if (brushBitmap == null) { brushBitmap = Bitmap.createBitmap(width, height, Bitmap.Config.ARGB_8888); brushCanvas = new Canvas(brushBitmap);
}
for (int i = 0; i < drawers.size(); i++) {
int saveCount = brushCanvas.save();
drawers.get(i).draw(brushCanvas, width, height, mCommonPaint);
brushCanvas.restoreToCount(saveCount);
}
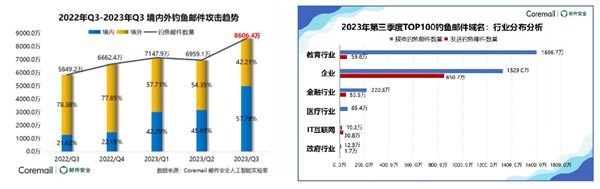
生成网格数据
float blockWidth = (squareWidth + padding);
int w = width;
int h = height;
int columNum = (int) Math.ceil(w / blockWidth);
int rowNum = (int) Math.ceil(h / blockWidth);
if (gridRects.isEmpty() && squareWidth > 1f) {
//通过rowNum * columNum方式降低时间复杂度
for (int i = 0; i < rowNum * columNum; i++) {
int alpha = 0;
int red = 0;
int green = 0;
int blue = 0;
int num = 0;
for (int c : sampleColors) {
if (c == Color.TRANSPARENT) {
//剔除全透明的颜色,必须剔除
continue;
}
int alphaC = Color.alpha(c);
if (alphaC <= 0) {
//剔除alpha为0的颜色,当然可以改大一点,防止降低清晰度
continue; }
alpha += alphaC;
red += Color.red(c);
green += Color.green(c);
blue += Color.blue(c);
num++;
}
if (num < 1) {
continue;
}
//求出平均值
int rectColor = Color.argb(alpha / num, red / num, green / num, blue / num);
if (rectColor != Color.TRANSPARENT) {
mGridPaint.setColor(rectColor);
// canvas.drawRect(rect, mGridPaint); //绘制矩形
canvas.drawCircle(rect.centerX(), rect.centerY(), squareWidth / 2, mGridPaint); //绘制圆
}
}
int width = getWidth();
int height = getHeight();
if (width <= padding || height <= padding) {
return;
}
if (brushBitmap == null) { brushBitmap = Bitmap.createBitmap(width, height, Bitmap.Config.ARGB_8888); brushCanvas = new Canvas(brushBitmap);
}
for (int i = 0; i < drawers.size(); i++) {
int saveCount = brushCanvas.save();
drawers.get(i).draw(brushCanvas, width, height, mCommonPaint);
brushCanvas.restoreToCount(saveCount);
}
float blockWidth = (squareWidth + padding);
int w = width;
int h = height;
int columNum = (int) Math.ceil(w / blockWidth);
int rowNum = (int) Math.ceil(h / blockWidth);
if (gridRects.isEmpty() && squareWidth > 1f) {
//通过rowNum * columNum方式降低时间复杂度
for (int i = 0; i < rowNum * columNum; i++) {
int alpha = 0;
int red = 0;
int green = 0;
int blue = 0;
int num = 0;
for (int c : sampleColors) {
if (c == Color.TRANSPARENT) {
//剔除全透明的颜色,必须剔除
continue;
}
int alphaC = Color.alpha(c);
if (alphaC <= 0) {
//剔除alpha为0的颜色,当然可以改大一点,防止降低清晰度
continue;
}
alpha += alphaC;
red += Color.red(c);
green += Color.green(c);
blue += Color.blue(c);
num++;
}
if (num < 1) {
continue;
}
//求出平均值
int rectColor = Color.argb(alpha / num, red / num, green / num, blue / num);
if (rectColor != Color.TRANSPARENT) {
mGridPaint.setColor(rectColor);
// canvas.drawRect(rect, mGridPaint); //绘制矩形
canvas.drawCircle(rect.centerX(), rect.centerY(), squareWidth / 2, mGridPaint); //绘制圆
}
}
mGridPaint.setColor(color);
// 初始化
final ValueNotifier<String> fristName = ValueNotifier('Tom');
final ValueNotifier<String> secondName = ValueNotifier('Joy');
late final ValueNotifier<String> fullName;
使用 Get 的响应式编程就像使用 setState 一样简单。
让我们想象一下,您有一个名称变量,并且希望每次更改它时,所有使用它的小组件都会自动刷新。
1、监听以及更新UI
//这是一个普通的字符串
var name = 'Jonatas Borges';
为了使观察变得更加可观察,你只需要在它的附加上添加“.obs”。
var name = 'Jonatas Borges'.obs;
而在UI中,当你想显示该值并在值变化时更新页面时,只需这样做。
Obx(() => Text("${controller.name}"));
③ 对返回值进行按位取反(所有正整数的按位取反是其本身+1的负数,所有负整数的按位取反是其本身+1的绝对值,零的按位取反是 -1。其中,按位取反也会对返回值进行强制转换,将字符串5转化为数字5,然后再按位取反。
