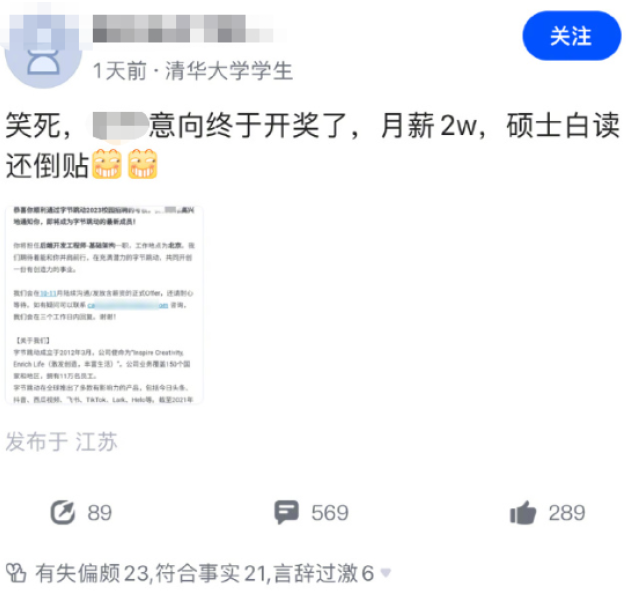
再过几天就要过大年了,最近周围也是一到晚上就是到处都在放烟花,看得我十分眼馋也想搞点烟花来放放,可惜周围实在是买不到,一打听全是托人在外省买的,算了太麻烦了,那真的烟花放不了,我就干脆决定写个烟花出来吧,应应景,也烘托点年味儿出来~刚好最近学了点Compose的动画,所以这个烟花就拿Compose来写,先上个最终效果图

不好意思...放错效果图了...这个才是

gif有点卡,真实效果还要流畅点,这些我们先不说,先来看看这个动画我们需要做些什么
- 一闪一闪(对..在闪)的小星星
- 逐渐上升的烟花火苗
- 烟花炸开的效果
- 炸开后闪光效果
开始开发
闪烁的星星
首先我们放烟花肯定是在晚上放烟花的,所以整体画布首先背景色就是黑色,模拟一个夜空的场景
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
) {
}
确定好了画布以后,我们先来想想如何画星星,夜空中的星星其实就是在画布上画几个小圆点,然后小圆点的颜色是白色的,最后星星看起来都是有大有小的,因为距离我们的距离不一样,所以我们的小圆点也要看起来大小不一样,也就是圆点的半径不一样,知道这些以后我们开始设计代码,先确定好需要的变量,比如画布的中心点xy坐标,星星的xy坐标,以及星星的颜色
val drawColor = colorResource(id = R.color.white)
val centerX = screenWidth() / 2
val centerY = screenHeight() / 2
val starXList = listOf(
screenWidth() / 12, screenWidth() / 6, screenWidth() / 4,
screenWidth() / 3, screenWidth() * 5 / 12, screenWidth() / 2, screenWidth() * 7 / 12,
screenWidth() * 2 / 3, screenWidth() * 3 / 4, screenWidth() * 5 / 6, screenWidth() * 11 / 12
)
val starYList = listOf(
centerY / 12, centerY / 6, centerY / 4,
centerY / 3, centerY * 5 / 12, centerY / 2, centerY * 7 / 12,
centerY * 2 / 3, centerY * 3 / 4, centerY * 5 / 6, centerY * 11 / 12
)
starXList放星星的横坐标,横坐标就是把画布宽十二等分,starYList放星星的纵坐标,纵坐标就是把画布高的二分之一再十二等分,这样作法的目的就是最终画圆点的时候,两个List可以随机选取下标值,达到星星随机散布在夜空的效果
drawCircle(drawColor, 5f, Offset(starXList[0], starYList[10]))
drawCircle(drawColor, 4f, Offset(starXList[1], starYList[9]))
drawCircle(drawColor, 3f, Offset(starXList[2], starYList[4]))
drawCircle(drawColor, 5f, Offset(starXList[3], starYList[6]))
drawCircle(drawColor, 6f, Offset(starXList[4], starYList[3]))
drawCircle(drawColor, 5f, Offset(starXList[5], starYList[7]))
drawCircle(drawColor, 6f, Offset(starXList[6], starYList[2]))
drawCircle(drawColor, 2f, Offset(starXList[7], starYList[1]))
drawCircle(drawColor, 5f, Offset(starXList[8], starYList[0]))
drawCircle(drawColor, 2f, Offset(starXList[9], starYList[5]))
drawCircle(drawColor, 2f, Offset(starXList[10], starYList[8]))
然后一闪一闪的效果怎么做呢,一闪一闪也就是圆点的半径循环在变大变小,所以我们需要用到Compose的循环动画rememberInfiniteTransition,这个函数可以通过它的animateXXX函数来创建循环动画,它里面有三个这样的函数

