

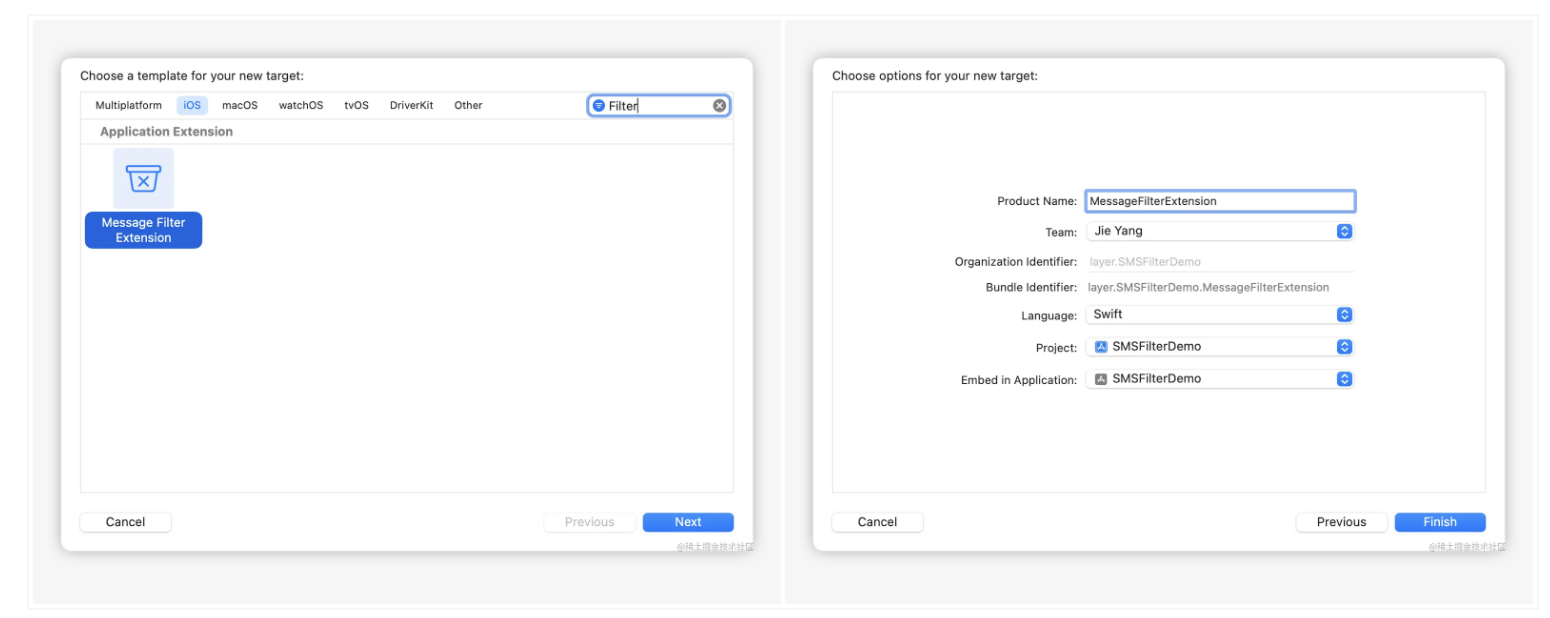
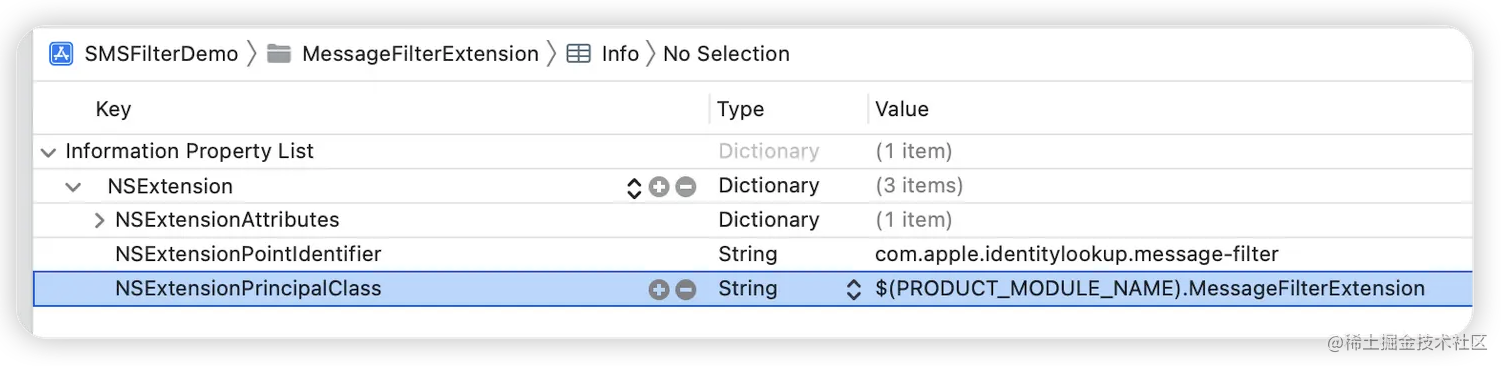
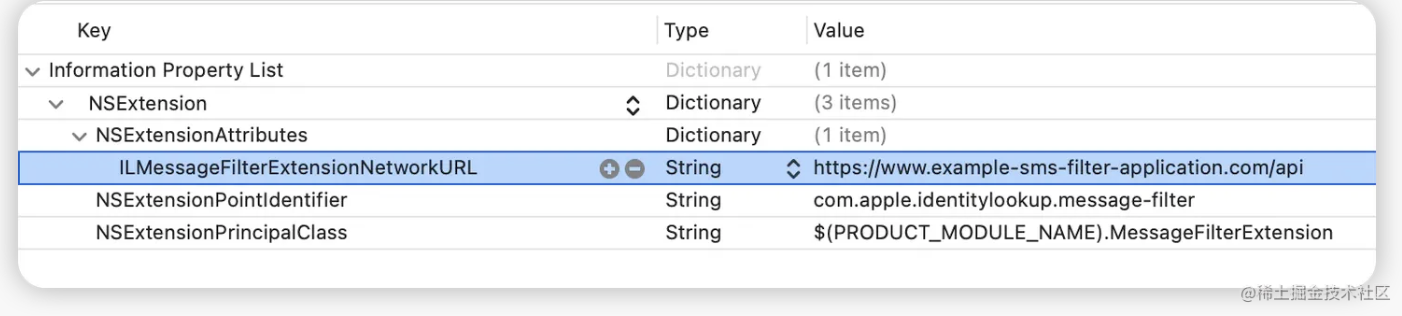
1. 前言
众所周知,一个完善的日志体系对于开发的顺利进行至关重要。尽管构建这样一个系统可能需要与开发几个功能模块相当的时间,但为了在日常开发中高效地记录日志,我进行了以下尝试。希望这些经验能为后端入门的同学和对日志管理不够熟悉的朋友们提供帮助。
(本文面向后端入门同学或是对日志管理缺乏深入了解的朋友)
2. 注解+手动记录
使用注解@Sl4j来自动创建日志类,再通过log.info()手动记录日志,是一种常见且相对灵活的方法。这样,我们可以在需要的任何地方记录所想要的日志内容。
然而,在实际开发中,这种方法可能会导致大量的日志与业务逻辑代码混杂,增加了代码与日志的耦合度。当需要修改业务逻辑时,往往还需要调整相关的日志,这可能导致重复记录,如请求参数和鉴权信息。
尽管如此,我并不是完全反对这种日志处理方法。其简单性和灵活性是其显著优点。但建议开发者结合其他方法,以减少日志与业务逻辑的耦合。
3. AOP统一处理
首先,我会介绍如何利用AOP自动记录日志以及哪些日志适合用AOP来处理。
3.1 请求详情日志
使用AOP统一处理请求详情日志能够有效地解耦控制层和业务层,这是一个非常高效的策略。以下是一个示例,展示如何使用AOP通知类记录详细的请求信息:
@Slf4j
@Aspect
@Component
public class LoggingAspect {
/* 日志输出被访问的接口url */
@Before("execution(* com.steadon.example.controller.*.*(..))")
