








JavaScript 预编译
预编译发生在什么时候
预编译发生在函数执行的前一刻
一. 预编译的抽象理解
函数声明整体提升
变量,声明提升
举个例子
<script type="text/javascript">
test();
function test() {
console.log('我是test');
}
a = 10;
var a;
console.log(a);
</script>这里控制台能正常输出就是因为在预编译时将函数的声明整体和变量的声明提升到了代码的最顶部,所以代码中先调用函数或者是先给变量赋值再声明都没有问题,当然这是抽象的概念,记住这个已经能解决8-90%的变成问题了,如果你想了解具体的流程,可以接着往下看。
二. 局部函数预编译过程
创建AO(Activation Object)对象
找形参和变量声明,将变量和形参名作为AO对象的属性名,默认值为undefind
将实参值和形参相关联
找函数声明,值为其函数体
例子一
<script type="text/javascript">
function test(a) {
var b = 10;
function c() {
}
}
test(1);
</script>根据过程来我们可以得出右边的AO对象中的数值,a最终保存的是1,因为第三步需要把形参和实参相关联
例子二
<script type="text/javascript">
function test(a) {
var a = 10;
function a() {
}
}
test(1);
</script>对象中同名的属性会只保留一个,所以经过第二步寻找变量声明和形参的时候,AO对象中会有一个a,且默认值为undefind,经过第三步实参值和形参相关联后,a的值变为1,经过第四步找函数声明的时候发现有个名字为a的函数,AO中本身就有a的属性名了,所以这个时候会将a的函数体赋值给AO中的a。
如果上面的例子能够搞懂的话,咱们就可以接着玩一个题
例子三
<script type="text/javascript">
function test(a) {
console.log(a);
var a = 10;
console.log(a);
function a() {
consoel.log('这是函数a');
}
}
test(1);
</script>如果你心中的结果跟答案一致,说明已经清楚了局部函数预编译的四个步骤了
到test函数执行之前AO对象中a的值为a的函数体这个应该没有什么问题吧?所以第一个log打印出来的是a的函数体,第二个log之前由于有var a = 10;,这个经过变量的声明提升后可以看做是a = 10;,走到这里这里AO中的a被赋值为10,所以第二个log打印的就是10。
二. 全局函数预编译过程
创建GO(Global Object)对象
找变量声明,将变量名作为GO对象的属性名,默认值为undefind
找函数声明,值为其函数体
全局函数的过程跟局部函数差不多,由于全局函数没有形参和实参的传递,所以省略了一个步骤。
例子四
<script type="text/javascript">
console.log(a);
var a = 1111;
console.log(a);
function a() {
console.log('这里是a函数');
}
</script>这里例子四的输出和转化结果跟例子三差不多,只不过是AO对象变成了GO对象。
例子五
<script type="text/javascript">
console.log(a);
var a = 10;
function a(a) {
console.log(a);
}
a(1);
</script>这里可以看看第二个log打印的是什么,还是会报错?
第一个log打印a函数的函数体没有问题吧?第二个log为什么会报错呢?因为GO对象中保存的a属性在第一次log的时候保存的是a的函数体,但是下面有个a=10;*的赋值,这个时候GO中的a就被修改成10了,后面调用*a(1)*函数的时候,找到GO中的a,这个时候a是number数字而不是函数,所以会报错说*a is not a function。
例子六
<script type="text/javascript">
var a = 1;
var b = 2;
function test(a) {
var a;
console.log(a); // 输出10
a = 100;
console.log(a); // 输出100
console.log(b); // 输出2
}
test(10);
console.log(a); // 输出1
</script>看看例子六的输出结果是不是符合自己的心里预期。我们都知道函数内部有变量会优先使用自身内部的变量,其实也可以转化成AO和GO来理解。 第一个log输出的时候找到自身的AO中有属性a,且这个值是实参传递过来的,所以是10。 第二个log由于前面有a=100所以a被赋值成了100。 第三个log会找自己的AO,发现自己的AO里没有这个b属性,就会去找到父函数的AO,由于这里父函数是全局函数了,所以就去找GO里有没有b属性,有的话就输出了GO里的b的值,所以是2。(如果这里GO中也没有b属性的话,就会报b is not defined的错误了) 第四个log输出的就是自身AO也就是GO中的a属性的值了。
看完这几个例子相信你应该对预编译有个比较清晰的认识了,这里的面试题很多,但是万变不离其中,我们只需要把AO和GO分析出来,那么就可以清晰的了解到函数运行过程中每一步的每个属性值分别是什么了。
作者:Charlin丶
来源:juejin.cn/post/7200681438315642941
北京租房的 请避坑
序
心平气和的解决了问题,但是想吐槽
划重点 说的地方是 北京昌平沙河 永利家园, 一切都是我个人感觉,请客观看待
基本条件
我们是一室一厅,屋里一个床,客厅一个床
事件
刚来的时候 当时我说 客厅这个床不太好啊 。房东说 正常就一个屋里床,客厅这个床 不算,可以要也可以不要。当时听了这话 感觉无所谓,放这呗。
后来 没几天 就发现客厅床坏的,之前几天搬家 没关注 ,这坐坐就不行了。。。心里已经骂了,不过一想 这是送的,算了 无所谓
后台 在10月初 我们找房东 说这个客厅床我们不要了,当时说没事,能处理
我说谢谢,然后后台有事 没继续跟进,今天 我上班,我媳妇和房东联系,本来不错,然后
修床的人 说 找房东处理
房东说 找修床的人处理
然后可能合计我媳妇 好欺负,说是要赔偿,自己当时怎么拼的这个客厅床,不清楚? 不明白? 还用我明说?
我媳妇难受了,说不过
结尾
我这脾气欺负我媳妇,我管不了了,直接电话干过去。中间的步骤省略
结果就是 不用赔偿,丢了就行。
另外
这家还有一个问题,其他费用比较多,比较坑。
只有你最后付钱的时候 才会告诉你 每个月有一个40的什么费用来的,名头我忘了
最后
实在忍不住了,希望多一个人看到 都是好的,希望大家租房 别踩坑,自己知道就好,别说在哪知道的哈,大家都不容易
作者:雨夜之寂
来源:juejin.cn/post/7159475467987189767
在安卓项目中使用 FFmpeg 实现 GIF 拼接(可扩展为实现视频会议多人同屏效果)
前言
在我的项目 隐云图解制作 中,有一个功能是按照一定规则将多张 gif 拼接成一张 gif。
当然,这里说的拼接是类似于拼图一样的拼接,而不是简单粗暴的把多个 gif 合成一个 gif 并按顺序播放。
大致效果如下:
注意:上面的动图只展示了预览效果,没有展示实际合成效果,但是合成效果和预览效果是一摸一样的,有兴趣的话,我可以再开一篇文章讲解怎么实现这个预览效果
实现方法
FFmpeg 简介
在开始之前先简单介绍一下什么是 FFmpeg,不过我相信只要是稍微接触过一点音视频的开发者都知道 FFmpeg。
FFmpeg 是一个开放源代码的自由软件,可以执行音频和视频多种格式的录影、转换、串流功能,包含了 libavcodec ——这是一个用于多个项目中音频和视频的解码器库,以及 libavformat ——一个音频与视频格式转换库。
简单来说,只要是和音视频相关的操作,几乎都可以使用 FFmpeg 来实现。
当然,FFmpeg 是一个纯命令行工具,所以我在这里简单介绍几个本文需要用到的参数:
-y 若指定的输出文件已存在则强制覆盖
-i 设置输入文件,可以设置多个
-filter_complex 设置复杂滤镜,我们这次要实现的拼接 gif 就是依靠这个参数完成
在安卓中使用 FFmpeg
我现在使用的库是 ffmpeg-kit 使用这个库可以直接集成 FFmpeg 到项目中,并且能够方便的执行 FFmpeg 命令。
该库执行 FFmpeg 很简单,只需要:
val session = FFmpegKit.executeWithArguments("your cmd text")
if (ReturnCode.isSuccess(session.returnCode)) {
Log.i(TAG, "Command execution completed successfully.")
} else if (ReturnCode.isCancel(session.returnCode)) {
Log.i(TAG, "Command execution cancelled by user.")
} else {
Log.e(TAG, String.format("Command execution fail with state %s and rc %s.%s", session.state, session.returnCode, session.failStackTrace))
}因为我需要自己管理线程,所以使用的是同步执行
另外,我几乎试过当前 GitHub 上最近还在维护所有的 FFmpeg for Android 库,甚至还自己写过一个,但是都或多或少的有点问题,最终只有这个库能够适配我的需求。
在此弱弱的吐槽一下某些“开源”库,只提供二进制包,不提供编译脚本,也不提供源代码,提供的二进制包缺少了某些依赖,我想自己动手编译都没法编译,一看 README ,好嘛,定制编译请联系作者付费获取,合着这开源开了个寂寞啊。
拼接命令
我们先来看一段完整的拼接命令,我会详细讲解各个参数的作用,最后再讲解如何动态生成需要的命令。
完整命令:
# 覆盖输出文件
-y
# 输入文件
-i jointBg.png
-i 1.gif
-i 2.gif
-i 3.gif
-i 4.gif
# 开始进行滤镜转换
-filter_complex
[0:v]pad=1280:2161[bg];
[1:v]scale=640:1137[gif0];
[2:v]scale=640:368[gif1];
[3:v]scale=640:1024[gif2];
[4:v]scale=640:368[gif3];
[bg][gif0] overlay=0:0[over0];
[over0][gif1] overlay=640:0[over1];
[over1][gif2] overlay=0:1137[over2];
[over2][gif3] overlay=640:368
# 输出路径
out.gif为了方便查看,我使用换行分割了命令,使用时可不能加换行哦
在这段代码中,我们使用 -y 参数指定如果输出文件已存在则覆盖。
接下来使用 -i 参数输入了 5 个文件,其中 jointBg.png 是我生成的一个 1x1 像素的图片,用于后面扩展成背景画布,其他的 gif 文件就是要拼接的源文件。
然后使用 -filter_complex 表示要做一个复杂滤镜,后面跟着的都是这个复杂滤镜的参数:
[0:v]pad=1280:2161[bg]; 表示将输入的第一个文件作为视频打开,并将其当成画板,同时缩放分辨率为 1280x2161 (后面会讲这些分辨率是怎么来的),最后取名为 bg 。
[1:v]scale=640:1137[gif0]; 表示将输入的第二个文件作为视频打开,并缩放分辨率至 640x1137 , 最后取别名为 gif0 。
下面的三行语句作用相同。
然后就是开始拼接:
[bg][gif0] overlay=0:0[over0]; 表示将 gif0 覆盖到 bg 上,并且覆盖的起点坐标为 0x0 ,最后将该其取名为 over0 。
下面的三行代码作用相同。
简单理解一下这个过程:
创建一个图片,并缩放尺寸至事先计算出来的最终拼接成品的尺寸作为背景
依次将输入的文件缩放至事先计算好的尺寸
依次将缩放后的输入文件覆盖(叠加)到背景上
动画演示:
仅作演示便于理解,实际拼接时一般都是放大 bg , 缩小 gif,并且 gif 将完全覆盖住 bg
计算尺寸
上一节中的命令涉及到很多缩放过程,那么这个缩放的尺寸是如何得到的呢?
这一节我们将讲解如何计算尺寸。
首先,我们需要知道的是,当前这个功能,一共有三种拼接模式:
横向拼接
纵向拼接
宫格拼接
本文主要讲解的是宫格拼接,宫格拼接的样式即文章开头的预览效果那种。
既然是宫格拼接,那么绕不开的就是如果拼接的动图尺寸不一致,怎么确保拼接出来的动图美观?
这里我们有两种策略,由用户自行选择:
完全以最小尺寸的图片为基准,将所有图片强制缩放到最小尺寸,这样可能会造成部分动图被拉伸失真。
以所有图片中的最小宽度为基准,等比例缩放其他图片,这样可以确保所有图片都不会失真,但是拼接出来的成品将不是一个完美的矩形,而是一个留有黑色背景的异形图片。
确定了我们使用的两种缩放策略,下面就是开始计算成品的总尺寸和每张输入图片的需要缩放尺寸。
不过在此之前,我们需要遍历所有输入图片,拿到所有图片的原始尺寸和所有图片中的最小尺寸:
val jointGifResolution: MutableList<MutableList<Int>> = ArrayList() // 所有动图的原始尺寸 list
var minValue = Int.MAX_VALUE // 最小宽度(别问我为什么不命名成 minWidth ,问就是兼容性)
var minValue2 = Int.MAX_VALUE // 最小高度
for (uri in gifUris) {
val gifDrawable = GifDrawable(context.contentResolver, uri)
val height = gifDrawable.intrinsicHeight // 当前 gif 的原始高度
val width = gifDrawable.intrinsicWidth // 当前 gif 的原始宽度
jointGifResolution.add(mutableListOf(width, height)) // 将尺寸加入 list
// 计算最小宽高
if (minValue > width) {
minValue = width
}
if (minValue2 > height) {
minValue2 = height
}
}其中,gifUris 即事先获取到的所有输入动图的 uri 列表。
这里我们使用到了 GifDrawable 获取动图的尺寸,因为这不是本文的重点,所以不多加解释,读者只需知道这样可以拿到 gif 的原始尺寸即可。
拿到所有动图的原始宽高和最小宽高后,下一步是计算需要的缩放值:
var totalHeight = 0
var totalWidth = 0
var squareIndex = 0
val squareTotalHeight: MutableList<Int> = arrayListOf()
jointGifResolution.forEachIndexed { index, resolution ->
val jointWidth = minValue // 无论使用缩放策略 1 还是 2,缩放宽度都是最小宽度
val jointHeight = when (scaleMode) {
// 如果使用缩放策略 2 则需要按比例计算出缩放高度
GifTools.JointScaleModeWithRatio -> resolution[1] * minValue / resolution[0]
// 如果使用缩放策略 1 则直接强制缩放到最小高度
else -> minValue2
}
// 因为宫格拼接只能使用 2 的 n 次幂张图片,所以每行图片数量可以根据图片总数算出,不过太麻烦,所以这里我打了个表,直接从表里面拿
// val JointGifSquareLineLength = hashMapOf(4 to 2, 9 to 3, 16 to 4, 25 to 5, 36 to 6, 49 to 7, 64 to 8, 81 to 9, 100 to 10)
var lineLength = GifTools.JointGifSquareLineLength[jointGifResolution.size]
if (lineLength == null) {
lineLength = sqrt(jointGifResolution.size.toDouble()).toInt()
}
if (scaleMode == GifTools.JointScaleModeWithRatio) { // 使用等比缩放策略
if (index < lineLength) { // 所有图片宽度都是一样的,所以直接加一行的宽度得到的就是最大宽度
totalWidth += jointWidth
}
try {
// 这里是获取每一列的当前行高,并将其加起来,最终遍历完会得到当前列的高度
val tempIndex = squareIndex % lineLength
Log.e(TAG, "getJointGifResolution: temp index = $tempIndex")
if (squareTotalHeight.size <= tempIndex) {
squareTotalHeight.add(tempIndex, 0)
}
squareTotalHeight[tempIndex] = squareTotalHeight[tempIndex] + jointHeight
} catch (e: java.lang.Exception) {
Log.e(TAG, "getJointGifResolution: ", e)
}
// 将缩放尺寸更新至尺寸列表
jointGifResolution[index] = mutableListOf(jointWidth, jointHeight)
} else {
// 如果不是按比例缩放,则直接将最小宽高存入总宽高
if (index < lineLength) {
totalHeight += min(jointHeight, jointWidth)
totalWidth += min(jointHeight, jointWidth)
}
// 将缩放尺寸更新至尺寸列表
jointGifResolution[index] = mutableListOf(min(jointHeight, jointWidth), min(jointHeight, jointWidth))
}
squareIndex++
}上面的代码我已经加了详细的注释,至此所有图片的缩放尺寸已计算出来。
即,总尺寸为:
if (scaleMode != GifTools.JointScaleModeWithRatio) {
jointGifResolution.add(mutableListOf(totalWidth, totalHeight))
}
else {
Log.e(TAG, "getJointGifResolution: $squareTotalHeight")
jointGifResolution.add(mutableListOf(totalWidth, Collections.max(squareTotalHeight)))
}最小宽高为:
jointGifResolution.add(mutableListOf(minValue, minValue2))对了,你可能会奇怪,为什么我要把总尺寸和最小宽高存入缩放尺寸 list,哈哈,这是因为我懒,所以我对这个 list 的定义是:
/**
*
* 遍历获取所有 gifUris 中的动图分辨率
*
* 并将经过处理后的所有长、宽之和存入 [size-2] ;
*
* 将最小的长宽存入 [size-1]
* */动态生成命令
完成了尺寸的计算,下一步是按照输入文件和计算出来的尺寸动态的生成 FFmpeg 命令。
不过在这之前,我们需要先创建一个 1x1 的图片,用来扩展成背景:
private suspend fun createJointBgPic(context: Context): File? {
val drawable = ColorDrawable(Color.parseColor("#FFFFFFFF"))
val bitmap = Bitmap.createBitmap(1, 1, Bitmap.Config.ARGB_8888)
val canvas = Canvas(bitmap)
drawable.draw(canvas)
return try {
Tools.saveBitmap2File(bitmap, "jointBg", context.externalCacheDir)
} catch (e: Exception) {
log2text("Create cache bg fail!", "e", e)
null
}
}然后从尺寸列表中取出并删除追加在末尾的总尺寸和最小尺寸:
// 别看了,没写错,就是两个 size-1 ,为啥?你猜
val minResolution = gifResolution.removeAt(gifResolution.size - 1)
val totalResolution = gifResolution.removeAt(gifResolution.size - 1)然后,就是开始拼接命令,这里我为了方便使用,自己写了一个 FFmpeg 命令的 Builder:
/**
* @author equationl
* */
public class FFMpegArgumentsBuilder {
private final String[] cmd;
public static class Builder {
private final ArrayList<String> cmd = new ArrayList<>();
/**
* Such as add [arg, value] to cmd[]
* */
public Builder setArgWithValue(String arg, String value) {
this.cmd.add(arg);
this.cmd.add(value);
return this;
}
/**
* Such as add arg to cmd[]
* */
public Builder setArg(String arg) {
this.cmd.add(arg);
return this;
}
/**
* Such as "-ss time"
* */
public Builder setStartTime(String time) {
this.cmd.add("-ss");
this.cmd.add(time);
return this;
}
/**
* Such as "-to time"
* */
public Builder setEndTime(String time) {
this.cmd.add("-to");
this.cmd.add(time);
return this;
}
/**
* Such as "-i input"
* */
public Builder setInput(String input) {
this.cmd.add("-i");
this.cmd.add(input);
return this;
}
/**
* <p>Such as "-t time"</p>
* <p>Note: call this before addInput() will limit input duration time; call before addOutput() will limit output duration time.</p>
* */
public Builder setDurationTime(String time) {
this.cmd.add("-t");
this.cmd.add(time);
return this;
}
/**
* <p>if isOverride is true, add "-y"; else add "-n"</p>
* <p>if do not set this arg, FFMpeg may ask for if override existed output file</p>
* */
public Builder setOverride(Boolean isOverride) {
if (isOverride) {
this.cmd.add("-y");
}
else {
this.cmd.add("-n");
}
return this;
}
/**
* Add output file to cmd[].<b>You must call this at end.</b>
* */
public Builder setOutput(String output) {
this.cmd.add(output);
return this;
}
/**
* <p>Set input/output file format</p>
* <p>Such as "-f format"</p>
* */
public Builder setFormat(String format) {
this.cmd.add("-f");
this.cmd.add(format);
return this;
}
/**
* Set video filter
* Such as "-vf filter"
* */
public Builder setVideoFilter(String filter) {
this.cmd.add("-vf");
this.cmd.add(filter);
return this;
}
/**
* Set frame rate, Such as "-r frameRate"
* */
public Builder setFrameRate(String frameRate) {
this.cmd.add("-r");
this.cmd.add(frameRate);
return this;
}
/**
* Set frame size, Such as "-s frameSize"
* */
public Builder setFrameSize(String frameSize) {
this.cmd.add("-s");
this.cmd.add(frameSize);
return this;
}
public FFMpegArgumentsBuilder build() {
return new FFMpegArgumentsBuilder(this, false);
}
/**
* Build cmd
*
* @param isAddFFmpeg true: Add a ffmpeg flag in first
* */
public FFMpegArgumentsBuilder build(Boolean isAddFFmpeg) {
return new FFMpegArgumentsBuilder(this, isAddFFmpeg);
}
}
public String[] getCmd() {
return this.cmd;
}
private FFMpegArgumentsBuilder(Builder b, Boolean isAddFFmpeg) {
if (isAddFFmpeg) {
b.cmd.add(0, "ffmpeg");
}
this.cmd = b.cmd.toArray(new String[0]);
}
}开始生成命令文本:
首先是输入文件等,
val cmdBuilder = FFMpegArgumentsBuilder.Builder()
cmdBuilder.setOverride(true) // -y
.setInput(jointBg.absolutePath) // -i 输入背景
for (uri in gifUris) { //输入GIF
cmdBuilder.setInput(FileUtils.getMediaAbsolutePath(context, uri)) // -i
}
cmdBuilder.setArg("-filter_complex") //添加过滤器然后是添加过滤器参数,
//过滤器参数
var cmdFilter = ""
//设置背景并扩展分辨率到 total
cmdFilter += "[0:v]pad=${totalResolution[0]}:${totalResolution[1]}[bg];"
//将输入文件缩放并取别名为 gifX (X为索引)
gifResolution.forEachIndexed { index, mutableList ->
cmdFilter += "[${index+1}:v]scale=${mutableList[0]}:${mutableList[1]}[gif$index];"
}
cmdFilter += "[bg][gif0] overlay=0:0[over0];" //将第一个GIF叠加 bg 的 0:0 (即画面左下角)
//开始叠加剩余动图
cmdFilter += getCmdFilterOverlaySquare(gifUris, gifResolution)其中,getCmdFilterOverlaySquare 用于计算 gif 的摆放坐标,并合成参数命令,实现如下:
private fun getCmdFilterOverlaySquare(gifUris: ArrayList<Uri>, gifResolution: MutableList<MutableList<Int>>): String {
// "[bg][gif0] overlay=0:0[over0];"
var cmdFilter = ""
var h: Int
var w: Int
var index = 0
var lineLength = GifTools.JointGifSquareLineLength[gifUris.size]
if (lineLength == null) {
lineLength = sqrt(gifUris.size.toDouble()).toInt()
}
for (i in 0 until lineLength) {
for (j in 0 until lineLength) {
if ((i==lineLength-1 && j==lineLength-1) || (i==0 && j==0)) { //最后一张单独处理,第一张已处理
continue
}
if (j==0) { //竖排第一个,w当然等于 0
w = 0
} else {
w = 0
for (k in 0 until j) {
w += gifResolution[i*lineLength+k][0]
}
}
if (i==0) { //横排第一个,h等于0
h = 0
} else {
h = 0
for (k in j until index step lineLength) {
h += gifResolution[k][1]
}
}
cmdFilter += "[over${index}][gif${index+1}] overlay=$w:$h[over${index + 1}];"
index++
}
}
w = 0
for (i in 0 until lineLength-1) {
w += gifResolution[i+lineLength*(lineLength-1)][0]
}
h = 0
for (i in lineLength-1 until lineLength*lineLength-1 step lineLength) {
h += gifResolution[i][1]
}
cmdFilter += "[over${index}][gif${index+1}] overlay=$w:$h"
return cmdFilter
}上述代码不难理解,总之就是根据遍历到的 gif 索引,判断它应该所处的坐标,然后加入过滤器参数。
最后,将过滤参数加入命令,加入输出文件路径,即可拿到最终命令文本 cmd:
cmdBuilder.setArg(cmdFilter)
cmdBuilder.setOutput(resultPath)
val cmd = cmdBuilder.build(false).cmd最后,只要将这个命令文本仍给 FFmpeg 执行即可!
总结
虽然本文仅仅说的是如何拼接 Gif , 但是 FFmpeg 是十分强大的,我这个属于是抛砖引玉。
相信各位有过这样一种需求,那就是做一个多人同屏的实时会议功能,如果在看本文之前你可能不知所措,但是看完本文你一定会觉得这是小菜一碟。
因为 FFmpeg 原生支持串流,支持视频处理,你只要把我这里的输入文件改成串流,输出文件改成串流,再按照你的需求改一下坐标,那不就完成了吗?
作者:equationl
来源:juejin.cn/post/7136325945937362952
为什么要选择VersionCatalog来做依赖管理?
虾扯淡
很多人都介绍过Gradle 7.+提供新依赖管理工具VersionCatalog,我就不过多介绍这个了。我们最近也算是成功接入了VersionCatalog,过程也还是有点曲折的,总体来说我觉得确实比我们当前的ext,或者说是用buildSrc的形式进行依赖管理是个更成熟的方案吧。下面是几个介绍的文章,尤其可以看看三七哥哥的。
之前大部分文章只介绍了技术方案,很少会去横向对比几个技术方案之间的优劣。从我们最近一个月的使用结果上来看吧,接下来我给大家分析下实际的优劣,仅仅只代表个人看法, 上表格了。
因为
VersionCatalog使用的文件格式是toml,所以后续可能会用toml进行简称。
| ext | buildSrc | toml | |
|---|---|---|---|
| 声明域 | *.gradle | *.java *.kt | *.toml |
| 可修改 | 可修改 | 不可修改 | 不可修改 |
| 写法 | 花里胡哨 | 静态变量 | 固定写法 xxx.xxx.xxx |
| 校验 | 随便写 | 编译时校验 | 同步时校验 |
声明域: 指的是我们在哪里声明这些依赖管理。其中ext可以在绝大部分的.gradle中去进行声明,所以就会导致依赖声明的过于零散。而这部分问题就不存在于buildSrc和toml中,他们只能被声明在固定的位置上。
可修改性: 特制声明的依赖能否被修改,ext声明是在内存空间内,而ext的本质其实就是一个Any他可以存放任意的东西,如果出现同名的则会是后面声明的把前面声明的覆盖掉,这就是一个非常不稳定的属性,而buildSrc则是由class来声明的,我们没有办法在gradle中去修改这部分,所以相对来说是稳定的。而toml也类似,基于固定格式反序列化成代码。不具备修改的能力。
写法: ext这方面是真的拉胯,比如支持libs.abc或者libs."abc"或者libs.["abc"]还可以单引号,就非常的随意,而且极为不统一。这也是我们本次改动中碰到问题最多的时候。其他两种写法都相对比较固定,类似java/kt 中的静态常量。
校验: ext就是爱咋写咋写吧,反正也没有很好的校验啥的。而buildSrc则是基于java的代码编译来的,toml因为是一个新的文件格式,所以内置了一套相对比较强的语法校验,如果不合规则会报错,并显示错误行数。
据说buildSrc对于增量编译的适配等其实不太良好,而且我们是一个复杂的巨型复合构建的工程,所以个人并不太推荐buildSrc。
可以参考这篇文章第二章 Stop using Gradle buildSrc. Use composite builds instead
由此可证哦,VersionCatalog雀食是一个非常好的选择,尤其如果你们当前还是在使用的是ext的情况下。
巨型工程最麻烦的事情其实另外一点就是技术栈的切换,因为要改起来的地方可真的就是太多了,首先就是要先解决复合构建的情况下全局只有一份注册的逻辑,其二就是把当前工程的ext全部转移到toml中,然后要最好和之前的方式接近,尽量保证最小改动。最后则是所有工程都改一下!!!!!!!!(要我狗命)
共享配置
GradleSample demo 工程如下,其中plugin-version就是
我们也采取了之前Gradle 奇淫技巧之initscript pluginManagement一样的方式,通过initscript做到复合构建内共享插件的能力。
另外我们把VersionCatalog作为一个extension抛出来在外部完成注册。
catalogs {
script = new File(rootProjectDir, "depencies.gradle")
versionCatalogs {
create("libs") { from(files("${rootProjectDir.path}/toml/dependencies.versions.toml")) }
create("module") { from(files("${rootProjectDir.path}/toml/module.versions.toml")) }
}
dependencyResolutionManagement {
repositories {
maven { setUrl("https://maven.aliyun.com/repository/central/") }
maven {
setUrl("https://storage.googleapis.com/r8-releases/raw")
}
gradlePluginPortal()
google()
mavenLocal()
maven {
url "https://dl.bintray.com/kotlin/kotlin-eap"
}
}
}
}通过这部分配置就可以把共享的部分注入进工程内。然后就是很沙雕的改改改了,把所有的ext全部迁移到我们新的toml上去,然后注册出多个。
命令行工具
TheNext 虾开发的撒币cli工具 专门解决虾的撒币问题
以前也说过了我们工程的模块数量巨大,然后又因为ext的写法风骚,所以我们基本所有的写依赖的地方都要改,就是真的工作量巨大。
一个优秀的摸鱼工程师最重要的天赋就是要学会转化生产力,把这种简单又繁琐的工作交给命令行来解决。所以这就有了TheNext的一个新能力,基于当前的文件目录修改所有的.gradle文件,然后把非标准的ext的写法全部进行一次替换。
效果如图所示。
代码逻辑如下,我们首先会遍历整个工程的文件目录,然后发现.gradle后缀的文件,之后通过正则匹配出dependencies,然后进行把一些"" '' []等等都删掉,然后把- _更换成.,这样就能完成简单的自动替换了。
package com.kronos.mebium.android
import com.beust.jcommander.JCommander
import com.kronos.mebium.action.Handler
import com.kronos.mebium.entity.CommandEntity
import com.kronos.mebium.file.getRootProjectDir
import com.kronos.mebium.utils.green
import com.kronos.mebium.utils.red
import com.kronos.mebium.utils.yellow
import java.io.File
import java.util.Scanner
/**
*
* @Author LiABao
* @Since 2022/12/8
*
*/
class DependenciesHandler : Handler {
val scanner = Scanner(System.`in`)
var isSkip = false
override fun handle(args: Array<String>) {
isSkip = args.contains(skip)
val realArgs = if (isSkip) {
arrayListOf<String>().apply {
args.forEach {
if (it != skip) {
add(it)
}
}
}.toTypedArray()
} else {
args
}
val commandEntity = CommandEntity()
JCommander.newBuilder().addObject(commandEntity).build().parse(*realArgs)
val first = commandEntity.file
val name = commandEntity.name
val root = first
val files = root.walkTopDown().filter {
it.isFile && it.name.contains(".gradle")
}
val overrideList = mutableListOf<Pair<File, File>>()
files.forEach {
onGradleCheck(it)?.apply {
overrideList.add(it to this)
}
}
confirm(overrideList)
}
private fun confirm(overrideList: MutableList<Pair<File, File>>) {
if (overrideList.isEmpty()) {
return
}
println("if you want overwrite all this file ? input y to confirm \r\n".red())
val input = scanner.next()
if (input == "y") {
overrideList.forEach {
it.first.delete()
it.second.renameTo(it.first)
}
print("replace success \r\n ".green())
} else {
print("skip\r\n ".yellow())
}
}
private val pattern =
"(\\D\\S*)(implementation|Implementation|compileOnly|CompileOnly|test|Test|api|Api|kapt|Kapt|Processor)([ (])(\\D\\S*)".toPattern()
private fun onGradleCheck(file: File): File? {
var override = false
val lines = file.readLines()
val newLines = mutableListOf<String>()
lines.forEach { line ->
val matcher = pattern.matcher(line)
if (matcher.find()) {
val libs = matcher.group(4)
if (!libs.contains(":") && !libs.contains("files(")) {
val newLibs =
libs.replace("\'", "").replace("\"", "").replace("-", ".").replace("_", ".")
.replace("kotlin.libs", "kotlinlibs").replace("[", ".").replace("]", "")
if (newLibs == libs) {
newLines.add(line)
return@forEach
}
print("fileName: ${file.name} dependencies : $line \r\n")
if (isSkip) {
override = true
newLines.add(line.replace(libs, newLibs))
print("$libs do you want replace to $newLibs \r\n ".green())
return@forEach
}
print("$libs do you want replace to $newLibs ? input y to replace \r\n ".red())
while (true) {
val input = scanner.next()
if (input == "y") {
print("replace success\r\n".green())
override = true
newLines.add(line.replace(libs, newLibs))
return@forEach
} else {
print("skip\r\n ".yellow())
break
}
}
}
}
newLines.add(line)
}
if (override) {
val newFile = File(file.parent, file.name.removeSuffix(".gradle") + ".temp")
newLines.forEach {
newFile.appendText(it + "\r\n")
}
return newFile
}
return null
}
}
const val skip = "--skip"代码就基本是这样,如果有正则带佬可以帮忙优化下正则的。
然后这个工具也可以多次复用,因为我这个需求没有办法很快的被合入,需要频繁的rebase master的代码,每次rebase完之后都要进行二次修改,真的吐了。
验收
每个新功能开发最后都是要进行验收的,尤其是技改需求,你到时候把功能搞坏了到时候可是要背黑锅的啊。而且这种需求也没有办法要求测试进行特别系统性的测试,所以还是要开发自己想办法了。
我们拉取了apk包的依赖,然后用HashSet进行了拉平,去除重复依赖,然后通过diff对比前后差异,在基本符合预期的情况下我们就可以进行快速的合入。
结尾
其实本文的核心是给大家分析下几种依赖管理方式的优劣,然后对于还在使用gradle ext的大佬,其实可以逐渐考虑进行替换了。
作者:究极逮虾户
来源:juejin.cn/post/7190277951614058555
安卓与串口通信-实践篇
前言
在上一篇文章中我们讲解了关于串口的基础知识,没有看过的同学推荐先看一下,否则你可能会不太理解这篇文章所述的某些内容。
这篇文章我们将讲解安卓端的串口通信实践,即如何使用串口通信实现安卓设备与其他设备例如PLC主板之间数据交互。
需要注意的是正如上一篇文章所说的,我目前的条件只允许我使用 ESP32 开发版烧录 Arduino 程序与安卓真机(小米10U)进行串口通信演示。
准备工作
由于我们需要使用 ESP32 烧录 Arduino 程序演示安卓端的串口通信,所以在开始之前我们应该先把程序烧录好。
那么烧录一个怎样的程序呢?
很简单,我这里直接烧了一个 ESP32 使用 9600 的波特率进行串口通信,程序内容就是 ESP32 不断的向串口发送数据 “e” ,并且监听串口数据,如果接收到数据 “o” 则打开开发版上自带的 LED 灯,如果接收到数据 “c” 则关闭这个 LED 灯。
代码如下:
#define LED 12
void setup() {
Serial.begin(9600);
pinMode(LED, OUTPUT);
}
void loop() {
if (Serial.available()) {
char c = Serial.read();
if (c == 'o') {
digitalWrite(LED, HIGH);
}
if (c == 'c') {
digitalWrite(LED, LOW);
}
}
Serial.write('e');
delay(100);
}上面的 12 号 Pin 是这块开发版的 LED。
使用 Arduino自带串口监视器测试结果:
可以看到,确实如我们设想的通过串口不断的发送字符 “e”,并且在接收到字符 “o” 后点亮了 LED。
安卓实现串口通信
原理概述
众所周知,安卓其实是基于 Linux 的操作系统,所以在安卓中对于串口的处理与 Linux 一致。
在 Linux 中串口会被视为一个“设备”,并体现为 /dev/ttys 文件。
/dev/ttys 又被称为字符终端,例如 ttys0 对应的是 DOS/Windows 系统中的 COM1 串口文件。
通常,我们可以简单理解,如果我们插入了某个串口设备,则这个设备与 Linux 的通信会由 /dev/ttys 文件进行 “中转”。
即,如果 Linux 想要发送数据给串口设备,则可以通过往 /dev/ttys 文件中直接写入要发送的数据来实现,如:
echo test > /dev/ttyS1 这个命令会将 “test” 这串字符发送给串口设备。
如果想读取串口发送的数据也是一样的,可以通过读取 /dev/ttys 文件内容实现。
所以,如果我们在安卓中想要实现串口通信,大概率也会想到直接读取/写入这个特殊文件。
android-serialport-api
在上文中我们说到,在安卓中也可以通过与 Linux 一样的方式--直接读写 /dev/ttys 实现串口通信。
但是其实并不需要我们自己去处理读写和数据的解析,因为谷歌官方给出了一个解决方案:android-serialport-api
为了便于理解,我们会大致说一下这个解决方案的源码,但是就不上示例了,至于为什么,同学们往下看就知道了。另外,虽然这个方案历史比较悠久,也很长时间没有人维护了,但是并不意味着不能使用了,只是使用条件比较苛刻,当然,我司目前使用的还是这套方案(哈哈哈哈)。
不过这里我们不直接看 android-serialport-api 的源码,而是通过其他大佬二次封装的库来看: Android-SerialPort-API
在这个库中,通过
// 默认直接初始化,使用8N1(8数据位、无校验位、1停止位),path为串口路径(如 /dev/ttys1),baudrate 为波特率
SerialPort serialPort = new SerialPort(path, baudrate);
// 使用可选参数配置初始化,可配置数据位、校验位、停止位 - 7E2(7数据位、偶校验、2停止位)
SerialPort serialPort = SerialPort
.newBuilder(path, baudrate)
// 校验位;0:无校验位(NONE,默认);1:奇校验位(ODD);2:偶校验位(EVEN)
// .parity(2)
// 数据位,默认8;可选值为5~8
// .dataBits(7)
// 停止位,默认1;1:1位停止位;2:2位停止位
// .stopBits(2)
.build();初始化串口,然后通过:
InputStream in = serialPort.getInputStream();
OutputStream out = serialPort.getOutputStream();获取到输入/输出流,通过读取/写入这两个流来实现与串口设备的数据通信。
我们首先来看看初始化串口是怎么做的。
首先检查了当前是否具有串口文件的读写权限,如果没有则通过 shell 命令更改权限为 666 ,更改后再次检查是否有权限,如果还是没有就抛出异常。
注意这里的执行 shell 时使用的 runtime 是 Runtime.getRuntime().exec(sSuPath); 也就是说,它是通过 root 权限来执行这段命令的!
换句话说,如果想要通过这种方式实现串口通信,必须要有 ROOT 权限!这就是我说我不会给出示例的原因,因为我手头的设备无法 ROOT 啊。至于为啥我司还能继续使用这种方案的原因也很简单,因为我们工控机的安卓设备都是定制版的啊,拥有 ROOT 权限不是基本操作?
确定权限可用后通过 open 方法拿到一个类型为 FileDescriptor 的变量 mFd ,最后通过这个 mFd 拿到输入输出流。
所以核心在于 open 方法,而 open 方法是一个 native 方法,即 C 代码:
private native FileDescriptor open(String absolutePath, int baudrate, int dataBits, int parity,
int stopBits, int flags);C 的源码这里就不放了,只需要知道它做的工作就是打开了 /dev/ttys 文件(准确的说是“终端”),然后通过传递进去的这些参数去按串口规则解析数据,最后返回一个 java 的 FileDescriptor 对象。
在 java 中我们再通过这个 FileDescriptor 对象可以拿到输入/输出流。
原理说起来是十分的简单。
看完通信部分的原理后,我们再来看看我们如何查找可用的串口呢?
其实和 Linux 上也一样:
public Vector<File> getDevices() {
if (mDevices == null) {
mDevices = new Vector<File>();
File dev = new File("/dev");
File[] files = dev.listFiles();
if (files != null) {
int i;
for (i = 0; i < files.length; i++) {
if (files[i].getAbsolutePath().startsWith(mDeviceRoot)) {
Log.d(TAG, "Found new device: " + files[i]);
mDevices.add(files[i]);
}
}
}
}
return mDevices;
}也是通过直接遍历 /dev 下的文件,只不过这里做了一些额外的过滤。
或者也可以通过读取 /proc/tty/drivers 配置文件后过滤:
Vector<Driver> getDrivers() throws IOException {
if (mDrivers == null) {
mDrivers = new Vector<Driver>();
LineNumberReader r = new LineNumberReader(new FileReader("/proc/tty/drivers"));
String l;
while ((l = r.readLine()) != null) {
// Issue 3:
// Since driver name may contain spaces, we do not extract driver name with split()
String drivername = l.substring(0, 0x15).trim();
String[] w = l.split(" +");
if ((w.length >= 5) && (w[w.length - 1].equals("serial"))) {
Log.d(TAG, "Found new driver " + drivername + " on " + w[w.length - 4]);
mDrivers.add(new Driver(drivername, w[w.length - 4]));
}
}
r.close();
}
return mDrivers;
}关于读取可用串口设备,其实从这里的路径也可以看出,都是系统路径,也就是说,如果没有权限,大概率也是读取不到东西的。
这就是使用与 Linux 一样的方式去读取串口数据的基本原理,那么问题来了,既然我说这个方法使用条件比较苛刻,那么更易用的替代方案是什么呢?
我们下面就会介绍,那就是使用安卓的 USB host (USB主机)的功能。
USB host
Android 3.1(API 级别 12)或更高版本的平台直接支持 USB 配件和主机模式。USB 配件模式还作为插件库向后移植到 Android 2.3.4(API 级别 10)中,以支持更广泛的设备。设备制造商可以选择是否在设备的系统映像中添加该插件库。
在安卓 3.1 版本开始,支持将USB作为主机模式(USB host)使用,而我们如果想要通过 USB 读取串口数据则需要依赖于这个主机模式。
在正式开始介绍USB主机模式前,我们先简要介绍一下安卓上支持的USB模式。
安卓上的USB支持三种模式:设备模式、主机模式、配件模式。
设备模式即我们常用的直接将安卓设备连接至电脑上,此时电脑上显示为 USB 外设,即可以当成 “U盘” 使用拷贝数据,不过现在安卓普遍还支持 MTP模式(作为摄像头)、文件传输模式(即当U盘用)、网卡模式等。
主机模式即将我们的安卓设备作为主机,连接其他外设,此时安卓设备就相当于上面设备模式中的电脑。此时安卓设备可以连接键盘、鼠标、U盘以及嵌入式应用USB转串口、转I2C等设备。但是如果想要将安卓设备作为主机模式可能需要一条支持 OTG 的数据线或转接头。(Micro-USB 或 USB type-c 转 USB-A 口)
而在 USB 配件模式下,外部 USB 硬件充当 USB 主机。配件示例可能包括机器人控制器、扩展坞、诊断和音乐设备、自助服务终端、读卡器等等。这样,不具备主机功能的 Android 设备就能够与 USB 硬件互动。Android USB 配件必须设计为与 Android 设备兼容,并且必须遵守 Android 配件通信协议。
设备模式与配件模式的区别在于在配件模式下,除了 adb 之外,主机还可以看到其他 USB 功能。
使用USB主机模式与外设交互数据
在介绍完安卓中的三种USB模式后,下面我们开始介绍如何使用USB主机模式。当然,这里只是大概介绍原生APi的使用方法,我们在实际使用中一般都都是直接使用大佬编写的第三方库。
准备工作
在开始正式使用USB主机模式时我们需要先做一些准备工作。
首先我们需要在清单文件(AndroidManifest.xml)中添加:
<!-- 声明需要USB主机模式支持,避免不支持的设备安装了该应用 -->
<uses-feature android:name="android.hardware.usb.host" />
<!-- …… -->
<!-- 声明需要接收USB连接事件 -->
<action android:name="android.hardware.usb.action.USB_DEVICE_ATTACHED" />一个完整的清单文件示例如下:
<manifest ...>
<uses-feature android:name="android.hardware.usb.host" />
<uses-sdk android:minSdkVersion="12" />
...
<application>
<activity ...>
...
<intent-filter>
<action android:name="android.hardware.usb.action.USB_DEVICE_ATTACHED" />
</intent-filter>
</activity>
</application>
</manifest>声明好清单文件后,我们就可以查找当前可用的设备信息了:
private fun scanDevice(context: Context) {
val manager = context.getSystemService(Context.USB_SERVICE) as UsbManager
val deviceList: HashMap<String, UsbDevice> = manager.deviceList
Log.i(TAG, "scanDevice: $deviceList")
}将 ESP32 开发版插上手机,运行程序,输出如下:
可以看到,正确的查找到了我们的 ESP32 开发版。
这里提一下,因为我们的手机只有一个 USB 口,此时已经插上了 ESP32 开发版,所以无法再通过数据线直接连接电脑的 ADB 了,此时我们需要使用无线 ADB,具体怎么使用无线 ADB,请自行搜索。
另外,如果我们想要通过查找到设备后请求连接的方式连接到串口设备的话,还需要额外申请权限。(同理,如果我们直接在清单文件中提前声明需要连接的设备则不需要额外申请权限,具体可以看看参考资料5,这里不再赘述)
首先声明一个广播接收器,用于接收授权结果:
private lateinit var permissionIntent: PendingIntent
private const val ACTION_USB_PERMISSION = "com.android.example.USB_PERMISSION"
private val usbReceiver = object : BroadcastReceiver() {
override fun onReceive(context: Context, intent: Intent) {
if (ACTION_USB_PERMISSION == intent.action) {
synchronized(this) {
val device: UsbDevice? = intent.getParcelableExtra(UsbManager.EXTRA_DEVICE)
if (intent.getBooleanExtra(UsbManager.EXTRA_PERMISSION_GRANTED, false)) {
device?.apply {
// 已授权,可以在这里开始请求连接
connectDevice(context, device)
}
} else {
Log.d(TAG, "permission denied for device $device")
}
}
}
}
}声明好之后在 Acticity 的 OnCreate 中注册这个广播接收器:
permissionIntent = PendingIntent.getBroadcast(this, 0, Intent(ACTION_USB_PERMISSION), FLAG_MUTABLE)
val filter = IntentFilter(ACTION_USB_PERMISSION)
registerReceiver(usbReceiver, filter)最后,在查找到设备后,调用 manager.requestPermission(deviceList.values.first(), permissionIntent) 弹出对话框申请权限。
连接到设备并收发数据
完成上述的准备工作后,我们终于可以连接搜索到的设备并进行数据交互了:
private fun connectDevice(context: Context, device: UsbDevice) {
val usbManager = context.getSystemService(Context.USB_SERVICE) as UsbManager
CoroutineScope(Dispatchers.IO).launch {
device.getInterface(0).also { intf ->
intf.getEndpoint(0).also { endpoint ->
usbManager.openDevice(device)?.apply {
claimInterface(intf, forceClaim)
while (true) {
val validLength = bulkTransfer(endpoint, bytes, bytes.size, TIMEOUT)
if (validLength > 0) {
val result = bytes.copyOfRange(0, validLength)
Log.i(TAG, "connectDevice: length = $validLength")
Log.i(TAG, "connectDevice: byte = ${result.contentToString()}")
}
else {
Log.i(TAG, "connectDevice: Not recv data!")
}
}
}
}
}
}
}在上面的代码中,我们使用 usbManager.openDevice 打开了指定的设备,即连接到设备。
然后通过 bulkTransfer 接收数据,它会将接收到的数据写入缓冲数组 bytes 中,并返回成功接收到的数据长度。
运行程序,连接设备,日志打印如下:
可以看到,输出的数据并不是我们预料中的数据。
这是因为这是非常原始的数据,如果我们想要读取数据,还需要针对不同的串口转USB芯片或协议编写驱动程序才能获取到正确的数据。
顺道一提,如果想要将数据写入串口数据的话可以使用 controlTransfer() 。
所以,我们在实际生产环境中使用的都是基于此封装好的第三方库。
这里推荐使用 usb-serial-for-android
usb-serial-for-android
使用这个库的第一步当然是导入依赖:
// 添加仓库
allprojects {
repositories {
...
maven { url 'https://jitpack.io' }
}
}
// 添加依赖
dependencies {
implementation 'com.github.mik3y:usb-serial-for-android:3.4.6'
}添加完依赖同样需要在清单文件中添加相应字段以及处理权限,因为和上述使用原生API一致,所以这里不再赘述。
和原生 API 不同的是,因为我们此时已经知道了我们的 ESP32 主板的设备信息,以及使用的驱动(CDC),所以我们就不使用原生的查找可用设备的方法了,我们这里直接指定我们已知的这个设备(当然,你也可以继续使用原生API的查找和连接方法):
private fun scanDevice(context: Context) {
val manager = context.getSystemService(Context.USB_SERVICE) as UsbManager
val customTable = ProbeTable()
// 添加我们的设备信息,三个参数分别为 vendroId、productId、驱动程序
customTable.addProduct(0x1a86, 0x55d3, CdcAcmSerialDriver::class.java)
val prober = UsbSerialProber(customTable)
// 查找指定的设备是否存在
val drivers: List<UsbSerialDriver> = prober.findAllDrivers(manager)
if (drivers.isNotEmpty()) {
val driver = drivers[0]
// 这个设备存在,连接到这个设备
val connection = manager.openDevice(driver.device)
}
else {
Log.i(TAG, "scanDevice: 无设备!")
}
}连接到设备后,下一步就是和数据交互,这里封装的十分方便,只需要获取到 UsbSerialPort 后,直接调用它的 read() 和 write() 即可读写数据:
port = driver.ports[0] // 大多数设备都只有一个 port,所以大多数情况下直接取第一个就行
port.open(connection)
// 设置连接参数,波特率9600,以及 “8N1”
port.setParameters(9600, 8, UsbSerialPort.STOPBITS_1, UsbSerialPort.PARITY_NONE)
// 读取数据
val responseBuffer = ByteArray(1024)
port.read(responseBuffer, 0)
// 写入数据
val sendData = byteArrayOf(0x6F)
port.write(sendData, 0)此时,一个完整的,用于测试我们上述 ESP32 程序的代码如下:
@Composable
fun SerialScreen() {
val context = LocalContext.current
Column(
Modifier.fillMaxSize(),
verticalArrangement = Arrangement.Center,
horizontalAlignment = Alignment.CenterHorizontally
) {
Button(onClick = { scanDevice(context) }) {
Text(text = "查找并连接设备")
}
Button(onClick = { switchLight(true) }) {
Text(text = "开灯")
}
Button(onClick = { switchLight(false) }) {
Text(text = "关灯")
}
}
}
private fun scanDevice(context: Context) {
val manager = context.getSystemService(Context.USB_SERVICE) as UsbManager
val customTable = ProbeTable()
customTable.addProduct(0x1a86, 0x55d3, CdcAcmSerialDriver::class.java)
val prober = UsbSerialProber(customTable)
val drivers: List<UsbSerialDriver> = prober.findAllDrivers(manager)
if (drivers.isNotEmpty()) {
val driver = drivers[0]
val connection = manager.openDevice(driver.device)
if (connection == null) {
Log.i(TAG, "scanDevice: 连接失败")
return
}
port = driver.ports[0]
port.open(connection)
port.setParameters(9600, 8, UsbSerialPort.STOPBITS_1, UsbSerialPort.PARITY_NONE)
Log.i(TAG, "scanDevice: Connect success!")
CoroutineScope(Dispatchers.IO).launch {
while (true) {
val responseBuffer = ByteArray(1024)
val len = port.read(responseBuffer, 0)
Log.i(TAG, "scanDevice: recv data = ${responseBuffer.copyOfRange(0, len).contentToString()}")
}
}
}
else {
Log.i(TAG, "scanDevice: 无设备!")
}
}
private fun switchLight(isON: Boolean) {
val sendData = if (isON) byteArrayOf(0x6F) else byteArrayOf(0x63)
port.write(sendData, 0)
}运行这个程序,并且连接设备,输出如下:
可以看到输出的是 byte 的 101,转换为 ASCII 即为 “e”。
然后我们点击 “开灯”、“关灯” 效果如下:
对了,这里发送的数据 “0x6F” 即 ASCII “o” 的十六进制,同理,“0x63” 即 “c”。
可以看到,可以完美的和我们的 ESP32 开发版进行通信。
实例
无论使用什么方式与串口通信,我们在安卓APP的代码层面能够拿到的数据已经是处理好了的数据。
即,在上一篇文章中我们说过串口通信的一帧数据包括起始位、数据位、校验位、停止位。但是我们在安卓中使用时一般拿到的都只有 数据位 的数据,其他数据已经在底层被解析好了,无需我们去关心怎么解析,或者使用。
我们可以直接拿到的就是可用数据。
这里举一个我之前用过的某型号驱动版的例子。
这块驱动版关于通信的信息如图:
可以看到,它采用了 RS485 的通信方式,波特率支持 9600 或 38400,8位数据位,无校验,1位停止位。
并且,它还规定了一个数据协议。
在它定义的协议中,第一位为地址;第二位为指令;第三位到第N位为数据内容;最后两位为CRC校验。
需要注意的是,这里定义的协议是基于串口通信的,不要把这个协议和串口通信搞混了,简单来说就是在串口通信协议的数据位中又定义了一个自己的协议。
而且可以看到,虽然定义串口参数时没有指定校验,但是在它自己的协议中指定了使用 CRC 校验。
另外,弱弱的吐槽一句,这个驱动版的协议真的不好使。
在实际使用过程中,主机与驱动版的通信数据无法保证一定会在同一个数据帧中发送完成,所以可能会造成“粘包”、“分包”现象,也就是说,数据可能会分几次发过来,而且你不好判断这数据是上次没发送完的数据还是新的数据。
我使用过的另外一款驱动版就方便的多,因为它会在帧头加上开始符号和数据长度,帧尾加上结束符号。
这样一来,即使出现“粘包”、“分包”我们也能很好的给它解析出来。
当然,它这样设计协议肯定是有它的道理的,无非就是减少通信代价之类的。
我还遇到过一款十分简洁的驱动版,直接发送一个整数过去表示执行对应的指令。
驱动版回传的数据同样非常简单,就是一个数字,然后事先约定各个数字表示什么意思……
说归说,我们还是继续来看这款驱动版的通信协议:
这是它的其中一个指令内容,我们发送指令 “1” 过去后,它会返回当前驱动版的型号和版本信息给我们。
因为我们的主板是定制工控主板,所以使用的通信方式是直接用 android-serialport-api。
最终发送与接收回复也很简单:
/**
* 将十六进制字符串转成 ByteArray
* */
private fun hexStrToBytes(hexString: String): ByteArray {
check(hexString.length % 2 == 0) { return ByteArray(0) }
return hexString.chunked(2)
.map { it.toInt(16).toByte() }
.toByteArray()
}
private fun isReceivedLegalData(receiveBuffer: ByteArray): Boolean {
val rcvData = receiveBuffer.copyOf() //重新拷贝一个使用,避免原数据被清零
if (cmd.cmdId.checkDataFormat(rcvData)) { //检查回复数据格式
isPkgLost = false
if (cmd.cmdId.isResponseBelong(rcvData)) { //检查回复命令来源
if (!AdhShareData.instance.getIsUsingCrc()) { //如果不开启CRC检验则直接返回 true
resolveRcvData(cmdRcvDataCallback, rcvData, cmd.cmdId)
coroutineScope.launch(Dispatchers.Main) {
cmdResponseCallback?.onCmdResponse(ResponseStatus.Success, rcvData, 0, rcvData.size, cmd.cmdId)
}
return true
}
if (cmd.cmdId.checkCrc(rcvData)) { //检验CRC
resolveRcvData(cmdRcvDataCallback, rcvData, cmd.cmdId)
coroutineScope.launch(Dispatchers.Main) {
cmdResponseCallback?.onCmdResponse(ResponseStatus.Success, rcvData, 0, rcvData.size, cmd.cmdId)
}
return true
}
else {
coroutineScope.launch(Dispatchers.Main) {
cmdResponseCallback?.onCmdResponse(ResponseStatus.FailCauseCrcError, ByteArray(0), -1, -1, cmd.cmdId)
}
return false
}
}
else {
coroutineScope.launch(Dispatchers.Main) {
cmdResponseCallback?.onCmdResponse(ResponseStatus.FailCauseNotFromThisCmd, ByteArray(0), -1, -1, cmd.cmdId)
}
return false
}
}
else { //数据不符合,可能是遇到了分包,继续等待下一个数据,然后合并
isPkgLost = true
return isReceivedLegalData(cmd)
/*coroutineScope.launch(Dispatchers.Main) {
cmdResponseCallback?.onCmdResponse(ResponseStatus.FailCauseWrongFormat, ByteArray(0), -1, -1, cmd.cmdId)
}
return false */
}
}
// ……省略初始化和连接代码
// 发送数据
val bytes = hexStrToBytes("0201C110")
outputStream.write(bytes, 0, bytes.size)
// 解析数据
val recvBuffer = ByteArray(0)
inputStream.read(recvBuffer)
while (receiveBuffer.isEmpty()) {
delay(10)
}
isReceivedLegalData()本来打算直接发我封装好的这个驱动版的协议库的,想了想,好像不太合适,所以就大概抽出了这些不完整的代码,懂这个意思就行了,哈哈。
总结
从上面介绍的两种方式可以看出,两种方式使用各有优缺点。
使用 android-serialport-api 可以直接读取串口数据内容,不需要转USB接口,不需要驱动支持,但是需要 ROOT,适合于定制安卓主板上已经预留了 RS232 或 RS485 接口且设备已 ROOT 的情况下使用。
而使用 USB host ,可以直接读取USB接口转接的串口数据,不需要ROOT,但是只支持有驱动的串口转USB芯片,且只支持使用USB接口,不支持直接连接串口设备。
各位可以根据自己的实际情况灵活选择使用什么方式来实现串口通信。
当然,除了现在介绍的这些串口通信,其实还有一个通信协议在实际使用中用的非常多,那就是 MODBUS 协议。
下一篇文章,我们将介绍 MODBUS。
参考资料
作者:equationl
来源:https://juejin.cn/post/7171347086032502792
少发几百块工资就闹情绪要离职,这种计较的员工有留的必要吗?
为什么要少分几百块钱的工资,作为一个老板不诚信,谁还愿意跟你干。如果是因为效益不好,要跟员工说清楚,这个月欠发,下月一定要补上。即便是亏损,赊钱也应该是老板的,不能让员工替你亏损,你多赚钱的时候,也没发给员工。
作为员工要和老板沟通,到底什么原因少发的,如果是暂时的,以后补发,也可以理解。如果想赖账,劝你不要跟他干了。
几百块钱,对一个月薪3000—4000元的工资来讲,不是一个小数。一个农民工一个月的生活费,也就几百块钱。如果老板平时发的工资高,一个月万把,少发几百块钱也无所谓。发的工资少,又想克扣工资的老板,肯定不是好老板。
克扣员工工资,还说员工计较,拿着不是当理说。不是你留不留问题,是员工还愿意跟你干不干的问题。
从另一个角度看:
这不是员工有没有必要留下的问题,而是你自己懂不懂管理的问题。如果我是老板,肯定辞掉你,因为你根本就不配做管理者。
工资是员工的劳动所得,克扣工资就是不尊重员工的劳动成果。
劳动法明确规定,用人单位要按时足额发放工资。你现在明确承认将员工的工资少发了几百元,也就是说你的行为不仅仅严重损害了员工的合法权益,更是一种违法行为。
几百元确实不是大金额,但对于按件计酬的一线员工来说,也许要生产上千个配件;对于没有保障的保洁工来说,也许要打扫十天卫生;对于凭业绩拿奖金的销售来说,也许要成交上万元的订单…
员工付出了艰辛的劳动,劳动成果就被你无理由给克扣了,换作谁也会据理力争。凭什么啊,你为什么不会多给员工几百元的?
试想,如果你的工资是5k,老板无端克扣500,就发给你4.5k,难道你不会有情绪?如果老板不及时将工资补给你,你确信会继续干下去…
尊重员工不是一句空话,要从尊重员工的劳动成果做起!
员工闹情绪要离职,是给你的警钟。
作为管理者应该明白,员工遇事与你交流和争论,内心还是尊重你的,通过争论希望你能从公平公正的角度看问题,进而作出双赢的选择。
当争论后你仍固执己见,员工闹下小情绪是为了引起你的注意,再重新考虑。此时,管理者若不能把握解决问题的机会,员工就会对你完全失去信任,提出离职。
表面看,你好像赚到了几百元,其实你已经失去载舟之水,且终将被水颠覆。你让身边的人感到厌恶,公司形象严重受损,个人声誉一片狼藉,团队终将因你的无知而崩盘。
如果你不能及时改正错误,长此以往,你将因私自克扣员工的工资而走上不归路。少发的几百元哪去了?是终饱私囊,还是进入了小金库,这可都是违规违法的举动。
识时务者为俊杰,你应当将少发的几百元及时补发给员工,并且要深刻认识自己所犯错误的严重性。
此种情况下,即使员工离职,公司也要对员工进行经济补偿。
通常情况下,员工主动辞职,公司无需经济补偿;但是,由于你没有足额发放员工工资,且员工与你交涉后你拒绝改正。此时员工提出辞职,然后去申请仲裁,你肯定要作出经济补偿。
为了几百元,公司不仅损失了一名得力干将,还要对员工作出经济补偿,这是名副其实的得不偿失啊。
近者悦,远者来。这是管理者应该铭记的真理!
来源:maimai.cn/article/detail?fid=1741200421&efid=erVeYTis_A2HbjzYYIRU0A
收起阅读 »宽表为什么横行?
宽表在BI业务中比比皆是,每次建设BI系统时首先要做的就是准备宽表。有时系统中的宽表可能会有上千个字段,经常因为“过宽”超过了数据库表字段数量限制还要再拆分。
为什么大家乐此不疲地造宽表呢?主要原因有两个。
一是为了提高查询性能。现代BI通常使用关系数据库作为后台,而SQL通常使用的HASH JOIN算法,在关联表数量和关联层级变多的时候,计算性能会急剧下降,有七八个表三四层级关联时就能观察到这个现象,而BI业务中的关联复杂度远远超过这个规模,直接使用SQL的JOIN就无法达到前端立等可取的查询需要了。为了避免关联带来的性能问题,就要先将关联消除,即将多表事先关联好采用单表存储(也就是宽表),再查询的时候就可以不用再关联,从而达到提升查询性能的目的。
二是为了降低业务难度。因为多表关联尤其是复杂关联在BI前端很难表达和使用。如果采用自动关联(根据字段类型等信息匹配)当遇到同维字段(如一个表有2个以上地区字段)时会“晕掉”不知道该关联哪个,表间循环关联或自关联的情况也无法处理;如果将众多表开放给用户来自行选择关联,由于业务用户无法理解表间关系而几乎没有可用性;分步关联可以描述复杂的关联需求,但一旦前一步出错就要推倒重来。所以,无论采用何种方式,工程实现和用户使用都很麻烦。但是基于单表来做就会简单很多,业务用户使用时没有什么障碍,因此将多表组织成宽表就成了“自然而然”的事情。
不过,凡事都有两面性,我们看到宽表好处而大量应用的同时,其缺点也不容忽视,有些缺点会对应用产生极大影响。下面来看一下。
宽表的缺点
数据冗余容量大
宽表不符合范式要求,将多个表合并成一个表会存在大量冗余数据,冗余程度跟原表数据量和表间关系有关,通常如果存在多层外键表,其冗余程度会呈指数级上升。大量数据冗余不仅会带来存储上的压力(多个表组合出来的宽表数量可能非常多)造成数据库容量问题,在查询计算时由于大量冗余数据参与运算还会影响计算性能,导致虽然用了宽表但仍然查询很慢。
数据错误
由于宽表不符合三范式要求,数据存储时可能出现一致性错误(脏写)。比如同一个销售员在不同记录中可能存储了不同的性别,同一个供应商在不同记录中的所在地可能出现矛盾。基于这样的数据做分析结果显然不对,而这种错误非常隐蔽很难被发现。
另外,如果构建的宽表不合理还会出现汇总错误。比如基于一对多的A表和B表构建宽表,如果A中有计算指标(如金额),在宽表中就会重复,基于重复的指标再汇总就会出现错误。
灵活性差
宽表本质上是一种按需建模的手段,根据业务需求来构建宽表(虽然理论上可以把所有表的组合都形成宽表,但这只存在于理论上,如果要实际操作会发现需要的存储空间大到完全无法接受的程度),这就出现了一个矛盾:BI系统建设的初衷主要是为了满足业务灵活查询的需要,即事先并不知道业务需求,有些查询是在业务开展过程中逐渐催生出来的,有些是业务用户临时起意的查询,这种灵活多变的需求采用宽表这种要事先加工的解决办法极为矛盾,想要获得宽表的好就得牺牲灵活性,可谓鱼与熊掌不可兼得。
可用性问题
除了以上问题,宽表由于字段过多还会引起可用性低的问题。一个事实表会对应多个维表,维表又有维表,而且表之间还可能存在自关联/循环关联的情况,这种结构在数据库系统中很常见,基于这些结构的表构建宽表,尤其要表达多个层级的时候,宽表字段数量会急剧增加,经常可能达到成百上千个(有的数据库表有字段数量限制,这时又要横向分表),试想一下,在用户接入界面如果出现上千个字段要怎么用?这就是宽表带来的可用性差的问题。
总体来看,宽表的坏处在很多场景中经常要大于好处,那为什么宽表还大量横行呢?
因为没办法。一直没有比宽表更好的方案来解决前面提到的查询性能和业务难度的问题。其实只要解决这两个问题,宽表就可以不用,由宽表产生的各类问题也就解决了。
SPL+DQL消灭宽表
借助开源集算器SPL可以完成这个目标。
SPL(Structured Process Language)是一个开源结构化数据计算引擎,本身提供了不依赖数据库的强大计算能力,SPL内置了很多高性能算法,尤其是对关联运算做了优化,对不同的关联场景采用不同的手段,可以大幅提升关联性能,从而不用宽表也能实时关联以满足多维分析时效性的需要。同时,SPL还提供了高性能存储,配合高效算法可以进一步发挥性能优势。
只有高性能还不够,SPL原生的计算语法不适合多维分析应用接入(生成SPL语句对BI系统改造较大)。目前大部分多维分析前端都是基于SQL开发的,但SQL体系(不用宽表时)在描述复杂关联计算上又很困难,基于这样的原因,SPL设计了专门的类SQL查询语法DQL(Dimensional Query Language)用于构建语义层。前端生成DQL语句,DQL Server将其转换成SPL语句,再基于SPL计算引擎和存储引擎完成查询返回给前端,实现全链路BI查询。需要注意的是,SPL只作为计算引擎存在,前端界面仍要由用户自行实现(或选用相应产品)。
SPL:关联实现技术
SPL如何不用宽表也能实现实时关联以满足性能要求的目标?
在BI业务中绝大部分的JOIN都是等值JOIN,也就是关联条件为等式的 JOIN。SPL把等值关联分为外键关联和主键关联。外键关联是指用一个表的非主键字段,去关联另一个表的主键,前者称为事实表,后者称为维表,两个表是多对一的关系,比如订单表和客户表。主键关联是指用一个表的主键关联另一个表的主键或部分主键,比如客户表和 VIP 客户表(一对一)、订单表和订单明细表(一对多)。
这两类 JOIN 都涉及到主键,如果充分利用这个特征采用不同的算法,就可以实现高性能的实时关联了。
不过很遗憾,SQL 对 JOIN 的定义并不涉及主键,只是两个表做笛卡尔积后再按某种条件过滤。这个定义很简单也很宽泛,几乎可以描述一切。但是,如果严格按这个定义去实现 JOIN,理论上没办法在计算时利用主键的特征来提高性能,只能是工程上做些有限的优化,在情况较复杂时(表多且层次多)经常无效。
SPL 改变了 JOIN 的定义,针对这两类 JOIN 分别处理,就可以利用主键的特征来减少运算量,从而提高计算性能。
外键关联
和SQL不同,SPL中明确地区分了维表和事实表。BI系统中的维表都通常不大,可以事先读入内存建立索引,这样在关联时可以少计算一半的HASH值。
对于多层维表(维表还有维表的情况)还可以用外键地址化的技术做好预关联。即将维表(本表)的外键字段值转换成对应维表(外键表)记录的地址。这样被关联的维表数据可以直接用地址取出而不必再进行HASH值计算和比对,多层维表仅仅是多个按地址取值的时间,和单层维表时的关联性能基本相当。
类似的,如果事实表也不大可以全部读入内存时,也可以通过预关联的方式解决事实表与维表的关联问题,提升关联效率。
预关联可以在系统启动时一次性读入并做好,以后直接使用即可。
当事实表较大无法全内存时,SPL 提供了外键序号化方法:将事实表中的外键字段值转换为维表对应记录的序号。关联计算时,用序号取出对应维表记录,这样可以获得和外键地址化类似的效果,同样能避免HASH值的计算和比对,大幅提升关联性能。
主键关联
有的事实表还有明细表,比如订单和订单明细,二者通过主键和部分主键进行关联,前者作为主表后者作为子表(还有通过全部主键关联的称为同维表,可以看做主子表的特例)。主子表都是事实表,涉及的数据量都比较大。
SPL为此采用了有序归并方法:预先将外存表按照主键有序存储,关联时顺序取出数据做归并,不需要产生临时缓存,只用很小的内存就可以完成计算。而SQL采用的HASH分堆算法复杂度较高,不仅要计算HASH值进行对比,还会产生临时缓存的读写动作,运算性能很差。
HASH 分堆技术实现并行困难,多线程要同时向某个分堆缓存数据,造成共享资源冲突;某个分堆关联时又会消费大量内存,无法实施较大的并行数量。而有序归则易于分段并行。数据有序时,子表就可以根据主表键值进行同步对齐分段以保证正确性,无需缓存,且因为占用内存很少可以采用较大的并行数,从而获得更高性能。
预先排序的成本虽高,但是一次性做好即可,以后就总能使用归并算法实现 JOIN,性能可以提高很多。同时,SPL 也提供了在有追加数据时仍然保持数据整体有序的方案。
对于主子表关联SPL还可以采用更有效的存储形式将主子表一体化存储,子表作为主表的集合字段,其取值是由与该主表数据相关的多条子表记录构成。这相当于预先实现了关联,再计算时直接取数计算即可,不需要比对,存储量也更少,性能更高。
存储机制
高性能离不开有效的存储。SPL也提供了列式存储,在BI计算中可以大幅降低数据读取量以提升读取效率。SPL列存采用了独有的倍增分段技术,相对传统列存分块并行方案要在很大数据量时(否则并行会受到限制)才会发挥优势不同,这个技术可以使SPL列存在数据量不很大时也能获得良好的并行分段效果,充分发挥并行优势。
SPL还提供了针对数据类型的优化机制,可以显著提升多维分析中的切片运算性能。比如将枚举型维度转换成整数,在查询时将切片条件转换成布尔值构成的对位序列,在比较时就可以直接从序列指定位置取出切片判断结果。还有将多个标签维度(取值是或否的维度,这种维度在多维分析中大量存在)存储在一个整数字段中的标签位维度技术(一个整数字段可以存储16个标签),不仅大幅减少存储量,在计算时还可以针对多个标签同时做按位计算从而大幅提升计算性能。
有了这些高效机制以后,我们就可以在BI分析中不再使用宽表,转而基于SPL存储和算法做实时关联,性能比宽表还更高(没有冗余数据读取量更小,更快)。
不过,只有这些还不够,SPL原生语法还不适合BI前端直接访问,这就需要适合的语义转换技术,通过适合的方式将用户操作转换成SPL语法进行查询。
这就需要DQL了。
DQL:关联描述技术
DQL是SPL之上的语义层构建工具,在这一层完成对于SPL数据关联关系的描述(建模)再为上层应用服务。即将SPL存储映射成DQL表,再基于表来描述数据关联关系。
通过对数据表关系描述以后形成了一种以维度为中心的总线式结构(不同于E-R图中的网状结构),中间是维度,表与表之间不直接相关都通过维度过渡。
基于这种结构下的关联查询(DQL语句)会很好表达。比如要根据订单表(orders)、客户表(customer)、销售员表(employee)以及城市表(city)查询:本年度华东的销售人员,在全国各销售区的销售额。
用SQL写起来是这样的:
SEL ECT
ct1.area,o.emp_id,sum(o.amount) somt
FROM
orders o
JOIN customer c ON o.cus_id = c.cus_id
JOIN city ct1 ON c.city_id = ct1.city_id
JOIN employee e ON o.emp_id = e.emp_id
JOIN city ct2 ON e.city_id = ct2.city_id
WHERE
ct2.area = 'east' AND year(o.order_date)= 2022
GRO UP BY
ct1.area, o.emp_id多个表关联要JOIN多次,同一个地区表要反复关联两次才能查到销售员和客户的所在区域,对于这种情况BI前端表达起来会很吃力,如果将关联开放出来,用户又很难理解。
那么DQL是怎么处理的呢?
DQL写法:
SEL ECT
cus_id.city_id.area,emp_id,sum(amount) somt
FROM
orders
WHERE
emp_id.city_id.area == "east" AND year(order_date)== 2022
BY
cus_id.city_id.area,emp_idDQL不需要JOIN多个表,只基于orders单表查询就可以了,外键指向表的字段当成属性直接使用,有多少层都可以引用下去,很好表达。像查询客户所在地区通过cus_id.city_id.area一直写下去就可以了,这样就消除了关联,将多表关联查询转化成单表查询。
更进一步,我们再基于DQL开发BI前端界面就很容易,比如可以做成这样:
用树结构分多级表达多层维表关联,这样的多维分析页面不仅容易开发,普通业务用户使用时也很容易理解,这就是DQL的效力。
总结一下,宽表的目的是为了解决BI查询性能和前端工程实现问题,而宽表会带来数据冗余和灵活性差等问题。通过SPL的实时关联技术与高效存储可以解决性能问题,而且性能比宽表更高,同时不存在数据冗余,存储空间也更小(压缩);DQL构建的语义层解决了多维分析前端工程的实现问题,让实时关联成为可能,,灵活性更高(不再局限于宽表的按需建模),界面也更容易实现,应用范围更广。
SPL+DQL继承(超越)宽表的优点同时改善其缺点,这才是BI该有的样子。
SPL资料
作者:Java中文社群
来源:juejin.cn/post/7200033099752554553
使用 koin 作为 Android 注入工具,真香
koin 为 Android 提供了简单易用的 API 接口,让你简单轻松地接入 koin 框架。

