








30个Python操作小技巧
1、列表推导
列表的元素可以在一行中进行方便的循环。
numbers = [1, 2, 3, 4, 5, 6, 7, 8]
even_numbers = [number for number in numbers if number % 2 == 0]
print(even_numbers)输出:
[1,3,5,7]同时,也可以用在字典上。
dictionary = {'first_num': 1, 'second_num': 2,
'third_num': 3, 'fourth_num': 4}
oddvalues = {key: value for (key, value) in dictionary.items() if value % 2 != 0}
print(oddvalues)Output: {'first_num': 1, 'third_num': 3}2、枚举函数
枚举是一个有用的函数,用于迭代对象,如列表、字典或文件。该函数生成一个元组,其中包括通过对象迭代获得的值以及循环计数器(从0的起始位置)。当您希望根据索引编写代码时,循环计数器很方便。
sentence = 'Just do It'
length = len(sentence)
for index, element in enumerate(sentence):
print('{}: {}'.format(index, element))
if index == 0:
print('The first element!')
elif index == length - 1:
print('The last element!')3、通过函数返回多个值
在设计函数时,我们经常希望返回多个值。这里我们将介绍两种典型的方法:
方法一
最简单的方式就是返回一个tuple。
get_student 函数,它根据员工的ID号以元组形式返回员工的名字和姓氏。
# returning a tuple.
def get_student(id_num):
if id_num == 0:
return 'Taha', 'Nate'
elif id_num == 1:
return 'Jakub', 'Abdal'
else:
raise Exception('No Student with this id: {}'.format(id_num))
Student = get_student(0)
print('first_name: {}, last_name: {}'.format(Student[0], Student[1]))方法二、
返回一个字典类型。因为字典是键、值对,我们可以命名返回的值,这比元组更直观。
# returning a dictionary
def get_data(id_num):
if id_num == 0:
return {'first_name': 'Muhammad', 'last_name': 'Taha', 'title': 'Data Scientist', 'department': 'A', 'date_joined': '20200807'}
elif id_num == 1:
return {'first_name': 'Ryan', 'last_name': 'Gosling', 'title': 'Data Engineer', 'department': 'B', 'date_joined': '20200809'}
else:
raise Exception('No employee with this id: {}'.format(id_num))
employee = get_data(0)
print('first_name: {},nlast_name: {},ntitle: {},ndepartment: {},ndate_joined: {}'.format(
employee['first_name'], employee['last_name'], employee['title'], employee['department'], employee['date_joined']))4、像数学一样比较多个数字
如果你有一个值,并希望将其与其他两个值进行比较,则可以使用以下基本数学表达式:1<x<30。
你也许经常使用的是这种
1<x and x<30在python中,你可以这么使用
x = 5
print(1<x<30)5、将字符串转换为字符串列表:
当你输入 "[[1, 2, 3],[4, 5, 6]]" 时,你想转换为列表,你可以这么做。
import ast
def string_to_list(string):
return ast.literal_eval(string)
string = "[[1, 2, 3],[4, 5, 6]]"
my_list = string_to_list(string)
print(my_list)6、对于Else方法
Python 中 esle 特殊的用法。
number_List = [1, 3, 8, 9,1]
for number in number_List:
if number % 2 == 0:
print(number)
break
else:
print("No even numbers!!")7、在列表中查找n个最大或n个最小的元素
使用 heapq 模块在列表中查找n个最大或n个最小的元素。
import heapq
numbers = [80, 25, 68, 77, 95, 88, 30, 55, 40, 50]
print(heapq.nlargest(5, numbers))
print(heapq.nsmallest(5, numbers))8、在不循环的情况下重复整个字符串
value = "Taha"
print(value * 5)
print("-" * 21)9、从列表中查找元素的索引
cities= ['Vienna', 'Amsterdam', 'Paris', 'Berlin']
print(cities.index('Berlin'))10、在同一行中打印多个元素?
print("Analytics", end="")
print("Vidhya")
print("Analytics", end=" ")
print("Vidhya")
print('Data', 'science', 'blogathon', '12', sep=', ')输出
AnalyticsVidhya
Analytics Vidhya
Data, science, blogathon, 12
11、把大数字分开以便于阅读
有时,当你试图打印一个大数字时,传递整数真的很混乱,而且很难阅读。然后可以使用下划线,使其易于阅读。
print(5_000_000_000_000)
print(7_543_291_635)输出:
5000000000000
7543291635
12、反转列表的切片
切片列表时,需要传递最小、最大和步长。要以相反的顺序进行切片,只需传递负步长。让我们来看一个例子:
sentence = "Data science blogathon"
print(sentence[21:0:-1])
输出
nohtagolb ecneics ata
13、 “is” 和 “==” 的区别。
如果要检查两个变量是否指向同一个对象,则需要使用“is”
但是,如果要检查两个变量是否相同,则需要使用“==”。
list1 = [7, 9, 4]
list2 = [7, 9, 4]
print(list1 == list2)
print(list1 is list2)
list3 = list1
print(list3 is list1)输出
True
False
True14、在一行代码中合并两个词典。
first_dct = {"London": 1, "Paris": 2}
second_dct = {"Tokyo": 3, "Seol": 4}
merged = {**first_dct, **second_dct}
print(merged)输出
{‘London’: 1, ‘Paris’: 2, ‘Tokyo’: 3, ‘Seol’: 4}15、识别字符串是否以特定字母开头
sentence = "Analytics Vidhya"
print(sentence.startswith("b"))
print(sentence.startswith("A"))16、获得字符的Unicode
print(ord("T"))
print(ord("A"))
print(ord("h"))
print(ord("a"))17、获取字典的键值对
cities = {'London': 1, 'Paris': 2, 'Tokyo': 3, 'Seol': 4}
for key, value in cities.items():
print(f"Key: {key} and Value: {value}")18、在列表的特定位置添加值
cities = ["London", "Vienna", "Rome"]
cities.append("Seoul")
print("After append:", cities)
cities.insert(0, "Berlin")
print("After insert:", cities)输出:
[‘London’, ‘Vienna’, ‘Rome’, ‘Seoul’] After insert: [‘Berlin’, ‘London’, ‘Vienna’, ‘Rome’, ‘Seoul’]19、Filter() 函数
它通过在其中传递的特定函数过滤特定迭代器,并且返回一个迭代器。
mixed_number = [8, 15, 25, 30,34,67,90,5,12]
filtered_value = filter(lambda x: x > 20, mixed_number)
print(f"Before filter: {mixed_number}")
print(f"After filter: {list(filtered_value)}")输出:
Before filter: [8, 15, 25, 30, 34, 67, 90, 5, 12]
After filter: [25, 30, 34, 67, 90]20、创建一个没有参数个数限制的函数
def multiplication(*arguments):
mul = 1
for i in arguments:
mul = mul * i
return mul
print(multiplication(3, 4, 5))
print(multiplication(5, 8, 10, 3))
print(multiplication(8, 6, 15, 20, 5))输出:
60
1200
7200021、一次迭代两个或多个列表
capital = ['Vienna', 'Paris', 'Seoul',"Rome"]
countries = ['Austria', 'France', 'South Korea',"Italy"]
for cap, country in zip(capital, countries):
print(f"{cap} is the capital of {country}")22、检查对象使用的内存大小
import sys
mul = 5*6
print(sys.getsizeof(mul))23、 Map() 函数
map() 函数用于将特定函数应用于给定迭代器。
values_list = [8, 10, 6, 50]
quotient = map(lambda x: x/2, values_list)
print(f"Before division: {values_list}")
print(f"After division: {list(quotient)}")24、计算 item 在列表中出现的次数
可以在 list 上调用 count 函数。
cities= ["Amsterdam", "Berlin", "New York", "Seoul", "Tokyo", "Paris", "Paris","Vienna","Paris"]
print("Paris appears", cities.count("Paris"), "times in the list")25、在元组或列表中查找元素的索引
cities_tuple = ("Berlin", "Paris", 5, "Vienna", 10)
print(cities_tuple.index("Paris"))
cities_list = ['Vienna', 'Paris', 'Seoul',"Amsterdam"]
print(cities_list.index("Amsterdam"))26、2个 set 进行 join 操作
set1 = {'Vienna', 'Paris', 'Seoul'}
set2 = {"Tokyo", "Rome",'Amsterdam'}
print(set1.union(set2))27、根据频率对列表的值进行排序
from collections import Counter
count = Counter([7, 6, 5, 6, 8, 6, 6, 6])
print(count)
print("Sort values according their frequency:", count.most_common())输出:
Counter({6: 5, 7: 1, 5: 1, 8: 1})
Sort values according their frequency: [(6, 5), (7, 1), (5, 1), (8, 1)]28、从列表中删除重复值
cities_list = ['Vienna', 'Paris', 'Seoul',"Amsterdam","Paris","Amsterdam","Paris"]
cities_list = set(cities_list)
print("After removing the duplicate values from the list:",list(cities_list))29、找出两个列表之间的差异
cities_list1 = ['Vienna', 'Paris', 'Seoul',"Amsterdam", "Berlin", "London"]
cities_list2 = ['Vienna', 'Paris', 'Seoul',"Amsterdam"]
cities_set1 = set(cities_list1)
cities_set2 = set(cities_list2)
difference = list(cities_set1.symmetric_difference(cities_set2))
print(difference)30、将两个不同的列表转换为一个字典
number = [1, 2, 3]
cities = ['Vienna', 'Paris', 'Seoul']
result = dict(zip(number, cities))
print(result)作者:程序员学长
来源:juejin.cn/post/7126728825274105886
Python办公软件自动化,5分钟掌握openpyxl操作
今天给大家分享一篇用openpyxl操作Excel的文章。
各种数据需要导入Excel?多个Excel要合并?目前,Python处理Excel文件有很多库,openpyxl算是其中功能和性能做的比较好的一个。接下来我将为大家介绍各种Excel操作。
打开Excel文件
新建一个Excel文件

打开现有Excel文件

打开大文件时,根据需求使用只读或只写模式减少内存消耗。

获取、创建工作表
获取当前活动工作表:

创建新的工作表:
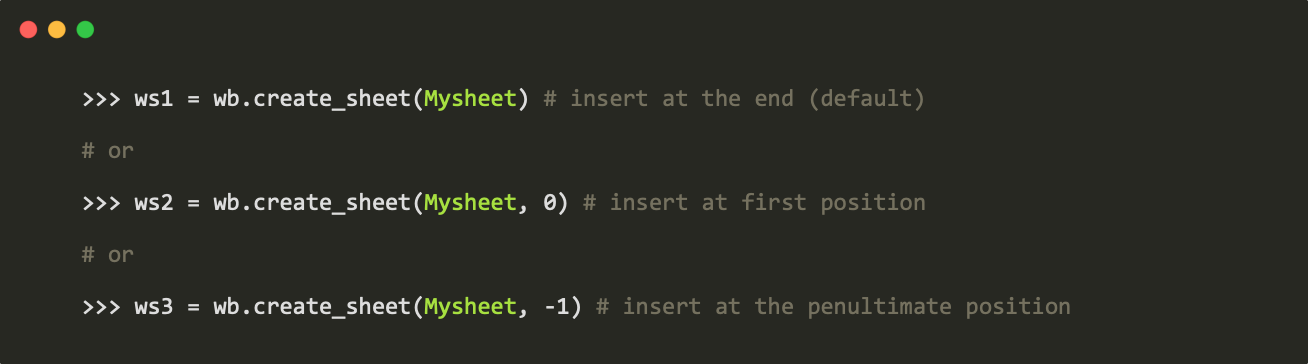
使用工作表名字获取工作表:

获取所有的工作表名称:

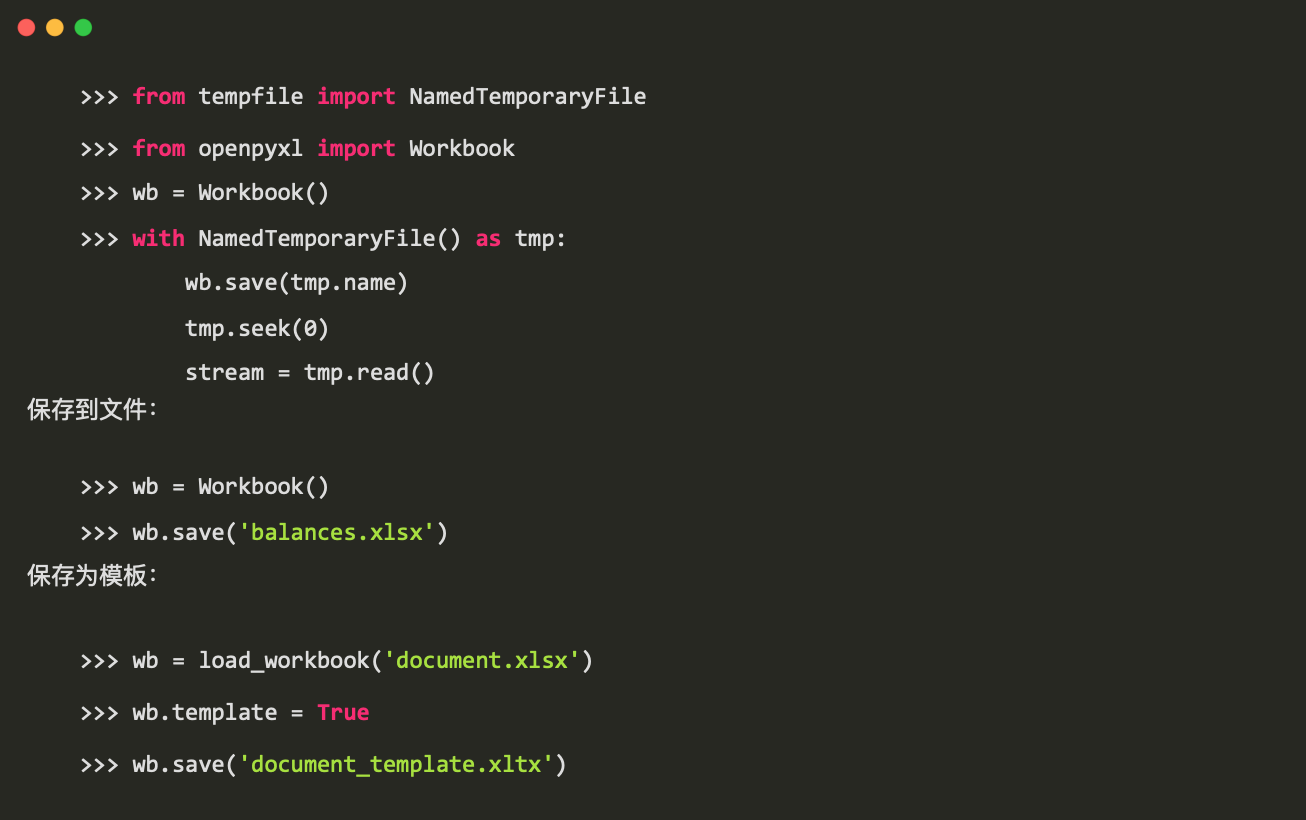
保存
保存到流中在网络中使用:





Worksheet.iter_rows()方法遍历行:
Worksheet.iter_cols()方法将遍历列: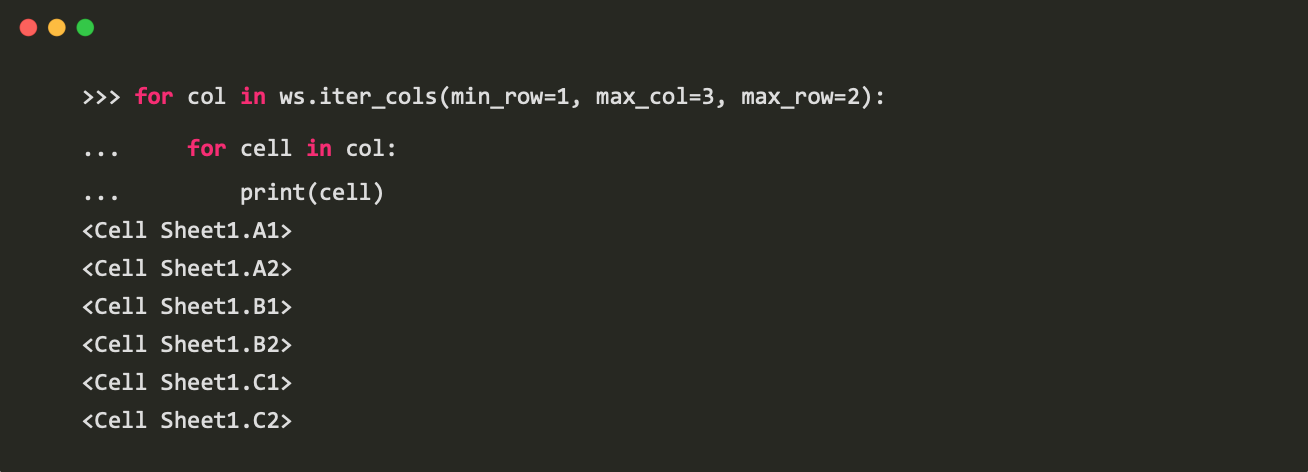
Worksheet.rows属性:
Worksheet.columns属性: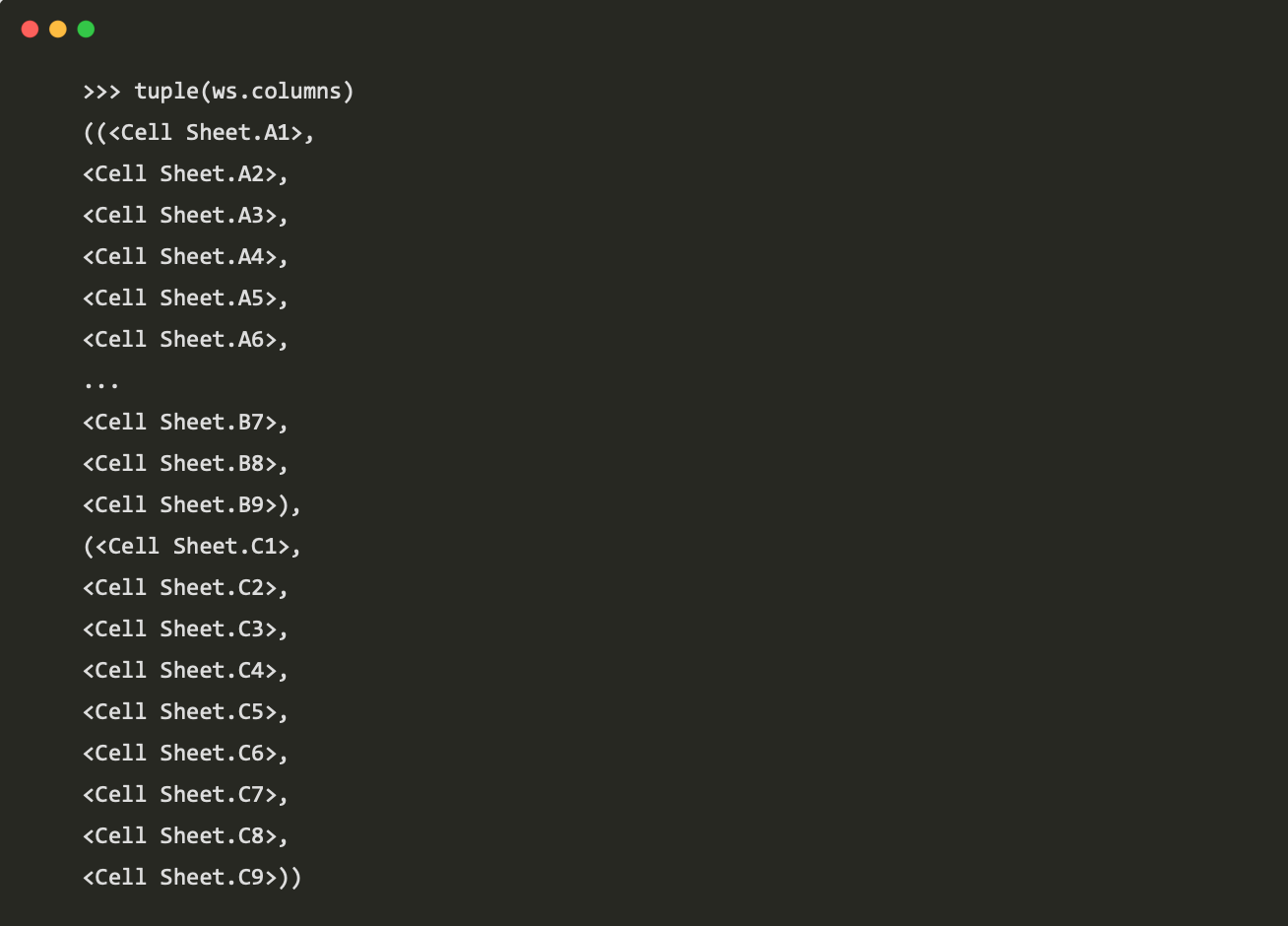
Worksheet.append()或者迭代使用Worksheet.cell()新增一行数据: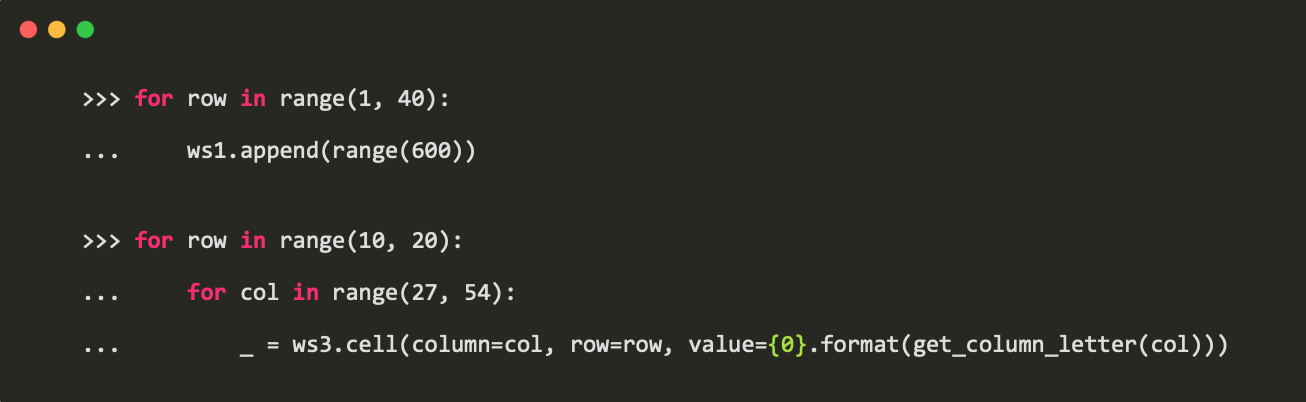
Worksheet.insert_rows()插入一行或几行: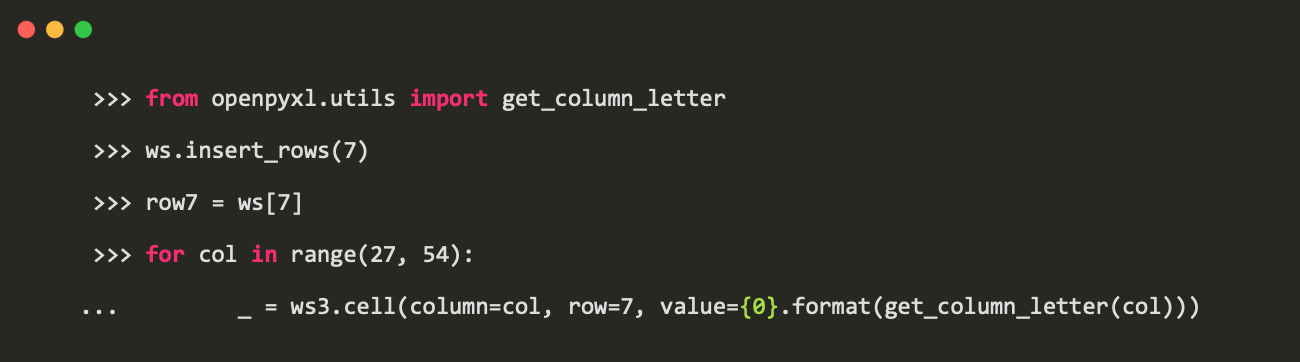
Worksheet.insert_cols()操作类似。Worksheet.delete_rows()和Worksheet.delete_cols()用来批量删除行和列。Worksheet.values属性遍历工作表中的所有行,但只返回单元格值:
Worksheet.iter_rows()和Worksheet.iter_cols()可以设置values_only参数来仅返回单元格的值:
Py大蟒蛇搞机器人
itchat使用教程
itchat是一个开源的微信个人号接口,使用python调用微信从未如此简单。使用不到三十行的代码,你就可以完成一个能够处理所有信息的微信机器人。
首先,在终端安装一下itchat:
#pip是pyth的包管理工具也就是pyth的应用商店专门用来安装和卸载库
pip install itchat
1.登录
login() - 每次运行程序都需要扫二维码
login(hotReload==True) - 下次登录不用再扫二维码
auto_login(loginCallback=登录成功回调函数, exitCallback=退出登录回调函数)
2.退出登录
logout() - 强制退出登录
3.获取好友信息
get_friends(update=True) - 获取所有的好友信息
get_chatrooms() - 获取群组
get_mps() - 获取公众号
get_msg() - 获取消息列表
get_head_img() - 获取个人头像
4.发送消息
send(msg=消息内容, toUserName=用户名)
1).msg的值会因为消息类型不同而不同:
文本消息 - 引号中直接写要发送的文字内容
发送文件 - @fil@文件路径
发送图片 - @img@图片路径
发送视频 - @vid@视频路径
2).toUserName: 发送对象,如果不填就发送给自己
5.接收消息
想要自动接收消息,需要先对不同类型的消息进行注册,如果没有注册,对应类型的消息将不会被接收.
注册的方式如下:
@itchat.msg_register(消息类型,isFriendChat=True, isGroupChat=True,isMpChat=True)
def 函数名(msg):
#接收到对应的消息会自动执行的代码段
#msg.download(msg['FileName']) #这个同样是下载文件的方式
#msg['Text'](msg['FileName']) #下载文件
1)消息类型:
| 参数 | 类型 | Text键值 |
|---|---|---|
| TEXT | 文本 | 文本内容(文字消息) |
| CARD | 名片 | 推荐人字典(推荐人的名片) |
| SHARING | 分享 | 分享名称(分享的音乐或者文章等) |
| RECORDING | 语音 | 下载方法 |
| ATTACHMENT | 附件 | 下载方法 |
| VIDEO | 小视频 | 下载方法 |
| FRIENDS | 好友邀请 | 添加好友所需参数 |
| SYSTEM | 系统消息 | 更新内容的用户或群聊的UserName组成的列表 |
| MAP | 地图 | 位置文本(位置分享) |
| NOTE | 通知 | 通知文本(消息撤回等) |
| PICTURE | 图片/表情 | 下载方法 |
来源:blog.csdn.net/weixin_46014553/article/details/110200748
收起阅读 »Python-可变和不可变类型
1. 不可变类型
不可变类型,内存中的数据不允许被修改(一旦被定义,内存中分配了小格子,就不能再修改内容了):
数字类型
int,bool,float,complex,long(2,x)字符串
str元组
tuple
2. 可变类型
可变类型,内存中的数据可以被修改(可以通过变量名调用方法来修改列表和字典内部的内容,而内存地址不发生变化):
列表
list字典
dict(注:字典中的key只能使用不可变类型的数据)
注:给变量赋新值的时候,只是改变了变量的引用地址,不是修改之前的内容
可变类型的数据变化,是通过方法来实现的
如果给一个可变类型的变量,复制了一个新的数据,引用会修改(变量从之前的数据上撕下来,贴到新赋值的数据上)
3. 代码演示
# 新建列表
a = [1, 2, 3]
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 追加元素
a.append(999)
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 移除元素
a.remove(2)
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 清空列表
a.clear()
print("列表a:", a)
print("列表a的地址:", id(a))
print("*"*50)
# 将空列表赋值给变量a
a = []
print("列表a的地址:", id(a)) # 通过输出可以看出地址发生了变化
print("*"*50)
# 新建字典
d = {"name": "xiaoming"}
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 追加键值对
d["age"] = 18
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 删除键值对
d.pop("age")
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 清空所有键值对
d.clear()
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)
# 对d赋值空字典
d = {}
print("字典d为:", d)
print("字典d的地址:", id(d))
print("*"*50)4. 运行结果
可变类型(列表和字典)的数据变化,是通过方法(比如append,remove,pop等)来实现的,不会改变地址。而重新赋值后地址会改变。具体运行结果如下图所示:
作者:ZacheryZHANG
来源:juejin.cn/post/7100423532655411213
Python 中的万能之王 Lambda 函数
Python 提供了非常多的库和内置函数。有不同的方法可以执行相同的任务,而在 Python 中,有个万能之王函数:lambda 函数,它可以以不同的方式在任何地方使用。今天将和大家一起研究下这个万能之王!
Lambda 函数简介
Lambda函数也被称为匿名(没有名称)函数,它直接接受参数的数量以及使用该参数执行的条件或操作,该参数以冒号分隔,并返回最终结果。为了在大型代码库上编写代码时执行一项小任务,或者在函数中执行一项小任务,便在正常过程中使用lambda函数。
lambda argument_list:expersion
argument_list是参数列表,它的结构与Python中函数(function)的参数列表是一样的
a,b
a=1,b=2
*args
**kwargs
a,b=1,*args
空
....
expression是一个关于参数的表达式,表达式中出现的参数需要在argument_list中有定义,并且表达式只能是单行的。
1
None
a+b
sum(a)
1 if a >10 else 0
[i for i in range(10)]
...
普通函数和Lambda函数的区别
没有名称
Lambda函数没有名称,而普通操作有一个合适的名称。Lambda函数没有返回值
使用def关键字构建的普通函数返回值或序列数据类型,但在Lambda函数中返回一个完整的过程。假设我们想要检查数字是偶数还是奇数,使用lambda函数语法类似于下面的代码片段。b = lambda x: "Even" if x%2==0 else "Odd" b(9)
函数只在一行中
Lambda函数只在一行中编写和创建,而在普通函数的中使用缩进不用于代码重用
Lambda函数不能用于代码重用,或者不能在任何其他文件中导入这个函数。相反,普通函数用于代码重用,可以在外部文件中使用。
为什么要使用Lambda函数?
一般情况下,我们不使用Lambda函数,而是将其与高阶函数一起使用。高阶函数是一种需要多个函数来完成任务的函数,或者当一个函数返回任何另一个函数时,可以选择使用Lambda函数。
什么是高阶函数?
通过一个例子来理解高阶函数。假设有一个整数列表,必须返回三个输出。
一个列表中所有偶数的和
一个列表中所有奇数的和
一个所有能被三整除的数的和
首先假设用普通函数来处理这个问题。在这种情况下,将声明三个不同的变量来存储各个任务,并使用一个for循环处理并返回结果三个变量。该方法常规可正常运行。
现在使用Lambda函数来解决这个问题,那么可以用三个不同的Lambda函数来检查一个待检验数是否是偶数,奇数,还是能被三整除,然后在结果中加上一个数。
def return_sum(func, lst):
result = 0
for i in lst:
#if val satisfies func
if func(i):
result = result + i
return result
lst = [11,14,21,56,78,45,29,28]
x = lambda a: a%2 == 0
y = lambda a: a%2 != 0
z = lambda a: a%3 == 0
print(return_sum(x, lst))
print(return_sum(y, lst))
print(return_sum(z, lst))
这里创建了一个高阶函数,其中将Lambda函数作为一个部分传递给普通函数。其实这种类型的代码在互联网上随处可见。然而很多人在使用Python时都会忽略这个函数,或者只是偶尔使用它,但其实这些函数真的非常方便,同时也可以节省更多的代码行。接下来我们一起看看这些高阶函数。
Python内置高阶函数
Map函数
map() 会根据提供的函数对指定序列做映射。
Map函数是一个接受两个参数的函数。第一个参数 function 以参数序列中的每一个元素调用 function 函数,第二个是任何可迭代的序列数据类型。返回包含每次 function 函数返回值的新列表。
map(function, iterable, ...)
Map函数将定义在迭代器对象中的某种类型的操作。假设我们要将数组元素进行平方运算,即将一个数组的每个元素的平方映射到另一个产生所需结果的数组。
arr = [2,4,6,8]
arr = list(map(lambda x: x*x, arr))
print(arr)
我们可以以不同的方式使用Map函数。假设有一个包含名称、地址等详细信息的字典列表,目标是生成一个包含所有名称的新列表。
students = [
{"name": "John Doe",
"father name": "Robert Doe",
"Address": "123 Hall street"
},
{
"name": "Rahul Garg",
"father name": "Kamal Garg",
"Address": "3-Upper-Street corner"
},
{
"name": "Angela Steven",
"father name": "Jabob steven",
"Address": "Unknown"
}
]
print(list(map(lambda student: student['name'], students)))
>>> ['John Doe', 'Rahul Garg', 'Angela Steven']
上述操作通常出现在从数据库或网络抓取获取数据等场景中。
Filter函数
Filter函数根据给定的特定条件过滤掉数据。即在函数中设定过滤条件,迭代元素,保留返回值为True 的元素。Map 函数对每个元素进行操作,而 filter 函数仅输出满足特定要求的元素。
假设有一个水果名称列表,任务是只输出那些名称中包含字符“g”的名称。
fruits = ['mango', 'apple', 'orange', 'cherry', 'grapes']
print(list(filter(lambda fruit: 'g' in fruit, fruits)))
filter(function or None, iterable) --> filter object
返回一个迭代器,为那些函数或项为真的可迭代项。如果函数为None,则返回为真的项。
Reduce函数
这个函数比较特别,不是 Python 的内置函数,需要通过from functools import reduce 导入。Reduce 从序列数据结构返回单个输出值,它通过应用一个给定的函数来减少元素。
reduce(function, sequence[, initial]) -> value将包含两个参数的函数(function)累计应用于序列(sequence)的项,从左到右,从而将序列reduce至单个值。
如果存在initial,则将其放在项目之前的序列,并作为默认值时序列是空的。
假设有一个整数列表,并求得所有元素的总和。且使用reduce函数而不是使用for循环来处理此问题。
from functools import reduce
lst = [2,4,6,8,10]
print(reduce(lambda x, y: x+y, lst))
>>> 30
还可以使用 reduce 函数而不是for循环从列表中找到最大或最小的元素。
lst = [2,4,6,8]
# 找到最大元素
print(reduce(lambda x, y: x if x>y else y, lst))
# 找到最小元素
print(reduce(lambda x, y: x if x<y else y, lst))
高阶函数的替代方法
列表推导式
其实列表推导式只是一个for循环,用于添加新列表中的每一项,以从现有索引或一组元素创建一个新列表。之前使用map、filter和reduce完成的工作也可以使用列表推导式完成。然而,相比于使用Map和filter函数,很多人更喜欢使用列表推导式,也许是因为它更容易应用和记忆。
同样使用列表推导式将数组中每个元素进行平方运算,水果的例子也可以使用列表推导式来解决。
arr = [2,4,6,8]
arr = [i**2 for i in arr]
print(arr)
fruit_result = [fruit for fruit in fruits if 'g' in fruit]
print(fruit_result)
字典推导式
与列表推导式一样,使用字典推导式从现有的字典创建一个新字典。还可以从列表创建字典。
假设有一个整数列表,需要创建一个字典,其中键是列表中的每个元素,值是列表中的每个元素的平方。
lst = [2,4,6,8]
D1 = {item:item**2 for item in lst}
print(D1)
>>> {2: 4, 4: 16, 6: 36, 8: 64}
# 创建一个只包含奇数元素的字典
arr = [1,2,3,4,5,6,7,8]
D2 = {item: item**2 for item in arr if item %2 != 0}
print(D2)
>>> {1: 1, 3: 9, 5: 25, 7: 49}
一个简单应用
如何快速找到多个字典的公共键
方法一
dl = [d1, d2, d3] # d1, d2, d3为字典,目标找到所有字典的公共键
[k for k in dl[0] if all(map(lambda d: k in d, dl[1:]))]
例
dl = [{1:'life', 2: 'is'},
{1:'short', 3: 'i'},
{1: 'use', 4: 'python'}]
[k for k in dl[0] if all(map(lambda d: k in d, dl[1:]))]
# 1解析
# 列表表达式遍历dl中第一个字典中的键
[k for k in dl[0]]
# [1, 2]
# lambda 匿名函数判断字典中的键,即k值是否在其余字典中
list(map(lambda d: 1 in d, dl[1:]))
# [True, True]
list(map(lambda d: 2 in d, dl[1:]))
#[False, False]
# 列表表达式条件为上述结果([True, True])全为True,则输出对应的k值
#1
方法二
# 利用集合(set)的交集操作
from functools import reduce
# reduce(lambda a, b: a*b, range(1,11)) # 10!
reduce(lambda a, b: a & b, map(dict.keys, dl))
写在最后
目前已经学习了Lambda函数是什么,以及Lambda函数的一些使用方法。随后又一起学习了Python中的高阶函数,以及如何在高阶函数中使用lambda函数。除此之外,还学习了高阶函数的替代方法:在列表推导式和字典推导式中执行之前操作。虽然这些方法看似简单,或者说你之前已经见到过这类方法,但你很可能很少使用它们。你可以尝试在其他更加复杂的函数中使用它们,以便使代码更加简洁。
作者:编程学习网
来源:https://juejin.cn/post/7084062324981497870
爬了下知乎神回复,笑死人了~
世界真是不公平呀!
一次被骗9万是很少见的体验
除了大学宿舍,哪怕树洞你再找个给我看看啊。
胃不好,饼太大,吃不下。
腰不好,锅太沉,背不动。
我们物理了
我们生物了
难道要我直接回答你才能明白?
只是她比较善良
善解人疑
善解人意
善解人衣
还嫌别人长得丑。
作者丨shenzhongqiang
来源丨Python与数据分析(ID:PythonML)
写了个自动批改小孩作业的代码(下)
2.4 切割图像
上帝说要有光,就有了光。
于是,当光投过来时,物体的背后就有了影。
我们就知道了,有影的地方就有东西,没影的地方是空白。
这就是投影。
这个简单的道理放在图像切割上也很实用。
我们把文字的像素做个投影,这样我们就知道某个区间有没有文字,并且知道这个区间文字是否集中。
下面是示意图:
2.4.1 投影大法
最有效的方法,往往都是用循环实现的。
要计算投影,就得一个像素一个像素地数,查看有几个像素,然后记录下这一行有N个像素点。如此循环。
首先导入包:
import numpy as np
import cv2
from PIL import Image, ImageDraw, ImageFont
import PIL
import matplotlib.pyplot as plt
import os
import shutil
from numpy.core.records import array
from numpy.core.shape_base import block
import time
比如说要看垂直方向的投影,代码如下:
# 整幅图片的Y轴投影,传入图片数组,图片经过二值化并反色
def img_y_shadow(img_b):
### 计算投影 ###
(h,w)=img_b.shape
# 初始化一个跟图像高一样长度的数组,用于记录每一行的黑点个数
a=[0 for z in range(0,h)]
# 遍历每一列,记录下这一列包含多少有效像素点
for i in range(0,h):
for j in range(0,w):
if img_b[i,j]==255:
a[i]+=1
return a
最终得到是这样的结构:[0, 79, 67, 50, 50, 50, 109, 137, 145, 136, 125, 117, 123, 124, 134, 71, 62, 68, 104, 102, 83, 14, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, ……38, 44, 56, 106, 97, 83, 0, 0, 0, 0, 0, 0, 0]表示第几行总共有多少个像素点,第1行是0,表示是空白的白纸,第2行有79个像素点。
如果我们想要从视觉呈现出来怎么处理呢?那可以把它立起来拉直画出来。
# 展示图片
def img_show_array(a):
plt.imshow(a)
plt.show()
# 展示投影图, 输入参数arr是图片的二维数组,direction是x,y轴
def show_shadow(arr, direction = 'x'):
a_max = max(arr)
if direction == 'x': # x轴方向的投影
a_shadow = np.zeros((a_max, len(arr)), dtype=int)
for i in range(0,len(arr)):
if arr[i] == 0:
continue
for j in range(0, arr[i]):
a_shadow[j][i] = 255
elif direction == 'y': # y轴方向的投影
a_shadow = np.zeros((len(arr),a_max), dtype=int)
for i in range(0,len(arr)):
if arr[i] == 0:
continue
for j in range(0, arr[i]):
a_shadow[i][j] = 255
img_show_array(a_shadow)
我们来试验一下效果:
我们将上面的原图片命名为question.jpg放到代码同级目录。
# 读入图片
img_path = 'question.jpg'
img=cv2.imread(img_path,0)
thresh = 200
# 二值化并且反色
ret,img_b=cv2.threshold(img,thresh,255,cv2.THRESH_BINARY_INV)
二值化并反色后的变化如下所示:
上面的操作很有作用,通过二值化,过滤掉杂色,通过反色将黑白对调,原来白纸区域都是255,现在黑色都是0,更利于计算。
计算投影并展示的代码:
img_y_shadow_a = img_y_shadow(img_b)
show_shadow(img_y_shadow_a, 'y') # 如果要显示投影
下面的图是上面图在Y轴上的投影
从视觉上看,基本上能区分出来哪一行是哪一行。
2.4.2 根据投影找区域
最有效的方法,往往还得用循环来实现。
上面投影那张图,你如何计算哪里到哪里是一行,虽然肉眼可见,但是计算机需要规则和算法。
# 图片获取文字块,传入投影列表,返回标记的数组区域坐标[[左,上,右,下]]
def img2rows(a,w,h):
### 根据投影切分图块 ###
inLine = False # 是否已经开始切分
start = 0 # 某次切分的起始索引
mark_boxs = []
for i in range(0,len(a)):
if inLine == False and a[i] > 10:
inLine = True
start = i
# 记录这次选中的区域[左,上,右,下],上下就是图片,左右是start到当前
elif i-start >5 and a[i] < 10 and inLine:
inLine = False
if i-start > 10:
top = max(start-1, 0)
bottom = min(h, i+1)
box = [0, top, w, bottom]
mark_boxs.append(box)
return mark_boxs
通过投影,计算哪些区域在一定范围内是连续的,如果连续了很长时间,我们就认为是同一区域,如果断开了很长一段时间,我们就认为是另一个区域。
通过这项操作,我们就可以获得Y轴上某一行的上下两个边界点的坐标,再结合图片宽度,其实我们也就知道了一行图片的四个顶点的坐标了mark_boxs存下的是[坐,上,右,下]。
如果调用如下代码:
(img_h,img_w)=img.shape
row_mark_boxs = img2rows(img_y_shadow_a,img_w,img_h)
print(row_mark_boxs)
我们获取到的是所有识别出来每行图片的坐标,格式是这样的:[[0, 26, 596, 52], [0, 76, 596, 103], [0, 130, 596, 155], [0, 178, 596, 207], [0, 233, 596, 259], [0, 282, 596, 311], [0, 335, 596, 363], [0, 390, 596, 415]]
2.4.3 根据区域切图片
最有效的方法,最终也得用循环来实现。这也是计算机体现它强大的地方。
# 裁剪图片,img 图片数组, mark_boxs 区域标记
def cut_img(img, mark_boxs):
img_items = [] # 存放裁剪好的图片
for i in range(0,len(mark_boxs)):
img_org = img.copy()
box = mark_boxs[i]
# 裁剪图片
img_item = img_org[box[1]:box[3], box[0]:box[2]]
img_items.append(img_item)
return img_items
这一步骤是拿着方框,从大图上用小刀划下小图,核心代码是img_org[box[1]:box[3], box[0]:box[2]]图片裁剪,参数是数组的[上:下,左:右],获取的数据还是二维的数组。
如果保存下来:
# 保存图片
def save_imgs(dir_name, imgs):
if os.path.exists(dir_name):
shutil.rmtree(dir_name)
if not os.path.exists(dir_name):
os.makedirs(dir_name)
img_paths = []
for i in range(0,len(imgs)):
file_path = dir_name+'/part_'+str(i)+'.jpg'
cv2.imwrite(file_path,imgs[i])
img_paths.append(file_path)
return img_paths
# 切图并保存
row_imgs = cut_img(img, row_mark_boxs)
imgs = save_imgs('rows', row_imgs) # 如果要保存切图
print(imgs)
图片是下面这样的:
2.4.4 循环可去油腻
还是循环。横着行我们掌握了,那么针对每一行图片,我们竖着切成三块是不是也会了,一个道理。
需要注意的是,横竖是稍微有区别的,下面是上图的x轴投影。
横着的时候,字与字之间本来就是有空隙的,然后块与块也有空隙,这个空隙的度需要掌握好,以便更好地区分出来是字的间距还是算式块的间距。
幸好,有种方法叫膨胀。
膨胀对人来说不积极,但是对于技术来说,不管是膨胀(dilate),还是腐蚀(erode),只要能达到目的,都是好的。
kernel=np.ones((3,3),np.uint8) # 膨胀核大小
row_img_b=cv2.dilate(img_b,kernel,iterations=6) # 图像膨胀6次
膨胀之后再投影,就很好地区分出了块。
根据投影裁剪之后如下图所示:
同理,不膨胀可截取单个字符。
这样,这是一块区域的字符。
一行的,一页的,通过循环,都可以截取出来。
有了图片,就可以识别了。有了位置,就可以判断识别结果的关系了。
下面提供一些代码,这些代码不全,有些函数你可能找不到,但是思路可以参考,详细的代码可以去我的github去看。
def divImg(img_path, save_file = False):
img_o=cv2.imread(img_path,1)
# 读入图片
img=cv2.imread(img_path,0)
(img_h,img_w)=img.shape
thresh = 200
# 二值化整个图,用于分行
ret,img_b=cv2.threshold(img,thresh,255,cv2.THRESH_BINARY_INV)
# 计算投影,并截取整个图片的行
img_y_shadow_a = img_y_shadow(img_b)
row_mark_boxs = img2rows(img_y_shadow_a,img_w,img_h)
# 切行的图片,切的是原图
row_imgs = cut_img(img, row_mark_boxs)
all_mark_boxs = []
all_char_imgs = []
# ===============从行切块======================
for i in range(0,len(row_imgs)):
row_img = row_imgs[i]
(row_img_h,row_img_w)=row_img.shape
# 二值化一行的图,用于切块
ret,row_img_b=cv2.threshold(row_img,thresh,255,cv2.THRESH_BINARY_INV)
kernel=np.ones((3,3),np.uint8)
#图像膨胀6次
row_img_b_d=cv2.dilate(row_img_b,kernel,iterations=6)
img_x_shadow_a = img_x_shadow(row_img_b_d)
block_mark_boxs = row2blocks(img_x_shadow_a, row_img_w, row_img_h)
row_char_boxs = []
row_char_imgs = []
# 切块的图,切的是原图
block_imgs = cut_img(row_img, block_mark_boxs)
if save_file:
b_imgs = save_imgs('cuts/row_'+str(i), block_imgs) # 如果要保存切图
print(b_imgs)
# =============从块切字====================
for j in range(0,len(block_imgs)):
block_img = block_imgs[j]
(block_img_h,block_img_w)=block_img.shape
# 二值化块,因为要切字符图片了
ret,block_img_b=cv2.threshold(block_img,thresh,255,cv2.THRESH_BINARY_INV)
block_img_x_shadow_a = img_x_shadow(block_img_b)
row_top = row_mark_boxs[i][1]
block_left = block_mark_boxs[j][0]
char_mark_boxs,abs_char_mark_boxs = block2chars(block_img_x_shadow_a, block_img_w, block_img_h,row_top,block_left)
row_char_boxs.append(abs_char_mark_boxs)
# 切的是二值化的图
char_imgs = cut_img(block_img_b, char_mark_boxs, True)
row_char_imgs.append(char_imgs)
if save_file:
c_imgs = save_imgs('cuts/row_'+str(i)+'/blocks_'+str(j), char_imgs) # 如果要保存切图
print(c_imgs)
all_mark_boxs.append(row_char_boxs)
all_char_imgs.append(row_char_imgs)
return all_mark_boxs,all_char_imgs,img_o
最后返回的值是3个,all_mark_boxs是标记的字符位置的坐标集合。[左,上,右,下]是指某个字符在一张大图里的坐标,打印一下是这样的:
[[[[19, 26, 34, 53], [36, 26, 53, 53], [54, 26, 65, 53], [66, 26, 82, 53], [84, 26, 101, 53], [102, 26, 120, 53], [120, 26, 139, 53]], [[213, 26, 229, 53], [231, 26, 248, 53], [249, 26, 268, 53], [268, 26, 285, 53]], [[408, 26, 426, 53], [427, 26, 437, 53], [438, 26, 456, 53], [456, 26, 474, 53], [475, 26, 492, 53]]], [[[20, 76, 36, 102], [38, 76, 48, 102], [50, 76, 66, 102], [67, 76, 85, 102], [85, 76, 104, 102]], [[214, 76, 233, 102], [233, 76, 250, 102], [252, 76, 268, 102], [270, 76, 287, 102]], [[411, 76, 426, 102], [428, 76, 445, 102], [446, 76, 457, 102], [458, 76, 474, 102], [476, 76, 493, 102], [495, 76, 511, 102]]]]
它是有结构的。它的结构是:
all_char_imgs这个返回值,里面是上面坐标结构对应位置的图片。img_o就是原图了。
2.5 识别
循环,循环,还是TM循环!
对于识别,2.3 预测数据已经讲过了,那次是对于2张独立图片的识别,现在我们要对整张大图切分后的小图集合进行识别,这就又用到了循环。
翠花,上代码!
all_mark_boxs,all_char_imgs,img_o = divImg(path,save)
model = cnn.create_model()
model.load_weights('checkpoint/char_checkpoint')
class_name = np.load('class_name.npy')
# 遍历行
for i in range(0,len(all_char_imgs)):
row_imgs = all_char_imgs[i]
# 遍历块
for j in range(0,len(row_imgs)):
block_imgs = row_imgs[j]
block_imgs = np.array(block_imgs)
results = cnn.predict(model, block_imgs, class_name)
print('recognize result:',results)
上面代码做的就是以块为单位,传递给神经网络进行预测,然后返回识别结果。
针对这张图,我们来进行裁剪和识别。
看底部的最后一行
recognize result: ['1', '0', '12', '2', '10']
recognize result: ['8', '12', '6', '10']
recognize result: ['1', '0', '12', '7', '10']
结果是索引,不是真实的字符,我们根据字典10: '=', 11: '+', 12: '-', 13: '×', 14: '÷'转换过来之后结果是:
recognize result: ['1', '0', '-', '2', '=']
recognize result: ['8', '-', '6', '=']
recognize result: ['1', '0', '-', '7', '=']
和图片是对应的:
2.6 计算并反馈
循环……
我们获取到了10-2=、8-6=2,也获取到了他们在原图的位置坐标[左,上,右,下],那么怎么把结果反馈到原图上呢?
往往到这里就剩最后一步了。
再来温习一遍需求:作对了,能打对号;做错了,能打叉号;没做的,能补上答案。
实现分两步走:计算(是作对做错还是没错)和反馈(把预期结果写到原图上)。
2.6.1 计算 python有个函数很强大,就是eval函数,能计算字符串算式,比如直接计算eval("5+3-2")。
所以,一切都靠它了。
# 计算数值并返回结果 参数chars:['8', '-', '6', '=']
def calculation(chars):
cstr = ''.join(chars)
result = ''
if("=" in cstr): # 有等号
str_arr = cstr.split('=')
c_str = str_arr[0]
r_str = str_arr[1]
c_str = c_str.replace("×","*")
c_str = c_str.replace("÷","/")
try:
c_r = int(eval(c_str))
except Exception as e:
print("Exception",e)
if r_str == "":
result = c_r
else:
if str(c_r) == str(r_str):
result = "√"
else:
result = "×"
return result
执行之后获得的结果是:
recognize result: ['8', '×', '4', '=']
calculate result: 32
recognize result: ['2', '-', '1', '=', '1']
calculate result: √
recognize result: ['1', '0', '-', '5', '=']
calculate result: 5
2.6.2 反馈
有了结果之后,把结果写到图片上,这是最后一步,也是最简单的一步。
但是实现起来,居然很繁琐。
得找坐标吧,得计算结果呈现的位置吧,我们还想标记不同的颜色,比如对了是绿色,错了是红色,补齐答案是灰色。
下面代码是在一个图img上,把文本内容text画到(left,top)位置,以特定颜色和大小。
# 绘制文本
def cv2ImgAddText(img, text, left, top, textColor=(255, 0, 0), textSize=20):
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype("fonts/fangzheng_shusong.ttf", textSize, encoding="utf-8")
# 绘制文本
draw.text((left, top), text, textColor, font=fontStyle)
# 转换回OpenCV格式
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
结合着切图的信息、计算的信息,下面代码提供思路参考:
# 获取切图标注,切图图片,原图图图片
all_mark_boxs,all_char_imgs,img_o = divImg(path,save)
# 恢复模型,用于图片识别
model = cnn.create_model()
model.load_weights('checkpoint/char_checkpoint')
class_name = np.load('class_name.npy')
# 遍历行
for i in range(0,len(all_char_imgs)):
row_imgs = all_char_imgs[i]
# 遍历块
for j in range(0,len(row_imgs)):
block_imgs = row_imgs[j]
block_imgs = np.array(block_imgs)
# 图片识别
results = cnn.predict(model, block_imgs, class_name)
print('recognize result:',results)
# 计算结果
result = calculation(results)
print('calculate result:',result)
# 获取块的标注坐标
block_mark = all_mark_boxs[i][j]
# 获取结果的坐标,写在块的最后一个字
answer_box = block_mark[-1]
# 计算最后一个字的位置
x = answer_box[2]
y = answer_box[3]
iw = answer_box[2] - answer_box[0]
ih = answer_box[3] - answer_box[1]
# 计算字体大小
textSize = max(iw,ih)
# 根据结果设置字体颜色
if str(result) == "√":
color = (0, 255, 0)
elif str(result) == "×":
color = (255, 0, 0)
else:
color = (192, 192,192)
# 将结果写到原图上
img_o = cv2ImgAddText(img_o, str(result), answer_box[2], answer_box[1],color, textSize)
# 将写满结果的原图保存
cv2.imwrite('result.jpg', img_o)
结果是下面这样的:
注意
同级新建fonts文件夹里拷贝一些字体文件,从这里找C:\Windows\Fonts,几十个就行。
get_character_pic.py 生成字体
cnn.py 训练数据
main.py 裁剪指定图片并识别,素材图片新建imgs文件夹,在imgs/question.png下,结果文件保存在imgs/result.png。
注意如果识别不成功,很可能是question.png的字体你没有训练(这幅图的字体是方正书宋简体,但是你只训练了楷体),这时候可以使用楷体自己编一个算式图。
原文:https://juejin.cn/post/7006732549451939847
收起阅读 »写了个自动批改小孩作业的代码(上)
一、亮出效果
最近一些软件的搜题、智能批改类的功能要下线。
退1024步讲,要不要自己做一个自动批改的功能啊?万一哪天孩子要用呢!
昨晚我做了一个梦,梦见我实现了这个功能,如下图所示:
功能简介:作对了,能打对号;做错了,能打叉号;没做的,能补上答案。
醒来后,我环顾四周,赶紧再躺下,希望梦还能接上。
二、实现步骤
基本思路
其实,搞定两点就成,第一是能识别数字,第二是能切分数字。
首先得能认识5是5,这是前提条件,其次是能找到5、6、7、8这些数字区域的位置。
前者是图像识别,后者是图像切割。
对于图像识别,一般的套路是下面这样的(CNN卷积神经网络):
对于图像切割,一般的套路是下面的这样(横向纵向投影法):
既然思路能走得通,那么咱们先搞图像识别。准备数据->训练数据并保存模型->使用训练模型预测结果。
2.1 准备数据
对于男友,找一个油嘴滑舌的花花公子,不如找一个闷葫芦IT男,亲手把他培养成你期望的样子。
咱们不用什么官方的mnist数据集,因为那是官方的,不是你的,你想要添加±×÷它也没有。
有些通用的数据集,虽然很强大,很方便,但是一旦放到你的场景中,效果一点也不如你的愿。
只有训练自己手里的数据,然后自己用起来才顺手。更重要的是,我们享受创造的过程。
假设,我们只给口算做识别,那么我们需要的图片数据有如下几类:
索引:0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
字符:0 1 2 3 4 5 6 7 8 9 = + - × ÷如果能识别这些,基本上能满足整数的加减乘除运算了。
好了,图片哪里来?!
是啊,图片哪里来?
吓得我差点从梦里醒来,500万都规划好该怎么花了,居然双色球还没有选号!
梦里,一个老者跟我说,图片要自己生成。我问他如何生成,他呵呵一笑,消失在迷雾中……
仔细一想,其实也不难,打字我们总会吧,生成数字无非就是用代码把字写在图片上。
字之所以能展示,主要是因为有字体的支撑。
如果你用的是windows系统,那么打开KaTeX parse error: Undefined control sequence: \Windows at position 3: C:\̲W̲i̲n̲d̲o̲w̲s̲\Fonts这个文件夹,你会发现好多字体。
我们写代码调用这些字体,然后把它打印到一张图片上,是不是就有数据了。
而且这些数据完全是由我们控制的,想多就多,想少就少,想数字、字母、汉字、符号都可以,今天你搞出来数字识别,也就相当于你同时拥有了所有识别!想想还有点小激动呢!
看看,这就是打工和创业的区别。你用别人的数据相当于打工,你是不用操心,但是他给你什么你才有什么。自己造数据就相当于创业,虽然前期辛苦,你可以完全自己把握节奏,需要就加上,没用就去掉。
2.1.1 准备字体
建一个fonts文件夹,从字体库里拷一部分字体放进来,我这里是拷贝了13种字体文件。
好的,准备工作做好了,肯定很累吧,休息休息休息,一会儿再搞!
2.1.2 生成图片
代码如下,可以直接运行。
from __future__ import print_function
from PIL import Image
from PIL import ImageFont
from PIL import ImageDraw
import os
import shutil
import time
# %% 要生成的文本
label_dict = {0: '0', 1: '1', 2: '2', 3: '3', 4: '4', 5: '5', 6: '6', 7: '7', 8: '8', 9: '9', 10: '=', 11: '+', 12: '-', 13: '×', 14: '÷'}
# 文本对应的文件夹,给每一个分类建一个文件
for value,char in label_dict.items():
train_images_dir = "dataset"+"/"+str(value)
if os.path.isdir(train_images_dir):
shutil.rmtree(train_images_dir)
os.makedirs(train_images_dir)
# %% 生成图片
def makeImage(label_dict, font_path, width=24, height=24, rotate = 0):
# 从字典中取出键值对
for value,char in label_dict.items():
# 创建一个黑色背景的图片,大小是24*24
img = Image.new("RGB", (width, height), "black")
draw = ImageDraw.Draw(img)
# 加载一种字体,字体大小是图片宽度的90%
font = ImageFont.truetype(font_path, int(width*0.9))
# 获取字体的宽高
font_width, font_height = draw.textsize(char, font)
# 计算字体绘制的x,y坐标,主要是让文字画在图标中心
x = (width - font_width-font.getoffset(char)[0]) / 2
y = (height - font_height-font.getoffset(char)[1]) / 2
# 绘制图片,在那里画,画啥,什么颜色,什么字体
draw.text((x,y), char, (255, 255, 255), font)
# 设置图片倾斜角度
img = img.rotate(rotate)
# 命名文件保存,命名规则:dataset/编号/img-编号_r-选择角度_时间戳.png
time_value = int(round(time.time() * 1000))
img_path = "dataset/{}/img-{}_r-{}_{}.png".format(value,value,rotate,time_value)
img.save(img_path)
# %% 存放字体的路径
font_dir = "./fonts"
for font_name in os.listdir(font_dir):
# 把每种字体都取出来,每种字体都生成一批图片
path_font_file = os.path.join(font_dir, font_name)
# 倾斜角度从-10到10度,每个角度都生成一批图片
for k in range(-10, 10, 1):
# 每个字符都生成图片
makeImage(label_dict, path_font_file, rotate = k)上面纯代码不到30行,相信大家应该能看懂!看不懂不是我的读者。
核心代码就是画文字。
draw.text((x,y), char, (255, 255, 255), font)翻译一下就是:使用某字体在黑底图片的(x,y)位置写白色的char符号。
核心逻辑就是三层循环。
如果代码你运行的没有问题,最终会生成如下结果:
好了,数据准备好了。总共15个文件夹,每个文件夹下对应的各种字体各种倾斜角的字符图片3900个(字符15类×字体13种×角度20个),图片的大小是24×24像素。
有了数据,我们就可以再进行下一步了,下一步是训练和使用数据。
2.2 训练数据
2.2.1 构建模型
你先看代码,外行感觉好深奥,内行偷偷地笑。
# %% 导入必要的包
import tensorflow as tf
import numpy as np
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
import pathlib
import cv2
# %% 构建模型
def create_model():
model = Sequential([
layers.experimental.preprocessing.Rescaling(1./255, input_shape=(24, 24, 1)),
layers.Conv2D(24,3,activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Conv2D(64,3, activation='relu'),
layers.MaxPooling2D((2,2)),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(15)]
)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
return model这个模型的序列是下面这样的,作用是输入一个图片数据,经过各个层揉搓,最终预测出这个图片属于哪个分类。
这么多层都是干什么的,有什么用?和衣服一样,肯定是有用的,内衣、衬衣、毛衣、棉衣各有各的用处。
2.2.2 卷积层 Conv2D
各个职能部门的调查员,搜集和整理某单位区域内的特定数据。我们输入的是一个图像,它是由像素组成的,这就是R e s c a l i n g ( 1. / 255 , i n p u t s h a p e = ( 24 , 24 , 1 ) ) Rescaling(1./255, input_shape=(24, 24, 1))Rescaling(1./255,input shape=(24,24,1))中,input_shape输入形状是24*24像素1个通道(彩色是RGB 3个通道)的图像。
卷积层代码中的定义是Conv2D(24,3),意思是用3*3像素的卷积核,去提取24个特征。
我把图转到地图上来,你就能理解了。以我大济南的市中区为例子。
卷积的作用就相当于从地图的某级单位区域中收集多组特定信息。比如以小区为单位去提取住宅数量、车位数量、学校数量、人口数、年收入、学历、年龄等等24个维度的信息。小区相当于卷积核。
提取完成之后是这样的。
第一次卷积之后,我们从市中区得到N个小区的数据。
卷积是可以进行多次的。
比如在小区卷积之后,我们还可在小区的基础上再来一次卷积,在卷积就是街道了。
通过再次以街道为单位卷积小区,我们就从市中区得到了N个街道的数据。
这就是卷积的作用。
通过一次次卷积,就把一张大图,通过特定的方法卷起来,最终留下来的是固定几组有目的数据,以此方便后续的评选决策。这是评选一个区的数据,要是评选济南市,甚至山东省,也是这么卷积。这和现实生活中评选文明城市、经济强省也是一个道理。
2.2.3 池化层 MaxPooling2D
说白了就是四舍五入。
计算机的计算能力是强大的,比你我快,但也不是不用考虑成本。我们当然希望它越快越好,如果一个方法能省一半的时间,我们肯定愿意用这种方法。
池化层干的就是这个事情。池化的代码定义是这样的M a x P o o l i n g 2 D ( ( 2 , 2 ) ) MaxPooling2D((2,2))MaxPooling2D((2,2)),这里是最大值池化。其中(2,2)是池化层的大小,其实就是在2*2的区域内,我们认为这一片可以合成一个单位。
再以地图举个例子,比如下面的16个格子里的数据,是16个街道的学校数量。
为了进一步提高计算效率,少计算一些数据,我们用2*2的池化层进行池化。
池化的方格是4个街道合成1个,新单位学校数量取成员中学校数量最大(也有取最小,取平均多种池化)的那一个。池化之后,16个格子就变为了4个格子,从而减少了数据。
这就是池化层的作用。
2.2.4 全连接层 Dense
弱水三千,只取一瓢。
在这里,它其实是一个分类器。
我们构建它时,代码是这样的D e n s e ( 15 ) Dense(15)Dense(15)。
它所做的事情,不管你前面是怎么样,有多少维度,到我这里我要强行转化为固定的通道。
比如识别字母a~z,我有500个神经元参与判断,但是最终输出结果就是26个通道(a,b,c,……,y,z)。
我们这里总共有15类字符,所以是15个通道。给定一个输入后,输出为每个分类的概率。
注意:上面都是二维的输入,比如24×24,但是全连接层是一维的,所以代码中使用了l a y e r s . F l a t t e n ( ) layers.Flatten()layers.Flatten()将二维数据拉平为一维数据([[11,12],[21,22]]->[11,12,21,22])。
对于总体的模型,调用m o d e l . s u m m a r y ( ) model.summary()model.summary()打印序列的网络结构如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_2 (Rescaling) (None, 24, 24, 1) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 22, 22, 24) 240
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 11, 11, 24) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 9, 9, 64) 13888
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 1024) 0
_________________________________________________________________
dense_4 (Dense) (None, 128) 131200
_________________________________________________________________
dense_5 (Dense) (None, 15) 1935
=================================================================
Total params: 147,263
Trainable params: 147,263
Non-trainable params: 0
_________________________________________________________________我们看到conv2d_5 (Conv2D) (None, 9, 9, 64) 经过2*2的池化之后变为max_pooling2d_5 (MaxPooling2 (None, 4, 4, 64)。(None, 4, 4, 64) 再经过F l a t t e n FlattenFlatten拉成一维之后变为(None, 1024),经过全连接变为(None, 128)再一次全连接变为(None, 15),15就是我们的最终分类。这一切都是我们设计的。
m o d e l . c o m p i l e model.compilemodel.compile就是配置模型的几个参数,这个现阶段记住就可以。
2.2.5 训练数据
执行就完了。
# 统计文件夹下的所有图片数量
data_dir = pathlib.Path('dataset')
# 从文件夹下读取图片,生成数据集
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir, # 从哪个文件获取数据
color_mode="grayscale", # 获取数据的颜色为灰度
image_size=(24, 24), # 图片的大小尺寸
batch_size=32 # 多少个图片为一个批次
)
# 数据集的分类,对应dataset文件夹下有多少图片分类
class_names = train_ds.class_names
# 保存数据集分类
np.save("class_name.npy", class_names)
# 数据集缓存处理
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
# 创建模型
model = create_model()
# 训练模型,epochs=10,所有数据集训练10遍
model.fit(train_ds,epochs=10)
# 保存训练后的权重
model.save_weights('checkpoint/char_checkpoint')执行之后会输出如下信息:
Found 3900 files belonging to 15 classes.
Epoch 1/10 122/122 [=========] - 2s 19ms/step - loss: 0.5795 - accuracy: 0.8615
Epoch 2/10 122/122 [=========] - 2s 18ms/step - loss: 0.0100 - accuracy: 0.9992
Epoch 3/10 122/122 [=========] - 2s 19ms/step - loss: 0.0027 - accuracy: 1.0000
Epoch 4/10 122/122 [=========] - 2s 19ms/step - loss: 0.0013 - accuracy: 1.0000
Epoch 5/10 122/122 [=========] - 2s 20ms/step - loss: 8.4216e-04 - accuracy: 1.0000
Epoch 6/10 122/122 [=========] - 2s 18ms/step - loss: 5.5273e-04 - accuracy: 1.0000
Epoch 7/10 122/122 [=========] - 3s 21ms/step - loss: 4.0966e-04 - accuracy: 1.0000
Epoch 8/10 122/122 [=========] - 2s 20ms/step - loss: 3.0308e-04 - accuracy: 1.0000
Epoch 9/10 122/122 [=========] - 3s 23ms/step - loss: 2.3446e-04 - accuracy: 1.0000
Epoch 10/10 122/122 [=========] - 3s 21ms/step - loss: 1.8971e-04 - accuracy: 1.0000我们看到,第3遍时候,准确率达到100%了。最后结束的时候,我们发现文件夹checkpoint下多了几个文件:
char_checkpoint.data-00000-of-00001
char_checkpoint.index
checkpoint上面那几个文件是训练结果,训练保存之后就不用动了。后面可以直接用这些数据进行预测。
2.3 预测数据
终于到了享受成果的时候了。
# 设置待识别的图片
img1=cv2.imread('img1.png',0)
img2=cv2.imread('img2.png',0)
imgs = np.array([img1,img2])
# 构建模型
model = create_model()
# 加载前期训练好的权重
model.load_weights('checkpoint/char_checkpoint')
# 读出图片分类
class_name = np.load('class_name.npy')
# 预测图片,获取预测值
predicts = model.predict(imgs)
results = [] # 保存结果的数组
for predict in predicts: #遍历每一个预测结果
index = np.argmax(predict) # 寻找最大值
result = class_name[index] # 取出字符
results.append(result)
print(results)我们找两张图片img1.png,img2.png,一张是数字6,一张是数字8,两张图放到代码同级目录下,验证一下识别效果如何。
图片要通过cv2.imread('img1.png',0) 转化为二维数组结构,0参数是灰度图片。经过处理后,图片转成的数组是如下所示(24,24)的结构:
我们要同时验证两张图,所以把两张图再组成imgs放到一起,imgs的结构是(2,24,24)。
下面是构建模型,然后加载权重。通过调用predicts = model.predict(imgs)将imgs传递给模型进行预测得出predicts。
predicts的结构是(2,15),数值如下面所示:
[[ 16.134243 -12.10675 -1.1994154 -27.766754 -43.4324 -9.633694 -12.214878 1.6287893 2.562174 3.2222707 13.834648 28.254173 -6.102874 16.76582 7.2586184] [ 5.022571 -8.762314 -6.7466817 -23.494259 -30.170597 2.4392672 -14.676962 5.8255725 8.855118 -2.0998626 6.820853 7.6578817 1.5132296 24.4664 2.4192357]]
意思是有2个预测结果,每一个图片的预测结果有15种可能。
然后根据 index = np.argmax(predict) 找出最大可能的索引。
根据索引找到字符的数值结果是[‘6’, ‘8’]。
下面是数据在内存中的监控:
可见,我们的预测是准确的。
下面,我们将要把图片中数字切割出来,进行识别了。
之前我们准备了数据,训练了数据,并且拿图片进行了识别,识别结果正确。
到目前为止,看来问题不大……没有大问题,有问题也大不了。
下面就是把图片进行切割识别了。
下面这张大图片,怎么把它搞一搞,搞成单个小数字的图片。
原文:https://juejin.cn/post/7006732549451939847
收起阅读 »研究生写脚本抢HPV九价疫苗:被采取强制措施,后果严重