public void beforeRequest(JoinPoint joinPoint) {
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.currentRequestAttributes()).getRequest();
String httpMethod = request.getMethod();
String remoteAddr = request.getRemoteAddr();
String requestURI = request.getRequestURI();
String queryString = request.getQueryString();
String params = "";
if ("POST".equalsIgnoreCase(httpMethod)) {
Object[] args = joinPoint.getArgs();
if (args != null && args.length > 0) {
params = Arrays.toString(args);
}
}
log.info("Request Info: IP [{}] HTTP_METHOD [{}] URL [{}] QUERY_STRING [{}] PARAMS [{}]",
remoteAddr, httpMethod, requestURI, queryString, params);
}
}
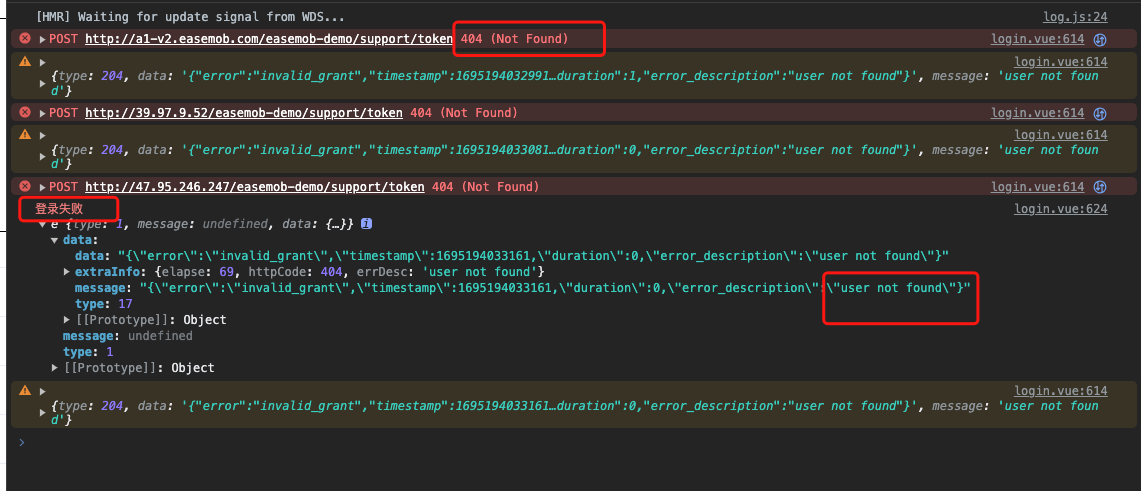
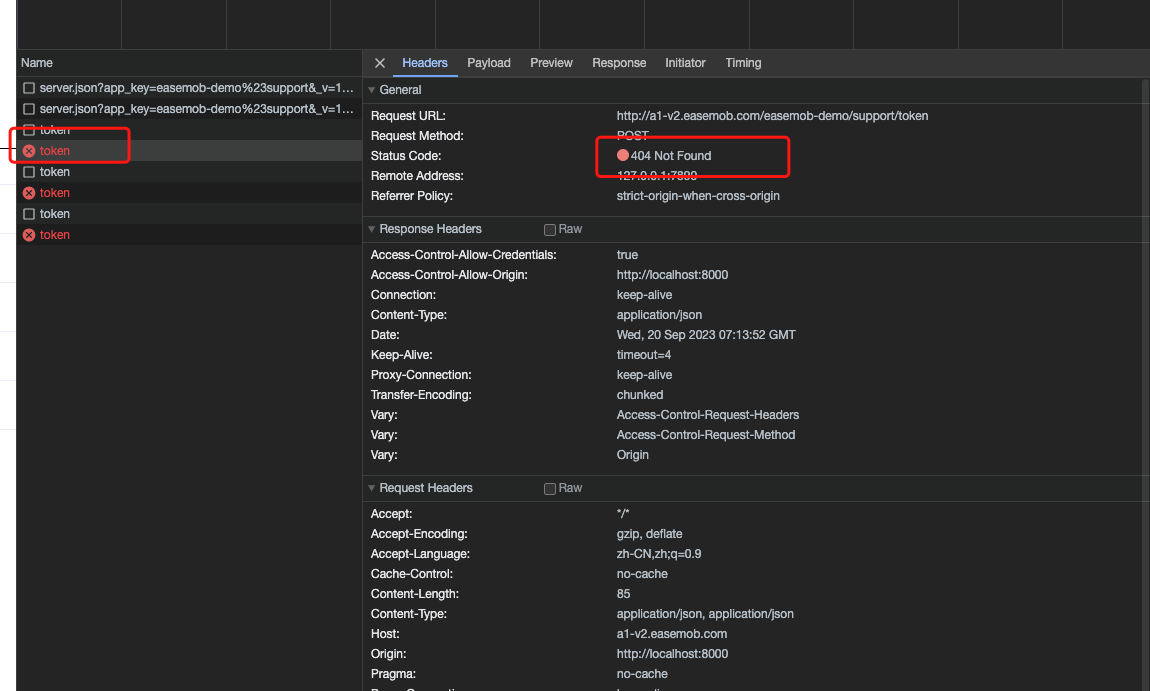
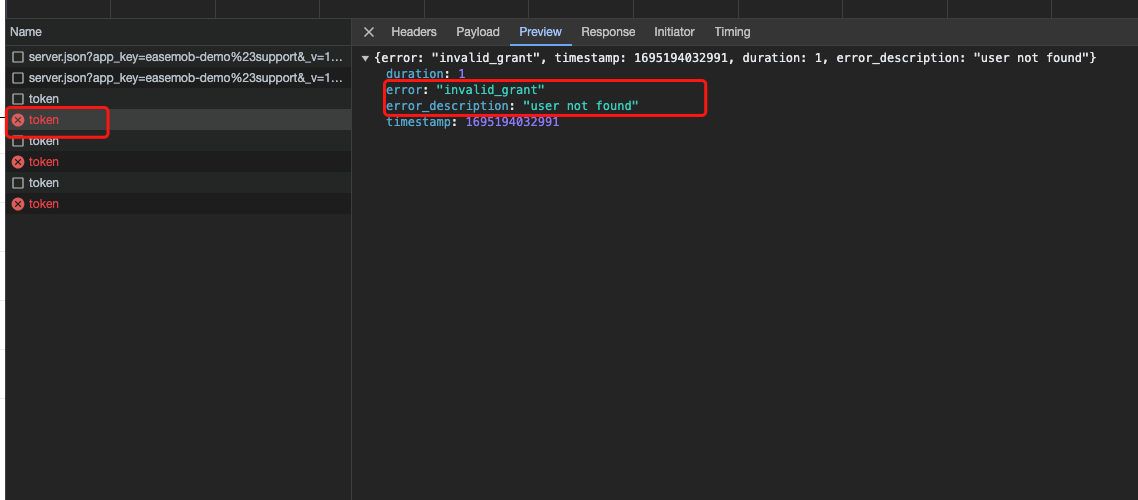
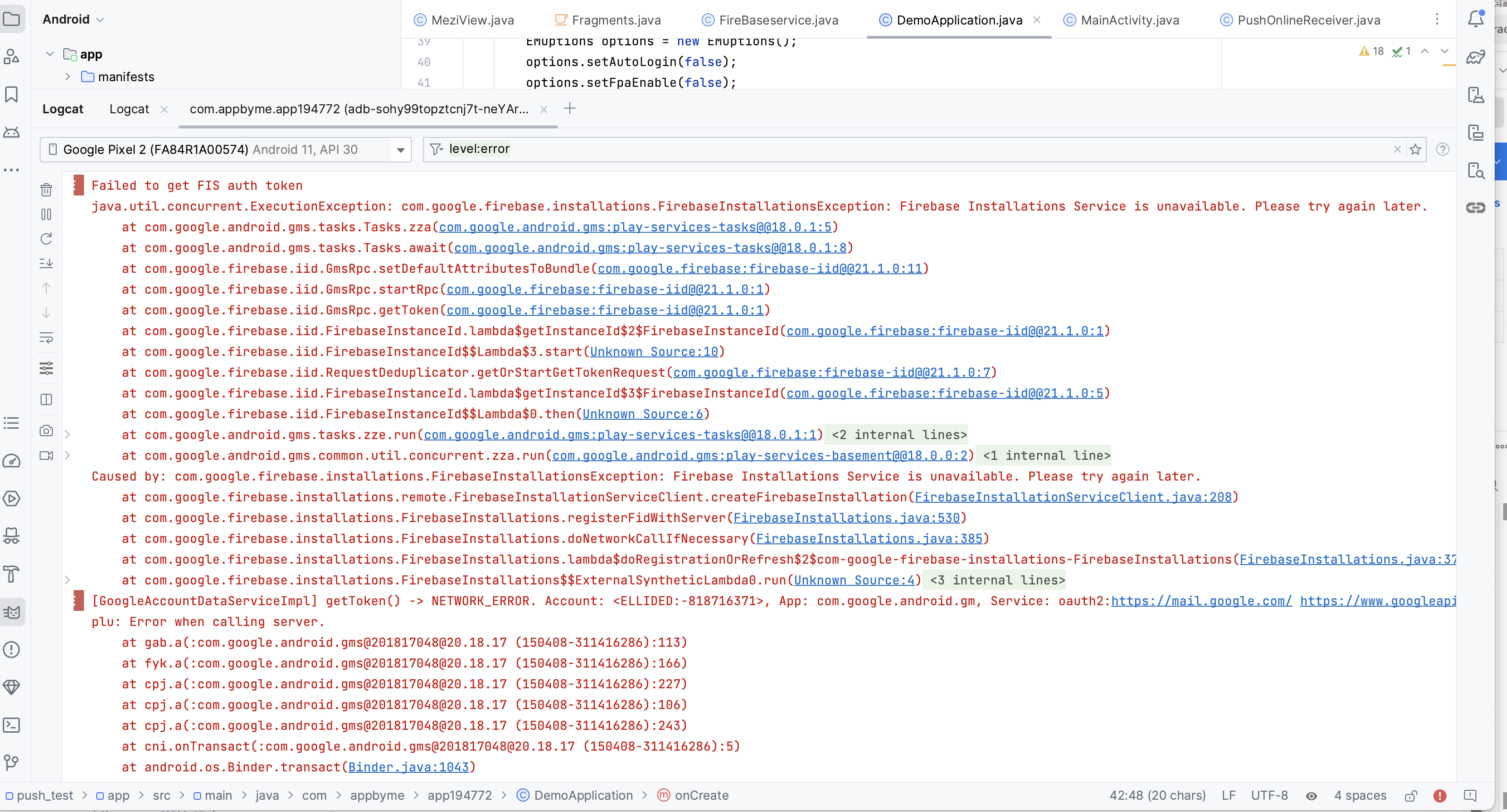
