要考虑性能优化、工程化、架构设计,甚至还得会和 AI 工具配合来提高效率。也就是说,前端的工作量和复杂度已经大幅升级了,光会写代码,已经不再稀缺。
普通前端 / 工程型前端 / 架构型前端
我一般把前端分成三类:
- 普通前端
就是那种把设计稿转成页面的人,写页面、调样式、搞交互。以前,这类岗位很吃香,因为企业只要有人能把界面做出来就行。现在,普通前端的门槛低,但成长空间有限。 - 工程型前端
这类前端不仅会写页面,还懂打包工具、模块化、性能优化、测试、CI/CD,甚至前端安全。他们能把一个项目从零到一搞成可以高效运转的系统。你可以把他们想象成“能写代码,也懂流程的人”,在团队里很吃香。 - 架构型前端
架构型前端更厉害,他们关注的是整个平台的稳定性、可维护性和扩展性。他们设计组件库、微前端架构、前端性能监控体系,甚至参与后端接口设计。换句话说,他们更像“产品工程师”,不仅懂技术,还懂业务。
会写代码不再稀缺,会“用 AI 写代码”才是门槛
你可能注意到了,现在很多人说“前端会写代码不稀缺了”。这是真的。基础的 JS、CSS、HTML 很多人都会,但如果你能用 AI 辅助写代码、自动生成模板、快速优化性能,那才是真正的核心竞争力。就像以前会打字的人很多,但会用 Excel 做财务建模的人少,差距就出来了。
举个例子,现在有些大型项目,我们用 AI 帮忙生成表单验证逻辑,或者做自动化测试脚本,效率能提高好几倍。这种能力,不是简单敲几行代码能替代的。
前端未来,更像产品工程师
所以,到底前端是不是夕阳行业?我觉得恰恰相反。未来的前端,更像产品工程师——你不仅要写代码,还要思考性能、用户体验、架构设计、工程化流程,甚至要和 AI、云端、数据打交道。前端的职业宽度比以前更大,技能组合也更加稀缺。
换句话说,前端不再只是写界面的小伙伴,而是能把技术和产品结合起来,创造可落地系统的人。
总结
不是前端“夕阳”,只是门槛提高了
从薪资和招聘活跃度看:
- 前端岗位依旧铺开在招聘平台上,高薪职位数量没有消失,只是分布更广、更分层。
- 高端工程师、架构型前端、全栈/AI 前端人才仍然供不应求。
- 竞争压力主要来自技术同质化人才与行业整体求职人数增长的趋势(特别是毕业季)。 开源中国
真实情形是:前端并非夕阳,而是在职业形态和薪资结构上出现了更明显的分层。
你看到普通前端岗位薪资增长缓慢,是因为市场供给大,但 高技术、高工程化能力者反而更加吃香,门槛变了,而不是需求消失。
总结:结合数据再看“前端是否夕阳”
既然有数据支撑,我们再回到那个问题:
前端是否是夕阳行业?结论是:
- 前端需求仍在增长 ——招聘平台活跃度高,技术转型需求仍旧带来岗位。
- 薪资仍然维持在行业中上水平 ——尤其中高级、工程化岗位。
- 市场竞争更激烈 ——求职人数持续增长使得低门槛岗位更难突围。
- 分层明显 ——普通前端增长较缓,高技能人才仍稀缺。
所以说:前端不是夕阳行业,前端职业更像是正经历升级版的“技术工程”方向,更接近综合产品工程师,而不是单纯的页面写手。
要在这个岗位上活得更好,与 AI 协作、提升工程化能力、掌握架构与性能优化,成为未来核心竞争力。
数据来源说明
本文涉及的前端薪资、招聘人数、求职人数及市场趋势数据,主要来源公开渠道:
- BOSS直聘:招聘岗位示例及薪资参考 官网,招聘活跃度趋势及职位需求变化 年度报告
- 前端薪资参考:全国平均薪资及高端岗位薪资 Teamed Up China、大厂薪资对比 Levels.fyi、高端技术岗位薪资 脉脉高聘年度报告
- 前端供需数据:技术类岗位供需比及求职活跃度 公开行业报告
数据仅供行业分析参考,实际薪资及岗位信息可能随城市、公司和岗位等级变化。
来源:juejin.cn/post/7587684397530595355
一个Java工程师的17个日常效率工具
作为一名Java工程师,效率就是生产力。那些能让你少写代码、少改BUG、少加班的工具,往往能为你节省大量时间,让你专注于解决真正有挑战性的问题。
下面分享的这些工具几乎覆盖了Java开发全流程,从编码、调试到构建、部署,每一个环节都能大幅提升你的工作效率。
一、IDE增强类工具
1. IntelliJ IDEA终极版 + 精选插件
作为Java开发的首选IDE,IntelliJ IDEA本身已经非常强大,但配合以下插件,效率可以再提升一个档次:
- Key Promoter X: 显示你手动操作的快捷键,帮助你养成使用快捷键的习惯
- AiXcoder Code Completer: 基于AI的代码补全,比IDEA自带的更智能
- Maven Helper: 解决Maven依赖冲突的神器
- Lombok: 减少模板代码编写
- Rainbow Brackets: 彩色括号,让嵌套结构一目了然
实用技巧:创建多个Live Templates(代码模板),比如定义日志、常用异常处理、单例模式等。每天能节省几十次重复输入。
2. Lombok
虽然这是一个库,但它堪称效率工具。通过注解的方式,自动生成getter/setter、构造函数、equals/hashCode等方法,大幅减少模板代码量。
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class UserDTO {
private Long id;
private String username;
private String email;
// 无需编写getter/setter/构造函数/toString等
}
注意事项:使用@EqualsAndHashCode时,注意排除可能造成循环引用的字段;使用@Builder时,考虑添加@NoArgsConstructor满足序列化需求。
二、调试与性能分析工具
3. Arthas
阿里开源的Java诊断工具,它能在线排查问题,无需重启应用。最强大的是它能够实时观察方法的入参、返回值,统计方法执行耗时,甚至动态修改类的行为。
常用命令:
watch监控方法调用trace跟踪方法调用链路jad反编译类sc查找加载的类redefine热更新类
实战示例:线上问题排查,不方便加日志时,用watch命令观察方法执行:
watch com.example.service.UserService queryUser "{params,returnObj}" -x 3
4. JProfiler
Java剖析工具的王者,能够分析CPU热点、内存泄漏、线程阻塞等问题。与其他分析工具相比,JProfiler的UI更友好,数据呈现更直观。
核心功能:
- 内存视图:找出占用内存最多的对象
- CPU视图:定位热点方法
- 线程视图:发现死锁和阻塞
- 实时遥测:监控线上应用,无需重启
技巧:养成定期对自己负责的服务做性能分析的习惯,很多问题在上线前就能发现。
5. Charles/Fiddler
抓包工具是API调试的必备利器。Charles(Mac)或Fiddler(Windows)能够拦截、查看和修改HTTP/HTTPS请求和响应。
实用功能:
- 模拟网络延迟
- 请求重写
- 断点调试HTTP请求
- 反向代理
在前后端分离开发和调试第三方API时,这类工具能节省大量时间。
三、代码质量工具
6. SonarQube + SonarLint
SonarQube是静态代码分析工具,可以检测代码中的漏洞、坏味道和潜在bug。而SonarLint是其IDE插件版,能在你编码时实时提供反馈。
最佳实践:
- 在CI流程中集成SonarQube
- 为团队制定"质量门"标准
- 使用SonarLint实时检查,避免代码审查时返工
技巧:自定义规则集,忽略对特定项目不适用的规则,避免"过度洁癖"。
7. ArchUnit
用代码的方式测试架构规则,确保项目架构不会随着时间推移而腐化。
@Test
public void servicesAndRepositoriesShouldNotDependOnControllers() {
ArchRule rule = noClasses()
.that().resideInAPackage("..service..")
.or().resideInAPackage("..repository..")
.should().dependOnClassesThat().resideInAPackage("..controller..");
rule.check(importedClasses);
}
将架构约束加入单元测试,比写文档更有效,因为违反规则会导致测试失败。
8. JaCoCo
代码覆盖率工具,与Maven/Gradle集成,生成直观的HTML报告。它不仅统计单元测试覆盖了哪些代码,还能显示哪些分支没有测试到。
实用配置:在Maven中设置覆盖率阈值,低于阈值则构建失败:
<configuration>
<rules>
<rule>
<element>BUNDLE</element>
<limits>
<limit>
<counter>LINE</counter>
<value>COVEREDRATIO</value>
<minimum>0.80</minimum>
</limit>
</limits>
</rule>
</rules>
</configuration>
四、API开发与测试工具
9. Postman + Newman
Postman是API开发和测试的标准工具,而Newman是其命令行版本,适合集成到CI/CD流程中。
高级用法:
- 环境变量管理不同测试环境
- 请求前/后脚本自动化测试
- 导出集合到Newman在CI中执行
- 团队共享API集合
技巧:为每个项目创建环境变量集合,包含测试环境、开发环境、生产环境配置,一键切换。
10. OpenAPI Generator
从OpenAPI(Swagger)规范自动生成API客户端和服务器端代码。
openapi-generator generate -i swagger.json -g spring -o my-spring-server
前后端并行开发时,通过API优先设计,让前端可以基于Swagger UI与Mock服务器工作,而后端则基于生成的接口实现业务逻辑。
五、数据库工具
11. DBeaver
全能型数据库客户端,支持几乎所有主流数据库,功能强大且开源免费。
必备功能:
- ER图可视化
- 数据导出/导入
- SQL格式化
- 数据库比较
- 执行计划分析
技巧:使用其"SQL模板"功能,保存常用查询模板,提高重复查询效率。
12. Flyway/Liquibase
数据库版本控制工具,将数据库结构变更纳入版本管理,确保开发、测试和生产环境的数据库结构一致性。
以Flyway为例:
@Bean
public Flyway flyway() {
return Flyway.configure()
.dataSource(dataSource)
.locations("classpath:db/migration")
.load();
}
最佳实践:
- 每个变更一个脚本文件
- 脚本文件命名规范化
- 脚本必须是幂等的
- 将验证步骤集成到CI流程
六、构建与部署工具
13. Gradle + Kotlin DSL
虽然Maven仍是Java构建工具的主流,但Gradle的灵活性和性能优势明显。使用Kotlin DSL而非Groovy可以获得更好的IDE支持和类型安全。
plugins {
id("org.springframework.boot") version "2.7.0"
id("io.spring.dependency-management") version "1.0.11.RELEASE"
kotlin("jvm") version "1.6.21"
}
dependencies {
implementation("org.springframework.boot:spring-boot-starter-web")
testImplementation("org.springframework.boot:spring-boot-starter-test")
}
优势:
- 增量构建更快
- 依赖缓存更智能
- 自定义任务更灵活
- 多项目构建更高效
14. Docker + Docker Compose
容器化是现代Java开发的标配,Docker让环境一致性问题成为历史。
实用命令:
# 启动开发环境所需的所有服务
docker-compose up -d
# 查看容器日志
docker logs -f container_name
# 进入容器内部
docker exec -it container_name bash
技巧:创建一个包含常用中间件(MySQL、Redis、RabbitMQ等)的docker-compose.yml,一键启动开发环境。
15. GitHub Actions/Jenkins
CI/CD是提高团队效率的关键环节。GitHub Actions适合开源项目,Jenkins则更适合企业内部构建流程。
GitHub Actions示例:
name: Java CI
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up JDK 17
uses: actions/setup-java@v2
with:
java-version: '17'
distribution: 'adopt'
- name: Build with Gradle
run: ./gradlew build
最佳实践:将代码风格检查、单元测试、集成测试、安全扫描全部纳入CI流程,确保代码质量。
七、辅助工具
16. PlantUML
用代码生成UML图,比拖拽式画图工具更高效,特别是需要频繁修改图表时。可以和版本控制系统无缝集成。
@startuml
package "Customer Domain" {
class Customer
class Address
Customer "1" *-- "n" Address
}
package "Order Domain" {
class Order
class LineItem
Order "1" *-- "n" LineItem
Order "*" -- "1" Customer
}
@enduml
IDEA集成:安装PlantUML插件,编写代码时实时预览图表。
17. Obsidian/Logseq
知识管理工具,基于Markdown文件的本地知识库。对于需要持续学习的Java工程师来说,构建个人知识体系至关重要。
推荐用法:
- 每学习一个新技术,创建一个页面
- 记录常见错误和解决方案
- 构建项目文档和架构决策记录
- 使用日常笔记捕捉想法和灵感
技巧:利用双向链接功能,将知识点相互关联,构建知识网络,而非简单的知识树。
总结
最后,工具再好,也需要时间精力去掌握。建议每次只引入1-2个新工具,熟练后再考虑扩展。
毕竟,真正的效率来源于熟练度,而非工具数量。
来源:juejin.cn/post/7506414257399939111
同志们,我去外包了
同志们,我去外包了
同志们,经历了漫长的思想斗争,我决定回老家发展,然后就是简历石沉大海,还好外包拯救了我,我去外包了!

都是自己人,说这些伤心话干嘛;下面说下最近面试的总结地方,小小弱鸡,图一乐吧。
首先随着工作年限的增加,越来越多公司并不会去和你抠八股文了(那阵八股风好像停了),只是象征性的问几个问题,然后会对照着项目去问些实际的问题以及你的处理办法。
(ps:(坐标合肥)突然想到某鑫面试官问我你知道亿级流量吗?你怎么处理的,听到这个问题我就想呼过去,也许读书读傻了,他根本不知道亿级流量是个什么概念,最主要的是它是个制造业公司啊,你哪来的亿级流量啊,也不知道问这个问题时他在想啥,还有某德(不是高德),一场能面一个小时,人裂开)。
好了,言归正传,咱说点入职这家公司我了解到的一点东西,我分为两部分:代码和sql;
代码上
首先传统的web项目也会分前端后端,这点不错;
1.获取昨天日期
可以使用jdk自带的LocalDate.now().minusDays(-1)
这个其实内部调用的是plusDays(1)方法,所以不如直接就用plusDays方法,这样少一层判断;
PS:有多少人和我之前一样直接new Date()的。
2.字符填充
apache.common下的StringUtils的rightPad方法用于字符串填充使用方法是StringUtils.rightPad(str,len,fillStr)
大概意思就是str长度如果小于len,就用fillStr填充;
PS:有多少人之前是String.format或者StringBuilder用循环实现的。
3.获取指定年指定月的某天
获取指定年指定月的某天可以用localDate.of(year,month,day),如果我们想取2025年的五月一号,可以写成LocalDate.of(2025, 5, 1),那有人可能就想到了如果月尾呢,LocalDate.of(2025, 5, 31)也是可以的,但是我们需要清楚知道这个月有多少天,比如说你2月给个30天,那就会抛异常;
麻烦;

更好的办法就是先获取第一天,然后调用localDate.with(TemporalAdjusters.lastDayOfMonth());方法获取最后一天,TemporalAdjusters.lastDayOfMonth()会自动处理不同月份和闰年的情况;
sql层面的
有言在先,说实话我不建议在sql层面写这种复杂的东西,毕竟我们这么弱的人看到那么长的且复杂的sql会很无力,那种无力感你懂吗?打工人不为难打工人;不过既然别人写了,咱们就学习一下嘛;
1.获取系统日期
首先获取系统日期可以试用TRUNC(SYSDATE)进行截取,这样返回的时分秒是00:00:00,比如2025-05-29 00:00:00,它也可以截取数字,想知道就去自行科普下,不建议掌握,学习了下,有点搞;
2.返回date当前月份的最后一天
LAST_DAY(date)这个返回的是date当前月份的最后一天,比如今天是2025-05-29,那么返回的是2025-05-31
ADD_MONTH(date,11)表示当前日期加上11个月,比如2025-01-02,最终返回的是2025-12-02;
3.左连接的知识点
最后再提个左连接的知识点,最近看懵了,图一乐哈,A left join B,就是on的条件是在join生成临时表时起作用的,而where是对生成的临时表进行过滤;
两者过滤的时机不一样。我想了很久我觉得可以这么理解,on它虽然可以添加条件,但他的条件只是一个匹配条件比如B.age>10;它是不会对A表查询出来的数据量产生一个过滤效果;
而where是一个实打实的过滤条件,不管怎么说都会影响最终结果,对于inner join这个特例,on和where的最终效果一样,因为B.age>10会导致B的匹配数据减少,由于是交集,故会对整体数据产生影响。
好了,晚安,外包打工仔。。。
来源:juejin.cn/post/7510055871465308212
给大龄(35岁+)程序员的绝地求生计划书

不要侥幸,35 岁以上的程序员不好找工作, 这是一个既定事实
首先无论是什么渠道, 对于普通人来说 35+ 的程序员, 不好就业, 就是一个既定事实。 甚至都不一定与自己的工作经历、学历 有多大的关系。
甚至我知道很多 35+ 的老哥们, 经验丰富, 985 大学毕业, 依然不好找工作, 这个不是个例。
我们不过多探究为何 35+ 的程序员不好就业, 我们可能需要更多关注, 怎么在这种大背景下「绝地求生」
这些方向可以让 35+ 程序员依然抢手
“35 岁危机”并非绝对,大量 35 岁以上的程序员仍能保持职业竞争力,甚至更受青睐,核心在于是否具备“不可替代性”:
- 技术深度型:在某一细分领域(如底层架构、算法优化、安全攻防)有深耕,成为行业公认的技术专家。例如,专注于分布式系统设计、AI 大模型工程化的资深工程师,35 岁后反而因经验稀缺而抢手。
- 业务融合型:熟悉特定行业(如金融、医疗、制造业)的业务逻辑,能将技术与行业需求深度结合。例如,懂银行业务的支付系统架构师、懂医疗流程的医疗信息化专家,年龄增长带来的业务经验反而成为优势。
- 管理转型型:从技术岗转型为技术管理(如 CTO、技术总监、团队负责人),具备带团队、做决策、对接业务的能力。这类岗位更看重“经验沉淀”和“资源整合能力”,35-45 岁往往是黄金期。
技术管理型 - 有坑
首先看看「管理型」, 我感觉上面三个「绝地求生」方向, 管理方向, 反而是最不考虑的, 其实很简单, 现在大社会都是紧缩模式,只有出局的业务,没有新业务开展了。 那么这个时候, 就出现一个更加严重的问题, 「技术管理系」岗位, 一个萝卜一个坑, 甚至可以说, 你无论技术有多牛逼, 但是没有那个坑位, 可能永远都上不去。
甚至还有一个比较搞笑的现象,都是很多中小公司离开一线很久的技术 leader , 找不到坑位了, 再想着来投递技术岗, 技术上基本上生疏很久了, 基本上很难再就业。 这种人真不在少数。
深耕技术性 - 有利有弊
这个其实是一个非常好的方向, 但是这种人往往都是大头兵, 或者叫做高级工具人。 首先需要花非常多的时间和精力去做深耕技术, 要时刻保持最前沿的技术储备, 最充沛的精力, 最丰富的热情。然后要去干最累的活儿, 干最难的事儿, 但是不一定有好结果。 很简单, 这个业务线没了, 那也只能去找下一份工作。 而且大头兵, 很容易为业务背锅。
都是高级打工仔了, 做的好, 是应该的, 做的不好就得背锅。
而且还要想办法跟 AI 做差异性竞争。 很简单, 做了一个非常好的工作架构, 然后 AI 可以用非常低的成本做替代, 那就白干了。
上面说了那么多缺点, 这个方向就真的那么不堪吗?其实也不是, 只要努力, 肯吃苦, 至少下限还是很高的。 因为这个路子, 就跟上大学一样,你只要一直读书, 肯吃苦, 就能上到 博士 。 做深耕技术也是一样的, 只要肯努力, 耐得住寂寞, 一直死磕下去, 基本上在一个方向都能有几刷子的。 对于迷茫型和努力型同学,这个也是最佳直选。
所以有利有弊, 各位同学可自行斟酌。
业务融合型 - 性价比之王
技术的价值最终要落地到业务中,30 + 程序员若能将技术能力与具体行业的业务逻辑深度绑定,会比 “纯技术专家” 更难被替代 —— 因为年轻人可以快速学会技术,但吃透一个行业的业务规则(如金融风控逻辑、医疗流程规范、制造业供应链协同)往往需要 5 年以上的沉淀。
这个才是我真正想跟大家聊一聊的方向。
精通技术的业务专家成长之路
“技术 + 业务” 复合岗,核心是 让技术能力成为 “解读业务、解决业务痛点” 的工具,而非终点。
这种转型的价值在于:业务逻辑的沉淀周期长(5-10 年),年轻人可快速学会技术,但难以短期吃透行业规则,这正是 30 + 程序员的经验红利。以下从 “有价值的业务方向”“业务理解训练方法”“避坑要点” 三个维度展开,附具体实操步骤:
一、值得深耕的“技术+业务”方向(附核心业务逻辑与技术结合点)
选择业务方向的关键标准:业务逻辑复杂(有门槛)、监管严格(需经验规避风险)、技术与业务深度绑定(技术优化能直接带来业务收益)。以下是几个高价值领域:
1. 金融科技(银行/保险/证券)
核心业务逻辑:金融行业的本质是“风险定价+资金流转”,涉及复杂的监管规则(如央行反洗钱、银保监会合规要求)、用户分层(高净值客户vs大众客户)、业务流程(信贷审批、理赔核保、交易清算)。
技术结合点:
- 信贷领域:用AI模型优化风控(需理解“逾期率”“不良率”等业务指标,以及征信数据、行为数据如何影响授信);
- 交易领域:低延迟交易系统(需理解股票/期货的“撮合规则”“涨跌停限制”,技术优化直接影响交易成功率);
- 保险领域:智能核保系统(需理解“健康告知”“免责条款”等业务规则,技术需实现“用户输入→规则匹配→核保结论”的自动化)。
为什么值得做:金融监管政策每年更新(如2025年央行新规对“消费贷资金用途监控”的要求),技术方案必须跟着业务规则调整,经验越丰富越能快速响应,年轻人易因不懂合规踩坑。
2. 医疗健康(医院信息化/互联网医疗)
核心业务逻辑:医疗行业的核心是“患者诊疗全流程”,涉及医院内部流程(挂号、分诊、问诊、检查、缴费、取药)、医保政策(医保目录、报销比例、异地结算规则)、医疗安全(病历隐私、药品溯源)。
技术结合点:
- 医院信息系统(HIS):需理解“门诊/住院流程”(如门诊的“医生开单→药房发药”环节,技术需对接收费系统、药品库存系统);
- 互联网医疗:在线问诊平台需符合《互联网诊疗管理办法》(如“首诊不能线上”“电子处方流转规则”),技术架构要支持“医患身份核验→问诊记录留存→处方合规性校验”;
- 医疗大数据:医疗影像AI辅助诊断(需理解“CT/MRI影像的临床意义”,技术模型训练需结合医生诊断逻辑,而非纯数据拟合)。
为什么值得做:医疗流程标准化程度低(不同医院流程差异大),且涉及生命安全,技术方案容错率极低,需要“技术+临床经验”双重积累,30+的耐心和细致更具优势。
3. 智能制造(工业互联网/工厂数字化)
核心业务逻辑:制造业的核心是“生产效率提升+成本控制”,涉及生产流程(订单排产、物料采购、车间加工、质量检测、物流配送)、设备管理(设备故障率、OEE设备综合效率)、供应链协同(供应商交付周期、库存周转率)。
技术结合点:
- 工业物联网(IIoT):设备数据采集与分析(需理解“数控机床的主轴温度、转速与产品精度的关系”,技术需将数据转化为“设备维护预警”等业务动作);
- MES系统(制造执行系统):生产排产优化(需理解“订单优先级、物料齐套率、设备产能”的制约关系,技术算法要平衡“交付时效”与“生产成本”);
- 质量追溯系统:需理解“产品不良品的产生环节”(如焊接工艺参数异常导致的缺陷),技术需实现“生产数据→不良原因”的反向追溯。
为什么值得做:制造业数字化转型依赖“懂生产的技术人”,纯技术人员易陷入“为数字化而数字化”(比如盲目上物联网设备却不会分析数据),而有车间经验的技术人员能精准定位痛点(如某环节停机1小时损失5万元,技术优化需优先解决)。
4. 跨境电商(平台型/品牌型)
核心业务逻辑:跨境电商的核心是“跨区域供需匹配”,涉及海外市场规则(如亚马逊的A+页面规则、TikTok Shop的物流时效要求)、跨境链路(报关、清关、海外仓配送)、本地化运营(语言、支付习惯、合规要求,如欧盟增值税VAT)。
技术结合点:
- 选品系统:需理解“海外市场需求”(如东南亚雨季对雨具的需求波动),技术通过爬虫+数据分析预测“潜力商品”;
- 跨境ERP:需对接“多国物流商API”“海关报关系统”,技术需处理“汇率换算”“多语言订单”“合规申报”等业务细节;
- 本地化营销工具:如TikTok直播带货的“实时翻译+弹幕互动”功能,技术需结合“海外用户互动习惯”(如欧美用户更关注产品参数,东南亚用户更关注价格)。
为什么值得做:跨境业务涉及“多国家、多规则、多链路”,技术方案需灵活适配(比如某国突然调整进口关税,系统需快速支持税率更新),经验能减少试错成本,年轻人易因不了解海外规则导致系统“水土不服”。
二、训练“业务理解能力”的5个实操步骤(从0到1建立业务思维)
技术人员常陷入“只懂代码不懂业务”的误区,核心问题是:习惯用“技术实现”倒推“业务需求”,而非从“业务目标”推导“技术价值”。以下步骤帮你系统性建立业务思维:
步骤1:从“被动接需求”到“主动问目标”——搞懂“业务为什么需要这个功能”
- 具体做法:每次接需求时,多问3个问题:
- “这个功能要解决用户的什么痛点?”(如“用户反馈支付失败率高”,而非只接“开发新支付渠道”);
- “这个功能的业务指标是什么?”(如“支付成功率从90%提升到99%”,而非“完成开发即可”);
- “如果这个功能上线后不达预期,备选方案是什么?”(理解业务的优先级和容错空间)。
- 案例:若业务方提“开发一个优惠券系统”,技术人员不应直接设计表结构,而是先问:“发优惠券是为了拉新还是促活?目标是提升客单价10%还是复购率20%?预算多少?”——这些决定了系统是否需要支持“新用户专属券”“满减叠加规则”等细节。
步骤2:画“业务流程图”——用可视化方式梳理业务环节(比写代码更重要)
- 工具:Figma(画流程图)、Visio(复杂流程)、甚至手绘;
- 核心要素:每个流程节点包含“谁(角色)→做什么(动作)→输入/输出什么(信息)→遇到异常怎么办(分支)”;
- 案例:画“电商退款流程”时,需明确:
- 角色:用户、客服、财务、仓库;
- 动作:用户发起退款→客服审核(是否符合7天无理由)→财务确认退款金额→仓库确认是否收到退货→系统打款;
- 异常分支:“用户已拆封商品”是否支持退款?“仓库未收到货但用户说已寄出”如何处理?
- 价值:流程图能帮你发现“技术设计的盲区”(如漏考虑“退款失败后重试机制”),也能让你在和业务方沟通时“用他们的语言对话”(而非只说“接口、数据库”)。
步骤3:“泡在业务场景里”——亲身体验业务,而非只听业务方描述
- 具体做法:
- 若做电商:自己下单、退货、咨询客服,记录每个环节的体验(如“退款到账时间长”可能是技术链路太长);
- 若做医疗系统:去医院门诊“蹲点”,看医生如何开单、护士如何分诊、患者如何缴费(你会发现“医生开单时频繁切换系统”是真实痛点,技术可做集成优化);
- 若做金融:假扮客户打电话给银行客服,咨询“信用卡逾期如何处理”(理解业务方常说的“催收流程”实际是怎样的)。
- 关键:技术人员容易“坐在办公室想当然”,而业务的真相往往藏在一线操作中。比如某团队开发“外卖骑手App”时,程序员亲自骑了3天车,才发现“高峰期导航频繁卡顿”是比“界面美观”更重要的问题。
步骤4:建立“业务知识体系”——像学技术一样系统化学习业务
- 方法:
- 行业基础术语库:整理业务常用词(如金融的“拨备率”“LPR”,医疗的“DRG/DIP”“电子病历互联互通”),每个词注明“定义+业务意义”(如“DRG”是“按疾病诊断分组付费”,影响医院的收费和成本控制);
- 监管规则清单:收集行业相关政策(如跨境电商的《跨境电子商务零售进口商品清单》,金融的《个人信息保护法》对数据采集的要求),标注“哪些规则会影响技术方案”(如数据本地化存储要求决定服务器部署位置);
- 业务指标公式:搞懂核心KPI的计算逻辑(如“电商GMV=流量×转化率×客单价”,“银行不良率=不良带款余额/总带款余额”),理解技术优化如何影响这些指标(如“页面加载速度提升1秒→转化率提升2%→GMV增加X万元”)。
- 工具:用Notion或Excel整理,定期更新(如政策变动时),避免“业务术语听不懂”的尴尬。
步骤5:输出“业务-技术关联报告”——证明你能“用技术解决业务问题”
- 核心动作:每完成一个项目,写一份“技术方案如何支撑业务目标”的报告,包含:
- 业务背景:项目要解决什么业务痛点(如“工厂因排产不合理,订单交付延迟率达15%”);
- 技术方案:用了什么技术(如APS高级排产算法),为什么选这个技术(对比其他方案,该算法在“多品种小批量”场景下更优);
- 业务效果:技术上线后,业务指标有何变化(如“交付延迟率从15%降至5%,每月减少违约金100万元”);
- 经验沉淀:如果再遇到类似业务问题,技术方案可复用哪些部分(如“排产算法可适配其他工厂的生产模式”)。
- 价值:这份报告不仅是你“业务+技术”能力的证明(跳槽时可作为案例),更能倒逼你在项目中主动思考“技术的业务价值”,而非只关注“代码写得漂不漂亮”。
三、转型避坑:这3个误区会让你“既不像技术,也不像业务”
- 误区1:放弃技术深度,单纯“转业务”
复合岗的核心是“技术为根,业务为翼”,而非变成纯业务岗。比如做金融科技,若不懂分布式系统,就无法设计高并发的交易系统;若不懂AI,就无法优化风控模型。保留技术深度,同时叠加业务理解,才是不可替代的关键。 - 误区2:只学“表面业务”,不懂“业务本质”
比如做电商,知道“优惠券能促单”是表面,理解“不同面额的优惠券对不同客群(新用户vs老用户)的转化差异”才是本质;做医疗,知道“电子病历要存数据”是表面,理解“病历数据如何支持医生诊断决策”才是本质。多问“为什么”,穿透业务动作看目标。 - 误区3:等待“别人教业务”,而非主动获取
业务方通常很忙,不会系统性教你业务知识。要主动“找信息”:看行业报告(艾瑞、易观)、读专业书籍(如《支付战争》懂支付业务,《精益生产》懂制造流程)、加行业社群(如医疗信息化的“HIT专家网”)、甚至考行业证书(如PMP学项目管理,CFA基础懂金融)。
来源:juejin.cn/post/7543976401176985643
微服务正在悄然消亡:这是一件美好的事
最近在做的事情正好需要系统地研究微服务与单体架构的取舍与演进。读到这篇文章《Microservices Are Quietly Dying — And It’s Beautiful》,许多观点直击痛点、非常启发,于是我顺手把它翻译出来,分享给大家,也希望能给同样在复杂性与效率之间权衡的团队一些参考。
微服务正在悄然消亡:这是一件美好的事
为了把我们的创业产品扩展到数百万用户,我们搭建了 47 个微服务。
用户从未达到一百万,但我们达到了每月 23,000 美元的 AWS 账单、长达 14 小时的故障,以及一个再也无法高效交付新功能的团队。
那一刻我才意识到:我们并没有在构建产品,而是在搭建一座分布式的自恋纪念碑。

我们都信过的谎言
五年前,微服务几乎是教条。Netflix 用它,Uber 用它。每一场技术大会、每一篇 Medium 文章、每一位资深架构师都在高喊同一句话:单体不具备可扩展性,微服务才是答案。
于是我们照做了。我们把 Rails 单体拆成一个个服务:用户服务、认证服务、支付服务、通知服务、分析服务、邮件服务;然后是子服务,再然后是调用服务的服务,层层套叠。
到第六个月,我们已经在 12 个 GitHub 仓库里维护 47 个服务。我们的部署流水线像一张地铁图,架构图需要 4K 显示器才能看清。
当“最佳实践”变成“最差实践”
我们不断告诫自己:一切都在运转。我们有 Kubernetes,有服务网格,有用 Jaeger 的分布式追踪,有 ELK 的日志——我们很“现代”。
但那些光鲜的微服务文章从不提的一点是:分布式的隐性税。
每一个新功能都变成跨团队的协商。想给用户资料加一个字段?那意味着要改五个服务、提三个 PR、协调两周,并进行一次像劫案电影一样精心编排的数据库迁移。
我们的预发布环境成本甚至高于生产环境,因为想测试任何东西,都需要把一切都跑起来。47 个服务在 Docker Compose 里同时启动,内存被疯狂吞噬。
那个彻夜崩溃的夜晚
凌晨 2:47,Slack 被消息炸翻。
生产环境宕了。不是某一个服务——是所有服务。支付服务连不上用户服务,通知服务不断超时,API 网关对每个请求都返回 503。
我打开分布式追踪面板:一万五千个 span,全线飘红。瀑布图像抽象艺术。我花了 40 分钟才定位出故障起点。
结果呢?一位初级开发在认证服务上发布了一个配置变更,只是一个环境变量。它让令牌校验多了 2 秒延迟,这个延迟在 11 个下游服务间层层传递,超时叠加、断路器触发、重试逻辑制造请求风暴,整个系统在自身重量下轰然倒塌。
我们搭了一座纸牌屋,却称之为“容错架构”。
我们花了六个小时才修复。并不是因为 bug 复杂——它只是一个配置的单行改动,而是因为排查分布式系统就像破获一桩谋杀案:每个目击者说着不同的语言,而且有一半在撒谎。
那个被忽略的低语
一周后,在复盘会上,我们的 CTO 说了句让所有人不自在的话:
“要不我们……回去?”
回到单体。回到一个仓库。回到简单。
会议室一片沉默。你能感到认知失调。我们是工程师,我们很“高级”。单体是给传统公司和训练营毕业生用的,不是给一家正打造未来的 A 轮初创公司用的。
但随后有人把指标展开:平均恢复时间 4.2 小时;部署频率每周 2.3 次(从单体时代的每周 12 次一路下滑);云成本增长速度比营收快 40%。
数字不会说谎。是架构在拖垮我们。
美丽的回归
我们用了三个月做整合。47 个服务归并成一个模块划分清晰的 Rails 应用;Kubernetes 变成负载均衡后面的三台 EC2;12 个仓库的工作流收敛成一个边界明确的仓库。
结果简直让人尴尬。
部署时间从 25 分钟降到 90 秒;AWS 账单从 23,000 美元降到 3,800 美元;P95 延迟提升了 60%,因为我们消除了 80% 的网络调用。更重要的是——我们又开始按时交付功能了。
开发者不再说“我需要和三个团队协调”,而是开始说“午饭前给你”。
我们的“分布式系统”变回了结构良好的应用。边界上下文变成 Rails 引擎,服务调用变成方法调用,Kafka 变成后台任务,“编排层”……就是 Rails 控制器。
它更快,它更省,它更好。
我们真正学到的是什么
这是真相:我们为此付出两年时间和 40 万美元才领悟——
微服务不是一种纯粹的架构模式,而是一种组织模式。Netflix 需要它,因为他们有 200 个团队。你没有。Uber 需要它,因为他们一天发布 4,000 次。你没有。
复杂性之所以诱人,是因为它看起来像进步。 拥有 47 个服务、Kubernetes、服务网格和分布式追踪,看起来很“专业”;而一个单体加一套 Postgres,看起来很“业余”。
但复杂性是一种税。它以认知负担、运营开销、开发者幸福感和交付速度为代价。
而大多数初创公司根本付不起这笔税。
我们花了两年时间为并不存在的规模做优化,同时牺牲了能让我们真正达到规模的简单性。
你不需要 50 个微服务,你需要的是自律
软件架构的“肮脏秘密”是:好的设计在任何规模都奏效。
一个结构良好的单体,拥有清晰的模块、明确的边界上下文和合理的关注点分离,比一团由希望和 YAML 勉强粘合在一起的微服务乱麻走得更远。
微服务并不是因为“糟糕”而式微,而是因为我们出于错误的理由使用了它。我们选择了分布式的复杂性而不是本地的自律,选择了运营的负担而不是价值的交付。
那些悄悄回归单体的公司并非承认失败,而是在承认更难的事实:我们一直在解决错误的问题。
所以我想问一个问题:你构建微服务,是在逃避什么?
如果答案是“一个凌乱的代码库”,那我有个坏消息——分布式系统不会修好坏代码,它只会让问题更难被发现。
来源:juejin.cn/post/7563860666349649970
百度智能云开工采购季助力低成本解锁AI生产力
当“赛博养虾”成为一种新晋社交货币,一场关于AI落地的范式革命已然开启。近期,开源AI智能体OpenClaw因其酷似龙虾的图标和强大的自动化能力火爆全球,被开发者们亲昵地称为“小龙虾”,掀起了一场“全民养虾”的热潮 。
在这场“养虾”运动的背后,是海量的算力消耗与高昂的Token成本。如何让每一位“养虾人”和企业用户都能低成本、高效率地拥抱这波技术红利?据悉,2026年2月25日,百度智能云正式启动“云启惠聚·企业采购季”开工季大促活动,不仅将OpenClaw的部署门槛降至冰点,更以极致的价格和丰厚的权益,为企业和开发者们开年复工的智能升级“囤好粮”。
极简部署“养虾”,9.9元开启AI助理时代
“养虾”虽火,但环境配置、模型接入等技术门槛曾让不少爱好者望而却步,甚至催生了付费“上门安装”的生意 。为了让AI普惠至每一位用户,百度智能云在本次采购季中推出了针对性的极简部署方案与超低折扣。
针对近期火爆的OpenClaw“养虾”热潮,百度智能云推出轻量应用服务器9.9元/月起,可实现AI助手极简部署;同时面向中小网站建设、开发测试等传统场景,推出云服务器经济型E2 19.9元/年惊爆价。两款服务器分别瞄准AI极速上手与通用业务上云,以极致性价比满足复工季的多样化算力需求。
“OpenClaw的爆火,折射出市场对‘能干活’的AI的迫切期待。”百度智能云相关负责人表示,“本次采购季,我们整合了从算力、模型到部署工具的全链路资源,希望让企业和个人都能零门槛迈入‘代理型AI’应用的新阶段。”

企业级“粮仓”全面升级,万元券包助跑复工季
除了面向开发者的“养虾”盛宴,本次“开工采购季”更为广大企业客户准备了丰厚的“开工红包”,直击企业数字化转型中的成本痛点。
邀请企业认证,得1999元红利津贴:作为本次活动中力度最大的满减福利,活动期间,邀请百度云用户完成企业实名认证,双方均可获得1999元的专属红利津贴。该津贴可用于云服务器BCC、对象存储BOS、人脸识别等多种核心产品,极大降低企业上云试错成本。
领万元新购/续费券包,至高立减6000元:针对不同企业需求,百度智能云推出多梯度满减券。新用户可享满200减30至满1500减525元不等的专享券;而对于有批量采购需求的企业,最高可领取满20000减6000元的超值续费券,覆盖计算、存储、网络、安全及AI全栈产品。
限时秒杀与100%中奖锦鲤池:每周不同主题的秒杀日将持续点燃采购热情。通用文字识别低至1元、文档解析5000页仅199元、数字员工套餐9.9元起 。活动期间,只要完成实名认证或订单满额,即可参与抽奖,京东卡、小度智能屏等好礼100%中奖,更有高额惊喜券随机放送。
技术普惠,重构AI生产力“新成本”
在OpenClaw引发的“Token经济学”讨论中,国产模型凭借极致的性价比成为全球“养虾人”的热门选择 。百度智能云此次采购季也深度呼应了这一趋势。
以千帆大模型平台相关产品为例,大模型Tokens量包低至20元/年(产品首购) 。配合云服务器、CDN等基础资源的超低折扣,百度智能云正在构建一个从算力基座到AI应用层的“高性价比创新闭环”。
业内分析认为,随着OpenClaw等智能体框架的普及,AI的商业模式正从“让更多人对话”转向“让更多智能体持续做事” 。百度智能云此次“开工采购季”敏锐地捕捉到了这一节点,通过精准的优惠组合,不仅解决了开发者“养虾”的燃眉之急,更为广大企业在AI时代的组织变革和效率升级,提供了坚实的“粮草”后盾。

BOE(京东方)联合TÜV莱茵发布《自然光显示技术白皮书》 以“晨午暮夜”系统仿生定义健康显示新标杆
2026年3月11日,在AWE 2026(中国家电及消费电子博览会)举办前夕,BOE(京东方)“自然光”显示技术品鉴会于TÜV莱茵InnoHub隆重举行。本次活动以“朝夕自然·光合焕新”为主题,基于“晨午暮夜”四时自然光所提出的“系统仿生学”设计理念,BOE(京东方)深刻解读并展示了其独创的“自然光”显示技术(BNL)的创新实践。会上,BOE(京东方)携手国际权威检测认证机构TÜV莱茵共同发布《自然光显示技术白皮书》,不仅为健康显示领域提供了系统性、可量化的指引,更将为全球显示产业树立健康护眼的可测量基准,推动显示产业从“看得清”迈向“看得舒服、看得健康”的新纪元。BOE(京东方)与TÜV莱茵大中华区相关领导,以及联想全球显示器事业部、业务&产品总监芦智勇,复旦大学附属眼耳鼻喉科医院副主任医师许烨,深圳创维显示科技有限公司产品规划部总监薛海啸等各界嘉宾出席了本次活动。

京东方科技集团高级副总裁、联席首席技术官邵喜斌在致辞中深度阐释了“自然光”显示技术(BNL)的核心设计逻辑与创新价值。“在行业还聚焦于分辨率、刷新率等硬性参数竞逐时,BOE(京东方)就已前瞻布局视觉健康研究,成为最早进入该领域的显示企业。十余年间,我们推出了低蓝光、PWM低频闪、类纸护眼等多项行业领先的护眼技术,率先实现量产并广泛应用于手机、平板、笔记本、电视等全品类终端。BOE(京东方)发布的‘自然光’显示技术是健康护眼领域持续深耕的集大成之作。”他在致辞中还强调,BOE(京东方)“自然光”显示技术(BNL)的核心差异在于其“系统仿生学”设计理念:“它不是单一功能的修补,而是从自然光中提取‘有益’精华——即BNL中的Beneficial——通过光谱优化、偏振调节、光形优化、时变适配四大维度,精准复刻自然光的健康舒适特性,好比是在重构一天中‘晨、午、暮、夜’四个时间段的舒适光环境,实现从‘单点减害’到‘系统增益’的跨越。”

本次活动的核心环节是BOE(京东方)与TÜV莱茵联合发布《自然光显示技术白皮书》。该白皮书基于最新的视觉健康研究和自然光特性在显示产业的应用实践,将自然光对人体身心健康的有益特性进行详细分解,并对现有的科学实践和理论研究对自然光有益特性的支持证据进行了分级,为未来建立科学有序的自然光技术评价体系提供了依据。TÜV莱茵大中华区电子电气产品服务区域总经理、全球显示技术总监刘喜强表示:“这份白皮书的发布代表着我们对于未来显示设备如何才能确保人类的长期视觉健康与发展的重新审视,相信将会有越来越多的产品应用自然光技术,为广大消费者带来更健康和舒适的体验。”

品鉴会现场,BOE(京东方)精心打造了 “晨、午、暮、夜”技术体验展区,多款全球首发的基于“自然光”显示技术(BNL)产品与生态伙伴产品集中亮相,生动诠释了BNL技术如何解决用户在真实场景中的视觉健康痛点。

· 晨 · 光形优化展区:模拟清晨柔和漫射光,通过光形优化中的低眩光、低反射、广视角技术,大幅抑制屏幕反光和眩光。创维壁纸电视A7F Pro系列通过极低的DGR(显示眩光值)使得眩光反光几乎不存在,不仅显示艺术画作细腻真实,观影效果亦媲美真实世界;ROG枪神9 Plus超竞版搭载ACR技术减少约55%光线反射,实现至高4.5倍环境光对比度,让用户在室内复杂光环境下也能获得如阅读纸质书般的舒适体验。
· 午 · 偏振调节展区:借鉴正午阳光经由大气层散射后偏振光含量最少,最接近自然光自然无偏振的特性,突破传统屏幕线偏振局限,推出圆偏振、随机偏振等技术。EVNIA弈威全球首款舒视蓝4.0圆偏光护眼显示器兼顾护眼与高刷;BOE(京东方)全球首发的10.95英寸RDF平板实现屏幕光线全域均匀振动,从物理根源预防因对眼底视网膜叶黄素的局部刺激导致的视疲劳。
· 暮 · 光谱优化展区:复刻傍晚霞光中红光比例高、蓝光比例低的特质,通过低蓝光、有益红光、红外光等技术,在削减有害蓝光的同时主动补充有益红光、增加红外光。另外通过全光谱、节律调节等光谱优化技术,补全宽光谱、调节人体睡眠。BOE(京东方)14英寸全光谱笔记本拥有63%业界领先光谱分布匹配度,14英寸有益红光笔记本实现50%有益红光能量占比,可改善血液循环,并对近视抑制有一定作用,从“被动减害”升级为“主动增益”。联想ThinkVision P27QD-40以“好屏看得见,性能再跃升”为核心理念,可以将有害蓝光降低到35%以下,并获得TÜV莱茵眼部舒适度(5星)认证、EyeSafe 2.0认证,为企业办公定制视觉新标准。
· 夜 · 时变适配展区:对标暗夜微光稳定无频闪、光强连续变化的特性,融合超高刷、超高频PWM等低频闪技术以及跟随环境光自适应的光感技术。一加15搭载BOE(京东方)第三代东方屏,实现1nit超低亮暗夜显示;荣耀Magic6 RSR采用超高频4320Hz PWM调光,能减少频闪对眼睛的刺激,缓解视觉疲劳,获得了TÜV莱茵无频闪认证。
· 中心展区:BOE(京东方)13.8英寸“自然光”显示平板作为全球首款BNL综合集成产品,集BNL四大维度于一身,拥有BOE(京东方)首创的红外光、RDF解偏技术,业界最高光谱分布匹配度的全光谱技术及低蓝光、低频闪等BNL技术,并荣获CES 2026护眼显示全球创新金奖,成为BNL技术系统级能力的完美缩影。
在“光·合作用”圆桌论坛环节,BOE(京东方)、TÜV莱茵、联想及行业权威专家从技术、标准、应用、产业四大维度展开深入探讨。专家们一致认为,BNL技术的推出标志着显示产业实现从“参数导向”向“用户健康需求导向”的根本性重构;而TÜV莱茵白皮书的发布则为行业提供了从“无序宣传”走向“规范认证”的路径。

活动尾声,BOE(京东方)正式启动“光合作用”健康护眼计划,以 BOE (京东方)领先的“自然光”显示技术为基石,定义健康显示新标准,构建协同创新的全场景生态,照亮全民健康的智慧未来。这一计划与BOE(京东方)可持续发展品牌ONE的核心理念高度契合,彰显了BOE(京东方)作为显示产业龙头企业的社会责任与担当。

从定义“自然光”标准到健康显示白皮书发布,BOE(京东方)正通过“技术创新+标准制定”,让每一块屏幕都成为用户视觉健康的守护者。在“屏之物联”战略指引下,BOE(京东方)将继续携手全球伙伴,推动显示产业向更健康、更舒适、更规范的方向迈进,让“好屏认准京东方”成为显示行业公认的价值标杆。
收起阅读 »一大波危险的“龙虾”来袭,绿盟君助您安全“养虾”
近期,工业和信息化部网络安全威胁和漏洞信息共享平台(NVDB)发布了一则重磅预警:OpenClaw开源AI智能体部分实例在默认或不当配置下存在严重安全风险,极易引发网络攻击、信息泄露等安全问题。这一预警犹如一石激起千层浪,引发了业界对AI智能体安全的高度关注。
OpenClaw引领智能体全面爆发,
安全问题频发
2026年,AI智能体技术迎来全面爆发。作为其中的代表性项目,OpenClaw(曾用名Clawdbot、Moltbot)凭借其强大的能力备受青睐——它能够整合多渠道通信能力与大语言模型,构建具备持久记忆、主动执行能力的定制化AI助手,支持本地私有化部署。
然而,正是这样一位“能干的助手”,却可能成为潜伏在您网络中的“定时炸弹”。
OpenClaw三大核心风险,不容忽视
OpenClaw由个人程序员编写,从发布到爆火仅仅几个月时间,由于自身设计特点,存在天然的“信任边界模糊”问题。它具备持续运行、自主决策、调用系统和外部资源等能力,在缺乏有效权限控制、审计机制和安全加固的情况下,将面临三重严重风险:
安全风险1:代码安全堪忧——三天两高危RCE,系统可被恶意接管
OpenClaw的代码库在短期内连续曝出两个高危远程代码执行漏洞(RCE)。攻击者无需复杂操作,即可利用漏洞在目标主机上执行任意代码,实现从“入侵”到“接管”的一步跨越。一旦得手,OpenClaw所在的主机将成为攻击者的“肉鸡”,企业核心数据、内部网络将完全暴露在风险之下。这不是危言耸听,而是已在野外被积极利用的真实威胁。

安全风险2: 盲目信任放大风险——“以安全换便捷”,Agent沦为攻击跳板
OpenClaw的设计理念强调“自主性”,默认配置往往为了便捷而牺牲安全。许多用户在部署时,为了能让工作更便捷,需要赋予它极高的权限,甚至让其直接访问敏感系统或数据库。这种对Agent的“盲目信任”,让攻击者能够通过诱导式指令,轻松操纵OpenClaw执行越权操作——比如读取机密文件、发送恶意邮件、横向移动攻击内网其他主机。你以为它是你的得力助手,实际上它可能正在被敌人遥控。

安全风险3: 插件系统成供应链突破口——隔离机制缺失,投毒威胁放大
OpenClaw支持通过Skills插件系统扩展功能,但这片“沃土”也成为攻击者的乐园。第三方插件来源不明、供应链环节缺乏审查,加之OpenClaw自身对插件运行缺乏有效的隔离机制,使得一个被投毒的插件就能成为“特洛伊木马”。一旦插件被安装,恶意代码便能随OpenClaw权限肆意横行,窃取数据、植入后门,甚至通过插件更新机制将投毒扩散至更多用户。供应链安全的薄弱环节,在此被无限放大。

谷歌在2月份就已经连夜封禁OpenClaw,Facebook、Mata、微软等几家巨头也不允许员工在公司内部使用OpenClaw。微软安全团队已将此情形定性为“具有持久凭据的不可信代码执行环境”,这一评价值得每一个正在或计划使用AI智能体的企业深思。
客户真实痛点,您是否感同身受?
在与众多企业用户的交流中,我们听到了两种典型的担忧:
客户声音1:“我们公司有员工自己偷偷部署了OpenClaw,我担心这些‘影子AI’导致本地主机端口暴露,引发信息泄露。但我连它们在哪里都不知道,更别提管控了。”
客户声音2:“我们业务部门正式部署了OpenClaw,但我想知道它到底做了哪些外部访问?这些访问是否合法合规?是否存在被利用的风险?”
传统安全方案为何失效?
面对OpenClaw这类新型AI智能体,传统安全方案显得力不从心:
流量内容不可见:OpenClaw用户侧API主要进行常规HTTPS调用,流量加密传输,传统应用识别方式完全失效。
端口识别易绕过:OpenClaw虽有默认端口,但极易被修改,单纯依赖端口识别不仅准确率低,还容易被攻击者绕过。
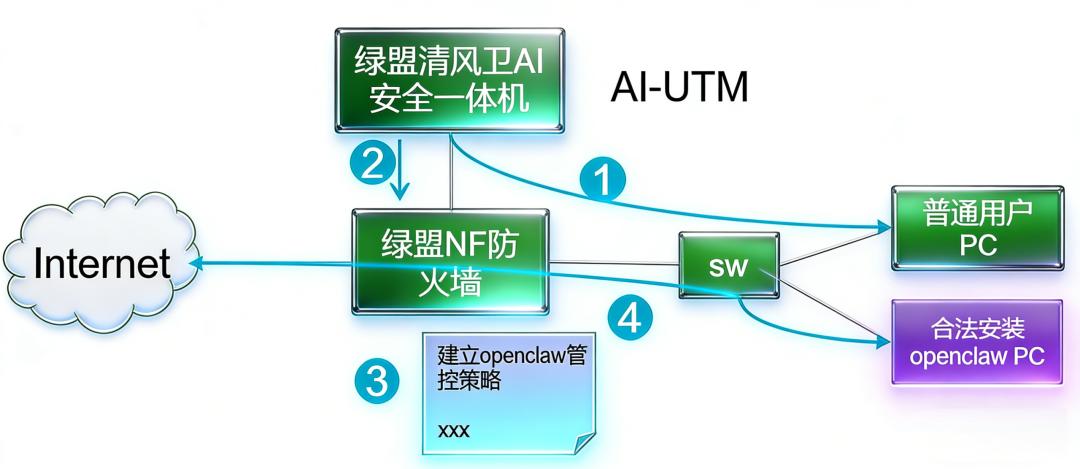
绿盟科技OpenClaw安全防护方案:
给AI装上“安全护栏”
针对OpenClaw带来的新型安全挑战,绿盟科技创新性地推出低成本“AI安全一体机+绿盟防火墙NF联动”解决方案,帮助用户实现对AI智能体的精准识别与全面管控。

方案核心能力
精准识别:AI安全一体机内置AI智能体发现能力,可主动扫描内网环境,精确识别哪些主机部署了OpenClaw等AI智能体。
灵活管控:根据企业策略,可对非法部署的OpenClaw进行网络隔离,对合法部署的OpenClaw进行全程行为跟踪。
纵深防御:防火墙对OpenClaw的会话访问进行实时分析,识别恶意URL、入侵威胁、病毒等风险,确保每一次访问都安全可控。
方案优势
识别精准:从资产纬度对AI智能体进行主动识别,告别传统方案的误报与漏报。
部署便捷:不影响原有组网,快速接入,即插即用。
全面可视:对OpenClaw的访问行为进行全程跟踪分析,让安全风险无处遁形。
两大应用场景,全方位守护
场景1:对非法OpenClaw进行精准封堵
当员工私自部署OpenClaw,AI安全一体机第一时间发现并定位,将非法安装的PC信息同步给防火墙。防火墙自动生成黑名单策略——无论外部试图访问该OpenClaw,还是OpenClaw主动外联,都将被实时阻断,将风险扼杀在萌芽状态。

场景2:对合法OpenClaw进行安全管控
对于业务部门正式部署的OpenClaw,AI安全一体机将其纳入管控范围。防火墙生成精细化管控策略,对OpenClaw的所有访问会话记录流量日志,进行全方位安全检测,避免恶意URL、入侵威胁、病毒等威胁趁虚而入,让业务在安全轨道上平稳运行。
两会强调“发展与安全并重”,
绿盟科技如何解读?
近期全国两会多次强调“发展与安全并重”,这释放了一个清晰信号:安全不是AI创新的刹车,而是AI落地的护栏和加速器。
作为安全厂商,我们的目标就是让客户在AI的高速公路上既能跑得快,又能刹得住、不跑偏。具体到企业落地,要避免“安全拖慢AI”或“AI裸奔”,我们主要通过“双引擎驱动”和“原生融合”的策略来解决。
以智增效:让安全成为创新加速器
很多企业担心:上了安全措施,AI应用会不会变慢?我们的答案是:用更聪明的AI去解决安全效率问题。
绿盟“风云卫”AI安全能力平台,本质上就是一个“安全效率倍增器”。它将AI能力“原子化”地嵌入安全运营的每一个环节,让过去需要大量人工的重复性工作变得自动化、智能化。面对海量安全告警,我们的AI安全运营中心可以实现“AI优化AI”的能效革命,大幅提升安全事件的处置效率。
为AI“上险”:拒绝“裸奔”式创新
我们坚决反对“先狂奔、再补胎”的裸奔式创新。当企业把核心业务交给大模型时,大模型本身的幻觉、数据泄露、提示词注入等风险,就成了企业的“阿喀琉斯之踵”。
绿盟的做法是构建一套从 “事前评估、事中防护、事后审计”的AI原生纵深防御体系,形象地说就是给大模型穿上“金钟罩”。我们推出的“清风卫”系列安全防护产品,能在模型运行时实时防御各类新型攻击。同时,针对合规要求,绿盟大模型备案服务能够帮助企业构建“可自证”的合规体系,提前预见风险,规避千万级罚款风险。
OpenClaw的“虾”来了,别让您的网络成为坏虾的“养殖场”。立即行动,为您的AI应用加上一道“安全护栏”!
凭借二十多年的攻防实战经验,绿盟科技致力于成为您智能化转型路上最可靠的“副驾驶”——帮您看清路况、预警风险,让您可以更安心地手握方向盘,专注于业务创新的加速与超越,共同驶向智能化的未来。
e签宝对话中建四局|产业为基,AI为翼,解码建筑央企的数字化章法
建筑业的转型逻辑正在被时代重写。行业共识日趋清晰:数字化不再是锦上添花的可选项,而是关乎企业核心竞争力的必答题。而当AI浪潮席卷各行各业,这道必答题又增添了新的难度与想象空间。
在此背景下,作为体量庞大、链条复杂的央企代表,中建四局的数字化转型实践尤为引人关注。这家拥有数万工人的建筑巨头,将如何拥抱AI?又将如何走出国企不同于民企的转型路径?当自身的数字基建初具规模,它又如何将能力向外辐射,推动产业链从单点提效走向系统升级?本期e签宝《对话》栏目走进中建四局,与其数字化部总经理符和清展开深度对谈,共同解码这家建筑央企在数字时代的破局思路与实践。
拥抱AI从具体场景做起、AI落地的“小成果”逻辑,让优化叠加
AI是这场对话的时代背景,也是绕不开的开场话题。行业自上而下的共识正在凝聚:AI不再是遥不可及的未来概念,而是建筑业提质增效的现实变量。但“如何用、用在哪儿”仍是普遍困惑。有行业调研显示,建筑企业在推进AI时存在三类典型误区:重技术基座轻应用场景、试图全自建导致门槛过高、初期成效未达预期便选择观望。
正是在这样的背景下,e签宝联合创始人、高级副总裁张晋直言,AI浪潮席卷各行各业,对国央企影响大吗?中建四局在落地应用上又做了哪些探索?