参考链接:
https://mp.weixin.qq.com/s/Umq6UjeKD0kwgyZgVA28zA
https://weibo.com/5044281310/LbhRgewXz
整理 | 王晓曼
收起阅读 »我去!爬虫遇到字体反爬,哭了
今天准备爬取某某点评店铺信息时,遇到了『字体』反爬。比如这样的:

还有这样的:

可以看到这些字体已经被加密(反爬)
竟然遇到这种情况,那辰哥就带大家如何去解决这类反爬(字体反爬类)
01 网页分析
在开始分析反爬之前,先简单的介绍一下背景(爬取的网页)

辰哥爬取的某某点评的店铺信息。一开始查看网页源码是这样的

这种什么也看不到,咱们换另一种方式:通过程序直接把整个网页源代码保存下来

获取到的网页源码如下:

比如这里看到评论数(4位数)都有对应着一个编号(相同的数字编号相同),应该是对应着网站的字体库。
下一步,我们需要找到这个网站的字体库。
02 获取字体库
这里的字体库建议在目标网站里面去获取,因为不同的网站的字体库是不一样,导致解码还原的字体也会不一样。
1、抓包获取字体库

在浏览器network里面可以看到一共有三种字体库。(三种字体库各有不同的妙用,后面会有解释)

把字体库链接复制在浏览器里面打开,就可以把字体库下载到本地。
2、查看字体库
这里使用FontCreator的工具查看字体库。
下载地址:
https://www.high-logic.com/font-editor/fontcreator/download
这里需要注册,邮箱验证才能下载,不过辰哥已经下载了,可以在公众号回复:FC,获取安装包。
安装之后,把刚刚下载的字体库在FontCreator中打开

可以看到字体的内容以及对应的编号。
比如数字7对应F399、数字8对应F572 ,咱们在原网页和源码对比,是否如此???