通过这个AOP通知类,我们可以轻松地记录详细的请求信息。在遇到问题时,分析此日志通常可以帮助我们迅速找到原因,例如前端参数传递错误或后端参数接收问题。效果图如下:

3.2 其他
你可以利用AOP来拦截几乎任何切点,无论是消息队列、Mybatis的Mapper操作,还是特定的循环,都可以织入相应的通知。然而,使用AOP时,我们也必须权衡其成本。
AOP的优势并不仅仅在于其性能或易用性,而是它出色的解耦能力。选择是否使用AOP应基于你的日志和业务逻辑之间的耦合程度。只有当耦合度足够高,需要解耦时,AOP才真正显示其价值。
4. Lark机器人 + 全局异常处理
我相信许多读者都已经熟悉飞书机器人(Lark机器人)。通过全局异常捕获并调用飞书机器人进行告警,这是一种极为有效的业务告警通知方式。你可能会想:“哦,这个我知道。” 但是,具体如何实现呢?其实操作起来并不复杂,接下来我会详细介绍:
4.1 创建告警群聊
对于简单的报警,我们通常选择创建群聊机器人,而不是单独的机器人应用。这样做的好处是,我们可以动态管理需要接收告警的开发团队成员。
4.2 创建自定义机器人
- 在群聊中,依次选择:设置 -> 群机器人 -> 添加机器人。

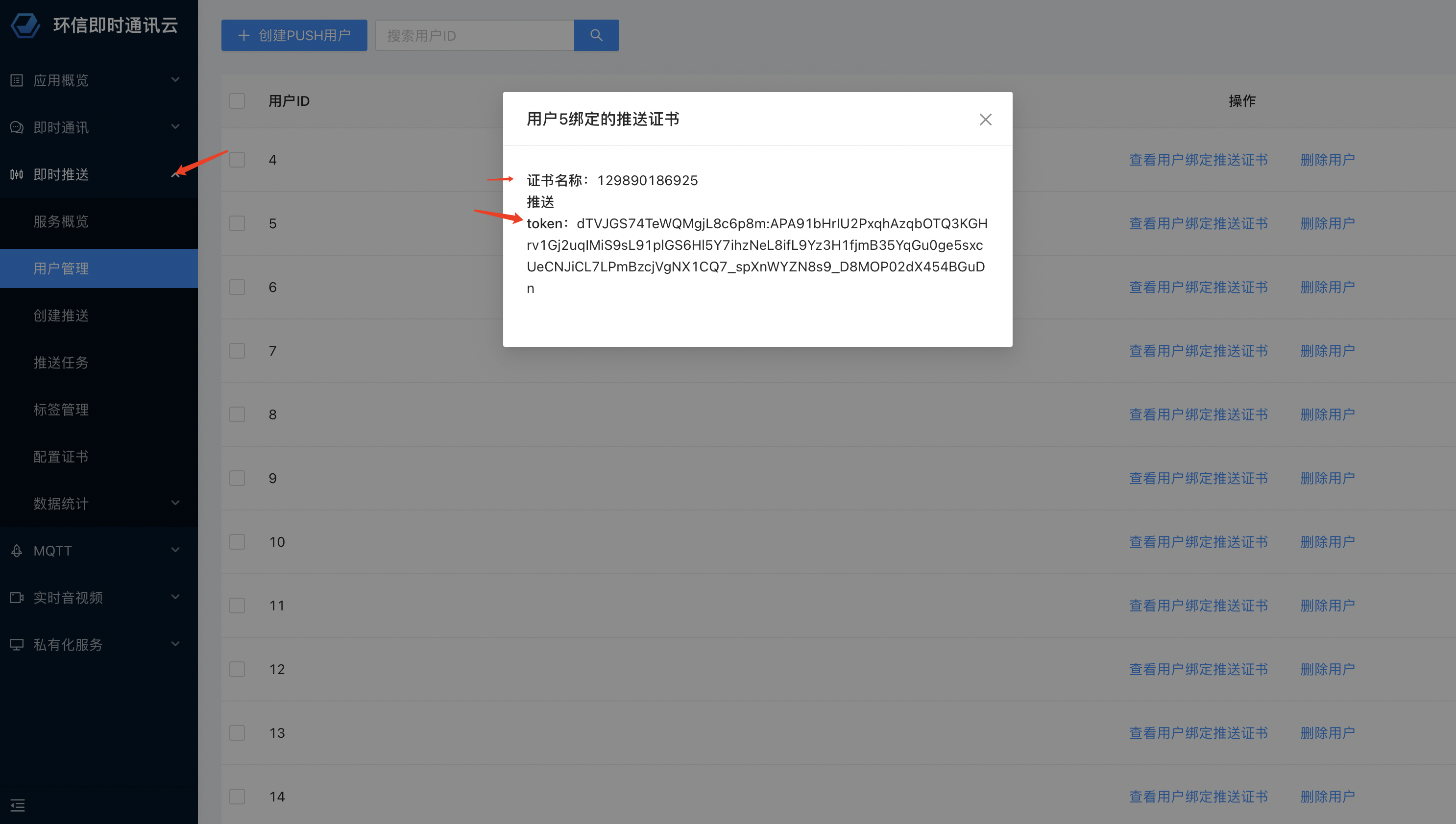
- 在机器人详情页面,获取
webhook地址。请确保此地址保密。

- 接下来,在代码中集成飞书机器人的告警功能。下面是如何在全局异常处理中集成飞书机器人的示例代码:
/* 飞书机器人告警 */
public String sendLarkNotification(String webhookUrl, String user, String title, String messageBody) throws Exception {
