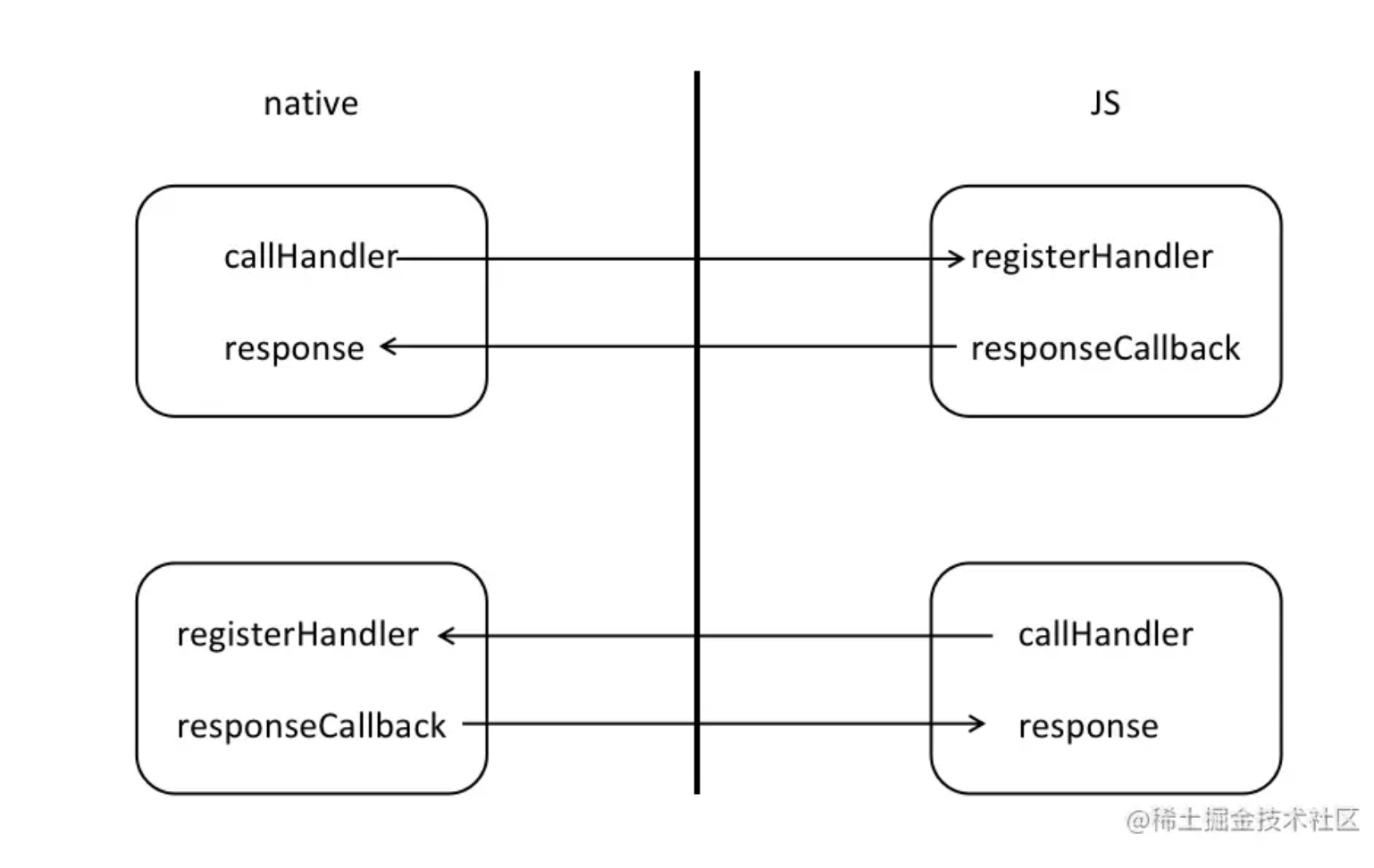
前言
从5月底离职到现在,一个半月的时间,通过内推+BOSS直聘,前前后后约到了10家面试,终于拿到了一个满意的offer,一家做saas系统的上市公司。
本文就跟大家分享下我这段时间找工作的心路历程,欢迎各位感兴趣的开发者阅读本文。
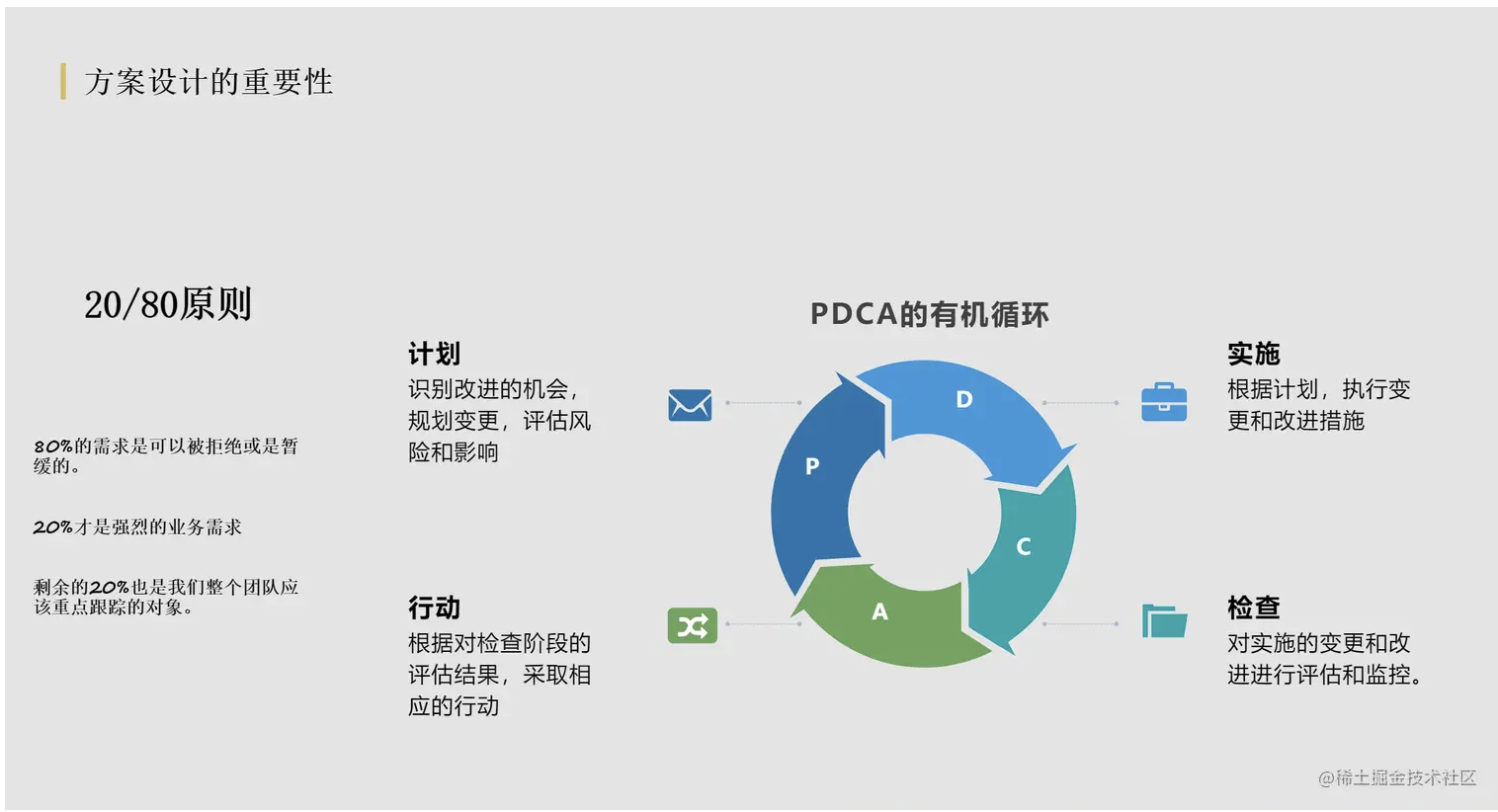
无所畏惧
6月1号,裸辞的第一天,制定了接下来的每日计划,终于可以全身心投入做自己喜欢的事情啦。
- 06:30,起床、洗漱、蒸包子
- 07:00,日常学英语
- 08:00,吃早餐,顺便刷一下BOSS直聘
- 08:30,日常学算法、看面试题
- 11:40,出门吃饭,午休
- 14:00,维护开源项目
- 18:00,出门吃饭,去附近的湖边逛一圈,放松下心情
- 20:30,将当天所学做一个总结,归纳成文章
- 23:00,洗澡睡觉,充实的一天结束


