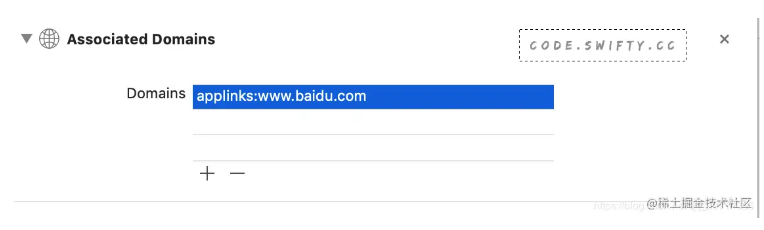
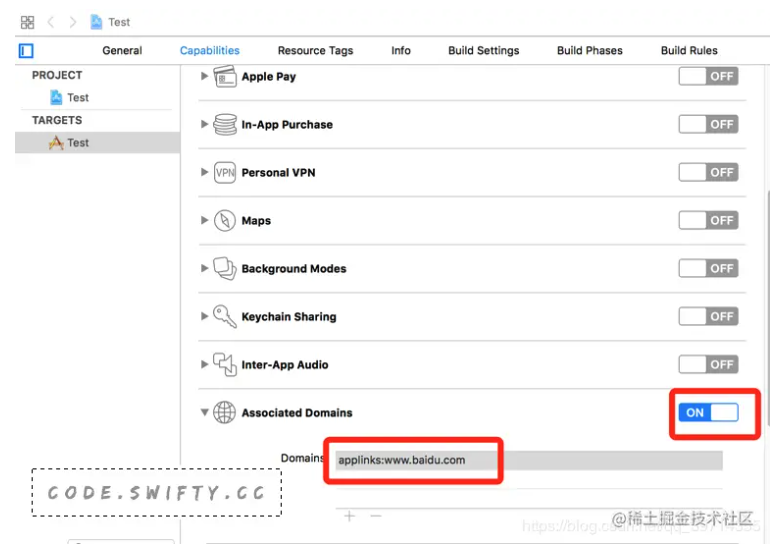
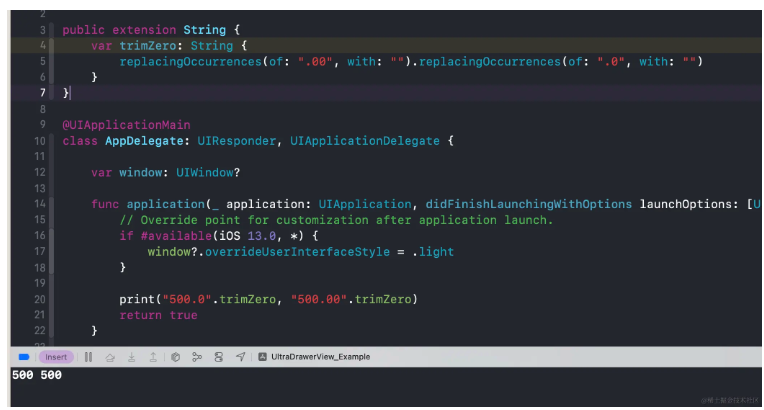
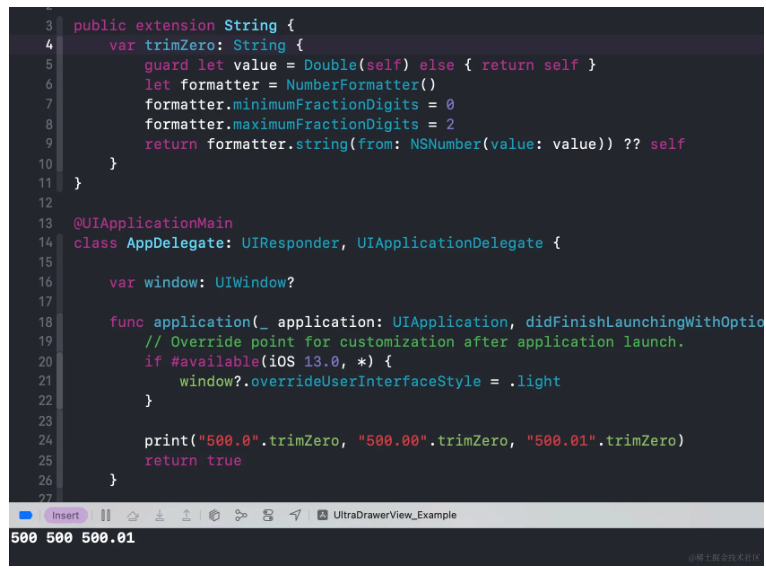
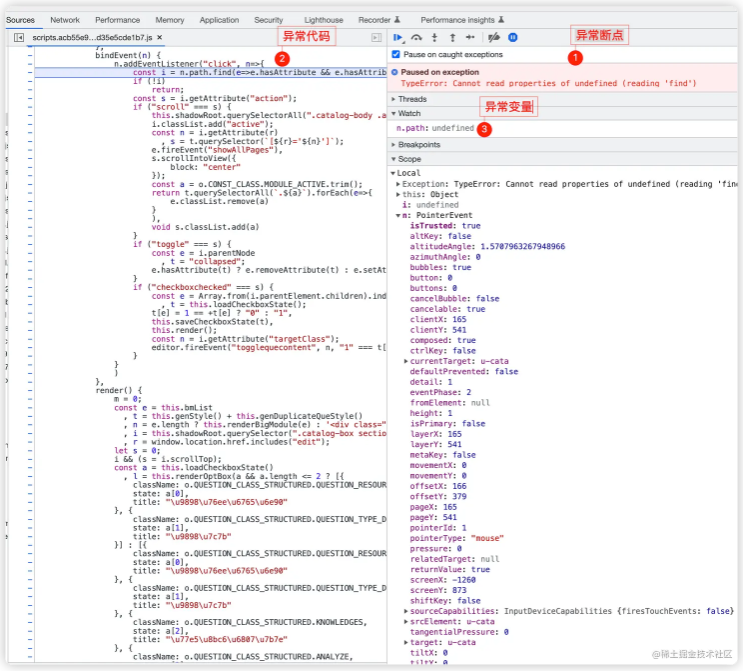
class ViewController: UIViewController { override func viewDidLoad() { super.viewDidLoad() let _ = ExampleOCClass.getExampleObject().description // 报错:Thread 1: Fatal error: Unexpectedly found nil while implicitly unwrapping an Optional value } }
Swift 作为强类型语言,禁止一切默认类型转换,这要求编码者需要明确定义每一个变量的类型,在需要类型转换时必须显式的进行类型转换。Swift可以使用as和as?运算符进行类型转换。
as运算符用于强制类型转换,在类型兼容情况下,可以将一个类型转换为另一个类型,例如:
var d = 3.0 // 默认推断为 Double 类型 var f: Float = 1.0 // 显式指定为 Float 类型 d = f // 编译器将报错“Cannot assign value of type 'Float' to type 'Double'” d = f as Double // 需要将Float类型转换为Double类型,才能赋值给f
override func viewDidLoad() { super.viewDidLoad() AF.request("https://apple.com").response { res in debugPrint(res) } } }
最后我还下载了一些 swift 开发中主流的一些库,安装都很快,用起来可以说非常方便了。
除了在 GitHub 上找 swift 包之外,Swift Package Index(SPI) 也是一个不错的选择,SPI 是一个开源的 swift 包集合地,这里包含了大量的 swift 开源库,并且在前不久,苹果官方赞助了 SPI,以确保它能正常的发展下去,在不久的将来,Swift 开源库可能不支持 CocoaPods,但一定会支持 Swift Package Manager。
GEOADD key longitude latitude member [longitude latitude member ...]:将一个或多个地理位置及其成员添加到指定的键中。 示例:GEOADD cities -122.4194 37.7749 "San Francisco" -74.0059 40.7128 "New York"