URL url = new URL(webhookUrl);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setDoOutput(true);
connection.setRequestMethod("POST");
connection.setRequestProperty("Content-Type", "application/json; charset=UTF-8");
ObjectMapper mapper = new ObjectMapper();
ObjectNode root = mapper.createObjectNode();
ObjectNode content = root.putObject("content").putObject("post").putObject("zh_cn");
content.put("title", title);
ArrayNode contentArray = content.putArray("content");
ArrayNode atUserArray = contentArray.addArray();
atUserArray.addObject().put("tag", "at").put("user_id", user);
ArrayNode messageArray = contentArray.addArray();
messageArray.addObject().put("tag", "text").put("text", messageBody);
root.put("msg_type", "post");
byte[] input = mapper.writeValueAsBytes(root);
try (OutputStream os = connection.getOutputStream()) {
os.write(input, 0, input.length);
}
try (BufferedReader br = new BufferedReader(new InputStreamReader(connection.getInputStream(), StandardCharsets.UTF_8))) {
StringBuilder response = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
response.append(line);
}
return response.toString();
}
}
代码相对简单,主要逻辑是通过HTTP请求向webhook地址发送带有告警信息的POST请求。为了实现这个请求,我们需要在全局异常处理中调用上述方法。为了便于展示,我直接在全局异常处理类中编写了这个方法。但读者可以考虑创建一个专门的工具类来实现这一功能。接下来,我将展示我的全局异常处理类的逻辑:
@ControllerAdvice
public class GlobalExceptionHandler {
@Value("${notifications.larkBotEnabled}")
private boolean larkBotEnabled;
@ExceptionHandler(value = Exception.class)
public CommonResult<String> handleException(Exception e) {
if (!larkBotEnabled) return CommonResult.fail();
// Send notification to Lark
String title = "线上BUG通报";
String user = "all";