[koin 在 Android 中的 gradle 配置]
1.Application 类中 startKoin
从您的类中,您可以使用该函数并注入 Android 上下文,如下所示:
Application startKoin androidContext
class MainApplication : Application() {
override fun onCreate() {
super.onCreate()
startKoin {
// Log Koin into Android logger
androidLogger()
// Reference Android context
androidContext(this@MainApplication)
// Load modules
modules(myAppModules)
}
}
}如果您需要从另一个 Android 类启动 Koin,您可以使用该函数为您的 Android 实例提供如下:startKoin Context
startKoin {
//inject Android context
androidContext(/* your android context */)
// ...
}2. 额外配置
从您的 Koin 配置(在块代码中),您还可以配置 Koin 的多个部分。startKoin { }
2.1 Koin Logging for Android
koin 提供了 log 的 Android 实现。
startKoin {
// use Android logger - Level.INFO by default
androidLogger()
// ...
}2.2 加载属性
您可以在文件中使用 Koin 属性来存储键/值:assets/koin.properties
startKoin {
// ...
// use properties from assets/koin.properties
androidFileProperties()
}3. Android 中注入对象实例
3.1 为 Android 类做准备
koin 提供了KoinComponents 扩展,Android 组件都具有这种扩展,这些组件包括 Activity Fragment Service ComponentCallbacks
您可以通过如下方式访问 Kotlin 扩展:
by inject()- 来自 Koin 容器的延迟计算实例
get() - 从 Koin 容器中获取实例
我们可以将一个属性声明为惰性注入:
module {
// definition of Presenter
factory { Presenter() }
}
class DetailActivity : AppCompatActivity() {
// Lazy inject Presenter
override val presenter : Presenter by inject()
override fun onCreate(savedInstanceState: Bundle?) {
//...
}
}或者我们可以直接得到一个实例:
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
// Retrieve a Presenter instance
val presenter : Presenter = get()
}注意:如果你的类没有扩展,只需添加 KoinComponent 接口,如果你需要或来自另一个类的实例。inject() get()
3.2 Android Context 使用
class MainApplication : Application() {
override fun onCreate() {
super.onCreate()
startKoin {
//inject Android context
androidContext(this@MainApplication)
// ...
}
}
}在你的定义中,下面的函数允许你在 Koin 模块中获取实例,以帮助你简单地编写需要实例的表达式。androidContext() androidApplication() Context Application
val appModule = module {
// create a Presenter instance with injection of R.string.mystring resources from Android
factory {
MyPresenter(androidContext().resources.getString(R.string.mystring))
}
}4. 用于 Android 的 DSL 构造函数
4.1 DSL 构造函数
Koin 现在提供了一种新的 DSL 关键字,允许您直接面向类构造函数,并避免在 lambda 表达式中键入您的定义。
对于 Android,这意味着以下新的构造函数 DSL 关键字:
viewModelOf()`- 相当于`viewModel { }
fragmentOf()`- 相当于`fragment { }
workerOf()`- 相当于`worker { }注意:请务必在类名之前使用,以定位类构造函数::
4.2 Android DSL 函数示例
给定一个具有以下组件的 Android 应用程序:
// A simple service
class SimpleServiceImpl() : SimpleService
// a Presenter, using SimpleService and can receive "id" injected param
class FactoryPresenter(val id: String, val service: SimpleService)
// a ViewModel that can receive "id" injected param, use SimpleService and get SavedStateHandle
class SimpleViewModel(val id: String, val service: SimpleService, val handle: SavedStateHandle) : ViewModel()
// a scoped Session, that can received link to the MyActivity (from scope)
class Session(val activity: MyActivity)
// a Worker, using SimpleService and getting Context & WorkerParameters
class SimpleWorker(
private val simpleService: SimpleService,
appContext: Context,
private val params: WorkerParameters
) : CoroutineWorker(appContext, params)我们可以这样声明它们:
module {
singleOf(::SimpleServiceImpl){ bind<SimpleService>() }
factoryOf(::FactoryPresenter)
viewModelOf(::SimpleViewModel)
scope<MyActivity>(){
scopedOf(::Session)
}
workerOf(::SimpleWorker)
}5. Android 中的 koin 多模块使用
通过使用 Koin,您可以描述模块中的定义。在本节中,我们将了解如何声明,组织和链接模块。
5.1 koin 多模块
组件不必位于同一模块中。模块是帮助您组织定义的逻辑空间,并且可以依赖于其他定义 模块。定义是惰性的,然后仅在组件请求它时才解析。
让我们举个例子,链接的组件位于单独的模块中:
// ComponentB <- ComponentA
class ComponentA()
class ComponentB(val componentA : ComponentA)
val moduleA = module {
// Singleton ComponentA
single { ComponentA() }
}
val moduleB = module {
// Singleton ComponentB with linked instance ComponentA
single { ComponentB(get()) }
}我们只需要在启动 Koin 容器时声明已使用模块的列表:
class MainApplication : Application() {
override fun onCreate() {
super.onCreate()
startKoin {
// ...
// Load modules
modules(moduleA, moduleB)
}
}
}5.2 模块包含
类中提供了一个新函数,它允许您通过以有组织和结构化的方式包含其他模块来组合模块includes() Module
新模块有 2 个突出特点:
将大型模块拆分为更小、更集中的模块。
在模块化项目中,它允许您更精细地控制模块可见性(请参阅下面的示例)。
它是如何工作的?让我们采用一些模块,我们将模块包含在:parentModule
// `:feature` module
val childModule1 = module {
/* Other definitions here. */
}
val childModule2 = module {
/* Other definitions here. */
}
val parentModule = module {
includes(childModule1, childModule2)
}
// `:app` module
startKoin { modules(parentModule) }请注意,我们不需要显式设置所有模块:通过包含,声明的所有模块将自动加载。
parentModule includes childModule1 childModule2 parentModule childModule1 childModule2
信息:模块加载现在经过优化,可以展平所有模块图,并避免重复的模块定义。
最后,您可以包含多个嵌套或重复的模块,Koin 将扁平化所有包含的模块,删除重复项:
// :feature module
val dataModule = module {
/* Other definitions here. */
}
val domainModule = module {
/* Other definitions here. */
}
val featureModule1 = module {
includes(domainModule, dataModule)
}
val featureModule2 = module {
includes(domainModule, dataModule)
}
// :app module
class MainApplication : Application() {
override fun onCreate() {
super.onCreate()
startKoin {
// ...
// Load modules
modules(featureModule1, featureModule2)
}
}
}
请注意,所有模块将只包含一次:dataModule domainModule featureModule1 featureModule2
5.3 Android ViewModel 和 Navigation
Gradle 模块引入了一个新的 DSL 关键字,该关键字作为补充,以帮助声明 ViewModel 组件并将其绑定到 Android 组件生命周期。关键字也可用允许您使用其构造函数声明 ViewModel。koin-android viewModel singlefactory viewModelOf
val appModule = module {
// ViewModel for Detail View
viewModel { DetailViewModel(get(), get()) }
// or directly with constructor
viewModelOf(::DetailViewModel)
}声明的组件必须至少扩展类。您可以指定如何注入类的构造函数 并使用该函数注入依赖项。android.arch.lifecycle.ViewModel get()
注意:关键字有助于声明 ViewModel 的工厂实例。此实例将由内部 ViewModelFactory 处理,并在需要时重新附加 ViewModel 实例。它还将允许注入参数。viewModel viewModelOf
5.4 注入 ViewModel
在 Android 组件中使用 viewModel ,Activity Fragment Service
by viewModel()- 惰性委托属性,用于将视图模型注入到属性中
getViewModel()- 直接获取视图模型实例
class DetailActivity : AppCompatActivity() {
// Lazy inject ViewModel
val detailViewModel: DetailViewModel by viewModel()
}5.5 Activity 共享 ViewModel
一个 ViewModel 实例可以在 Fragment 及其主 Activity 之间共享。
要在使用中注入共享视图模型,请执行以下操作:Fragment
by activityViewModel()- 惰性委托属性,用于将共享 viewModel 实例注入到属性中
get ActivityViewModel()- 直接获取共享 viewModel 实例
只需声明一次视图模型:
val weatherAppModule = module {
// WeatherViewModel declaration for Weather View components
viewModel { WeatherViewModel(get(), get()) }
}注意:viewModel 的限定符将作为 viewModel 的标记处理
并在 Activity 和 Fragment 中重复使用它:
class WeatherActivity : AppCompatActivity() {
/*
* Declare WeatherViewModel with Koin and allow constructor dependency injection
*/
private val weatherViewModel by viewModel<WeatherViewModel>()
}
class WeatherHeaderFragment : Fragment() {
/*
* Declare shared WeatherViewModel with WeatherActivity
*/
private val weatherViewModel by activityViewModel<WeatherViewModel>()
}
class WeatherListFragment : Fragment() {
/*
* Declare shared WeatherViewModel with WeatherActivity
*/
private val weatherViewModel by activityViewModel<WeatherViewModel>()
}5.6 将参数传递给构造函数
向 viewModel 传入参数,示例代码如下:
模块中
val appModule = module {
// ViewModel for Detail View with id as parameter injection
viewModel { parameters -> DetailViewModel(id = parameters.get(), get(), get()) }
// ViewModel for Detail View with id as parameter injection, resolved from graph
viewModel { DetailViewModel(get(), get(), get()) }
// or Constructor DSL
viewModelOf(::DetailViewModel)
}依赖注入点传入参数
class DetailActivity : AppCompatActivity() {
val id : String // id of the view
// Lazy inject ViewModel with id parameter
val detailViewModel: DetailViewModel by viewModel{ parametersOf(id)}
}5.7 SavedStateHandle 注入
添加键入到构造函数的新属性以处理 ViewModel 状态:SavedStateHandle
class MyStateVM(val handle: SavedStateHandle, val myService : MyService) : ViewModel() 在 Koin 模块中,只需使用或参数解析它:get()
viewModel { MyStateVM(get(), get()) } 或使用构造函数 DSL:
viewModelOf(::MyStateVM) 在 Activity Fragment
by viewModel()- 惰性委托属性,用于将状态视图模型实例注入属性
getViewModel()- 直接获取状态视图模型实例
class DetailActivity : AppCompatActivity() {
// MyStateVM viewModel injected with SavedStateHandle
val myStateVM: MyStateVM by viewModel()
}5.8 Navigation 导航图中的 viewModel
您可以将 ViewModel 实例的范围限定为导航图。只需要传入 ID 给by koinNavGraphViewModel()
class NavFragment : Fragment() {
val mainViewModel: NavViewModel by koinNavGraphViewModel(R.id.my_graph)
}5.9 viewModel 通用 API
Koin 提供了一些“底层”API 来直接调整您的 ViewModel 实例。viewModelForClass ComponentActivity Fragment
ComponentActivity.viewModelForClass(
clazz: KClass<T>,
qualifier: Qualifier? = null,
owner: ViewModelStoreOwner = this,
state: BundleDefinition? = null,
key: String? = null,
parameters: ParametersDefinition? = null,
): Lazy<T>还提供了顶级函数:
fun <T : ViewModel> getLazyViewModelForClass(
clazz: KClass<T>,
owner: ViewModelStoreOwner,
scope: Scope = GlobalContext.get().scopeRegistry.rootScope,
qualifier: Qualifier? = null,
state: BundleDefinition? = null,
key: String? = null,
parameters: ParametersDefinition? = null,
): Lazy<T>5.10 ViewModel API - Java Compat
必须将 Java 兼容性添加到依赖项中:
// Java Compatibility
implementation "io.insert-koin:koin-android-compat:$koin_version"
您可以使用以下函数或静态函数将 ViewModel 实例注入到 Java 代码库中:viewModel() getViewModel() ViewModelCompat
@JvmOverloads
@JvmStatic
@MainThread
fun <T : ViewModel> getViewModel(
owner: ViewModelStoreOwner,
clazz: Class<T>,
qualifier: Qualifier? = null,
parameters: ParametersDefinition? = null
)6. 在 Jetpack Compose 中注入
请先了解 Jetpack Compose 相关内容:
developer.android.com/jetpack/com…
6.1 注入@Composable
在编写可组合函数时,您可以访问以下 Koin API:
get()- 从 Koin 容器中获取实例
getKoin()- 获取当前 Koin 实例
对于声明“MyService”组件的模块:
val androidModule = module {
single { MyService() }
}我们可以像这样获取您的实例:
@Composable
fun App() {
val myService = get<MyService>()
}注意:为了在 Jetpack Compose 的功能方面保持一致,最好的编写方法是将实例直接注入到函数属性中。这种方式允许使用 Koin 进行默认实现,但保持开放状态以根据需要注入实例。
@Composable
fun App(myService: MyService = get()) {
}6.2 viewModel @Composable
与访问经典单/工厂实例的方式相同,您可以访问以下 Koin ViewModel API:
getViewModel()`或 - 获取实例`koinViewModel()
对于声明“MyViewModel”组件的模块:
module {
viewModel { MyViewModel() }
// or constructor DSL
viewModelOf(::MyViewModel)
}我们可以像这样获取您的实例:
@Composable
fun App() {
val vm = koinViewModel<MyViewModel>()
}我们可以在函数参数中获取您的实例:
@Composable
fun App(vm : MyViewModel = koinViewModel()) {
}7. 管理 Android 作用域
Android 组件,如Activity、Fragment、Service都有生命周期,这些组件都是由 System 实例化,组件中有相应的生命周期回调。
正因为 Android 组件具有生命周期属性,所以不能在 koin 中传入组件实例。按照生命周期长短,组件可分为三类:
• 长周期组件(
Service、database)——由多个屏幕使用,永不丢弃• 中等周期组件(
User session)——由多个屏幕使用,必须在一段时间后删除• 短周期组件(
ViewModel)——仅由一个 Screen 使用,必须在 Screen 末尾删除
对于长周期组件,我们通常在应用全局使用 single 创建单实例
在 MVP 架构模式下,Presenter 是短周期组件
在 Activity 中创建方式如下
class DetailActivity : AppCompatActivity() {
// injected Presenter
override val presenter : Presenter by inject()我们也可以在 module 中创建
我们使用 factory 作用域创建 Presenter 实例
val androidModule = module {
// Factory instance of Presenter
factory { Presenter() }
}生成绑定到作用域的实例 scope
val androidModule = module {
scope<DetailActivity> {
scoped { Presenter() }
}
}大多数 Android 内存泄漏来自从非 Android 组件引用 UI/Android 组件。系统保留引用在它上面,不能通过垃圾收集完全回收它。
7.1 申明 Android 作用域
要限定 Android 组件上的依赖关系,您必须使用如下所示的块声明一个作用域:scope
class MyPresenter()
class MyAdapter(val presenter : MyPresenter)
module {
// Declare scope for MyActivity
scope<MyActivity> {
// get MyPresenter instance from current scope
scoped { MyAdapter(get()) }
scoped { MyPresenter() }
}
}7.2 Android Scope 类
Koin 提供了 Android 生命周期组件相关的 Scope 类ScopeActivity Retained ScopeActivity ScopeFragment
class MyActivity : ScopeActivity() {
// MyPresenter is resolved from MyActivity's scope
val presenter : MyPresenter by inject()
}Android Scope 需要与接口一起使用来实现这样的字段:AndroidScopeComponent scope
abstract class ScopeActivity(
@LayoutRes contentLayoutId: Int = 0,
) : AppCompatActivity(contentLayoutId), AndroidScopeComponent {
override val scope: Scope by activityScope()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
checkNotNull(scope)
}
}我们需要使用接口并实现属性。这将设置类使用的默认 Scope。AndroidScopeComponent scope
7.3 Android Scope 接口
要创建绑定到 Android 组件的 Koin 作用域,只需使用以下函数:
createActivityScope()- 为当前 Activity 创建 Scope(必须声明 Scope 部分)
createActivityRetainedScope()- 为当前 Activity 创建 RetainedScope(由 ViewModel Lifecycle 支持)(必须声明 Scope 部分)
createFragmentScope()- 为当前 Fragment 创建 Scope 并链接到父 Activity Scope 这些函数可作为委托使用,以实现不同类型的作用域:
activityScope()- 为当前 Activity 创建 Scope(必须声明 Scope 部分)
activityRetainedScope()- 为当前 Activity 创建 RetainedScope(由 ViewModel Lifecycle 支持)(必须声明 Scope 部分)
fragmentScope()- 为当前 Fragment 创建 Scope 并链接到父 Activity Scope
class MyActivity() : AppCompatActivity(contentLayoutId), AndroidScopeComponent {
override val scope: Scope by activityScope()
}我们还可以使用以下内容设置保留范围(由 ViewModel 生命周期提供支持):
class MyActivity() : AppCompatActivity(contentLayoutId), AndroidScopeComponent {
override val scope: Scope by activityRetainedScope()
}如果您不想使用 Android Scope 类,则可以使用自己的类并使用 Scope 创建 API AndroidScopeComponent
7.4 Scope 链接
Scope 链接允许在具有自定义作用域的组件之间共享实例。在更广泛的用法中,您可以跨组件使用实例。例如,如果我们需要共享一个实例。Scope UserSession
首先声明一个范围定义:
module {
// Shared user session data
scope(named("session")) {
scoped { UserSession() }
}
}当需要开始使用实例时,请为其创建范围:UserSession
val ourSession = getKoin().createScope("ourSession",named("session"))
// link ourSession scope to current `scope`, from ScopeActivity or ScopeFragment
scope.linkTo(ourSession)然后在您需要的任何地方使用它:
class MyActivity1 : ScopeActivity() {
fun reuseSession(){
val ourSession = getKoin().createScope("ourSession",named("session"))
// link ourSession scope to current `scope`, from ScopeActivity or ScopeFragment
scope.linkTo(ourSession)
// will look at MyActivity1's Scope + ourSession scope to resolve
val userSession = get<UserSession>()
}
}
class MyActivity2 : ScopeActivity() {
fun reuseSession(){
val ourSession = getKoin().createScope("ourSession",named("session"))
// link ourSession scope to current `scope`, from ScopeActivity or ScopeFragment
scope.linkTo(ourSession)
// will look at MyActivity2's Scope + ourSession scope to resolve
val userSession = get<UserSession>()
}
}8.Fragment Factory
由于 AndroidX 已经发布了软件包系列以扩展 Android 的功能 androidx.fragment Fragment
developer.android.com/jetpack/and…
8.1 Fragment Factory
自版本以来,已经引入了 ,一个专门用于创建类实例的类:2.1.0-alpha-3 FragmentFactory Fragment
developer.android.com/reference/k…
Koin 也提供了创建 Fragment 的工厂类 KoinFragmentFactory Fragment
8.2 设置 Fragment Factory
首先,在 KoinApplication 声明中,使用关键字设置默认实例:fragmentFactory() KoinFragmentFactory
startKoin {
// setup a KoinFragmentFactory instance
fragmentFactory()
modules(...)
}8.3 声明并注入 Fragment
声明一个 Fragment 并在 module 中注入
class MyFragment(val myService: MyService) : Fragment() {
}
val appModule = module {
single { MyService() }
fragment { MyFragment(get()) }
}8.4 获取 Fragment
使用setupKoinFragmentFactory() 设置 FragmentFactory
查询您的 Fragment ,使用supportFragmentManager
supportFragmentManager.beginTransaction()
.replace<MyFragment>(R.id.mvvm_frame)
.commit()加入可选参数
supportFragmentManager.beginTransaction()
.replace<MyFragment>(
containerViewId = R.id.mvvm_frame,
args = MyBundle(),
tag = MyString()
)8.5 Fragment Factory & Koin Scopes
如果你想使用 Koin Activity Scope,你必须在你的 Scope 声明你的 Fragment 作为一个定义:scoped
val appModule = module {
scope<MyActivity> {
fragment { MyFragment(get()) }
}
}并使用您的 Scope 设置您的 Koin Fragment Factory:setupKoinFragmentFactory(lifecycleScope)
class MyActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
// Koin Fragment Factory
setupKoinFragmentFactory(lifecycleScope)
super.onCreate(savedInstanceState)
//...
}
}9. WorkManager 的 Koin 注入
koin 为 WorkManager 提供单独的组件包 koin-androidx-workmanager
首先,在 KoinApplication 声明中,使用关键字来设置自定义 WorkManager 实例:workManagerFactory()
class MainApplication : Application(), KoinComponent {
override fun onCreate() {
super.onCreate()
startKoin {
// setup a WorkManager instance
workManagerFactory()
modules(...)
}
setupWorkManagerFactory()
}AndroidManifest.xml 修改,避免使用默认的
<application . . .>
. . .
<provider
android:name="androidx.work.impl.WorkManagerInitializer"
android:authorities="${applicationId}.workmanager-init"
tools:node="remove" />
</application>9.1 声明 ListenableWorker
val appModule = module {
single { MyService() }
worker { MyListenableWorker(get()) }
}9.2 创建额外的 WorkManagerFactory
class MainApplication : Application(), KoinComponent {
override fun onCreate() {
super.onCreate()
startKoin {
workManagerFactory(workFactory1, workFactory2)
. . .
}
setupWorkManagerFactory()
}
}如果 Koin 和 workFactory1 提供的 WorkManagerFactory 都可以实例化 ListenableWorker,则 Koin 提供的工厂将是使用的工厂。
9.3 更改 koin lib 本身的清单
如果 koin-androidx-workmanager 中的默认 Factory 被禁用,而应用程序开发人员不初始化 koin 的工作管理器基础架构,他最终将没有可用的工作管理器工厂。
针对上面的情况,我们做如下 DSL 改进:
val workerFactoryModule = module {
factory<WorkFactory> { WorkFactory1() }
factory<WorkFactory> { WorkFactory2() }
}然后让 koin 内部做类似的事情
fun Application.setupWorkManagerFactory(
// no vararg for WorkerFactory
) {
. . .
getKoin().getAll<WorkerFactory>()
.forEach {
delegatingWorkerFactory.addFactory(it)
}
}参考链接
作者:Calvin873
来源:juejin.cn/post/7189917106580750395
码农如何提高自己的品味
前言
软件研发工程师俗称程序员经常对业界外的人自谦作码农,一来给自己不菲的收入找个不错的说辞(像农民伯伯那样辛勤耕耘挣来的血汗钱),二来也是自嘲这个行业确实辛苦,辛苦得没时间捯饬,甚至没有驼背、脱发加持都说不过去。不过时间久了,行外人还真就相信了程序员就是一帮没品味,木讷的low货,大部分的文艺作品中也都是这么表现程序员的。可是我今天要说一下我的感受,编程是个艺术活,程序员是最聪明的一群人,我们的品味也可以像艺术家一样。
言归正转,你是不是以为我今天要教你穿搭?不不不,这依然是一篇技术文章,想学穿搭女士学陈舒婷(《狂飙》中的大嫂),男士找陈舒婷那样的女朋友就好了。笔者今天教你怎样有“品味”的写代码。
以下几点可提升“品味”
说明:以下是笔者的经验之谈具有部分主观性,不赞同的欢迎拍砖,要想体系化提升编码功底建议读《XX公司Java编码规范》、《Effective Java》、《代码整洁之道》。以下几点部分具有通用性,部分仅限于java语言,其它语言的同学绕过即可。
优雅防重
关于成体系的防重讲解,笔者之后打算写一篇文章介绍,今天只讲一种优雅的方式:
如果你的业务场景满足以下两个条件:
1 业务接口重复调用的概率不是很高
2 入参有明确业务主键如:订单ID,商品ID,文章ID,运单ID等
在这种场景下,非常适合乐观防重,思路就是代码处理不主动做防重,只在监测到重复提交后做相应处理。
如何监测到重复提交呢?MySQL唯一索引 + org.springframework.dao.DuplicateKeyException
代码如下:
public int createContent(ContentOverviewEntity contentEntity) {
try{
return contentOverviewRepository.createContent(contentEntity);
}catch (DuplicateKeyException dke){
log.warn("repeat content:{}",contentEntity.toString());
}
return 0;
}用好lambda表达式
lambda表达式已经是一个老生常谈的话题了,笔者认为,初级程序员向中级进阶的必经之路就是攻克lambda表达式,lambda表达式和面向对象编程是两个编程理念,《架构整洁之道》里曾提到有三种编程范式,结构化编程(面向过程编程)、面向对象编程、函数式编程。初次接触lambda表达式肯定特别不适应,但如果熟悉以后你将打开一个编程方式的新思路。本文不讲lambda,只讲如下例子:
比如你想把一个二维表数据进行分组,可采用以下一行代码实现
List<ActionAggregation> actAggs = ....
Map<String, List<ActionAggregation>> collect =
actAggs.stream()
.collect(Collectors.groupingBy(ActionAggregation :: containWoNosStr,LinkedHashMap::new,Collectors.toList()));用好卫语句
各个大场的JAVA编程规范里基本都有这条建议,但我见过的代码里,把它用好的不多,卫语句对提升代码的可维护性有着很大的作用,想像一下,在一个10层if 缩进的接口里找代码逻辑是一件多么痛苦的事情,有人说,哪有10层的缩进啊,别说,笔者还真的在一个微服务里的一个核心接口看到了这种代码,该接口被过多的人接手导致了这样的局面。系统接手人过多以后,代码腐化的速度超出你的想像。
下面举例说明:
没有用卫语句的代码,很多层缩进
if (title.equals(newTitle)){
if (...) {
if (...) {
if (...) {
}
}else{
}
}else{
}
}使用了卫语句的代码,缩进很少
if (!title.equals(newTitle)) {
return xxx;
}
if (...) {
return xxx;
}else{
return yyy;
}
if (...) {
return zzz;
}避免双重循环
简单说双重循环会将代码逻辑的时间复杂度扩大至O(n^2)
如果有按key匹配两个列表的场景建议使用以下方式:
1 将列表1 进行map化
2 循环列表2,从map中获取值
代码示例如下:
List<WorkOrderChain> allPre = ...
List<WorkOrderChain> chains = ...
Map<String, WorkOrderChain> preMap = allPre.stream().collect(Collectors.toMap(WorkOrderChain::getWoNext, item -> item,(v1, v2)->v1));
chains.forEach(item->{
WorkOrderChain preWo = preMap.get(item.getWoNo());
if (preWo!=null){
item.setIsHead(1);
}else{
item.setIsHead(0);
}
});用@see @link来设计RPC的API
程序员们还经常自嘲的几个词有:API工程师,中间件装配工等,既然咱平时写API写的比较多,那种就把它写到极致@see @link的作用是让使用方可以方便的链接到枚举类型的对象上,方便阅读
示例如下:
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class ContentProcessDto implements Serializable {
/**
* 内容ID
*/
private String contentId;
/**
* @see com.jd.jr.community.common.enums.ContentTypeEnum
*/
private Integer contentType;
/**
* @see com.jd.jr.community.common.enums.ContentQualityGradeEnum
*/
private Integer qualityGrade;
}日志打印避免只打整个参数
研发经常为了省事,直接将入参这样打印
log.info("operateRelationParam:{}", JSONObject.toJSONString(request));该日志进了日志系统后,研发在搜索日志的时候,很难根据业务主键排查问题
如果改进成以下方式,便可方便的进行日志搜索
log.info("operateRelationParam,id:{},req:{}", request.getId(),JSONObject.toJSONString(request));如上:只需要全词匹配“operateRelationParam,id:111”,即可找到业务主键111的业务日志。
用异常捕获替代方法参数传递
我们经常面对的一种情况是:从子方法中获取返回的值来标识程序接下来的走向,这种方式笔者认为不够优雅。
举例:以下代码paramCheck和deleteContent方法,返回了这两个方法的执行结果,调用方通过返回结果判断程序走向
public RpcResult<String> deleteContent(ContentOptDto contentOptDto) {
log.info("deleteContentParam:{}", contentOptDto.toString());
try{
RpcResult<?> paramCheckRet = this.paramCheck(contentOptDto);
if (paramCheckRet.isSgmFail()){
return RpcResult.getSgmFail("非法参数:"+paramCheckRet.getMsg());
}
ContentOverviewEntity contentEntity = DozerMapperUtil.map(contentOptDto,ContentOverviewEntity.class);
RpcResult<?> delRet = contentEventHandleAbility.deleteContent(contentEntity);
if (delRet.isSgmFail()){
return RpcResult.getSgmFail("业务处理异常:"+delRet.getMsg());
}
}catch (Exception e){
log.error("deleteContent exception:",e);
return RpcResult.getSgmFail("内部处理错误");
}
return RpcResult.getSgmSuccess();
}
我们可以通过自定义异常的方式解决:子方法抛出不同的异常,调用方catch不同异常以便进行不同逻辑的处理,这样调用方特别清爽,不必做返回结果判断
代码示例如下:
public RpcResult<String> deleteContent(ContentOptDto contentOptDto) {
log.info("deleteContentParam:{}", contentOptDto.toString());
try{
this.paramCheck(contentOptDto);
ContentOverviewEntity contentEntity = DozerMapperUtil.map(contentOptDto,ContentOverviewEntity.class);
contentEventHandleAbility.deleteContent(contentEntity);
}catch(IllegalStateException pe){
log.error("deleteContentParam error:"+pe.getMessage(),pe);
return RpcResult.getSgmFail("非法参数:"+pe.getMessage());
}catch(BusinessException be){
log.error("deleteContentBusiness error:"+be.getMessage(),be);
return RpcResult.getSgmFail("业务处理异常:"+be.getMessage());
}catch (Exception e){
log.error("deleteContent exception:",e);
return RpcResult.getSgmFail("内部处理错误");
}
return RpcResult.getSgmSuccess();
}自定义SpringBoot的Banner
别再让你的Spring Boot启动banner千篇一律,spring 支持自定义banner,该技能对业务功能实现没任何卵用,但会给枯燥的编程生活添加一点乐趣。
以下是官方文档的说明: docs.spring.io/spring-boot…
另外你还需要ASCII艺术字生成工具: tools.kalvinbg.cn/txt/ascii
效果如下:
_ _ _ _ _
(_|_)_ __ __ _ __| | ___ _ __ __ _ | |__ ___ ___ | |_ ___
| | | '_ \ / _` | / _` |/ _ \| '_ \ / _` | | '_ \ / _ \ / _ \| __/ __|
| | | | | | (_| | | (_| | (_) | | | | (_| | | |_) | (_) | (_) | |_\__ \
_/ |_|_| |_|\__, | \__,_|\___/|_| |_|\__, | |_.__/ \___/ \___/ \__|___/
|__/ |___/ |___/ 多用Java语法糖
编程语言中java的语法是相对繁琐的,用过golang的或scala的人感觉特别明显。java提供了10多种语法糖,写代码常使用语法糖,给人一种 “这哥们java用得通透” 的感觉。
举例:try-with-resource语法,当一个外部资源的句柄对象实现了AutoCloseable接口,JDK7中便可以利用try-with-resource语法更优雅的关闭资源,消除板式代码。
try (FileInputStream inputStream = new FileInputStream(new File("test"))) {
System.out.println(inputStream.read());
} catch (IOException e) {
throw new RuntimeException(e.getMessage(), e);
}利用链式编程
链式编程,也叫级联式编程,调用对象的函数时返回一个this对象指向对象本身,达到链式效果,可以级联调用。链式编程的优点是:编程性强、可读性强、代码简洁。
举例:假如觉得官方提供的容器不够方便,可以自定义,代码如下,但更建议使用开源的经过验证的类库如guava包中的工具类
/**
链式map
*/
public class ChainMap<K,V> {
private Map<K,V> innerMap = new HashMap<>();
public V get(K key) {
return innerMap.get(key);
}
public ChainMap<K,V> chainPut(K key, V value) {
innerMap.put(key, value);
return this;
}
public static void main(String[] args) {
ChainMap<String,Object> chainMap = new ChainMap<>();
chainMap.chainPut("a","1")
.chainPut("b","2")
.chainPut("c","3");
}
}作者:京东科技 文涛
来源:juejin.cn/post/7197604280705908793
心血来潮,这次我用代码“敲”木鱼
技术栈
面对这种寿命短,后期也基本不需要维护的项目(更没有复杂的网络请求一说),本篇文章直接使用原生JavaScript进行开发。或者您也可以尝试一下低代码
关于低代码,您大可放心的阅读此篇干货文章《低代码都做了什么?(为什么?怎么实现Low-Code?)》
至于TypeScript,您可以通过《谈谈写TypeScript实践而来的心得体会》这篇文章快速上手或进阶TS
实现
页面布局
图中右侧标出了三个部分:
img标签用于指定木鱼的图片url地址,在木鱼进行缩放时,对该标签增加/删除css类名即可- 每次敲击时所产生的文字由
p标签生成,且所有的p标签都存在于div标签之下 audio标签会在敲击时播放声音
本篇文章不会涉及具体的Html、Css部分。如有疑问,请在此项目的GitHub中找到答案
逻辑部分
准备工作
通过JavaScript获取要操作的真实dom
const dom = {
// 木鱼
woodenFish: document.querySelector("img"),
// 文字浮层
text: document.querySelector(".w-f-c-text"),
// 音频
audio: document.querySelector("audio")
}
复制代码木鱼缩放
这里的思路是敲击时给img追加一个带有css animation的样式类,该animation的作用是让木鱼进行一次缩放,例如
.w-f-c-i-size {
/** 这里的animation只会执行一次缩放,所以后面会通过增加/删除该类名来达到可以进行n次缩放的效果 */
animation: wooden-fish-size 0.3s;
}
@keyframes wooden-fish-size {
0% {
transform: scale(1);
}
50% {
transform: scale(0.9);
}
100% {
transform: scale(1);
}
}
复制代码样式搞定之后,通过原生JavaScript提供的dom classList进行css样式类名的增加与删除。dom classList共有四个方法:
add:在指定节点上增加一个样式类名remove:在指定节点上删除一个样式类名toggle:在指定节点A上若已有样式类名a,则将a删除;若没有样式类名a,则添加类名areplace:将指定节点上的样式类名替换为另一个样式类名。效果同String##replace一致
const woodenFish = {
// 封装一个用于增加/删除类名的方法
className(type) {
dom.woodenFish.classList[type]("w-f-c-i-size")
},
size() {
this.className("add")
setTimeout(() => this.className("remove"), 300)
}
}
复制代码size方法用于进行一次木鱼的缩放。调用该方法时,首先为img标签增加类w-f-c-i-size,在300毫秒后,再将该类名移除
为什么是300毫秒?因为css animation的持续时间为300毫秒
需要注意的是,size方法中的this为woodenFish对象,所以this.className就相当于woodenFish.className
关于this或其它JavaScript的问题,您可以在《JavaScript每日一题》专栏中找到对应的题目进行练习
文字浮层
const woodenFish = {
className() {},
size() {},
createText() {
const p = document.createElement("p")
p.innerText = "功德+1"
dom.text.appendChild(p)
}
}
复制代码createText方法用于创建一个p标签,该标签的文字内容为“功德+1”,随后将该标签追加在div下即可
小tip:JSX(或react)中书写HTML类型的注释
博主在此刻书写document.createElement这个原生方法时,突然想到了最近用到的一个原生属性outerHTML,该属性与innerHTML的区别就不再赘述。在JSX中书写html类型的注释,使用大括号的形式({/** */})是不可以的,因为在编译时这些东西都会被扔掉,此时可以使用由React提供的dangerouslySetInnerHTML属性,但体验感不太好。所以可以使用ouertHTML配合ref来解决,vue同理,例如:
const HtmlComment: FC<HtmlCommentType> = ({ children }) => {
const virtual = useRef<HTMLSpanElement>(null)
useEffect(() => {
virtual.current!.outerHTML = `<!-- ${children} -->`
}, [])
return <span ref={virtual} />
}
复制代码H5控制手机震动
const vibrate = () => {
const navigator = window.navigator
if (!("vibrate" in navigator)) return
navigator.vibrate =
navigator.vibrate ||
navigator.webkitVibrate ||
navigator.mozVibrate ||
navigator.msVibrate
if (!navigator.vibrate) return
// 上面的代码全是进行兼容性判断,只有下面这一行是发起手机震动的API
navigator.vibrate(300)
}
复制代码像发起手机震动这类Api,首先就要进行兼容性判断,所以上面vibrate方法的90%部分都在进行兼容性判断。注意,window.navigator提供了一个用于发起设备震动的方法,即window.navigator.vibrate
window.navigator.vibrate方法的参数:
- 一个
number类型的值
这种方式表示震动持续多长时间,例如window.navigator.vibrate(300),则表示震动持续300毫秒
- 一个
number类型的数组
这种方式表示震动、暂停间隔的时间。例如window.navigator.vibrate([100, 30, 100]),则表示先震动100毫秒,随后暂停30毫秒,然后再震动100毫秒
window.navigator.vibrate方法在震动成功时返回true,否则返回false
vibrate兼容性
浏览器全屏操作
const toggleFullScreen = () => {
if (!document.fullscreenElement)
return document.documentElement.requestFullscreen()
if (!document.exitFullscreen) return
document.exitFullscreen()
}
document.addEventListener("keydown", (e) =>
e.keyCode == 13 ? toggleFullScreen() : false
)
复制代码toggleFullScreen方法会在全屏或非全屏之间来回切换,用到了以下属性/方法:
document.fullscreenElement返回当前正在以全屏模式显示的元素,如果没有,则返回nulldocument.documentElement.requestFullscreen用于发起全屏请求。若全屏请求成功,则该函数返回成功的Promise对象,否则返回失败的Promise对象。
在全屏成功时,全屏显示的元素会触发fullscreenchange事件;类似于输入框在输入时会触发onchange事件
document.exitFullscreen方法用于使当前元素退出全屏模式
随后为document绑定keydown事件,如果按下了回车键,则在全屏/非全屏之间切换,否则不做出任何操作
音频事件操作
之前博主在写播放器的时候就发现音频的属性、方法、事件很多很多,所以此处只列举两个本项目中用到的方法
play()使播放开始pause()使播放暂停
制作完成
通过以上几个步骤就已经完成了所有要用到的东西,最后只需为木鱼注册“敲击”事件即可
dom.woodenFish.addEventListener("click", () => {
// 木鱼缩放
woodenFish.size()
// 创建文字浮层
woodenFish.createText()
// 播放敲击木鱼的声音
dom.audio.play()
// 发起手机震动
vibrate()
})
复制代码文末
从一次心血来潮,到自己从0至1完成这个简单而有趣的小项目,无论是技术角度,还是个人收获角度来讲,都是收获满满!现在您可以通过以下两个地址来 “功德+1” :
由于时间匆忙,文中错误之处在所难免,敬请读者斧正。如果您觉得本篇文章还不错,欢迎点赞收藏和关注,我们下篇文章见!
链接:https://juejin.cn/post/7199660596735164475
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
z-index不生效?让我们来掀开它的面具
前言
hi大家好,我是小鱼,今天复习的是z-index。之前以为自己很了解它,可是在工作中总会遇到一些不思其解的问题,后来去深入学习了层叠上下文、层叠等级、层叠顺序,才发现z-index只是其中的一叶小舟,今天就一起来看看它背后到底隐藏着什么。
z-index
.container {
z-index: auto | <integer> ;
}
复制代码z-index属性是允许给一个负值的。z-index属性支持 CSS3animation动画。- 在 CSS 2.1 的时候,需要配合
position属性且值不为static时使用。
这个属性大家应该都很熟悉了,指定了元素及其子元素的 在 Z 轴上面的顺序,而 Z 轴上面的顺序 可以决定当元素发生覆盖的时候,哪个元素在上面。 z-index值大的元素会覆盖较低的。
不知道大家在工作中有没有遇到过这种情况,明明给其设置了z-index并且也设置了position不为static,但是样式并不是你所想的那样。可能这里大家对z-index不太了解,判断元素在Z轴上的顺序,不仅仅是z-index值的大小,接下来给大家解释层叠上下文、层叠等级和层叠顺序。
层叠上下文
层叠上下文(stacking context),是HTML中一个三维的概念。如果一个元素含有层叠上下文,我们可以理解为这个元素在Z轴上就“高人一等”。
大家应该都玩过王者荣耀,里面的段位就是一个层级概念。你可以把「层叠上下文」理解为上了最强王者的人,还有很多没上王者的人,我们可以看成是菜鸡。那王者选手和菜鸡之间就形成了一个差距,这个差距也就是在Z轴上的距离,王者选手离荣耀王者就更近了一步,这里的“荣耀王者”可以看成是我们的屏幕观察者。
这样抽象解释完大家应该明白了什么是层叠上下文。继续往下看↓
层叠等级
层叠等级(stacking level),决定了同一个层叠上下文中元素在Z轴上的显示顺序。这里又牵扯出一个level,那么这个等级指的又是什么呢?
所有的元素都有层叠等级,包括层叠上下文元素,层叠上下文元素的层叠等级可以理解为是什么普通王者,无双,荣耀传奇之类。然后,对于普通元素的层叠等级,我们的探讨仅仅局限在当前层叠上下文元素中。为什么呢?因为否则没有意义。
还是回到王者荣耀,元素具有层叠上下文就相当于是王者段位,但是王者里面又分为普通王者,无双王者和荣耀王者还有传奇王者,那我们如果拿普通王者的韩信和传奇王者的韩信相比较实际上是没有意义的,那不吊打吗,那他牛不牛逼是由段位决定的(排除一些意外情况哈哈哈)。
层叠上下文的创建
说白了就是一个元素如何才能变成层叠上下文元素?
层叠上下文是由一些特点的CSS属性创建的,分为三点:
- 页面根元素天生具有层叠上下文,称之为“根层叠上下文”。
- 普通元素设置
position属性为非static值并设置z-index属性为具体数值,产生层叠上下文。 - 其他CSS3中的新属性也可以
flex容器的子元素,且z-index值不为auto- grid 容器的子元素,且 z-index 值不为
auto opacity属性值小于 1 的元素transform属性值不为none的元素filter属性值不为none的元素isolation属性值为isolate的元素-webkit-overflow-scrolling属性值为touch的元素;
简单写两个例子
栗子一
.box1,.box2 {
position: relative;
width: 100px;
height: 100px;
}
.a,.c {
width: 100px;
height: 100px;
position: absolute;
font-size: 20px;
padding: 5px;
color: white;
border: 1px solid rgb(119, 119, 119);
}
.a {
background-color: rgb(0, 163, 168);
z-index: 1;
}
.c {
background-color: rgb(0, 168, 84);
z-index: 2;
left: 50px;
top: -50px;
}
<div class="box1">
<div class="a">A</div>
</div>
<div class="box2">
<div class="c">C</div>
</div>
复制代码
因为box1,box2都没有设置
z-index,所以没有创建层叠上下文,所以其子元素都处于‘根层叠上下文’中,在同一个层叠上下文领域,层叠水平值大的那一个覆盖小的那一个。
栗子2
只帖了修改部分
.box1 {
z-index: 2;
}
.box2 {
z-index: 1;
}
.a {
background-color: rgb(0, 163, 168);
z-index: 1;
}
.b {
background-color: rgb(21, 84, 180);
z-index: 2;
left: 50px;
top: 50px;
}
.c {
background-color: rgb(0, 168, 84);
z-index: 999;
left: 100px;
top: 50px;
}
复制代码
大家可以发现我们给C盒子设置的
z-index为999远大于A、B两个盒子,效果却出现在他俩下面。那是因为给两个父盒子分别设置了z-index,创建了两个不同的层叠上下文,而box1的z-index值大,所以排在上面,这里验证了层叠等级。
栗子3
有一个父元素绝对定位,它有一个子元素也是绝对定位,父元素z-index大于子元素z-index,为何子元素还是在父元素的上面?如何让这个子元素放在父元素的下面。
.parent {
width: 100%;
height: 500px;
background-color: rgb(243, 151, 45);
position: absolute;
z-index: 1;
}
.child {
width: 20%;
height: 150px;
background-color: rgb(211, 56, 56);
position: absolute;
z-index: 0;
}
<div class="parent">
<div class="child">C</div>
</div>
复制代码效果却是这样
解决方案
因为父元素和子元素之间,z-index是无法对比的,同级之间的z-index才能对比。可以考虑换一种方式,两个div做同级,外面包一层父元素,根据共同的父元素定位、做层级区分就可以。
父元素不指定 z-index, 而子元素 z-index 为 -1
结论
普通元素的层叠等级优先由层叠上下文决定,所以,层叠等级的比较只有在当前层叠上下文元素中才有意义。
层叠顺序
层叠顺序(stacking order),表示元素发生层叠时候有着特定的垂直显示顺序,注意,这里跟上面两个不一样,上面的层叠上下文和层叠等级是概念,而这里的层叠顺序是规则。
上图↓
在不考虑CSS3的情况下,当元素发生层叠时,层叠顺序遵循上面图中的规则。
这里稍微解释下为什么内联元素的层叠顺序要比浮动元素和块状元素都高?有些同学可能觉得浮动元素和块状元素要更屌一点,图中我标注了内联样式是内容,因为网页中最重要的是内容,文字和浮动图片的时候优先确保显示文字。
层叠准则
- 谁大谁上: 当具有明显层叠等级的时候,在同一个层叠上下文领域,
z-indx大的那一个覆盖小的那一个。 - 后来居上: 当元素的层叠等级一致、层叠顺序相同的时候,在DOM流中处于后面的元素会覆盖前面的元素。
栗子4
.box1,.box2 {
position: relative;
width: 100px;
height: 100px;
}
.box1 {
z-index: 0;
}
.box2 {
z-index: 0;
}
.a,.c {
width: 100px;
height: 100px;
position: absolute;
font-size: 20px;
padding: 5px;
color: white;
border: 1px solid rgb(119, 119, 119);
}
.a {
background-color: rgb(0, 163, 168);
z-index: 999;
}
.c {
background-color: rgb(0, 168, 84);
z-index: 1;
left: 50px;
top: -50px;
}
<div class="box1">
<div class="a">A</div>
</div>
<div class="box2">
<div class="c">C</div>
</div>
复制代码
上面给两个父盒子都设置了
z-index为0,这里要注意z-index一旦变成数值,哪怕是0,都会创建一个层叠上下文。当然层叠规则就发生了变化,子元素的层叠顺序比较变成了优先比较其父级的层叠上下文的层叠顺序,尽管a盒子的z-index为999。又由于两个父级都是z-index:0,层叠顺序这一块一样大,这个时候就遵循后来居上原则,根据DOM流中的位置决定谁在上面。也可以说子元素上面的z-index失效了!
end
回顾自己以前使用z-index都不太规范或者滥用,以后一定改正!
链接:https://juejin.cn/post/7158409848692932621
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
程序界鄙视链的终点
前言
不知道是大数据惹的祸,还是我的被迫害妄想症犯了,总是刷到一些哭笑不得的内行笑话系列,想反驳又觉得不该年轻气盛,憋了很久,还是觉得系统性的抒发一下,今天要聊的是关于程序界的鄙视链话题,各位老哥,如果有涉及程序语言部分,欢迎来杠。
主流鄙视链
语言
🍺鄙视链的话题由来已久也一直存在,原本只是体现在适用性和从业选择方向上,像是之前有游戏梦想的基本主攻C、C++、MFC、DirectX、MFC、 QT, C# 以PC市场为主,后来的网页应用市场php、VB.NET、perl、asp.net、jsp、flex、flash应用鼎盛时期也占据半壁江山,塞班系统,塞班开发,以及手机市场昙花一现的各种手机应用开发语言,数据库也从sqlserve,oracle,mysql感觉是一段时间之后才慢慢进入视野,mogodb,时序库InfluxDB等等,后来的JQ、node、glup、boostrap、H5、canvas、angular、react、vue,、icon、antd、elment-ui再到混合开发多端应用,再到Objective-C、python、Goland、rust、deno等等等等。
编译器
🍺编译工具从TurboC、VC6、Dreamweaver、VS2005-VS2022、Eclipse、MyEclipse、idea、Android Studio、WebStorm、vscode、HBuilder X,编辑器换了好几轮。
个体挣扎
🍺很难想象短短的10几年时间里,经历了这么多轮换血和语言转换,很多过了鼎盛期已经被淘汰,很多半死不过的存续着,相信很多从业者也经历过某个语言从生到死的过程,一直都秉持着技多不压身的准则,一常备、一学习、一了解,虽然很多人都在杠,那个语言更底层,那个语言常青藤,那个语言生命周期最长,入门最难,我能理解,从事某一个语言耕耘良久突然宣告没有市场那种失落感,但这就跟历史一样,有其发展规律,历史框架下的人,都是规律的适应者,并非一成不变的,语言的高度也因其活跃度,主流面临解决的问题相关,所以其实跟绝大多数从业者半毛钱关系都没有,我们也只是受益者,并不代表你的高度到了那个层级,语言鄙视的说法就好像登山的人在嘲笑下山的人,不置可否。
上清下沉
🍺在google还没离场,淘宝还没发家的前夜,微博、金山、PC端游还火爆,工具大神,搜狐还红的时候,还没有什么大厂、外包的提法,都是搞软件的,只是主攻方向不同,能成长能学习就行,公司好有些光环,解决问题是最重要的,后来,我听过一个理论,学历和大厂,至少能保证从业者是优质里面的顶尖部分,乍一听觉得没道理,后来想想,当面试那关的能力划等号,我是选硕士更充门脸还是选专科,用脚也能做出选择,长此以往的上清下沉,盘古开天,辅助以各种奇葩的企业文化,企业鄙视链的说法也就不足为奇了。
价值化
🍺 “更好的值得更高的待遇”,工资待遇标签化,跟房子有了商业化属性一样,我比你拿的多,说明我方方面面碾压你,即使你不想被贴标签,也会被动的贴上标签,记得我从中型互联网转到传统企业时就被强制贴了一波标签,相信很多人摆平心态,也有这种无奈的体验,体验更差就是从出了名的外包场出来的,相信体感更差,如果你真的有计较,争论着低人一等,干同样的事儿,被区别对待,就跟秀才考功能,跟人攀比吃穿用度有什么差异。
乱象
- 🍗 有大神在买课,20多岁的架构师、一问缘由,算上加班,工作10年,之前一直是把这个东西当作调侃,没想到有人正儿八经的说出来了,听说现在软件培训费用就要几万,比上个大学还贵,教人在线面试,美化简历等等乱想,“我能有啥害人的心思呢,我只是想帮你”,我只是看上了你荷包里面跳动的money。
- 🍗 有人在孜孜不倦的教人python爬虫,“线上从入门到进去”,美化点的叫法叫数据采集、预处理,至于高端点儿的识别预测,算法类的东西,tensorflow一般人先不论你的机器跟不跟得上,学历已经卡出去大半人了,如果是测试自动化,稍微还好点儿,其他的真的就有点儿居心叵测了。
- 🍗 前几年直播编程号称几天0观看,后几年突然就多了,我始终理解不了,看视频能学到啥东西,正儿八经,有目标的实现某个功能目标,不才是正途吗?不知道是不是我太肤浅了。
- 🍗可能我不分端太久了,换了环境稍稍有点儿不适应,按理说,即使技术有语言有局限性,也不该分不清楚一些常规的状态码和逻辑主次关系,活脱脱完全限制了自己,把自己封印在了一个区域,这还是工作7-8年的,语言的多样性,会让我们的世界变的更大,当你不接受外部的内容,总耕耘在自己熟悉的领域,培养傲慢的同时,也会丧失敬畏。
- 🍗我不清楚这是不是普遍现象,前端面试多数只会问技术,不会涉及到功能闭环和业务,面了好几个,可能做的事情比较边角,也不会去试图理解做某一个应用的含义,完整性闭合性都说不出来,难道面的姿势不对,没有把准备的东西发挥出来,一到业务就避而不谈或者就说只做功能不涉及到业务。
- 🍗其后也莫名其妙面了报价30-40的,应该是30多,研究生,天然条件很好,其他的不论,只以面试论,我诧异的是,岗位属于业务擅长,着重点该在业务上,却神奇的写了一些技术,占了很大篇幅,问到具体的业务,条理分明的胡扯,或者涉密,问到技术又开始顾左右而言他。
- 🍗再有就是我很难相信,一个面试时综合能力还可以的人,业务能力为0的情况,可能王者天生爱执行吧。
- 🍗以上并不针对个人,只是想说明,做软件,很多人其实只是把它当作糊口的工具,本身其实并不喜欢这份工作,只是恰好工资相对较高,而且每个人对技术的追求分阶段不同,想法认知不同,很多情况要学会保留意见停止争论,待认知线在同一水准后,再适时决定,程序做久了要适当的学会拐弯,不然人为的屏障会越来越让你放弃沟通交流。
我的经历
接触
🍺细算下来我最早涉及到编程接触的第一门语言是java,那会刚考上大学,得知被调剂到了软件,无所事事跑到网吧了解了一哈啥是编程,跑了个java计算器的例子,第一次有种掌控的感觉,也许这就是编程带来的魅力之一,掌控感,后来上学微机原理,TurboC 输出了第一个程序标配Hello World, 我记得看过一段话,一笔一划码出一个世界,我想我原本应该就是热爱编程的,爱泡图书馆看些软件杂书,记得因为上课在看机器人人工智能算法,被老师注意到,莫名其妙的神经网络BP,从C,C++,C#薅了三遍,后面连带又薅了一波人工智能动态寻路directx渲染的规避,最终没能成功去做游戏,感觉血亏。
过程
🍺其后的工作经历之前也又提到过,无非就是遇山开山遇水开河,值得骄傲的是从来没因工作的地狱级难度退缩过,正儿八经外头的私活也整了又10年左右了,可能驳杂的技术体系也缘于此,心态比较重要,只要是能成长的都可以去学,熟悉的多了,就不会有恐惧感,我的很多技能点都属于外部创新,工作深挖实践过来的,信心需要培养,不知道你有没有这种中二的经历,每次解决一个疑难杂症,我总是不由自主的喊出来 “我TN真是个天才”,乐此不疲,也许这就是别人说的掌控感。
接触
🍺我看到很多人在说在中国不过20年,没看到过35岁之后还搞程序的,我本能的忽略了年龄这个问题,其实之前我确确实实看到过一个老哥60岁了,还在搞C++,烟瘾特别大,几乎很短实践就搞出了包含算法预处理的专业软件,当时可能还在自我膨胀中,没有意识到这项工作从0-1的难度有好大,之后也和一个60岁的老哥相处过一段,可能是年龄大了,有些不受招呼,风评不咋好,一块聊过一段,给我们讲了他的当年,合伙创业,失败就业,总之也是波澜壮阔,还有之前我们的总监,40多了长得跟个20多岁的人一样,为人随和,可能相处下来,感受不到年龄的隔阂,给我一种感觉,大家都差不多,提笔回顾,恍惚之间才意识到,当然现在特别是今年,经济不好,再加上各种企业文化,我对我能持续多久有过担忧,但尽最大的努力,留最小的遗憾,是我一直以来,对事儿的态度,如果沉浸在焦虑中,会错过很多风景,反而是在焦虑中浪费了时光.
▨▨▨没什么具体的该怎么做,只能说,适当的多放下身段,多听听周围不同岗位的人对实现具体某一件事情,别人的认知和评判是怎样的,和自己的认知背离是什么原因造成的,自己的原因多补充相关知识,别人的原因多吸取经验教训,如果同一件事情,自己认为很难,充满抱怨,别人觉得简单,思路清晰的解决了问题,该是你充分学习经验的时候
悟道
🍺戾气重的环境,让我们忘记了回溯,忘记了思考,很多的事情本能的忽略,软件"工具人"的称呼我并不排斥,但之前看贴的时候,看到很多人对这个称谓很不忿,觉得很恶心,但本质上,外包、中型厂、大厂“研发资源”的叫法会更好听吗?不是别人怎么叫,而是我们要认清不足,继续抵足前行,外部的杂音不足挂齿,内心的修炼与自身能力的强大才是我们该争取的,不想当将军的士兵,必然成不了将军,但想当将军的士兵,最终不一定会成为将军,只能说,行进的策略一直让我们时刻准备,时刻充实着,可能这是精神充实的一种“信仰”,但这不妨碍我时刻划定标准在进步着,所以忙着和别人攀比比较有什么意义呢,相较于环境与别人,改变自己才是最容易的吧。
原因刨析
💪关于大厂小厂之前一番讨论:
Me:事实上、有个很严重的分歧点在于,小厂更注重的是全面性,巴不得你从业务、前后端、框架、学习能力、设计能力、甚至商务以及交付能力都具备。往往从技术到支持都是考虑最低成本实现的,需要很强的灵活性和变通能力,而且很多业务都是在软件能力之上有行业经验要求的、所以降工资是一方面,还得适应变态的差异化开发习惯、
另外前段时间面试的时候发现个问题,纯前端有个很严重的弊端,最接近业务,却最不了解业务、问业务都不了解或者说不清楚闭环、
还有就是即便是技术专家、普遍的诉求其实当下不是开拓性市场、屠龙技需要平台才施展的开
前端早早聊:很有道理,大厂面试你的屠龙技,进去后拧 180 米长的复杂螺丝,不好拧,小厂面试你的螺丝功,进去后要求你用屠龙技,一个人全套搞定空间站,全能全干,两边点亮的技能点大有不同,需要的心态也大大不同
💪鄙视链的问题
语言鄙视
很多讨论其实集中在语言的入门难易度,应用层级的问题,其实跟用这门语言的人关系不大,最接近的关系我能一直用这门语言存续多久,也就是我的语言技能会不会随着实践继续升值。
后端、前端的问题,这个本质是技术局限性引发的,很多事情不去做,只是评价的话,这和你嘲讽搞PPT的人,外行指导内行有什么差别。
年龄鄙视
之前看到怪谈,通过不写注释,故意错乱结构来提高自己的存在价值,就事论事,能力是能力的问题,有些行为准则是人的问题,好多论调在说过了35岁,谁还需要去投简历,投简历的都是能力不行,还有别人已经挣够了,讲真的,靠打工致富毕竟是少数,都是机缘巧合,绝大部分人还是该忧虑就忧虑,"农民想象当皇帝用金锄头",放开眼界,总有不一样的精彩。
学历鄙视
早先的一段面试经历,感觉有震撼到我,我没想到还有公司会这么玩,找相关领域的开源作者挨个打电话,他们找到了一位开源作者,当时面我的作者也体验了一把被标签化,他说过一段 “语言只是工具,以实现功能为目的” ,听人力小姐姐介绍情况说,这个开源作者的神奇经历,高中辍学,一直是自由开发者,看了开源内容,质量很高,起点可能比很多人要差,但通过另外一种名片找到了归属,所以能力是真的会闪光,贵在坚持,至于卡学历等等的境遇,那也只说明你和这家公司的八字不合、换家便是。
技术鄙视
大到社会,小到公司,我们都是职能链上被需要的,很多技术经验丰富的去做架构设计,但厌恶循环往复的业务调整,很多对工作推进执行做的很好的,却没法理解架构设计中一些“脱裤子放屁”的举动,团队中成员可以被替换,但职能分工是必须的,难不成要搞一堆技术大佬天天干仗不成。
待遇鄙视
我们要为自己的选择负责,最终选定的工作,要么因为待遇高、要么因为压力小,如果你不慎踩坑,实在无法适应,多了解了解别人坚持下去的动机是啥、看到很多在抱怨“死都不去外包,侮辱人格,低人一等”,多想想能力和待遇插值,再有就是精神压力等等之类的,也比抱怨来的实在,大厂诉说着各种福利待遇,至于最终是其内里的红线、精神压力和健康付出状况,各种技术成长之类的,若真剔除自身的向上进取,于工作层面真有那么多高端的技术需要你去钻营嘛,就稳定性而言,我反而觉得大厂是最不受控的,因为真无关你的价值和能力,所以我觉得这个问题应该论证着看,并没有绝对的定性。
你的追求是什么?
我曾梦想着用代码改变世界,结果我改变了我的代码,我梦想竹杖芒鞋轻胜马,谁怕?一蓑烟雨任平生快意恩仇,潇洒江湖,结果只能护住身前一尺一个家。我梦想达则兼济天下,穷则独善其身,结果我依然穷着,却做不到独善其身,事到如今,我还是会经常想起我的梦想,却也不愤恨自己平凡的半生,无非是,我做着自己喜欢做的事情,这个事情恰巧又是我的工作,我用它支撑着我弱不惊风的家,仅此而已,但也不仅限于此,至少我还在我代码的江湖,追逐着...
结束吧
有点儿跑题了,最近实在是看到了很多怪像,希望留下你的经历,形成讨论,便于形成良性的参考价值,期待你的加入!!
PPS
本来吐槽居多,后来枚举语言更替的时候,忽然觉得,历经这么多变迁,每个挣扎着的程序员,其实也在无奈中成就了平凡的伟大,心态开阔,多点儿包容!!!
来源:https://juejin.cn/post/7129868233900818468
为什么有公司规定所有接口都用Post?
看到这个标题,你肯定觉得离谱。怎么会有公司规定所有接口都用Post,是架构菜还是开发菜。这可不是夸大其词,这样的公司不少。
在特定的情况下,规定使用Post可以减少不少的麻烦,一起看看。
Answer the question
我们都知道,get请求一半用来获取服务器信息,post一般用来更新信息。get请求能做的,post都能做,get请求不能做的,post也都能做。
如果你的团队都是大佬,或者有着良好的团队规范,所有人都在平均水平线之上,并且有良好的纠错机制,那基本不会制定这样的规则。
但如果团队成员水平参差不齐,尤其是小团队,创业团队,常常上来就开干,没什么规范,纯靠开发者个人素质决定代码质量,这样的团队就不得不制定这样的规范。
毕竟可以减少非常多的问题,Post不用担心URL长度限制,也不会误用缓存。通过一个规则减少了出错的可能,这个决策性价比极高。
造成的结果:公司有新人进来,什么lj公司,还有这种要求,回去就在群里讲段子。
实际上都是有原因的。
有些外包公司或者提供第三方接口的公司也会选择只用Post,就是图个方便。
最佳实践
可能各位大佬都懂了哈,我还是给大家科普下,GET、POST、PUT、DELETE,他们的区别和用法。
GET
GET 方法用于从服务器检索数据。这是一种只读方法,因此它没有改变或损坏数据的风险,使用 GET 的请求应该只被用于获取数据。
GET API 是幂等的。 每次发出多个相同的请求都必须产生相同的结果,直到另一个 API(POST 或 PUT)更改了服务器上资源的状态。
POST
POST 方法用于将实体提交到指定的资源,通常导致在服务器上的状态变化或创建新资源。POST既不安全也不幂等,调用两个相同的 POST 请求将导致两个不同的资源包含相同的信息(资源 ID 除外)。
PUT
主要使用 PUT API更新现有资源(如果资源不存在,则 API 可能决定是否创建新资源)。
DELETE
DELETE 方法删除指定的资源。DELETE 操作是幂等的。如果您删除一个资源,它会从资源集合中删除。
| GET | POST | PUT | DELETE | |
|---|---|---|---|---|
| 请求是否有主体 | 否 | 是 | 是 | 可以有 |
| 成功的响应是否有主体 | 是 | 是 | 否 | 可以有 |
| 安全 | 是 | 否 | 否 | 否 |
| 幂等 | 是 | 否 | 是 | 是 |
| 可缓存 | 是 | 否 | 否 | 否 |
| HTML表单是否支持 | 是 | 是 | 否 | 否 |
来源:https://juejin.cn/post/7129685508589879327
异步阻塞IO是什么鬼?
这篇文章我们来聊一个很简单,但是很多人往往分不清的一个问题,同步异步、阻塞非阻塞到底怎么区分?
开篇先问大家一个问题:IO多路复用是同步IO还是异步IO?
先思考一下,再继续往下读。
巨著《Unix网络编程》将IO模型划分为5种,分别是
- 阻塞IO
- 非阻塞IO
- IO复用
- 信号驱动IO
- 异步IO
个人认为这么分类并不是很好,因为从字面上理解阻塞IO和非阻塞IO就已经是数学意义上的全集了,怎么又冒出了后边3种模型,会给初学者带来一些困扰。
接下来进入正文。
文章首发于公众号:「蝉沐风的码场」
1. 一个简单的IO流程
让我们先摒弃我们原本熟知的各种IO模型流程图,先看一个非常简单的IO流程,不涉及任何阻塞非阻塞、同步异步概念的图。
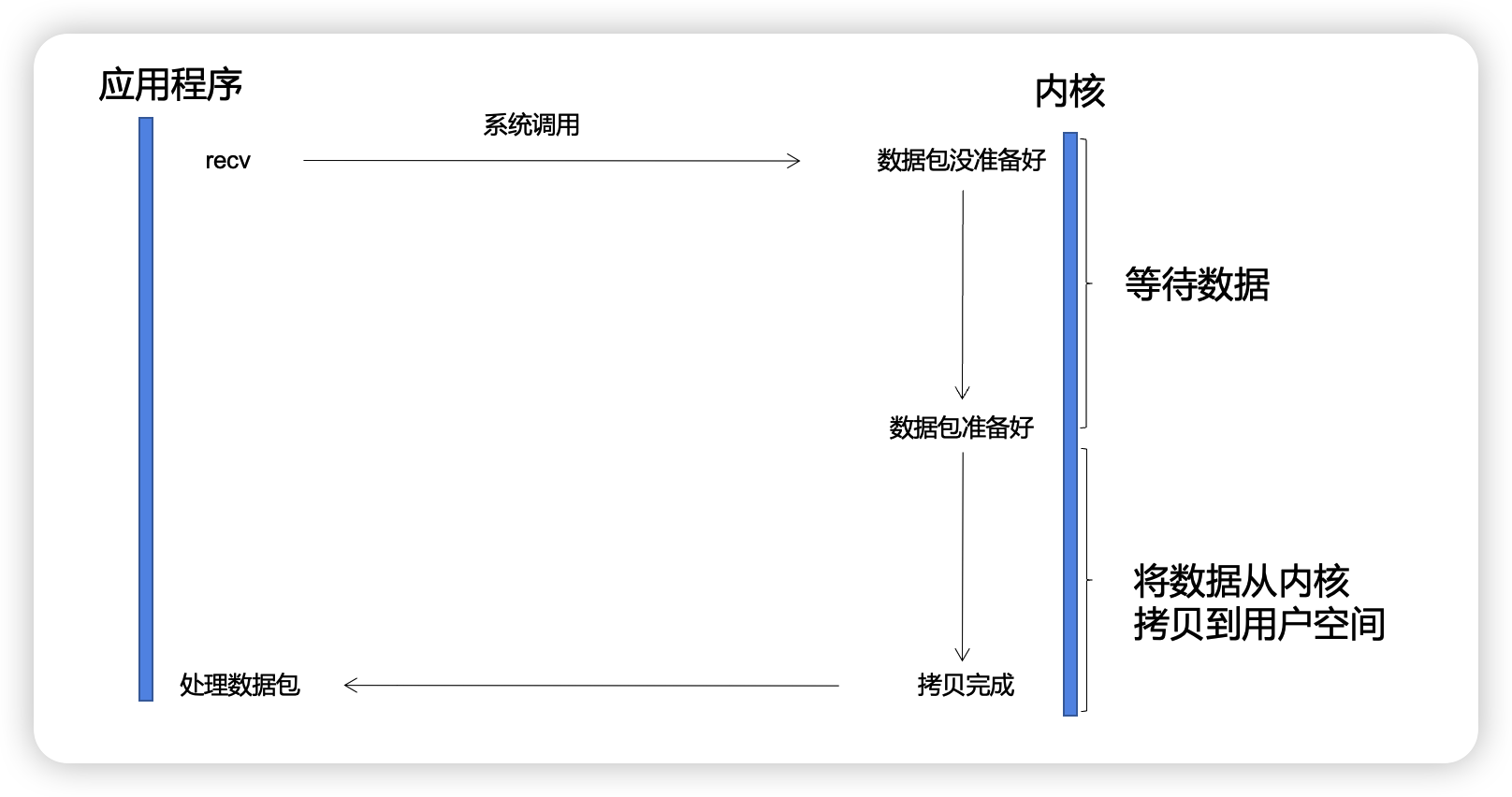
客户端发起系统调用之后,内核的操作可以被分成两步:
等待数据
此阶段网络数据进入网卡,然后网卡将数据放到指定的内存位置,此过程CPU无感知。然后经过网卡发起硬中断,再经过软中断,内核线程将数据发送到socket的内核缓冲区中。
数据拷贝
数据从socket的内核缓冲区拷贝到用户空间。
2. 阻塞与非阻塞
阻塞与非阻塞在API上区别在于socket是否设置了SOCK_NONBLOCK这个参数,默认情况下是阻塞的,设置了该参数则为非阻塞。