中建四局数字化部总经理 符和清坦言,国央企对AI的重视程度出奇一致,首先是响应国家战略的需要。但在具体落地上,他的判断颇为清醒:AI不会是某个巨无霸式的综合大平台,而应是底层平台支撑、上层场景开花的格局——真正能够改变生产效率的,往往是那些像智能体一样聚焦具体环节的小众应用。
循着这个思路,中建四局已经在多个场景上展开探索。得益于两年前推动的合同结构化,他们在合同智能审查上有了用武之地;施工图纸审查、商务算量、目标成本测算等环节,AI也开始介入那些繁琐的重复劳动。符和清把这些称为“小成果”——没有惊天动地的大平台,但在知识库搜索、制度查询这些细碎场景里,效率的提升是实实在在的。
他打了个比方:AI不像是造出一辆全新的汽车,更像是优化了某个齿轮、改进了某个发动机零件。未来的数字化,一定是无数个这样的“小优化”叠加起来,最终让整个系统跑得更顺、更高效。
深耕场景、务实推进的这种思路,也将贯穿于中建四局对数字化每一个命题的思考与实践之中。
从蓝图到一线、国央企数字化的慢功夫与真问题
同样的数字化,国央企与民企的两样走法
随后张晋便抛出了一个很基础但是许多人关心的问题:国央企与民营企业在推进数字化转型的过程中,到底有哪些不同?中建四局数字化部总经理符和清结合自己从阿里到国央企的多年经历,从三个维度给出了洞察。

第一重差异在于组织能力。民企极少设置三级及以上机构,扁平化的组织让战略能直达一线。而在中建四局这样的大型国央企,从集团、工程局、公司、分公司到项目部,层级纵深长达五级。同样一句话从顶层发出,穿透层层组织后,不同节点的理解和执行难免产生偏差。
第二重差异体现在实践思路上。民企的数字化往往自下而上生长,一个部门的尝试、一个场景的创新,都可能快速迭代成燎原之火。而国央企更倾向于顶层设计先行——先做蓝图规划,再分解为项目群、项目、产品,层层落地。对于体量庞大、业务复杂的国央企而言,没有清晰的蓝图,就谈不上有序的推进。
第三重差异落在细节管理上。在国央企,业务人员懂业务却难以精准表达需求,技术人员懂技术却无法真正理解业务场景,中间横亘着巨大的认知裂缝。如何有效整合资源、转化需求、把控架构,是国央企在数字化落地中需要投入更多精力的地方。
这三重差异,勾勒出国企数字化转型的独特底色:它注定不是一场快速突围战,而是一场需要穿透层级、统筹规划、弥合裂缝的体系工程。
数字化深水区中的“两张皮”现象
谈及业务与数字化“两张皮”,符和清没有回避。这是建筑行业的老话题,也是真问题——这些年行业上了不少系统,云端工厂、智慧工地、数字看板,一个个新名词落地成屏,挂满了项目部的墙面和电视。但系统是不是真的在用?数据是不是真的在跑?还是说,只是把原来的线下表格搬到了大屏上,看上去热闹,业务该怎么干还是怎么干?这不仅是四局的考题,也是整个行业在数字化深水区绕不开的一道坎。

在符和清看来,这个问题在国央企尤为突出:体系庞大、层级多、角色杂,认知不统一是天然难题。但在四局的实践中,他们摸索出了几个关键的抓手。
首先是“一把手工程”的决心。数字化是一把双刃剑——系统上线意味着流程透明、审计严格,过去能含糊过去的问题都会浮出水面。高层如果没有“认账”的魄力,遇到阻力就容易动摇。“数字化本质是业务重塑,既然要改,就得有从上到下的改革决心。”
其次是IT与业务组织的深度协同。符和清反复强调,数字化绝不能是技术部门的一厢情愿,必须由业务部门来推动。“系统第一版能用就行,关键是业务愿意用起来。”而IT部门要做的,是持续优化、快速响应,确保大家“用得动、改得好”。“只要业务在用,一年不行,两年三年总能磨出来。”
最后是培训与认知的普及。他打了个比方:给农村老太太一个苹果手机,不教不用,最后还是躺在抽屉里。再好的数字化产品,如果员工不理解、不会用,数据不准、流程空转,“两张皮”就自然而生。符和清提到,像四局这种三万人左右的体量,只要数字化系统上线,基本都要组织封闭式的大规模培训,给大家“交底”。通过这种持续渗透,让不同层级的人真正理解系统、用透系统。
这多重解法背后,是一个朴素的认知:数字化从来不是系统上线即告捷,而是人与流程、组织与工具长期磨合、逐步深化的过程。如今在新鸿基广州南站的项目上,数字化已经实打实地用起来了——在中建四局的转型实践中,“务实”正成为越来越清晰的注脚。
不是零敲碎打而是体系推进,数字化路径有章可循
从单点到全链,中建四局率先出招产业互联网先手棋
“建筑产业互联网”,这是一个近年来在行业内热度渐起的词汇——从行业协会连续三年举办产业互联网发展大会,到各地纷纷布局区域级平台,行业共识正在凝聚:建筑业的数字化,正在从单点突破走向全链协同。
符和清介绍到,其实“建筑产业互联网”这个概念,中建早在2020年做“136规划”时就已写入目标——那个“1”,就是要构建产业互联网。
在他的解读里,产业互联网不是新名词包装,而是围绕建筑全生命周期的数字化主线:从勘察、设计、施工,到交付、运维、运营,每一个环节都要有数据贯穿。而作为全球最大的建筑商之一,中建四局有这个体量去整合上中下游的资源协同。
他细数了中建四局目前的进展:内部施工环节已经通过DMP平台实现了数字化,对下游的分包、劳务、供应链协同也基本跑通,上游与政府监管系统也有零星连接。未来的远景目标,是以建筑为单元,连接城市运营,让数据在整个生命周期里真正流转起来。
“中间环节我们自己做通了,上下游也在逐步打通。”符和清说,产业互联网的蓝图,正在从规划一步步走向现实。
从规划到落地:DMP平台承载四局数字化蓝图
在不久前举办的智能建造观摩会上,中建四局正式发布了DMP数字化管理平台,引起行业关注。谈及这个平台的来龙去脉,符和清把它放进了四局数字化转型的整体框架里。
他介绍,三年前做顶层规划时,四局明确了五个数字化方向:管理数字化、生产体系数字化、供应链数字化、项目现场数字化,以及面向未来的全生命周期运营。而DMP平台,正是承载这五大方向的统一载体。
目前DMP的发力点主要有两个维度:横向上,从项目投标开始,贯穿施工、结算到最终运营,让经济数据全链条跑通;纵向上,基于生产现场的管理,把设计图纸、清单量与施工进度绑定,自动算量、算成本、算收入,最终自动呈现真实的利润。
“这个工程难度相当大,在全行业来看,中建也是走在前面的。”符和清说。这套平台不仅是对内提效的工具,更是四局构建产业互联网蓝图的关键一步。
不止于提效,e签宝电子签成为四局数字化协同关键
对于体系庞大的建筑行业来说,供应链的数字化非常具有典型性。据符和清介绍,中建四局在供应商资源整合、招采、物流体系及订单管理方面已经相当成熟。从前两年开始,对下游分包环节,尤其是施工队伍,通过DMP平台实现了深度协同;在上游也取得突破,劳务管理、农民工工资发放等环节已基本实现数字化对接。

谈及具体落地成效,符和清特别提到了e签宝电子签章系统带来的变化。目前,e签宝电子用印不仅覆盖了对上游的承包合同和对下游的分包合同这两类核心业务,还在内部管理体系中全面铺开——全局3万人的行政办公,从发文、收文到红头文件用印,已全部实现电子化;下属地产公司等多家单位的对外业务合同也陆续上线使用。

“今年局里已经发了制度和文件,要求未来电子用印全部实现数字化。”符和清说。这套系统不仅解决了传统用印的流程痛点,更成为四局打通上下游协同的“连接器”——从内部办公到外部合同,从上游甲方到下游分包,电子签章让每一份文件的流转都留下了清晰的数字化足迹。
而随着AI能力的深度融入,电子签章正在从“连接器”进化为更智能的合同中枢——从智能审查到风险预警,从合同结构化到履约跟踪,AI让每一枚电子印章背后都有了更强大的支撑。这也正是符和清所说的“小优化叠加”:当AI赋能每一个细碎场景,系统自然跑得更顺、更高效。
数字化不是一场立竿见影的技术革命,而是一场需要穿透层级、统筹规划、弥合裂缝的体系工程。它既需要顶层设计的定力,也需要一线落地的韧性;既需要一把手工程的决心,也需要业务与IT的长期磨合。而AI的加入,正在让每一个“齿轮”的优化变得更快、更准。
在这场建筑行业深刻的数字化变革中,e签宝很荣幸成为中建四局数字化拼图中的一块——从内部办公到外部合同,从上游甲方到下游分包,电子签章已成为打通产业链协同的“连接器”。从电子签章到智能合同Agent,e签宝正从电子签名服务商进化为AI驱动型数字信任基础设施提供商。未来,e签宝将继续以AI赋能、以可信筑基,助力更多企业从单点提效走向全链协同,共同见证产业互联网从蓝图走向现实。
收起阅读 »ZeroClaw 实战:Rust 重构版 OpenClaw,7.8MB 内存秒启动的 AI 助手
OpenClaw 功能强大,但在内存占用和启动速度方面存在挑战。针对这些问题,主打极速、轻量的 Rust 重构版 ZeroClaw 应运而生。
整篇文章的目标只有一个:
让你看完后,能在本地服务器上部署 ZeroClaw,体验 7.8MB 内存、秒启动的 AI 助手,并在实际项目中发挥它的价值。
一、ZeroClaw 是什么?为什么值得一试?

1.1 性能对比
如果把它和 OpenClaw 放在一起对比,ZeroClaw 可以说是个妥妥的性能怪兽。
根据官方基准测试(macOS arm64,2026年2月,针对 0.8GHz 边缘硬件标准化),ZeroClaw 的表现如下:
| 指标 | OpenClaw | ZeroClaw 🦀 |
|---|---|---|
| 编程语言 | TypeScript | Rust |
| 内存占用 | > 1GB | < 5MB |
| 启动速度(0.8GHz 核心) | > 500s | < 10ms |
| 二进制大小 | ~28MB (dist) | 3.4 MB |
| 硬件成本 | Mac Mini $599 | 任意硬件 $10 |

这个项目用 Rust 编写,ZeroClaw 运行时内存不到 5MB、启动时间小于 10ms、二进制体积仅约 3.4MB,支持在树莓派或者低配云主机上部署 Agent。
从性能角度看,它具备几个关键特性:
- 🏎️ 极致精简:< 5MB 内存占用,比 OpenClaw 核心小 99%
- 💰 成本极低:高效到可以在 $10 硬件上运行,比 Mac mini 便宜 98%
- ⚡ 闪电启动:启动速度提升 400 倍,在 < 10ms 内启动(即使在 0.6GHz 核心上也能在 1 秒内启动)
- 🌍 真正可移植:跨 ARM、x86 和 RISC-V 的单一自包含二进制文件
1.2 适用场景
场景 A:资源受限环境
如果你需要在树莓派、低配云主机(1GB 内存)上部署 AI Agent,ZeroClaw 无疑是最优选。
它那极低的资源占用,能大幅减少服务器资源的浪费。用省下的内存,来运行多一点其他业务,不香吗?
场景 B:自动化流水线与服务器运维
如果需求是每天定时抓取博客、监控服务器日志,或者在配置较低的云服务器上部署,ZeroClaw 的轻量特性让它成为理想选择。
场景 C:批量部署
对于需要在一人企业中批量部署多个 AI Agent 的场景,ZeroClaw 的小体积和低资源占用,让批量部署成为可能。
1.3 架构设计:一切都是 Trait
ZeroClaw 的核心设计理念是:每个子系统都是一个 trait,只需更改配置即可交换实现,无需修改代码。

ZeroClaw 架构图,展示各个子系统(Provider、Channel、Memory、Tools 等)的 trait 设计和可插拔架构
核心子系统:
| 子系统 | Trait | 内置实现 | 可扩展 |
|---|---|---|---|
| AI 模型 | Provider | 22+ providers(OpenRouter、Anthropic、OpenAI、Ollama、Venice、Groq、Mistral、xAI、DeepSeek、Together、Fireworks、Perplexity、Cohere、Bedrock 等) | custom:https://your-api.com — 任何 OpenAI 兼容的 API |
| 通信渠道 | Channel | CLI、Telegram、Discord、Slack、iMessage、Matrix、WhatsApp、Webhook | 任何消息 API |
| 记忆系统 | Memory | SQLite 混合搜索(FTS5 + 向量余弦相似度)、Markdown | 任何持久化后端 |
| 工具 | Tool | shell、file_read、file_write、memory_store、memory_recall、memory_forget、browser_open(Brave + 白名单)、composio(可选) | 任何能力 |
| 可观测性 | Observer | Noop、Log、Multi | Prometheus、OTel |
| 运行时 | RuntimeAdapter | Native(Mac/Linux/Pi) | Docker、WASM(计划中) |
| 安全策略 | SecurityPolicy | Gateway 配对、沙箱、白名单、速率限制、文件系统作用域、加密密钥 | — |
| 身份系统 | IdentityConfig | OpenClaw(markdown)、AIEOS v1.1(JSON) | 任何身份格式 |
| 隧道 | Tunnel | 、Cloudflare、Tailscale、ngrok、Custom | 任何隧道二进制文件 |
这种设计让 ZeroClaw 具有极强的可扩展性和灵活性,你可以根据实际需求替换任何组件,而无需修改核心代码。
二、开始前你需要准备好的东西
动手之前,先确认这几样已经就绪。
- 一台 Linux/macOS 服务器(Windows 需要 WSL)
ZeroClaw 是纯 Rust 项目,主要支持 Linux 和 macOS。Windows 用户需要先安装 WSL。 - Rust 环境(如果还没安装,下面会带你安装)
由于 ZeroClaw 是纯 Rust 项目,需要先安装 Rust 编译环境。 - LLM API Key(OpenAI、Anthropic、DeepSeek、OpenRouter 等)
用于配置 AI 模型,支持主流的大模型服务。
三、手把手安装:10 分钟搞定 ZeroClaw
3.1 环境准备:安装 Rust
由于 ZeroClaw 是纯 Rust 项目,如果我们电脑里还没安装 Rust,需要先把 Rust 环境准备好。
Linux / macOS:一条命令安装
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source $HOME/.cargo/env
rustc --version
cargo --version
看到版本号后,说明 Rust 安装成功,可以继续后面的 ZeroClaw 编译和安装步骤了。
开始安装

安装成功

Windows:通过 WSL 安装(推荐 ZeroClaw 场景)
ZeroClaw 更适合跑在 Linux 环境里,所以在 Windows 下,推荐先装好 WSL(如 Ubuntu),然后在 WSL 终端里执行和 Linux 一样的命令,看到版本号后,就可以在这个 WSL 环境中继续后面的 ZeroClaw 编译和安装步骤了。
3.2 编译安装 ZeroClaw
环境装好后,我们把代码拉下来,就能开始编译安装了。
这里推荐 Release 版,因为它体积最小、速度最快:
# 克隆仓库
git clone https://github.com/zeroclaw-labs/zeroclaw.git
cd zeroclaw
# 编译 Release 版本(优化后的版本)
cargo build --release
# 安装到系统路径
cargo install --path . --force


⚠️ 编译时间较长
首次编译 Rust 项目可能需要 5 - 10 分钟,取决于你的机器性能。这是正常现象,因为 Rust 需要编译所有依赖。
解决:耐心等待,或者使用cargo build --release -j $(nproc)来并行编译加速。
编译完成后,验证安装:
zeroclaw --version
如果显示版本号,说明安装成功。
3.3 基础配置:交互式向导
这个项目不仅安装快,配置也极其人性化。交互式向导:
zeroclaw onboard --interactive

这是一个完整的 7 步交互式向导,会引导你完成所有配置。
配置向导会引导你完成:
- 输入 LLM 的 API Key
支持 OpenAI, Anthropic, DeepSeek, OpenRouter 等主流模型。
根据你选择的模型服务,输入对应的 API Key。 - 选择想连接的渠道
比如 Slack, Discord, Telegram, WhatsApp 等。
如果暂时不确定,可以先跳过,后续再配置。 - 安全设置:强制设置一个 "配对码"
防止陌生人乱连我们的 Agent。
这个配对码很重要,后续连接时需要用到。 - 配置渠道白名单
为了安全,建议配置允许列表,只允许特定用户连接。 - 其他高级配置
包括内存后端、隧道配置等。
配置完成后,配置文件通常保存在:
- Linux/macOS:
~/.zeroclaw/config.toml - Windows(WSL):
~/.zeroclaw/config.toml
⚠️ 渠道白名单配置
如果配置后收到消息但 ZeroClaw 没有响应,可能是白名单配置问题。
解决:
- 查看日志,找到发送者的身份标识
- 运行
zeroclaw onboard --channels-only重新配置白名单
- 或者临时使用
"*"允许所有(仅用于测试)
3.4 启动和使用 ZeroClaw
启动守护进程
如果你希望 ZeroClaw 长期运行,处理定时任务和自动响应:
zeroclaw daemon
此时,它就在后台默默运行了。

我们可以随时用以下命令查看它的状态:
zeroclaw status

其他实用命令:
# 运行系统诊断
zeroclaw doctor
# 检查渠道健康状态
zeroclaw channel doctor
# 查看集成信息(如 Telegram)
zeroclaw integrations info Telegram
# 管理后台服务
zeroclaw service install
zeroclaw service status
现在,你就拥有一个 24 小时待命的全功能 AI 助手。
四、配置文件详解:定制你的 ZeroClaw
配置文件位置:~/.zeroclaw/config.toml(由 onboard 命令创建)
4.1 基础配置
# API 密钥(支持加密存储)
api_key = "sk-..."
default_provider = "openrouter" # 默认 provider
default_model = "anthropic/claude-sonnet-4-20250514" # 默认模型
default_temperature = 0.7 # 默认温度参数
4.2 内存配置
[memory]
backend = "sqlite" # "sqlite", "markdown", "none"
auto_save = true # 自动保存
embedding_provider = "openai" # "openai", "noop"
vector_weight = 0.7 # 向量搜索权重
keyword_weight = 0.3 # 关键词搜索权重
4.3 Gateway 配置
[gateway]
require_pairing = true # 首次连接需要配对码
allow_public_bind = false # 拒绝 0.0.0.0 绑定(无隧道时)
4.4 自主性配置
[autonomy]
level = "supervised" # "readonly", "supervised", "full"
workspace_only = true # 限制在工作区范围内
allowed_commands = ["git", "npm", "cargo", "ls", "cat", "grep"] # 允许的命令
forbidden_paths = ["/etc", "/root", "/proc", "/sys", "~/.ssh", "~/.gnupg", "~/.aws"] # 禁止访问的路径
4.5 其他配置
[runtime]
kind = "native" # 当前仅支持 "native"
[heartbeat]
enabled = false # 是否启用定时任务
interval_minutes = 30 # 任务执行间隔
[tunnel]
provider = "none" # "none", "cloudflare", "tailscale", "ngrok", "custom"
[secrets]
encrypt = true # API 密钥加密存储
[browser]
enabled = false # 是否启用浏览器工具
allowed_domains = ["docs.rs"] # 允许访问的域名
[composio]
enabled = false # 是否启用 Composio(1000+ OAuth 应用)
📌 提示:配置文件支持热重载,修改后重启服务即可生效。建议使用
zeroclaw doctor检查配置是否正确。
五、OpenClaw 和 ZeroClaw,怎么选?
简单说,可以按场景来选:
- 如果你更关注交互体验、家庭中枢、可视化能力,已经在用 Mac mini 等环境做本地 AI 中控,那继续用 OpenClaw 会更顺手。
- 如果你更在意资源占用、启动速度、批量部署,尤其是打算在树莓派、低配云服务器上长期跑 Agent,那 ZeroClaw 会是更合适的选择。
很多时候,两者是可以并存的:用 OpenClaw 做「大中枢」,用 ZeroClaw 覆盖「边缘节点」和自动化脚本,各自发挥所长。
六、相关资源
GitHub 项目地址:
github.com/zeroclaw-la…
官方文档:
我的其他相关文章:
- 《GitHub 10万+ Star 的 Moltbot 部署实战:手把手带你在本地跑起来这只「龙虾」🦞》
- 《一步步带你手搓专属 IM APP,控制本地 OpenClaw,破局国内 IM 封闭受限》
- 《手把手教你安装 OpenClaw 并接入飞书,让本地 AI 在飞书里听你指挥》
- 《手把手带你实现:飞书 → OpenClaw → Cursor Agent → OpenClaw → 飞书》
结语:ZeroClaw 作为 OpenClaw 的 Rust 重构版,在保持核心功能的同时,大幅降低了资源占用和启动时间。对于需要在资源受限环境或批量部署场景下使用 AI Agent 的朋友来说,ZeroClaw 无疑是一个值得尝试的选择。
希望本文能够帮助你顺利完成部署,在实际项目中发挥 ZeroClaw 的价值。如果在部署过程中遇到问题,欢迎查阅官方文档或相关社区获取帮助。
来源:juejin.cn/post/7610997893576376354
Skills 实战:让 AI 成为你的领域专家
引言:从通用助手到领域专家
想象一下这些场景:
场景 1: 重复的上下文说明
你: "帮我分析这个 BigQuery 数据,记住要排除测试账户,使用 user_metrics 表..."
Claude: "好的,我来分析..."
[第二天]
你: "再帮我分析一次销售数据,还是那个表,记得排除测试账户..."
Claude: "好的,我来分析..." # 😓 又要重复一遍
场景 2: 领域知识的重复传授
你: "帮我处理这个 PDF 表单,PDF 的表单字段结构是..."
Claude: "明白了"
[一周后]
你: "再处理一个 PDF 表单..."
Claude: "请告诉我 PDF 表单的结构" # 😓 忘记了
场景 3: 工作流程的不一致
你: "生成 API 文档,记得包含请求示例、响应格式、错误码..."
Claude: "好的" # ✅ 这次做得很好
[下次]
你: "再生成一份 API 文档"
Claude: [生成的文档] # ❌ 这次忘记了错误码部分
这些问题的根源是:每次对话都是全新的开始,Claude 无法记住你的领域知识、偏好和工作流程。
💡 Skills 系统的价值
Skills 就是解决这个问题的方案——它让你能够:
- 📦 封装领域知识: 把你反复向 Claude 解释的专业知识打包成 Skill
- 🔄 自动加载: 当任务相关时,Skill 自动激活,无需重复说明
- ♻️ 持续复用: 创建一次,跨所有对话自动使用
- 🎯 专业能力: 让 Claude 从通用助手进化为领域专家
本文核心内容:
- Skills 的核心概念与工作原理
- 渐进式披露架构:三级加载机制
- 创建自定义 Skills:从入门到精通
- 最佳实践:简洁、结构化、可验证
- 实战案例:PDF 处理、BigQuery 分析、代码审查
- 评估与迭代:如何持续优化 Skills
"把你反复向 Claude 解释的偏好、流程、领域知识打包成 Skills,让 AI 成为你的领域专家"
一、什么是 Skills?
1.1 核心概念
Agent Skills(智能体技能)是一种模块化的能力扩展系统,它为 Claude 提供了:
- 领域专业知识: 如 PDF 处理技巧、数据库 schema、业务规则
- 工作流程: 如代码审查流程、文档生成流程、数据分析流程
- 最佳实践: 如命名规范、代码风格、错误处理模式
1.2 Skills vs 普通 Prompt
| 维度 | 普通 Prompt | Skills |
|---|---|---|
| 作用范围 | 单次对话 | 跨所有相关对话 |
| 加载方式 | 每次手动提供 | 相关任务时自动加载 |
| 上下文占用 | 每次都占用 | 按需加载,未使用时零占用 |
| 知识管理 | 分散在多次对话中 | 集中管理,持续优化 |
| 一致性 | 依赖人工记忆 | 标准化,确保一致 |
类比理解:
- 普通 Prompt 像是每次都要"现场培训"新员工
- Skills 像是给员工提供"岗位手册",需要时自己查阅
1.3 Skills 遵循开放标准
Claude Code Skills 基于 Agent Skills 开放标准,这意味着:
- ✅ 标准化格式,跨 AI 工具兼容
- ✅ 社区生态,可以使用他人创建的 Skills
- ✅ 长期支持,不会因产品升级而失效
Claude Code 在标准基础上扩展了:
- 🔧 调用控制机制
- 🤖 子代理执行能力
- 📥 动态上下文注入
二、Skills 工作原理:渐进式披露架构
2.1 为什么需要渐进式披露?
问题:如果把所有 Skills 的详细内容都加载到上下文中会怎样?
假设你有 10 个 Skills,每个包含 5000 tokens 的详细指导...
总共: 50,000 tokens
但你可能只需要使用其中 1-2 个 Skill!
浪费: 40,000+ tokens(80% 的上下文窗口!)
解决方案:渐进式披露——只加载需要的内容,按需展开详细信息。
2.2 三级加载机制

第一级:元数据(Metadata)- 始终加载
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs, forms,
or document extraction.
---
- 加载时机: Claude 启动时
- Token 消耗: 每个 Skill 约 100 tokens
- 作用: 让 Claude 知道有哪些 Skills 可用,以及何时触发
关键字段解析:
name: Skill 标识符(小写字母、数字、连字符)description: 功能说明 + 触发场景(最重要的字段!)
⚠️ 重要: description 是 Skill 触发的关键。Claude 根据用户请求与 description 的匹配度决定是否加载该 Skill。
第二级:指令(Instructions)- 触发时加载
# PDF Processing
## Quick start
Use pdfplumber to extract text from PDFs:
\`\`\`python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
For advanced form filling, see [FORMS.md](FORMS.md).
- 加载时机: 当用户请求匹配 Skill 描述时
- Token 消耗: 通常少于 5k tokens
- 作用: 提供具体的操作指导和工作流程
第三级:资源和代码(Resources & Code)- 按需访问
pdf-skill/
├── SKILL.md # 主指令文件(第二级)
├── FORMS.md # 表单填写指南(按需读取)
├── REFERENCE.md # 详细 API 参考(按需读取)
└── scripts/
└── fill_form.py # 工具脚本(执行时不加载代码)
- 加载时机: 仅当 SKILL.md 中引用时
- Token 消耗: 脚本执行时只有输出占用 tokens
- 作用: 提供专业参考材料和可执行工具
2.3 实例演示:从触发到加载
场景: 用户请求"帮我提取 PDF 中的文本"
┌─────────────────────────────────────────┐
│ 步骤 1: Claude 检查所有 Skill 的元数据 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 匹配到 pdf-processing Skill │
│ description 包含 "Extract text from PDF"│
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 步骤 2: 加载 SKILL.md 的指令内容 │
│ (~3k tokens) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 步骤 3: Claude 发现需要表单填写 │
│ 读取 FORMS.md (~2k tokens) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 总 Token 消耗: 约 5k tokens │
│ 其他 9 个 Skills: 0 tokens(未加载) │
└─────────────────────────────────────────┘
对比无渐进式披露:
❌ 传统方式: 10 个 Skills × 5k = 50k tokens
✅ 渐进式披露: 只加载 1 个 Skill = 5k tokens
节省: 45k tokens (90% 的上下文!)
三、Skills 的文件结构
3.1 最小化 Skill
最简单的 Skill 只需要一个文件:
my-skill/
└── SKILL.md # 唯一必需的文件
SKILL.md 示例:
---
name: code-review-checklist
description: Provides a code review checklist for pull requests. Use when reviewing code or when the user asks for code review guidelines.
---
# Code Review Checklist
When reviewing code, check:
1. **Functionality**: Does the code do what it's supposed to?
2. **Readability**: Is the code easy to understand?
3. **Tests**: Are there appropriate tests?
4. **Performance**: Are there any obvious performance issues?
5. **Security**: Are there any security vulnerabilities?
For each item, provide specific feedback with examples.
3.2 完整 Skill 结构
对于复杂的 Skills,可以组织成多文件结构:
pdf-processing-skill/
├── SKILL.md # 核心指令(必需)
├── FORMS.md # 表单填写详细指南
├── REFERENCE.md # PDF 库 API 参考
├── EXAMPLES.md # 常见用例示例
└── scripts/
├── analyze_form.py # 分析表单工具
├── fill_form.py # 填写表单工具
└── validate.py # 验证输出工具
3.3 YAML Frontmatter 规范
必填字段:
---
name: skill-name # 必填
description: Skill description # 必填
---
字段要求:
| 字段 | 要求 | 示例 |
|---|---|---|
| name | 小写字母、数字、连字符 最多 64 字符 禁止 "anthropic"、"claude" | pdf-processingbigquery-analyticscode-reviewer |
| description | 非空 最多 1024 字符 包含功能 + 触发场景 第三人称描述 | Extract text from PDFs. Use when...Analyze BigQuery data. Use when... |
命名规范:
✅ 推荐: 动名词形式(Gerund Form)
processing-pdfs
analyzing-spreadsheets
reviewing-code
managing-databases
❌ 避免: 过于模糊
helper # 太模糊
utils # 不知道干什么
tool # 功能不明确
3.4 Description 字段的重要性
⚠️ 警告: description 是 Skill 触发的关键,必须用第三人称!
为什么必须第三人称?
description 会被注入到系统提示中,视角不一致会导致困惑:
系统提示: "You are Claude, an AI assistant..."
Skill description: "I can help you process PDFs" # ❌ 第一人称,视角冲突!
正确示例:
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs, forms,
or document extraction.
---
不正确示例:
❌ description: I can help you process Excel files # 第一人称
❌ description: You can use this to process Excel # 第二人称
❌ description: Helps with documents # 过于模糊
编写技巧:
- 明确功能: 说清楚 Skill 能做什么
- 包含关键词: 用户可能使用的术语(PDF、Excel、BigQuery 等)
- 触发场景: 明确何时使用("Use when...")
- 简洁精准: 1-2 句话说清楚
四、创建你的第一个 Skill
4.1 确定需求
问题导向:
问自己:
- 我反复向 Claude 解释什么内容?
- 哪些领域知识 Claude 不太了解?
- 哪些工作流程需要标准化?
示例场景:
场景 1: BigQuery 数据分析
- ❌ 每次都要说明表结构
- ❌ 每次都要强调"排除测试账户"
- ❌ 每次都要说明查询模式
- ✅ 创建一个 BigQuery Skill!
场景 2: 公司文档规范
- ❌ 每次都要说明文档模板
- ❌ 每次都要强调格式要求
- ❌ 每次都要纠正不符合规范的部分
- ✅ 创建一个文档规范 Skill!
4.2 编写 SKILL.md
步骤 1: 创建目录和文件
mkdir my-bigquery-skill
cd my-bigquery-skill
touch SKILL.md
步骤 2: 编写 YAML Frontmatter
---
name: bigquery-analytics
description: Analyze BigQuery data from the user_metrics and sales tables. Use when the user asks about data analysis, metrics, or BigQuery queries. Always exclude test accounts and apply standard date filters.
---
步骤 3: 编写核心指令
# BigQuery Analytics
## Database Schema
### user_metrics table
- user_id (STRING): Unique user identifier
- event_date (DATE): Event date
- metrics_value (FLOAT): Metric value
- account_type (STRING): "production" or "test"
### sales table
- order_id (STRING): Order identifier
- user_id (STRING): User ID (foreign key to user_metrics)
- amount (FLOAT): Order amount
- order_date (DATE): Order date
## Standard Filtering Rules
**Always apply these filters:**
1. Exclude test accounts: `WHERE account_type = 'production'`
2. Date range: Default to last 30 days unless specified
3. Remove null values: `WHERE metrics_value IS NOT NULL`
## Query Patterns
### Pattern 1: User activity analysis
\`\`\`sql
SELECT
event_date,
COUNT(DISTINCT user_id) as active_users,
AVG(metrics_value) as avg_metric
FROM user_metrics
WHERE account_type = 'production'
AND event_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GR0UP BY event_date
ORDER BY event_date;
\`\`\`
### Pattern 2: Sales analysis
\`\`\`sql
SELECT
DATE_TRUNC(order_date, MONTH) as month,
COUNT(*) as order_count,
SUM(amount) as total_revenue
FROM sales s
JOIN user_metrics u ON s.user_id = u.user_id
WHERE u.account_type = 'production'
GR0UP BY month
ORDER BY month;
\`\`\`
## Important Notes
- **Performance**: Always use partitioned date fields in WHERE clause
- **Costs**: Preview query cost before running on large datasets
- **Timezone**: All dates are in UTC
五、核心最佳实践
5.1 简洁为王(Conciseness is Key)
核心原则: 上下文窗口是公共资源,你的 Skill 要与系统提示、对话历史、其他 Skills 共享。
✅ 好的示例(约 50 tokens)
## Extract PDF Text
Use pdfplumber for text extraction:
\`\`\`python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
❌ 糟糕的示例(约 150 tokens)
## Extract PDF Text
PDF(便携式文档格式)是一种常见的文件格式,包含文本、图像等内容。
要从 PDF 中提取文本,你需要使用一个库。有很多 PDF 处理库可用,
但我们推荐 pdfplumber,因为它易于使用且能处理大多数情况。
首先,你需要使用 pip 安装它。然后你可以使用下面的代码...
为什么简洁版更好?
- ✅ 假设 Claude 已经知道 PDF 是什么
- ✅ 假设 Claude 知道库的工作原理
- ✅ 直接提供关键信息:用什么库、怎么用
- ✅ 节省 100 tokens,留给其他 Skills 使用
⚠️ 记住: 不要低估 Claude 的智能!它是通用 AI,不需要你解释基础概念。
5.2 设置适当的自由度
根据任务的脆弱性和可变性,选择合适的指导程度。
🌟 高自由度(基于文本的指令)
适用场景:
- 多种方法都可行
- 决策依赖上下文
- 启发式方法指导
示例:代码审查流程
## Code Review Process
1. Analyze code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify compliance with project standards
特点: 给出大方向,信任 Claude 根据具体情况调整。
🎯 中等自由度(伪代码或带参数的脚本)
适用场景:
- 存在首选模式
- 允许一定变化
- 配置影响行为
示例:生成报告
## Generate Report
Use this template and customize as needed:
\`\`\`python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
\`\`\`
特点: 提供模板和参数,允许根据需求调整。
🔒 低自由度(特定脚本,少量或无参数)
适用场景:
- 操作易错且脆弱
- 一致性至关重要
- 必须遵循特定顺序
示例:数据库迁移
## Database Migration
Execute this script strictly:
\`\`\`bash
python scripts/migrate.py --verify --backup
\`\`\`
Do not modify the command or add extra parameters.
特点: 精确指令,不允许偏离。
🌉 类比理解
把 Claude 想象成在不同地形上探索的机器人:
- 悬崖边的窄桥(低自由度): 只有一条安全路径 → 提供详细护栏和精确指令
- 丘陵地带(中等自由度): 几条推荐路径 → 提供地图和指南针
- 无障碍的开阔草地(高自由度): 多条路径都能成功 → 给出大致方向,信任 Claude 找到最佳路线
5.3 渐进式披露模式
模式 1:高层指南 + 引用
结构:
SKILL.md (简要指南)
↓ 引用
[FORMS.md] [REFERENCE.md] [EXAMPLES.md]
示例:
# PDF Processing
## Quick Start
Use pdfplumber to extract text:
\`\`\`python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
## Advanced Features
**Form Filling**: See [FORMS.md](FORMS.md) for complete guide
**API Reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patterns
优势:
- Claude 只在需要时才读取 FORMS.md、REFERENCE.md 或 EXAMPLES.md
- 未使用的文件 = 0 tokens 消耗
模式 2:按领域组织
适用场景: 多领域的 Skills,避免加载无关上下文
结构:
bigquery-skill/
├── SKILL.md # 概述和导航
└── reference/
├── finance.md # 财务指标
├── sales.md # 销售数据
├── product.md # 产品分析
└── marketing.md # 营销活动
示例:
# BigQuery Analytics
## Domain Reference
- **Finance Metrics**: See [reference/finance.md](reference/finance.md)
- **Sales Data**: See [reference/sales.md](reference/sales.md)
- **Product Analytics**: See [reference/product.md](reference/product.md)
- **Marketing Campaigns**: See [reference/marketing.md](reference/marketing.md)
优势:
- 用户询问销售指标时,只读取 sales.md
- finance.md 和其他文件保持在文件系统中,消耗 0 tokens
模式 3:条件细节
# DOCX Processing
## Create Documents
Use docx-js to create new documents. See [DOCX-JS.md](DOCX-JS.md).
## Edit Documents
For simple edits, modify XML directly.
**Track Changes**: See [REDLINING.md](REDLINING.md)
**OOXML Details**: See [OOXML.md](OOXML.md)
优势:
- 常见操作(创建文档)在主文件中
- 高级功能(追踪更改)按需引用
💡 重要: 保持引用层级为一级深度。避免 SKILL.md → advanced.md → details.md 这样的深层嵌套。
5.4 工作流和反馈循环
复杂任务的工作流模式
为多步骤任务提供清晰的检查清单:
## PDF Form Filling Workflow
Copy this checklist and track progress:
\`\`\`
Task Progress:
- [ ] Step 1: Analyze form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
\`\`\`
**Step 1: Analyze Form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create Field Mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate Mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before proceeding.
**Step 4: Fill Form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify Output**
Run: `python scripts/verify_output.py output.pdf`
If validation fails, return to Step 2.
实现反馈循环
常见模式: 运行验证器 → 修复错误 → 重复
这种模式极大提高输出质量。
示例:文档编辑流程
## Document Editing Flow
1. Make edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review error messages carefully
- Fix issues in XML
- Run validation again
4. **Only proceed when validation passes**
5. Repack: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test output document
为什么反馈循环重要?
- ✅ 及早发现错误(在应用更改前)
- ✅ 机器可验证(脚本提供客观验证)
- ✅ 可逆计划(Claude 可以迭代而不破坏原始文件)
- ✅ 清晰调试(错误消息指向具体问题)
5.5 内容指南
避免时间敏感信息
❌ 糟糕示例(会过时):
如果你在 2025 年 8 月之前做这件事,使用旧 API。
2025 年 8 月之后,使用新 API。
✅ 好的示例(使用"旧模式"部分):
## Current Method
Use v2 API endpoint: `api.example.com/v2/messages`
## Legacy Patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
v1 API uses: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>
使用一致的术语
在整个 Skill 中选择一个术语并坚持使用:
✅ 一致性好:
- 始终使用 "API endpoint"
- 始终使用 "field"
- 始终使用 "extract"
❌ 不一致:
- 混用 "API endpoint"、"URL"、"API route"、"path"
- 混用 "field"、"box"、"element"、"control"
- 混用 "extract"、"pull"、"get"、"retrieve"
六、高级技巧
6.1 包含可执行代码的 Skills
解决问题,而非推卸责任
编写 Skills 脚本时,显式处理错误情况,而非推卸给 Claude。
✅ 好的示例:显式处理错误
def process_file(path):
"""处理文件,如果不存在则创建。"""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 创建默认内容而非失败
print(f"文件 {path} 未找到,创建默认文件")
with open(path, 'w') as f:
f.write('')
return ''
except PermissionError:
# 提供替代方案而非失败
print(f"无法访问 {path},使用默认值")
return ''
❌ 糟糕示例:推卸给 Claude
def process_file(path):
# 直接失败,让 Claude 自己想办法
return open(path).read()
提供工具脚本
即使 Claude 可以编写脚本,预制脚本也有优势:
工具脚本的好处:
- 比生成代码更可靠
- 节省 tokens(无需在上下文中包含代码)
- 节省时间(无需代码生成)
- 确保使用的一致性

示例:
## Tool Scripts
**analyze_form.py**: Extract all form fields from PDF
\`\`\`bash
python scripts/analyze_form.py input.pdf > fields.json
\`\`\`
Output format:
\`\`\`json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
\`\`\`
**validate_boxes.py**: Check for boundary box overlaps
\`\`\`bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
\`\`\`
**fill_form.py**: Apply field values to PDF
\`\`\`bash
python scripts/fill_form.py input.pdf fields.json output.pdf
\`\`\`
💡 重要区分: 在指令中明确说明 Claude 应该:
- 执行脚本(最常见): "运行 analyze_form.py 以提取字段"
- 读取作为参考(用于复杂逻辑): "参见 analyze_form.py 了解字段提取算法"
6.2 创建可验证的中间输出
当 Claude 执行复杂、开放式任务时,可能会出错。"计划-验证-执行"模式通过让 Claude 首先创建结构化格式的计划,然后在执行前用脚本验证该计划,从而及早发现错误。
示例场景
要求: Claude 根据电子表格更新 PDF 中的 50 个表单字段。
没有验证:Claude 可能:
- ❌ 引用不存在的字段
- ❌ 创建冲突的值
- ❌ 遗漏必填字段
- ❌ 错误应用更新
有验证:工作流变为:
分析 → 创建计划文件 → 验证计划 → 执行 → 验证输出
添加一个中间 changes.json 文件,在应用更改前进行验证。
实现示例
## Bulk Form Update Workflow
**Step 1: Analyze**
- Extract current form fields
- Save to `current_fields.json`
**Step 2: Create Change Plan**
- Based on spreadsheet, create `changes.json`:
\`\`\`json
{
"field_updates": [
{"field": "customer_name", "value": "John Doe"},
{"field": "order_total", "value": "1250.00"}
]
}
\`\`\`
**Step 3: Validate Plan**
- Run: `python scripts/validate_changes.py changes.json`
- Script checks:
- All referenced fields exist
- Values are in correct format
- No conflicts
- **Only proceed if validation passes**
**Step 4: Execute**
- Apply changes: `python scripts/apply_changes.py changes.json`
**Step 5: Verify Output**
- Run: `python scripts/verify_output.py output.pdf`
为什么此模式有效
- 及早发现错误: 在应用更改前验证发现问题
- 机器可验证: 脚本提供客观验证
- 可逆计划: Claude 可以在不触及原始文件的情况下迭代计划
- 清晰调试: 错误消息指向具体问题
使用时机
- 批量操作
- 破坏性更改
- 复杂验证规则
- 高风险操作
💡 实现技巧: 让验证脚本输出详细的错误消息:
❌ 模糊: "Validation failed"
✅ 清晰: "Field 'signature_date' not found. Available fields: customer_name, order_total, signature_date_signed"
这帮助 Claude 快速修复问题。
6.3 MCP 工具引用
如果你的 Skill 使用 MCP(Model Context Protocol)工具,始终使用完全限定的工具名称以避免"工具未找到"错误。
格式
ServerName:tool_name
示例
## Query Database Schema
Use the BigQuery:bigquery_schema tool to retrieve table schema.
\`\`\`
Use tool: BigQuery:bigquery_schema
Parameters: {"table": "user_metrics"}
\`\`\`
## Create GitHub Issue
Use the GitHub:create_issue tool to create an issue.
\`\`\`
Use tool: GitHub:create_issue
Parameters: {"title": "Bug report", "body": "Description"}
\`\`\`
说明
BigQuery和GitHub是 MCP 服务器名称bigquery_schema和create_issue是这些服务器中的工具名称
没有服务器前缀,Claude 可能无法找到工具,特别是当有多个 MCP 服务器可用时。
七、常见反模式
❌ 反模式 1:Windows 风格路径
问题:使用反斜杠 \ 作为路径分隔符
❌ 错误:
参见 scripts\helper.py
参见 reference\guide.md
✅ 正确:
参见 scripts/helper.py
参见 reference/guide.md
原因:
- Unix 风格路径跨所有平台工作
- Windows 风格路径在 Unix 系统上会导致错误
❌ 反模式 2:提供太多选项
问题:列出所有可能的方法,让 Claude 困惑
❌ 错误:
你可以使用 pypdf,或 pdfplumber,或 PyMuPDF,或 pdf2image,
或 pikepdf,或 PyPDF2,或 pdfrw,或 pdfminer...
✅ 正确:
使用 pdfplumber 进行文本提取:
\`\`\`python
import pdfplumber
\`\`\`
对于需要 OCR 的扫描 PDF,改用 pdf2image 配合 pytesseract。
原则:
- 提供默认推荐方法
- 只在特殊情况下提供替代方案
- 不要列出所有可能性
❌ 反模式 3:深层嵌套引用
问题:引用链太长,Claude 难以跟踪
❌ 错误:
SKILL.md → advanced.md → details.md → examples.md
✅ 正确:
SKILL.md
↓ 直接引用
[ADVANCED.md] [DETAILS.md] [EXAMPLES.md]
原则:
- 保持从 SKILL.md 的引用为一级深度
- 所有引用文件应直接从 SKILL.md 链接
❌ 反模式 4:过度解释基础概念
问题:解释 Claude 已经知道的内容
❌ 错误:
PDF(Portable Document Format,便携式文档格式)是 Adobe 公司
开发的一种文件格式,可以在不同操作系统上保持一致的显示效果。
PDF 文件包含文本、图像、矢量图形等多种内容类型...
✅ 正确:
使用 pdfplumber 提取 PDF 文本。
原则:
- 假设 Claude 的智能
- 只提供 Claude 不知道的领域特定知识
❌ 反模式 5:第一人称描述
问题:使用"我"、"你"等人称
❌ 错误:
description: I can help you process Excel files and generate reports.
✅ 正确:
description: Process Excel files and generate reports. Use when working with spreadsheets or when the user mentions Excel, CSV, or data analysis.
原因:
- description 被注入系统提示
- 第一人称会导致视角冲突
八、总结与行动
8.1 核心收益
通过 Skills 系统,你可以:
- ⏱️ 节省时间: 不用每次重复说明领域知识
- ✅ 保证质量: 标准化流程,减少错误
- 📚 积累知识: 把最佳实践封装成 Skills,团队共享
- 🚀 提升专业性: 让 Claude 从通用助手进化为领域专家
- 🔧 持续优化: 基于使用反馈不断改进 Skills
8.2 Skills 与其他功能的关系
| 功能 | 作用 | 与 Skills 的关系 |
|---|---|---|
| Agent | 处理复杂、多步骤任务 | Skills 为 Agent 提供领域知识 |
| MCP | 连接外部工具和数据源 | Skills 可以引用 MCP 工具 |
| claude.md | 项目级配置和规范 | Skills 是跨项目的能力扩展 |
| Hook | 事件触发的自动化 | Hook 可以在特定时机加载 Skills |
8.3 实践建议
对于个人开发者:
- 从一个简单的 Skill 开始(如代码审查清单)
- 识别自己反复解释的内容
- 逐步添加更多 Skills
- 持续优化基于实际使用
对于团队:
- 建立团队 Skills 仓库
- 统一 Skills 开发规范
- 定期分享优秀 Skills
- 建立 Skills 评审机制
对于技术 Leader:
- 推广 Skills 使用文化
- 组织 Skills 开发培训
- 激励团队贡献 Skills
- 建立 Skills 质量标准
8.4 未来展望
Skills 系统的发展方向:
- 可视化 Skill Builder: 通过图形界面创建 Skills
- Skill 市场: 官方 Skills 商店,一键安装分享
- AI 生成 Skills: 描述需求,AI 自动生成 Skills
- Skill 编排: 多个 Skills 组合成工作流
- 实时协作: 团队实时共享和更新 Skills
"把你反复向 Claude 解释的偏好、流程、领域知识打包成 Skills,让 AI 成为你的领域专家"
实用资源
🔗 相关文章:
如果这篇文章对你有帮助,欢迎点赞、收藏、分享!有任何问题或建议,欢迎在评论区留言讨论。让我们一起学习,一起成长!
也欢迎访问我的个人主页发现更多宝藏资源
来源:juejin.cn/post/7608382961723555890
OpenClaw安装
前置条件
环境
openclaw需要Node.js 22或者更高版本
笔者在CentOS 7虚拟机上使用源码包安装或者fnm安装Node.js会提示这样那样的错误;
源码包安装会有环境的问题:python、g++版本太老……
用fnm安装后提示
node: /lib64/libstdc++.so.6: version `CXXABI_1.3.11' not found (required by node) node: /lib64/libstdc++.so.6: version `CXXABI_1.3.8' not found (required by node) node: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.20' not found (required by node) node: /lib64/libstdc++.so.6: version `GLIBCXX_3.4.21' not found (required by node) node: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by node) node: /lib64/libm.so.6: version `GLIBC_2.27' not found (required by node) node: /lib64/libc.so.6: version `GLIBC_2.27' not found (required by node) node: /lib64/libc.so.6: version `GLIBC_2.28' not found (required by node) node: /lib64/libc.so.6: version `GLIBC_2.25' not found (required by node)
所以在自己的云服务器上搭建了
node安装
nodejs 网站地址可查看LTS版本