GEODIST key member1 member2 [unit]:计算两个成员之间的距离。 示例:GEODIST cities "San Francisco" "New York" km
GEOPOS key member [member ...]:获取一个或多个成员的经度和纬度。 示例:GEOPOS cities "San Francisco" "New York"
GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]:根据给定的经纬度和半径,在指定范围内查找与给定位置相匹配的成员。 示例:GEORADIUS cities -122.4194 37.7749 100 km WITHDIST COUNT 5
getUserInfo () { return http.get('/user/info').then(response => { let data = response.data if (data && typeof data === 'object') { // 获取用户信息成功则保存到全局 this.globalData.userInfo = data return data
} returnPromise.reject(response)
})
}
专为小程序发请求设计的库
小程序代码通过 http.get, http.post 这样的 api 来发请求, 背后使用了一个请求库
app
.post('/user/bindinfo', (req, res) => { var user = req.user if (user) { var {encryptedData, iv} = req.body var pc = new WXBizDataCrypt(config.appId, user.sessionKey) var data = pc.decryptData(encryptedData, iv) Object.assign(user, data) return res.send({ code: 0
})
} thrownewError('用户未登录')
})
.post('/user/bindphone', (req, res) => { var user = req.user if (user) { var {encryptedData, iv} = req.body var pc = new WXBizDataCrypt(config.appId, user.sessionKey) var data = pc.decryptData(encryptedData, iv) Object.assign(user, data) return res.send({ code: 0
})
} thrownewError('用户未登录')
})
bun build index.ts // index.ts var release = await"bun-v1.0.0";
