前一阵,看到一位掘友分享了一篇文章:Android简单的两级评论功能实现,看得出来,是一位Android萌新记录的学习过程。我当时还留了一条建议:
建议用单RecyclerView+多ItemType+ListAdapter实现,保持UI层的清洁,把逻辑处理集中在数据源的转换上,比如展开/收起二级评论可以利用flatMap和groupBy等操作符转换
其实我之前在工作中,也曾经做过类似抖音的二级评论的需求。但那个时候自己很菜,还没有用过Kotlin,协程更是没有接触过,这个功能和另一位同事一起开发了两周才搞定。
刚好这个周末没啥事,就想着写一个简单实现抖音二级评论基本功能的Demo。一方面,想试试自己现在开发这样一个需求会是什么样的体验;另一方面,也算是给Android掘友,尤其是萌新,分享一点业务开发的心得。
先上个效果图(没有UI,将就看吧),写代码的整个过程花了4个小时左右,相比当初自己开发需求已经快了很多了哈。
给产品估个两天时间,摸一天半的鱼不过分吧(手动斜眼)

需求拆分
这种大家常用的评论功能其实也就没啥好拆分的了,简单列一下:
- 默认展示一级评论和二级评论中的热评,可以上拉加载更多。
- 二级评论超过两条时,可以点击展开加载更多二级评论,展开后可以点击收起折叠到初始状态。
- 回复评论后插入到该评论的下方。
技术选型
前面我在给掘友的评论中,也提到了技术选型的要点:
单RecyclerView + 多ItemType + ListAdapter
这是基本的UI框架。
为啥要只用一个RecyclerView?最重要的原因,就是在RecyclerView中嵌套同方向RecyclerView,会有性能问题和滑动冲突。其次,当下声明式UI正是各方大佬推崇的最佳开发实践之一,虽然我们没有使用声明式UI基础上开发的Compose/Flutter技术,但其构建思想仍然对我们的开发具有一定的指导意义。我猜测,androidx.recyclerview.widget.ListAdapter可能也是响应声明式UI号召的一个针对RecyclerView的解决方案吧。
数据源的转换
数据驱动UI!
既然选用了ListAdapter,那么我们就不应该再手动操作adapter的数据,再用各种notifyXxx方法来更新列表了。更提倡的做法是,基于data class的浅拷贝,用Collection操作符对数据源的进行转换,然后将转换后的数据提交到adapter。为了提高数据转换性能,我们可以基于协程进行异步处理。
graph LR
start[原List] --异步数据处理--> 新List --> stop[ListAdapter.submitList]
stop --> start
要点:
低成本生成一个全新的对象,以保证数据源的安全性。
data class Foo(val id: Int, val content: String)
val foo1 = Foo(0, "content")
val foo2 = foo1.copy(content = "updated content")
Kotlin中提供了大量非常好用的Collection操作符,能灵活使用的话,非常有利于咱们向声明式UI转型。
前面我提到了groupBy和flatMap这两个操作符。怎么使用呢?
以这个需求为例,我们需要显示一级评论、二级评论和展开更多按钮,想要分别用一个data class来表示,但是后端返回的数据中又没有“展开更多”这样的数据,就可以这样处理:
val loaded: List<CommentItem> = ...
val grouped = loaded.groupBy {
(it as? CommentItem.Level1)?.id ?: (it as? CommentItem.Level2)?.parentId
?: throw IllegalArgumentException("invalid comment item")
}.flatMap {
it.value + CommentItem.Folding(
parentId = it.key,
)
}
前面我们描述的数据源的转换过程,在Kotlin中,可以简单地被抽象为一个操作:
List<CommentItem>.() -> List<CommentItem>
对于这个需求,数据源转换操作就包括了:分页加载,展开二级评论,收起二级评论,回复评论等。按照惯例,抽象一个接口出来。既然我们要在协程框架下进行异步处理,需要给这个操作加一个suspend关键字。
interface Reducer {
val reduce: suspend List<CommentItem>.() -> List<CommentItem>
}
为啥我给这个接口取名Reducer?如果你知道它的意思,说明你可能已经了解过MVI架构了;如果你还不知道它的意思,说明你可以去了解一下MVI了。哈哈!