可以看到,真是一模一样对应着解码就可以还原字体。
3、为什么会有三个字体库

在查看加密字体的CSS样式时,方式有css内容是这样的

字体库1:d35c3812.woff 对应解码class为 shopNum
字体库2:084c9fff.woff 对应解码class为 reviewTag和address
字体库3:73f5e6f3.woff 对应解码class为 tagName
也就是说,字体所属的不同class标签,对应的解密字体库是不一样的,辰哥这里不得不说一句:太鸡贼了

咱们这里获取的评论数,clas为shopNum,需要用到字体库d35c3812.woff
03 代码实现解密
1、加载字体库
既然我们已经知道了字体反爬的原理,那么我们就可以开始编程实现解密还原。
加载字体库的Python库包是:fontTools ,安装命令如下:
pip install fontTools

将字体库的内容对应关系保存为xml格式

code和name是一一对应关系


可以看到网页源码中的编号后四位对应着字体库的编号。
因此我们可以建立应该字体对应集合

建立好映射关系好,到网页源码中去进行替换


这样我们就成功的将字体反爬处理完毕。后面提取内容大家基本都没问题。
2、完整代码

输出结果:

可以看到加密的数字全部都还原了。
04 小结
辰哥在本文中主要讲解了如此处理字体反爬问题,并以某某点评为例去实战演示分析。辰哥在文中处理的数字类型,大家可以尝试去试试中文如何解决。
作者:Python研究者
来源:https://juejin.cn/post/6970933428145356831
python协程(超详细)
1、迭代
1.1 迭代的概念
使用for循环遍历取值的过程叫做迭代,比如:使用for循环遍历列表获取值的过程
# Python 中的迭代
for value in [2, 3, 4]:
print(value)1.2 可迭代对象
标准概念:在类里面定义
__iter__方法,并使用该类创建的对象就是可迭代对象简单记忆:使用for循环遍历取值的对象叫做可迭代对象, 比如:列表、元组、字典、集合、range、字符串
1.3 判断对象是否是可迭代对象
# 元组,列表,字典,字符串,集合,range都是可迭代对象
from collections import Iterable
# 如果解释器提示警告,就是用下面的导入方式
# from collections.abc import Iterable
# 判断对象是否是指定类型
result = isinstance((3, 5), Iterable)
print("元组是否是可迭代对象:", result)
result = isinstance([3, 5], Iterable)
print("列表是否是可迭代对象:", result)
result = isinstance({"name": "张三"}, Iterable)
print("字典是否是可迭代对象:", result)
result = isinstance("hello", Iterable)
print("字符串是否是可迭代对象:", result)
result = isinstance({3, 5}, Iterable)
print("集合是否是可迭代对象:", result)
result = isinstance(range(5), Iterable)
print("range是否是可迭代对象:", result)
result = isinstance(5, Iterable)
print("整数是否是可迭代对象:", result)
# 提示: 以后还根据对象判断是否是其它类型,比如以后可以判断函数里面的参数是否是自己想要的类型
result = isinstance(5, int)
print("整数是否是int类型对象:", result)
class Student(object):
pass
stu = Student()
result = isinstance(stu, Iterable)
print("stu是否是可迭代对象:", result)
result = isinstance(stu, Student)
print("stu是否是Student类型的对象:", result)1.4 自定义可迭代对象
在类中实现
__iter__方法
自定义可迭代类型代码
from collections import Iterable
# 如果解释器提示警告,就是用下面的导入方式
# from collections.abc import Iterable
# 自定义可迭代对象: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
pass
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
result = isinstance(my_list, Iterable)
print(result)
for value in my_list:
print(value)执行结果:
Traceback (most recent call last):
True
File "/Users/hbin/Desktop/untitled/aa.py", line 24, in <module>
for value in my_list:
TypeError: iter() returned non-iterator of type 'NoneType'通过执行结果可以看出来,遍历可迭代对象依次获取数据需要迭代器
总结
在类里面提供一个__iter__创建的对象是可迭代对象,可迭代对象是需要迭代器完成数据迭代的
2、迭代器
2.1 自定义迭代器对象
自定义迭代器对象: 在类里面定义
__iter__和__next__方法创建的对象就是迭代器对象
from collections import Iterable
from collections import Iterator
# 自定义可迭代对象: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
my_iterator = MyIterator(self.my_list)
return my_iterator
# 自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
class MyIterator(object):
def __init__(self, my_list):
self.my_list = my_list
# 记录当前获取数据的下标
self.current_index = 0
# 判断当前对象是否是迭代器
result = isinstance(self, Iterator)
print("MyIterator创建的对象是否是迭代器:", result)
def __iter__(self):
return self
# 获取迭代器中下一个值
def __next__(self):
if self.current_index < len(self.my_list):
self.current_index += 1
return self.my_list[self.current_index - 1]
else:
# 数据取完了,需要抛出一个停止迭代的异常
raise StopIteration
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
result = isinstance(my_list, Iterable)
print(result)
for value in my_list:
print(value)运行结果:
True
MyIterator创建的对象是否是迭代器: True
1
2
2.2 iter()函数与next()函数
iter函数: 获取可迭代对象的迭代器,会调用可迭代对象身上的
__iter__方法next函数: 获取迭代器中下一个值,会调用迭代器对象身上的
__next__方法
# 自定义可迭代对象: 在类里面定义__iter__方法创建的对象就是可迭代对象
class MyList(object):
def __init__(self):
self.my_list = list()
# 添加指定元素
def append_item(self, item):
self.my_list.append(item)
def __iter__(self):
# 可迭代对象的本质:遍历可迭代对象的时候其实获取的是可迭代对象的迭代器, 然后通过迭代器获取对象中的数据
my_iterator = MyIterator(self.my_list)
return my_iterator
# 自定义迭代器对象: 在类里面定义__iter__和__next__方法创建的对象就是迭代器对象
# 迭代器是记录当前数据的位置以便获取下一个位置的值
class MyIterator(object):
def __init__(self, my_list):
self.my_list = my_list
# 记录当前获取数据的下标
self.current_index = 0
def __iter__(self):
return self
# 获取迭代器中下一个值
def __next__(self):
if self.current_index < len(self.my_list):
self.current_index += 1
return self.my_list[self.current_index - 1]
else:
# 数据取完了,需要抛出一个停止迭代的异常
raise StopIteration
# 创建了一个自定义的可迭代对象
my_list = MyList()
my_list.append_item(1)
my_list.append_item(2)
# 获取可迭代对象的迭代器
my_iterator = iter(my_list)
print(my_iterator)
# 获取迭代器中下一个值
# value = next(my_iterator)
# print(value)
# 循环通过迭代器获取数据
while True:
try:
value = next(my_iterator)
print(value)
except StopIteration as e:
break2.3 for循环的本质
遍历的是可迭代对象
for item in Iterable 循环的本质就是先通过iter()函数获取可迭代对象Iterable的迭代器,然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
遍历的是迭代器
for item in Iterator 循环的迭代器,不断调用next()方法来获取下一个值并将其赋值给item,当遇到StopIteration的异常后循环结束。
2.4 迭代器的应用场景
我们发现迭代器最核心的功能就是可以通过next()函数的调用来返回下一个数据值。如果每次返回的数据值不是在一个已有的数据集合中读取的,而是通过程序按照一定的规律计算生成的,那么也就意味着可以不用再依赖一个已有的数据集合,也就是说不用再将所有要迭代的数据都一次性缓存下来供后续依次读取,这样可以节省大量的存储(内存)空间。
举个例子,比如,数学中有个著名的斐波拉契数列(Fibonacci),数列中第一个数为0,第二个数为1,其后的每一个数都可由前两个数相加得到:
0, 1, 1, 2, 3, 5, 8, 13, 21, 34, ...
现在我们想要通过for...in...循环来遍历迭代斐波那契数列中的前n个数。那么这个斐波那契数列我们就可以用迭代器来实现,每次迭代都通过数学计算来生成下一个数。
class Fibonacci(object):
def __init__(self, num):
# num:表示生成多少fibonacci数字
self.num = num
# 记录fibonacci前两个值
self.a = 0
self.b = 1
# 记录当前生成数字的索引
self.current_index = 0
def __iter__(self):
return self
def __next__(self):
if self.current_index < self.num:
result = self.a
self.a, self.b = self.b, self.a + self.b
self.current_index += 1
return result
else:
raise StopIteration
fib = Fibonacci(5)
# value = next(fib)
# print(value)
for value in fib:
print(value)执行结果:
0
1
1
2
3小结
迭代器的作用就是是记录当前数据的位置以便获取下一个位置的值
3、生成器
3.1 生成器的概念
生成器是一类特殊的迭代器,它不需要再像上面的类一样写
__iter__()和__next__()方法了, 使用更加方便,它依然可以使用next函数和for循环取值
3.2 创建生成器方法1
第一种方法很简单,只要把一个列表生成式的 [ ] 改成 ( )
my_list = [i * 2 for i in range(5)]
print(my_list)
# 创建生成器
my_generator = (i * 2 for i in range(5))
print(my_generator)
# next获取生成器下一个值
# value = next(my_generator)
#
# print(value)
for value in my_generator:
print(value)执行结果:
[0, 2, 4, 6, 8]
<generator object <genexpr> at 0x101367048>
0
2
4
6
83.3 创建生成器方法2
在def函数里面看到有yield关键字那么就是生成器
def fibonacci(num):
a = 0
b = 1
# 记录生成fibonacci数字的下标
current_index = 0
print("--11---")
while current_index < num:
result = a
a, b = b, a + b
current_index += 1
print("--22---")
# 代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
yield result
print("--33---")
fib = fibonacci(5)
value = next(fib)
print(value)
value = next(fib)
print(value)
value = next(fib)
print(value)
# for value in fib:
# print(value)在使用生成器实现的方式中,我们将原本在迭代器__next__方法中实现的基本逻辑放到一个函数中来实现,但是将每次迭代返回数值的return换成了yield,此时新定义的函数便不再是函数,而是一个生成器了。
简单来说:只要在def中有yield关键字的 就称为 生成器
3.4 生成器使用return关键字
def fibonacci(num):
a = 0
b = 1
# 记录生成fibonacci数字的下标
current_index = 0
print("--11---")
while current_index < num:
result = a
a, b = b, a + b
current_index += 1
print("--22---")
# 代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
yield result
print("--33---")
return "嘻嘻"
fib = fibonacci(5)
value = next(fib)
print(value)
# 提示: 生成器里面使用return关键字语法上没有问题,但是代码执行到return语句会停止迭代,抛出停止迭代异常
# return 和 yield的区别
# yield: 每次启动生成器都会返回一个值,多次启动可以返回多个值,也就是yield可以返回多个值
# return: 只能返回一次值,代码执行到return语句就停止迭代
try:
value = next(fib)
print(value)
except StopIteration as e:
# 获取return的返回值
print(e.value)提示:
生成器里面使用return关键字语法上没有问题,但是代码执行到return语句会停止迭代,抛出停止迭代异常
3.5 yield和return的对比
使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
每次启动生成器都会返回一个值,多次启动可以返回多个值,也就是yield可以返回多个值
return只能返回一次值,代码执行到return语句就停止迭代,抛出停止迭代异常
3.6 使用send方法启动生成器并传参
send方法启动生成器的时候可以传参数
def gen():
i = 0
while i<5:
temp = yield i
print(temp)
i+=1
执行结果:
In [43]: f = gen()
In [44]: next(f)
Out[44]: 0
In [45]: f.send('haha')
haha
Out[45]: 1
In [46]: next(f)
None
Out[46]: 2
In [47]: f.send('haha')
haha
Out[47]: 3
In [48]:**注意:如果第一次启动生成器使用send方法,那么参数只能传入None,一般第一次启动生成器使用next函数
小结
生成器创建有两种方式,一般都使用yield关键字方法创建生成器
yield特点是代码执行到yield会暂停,把结果返回出去,再次启动生成器在暂停的位置继续往下执行
4、协程
4.1 协程的概念
协程,又称微线程,纤程,也称为用户级线程,在不开辟线程的基础上完成多任务,也就是在单线程的情况下完成多任务,多个任务按照一定顺序交替执行 通俗理解只要在def里面只看到一个yield关键字表示就是协程
协程是也是实现多任务的一种方式
协程yield的代码实现
简单实现协程
import time
def work1():
while True:
print("----work1---")
yield
time.sleep(0.5)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.5)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
if __name__ == "__main__":
main()运行结果:
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
...省略...小结
协程之间执行任务按照一定顺序交替执行
5、greenlet
5.1 greentlet的介绍
为了更好使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变的更加简单
使用如下命令安装greenlet模块:
pip3 install greenlet
使用协程完成多任务
import time
import greenlet
# 任务1
def work1():
for i in range(5):
print("work1...")
time.sleep(0.2)
# 切换到协程2里面执行对应的任务
g2.switch()
# 任务2
def work2():
for i in range(5):
print("work2...")
time.sleep(0.2)
# 切换到第一个协程执行对应的任务
g1.switch()
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = greenlet.greenlet(work1)
g2 = greenlet.greenlet(work2)
# 切换到第一个协程执行对应的任务
g1.switch()
运行效果
work1...
work2...
work1...
work2...
work1...
work2...
work1...
work2...
work1...
work2...6、gevent
6.1 gevent的介绍
greenlet已经实现了协程,但是这个还要人工切换,这里介绍一个比greenlet更强大而且能够自动切换任务的第三方库,那就是gevent。
gevent内部封装的greenlet,其原理是当一个greenlet遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证总有greenlet在运行,而不是等待IO
安装
pip3 install gevent6.2 gevent的使用
import gevent
def work(n):
for i in range(n):
# 获取当前协程
print(gevent.getcurrent(), i)
g1 = gevent.spawn(work, 5)
g2 = gevent.spawn(work, 5)
g3 = gevent.spawn(work, 5)
g1.join()
g2.join()
g3.join()运行结果
<Greenlet "Greenlet-0" at 0x26d8c970488: work(5)> 0
<Greenlet "Greenlet-1" at 0x26d8c970598: work(5)> 0
<Greenlet "Greenlet-2" at 0x26d8c9706a8: work(5)> 0
<Greenlet "Greenlet-0" at 0x26d8c970488: work(5)> 1
<Greenlet "Greenlet-1" at 0x26d8c970598: work(5)> 1
<Greenlet "Greenlet-2" at 0x26d8c9706a8: work(5)> 1
<Greenlet "Greenlet-0" at 0x26d8c970488: work(5)> 2
<Greenlet "Greenlet-1" at 0x26d8c970598: work(5)> 2
<Greenlet "Greenlet-2" at 0x26d8c9706a8: work(5)> 2
<Greenlet "Greenlet-0" at 0x26d8c970488: work(5)> 3
<Greenlet "Greenlet-1" at 0x26d8c970598: work(5)> 3
<Greenlet "Greenlet-2" at 0x26d8c9706a8: work(5)> 3
<Greenlet "Greenlet-0" at 0x26d8c970488: work(5)> 4
<Greenlet "Greenlet-1" at 0x26d8c970598: work(5)> 4
<Greenlet "Greenlet-2" at 0x26d8c9706a8: work(5)> 4可以看到,3个greenlet是依次运行而不是交替运行
6.3 gevent切换执行
import gevent
def work(n):
for i in range(n):
# 获取当前协程
print(gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(work, 5)
g2 = gevent.spawn(work, 5)
g3 = gevent.spawn(work, 5)
g1.join()
g2.join()
g3.join()运行结果
<Greenlet at 0x7fa70ffa1c30: f(5)> 0
<Greenlet at 0x7fa70ffa1870: f(5)> 0
<Greenlet at 0x7fa70ffa1eb0: f(5)> 0
<Greenlet at 0x7fa70ffa1c30: f(5)> 1
<Greenlet at 0x7fa70ffa1870: f(5)> 1
<Greenlet at 0x7fa70ffa1eb0: f(5)> 1
<Greenlet at 0x7fa70ffa1c30: f(5)> 2
<Greenlet at 0x7fa70ffa1870: f(5)> 2
<Greenlet at 0x7fa70ffa1eb0: f(5)> 2
<Greenlet at 0x7fa70ffa1c30: f(5)> 3
<Greenlet at 0x7fa70ffa1870: f(5)> 3
<Greenlet at 0x7fa70ffa1eb0: f(5)> 3
<Greenlet at 0x7fa70ffa1c30: f(5)> 4
<Greenlet at 0x7fa70ffa1870: f(5)> 4
<Greenlet at 0x7fa70ffa1eb0: f(5)> 46.4 给程序打补丁
import gevent
import time
from gevent import monkey
# 打补丁,让gevent框架识别耗时操作,比如:time.sleep,网络请求延时
monkey.patch_all()
# 任务1
def work1(num):
for i in range(num):
print("work1....")
time.sleep(0.2)
# gevent.sleep(0.2)
# 任务1
def work2(num):
for i in range(num):
print("work2....")
time.sleep(0.2)
# gevent.sleep(0.2)
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = gevent.spawn(work1, 3)
g2 = gevent.spawn(work2, 3)
# 主线程等待协程执行完成以后程序再退出
g1.join()
g2.join()运行结果
work1....
work2....
work1....
work2....
work1....
work2....6.5 注意
当前程序是一个死循环并且还能有耗时操作,就不需要加上join方法了,因为程序需要一直运行不会退出
示例代码
import gevent
import time
from gevent import monkey
# 打补丁,让gevent框架识别耗时操作,比如:time.sleep,网络请求延时
monkey.patch_all()
# 任务1
def work1(num):
for i in range(num):
print("work1....")
time.sleep(0.2)
# gevent.sleep(0.2)
# 任务1
def work2(num):
for i in range(num):
print("work2....")
time.sleep(0.2)
# gevent.sleep(0.2)
if __name__ == '__main__':
# 创建协程指定对应的任务
g1 = gevent.spawn(work1, 3)
g2 = gevent.spawn(work2, 3)
while True:
print("主线程中执行")
time.sleep(0.5)执行结果:
主线程中执行work1....work2....work1....work2....work1....work2....主线程中执行主线程中执行主线程中执行..省略..如果使用的协程过多,如果想启动它们就需要一个一个的去使用join()方法去阻塞主线程,这样代码会过于冗余,可以使用gevent.joinall()方法启动需要使用的协程
实例代码
import time
import gevent
def work1():
for i in range(5):
print("work1工作了{}".format(i))
gevent.sleep(1)
def work2():
for i in range(5):
print("work2工作了{}".format(i))
gevent.sleep(1)
if __name__ == '__main__':
w1 = gevent.spawn(work1)
w2 = gevent.spawn(work2)
gevent.joinall([w1, w2]) # 参数可以为list,set或者tuple7、进程、线程、协程对比
7.1 进程、线程、协程之间的关系
一个进程至少有一个线程,进程里面可以有多个线程
一个线程里面可以有多个协程