我们这里就使用animateFloat来创建可以变化的半径
val startRadius by transition.animateFloat(
initialValue = 0f,
targetValue = 1f,
animationSpec = infiniteRepeatable(tween(1000, easing = LinearEasing))
)
这个函数返回的是一个Float类型的值,前两个参数很好理解,初始值跟最终值,第三个参数是一个
InfiniteRepeatableSpec的对象,它决定这个循环动画的一些参数,duration决定动画持续时间,delayMillis延迟执行的时间,easing决定动画执行的速度
- LinearEasing 匀速执行
- FastOutLinearInEasing 逐渐加速
- FastOutSlowInEasing 先加速后减速
- LinearOutSlowInEasing 逐渐减速
这里的星星的动画就选择匀速执行就好,我们把starRadius设置到星星的绘制流程里面去
drawCircle(drawColor, 5f + startRadius, Offset(starXList[0], starYList[10]))
drawCircle(drawColor, 4f + startRadius, Offset(starXList[1], starYList[9]))
drawCircle(drawColor, 3f + startRadius, Offset(starXList[2], starYList[4]))
drawCircle(drawColor, 5f + startRadius, Offset(starXList[3], starYList[6]))
drawCircle(drawColor, 6f + startRadius, Offset(starXList[4], starYList[3]))
drawCircle(drawColor, 5f + startRadius, Offset(starXList[5], starYList[7]))
drawCircle(drawColor, 6f + startRadius, Offset(starXList[6], starYList[2]))
drawCircle(drawColor, 2f + startRadius, Offset(starXList[7], starYList[1]))
drawCircle(drawColor, 5f + startRadius, Offset(starXList[8], starYList[0]))
drawCircle(drawColor, 2f + startRadius, Offset(starXList[9], starYList[5]))
drawCircle(drawColor, 2f + startRadius, Offset(starXList[10], starYList[8]))
效果就是这样的

烟花火苗
现在开始绘制烟花部分,首先是上升的火苗,火苗也是个小圆点,它的起始坐标跟终点坐标很好确定,横坐标都是centerX即画布的一半,纵坐标开始位置是在画布高度位置,结束是在centerY即画布一半高度位置,而一次放烟花的过程中,烟花炸开的次数有很多次,伴随着火苗上升次数也很多次,所以这个也是个循环动画,整个过程代码实现如下
val fireDuration = 3000
val shootHeight by transition.animateFloat(
screenHeight(),
screenHeight() / 2,
animationSpec = InfiniteRepeatableSpec(tween(fireDuration,
easing = FastOutSlowInEasing))
)
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
由于火苗上升会随着重力逐渐减速,所以这里选择的是先快后慢的动画效果,效果如下

烟花炸开
这一部分难度开始增加了,因为烟花炸开这个效果是要等到火苗上升到最高点的位置然后在炸开的,这两个动画有个先后关系,用惯了Androi属性动画的我刚开始还不以为然,认为肯定会有个动画回调或者监听器之类的东西,然而看了下循环动画的源码发现并没有找到想要的监听器

那只能换个思路了,刚刚说到炸开的动画是在火苗上升到最高点的时候才开始的,那这个最高点就是个开关,当火苗到达最高点的时候,让火苗的动画“暂停”,然后开始炸开的动画,现在问题的关键是,如何让火苗的动画“暂停”,我们知道火苗的动画是一个循环动画,循环动画是从初始值到最终值循环变化的过程,那么我们是不是只要让这两个值都为同一个,让它们没有变化的空间,是不是就等于让这个动画“暂停”了呢,我们开始设计这个过程
var turnOn by remember { mutableStateOf(false) }
val distance = remember { Animatable(screenHeight().dp, Dp.VectorConverter) }
LaunchedEffect(turnOn) {
distance.snapTo(if (turnOn) screenHeight().dp else 0.dp)
}
turnOn是个开关,true的时候表示火苗动画开始,false的时候表示火苗动画已经到达最高点,distance是一个Animatable的对象,Animatable是啥呢,从字面上就能理解它也是个动画,但与我们刚刚接触的循环动画不一样,它只有从初始值到最终值的单向变化,而后面的LaunchedEffect是啥呢,我们点到里面去看下它的源码
fun LaunchedEffect(
key1: Any?,
block: suspend CoroutineScope.() -> Unit
) {
val applyContext = currentComposer.applyCoroutineContext
remember(key1) { LaunchedEffectImpl(applyContext, block) }
}
这里我们看到key1是任何值,被remember保存了起来,block是个挂起的函数类型对象,也就是block是运行在协程里面的,我们再去LaunchedEffectImpl里面看看