内推情况
通过在掘金、V站和技术群发的文章,为我带来了20多个内推,从大厂到中厂到小厂,约到面试的只有4个。其他的技术部认可我,但是HR卡学历(统招本科)。




无响应式网站开发经验被拒
这是一家杭州的公司,可以远程办公,跟我约了线上面试。做完自我介绍后,他对我的开源项目比较感兴趣,问了我:
- 你为什么会选择写一个聊天工具来作为开源项目?
- 你的截图功能是怎么实现的?
行,那我们来聊几个技术问题吧。
- 讲一下webpack的打包流程
- webpack的热更新原理是怎样的?
- 讲一下你对webpack5模块联邦的理解
这些问题回答完后,他问我你有做过响应式网站开发吗?
我:我知道怎么写一个响应式网站,在工作中我没接触过这方面的业务。
面试官:行,那你讲一下要怎么实现一个响应式网站?
我:用css3的媒体查询来实现,如果移动端跟PC端布局差异很大的话,就写两套页面,对应两个域名,服务端根据http请求头判断设备类型来决定是否要重定向到移动端。
面试官:还有其他方案吗?
我:嗯...,应该没有了吧,我只了解过这两种方式。
面试官:好吧,在seo优化方面,前端要从哪些点去考虑?
我:标签语义化、ssr服务端渲染、img标签添加alt属性来、在head中添加meta标签、优化网站的加载速度,提高搜索引擎的排名。
面试官:我的问题问完了,你有什么想了解的?
我:团队人员配比是怎么样的?
面试官:我们这个团队,前端的话有4个人,有2个后端。然后,前端有时候需要用node写一些接口。
我:如果我进去的话,主要负责哪块业务的开发?
面试官:负责一些响应式网站业务的开发,再就是负责我们内部系统的一个开发。
我:行,我的问题就这些。
面试官:OK,那今天的面试就先到这。
大概过了3天时间,也没有给我答复。因为这个是他们老板在v站看到了我的文章,觉得我还不错,加了微信,让他们技术面的我,我也不好意思问结果。
很大可能是因为我没有响应式网站的实际开发经验,所以拒了我吧。😔
期望太高被拒
这是一家上海的公司,他们的主要业务是做产品包装。有自己品牌的网站、小程序、app。他们公司一个负责公司内部事务的人加了我微信,跟我简单聊了下,让我体验下他们的产品,看看有没有什么我能帮到他们的地方。