7.2 进程、线程、线程的对比
进程是资源分配的单位
线程是操作系统调度的单位
进程切换需要的资源最大,效率很低
线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
协程切换任务资源很小,效率高
多进程、多线程根据cpu核数不一样可能是并行的,但是协程是在一个线程中 所以是并发
小结
进程、线程、协程都是可以完成多任务的,可以根据自己实际开发的需要选择使用
由于线程、协程需要的资源很少,所以使用线程和协程的几率最大
开辟协程需要的资源最少
作者:y大壮
来源:https://juejin.cn/post/6971037591952949256
女友半夜加班发自拍 python男友用30行代码发现惊天秘密
事情是这样的
正准备下班的python开发小哥哥
接到女朋友今晚要加班的电话
并给他发来一张背景模糊的自拍照
如下 ↓ ↓ ↓
敏感的小哥哥心生疑窦,难道会有原谅帽
然后python撸了一段代码 分析照片
分析下来 emmm拍摄地址居然在 XXX酒店
小哥哥崩溃之余 大呼上当
python分析照片
小哥哥将发给自己的照片原图下载下来
并使用python写了一个脚本
读取到了照片拍摄的详细的地址
详细到了具体的街道和酒店名称
引入exifread模块
首先安装python的exifread模块,用于照片分析
pip install exifread 安装exfriead模块
PS C:\WINDOWS\system32> pip install exifread
Collecting exifread
Downloading ExifRead-2.3.2-py3-none-any.whl (38 kB)
Installing collected packages: exifread
Successfully installed exifread-2.3.2
PS C:\WINDOWS\system32> pip install jsonGPS经纬度信息
其实我们平时拍摄的照片里,隐藏了大量的私密信息
包括 拍摄时间、极其精确 具体的GPS信息。
下面是通过exifread模块,来读取照片内的经纬度信息。
#读取照片的GPS经纬度信息
def find_GPS_image(pic_path):
GPS = {}
date = ''
with open(pic_path, 'rb') as f:
tags = exifread.process_file(f)
for tag, value in tags.items():
#纬度
if re.match('GPS GPSLatitudeRef', tag):
GPS['GPSLatitudeRef'] = str(value)
#经度
elif re.match('GPS GPSLongitudeRef', tag):
GPS['GPSLongitudeRef'] = str(value)
#海拔
elif re.match('GPS GPSAltitudeRef', tag):
GPS['GPSAltitudeRef'] = str(value)
elif re.match('GPS GPSLatitude', tag):
try:
match_result = re.match('\[(\w*),(\w*),(\w.*)/(\w.*)\]', str(value)).groups()
GPS['GPSLatitude'] = int(match_result[0]), int(match_result[1]), int(match_result[2])
except:
deg, min, sec = [x.replace(' ', '') for x in str(value)[1:-1].split(',')]
GPS['GPSLatitude'] = latitude_and_longitude_convert_to_decimal_system(deg, min, sec)
elif re.match('GPS GPSLongitude', tag):
try:
match_result = re.match('\[(\w*),(\w*),(\w.*)/(\w.*)\]', str(value)).groups()
GPS['GPSLongitude'] = int(match_result[0]), int(match_result[1]), int(match_result[2])
except:
deg, min, sec = [x.replace(' ', '') for x in str(value)[1:-1].split(',')]
GPS['GPSLongitude'] = latitude_and_longitude_convert_to_decimal_system(deg, min, sec)
elif re.match('GPS GPSAltitude', tag):
GPS['GPSAltitude'] = str(value)
elif re.match('.*Date.*', tag):
date = str(value)
return {'GPS_information': GPS, 'date_information': date}百度API将GPS转地址
这里需要使用调用百度API,将GPS经纬度信息转换为具体的地址信息。
这里,你需要一个调用百度API的ak值,这个可以注册一个百度开发者获得,当然,你也可以使用博主的这个ak
调用之后,就可以将拍摄时间、拍摄详细地址都解析出来。
def find_address_from_GPS(GPS):
secret_key = 'zbLsuDDL4CS2U0M4KezOZZbGUY9iWtVf'
if not GPS['GPS_information']:
return '该照片无GPS信息'
#经纬度信息
lat, lng = GPS['GPS_information']['GPSLatitude'], GPS['GPS_information']['GPSLongitude']
baidu_map_api = "http://api.map.baidu.com/geocoder/v2/?ak={0}&callback=renderReverse&location={1},{2}s&output=json&pois=0".format(
secret_key, lat, lng)
response = requests.get(baidu_map_api)
#百度API转换成具体的地址
content = response.text.replace("renderReverse&&renderReverse(", "")[:-1]
print(content)
baidu_map_address = json.loads(content)
#将返回的json信息解析整理出来
formatted_address = baidu_map_address["result"]["formatted_address"]
province = baidu_map_address["result"]["addressComponent"]["province"]
city = baidu_map_address["result"]["addressComponent"]["city"]
district = baidu_map_address["result"]["addressComponent"]["district"]
location = baidu_map_address["result"]["sematic_description"]
return formatted_address,province,city,district,location
if __name__ == '__main__':
GPS_info = find_GPS_image(pic_path='C:/女友自拍.jpg')
address = find_address_from_GPS(GPS=GPS_info)
print("拍摄时间:" + GPS_info.get("date_information"))
print('照片拍摄地址:' + str(address))老王得到的结果是这样的
照片拍摄地址:('云南省红河哈尼族彝族自治州弥勒县', '云南省', '红河哈尼族彝族自治州', '弥勒县', '湖泉酒店-A座东南128米')
云南弥勒湖泉酒店,这明显不是老王女友工作的地方,老王搜索了一下,这是一家温泉度假酒店。
顿时就明白了
{"status":0,"result":{"location":{"lng":103.41424699999998,"lat":24.410461020097278},
"formatted_address":"云南省红河哈尼族彝族自治州弥勒县",
"business":"",
"addressComponent":{"country":"中国",
"country_code":0,
"country_code_iso":"CHN",
"country_code_iso2":"CN",
"province":"云南省",
"city":"红河哈尼族彝族自治州",
"city_level":2,"district":"弥勒县",
"town":"","town_code":"","adcode":"532526",
"street_number":"",
"direction":"","distance":""},
"sematic_description":"湖泉酒店-A座东南128米",
"cityCode":107}}
拍摄时间:2021:5:03 20:05:32
照片拍摄地址:('云南省红河哈尼族彝族自治州弥勒县', '云南省', '红河哈尼族彝族自治州', '弥勒县', '湖泉酒店-A座东南128米')完整代码如下
import exifread
import re
import json
import requests
import os
#转换经纬度格式
def latitude_and_longitude_convert_to_decimal_system(*arg):
"""
经纬度转为小数, param arg:
:return: 十进制小数
"""
return float(arg[0]) + ((float(arg[1]) + (float(arg[2].split('/')[0]) / float(arg[2].split('/')[-1]) / 60)) / 60)
#读取照片的GPS经纬度信息
def find_GPS_image(pic_path):
GPS = {}
date = ''
with open(pic_path, 'rb') as f:
tags = exifread.process_file(f)
for tag, value in tags.items():
#纬度
if re.match('GPS GPSLatitudeRef', tag):
GPS['GPSLatitudeRef'] = str(value)
#经度
elif re.match('GPS GPSLongitudeRef', tag):
GPS['GPSLongitudeRef'] = str(value)
#海拔
elif re.match('GPS GPSAltitudeRef', tag):
GPS['GPSAltitudeRef'] = str(value)
elif re.match('GPS GPSLatitude', tag):
try:
match_result = re.match('\[(\w*),(\w*),(\w.*)/(\w.*)\]', str(value)).groups()
GPS['GPSLatitude'] = int(match_result[0]), int(match_result[1]), int(match_result[2])
except:
deg, min, sec = [x.replace(' ', '') for x in str(value)[1:-1].split(',')]
GPS['GPSLatitude'] = latitude_and_longitude_convert_to_decimal_system(deg, min, sec)
elif re.match('GPS GPSLongitude', tag):
try:
match_result = re.match('\[(\w*),(\w*),(\w.*)/(\w.*)\]', str(value)).groups()
GPS['GPSLongitude'] = int(match_result[0]), int(match_result[1]), int(match_result[2])
except:
deg, min, sec = [x.replace(' ', '') for x in str(value)[1:-1].split(',')]
GPS['GPSLongitude'] = latitude_and_longitude_convert_to_decimal_system(deg, min, sec)
elif re.match('GPS GPSAltitude', tag):
GPS['GPSAltitude'] = str(value)
elif re.match('.*Date.*', tag):
date = str(value)
return {'GPS_information': GPS, 'date_information': date}
#通过baidu Map的API将GPS信息转换成地址。
def find_address_from_GPS(GPS):
"""
使用Geocoding API把经纬度坐标转换为结构化地址。
:param GPS:
:return:
"""
secret_key = 'zbLsuDDL4CS2U0M4KezOZZbGUY9iWtVf'
if not GPS['GPS_information']:
return '该照片无GPS信息'
lat, lng = GPS['GPS_information']['GPSLatitude'], GPS['GPS_information']['GPSLongitude']
baidu_map_api = "http://api.map.baidu.com/geocoder/v2/?ak={0}&callback=renderReverse&location={1},{2}s&output=json&pois=0".format(
secret_key, lat, lng)
response = requests.get(baidu_map_api)
content = response.text.replace("renderReverse&&renderReverse(", "")[:-1]
print(content)
baidu_map_address = json.loads(content)
formatted_address = baidu_map_address["result"]["formatted_address"]
province = baidu_map_address["result"]["addressComponent"]["province"]
city = baidu_map_address["result"]["addressComponent"]["city"]
district = baidu_map_address["result"]["addressComponent"]["district"]
location = baidu_map_address["result"]["sematic_description"]
return formatted_address,province,city,district,location
if __name__ == '__main__':
GPS_info = find_GPS_image(pic_path='C:/Users/pacer/desktop/img/5.jpg')
address = find_address_from_GPS(GPS=GPS_info)
print("拍摄时间:" + GPS_info.get("date_information"))
print('照片拍摄地址:' + str(address))作者:LexSaints
来源:https://juejin.cn/post/6967563349609414692
使用 Python 程序实现摩斯密码翻译器
摩斯密码是一种将文本信息作为一系列通断的音调、灯光或咔嗒声传输的方法,无需特殊设备,熟记的小伙伴即可直接翻译。它以电报发明者Samuel F. B. Morse的名字命名。
算法
算法非常简单。英语中的每个字符都被一系列“点”和“破折号”代替,或者有时只是单数的“点”或“破折号”,反之亦然。
加密
在加密的情况下,我们一次一个地从单词中提取每个字符(如果不是空格),并将其与存储在我们选择的任何数据结构中的相应摩斯密码匹配(如果您使用 python 编码,字典可以变成在这种情况下非常有用)
将摩斯密码存储在一个变量中,该变量将包含我们编码的字符串,然后我们在包含结果的字符串中添加一个空格。
在用摩斯密码编码时,我们需要在每个字符之间添加 1 个空格,在每个单词之间添加 2 个连续空格。
如果字符是空格,则向包含结果的变量添加另一个空格。我们重复这个过程,直到我们遍历整个字符串
解密
在解密的情况下,我们首先在要解码的字符串末尾添加一个空格(这将在后面解释)。
现在我们继续从字符串中提取字符,直到我们没有任何空间。
一旦我们得到一个空格,我们就会在提取的字符序列(或我们的莫尔斯电码)中查找相应的英语字符,并将其添加到将存储结果的变量中。
请记住,跟踪空间是此解密过程中最重要的部分。一旦我们得到 2 个连续的空格,我们就会向包含解码字符串的变量添加另一个空格。
字符串末尾的最后一个空格将帮助我们识别莫尔斯电码字符的最后一个序列(因为空格充当提取字符并开始解码它们的检查)。
执行
Python 提供了一种称为字典的数据结构,它以键值对的形式存储信息,这对于实现诸如摩尔斯电码之类的密码非常方便。我们可以将摩斯密码表保存在字典中,其中 (键值对)=>(英文字符-莫尔斯电码) 。明文(英文字符)代替密钥,密文(摩斯密码)形成相应密钥的值。键的值可以从字典中访问,就像我们通过索引访问数组的值一样,反之亦然。
摩斯密码对照表

# 实现摩斯密码翻译器的 Python 程序
'''
VARIABLE KEY
'cipher' -> '存储英文字符串的摩斯翻译形式'
'decipher' -> '存储摩斯字符串的英文翻译形式'
'citext' -> '存储单个字符的摩斯密码'
'i' -> '计算摩斯字符之间的空格'
'message' -> '存储要编码或解码的字符串
'''
# 表示摩斯密码图的字典
MORSE_CODE_DICT = { 'A':'.-', 'B':'-...',
'C':'-.-.', 'D':'-..', 'E':'.',
'F':'..-.', 'G':'--.', 'H':'....',
'I':'..', 'J':'.---', 'K':'-.-',
'L':'.-..', 'M':'--', 'N':'-.',
'O':'---', 'P':'.--.', 'Q':'--.-',
'R':'.-.', 'S':'...', 'T':'-',
'U':'..-', 'V':'...-', 'W':'.--',
'X':'-..-', 'Y':'-.--', 'Z':'--..',
'1':'.----', '2':'..---', '3':'...--',
'4':'....-', '5':'.....', '6':'-....',
'7':'--...', '8':'---..', '9':'----.',
'0':'-----', ', ':'--..--', '.':'.-.-.-',
'?':'..--..', '/':'-..-.', '-':'-....-',
'(':'-.--.', ')':'-.--.-'}
# 根据摩斯密码图对字符串进行加密的函数
def encrypt(message):
cipher = ''
for letter in message:
if letter != ' ':
# 查字典并添加对应的摩斯密码
# 用空格分隔不同字符的摩斯密码
cipher += MORSE_CODE_DICT[letter] + ' '
else:
# 1个空格表示不同的字符
# 2表示不同的词
cipher += ' '
return cipher
# 将字符串从摩斯解密为英文的函数
def decrypt(message):
# 在末尾添加额外空间以访问最后一个摩斯密码
message += ' '
decipher = ''
citext = ''
for letter in message:
# 检查空间
if (letter != ' '):
# 计数器来跟踪空间
i = 0
# 在空格的情况下
citext += letter
# 在空间的情况下
else:
# 如果 i = 1 表示一个新字符
i += 1
# 如果 i = 2 表示一个新词
if i == 2 :
# 添加空格来分隔单词
decipher += ' '
else:
# 使用它们的值访问密钥(加密的反向)
decipher += list(MORSE_CODE_DICT.keys())[list(MORSE_CODE_DICT
.values()).index(citext)]
citext = ''
return decipher
# 硬编码驱动函数来运行程序
def main():
message = "JUEJIN-HAIYONG"
result = encrypt(message.upper())
print (result)
message = ".--- ..- . .--- .. -. -....- .... .- .. -.-- --- -. --."
result = decrypt(message)
print (result)
message = "I LOVE YOU"
result = encrypt(message.upper())
print (result)
message = ".. .-.. --- ...- . -.-- --- ..-"
result = decrypt(message)
print (result)
# 执行主函数
if __name__ == '__main__':
main()输出:
.--- ..- . .--- .. -. -....- .... .- .. -.-- --- -. --.
JUEJIN-HAIYONG
.. .-.. --- ...- . -.-- --- ..-
I LOVE YOU作者:海拥
来源:https://juejin.cn/post/6990223674758397960
Python编程需要遵循的一些规则v2
Python编程需要遵循的一些规则v2
使用 pylint
pylint 是一个在 Python 源代码中查找 bug 的工具. 对于 C 和 C++ 这样的强类型静态语言来说, 这些 bug 通常由编译器来捕获. 由于 Python 的动态特性, 有些警告可能不对. 不过虚报的情况应该比较少. 确保对你的代码运行 pylint. 在 CI 流程中加入 pylint 检查的步骤. 抑制不准确的警告, 以便其他正确的警告可以暴露出来。
自底向上编程
自底向上编程(bottom up): 从最底层,依赖最少的地方开始设计结构及编写代码, 再编写调用这些代码的逻辑, 自底向上构造程序.
采取自底向上的设计方式会让代码更少以及开发过程更加敏捷.
自底向上的设计更容易产生符合单一责任原则(SRP) 的代码.
组件之间的调用关系清晰, 组件更易复用, 更易编写单元测试案例.
如:需要编写调用外部系统 API 获取数据来完成业务逻辑的代码.
应该先编写一个独立的模块将调用外部系统 API 获取数据的接口封装在一些函数中, 然后再编写如何调用这些函数 来完成业务逻辑.
不可以先写业务逻辑, 然后在需要调用外部 API 时再去实现相关代码, 这会产生调用 API 的代码直 接耦合在业务逻辑中的代码.
防御式编程
使用 assert 语句确保程序处于的正确状态 不要过度使用 assert, 应该只用于确保核心的部分.
注意 assert 不能代替运行时的异常, 不要忘记 assert 语句可能会被解析器忽略.
assert 语句通常可用于以下场景:
确保公共类或者函数被正确地调用 例如一个公共函数可以处理 list 或 dict 类型参数, 在函数开头使用
assert isinstance(param, (list, dict))确保函数接受的参数是 list 或 dictassert 用于确保不变量. 防止需求改变时引起代码行为的改变
if target == x:
run_x_code()
elif target == y:
run_y_code()
else:
run_z_code()
假设该代码上线时是正确的, target 只会是 x, y, z 三种情况, 但是稍后如果需求改变了, target 允许 w 的 情况出现. 当 target 为 w 时该代码就会错误地调用 run_z_code, 这通常会引起糟糕的后果.
使用 assert 来确保不变量
assert target in (x, y, z)
if target == x:
run_x_code()
elif target == y:
run_y_code()
else:
assert target == z
run_z_code()
不使用 assert 的场景:
不使用 assert 在校验用户输入的数据, 需要校验的情况下应该抛出异常
不将 assert 用于允许正常失败的情况, 将 assert 用于检查不允许失败的情况.
用户不应该直接看到 AssertionError, 如果用户可以看到, 将这种情况视为一个 BUG
避免使用 magic number
赋予特殊的常量一个名字, 避免重复地直接使用它们的字面值. 合适的时候使用枚举值 Enum.
使用常量在重构时只需要修改一个地方, 如果直接使用字面值在重构时将修改所有使用到的地方.
建议
GRAVITATIONAL_CONSTANT = 9.81
def get_potential_energy(mass, height):
return mass * height * GRAVITATIONAL_CONSTANT
class ConfigStatus:
ENABLED = 1
DISABLED = 0
Config.objects.filter(enabled=ConfigStatus.ENABLED)
不建议
def get_potential_energy(mass, height):
return mass * height * 9.81
# Django ORM
Config.objects.filter(enabled=1)
处理字典 key 不存在时的默认值
使用 dict.setdefault 或者 defaultdict
# group words by frequency
words = [(1, 'apple'), (2, 'banana'), (1, 'cat')]
frequency = {}
dict.setdefault
建议
for freq, word in words:
frequency.setdefault(freq, []).append(word)
或者使用 defaultdict
from collections import defaultdict
frequency = defaultdict(list)
for freq, word in words:
frequency[freq].append(word)
不建议
for freq, word in words:
if freq not in frequency:
frequency[freq] = []
frequency[freq].append(word)
注意在 Python 3 中 map filter 返回的是生成器而不是列表, 在隋性计算方面有所区别
禁止使用 import *
原则上禁止避免使用 import *, 应该显式地列出每一个需要导入的模块
使用 import * 会污染当前命名空间的变量, 无法找到变量的定义是来哪个模块, 在被 import 的模块上的改动可 能会在预期外地影响到其它模块, 可能会引起难以排查的问题.
在某些必须需要使用或者是惯用法 from foo import * 的场景下, 应该在模块 foo 的末尾使用 all 控制被导出的变量.
# foo.py
CONST_VALUE = 1
class Apple:
...
__all__ = ("CONST_VALUE", "Apple")
# bar.py
# noinspection PyUnresolvedReferences
from foo import *
作者:未来现相
来源:https://mp.weixin.qq.com/s/QinR-bHolVlr0z8IyhCqfg
Python对象的浅拷贝与深拷贝
在讲我们深浅拷贝之前,我们需要先区分一下拷贝和赋值的概念。看下面的例子
a = [1,2,3]赋值:
b = a拷贝:
b = a.copy()上面的两行代码究竟有什么不同呢?带着这个问题,继续

看了上面这张图,相信大家已经对直接赋值和拷贝有了一个比较清楚的认识。
直接赋值:复制一个对象的引用给新变量
拷贝:复制一个对象到新的内存地址空间,并且将新变量引用到复制后的对象
我们的深浅拷贝只是对于可变对象来讨论的。 不熟悉的朋友需要自己去了解可变对象与不可变对象哦。
1 对象的嵌套引用
a = { "list": [1,2,3] }上面的代码,在内存中是什么样子的呢?请看下图:

原来,在我们的嵌套对象中,子对象也是一个引用。
2 浅拷贝

如上图所示,我们就可以很好的理解什么叫做浅拷贝了。
浅拷贝:只拷贝父对象,不会拷贝对象的内部的子对象。内部的子对象指向的还是同一个引用
上面 的 a 和 c 是一个独立的对象,但他们的子对象还是指向统一对象
2.1 浅拷贝的方法
.copy()
a = {"list": [1,2,3] }
b = a.copy()
copy模块
import copy
a = {"list": [1,2,3] }
b = copy.copy(a)
列表切片[:]
a = [1,2,3,[1,2,3]]
b = a[1:]
for循环
a = [1,2,3,[1,2,3]]
b = []
for i in a:
b.append(i)
2.2 浅拷贝的影响
a = {"list":[1,2,3]}
b = a.copy()
a["list"].append(4)
print(a)
# {'list': [1, 2, 3, 4]}
print(b)
# {'list': [1, 2, 3, 4]}
在上面的例子中,我们明明只改变 a 的子对象,却发现 b 的子对象也跟着改变了。这样在我们的程序中也许会引发很多的BUG。
3 深拷贝
上面我们知道了什么是浅拷贝,那我们的深拷贝就更好理解了。

深拷贝:完全拷贝了父对象及其子对象,两者已经完成没有任何关联,是完全独立的。
import copy
a = {"list":[1,2,3]}
b = copy.deepcopy(a)
a["list"].append(4)
print(a)
# {'list': [1, 2, 3, 4]}
print(b)
# {'list': [1, 2, 3,]}
上面的例子中,我们再次修改 a 的子对象对 b 已经没有任何影响
4 手动实现一个深拷贝
主要采用递归的方法解决问题。判断拷贝的每一项子对象是否为引用对象。如果是就采用递归的方式将子对象进行复制。
def deepcopy(instance):
if isinstance(instance, dict):
return {k:deepcopy(v) for k,v in instance.items() }
elif isinstance(instance, list):
return [deepcopy(x) for x in instance]
else:
return instance
a = {"list": [1,2,3]}
b = deepcopy(a)
print(a)
# {'list': [1, 2, 3]}
print(b)
# {'list': [1, 2, 3]}
a["list"].append(4)
print(a)
# {'list': [1, 2, 3, 4]}
print(b)
# {'list': [1, 2, 3]}
创作不易,且读且珍惜。如有错漏还请海涵并联系作者修改,内容有参考,如有侵权,请联系作者删除。如果文章对您有帮助,还请动动小手,您的支持是我最大的动力。
作者:趣玩Python来源:https://blog.51cto.com/u_14666251/4716452 收起阅读 »
Python内存驻留机制
字符串驻留机制在许多面向对象编程语言中都支持,比如Java、python、Ruby、PHP等,它是一种数据缓存机制,对不可变数据类型使用同一个内存地址,有效的节省了空间,本文主要介绍Python的内存驻留机制。
驻留
字符串驻留就是每个字符串只有一个副本,多个对象共享该副本,驻留只针对不可变数据类型,比如字符串,布尔值,数字等。在这些固定数据类型处理中,使用驻留可以有效节省时间和空间,当然在驻留池中创建或者插入新的内容会消耗一定的时间。
下面举例介绍python中的驻留机制。
python内存驻留
在Python对象及内存管理机制一文中介绍了python的参数传递以及以及内存管理机制,来看下面一段代码:
l1 = [1, 2, 3, 4]
l2 = [1, 2, 3, 4]
l3 = l2
print(l1 == l2)
print(l1 is l2)
print(l2 == l3)
print(l2 is l3)知道结果是什么吗?下面是执行结果:
True
False
True
True
l1和l2内容相同,却指向了不同的内存地址,l2和l3之间使用等号赋值,所以指向了同一个对象。因为列表是可变对象,每创建一个列表,都会重新分配内存,列表对象是没有“内存驻留”机制的。下面来看不可变数据类型的驻留机制。
整型驻留
在Jupyter或者控制台交互环境中执行下面代码:
a1 = 300
b1 = 300
c1 = b1
print(a1 is b1)
print(c1 is b1)
a2 = 200
b2 = 200
c2 = b2
print(a2 is b2)
print(c2 is b2)执行结果:
False
True
True
True
可以发现a1和b1指向了不同的地址,a2和b2指向了相同的地址,这是为什么呢?
因为启动时,Python 将一个 -5~256 之间整数列表预加载(缓存)到内存中,我们在这个范围内创建一个整数对象时,python会自动引用缓存的对象,不会创建新的整数对象。
浮点型不支持:
a = 1.0
b = 1.0
print(a is b)
print(a == b)
# 结果
# False
# True如果上面的代码在非交互环境,也就是将代码作为python脚本运行的结果是什么呢?(运行环境为python3.7)
True
True
True
True
True
True
全为True,没有明确的限定临界值,都进行了驻留操作。这是因为使用不同的环境时,代码的优化方式不同。
字符串驻留
在Jupyter或者控制台交互环境中:
满足标识符命名规范的字符串都会被驻留,长度不限。
空字符串会驻留
使用乘法得到的字符串且满足标识符命名规范的字符串:长度小于等于20会驻留(peephole优化),Python 3.7改为4096(AST优化器)。
长度为1的特殊字符(ASCII 字符中的)会驻留
空元组或者只有一个元素且元素范围为-5~256的元组会驻留
满足标识符命名规范的字符:
a = 'Hello World'
b = 'Hello World'
print(a is b)
a = 'Hello_World'
b = 'Hello_World'
print(a is b)结果:
False
True
乘法获取字符串(运行环境为python3.7)
a = 'aa'*50
b = 'aa'*50
print(a is b)
a = 'aa'*5000
b = 'aa'*5000
print(a is b)结果:
True
False
在非交互环境中:
默认字符串都会驻留
使用乘法运算得到的字符串与在控制台相同
元组类型(元组内数据为不可变数据类型)会驻留
函数、类、变量、参数等的名称以及关键字都会驻留
注意:字符串是在编译时进行驻留,也就是说,如果字符串的值不能在编译时进行计算,将不会驻留。比如下面的例子:
letter = 'd'
a = 'Hello World'
b = 'Hello World'
c = 'Hello Worl' + 'd'
d = 'Hello Worl' + letter
e = " ".join(['Hello','World'])
print(id(a))
print(id(b))
print(id(c))
print(id(d))
print(id(e))在交互环境执行结果如下:
1696903309168
1696903310128
1696903269296
1696902074160
1696903282800都指向不同的内存。
python 3.7 非交互环境执行结果:
1426394439728
1426394439728
1426394439728
1426394571504
1426394571440发现d和e指向不同的内存,因为d和e不是在编译时计算的,而是在运行时计算的。前面的a = 'aa'*50是在编译时计算的。
强行驻留
除了上面介绍的python默认的驻留外,可以使用sys模块中的intern()函数来指定驻留内容
import sys
letter_d = 'd'
a = sys.intern('Hello World')
b = sys.intern('Hello World')
c = sys.intern('Hello Worl' + 'd')
d = sys.intern('Hello Worl' + letter)
e = sys.intern(" ".join(['Hello','World']))
print(id(a))
print(id(b))
print(id(c))
print(id(d))
print(id(e))结果:
1940593568304
1940593568304
1940593568304
1940593568304
1940593568304使用intern()后,都指向了相同的地址。
总结
本文主要介绍了python的内存驻留,内存驻留是python优化的一种策略,注意不同运行环境下优化策略不一样,不同的python版本也不相同。注意字符串是在编译时进行驻留。
作者:测试开发小记
来源:https://blog.51cto.com/u_15441270/4714515
能让你更早下班的Python垃圾回收机制
人生苦短,只谈风月,谈什么垃圾回收。
能让你更早下班的Python垃圾回收机制_内存空间

