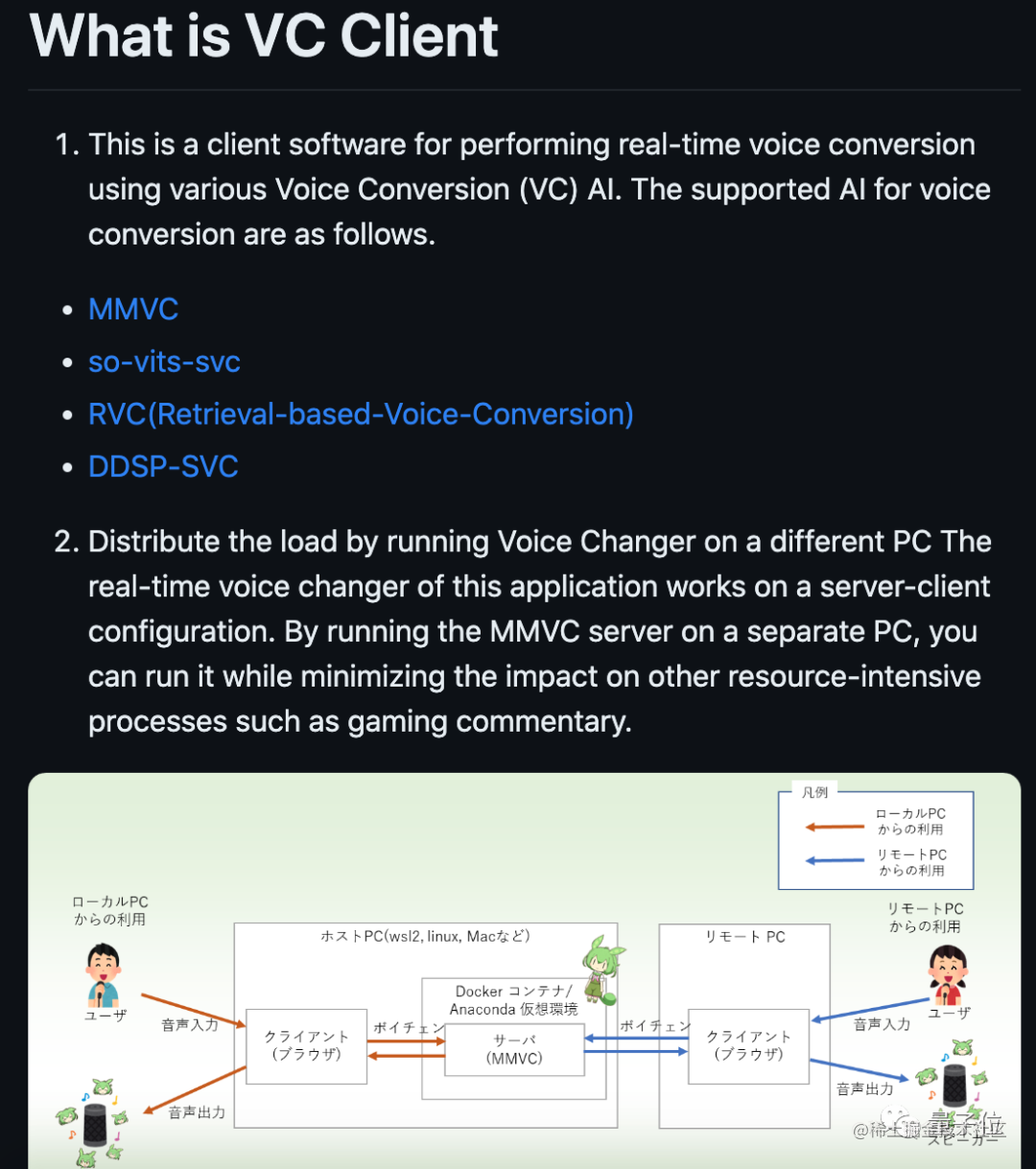
前言
之前在整理知识的时候,看到android屏幕刷新机制这一块,以前一直只是知道,Android每16.6ms会去刷新一次屏幕,也就是我们常说的60fpx,那么问题也来了:
16.6ms刷新一次是什么一次,是以这个固定的频率去重新绘制吗?但是请求绘制的代码时机调用是不同的,如果操作是在16.6ms快结束的时候去绘制的,那么岂不是就是时间少于16.6ms,也会产生丢帧的问题?再者熟悉绘制的朋友都知道请求绘制是一个Message对象,那这个Message是会放进主线程Looper的队列中吗,那怎么能保证在16.6ms之内会执行到这个Message呢?