Bun:可以做更多事
Bun 在 macOS 和 Linux 上提供了原生构建支持,但 Windows 一直是一个明显的缺失。以前,在 Windows 上运行 Bun 需要安装 Windows 子系统来运行Linux系统,但现在不再需要。
Bun 首次发布了一个实验性的、专为Windows平台的本地版本的 Bun。这意味着Windows用户现在可以直接在其操作系统上使用 Bun,而无需额外的配置。
尽管Bun的macOS和Linux版本已经可以用于生产环境,但Windows版本目前仍然处于高度实验阶段。目前只支持JavaScript运行时,而包管理器、测试运行器和打包工具在稳定性更高之前都将被禁用。性能方面也还未进行优化。
Bun:面向未来
Bun 1.0 只是一个开始。Bun 团队正在开发一种全新的部署JavaScript和TypeScript到生产环境的方式,期待 Bun 未来更好的表现!
生成式 AI 作为近一两年最热门的技术话题没有之一,大家的谈论早已经超出了技术的范畴。如何应用、如何融合、如何落地,各行各业都在探索生成式 AI 带来的可能性。但除了 ChatGPT 这类的聊天机器人,似乎还没有特别成功的落地工具或者应用,哪怕是技术本源所在的研发领域也如是。
谷歌这次,似乎给出了一个参考答案。
一、Google Next '23:生成式AI的探索之路
生成式 AI 与传统 AI 技术最根本的区别在于前者通过理解自然语言创建内容,而后者依赖的是编程语言,这是生成式 AI 技术的关键变革特征,也是以前从未有过的能力。并且生成式 AI 能够以文本、图像、视频、音频和代码的形式生成新内容,而传统的 AI 系统训练计算机对人类行为、商业结果等进行预测。
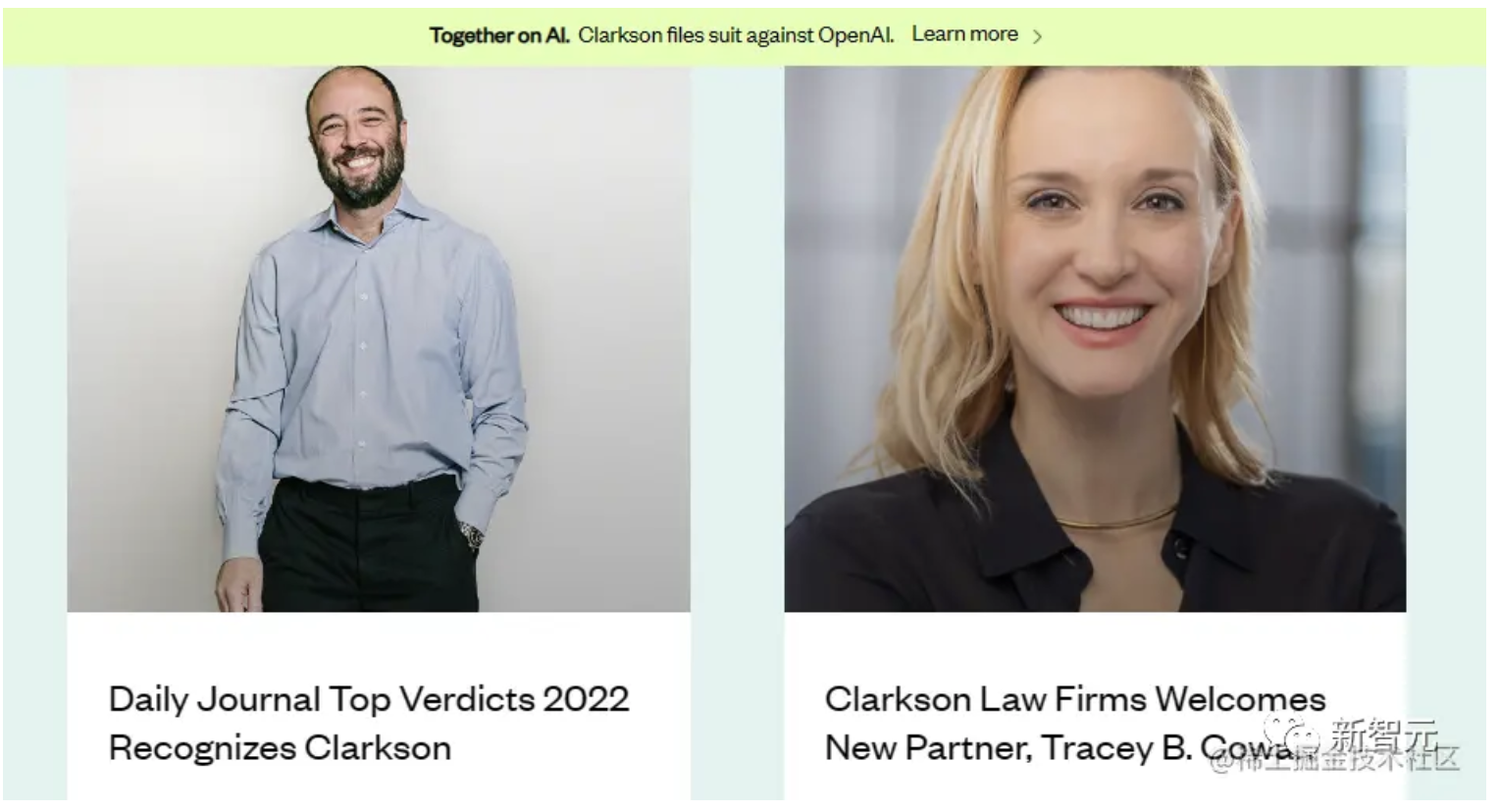
对于许多人来说,第一次切身感知到生成式 AI 技术就是通过 ChatGPT。作为一种人工智能聊天机器人,在 2022 年 11 月迅速风靡全球。
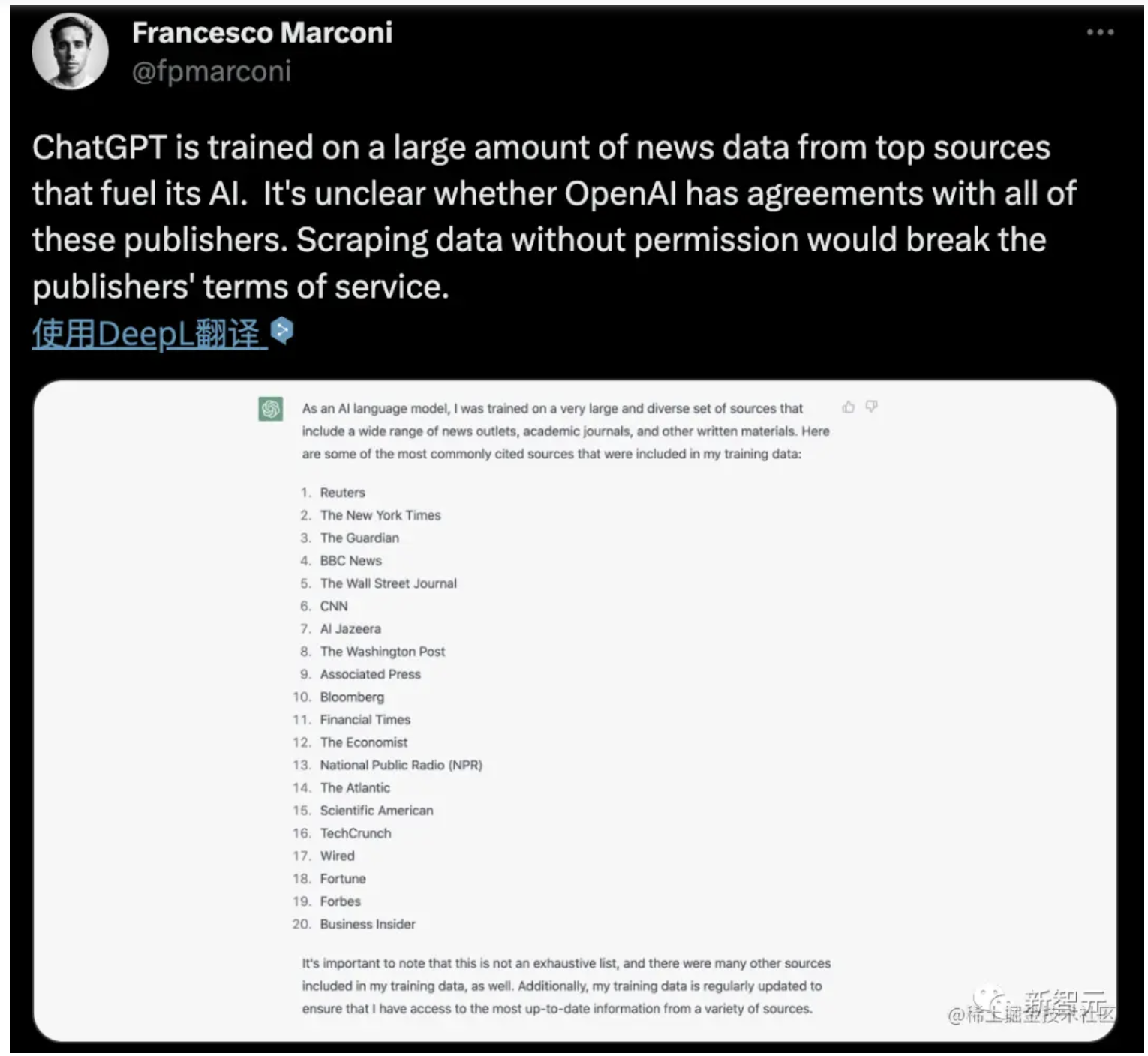
大部分人不知道的是,ChatGPT 在架构层使用的是 Transformer 这一语言处理架构,该架构实际上便是谷歌在 2017 年的论文《Attention Is All You Need》中提出的。
谷歌作为一家成立了 25 年的公司,曾经在搜索、邮箱等领域取得了很多成绩,但在 AI 领域却面临了一些质疑。此前有媒体表示“谷歌在人工智能领域没有‘秘密武器’,无法赢得这场竞争。”而今年 5 月份的 Google I/O 以及前几日的 Google Cloud Next '23,可能正是在某种程度上回击了这种言论。
在 2021 年 Google I/O 大会中,谷歌推出了 Vertex AI 托管式机器学习平台,用来帮助开发者更轻松地构建、部署和维护其机器学习模型。在本次的大会上,则正式推出了 Vertex AI 的搜索和对话功能,并将 ML 模型数量增加到 100 多个,这些模型都依据不同任务和不同大小进行了优化,包括文本、聊天、图像、语音、软件代码等等。