不过今天不谈MVI,对于这样一个小Demo,完全没必要上架构。但是,优秀架构为我们提供的代码构建思路是有必要的!
这个Reducer,在这里就算是咱们的小小业务架构了。
前面谈到异步,我们印象中可能主要是网络请求、数据库/文件读写等IO操作。
这里我想要延伸一下。
Activity的startActivityForResult/onActivityResult,Dialog的拉起/回调,其实也可以看着是异步操作。异步与是否在主线程无关,而在于是否是实时返回结果。毕竟在主线程上跳转到其他页面,获取数据再回调回去使用,也是花了时间的啊。所以在协程的框架下,有一个更适合描述异步的词语:挂起(suspend)。
说这有啥用呢?仍以这个需求为例,我们点击“回复”后拉起一个对话框,输入评论确认后回调给Activity,再进行网络请求:
class ReplyDialog(context: Context, private val callback: (String) -> Unit) : Dialog(context) {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.dialog_reply)
val editText = findViewById<EditText>(R.id.content)
findViewById<Button>(R.id.submit).setOnClickListener {
if (editText.text.toString().isBlank()) {
Toast.makeText(context, "评论不能为空", Toast.LENGTH_SHORT).show()
return@setOnClickListener
}
callback.invoke(editText.text.toString())
dismiss()
}
}
}
suspend List<CommentItem>.() -> List<CommentItem> = {
val content = withContext(Dispatchers.Main) {
suspendCoroutine { continuation ->
ReplyDialog(context) {
continuation.resume(it)
}.show()
}
}
...进行其他操作,如网络请求
}
技术选型,或者说技术框架,咱们就实现了,甚至还谈到了部分细节了。接下来进行完整实现细节分享。
实现细节
MainActivity
基于上一章节的技术选型,咱们的MainActivity的完整代码就是这样了。
class MainActivity : AppCompatActivity() {
private lateinit var commentAdapter: CommentAdapter
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
val recyclerView = findViewById<RecyclerView>(R.id.recyclerView)
commentAdapter = CommentAdapter {
lifecycleScope.launchWhenResumed {
val newList = withContext(Dispatchers.IO) {
reduce.invoke(commentAdapter.currentList)
}
val firstSubmit = commentAdapter.itemCount == 1
commentAdapter.submitList(newList) {
if (firstSubmit) {
recyclerView.scrollToPosition(0)
} else if (this@CommentAdapter is FoldReducer) {
val index = commentAdapter.currentList.indexOf(this@CommentAdapter.folding)
recyclerView.scrollToPosition(index)
}
}
}
}
recyclerView.adapter = commentAdapter
}
}
给RecyclerView设置一个CommentAdapter就行了,回调时也只需要把回调过来的Reducer调度到IO线程跑一下,得到新的数据list再submitList就完事了。如果不是submitList后有列表的定位问题,代码还能更精简。如果有知道更好的解决办法的朋友,麻烦留言分享一下,感谢!
CommentAdapter
别以为我把逻辑处理扔到adapter中了哦!