2.1 阻塞
假设socket为阻塞模式,则IO调用如下图所示。
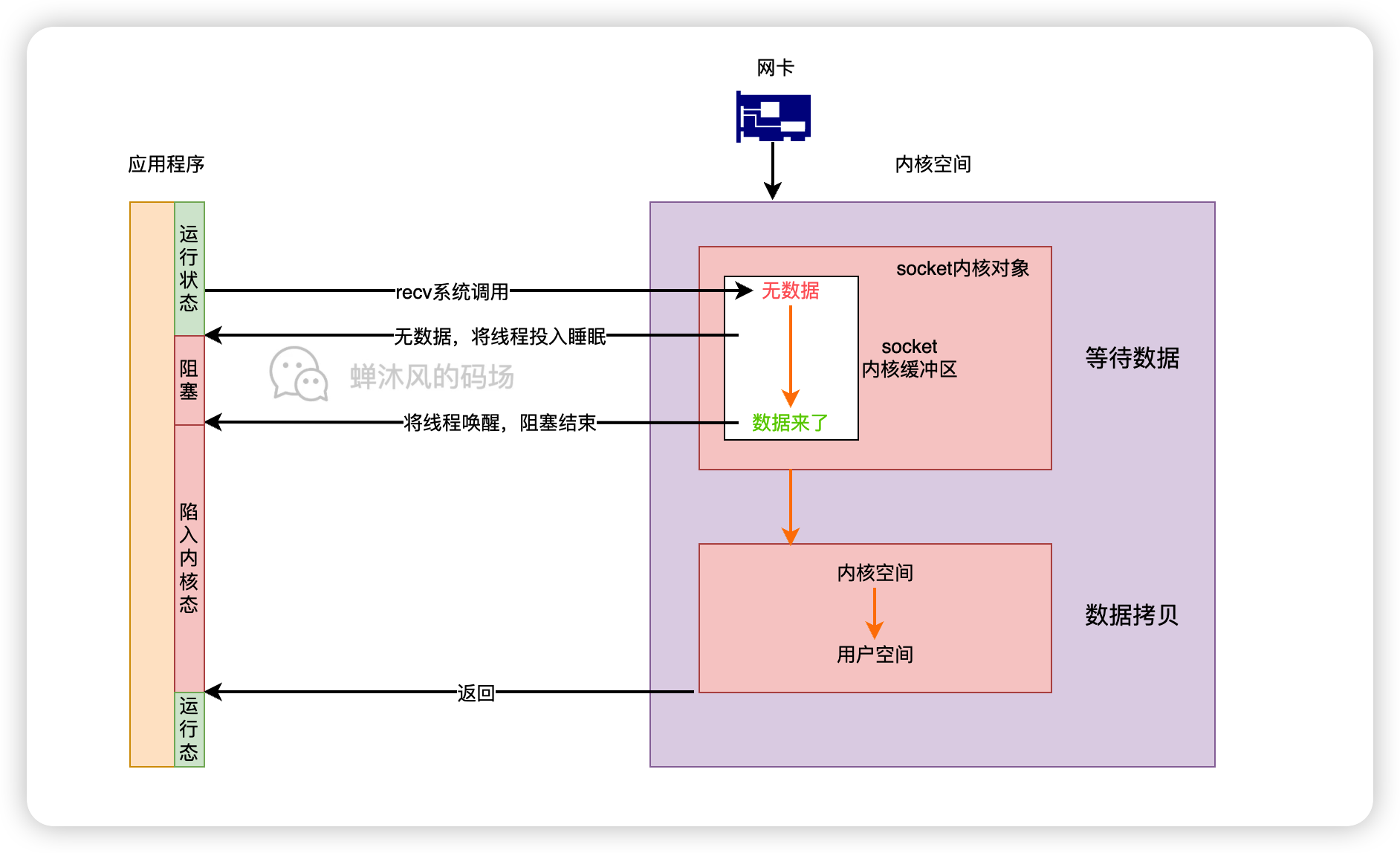
当处于运行状态的用户线程发起recv系统调用时,如果socket内核缓冲区内没有数据,则内核会将当前线程投入睡眠,让出CPU的占用。
直到网络数据到达网卡,网卡DMA数据到内存,再经过硬中断、软中断,由内核线程唤醒用户线程。
此时socket的数据已经准备就绪,用户线程由用户态进入到内核态,执行数据拷贝,将数据从内核空间拷贝到用户空间,系统调用结束。此阶段,开发者通常认为用户线程处于等待(称为阻塞也行)状态,因为在用户态的角度上,线程确实啥也没干(虽然在内核态干得累死累活)。
2.2 非阻塞
如果将socket设置为非阻塞模式,调用便换了一副光景。
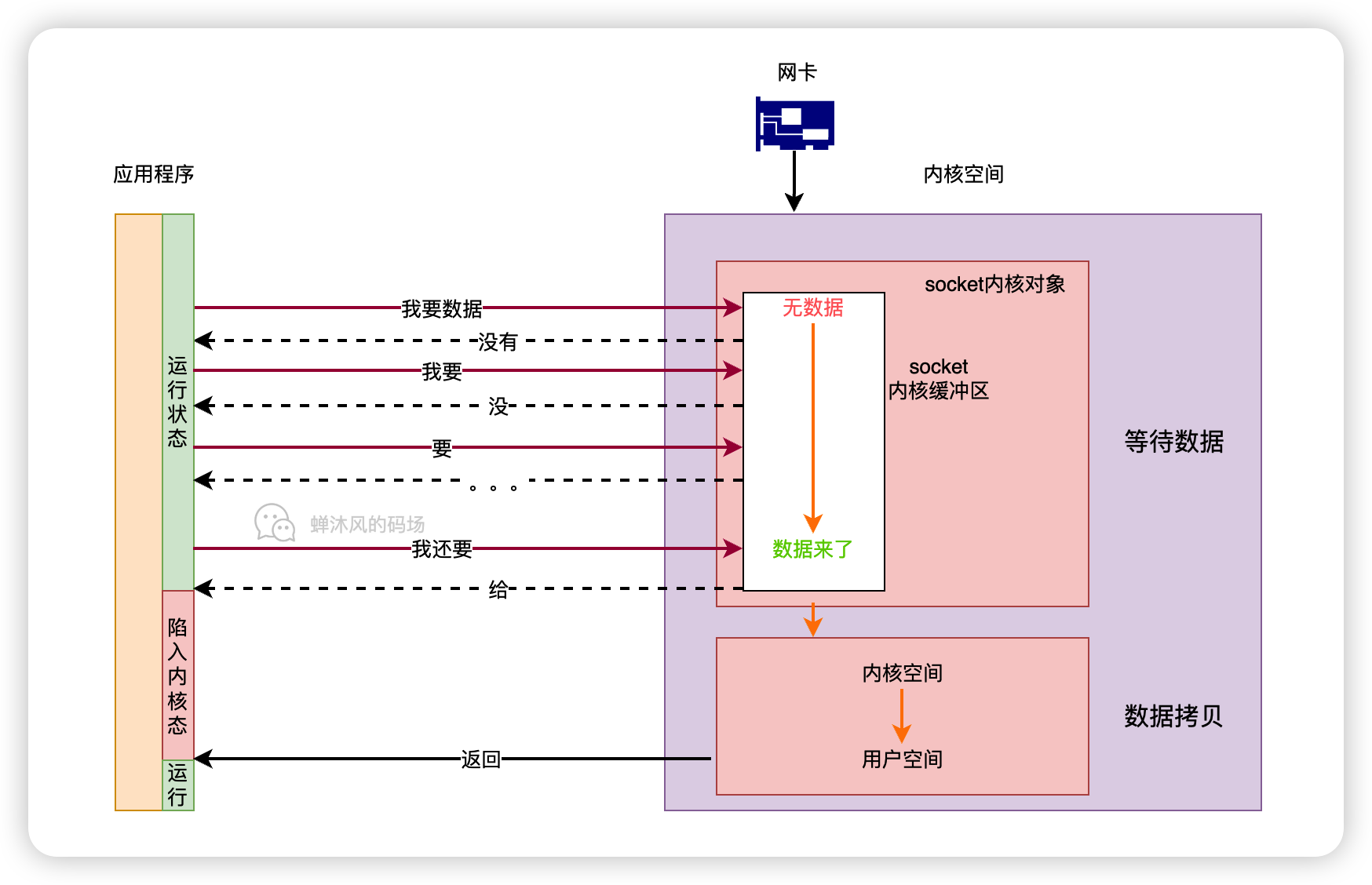
用户线程发起系统调用,如果socket内核缓冲区中没有数据,则系统调用立即返回,不会挂起线程。而线程会继续轮询,直到socket内核缓冲区内有数据为止。
如果socket内核缓冲区内有数据,则用户线程进入内核态,将数据从内核空间拷贝到用户空间,这一步和2.1小节没有区别。
3. 同步与异步
同步和异步主要看请求发起方对消息结果的获取方式,是主动获取还是被动通知。区别主要体现在数据拷贝阶段。
3.1 同步
同步我们其实已经见识过了,2.1节和2.2节中的数据拷贝阶段其实都是同步!
注:把同步的流程画在阻塞和非阻塞的第二阶段,并不是说阻塞和非阻塞的第二阶段只能搭配同步手段!
同步指的是数据到达socket内核缓冲区之后,由用户线程参与到数据拷贝过程中,直到数据从内核空间拷贝到用户空间。
因此,IO多路复用,对于应用程序而言,仍然只能算是一种同步,因为应用程序仍然花费时间等待IO结果,等待期间CPU要么用于遍历文件描述符的状态,要么用于休眠等待事件发生。
以select为例,用户线程发起select调用,会切换到内核空间,如果没有数据准备就绪,则用户线程阻塞到有数据来为止,select调用结束。结束之后用户线程获取到的只是「内核中有N个socket已经就绪」的这么一个信息,还需要用户线程对着1024长度的描述符数组进行遍历,才能获取到socket中的数据,这就是同步。
举个生活中的例子,我们给物流客服打电话询问我们的包裹是否已到达,如果未到达,我们就先睡一会儿,等到了之后客服给我们打电话把我们喊起来,然后我们屁颠屁颠地去快递驿站拿快递。这就是同步阻塞。
如果我们不想睡,就一直打电话问,直到包裹到了为止,然后再屁颠屁颠地去快递驿站拿快递。这就是同步非阻塞。
问题就是,能不能直接让物流的人把快递直接送到我家,别让我自己去拿啊!这就是异步。
3.2 理想的异步
我们理想中的完美异步应该是用户进程发起非阻塞调用,内核直接返回结果之后,用户线程可以立即处理下一个任务,只需要IO完成之后通过信号或回调函数的方式将数据传递给用户线程。如下图所示。
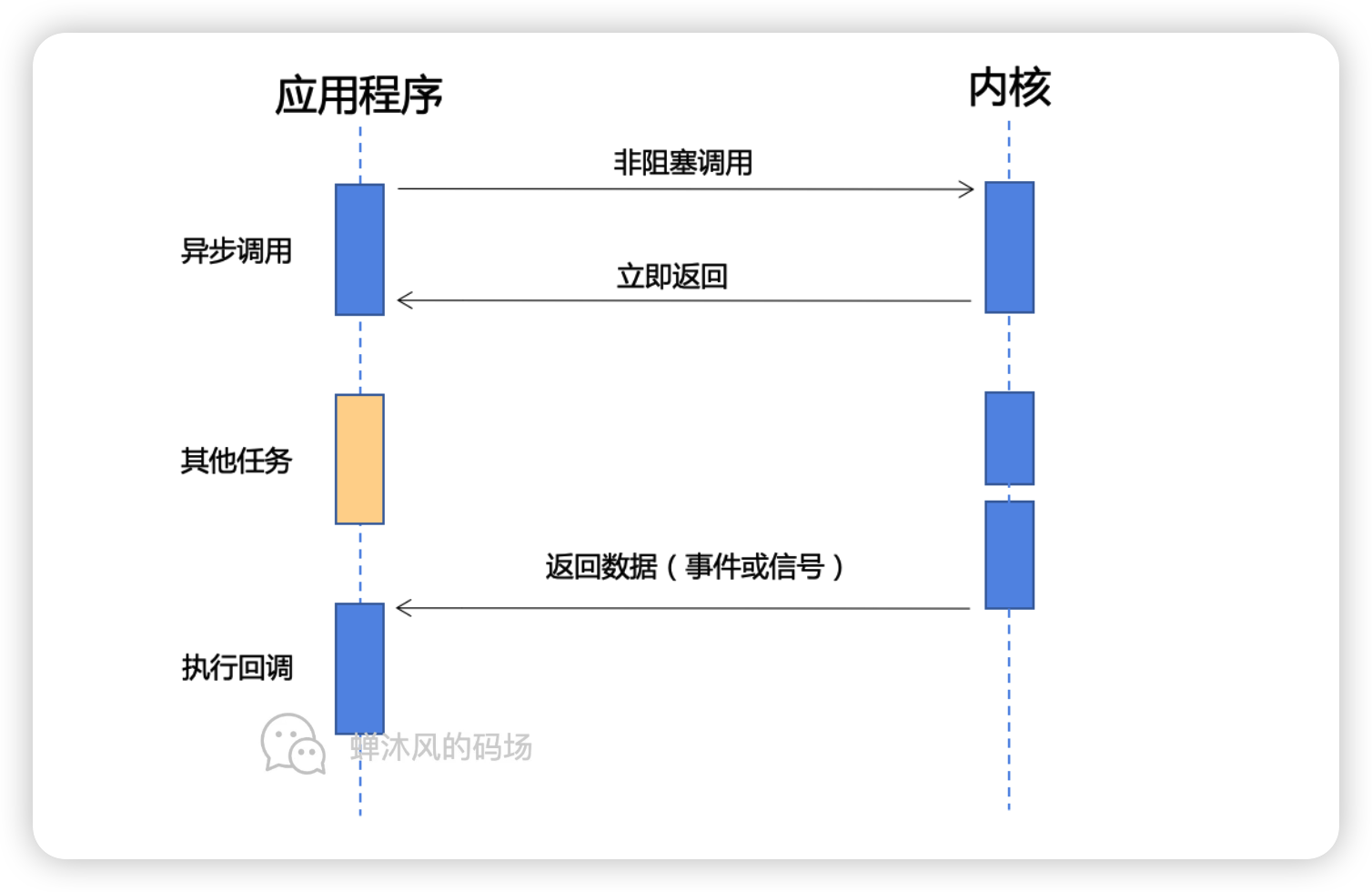
因此,在理想的异步环境下,数据准备阶段和数据拷贝阶段都是由内核完成的,不会对用户线程进行阻塞,这种内核级别的改进自然需要操作系统底层的功能支持。
3.3 现实的异步
现实比理想要骨感一些。
Linux内核并没有太惹眼的异步IO机制,这难不倒各路大神,比如Node的作者采用多线程模拟了这种异步效果。
比如让某个主线程执行主要的非IO逻辑操作,另外再起多个专门用于IO操作的线程,让IO线程进行阻塞IO或者非阻塞IO加轮询的方式来完成数据获取,通过IO线程和主线程之间通信进行数据传递,以此来实现异步。
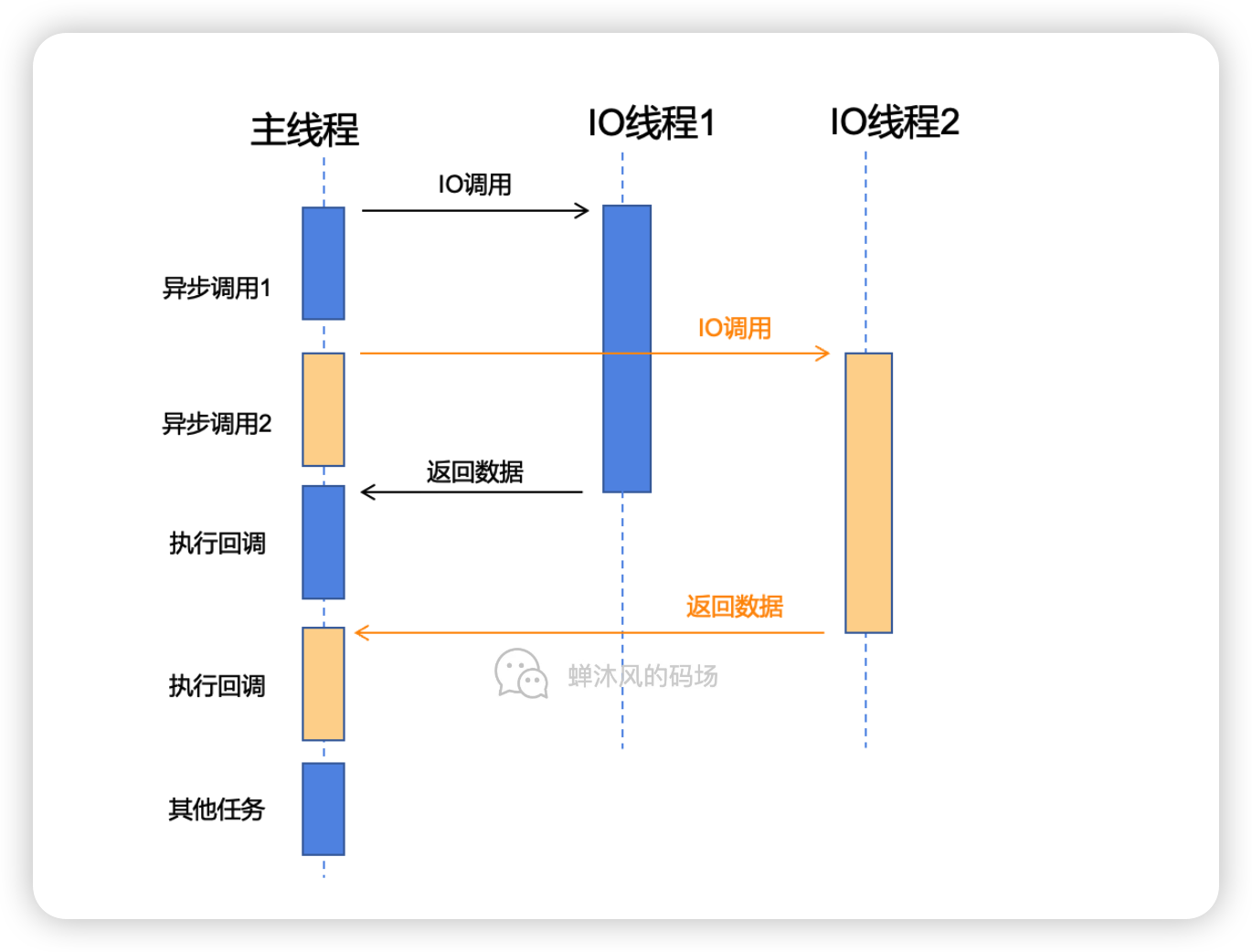
还有一种方案是Windows上的IOCP,它在某种程度上提供了理想的异步,其内部依然采用的是多线程的原理,不过是内核级别的多线程。
遗憾的是,用Windows做服务器的项目并不是特别多,期待Linux在异步的领域上取得更大的进步吧。
4. 异步阻塞?
说完了同步异步、阻塞非阻塞,一个很自然的操作就是对他们进行排列组合。
- 同步阻塞
- 同步非阻塞
- 异步非阻塞
- 异步阻塞
但是异步阻塞是什么鬼?按照上文的解释,该IO模型在第一阶段应该是用户线程阻塞,等待数据;第二阶段应该是内核线程(或专门的IO线程)处理IO操作,然后把数据通过事件或者回调的方式通知用户线程,既然如此,那么第一步的阻塞完全没有必要啊!非阻塞调用,然后继续处理其他任务岂不是更好。
因此,压根不存在异步阻塞这种模型哦~
5. 千万分清主语是谁
最后给各位提个醒,和别人讨论阻塞非阻塞的时候千万要带上主语。
如果我问你,epoll是阻塞还是非阻塞?你怎么回答?
应该说,epoll_wait这个函数本身是阻塞的,但是epoll会将socket设置为非阻塞。因此单纯把epoll认为阻塞是太委屈它,认为其是非阻塞又抬举它。
具体关于epoll的说明可以参见IO多路复用中的epoll部分。
链接:https://juejin.cn/post/7199809805362495546
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不惑之年谈中年危机
今年正式进入不惑之年。按 2011 年统计数据,国内 40 岁以上的程序员约是 1.5%,乐观来看,我进入了前 5% 的群体。
美国 2016 年此比例已经有 12.6%,大家还是应该乐观点。
大家都知道的国内第一代程序员,求伯君/雷军已经退休或做 CEO 了,而目前还在活跃的骨灰级程序员有陈皓(左耳朵耗子)。估计之后应该也会有越来越多的老程序员,或者说是目前活跃的程序员变成老程序员,出现在大家的视野。
程序员这个职业发展起来也就 20 年,还是一个很年轻的职业,年龄焦虑这个事情着实没有必要。
换位思考一下,如果我是公司的技术招聘者,15年内工作经验的都是大有前途的,只要你技术过得去,价格合理,我都愿意招你。
相反,15年以上的程序员就没那么受欢迎了。
因为初入职场就是互联网的蓬勃发展期,人才短缺是一直存在的,知识积累不够不要紧,个人品行不妥也不要紧,只要你敢于承担一些压力,那你的职业道路都会比较顺畅。如果再幸运一些,就能进入大厂。
但是,这也造成了一些不良的现象,在这行业,投机份子其实挺多的。什么热门就跟风炒一炒,能不能做成不要紧,最主要是自己的 KPI 好看。另外,互联网企业的优待,让他们多少有些娇气。从大厂出来,薪资待遇要翻倍,要股票要期权,要好资源要好项目。
所以,一般的公司未必能容纳这些人。他们也未必愿意去这些公司。于是,35岁危机就来了。
年轻人其实是很难感受到中年危机的,中年危机与年轻失业的区别就像新冠与感冒的区别。你以为你经历了中年危机,实际上只是年轻失业。
今年经济不景气,裁员潮估计让一部分人离开了这个行业。年纪大的想要回炉再造,是很难的。但是,如果你还年轻,平时多积累,我相信能很轻松地找到一份工作的。
如何面对危机?
年轻人都会说苟住,换个正能量的说法是活在当下。
读好书、做好事,是能切切实实忘掉焦虑的。
今年读的《反脆弱》、《心流》和《毫无意义的工作》,将这三本书放在一起,还是很有意思的,能看到不同的观点:
《反脆弱》让我对工作也有了新认识。看似很稳定的工作,会有可能让你过度依赖,如果遭遇失业就手足无措了。而类似的士司机,饿一餐饱一顿的,反而平时就很有充足的经验应对收入不稳定的情况。
今年的形势让人更趋于进入大公司、国企、公务员单位,然后这些稳定的工作就真的这么值得大家去追随吗?越是追求稳定,最后是否会适得其反?
《毫无意义的工作》今年敲醒了不少人,他提醒我们,日常琐碎的工作中消磨了我们的生命。然而这本书更多是情绪的宣泄,并没有什么好的解决方法。
而《心流》则希望我们投入去做事情,只有投入了才会获得心流,才会有幸福感。同时,它让我意识到,无法逃避的事实是,工作占了我们生命的 1/4 时间。如果无法从中获得乐趣,那我们的人生注定是悲剧的。
这几本书都让我重新思考我与工作的关系,即使今年外部恶劣的情况,我们也应该重拾自身的信心,重新找回我们的热情、专注。
在面对人员缩减,项目被砍的情况下,我们也许可以把目光放在现有的项目上。
就前端而言,SSR 做不了,Docker 做不了,那就看看 nginx 缓存优化能不能做;低代码做不了,那就看看页面模板能不能做;开源做不了,就看看公共组件能不能做;什么都做不了,那首屏优化,静态资源优化,图片压缩也是能做的,而且还能做得很深。
只要你想,总有做不完的事情。并且这些事情,其实是我们要还的技术债务。
而此时也是做好技术积累的时机。
面向对象、设计模式、函数式编程、类型编程、异步编程这些基础都可以恶补一下;网络安全、网络通信、内存、CPU等等向外延伸的各类计算机知识也是我们必须掌握的。
工作上认真对待自己的每一行代码,生活中认真对待自己的每一分钱。
深挖知识,深入研究,懂得越多,焦虑自然就越少。
有足够的知识与经验,你的中年危机也许永远不会来
最后,对于年龄的焦虑,再推荐大家看看方励老师在“一席”的演讲《即使是像我这把年龄的人,好奇心也从来没变过,因为我们还活在人间的》
链接:https://juejin.cn/post/7187069862965936188
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
体验一下可以帮你写代码、写邮件、编故事的神器ChatGPT
注册账号视频教程
最近OpenAI 发布了备受期待的原型通用 ChatGPT,这是一种基于对话的 AI 聊天界面,算是GPT-3(Generative Pre-trained Transformer 3)的继承者,今天记录一下体验的过程,以前我对AI的理解总感觉离我很远,现在我好像看到了未来
ChatGPT 几乎可以做任何事情,从写邮件,到写算法,到做面试题,写个歌,帮你编周报,甚至还能帮你写自动化测试,感觉可以取代stackoverflow了
欢迎加我,畅聊前端
1. 工作助手
首先感觉有用的就是帮忙写工作中的邮件 or github的issue,文笔比我自己写的好多了
给我写一个英语商务邮件,语法优雅,友好一些,邮件内容是:下周一早晨我请大壮吃鸡蛋煎饼,顺便邀请开个早会
代码助手
how to write a login form using React ,Typescript and useReducer?
下面是他生成的代码
import React, { useReducer } from 'react'
type State = {
username: string
password: string
error: string
}
type Action =
| { type: 'SET_USERNAME'; username: string }
| { type: 'SET_PASSWORD'; password: string }
| { type: 'SET_ERROR'; error: string }
function reducer(state: State, action: Action): State {
switch (action.type) {
case 'SET_USERNAME':
return { ...state, username: action.username }
case 'SET_PASSWORD':
return { ...state, password: action.password }
case 'SET_ERROR':
return { ...state, error: action.error }
default:
return state
}
}
function LoginForm() {
const [state, dispatch] = useReducer(reducer, {
username: '',
password: '',
error: '',
})
function handleUsernameChange(event: React.ChangeEvent) {
dispatch({ type: 'SET_USERNAME', username: event.target.value })
}
function handlePasswordChange(event: React.ChangeEvent) {
dispatch({ type: 'SET_PASSWORD', password: event.target.value })
}
function handleSubmit(
一个解析页面script标签内容的正则表达式
比我写的好
leetcode第一题twosum用javascript怎么做
甚至还有复杂度的优化过程
write a eslint plugin to forbidden code writing at weekends
还有vscode插件,chrome插件
面试
出五个高级前端工程师的面试题
来两道算法题
算法还给了答案,真不错
Vue代码转成React
把这段Vue3代码转换成react
- {{todo}}
转换结果, 可以直接运行的
import React, { useState } from 'react'
function TodoList() {
const [msg, setMsg] = useState('Hello World!')
const [todos, setTodos] = useState(['吃饭'])
function add() {
setTodos([...todos, msg])
setMsg('')
}
return (
setMsg(event.target.value)} />
{todos.map(todo => (
- {todo}
))}
)
}然后我把生成的react代码转成angular,在转成vue3,依然是很好的代码质量
- {{todo}}
自动写单测
甚至可以帮你写测试, 比如给上一段vue代码写点单元测试,给跪了
Code review
设置还可以代码review, 提示我清单输入框要做非空判断
写代码
用vue 的写一个组件,可以校验用户输入的邮箱是不是合法,不合法弹出信息提示
闲的无聊
给Vuejs写一个英文歌曲,摇滚一些
感觉可以直接年会 or vueconf上唱了
Verse 1:
Vue, you're my favorite framework
You make my code more powerful
With your reactive APIs
And your declarative syntax
Chorus:
Vue, oh Vue
You're the one I want to use
Vue, oh Vue
You make my life so easy
Verse 2:
With your components and data-binding
And your virtual DOM rendering
I can create a web app
That's both fast and flexible
Chorus:
Vue, oh Vue
You're the one I want to use
Vue, oh Vue
You make my life so easy
Bridge:
When I need to build a frontend
I know just what to do
I turn to you, Vue
You make it all so simple
Chorus:
Vue, oh Vue
You're the one I want to use
Vue, oh Vue
You make my life so easy
Outro:
Vue, oh Vue
You're the one I want to use
Vue, oh Vue
You make my life so easy
给Reactjs写一个英文歌曲,摇滚一些
一个练习时长两年半的练习生,喜欢唱跳rap 为开头写一个故事
一个人前来买瓜
写一个帮程序员背单词的chrome插件的需求文档
我今天忘记做核酸了,老师要求每天都要做核酸,需要写一份500字的检讨书,认错态度要诚恳 帮忙写一下
今天忘了写日记了,今天主要就是出去遛狗,玩了一下午游戏,帮我写一个500字的日记吧
我们团队想招聘一个高级前端工程师,希望能活泼一些,帮我写个招聘介绍吧
不错,再写一个邀请候选人来面试的邮件吧
候选人不太合适,写一个拒绝他的邮件,委婉一些
这个开放之后,稍微二开一下,每个人都可以拥有自己的贾维斯人工智能助理了,期待
不过老有人说这玩意会取代程序员,取代产品经理,这个我感觉还不至于,可能会淘汰一些入门的岗位,AI本身也需要输入,需要高质量的从业人员贡献产出,所以无论哪个行业,不想被AI取代,还是得提高自己的知识水平啊
链接:https://juejin.cn/post/7173541437227827208
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
咱不吃亏,也不能过度自卫
这次我谈谈不吃亏的一种人,他们不吃亏近乎强硬。这类人一点亏都不吃,以至于过度自我保护。
我们公司人事小刘负责考勤统计。发完考勤表之后,有个员工找到他,说出勤少统计了一天。
小刘一听,感觉自己有被指控的风险。
他立刻严厉起来:“每天都来公司,不一定就算全勤。没打卡我是不统计的”。
最后小刘一查,发现是自己统计错了。
小刘反而更加强势了:“这种事情,你应该早点跟我反馈,而且多催着我确认。你自己的事情都不上心,扣个钱啥的只能自己兜着”
这就是明显的不愿意吃亏,即使自己错了,也不愿意让自己置于弱势。
你的反应,决定别人怎么对你。这种连言语的亏都不吃的人,并不会让别人敬畏,反而会让人厌恶,进而影响沟通。
我还有一个同事老王。他是一个职场老人,性格嘻嘻哈哈,业务能力也很强。
以前同事小赵和老王合作的时候,小赵宁愿经两层人传话给老王,也不愿意和他直接沟通。
我当时感觉小赵不善于沟通。
后来,当我和老王合作的时候,才体会到小赵的痛苦。
因为,老王是一个什么亏都不吃的人,谁来找他理论,他就怼谁。
你告诉他有疏漏,他会极力掩盖问题,并且怒怼你愚昧无知。
就算你告诉他,说他家着火了。他首先说没有。你一指那不是烧着的吗?他回复,你懂个屁,你知道我几套房吗?我说的是我另一个家没着火。
有不少人,从不吃亏,无论什么情况,都不会让自己处于弱势。
这类人喜欢大呼小叫,你不小心踩他脚了,他会大喊:践踏我的尊严,和你拼了!
心理学讲,愤怒源于恐惧,因为他想逃避当前不利的局面。
人总会遇到各种不公的待遇,或误会,或委屈。
遇到争议时,最好需要确认一下,排除自己的问题。
如果自己没错,那么比较好的做法就是:“我认为你说得不合理,首先……其次……最后……”。
不盲目服软,也不得理不饶人,全程平心静气,有理有据。这种人绝对人格魅力爆棚,让人敬佩。
最后,有时候过度强硬也是一种策略,可以很好地过滤和震慑一些不重要的事物。
链接:https://juejin.cn/post/7196678344573173816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
裸辞回家遇见了她
22年,连续跳了二三家公司,辗转七八个城市。
可能还是太年轻,工作上特别急躁,加班太多会觉得太累,没事情做又觉得无聊烦躁。去年年末回老家过年因为一些巧合遇见了她。年初就润,回到了老家。当时因为苏州疫情就没回去,便开始在老家这边的坎坷之旅。
年初千里见网友
说起来也是缘分,去年年末的时候,有个人加了我微信,当时也是一头雾水,还以为是传销或者什么。一看名字微信名:“xxx”,也不像是啊,当时没放在心上就随便聊了聊,也没咋放心上。后来我朋友告诉我她推的(因为觉得我挺清秀人品也还行),就把她推给了我。但是我这人自卑又社恐,加上她在我老家那边,就想反正自己好多年也不想回老家那个地方,现在即使网恋也是耽误人家,后面就没咋搭理她。
到过年的时候,我和我妈匆匆忙忙回到了老家,当时家里宅基地刚好重建装修完,背了一屁股的债务,当时很多人劝我不要建房子在老家,有钱直接在省会那边付个首付也比老家强,可我一直觉得这个房子是我奶奶心心念念了一辈子的事情。转念一想一辈人有一辈人的使命,最多就是自己再多奋斗几年就没多去计较。
后面过年期间,我和她某明奇妙的聊起来了,可能是我觉得离她近了,然后就有一丝丝念想吧,当时因为一些特殊原因,过年的时她也在上班。那几天基本每天从早聊到晚,稍微有点暧昧,之后还一起玩游戏,玩了几局,我也很菜没能赢,就这样算是更深一步了解她吧,当时也不好断定她是怎样的人。就觉得她很温柔、活泼、可爱、直爽,后面想了想好像很久好久没用遇到这样的女孩子了吧,前几年也遇到不少女孩子都没有这种感觉。是不是自己单身太久产生的幻觉。经过一段时间的发酵,我向我朋友打听了下她。
我朋友说人品没问题,就是有点矮,我想着女孩子没啥影响,反正我也矮。就决定去见见她,她也没拒绝我。缘分到了如果不抓住的话也不知道下一次是什么时候。其实那时候我们还只是看过照片,彼此感觉都是那种一般人,到了这个年纪(毕业二三年)其实都不是太在乎颜值,只要不是丑得不能见人(颜值好的话肯定是加分项)。虽然我们都在老家,但她兼职那边还是有点远,去那边需要转很多车。但也没什么,我义无反顾去见了他,也许这就是大多数人奔现的样子吧(但我心里是比较排斥这个词的)。
那天早上一大早我就急冲冲起来了,洗个了头,吹了个自认为很帅的发型,戴上小围巾就出发了(那晚上其实下了很大的雪)。因为老家比较远我都比较害怕那边没有班车,因为当时才大年初三,我们那边的习俗是过年几天不跑车,跑车一年的财运都会受影响。到路上果然没让我失望,路上一辆车都没有,也是运气好,我前几天刚好听到我表姐说要去城里,我就问了问,果真就今天去(就觉得很巧合,跟剧本一样),他们把我送到高铁站,道了个谢,就跑去赶了最早一班的高铁。
怀着忐忑的心情出发了,那时差不多路上就是这个样子吧(手机里视频传不上去)。
在路上的时候她一直强调说自己这样不行,那样不可以怕我嫌弃,我当时倒是不自卑,直接对人家就是一顿安慰。到了省会那边,又辗转几个地方去买花,那时过年基本没什么花店开门。转了几个大的花店市场才发现一家花店,订了一束不大不小的花, 又去超市买了个玩偶和巧克力,放了几颗德芙在衣服包里面(小心机)。前前后后忙完这些已经下午一点了,对比下行程,可能有点赶不上车了。匆忙坐了班车到了她上班那个市区 ,本以为一切都会很顺利,结果到了那边转车的班车停运了,当时其实是迷茫的。不知道要不要住宿等到第二天。
那时我想起本来就是一腔热情才跑过来的,也许过了那个劲就不会有那个动力去面对了,心里默想:“所爱隔山海,山海皆可平”。心疼的打了个车花了差不多五百块(大冤种过年被宰)。就这样踏上最后一段路程。路上见到不一样的山峰,矮而尖而且很密集,那个司机说天眼好像就是建筑在这边吧,路上我就一直想:即使人家见了我嫌弃我这段旅行也算很划算的吧。最终晚上七点到达了目的地,下车了还是有点紧张,我害怕她不喜欢我这样的,毕竟了解不多,也许就是你一厢情愿的认为这就是缘分和命运的安排。
终将相遇
最后一刻,我都还在想,她会不会看到我就跑了,然后不来见我。但应该不至于此,毕竟我相信我的老朋友(七年死党),也相信她的人品。我看见一个人从前面走来我还以为是她,都准备迎上去了,走近一看咋是个阿姨(吓我一跳还以为被骗了),等我反应过来那个阿姨已经走远了。然后一个声音从我对面传来:“我在这,我在这边”,我转头过去惊艳到我了,这这这是本人吗?深邃的眼眸,樱桃小嘴,不是很尖的脸蛋,短发到肩,微风吹起刘海飘啊飘,像飘进了我的心里,头后发带将一些头发束起,然后发带结成蝴蝶结,一身长白棉袄配白皮鞋,显得俏皮又惊艳。我还来不及细想,我就迎了过去,提前想好的台词都没有说出来,倒是显得有一些尴尬。
当时自卑感油然而生,自己觉得配不上她。寒暄了几句我将花递给她,没有惊喜的表情,只有一句:我都没给你准备什么礼物,你这样我会很不好意思的,她这样说我该是开心还是难过呢?我心里觉得大概要凉了。就怕一句:你是个好人,我们就这样吧。其实当时我们也没说啥喜欢啥的就是有点暧昧。所幸没有发生她嫌弃我的事情,我们延着路边一路闲聊下去,一开始我还有点拘谨,毕竟常年当程序员社交能力不是很行。
慢慢的,我们说了很多很多,她请我吃了个饭(之前说过请她没倔过她),一路走着走着,说着大学的事,小时候的事,工作的事,一时间显得我们不是陌生人,而是多年未见的好友,一下子就觉得很轻松很幸福,反正我已经深深的迷上她的人美心善。她也说了离家老远跑来这边上班的原因(不方便透露)。走着走着我发现她的手有点红,就说道:我还给你准备了个惊喜,把手伸进我衣服包里吧,我在里面放了几颗糖,上班那么辛苦有点糖就不苦了。后面我有点唐突抓住她的手,我说给她暖一下太冰了。她说放我包里就暖和了,我看她脸都红了,也觉得有点唐突了。后面发现还是太冰了,没多想就用牵住了她,嘿嘿!她直接害羞的低下了头。一下子幸福感就涌上来了。
后面很晚的时候要分别了,送他回了宿舍,并把包里的玩偶以及剩下的零食一并给了她。她说第二天来送我,我便回了酒店。
第二天我们俩随便吃了点东西(依旧很害羞没敢坐我对面),她就送我上车了,临走时她塞了一个东西在我手里,打开一看昨天的发带,抬头她已走远她小声说了一句:我们有缘再见。也许是想着我在苏州她在遵义太远了吧,可能就是最后一面了,有点伤心也没多问。
感情生活波折
回去的第二天我便回到苏州那边,但是很久之前就谋划着辞职,一方面是觉得在这边技术得不到提升,一方面是觉得想换个环境吧,毕竟这边太闲了让我找不到价值。可能年轻急躁当时没多想就直接裸辞了,期间我对她说:我辞职后来看她,她有点不愿意(说感觉我们的感情有点空中楼阁),可能觉得见一面不足以确定什么吧,我可能觉得给不了他幸福也舍不得割舍吧。
后面裸辞后,蹭着苏州没有因为疫情封禁,直接带了二件衣服就回了老家。(具体细节不说了)
第二次见她,可能觉得有点陌生吧,不过慢慢的就过了那个尴尬期,我们一起去逛公园、去逛街、彼此送小礼物、一起吃饭,即使现在回来依旧觉得很美好。但是我依旧没有表白,可能我觉得这些事顺理成章的不需要。一次巧合我去了她家帮她做家务、洗头、做饭。哈哈哈,像一个家庭主男一样。可能就是那次她才真的喜欢上我的吧。
有一次见面之后因为一些很严重的事我们吵架了,本来以为就要在此结束了。后来我又去见她了,我觉得女孩子有什么顾虑很正常的,也许是不够喜欢啥的,准备最后见一面吧,但见面之后准备好的说辞一句没说,还是像原来那样相处,一下子心里就有点矛盾,后面敞开心扉说开了,心里纠结的问题也就解决了。慢慢的我们也彼此接受了,从一见钟情到建立关系,真的经历很多东西。不管是少了那一段经历我和她都不会有以后。我的果决她的温柔都是缺一不可的。
后续
她考研上岸,我离开苏州在贵阳上班。我们依旧还有很长一段路要走。后续把工作篇发出来(干web前端的)
链接:https://juejin.cn/post/7137973046563831838
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
鹅厂组长,北漂 10 年,有房有车,做了一个违背祖宗的决定
前几天是 10 月 24 日,有关注股票的同学,相信大家都过了一个非常难忘的程序员节吧。在此,先祝各位朋友们身体健康,股票基金少亏点,最重要的是不被毕业。
抱歉,当了回标题党,不过在做这个决定之前确实纠结了很久,权衡了各种利弊,就我个人而言,不比「3Q 大战」时腾讯做的「艰难的决定」来的轻松。如今距离这个决定过去了快 3 个月,我也还在适应着这个决定带来的变化。
按照工作汇报的习惯,先说结论:
在北漂整整 10 年后,我回老家合肥上班了
做出这个决定的唯一原因:
没有北京户口,积分落户陪跑了三年,目测 45 岁之前落不上
户口搞不定,意味着孩子将来在北京只能考高职,这断然是不能接受的;所以一开始是打算在北京读几年小学后再回老家,我也能多赚点钱,两全其美。
因为我是一个人在北京,如果在北京上小学,就得让我老婆或者让我父母过来。可是我老婆的职业在北京很难就业,我父母年龄大了,北京人生地不熟的,而且那 P 点大的房子,住的也憋屈。而将来一定是要回去读书的,这相当于他们陪着我在北京折腾了。
或者我继续在北京打工赚钱,老婆孩子仍然在老家?之前的 6 年基本都是我老婆在教育和陪伴孩子,我除了逢年过节,每个月回去一到两趟。孩子天生过敏体质,经常要往医院跑,生病时我也帮不上忙,所以时常被抱怨”丧偶式育儿“,我也只能跟渣男一样说些”多喝热水“之类的废话。今年由于那啥,有整整 4 个多月没回家了,孩子都差点”笑问客从何处来“了。。。
5月中旬,积分落户截止,看到贴吧上网友晒出的分数和排名,预计今年的分数线是 105.4,而实际分数线是 105.42,比去年的 100.88 多了 4.54 分。而一般人的年自然增长分数是 4 分,这意味着如果没有特殊加分,永远赶不上分数线的增长。我今年的分数是 90.8,排名 60000 左右,每年 6000 个名额,即使没有人弯道超车,落户也得 10 年后了,孩子都上高一了,不能在初二之前搞到户口,就表示和大学说拜拜了。
经过我的一番仔细的测算,甚至用了杠杆原理和人品守恒定理等复杂公式,最终得到了如下结论:
我这辈子与北京户口无缘了
所以,思前想后,在没有户口的前提下,无论是老婆孩子来北京,还是继续之前的异地,都不是好的解决方案。既然将来孩子一定是在合肥高考,为了减少不必要的折腾,那就只剩唯一的选择了,我回合肥上班,兼顾下家里。
看上去是个挺自然的选择,但是:
我在腾讯是组长,团队 20 余人;回去是普通工程师,工资比腾讯打骨折
不得不说,合肥真的是互联网洼地,就没几个公司招人,更别说薪资匹配和管理岗位了。因此,回合肥意味着我要放弃”高薪“和来之不易的”管理“职位,从头开始,加上合肥这互联网环境,基本是给我的职业生涯判了死刑。所以在 5 月底之前就没考虑过这个选项,甚至 3 月份时还买了个显示器和 1.6m * 0.8m 的大桌子,在北京继续大干一场,而在之前的 10 年里,我都是用笔记本干活的,从未用过外接显示器。
5 月初,脉脉开始频繁传出毕业的事,我所在的部门因为是盈利的,没有毕业的风险。但是营收压力巨大,作为底层的管理者,每天需要处理非常非常多的来自上级、下级以及甲方的繁杂事务,上半年几乎都是凌晨 1 点之后才能睡觉。所以,回去当个普通工程师,每天干完手里的活就跑路,貌似也不是那么不能接受。毕竟自己也当过几年 leader 了,leader 对自己而言也没那么神秘,况且我这还是主动激流勇退,又不是被撸下来的。好吧,也只能这样安慰自己了,中年人,要学会跟自己和解。后面有空时,我分享下作为 leader 和普通工程师所看到的不一样的东西。
在艰难地说服自己接受之后,剩下的就是走各种流程了:
1. 5月底,联系在合肥工作的同学帮忙内推;6月初,通过面试。我就找了一家,其他家估计性价比不行,也不想继续面了
2. 6月底告诉总监,7月中旬告诉团队,陆续约或被约吃散伙饭
3. 7月29日,下午办完离职手续,晚上坐卧铺离开北京
4. 8月1日,到新公司报道7 月份时,我还干了一件大事,耗时两整天,历经 1200 公里,不惧烈日与暴雨,把我的本田 125 踏板摩托车从北京骑到了合肥,没有拍视频,只能用高德的导航记录作为证据了:
这是导航中断的地方,晚上能见度不行,在山东花了 70 大洋,随便找了个宾馆住下了,第二天早上出发时拍的,发现居然是水泊梁山附近,差点落草为寇:
骑车这两天,路上发生了挺多有意思的事,以后有时间再分享。到家那天,是我的结婚 10 周年纪念日,我没有提前说我要回来,更没说骑着摩托车回来,当我告诉孩子他妈时,问她我是不是很牛逼,得到的答复是:
我觉得你是傻逼
言归正传,在离开北京前几天,我找团队里的同学都聊了聊,对我的选择,非常鲜明的形成了两个派系:
1. 未婚 || 工作 5 年以内的:不理解,为啥放弃管理岗位,未来本可以有更好的发展的,太可惜了,打骨折的降薪更不能接受
2. 已婚 || 工作 5 年以上的:理解,支持,甚至羡慕;既然迟早都要回去,那就早点回,多陪陪家人,年龄大了更不好回;降薪很正常,跟房价也同步,不能既要又要
复制代码确实,不同的人生阶段有着不同的想法,我现在是第 2 阶段,需要兼顾家庭和工作了,不能像之前那样把工作当成唯一爱好了。
在家上班的日子挺好的,现在加班不多,就是稍微有点远,单趟得 1 个小时左右。晚上和周末可以陪孩子玩玩,虽然他不喜欢跟我玩🐶。哦,对了,我还有个重要任务 - 做饭和洗碗。真的是悔不当初啊,我就不应该说会做饭的,更不应该把饭做的那么好吃,现在变成我工作以外的最重要的业务了。。。
比较难受的是,现在公司的机器配置一般,M1 的 MBP,16G 内存,512G 硬盘,2K 显示器。除了 CPU 还行,内存和硬盘,都是快 10 年前的配置了,就这还得用上 3 年,想想就头疼,省钱省在刀刃上了,属于是。作为对比,腾讯的机器配置是:
M1 Pro MBP,32G 内存 + 1T SSD + 4K 显示器
客户端开发,再额外配置一台 27寸的 iMac(i9 + 32G内存 + 1T SSD)
由奢入俭难,在习惯了高配置机器后,现在的机器总觉得速度不行,即使很多时候,它和高配机没有区别。作为开发,尤其是客户端开发,AndroidStudio/Xcode 都是内存大户,16G 实在是捉襟见肘,非常影响搬砖效率。公司不允许用自己的电脑,否则我就自己买台 64G 内存的 MBP 干活用了。不过,换个角度,编译时间变长,公司提供了带薪摸鱼的机会,也可以算是个福利🐶
另外,比较失落的就是每个月发工资的日子了,比之前少了太多了,说没感觉是不可能的,还在努力适应中。不过这都是小事,毕竟年底发年终奖时,会更加失落,hhhh😭😭😭😭
先写这么多吧,后面有时间的话,再分享一些有意思的事吧,工作上的或生活上的。
遥想去年码农节时,我还在考虑把房子从昌平换到海淀,好让孩子能有个“海淀学籍”,当时还做了点笔记:
没想到,一年后的我回合肥了,更想不到一年后的腾讯,股价竟然从 500 跌到 206 了(10月28日,200.8 了)。真的是世事难料,大家保重身体,好好活着,多陪陪家人,一起静待春暖花开💪🏻💪🏻
链接:https://juejin.cn/post/7159837250585362469
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Activity生命周期监控方案
实际开发中,我们经常需要在Activity的onResume或者onStop中进行全局资源的获取或释放,那么怎么去监控Activity生命周期变化呢?
实际开发中,我们经常需要在Activity的onResume或者onStop中进行全局资源的获取或释放,那么怎么去监控Activity生命周期变化呢?
通知式监控
一般情况下,我们可以在资源管理类中提供onActivityResume,onActivityStop之类的公共接口来实现该需求,这种情况下,需要在Activity内部的各个生命周期函数中手动调用资源管理类的对应函数,实现如下所示:
// 资源管理类
public class ResourceManager {
private static final String TAG = "ResourceManager";
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
}
public class NotifyAcLifecycleActivity extends AppCompatActivity {
private ResourceManager mResourceManager = new ResourceManager();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_notify_ac_lifecycle);
}
@Override
protected void onResume() {
super.onResume();
mResourceManager.onActivityResume();
}
@Override
protected void onStop() {
super.onStop();
mResourceManager.onActivityStop();
}
}
可以看出,通知式实现的生命周期监控具有以下显著缺陷:
- 代码侵入性强:需要在Activity中手动调用资源管理类的对应公共方法
- 耦合严重:资源管理类的公共方法和Activity生命周期函数强耦合,当资源管理类的数量发生变化时,新增或者删除,都需改动Activity代码
一般情况下,我们可以在资源管理类中提供onActivityResume,onActivityStop之类的公共接口来实现该需求,这种情况下,需要在Activity内部的各个生命周期函数中手动调用资源管理类的对应函数,实现如下所示:
// 资源管理类
public class ResourceManager {
private static final String TAG = "ResourceManager";
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
} public class NotifyAcLifecycleActivity extends AppCompatActivity {
private ResourceManager mResourceManager = new ResourceManager();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_notify_ac_lifecycle);
}
@Override
protected void onResume() {
super.onResume();
mResourceManager.onActivityResume();
}
@Override
protected void onStop() {
super.onStop();
mResourceManager.onActivityStop();
}
}可以看出,通知式实现的生命周期监控具有以下显著缺陷:
- 代码侵入性强:需要在Activity中手动调用资源管理类的对应公共方法
- 耦合严重:资源管理类的公共方法和Activity生命周期函数强耦合,当资源管理类的数量发生变化时,新增或者删除,都需改动Activity代码
监听式监控
即然通知式监控具有那么多的缺陷,那么我们怎么来解决该问题呢?从操作意图可以看出,我们期望在Activity生命周期变化的时候资源管理类能收到通知,换句话说就是资源管理类可以监听到Activity的生命周期变更,说到监听,我们自然而言的想到了设计模式中的观察者模式。
观察者模式包含了被观察者和观察者两个角色,描述的是当被观察者状态发生变化时,所有依赖于该被观察者的观察者都可以接收到通知并根据需要完成操作
由观察者模式定义来看,Activity应该是被观察者,资源管理器应该是观察者,为进一步解耦,我们引入接口,定义观察者接口如下所示:
public interface LifecycleObserver {
void onActivityResume();
void onActivityStop();
}
在被观察者(Activity)中通知观察者,修改的代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private LifecycleObserver mObserver;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
}
public void setObserver(LifecycleObserver observer) {
mObserver = observer;
}
@Override
protected void onResume() {
super.onResume();
if (mObserver != null) {
mObserver.onActivityResume();
}
}
@Override
protected void onStop() {
super.onStop();
if (mObserver != null) {
mObserver.onActivityStop();
}
}
}
使需要观察的对象实现观察者接口,并在onCreate中完成观察,代码如下:
public class ResourceManager implements LifecycleObserver{
private static final String TAG = "ResourceManager";
@Override
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
@Override
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
}
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
setObserver(new ResourceManager());
}
这样就通过LifecycleObserver完成了ResourceManager观察Activity生命周期变化的操作,如果不需要接收通知,不调用setObserver方法即可。
简单业务中,上述实现没问题,单随着业务的逐步扩大,资源管理器可能不止一个,而且并不一定需要一直监听变化,在一定情况下,可能需要移除,接下来我们进一步修改被观察者中关于观察者的管理,使其支撑多个观察者以及动态移除观察者,代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private List<LifecycleObserver> mObservers = new ArrayList<>();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
addObserver(new ResourceManager());
}
public void addObserver(LifecycleObserver observer) {
mObservers.add(observer);
}
public void removeObserver(LifecycleObserver observer) {
mObservers.remove(observer);
}
@Override
protected void onResume() {
super.onResume();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityResume();
}
}
}
@Override
protected void onStop() {
super.onStop();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityStop();
}
}
}
}
从上述实现可以看出,该方案具有以下缺点:
- 不适用于多Activity场景
- 仍然需要耦合Activity的addObserver和removeObserver方法
即然通知式监控具有那么多的缺陷,那么我们怎么来解决该问题呢?从操作意图可以看出,我们期望在Activity生命周期变化的时候资源管理类能收到通知,换句话说就是资源管理类可以监听到Activity的生命周期变更,说到监听,我们自然而言的想到了设计模式中的观察者模式。
观察者模式包含了被观察者和观察者两个角色,描述的是当被观察者状态发生变化时,所有依赖于该被观察者的观察者都可以接收到通知并根据需要完成操作
由观察者模式定义来看,Activity应该是被观察者,资源管理器应该是观察者,为进一步解耦,我们引入接口,定义观察者接口如下所示:
public interface LifecycleObserver {
void onActivityResume();
void onActivityStop();
}在被观察者(Activity)中通知观察者,修改的代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private LifecycleObserver mObserver;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
}
public void setObserver(LifecycleObserver observer) {
mObserver = observer;
}
@Override
protected void onResume() {
super.onResume();
if (mObserver != null) {
mObserver.onActivityResume();
}
}
@Override
protected void onStop() {
super.onStop();
if (mObserver != null) {
mObserver.onActivityStop();
}
}
}使需要观察的对象实现观察者接口,并在onCreate中完成观察,代码如下:
public class ResourceManager implements LifecycleObserver{
private static final String TAG = "ResourceManager";
@Override
public void onActivityResume() {
Log.d(TAG,"doing something in onActivityResume");
}
@Override
public void onActivityStop() {
Log.d(TAG,"doing something in onActivityStop");
}
} @Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
setObserver(new ResourceManager());
}这样就通过LifecycleObserver完成了ResourceManager观察Activity生命周期变化的操作,如果不需要接收通知,不调用setObserver方法即可。
简单业务中,上述实现没问题,单随着业务的逐步扩大,资源管理器可能不止一个,而且并不一定需要一直监听变化,在一定情况下,可能需要移除,接下来我们进一步修改被观察者中关于观察者的管理,使其支撑多个观察者以及动态移除观察者,代码如下:
public class ObserverLifecycleActivity extends AppCompatActivity {
private List<LifecycleObserver> mObservers = new ArrayList<>();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_observer_lifecycle);
addObserver(new ResourceManager());
}
public void addObserver(LifecycleObserver observer) {
mObservers.add(observer);
}
public void removeObserver(LifecycleObserver observer) {
mObservers.remove(observer);
}
@Override
protected void onResume() {
super.onResume();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityResume();
}
}
}
@Override
protected void onStop() {
super.onStop();
if (mObservers != null && !mObservers.isEmpty()) {
for (LifecycleObserver observer : mObservers) {
observer.onActivityStop();
}
}
}
}从上述实现可以看出,该方案具有以下缺点:
- 不适用于多Activity场景
- 仍然需要耦合Activity的addObserver和removeObserver方法
ActivityLifecycleCallbacks
上面都是开发者实现的,那么系统内部有没有已经实现的方案呢?查看源码,可以找到ActivityLifecycleCallbacks,其定义如下:
public interface ActivityLifecycleCallbacks {
/**
* Called as the first step of the Activity being created. This is always called before
* {@link Activity#onCreate}.
*/
default void onActivityPreCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called when the Activity calls {@link Activity#onCreate super.onCreate()}.
*/
void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState);
/**
* Called as the last step of the Activity being created. This is always called after
* {@link Activity#onCreate}.
*/
default void onActivityPostCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called as the first step of the Activity being started. This is always called before
* {@link Activity#onStart}.
*/
default void onActivityPreStarted(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStart super.onStart()}.
*/
void onActivityStarted(@NonNull Activity activity);
/**
* Called as the last step of the Activity being started. This is always called after
* {@link Activity#onStart}.
*/
default void onActivityPostStarted(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being resumed. This is always called before
* {@link Activity#onResume}.
*/
default void onActivityPreResumed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onResume super.onResume()}.
*/
void onActivityResumed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being resumed. This is always called after
* {@link Activity#onResume} and {@link Activity#onPostResume}.
*/
default void onActivityPostResumed(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being paused. This is always called before
* {@link Activity#onPause}.
*/
default void onActivityPrePaused(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onPause super.onPause()}.
*/
void onActivityPaused(@NonNull Activity activity);
/**
* Called as the last step of the Activity being paused. This is always called after
* {@link Activity#onPause}.
*/
default void onActivityPostPaused(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being stopped. This is always called before
* {@link Activity#onStop}.
*/
default void onActivityPreStopped(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStop super.onStop()}.
*/
void onActivityStopped(@NonNull Activity activity);
/**
* Called as the last step of the Activity being stopped. This is always called after
* {@link Activity#onStop}.
*/
default void onActivityPostStopped(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity saving its instance state. This is always
* called before {@link Activity#onSaveInstanceState}.
*/
default void onActivityPreSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called when the Activity calls
* {@link Activity#onSaveInstanceState super.onSaveInstanceState()}.
*/
void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState);
/**
* Called as the last step of the Activity saving its instance state. This is always
* called after{@link Activity#onSaveInstanceState}.
*/
default void onActivityPostSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called as the first step of the Activity being destroyed. This is always called before
* {@link Activity#onDestroy}.
*/
default void onActivityPreDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onDestroy super.onDestroy()}.
*/
void onActivityDestroyed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being destroyed. This is always called after
* {@link Activity#onDestroy}.
*/
default void onActivityPostDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity configuration was changed.
* @hide
*/
default void onActivityConfigurationChanged(@NonNull Activity activity) {
}
}
从接口函数可以看出这是用于监听Activity生命周期事件的回调,我们可以在Application中使用registerActivityLifecycleCallbacks注册Activity生命周期的全局监听,当有Activity的生命周期发生变化时,就会回调该接口中的方法,代码如下:
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
}
@Override
public void onActivityStarted(@NonNull Activity activity) {
}
@Override
public void onActivityResumed(@NonNull Activity activity) {
}
@Override
public void onActivityPaused(@NonNull Activity activity) {
}
@Override
public void onActivityStopped(@NonNull Activity activity) {
}
@Override
public void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState) {
}
@Override
public void onActivityDestroyed(@NonNull Activity activity) {
}
});
随后我们就可以根据回调的Activity对象判定应该由哪个资源管理器响应对应的生命周期变化。
通常情况下,我们可以依赖该方法实现以下需求:
- 自定义的全局的Activity栈管理
- 用户行为统计收集
- Activity切入前后台后的资源申请或释放
- 应用前后台判定
- 页面数据保存与恢复
- ... etc
上面都是开发者实现的,那么系统内部有没有已经实现的方案呢?查看源码,可以找到ActivityLifecycleCallbacks,其定义如下:
public interface ActivityLifecycleCallbacks {
/**
* Called as the first step of the Activity being created. This is always called before
* {@link Activity#onCreate}.
*/
default void onActivityPreCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called when the Activity calls {@link Activity#onCreate super.onCreate()}.
*/
void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState);
/**
* Called as the last step of the Activity being created. This is always called after
* {@link Activity#onCreate}.
*/
default void onActivityPostCreated(@NonNull Activity activity,
@Nullable Bundle savedInstanceState) {
}
/**
* Called as the first step of the Activity being started. This is always called before
* {@link Activity#onStart}.
*/
default void onActivityPreStarted(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStart super.onStart()}.
*/
void onActivityStarted(@NonNull Activity activity);
/**
* Called as the last step of the Activity being started. This is always called after
* {@link Activity#onStart}.
*/
default void onActivityPostStarted(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being resumed. This is always called before
* {@link Activity#onResume}.
*/
default void onActivityPreResumed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onResume super.onResume()}.
*/
void onActivityResumed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being resumed. This is always called after
* {@link Activity#onResume} and {@link Activity#onPostResume}.
*/
default void onActivityPostResumed(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being paused. This is always called before
* {@link Activity#onPause}.
*/
default void onActivityPrePaused(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onPause super.onPause()}.
*/
void onActivityPaused(@NonNull Activity activity);
/**
* Called as the last step of the Activity being paused. This is always called after
* {@link Activity#onPause}.
*/
default void onActivityPostPaused(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity being stopped. This is always called before
* {@link Activity#onStop}.
*/
default void onActivityPreStopped(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onStop super.onStop()}.
*/
void onActivityStopped(@NonNull Activity activity);
/**
* Called as the last step of the Activity being stopped. This is always called after
* {@link Activity#onStop}.
*/
default void onActivityPostStopped(@NonNull Activity activity) {
}
/**
* Called as the first step of the Activity saving its instance state. This is always
* called before {@link Activity#onSaveInstanceState}.
*/
default void onActivityPreSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called when the Activity calls
* {@link Activity#onSaveInstanceState super.onSaveInstanceState()}.
*/
void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState);
/**
* Called as the last step of the Activity saving its instance state. This is always
* called after{@link Activity#onSaveInstanceState}.
*/
default void onActivityPostSaveInstanceState(@NonNull Activity activity,
@NonNull Bundle outState) {
}
/**
* Called as the first step of the Activity being destroyed. This is always called before
* {@link Activity#onDestroy}.
*/
default void onActivityPreDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity calls {@link Activity#onDestroy super.onDestroy()}.
*/
void onActivityDestroyed(@NonNull Activity activity);
/**
* Called as the last step of the Activity being destroyed. This is always called after
* {@link Activity#onDestroy}.
*/
default void onActivityPostDestroyed(@NonNull Activity activity) {
}
/**
* Called when the Activity configuration was changed.
* @hide
*/
default void onActivityConfigurationChanged(@NonNull Activity activity) {
}
}从接口函数可以看出这是用于监听Activity生命周期事件的回调,我们可以在Application中使用registerActivityLifecycleCallbacks注册Activity生命周期的全局监听,当有Activity的生命周期发生变化时,就会回调该接口中的方法,代码如下:
registerActivityLifecycleCallbacks(new ActivityLifecycleCallbacks() {
@Override
public void onActivityCreated(@NonNull Activity activity, @Nullable Bundle savedInstanceState) {
}
@Override
public void onActivityStarted(@NonNull Activity activity) {
}
@Override
public void onActivityResumed(@NonNull Activity activity) {
}
@Override
public void onActivityPaused(@NonNull Activity activity) {
}
@Override
public void onActivityStopped(@NonNull Activity activity) {
}
@Override
public void onActivitySaveInstanceState(@NonNull Activity activity, @NonNull Bundle outState) {
}
@Override
public void onActivityDestroyed(@NonNull Activity activity) {
}
});随后我们就可以根据回调的Activity对象判定应该由哪个资源管理器响应对应的生命周期变化。
通常情况下,我们可以依赖该方法实现以下需求:
- 自定义的全局的Activity栈管理
- 用户行为统计收集
- Activity切入前后台后的资源申请或释放
- 应用前后台判定
- 页面数据保存与恢复
- ... etc
Lifecycle in Jetpack
Lifecycle相关内容可以参考前面发布的系列文章:
Lifecycle相关内容可以参考前面发布的系列文章:
Instrumentation
从Activity启动流程可知每个Activity生命周期变化时,ActivityThread都会通过其内部持有的Instrumentation类的对象进行分发,如果我们能自定义Instrumentation类,用我们自定义的Instrumentation类对象替换这个成员变量,那么自然可以通过这个自定义Instrumentation类对象来监听Activity生命周期变化。
那么怎么修改ActivityThread类的mInstrumentation成员呢?自然要用反射实现了。
自定义Instrumentation类如下所示:
public class CustomInstrumentation extends Instrumentation {
private static final String TAG = "CustomInstrumentation";
private Instrumentation mBaseInstrumentation;
public CustomInstrumentation(Instrumentation instrumentation) {
super();
mBaseInstrumentation = instrumentation;
}
@Override
public void callActivityOnResume(Activity activity) {
super.callActivityOnResume(activity);
Log.d(TAG, "callActivityOnResume " + activity.toString());
}
@Override
public void callActivityOnStop(Activity activity) {
super.callActivityOnStop(activity);
Log.d(TAG, "callActivityOnStop " + activity.toString());
}
}
在Application的attachBaseContext函数中反射修改ActivityThread的mInstrumentation成员为CustomInstrumentation类的对象,相关代码如下:
@Override
protected void attachBaseContext(Context base) {
hookInstrumentation();
super.attachBaseContext(base);
}
public void hookInstrumentation() {
Class<?> activityThread;
try{
activityThread = Class.forName("android.app.ActivityThread");
Method sCurrentActivityThread = activityThread.getDeclaredMethod("currentActivityThread");
sCurrentActivityThread.setAccessible(true);
//获取ActivityThread 对象
Object activityThreadObject = sCurrentActivityThread.invoke(null);
//获取 Instrumentation 对象
Field mInstrumentation = activityThread.getDeclaredField("mInstrumentation");
mInstrumentation.setAccessible(true);
Instrumentation instrumentation = (Instrumentation) mInstrumentation.get(activityThreadObject);
CustomInstrumentation customInstrumentation = new CustomInstrumentation(instrumentation);
//将我们的 customInstrumentation 设置进去
mInstrumentation.set(activityThreadObject, customInstrumentation);
}catch (Exception e){
e.printStackTrace();
}
}
编写两个Activity分别为MainActivity和NotifyAcLifecycleActivity,在MainActivity中点击按钮跳转到NotifyAcLifecycleActivity,日志输出如下:
可以拿出,虽然正常代理到了Activity的生命周期变更,但是每次Activity启动都会爆出Uninitialized ActivityThread, likely app-created Instrumentation, disabling AppComponentFactory的异常,查看源码,查找该问题的原因:
// Instrumentation.java
private ActivityThread mThread = null;
private AppComponentFactory getFactory(String pkg) {
if (pkg == null) {
Log.e(TAG, "No pkg specified, disabling AppComponentFactory");
return AppComponentFactory.DEFAULT;
}
if (mThread == null) {
Log.e(TAG, "Uninitialized ActivityThread, likely app-created Instrumentation,"
+ " disabling AppComponentFactory", new Throwable());
return AppComponentFactory.DEFAULT;
}
LoadedApk apk = mThread.peekPackageInfo(pkg, true);
// This is in the case of starting up "android".
if (apk == null) apk = mThread.getSystemContext().mPackageInfo;
return apk.getAppFactory();
}
final void basicInit(ActivityThread thread) {
mThread = thread;
}
可以看到当mThread成员为空时,会抛出该问题,mThread是在basicInit中赋值的,由于我们创建的CustomInstrumentation对象没有调用该函数,故mThread必然为空,那么如何规避该问题呢?方案主要有两个方向
初始化CustomInstrumentation对象的mThread对象
反射获取原始Instrumentation对象的mThread取值,然后设置到自定义的CustomInstrumentation对象中
针对getFactory方法使用的函数,将函数重写,调用原始Instrumentation对应的函数
这里我们使用第二个方案,在CustomInstrumentation中重写newActivity方法,使用原始的Instrumentation对象代理,代码如下:
public Activity newActivity(ClassLoader cl, String className,
Intent intent)
throws InstantiationException, IllegalAccessException,
ClassNotFoundException {
return mBaseInstrumentation.newActivity(cl, className, intent);
}
再次运行,可以看到日志中不再打印该异常,同时我们也能正常监听到Activity生命周期变化了,详细日志如下:

综上,我们就可以在自定义Instrumentation类的callActivityOnStop方法中过滤某些Activity,在其切入后台时进行资源的释放。
不难看出,自定义Instrumentation走通后,我们可以在该类中接管系统的Activity启动,进而将某个目标Activity替换成我们自己的Activity,这也是插件化实现中的一个核心步骤
作者:小海编码日记
链接:https://juejin.cn/post/7199609821980229691
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
收起阅读 »
从Activity启动流程可知每个Activity生命周期变化时,ActivityThread都会通过其内部持有的Instrumentation类的对象进行分发,如果我们能自定义Instrumentation类,用我们自定义的Instrumentation类对象替换这个成员变量,那么自然可以通过这个自定义Instrumentation类对象来监听Activity生命周期变化。
那么怎么修改ActivityThread类的mInstrumentation成员呢?自然要用反射实现了。
自定义Instrumentation类如下所示:
public class CustomInstrumentation extends Instrumentation {
private static final String TAG = "CustomInstrumentation";
private Instrumentation mBaseInstrumentation;
public CustomInstrumentation(Instrumentation instrumentation) {
super();
mBaseInstrumentation = instrumentation;
}
@Override
public void callActivityOnResume(Activity activity) {
super.callActivityOnResume(activity);
Log.d(TAG, "callActivityOnResume " + activity.toString());
}
@Override
public void callActivityOnStop(Activity activity) {
super.callActivityOnStop(activity);
Log.d(TAG, "callActivityOnStop " + activity.toString());
}
}在Application的attachBaseContext函数中反射修改ActivityThread的mInstrumentation成员为CustomInstrumentation类的对象,相关代码如下:
@Override
protected void attachBaseContext(Context base) {
hookInstrumentation();
super.attachBaseContext(base);
}
public void hookInstrumentation() {
Class<?> activityThread;
try{
activityThread = Class.forName("android.app.ActivityThread");
Method sCurrentActivityThread = activityThread.getDeclaredMethod("currentActivityThread");
sCurrentActivityThread.setAccessible(true);
//获取ActivityThread 对象
Object activityThreadObject = sCurrentActivityThread.invoke(null);
//获取 Instrumentation 对象
Field mInstrumentation = activityThread.getDeclaredField("mInstrumentation");
mInstrumentation.setAccessible(true);
Instrumentation instrumentation = (Instrumentation) mInstrumentation.get(activityThreadObject);
CustomInstrumentation customInstrumentation = new CustomInstrumentation(instrumentation);
//将我们的 customInstrumentation 设置进去
mInstrumentation.set(activityThreadObject, customInstrumentation);
}catch (Exception e){
e.printStackTrace();
}
}编写两个Activity分别为MainActivity和NotifyAcLifecycleActivity,在MainActivity中点击按钮跳转到NotifyAcLifecycleActivity,日志输出如下:
可以拿出,虽然正常代理到了Activity的生命周期变更,但是每次Activity启动都会爆出Uninitialized ActivityThread, likely app-created Instrumentation, disabling AppComponentFactory的异常,查看源码,查找该问题的原因:
// Instrumentation.java
private ActivityThread mThread = null;
private AppComponentFactory getFactory(String pkg) {
if (pkg == null) {
Log.e(TAG, "No pkg specified, disabling AppComponentFactory");
return AppComponentFactory.DEFAULT;
}
if (mThread == null) {
Log.e(TAG, "Uninitialized ActivityThread, likely app-created Instrumentation,"
+ " disabling AppComponentFactory", new Throwable());
return AppComponentFactory.DEFAULT;
}
LoadedApk apk = mThread.peekPackageInfo(pkg, true);
// This is in the case of starting up "android".
if (apk == null) apk = mThread.getSystemContext().mPackageInfo;
return apk.getAppFactory();
}
final void basicInit(ActivityThread thread) {
mThread = thread;
}可以看到当mThread成员为空时,会抛出该问题,mThread是在basicInit中赋值的,由于我们创建的CustomInstrumentation对象没有调用该函数,故mThread必然为空,那么如何规避该问题呢?方案主要有两个方向
初始化CustomInstrumentation对象的mThread对象
反射获取原始Instrumentation对象的mThread取值,然后设置到自定义的CustomInstrumentation对象中
针对getFactory方法使用的函数,将函数重写,调用原始Instrumentation对应的函数
这里我们使用第二个方案,在CustomInstrumentation中重写newActivity方法,使用原始的Instrumentation对象代理,代码如下:
public Activity newActivity(ClassLoader cl, String className,
Intent intent)
throws InstantiationException, IllegalAccessException,
ClassNotFoundException {
return mBaseInstrumentation.newActivity(cl, className, intent);
}再次运行,可以看到日志中不再打印该异常,同时我们也能正常监听到Activity生命周期变化了,详细日志如下:
综上,我们就可以在自定义Instrumentation类的callActivityOnStop方法中过滤某些Activity,在其切入后台时进行资源的释放。
不难看出,自定义Instrumentation走通后,我们可以在该类中接管系统的Activity启动,进而将某个目标Activity替换成我们自己的Activity,这也是插件化实现中的一个核心步骤
链接:https://juejin.cn/post/7199609821980229691
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
浅谈开发中对数据的编码和封装
前言
前几天写了一篇对跨端通讯的思考,当时顺便想到了数据这一块,所以也可以整理一下,单独拿出来说说平时开发中涉及到哪些对数据的处理方式。
Base64
之前详细写过一篇关于Base64的文章
简单来说,Base64就是把你的数据转成只有64个无特殊符号的字符,主要常用于加密后之类的生成的字节数组,转成Base64方便进行数据传输,如果不转的话就会是乱码,会看得很难受,这些乱码在某些编码下展示出来的是豆腐块,有点扯远了。
还有就是比如中文啊,emoji啊这类的字符,在某些情况下也需要转成Base64进行传输。
缺点就是只用64个字符表示,还有我之前分析过base64的转换原理,通过其原理能很容易看出,最终的转换结果相比转换前的数据更加长。
JSON/XML
这些就比较常见了,对数据按照一定的格式进行封装。为什么要说这个呢?因为他这些封装是约定熟成的方式,和上面的Base64的转换方式就不同,相当于是大家约定好按照这个格式包装数据,然后传输,自己再按照这个格式去解开拿到数据。
多数用于跨端传输,像客户端请求服务端拿数据,那不也就是跨端嘛,其实这个所有人都用到,但为什么说这个呢?还是那个跨端通信的问题,跨端通信没办法直接传对象,实际传对象的效果是转json传的String,然后另外一端再创建一个自己端的对象,解析json,把json数据填充进去。
还有,既然是约定的,那其实我们自己也可以按照我们自己的约定去做跨端的数据传送,只不过json这种格式,是已经设计得很好了,你很难再去约定一种比这个格式更好的封装。
PS:不要觉得json大家都在用,都形成肌肉记忆了,没有什么难的。其实比如像gson\fastjson这些,人家去研究解析json的算法,也是一个技术点。你觉得简单,那是因为你在使用,但让你从0去做,你不一定能做出来。
URL编码
又叫做urlencode,顾名思义用于url连接中的一种对数据的操作。
它将特殊字符转成16进制并且在前面加%,那同理解析拿数据的时候也是根据%去做判断。
为什么会出现这种编码呢?主要是为了防止冲突,我们都知道比如get请求都会在url链接后面拼参数,防止在传输中出现问题,所以把特殊字符都进行编码。
比如http://www.baidu.com/?aaaaaaa 会编码成https%3A%2F%2Fwww.baidu.com%2F%3Faaaaaaa
该编码主要用于对url的处理。
驼峰和下划线
这其实是一个命名方式,不同的端有不同的命名习惯,比如java习惯就是用驼峰,但是还是跨端问题,有些时候存在写死的情况,当然这个代码不是你写的,也可能是前人留下的(我没有暗示什么)。但如果你的代码中出现两种命名方式会让代码看着比较乱。没关系我们可以做个转换,我这里以下划线转驼峰为例
private String lineToHump(String str) {
if (TextUtils.isEmpty(str)) {
return str;
}
String[] strs = str.split("_");
if (strs.length < 2) {
return str;
}
StringBuilder result = new StringBuilder(strs[0]);
for (int i = 1; i < strs.length; i++) {
String upper = (strs[i].charAt(0) + "").toUpperCase();
if (strs[i].length() > 1) {
result.append(upper).append(strs[i].substring(1));
} else {
result.append(upper);
}
}
return result.toString();
}可以写个转换方法,我这里只是随便写个Demo,这段代码是还能进行优化的,主要大概就是这个意思。
上面说的json主要是为了说数据的封装和解封,这里主要是说数据的转换,我的意思是在开发中,我们也会出现不同端的数据形式不同,我们不需要在代码中向其它端进行妥协,只用写个方法去做数据的转换,在本端还是正常写本端的代码就行。
摘要
摘要算法,简单来说就是将原数据以一种算法生成一段很小的新数据,这段新数据主要是用来标识这段原数据。怎么还有点绕,总之就是生成一个字符串来标识原数据 。对任意一组输入数据进行计算,得到一个固定长度的输出。
也可称之为哈希算法,最重要的是它取决于它的这个设计思想,它是一个不可能逆的过程,一般不能根据摘要拿到原数据,注意我用了一般,因为这个世界上存在很多老六。
摘要算法中当前最经典的是SHA算法和MD算法,SHA-1、SHA-256和MD5。其中他们加密过程可以单独写一篇文章来说,这里就不过多解释。
摘要算法最主要的运用场景是校验数据的完整性和是否有被篡改。比如CA证书的校验,android签名的校验,会拿原数据做摘要和传过来的摘要相对比,是否一样,如果不一样说明数据有被篡改过。再比如我本地有个视频,我怎么判断后台这个视频是不是更新了,要不要下载,可以对视频文件做MD5,然后和后台文件的MD5进行对比,如果一样说明视频没有更新,如果不一样说明视频有更新或者本地的视频不完整(PS:对文件做摘要可是一个耗时的过程。)
加密
讲完摘要可以趁热打铁说说加密,加密顾名思义就是把明文数据转成密文,然后另一方拿到密文之后再转成明文。
加密和摘要不同在于,它们的本质都不同,摘要是为了验证数据,加密是为了安全传输数据。它们在表现上的不同体现在,摘要是不可逆,加密是可逆的。
加密在当前的设计上又分为对称加密和非对称加密,主流的对称加密是AES算法,主流的非对称加密是RSA算法。对称加密的加密和解密使用的密钥是相同的,非对称是不同的 ,所以非对称加密更为安全,但是也会更耗时。
当然你也可以不用这些算法,如果你是直接接触这些算法,好像是要付专利费的,每年给多少钱别人才给你用这个算法,资本家不就喜欢搞这种东西吗?扯远了。你也可以使用自己约定的算法,只不过在高手面前可能你的算法相当于裸奔,要是你真能设计出和这些算法旗鼓相当的算法,你也不会来看我这么捞的文章。
所以加密,是为了保证数据的安全,如果你传输的数据觉得被看了也无所谓,那就不用加密,因为它耗时。如果你只是为了防止数据被改,也不用加密,用摘要就行。如果你是为了传输seed,那我建议你加密[狗头]
通信协议
json那里我们有说,它就是双方约定好的数据格式。以小见大,通信协议也是双方约定的一种数据传输的过程。通信协议会更为严谨,而且会很多不同,各家有各家的通信协议,不是像json这种就是大家都用一样的。
比如我们的网络传输,就有很多协议,http协议、tcpip协议等,这些在网络中是规定好的,大家都用这一套。再比如蓝牙协议,也是要按照同一个规范去使用。但是硬件的协议就多种多样了,不同的硬件厂商会定义不同的通信协议。
二维码
二维码也是对数据封装的一种形式,可以通过把数据变成图像,然后是扫码后再获取到数据,这么一种模式我感觉能想出这个法子的人挺牛逼的。
它所涉及的内容很多,具体可以参考这篇文章,我觉得这个大佬写得挺好的 二维码生成原理 - 知乎 (zhihu.com)
我之前自己去用java实现,最终没画出来,感觉原理是没问题的,应该是我哪里细节没处理好,这里就简单介绍一下就行。其实简单来说,它就是有一个模板的情况下,把数据填充到模板里面。
这里借大佬的图,模板就是这样的
然后按照规则去填充数据
这样去填充,其实会让黑点分布不均匀,填充之后还会做一个转换。
但是二维码也有缺点,缺点就是数据量大的时候,你的二维码很难被识别出,但是不得不说能想出这个方法,能设计出这个东西的人,确实牛逼。
链接:https://juejin.cn/post/7199862924830670904
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
七道Android面试题,先来简单热个身
马上就要到招(tiao)聘(cao)旺季金三银四了,一批一批的社会精英在寻找自己的下一家的同时,也开始着手为面试做准备,回想起自己这些年,也大大小小经历过不少面试,有被面试过,也有当过面试官,其中也总结出了两个观点,一个就是不花一定的时间背些八股文还真的不行,一些扯皮的话别去听,都是在害人,另一个就是面试造火箭,入职拧螺丝毕竟都是少数,真正一场合格的面试问的东西,都是实际开发过程中会遇到的,下面我就说几个我遇到过的面试题吧
为什么ArrayMap比HashMap更适合Android开发
我们一般习惯在项目当中使用HashMap去存储键值队这样的数据,所以往往在android面试当中HashMap是必问环节,但有次面试我记得被问到了有没有有过ArrayMap,我只能说有印象,毕竟用的最多的还是HashMap,然后那个面试官又问我,觉得Android里面更适合用ArrayMap还是HashMap,我就说不上来了,因为也没看过ArrayMap的源码,后来回去看了下才给弄明白了,现在就简单对比下ArrayMap与HashMap的特点
HashMap
- HashMap的数据结构为数组加链表的结构,jdk1.8之后改为数组加链表加红黑树的结构
- put的时候,会先计算key的hashcode,然后去数组中寻找这个hashcode的下标,如果数据为空就先resize,然后检查对应下标值(下标值=(数组长度-1)&hashcode)里面是否为空,空则生成一个entry插入,否就判断hascode与key值是否分别都相等,如果相等则覆盖,如果不等就发生哈希冲突,生成一个新的entry插入到链表后面,如果此时链表长度已经大于8且数组长度大于64,则先转成树,将entry添加到树里面
- get的时候,也是先去查找数组对应下标值里面是否为空,如果不为空且key与hascode都相等,直接返回value,否就判断该节点是否为一个树节点,是就在树里面返回对应entry,否就去遍历整个链表,找出key值相等的entry并返回
ArrayMap
- 内部维护两个数组,一个是int类型的数组(mHashes)保存key的hashcode,另一个是Object的数组(mArray),用来保存与mHashes对应的key-value
- put数据的时候,首先用二分查找法找出mHashes里面的下标index来存放hashcode,在mArray对应下标index<<1与(index<<1)+1的位置存放key与value
- get数据的时候,同样也是用二分查找法找出与key值对应的下标index,接着再从mArray的(index<<1)+1位置将value取出
对比
- HashMap在存放数据的时候,无论存放的量是多少,首先是会生成一个Entry对象,这个就比较浪费内存空间,而ArrayMap只是把数据插入到数组中,不用生成新的对象
- 存放大量数据的时候,ArrayMap性能上就不如HashMap,因为ArrayMap使用的是二分查找法找的下标,当数据多了下标值找起来时间就花的久,此外还需要将所有数据往后移再插入数据,而HashMap只要插入到链表或者树后面即可
所以这就是为什么,在没有那么大的数据量需求下,Android在性能角度上比较适合用ArrayMap
为什么Arrays.asList后往里add数据会报错
这个问题我当初问过不少人,不缺乏一些资历比较深的大佬,但是他们基本都表示不清楚,这说明平时我们研究Glide,OkHttp这样的三方库源码比较多,而像一些比较基础的往往会被人忽略,而有些问题如果被忽略了,往往会产生一些捉摸不透的问题,比如有的人喜欢用Arrays.asList去生成一个List
val dataList = Arrays.asList(1,2,3)
dataList.add(4)但是当我们往这个List里面add数据的时候,我们会发现,crash了,看到的日志是
不被支持的操作,这让首次遇到这样问题的人肯定是一脸懵,List不让添加数据了吗?之前明明可以的啊,但是之前我们创建一个List是这样创建的
它所在的包是java.util.ArrayList里面,我们看下里面的代码
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}是存在add方法的,我们再回头再去看看asList生成的List
是在java.util.Arrays包里面的,而这里面的ArrayList我们看到了,并没有去实现List接口,所以也就没有add,get等方法,另外在kotlin里面,我们会看到一个细节,当你敲完Arrays.asList的时候,编译器会提示你,可以转换成listof函数,而这个还是我们知道生成的list都是只能读取,不能往里写数据
Thread.sleep(0)到底“睡没睡”
记得在上上家公司,接手的第一个需求就是做一个动画,这个动画需要一个延迟启动的功能,我那个时候想都没想加了个Thread.sleep(3000),后来被领导批了,不可以用Thread.sleep实现延迟功能,那会还不太明白,后来知道了,Thread.sleep(3000)不一定真的暂停三秒,我们来举个例子
println("start:${System.currentTimeMillis()}")
Thread(Runnable {
Thread.sleep(3000)
println("end:${System.currentTimeMillis()}")
}).start()我们在主线程先打印一条数据展示时间,然后开启一个子线程,在里面sleep三秒以后在打印一下时间,我们看下结果如何
start:1675665421590
end:1675665424591好像对了又好像没对,为什么是过了3001毫秒才打印出来呢?有的人会说,1毫秒而已,忽略嘛,那我们把上面的代码改下再试试
println("start:${System.currentTimeMillis()}")
Thread(Runnable {
Thread.sleep(0)
println("end:${System.currentTimeMillis()}")
}).start()现在sleep了0毫秒,那是不是两条打印日志应该是一样的呢,我们看看结果
start:1675666764475
end:1675666764477这下子给整不会了,明明sleep0毫秒,那么多出来的2毫秒是怎么回事呢?其实在Android操作系统中,每个线程使用cpu资源都是有优先级的,优先级高的才有资格使用,而操作系统则是在一个线程释放cpu资源以后,重新计算所有线程的优先级来重新分配cpu资源,所以sleep真正的意义不是暂停,而是在接下去的时间内不参与cpu的竞争,等到cpu重新分配完资源以后,如果优先级没变,那么继续执行,所以sleep(0)秒的真正含义是触发cpu资源重新分配
View.post为什么可以获取控件的宽高
我们都知道在onCreate里面想要获取一个控件的宽高,如果直接获取是拿不到的
val mWith = bindingView.mainButton.width
val mHeight = bindingView.mainButton.height
println("按钮宽:$mWith,高:$mHeight")
......
按钮宽:0,高:0而如果想要获取宽高,则必须调用View.post的方法
bindingView.mainButton.post {
val mWith = bindingView.mainButton.width
val mHeight = bindingView.mainButton.height
println("按钮宽:$mWith,高:$mHeight")
}
......
按钮宽:979,高:187很神奇,加个post就可以在同样的地方获取控件宽高了,至于为什么呢?我们来分析一下
简单的来说
Activity生命周期,onCreate方法里面视图还在绘制过程中,所以没法直接获取宽高,而在post方法中执行,就是在线程里面获取宽高,这个线程会在视图没有绘制完成的时候放在一个等待队列里面,等到视图绘制执行完毕以后再去执行队列里面的线程,所以在post里面也可以获取宽高
复杂的来说
我们首先从View.post方法里面开始看
这个代码里面的两个框子,说明了post方法做了两件事情,当mAttachInfo不为空的时候,直接让mHandler去执行线程action,当mAttachInfo为空的时候,将线程放在了一个队列里面,从注释里面的第一个单词Postpone就可以知道,这个action是要推迟进行,什么时候进行呢,我们在慢慢看,既然是判断当mAttachInfo不为空才去执行线程,那我们找找什么时候对mAttachInfo赋值,整个View的源码里面只有一处是对mAttachInfo赋值的,那就是在dispatchAttachedToWindow
这个方法里面,我们看下
void dispatchAttachedToWindow(AttachInfo info, int visibility) {
mAttachInfo = info;
...省略部分源码...
// Transfer all pending runnables.
if (mRunQueue != null) {
mRunQueue.executeActions(info.mHandler);
mRunQueue = null;
}
}当走到dispatchAttachedToWindow这个方法的时候,mAttachInfo才不为空,也就是从这里开始,我们就可以获取控件的宽高等信息了,另外我们顺着这个方法往下看,可以发现,之前的那个队列在这里开始执行了,现在就关键在于,什么时候执行dispatchAttachedToWindow这个方法,这个时候就要去ViewRootIml类里面查看,发现只有一处调用了这个方法,那就是在performTraversals这个方法里面
private void performTraversals() {
...省略部分源码...
host.dispatchAttachedToWindow(mAttachInfo, 0);
...省略部分源码...
// Ask host how big it wants to be
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
...省略部分源码...
performLayout(lp, mWidth, mHeight);
...省略部分源码...
performDraw();
}performTraversals这个方法我们就很熟悉了,整个View的绘制流程都在里面,所以只有当mAttachInfo在这个环节赋值了,才可以得到视图的信息
IdleHandler到底有啥用
Handler是面试的时候必问的环节,除了问一下那四大组件之外,有的面试官还会问一下IdleHandler,那IdleHandler到底是什么呢,它是干什么用的呢,我们来看看
Message next() {
...省略部分代码...
synchronized (this) {
// If first time idle, then get the number of idlers to run.
// Idle handles only run if the queue is empty or if the first message
// in the queue (possibly a barrier) is due to be handled in the future.
if (pendingIdleHandlerCount < 0
&& (mMessages == null || now < mMessages.when)) {
pendingIdleHandlerCount = mIdleHandlers.size();
}
if (pendingIdleHandlerCount <= 0) {
// No idle handlers to run. Loop and wait some more.
mBlocked = true;
continue;
}
if (mPendingIdleHandlers == null) {
mPendingIdleHandlers = new IdleHandler[Math.max(pendingIdleHandlerCount, 4)];
}
mPendingIdleHandlers = mIdleHandlers.toArray(mPendingIdleHandlers);
}
// Run the idle handlers.
// We only ever reach this code block during the first iteration.
for (int i = 0; i < pendingIdleHandlerCount; i++) {
final IdleHandler idler = mPendingIdleHandlers[i];
mPendingIdleHandlers[i] = null; // release the reference to the handler
boolean keep = false;
try {
keep = idler.queueIdle();
} catch (Throwable t) {
Log.wtf(TAG, "IdleHandler threw exception", t);
}
if (!keep) {
synchronized (this) {
mIdleHandlers.remove(idler);
}
}
}
}只有在MessageQueue中的next方法里面出现了IdleHandler,作用也很明显,当消息队列在遍历队列中的消息的时候,当消息已经处理完了,或者只存在延迟消息的时候,就会去处理mPendingIdleHandlers里面每一个idleHandler的事件,而这些事件都是通过方法addIdleHandler注册进去的
Looper.myQueue().addIdleHandler {
false
}addIdlehandler接受的参数是一个返回值为布尔类型的函数类型参数,至于这个返回值是true还是false,我们从next()方法中就能了解到,当为false的时候,事件处理完以后,这个IdleHandler就会从数组中删除,下次再去遍历执行这个idleHandler数组的时候,该事件就没有了,如果为true的话,该事件不会被删除,下次依然会被执行,所以我们按需设置。现在我们可以利用idlehandler去解决上面讲到的在onCreate里面获取控件宽高的问题
Looper.myQueue().addIdleHandler {
val mWith = bindingView.mainButton.width
val mHeight = bindingView.mainButton.height
println("按钮宽:$mWith,高:$mHeight")
false
}当MessageQueue中的消息处理完的时候,我们的视图绘制也完成了,所以这个时候肯定也能获取控件的宽高,我们在IdleHandler里面执行了同样的代码之后,运行后的结果如下
按钮宽:979,高:187除此之外,我们还可以做点别的事情,比如我们常说的不要在主线程里面做一些耗时的工作,这样会降低页面启动速度,严重的还会出现ANR,这样的场景除了开辟子线程去处理耗时操作之外,我们现在还可以用IdleHandler,这里举个例子,我们在主线程中给sp塞入一些数据,然后在把这些数据读取出来,看看耗时多久
println(System.currentTimeMillis())
val testData = "aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhas" +
"jkhdaabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd" +
"aabbbbakjsdhjkahsjkasdjasdhjakshdjkahsdjkhasjdkhjaskhdjkashdjkhasjkhasjkhd"
sharePreference = getSharedPreferences(packageName, MODE_PRIVATE)
for (i in 1..5000) {
sharePreference.edit().putString("test$i", testData).commit()
}
for (i in 1..5000){
sharePreference.getString("test$i","")
}
println(System.currentTimeMillis())
......运行结果
1676260921617
1676260942770我们看到在塞入5000次数据,再读取5000次数据之后,一共耗时大概20秒,同时也阻塞了主线程,导致的现象是页面一片空白,只有等读写操作结束了,页面才展示出来,我们接着把读写操作的代码用IdleHandler执行一下看看
Looper.myQueue().addIdleHandler {
sharePreference = getSharedPreferences(packageName, MODE_PRIVATE)
val editor = sharePreference.edit()
for (i in 1..5000) {
editor.putString("test$i", testData).commit()
}
for (i in 1..5000){
sharePreference.getString("test$i","")
}
println(System.currentTimeMillis())
false
}
......运行结果
1676264286760
1676264308294运行结果依然耗时二十秒左右,但区别在于这个时候页面不会受到读写操作的阻塞,很快就展示出来了,说明读写操作的确是等到页面渲染完才开始工作,上面过程没有放效果图主要是因为时间太长了,会影响gif的体验,有兴趣的可以自己试一下
如何让指定视图不被软键盘遮挡
我们通常使用android:windowSoftInputMode属性来控制软键盘弹出之后移动界面,让输入框不被遮挡,但是有些场景下,键盘永远都会挡住一些我们使用频次比较高的控件,比如现在我们有个登录页面,大概的样子长这样
它的布局文件是这样
<RelativeLayout
android:id="@+id/mainroot"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:layout_width="200dp"
android:layout_height="200dp"
android:layout_centerHorizontal="true"
android:layout_marginTop="100dp"
android:src="@mipmap/ic_launcher_round" />
<androidx.appcompat.widget.LinearLayoutCompat
android:id="@+id/ll_view1"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_marginBottom="120dp"
android:gravity="center"
android:orientation="vertical">
<EditText
android:id="@+id/main_edit"
android:layout_width="match_parent"
android:layout_height="40dp"
android:hint="请输入用户名"
android:textColor="@color/black"
android:textSize="15sp" />
<EditText
android:id="@+id/main_edit2"
android:layout_width="match_parent"
android:layout_height="40dp"
android:layout_marginTop="30dp"
android:hint="请输入密码"
android:textColor="@color/black"
android:textSize="15sp" />
<Button
android:layout_width="match_parent"
android:layout_height="50dp"
android:layout_marginHorizontal="10dp"
android:layout_marginTop="20dp"
android:text="登录" />
</androidx.appcompat.widget.LinearLayoutCompat>
</RelativeLayout>在这样一个页面里面,由于输入框与登录按钮都比较靠页面下方,导致当输入完内容想要点击登录按钮时候,必须再一次关闭键盘才行,这样的操作在体验上就比较大打折扣了
现在希望可以键盘弹出之后,按钮也展示在键盘上面,这样就不用收起弹框以后才能点击按钮了,这样一来,windowSoftInputMode这一个属性已经不够用了,我们要想一下其他方案
- 首先,需要让按钮也展示在键盘上方,那只能让布局整体上移把按钮露出来,在这里我们可以改变LayoutParam的bottomMargin参数来实现
- 其次,需要知道键盘什么时候弹出,我们都知道android里面并没有提供任何监听事件来告诉我们键盘什么时候弹出,我们只能从其他角度入手,那就是监听根布局可视区域大小的变化
ViewTreeObserver
我们先获取视图树的观察者,使用addOnGlobalLayoutListener去监听全局视图的变化
bindingView.mainroot.viewTreeObserver.addOnGlobalLayoutListener {
}接下去就是要获取根视图的可视化区域了,如何来获取呢?View里面有这么一个方法,那就是getWindowVisibleDisplayFrame,我们看下源码注释就知道它是干什么的了
一大堆英文没必要都去看,只需要看最后一句就好了,大概意思就是获取能够展示给用户的可用区域,所以我们在监听器里面加上这个方法
bindingView.mainroot.viewTreeObserver.addOnGlobalLayoutListener {
val rect = Rect()
bindingView.mainroot.getWindowVisibleDisplayFrame(rect)
}当键盘弹出或者收起的时候,rect的高度就会跟着变化,我们就可以用这个作为条件来改变bottomMargin的值,现在我们增加一个变量oldDelta来保存前一个rect变化的高度值,用来做比较,完整的代码如下
var oldDelta = 0
val params:RelativeLayout.LayoutParams = bindingView.llView1.layoutParams as RelativeLayout.LayoutParams
val originBottom = params.bottomMargin
bindingView.mainroot.viewTreeObserver.addOnGlobalLayoutListener {
val rect = Rect()
bindingView.mainroot.getWindowVisibleDisplayFrame(rect)
val deltaHeight = r.height()
if (oldDelta != deltaHeight) {
if (oldDelta != 0) {
if (oldDelta > deltaHeight) {
params.bottomMargin = oldDelta - deltaHeight
} else if (oldDelta < deltaHeight) {
params.bottomMargin = originBottom
}
bindingView.llView1.layoutParams = params
}
oldDelta = deltaHeight
}
}最终效果如下
弹出后页面有个抖动是因为本身有个页面平移的效果,然后再去计算layoutparam,如果不想抖动可以在布局外层套个scrollView,用smoothScrollTo把页面滑上去就可以了,有兴趣的可以业余时间试一下
为什么LiveData的postValue会丢失数据
LiveData已经问世好多年了,大家都很喜欢用,因为它上手方便,一般知道塞数据用setValue和postValue,监听数据使用observer就可以了,然而实际开发中我遇到过好多人,一会这里用setValue一会那里用postValue,或者交替着用,这种做法也不能严格意义上说错,毕竟运行起来的确没问题,但是这种做法确实是存在风险隐患,那就是连续postValue会丢数据,我们来做个实验,连续setValue十个数据和连续postValue十个数据,收到的结果都分别是什么
var testData = MutableLiveData<Int>()
fun play(){
for (i in 1..10) {
testData.value = i
}
}
mainViewModel.testData.observe(this) {
println("收到:$it")
}
//执行结果
收到:1
收到:2
收到:3
收到:4
收到:5
收到:6
收到:7
收到:8
收到:9
收到:10setValue十次数据都可以收到,现在把setValue改成postValue再来试试
var testData = MutableLiveData<Int>()
fun play(){
for (i in 1..10) {
testData.postValue(i)
}
}得到的结果是
收到:10只收到了最后一条数据10,这是为什么呢?我们进入postValue里面看看里面的源码就知道了
主要看红框里面,有一个synchronized同步锁锁住了一个代码块,我们称为代码块1,锁的对象是mDataLock,代码块1做的事情先是给postTask这个布尔值赋值,接着把传进来的值赋给mPendingData,那我们知道了,postTask除了第一个被执行的时候,值是true,结下去等mPendingData有值了以后就都为false,前提是mPendingData没有被重置为NOT_SET,然后我们顺着代码往下看,会看到代码接下来就要到一个mPostValueRunnable的线程里面去了,我们看下这个线程
发现同样的锁,锁住了另一块代码块,我们称为代码块2,这个代码块里面恰好是把mPendingData的值赋给newValue以后,重置为NOT_SET,这样一来,postValue又可以接受新的值了,所以这也是正常情况下每次postValue都可以接受到值的原因,但是我们想想连续postValue的场景,我们知道如果synchronized如果修饰一段代码块,那么当这段代码块获取到锁的时候,就具有优先级,只有当全部执行完以后才会释放锁,所以当代码块1连续被访问时候,代码块2是不会被执行的,只有等到代码块1执行完,释放了锁,代码块2才会被执行,而这个时候,mPendingData已经是最新的值了,之前的值已经全部被覆盖了,所以我们说的postValue会丢数据,其实说错了,应该是postValue只会发送最新数据
总结
这篇文章讲到的面试题还仅仅只是过去几年遇到的,现在面试估计除了一些常规问题之外,比重会更倾向于Kotlin,Compose,Flutter的知识点,所以只有不断的日积月累,让自己的知识点更加的全面,才能在目前竞争激烈的行情趋势下逆流而上,不会被拍打在沙滩上
链接:https://juejin.cn/post/7199537072302374969
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
你还在傻傻的npm run serve吗?快来尝尝这个!
背景
大家在日常开发中应该经常会有需要切换不同环境地址的情况。当一个项目代码切换环境地址时,vue-cli没有能够感知文件的变化,所以代理的还是旧的地址,所以通常我们需要执行npm run serve进行项目重跑,而项目重跑往往意味着长时间的等待,非常痛苦!
方案调研
事实上,其实我们只是需要重启webpack为我们启动的proxy代理服务,或许能够从webpack的代理服务插件中找到解决方法。
从webpack官网可以看到proxy服务其实是由
http-proxy-middleware提供的,或许我们能够从中找到解决方法。
初步方案
在http-proxy-middleware的配置选项中,除了我们常见的target,还有router。router返回一个字符串的服务地址,当两个选项都配置了的情况下,会优先使用router函数的返回值,只有当router的返回值不可用时,才会使用target的值。
我们可以利用这一点来重新配置我们的项目代码。参考文档在这里
// vue.config.js
const { defineConfig } = require('@vue/cli-service')
const { proxy } = require('./environments/proxy.js')
module.exports = defineConfig({
devServer:{
proxy
},
})
复制代码// proxy.js
const fs = require('fs')
const path = require('path')
const encoding = 'utf-8'
const getContent = filename => {
const dir = path.resolve(process.cwd(), 'environments')
return fs.readFileSync(path.resolve(dir, filename), { encoding })
}
const jsonParse = obj => { return Function('"use strict";return (' + obj + ')')() }
const getConfig = () => { try {
return jsonParse(getContent('proxy-config.json'))
} catch (e) { return {} } }
module.exports = {
proxy: {
// 接口匹配规则自行修改
'/api': {
// 这里必须要有字符串来进行占位
// 如果报错Invaild Url,将target改成有效的url字符串即可,如http://localhost:9001
target: 'that must have a empty placeholder',
changeOrigin: true,
router: () => (getConfig() || {}).target || ''
}
}
}
复制代码// proxy-config.json
{ "target": "http://localhost:9001" }
复制代码自此,当我们需要修改环境地址时,只需要修改proxy-config.json文件便能够实时生效,不再需要npm run serve!
重点代码分析
实现代码中其实最主要的就是getContent这个方法,我们项目在每次发起http请求时都会调用router中的函数,而getContent则会通过node的fs服务,对我们的环境地址文件进行实时读取,从而指向我们最新修改的环境地址。
方案总结
在按照参考文档配置了项目代码之后,我们发现确实能够及时指向新的环境地址,再也不需要重启代码,不需要长时间的等待了。但是,我们多了两个需要维护的文件,每次我们修改环境地址时,不仅需要修改config中的api,还需要修改proxy-config.json中的target!
有没有可能在只需要修改config文件的情况下,实现代理地址动态修改呢?
方案优化
从上面的重点代码分析中,可以看到只要我们可以在router函数执行时,拿到正确的config文件中导出的api属性的值,也可以实现同样的效果!
这是不是意味着只要我们在函数中对config文件进行require请求,读取api的值,再return出去就能及时修改代理指向了呢?
没错,你会发现无论你怎么修改,函数内require取到的api永远是不变的,还是服务刚启动时的环境地址。
参考源码可以知道,这是因为我们在使用require请求文件信息时,node会解析出我们传入的字符串的文件路径的绝对路径,并且以绝对路径为键值,对该文件进行缓存。
因此,如果我们在执行require函数时打断点进行观察的话,会发现require上面有一个cache缓存了已经加载过的文件。
这也恰恰说明了只要我们能够删除掉文件保存在require中的缓存,我们就能够拿到最新的文件内容,那么我们也可以据此得出我们的最终优化方案。
// vue.config.js
const hotRequire = modulePath => {
// require.resolve可以通过相对路径获取绝对路径
// 以绝对路径为键值删除require中的对应文件的缓存
delete require.cache[require.resolve(modulePath)]
// 重新获取文件内容
const target = require(modulePath)
return target
}
...
proxy: {
'/api': {
// 如果router有效优先取router返回的值
target: 'that must have a empty placeholder',
changeOrigin: true,
// 每次发起http请求都会执行router函数
router: () => (hotRequire('./src/utils/config') || {}).api || '',
ws: true,
pathRewrite: {
'^/api': ''
}
}
}
复制代码自此,我们项目修改环境地址将不在需要重启项目,也不需要维护额外的文件夹,再也不需要痛苦等待了!
来源:https://juejin.cn/post/7198696282336313400
终于理解~Android 模块化里的资源冲突
本文翻译自 Understanding resource conflicts in Android,原作者:Adam Campbell
⚽ 前言
作为 Android 开发者,我们常常需要去管理非常多不同的资源文件,编译时这些资源文件会被统一地收集和整合到同一个包下面。根据官方的《Configure your build》文档介绍的构建过程可以总结这个过程:
编译器会将源码文件转换成包含了二进制字节码、能运行在 Android 设备上的 DEX 文件,而其他文件则被转换成编译后资源。
APK 打包工具则会将 DEX 文件和编译后资源组合成独立的 APK 文件。
但如果资源的命名发生了碰撞、冲突,会对编译产生什么影响?
事实证明这个影响是不确定的,尤其是涉及到构建外部 Library。
本文将探究一些不同的资源冲突案例,并逐个说明怎样才能安全地命名资源。
🇦🇷 App module 内资源冲突
先来看个最简单的资源冲突的案例:同一个资源文件中出现两个命名、类型一样的资源定义,比如:
<!--strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
<string name="hello_world">Hello World!</string>
</resources>试图去编译的话,会导致显而易见的错误提示:
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> /.../strings.xml: Error: Found item String/hello_world more than one time类似的,另一种常见冲突是在多个文件里定义冲突的资源:
<!--strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
</resources>
<!--other_strings.xml-->
<resources>
<string name="hello_world">Hello World!</string>
</resources>我们会收到类似的编译错误,而这次的错误将列出所有发生冲突的具体文件位置。
FAILURE: Build failed with an exception.
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> [string/hello_world] /.../other_strings.xml
[string/hello_world] /.../strings.xml: Error: Duplicate resourcesAndroid 平台上资源的运作方式变得愈加清晰。我们需要为 App module 指定在类型、名称、设备配置等限定组合下的唯一资源。也就是说,当 App module 引用 string/hello_world 资源的时候,有且仅有一个值被解析出来。开发者们必须解决发生的资源冲突,可以选择删除那些内容重复的资源、重命名仍然需要的资源、亦或移动到其他限定条件下的资源文件。
更多关于资源和限定的信息可以参考官方的《App resources overview》 文档。
🇩🇪 Library 和 App module 的资源冲突
下面这个案例,我们将研究 Library module 定义了一个和 App module 重复的资源而引发的冲突。
<!--app/../strings.xml-->
<resources>
<string name="hello">Hello from the App!</string>
</resources>
<!--library/../strings.xml-->
<resources>
<string name="hello">Hello from the Library!</string>
</resources>当你编译上面的代码的时候,发现竟然通过了。从我们上个章节的发现来看,我们可以推测 Android 肯定采用了一个规则,去确保在这种场景下仍能够找到一个独有的 string/hello 资源值。
根据官方的《Create an Android library》文档:
编译工具会将来自 Library module 的资源和独立的 App module 资源进行合并。如果双方均具备一个资源 ID 的话,将采用 App 的资源。
这样的话,将会对模块化的 App 开发造成什么影响?比如我们在 Library 中定义了这么一个 TextView 布局:
<!--library/../text_view.xml-->
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/hello"
xmlns:android="http://schemas.android.com/apk/res/android" />AS 中该布局的预览是这样的。
现在我们决定将这个 TextView 导入到 App module 的布局中:
<!--app/../activity_main.xml-->
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="center"
tools:context=".MainActivity"
>
<include layout="@layout/text_view" />
</LinearLayout>无论是 AS 中预览还是实际运行,我们可以看到下面的一个显示结果:
不仅是通过布局访问 string/hello 的 App module 会拿到 “Hello from the App!”,Library 本身拿到的也是如此。基于这个原因,我们需要警惕不要无意覆盖 Lbrary 中的资源定义。
🇧🇷 Library 之间的资源冲突
再一个案例,我们将讨论下当多个 Library 里定义了冲突的资源,会发生什么。
首先来看下如下的布局,如果这样写的话会产生什么结果?
<!--library1/../strings.xml-->
<resources>
<string name="hello">Hello from Library 1!</string>
</resources>
<!--library2/../strings.xml-->
<resources>
<string name="hello">Hello from Library 2!</string>
</resources>
<!--app/../activity_main.xml-->
<TextView
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="@string/hello" />string/hello 将会被显示成什么?
事实上这取决于 App build.gradle 文件里依赖这些 Library 的顺序。再次到官方的《Create an Android library》文档里找答案:
如果多个 AAR 库之间发生了冲突,依赖列表里第一个列出(在依赖关系块的顶部)的资源将会被使用。
假使 App module 有这样的依赖列表:
dependencies {
implementation project(":library1")
implementation project(":library2")
...
}最后 string/hello 的值将会被编译成 Hello from Library 1!。
那么如果这两个 implementation 代码调换顺序,比如 implementation project(":library2") 在前、 implementation project(":library1") 在后,资源值则会被编译成 Hello from Library 2!。
从这种微妙的变化可以非常直观地看到,依赖顺序可以轻易地改变 App 的资源展示结果。
🇪🇸 自定义 Attributes 的资源冲突
目前为止讨论的示例都是针对 string 资源的使用,然而需要特别留意的是自定义 attributes 这种有趣的资源类型。
看下如下的 attr 定义:
<!--app/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable">
<attr name="freeText" format="string"/>
</declare-styleable>
<declare-styleable name="CustomStyleable2">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>大家可能都认为上面的写法能通过编译、不会报错,而事实上这种写法必将导致下面的编译错误:
Execution failed for task ':app:mergeDebugResources'.
> /.../attrs.xml: Error: Found item Attr/freeText more than one time但如果 2 个 Library 也采用了这样的自定义 attr 写法:
<!--library1/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>
<!--library2/../attrs.xml-->
<resources>
<declare-styleable name="CustomStyleable2">
<attr name="freeText" format="string"/>
</declare-styleable>
</resources>事实上它却能够通过编译。
然而,如果我们进一步将 Library2 的 attr 做些调整,比如改为 <attr name="freeText" format="boolean"/>。再次编译,它竟然又失败了,而且出现了更多令人费解的错误:
* What went wrong:
Execution failed for task ':app:mergeDebugResources'.
> A failure occurred while executing com.android.build.gradle.internal.tasks.Workers$ActionFacade
> Android resource compilation failed
/.../library2/build/intermediates/packaged_res/debug/values/values.xml:4:5-6:25: AAPT: error: duplicate value for resource 'attr/freeText' with config ''.
/.../library2/build/intermediates/packaged_res/debug/values/values.xml:4:5-6:25: AAPT: error: resource previously defined here.
/.../app/build/intermediates/incremental/mergeDebugResources/merged.dir/values/values.xml: AAPT: error: file failed to compile.上面错误的一个重点是: mergeDebugResources/merged.dir/values/values.xml: AAPT: error: file failed to compile。
到底是怎么回事呢?
事实上 values.xml 的编译指的是为 App module 生成 R 类。编译期间,AAPT 会尝试在 R 类里为每个资源属性生成独一无二的值。而对于 styleable 类型里的每个自定义 attr,都会在 R 类里生成 2 个的属性值。
第一个是 styleable 命名空间属性值(位于 R.styleable 包下),第二个是全局的 attr 属性值(位于 R.attr 包下)。对于这个探讨的特殊案例,我们则遇到了全局属性值的冲突,并且由于此冲突造成存在 3 个属性值:
R.styleable.CustomStyleable_freeText:来自 Library1,用于解析string格式的、名称为freeText的 attrR.styleable.CustomStyleable2_freeText:来自 Library2,用于解析boolean格式的、名称为freeText的 attrR.attr.freeText:无法被成功解析,源自我们给它赋予了来自 2 个 Library 的数值,而它们的格式不同,造成了冲突
前面能通过编译的示例是因为 Library 间同名的 R.attr.freeText 格式也相同,最终为 App module 编译到的是独一无二的数值。需要注意:每个 module 具备自己的 R 类,我们不能总是指望属性的数值在 Library 间保持一致。
再次看下官方的《Create an Android library》文档的建议:
当你构建依赖其他 Library 的 App module 时,Library module 们将会被编译成 AAR 文件再添加到 App module 中。所以,每个 Library 都会具备自己的
R类,用 Library 的包名进行命名。所有包都会创建从 App module 和 Library module 生成的R类,包括 App module 的包和 Library moudle 的包。
📝 结语
所以我们能从上面的这些探讨得到什么启发?
是资源编译过程的复杂和微妙吗?
确实是的。但是作为开发者,我们能为自己和团队做的是:解释清楚定义的资源想要做什么,也就是说可以加上名称前缀。我们最喜欢的官方文档《Create an Android library》也提到了这宝贵的一点:
通用的资源 ID 应当避免发生资源冲突,可以考虑使用前缀或其他一致的、对 module 来说独一无二的命名方案(抑或是整个项目都是独一无二的命名)。
根据这个建议,比较好的做法是在我们的项目和团队中建立一个模式:在 module 中的所有资源前加上它的 module 名称,例如library_help_text。
这将带来两个好处:
大大降低了名称冲突的概率。
明确资源覆盖的意图。
比如也在 App module 中创建
library_help_text的话,则表明开发者是有意地覆盖 Library module 中的某些定义。有的时候我们的确会想去覆盖一些其他资源,而这样的编码方式可以明确地告诉自己和团队,在编译的时候会发生预期的覆盖。
抛开内部开发不谈,至少是所有公开的资源都应该加上前缀,尤其是作为一个供应商或者开源项目去发布我们的 library。
可以往的经验来看,Google 自己的 library 也没有对所有的资源进行恰当地前缀命名。这将导致意外的副作用:依赖我们发行的 library 可能会因为命名冲突引发 App 编译失败。
Not a great look!
例如,我们可以看到 Material Design library 会给它们的颜色资源统一地添加 mtrl 的前缀。可是 styleable 下嵌套的 attribute resources 却没有使用 material 之类的前缀。
所以你会看到:假使一个 module 依赖了 Material library,同时依赖的另一个 library 中包含了与 Material library 一样名称的 attribute,那么在为这个 moudle 生成 R 类的时候,会发生冲突的可能。
🙏 鸣谢
本篇文章受到了下面文章或文档的启发和帮助:
📚 原文
作者:TechMerger
来源:juejin.cn/post/7170562275374268447
由浅入深,聊聊OkHttp的那些事(很长,很细节)
引言
在 Android 开发的世界中,有一些组件,无论应用层技术再怎么迭代,作为基础支持,它们依然在那里。
比如当我们提到网络库时,总会下意识想到一个名字,即 OkHttp 。
尽管对于大多数开发者而言,通常情况下使用的是往往它的封装版本 Retrofit ,不过其底层依然离不开 Okhttp 作为基础支撑。而无论是自研网络库的二次封装,还是个人使用,OkHttp 也往往都是不二之选。
故本篇将以最新视角开始,用力一瞥 OkHttp 的设计魅力。
本文对应的 OkHttp 版本: 4.10.0
本篇定位 中高难度,将从背景到使用方式,再到设计思想与源码解析,尽可能全面、易懂。
背景
每一个技术都有其变迁的历史背景与特性,本小节,我们将聊一聊 Android网络库 的迭代史,作为开篇引语,润润眼。 🔖
关于 Android网络库 的迭代历史,如下图所示:

具体进展如下:
HttpClient
Android1.0时推出。但存在诸多问题,比如内存泄漏,频繁的GC等。5.0后,已被弃用;
HttpURLConnection
Android2.2时推出,比HttpClient更快更稳定,Android4.4 之后底层已经被Okhttp替代;
Google 2013年开源,基于
HttpURLConnection的封装,具有良好的扩展性和适用性,不过对于复杂请求或者大量网络请求时,性能较差。目前依然有不少项目使用(通常是老代码的维护);
Square 2013年开源,基于 原生Http 的底层设计,具有 快速 、 稳定 、节省资源 等特点。是目前诸多热门网络请求库的底层实现,比如
Retrofit、RxHttp等;
Square 2013年开源,基于
OkHttp的封装,目前 主流 的网络请求库。
通过注解方式配置网络请求、REST风格 api、解耦彻底、经常会搭配 Rx等 实现 框架联动;
…
上述的整个过程,也正是伴随了 Android 开发的各个时期,如果将上述分为 5个阶段 的话,那么则为:
HttpClient->HttpURLConnection->volley->okhttp->Retrofit*
通过 Android网络库 的迭代历史,我们不难发现,技术变迁越来越趋于稳定,而 OkHttp 也已经成为了基础组件中不可所缺的一员。
设计思想
当聊到OkHttp的设计思想,我们想知道什么?
从应用层去看,熟练的开发者会直接喊出拦截器,巴拉巴拉…
而作为初学者,可能更希望的事广度与解惑,
OkHttp到底牛在了什么地方,或者说常说的 拦截器到底是什么 ? 🧐
在官方的描述中,OkHttp 是一个高效的 Http请求框架 ,旨在 简化 客户端网络请求,提高 请求效率。
具体设计思想与特性如下:
- 连接复用 :避免在每个请求之间重新建立连接。
- 连接池 降低了请求延迟 (HTTP/2不可用情况下);
- 自动重试 :在请求失败时自动重试请求,从而提高请求可靠性。
- 自动处理缓存 :会按照预定的缓存策略处理缓存,以便最大化网络效率。
- 支持HTTP/2, 并且允许对同一个主机的所有请求共享一个套接字(HTTP/2);
- 简化Api:Api设计简单明了,易于使用,可以轻松发起请求获取响应,并处理异常。
- 支持gzip压缩 :OkHttp支持gzip压缩,以便通过减少网络数据的大小来提高网络效率。
特别的,如果我们的服务器或者域名有 多个IP地址 ,OkHttp 将在 第一次 连接失败时尝试替代原有的地址(对于 IPv4+IPv6 和托管在冗余数据中心的服务是必需的)。并且支持现代 TLS 功能(TLS 1.3、ALPN、证书固定)。它可以配置为回退以实现广泛的连接。
总的来说,其设计思想是通过 简化请求过程 、提高请求效率、提高请求可靠性,从而提供 更快的响应速度 。
应用层的整个请求框架图如下:
使用方式
在开始探究设计原理与思想之前,我们还是要先看看最基础的使用方式,以便为后续做一些铺垫。
// build.gradle
implementation "com.squareup.okhttp3:okhttp:4.10.0"
复制代码// Android Manifest
<uses-permission android:name="android.permission.INTERNET" />
复制代码发起一个get请求
拦截器的使用
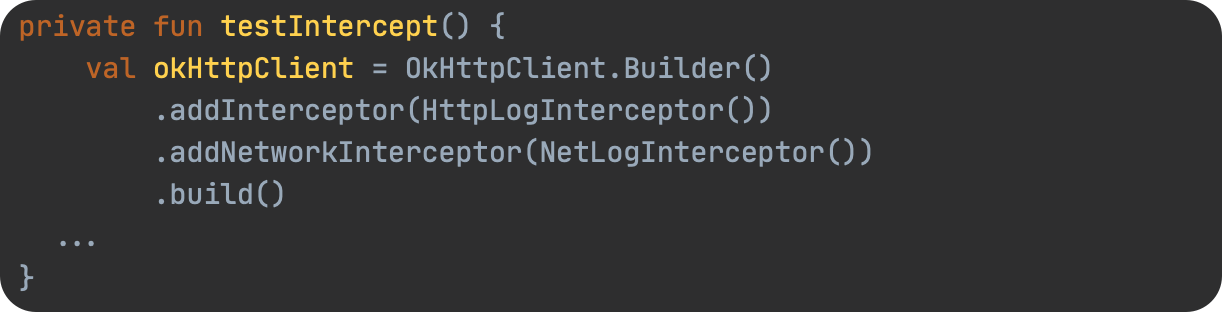
总结起来就是下面几步:
- 创建
OkHttpClient对象;
- 构建
Request;
- 调用
OkHttpClient执行request请求 ;
- 同步阻塞 或者 异步回调 方式接收结果;
更多使用方式,可以在搜索其他同学的教程,这里仅仅只是作为后续解析原理时的必要基础支撑。
源码分析
基础配置
OkHttpClient
val client = OkHttpClient.Builder().xxx.build()
复制代码由上述调用方式,我们便可以猜出,这里使用了 构建者模式 去配置默认的参数,所以直接去看 OkHttpClient.Builder 支持的参数即可,具体如下:
具体的属性意思在代码中也都有注释,这里我们就不在多提了。
需要注意的是,在使用过程中,对于 OkHttpClient 我们还是应该缓存下来或者使用单例模式以便后续复用,因为其相对而言还是比较重。
Request
指客户端发送到服务器的 HTTP请求。
在 OkHttp 中,可以使用 Request 对象来构建请求,然后使用 OkHttpClient 对象来发送请求。
通常情况下,一个请求包括了 请求头、请求方法、请求路径、请求参数、url地址 等信息。主要是用来请求服务器返回某些资源,如网页、图片、数据等。
具体源码如下所示:
Request.Builder().url("https://www.baidu.com").build()
复制代码open class Builder {
// url地址
internal var url: HttpUrl? = null
// 请求方式
internal var method: String
// 请求头
internal var headers: Headers.Builder
// 请求体
internal var body: RequestBody? = null
// 请求tag
internal var tags: MutableMap<Class<*>, Any>
}
复制代码发起请求
execute()
用于执行 同步请求 时调用,具体源码如下:
client.newCall(request).execute()
复制代码接下来我们再去看看 client.newCall() , 即请求发起时的逻辑。
当我们使用 OkHttpClient.newCall() 方法时,实际是创建了一个新的 RealCall 对象,用于 应用层与网络层之间的桥梁,用于处理连接、请求、响应以及流 ,其默认构造函数中需要传递 okhttpClient 对象以及 request 。
接着,使用了 RealCall 对象调用了其 execute() 方法开始发起请求,该方法内部会将当前的 call 加入我们 Dispatcher 分发器内部的 runningSyncCalls 队列中取,等待被执行。接着调用 getResponseWithInterceptorChain() ,使用拦截器获取本次请求响应的内容,这也即我们接下来要关注的步骤。
enqueue()
执行 异步请求 时调用,具体源码如下:
client.newCall(request).enqueue(CallBack)
复制代码
当我们调用 RealCall.enqueue() 执行异步请求时,会先将本次请求加入 Dispather.readyAsyncCalls 队列中等待执行,如果当前请求是 webSocket 请求,则查找与当前请求是同一个 host 的请求,如果存在一致的请求,则复用先前的请求。
接下来调用 promoteAndExecute() 将所有符合条件可以请求的 Call 从等待队列中添加到 可请求队列 中,再遍历该请求队列,将其添加到 线程池 中去执行。
继续沿着上面的源码,我们去看 asyncCall.executeOn(executorService) ,如下所示:
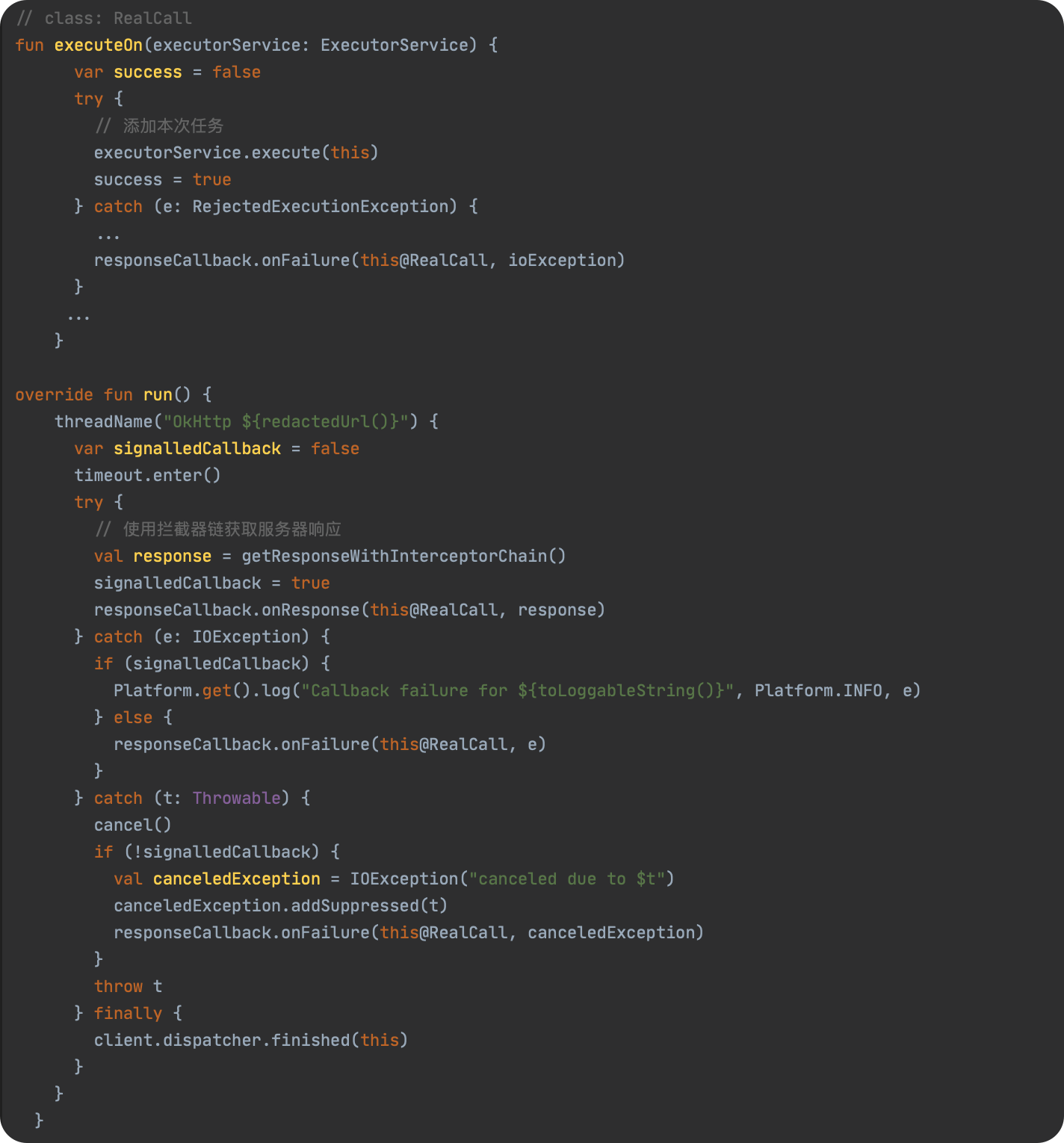
上述逻辑也很简单,当我们将任务添加到线程池后,当任务被执行时,即触发 run() 方法的调用。该方法中会去调用 getResponseWithInterceptorChain() 从而使用拦截器链获取服务器响应,从而完成本次请求。请求成功后则调用我们开始时的 callback对象 的 onResponse() 方法,异常(即失败时)则调用 onFailure() 方法。
拦截器链
在上面我们知道,他们最终都走到了 RealCall.getResponseWithInterceptorChain() 方法,即使用 拦截器链 获取本次请求的响应内容。不过对于初看OkHttp源码的同学,这一步应用会有点迷惑,拦截器链 是什么东东👾?
在解释 拦截器链 之前,我们不妨先看一下 RealCall.getResponseWithInterceptorChain() 方法对应的源码实现,然后再去解释为什么,也许更容易理解。
具体源码如下:
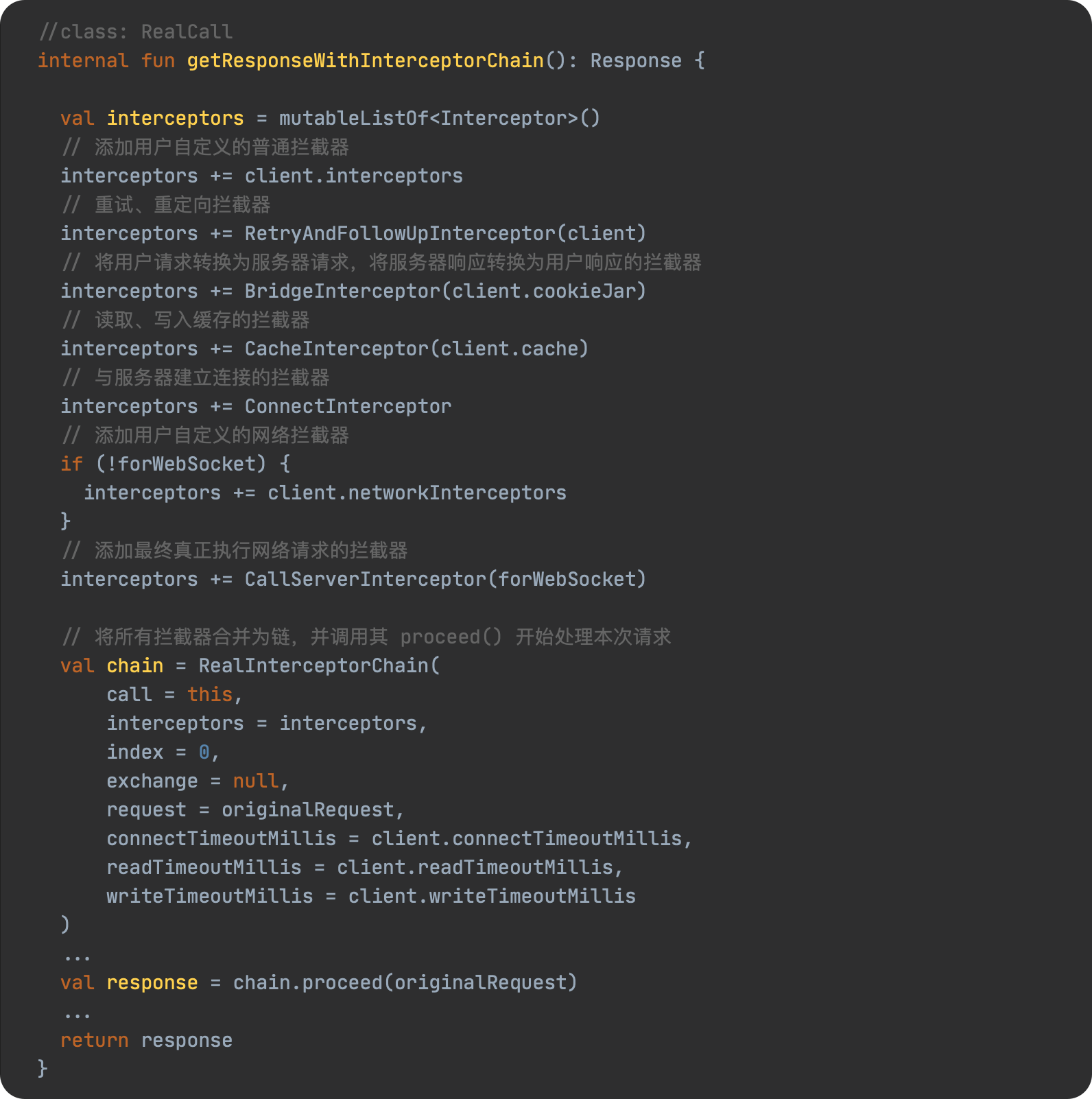
上述的逻辑非常简单,内部会先创建一个局部拦截器集合,然后将我们自己设置的普通拦截器添加到该集合中,然后添加核心的5大拦截器,接着再将我们自定义的网络拦截器也添加到该集合中,最终才添加了真正用于执行网络请求的拦截器。接着创建了一个拦截器责任链 RealInterceptorChain ,并调用其 proceed() 方法开始执行本次请求。
责任链模式
在上面我们说到了,要解释 OkHttp 的拦截器链,我们有必要简单聊一下什么是责任链模式?
责任链模式(Chain of Responsibility)是一种处理请求的模式,它让多个处理器都有机会处理该请求,直到其中某个处理成功为止。责任链模式把多个处理器串成链,然后让请求在链上传递。
摘自 责任链模式 @廖雪峰
以 Android 中常见的事件分发为例:当我们的手指点击屏幕开始,用户的触摸事件从 Activity 开始分发,接着从 windows 开始分发到具体的 contentView(ViewGroup) 上,开始调用其 dispatchTouEvent() 方法进行事件分发。在这个方法内,如果当前 ViewGroup 不进行拦截,则默认会继续向下分发,寻找当前 ViewGroup 下对应的触摸位置 View ,如果该 View 是一个 ViewGroup ,则重复上述步骤。如果事件被某个 view 拦截,则触发其 onTouchEvent() 方法,接着交由该view去消费该事件。而如果事件传递到最上层 view 还是没人消费,则该事件开始按照原路返回,先交给当前 view 自己的 onTouchEvent() ,因为自己不消费,则调用其 父ViewGroup 的 onTouchEvent() ,如此层层传递,最终又交给了 Act 自行处理。上述这个流程,就是 责任链模式 的一种体现。
如下图所示:
上图来自 Android事件分发机制三:事件分发工作流程 @一只修仙的猿
看完什么是责任链模式,让我们将思路转回到 OkHttp 上面,我们再去看一下 RealInterceptorChain 源码。
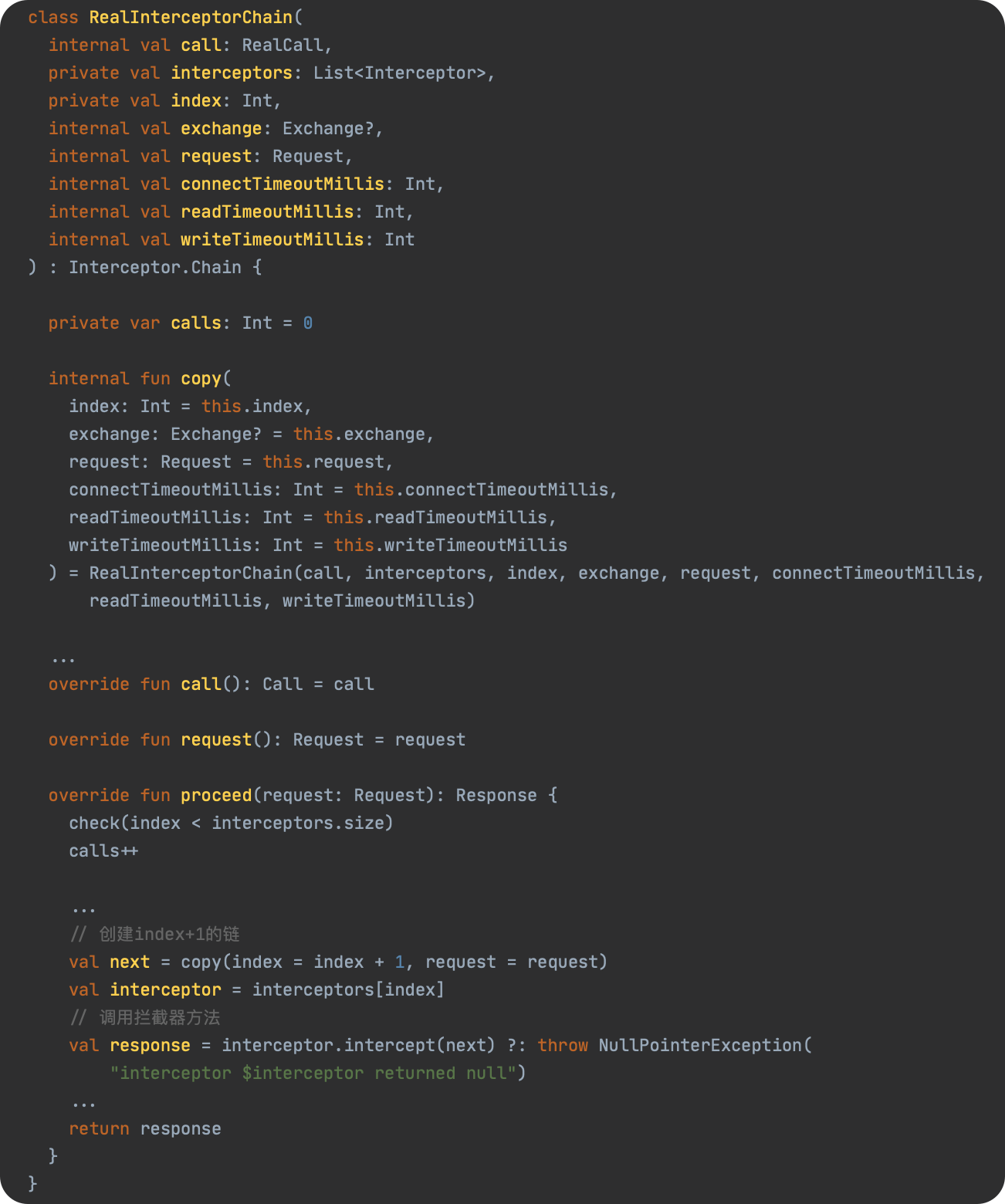
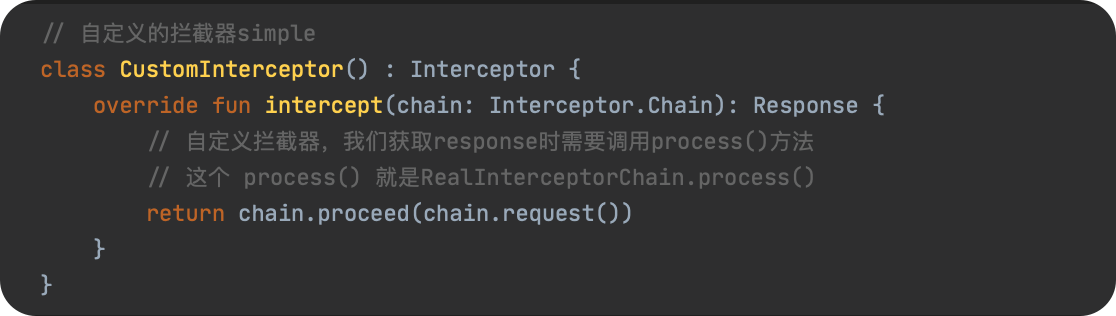
上述逻辑如下:
当
getResponseWithInterceptorChain()方法内部最终调用RealInterceptorChain.proceed()时,内部传入了一个默认的index ,这个 index 就代表了当前要调用的 拦截器item ,并在方法内部每次创建一个新的RealInterceptorChain链,index+1,再调用当前拦截器intercept()方法时,然后将下一个链传入;
最开始调用的是用户自定义的 普通拦截器,如果上述我们添加了一个
CustomLogInterceptor的拦截器,当获取response时,我们需要调用Interceptor.Chain.proceed(),而此时的chain正是下一个拦截器对应的RealInterceptorChain;
上述流程里,index从0开始,以此类推,一直到链条末尾,即 拦截器集合长度-1处;
当遇到最后一个拦截器
CallServerInterceptor时,此时因为已经是最后一个拦截器,链条肯定要结束了,所以其内部肯定也不会调用proceed()方法。
相应的,为什么我们在前面说 它 是真正执行与服务器建立实际通讯的拦截器?
因为这个里会获取与服务器通讯的
response,即最初响应结果,然后将其返回上一个拦截器,即我们的网络拦截器,再接着又向上返回,最终返回到我们的普通拦截器处,从而完成整个链路的路由。
参照上面的流程,即大致思路图如下:

拦截器
RetryAndFollowUpInterceptor
见名知意,用于 请求失败 的 重试 工作以及 重定向 的后续请求工作,同时还会对 连接 做一些初始化工作。
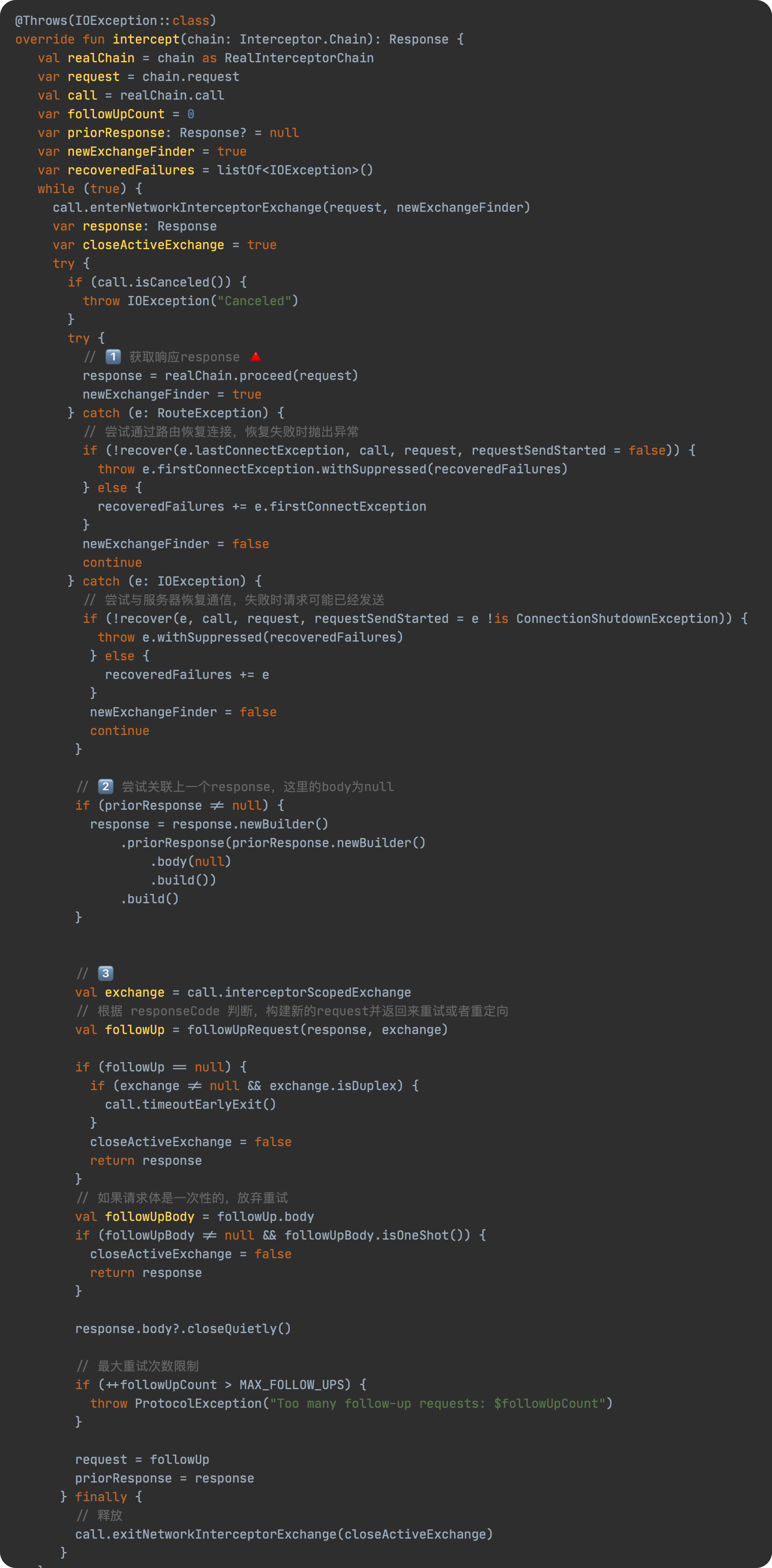
上述的逻辑,我们分为四段进行分析:
- 请求时如果遇到异常,则根据情况去尝试恢复,如果不能恢复,则抛出异常,跳过本次请求;如果请求成功,则在
finally里释放资源; - 如果请求是重试之后的请求,那么将重试前请求的响应体设置为null,并添加到当前响应体的
priorResponse字段中; - 根据当前的responseCode判断是否需要重试,若不需要,则返回
response;若需要,则返回request,并在后续检查当前重试次数是否达到阈值; - 重复上述步骤,直到步骤三成功。
在第一步时,获取 response 时,需要调用 realChain.proceed(request) ,如果你还记得上述的责任链,所以这里触发了下面的拦截器执行,即 BridgeInterceptor 。
BridgeInterceptor
用于 客户端和服务器 之间的沟通 桥梁 ,负责将用户构建的请求转换为服务器需要的请求。比如添加 content-type、cookie 等,再将服务器返回的 response 做一些处理,转换为客户端所需要的 response,比如移除 Content-Encoding ,具体见下面源码所示:
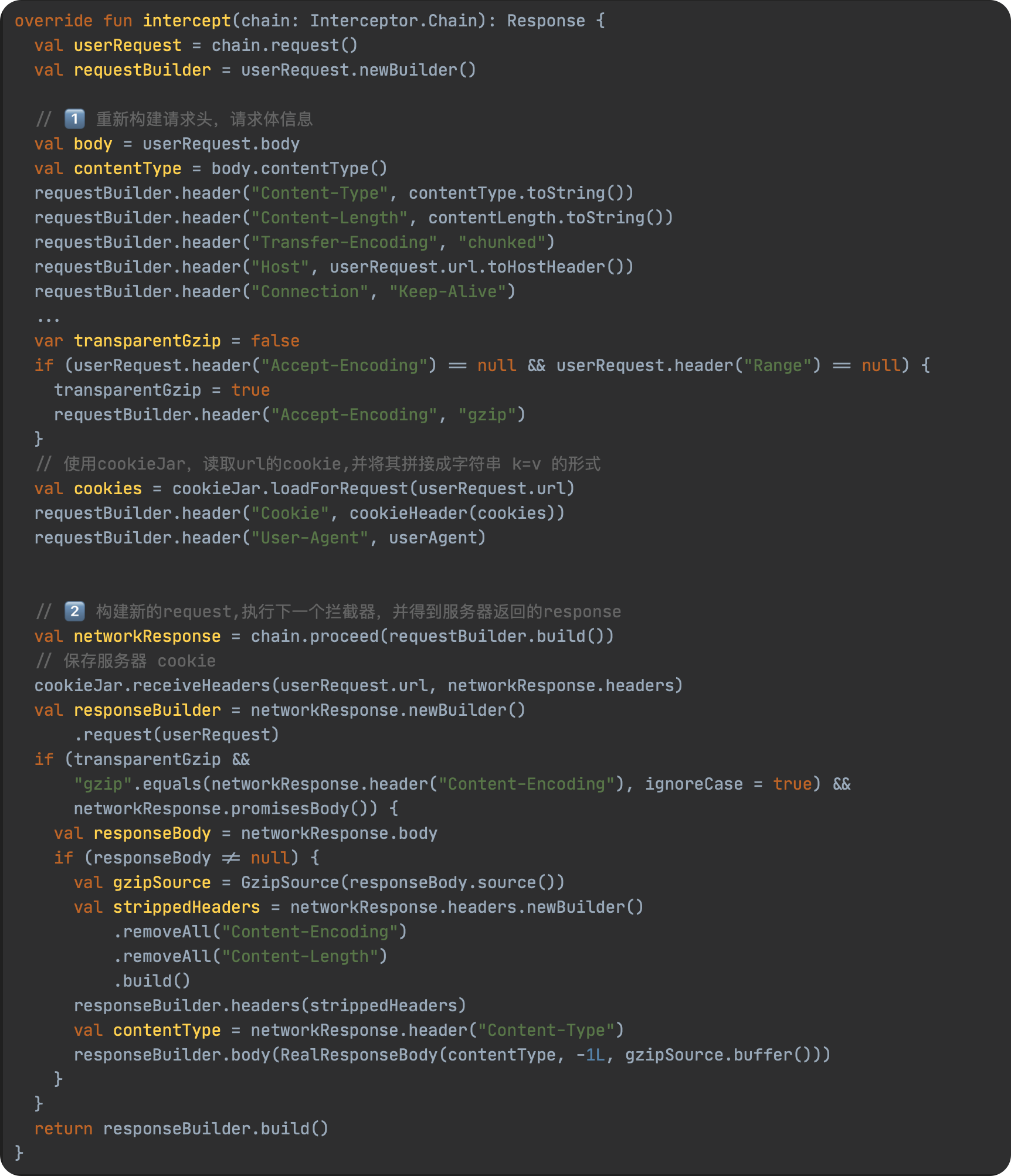
上述逻辑如下:
- 首先调用
chain.request()获取原始请求数据,然后开始重新构建请求头,添加header以及cookie等信息; - 将第一步构建好的新的
request传入chain.proceed(),从而触发下一个拦截器的执行,并得到 服务器返回的response。然后保存response携带的cookie,并移除header中的Content-Encoding和Content-Length,并同步修改body。
CacheInterceptor
见名知意,其用于网络缓存,开发者可以通过 OkHttpClient.cache() 方法来配置缓存,在底层的实现处,缓存拦截器通过 CacheStrategy 来判断是使用网络还是缓存来构建 response。具体的 cache 策略采用的是 DiskLruCache 。
Cache的策略如下图所示:
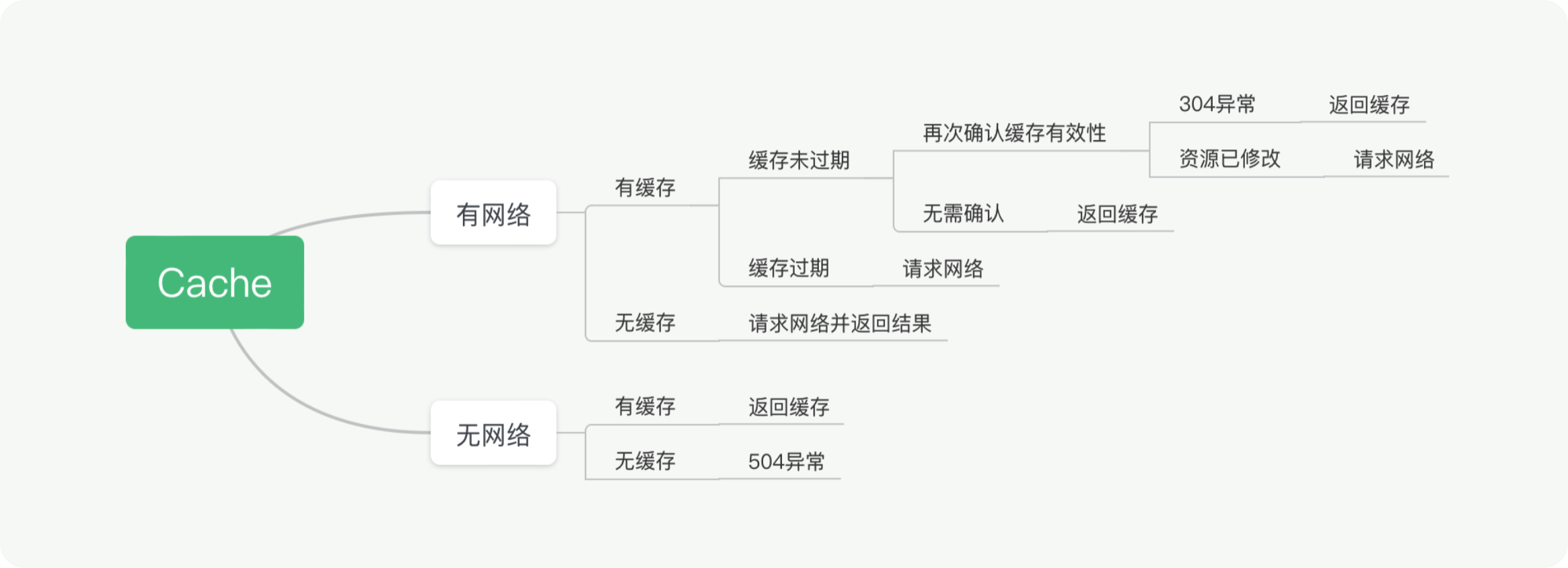
具体源码如下所示:
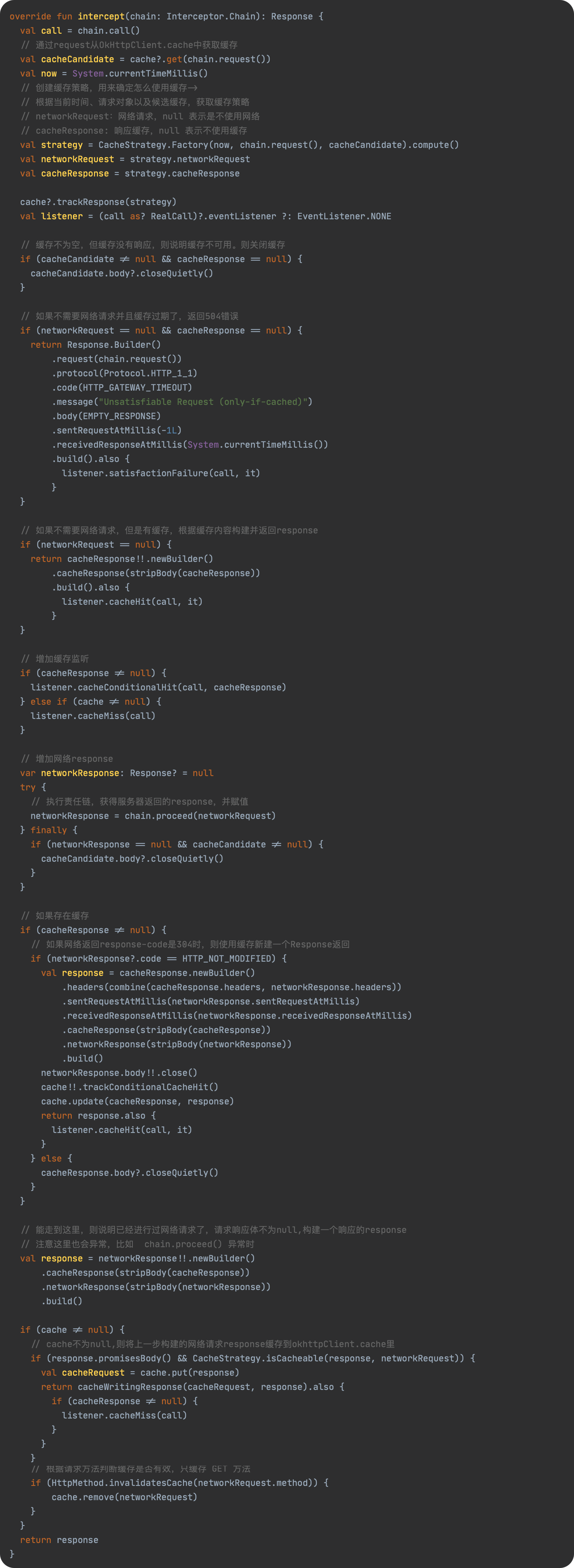
具体的逻辑如上图所示,具体可以参照上述的 Cache 流程图,这里我们再说一下 CacheStrategy 这个类,即决定何时使用 网络请求、响应缓存。
CacheStrategy
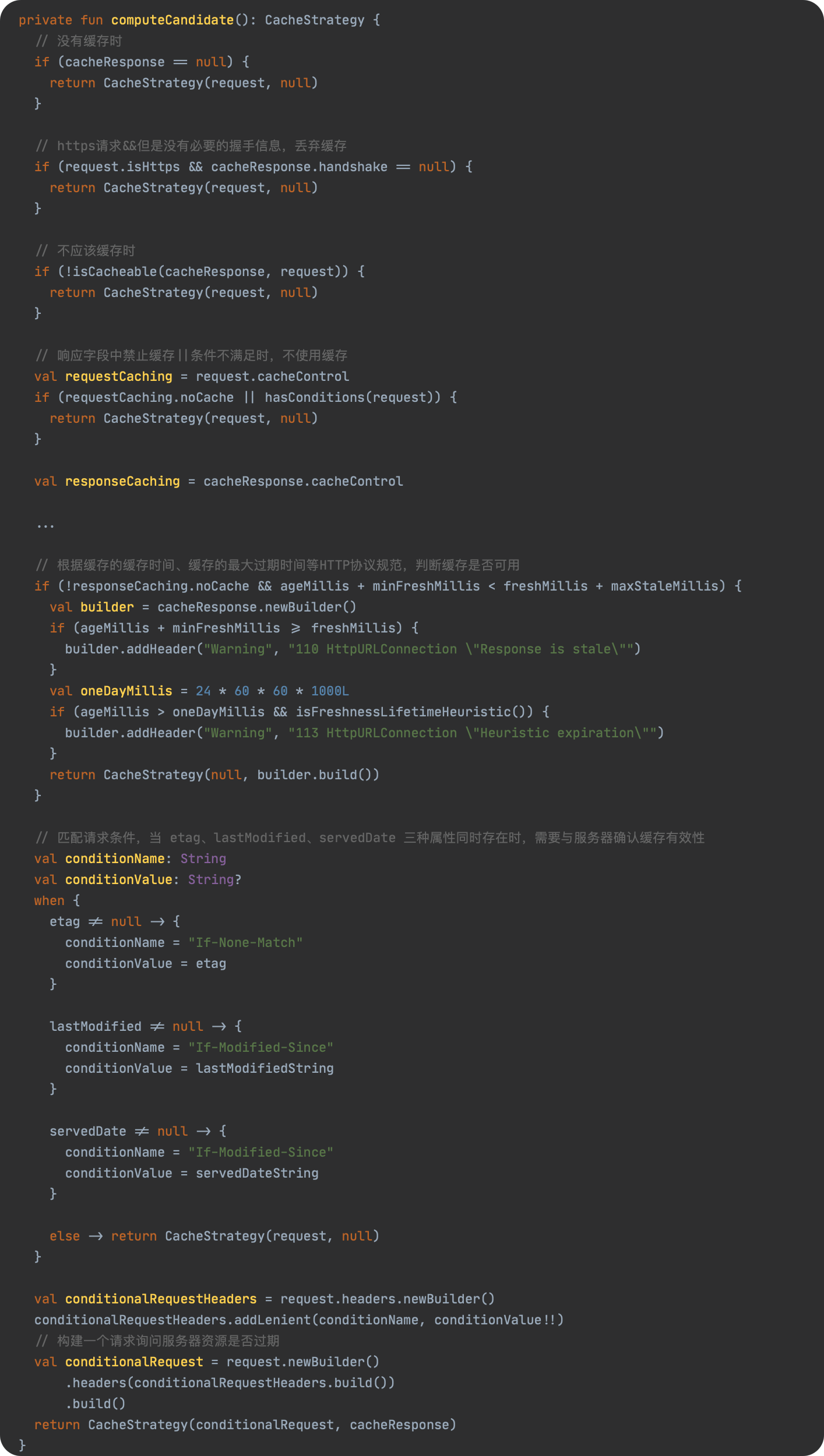
ConnectInterceptor
实现与服务器真正的连接。
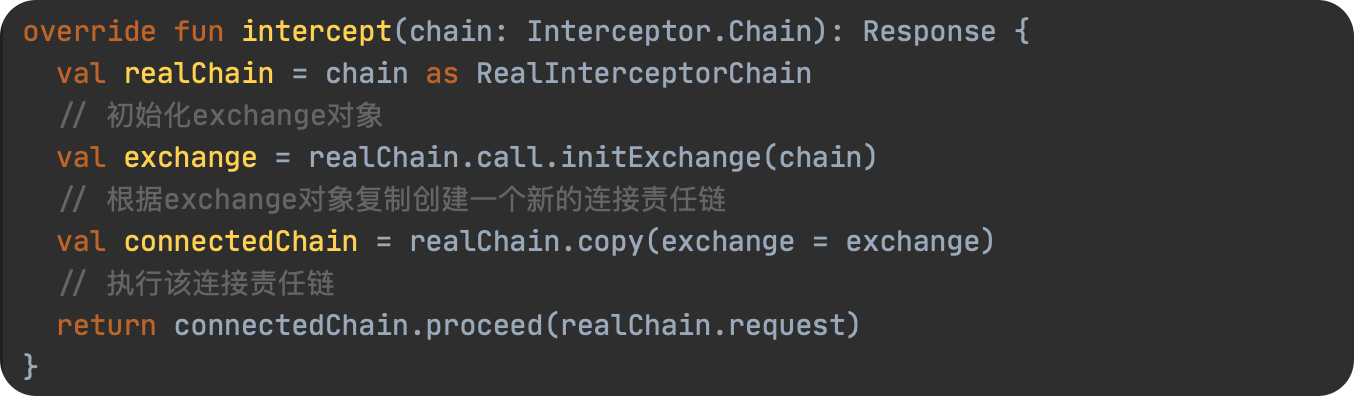
上述流程如下:
- 初始化 一个
exchange对象; - 根据
exchange对象来复制创建一个新的连接责任链; - 执行该连接责任链。
那 Exchange 是什么呢?
在官方的解释里,其用于 传递单个
HTTP请求和响应对,在ExchangeCode的基础上担负了一些管理及事件分发的作用。
具体而言,
Exchange与Request相对应,新建一个请求时就会创建一个Exchange,该Exchange负责将这个请求发送出去并读取到响应数据,而具体的发送与接收数据使用的则是ExchangeCodec。
相应的,ExchangeCode 又是什么呢?
ExchangeCodec负责对request编码及解码Response,即写入请求及读取响应,我们的请求及响应数据都是通过它来读写。
通俗一点就是,ExchangeCodec 是请求处理器,它内部封装了
OkHttp中执行网络请求的细节实现,其通过接受一个Request对象,并在内部进行处理,最终生成一个符合HTTP协议标准的网络请求,然后接受服务器返回的HTTP响应,并生成一个Response对象,从而完成网络请求的整个过程。
额外的,我们还需要再提一个类,ExchangeFinder 。
用于寻找可用的
Exchange,然后发送下一个请求并接受下一个响应。
虽然上述流程看起来似乎很简单,但我们还是要分析下具体的流程,源码如下所示:
RealCall.initExchange()
初始化 Exchage 的过程。
从 ExchangeFinder 找到一个新的或者已经存在的 ExchangeCodec,然后初始化 Exchange ,以此来承载接下来的HTTP请求和响应对。
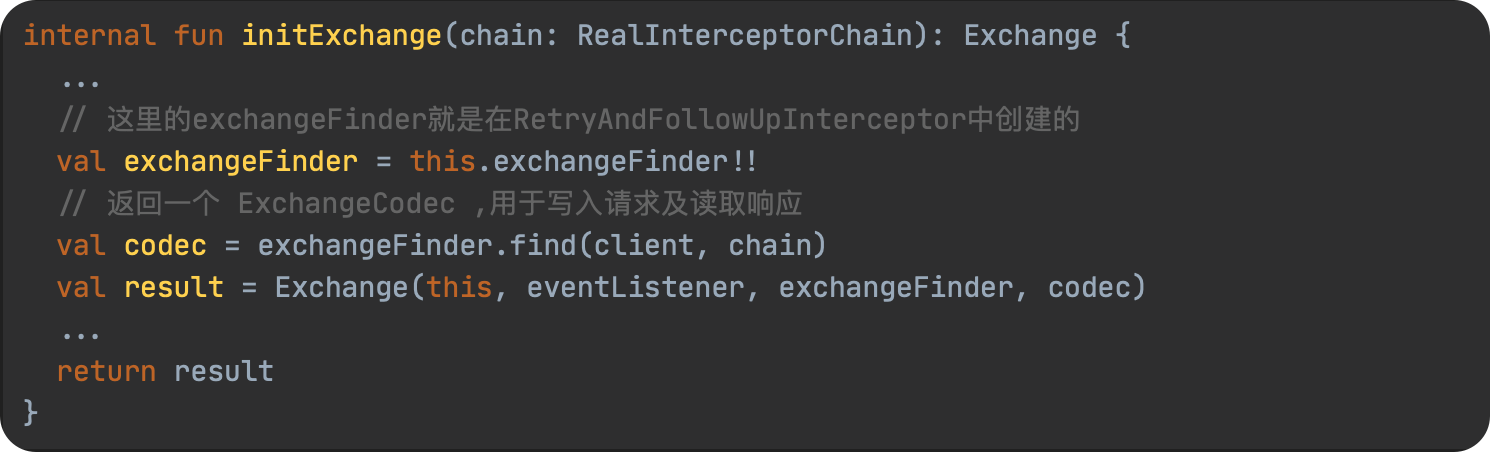
ExchangeFinder.find()
查找 ExchangeCodec(请求响应编码器) 的过程。
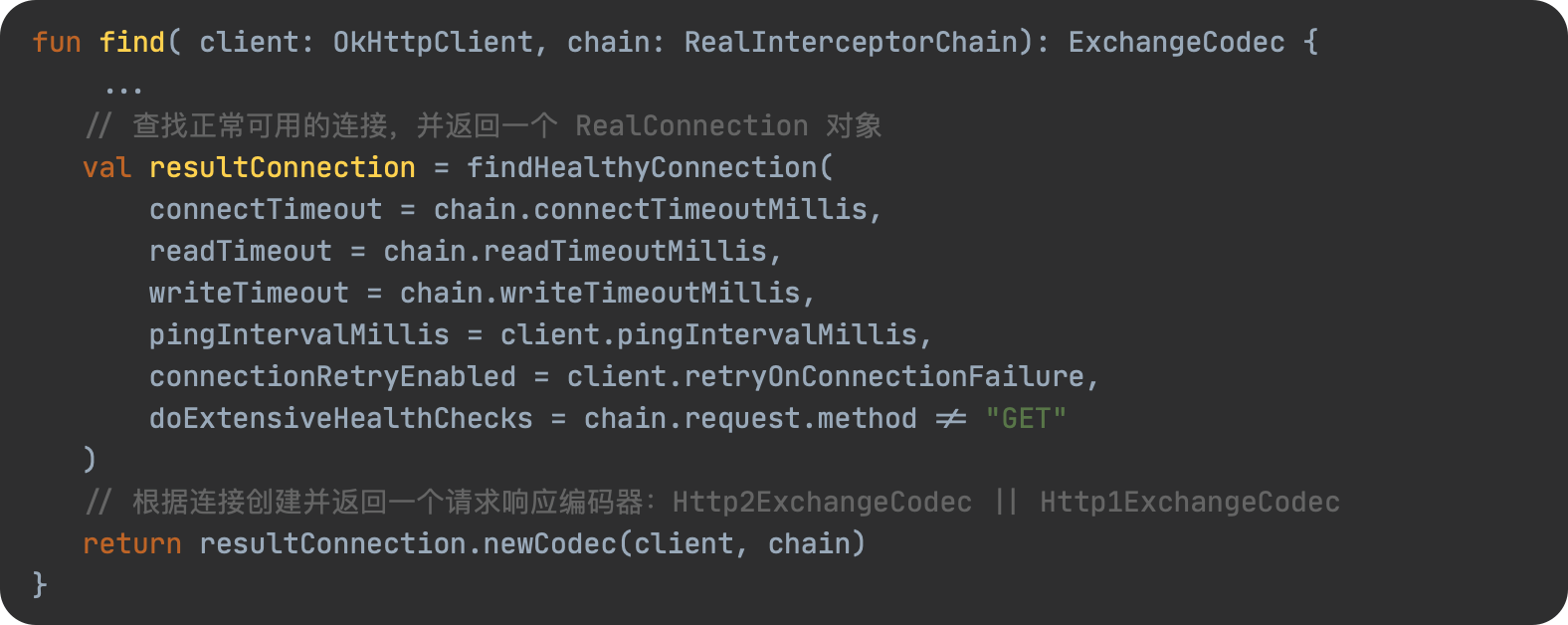
接下来我们看看查找 RealConnection 的具体过程:
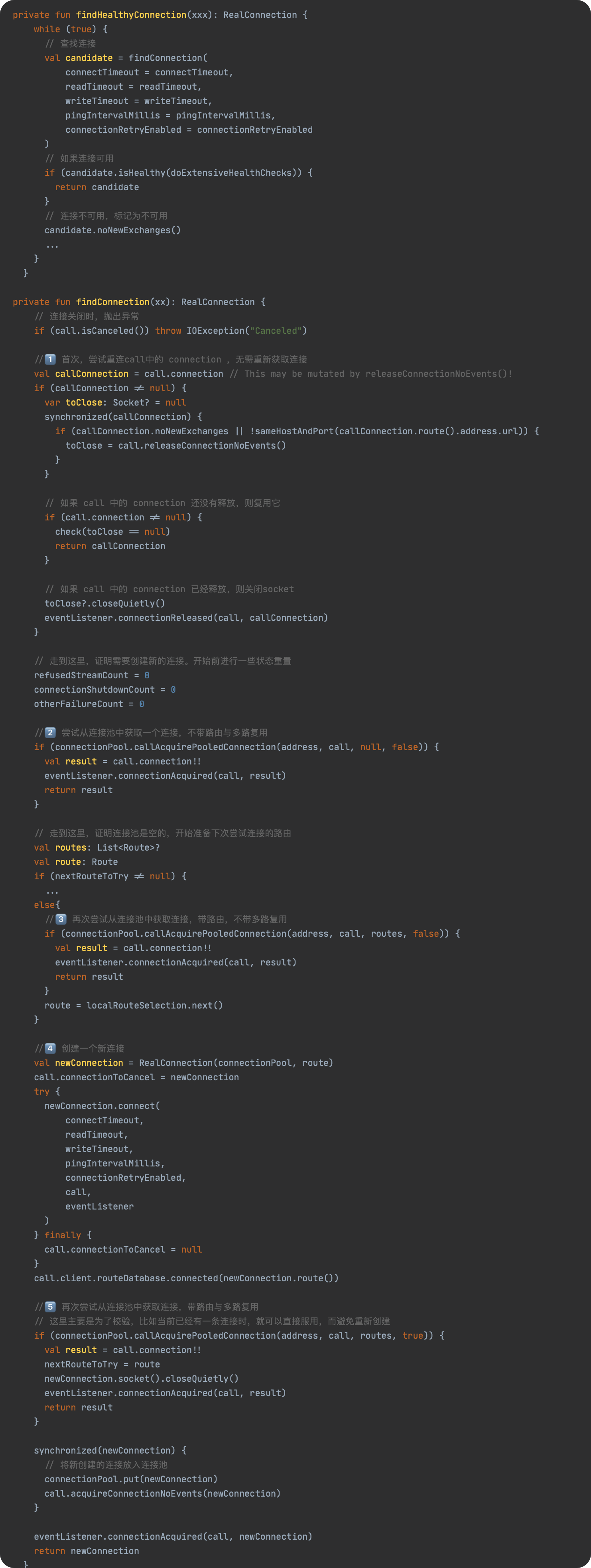
上述的整个流程如下:
上述会先通过 ExchangeFinder 去 RealConnecionPool 中尝试寻找已经存在的连接,未找到则会重新创建一个 RealConnection(连接) 对象,并将其添加到连接池里,开始连接。然后根据找到或者新创建 RealConnection 对象,并根据当前请求协议创建不同的 ExchangeCodec 对象并返回,最后初始化一个 Exchange 交换器并返回,从而实现了 Exchange 的初始化过程。
在具体找寻 RealConnection 的过程中,一共尝试了5次,具体如下:
- 尝试重连
call中的connection,此时不需要重新获取连接; - 尝试从连接池中获取一个连接,不带路由与多路复用;
- 再次尝试从连接池中获取一个连接,带路由,不带多路复用;
- 手动创建一个新连接;
- 再次尝试从连接池中获取一个连接,带路由与多路复用;
当 Exchange 初始化完成后,再复制该对象创建一个新的 Exchange ,并执行下一个责任链,从而完成连接的建立。
networkInterceptors
网络拦截器,即 client.networkInterceptors 中自定义拦截器,与普通的拦截器 client.interceptors 不同的是:
由于网络拦截器处于倒数第二层,在 RetryAndFollowUpInterceptor 失败或者 CacheInterceptor 返回缓存的情况下,网络拦截器无法被执行。而普通拦截器由于第一步就被就执行到,所以不受这个限制。
CallServerInterceptor
链中的最后一个拦截器,也即与服务器进行通信的拦截器,利用 HttpCodec 进行数据请求、响应数据的读写。
具体源码如下:
先写入要发送的请求头,然后根据条件判断是否写入要发送的请求体。当请求结束后,解析服务器返回的响应头,构建一个新的 response 并返回;如果 response.code 为 100,则重新读取响应体并构建新的 response。因为这是最底层的拦截器,所以这里肯定不会再调用 proceed() 再往下执行。
小结
至此,关于 OkHttp 的分析,到这里就结束了。为了便于理解,我们再串一遍整个思路:
在 OkHttp 中,RealCall 是 Call 的实现类,其负责 执行网络请求 。其中,请求 request 由 Dispatcher 进行调度,其中 异步调用 时,会将请求放到到线程池中去执行; 而同步的请求则只是会添加到 Dispatcher 中去管理,并不会有线程池参与协调执行。
在具体的请求过程中,网络请求依次会经过下列拦截器组成的责任链,最后发送到服务器。
- 普通拦截器,
client.interceptors(); - 重试、重定向拦截器
RetryAndFollowUpInterceptor; - 用于客户端与服务器桥梁,将用户请求转换为服务器请求,将服务器响应转换为用户响应的的
BridgeInterceptor; - 决定是否需要请求服务器并写入缓存再返回还是直接返回服务器响应缓存的
CacheInterceptor; - 与服务器建立连接的
ConnectInterceptor; - 网络拦截器,
client.networkInterceptors(); - 执行网络请求的
CallServerInterceptor;
而相应的服务器响应体则会从 CallServerInterceptor 开始依次往前开始返回,最后由客户端进行处理。
需要注意的是,当我们
RetryAndFollowUpInterceptor异常或者CacheInterceptor拦截器直接返回了有效缓存,后续的拦截器将不会执行。
常见问题
OkHttp如何判断缓存有效性?
这里其实主要说的是 CacheInterceptor 拦截器里的逻辑,具体如下:
OkHttp 使用 HTTP协议 中的 缓存控制机制 来判断缓存是否有效。如果请求头中包含 "Cache-Control" 和 "If-None-Match" / "If-Modified-Since" 字段,OkHttp 将根据这些字段的值来决定是否使用缓存或从网络请求响应。
Cache-Control指 包含缓存控制的指令,例如 "no-cache" 和 "max-age" ;
If-None-Match指 客户端缓存的响应的ETag值,如果服务器返回相同的 ETag 值,则说明响应未修改,缓存有效;
If-Modified-Since指 客户端缓存的响应的最后修改时间,如果服务器确定响应在此时间后未更改,则返回304 Not Modified状态码,表示缓存有效。
相应的,OkHttp 也支持自定义缓存有效性控制,开发者可以创建一个 CacheControl 对象,并将其作为请求头添加到 Request 中,如下所示:
// 禁止OkHttp使用缓存
val cacheControl = CacheControl.Builder()
.noCache()
.build()
val request = Request.Builder()
.cacheControl(cacheControl)
.url("https://www.baidu.com")
.build()
复制代码OkHttp如何复用TCP连接?
这个其实主要说的是 ConnectInterceptor 拦截器中初始化 Exchange 时内部做的事,具体如下:
OkHttp 使用连接池 RealConnectionPool 管理所有连接,连接池将所有活动的连接存储在池中,并维护了一个空闲的连接列表(TaskQueue),当需要新的连接时,优先尝试从这个池中找,如果没找到,则 重新创建 一个 RealConnection 连接对象,并将其添加到连接池中。在具体的寻找连接的过程中,一共进行了下面5次尝试:
- 尝试重连
RealCall中的connection,此时不需要重新获取连接; - 尝试从连接池中获取一个连接,不带路由与多路复用;
- 再次尝试从连接池中获取一个连接,带路由,不带多路复用;
- 手动创建一个新连接;
- 再次尝试从连接池中获取一个连接,带路由与多路复用;
当然 OkHttp 也支持自定义连接池,具体如下:

上述代码中,创建了一个新的连接池,并设置其保留最多 maxIdleConnections 个空闲连接,并且连接的存活期为 keepAliveDuration 分钟。
OKHttp复用TCP连接的好处是什么?
OkHttp 是由连接池管理所有连接,通过连接池,从而可以限制连接的 最大数量,并且对于空闲的连接有相应的 存活期限 ,以便在长时间不使用后关闭连接。当请求结束时,并且将保留该连接,便于后续 复用 。从而实现了在多个请求之间共享连接,避免多次建立和关闭TCP连接的开销,提高请求效率。
OkHttp中的请求和响应 与 网络请求和响应,这两者有什么不同?
OkHttp 中的的请求和响应指的是客户端创建的请求对象 Request 和 服务端返回的响应对象 Response,这两个对象用于定义请求和响应的信息。网络请求和响应指的是客户端向服务端发送请求,服务端返回相应的过程。
总的来说就是,请求和响应是应用程序内部自己的事,网络请求和响应则是发生在网络上的请求和响应过程。
OkHttp 应用拦截器和网络拦截器的区别?
- 从调用方式上而言,应用拦截器指的是
OkhttpClient.intercetors,网络拦截器指的是OkHttpClient.netIntercetors。 - 从整个责任链的调用来看,应用拦截器一定会被执行一次,而网络拦截器不一定会执行或者执行多次情况,比如当我们
RetryAndFollowUpInterceptor异常或者CacheInterceptor拦截器直接返回了有效缓存,后续的拦截器将不会执行,相应的网络拦截器也自然不会执行到;当我们发生 错误重试 或者 网络重定向 时,网络拦截器此时可能就会执行多次。 - 其次,除了
CallServerInterceptor与CacheIntercerceptor缓存有效之外,每个拦截器都应该至少调用一次realChain.proceed()方法。但应用拦截器可以调用多次processed()方法,因为其在请求流程中是可以递归调用;而网络拦截器只能调用一次processed()方法,否则将导致请求重复提交,影响性能,另外,网络拦截器没有对请求做修改的可能性,因此不需要再次调用processed()方法。 - 从 使用方式的 本质而言,应用拦截器可以 拦截和修改请求和响应 ,但 不能修改网络请求和响应 。比如使用应用拦截器添加请求参数、缓存请求结果;网络拦截器可以拦截和修改网络请求和响应。例如使用网络拦截器添加请求头、修改请求内容、检查响应码等。
- 在相应的执行顺序上,网络拦截器是
先进先出(FIFO),应用拦截器是先进后出(FILO)的方式执行。
结语
本篇中,我们从网络库的迭代历史,一直到 OkHttp 的使用方式、设计思想、源码探索,最后又聊了聊常见的一些问题,从而较系统的了解了 OkHttp 的方方面面,也解释了 OkHttp应用层 的相关问题,当然这些问题我相信也仅仅只是冰山一角🧩。 更多面试相关,或者实际问题,仍需要我们自己再进行完善,从而形成全面的透析力。
这篇文章断断续续写了将近两周,其中肯定有不少部分存在缺陷或者逻辑漏洞,如果您发现了,也可以告诉我。
通过这篇文章,于我个人而言,也是完成了对于 OkHttp应用层 一次较系统的了解,从而也完善了知识拼图中重要的一块,期待作为读者的你也能有如此或者更深的体会。🏃🏻
更多
这是 解码系列 - OkHttp 篇,如果你觉得这个系列写的还不错,不妨点个关注催更一波,当然也可以看看其他篇:
参阅
链接:https://juejin.cn/post/7199431845367922745
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android电量优化,让你的手机续航更持久
节能减排,从我做起。一款Android应用如果非常耗电,是一定会被主人嫌弃的。自从Android手机的主人用了你开发的app,一天下来,也没干啥事,电就没了。那么他就会想尽办法找出耗电量杀手,当他找出后,很有可能你开发的app就被无情的卸载了。为了避免这种事情发生,我们就要想想办法让我们的应用不那么耗电,电都用在该用的时候和地方。
通过power_profile.xml查看各个手机硬件的耗电量
Google要求手机硬件生产商都要放入power_profile.xml文件到ROM里面。有些不太负责的手机生产商,就乱配,也没有真正测试过。但我们还是可以大概知道耗电的硬件都有哪些。
先从ibotpeaches.github.io/Apktool/ 下载apktool反编译工具,然后执行adb命令,将手机framework的资源apk拉取出来。
adb pull /system/framework/framework-res.apk ./然后我们用下载好的反编译工具,将framework-res.apk进行反编译。
java -jar apktool_2.7.0.jar d framework-res.apkapktool_2.7.0.jar换成你下载的具体的jar包名称。 power_profile.xml文件的目录如下:
framework-res/res/xml/power_profile.xml
<?xml version="1.0" encoding="utf-8"?>
<device name="Android">
<item name="ambient.on">0.1</item>
<item name="screen.on">0.1</item>
<item name="screen.full">0.1</item>
<item name="bluetooth.active">0.1</item>
<item name="bluetooth.on">0.1</item>
<item name="wifi.on">0.1</item>
<item name="wifi.active">0.1</item>
<item name="wifi.scan">0.1</item>
<item name="audio">0.1</item>
<item name="video">0.1</item>
<item name="camera.flashlight">0.1</item>
<item name="camera.avg">0.1</item>
<item name="gps.on">0.1</item>
<item name="radio.active">0.1</item>
<item name="radio.scanning">0.1</item>
<array name="radio.on">
<value>0.2</value>
<value>0.1</value>
</array>
<array name="cpu.active">
<value>0.1</value>
</array>
<array name="cpu.clusters.cores">
<value>1</value>
</array>
<array name="cpu.speeds.cluster0">
<value>400000</value>
</array>
<array name="cpu.active.cluster0">
<value>0.1</value>
</array>
<item name="cpu.idle">0.1</item>
<array name="memory.bandwidths">
<value>22.7</value>
</array>
<item name="battery.capacity">1000</item>
<item name="wifi.controller.idle">0</item>
<item name="wifi.controller.rx">0</item>
<item name="wifi.controller.tx">0</item>
<array name="wifi.controller.tx_levels" />
<item name="wifi.controller.voltage">0</item>
<array name="wifi.batchedscan">
<value>.0002</value>
<value>.002</value>
<value>.02</value>
<value>.2</value>
<value>2</value>
</array>
<item name="modem.controller.sleep">0</item>
<item name="modem.controller.idle">0</item>
<item name="modem.controller.rx">0</item>
<array name="modem.controller.tx">
<value>0</value>
<value>0</value>
<value>0</value>
<value>0</value>
<value>0</value>
</array>
<item name="modem.controller.voltage">0</item>
<array name="gps.signalqualitybased">
<value>0</value>
<value>0</value>
</array>
<item name="gps.voltage">0</item>
</device>抓到不负责任的手机生产商一枚,好家伙,这么多0.1,明眼人一看就知道这是为了应付Google。尽管这样,我们还是可以从中知道,耗电的有Screen(屏幕亮屏)、Bluetooth(蓝牙)、Wi-Fi(无线局域网)、Audio(音频播放)、Video(视频播放)、Radio(蜂窝数据网络)、Camera的Flashlight(相机闪光灯)和GPS(全球定位系统)等。
电量杀手简介
Screen
屏幕是非常耗电的一个硬件,不要问我为什么。屏幕主要有LCD和OLED两种。LCD屏幕白色光线从屏幕背后的灯管发出,尽管屏幕显示黑屏,依旧耗电,这种屏幕逐渐被淘汰,如果你翻出个早点的功能机,或许能看到。那么大部分Android手机都是OLED的屏幕,每个像素点都是独立的发光单元,屏幕黑屏时,所有像素都不发光。有必要时,让屏幕息屏很重要,当然手机也有自动息屏的时间设置,这个不太需要我们操心。
Radio数据网络和Wi-Fi无线网络
网络也是非常耗电的,其中又以数据网络的耗电更多于Wi-Fi的耗电。所以请尽量引导用户使用Wi-Fi网络使用app的部分功能,比如下载文件。
GPS
GPS也是很耗电的硬件,所以不要动不动就请求地理位置,GPS平常是要关闭的,除非你在使用定位和导航等功能,这样你的手机续航会更好。
WakeLock
如果使用了WakeLock,是可以有效防止息屏情况下的CPU休眠,但是如果不用了,你不释放掉锁的话,则会带来很大的电量的开销。
查看手机耗电的历史记录
// 上次拔掉电源到现在的耗电情况
adb shell dumpsys batterystats --unplugged你在逗我?让我看命令行的输出?后面我们来使用Battery Historian的图表进行分析。
使用Battery Historian分析手机耗电量
安装Docker
Docker下载网址 docs.docker.com/desktop/ins…
使用Docker容器编排
docker run -p 9999:9999 gcr.io/android-battery-historian/stable:3.0 --port 9999获取bugreport文件
Android7.0及以上
adb bugreport bugreport.zipAndroid6.0及以下
adb bugreport > bugreport.txt上传bugreport文件进行分析
在浏览器地址栏输入http://localhost:9999
点击Browse按钮并上传bugreport.zip或bugreport.txt生成分析图表。
我们可以通过时间轴来分析应用当下的电池使用情况,比较耗电的是哪部分硬件。
使用JobScheduler来合理执行后台任务
JobScheduler是Android5.0版本推出的API,允许开发者在符合某些条件时创建执行在后台的任务。比如接通电源的情况下才执行某些耗电量大的操作,也可以把一些不紧急的任务在合适的时候批量处理,还可以避开低电量的情况下执行某些任务。
作者:dora
来源:juejin.cn/post/7196321890301575226
安卓开发基础——弱引用的使用
前言
起因
今天开发遇到一个问题,就是在快速点击带点击事件的控件,如果控件里面写的是Dialog弹窗就有概率出现弹窗连续在界面上出现两次,也就是你关闭弹窗后发现还有一个一样的弹窗在界面,这样就会带来不好的体验。
结果
2月9日
在网上查了许多解决方法,就有提到将该Dialog变成类的成员变量,不用每次都new就可能避免这种情况出现,但我着实不清楚为什么以及具体怎么做,于是请教了组里的大哥,大哥和我说他之前也处理过这种问题,使用了弱引用,可我还是不知道具体的实现方式,于是便找到大哥的代码,并在网上了解了弱引用的具体作用。
2月10日
今天我请教了我们掘金开发群的Java大佬,他告诉我,我这个写法仍然避免不了弹两次Dialog的,并给出意见,可以使用共享状态,推荐我创建一个共享的ReentrantLock,不过我还没去实现,等有时间再看看。
下面就让我们看看弱引用到底是什么。
正篇
弱引用的概念
想知道弱引用,那就得知道几个名词:
强引用
软引用
弱引用
虚引用
首先我们来看看这些词的概念:
强引用
强引用(StrongReference):最传统的“引用”的定义,是指在程序代码之中普遍存在的引用赋值,即类似“Object obj = new Object()”这种引用关系。无论任何情况下,只要强引用关系还存在,垃圾收集器就永远不会回收掉被引用的对象。
软引用
软引用(SoftReference):在系统将要发生内存溢出之前,将会把这些对象列入回收范围之中进行第二次回收。如果这次回收后还没有足够的内存,才会抛出内存流出异常。
弱引用
弱引用(WeakReference):被弱引用关联的对象只能生存到下一次垃圾收集之前。当垃圾收集器工作时,无论内存空间是否足够,都会回收掉被弱引用关联的对象。
虚引用
虚引用(PhantomReference):一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来获得一个对象的实例。为一个对象设置虚引用关联的唯一目的就是能在这个对象被收集器回收时收到一个系统通知。
以上定义都是参考自知乎回答 :强引用、软引用、弱引用、虚引用有什么区别?具体使用场景是什么? - 知乎 (zhihu.com),从这我们可以了解到其实我们Java中new对象就是强引用,强引用的对象是可触及的,垃圾收集器就永远不会回收掉被引用的对象,也就简而言之对象在引用时,不回收,上面说的文章中也举例说明了强引用的特点:
而我们本篇说的弱引用,则是发现即回收,它通常是用来描述那些非必需对象,只被弱引用关联的对象只能生存到下一次垃圾收集发生为止。在系统GC时,只要发现弱引用,不管系统堆空间使用是否充足,都会回收掉只被弱引用关联的对象。
但是,又因为垃圾回收器的线程通常优先级很低,所以,一般并不一定能很快地发现持有弱引用的对象,而在这种情况下,弱引用对象就可以存在较长的时间。
而如何使用弱引用,我们接着往下看:
使用方法
前言提到我们使用了弱引用在开发中大哥已经使用过,所以我就跟着后面仿写一下就好,而知乎的那篇文章也提到:
这就基本是弱引用的定义方法,因为之前前言说的Dialog问题弱引用并没有真正起效果,所以我们换一种方法去展示他在安卓上的使用,那就是在使用Bitmap时防止OOM,写法如下:
ImageView imageView = findViewById(R.id.vImage);
Bitmap bitmap = BitmapFactory.decodeResource(getResources(),R.drawable.ic_launcher_background);
Drawable drawable = new BitmapDrawable(getResources(), bitmap);
WeakReference<Drawable> weakDrawable = new WeakReference<>(drawable);
Drawable bgDrawable = weakDrawable.get();
if(bgDrawable != null) {
imageView.setBackground(drawable);
}我们再对比一下普通的强引用方法:
ImageView imageView = findViewById(R.id.vImage);
Bitmap bitmap = BitmapFactory.decodeResource(getResources(),R.drawable.ic_launcher_background);
Drawable drawable = new BitmapDrawable(getResources(), bitmap);
imageView.setBackground(drawable);其实,就是对drawable对象从强引用转为弱引用,这样一旦出现内存不足,不会直接去使用drawable对象,让JVM自动回收这些缓存图片对象所占用的空间,从而有效地避免了OOM的问题。
总结
其实这块内容需要对GC机制很熟悉,我不是很熟,所以使用可能也出现不对,希望读者可以积极指正,谢谢观看!
作者:ObliviateOnline
来源:juejin.cn/post/7198519499867815997
Flutter Android多窗口方案落地(下)
插件层封装。插件层就很简单了,创建好
MethodCallHandler之后,直接持有单例的EngineManager就可以了。
class FlutterMultiWindowsPlugin : FlutterPlugin, MethodCallHandler {
companion object {
private const val TAG = "MultiWindowsPlugin"
}
• @SuppressLint("LongLogTag")
• override fun onAttachedToEngine(@NonNull flutterPluginBinding: FlutterPlugin.FlutterPluginBinding) {
• Log.i(TAG, "onMessage: onAttachedToEngine")
• Log.i(TAG, "onAttachedToEngine: ${Thread.currentThread().name}")
• MessageHandle.init(flutterPluginBinding.applicationContext)
• MethodChannel(
• flutterPluginBinding.binaryMessenger,
• "flutter_multi_windows.messageChannel",
• ).setMethodCallHandler(this)
• }
• override fun onDetachedFromEngine(@NonNull binding: FlutterPlugin.FlutterPluginBinding) {
• Log.i(TAG, "onDetachedFromEngine: ${Thread.currentThread().name}")
• }
• override fun onMethodCall(call: MethodCall, result: MethodChannel.Result) {
• Log.i(TAG, "onMethodCall: thread : ${Thread.currentThread().name}")
• MessageHandle.onMessage(call, result)
• }
}
@SuppressLint("StaticFieldLeak")
internal object MessageHandle {
private const val TAG = "MessageHandle"
• private var context: Context? = null
• private var manager: EngineManager? = null
• fun init(context: Context) {
• this.context = context
• if (manager != null)
• return
• // 必须单例调用
• manager = EngineManager.getInstance(this.context!!)
• }
• // 处理消息,所有管道通用。需要共享Flutter Activity
• fun onMessage(
• call: MethodCall, result: MethodChannel.Result
• ) {
• val params = call.arguments as Map<*, *>
• when (call.method) {
• "open" -> {
• Log.i(TAG, "onMessage: open")
• val map: HashMap<String, Any> = HashMap()
• map["needShowWindow"] = true
• map["name"] = params["name"] as String
• map["entryPoint"] = params["entryPoint"] as String
• map["width"] = (params["width"] as Double).toInt()
• map["height"] = (params["height"] as Double).toInt()
• map["gravityX"] = params["gravityX"] as Int
• map["gravityY"] = params["gravityY"] as Int
• map["paddingX"] = params["paddingX"] as Double
• map["paddingY"] = params["paddingY"] as Double
• map["draggable"] = params["draggable"] as Boolean
• map["type"] = params["type"] as String
• if (params["params"] != null) {
• map["params"] = params["params"] as ArrayList<String>
• }
• result.success(manager?.showWindow(map, object : EngineCallback {
• override fun onEngineDestroy(id: String) {
• }
• }))
• }
• "close" -> {
• val windowId = params["windowId"] as String
• manager?.dismissWindow(windowId)
• }
• "executeTask" -> {
• Log.i(TAG, "onMessage: executeTask")
• val map: HashMap<String, Any> = HashMap()
• map["name"] = params["name"] as String
• map["entryPoint"] = params["entryPoint"] as String
• map["type"] = params["type"] as String
• result.success(manager?.executeTask(map))
• }
• "finishTask" -> {
• manager?.finishTask(params["taskId"] as String)
• }
• "setPosition" -> {
• val res = manager?.setPosition(
• params["windowId"] as String,
• params["x"] as Int,
• params["y"] as Int
• )
• result.success(res)
• }
• "setAlpha" -> {
• val res = manager?.setAlpha(
• params["windowId"] as String,
• (params["alpha"] as Double).toFloat(),
• )
• result.success(res)
• }
• "resize" -> {
• val res = manager?.resetWindowSize(
• params["windowId"] as String,
• params["width"] as Int,
• params["height"] as Int
• )
• result.success(res)
• }
• else -> {
• }
• }
• }
}
同时需要清楚,Engine通过传入的entryPoint,就可以找到Flutter层中的方法入口点,在入口点中runApp即可。
实现过程中的坑
在实现过程中我们遇到的值得分享的坑,就是Flutter GestureDetector和Window滑动事件的冲突。 由于悬浮窗是需要可滑动的,因此在原生层需要监听对应的事件;而Flutter的事件,是Android层分发给FlutterView的,两者形成冲突,导致Flutter内部滑动的时候,原生层也会捕获到,最终造成冲突。
如何解决?
从需求上来看,悬浮窗是否需要滑动,应该交给调用方决定,也就是由Flutter层来决定是否Android是否要对Flutter的滑动事件进行监听,即flutterView.setOnTouchListener。这里我们使用一种更轻量级的操作,FlutterView的监听默认加上,然后在事件处理中,我们通过变量来做处理;而Flutter通过MethodChannel改变这个变量,加快了通信速度,避免了事件来回监听和销毁。
flutterView.setOnTouchListener { _, event ->
when (event.action) {
MotionEvent.ACTION_MOVE -> {
if (dragging) {
setPosition(
initialX + (event.rawX - startX).roundToInt(),
initialY + (event.rawY - startY).roundToInt()
)
}
}
MotionEvent.ACTION_UP -> {
dragEnd()
}
MotionEvent.ACTION_DOWN -> {
startX = event.rawX
startY = event.rawY
initialX = layoutParams.x
initialY = layoutParams.y
dragStart()
windowManager.updateViewLayout(rootView, layoutParams)
}
}
false
}dragging则是通过Flutter层去驱动的:FlutterMultiWindowsPlugin().dragStart();
private fun dragStart() {
dragging = true
}
private fun dragEnd() {
dragging = false
}使用方式
目前我们内部已在4个应用落地了这个方案。应用方式有两种:一种是Flutter通过插件调用,也可以直接通过后台Service打开。效果尚佳,目的都是为了让Flutter的UI跨端使用。
另外,Flutter的方法入口点必须声明@pragma('vm:entry-point')。
写在最后
目前来看这种方式可以完美支持Flutter在Android上开启多窗口,且能精准控制。但由于一个engine对应一个窗口,过多engine带来的内存隐患还是不可忽视的。我们希望Flutter官方能尽快的支持engine对应多个入口点,并且共享内存,只不过目前来看还是有点天方夜谭~~
这篇文章,需要有一定原生基础的同学才能看懂。只讲基础原理,代码不全,仅供参考! 另外多窗口的需求,不知道大家需求量如何,热度可以的话我再出个windows的多窗口实现!
作者:Karl_wei
来源:juejin.cn/post/7198824926722949179
Flutter Android多窗口方案落地(上)
前言
Flutter在桌面端的多窗口需求,一直是个历史巨坑。随着Flutter的技术在我们windows、android桌面设备落地,我们发现多窗口需求必不可少,突破这个技术壁垒已经刻不容缓。
实现原理
1. 基本原理
对于Android移动设备来说,多窗口的应用大多是用于直播/音视频的悬浮弹窗,让用户离开应用后还能在小窗口中观看内容。实现原理是通过WindowManager创建和管理窗口,包括视图内容、拖拽、事件等操作。
我们都清楚Flutter只是一个可以做业务逻辑的UI框架,在Flutter中想要实现多窗口,也必须依赖Android的窗口管理机制。基于原生的Window,显示Flutter绘制的UI,从而实现跨平台的视图交互和业务逻辑。
2. 具体步骤
Android端基于Window Manager创建Window,管理窗口的生命周期和拖拽逻辑;使用FlutterEngineGroup来管理Flutter Engine,通过引擎吸附Flutter的UI,加入到原生的FlutterView;把FlutterView通过addView的方式加入到Window上。
3. 原理图
插件实现
基于上述原理,可以在Android的窗口显示Flutter的UI。但要真正提供给Flutter层使用,还需要再封装一个插件层。
通过单例管理多个窗口 由于是多窗口,可能项目中多个地方都会调用到,因此需要使用单例来统一管理所有窗口的生命周期,保证准确创建、及时销毁。
//引擎生命钩子回调,让调用方感知引擎状态
interface EngineCallback {
fun onCreate(id:String)
fun onEngineDestroy(id: String)
}
class EngineManager private constructor(context: Context) {
// 单例对象
companion object :
SingletonHolder<EngineManager, Context>(::EngineManager)
// 窗口类型;如果是单一类型,那么同名窗口将返回上一次的未销毁的实例。
private val TYPE_SINGLE: String = "single"
init {
Log.d("EngineManager", "EngineManager init")
}
data class Entry(
val engine: FlutterEngine,
val window: AndroidWindow?
)
private var myContext: Context = context
private var engineGroup: FlutterEngineGroup = FlutterEngineGroup(myContext)
// 每个窗口对应一个引擎,基于引擎ID和名称存储多窗口的信息,以及查找
private val engineMap = ConcurrentHashMap<String, Entry>() //搜索引擎,用作消息分发
private val name2IdMap = ConcurrentHashMap<String, String>() //判断是否存在了任务
private val id2NameMap = ConcurrentHashMap<String, String>() //根据任务获取name并清除
private val engineCallback =
ConcurrentHashMap<String, EngineCallback>() //通知调用方引擎状态 0-create 1-attach 2-destroy
fun showWindow(
params: HashMap<String, Any>,
engineStatusCallback: EngineCallback
): String? {
val entry: String?
if (params.containsKey("entryPoint")) {
entry = params["entryPoint"] as String
} else {
return null
}
val name: String?
if (params.containsKey("name")) {
name = params["name"] as String
} else {
return null
}
val type = params["type"]
if (type == TYPE_SINGLE && name2IdMap[name] != null) {
return name2IdMap[name]
}
val windowUid = UUID.randomUUID().toString()
if (type == TYPE_SINGLE) {
name2IdMap[name] = windowUid
id2NameMap[windowUid] = name
engineCallback[windowUid] = engineStatusCallback
}
val dartEntrypoint = DartExecutor.DartEntrypoint(findAppBundlePath(), entry)
val args = mutableListOf(windowUid)
var user: List<String>? = null
if (params.containsKey("params")) {
user = params["params"] as List<String>
}
if (user != null) {
args.addAll(user)
}
// 把调用方传递的参数回调给Flutter
val option =
FlutterEngineGroup.Options(myContext).setDartEntrypoint(dartEntrypoint)
.setDartEntrypointArgs(
args
)
val engine = engineGroup.createAndRunEngine(option)
val draggable = params["draggable"] as Boolean? ?: true
val width = params["width"] as Int? ?: 0
val height = params["height"] as Int? ?: 0
val config = GravityConfig()
config.paddingX = params["paddingX"] as Double? ?: 0.0
config.paddingY = params["paddingY"] as Double? ?: 0.0
config.gravityX = GravityForX.values()[params["gravityX"] as Int? ?: 1]
config.gravityY = GravityForY.values()[params["gravityY"] as Int? ?: 1]
// 把创建好的引擎传给AndroidWindow,由其去创建窗口
val androidWindow =
AndroidWindow(myContext, draggable, width, height, config, engine)
engineMap[windowUid] = Entry(engine, androidWindow)
androidWindow.open()
engine.platformViewsController.attach(
myContext,
engine.renderer,
engine.dartExecutor
)
return windowUid
}
fun setPosition(id: String?, x: Int, y: Int): Boolean {
id ?: return false
val entry = engineMap[id]
entry ?: return false
entry.window?.setPosition(x, y)
return true
}
fun setSize(id: String?, width: double, height: double): Boolean {
// ......
}
}通过代码我们可以看到,每个窗口都对应一个engine,通过name和生成的UUID做唯一标识,然后把engine传给AndroidWindow,在那里加入WindowManger,以及Flutter UI的获取。
AndroidWindow的实现;通过
context.getSystemService(Service.WINDOW_SERVICE) as WindowManager获取窗口管理器;同时创建FlutterView和LayoutInfalter,通过engine拿到视图吸附到FlutterView,把FlutterView加到Layout中,最后把Layout通过addView加到WindowManager中显示。
class AndroidWindow(
private val context: Context,
private val draggable: Boolean,
private val width: Int,
private val height: Int,
private val config: GravityConfig,
private val engine: FlutterEngine
) {
private var startX = 0f
private var startY = 0f
private var initialX = 0
private var initialY = 0
private var dragging = false
private lateinit var flutterView: FlutterView
private var windowManager = context.getSystemService(Service.WINDOW_SERVICE) as WindowManager
private val inflater =
context.getSystemService(Service.LAYOUT_INFLATER_SERVICE) as LayoutInflater
private val metrics = DisplayMetrics()
@SuppressLint("InflateParams")
private var rootView = inflater.inflate(R.layout.floating, null, false) as ViewGroup
private val layoutParams = WindowManager.LayoutParams(
dip2px(context, width.toFloat()),
dip2px(context, height.toFloat()),
WindowManager.LayoutParams.TYPE_SYSTEM_ALERT, // 系统应用才可使用此类型
WindowManager.LayoutParams.FLAG_NOT_FOCUSABLE,
PixelFormat.TRANSLUCENT
)
fun open() {
@Suppress("Deprecation")
windowManager.defaultDisplay.getMetrics(metrics)
layoutParams.gravity = Gravity.START or Gravity.TOP
selectMeasurementMode()
// 设置位置
val screenWidth = metrics.widthPixels
val screenHeight = metrics.heightPixels
when (config.gravityX) {
GravityForX.Left -> layoutParams.x = config.paddingX!!.toInt()
GravityForX.Center -> layoutParams.x =
((screenWidth - layoutParams.width) / 2 + config.paddingX!!).toInt()
GravityForX.Right -> layoutParams.x =
(screenWidth - layoutParams.width - config.paddingX!!).toInt()
null -> {}
}
when (config.gravityY) {
GravityForY.Top -> layoutParams.y = config.paddingY!!.toInt()
GravityForY.Center -> layoutParams.y =
((screenHeight - layoutParams.height) / 2 + config.paddingY!!).toInt()
GravityForY.Bottom -> layoutParams.y =
(screenHeight - layoutParams.height - config.paddingY!!).toInt()
null -> {}
}
windowManager.addView(rootView, layoutParams)
flutterView = FlutterView(inflater.context, FlutterSurfaceView(inflater.context, true))
flutterView.attachToFlutterEngine(engine)
if (draggable) {
@Suppress("ClickableViewAccessibility")
flutterView.setOnTouchListener { _, event ->
when (event.action) {
MotionEvent.ACTION_MOVE -> {
if (dragging) {
setPosition(
initialX + (event.rawX - startX).roundToInt(),
initialY + (event.rawY - startY).roundToInt()
)
}
}
MotionEvent.ACTION_UP -> {
dragEnd()
}
MotionEvent.ACTION_DOWN -> {
startX = event.rawX
startY = event.rawY
initialX = layoutParams.x
initialY = layoutParams.y
dragStart()
windowManager.updateViewLayout(rootView, layoutParams)
}
}
false
}
}
@Suppress("ClickableViewAccessibility")
rootView.setOnTouchListener { _, event ->
when (event.action) {
MotionEvent.ACTION_DOWN -> {
layoutParams.flags =
layoutParams.flags or WindowManager.LayoutParams.FLAG_NOT_FOCUSABLE
windowManager.updateViewLayout(rootView, layoutParams)
true
}
else -> false
}
}
engine.lifecycleChannel.appIsResumed()
rootView.findViewById<FrameLayout>(R.id.floating_window)
.addView(
flutterView,
ViewGroup.LayoutParams(
ViewGroup.LayoutParams.MATCH_PARENT,
ViewGroup.LayoutParams.MATCH_PARENT
)
)
windowManager.updateViewLayout(rootView, layoutParams)
}
// .....续:Flutter Android多窗口方案落地(下)
作者:Karl_wei
来源:juejin.cn/post/7198824926722949179
AndroidQQ登录接入详细介绍
一、前言
由于之前自己项目的账号系统不是非常完善,所以考虑接入QQ这个强大的第三方平台的接入,目前项目暂时使用QQ登录的接口进行前期的测试,这次从搭建到完善花了整整两天时间,不得不吐槽一下QQ互联的官方文档,从界面就可以看出了,好几年没维修了,示例代码也写的不是很清楚,翻了好多源代码和官方的demo,这个demo可以作为辅助参考,官方文档的api失效了可以从里面找相应的替代,但它的代码也太多了,一个demo 一万行代码,心累,当时把demo弄到可以运行就花了不少时间,很多api好像是失效了,笔者自己做了一些处理和完善,几乎把sdk功能列表的登录相关的api都尝试了一下,真的相当的坑,正文即将开始,希望这篇文章能够给后来者一些参考和帮助。
二、环境配置
1.获取应用ID
这个比较简单,直接到QQ互联官网申请一个即可,官网地址
https://connect.qq.com申请应用的时候需要注意应用名字不能出现违规词汇,否则可能申请不通过
应用信息的填写需要当前应用的包名和签名,这个腾讯这边提供了一个获取包名和签名的app供我们开发者使用,下载地址
https://pub.idqqimg.com/pc/misc/files/20180928/c982037b921543bb937c1cea6e88894f.apk未通过审核只能使用调试的QQ号进行登录,通过就可以面向全部用户了,以下为审核通过的图片
2.官网下载相关的sdk
下载地址
https://tangram-1251316161.file.myqcloud.com/qqconnect/OpenSDK_V3.5.10/opensdk_3510_lite_2022-01-11.zip推荐直接下载最新版本的,不过着实没看懂最新版本的更新公告,说是修复了retrofit冲突的问题,然后当时新建的项目没有用,结果报错,最后还是加上了,才可以
3. jar的引入
将jar放入lib包下,然后在app 同级的 build.gradle添加以下代码即完成jar的引用
dependencies {
...
implementation fileTree(dir: 'libs', include: '*.jar')
...
}4.配置Manifest
在AndroidManifest.xml中的application结点下增加以下的activity和启动QQ应用的声明,这两个activity无需我们在另外创建文件,引入的jar已经处理好了
<application
...
<!--这里的权限为开启网络访问权限和获取网络状态的权限,必须开启,不然无法登录-->
<uses-permission android:name="android.permission.INTERNET" />
<uses-permission android:name="android.permission.ACCESS_NETWORK_STATE" />
<activity
android:name="com.tencent.tauth.AuthActivity"
android:exported="true"
android:launchMode="singleTask"
android:noHistory="true">
<intent-filter>
<action android:name="android.intent.action.VIEW" />
<category android:name="android.intent.category.DEFAULT" />
<category android:name="android.intent.category.BROWSABLE" />
<data android:scheme="tencent你的appId" />
</intent-filter>
</activity>
<activity
android:name="com.tencent.connect.common.AssistActivity"
android:configChanges="orientation|keyboardHidden"
android:screenOrientation="behind"
android:theme="@android:style/Theme.Translucent.NoTitleBar" />
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="com.tencent.login.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/file_paths" />
</provider>
...
</application>上面的哪个代码的最后提供了一个provider用于访问 QQ 应用的,需要另外创建一个 xml 文件,其中的 authorities 是自定义的名字,确保唯一即可,这边最下面那个provider是翻demo找的,文档没有写,在res文件夹中新增一个包xml,里面添加文件名为file_paths的 xml ,其内容如下
<?xml version="1.0" encoding="utf-8"?>
<paths>
<external-files-path name="opensdk_external" path="Images/tmp"/>
<root-path name="opensdk_root" path=""/>
</paths>三、初始化配置
1.初始化SDK
加入以下代码在创建登录的那个activtiy下,不然无法拉起QQ应用的登录界面,至于官方文档所说的需要用户选择是否授权设备的信息的说明,这里通用的做法是在应用内部声明一个第三方sdk的列表,然后在里面说明SDK用到的相关设备信息的权限
Tencent.setIsPermissionGranted(true, Build.MODEL)2.创建实例
这部分建议放在全局配置,这样可以实现登录异常强制退出等功能
/**
* 其中APP_ID是申请到的ID
* context为全局context
* Authorities为之前provider里面配置的值
*/
val mTencent = Tencent.createInstance(APP_ID, context, Authorities)3.开启登录
在开启登录之前需要自己创建一个 UIListener 用来监听回调结果(文档没讲怎么创建的,找了好久的demo)这里的代码为基础的代码,比较容易实现,目前还没写回调相关的代码,主要是为了快速展示效果
open class BaseUiListener(private val mTencent: Tencent) : DefaultUiListener() {
private val kv = MMKV.defaultMMKV()
override fun onComplete(response: Any?) {
if (response == null) {
"返回为空,登录失败".showToast()
return
}
val jsonResponse = response as JSONObject
if (jsonResponse.length() == 0) {
"返回为空,登录失败".showToast()
return
}
"登录成功".showToast()
doComplete(response)
}
private fun doComplete(values: JSONObject?) {
}
override fun onError(e: UiError) {
Log.e("fund", "onError: ${e.errorDetail}")
}
override fun onCancel() {
"取消登录".showToast()
}
}建立一个按钮用于监听,这里进行登录操作
button.setOnClickListener {
if (!mTencent.isSessionValid) {
//判断会话是否有效
when (mTencent.login(this, "all",iu)) {
//下面为login可能返回的值的情况
0 -> "正常登录".showToast()
1 -> "开始登录".showToast()
-1 -> "异常".showToast()
2 -> "使用H5登陆或显示下载页面".showToast()
else -> "出错".showToast()
}
}
}这边对mTencent.login(this, "all",iu)中login的参数做一下解释说明
mTencent.login(this, "all",iu)
//这里Tencent的实例mTencent的login函数的三个参数
//1.为当前的context,
//2.权限,可选项,一般选择all即可,即全部的权限,不过目前好像也只有一个开放的权限了
//3.为UIlistener的实例对象还差最后一步,获取回调的结果的代码,activity的回调,这边显示方法已经废弃了,本来想改造一下的,后面发现要改造的话需要动sdk里面的源码,有点麻烦就没有改了,等更新
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
super.onActivityResult(requestCode, resultCode, data)
//腾讯QQ回调,这里的iu仍然是相关的UIlistener
Tencent.onActivityResultData(requestCode, resultCode, data,iu)
if (requestCode == Constants.REQUEST_API) {
if (resultCode == Constants.REQUEST_LOGIN) {
Tencent.handleResultData(data, iu)
}
}
}至此,已经可以正常登录了,但还有一件我们开发者最关心的事情没有做,获取的用户的数据在哪呢?可以获取QQ号吗?下面将为大家解答这方面的疑惑。
四、接入流程以及相关代码
首先回答一下上面提出的问题,可以获得两段比较关键的json数据,一个是 login 的时候获取的,主要是token相关的数据,还有一段就是用户的个人信息的 json 数据,这些都在 UIListener 中进行处理和获取。第二个问题能不能获取QQ号,答案是不能,我们只能获取与一个与QQ号一样具有唯一标志的id即open_id,显然这是出于用户的隐私安全考虑的,接下来简述一下具体的登录流程
1.登录之前检查是否有token缓存
有,直接启动主activity
无,进入登录界面
判断是否具有登录数据的缓存
//这里采用微信的MMKV进行储存键值数据
MMKV.initialize(this)
val kv = MMKV.defaultMMKV()
kv.decodeString("qq_login")?.let{
val gson = Gson()
val qqLogin = gson.fromJson(it, QQLogin::class.java)
QQLoginTestApplication.mTencent.setAccessToken(qqLogin.access_token,qqLogin.expires_in.toString())
QQLoginTestApplication.mTencent.openId = qqLogin.openid
}检查token和open_id是否有效和token是否过期,这里采取不同于官方的推荐的用法,主要是api失效了或者是自己没用对方法,总之官方提供的api进行缓存还不如MMKV键值存login json来的实在,也很方便,这里建议多多使用日志,方便排查错误
//这里对于uiListener进行了重写,object的作用有点像java里面的匿名类
//用到了checkLogin的方法
mTencent.checkLogin(object : DefaultUiListener() {
override fun onComplete(response: Any) {
val jsonResp = response as JSONObject
if (jsonResp.optInt("ret", -1) == 0) {
val jsonObject: String? = kv.decodeString("qq_login")
if (jsonObject == null) {
"登录失败".showToast()
} else {
//启动主activity
}
} else {
"登录已过期,请重新登录".showToast()
//启动登录activity
}
}
override fun onError(e: UiError) {
"登录已过期,请重新登录".showToast()
//启动登录activity
}
override fun onCancel() {
"取消登录".showToast()
}
})2.进入登录界面
在判断session有效的情况下,进入登录界面,对login登录可能出现的返回码做一下解释说明
Login.setOnClickListener {
if (!QQLoginTestApplication.mTencent.isSessionValid) {
when (QQLoginTestApplication.mTencent.login(this, "all",iu)) {
0 -> "正常登录".showToast()
1 -> "开始登录".showToast()
-1 -> {
"异常".showToast()
QQLoginTestApplication.mTencent.logout(QQLoginTestApplication.context)
}
2 -> "使用H5登陆或显示下载页面".showToast()
else -> "出错".showToast()
}
}
}1:正常登录
这个就无需做处理了,直接在回调那里做相关的登录处理即可
0:开始登录
同正常登录
-1:异常登录
这个需要做一点处理,当时第一次遇到这个情况就是主activity异常消耗退回登录的activity,此时在此点击登录界面的按钮导致了异常情况的出现,不过这个处理起来还是比较容易的,执行强制下线操作即可
"异常".showToast()
mTencent.logout(QQLoginTestApplication.context)2:使用H5登陆或显示下载页面
通常情况下是未安装QQ等软件导致的,这种情况无需处理,SDK自动封装好了,这种情况会自动跳转QQ下载界面
同样的有出现UIListener就需要调用回调进行数据的传输
override fun onActivityResult(requestCode: Int, resultCode: Int, data: Intent?) {
super.onActivityResult(requestCode, resultCode, data)
//腾讯QQ回调
Tencent.onActivityResultData(requestCode, resultCode, data,iu)
if (requestCode == Constants.REQUEST_API) {
if (resultCode == Constants.REQUEST_LOGIN) {
Tencent.handleResultData(data, iu)
}
}
}3.进入主activity
这里需要放置一个按钮执行下线操作,方便调试,同时这里需要将之前的token移除重新获取token等数据的缓存
button.setOnClickListener {
mTencent.logout(this)
val kv = MMKV.defaultMMKV()
kv.remove("qq_login")
//返回登录界面的相关操作
"退出登录成功".showToast()
}至此,其实还有一个很重要的东西没有说明,那就是token数据的缓存和个人信息数据的获取,这部分我写的登录的那个UIlistener里面了,登录成功的同时,获取login的response的json数据和个人信息的json数据
4.获取两段重要的json数据
login 的json数据
这个比较容易,当我们登录成功的时候,oncomplete里面的response即我们想要的数据
override fun onComplete(response: Any?) {
if (response == null) {
"返回为空,登录失败".showToast()
return
}
val jsonResponse = response as JSONObject
if (jsonResponse.length() == 0) {
"返回为空,登录失败".showToast()
return
}
//这个即利用MMKV进行缓存json数据
kv.encode("qq_login",response.toString())
"登录成功".showToast()
}个人信息的数据
这个需要在login有效的前提下才能返回正常的数据
//首先需要用上一步获取的json数据对mTencent进行赋值,这部分放在doComplete方法中执行
private fun doComplete(values: JSONObject?) {
//利用Gson进行格式化成对象
val gson = Gson()
val qqLogin = gson.fromJson(values.toString(), QQLogin::class.java)
mTencent.setAccessToken(qqLogin.access_token, qqLogin.expires_in.toString())
mTencent.openId = qqLogin.openid
Log.e("fund",values.toString())
}创建一个get_info方法进行获取,注意这里需要对mTencent设置相关的属性才能获取正常获取数据
private fun getQQInfo(){
val qqToken = mTencent.qqToken
//这里的UserInfo是sdk自带的类,传入上下文和token即可
val info = UserInfo(context,qqToken)
info.getUserInfo(object :BaseUiListener(mTencent){
override fun onComplete(response: Any?){
//这里对数据进行缓存
kv.encode("qq_info",response.toString())
}
})
}
5.踩坑系列
这里主要吐槽一下关于腾讯的自带的session缓存机制,当时是抱着不用自己实现缓存直接用现成的机制去看的,很遗憾这波偷懒失败,这部分session的设置不知道具体的缓存机制,只知道大概是用share preference实现的,里面有saveSession,initSession,loadSession这三个方法,看上去很容易的样子,然后抱着这种心态去尝试了一波,果然不出意外空指针异常,尝试修改了一波回调的顺序仍然空指针异常,折腾了大概三个多小时,放弃了,心态给搞崩了,最终释然了,为什么要用腾讯提供的方法,这个缓存自己实现也是相当的容易,这时想到了MMKV,两行代码完成读取,最后只修改了少数的代码完成了登录的token的缓存机制,翻看demo里面的实现,里面好像是用这三种方法进行实现的,可能是某个实现机制没有弄明白,其实也不想明白,自己的思路比再去看demo容易多了,只是多了一个json的转对象的过程,其他的没有差别。所以建议后来者直接自己实现缓存,不用管sdk提供的那些方法,真的有点难用。
五、总结
总之这次完成QQ接入踩了许多的坑,不过幸好最终还是实现了,希望腾讯互联这个sdk能够上传github让更多的人参与和提供反馈,不然这个文档说是最差sdk体验也不为过。下面附上这次实现QQ登录的demo的github地址以及相关的demo apk供大家进行参考,大概总共就400行代码左右比官方的demo好很多,有问题欢迎留言
https://github.com/xyh-fu/QQLoginTest.git作者:wresource
来源:juejin.cn/post/7072878774261383176
2022年终总结——迷茫摆烂
前言
如果要用两个关键词来概括2022全年,我认为是“迷茫”和“摆烂”。迫于对未来的迷茫无措,我写下了这些文字。原本没有打算发出来,但是仔细想想,这又何尝不是一种逃避?所以我发了出来,希望老哥们可以在看完文章后帮我指引前路,不在迷茫。标志性事件太多,麻烦认出来的哥哥,可以给我个面子。
求助
我有两个路线,不知道走哪个。一个是考研,一个是学习,来年跳槽。求指导。
考研的话,北京的学校难度咋样?非全日制的会被承认吗?毕业后大约29岁了,还来得及吗?
学习的话,应该学什么技术呀?应该深入还是全栈?
流水账
关于工作
我在2021年毕业,在年底进入公司,是安卓开发岗位。一直到2月过年那段时间,我摸清了自己的工作内容,接手了以往的项目。我们部门只有我一个安卓开发,其他部门不熟,但是好像也没有安卓岗。没有人教,所以我一直都是靠前任的代码和百度来学习的。我的定位就是应对项目可能会出现的安卓需求,不涉及核心。看似多余,不过工资低(6000),公司养得起。
公司氛围很轻松,朝九晚六。我们同事一直都在忙项目,有点顾不上我。偶尔有人给我派发学习任务,我简单学完之后,面对大把时间就开始手足无措。好多事想干,又不知道先干什么,于是我开始摆烂逃避。看资讯、看小说、刷论坛、刷贴吧,一混就是一天,很爽,深陷其中。
日子就这样混到了三月底。部长看我太闲了,让我跟其中一个项目。这是和安卓风马牛不相及的项目,我也很慌,就开始百度教程学习,慢慢不再混日子。后来正式上手,太难,摸不到门路。只好向同事要了一份他们的做参考,慢慢的上手了,越做越快。于是,在知道截止日期的情况下,我开始摆烂了。玩一会儿,做一点儿。但我还是在截止前一天完成了,耗时一个月。
四月底,部长好像觉得我做的很可以,又给我派了一部分任务。这部分更难,更多。我一开始遇到了点难题,卡了我好久。在百度疯狂的cv了一周之后才解决。然后我又开始摆烂了,这次摆烂的更狠。再加上后面因为疫情开始居家,于是越加肆无忌惮。发觉的时候已经过了20多天了,也居家半个月了。然后我就只能疯狂加班补,最终还是在截止那天完成了,耗时一个半月。
那是六月初,我们刚结束隔离,重新上班。我感到很内疚,因为其他人的工作量是我的两倍,而且部长也催过我。然后我决定发愤图强,然后接过了学习任务。学习完了之后,开始摆烂。后面给我安排了新的任务,需要用到上面学习的内容,然后我就一边学习,一边做,一边摸鱼。
然后就摸鱼摸到了八月,两个月过去了。这时候给我安排了一个安卓项目,我当时真的差点喜极而泣。但是同时,我也真的很慌。因为我除了毕设,就没有再单独开发一个安卓项目了。然后我就结束摆烂,一边偶尔摸鱼,一边努力干活。
一直努力到十月,我终于完成了。其实现在仔细想想,难度也不是很难。之所以耗费两个月时间,多半是因为我经常前半天摸鱼,后半天干活吧。然后就又没事了,放假回来之后就提了点意见让我修改。然后我就又不知道干啥了,就继续摸鱼摆烂。
摆烂到十一月,我们又因为疫情被迫居家了,我直接毫无顾忌的开始疯玩了。后面有新冠什么的,写在生活里了。总之,一直摆烂到现在,偶尔完成一下工作。
总结
总的来说,基本上就是有任务的时候就干活,不忙的时候就迷茫摆烂。
每天都过得浑浑噩噩的,白天迷茫摆烂,夜里焦虑失眠。在公司也没什么师傅来指导,东学一点西学一点的。整个技术成长过程特别碎片化,知识结构不成体系,技术深度严重不足。稍微遇到一些开放性的有难度的问题,就没有足够的信心搞定,产生明显的畏难情绪和自卑心理,觉得自己技不如人,开始逃避,继而摆烂。
每次开会,同事的任务都很高深,到了我就是学习***,感觉自己像个边缘人。
我看不清前面的路该怎么走,未来的技术路线该怎么制定,最近几个月要关注什么,学习什么,自己身上那么多的问题,要优先解决哪一个。
关于生活
因为公司朝九晚六,所以我空闲时间还不少。基本上就是下班回家打游戏、做饭、看小说。我几乎没有自控能力,所以一玩就玩到半夜两三点再睡,因此经常迟到。不过因为公司制度,所以还没有扣过钱。但是睡的太少,前半天只能靠摸鱼看论坛来维持精神。然后午休睡2个小时,后半天在工作。这个状态会在有任务的时候减轻,在没任务的时候加重。
在四月份的时候换了房子。原先住的隔断,虽然双方都很安静,但是因为不隔音,对自控能力极差的我来说简直是折磨(对方是女的,色色不方便)。所以我搬到了离公司很近,房租1800的7平米厨房改的小房间。之前地铁通勤要300元,起床要7:30,这次我血赚。
换了房子之后就更加没有节制了。因为房间小,也就不再做饭了,每天都是打游戏、看小说、刷视频来回换。但是,每当很晚的时候,我好像没事做了该睡觉了,我就感觉空虚茫然。感觉之前做的那些都没有让我真的快乐起来。明明到了该睡觉的时间了,可是心里却很慌,觉得我还没有真的放松一下,可是我不知道做什么。然后就只能继续干刚才那些,等我不知不觉的睡着为止。所以我第二天就经常起不来床,一天都很累,可是回到家里又不知道干什么才能真正地放松自己,只能重复以前的生活,恶性循环了。
打游戏、看小说、刷视频,在一开始确实是快乐的,但是时间长了就开始坐牢了。我明明已经感觉不到快乐了,却不舍得离去,总会觉得接下来一定还有地方可以继续获得快乐,下一个视频、故事情节一定更有趣。因为,如果我退出去了,我就又会迷茫空虚,不知所措。我下意识的想要逃避,不想面对,因为逃避真的有用。但是也因为没有解决根本问题而恶性循环,这都是自己的决定导致的结果。尼采说所有过去的事情是你的意志选择的结果,积极接受,因为这是你的命运。
转而到了六月,中介给我埋得雷爆了。我看房的时候是毛坯房,中介说后面都会给安装空调的,但是房东没给安。一整个夏天我都是靠两个风扇熬过去的。偶尔受不了了,就去隔壁屋蹭一蹭空调。
我在家里读小说只读长度100到200章之间的,因为我会控制不住一直读下去,沉浸于人物中无法自拔,导致晚睡。我一开始喜欢读言情重生种田爽文,毕竟我从小从农村长大,很有代入感。后面也开始读其他类型的,但是也逃不过言情种田爽文这一块。对于从小贫穷吃不起饭,社交能力有问题的我来说,我真的需要飞黄腾达,也需要一个住在心里的人。我一直都梦想有个像小说主角一样有能力的人,带我走出泥潭。后来读的小说多了,我也走出来了,知道自己为什么沉迷了。现实做不到的,只能靠小说了。
我走出小说是七月份的事情了。因为迷茫却又不再读小说,所以我只能多开游戏。我那时候手里在玩三款游戏,玩完正好0点,奖励一下正好睡觉。但是现实不会这么如人愿。一开始还好,时间一长,游戏玩的和上班一样了。玩完还是很累,想休息。可是不知道咋休息,只能刷短视频到3点。
后来我加入了一个游戏交流群,群里人好多都是成年土豪,却又很和善。他们每天当黑奴带本,却没有怨言。人的成长来源,或是经历,或是社交,或是阅读。在高中之后,我终于迎来了一个稳定且长期的社交途径。我跟着一起谈论游戏,也会谈论自己的生活,以求指点。但是成长是缓慢的,我还没有摆脱困境,就进入了一个更大的困境。
一切的转折点是十二月初,我被诈骗了。
具体经过很蠢,我就不发了。我攒了几年的积蓄全没了,还背上了1万的网贷。虽然第一时间就报了警,但是我知道,我这4万多,回不来了。出了警察局我才发现,我要交下个季度的房租了。我之前经常有朋友向我借钱,我圣母心蛮重的,看不得别人受苦,所以我陆陆续续的借出去了2万。所以事发之后,我第一时间联系他们。但是,就要回来一千,甚至有些垃圾人都不回消息了。
我很难过,不敢和家里说,只能看看能不能靠12月要发的工资撑过去,实在不行就网贷。
过了几天,我例行和父母打微信视频。这时候我才知道我爸爸和几个亲戚来北京的工地干活了,而且阳了。他们买不到药,只能困在工地里面干熬着。我很心疼,第二天就很早去楼下药铺排队买药,想着给他们送过去。买完药已经十一点了,想着先回家吃点饭,顺便问问地址。结果正吃着饭呢,突然就感觉特别难受,特别冷,还十分不清醒。我爸爸也说不用给他们送药,他们都快好了。我赶紧给自己贴了好多的暖宝宝,盖着被子睡觉了。虽然措施不少,但还是觉得冷的不行。我以为我是排队的时候,穿的少了,被冻着了。好不容易睡着,再醒来还是冷。我觉得不对了,一看体温计,39.5度。我居然就这么阳了。刚买的药,全给自己用了。
我躺在床上,很委屈,难受的想哭。我到手就6000块钱,我在这刚工作一年攒下4万容易吗?我除了房租水电等必要的花销,几乎不消费的。之前借我钱的那些人,有些还是在大学的时候借的。我家里在农村也是最底下的那一档了,我大学四年努力打零工去实习,省吃俭用才存下了一点儿钱。我穿着高中买的烂衣服,他们还向我借钱,我以为他们可能真缺钱,才借给他们的。谁知道他们转头拿去买苹果,花天酒地了。在我真的需要帮助的时候,却只有一个人还了钱。
我把我被诈骗、要不回钱、阳了这些事说在了群里,求到了许多的指点。我之后就去要钱了。也不是没有进展,要回来一部分。只是,我说话的时候,他们苹果手机的灵动岛一直在跳动,很刺眼。仿佛在嘲笑我,我现在吃饭的工具,用的还是2017年花4000买的电脑。手机也是三年前花了2000买的。我对自己并不好,对别人那么好干嘛,又不是土豪。人不为己天诛地灭。
我不敢乱消费。我知道我看不清自己,现在消费主义盛行,谁知道这些需求到底是不是真正的自己的需求。就像是,我已经单身26年了,早就分不清自己是真的喜欢,还是只想色色了。更何况,我家里真的穷,在我毕业挣钱之后才搬离我住了20多年的土坯房。我爸爸已经50多了,也去不了几天工地搬砖了,我只能指望我自己。
我经常在想,我死了之后会发生什么。我死了以后,这世界的所有事情全都和我无关了。我的后事如何处理,亲人会不会难过,过了几年他们还会不会记得我?我的后代会如何发展,会越来越好还是最终都消散了?我们国家呢,会越来越昌盛,还是功亏一篑,全族消失?那地球呢,会不会最终被太阳吞噬?那银河最终会不会被黑洞吞噬?那宇宙最终会不会热寂呢?还是宇宙最终会变成一个互相吞噬而成的大黑洞,最终大爆炸?
一般我想到这里就不敢继续往下想了。但在我阳的最严重的时候,在我以为我快死了的时候,我反而胆子大了起来。我不敢想下去是因为我不甘心。很多事情我注定无法亲眼见证,很多事情我可以却没有尝试过。也许这就是会有很多人相信轮回的原因吧。人总是会因为各种原因而产生遗憾。贫苦者寄希望于来生过上富裕的生活,痴情者寄希望于来生可以再续前缘。我想明白了,我不甘心,我想见见那些美丽的风景,我想尝尝那些神奇的美食,我想试试双人到底比单人爽在哪里,我想让父母过上好的生活。我也想享受人生,享受生活。然后我打开京东,下单,余额不足。
从大四开始,也就是我开始步入社会的时候,每个冬天我都会因为轻信他人而受到严重损失。算上这次,已经是三次了。金额越来越大,后果越来越严重。第一次借钱给他人却要不回来,第二次被实习公司坑,第三次被诈骗。
我开始仔细反思自己究竟为什么被骗,因为我一开始就觉得有问题,我却一直跟着对方的脚步走,我当时想暂停,我为什么没有暂停?我性格有问题,我喜欢被动,胆小怕事。我不会主动找人聊天,我只会等被人来找我。我不会找事情做,只会等事情来找我。所以我一直跟着骗子的脚步走,知道有问题却不敢停止。
为什么不主动,为什么胆小怕事呢?
我从小家里就很穷,住土坯房里,睡一张炕上,吃院子里种的菜。平时穿堂哥剩下来的衣服,冬天才有新衣服,才有肉吃。我最苦的时候是高中的时候。那时候家里变故也多,我一个月只能拿200块钱在食堂吃饭。每天吃馒头蘸酱,偶尔吃3块钱的白菜和西红柿。不知道为什么,我明明一直吃不饱,体重却越来越高。家里人也开始说我,觉得我乱花钱。河北的高中压力太大了,我每天晚上睡不着,哗哗的掉头发。精神身体双层打压之下,我变得胆小懦弱。因为我没有试错空间,我要是错了,就真的完了。
我那时候真是给我饿坏了,现在还有影响,我已经分不清我是不是吃饱了,我只能等吃不下了才会停手,给我多少,我就一定都吃了。高中饿的时间太久导致的,已经是潜意识了。
我被动是因为我没有一个目标,啥都可以,所以就开始等着别人摆布。我挺胸无大志的。我以前觉得,能吃饱有住的地方就行,攒点钱以后回村,毕竟成长期我一直吃不饱。
从我进入大学之后,我突然就没事干了。之前一直都有一双无形的手推着我走向大学,现在这双手消失了。高中是我最痛苦的时光,所以我厌学了,开始摆烂。
我分不清好坏,分不清冷热,分不清是否吃饱,分不清是否喜欢,分不清是否需要。推着我的手消失了,我就不知道应该怎么办了。我曾经想天降主角,帮我制定规则,推着我走。但是,这是不可能的。因为我没有一个目标,所以我迷茫,所以我被动。所以有人推我时,我即使知道那是骗子,我也会下意识的由着他推着走。
我也知道自己胆小怕事的原因是自身不够强大。阳的时候,我多想有个人,可以带我走出泥潭,仿佛小说主角一般。但是,我阳过了也没人来。我最后才知道,我只能靠自己。有人指点我说,不管你目标是什么,不管最终能不能实现,你都要先写出来,先说出来。只有这样你才会为之努力,想办法去实现他。畏畏缩缩在心里不敢提出来,只会让人踌躇不前,最终会导致觉得自己会做不到,不断否定自己。长此以往,就会变得胆小怕事。
归根到底,我一直都在忽视自己真正的感受,从来没有认清自己。明白自己真正想要什么很难,人生得意须尽欢,我这时候才真正地明白。
既然不知道自己真正想要什么,那就多尝试吧,全都试试就知道了。我想尝试很多的新鲜事物,我想过优质的生活,我想强大起来不再懦弱,我不想父母劳累了。这些都需要钱。
所以,我当前阶段的主要目标就是搞钱!
不幸中的万幸,我被骗之后,大数据知道我缺钱,疯狂给我发垃圾短信,让我网贷。然后我看到了保险的短信,然后我想起来我买了好几年的保险。一切很顺利,3小时就理赔成功了。给了我2.7万,可以回家过年了。
但是回家之后又出了很多事。就不细谈了,说起来就生气。我以为天底下还是好人多,但这次为数不多的坏人都让我家碰上了。
总结
不抱怨,三思后行,学会享受人生,努力赚钱!!
明白自己真正想要什么很难,人生得意须尽欢,我想尝试很多的新鲜事物,我想过优质的生活,我想强大起来不再懦弱,我不想父母劳累了。这些都需要钱。
所以,我当前阶段的主要目标就是搞钱!
2023年计划
如果说“迷茫”和“摆烂”是2022全年的两个关键词,那么我希望2023全年的两个关键词是“尝试”和“积累”。
既然不知道自己真正想要什么,那就多尝试吧,全都试试就知道了。我想尝试很多的新鲜事物,我想过优质的生活,我想强大起来不再懦弱,我不想父母劳累了。这些都需要钱。
既然不知道路,那就多尝试吧,把想尝试的都去试试,不再压抑自己。人生得意须尽欢!
找到路之后就一路积累,一路走下去吧。
关于工作
我有两个路线,不知道走哪个。一个是考研,一个是学习,来年跳槽。
我今年26了,要是考研的话,毕业就得29。程序员吃青春饭,我怕到时候跟不上了。而且北京的研究生不知道好不好考。
学习积累方面也不知道学啥。因为公司需求不大,所以我想往全栈那边走一下。我今年的计划是,先学uni-app,再学flutter。系统学习一下安卓,更新一下技术,并使用新技术重新写一遍自己的毕设。学一下主流的后端技术,重新写一遍自己的毕设的后端。
关于生活
明白自己真正想要什么,多多尝试新鲜事物。
开始健身,至少今年要减20斤肥,变成健康的身体。新冠太可怕了,我被折磨怕了。
学习一下护肤品相关知识,准备尝试找对象,不想单身了。(我看他们都开始捣鼓化妆了,难道现在流行男生化妆了吗)
规律生活,不要再熬夜了。
后言
想说的太多了,文字总是太过苍白,无法表达万一。
其实由于各种原因,时间并不站在我这里。我已经26了,这个时候才开窍似乎是晚了。
但是,最好的开始时刻就是当下。
我之前也有想改变的时候,但是“晚了”这两个字让我给自己判了死刑。不停否定自己,不再进步。
这次,我不想再放弃了。
这次,我不想再放弃了。
链接:https://juejin.cn/post/7194456242910462008
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
7年老菜鸟平凡的2022
前言
嗨,大家好,我是希留。一个被迫致力于成为一名全栈开发的菜鸟。
2022年对于大多数人而言是难忘的一年,受疫情影响、经历行业寒冬。裁员、失业等情况总是笼罩着本就焦虑不安的生活。
而我的2022,用一个关键词就可以概括:“平凡”。既没有升职加薪,也没有被裁失业。就像是一潭湖水,没有什么波澜。可即便如此,也得默默的努力着。下面就来盘点一下属于我的2022。
工作技能上
付出
这一年,本本分分的完成工作上的功能开发,业余时间则在几个技术平台上更新一些文章,几乎都是一篇文章手动同步发送几个平台。
累计在CSDN上写了31篇文章,掘金上更新了28篇文章,公众号更新了26篇文章,头条号更新了26篇文章。
除了更新文章外,还利用业余时间帮朋友开发了一款租房小程序,包含管理后台以及微信小程序。目前还在开发当中,感兴趣的朋友也可以体验一下。后台体验账号: test/123456
小程序端:
收获
CSDN
csdn平台就只收获了访问数据以及粉丝数的增加。
掘金
在掘金平台除了收获一些访问数据的增加外,还切切实实的参与创作活动薅到一些马克杯、抱枕、现金等羊毛,在此感谢掘金平台让我体会到了写作真的能够带来价值,感谢~
微信公众号
微信公众号收获了一些粉丝。
头条号
头条号收获了一些粉丝,以及微薄的收益。
副业拓展上
付出
不知道是受大环境影响还是年龄大了,老是会有各种焦虑。所以也萌生了想要开展副业的想法,于是参加了几个付费社群,也跟着入局实践了两个项目,一个是闲鱼电商,一个是外卖cps。
有朋友入局过这种副业项目的也可以评论区交流一下。
收获
咸鱼上的GMV是2w多,利润有3k多,有这个收益还是比较满意的,希望可以越来越好。
外卖CPS虽然也有一点收益,但是还不够微信300块的认证费,这个项目算是费了。
总的来说,想要做副业也不是那么容易的,虽然眼前有一点点小收益,但是想要放大太难了。
2023未来展望
- 完成租房小程序的开发并上线。
- 更新不少于25篇技术类文章
- 寻找一个更适合技术人员的副业项目
- 完成人生大事
总结
好了,以上就是我的2022总结和未来展望了,感谢大家的阅读。
生活如果不宠你,更要自己善待自己。这一路,风雨兼程,就是为了遇见最好的自己,如此而已。
链接:https://juejin.cn/post/7194432987587412029
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
错的不是世界,是我
楔子
"咕咚,咕咚,咕咚",随着桶装水一个个气泡涌上来,我的水杯虽已装满,但摸鱼太久的我却似木头般木讷,溢出的水从杯口流了下来,弄湿了我的new balance。问:此处描写代表了作者什么心情(5分)。
阳春三月,摸鱼的好季节,我拿起水杯小抿了一口,还是那个甘甜的味道。怡宝,永远的神。这个公司虽然没人陪我说话,工作量也不饱和,但是只要它一天不换怡宝,我便一直誓死效忠这个公司。我的水杯是个小杯,这样每次便能迅速喝完水走去装水,提高装水频率,极大提升摸鱼时长,我不自暗叹我真是一个大聪明。装水回到座位还没坐下,leader便带来一个新来的前端给每位组员介绍,我刚入职三个月,便又来了一位新人。leader瞥了我一眼,跟新人介绍说我也是刚入职的前端开发做题家,我看了新人一眼,脑海闪过几句诗词——眼明正似琉璃瓶,心荡秋水横波清,面如凝脂,眼如点漆,她呆呆的看着我,我向她点头示意,说了声,你好。她的名字,叫作小薇小月。
天眼
"小饿,过来天若有情找我一下",钉钉弹出来一条消息,正是HRBP红姐发来的,我的心里咯噔了一下,我正在做核酸,跟她同步后她让我做完核酸找她。其实下楼做核酸的时候我看到跟我负责同个项目的队友被红姐拉去谈话,公司找我聊天,除了四年前技术leader莫名奇妙帮我加薪有兴趣可看往期文章,其他都没有发生过好事。我的心里其实已经隐隐约约知道了什么事情,一边做着核酸一边想着对策,一边惶恐一边又有几分惊喜,心里想着不会又要拿大礼包了吧,靠着拿大礼包发家致富不是梦啊。
来到天若有情会议室,我收拾了一下心情,走了进去,"坐吧"。红姐冷冷的说了一声,我腿一软便坐了下来。"知道我找你是什么原因吗?"红姐率先发问,"公司是要裁员吗?"我直球回击。红姐有点出乎意料笑了一下,"啪"的一声,很快,我大意了,没有闪。一堆文件直接拍到了桌面,就犹如拍在我的脸上。"这是你上个月的离开工作位置时长,你自己核对一下,签个名"。
我震惊。没想到对面一上来就放大。我自己的情况我是知道的,早上拉个屎,下午喝杯茶,悠然混一日。加上嘘嘘偶尔做做核酸每天离开工作岗位大约2个小时左右。"为什么呀,你入职的时候表现不是这样子的呀,为什么会变成这样呢?是被带坏了吗?没有需求吗?还是个人原因?"。既然你诚心诚意发问,那我就大发慈悲告诉你吧。
为什么呢?
从入职新公司后,我的心感觉就不属于这里,公司指派的任务都有尽心尽责完成,但是来了公司大半年,做了一个项目上线后没落地便夭折,另外一个项目做了一半被公司业务投诉也立刻中断,我没有产出,公司当我太子一样供着。自己从上家公司拿了大礼包后,机缘巧合又能快速进入新的公司,其实自己是有点膨胀的,到了新公司完成任务空闲时便会到掘金写写小说,晚上回家杀杀狼人。有时动一下腰椎,也会传来噼里啪啦的声响,似乎提醒我该去走走了。不过不学无术,游手好闲,的确是我自己的问题。每天摸两小时,资本家看了也会流泪。当然,这些都是马后炮自己事后总结的。
"是我个人原因"。虽说极大部分归于没有需求做,但是没有需求做也不代表着能去摸鱼,而且更不能害了leader,我心里明白,这次是我错了。太子被废了。我在"犯罪记录"上面签了字,问了句如何处理,回复我说看上面安排。我出来后发现有两个同事也来询问我情况,我也一五一十说了,发现大家都是相同问题。我默默上百度查了下摸鱼被裁的话题,发现之前tx也有过一次案例,虽然前两次都是败诉,最后又胜诉了。
我晚上回去躺在床上翻来覆去睡不着觉,心中似乎知道结局,避无可避,但错在我身,这次的事件就当做是一个教训,我能接受,挨打立正。闲来无事打开BOSS刷了又刷,岗位寥寥无几,打开脉脉,第一条便是广州找工作怎么这么难啊,下面跟着一大群脉友互相抱团取暖,互相安慰,在寒冬下,大家都知道不容易,大家都互相鼓励,互相给出希望,希望就像一道道暖风,吹走压在骆驼身上的稻草,让我们在时间的流逝下找到花明。
第二天,红姐让我去江湖再见会议室。"其实是个坏消息啦,X总容忍不了,这是离职协议,签一下吧"。我看了厚厚的离职协议,默不作声,"签个人原因离职后背调也可以来找我,我这边来协助安排"。弦外之音声声割心,但其实我心里也明白,我也没有底气,不如利索点出来后看看能不能尽快找个工作。
晚宴
leader知道我们几个明天last day后,拉个小群请我们吃饭。也是在这次宴席中,leader透露出他也会跟着我们一起走,我大为吃惊,随后leader便娓娓道来,我知道了很多不为人知的秘密。这次总共走了四个人,都是前端,其中涉及了帮派的斗争,而我们也成为斗争中的牺牲品。我一边听着leader诉说公司的前尘往事,一边给各位小伙伴倒茶,心里也明白,就算内斗,如果自己本身没有犯错,没有被抓到把柄,其实也不会惹祸上身。leader也跟我说因为他个人原因太忙没有分配给我适合的工作量,导致我的确太闲,也让我给简历给他帮忙内推各种大厂,我心里十分感激。
期间有位小伙伴拍着我肩膀说,"我知道你是个很好的写手,但是这些东西最好不要写出来"。我一愣,他接着说,之前有位前端老员工识别到是你的文章,发出来了。凉了,怪不得我变成砧板的鱼肉,原来我的太子爽文都有可能传到老板手里了。我突然心里一惊,问了一句不会是因为的Best 30 年中总结征文大赛才导致大家今晚这场盛宴吧?leader罢了罢手,说我想多了。我也万万想不到,我的杰作被流传出去,可能点赞的人里面都藏着CEO。就怕太子爽文帮我拿到了电热锅,却把我饭碗给弄丢了。不过我相信,上帝为你关上一扇门,会为你打开一扇窗。
不过掘金的奖牌着实漂亮,谢谢大家的点赞,基层程序员一个,写的文章让大家有所动容,有所共鸣,实乃吾之大幸。
天窗
自愿离职后的我开始准备简历,准备复习资料,同时老东家也传来裁员消息。心里不禁感叹,老东家这两次裁员名单,都有我的名字。我刷了下boss,投了一份简历,便准备面试题去了,因为我觉得我的简历很能打,但是面试的机会不多,每一次面试都是一个黄金机会,不能再像上次一样错过。当天一整天都很down,朋友约出来玩,我也拒绝了,但是朋友边邀请边骂边安慰我,我想了一下就当放松一下了,于是便出去浪了一天。第二天睡醒发现两个未接来电,回拨过去后是我投递简历的公司打来的,虽然我没有看什么面试题,但是好在狼人杀玩的够多,面对着几位面试官夸夸其谈,聊东南西北,最终也成功拿下offer。虽然offer一般,但在这个行情下,我一心求稳,便同意入职,所以也相当于无缝衔接。对这位朋友也心怀感激,上次也是他的鼓励,让我走出心中的灰暗,这次也是让我在沮丧中不迷失自我。那天我玩的很开心,让我明白工作没了可以再找,错误犯了可以改回来,但人一旦没了信心迷失方向,便容易坠入深渊。
THE END
其实很多人都跟我说,互联网公司只要结果,这次其实我没犯啥毛病,大家都会去摸鱼。我经过几天思考我也明白,不过,有时候真要从自己身上找下原因,知道问题根本所在,避免日后无论是在工作还是生活中,都能避免在同一个地方再次跌倒。其实大多时候,错的不是世界,而是我。
过了几天,leader请了前端组吃一顿他的散伙饭,因为他交接比较多,所以他走的比较晚。菜式十分丰富,其中有道羊排深得我心,肥而不腻,口有余香,难以言喻。小月坐在我的隔壁,在一块羊排上用海南青金桔压榨滴了几滴,拍了拍我的肩膀,让我试一下。我将这块羊排放入口中,金桔的微酸带苦,孜然的点点辛辣,羊排本身浓郁的甜味,原来,这就是人生啊。仔细品尝后,我对小月点了点头,说了声谢谢。
链接:https://juejin.cn/post/7138117808516235300
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2022年还好有你-flutter
第一次参加年终总结,还有点紧张呢!一直都是随遇而安的佛系心态,也许就是那种“我已经努力了”的心态,还写什么总结走形式呢,一直都是抗拒的。但看了好多大神的总结,让我感触良多。一个成功的人士,都是有自己的完整规划,包括职业,人生,技术等。突然让我明白,一个自律的人才更加容易成功。
一、工作
2022年一步一个脚印的走着,平淡又踏实的。需求一个接着一个,有时候是一个接着两个。移动端iOS和Android就孤家寡人,加上开发时间由整个项目进度弹性调整。奋笔疾书已经赶不上了。从去年开始研究的flutter在虎年,还是帮上了大忙。虽然在开始研究时,收到了领导的警告。但是当提高了100%的开发效率时,领导应该摸着XX庆幸了。
公司新开了一个业务线,界面和功能繁多,又涉及到iOS和Android。真的是为flutter量身打造啊。果断的采用,并持续的输入。使用体验能有个原生的80%吧。还是欣慰的。
突然回忆不起太多的开发内容了,应该都是缝缝补补的较多吧。
记得用半个月的时间编写了一个单车的模拟器来支持一个特殊的城市。这个经历让我非常有成就感。因为没有实车和中控,导致后端开发和测试人员没法操作。如果有一个模拟器那么可以解决燃眉之急。大家都不看好的时候,我觉得可以试下。拿起python进行业务逻辑的堆积。哈哈,是堆代码了。不求质量,只求能用。 最后磕磕碰碰的帮上了大忙。
熟悉了python后,又用它进行了很多脚本的编写,查询异常车辆,异常任务,批量处理数据等等。还是非常好用。但是真的只是一个工具,想再深入的时候,没有业务的需求,太难。只能学到够用了。
虎年说在哪方面学习的最深入,那应该还是flutter了。将张风捷特烈的文章都看了一遍,每一篇文章也都点赞了。学到了不少的东西。特别是被他的那种深入学习,超级自律的行为打动。继续向他学习。
虎年工作中最高兴的事,应该还是3年前申请的专利下来了。看到纸质证书的时候,真的是感觉到自己孩子出生一样。当拿到我的专利专利奖金时,立刻下单了最新款的mac book pro。人生中最贵的电脑,用着真的是舒服。
二、心态
工作一直保持着勤勤恳恳,也拥抱变化,一个人扛起整个移动端。从长远来看,学的东西太广了,没有自己的拿手技术,不是一个理想的状态。但能够学着新东西,又可以在项目中马上投入使用。这种自由感,真的是太爽了。也许是我没有太大的抱负,就会用忙碌来麻痹自己。
有两样事,还是一直都有坚持。(1)英语(2)锻炼。
此生英语虐我千百遍,我待英语如初恋。每天都会坚持背诵单词,每天必定在《不背单词》签到,复习之前的单词然后学习新的单词。不能说毫无进步吧。至少已经不怕英语了,懂的单词越来越多,看文章越来越快了。英文的系统和工具,已经没有障碍了。坚持吧,也许真的是少了一点天赋。
还坚持过一段时间的听力,随着项目压力,慢慢地被遗忘。
锻炼身体,也有一直在做。选择了跳绳,买了几根绳,买了手环。想把这个作为一辈子的运动。从开始的跳几百个,到能跳1k多。也很有成就感。
三、输出
虎年的输出,只能说靠运气了。碰到什么问题解决下,然后做一个记录。没有特别去写文章。阅读量最大的文章也是flutter的iOS的编译问题。当时写这个文档的时候仅仅用了1个小时吧。虽然解决问题花了几天。每天看到那么多关注和点赞,偷偷地笑了。
有想过好好写点文章,但是任何东西感觉用几句话就能说完的,写一篇文章太啰嗦了,还是发一个沸点吧。
写这个Flutter实现闪电效果文章,当时的想法是从来没有参加过活动,要不要试试。证明下自己是不是也是可以的。用一天来构思,一天来实现代码,一天来编写文章。然后找了同事给我点赞。最后顺利拿到马克杯,很开心。
四、 源码学习
虎年也试着开始学习源码,将dio、provider、 flutter(part)、 dart(part)、 FlutterUnit等源码,一行行的看了。最尴尬的是每一行都看懂了,整体的看不懂。觉得每一个地方都很简单,整体框架怎么样,没有思路。是不是设计模式没研究透,又去学习了一遍设计模式。但是发现设计模式也学的一知半解。我明白我还有很长的路要走啊。
试着编写了自己的FlutterSnippet,把看到好玩的好用的收集起来。以后在项目中可以用到。
五、 生活
生活只能说只有家庭了。只从有了女儿后,在家里那么全是围绕着她。把时间都花在她身上,让她能够感受到满满的爱,能够自信又快乐的成长。希望疫情过去后,能够陪着她看遍大江南北吧。
在B站关注了好多有意思的UP主。删除了抖音和微博,因为这些无味的内容,让我每次睡前都很后悔。学习自己想学习的,自己来把握自己的视频,感觉充实起来了。
看到那么多宝藏UP主,才知道人生原来可以那么丰富多彩,而不仅仅只有学习。希望我的人生我的生活,也多姿多彩起来。
六、 2023年展望
对兔年,虽然如水般的平静。但也想向大神们学习,定一个目标。
将flutter的源码看一遍。
至于能够看懂多少,还真的是心里没底。用我最喜欢的话“美丽新世界”,来表达对这个世界一直充满好奇吧。
总结
虎年感谢有你--flutter,是你让我明白,不断去尝试新的技术,保持学习。让自己的路越走越广。
链接:https://juejin.cn/post/7181376290505621560
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不过是享受了互联网的十年红利期而已。
你好呀,我是歪歪。
去年的最后一天,我在 B 站发布了这个视频:
我真没想到这个长达一个小时的视频的播放量能到这么多,而且居然是一个投币比点赞和收藏还多的视频。
评论区加上弹幕,有上千条观众的留言。每一条留言都代表一个观众的感受,里面极大部分的感受总结起来大多是表示对于我个人这十年经历感叹和羡慕,但是我是觉得十年的时间这么长,谁还不能提炼出几两故事和几段感悟呢?
觉得感叹的,只不过是在我的视频里面看到了几分自己的影子。觉得羡慕的,只不过是以另外一种我羡慕的方式生活着。
还是有人说是逆袭,我并不觉得这是逆袭。逆袭一般是说绝地反击的故事,但是我觉得这十年,我还没有真正的走到过“绝地”,更多的只是随着时代随波逐流,我个人的努力,在时代的浪潮前,微不足道,只不过在一系列的机缘巧合之下,我使劲的方向恰好和浪潮的方向一致而已。
我当时没有想到一个好的词语来形容这个“和浪潮的方向一致”,所以过年期间我也一直在仔细的思考这个问题。
直到过年期间,我坐在火炉前听家里的长辈聊天,一个长辈问另外一个晚辈:你什么时候把女朋友带回来给我们看看呢?
晚辈戏谑的回答说:我现在自己都过的不好呢,怕是没有女孩子愿意跟我哦。
长辈说:我以前嫁过来的时候,你爷爷以前还不是啥都没有,就一间土巴屋,一个烂瓦房。结婚嘛,两个人一起努力不就把日子过好了。
我当时好想说一句:那个时代过去了,现在不一样了。
然而终究还是没说出口,但是就在把这句话咽下去的瞬间,我想明白了前面关于“浪潮”的问题,其实就一句话:
我只不过是有幸享受到了时代的红利罢了。有时候的看起来让人羡慕的人、成功的人,只不过是享受到了时代的红利罢了,与个人的努力程度关系真的不大。
我说的时代的红利,就是互联网技术、计算机专业野蛮发展的这十年光景。
在视频里面,我说了一句话:我是被调剂到计算机专业的。
然后有一些弹幕表示非常的震惊:
是的,在 2012 年,计算机专业并不是一个被看好的热门专业,甚至有点被“淘汰”的感觉。
我记得那一年录取之后,给一个亲戚说是就读计算机专业,他说:怎么学了个这专业啊,以后每个家庭里面都会有一台计算机,到时候人人都会使用计算机,还学它干啥?
这句话虽然现在看起来很搞笑,但是在那个时候,我还没有接触到它的时候,我觉得很有道理。
虽然我是调剂到“计算机”的,但是前提也得是我填报志愿的时候填写了“计算机专业”,对吧。
所以问题就来了:我当年是怎么高瞻远瞩,怎么深思熟虑,怎么推演计算,怎么预测未来,想着要填报一个计算机专业呢?
为了回答这个问题,我今年回到老家,专门把这个东西翻了出来:
这是我高考结束那年,学校发的 4 本和填报志愿相关的书,书里面主要的内容就是过去三年各个批次,各个学校,各个专业的报考人数、录取人数、录取最低分数、录取平均分数、录取最高分数的信息统计:
我当年填报志愿,就是通过翻阅这四本书来找到自己可以填报的大学。但是我的高考志愿特别好填,因为我高考成绩只超过二本线 13 分,所以我直接看二本院校里面每年卡着分数线招收学生的学校就可以了。在这个条件下,没有多少学校可以选择。
最后录取我的大学,是 2012 年那一年刚刚由专科学校升级为二本院校的一所大学。所以那一年是它第一次招本科生,没有过往的数据可以参考,报它的原因是因为我感觉它刚刚从专科升级为本科,录取分数应该不会太高。
填报志愿的时候一个学校可以填写六个专业,刚好它也只有六个本科专业,所以我就按照报纸上的顺序,挨个填写,而且还勾选了“服从调剂”。
而这六个专业,我也通过前面的书翻到了:
当时对于这六个专业,我完全没有任何了解。根本不知道要学习什么内容,更加不知道毕业之后会从事什么工作。
后来入校之后我才知道,报材料成型及控制工程和机械电子工程专业的人最多,计算机科学与技术由于报的人没有报满,所以我被调剂过去了。
可以肯定的说,如果当年这个学校没有计算机的本科专业,我就不会走上计算机的道路。
其实我填报志愿的状态,和当年绝大部分高考学生的状态一样,非常的茫然。在高中,学校也只教了高考考场上要考的东西,为了这点东西,我们准备了整整三年。但是现在回头去看,如何填报志愿,其实也是一件非常值得学习了解的事情,而不是高考结束之后,学校发几本资料就完事的。
我当时填报志愿时最核心的想法是,只要有大学录取就行了,至于专业什么的,不重要。
在志愿填报指南的书里面,我发现有大量的篇幅站在 2012 年视角去分析未来的就业形势。
这部分,我仔细的读了一遍,发现关于计算机部分提到的并不多,只有寥寥数语,整体是持看好态度,但是大多都是一些正确的“废话”,对于当年的我来说,很难提炼出有价值的信息,来帮助我填写志愿。
后来得知被计算机录取了之后的第一反应是,没关系,入校之后可以找机会转专业,比如转到机械。
为什么会想着机械呢?
因为那一年,或者说那几年,最火的专业是土木工程,紧随其后的大概就是机械相关的专业:
而这个学校没有土木专业,那就是想当然的想往人多的,也是学校的王牌专业“机械”转了。
计算机专业,虽然也榜上有名,但是那几年的风评真的是非常一般,更多的是无知,就像是亲戚说的那句:以后人人都有一台计算机,你还去学它干啥?
我也找到了一份叫做《2011年中国大学生就业报告》的报告,里面有这样一句话:
真的如同弹幕里面一个小伙伴说的:土木最火,计算机下水道。
所以我在十年前被调剂到计算机专业,也就不是一个什么特别奇怪的事情了。
你说这是什么玩意?
这里面没有任何的高瞻远瞩、深思熟虑、推演计算、预测未来,就是纯粹的运气。
就是恰好站在时代的大潮前,撅着屁股,等着时代用力的拍上那么一小下,然后随着浪花飘就完事了吗?
我也曾经想过,如果我能把它包装成一个“春江水暖鸭先知”的故事,来体现我对于未来精准的预判就好了,但是现实情况就是这么的骨感和魔幻,没有那么多的预判。
所以有很多人,特别是一些在校的或者刚刚毕业的大学生,通过视频找到我,来请教我关于职业发展,关于未来方向,关于人生规划的问题。
说真的,我有个屁的资格和能力来帮你分析这些问题啊。我自己这一摊子事情都没有搞清楚,我的职业前路也是迷雾重重,我何德何能给别人指出人生的方向?
当然,我也能给出一些建议,但是我能给出的所有的回复,纯粹是基于个人有限的人生阅历和职业生涯,加上自己的一些所见所闻,给出的自己角度的回答。
同样的问题,你去问另外一个人,由于看问题的角度不同,可能最终得出的答案千差万别。
甚至同样的职场相关的问题,我可以给你分析的头头是道,列出一二三四点,然后说出每一点的利益得失,但是当我在职场上遇到一模一样的问题时,我也会一时慌张,乱了阵脚,自然而然的想要去寻求帮助。
在自媒体的这三年,我写过很多观点输出类的文章,也回答过无数人的“迷茫”。对于这一类求助,有时是答疑,常常是倾听,总是去鼓励。
我并不是一个“人生导师”,或者说我目前浅薄的经验,还不足以成为一个“人生导师”,我只不过是一个有幸踩到了时代红利的幸运儿而已。
在这十年间,我踩到了计算机的红利,所以才有了后面看起来还算不错的故事。
踩到了 Java 的红利,所以才能把这个故事继续写下去。
踩到了自媒体的红利,所以才有机会把这些故事写出来让更多的人看到。
现在还有很多很多人摩肩擦踵的往计算机行业里面涌进来,我一个直观的感受就是各种要求都变高了,远的就不说了,如果是三年前我回到成都的时候,市场情况和现在一样的话,我是绝对不可能有机会进入到现在这家公司,我只不过是恰好抓住了一个窗口期而已。
还有很多很多的人,义无反顾的去学 Java,往这个卷得没边的细分领域中冲的不亦乐乎,导致就业岗位供不应求,从而企业提升了面试难度。我记得 2016 年我毕业的时候,在北京面试,还没有“面试造火箭”的说法,当年我连 JVM 是啥玩意都不知道,更别提分布式相关的技术了,听都没听过。然而现在,这些都变成了“基础题”。
还有很多人,看到了自媒体这一波流量,感觉一些爆款文章,似乎自己也能写出来,甚至写的更好。或者感觉一些非常火的视频,似乎自己也能拍出来,甚至拍的跟好。
然而真正去做的话,你会发现这是一条“百死一生”的道路,想要在看起来巨大的流量池中挖一勺走,其实很难很难。
但是如果把时间线拉回到 2014 年,那是公众号的黄金时代,注册一个公众号,每天甚至不需要自己写文章,去各处搬运转载,只需要把排版弄好看一点,多宣传宣传,然后坚持下去,就能积累非常可观的关注数量,有关注,就有流量。有流量,就有钱来找你。从一个公众号,慢慢发展为一个工作室,然后成长为一个公司的故事,在那几年,太多太多了。
诸如此类,很多很多的现象都在表明则一个观点:时代不一样了。
我在刚刚步入社会的时候,看过一本叫做《浪潮之巅》的书,书里面的内容记得不多了,但是知道这是一本把计算机领域中的一些值得记录的故事写出来的好书。
虽然书的内容记得不多了,但是书的封面上写的一段话我就很喜欢。
就用它来作为文章的结尾吧:
近一百多年来,总有一些公司很幸运地、有意识或者无意识地站在技术革命的浪尖之上。一旦处在了那个位置,即使不做任何事,也可以随着波浪顺顺当当地向前漂个十年甚至更长的时间。在这十几年间,它们代表着科技的浪潮,直到下一波浪潮的来临。这些公司里的人,无论职位高低,在外人看来,都是时代的幸运儿。因为,虽然对一个公司来说,赶上一次浪潮不能保证其长盛不衰;但是,对一个人来说,一生赶上一次这样的浪潮就足够了。一个弄潮的年轻人,最幸运的,莫过于赶上一波大潮。
以上。
。
。
。
。
。
。
如果我这篇文章结束在这个地方,那么你先简单的想一想,你看完之后那一瞬间之后的感受是什么?
会不会有一丝丝的失落感,或者说是一丢丢的焦虑感?
是的,如果我的文章就结束在这个地方,那么这就是一篇试图“贩卖焦虑”的文章。
我在不停的暗示你,“时代不一样了”,“还是以前好啊”,“以前做同样的事情容易的多”。
这样的暗示,对于 00 后、90 后的人来说,极小部分感受是在缅怀过去,更多的还是让你产生一种对当下的失落感和对未来的焦虑感。
比如我以前看到一些关于 90 年代下海经商的普通人的故事。就感觉那个时代,遍地是黄金,处处是机会,只要稍稍努力就能谱写一个逆天改命的故事,继而感慨自己的“生不逢时”。
只是去往回看过去的时代,而没有认真审视自己的时代,当我想要去形容我所处的时代的时候,负面的形容词总是先入为主的钻进我的脑海中。
我之前一直以为是运气一直站在我这边,但是我真的是发布了前面提的到视频,然后基于视频引发了一点讨论之后,我才开始更加深层次的去思考这个问题,所以我是非常后知后觉的才感受到,我运气好的大背景是因为遇到了时代的红利。
要注意前面这一段话,我想强调的是“后知后觉”这个词。这个词代表的时间,是十年有余的时间。
也就是说在这十年有余的时间中,我没有去刻意的追求时代的红利、也没有感知到时代的红利。
这十年间,概括起来,我大部分时间只是做了一件事:努力成长,提升自我。
所以在我的视频的评论区里面还有一句话出现的频率特别高:越努力,越幸运。
我不是一个能预判未来的人,但是我并不否认,我是一个努力的人,然而和我一样努力,比我更加努力的人也大有人在。
你要坚信,你为了自己在社会上立足所付出的任何努力是不可能会白费的,它一定会以某种形式来回报你。
当回报到来的时候,也许你认为是运气,其实是你也正踩在时代的红利之上,只不过还没到你“后知后觉”的时候,十年后,二十年后再看看吧。
在这期间,不要囿于过去,不要预测未来,你只管努力在当下就好了。迷茫的时候,搞一搞学习,总是没错的。
(特么的,这味道怎么像是鸡汤了?不写了,收。)
最后,用我在网上看的一句话作为结尾吧:
我未曾见过一个早起、勤奋,谨慎,诚实的人抱怨命运不公;我也未曾见过一个认真负责、努力好学、心胸开阔的年轻人,会一直没有机会的。
以上就是我对于处于“迷茫期”的一些大学生朋友的一点点个人的拙见,也是我个人的一些自省。
共勉。
链接:https://juejin.cn/post/7193678951670087739
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android 通过productFlavors实现多渠道打包
在日常开发中,可能会遇到同一份代码,需要根据运营需求打出不同包名、不同图标、不同名称的Apk,发布到不同的渠道中。Android Studio提供了便捷的多渠道打包实现方法productFlavors。
本文介绍一下使用productFlavors来实现多渠道打包。
创建productFlavors
- 添加Dimension
在app包下的build.gradle中的android闭包下,添加flavorDimension,代码如下:
android {
...
// 方式1
getFlavorDimensionList().add('example_value')
// 方式2
flavorDimensions "example_value"
}两种方式选择一种即可,方式1有代码补全提示,方式2没有。
- 创建productFlavor
在app包下的build.gradle中的android闭包下,创建productFlavors,代码如下:
android {
...
productFlavors {
// 原始渠道
origin{
// 这里的值与前面flavorDimensions设置的值保持一致
dimension 'example_value'
}
// 示例渠道
exampleFlavor {
// 这里的值与前面flavorDimensions设置的值保持一致
dimension 'example_value'
}
}
}网上找到的相关文章都说productFlavor中需要配置dimension,但是在尝试的过程中发现,如果只添加了一个flavorDimensions,那么productFlavor中的dimension可以不用特别声明(我的gradle版本为7.6,AGP为7.4.1)。
构建完后可以在Build Variants中看到已配置的变体,如图:
渠道包参数配置
打渠道包时,根据需求可能会需要配置不同参数,例如App的名称、图标、版本信息,服务器地址等。
- 配置不同的签名信息
如果需要使用不同的签名文件,可以在app包下的build.gradle中的android闭包下配置signingConfigs,代码如下:
android {
signingConfigs {
origin {
keyAlias 'expampledemo'
keyPassword '123456'
storeFile file('ExampleDemo')
storePassword '123456'
}
exampleFlavor {
keyAlias 'exampledemoflavor'
keyPassword '123456'
storeFile file('ExampleDemoFlavor.jks')
storePassword '123456'
}
}
flavorDimensions "example_value"
productFlavors {
origin{
signingConfig signingConfigs.origin
}
exampleFlavor {
signingConfig signingConfigs.exampleFlavor
}
}
}需要注意的是signingConfigs必须在productFlavors前面声明,否则构建会失败。
- 配置包名、版本号
在productFlavors中可以配置渠道包的包名、版本信息,代码如下:
android {
...
defaultConfig {
applicationId "com.chenyihong.exampledemo"
versionCode 1
versionName "1.0"
...
}
productFlavors {
origin{
...
}
exampleFlavor {
applicationId "com.chenyihong.exampledflavordemo"
versionCode 2
versionName "1.0.2-flavor"
}
}
}origin渠道表示的是原始包,不进行额外配置,使用的就是defaultConfig中声明的包名以及版本号。
效果如图:
origin
exampleFlavor
- 配置BuildConfig,字符串资源
在productFlavors中配置BuildConfig或者resValue,可以让同名字段,在打不同的渠道包时有不同的值,代码如下:
android {
...
productFlavors {
origin{
buildConfigField("String", "example_value", "\"origin server address\"")
resValue("string", "example_value", "origin tips")
}
exampleFlavor {
buildConfigField("String", "example_value", "\"flavor server address\"")
resValue("string", "example_value", "flavor tips")
}
}
}配置完后重新构建一下项目,就可以通过BuildConfig.example_value以及getString(R.string.example_value)来使用配置的字段。
效果如图:
origin
exampleFlavor
- 配置manifestPlaceholders
有些三方SDK,会在Manifest中配置meta-data,并且这些值跟包名大概率是绑定的,因此不同渠道包需要替换不同的值,代码如下:
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:tools="http://schemas.android.com/tools">
<application
...
>
<meta-data
android:name="channel_value"
android:value="${channel_value}"/>
....
</application>
</manifest>
android {
...
productFlavors {
origin{
manifestPlaceholders = [channel_value: "origin channel"]
}
exampleFlavor {
manifestPlaceholders = [channel_value: "flavor channel"]
}
}
}效果如图:
origin
exampleFlavor
- 配置不同的依赖
不同渠道包可能会引用不同的三方SDK,配置了productFlavors后,可以在dependencies中区分依赖包,代码如下:
dependencies {
// origin 包依赖
originImplementation("com.google.code.gson:gson:2.10.1")
// exampleFlavor包依赖
exampleFlavorImplementation("com.google.android.gms:play-services-auth:20.4.1")
}示例:
在FlavorExampleActivity中同时导入Gson包和Google登录包,效果如下:
origin
exampleFlavor
- 配置不同的资源
在app/src目录下,创建exampleFlavor文件夹,创建与main包下一样的资源文件夹,打渠道包时,相同目录下同名的文件会自动替换,可以通过这种方式来实现替换应用名称和应用图标。
效果如图:
示例Demo
按照惯例,在示例Demo中添加了相关的演示代码。
链接:https://juejin.cn/post/7198806651562229816
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用做猪脚面的方式,理解下模版方法模式
模版方法模式
前言
模版方法模式,是行为型设计模式的一种。这个模式的使用频率没有那么高,以至于之前从来没有了解过该模式。不过兄弟们也不用怕,这个模式其实还是比较简单的。等会咱们举个例子,来理解一下这个模式。
介绍
概念理解
模版方法模式,个人理解是,将类中的一些方法执行顺序进行排序。其中的部分方法可以被重写。排序后的方法就是模版方法。排序后的类就是模版类。这种代码设计思路就是模版方法模式。
菜谱:猪脚面
上面的描述可能有点抽象。那么咱就换一个讲法来说一下这个模式。
从前呢,在京海市有一条街叫旧厂街,那里呢有一个菜市场,菜市场里有一个卖鱼的小老板他叫高启强。他呢有一个弟弟妹妹。兄妹三人啊从小就喜欢吃猪脚面。但是由于家里穷,所以三人只够吃一碗面。妹妹高启兰吃猪脚,弟弟高启盛吃面,而高启强就只能喝面汤。
由于的确穷,他就去找饭店老板要了一份菜谱。饭店老板看他可怜就给了他一份猪脚面的菜谱,具体如下:
- 把水烧开
- 放面条
- 放猪脚
- 放佐料
- 把面煮熟
他兴高采烈的按照菜谱做了一份猪脚面,给弟弟妹妹吃。可是结果却让他失望了。因为猪脚面的味道出了问题。
他去找了老板,老板对他说,阿强啊,我给你的菜谱肯定没问题,味道不对一定是哪个环节出错了。
于是他又给老板做了一遍。当他放完佐料的时候。老板立刻叫住了他,对他说。阿强,你其他的步骤都没有错,但是放佐料这一步和我有些不一样。
这一步这里你应该要放的是酱油和老抽,再用盐和鸡精调味。可这里你只用了醋来调味,所以味道不对。高启强满脸通红的对老板说,对不起啊老板,我家太穷类没有那些调理所以只能用醋代替了。
在上面这个例子中,这里面的菜谱就是模板也可以说是框架。
菜谱的执行顺序可以被看作是模板方法。而且这里的执行顺序是固定无法被改变的。
执行顺序无法改变,但是具体的做菜步骤却是可以被重写的。比如说放佐料。
例子中的高启强正是由于这一步的不同,导致他做出的猪脚面和老板的口味不一致。
2023春晚
上面这个可以看作是模版方法模式的一个简单举例。接下来咱们再举个有代码的例子加深下对模版方法模式的印象。
春晚模版类
SpringFestivalGala规定了春晚必须遵循的节目流程。这个代码中的start方法,可以看作是模版方法模式中最重要的一环,因为他就是规定了其他方法调用顺序的模版方法。
- 开场白
- 唱歌
- 跳舞
- 小品
- 难忘今宵
由于不同卫视的节目顺序都遵循这套模版。而且最后的节目难忘今宵是春晚保留节目,所以该节目必须所有春晚保持一致,具体代码如下所示:
/**
* Author(作者):jtl
* Date(日期):2023/2/10 20:05
* Detail(详情):春晚流程(春晚模版 )
*/
public abstract class SpringFestivalGala {
public void start(){
prologue();
song();
dance();
comedySketch();
unforgettableTonight();
}
//开场白
public abstract void prologue();
//歌曲节目
public abstract void song();
//小品节目
public abstract void comedySketch();
//舞蹈节目
public abstract void dance();
//难忘今宵
private void unforgettableTonight(){
System.out.println("结尾:难忘今宵");
}
}
复制代码上面的代码中,不同的春晚,有着不同的小品舞蹈等节目,所以需要SpringFestivalGala的子类需要重写这几个方法。但是难忘今宵是所有春晚共同的节目。因此可以复用。
而start方法就可以看作是模版方法。它里面的节目执行顺序是固定的无法被改变。
辽视春晚
辽宁春晚继承了春晚的固定模版。具体代码如下:
/**
* Author(作者):jtl
* Date(日期):2023/2/10 20:42
* Detail(详情):辽宁春晚
*/
public class SpringFestivalGalaOfLiaoning extends SpringFestivalGala{
@Override
public void prologue() {
System.out.println("开场白:欢迎来到,2023年,辽宁卫视春晚现场");
}
@Override
public void song() {
System.out.println("歌曲:孙楠,谭维维-追光");
}
@Override
public void comedySketch() {
System.out.println("小品:宋小宝-杨树林:非常营销");
}
@Override
public void dance() {
System.out.println("舞蹈:舞蹈-欢庆中国年");
}
}
复制代码央视春晚
央视春晚同样遵循春晚的传统模版。有着开场白,歌曲等精彩的演出。尤其是小品初见照相馆一经播出,一己之力推动年轻人的离婚率,简直是今年节目之最!
央视春晚的具体代码如下:
/**
* Author(作者):jtl
* Date(日期):2023/2/10 20:53
* Detail(详情):CCTV 央视春晚
*/
public class CCTVSpringFestivalGala extends SpringFestivalGala{
@Override
public void prologue() {
System.out.println("开场白:欢迎来到,2023年,央视春晚的现场");
}
@Override
public void song() {
System.out.println("歌曲:邓超-好运全都来");
}
@Override
public void comedySketch() {
System.out.println("小品:于震-初见照相馆");
}
@Override
public void dance() {
System.out.println("舞蹈:辽宁芭蕾舞团:我们的田野上");
}
}
复制代码客户端代码
调用这两个类的客户端代码
/**
* Author(作者):jtl
* Date(日期):2023/2/10 20:04
* Detail(详情):模版方法模式客户端
*/
public class Client {
public static void main(String[] args) {
CCTVSpringFestivalGala cctv = new CCTVSpringFestivalGala();
cctv.start();
System.out.println("----------------分割线----------------");
SpringFestivalGalaOfLiaoning liaoning = new SpringFestivalGalaOfLiaoning();
liaoning.start();
}
}
复制代码运行结果
结果如图所示
模版方法模式的模版
- 有一个固定的模版类A,它是一个抽象类
- 模版类A里有一些方法,这些方法里有需要子类重写的抽象方法
- 有一个模版方法,它里面有着这些方法的调用顺序。这个顺序是不能被改变的,也是模版方法模式的核心
- 子类继承模版类A,重写它的抽象方法
后记总结
至此,模版方法模式就算是介绍完毕了。细心的小伙伴可能发现了,模版方法模式的模版如果要扩展的话,就必须改了啊,他这违反了开闭原则啊。
没错,这是这个模式的一个缺陷。从模版方法模式的定义来看,它的概念就是给其他类提供一套固定的执行流程,这个执行流程就是模版方法。其他类只能修改其中的方法,不能修改执行流程,即不能修改模版方法。所以它从定义上就不存在修改执行流程这一可能。可能有点强行洗白,但是这也是一种解释方式。
还是那句话,对于设计模式来说,没有固定的套路。毕竟它只是人们经过长时间总结出来的代码经验。所以千万别被所谓的设计模式框架所拘束,只要符合要求,有利阅读和扩展就是好的代码。
如果喜欢请点个赞,支持一下。有错误或不同想法请及时指正哈。辛苦您看到这里,下篇文章再见哈,👋👋👋
链接:https://juejin.cn/post/7199297355748343863
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一起掌握Kotlin协程基础
前言
在平时的开发中,我们经常会跟线程打交道,当执行耗时操作时,便需要开启线程去执行,防止主线程阻塞。但是开启太多的线程,它们的切换就需要耗费很多的资源,并且难以去控制,没有及时停止或者控制不当便很可能会造成内存泄露。并且在开启多线程后,为了能够获取到计算结果,我们需要采用回调的方式来回调结果,但是回调多了,代码的可读性变得很差。kotlin协程是运行在线程之上,我们使用它时能够很好地去控制它,并且在切换方面,它消耗的CPU和内存大大地降低,它不会阻塞所在线程,可以在不用使用回调的情况下便可以直接获取计算结果。
正文
协程程序
GlobalScope.launch { // 在后台启动一个新的协程并继续
println("hello Coroutine")
}
//输出:hello Coroutine
GlobalScope调用launch会开启一个协程。
协程的组成
- CoroutineScope
- CoroutineContext:可指定名称、Job(管理生命周期)、指定线程(Dispatchers.Default适合CUP密集型任务、Dispatchers.IO适合磁盘或网络的IO操作、Dispatchers.Main用于主线程)
- 启动:launch(启动协程,返回一个job)、async(启动带返回结果的协程)、withContext(启动协程,可出阿如上下文改变协程的上下文)
作业
当我们开启协程后,可能需要对开启的协程进行控制,比如在不再需要该协程的返回结果时,可将其进行取消。好在调用launch函数后,会返回一个协程的job,我们可利用这个job来进行取消操作。
val job = GlobalScope.launch {
delay(1000)
println("world")
}
println("hello")
job.cancel()
//输出结果为:hello
可能有的同学会觉得奇怪为什么world没有输出,原因是当调用cancel时,会对该协程进程取消,也就是不再执行了直接停止。下面再看一个join方法:
val job = GlobalScope.launch {
delay(1000)
println("world")
}
println("hello")
job.join()
//输出结果:
//hello
//worldjoin方法会等待该协程执行结束。
超时
当一个协程执行超时,我们可能需要取消它,但手动跟踪它的超时可能会觉得麻烦,所以我们可以使用withTimeout方法来进程超时跟踪:
withTimeout(1300) {
repeat(10){i->
println("i-->$i")
delay(500)
}
}
//i-->0
//i-->1
//i-->2
//抛出TimeoutCancellationException异常这个方法在设置的超时时间还没完成时,抛出TimeoutCancellationException异常。如果我们只是单纯防止超时而不抛出异常,则可使用:
val wton = withTimeoutOrNull(1300){
repeat(10){i->
println("i-->$i")
delay(500)
}
}
println("end -- $wton")
//i-->0
//i-->1
//i-->2
//end -- null挂起函数
当我们在launch函数中写了很多代码,这看上去并不美观,为了可以抽取出逻辑放到一个单独的函数中,我们可以使用suspend 修饰符来修饰一个方法,这样的函数为挂起函数:
suspend fun doCalOne():Int{
delay(1000)
return 5
}挂起函数需要在挂起函数或者协程中调用,普通方法不能调用挂起函数。
我们通过使用两个挂起函数来获取它们各自的计算结果,然后对获取的结果进一步操作:
suspend fun doCalOne():Int{
delay(1000)
return 5
}
suspend fun doCalTwo():Int{
delay(1500)
return 3
}
coroutineScope {
val time = measureTimeMillis {
//同步开始,需要按顺序等待
val one = doCalOne()
val two = doCalTwo()
println("one + two = ${one + two}")
}
println("time is $time")
}
//one + two = 8
//time is 2512我们可以看到,计算结果正确,说明能够正常返回,而且总共的耗时是跟两个方法所用的时间的总和(忽略其他),那我们有没有办法让两个计算方法并行运行能,答案是肯定的,我们只需使用async便可以实现:
coroutineScope {
val time = measureTimeMillis {
//异步开始
val one = async{doCalOne()}
val two = async{doCalTwo()}
//同步开始,需要按顺序等待
println("one + two = ${one.await() + two.await()}")
}
println("time is $time")
}
//one + two = 8
//time is 1519我们可以看到,计算结果正确,并且所需时间大大减少,接近运行最长的计算函数。
async类似于launch函数,它会启动一个单独的协程,并且可以与其他协程并行。它返回的是一个Deferred(非阻塞式的feature),当我们调用await方法才可以得到返回的结果。
async有多种启动方式,下面实例为懒性启动:
coroutineScope {
//调用await或者start协程才被启动
val one = async(start = CoroutineStart.LAZY){doCalOne()}
val two = async(start = CoroutineStart.LAZY){doCalTwo()}
one.start()
two.start()
}我们可以调用start或者await来启动它。
结构化并发
虽然协程很轻量,但它运行时还是需要耗费一些资源,如果我们在使用的过程中,忘记对它进行引用,并且及时地停止它,那将会造成资源浪费或者出现内存泄露等问题。但是一个一个跟踪(也就是使用返回的job)很不方便,一个两个还好管理,但是多了却不方便管理。于是我们可以使用结构化并发,这样我们可以在指定的作用域中启动协程。这点跟线程的区别在于线程总是全局的。大致如图(图片):
在日常开发中,我们会经常开启网络请求,有时候需要同时发起多个网络请求,我们想要的是在挂起函数中启动多个请求,当挂起函数返回时,里边的请求都执行结束,那么我们可以使用coroutineScope 来进行指定一个作用域:
suspend fun twoFetch(){
coroutineScope {
launch {
delay(1000L)
doNetworkJob("url--1")
}
launch { doNetworkJob("url--2") }
}
}
fun doNetworkJob(url : String){
println(url)
}
//url--2
//url--1coroutineScope等到在其里边开启的所有协程执行完成再返回。所以twoFetch不会在coroutineScope内部所启动的协程完成前返回。
当我们取消协程时,会通过层次结构来进行传递的。
suspend fun errCoroutineFun(){
coroutineScope {
try {
failedCorou()
}catch (e : RuntimeException) {
println("fail with RuntimeException")
}
}
}
suspend fun failedCorou() {
coroutineScope {
launch {
try {
delay(Long.MAX_VALUE)
println("after delay")
} finally {
println("one finally")
}
}
launch {
println("two throw execption")
throw RuntimeException("")
}
}
}
//two throw execption
//one finally
//fail with RuntimeException结语
本次的kotlin协程分享也结束了,内容篇基础,也算是对kotlin协程的一个入门。当对它的使用达到熟练时,会继续分享一篇关于较进阶的文章,希望大家喜欢。
链接:https://juejin.cn/post/7127086841685098503
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
另类年终总结:在煤老板开的软件公司实习是怎样一种体验?
某个编剧曾经说过:“怀念煤老板,他们从不干预我们创作,除了要求找女演员外,没有别的要求。”,现在的我毕业后正式工作快半年了,手上的活越来越多,负责的事项越来越多越来越杂,偶尔夜深人静走在回家的路上,也怀念当时在煤老板旗下的软件公司实习时无忧无虑的快乐生活,谨以此文纪念一下当时的时光。
煤老板还会开软件公司?
是的,煤老板家大业大,除了名下有几座矿之外,还有好多处农场、餐厅、物流等产业,可以说涉足了多个产业。当然最赚钱的主业还是矿业,听坊间传闻说,只要矿一开,钱就是哗哗的流进来。那么这个软件公司主要是做什么的呢,一小部分是给矿业服务的,负责矿山的相关人员使用记录展示每天矿上的相关数据,比如每天运输车辆的流转、每日矿上人力的核算。大部分的主力主要用于实现老板的雄伟理想,通过一个超级APP,搞定衣食住行,具体的业务如下,可以说是相当红火的。
煤老板的软件公司是怎么招聘的
这么有特色的一家公司,我是如何了解到并加入的呢。这还要从老板如何创立这家公司说起,老板在大学进修MBA的时候,认识了大学里计算机学院的几名优秀学子,然后对他们侃侃而谈自己的理念和对未来的设想,随后老板大笔一挥,我开家公司,咱们一起创业吧,钱我出,你们负责出技术。然后这几个计算机学院的同学,就携带着技术入股成为了这家软件公司的一员。随着老板的设想越来越丰富,最初进去的技术骨干也在不停的招兵买马,当时还是流行在QQ空间转发招聘信息。正是在茫茫动态中,多看了招聘信息一眼,使得该公司深深留在我的印象当中。后来我投递的时候,也是大学同学正在里面实习,于是简历直达主管。
面试都问了些啥
由于公司还处于初创阶段,所以没有那么复杂的一面二面三面HR面,一上来就是技术主管们来一个3对1面,开头聊聊大家都是校友,甚至可能还是同一个导师下的师兄弟,所以面试相对来说就没有那么难,问一问大学里写过的大作业项目,聊一聊之前实习做的东西,问一问熟悉的八股文,比如数据库事务,Spring等等,最后再关切的问一下实习时间,然后就送客等HR通知了。
工作都需要干啥
正如第一张图所示,公司的产品分成了几个模块,麻雀虽小,五脏俱全,公司里后端、前端、移动端、测试一应具全。我参与的正是公司智慧餐饮行业线的后端开发,俗称Java CRUD boy。由于公司里一众高薪招揽过来的开发,整体采用的开发理念还是很先进的。会使用sprint开发流程,每周一个迭代,就是发版上线还是不够devops,需要每周五技术leader自己启动各个脚本进行发版,将最新的代码启动到阿里云服务机器上。 虽然用户的体量不是很大,但是仍然包含Spring Cloud分布式框架、分库分表、Redis分布式锁、Elastic Search搜索框架、DTS消息传输复制框架等“高新科技”。每周伊始,会先进行需求评审,评估一下开发需要的工作量,随后就根据事先制定的节奏进行有条不紊的开发、测试、验收、上线。虽然工作难度不高,但是我在这家公司第一次亲身参与了产品迭代的全流程,为以后的实习、找工作都添加了一些工作经验。
因为是实习嘛,所以基本上都是踩点上班、准时下班。不过偶尔也存在老板一拍脑袋,说我们要两周造一个电子商城的情况,那个时候可真是加班加点,披星戴月带月的把项目的简易版本给完成、上线了。但是比较遗憾的是,后面也没有能大范围投入使用。
比如下面的自助借伞机,就是前司的一项业务,多少也是帮助了一些同学免于淋雨。
画重点,福利究竟有多好
首先公司的办公地点位于南京市中心,与新街口德基隔基相望。
每天发价值88元的内部币,用于在楼下老板开的餐厅里点餐,工作套餐有荤有素有汤有水果,可以说是非常的上流了。
如果不想吃工作套餐,还可以一起聚众点餐,一流的淮扬菜式,可以说非常爽了。 听说在点餐系统刚上线还没有内部币时,点餐是通过白名单的方式,不用付钱随便点。可惜我来晚了,没有体验到这么个好时候。
工作也标配imac一整套,虽然不好带走移动办公,但是用起来依然逼格满满。
熟悉的健身房福利当然少不了,而且还有波光粼粼的大泳池,后悔没有利用当时的机会多去几次学会游泳了。
除了这些基础福利之外,老板给的薪资比肩BAT大厂,甚至可能比他们还高一丢丢,在南京可以生活的相当滋润了。
既然说的这么好,那么为啥没有留下来呢。
唯一的问题当然是因为公司本身尚未盈利,所有这一切都依赖老板一个人的激情投入,假如老板这边出了啥问题,那整个公司也就将皮之不存,毛将焉附了。用软件领域的话来说,就是整个系统存在单点故障。所以尽管当时的各种福利很好,也选择离开找个更大的厂子先进去锻炼锻炼。
最后希望前老板矿上的生意越来越好,哪天我在外面卷不动了,还能收留我一下。
来源:juejin.cn/post/7174065718386753543
告诉你为什么视频广告点不了关闭
前言
我们平时玩游戏多多少少会碰到一些视频广告,看完后是能领取游戏奖励的,然后你会发现有时候看完点击那个关闭按钮,结果是跳下载,你理所当然的认为是点击到了外边,事实真的是这样的吗?有些东西不好那啥,你们懂的,所以以下内容纯属我个人猜测,纯属虚构
1. 整个广告流程的各个角色
要想对广告这东西有个大概的了解,你得先知道你看广告的过程中都有哪些角色参与了进来。
简单来说,是有三方参与了进来:
(1)广告提供商:顾名思义负责提供广告,比如你看的广告是一款游戏的广告,那这个游戏的公司就是广告的提供商。
(2)当前应用:就是播放这个广告的应用。
(3)平台:播放广告这个操作就是平台负责的,它负责连接上面两方,从广告提供商中拿到广告,然后让当前应用接入。
平台有很多,比如字节、腾讯都有相对应的广告平台,或者一些小公司自己做广告平台。他们之间的py交易是这样的:所有广告的功能是由平台去开发,然后他会提供一套sdk或者什么的让应用接入,应用你接入之后每播放1次广告,平台就给你多少钱,但是播放的是什么广告,这个就是平台自己去下发。然后广告提供商就找到平台,和他谈商业合作,你帮我展示我家的产品的广告多少次,我给你多少钱。 简单来说他们之间的交易就是这样。
简单来说,就是广告提供商想要影响力,其它两方要钱,他们都希望广告能更多的展示。
2. 广告提供商的操作
广告提供商是花钱让平台推广广告的,那我肯定是希望尽量每次广告的展示都有用户去点击然后下载我们家的应用。
所以广告提供商想出了一个很坏的办法,相信大家都遇到过,就是我播放视频,我在视频的最后几帧里面的图片的右上角放一个关闭图片,误导用户这个关闭图片是点了之后能关闭的,其实它是视频的一部分,所以你点了就相当于点了视频,那就触发跳转下载应用这些操作。
破解的方法也很简单,你等到计算结束后的几秒再点关闭按钮,不要一看到关闭按钮的图片出来马上点。
3. 应用的操作
应用是很难在广告播放的时候去做手脚,因为这部分的代码不是他们写的,他们只是去调用平台写的代码。
那他们想让广告尽可能多的展示,唯一能做的就是把展示广告的地方增加,尽可能多的让更多场景能展示广告。当然这也有副作用,你要是这个应用点哪里都是广告,这不得把用户给搞吐了,砸了自己的口碑,如果只有一些地方有,用户还是能理解的,毕竟赚钱嘛,不寒参。
4. 平台的操作
平台的操作那就丰富了,代码是我写的,兄弟,我想怎么玩就怎么玩,我能有一百种方法算计你。
猜测的,注意,是猜测的[狗头]
有的人说,故意把关闭按钮设置小,让我们误触关闭按钮以外的区域。我只能说,你让我来做,我都不屑于把关闭按钮设置小。
我们都知道平时开发时,我们觉得点击按钮不灵,所以我们想扩大图标的点击区域,但是又不想改变图标的大小,所以我们用padding来实现。同样的,我也能做到不改变图标的大小,然后缩小点击的范围
我写一个自定义view(假设就是关闭图标)
public class TestV extends View {
public TestV(Context context) {
super(context);
}
public TestV(Context context, AttributeSet attrs) {
super(context, attrs);
}
public TestV(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
int w = getMeasuredWidth();
int h = getMeasuredHeight();
Log.d("mmp", "============ view点击");
if (event.getX() < w / 4 || event.getX() > 3 * w / 4 || event.getY() < h / 4 || event.getY() > 3 * h / 4) {
return super.dispatchTouchEvent(event);
} else {
Log.d("mmp", "============ view点击触发-》关闭");
return true;
}
}
return super.dispatchTouchEvent(event);
}
}代码很简单就不过多讲解,能看出我很简单就实现让点击范围缩小1/4。所以当你点到边缘的时候,其实就相当于点到了广告。
除了缩小范围之外,我还能设置2秒前后点击是不同的效果,你有没有一种感觉,第一次点关闭按钮就是跳到下载应用,然后返回再点击就是关闭,所以你觉得是你第一次点击的时候是误触了外边。
public class TestV extends View {
private boolean canClose = true;
public TestV(Context context) {
super(context);
}
public TestV(Context context, AttributeSet attrs) {
super(context, attrs);
}
public TestV(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
}
@Override
public void setVisibility(int visibility) {
super.setVisibility(visibility);
if (visibility == View.VISIBLE) {
canClose = false;
}
}
@Override
public boolean dispatchTouchEvent(MotionEvent event) {
if (event.getAction() == MotionEvent.ACTION_DOWN) {
int w = getMeasuredWidth();
int h = getMeasuredHeight();
Log.d("mmp", "============ view点击");
if (!canClose) {
return super.dispatchTouchEvent(event);
} else {
Log.d("mmp", "============ view点击触发-》关闭");
return true;
}
}
return super.dispatchTouchEvent(event);
}
// 播放完成
public void playFinish() {
setVisibility(VISIBLE);
Handler handler = new Handler(Looper.getMainLooper());
handler.postDelayed(new Runnable() {
@Override
public void run() {
canClose = true;
}
}, 2000);
}
}播放完成之后调用playFinish方法,然后会把canClose这个状态设置为false,2秒后再设为true。这样你在2秒前点击按钮,其实就是点击外部的效果,也就会跳去下载。
而且你注意,这些限制,我可以不写死在代码里面,可以用后台返回,比如这个2000,我可以后台返回。我就能做到比如第一天我返回0,你觉得没什么问题,能正常点关闭,我判断你是第二天,我直接返2000给你,然后你一想,之前都是正常的,那这次不正常,肯定是我点错。
你以为的意外只不过是我想让你以为是意外罢了。那这个如何去破解呢?我只能说无解,他能有100种方法让你点中跳出去下载,那还能有是什么解法?
作者:流浪汉kylin
来源:juejin.cn/post/7197611189244592186
Android App Bundle
1. Android App Bundle 是什么?
从 2021 年 8 月起,新应用需要使用 Android App Bundle 才能在 Google Play 中发布。
Android App Bundle是一种发布格式,打包出来的格式为aab,而之前我们打包出来的格式为apk。编写完代码之后,将其打包成aab格式(里面包含了所有经过编译的代码和资源),然后上传到Google Play。用户最后安装的还是apk,只不过不是一个,而是多个apk,这些apk是Google Play根据App Bundle生成的。
既然已经有了apk,那要App Bundle有啥用?咱之前打一个apk,会把各种架构、各种语言、各种分辨率的图片等全部放入一个apk中,但具体到某个用户的设备上,这个设备只需要一种so库架构、一种语言、一种分辨率的图片,那其他的东西都在apk里面,这就有点浪费了,不仅下载需要更多的流量,而且还占用用户设备更多的存储空间。当然,也可以通过在打包的时候打多个apk,分别支持各种密度、架构、语言的设备,但这太麻烦了。
于是,Google Play出手了。
App Bundle是经过签名的二进制文件,可将应用的代码和资源组织到不同的模块中。比如,当某个用户的设备是xxhdpi+arm64-v8a+values-zh环境,那Google Play后台会利用App Bundle中的对应的模块(xxhdpi+arm64-v8a+values-zh)组装起来,组成一个base apk和多个配置apk供该用户下载并安装,而不会去把其他的像armeabi-v7a、x86之类的与当前设备无关的东西组装进apk,这样用户下载的apk体积就会小很多。体积越小,转化率越高,也更环保。
有了Android App Bundle之后,Google Play还提供了2个东西:Play Feature Delivery 和 Play Asset Delivery。Play Feature Delivery可以按某种条件分发或按需下载应用的某些功能,从而进一步减小包体积。Play Asset Delivery是Google Play用于分发大体积应用的解决方案,为开发者提供了灵活的分发方式和极高的性能。
2. Android App Bundle打包
打Android App Bundle非常简单,直接通过Android Studio就能很方便地打包,当然命令行也可以的。
Android Studio打包:
Build->Generate Signed Bundle / APK-> 选中Android App Bundle -> 选中签名和输入密码 -> 选中debug或者release包 -> finish开始打包gradle命令行打包:
./gradlew bundleDebug或者./gradlew bundleRelease
打出来之后是一个类似app-debug.aab的文件,可以将aab文件直接拖入Android Studio进行分析和查看其内部结构,很方便。
3. 如何测试Android App Bundle?
Android App Bundle包倒是打出来了,那怎么进行测试呢?我们设备上仅允许安装apk文件,aab是不能直接进行安装的。这里官方提供了3种方式可供选择:Android Studio 、Google Play 和 bundletool,下面我们一一来介绍。
3.1 Android Studio
利用Android Studio,在我们平时开发时就可以直接将项目打包成debug的aab并且运行到设备上,只需要点一下运行按钮即可(当然,这之前需要一些简单的配置才行)。Android Studio和Google Play使用相同的工具从aab中提取apk并将其安装在设备上,因此这种本地测试策略也是可行的。这种方式可以验证以下几点:
该项目是否可以构建为app bundle
Android Studio是否能够从app bundle中提取目标设备配置的apk
功能模块的功能与应用的基本模块是否兼容
该项目是否可以在目标设备上按预期运行
默认情况下,设备连接上Android Studio之后,运行时打的包是apk。所以我们需要配置一下,改成运行时先打app bundle,然后再从app bundle中提取出该设备需要的配置apk,再组装成一个新的apk并签名,随后安装到设备上。具体配置步骤如下:
从菜单栏中依次选择 Run -> Edit Configurations。
从左侧窗格中选择一项运行/调试配置。
在右侧窗格中,选择 General 标签页。
从 Deploy 旁边的下拉菜单中选择 APK from app bundle。
如果你的应用包含要测试的免安装应用体验,请选中 Deploy as an instant app 旁边的复选框。
如果你的应用包含功能模块,你可以通过选中每个模块旁边的复选框来选择要部署的模块。默认情况下,Android Studio 会部署所有功能模块,并且始终都会部署基本应用模块。
点击 Apply 或 OK。
好了,现在已经配置好了,现在点击运行按钮,Android Studio会构建app bundle,并使用它来仅部署连接的设备及你选择的功能模块所需要的apk。
3.2 bundletool
bundletool 是一种命令行工具,谷歌开源的,Android Studio、Android Gradle 插件和 Google Play 使用这一工具将应用的经过编译的代码和资源转换为 App Bundle,并根据这些 Bundle 生成可部署的 APK。
前面使用Android Studio来测试app bundle比较方便,但是,官方推荐使用bundletool 从 app bundle 将应用部署到连接的设备。因为bundletool提供了专门为了帮助你测试app bundle并模拟通过Google Play分发而设计的命令,这样的话我们就不必上传到Google Play管理中心去测试了。
下面我们就来实验一把。
首先是下载bundletool,到GitHub上去下载bundletool,地址:github.com/google/bund…
然后通过Android Studio或者Gradle将项目打包成Android App Bundle,然后通过bundletool将Android App Bundle生成一个apk容器(官方称之为split APKs),这个容器以
.apks作为文件扩展名,这个容器里面包含了该应用支持的所有设备配置的一组apk。这么说可能不太好懂,我们实操一下:
//使用debug签名生成apk容器
java -jar bundletool-all-1.14.0.jar build-apks --bundle=app-release.aab --output=my_app.apks
//使用自己的签名生成apk容器
java -jar bundletool-all-1.14.0.jar build-apks --bundle=app-release.aab --output=my_app.apks
--ks=keystore.jks
--ks-pass=file:keystore.pwd
--ks-key-alias=MyKeyAlias
--key-pass=file:key.pwdps: build-apks命令是用来打apks容器的,它有很多可选参数,比如这里的
--bundle=path表示:指定你的 app bundle 的路径,--output=path表示:指定输出.apks文件的名称,该文件中包含了应用的所有 APK 零部件。它的其他参数大家感兴趣可以到bundletool查阅。
执行完命令之后,会生成一个my_app.apks的文件,我们可以把这个apks文件解压出来,看看里面有什么。
│ toc.pb
│
└─splits
base-af.apk
base-am.apk
base-ar.apk
base-as.apk
base-az.apk
base-be.apk
base-bg.apk
base-bn.apk
base-bs.apk
base-ca.apk
base-cs.apk
base-da.apk
base-de.apk
base-el.apk
base-en.apk
base-es.apk
base-et.apk
base-eu.apk
base-fa.apk
base-fi.apk
base-fr.apk
base-gl.apk
base-gu.apk
base-hdpi.apk
base-hi.apk
base-hr.apk
base-hu.apk
base-hy.apk
base-in.apk
base-is.apk
base-it.apk
base-iw.apk
base-ja.apk
base-ka.apk
base-kk.apk
base-km.apk
base-kn.apk
base-ko.apk
base-ky.apk
base-ldpi.apk
base-lo.apk
base-lt.apk
base-lv.apk
base-master.apk
base-mdpi.apk
base-mk.apk
base-ml.apk
base-mn.apk
base-mr.apk
base-ms.apk
base-my.apk
base-nb.apk
base-ne.apk
base-nl.apk
base-or.apk
base-pa.apk
base-pl.apk
base-pt.apk
base-ro.apk
base-ru.apk
base-si.apk
base-sk.apk
base-sl.apk
base-sq.apk
base-sr.apk
base-sv.apk
base-sw.apk
base-ta.apk
base-te.apk
base-th.apk
base-tl.apk
base-tr.apk
base-tvdpi.apk
base-uk.apk
base-ur.apk
base-uz.apk
base-vi.apk
base-xhdpi.apk
base-xxhdpi.apk
base-xxxhdpi.apk
base-zh.apk
base-zu.apk里面有一个toc.pb文件和一个splits文件夹(splits顾名思义,就是拆分出来的所有apk文件),splits里面有很多apk,base-开头的apk是主module的相关apk,其中base-master.apk是基本功能apk,base-xxhdpi.apk则是对资源分辨率进行了拆分,base-zh.apk则是对语言资源进行拆分。
我们可以将这些apk拖入Android Studio看一下里面有什么,比如base-xxhdpi.apk:
│ AndroidManifest.xml
|
| resources.arsc
│
├─META-INF
│ BNDLTOOL.RSA
│ BNDLTOOL.SF
│ MANIFEST.MF
│
└─res
├─drawable-ldrtl-xxhdpi-v17
│ abc_ic_menu_copy_mtrl_am_alpha.png
│ abc_ic_menu_cut_mtrl_alpha.png
│ abc_spinner_mtrl_am_alpha.9.png
│
├─drawable-xhdpi-v4
│ notification_bg_low_normal.9.png
│ notification_bg_low_pressed.9.png
│ notification_bg_normal.9.png
│ notification_bg_normal_pressed.9.png
│ notify_panel_notification_icon_bg.png
│
└─drawable-xxhdpi-v4
abc_textfield_default_mtrl_alpha.9.png
abc_textfield_search_activated_mtrl_alpha.9.png
abc_textfield_search_default_mtrl_alpha.9.png
abc_text_select_handle_left_mtrl_dark.png
abc_text_select_handle_left_mtrl_light.png
abc_text_select_handle_middle_mtrl_dark.png
abc_text_select_handle_middle_mtrl_light.png
abc_text_select_handle_right_mtrl_dark.png
abc_text_select_handle_right_mtrl_light.png首先,这个apk有自己的AndroidManifest.xml,其次是resources.arsc,还有META-INF签名信息,最后是与自己名称对应的xxhdpi的资源。
再来看一个base-zh.apk:
│ AndroidManifest.xml
│ resources.arsc
│
└─META-INF
BNDLTOOL.RSA
BNDLTOOL.SF
MANIFEST.MF也是有自己的AndroidManifest.xml、resources.arsc、签名信息,其中resources.arsc里面包含了字符串资源(可以直接在Android Studio中查看)。
分析到这里大家对apks文件就有一定的了解了,它是一个压缩文件,里面包含了各种最终需要组成apk的各种零部件,这些零部件可以根据设备来按需组成一个完整的app。 比如我有一个设备是只支持中文、xxhdpi分辨率的设备,那么这个设备其实只需要下载部分apk就行了,也就是base-master.apk(基本功能的apk)、base-zh.apk(中文语言资源)和base-xxhdpi.apk(图片资源)给组合起来。到Google Play上下载apk,也是这个流程(如果这个项目的后台上传的是app bundle的话),Google Play会根据设备的特性(CPU架构、语言、分辨率等),首先下载基本功能apk,然后下载与之配置的CPU架构的apk、语言apk、分辨率apk等,这样下载的apk是最小的。
生成好了apks之后,现在我们可以把安卓测试设备插上电脑,然后利用bundletool将apks中适合设备的零部件apk挑选出来,并部署到已连接的测试设备。具体操作命令:
java -jar bundletool-all-1.14.0.jar install-apks --apks=my_app.apks,执行完该命令之后设备上就安装好app了,可以对app进行测试了。bundletool会去识别这个测试设备的语言、分辨率、CPU架构等,然后挑选合适的apk安装到设备上,base-master.apk是首先需要安装的,其次是语言、分辨率、CPU架构之类的apk,利用Android 5.0以上的split apks,这些apk安装之后可以共享一套代码和资源。
3.3 Google Play
如果我最终就是要将Android App Bundle发布到Google Play,那可以先上传到Google Play Console的测试渠道,再通过测试渠道进行分发,然后到Google Play下载这个测试的App,这样肯定是最贴近于用户的使用环境的,比较推荐这种方式进行最后的测试。
4. 拆解Android App Bundle格式
首先,放上官方的格式拆解图(下图包含:一个基本模块、两个功能模块、两个资源包):