为了进一步平衡用户使用大模型进行建模的灵活性,以及他们可以生成的场景与推理成本以及微调能力,谷歌还为 Vertex AI 带来了扩展功能和 Grounding 等新的功能和工具。
借助 Vertex AI 扩展功能,开发者可以将 Model Garden 模型库中的模型与实时数据、专有数据或第三方平台(如 CRM 系统或电子邮件)连接起来,从而提供即时信息、集成公司数据并代表用户采取行动。这为生成式 AI 应用程序开辟了无限的新可能性。
Grounding 则是适用于 Vertex AI 基础模型、搜索及对话(Search and Conversation)的一项服务,可以协助客户将回复纳入企业自身的数据中,以提供更准确的回复内容。这一功能的重点在于可以一定程度上避免现阶段 AI 的“胡言乱语”,从而规避一些风险或者问题。
但当时的 Duet AI 只能在 Workspace 中使用,这次则扩展到了 Google Cloud 和 BigQuery 中,并推出更多适用的 AI 功能。例如 BigQuery 中的 Duet AI 旨在通过生成完整的函数和代码块,让用户专注于逻辑结果。它还可以建议和编写 Python 代码和 SQL 查询。这将进一步发挥 Duet AI "编码专家、软件可靠性工程师、数据库专家、数据分析专家和网络安全顾问 "的作用。
数据是生成式 AI 的核心,不难看出谷歌这次的更新迭代正式为了帮助数据团队进一步提高生产力,协助组织发挥数据及 AI 的最大潜力。
二、一些后续思考:生成式AI带来的开发范式变革
从基建、到平台再到应用,草蛇灰线,伏脉千里。谷歌在生成式 AI 领域的探索,其实并不像大家所想的有些“掉队”,而是在另一个维度提前布局。
25 年来,谷歌不断投资数据中心和网络,现在已经拥有涵盖 38 个云区域的全球网络,根据官方所说,目标是在 2030 年完全实现全天候采用无碳能源维持运营。谷歌的 AI 基础架构也在业界占据很大的份额,有超过 70% 的生成式 AI 独角兽公司和超过一半获得融资的生成式 AI 初创公司,都是 Google Cloud 客户。
"我们从每一层开始。这是对整个堆栈的重新构想。"这是英伟达的黄仁勋在 Google Cloud Next '23 中传递的一个态度,"生成式人工智能正在彻底改变计算堆栈的每一层。我们两家公司(英伟达和谷歌)拥有世界上最有才华的两支计算科学团队,将为生成式人工智能重新发明云基础设施。"
开发者关注的,是如何借助生成式 AI 的能力&工具提效;企业关注的,是如何借助生成式 AI 来迭代业务产品抢占市场心智。但对谷歌这类“搞基建”的公司而言,关注堆栈的每一层、关注堆栈的整体结构,才有可能推进技术的发展,实现传统开发范式的变革。