Adapter和ViewHolder都是UI组件,我们也需要尽量保持它们的清洁。
贴一下CommentAdapter的
class CommentAdapter(private val reduceBlock: Reducer.() -> Unit) :
ListAdapter<CommentItem, VH>(object : DiffUtil.ItemCallback<CommentItem>() {
override fun areItemsTheSame(oldItem: CommentItem, newItem: CommentItem): Boolean {
return oldItem.id == newItem.id
}
override fun areContentsTheSame(oldItem: CommentItem, newItem: CommentItem): Boolean {
if (oldItem::class.java != newItem::class.java) return false
return (oldItem as? CommentItem.Level1) == (newItem as? CommentItem.Level1)
|| (oldItem as? CommentItem.Level2) == (newItem as? CommentItem.Level2)
|| (oldItem as? CommentItem.Folding) == (newItem as? CommentItem.Folding)
|| (oldItem as? CommentItem.Loading) == (newItem as? CommentItem.Loading)
}
}) {
init {
submitList(listOf(CommentItem.Loading(page = 0, CommentItem.Loading.State.IDLE)))
}
override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): VH {
val inflater = LayoutInflater.from(parent.context)
return when (viewType) {
TYPE_LEVEL1 -> Level1VH(
inflater.inflate(R.layout.item_comment_level_1, parent, false),
reduceBlock
)
TYPE_LEVEL2 -> Level2VH(
inflater.inflate(R.layout.item_comment_level_2, parent, false),
reduceBlock
)
TYPE_LOADING -> LoadingVH(
inflater.inflate(
R.layout.item_comment_loading,
parent,
false
), reduceBlock
)
else -> FoldingVH(
inflater.inflate(R.layout.item_comment_folding, parent, false),
reduceBlock
)
}
}
override fun onBindViewHolder(holder: VH, position: Int) {
holder.onBind(getItem(position))
}
override fun getItemViewType(position: Int): Int {
return when (getItem(position)) {
is CommentItem.Level1 -> TYPE_LEVEL1
is CommentItem.Level2 -> TYPE_LEVEL2
is CommentItem.Loading -> TYPE_LOADING
else -> TYPE_FOLDING
}
}
companion object {
private const val TYPE_LEVEL1 = 0
private const val TYPE_LEVEL2 = 1
private const val TYPE_FOLDING = 2
private const val TYPE_LOADING = 3
}
}
可以看到,就是一个简单的多ItemType的Adapter,唯一需要注意的就是,在Activity里传入的reduceBlock: Reducer.() -> Unit,也要传给每个ViewHolder。
ViewHolder
篇幅原因,就只贴其中一个:
abstract class VH(itemView: View, protected val reduceBlock: Reducer.() -> Unit) :
ViewHolder(itemView) {
abstract fun onBind(item: CommentItem)
}
class Level1VH(itemView: View, reduceBlock: Reducer.() -> Unit) : VH(itemView, reduceBlock) {
private val avatar: TextView = itemView.findViewById(R.id.avatar)
private val username: TextView = itemView.findViewById(R.id.username)
private val content: TextView = itemView.findViewById(R.id.content)
private val reply: TextView = itemView.findViewById(R.id.reply)
override fun onBind(item: CommentItem) {
avatar.text = item.userName.subSequence(0, 1)
username.text = item.userName
content.text = item.content
reply.setOnClickListener {
reduceBlock.invoke(ReplyReducer(item, itemView.context))
}
}
}
也是很简单,唯一特别一点的处理,就是在onClickListener中,让reduceBlock去invoke一个Reducer实现。
Reducer
刚才在技术选型章节,已经提前展示了“回复评论”这一操作的Reducer实现了,其他Reducer也差不多,比如展开评论操作,也封装在一个Reducer实现ExpandReducer中,以下是完整代码:
data class ExpandReducer(
val folding: CommentItem.Folding,
) : Reducer {
private val mapper by lazy { Entity2ItemMapper() }
override val reduce: suspend List<CommentItem>.() -> List<CommentItem> = {
val foldingIndex = indexOf(folding)
val loaded =
FakeApi.getLevel2Comments(folding.parentId, folding.page, folding.pageSize).getOrNull()
?.map(mapper::invoke) ?: emptyList()
toMutableList().apply {
addAll(foldingIndex, loaded)
}.map {
if (it is CommentItem.Folding && it == folding) {
val state =
if (it.page > 5) CommentItem.Folding.State.LOADED_ALL else CommentItem.Folding.State.IDLE
it.copy(page = it.page + 1, state = state)
} else {
it
}
}
}
}
短短一段代码,我们做了这些事:
- 请求网络数据
Entity list(假数据)
- 通过
mapper转换成显示用的Item数据list
- 将
Item数据插入到“展开更多”按钮前面
- 最后,根据二级评论加载是否完成,将“展开更多”的状态置为
IDLE或LOADED_ALL
一个字:丝滑!