View ## invalidate()
既然是绘制,那么就从这个方法看起吧
public void invalidate() {
invalidate(true);
}
public void invalidate(boolean invalidateCache) {
invalidateInternal(0, 0, mRight - mLeft, mBottom - mTop, invalidateCache, true);
}
void invalidateInternal(int l, int t, int r, int b, boolean invalidateCache,
boolean fullInvalidate) {
......
final AttachInfo ai = mAttachInfo;
final ViewParent p = mParent;
if (p != null && ai != null && l < r && t < b) {
final Rect damage = ai.mTmpInvalRect;
damage.set(l, t, r, b);
p.invalidateChild(this, damage);
}
.....
}
}
主要关注这个p,最终调用的是它的invalidateChild()方法,那么这个p到底是个啥,ViewParent是一个接口,那很明显p是一个实现类,答案是ViewRootImpl,我们知道View树的根节点是DecorView,那DecorView的Parent是不是ViewRootImpl呢
熟悉Activity启动流程的朋友都知道,Activity 的启动是在 ActivityThread 里完成的,handleLaunchActivity() 会依次间接的执行到 Activity 的 onCreate(), onStart(), onResume()。在执行完这些后 ActivityThread 会调用 WindowManager#addView(),而这个 addView()最终其实是调用了 WindowManagerGlobal 的 addView() 方法,我们就从这里开始看,因为是隐藏类,所以这里借助Source Insight查看WindowManagerGlobal
public void addView(View view, ViewGroup.LayoutParams params,
Display display, Window parentWindow) {
synchronized (mLock) {
.....
root = new ViewRootImpl(view.getContext(), display);
view.setLayoutParams(wparams);
mViews.add(view);
mRoots.add(root);
mParams.add(wparams);
}
try {
root.setView(view, wparams, panelParentView);
} catch (RuntimeException e) {
synchronized (mLock) {
final int index = findViewLocked(view, false);
if (index >= 0) {
removeViewLocked(index, true);
}
}
throw e;
}
}
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
synchronized (this) {
....
view.assignParent(this);
...