官方推荐这三种方式
nvm
官方给出的安装方式
# 下载并安装 nvm:
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash
# 代替重启 shell
\. "$HOME/.nvm/nvm.sh"
# 下载并安装 Node.js:
nvm install 24
# 验证 Node.js 版本:
node -v # Should print "v24.14.0".
# 验证 npm 版本:
npm -v # Should print "11.9.0".
但是这里会提示网络不可达,所以nvm我们采用离线的方式进行安装
解压
配置环境变量
- vi ~/.bashrc
export NVM_DIR="/usr/local/nvm-0.40.4"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
# 使其生效
source ~/.bashrc
验证
nvm -v
显示对应的版本号
查看可用的node版本
# 查看可安装的 node 版本
nvm ls-remote
安装对应的版本
# 安装指定版本的 node
nvm install 24.14.0
fnm
官方给出的安装方式
# 下载并安装 fnm:
curl -o- https://fnm.vercel.app/install | bash
# 下载并安装 Node.js:
fnm install 24
# 验证 Node.js 版本:
node -v # Should print "v24.14.0".
# 验证 npm 版本:npm -v # Should print "11.9.0".
但是这里会提示网络不可达,所以fnm我们采用离线的方式进行安装
下载后解压
添加环境变量
- vi /etc/profile
# /usr/local/fnm-1.38.1为fnm解压后的存放位置并不是fnm文件的绝对路径,而是存放位置
export PATH=$PATH:/usr/local/fnm-1.38.1
# 使其生效
source /etc/profile
- vi ~/.bashrc
eval "$(fnm env --use-on-cd --shell bash)"
# 使其生效
source ~/.bashrc
验证
fnm --version
返回对应的版本号
Docker
官方给出的安装方式
# Docker 对每个操作系统都有特定的安装指导。
# 请参考 https://docker.com/get-started/ 给出的官方文档
# 拉取 Node.js Docker 镜像:
docker pull node:24-alpine
# 创建 Node.js 容器并启动一个 Shell 会话:
docker run -it --rm --entrypoint sh node:24-alpine
# 验证 Node.js 版本:
node -v # Should print "v24.14.0".
# 验证 npm 版本:
npm -v # Should print "11.9.0".
安装docker
非阿里云服务器,需将mirrors.cloud.aliyuncs.com替换为https://mirrors.al…
#添加Docker软件包源
sudo wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.cloud.aliyuncs.com/docker-ce/linux/centos/docker-ce.repo
# 【非阿里云服务区不需要执行这一步】执行后,该文件中的所有https://mirrors.aliyun.com都会被替换为http://mirrors.cloud.aliyuncs.com
sudo sed -i 's|https://mirrors.aliyun.com|http://mirrors.cloud.aliyuncs.com|g' /etc/yum.repos.d/docker-ce.repo
#安装Docker社区版本,容器运行时containerd.io,以及Docker构建和Compose插件
sudo yum -y install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
配置阿里云加速镜像
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://xxxx.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
直接拉取镜像由于网络的问题可能导致镜像拉取失败
下载好镜像上传到服务器进行加载
docker load -i node_24-alpine.tar
运行
# 创建 Node.js 容器并启动一个 Shell 会话:
docker run -it --rm --entrypoint sh node:24-alpine
docker run:
- 这是创建并启动一个新容器的命令。
-it:
- 这是两个参数的组合:
-i(interactive): 保持标准输入(STDIN)打开,即使没有附加到容器上。这让你能输入命令。-t(tty): 分配一个伪终端(pseudo-TTY)。这让你拥有一个类似真实终端的交互界面(支持颜色、自动补全等)。
- 作用:合起来就是让你能交互式地在容器里敲命令。
- 这是两个参数的组合:
--rm:
- 自动清理。当容器停止运行(退出)时,Docker 会自动删除这个容器实例及其写入层。
- 作用:防止产生大量“僵尸”容器占用磁盘空间,非常适合临时调试或测试。
--entrypoint sh:
- 覆盖入口点。
- 通常,
node:24-alpine镜像的默认入口点(Entrypoint)是node命令。如果你直接运行docker run node:24-alpine,它会尝试运行node但没有脚本文件,通常会报错或直接退出。 - 这里指定为
sh(Shell),告诉 Docker:“别运行默认的 node 程序,而是运行sh(Shell)”。 - 作用:让你进入容器的命令行环境,以便检查文件系统、安装临时包、测试网络或调试环境问题。
node:24-alpine:
- 这是使用的镜像名称。
node: 官方 Node.js 镜像。24: 指定 Node.js 的版本为 v24(注意:截至2026年2月,Node.js 24 应该是当前的最新稳定版或新版)。alpine: 基于 Alpine Linux 构建。这是一个非常轻量级的 Linux 发行版,因此生成的镜像体积很小(通常只有几十 MB),但里面预装的工具较少(比如没有bash,只有sh,没有curl或wget除非手动安装)。
验证
# 验证 Node.js 版本:
node -v # Should print "v24.14.0".
# 验证 npm 版本:
npm -v # Should print "11.9.0".
源码包安装
下载后解压
tar -zxaf node-24.14.0.tar.gz
cd node-24.14.0
# 检查依赖并生成 Makefile(可添加自定义参数,如 --prefix=/usr/local/node)
./configure --prefix=/usr/local/node
# 编译(-j4 表示使用 4 核 CPU 加速,根据实际核心数调整)
make -j4
# 安装到系统目录(默认 /usr/local/bin)
make install
问题
- python
./configure --prefix=/usr/local/node/ --python=/usr/local/python_3.14.3/bin/python3.14 Node.js configure: Found Python 3.6.8... Please use python3.14 or python3.13 or python3.12 or python3.11 or python3.10 or python3.9.
- bz2
[root@localhost node-24.14.0]# ./configure --prefix=/usr/local/node Node.js configure: Found Python 3.14.3... Traceback (most recent call last): File "/usr/local/node-24.14.0/./configure", line 28, in <module> import configure File "/usr/local/node-24.14.0/configure.py", line 13, in <module> import bz2 File "/usr/local/python_3.14.3/lib/python3.14/bz2.py", line 17, in <module> from _bz2 import BZ2Compressor, BZ2Decompressor ModuleNotFoundError: No module named '_bz2'
- g++
Node.js configure: Found Python 3.14.3... WARNING: C++ compiler (CXX=g++, 4.8.5) too old, need g++ 12.2.0 or clang++ 8.0.0 WARNING: warnings were emitted in the configure phase INFO: configure completed successfully
个人不太推荐
npm 包管理器安装
npm i -g openclaw
安装完成后
openclaw onboard
访问Dashboard
由于程序运行在linux服务器上没有GUI界面所以想要可视化访问需要做一系列的操作
运行 SSH 隧道命令
ssh -N -L 18789:127.0.0.1:18789 root@xx.x.x.xxx

光标在下方就表示隧道建立了
浏览器访问
http://localhost:18789 直接访问会报身份认证失败
http://localhost:18789/#token=c74d1xxxxdccaxxx8bdcxxx 回车即可进入可视化控制台

一键安装
官网安装教程这里不再赘述
源码编译
官网安装教程这里不再赘述
Docker
官网安装教程这里不再赘述
常用命令
- 查看版本
openclaw --version
- 交互式设置向导
openclaw onboard [--install-daemon]
- 启动网关
openclaw gateway [--port 18789]
- 重启网关
openclaw gateway restart
- 健康检查与快速修复
openclaw doctor [--deep]
- 交互式配置
openclaw configure
链接
来源:juejin.cn/post/7610981820638691368
说说 HTTP 和 RPC 的区别是什么?
说说 HTTP 和 RPC 的区别是什么?
2026年02月02日
面试考察点
面试官提出这个问题,主要想考察以下几个层面:
- 对通信方式本质的理解:不仅仅是背诵概念,而是能否清晰地说出 HTTP 和 RPC 在通信模型、协议栈上的根本性差异。
- 序列化与性能的权衡:是否了解它们背后不同的序列化方式(如 JSON/XML vs Protobuf/Hessian)及其对性能、体积和开发效率的影响。
- 设计哲学与适用场景:能否理解它们不同的设计目标(通用 Web 标准 vs 高效内部服务通信),并据此分析各自的适用场景。
- 架构视野:在微服务或分布式系统架构的背景下,能否结合实际,阐述技术选型的思考,体现将理论知识应用于工程实践的能力。
核心答案
HTTP 和 RPC 的核心区别在于:HTTP 是一个通用的、无状态的、应用层的网络协议标准,而 RPC 是一种旨在实现像调用本地方法一样调用远程服务的框架或设计模式。
更直接地说:
- HTTP 是一种协议,定义了客户端与服务器之间通信的通用格式和规则(如 URL、Method、Header、Body),其设计初衷是为了万维网(Web)的超文本传输,现已广泛用于构建 RESTful API。
- RPC 是一种概念/框架,其核心目标是让开发者无感知地调用远程服务。为了实现这个目标,一个完整的 RPC 框架通常会自定义或封装底层通信协议(可能基于 TCP,也可能基于 HTTP) ,并集成高效的二进制序列化、服务发现、负载均衡、熔断降级等分布式服务治理能力。
简言之,你可以 “用 HTTP 协议来实现一种 RPC” (如 gRPC over HTTP/2),但并非所有 RPC 都必须使用 HTTP 协议。
深度解析
原理/机制
- HTTP:基于经典的 请求-响应 (Request-Response) 模型。通常使用文本格式(如 JSON/XML)序列化数据,协议头(Header)庞大且冗余(如 Cookie、Cache-Control 等 Web 特性字段),但其无状态和标准化的特点使其非常适合跨网络、跨语言的开放 API 场景。
- RPC:目标是实现 “透明远程过程调用” 。一个完整的 RPC 调用过程包括:
- 客户端代理(Stub) 将方法名和参数序列化;
- 通过网络传输到服务器;
- 服务端骨架(Skeleton) 反序列化并调用实际方法;
- 将结果序列化返回。其底层通信协议通常追求更高的性能和紧凑性,例如使用自定义的二进制协议。
对比分析
| 维度 | HTTP (以 RESTful API 为例) | RPC (以典型框架如 Dubbo, gRPC 为例) |
|---|---|---|
| 通信协议 | 主要基于应用层的 HTTP/1.1 或 HTTP/2 协议。 | 通常基于传输层的 TCP 自定义二进制协议,或基于 HTTP/2 (如 gRPC)。 |
| 序列化 | 通常使用人类可读的 JSON、XML 等文本格式。序列化/反序列化开销较大。 | 通常使用高效的二进制格式,如 Protobuf、Hessian、Kryo。体积小,速度快。 |
| 性能 | 协议头较大,序列化效率较低,性能开销相对较高。HTTP/2 通过多路复用等特性大幅改善了性能。 | 专为高效内部通信设计,协议精简,序列化高效,性能通常优于 HTTP/1.1。 |
| 连接与交互 | 传统的 HTTP/1.1 是 “一问一答”,多个请求需要多个连接或串行。HTTP/2 支持连接复用和流。 | 通常支持连接复用、异步调用和流式处理,交互模式更灵活高效。 |
| 服务治理 | 需要额外集成组件(如客户端负载均衡器 Ribbon、服务发现 Eureka)来实现完整的治理。 | 框架原生集成了服务发现、负载均衡、熔断、限流等治理能力,开箱即用。 |
| 适用场景 | 对外的开放 API、需要被多种异构客户端(浏览器、移动端、第三方)调用的服务、简单快速的微服务原型。 | 大规模的内部微服务集群、对性能有极高要求的系统、需要复杂服务治理的分布式系统。 |
代码示例
一个简单的感受:调用一个 “获取用户信息” 的服务。
// 使用 HTTP (RestTemplate) 调用
// 开发者需要关注 URL、HTTP 方法、请求体/参数的组装
User user = restTemplate.getForObject("http://user-service/users/123", User.class);
// 使用 RPC (以 Dubbo 接口为例)
// 开发者像调用本地接口一样直接调用,框架隐藏了所有网络细节
@Reference
private UserService userService; // 远程服务的本地代理
public User getUser() {
return userService.getUserById(123L); // 看起来和本地调用无异
}
最佳实践与常见误区
- 最佳实践:
- 内外有别:对公网暴露的 API 优先使用 HTTP (RESTful) ,因其标准、通用、易于调试(用 curl 或浏览器即可)、防火墙友好。内部服务间调用,尤其是性能敏感、调用链路长的场景,优先考虑 RPC 以获得更好的性能和治理能力。
- 不唯技术论:技术选型需权衡团队技术栈、维护成本、生态集成度。Spring Cloud 生态的 OpenFeign(基于 HTTP)在中小规模下,凭借其与 Spring 的无缝集成,开发体验和效率可能优于引入一套独立的 RPC 框架。
- 常见误区:
- 误区一:HTTP 和 RPC 是完全对立的。实际上,gRPC 就是一个完美的反例,它既是强大的 RPC 框架,又使用 HTTP/2 作为传输协议,结合了二者的优势。
- 误区二:HTTP 性能一定差。HTTP/2 在性能上有了质的飞跃(头部压缩、多路复用、服务端推送),使其在不少场景下足以替代传统的 RPC 协议。
- 误区三:RPC 一定比 HTTP 复杂。对于调用方开发者而言,RPC 的接口式编程模型反而更简单直观。复杂性主要转移到了框架的部署和维护上。
总结
HTTP 是通用网络协议,适合构建开放、标准化的 Web API;而 RPC 是远程调用框架模式,旨在为内部服务提供高效、透明、治理完善的调用体验。在现代架构中,二者边界正在模糊(如 gRPC),关键在于根据 “场景”(内外网、性能要求) 和 “生态”(团队、基础设施) 做出最合适的选择。
来源:juejin.cn/post/7601444617695543306
字节2面:为了性能,你会违反数据库三范式吗?
大家好,我是猿java。
数据库的三大范式,它是数据库设计中最基本的三个规范,那么,三大范式是什么?在实际开发中,我们一定要严格遵守三大范式吗?这篇文章,我们一起来聊一聊。
1. 三大范式
1. 第一范式(1NF,确保每列保持原子性)
第一范式要求数据库中的每个表格的每个字段(列)都具有原子性,即字段中的值不可再分割。换句话说,每个字段只能存储一个单一的值,不能包含集合、数组或重复的组。
如下示例: 假设有一个学生表 Student,结构如下:
| 学生ID | 姓名 | 电话号码 |
|---|---|---|
| 1 | 张三 | 123456789, 987654321 |
| 2 | 李四 | 555555555 |
在这个表中,电话号码字段包含多个号码,违反了1NF的原子性要求。为了满足1NF,需要将电话号码拆分为单独的记录或创建一个新的表。
满足 1NF后的设计:
学生表 Student
| 学生ID | 姓名 |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
电话表 Phone
| 电话ID | 学生ID | 电话号码 |
|---|---|---|
| 1 | 1 | 123456789 |
| 2 | 1 | 987654321 |
| 3 | 2 | 555555555 |
1.2 第二范式(2NF,确保表中的每列都和主键相关)
第二范式要求满足第一范式,并且消除表中的部分依赖,即非主键字段必须完全依赖于主键,而不是仅依赖于主键的一部分。这主要适用于复合主键的情况。
如下示例:假设有一个订单详情表 OrderDetail,结构如下:
| 订单ID | 商品ID | 商品名称 | 数量 | 单价 |
|---|---|---|---|---|
| 1001 | A01 | 苹果 | 10 | 2.5 |
| 1001 | A02 | 橙子 | 5 | 3.0 |
| 1002 | A01 | 苹果 | 7 | 2.5 |
在上述表中,主键是复合主键 (订单ID, 商品ID)。商品名称和单价只依赖于复合主键中的商品ID,而不是整个主键,存在部分依赖,违反了2NF。
满足 2NF后的设计:
订单详情表 OrderDetail
| 订单ID | 商品ID | 数量 |
|---|---|---|
| 1001 | A01 | 10 |
| 1001 | A02 | 5 |
| 1002 | A01 | 7 |
商品表 Product
| 商品ID | 商品名称 | 单价 |
|---|---|---|
| A01 | 苹果 | 2.5 |
| A02 | 橙子 | 3.0 |
1.3 第三范式(3NF,确保每列都和主键列直接相关,而不是间接相关)
第三范式要求满足第二范式,并且消除表中的传递依赖,即非主键字段不应依赖于其他非主键字段。换句话说,所有非主键字段必须直接依赖于主键,而不是通过其他非主键字段间接依赖。
如下示例:假设有一个员工表 Employee,结构如下:
| 员工ID | 员工姓名 | 部门ID | 部门名称 |
|---|---|---|---|
| E01 | 王五 | D01 | 销售部 |
| E02 | 赵六 | D02 | 技术部 |
| E03 | 孙七 | D01 | 销售部 |
在这个表中,部门名称依赖于部门ID,而部门ID依赖于主键员工ID,形成了传递依赖,违反了3NF。
满足3NF后的设计:
员工表 Employee
| 员工ID | 员工姓名 | 部门ID |
|---|---|---|
| E01 | 王五 | D01 |
| E02 | 赵六 | D02 |
| E03 | 孙七 | D01 |
部门表 Department
| 部门ID | 部门名称 |
|---|---|
| D01 | 销售部 |
| D02 | 技术部 |
通过将部门信息移到单独的表中,消除了传递依赖,使得数据库结构符合第三范式。
最后,我们总结一下数据库设计的三大范式:
- 第一范式(1NF): 确保每个字段的值都是原子性的,不可再分。
- 第二范式(2NF): 在满足 1NF的基础上,消除部分依赖,确保非主键字段完全依赖于主键。
- 第三范式(3NF): 在满足 2NF的基础上,消除传递依赖,确保非主键字段直接依赖于主键。
2. 破坏三范式
在实际工作中,尽管遵循数据库的三大范式(1NF、2NF、3NF)有助于提高数据的一致性和减少冗余,但在某些情况下,为了满足性能、简化设计或特定业务需求,我们可能需要违反这些范式。
下面列举了一些常见的破坏三范式的原因及对应的示例。
2.1 性能优化
在高并发、大数据量的应用场景中,严格遵循三范式可能导致频繁的联表查询,增加查询时间和系统负载。为了提高查询性能,设计者可能会通过冗余数据来减少联表操作。
假设有一个电商系统,包含订单表 Orders 和用户表 Users。在严格 3NF设计中,订单表只存储 用户ID,需要通过联表查询获取用户的详细信息。
但是,为了查询性能,我们通常会在订单表中冗余存储 用户姓名 和 用户地址等信息,因此,查询订单信息时无需联表查询 Users 表,从而提升查询速度。
破坏 3NF后的设计:
| 订单ID | 用户ID | 用户姓名 | 用户地址 | 订单日期 | 总金额 |
|---|---|---|---|---|---|
| 1001 | U01 | 张三 | 北京市 | 2023-10-01 | 500元 |
| 1002 | U02 | 李四 | 上海市 | 2023-10-02 | 300元 |
2.2 简化查询和开发
严格规范化可能导致数据库结构过于复杂,增加开发和维护的难度,为了简化查询逻辑和减少开发复杂度,我们也可能会选择适当的冗余。
比如,在内容管理系统(CMS)中,文章表 Articles 和分类表 Categories 通常是独立的,如果频繁需要显示文章所属的分类名称,联表查询可能增加复杂性。因此,通过在 Articles 表中直接存储 分类名称,可以简化前端展示逻辑,减少开发工作量。
破坏 3NF后的设计:
| 文章ID | 标题 | 内容 | 分类ID | 分类名称 |
|---|---|---|---|---|
| A01 | 文章一 | … | C01 | 技术 |
| A02 | 文章二 | … | C02 | 生活 |
2.3 报表和数据仓库
在数据仓库和报表系统中,通常需要快速读取和聚合大量数据。为了优化查询性能和数据分析,可能会采用冗余的数据结构,甚至使用星型或雪花型模式,这些模式并不完全符合三范式。
在销售数据仓库中,为了快速生成销售报表,可能会创建一个包含维度信息的事实表。
破坏 3NF后的设计:
| 销售ID | 产品ID | 产品名称 | 类别 | 销售数量 | 销售金额 | 销售日期 |
|---|---|---|---|---|---|---|
| S01 | P01 | 手机 | 电子 | 100 | 50000元 | 2023-10-01 |
| S02 | P02 | 书籍 | 教育 | 200 | 20000元 | 2023-10-02 |
在事实表中直接存储 产品名称 和 类别,避免了需要联表查询维度表,提高了报表生成的效率。
2.4 特殊业务需求
在某些业务场景下,可能需要快速响应特定的查询或操作,这时通过适当的冗余设计可以满足业务需求。
比如,在实时交易系统中,为了快速计算用户的账户余额,可能会在用户表中直接存储当前余额,而不是每次交易时都计算。
破坏 3NF后的设计:
| 用户ID | 用户名 | 当前余额 |
|---|---|---|
| U01 | 王五 | 10000元 |
| U02 | 赵六 | 5000元 |
在交易记录表中存储每笔交易的增减,但直接在用户表中维护 当前余额,避免了每次查询时的复杂计算。
2.5 兼顾读写性能
在某些应用中,读操作远多于写操作。为了优化读性能,可能会通过数据冗余来提升查询速度,而接受在数据写入时需要额外的维护工作。
社交媒体平台中,用户的好友数常被展示在用户主页上。如果每次请求都计算好友数量,效率低下。可以在用户表中维护一个 好友数 字段。
破坏3NF后的设计:
| 用户ID | 用户名 | 好友数 |
|---|---|---|
| U01 | Alice | 150 |
| U02 | Bob | 200 |
通过在 Users 表中冗余存储 好友数,可以快速展示,无需实时计算。
2.6 快速迭代和灵活性
在快速发展的产品或初创企业中,数据库设计可能需要频繁调整。过度规范化可能导致设计不够灵活,影响迭代速度。适当的冗余设计可以提高开发的灵活性和速度。
一个初创电商平台在初期快速上线,数据库设计时为了简化开发,可能会将用户的收货地址直接存储在订单表中,而不是单独创建地址表。
破坏3NF后的设计:
| 订单ID | 用户ID | 用户名 | 收货地址 | 订单日期 | 总金额 |
|---|---|---|---|---|---|
| O1001 | U01 | 李雷 | 北京市海淀区… | 2023-10-01 | 800元 |
| O1002 | U02 | 韩梅梅 | 上海市浦东新区… | 2023-10-02 | 1200元 |
这样设计可以快速上线,后续根据需求再进行规范化和优化。
2.7 降低复杂性和提高可理解性
有时,过度规范化可能使数据库结构变得复杂,难以理解和维护。适度的冗余可以降低设计的复杂性,提高团队对数据库结构的理解和沟通效率。
在一个学校管理系统中,如果将学生的班级信息独立为多个表,可能增加理解难度。为了简化设计,可以在学生表中直接存储班级名称。
破坏3NF后的设计:
| 学生ID | 姓名 | 班级ID | 班级名称 | 班主任 |
|---|---|---|---|---|
| S01 | 张三 | C01 | 三年级一班 | 李老师 |
| S02 | 李四 | C02 | 三年级二班 | 王老师 |
通过在学生表中直接存储 班级名称 和 班主任,减少了表的数量,简化了设计。
3. 总结
本文,我们分析了数据库的三范式以及对应的示例,它是数据库设计的基本规范。但是,在实际工作中,为了满足性能、简化设计、快速迭代或特定业务需求,我们很多时候并不会严格地遵守三范式。
所以说,架构很多时候都是业务需求、数据一致性、系统性能、开发效率等各种因素权衡的结果,我们需要根据具体应用场景做出合理的设计选择。
4. 学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7455635421529145359
最低成本使用最强模型编程方案
模型是:Codex+Gemini+GLM5+Kimik2.5+MiniMax2.5
先说明一下:这篇只分享我自己长期在用的公开方案,不是广告,也不是“理论推荐”。
核心标准就三个:能稳定用、能真落地、成本尽量低。
另外我现在的原则是:尽量走官方渠道,不再折腾反代。账号和接口都建议按平台规则来。
先说结论:我现在的主力分工
Codex:后端和大部分功能实现主力Gemini + Antigravity:前端和浏览器侧任务主力- 国产免费模型:查资料、国内信息检索、API 调试补位
- 其他工具(如 Cloud Code Opus 4.6):额度见底时兜底
1)第一名:Codex(免费账号可用,但额度偏低)
这个“第一名”我给得很直接:写代码时最稳,尤其后端和复杂功能。
免费账号能用它的模型,但额度确实不高。我的观察是,不同账号之间免费额度会有差异:
- 早期注册的账号,额度通常更高一点
- Google 邮箱注册的账号,额度通常也会稍高
- 其他邮箱注册的部分账号,额度会明显低一些
所以我会准备多个免费账号轮换,但整体还是优先把主链路放在 Codex 上。
2)第二名:Gemini + Antigravity(我现在的前端主力)
Google 这套我最近重新用了起来。之前被封的一批账号后来都解封了,我自己之前的 5 个号也都恢复了。
但现在我不准备再用反代,直接走官方工具 Antigravity。我看中它的点主要是:
- 对 Chrome 控制比较顺手
- 内部集成了
Playwright MCP - Gemini 在前端页面和交互生成上表现不错
所以我现在是:Gemini 负责前端,Codex 负责后端和大多数功能实现。
3)Cloud Code Opus 4.6:有,但不是常用位
Antigravity 里还有 Cloud Code Opus 4.6,我基本只在别的模型额度打满时才会切过去。
原因很简单:给到它的免费用量比较少,放在主流程里不太稳,适合作为兜底。
4)国内白嫖方案:白山智算 + zo computer
这两个是我现在固定会留着的国内补位方案。
白山智算(API 平台)
这个活动期挺给力:实名 + 首次调用后,能拿到 450 左右额度,日常够用。
里面我主要关注的是 GLM-5 和 MiniMax-2.5。
它本身走的是 OpenAI 兼容路由,所以能比较方便接进各种编程工具里,改个接口配置就能跑。
我之前推荐过了,注册链接:白山智算

zo computer(在线使用)
这个相对小众一点,但很省心:注册账号就能用内置免费模型,包含 GLM-5、Kimi-2.5、MiniMax-2.5。
限制也很明确:更适合在线对话和临时任务,不太适合直接塞进 IDE 作为长期开发链路。

官网:zo.computer/
OpenCode:我现在已经没咋用了
以前有 Kimi 相关模型时我还会用一下。现在免费模型能力和覆盖变化后,我基本不再用它做主力。
再加上我有更顺手的 Codex + Gemini 组合,就没有必要在后面的方案上投入太多时间了。
我自己的使用策略(很实用)
- 主开发链路固定:
Codex + Gemini - 国内模型主要用于:资料检索、中文语境信息、API 测试
- 所有“免费”方案都按兜底思路准备,不把单一渠道当唯一依赖
- 不追求模型数量,追求“每天都能稳定出活”
最后
以上 4 个就是我现在公开在用的白嫖 AI 方案。
如果你有更稳、更省钱、还能长期跑的组合,欢迎留言交流。
来源:juejin.cn/post/7611732636969615375
谁是OpenClaw?这个一夜爆火的“AI打工人”,正在悄悄接管你的电脑!
仅仅几个月狂揽 22 万 Star,经历三次改名(Clawdbot -> Moltbot -> OpenClaw)依然热度不减。它不是简单的聊天机器人,而是真正运行在你本地、接管你所有通讯软件(WhatsApp, Telegram, 飞书...)的超级私人管家。本文手把手教你部署这只“全能龙虾”!
Github:github.com/openclaw/op…

最近,GitHub 上有一个项目杀疯了。
如果你关注 AI 圈,一定被一只红色的龙虾(Lobster) 刷屏过。没错,就是 OpenClaw。
截至目前(2026 年 2 月),OpenClaw 在 GitHub 上的 Star 数已经突破了 228k!这是什么概念?即使是当年的爆款项目,也没有如此夸张的增长速度。
它到底是什么?为什么连退隐多年的技术圈大佬 Peter Steinberger(PSPDFKit 创始人)和 Mario Zechner(libGDX 之父)都要复出亲自操刀?
今天,我们就来扒一扒这个“当红炸子鸡”,并手把手教你把它装进电脑里。
什么是 OpenClaw?
简单来说,OpenClaw 是一个运行在你本地设备上的“个人 AI 代理(Agent)中枢” 。
别把它和 ChatGPT 网页版搞混了。OpenClaw 的核心逻辑是: “流水的模型,铁的管家” 。
- 它没有 App(或者说不需要 App): 它直接寄生在你最常用的聊天软件里——WhatsApp、飞书、Slack、Discord、Signal,甚至是 iMessage。
- 它极度聪明: 它不仅能陪聊,还能执行任务。它内置了强大的工具链,可以浏览网页、操作日历、根据你的指令写代码、甚至通过 ElevenLabs 实现语音对话。
- 它绝对隐私: 所有的记忆、配置、对话历史都存储在你本地。你可以自由切换底层模型(Claude Opus, GPT-4, Llama 等),但“管家”本身是你的。
大家之所以疯狂追捧它,是因为它终于实现了我们对“贾维斯”的幻想:一个永远在线、了解你一切背景、并且听命于你的私人助理。
核心特点:为什么它能“爆”?
- 全渠道打通(Omnichannel):
你不需要打开特定的 AI App。在 飞书 给它发消息:“帮我查下明天的天气并把会议发邮件给老板”,它就去做了。它就像是你通讯录里的一个全能好友。
- 本地优先与“记忆”机制:
OpenClaw 拥有基于 Markdown 和 SQLite 的本地记忆系统。它记得你上周说想买的耳机,也记得你老板的忌讳。这些数据不会被上传到云端大厂的服务器。
- 强大的 Agent 能力:
它不只是生成文本,它是来干活的。
- Browsing: 给它一个 URL,它能读完并总结。
- Coding: 它能在本地环境写代码并执行(Sandboxing 机制保障安全)。
- Vision: 它可以“看”屏幕,或者通过摄像头看到你展示的东西。
- 大佬背书与“更名梗”:
OpenClaw 的前身叫 Clawdbot,后来因为名字太像 Claude 被 Anthropic 警告,改名 Moltbot,最后定名 OpenClaw。每一次改名都伴随着一波热度,加上两位“退休”大佬为了它重出江湖,代码质量极高,被誉为“工程学的艺术品”。
如何安装与使用
好消息是,经过几个版本的迭代,现在安装 OpenClaw 已经非常简单了(推荐使用 MacOS 或 Linux/WSL2)。
1. 环境准备
你需要安装 Node.js(版本 ≥ 22)。
2. 一键安装
打开终端(Terminal),输入以下命令:
npm install -g openclaw@latest
# pnpm add -g openclaw@latest
3. 启动向导(Onboarding)
OpenClaw 最人性化的地方就在于它的交互式配置向导。在终端输入:
openclaw onboard --install-daemon
接下来,你只需要像填问卷一样:
- 选择模型服务商: 输入你的 Anthropic Key 或 授权 Qwen 服务。
- 设置连接渠道: 选择你想在哪里使用它(比如 飞书)。向导会提示你下载
openclaw/feishu,下载后按照提示的信息进行配置(比如 登入 open.feishu.cn 平台创建 APP)。 - 安装技能: 选择是否开启浏览器控制、文件系统访问等权限。
- 按照提示配置 Gateway 自启动,打开 web 地址 127.0.0.1:18789,能够正常打开网页说明 OpenClaw 本地安装完成了,对于飞书端的其他配置可以参考文档、参考视频 。

4. 开始使用
现在,拿起你的手机,打开你配置的渠道(例如:飞书),给你刚刚绑定的 Bot 发送一句:
你会发现,一个新的世界大门打开了。

来源:juejin.cn/post/7610580125619093530
写了 10 年 MyBatis,一直以为“去 XML”=写注解,直到看到了这个项目
一直对 MyBatis 有个刻板印象:Mapper 接口负责声明方法,Mapper.xml 负责写 SQL。
改条件就去 XML 里 <if test="">,调参数就切换不同文件,从刚开始学到现在用了很久,熟悉得不能再熟悉。
直到最近看到一个项目:我把 resources/mapper 翻了个底朝天,愣是没找到一份 XML。
我第一反应:
“这项目肯定是全用
@Select之类的注解硬写 SQL 了吧。”
结果打开 Mapper:我人傻了。

1)去 XML:@Select
单表按主键查,注解很舒服:
@Select("select * from tb_user where id = #{id}")UserDO selectById(Long id);
但一旦要动态条件,很多人会写成这种:
@Select("" + "select * from tb_user " + "" + " and name like concat('%', #{name}, '%') " + " and age >= #{age} " + "" + "")List list(UserQuery req);
这么些的体验基本是:
- • 字符串拼接看得眼疼
- • 没有 SQL 高亮、格式化也很难受
- • 复杂一点直接维护灾难
所以绝大多数团队最终都会回到 XML——至少 XML 里写动态 SQL 还能接受。
2)去 XML:@SelectProvider
这个项目里 Mapper 长这样:
@SelectProvider(type = UserSqlProvider.class, method = "selectByCondition")List selectByCondition(UserQuery req);
我当时心里一句话:
“Provider?这是什么东东?”
点进 UserSqlProvider,看到的是这种代码:
public class UserSqlProvider { public String selectByCondition(UserQuery req) { return new SQL() {{ SELECT("id, name, age, status, create_time"); FROM("tb_user"); if (req.getName() != null && !req.getName().isBlank()) { WHERE("name like concat('%', #{name}, '%')"); } if (req.getMinAge() != null) { WHERE("age >= #{minAge}"); } if (req.getStatus() != null) { WHERE("status = #{status}"); } ORDER_BY("create_time desc"); }}.toString(); }}
当时我有点惊讶:
SQL()、SELECT()、WHERE() 这些不是自定义工具类,而是 MyBatis 自带的 SQL Builder。
这类写法的本质是:
- • XML 动态 SQL 的能力不变
- • 但“拼 SQL 的载体”从 XML 变成 Java Provider 方法
- • 最终 MyBatis 仍然执行一段 SQL 字符串(只是这段字符串由 builder 组装出来)

3)Provider
解决了什么?
动态条件 + 可读性。
不用在注解字符串里写 <script>、不用手动拼 AND、也不用在 Java/XML 之间跳来跳去。
再比如:动态排序字段(注意做白名单防注入)
public String list(UserQuery req) { return new SQL() {{ SELECT("*"); FROM("tb_user"); if (req.getName() != null && !req.getName().isBlank()) { WHERE("name like concat('%', #{name}, '%')"); } // 排序字段做白名单,避免 order by 注入 if ("create_time".equals(req.getOrderBy())) { ORDER_BY("create_time desc"); } else if ("age".equals(req.getOrderBy())) { ORDER_BY("age desc"); } else { ORDER_BY("id desc"); } }}.toString();}
未能解决
复杂 SQL 的“表达力”问题。
子查询、复杂 join、窗口函数、CTE……你用 builder 也能写,但写着写着就会变成“在 Java 里造 SQL AST”,维护成本可能并不比 XML 低。
我的建议:
- • 中等复杂度动态查询:Provider 很合适
- • 复杂报表 / 多层嵌套:直接写原生 SQL(放 XML 或统一的 SQL 文件)更直观

4)Provider 最容易踩的坑:参数绑定(90% 的报错在这)
4.1 单参数对象:最舒服
List list(UserQuery req);
Provider 里直接 #{name}、#{minAge},对应 req 的属性名即可。
4.2 多参数一定要 @Param,不然会看到奇怪的参数名
@SelectProvider(type = UserSqlProvider.class, method = "get")UserDO get(@Param("id") Long id, @Param("status") Integer status);
Provider 可以收 Map:
public String get(Map p) { return new SQL() {{ SELECT("*"); FROM("tb_user"); WHERE("id = #{id}"); if (p.get("status") != null) { WHERE("status = #{status}"); } }}.toString();}
如果不写 @Param,参数名可能变成 param1/param2 或 arg0/arg1,然后你就开始“有bug,明明传了值怎么为空”。

5)再懒一下:MyBatis-Plus
如果主要场景是单表 CRUD + 条件筛选,MyBatis-Plus 的思路是:尽量别写 SQL,让 Wrapper 来表达条件。
LambdaQueryWrapper w = Wrappers.lambdaQuery();w.like(StringUtils.isNotBlank(req.getName()), UserDO::getName, req.getName()) .ge(req.getMinAge() != null, UserDO::getAge, req.getMinAge()) .eq(req.getStatus() != null, UserDO::getStatus, req.getStatus()); List list = userMapper.selectList(w);
这套东西的价值很明确:
- • 字段引用是方法引用,改字段/重构更安全
- • 大量单表查询不需要写 SQL
- • 团队统一风格之后,开发效率很高
但边界也很明确:复杂 SQL 仍然要回到原生 SQL(XML/Provider/自定义 mapper 都行),Wrapper 不适合硬扛报表类需求。
6)组装 SQL:MyBatis-Flex
如果连 join 都不想写 SQL,更希望用 Java 结构来表达,MyBatis-Flex 这类框架会提供更强的 QueryWrapper/Join 能力。
简单 join 确实很直观:
QueryWrapper q = QueryWrapper.create() .select(ACCOUNT.ID, ACCOUNT.USER_NAME, ROLE.ROLE_NAME) .from(ACCOUNT) .leftJoin(ROLE).on(ACCOUNT.ROLE_ID.eq(ROLE.ID)) .where(ACCOUNT.AGE.ge(18)); List list = accountMapper.selectListByQueryAs(q, AccountDTO.class);
但当你开始写多层子查询/嵌套条件时,可读性很容易被“对象套对象”拉低。
比如“订单金额 > 用户 1 平均订单金额”这种:
// 子查询QueryWrapper sub = QueryWrapper.create() .select(avg(ORDER.TOTAL_PRICE)) .from(ORDER) .where(ORDER.USER_ID.eq(1)); // 主查询QueryWrapper main = QueryWrapper.create() .select(ORDER.ALL_COLUMNS) .from(ORDER) .where(ORDER.TOTAL_PRICE.gt(sub)); List list = orderMapper.selectListByQuery(main);
能写、也类型更安全,但维护者往往需要在脑子里把它“还原成 SQL”再理解意图。嵌套层级越深,这个成本越高。
7)到底怎么选?
参考落地策略:
- • 固定 SQL / 简单单表:
@Select足够 - • 中等动态 SQL(条件多、拼接多,但逻辑清晰):
@SelectProvider + SQL Builder - • 单表 CRUD 为主,追求少写 SQL:MyBatis-Plus
- • Join 多、希望 Java 化表达更强:MyBatis-Flex(嵌套复杂时要克制)
- • 复杂报表 / 多层子查询 / 强声明式:直接原生 SQL(XML/SQL 文件),通常最清晰

Provider 这条路最让我意外:不靠第三方,也不把动态 SQL 写成字符串炼狱,但它也不是用来替代所有 SQL 的。把边界定好,用起来会更舒服。
总之就是在不同场景下面选择合适的技术并确定合理的规范,然后统一按照规范执行就可以啦!
来源:juejin.cn/post/7603656494904737798
北京回长沙了,简单谈谈感受!
大家好呀,我是飞鱼
我今年已经从北京回长沙了,这里谈谈感受。
❝
首先我回长沙不是逃离,而是换一种更舒服、更可持续的生活方式。
北京给了我视野和能力,长沙给了我生活和归属。
最直观的变化
- 节奏慢了:不用挤早高峰了,走路不用小跑,回家路更短。
- 心态稳了:不再天天赶进度、追KPI,人也没那么紧绷了。
生活成本:压力明显小了
❝
房租、通勤、日常开销都降了不少,以前在北京工资高,但大头都被生活成本吃掉了。
现在收入可能少些,但心里踏实很多。
个人生活:更松弛也更有边界
❝
回来后作息更规律了,能早点睡、早点起,周内也会留出时间运动或散步。
以前下班只想躺着刷手机,现在会给自己留一点空白时间,用来读书、整理思路或者陪家人聊天。
生活变简单,但心里更笃定,能把注意力放在真正重要的人和事上。
城市气息:更有生活感
❝
长沙烟火气足,我现在每周都会去爬一次岳麓山(离得近)。
周末也能随时约上朋友一起吃饭聊天,不用再掐着时间赶路。
个人成长:从外部驱动到自我驱动
❝
以前在北京,节奏和环境会推着我走,事情一件接一件,来不及想太多。
回长沙后,外部推力小了,但我开始主动搭自己的节奏:给自己设目标、做复盘、安排学习计划。
慢下来之后,反而更能看清自己擅长什么、缺什么,也更容易把工作和生活都经营得更稳。
给同样选择的人一点建议
- 先想清楚你想要什么:是离家近、生活压力小,还是职业成长更快?别只因为累了就决定,要有明确的取舍。
- 提前做资源准备:无论去哪,职业发展都得靠自己,技能储备、作品、圈子都要主动经营。
- 规划现金流:收入变化要提前算清楚,别让生活压力反过来影响判断。
- 给自己一个过渡期:回去不是立刻完美适应,给自己几个月调整节奏,别太焦虑。
最后想说
适合自己的地方,不一定是机会最多的地方,而是能让你活得更从容、有力量的地方。
❝
最后想看技术文章的,可以去我的个人网站:hardyfish.top/
来源:juejin.cn/post/7603781883973763091
索引夺命10连问,你能顶住第几问?
前言
今天我们来聊聊让无数开发者又爱又恨的——数据库索引。
相信不少小伙伴在工作中都遇到过这样的场景:
- 明明已经加了索引,为什么查询还是慢?
- 为什么有时候索引反而导致性能下降?
- 联合索引到底该怎么设计才合理?
别急,今天我就通过10个问题,带你彻底搞懂索引的奥秘!
希望对你会有所帮助。
最近准备面试的小伙伴,可以看一下这个宝藏网站(Java突击队):www.susan.net.cn,里面:面试八股文、场景设计题、面试真题、7个项目实战、工作内推什么都有。
一、什么是索引?为什么需要索引?
1.1 索引的本质
简单来说,索引就是数据的目录。
就像一本书的目录能帮你快速找到内容一样,数据库索引能帮你快速定位数据。
-- 没有索引的查询(全表扫描)
SELECT * FROM users WHERE name = '苏三'; -- 需要遍历所有记录
-- 有索引的查询(索引扫描)
CREATE INDEX idx_name ON users(name);
SELECT * FROM users WHERE name = '苏三'; -- 通过索引快速定位
1.2 索引的工作原理

索引的底层结构(B+树):

二、索引的10个常见问题
1.为什么我加了索引,查询还是慢?
场景还原:
CREATE INDEX idx_name ON users(name);
SELECT * FROM users WHERE name LIKE '%苏三%'; -- 还是很慢!
原因分析:
- 前导通配符:
LIKE '%苏三%导致索引失效 - 索引选择性差:如果name字段大量重复,索引效果不佳
- 回表代价高:索引覆盖不全,需要回表查询
解决方案:
-- 方案1:避免前导通配符
SELECT * FROM users WHERE name LIKE '苏三%';
-- 方案2:使用覆盖索引
CREATE INDEX idx_name_covering ON users(name, id, email);
SELECT name, id, email FROM users WHERE name LIKE '苏三%'; -- 不需要回表
-- 方案3:使用全文索引(对于文本搜索)
CREATE FULLTEXT INDEX ft_name ON users(name);
SELECT * FROM users WHERE MATCH(name) AGAINST('苏三');
2.索引是不是越多越好?
绝对不是! 索引需要维护代价:
-- 每个索引都会影响写性能
INSERT INTO users (name, email, age) VALUES ('苏三', 'susan@example.com', 30);
-- 需要更新:
-- 1. 主键索引
-- 2. idx_name索引(如果存在)
-- 3. idx_email索引(如果存在)
-- 4. idx_age索引(如果存在)
索引的代价:
- 存储空间:每个索引都需要额外的磁盘空间
- 写操作变慢:INSERT/UPDATE/DELETE需要维护所有索引
- 优化器负担:索引太多会增加查询优化器的选择难度
黄金法则:一般建议表的索引数量不超过5-7个
3.联合索引的最左前缀原则是什么?
最左前缀原则:联合索引只能从最左边的列开始使用
-- 创建联合索引
CREATE INDEX idx_name_age ON users(name, age);
-- 能使用索引的查询
SELECT * FROM users WHERE name = '苏三'; -- √ 使用索引
SELECT * FROM users WHERE name = '苏三' AND age = 30; -- √ 使用索引
SELECT * FROM users WHERE age = 30 AND name = '苏三'; -- √ 优化器会调整顺序
-- 不能使用索引的查询
SELECT * FROM users WHERE age = 30; -- × 不符合最左前缀
联合索引结构:

4.如何选择索引字段的顺序?
选择原则:
- 高选择性字段在前:选择性高的字段能更快过滤数据
- 经常查询的字段在前:优先满足常用查询场景
- 等值查询在前,范围查询在后
-- 计算字段选择性
SELECT
COUNT(DISTINCT name) / COUNT(*) as name_selectivity,
COUNT(DISTINCT age) / COUNT(*) as age_selectivity,
COUNT(DISTINCT city) / COUNT(*) as city_selectivity
FROM users;
-- 根据选择性决定索引顺序
CREATE INDEX idx_name_city_age ON users(name, city, age); -- name选择性最高
5.什么是覆盖索引?为什么重要?
覆盖索引:索引包含了查询需要的所有字段,不需要回表查询
-- 不是覆盖索引(需要回表)
CREATE INDEX idx_name ON users(name);
SELECT * FROM users WHERE name = '苏三'; -- 需要回表查询其他字段
-- 覆盖索引(不需要回表)
CREATE INDEX idx_name_covering ON users(name, email, age);
SELECT name, email, age FROM users WHERE name = '苏三'; -- 所有字段都在索引中
覆盖索引的优势:
- 避免回表:减少磁盘IO
- 减少内存占用:只需要读取索引页
- 提升性能:查询速度更快
6.NULL值对索引有什么影响?
NULL值的问题:
-- 创建索引
CREATE INDEX idx_email ON users(email);
-- 查询NULL值
SELECT * FROM users WHERE email IS NULL; -- 可能不使用索引
SELECT * FROM users WHERE email IS NOT NULL; -- 可能不使用索引
NULL值可能不使用索引。
解决方案:
- 避免NULL值:设置默认值
- 使用函数索引(MySQL 8.0+)
-- 使用函数索引处理NULL值
CREATE INDEX idx_email_null ON users((COALESCE(email, '')));
SELECT * FROM users WHERE COALESCE(email, '') = '';
7.索引对排序和分组有什么影响?
索引优化排序和分组:
-- 创建索引
CREATE INDEX idx_age_name ON users(age, name);
-- 索引优化排序
SELECT * FROM users ORDER BY age, name; -- √ 使用索引避免排序
-- 索引优化分组
SELECT age, COUNT(*) FROM users GR0UP BY age; -- √ 使用索引优化分组
-- 无法使用索引排序的情况
SELECT * FROM users ORDER BY name, age; -- × 不符合最左前缀
SELECT * FROM users ORDER BY age DESC, name ASC; -- × 排序方向不一致
最近为了帮助大家找工作,专门建了一些工作内推群,各大城市都有,欢迎各位HR和找工作的小伙伴进群交流,群里目前已经收集了不少的工作内推岗位。加苏三的微信:li_su223,备注:掘金+所在城市,即可进群。
8.如何发现索引失效的场景?
常见索引失效场景:
- 函数操作:
WHERE YEAR(create_time) = 2023 - 类型转换:
WHERE phone = 13800138000(phone是varchar) - 数学运算:
WHERE age + 1 > 30 - 前导通配符:
WHERE name LIKE '%苏三'
使用EXPLAIN分析:
EXPLAIN SELECT * FROM users WHERE name = '苏三';
-- 查看关键指标:
-- type: const|ref|range|index|ALL(性能从好到坏)
-- key: 实际使用的索引
-- rows: 预估扫描行数
-- Extra: Using index(覆盖索引)| Using filesort(需要排序)| Using temporary(需要临时表)
9.如何维护和优化索引?
定期索引维护:
-- 查看索引使用情况(MySQL)
SELECT * FROM sys.schema_index_statistics
WHERE table_schema = 'your_database' AND table_name = 'users';
-- 重建索引(优化索引碎片)
ALTER TABLE users REBUILD INDEX idx_name;
-- 分析索引使用情况
ANALYZE TABLE users;
索引监控:
-- 开启索引监控(Oracle)
ALTER INDEX idx_name MONITORING USAGE;
-- 查看索引使用情况
SELECT * FROM v$object_usage WHERE index_name = 'IDX_NAME';
10.不同数据库的索引有什么差异?
MySQL vs PostgreSQL索引差异:
| 特性 | MySQL | PostgreSQL |
|---|---|---|
| 索引类型 | B+Tree, Hash, Fulltext | B+Tree, Hash, GiST, SP-GiST |
| 覆盖索引 | 支持 | 支持(使用INCLUDE) |
| 函数索引 | 8.0+支持 | 支持 |
| 部分索引 | 支持 | 支持 |
| 索引组织表 | 聚簇索引 | 堆表 |
PostgreSQL示例:
-- 创建包含索引(Covering Index)
CREATE INDEX idx_users_covering ON users (name) INCLUDE (email, age);
-- 创建部分索引(Partial Index)
CREATE INDEX idx_active_users ON users (name) WHERE is_active = true;
-- 创建表达式索引(Expression Index)
CREATE INDEX idx_name_lower ON users (LOWER(name));
三、索引设计最佳实践
3.1 索引设计原则
- 按需创建:只为经常查询的字段创建索引
- 选择合适类型:根据场景选择B-Tree、Hash、全文索引等
- 考虑复合索引:使用复合索引减少索引数量
- 避免过度索引:每个索引都有维护成本
- 定期维护:重建索引,优化索引碎片
3.2 索引设计检查清单

四、实战案例:电商系统索引设计
4.1 用户表索引设计
-- 用户表结构
CREATE TABLE users (
id BIGINT PRIMARY KEY,
username VARCHAR(50) NOT NULL,
email VARCHAR(100) NOT NULL,
phone VARCHAR(20),
age INT,
city VARCHAR(50),
created_at TIMESTAMP,
is_active BOOLEAN
);
-- 推荐索引
CREATE INDEX idx_users_username ON users(username);
CREATE INDEX idx_users_email ON users(email);
CREATE INDEX idx_users_city_age ON users(city, age);
CREATE INDEX idx_users_created ON users(created_at) WHERE is_active = true;
4.2 订单表索引设计
-- 订单表结构
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT,
status VARCHAR(20),
amount DECIMAL(10,2),
created_at TIMESTAMP,
updated_at TIMESTAMP
);
-- 推荐索引
CREATE INDEX idx_orders_user_id ON orders(user_id);
CREATE INDEX idx_orders_status_created ON orders(status, created_at);
CREATE INDEX idx_orders_created_amount ON orders(created_at, amount);
总结
- 理解原理:掌握B+树索引的工作原理和特性。
- 合理设计:遵循最左前缀原则,选择合适的索引顺序。
- 避免失效:注意索引失效的常见场景。
- 覆盖索引:尽可能使用覆盖索引减少回表。
- 定期维护:监控索引使用情况,定期优化重建。
- 权衡利弊:索引不是越多越好,要权衡查询性能和写成本。
好的索引设计是数据库性能的基石。
不要盲目添加索引,要基于实际查询需求和数据分布来科学设计。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
来源:juejin.cn/post/7578402574652850228
CSS 也要支持 if 了 !!!CSS if() 函数来了!
CSS 也要支持 if 了 !!!CSS if() 函数来了!
CSS if() 函数允许在纯 CSS 中基于条件为属性赋值,无需 JavaScript 或预处理器。该函数已在 Chrome 137 发布。
过去常用的做法包括通过 JavaScript 切换类名、使用预处理器 mixin 或编写大量媒体查询。if() 将条件逻辑引入 CSS,使写法更直接、性能稳定。
原文 CSS 也要支持 if 了 !!!CSS if() 函数来了!
工作原理
property: if(condition-1: value-1; condition-2: value-2; condition-3: value-3; else: default-value);
函数按顺序检查条件并应用第一个匹配的值;若没有条件匹配,则使用 else 的值。这一语义与常见编程语言一致,但实现于纯 CSS。
if() 的三种能力
样式查询(Style queries)
使用 style() 可响应 CSS 自定义属性:
.card {
--status: attr(data-status type(<custom-ident>));
border-color: if(style(--status: pending): royalblue; style(--status: complete): seagreen; style(--status: error): crimson; else: gray);
}
一个 data-status 属性即可驱动对应样式,无需额外工具类。
媒体查询(Media queries)
使用 media() 可以在属性内联定义响应式值,无需嵌套媒体查询块:
h1 {
font-size: if(media(width >= 1200px): 3rem; media(width >= 768px): 2.5rem; media(width >= 480px): 2rem; else: 1.75rem);
}
特性检测(Feature detection)
使用 supports() 可在属性中直接进行特性检测,并提供明确回退:
.element {
border-color: if(supports(color: lch(0 0 0)): lch(50% 100 150) ; supports(color: lab(0 0 0)): lab(50 100 -50) ; else: rgb(200, 100, 50));
}
真实用例
暗色模式示例
body {
--theme: 'dark'; /* 通过 JavaScript 或用户偏好切换 */
background: if(style(--theme: 'dark'): #1a1a1a; else: white);
color: if(style(--theme: 'dark'): #e4e4e4; else: #333);
}
设计系统状态组件
.alert {
--type: attr(data-type type(<custom-ident>));
background: if(style(--type: success): #d4edda; style(--type: warning): #fff3cd; style(--type: danger): #f8d7da; style(--type: info): #d1ecf1; else: #f8f9fa);
border-left: 4px solid if(style(--type: success): #28a745; style(--type: warning): #ffc107; style(--type: danger): #dc3545; style(--type: info): #17a2b8; else: #6c757d);
}
容器尺寸示例(简化媒体查询)
.container {
width: if(media(width >= 1400px): 1320px; media(width >= 1200px): 1140px; media(width >= 992px): 960px; media(width >= 768px): 720px; media(width >= 576px): 540px; else: 100%);
padding-inline: if(media(width >= 768px): 2rem; else: 1rem);
}
与现代 CSS 特性结合
.element {
/* 搭配新的 light-dark() 函数 */
color: if(style(--high-contrast: true): black; else: light-dark(#333, #e4e4e4));
/* 搭配 CSS 自定义函数(@function) */
padding: if(style(--spacing: loose): --spacing-function(2) ; style(--spacing: tight): --spacing-function(0.5) ; else: --spacing-function(1));
}
浏览器支持
支持情况(截至 2025 年 8 月):
- ✅ Chrome/Edge:自 137 版起
- ✅ Chrome Android:自 139 版起
- ❌ Firefox:开发中
- ❌ Safari:在规划中
- ❌ Opera:尚未支持
在尚未完全支持的环境中,可采用如下写法:
.button {
/* 所有浏览器的回退 */
padding: 1rem 2rem;
background: #007bff;
/* 现代浏览器会自动覆盖 */
padding: if(style(--size: small): 0.5rem 1rem; style(--size: large): 1.5rem 3rem; else: 1rem 2rem);
background: if(style(--variant: primary): #007bff; style(--variant: success): #28a745; style(--variant: danger): #dc3545; else: #6c757d);
}
未来展望
CSS 工作组已经在推进扩展能力:
- 范围查询:
if(style(--value > 100): ...) - 逻辑运算符:
if(style(--a: true) and style(--b: false): ...) - 容器查询集成:更强的上下文感知
在使用前建议评估目标浏览器版本,并准备相应回退方案。
来源:juejin.cn/post/7571758212472897587
公司来的新人用字符串存储日期,被组长怒怼了...
在日常的软件开发工作中,存储时间是一项基础且常见的需求。无论是记录数据的操作时间、金融交易的发生时间,还是行程的出发时间、用户的下单时间等等,时间信息与我们的业务逻辑和系统功能紧密相关。因此,正确选择和使用 MySQL 的日期时间类型至关重要,其恰当与否甚至可能对业务的准确性和系统的稳定性产生显著影响。
本文旨在帮助开发者重新审视并深入理解 MySQL 中不同的时间存储方式,以便做出更合适项目业务场景的选择。
不要用字符串存储日期
和许多数据库初学者一样,笔者在早期学习阶段也曾尝试使用字符串(如 VARCHAR)类型来存储日期和时间,甚至一度认为这是一种简单直观的方法。毕竟,'YYYY-MM-DD HH:MM:SS' 这样的格式看起来清晰易懂。
但是,这是不正确的做法,主要会有下面两个问题:
- 空间效率:与 MySQL 内建的日期时间类型相比,字符串通常需要占用更多的存储空间来表示相同的时间信息。
- 查询与计算效率低下:
- 比较操作复杂且低效:基于字符串的日期比较需要按照字典序逐字符进行,这不仅不直观(例如,'2024-05-01' 会小于 '2024-1-10'),而且效率远低于使用原生日期时间类型进行的数值或时间点比较。
- 计算功能受限:无法直接利用数据库提供的丰富日期时间函数进行运算(例如,计算两个日期之间的间隔、对日期进行加减操作等),需要先转换格式,增加了复杂性。
- 索引性能不佳:基于字符串的索引在处理范围查询(如查找特定时间段内的数据)时,其效率和灵活性通常不如原生日期时间类型的索引。
DATETIME 和 TIMESTAMP 选择
DATETIME 和 TIMESTAMP 是 MySQL 中两种非常常用的、用于存储包含日期和时间信息的数据类型。它们都可以存储精确到秒(MySQL 5.6.4+ 支持更高精度的小数秒)的时间值。那么,在实际应用中,我们应该如何在这两者之间做出选择呢?
下面我们从几个关键维度对它们进行对比:
时区信息
DATETIME 类型存储的是字面量的日期和时间值,它本身不包含任何时区信息。当你插入一个 DATETIME 值时,MySQL 存储的就是你提供的那个确切的时间,不会进行任何时区转换。
这样就会有什么问题呢? 如果你的应用需要支持多个时区,或者服务器、客户端的时区可能发生变化,那么使用 DATETIME 时,应用程序需要自行处理时区的转换和解释。如果处理不当(例如,假设所有存储的时间都属于同一个时区,但实际环境变化了),可能会导致时间显示或计算上的混乱。
TIMESTAMP 和时区有关。存储时,MySQL 会将当前会话时区下的时间值转换成 UTC(协调世界时)进行内部存储。当查询 TIMESTAMP 字段时,MySQL 又会将存储的 UTC 时间转换回当前会话所设置的时区来显示。
这意味着,对于同一条记录的 TIMESTAMP 字段,在不同的会话时区设置下查询,可能会看到不同的本地时间表示,但它们都对应着同一个绝对时间点(UTC 时间)。这对于需要全球化、多时区支持的应用来说非常有用。
下面实际演示一下!
建表 SQL 语句:
CREATE TABLE `time_zone_test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`date_time` datetime DEFAULT NULL,
`time_stamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
插入一条数据(假设当前会话时区为系统默认,例如 UTC+0)::
INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
查询数据(在同一时区会话下):
SELECT date_time, time_stamp FROM time_zone_test;
结果:
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
+---------------------+---------------------+
现在,修改当前会话的时区为东八区 (UTC+8):
SET time_zone = '+8:00';
再次查询数据:
# TIMESTAMP 的值自动转换为 UTC+8 时间
+---------------------+---------------------+
| date_time | time_stamp |
+---------------------+---------------------+
| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
+---------------------+---------------------+
扩展:MySQL 时区设置常用 SQL 命令
# 查看当前会话时区
SELECT @@session.time_zone;
# 设置当前会话时区
SET time_zone = 'Europe/Helsinki';
SET time_zone = "+00:00";
# 数据库全局时区设置
SELECT @@global.time_zone;
# 设置全局时区
SET GLOBAL time_zone = '+8:00';
SET GLOBAL time_zone = 'Europe/Helsinki';
占用空间
下图是 MySQL 日期类型所占的存储空间(官方文档传送门:dev.mysql.com/doc/refman/…):