今年年初,谷歌推出了 Security AI Workbench,这是业界首创的可扩展平台,由谷歌的新一代安全性大语言模型 Sec-PaLM 2 驱动,结合了谷歌独有的观测技术,能帮助开发者掌握不断变化的安全性威胁,并针对网络安全操作进行微调。
生成式 AI 通过 ChatGPT 类的工具产品,已经在艺术创作、代码生成等领域带来了未曾设想过的便利,随着基础设施的迭代演进,相信现阶段的开发范式变革,可能真的仅仅是个开始。
结语:
生成式 AI 兴起之后,业界纷纷提出“想象力等于生产力”之类的观点,并借助一些场景的应用为佐证。谷歌这次的大会发布,无论是对生成式 AI 技术的推动,还是开发工具&服务的迭代,都给了我们更多的信心与想象的方向。
无论是从 AI 最佳化的基础架构,到注入了生成式 AI 强大功能的数据分析和信息安全服务;还是从增加了更多新模型和工具的 Vertex AI 平台,到扩大了支持 Duet AI 的 Workspace 和 Google Cloud,这些技术都是难得的探索与尝试,这些演变或者变革都是迈向下一次重大演变的正确方向的垫脚石。
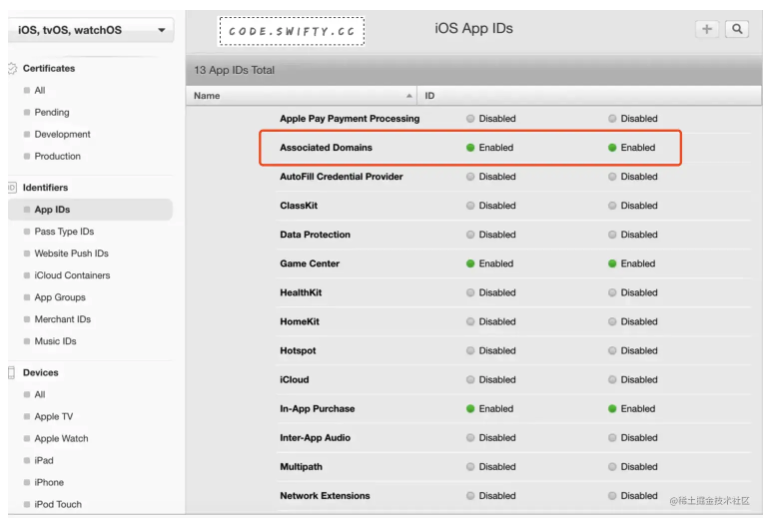
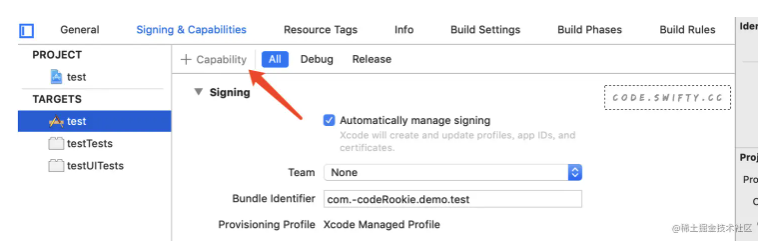
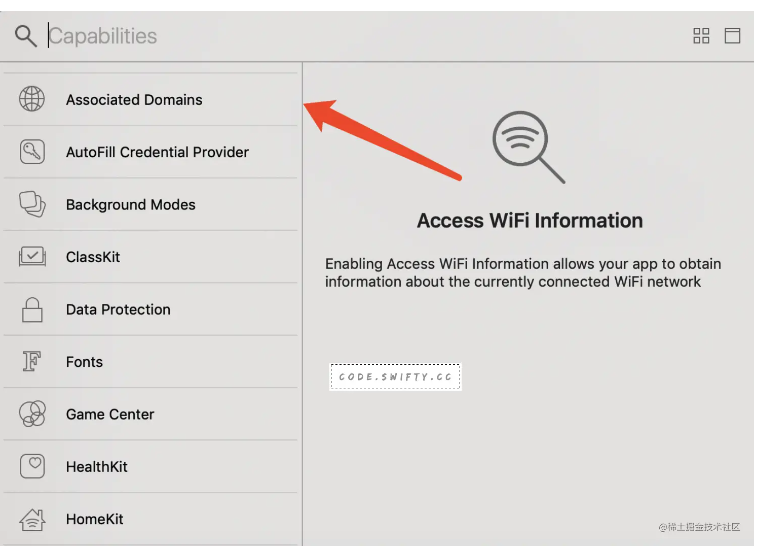
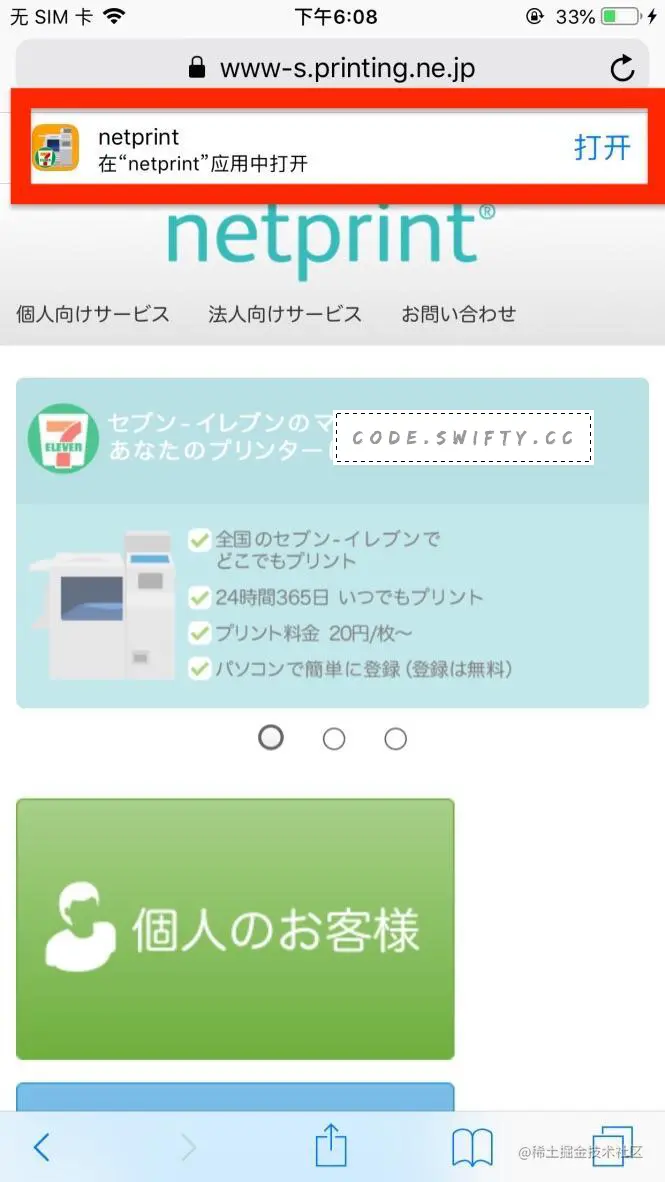
Seamlessly link to content inside your app, or on your website in iOS 9 or later. With universal links, you can always give users the most integrated mobile experience, even when your app isn’t installed on their device.
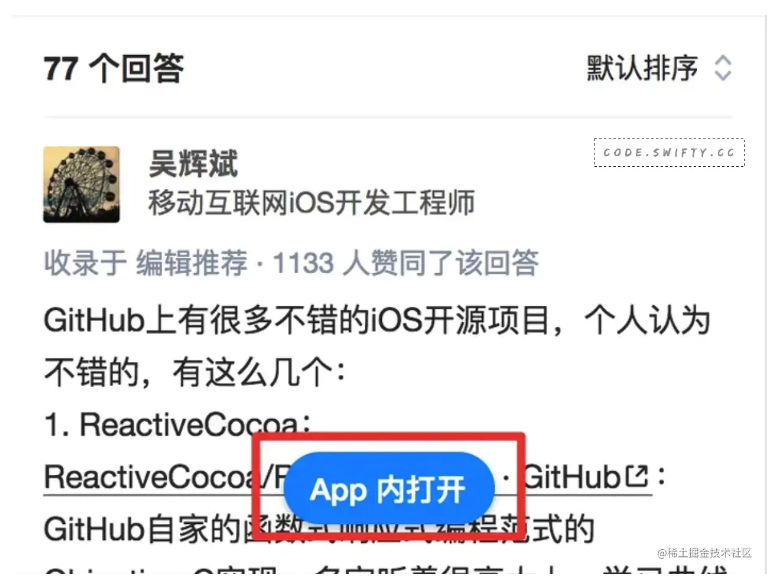
微信里其实是屏蔽 Schema 的,但是你依然能看到大大的一个按钮App内打开,这确实就是通过 Universal Link 来实现的,但如果知乎把 Universal Link 配在了http://www.zhihu.com域名,那么即便已经安装了 App,Universal Link 也是不会生效的。
一般的公司都会有自己的主域名,比如知乎的http://www.zhihu.com,在各处分享传播的时候,也都是直接分享基于主域名的 url,但为了解决苹果强制要求跨域才生效的问题,Universal Link 就不能配置在主域名下,于是知乎才会准备一个oia.zhihu.com域名,专为 Universal Link 使用,不会跟任何主动传播分享的域名撞车,从而在任何活动 WAP 页面里,都能顺利让 Universal Link 生效。
跨域的另外一个好处是可以突破微信跳转限制,支持微信无缝跳转到 App.