}
}
void assignParent(ViewParent parent) {
if (mParent == null) {
mParent = parent;
} else if (parent == null) {
mParent = null;
}
}
参数是ViewParent,所以在这里就直接将DecorView和ViewRootImpl给绑定起来了,所以也验证了上述的结论,子 View 里执行 invalidate() 之类的操作,最后都会走到 ViewRootImpl 里来
ViewRootImpl##scheduleTraversals
根据上面的链路最终是会执行到scheduleTraversals方法
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
复制代码方法不长,首先如果mTraversalScheduled为false,进入判断,同时将此标志位置位true,第二句暂时不管,后续会讲到,主要看postCallback方法,传递进去了一个mTraversalRunnable对象,可以看到这里是一个请求绘制的Runnable对象
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
if (mProfile) {
Debug.startMethodTracing("ViewAncestor");
}
performTraversals();
if (mProfile) {
Debug.stopMethodTracing();
mProfile = false;
}
}
}
doTraversal方法里面,又将mTraversalScheduled置位了false,对应上面的scheduleTraversals方法,可以看到一个是postSyncBarrier(),而在这里又是removeSyncBarrier(),这里其实涉及到一个很有意思的东西,叫同步屏障,等会会拉出来单独讲解,然后调用了performTraversals(),这个方法应该都知道了,View 的测量、布局、绘制都是在这个方法里面发起的,代码逻辑太多了,就不贴出来了,暂时只需要知道这个方法是发起测量的开始。
这里我们暂时总结一下,当子View调用invalidate的时候,最终是调用到ViewRootImpl的performTraversals()方法的,performTraversals()方法又是在doTraversal里面调用的,doTraversal又是封装在mTraversalRunnable之中的,那么这个Runnable的执行时机又在哪呢
Choreographer##postCallback
回到上面的scheduleTraversals方法中,mTraversalRunnable是传递进了Choreographer的postCallback方法之中
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
if (DEBUG_FRAMES) {
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
if (dueTime <= now) {
scheduleFrameLocked(now);
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_CALLBACK, action);
msg.arg1 = callbackType;
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, dueTime);
}
}
}
可以看到内部好像有一个类似MessageQueue的东西,将Runnable通过delay时间给存储起来的,因为我们这里传递进来的delay是0,所以执行scheduleFrameLocked(now)方法
private void scheduleFrameLocked(long now) {
if (!mFrameScheduled) {
mFrameScheduled = true;
if (isRunningOnLooperThreadLocked()) {
scheduleVsyncLocked();
} else {
Message msg = mHandler.obtainMessage(MSG_DO_SCHEDULE_VSYNC);
msg.setAsynchronous(true);
mHandler.sendMessageAtFrontOfQueue(msg);
}
}
}
private boolean isRunningOnLooperThreadLocked() {
return Looper.myLooper() == mLooper;
}
这里有一个判断isRunningOnLooperThreadLocked,看着像是判断当前线程是否是主线程,如果是的话,调用scheduleVsyncLocked()方法,不是的话会发送一个MSG_DO_SCHEDULE_VSYNC消息,但是最终都会调用这个方法
public void scheduleVsync() {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to schedule a vertical sync pulse but the display event "
+ "receiver has already been disposed.");
} else {
nativeScheduleVsync(mReceiverPtr);
}
}
如果mReceiverPtr不等于0的话,会去调用nativeScheduleVsync(mReceiverPtr),这是个native方法,暂不跟踪到C++里面去了,看着英文方法像是一个安排信号的意思 之前是把CallBack存储在一个Queue之中了,那么必然有执行的方法
void doCallbacks(int callbackType, long frameTimeNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
try {
Trace.traceBegin(Trace.TRACE_TAG_VIEW, CALLBACK_TRACE_TITLES[callbackType]);
for (CallbackRecord c = callbacks; c != null; c = c.next) {
if (DEBUG_FRAMES) {
Log.d(TAG, "RunCallback: type=" + callbackType
+ ", action=" + c.action + ", token=" + c.token
+ ", latencyMillis=" + (SystemClock.uptimeMillis() - c.dueTime));
}
c.run(frameTimeNanos);
}
} finally {
synchronized (mLock) {
mCallbacksRunning = false;
do {
final CallbackRecord next = callbacks.next;
recycleCallbackLocked(callbacks);
callbacks = next;
} while (callbacks != null);
}
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
}
看一下这个方法在哪里调用的,走到了doFrame方法里面
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
try {
.....
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos);
} finally {
AnimationUtils.unlockAnimationClock();
Trace.traceEnd(Trace.TRACE_TAG_VIEW);
}
.....