String webhookUrl = "https://open.feishu.cn/open-apis/bot/v2/hook/f4150b6c-xxxx-xxxx-xxxx-xxxx-xxxx";
try {
String s = sendLarkNotification(webhookUrl, user, title, e.getMessage());
return CommonResult.fail(s);
} catch (Exception ex) {
throw new RuntimeException(ex);
}
}
你可能会对larkBotEnabled感到好奇。实际上,全局异常捕获并不会自动区分线上环境与开发环境。为了能够在不同的环境中控制是否发送告警,我们使用了这个变量。通过在线上和本地的配置文件中设置不同的值,我们可以轻松地区分这两种环境。
application.yml
spring:
profiles:
active: dev #决定是否使用本地配置
application:
name: app-name
notifications:
larkBotEnabled: true #自定义字段控制报警行为
application-dev.yml
notifications:
larkBotEnabled: false
这样,我们就可以根据不同的环境来决定是否发送告警。以下是告警效果的示例:

这种告警方式既简洁又直观,帮助我们迅速定位问题。当然,针对不同的问题,我们还可以进一步对告警进行分级处理。
总结:在大型项目中,日志体系的构建需要大量的时间和资源。虽然在实际业务中,我们可能会使用更复杂的日志系统和告警机制,但本文提供的方法对于日常开发已经足够使用。如有任何建议或纠正,欢迎在评论区提出!
来源:juejin.cn/post/7280864416554500131