false被转化为0,true会被转化为1。
其他非数字或不能转化为数字类型的返回值,统一当做0处理)
const visibleIndex = newSet(); //全局创建一个不重复的集合 let ob = newIntersectionObserver((entries) => { for (const e of entries) { const index = e.target.dataset.index; //isIntersecting为true就代表在视口内 if (e.isIntersecting) {
visibleIndex.add(index);
} else {
visibleIndex.delete(index);
}
} debounceLoadPage();// 防抖后的loadpage
});
3.获取集合的最大及最小的索引
functiongetRange() { if (visibleIndex.size === 0) return [0, 0]; const max = Math.max(...visibleIndex); const min = Math.min(...visibleIndex); return [min, max];
}
4.加载视口内的元素的资源
functionloadPage() { // 得到当前能看到的元素索引范围 const [minIndex, maxIndex] = getRange(); const pages = newSet(); // 不重复的页码集合 for (let i = minIndex; i <= maxIndex; i++) {
pages.add(getPage(i, SIZE));// 遍历将侦查器集合范围内的所在页面都加入到pages的集合内
} // 遍历页码集合 for (const page of pages) { const [minIndex, maxIndex] = getIndexRange(page, SIZE);//获取页码的索引范围 if (contain.children[minIndex].dataset.loaded) { //如果页码最小索引的元素有自定义属性就跳过,代表加载过 continue;
}
contain.children[minIndex].dataset.loaded = true;//如果没有就代表没有加载过,添加上自定义属性 //将当前页码传给获取资源的函数 getVideo(page, SIZE).then((res) => { //拿到当前页面需要的数据数组,遍历渲染到页面上 for (let i = minIndex; i < maxIndex; i++) { const item = contain.children[i];
item.innerHTML = `<img src="${res[i - minIndex].cover}" alt="">`;
}
});
}
}
<body> <divclass="contain"></div> <divclass="btn"> <buttonclass="full-rounded"> <span>刚刚看过</span> <divclass="border full-rounded"></div> </button> </div> <scriptsrc="./api.js"></script> <scriptsrc="./index.js"></script> <script> constSIZE = 15; let contain = document.querySelector(".contain"); let btn = document.querySelector(".btn"); // 页码 let i = 1;
const visibleIndex = newSet();
// 视口观察器 let ob = newIntersectionObserver((entries) => { for (const e of entries) { const index = e.target.dataset.index; if (e.isIntersecting) { // 将在视口内的元素添加到集合内
visibleIndex.add(index);
} else { // 将不在视口内的元素从集合内删除
visibleIndex.delete(index);
}
} debounceLoadPage();
});
functiongetRange() { if (visibleIndex.size === 0) return [0, 0]; const max = Math.max(...visibleIndex); const min = Math.min(...visibleIndex); return [min, max];
}
第一次先点击快照记录初始的内存情况,然后我们多次点击按钮后再次点击快照,记录此时的内存情况,发现从原来的1.1M内存空间变成了1.4M内存空间,然后我们选中第二条快照记录,可以看到右上角有个All objects的字段,其表示展示的是当前选中的快照记录所有对象的分配情况,而我们想要知道的是第二条快照与第一条快照的区别在哪,所以选择Object allocated between Snapshot1 and Snapshot2即展示第一条快照和第二条快照存在差异的内存对象分配情况,此时可以看到Array的百分比很高,初步可以判断是该变量存在问题,点击查看详情后就能查看到该变量对应的具体数据了
mSolidPaint = new Paint();
mSolidPaint.setFlags(Paint.ANTI_ALIAS_FLAG); mPorterDuffXfermode = new PorterDuffXfermode(PorterDuff.Mode.SRC_IN); point = new PointF(0, 0); mTargetZone = 1;
let left = startPos.current.left; let top = startPos.current.top; const width = Math.abs(e.clientX - startPos.current.left); const height = Math.abs(e.clientY - startPos.current.top);
// 当后面位置小于前面位置的时候,需要把框的坐标设置为后面的位置 if (e.clientX < startPos.current.left) {
left = e.clientX;
}
if (e.clientY < startPos.current.top) {
top = e.clientY;
}



















































































































































































![Screenshot_2023-12-06-15-03-55-64[1].png](https://www.imgeek.net/uploads/article/20231207/d7aa5786c3a4d6d3ffb9a1d1aba01066.jpg)