}
那么这样一来,就找到关键的方法了:doFrame(),这个方法里会根据一个时间戳去队列里取任务出来执行,而这个任务就是 ViewRootImpl 封装起来的 doTraversal() 操作,而 doTraversal() 会去调用 performTraversals() 开始根据需要测量、布局、绘制整颗 View 树。所以剩下的问题就是 doFrame() 这个方法在哪里被调用了。
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper, int vsyncSource) {
super(looper, vsyncSource);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
scheduleVsync();
return;
}
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
可以看到,是在onVsync回调中,Message msg = Message.obtain(mHandler, this),传入了this,然后会执行到run方法里面,自然也就执行了doFrame方法,所以最终问题也就来了,这个onVsync()这个是什么时候回调来的,这里查询了网上的一些资料,是这么解释的
FrameDisplayEventReceiver继承自DisplayEventReceiver接收底层的VSync信号开始处理UI过程。VSync信号由SurfaceFlinger实现并定时发送。FrameDisplayEventReceiver收到信号后,调用onVsync方法组织消息发送到主线程处理。这个消息主要内容就是run方法里面的doFrame了,这里mTimestampNanos是信号到来的时间参数。
那也就是说,onVsync是底层回调回来的,那也就是每16.6ms,底层会发出一个屏幕刷新的信号,然后会回调到onVsync方法之中,但是有一点很奇怪,底层怎么知道上层是哪个app需要这个信号来刷新呢,结合日常开发,要实现这种一般使用观察者模式,将app本身注册下去,但是好像也没有看到哪里有往底层注册的方法,对了,再次回到上面的那个native方法,nativeScheduleVsync(mReceiverPtr),那么这个方法大体的作用也就是注册监听了,
同步屏障
总结下上面的知识,我们调用了 invalidate(),requestLayout(),等之类刷新界面的操作时,并不是马上就会执行这些刷新的操作,而是通过 ViewRootImpl 的 scheduleTraversals() 先向底层注册监听下一个屏幕刷新信号事件,然后等下一个屏幕刷新信号来的时候,才会去通过 performTraversals() 遍历绘制 View 树来执行这些刷新操作。
那么这样是不是产生一个问题,因为我们知道,平常Handler发送的消息都是同步消息的,也就是Looper会从MessageQueue中不断去取Message对象,一个Message处理完了之后,再去取下一个Message,那么绘制的这个Message如何尽量保证能够在16.6ms之内执行到呢,
这里就使用到了一个同步屏障的东西,再次回到scheduleTraversals代码
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
mHandler.getLooper().getQueue().postSyncBarrier(),这一句上面没有分析,进入到方法里
private int postSyncBarrier(long when) {
synchronized (this) {
final int token = mNextBarrierToken++;
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
Message prev = null;
Message p = mMessages;
if (when != 0) {
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
}
if (prev != null) {
msg.next = p;
prev.next = msg;
} else {
msg.next = p;
mMessages = msg;
}
return token;
}
}
可以看到,就是生成Message对象,然后进一些赋值,但是细心的朋友可能会发现,这个msg为什么没有设置target,熟悉Handler流程的朋友应该清楚,最终消息是通过msg.target发送出去的,一般是指Handler对象
那我们再次回到MessageQueue的next方法中看看
Message next() {
for (;;) {
....
synchronized (this) {
...
if (msg != null && msg.target == null) {
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
nextPollTimeoutMillis = -1;
}
}
}
可以看到有一个Message.target==null的判断, do while循环遍历消息链表,跳出循环时,msg指向离表头最近的一个消息,此时返回msg对象
可以看到,当设置了同步屏障之后,next函数将会忽略所有的同步消息,返回异步消息。换句话说就是,设置了同步屏障之后,Handler只会处理异步消息。再换句话说,同步屏障为Handler消息机制增加了一种简单的优先级机制,异步消息的优先级要高于同步消息
这样的话,能够尽快的将绘制的Message给取出来执行,嗯,这里为什么说是尽快呢,因为,同步屏障是在 scheduleTraversals() 被调用时才发送到消息队列里的,也就是说,只有当某个 View 发起了刷新请求时,在这个时刻后面的同步消息才会被拦截掉。如果在 scheduleTraversals() 之前就发送到消息队列里的工作仍然会按顺序依次被取出来执行
作者:花海blog
来源:juejin.cn/post/7267528065809907727