



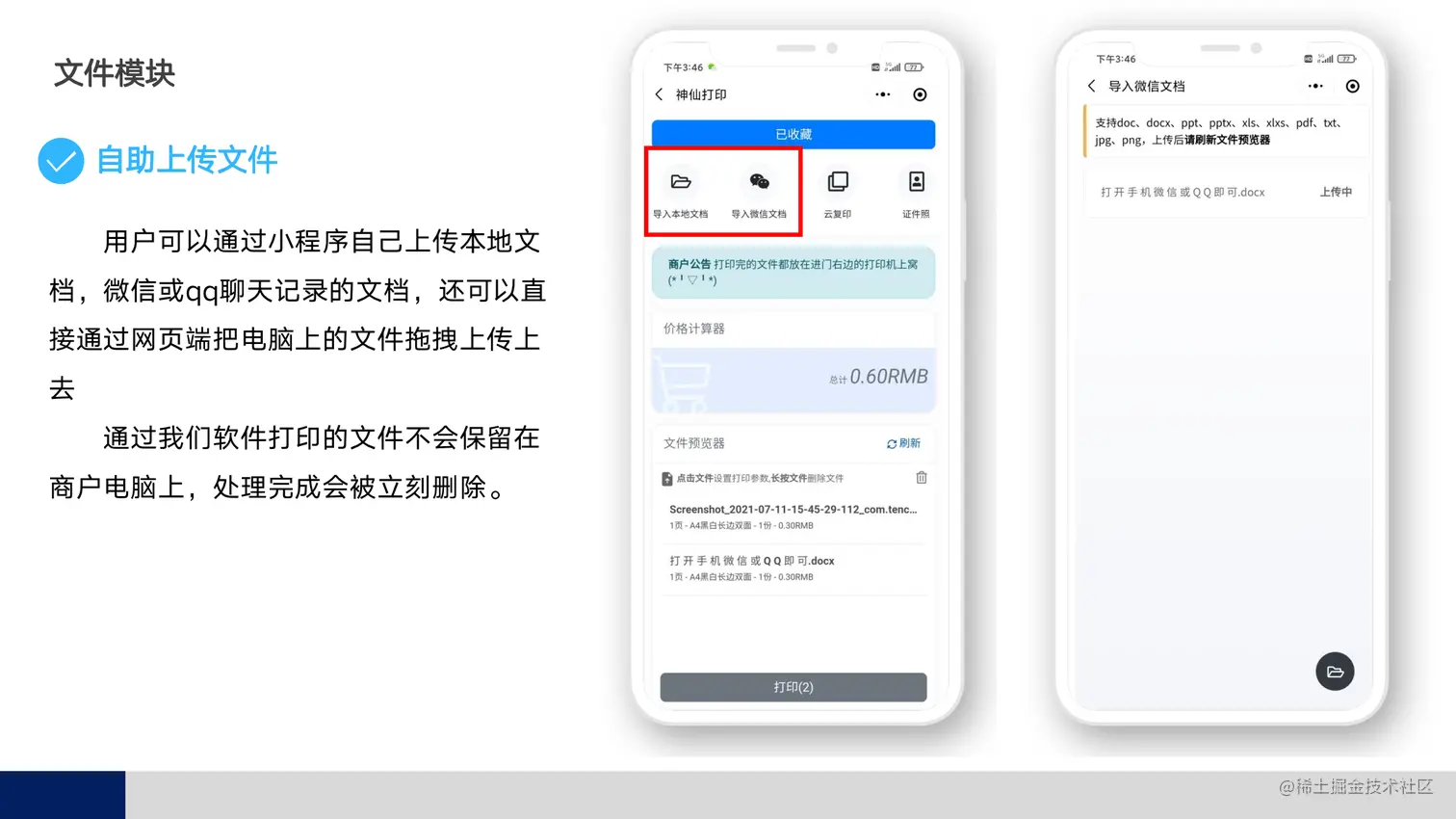