我们看到了这个协程是在被remember的值发生改变以后才去执行的,那现在清楚了,每次改变turnOn的值,distance就会来回从screenHeight()和0之间切换,而切换的条件就是火苗上升高度到达了画布的一半,我们改一下刚刚火苗的动画,让shootHeight随着distance变化而变化,另外我们给画布添加个点击事件,每次点击让turnOn的值发生改变,目的让动画多进行几次
val shootHeight by transition.animateFloat(
distance.value.value,
distance.value.value / 2,
animationSpec = InfiniteRepeatableSpec(tween(fireDuration,
easing = FastOutSlowInEasing))
)
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
turnOn = false
}
}
我们看下效果是不是我们想要的

So far so good~动画已经分离开来了,现在就要开始炸开效果的开发,我们先脑补下炸开是什么样子的,是由火苗开始,向四周延伸出去若干条烟火,或者换句话说就是以火苗为圆心,向四周画线条,这样说我们思路有了,这是一个由圆心开始向外drawLine的过程,drawLine这个api大家很熟悉了,最主要的就是确定开始跟结束两处的坐标,但是无论开始还是结束,这两个坐标都是分布在一个圆周上的,所以我们第一步先要确定在哪几个角度上面画线
val anglist = listOf(30, 75, 120, 165, 210, 255, 300, 345)
知道了角度以后,就要去计算xy坐标了,这个就要用到正弦余弦公式
private fun calculateX(centerX: Float, fl: Int, endCor: Boolean): Float {
val angle = Math.toRadians(fl.toDouble())
return centerX - cos(angle).toFloat() * (if (endCor) screenWidth() / 2 else screenWidth() / 12)
}
private fun calculateY(centerY: Float, fl: Int, endCor: Boolean): Float {
val angle = Math.toRadians(fl.toDouble())
return centerY - sin(angle).toFloat() * (if (endCor) screenWidth() / 2 else screenWidth() / 12)
}
其中endColor是true就是画终点的坐标,false就是起点的坐标,我们先画一条线,剩下的线的代码都相同
val startfireOneX = calculateX(centerX, anglist[0], false)
val startfireOneY = calculateY(centerY, anglist[0], false)
val endfireOneX = calculateX(centerX, anglist[0], true)
val endfireOneY = calculateY(centerY, anglist[0], true)
var fireColor = colorResource(id = R.color.color_03DAC5)
var fireOn by remember { mutableStateOf(false) }
val fireOneXValue = remember { Animatable(startfireOneX, Float.VectorConverter) }
val fireOneYValue = remember { Animatable(startfireOneY, Float.VectorConverter) }
val fireStroke = remember { Animatable(0f, Float.VectorConverter) }
LaunchedEffect(fireOn){
fireStroke.snapTo(if(fireOn) 20f else 0f)
fireOneXValue.snapTo(if(fireOn) endfireOneX else startfireOneX)
fireOneYValue.snapTo(if(fireOn) endfireOneY else startfireOneY)
}
fireOneXValue是第一条线横坐标的变化动画,fireOneYValue是纵坐标的变化动画,它们的改变都有fireOn去控制,fireOn打开的时机就是火苗上升到最高点的时候,同时我们也增加了fireStroke,表示线条粗细的变化动画,也随着fireOn的改变而改变,我们现在去创建横坐标,纵坐标以及线条粗细的循环动画
val fireOneX by transition.animateFloat(
startfireOneX, fireOneXValue.value,
infiniteRepeatable(tween(fireDuration, easing = FastOutSlowInEasing))
)
val fireOneY by transition.animateFloat(
startfireOneY, fireOneYValue.value,
infiniteRepeatable(tween(fireDuration, easing = FastOutSlowInEasing))
)
val strokeW by transition.animateFloat(
initialValue = fireStroke.value/20,
targetValue = fireStroke.value,
animationSpec = infiniteRepeatable(tween(fireDuration,
easing = FastOutSlowInEasing))
)
我们现在可以去绘制第一根线了,在Canvas里面增加第一个drawLine
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
turnOn = false
fireOn = true
}
drawLine(
fireColor, Offset(startfireOneX, startfireOneY),
Offset(fireOneX, fireOneY), cap = StrokeCap.Round, strokeWidth = strokeW
)
}
到了这一步,我们应该考虑的是,如何让动画衔接起来,也就是炸开动画完成以后,继续执行火苗动画,那么我们就要找出炸开动画结束的那个点,这里总共有三个值,我们选择strokeW,当线条粗细到达最大值的时候,将fireOn关闭,将turnOn打开,我们在drawLine后面加上这段逻辑
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
turnOn = false
fireOn = true
}
drawLine(
fireColor, Offset(startfireOneX, startfireOneY),
Offset(fireOneX, fireOneY), cap = StrokeCap.Round, strokeWidth = strokeW
)
if(strokeW == 19){
fireOn = false
turnOn = true
}
}
这个时候,两个动画就连起来了,我们运行下看看效果