聊完后,他一直没有主动联系我,我也没有约到其他面试,我就主动出击了,看能不能确定下来,约个面试。



我整理了一套方案,发到了他的邮箱,期望薪资我写了20k,过了两天,他给了我答复,告诉我期望太高。我说薪资可以商量的,但无济于事。

白嫖劳动力
这家公司是做物流的,是一个群友曾经面过的公司,但是最后没去。看到hr在朋友圈发了招聘信息,在招高级前端,就推给我了,约了线下面试。
到公司后,按照惯例填了一张表,写了基本信息。过了一会,一个男的来面我,让我做了自我介绍,顺着我的回答提问了公司的规模以及业务。
提问完成后,他说我看你期望薪资写了15k,你上家才12k,为什么涨幅会这么高?
我:因为我经过两年的努力以及公司业务的积累,自己的技术水平有显著提升。我对这一行很喜欢,平常80%的业余时间都用来学习了。
面试官:好,我让技术来面下你,看看你实力如何。
等了5分钟左右,他来了告诉我说:技术在开会,我先带你做一下机试吧。你把这两个页面(后台管理系统登陆页与后台首页)画出来就行。
我把页面画出来后,又过来一个人看我做的,他说 你就把页面画出来了?我说:对啊,刚才带我过来那个人说让我画页面出来的。
他说,那可能是他没说清楚,那这样肯定是不行的,你要自己重新建项目,把页面画出来后,要调接口的,把整个流程走通才行的。现在已经11点40多了,你下午再过来继续弄吧。
我直接满脸问号,把整个流程走通只是时间问题,你们这个机试到底想考察啥呢?
他说,页面在我们这里不重要,调接口,走通整个流程才重要。
我直接无语了,就说 抱歉,我下午有其他安排了,我就先走了。

焦虑不安
时间来到6月20日,已经好多天没有约到面试了,逐渐焦虑起来了,虽然兜里余粮还有很多,但始终无法静下心来做事情,充满了对未知的恐惧。
就在这时,我还迎来了别人的嘲讽。他成功让我生气了,我努力的平复心情,告诉自己不要把这件事放在心上,通过让自己忙起来转移注意力,通过学习来克制焦虑。


白天我可以通过学习来缓解焦虑,但是一到晚上躺在床上,我就会开始胡思乱想。想着自己一直找不到工作怎么办,难道我真的不适合吃这碗饭吗,我怎么这么差劲,连个面试都约不到...唉,怎么会这样,我明明已经很努力了,为什么结果会是这样...
完善打招呼语
内推无望,BOSS直聘发消息也是送达、已读未回。这个时候,有个网友建议我把招呼语改改,hr不懂什么开源不开源的,他们只会关键词匹配,只要包含了,就会收你简历,于是我就把打招呼语改成了:

招呼语改完后,效果好了一些,终于有HR愿意收我简历了🥳
学历歧视、贬低、pua、拒了offer
改完打招呼语后,我在BOSS直聘上约到了第一家面试,这家公司是做可视化VR编辑器的,团队有30来个人,BOSS直聘的薪资范围是20K~25K。
我经历了五轮面试,拿到了offer,给了18K,但是最终还是拒绝了,本章节就跟大家分享下这段故事。
技术面
技术面是去线下的,按照惯例做完自我介绍,面试官提问了我:
- 你刚才说你写了个web端的截图插件,你能讲一下你是怎么实现的吗?
- 我看你上家公司是做动画编辑器的,你在做这个项目的时候有遇到过哪些难点吗?
- 你刚才提到了你为编辑器做了一些性能优化,你都做了哪些优化?
- 你刚才说你还实现了svg类型的文本组件搜索功能,你能讲讲你是如何实现的吗?
问完这些后,他说我的问题问完了,你有什么想要了解的吗?
我:团队人员配比是怎么样的?
面试官:我们这边是重前端的,因为是做编辑器嘛,难点在前端这块,目前有4个前端,计划再招3个,再就是有几个做算法的、做c++的,1个产品经理,2个后端,2个UI,3个测试。
我:如果我进去的话,是做哪方面的项目?
面试官:你进来的话,主要是负责VR编辑器项目的,这个项目刚开始做。目前的话,比较累,会加班,基本上是早9晚8,有时候可能要10点才能走。再就是,我们这边是大小周,你能接受的吧?
我:哦哦 明白了,我可以接受
面试官:那行,你稍等下,我让我们的产品经理面下你。
产品经理面
过了一会儿,产品经理过来了。他说:我们的技术对你的评价很高,我再来面面你,你先做个自我介绍吧。做完自我介绍后,产品经理顺着我的介绍进行了提问:
- 你刚才说你这个截图插件Gitee的产品经理在网上看到了,是码云官方的吗?
- 我看你上家公司也是做编辑器的,你们这个产品主要面向的用户群体是哪些?
- 你们这个产品啥时候上线的,你主要负责的是什么?
- 你们的团队配比是怎么样的?
- 你们在开发项目时,是如何管理git分支的?
问完这些后,他让我稍等下,让HR来面下我。
过了3分钟左右,他过来说:我们HR这会儿太忙了,抽不开身,这样,你今晚有空吧,我让她跟你电话聊聊。我回答说,7点后我都有空。
HR电话面
因为约了晚上7点的电话面试,所以我就随便吃了点,就匆匆忙忙回家等电话了。我等到了晚上9点,也没电话打过来,我就在boss直聘问了下,对方说:可能是HR忙忘了,我让她明天给你打。
晚上躺床上睡觉的时候,不出意外,我又开始胡思乱想了,心想:我这煮熟的鸭子该不会飞了吧,会不会是面试表现的不好人家婉拒我了呢,会不会是...,又焦虑了。
到了第二天下午2点多的时候,HR终于给我打了电话,问我期望薪资多少。我说22k,她问我上家薪资多少,我说12k。不出意外,她很震惊:你这涨幅也太大了吧,能说说原因吗?我说:你们这里是大小周,工作强度比较大,而且做的项目也是较为复杂的,我看BOSS直聘标的价格也是20k~25k。
她说:我们这个岗位是中、高级前端都招聘的,你这边最低能接受的薪资是多少呢?
我说:20k
她说:行,了解了,我再跟面试官对接下,晚些时候我加你微信聊。
又过了一天,她加了我微信,跟我说:我只匹配他们的中级开发岗位,让架构师再跟我聊聊。