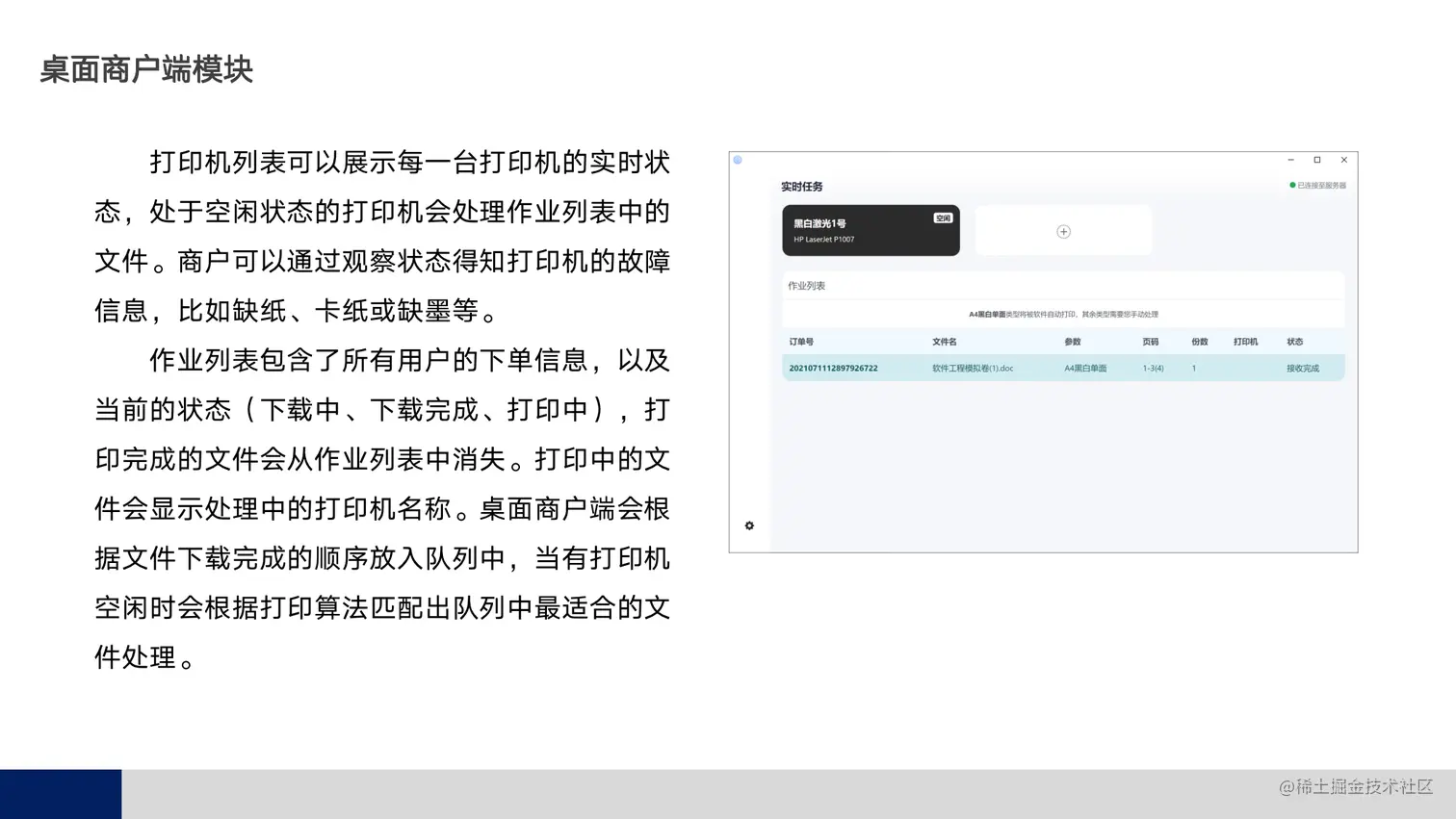








webp的几个问题
1. 什么是webp?