据说上图是某语言的垃圾回收机制。。。
我们写过C语言、C++的朋友都知道,我们的C语言是没有垃圾回收这种说法的。手动分配、释放内存都需要我们的程序员自己完成。不管是“内存泄漏” 还是野指针都是让开发者非常头疼的问题。所以C语言开发这个讨论得最多的话题就是内存管理了。但是对于其他高级语言来说,例如Java、C#、Python等高级语言,已经具备了垃圾回收机制。这样可以屏蔽内存管理的复杂性,使开发者可以更好的关注核心的业务逻辑。
对我们的Python开发者来说,我们可以当甩手掌柜。不用操心它怎么回收程序运行过程中产生的垃圾。但是这毕竟是一门语言的内心功法,难道我们甘愿一辈子做一个API调参侠吗?
1.什么是垃圾?
当我们的Python解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,而内存的容量是有限的,这就涉及到变量值所占用内存空间的回收问题。
当一个对象或者说变量没有用了,就会被当做“垃圾“。那什么样的变量是没有用的呢?
a = 10000当解释器执行到上面这里的时候,会划分一块内存来存储 10000 这个值。此时的 10000 是被变量 a 引用的
a = 30000当我们修改这个变量的值时,又划分了一块内存来存 30000 这个值,此时变量a引用的值是30000。
这个时候,我们的 10000 已经没有变量引用它了,我们也可以说它变成了垃圾,但是他依旧占着刚才给他的内存。那我们的解释器,就要把这块内存地盘收回来。
2.内存泄露和内存溢出
上面我们了解了什么是程序运行过程中的“垃圾”,那如果,产生了垃圾,我们不去处理,会产生什么样的后果呢?试想一下,如果你家从不丢垃圾,产生的垃圾就堆在家里会怎么呢?
家里堆满垃圾,有个美女想当你对象,但是已经没有空间给她住了。
你还能住,但是家里的垃圾很占地方,而且很浪费空间,慢慢的,总有一天你的家里会堆满垃圾
上面的结果其实就是计算机里面让所有程序员都闻风丧胆的问题,内存溢出和内存泄露,轻则导致程序运行速度减慢,重则导致程序崩溃。
内存溢出:程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory
内存泄露:程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光
3.引用计数
前面我们提到过垃圾的产生的是因为,对象没有再被其他变量引用了。那么,我们的解释器究竟是怎么知道一个对象还有没有被引用的呢?
答案就是:引用计数。python内部通过引用计数机制来统计一个对象被引用的次数。当这个数变成0的时候,就说明这个对象没有被引用了。这个时候它就变成了“垃圾”。
这个引用计数又是何方神圣呢?让我们看看代码
text = "hello,world"上面的一行代码做了哪些工作呢?
创建字符串对象:它的值是hello,world
开辟内存空间:在对象进行实例化的时候,解释器会为对象分配一段内存地址空间。把这个对象的结构体存储在这段内存地址空间中。
我们再来看看这个对象的结构体
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
熟悉c语言或者c++的朋友,看到这个应该特别熟悉,他就是结构体。这是因为我们Python官方的解释器是CPython,它底层调用了很多的c类库与接口。所以一些底层的数据是通过结构体进行存储的。看不懂的朋友也没有关系。
这里,我们只需要关注一个参数:ob_refcnt
这个参数非常神奇,它记录了这个对象的被变量引用的次数。所以上面 hello,world 这个对象的引用计数就是 1,因为现在只有text这个变量引用了它。
3.1 变量初始化赋值:
text = "hello,world"
3.2 变量引用传递:
new_text = text
3.3 删除第一个变量:
del text
3.4 删除第二个变量:
del new_text
此时 “hello,world” 对象的引用计数为:0,被当成了垃圾。下一步,就该被我们的垃圾回收器给收走了。

4.引用计数如何变化
上面我们了解了什么是引用计数。那这个参数什么时候会发生变化呢?
4.1 引用计数加一的情况
对象被创建
a = "hello,world"对象被别的变量引用(赋值给一个变量)
b = a对象被作为元素,放在容器中(比如被当作元素放在列表中)
list = []
list.append(a)
对象作为参数传递给函数
func(a)4.2 引用计数减一
对象的引用变量被显示销毁
del a对象的引用变量赋值引用其他对象
a = "hello, Python" # a的原来的引用对象:a = "hello,world"对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
del listlist.remove(a)一个引用离开了它的作用域
func():
a = "hello,world"
return
func() # 函数执行结束以后,函数作用域里面的局部变量a会被释放
4.3 查看对象的引用计数
如果要查看对象的引用计数,可以通过内置模块 sys 提供的 getrefcount 方法去查看。
import sys
a = "hello,world"
print(sys.getrefcount(a))
注意:当使用某个引用作为参数,传递给 getrefcount() 时,参数实际上创建了一个临时的引用。因此,getrefcount() 所得到的结果,会比期望的多 1
5.垃圾回收机制
其实Python的垃圾回收机制,我们前面已经说得差不多了。
Python通过引用计数的方法来说实现垃圾回收,当一个对象的引用计数为0的时候,就进行垃圾回收。但是如果只使用引用计数也是有点问题的。所以,python又引进了标记-清除和分代收集两种机制。
Python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略。
前面的引用计数我们已经了解了,那这个标记-清除跟分代收集又是什么呢?
5.1 引用计数机制缺点
Python语言默认采用的垃圾收集机制是“引用计数法 ”,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。
引用计数法:每个对象维护一个 ob_refcnt 字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数ob_refcnt加1,每当该对象的引用失效时计数ob_refcnt减1,一旦对象的引用计数为0,该对象立即被回收,对象占用的内存空间将被释放。
缺点:
需要额外的空间维护引用计数
无法解决循环引用问题
什么是循环引用问题?看看下面的例子
a = {"key":"a"} # 字典对象a的引用计数:1
b = {"key":"b"} # 字典对象b的引用计数:1
a["b"] = b # 字典对象b的引用计数:2
b["a"] = a # 字典对象a的引用计数:2
del a # 字典对象a的引用计数:1
del b # 字典对象b的引用计数:1
看上面的例子,明明两个变量都删除了,但是这两个对象却没有得到释放。原因是他们的引用计数都没有减少到0。而我们垃圾回收机制只有当引用计数为0的时候才会释放对象。这是一个无法解决的致命问题。这两个对象始终不会被销毁,这样就会导致内存泄漏。
那怎么解决这个问题呢?这个时候 标记-清除 就排上了用场。标记清除可以处理这种循环引用的情况。
5.2 标记-清除策略
Python采用了标记-清除策略,解决容器对象可能产生的循环引用问题。
该策略在进行垃圾回收时分成了两步,分别是:
标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达;
清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收
这里简单介绍一下标记-清除策略的流程

可达(活动)对象:从root集合节点有(通过链式引用)路径达到的对象节点
不可达(非活动)对象:从root集合节点没有(通过链式引用)路径到达的对象节点
流程:
首先,从root集合节点出发,沿着有向边遍历所有的对象节点
对每个对象分别标记可达对象还是不可达对象
再次遍历所有节点,对所有标记为不可达的对象进行垃圾回收、销毁。
标记-清除是一种周期性策略,相当于是一个定时任务,每隔一段时间进行一次扫描。
并且标记-清除工作时会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
5.3 分代回收策略
分代回收建立标记清除的基础之上,因为我们的标记-清除策略会将我们的程序阻塞。为了减少应用程序暂停的时间,Python 通过“分代回收”(Generational Collection)策略。以空间换时间的方法提高垃圾回收效率。
分代的垃圾收集技术是在上个世纪 80 年代初发展起来的一种垃圾收集机制。
简单来说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集
Python 将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python 将内存分为了 3“代”,分别为年轻代(第 0 代)、中年代(第 1 代)、老年代(第 2 代)。
那什么时候会触发分代回收呢?
import gc
print(gc.get_threshold())
# (700, 10, 10)
# 上面这个是默认的回收策略的阈值
# 也可以自己设置回收策略的阈值
gc.set_threshold(500, 5, 5)700:表示当分配对象的个数达到700时,进行一次0代回收
10:当进行10次0代回收以后触发一次1代回收
10:当进行10次1代回收以后触发一次2代回收

5.4 gc模块
gc.get_count():获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
gc.get_threshold():获取gc模块中自动执行垃圾回收的频率,默认是(700, 10, 10)
gc.set_threshold(threshold0[,threshold1,threshold2]):设置自动执行垃圾回收的频率
gc.disable():python3默认开启gc机制,可以使用该方法手动关闭gc机制
gc.collect():手动调用垃圾回收机制回收垃圾
其实,既然我们选择了python,性能就不是最重要的了。我相信大部分的python工程师甚至都还没遇到过性能问题,因为现在的机器性能可以弥补。而对于内存管理与垃圾回收,python提供了甩手掌柜的方式让我们更关注业务层,这不是更加符合人生苦短,我用python的理念么。如果我还需要像C++那样小心翼翼的进行内存的管理,那我为什么还要用python呢?咱不就是图他的便利嘛。所以,放心去干吧。越早下班越好!
创作不易,且读且珍惜。如有错漏还请海涵并联系作者修改,内容有参考,如有侵权,请联系作者删除。如果文章对您有帮助,还请动动小手,您的支持是我最大的动力。
作者: 趣玩Python
来源:https://blog.51cto.com/u_14666251/4674779
黑科技,Python 脚本帮你找出微信上删除你好友的人
查看被删的微信好友
原理就是新建群组,如果加不进来就是被删好友了(不要在群组里讲话,别人是看不见的)
用的是微信网页版的接口
查询结果可能会引起一些心理上的不适,请小心使用..(逃
还有些小问题:
结果好像有疏漏一小部分,原因不明..
最终会遗留下一个只有自己的群组,需要手工删一下
没试过被拉黑的情况
新手步骤 Mac 上步骤:
在 Mac 上操作,下载代码文件wdf.py
打开 Terminal 输入:python +空格,然后拖动刚才下载的 wdf.py 到 Terminal 后回车。格式: python wdf.py
接下来按步骤操作即可;
代码如下:
#!/usr/bin/env python
# coding=utf-8
import os
import urllib, urllib2
import re
import cookielib
import time
import xml.dom.minidom
import json
import sys
import math
DEBUG = False
MAX_GROUP_NUM = 35 # 每组人数
QRImagePath = os.getcwd() + '/qrcode.jpg'
tip = 0
uuid = ''
base_uri = ''
redirect_uri = ''
skey = ''
wxsid = ''
wxuin = ''
pass_ticket = ''
deviceId = 'e000000000000000'
BaseRequest = {}
ContactList = []
My = []
def getUUID():
global uuid
url = 'https://login.weixin.qq.com/jslogin'
params = {
'appid': 'wx782c26e4c19acffb',
'fun': 'new',
'lang': 'zh_CN',
'_': int(time.time()),
}
request = urllib2.Request(url = url, data = urllib.urlencode(params))
response = urllib2.urlopen(request)
data = response.read()
# print data
# window.QRLogin.code = 200; window.QRLogin.uuid = "oZwt_bFfRg==";
regx = r'window.QRLogin.code = (\d+); window.QRLogin.uuid = "(\S+?)"'
pm = re.search(regx, data)
code = pm.group(1)
uuid = pm.group(2)
if code == '200':
return True
return False
def showQRImage():
global tip
url = 'https://login.weixin.qq.com/qrcode/' + uuid
params = {
't': 'webwx',
'_': int(time.time()),
}
request = urllib2.Request(url = url, data = urllib.urlencode(params))
response = urllib2.urlopen(request)
tip = 1
f = open(QRImagePath, 'wb')
f.write(response.read())
f.close()
if sys.platform.find('darwin') >= 0:
os.system('open %s' % QRImagePath)
elif sys.platform.find('linux') >= 0:
os.system('xdg-open %s' % QRImagePath)
else:
os.system('call %s' % QRImagePath)
print '请使用微信扫描二维码以登录'
def waitForLogin():
global tip, base_uri, redirect_uri
url = 'https://login.weixin.qq.com/cgi-bin/mmwebwx-bin/login?tip=%s&uuid=%s&_=%s' % (tip, uuid, int(time.time()))
request = urllib2.Request(url = url)
response = urllib2.urlopen(request)
data = response.read()
# print data
# window.code=500;
regx = r'window.code=(\d+);'
pm = re.search(regx, data)
code = pm.group(1)
if code == '201': #已扫描
print '成功扫描,请在手机上点击确认以登录'
tip = 0
elif code == '200': #已登录
print '正在登录...'
regx = r'window.redirect_uri="(\S+?)";'
pm = re.search(regx, data)
redirect_uri = pm.group(1) + '&fun=new'
base_uri = redirect_uri[:redirect_uri.rfind('/')]
elif code == '408': #超时
pass
# elif code == '400' or code == '500':
return code
def login():
global skey, wxsid, wxuin, pass_ticket, BaseRequest
request = urllib2.Request(url = redirect_uri)
response = urllib2.urlopen(request)
data = response.read()
# print data
'''
0
OK
xxx
xxx
xxx
xxx
1
'''
doc = xml.dom.minidom.parseString(data)
root = doc.documentElement
for node in root.childNodes:
if node.nodeName == 'skey':
skey = node.childNodes[0].data
elif node.nodeName == 'wxsid':
wxsid = node.childNodes[0].data
elif node.nodeName == 'wxuin':
wxuin = node.childNodes[0].data
elif node.nodeName == 'pass_ticket':
pass_ticket = node.childNodes[0].data
# print 'skey: %s, wxsid: %s, wxuin: %s, pass_ticket: %s' % (skey, wxsid, wxuin, pass_ticket)
if skey == '' or wxsid == '' or wxuin == '' or pass_ticket == '':
return False
BaseRequest = {
'Uin': int(wxuin),
'Sid': wxsid,
'Skey': skey,
'DeviceID': deviceId,
}
return True
def webwxinit():
url = base_uri + '/webwxinit?pass_ticket=%s&skey=%s&r=%s' % (pass_ticket, skey, int(time.time()))
params = {
'BaseRequest': BaseRequest
}
request = urllib2.Request(url = url, data = json.dumps(params))
request.add_header('ContentType', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
data = response.read()
if DEBUG == True:
f = open(os.getcwd() + '/webwxinit.json', 'wb')
f.write(data)
f.close()
# print data
global ContactList, My
dic = json.loads(data)
ContactList = dic['ContactList']
My = dic['User']
ErrMsg = dic['BaseResponse']['ErrMsg']
if len(ErrMsg) > 0:
print ErrMsg
Ret = dic['BaseResponse']['Ret']
if Ret != 0:
return False
return True
def webwxgetcontact():
url = base_uri + '/webwxgetcontact?pass_ticket=%s&skey=%s&r=%s' % (pass_ticket, skey, int(time.time()))
request = urllib2.Request(url = url)
request.add_header('ContentType', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
data = response.read()
if DEBUG == True:
f = open(os.getcwd() + '/webwxgetcontact.json', 'wb')
f.write(data)
f.close()
# print data
dic = json.loads(data)
MemberList = dic['MemberList']
# 倒序遍历,不然删除的时候出问题..
SpecialUsers = ['newsapp', 'fmessage', 'filehelper', 'weibo', 'qqmail', 'fmessage', 'tmessage', 'qmessage', 'qqsync', 'floatbottle', 'lbsapp', 'shakeapp', 'medianote', 'qqfriend', 'readerapp', 'blogapp', 'facebookapp', 'masssendapp', 'meishiapp', 'feedsapp', 'voip', 'blogappweixin', 'weixin', 'brandsessionholder', 'weixinreminder', 'wxid_novlwrv3lqwv11', 'gh_22b87fa7cb3c', 'officialaccounts', 'notification_messages', 'wxid_novlwrv3lqwv11', 'gh_22b87fa7cb3c', 'wxitil', 'userexperience_alarm', 'notification_messages']
for i in xrange(len(MemberList) - 1, -1, -1):
Member = MemberList[i]
if Member['VerifyFlag'] & 8 != 0: # 公众号/服务号
MemberList.remove(Member)
elif Member['UserName'] in SpecialUsers: # 特殊账号
MemberList.remove(Member)
elif Member['UserName'].find('@@') != -1: # 群聊
MemberList.remove(Member)
elif Member['UserName'] == My['UserName']: # 自己
MemberList.remove(Member)
return MemberList
def createChatroom(UserNames):
MemberList = []
for UserName in UserNames:
MemberList.append({'UserName': UserName})
url = base_uri + '/webwxcreatechatroom?pass_ticket=%s&r=%s' % (pass_ticket, int(time.time()))
params = {
'BaseRequest': BaseRequest,
'MemberCount': len(MemberList),
'MemberList': MemberList,
'Topic': '',
}
request = urllib2.Request(url = url, data = json.dumps(params))
request.add_header('ContentType', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
data = response.read()
# print data
dic = json.loads(data)
ChatRoomName = dic['ChatRoomName']
MemberList = dic['MemberList']
DeletedList = []
for Member in MemberList:
if Member['MemberStatus'] == 4: #被对方删除了
DeletedList.append(Member['UserName'])
ErrMsg = dic['BaseResponse']['ErrMsg']
if len(ErrMsg) > 0:
print ErrMsg
return (ChatRoomName, DeletedList)
def deleteMember(ChatRoomName, UserNames):
url = base_uri + '/webwxupdatechatroom?fun=delmember&pass_ticket=%s' % (pass_ticket)
params = {
'BaseRequest': BaseRequest,
'ChatRoomName': ChatRoomName,
'DelMemberList': ','.join(UserNames),
}
request = urllib2.Request(url = url, data = json.dumps(params))
request.add_header('ContentType', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
data = response.read()
# print data
dic = json.loads(data)
ErrMsg = dic['BaseResponse']['ErrMsg']
if len(ErrMsg) > 0:
print ErrMsg
Ret = dic['BaseResponse']['Ret']
if Ret != 0:
return False
return True
def addMember(ChatRoomName, UserNames):
url = base_uri + '/webwxupdatechatroom?fun=addmember&pass_ticket=%s' % (pass_ticket)
params = {
'BaseRequest': BaseRequest,
'ChatRoomName': ChatRoomName,
'AddMemberList': ','.join(UserNames),
}
request = urllib2.Request(url = url, data = json.dumps(params))
request.add_header('ContentType', 'application/json; charset=UTF-8')
response = urllib2.urlopen(request)
data = response.read()
# print data
dic = json.loads(data)
MemberList = dic['MemberList']
DeletedList = []
for Member in MemberList:
if Member['MemberStatus'] == 4: #被对方删除了
DeletedList.append(Member['UserName'])
ErrMsg = dic['BaseResponse']['ErrMsg']
if len(ErrMsg) > 0:
print ErrMsg
return DeletedList
def main():
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookielib.CookieJar()))
urllib2.install_opener(opener)
if getUUID() == False:
print '获取uuid失败'
return
showQRImage()
time.sleep(1)
while waitForLogin() != '200':
pass
os.remove(QRImagePath)
if login() == False:
print '登录失败'
return
if webwxinit() == False:
print '初始化失败'
return
MemberList = webwxgetcontact()
MemberCount = len(MemberList)
print '通讯录共%s位好友' % MemberCount
ChatRoomName = ''
result = []
for i in xrange(0, int(math.ceil(MemberCount / float(MAX_GROUP_NUM)))):
UserNames = []
NickNames = []
DeletedList = ''
for j in xrange(0, MAX_GROUP_NUM):
if i * MAX_GROUP_NUM + j >= MemberCount:
break
Member = MemberList[i * MAX_GROUP_NUM + j]
UserNames.append(Member['UserName'])
NickNames.append(Member['NickName'].encode('utf-8'))
print '第%s组...' % (i + 1)
print ', '.join(NickNames)
print '回车键继续...'
raw_input()
# 新建群组/添加成员
if ChatRoomName == '':
(ChatRoomName, DeletedList) = createChatroom(UserNames)
else:
DeletedList = addMember(ChatRoomName, UserNames)
DeletedCount = len(DeletedList)
if DeletedCount > 0:
result += DeletedList
print '找到%s个被删好友' % DeletedCount
# raw_input()
# 删除成员
deleteMember(ChatRoomName, UserNames)
# todo 删除群组
resultNames = []
for Member in MemberList:
if Member['UserName'] in result:
NickName = Member['NickName']
if Member['RemarkName'] != '':
NickName += '(%s)' % Member['RemarkName']
resultNames.append(NickName.encode('utf-8'))
print '---------- 被删除的好友列表 ----------'
print '\n'.join(resultNames)
print '-----------------------------------'
# windows下编码问题修复
# http://blog.csdn.net/heyuxuanzee/article/details/8442718
class UnicodeStreamFilter:
def __init__(self, target):
self.target = target
self.encoding = 'utf-8'
self.errors = 'replace'
self.encode_to = self.target.encoding
def write(self, s):
if type(s) == str:
s = s.decode('utf-8')
s = s.encode(self.encode_to, self.errors).decode(self.encode_to)
self.target.write(s)
if sys.stdout.encoding == 'cp936':
sys.stdout = UnicodeStreamFilter(sys.stdout)
if __name__ == '__main__' :
print '本程序的查询结果可能会引起一些心理上的不适,请小心使用...'
print '回车键继续...'
raw_input()
main()
print '回车键结束'
raw_input()作者: 0x5e(github id)
来源:https://juejin.cn/post/6844903425629487112
收起阅读 »就业寒冬,从拉勾招聘看Python就业前景
1.数据采集
事情的起源是这样的,某个风和日丽的下午... 习惯性的打开知乎准备划下水,看到一个问题刚好邀请回答