前端架构师面
跟架构师约的是电话面试,做完自我介绍后,他提问了我:
- 讲一下webpack的打包原理
- 讲一下webpack的loader和plugin
- 讲一下webpack5的模块联邦
- 讲一下Babel的原理,讲一下AST抽象语法树
- 讲一下你所知道的设计模式
- 讲一下浏览器的垃圾回收机制
- 讲一下浏览器的渲染流程
- 讲一下浏览器多进程的渲染优势
- 谈谈你对浏览器架构的理解
我回答完之后,他说:我大概知道你的技术水平了。你现在的水平还不到P6,也就P5多一点,远远不及P7。
我刚才问你的问题,你每回答完一个我都问你有没有要补充的,你都说没有,我从你嘴里没听到任何性能优化相关的东西,这些知识现在还都不是你的,你只知道这么个东西,缺乏实践。就好比,我刚问了你垃圾回收机制,你回答的是chrome的,那火狐呢?edge呢?
你对你未来的规划是怎么样的?
我说:我还是以技术为主,我会继续学习来充实自己,未来如果有机会的话,希望能做到技术管理的位置。
面试官冷笑了下说:你一个大专怎么做管理?
我沉默了一会儿说:未来我会把自己的学历提升下的
面试官:你要认清自己的地位,你要想一下你的价值是什么?你能给我们公司带来什么?我们要用到three.js,你只是学过它,没有落地项目做支撑,你进来后我们还是要给你时间来熟悉项目的,跟没学过的人没啥两样。就好比,我问你three.js的坐标系用的是啥,你都不知道。
我:这个我知道,它用的是右手坐标系
面试官楞了一下说:你知道这个也没啥的,这很简单的,我们这边随便拉一个人都会这些,而且比你厉害。
我继续保持沉默。
面试官:我对你的评价就这么多,你在我们这边是能学到很多东西的,你多想想我今天跟你说的,我不知道你的业务能力怎么样,回头我再跟其他面试官聊聊,今天的面试就先到这。
第二天,HR联系我了,跟我说薪资在16k~18k左右,跟我约了下午1点30的面试。


老板面
到公司后,HR直接带我进了老板办公室,跟我说这个是X总,你们聊吧。 跟老板聊了一个多小时,聊的内容大概是谈人生、理想,大概能记得起的一些问题有:
- 你觉得你是一个什么样的人?
- 你有哪些优点?
- 你想成为一个什么样的人?
- 你觉得你的技术水平怎么样?
- 如果让你给自己打标签,你会打什么标签?
- 回看你的过往人生,你后悔吗?
考虑再三 终拒offer
从公司回来后的第二天,HR告诉我面试结束了,最终给我定的薪资是17k,发了offer。

发了offer后,我本该高兴的,但是我却高兴不起来,那一晚我想了很多,觉得早9晚8,大小周。这个钱还是太少了,而且那个前端架构师说的话让我很不舒服,pua的气息太重了。入职后,跟这种人一起工作,我也不会开心。思考再三后,我最终还是拒掉了这个offer。