用于转换Entity到Item的mapper的代码也贴一下吧:
typealias Mapper<I, O> = (I) -> O
class Entity2ItemMapper : Mapper<ICommentEntity, CommentItem> {
override fun invoke(entity: ICommentEntity): CommentItem {
return when (entity) {
is CommentLevel1 -> {
CommentItem.Level1(
id = entity.id,
content = entity.content,
userId = entity.userId,
userName = entity.userName,
level2Count = entity.level2Count,
)
}
is CommentLevel2 -> {
CommentItem.Level2(
id = entity.id,
content = if (entity.hot) entity.content.makeHot() else entity.content,
userId = entity.userId,
userName = entity.userName,
parentId = entity.parentId,
)
}
else -> {
throw IllegalArgumentException("not implemented entity: $entity")
}
}
}
}
细心的朋友可以看到,在这里我顺便也将热评也处理了:
if (entity.hot) entity.content.makeHot() else entity.content
makeHot()就是用buildSpannedString来实现的:
fun CharSequence.makeHot(): CharSequence {
return buildSpannedString {
color(Color.RED) {
append("热评 ")
}
append(this@makeHot)
}
}
这里可以提一句:尽量用CharSequence来抽象表示字符串,可以方便我们灵活地使用Span来减少UI代码。
data class
也贴一下相关的数据实体得了。
interface ICommentEntity {
val id: Int
val content: CharSequence
val userId: Int
val userName: CharSequence
}
data class CommentLevel1(
override val id: Int,
override val content: CharSequence,
override val userId: Int,
override val userName: CharSequence,
val level2Count: Int,
) : ICommentEntity
sealed interface CommentItem {
val id: Int
val content: CharSequence
val userId: Int
val userName: CharSequence
data class Loading(
val page: Int = 0,
val state: State = State.LOADING
) : CommentItem {
override val id: Int=0
override val content: CharSequence
get() = when(state) {
State.LOADED_ALL -> "全部加载"
else -> "加载中..."
}
override val userId: Int=0
override val userName: CharSequence=""
enum class State {
IDLE, LOADING, LOADED_ALL
}
}
data class Level1(
override val id: Int,
override val content: CharSequence,
override val userId: Int,
override val userName: CharSequence,
val level2Count: Int,
) : CommentItem
data class Level2(
override val id: Int,
override val content: CharSequence,
override val userId: Int,
override val userName: CharSequence,
val parentId: Int,
) : CommentItem
data class Folding(
val parentId: Int,
val page: Int = 1,
val pageSize: Int = 3,
val state: State = State.IDLE
) : CommentItem {
override val id: Int
get() = hashCode()
override val content: CharSequence
get() = when {
page <= 1 -> "展开20条回复"
page >= 5 -> ""
else -> "展开更多"
}
override val userId: Int = 0
override val userName: CharSequence = ""
enum class State {
IDLE, LOADING, LOADED_ALL
}
}
}
这部分没啥好说的,可以注意两个点:
data class也是可以抽象的。但这边我处理不是很严谨,比如CommentItem我把userId和userName也抽象出来了,其实不应该抽象出来。
- 在基于
Reducer的框架下,最好是把data class的属性都定义为val。
结语
更多的代码就不贴了,贴太多影响观感。有兴趣的朋友可以移步源码。
总结一下实现心得:
- 数据驱动UI
- 对业务的精准抽象
- 对异步的延伸理解
- 灵活使用
Collection操作符
- 没有UI和PM,写代码真TM爽!