最直接的就是一个图片的后缀是.webp而不是.png/.jpeg等,官方的说法就是由Google开发的一种用于图像压缩的现代格式,目的就是减小图片的大小从而提高网页加载速;
2. 是不是所有浏览器都支持webp图片?如何判断浏览器是否支持webp格式的图片
不是所有的浏览器都支持 WebP 图片格式,但大多数主流的现代浏览器都已经支持了。以下是一些常见的浏览器对 WebP 格式的支持情况:
- Google Chrome:支持 WebP 格式。
- Mozilla Firefox:支持 WebP 格式。
- Microsoft Edge:支持 WebP 格式。
- Safari:从 Safari 14 开始,支持 WebP 格式
要判断浏览器是否支持 WebP 格式的图片,可以使用 JavaScript 进行检测。以下是一种常用的方法:
function isWebPSupported() {
var elem = document.createElement('canvas');
if (!!(elem.getContext && elem.getContext('2d'))) {
// canvas 支持
return elem.toDataURL('image/webp').indexOf('data:image/webp') === 0;
}
// canvas 不支持
return false;
}
if (isWebPSupported()) {
console.log('浏览器支持 WebP 格式');
} else {
console.log('浏览器不支持 WebP 格式');
}
上述代码通过创建一个 canvas 元素,并尝试将其转换为 WebP 格式的图片。如果浏览器支持 WebP 格式,则会返回一个以 "data:image/webp" 开头的数据 URL。
通过这种方式,你可以在网页中使用 JavaScript 检测浏览器是否支持 WebP 格式,并根据需要提供适当的替代图片
3. 图片转换成webp之后一定会比之前的图片更小吗?
答案是否定的。一般来说,具有大量细节、颜色变化和复杂结构的图像可能会在转换为 WebP 格式后获得更好的压缩效果,反之有些转换后可能会比之前更大;所以最好是图片转换为 WebP 格式之前,建议进行测试和比较不同压缩参数和质量级别的结果,以找到最佳的压缩设置,对最终转换后变成更大的建议不做转换