比较钟意的小外企
这是我在BOSS直聘约到的第二家面试(15k~20k),面试体验很好。到公司后,接待我的人很有礼貌,告诉我前端是技术总监来面的,他还没来,你先坐着等他一会儿。
等了一会儿后,看到了技术总监,主动跟我握了个手。然后说:他临时有个会开,让我稍等下他,然后安排我在会议室坐了会儿,倒了一杯水给我。
我在会议室坐了40多分钟,他会开完了,喊我去办公室聊,按照惯例做完自我介绍后。他问我:
- 你刚才提到了你做了编辑器的性能优化,你具体是怎么做的?
- 你们这个编辑器前端编辑的应该是dom吧,最后生成的视频是怎么生成的?
- 我看你的项目经验都是vue,你应该对vue全家桶都很熟了吧?
问完这些问题后,他用笔记本打开了我简历上的项目,边看边问我这块你是怎么实现的,有没有遇到过啥问题,你是怎么解决的。项目看完后,他说你技术没问题,我了解完了。我跟你介绍下我们这边的项目,我们在做...。介绍完了后,他问了我离职原因,以及我的期望薪资。
我说了20k,他说,站在客观角度来说,你的学历是大专,在我们这里拿到这个数很难,我们也不是什么特别有钱的公司。但是,我们的产品是很有发展前景的,已经拿了一轮800w美金的融资了,这个岗位我在boss直聘挂了1个月了,收到了300多份简历,有很多大厂出来的,但是我都不太满意,偶然间看到你的简历,觉得你是一个爱学习、肯钻研的人,就约你来面试了。你是我面的第一个前端。
我听他这么说后,我就说:那薪资17、18也可以。
他说:行,明白了,我回头跟老板说说,尽量帮你争取。我们这边工作氛围很棒,团队是一支很精湛的团队组成的,我们这边做算法的是麻省理工毕业的,这边的一个后端是之前抖音短视频架构组出来的。你在这里也能学到很多前端之外的东西,我们是早上10点上班,晚上6点30下班,不打卡,双休。
我听他这么说后,觉得很不错,就说:那15k也行。
他说:你也不用太勉强,不然你进来了也不开心,我们这里发展空间很大的,未来拿到更多的融资,你在这里是可以涨薪的。那今天我们就先到这里,后天就是端午节了,这样,我端午节后的那周给你具体的答复。
就这样,我又进入了焦灼的等待期。
端午节后的第2天,那边还没答复,我就主动问了下,他给我的答复是:

又过了3天,一直没约到面试,焦虑的很。我就又厚着脸皮问了下情况,得来的答复是他们还没找到合适的产品经理。(这个时候,心里很难受到极点了,泪水在眼珠里打转,我焦虑到哭了😔)

晚上躺在床上又开始胡思乱想了,觉得老天很不公平,为什么好运总是不能降临到我头上。唉...就这样想着想着,不知想了多久,也不知道自己睡着了没,只记得手机的闹钟响了,关了闹钟继续睡去了...
随遇而安
又浑浑噩噩的过了几天,时间来到7月3日,BOSS直聘有人跟我约面试了,一天下来约了3个面试,都是很多天之前联系的,今天才收了我简历,我的心情终于好了一些。
做物联网的公司
这家公司距离我住的地方很近,步行1.1公里就能到。BOSS直聘标的价格是(15k~18k),到了公司后,前台让我扫二维码关注他们的公众号,填写面试登记表(基本信息、期望薪资、上家公司薪资)。
填写完后,前台带我进了公司,等了5分钟左右,面试官来了,按照惯例做完自我介绍后,他问了我:
- 你讲一下vue双向绑定的原理
- 讲一下vue3相比vue2,它在diff算法上做了哪些优化?
- Vue2为什么要对数组的常用方法进行重写?
- Vue的nextTick是怎么实现的?
- 讲一下你对EventLoop的理解吧
- 讲一下webpack5的模块联邦
这里我讲一下EventLoop这个问题吧,我回答完之后,他反问我:你确定宏任务先执行的吗?我很确信的说,是的,宏任务先执行的。(之所以这么自信是因为我之前特意研究了这方面的知识,写了大量的用例做验证,写了文章做总结,绝对错不了)
那你意思是,setTimeout比Promise().then()先执行,
我回答:是的。
面试官:你回去再查查资料吧,看一看到底是哪个先执行吧。我的问题问完了,你有什么想问我的吗?
我问了他部门做的产品是什么、团队情况、如果我进来的话负责的是哪块的东西。了解完之后,他让我稍等下。
过了3分钟左右,HR过来了,她问我觉得这场面试咋样,刚才面你的人职级在我们这里算是比较高的了,然后她就跟我介绍了她们公司的情况以及福利制度。介绍完之后,她问我说:我对你写的这个期望薪资比较好奇,我看你上家薪资是12k,怎么期望薪资写了18k呢?涨幅这么高。
我说了理由后,她说:今年市场很差,求职者很多,很多公司都在降低成本,你要是放在互联网红利的时候,你这个涨幅没问题,但2023年这个大环境,你这个涨幅是不可能的。你这边最低期望薪资是多少?
我说:16k,她在求职表上用笔写了下。随后她说,那行,今天的面试就先到这,后面我们电话联系。
回到家后,我立马查了我写的那篇事件循环的文章,验证下我有没有记错。看完之后我发现我并没有记错,于是我又问了下AI,他给我的答案是:

我就纳闷儿了,于是我说宏任务先执行的吧,它的回答是:

它还在嘴硬,我就反问了句,你确定?它终于改变口风了。

这家公司是7月5号面的,等了3天都没联系我,看来是有人要价比我低🌚
做交易所的公司
这家公司是在一个技术交流群看到的招聘信息,公司在海外,远程办公的方式,给的薪资是20k~25k。按照惯例做完自我介绍后他问我:
- 讲一下vue的生命周期
- 讲一下computed与watch的区别
- 讲一下vue的双向绑定和原理
- 讲一下vue3相比vue2有哪些提升
- 你有开发过不用脚手架的项目吗?
- seo优化有了解过吗?讲一下你的见解
- 响应式网站开发你知道哪些方案?
回答完这些问题后,按照惯例我问了他团队的人员情况以及项目情况,就结束了这场面试。他问的问题也很简单,我回答的也不错。但是,过了3天,最终还是没下文。
做工具软件的公司
这家公司是朋友内推的,经历了三轮面试,我看了下BOSS直聘标价是15k~25k。先是用腾讯会议,让打开屏幕共享和摄像头,做一份笔试题。内容是填空题、判断题、代码题。填空跟判断就是一些简单的问题,代码题是:
- 观察一组数列,写一个方法求出第31个数字是什么?(通过观察后,发现那是一组斐波那契数列)
- 实现一个深拷贝函数
- 写一个通用的方法来获取地址栏的某个参数对应的值,不能使用正则表达式。
线上技术面
笔试题做完发给HR后,等待了半个小时,面试官进入了腾讯会议,按照惯例做完自我介绍后他问我:
- vue3的diff算法做了哪些改进
- vue双向绑定的原理是什么
- 假设要设计一个全局的弹窗组件你会怎么设计?
- 如果这个弹窗组件可以弹出多个,消息会垂直排列,新消息会把旧消息顶起来,每个消息都可以设置一个停留时间,到了时间后就会消失,这一块你会怎么设计?
- 你了解堆这种数据结构吗?讲一讲你对它的理解
回答完这些问题后,我按照惯例问了他项目情况以及我进去后所负责的模块,就结束了这场线上面试,第二天收到了一面通过的答复。

线下总监面
时间来到7月6日,本来是7月5日面试的,但是面试官临时有事改了时间。

这家公司在林和西地铁站这边,地处CBD,公司应该是很有钱的。到了公司后,HR接待了我,带我进了会议室,等了3分钟左右,技术总监过来了,做完自我介绍后,他问我:
- 挑一个你最拿手的项目讲一下吧
- 看你写了很多开源项目,是个爱捣鼓的人,讲一下你的开源项目吧
- 你会Java,是用的SpringBoot吗?你讲一下你这个开源项目的后端服务是怎么设计的吧
- 你都知道哪些数据库?进行SQL查询时,你有哪些优化手段来优化查询效率
- 你讲下vue3和vue2的一个区别吧
- 你觉得你跟别人相比,你的优势是什么?
回答完这些问题后,我问了他团队的规模以及公司的人员情况,他跟我说:我们公司总共有52个人,很大一部分都是程序员,他们都是全能的,任何一个人拉出来,前端、后端、运维都能做,就好比你让运维来写前端的业务代码他也能写,你也看到了,我们目前不缺人,是想招一个优秀的人做候补。我们这边的技术栈是vue和Electron,你进来的话,负责前端页面以及一些node后端服务的编写。你稍等下,我让我们的HR来面下你。
线下HR面
等了4分钟左右,HR来了,她带我去到了另一个会议室聊,她问了我:
- 你的离职原因是什么?
- 你对新工作的期望是怎么样的?
- 如果公司让你休年假,你必须要做一件事情,你会做什么事情?
问完这些问题后,她问了我期望薪资,我说了20k,她说了一些其他的东西,大概意思就是给不到的话你最低期望是多少,我说18k。
她说:行,了解了,我们这边要做一下横向对比,尽快给你答复,你放心无论结果如何,我们都会给你一个答复的。
面试完的第二天,那个hr跟我发消息说结果还没定。

进入新的一周后,她给我发来了感谢信。

只能感叹卷王太多了,全干工程师的价格已经被你们打到18k以下了👍
做旅游的公司
这是一家在BOSS直聘上约到的面试(11k~17k),到了公司后,HR先让我做了一份笔试题,这份笔试题全是八股文,我把答案短的都写了,比较长的就写了面试时候讲。
做完笔试题后,她带我进了会议室,是两个人面我,一个是前端负责人,另一个是他的领导,做完自我介绍后,那个前端负责人说:我之前在网上看到过你的截图插件,写的很不错。我相信你的技术肯定没问题的,他和他的领导交叉问了我问题:
- vue3相比vue2做了哪些提升?
- 讲一下vue的diff算法吧
- 讲一下V8的垃圾回收机制
- 讲一下chrome是如何渲染一个网页的
- 大文件分块上传以及断点续传,你会怎么实现
回答问这些问题后,他们让我稍等下,找来了HR跟我聊,HR问了我期望薪资,我说17K,她也惊讶的说,你上家才给你12k,你怎么一下子要求涨幅这么多,是出于什么考虑呢?我说了理由后,她说:结合我们公司的情况和制度,我们这边给不到你这么多。
我:那大概能给到多少呢?
HR:15k,有些事情我要提前跟你说清楚,我们这边试用期是一个月,现在项目组比较忙,是需要加班的,基本上是996,大概要忙到9月份,项目第一期做好后,就可以按照正常时间上下班了。忙的这段时间是可以累积调休的。试用期不缴纳社保,我们只有五险,没有公积金。
我听了这些后,头皮发麻,一时不知道说啥,我就说了:哦哦 好
HR:如果你能接受的话,我这边是没问题的。
我:我要考虑考虑,晚些时候给你答复。
到了第二天,HR在boss直聘上给我发了消息,问我考虑的如何了,我拒绝了她。