于是就萌生了采集下某招聘网站Python岗位招聘的信息,看一下目前的薪水和岗位分布,说干就干。
先说下数据采集过程中遇到的问题,首先请求头是一定要伪装的,否则第一步就会给你弹出你的请求太频繁,请稍后再试,其次网站具有多重反爬策略,解决方案是每次先获取session然后更新我们的session进行抓取,最后拿到了想要的数据。
Chrome浏览器右键检查查看network,找到链接https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false

可以看到返回的数据正是页面的Python招聘详情,于是我直接打开发现直接提示{"status":false,"msg":"您操作太频繁,请稍后再访问","clientIp":"124.77.161.207","state":2402},机智的我察觉到事情并没有那么简单

真正的较量才刚刚开始,我们先来分析下请求的报文,


可以看到请求是以post的方式传递的,同时传递了参数
datas = {
'first': 'false',
'pn': x,
'kd': 'python',
}同时不难发现每次点击下一页都会同时发送一条get请求


经过探索,发现这个get请求和我们post请求是一致的,那么问题就简单许多,整理一下思路

关键词:python 搜索范围:全国 数据时效:2019.05.05
#!/usr/bin/env python3.4
# encoding: utf-8
"""
Created on 19-5-05
@title: ''
@author: Xusl
"""
import json
import requests
import xlwt
import time
# 获取存储职位信息的json对象,遍历获得公司名、福利待遇、工作地点、学历要求、工作类型、发布时间、职位名称、薪资、工作年限
def get_json(url, datas):
my_headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36",
"Referer": "https://www.lagou.com/jobs/list_Python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=",
"Content-Type": "application/x-www-form-urlencoded;charset = UTF-8"
}
time.sleep(5)
ses = requests.session() # 获取session
ses.headers.update(my_headers) # 更新
ses.get("https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=")
content = ses.post(url=url, data=datas)
result = content.json()
info = result['content']['positionResult']['result']
info_list = []
for job in info:
information = []
information.append(job['positionId']) # 岗位对应ID
information.append(job['city']) # 岗位对应城市
information.append(job['companyFullName']) # 公司全名
information.append(job['companyLabelList']) # 福利待遇
information.append(job['district']) # 工作地点
information.append(job['education']) # 学历要求
information.append(job['firstType']) # 工作类型
information.append(job['formatCreateTime']) # 发布时间
information.append(job['positionName']) # 职位名称
information.append(job['salary']) # 薪资
information.append(job['workYear']) # 工作年限
info_list.append(information)
# 将列表对象进行json格式的编码转换,其中indent参数设置缩进值为2
# print(json.dumps(info_list, ensure_ascii=False, indent=2))
# print(info_list)
return info_list
def main():
page = int(input('请输入你要抓取的页码总数:'))
# kd = input('请输入你要抓取的职位关键字:')
# city = input('请输入你要抓取的城市:')
info_result = []
title = ['岗位id', '城市', '公司全名', '福利待遇', '工作地点', '学历要求', '工作类型', '发布时间', '职位名称', '薪资', '工作年限']
info_result.append(title)
for x in range(1, page+1):
url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
datas = {
'first': 'false',
'pn': x,
'kd': 'python',
}
try:
info = get_json(url, datas)
info_result = info_result + info
print("第%s页正常采集" % x)
except Exception as msg:
print("第%s页出现问题" % x)
# 创建workbook,即excel
workbook = xlwt.Workbook(encoding='utf-8')
# 创建表,第二参数用于确认同一个cell单元是否可以重设值
worksheet = workbook.add_sheet('lagouzp', cell_overwrite_ok=True)
for i, row in enumerate(info_result):
# print(row)
for j, col in enumerate(row):
# print(col)
worksheet.write(i, j, col)
workbook.save('lagouzp.xls')
if __name__ == '__main__':
main()

当然存储于excel当然是不够的,之前一直用matplotlib做数据可视化,这次换个新东西pyecharts。
2.了解pyecharts
pyecharts是一款将python与echarts结合的强大的数据可视化工具,包含多种图表
Bar(柱状图/条形图)
Bar3D(3D 柱状图)
Boxplot(箱形图)
EffectScatter(带有涟漪特效动画的散点图)
Funnel(漏斗图)
Gauge(仪表盘)
Geo(地理坐标系)
Graph(关系图)
HeatMap(热力图)
Kline(K线图)
Line(折线/面积图)
Line3D(3D 折线图)
Liquid(水球图)
Map(地图)
Parallel(平行坐标系)
Pie(饼图)
Polar(极坐标系)
Radar(雷达图)
Sankey(桑基图)
Scatter(散点图)
Scatter3D(3D 散点图)
ThemeRiver(主题河流图)
WordCloud(词云图)
用户自定义
Grid 类:并行显示多张图
Overlap 类:结合不同类型图表叠加画在同张图上
Page 类:同一网页按顺序展示多图
Timeline 类:提供时间线轮播多张图
另外需要注意的是从版本0.3.2 开始,为了缩减项目本身的体积以及维持 pyecharts 项目的轻量化运行,pyecharts 将不再自带地图 js 文件。如用户需要用到地图图表(Geo、Map),可自行安装对应的地图文件包。
全球国家地图: echarts-countries-pypkg (1.9MB): 世界地图和 213 个国家,包括中国地图
中国省级地图: echarts-china-provinces-pypkg (730KB):23 个省,5 个自治区
中国市级地图: echarts-china-cities-pypkg (3.8MB):370 个中国城市
也可以使用命令进行安装
pip install echarts-countries-pypkg
pip install echarts-china-provinces-pypkg
pip install echarts-china-cities-pypkg3.数据可视化(代码+展示)
各城市招聘数量
from pyecharts import Bar
city_nms_top10 = ['北京', '上海', '深圳', '成都', '杭州', '广州', '武汉', '南京', '苏州', '郑州', '天津', '西安', '东莞', '珠海', '合肥', '厦门', '宁波','南宁', '重庆', '佛山', '大连', '哈尔滨', '长沙', '福州', '中山']
city_nums_top10 = [149, 95, 77, 22, 17, 17, 16, 13, 7, 5, 4, 4, 3, 2, 2, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1]
bar = Bar("Python岗位", "各城市数量")
bar.add("数量", city_nms, city_nums, is_more_utils=True)
# bar.print_echarts_options() # 该行只为了打印配置项,方便调试时使用
bar.render('Python岗位各城市数量.html') # 生成本地 HTML 文件
地图分布展示(这个场景意义不大,不过多分析)
from pyecharts import Geo
city_datas = [('北京', 149), ('上海', 95), ('深圳', 77), ('成都', 22), ('杭州', 17), ('广州', 17), ('武汉', 16), ('南京', 13), ('苏州', 7), ('郑州', 5), ('天津', 4), ('西安', 4), ('东莞', 3), ('珠海', 2), ('合肥', 2), ('厦门', 2), ('宁波', 1), ('南宁', 1), ('重庆', 1), ('佛山', 1), ('大连', 1), ('哈尔滨', 1), ('长沙', 1), ('福州', 1), ('中山', 1)]
geo = Geo("Python岗位城市分布地图", "数据来源拉勾", title_color="#fff",
title_pos="center", width=1200,
height=600, background_color='#404a59')
attr, value = geo.cast(city_datas)
geo.add("", attr, value, visual_range=[0, 200], visual_text_color="#fff",symbol_size=15, is_visualmap=True)
geo.render("Python岗位城市分布地图_scatter.html")
geo = Geo("Python岗位城市分布地图", "数据来源拉勾", title_color="#fff",
title_pos="center", width=1200,
height=600, background_color='#404a59')
attr, value = geo.cast(city_datas)
geo.add("", attr, value, type="heatmap", visual_range=[0,10],visual_text_color="#fff",symbol_size=15,is_visualmap=True)
geo.render("Python岗位城市分布地图_heatmap.html")

各个城市招聘情况
from pyecharts import Pie
city_nms_top10 = ['北京', '上海', '深圳', '成都', '广州', '杭州', '武汉', '南京', '苏州', '郑州']
city_nums_top10 = [149, 95, 77, 22, 17, 17, 16, 13, 7, 5]
pie = Pie()
pie.add("", city_nms_top10, city_nums_top10, is_label_show=True)
# pie.show_config()
pie.render('Python岗位各城市分布饼图.html')
北上深的岗位明显碾压其它城市,这也反映出为什么越来越多的it从业人员毕业以后相继奔赴一线城市,除了一线城市的薪资高于二三线这个因素外,还有一个最重要的原因供需关系,因为一线岗位多,可选择性也就比较高,反观二三线的局面,很有可能你跳个几次槽,发现同行业能呆的公司都待过了...
薪资范围

由此可见,python的岗位薪资多数在10k~20k,想从事Python行业的可以把工作年限和薪资结合起来参考一下。
学历要求 + 工作年限

从工作年限来看,1-3年或者3-5年工作经验的招聘比较多,而应届生和一年以下的寥寥无几,对实习生实在不太友好,学历也普遍要求本科,多数公司都很重视入职人员学历这点毋容置疑,虽然学历不代表一切,但是对于一个企业来说,想要短时间内判断一个人的能力,最快速有效的方法无疑是从学历入手。学历第一关,面试第二关。
但是,这不代表学历不高的人就没有好的出路,现在的大学生越来越多,找工作也越来越难,竞争越来越激烈,即使具备高学历,也不能保证你一定可以找到满意的工作,天道酬勤,特别是it这个行业,知识的迭代,比其他行业来的更频密。不断学习,拓展自己学习的广度和深度,才是最正确的决定。
就业寒冬来临,我们需要的是理性客观的看待,而不是盲目地悲观或乐观。从以上数据分析,如果爱好Python,仍旧可以入坑,不过要注意一个标签有工作经验,就算没有工作经验,自己在学习Python的过程中一定要尝试独立去做一个完整的项目,爬虫也好,数据分析也好,亦或者是开发,都要尝试独立去做一套系统,在这个过程中培养自己思考和解决问题的能力。持续不断的学习,才是对自己未来最好的投资,也是度过寒冬最正确的姿势。
作者:一只写程序的猿
来源:https://juejin.cn/post/6844903837698883597
Fiddler抓取抖音视频数据
本文仅供参考学习,禁止用于任何形式的商业用途,违者自行承担责任。
准备工作:
手机(安卓、ios都可以)/安卓模拟器,今天主要以安卓模拟器为主,操作过程一致。
抓包工具:Fiddel 下载地址:(https://www.telerik.com/download/fiddler )
编程工具:pycharm
安卓模拟器上安装抖音(逍遥安装模拟器)
一、fiddler配置
在tools中的options中,按照图中勾选后点击Actions
配置远程链接:
选择允许监控远程链接,端口可以随意设置,只要别重复就行,默认8888
然后:重启fiddler!!!这样配置才能生效。
二、安卓模拟器/手机配置
首先查看本机的IP:在cmd中输入ipconfig,记住这个IP
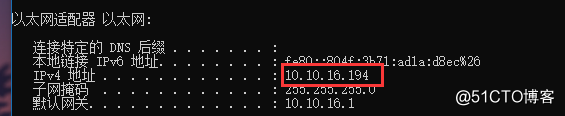
手机确保和电脑在同一局域网下。
手机配置:配置已连接的WiFi,代理选择手动,然后输入上图ip端口号为8888
模拟器配置:设置中长按已连接wifi,代理选择手动,然后输入上图ip端口号为8888

代理设置好后,在浏览器中输入你设置的ip:端口,例如10.10.16.194:8888,就会打开fiddler的页面。然后点击fiddlerRoot certificate安装证书,要不手机会认为环境不安全。
证书名称随便设,可能还需要设置一个锁屏密码。
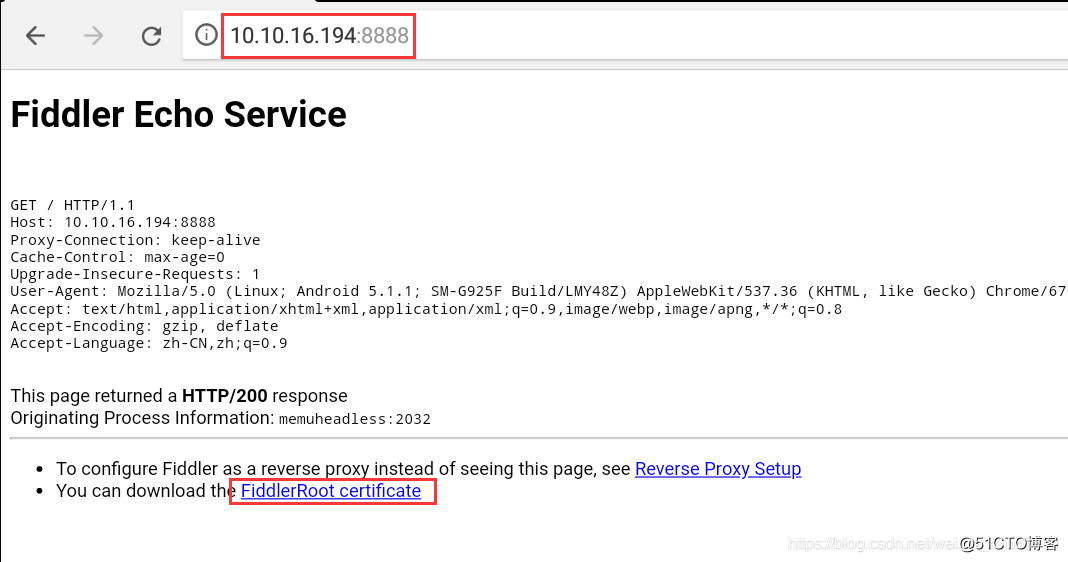
接下来就可以在fiddler中抓到手机/模拟器软件的包了。
三、抖音抓包
打开抖音,然后观察fiddler中所有的包
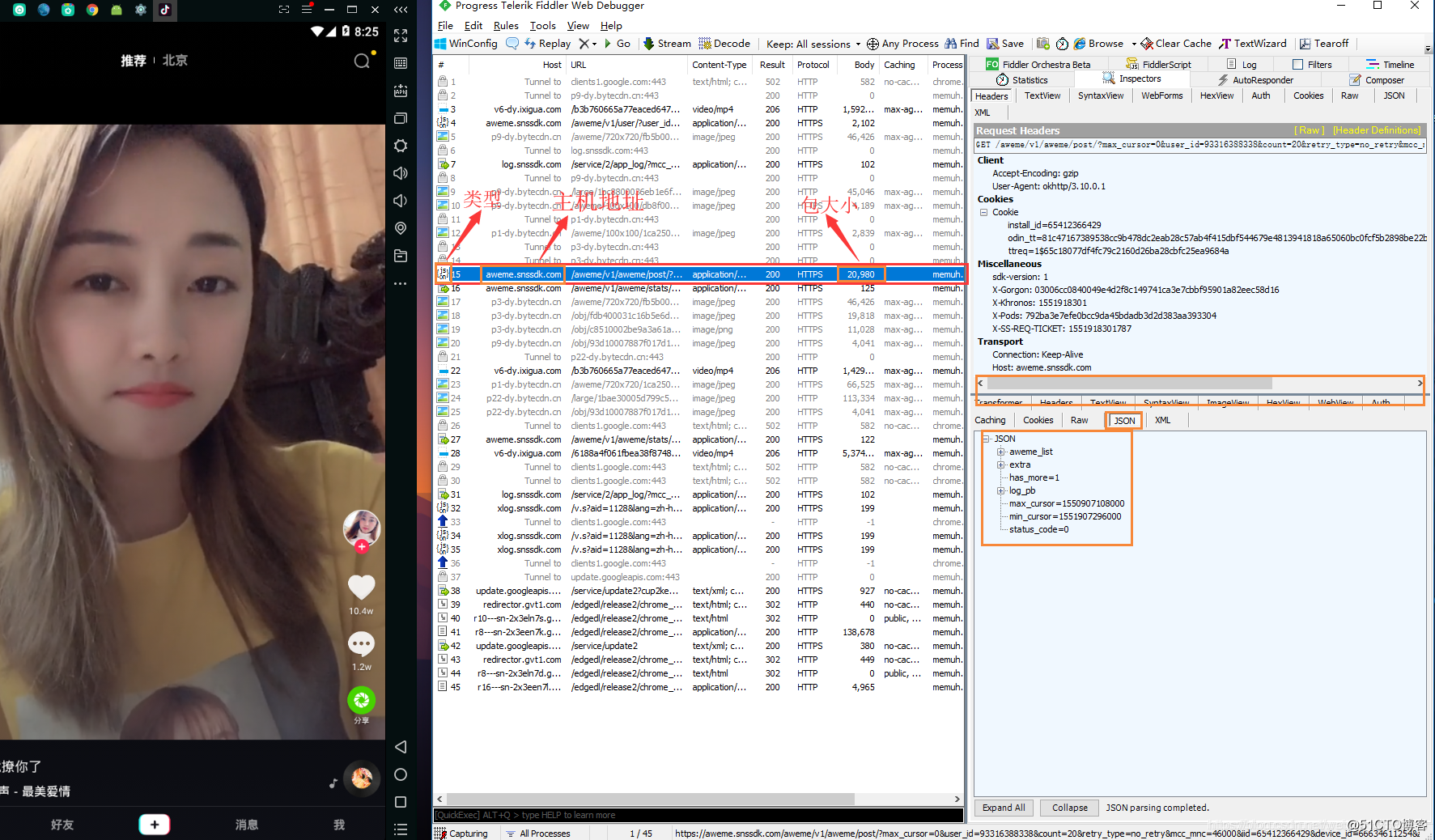
其中有个包,包类型为json(json就是网页返回的数据,具体百度),主机地址如图,包大小一般不小,这个就是视频包。
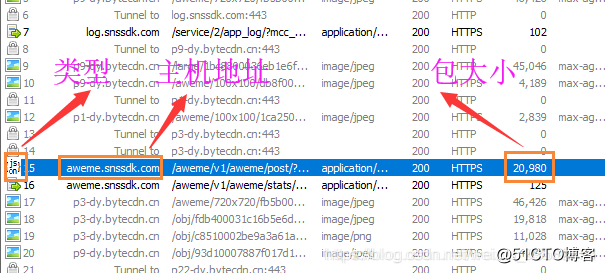
点击这个json包,在fidder右侧,点击解码,我们将视频包的json解码