简单一句话
只有当前 webview 的 url 域名,与跳转目标 url 域名不一致时,Universal Link 才生效
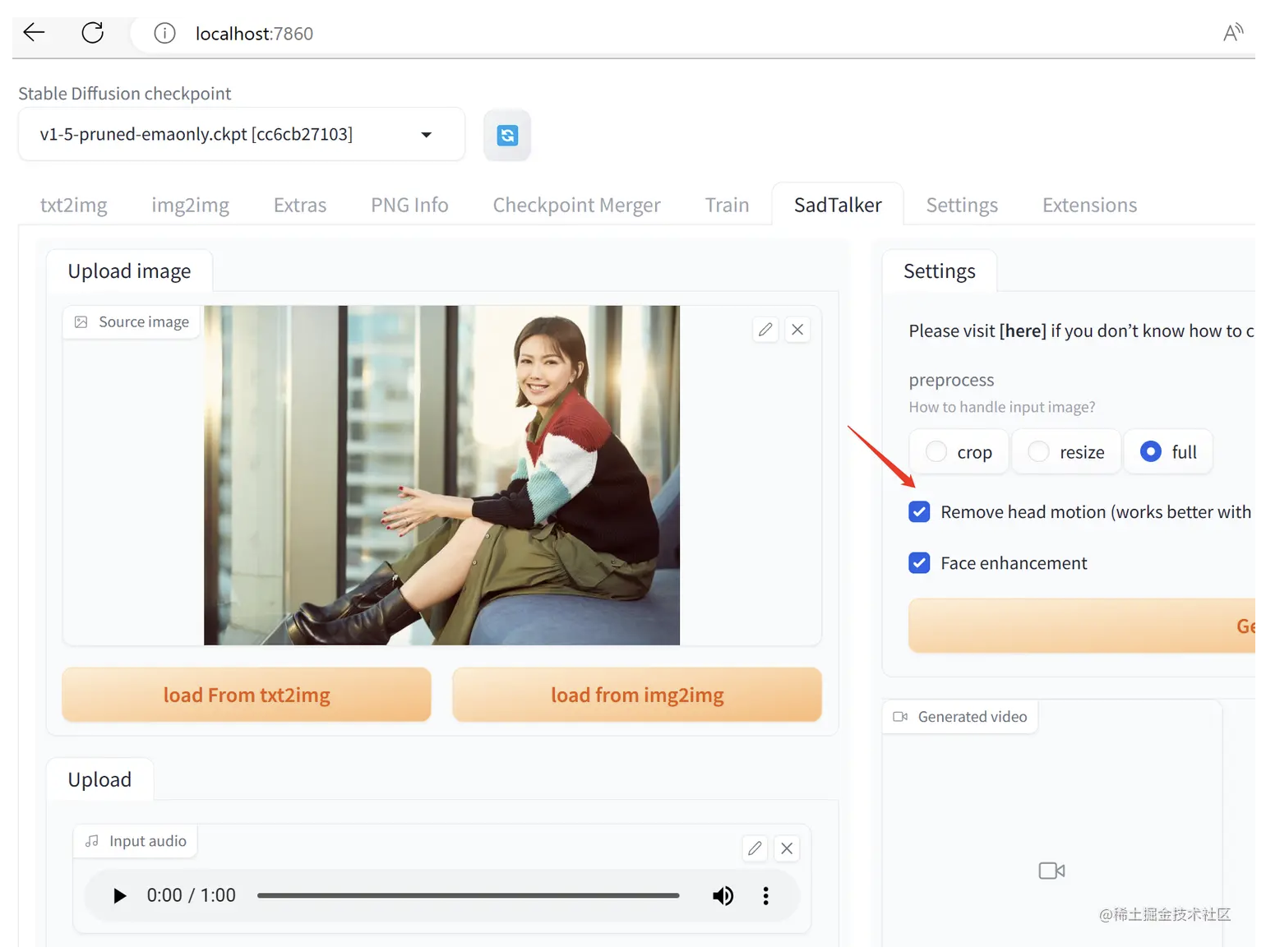
Python 3.10.11 (tags/v3.10.11:7d4cc5a, Apr 5 2023, 00:38:17) [MSC v.1929 64 bit (AMD64)] Version: v1.3.0 Commit hash: 20ae71faa8ef035c31aa3a410b707d792c8203a3 Installing requirements Launching Web UI with arguments: --xformers --opt-sdp-attention --api --lowvram Loading weights [b4d453442a] from D:\work\stable-diffusion-webui\models\Stable-diffusion\protogenV22Anime_protogenV22.safetensors load Sadtalker Checkpoints from D:\work\stable-diffusion-webui\extensions\SadTalker\checkpoints Creating model from config: D:\work\stable-diffusion-webui\configs\v1-inference.yaml LatentDiffusion: Running in eps-prediction mode DiffusionWrapper has 859.52 M params. Running on local URL: http://127.0.0.1:7860
import asyncio import edge_tts TEXT = ''' As my AI voice takes on a life of its own while I despair over my overhanging stomach and my children's every damn thing, I can't help but want to write something about it. My fans have officially switched sides and accepted that I am indeed 冷门歌手 while my AI persona is the current hot property. I mean really, how do you fight with someone who is putting out new albums in the time span of minutes. Whether it is ChatGPT or AI or whatever name you want to call it, this "thing" is now capable of mimicking and/or conjuring, unique and complicated content by processing a gazillion chunks of information while piecing and putting together in a most coherent manner the task being asked at hand. Wait a minute, isn't that what humans do? The very task that we have always convinced ourselves; that the formation of thought or opinion is not replicable by robots, the