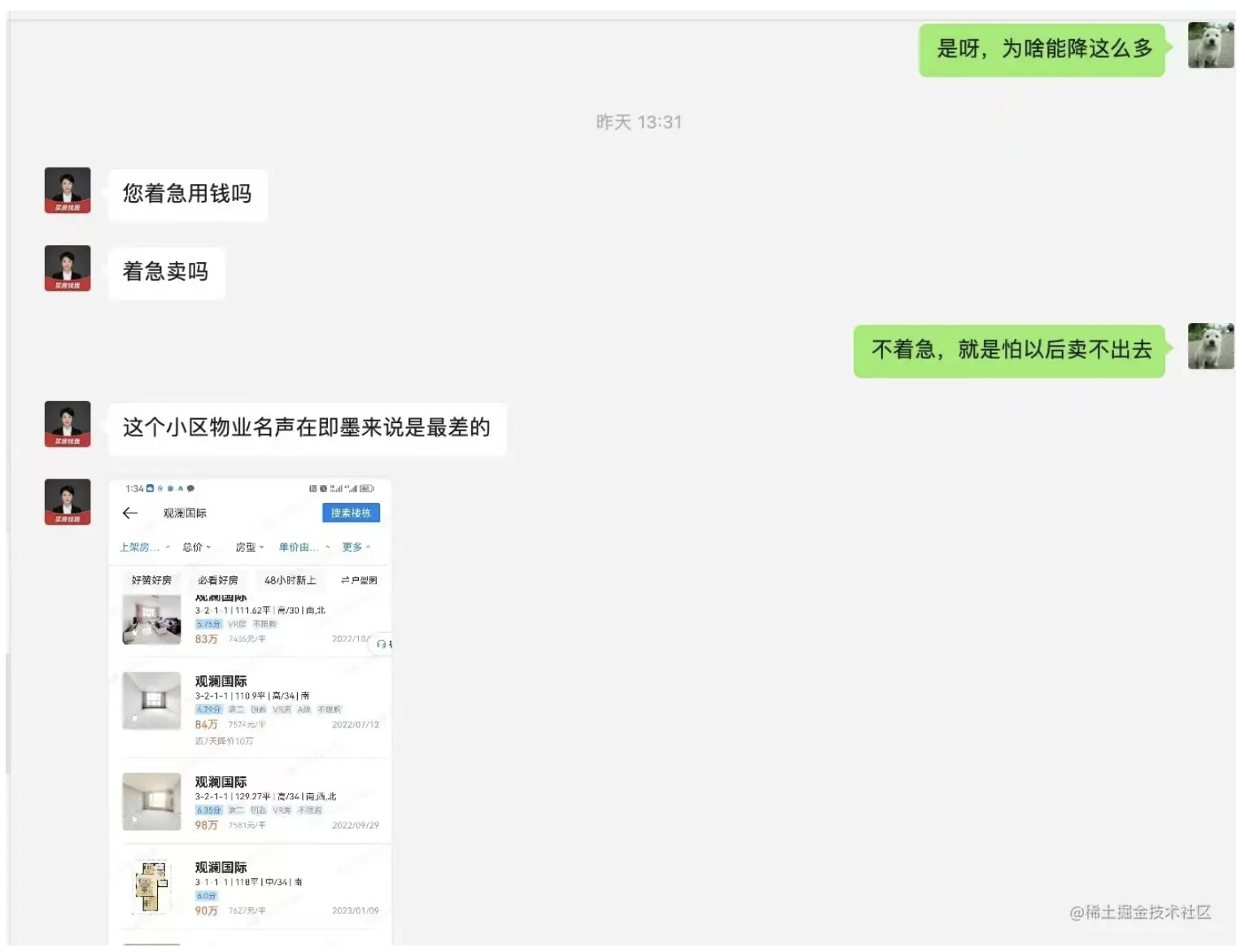
做saas系统的上市公司
这家公司是我6月13号在BOSS直聘上沟通的,6月27号收了我简历,7月3号跟我约了面试,一直持续到7月14号,经历了三轮面试,最终拿到了offer。
HR面(线上)
按照惯例做完自我介绍后,HR让我介绍下公司的产品,以及我在公司的一个职位,技术水平在公司排第几,为什么离职,职业规划和一些其他问题:
HR:你能接受出差吗?
我:这个看情况,如果距离不是很远,出差时间不超过1周,交通、住宿这些都能报销的话,我是接受的。
HR:交通、住宿这些肯定都报销,不然谁愿意出差,我们除了这个外,每天还有一个xxx块的补贴。你在广州这边,出差的话就是去深圳,一般也就去个3、4天,你是前端,几乎不怎么出差。
我:哦哦 那可以的
HR:你对加班是怎么看的?
我:加班的话,如果是项目比较急,我是没问题的,但是如果是其他原因的一些强迫加班,我就不太能接受了
HR:我们这边加班的话,是项目比较急的时候才会,加班不会太频繁。如果加班的话,是可以1:1兑换成调休的,法定节假日加班的话,我们会按照法律规定发放3倍工资
我:哦哦 行
HR:你这边是在广州,如果面试通过的话,是广州的编制。我们广州分部在xx,距离这块的话,你能接受吧?
我:我有查过公司的位置,从我住的这边过去也挺近的,40分钟左右就到了,我可以接受
HR:那行,今天的面试就先到这,后面会安排我们的技术面下你。
技术面(线上)
HR面完后,过了一天,跟我约了技术面。