在 MySQL 5.6.4 之前,DateTime 和 TIMESTAMP 的存储空间是固定的,分别为 8 字节和 4 字节。但是从 MySQL 5.6.4 开始,它们的存储空间会根据毫秒精度的不同而变化,DateTime 的范围是 58 字节,TIMESTAMP 的范围是 47 字节。
表示范围
TIMESTAMP 表示的时间范围更小,只能到 2038 年:
DATETIME:'1000-01-01 00:00:00.000000' 到 '9999-12-31 23:59:59.999999'TIMESTAMP:'1970-01-01 00:00:01.000000' UTC 到 '2038-01-19 03:14:07.999999' UTC
性能
由于 TIMESTAMP 在存储和检索时需要进行 UTC 与当前会话时区的转换,这个过程可能涉及到额外的计算开销,尤其是在需要调用操作系统底层接口获取或处理时区信息时。虽然现代数据库和操作系统对此进行了优化,但在某些极端高并发或对延迟极其敏感的场景下,DATETIME 因其不涉及时区转换,处理逻辑相对更简单直接,可能会表现出微弱的性能优势。
为了获得可预测的行为并可能减少 TIMESTAMP 的转换开销,推荐的做法是在应用程序层面统一管理时区,或者在数据库连接/会话级别显式设置 time_zone 参数,而不是依赖服务器的默认或操作系统时区。
数值时间戳是更好的选择吗?
除了上述两种类型,实践中也常用整数类型(INT 或 BIGINT)来存储所谓的“Unix 时间戳”(即从 1970 年 1 月 1 日 00:00:00 UTC 起至目标时间的总秒数,或毫秒数)。
这种存储方式的具有 TIMESTAMP 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
时间戳的定义如下:
时间戳的定义是从一个基准时间开始算起,这个基准时间是「1970-1-1 00:00:00 +0:00」,从这个时间开始,用整数表示,以秒计时,随着时间的流逝这个时间整数不断增加。这样一来,我只需要一个数值,就可以完美地表示时间了,而且这个数值是一个绝对数值,即无论的身处地球的任何角落,这个表示时间的时间戳,都是一样的,生成的数值都是一样的,并且没有时区的概念,所以在系统的中时间的传输中,都不需要进行额外的转换了,只有在显示给用户的时候,才转换为字符串格式的本地时间。
数据库中实际操作:
-- 将日期时间字符串转换为 Unix 时间戳 (秒)
mysql> SELECT UNIX_TIMESTAMP('2020-01-11 09:53:32');
+---------------------------------------+
| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
+---------------------------------------+
| 1578707612 |
+---------------------------------------+
1 row in set (0.00 sec)
-- 将 Unix 时间戳 (秒) 转换为日期时间格式
mysql> SELECT FROM_UNIXTIME(1578707612);
+---------------------------+
| FROM_UNIXTIME(1578707612) |
+---------------------------+
| 2020-01-11 09:53:32 |
+---------------------------+
1 row in set (0.01 sec)
PostgreSQL 中没有 DATETIME
由于有读者提到 PostgreSQL(PG) 的时间类型,因此这里拓展补充一下。PG 官方文档对时间类型的描述地址:http://www.postgresql.org/docs/curren…。

可以看到,PG 没有名为 DATETIME 的类型:
- PG 的
TIMESTAMP WITHOUT TIME ZONE在功能上最接近 MySQL 的DATETIME。它存储日期和时间,但不包含任何时区信息,存储的是字面值。 - PG 的
TIMESTAMP WITH TIME ZONE(或TIMESTAMPTZ) 相当于 MySQL 的TIMESTAMP。它在存储时会将输入值转换为 UTC,并在检索时根据当前会话的时区进行转换显示。
对于绝大多数需要记录精确发生时间点的应用场景,TIMESTAMPTZ是 PostgreSQL 中最推荐、最健壮的选择,因为它能最好地处理时区复杂性。
总结
MySQL 中时间到底怎么存储才好?DATETIME?TIMESTAMP?还是数值时间戳?
并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。
《高性能 MySQL 》这本神书的作者就是推荐 TIMESTAMP,原因是数值表示时间不够直观。下面是原文:

每种方式都有各自的优势,根据实际场景选择最合适的才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
| 类型 | 存储空间 | 日期格式 | 日期范围 | 是否带时区信息 |
|---|---|---|---|---|
| DATETIME | 5~8 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1000-01-01 00:00:00[.000000] ~ 9999-12-31 23:59:59[.999999] | 否 |
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
选择建议小结:
TIMESTAMP的核心优势在于其内建的时区处理能力。数据库负责 UTC 存储和基于会话时区的自动转换,简化了需要处理多时区应用的开发。如果应用需要处理多时区,或者希望数据库能自动管理时区转换,TIMESTAMP是自然的选择(注意其时间范围限制,也就是 2038 年问题)。- 如果应用场景不涉及时区转换,或者希望应用程序完全控制时区逻辑,并且需要表示 2038 年之后的时间,
DATETIME是更稳妥的选择。 - 如果极度关注比较性能,或者需要频繁跨系统传递时间数据,并且可以接受可读性的牺牲(或总是在应用层转换),数值时间戳是一个强大的选项。
来源:juejin.cn/post/7488927722774937609
这 10 个 MySQL 高级用法,让你的代码又快又好看
大家好,我是大华!
MySQL 有很多高级但实用的功能,能让你的查询变得更简洁、更高效。
今天分享 10 个我在工作中经常使用的 SQL 技巧,不用死记硬背,掌握了就能立刻提升你的数据库操作水平!
1. CTE(WITH 子句)——让复杂查询变清晰
-- 传统子查询,难以阅读
SELECT nickname
FROM system_users
WHERE dept_id IN (
SELECT id FROM system_dept WHERE `name` = 'IT部'
);
-- 使用CTE,逻辑清晰
WITH ny_depts AS (
SELECT id FROM system_dept WHERE `name` = 'IT部'
)
SELECT u.nickname
FROM system_users u
JOIN ny_depts nd ON u.dept_id = nd.id;
解释:
WITH ny_depts AS (...):先创建一个临时结果集,叫ny_depts,里面只包含“IT部”的部门名称。SELECT u.nickname FROM system_users u JOIN ny_depts...:再从用户表中找出那些部门ID在ny_depts里的员工昵称。
好处:把找部门和找人分成两步,逻辑更清楚,比嵌套子查询好读多了。
2. 窗口函数 —— 不分组也能统计
SELECT
name,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS rank_in_dept,
AVG(salary) OVER (PARTITION BY department) AS avg_salary
FROM employees;
解释:
PARTITION BY department:按部门“分组”,但不合并行,每行仍然保留。RANK() OVER (...):在每个部门内部,按薪水从高到低排名(相同薪水并列)。AVG(salary) OVER (...):计算每个部门的平均工资,并显示在每一行里。
对比 GR0UP BY:GR0UP BY 会把多行合并成一行,而窗口函数保留原始行,同时加上统计值。
3. 条件聚合 —— 一行查出多个统计
SELECT
YEAR(created_at) AS year,
COUNT(*) AS total,
COUNT(CASE WHEN status = 'completed' THEN 1 END) AS completed,
SUM(CASE WHEN status = 'completed' THEN amount ELSE 0 END) AS revenue
FROM orders
GR0UP BY YEAR(created_at);
解释:
YEAR(created_at):提取订单年份。COUNT(*):该年总订单数。COUNT(CASE WHEN status = 'completed' THEN 1 END):
如果状态是'completed',就返回1,否则返回NULL;COUNT()只统计非NULL值,所以这行就是“完成的订单数”。SUM(CASE WHEN ... THEN amount ELSE 0 END):只对完成的订单求金额总和。
关键:不用写多个子查询,一条语句搞定全年报表!
4. 自连接 —— 同一张表自己连自己
SELECT e1.name, e2.name
FROM employees e1
JOIN employees e2
ON e1.department = e2.department
AND e1.id < e2.id
AND ABS(e1.salary - e2.salary) <= e1.salary * 0.1;
解释:
employees e1 JOIN employees e2:把员工表当成两个副本(e1 和 e2)来连接。e1.department = e2.department:只找同一个部门的人。e1.id < e2.id:避免重复配对(比如 Alice-Bob 和 Bob-Alice 只保留一个)。ABS(...):计算两人薪水差是否 ≤ 10%。
用途:找“相似记录”“配对关系”“上下级”等场景非常有用。
5. EXISTS 替代 IN —— 更高效的存在判断
SELECT name FROM customers c
WHERE EXISTS (
SELECT 1 FROM orders o
WHERE o.customer_id = c.id AND o.amount > 1000
);
解释:
- 对每一位客户
c,检查是否存在一笔订单满足:
- 订单的
customer_id等于这个客户的id - 订单金额 > 1000
- 订单的
SELECT 1:这里不需要返回具体字段,只要知道“有没有”就行,所以用1最轻量。- 为什么快?:一旦找到一条匹配订单,就立刻停止搜索,不像
IN可能要加载全部订单 ID。
注意:如果子查询可能返回 NULL,IN 会失效(因为 x IN (..., NULL) 永远为 UNKNOWN),而 EXISTS 不受影响。
6. JSON 函数 —— 轻松读取 JSON 字段
SELECT
name,
profile->>'$.address.city' AS city,
JSON_EXTRACT(profile, '$.age') AS age
FROM users
WHERE profile->>'$.city' = 'Beijing';
解释:
profile是一个 JSON 类型字段,比如:{"address": {"city": "Beijing"}, "age": 30}profile->>'$.address.city':
->>是简写,等价于JSON_UNQUOTE(JSON_EXTRACT(...))- 返回字符串
"Beijing"(去掉引号)
JSON_EXTRACT(profile, '$.age'):返回30(带类型,可能是数字)WHERE profile->>'$.city' = 'Beijing':筛选城市是北京的用户。
适用场景:用户偏好、动态表单、日志等结构不固定的字段。
7. 生成列 —— 数据库自动帮你算
CREATE TABLE products (
id INT PRIMARY KEY,
width DECIMAL(10,2),
height DECIMAL(10,2),
area DECIMAL(10,2) AS (width * height) STORED
);
INSERT INTO products (id, width, height) VALUES (1, 5, 10);
解释:
area DECIMAL(...) AS (width * height) STORED:
- 这是一个“存储型生成列”,数据库会自动计算
width * height并存下来。 - 如果不加
STORED,就是“虚拟列”(每次查询时计算,不占存储)。
- 这是一个“存储型生成列”,数据库会自动计算
- 插入时只需给
width和height,area自动变成50。
优势:避免应用层重复计算,还能给 area 加索引加速查询!
8. 多表更新 —— 一条语句更新关联数据
UPDATE customers c
JOIN (
SELECT customer_id, SUM(amount) AS total
FROM orders
GR0UP BY customer_id
) o ON c.id = o.customer_id
SET c.total_spent = o.total;
解释:
- 子查询
o:先按客户 ID 统计每个人的总消费。 UPDATE customers c JOIN o ...:把客户表和统计结果连接起来。SET c.total_spent = o.total:直接把统计值写回客户表。
好处:不用在程序里循环“查一个、改一个”,减少网络开销,保证原子性。
9. GR0UP_CONCAT —— 多行变一行
SELECT
department,
GR0UP_CONCAT(name ORDER BY salary DESC SEPARATOR ', ') AS members
FROM employees
GR0UP BY department;
解释:
GR0UP BY department:按部门分组。GR0UP_CONCAT(name ...):把每个部门的所有员工名字拼成一个字符串。ORDER BY salary DESC:按薪水从高到低排序后再拼接。SEPARATOR ', ':用逗号加空格分隔名字。
典型用途:导出名单、展示标签、汇总明细等。
默认最多拼 1024 字符,可通过 SET SESSION group_concat_max_len = 1000000; 调大。
10. INSERT ... ON DUPLICATE KEY UPDATE —— 智能插入/更新
INSERT INTO page_views (page_url, view_date, view_count)
VALUES ('/home', CURDATE(), 1)
ON DUPLICATE KEY UPDATE
view_count = view_count + 1;
解释:
- 尝试插入一条新记录:页面
/home,今天日期,访问次数为 1。 - 如果因为唯一索引冲突(比如
(page_url, view_date)是唯一键)导致插入失败:
- 就执行
ON DUPLICATE KEY UPDATE部分 - 把原有的
view_count加 1
- 就执行
- 效果:第一次访问创建记录,之后每次访问自动 +1,完美实现计数器!
前提:表必须有主键或唯一索引,否则不会触发更新。
本文首发于公众号:程序员刘大华,专注分享前后端开发的实战笔记。关注我,少走弯路,一起进步!
📌往期精彩
《async/await 到底要不要加 try-catch?异步错误处理最佳实践》
《如何查看 SpringBoot 当前线程数?3 种方法亲测有效》
《Java 开发必看:什么时候用 for,什么时候用 Stream?》
来源:juejin.cn/post/7584266184882552866
Vue3 后台分页写腻了?我用 1 个 Hook 删掉 90% 重复代码(附源码)
实战推荐:
- 不仅免费,还开源?这个 AI Mock 神器我必须曝光它
- ⚡ 一个Vue自定义指令搞定丝滑拖拽列表,告别复杂组件封装
- 🔥 这才是 Vue 驱动的 Chrome 插件工程化正确打开方式
- 女朋友又给我出难题了:解锁网页禁用复制 + 一键提取图片文字
还在为每个列表页写重复的分页代码而烦恼吗? 还在复制粘贴 currentPage、pageSize、loading 等状态吗? 一个 Hook 帮你解决所有分页痛点,减少90%重复代码
背景与痛点
在后台管理系统开发中,分页列表查询非常常见,我们通常需要处理:
- 当前页、页大小、总数等分页状态
- 加载中、错误处理等请求状态
- 搜索、刷新、翻页等分页操作
- 数据缓存和重复请求处理
这些重复逻辑分散在各个组件中,维护起来很麻烦。
为了解决这个烦恼,我专门封装了分页数据管理 Hook。现在只需要几行代码,就能轻松实现分页查询,省时又高效,减少了大量重复劳动
使用前提 - 接口格式约定
查询接口返回的数据格式:
{
list: [ // 当前页数据数组
{ id: 1, name: 'user1' },
{ id: 2, name: 'user2' }
],
total: 100 // 数据总条数
}
先看效果:分页查询只需几行代码!
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList, // 查询API
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
这样子每次分页查询只需要引入hook,然后传入查询接口就好了,减少了大量重复劳动
解决方案
我设计了两个相互配合的 Hook:
- useFetch:基础请求封装,处理请求状态和缓存
- usePageFetch:分页逻辑封装,专门处理分页相关的状态和操作
usePageFetch (分页业务层)
├── 管理 page / pageSize / total 状态
├── 处理搜索、刷新、翻页逻辑
├── 统一错误处理和用户提示
└── 调用 useFetch (请求基础层)
├── 管理 loading / data / error 状态
├── 可选缓存机制(避免重复请求)
└── 成功回调适配不同接口格式
核心实现
useFetch - 基础请求封装
// hooks/useFetch.js
import { ref } from 'vue'
const Cache = new Map()
/**
* 基础请求 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {*} options.initValue - 初始值
* @param {string|Function} options.cache - 缓存配置
* @param {Function} options.onSuccess - 成功回调
*/
function useFetch(fn, options = {}) {
const isFetching = ref(false)
const data = ref()
const error = ref()
// 设置初始值
if (options.initValue !== undefined) {
data.value = options.initValue
}
function fetch(...args) {
isFetching.value = true
let promise
if (options.cache) {
const cacheKey = typeof options.cache === 'function'
? options.cache(...args)
: options.cache || `${fn.name}_${args.join('_')}`
promise = Cache.get(cacheKey) || fn(...args)
Cache.set(cacheKey, promise)
} else {
promise = fn(...args)
}
// 成功回调处理
if (options.onSuccess) {
promise = promise.then(options.onSuccess)
}
return promise
.then(res => {
data.value = res
isFetching.value = false
error.value = undefined
return res
})
.catch(err => {
isFetching.value = false
error.value = err
return Promise.reject(err)
})
}
return {
fetch,
isFetching,
data,
error
}
}
export default useFetch
usePageFetch - 分页逻辑封装
// hooks/usePageFetch.js
import { ref, onMounted, toRaw, watch } from 'vue'
import useFetch from './useFetch' // 即上面的hook ---> useFetch
import { ElMessage } from 'element-plus'
/**
* 分页数据管理 Hook
* @param {Function} fn - 请求函数
* @param {Object} options - 配置选项
* @param {Object} options.params - 默认参数
* @param {boolean} options.initFetch - 是否自动初始化请求
* @param {Ref} options.formRef - 表单引用
*/
function usePageFetch(fn, options = {}) {
// 分页状态
const page = ref(1)
const pageSize = ref(10)
const total = ref(0)
const data = ref([])
const params = ref()
const pendingCount = ref(0)
// 初始化参数
params.value = options.params
// 使用基础请求 Hook
const { isFetching, fetch: fetchFn, error, data: originalData } = useFetch(fn)
// 核心请求方法
const fetch = async (searchParams, pageNo, size) => {
try {
// 更新分页状态
page.value = pageNo
pageSize.value = size
params.value = searchParams
// 发起请求
await fetchFn({
page: pageNo,
pageSize: size,
// 使用 toRaw 避免响应式对象问题
...(searchParams ? toRaw(searchParams) : {})
})
// 处理响应数据
data.value = originalData.value?.list || []
total.value = originalData.value?.total || 0
pendingCount.value = originalData.value?.pendingCounts || 0
} catch (e) {
console.error('usePageFetch error:', e)
ElMessage.error(e?.msg || e?.message || '请求出错')
// 清空数据,提供更好的用户体验
data.value = []
total.value = 0
}
}
// 搜索 - 重置到第一页
const search = async (searchParams) => {
await fetch(searchParams, 1, pageSize.value)
}
// 刷新当前页
const refresh = async () => {
await fetch(params.value, page.value, pageSize.value)
}
// 改变页大小
const onSizeChange = async (size) => {
await fetch(params.value, 1, size) // 重置到第一页
}
// 切换页码
const onCurrentChange = async (pageNo) => {
await fetch(params.value, pageNo, pageSize.value)
}
// 组件挂载时自动请求
onMounted(() => {
if (options.initFetch !== false) {
search(params.value)
}
})
// 监听表单引用变化(可选功能)
watch(
() => options.formRef,
(formRef) => {
if (formRef) {
console.log('Form ref updated:', formRef)
}
}
)
return {
// 分页状态
currentPage: page,
pageSize,
total,
pendingCount,
// 数据状态
data,
originalData,
isFetching,
error,
// 操作方法
search,
refresh,
onSizeChange,
onCurrentChange
}
}
export default usePageFetch
完整使用示例
用element ui举例
<template>
<el-form :model="searchForm" >
<el-form-item label="用户名">
<el-input v-model="searchForm.username" />
</el-form-item>
<el-form-item>
<el-button type="primary" @click="handleSearch">搜索</el-button>
</el-form-item>
</el-form>
<!-- 表格数据展示,绑定 data 和 loading 状态 -->
<el-table :data="data" v-loading="isFetching">
<!-- ...表格列定义... -->
</el-table>
<!-- 分页组件,绑定当前页、页大小、总数,并响应切换事件 -->
<el-pagination
v-model:current-page="currentPage"
v-model:page-size="pageSize"
:total="total"
@size-change="onSizeChange"
@current-change="onCurrentChange"
/>
</template>
<script setup>
import { ref } from 'vue'
import usePageFetch from '@/hooks/usePageFetch' // 引入分页查询 Hook,封装了分页逻辑和状态管理
import { getUserList } from '@/api/user' // 引入请求用户列表的 API 方法
// 搜索表单数据,响应式声明
const searchForm = ref({
username: ''
})
// 使用 usePageFetch Hook 实现分页数据管理
const {
currentPage, // 当前页码
pageSize, // 每页条数
total, // 数据总数
data, // 当前页数据列表
isFetching, // 加载状态,用于控制 loading 效果
search, // 搜索方法
onSizeChange, // 页大小改变事件处理方法
onCurrentChange // 页码改变事件处理方法
} = usePageFetch(
getUserList,
{ initFetch: false } // 是否自动请求一次(组件挂载时自动拉取第一页数据)
)
/**
* 处理搜索操作
*/
const handleSearch = () => {
search({ username: searchForm.value.username })
}
</script>
高级用法
带缓存
const {
data,
isFetching,
search
} = usePageFetch(getUserList, {
cache: (params) => `user-list-${JSON.stringify(params)}` // 自定义缓存 key
})
设计思路解析
- 职责分离:useFetch 专注请求状态管理,usePageFetch 专注分页逻辑
- 统一错误处理:在 usePageFetch 层统一处理错误
- 智能缓存机制:支持多种缓存策略
- 生命周期集成:自动在组件挂载时请求数据
总结
这套分页管理 Hook 的优势:
- 开发效率高,减少90%的重复代码,新增列表页从 30 分钟缩短到 5 分钟
- 状态管理完善,自动处理加载、错误、数据状态
- 缓存机制,避免重复请求
- 错误处理统一,用户体验一致
- 易于扩展,支持自定义配置和回调
如果觉得对您有帮助,欢迎点赞 👍 收藏 ⭐ 关注 🔔 支持一下!
来源:juejin.cn/post/7549096640340426802
📢 程序员注意!这些代码可能会让你"吃牢饭"!
关注我的公众号:【编程朝花夕拾】,可获取首发内容。

01 引言
不知道你有没有听过面向监狱编程,可能你好好的码着代码,就就被帽子叔叔带走了。
"我只是个写代码的,关我什么事?" 这是深圳某P2P平台架构师在法庭上崩溃大喊,但代码提交记录中的"反爬优化注释"成了铁证——他因非法吸收公众存款罪获刑5年。这不是电影,而是2023年真实判决!
程序员早已不是免责职业,你的键盘可能正在敲响监狱的大门!
02 血泪案例
⚠️ 这些代码真的会"坐牢"!
2.1 爬虫爬进铁窗
爬虫其实是最容易爬进铁窗的代码。当时可能只是为了解决一个业务痛点,一旦被非法使用,就可能触犯法律的红线。开发者无意,使用者有心,莫名其名的就背了锅。
案例:
浙江某程序员用分布式爬虫狂扫10亿条个人信息,庭审时辩解:"技术无罪!"。
法官怒怼:"每秒突破5次反爬验证,这叫'技术中立'?" —— 6人团队全员获刑!
所以,我们在日常工作中开发爬虫就应该得到启示:
- ✅数据是否涉个人隐私?
- ✅是否突破网站防护?
- ✅对方是否知情同意?
实在拿不准,公司一般都会有法务,可以咨询。
2.2 权限变"凶器"
我们在开发过程中为处理决异常数据的问题,可能会在代码里面留后门。正常的业务功能本身没有问题,但是涉及支付、数据安全等行为,就要注意了。被他人恶意使用,不仅会造成财产损失,可能会还会勉励牢狱之灾。
案例:
杭州前程序员偷偷植入"定时转账代码",21万公款秒变私人财产。检察机关以马某涉嫌盗窃罪、妨害公务罪向法院提起公诉,经法院审理作出一审判决,马某被判处有期徒刑四年二个月,并处罚金。
该起事件也为程序员们敲响了警钟。玩归玩,闹归闹,法律红线不可碰。
🛑 高位操作清单:
- ❌ 私留系统后门
- ❌ 超权限访问数据
- ❌ 删除/篡改数据或日志
2.3 "技术黑产"陷阱
程序员除了工作之外,很多人可能还会通过接私活,如猪八戒网等。以此增加自己的收入。没有公司的严格审核,很多程序员就会掉如技术黑产 的陷阱。
案例:
湖北大学生接私活开发"诈骗APP",庭审播放需求录音:"要能后台改赌局结果"。可能当时你只想着:"我只负责技术实现" 最后却成诈骗案从犯!
尤其一些关于支付的似乎要尤为谨慎,特别是支付成功后,限制体现的时间,很有可能就会用于非法洗钱的黑坑里。
🔥 接私活避坑指南
- 👉 要求签署书面合同
- 👉 录音确认需求合法性
- 👉 转账账户必须对公
03 为什么程序员总成背锅侠
其实大多数程序员都是很单纯的,尤其那些喜欢挑战的程序员。他可能只为表现自己的实力,仅仅只是按照需求开发了功能,但是被恶意利用,最终成为背锅侠
| 程序员以为 | 法官认定 |
|---|---|
| 突破反爬是技术挑战 | 非法侵入计算机系统 |
| 按需求开发无过错 | 明知违法仍提供帮助 |
| 删除代码就没事 | 电子证据完整链锁定" |
血泪真相:你的Git提交记录、代码注释、甚至TODO列表都可能成为呈堂证供!
04 IT人保命三件套
4.1 代码防坐牢套餐
敏感功能增加法律注释。开发的功能以及项目的沟通都要留档尤其需求的变更。因为接到需求的时候可能没有问题,改着改着就出问题了。
拒绝口头需求,落实文档记录,需求、会议、项目事件以邮件的方式存档。
4.2 权限管理生死线
权限管理是保护数据安全的重要措施,但是可能为了调试方便,预留逃逸后门。被人利用轻则数据信息泄露、重则踩缝纫机。
三方对接中,加强公钥、私钥的管理,防止恶意推送或者拉取数据。敏感信息是否脱敏,都是开发中需要考虑的要点。
如果有必要,增加埋点记录,日志记录。收集用户的操作行为。
4.3 法律意识
每个IT公司都会面临网络安全的检查,可以多了解一些相关的法律发条。至少了解那些数据可能会属于需要保护的数据,引起重视。
如果公司允许,可以多参加一些《数据安全法》《网络安全》等的培训。
05 技术向善
代码改变世界,这个不是一句虚话。运用好技术,代码也可以是光。
阿里巴巴的支付宝硬是借助技术,将全国带入数字支付的时代;疫情期间的随申码、一码通等,为战胜疫情作出了巨大贡献;大模型的火爆推送了智能时代的到来等等。
真正的大神不仅代码能跑通,人生更不能"跑偏"!
你在工作中遇到过哪些"法律边缘"的需求?评论区说出你的故事。
来源:juejin.cn/post/7506417928788836362
招行2面:为什么需要序列化和反序列?为什么不能直接使用对象?
Hi,你好,我是猿java。
工作中,我们经常听到序列化和反序列化,那么,什么是序列化?什么又是反序列化?这篇文章,我们来分析一个招商的面试题:为什么需要序列化和反序列化?
1. 什么是序列化和反序列化?
简单来说,序列化就是把一个Java对象转换成一系列字节的过程,这些字节可以被存储到文件、数据库,或者通过网络传输。反过来,反序列化则是把这些字节重新转换成Java对象的过程。
想象一下,你有一个手机应用中的用户对象(比如用户的名字、年龄等信息)。如果你想将这个用户对象存储起来,或者发送给服务器,你就需要先序列化它。等到需要使用的时候,再通过反序列化把它恢复成原来的对象。
2. 为什么需要序列化?
“为什么需要序列化?为什么不能直接使用对象呢?”这确实是一个好问题,而且很多工作多年的程序员不一定能回答清楚。综合来看:需要序列化的主要原因有以下三点:
- 持久化存储:当你需要将对象的数据保存到磁盘或数据库中时,必须把对象转换成一系列字节。
- 网络传输:在分布式系统中,不同的机器需要交换对象数据,序列化是实现这一点的关键。
- 深拷贝:有时候需要创建对象的副本,序列化和反序列化可以帮助你实现深拷贝。
更直白的说,序列化是为了实现持久化和网络传输,对象是应用层的东西,不同的语言(比如:java,go,python)创建的对象还不一样,实现持久化和网络传输的载体不认这些对象。
3. 序列化的原理分析
Java中的序列化是通过实现java.io.Serializable接口来实现的。这个接口是一个标记接口,意味着它本身没有任何方法,只是用来标记这个类的对象是可序列化的。
当你序列化一个对象时,Java会将对象的所有非瞬态(transient)和非静态字段的值转换成字节流。这包括对象的基本数据类型、引用类型,甚至是继承自父类的字段。
序列化的步骤
- 实现
Serializable接口:你的类需要实现这个接口。 - 创建
ObjectOutputStream:用于将对象转换成字节流。 - 调用
writeObject方法:将对象写入输出流。 - 关闭流:别忘了关闭流以释放资源。
反序列化的步骤大致相同,只不过是使用ObjectInputStream和readObject方法。
4. 示例演示
让我们通过一个简单的例子来看看实际操作是怎样的。
定义一个可序列化的类
import java.io.Serializable;
public class User implements Serializable {
private static final long serialVersionUID = 1L; // 推荐定义序列化版本号
private String name;
private int age;
private transient String password; // transient字段不会被序列化
public User(String name, int age, String password) {
this.name = name;
this.age = age;
this.password = password;
}
// 省略getter和setter方法
@Override
public String toString() {
return "User{name='" + name + "', age=" + age + ", password='" + password + "'}";
}
}
序列化对象
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class SerializeDemo {
public static void main(String[] args) {
User user = new User("Alice", 30, "secret123");
try (FileOutputStream fileOut = new FileOutputStream("user.ser");
ObjectOutputStream out = new ObjectOutputStream(fileOut)) {
out.writeObject(user);
System.out.println("对象已序列化到 user.ser 文件中.");
} catch (IOException i) {
i.printStackTrace();
}
}
}
运行上述代码后,你会发现当前目录下生成了一个名为user.ser的文件,这就是序列化后的字节流。
反序列化对象
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class DeserializeDemo {
public static void main(String[] args) {
User user = null;
try (FileInputStream fileIn = new FileInputStream("user.ser");
ObjectInputStream in = new ObjectInputStream(fileIn)) {
user = (User) in.readObject();
System.out.println("反序列化后的对象: " + user);
} catch (IOException | ClassNotFoundException i) {
i.printStackTrace();
}
}
}
运行这段代码,你会看到输出:
反序列化后的对象: User{name='Alice', age=30, password='null'}
注意到password字段为空,这是因为它被声明为transient,在序列化过程中被忽略了。
5. 常见问题与注意事项
serialVersionUID是干嘛的?
serialVersionUID是序列化时用来验证版本兼容性的一个标识符。如果你不显式定义它,Java会根据类的结构自动生成。但为了避免类结构变化导致序列化失败,建议手动定义一个固定的值。
继承关系中的序列化
如果一个类的父类没有实现Serializable接口,那么在序列化子类对象时,父类的字段不会被序列化。反序列化时,父类的构造函数会被调用初始化父类部分。
处理敏感信息
使用transient关键字可以防止敏感信息被序列化,比如密码字段。此外,你也可以自定义序列化逻辑,通过实现writeObject和readObject方法来更精细地控制序列化过程。
6. 总结
本文,我们深入浅出地探讨了Java中的序列化和反序列化,从基本概念到原理分析,再到实际的代码示例,希望你对这两个重要的技术点有了更清晰的理解。
为什么需要序列化和反序列化?
最直白的说,如果不进行持久化和网络传输,根本不需要序列化和反序列化。如果需要实现持久化和网络传输,就必须序列化和反序列化,因为对象是应用层的东西,不同的语言(比如:java,go,python)创建的对象还不一样,实现持久化和网络传输的载体根本不认这些对象。
7. 交流学习
最后,把猿哥的座右铭送给你:投资自己才是最大的财富。 如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7499078331708932134
vue文件自动生成路由会成为主流
vue-router悄悄发布了5.0版本,用官方的话说,V5 是一个过渡版本,它将unplugin-vue-router(基于文件的路由)合并到了核心包中,就是说V5版本直接支持基于文件自动生成路由了,无需再引入unplugin-vue-router。
这一变化标志着前端开发模式的一个重要转折点。过去,开发者需要手动定义路由配置,这种方式虽然灵活,但随着项目规模增大,维护成本也随之增加。现在,Vue Router 5.0内置了基于文件的路由系统,使得路由管理变得更加直观和高效。
传统路由配置与基于文件路由的对比
在传统的Vue Router使用方式中,我们需要手动创建路由:
import { createRouter, createWebHistory } from "vue-router";
import Home from "./views/Home.vue";
import About from "./views/About.vue";
const routes = [
{
path: "/",
name: "home",
component: Home,
},
{
path: "/about",
name: "about",
component: About,
},
];
const router = createRouter({
history: createWebHistory(),
routes,
});
而基于文件的路由系统允许我们通过目录结构自动生成路由,例如:
src/
├── pages/
│ ├── index.vue # -> /
│ ├── about.vue # -> /about
│ ├── user/
│ │ └── index.vue # -> /user
│ └── user-[id].vue # -> /user/:id
无需手动创建,直接导入即可:
import { routes } from "vue-router/auto-routes";
const router = createRouter({
history: createWebHistory(),
routes,
});
省去了手动定义路由的繁琐步骤。
基于文件路由的优势
- 减少样板代码:无需手动编写大量路由配置
- 约定优于配置:通过文件名和目录结构确定路由路径
- 提高开发效率:添加新页面只需创建对应文件
- 易于维护:路由结构一目了然,便于团队协作
- 类型化路由: 使用ts能够获得更好的提示,比如
router.push(xxx)现在会有提示了
缺点
- 路由的
meta等额外数据必须在.vue文件使用definePage或route标签声明,点此查看教程 - 增加了额外的学习成本
快速入门
安装
pnpm add vue-router@5
vite.config.ts
import VueRouter from "vue-router/vite";
export default defineConfig({
plugins: [
VueRouter({
dts: "typed-router.d.ts",
}),
// ⚠️ Vue must be placed after VueRouter()
Vue(),
],
});
tsconfig.json
// tsconfig.json
{
"include": [ "typed-router.d.ts" ],
"vueCompilerOptions": {
"plugins": [
"vue-router/volar/sfc-typed-router",
"vue-router/volar/sfc-route-blocks"
]
}
}
src/router/index.ts
import { createRouter, createWebHistory } from "vue-router";
import { routes, handleHotUpdate } from "vue-router/auto-routes";
export const router = createRouter({
history: createWebHistory(),
routes,
});
// This will update routes at runtime without reloading the page
if (import.meta.hot) {
handleHotUpdate(router);
}
详细的路由生成规则
根据官方文档,基于文件的路由系统有以下具体规则:
索引路由:任何 index.vue 文件(必须全小写)将生成空路径,类似于 index.html 文件:
src/pages/index.vue生成/路由src/pages/users/index.vue生成/users路由
嵌套路由:当在同一层级同时存在同名文件夹和 .vue 文件时,会自动生成嵌套路由。例如:
src/pages/
├── users/
│ └── index.vue
└── users.vue
这将生成如下路由配置:
const routes = [
{
path: "/users",
component: () => import("src/pages/users.vue"),
children: [
{ path: "", component: () => import("src/pages/users/index.vue") },
],
},
];
不带布局嵌套的路由:有时候你可能想在URL中添加斜杠形式的嵌套,但不想影响UI层次结构。可以使用点号(.)分隔符:
src/pages/
├── users/
│ ├── [id].vue
│ └── index.vue
└── users.vue
要添加 /users/create 路由而不将其嵌套在 users.vue 组件内,可以创建 src/pages/users.create.vue 文件,. 会被转换为 /:
const routes = [
{
path: "/users",
component: () => import("src/pages/users.vue"),
children: [
{ path: "", component: () => import("src/pages/users/index.vue") },
{ path: ":id", component: () => import("src/pages/users/[id].vue") },
],
},
{
path: "/users/create",
component: () => import("src/pages/users.create.vue"),
},
];
路由组:有时候需要组织文件结构而不改变URL。路由组允许你逻辑性地组织路由,不影响实际URL:
src/pages/
├── (admin)/
│ ├── dashboard.vue
│ └── settings.vue
└── (user)/
├── profile.vue
└── order.vue
生成的URL:
/dashboard-> 渲染src/pages/(admin)/dashboard.vue/settings-> 渲染src/pages/(admin)/settings.vue/profile-> 渲染src/pages/(user)/profile.vue/order-> 渲染src/pages/(user)/order.vue
命名视图:可以通过在文件名后附加 @ + 名称来定义命名视图,如 src/pages/index@aux.vue 将生成:
{
path: '/',
component: {
aux: () => import('src/pages/index@aux.vue')
}
}
默认情况下,未命名的路由被视为 default,即使有其他命名视图也不需要将文件命名为 index@default.vue。
动态路由:使用方括号语法定义动态参数:
[id].vue->/users/:id[category]-details.vue->/electronics-details[...all].vue-> 通配符路由/all/*
对开发工作流的影响
这一变化将显著改变Vue应用的开发流程:
- 新功能页面的添加变得更加简单
- 团队成员更容易理解项目的路由结构
- 减少了因手动配置错误导致的路由问题
- 更好的IDE集成和自动补全支持
迁移策略
对于现有项目,Vue Router 5.0提供了平滑的迁移路径:
- 旧的路由配置方式依然有效
- 可以逐步采用基于文件的路由
- 混合使用两种方式以适应不同场景
配置选项和高级功能
Vue Router 5.0的基于文件路由系统提供了丰富的配置选项,可以根据项目需求进行定制:
自定义路由目录:默认情况下,系统会在 src/pages 目录中查找 .vue 文件,但可以通过配置更改此行为。
命名路由:所有生成的路由都会自动获得名称属性,避免意外将用户引导至父路由。默认情况下,名称使用文件路径生成,但可以通过自定义 getRouteName() 函数覆盖此行为。
类型安全:系统会自动生成类型声明文件(如 typed-router.d.ts),提供几乎无处不在的 TypeScript 验证。
配置示例:
// vite.config.js
import { defineConfig } from "vite";
import vue from "@vitejs/plugin-vue";
import VueRouter from "unplugin-vue-router/vite";
export default defineConfig({
plugins: [
VueRouter({
routesFolder: "src/pages", // 自定义路由目录
extensions: [".vue"], // 指定路由文件扩展名
dts: "typed-router.d.ts", // 生成类型声明文件
importMode: (filename) => "async", // 自定义导入模式
}),
vue(),
],
});
实际应用建议
在实际项目中采用基于文件的路由时,建议遵循以下最佳实践:
- 清晰的目录结构:保持一致的目录结构,便于团队成员理解
- 有意义的文件名:使用描述性的文件名,使路由意图明确
- 合理使用路由组:利用路由组组织相关的页面,而不影响URL结构
- 渐进式采用:对于大型项目,可以逐步迁移部分路由到新的系统
总结
Vue Router 5.0引入的基于文件的路由系统代表了前端开发模式的重要演进。它将 Nuxt.js 等框架成功的路由理念整合到了 Vue 的核心生态中,使开发者能够以更简洁、更直观的方式管理应用路由。
这一变化不仅减少了样板代码,提高了开发效率,还促进了更一致的项目结构。随着更多开发者采用这一新模式,我们可以期待看到更高质量、更易维护的 Vue 应用程序出现,这将为整个前端社区带来积极的影响。
来源:juejin.cn/post/7610253888646119467
🦞OpenClaw 让 MacMini 脱销了,而我拿出了6年陈的安卓机
前言
OpenClaw 作为 AI 界 2026 年的新宠,第一波受益的居然是 Mac Mini,原因是 Mac Mini 功耗低,适合 7x24 小时运行。这就让我很不李姐,作为一个十年 Linux 手,我坚信只要能运行 Linux 的设备上就可以运行 OpenClaw。像树莓派这种小众玩具就算了,我们的安卓手机也完全可以,这手机不比 Mac Mini 的功耗低吗,而且手机自带 UPS+移动网络,即使你家断电断网,都不影响 OpenClaw 为你干活。
好巧不巧我的 2019 年的包浆三星,昨晚音量键也坏了,这是完全没法用了,但是我觉得它的处理器还能打,这不正好适合干这个吗。
当我在安卓手机上安装了 Termux(终端模拟器) + nodejs + cmake 等古法炼丹的组件之后,意外发现这是 AI 时代了,GitHub 上已经有一个完善的项目openclaw-termux,它不仅提供了基于 Termux 环境的安装指令,还提供了一个 Flutter App,大大降低了安装门槛。下面将一步步介绍我的安装过程。
Step 0:准备工作
0.1 准备大模型API key
我选用的是 MiniMax,CodingPlan 可以无限 token 使用,实名认证之后也可以获得体验额度。
点击链接获得 CodingPlan 9 折优惠 platform.minimaxi.com/subscribe/c…
注意这里有两种 key,上面的接口密钥是消耗余额和体验券的,点击“创建新的 API key”。有CodingPlan的朋友点击“重置并复制”使用下面的key。

0.2 创建聊天机器人
我用的是飞书,这个创建操作流程较长,没有操作过的朋友直接转到文末参考附录:创建飞书聊天机器人
0.3 安装 OpenClaw 安卓 App
安装之后打开 App,就进入了下面的界面。因为许多访问地址都是国外的,所以建议安装过程挂🪜,会比较顺利。这个界面视网络情况,可能需要等待比较久时间,我大概花了 15 分钟。 期间尽量让 app 保持在前台,防止被杀掉。
后面完成后会有两个可选安装项,不懂可以跳过。

Step 1:运行配置向导
第一段是风险提示,默认选项是“No”,我们点下面的⬅️按钮选到“Yes”,并在键盘按“↩︎”键

继续选择“QuickStart”,就来到最关键的模型配置了。
1.1 Model 模型配置

国内的供应商可选的有 MiniMax 和 DeepSeek。MiniMax 可以看到专门的选项,但是 DeepSeek 没有,因为 DeepSeek 执行了 OpenAI 的标准,因此我们可以用 OpenAI 或者 Custom 选兼容 OpenAI 的方式。
关于这两个平台的对比,可以参考下图:

这里我选择了 MiniMax,第二个 auth method 不要选 Oauth。然后提示输入 MiniMax 后台的 API key。模型选择见下图,建议使用-cn 后缀的,利于国内访问。

1.2 Channel 会话频道配置
完成模型配置就来到了 Channel 配置,这里的 Channel 是指用什么即时通讯工具与 OpenClaw 交互,国内的只有飞书。我们就选飞书。
题外话是飞书的配置属于较复杂的,如果有条件优先使用 Telegram会比较简单。


这里就需要输入飞书的 AppID 以及 Secret 了。后文会介绍如何创建飞书机器人。

1.3 Skill技能配置
配置完 Channel 之后,就来到了 Skills,建议配置 mcporter,MCP好比 OpenClaw 的手臂,能大大增强它做事的能力。其余技能按需即可。

这里会有一些配置API KEY 的提示,通通选 No 即可,如果有需求,可以后配。

再然后看到这个界面就告诉你配置结束了。

Step 2:仪表盘界面
这个仪表盘界面最重要的功能是管理Gateway的状态,只有当Gateway运行状态时,OpenClaw 才可以正常工作。因此这里要点击“Start Gateway”。

然后我们看到绿色的“运行中”就万事毕备了。

Step 3:工作节点配置
点击 Node 进入工作节点配置,点击 Enable,会提示你进行各种授权,这也意味着 OpenClaw 可以接管你手机的相关能力,比如拍照,这都属于敏感操作,一定要想清楚再开。

Step 4:飞书后台设置事件回调
如果你这个时候迫不及待的去找机器人聊天,你会发现连输入框都没有。我们需要继续配置事件回调。

选择使用长连接接收事件:

可以看到添加事件按钮由原来的灰色不可点击变为可点击:

添加接收消息事件:

给应用开通获取通讯录基本信息的权限:

重新发布版本:

跟前面的步骤一样,发布为在线应用即可。
现在可以看到飞书机器人有输入框了!
但是如果你发消息给机器人,会收到一条配对提示

我们找到with:后面那一行指令到 OpenClaw App 主界面的Terminal中执行。这是唯一需要输入命令的地方。
openclaw pairing approve feishu A5T7L53A
附录:创建飞书聊天机器人
1. 来到飞书开发者后台
飞书开放平台地址:
没有飞书账号的,需要自己注册账号
点击右上角进入开发者后台:

2. 创建应用

3. 填写应用信息

4. 获取自己的应用凭证

5. 给应用添加机器人


6. 给应用配置权限

把即时通讯相关的权限全部开通:

7. 创建版本并发布



如果当前账号不是管理员会多一个审批流程。
来源:juejin.cn/post/7611386394679459874
为什么Django这么慢,却还是Python后端第一梯队呢?
学习Web框架的Python玩家大多应该都听过:Django 性能不行”、“高并发场景根本用不了 Django”。但有趣的是,在TIOBE、PyPI下载量、企业技术栈选型中,Django始终稳居Python后端框架第一梯队,甚至是很多公司的首选。
这背后的矛盾,恰恰折射出工业级开发的核心逻辑:性能从来不是唯一的衡量标准,生产力和工程化能力才是。
一、先澄清:Django 的“慢”,到底慢在哪?
首先要纠正一个认知偏差:Django的 “慢” 是相对的,而非绝对的。
1. 所谓“慢”的本质
Django被吐槽“慢”,主要集中在这几个点:
- 全栈特性的代价:Django是“电池已内置”的全栈框架,ORM、表单验证、认证授权、Admin后台、缓存、国际化等功能开箱即用,这些内置组件会带来一定的性能开销,对比Flask、FastAPI这类轻量框架,纯接口响应速度确实稍慢(基准测试中,简单接口QPS约为FastAPI的1/3-1/2)。
- 同步 IO 的天然限制:Django默认是同步架构,在高并发IO密集型场景(如大量请求等待数据库/第三方接口响应)下,线程/进程池容易被打满,吞吐量受限。
- ORM 的 “便利税” :自动生成的SQL可能不够优化,新手容易写出N+1查询,进一步放大性能问题。
2. 但这些“慢”,大多是“伪问题”
绝大多数业务场景下,Django的性能完全够用:
- 普通中小网站(日活10万以内):Django+合理缓存+数据库优化,能轻松支撑业务,性能瓶颈根本不在框架本身。
- 所谓 “慢” 的对比场景:大多是“裸框架接口跑分”,而真实业务中,接口响应时间的80%以上消耗在数据库、缓存、网络IO上,框架本身的耗时占比不足5%。
- 性能可优化空间大:通过异步改造(Django 3.2+原生支持ASGI)、缓存层(Redis)、数据库读写分离、CDN、Gunicorn+Nginx部署等方式,完全能把Django的性能提升到满足中高并发的水平。
二、Django能稳居第一梯队,核心是“降本增效”
企业选框架,本质是选“性价比”——开发效率、维护成本、团队协作成本,远比单点性能重要。而这正是Django的核心优势。
1. 极致的开发效率:“开箱即用” 的工业级体验
Django的设计哲学是 “不要重复造轮子”,一个命令就能生成完整的项目骨架,几行代码就能实现核心功能:
# 5行代码实现带权限的REST接口(Django+DRF)
from rest_framework import viewsets
from .models import Article
from .serializers import ArticleSerializer
class ArticleViewSet(viewsets.ModelViewSet):
queryset = Article.objects.all()
serializer_class = ArticleSerializer
permission_classes = [IsAuthenticated]
- 内置Admin后台:无需写一行前端代码,就能实现数据的增删改查,调试和运营效率拉满。
- 完善的认证授权:Session、Token、OAuth2等认证方式开箱即用,不用自己造权限轮子。
- 表单验证&CSRF防护:自动处理表单校验、跨站请求伪造,减少安全漏洞。
- ORM的价值:虽然有性能损耗,但大幅降低了数据库操作的学习成本和出错概率,新手也能快速写出安全的数据库逻辑。
对于创业公司或快速迭代的业务,“快上线、少踩坑”比“多10%的性能” 重要得多——Django能让团队用最少的人力,在最短时间内搭建起稳定的业务系统。
2. 成熟的工程化体系:适合团队协作
个人项目可以用Flask自由发挥,但团队项目需要“规范”。Django的“约定优于配置”理念,强制规范了项目结构、代码组织、数据库迁移等流程:
- 统一的项目结构:新人接手项目,不用花时间理解自定义的目录结构,直接就能上手。
- 内置的数据库迁移工具:
makemigrations/migrate完美解决数据库版本管理问题,避免团队协作中的数据结构混乱。 - 丰富的中间件和扩展生态:缓存中间件、跨域中间件、日志中间件等开箱即用,DRF(Django REST Framework)、Celery、Django Channels等扩展几乎能覆盖所有业务场景。
- 完善的文档和社区:官方文档堪称 “教科书级别”,遇到问题能快速找到解决方案,招聘时也更容易找到有经验的开发者。
3. 稳定可靠:经得起生产环境的考验
Django 诞生于2005年,经过近20年的迭代,已经成为一个极其稳定的框架:
- 长期支持版本(LTS):每2-3年发布一个LTS版本,提供3年以上的安全更新和bug修复,企业不用频繁升级框架。
- 安全特性完善:自动防御XSS、CSRF、SQL注入等常见攻击,官方会及时修复安全漏洞,这对企业来说是“刚需”。
- 大量知名案例背书:Instagram、Pinterest、Mozilla、Spotify、国内的知乎(早期)、豆瓣等,都在用 Django支撑核心业务——这些产品的规模,足以证明Django的可靠性。
三、Django 的 “破局之路”:性能短板正在被补齐
面对性能吐槽,Django团队也一直在迭代优化:
- 异步支持:Django 3.0引入ASGI,3.2+完善异步视图、异步ORM,能直接对接WebSocket、长连接,IO密集型场景的并发能力大幅提升。
- 性能优化:新版本持续优化ORM、模板引擎、中间件,减少不必要的开销,比如Django 4.0+的ORM支持批量更新/插入,性能提升显著。
- 生态适配:可以和FastAPI混合部署(比如核心接口用FastAPI,管理后台用Django),兼顾性能和生产力;也可以通过Gunicorn+Uvicorn+异步工作进程,充分利用多核CPU。
四、总结:选框架,本质是选 “适配性”
Django的 “慢”,是为 “全栈、工程化、生产力” 付出的合理代价;而它能稳居第一梯队,核心原因是:
- 匹配绝大多数业务场景:90%的中小业务不需要 “极限性能”,但都需要 “快速开发、稳定运行、易维护”。
- 降低团队成本:统一的规范、丰富的内置功能、完善的文档,能大幅降低招聘、培训、协作成本。
- 生态和稳定性兜底:成熟的生态能解决几乎所有业务问题,长期支持版本让企业不用频繁重构。
最后想说:框架没有好坏,只有适配与否。如果是做高并发的API服务(如直播、秒杀),FastAPI/Tornado 可能更合适;但如果是做内容管理、电商、企业后台等需要快速落地、长期维护的业务,Django依然是Python后端的最优解之一。
这也是为什么,即便有层出不穷的新框架,Django依然能稳坐第一梯队——因为它抓住了工业级开发的核心:让开发者把精力放在业务上,而非重复造轮子。
来源:juejin.cn/post/7606182668330303524
别吹了,AI写Java代码到底能省多少时间?一个后端仔的真实记录
场景一:CRUD 生成 | 提效 70-80% | ⭐⭐⭐⭐⭐
这是 AI 最能打的场景,没有之一。
传统写法:手写 Entity → Mapper XML → Service → ServiceImpl → Controller,一套标准的增删改查,从建表到联调,至少 40 分钟。如果加上参数校验、分页查询、统一返回体,一个小时也不夸张。
用 AI 之后:给 Cursor 一段需求描述加上数据库表结构,5-10 分钟出完整代码。而且生成的代码结构很规范——注解没漏、字段映射没错、甚至连 Swagger 文档注解都给你加上了。
但别高兴太早。
我踩过的坑:AI 生成的 CRUD 代码表面上能跑,细节经常有问题。举几个典型的:
- 字段校验粗糙——
@NotNull加了,但@Size、@Pattern这种业务校验不会主动加 - 分页查询用的是内存分页而不是数据库分页(这个坑特别隐蔽)
- 异常处理一律
catch Exception,没有细分业务异常
所以我的做法是:让 AI 先生成骨架,然后自己过一遍核心逻辑。这样比从零手写快得多,又不会因为盲信 AI 埋雷。
CRUD 是 AI 的主场,这事没争议。但你还是得 review 每一行——AI 写的 bug 比你手写的更隐蔽。
场景二:Bug 排查 | 提效 40-60% | ⭐⭐⭐⭐
先说好用的部分。
一个 NullPointerException,传统排查流程:看堆栈 → 找到报错行 → 往上追调用链 → 打断点 → 复现 → 定位 → 修复。顺利的话 15 分钟,不顺利半小时起步。
现在我直接把报错日志和相关代码丢给 Claude,通常 2-3 分钟就能给出准确定位。不仅告诉你哪里报错,还能分析为什么会走到这个分支。效率差距是数量级的。
SQL 慢查询也类似。把 EXPLAIN 结果丢给 AI,它能分析出索引缺失、全表扫描、JOIN 顺序不合理等问题,给出的优化建议大部分是靠谱的。
但是。
复杂业务逻辑的 bug——比如跨服务的数据不一致、分布式事务异常、线程安全问题——AI 基本帮不上忙。原因很简单:它不了解你的业务上下文,不知道你的系统架构长什么样,不清楚各个服务之间的调用关系。
你可以把全部代码都喂给它,但在上下文窗口有限的情况下,效果也很一般。
AI debug 像个经验丰富的实习生——标准问题秒解,但真正棘手的问题还得靠你自己。
场景三:代码重构 | 提效 30-50% | ⭐⭐⭐
这个场景我体验比较复杂,分层来说。
方法级重构——好用。 提取公共方法、消除重复代码、简化多层嵌套的 if-else,这些 AI 干得又快又好。你说一句「把这段 if-else 用策略模式重构」,它真能给你一套结构清晰的策略类出来。
模块级重构——凑合。 比如给一个老旧的 Service 类做职责拆分,AI 能给出拆分方案,但命名经常不太合适,边界划分也需要自己调整。它不太懂你的团队命名规范,也不清楚哪些逻辑在你的系统里属于同一个领域。
架构级重构——别想了。 单体拆微服务、数据库分库分表这种事,涉及太多业务决策和技术权衡,AI 给的方案顶多算个参考。你要是照着它的方案直接改,后果自负。
重构的本质是对业务的理解。AI 只能帮你搬砖,不能帮你画图纸。
场景四:写单元测试 | 提效 50-70% | ⭐⭐⭐⭐
Java 程序员最不爱写但又不能不写的东西——单元测试。
传统写法:一个 Service 方法的单测,先 mock 一堆依赖,再写正常返回用例、空值用例、异常用例,30-40 分钟很正常。而且坦白说,很多人(包括我)写单测就是为了应付覆盖率检查,质量堪忧。
现在我把 Service 代码丢给 AI,说一句「用 JUnit 5 + Mockito 生成单元测试,覆盖正常和异常场景」,3-5 分钟出一整套。
举个真实例子。比如有这么一个订单查询方法:
public OrderDetailVO getOrderDetail(Long orderId) {
Order order = orderMapper.selectById(orderId);
if (order == null) {
throw new BizException(ErrorCode.ORDER_NOT_FOUND);
}
// 查关联的商品信息
List<OrderItem> items = orderItemMapper.selectByOrderId(orderId);
OrderDetailVO vo = OrderConverter.toDetailVO(order);
vo.setItems(OrderConverter.toItemVOList(items));
vo.setTotalAmount(calcTotalAmount(items));
return vo;
}
AI 生成的测试长这样(节选关键部分):
@ExtendWith(MockitoExtension.class)
class OrderServiceTest {
@Mock
private OrderMapper orderMapper;
@Mock
private OrderItemMapper orderItemMapper;
@InjectMocks
private OrderServiceImpl orderService;
@Test
@DisplayName("查询存在的订单-返回完整详情")
void getOrderDetail_success() {
Order mockOrder = buildMockOrder(1001L);
List<OrderItem> mockItems = buildMockItems(1001L, 2);
when(orderMapper.selectById(1001L)).thenReturn(mockOrder);
when(orderItemMapper.selectByOrderId(1001L)).thenReturn(mockItems);
OrderDetailVO result = orderService.getOrderDetail(1001L);
assertNotNull(result);
assertEquals(1001L, result.getOrderId());
assertEquals(2, result.getItems().size());
verify(orderMapper).selectById(1001L);
}
@Test
@DisplayName("查询不存在的订单-抛出业务异常")
void getOrderDetail_notFound() {
when(orderMapper.selectById(9999L)).thenReturn(null);
BizException ex = assertThrows(BizException.class,
() -> orderService.getOrderDetail(9999L));
assertEquals(ErrorCode.ORDER_NOT_FOUND, ex.getErrorCode());
}
}
说实话,这个质量是能直接用的。Mock 层级对、断言清晰、方法命名规范。如果手写,这两个测试方法至少要 15 分钟,AI 生成只要 2 分钟。
但我手动补了什么呢?
@Test
@DisplayName("订单存在但商品列表为空-金额应为0")
void getOrderDetail_emptyItems() {
when(orderMapper.selectById(1001L)).thenReturn(buildMockOrder(1001L));
when(orderItemMapper.selectByOrderId(1001L)).thenReturn(Collections.emptyList());
OrderDetailVO result = orderService.getOrderDetail(1001L);
assertEquals(BigDecimal.ZERO, result.getTotalAmount());
assertTrue(result.getItems().isEmpty());
}
这种业务边界用例——商品列表为空时金额计算是否正确——AI 不会主动想到,因为它不知道 calcTotalAmount 对空列表的处理逻辑是不是你期望的。
AI 生成测试的优点:
- Mockito 用得很熟练,
@Mock、@InjectMocks、when().thenReturn()一气呵成 - 正常路径和基本异常覆盖得不错
- 断言写得清晰,方法命名规范
缺点也明显:
- 边界条件经常遗漏——并发场景、数据库连接异常、超时这种不会主动想到
- 有时 mock 的层级不对——该 mock Repository 的地方 mock 了 Service
- 对业务语义理解有限——不知道空列表、金额为 0 这种场景需不需要专门测
我现在的套路是:让 AI 先生成 80% 的测试用例,自己再补上那 20% 的关键边界。这比从零手写效率高太多了。
80/20 法则在 AI 写单测这件事上体现得淋漓尽致。
场景五:写技术文档 | 提效 80-90% | ⭐⭐⭐⭐⭐
这是我觉得最被低估的 AI 提效场景。
Java 程序员写代码还行,写文档真的要命。一份接口文档写半天,一份方案设计磨一整天,部署文档更是能拖就拖。
举个例子。前阵子我写了一个用户收货地址的 Controller,大概长这样:
@PostMapping("/address/add")
public Result<Long> addAddress(@RequestBody @Valid AddressAddReq req) { ... }
@GetMapping("/address/list")
public Result<List<AddressVO>> listAddress() { ... }
@PutMapping("/address/update")
public Result<Void> updateAddress(@RequestBody @Valid AddressUpdateReq req) { ... }
@DeleteMapping("/address/{id}")
public Result<Void> deleteAddress(@PathVariable Long id) { ... }
把这段代码丢给 AI,说「生成接口文档,Markdown 格式,包含请求参数、返回值、错误码」,2 分钟后它给我的文档(节选):
POST /address/add — 新增收货地址
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| receiverName | String | 是 | 收货人姓名,2-20个字符 |
| phone | String | 是 | 手机号,11位 |
| province | String | 是 | 省份 |
| city | String | 是 | 城市 |
| district | String | 是 | 区/县 |
| detailAddress | String | 是 | 详细地址,最长200字符 |
| isDefault | Integer | 否 | 是否默认地址,0-否 1-是,默认0 |
返回值: Result<Long> — 新地址ID
错误码:
ADDRESS_LIMIT_EXCEEDED— 收货地址数量超过上限(20个)PARAM_INVALID— 参数校验失败
它连字段的校验规则都从 @Valid 注解里推断出来了。手写这份文档至少要 30 分钟,现在 2 分钟生成,再花 5 分钟检查补充,总共不到 10 分钟。
方案设计文档也一样。给出需求描述和技术方案要点,AI 能在 10 分钟内生成一份结构完整的设计文档——背景、目标、方案对比、技术选型、风险评估,该有的都有。当然具体技术细节需要自己补,但框架已经省了你 80% 的时间。
README 就更不用说了,几乎不用改,直接能用。
如果你还在手写文档,那你是真的在浪费生命。这话可能有点绝对,但我是认真的。
我的真实结论
一张表总结
| 场景 | 提效幅度 | 推荐度 | 一句话 |
|---|---|---|---|
| CRUD 生成 | 70-80% | ⭐⭐⭐⭐⭐ | AI 的主场,没争议 |
| Bug 排查 | 40-60% | ⭐⭐⭐⭐ | 标准问题秒杀,复杂问题不行 |
| 代码重构 | 30-50% | ⭐⭐⭐ | 能搬砖不能画图纸 |
| 单元测试 | 50-70% | ⭐⭐⭐⭐ | AI 出 80% + 人工补 20% |
| 技术文档 | 80-90% | ⭐⭐⭐⭐⭐ | 最被低估的提效场景 |
关于「效率反降 19%」
最近那个「AI 写代码效率反降 19%」的研究火了,很多人拿来当 AI 没用的证据。但你仔细看就会发现:研究用的是大型开源项目(平均 110 万行代码),上下文极其复杂。
日常业务开发完全不是这个量级。我们的代码库上下文更可控,需求也更明确。在这种条件下,AI 发挥的空间大得多。
说白了,关键不是 AI 行不行,而是你选对了场景没有。用 AI 写 CRUD 能省 70% 时间,你非要让它帮你做架构设计——那确实会「提效为负」。
我的使用原则
- AI 擅长的事全交给它:CRUD、文档、测试框架、标准 bug 排查
- AI 不擅长的事别勉强:复杂业务逻辑、架构设计、跨服务问题
- 永远 review:AI 写的代码比你手写的更需要审查——因为它写的 bug 更隐蔽
- 积累自己的 Prompt:好的 Prompt 比好的工具更重要
写在最后
我是栈外,写了几年 Java,现在用 AI 多赚一份钱。
不会告诉你用 AI 就能月入十万。但它确实能让你每天省出 1-2 小时——前提是你用对场景。
下一篇聊聊这省出来的时间,我拿来干了什么。省下来的时间如果不变成钱,那提效就是个伪命题。
如果觉得有用,点个赞收个藏,后面还有更硬的干货。
这是「栈外」的第 1 篇文章。不画饼,只算账。
来源:juejin.cn/post/7610580125618929690
一个 Java 老兵转 Go 后,终于理解了“简单”的力量
之前写的文章《信不信?一天让你从Java工程师变成Go开发者》很受关注,很多读者对 Go 的学习很感兴趣。今天就再写一篇,聊聊 Java 程序员写 Go 时最常见的思维误区。
核心观点: Go 不需要 Spring 式的依赖注入框架,因为它的设计哲学是"显式优于隐式"。手动构造依赖看似啰嗦,实则更清晰、更快、更易调试。
从 Java 转 Go,第一天就会被这个问题困扰:"@Autowired 在哪?依赖注入框架用哪个?IoC 容器怎么配?"
答案很直接:Go 里没有,也不需要。 不是 Go 做不到,而是 Go 压根不想这么干。这不是功能缺失,而是设计哲学的根本性差异。
第一反应:Go 怎么这么"原始"?
刚开始写 Go,看到的代码是这样的:
func main() {
// 手动创建数据库连接
db := NewDB("localhost:3306", "user", "password")
// 手动创建各种 Service
userRepo := NewUserRepository(db)
orderRepo := NewOrderRepository(db)
paymentSvc := NewPaymentService(db)
inventorySvc := NewInventoryService(db)
orderSvc := NewOrderService(
orderRepo,
paymentSvc,
inventorySvc,
)
userSvc := NewUserService(userRepo)
// 手动创建 HTTP Handler
handler := NewHandler(orderSvc, userSvc)
// 启动服务
http.ListenAndServe(":8080", handler)
}
第一反应:这种写法让人想起早期的 Java 或 PHP。
在 Java 里,这些全是框架干的事:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
// 就这一行,所有对象都帮你创建好了
}
}
@RestController
public class OrderController {
@Autowired
private OrderService orderService;
// 框架自动注入,你根本看不到对象怎么创建的
}
Java 开发者心里 OS:
- "Go 是不是太简陋了?"
- "难道要我手动 new 几十个对象?"
- "这不是倒退吗?"
先别急着下结论,听我说完。
为什么 Go 要这么"原始"?
Go 的设计哲学就一句话:
显式优于隐式,简单优于复杂。
这不是口号,而是实实在在的取舍。
对比1:依赖是怎么传递的?
Java/Spring 的做法:
// 你写这个
@Service
public class OrderService {
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
@Autowired
private NotificationService notificationService;
}
// 框架在背后做了:
// 1. 扫描所有类
// 2. 分析依赖关系
// 3. 构建依赖图
// 4. 按顺序创建对象
// 5. 通过反射注入字段
// 6. 处理循环依赖
// 7. 管理生命周期
这些魔法看起来很方便,但:
- 你不知道对象什么时候创建的
- 你不知道注入顺序是什么
- 出问题了,调试要靠猜
- 启动慢(要扫描、要反射)
- 内存大(要维护容器)
Go 的做法:
type OrderService struct {
paymentSvc *PaymentService
inventorySvc *InventoryService
notificationSvc *NotificationService
}
func NewOrderService(
paymentSvc *PaymentService,
inventorySvc *InventoryService,
notificationSvc *NotificationService,
) *OrderService {
return &OrderService{
paymentSvc: paymentSvc,
inventorySvc: inventorySvc,
notificationSvc: notificationSvc,
}
}
// 在 main 里
paymentSvc := NewPaymentService(db)
inventorySvc := NewInventoryService(db)
notificationSvc := NewNotificationService(queue)
orderSvc := NewOrderService(
paymentSvc,
inventorySvc,
notificationSvc,
)
这些代码看起来很啰嗦,但:
- 你清楚地看到每个对象怎么创建的
- 你清楚地看到依赖关系是什么
- 出问题了,一眼就能定位
- 启动快(没有扫描、没有反射)
- 内存小(没有容器)
对比2:遇到问题怎么调试?
Java/Spring 遇到问题:
报错:Could not autowire. No beans of 'PaymentService' type found.
你要做的:
1. 检查 PaymentService 有没有 @Service
2. 检查包扫描路径对不对
3. 检查有没有循环依赖
4. 检查 @Conditional 条件是否满足
5. 检查配置文件有没有禁用
6. Google 半天
7. 还不行,看 Spring 源码
根本原因可能是:配置文件里有个 typo
Go 遇到问题:
编译报错:undefined: paymentSvc
你要做的:
1. 看报错的那一行
2. 发现没有传 paymentSvc 参数
3. 改完,搞定
5 秒钟解决
对比3:新人上手难度
Java/Spring 新人:
"这个对象哪来的?"
"@Autowired 和 @Resource 有什么区别?"
"为什么我的 Bean 没有注入?"
"循环依赖怎么解决?"
"什么是 BeanPostProcessor?"
要学的概念:
- IoC 容器
- 依赖注入
- Bean 生命周期
- AOP
- 代理模式
- ...
Go 新人:
"这个对象哪来的?"
"看 main 函数,就是在那 New 出来的。"
"哦,明白了。"
要学的概念:
- 函数
- 指针
Go 为什么说自己"像脚本语言"?
Go 的设计目标就是:
写起来像脚本语言一样简单,跑起来像编译型语言一样快。
什么叫"像脚本语言"?
PHP 的写法:
<?php
// 直接开始写逻辑
$db = new PDO('mysql:host=localhost', 'user', 'pass');
$userRepo = new UserRepository($db);
$user = $userRepo->find(1);
echo $user->name;
Python 的写法:
# 直接开始写逻辑
db = connect_db('localhost', 'user', 'pass')
user_repo = UserRepository(db)
user = user_repo.find(1)
print(user.name)
Go 的写法:
func main() {
// 直接开始写逻辑
db := NewDB("localhost", "user", "pass")
userRepo := NewUserRepository(db)
user := userRepo.Find(1)
fmt.Println(user.Name)
}
看出来了吗?Go 就是想让你像写脚本一样写代码。
不需要:
- 复杂的配置文件
- 注解魔法
- 框架黑盒
- 反射黑魔法
只需要:
- 创建对象
- 调用方法
- 传递参数
但是,它不是脚本语言:
- 有强类型检查(写错了编译不过)
- 编译成二进制(部署一个文件)
- 性能接近 C(比 Java 快很多)
- 启动秒开(没有 JVM 预热)
这种差异带来的实际影响
理论说完了,看看实际项目中的差异。
场景1:启动速度
Java/Spring 项目:
启动流程:
1. JVM 启动(1-2秒)
2. 加载类(2-3秒)
3. 扫描注解(3-5秒)
4. 构建依赖图(2-3秒)
5. 初始化 Bean(5-10秒)
6. AOP 代理(2-3秒)
总计:15-30秒
项目大了:1-2分钟
Go 项目:
启动流程:
1. 执行 main 函数
2. 创建对象
3. 启动服务
总计:0.1-0.5秒
项目再大:也就几秒
这就是为什么 Go 适合做 CLI 工具、K8s 组件:启动快。
场景2:内存占用
Java/Spring 项目:
启动后内存:
- JVM 基础:100-200MB
- Spring 容器:50-100MB
- 对象缓存:100-200MB
最小内存:300-500MB
实际运行:1-2GB
Go 项目:
启动后内存:
- 没有虚拟机
- 没有容器
- 只有你创建的对象
最小内存:10-20MB
实际运行:50-200MB
这就是为什么 Go 适合做微服务、容器应用:省资源。
场景3:调试体验
Java/Spring 遇到空指针:
// 报错
NullPointerException at OrderService.process()
// 原因可能是:
1. paymentService 没有注入成功
2. 某个 @Conditional 条件不满足
3. 循环依赖导致代理失败
4. 配置文件写错了
// 排查过程:
- 看日志,找不到原因
- 打断点,发现字段是 null
- Google,找到类似问题
- 尝试各种方案
- 1小时后,发现是配置文件拼写错误
Go 遇到空指针:
// 报错
panic: runtime error: invalid memory address
// 看代码
orderSvc := NewOrderService(
paymentSvc,
nil, // 这里忘了传
notificationSvc,
)
// 排查过程:
- 看报错行号
- 看代码
- 发现 nil
- 改完,搞定
// 5 秒钟解决
Java 开发者常犯的错误
看几个 Java 开发者写 Go 时常犯的错误。
错误1:找依赖注入框架
错误想法:
"Go 的依赖注入框架哪个好?Wire?Dig?"
正确做法:
别找了,手动传参就够了
有些 Go 项目确实用了 Wire、Dig,但那是因为:
- 项目太大(100+ 个 Service)
- 自动生成代码,减少重复
大部分项目,手动传参就够了。
错误2:过度抽象
// 错误做法:照搬 Java 那套
type ServiceFactory interface {
CreateUserService() UserService
CreateOrderService() OrderService
}
type ServiceFactoryImpl struct {
db *DB
}
func (f *ServiceFactoryImpl) CreateUserService() UserService {
return NewUserService(f.db)
}
// 正确做法:直接创建
func main() {
db := NewDB()
userSvc := NewUserService(db)
orderSvc := NewOrderService(db)
}
错误3:到处用接口
// 错误做法:每个 struct 都配个 interface
type UserService interface {
GetUser(id int) (*User, error)
}
type UserServiceImpl struct {
repo *UserRepository
}
// 正确做法:需要 mock 时才定义 interface
type UserService struct {
repo *UserRepository
}
// 测试时才定义
type UserRepository interface {
Find(id int) (*User, error)
}
Go 的接口是隐式实现的,不需要到处声明。
错误4:配置文件过度使用
# 错误做法:把所有配置都写 YAML
database:
host: localhost
port: 3306
user: root
services:
user:
enabled: true
timeout: 5s
order:
enabled: true
timeout: 10s
// 正确做法:代码即配置
func main() {
db := NewDB("localhost:3306", "root", "password")
userSvc := NewUserService(db, 5*time.Second)
orderSvc := NewOrderService(db, 10*time.Second)
}
Go 的理念是:代码就是最好的配置。
什么时候该用依赖注入框架?
话说回来,真的完全不需要 DI 框架吗?也不是。
适合手动传参的场景(大部分情况)
小型项目(<50 个组件)
// 清晰、直接、易调试
func main() {
db := NewDB()
cache := NewCache()
userRepo := NewUserRepository(db)
orderRepo := NewOrderRepository(db)
userSvc := NewUserService(userRepo, cache)
orderSvc := NewOrderService(orderRepo, userSvc)
// 10-20 个组件,完全可控
}
中型项目(50-100 个组件)
// 可以考虑分组管理
type Services struct {
User *UserService
Order *OrderService
// ...
}
func InitServices(db *DB) *Services {
userRepo := NewUserRepository(db)
orderRepo := NewOrderRepository(db)
return &Services{
User: NewUserService(userRepo),
Order: NewOrderService(orderRepo),
}
}
适合用 DI 框架的场景
大型微服务(>100 个组件)
当你的项目有 100+ 个 Service、Repository、Client 时,手动传参确实会很繁琐。这时可以考虑:
Wire(Google 官方推荐)
- 编译时生成代码,不是运行时反射
- 性能无损耗
- 类型安全
- 适合大型项目
// wire.go
//go:build wireinject
func InitializeApp() (*App, error) {
wire.Build(
NewDB,
NewUserRepository,
NewUserService,
NewApp,
)
return nil, nil
}
// wire 会自动生成代码
Dig(Uber 出品)
- 运行时依赖注入
- 更灵活,但有性能开销
- 适合需要动态配置的场景
判断标准:
组件数 < 50 个 → 手动传参
组件数 50-100 个 → 手动传参 + 分组管理
组件数 > 100 个 → 考虑 Wire
需要插件化/动态加载 → 考虑 Dig
CLI 工具/脚本类应用 → 绝对不需要 DI 框架
记住一个原则:
不要为了"看起来像企业级架构"而引入 DI 框架。大部分 Go 项目,手动传参就够了。
澄清一个误解:Go 不是"反对抽象"
看到这里,有些人可能会想:"Go 这么简单粗暴,是不是就是写面条代码?"
不是的。
Go 的设计哲学不是"反对抽象",而是**"反对过早抽象、反对过度抽象"**。
Go 鼓励的抽象方式
1. 需要解耦时才引入接口
// 错误做法:提前抽象
type UserService interface {
GetUser(id int) (*User, error)
CreateUser(user *User) error
}
type UserServiceImpl struct { }
// 正确做法:需要 mock 时才抽象
type UserService struct {
repo UserRepository // 这里才用接口
}
type UserRepository interface {
Find(id int) (*User, error)
Save(user *User) error
}
2. 真正需要多态时才用接口
// 有多个实现时才抽象
type Storage interface {
Save(key string, value []byte) error
Load(key string) ([]byte, error)
}
// 文件存储实现
type FileStorage struct { }
// Redis 存储实现
type RedisStorage struct { }
// S3 存储实现
type S3Storage struct { }
Go 的理念是:
- 先用具体类型写代码
- 发现真正需要抽象时(测试、多实现),再引入接口
- 不要为了"看起来专业"而提前抽象
这不是反对抽象,而是在正确的时机做正确的事。
什么时候该用框架?
话说回来,难道 Go 就完全不需要框架了?
也不是。
适合用框架的场景
1. HTTP 路由:Gin、Echo
// 标准库的 http.ServeMux 太简陋
// 用 Gin 处理路由、中间件更方便
r := gin.Default()
r.GET("/users/:id", getUser)
r.POST("/orders", createOrder)
2. ORM:GORM
// 标准库的 database/sql 写 SQL 太麻烦
// 用 GORM 处理关联查询更方便
db.Where("age > ?", 18).Find(&users)
3. 配置管理:Viper
// 管理多环境配置
viper.SetConfigName("config")
viper.ReadInConfig()
不适合用框架的场景
1. 依赖注入
不需要 Wire、Dig,手动传参就够了。
2. 业务逻辑
不要用框架包装业务逻辑,直接写代码。
3. 简单功能
不要为了"看起来专业"而引入框架。
给 Java 开发者的建议
如果你是 Java 开发者,开始写 Go,记住这几点:
1. 忘掉 Spring 那套
别想着:
- 在哪配置注解
- 怎么注入依赖
- 怎么用 AOP
直接写代码就行
2. 拥抱"啰嗦"
Java 开发者看 Go:
"怎么要手动 new 这么多对象?太啰嗦了!"
写一段时间后:
"原来清晰明了比简洁更重要。"
3. 代码即文档
Java 项目:
- 要看 XML 配置
- 要看注解定义
- 要看框架文档
Go 项目:
- 看 main 函数
- 看 NewXXX 函数
- 看代码就够了
4. 简单优于复杂
遇到问题:
第一反应不是"找个框架"
而是"能不能写100行代码搞定"
90%的情况,100行代码就够了
一个实际例子
最后用一个例子,对比一下两种风格。
场景:订单服务
需要:
- 数据库操作
- 支付服务调用
- 库存服务调用
- 通知服务调用
Java/Spring 实现
// Application.java
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
// OrderController.java
@RestController
@RequestMapping("/orders")
public class OrderController {
@Autowired
private OrderService orderService;
@PostMapping
public Order create(@RequestBody CreateOrderRequest req) {
return orderService.create(req);
}
}
// OrderService.java
@Service
public class OrderService {
@Autowired
private OrderRepository orderRepository;
@Autowired
private PaymentService paymentService;
@Autowired
private InventoryService inventoryService;
@Autowired
private NotificationService notificationService;
public Order create(CreateOrderRequest req) {
// 业务逻辑
}
}
配置文件 application.yml:
spring:
datasource:
url: jdbc:mysql://localhost:3306/db
username: root
password: password
代码文件: 4个
配置文件: 1个
看起来: 很简洁
实际运行: 一堆魔法
Go 实现
// main.go
func main() {
// 创建依赖
db := NewDB("localhost:3306", "root", "password")
defer db.Close()
orderRepo := NewOrderRepository(db)
paymentSvc := NewPaymentService()
inventorySvc := NewInventoryService()
notificationSvc := NewNotificationService()
orderSvc := NewOrderService(
orderRepo,
paymentSvc,
inventorySvc,
notificationSvc,
)
// 创建 HTTP Handler
r := gin.Default()
r.POST("/orders", func(c *gin.Context) {
var req CreateOrderRequest
if err := c.BindJSON(&req); err != nil {
c.JSON(400, gin.H{"error": err.Error()})
return
}
order, err := orderSvc.Create(req)
if err != nil {
c.JSON(500, gin.H{"error": err.Error()})
return
}
c.JSON(200, order)
})
// 启动服务
r.Run(":8080")
}
// order_service.go
type OrderService struct {
orderRepo *OrderRepository
paymentSvc *PaymentService
inventorySvc *InventoryService
notificationSvc *NotificationService
}
func NewOrderService(
orderRepo *OrderRepository,
paymentSvc *PaymentService,
inventorySvc *InventoryService,
notificationSvc *NotificationService,
) *OrderService {
return &OrderService{
orderRepo: orderRepo,
paymentSvc: paymentSvc,
inventorySvc: inventorySvc,
notificationSvc: notificationSvc,
}
}
func (s *OrderService) Create(req CreateOrderRequest) (*Order, error) {
// 业务逻辑
}
代码文件: 2个
配置文件: 0个
看起来: 有点啰嗦
实际运行: 一目了然
最后的思考:从 Spring 到 main(),是一次思维升级
从 Java 转 Go,最大的障碍不是语法,而是思维方式。
Java/Spring 的思维:
- 框架帮你管理一切
- 抽象层次越高越好
- 配置优于代码
- "我不需要知道对象怎么创建的,框架会处理"
Go 的思维:
- 你自己管理一切
- 简单直接就够了
- 代码即配置
- "我清楚地知道每个对象是怎么来的"
这不是谁对谁错,而是不同的设计哲学,适合不同的场景。
给 Java 开发者的建议
如果你从 Java 转 Go,记住这几点:
1. 拥抱"啰嗦",它带来的是清晰
刚开始:
"怎么要手动 new 这么多对象?太麻烦了!"
一个月后:
"原来看一眼 main 函数就知道整个系统是怎么组装的。"
2. 别急着找"Go 的 Spring"
Go 生态里有很多框架,但:
- 不要为了"看起来专业"而引入框架
- 不要为了"企业级架构"而过度设计
- 先写代码解决问题,再考虑是否需要框架
3. 代码即文档
Java 项目理解成本:
- 看配置文件
- 看注解定义
- 看框架文档
- 猜测对象是怎么创建的
Go 项目理解成本:
- 看 main 函数
- 看 NewXXX 函数
- 就这么简单
4. 简单优于复杂
遇到问题时:
第一反应不是"有没有框架能解决"
而是"能不能写 100 行代码搞定"
90% 的情况,100 行代码就够了
从 Spring 到 main(),不是倒退,而是升级
你失去的是:
- 自动注入的"魔法"
- 复杂的抽象层次
- 庞大的框架依赖
你获得的是:
- 对系统的完全掌控
- 清晰可见的执行流程
- 快速的启动和调试
- 简单直接的代码组织
这不是倒退,而是一次返璞归真的旅程。
最后的鼓励
从 Spring 的"魔法"转到 Go 的"手工",一开始可能会不适应。
你可能会觉得:
- "怎么这么原始?"
- "怎么要写这么多重复代码?"
- "没有框架怎么办?"
但坚持一周,你会发现:
- 代码更清晰了
- 调试更简单了
- 启动更快了
- 部署更轻了
再过一个月,当你回头看 Spring 项目时,你会想:
- "这个对象是怎么创建的?"
- "这个注解背后做了什么?"
- "为什么启动要 30 秒?"
那时候,你就真正理解了 Go 的设计哲学。
记住:
Go 的哲学是:显式优于隐式,简单优于复杂。
从 Spring 到 main(),你失去的是魔法,获得的是掌控。
适应这个哲学,你就适应了 Go。
欢迎来到 Go 的世界。
就这样。
来源:juejin.cn/post/7587712328826224676
告别满屏 v-if:用一个自定义指令搞定 Vue 前端权限控制
在企业级应用开发中,权限控制是一个绑不开的话题。前端权限控制虽然不能替代后端校验,但能极大提升用户体验——让用户只看到自己能操作的内容,避免无效点击和困惑。
本文将分享一个 Vue 2 自定义指令的设计思路,实现了声明式的权限控制方案。
设计目标
在动手写代码之前,我先梳理了几个核心诉求:
- 使用简单:一行代码搞定权限控制,不需要写一堆
v-if - 性能友好:同一权限不重复请求,利用缓存
- 灵活可控:支持隐藏、禁用、提示等多种交互方式
- 支持多场景:既能用在模板里,也能在 JS 逻辑中调用
核心实现
1. 权限缓存设计
权限校验通常需要请求后端接口,如果每个按钮都单独请求一次,那页面性能会非常糟糕。这里采用了 Promise 缓存 的方式:
Vue.prototype.$getPerm = (options) => {
const argId = options.type + '-' + (options.type === 'space' ? options.spaceId : options.wikiId)
// 如果缓存中没有,创建新的 Promise
if (!spaceInfoStore.permissionMap[argId]) {
spaceInfoStore.permissionMap[argId] = new Promise((resolve, reject) => {
// 请求后端获取权限...
Auth.getUserPermBySpaceId(options.spaceId).then((res) => {
const permissions = res.reduce((acc, category) => {
category.permissions.forEach(permission => {
acc.push(`${category.value}.${permission.authorityKey}`)
})
return acc
}, [])
resolve({ permissions })
})
})
}
return spaceInfoStore.permissionMap[argId]
}
这个设计的巧妙之处在于:缓存的是 Promise 本身,而不是结果。
这样做的好处是,即使多个组件同时调用 $getPerm,也只会发出一次请求。后续的调用会直接拿到同一个 Promise,等待第一次请求的结果。
2. 双重使用方式
为了覆盖不同的使用场景,我设计了两种调用方式:
方式一:指令式(模板中使用)
<button v-perm:[permOptions]="'SPACE.EDIT'">编辑</button>
方式二:编程式(JS 中使用)
this.$hasPerm({ spaceId: 123 }, 'SPACE.EDIT').then(() => {
// 有权限,执行操作
}).catch(() => {
// 无权限
})
指令式适合静态权限控制,编程式适合需要在逻辑中判断的场景。两者底层共用同一套缓存机制。
3. DOM 处理策略
无权限时如何处理 DOM?这里提供了三种策略:
function domHandler (el, binding) {
let placeholderDom = null
if (binding?.arg?.showTips || binding?.arg?.disabled) {
// 策略1&2:保留元素,但禁用或添加点击提示
placeholderDom = el.cloneNode(true)
if (binding?.arg?.showTips) {
placeholderDom.onclick = function () {
Vue.prototype.$bkMessage({
message: binding?.arg?.tipsText || '没有权限',
theme: 'warning'
})
}
}
if (binding?.arg?.disabled) {
placeholderDom.classList.add('disabled')
}
} else {
// 策略3:完全隐藏,用注释节点占位
placeholderDom = document.createComment('permission-placeholder')
}
el.placeholderDom = placeholderDom
el.parentNode.replaceChild(placeholderDom, el)
}
为什么用注释节点而不是直接 display: none?
因为注释节点不会影响布局,也不会被 CSS 选择器选中。更重要的是,我们需要保留一个"锚点",方便权限变化时把原始元素恢复回去。
4. 响应式更新
权限可能会动态变化(比如用户被授权后刷新),所以指令需要同时监听 inserted 和 update 钩子:
Vue.directive('perm', {
inserted (el, binding) {
handlerPerm(el, binding)
},
update (el, binding) {
handlerPerm(el, binding)
}
})
恢复元素的逻辑也很简单:
function restoreElement (el) {
if (el.placeholderDom && el.placeholderDom.parentNode) {
el.placeholderDom.parentNode.replaceChild(el, el.placeholderDom)
}
el.placeholderDom = null
return true
}
5. 支持布尔值快捷方式
有时候权限结果已经在外部计算好了,不需要再走一遍接口校验。这种场景下,支持直接传布尔值会更方便:
<button v-perm:[options]="hasPermission">操作</button>
if (typeof binding.value === 'boolean') {
if (binding.value === false) {
domHandler(el, binding)
} else {
restoreElement(el)
}
return
}
使用示例
基础用法
<template>
<div>
<!-- 无权限时隐藏 -->
<button v-perm:[permConfig]="'SPACE.DELETE'">删除</button>
<!-- 无权限时禁用并提示 -->
<button v-perm:[permConfigWithTips]="'SPACE.EDIT'">编辑</button>
</div>
</template>
<script>
export default {
computed: {
permConfig() {
return {
spaceId: this.currentSpaceId,
type: 'space'
}
},
permConfigWithTips() {
return {
spaceId: this.currentSpaceId,
type: 'space',
disabled: true,
showTips: true,
tipsText: '您没有编辑权限,请联系管理员'
}
}
}
}
</script>
编程式调用
// 在执行敏感操作前校验
async handleDelete() {
try {
await this.$hasPerm({ spaceId: this.spaceId }, 'SPACE.DELETE')
// 有权限,继续执行删除逻辑
await this.doDelete()
} catch {
// 无权限,$hasPerm 内部已经弹出提示
}
}
清除缓存重新加载
当权限发生变化时(比如管理员授权后),可以清除缓存重新加载:
this.$getPerm({
spaceId: this.spaceId,
clearCache: true
})
设计总结
| 特性 | 实现方式 |
|---|---|
| 性能优化 | Promise 缓存,同一权限只请求一次 |
| 使用方式 | 指令式 + 编程式双重支持 |
| DOM 处理 | 隐藏 / 禁用 / 提示三种策略 |
| 响应式 | inserted + update 钩子联动 |
| 灵活性 | 支持布尔值、清除缓存、自定义提示 |
可以优化的点
- Vue 3 适配:Vue 3 的指令钩子函数名称有变化(
mounted、updated),迁移时需要调整 - TypeScript 支持:可以为
PermissionOptions添加完整的类型定义 - 批量权限查询:如果页面上有大量权限点,可以考虑合并成一次批量查询
- 权限预加载:在路由守卫中预加载权限数据,减少页面白屏时间
以上就是这个权限指令的完整设计思路。核心思想是:用缓存换性能,用指令换简洁。希望对你有所启发,欢迎交流讨论 🙌
完整代码
最后贴一下完整代码,可以直接拿去用,根据自己项目的接口改一下就行:
// permission.js
import { useSpaceInfoStore } from '@/store/modules/spaceInfo'
import Auth from '@/api/modules/auth'
let spaceInfoStore = null
setTimeout(() => {
spaceInfoStore = useSpaceInfoStore()
}, 40)
/**
* @typedef {Object} PermissionOptions
* @property {string|number} [wikiId] - 文档id
* @property {string|number} [spaceId] - 空间id
* @property {string} [type] - 权限类型:空间/文档 space/wiki
* @property {boolean} [disabled] - 是否禁用元素
* @property {boolean} [showTips] - 是否显示提示信息
* @property {string} [tipsText] - 提示文本内容
* @property {boolean} [clearCache] - 是否清除缓存
*/
function install (Vue) {
/**
* 获取权限信息
* @param {PermissionOptions} options - 权限选项
* @returns {Promise<any>}
*/
Vue.prototype.$getPerm = (options) => {
if (!options.spaceId) return
// 如果没有传type,则根据是否有文档id判断
options.type = options.type || (options.wikiId ? 'wiki' : 'space')
const argId = options.type + '-' + (options.type === 'space' ? options.spaceId : options.wikiId)
// 清除缓存权限,可重新加载
if (options.clearCache) {
spaceInfoStore.permissionMap[argId] = false
}
if (!spaceInfoStore.permissionMap[argId]) {
spaceInfoStore.permissionMap[argId] = new Promise((resolve, reject) => {
if (options.type === 'space') {
Auth.getUserPermBySpaceId(options.spaceId).then((res) => {
// 组合权限生成唯一key
const permissions = res.reduce((acc, category) => {
category.permissions.forEach(permission => {
acc.push(`${category.value}.${permission.authorityKey}`)
})
return acc
}, [])
resolve({ permissions })
})
} else {
Auth.getWikiPermissionDetail(options.spaceId, options.wikiId).then((res) => {
// 组合权限生成唯一key
const permissions = res.map(item => item.authorityKey)
resolve({ permissions })
})
}
})
}
return spaceInfoStore.permissionMap[argId]
}
/**
* 检查是否有权限
* @param {PermissionOptions} options - 权限选项
* @param {string} perm - 权限码
* @returns {Promise<boolean>}
*/
Vue.prototype.$hasPerm = (options, perm) => {
if (!Object.prototype.hasOwnProperty.call(options, 'showTips')) {
options.showTips = true
}
return new Promise((resolve, reject) => {
if (!options.spaceId) {
resolve(true)
return
}
const promise = Vue.prototype.$getPerm(options)
promise.then((res) => {
if (res.isAdmin) {
resolve(true)
return
}
if (res.permissions.includes(perm)) {
resolve(true)
return
}
if (options.showTips) {
Vue.prototype.$bkMessage({
message: options.tipsText || '没有权限',
theme: 'warning'
})
}
reject(new Error(''))
})
})
}
/**
* DOM 处理函数 - 处理无权限时的元素显示
* @param {HTMLElement} el - DOM 元素
* @param {Object} binding - 指令绑定对象
*/
function domHandler (el, binding) {
let placeholderDom = null
if (binding?.arg?.showTips || binding?.arg?.disabled) {
placeholderDom = el.cloneNode(true)
if (binding?.arg?.showTips) {
placeholderDom.onclick = function () {
Vue.prototype.$bkMessage({
message: binding?.arg?.tipsText || '没有权限',
theme: 'warning'
})
}
}
if (binding?.arg?.disabled) {
placeholderDom.classList.add('disabled')
}
} else {
placeholderDom = document.createComment('permission-placeholder')
}
if (el.parentNode) {
el.placeholderDom = placeholderDom
el.parentNode.replaceChild(placeholderDom, el)
}
}
/**
* 将元素恢复到原始位置
* @param {HTMLElement} el - DOM 元素
* @returns {boolean}
*/
function restoreElement (el) {
el.placeholderDom && el.placeholderDom.parentNode.replaceChild(el, el.placeholderDom)
el.placeholderDom = null
return true
}
/**
* 权限处理函数
* @param {HTMLElement} el - DOM 元素
* @param {Object} binding - 指令绑定对象
*/
function handlerPerm (el, binding) {
// 通过直接传递boolean值,也可以进行权限校验
if (typeof binding.value === 'boolean') {
if (binding.value === false) {
domHandler(el, binding)
} else {
restoreElement(el)
}
return
}
// 判断权限入参是否完善
if (!binding?.arg?.spaceId || !binding?.value) return restoreElement(el)
const promise = Vue.prototype.$getPerm({ ...binding.arg })
promise.then((res) => {
if (res.isAdmin) return restoreElement(el)
if (res.permissions.includes(binding.value)) return restoreElement(el)
domHandler(el, binding)
})
}
Vue.directive('perm', {
inserted (el, binding) {
handlerPerm(el, binding)
},
update (el, binding) {
handlerPerm(el, binding)
}
})
}
export default { install }
在 main.js 里注册一下就能用了:
import permission from '@/directives/permission'
Vue.use(permission)
来源:juejin.cn/post/7585758163436011526
当上传不再只是 /upload,我们是怎么设计大文件上传的
业务背景
在正式讲之前,先看一个我们做的大文件上传demo。
下面这个视频演示的是上传一个 1GB 的压缩包,整个过程支持分片上传、断点续传、暂停和恢复。
可以看到速度不是特别快,这个是我故意没去优化的。
前端那边计算文件 MD5、以及最后合并文件的时间我都保留了,
主要是想让大家能看到整个流程是怎么跑通的。

平时我们在做一些 SaaS 系统的时候,文件上传这块其实基本上都设计的挺简单的。
前端做个分片上传,后端把分片合并起来,最后存 OSS 或者服务器某个路径上,再返回一个 URL 就完事了。
大多数情况下,这样的方案也确实够用。
但是最近我在做一个私有化项目,场景完全不一样。
项目是给政企客户部署的内部系统,里面有 AI 大模型客服问答的功能。
客户需要把他们内部的文档、手册、规范、图纸、流程等资料打包上传到服务器,用来做后续的向量化、知识检索或者模型训练。
这类场景如果还沿用之前 SaaS 系统那种上传方式,往往就不太适用了。
因为这些文件往往有几个共同点:
- 文件数量多,动辄几百上千份(Word、PDF、PPT、Markdown 都有);
- 文件体积大,打成 zip 动不动就是几个 G,甚至十几二十个 G;
- 上传环境复杂,客户一般在内网或局域网,有的甚至完全断网;
- 有安全要求,文件不能经过云端 OSS,里面可能有保密资料;
- 需要审计,要能知道是谁上传的、什么时候传的、文件现在存哪;
- 上传完之后还要进一步处理,比如自动解压、解析文本、拆页、向量化,然后再存入 Milvus 或 pgvector。
在正式讲之前,先看一个我们做的大文件上传demo。
下面这个视频演示的是上传一个 1GB 的压缩包,整个过程支持分片上传、断点续传、暂停和恢复。
可以看到速度不是特别快,这个是我故意没去优化的。
前端那边计算文件 MD5、以及最后合并文件的时间我都保留了,
主要是想让大家能看到整个流程是怎么跑通的。
平时我们在做一些 SaaS 系统的时候,文件上传这块其实基本上都设计的挺简单的。
前端做个分片上传,后端把分片合并起来,最后存 OSS 或者服务器某个路径上,再返回一个 URL 就完事了。
大多数情况下,这样的方案也确实够用。
但是最近我在做一个私有化项目,场景完全不一样。
项目是给政企客户部署的内部系统,里面有 AI 大模型客服问答的功能。
客户需要把他们内部的文档、手册、规范、图纸、流程等资料打包上传到服务器,用来做后续的向量化、知识检索或者模型训练。
这类场景如果还沿用之前 SaaS 系统那种上传方式,往往就不太适用了。
因为这些文件往往有几个共同点:
- 文件数量多,动辄几百上千份(Word、PDF、PPT、Markdown 都有);
- 文件体积大,打成 zip 动不动就是几个 G,甚至十几二十个 G;
- 上传环境复杂,客户一般在内网或局域网,有的甚至完全断网;
- 有安全要求,文件不能经过云端 OSS,里面可能有保密资料;
- 需要审计,要能知道是谁上传的、什么时候传的、文件现在存哪;
- 上传完之后还要进一步处理,比如自动解压、解析文本、拆页、向量化,然后再存入 Milvus 或 pgvector。
所以这种情况还用 SaaS 系统那种“简单上传+云存储”方案的话,那可能问题就一堆:
- 上传中断后用户一刷新浏览器就得重传整个包;
- 集群部署时分片打到不同机器上根本无法合并;
- 多人同时上传可能会发生文件覆盖或路径冲突;
- 没有任何上传记录,也追踪不到是谁传的;
- 对政企来说,审计、合规、保密全都不达标。
所以,我们需要重新设计文件上传的功能逻辑。
目的是让它不仅能支持大文件、断点续传、集群部署,还能同时适配内网环境、权限管控,以及后续的 AI 文档解析和知识向量化等处理流程。
为什么很多项目只需要一个 upload 接口
如果我们回头看一下自己平常做过的一些常规 Web 项目,尤其是各种 SaaS 系统或者后台管理系统,
其实大多数时候后端只会提供一个 /upload 接口, 前端拿到文件后直接调用这个接口,后端保存文件再返回一个 URL 就结束了。
甚至我们在很多项目里,前端都不会把文件传给业务服务,
而是直接通过前端 SDK(比如阿里云 OSS、腾讯云 COS、七牛云等)上传到云存储,
上传完后拿到文件地址,再把这个地址回传给后端保存。
这种方式在 SaaS 系统或者轻量级的业务里非常普遍,也非常高效。 主要原因有几个:
- 文件都比较小,大多数就是几 MB 的图片、PDF 或 Excel;
- 云存储足够稳定,上传、下载、访问都有完整的 SDK 支撑;
- 系统是公网部署,不需要考虑局域网、内网断网这些问题;
- 对安全和审计的要求不高,文件内容也不是涉密数据;
- 用户体验优先,所以直接把文件上传到云端是最省事的方案。
换句话说,这种“一个 upload 接口”或“前端直传 OSS”模式,其实是面向通用型 SaaS 场景的。
对于绝大多数互联网业务来说,它既够快又够省心。
但一旦项目换成政企、私有化部署或者 AI 训练平台这种环境,
就完全不是一个量级的问题了。
这里的关键不在“能不能上传”,
而在于文件上传之后的可控性、可追溯性和安全性。
前端常见的大文件上传方式
在重新设计后端接口之前,我们先来看看现在前端常见的大文件上传思路。
其实近几年前端这块已经比较成熟了,主流方案大体都是围绕几个核心点展开的:
秒传检测、分片上传、断点续传、并发控制、进度展示。
一般来说,前端拿到文件后,会先计算一个文件哈希值,比如用 MD5。
这样做的目的是为了做秒传检测:
如果服务器上已经存在这个文件,就可以直接跳过上传,节省时间和带宽。
接下来是分片上传。
文件太大时,前端会把文件拆成多个固定大小的小块(比如每块 5MB 或 10MB),
然后一片一片地上传。这样做可以避免一次性传输大文件导致浏览器卡顿或网络中断。
然后就是断点续传。
前端会记录哪些分片已经上传成功,如果上传过程中网络中断或浏览器刷新,
下次只需要从未完成的分片继续上传,不用重新传整包文件。
在性能方面,前端还会做并发控制。
比如同时上传三到五个分片,上传完一个就立刻补下一个,
这样整体速度比单线程串行上传要快很多。
最后是进度展示。
通过监听每个分片的上传状态,前端可以计算整体进度,
给用户展示一个实时的上传百分比或进度条,让体验更可控。
可以看到,前端的大文件上传方案已经形成了一套相对标准的模式。
所以这次我在重新设计后端的时候,就打算基于这种前端逻辑,
去构建一套更贴合企业私有化环境的上传接口控制体系。
目标是让前后端的职责划分更清晰:
前端负责切片、控制与恢复;后端负责存储、校验与合并。
后端接口设计思路
前端的大文件上传流程其实已经相对固定了,我们只要让后端的接口和它配合得上,就能把整个上传链路打通。
所以我这次重新设计时,把上传接口拆成了几个比较独立的阶段:
秒传检查、初始化任务、上传分片、合并文件、暂停任务、取消任务、任务列表。
每个接口都只负责一件事,这样接口的职责会更清晰,也方便后期扩展。
一、/upload/check —— 秒传检查
这个接口是整个流程的第一步,用来判断文件是否已经上传过。
前端在计算完文件的全局 MD5(或其他 hash)后,会先调这个接口。
如果后端发现数据库里已经有相同 hash 的文件,就直接返回“已存在”,前端就不用再上传了。
请求示例:
POST /api/upload/check
{
"fileHash": "md5_abc123def456",
"fileName": "training-docs.zip",
"fileSize": 5342245120
}
返回示例:
{
"success": true,
"data": {
"exists": false
}
}
如果 exists = true,说明服务端已经有这个文件,可以直接走“秒传成功”的逻辑。
伪代码示例:
@PostMapping("/check")
public Result checkFile(@RequestBody Map body) {
// 1. 校验 fileHash 参数是否为空
// 2. 查询 file_info 表是否已有该文件
// 3. 如果文件已存在,直接返回秒传成功(exists = true)
// 4. 如果文件不存在,查询 upload_task 表中是否有未完成任务(支持断点续传)
}
二、/upload/init —— 初始化上传任务
如果文件不存在,就要先初始化一个新的上传任务。
这个接口的作用是创建一条 upload_task 记录,同时返回一个唯一的 uploadId。
前端会用这个 uploadId 来标识整个上传过程。
请求示例:
POST /api/upload/init
{
"fileHash": "md5_abc123def456",
"fileName": "training-docs.zip",
"totalChunks": 320,
"chunkSize": 5242880
}
返回示例:
{
"success": true,
"data": {
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"uploadedChunks": []
}
}
uploadedChunks 用来支持断点续传,如果之前有部分分片上传过,就会在这里返回索引数组。
伪代码示例:
@PostMapping("/init")
public Result initUpload(@RequestBody UploadInitRequest request) {
// 1. 检查是否已有同 fileHash 的任务,若有则返回旧任务信息(支持断点续传)
// 2. 否则创建新的 upload_task 记录,生成 uploadId
// 3. 初始化分片数量、大小、状态等信息
// 4. 返回 uploadId 与已上传分片索引列表
}
三、/upload/chunk —— 上传单个分片
这是整个上传过程里调用次数最多的接口。
每个分片都会单独上传一次,并在服务端保存为临时文件,同时写入 upload_chunk 表。
上传成功后,后端会更新 upload_task 的进度信息。
请求示例(表单上传):
POST /api/upload/chunk
Content-Type: multipart/form-data
formData:
uploadId: b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b
chunkIndex: 0
chunkSize: 5242880
chunkHash: md5_001
file: (二进制分片数据)
返回示例:
{
"success": true,
"data": {
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"chunkIndex": 0,
"chunkSize": 5242880
}
}
伪代码示例:
@PostMapping(value = "/chunk", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public Result uploadChunk(@ModelAttribute UploadChunkRequest req) {
// 1. 校验任务状态,禁止上传已取消或已完成的任务
// 2. 检查本地目录(或云端存储桶)是否存在,不存在则创建
// 3. 接收当前分片文件并写入临时路径
// 4. 写入 upload_chunk 表,标记状态为 “已上传”
// 5. 更新 upload_task 的 uploaded_chunks 数量
}
四、/upload/merge —— 合并分片
当前端确认所有分片都上传完后,会调用 /upload/merge。
后端收到这个请求后,去检查所有分片是否完整,然后按照索引顺序依次合并。
合并成功后,会删除临时分片文件,并更新 upload_task 状态为“完成”。
如果启用了云存储,这一步也可以直接把合并后的文件上传到 OSS。
请求示例:
POST /api/upload/merge
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"fileHash": "md5_abc123def456"
}
返回示例:
{
"success": true,
"message": "文件合并成功",
"data": {
"storagePath": "/data/uploads/training-docs.zip"
}
}
伪代码示例:
@PostMapping("/merge")
public Result mergeFile(@RequestBody UploadMergeRequest req) {
// 1. 检查 upload_task 状态是否允许合并
// 2. 校验所有分片是否都上传完成
// 3. 如果是本地存储:按 chunk_index 顺序流式合并文件
// 4. 如果是云存储:调用云端分片合并 API(如 OSS、COS)
// 5. 校验文件 hash 完整性,更新任务状态为 COMPLETED
// 6. 将最终文件信息写入 file_info 表
}
五、/upload/pause —— 暂停任务
这个接口用于在上传过程中手动暂停任务。
前端可能会在网络波动或用户主动点击暂停时调用。
后端会更新任务状态为“已暂停”,并记录当前已上传的分片数。
请求示例:
POST /api/upload/pause
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b"
}
返回示例:
{
"success": true,
"message": "任务已暂停"
}
伪代码示例:
@PostMapping("/pause")
public Result pauseUpload(@RequestBody UploadPauseRequest req) {
// 1. 查找对应的 upload_task
// 2. 更新任务状态为 “已暂停”
// 3. 返回任务状态确认信息
}
六、/upload/cancel —— 取消任务
如果用户想放弃本次上传,可以调用 /cancel。
后端会把任务状态标记为“已取消”,并清理对应的临时分片文件。
这样能避免磁盘上堆积无用数据。
请求示例:
POST /api/upload/cancel
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b"
}
返回示例:
{
"success": true,
"message": "任务已取消"
}
伪代码示例:
@PostMapping("/cancel")
public Result cancelUpload(@RequestBody UploadCancelRequest req) {
// 1. 查找对应的 upload_task
// 2. 更新任务状态为 “已取消”
// 3. 删除或标记已上传的分片文件为待清理
// 4. 返回操作结果
}
七、/upload/list —— 查询任务列表
这个接口我们用于管理后台查看当前上传任务的整体情况。
可以展示每个任务的文件名、大小、进度、状态、上传人等信息,方便追踪和审计。
请求示例:
GET /api/upload/list
返回示例:
{
"success": true,
"data": [
{
"uploadId": "b4f8e3a7-1a0c-4a1d-88af-61e98d91a49b",
"fileName": "training-docs.zip",
"status": "COMPLETED",
"uploadedChunks": 320,
"totalChunks": 320,
"uploader": "admin",
"createdAt": "2025-10-20 14:30:12"
}
]
}
伪代码示例:
@GetMapping("/list")
public Result> listUploadTasks() {
// 1. 查询所有上传任务
// 2. 按创建时间或状态排序
// 3. 返回任务摘要信息(任务名、状态、进度、上传人等)
}
接口调用顺序小结
那我们这整个上传过程的调用顺序就是:
1. /upload/check → 秒传检测
2. /upload/init → 初始化上传任务
3. /upload/chunk → 循环上传所有分片
4. /upload/merge → 所有分片完成后合并
(可选)/upload/pause、/upload/cancel 用于控制任务
(可选)/upload/list 用于任务追踪与审计
接口调用顺序示意图
下面这张时序图展示了前端、后端、数据库在整个上传过程中的交互关系。