一条线完成了,那么其余几根线道理也是一样的,代码有点多篇幅关系就不贴出来了,直接看效果图吧

基本的样子已经出来了,现在给这个烟花优化一下,我们知道放烟花时候,每次炸开的样子都是不一样的,红橙黄绿啥颜色都有,我们这边也让每次炸开时候,颜色都不一样,那首先我们要弄一个颜色的集合
val colorList = listOf(
colorResource(id = R.color.color_03DAC5), colorResource(id = R.color.color_BB86FC),
colorResource(id = R.color.color_E6A639), colorResource(id = R.color.color_01B9FF),
colorResource(id = R.color.color_FF966B), colorResource(id = R.color.color_FFEBE7),
colorResource(id = R.color.color_FF4252), colorResource(id = R.color.color_EC4126)
)
并且让fireColor在每次炸开之前,更换一次颜色,随机换也行,按照下标顺序替换也行,这边我选择顺序换了,位置就是炸开动画开始的地方
var colorIndex by remember { mutableStateOf(0) }
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
if (shootHeight.toInt() != screenHeight().toInt() / 2) {
if (shootHeight.toInt() != 0) {
drawCircle(drawColor, 6f, Offset(centerX, shootHeight))
}
} else {
if (strokeW.toInt() == 0) {
colorIndex += 1
if (colorIndex > 7) colorIndex = 0
fireColor = colorList[colorIndex]
}
turnOn = false
fireOn = true
}
drawLine(
fireColor, Offset(startfireOneX, startfireOneY),
Offset(fireOneX, fireOneY), cap = StrokeCap.Round, strokeWidth = strokeW
)
if(strokeW == 19){
fireOn = false
turnOn = true
}
}
我们再想想看,烟花结束以后是不是还会有一些闪光,有的烟花的闪光还会有声音,声音我们弄不出来,但是闪光还是可以的,还记得我们星星怎么画的吗,不就是几个圆圈在那里不断绘制,然后一闪一闪的效果就是不断改变圆圈的半径,那我们烟花的闪光效果也可以这么做,首先我们先确定好需要绘制圆圈的坐标
val endXAnimList = listOf(
calculatePointX(centerX, anglist[0]),
calculatePointX(centerX, anglist[1]),
calculatePointX(centerX, anglist[2]),
calculatePointX(centerX, anglist[3]),
calculatePointX(centerX, anglist[4]),
calculatePointX(centerX, anglist[5]),
calculatePointX(centerX, anglist[6]),
calculatePointX(centerX, anglist[7])
)
val endYAnimList = listOf(
calculatePointY(centerY, anglist[0]),
calculatePointY(centerY, anglist[1]),
calculatePointY(centerY, anglist[2]),
calculatePointY(centerY, anglist[3]),
calculatePointY(centerY, anglist[4]),
calculatePointY(centerY, anglist[5]),
calculatePointY(centerY, anglist[6]),
calculatePointY(centerY, anglist[7])
)
然后烟花放完以后会有个逐渐暗淡的过程,在这里我们就让圆圈的半径也有个逐渐变小的过程,那我们就创建个变小的动画
val pointDuration = 3000
val firePointRadius = remember{ Animatable(0f, Float.VectorConverter) }
val pointRadius by transition.animateFloat(
initialValue = firePointRadius.value,
targetValue = firePointRadius.value / 6,
animationSpec = infiniteRepeatable(tween(pointDuration,
easing = FastOutLinearInEasing))
)
有了这个闪光的动画以后,接下去就要让它跟炸开的动画衔接起来了,这边也跟其他动画一样,增加一个开关去控制,当开关打开之后,firePointRadius设置成最大,开启这个闪光动画,当开关关闭以后,就让firePointRadius设置为0,也就是关闭闪光动画,代码如下
var pointOn by remember { mutableStateOf(false) }
LaunchedEffect(pointOn) {
firePointRadius.snapTo(if (pointOn) 12f else 0f)
}
参数都设置好了以后,我们可以去绘制闪光的圆圈了,这边我们让闪光的开关在炸开动画完毕之后打开,原本要开启的火苗动画我们暂时先不打开,而闪光动画的颜色我们让它跟炸开的动画颜色一致,让整个过程看上去像是烟花自己炸开然后变成小颗粒的样子
Canvas(
modifier = Modifier
.size(screenWidth().dp, screenHeight().dp)
.background(color = Color.Black)
.clickable { turnOn = !turnOn }
) {
....此处省略前面两个烟花动画的绘制过程.....
if(strokeW == 19){
fireOn = false
pointOn = true
}
if(pointOn){
repeat(endXAnimList.size) {
drawCircle(
colorList[colorIndex], pointRadius,
Offset(endXAnimList[it], endYAnimList[it])
)
}
}
}
到了这里感觉好像漏了点什么,没错,之前我们暂时把火苗开关打开的时机取消了,那这个开关得打开呀,不然我们的烟花没办法连在一起放,现在就是要找到这个临界值,我们发现这个绘制圆圈的过程,只有圆圈的半径在随着时间的递进逐渐变小的,它的最小值是当pointOn开关打开之后,targetValue的值也就是2,所以我们可以判断当pointRadius变成2的时候,将闪光动画关闭,火苗动画打开,我们将这个判断加到绘制圆圈的后面
if(pointOn){
repeat(endXAnimList.size) {
drawCircle(
colorList[colorIndex], pointRadius,
Offset(endXAnimList[it], endYAnimList[it])
)
}
if (pointRadius.toInt() == 2) {
pointOn = false
turnOn = true
}
}
现在动画已经都衔接起来了,我们看下效果吧