时间来到7月5号,一男一女,两个人一起面的我。按照惯例做完自我介绍后,他们问了我:
- 我看你写了很多开源项目和技术文章,这是一个很好的习惯,能很多年坚持做一件事,并且能把这件事情做好,你很厉害。
- 刚才听你自我介绍说你会Java,你Java目前是一个什么水平?
- 我看你们公司项目是做web动画编辑器的,你在这个项目中担任的角色是什么?有没有什么印象比较深刻的难题,你是如何解决的?
- 我看你简历上还写了一个海外项目的重构经验,你能介绍下这个项目吗?以及你在这里面担任的角色是什么?
- 我看你简历上的项目都是以Vue为主的,那你应该对Vue很熟悉,你讲一下watch与computed的区别
- vue中组件通信都有哪些方式?
- vuex刷新后数据会丢失,除了把数据放本地存储外,你还知道其他什么方法吗?
- 我看你写的那个截图的开源项目用到了canvas,你应该对canvas很熟悉了吧,有这样一个场景:超市中的货架,上面有很多商品。现在要把这个货架用canvas画出来,商品需要支持一些交互,调整大小,移动位置,你会怎么实现?
问完这些问题后,按照惯例,我问了下他们的团队情况以及所做的业务,我进去后所负责的模块,就结束了这场面试。
事业部总经理面(线上)
过了一天,告知我技术面通过了,跟我约了第二天的面试,我看到她说:总经理同时面我跟其他两位候选人。我就压力有点大,从业4年了,第一次遇到这种大场面😂


到了约定好的面试时间,我跟其他两位候选人都进入了会议,过了10分钟,总经理还是没有进来,我就私聊问了下HR。过了一会儿,HR进入了会议。她说:总经理临时有点事情,要换个时间约面试了,真不好意思。

时间来到7月10号,总经理进入腾讯会议后,他先让我们轮流做自我介绍,然后抛出问题,让我们挨个回答,最后他做了总结,给我们三个人做了评价:
- A(1号面试者):你的组织协调能力应该不错
- B(我):我看了你在掘金上发的文章以及个人网站,能看出来你的技术实力是最强的。
- C(3号面试者):你的业务能力应该不错
说完这些后,总经理说晚上会抽时间再单独打电话给我们再聊聊,到了第二天早上我一直没等到电话,我就问了下HR。

过了半个小时左右,电话打来了,他问了我离职原因和两个场景题:
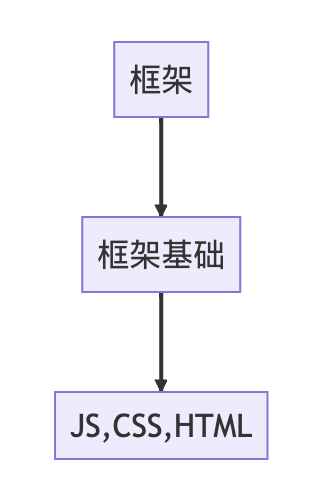
- 前端的框架有很多,当有新项目的时候,你会通过哪些方面来考虑应该使用哪个框架?
- 有一个上线的项目它是vue2写的,如果想升级到vue3,但是没有太多的专用时间来做这件事,此时你会怎么做?
回答完这些问题后,挂断了电话,下午1点40多的时候,HR联系我说面试通过了,开始走发offer流程了,到时候会有她的另一个同事联系我。
时间来到7月14号,第一面面我的那个人打电话给我了,跟我聊了薪资、福利制度和五险一金,她说我们公司的五险一金是按照实际工资进行缴纳的,没有绩效,有季度奖和年终奖,会按照公司的盈利情况以及你的工作表现进行发放,后面还有其他问题的话,你随时联系加你微信的那个HR,她是华南区域的负责人。
电话挂断后,过了2小时左右吧,HR联系我说发offer了,我突然想到忘记问上下班时间了,我就确认了下(BOSS直聘标记了时间)。


截止发文时间,我已经入职这家公司很多天了,团队氛围很棒。入职的第一天下午,我接到了我们主管的电话,他让我第二天去一趟武汉,事业部的总经理是在武汉分部的,他要见一下你,那边也有前端在,跟你讲解下业务,熟悉熟悉团队的人。
广州这边的后端架构师同事告诉我出差是不需要自己花钱的,公司内部有一个平台可以直接在上面定高铁票和酒店,我的内部OA和钉钉账号后,他教了我怎么操作。
来武汉后,跟这边的团队成员熟悉了下,聊了下业务,主管告诉我说大概7月26号左右就可以回广州了。我们是双休,我入职后的第一个周六、日是在武汉过的,在这边跟群友面了基,逛了下附近的粮道街,去了玫瑰街、黄鹤楼等地方🥳
作者:神奇的程序员
来源:juejin.cn/post/7258952063219384376