4. 如何将图片转换成webp
- 图像编辑软件 如 Adobe Photoshop、GIMP 或在线工具,如 Google 的 WebP 编码器。这些工具可以让你将现有的图像转换为 WebP 格式,并选择压缩质量和压缩类型(有损或无损)
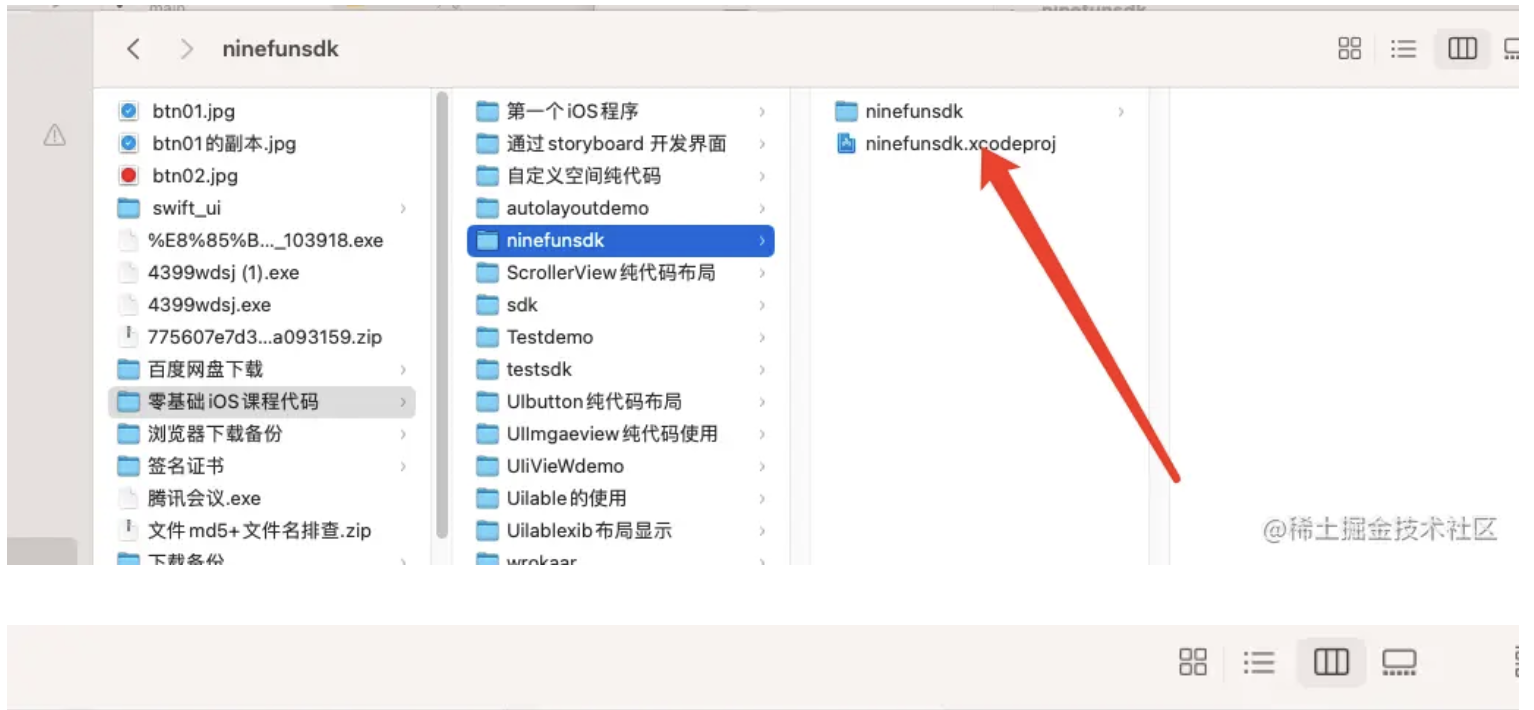
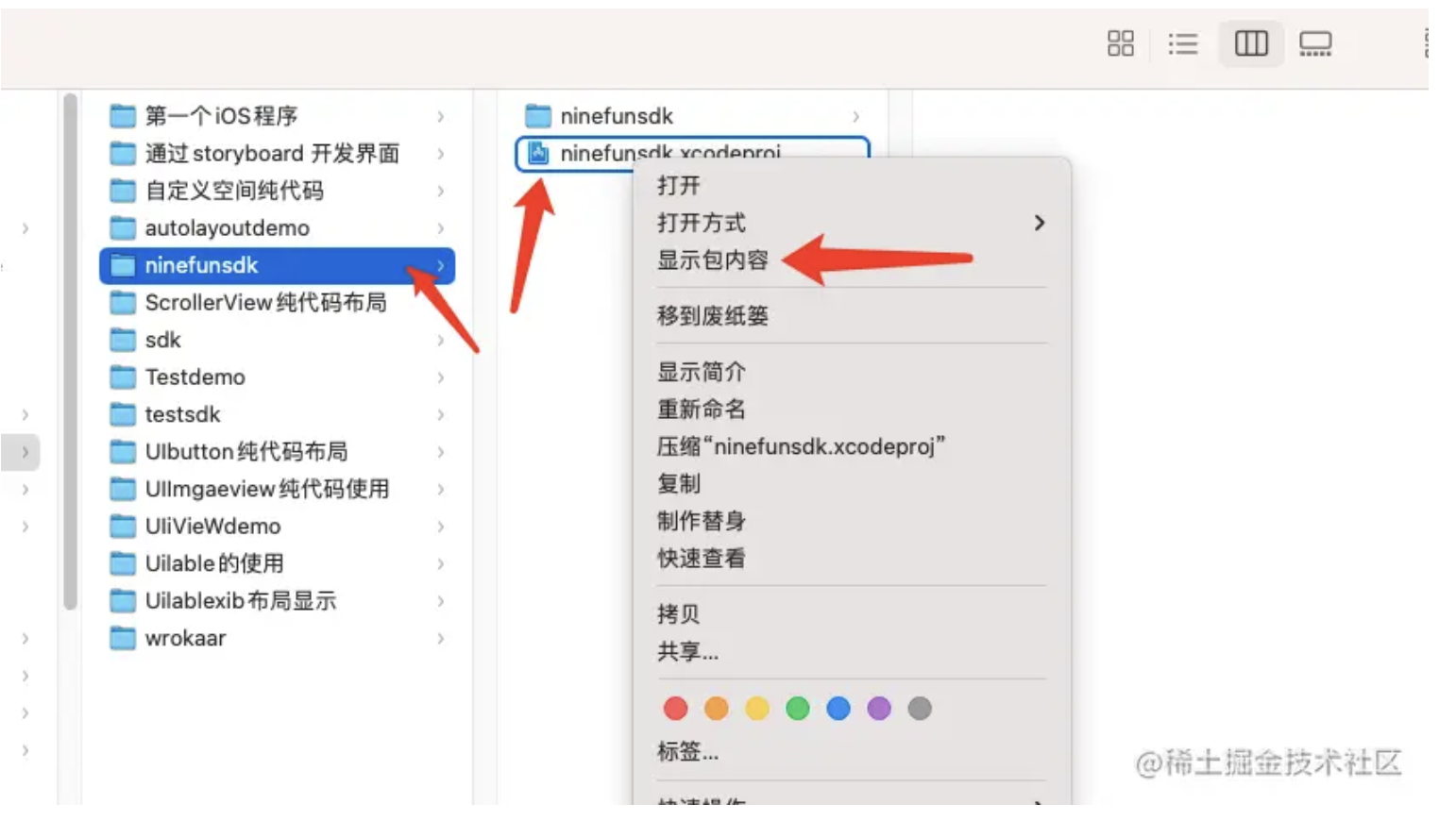
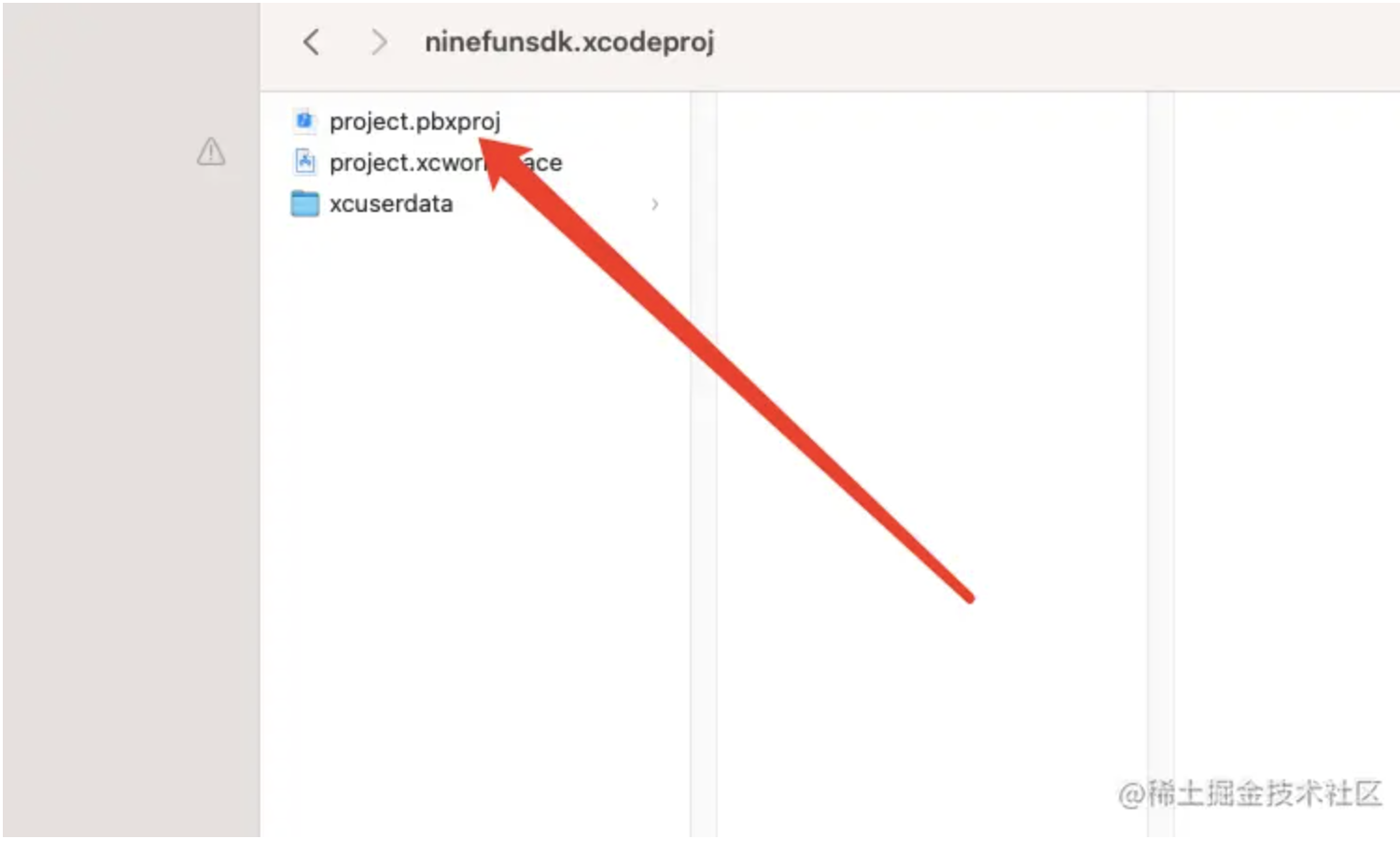
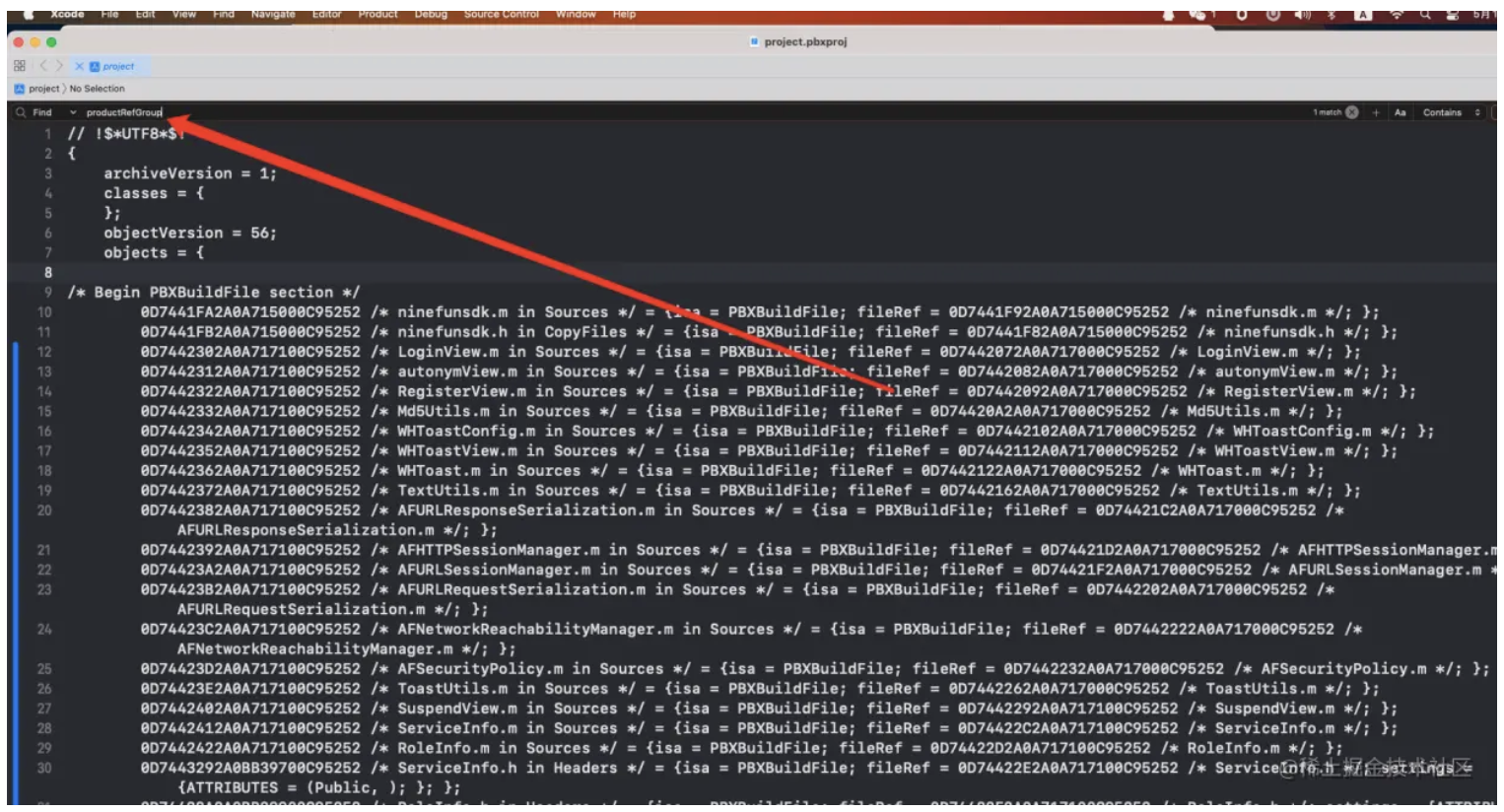
- 插件转换webp插件文档链接接入

5. 项目中如何接入??