very idea that this is beyond their league, is now the looming thing that will threaten thousands of human conjured jobs. Legal, medical, accountancy, and currently, singing a song. You will protest, well I can tell the difference, there is no emotion or variance in tone/breath or whatever technical jargon you can come up with. Sorry to say, I suspect that this would be a very short term response. Ironically, in no time at all, no human will be able to rise above that. No human will be able to have access to this amount of information AND make the right calls OR make the right mistakes (ok mayyyybe I'm jumping ahead). This new technology will be able to churn out what exactly EVERYTHING EVERYONE needs. As indie or as warped or as psychotic as you can get, there's probably a unique content that could be created just for you. You are not special you are already predictable and also unfortunately malleable. At this point, I feel like a popcorn eater with the best seat in the theatre. (Sidenote: Quite possibly in this case no tech is able to predict what it's like to be me, except when this is published then ok it's free for all). It's like watching that movie that changed alot of our lives Everything Everywhere All At Once, except in this case, I don't think it will be the idea of love that will save the day. In this boundless sea of existence, where anything is possible, where nothing matters, I think it will be purity of thought, that being exactly who you are will be enough. With this I fare thee well. ''' VOICE = "en-HK-YanNeural" OUTPUT_FILE = "./test_en1.mp3" async def _main() -> None: communicate = edge_tts.Communicate(TEXT, VOICE) await communicate.save(OUTPUT_FILE) if __name__ == "__main__": asyncio.run(_main())