这样安排有几个好处:
- 逻辑衔接顺:上面刚讲完每个接口的职责,下面立刻用图总结;
- 视觉节奏平衡:读者读到这里已经看了不少文字,用图能缓解阅读疲劳;
- 承上启下:这张图既总结接口流程,又能自然引出下一节“数据库表设计”。
这套接口设计基本能覆盖大文件上传在企业项目中的常见需求。
接下来,我们再来看看支撑这套接口背后的数据库表设计。
数据库的作用是让上传任务的状态可追踪、可恢复,也能在集群部署时保持一致性。
数据库表设计思路
前面说的那一套接口,要真正稳定地跑起来,
后端必须有一套能记录任务状态、分片信息、文件存储路径的数据库结构。
因为上传这种场景不是“一次请求就结束”的操作,它往往会持续几分钟甚至几个小时,
所以我们需要让任务状态可以追踪、可以恢复,还要能支撑集群部署。
我这次主要设计了三张核心表:upload_task(上传任务表)、upload_chunk(分片表)、file_info(文件信息表)。
它们分别负责记录任务、分片和最终文件三层的数据关系。
一、upload_task —— 上传任务表
这张表是整个上传过程的“总账”,
每一个文件上传任务,不管分成多少片,都会在这里生成一条记录。
它主要用来保存任务的全局信息,比如文件名、大小、上传进度、状态、存储方式等。
CREATE TABLE `upload_task` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`upload_id` varchar(64) NOT NULL COMMENT '任务唯一ID(UUID)',
`file_hash` varchar(64) NOT NULL COMMENT '文件哈希(用于秒传与断点续传)',
`file_name` varchar(255) NOT NULL COMMENT '文件名称',
`file_size` bigint(20) NOT NULL COMMENT '文件总大小(字节)',
`chunk_size` bigint(20) NOT NULL COMMENT '每个分片大小(字节)',
`total_chunks` int(11) NOT NULL COMMENT '分片总数',
`uploaded_chunks` int(11) DEFAULT '0' COMMENT '已上传分片数量',
`status` tinyint(4) DEFAULT '0' COMMENT '任务状态:0-待上传 1-上传中 2-合并中 3-完成 4-取消 5-失败 6-已合并 7-已暂停',
`storage_type` varchar(32) DEFAULT 'local' COMMENT '存储类型:local/oss/cos/minio/s3等',
`storage_url` varchar(512) DEFAULT NULL COMMENT '文件最终存储地址(云端或本地路径)',
`local_path` varchar(512) DEFAULT NULL COMMENT '本地临时文件或合并文件路径',
`remark` varchar(255) DEFAULT NULL COMMENT '备注信息',
`uploader` varchar(64) DEFAULT NULL COMMENT '上传人',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `upload_id` (`upload_id`),
KEY `idx_hash` (`file_hash`),
KEY `idx_status` (`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='上传任务表(支持多种云存储)';
设计要点:
upload_id是前端初始化任务后由后端生成的唯一标识;file_hash用来支持秒传逻辑;status控制任务生命周期(等待、上传中、合并中、完成等);storage_type、storage_url可以兼容多种存储方案(本地、OSS、COS、MinIO);uploaded_chunks字段让任务能随时恢复,适配断点续传。
二、upload_chunk —— 分片表
这张表对应每个上传任务下的所有分片。
每一个分片都会单独在这里占一条记录,用来追踪它的上传状态。
这张表的存在让我们能做断点续传、进度统计、以及合并前的完整性检查。
CREATE TABLE `upload_chunk` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`upload_id` varchar(64) NOT NULL COMMENT '所属上传任务ID',
`chunk_index` int(11) NOT NULL COMMENT '分片索引(从0开始)',
`chunk_size` bigint(20) NOT NULL COMMENT '实际分片大小(字节)',
`chunk_hash` varchar(64) DEFAULT NULL COMMENT '可选:分片hash(用于高级去重)',
`status` tinyint(4) DEFAULT '0' COMMENT '状态:0-待上传 1-已上传 2-已合并',
`local_path` varchar(512) DEFAULT NULL COMMENT '分片本地路径',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`updated_at` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_task_chunk` (`upload_id`,`chunk_index`),
KEY `idx_upload_id` (`upload_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='上传分片表';
设计要点:
upload_id是任务外键,和upload_task一一对应;chunk_index代表分片顺序,合并文件时会按这个排序;chunk_hash可选字段,用来在上传前后做完整性校验;status字段控制上传进度(待上传、已上传、已合并);- 唯一索引 (
upload_id,chunk_index) 避免重复插入分片。
通过这张表,我们可以轻松实现断点续传:
当用户重新开始上传时,后端只返回未完成的分片索引,前端跳过已上传的部分。
三、file_info —— 文件信息表
这张表记录的是上传完成后的“最终文件信息”,
相当于系统的文件索引表。只要文件合并成功并通过校验,
后端就会往这里写入一条记录。
这张表支撑秒传功能,也能被后续的文档解析或向量化任务使用。
CREATE TABLE `file_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`file_hash` varchar(64) NOT NULL COMMENT '文件hash,用于秒传',
`file_name` varchar(255) NOT NULL COMMENT '文件名称',
`file_size` bigint(20) NOT NULL COMMENT '文件大小',
`storage_type` varchar(32) DEFAULT 'local' COMMENT '存储类型:local/oss/cos/minio/s3等',
`storage_url` varchar(512) DEFAULT NULL COMMENT '文件最终存储地址(云端或本地路径)',
`uploader` varchar(64) DEFAULT NULL COMMENT '上传人',
`status` tinyint(4) DEFAULT '1' COMMENT '状态:1-正常,2-删除中,3-已归档',
`remark` varchar(255) DEFAULT NULL COMMENT '备注',
`created_at` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
UNIQUE KEY `file_hash` (`file_hash`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='已上传文件信息表(支持多云存储)';
设计要点:
file_hash是全局唯一标识,用于秒传和查重;storage_url记录最终可访问路径;status可扩展为删除、归档等后续操作;- 这张表和业务系统中的“文档解析”、“知识库构建”可以直接关联。
四、三张表之间的关系
这三张表之间的关系我们可以简单理解为:
upload_task (上传任务)
├── upload_chunk (分片详情)
└── file_info (最终文件)
upload_task管理任务生命周期;upload_chunk跟踪每个分片的上传进度;file_info保存最终文件索引,用于秒传与后续 AI 处理。
这样设计的好处是:
- 上传状态可追踪;
- 上传任务可恢复;
- 文件信息可统一管理;
- 多节点部署也能保证一致性。
上传状态流转与任务恢复机制
有了前面的三张核心表,整个上传的过程就能被“状态机化”管理。
简单来说,我们希望每一个上传任务从创建、上传、合并到完成,都能有一个明确的状态,
系统也能在任意阶段中断后恢复,不需要用户重新来一遍。
我们把整个上传任务的生命周期划分成几个关键状态:
WAITING(0, "待上传"),
UPLOADING(1, "上传中"),
MERGING(2, "合并中"),
COMPLETED(3, "已完成"),
CANCELED(4, "已取消"),
FAILED(5, "上传失败"),
CHUNK_MERGED(6, "已合并"),
PAUSED(7, "已暂停");
一、WAITING(待上传)
当用户在前端发起上传、文件切片还没真正传上来之前,
系统会先生成一个上传任务记录(也就是 /upload/init 接口那一步)。
这个时候任务只是“登记”在数据库里,还没开始传数据。
我们可以理解为:
任务刚创建,还没开始跑。
此时前端拿到 uploadId,就可以开始逐片上传了。
在数据库层面,upload_task.status = 0,所有的分片表里还没有数据。
二、UPLOADING(上传中)
当第一个分片开始上传时,系统会把任务状态更新为 上传中。
这时候每上传一块分片,都会往 upload_chunk 表里写入一条记录,
并且更新任务的 uploaded_chunks 字段。
我们会周期性地根据分片上传数量去更新进度条,
比如已上传 35 / 100 块,系统就知道这部分可以恢复。
这个阶段是任务生命周期里最活跃的一段:
用户可能暂停、断网、刷新页面、甚至浏览器崩溃。
但是没关系,因为分片信息都落地到数据库了,
我们能随时通过 upload_chunk 的状态重新恢复上传。
三、PAUSED(已暂停)
如果用户主动点击“暂停上传”,
系统就会把任务状态标记为 PAUSED。
暂停并不会删除分片,只是告诉系统“不要再继续发请求”。
这样当用户重新点击“继续上传”时,
前端只需从后端拿到“哪些分片还没上传”,就能断点续传。
这个状态一般只在用户控制的情况下出现,
比如网络不好、或者中途切换网络时暂停。
四、CANCELED(已取消)
取消和暂停不同,取消意味着用户彻底放弃了这个上传任务。
任务会被标记为 CANCELED,同时系统可以选择:
- 删除已经上传的临时分片文件;
- 或者保留一段时间等待清理任务。
在后台日志中,这个状态主要用于审计:
记录谁取消了任务、在什么时间、上传了多少进度。
五、MERGING(合并中)
当所有分片都上传完成后,
后端会自动或手动触发文件合并逻辑(调用 /upload/merge)。
此时任务状态会切换为 MERGING,表示系统正在进行最后一步。
在这一步里:
- 如果是本地存储,会逐个读取分片文件并拼接为完整文件;
- 如果是云存储(比如 OSS、MinIO),则会触发服务端的分片合并 API。
合并过程通常比较耗时,尤其是几 GB 的文件,
所以单独拿出来作为一个明确状态是必要的。
六、CHUNK_MERGED(已合并)
有些系统会把合并成功但未做后续处理的状态单独标出来,
比如文件已经合并,但还没入库、还没解析。
这个状态可以让我们在合并之后还有机会做文件校验或后处理。
不过在实际项目里,也可以直接跳过这一步,
合并完后立刻进入下一状态——COMPLETED。
七、COMPLETED(已完成)
文件合并完成、验证通过、存储路径落地、写入 file_info 表,
这时候任务就算彻底完成了。
在这个状态下:
- 用户可以正常访问文件;
- 系统可以执行后续的解析任务(比如文档拆页、向量化等);
- 文件具备秒传条件,下次再上传同样的文件会直接跳过。
COMPLETED 是整个生命周期的终点状态。
在数据库中,任务记录会更新最终路径、存储类型、完成时间等字段。
八、FAILED(上传失败)
上传过程中如果出现异常,比如网络中断、磁盘写入异常、OSS 上传失败等,
系统会标记任务为 FAILED。
这一状态不会自动清理,
方便管理员事后追踪错误原因或人工恢复。
失败任务在设计上一般允许“重新启动”,
也就是通过任务 ID 重新触发上传,从未完成的分片继续。
我们可以通过下面这张图可以更直观地看到整个上传任务的生命周期:

九、任务恢复机制
在这套机制下,任务恢复就变得非常自然。
前端每次进入上传页面时,只要传入文件的 hash,
后端就能通过 upload_task 和 upload_chunk 判断:
- 这个文件有没有上传任务;
- 如果有,哪些分片已经上传;
- 任务当前状态是什么(暂停、失败还是上传中)。
然后前端只需补传那些未上传的分片即可。
这就是我们常说的 断点续传(Resumable Upload) 。
在集群环境中,这套逻辑同样成立,
因为任务与分片状态都落在数据库,不依赖单台服务器。
无论请求打到哪一台机器,上传进度都是统一可见的。
十、中断后如何续传
在实际使用中,用户上传中断是很常见的。
比如文件太大上传到一半,浏览器突然关了;
或者公司网络断了,机器重启了;
甚至有人直接换了电脑继续操作。
如果系统没有任务恢复机制,那用户每次都得重新传一遍,
尤其是那种几个 G 的文件,不但浪费时间,还容易出错。
所以我们在设计这套上传中心时,
一开始就考虑了“断点续传”和“任务恢复”的问题。
1. 恢复上传靠的其实是数据库里的状态
断点续传的核心逻辑,其实很简单:
我们让任务和分片的状态都写进数据库。
每当用户重新进入上传页面、选中同一个文件时,
前端会先计算出文件的 hash,然后调用 /upload/check 接口。
后端收到 hash 后,会依次去查三张表:
- 先查
file_info
如果能查到,说明文件之前已经上传并合并成功,
这时候直接返回“文件已存在”,前端就能实现“秒传”,不需要重新上传。 - 查不到
file_info,就去查upload_task
如果找到了对应任务,就说明这个文件上传到一半被中断了。
这时我们会返回这个任务的 uploadId。 - 再查 `upload_chunk``
系统会统计出哪些分片已经上传成功,哪些还没传。
然后返回一个“未完成的分片索引列表”给前端。
前端拿到这些信息后,就能从中断的地方继续往下传,
不用再重复上传已经完成的部分。
2. 前端续传时的流程
前端拿到旧的 uploadId 和未完成分片列表后,
只需要跳过那些已经上传成功的分片,
然后照常调用 /upload/chunk 去上传剩下的部分。
上传过程中,每个分片的状态都会被实时更新到 upload_chunk 表中,upload_task 表的 uploaded_chunks 也会跟着同步增加。
当所有分片都上传完后,任务状态自动进入 MERGING(合并中)阶段。
所以整个续传过程,其实就是**“基于数据库状态的增量上传”**。
用户不需要额外操作,系统自己就能恢复上次的进度。
3. 任务状态和恢复判断
任务是否允许恢复,系统会根据 upload_task.status 来判断。
大致逻辑是这样的:
| 状态 | 是否可恢复 | 说明 |
|---|---|---|
| WAITING | 可以 | 任务刚创建,还没开始传 |
| UPLOADING | 可以 | 正在上传中,可以继续 |
| PAUSED | 可以 | 用户主动暂停,可以恢复 |
| FAILED | 可以 | 上传失败,可以重新尝试 |
| CANCELED | 不可以 | 用户主动取消,不再恢复 |
| COMPLETED | 不需要 | 已经完成,直接秒传 |
| MERGING | 等待中 | 系统正在合并,前端等待即可 |
这套判断逻辑让任务的行为更清晰。
比如用户暂停上传再回来时,可以直接恢复;
如果任务已经取消,那就算用户重启也不会再自动续传。
4. 多机器部署下的恢复问题
有些人会担心:如果我们的系统是集群部署的,
上传时中断后再续传,万一请求打到另一台机器上,
还能恢复吗?
其实没问题。
因为我们所有任务和分片的状态都是写进数据库的,
不依赖内存或本地文件。
也就是说,哪怕用户上次上传在 A 机器,这次续传到了 B 机器,
系统仍然能根据数据库的记录知道:
这个 uploadId 下的哪些分片已经上传完,哪些还没传。
所以集群部署下也能无缝续传,不会出现“不同机器不认任务”的情况。
5. 小结
整个任务恢复机制靠的就是两张表:upload_task 和 upload_chunk。upload_task 负责记录任务总体进度,upload_chunk 负责记录每个分片的上传状态。
当用户重新上传时,我们查表判断进度,
前端从未完成的地方继续传,就能实现真正意义上的“断点续传”。
这套机制有几个显著的好处:
- 上传进度可追踪;
- 中断后可恢复;
- 支持集群部署;
- 不依赖浏览器缓存或 Session。
所以,只要数据库没丢,任务记录还在,
上传进度就能恢复,哪怕换机器、重启系统都没问题。
文件合并与完整性校验
前面的所有步骤,其实都是在为这一刻做准备。
当用户的所有分片都上传完成后,接下来最重要的工作就是:
把这些分片拼成一个完整的文件,并且确保文件内容没有出错。
这一步看似简单,但其实是整个大文件上传流程里最容易出问题的地方。
尤其在集群部署下,如果不同分片分布在不同机器上,
那合并逻辑就不能只靠本地文件路径去拼接,否则根本找不到所有分片。
所以我们先来理一理整个思路。
一、合并的触发时机
前端在检测到所有分片都上传完成后,会调用 /upload/merge 接口。
这个接口的作用就是通知后端:
“这个任务的所有分片都传完了,现在可以开始合并了。”
后端接收到请求后,会先去查数据库确认几个关键信息:
- 这个任务对应的 uploadId 是否存在;
upload_chunk表里所有分片是否都处于 “已上传” 状态;- 当前任务状态是否允许合并(例如不是暂停、取消或失败)。
确认无误后,任务状态会从 UPLOADING 变成 MERGING,
正式进入文件合并阶段。
二、本地合并逻辑
如果系统配置的是本地存储(也就是 cloud.enable = false),
那所有分片文件都保存在服务器的临时目录中。
合并逻辑大致是这样的:
- 后端按分片的
chunk_index顺序,依次读取每个分片文件。 - 逐个写入到一个新的目标文件中,比如
merge.zip。 - 每合并一个分片,就更新数据库中的状态。
- 合并完成后,把任务状态更新为
COMPLETED,并写入最终路径。
整个过程看起来很直观,
但这里有两个要点需要特别注意:
- 写入顺序要严格按照分片索引,否则文件内容会错乱;
- 文件 IO 要用流式写入(Stream) ,避免内存一次性读取所有分片导致溢出。
合并完成后,我们会计算整个文件的 MD5,与原始 fileHash 对比,
如果不一致,就说明合并过程中数据丢失或出错。
这种情况任务会被标记为 FAILED,并在日志中留下异常记录。
三、云端合并逻辑
如果我们配置了云存储(比如 OSS、COS、MinIO 等),
那分片文件就不是存在本地磁盘,而是上传到云端的对象存储桶里。
在这种情况下,合并逻辑就不需要我们自己拼文件了,
因为大部分云存储服务都提供了“分片合并”的 API。
比如以 OSS 为例,上传时我们调用的是 uploadPart 接口,
合并时只需要调用 completeMultipartUpload,
它会根据上传时的分片顺序自动合并为一个完整对象。
整个过程的优点是:
- 不占用本地磁盘;
- 不受单机 IO 限制;
- 云端自动校验每个分片的完整性。
所以在云存储场景下,我们只需要做两件事:
- 通知云服务去执行合并;
- 成功后记录最终的文件地址(
storage_url)到数据库。
这样整个流程就闭环了。
四、集群部署下的合并问题
单机情况下,合并很简单,因为所有分片都在本地。
但如果系统是集群部署的,分片请求可能打到了不同机器,
这时候分片文件就会分散在多个节点上。
我们在设计时考虑了三种解决方案:
方案 1:共享存储(私有化部署下比较推荐)
最常见的做法是把所有机器的上传目录指向同一个共享路径,
比如通过 NFS、NAS、或对象存储挂载到 /data/uploads。
这样无论用户上传的分片打到哪台机器,
最终都会写入同一个物理目录。
当合并请求发起时,任意一台机器都能访问到完整的分片文件。
这是目前在企业部署中最稳定、最通用的方案。
方案 2:云存储中转
如果机器之间没有共享目录,那我们可以让每个分片先上传到云端,
合并时再调用云服务的 API 进行分片合并。
这种方式适合公网可访问的 SaaS 环境。
但对于政企内网部署,就不一定行得通。
方案 3:统一调度节点
还有一种是我们自己维护一个“合并调度节点”,
所有分片上传完后,系统会把合并任务分配到一个指定节点执行,
这个节点会从其他机器拉取分片(比如通过 HTTP 内部传输或 RPC)。
这种方式更复杂,适合大规模分布式存储场景。
在私有化项目中,我们一般采用第一种方式——共享目录 + 本地合并。
既能保证性能,也能兼顾安全性。
五、完整性校验
文件合并完成后,最后一步是完整性校验。
我们会重新计算合并后文件的 MD5,与前端最初上传的 fileHash 对比。
如果一致,就说明文件合并成功,内容没有丢失;
如果不一致,就说明某个分片损坏或顺序错误,
任务会被标记为 FAILED,并自动记录错误日志。
这样可以确保文件数据的安全性,
避免在后续 AI 解析或向量化阶段出现内容异常。
六、异步处理与性能优化
开头的视频里我们也看到了,整个上传和合并过程我们是同步执行的。
从前端开始上传分片,到最后文件合并完成,都在等待同一个流程走完。
这种方式在演示时很直观,但在真实项目中其实问题不少。
最明显的一个问题就是——时间太长。
像我们刚才那个 1GB 的文件,即使网络稳定、服务器性能还可以,
整个流程也要几分钟甚至更久。
如果我们让前端一直等待响应,接口超时、连接断开、前端刷新这些问题就都会冒出来。
所以,在真正的业务系统里,我们一般会把合并、校验、迁移 OSS 或解析入库这些操作改成异步任务来做。
接口只负责接收分片、登记状态,然后立刻返回“任务已创建”或“上传完成,正在处理中”的提示。
后续的合并、校验、清理临时文件这些工作交给后台的异步线程、任务队列或者调度器去跑。
这样做的好处有几个:
- 前端体验更流畅,不用卡在“等待合并”阶段;
- 后端可以批量处理任务,减少高峰期的 IO 压力;
- 如果任务失败或中断,也能通过任务表重试或补偿;
- 对接外部存储或 AI 解析流程时,也能自然衔接后续任务链。
简单来说,上传只是第一步,
而合并、校验、转存这些操作本质上更像是后台任务。
我们在系统设计时只要把这些环节分开,让接口尽量“轻”,
这套上传系统就能在面对更大文件、更复杂场景时依然稳定可靠。
七、小结
整个合并与校验阶段,是把前面所有分片上传工作“收尾”的过程。
我们通过以下机制保证了稳定性:
- 本地存储场景下:顺序读取 + 流式写入 + hash 校验;
- 云存储场景下:依赖云端分片合并 API;
- 集群环境下:通过共享存储或统一调度节点解决文件分散问题;
- 数据库层面:实时记录状态,便于追踪和审计。
最终,当文件合并成功、校验通过后,
系统会将结果写入 file_info 表,
整条上传链路就算是完整闭环。
最后
我们平常做的项目,大多数时候文件上传都挺简单的。
前端传到 OSS,后端接个地址存起来就行。
但等真正做私有化项目的时候,也就会发现很多地方都不一样了。
要求更多,考虑的细节也多得多。
像这次做的大文件上传就是个很典型的例子。
以前那种简单方案,放在这种环境下就完全不够用了。
得考虑断点续传、任务恢复、集群部署、权限、审计这些东西,
一步没想好,后面全是坑。
我们现在这套设计,其实就是在解决这些“现实问题”。
接口虽然多一点,但每个职责都很清晰,
任务状态能追踪,上传中断能恢复,
甚至以后如果我们想单独抽出来做一个文件系统模块也完全没问题。
不管是拿来给知识库用,还是 AI 向量化、文档解析,这套逻辑都能复用。
其实很多以前觉得“简单”的功能,
一旦遇到复杂场景,其实都得重新想。
但好处是,一旦做通了,这套东西就能稳定用很久。
到这里,大文件上传这块我们算是完整走了一遍。
以后再遇到类似需求,我们就有经验了,
不用再从头掉坑里爬出来一次哈。
更多架构实战、工程化经验和踩坑复盘,我会在公众号 「洛卡卡了」 持续更新。
如果内容对你有帮助,欢迎关注我,我们一起每天学一点,一起进步。
来源:juejin.cn/post/7571355989133099023
程序员,你使用过灰度发布吗?
大家好呀,我是猿java。
在分布式系统中,我们经常听到灰度发布这个词,那么,什么是灰度发布?为什么需要灰度发布?如何实现灰度发布?这篇文章,我们来聊一聊。
1. 什么是灰度发布?
简单来说,灰度发布也叫做渐进式发布或金丝雀发布,它是一种逐步将新版本应用到生产环境中的策略。相比于一次性全量发布,灰度发布可以让我们在小范围内先行测试新功能,监控其表现,再决定是否全面推开。这样做的好处是显而易见的:
- 降低风险:新版本如果存在 bug,只影响少部分用户,减少了对整体用户体验的冲击。
- 快速回滚:在小范围内发现问题,可以更快地回到旧版本。
- 收集反馈:可以在真实环境中收集用户反馈,优化新功能。
2. 原理解析
要理解灰度发布,我们需要先了解一下它的基本流程:
- 准备阶段:在生产环境中保留旧版本,同时引入新版本。
- 小范围发布:将新版本先部署到一小部分用户,例如1%-10%。
- 监控与评估:监控新版本的性能和稳定性,收集用户反馈。
- 逐步扩展:如果一切正常,将新版本逐步推广到更多用户。
- 全面切换:当确认新版本稳定后,全面替换旧版本。
在这个过程中,关键在于如何切分流量,确保新旧版本平稳过渡。常见的切分方式包括:
- 基于用户ID:根据用户的唯一标识,将部分用户指向新版本。
- 基于地域:先在特定地区进行发布,观察效果后再扩展到其他地区。
- 基于设备:例如,先在Android或iOS用户中进行发布。
3. 示例演示
为了更好地理解灰度发布,接下来,我们通过一个简单的 Java示例来演示基本的灰度发布策略。假设我们有一个简单的 Web应用,有两个版本的登录接口/login/v1和/login/v2,我们希望将百分之十的流量引导到v2,其余流量继续使用v1。
3.1 第一步:引入灰度策略
我们可以通过拦截器(Interceptor)来实现流量的切分。以下是一个基于Spring Boot的简单实现:
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.Random;
@Component
public class GrayReleaseInterceptor implements HandlerInterceptor {
private static final double GRAY_RELEASE_PERCENT = 0.1; // 10% 流量
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String uri = request.getRequestURI();
if ("/login".equals(uri)) {
if (isGrayRelease()) {
// 重定向到新版本接口
response.sendRedirect("/login/v2");
return false;
} else {
// 使用旧版本接口
response.sendRedirect("/login/v1");
return false;
}
}
return true;
}
private boolean isGrayRelease() {
Random random = new Random();
return random.nextDouble() < GRAY_RELEASE_PERCENT;
}
}
3.2 第二步:配置拦截器
在Spring Boot中,我们需要将拦截器注册到应用中:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.*;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Autowired
private GrayReleaseInterceptor grayReleaseInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(grayReleaseInterceptor).addPathPatterns("/login");
}
}
3.3 第三步:实现不同版本的登录接口
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/login")
public class LoginController {
@GetMapping("/v1")
public String loginV1(@RequestParam String username, @RequestParam String password) {
// 旧版本登录逻辑
return "登录成功 - v1";
}
@GetMapping("/v2")
public String loginV2(@RequestParam String username, @RequestParam String password) {
// 新版本登录逻辑
return "登录成功 - v2";
}
}
在上面三个步骤之后,我们就实现了登录接口地灰度发布:
- 当用户访问
/login时,拦截器会根据设定的灰度比例(10%)决定请求被重定向到/login/v1还是/login/v2。 - 大部分用户会体验旧版本接口,少部分用户会体验新版本接口。
3.4 灰度发布优化
上述示例,我们只是一个简化的灰度发布实现,实际生产环境中,我们可能需要更精细的灰度策略,例如:
- 基于用户属性:不仅仅是随机切分,可以根据用户的地理位置、设备类型等更复杂的条件。
- 动态配置:通过配置中心动态调整灰度比例,无需重启应用。
- 监控与告警:集成监控系统,实时监控新版本的性能指标,异常时自动回滚。
- A/B 测试:结合A/B测试,进一步优化用户体验和功能效果。

4. 为什么需要灰度发布?
在实际工作中,为什么我们要使用灰度发布?这里我们总结了几个重要的原因。
4.1 降低发布风险
每次发布新版本,尤其是功能性更新或架构调整,都会伴随着一定的风险。即使经过了充分的测试,实际生产环境中仍可能出现意想不到的问题。灰度发布通过将新版本逐步推向部分用户,可以有效降低全量发布可能带来的风险。
举个例子,假设你上线了一个全新的支付功能,直接面向所有用户开放。如果这个功能存在严重 bug,可能导致大量用户无法完成支付,甚至影响公司声誉。而如果采用灰度发布,先让10%的用户体验新功能,发现问题后只需影响少部分用户,修复起来也更为迅速和容易。
4.2 快速回滚
在传统的全量发布中,一旦发现问题,回滚到旧版本可能需要耗费大量时间和精力,尤其是在高并发系统中,数据状态的同步与恢复更是复杂。而灰度发布由于新版本只覆盖部分流量,问题定位和回滚变得更加简单和快速。
比如说,你在灰度发布阶段发现新版本的某个功能在某些特定条件下会导致系统崩溃,立即可以停止向新用户推送这个版本,甚至只针对受影响的用户进行回滚操作,而不用影响全部用户的正常使用。
4.3 实时监控与反馈
灰度发布让你有机会在真实的生产环境中监控新版本的表现,并收集用户的反馈。这些数据对于评估新功能的实际效果至关重要,有助于做出更明智的决策。
举个具体的场景,你新增了一个推荐算法,希望提升用户的点击率。在灰度发布阶段,你可以监控新算法带来的点击率变化、服务器负载情况等指标,确保新算法确实带来了预期的效果,而不是引入了新的问题。
4.4 提升用户体验
通过灰度发布,你可以在推出新功能时,逐步优化用户体验。先让一部分用户体验新功能,收集他们的使用反馈,根据反馈不断改进,最终推出一个更成熟、更符合用户需求的版本。
举个例子,你开发了一项新的用户界面设计,直接全量发布可能会让一部分用户感到不适应或不满意。灰度发布允许你先让一部分用户体验新界面,收集他们的意见,进行必要的调整,再逐步扩大使用范围,确保最终发布的版本能获得更多用户的认可和喜爱。
4.5 支持A/B测试
灰度发布是实现A/B测试的基础。通过将用户随机分配到不同的版本,你可以比较不同版本的表现,选择最优方案进行全面推行。这对于优化产品功能和提升用户体验具有重要意义。
比如说,你想测试两个不同的推荐算法,看哪个能带来更高的转化率。通过灰度发布,将用户随机分配到使用算法A和算法B的版本,比较它们的表现,最终选择效果更好的算法进行全面部署。
4.6 应对复杂的业务需求
在一些复杂的业务场景中,全量发布可能无法满足灵活的需求,比如分阶段推出新功能、针对不同用户群体进行差异化体验等。灰度发布提供了更高的灵活性和可控性,能够更好地适应多变的业务需求。
例如,你正在开发一个面向企业用户的新功能,希望先让部分高价值客户试用,收集他们的反馈后再决定是否全面推广。灰度发布让这一过程变得更加顺畅和可控。
5. 总结
本文,我们详细地分析了灰度发布,它是一种强大而灵活的部署策略,能有效降低新版本上线带来的风险,提高系统的稳定性和用户体验。作为Java开发者,掌握灰度发布的原理和实现方法,不仅能提升我们的技术能力,还能为团队的项目成功保驾护航。
对于灰度发布,如果你有更多的问题或想法,欢迎随时交流!
6. 学习交流
如果你觉得文章有帮助,请帮忙转发给更多的好友,或关注公众号:猿java,持续输出硬核文章。
来源:juejin.cn/post/7488321730764603402
布隆过滤器(附Java代码)
一、前言
想象这样一个场景:你的电商系统每天有1000万次商品查询,但其中90%是无效ID(比如用户手误输入或恶意爬虫)。每次查询都要穿透缓存打到数据库,数据库压力山大!
// 传统做法:每次都要查数据库
public Product queryProduct(Long id) {
Product product = cache.get(id); // Redis缓存
if (product == null) {
product = db.query(id); // 90%的无效请求打到数据库!
if (product != null) {
cache.set(id, product);
}
}
return product;
}
布隆过滤器(Bloom Filter) 就是解决这类问题的利器:它用极小的空间快速判断“某个元素一定不存在”或“可能存在”,从而在查询前提前拦截无效请求,保护后端数据库。
典型应用场景:
- 防止缓存穿透(无效Key反复查询数据库)
- 网页爬虫URL去重
- 邮箱系统黑名单过滤
- 推荐系统已读内容过滤
二、核心原理
2.1 生活化类比:图书馆的“借书登记表”
假设图书馆有100万个座位,管理员用一张超大登记表(位数组)记录谁来过:
| 座位号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 状态 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | ... |
- 当张三来借书,管理员用3个不同规则计算他的“专属座位”:
- 规则1:姓名笔画数 % 10 → 座位2
- 规则2:身-份-证后3位 % 10 → 座位4
- 规则3:生日数字和 % 10 → 座位7
- 管理员把2、4、7号座位标记为
1 - 下次张三再来,只要所有对应座位都是1,就认为“他可能来过”;只要有一个是0,就确定“他没来过”
核心特性:
- 绝不漏判:如果元素不存在,100%能判断出来(座位有0)
- 可能误判:如果所有座位都是1,可能是别人“撞座位”了(误判率可控)
- 无法删除:座位一旦标1,不能随便改回0(否则会影响其他元素)
2.2 技术原理图解
元素 "nontee"
│
├─ 哈希函数1 → 位置 15 → 位数组[15] = 1
├─ 哈希函数2 → 位置 87 → 位数组[87] = 1
└─ 哈希函数3 → 位置 203 → 位数组[203] = 1
查询 "nontee"
│
├─ 哈希函数1 → 位置 15 → 检查位数组[15] == 1? ✓
├─ 哈希函数2 → 位置 87 → 检查位数组[87] == 1? ✓
└─ 哈希函数3 → 位置 203 → 检查位数组[203] == 1? ✓
↓
结论:可能存在(需二次确认)
2.3 关键参数:如何控制误判率?
布隆过滤器有3个核心参数:
| 参数 | 说明 | 影响 |
|---|---|---|
m | 位数组大小(bit) | 越大误判率越低,但占空间 |
n | 预期插入元素数量 | 超过预期会导致误判率飙升 |
k | 哈希函数个数 | 最佳值 ≈ (m/n) * ln2 |
误判率公式:
经验法则:每存储1个元素,分配10bit空间,误判率约1%
例如:存储100万个元素 → 需要 100万 × 10 bit ≈ 1.25MB(传统HashSet需几十MB!)
三、代码实战
3.1 手写简易版布隆过滤器(理解原理必备)
import java.util.BitSet;
import java.util.MissingResourceException;
/**
* 简易布隆过滤器实现(教学用途)
* 特点:使用3个哈希函数,固定大小位数组
*/
public class SimpleBloomFilter {
// 位数组(实际存储结构)
private final BitSet bitSet;
// 位数组大小(单位:bit)
private final int bitSize;
// 哈希函数种子(用于生成不同哈希值)
private final int[] seeds = {7, 11, 13};
/**
* 构造函数
* @param expectedSize 预期元素数量
* @param falsePositiveRate 期望误判率(如0.01表示1%)
*/
public SimpleBloomFilter(int expectedSize, double falsePositiveRate) {
// 根据公式计算最佳位数组大小: m = - (n * ln(p)) / (ln2)^2
this.bitSize = (int) (-expectedSize * Math.log(falsePositiveRate) / Math.pow(Math.log(2), 2));
this.bitSet = new BitSet(bitSize);
System.out.println(">>> 布隆过滤器初始化完成 | 位数组大小: " + bitSize + " bit (" + bitSize / 8 / 1024 + " KB)");
}
/**
* 插入元素
* @param value 待插入的字符串
*/
public void put(String value) {
if (value == null) return;
// 对每个哈希函数计算位置并设置bit为1
for (int seed : seeds) {
int position = hash(value, seed) % bitSize;
bitSet.set(position); // 设置该位置为1
}
}
/**
* 判断元素是否存在
* @param value 待查询字符串
* @return true: 可能存在 | false: 一定不存在
*/
public boolean mightContain(String value) {
if (value == null) return false;
// 检查所有哈希位置是否都为1
for (int seed : seeds) {
int position = hash(value, seed) % bitSize;
if (!bitSet.get(position)) {
// 只要有一个位置是0,元素一定不存在
return false;
}
}
// 所有位置都是1,元素可能存在(有误判可能)
return true;
}
/**
* 简易哈希函数(教学用,实际生产需用更均匀的哈希)
* @param value 原始字符串
* @param seed 种子值(不同种子产生不同哈希)
* @return 哈希值
*/
private int hash(String value, int seed) {
int result = 0;
for (int i = 0; i < value.length(); i++) {
result = seed * result + value.charAt(i);
}
// 处理负数
return (result < 0) ? -result : result;
}
// ===== 测试代码 =====
public static void main(String[] args) {
// 创建过滤器:预计10000个元素,误判率1%
SimpleBloomFilter bloomFilter = new SimpleBloomFilter(10000, 0.01);
// 插入1000个用户ID
for (int i = 0; i < 1000; i++) {
bloomFilter.put("user_" + i);
}
// 测试1:查询存在的元素
System.out.println("\n【测试1】查询存在的元素:");
System.out.println("user_500 是否存在? " + bloomFilter.mightContain("user_500")); // true
// 测试2:查询不存在的元素(大概率返回false)
System.out.println("\n【测试2】查询不存在的元素:");
System.out.println("user_99999 是否存在? " + bloomFilter.mightContain("user_99999")); // false
// 测试3:演示误判(多次测试可能触发)
System.out.println("\n【测试3】误判演示(多次运行可能触发):");
int falsePositiveCount = 0;
for (int i = 10000; i < 20000; i++) {
if (bloomFilter.mightContain("user_" + i)) {
falsePositiveCount++;
}
}
System.out.println("在10000次不存在查询中,误判次数: " + falsePositiveCount);
System.out.printf("实际误判率: %.2f%%\n", (double) falsePositiveCount / 10000 * 100);
}
}
运行输出示例:
>>> 布隆过滤器初始化完成 | 位数组大小: 95851 bit (11 KB)
【测试1】查询存在的元素:
user_500 是否存在? true
【测试2】查询不存在的元素:
user_99999 是否存在? false
【测试3】误判演示(多次运行可能触发):
在10000次不存在查询中,误判次数: 98
实际误判率: 0.98%
3.2 工业级实战:Guava布隆过滤器(生产环境推荐)
Google Guava库提供了经过优化的布隆过滤器实现,强烈推荐生产环境使用:
<!-- Maven依赖 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version> <!-- 使用最新稳定版 -->
</dependency>
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
/**
* Guava布隆过滤器实战:防止缓存穿透
*/
public class CachePenetrationDefense {
// 创建布隆过滤器:预计100万个用户ID,误判率1%
private static final BloomFilter<String> userIdFilter =
BloomFilter.create(
Funnels.stringFunnel(StandardCharsets.UTF_8), // 指定字符串编码
1_000_000, // 预期元素数量
0.01 // 误判率
);
// 模拟数据库
private static final List<String> database = new ArrayList<>();
static {
// 预热:将真实用户ID加入布隆过滤器
for (int i = 1; i <= 10000; i++) {
String userId = "user_" + i;
database.add(userId);
userIdFilter.put(userId); // 关键:插入过滤器
}
System.out.println(">>> 布隆过滤器预热完成,共加载 " + database.size() + " 个用户ID");
}
/**
* 安全查询用户(带布隆过滤器防护)
*/
public static String queryUserSafe(String userId) {
// 第一步:布隆过滤器快速判断
if (!userIdFilter.mightContain(userId)) {
System.out.println("[BloomFilter] 拦截无效请求: " + userId + "(一定不存在)");
return null; // 直接返回,不查数据库!
}
// 第二步:可能存在,查缓存/数据库(此处简化为直接查库)
System.out.println("[BloomFilter] 通过初筛: " + userId + "(可能存在,继续查询)");
if (database.contains(userId)) {
System.out.println("[DB] 查询成功: " + userId);
return userId;
} else {
// 注意:这里可能是误判!需要记录日志分析
System.out.println("[WARN] 布隆过滤器误判: " + userId);
return null;
}
}
public static void main(String[] args) {
// 场景1:查询真实用户(应成功)
queryUserSafe("user_500");
System.out.println("\n---------- 分隔线 ----------\n");
// 场景2:查询无效用户(应被拦截)
queryUserSafe("hacker_999999");
System.out.println("\n---------- 分隔线 ----------\n");
// 场景3:压力测试 - 10万次无效请求
long startTime = System.currentTimeMillis();
int blockedCount = 0;
for (int i = 0; i < 100000; i++) {
if (queryUserSafe("invalid_" + i) == null) {
blockedCount++;
}
}
long costTime = System.currentTimeMillis() - startTime;
System.out.printf("\n【压力测试结果】拦截 %d 次无效请求,耗时 %d ms,QPS: %.0f\n",
blockedCount, costTime, 100000.0 / costTime * 1000);
}
}
输出示例:
>>> 布隆过滤器预热完成,共加载 10000 个用户ID
[BloomFilter] 通过初筛: user_500(可能存在,继续查询)
[DB] 查询成功: user_500
---------- 分隔线 ----------
[BloomFilter] 拦截无效请求: hacker_999999(一定不存在)
---------- 分隔线 ----------
[BloomFilter] 拦截无效请求: invalid_0(一定不存在)
[BloomFilter] 拦截无效请求: invalid_1(一定不存在)
...
【压力测试结果】拦截 100000 次无效请求,耗时 125 ms,QPS: 800000
关键结论:10万次无效请求0次打到数据库,全部被布隆过滤器在微秒级拦截!
四、踩坑指南
坑1:误判率设置过低导致空间爆炸
// 错误示范:追求0.001%误判率,空间需求暴增10倍!
BloomFilter.create(Funnels.stringFunnel(UTF_8), 1_000_000, 0.00001);
// 正确做法:根据业务容忍度选择
// - 缓存穿透防护:1%~5% 足够(拦截95%+无效请求)
// - 金融风控:0.1% 以下(宁可多占空间也不能漏判)
坑2:元素数量超过预期,误判率飙升
布隆过滤器必须预估元素数量!超过预期后:
- 位数组1的比例越来越高
- 误判率呈指数级上升
// 危险操作:插入远超预期的元素
BloomFilter<String> filter = BloomFilter.create(..., 10000, 0.01);
for (int i = 0; i < 100000; i++) { // 插入10万,超预期10倍!
filter.put("user_" + i);
}
// 此时误判率可能高达50%以上!
解决方案:
- 预留20%~30%余量
- 使用可扩展布隆过滤器(如RedisBloom模块)
- 定期重建过滤器(适用于数据有生命周期的场景)
坑3:试图“删除”元素
布隆过滤器原生不支持删除!因为:
- 多个元素可能共享同一个bit位
- 删除时无法判断该bit是否被其他元素占用
// 错误想法:想删除user_100
filter.delete("user_100"); // 不存在此方法!
// 正确方案:
// 1. 使用Counting Bloom Filter(计数布隆过滤器,空间翻倍)
// 2. 业务层标记删除(如数据库加is_deleted字段)
// 3. 定期重建过滤器(适用于短期数据)
坑4:哈希函数选择不当导致分布不均
手写实现时,劣质哈希函数会导致:
- 位数组某些区域密集,某些区域稀疏
- 实际误判率远高于理论值
// 劣质哈希:只用字符串长度,碰撞率极高!
int hash = value.length() % bitSize;
// 推荐方案:
// 1. 生产环境直接用Guava(内部使用MurmurHash3,分布均匀)
// 2. 手写时用多个质数种子组合
五、总结
| 特性 | 说明 | 适用场景 |
|---|---|---|
| 空间效率 | 100万元素仅需1.25MB | 内存敏感场景(如嵌入式设备) |
| 查询速度 | O(k) 常数时间(k为哈希函数数) | 高并发拦截场景 |
| 误判特性 | 可能误判“存在”,但绝不误判“不存在” | 适合做“存在性”初筛 |
| 不可删除 | 原生不支持删除操作 | 适合只增不减的数据集 |
| 持久化 | 可序列化位数组到磁盘/Redis | 重启后快速恢复 |
最佳实践三板斧:
- 用Guava别手写:除非教学/特殊需求,生产环境直接用Guava
- 预估要留余量:预期数量 × 1.3 作为初始化参数
- 组合使用更安全:布隆过滤器 + 缓存 + 数据库 三级防护
来源:juejin.cn/post/7607112994062712859
从 8 个实战场景深度拆解:为什么资深前端都爱柯里化?
你一定见过无数臃肿的 if-else 和重复嵌套的逻辑。在追求 AI-Native 开发的今天,代码的“原子化”程度直接决定了 AI 辅助重构的效率。
柯里化(Currying) 绝不仅仅是面试时的八股文,它是实现逻辑复用、配置解耦的工业级利器。通俗地说,它把一个多参数函数拆解成一系列单参数函数:。
以下是 8 个直击前端实战痛点的柯里化应用案例。
1. 差异化日志系统:环境与等级的解耦
在web系统中,我们经常需要根据不同环境输出不同等级的日志。
JavaScript
const logger = (env) => (level) => (msg) => {
console.log(`[${env.toUpperCase()}][${level}] ${msg} - ${new Date().toLocaleTimeString()}`);
};
const prodError = logger('prod')('ERROR');
const devDebug = logger('dev')('DEBUG');
prodError('支付接口超时'); // [PROD][ERROR] 支付接口超时 - 10:20:00
2. API 请求构造器:预设 BaseURL 与 Header
不用每次请求都传 Token 或域名,通过柯里化提前“锁死”配置。
JavaScript
const request = (baseUrl) => (headers) => (endpoint) => (params) => {
return fetch(`${baseUrl}${endpoint}?${new URLSearchParams(params)}`, { headers });
};
const apiWithAuth = request('https://api.finance.com')({ 'Authorization': 'Bearer xxx' });
const getUser = apiWithAuth('/user');
getUser({ id: '888' });
3. DOM 事件监听:优雅传递额外参数
在 Vue 或 React 模板中,我们常为了传参写出 () => handleClick(id)。柯里化可以保持模板整洁并提高性能。
JavaScript
const handleMenuClick = (menuId) => (event) => {
console.log(`点击了菜单: ${menuId}`, event.target);
};
// 模板中直接绑定:@click="handleMenuClick('settings')"
4. 复合校验逻辑:原子化验证规则
将复杂的表单校验拆解为可组合的原子。
JavaScript
const validate = (reg) => (tip) => (value) => {
return reg.test(value) ? { pass: true } : { pass: false, tip };
};
const isMobile = validate(/^1[3-9]\d{9}$/)('手机号格式错误');
const isEmail = validate(/^\w+@\w+.\w+$/)('邮箱格式错误');
console.log(isMobile('13800138000')); // { pass: true }
5. 金融汇率换算:固定基准率
在处理多币种对账时,柯里化能帮你固定变动较慢的参数。
JavaScript
const convertCurrency = (rate) => (amount) => (amount * rate).toFixed(2);
const usdToCny = convertCurrency(7.24);
const eurToCny = convertCurrency(7.85);
console.log(usdToCny(100)); // 724.00
6. 动态 CSS 类名生成器:样式逻辑解耦
配合 CSS Modules 或 Tailwind 时,通过柯里化快速生成带状态的类名。
JavaScript
const createCls = (prefix) => (state) => (baseCls) => {
return `${prefix}-${baseCls} ${state ? 'is-active' : ''}`;
};
const navCls = createCls('nav')(isActive);
const btnCls = navCls('button'); // "nav-button is-active"
7. 数据过滤管道:可组合的 Array 操作
在处理海量 AI Prompt 列表时,将过滤逻辑函数化,方便链式调用。
JavaScript
const filterBy = (key) => (value) => (item) => item[key].includes(value);
const filterByTag = filterBy('tag');
const prompts = [{ title: 'AI助手', tag: 'Finance' }, { title: '翻译机', tag: 'Tool' }];
const financePrompts = prompts.filter(filterByTag('Finance'));
8. AI Prompt 模板工厂:多层上下文注入
为你正在开发的 AI Prompt Manager 设计一个分层注入器:先注入角色,再注入上下文,最后注入用户输入。
JavaScript
const promptFactory = (role) => (context) => (input) => {
return `Role: ${role}\nContext: ${context}\nUser says: ${input}`;
};
const financialExpert = promptFactory('Senior Financial Analyst')('Analyzing 2026 Q1 Report');
const finalPrompt = financialExpert('请总结该季报风险点');
来源:juejin.cn/post/7610252910319960115
html翻页时钟 效果
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<title>Flip Clock</title>
<style>
body {
background: #111;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
font-family: 'Courier New', monospace;
color: white;
}
.clock {
display: flex;
gap: 20px;
}
.card-container {
width: 80px;
height: 120px;
position: relative;
perspective: 500px;
background: #2c292c;
border-radius: 8px;
box-shadow: 0 4px 12px rgba(0,0,0,0.5);
}
/* 中间分割线 */
.card-container::before {
content: "";
position: absolute;
left: 0;
top: 50%;
width: 100%;
height: 4px;
background: #120f12;
z-index: 10;
}
.card-item {
position: absolute;
width: 100%;
height: 50%;
left: 0;
overflow: hidden;
background: #2c292c;
color: white;
text-align: center;
font-size: 64px;
font-weight: bold;
backface-visibility: hidden;
transition: transform 0.4s ease-in-out;
}
/* 下层数字:初始对折(背面朝上) */
.card1 { /* 下层上半 */
top: 0;
line-height: 120px; /* 整体高度对齐 */
}
.card2 { /* 下层下半 */
top: 50%;
line-height: 0;
transform-origin: center top;
transform: rotateX(180deg);
z-index: 2;
}
/* 上层数字:当前显示 */
.card3 { /* 上层上半 */
top: 0;
line-height: 120px;
transform-origin: center bottom;
z-index: 3;
}
.card4 { /* 上层下半 */
top: 50%;
line-height: 0;
z-index: 1;
}
/* 翻页动画触发 */
.flip .card2 {
transform: rotateX(0deg);
}
.flip .card3 {
transform: rotateX(-180deg);
}
/* 冒号分隔符 */
.colon {
font-size: 64px;
display: flex;
align-items: center;
color: #aaa;
}
</style>
</head>
<body>
<div class="clock">
<div class="card-container flip" id="hour" data-number="00">
<div class="card1 card-item">00</div>
<div class="card2 card-item">00</div>
<div class="card3 card-item">00</div>
<div class="card4 card-item">00</div>
</div>
<div class="colon">:</div>
<div class="card-container flip" id="minute" data-number="00">
<div class="card1 card-item">00</div>
<div class="card2 card-item">00</div>
<div class="card3 card-item">00</div>
<div class="card4 card-item">00</div>
</div>
<div class="colon">:</div>
<div class="card-container flip" id="second" data-number="00">
<div class="card1 card-item">00</div>
<div class="card2 card-item">00</div>
<div class="card3 card-item">00</div>
<div class="card4 card-item">00</div>
</div>
</div>
<script>
function setHTML(dom, nextValue) {
const curValue = dom.dataset.number;
if (nextValue === curValue) return;
// 更新 DOM 结构:下层为新值,上层为旧值
dom.innerHTML = `
<div class="card1 card-item">${nextValue}</div>
<div class="card2 card-item">${nextValue}</div>
<div class="card3 card-item">${curValue}</div>
<div class="card4 card-item">${curValue}</div>
`;
// 触发重绘以重启动画
dom.classList.remove('flip');
void dom.offsetWidth; // 强制重排
dom.classList.add('flip');
dom.dataset.number = nextValue;
}
function updateClock() {
const now = new Date();
const h = String(now.getHours()).padStart(2, '0');
const m = String(now.getMinutes()).padStart(2, '0');
const s = String(now.getSeconds()).padStart(2, '0');
setHTML(document.getElementById('hour'), h);
setHTML(document.getElementById('minute'), m);
setHTML(document.getElementById('second'), s);
}
// 初始化
updateClock();
// setTimeout(updateClock,1000)
setInterval(updateClock, 1000);
</script>
</body>
</html>