作者:blackfrog
来源:juejin.cn/post/7276808079143190565










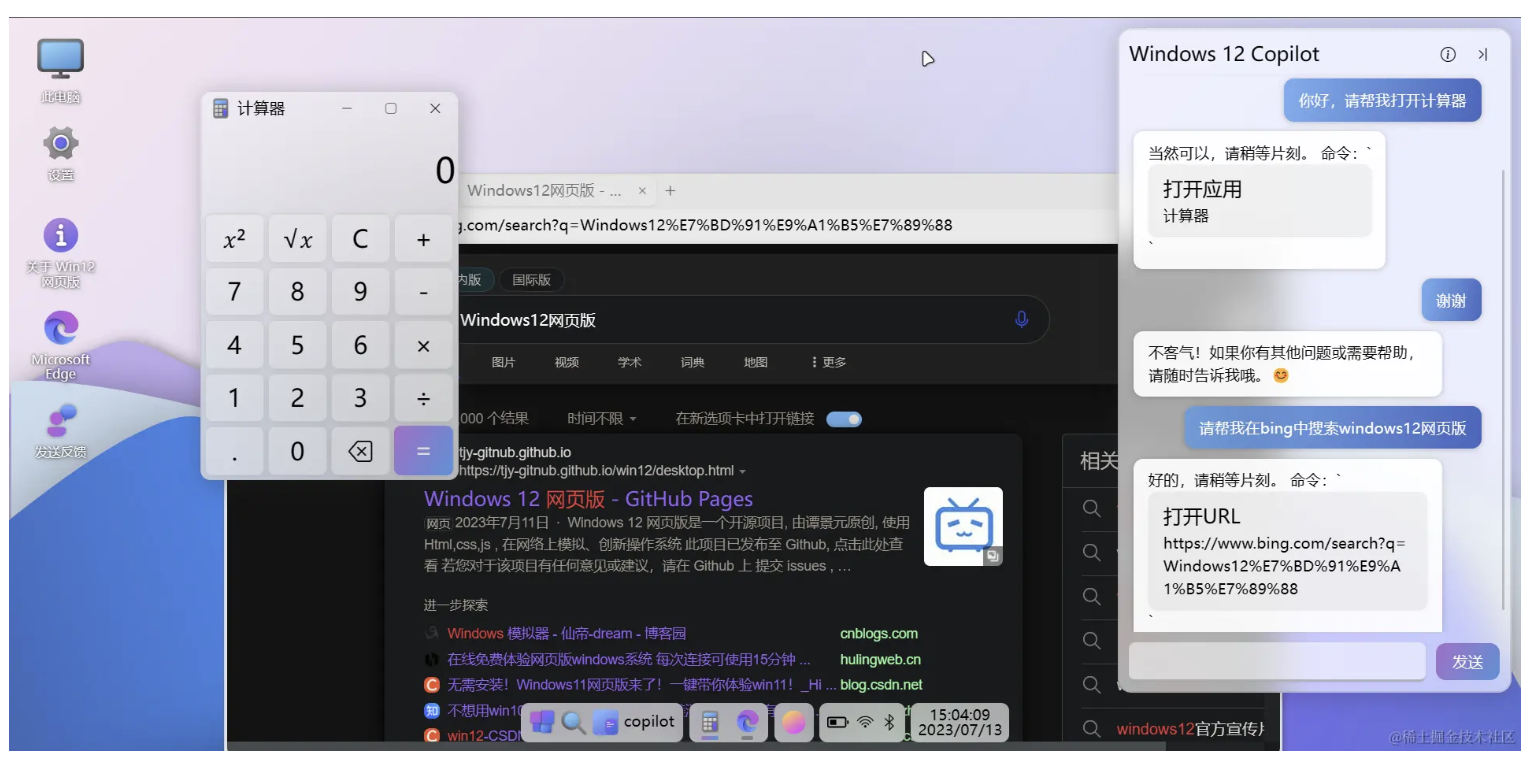
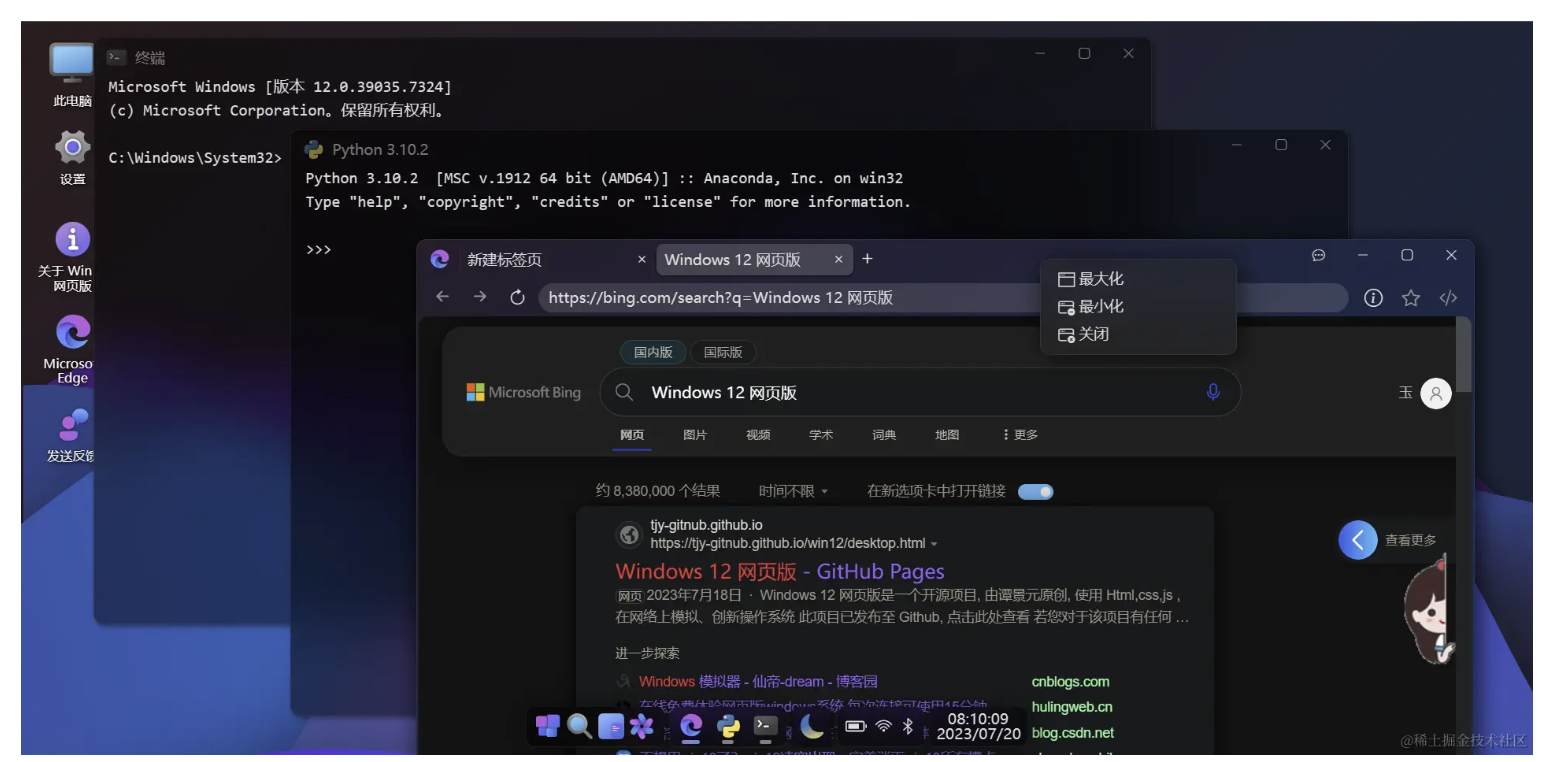


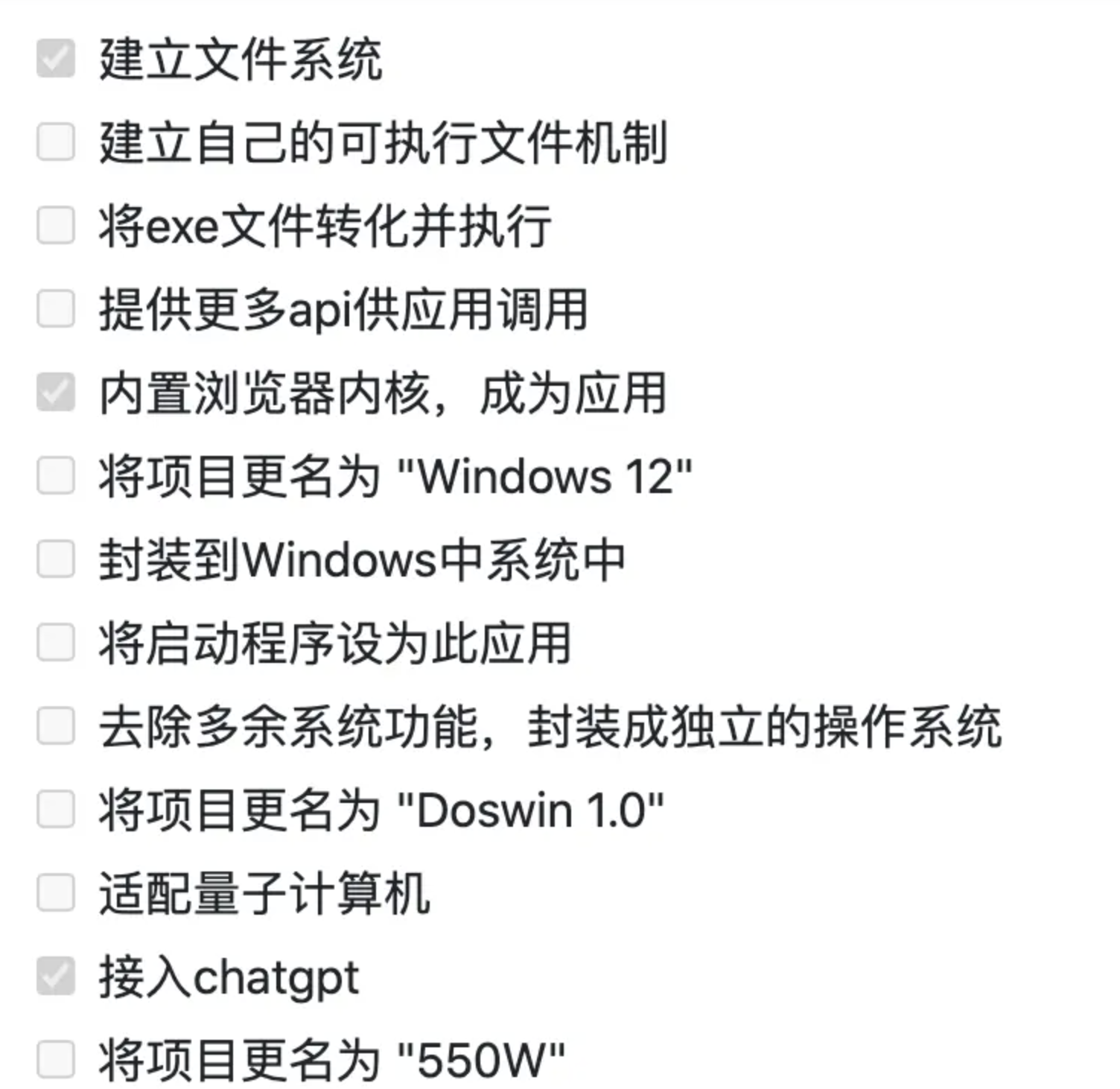


































































































































 在2.17入职之后,也算是正式开启了社畜的角色。奈何在公司工作不到半个月之后,开始迎来了为期三个多月的疫情,疫情不仅是对公司有着强烈的冲击,对打工人也是晴天霹雳。
在2.17入职之后,也算是正式开启了社畜的角色。奈何在公司工作不到半个月之后,开始迎来了为期三个多月的疫情,疫情不仅是对公司有着强烈的冲击,对打工人也是晴天霹雳。






