额~~感觉怪怪的,说好的闪光呢,但就动画而言圆圈的确是完成了半径逐渐变小的绘制过程,那么问题出在哪里呢?我们回到代码中再检查一遍,发现了这一处代码
Offset(endXAnimList[it], endYAnimList[it])
复制代码
这个圆点绘制的位置是均匀分布在一个圆周上的,也就是只绘制了八个圆点,但是真实效果里面的圆点有很多个,那我们是不是只要将endXAnimList,endYAnimList这两个数组里面的坐标打乱随机组成一个圆点不就好了,这样一来最多会绘制出64个圆点,再配合动画不就能达到闪光的效果了吗,所以我们先写一个随机函数
private fun randomCor(): Int {
return (Math.random() * 8).toInt()
}
然后将原来绘制圆点的坐标的下标改成随机数
if(pointOn){
repeat(endXAnimList.size) {
drawCircle(
colorList[colorIndex], pointRadius,
Offset(endXAnimList[randomCor()], endYAnimList[randomCor()])
)
}
if (pointRadius.toInt() == 2) {
pointOn = false
turnOn = true
}
}
现在我们再来看看效果如何

总结
完整的动画效果已经出来了,整个开发过程还是相对来讲比较吃力的,我想这应该是刚开始接触Compose动画这一部分吧,后面再多开发几个动画应该会得心应手一些,但还是有点收获的,比如
- 循环动画如果中途需要暂停,然后过段时间再打开的话,不能直接对它的initValue跟targetValue设置值,这样是无效的,必须搭配着Animatable动画一起使用才行
- LaunchedEffect虽说是在Compose里面是提供给协程运行的函数,不看源码的话以为它里面只能做一件事情,其他事情会被堵塞,其实LaunchedEffect已经封装好了,它的block就是一个协程,所以无论在LaunchedEffect做几件事情,它们都只是运行在一个协程里面
也有一些遗憾与不足
- 动画衔接的地方都是判断一个值有没有到达一个具体值,然后用开关去控制,感觉应该有更好的方式,比如可以配合着delayMillis,让动画延迟一会再开始
- 烟花本身其实可以用曲线来代替直线,比如贝塞尔,这个是在开发过程中才想到的,我先去试试看,等龙年再画个更好的烟花~~