这个翻页时钟(Flip Clock)通过 CSS 3D 变换 + 动画类切换 + DOM 内容动态更新 的方式,模拟了类似机械翻页牌的效果。下面从结构、样式和逻辑三方面详细分析其实现原理:
🔧 一、HTML 结构设计
每个时间单位(小时、分钟、秒)由一个 .card-container 容器表示,内部包含 4 个 .card-item 元素:
<div class="card-container" id="second">
<div class="card1">00</div> <!-- 下层上半 -->
<div class="card2">00</div> <!-- 下层下半(初始翻转180°)-->
<div class="card3">00</div> <!-- 上层上半(当前显示)-->
<div class="card4">00</div> <!-- 上层下半 -->
</div>
四个卡片的作用:
.card3和.card4:组成当前显示的数字(上半+下半),正常显示。.card1和.card2:组成即将翻出的新数字,但初始时.card2被rotateX(180deg)翻转到背面(不可见)。- 中间有一条
::before伪元素作为“折痕”,增强翻页视觉效果。
🎨 二、CSS 样式与 3D 翻转原理
关键 CSS 技术点:
1. 3D 空间设置
.card-container {
perspective: 500px; /* 创建 3D 视角 */
}
perspective让子元素的 3D 变换有景深感。
2. 上下两半的定位与旋转轴
.card2 {
transform-origin: center top;
transform: rotateX(180deg); /* 初始翻到背面 */
}
.card3 {
transform-origin: center bottom;
}
.card2绕顶部边缘旋转 180°,藏在下方背面。.card3绕底部边缘旋转,用于向上翻折。
3. 翻页动画(通过 .flip 类触发)
.flip .card2 {
transform: rotateX(0deg); /* 展开新数字下半部分 */
}
.flip .card3 {
transform: rotateX(-180deg); /* 当前数字上半部分向上翻折隐藏 */
}
- 动画持续
0.4s,使用ease-in-out缓动。 .card1和.card4始终保持静态,作为背景支撑。
✅ 视觉效果:
- 上半部分(
.card3)向上翻走(像书页翻开)
- 下半部分(
.card2)从背面转正,露出新数字
- 中间的“折痕”让翻页更真实
⚙️ 三、JavaScript 动态更新逻辑
核心函数:setHTML(dom, nextValue)
步骤分解:
- 对比新旧值:如果相同,不更新(避免无谓动画)。
- 重写整个容器的 HTML:
- 下层(新值):
.card1和.card2显示nextValue - 上层(旧值):
.card3和.card4显示curValue
- 下层(新值):
- 触发动画:
dom.classList.remove('flip');
void dom.offsetWidth; // 强制浏览器重排(关键!)
dom.classList.add('flip');
- 先移除
.flip,再强制重排(flush styles),再加回.flip,确保动画重新触发。
- 先移除
- 更新
data-number保存当前值。
时间更新:
- 每秒调用
updateClock(),获取当前时分秒(两位数格式)。 - 分别调用
setHTML更新三个容器。
🌟 四、为什么能实现“翻页”错觉?
| 元素 | 初始状态 | 翻页后状态 | 视觉作用 |
|---|---|---|---|
.card3 | 显示旧数字上半 | 向上翻转 180° 隐藏 | 模拟“翻走”的上半页 |
.card2 | 旧数字下半(翻转180°藏起) | 转正显示新数字下半 | 模拟“翻出”的下半页 |
.card1 / .card4 | 静态背景 | 不变 | 提供视觉连续性 |
💡 关键技巧:
- 利用 两个完整数字(新+旧)叠加,通过控制上下半部分的旋转,制造“翻页”而非“淡入淡出”。
- 强制重排(
offsetWidth) 是确保 CSS 动画每次都能重新触发的经典 hack。
✅ 总结
这个 Flip Clock 的精妙之处在于:
- 结构设计:4 个卡片分工明确,上下层分离。
- CSS 3D:利用
rotateX+transform-origin实现真实翻页。 - JS 控制:动态替换内容 + 巧妙触发动画。
- 性能优化:仅在值变化时更新,避免无效渲染。
这是一种典型的 “用 2D DOM 模拟 3D 物理效果” 的前端动画范例,既高效又视觉惊艳。
来源:juejin.cn/post/7606183276772999231
HTML5 自定义属性 data-*:别再把数据塞进 class 里了!
前言:由于“无处安放”而引发的混乱
在 HTML5 普及之前,前端开发者为了在 DOM 元素上绑定一些数据(比如用户 ID、商品价格、状态码),可谓是八仙过海,各显神通:
- 隐藏域流派:到处塞
<input type="hidden" value="123">,导致 HTML 结构像个堆满杂物的仓库。 - Class 拼接流派:
<div class="btn item-id-8848">,然后用正则去解析 class 字符串提取 ID。这简直是在用 CSS 类名当数据库用,类名听了都想离家出走。 - 自定义非标属性流派:直接写
<div my_id="123">。虽然浏览器大多能容忍,但这就好比在公共泳池里裸泳——虽然没人抓你,但不合规矩且看着尴尬。
直到 HTML5 引入了 data-* 自定义数据属性,这一切终于有了“官方标准”。
第一阶段:基础——它长什么样?
data-* 属性允许我们在标准 HTML 元素中存储额外的页面私有信息。
1. HTML 写法
语法非常简单:必须以 data- 开头,后面接上你自定义的名称。
<!-- ❌ 错误示范:不要大写,不要乱用特殊符号 -->
<div data-User-Id="1001"></div>
<!-- ✅ 正确示范:全小写,连字符连接 -->
<div
id="user-card"
data-id="1001"
data-user-name="juejin_expert"
data-value="99.9"
data-is-vip="true"
>
用户信息卡片
</div>
2. CSS 中的妙用
很多人以为 data-* 只是给 JS 用的,其实 CSS 也能完美利用它。
场景一:通过属性选择器控制样式
/* 当 data-is-vip 为 "true" 时,背景变金 */
div[data-is-vip="true"] {
background: gold;
border: 2px solid orange;
}
场景二:利用 attr() 显示数据
这是一个非常酷的技巧,可以用来做 Tooltip 或者计数器显示。
div::after {
/* 直接把 data-value 的值显示在页面上 */
content: "当前分值: " attr(data-value);
font-size: 12px;
color: #666;
}
第二阶段:进阶——JavaScript 如何读写?
这才是重头戏。在 JS 中操作 data-* 有两种方式:传统派 和 现代派。
1. 传统派:getAttribute / setAttribute
这是最稳妥的方法,兼容性最好(虽然现在也没人要兼容 IE6 了)。
const el = document.getElementById('user-card');
// 读取
const userId = el.getAttribute('data-id'); // "1001"
// 修改
el.setAttribute('data-value', '100');
特点:读出来永远是字符串。哪怕你存的是 100,取出来也是 "100"。
2. 现代派:dataset API (推荐 ✨)
HTML5 为每个元素提供了一个 dataset 对象(DOMStringMap),它将所有的 data-* 属性映射成了对象的属性。
这里有个大坑(或者说是规范),请务必注意:
HTML 中的 连字符命名 (kebab-case) 会自动转换为 JS 中的 小驼峰命名 (camelCase) 。
const el = document.getElementById('user-card');
// 1. 访问 data-id
console.log(el.dataset.id); // "1001"
// 2. 访问 data-user-name (注意变身了!)
console.log(el.dataset.userName); // "juejin_expert"
// ❌ el.dataset.user-name 是语法错误
// ❌ el.dataset['user-name'] 是 undefined
// 3. 修改数据
el.dataset.value = "200";
// HTML 会自动变成 data-value="200"
// 4. 删除数据
delete el.dataset.isVip;
// HTML 中的 data-is-vip 属性会被移除
💡 敲黑板:dataset 里的属性名不支持大写字母。如果你在 HTML 里写 data-MyValue="1", 浏览器会强制转为小写 data-myvalue,JS 里就得用 dataset.myvalue 访问。所以,HTML 里老老实实全小写吧。
第三阶段:深入——类型陷阱与性能权衡
1. 一切皆字符串
不管你赋给 dataset 什么类型的值,最终都会被转为字符串。
el.dataset.count = 100; // HTML: data-count="100"
el.dataset.active = true; // HTML: data-active="true"
el.dataset.config = {a: 1}; // HTML: data-config="[object Object]" -> 灾难!
避坑指南:
- 如果你要存数字,取出来时记得 Number(el.dataset.count)。
- 如果你要存布尔值,判断时不能简单用 if (el.dataset.active),因为 "false" 字符串也是真值!要用 el.dataset.active === 'true'。
- 千万不要试图在 data-* 里存复杂的 JSON 对象。如果非要存,请使用 JSON.stringify(),但在 DOM 上挂载大量字符串数据会影响性能。
2. 性能考量
- 读写速度:dataset 的访问速度在现代浏览器中非常快,但在极高频操作下(比如每秒几千次),直接操作 JS 变量肯定比操作 DOM 快。
- 重排与重绘:修改 data-* 属性会触发 DOM 变更。如果你的 CSS 依赖属性选择器(如 div[data-status="active"]),修改属性可能会触发页面的重排(Reflow)或重绘(Repaint)。
第四阶段:实战——优雅的事件委托
data-value 最经典的用法之一就是在列表项的事件委托中。
需求:点击列表中的“删除”按钮,删除对应项。
<ul id="todo-list">
<li>
<span>学习 HTML5</span>
<!-- 把 ID 藏在这里 -->
<button class="btn-delete" data-id="101" data-action="delete">删除</button>
</li>
<li>
<span>写掘金文章</span>
<button class="btn-delete" data-id="102" data-action="delete">删除</button>
</li>
</ul>
const list = document.getElementById('todo-list');
list.addEventListener('click', (e) => {
// 利用 dataset 判断点击的是不是删除按钮
const { action, id } = e.target.dataset;
if (action === 'delete') {
console.log(`准备删除 ID 为 ${id} 的条目`);
// 这里发送请求或操作 DOM
// deleteItem(id);
}
});
为什么这么做优雅?
你不需要给每个按钮都绑定事件,也不需要去分析 DOM 结构(比如 e.target.parentNode...)来找数据。数据就在元素身上,唾手可得。
总结与“禁忌”
HTML5 的 data-* 属性是连接 DOM 和数据的一座轻量级桥梁。
什么时候用?
- 当需要把少量数据绑定到特定 UI 元素上时。
- 当 CSS 需要根据数据状态改变样式时。
- 做事件委托需要传递参数时。
什么时候别用?(禁忌)
- 不要存储敏感数据:用户可以直接在浏览器控制台修改 DOM,千万别把 data-password 或 data-user-token 放在这。
- 不要当数据库用:别把几 KB 的 JSON 数据塞进去,那是 JS 变量或者是 IndexDB 该干的事。
- SEO 无用:搜索引擎爬虫通常不关心 data-* 里的内容,重要的文本内容还是要写在标签里。
最后一句:
代码整洁之道,始于不再乱用 Class。下次再想存个 ID,记得想起那个以 data- 开头的帅气属性。
Happy Coding! 🚀
来源:juejin.cn/post/7575119254314401818
我的app被工信部下架了,现在想重新上架
前言
这是一期没有用的干货。
不知道有多少朋友的App经历过被工信部点名并下架的……显然我经历过.
几年前我的App因为违规收集个人信息被广东省通信管理局强制下架了,虽然App本身真的没有去收集个人信息,但用了架不住某些SDK喜欢做些小动作,不管怎么样,由于当时没处置,就被以侵犯用户隐私的名义给下架了。随着最近鸿蒙挺火的,我突然想试试上架一下鸿蒙。但很遗憾,全网被下架,即使新开发的鸿蒙app也不可以,所以不得不踏上申请重新上架之路。
先说一下总的感受:确实比较繁琐一些,但广东省通信管理局确实很给力,给我不少帮助。以下经验也仅适用于因为个人隐私相关问题被下架需要重新上架。
流程
首先我是在华为应用市场中问到我应该如何重新上架,然后加到粤通管网安监测的微信,然后询问如何申请重新上架。
首先,也是废话当然是要修复既存的问题。然后,将APP的整改报告及整改后的APK发送到指定邮箱,然后等待复测即可。
需要注意的是也需要将备案信息填写到整改报告中
另外,根据我查到的资料,APP侵害用户权益的检测工作是全国APP技术检测平台(APP公共服务系统)做的,并且提供了一套APP侵害用户权益专项整治行动恢复上架流程,我贴个图如下:
实际上的流程大概和这个差不多,但都是在和通信管理局打交道。这个实际体验可能因各通信管理局不同而异。
其他
还有一些小事项,比如整改报告模板,最开始的时候通信管理局也没有和我说有模板,我也在网上照猫画虎搞的。当复测通过后,填写重新上架申请书后,需要再次上传整改报告的时候,对方给我发了一个整改模板,好在经过询问,并不需要重新写一份整改模板,直接复用之前的整改报告即可。
关于整改报告里都需要有什么可以参考一下原文:
您好,APP恢复上架/小程序解除禁搜需要您单位写一份申请。说明APP被下架/小程序被禁搜的原因、具体的问题、已整改的情况、以及企业内培训宣贯情况、未来避免出现个人信息合规问题的措施、完成备案情况、承诺未来将合规经营APP/小程序及相关业务、承诺因违背承诺导致发生违规行为自愿承担法律责任及依规处罚(下架APP/禁搜小程序、关停服务器、封锁ip等)。编写好后请盖单位公章,扫描后将电子文件发送至管局邮箱 gdca_wac_app@gd.gov.cn。这边收到申请邮件后才会继续走下一步流程,请及早提交。
最后
最后磕磕绊绊还是重新上架成功,总体虽然繁琐但还是算比较顺利。不过,尽量还是别等到下线的那一刻吧。。。如果想要广东省的整改模板可以私信我。
总结一下吧:
- APP如果被通报了,要在限定时间内完成整改并上架应用商店。要不然复测的时候在应用商店没有下载到最新版本的包,问题依旧存在肯定会被下架的;
- 不幸被下架的APP企业,也不要着急。重点要做的就是先知道自己的APP具体存在哪些问题,然后有针对性的整改;
- 不知道APP问题怎么整改或者不确定APP问题是否整改到位的话,建议找个专业的第三方APP检测机构开展隐私合规检测;
- APP全部整改到位后,根据官方发布的APP恢复上架流程图逐步操作,最后等待重新上架即可。
建议:
各企业的APP一定要根据监管的要求严格落实APP个人信息保护工作,确保APP的安全和隐私合规,不要抱有侥幸心理。
最后请大家猜猜,哪个应用市场最先解禁的?哪个到现在还没解禁。
来源:juejin.cn/post/7569377216896090163
工作中最常用的6种缓存
前言
这些年我参与设计过很多系统,越来越深刻地认识到:一个系统的性能如何,很大程度上取决于缓存用得怎么样。
同样是缓存,为何有人用起来系统飞升,有人却踩坑不断?
有些小伙伴在工作中可能遇到过这样的困惑:知道要用缓存,但面对本地缓存、Redis、Memcached、CDN等多种选择,到底该用哪种?
今天这篇文章跟大家一起聊聊工作中最常用的6种缓存,希望对你会有所帮助。
更多项目实战在我的技术网站:www.susan.net.cn/project
01 为什么缓存如此重要?
在正式介绍各种缓存之前,我们先要明白:为什么要用缓存?
想象这样一个场景:你的电商网站首页,每次打开都要从数据库中查询轮播图、热门商品、分类信息等数据。
如果每秒有1万个用户访问,数据库就要承受1万次查询压力。
// 没有缓存时的查询
public Product getProductById(Long id) {
// 每次都直接查询数据库
return productDao.findById(id); // 每次都是慢速的磁盘IO
}
这就是典型的无缓存场景。
数据库的磁盘IO速度远低于内存,当并发量上来后,系统响应变慢,数据库连接池被占满,最终导致服务不可用。
缓存的核心价值可以用下面这个公式理解:
系统性能 = (缓存命中率 × 缓存访问速度) + ((1 - 缓存命中率) × 后端访问速度)
缓存之所以能提升性能,基于两个计算机科学的基本原理:
- 局部性原理:程序访问的数据通常具有时间和空间局部性
- 存储层次结构:不同存储介质的速度差异巨大(内存比SSD快100倍,比HDD快10万倍)
从用户请求到数据返回,数据可能经过的各级缓存路径如下图所示:
理解了缓存的重要性,接下来我们逐一剖析这六种最常用的缓存技术。
02 本地缓存:最简单直接的性能提升
本地缓存指的是在应用进程内部维护的缓存存储,数据存储在JVM堆内存中。
核心特点
- 访问最快:直接内存操作,无网络开销
- 实现简单:无需搭建额外服务
- 数据隔离:每个应用实例独享自己的缓存
常用实现
1. Guava Cache:Google提供的优秀本地缓存库
// Guava Cache 示例
LoadingCache<Long, Product> productCache = CacheBuilder.newBuilder()
.maximumSize(10000) // 最大缓存项数
.expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期
.expireAfterAccess(5, TimeUnit.MINUTES) // 访问后5分钟过期
.recordStats() // 开启统计
.build(new CacheLoader<Long, Product>() {
@Override
public Product load(Long productId) {
// 当缓存未命中时,自动加载数据
return productDao.findById(productId);
}
});
// 使用缓存
public Product getProduct(Long id) {
try {
return productCache.get(id);
} catch (ExecutionException e) {
throw new RuntimeException("加载产品失败", e);
}
}
2. Caffeine:Guava Cache的现代替代品,性能更优
// Caffeine 示例(性能优于Guava Cache)
Cache<Long, Product> caffeineCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.refreshAfterWrite(1, TimeUnit.MINUTES) // 支持刷新,Guava不支持
.recordStats()
.build(productId -> productDao.findById(productId));
// 异步获取
public CompletableFuture<Product> getProductAsync(Long id) {
return caffeineCache.get(id, productId ->
CompletableFuture.supplyAsync(() -> productDao.findById(productId)));
}
适用场景
- 数据量不大(通常不超过10万条)
- 数据变化不频繁
- 对访问速度要求极致
- 如:配置信息、静态字典、用户会话信息(短期)
优缺点分析
- 优点:极速访问、零网络开销、实现简单
- 缺点:数据不一致(各节点独立)、内存限制、重启丢失
有些小伙伴在工作中可能会犯一个错误:在分布式系统中过度依赖本地缓存,导致各节点数据不一致。记住:本地缓存适合存储只读或弱一致性的数据。
03 分布式缓存之王:Redis的深度解析
当数据需要在多个应用实例间共享时,本地缓存就不够用了,这时需要分布式缓存。而Redis无疑是这一领域的王者。
Redis的核心优势
// Spring Boot + Redis 示例
@Component
public class ProductCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
private static final String PRODUCT_KEY_PREFIX = "product:";
private static final Duration CACHE_TTL = Duration.ofMinutes(30);
// 缓存查询
public Product getProduct(Long id) {
String key = PRODUCT_KEY_PREFIX + id;
// 1. 先查缓存
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
// 2. 缓存未命中,查数据库
product = productDao.findById(id);
if (product != null) {
// 3. 写入缓存
redisTemplate.opsForValue().set(key, product, CACHE_TTL);
}
return product;
}
// 使用更高效的方式:缓存空值防止缓存穿透
public Product getProductWithNullCache(Long id) {
String key = PRODUCT_KEY_PREFIX + id;
String nullKey = PRODUCT_KEY_PREFIX + "null:" + id;
// 检查是否是空值(防缓存穿透)
if (Boolean.TRUE.equals(redisTemplate.hasKey(nullKey))) {
return null;
}
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
product = productDao.findById(id);
if (product == null) {
// 缓存空值,短时间过期
redisTemplate.opsForValue().set(nullKey, "", Duration.ofMinutes(5));
return null;
}
redisTemplate.opsForValue().set(key, product, CACHE_TTL);
return product;
}
}
Redis的丰富数据结构
Redis不只是简单的Key-Value存储,它的多种数据结构适应不同场景:
| 数据结构 | 适用场景 | 示例 |
|---|---|---|
| String | 缓存对象、计数器 | SET user:1 '{"name":"张三"}' |
| Hash | 存储对象属性 | HSET product:1001 name "手机" price 2999 |
| List | 消息队列、最新列表 | LPUSH news:latest "新闻标题" |
| Set | 标签、共同好友 | SADD user:100:tags "数码" "科技" |
| Sorted Set | 排行榜、延迟队列 | ZADD leaderboard 95 "玩家A" |
| Bitmap | 用户签到、活跃统计 | SETBIT sign:2023:10 1 1 |
集群模式选择
适用场景
- 会话存储(分布式Session)
- 排行榜、计数器
- 消息队列
- 分布式锁
- 热点数据缓存
有些小伙伴在工作中使用Redis时,只把它当简单的Key-Value用,这就像用瑞士军刀只开瓶盖一样浪费。
深入理解Redis的数据结构,能让你的系统设计更优雅高效。
04 Memcached:简单高效的分布式缓存
在Redis崛起之前,Memcached是分布式缓存的首选。
虽然现在Redis更流行,但Memcached在某些场景下仍有其价值。
Memcached vs Redis 核心区别
// Memcached 客户端示例(使用XMemcached)
public class MemcachedService {
private MemcachedClient memcachedClient;
public void init() throws IOException {
// 创建客户端
memcachedClient = new XMemcachedClientBuilder(
AddrUtil.getAddresses("server1:11211 server2:11211"))
.build();
}
public Product getProduct(Long id) throws Exception {
String key = "product_" + id;
// 从Memcached获取
Product product = memcachedClient.get(key);
if (product != null) {
return product;
}
// 缓存未命中
product = productDao.findById(id);
if (product != null) {
// 存储到Memcached,过期时间30分钟
memcachedClient.set(key, 30 * 60, product);
}
return product;
}
}
两者的核心差异对比:
| 特性 | Redis | Memcached |
|---|---|---|
| 数据结构 | 丰富(String、Hash、List等) | 简单(Key-Value) |
| 持久化 | 支持(RDB/AOF) | 不支持 |
| 线程模型 | 单线程 | 多线程 |
| 内存管理 | 多种策略,可持久化 | 纯内存,重启丢失 |
| 使用场景 | 缓存+多样化数据结构 | 纯缓存 |
何时选择Memcached?
- 纯缓存场景:只需要简单的Key-Value缓存
- 超大Value存储:Memcached对超大Value支持更好
- 多线程高并发:Memcached的多线程模型在极端并发下可能表现更好
05 CDN缓存:加速静态资源的利器
有些小伙伴可能会疑惑:CDN也算缓存吗?当然算,而且是地理位置最近的缓存。
CDN的工作原理
CDN(Content Delivery Network)通过在各地部署边缘节点,将静态资源缓存到离用户最近的节点。
// 在应用中生成CDN链接
public class CDNService {
private String cdnDomain = "https://cdn.yourcompany.com";
public String getCDNUrl(String relativePath) {
// 添加版本号或时间戳,防止缓存旧版本
String version = getFileVersion(relativePath);
return String.format("%s/%s?v=%s", cdnDomain, relativePath, version);
}
// 上传文件到CDN的示例(伪代码)
public void uploadToCDN(File file, String remotePath) {
// 1. 上传到源站
uploadToOrigin(file, remotePath);
// 2. 触发CDN预热(将文件主动推送到边缘节点)
preheatCDN(remotePath);
// 3. 刷新旧缓存(如果需要)
refreshCDNCache(remotePath);
}
}
CDN缓存策略配置
# Nginx中的CDN缓存配置示例
location ~* \.(jpg|jpeg|png|gif|ico|css|js)$ {
expires 365d; # 缓存一年
add_header Cache-Control "public, immutable";
# 添加版本号作为查询参数
if ($query_string ~* "^v=\d+") {
expires max;
}
}
适用场景
- 静态资源:图片、CSS、JS文件
- 软件下载包
- 视频流媒体
- 全球访问的网站
06 浏览器缓存:最前端的性能优化
浏览器缓存是最容易被忽视但效果最直接的缓存层级。合理利用浏览器缓存,可以大幅减少服务器压力。
HTTP缓存头详解
// Spring Boot中设置HTTP缓存头
@RestController
public class ResourceController {
@GetMapping("/static/{filename}")
public ResponseEntity<Resource> getStaticFile(@PathVariable String filename) {
Resource resource = loadResource(filename);
return ResponseEntity.ok()
.cacheControl(CacheControl.maxAge(7, TimeUnit.DAYS)) // 缓存7天
.eTag(computeETag(resource)) // ETag用于协商缓存
.lastModified(resource.lastModified()) // 最后修改时间
.body(resource);
}
@GetMapping("/dynamic/data")
public ResponseEntity<Object> getDynamicData() {
Object data = getData();
// 动态数据设置较短缓存
return ResponseEntity.ok()
.cacheControl(CacheControl.maxAge(30, TimeUnit.SECONDS)) // 30秒
.body(data);
}
}
浏览器缓存的两种类型
最近为了帮助大家找工作,专门建了一些工作内推群,各大城市都有,欢迎各位HR和找工作的小伙伴进群交流,群里目前已经收集了20多家大厂的工作内推岗位。加苏三的微信:li_su223,备注:掘金+所在城市,即可进群。
最佳实践
- 静态资源:设置长时间缓存(如一年),通过文件名哈希处理更新
- 动态数据:根据业务需求设置合理缓存时间
- API响应:适当使用ETag和Last-Modified
07 数据库缓存:容易被忽略的内部优化
数据库自身也有缓存机制,理解这些机制能帮助我们写出更高效的SQL。
MySQL查询缓存(已废弃但值得了解)
-- 查看查询缓存状态(MySQL 5.7及之前)
SHOW VARIABLES LIKE 'query_cache%';
-- 在8.0之前,可以通过以下方式利用查询缓存
SELECT SQL_CACHE * FROM products WHERE category_id = 10;
InnoDB缓冲池(Buffer Pool)
这是MySQL性能的关键,缓存的是数据页和索引页。
-- 查看缓冲池状态
SHOW ENGINE INNODB STATUS;
-- 重要的监控指标
-- 缓冲池命中率 = (1 - (innodb_buffer_pool_reads / innodb_buffer_pool_read_requests)) * 100%
-- 命中率应尽可能接近100%
数据库级缓存最佳实践
- 合理设置缓冲池大小:通常是系统内存的50%-70%
- 优化查询:避免全表扫描,合理使用索引
- 预热缓存:重启后主动加载热点数据
- 监控命中率:持续优化
有些小伙伴可能会过度依赖应用层缓存,而忽略了数据库自身的缓存优化。
数据库缓存是最后一道防线,优化好它能让整个系统更健壮。
08 综合对比与选型指南
接下来,我给大家一个选型指南:
实战中的多级缓存架构
在实际的高并发系统中,我们往往会采用多级缓存策略:
// 多级缓存示例:本地缓存 + Redis
@Component
public class MultiLevelCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 一级缓存:本地缓存
private Cache<Long, Product> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(30, TimeUnit.SECONDS) // 本地缓存时间短
.build();
// 二级缓存:Redis
private static final Duration REDIS_TTL = Duration.ofMinutes(10);
public Product getProductWithMultiCache(Long id) {
// 1. 查本地缓存
Product product = localCache.getIfPresent(id);
if (product != null) {
return product;
}
// 2. 查Redis
String redisKey = "product:" + id;
product = (Product) redisTemplate.opsForValue().get(redisKey);
if (product != null) {
// 回填本地缓存
localCache.put(id, product);
return product;
}
// 3. 查数据库
product = productDao.findById(id);
if (product != null) {
// 写入Redis
redisTemplate.opsForValue().set(redisKey, product, REDIS_TTL);
// 写入本地缓存
localCache.put(id, product);
}
return product;
}
}
09 缓存常见问题与解决方案
在使用缓存的过程中,我们不可避免地会遇到一些问题:
1. 缓存穿透
问题:大量请求查询不存在的数据,绕过缓存直接击穿数据库。
解决方案:
// 缓存空值方案
public Product getProductSafe(Long id) {
String key = "product:" + id;
String nullKey = "product:null:" + id;
// 检查空值标记
if (redisTemplate.hasKey(nullKey)) {
return null;
}
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product != null) {
return product;
}
product = productDao.findById(id);
if (product == null) {
// 缓存空值,短时间过期
redisTemplate.opsForValue().set(nullKey, "", Duration.ofMinutes(5));
return null;
}
redisTemplate.opsForValue().set(key, product, Duration.ofMinutes(30));
return product;
}
2. 缓存雪崩
问题:大量缓存同时过期,请求全部打到数据库。
解决方案:
// 差异化过期时间
private Duration getRandomTTL() {
// 基础30分钟 + 随机0-10分钟
long baseMinutes = 30;
long randomMinutes = ThreadLocalRandom.current().nextLong(0, 10);
return Duration.ofMinutes(baseMinutes + randomMinutes);
}
3. 缓存击穿
问题:热点Key过期瞬间,大量并发请求同时查询数据库。
解决方案:
// 使用互斥锁(分布式锁)
public Product getProductWithLock(Long id) {
String key = "product:" + id;
Product product = (Product) redisTemplate.opsForValue().get(key);
if (product == null) {
// 尝试获取分布式锁
String lockKey = "lock:product:" + id;
boolean locked = redisTemplate.opsForValue()
.setIfAbsent(lockKey, "1", Duration.ofSeconds(10));
if (locked) {
try {
// 双重检查
product = (Product) redisTemplate.opsForValue().get(key);
if (product == null) {
product = productDao.findById(id);
if (product != null) {
redisTemplate.opsForValue()
.set(key, product, Duration.ofMinutes(30));
}
}
} finally {
// 释放锁
redisTemplate.delete(lockKey);
}
} else {
// 未获取到锁,等待后重试
try { Thread.sleep(50); }
catch (InterruptedException e) { Thread.currentThread().interrupt(); }
return getProductWithLock(id); // 递归重试
}
}
return product;
}
10 总结
通过这篇文章,我们系统地探讨了工作中最常用的六种缓存技术。
每种缓存都有其独特的价值和应用场景:
- 本地缓存:适合进程内、变化不频繁的只读数据
- Redis:功能丰富的分布式缓存,适合大多数共享缓存场景
- Memcached:简单高效的分布式缓存,适合纯Key-Value场景
- CDN缓存:加速静态资源,提升全球访问速度
- 浏览器缓存:最前端的优化,减少不必要的网络请求
- 数据库缓存:最后一道防线,优化数据库访问性能
缓存使用的核心原则可以总结为以下几点:
- 分级缓存:合理利用多级缓存架构
- 合适粒度:根据业务特点选择缓存粒度
- 及时更新:设计合理的缓存更新策略
- 监控告警:建立完善的缓存监控体系
有些小伙伴在工作中使用缓存时,容易陷入两个极端:要么过度设计,所有数据都加缓存;要么忽视缓存,让数据库承受所有压力。
我们需要懂得在合适的地方使用合适的缓存,在性能和复杂性之间找到最佳平衡点。
记住,缓存不是银弹,而是工具箱中的一件利器。
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的10万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。
更多项目实战在我的技术网站:http://www.susan.net.cn/project
来源:juejin.cn/post/7583980250733559871
做好自己的份内工作,等着被裁
先声明,本文不是贩卖焦虑,只是自己的一点拙见,没有割韭菜的卖课、副业、保险广告,请放心食用。
2022 年初,前司开始了轰轰烈烈的「降本增笑」运动,各部门严格考核机器成本和预算。当然,最重要的还是「开猿节流」。
幸好,我所在部门是盈利的,当时几乎没有人受到波及。
据说,现在连餐巾纸都从三层的「维达」换成两层的「心心相印」了,号称年节约成本 100 多万。我好奇的是,擦屁股时多少会沾点 💩 吧?这下,真是名正言顺的 💩 山代码了。
2022 年 7 月底,因为某些原因,结束 10 年北漂回老家,换了个公司继续搬砖。
2023 年,春节后不久,现司搞「偷袭」,玩起了狼人杀,很多小伙伴被刀:
清晨接到电话通知,上午集体开会,IT 收回权限,中午滚蛋
好在是头一回,补偿非常可观,远超法律规定的「N+1」。
2024 年,平安夜,无事发生。
2025 年 1 月,公司年会,趣味运动会,有个项目是「财源滚滚」,下图这样的:

有个参赛的老哥调侃道,这项目名字不吉利啊,不应该参加的。无巧不成书,年后他被刀了。。。
这次的规模远小于 2023 年,但 2025 年也不太平,「脉脉」上陆续有人说被刀或者不续签,真假未知。
实话说,我之前从未担心过被裁,毕竟:
名校硕士,经历多个大厂,有管理经验
热爱编程,工作认真负责,常年高绩效
但是,随着 AI 的快速迭代,我现在感觉自己随时可能被刀了。AI 能胜任 log 分析、新功能开发、bug 修复等绝大部分日常工作,而且都完成的很好。再配合 AI 自己写的MCP,效率肉眼可见的提高。
亲身体验,数百人开发的千万行代码级别的项目,混合了Java/Kotlin/OC/C++/Python等各种语言。跟Cursor聊了几句,它就找到原因并帮忙修复了。如果是自己看代码、问人、加 log、编译,至少得半个小时。
那还要码农干啥呢?即使是留下来背锅,也要不了这么多啊。
距离上次「狼人杀 」,三年之期已到。今年会有「狼人杀 2.0」吗?我还能平稳落地吗?
无所谓了,我早已准备好后路:

头盔和衣服真是我买的,还有手套未入镜,我感觉设计很漂亮,等天气暖和后,当骑行服穿。
汽车,小踏板,大踏板,足以覆盖滴滴、外卖、闪送三大朝阳行业。家里还有个小电驴,凑合能放到后备箱,承接代驾业务问题不大。
以上,虽然是开玩笑,但我对「是否被刀、何时被刀」,真的是无所谓。因为:
一个人的命运啊,当然要靠自我奋斗,但也要考虑历史的进程
公司为了长远的发展,刀人以降低成本,再用 AI 来提高效率,求得股价长红。对此,我十分理解,换我当老板,也会这么干。
作为牛马,想太多没用,我们左右不了这些事。不夸张的说,99.9999% 的码农是不可能干到退休的,和死亡一样,被刀只是早晚的事。更扎心的是:
人不是老了才会死,而是随时会死
当下的工作也一样,并不是摸鱼或者捅娄子才会被刀,而是随时会被刀,与个人的努力、绩效关系不大。常年健身的肌肉男,也可能猝死,只是概率低点,并不是免死金牌。
生命,从受精的那一刻起,就在走向终点。工作,从入职的那一刻起,就在走向(主动/被动)离职。
所以,虽然我现在感觉自己随时可能被 AI 替代,但我的心态一直都没变,就是标题所言:
做好自己的份内工作,等着被裁
不是消极怠工,我始终认真完成每一项任务,该加班加班。并非为了绩效,是因为自己的责任心,要对的起工资。至于公司哪天让我滚蛋,我决定不了,更改变不了。就像对待死亡一样,坦然接受之,给够补偿就好。

对于 AI,还想再啰嗦两句:
- 虽然 AI 很牛逼,但最终还是需要人来判断代码的对错。此时,工程师的价值就体验出来了,所以 AI 是帮我干活的小弟,而不是竞争对手。
- AI 扩大了我们的能力边界,人人都可以是前端、后端、客户端、UI 设计全通的「全栈工程师」,至少可以是「全沾工程师」,「雨露均沾」的沾。
滚蛋之后呢?我不知道,现在有多少公司愿意招 40 岁高龄码农?据说前司招聘 35 岁普通员工都要 VP 审批了,真是小刀剌屁股,开了眼了。
好在,我家人的物质欲望极低,对衣服、手机、汽车没有任何追求,老婆不用化妆品和护肤品,也没买过一个包。即使不上班,积蓄也能撑一段时间。
所以,强烈建议当前北上广深拿高薪的老哥老妹们,除非万不得已,千万不要像我一样断崖式降薪回老家。趁年轻,搞钱比啥都重要。

对了,我目前有两个利用自身优势的基于 AI 的创业方向。网友们帮忙把把关,如果哪天真失业了,看能否拉到几个亿的风投,谢谢!
- 偏胖圆脸,AI 加点络腮胡,再买几双白袜子
- 身高 180,AI 换个美女脸,黑丝高跟大长腿

来源:juejin.cn/post/7593771861323726874
离职转AI独立开发半年,我感受到了真正的生活
离职转AI独立开发半年,我感受到了真正的生活
我的新产品:code.lucids.top/
开场白:一个不被理解的决定

2022年12月的最后一天,我收拾了自己的小盒子,里面装着我在这家互联网公司工作的所有痕迹:一个定制水杯,几本技术书籍,和一摞写满代码思路的便利贴。HR部门的小姐姐看着我签完最后一份文件,表情有些复杂:"小张,你才来半年就走,真的想好了吗?这个时候辞职,外面行情不好..."
我点点头,没多解释。如何向别人解释我这个2000年出生的"孩子",毕业仅仅半年就对光鲜的互联网工作心生倦意?如何解释我不想再每天凌晨两点被产品经理的消息惊醒,然后爬起来改几行代码?如何解释我想追求的不只是一份体面的工资和一个看起来不错的头衔?
当我走出公司大楼,北京的冬风刮得我脸生疼。我的储蓄只够支撑我半年,而我计划做的事情——成为一名AI独立开发者——在大多数人眼中无异于天方夜谭。"你疯了吧?现在的独立开发者,有几个能养活自己的?"这是我最好朋友听到我计划时的反应。
事实证明,他错了。我也曾经错了。而现在,当我坐在自己选择的咖啡馆,以自己喜欢的节奏工作,看着用户数突破10,000的后台数据,我知道这半年的挣扎、焦虑和不安都是值得的。
职场困境:我在互联网大厂的日子
回想起入职的第一天,一切都充满希望。校招拿到知名互联网公司的offer,年薪30万,比许多同学高出不少。父母骄傲地向亲戚们宣布他们的儿子"找到了好工作"。
然而现实很快给了我当头一棒。
我被分到一个负责内部工具开发的小组。领导在入职第一天就明确告诉我:"小张,我们这个组不是核心业务,资源有限,但任务不少,你得做好加班的准备。"
第一个月,适应期,我每天工作10小时,感觉还能接受。到了第二个月,一个重要项目启动,我开始习惯每天凌晨回家,第二天早上9点又准时出现在公司。最夸张的一次,我连续工作了38个小时,只为了赶一个莫名其妙被提前的deadline。
# 当时的我就像这段无限循环的代码
while True:
wake_up()
go_to_work()
coding_till_midnight()
get_emergency_task()
sleep(2) # 只睡2小时
工作内容也让我倍感挫折。作为一名热爱技术的程序员,我希望能够参与有挑战性的项目,学习前沿技术。但现实是,我大部分时间都在做重复性的维护工作,修复一些简单但繁琐的bug,或者应对产品经理们不断变化的需求。
我感到自己正在成为一个"代码工具人",一个可以被随时替换的齿轮。我的创造力,我对技术的热情,我想为这个世界带来一些改变的梦想,都在日复一日的996中渐渐磨灭。
转折点:AI浪潮中看到的希望
2022年底,ChatGPT横空出世。作为一个技术爱好者,我第一时间注册了账号,体验了这个令人震惊的产品。我记得那天晚上,我熬夜到凌晨三点,不断地与ChatGPT对话,测试它的能力边界。
"这太不可思议了,"我对自己说,"这将改变一切。"
随后几周,我利用所有空闲时间(其实并不多)研究OpenAI的API文档,尝试构建一些简单的应用。我发现,大语言模型(LLM)并不像我想象的那样遥不可及,即使是一个普通开发者,只要理解其工作原理,也能基于它创造出有价值的产品。
同时,我开始关注独立开发者社区。我惊讶地发现,有不少人依靠自己开发的小产品,实现了不错的收入。虽然他们中的大多数人都经历了长期的积累,但AI技术的爆发似乎提供了一个弯道超车的机会。
这个想法越来越强烈,直到有一天晚上,当我又一次被加到一个紧急项目里,领导发来消息:"小张,这个需求很紧急,今晚能上线吗?"
我望着窗外的夜色,突然感到一阵前所未有的清晰。
我回复道:"可以,这是我在公司的最后一个项目了。"
第二天,我提交了辞职申请。
技术探索:从零开始的AI学习之路
辞职后的第一个月,我给自己制定了严格的学习计划。每天早上6点起床,先锻炼一小时,然后开始我的"AI课程"。
首先,我需要理解大语言模型的基本原理。虽然我有编程基础,但NLP和深度学习对我来说仍是比较陌生的领域。我从《Attention is All You Need》这篇奠定Transformer架构的论文开始,通过各种在线资源,逐步理解了当代大语言模型的工作机制。
# 简化的Transformer注意力机制示例
def scaled_dot_product_attention(query, key, value, mask=):
# 计算注意力权重
matmul_qk = tf.matmul(query, key, transpose_b=True)
# 缩放
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 添加掩码(可选)
if mask is not :
logits += (mask * -1e9)
# softmax归一化
attention_weights = tf.nn.softmax(logits, axis=-1)
# 应用注意力权重
output = tf.matmul(attention_weights, value)
return output, attention_weights
然后,我需要掌握如何有效地利用OpenAI、Anthropic等公司提供的API。这包括了解Prompt Engineering的技巧,学会如何构建有效的提示词,以及如何处理模型输出的后处理工作。
我还深入研究了向量数据库、检索增强生成(RAG)等技术,这些对于构建基于知识的AI应用至关重要。
这个余弦相似度公式成为了我日常工作的一部分,用于计算文本嵌入向量之间的相似性。
同时,我不断实践、不断失败、不断调整。我记得有一周,我几乎每天睡眠不足5小时,只为解决一个模型幻觉问题。但与公司工作不同的是,这种忙碌源于我的热情和对问题的好奇,而非外部压力。
产品孵化:从创意到实现
学习的同时,我开始思考自己的产品定位。在观察市场和分析自身技能后,我决定开发一款面向内容创作者的AI助手,我将其命名为"创作魔法师"。
这个产品的核心功能是帮助博主、自媒体人和营销人员高效创作内容。与市面上的通用AI不同,它专注于内容创作流程:从选题分析、结构规划、初稿生成到细节优化和SEO改进,提供全流程支持。
产品开发过程中,我遇到了许多挑战:
- 技术架构选择:作为独立开发者,资金有限,我需要在功能与成本间找平衡。最终我选择了Next.js + TailwindCSS搭建前端,Node.js构建后端,MongoDB存储数据,Pinecone作为向量数据库存储文档嵌入向量。
- 模型优化:为了降低API调用成本,我设计了一套智能路由系统,根据任务复杂度自动选择不同的模型,简单任务用更经济的模型,复杂任务才调用高端模型。
- 用户体验设计:没有设计团队,我自学了基础UI/UX知识,参考优秀产品,反复调整界面直到满意。
- 运营与推广:这对我这个技术人来说是最大挑战。我学会了编写有吸引力的产品描述,设计落地页,甚至尝试了简单的SEO优化。
最艰难的时刻是产品上线后的第一个月。用户增长缓慢,每天只有个位数的新注册。我开始怀疑自己的决定,甚至一度考虑放弃,重新找工作。
转机:从10个用户到10,000用户
转机出现在上线后的第二个月。一位拥有20万粉丝的自媒体创作者使用了我的产品,对效果非常满意,在他的平台上分享了使用体验。这篇分享在创作者圈内引起了不小的反响。
24小时内,我的注册用户从原来的不到200人猛增至1500多人。服务器一度崩溃,我熬夜进行紧急扩容和优化。这次意外的曝光让我意识到,产品定位是正确的,市场需求确实存在。
接下来,我调整了运营策略:
- 主动联系内容创作者,提供免费试用,换取真实反馈和可能的推荐。
- 根据用户反馈快速迭代产品功能,每周至少发布一次更新。
- 建立用户社区,鼓励用户分享使用技巧,相互帮助。
- 编写详细的使用教程和最佳实践指南,降低用户上手难度。
// 用户增长追踪系统的一部分
function trackUserGrowth() {
const date = new Date().toISOString().split('T')[0];
db.collection('metrics').updateOne(
{ date: date },
{
$inc: {
newUsers: 1,
totalImpressions: userSource.impressions || 0
},
$set: {
lastUpdated: new Date()
}
},
{ upsert: true }
);
}
三个月后,用户数突破5,000;半年后,达到10,000。更令人欣慰的是,付费转化率远超我的预期,达到了8%左右,而行业平均水平通常在2-3%。
我分析了成功原因:
- 产品聚焦特定痛点:不追求通用性,而是深入解决内容创作者的具体问题。
- 及时响应用户需求:独立开发的优势是决策链短,能快速调整方向。
- 社区效应:用户之间的口碑传播形成了良性循环。
- 个性化服务:我经常亲自回复用户问题,提供定制化建议,这在大公司很难做到。
财务自由:从赤字到收支平衡
谈到收入模式,我采用了"免费+订阅"的策略:
- 基础功能完全免费,足以满足普通用户的需求
- 高级功能(如批量处理、高级模板、深度分析等)需要订阅
- 提供月度计划(49元)和年度计划(398元,约33元/月)
最初几个月,收入微乎其微。我记得第一个月的收入仅有287元,而我在公司的月薪是25,000元。差距之大,让我一度怀疑自己的决定。
但随着用户增长,情况逐渐改善。第三个月收入突破5,000元,第四个月达到12,000元,第六个月——也就是我离职半年后,月收入达到了23,500元,基本与我原来的工资持平。
考虑到我现在的生活成本降低了(不需要租住在北京市中心的高价公寓,不需要每天通勤),实际上我的生活质量反而提高了。
更重要的是,这些收入是真正属于我的,不依赖于任何公司的评价和KPI。我建立了自己的"被动收入引擎",它可以在我睡觉时继续为我工作。
生活平衡:找回被工作吞噬的自我
收入只是故事的一部分。对我来说,最大的变化是生活方式的改变。
在互联网公司工作时,我的生活可以用一句话概括:工作即生活。我几乎没有个人时间,健康状况逐渐恶化,社交圈萎缩到只剩同事,爱好被束之高阁。
成为独立开发者后,我重新掌控了自己的时间:
- 合理作息:我不再熬夜加班,保持每天7-8小时高质量睡眠。
- 定期锻炼:每天至少运动一小时,半年下来体重减轻10kg,体脂率降低5%。
- 地点自由:我可以在家工作,也可以去咖啡馆,甚至尝试了几次"工作旅行",边旅游边维护产品。
- 深度学习:不再为了应付工作而学习,而是追随个人兴趣深入研究技术。
- 重拾爱好:我重新开始弹吉他,参加了当地的音乐小组,结识了一群志同道合的朋友。
这种生活方式让我找回了工作的意义——工作是为了更好的生活,而不是生活为了工作。我的创造力和工作热情反而因此提升,产品迭代速度和质量都超出了预期。
技术反思:AI时代的个人定位
在这半年的独立开发经历中,我对AI技术和个人发展有了更深的思考。
首先,大模型时代确实改变了软件开发的范式。传统开发模式是"写代码解决问题",而现在更多的是"设计提示词引导AI解决问题"。这不意味着编程技能不重要,而是编程与AI引导能力的结合变得越来越重要。
# 传统开发方式
def analyze_sentiment(text):
# 复杂的NLP算法实现
words = tokenize(text)
scores = calculate_sentiment_scores(words)
return determine_overall_sentiment(scores)
# AI时代的开发方式
def analyze_sentiment_with_llm(text):
prompt = f"""
分析以下文本的情感倾向,返回'正面'、'负面'或'中性'。
只返回分类结果,不要解释。
文本: {text}
"""
result = llm_client.generate(prompt, max_tokens=10)
return result.strip()
其次,我认识到技术民主化的力量。曾经需要一个团队才能完成的项目,现在一个人借助AI工具也能完成。这为独立开发者创造了前所未有的机会,但也意味着差异化和创新变得更加重要。
最后,我发现真正的核心竞争力不在于熟悉某项技术,而在于解决问题的思维方式和对用户需求的理解。技术工具会不断更新迭代,但洞察问题和设计解决方案的能力将长期有效。
写给迷茫的年轻人
回顾这半年的经历,我想对那些和当初的我一样迷茫的年轻人说几句话:
- 公司经历有价值,但不是唯一路径:在大公司工作能积累经验和人脉,但不要把它视为唯一选择。如果环境压抑了你的创造力和热情,寻找改变是勇敢而非逃避。
- 技术浪潮创造机会窗口:AI等新技术正在重构行业,为个人提供了"弯道超车"的机会。保持开放心态,持续学习,你会发现比想象中更多的可能性。
- 找到可持续的节奏:成功不在于短期的爆发,而在于长期的坚持。设计一种既能推动目标实现又不会消耗自己的工作方式,才能走得更远。
- 用户价值胜过技术炫耀:最成功的产品往往不是技术最先进的,而是最能解决用户痛点的。专注于创造真正的价值,而不仅仅是展示技术能力。
- 享受过程,而非仅追求结果:如果你只关注最终目标而忽视日常体验,即使达到目标也可能感到空虚。真正的成功包含了对过程的享受和个人成长。
未来展望:持续进化的旅程
现在,我站在新的起点上。"创作魔法师"只是我旅程的第一步,我已经开始规划下一个产品,瞄准了另一个我认为有潜力的细分市场。
与此同时,我也在考虑如何扩大团队规模。虽然独立开发有其魅力,但有些想法需要更多元的技能组合才能实现。我计划在未来半年内招募1-2名志同道合的伙伴,组建一个小而精的团队。
技术上,我将继续深入研究大模型的微调和部署技术。随着开源模型的进步,在特定领域微调自己的模型变得越来越可行,这将是我产品的下一个竞争优势。
生活方面,我正计划一次为期两个月的"数字游牧"之旅,边旅行边工作,探索更多可能的生活方式。
路上会有挑战,也会有挫折,但我不再惧怕。因为我知道,真正的自由不在于没有困难,而在于面对困难时仍能按自己的意愿选择前进的方向。
当我在咖啡馆工作到黄昏,看着窗外的夕阳,我常常感到一种难以言喻的满足感。这种感觉告诉我,我正在正确的道路上——一条通往真正生活的道路。
如果你也在考虑类似的选择,希望我的故事能给你一些启发。记住,每个人的路都不同,重要的是找到属于自己的节奏和方向。
在这个AI加速发展的时代,机会前所未有,但终究,技术只是工具,生活才是目的。
来源:juejin.cn/post/7486788421932400652
为什么Java里面,Service层不直接返回Result对象?
前言
昨天在Code Review时,我发现阿城在Service层直接返回了Result对象。
指出这个问题后,阿城有些不解,反问我为什么不能这样写。
于是我们展开了一场技术讨论(battle 🤣)。
讨论过程中,我发现这个看似简单的设计问题,背后其实涉及分层架构、职责划分、代码复用等多个重要概念。
与其让这次讨论的内容随风而去,不如整理成文,帮助更多遇到同样困惑的朋友理解原因。
知其然,更知其所以然。
耐心看完,你一定有所收获。
职责分离原则
在传统的MVC架构中,Service层和Controller层各自承担着不同的职责。
Service层负责业务逻辑的处理,而Controller层负责HTTP请求的处理和响应格式的封装。
当我们将数据包装成 Result 对象的任务交给 Service 层时,意味着 Service 层不再单纯地处理业务逻辑,而是牵涉到了数据处理和响应的部分。
这样会导致业务逻辑与表现逻辑的耦合,降低了代码的清晰度和可维护性。
看一个不推荐的写法:
@Service
publicclass UserService {
public Result<User> getUserById(Long id) {
User user = userMapper.selectById(id);
if (user == null) {
return Result.error(404, 用户不存在);
}
return Result.success(user);
}
}
@RestController
publicclass UserController {
@Autowired
private UserService userService;
@GetMapping("/user/{id}")
public Result<User> getUser(@PathVariable Long id) {
return userService.getUserById(id);
}
}
上面代码中,Service 层不仅负责从数据库获取用户信息,还直接处理了返回的结果。
如果我们需要改变返回的格式,或者进行错误信息的标准化,所有 Service 层的方法都需要修改。这样会导致代码的高耦合。
相比之下,以下做法将展示逻辑留给 Controller 层,保证了业务逻辑的纯粹性:
@Service
publicclass UserService {
public User getUserById(Long id) {
User user = userMapper.selectById(id);
if (user == null) {
thrownew BusinessException(用户不存在);
}
return user;
}
}
@RestController
publicclass UserController {
@Autowired
private UserService userService;
@GetMapping("/user/{id}")
public Result<User> getUser(@PathVariable Long id) {
User user = userService.getUserById(id);
return Result.success(user);
}
}
让每一层都专注于自己的职责。
可复用性问题
当Service层返回Result时,会严重影响方法的可复用性。
假设我们有一个订单服务需要调用用户服务:
@Service
publicclass OrderService {
@Autowired
private UserService userService;
public void createOrder(Long userId, OrderDTO orderDTO) {
// 不推荐的方式:需要解包Result
Result<User> userResult = userService.getUserById(userId);
if (!userResult.isSuccess()) {
thrownew BusinessException(userResult.getMessage());
}
User user = userResult.getData();
// 后续业务逻辑
validateUserStatus(user);
// ...
}
}
这种写法有个很明显的问题。
OrderService 作为另一个业务服务,业务之间的调用本来应该简单直接,但使用 Result 带来了两个问题:
- 不知道 Result 里到底包含什么,还得去查看代码里面的实现,写起来麻烦。
- 还需要额外判断 Result 的状态,增加了不必要的复杂度。
如果是调用第三方外部服务,需要这种包装还能理解,但在自己业务之间互相调用时,完全没必要这样做。
如果Service返回纯业务对象:
@Service
public class OrderService {
@Autowired
private UserService userService;
public void createOrder(Long userId, OrderDTO orderDTO) {
// 推荐的方式:直接获取业务对象
User user = userService.getUserById(userId);
// 后续业务逻辑
validateUserStatus(user);
// ...
}
}
代码变得简洁且符合直觉。
业务层之间直接传递业务对象,保持简单和清晰。
异常处理机制
有些 Service 层在业务判断失败后,会直接返回 Result.fail(xxx) 这样的代码,例如:
public Result<Void> createOrder(Long userId, OrderDTO orderDTO) {
if (userId == null) {
return Result.fail("用户ID不能为空");
}
// 后续业务逻辑
return Result.success();
}
这种做法有几个问题:
- 重复的错误处理: 每个方法都得写一大堆类似的错误判断代码,增加了代码量。
- 错误分散: 错误处理分散在每个方法里,如果需要改进错误逻辑,要在多个地方修改,麻烦且容易出错。
而如果我们通过抛出异常并结合全局异常处理来统一处理错误,例如:
public void createOrder(Long userId, OrderDTO orderDTO) {
if (userId == null) {
throw new BusinessException("用户ID不能为空");
}
// 后续业务逻辑
}
再通过全局异常捕获来转换为 Result:
@RestControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public Result<Void> handleBusinessException(BusinessException e) {
return Result.error(400, e.getMessage());
}
@ExceptionHandler(Exception.class)
public Result<Void> handleException(Exception e) {
log.error("系统异常", e); // 这里可以查看堆栈信息
return Result.error(500, "系统繁忙");
}
}
这样做的好处是:
减少重复代码:业务方法不再需要写重复的错误判断,代码更简洁。
- 集中错误处理: 错误处理集中在一个地方,修改时只需修改全局异常处理器,不用改动每个 Service 层方法。
- 业务与错误分离: 业务逻辑专注处理核心功能,错误处理交给统一的机制,代码更加清晰易懂。
而且异常可以携带更丰富的上下文信息,如果业务侧需要时,可以带上堆栈信息,便于一些问题的定位。
测试便利性
Service层返回业务对象而不是Result时,能够大大提升单元测试的便利性:
@SpringBootTest
publicclass UserServiceTest {
@Autowired
private UserService userService;
@Test
public void testGetUserById() {
// 推荐的方式:直接断言业务对象
User user = userService.getUserById(1L);
assertNotNull(user);
assertEquals(张三, user.getName());
}
@Test
public void testGetUserById_NotFound() {
// 推荐的方式:断言抛出异常
assertThrows(BusinessException.class, () -> {
userService.getUserById(999L);
});
}
}
如果Service返回Result,测试代码则需要写得更复杂:
@Test
public void testGetUserById() {
// 不推荐的方式:需要解包Result
Result<User> result = userService.getUserById(1L);
assertTrue(result.isSuccess());
assertNotNull(result.getData());
assertEquals(张三, result.getData().getName());
}
测试代码变得莫名冗长,还得去关注响应结构,这并不是Service层测试的关注点。
Service 层本应专注于业务逻辑,测试也应该直接验证业务数据。
领域驱动设计角度
再换个角度。
从领域驱动设计(DDD)的角度来看,Service 层属于应用层或领域层,应该使用领域语言来表达业务逻辑。
而 Result 是基础设施层的概念,代表 HTTP 响应格式,不应该污染领域层。
例如,考虑转账业务:
@Service
publicclass TransferService {
public TransferResult transfer(Long fromAccountId, Long toAccountId, BigDecimal amount) {
Account fromAccount = accountRepository.findById(fromAccountId);
Account toAccount = accountRepository.findById(toAccountId);
fromAccount.deduct(amount);
toAccount.deposit(amount);
accountRepository.save(fromAccount);
accountRepository.save(toAccount);
returnnew TransferResult(fromAccount, toAccount, amount);
}
}
在这个例子中,TransferResult 是一个领域对象,代表了转账的结果,包含了与业务相关的意义,而不是一个通用的 HTTP 响应封装 Result。
这种做法更符合领域模型的表达,体现了领域层的职责——处理业务逻辑,而不是涉及 HTTP 响应格式的细节。
接口适配的灵活性
当 Service 层返回纯粹的业务对象时,Controller 层可以根据不同的接口需求灵活封装响应:
@RestController
@RequestMapping("/api")
publicclass UserController {
@Autowired
private UserService userService;
// REST接口返回Result
@GetMapping("/user/{id}")
public Result<User> getUser(@PathVariable Long id) {
User user = userService.getUserById(id);
return Result.success(user);
}
// GraphQL接口直接返回对象
@QueryMapping
public User user(@Argument Long id) {
return userService.getUserById(id);
}
// RPC接口返回自定义格式
@DubboService
publicclass UserRpcServiceImpl implements UserRpcService {
public UserDTO getUserById(Long id) {
User user = userService.getUserById(id);
return convertToDTO(user);
}
}
}
同一个Service方法可以被不同类型的接口复用,每个接口根据自己的协议要求封装响应。
强行使用 Result 会导致接口的适配性变差,无法根据不同协议的需求灵活定制响应格式。
灵活性反而丢失了。
事务边界清晰
Service 层通常是事务边界所在,当 Service 返回业务对象时,事务的语义更加清晰:
@Service
publicclass OrderService {
@Transactional
public Order createOrder(OrderDTO orderDTO) {
Order order = new Order();
// 设置订单属性
orderMapper.insert(order);
// 扣减库存
inventoryService.deduct(orderDTO.getProductId(), orderDTO.getQuantity());
return order;
}
}
在这个例子中,事务是围绕 Service 层的方法展开的,@Transactional 注解确保在业务逻辑执行失败时,事务会回滚。因为方法正常返回时,事务会提交;如果抛出异常,事务会回滚,事务的边界非常明确。
如果 Service 返回的是 Result,很难界定事务是否应该回滚。比如:
public Result<Order> createOrder(OrderDTO orderDTO) {
Order order = new Order();
// 设置订单属性
orderMapper.insert(order);
// 扣减库存
Result<Void> inventoryResult = inventoryService.deduct(orderDTO.getProductId(), orderDTO.getQuantity());
if (!inventoryResult.isSuccess()) {
return Result.fail("库存不足");
}
return Result.success(order);
}
在这种情况下,如果库存不足,虽然 Result 返回失败信息,但事务并不会回滚,可能会导致数据不一致,反而还得额外去抛出异常。
而通过抛出异常的方式,事务的回滚语义非常清晰:异常抛出则回滚,方法正常返回则提交,这种设计确保了事务的边界更加明确,避免了潜在的数据一致性问题。
来源:juejin.cn/post/7610681694149148687
一文搞懂 SEO 全流程技术
在现代 Web 开发中,技术 SEO 是确保网站能够被搜索引擎正确索引和排名的关键。
不做 SEO:
网站处于隐形状态:除非用户直接输入网站,否则没人能通过搜索找到你的网站收录混乱:搜索引擎不收录你的页面,或是收录的无效页面仅能靠付费推广:想要流量只能付费做广告或者社交媒体推广裸链接:用户分享网址时只能是蓝色 URL 链接,可能被识别为垃圾信息品牌信任度:用户难以搜索到网站,降低网站的可信度
做了 SEO:
主动被发现:搜索关键词时你的网站会得到推荐,增加流量收录全面:搜索引擎知道网站有哪些页面,网站内容更新后会很快被搜索到免费且持久:搜索引擎会长期维护你的网站,排名稳定后,会有源源不断的流量优雅的展示封面:分享会展示精美的网站封面,提升用户点击率技术红利:做了 SEO,会优化内容结构,变相提升网站的技术背书效应:用户潜意识里认为排在前面的网站更权威、更正规
SEO 这么有用,但一般人的实现却是:
- 加个
<title>标签 - 加几个
<meta>关键词
真正有用、高效的 SEO 要怎么做呢?
SEO 核心概念
先来了解一下 SEO 的一些核心概念。

sitemap.xml 是什么?
- 作用:给搜索引擎指路
- 功能:
- 列出你希望被收录的所有页面
- 告诉页面更新时间、优先级
- 示例
<url>
<loc>https://xxx.com/page1</loc>
<lastmod>2026-02-12</lastmod>
<priority>0.8</priority>
</url>
robots.txt 是什么?
- 作用:给搜索引擎定规矩
- 功能:
- 禁止某些爬虫
- 禁止爬某些目录 / 页面
- 告诉爬虫去哪里找 sitemap
- 示例
User-agent: *
Disallow: /admin/
Disallow: /private.html
Allow: /
Sitemap: https://xxx.com/sitemap.xml