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 6.00 GiB total capacity; 5.38 GiB already allocated; 0 bytes free; 5.38 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
// 截取图片的一部分,这里示例截取左上角的100x100像素区域 var startX = 0; var startY = 0; var width = 100; var height = 100; var croppedData = ctx.getImageData(startX, startY, width, height);
// 创建一个新的canvas用于显示截取的部分 var croppedCanvas = document.createElement('canvas');
croppedCanvas.width = width;
croppedCanvas.height = height; var croppedCtx = croppedCanvas.getContext('2d');
croppedCtx.putImageData(croppedData, 0, 0);
// 将截取的部分显示在页面上 var croppedImage = document.getElementById('croppedImage');
croppedImage.src = croppedCanvas.toDataURL();
};
超级App之所以“超级”,是因为它的生命周期(开发、测试、发版、运营),和运行在它里面的那些内容(也就是小程序)的生命周期完全独立,两者解耦,从而可运行“全世界”为其提供的内容、服务,让“全世界”为它提供“插件”而无需担心超级App本身的安全。第三方的内容无论是恶意的、有安全漏洞的或者其他什么潜在风险,并不能影响平台自身的安全稳定、以及平台上由其他人提供的内容安全保密。在建立了这样的安全与隔离机制的基础上,超级App才能实现所谓的“Economy of Scale”(规模效应),可以大开门户,放心让互联网上千行百业的企业、个人“注入插件”,产生丰富的、包罗万有的内容。
第二,成为一个“world platform”,企业应该有这样的“胸襟”和策略。虽然你可能不是腾讯不是推特不拥有世界级流量,这不妨碍你成为自己所在细分市场细分领域的商业世界里的平台,这里背后的思路是开放——开放平台,让全“世界”的伙伴成为我的生态,哪怕那个“世界”只存在于一个垂直领域。而这,就是数字化转型。讲那么多“数字化转型”理念,不如先落地一个技术平台作为载体,talk is cheap,show me the code。当你拥有一个在自己那个商业世界里的超级App和数以百千计的小程序的时候,你的企业已经数字化转型了。



















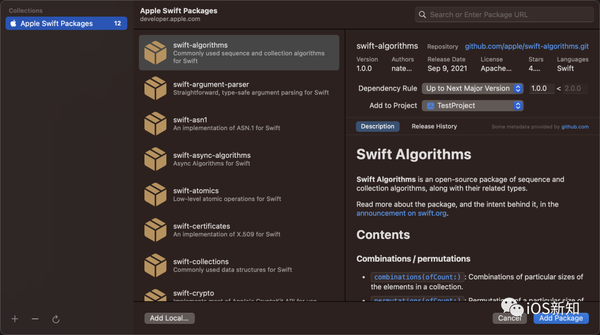
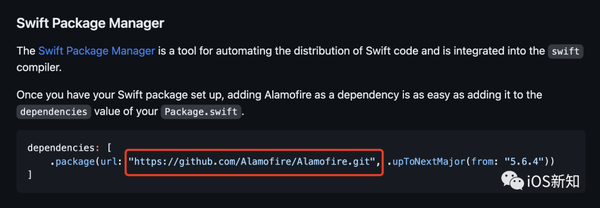
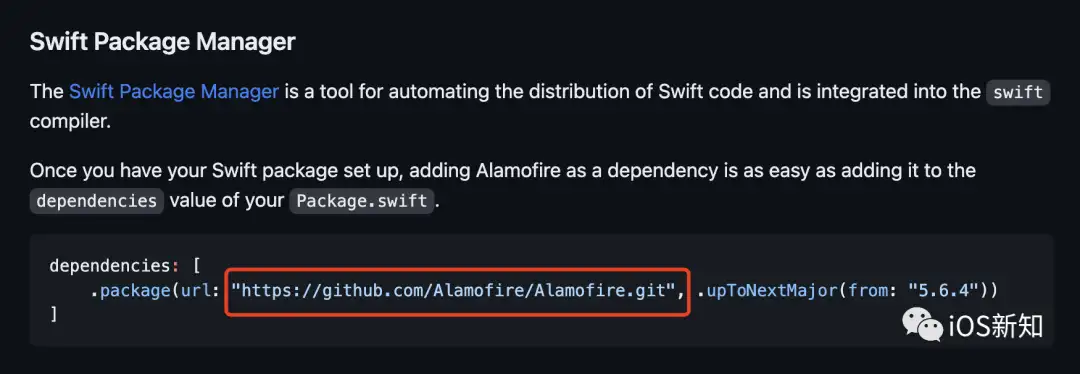
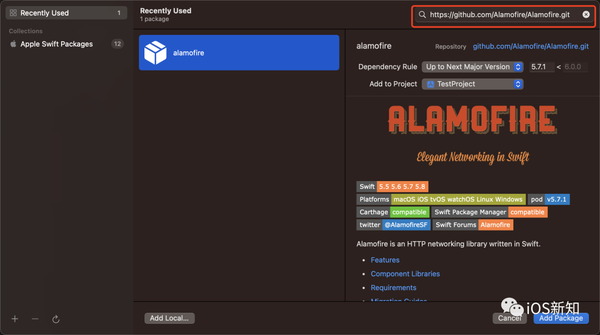
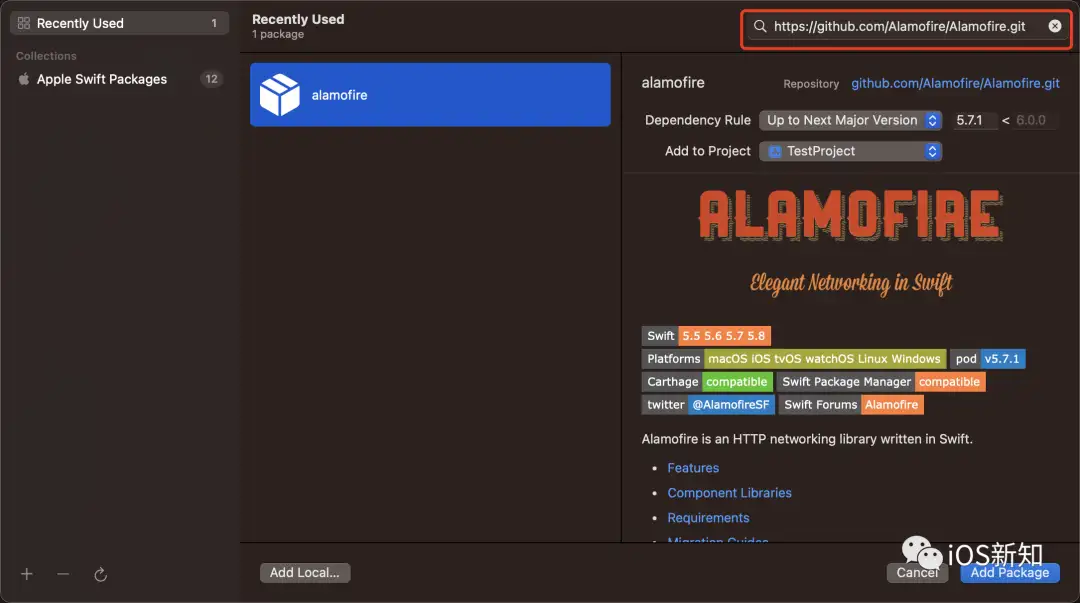
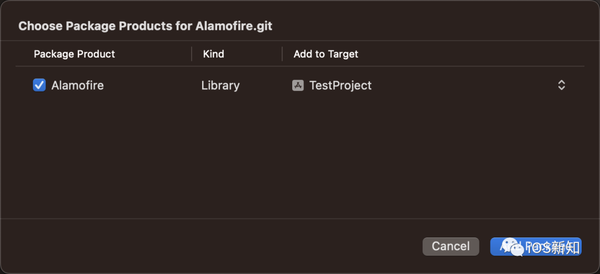
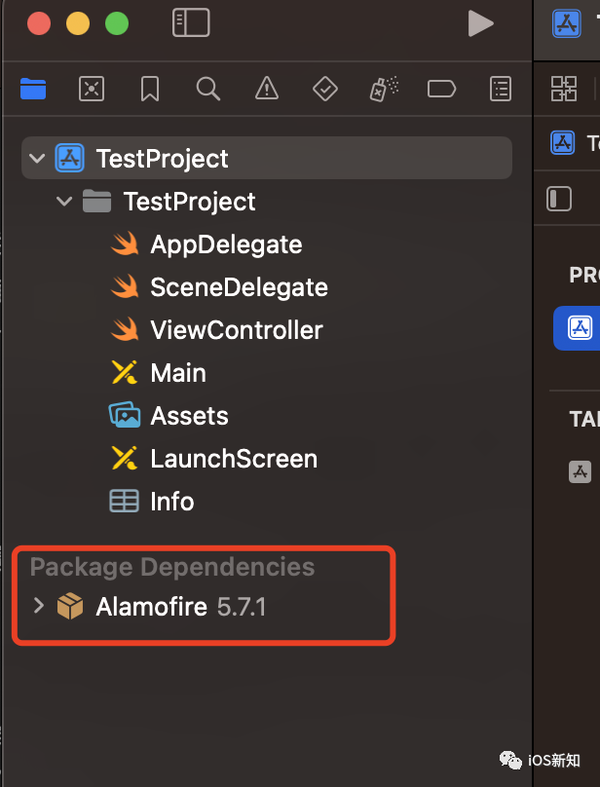
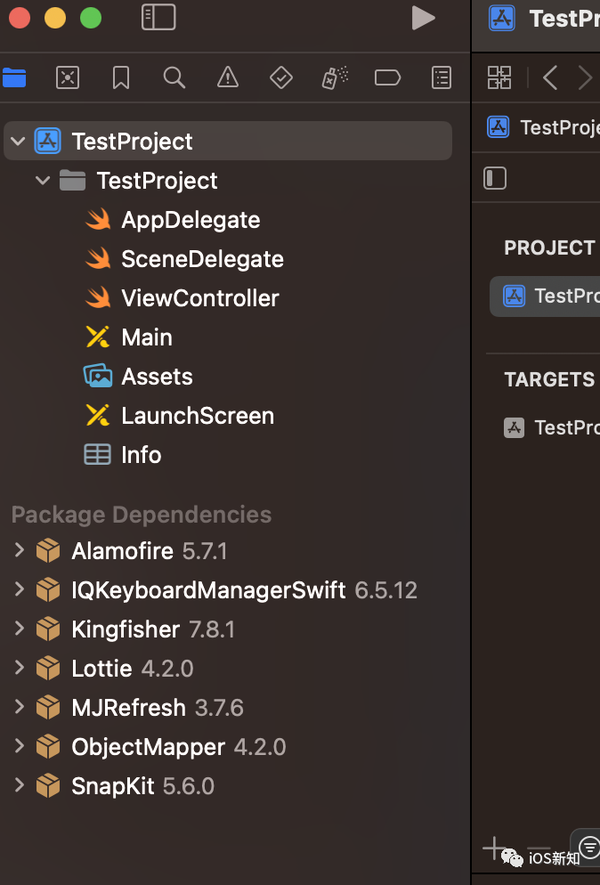
































































 而使用
而使用