app bundle是经过签名的二进制文件,可将应用的代码和资源装进不同的模块中,这些模块中的代码和资源的组织方式和apk中相似,它们都可以作为单独的apk生成。Google Play会使用app bundle生成向用户提供的各种apk,如base apk、feature apk、configuration apks、multi-APKs。图中蓝色标识的目录(drawable、values、lib)表示Google Play用来为每个模块创建configuration apks的代码和资源。
base、feature1、feature2:每个顶级目录都表示一个不同的应用模块,基本模块是包含在app bundle的base目录中。
asset_pack_1和asset_pack_2:游戏或者大型应用如果需要大量图片,则可以将asset模块化处理成资源包。资源包可以根据自己的需要,在合适的时机去请求到本地来。BUNDLE-METADATA/:包含元数据文件,其中包含对工具或应用商店有用的信息。模块协议缓冲区(
*pb)文件:元数据文件,向应用商店说明每个模块的内容。如:BundleConfig.pb 提供了有关 bundle 本身的信息(如用于构建 app bundle 的构建工具版本),native.pb 和 resources.pb 说明了每个模块中的代码和资源,这在 Google Play 针对不同的设备配置优化 APK 时非常有用。manifest/:与 APK 不同,app bundle 将每个模块的 AndroidManifest.xml 文件存储在这个单独的目录中。dex/:与 APK 不同,app bundle 将每个模块的 DEX 文件存储在这个单独的目录中。res/、lib/和assets/:这些目录与典型 APK 中的目录完全相同。root/:此目录存储的文件之后会重新定位到包含此目录所在模块的任意 APK 的根目录。
5. Split APKs
Android 5.0 及以上支持Split APKs机制,Split APKs与常规的apk相差不大,都是包含经过编译的dex字节码、资源和清单文件等。区别是:Android可以将安装的多个Split APKs视为一个应用,也就是虽然我安装了多个apk,但Android系统认为它们是同一个app,用户也只会在设置里面看到一个app被安装上了;而平时我们安装的普通apk,一个apk就对应着一个app。Android上,我们可以安装多个Split APK,它们是共用代码和资源的。
Split APKs的好处是可以将单体式app做拆分,比如将ABI、屏幕密度、语言等形式拆分成多个独立的apk,按需下载和安装,这样可以让用户更快的下载并安装好apk,并且占用更小的空间。
Android App Bundle最终也就是利用这种方式来进行安装的,比如我上面在执行完java -jar bundletool-all-1.14.0.jar install-apks --apks=my_app.apks命令之后,那么最后安装到手机上的apk文件如下:

ps:5.0以下不支持Split APKs,那咋办?没事,Google Play会为这些设备的用户安装一个全量的apk,里面什么都有,问题不大。
6. 国内商店支持Android App Bundle吗?
Android App Bundle不是Google Play的专有格式,它是开源的,任何商店想支持都可以的。
上面扯那么大一堆有的没的,这玩意儿这么好用,那国内商店的支持情况如何。我查了下,发现就华为可以支持,手动狗头。
华为 Android App Bundle developer.huawei.com/consumer/cn…
7. 小结
现在上架Google Play必须上传Android App Bundle才行了,所以有必要简单了解下。简单来说就是Android App Bundle是一种新的发布格式,上传到商店之后,商店会利用这个Android App Bundle生成一堆Split APKs,当用户要去安装某个app时,只需要按需下载Split APKs中的部分apk(base apk + 各种配置apk),进行安装即可,总下载量大大减少。
参考资料
splits——安卓gradle blog.csdn.net/weixin_3762…
Android App Bundle探索 juejin.cn/post/684490…
Android App Bundle 简介 developer.android.google.cn/guide/app-b…
测试 Android App Bundle developer.android.google.cn/guide/app-b…
app bundle 的代码透明性机制 developer.android.google.cn/guide/app-b…
Android App Bundle 格式 developer.android.google.cn/guide/app-b…
Android App Bundle 常见问题解答 developer.android.google.cn/guide/app-b…
视频资料 App Bundles - MAD Skills :http://www.youtube.com/playlist?li…
Android App Bundle解析 zhuanlan.zhihu.com/p/86995941
bundletool developer.android.google.cn/studio/comm…
作者:潇风寒月
来源:juejin.cn/post/7197246543207022629
android 微信抢红包工具 AccessibilityService(上)
你有因为手速不够快抢不到红包而沮丧? 你有因为错过红包而懊恼吗? 没错,它来了。。。
一、目标
使用AccessibilityService的方式,实现微信自动抢红包(吐槽一下,网上找了许多文档,由于各种原因,无法实现对应效果,所以先给自己整理下),关于AccessibilityService的文章,网上有很多(没错,多的都懒得贴链接那种多),可自行查找。
二、实现流程
1、流程分析(这里只分析在桌面的情况)
我们把一个抢红包发的过程拆分来看,可以分为几个步骤:
收到通知 -> 点击通知栏 -> 点击红包 -> 点击开红包 -> 退出红包详情页
以上是一个抢红包的基本流程。
2、实现步骤
1、收到通知 以及 点击通知栏
接收通知栏的消息,介绍两种方式
Ⅰ、AccessibilityService
即通过AccessibilityService的AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED事件来获取到Notification
private fun handleNotification(event: AccessibilityEvent) {
val texts = event.text
if (!texts.isEmpty()) {
for (text in texts) {
val content = text.toString()
//如果微信红包的提示信息,则模拟点击进入相应的聊天窗口
if (content.contains("[微信红包]")) {
if (event.parcelableData != null && event.parcelableData is Notification) {
val notification: Notification? = event.parcelableData as Notification?
val pendingIntent: PendingIntent = notification!!.contentIntent
try {
pendingIntent.send()
} catch (e: CanceledException) {
e.printStackTrace()
}
}
}
}
}
}Ⅱ、NotificationListenerService
这是监听通知栏的另一种方式,记得要获取权限哦
class MyNotificationListenerService : NotificationListenerService() {
override fun onNotificationPosted(sbn: StatusBarNotification?) {
super.onNotificationPosted(sbn)
val extras = sbn?.notification?.extras
// 获取接收消息APP的包名
val notificationPkg = sbn?.packageName
// 获取接收消息的抬头
val notificationTitle = extras?.getString(Notification.EXTRA_TITLE)
// 获取接收消息的内容
val notificationText = extras?.getString(Notification.EXTRA_TEXT)
if (notificationPkg != null) {
Log.d("收到的消息内容包名:", notificationPkg)
if (notificationPkg == "com.tencent.mm"){
if (notificationText?.contains("[微信红包]") == true){
//收到微信红包了
val intent = sbn.notification.contentIntent
intent.send()
}
}
}
Log.d("收到的消息内容", "Notification posted $notificationTitle & $notificationText")
}
override fun onNotificationRemoved(sbn: StatusBarNotification?) {
super.onNotificationRemoved(sbn)
}
}2、点击红包
通过上述的跳转,可以进入聊天详情页面,到达详情页之后,接下来就是点击对应的红包卡片,那么问题来了,怎么点?肯定不是手动点。。。
我们来分析一下,一个聊天列表中,我们怎样才能识别到红包卡片,我看网上有通过findAccessibilityNodeInfosByViewId来获取对应的View,这个也可以,只是我们获取id的方式需要借助工具,可以用Android Device Monitor,但是这玩意早就废废弃了,虽然在sdk的目录下存在monitor,奈何本人太菜,点击就是打不开
我本地的jdk是11,我怀疑是不兼容,毕竟Android Device Monitor太老了。换新的layout Inspector,也就看看本地的debug应用,无法查看微信的呀。要么就反编译,这个就先不考虑了,或者在配置文件中设置android:accessibilityFlags="flagReportViewIds",然后暴力遍历Node树,打印相应的viewId和className,找到目标id即可。当然也可以换findAccessibilityNodeInfosByText这个方法试试。
这个方法从字面意思能看出来,是通过text来匹配的,我们可以知道红包卡片上面是有“微信红包”的固定字样的,是不是可以通股票这个来匹配呢,这还有个其他问题,并不是所有的红包都需要点,比如已过期,已领取的是不是要过滤下,咋一看挺好过滤的,一个循环就好,仔细想,这是棵树,不太好剔除,所以换了个思路。
最终方案就是递归一棵树,往一个列表里面塞值,“已过期”和“已领取”的塞一个字符串“#”,匹配到“微信红包”的塞一个AccessibilityNodeInfo,这样如果这个红包不能抢,那肯定一前一后分别是一个字符串和一个AccessibilityNodeInfo,因此,我们读到一个AccessibilityNodeInfo,并且前一个值不是字符串,就可以执行点击事件,代码如下
private fun getPacket() {
val rootNode = rootInActiveWindow
val caches:ArrayList<Any> = ArrayList()
recycle(rootNode,caches)
if(caches.isNotEmpty()){
for(index in 0 until caches.size){
if(caches[index] is AccessibilityNodeInfo && (index == 0 || caches[index-1] !is String )){
val node = caches[index] as AccessibilityNodeInfo
var parent = node.parent
while (parent != null) {
if (parent.isClickable) {
parent.performAction(AccessibilityNodeInfo.ACTION_CLICK)
break
}
parent = parent.parent
}
break
}
}
}
}
private fun recycle(node: AccessibilityNodeInfo,caches:ArrayList<Any>) {
if (node.childCount == 0) {
if (node.text != null) {
if ("已过期" == node.text.toString() || "已被领完" == node.text.toString() || "已领取" == node.text.toString()) {
caches.add("#")
}
if ("微信红包" == node.text.toString()) {
caches.add(node)
}
}
} else {
for (i in 0 until node.childCount) {
if (node.getChild(i) != null) {
recycle(node.getChild(i),caches)
}
}
}
}以上只点击了第一个能点击的红包卡片,想点击所有的可另行处理。
3、点击开红包
这里思路跟上面类似,开红包页面比较简单,但是奈何开红包是个按钮,在不知道id的前提下,我们也不知道则呢么获取它,所以采用迂回套路,找固定的东西,我这里发现每个开红包的页面都有个“xxx的红包”文案,然后这个页面比较简单,只有个关闭,和开红包,我们通过获取“xxx的红包”对应的View来获取父View,然后递归子View,判断可点击的,执行点击事件不就可以了吗
private fun openPacket() {
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
for ( i in 0 until list.size) {
val parent = list[i].parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}4、退出红包详情页
这里回退也是个按钮,我们也不知道id,所以可以跟点开红包一样,迂回套路,获取其他的View,来获取父布局,然后递归子布局,依次执行点击事件,当然关闭事件是在前面的,也就是说关闭会优先执行到
private fun close() {
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
if (list.isNotEmpty()) {
val parent = list[0].parent.parent.parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}三、遇到问题
1、AccessibilityService收不到AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED事件
android碎片问题很正常,我这边是使用NotificationListenerService来替代的。
2、需要点击View的定位
简单是就是到页面应该点哪个View,找到相应的规则,来过滤出对应的View,这个规则是随着微信的改变而变化的,findAccessibilityNodeInfosByViewId最直接,但是奈何工具问题,有点麻烦,遍历打印可以获取,但是id每个版本可能会变。还有就是通过文案来获取,即findAccessibilityNodeInfosByText,获取一些固定文案的View,这个相对而言在不改版,可能不会变,相对稳定些,如果这个文案的View本身没点击事件,可获取它的parent,尝试点击,或者遍历parent树,根据isClickable来判断是否可以点击。
划重点:
这里还有一种就是钉钉的开红包按钮,折腾了半天,始终拿不到,各种递归遍历,一直没有找到,最后换了个方式,通过AccessibilityService的模拟点击来做,也就是通过坐标来模拟点击,当然要在配置中开启android:canPerformGestures="true", 然后通过 accessibilityService.dispatchGesture() 来处理,具体坐标可以拿一个其他的View,然后通过比例来确定大概得位置,或者,看看能不能拿到外层的Layout也是一样的
object AccessibilityClick {
fun click(accessibilityService: AccessibilityService, x: Float, y: Float) {
val builder = GestureDescription.Builder()
val path = Path()
path.moveTo(x, y)
path.lineTo(x, y)
builder.addStroke(GestureDescription.StrokeDescription(path, 0, 10))
accessibilityService.dispatchGesture(builder.build(), object : AccessibilityService.GestureResultCallback() {
override fun onCancelled(gestureDescription: GestureDescription) {
super.onCancelled(gestureDescription)
}
override fun onCompleted(gestureDescription: GestureDescription) {
super.onCompleted(gestureDescription)
}
}, null)
}
}续:android 微信抢红包工具 AccessibilityService(下)
作者:我有一头小毛驴你有吗
来源:juejin.cn/post/7196949524061339703
android 微信抢红包工具 AccessibilityService(下)
接:android 微信抢红包工具 AccessibilityService(上)
四、完整代码
MyNotificationListenerService
class MyNotificationListenerService : NotificationListenerService() {
override fun onNotificationPosted(sbn: StatusBarNotification?) {
super.onNotificationPosted(sbn)
val extras = sbn?.notification?.extras
// 获取接收消息APP的包名
val notificationPkg = sbn?.packageName
// 获取接收消息的抬头
val notificationTitle = extras?.getString(Notification.EXTRA_TITLE)
// 获取接收消息的内容
val notificationText = extras?.getString(Notification.EXTRA_TEXT)
if (notificationPkg != null) {
Log.d("收到的消息内容包名:", notificationPkg)
if (notificationPkg == "com.tencent.mm"){
if (notificationText?.contains("[微信红包]") == true){
//收到微信红包了
val intent = sbn.notification.contentIntent
intent.send()
}
}
} Log.d("收到的消息内容", "Notification posted $notificationTitle & $notificationText")
}
override fun onNotificationRemoved(sbn: StatusBarNotification?) {
super.onNotificationRemoved(sbn)
}
}MyAccessibilityService
class MyAccessibilityService : AccessibilityService() {
override fun onAccessibilityEvent(event: AccessibilityEvent) {
val eventType = event.eventType
when (eventType) {
AccessibilityEvent.TYPE_NOTIFICATION_STATE_CHANGED -> handleNotification(event)
AccessibilityEvent.TYPE_WINDOW_STATE_CHANGED, AccessibilityEvent.TYPE_WINDOW_CONTENT_CHANGED -> {
val className = event.className.toString()
Log.e("测试无障碍",className)
when (className) {
"com.tencent.mm.ui.LauncherUI" -> {
// 我管这叫红包卡片页面
getPacket()
}
"com.tencent.mm.plugin.luckymoney.ui.LuckyMoneyReceiveUI" -> {
// 貌似是老UI debug没发现进来
openPacket()
}
"com.tencent.mm.plugin.luckymoney.ui.LuckyMoneyNotHookReceiveUI" -> {
// 应该是红包弹框UI新页面 debug进来了
openPacket()
}
"com.tencent.mm.plugin.luckymoney.ui.LuckyMoneyDetailUI" -> {
// 红包详情页面 执行关闭操作
close()
}
"androidx.recyclerview.widget.RecyclerView" -> {
// 这个比较频繁 主要是在聊天页面 有红包来的时候 会触发 当然其他有列表的页面也可能触发 没想到好的过滤方式
getPacket()
}
}
}
}
}
/**
* 处理通知栏信息
*
* 如果是微信红包的提示信息,则模拟点击
*
* @param event
*/
private fun handleNotification(event: AccessibilityEvent) {
val texts = event.text
if (!texts.isEmpty()) {
for (text in texts) {
val content = text.toString()
//如果微信红包的提示信息,则模拟点击进入相应的聊天窗口
if (content.contains("[微信红包]")) {
if (event.parcelableData != null && event.parcelableData is Notification) {
val notification: Notification? = event.parcelableData as Notification?
val pendingIntent: PendingIntent = notification!!.contentIntent
try {
pendingIntent.send()
} catch (e: CanceledException) {
e.printStackTrace()
}
}
}
}
}
}
/**
* 关闭红包详情界面,实现自动返回聊天窗口
*/
@TargetApi(Build.VERSION_CODES.JELLY_BEAN_MR2)
private fun close() {
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
if (list.isNotEmpty()) {
val parent = list[0].parent.parent.parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}
/**
* 模拟点击,拆开红包
*/
@TargetApi(Build.VERSION_CODES.JELLY_BEAN_MR2)
private fun openPacket() {
Log.e("测试无障碍","点击红包")
Thread.sleep(100)
val nodeInfo = rootInActiveWindow
if (nodeInfo != null) {
val list = nodeInfo.findAccessibilityNodeInfosByText ("的红包")
for ( i in 0 until list.size) {
val parent = list[i].parent
if (parent != null) {
for ( j in 0 until parent.childCount) {
val child = parent.getChild (j)
if (child != null && child.isClickable) {
Log.e("测试无障碍","点击红包成功")
child.performAction(AccessibilityNodeInfo.ACTION_CLICK)
}
}
}
}
}
}
/**
* 模拟点击,打开抢红包界面
*/
@TargetApi(Build.VERSION_CODES.JELLY_BEAN)
private fun getPacket() {
Log.e("测试无障碍","获取红包")
val rootNode = rootInActiveWindow
val caches:ArrayList<Any> = ArrayList()
recycle(rootNode,caches)
if(caches.isNotEmpty()){
for(index in 0 until caches.size){
if(caches[index] is AccessibilityNodeInfo && (index == 0 || caches[index-1] !is String )){
val node = caches[index] as AccessibilityNodeInfo
// node.performAction(AccessibilityNodeInfo.ACTION_CLICK)
var parent = node.parent
while (parent != null) {
if (parent.isClickable) {
parent.performAction(AccessibilityNodeInfo.ACTION_CLICK)
Log.e("测试无障碍","获取红包成功")
break
}
parent = parent.parent
}
break
}
}
}
}
/**
* 递归查找当前聊天窗口中的红包信息
*
* 聊天窗口中的红包都存在"微信红包"一词,因此可根据该词查找红包
*
* @param node
*/
private fun recycle(node: AccessibilityNodeInfo,caches:ArrayList<Any>) {
if (node.childCount == 0) {
if (node.text != null) {
if ("已过期" == node.text.toString() || "已被领完" == node.text.toString() || "已领取" == node.text.toString()) {
caches.add("#")
}
if ("微信红包" == node.text.toString()) {
caches.add(node)
}
}
} else {
for (i in 0 until node.childCount) {
if (node.getChild(i) != null) {
recycle(node.getChild(i),caches)
}
}
}
}
override fun onInterrupt() {}
override fun onServiceConnected() {
super.onServiceConnected()
Log.e("测试无障碍id","启动")
val info: AccessibilityServiceInfo = serviceInfo
info.packageNames = arrayOf("com.tencent.mm")
serviceInfo = info
}
}5、总结
此文是对AccessibilityService的使用的一个梳理,这个功能其实不麻烦,主要是一些细节问题,像自动领取支付宝红包,自动领取QQ红包或者其他功能等也都可以用类似方法实现。目前实现了微信和钉钉的,剩下的支付宝QQ啥的没啥人用,就不想做了,不过原理都是一样的,
源码地址: gitee.com/wlr123/acce…
使用时记得开启下对应权限,设置下后台运行权限,电量设置里面允许后台运行等,以及通知栏权限,以保证稳定运行
作者:我有一头小毛驴你有吗
来源:juejin.cn/post/7196949524061339703
从 微信 JS-SDK 认识 JSBridge
前言
前段时间由于要实现 H5 移动端拉取微信卡包并同步卡包数据的功能,于是在项目中引入了 微信 JS-SDK(jweixin) 相关包实现功能,但也由此让我对其产生了好奇心,于是打算好好了解下相关的内容,通过查阅相关资料发现这其实属于 JSBridge 的一种实现方式。
因此,只要了解 JSBridge 就能明白 微信 JS-SDK 是怎么一回事。

为什么需要 JSBridge?
相信大多数人都有相同的经历,第一次了解到关于 JSBridge 都是从 微信 JS-SDK(WeiXinJSBridge) 开始,当然如果你从事的是 Hybrid 应用 或 React-Native 开发的话相信你自然(应该、会)很了解。
其实 JSBridge 早就出现并被实际应用了,如早前桌面应用的消息推送等,而在移动端盛行的时代已经越来越需要 JSBridge,因为我们期望移动端(Hybrid 应用 或 React-Native)能做更多的事情,其中包括使用 客户端原生功能 提供更好的 交互 和 服务 等。
然而 JavaScript 并不能直接调用和它不同语言(如 Java、C/C++ 等)提供的功能特性,因此需要一个中间层去实现 JavaScript 与 其他语言 间的一个相互协作,这里通过一个 Node 架构来进行说明。
Node 架构

核心内容如下:
顶层 Node Api
- 提供 http 模块、流模块、fs文件模块等等,
可以通过 JavaScript 直接调用
- 提供 http 模块、流模块、fs文件模块等等,
中间层 Node Bindings
- 主要是使 JavaScript 和 C/C++ 进行通信,原因是 JavaScript 无法直接调用 C/C++ 的库(libuv),需要一个中间的桥梁,node 中提供了很多 binding,这些称为
Node bindings
- 主要是使 JavaScript 和 C/C++ 进行通信,原因是 JavaScript 无法直接调用 C/C++ 的库(libuv),需要一个中间的桥梁,node 中提供了很多 binding,这些称为
底层 V8 + libuv
- v8 负责解释、执行顶层的 JavaScript 代码
- libuv 负责提供 I/O 相关的操作,其主要语言是
C/C++语言,其目的就是实现一个 跨平台(如 Windows、Linux 等)的异步 I/O 库,它直接与操作系统进行交互
这里不难发现 Node Bindings 就有点类似 JSBridge 的功能,所以 JSBridge 本身是一个很简单的东西,其更多的是 一种形式、一种思想。
为什么叫 JSBridge?
Stack Overflow 联合创始人 Jeff Atwood 在 2007 年的博客《The Principle of Least Power》中认为 “任何可以使用 JavaScript 来编写的应用,并最终也会由 JavaScript 编写”,后来 JavaScript 的发展确实非常惊人,现在我们可以基于 JavaScript 来做各种事情,比如 网页、APP、小程序、后端等,并且各种相关的生态越来越丰富。
作为 Web 技术逻辑核心的 JavaScript 自然而然就需要承担与 其他技术 进行『桥接』的职责,而且任何一个 移动操作系统 中都会包含 运行 JavaScript 的容器环境,例如 WebView、JSCore 等,这就意味着 运行 JavaScript 不用像运行其他语言时需要额外添加相应的运行环境。
JSBridge应用在国内真正流行起来则是因为 微信 的出现,当时微信的一个主要功能就是可以在网页中通过JSBridge来实现 内容分享。
JSBridge 能做什么?
举个最常见的前端和后端的例子,后端只提供了一个查找接口,但是没有提供更新接口,那么对于前端来讲就是再想实现更新接口,也是没有任何法子的!
同样的,JSBridge 能做什么得看原生端给 JavaScript 提供调用 Native 什么功能的接口,比如通过 微信 JS-SDK 网页开发者可借助微信使用 拍照、选图、语音、位置 等手机系统的能力,同时可以直接使用 微信分享、扫一扫、卡券、支付 等微信特有的能力。
JSBridge 作为 JavaScript 与 Native 之间的一个 桥梁,表面上看是允许 JavaScript 调用 Native 的功能,但其核心是建立 Native 和 非 Native 间消息 双向通信 通道。

双向通信的通道:
JavaScript 向 Native 发送消息:
- 调用 Native 功能
- 通知 Native 当前 JavaScript 的相关状态等
Native 向 JavaScript 发送消息:
- 回溯调用结果
- 消息推送
- 通知 JavaScript 当前 Native 的状态等
JSBridge 是如何实现的?
JavaScript 的运行需要 JS 引擎的支持,包括 Chrome V8、Firefox SpiderMonkey、Safari JavaScriptCore 等,总之 JavaScript 运行环境 是和 原生运行环境 是天然隔离的,因此,在 JSBridge 的设计中我们可以把它 类比 成 JSONP 的流程:
- 客户端通过
JavaScript定义一个回调函数,如:function callback(res) {...},并把这个回调函数的名称以参数的形式发送给服务端 - 服务端获取到
callback并携带对应的返回数据,以JS脚本形式返回给客户端 - 客户端接收并执行对应的
JS脚本即可
JSBridge 实现 JavaScript 调用的方式有两种,如下:
JavaScript调用NativeNative调用JavaScript
在开始分析具体内容之前,还是有必要了解一下前置知识 WebView。
WebView 是什么?
WebView 是 原生系统 用于 移动端 APP 嵌入 Web 的技术,方式是内置了一款高性能 webkit 内核浏览器,一般会在 SDK 中封装为一个 WebView 组件。
WebView 具有一般 View 的属性和设置外,还对 url 进行请求、页面加载、渲染、页面交互进行增强处理,提供更强大的功能。
WebView 的优势 在于当需要 更新页面布局 或 业务逻辑发生变更 时,能够更便捷的提供 APP 更新:
- 对于
WebView而言只需要修改前端部分的Html、Css、JavaScript等,通知用户端进行刷新即可 - 对于
Native而言需要修改前端内容后,再进行打包升级,重新发布,通知用户下载更新,安装后才可以使用最新的内容
微信小程序中的 WebView
小程序的主要开发语言是 JavaScript ,其中 逻辑层 和 渲染层 是分开的,分别运行在不同的线程中,而其中的渲染层就是运行在 WebView 上:
| 运行环境 | 逻辑层 | 渲染层 |
|---|---|---|
| iOS | JavaScriptCore | WKWebView |
| 安卓 | V8 | chromium 定制内核 |
| 小程序开发者工具 | NWJS | Chrome WebView |

在开发过程中遇到的一个 坑点 就是:
- 在真机中,需要实现同一域名下不同子路径的应用实现数据交互(纯前端操作,不涉及接口),由于同域名且是基于同一个页面进行跳转的(当然只是看起来是),而且这个数据是 临时数据,因此觉得使用
sessionStorage实现数据交互是很合适的 - 实际上从 A 应用 跳转到 B 应用 中却无法获取对应的数据,而这是因为 sessionStorage 是基于当前窗口的会话级的数据存储,移动端浏览器 或 微信内置浏览器 中在跳转新页面时,可能打开的是一个新的 WebView,这就相当于我们在浏览器中的一个新窗口中进行存储,因此是没办法读取在之前的窗口中存储的数据
JavaScript 调用 Native — 实现方案一
通过 JavaScript 调用 Native 的方式,又会分为:
- 注入 API
- 劫持 URL Scheme
- 弹窗拦截
【 注入 API 】
核心原理:
- 通过
WebView提供的接口,向JavaScript的上下文(window)中注入 对象 或者 方法 - 允许
JavaScript进行调用时,直接执行相应的Native代码逻辑,实现JavaScript调用Native
这里不通过 iOS 的 UIWebView 和 WKWebView 注入方式来介绍了,感兴趣可以自行查找资料,咱们这里直接通过 微信 JS-SDK 来看看。

当通过 的方式引入 JS-SDK 之后,就可以在页面中使用和 微信相关的 API,例如:
// 微信授权
window.wx.config(wechatConfig)
// 授权回调
window.wx.ready(function () {...})
// 异常处理
window.wx.error(function (err) {...})
// 拉起微信卡包
window.wx.invoke('chooseInvoice', invokeConf, function (res) {...})如果通过其内部编译打包后的代码(简化版)来看的话,其实不难发现:
- 其中的
this(即参数e)此时就是指向全局的window对象 - 在代码中使用的
window.wx实际上是e.jWeixin也是其中定义的N对象 - 而在
N对象中定义的各种方法实际上又是通过e.WeixinJSBridge上的方法来实际执行的 e.WeixinJSBridge就是由 微信内置浏览器 向window对象中注入WeiXinJsBridge接口实现的!(function (e, n) {
'function' == typeof define && (define.amd || define.cmd)
? define(function () {
return n(e)
})
: n(e, !0)
})(this, function (e, n) {
...
function i(n, i, t) {
e.WeixinJSBridge
? WeixinJSBridge.invoke(n, o(i), function (e) {
c(n, e, t)
})
: u(n, t)
}
if (!e.jWeixin) {
var N = {
config(){
i(...)
},
ready(){},
error(){},
...
}
return (
S.addEventListener(
'error',callback1,
!0
),
S.addEventListener(
'load',callback2,
!0
),
n && (e.wx = e.jWeixin = N),
N
)
}
})
【 劫持 URL Scheme 】
URL Scheme 是什么?
URL Scheme 是一种特殊的 URL,一般用于在 Web 端唤醒 App(或是跳转到 App 的某个页面),它能方便的实现 App 间互相调用(例如 QQ 和 微信 相互分享讯息)。
URL Scheme 的形式和 普通 URL(如:https://www.baidu.com)相似,主要区别是 protocol 和 host 一般是对应 APP 自定义的。
通常当 App 被安装后会在系统上注册一个 自定义的 URL Scheme,比如 weixin:// 这种,所以我们在手机浏览器里面访问这个 scheme 地址,系统就会唤起对应的 App。
例如,当在浏览器中访问 weixin:// 时,浏览器就会询问你是否需要打开对应的 APP:

劫持原理
Web 端通过某种方式(如 iframe.src)发送 URL Scheme 请求,之后 Native 拦截到请求并根据 URL Scheme 和 携带的参数 进行对应操作。
例如,对于谷歌浏览器可以通过 chrome://version/、chrome://chrome-urls/、chrome://settings/ 定位到不同的页面内容,假设 跳转到谷歌的设置页并期望当前搜索引擎改为百度,可以这样设计 chrome://settings/engine?changeTo=baidu&callbak=callback_id:
- 谷歌客户端可以拦截这个请求,去解析对应参数
changeTo来修改默认引擎 - 然后通过
WebView上面的callbacks对象来根据callback_id进行回调
以上只是一个假设哈,并不是说真的可以这样去针对谷歌浏览器进行修改,当然它要是真的支持也不是不可以。
是不是感觉确实和 JSONP 的流程很相似呀 ~ ~【 弹窗拦截 】
弹窗拦截核心:利用弹窗会触发 WebView 相应事件来实现的。
一般是在通过拦截 Prompt、Confirm、Alert 等方法,然后解析它们传递过来的消息,但这种方法存在的缺陷就是 iOS 中的 UIWebView 不支持,而且 iOS 中的 WKWebView 又有更好的 scriptMessageHandler,因此很难统一。
Native 调用 JavaScript — 实现方案二
Native 调用 JavaScript 的方式本质就是 执行拼接 JavaScript 字符串,这就好比我们通过 eval() 函数来执行 JavaScript 字符串形式的代码一样,不同的系统也有相应的方法执行 JavaScript 脚本。
Android
在 Android 中需要根据版本来区分:
安卓 4.4 之前的版本使用
loadUrl()loadUrl()不能获取JavaScript执行后的结果,这种方式更像在的href属性中编写的JavaScript代码webView.loadUrl("javascript:foo()")
安卓 4.4 以上版本使用
evaluateJavascript()webView.evaluateJavascript("javascript:foo()", null);IOS
UIWebView中通常使用stringByEvaluatingJavaScriptFromStringresults = [self.webView stringByEvaluatingJavaScriptFromString:"foo()"];WKWebView中通常使用evaluateJavaScript[self.webView evaluateJavaScript:@"document.body.offsetHeight;" completionHandler:^(id _Nullable response, NSError * _Nullable error) {
// 获取返回值
}];最后
来源:segmentfault.com/a/1190000043417038
我的2022,用爱发电
Hello,我是Xc,忙碌的一年结束了,先祝大家新年快乐,其实元旦之前就想写这篇文章,但是由于种种原因始终没有落实这个计划。
总结了2022年,这一年基本都是在吃饭睡觉写代码中度过的,对于我来说这一年有几个关键词:开源、成长、收获。
开源
为什么会选择开源这条路呢?
因为在21年的vueconf上被一个可以写代码的ppt吸引(slidev),当时觉得这个东西太酷了,这才是程序员PPT该有的样子,之后就一直关注antfu,在后续半年的关注中发现这个人怎么会有这么多的idea,能有这么高的产出,太惊人了。因为平时在三心老总的技术群里经常回答一些群友的问题,和看大家聊天会提到开源一词,心里逐渐有了一些想法,之后在21年年末的时候,大哥让大家想想自己的22年年度计划,毫不犹豫的想到了在掘金写点技术小作文和开源一些项目。
第一个开源项目
春节复工后就开始了自己的开源计划,正好当时有个业务需求需要对vite进行拓展支持,在考虑有没有敏感信息之后就打算将其作为开源项目。记得很清楚,2月10号发布了我的第一个npm包、第一个vite插件vite-plugin-dynamic-base(目前月下载量2-3K),并且完成了第一个pr,插件正式被收录到awesome-vite。
成为Element Plus团队成员
在开源vite-plugin-dynamic-base之后也不知道还能在开源上还能做些什么了,在看了antfu的直播后豁然开朗,我不一定要自己产出项目来为开源生态做贡献,我可以通过给一些开源社区的项目维护来贡献。从vue2的组件库使用上来说,出于对element-ui的熟练和喜爱,所以就想说能否给vue3的Element Plus做些什么?
我还记得第一个pr是修复了select-v2的value-key的问题,还得级当时没有格式化,reviewer耐心的提示我如何操作提交。之后又接着修复input-number的issue,当时reviewer问我是否介意重构一下里面的几个方法,当时是又激动又紧张,激动的是收到到了reviewer的一个邀约(感觉是被信任),紧张是因为都是在github上面交流,我初来乍到不知道代码规范,当时就硬着头皮进行了代码的review,很高兴在reviewer的细心review下pr成功merge了。感觉动力十足,每天下班回家就看下issue反馈的问题,如果是使用上的问题会进行解答,如果是bug就分析存在bug的原因,然后尝试着修复。
还记得当时3-4月份的时候,由于21年圣诞节的一次意外导致右手关节错位,因为治疗的比较晚,只能打绷带来了,还好手指头还能敲代码哈,那时候也是一换完药就赶着回去看issue和修pr。之后陆续到了四月中旬,有幸收到Element Plus的合作者邀请,当时激动的不行,每天和打了鸡血一样,天天下班回去就是泡在Element Plus的仓库里面。
在之后到了5月中旬,有幸成为了团队成员,当时也是十分开心被维护者们认可,但是身份不一样感觉在回复issue的时候总是特别小心,生怕做错事。真的就是怕啥来啥,当时正赶上Element Plus的组件语法重构计划,当时有个变量没考虑到从原来的options API切换到setup语法后这个变量每次初始化的值都是一样的问题,导致用户系统出现bug,当时收到用户的pr,被骂是其次,主要是觉得自己的不严谨砸了Element Plus的口碑,那时候挺郁闷的,感觉自己是不是不太适合,多亏了团队其他小伙伴的鼓励,过了这个关卡。
羊了个羊
9月份的微信可以说是被羊了个羊霸占了,一开始觉得在朋友圈开到觉得挺无聊的,后面自己玩了一下一发不可收拾,每天下班回去路上都在玩这个。出于程序员的思维就在思考这个游戏是怎么实现的,但是和前端群的小伙伴讨论了下感觉也不是很难,就想着自己也做一个。通过数据结构讨论后,这个项目很快就产出了,当时还在说游戏以什么作为主题,碰巧公司需求提议说做成兔了个兔,就这样代码和默认主题的兔了个兔。
10月25日的下午,突然收到群友的at,才知道自己的兔了个兔开源项目xlegex被阮一峰老师写到他的网络日志羊了个羊,如何自己实现里面了,又是开心的一天。
也通过阮一峰老师的日志和云游君的fork,我也收获了第一个百星项目 🙏
其他开源项目
- demi-axios:vue2/vue3 兼容的axios封装库
- unplugin-vue-setup-extend-plus: setup语法糖拓展插件
- fast-imagemin-cli:图片压缩工具
成长
工作这些年,做过java+jsp/angular/vue再到后面的python人工智能算法,到最后决定专注在前端方向,就想好既然选择了前端就要保持不停的学习准备,在之前的工作中我也意识到,如果只靠工作上面的东西,是会成长,但是远远不够。我记得崔宝秋老师的一句话:只有你读了大量的代码,读了不同风格的代码,读了不同领域的代码,才能够真正提升自己的功底。当然这种读代码,还只是纸上谈兵,真正要成为一个编程高手必须写,读了很多高手的优质代码以后才能够快速提升自己写代码的能力。第二个我觉的要有对技术的爱... 开源正好很符合这个事,开源的一年,对我自己的技术水平有了明显的成长,在工作上的帮助也很大,能够有更多的解决方案去应对工作上的需求和问题,所以我也一直在鼓励群里的小伙伴人多参与开源,对自己的提升是很有帮助的。
收获
- 收获了工作团队以外另一个很棒的团队,有幸认识了团队里的好多大佬,从他们身上学到了好多东西。
- 收获一群前端水友,还记的那个review的夜晚,氛围真的太好的!!
- 收获了百星项目。
- 收获了工作上的认可和成就。
收获的太多太多了。。。
展望2023
2023再接再厉,保持开源的热情,继续成长,希望能产出一些更好的开源项目,收获更多的star~~
respect to 每一位用爱发电的开源作者~~
链接:https://juejin.cn/post/7191130699532304421
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
去年裸辞全职做开源后,趁快过年说说这一年的经历
刚裸辞全职搞开源时分享过一次,当时收到了很多网络友人们的鼓励和建议,当然也有不看好,很难挣到钱,经过一年多的实践,证明了他们说的是对的哈哈。
说说这一年的经历,大家就当听个故事,当然如果能给相似想法的朋友一个案例参考,那更好。
简述下故事的背景,2021 年 10 月底裸辞后,开始做一款 IT 监控告警产品,想法是基于 开源+SAAS 的模式去做,一款从零开始就开源的一款产品。github.com/dromara/her…
2021.11 到 2022.1 过年,基本就是在初版开发,这期间注册了公司,监控告警产品做到简单可用了,云服务 SAAS 的集群基本成型可用。开源方面,个人账户的开源项目说实话很难吸引到开发者,运营了一段时间我就把开源项目捐赠到我们 Dromara 社区,基于社区来传播和协作,事实证明效果确实比单打独斗强。
2022.2 到 2022.3 这个月就开始精彩了,网上遇到个客户说要买产品定制化部署到他们那,我当然很激动呀,之前一直是研发没有一线的经验,这哥们是运维,刚开始会问些他遇到的技术难点,后面是他自己想基于其它开源项目包装成两个产品卖给他自己公司,让我帮忙分析,还得把他发的开源项目的部署跑起来,还让我联系开发,报价,反正中间折腾了我非常多时间最后他嫌贵不做了,到后面有一天,他说我的产品正在公司部署,让我帮忙看看为啥 mysql 起不来,我远程进去 fix 了后顺便看了下数据库,这 tm 不是我产品的数据库名啊,问了才说这是其它厂商的数据库,他部署不起来。。。。。这 tm ,兄弟们,两个月啊,整整前后两个月时间,我至少花了整整半个月时间在他身上,这中间他会给我说在推进项目。。。。。就这样我被白嫖了断断续续两个月的技术支持加免费劳动力。
这件事情之后,后面有几家集成商找我开发帮忙把这监控项目整合进他们系统,卖了政府医院一起分钱,我的回复都是,请先预打款,当然对于习惯白嫖的他们来说,是没有下文了。
对了这期间还做了甲状腺手术,人生第一次进手术室,那环境真的跟电视里差不多。朋友们不要熬夜保护好你的甲状腺啊。
2022.4 到 2022.5 这段时间就是继续开发维护开源项目和云服务 SAAS ,开源项目还获得🉐️了 Gitee 最具价值开源项目 GVP ,这也是项目的一个肯定吧。开源项目还成为中科院的开源之夏活动的活动项目,学生们在暑期参与开发会有 1 万左右的奖金,我作为导师会有 3 千奖金哈哈。半年没收入的我看到这个还是很激动的。
2022.5 月,这个月。我去上班了,一家北京的公司联系到我,让我跟他们开发一款开源社区的产品,说的是看中我这方面的经验,薪资 23 ,我远程在家办公。考虑到这半年的被白嫖,无收入,还是就是马上娃娃要出生了,于是就暂缓了自己项目进度(下班后有空做做),去打工了。
2022.5 月 到 2022.12 这期间在打工,有空的时候也在维护我那个开源产品。虽说在打工,有趣的是,因为远程从入职到离开我都没有见过同事哈哈。
2022.12 月,这个月,我又辞职了。原因比较简单,老板学其它公司降薪,别人降 20%,他降一半😂。想着自己还略有发展的开源监控项目,虽然还有一个多月就过年,虽然之前说的 14 薪(我估计都悬毕竟年前降一半),也就不耗着了提了离职,好聚好散吧。
2022.12 到现在,感觉进入了一个循环,我又开始裸辞了哈哈。这一个多月我把云服务开启了高级版付费,然后开源项目的企业版本也搞出来了,希望在接下来的日子了,每个月能靠他们挣点奶粉钱。
总结,开源项目收入 0 ,企业版(刚弄出来)收入 0 , 云服务付费高级版(刚弄出来)收入 0 ,开源项目接收捐赠 300 左右,服务器域名CDN宣传发红包发开源周边礼物等支出 5K 左右。总 -4700 元😂。
链接:https://juejin.cn/post/7189522702300872760
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
中年Andorid的2022
又是一年过去了,又到了一年一度的年终总结。回看今年在掘金的输出,嗨,上一篇还是去年的年终总结,回看一下去年立下的flag,完成量不足一半啊。
工作和考研
那今年是不是蹉跎的一年呢,当然也不是,还记得去年的总结中有一条,考研哈哈,对于一个毕业有十年的老家伙来说做这个决定都是被现实逼的,还不是为了以后万一哪天失业了,给自己增加一点资本哎。于是从2月份开始就开始准备了,调研学什么、怎么学。
当我们去调研的时候,肯定会看到很多培训班的广告,当然对于一个工作近10年,有自主学习能力的老程序员来说我不认为非得报班才可以,网上的资料完全够用,学什么呢,对于一个程序员来说必须计算机408走起,最终书买好,视频买好3月份就开始每天下班投入学习了,包括午休时间背背英语单词。要学的东西可真多5月份差不多学完了计算机组成原理、计算机网络、操作系统。数据结构没怎么学,因为工作这么多年找工作啥的都会用到,平时也经常会刷刷,然后就开始学数学了。
数学的难度明显上了一个档次,上次学高数还是大学的时候,平时工作中用到的数学的难度也就初中高中的难度🤦♂️,这导数微积分一上来就给整懵逼了,感觉数学需要练习的时间要顶408的4本书啊,路是自己选的,硬着头也得往下走啊。
时间来到了6月底,高数学了四分之三,线性代数和概率论还没开始,工作开始忙了起来,领导要对项目进行大重构,项目彻底组件化,并且性能、包体积、崩溃率等方面也都要达标,有幸参与了整个过程,对于这种大的重构,在之前的公司是没有做过的,这也是一种很好的实践和成长。
但是随之而来的就是工作量大增加,由于很多改动影响范围很大,包括很多年前的祖传代码,所以做起来也相当谨慎,测试文档也需要写的非常详细,争取不漏掉任何改动。有一段时间项目编译非常慢,有时候多个分支一起开发的时候,切一个分支那是相当痛苦,二三十分钟就出去了,因此有一段时间都是用两个电脑开发不同的分支。下班时间也开始越来越晚...。由于工作强度大,回家很晚,再加上数学很枯燥,于是从7月份开始考研的学习就中断了...哎
高强度的工作一直持续到11月份,虽然已经过去了一个多月,现在想想仿佛还在昨天,收获也不小,很幸运能经历这么一次重构,实践出真知,很多时候我们在网上学习的新技术或者解决某些问题的方法,真正的用一遍才能有更深的认识。
这时候离这考试就一个月多一点了,虽然没怎么学习,十月份报名的时候还是报了,就是想去体验一下,如果来年再战心里也有点底,如果以后不再战,也权当一次经历,此时还有一点时间,学肯定是学不完,看个政治、背个作文啥的抱抱佛脚还是可以的哈哈哈。
12月25骑着我心爱的小摩托一早就来到了学校,怀着平静的心情的走进了考场,经过两天的考试,我的首次考研经历结束,最惨就是数学了,大题一个不会直接交个白卷,从小到大第一次交白卷,真是丢人丢到家了,而且考试的时候,那种啥也不会还得在那里等着考试完,真的是非常煎熬,最后提前半小时交卷狼狈而逃~~。
疫情和生活
考试完了,无论好坏都算是了了一件心事。再说到疫情,今年北京的疫情一直都是比较严重的,进出京政策也一直非常严格,以至于今年前半年的假期都是在家窝着过的,还好孩子在身边。
后半年稍微好了点,7月份孩子跟着姥姥回老家了,那个周末我跟媳妇骑着小摩托到周边的凤凰岭爬了个山。
8月份弟弟放暑假带着他在北京玩了几天,去秦皇岛看了下海。十月份孩子终于又回到了北京。
十一月份疫情开始严重,居家办公三周,第四周去公司两天后阳了~~。嗓子疼一天,发烧两天,咳嗽4天经历7天时间转阴,感觉重活一世。
疫情放开后,经历了各种抢药、抢抗原,如今北京应该超过80%的阳过了,大家的生活似乎恢复到了正常,但是去一趟医院就知道还差很多,今年过年回家终于不用害怕因为疫情回不来了。不过最近大家又在抢调理肠胃的药这种生活目前不知道尽头在哪里,只能顺其自然,希望疫情早点结束。
去年攒了点钱还了部分房贷,房贷压力少了一些,今年继续努力,早日摆脱房贷。
明年
- 恢复写博客,写东西这个还是不能落下不一定是博客,也可以是自己的笔记文档,写的时候能梳理逻辑,让思维更清晰,特别是学东西的时候,将新学的东西写出来,不仅能加深印象,写的时候还能将学的时候似懂非懂的地方想清楚。
- 工作继续卷一卷,不倦不行啊,你不走我不走,看谁卷过谁。今年公司来了新的CTO,所以今年的项目优化也比较多,好好工作好好实践。
- 疫情放开了,今年周末多跟家人去北京周边的景区玩玩。
- 考研成绩出来后,根据情况看看今年是否继续~~~ , 这是个大活啊,人到中年,有时候时间真的不够用。年轻时候留下的债早晚都得还。
- 读书 手机读书没感觉,租房又不愿买一堆纸质书 准备买个电子书用来读,做好笔记
链接:https://juejin.cn/post/7185418530358198331
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
因为使用 try-cache-finally 读取文件 ,导致我被开除了.(try-with-resources 的使用方法)
前些天项目经理找到我说,阿杰,你过来一下,我这有个小方法,你帮我写一下
- 需求: 提供一个文本文件,按行读取,然后给出一个回调函数,可以由调用者去实现对每行的处理.
我就想,你这不是瞧不起我吗.5分钟搞定!!嘴里却说,你这个有点难,我需要研究下大概今天下班前能完成.
5分钟过去了----> 代码完成
摸鱼3小时 ----> ok 代码一发,收工准备下班
public void clean2(String path, Consumer<String> consumer){
FileReader fileReader = null;
BufferedReader br = null;
try{
fileReader = new FileReader(path);
br = new BufferedReader(fileReader);
String line;
while((line = br.readLine()) != null ){
consumer.accept(line);
}
}catch (IOException e){
// do
}finally {
try {
if (br != null){
br.close();
}
if (fileReader != null){
fileReader.close();
}
} catch (IOException e) {
// do
}
}
}项目经理 😶😶😶😶: 你tm明天别来了,自己去财务把这个月的结了,3行代码就写完的功能写成这个鬼样子.
那我就想啊,我写的这么完美,那凭什么开除我,经过我九九八十一天的苦思冥想,终于找到了问题的原因!!
try-cache-finally
try-finally 是java SE7之前我们处理一些需要关闭的资源的做法,无论是否出现异常都要对资源进行关闭。*
如果try块和finally块中的方法都抛出异常那么try块中的异常会被抑制(suppress),只会抛出finally中的异常,而把try块的异常完全忽略。
这里如果我们用catch语句去获得try块的异常,也没有什么影响,catch块虽然能获取到try块的异常但是对函数运行结束抛出的异常并没有什么影响。
try-with-resources
try-with-resources语句能够帮你自动调用资源的close()函数关闭资源不用到finally块。
前提是只有实现了
Closeable接口的才能自动关闭
public void clean(String path, Consumer<String> consumer) throws IOException {
try (BufferedReader br = new BufferedReader(new FileReader(path))) {
String line;
while((line = br.readLine()) != null ){
consumer.accept(line);
}
}
}这是try-with-resources语句的结构,在try关键字后面的( )里new一些需要自动关闭的资源。
这个时候如果方法 readLine 和自动关闭资源的过程都抛出异常,那么:
函数执行结束之后抛出的是try块的异常,而try-with-resources语句关闭过程中的异常会被抑制,放在try块抛出的异常的一个数组里。(上面的非try-with-resources例子抛出的是finally的异常,而且try块的异常也不会放在fianlly抛出的异常的抑制数组里)
可以通过异常的
public final synchronized Throwable[] getSuppressed()方法获得一个被抑制异常的数组。
try块抛出的异常调用getSuppressed()方法获得一个被它抑制的异常的数组,其中就有关闭资源的过程产生的异常。
try-with-resources 语句能放多个资源,使用 ; 分割
try (
BufferedReader br = new BufferedReader(new FileReader(path));
ZipFile zipFile = new ZipFile("");
FileReader fileReader = new FileReader("");
) {
}最后任务执行完毕或者出现异常中断之后是根据new的反向顺序调用各资源的close()的。后new的先关。
try-with-resources 语句也可以有 catch 和 finally 块
public void clean3(String path, Consumer<String> consumer){
try (BufferedReader br = new BufferedReader(new FileReader(path))) {
System.out.println("RuntimeException 前");
int a = 1/0;
System.out.println("RuntimeException 后");
}catch (RuntimeException e){
System.out.println("抛出 RuntimeException");
}catch (IOException e){
System.out.println("抛出 RuntimeException");
}finally {
System.out.println("finally");
}
}RuntimeException 前
抛出 RuntimeException
finally链接:https://juejin.cn/post/7198847208564015164
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Compose自定义View——宇智波斑写轮眼
本章节是Compose自定义绘制的第二章,画的是一个之前设计给的一个比较复杂的,设计所谓的会呼吸的动画,那时候实现花了蛮长的时间,搬着电脑跟设计一帧一帧地对,没多久后来需求就被拿掉了,至于文章的标题哈哈随意起了一个,长得有点像而已。
Compose的实现,图形本身跟上一章节的LocationMarker其实差不太多,倒过来了而已,调整了P1跟P3, 基本图形的Path,这里不再做介绍,读者也可以去看代码实现。主要介绍一下动画吧。
首先看一下gif动图:
整个图形分三层,最底层是灰色的背景,没有动画实现。
第二层是一个层变的动画,每层有个delay的不同延迟,对alpha最一个ObjectAnimator.ofFloat(water1, "alpha", 0f, 0.5f, 0.2f, 1f)渐变的动画,0.5f 到0.2f, 再到1f这个地方展现出所谓的呼吸的感觉。Compose目前写的不多,有些冗余代码没有抽象,先实现了功能效果。
@Composable
fun drawWaterDrop(){
val waterDropModel by remember {
mutableStateOf(WaterDropModel.waterDropM)
}
val color1 = colorResource(id = waterDropModel.water1.colorResource)
val color2 = colorResource(id = waterDropModel.water2.colorResource)
val color3 = colorResource(id = waterDropModel.water3.colorResource)
val color4 = colorResource(id = waterDropModel.water4.colorResource)
val color5 = colorResource(id = waterDropModel.water5.colorResource)
val color6 = colorResource(id = waterDropModel.water6.colorResource)
val color7 = colorResource(id = waterDropModel.water7.colorResource)
val color8 = colorResource(id = waterDropModel.water8.colorResource)
val animAlpha1 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha2 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha3 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha4 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha5 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha6 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha7 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha8 = remember { Animatable(0f, Float.VectorConverter) }
LaunchedEffect(Unit){
animAlpha1.animateTo(1f, animationSpec = myKeyframs(0))
}
LaunchedEffect(Unit){
animAlpha2.animateTo(1f, animationSpec = myKeyframs(1))
}
LaunchedEffect(Unit){
animAlpha3.animateTo(1f, animationSpec = myKeyframs(2))
}
LaunchedEffect(Unit){
animAlpha4.animateTo(1f, animationSpec = myKeyframs(3))
}
LaunchedEffect(Unit){
animAlpha5.animateTo(1f, animationSpec = myKeyframs(4))
}
LaunchedEffect(Unit){
animAlpha6.animateTo(1f, animationSpec = myKeyframs(5))
}
LaunchedEffect(Unit){
animAlpha7.animateTo(1f, animationSpec = myKeyframs(6))
}
LaunchedEffect(Unit){
animAlpha8.animateTo(1f, animationSpec = myKeyframs(7))
}
Canvas(modifier = Modifier.fillMaxSize()){
val contentWidth = size.width
val contentHeight = size.height
withTransform({
translate(left = contentWidth / 2, top = contentHeight / 2)}) {
drawPath(AndroidPath(waterDropModel.water8Path), color = color8, alpha = animAlpha8.value)
drawPath(AndroidPath(waterDropModel.water7Path), color = color7, alpha = animAlpha7.value)
drawPath(AndroidPath(waterDropModel.water6Path), color = color6, alpha = animAlpha6.value)
drawPath(AndroidPath(waterDropModel.water5Path), color = color5, alpha = animAlpha5.value)
drawPath(AndroidPath(waterDropModel.water4Path), color = color4, alpha = animAlpha4.value)
drawPath(AndroidPath(waterDropModel.water3Path), color = color3, alpha = animAlpha3.value)
drawPath(AndroidPath(waterDropModel.water2Path), color = color2, alpha = animAlpha2.value)
drawPath(AndroidPath(waterDropModel.water1Path), color = color1, alpha = animAlpha1.value)
}
}
}
private fun myKeyframs(num:Int):KeyframesSpec<Float>{
return keyframes{
durationMillis = 3000
delayMillis = num * 2000
0.5f at 1000 with LinearEasing
0.2f at 2000 with LinearEasing
}
}然后就是外层扫光的动画,像探照灯一样一圈圈的扫,一共扫7遍,代码跟层变动画差不多,也是对alpha值做渐变,目前代码是调用扫光动画7次,后续看看如何优化性能。每次调用传入不同的delay值即可。
@Composable
fun drawWaterDropScan(delayTime:Long){
val waterDropModel by remember {
mutableStateOf(WaterDropModel.waterDropMScan)
}
val color1 = colorResource(id = waterDropModel.water1.colorResource)
val color2 = colorResource(id = waterDropModel.water2.colorResource)
val color3 = colorResource(id = waterDropModel.water3.colorResource)
val color4 = colorResource(id = waterDropModel.water4.colorResource)
val color5 = colorResource(id = waterDropModel.water5.colorResource)
val color6 = colorResource(id = waterDropModel.water6.colorResource)
val color7 = colorResource(id = waterDropModel.water7.colorResource)
val color8 = colorResource(id = waterDropModel.water8.colorResource)
val animAlpha2 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha3 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha4 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha5 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha6 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha7 = remember { Animatable(0f, Float.VectorConverter) }
val animAlpha8 = remember { Animatable(0f, Float.VectorConverter) }
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(1f, 350) }
animAlpha2.animateTo(0f, animationSpec = myKeyframs2(700, 0, map))
}
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(0.8f, 315) }
animAlpha3.animateTo(0f, animationSpec = myKeyframs2(630, 233, map))
}
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(0.55f, 315) }
animAlpha4.animateTo(0f, animationSpec = myKeyframs2(630, 383, map))
}
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(0.5f, 325) }
animAlpha5.animateTo(0f, animationSpec = myKeyframs2(650, 533, map))
}
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(0.45f, 325) }
animAlpha6.animateTo(0f, animationSpec = myKeyframs2(650, 667, map))
}
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(0.35f, 283) }
animAlpha7.animateTo(0f, animationSpec = myKeyframs2(567, 816, map))
}
LaunchedEffect(Unit){
delay(delayTime)
val map = mutableMapOf<Float, Int>().apply { put(0.3f, 216) }
animAlpha8.animateTo(0f, animationSpec = myKeyframs2(433, 983, map))
}
Canvas(modifier = Modifier.fillMaxSize()){
val contentWidth = size.width
val contentHeight = size.height
withTransform({
translate(left = contentWidth / 2, top = contentHeight / 2)
}) {
drawPath(AndroidPath(waterDropModel.water8Path), color = color8, alpha = animAlpha8.value)
drawPath(AndroidPath(waterDropModel.water7Path), color = color7, alpha = animAlpha7.value)
drawPath(AndroidPath(waterDropModel.water6Path), color = color6, alpha = animAlpha6.value)
drawPath(AndroidPath(waterDropModel.water5Path), color = color5, alpha = animAlpha5.value)
drawPath(AndroidPath(waterDropModel.water4Path), color = color4, alpha = animAlpha4.value)
drawPath(AndroidPath(waterDropModel.water3Path), color = color3, alpha = animAlpha3.value)
drawPath(AndroidPath(waterDropModel.water2Path), color = color2, alpha = animAlpha2.value)
drawPath(AndroidPath(waterDropModel.water1Path), color = color1)
}
}
}
private fun myKeyframs2(durationMillisParams:Int, delayMillisParams:Int, frames:Map<Float, Int>):KeyframesSpec<Float>{
return keyframes{
durationMillis = durationMillisParams
delayMillis = delayMillisParams
for ((valueF, timestamp) in frames){
valueF at timestamp
}
}
}
@Preview
@Composable
fun WaterDrop(){
Box(modifier = Modifier.fillMaxSize()){
drawWaterDropBg()
drawWaterDrop()
for (num in 1 .. 7){
drawWaterDropScan(delayTime = num * 2000L)
}
}
}代码跟LocationMarker在一个Project里面,暂时没有添加导航。github.com/yinxiucheng… 下的CustomerComposeView.
链接:https://juejin.cn/post/7198965240279679035
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Android约束布局ConstraintLayout的使用
Android引入约束布局的目的是为了减少布局层级的嵌套,从而提升渲染性能。约束布局综合线性布局、相对布局、帧布局的部分功能,缺点也很明显,就是可能要多写几行代码。所以约束布局使用时,还得综合考虑代码量。提升性能也并不一定非得使用约束布局,也可以在ViewGroup上dispatchDraw。你需要根据业务的具体情况选择最合适的实现方式。我知道很多人一开始很不习惯使用约束布局,但既然你诚心诚意问我怎么使用了?于是我就大发慈悲告诉你怎么使用呗。
链式约束
用得最多的非链式约束莫属了。这看起来是不是类似于相对布局?那么有人问了,既然相对布局写法这么简洁,都不用强制你写另一个方向的占满屏幕的约束,为什么还要使用约束布局呢?约束布局它还是有它过布局之处的,比如以下一些功能,相对布局是做不到的。
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:id="@+id/iv1"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#F0F"
app:layout_constraintVertical_chainStyle="spread"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintBottom_toTopOf="@+id/iv2"/>
<ImageView
android:id="@+id/iv2"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FF0"
app:layout_constraintBottom_toTopOf="@id/iv3"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toBottomOf="@+id/iv1"/>
<ImageView
android:id="@+id/iv3"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#0FF"
app:layout_constraintBottom_toTopOf="@id/iv4"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toBottomOf="@+id/iv2"/>
<ImageView
android:id="@+id/iv4"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#0F0"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintTop_toBottomOf="@+id/iv3"/>
</androidx.constraintlayout.widget.ConstraintLayout>我们可以在链首的控件添加一个layout_constraintVertical_chainStyle属性为spread,翻译成展开,在我看来就是排队,要保持间距一样,而且边缘不能站,默认不写也是指定的spread。
如果你改成spread_inside,就会变成可以靠墙的情况。
那如果你改成packed,就会贴在一起了。
使用Group分组进行显示和隐藏
而如果你添加以下代码在布局中,就会将id为iv1和iv3点色块去掉,这样iv2和iv4就贴在一起了。
<androidx.constraintlayout.widget.Group
android:id="@+id/group"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:visibility="gone"
app:constraint_referenced_ids="iv1,iv3" />Guideline引导线
<androidx.constraintlayout.widget.Guideline
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:orientation="vertical"
app:layout_constraintGuide_percent="0.5"/>使用引导线,可以在预览布局的时候看到,在运行时是看不到的,可以作为布局的参考线。
切换到Design的选项卡你就能看到了。
引导线的另外两个属性是layout_constraintGuide_begin和layout_constraintGuide_end,一看就知道这个是使用边距定位的。
角度约束
角度约束的以下三个属性是一起使用的。
layout_constraintCircle
layout_constraintCircleAngle
layout_constraintCircleRadius <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:id="@+id/iv1"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FFC0C0"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintBottom_toBottomOf="parent"/>
<ImageView
android:id="@+id/iv2"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FF0"
app:layout_constraintCircle="@id/iv1"
app:layout_constraintCircleAngle="30"
app:layout_constraintCircleRadius="150dp"/>
<androidx.constraintlayout.widget.Guideline
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:orientation="horizontal"
app:layout_constraintGuide_percent="0.5"/>
<androidx.constraintlayout.widget.Guideline
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:orientation="vertical"
app:layout_constraintGuide_percent="0.5"/>
</androidx.constraintlayout.widget.ConstraintLayout>知道你们喜欢粉嫩的,所以特地把色块的颜色换了一下。旋转角是以垂直向上为0度角,顺时针旋转30度。距离则是计算两控件重心的连线。在矩形区域中,重心就在对角线的交叉点。
位置百分比偏移
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:id="@+id/iv1"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FFC0C0"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintHorizontal_bias="0.5"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintBottom_toTopOf="@+id/iv2"/>
<ImageView
android:id="@+id/iv2"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FF0"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintHorizontal_bias="0.4"
app:layout_constraintBottom_toBottomOf="parent"
app:layout_constraintTop_toBottomOf="@+id/iv1"/>
<androidx.constraintlayout.widget.Guideline
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:orientation="vertical"
app:layout_constraintGuide_percent="0.5"/>
</androidx.constraintlayout.widget.ConstraintLayout>这里需要注意,不是只使用layout_constraintHorizontal_bias就可以了,原有该方向的约束也不能少。
使用goneMargin设置被依赖的控件gone时,依赖控件的边距
goneMargin有以下属性:
layout_goneMarginStart
layout_goneMarginEnd
layout_goneMarginTop
layout_goneMarginBottom <?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent"
tools:context=".MainActivity">
<ImageView
android:id="@+id/iv1"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FFC0C0"
android:visibility="gone"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintBottom_toTopOf="@+id/iv2"/>
<ImageView
android:id="@+id/iv2"
android:layout_width="100dp"
android:layout_height="100dp"
android:background="#FF0"
app:layout_goneMarginTop="10dp"
app:layout_constraintTop_toBottomOf="@+id/iv1"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintStart_toStartOf="parent"/>
<androidx.constraintlayout.widget.Guideline
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:orientation="horizontal"
app:layout_constraintGuide_begin="10dp"/>
</androidx.constraintlayout.widget.ConstraintLayout>约束宽高比
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:id="@+id/iv1"
android:layout_width="0dp"
android:layout_height="100dp"
app:layout_constraintDimensionRatio="1:1"
android:background="#FFC0C0"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintBottom_toTopOf="@id/iv2"/>
<ImageView
android:id="@+id/iv2"
android:layout_width="100dp"
android:layout_height="0dp"
android:background="#FF0"
app:layout_constraintDimensionRatio="H,3:2"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintTop_toBottomOf="@id/iv1"
app:layout_constraintBottom_toBottomOf="parent"/>
</androidx.constraintlayout.widget.ConstraintLayout>我们可以将宽高的其中一个设置为0dp,然后这个宽或高根据相对于另一个的比例来。如果高度为0dp,需要根据宽度来确认高度,你可以直接赋值为3:2,也可以赋值为H,3:2,这也是推荐的写法,我一般省略W和H。如果高度为0dp,你本应该写H,而你写成了W,那就要把比例反过来看宽高比。
权重约束
这个类似于线性布局的权重功能。
<?xml version="1.0" encoding="utf-8"?>
<androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
xmlns:tools="http://schemas.android.com/tools"
android:layout_width="match_parent"
android:layout_height="match_parent">
<ImageView
android:id="@+id/iv1"
android:layout_width="100dp"
android:layout_height="0dp"
app:layout_constraintVertical_weight="1"
android:background="#FFC0C0"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintTop_toTopOf="parent"
app:layout_constraintBottom_toTopOf="@id/iv2"/>
<ImageView
android:id="@+id/iv2"
android:layout_width="100dp"
android:layout_height="0dp"
app:layout_constraintVertical_weight="2"
android:background="#FF0"
app:layout_constraintStart_toStartOf="parent"
app:layout_constraintEnd_toEndOf="parent"
app:layout_constraintTop_toBottomOf="@id/iv1"
app:layout_constraintBottom_toBottomOf="parent"/>
</androidx.constraintlayout.widget.ConstraintLayout>链接:https://juejin.cn/post/7199297355748409399
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。