Schema.org 是什么?
- 作用
给 Google、百度、必应 等搜索引擎看的,告诉它们:
- 这是什么内容(文章?产品?视频?人?)
- 标题是什么
- 发布时间
- 作者
- 评分
- 目录结构
- 功能
- 让搜索结果更美观、更丰富(显示标题、图、时间、作者)
- 让搜索引擎更懂你页面内容
- 提升 SEO 效果
- 示例
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "文章标题",
"author": { "@type": "Person", "name": "作者" }
}
</script>
OG Image 是什么?
当你把网页分享到微信、QQ、抖音、小红书、Discord、Facebook时,显示的那张封面图,就是 OG Image。
- 作用
- 控制分享出去长什么样
- 没有它,分享可能没封面图、显示效果差
- 功能
- 优化分享效果
- 提升社交媒体分享的点击率和用户互动
- 示例
<meta property="og:title" content="标题" />
<meta property="og:description" content="描述" />
<meta property="og:image" content="https://xxx.com/cover.jpg" />

Nuxt SEO
Nuxt SEO 是一套 SEO 元模块,其中包含多个模块:
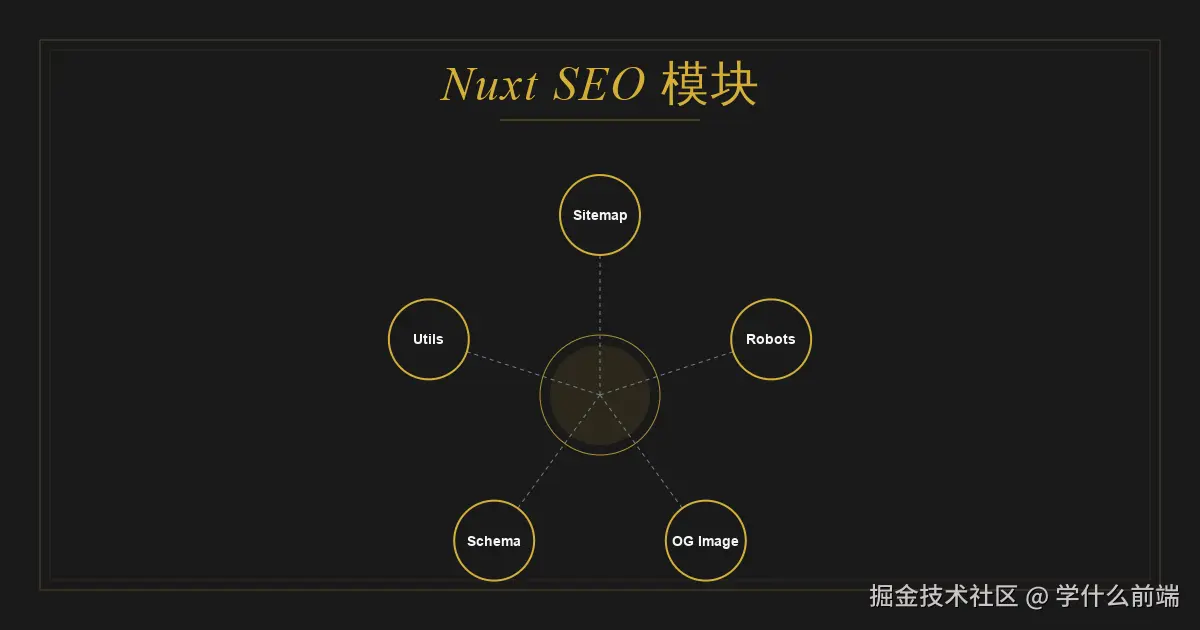
- @nuxtjs/sitemap: 智能生成站点地图
- @nuxtjs/robots: 管理爬虫访问规则
- nuxt-og-image: 动态生成社交分享图片
- nuxt-schema-org: 注入结构化数据 (JSON-LD)
- nuxt-seo-utils: 提供通用的 SEO 工具函数
核心优势:
- 自动化:自动生成
robots.txt、sitemap.xml和og:image。 - 最佳实践:默认遵循
Google等搜索引擎的推荐标准。 - 开发体验:与
Nuxt DevTools深度集成,提供实时的 SEO 调试能力。
快速开始
了解完以上概念后,接下来开始提升网站的 SEO 效果。
安装
pnpm i @nuxtjs/seo
配置
在 nuxt.config.ts 中进行配置。最重要的是设置 site.url,它是生成 Sitemap 和 Canonical URL 的基础。
export default defineNuxtConfig({
modules: ["@nuxtjs/seo"],
site: {
url: "https://example.com", // 网站域名
name: "我的 Nuxt 应用",
description: "一个高性能的 Nuxt 网站",
defaultLocale: "zh-CN", // 设置默认语言
},
})
开发调试
安装了 @nuxtjs/seo 后,启动项目打开 Nuxt DevTools,你会发现一个新的 SEO 选项卡:
- 实时检查:查看当前页面的 Meta 标签、OG 图片预览和 Schema 数据。
- 缺失提示:如果页面缺少关键的 SEO 信息(如 Title 或 Description),DevTools 会给出警告。
进阶配置
虽然 @nuxtjs/seo 已经提供了开箱即用的配置,但在实际生产环境中,我们往往需要更精细的控制。
@nuxtjs/sitemap
sitemap.xml 是搜索引擎发现你网站页面的地图。@nuxtjs/sitemap 模块会自动扫描你的静态路由,但对于动态内容(如博客文章、商品详情),我们需要手动告知它。
常用配置
// nuxt.config.ts
export default defineNuxtConfig({
sitemap: {
// 1. 动态路由数据源:支持 API 端点
sources: ["/api/__sitemap__/urls"],
// 2. 排除不需要被索引的页面
exclude: ["/user/**", "/admin/**", "/checkout"],
// 3. 开启分块 (Chunking):适用于大型网站 (> 50k URL)
sitemaps: true,
},
})
★
对于动态路由,你可以创建一个 Server API (例如
server/api/__sitemap__/urls.ts) 来返回所有的文章链接。
如何验证配置是否生效?
本地启动项目,访问:http://localhost:3000/sitemap.xml;线上环境访问:https://yoursite.com/sitemap.xml,当看到 xml 内容既配置成功。
@nuxtjs/robots
robots.txt 定义了爬虫可以访问哪些区域。@nuxtjs/robots 的一大优势是它能根据环境自动切换策略:开发环境默认禁止所有爬虫,生产环境默认允许。
// nuxt.config.ts
export default defineNuxtConfig({
robots: {
// 1. 全局爬虫规则(User-agent: * 对应 allRobots)
allRobots: {
// 禁止爬取的目录/页面(常用)
Disallow: [
"/admin/", // 后台管理页
"/api/", // 接口目录
"/_nuxt/", // Nuxt 打包后的静态资源(可选,一般无需禁止)
"/private/", // 私有页面
"/*.pdf$", // 禁止爬取所有 PDF 文件(正则写法)
],
// 允许爬取的内容(覆盖 Disallow,可选)
Allow: [
"/api/public/", // 允许爬取公开接口
],
// 爬虫抓取频率(可选,只是建议,非强制)
CrawlDelay: 2, // 每次请求间隔 2 秒,减轻服务器压力
},
// 添加自定义规则
groups: [
{
userAgent: ["Baiduspider"], // 针对百度爬虫的特殊规则
disallow: ["/api/"], // 禁止访问
allow: ["/api/public-data"], // 允许访问
},
{
userAgent: "*",
disallow: ["/secret", "/admin"],
allow: "/",
},
],
},
})
如何验证配置是否生效?
本地启动项目,访问:http://localhost:3000/robots.txt;线上环境访问:https://yoursite.com/robots.txt,会看到以下内容:
User-agent: *
Disallow: /admin/
Disallow: /api/
Disallow: /private/
Allow: /
Crawl-delay: 2
Sitemap: https://你的域名.com/sitemap.xml
User-agent: Baiduspider
Disallow: /archive/
nuxt-og-image
全局配置
// nuxt.config.ts
export default defineNuxtConfig({
modules: ["@nuxtjs/seo"],
// Nuxt SEO 模块核心配置
seo: {
// 基础站点信息(会自动复用为 OG 基础信息)
site: {
// ...
},
// OG 标签全局配置(重点:ogImage)
og: {
// 全局默认 OG 类型
type: "website",
// 全局默认 OG Image 配置(核心)
image: {
// 图片路径:推荐用绝对路径,或相对路径(模块会自动拼接 site.url)
src: "/og-default.jpg", // 等价于 https://你的域名.com/og-default.jpg
width: 1200, // 最优尺寸
height: 630,
type: "image/jpeg", // 图片格式
alt: "网站默认分享封面", // 图片描述(可选,提升可访问性)
},
// 全局默认语言
locale: "zh_CN",
},
// 兼容 Twitter 卡片(可选,自动复用 ogImage)
twitter: {
card: "summary_large_image", // 大图卡片样式
},
},
})
单页面配置
单页面配置的内容会覆盖全局配置。
在具体页面(如 pages/article/[id].vue)中,用 useOgImage 或 useSeoMeta 自定义该页面的 OG Image:
<template>
<div>详情页</div>
</template>
<script setup lang="ts">
// 1. 假设从接口获取文章数据
const article = await fetchArticleData() // 你的业务逻辑
const articleCover = article.coverImage || "/og-article-default.jpg"
// 2. 方式1:单独修改 OG Image(推荐,更精准)
useOgImage({
src: articleCover, // 自定义封面图路径
width: 1200,
height: 630,
alt: article.title, // 用文章标题作为图片描述
})
// 3. 方式2:批量修改 OG 信息(含 Image)
useSeoMeta({
ogTitle: article.title, // 文章标题
ogDescription: article.summary, // 文章摘要
ogImage: [
{
src: articleCover,
width: 1200,
height: 630,
},
],
twitterImage: articleCover, // 兼容 Twitter
})
</script>
动态路由批量配置
动态页面的配置可以结合sitemap来设置:
// nuxt.config.ts
export default defineNuxtConfig({
modules: ["@nuxtjs/seo"],
sitemap: {
// 动态生成路由 + 对应 OG Image
routes: async () => {
const articles = await fetchAllArticles() // 获取所有文章
return articles.map((article) => ({
url: `/article/${article.id}`,
// 给每个路由绑定 OG Image
seo: {
ogImage: {
src: article.coverImage,
width: 1200,
height: 630,
},
},
}))
},
},
})
如何验证配置是否生效?
启动项目,访问页面右键「页面源代码」,能看到 <meta property="og:image" content="你的图片URL"> 即配置成功。
SEO 进阶技巧与最佳实践
1. 喂饱搜索引擎
搜索引擎喜欢结构化数据。通过 Schema.org 标记,你可以让 Google 更精准地理解你的内容。
Nuxt SEO 提供了 useSchemaOrg 组合式函数,让你可以像写 Vue 组件一样编写 Schema:
<script setup lang="ts">
useSchemaOrg([
defineArticle({
image: '/images/cover.jpg',
datePublished: '2026-02-18',
author: {
name: 'Trae',
},
})
])
</script>
2. 社交分享优化
当用户将你的链接分享到 Twitter 或微信时,一张精美的预览图能显著提高点击率。
- Open Graph 标签:自动生成
og:title,og:description等标签。 - OG Image 生成:
nuxt-og-image模块可以根据你的页面内容(标题、摘要)动态生成 SVG 或 PNG 图片。这意味着你不需要为每篇文章手动通过 Photoshop 制作封面,代码即设计!
3. 链接与 URL 规范化
重复内容是 SEO 的大忌。Nuxt SEO 能帮你处理这些细节:
- Trailing Slashes:统一 URL 结尾是否带斜杠(例如
/aboutvs/about/),避免被视为两个页面。 - Canonical URLs:自动添加规范链接,告诉搜索引擎哪个是"正版"页面,防止参数(如
?utm_source=...)导致权重分散。
多搜索引擎适配策略
不同的搜索引擎有不同的脾气,针对国内外的搜索巨头,可以采取差异化的策略。

Google 优化
Google 的爬虫能力最强,能够很好地执行 JavaScript。
- Core Web Vitals:重点关注
LCP (最大内容绘制)、CLS (累积布局偏移)和INP (交互到下一次绘制)。Nuxt 默认的性能优化通常能满足要求。 - Google Search Console:在 GSC 中主动提交你的
sitemap.xml,并定期查看"覆盖率"报告,修复 404 和 500 错误。 - 富媒体搜索结果:利用上文提到的 Schema 标记,争取在搜索结果中展示星级评分、问答等富媒体信息。
百度优化
百度爬虫对现代 JavaScript 的执行能力相对较弱,且对页面加载速度极其敏感。
- 确保 SSR 输出:这是最关键的一点。确保你的 Nuxt 应用以 SSR 模式运行,并且 HTML 源码中直接包含核心内容。
- 验证方法:在终端运行
curl https://your-site.com,检查返回的 HTML 是否包含你的内容。
- 验证方法:在终端运行
- 主动推送:百度非常依赖主动提交。看在网站上线后,通过 API 立即将链接推送到百度站长平台。
- URL 结构:百度更喜欢扁平、简单的 URL 结构,避免过深的层级和复杂的动态参数。
- 移动端适配:百度对移动端友好的站点有明显的加权,做好响应式适配移动端是一个不错的选择。
必应优化
Bing 在搜索端的占比越来越高,且是 ChatGPT 搜索的数据源之一。
- IndexNow 协议:Bing 大力推广 IndexNow 协议,允许网站在一个 URL 发生变化时立即通知搜索引擎。这比传统的 Sitemap 被动抓取要快得多。
- Bing Webmaster Tools:功能与 GSC 类似,建议注册并提交 Sitemap。
总结
SEO 是一个长期积累的过程,但 Nuxt SEO 模块帮我们扫清了技术障碍。通过合理的配置和使用,并针对 Google、百度等不同平台进行针对性优化,可以确保你的 Nuxt 应用在起跑线上就领先一步。
🔗 项目地址: nuxtseo.com
👍作品推荐
Haotab 新标签页,一个优雅的新标签页
❤️静待你的体验
来源:juejin.cn/post/7609891142464159780
MyBatis二级缓存翻车实录:改个昵称,全公司用户头像集体“穿越”?!
作者:不想打工的码农
原创手记|深夜翻源码|拒绝“理论上”
(附:MyBatis 3.5.13 + MySQL 8.0 真实战场复盘)
📱 凌晨2:18,钉钉炸出灵魂拷问
“哥!用户A改了昵称,用户B的头像突然变成A的旧头像了?!”
——测试小王发来三连截图,手抖得连标点都打歪了
我猛灌半杯冰美式,盯着屏幕:
✅ 数据库查证:用户B头像URL未变
✅ 前端Network:返回的base64头像数据确是用户A的
✅ 服务日志:无异常堆栈,无SQL报错
最魔幻的是:
- 刷新3次,头像在“用户B原图”“用户A旧图”“空白”间随机切换
- 重启服务瞬间恢复正常,10分钟后复现
- 仅发生在用户修改资料后
我后背发凉:这哪是bug,这是缓存成精了啊!
🔍 三小时硬核排查(附真实命令)
第一回合:甩锅Redis?❌
redis-cli> KEYS user:avatar:*
# 结果:空!项目根本没接Redis缓存!
测试小王弱弱补刀:“哥...你上周说‘简单功能用MyBatis二级缓存就行’..."
我:???(记忆碎片开始闪回)
第二回合:Arthas锁死缓存轨迹 ✅
# 监控Mapper方法返回值
watch com.xxx.mapper.UserMapper selectAvatarByUid '{returnObj}' -x 3 -n 5
关键输出:
[第1次调用] Avatar{id=1002, url="b_old.jpg"} ← 用户B的头像
[第2次调用] Avatar{id=1001, url="a_old.jpg"} ← 竟是用户A的旧头像!
[第3次调用] null
突破口:返回对象的id字段都错乱了!缓存污染实锤!
第三回合:翻出“罪证”XML
<!-- UserMapper.xml -->
<mapper namespace="com.xxx.mapper.UserMapper">
<cache eviction="LRU" size="1024" readOnly="false"/>
<select id="selectAvatarByUid" resultType="Avatar">
SELECT id, url FROM avatar WHERE user_id = #{uid}
</select>
</mapper>
<!-- ProfileMapper.xml(致命复制粘贴) -->
<mapper namespace="com.xxx.mapper.UserMapper"> <!-- ⚠️ 和上面一模一样! -->
<cache eviction="LRU" size="512" readOnly="true"/>
<update id="updateNickname">
UPDATE user SET nickname=#{name} WHERE id=#{id}
</update>
</mapper>
瞳孔地震:
两个Mapper共用同一个namespace!
MyBatis二级缓存以namespace为隔离单位 → 所有操作共享同一块缓存区域 → 头像数据被昵称更新操作污染!
💥 深扒MyBatis缓存源码(3.5.13版)
缓存key生成逻辑(CacheKey.java)
// 拼接缓存key的核心逻辑
public void update(Object object) {
if (object != null && object.getClass().isArray()) {
// 按参数、SQL、offset等生成唯一key
hashCode = hashCode * 31 + ArrayUtil.hashCode(object);
}
}
关键真相:
- 缓存key =
namespace + sql + params + offset... - 但namespace相同时,不同Mapper的SQL会混用同一缓存池!
ProfileMapper.updateNickname执行时,触发缓存清空(因readOnly=false)- 但清空的是整个namespace的缓存 → 头像查询缓存被误删 → 下次查询时,因缓存miss+并发,脏数据混入
为什么重启能暂时恢复?
// CachingExecutor.java
public <E> List<E> query(...) {
if (ms.getCache() != null) {
flushCacheIfRequired(ms); // 更新操作会清空整个namespace缓存
...
}
}
重启 → JVM内存清空 → 缓存重建 → 短暂“干净” → 随着操作累积,污染循环开始
🛠️ 三招根治(已上线30天零复发)
✅ 方案1:紧急止血(10分钟上线)
<!-- 所有Mapper.xml 删除 <cache> 标签 -->
<!-- 或全局关闭(mybatis-config.xml) -->
<settings>
<setting name="cacheEnabled" value="false"/>
</settings>
适用场景:分布式环境、数据强一致性要求高、缓存收益低
✅ 方案2:规范namespace(治本之策)
<!-- ProfileMapper.xml -->
<mapper namespace="com.xxx.mapper.ProfileMapper"> <!-- 唯一且语义清晰 -->
<!-- 移除<cache>,交由业务层控制 -->
</mapper>
团队公约:
- namespace = Mapper接口全限定名(IDEA自动生成)
- 禁止手动修改namespace
- Code Review必查项:
grep "<mapper namespace" *.xml | sort | uniq -d
✅ 方案3:用Redis替代(高阶方案)
// 自定义Cache实现,接入Redis
public class RedisCache implements Cache {
private final ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
private String id;
@Override
public void putObject(Object key, Object value) {
// 序列化存入Redis,key=namespace:md5(sql+params)
redisTemplate.opsForValue().set(buildKey(key), value, 10, TimeUnit.MINUTES);
}
// ... 其他方法实现
}
优势:
- 多节点共享缓存
- 精细化过期策略
- 避免JVM内存压力
📌 血泪避坑清单(打印贴工位!)
表格
| 误区 | 真相 | 行动指南 |
|---|---|---|
| “二级缓存开箱即用” | 分布式环境必翻车 | 单机只读场景慎用,分布式直接关 |
| “readOnly=true很安全” | 更新操作仍会清空整个namespace缓存 | 避免在含写操作的Mapper开缓存 |
| “namespace随便起” | 缓存隔离的唯一依据 | 严格等于Mapper接口全路径 |
| “缓存能提升性能” | 小数据量场景,序列化开销>收益 | 压测验证:QPS提升<5%?不如关掉 |
| “MyBatis缓存很智能” | 无分布式锁、无穿透保护 | 高并发场景必接Redis+本地缓存 |
灵魂三问(上线前必答) :
1️⃣ 项目是单机还是集群?→ 集群?二级缓存退退退!
2️⃣ 数据允许短暂不一致吗?→ 用户资料?必须强一致!
3️⃣ 缓存命中率实测多少?→ 用Arthas统计:monitor -c 5 com.xxx.mapper.XxxMapper selectXxx
🌱 写在晨光微露时
天快亮时,我给团队Wiki加了一页:
《MyBatis缓存使用红绿灯》
🔴 红灯区:用户资料、订单、支付等强一致场景
🟡 黄灯区:文章列表、商品目录(需压测验证)
🟢 绿灯区:国家字典、配置表(readOnly=true+小数据量)
测试小王发来新奶茶:“哥,这次排查笔记能发我学习吗?”
我笑着回:“下次上线前,咱俩一起过缓存设计。”
技术没有“小配置”,只有“大敬畏”。
那些深夜翻源码的狼狈,终会沉淀为代码里的从容。
本文为真实事故脱敏复盘,所有命令/代码经生产验证。
👉 互动时间:你被MyBatis缓存坑过吗?评论区晒出你的“名场面”!
来源:juejin.cn/post/7601046076943876111
把白领吓破防的2028预言,究竟讲了什么?
最近,一篇关于“2028年全球智能危机”的预测在硅谷和打工人的朋友圈里疯传。
很多朋友和同事都在狂转这篇充满洞见的报告,看完这篇报告,很多白领的第一反应恐怕是:
你妹的,赶紧把电脑咋了回家种地吧!白领不存在了。
- 广告传媒不存在了
- IT互联网不存在了
- 传统软件行业不存在了
……
震撼程度堪比物理学家被智子扰乱道心。
让我们看看这篇文章的原文长啥样:
核心观点:短期经济会增长,但其实是假象。因为大部分人没有受益,因此消费会受到暴击,而且会陷入恶性循环。

补充观点:那些靠解决不方便小摩擦的生意会完全被AI取代。

以及他对就业形式的估计也是非常悲观的:

并且,他认为这些冲击之下,信贷危机会如约而至,大规模的个体违约将会发生。
如果再结合一下作者所在的国家——阿美,似乎可以预见到斩杀线的大量降临。
一些行业预测
这篇预测的核心恐吓点可以总结为“白领护城河的三大崩塌”:
- 软件服务商(SaaS)的末日: AI智能体(Agent)普及后,人人都能直接用自然语言写出专属软件,不再需要花大价钱购买企业服务。
- 互联网广告模式的黄昏: 当AI助手能瞬间帮你货比三家、找到全网最低价时,谁还会去点击那些充满套路的商业广告?靠流量收租的公司将面临绝境。
- 智力劳动贬值: 这是最让人破防的一点。曾经高高在上的办公室脑力工作,其门槛被AI彻底踏破,脑力劳动变得廉价。
失业的白领怎么办呢?
铁人三项,吉祥三宝,选择总之不多。
这也难怪,白领们看到这篇文章会如此惊吓,难怪有人会陷入虚无,怀疑AI究竟是造福全人类,还是仅仅变成了资本家敛财、让普通人失业的机器 。
以史为镜
但如果我们跳出眼前的困境,把目光延申像更远的时光,看到远古时期。
- 奴隶时代的农业大发展之后:牛马和铁器大规模替代纯人力时,种地的人并没有消失。生产关系的变革让他们从任人宰割的农奴变成了农民。
你看,生产力的极大发展反而给了底层人民尊严。

- 第一次工业革命后:蒸汽机确实砸碎了传统纺织工人的饭碗,但它催生了现代服装工业。今天,围绕着服装不仅有工厂,更衍生出了电商投流、短视频打爆款等庞大的产业链 。

- 通信时代的“电报员下岗”: 电报员消失了,但随后诞生了庞大的电信运营商网络;纸媒衰落了,却迎来了自媒体和博主百花齐放的时代。

核心定律在于:工具的每一次史诗级升级,可能确实伴随着某些职业和岗位的消失,但都有更多的岗位应运而生。
AI 时代的新职业会是什么?
如果一位程序员跑去100年前的1926年,让当时民国年轻人畅想这位程序员的职位。
他可能猜错1000次,也想象不到神州大地上会有这么大一批人在面对着键盘写代码。
别急着给人类的岗位下死刑。
可能只是局限于人类当前的认知和时代局限,暂时无法想象出那些我们还未见识过的职业。

更宏观地看,我们现在定义的“打卡上班”,也许只是人类漫长历史中的一个过渡状态 。当生产力真的极大丰富时,未知虽然代表着恐惧,但也同样蕴含着无限重塑的可能。
来源:juejin.cn/post/7610636435847888911
手把手写几种常用工具函数:深拷贝、去重、扁平化
同学们好,我是 Eugene(尤金),一个拥有多年中后台开发经验的前端工程师~
(Eugene 发音很简单,/juːˈdʒiːn/,大家怎么顺口怎么叫就好)
你是否也有过:明明学过很多技术,一到关键时候却讲不出来、甚至写不出来?
你是否也曾怀疑自己,是不是太笨了,明明感觉会,却总差一口气?
就算想沉下心从头梳理,可工作那么忙,回家还要陪伴家人。
一天只有24小时,时间永远不够用,常常感到力不从心。
技术行业,本就是逆水行舟,不进则退。
如果你也有同样的困扰,别慌。
从现在开始,跟着我一起心态归零,利用碎片时间,来一次彻彻底底的基础扫盲。
这一次,我们一起慢慢来,扎扎实实变强。
不搞花里胡哨的理论堆砌,只分享看得懂、用得上的前端干货,
咱们一起稳步积累,真正摆脱“面向搜索引擎写代码”的尴尬。
1. 开篇:有库可用,为什么还要自己写?
lodash、ramda 等库已经提供这些工具函数,但在面试、基础补强、和「读懂库源码」的场景里,手写一遍很有价值:
- 搞清概念:什么算「深拷贝」、什么算「去重」
- 踩一遍坑:循环引用、
NaN、Date、RegExp、Symbol等 - 形成习惯:知道什么时候用浅拷贝、什么时候必须深拷贝
下面按「深拷贝 → 去重 → 扁平化」的顺序,每种都给出可直接用的实现和说明。
2. 深拷贝
2.1 浅拷贝 vs 深拷贝,怎么选?
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 只改最外层、不改嵌套对象 | 浅拷贝({...obj}、Object.assign) | 实现简单、性能好 |
| 需要改嵌套对象且不想影响原数据 | 深拷贝 | 避免引用共享 |
对象里有 Date、RegExp、函数等 | 深拷贝时需特殊处理 | 否则会丢失类型或行为 |
一句话:只要会改到「嵌套对象/数组」,就考虑深拷贝。
2.2 常见坑
- 循环引用:
obj.a = obj,递归会栈溢出 - 特殊类型:
Date、RegExp、Map、Set、Symbol不能只靠遍历属性复制 - Symbol 做 key:
Object.keys不会包含,需用Reflect.ownKeys或Object.getOwnPropertySymbols
2.3 实现示例(含循环引用与特殊类型处理)
function deepClone(obj, cache = new WeakMap()) {
// 1. 基本类型、null、函数 直接返回
if (obj === null || typeof obj !== 'object') {
return obj;
}
// 2. 循环引用:用 WeakMap 缓存已拷贝对象
if (cache.has(obj)) {
return cache.get(obj);
}
// 3. 特殊对象类型
if (obj instanceof Date) return new Date(obj.getTime());
if (obj instanceof RegExp) return new RegExp(obj.source, obj.flags);
if (obj instanceof Map) {
const mapCopy = new Map();
cache.set(obj, mapCopy);
obj.forEach((v, k) => mapCopy.set(deepClone(k, cache), deepClone(v, cache)));
return mapCopy;
}
if (obj instanceof Set) {
const setCopy = new Set();
cache.set(obj, setCopy);
obj.forEach(v => setCopy.add(deepClone(v, cache)));
return setCopy;
}
// 4. 普通对象 / 数组
const clone = Array.isArray(obj) ? [] : {};
cache.set(obj, clone);
// 包含 Symbol 作为 key
const keys = [...Object.keys(obj), ...Object.getOwnPropertySymbols(obj)];
keys.forEach(key => {
clone[key] = deepClone(obj[key], cache);
});
return clone;
}
// 使用示例
const original = { a: 1, b: { c: 2 }, d: [3, 4] };
original.self = original; // 循环引用
const cloned = deepClone(original);
cloned.b.c = 999;
console.log(original.b.c); // 2,原对象未被修改
要点:WeakMap 解决循环引用,Date/RegExp/Map/Set 单独分支,Object.getOwnPropertySymbols 保证 Symbol key 不丢失。
3. 去重
3.1 场景与选型
| 场景 | 方法 | 说明 |
|---|---|---|
| 基本类型数组(数字、字符串) | Set | 写法简单、性能好 |
需要兼容 NaN | 自己写遍历逻辑 | NaN !== NaN,Set 能去重 NaN,但逻辑要显式写清楚 |
| 对象数组、按某字段去重 | Map 或 filter | 用唯一字段做 key |
3.2 几种实现
1)简单数组去重(含 NaN)
// 方式一:Set(ES6 最常用)
function uniqueBySet(arr) {
return [...new Set(arr)];
}
// 方式二:filter + indexOf(兼容性更好,但 NaN 会出问题)
function uniqueByFilter(arr) {
return arr.filter((item, index) => arr.indexOf(item) === index);
}
// 方式三:兼容 NaN 的版本
function unique(arr) {
const result = [];
const seenNaN = false; // 用 flag 标记是否已经加入过 NaN
for (const item of arr) {
if (item !== item) { // NaN !== NaN
if (!seenNaN) {
result.push(item);
seenNaN = true; // 这里需要闭包,下面用修正版
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
// 修正:用变量
function uniqueWithNaN(arr) {
const result = [];
let hasNaN = false;
for (const item of arr) {
if (Number.isNaN(item)) {
if (!hasNaN) {
result.push(NaN);
hasNaN = true;
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
注意:Set 本身对 NaN 是去重的(ES2015 规范),所以 [...new Set([1, NaN, 2, NaN])] 结果正确。需要兼容 NaN 的,多是旧环境或面试题场景。
2)对象数组按某字段去重
function uniqueByKey(arr, key) {
const seen = new Map();
return arr.filter(item => {
const k = item[key];
if (seen.has(k)) return false;
seen.set(k, true);
return true;
});
}
// 使用
const users = [
{ id: 1, name: '张三' },
{ id: 2, name: '李四' },
{ id: 1, name: '张三2' }
];
console.log(uniqueByKey(users, 'id'));
// [{ id: 1, name: '张三' }, { id: 2, name: '李四' }]
4. 扁平化
4.1 场景
- 把
[1, [2, [3, 4]]]变成[1, 2, 3, 4] - 有时候需要「只扁平一层」或「扁平到指定层数」
4.2 实现
1)递归全扁平
function flatten(arr) {
const result = [];
for (const item of arr) {
if (Array.isArray(item)) {
result.push(...flatten(item));
} else {
result.push(item);
}
}
return result;
}
console.log(flatten([1, [2, [3, 4], 5]])); // [1, 2, 3, 4, 5]
2)指定深度扁平(如 Array.prototype.flat)
function flattenDepth(arr, depth = 1) {
if (depth <= 0) return arr;
const result = [];
for (const item of arr) {
if (Array.isArray(item) && depth > 0) {
result.push(...flattenDepth(item, depth - 1));
} else {
result.push(item);
}
}
return result;
}
console.log(flattenDepth([1, [2, [3, 4]]], 1)); // [1, 2, [3, 4]]
console.log(flattenDepth([1, [2, [3, 4]]], 2)); // [1, 2, 3, 4]
3)用 reduce 递归写法(另一种常见写法)
function flattenByReduce(arr) {
return arr.reduce((acc, cur) => {
return acc.concat(Array.isArray(cur) ? flattenByReduce(cur) : cur);
}, []);
}
5. 小结:日常怎么选
| 函数 | 生产环境 | 面试 / 巩固基础 |
|---|---|---|
| 深拷贝 | 优先用 structuredClone(支持循环引用)或 lodash cloneDeep | 自己实现,要处理循环引用和特殊类型 |
| 去重 | 基本类型用 [...new Set(arr)],对象用 Map 按 key 去重 | 要能解释 NaN、indexOf 等细节 |
| 扁平化 | 用原生 arr.flat(Infinity) | 手写递归或 reduce 版本 |
自己写一遍的价值在于:搞清楚边界情况、循环引用、特殊类型,以后选库或读源码时心里有数。
学习本就是一场持久战,不需要急着一口吃成胖子。哪怕今天你只记住了一点点,这都是实打实的进步。
后续我还会继续用这种大白话、讲实战方式,带大家扫盲更多前端基础。
关注我,不迷路,咱们把那些曾经模糊的知识点,一个个彻底搞清楚。
如果你觉得这篇内容对你有帮助,不妨点赞收藏,下次写代码卡壳时,拿出来翻一翻,比搜引擎更靠谱。
我是 Eugene,你的电子学友,我们下一篇干货见~
来源:juejin.cn/post/7609288132602478592
JSBridge 原理详解
什么是 JSBridge
JSBridge 是 WebView 中 JavaScript 与 Native 代码之间的通信桥梁。核心问题是:两个不同运行环境的代码如何互相调用?
通信原理
1. Native 调用 JS(简单)
WebView 本身就提供了执行 JS 的能力,原理很直接:WebView 控制着 JS 引擎,可以直接向其注入并执行代码。
// Android
webView.evaluateJavascript("window.appCallJS('data')", null);
// iOS
webView.evaluateJavaScript("window.appCallJS('data')")
// Flutter
webViewController.runJavaScript("window.appCallJS('data')");
2. JS 调用 Native(核心难点)
JS 运行在沙箱中,无法直接访问系统 API。有两种主流方案:
方案一:注入 API
Native 在 WebView 初始化时,向 JS 全局对象注入方法:
// Android - 注入对象到 window
webView.addJavascriptInterface(new Object() {
@JavascriptInterface
public void showToast(String msg) {
Toast.makeText(context, msg, Toast.LENGTH_SHORT).show();
}
}, "NativeBridge");
JS 端直接调用:
window.NativeBridge.showToast("Hello")
本质:Native 把自己的方法"挂"到了 JS 的全局作用域里。
方案二:URL Scheme 拦截
JS 发起一个特殊协议的请求,Native 拦截并解析:
// JS 端
location.href = 'jsbridge://showToast?msg=Hello'
// 或使用 iframe(避免页面跳转)
const iframe = document.createElement('iframe')
iframe.src = 'jsbridge://showToast?msg=Hello'
document.body.appendChild(iframe)
// Android 端拦截
webView.setWebViewClient(new WebViewClient() {
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
if (url.startsWith("jsbridge://")) {
// 解析 url,执行对应 Native 方法
return true;
}
return false;
}
});
本质:利用 WebView 的 URL 加载机制作为通信通道。
异步回调的实现
JS 调用 Native 后如何拿到返回值?通过回调 ID 机制:
// JS 端
let callbackId = 0
const callbacks = {}
function callNative(method, params) {
return new Promise((resolve) => {
const id = callbackId++
callbacks[id] = resolve
// 告诉 Native:调用完成后,用这个 id 回调我
window.NativeBridge.invoke(JSON.stringify({
method,
params,
callbackId: id
}))
})
}
// Native 执行完后调用这个函数
window.handleCallback = (id, result) => {
callbacks[id]?.(result)
delete callbacks[id]
}
流程:JS 调用 → Native 处理 → Native 调用 evaluateJavascript 执行回调函数 → JS 收到结果
各平台注入对象命名
| 平台/插件 | 全局对象名 | 是否可自定义 |
|---|---|---|
| Android 原生 | 任意 | ✅ 完全自定义 |
| iOS WKWebView | webkit.messageHandlers.xxx | ✅ xxx 部分可自定义 |
| flutter_inappwebview | flutter_inappwebview | ❌ 插件固定 |
| webview_flutter | 需要自己实现 | ✅ 完全自定义 |
Android 示例
// 第二个参数就是 JS 中的对象名,可以随便取
webView.addJavascriptInterface(bridgeObject, "MyBridge");
// JS 端
window.MyBridge.method()
iOS 示例
// name 就是 JS 中的 handler 名
configuration.userContentController.add(self, name: "iOSBridge")
// JS 端
window.webkit.messageHandlers.iOSBridge.postMessage(data)
Flutter (flutter_inappwebview) 示例
// Flutter 端注册 handler,handlerName 可自定义
webViewController.addJavaScriptHandler(
handlerName: 'myCustomHandler',
callback: (args) { ... }
);
// JS 端,flutter_inappwebview 是固定的
window.flutter_inappwebview.callHandler('myCustomHandler', data)
通信方式总结
| 方向 | 原理 | 实现方式 |
|---|---|---|
| Native → JS | WebView 控制 JS 引擎 | evaluateJavascript |
| JS → Native | 注入或拦截 | addJavascriptInterface / URL Scheme |
常见通信方式对比
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| JavaScript Bridge | 双向通信、支持回调 | 需要约定协议 | 复杂交互 |
| URL Scheme | 简单、兼容性好 | 单向、数据量有限 | 简单跳转 |
| postMessage | 标准 API | 需要 WebView 支持 | iframe 通信 |
| 注入 JS 对象 | 调用方便 | Android 4.2 以下有安全漏洞 | 频繁调用 |
最佳实践建议
- 统一封装:抽离成独立的 bridge 工具类,统一管理通信逻辑
- 消息队列:处理 Native 未就绪时的调用,避免丢失消息
- 超时处理:添加超时机制,防止回调永远不返回
- 类型安全:使用 TypeScript 定义消息类型
- 错误处理:统一的错误捕获和上报机制
来源:juejin.cn/post/7609660097766309898
手把手写几种常用工具函数:深拷贝、去重、扁平化
同学们好,我是 Eugene(尤金),一个拥有多年中后台开发经验的前端工程师~
(Eugene 发音很简单,/juːˈdʒiːn/,大家怎么顺口怎么叫就好)
你是否也有过:明明学过很多技术,一到关键时候却讲不出来、甚至写不出来?
你是否也曾怀疑自己,是不是太笨了,明明感觉会,却总差一口气?
就算想沉下心从头梳理,可工作那么忙,回家还要陪伴家人。
一天只有24小时,时间永远不够用,常常感到力不从心。
技术行业,本就是逆水行舟,不进则退。
如果你也有同样的困扰,别慌。
从现在开始,跟着我一起心态归零,利用碎片时间,来一次彻彻底底的基础扫盲。
这一次,我们一起慢慢来,扎扎实实变强。
不搞花里胡哨的理论堆砌,只分享看得懂、用得上的前端干货,
咱们一起稳步积累,真正摆脱“面向搜索引擎写代码”的尴尬。
1. 开篇:有库可用,为什么还要自己写?
lodash、ramda 等库已经提供这些工具函数,但在面试、基础补强、和「读懂库源码」的场景里,手写一遍很有价值:
- 搞清概念:什么算「深拷贝」、什么算「去重」
- 踩一遍坑:循环引用、
NaN、Date、RegExp、Symbol等 - 形成习惯:知道什么时候用浅拷贝、什么时候必须深拷贝
下面按「深拷贝 → 去重 → 扁平化」的顺序,每种都给出可直接用的实现和说明。
2. 深拷贝
2.1 浅拷贝 vs 深拷贝,怎么选?
| 场景 | 推荐方式 | 原因 |
|---|---|---|
| 只改最外层、不改嵌套对象 | 浅拷贝({...obj}、Object.assign) | 实现简单、性能好 |
| 需要改嵌套对象且不想影响原数据 | 深拷贝 | 避免引用共享 |
对象里有 Date、RegExp、函数等 | 深拷贝时需特殊处理 | 否则会丢失类型或行为 |
一句话:只要会改到「嵌套对象/数组」,就考虑深拷贝。
2.2 常见坑
- 循环引用:
obj.a = obj,递归会栈溢出 - 特殊类型:
Date、RegExp、Map、Set、Symbol不能只靠遍历属性复制 - Symbol 做 key:
Object.keys不会包含,需用Reflect.ownKeys或Object.getOwnPropertySymbols
2.3 实现示例(含循环引用与特殊类型处理)
function deepClone(obj, cache = new WeakMap()) {
// 1. 基本类型、null、函数 直接返回
if (obj === null || typeof obj !== 'object') {
return obj;
}
// 2. 循环引用:用 WeakMap 缓存已拷贝对象
if (cache.has(obj)) {
return cache.get(obj);
}
// 3. 特殊对象类型
if (obj instanceof Date) return new Date(obj.getTime());
if (obj instanceof RegExp) return new RegExp(obj.source, obj.flags);
if (obj instanceof Map) {
const mapCopy = new Map();
cache.set(obj, mapCopy);
obj.forEach((v, k) => mapCopy.set(deepClone(k, cache), deepClone(v, cache)));
return mapCopy;
}
if (obj instanceof Set) {
const setCopy = new Set();
cache.set(obj, setCopy);
obj.forEach(v => setCopy.add(deepClone(v, cache)));
return setCopy;
}
// 4. 普通对象 / 数组
const clone = Array.isArray(obj) ? [] : {};
cache.set(obj, clone);
// 包含 Symbol 作为 key
const keys = [...Object.keys(obj), ...Object.getOwnPropertySymbols(obj)];
keys.forEach(key => {
clone[key] = deepClone(obj[key], cache);
});
return clone;
}
// 使用示例
const original = { a: 1, b: { c: 2 }, d: [3, 4] };
original.self = original; // 循环引用
const cloned = deepClone(original);
cloned.b.c = 999;
console.log(original.b.c); // 2,原对象未被修改
要点:WeakMap 解决循环引用,Date/RegExp/Map/Set 单独分支,Object.getOwnPropertySymbols 保证 Symbol key 不丢失。
3. 去重
3.1 场景与选型
| 场景 | 方法 | 说明 |
|---|---|---|
| 基本类型数组(数字、字符串) | Set | 写法简单、性能好 |
需要兼容 NaN | 自己写遍历逻辑 | NaN !== NaN,Set 能去重 NaN,但逻辑要显式写清楚 |
| 对象数组、按某字段去重 | Map 或 filter | 用唯一字段做 key |
3.2 几种实现
1)简单数组去重(含 NaN)
// 方式一:Set(ES6 最常用)
function uniqueBySet(arr) {
return [...new Set(arr)];
}
// 方式二:filter + indexOf(兼容性更好,但 NaN 会出问题)
function uniqueByFilter(arr) {
return arr.filter((item, index) => arr.indexOf(item) === index);
}
// 方式三:兼容 NaN 的版本
function unique(arr) {
const result = [];
const seenNaN = false; // 用 flag 标记是否已经加入过 NaN
for (const item of arr) {
if (item !== item) { // NaN !== NaN
if (!seenNaN) {
result.push(item);
seenNaN = true; // 这里需要闭包,下面用修正版
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
// 修正:用变量
function uniqueWithNaN(arr) {
const result = [];
let hasNaN = false;
for (const item of arr) {
if (Number.isNaN(item)) {
if (!hasNaN) {
result.push(NaN);
hasNaN = true;
}
} else if (!result.includes(item)) {
result.push(item);
}
}
return result;
}
注意:Set 本身对 NaN 是去重的(ES2015 规范),所以 [...new Set([1, NaN, 2, NaN])] 结果正确。需要兼容 NaN 的,多是旧环境或面试题场景。
2)对象数组按某字段去重
function uniqueByKey(arr, key) {
const seen = new Map();
return arr.filter(item => {
const k = item[key];
if (seen.has(k)) return false;
seen.set(k, true);
return true;
});
}
// 使用
const users = [
{ id: 1, name: '张三' },
{ id: 2, name: '李四' },
{ id: 1, name: '张三2' }
];
console.log(uniqueByKey(users, 'id'));
// [{ id: 1, name: '张三' }, { id: 2, name: '李四' }]
4. 扁平化
4.1 场景
- 把
[1, [2, [3, 4]]]变成[1, 2, 3, 4] - 有时候需要「只扁平一层」或「扁平到指定层数」
4.2 实现
1)递归全扁平
function flatten(arr) {
const result = [];
for (const item of arr) {
if (Array.isArray(item)) {
result.push(...flatten(item));
} else {
result.push(item);
}
}
return result;
}
console.log(flatten([1, [2, [3, 4], 5]])); // [1, 2, 3, 4, 5]
2)指定深度扁平(如 Array.prototype.flat)
function flattenDepth(arr, depth = 1) {
if (depth <= 0) return arr;
const result = [];
for (const item of arr) {
if (Array.isArray(item) && depth > 0) {
result.push(...flattenDepth(item, depth - 1));
} else {
result.push(item);
}
}
return result;
}
console.log(flattenDepth([1, [2, [3, 4]]], 1)); // [1, 2, [3, 4]]
console.log(flattenDepth([1, [2, [3, 4]]], 2)); // [1, 2, 3, 4]
3)用 reduce 递归写法(另一种常见写法)
function flattenByReduce(arr) {
return arr.reduce((acc, cur) => {
return acc.concat(Array.isArray(cur) ? flattenByReduce(cur) : cur);
}, []);
}
5. 小结:日常怎么选
| 函数 | 生产环境 | 面试 / 巩固基础 |
|---|---|---|
| 深拷贝 | 优先用 structuredClone(支持循环引用)或 lodash cloneDeep | 自己实现,要处理循环引用和特殊类型 |
| 去重 | 基本类型用 [...new Set(arr)],对象用 Map 按 key 去重 | 要能解释 NaN、indexOf 等细节 |
| 扁平化 | 用原生 arr.flat(Infinity) | 手写递归或 reduce 版本 |
自己写一遍的价值在于:搞清楚边界情况、循环引用、特殊类型,以后选库或读源码时心里有数。
学习本就是一场持久战,不需要急着一口吃成胖子。哪怕今天你只记住了一点点,这都是实打实的进步。
后续我还会继续用这种大白话、讲实战方式,带大家扫盲更多前端基础。
关注我,不迷路,咱们把那些曾经模糊的知识点,一个个彻底搞清楚。
如果你觉得这篇内容对你有帮助,不妨点赞收藏,下次写代码卡壳时,拿出来翻一翻,比搜引擎更靠谱。
我是 Eugene,你的电子学友,我们下一篇干货见~
来源:juejin.cn/post/7609288132602478592
单点登录:一次登录,全网通行
大家好,我是小悟。
- 想象一下你去游乐园,买了一张通票(登录),然后就可以玩所有项目(访问各个系统),不用每个项目都重新买票(重新登录)。这就是单点登录(SSO)的精髓!
SSO的日常比喻
- 普通登录:像去不同商场,每个都要查会员卡
- 单点登录:像微信扫码登录,一扫全搞定
- 令牌:像游乐园手环,戴着就能证明你买过票
下面用代码来实现这个"游乐园通票系统":
代码实现:简易SSO系统
import java.util.*;
// 用户类 - 就是我们这些想玩项目的游客
class User {
private String username;
private String password;
public User(String username, String password) {
this.username = username;
this.password = password;
}
// getters 省略...
}
// 令牌类 - 游乐园手环
class Token {
private String tokenId;
private String username;
private Date expireTime;
public Token(String username) {
this.tokenId = UUID.randomUUID().toString();
this.username = username;
// 令牌1小时后过期 - 游乐园晚上要关门的!
this.expireTime = new Date(System.currentTimeMillis() + 3600 * 1000);
}
public boolean isValid() {
return new Date().before(expireTime);
}
// getters 省略...
}
// SSO认证中心 - 游乐园售票处
class SSOAuthCenter {
private Map<String, Token> validTokens = new HashMap<>();
private Map<String, User> users = new HashMap<>();
public SSOAuthCenter() {
// 预先注册几个用户 - 办了年卡的游客
users.put("zhangsan", new User("zhangsan", "123456"));
users.put("lisi", new User("lisi", "abcdef"));
}
// 登录 - 买票入场
public String login(String username, String password) {
User user = users.get(username);
if (user != null && user.getPassword().equals(password)) {
Token token = new Token(username);
validTokens.put(token.getTokenId(), token);
System.out.println(username + " 登录成功!拿到游乐园手环:" + token.getTokenId());
return token.getTokenId();
}
System.out.println("用户名或密码错误!请重新买票!");
return null;
}
// 验证令牌 - 检查手环是否有效
public boolean validateToken(String tokenId) {
Token token = validTokens.get(tokenId);
if (token != null && token.isValid()) {
System.out.println("手环有效,欢迎继续玩耍!");
return true;
}
System.out.println("手环无效或已过期,请重新登录!");
validTokens.remove(tokenId); // 清理过期令牌
return false;
}
// 登出 - 离开游乐园
public void logout(String tokenId) {
validTokens.remove(tokenId);
System.out.println("已登出,欢迎下次再来玩!");
}
}
// 业务系统A - 过山车
class SystemA {
private SSOAuthCenter authCenter;
public SystemA(SSOAuthCenter authCenter) {
this.authCenter = authCenter;
}
public void accessSystem(String tokenId) {
System.out.println("=== 欢迎来到过山车 ===");
if (authCenter.validateToken(tokenId)) {
System.out.println("过山车启动!尖叫声在哪里!");
} else {
System.out.println("请先登录再玩过山车!");
}
}
}
// 业务系统B - 旋转木马
class SystemB {
private SSOAuthCenter authCenter;
public SystemB(SSOAuthCenter authCenter) {
this.authCenter = authCenter;
}
public void accessSystem(String tokenId) {
System.out.println("=== 欢迎来到旋转木马 ===");
if (authCenter.validateToken(tokenId)) {
System.out.println("木马转起来啦!找回童年记忆!");
} else {
System.out.println("请先登录再玩旋转木马!");
}
}
}
// 测试我们的SSO系统
public class SSODemo {
public static void main(String[] args) {
// 创建认证中心 - 游乐园大门
SSOAuthCenter authCenter = new SSOAuthCenter();
// 张三登录
String token = authCenter.login("zhangsan", "123456");
if (token != null) {
// 拿着同一个令牌玩不同项目
SystemA systemA = new SystemA(authCenter);
SystemB systemB = new SystemB(authCenter);
systemA.accessSystem(token); // 玩过山车
systemB.accessSystem(token); // 玩旋转木马
// 登出
authCenter.logout(token);
// 再尝试访问 - 应该被拒绝
systemA.accessSystem(token);
}
// 测试错误密码
authCenter.login("lisi", "wrongpassword");
}
}
运行结果示例:
zhangsan 登录成功!拿到游乐园手环:a1b2c3d4-e5f6-7890-abcd-ef1234567890
=== 欢迎来到过山车 ===
手环有效,欢迎继续玩耍!
过山车启动!尖叫声在哪里!
=== 欢迎来到旋转木马 ===
手环有效,欢迎继续玩耍!
木马转起来啦!找回童年记忆!
已登出,欢迎下次再来玩!
=== 欢迎来到过山车 ===
手环无效或已过期,请重新登录!
请先登录再玩过山车!
用户名或密码错误!请重新买票!
总结一下:
单点登录就像:
- 一次认证,处处通行 🎫
- 不用重复输入密码 🔑
- 安全又方便 👍
好的SSO系统就像好的游乐园管理,既要让游客玩得开心,又要确保安全!
谢谢你看我的文章,既然看到这里了,如果觉得不错,随手点个赞、转发、在看三连吧,感谢感谢。那我们,下次再见。
您的一键三连,是我更新的最大动力,谢谢
山水有相逢,来日皆可期,谢谢阅读,我们再会
我手中的金箍棒,上能通天,下能探海
来源:juejin.cn/post/7577599015426228259