思路:
- 第一步肯定是转化将项目中的存储的图片文件通过插件转换出webp格式的图片
- 判断网页运行的浏览器是否支持webp格式的图片,如果支持,将项目中所有使用png/jpeg的图片的全部替换成webp
6. 转换出项目中图片的webp格式的图片
const imagemin = require("imagemin");
const imageminWebp = require("imagemin-webp");
function transformToWebp(destination, filePaths) {
await imagemin([filePath || `${destination}/*.{jpg,png}`], {
destination: `${destination}/webp/`, // 转换出的webp图片放置在什么目录
plugins: [imageminWebp({quality: 75})] // 使用imageminWebp转换转换质量级别设置多少
})
}
具体到项目中,我们只希望转换我们当前正在开发的文件夹中的图片,而且已经转化的未作修改的就不要再重复转化; 如何知道哪些是新增的或者修改的呢? 想一想🤔️,是不是“git status”可以看到
所以开始做如下调整
// 获取git仓库中发生变更的文件列表
function getGitStatusChangedImgFiles() {
return String(execSync('git status -s'))
.split('\n')
.map(item => item.split(' ').pop()
.filter(path => path.match(/\.(jpg)|(png)/))
);
};
返回一个包含变更图片文件路径的数组['src/example/image/a.png','src/example/image/b.png', '……']
const imgPaths = getGitStatusChangedImgFiles()
async function transformAllChangedImgToWebp() {
const resData = await promise.all(
imgPaths.map(path => {
const imgDir = path.replace(/([^\\/]+)\.([^\\/]+)/i, "") // src/banners/guardian_8/img/95_copy.png => src/banners/guardian_8/img/
return transformToWebp(imgDir, path)
})
)
const allDestinationPaths = resData.map((subArr) => subArr[0].destinationPath)
// 如果这里我们想将生成的webp图片自动的add上去,那么就这样:
execSync(`git add ${allDestinationPaths.join(" ")}`);
}

什么时候转换成webp最好?
我们在commit的时候进行转换图片,以及自动将转换的图片进行提交
这样我们就可以运用git的钩子函数处理了;
npm install husky --save-dev
// .husky/pre-commit中
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
current_branch=`git rev-parse --abbrev-ref HEAD`
if [[ $current_branch === 'main']]; then
# 生成 webp 图片
npm run webp -- commit
fi
这样在我们commit时就会自动触发pre-commit钩子函数,在package.json中配置webp执行的脚步,执行上述transformAllChangedImgToWebp函数,然后在里面转换出webp图片并将新生成的webp自动git add上去,最后一并commit;
知识点
1. execSync是什么?
execSync 是一个 Node.js 内置模块 child_process 中的方法,用于同步执行外部命令。在 Node.js 中,child_process 模块提供了一组用于创建子进程的函数,其中包括 execSync 方法。execSync 方法用于执行指定的命令,并等待命令执行完成后返回结果。
const { execSync } = require('child_process'); const output = execSync(command, options);
2. git status -s 会显示每个文件的状态信息
A:新增文件M:修改文件D:删除文件R:文件名修改C:文件的拷贝U:未知状态

3. execSync('git status -s')返回值是什么?

通过String后就可以变成可见的字符串了,然后通过分割等就能拿到具体的修改的文件路径
4. Husky是什么?
Husky 是一个用于在 Git 提交过程中执行脚本的工具。它可以帮助开发人员在代码提交前或提交后执行一些自定义的脚本,例如代码格式化、代码质量检查、单元测试等。Husky 可以确保团队成员在提交代码之前遵循一致的规范和约定。
Husky 的工作原理是通过在 Git 钩子(Git hooks)中注册脚本来实现的。Git 钩子是在特定的 Git 事件发生时执行的脚本,例如在提交代码前执行 pre-commit 钩子,或在提交代码后执行 post-commit 钩子。push代码前执行pre-push的钩子、编写提交信息时执行commit-msg的钩子可用于提交什么规范
小结
- 通过
execSync('git status -s')从中获取筛选当前新增/修改过的图片; - 调用
imagemin和imagemin-webp将图片转换出webp格式的图片 - 在
husky的pre-commit中触发上述调用执行,并在里面顺道将新生成的webp一并add上去 - 至于后续生成的webp图片怎么使用,这将在下一篇文章中学习
来源:juejin.cn/post/7260016275300155449