解码后:点击aweme_list,其中每个大括号代表一个视频,这个和bilibili弹幕或者快手一样,每次加载一点出来,等你看完预加载的,再重新加载一些。
Json是一个字典,我们的视频链接在:aweme_list中,每个视频下的video下的play_addr下的url_list中,一共有6个url,是完全一样的视频,可能是为了应付不同环境,但是一般第3或4个链接的视频不容易出问题,复制链接,浏览器中粘贴就能看到视频了。
接下来解决几个问题,
1、视频数量,每个包中只有这么几个视频,那如何抓取更多呢?
这时候需要借助模拟器的模拟鼠标翻页,让模拟器一直翻页,这样就不断会出现json包了。
2、如何json保存在本地使用
一种方法可以手动复制粘贴,但是这样很low。
所以我们使用fidder自带的脚本,在里面添加规则,当视频json包刷出来后自动保存json包。
自定义规则包:
链接:https://pan.baidu.com/s/1wmtUUMChzuSDZFYGSyUhCg
提取码:7z0l
点击规则脚本,然后将自定义规则放在如图所示位置:
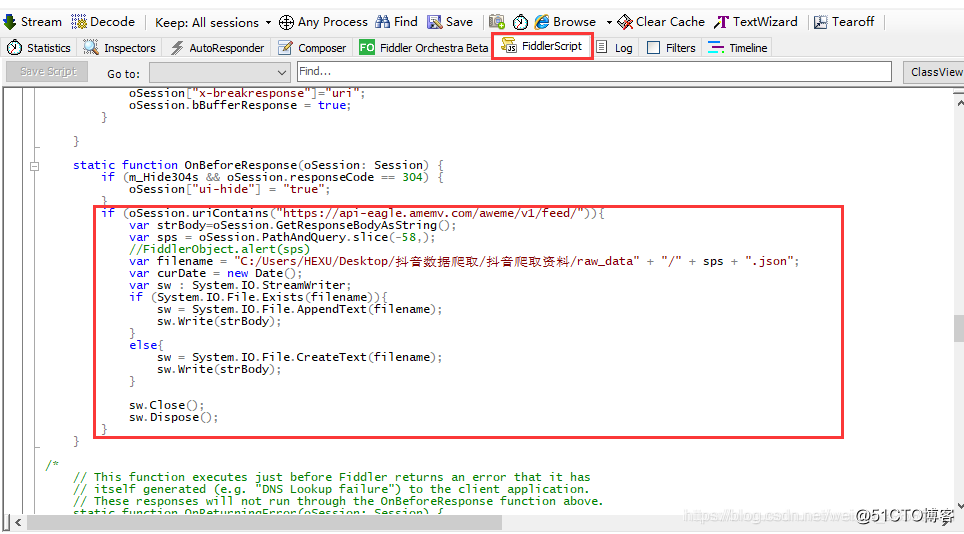
这个脚本有两点需要修改的:
(1)第一行的网址:
这个是从视频包的url中摘出来的,抖音会时不时更新这个url,所以不能用了也要去更新:
比如现在的已经和昨天不同了,记着修改。
(2)路径,那个是我设置json包保存的地址,自己一定要去修改,并创建文件夹,修改完记着点保存。
打开设置好模拟器和脚本后,等待一会,就可以看到文件夹中保存的包了:
四、爬虫脚本
接下来在pycharm中写脚本获取json包里的视频链接:
导包:
import os,json,requests伪装头:
headers = {‘User-Agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36’}逻辑代码:
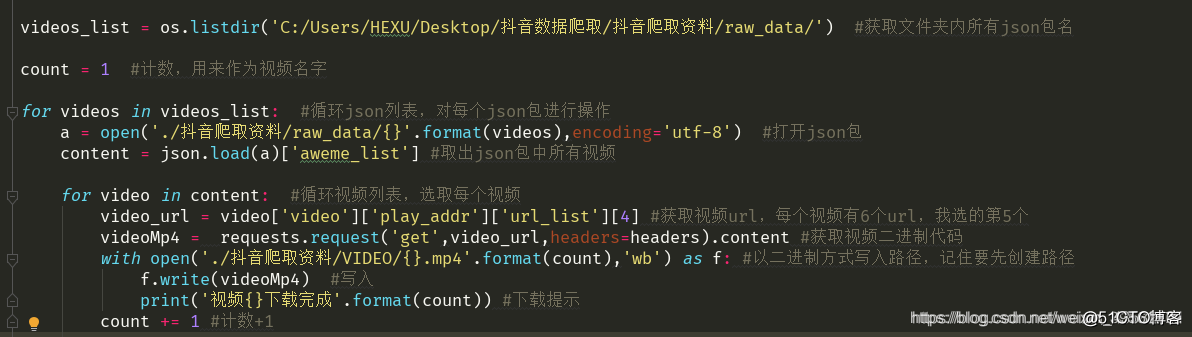
运行代码:
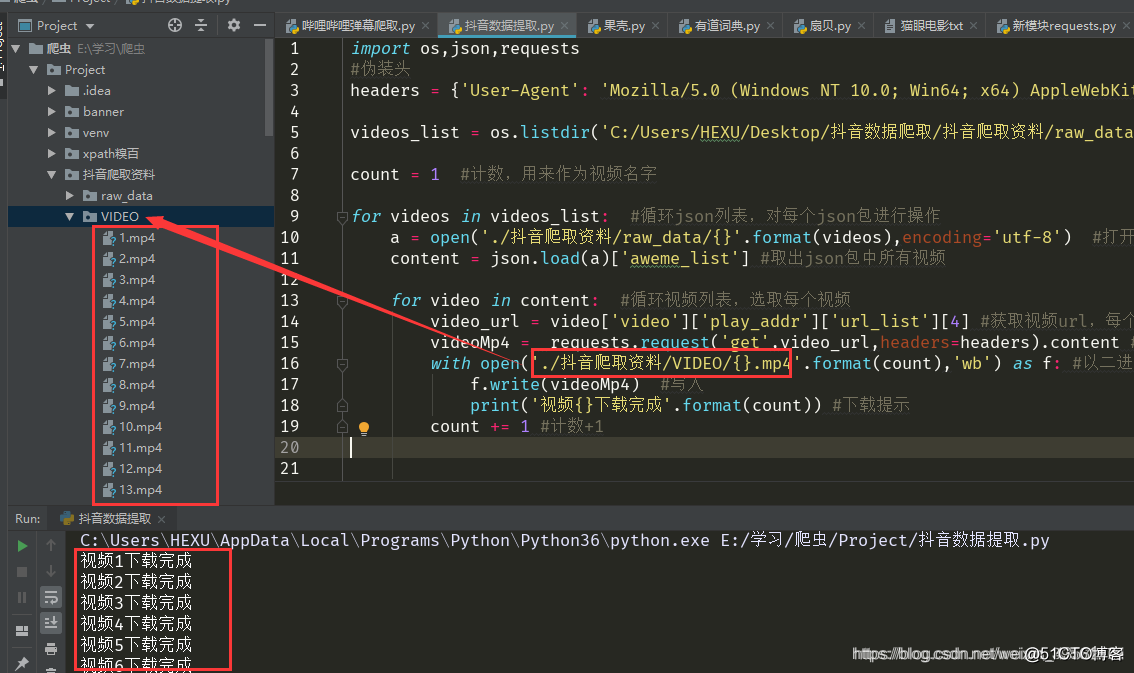
效果:
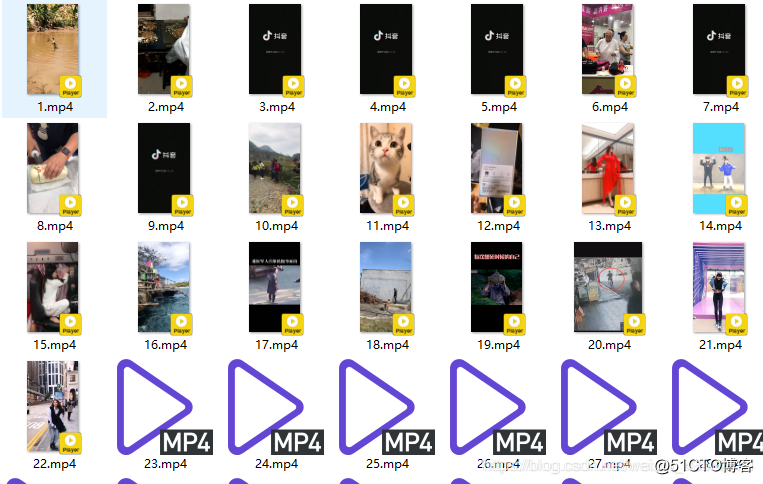
源码:
import os, json, requests# 伪装头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
}
videos_list = os.listdir(
'C:/Users/HEXU/Desktop/抖音数据爬取/抖音爬取资料/raw_data/')# 获取文件夹内所有json包名
count = 1# 计数, 用来作为视频名字
for videos in videos_list: #循环json列表, 对每个json包进行操作
a = open('./抖音爬取资料/raw_data/{}'.format(videos), encoding = 'utf-8')# 打开json包
content = json.load(a)['aweme_list']# 取出json包中所有视频
for video in content: #循环视频列表, 选取每个视频
video_url = video['video']['play_addr']['url_list'][4]# 获取视频url, 每个视频有6个url, 我选的第5个
videoMp4 = requests.request('get', video_url, headers = headers).content# 获取视频二进制代码
with open('./抖音爬取资料/VIDEO/{}.mp4'.format(count), 'wb') as f: #
以二进制方式写入路径, 记住要先创建路径
f.write(videoMp4)# 写入
print('视频{}下载完成'.format(count))# 下载提示
count += 1# 计数 + 1Python操作Redis
Part1前言
前面我们都是使用 Redis 客户端对 Redis 进行使用的,但是实际工作中,我们大多数情况下都是通过代码来使用 Redis 的,由于小编对 Python 比较熟悉,所以我们今天就一起来学习下如何使用 Python 来操作 Redis。
Part2环境准备
Redis首先需要安装好。Python安装好(建议使用Python3)。Redis的Python库安装好(pip install redis)。
Part3开始实践
1小试牛刀
例:我们计划通过 Python 连接到 Redis。然后写入一个 kv,最后将查询到的 v 打印出来。
直接连接
#!/usr/bin/python3
import redis # 导入redis模块
r = redis.Redis(host='localhost', port=6379, password="pwd@321", decode_responses=True) # host是redis主机,password为认证密码,redis默认端口是6379
r.set('name', 'phyger-from-python-redis') # key是"name" value是"phyger-from-python-redis" 将键值对存入redis缓存
print(r['name']) # 第一种:取出键name对应的值
print(r.get('name')) # 第二种:取出键name对应的值
print(type(r.get('name')))

其中的
get为连接池最后一个执行的命令。
连接池
通常情况下,需要连接 redis 时,会创建一个连接,基于这个连接进行 redis 操作,操作完成后去释放。正常情况下,这是没有问题的,但是并发量较高的情况下,频繁的连接创建和释放对性能会有较高的影响,于是连接池发挥作用。
连接池的原理:预先创建多个连接,当进行 redis 操作时,直接获取已经创建好的连接进行操作。完成后,不会释放这个连接,而是让其返回连接池,用于后续 redis 操作!这样避免连续创建和释放,从而提高了性能!
#!/usr/bin/python3
import redis,time # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库
pool = redis.ConnectionPool(host='localhost', port=6379, password="pwd@321", decode_responses=True) # host是redis主机,需要redis服务端和客户端都起着 redis默认端口是6379
r = redis.Redis(connection_pool=pool)
r.set('name', 'phyger-from-python-redis')
print(r['name'])
print(r.get('name')) # 取出键name对应的值
print(type(r.get('name')))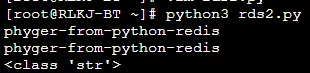
你会发现,在实际使用中直连和使用连接池的效果是一样的,只是在高并发的时候会有明显的区别。
2基操实践
对于众多的 Redis 命令,我们在此以 SET 命令为例进行展示。
格式: set(name, value, ex=None, px=None, nx=False, xx=False)
在 redis-py 中 set 命令的参数:
| 参数名 | 释义 |
|---|---|
| ex | |
| px | |
| nx | |
| xx | |
ex
我们计划创建一个 kv 并且设置其 ex 为 3,期待 3 秒后此 k 的 v 会变为 None。
#!/usr/bin/python3
import redis,time # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库
pool = redis.ConnectionPool(host='localhost', port=6379, password="pwd@321", decode_responses=True) # host是redis主机,需要redis服务端和客户端都起着 redis默认端口是6379
r = redis.Redis(connection_pool=pool)
r.set('name', 'phyger-from-python-redis',ex=3)
print(r['name']) # 应当有v
time.sleep(3)
print(r.get('name')) # 应当无v
print(type(r.get('name')))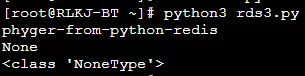
nx
由于 px 的单位太短,我们就不做演示,效果和 ex 相同。
我们计划去重复 set 前面已经 set 过的 name,不出意外的话,在 nx 为真时,我们将会 set 失败。但是人如果 set 不存在的 name1,则会成功。
#!/usr/bin/python3
import redis,time # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库
pool = redis.ConnectionPool(host='localhost', port=6379, password="pwd@321", decode_responses=True) # host是redis主机,需要redis服务端和客户端都起着 redis默认端口是6379
r = redis.Redis(connection_pool=pool)
r.set('name', 'phyger-0',nx=3) # set失败
print(r['name']) # 应当不生效
r.set('name1', 'phyger-1',nx=3) # set成功
print(r.get('name1')) # 应当生效
print(type(r.get('name')))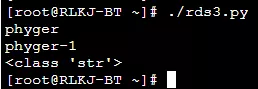
如上,你会发现
name的set未生效,因为name已经存在于数据库中。而name1的set已经生效,因为name1是之前在数据库中不存在的。
xx
我们计划去重复 set 前面已经 set 过的 name,不出意外的话,在 nx 为真时,我们将会 set 成功。但是人如果 set 不存在的 name2,则会失败。
#!/usr/bin/python3
import redis,time # 导入redis模块,通过python操作redis 也可以直接在redis主机的服务端操作缓存数据库
pool = redis.ConnectionPool(host='localhost', port=6379, password="pwd@321", decode_responses=True) # host是redis主机,需要redis服务端和客户端都起着 redis默认端口是6379
r = redis.Redis(connection_pool=pool)
r.set('name', 'phyger-0',xx=3) # set失败
print(r['name']) # 应当变了
r.set('name2', 'phyger-1',xx=3) # set成功
print(r.get('name2')) # 应当没有set成功
print(type(r.get('name')))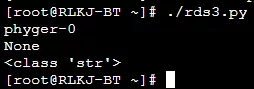
以上,就是今天全部的内容,更多信息建议参考
redis官方文档。
作者:phyger
来源:https://mp.weixin.qq.com/s/bsv57OPKubD2dz0Wskn6eQ
Python列表和集合的查找原理
集合与列表查找对比
关于大量数据查找,效率差距到底有多大?
先看一组实例:
import time
import random
nums = [random.randint(0, 2000000) for i in range(1000)]
list_test = list(range(1000000))
set_test = set(list_test)
count_list, count_set = 0, 0
t1 = time.time() #测试在列表中进行查找
for num in nums:
if num in list_test:
count_list += 1
t2 = time.time()
for num in nums: #测试在集合中进行查找
if num in set_test:
count_set += 1
t3 = time.time() #测试在集合中进行查找
print('找到个数,列表:{},集合:{}'.format(count_list, count_set))
print('使用时间,列表:{:.4f}s'.format(t2 - t1))
print('使用时间,集合:{:.4f}s'.format(t3 - t2))
输出结果为:
找到个数,列表:528,集合:528
使用时间,列表:7.9329s
使用时间,集合:0.0010s
对于大数据集量来说,我们清晰地看到,集合的查找效率远远的高于列表,那么本文接下来会从Python底层数据结构的角度分析为何出现如此情况。
list列表的原理
Python中的list作为一个常用数据结构,在很多程序中被用来当做数组使用,可能很多人都觉得list无非就是一个动态数组,就像C++中的vector或者Go中的slice一样。但事实真的是这样的吗?
我们来思考一个简单的问题,Python中的list允许我们存储不同类型的数据,既然类型不同,那内存占用空间就就不同,不同大小的数据对象又是如何存入数组中呢?
比如下面的代码中,我们分别在数组中存储了一个字符串,一个整形,以及一个字典对象,假如是数组实现,则需要将数据存储在相邻的内存空间中,而索引访问就变成一个相当困难的事情了,毕竟我们无法猜测每个元素的大小,从而无法定位想要的元素位置。
>>> test = ["hello world", 456, {}]
>>> test
['hello world', 456, {}]
是通过链表结构实现的吗?毕竟链表支持动态的调整,借助于指针可以引用不同类型的数据。但是这样的话使用下标索引数据的时候,需要依赖于遍历的方式查找,O(n)的时间复杂度访问效率实在是太低。
同时使用链表的开销也较大,每个数据项除了维护本地数据指针外,还要维护一个next指针,因此还要额外分配8字节数据,同时链表分散性使其无法像数组一样利用CPU的缓存来高效的执行数据读写。
实现的细节可以从其Python的源码中找到, 定义如下:
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item;
Py_ssize_t allocated;
} PyListObject;
内部list的实现的是一个C结构体,该结构体中的obitem是一个指针数组,存储了所有对象的指针数据,allocated是已分配内存的数量, PyObjectVAR_HEAD是一个宏扩展包含了更多扩展属性用于管理数组,比如引用计数以及数组大小等内容。
所以我们可以看出,用动态数组作为第一层数据结构,动态数组里存储的是指针,指向对应的数据。
既然是一个动态数组,则必然会面临一个问题,如何进行容量的管理,大部分的程序语言对于此类结构使用动态调整策略,也就是当存储容量达到一定阈值的时候,扩展容量,当存储容量低于一定的阈值的时候,缩减容量。
道理很简单,但实施起来可没那么容易,什么时候扩容,扩多少,什么时候执行回收,每次又要回收多少空闲容量,这些都是在实现过程中需要明确的问题。
假如我们使用一种最简单的策略:超出容量加倍,低于一半容量减倍。这种策略会有什么问题呢?设想一下当我们在容量已满的时候进行一次插入,随即删除该元素,交替执行多次,那数组数据岂不是会不断地被整体复制和回收,已经无性能可言了。
对于Python list的动态调整规则程序中定义如下, 当追加数据容量已满的时候,通过下面的方式计算再次分配的空间大小,创建新的数组,并将所有数据复制到新的数组中。这是一种相对数据增速较慢的策略,回收的时候则当容量空闲一半的时候执行策略,获取新的缩减后容量大小。
具体规则如下:
new_allocated = (newsize >> 3) + (newsize < 9 ? 3 : 6)
new_allocated += newsize
动态数组扩容规则是:当出现数组存满时,扩充容量新加入的长度和额外3个,如果新加入元素大于9时,则扩6额外。
其实对于Python列表这种数据结构的动态调整,在其他语言中也都存在,只是大家可能在日常使用中并没有意识到,了解了动态调整规则,我们可以通过比如手动分配足够的空间,来减少其动态分配带来的迁移成本,使得程序运行的更高效。
另外如果事先知道存储在列表中的数据类型都相同,比如都是整形或者字符等类型,可以考虑使用arrays库,或者numpy库,两者都提供更直接的数组内存存储模型,而不是上面的指针引用模型,因此在访问和存储效率上面会更高效一些。
从上面的数据结构可以得出,Python list的查找时间复杂度为O(n),因为作为一个动态数组,需要遍历每一个元素去找到目标元素,故而是一种较为低效的查找方式。
set集合的原理
说到集合,就不得不提到Python中的另一种数据结构,就是字典。字典和集合有异曲同工之妙。
在Python中,字典是通过散列表或说哈希表实现的。字典也被称为关联数组,还称为哈希数组等。也就是说,字典也是一个数组,但数组的索引是键经过哈希函数处理后得到的散列值。
哈希函数的目的是使键均匀地分布在数组中,并且可以在内存中以O(1)的时间复杂度进行寻址,从而实现快速查找和修改。哈希表中哈希函数的设计困难在于将数据均匀分布在哈希表中,从而尽量减少哈希碰撞和冲突。由于不同的键可能具有相同的哈希值,即可能出现冲突,高级的哈希函数能够使冲突数目最小化。
Python中并不包含这样高级的哈希函数,几个重要(用于处理字符串和整数)的哈希函数是常见的几个类型。
通常情况下建立哈希表的具体过程如下:
数据添加:把key通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
数据查询:再次使用哈希函数将key转换为对应的数组下标,并定位到数组的位置获取value。
哈希函数就是一个映射,因此哈希函数的设定很灵活,只要使得任何关键字由此所得的哈希函数值都落在表长允许的范围之内即可。本质上看哈希函数不可能做成一个一对一的映射关系,其本质是一个多对一的映射,这也就引出了下面一个概念——哈希冲突或者说哈希碰撞。哈希碰撞是不可避免的,但是一个好的哈希函数的设计需要尽量避免哈希碰撞。
Python中使用开放地址法解决冲突
CPython使用伪随机探测(pseudo-random probing)的散列表(hash table)作为字典的底层数据结构。由于这个实现细节,只有可哈希的对象才能作为字典的键。字典的三个基本操作(添加元素,获取元素和删除元素)的平均事件复杂度为O(1)。
Python中所有不可变的内置类型都是可哈希的。可变类型(如列表,字典和集合)就是不可哈希的,因此不能作为字典的键。
常见的哈希碰撞解决方法:
开放寻址法(open addressing) 开放寻址法中,所有的元素都存放在散列表里,当产生哈希冲突时,通过一个探测函数计算出下一个候选位置,如果下一个获选位置还是有冲突,那么不断通过探测函数往下找,直到找个一个空槽来存放待插入元素。开放地址的意思是除了哈希函数得出的地址可用,当出现冲突的时候其他的地址也一样可用,常见的开放地址思想的方法有线性探测再散列,二次探测再散列等,这些方法都是在第一选择被占用的情况下的解决方法。 再哈希法 这个方法是按顺序规定多个哈希函数,每次查询的时候按顺序调用哈希函数,调用到第一个为空的时候返回不存在,调用到此键的时候返回其值。 链地址法 将所有关键字哈希值相同的记录都存在同一线性链表中,这样不需要占用其他的哈希地址,相同的哈希值在一条链表上,按顺序遍历就可以找到。 公共溢出区 其基本思想是:所有关键字和基本表中关键字为相同哈希值的记录,不管他们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表。 装填因子α 一般情况下,处理冲突方法相同的哈希表,其平均查找长度依赖于哈希表的装填因子。哈希表的装填因子定义为表中填入的记录数和哈希表长度的比值,也就是标志着哈希表的装满程度。直观看来,α越小,发生冲突的可能性就越小,反之越大。一般0.75比较合适,涉及数学推导。
在Python中一个key-value是一个entry,entry有三种状态:
Unused:me_key == me_value == NULL
Unused是entry的初始状态,key和value都为NULL。插入元素时,Unused状态转换成Active状态。这是me_key为NULL的唯一情况。
Active:me_key != NULL and me_key != dummy 且 me_value != NULL
插入元素后,entry就成了Active状态,这是me_value唯一不为NULL的情况,删除元素时Active状态可转换成Dummy状态。
Dummy:me_key == dummy 且 me_value == NULL
此处的Dummy对象实际上一个PyStringObject对象,仅作为指示标志。Dummy状态的元素可以在插入元素的时候将它变成Active状态,但它不可能再变成Unused状态。
为什么entry有Dummy状态呢?
这是因为采用开放寻址法中,遇到哈希冲突时会找到下一个合适的位置,例如某元素经过哈希计算应该插入到A处,但是此时A处有元素的,通过探测函数计算得到下一个位置B,仍然有元素,直到找到位置C为止,此时ABC构成了探测链,查找元素时如果hash值相同,那么也是顺着这条探测链不断往后找,当删除探测链中的某个元素时,比如B,如果直接把B从哈希表中移除,即变成Unused状态,那么C就不可能再找到了,因为AC之间出现了断裂的现象,正是如此才出现了第三种状态-Dummy,Dummy是一种类似的伪删除方式,保证探测链的连续性。
set集合和dict一样也是基于散列表的,只是他的表元只包含键的引用,而没有对值的引用,其他的和dict基本上是一致的,所以在此就不再多说了。并且dict要求键必须是能被哈希的不可变对象,因此普通的set无法作为dict的键,必须选择被“冻结”的不可变集合类:frozenset。顾名思义,一旦初始化,集合内数据不可修改。
一般情况下普通的顺序表数组存储结构也可以认为是简单的哈希表,虽然没有采用哈希函数(取余),但同样可以在O(1)时间内进行查找和修改。但是这种方法存在两个问题:
扩展性不强 浪费空间
dict是用来存储键值对结构的数据的,set其实也是存储的键值对,只是默认键和值是相同的。Python中的dict和set都是通过散列表来实现的。下面来看与dict相关的几个比较重要的问题:
dict中的数据是无序存放的。操作的时间复杂度,插入、查找和删除都可以在O(1)的时间复杂度。这是因为查找相当于将查找值通过哈希函数运算之后,直接得到对应的桶位置(不考虑哈希冲突的理想情况下),故而复杂度为O(1)。
由于键的限制,只有可哈希的对象才能作为字典的键和set的值。可hash的对象即Python中的不可变对象和自定义的对象。可变对象(列表、字典、集合)是不能作为字典的键和set的值的。
与list相比:list的查找和删除的时间复杂度是O(n),添加的时间复杂度是O(1)。但是dict使用hashtable内存的开销更大。为了保证较少的冲突,hashtable的装载因子,一般要小于0.75,在Python中当装载因子达到2/3的时候就会自动进行扩容。
参考资料:
Python dict和set的底层原理:https://blog.csdn.net/liuweiyuxiang/article/details/98943272
python 图解Python List数据结构:https://blog.csdn.net/u014029783/article/details/107992840
作者:严天宇
来源:https://mp.weixin.qq.com/s/wvgf7GpbCoeDsLOp1WAFPg
Python运算符优先级及结合性
当多个运算符出现在一起需要进行运算时,Python 会先比较各个运算符的优先级,按照优先级从高到低的顺序依次执行;
当遇到优先级相同的运算符时,再根据结合性决定先执行哪个运算符:如果是左结合性就先执行左边的运算符,如果是右结合性就先执行右边的运算符。
运算符的优先级
在数学运算2 + 4 * 3中,要先计算乘法,再计算加法,否则结果就是错误的。所谓优先级,就是当多个运算符出现在一起时,需要先执行哪个运算符,那么这个运算符的优先级就更高。
Python中运算符优先级如下表所示,括号的优先级是最高的,无论任何时候优先计算括号里面的内容,逻辑运算符的优先级最低,在表中处在同一行运算符的优先级一致,上一层级的优先级高于下一层级的。算术运算符可以分为四种,幂运算最高,其次是正负号,然后是 “* / // %”,最后才是加减“+ -”。
运算符 | 描述 |
() | 括号 |
** | 幂运算 |
~ | 按位取反 |
+、- | 正号、负号 |
* 、/、 %、 // | 乘、除、取模、取整除 |
+ 、- | 加、减 |
>> 、<< | 右移、左移 |
& | 按位“与” |
^ 、| | 按位“异或”,按位“或” |
<= 、< 、>、 >= | 比较运算符 |
==、!= | 等于、不等于 |
=、%=、/=、//=、-=、+=、*=、**= | 赋值运算符 |
is、is not | 身份运算符 |
in、not in | 成员运算符 |
and or not | 逻辑运算符 |
运算符的结合性
在多种运算符在一起进行运算时,除了要考虑优先级,有时候还需要考虑结合性。当同时出现多个优先级相同的运算符时,先执行左边的叫左结合性,先执行右边的叫右结合性。如:5 / 2 * 4,由于/和*的优先级相同,所以只能参考运算符的结合性了,/和*都是左结合性的,所以先计算除法,再计算乘法,结果是10.0。Python中大部分运算符都具有左结合性,其中,幂运算**、正负号、赋值运算符等具有右结合性。
>>> 5 / 2* 4# 左结合性运算符
10.0
>>> 2 ** 2 ** 3# 右结合性,等同于2 ** (2 **3)
256虽然Python运算符存在优先级的关系,但写程序时不建议写很长的表达式,过分依赖运算符的优先级,比如:2 ** -1 % 3 / 5 ** 3 *4,这样的表达式会大大降低程序的可读性。因此,建议写程序时,遵守以下两点原则,保证运算逻辑清晰明了。
尽量不要把一个表达式写的过长过于复杂,如果计算过程的确需要,可以尝试将它拆分几部分来写。 尽量多使用()来控制运算符的执行顺序,使用()可以让运算的先后顺序变得十分清楚。
作者:刘文飞





